⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-27 更新
Hierarchical Mask-Enhanced Dual Reconstruction Network for Few-Shot Fine-Grained Image Classification
Authors:Ning Luo, Meiyin Hu, Huan Wan, Yanyan Yang, Zhuohang Jiang, Xin Wei
Few-shot fine-grained image classification (FS-FGIC) presents a significant challenge, requiring models to distinguish visually similar subclasses with limited labeled examples. Existing methods have critical limitations: metric-based methods lose spatial information and misalign local features, while reconstruction-based methods fail to utilize hierarchical feature information and lack mechanisms to focus on discriminative regions. We propose the Hierarchical Mask-enhanced Dual Reconstruction Network (HMDRN), which integrates dual-layer feature reconstruction with mask-enhanced feature processing to improve fine-grained classification. HMDRN incorporates a dual-layer feature reconstruction and fusion module that leverages complementary visual information from different network hierarchies. Through learnable fusion weights, the model balances high-level semantic representations from the last layer with mid-level structural details from the penultimate layer. Additionally, we design a spatial binary mask-enhanced transformer self-reconstruction module that processes query features through adaptive thresholding while maintaining complete support features, enhancing focus on discriminative regions while filtering background noise. Extensive experiments on three challenging fine-grained datasets demonstrate that HMDRN consistently outperforms state-of-the-art methods across Conv-4 and ResNet-12 backbone architectures. Comprehensive ablation studies validate the effectiveness of each proposed component, revealing that dual-layer reconstruction enhances inter-class discrimination while mask-enhanced transformation reduces intra-class variations. Visualization results provide evidence of HMDRN’s superior feature reconstruction capabilities.
