⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-26 更新
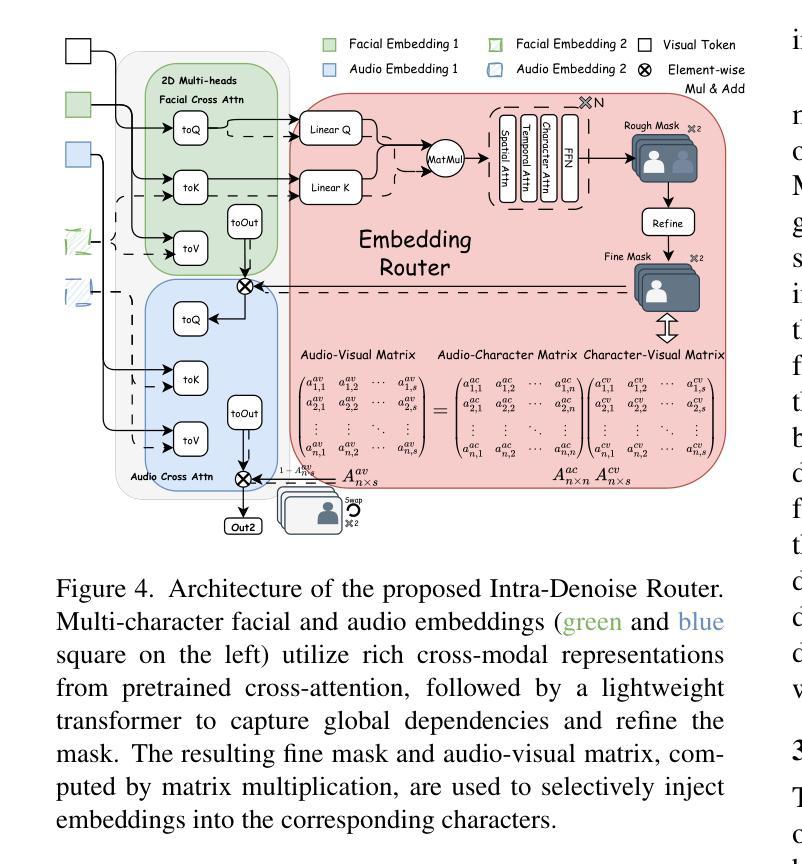
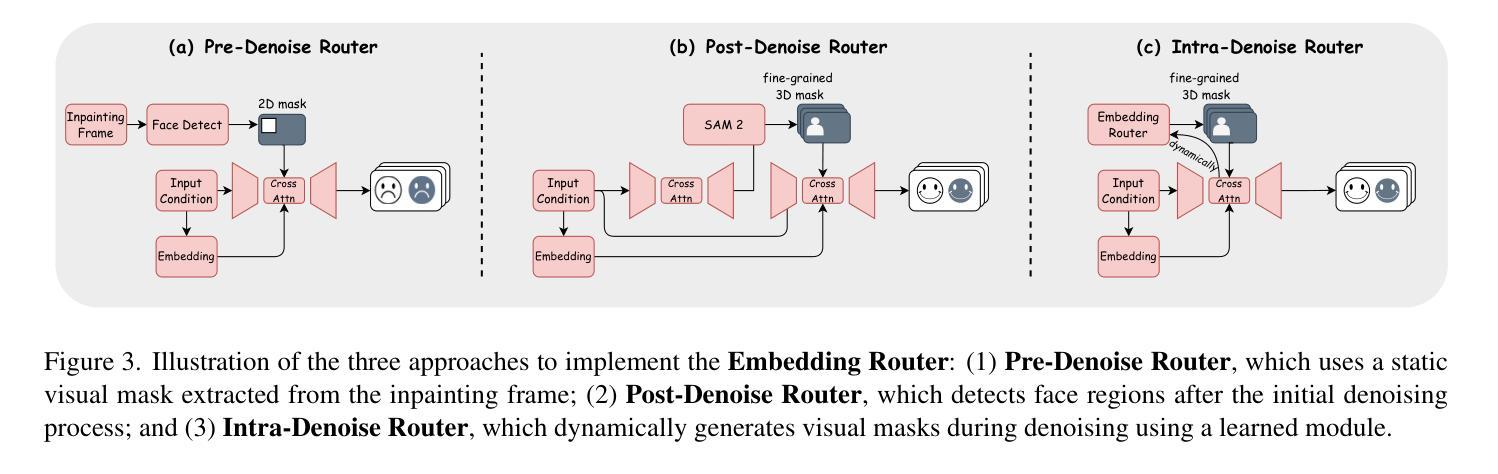
Bind-Your-Avatar: Multi-Talking-Character Video Generation with Dynamic 3D-mask-based Embedding Router
Authors:Yubo Huang, Weiqiang Wang, Sirui Zhao, Tong Xu, Lin Liu, Enhong Chen
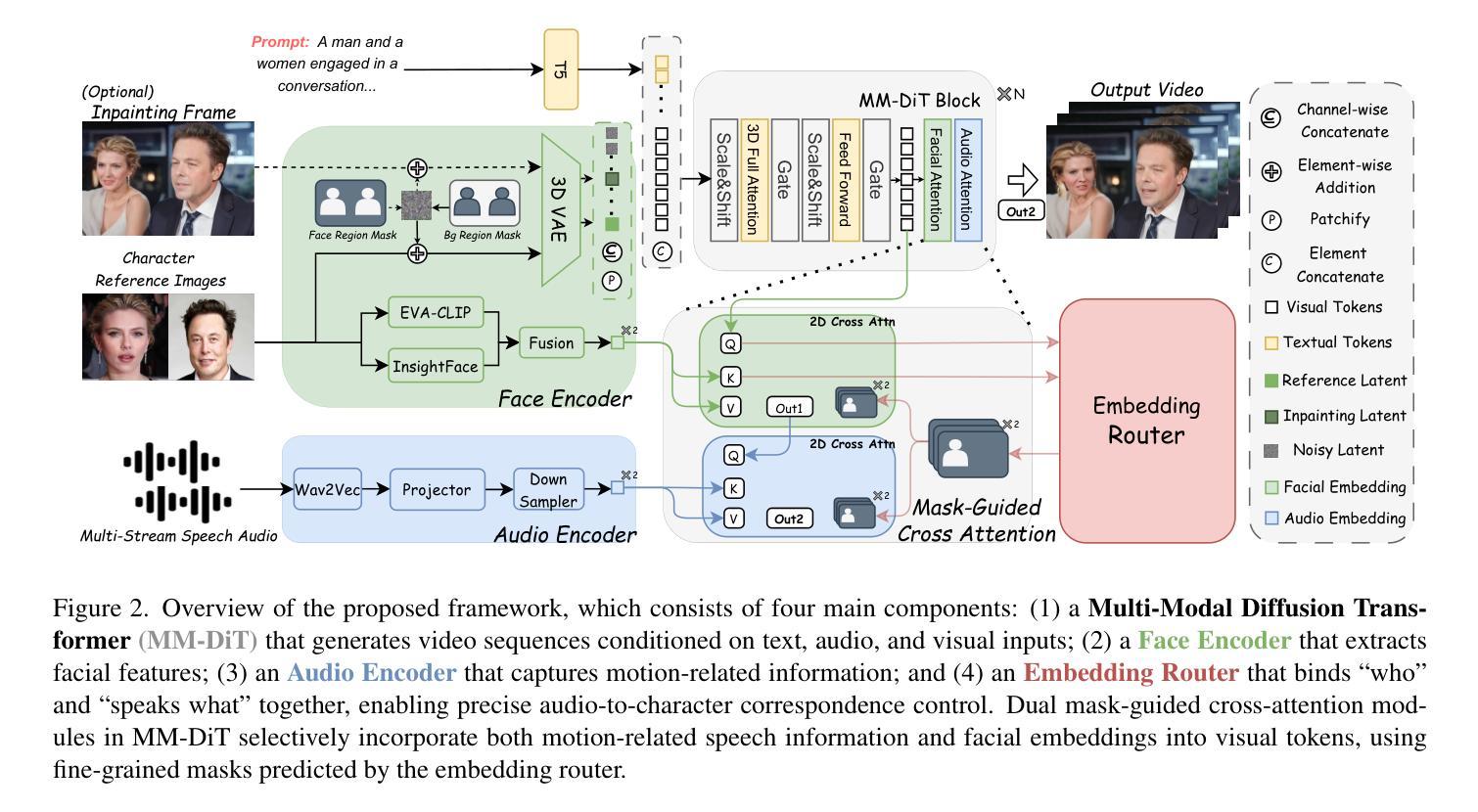
Recent years have witnessed remarkable advances in audio-driven talking head generation. However, existing approaches predominantly focus on single-character scenarios. While some methods can create separate conversation videos between two individuals, the critical challenge of generating unified conversation videos with multiple physically co-present characters sharing the same spatial environment remains largely unaddressed. This setting presents two key challenges: audio-to-character correspondence control and the lack of suitable datasets featuring multi-character talking videos within the same scene. To address these challenges, we introduce Bind-Your-Avatar, an MM-DiT-based model specifically designed for multi-talking-character video generation in the same scene. Specifically, we propose (1) A novel framework incorporating a fine-grained Embedding Router that binds who' and speak what’ together to address the audio-to-character correspondence control. (2) Two methods for implementing a 3D-mask embedding router that enables frame-wise, fine-grained control of individual characters, with distinct loss functions based on observed geometric priors and a mask refinement strategy to enhance the accuracy and temporal smoothness of the predicted masks. (3) The first dataset, to the best of our knowledge, specifically constructed for multi-talking-character video generation, and accompanied by an open-source data processing pipeline, and (4) A benchmark for the dual-talking-characters video generation, with extensive experiments demonstrating superior performance over multiple state-of-the-art methods.
