⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-27 更新
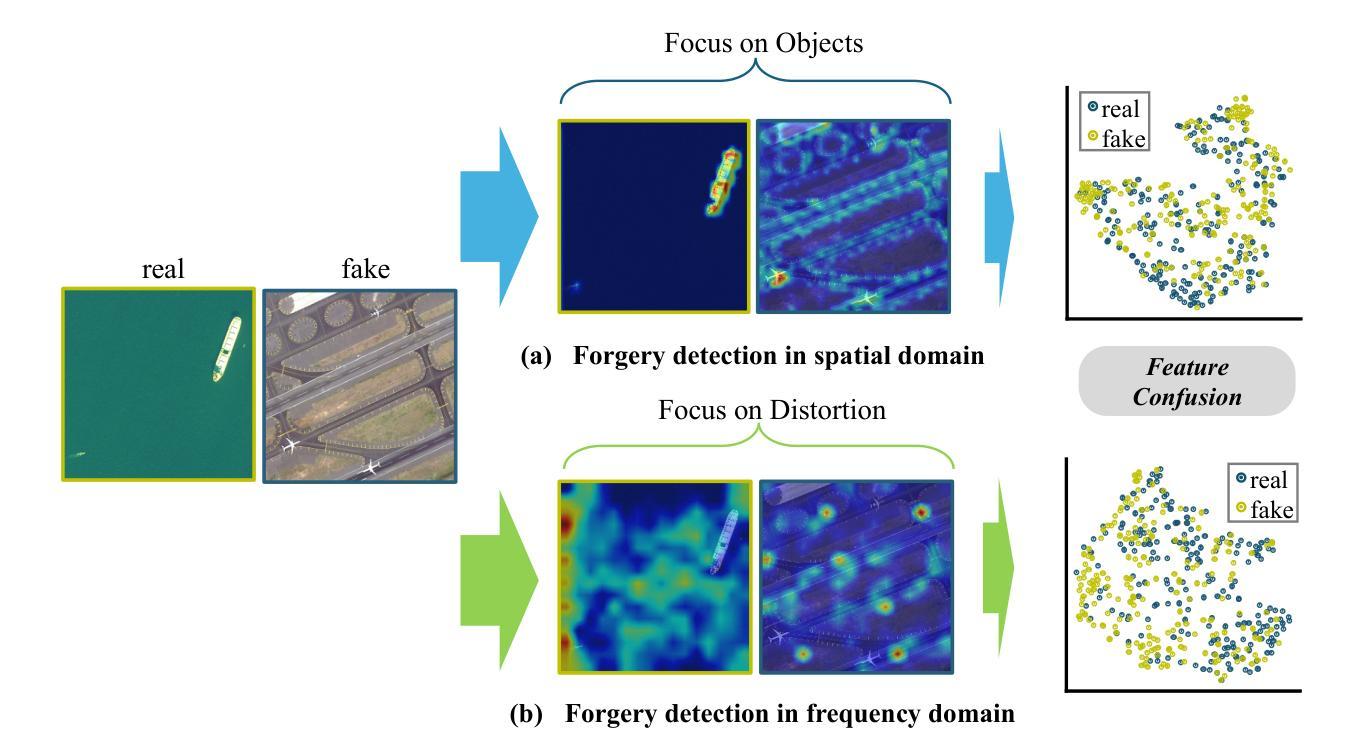
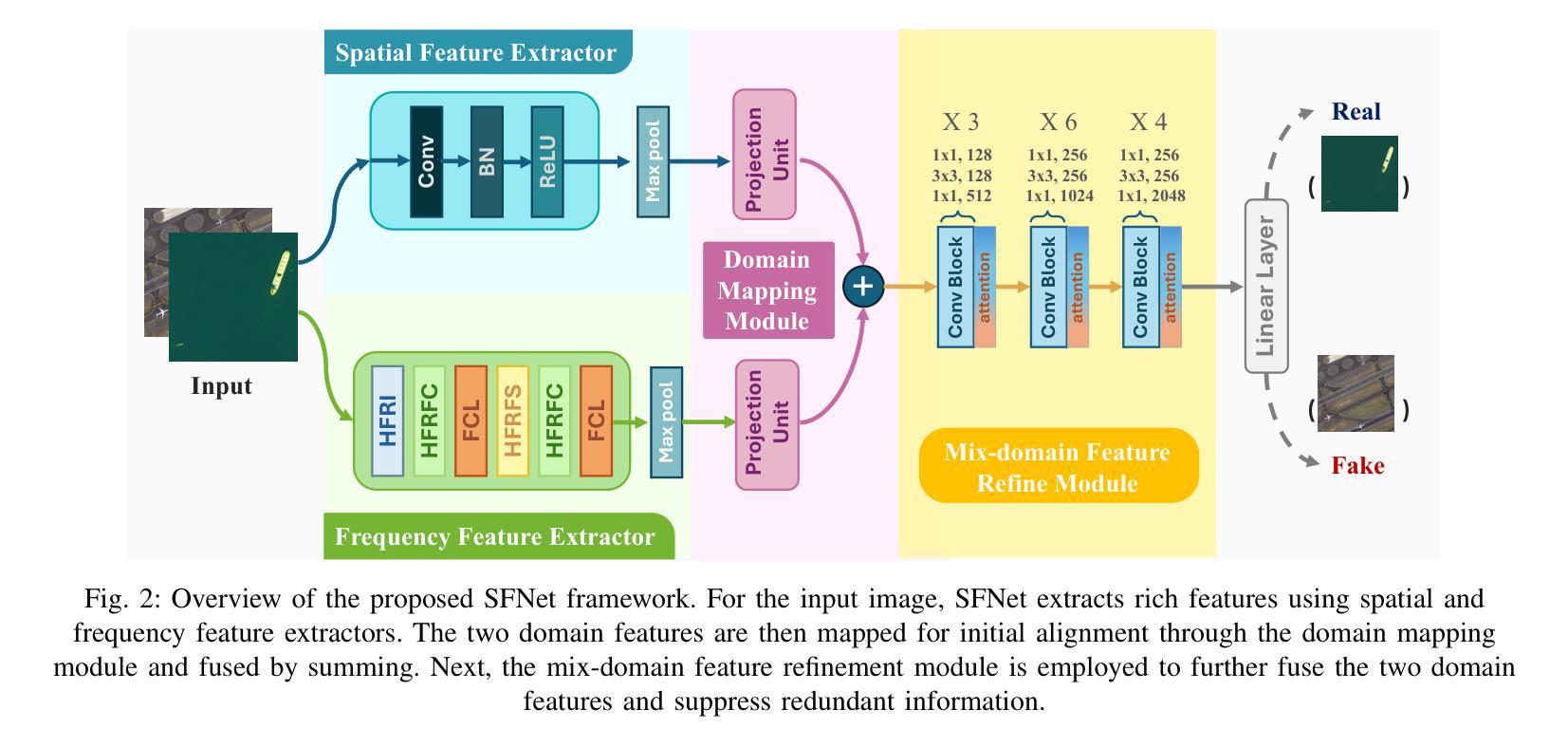
SFNet: Fusion of Spatial and Frequency-Domain Features for Remote Sensing Image Forgery Detection
Authors:Ji Qi, Xinchang Zhang, Dingqi Ye, Yongjia Ruan, Xin Guo, Shaowen Wang, Haifeng Li
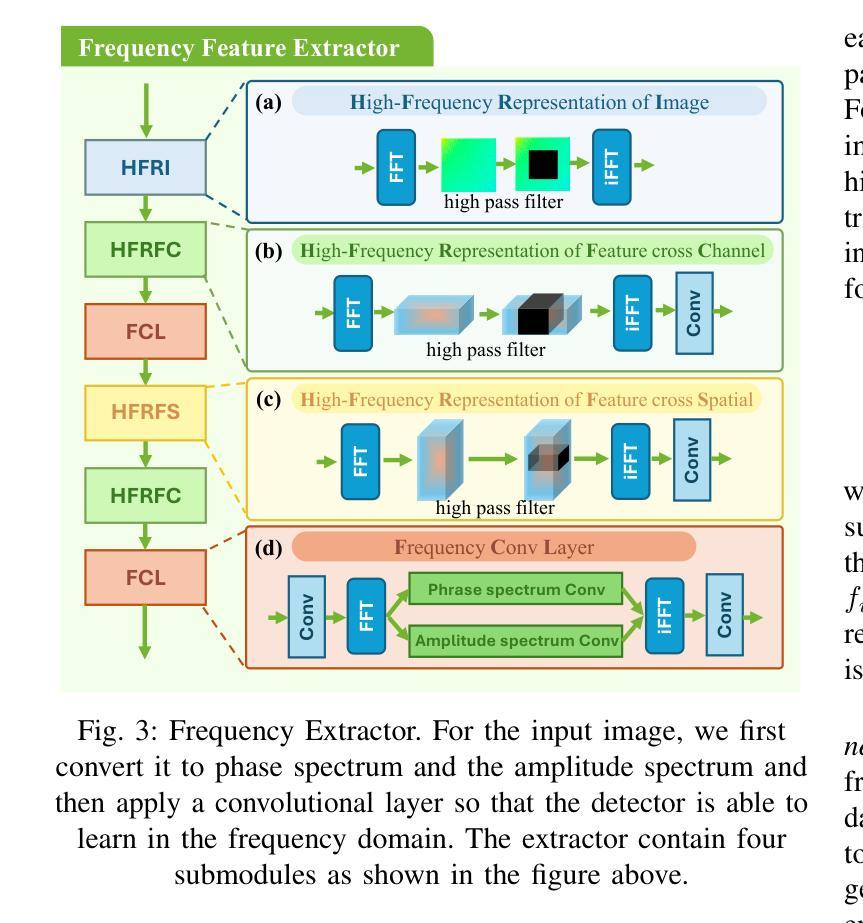
The rapid advancement of generative artificial intelligence is producing fake remote sensing imagery (RSI) that is increasingly difficult to detect, potentially leading to erroneous intelligence, fake news, and even conspiracy theories. Existing forgery detection methods typically rely on single visual features to capture predefined artifacts, such as spatial-domain cues to detect forged objects like roads or buildings in RSI, or frequency-domain features to identify artifacts from up-sampling operations in adversarial generative networks (GANs). However, the nature of artifacts can significantly differ depending on geographic terrain, land cover types, or specific features within the RSI. Moreover, these complex artifacts evolve as generative models become more sophisticated. In short, over-reliance on a single visual cue makes existing forgery detectors struggle to generalize across diverse remote sensing data. This paper proposed a novel forgery detection framework called SFNet, designed to identify fake images in diverse remote sensing data by leveraging spatial and frequency domain features. Specifically, to obtain rich and comprehensive visual information, SFNet employs two independent feature extractors to capture spatial and frequency domain features from input RSIs. To fully utilize the complementary domain features, the domain feature mapping module and the hybrid domain feature refinement module(CBAM attention) of SFNet are designed to successively align and fuse the multi-domain features while suppressing redundant information. Experiments on three datasets show that SFNet achieves an accuracy improvement of 4%-15.18% over the state-of-the-art RS forgery detection methods and exhibits robust generalization capabilities. The code is available at https://github.com/GeoX-Lab/RSTI/tree/main/SFNet.