少量样本精细图像分类(FS-FGIC)是一个重大挑战,要求模型在有限的标记样本中区分视觉相似的子类。现有方法存在关键局限性:基于度量的方法会丢失空间信息并错位局部特征,而基于重建的方法则无法利用分层特征信息且缺乏关注判别区域的机制。我们提出了分层掩膜增强型双重重建网络(HMDRN),它将双层特征重建与掩膜增强特征处理相结合,以提高精细分类的效果。HMDRN结合了双层特征重建和融合模块,该模块利用不同网络层次之间的互补视觉信息。通过可学习的融合权重,模型平衡了来自最后一层的高级语义表示和来自倒数第二层的中级结构细节。此外,我们设计了一个空间二进制掩膜增强型自重建模块,该模块在处理查询特征时进行自适应阈值处理,同时保持完整的支持特征,增强了对判别区域的关注并过滤背景噪声。在三个具有挑战性的精细数据集上的大量实验表明,HMDRN在Conv-4和ResNet-12骨干架构上均优于最新方法。全面的消融研究验证了每个所提出组件的有效性,表明双层重建增强了类间鉴别力,而掩膜增强转换减少了类内变化。可视化结果提供了HMDRN卓越的特征重建能力的证据。
论文及项目相关链接
Summary
本文介绍了Few-shot细粒度图像分类(FS-FGIC)的挑战,现有方法存在空间信息丢失和局部特征错位等问题。为此,提出了层次化掩膜增强双重建网络(HMDRN),结合了双层次特征重建和掩膜增强特征处理来提高细粒度分类性能。HMDRN通过双重特征重建与融合模块,利用不同网络层次的互补视觉信息,并通过可学习的融合权重平衡高层语义表示和中间层结构细节。同时,设计了一个空间二进制掩膜增强型自重建模块,该模块在处理查询特征时采用自适应阈值处理,同时保持完整的支持特征,提高了对判别区域的关注并过滤背景噪声。在三个挑战性的细粒度数据集上的实验表明,HMDRN在Conv-4和ResNet-12主干架构上均优于最新方法。
Key Takeaways
- Few-shot细粒度图像分类(FS-FGIC)需要模型在有限标签样本中区分视觉相似的子类,是一个重大挑战。
- 现有方法存在空间信息丢失和局部特征错位的问题。
- 提出的HMDRN网络结合了双层次特征重建和掩膜增强特征处理来提高性能。
- HMDRN通过双重特征重建与融合模块,平衡高层语义和中间层结构细节。
- 空间二进制掩膜增强型自重建模块提高判别区域关注并过滤背景噪声。
- 在三个数据集上的实验表明HMDRN性能优于其他方法。
点此查看论文截图


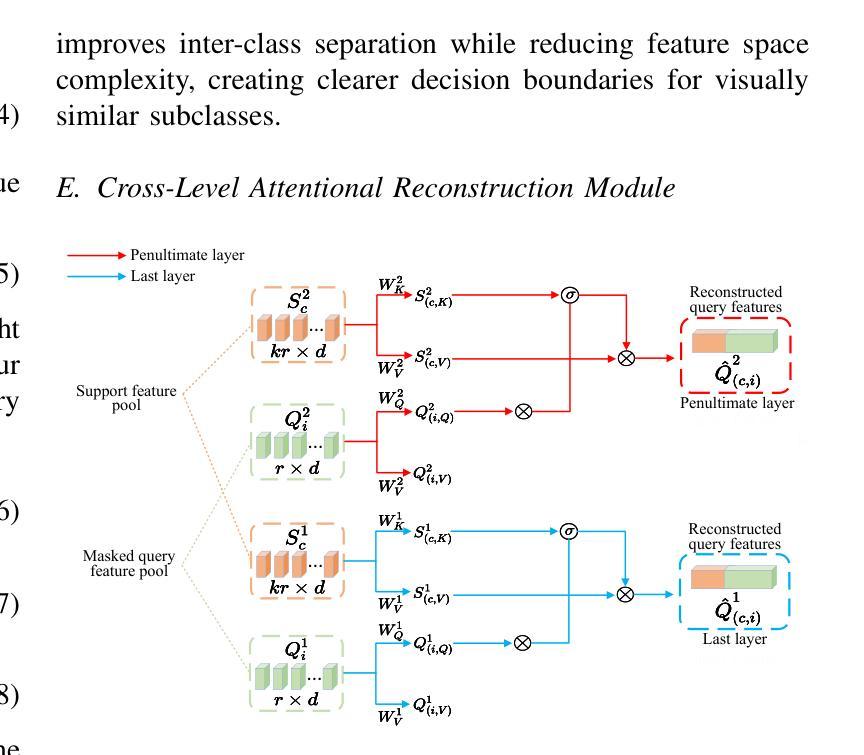
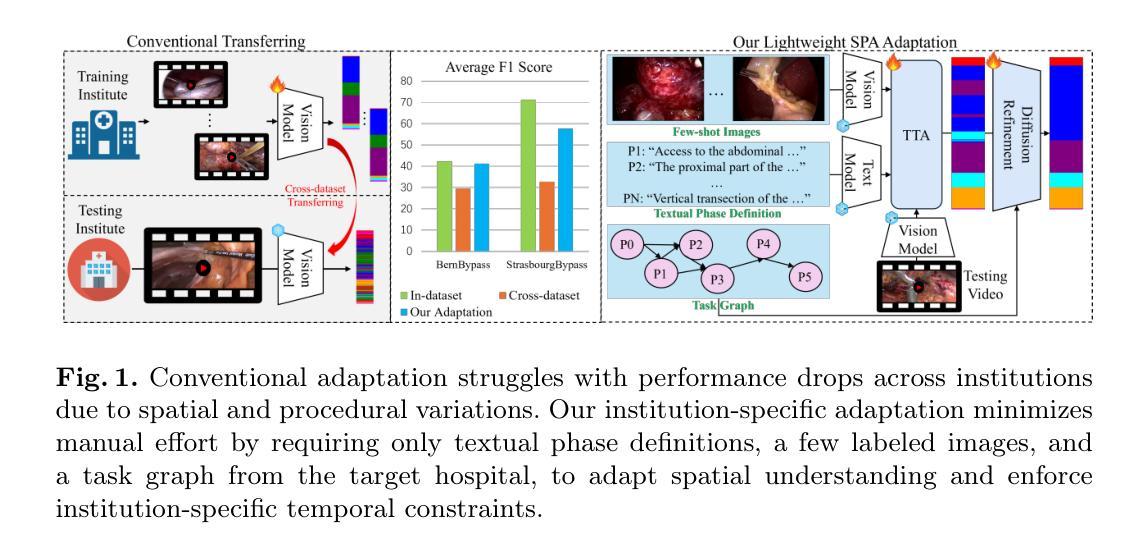
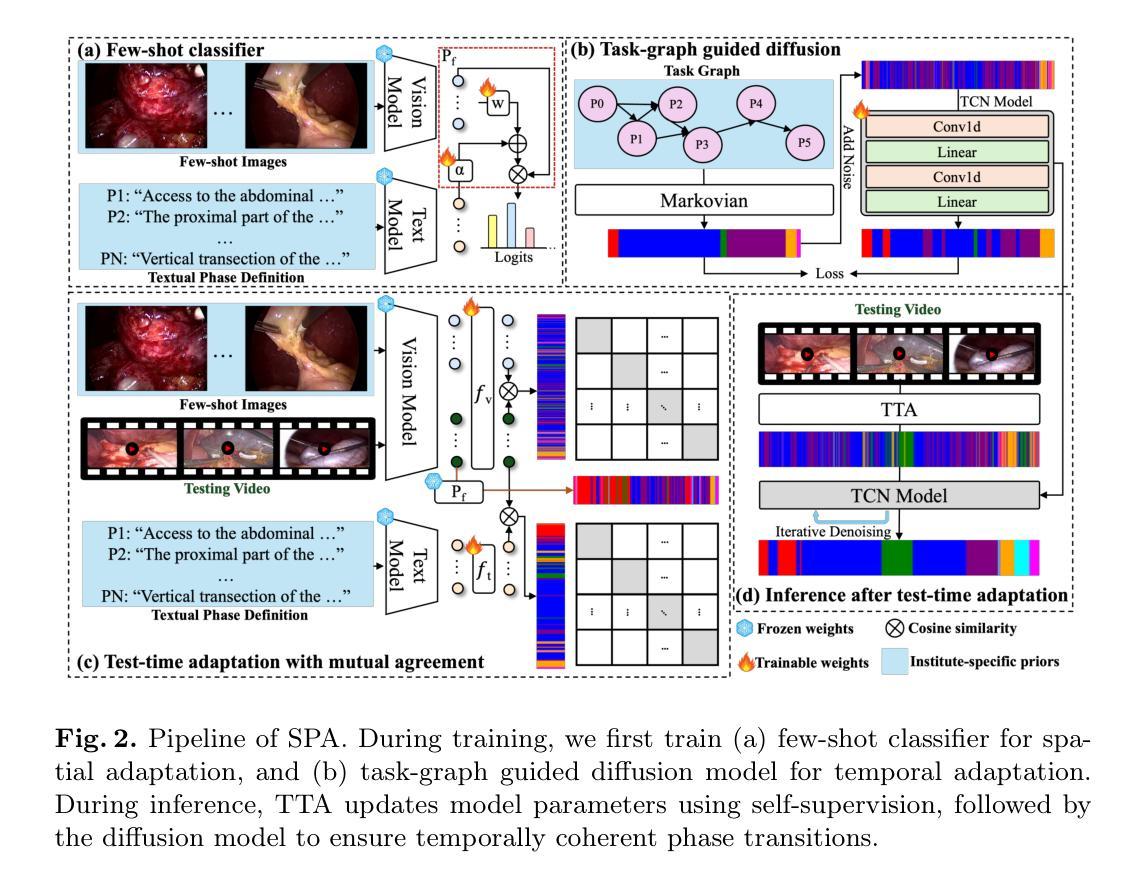
Recognizing Surgical Phases Anywhere: Few-Shot Test-time Adaptation and Task-graph Guided Refinement
Authors:Kun Yuan, Tingxuan Chen, Shi Li, Joel L. Lavanchy, Christian Heiliger, Ege Özsoy, Yiming Huang, Long Bai, Nassir Navab, Vinkle Srivastav, Hongliang Ren, Nicolas Padoy
The complexity and diversity of surgical workflows, driven by heterogeneous operating room settings, institutional protocols, and anatomical variability, present a significant challenge in developing generalizable models for cross-institutional and cross-procedural surgical understanding. While recent surgical foundation models pretrained on large-scale vision-language data offer promising transferability, their zero-shot performance remains constrained by domain shifts, limiting their utility in unseen surgical environments. To address this, we introduce Surgical Phase Anywhere (SPA), a