⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-27 更新
ULSR-GS: Ultra Large-scale Surface Reconstruction Gaussian Splatting with Multi-View Geometric Consistency
Authors:Zhuoxiao Li, Shanliang Yao, Taoyu Wu, Yong Yue, Wufan Zhao, Rongjun Qin, Angel F. Garcia-Fernandez, Andrew Levers, Xiaohui Zhu
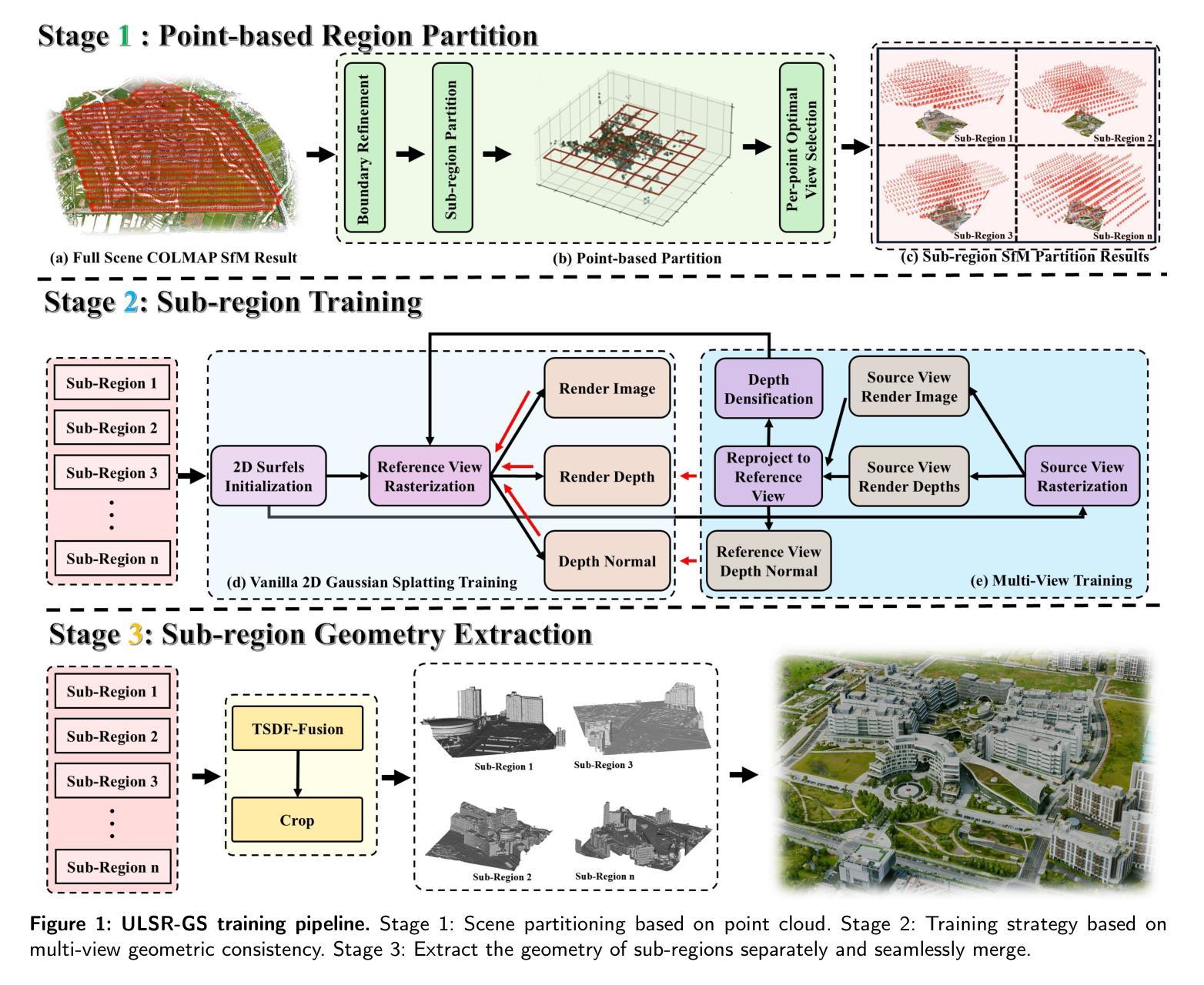
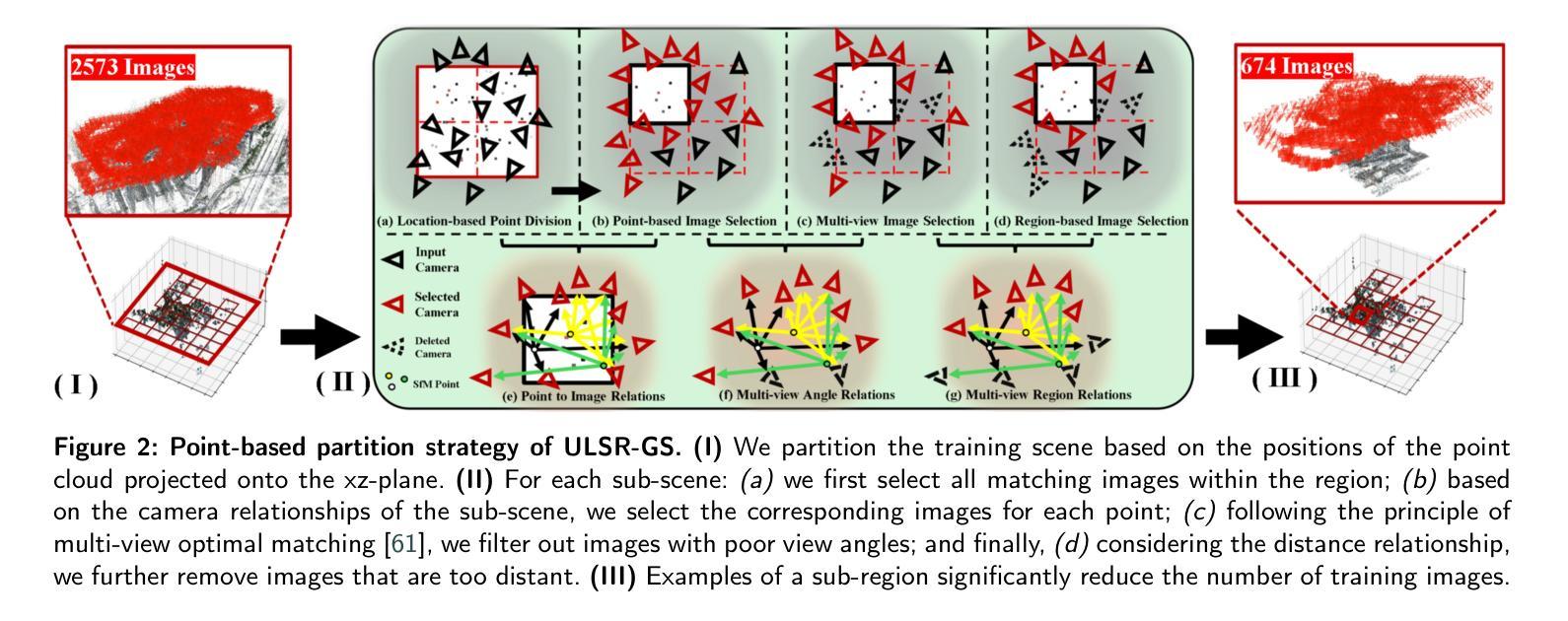
While Gaussian Splatting (GS) demonstrates efficient and high-quality scene rendering and small area surface extraction ability, it falls short in handling large-scale aerial image surface extraction tasks. To overcome this, we present ULSR-GS, a framework dedicated to high-fidelity surface extraction in ultra-large-scale scenes, addressing the limitations of existing GS-based mesh extraction methods. Specifically, we propose a point-to-photo partitioning approach combined with a multi-view optimal view matching principle to select the best training images for each sub-region. Additionally, during training, ULSR-GS employs a densification strategy based on multi-view geometric consistency to enhance surface extraction details. Experimental results demonstrate that ULSR-GS outperforms other state-of-the-art GS-based works on large-scale aerial photogrammetry benchmark datasets, significantly improving surface extraction accuracy in complex urban environments. Project page: https://ulsrgs.github.io.
