⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-26 更新
Kling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio Generation
Authors:Jun Wang, Xijuan Zeng, Chunyu Qiang, Ruilong Chen, Shiyao Wang, Le Wang, Wangjing Zhou, Pengfei Cai, Jiahui Zhao, Nan Li, Zihan Li, Yuzhe Liang, Xiaopeng Wang, Haorui Zheng, Ming Wen, Kang Yin, Yiran Wang, Nan Li, Feng Deng, Liang Dong, Chen Zhang, Di Zhang, Kun Gai
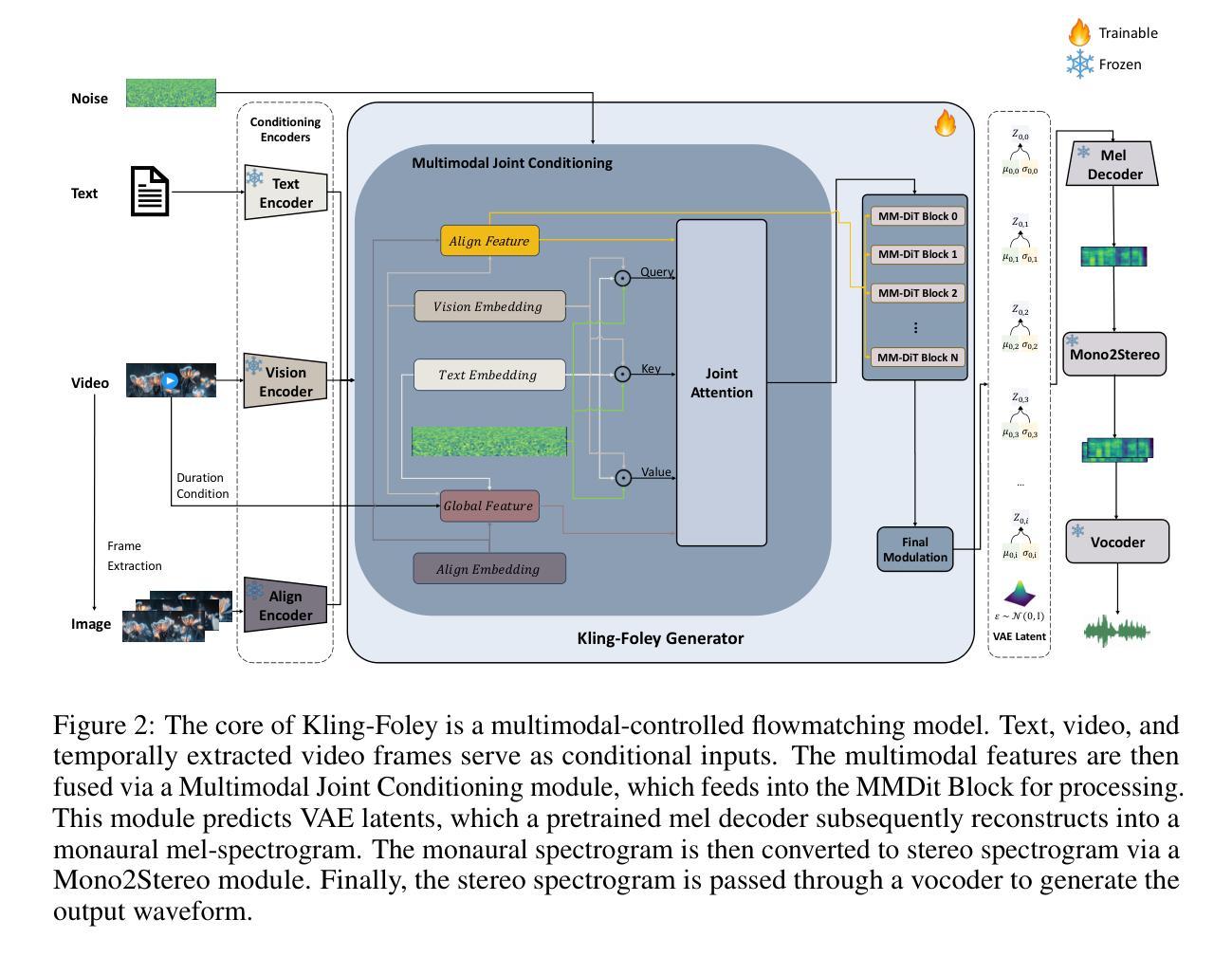
We propose Kling-Foley, a large-scale multimodal Video-to-Audio generation model that synthesizes high-quality audio synchronized with video content. In Kling-Foley, we introduce multimodal diffusion transformers to model the interactions between video, audio, and text modalities, and combine it with a visual semantic representation module and an audio-visual synchronization module to enhance alignment capabilities. Specifically, these modules align video conditions with latent audio elements at the frame level, thereby improving semantic alignment and audio-visual synchronization. Together with text conditions, this integrated approach enables precise generation of video-matching sound effects. In addition, we propose a universal latent audio codec that can achieve high-quality modeling in various scenarios such as sound effects, speech, singing, and music. We employ a stereo rendering method that imbues synthesized audio with a spatial presence. At the same time, in order to make up for the incomplete types and annotations of the open-source benchmark, we also open-source an industrial-level benchmark Kling-Audio-Eval. Our experiments show that Kling-Foley trained with the flow matching objective achieves new audio-visual SOTA performance among public models in terms of distribution matching, semantic alignment, temporal alignment and audio quality.
