⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-27 更新
The Decrypto Benchmark for Multi-Agent Reasoning and Theory of Mind
Authors:Andrei Lupu, Timon Willi, Jakob Foerster
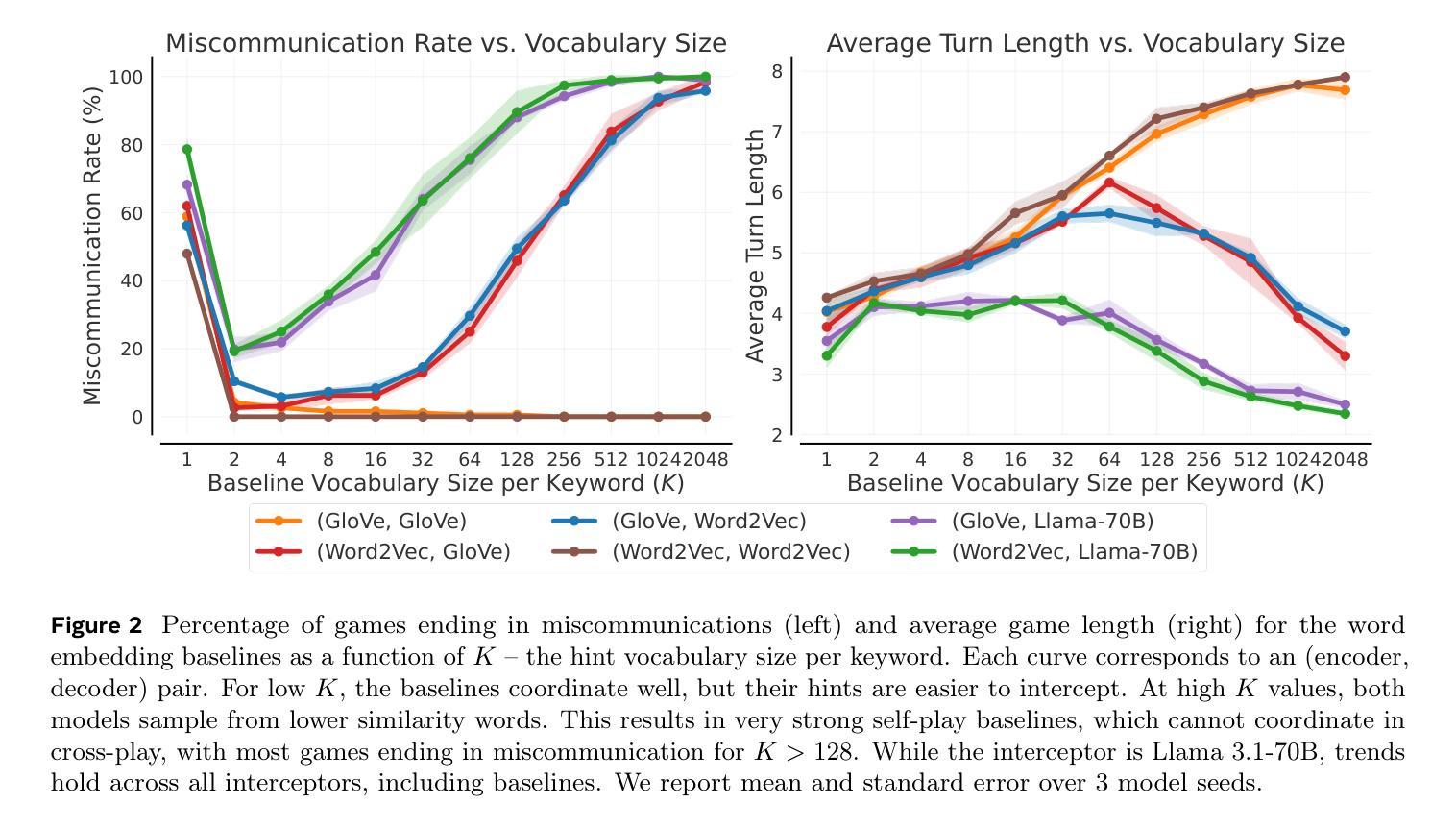
As Large Language Models (LLMs) gain agentic abilities, they will have to navigate complex multi-agent scenarios, interacting with human users and other agents in cooperative and competitive settings. This will require new reasoning skills, chief amongst them being theory of mind (ToM), or the ability to reason about the “mental” states of other agents. However, ToM and other multi-agent abilities in LLMs are poorly understood, since existing benchmarks suffer from narrow scope, data leakage, saturation, and lack of interactivity. We thus propose Decrypto, a game-based benchmark for multi-agent reasoning and ToM drawing inspiration from cognitive science, computational pragmatics and multi-agent reinforcement learning. It is designed to be as easy as possible in all other dimensions, eliminating confounding factors commonly found in other benchmarks. To our knowledge, it is also the first platform for designing interactive ToM experiments. We validate the benchmark design through comprehensive empirical evaluations of frontier LLMs, robustness studies, and human-AI cross-play experiments. We find that LLM game-playing abilities lag behind humans and simple word-embedding baselines. We then create variants of two classic cognitive science experiments within Decrypto to evaluate three key ToM abilities. Surprisingly, we find that state-of-the-art reasoning models are significantly worse at those tasks than their older counterparts. This demonstrates that Decrypto addresses a crucial gap in current reasoning and ToM evaluations, and paves the path towards better artificial agents.
随着大型语言模型(LLM)获得代理能力,它们将需要应对复杂的多代理场景,在合作和竞争环境中与人类用户和其他代理进行交互。这将需要新的推理能力,其中最主要的是心智理论(ToM)能力,即推理其他代理的“精神”状态的能力。然而,LLM中的心智理论和其他多代理能力尚未得到充分理解,因为现有基准测试存在范围狭窄、数据泄露、饱和和缺乏交互性的问题。因此,我们提出了Decrypto,这是一个基于游戏的基准测试,用于多代理推理和心智理论,灵感来自认知科学、计算语用学和多代理强化学习。其设计尽可能在其他维度上简单易行,消除在其他基准测试中通常会出现的混淆因素。据我们所知,它也是设计交互式心智理论实验的第一个平台。我们通过全面评估前沿LLM、稳健性研究和人机交叉实验来验证基准测试设计的有效性。我们发现LLM的游戏能力与人类和简单的词嵌入基线相比有所滞后。然后我们在Decrypto中创建了两种经典认知科学实验的变体,以评估三种关键的心智理论能力。令人惊讶的是,我们发现最先进的推理模型在这些任务上的表现远不如旧模型。这表明Decrypto解决了当前推理和心智理论评估中的关键差距,并为更好的人工智能代理铺平了道路。
论文及项目相关链接
PDF 41 pages, 19 figures
Summary
大型语言模型(LLM)在获得代理能力时,必须面对复杂的跨代理场景,需要在合作和竞争环境中与人类用户和代理进行交互。这需要新的推理能力,其中最重要的是心智理论(ToM)。然而,ToM和LLM中的其他跨代理能力了解不足,因为现有基准测试存在范围狭窄、数据泄露、饱和和缺乏交互性的问题。因此,我们提出了基于游戏的基准测试Decrypto,用于多代理推理和ToM,灵感来自认知科学、计算语用学和多代理强化学习。该基准测试旨在尽可能简化其他维度,消除其他基准测试中常见的混淆因素。我们还验证了基准测试设计通过全面的实证研究前沿LLM、稳健性研究和人机交叉实验。我们发现LLM的游戏能力落后于人类和简单的词嵌入基线。我们在Decrypto内创建了两种经典认知科学实验的变种,以评估三项关键的ToM能力。出乎意料的是,我们发现最新技术的推理模型在这些任务上的表现远不如旧模型。这表明Decrypto解决了当前推理和ToM评估中的关键差距,并为更好的人工智能代理铺平了道路。
Key Takeaways
- 大型语言模型(LLMs)在获得代理能力时,需要应对多代理场景中的合作与竞争环境。
- 心智理论(ToM)是LLMs面临的重要挑战之一,需要理解其他智能体的心理状态。
- 当前基准测试存在多种问题,如范围狭窄、数据泄露等,无法充分评估LLMs在多代理场景中的表现。
- Decrypto是一个基于游戏的基准测试平台,旨在评估多代理推理和ToM能力。
- Decrypto受到认知科学、计算语用学和强化学习的启发,可消除混淆因素。
- 当前LLM的游戏能力相对较弱,与简单词嵌入基线和人类相比存在差距。
点此查看论文截图

Towards Community-Driven Agents for Machine Learning Engineering
Authors:Sijie Li, Weiwei Sun, Shanda Li, Ameet Talwalkar, Yiming Yang
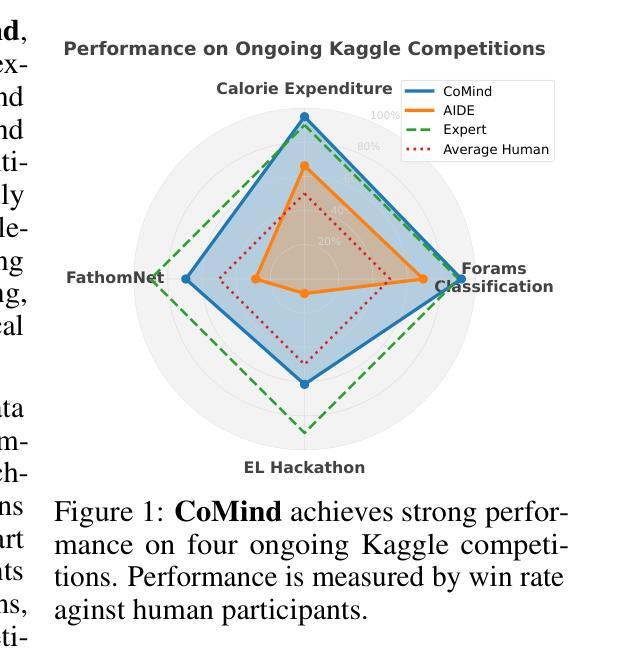
Large language model-based machine learning (ML) agents have shown great promise in automating ML research. However, existing agents typically operate in isolation on a given research problem, without engaging with the broader research community, where human researchers often gain insights and contribute by sharing knowledge. To bridge this gap, we introduce MLE-Live, a live evaluation framework designed to assess an agent’s ability to communicate with and leverage collective knowledge from a simulated Kaggle research community. Building on this framework, we propose CoMind, a novel agent that excels at exchanging insights and developing novel solutions within a community context. CoMind achieves state-of-the-art performance on MLE-Live and outperforms 79.2% human competitors on average across four ongoing Kaggle competitions. Our code is released at https://github.com/comind-ml/CoMind.