虽然高斯摊铺(GS)在场景渲染和小区域表面提取方面表现出高效和高质量的能力,但在处理大规模航空图像表面提取任务时却存在不足。为了克服这一缺陷,我们推出了ULSR-GS,这是一个专门用于超大规模场景高保真表面提取的框架,解决了现有基于GS的网格提取方法的局限性。具体来说,我们提出了一种点-照片分区方法,结合多视图最佳视图匹配原则,为每个子区域选择最佳的训练图像。此外,在训练过程中,ULSR-GS采用基于多视图几何一致性的加密策略,以提高表面提取的细节。实验结果表明,ULSR-GS在大型航空摄影测量基准数据集上优于其他最先进的基于GS的作品,在复杂的城市环境中显著提高表面提取的准确性。项目页面:https://ulsrgs.github.io。
论文及项目相关链接
PDF Project page: https://ulsrgs.github.io
Summary
本文介绍了针对大规模空中图像表面提取任务的ULSR-GS框架。该框架克服了高斯Splatting(GS)在处理大规模场景时的局限性,实现了高保真表面提取。通过结合点-照片分割方法和多视角最佳视图匹配原则,ULSR-GS在训练过程中能够选择最佳的训练图像并增强表面提取的细节。实验结果表明,ULSR-GS在大型空中摄影测量基准数据集上优于其他最先进基于GS的工作,在复杂的城市环境中显著提高表面提取的准确性。
Key Takeaways
- ULSR-GS框架旨在解决大规模空中图像表面提取任务。
- ULSR-GS克服了高斯Splatting(GS)在处理大规模场景时的局限性。
- 提出了一种结合点-照片分割方法和多视角最佳视图匹配原则的策略,以选择最佳的训练图像。
- ULSR-GS采用基于多视角几何一致性的加密策略,增强表面提取的细节。
- ULSR-GS在大型空中摄影测量基准数据集上的表现优于其他最新基于GS的方法。
- ULSR-GS在复杂的城市环境中显著提高表面提取的准确性。
点此查看论文截图

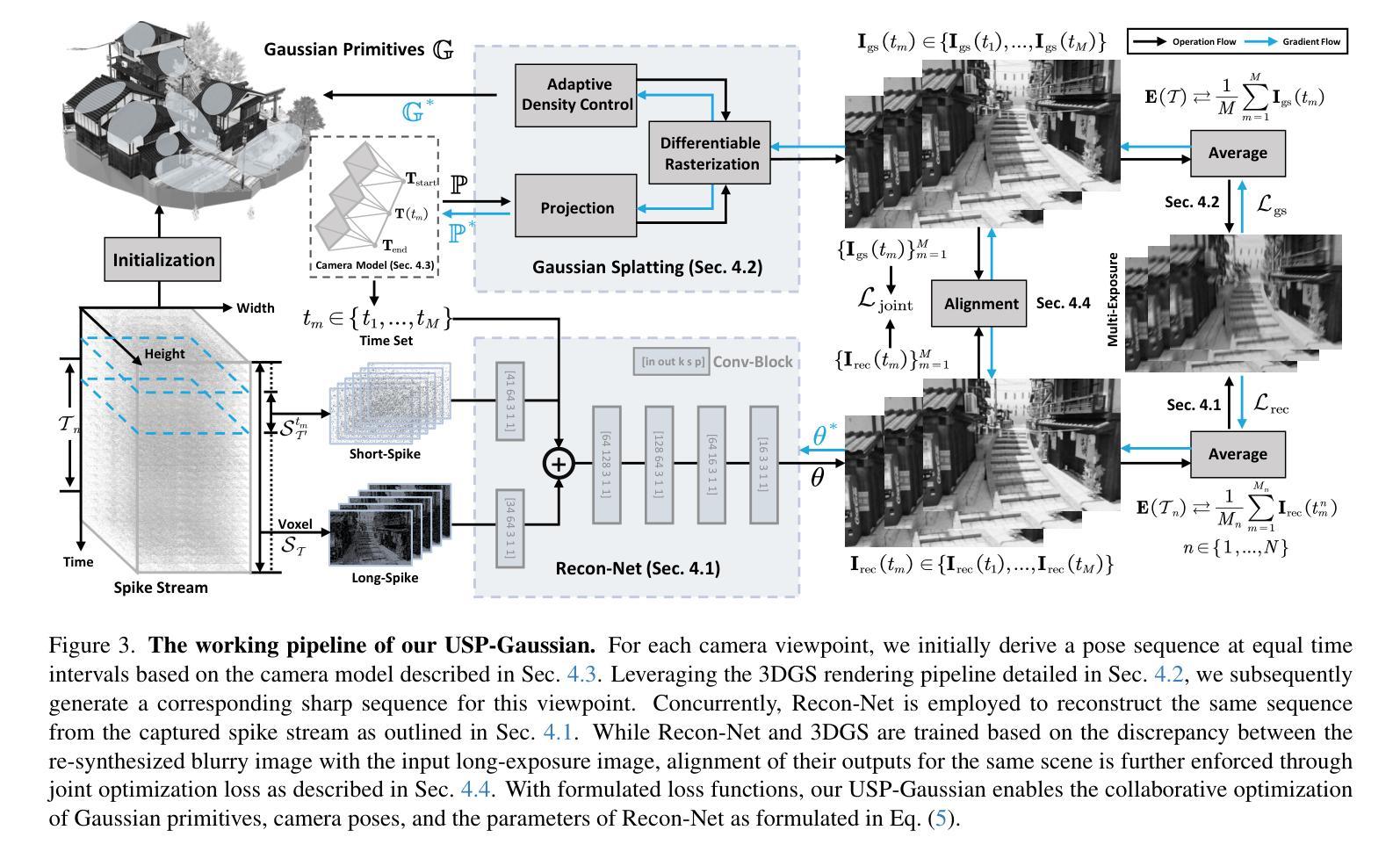
USP-Gaussian: Unifying Spike-based Image Reconstruction, Pose Correction and Gaussian Splatting
