⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-27 更新
WoundAmbit: Bridging State-of-the-Art Semantic Segmentation and Real-World Wound Care
Authors:Vanessa Borst, Timo Dittus, Tassilo Dege, Astrid Schmieder, Samuel Kounev
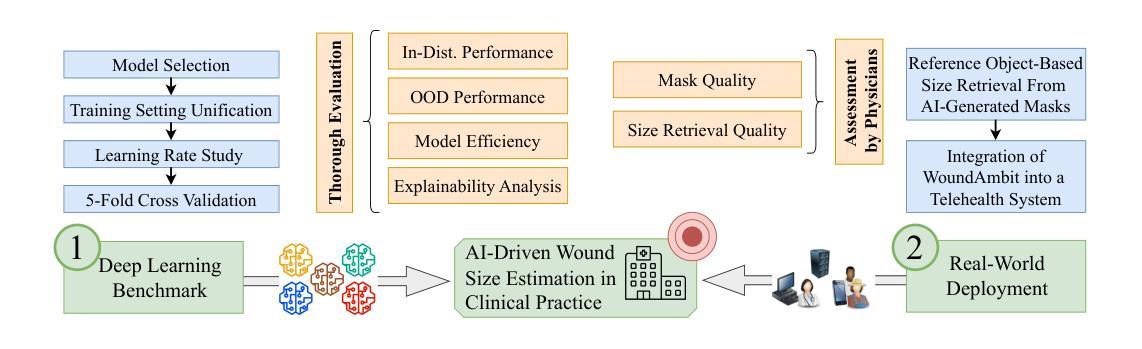
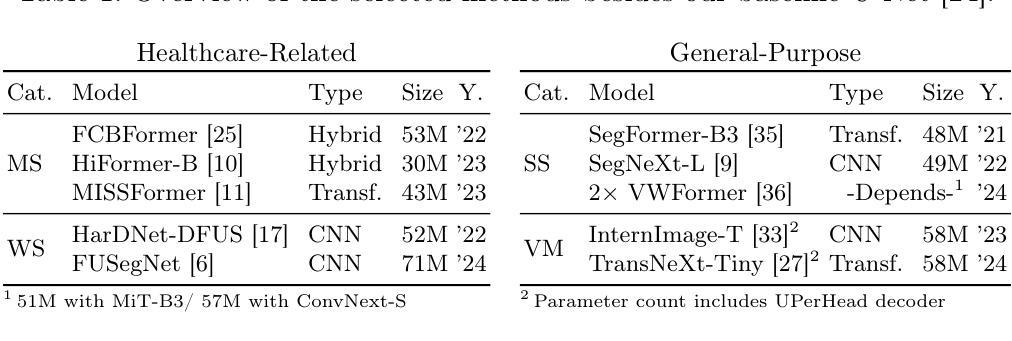
Chronic wounds affect a large population, particularly the elderly and diabetic patients, who often exhibit limited mobility and co-existing health conditions. Automated wound monitoring via mobile image capture can reduce in-person physician visits by enabling remote tracking of wound size. Semantic segmentation is key to this process, yet wound segmentation remains underrepresented in medical imaging research. To address this, we benchmark state-of-the-art deep learning models from general-purpose vision, medical imaging, and top methods from public wound challenges. For a fair comparison, we standardize training, data augmentation, and evaluation, conducting cross-validation to minimize partitioning bias. We also assess real-world deployment aspects, including generalization to an out-of-distribution wound dataset, computational efficiency, and interpretability. Additionally, we propose a reference object-based approach to convert AI-generated masks into clinically relevant wound size estimates and evaluate this, along with mask quality, for the five best architectures based on physician assessments. Overall, the transformer-based TransNeXt showed the highest levels of generalizability. Despite variations in inference times, all models processed at least one image per second on the CPU, which is deemed adequate for the intended application. Interpretability analysis typically revealed prominent activations in wound regions, emphasizing focus on clinically relevant features. Expert evaluation showed high mask approval for all analyzed models, with VWFormer and ConvNeXtS backbone performing the best. Size retrieval accuracy was similar across models, and predictions closely matched expert annotations. Finally, we demonstrate how our AI-driven wound size estimation framework, WoundAmbit, is integrated into a custom telehealth system.
