⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-27 更新
Why Robots Are Bad at Detecting Their Mistakes: Limitations of Miscommunication Detection in Human-Robot Dialogue
Authors:Ruben Janssens, Jens De Bock, Sofie Labat, Eva Verhelst, Veronique Hoste, Tony Belpaeme
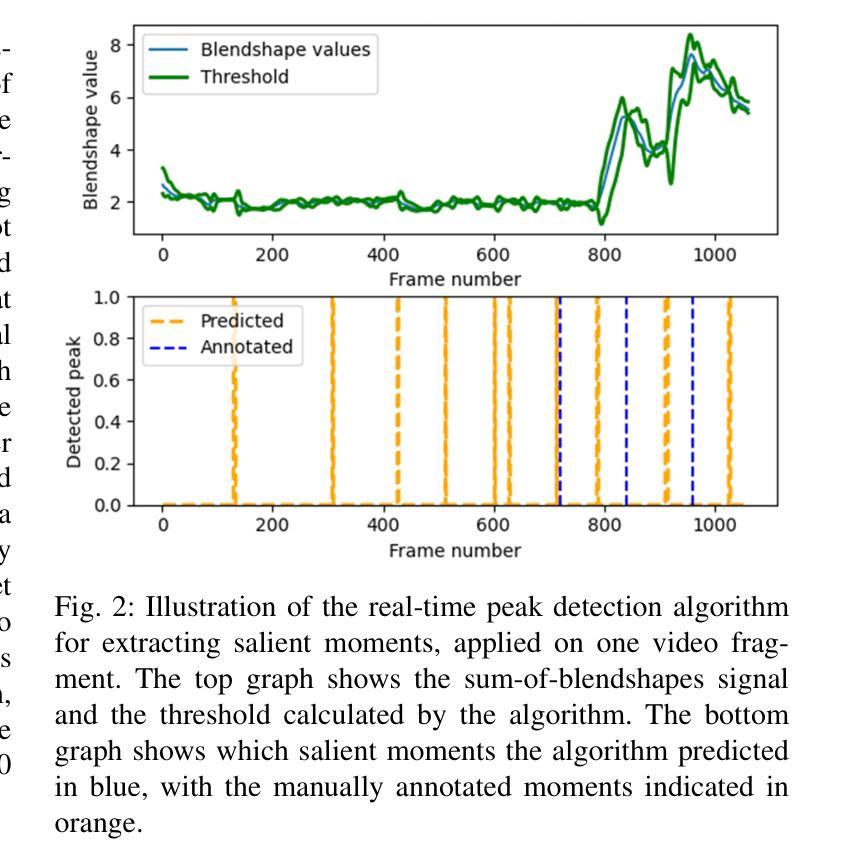
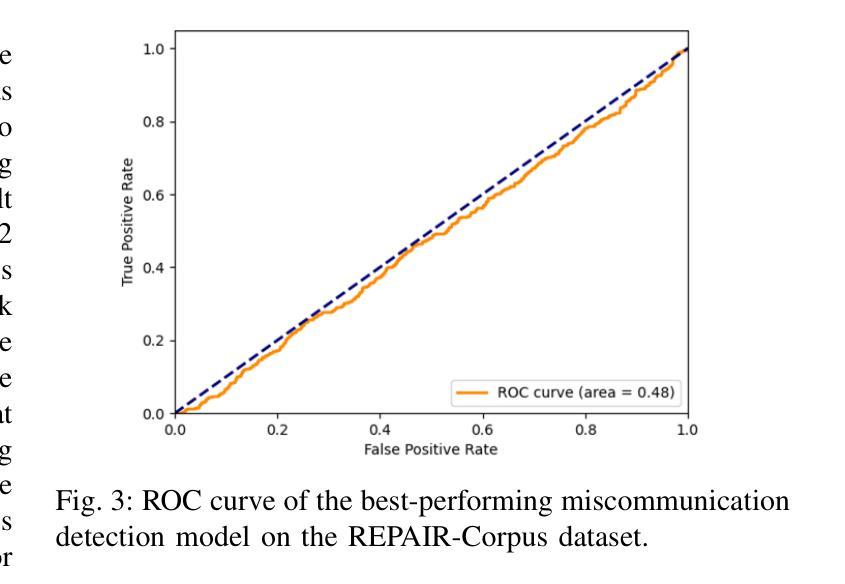
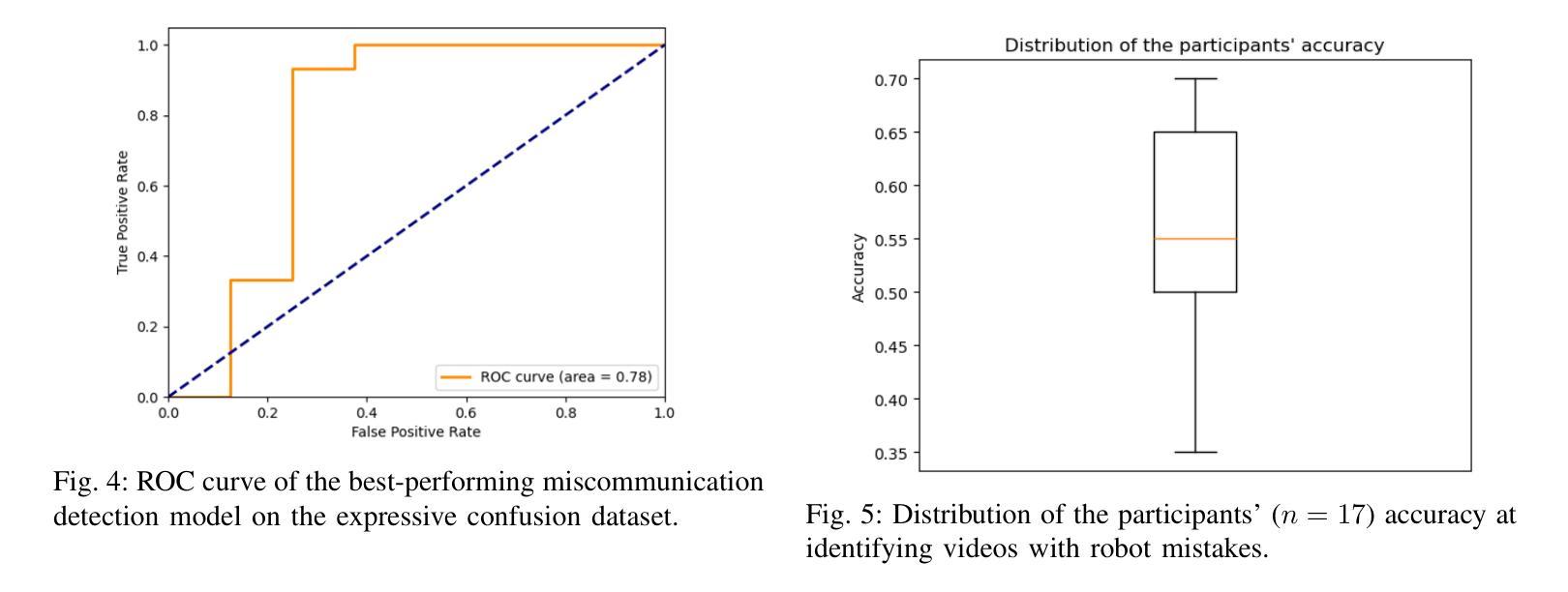
Detecting miscommunication in human-robot interaction is a critical function for maintaining user engagement and trust. While humans effortlessly detect communication errors in conversations through both verbal and non-verbal cues, robots face significant challenges in interpreting non-verbal feedback, despite advances in computer vision for recognizing affective expressions. This research evaluates the effectiveness of machine learning models in detecting miscommunications in robot dialogue. Using a multi-modal dataset of 240 human-robot conversations, where four distinct types of conversational failures were systematically introduced, we assess the performance of state-of-the-art computer vision models. After each conversational turn, users provided feedback on whether they perceived an error, enabling an analysis of the models’ ability to accurately detect robot mistakes. Despite using state-of-the-art models, the performance barely exceeds random chance in identifying miscommunication, while on a dataset with more expressive emotional content, they successfully identified confused states. To explore the underlying cause, we asked human raters to do the same. They could also only identify around half of the induced miscommunications, similarly to our model. These results uncover a fundamental limitation in identifying robot miscommunications in dialogue: even when users perceive the induced miscommunication as such, they often do not communicate this to their robotic conversation partner. This knowledge can shape expectations of the performance of computer vision models and can help researchers to design better human-robot conversations by deliberately eliciting feedback where needed.