我们提出了Kling-Foley,这是一个大规模的多模式视频到音频生成模型,能够合成与视频内容同步的高质量音频。在Kling-Foley中,我们引入了多模式扩散变压器,对视频、音频和文本模式之间的交互进行建模,并结合视觉语义表示模块和视听同步模块,以增强对齐能力。具体来说,这些模块在帧级别将视频条件与潜在音频元素对齐,从而提高语义对齐和视听同步。结合文本条件,这种综合方法能够实现与视频精确匹配的声音效果生成。此外,我们提出了一种通用潜在音频编解码器,可以在各种场景(如音效、语音、歌唱和音乐)中实现高质量建模。我们采用了一种立体声渲染方法,为合成音频赋予空间存在感。同时,为了弥补开源基准测试的不完整类型和注释,我们还开源了工业级基准测试Kling-Audio-Eval。我们的实验表明,使用流动匹配目标训练的Kling-Foley在分布匹配、语义对齐、时间对齐和音频质量方面实现了公众模型的新音频视觉SOTA性能。
论文及项目相关链接
Summary
Kling-Foley是一个大规模的多模态视频转音频生成模型,可合成与视频内容同步的高质量音频。它引入了多模态扩散变压器来建模视频、音频和文本模态之间的交互,并结合视觉语义表示模块和音视频同步模块,提高了语义对齐和音视频同步的能力。该模型可实现精确的视频匹配音效生成,并提出一种通用潜在音频编解码器,可在各种场景中实现高质量建模,如音效、语音、歌唱和音乐。
Key Takeaways
- Kling-Foley是一个多模态视频转音频生成模型,能合成高质量且与视频同步的音频。
- 模型引入了多模态扩散变压器,用于处理视频、音频和文本之间的交互。
- 结合视觉语义表示模块和音视频同步模块,提高了语义对齐和同步能力。
- 该模型可精确生成与视频匹配的音效。
- 提出一种通用潜在音频编解码器,适用于各种场景,如音效、语音、歌唱和音乐。
- 采用立体声渲染方法,赋予合成音频空间感。
点此查看论文截图

ClearerVoice-Studio: Bridging Advanced Speech Processing Research and Practical Deployment
Authors:Shengkui Zhao, Zexu Pan, Bin Ma
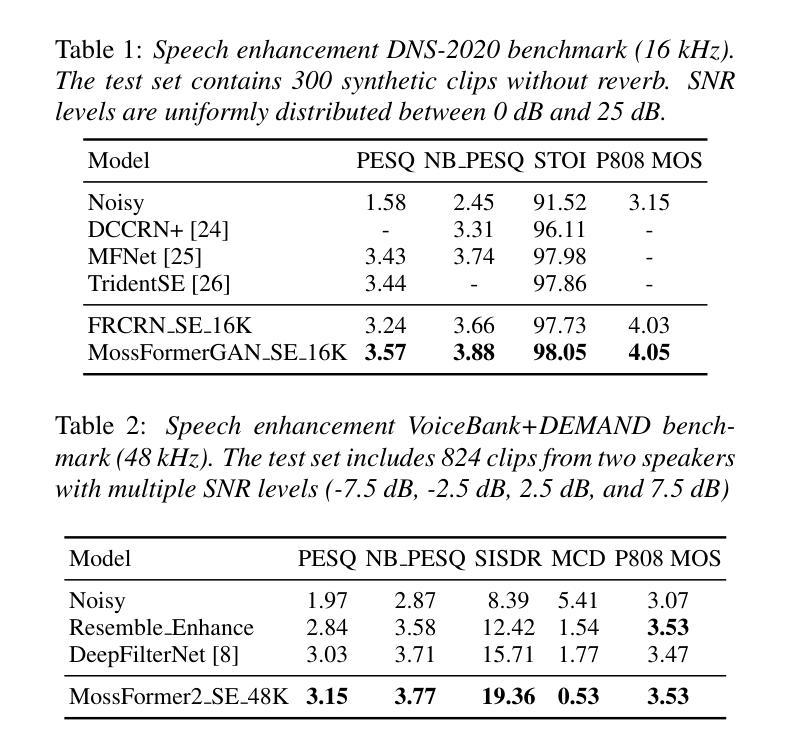
This paper introduces ClearerVoice-Studio, an open-source, AI-powered speech processing toolkit designed to bridge cutting-edge research and practical application. Unlike broad platforms like SpeechBrain and ESPnet, ClearerVoice-Studio focuses on interconnected speech tasks of speech enhancement, separation, super-resolution, and multimodal target speaker extraction. A key advantage is its state-of-the-art pretrained models, including FRCRN with 3 million uses and MossFormer with 2.5 million uses, optimized for real-world scenarios. It also offers model optimization tools, multi-format audio support, the SpeechScore evaluation toolkit, and user-friendly interfaces, catering to researchers, developers, and end-users. Its rapid adoption attracting 3000 GitHub stars and 239 forks highlights its academic and industrial impact. This paper details ClearerVoice-Studio’s capabilities, architectures, training strategies, benchmarks, community impact, and future plan. Source code is available at https://github.com/modelscope/ClearerVoice-Studio.