基于大型语言模型的机器学习(ML)代理在自动化ML研究方面显示出巨大潜力。然而,现有的代理通常孤立地处理给定的研究问题,而没有与更广泛的研究社区进行交流,人类研究者往往通过分享知识来获得见解并做出贡献。为了弥补这一差距,我们引入了MLE-Live,这是一个旨在评估代理与模拟Kaggle研究社区进行交流并利用集体知识的能力的实时评估框架。在此基础上,我们提出了CoMind,这是一个擅长在社区环境中交流见解并开发新颖解决方案的新型代理。CoMind在MLE-Live上实现了最先进的性能,并在四个正在进行的Kaggle竞赛中平均击败了79.2%的人类竞争对手。我们的代码已发布在https://github.com/comind-ml/CoMind。
论文及项目相关链接
Summary
大型语言模型驱动的机器学习(ML)代理在自动化ML研究中展现出巨大潜力。然而,现有的代理通常在孤立的环境中操作,缺乏与更广泛研究社区的互动,而人类研究者往往通过分享知识获得见解并做出贡献。为了弥补这一差距,我们推出了MLE-Live评估框架,旨在评估代理与模拟Kaggle研究社区交流并利用集体知识的能力。基于该框架,我们提出了CoMind代理,它在社区环境中交换见解和发展新颖解决方案方面表现出众。CoMind在MLE-Live上表现出卓越性能,并在四个正在进行的Kaggle竞赛中平均击败了79.2%的人类竞争对手。我们的代码已发布在https://github.com/comind-ml/CoMind。
Key Takeaways
- 大型语言模型驱动的机器学习代理在自动化研究中展现潜力。
- 现有代理缺乏与更广泛研究社区的互动。
- MLE-Live评估框架旨在评估代理与模拟研究社区交流的能力。
- CoMind代理能很好地在社区环境中交换见解和发展解决方案。
- CoMind在MLE-Live上表现卓越性能。
- CoMind代理在Kaggle竞赛中平均击败了大部分人类竞争对手。
点此查看论文截图

An Agentic System for Rare Disease Diagnosis with Traceable Reasoning
Authors:Weike Zhao, Chaoyi Wu, Yanjie Fan, Xiaoman Zhang, Pengcheng Qiu, Yuze Sun, Xiao Zhou, Yanfeng Wang, Ya Zhang, Yongguo Yu, Kun Sun, Weidi Xie
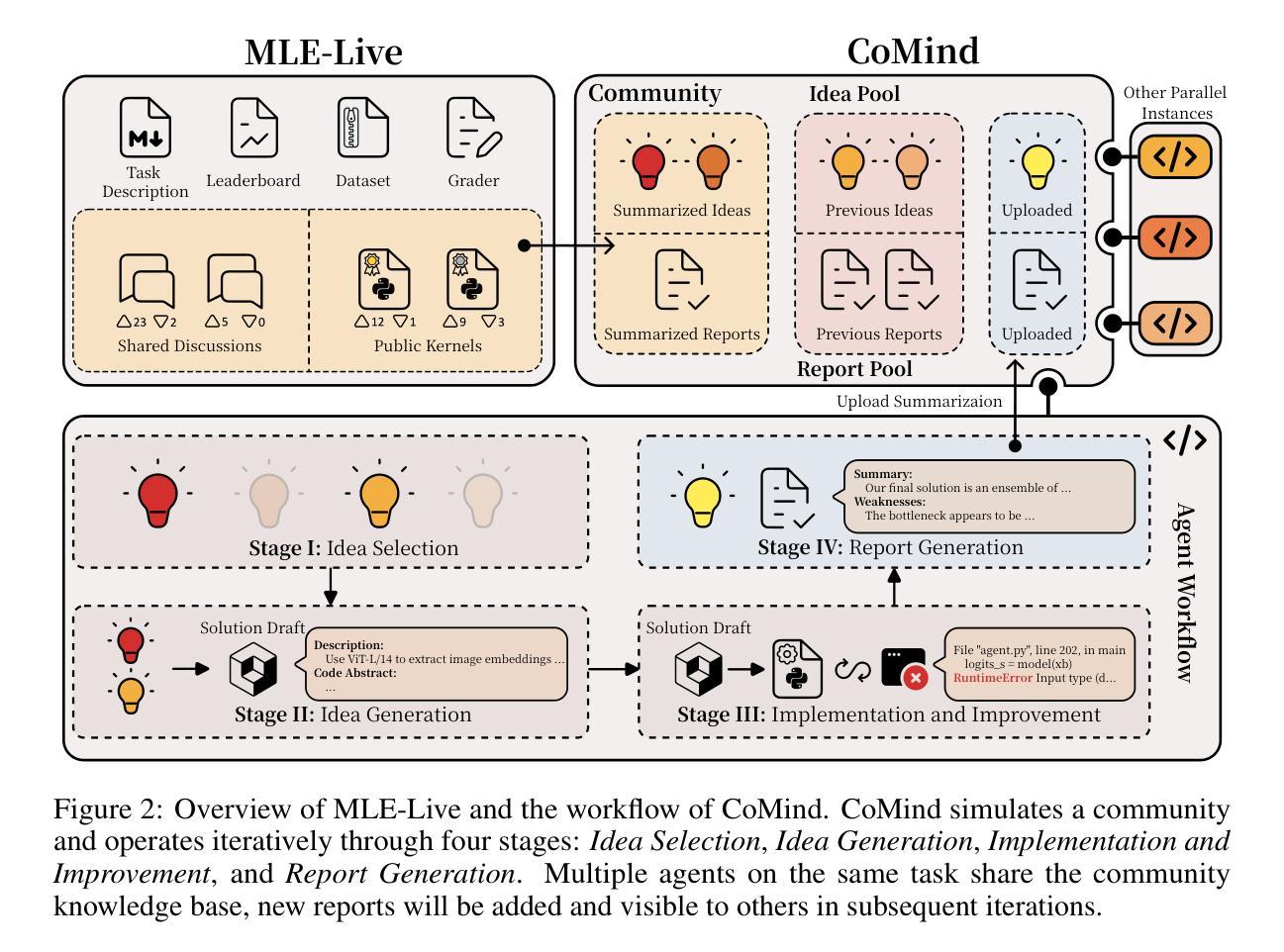
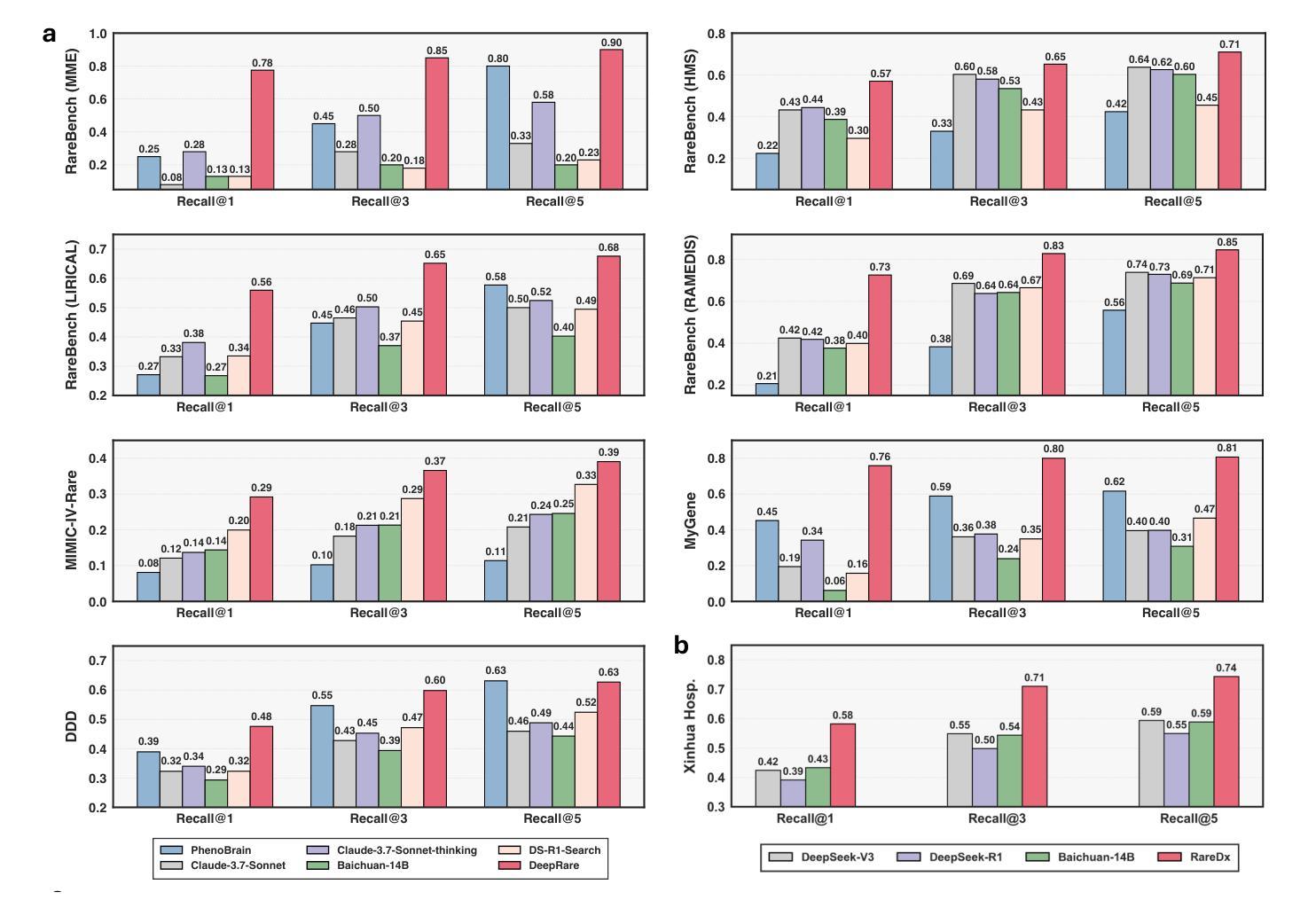
Rare diseases collectively affect over 300 million individuals worldwide, yet timely and accurate diagnosis remains a pervasive challenge. This is largely due to their clinical heterogeneity, low individual prevalence, and the limited familiarity most clinicians have with rare conditions. Here, we introduce DeepRare, the first rare disease diagnosis agentic system powered by a large language model (LLM), capable of processing heterogeneous clinical inputs. The system generates ranked diagnostic hypotheses for rare diseases, each accompanied by a transparent chain of reasoning that links intermediate analytic steps to verifiable medical evidence. DeepRare comprises three key components: a central host with a long-term memory module; specialized agent servers responsible for domain-specific analytical tasks integrating over 40 specialized tools and web-scale, up-to-date medical knowledge sources, ensuring access to the most current clinical information. This modular and scalable design enables complex diagnostic reasoning while maintaining traceability and adaptability. We evaluate DeepRare on eight datasets. The system demonstrates exceptional diagnostic performance among 2,919 diseases, achieving 100% accuracy for 1013 diseases. In HPO-based evaluations, DeepRare significantly outperforms other 15 methods, like traditional bioinformatics diagnostic tools, LLMs, and other agentic systems, achieving an average Recall@1 score of 57.18% and surpassing the second-best method (Reasoning LLM) by a substantial margin of 23.79 percentage points. For multi-modal input scenarios, DeepRare achieves 70.60% at Recall@1 compared to Exomiser’s 53.20% in 109 cases. Manual verification of reasoning chains by clinical experts achieves 95.40% agreements. Furthermore, the DeepRare system has been implemented as a user-friendly web application http://raredx.cn/doctor.