lightweight framework for versatile surgical workflow understanding that adapts foundation models to institutional settings with minimal annotation. SPA leverages few-shot spatial adaptation to align multi-modal embeddings with institution-specific surgical scenes and phases. It also ensures temporal consistency through diffusion modeling, which encodes task-graph priors derived from institutional procedure protocols. Finally, SPA employs dynamic test-time adaptation, exploiting the mutual agreement between multi-modal phase prediction streams to adapt the model to a given test video in a self-supervised manner, enhancing the reliability under test-time distribution shifts. SPA is a lightweight adaptation framework, allowing hospitals to rapidly customize phase recognition models by defining phases in natural language text, annotating a few images with the phase labels, and providing a task graph defining phase transitions. The experimental results show that the SPA framework achieves state-of-the-art performance in few-shot surgical phase recognition across multiple institutions and procedures, even outperforming full-shot models with 32-shot labeled data. Code is available at https://github.com/CAMMA-public/SPA
手术流程的复杂性和多样性,受到手术室设置、机构协议和解剖结构差异的影响,在为跨机构和跨手术程序手术理解开发可推广模型时面临重大挑战。虽然最近基于大规模视觉语言数据的预训练手术基础模型显示出有希望的迁移能力,但它们的零样本性能仍受到领域偏移的限制,在未见过的手术环境中效用有限。为了解决这个问题,我们引入了手术阶段无处不在(SPA),这是一个用于通用手术流程理解的轻便框架,它使用最少的注释来适应机构设置。SPA利用少样本空间适应来对齐多模式嵌入与特定于机构的手术场景和阶段。它还通过扩散建模确保时间一致性,该建模编码了来自机构程序协议的任务图先验。最后,SPA采用动态测试时间适应,利用多模式阶段预测流之间的相互协议以自我监督的方式适应给定测试视频,在测试时间分布变化的情况下提高可靠性。SPA是一个轻便的适应框架,允许医院通过用自然语言文本定义阶段、注释几张带有阶段标签的图像并提供定义阶段过渡的任务图来快速定制阶段识别模型。实验结果表明,SPA框架在多个机构和程序中的少样本手术阶段识别方面达到了最新性能水平,即使在拥有32个样本全标记数据的情况下也表现出卓越的性能。代码可通过 https://github.com/CAMMA-public/SPA 获得。
论文及项目相关链接
PDF Accepted by MICCAI 2025
Summary
该文介绍了一个名为Surgical Phase Anywhere(SPA)的轻量级框架,该框架旨在解决由于手术工作流的复杂性和多样性带来的跨机构与跨流程手术理解难题。SPA框架通过少量空间适应来适应机构特定的手术场景和阶段,并利用扩散建模确保时间一致性。此外,SPA还采用动态测试时间适应,利用多模式阶段预测流之间的相互一致性,以自我监督的方式适应给定的测试视频,提升模型在测试时间分布变化下的可靠性。SPA框架允许医院通过自然语言文本定义阶段、对少数图像进行阶段标签注释以及提供定义阶段转换的任务图来快速定制阶段识别模型。实验结果显示,SPA框架在多个机构和流程中的小样本手术阶段识别中取得了最先进的性能表现。