近年来,音频驱动说话人头部生成技术取得了显著进展。然而,现有方法主要集中在单人场景上。虽然一些方法能够创建两个人之间的单独对话视频,但在同一空间环境中生成多人同时对话的统一对话视频的关键挑战仍未得到广泛解决。这种设置带来了两个主要挑战:音频与角色的对应控制以及缺乏适合在同一场景内多角色对话的视频数据集。为解决这些挑战,我们引入了Bind-Your-Avatar,这是一款基于MM-DiT的模型,专门设计用于同一场景中的多角色对话视频生成。具体来说,我们提出了(1)一个结合精细嵌入路由器的全新框架,将“谁”和“说什么”绑定在一起,以解决音频与角色之间的对应控制问题。(2)两种实现3D掩模嵌入路由器的方法,实现对单个角色的帧级精细控制,基于观察到的几何先验的独特损失函数和掩模细化策略,以提高预测掩模的准确性和时间平滑度。(3)据我们所知,专门构建用于多角色对话视频生成的第一份数据集,并配有开源数据处理管道;(4)双角色对话视频生成的基准测试,大量实验表明其性能优于多种最先进的方法。
论文及项目相关链接
Summary
本文介绍了音频驱动下的说话人头部生成技术的最新进展。现有方法主要关注单角色场景,尽管有些方法能够创建两个人之间的对话视频,但在同一场景中生成多角色对话视频的挑战仍未得到妥善解决。为此,本文引入了Bind-Your-Avatar模型,专门设计用于同一场景中的多角色对话视频生成。该模型通过嵌入路由器解决了音频与角色的对应关系控制问题,并提供了实施3D蒙版嵌入路由器的方法,实现了对各个角色的逐帧精细控制。此外,本文还构建了首个专门针对多角色对话视频生成的数据集,并设立了双角色对话视频生成的基准测试,实验表明该模型在多个最先进的方法中具有优越性能。
Key Takeaways
- 音频驱动下的说话人头部生成技术面临多角色对话视频生成的挑战。
- Bind-Your-Avatar模型专门设计用于同一场景中的多角色对话视频生成。
- 通过嵌入路由器解决音频与角色的对应关系控制问题。
- 实施3D蒙版嵌入路由器的方法,实现逐帧精细的角色控制。
- 构建了首个专门针对多角色对话视频生成的数据集。
- 设立了双角色对话视频生成的基准测试。
点此查看论文截图


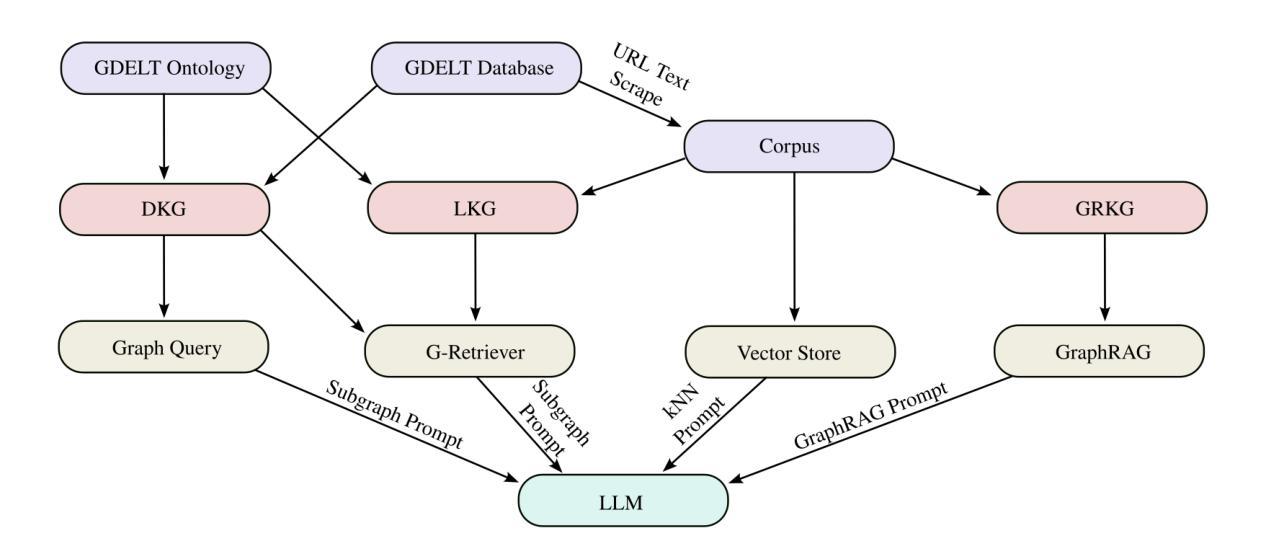
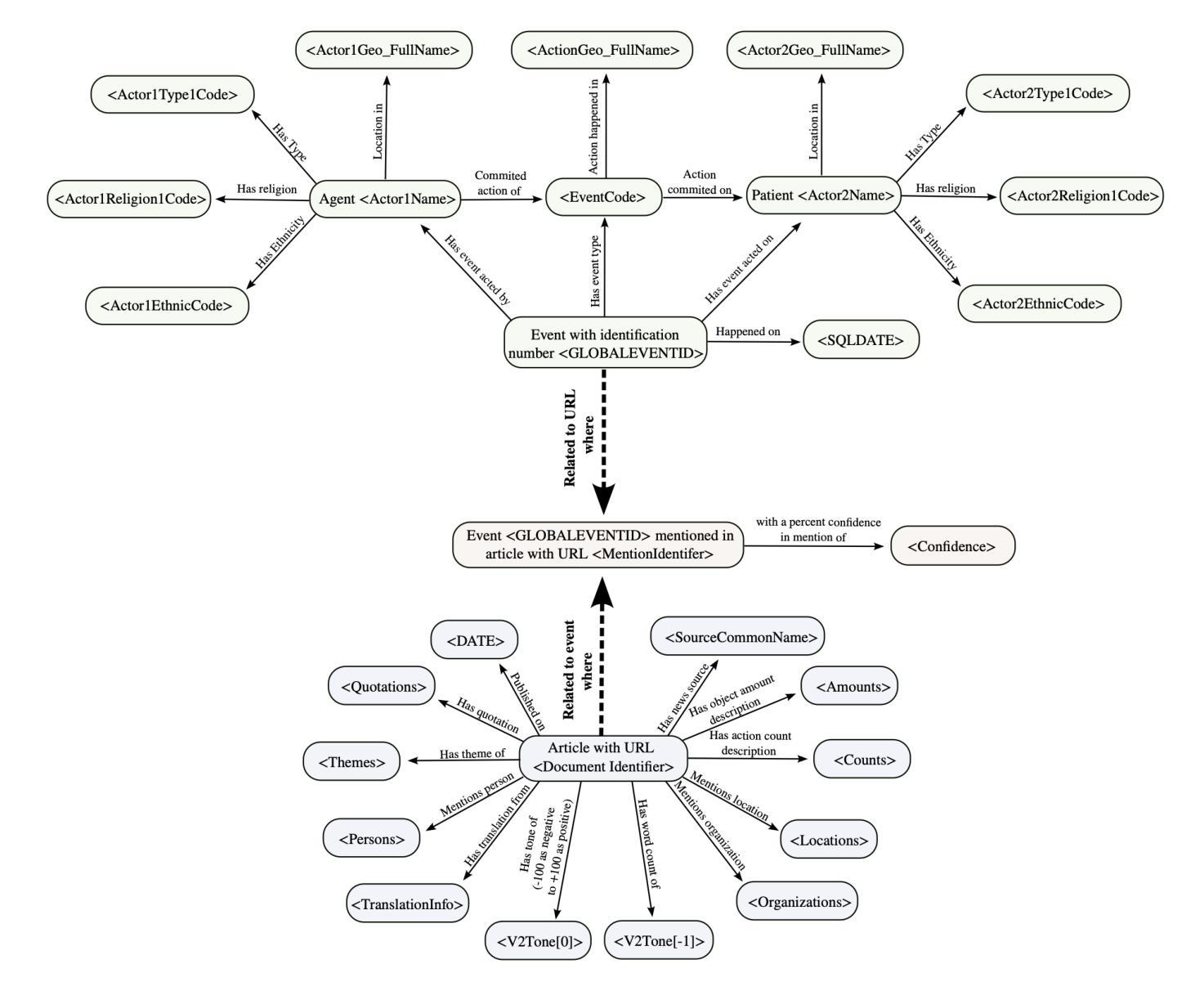
Talking to GDELT Through Knowledge Graphs
Authors:Audun Myers, Max Vargas, Sinan G. Aksoy, Cliff Joslyn, Benjamin Wilson, Lee Burke, Tom Grimes