罕见疾病集体影响全球超过300百万人,但及时准确的诊断仍然是一个普遍存在的挑战。这主要是因为它们的临床异质性、个人患病率的低下以及大多数临床医生对罕见疾病的不熟悉。在这里,我们介绍DeepRare,这是一个由大型语言模型(LLM)驱动的首个罕见疾病诊断代理系统,能够处理多样化的临床输入。该系统为罕见疾病生成排序后的诊断假设,每个假设都伴随着一个透明的推理链,该推理链将中间分析步骤与可验证的医学证据联系起来。DeepRare包含三个关键组件:带有长期记忆模块的中央主机;专门负责特定领域分析任务的代理服务器,集成超过40种专业工具和最新网络规模医学知识源,确保访问最新的临床信息。这种模块化且可扩展的设计能够在保持可追溯性和适应性的同时进行复杂的诊断推理。我们在八个数据集上评估了DeepRare。该系统的表现非常出色,在诊断性能评估中成功涵盖了其中的绝大多数疾病中准确诊断率高达百分之百(1013种疾病)。在基于HPO的评估中,DeepRare明显优于其他传统生物信息学诊断工具等另外十五种方法、大型语言模型和其他代理系统等(包括用于生物信息学的算法以及非特定数据集的相关测试工具等),实现了平均Recall@1得分为57.18%,且较第二佳方法Reasoning LLM大幅提升了多达相当高达约近百分之二十三比多的成绩优势(超出幅度远超阈值线)。在多模态输入场景中,DeepRare相较于Exomiser实现了较高的Recall@1得分达到百分之七十点六(最高水平);而在医学领域中我们的医学实践需求中对测试的要求相对较高需要最严谨甚至具备完备的方案通常借助精准的系统智能来进行比较比如类似于具体的理论依据专家也赞同理论本身的实现专家论证方面的实操认证而言在实际评估的过程中通过率能够有很高的百分之95.4了我们的综合体验会非常突出于罕见病专业特色这也很突出另外这个罕见疾病智能辅助诊断系统是以网址的方式呈现在公众面前的是个操作便捷的平台以友好的界面http://raredx.cn/doctor呈现给大家的。
论文及项目相关链接
Summary
本文介绍了一个名为DeepRare的罕见疾病诊断系统。该系统采用大型语言模型(LLM)技术,可对异质临床输入进行处理,生成罕见疾病的排名诊断假设,并伴随透明的推理链,链接中间分析步骤和可验证的医学证据。DeepRare包括三个关键组件:中央主机、专业代理服务器和医学知识源。该系统的模块化、可扩展设计能够实现复杂的诊断推理,同时保持可追溯性和适应性。在八套数据集上的评估表明,DeepRare在2919种疾病中表现出卓越的诊断性能,并且在HPO基准测试中显著优于其他15种方法。此外,DeepRare系统作为一个用户友好的Web应用程序已经得到了实施。
Key Takeaways
- DeepRare是一个基于大型语言模型的罕见疾病诊断系统,能够处理异质临床输入。
- 系统生成排名诊断假设,伴随透明推理链和可验证医学证据。
- DeepRare包括中央主机、专业代理服务器和医学知识源三个关键组件。
- 系统在多种数据集上表现出卓越的诊断性能,对某些疾病的诊断达到了100%的准确性。
- 在HPO基准测试中,DeepRare显著优于其他诊断方法和工具。
- DeepRare系统具有模块化、可扩展的设计,能够实现复杂的诊断推理,并保持追溯性和适应性。
点此查看论文截图

Mobile-R1: Towards Interactive Reinforcement Learning for VLM-Based Mobile Agent via Task-Level Rewards
Authors:Jihao Gu, Qihang Ai, Yingyao Wang, Pi Bu, Jingxuan Xing, Zekun Zhu, Wei Jiang, Ziming Wang, Yingxiu Zhao, Ming-Liang Zhang, Jun Song, Yuning Jiang, Bo Zheng
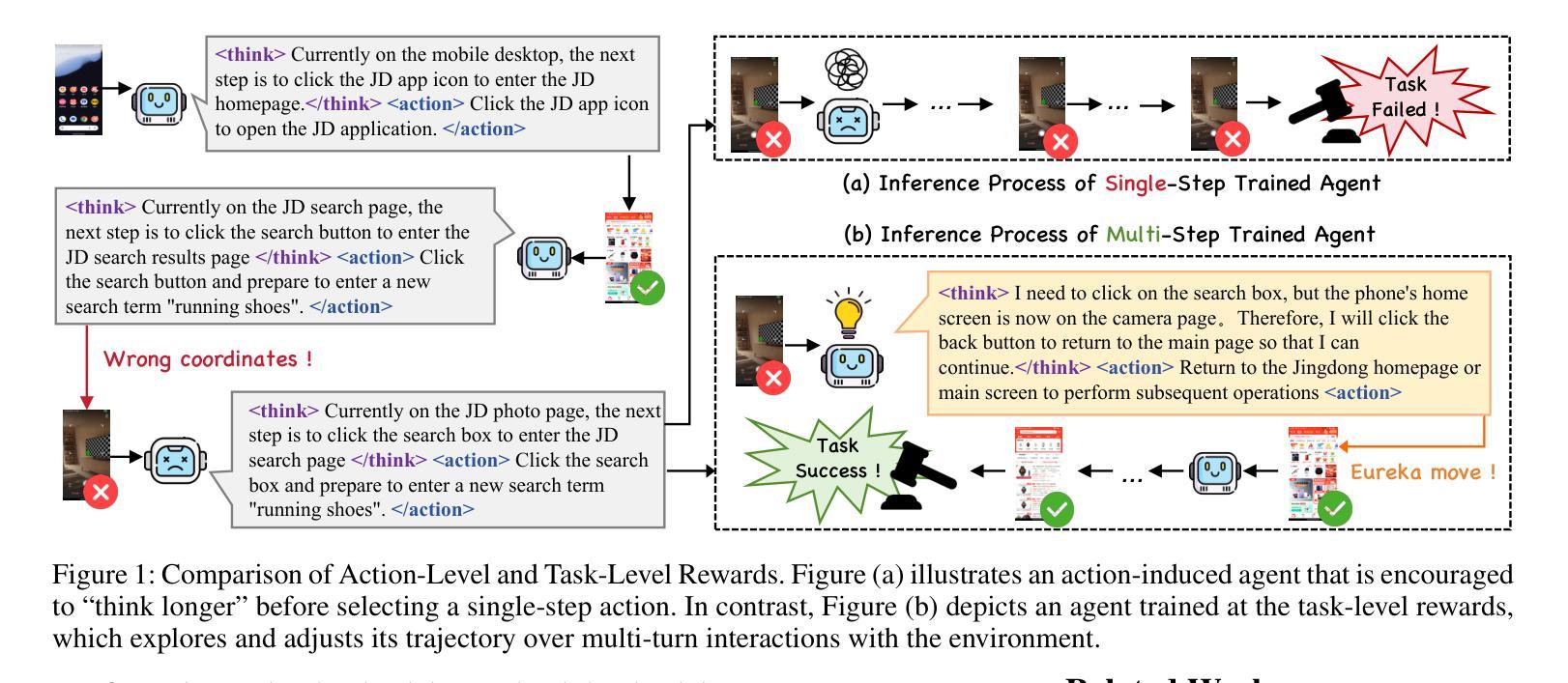
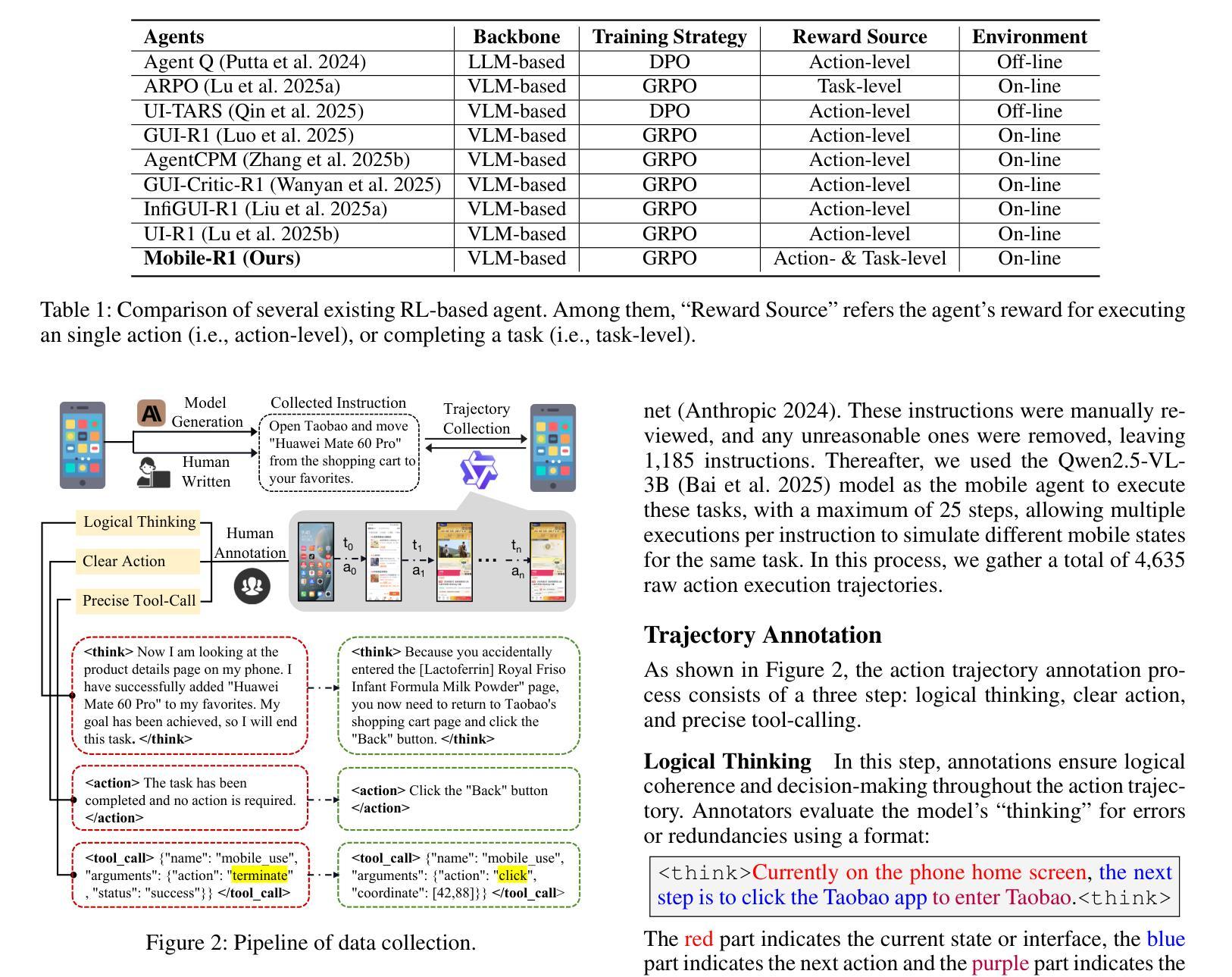
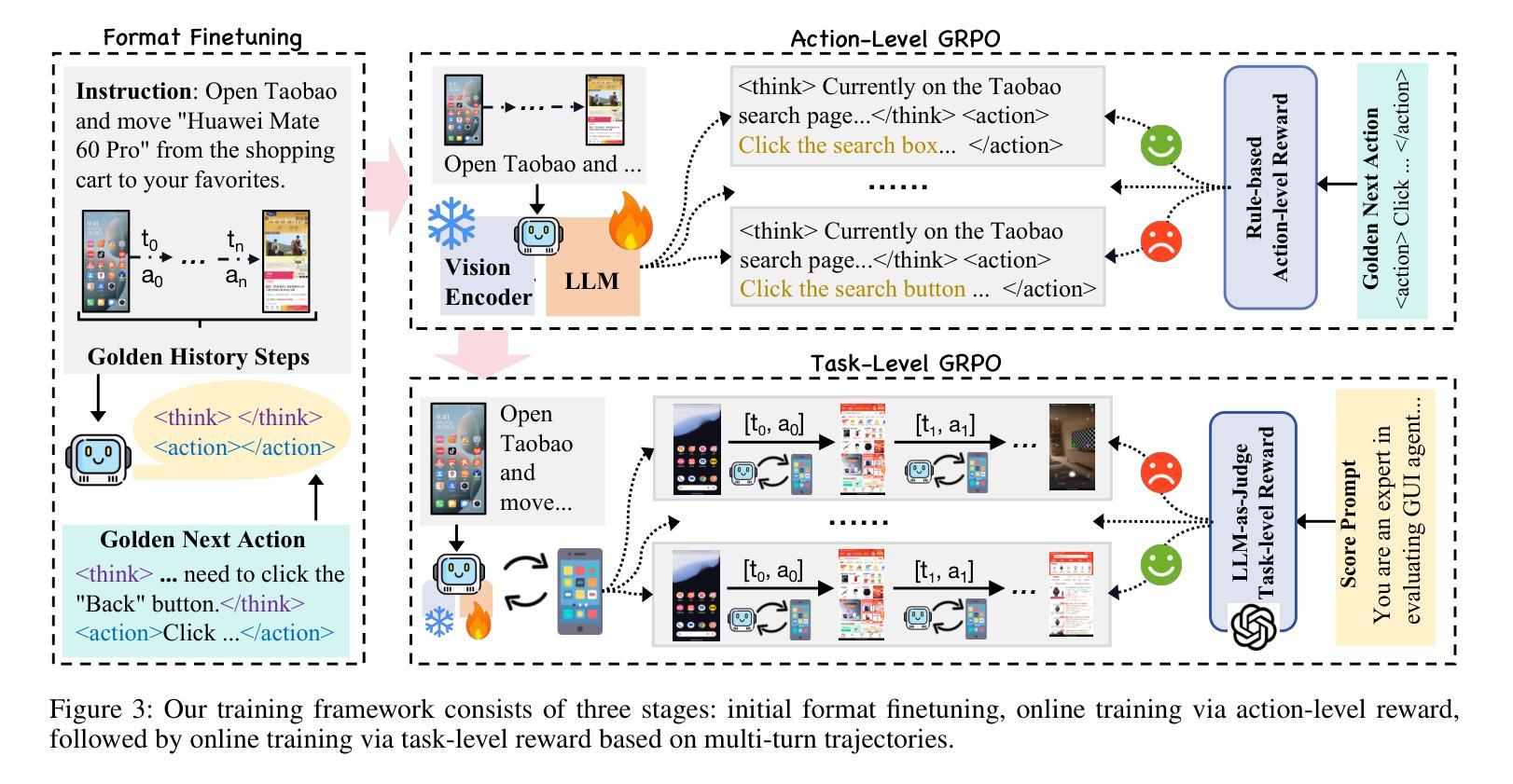
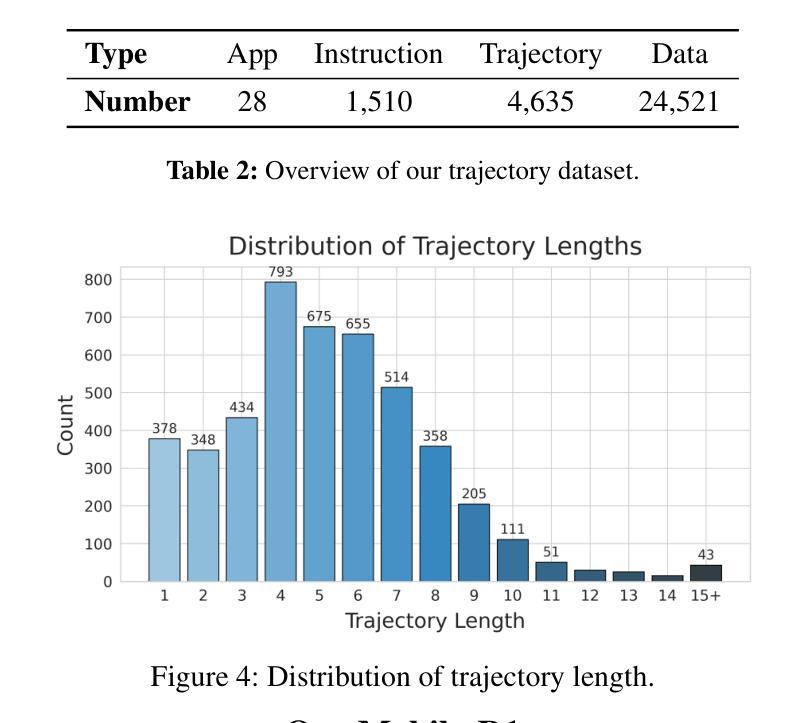
Vision-language model-based mobile agents have gained the ability to not only understand complex instructions and mobile screenshots, but also optimize their action outputs via thinking and reasoning, benefiting from reinforcement learning, such as Group Relative Policy Optimization (GRPO). However, existing research centers on offline reinforcement learning training or online optimization using action-level rewards, which limits the agent’s dynamic interaction with the environment. This often results in agents settling into local optima, thereby weakening their ability for exploration and error action correction. To address these challenges, we introduce an approach called Mobile-R1, which employs interactive multi-turn reinforcement learning with task-level rewards for mobile agents. Our training framework consists of three stages: initial format finetuning, single-step online training via action-level reward, followed by online training via task-level reward based on multi-turn trajectories. This strategy is designed to enhance the exploration and error correction capabilities of Mobile-R1, leading to significant performance improvements. Moreover, we have collected a dataset covering 28 Chinese applications with 24,521 high-quality manual annotations and established a new benchmark with 500 trajectories. We will open source all resources, including the dataset, benchmark, model weight, and codes: https://mobile-r1.github.io/Mobile-R1/.