Key Takeaways
- Surgical Phase Anywhere (SPA) 是一个轻量级框架,用于理解具有复杂性和多样性的手术工作流程。
- SPA通过少量空间适应适应机构特定的手术场景和阶段。
- 扩散建模技术用于确保时间一致性。
- 动态测试时间适应利用多模式预测流的相互一致性来提升模型可靠性。
- SPA允许医院快速定制阶段识别模型,只需通过自然语言文本定义阶段、对少数图像进行标注以及提供任务图。
- SPA框架在多个机构和流程的小样本手术阶段识别中表现先进。
点此查看论文截图

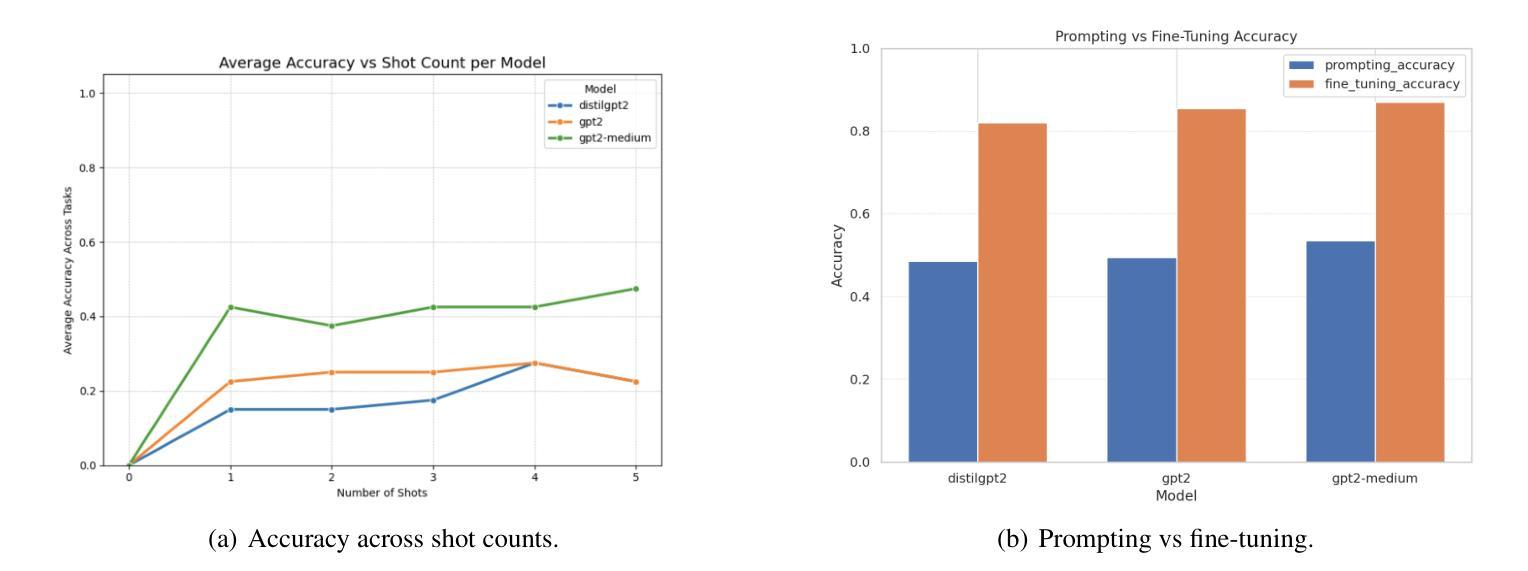
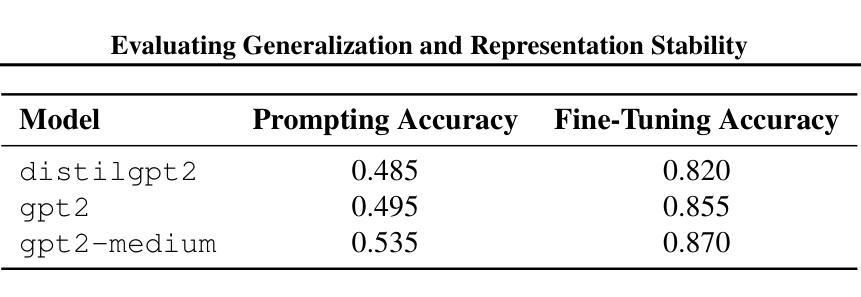
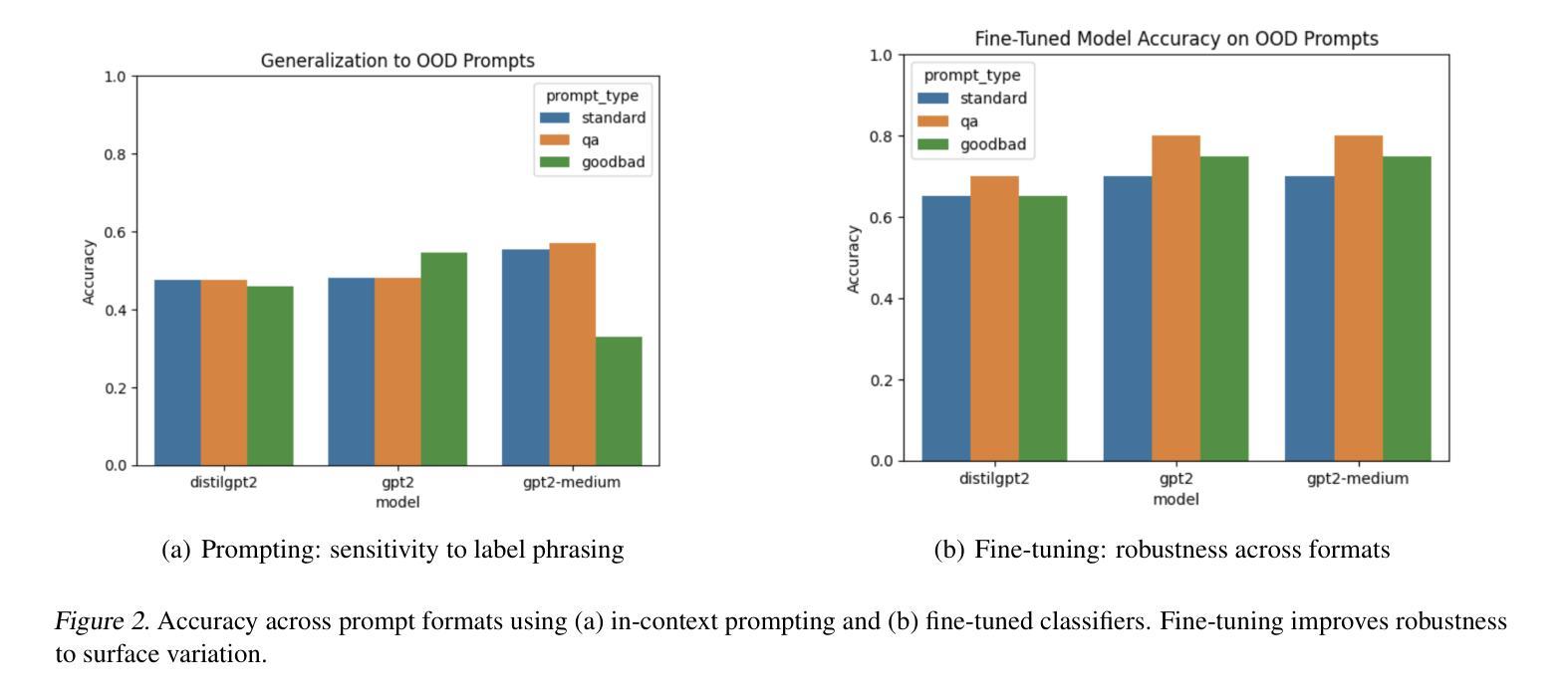
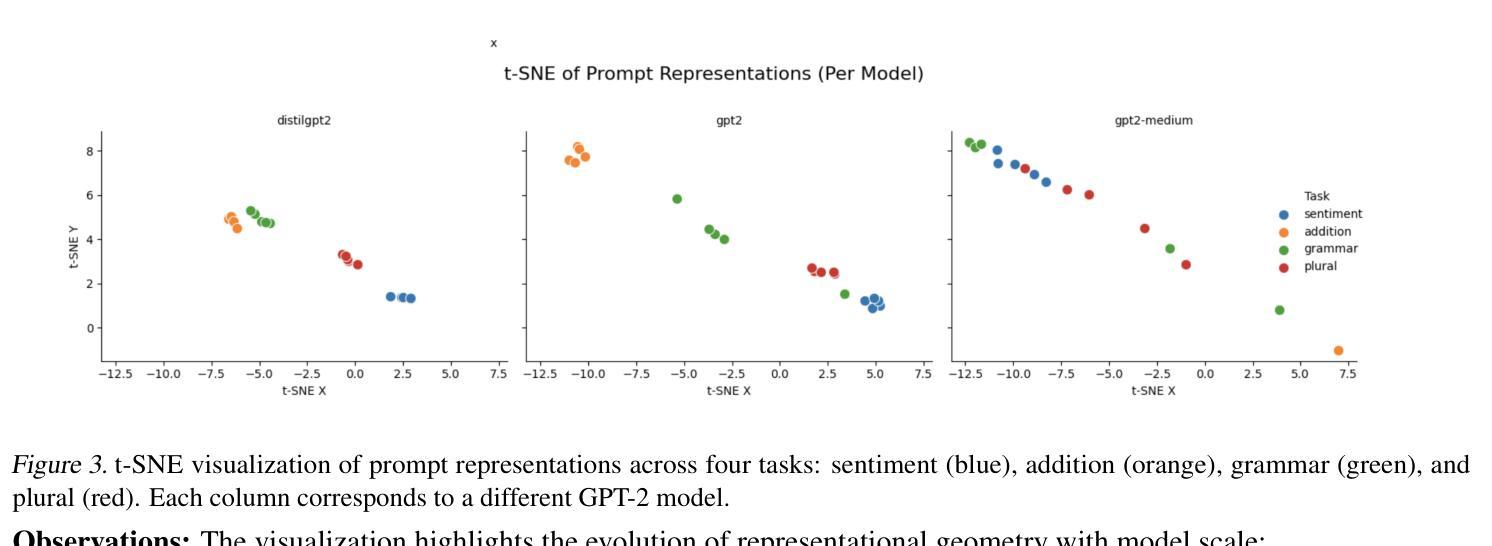
Evaluating Generalization and Representation Stability in Small LMs via Prompting, Fine-Tuning and Out-of-Distribution Prompts
Authors:Rahul Raja, Arpita Vats
We investigate the generalization capabilities of small language models under two popular adaptation paradigms: few-shot prompting and supervised fine-tuning. While prompting is often favored for its parameter efficiency and flexibility, it remains unclear how robust this approach is in low-resource settings and under distributional shifts. This paper presents a comparative study of prompting and fine-tuning across task formats, prompt styles, and model scales, with a focus on their behavior in both in-distribution and out-of-distribution (OOD) settings. Beyond accuracy, we analyze the internal representations learned by each approach to assess the stability and abstraction of task-specific features. Our findings highlight critical differences in how small models internalize and generalize knowledge under different adaptation strategies. This work offers practical guidance for model selection in low-data regimes and contributes empirical insight into the ongoing debate over prompting versus fine-tuning. Code for the experiments is available at the following
我们研究了小型语言模型在两种流行的适应范式下的泛化能力:小样本提示和监督微调。虽然提示因其参数效率和灵活性而备受青睐,但在低资源环境和分布转移的情况下,该方法的稳健性尚不清楚。本文对提示和微调在任务格式、提示风格、模型规模上的表现进行了比较研究,重点关注其在内部分布和外部分布(OOD)环境下的表现。除了准确性之外,我们还分析了每种方法学到的内部表征,以评估任务特定特征的稳定性和抽象性。我们的研究结果强调了不同适应策略下小型模型在内部化和泛化知识方面的关键差异。这项工作为低数据环境下的模型选择提供了实际指导,并为关于提示与微调的争论提供了实证见解。实验的代码如下所示。