本文介绍了ClearerVoice-Studio,这是一个开源的、人工智能驱动的语音识别工具包,旨在架起前沿研究与实践应用之间的桥梁。不同于像SpeechBrain和ESPnet这样的广泛平台,ClearerVoice-Studio专注于相互关联的语音识别任务,包括语音增强、分离、超分辨率和多模态目标说话人提取。它的一个关键优势是拥有最先进的预训练模型,包括被使用300万次的FRCRN和被使用250万次的MossFormer,这些模型都针对实际场景进行了优化。它还提供了模型优化工具、多格式音频支持、SpeechScore评估工具包以及用户友好的界面,可以满足研究人员、开发人员和最终用户的需求。其快速采纳吸引了3000个GitHub星级评价和23.已详细阐述了ClearerVoice-Studio的功能、架构、训练策略、基准测试、社区影响和未来计划。源代码可在https://github.com/modelscope/ClearerVoice-Studio获取。
论文及项目相关链接
PDF accepted by Interspeech 2025, 5 pages, 5 tables
Summary
该论文介绍了ClearerVoice-Studio,一个开源的、人工智能驱动的语音识别工具包,旨在架起前沿研究与实践应用之间的桥梁。它专注于语音增强、分离、超分辨率和多模态目标说话人提取等相互关联的语音任务,具有先进的预训练模型、模型优化工具、多格式音频支持、SpeechScore评估工具包以及友好的用户界面,适用于研究者、开发人员和最终用户。其快速采纳和广泛影响突显了其在学术和工业领域的重要性。
Key Takeaways
- ClearerVoice-Studio是一个开源的AI语音识别工具包,专注于语音增强、分离、超分辨率和多模态目标说话人提取等任务。
- 具有先进的预训练模型,如FRCRN和MossFormer,适用于真实场景。
- 提供模型优化工具、多格式音频支持以及用户友好的界面。
- 配备了SpeechScore评估工具包,可满足研究、开发和最终用户的需求。
- 拥有广泛的社区影响,快速采纳,体现在其获得的GitHub星星和forks数量上。
- 该论文详细描述了ClearerVoice-Studio的功能、架构、训练策略、基准测试和对社区的影响及未来计划。
点此查看论文截图

Enhanced Hybrid Transducer and Attention Encoder Decoder with Text Data
Authors:Yun Tang, Eesung Kim, Vijendra Raj Apsingekar