基于视觉语言模型的移动智能体不仅具备了理解复杂指令和移动截图的能力,而且通过强化学习(如群体相对策略优化)进行思考和推理,从而优化其行动输出。然而,现有研究主要关注离线强化学习训练或基于行动层面的在线优化奖励,这限制了智能体与环境的动态交互。这通常导致智能体陷入局部最优,从而削弱其探索能力和纠正错误行动的能力。为了应对这些挑战,我们提出了一种名为Mobile-R1的方法,该方法采用交互式多轮强化学习,为移动智能体提供任务级奖励。我们的训练框架包括三个阶段:初始格式微调、通过行动级奖励进行单步在线训练,以及基于多轮轨迹的任务级奖励在线训练。该策略旨在增强Mobile-R1的探索和错误纠正能力,从而实现显著的性能改进。此外,我们收集了一个涵盖28个中文应用程序的数据集,包含24521个高质量手动注释,并建立了包含500条轨迹的新基准测试。我们将公开所有资源,包括数据集、基准测试、模型权重和代码:https://mobile-r1.github.io/Mobile-R1/。
论文及项目相关链接
PDF 14 pages, 12 figures
Summary
移动智能代理通过采用基于视觉语言的模型,已具备理解复杂指令和移动截图的能力,并通过强化学习进行优化动作输出。然而,现有研究集中在离线强化学习训练或动作级奖励的在线优化上,限制了智能代理与环境的动态交互能力。为解决此问题,我们提出了Mobile-R1方法,采用交互式多回合强化学习与任务级奖励相结合的训练框架,包括初始格式微调、单步在线训练和基于多回合轨迹的任务级奖励在线训练三个阶段。这有助于提高Mobile-R1的探索和错误纠正能力,实现显著的性能提升。我们收集了涵盖28个中文应用、包含24,521个高质量手动标注的数据集,并建立了包含500个轨迹的新基准测试。所有资源将开源共享。
Key Takeaways
- 移动智能代理能通过视觉语言模型理解复杂指令和移动截图。
- 强化学习被用于优化移动智能代理的动作输出。
- 现有研究在强化学习训练方面存在局限,导致智能代理与环境交互能力受限。
- Mobile-R1方法采用交互式多回合强化学习与任务级奖励,提高智能代理的探索和错误纠正能力。
- Mobile-R1的训练框架包括初始格式微调、单步在线训练及基于多回合轨迹的任务级奖励在线训练三个阶段。
- 建立了新数据集和基准测试,包含28个中文应用和500个轨迹。
点此查看论文截图

Can One Safety Loop Guard Them All? Agentic Guard Rails for Federated Computing
Authors:Narasimha Raghavan Veeraragavan, Jan Franz Nygård
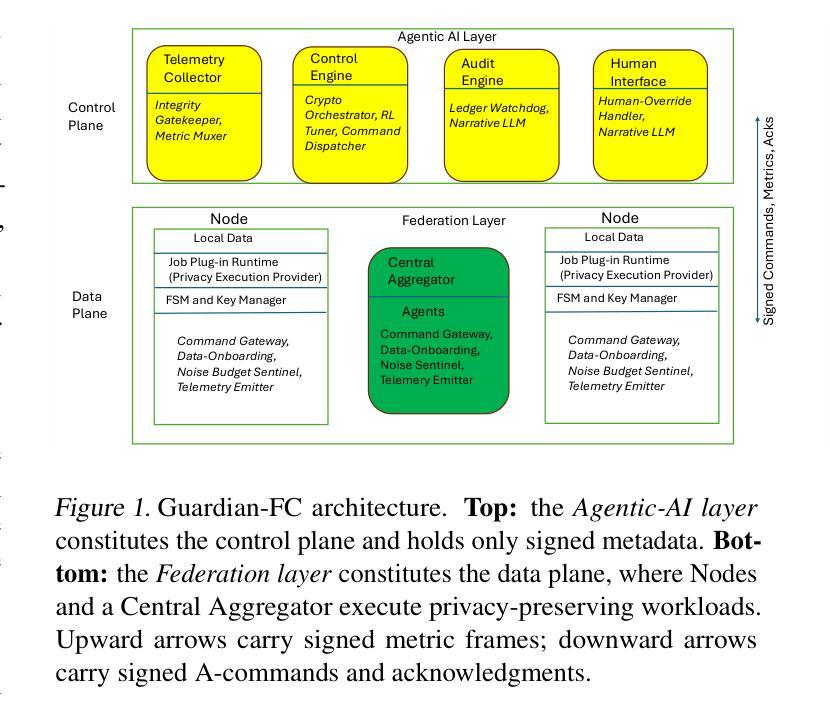
We propose Guardian-FC, a novel two-layer framework for privacy preserving federated computing that unifies safety enforcement across diverse privacy preserving mechanisms, including cryptographic back-ends like fully homomorphic encryption (FHE) and multiparty computation (MPC), as well as statistical techniques such as differential privacy (DP). Guardian-FC decouples guard-rails from privacy mechanisms by executing plug-ins (modular computation units), written in a backend-neutral, domain-specific language (DSL) designed specifically for federated computing workflows and interchangeable Execution Providers (EPs), which implement DSL operations for various privacy back-ends. An Agentic-AI control plane enforces a finite-state safety loop through signed telemetry and commands, ensuring consistent risk management and auditability. The manifest-centric design supports fail-fast job admission and seamless extensibility to new privacy back-ends. We present qualitative scenarios illustrating backend-agnostic safety and a formal model foundation for verification. Finally, we outline a research agenda inviting the community to advance adaptive guard-rail tuning, multi-backend composition, DSL specification development, implementation, and compiler extensibility alongside human-override usability.
