⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-26 更新
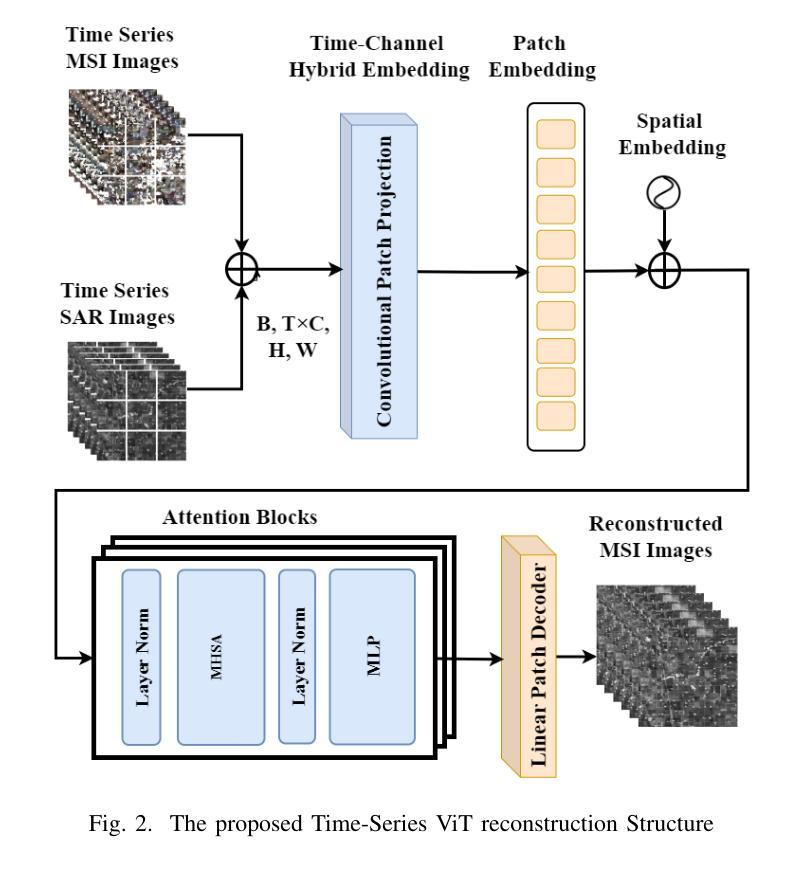
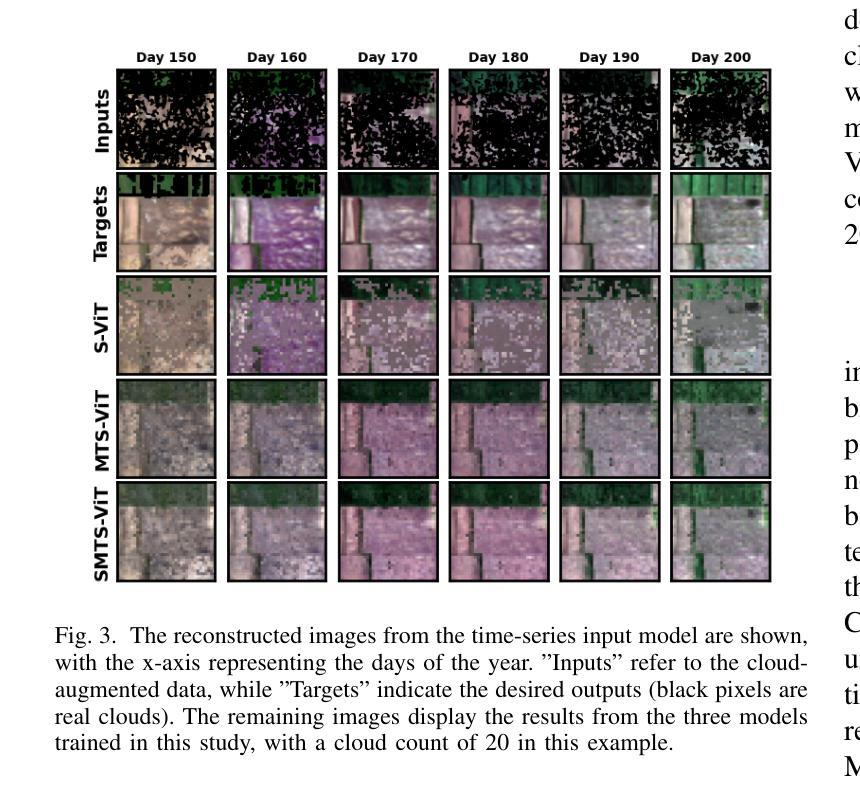
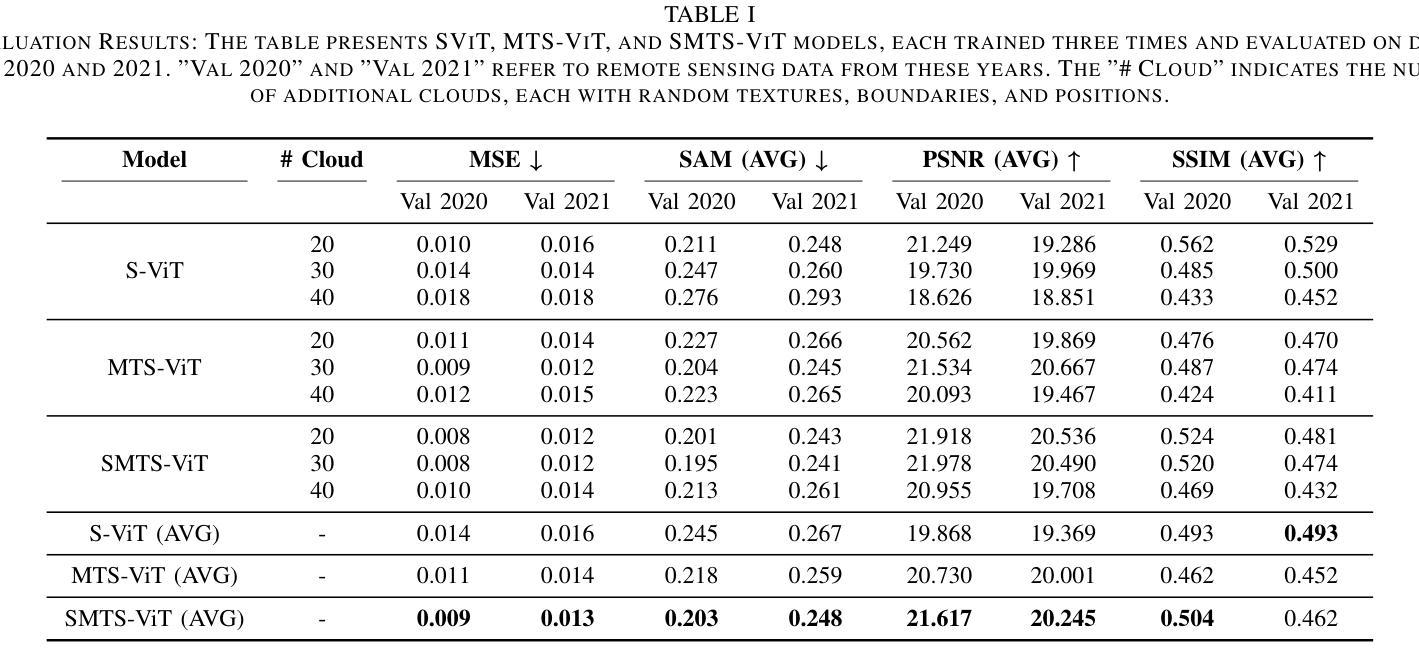
Vision Transformer-Based Time-Series Image Reconstruction for Cloud-Filling Applications
Authors:Lujun Li, Yiqun Wang, Radu State
Cloud cover in multispectral imagery (MSI) poses significant challenges for early season crop mapping, as it leads to missing or corrupted spectral information. Synthetic aperture radar (SAR) data, which is not affected by cloud interference, offers a complementary solution, but lack sufficient spectral detail for precise crop mapping. To address this, we propose a novel framework, Time-series MSI Image Reconstruction using Vision Transformer (ViT), to reconstruct MSI data in cloud-covered regions by leveraging the temporal coherence of MSI and the complementary information from SAR from the attention mechanism. Comprehensive experiments, using rigorous reconstruction evaluation metrics, demonstrate that Time-series ViT framework significantly outperforms baselines that use non-time-series MSI and SAR or time-series MSI without SAR, effectively enhancing MSI image reconstruction in cloud-covered regions.