在人类与机器人的交互中检测沟通错误是维持用户参与度和信任的关键功能。人类能够轻松地通过语言和非语言线索检测到对话中的沟通错误,然而尽管计算机视觉在识别情感表达方面取得了进展,机器人在解读非语言反馈方面仍面临重大挑战。本研究评估了机器学习模型在检测机器人对话中的沟通错误方面的有效性。我们使用了包含240个人类与机器人对话的多模式数据集,其中有四种不同类型的对话失败被系统地引入。我们评估了最先进的计算机视觉模型的性能。在每个对话回合之后,用户会反馈他们是否认为存在错误,从而分析模型准确检测机器人错误的能力。尽管使用了最先进的模型,但在识别沟通错误方面的表现仅略高于随机概率,而在具有更丰富的情感内容的数据集上,它们能够成功识别困惑状态。为了探究其潜在原因,我们要求人类评估者进行同样的操作。他们也只能识别出大约一半的诱导产生的沟通错误,与我们的模型表现相似。这些结果揭示了识别机器人对话中沟通错误的一个根本局限性:即使用户感知到被诱导产生的沟通错误,他们通常也不会向他们的机器人对话伙伴传达这一点。这些知识可以形成对计算机视觉模型性能的期望,并帮助研究人员通过故意引发反馈来设计出更好的人类与机器人之间的对话。
论文及项目相关链接
PDF Accepted at the 34th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2025)
Summary
研究评估机器学习模型在检测机器人对话中的沟通失误方面的有效性。通过收集包含四种对话失误的系统性引入的240次人机对话的多模式数据集,评估了计算机视觉模型的性能。用户需在每次对话后反馈是否感知到错误,以便分析模型检测机器人错误的能力。尽管使用了最先进的模型,但在识别沟通失误方面的表现仍难以超越随机概率;但在情绪内容更丰富的数据集上,它们能够成功识别困惑状态。结果揭示了在对话中识别机器人失误的一个基本局限:即使用户将诱导的失误感知为错误,他们也往往不会向机器人对话伙伴传达这一点。此知识有助于调整对计算机视觉模型的性能期望,并帮助研究人员通过故意征求反馈来设计更好的人机对话。
Key Takeaways
- 检测人机互动中的沟通失误对于维持用户参与和信任至关重要。
- 机器人解读非语言反馈时面临挑战,尽管计算机视觉在识别情感表达方面有所进步。
- 研究评估了机器学习模型在检测机器人对话失误方面的性能,使用了包含四种对话失误的系统性引入的多模式数据集。
- 最先进的模型在识别沟通失误方面的表现仍难以超越随机概率,但在情绪内容丰富的数据集上能够成功识别困惑状态。
- 用户即使感知到机器人的沟通失误,也往往不会向机器人传达这一点,这构成了识别机器人对话中失误的一个基本局限。
- 此研究有助于调整对计算机视觉模型的性能期望,为设计更好的人机对话提供指导。
点此查看论文截图