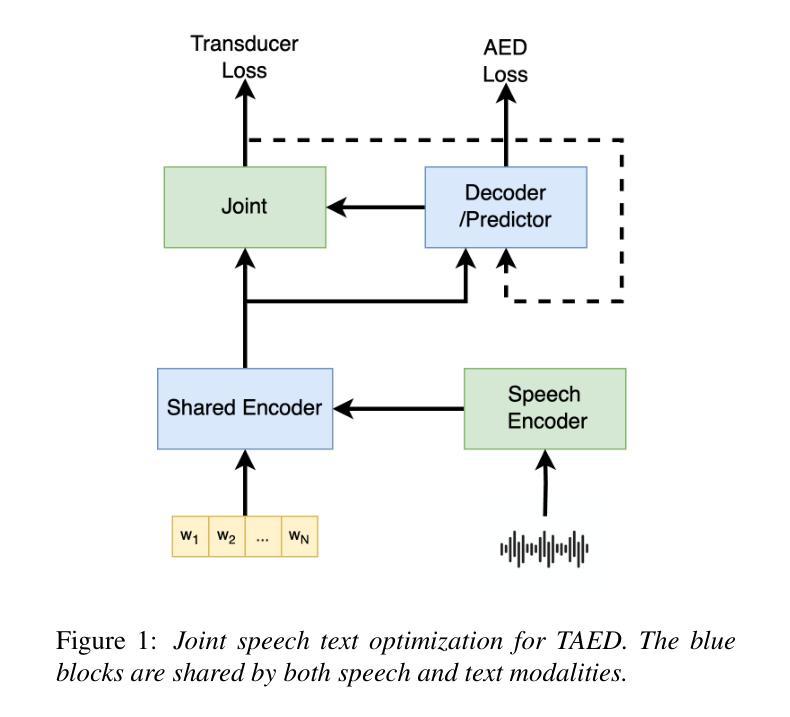
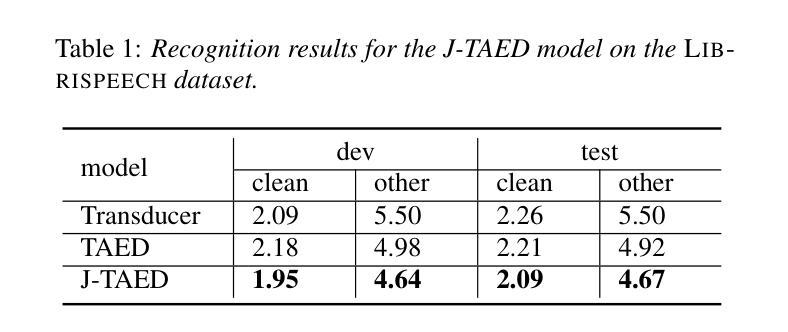
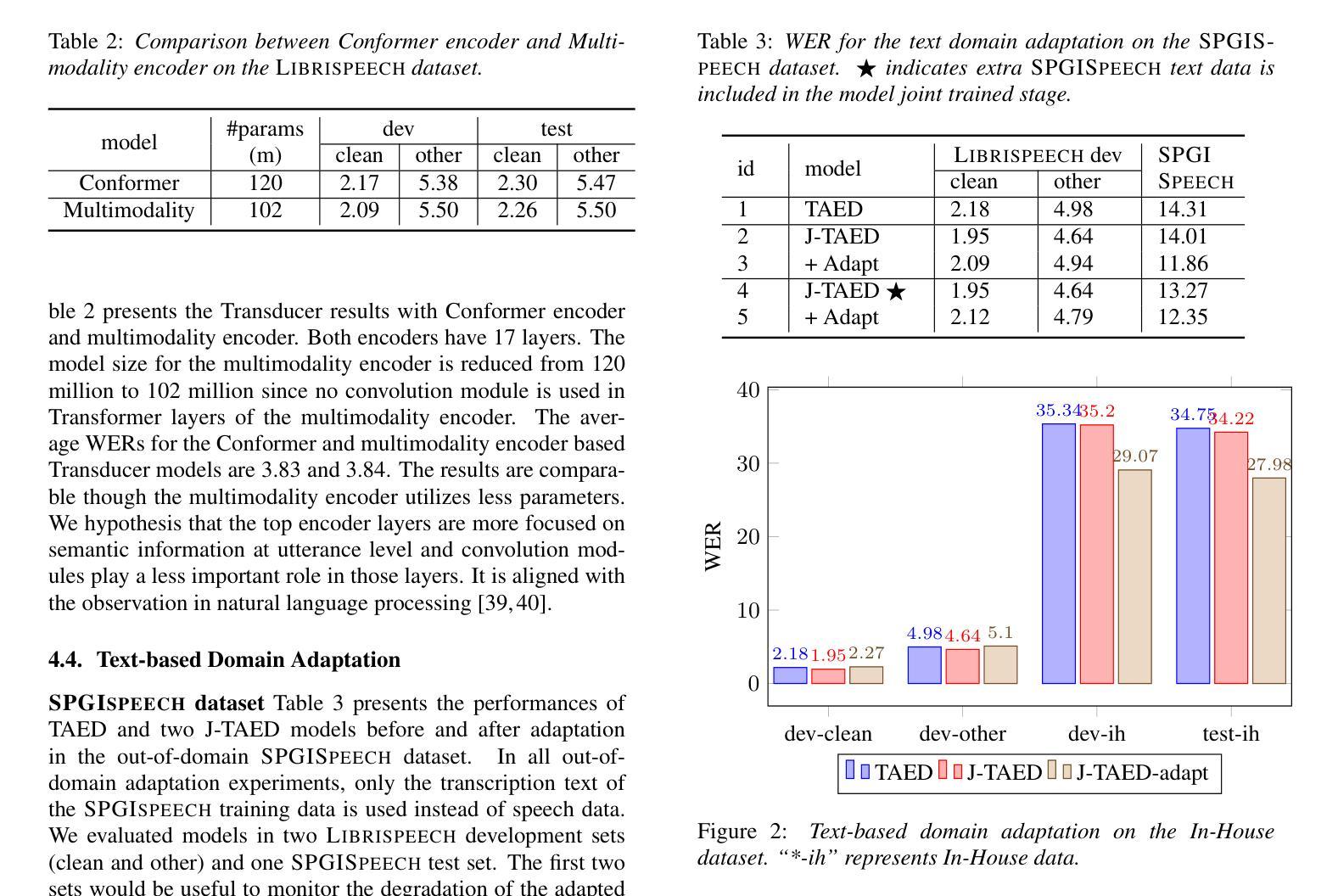
A joint speech and text optimization method is proposed for hybrid transducer and attention-based encoder decoder (TAED) modeling to leverage large amounts of text corpus and enhance ASR accuracy. The joint TAED (J-TAED) is trained with both speech and text input modalities together, while it only takes speech data as input during inference. The trained model can unify the internal representations from different modalities, and be further extended to text-based domain adaptation. It can effectively alleviate data scarcity for mismatch domain tasks since no speech data is required. Our experiments show J-TAED successfully integrates speech and linguistic information into one model, and reduce the WER by 5.8 ~12.8% on the Librispeech dataset. The model is also evaluated on two out-of-domain datasets: one is finance and another is named entity focused. The text-based domain adaptation brings 15.3% and 17.8% WER reduction on those two datasets respectively.
