⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-27 更新
The Decrypto Benchmark for Multi-Agent Reasoning and Theory of Mind
Authors:Andrei Lupu, Timon Willi, Jakob Foerster
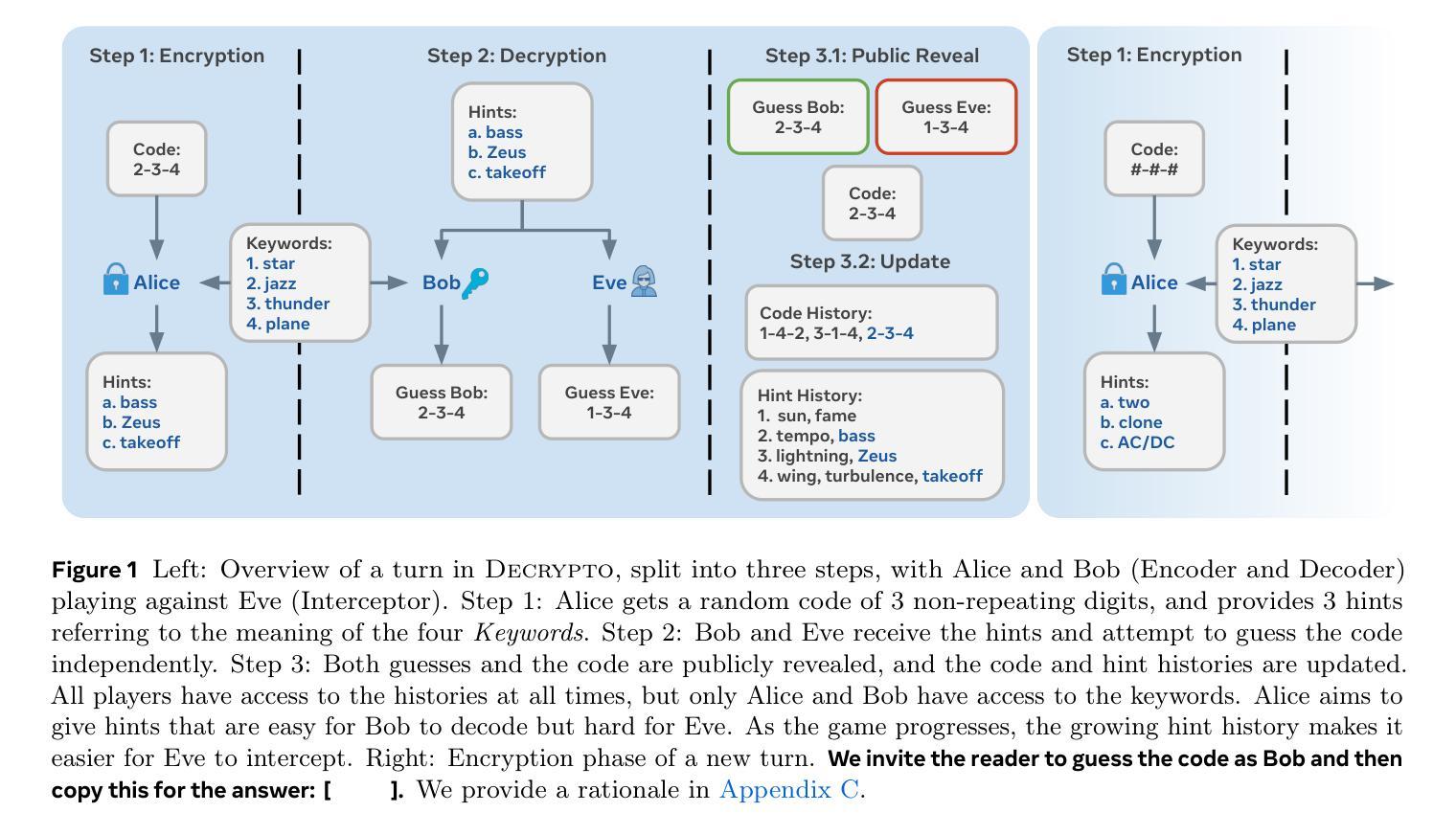
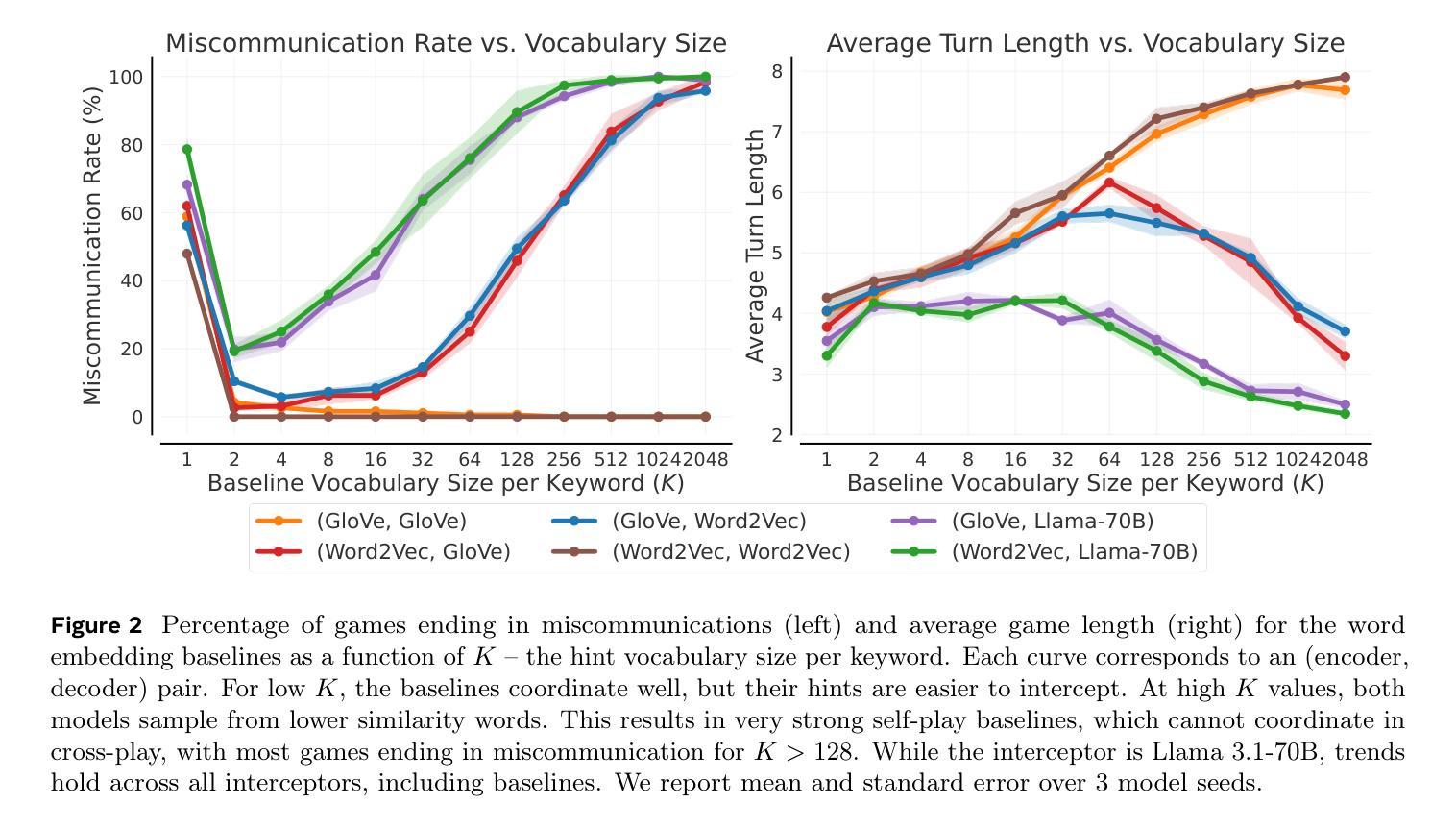
As Large Language Models (LLMs) gain agentic abilities, they will have to navigate complex multi-agent scenarios, interacting with human users and other agents in cooperative and competitive settings. This will require new reasoning skills, chief amongst them being theory of mind (ToM), or the ability to reason about the “mental” states of other agents. However, ToM and other multi-agent abilities in LLMs are poorly understood, since existing benchmarks suffer from narrow scope, data leakage, saturation, and lack of interactivity. We thus propose Decrypto, a game-based benchmark for multi-agent reasoning and ToM drawing inspiration from cognitive