生成式人工智能的快速发展正在产生越来越难以检测的虚假遥感图像(RSI),这可能导致错误的情报、虚假新闻,甚至阴谋论。现有的伪造检测手段通常依赖于单一视觉特征来捕捉预定义的伪迹,如基于空间域的线索来检测遥感图像中的伪造对象(如道路或建筑物),或通过频域特征来识别生成对抗网络(GANs)中的上采样操作产生的伪迹。然而,伪迹的性质可能因地理地形、土地覆盖类型或遥感图像内的特定特征而大相径庭。此外,随着生成模型变得越来越复杂,这些复杂的伪迹也不断发展变化。简而言之,过分依赖单一视觉线索使得现有伪造检测器在应对多样化遥感数据时难以通用化。本文提出了一种新型的伪造检测框架SFNet,旨在利用空间域和频域特征在多样化的遥感数据中识别虚假图像。具体而言,为了获取丰富而全面的视觉信息,SFNet采用两个独立的特征提取器从输入遥感图像中提取空间和频域特征。为了充分利用互补领域特征,SFNet设计了领域特征映射模块和混合领域特征细化模块(CBAM注意力模块),以按顺序对齐并融合多领域特征,同时抑制冗余信息。在三个数据集上的实验表明,与最新的遥感伪造检测方法相比,SFNet在准确率上提高了4%-15.18%,并表现出稳健的泛化能力。代码可在https://github.com/GeoX-Lab/RSTI/tree/main/SFNet获得。
论文及项目相关链接
Summary
这篇论文针对遥感图像伪造检测的问题,提出了一种名为SFNet的新型检测框架。该框架通过结合空间域和频域特征,旨在识别不同遥感数据中的虚假图像。SFNet采用两个独立特征提取器获取丰富的视觉信息,并通过特征映射和混合特征细化模块融合多域特征,从而提高检测准确率并展现出良好的泛化能力。
Key Takeaways
- 生成式人工智能的快速发展产生了越来越难以检测的伪造遥感图像,可能导致情报错误、虚假新闻和阴谋论等问题。
- 传统遥感图像伪造检测主要依赖单一视觉特征来捕捉预设的伪像,如空间域线索或频率域特征。
- 伪像的性质可根据地理地形、地面覆盖类型或遥感图像中的特定特征而显著不同。
- 随着生成模型变得更加复杂,伪像的性质也会不断演变。
- 过多的依赖单一视觉线索使得现有的伪造检测器在多样化的遥感数据上难以通用化。
- SFNet框架通过结合空间域和频率域特征,旨在识别不同遥感数据中的虚假图像,提高了检测准确性并表现出强大的泛化能力。
点此查看论文截图

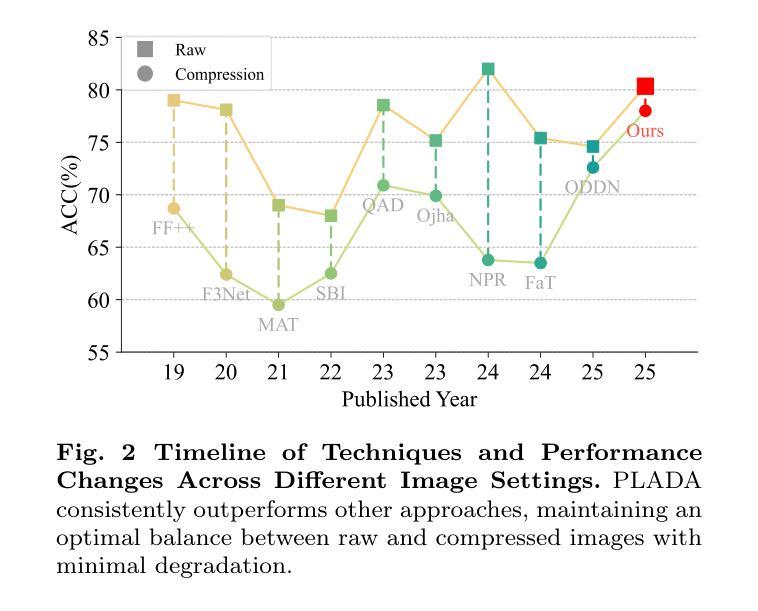
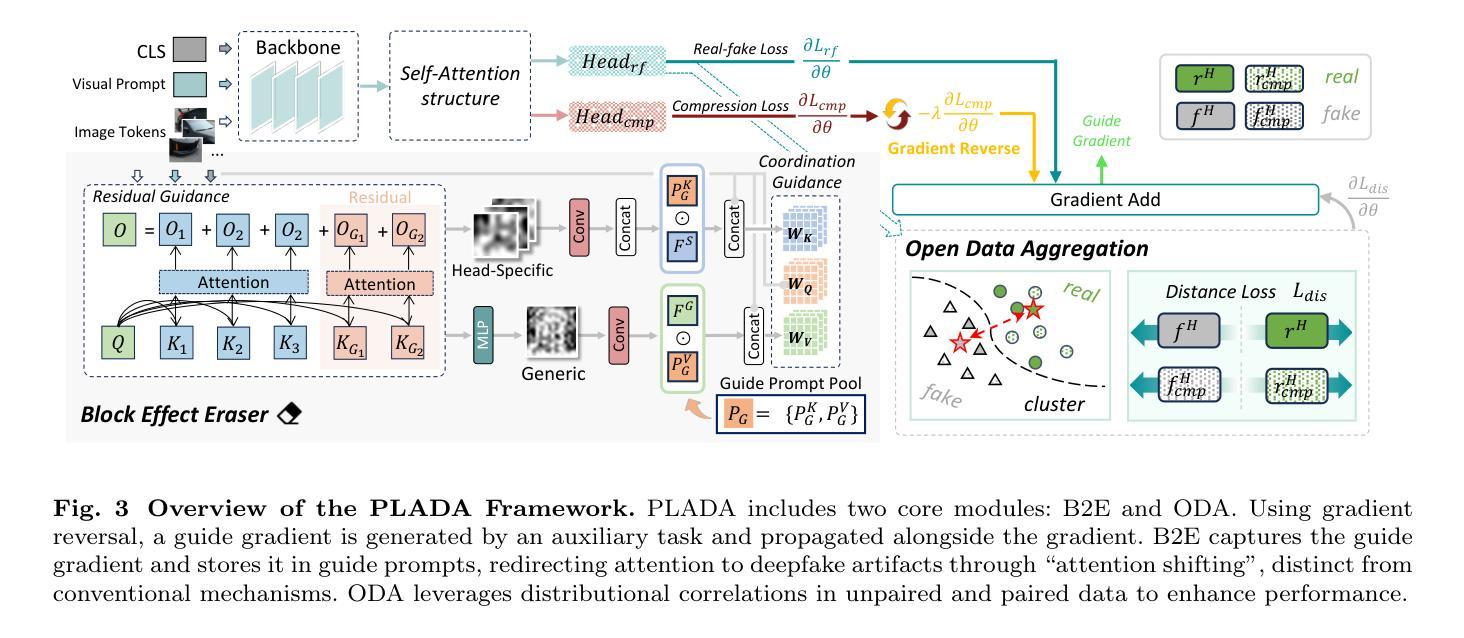
Pay Less Attention to Deceptive Artifacts: Robust Detection of Compressed Deepfakes on Online Social Networks
Authors:Manyi Li, Renshuai Tao, Yufan Liu, Chuangchuang Tan, Haotong Qin, Bing Li, Yunchao Wei, Yao Zhao
With the rapid advancement of deep learning, particularly through generative adversarial networks (GANs) and diffusion models (DMs), AI-generated images, or deepfakes", have become nearly indistinguishable from real ones. These images are widely shared across Online Social Networks (OSNs), raising concerns about their misuse. Existing deepfake detection methods overlook the block effects” introduced by compression in OSNs, which obscure deepfake artifacts, and primarily focus on raw images, rarely encountered in real-world scenarios. To address these challenges, we propose PLADA (Pay Less Attention to Deceptive Artifacts), a novel framework designed to tackle the lack of paired data and the ineffective use of compressed images. PLADA consists of two core modules: Block Effect Eraser (B2E), which uses a dual-stage attention mechanism to handle block effects, and Open Data Aggregation (ODA), which processes both paired and unpaired data to improve detection. Extensive experiments across 26 datasets demonstrate that PLADA achieves a remarkable balance in deepfake detection, outperforming SoTA methods in detecting deepfakes on OSNs, even with limited paired data and compression. More importantly, this work introduces the ``block effect” as a critical factor in deepfake detection, providing a robust solution for open-world scenarios. Our code is available at https://github.com/ManyiLee/PLADA.