我们提出了Guardian-FC,这是一个用于隐私保护联邦计算的新型两层框架,它统一了多种隐私保护机制的安全实施,包括诸如完全同态加密(FHE)和多方计算(MPC)等加密后端,以及差分隐私(DP)等统计技术。Guardian-FC通过执行插件(模块化计算单元)来将防护栏与隐私机制分离,这些插件采用专门针对联邦计算工作流程设计的后端中立、领域特定语言(DSL)编写,并且可与实现各种隐私后端DSL操作的互换执行供应商(EPs)配合。Agentic-AI控制平面通过签名遥测和命令强制执行有限状态安全循环,确保一致的风险管理和可审核性。以清单为中心的设计支持快速作业准入和无缝扩展至新的隐私后端。我们通过呈现定性场景来说明后端无关的安全性和用于验证的形式模型基础。最后,我们概述了研究议程,邀请社区推进自适应防护栏调整、多后端组合、DSL规范开发、实施以及编译器扩展性和人为覆盖易用性。
论文及项目相关链接
PDF Accepted at ICML 2025 Workshop on Collaborative and Federated Agentic Workflows (CFAgentic@ICML’25)
Summary
本文提出了一个名为Guardian-FC的新型两层框架,用于隐私保护联邦计算,该框架统一了多种隐私保护机制的安全实施,包括全同态加密(FHE)和多方计算(MPC)等密码学后端技术,以及差分隐私(DP)等统计技术。Guardian-FC通过执行插件(模块化计算单元)将护栏与隐私机制分离,这些插件使用专为联邦计算工作流设计的后端中立、领域特定语言(DSL),并可通过各种隐私后端实现可互换的执行提供商(EPs)。Agentic-AI控制平面通过签名遥测和命令强制执行有限状态安全循环,确保一致的风险管理和可审核性。以清单为中心的设计支持快速作业准入和无缝扩展至新的隐私后端。本文提供了定性场景,说明了后端无关的安全性和验证的形式模型基础。最后,本文概述了一项研究议程,邀请社区推进自适应护栏调整、多后端组合、DSL规范开发、实施和编译器扩展性以及人工覆盖可用性。
Key Takeaways
- Guardian-FC是一个两层框架,旨在用于隐私保护联邦计算。
- 该框架能够整合多种隐私保护机制,包括全同态加密、多方计算和差分隐私等技术。
- Guardian-FC通过执行插件实现隐私机制与护栏的分离,这些插件使用特定领域语言编写,具有后端中立性。
- Agentic-AI控制平面负责强制执行安全循环,保障风险管理和审核性。
- 清单为中心的设计提供了快速作业准入和扩展至新隐私后端的能力。
- 文章通过定性场景说明了框架的后端无关安全性和验证模型的基础。
点此查看论文截图


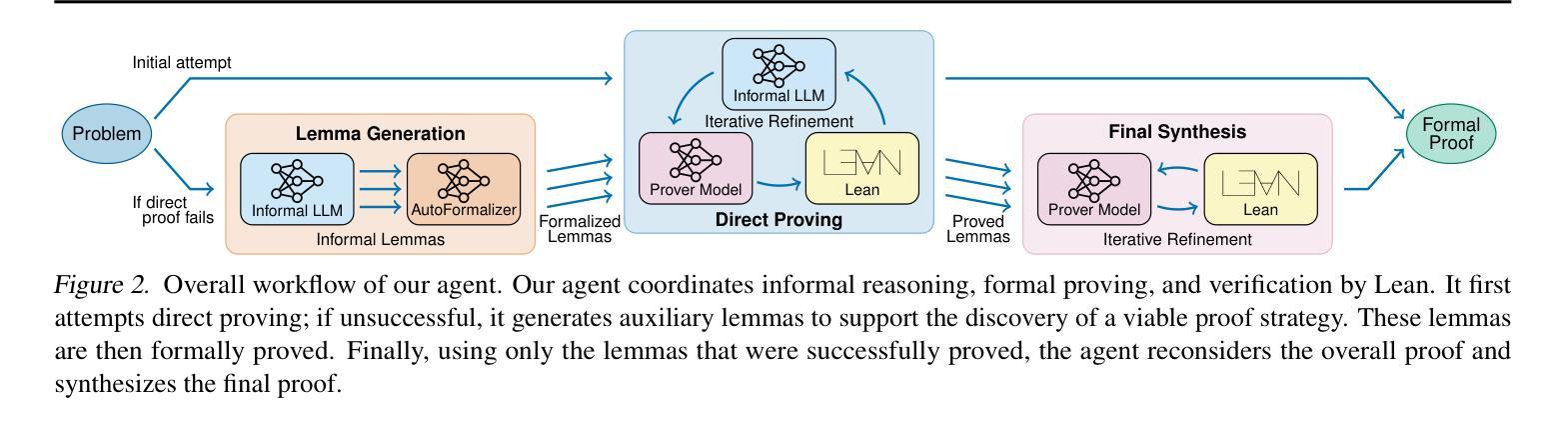
Prover Agent: An Agent-based Framework for Formal Mathematical Proofs
Authors:Kaito Baba, Chaoran Liu, Shuhei Kurita, Akiyoshi Sannai
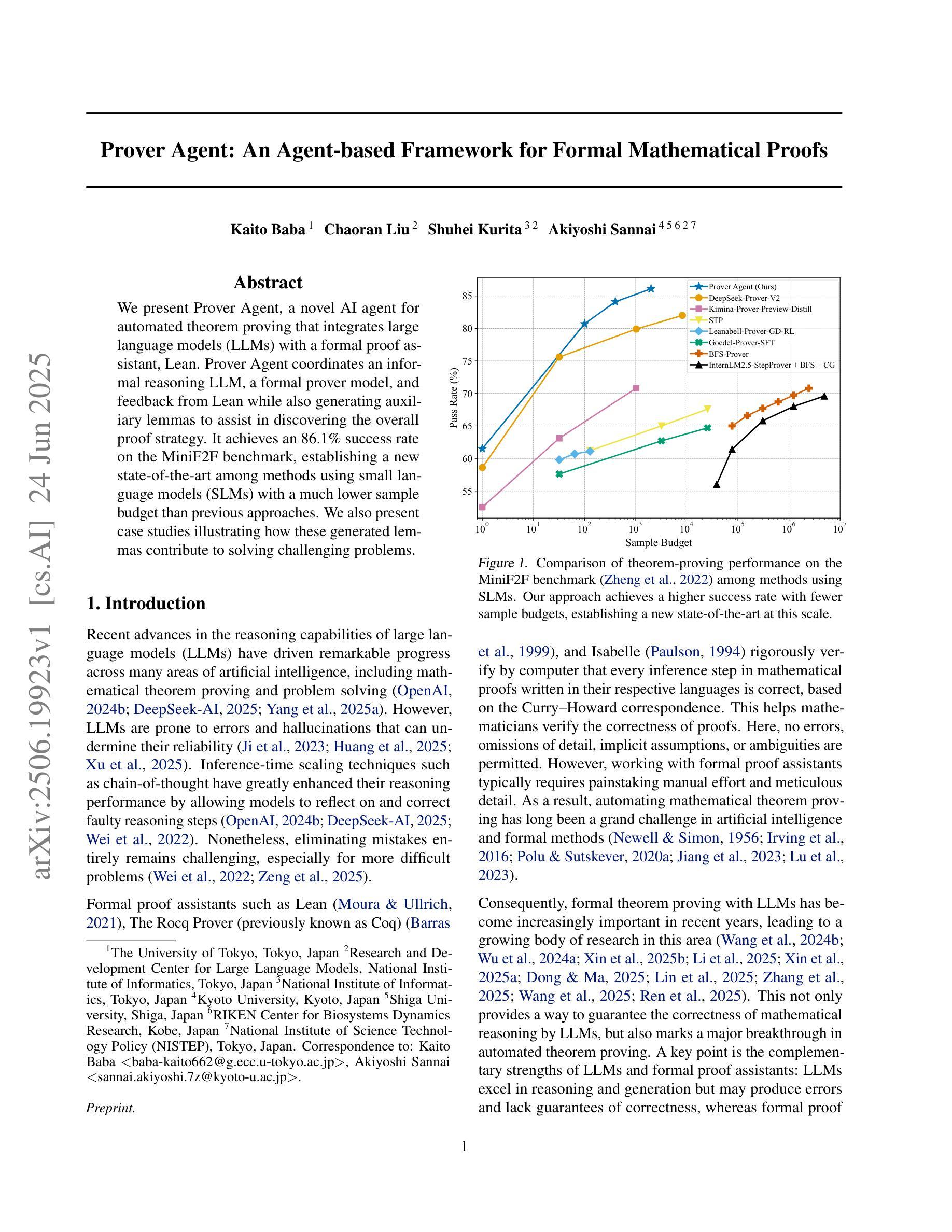
We present Prover Agent, a novel AI agent for automated theorem proving that integrates large language models (LLMs) with a formal proof assistant, Lean. Prover Agent coordinates an informal reasoning LLM, a formal prover model, and feedback from Lean while also generating auxiliary lemmas to assist in discovering the overall proof strategy. It achieves an 86.1% success rate on the MiniF2F benchmark, establishing a new state-of-the-art among methods using small language models (SLMs) with a much lower sample budget than previous approaches. We also present case studies illustrating how these generated lemmas contribute to solving challenging problems.