慢性伤口影响大量人群,尤其是行动不便且存在其他健康问题的老年人和糖尿病患者。通过移动图像捕捉进行自动伤口监测,可以通过远程追踪伤口大小减少亲自就医的次数。语义分割是这一过程中的关键,但伤口分割在医学成像研究中的代表性仍然不足。为解决这一问题,我们对比了最先进的深度学习模型,包括通用视觉、医学成像以及公开伤口挑战中的顶尖方法。为了公平比较,我们标准化了训练、数据增强和评估,并进行交叉验证以最小化分区偏差。我们还评估了实际部署方面的因素,包括在伤口数据集之外的泛化能力、计算效率和可解释性。此外,我们提出了一种基于参考对象的方法,将AI生成的蒙版转换为临床上相关的伤口大小估计,并针对五种最佳架构对此进行评估,同时评估蒙版质量,以医生评估为基础。总体而言,基于变压器的TransNeXt表现出最高的泛化能力。尽管推理时间有所变化,但所有模型在CPU上的处理速度至少为每秒一张图像,这被认为足以满足预期应用的需求。可解释性分析通常显示伤口区域的激活突出,强调临床上相关特征的重点。专家评估显示,所有分析模型的蒙版均获得高度评价,其中VWFormer和ConvNeXtS表现最佳。各模型在大小检索准确性方面相似,预测结果与专家注释非常接近。最后,我们展示了我们的AI驱动伤口大小估计框架WoundAmbit如何集成到定制的远程医疗系统中。
论文及项目相关链接
PDF Main paper: 18 pages; supplementary material: 15 pages; the paper has been accepted for publication at the Applied Data Science (ADS) track of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD 2025)
摘要
自动化伤口监测对减少医生现场访问、实现远程追踪伤口大小具有关键作用。文章通过移动图像捕获实现自动化伤口监测,重点研究语义分割在其中的作用。文章对比了通用视觉、医学影像等多个领域的深度学习模型在伤口分割上的表现,并通过标准化训练、数据增强和评估保证公平比较。同时,文章还考虑了模型在实际应用中的部署问题,包括跨分布伤口数据集的泛化能力、计算效率和可解释性。最终,基于医师评估,提出了一种参考对象法来将AI生成的掩膜转换为临床相关的伤口大小估计值。研究显示,基于transformer的TransNeXt模型泛化能力最强,尽管推理时间有所不同,但在CPU上至少能处理每秒一张图像,适用于实际应用场景。可解释性分析显示,模型主要关注伤口区域的临床相关特征。专家评估表明,所有模型的掩膜审批通过率高,其中VWFormer和ConvNeXtS表现最佳。最终展示了AI驱动的伤口大小估算框架WoundAmbit集成到自定义远程医疗系统的情况。