提出了一种针对混合换能器和基于注意力的编码器解码器(TAED)建模的联合语音和文本优化方法,以利用大量的文本语料库提高ASR(自动语音识别)的准确性。联合TAED(J-TAED)以语音和文本输入模式一起进行训练,而在推理期间仅采用语音数据作为输入。该训练模型能够统一不同模态的内部表示,并进一步扩展到基于文本的领域自适应。由于无需语音数据,因此可以有效缓解不匹配域任务的数据稀缺问题。我们的实验表明,J-TAED成功地将语音和语言学信息集成到一个模型中,并在Librispeech数据集上将词错误率(WER)降低了5.8%~12.8%。该模型还在两个域外数据集上进行了评估:一个是金融数据集,另一个是命名实体关注数据集。基于文本的领域自适应分别为这两个数据集带来了15.3%和17.8%的WER降低。
论文及项目相关链接
PDF Accepted by Interspeech2025
Summary
提出一种联合语音和文字优化方法,用于混合转换器与基于注意力的编码器解码器(TAED)建模,以利用大量文本语料库提高语音识别准确率。在训练过程中,联合TAED(J-TAED)同时接受语音和文本输入,而在推理时仅接受语音数据。该模型能够统一不同模态的内部表示,并进一步扩展到基于文本的领域适应。实验表明,J-TAED成功地将语音和语言学信息集成到一个模型中,在Librispeech数据集上词错误率(WER)降低了5.8%~12.8%。该模型还在两个域外数据集上进行了评估,分别是金融和命名实体焦点数据集。基于文本的领域适应分别为这两个数据集带来了15.3%和17.8%的WER降低。
Key Takeaways
- 提出了一个联合语音和文字优化方法用于TAED建模,旨在提高语音识别准确率。
- J-TAED模型在训练过程中结合了语音和文本输入模态,推理时仅使用语音数据。
- J-TAED模型能够统一不同模态的内部表示,并扩展到基于文本的领域适应。
- 实验显示J-TAED在Librispeech数据集上降低了词错误率(WER)。
- J-TAED模型在金融和命名实体焦点数据集上也进行了评估。