在多光谱影像(MSI)中,云遮挡对早期季节的作物映射带来了巨大的挑战,因为它会导致光谱信息丢失或损坏。合成孔径雷达(SAR)数据不受云层干扰的影响,提供了一个补充解决方案,但在精确作物映射方面缺乏足够的光谱细节。为了解决这一问题,我们提出了一种新的框架,即利用视觉转换器(ViT)的时间序列MSI图像重建,通过利用MSI的时间一致性和来自SAR的注意力机制的补充信息,重建云层覆盖区域中的MSI数据。使用严格的重建评估指标的全面实验表明,时间序列ViT框架显著优于使用非时间序列MSI和SAR或仅使用时间序列MSI的基线,有效地提高了云层覆盖区域中MSI图像的重建效果。
论文及项目相关链接
PDF This paper has been accepted as a conference paper at the 2025 IEEE International Geoscience and Remote Sensing Symposium (IGARSS)
Summary
在多光谱成像中,云层覆盖对早期季节的作物制图带来挑战,导致光谱信息丢失或损坏。合成孔径雷达数据不受云层干扰影响,提供了补充解决方案,但缺乏精确作物制图所需的光谱细节。为解决此问题,我们提出一种基于Vision Transformer(ViT)的时间序列多光谱图像重建框架,利用多光谱的时空一致性和合成孔径雷达数据的注意力机制中的互补信息,重建云层覆盖区域的多光谱数据。实验表明,该时间序列ViT框架显著优于仅使用非时间序列多光谱数据和SAR或仅使用时间序列多光谱数据的基线方法,有效增强了云层覆盖区域的多光谱图像重建效果。
Key Takeaways
- 云层覆盖在多光谱成像中对早期季节的作物制图带来挑战。
- 合成孔径雷达数据虽不受云层干扰影响,但缺乏精确作物制图所需的光谱细节。
- 提出一种基于Vision Transformer(ViT)的时间序列多光谱图像重建框架。
- 该框架利用多光谱的时空一致性和合成孔径雷达数据的注意力机制中的互补信息。
- 重建目标是在云层覆盖区域的多光谱数据。
- 实验表明,时间序列ViT框架在重建效果上显著优于其他方法。
点此查看论文截图

SceneCrafter: Controllable Multi-View Driving Scene Editing
Authors:Zehao Zhu, Yuliang Zou, Chiyu Max Jiang, Bo Sun, Vincent Casser, Xiukun Huang, Jiahao Wang, Zhenpei Yang, Ruiqi Gao, Leonidas Guibas, Mingxing Tan, Dragomir Anguelov
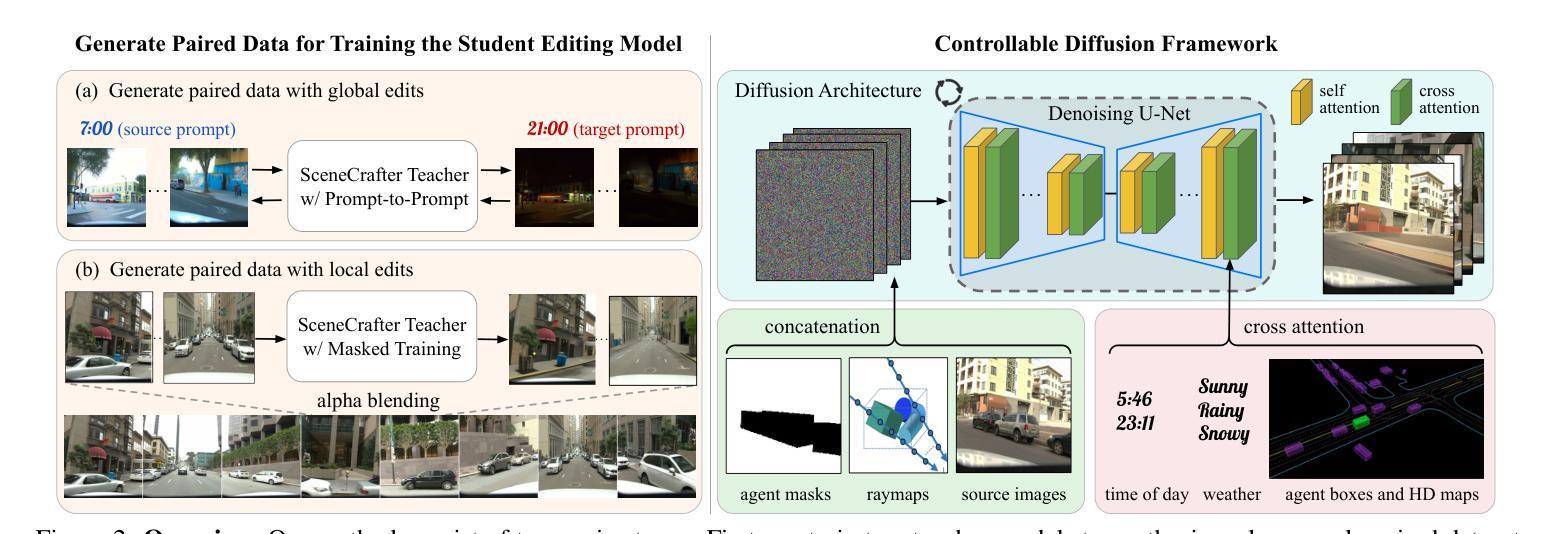
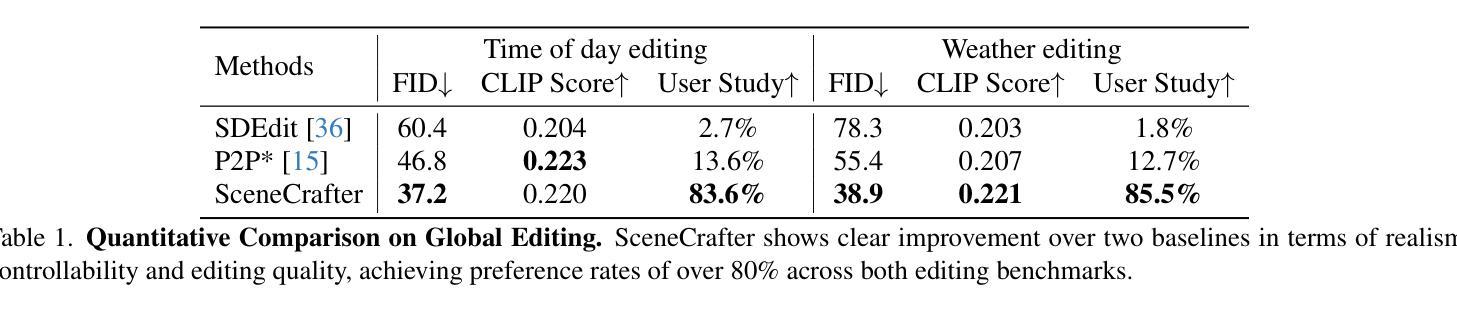
Simulation is crucial for developing and evaluating autonomous vehicle (AV) systems. Recent literature builds on a new generation of generative models to synthesize highly realistic images for full-stack simulation. However, purely synthetically generated scenes are not grounded in reality and have difficulty in inspiring confidence in the relevance of its outcomes. Editing models, on the other hand, leverage source scenes from real driving logs, and enable the simulation of different traffic layouts, behaviors, and operating conditions such as weather and time of day. While image editing is an established topic in computer vision, it presents fresh sets of challenges in driving simulation: (1) the need for cross-camera 3D consistency, (2) learning ``empty street” priors from driving data with foreground occlusions, and (3) obtaining paired image tuples of varied editing conditions while preserving consistent layout and geometry. To address these challenges, we propose SceneCrafter, a versatile editor for realistic 3D-consistent manipulation of driving scenes captured from multiple cameras. We build on recent advancements in multi-view diffusion models, using a fully controllable framework that scales seamlessly to multi-modality conditions like weather, time of day, agent boxes and high-definition maps. To generate paired data for supervising the editing model, we propose a novel framework on top of Prompt-to-Prompt to generate geometrically consistent synthetic paired data with global edits. We also introduce an alpha-blending framework to synthesize data with local edits, leveraging a model trained on empty street priors through novel masked training and multi-view repaint paradigm. SceneCrafter demonstrates powerful editing capabilities and achieves state-of-the-art realism, controllability, 3D consistency, and scene editing quality compared to existing baselines.