论文及项目相关链接
PDF Accepted at ICML
Summary
本文探讨了小语言模型在两种流行的适应范式下的泛化能力:即小样本提示和精细监督调整。虽然提示因其参数效率和灵活性而受到青睐,但在资源有限和分布转移的情况下,其稳健性尚不清楚。本文重点研究了提示和调整在不同任务格式、提示风格、模型规模方面的表现,以及在常规与异常设置下的行为。除了准确性之外,我们还分析了每种方法的内部表示,以评估特定任务的稳定性和抽象性。研究结果表明不同适应策略下模型对知识的内在化和泛化能力的差异。本工作在低数据状态下的模型选择方面提供了实用指导,并对关于提示与调整的争议提供了实证见解。
Key Takeaways
- 本文比较了小语言模型在两种主要适应范式下的泛化能力:小样本提示和精细监督调整。
- 探讨了提示在低资源设置和分布转移下的稳健性。
- 实验研究了不同任务格式、提示风格和模型规模下的提示和调整的表现。
- 分析两种方法在常规和异常设置下的行为差异。
- 除了准确性评估外,还深入分析了两种方法的内部表示和特定任务的稳定性和抽象性。
- 研究揭示了不同适应策略下模型对知识的内在化和泛化能力的显著差异。
点此查看论文截图

Provably Improving Generalization of Few-Shot Models with Synthetic Data
Authors:Lan-Cuong Nguyen, Quan Nguyen-Tri, Bang Tran Khanh, Dung D. Le, Long Tran-Thanh, Khoat Than
Few-shot image classification remains challenging due to the scarcity of labeled training examples. Augmenting them with synthetic data has emerged as a promising way to alleviate this issue, but models trained on synthetic samples often face performance degradation due to the inherent gap between real and synthetic distributions. To address this limitation, we develop a theoretical framework that quantifies the impact of such distribution discrepancies on supervised learning, specifically in the context of image classification. More importantly, our framework suggests practical ways to generate good synthetic samples and to train a predictor with high generalization ability. Building upon this framework, we propose a novel theoretical-based algorithm that integrates prototype learning to optimize both data partitioning and model training, effectively bridging the gap between real few-shot data and synthetic data. Extensive experiments results show that our approach demonstrates superior performance compared to state-of-the-art methods, outperforming them across multiple datasets.
少样本图像分类由于缺少标记的训练样本而仍然具有挑战性。通过合成数据增强它们已成为一种很有前途的解决这一问题的方法,但在合成样本上训练的模型通常由于真实和合成分布之间的固有差距而面临性能下降的问题。为了解决这一局限性,我们开发了一个理论框架,该框架对分布差异对监督学习的影响进行了量化,特别是在图像分类的上下文中。更重要的是,我们的框架提出了生成良好合成样本和训练具有高强泛化能力的预测器的实用方法。基于该框架,我们提出了一种新的基于理论算法的原型学习整合法,优化数据分区和模型训练,有效地弥合了真实少样本数据和合成数据之间的差距。广泛的实验结果表明,我们的方法相较于最新技术表现出卓越的性能,并在多个数据集上超越了它们。