要点速览
- 自动化伤口监测可减少医生现场访问次数,远程追踪伤口大小至关重要。
- 语义分割在自动化伤口监测中起关键作用,但伤口分割在医学影像研究中被忽视。
- 文章对比了多个领域的深度学习模型在伤口分割上的表现,并进行了标准化训练和评估。
- 模型在实际应用中的部署考虑了跨分布数据集的泛化能力、计算效率和可解释性。
- 提出参考对象法转换AI生成的掩膜为临床相关的伤口大小估计值。
- 基于transformer的TransNeXt模型泛化能力最强,处理速度快,适用于实际应用场景。
点此查看论文截图

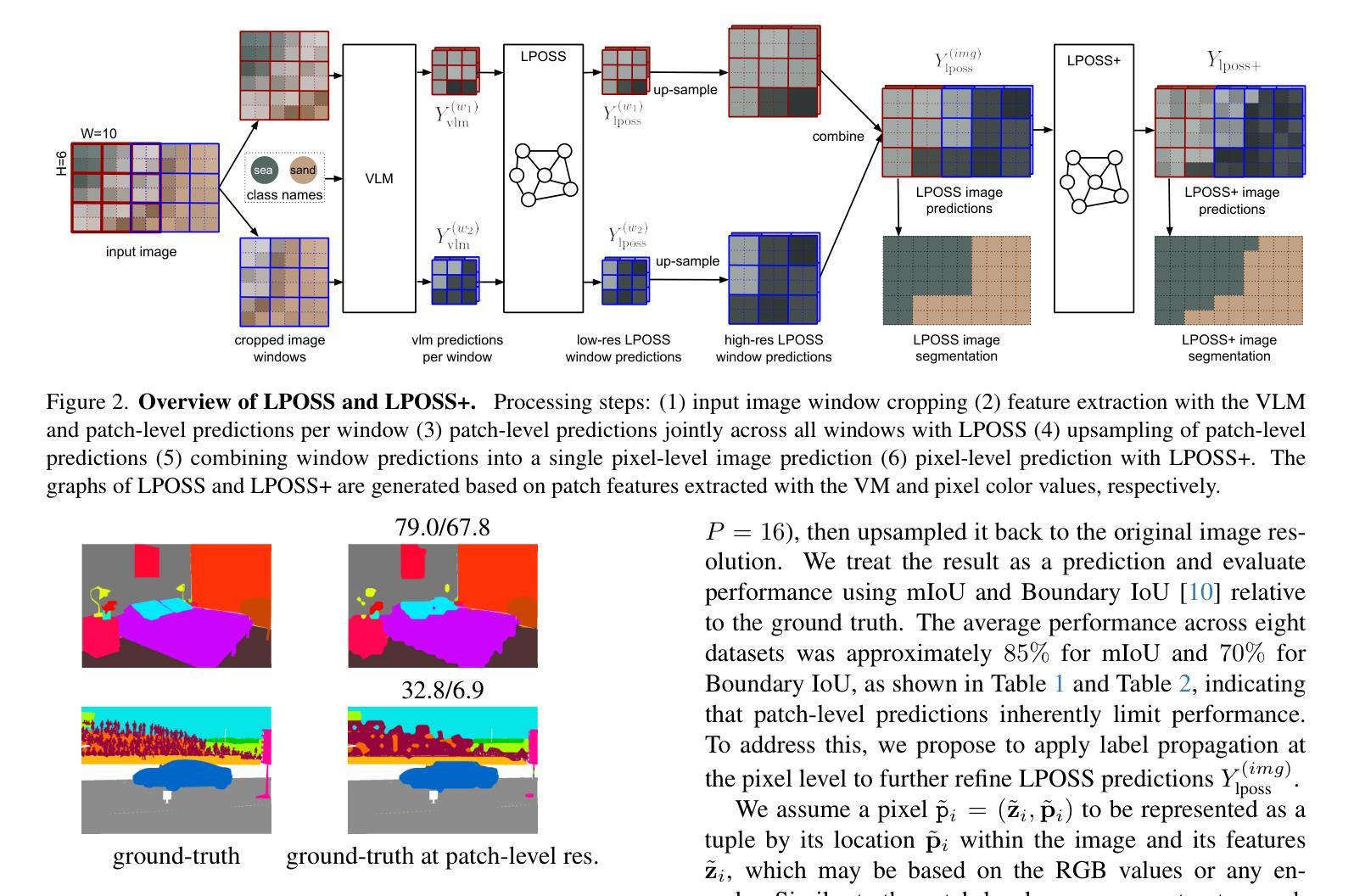
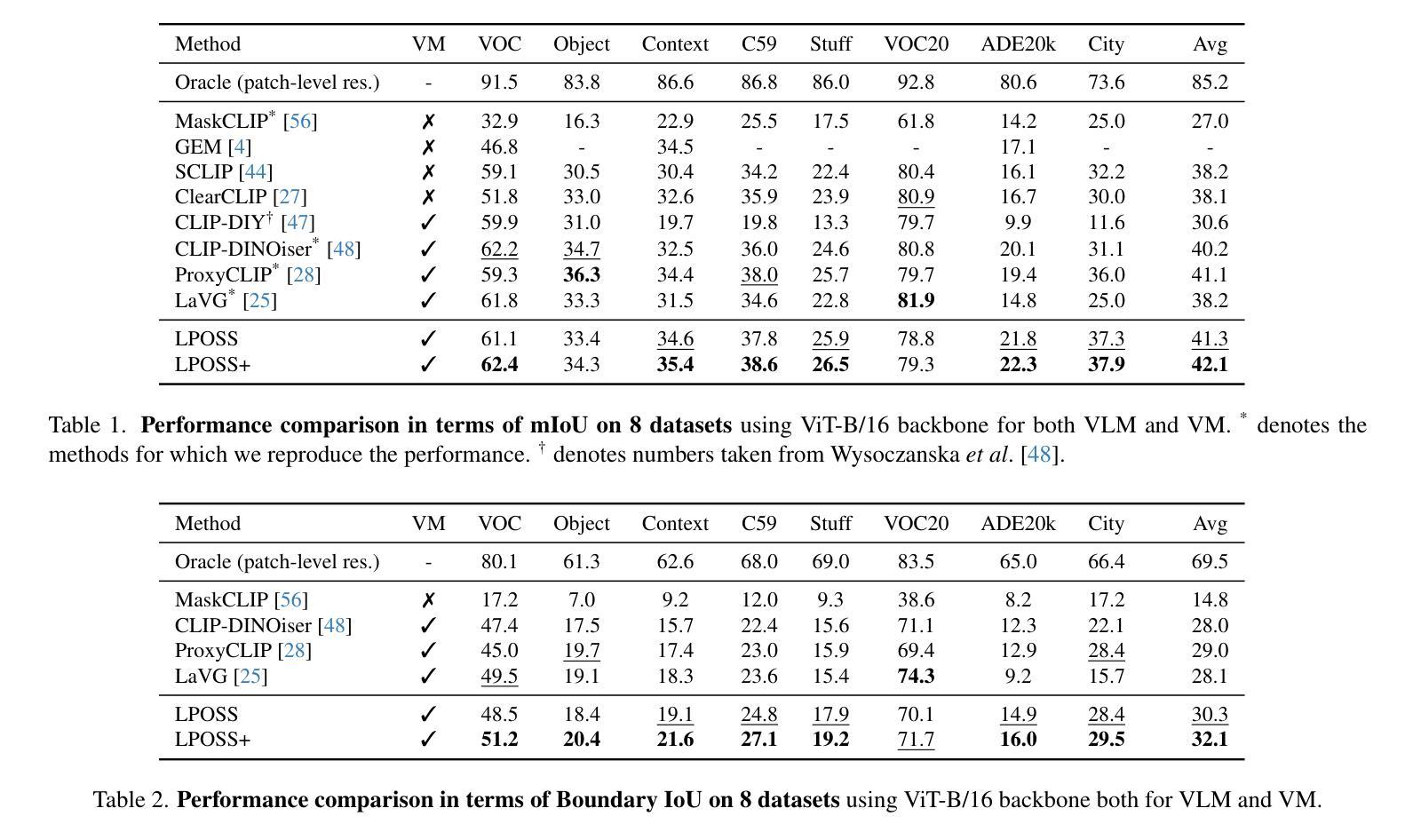
LPOSS: Label Propagation Over Patches and Pixels for Open-vocabulary Semantic Segmentation
Authors:Vladan Stojnić, Yannis Kalantidis, Jiří Matas, Giorgos Tolias
We propose a training-free method for open-vocabulary semantic segmentation using Vision-and-Language Models (VLMs). Our approach enhances the initial per-patch predictions of VLMs through label propagation, which jointly optimizes predictions by incorporating patch-to-patch relationships. Since VLMs are primarily optimized for cross-modal alignment and not for intra-modal similarity, we use a Vision Model (VM) that is observed to better capture these relationships. We address resolution limitations inherent to patch-based encoders by applying label propagation at the pixel level as a