In this work we study various Retrieval Augmented Regeneration (RAG) approaches to gain an understanding of the strengths and weaknesses of each approach in a question-answering analysis. To gain this understanding we use a case-study subset of the Global Database of Events, Language, and Tone (GDELT) dataset as well as a corpus of raw text scraped from the online news articles. To retrieve information from the text corpus we implement a traditional vector store RAG as well as state-of-the-art large language model (LLM) based approaches for automatically constructing KGs and retrieving the relevant subgraphs. In addition to these corpus approaches, we develop a novel ontology-based framework for constructing knowledge graphs (KGs) from GDELT directly which leverages the underlying schema of GDELT to create structured representations of global events. For retrieving relevant information from the ontology-based KGs we implement both direct graph queries and state-of-the-art graph retrieval approaches. We compare the performance of each method in a question-answering task. We find that while our ontology-based KGs are valuable for question-answering, automated extraction of the relevant subgraphs is challenging. Conversely, LLM-generated KGs, while capturing event summaries, often lack consistency and interpretability. Our findings suggest benefits of a synergistic approach between ontology and LLM-based KG construction, with proposed avenues toward that end.
在这项工作中,我们研究了各种基于检索增强的再生(RAG)方法,以了解每种方法在问答分析中的优缺点。为了获得这种理解,我们使用了全球事件、语言和情感数据库(GDELT)数据集的一个案例研究子集以及从在线新闻文章中抓取的大量原始文本语料库。我们从文本语料库中检索信息,实现了传统的向量存储RAG以及基于最新大型语言模型(LLM)自动构建知识图谱和检索相关子图的方法。除了这些语料库方法外,我们还开发了一种基于本体构建知识图谱(KGs)的新框架,该框架直接从GDELT中提取信息,并利用GDELT的底层模式创建全球事件的结构化表示。我们从基于本体的知识图谱中检索相关信息,实现了直接图形查询和最新的图形检索方法。我们在问答任务中比较了每种方法的性能。我们发现,虽然我们的基于本体的知识图谱对于问答任务很有价值,但自动提取相关子图具有挑战性。相比之下,虽然LLM生成的知识图谱能够捕捉事件摘要,但往往缺乏一致性和可解释性。我们的研究结果暗示了本体和LLM之间协同构建知识图谱的方法的好处,并提出了实现这一目标的方向。
论文及项目相关链接
Summary
在这个研究中,我们研究了不同的检索增强再生(RAG)方法,以了解每种方法在问答分析中的优缺点。我们使用了全球事件、语言和语调数据库(GDELT)的子集案例研究以及从在线新闻文章中抓取的大量原始文本语料库。我们实现了传统的向量存储RAG以及基于最新大型语言模型(LLM)自动构建知识图谱和检索相关子图的方法。此外,我们还开发了一种基于本体构建知识图谱的新框架,该框架利用GDELT的底层架构创建全球事件的结构化表示。对于从基于本体的知识图谱中检索相关信息,我们实现了直接图形查询和最新的图形检索方法。在问答任务中比较了每种方法的性能。我们发现,虽然基于本体的知识图谱对问答有价值,但自动提取相关子图具有挑战性。相反,虽然LLM生成的知识图谱能够捕捉事件摘要,但往往缺乏一致性和可解释性。我们的发现表明,本体和LLM知识图谱构建之间的协同方法具有优势,并提出了未来的发展方向。
Key Takeaways
- 研究了多种检索增强再生(RAG)方法以应用于问答分析。
- 利用GDELT数据集和在线新闻文章构建的语料库进行实证研究。
- 实现传统的向量存储RAG方法和基于最新大型语言模型(LLM)的方法。
- 提出一种基于本体的新型知识图谱构建框架,利用GDELT的底层架构。
- 通过直接图形查询和图形检索方法从基于本体的知识图谱中检索信息。
- 发现基于本体的知识图谱对问答有价值,但自动提取相关子图具有挑战性。
点此查看论文截图