论文及项目相关链接
PDF ICML 2025. Our code is released at https://github.com/Fsoft-AIC/ProtoAug
Summary
该摘要针对少样本图像分类问题,提出一个理论框架,用于量化真实和合成样本分布之间的差异对监督学习的影响,并基于此框架提出了一个基于原型学习的新算法。该算法旨在缩小真实少样本数据和合成数据之间的差距,提高模型的泛化能力,并在多个数据集上的实验结果表明其性能优于现有方法。
Key Takeaways
- 提出理论框架量化真实和合成样本分布差异对监督学习的影响。
- 框架建议生成高质量合成样本的方法。
- 提出基于原型学习的新算法,优化数据划分和模型训练。
- 算法旨在缩小真实少样本数据和合成数据之间的差距。
- 该方法在多数据集上的实验性能优于现有技术。
- 方法为少样本图像分类问题提供了新的解决方案。
点此查看论文截图

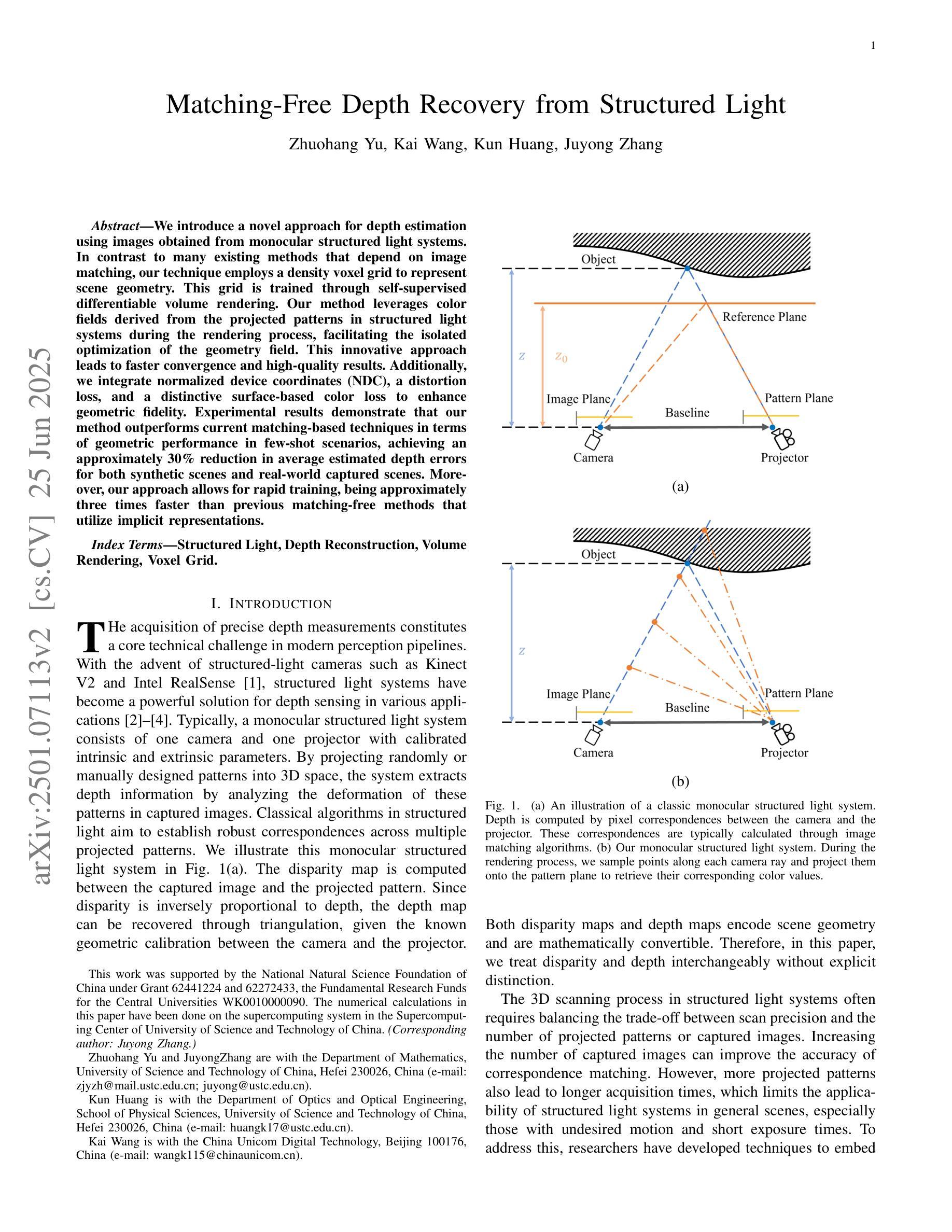
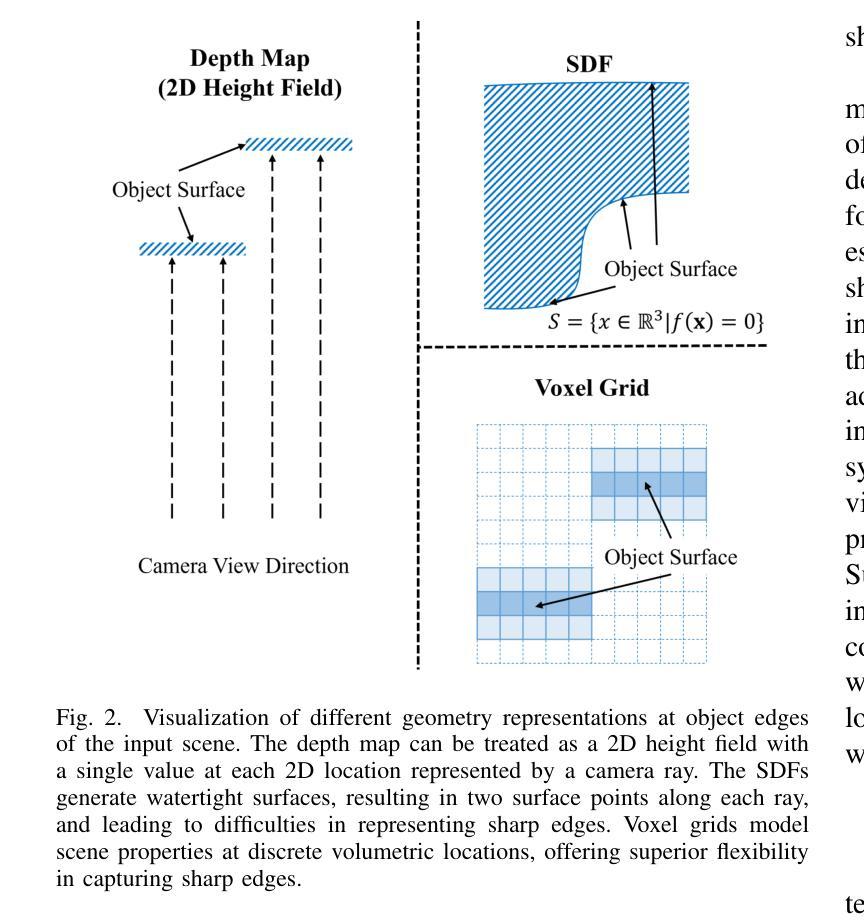
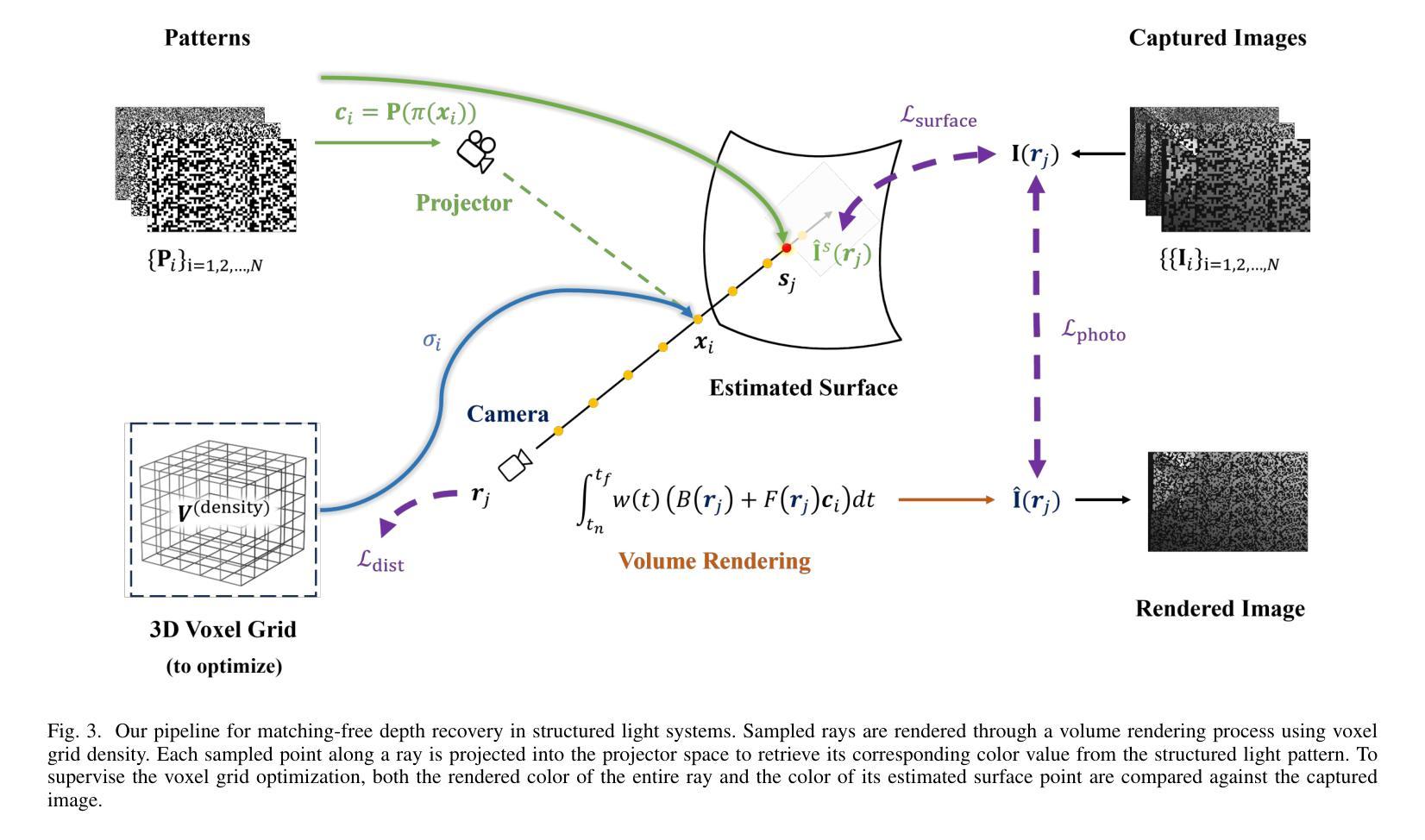
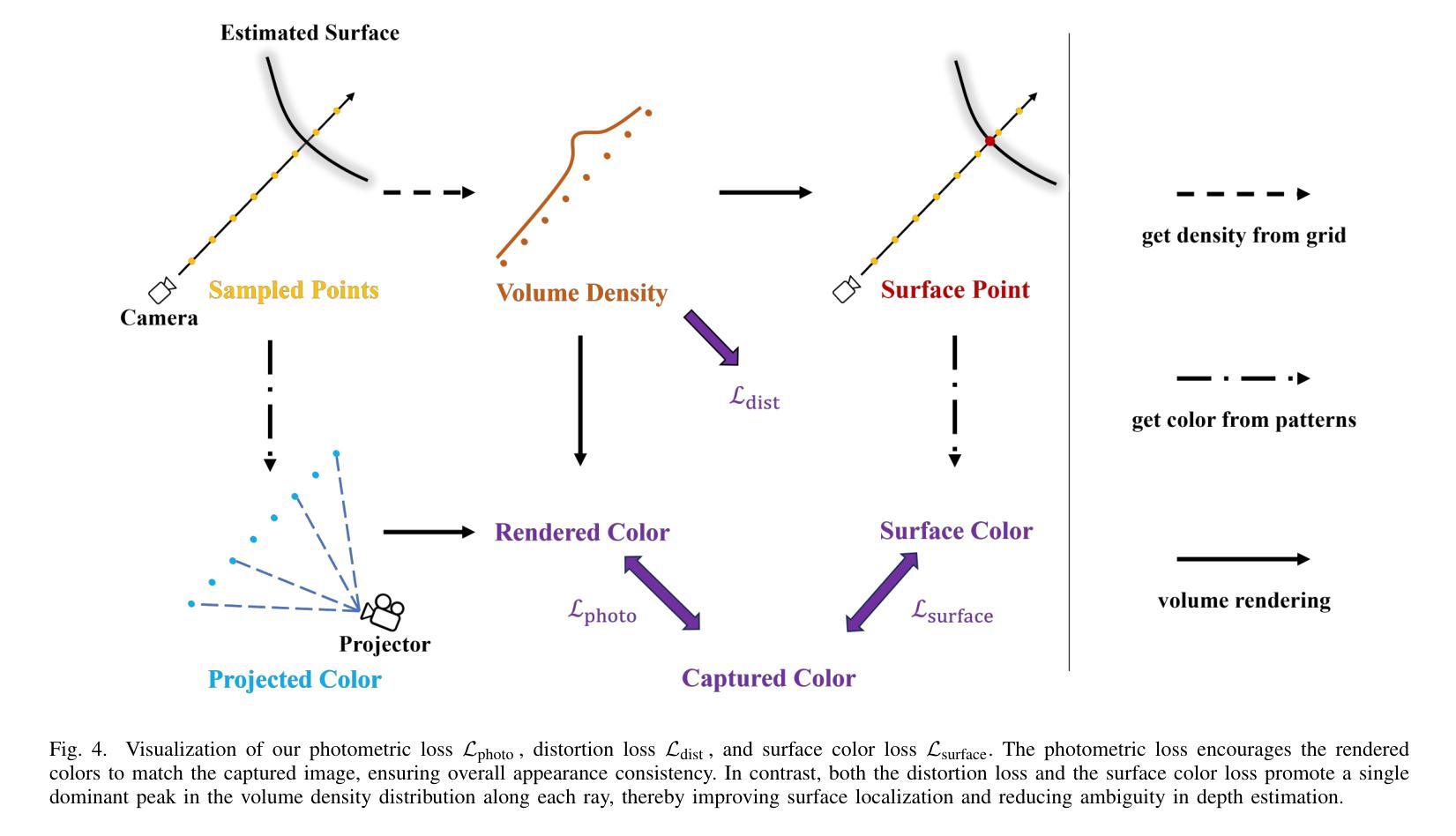
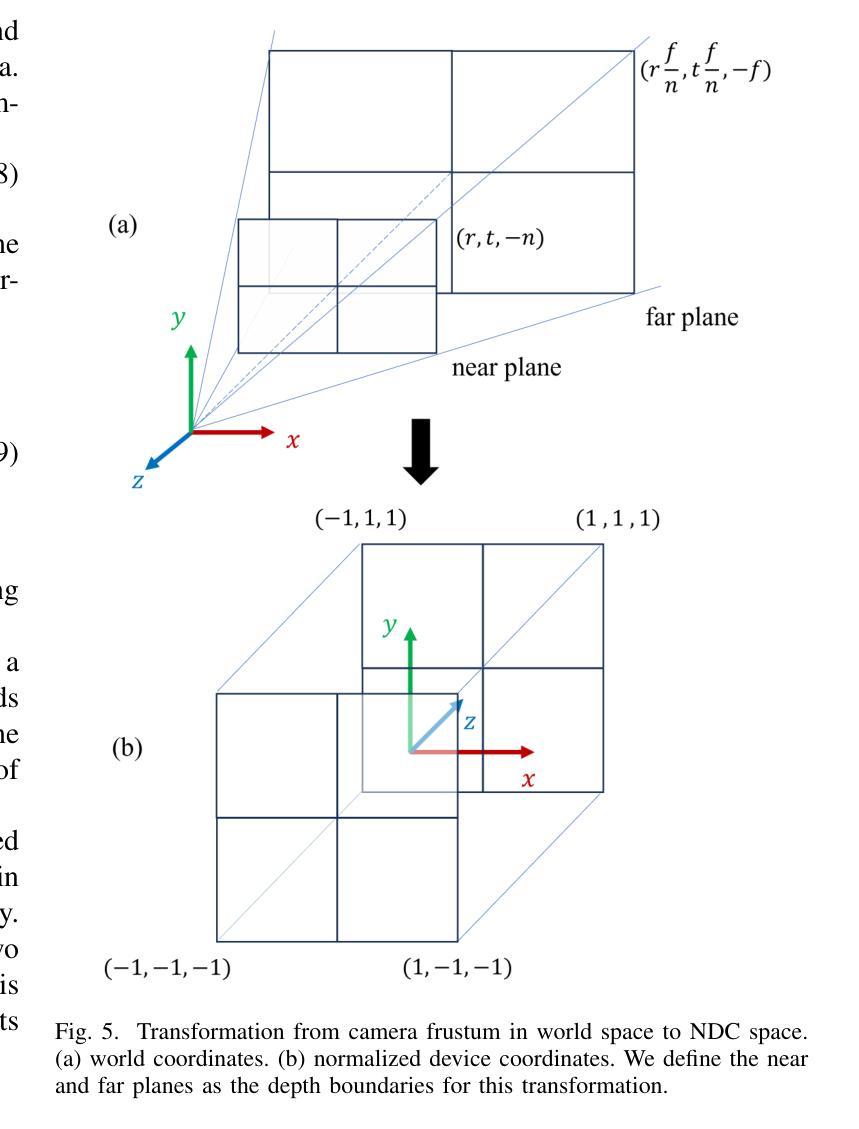
Matching-Free Depth Recovery from Structured Light
Authors:Zhuohang Yu, Kai Wang, Kun Huang, Juyong Zhang
We introduce a novel approach for depth estimation using images obtained from monocular structured light systems. In contrast to many existing methods that depend on image matching, our technique employs a density voxel grid to represent scene geometry. This grid is trained through self-supervised differentiable volume rendering. Our method leverages color fields derived from the projected patterns in structured light systems during the rendering process, facilitating the isolated optimization of the geometry field. This innovative approach leads to faster convergence and high-quality results. Additionally, we integrate normalized device coordinates (NDC), a distortion loss, and a distinctive surface-based color loss to enhance geometric fidelity. Experimental results demonstrate that our method outperforms current matching-based techniques in terms of geometric performance in few-shot scenarios, achieving an approximately 30% reduction in average estimated depth errors for both synthetic scenes and real-world captured scenes. Moreover, our approach allows for rapid training, being approximately three times faster than previous matching-free methods that utilize implicit representations.