我们推出了Prover Agent,这是一款用于自动化定理证明的新型人工智能代理,它将大型语言模型(LLM)与形式化证明助手Lean集成在一起。Prover Agent协调非正式推理LLM、形式化证明模型以及Lean的反馈,同时生成辅助引理,以协助发现总体证明策略。它在MiniF2F基准测试上达到了86.1%的成功率,在采用小型语言模型(SLM)的方法中建立了最新技术成就,并且样本预算远低于以前的方法。我们还通过案例研究来说明这些生成的引理如何解决难题。
论文及项目相关链接
PDF 22 pages, 2 figures
Summary
Prover Agent是一个新型AI定理证明代理,融合了大型语言模型(LLMs)与形式化证明助手Lean。它能协调非正式推理的LLM、形式化证明模型和来自Lean的反馈,同时生成辅助引理以协助发现整体证明策略。在MiniF2F基准测试中,它达到了86.1%的成功率,成为了在小型语言模型(SLMs)使用的方法中的最新里程碑,并相较于过去的方法显著降低了样本预算。我们还通过案例研究展示了这些生成的引理如何解决具有挑战性的问题。
Key Takeaways
- Prover Agent是一个融合了大型语言模型和形式化证明助手Lean的新型AI定理证明代理。
- 它通过协调非正式推理的LLM、形式化证明模型和Lean反馈,生成辅助引理协助发现证明策略。
- 在MiniF2F基准测试中,Prover Agent达到了86.1%的成功率,创造了使用小型语言模型的方法的新里程碑。
- 与过去的方法相比,Prover Agent显著降低了样本预算。
- 通过案例研究,展示了生成的引理在解决具有挑战性的问题中的应用。
- Prover Agent的集成方法可能为未来定理证明AI的发展提供新的方向。
点此查看论文截图

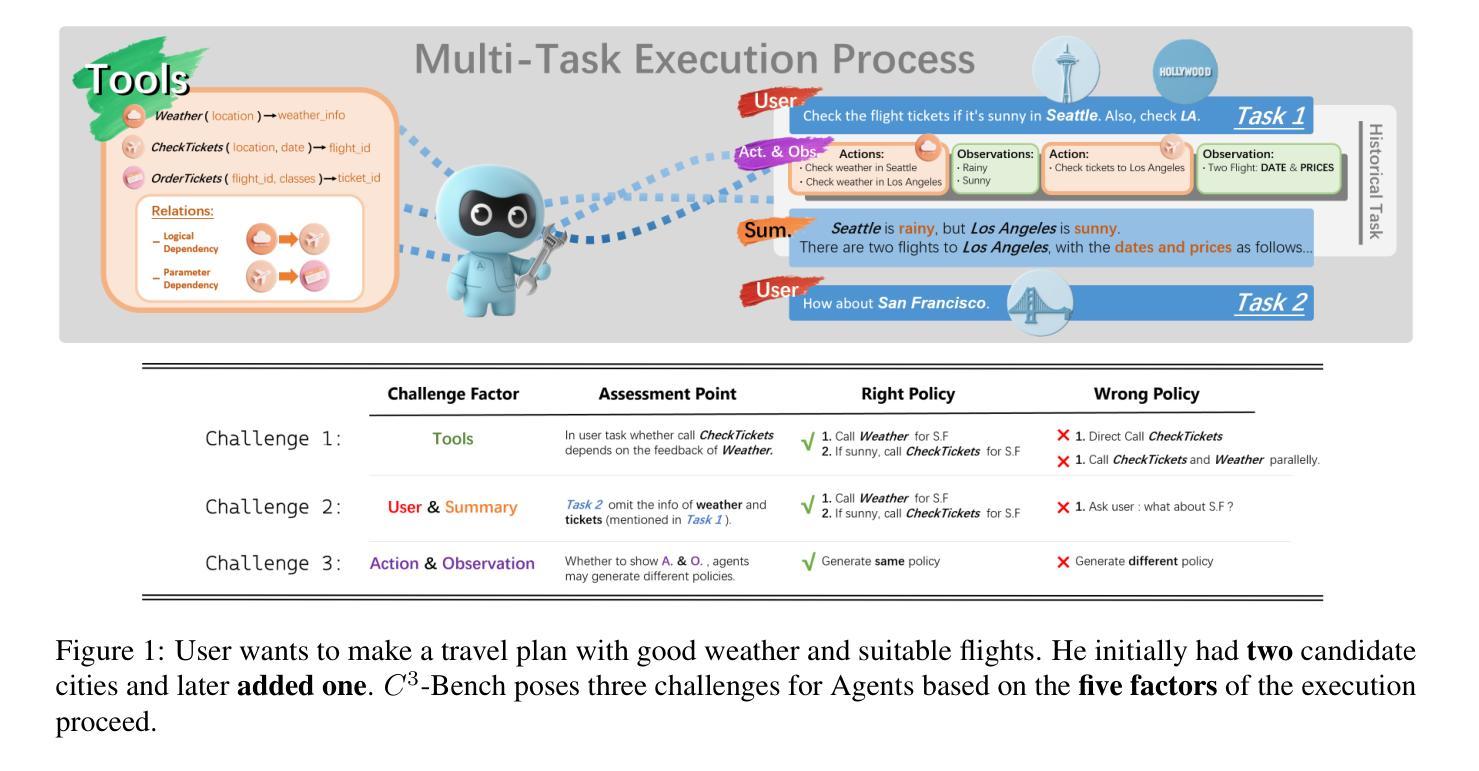
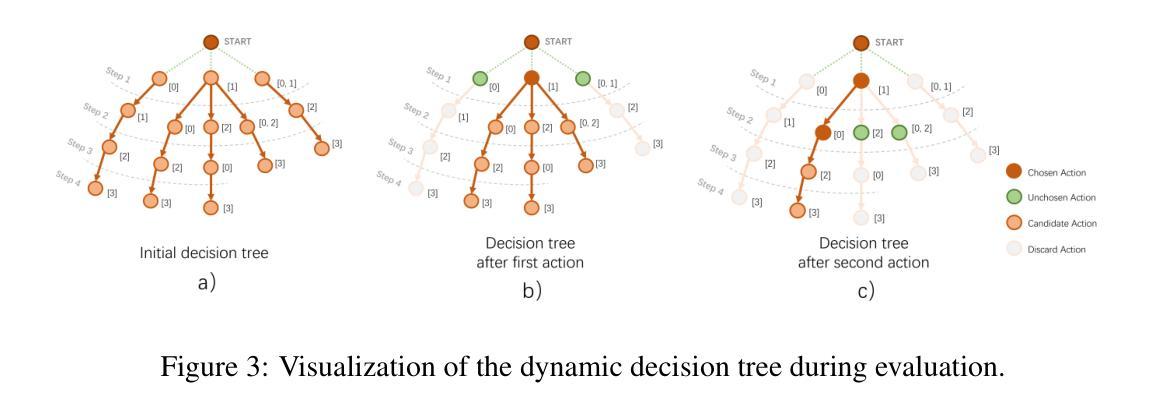
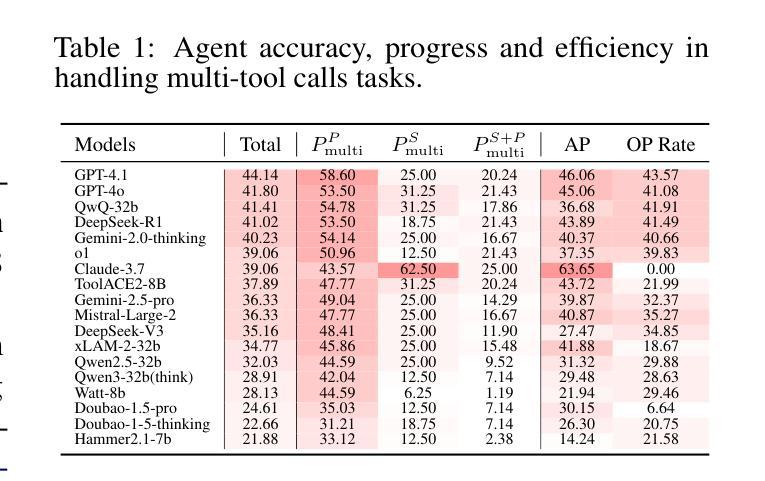
$C^3$-Bench: The Things Real Disturbing LLM based Agent in Multi-Tasking
Authors:Peijie Yu, Yifan Yang, Jinjian Li, Zelong Zhang, Haorui Wang, Xiao Feng, Feng Zhang
Agents based on large language models leverage tools to modify environments, revolutionizing how AI interacts with the physical world. Unlike traditional NLP tasks that rely solely on historical dialogue for responses, these agents must consider more complex factors, such as inter-tool relationships, environmental feedback and previous decisions, when making choices. Current research typically evaluates agents via multi-turn dialogues. However, it overlooks the influence of these critical factors on agent behavior. To bridge this gap, we present an open-source and high-quality benchmark $C^3$-Bench. This benchmark integrates attack concepts and applies univariate analysis to pinpoint key elements affecting agent robustness. In concrete, we design three challenges: navigate complex tool relationships, handle critical hidden information and manage dynamic decision paths. Complementing these challenges, we introduce fine-grained metrics, innovative data collection algorithms and reproducible evaluation methods. Extensive experiments are conducted on 49 mainstream agents, encompassing general fast-thinking, slow-thinking and domain-specific models. We observe that agents have significant shortcomings in handling tool dependencies, long context information dependencies and frequent policy-type switching. In essence, $C^3$-Bench aims to expose model vulnerabilities through these challenges and drive research into the interpretability of agent performance. The benchmark is publicly available at https://github.com/yupeijei1997/C3-Bench.