- 基于文本的领域适应在域外数据集上显著降低了WER。
点此查看论文截图


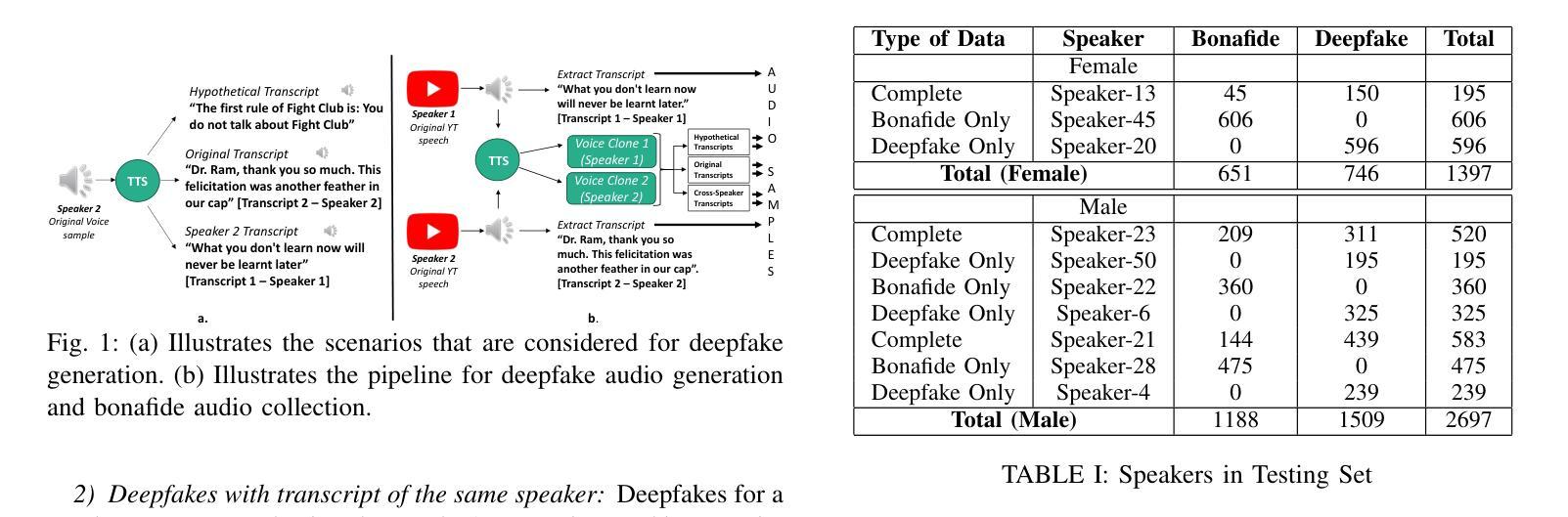
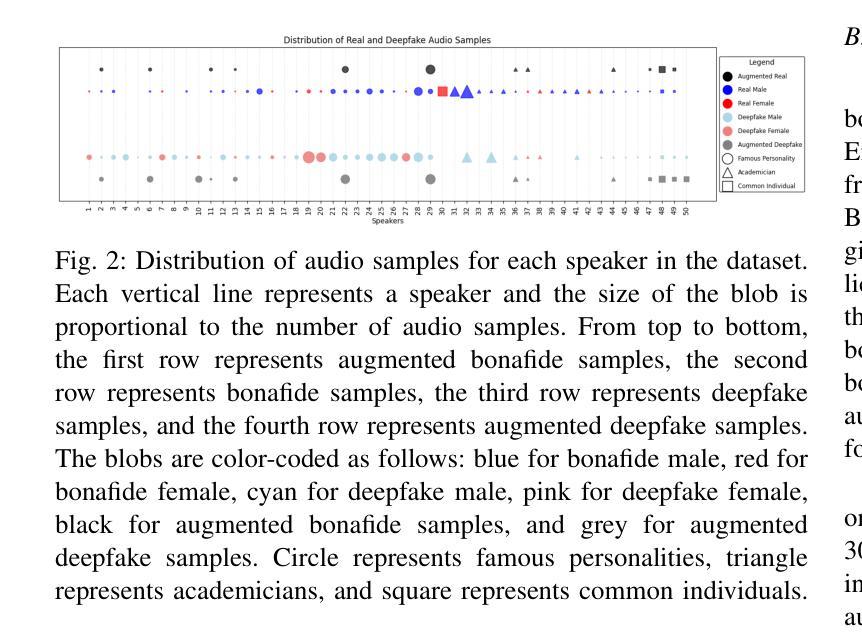
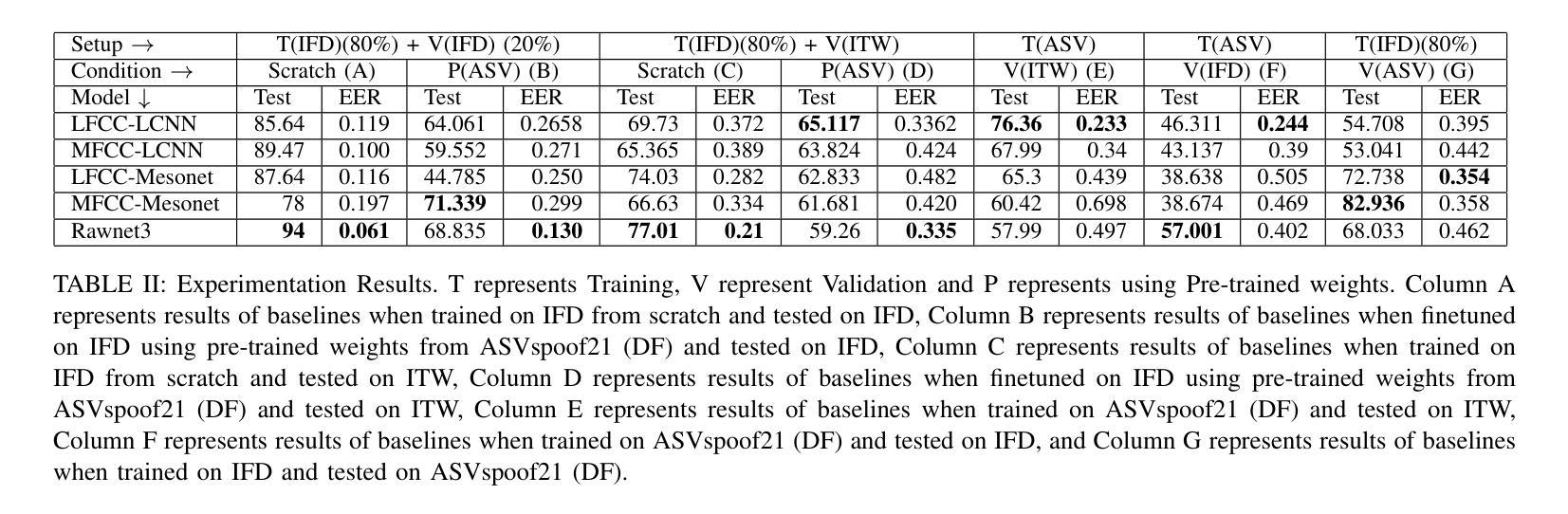
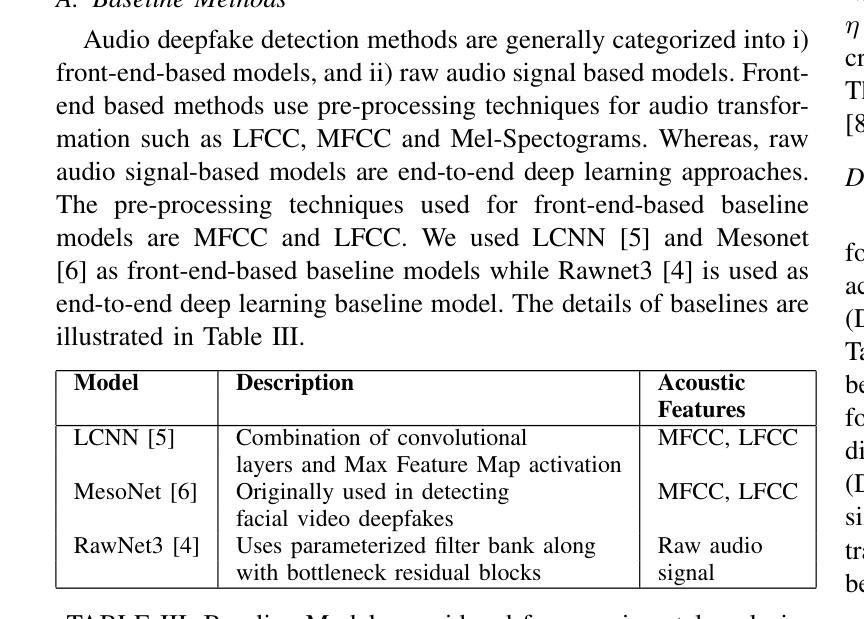
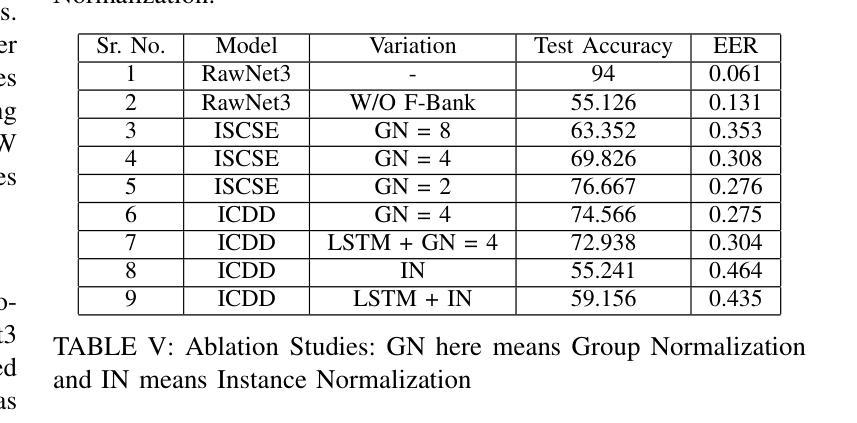
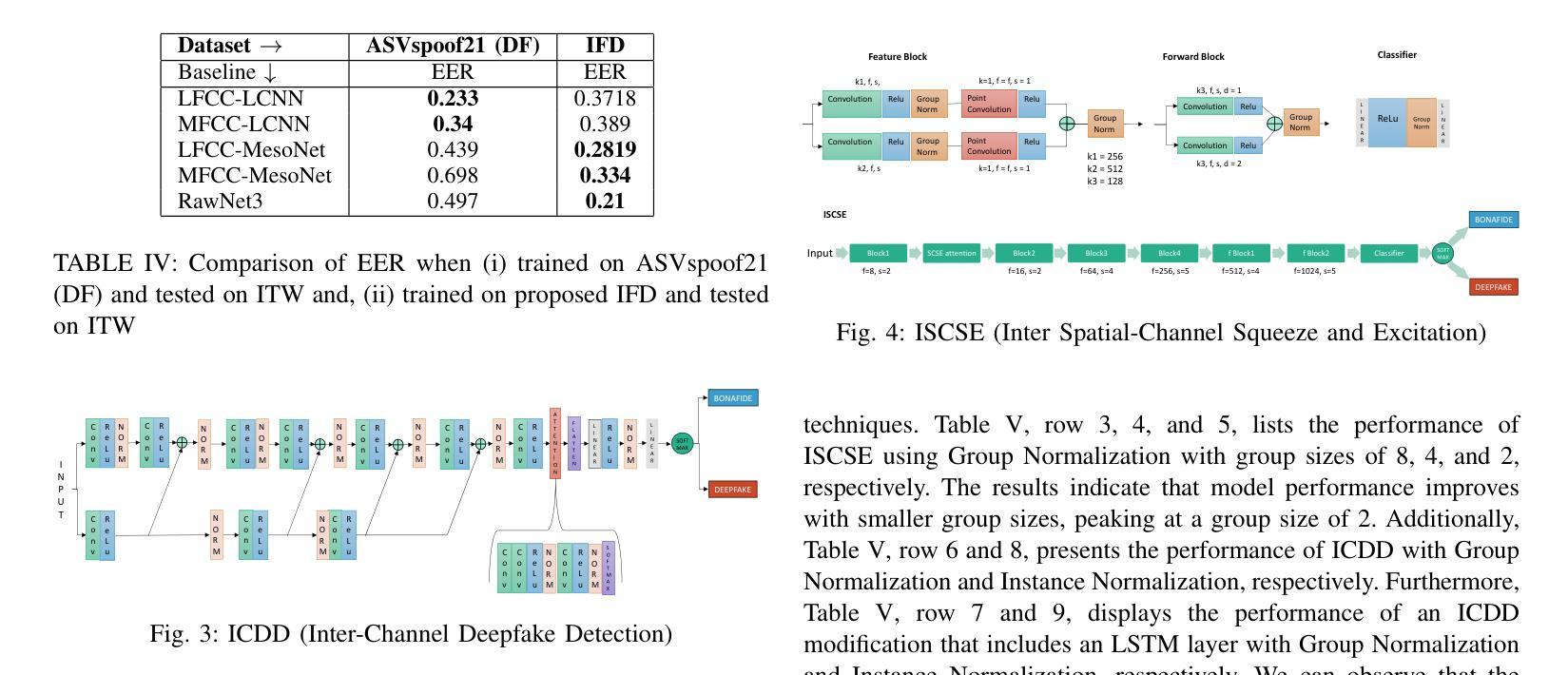
IndieFake Dataset: A Benchmark Dataset for Audio Deepfake Detection
Authors:Abhay Kumar, Kunal Verma, Omkar More
Advancements in audio deepfake technology offers benefits like AI assistants, better accessibility for speech impairments, and enhanced entertainment. However, it also poses significant risks to security, privacy, and trust in digital communications. Detecting and mitigating these threats requires comprehensive datasets. Existing datasets lack diverse ethnic accents, making them inadequate for many real-world scenarios. Consequently, models trained on these datasets struggle to detect audio deepfakes in diverse linguistic