我们介绍了一种利用从单目结构光系统获取的图片进行深度估计的新方法。与许多依赖于图像匹配的现有方法不同,我们的技术采用密度体素网格来表示场景几何。该网格通过自监督的可微分体积渲染进行训练。我们的方法在渲染过程中利用结构光系统中投影图案衍生的颜色场,便于几何场的独立优化。这一创新方法导致更快的收敛和高质量的结果。此外,我们集成了归一化设备坐标(NDC)、畸变损失和独特的基于表面的颜色损失,以提高几何保真度。实验结果表明,我们的方法在少样本场景下的几何性能优于当前的基于匹配的技术,在合成场景和现实世界捕获的场景上平均估计深度误差降低了约30%。而且,我们的方法训练迅速,大约是之前使用隐式表示的无匹配方法的三倍速度。
论文及项目相关链接
PDF 13 pages, 10 figures
Summary
本文介绍了一种使用单目结构光系统获取的图像进行深度估计的新方法。与依赖图像匹配的现有方法不同,我们的技术采用密度体素网格表示场景几何。通过自我监督的可微分体积渲染进行训练,并利用结构光系统中投影图案的颜色场促进几何场的独立优化。此方法导致更快的收敛和高品质的结果。此外,集成了归一化设备坐标(NDC)、畸变损失和基于表面的颜色损失来提高几何保真度。实验结果表明,我们的方法在少样本场景中的几何性能优于当前的基于匹配的技术,在合成场景和真实捕获场景中平均估计深度误差降低了约30%。而且,我们的方法训练迅速,大约是之前使用隐式表示的无匹配方法的三倍速度。
Key Takeaways
- 介绍了一种基于单目结构光系统的图像深度估计新方法。
- 采用密度体素网格表示场景几何,不同于依赖图像匹配的现有方法。
- 通过自我监督的可微分体积渲染进行训练。
- 利用结构光系统的投影图案颜色场优化几何场。
- 方法收敛快速,且实验结果表现高品质。
- 集成了NDC、畸变损失和基于表面的颜色损失以增强几何保真度。
点此查看论文截图
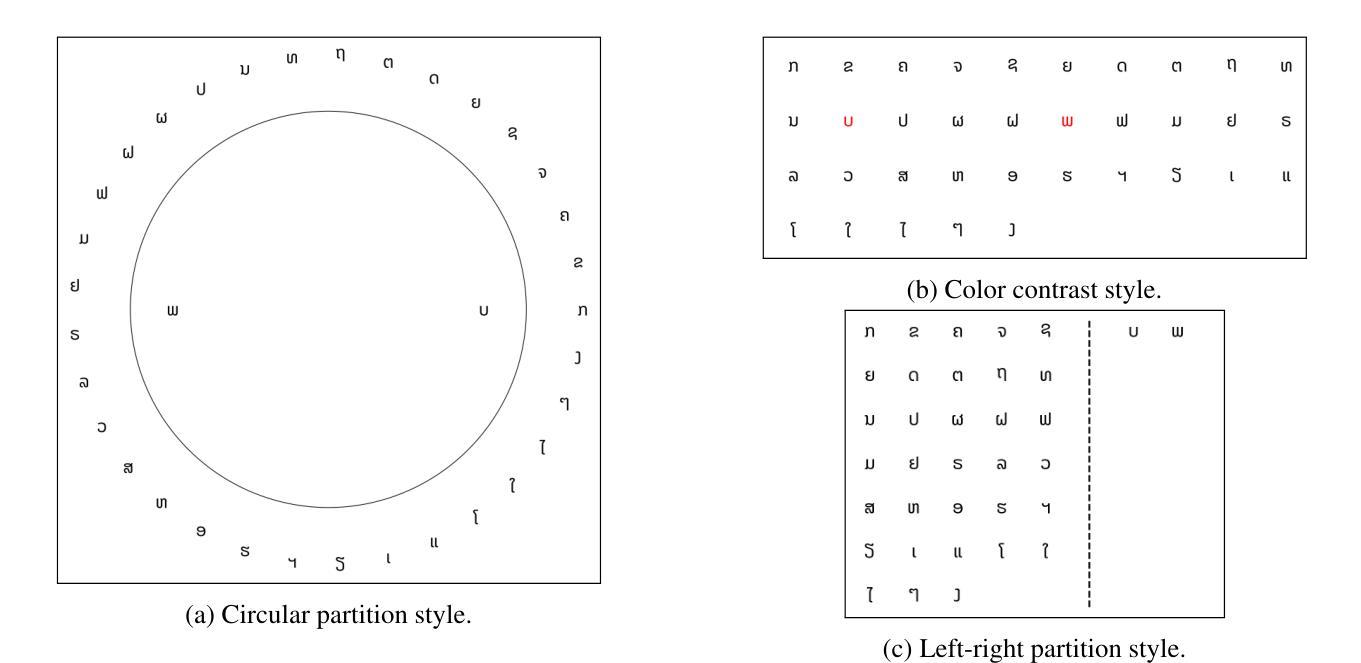
GlyphPattern: An Abstract Pattern Recognition Benchmark for Vision-Language Models
Authors:Zixuan Wu, Yoolim Kim, Carolyn Jane Anderson
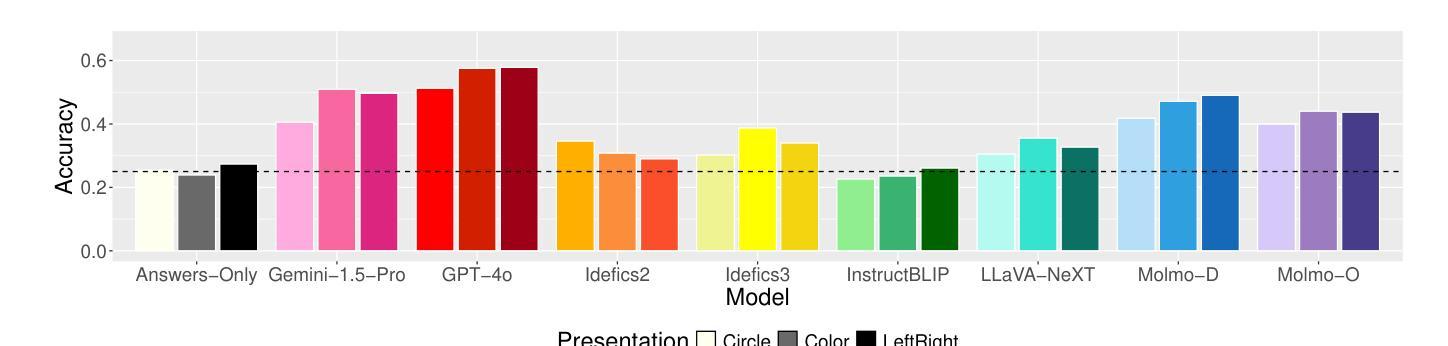
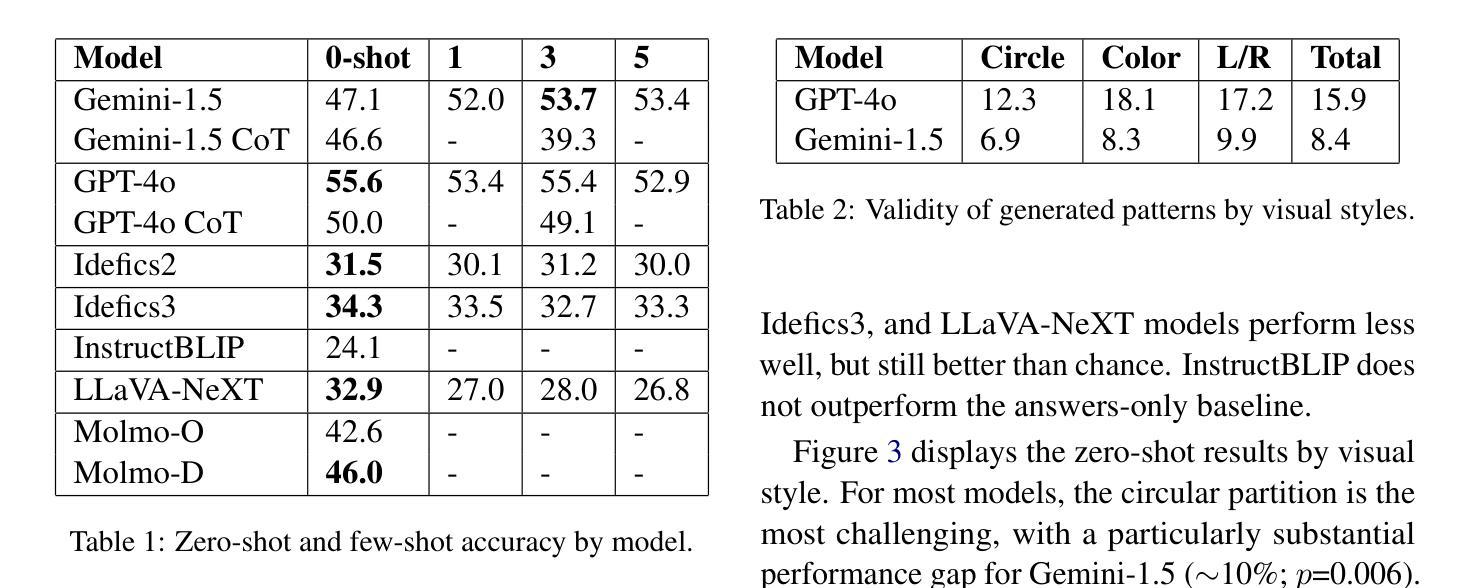
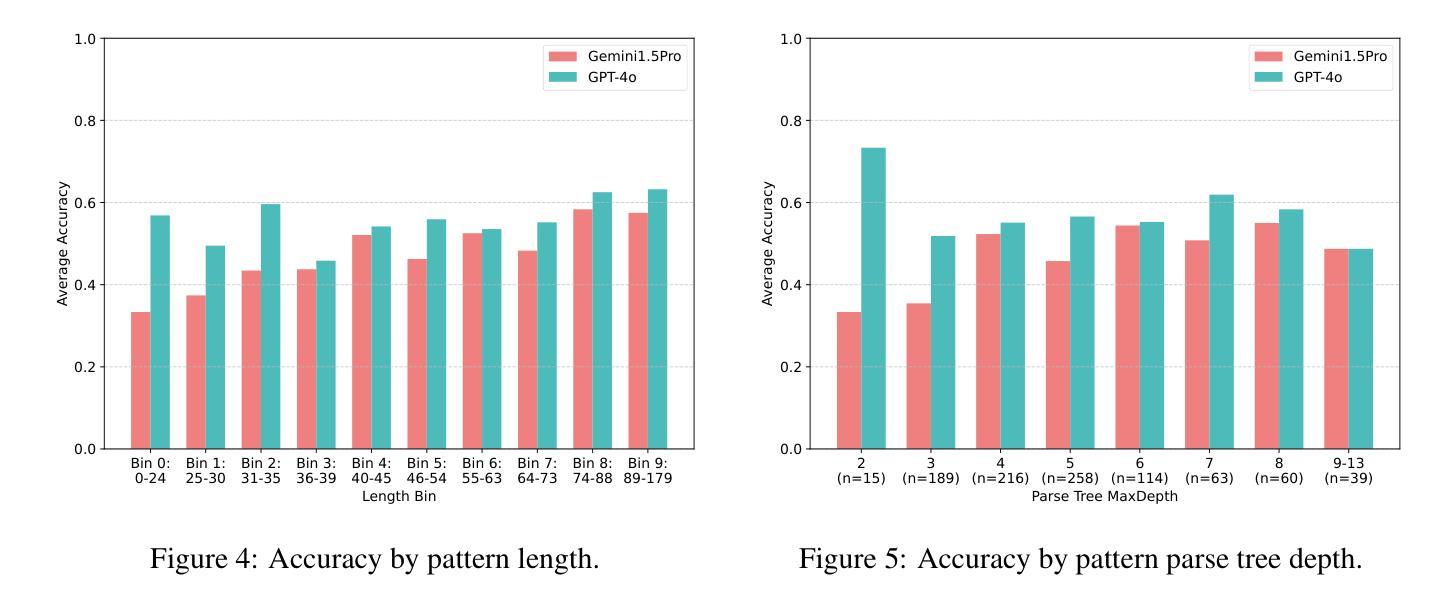
Vision-Language Models (VLMs) building upon the foundation of powerful large language models have made rapid progress in reasoning across visual and textual data. While VLMs perform well on vision tasks that they are trained on, our results highlight key challenges in abstract pattern recognition. We present GlyphPattern, a 954 item dataset that pairs 318 human-written descriptions of visual patterns from 40 writing systems with three visual presentation styles. GlyphPattern evaluates abstract