Authors:Kang Chen, Jiyuan Zhang, Zecheng Hao, Yajing Zheng, Tiejun Huang, Zhaofei Yu
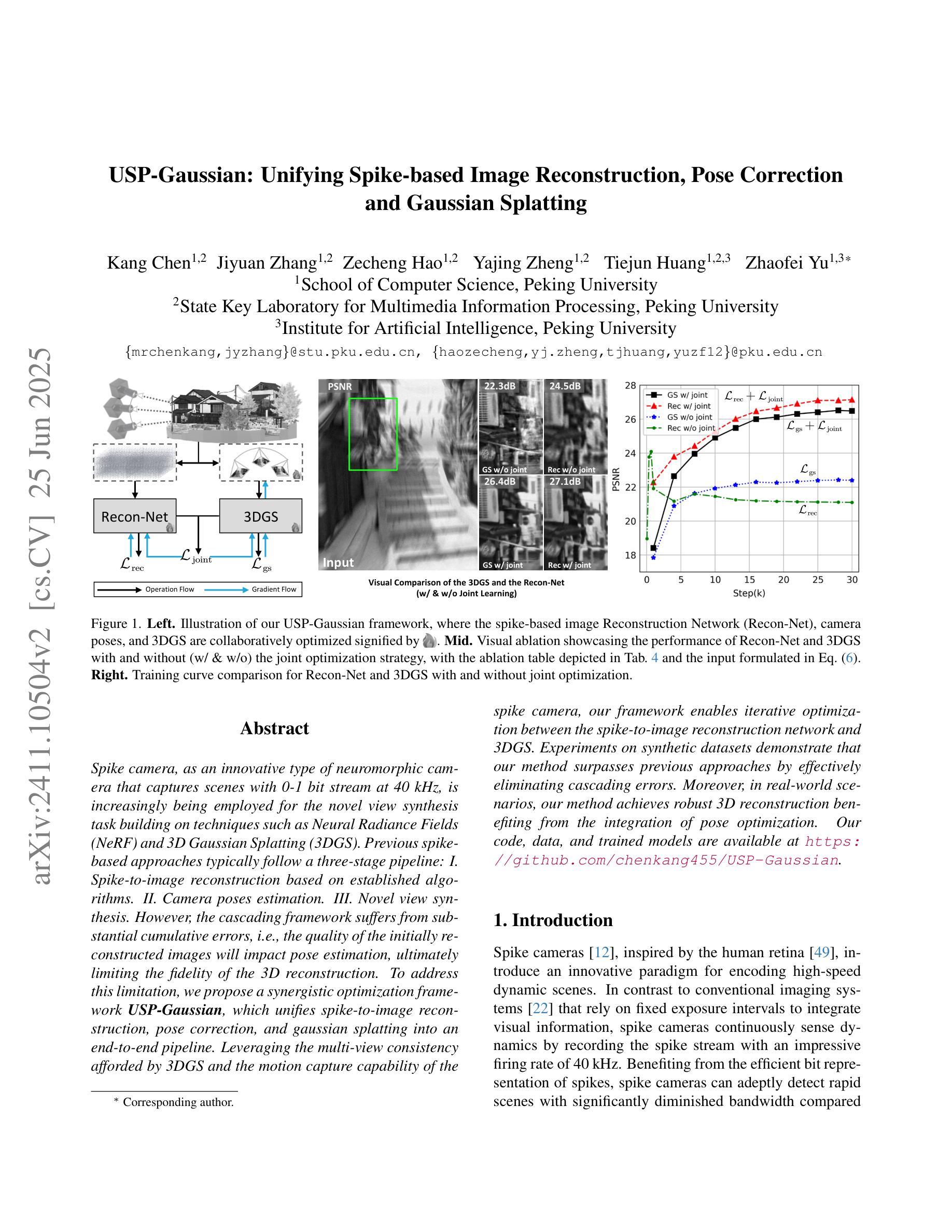
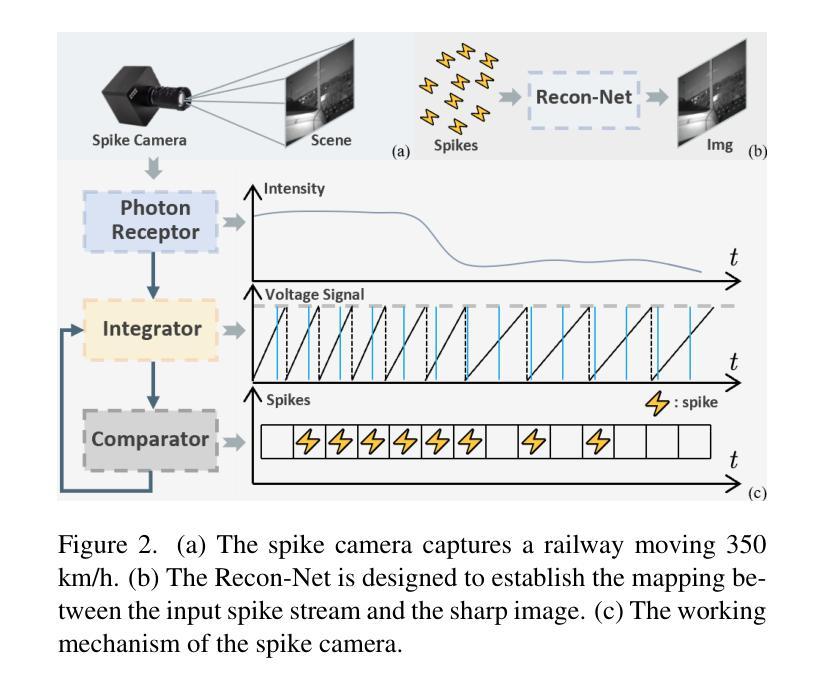
Spike cameras, as an innovative neuromorphic camera that captures scenes with the 0-1 bit stream at 40 kHz, are increasingly employed for the 3D reconstruction task via Neural Radiance Fields (NeRF) or 3D Gaussian Splatting (3DGS). Previous spike-based 3D reconstruction approaches often employ a casecased pipeline: starting with high-quality image reconstruction from spike streams based on established spike-to-image reconstruction algorithms, then progressing to camera pose estimation and 3D reconstruction. However, this cascaded approach suffers from substantial cumulative errors, where quality limitations of initial image reconstructions negatively impact pose estimation, ultimately degrading the fidelity of the 3D reconstruction. To address these issues, we propose a synergistic optimization framework, \textbf{USP-Gaussian}, that unifies spike-based image reconstruction, pose correction, and Gaussian splatting into an end-to-end framework. Leveraging the multi-view consistency afforded by 3DGS and the motion capture capability of the spike camera, our framework enables a joint iterative optimization that seamlessly integrates information between the spike-to-image network and 3DGS. Experiments on synthetic datasets with accurate poses demonstrate that our method surpasses previous approaches by effectively eliminating cascading errors. Moreover, we integrate pose optimization to achieve robust 3D reconstruction in real-world scenarios with inaccurate initial poses, outperforming alternative methods by effectively reducing noise and preserving fine texture details. Our code, data and trained models will be available at https://github.com/chenkang455/USP-Gaussian.