随着深度学习尤其是生成对抗网络(GANs)和扩散模型(DMs)的快速发展,人工智能生成的图像,即所谓的“深度伪造”(deepfakes)图像,已经变得几乎与真实图像无法区分。这些图像在在线社交网络(OSNs)上被广泛共享,引发了关于其误用的担忧。现有的深度伪造检测方法忽视了OSN中的压缩所引入的“块效应”,这掩盖了深度伪造的痕迹,并且主要关注原始图像,这在现实场景中很少见。为了应对这些挑战,我们提出了PLADA(少关注欺骗性痕迹),这是一个旨在解决数据配对缺乏和压缩图像无效使用的新型框架。PLADA由两个核心模块组成:块效应消除器(B2E),它使用两阶段注意力机制来处理块效应;开放数据聚合(ODA),它处理配对和非配对数据以提高检测能力。在26个数据集上的大量实验表明,PLADA在深度伪造检测方面实现了显著的平衡,在OSN上检测深度伪造时表现出色,即使在配对数据有限和存在压缩的情况下也是如此。更重要的是,这项工作引入了“块效应”作为深度伪造检测的关键因素,为开放世界场景提供了稳健的解决方案。我们的代码位于https://github.com/ManyiLee/PLADA。
论文及项目相关链接
PDF 20 pages, 10 figures
Summary
随着深度学习尤其是生成对抗网络(GANs)和扩散模型(DMs)的快速发展,AI生成的图像(“深度伪造”)已几乎无法与真实图像区分。这些图像在在线社交网络上广泛传播,引发了关于其滥用的担忧。现有的深度伪造检测方法忽视了在线社交网络中压缩引入的“块效应”,该效应掩盖了深度伪造的特征,并且主要关注原始图像,在现实世界场景中很少见。针对这些挑战,我们提出了PLADA(少关注欺骗性特征)框架,该框架旨在解决配对数据缺乏和压缩图像使用不当的问题。PLADA由两个核心模块组成:块效应消除器(B2E)使用双阶段注意力机制处理块效应,开放数据聚合(ODA)处理配对和非配对数据以提高检测能力。在26个数据集上的大量实验表明,PLADA在OSN上的深度伪造检测中实现了出色的平衡,在有限的配对数据和压缩情况下也优于最新方法。更重要的是,这项工作将“块效应”作为深度伪造检测的关键因素,为开放世界场景提供了稳健的解决方案。
Key Takeaways
- AI生成的图像(深度伪造)与真实图像难以区分,已在在线社交网络上广泛传播。
- 现有深度伪造检测方法主要关注原始图像,忽视了在线社交网络中压缩图像的“块效应”。
- PLADA框架由两个核心模块组成:块效应消除器和开放数据聚合。
- 块效应消除器使用双阶段注意力机制处理块效应。
- 开放数据聚合能处理配对和非配对数据,提高检测能力。
- PLADA在多个数据集上表现出优秀的深度伪造检测性能,尤其在有限的配对数据和压缩情况下。
- “块效应”是深度伪造检测的关键因素。
点此查看论文截图