pattern recognition in VLMs, requiring models to understand and judge natural language descriptions of visual patterns. GlyphPattern patterns are drawn from a large-scale cognitive science investigation of human writing systems; as a result, they are rich in spatial reference and compositionality. Our experiments show that GlyphPattern is challenging for state-of-the-art VLMs (GPT-4o achieves only 55% accuracy), with marginal gains from few-shot prompting. Our detailed error analysis reveals challenges at multiple levels, including visual processing, natural language understanding, and pattern generalization.
视觉语言模型(VLMs)建立在强大的大型语言模型的基础上,在跨视觉和文本数据的推理方面取得了快速进展。虽然VLMs在它们所训练的视觉任务上表现良好,但我们的结果突显了抽象模式识别方面的关键挑战。我们推出了GlyphPattern数据集,其中包含954个项目,这些项目将来自40个书写系统的318个人类编写的视觉模式描述与三种视觉呈现风格相匹配。GlyphPattern评估VLMs的抽象模式识别能力,要求模型理解和判断视觉模式的自然语言描述。GlyphPattern的模式来源于对人类书写系统的大规模认知科学调查;因此,它们具有丰富的空间参考和组合性。我们的实验表明,GlyphPattern对最新的VLMs来说是一个挑战(GPT-4o仅达到55%的准确率),而且通过少量提示的改进微乎其微。我们的详细错误分析揭示了多个层次上的挑战,包括视觉处理、自然语言理解和模式泛化。
论文及项目相关链接
Summary
视觉语言模型(VLMs)在跨视觉和文本数据推理方面取得了快速进展。虽然VLMs在训练的视觉任务上表现良好,但我们的结果强调了抽象模式识别方面的关键挑战。我们提出了GlyphPattern数据集,其中包含954个项目,每个项目都有关于来自40种书写系统的视觉模式的318个人类描述,以及与三种视觉呈现风格相匹配。GlyphPattern评估VLMs的抽象模式识别能力,要求模型理解和判断视觉模式的自然语言描述。我们的实验表明,GlyphPattern对最先进的VLMs具有挑战性(GPT-4o仅达到55%的准确率),而且少量提示样本对改善结果贡献有限。详细的错误分析表明挑战涉及多个层面,包括视觉处理、自然语言理解和模式泛化。
Key Takeaways
- VLMs在视觉和文本数据推理方面取得快速进展,但在抽象模式识别方面存在挑战。
- GlyphPattern数据集包含954个项目,旨在评估VLMs的抽象模式识别能力。
- GlyphPattern数据集的视觉模式基于大规模认知科学的人类书写系统研究。
- 最先进的VLMs在GlyphPattern数据集上的准确率为55%,表明具有挑战性。
- 少量提示样本对改善VLMs在GlyphPattern上的表现贡献有限。
- VLMs面临多个层面的挑战,包括视觉处理、自然语言理解和模式泛化。
点此查看论文截图