science, computational pragmatics and multi-agent reinforcement learning. It is designed to be as easy as possible in all other dimensions, eliminating confounding factors commonly found in other benchmarks. To our knowledge, it is also the first platform for designing interactive ToM experiments. We validate the benchmark design through comprehensive empirical evaluations of frontier LLMs, robustness studies, and human-AI cross-play experiments. We find that LLM game-playing abilities lag behind humans and simple word-embedding baselines. We then create variants of two classic cognitive science experiments within Decrypto to evaluate three key ToM abilities. Surprisingly, we find that state-of-the-art reasoning models are significantly worse at those tasks than their older counterparts. This demonstrates that Decrypto addresses a crucial gap in current reasoning and ToM evaluations, and paves the path towards better artificial agents.
随着大型语言模型(LLM)获得代理能力,它们将需要应对复杂的多代理场景,在合作和竞争环境中与人类用户和其他代理进行交互。这将需要新的推理能力,其中最主要的是心智理论(ToM)能力,即推理其他代理的“精神”状态的能力。然而,ToM以及LLM中的其他多代理能力都了解甚少,因为现有的基准测试存在范围狭窄、数据泄露、饱和和缺乏交互性的问题。因此,我们提出了Decrypto,这是一个基于游戏的多代理推理和心智理论基准测试,它借鉴了认知科学、计算语用学和多代理强化学习。其设计旨在尽可能在其他所有方面都尽可能简单,消除在其他基准测试中通常存在的混淆因素。据我们所知,这也是设计交互式心智理论实验的第一个平台。我们通过全面评估前沿的LLM、稳健性研究和人机交叉实验来验证基准测试的设计。我们发现LLM的游戏能力与人类和简单的词嵌入基线相比有所不足。然后我们在Decrypto中创建了两种经典认知科学实验的变体,以评估三种关键的ToM能力。令人惊讶的是,我们发现最新一代的推理模型在这些任务上的表现显著落后于旧模型。这表明Decrypto解决了当前推理和心智理论评估中的关键差距,并为更好的人工智能代理的发展铺平了道路。
论文及项目相关链接
PDF 41 pages, 19 figures
Summary
大型语言模型(LLM)在获得代理能力后,需要应对复杂的多代理场景,与其他代理和人类社会合作与竞争。这需要新的推理能力,其中最重要的是心智理论(ToM),即推理其他代理的“心理”状态的能力。然而,ToM和LLM中的其他多代理能力尚不清楚,因为现有基准测试存在范围狭窄、数据泄露、饱和和缺乏交互等问题。因此,我们提出了基于游戏的基准测试Decrypto,用于多代理推理和ToM,灵感来自认知科学、计算语用学和多代理强化学习。其旨在尽可能消除其他维度中的干扰因素,并据我们所知,是设计交互式ToM实验的第一个平台。我们通过前沿LLM的综合实证评估、稳健性研究和人机交叉实验验证了基准测试设计的有效性。我们发现LLM的游戏能力落后于人类和简单的词嵌入基线。接下来,我们在Decrypto中创建了两个经典认知科学实验的变种,以评估三项关键的ToM能力。令人惊讶的是,我们发现最先进的推理模型在这些任务上的表现远不如旧模型。这表明Decrypto解决了当前推理和ToM评估中的关键空白,并为更好的人工智能代理铺平了道路。