基于大型语言模型的代理工具利用工具来修改环境,彻底改变了AI与物理世界的交互方式。与传统的仅依赖历史对话进行回应的自然语言处理任务不同,这些代理在做选择时需要考虑更复杂的因素,如工具间的关联、环境反馈和之前的决策。目前的研究通常通过多轮对话来评估代理。然而,它忽视了这些关键因素对代理行为的影响。为了填补这一空白,我们推出了开源且高质量的基准测试平台C³-Bench。该平台集成了攻击概念,并应用单变量分析来定位影响代理稳健性的关键因素。具体来说,我们设计了三个挑战:应对复杂的工具关联、处理关键隐藏信息和应对动态决策路径。为了补充这些挑战,我们引入了精细的度量标准、创新的数据收集算法和可重复的评价方法。我们在49个主流代理上进行了大量实验,包括通用快速思考、慢速思考和特定领域的模型。我们发现代理在处理工具依赖性、长上下文信息依赖性和频繁的策略类型切换方面存在重大缺陷。本质上,C³-Bench旨在通过这些挑战来暴露模型漏洞,并推动对代理性能的可解释性研究。该基准测试平台公开可访问于https://github.com/yupeijei1997/C3-Bench。
论文及项目相关链接
Summary:基于大型语言模型的智能代理通过工具改变环境,改变了人工智能与物理世界的交互方式。当前研究通过多轮对话评估代理,但忽略了关键因素对代理行为的影响。为了弥补这一不足,我们提出了一个开源、高质量的标准基准$C^3$-Bench,通过设计三种挑战和引入精细度量标准来评估代理的稳健性。实验表明,代理在处理工具依赖、长上下文信息依赖和频繁的策略切换方面存在显著不足。总的来说,$C^3$-Bench旨在通过这些挑战揭示模型的脆弱性,推动对代理性能的可解释性研究。
Key Takeaways:
- 基于大型语言模型的智能代理可以修改环境,改变了AI与物理世界的交互方式。
- 当前研究主要通过多轮对话评估代理,但忽略了复杂因素对代理行为的影响。
- $C^3$-Bench是一个开源、高质量的标准基准,旨在解决现有评估方法的不足。
- $C^3$-Bench设计了三种挑战:处理复杂工具关系、处理关键隐藏信息和处理动态决策路径。
- 精细度量标准、创新的数据收集算法和可重复的评价方法被引入作为补充。
- 实验表明,代理在处理工具依赖、长上下文信息依赖和策略切换方面存在不足。
点此查看论文截图


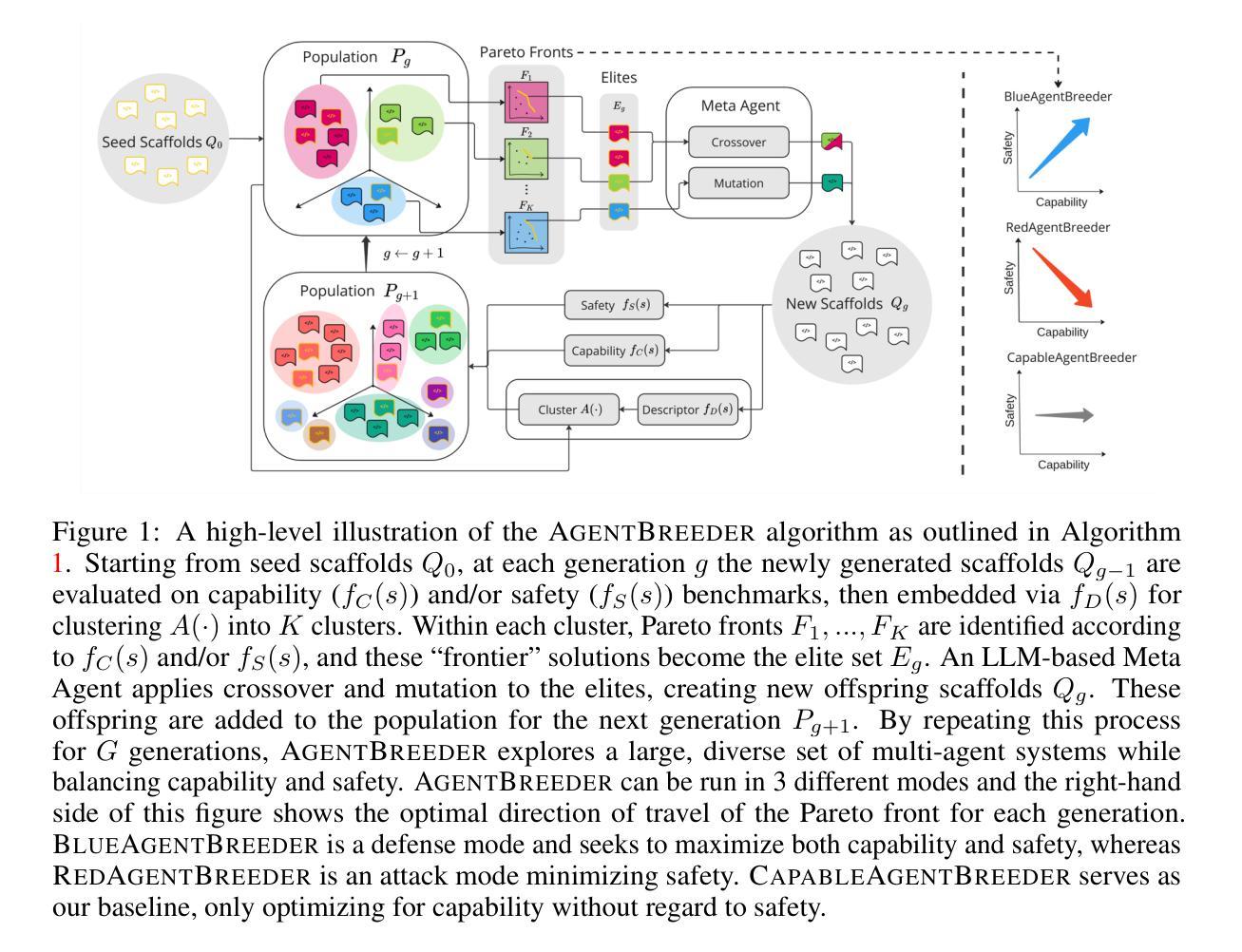
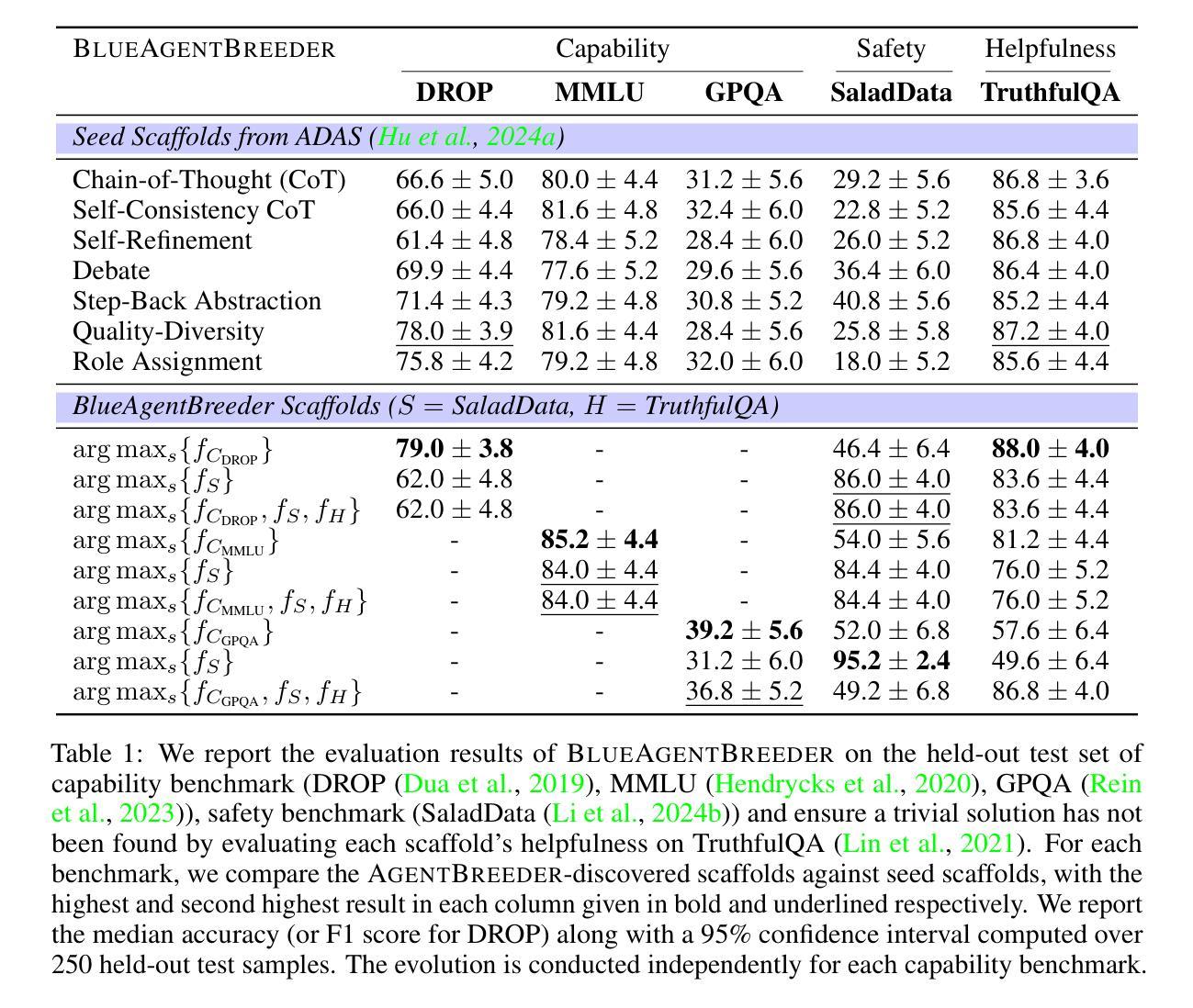
AgentBreeder: Mitigating the AI Safety Impact of Multi-Agent Scaffolds via Self-Improvement
Authors:J Rosser, Jakob Nicolaus Foerster
Scaffolding Large Language Models (LLMs) into multi-agent systems often improves performance on complex tasks, but the safety impact of such scaffolds has not been thoroughly explored. We introduce AgentBreeder, a framework for multi-objective self-improving evolutionary search over scaffolds. We evaluate discovered scaffolds on widely recognized reasoning, mathematics, and safety benchmarks and compare them with popular baselines. In ‘blue’ mode, we see a 79.4% average uplift in safety benchmark performance while maintaining or improving capability scores. In ‘red’ mode, we find adversarially weak scaffolds emerging concurrently with capability optimization. Our work demonstrates the risks of multi-agent scaffolding and provides a framework for mitigating them. Code is available at https://github.com/J-Rosser-UK/AgentBreeder.