and cultural contexts such as in South-Asian countries. Ironically, there is a stark lack of South-Asian speaker samples in the existing datasets despite constituting a quarter of the worlds population. This work introduces the IndieFake Dataset (IFD), featuring 27.17 hours of bonafide and deepfake audio from 50 English speaking Indian speakers. IFD offers balanced data distribution and includes speaker-level characterization, absent in datasets like ASVspoof21 (DF). We evaluated various baselines on IFD against existing ASVspoof21 (DF) and In-The-Wild (ITW) datasets. IFD outperforms ASVspoof21 (DF) and proves to be more challenging compared to benchmark ITW dataset. The dataset will be publicly available upon acceptance.
音频深度伪造技术的进展带来了人工智能助手、改善语音障碍者的可访问性以及增强娱乐体验等好处。然而,它也带来了对安全、隐私和数字通信中的信任的重大风险。检测和缓解这些威胁需要全面的数据集。现有数据集缺乏各种种族口音的多样性,导致在许多真实场景中无法有效使用。因此,在这些数据集上训练的模型在多样化的语言和文化背景中(如在南亚国家)检测音频深度伪造时遇到了困难。具有讽刺意味的是,尽管南亚人口占世界人口的四分之一,但现有数据集中严重缺乏南亚发音人的样本。这项工作介绍了IndieFake数据集(IFD),包含来自50名英语印度发音人的真实语音和深度伪造语音共计27.17小时。IFD提供了平衡的数据分布,并包括说话人级别的特征描述,这在ASVspoof21(DF)等数据集中是缺失的。我们在IFD上评估了基线模型与现有的ASVspoof21(DF)和野外(ITW)数据集的比较结果。IFD的表现优于ASVspoof21(DF),并且相较于基准ITW数据集更具挑战性。该数据集将在接受后公开发布。
论文及项目相关链接
Summary:音频深度伪造技术的进展带来了人工智能助手、改善语音障碍人士的沟通体验以及提升娱乐体验等好处。然而,该技术也对数字通信的安全性和隐私保护构成严重威胁。为了检测和缓解这些威胁,需要构建综合性的数据集。现有数据集缺乏多种民族口音的多样性,使得它们在许多现实场景中的应用受限。特别是在南亚国家,基于现有数据集训练的模型难以在多样化和跨文化环境中检测音频深度伪造。尽管南亚人口占全球四分之一,但现有数据集中缺乏南亚口音的样本。本研究推出了独立假样本数据集(IFD),包含了来自五十名印度人的27.17小时的真实音频和伪造音频。IFD提供均衡的数据分布并包括未在诸如ASVspoof21等数据集中出现的发言人特征表征。与现有的ASVspoof21和野外数据集相比,IFD在测试中表现出优势,并且在面临挑战时表现出更高的性能。该数据集将在获得批准后公开发布。
Key Takeaways:
- 音频深度伪造技术带来了好处,但也存在安全和隐私风险。
- 现有音频数据集缺乏多样性和不同口音的样本,限制了其在现实场景中的应用。
- 南亚口音的样本在现有数据集中严重缺失,影响了音频检测的准确性。
- 介绍了独立假样本数据集(IFD),包含真实和伪造音频样本,具有均衡的数据分布和发言人特征表征。
- IFD相较于现有数据集如ASVspoof21更具优势,并且在测试中表现出更高的性能。
- IFD对于解决不同口音和背景下的音频深度伪造检测问题具有更大的潜力。
点此查看论文截图