refinement step, significantly improving segmentation accuracy near class boundaries. Our method, called LPOSS+, performs inference over the entire image, avoiding window-based processing and thereby capturing contextual interactions across the full image. LPOSS+ achieves state-of-the-art performance among training-free methods, across a diverse set of datasets. Code: https://github.com/vladan-stojnic/LPOSS
我们提出了一种基于视觉和语言模型(VLMs)的无训练开放词汇语义分割方法。我们的方法通过标签传播增强VLMs的初始补丁预测,通过结合补丁之间的关联来共同优化预测。由于VLM主要针对跨模态对齐进行优化,而非针对模态内相似性,因此我们使用观察到的可以更好地捕获这些关系的视觉模型(VM)。我们通过标签传播的像素级细化步骤来解决基于补丁编码器的固有分辨率限制问题,从而显著提高类边界附近的分割精度。我们的方法称为LPOSS+,在整个图像上进行推理,避免了基于窗口的处理,从而捕获了全图的上下文交互。LPOSS+在多种数据集上均达到了无训练方法中的最佳性能。代码:https://github.com/vladan-stojnic/LPOSS
论文及项目相关链接
Summary
基于视觉和语言模型(VLMs)的无训练语义分割方法提出通过标签传播提升初始补丁预测精度。此方法结合补丁间的关系进行优化预测,使用针对内部相似性优化的视觉模型改进交叉模态对齐问题。在像素级别应用标签传播以改善基于补丁编码器的固有分辨率限制,从而提高类边界处的分割精度。名为LPOSS+的方法在整个图像上进行推理,避免了基于窗口的处理,从而捕获整个图像的上下文交互。在多种数据集上,LPOSS+在无需训练的方法中表现最佳。代码地址:链接。
Key Takeaways
- 提出一种无训练语义分割方法,使用视觉和语言模型(VLMs)。
- 通过标签传播提升初始补丁预测精度。
- 结合补丁间的关系进行优化预测。
- 利用视觉模型改进交叉模态对齐问题,优化内部相似性。
- 应用标签传播改善基于补丁编码器的分辨率限制。
- 提高类边界处的分割精度。
- LPOSS+在整个图像上进行推理,捕获上下文交互。
点此查看论文截图