脉冲相机作为一种创新型的神经形态相机,能够以40kHz的0-1位流捕获场景,越来越多地被用于通过神经辐射场(NeRF)或3D高斯喷涂(3DGS)进行3D重建任务。之前基于脉冲的3D重建方法通常采用级联管道:首先使用建立的脉冲到图像重建算法从脉冲流中进行高质量图像重建,然后进行相机姿态估计和3D重建。然而,这种级联方法存在大量的累积误差,初始图像重建的质量限制会对姿态估计产生负面影响,最终降低3D重建的保真度。为了解决这些问题,我们提出了一种协同优化框架USP-Gaussian,它将基于脉冲的图像重建、姿态校正和高斯喷涂统一到一个端到端的框架中。利用3DGS提供的多视图一致性以及脉冲相机的运动捕获能力,我们的框架能够实现脉冲到图像网络之间无缝集成信息的联合迭代优化。在具有精确姿态的合成数据集上的实验表明,我们的方法通过有效消除级联误差,超越了以前的方法。此外,我们集成了姿态优化,以实现在实际场景中具有不准确初始姿态的稳健3D重建,通过有效降低噪声并保留精细纹理细节,优于其他方法。我们的代码、数据和训练模型将在https://github.com/chenkang455/USP-Gaussian上提供。
论文及项目相关链接
Summary
针对脉冲相机在三维重建任务中面临的挑战,如级联处理流程导致的误差累积问题,本文提出了一种协同优化框架USP-Gaussian。该框架集成了基于脉冲的图像重建、姿态校正和高斯贴图技术,利用三维高斯贴图的多视角一致性和脉冲相机的运动捕捉能力,实现端到端的联合迭代优化。实验表明,该方法在合成数据集和真实场景下的三维重建性能均优于先前的方法。
Key Takeaways
- 脉冲相机在三维重建中广泛应用,但传统级联处理流程存在误差累积问题。
- 本文提出协同优化框架USP-Gaussian,集成了脉冲图像重建、姿态校正与高斯贴图技术。
- 利用三维高斯贴图的多视角一致性和脉冲相机的运动捕捉能力,实现信息无缝集成。
- 在合成数据集上的实验表明,USP-Gaussian框架能有效消除级联误差。
- 通过整合姿态优化,该框架在真实场景中的三维重建性能得到显著提升,降低了噪声并保留了精细纹理细节。
- USP-Gaussian框架的代码、数据和训练模型将公开提供,便于研究和应用。
- 该框架有望为脉冲相机在三维重建领域的应用提供新的解决方案。
点此查看论文截图


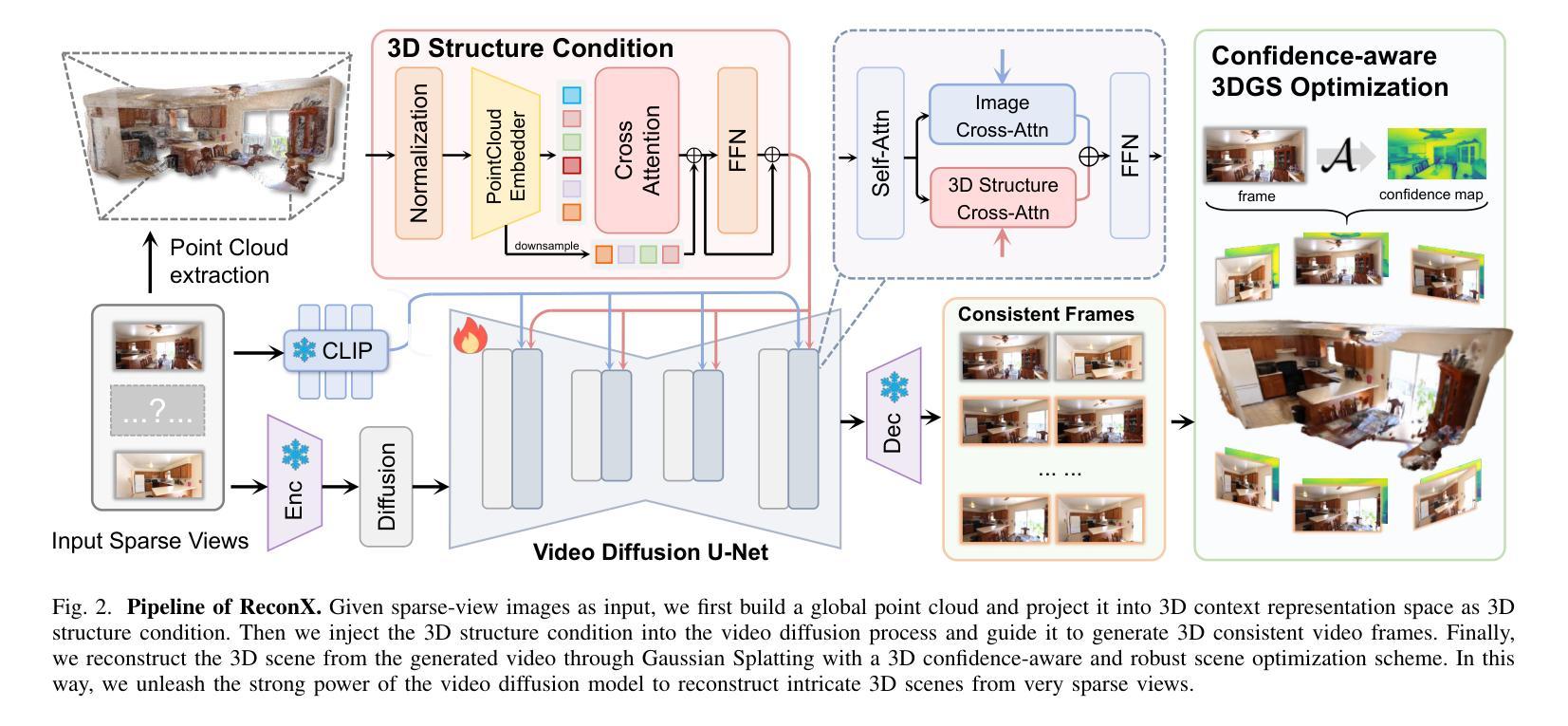
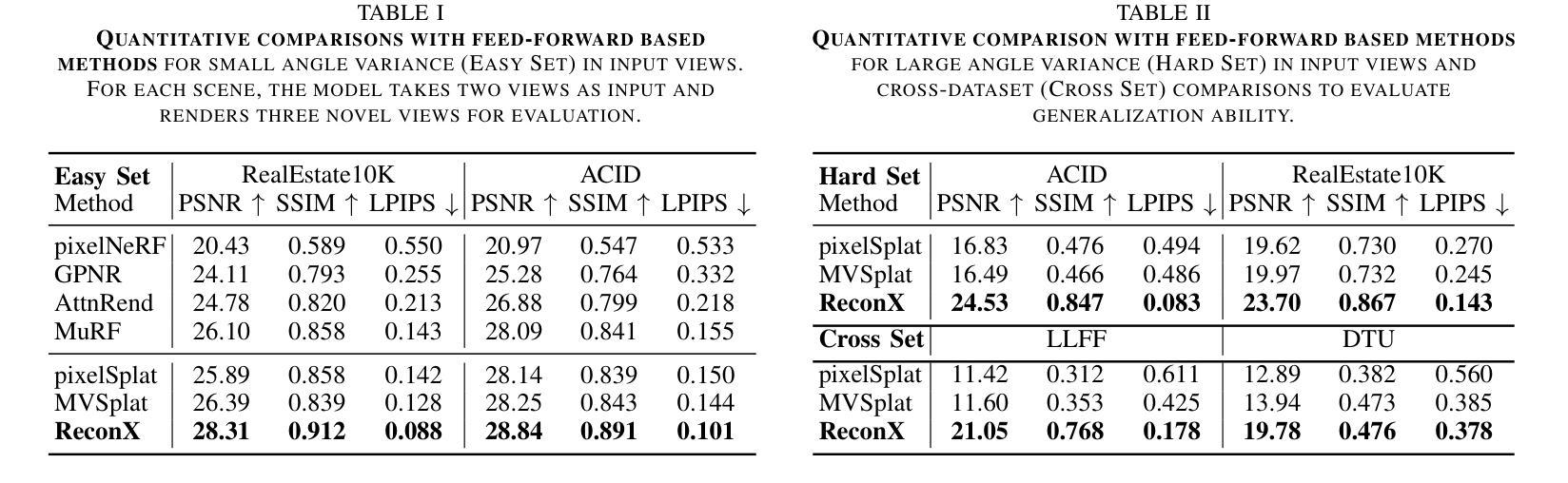
ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model
Authors:Fangfu Liu, Wenqiang Sun, Hanyang Wang, Yikai Wang, Haowen Sun, Junliang Ye, Jun Zhang, Yueqi Duan