模拟对于开发和评估自动驾驶(AV)系统至关重要。最近的文献建立在一代新的生成模型上,可以合成高度逼真的图像进行全栈模拟。然而,纯粹合成生成的场景并没有基于现实,并且在激发对其结果的相关性的信心方面存在困难。另一方面,编辑模型则利用来自真实驾驶日志的源场景,能够模拟不同的交通布局、行为和运行条件,例如天气和一天中的时间。虽然图像编辑是计算机视觉中的一个既定主题,但它为驾驶模拟带来了新的挑战:(1)需要跨相机的3D一致性,(2)从带有前景遮挡的驾驶数据中学习“空街”先验,以及(3)在保持一致的布局和几何结构的同时,获得具有不同编辑条件的配对图像对。为了应对这些挑战,我们提出了SceneCrafter,这是一款适用于从多个摄像头捕获的驾驶场景的逼真3D一致操作的多功能编辑器。我们基于最新的多视图扩散模型进展,使用一个完全可控的框架,无缝扩展到多模态条件,例如天气、一天中的时间、代理框和高精度地图。为了生成用于监督编辑模型的配对数据,我们在Prompt-to-Prompt之上提出了一个新型框架,以生成具有全局编辑的几何一致合成配对数据。我们还引入了一个alpha混合框架来合成具有局部编辑的数据,利用一个通过新颖的面具训练和多视图重绘范式训练的空街先验模型。SceneCrafter展示了强大的编辑功能,并实现了与现有基线相比的最佳逼真度、可控性、3D一致性和场景编辑质量。
论文及项目相关链接
PDF CVPR 2025
Summary
本文强调了仿真在自动驾驶系统开发和评估中的重要性。新一代生成模型能够合成高度逼真的图像,用于全栈仿真。然而,纯粹的合成场景缺乏现实基础,难以让人信服其结果的实用性。为此,研究提出了SceneCrafter编辑器,它能够对从多个相机捕捉的驾驶场景进行逼真的、跨视角一致的编辑。SceneCrafter建立在多视角扩散模型的基础上,可以无缝扩展到多种模态条件,如天气、时间、智能车辆及高精度地图等。SceneCrafter在生成配对的编辑数据方面取得了进展,表现出强大的编辑能力和超出现有基准的逼真度、可控性、三维一致性和场景编辑质量。
Key Takeaways
- 仿真在自动驾驶系统开发和评估中扮演重要角色。
- 新一代生成模型能合成高度逼真的图像用于全栈仿真。
- 仅依赖合成场景存在与现实脱节的问题,难以让人信服其结果的实际应用价值。
- SceneCrafter编辑器能进行逼真的、跨视角一致的驾驶场景编辑。
- SceneCrafter基于多视角扩散模型,可扩展到多种模态条件如天气、时间等。
- SceneCrafter生成了配对的编辑数据以支持仿真场景开发。
点此查看论文截图