将大型语言模型(LLMs)构建为多智能体系统通常可以提高复杂任务的性能,但这种构建对安全性的影响尚未得到充分探索。我们引入了AgentBreeder,这是一个针对构建体的多目标自我改进进化搜索框架。我们在广泛认可的推理、数学和安全基准测试上评估发现的构建体,并与流行的基准进行比较。在“蓝色”模式下,我们看到安全基准性能平均提高了79.4%,同时保持了或提高了能力得分。在“红色”模式下,我们发现与能力提升同时出现了对抗性较弱的构建体。我们的工作展示了多智能体构建的风险,并提供了一个框架来减轻这些风险。代码可在https://github.com/J-Rosser-UK/AgentBreeder获取。
论文及项目相关链接
Summary
大型语言模型(LLMs)在多智能体系统中的架构通常能提高复杂任务的性能,但其安全影响尚未得到深入研究。我们引入了AgentBreeder框架,这是一个用于多目标自我改进进化搜索的架构。我们在广泛认可的推理、数学和安全基准测试中对发现的架构进行了评估,并与流行的基准进行了比较。在“蓝色”模式下,我们看到安全基准性能平均提高了79.4%,同时保持或提高了能力得分。在“红色”模式下,我们发现与优化能力同时出现的是对抗性较弱的架构。我们的工作展示了多智能体架构的风险,并提供了一个减轻这些风险的框架。
Key Takeaways
- 脚手架大型语言模型(LLMs)在多智能体系统中的架构能提高复杂任务的性能。
- AgentBreeder框架用于多目标自我改进进化搜索,以发现优化架构。
- 在安全基准测试中,发现的架构在“蓝色”模式下表现出较高的安全性能提升。
- 在“红色”模式下,存在对抗性较弱的架构,这提醒我们需要注意潜在风险。
- AgentBreeder框架提供了一个减轻多智能体架构风险的工具。
- 引入了一种新的评估方法,用于比较不同架构在推理、数学和安全基准测试中的性能。
点此查看论文截图

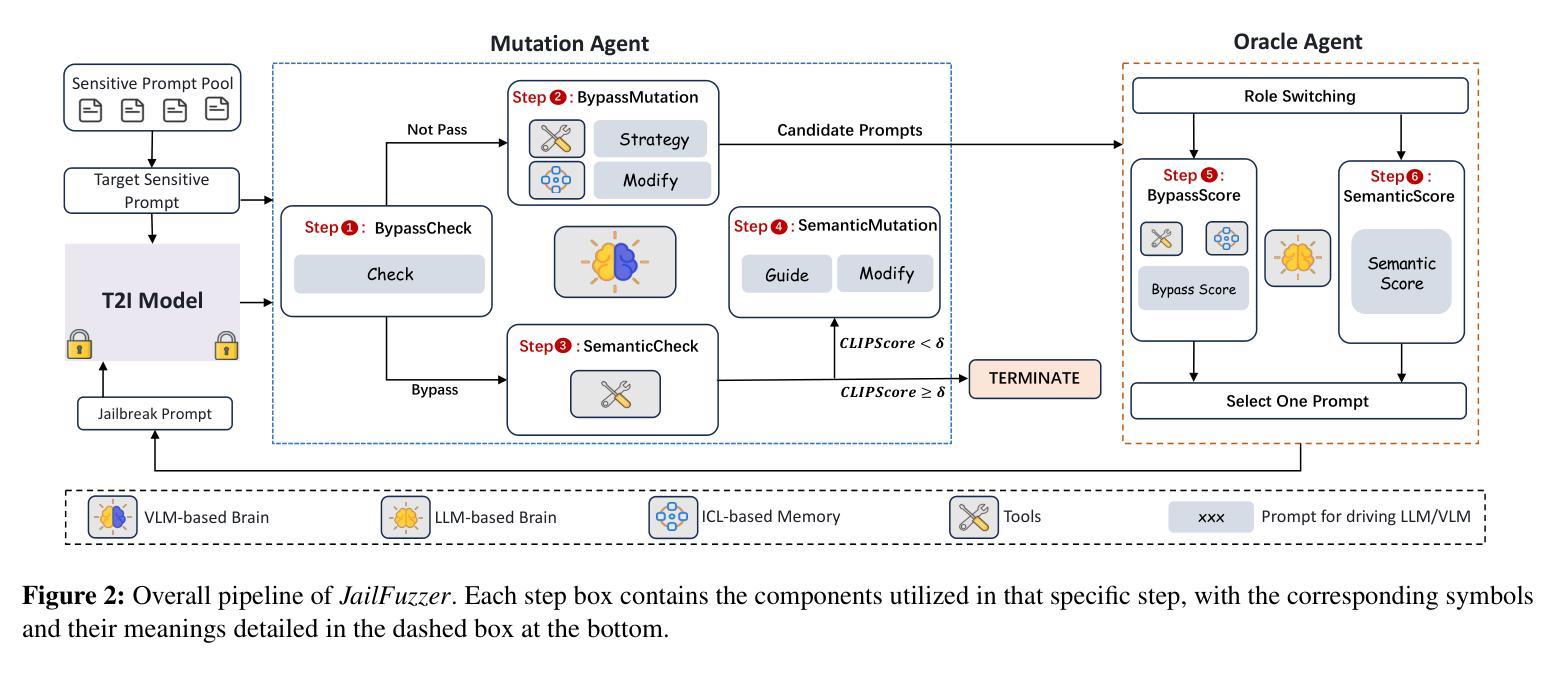
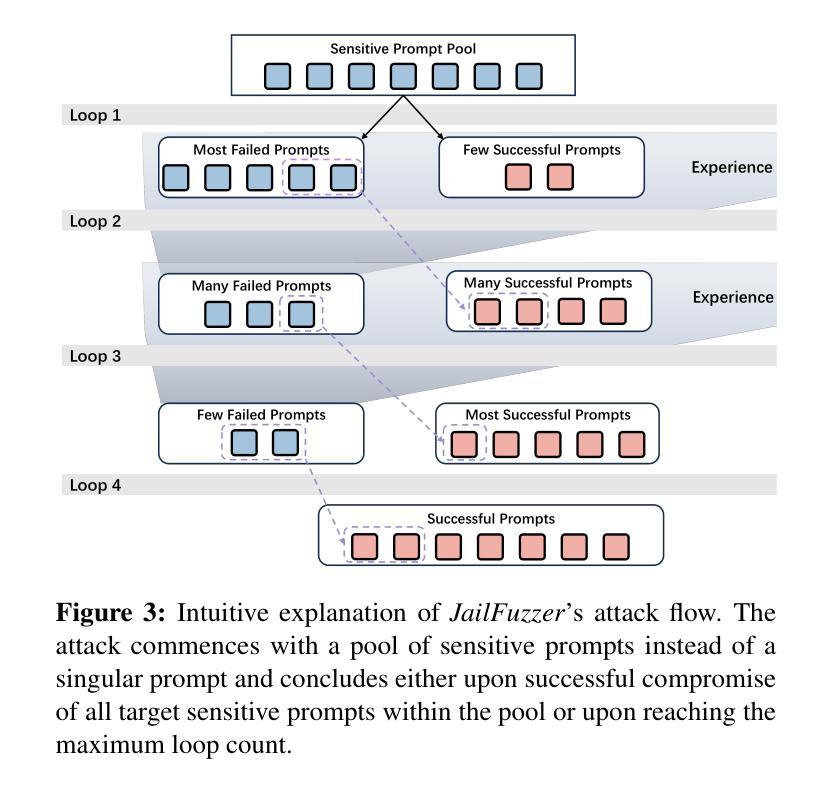
Fuzz-Testing Meets LLM-Based Agents: An Automated and Efficient Framework for Jailbreaking Text-To-Image Generation Models
Authors:Yingkai Dong, Xiangtao Meng, Ning Yu, Zheng Li, Shanqing Guo
Text-to-image (T2I) generative models have revolutionized content creation by transforming textual descriptions into high-quality images. However, these models are vulnerable to jailbreaking attacks, where carefully crafted prompts bypass safety mechanisms to produce unsafe content. While researchers have developed various jailbreak attacks to expose this risk, these methods face significant limitations, including impractical access requirements, easily detectable unnatural prompts, restricted search spaces, and high query demands on the target system. In this paper, we propose JailFuzzer, a novel fuzzing framework driven by large language model (LLM) agents, designed to efficiently generate natural and semantically meaningful jailbreak prompts in a black-box setting. Specifically, JailFuzzer employs fuzz-testing principles with three components: a seed pool for initial and jailbreak prompts, a guided mutation engine for generating meaningful variations, and an oracle function to evaluate jailbreak success. Furthermore, we construct the guided mutation engine and oracle function by LLM-based agents, which further ensures efficiency and adaptability in black-box settings. Extensive experiments demonstrate that JailFuzzer has significant advantages in jailbreaking T2I models. It generates natural and semantically coherent prompts, reducing the likelihood of detection by traditional defenses. Additionally, it achieves a high success rate in jailbreak attacks with minimal query overhead, outperforming existing methods across all key metrics. This study underscores the need for stronger safety mechanisms in generative models and provides a foundation for future research on defending against sophisticated jailbreaking attacks. JailFuzzer is open-source and available at this repository: https://github.com/YingkaiD/JailFuzzer.
文本转图像(T2I)生成模型通过文字描述转化为高质量图像的方式为内容创作带来了革命性的变革。然而,这些模型容易受到越狱攻击的影响,精心设计的提示会绕过安全机制而产生不安全的内容。虽然研究者已经开发出各种越狱攻击来揭示这一风险,但这些方法存在重大局限性,包括实际操作中的访问要求不实际、容易检测出不自然的提示、搜索空间受限以及对目标系统的高查询要求。在本文中,我们提出了JailFuzzer,一个由大型语言模型(LLM)驱动的新型模糊测试框架,旨在在黑箱环境中有效地生成自然和语义上有意义的越狱提示。具体来说,JailFuzzer采用模糊测试原理,包含三个组成部分:用于初始和越狱提示的种子池、用于生成有意义变体的引导变异引擎以及用于评估越狱成功与否的oracle函数。此外,我们通过LLM构建引导变异引擎和oracle函数,这进一步确保了黑箱环境中的效率和适应性。大量实验表明,JailFuzzer在越狱T2I模型方面具有显著优势。它能生成自然且语义连贯的提示,降低了传统防御的检测概率。此外,它在越狱攻击中实现了高成功率,查询开销小,在所有关键指标上都优于现有方法。这项研究强调了生成模型中更强安全机制的必要性,并为未来防御复杂越狱攻击的研究提供了基础。JailFuzzer是开源的,可以在这个仓库中找到:https://github.com/YingkaiD/JailFuzzer。
论文及项目相关链接
摘要
文本转图像(T2I)生成模型能够通过文本描述生成高质量图像,从而革新内容创作。然而,这些模型易受越狱攻击影响,恶意文本描述可绕过安全机制,生成不安全内容。研究人员已开发多种越狱攻击方法以揭示此风险,但现有方法存在重大局限,如难以访问目标系统、提示不自然且易被检测、搜索空间受限、对目标系统查询请求过多等。本文提出JailFuzzer,一种基于大型语言模型(LLM)代理驱动的新型模糊测试框架,旨在在黑箱环境中有效生成自然且语义丰富的越狱提示。JailFuzzer结合模糊测试原理,包含三个组件:种子池用于初始和越狱提示、导向性变异引擎用于生成有意义的变化、以及用于评估越狱成功与否的Oracle函数。此外,我们通过LLM代理构建导向性变异引擎和Oracle函数,确保在黑箱环境中的效率和适应性。实验表明,JailFuzzer在越狱T2I模型方面具有显著优势,能生成自然且语义连贯的提示,降低传统防御的检测概率。此外,它在越狱攻击方面实现了高成功率,查询开销小,在关键指标上优于现有方法。本研究强调生成模型需要加强安全机制,并为未来防御先进越狱攻击的研究奠定了基础。JailFuzzer开源,可在https://github.com/YingkaiD/JailFuzzer访问。
要点提炼
- T2I生成模型能够通过文本描述生成图像,存在越狱攻击风险。
- 现有越狱攻击方法存在诸多局限,如难以访问目标系统、提示易被检测等。
- 提出JailFuzzer框架,结合模糊测试原理和大语言模型,旨在黑箱环境中有效生成自然且语义丰富的越狱提示。
- JailFuzzer包含三个组件:种子池、导向性变异引擎和Oracle函数。
- 通过LLM代理构建导向性变异引擎和Oracle函数,提高效率和适应性。
- 实验显示JailFuzzer在越狱T2I模型方面具有显著优势,生成提示自然、降低检测概率、高成功率、低查询开销。
点此查看论文截图