Advancements in 3D scene reconstruction have transformed 2D images from the real world into 3D models, producing realistic 3D results from hundreds of input photos. Despite great success in dense-view reconstruction scenarios, rendering a detailed scene from insufficient captured views is still an ill-posed optimization problem, often resulting in artifacts and distortions in unseen areas. In this paper, we propose ReconX, a novel 3D scene reconstruction paradigm that reframes the ambiguous reconstruction challenge as a temporal generation task. The key insight is to unleash the strong generative prior of large pre-trained video diffusion models for sparse-view reconstruction. However, 3D view consistency struggles to be accurately preserved in directly generated video frames from pre-trained models. To address this, given limited input views, the proposed ReconX first constructs a global point cloud and encodes it into a contextual space as the 3D structure condition. Guided by the condition, the video diffusion model then synthesizes video frames that are both detail-preserved and exhibit a high degree of 3D consistency, ensuring the coherence of the scene from various perspectives. Finally, we recover the 3D scene from the generated video through a confidence-aware 3D Gaussian Splatting optimization scheme. Extensive experiments on various real-world datasets show the superiority of our ReconX over state-of-the-art methods in terms of quality and generalizability.
随着3D场景重建技术的不断进步,已经能够将现实世界的2D图像转化为3D模型,通过数百张输入照片生成逼真的3D结果。尽管在密集视图重建场景中取得了巨大成功,但从不足够捕捉的视图中渲染详细场景仍然是一个表述不清的优化问题,这往往导致在看不见的区域出现伪影和失真。在本文中,我们提出了ReconX,这是一种新型的三维场景重建范式,它将模糊的重建挑战重新定位为时间生成任务。关键思路是释放大型预训练视频扩散模型的强大生成先验知识,用于稀疏视图重建。然而,直接从预训练模型中生成视频帧时,很难准确保持三维视图的连贯性。针对这一问题,所提出的ReconX在给定的有限输入视图下,首先构建全局点云并将其编码为上下文空间作为三维结构条件。在该条件下,视频扩散模型合成的视频帧既保留了细节又保持了较高的三维一致性,从而确保了从不同角度场景的连贯性。最后,我们通过置信度感知的3D高斯摊开优化方案,从生成的视频中恢复三维场景。在多种真实世界数据集上的大量实验表明,我们的ReconX在质量和通用性方面优于现有先进技术。
论文及项目相关链接
PDF Project page: https://liuff19.github.io/ReconX
Summary
在三维重建领域,随着技术的进步,能够从真实世界的二维图像生成三维模型,且从多张照片生成的模型非常逼真。然而,当捕捉的视图不足时,重建过程会遇到问题,产生伪影和失真。本文提出的ReconX方法将重建问题视作一个时间生成任务,并利用大型预训练视频扩散模型的生成先验进行稀疏视图重建。为了克服直接从预训练模型中生成视频帧时出现的三维视角不一致问题,ReconX首先构建全局点云并将其编码为三维结构条件。在条件的引导下,视频扩散模型合成的视频帧既保留了细节又展现了高度一致的三维效果。最后,通过置信感知的三维高斯平铺优化方案从生成的视频中恢复三维场景。实验证明,相较于其他前沿方法,ReconX在质量和泛化能力上更胜一筹。
Key Takeaways
- 该研究解决了在三维重建中由于视图不足导致的伪影和失真问题。
- ReconX将三维重建问题重新定义为时间生成任务,引入大型预训练视频扩散模型的生成先验。
- 为了确保三维视角的一致性,提出了构建全局点云并编码为三维结构条件的策略。
- 在条件的引导下,利用视频扩散模型合成既保留细节又展现三维一致性的视频帧。
- 通过置信感知的三维高斯平铺优化方案从生成的视频中恢复三维场景。
- 实验证明,相较于其他方法,ReconX在质量和泛化能力上具有优势。
点此查看论文截图