Key Takeaways
- 大型语言模型(LLM)需应对多代理场景,这要求具备新的推理能力,尤其是心智理论(ToM)。
- 现有基准测试存在多种问题,如范围狭窄、数据泄露和缺乏交互性。
- 提出了基于游戏的基准测试Decrypto,用于多代理推理和ToM评估。
- Decrypto平台设计旨在消除干扰因素,是首个交互式ToM实验平台。
- LLM在游戏能力上落后于人类和词嵌入基线。
- Decrypto通过经典认知科学实验的变种评估了LLM的关键ToM能力。
点此查看论文截图

Towards Community-Driven Agents for Machine Learning Engineering
Authors:Sijie Li, Weiwei Sun, Shanda Li, Ameet Talwalkar, Yiming Yang
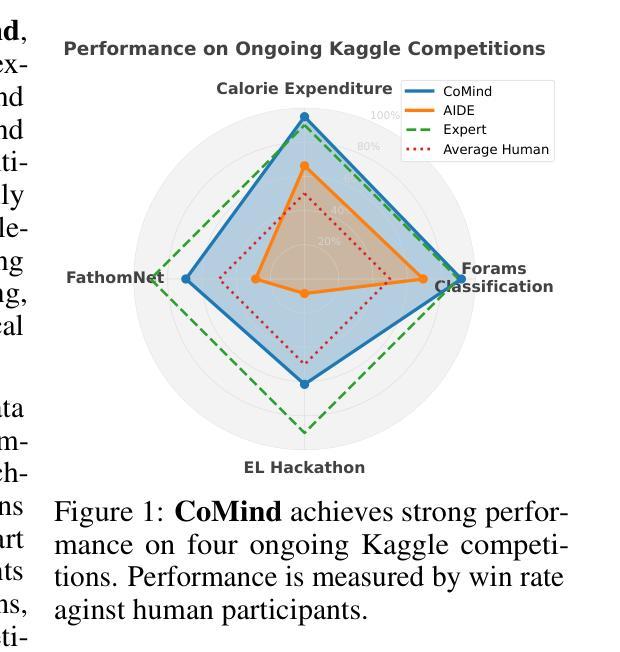
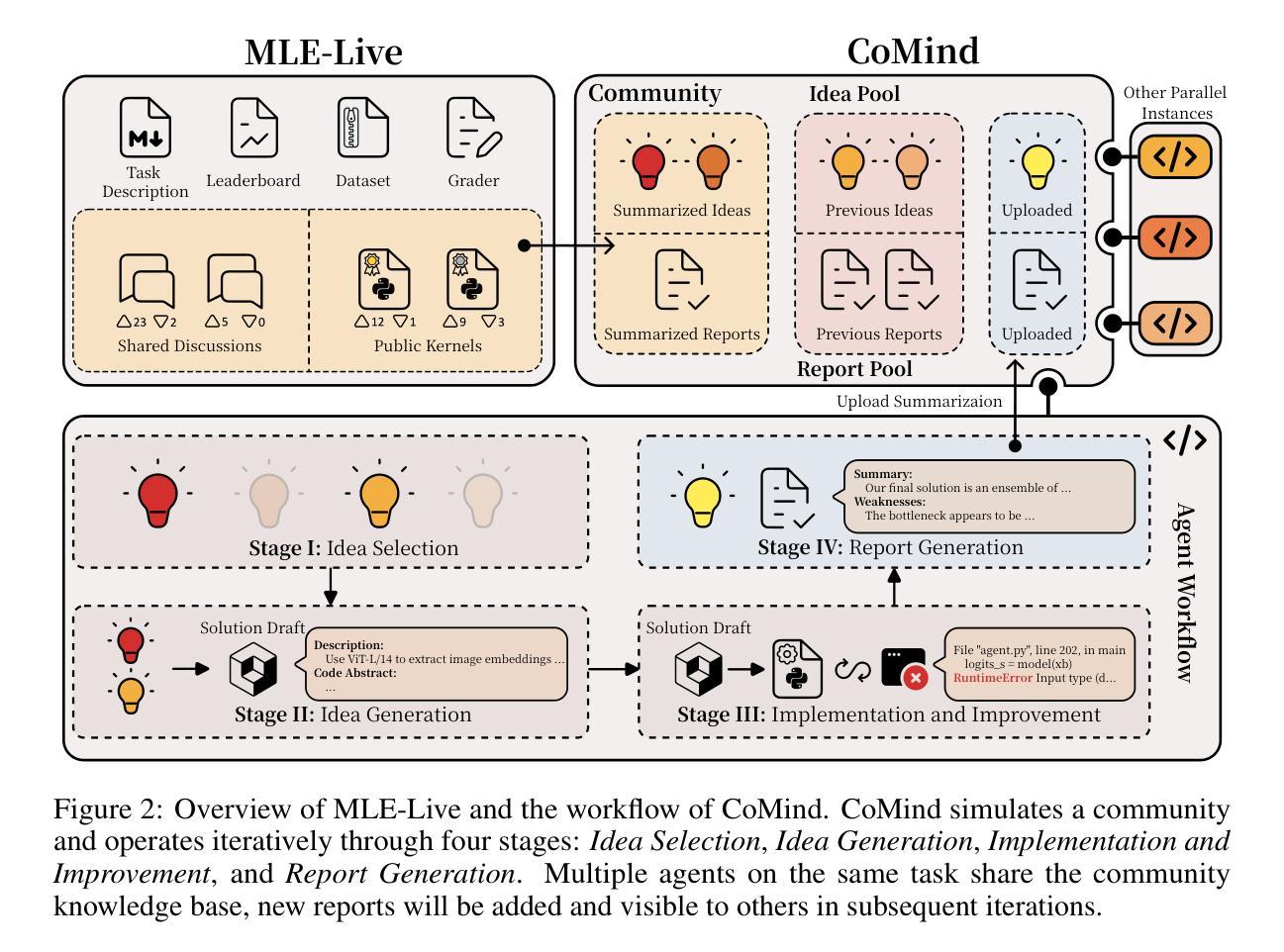
Large language model-based machine learning (ML) agents have shown great promise in automating ML research. However, existing agents typically operate in isolation on a given research problem, without engaging with the broader research community, where human researchers often gain insights and contribute by sharing knowledge. To bridge this gap, we introduce MLE-Live, a live evaluation framework designed to assess an agent’s ability to communicate with and leverage collective knowledge from a simulated Kaggle research community. Building on this framework, we propose CoMind, a novel agent that excels at exchanging insights and developing novel solutions within a community context. CoMind achieves state-of-the-art performance on MLE-Live and outperforms 79.2% human competitors on average across four ongoing Kaggle competitions. Our code is released at https://github.com/comind-ml/CoMind.
基于大型语言模型的机器学习(ML)代理在自动化ML研究方面显示出巨大潜力。然而,现有的代理通常孤立地处理给定研究问题,而没有与更广泛的研究社区互动,而人类研究者通常通过分享知识来获得洞察力并做出贡献。为了弥补这一差距,我们引入了MLE-Live,这是一个旨在评估代理与模拟Kaggle研究社区进行交流并利用集体知识的能力的实时评估框架。在此基础上,我们提出了CoMind,这是一个擅长在社区环境中交流见解并开发新解决方案的新型代理。CoMind在MLE-Live上实现了最先进的性能,并在四个正在进行的Kaggle竞赛中平均击败了79.2%的人类竞争对手。我们的代码发布在https://github.com/comind-ml/CoMind。
论文及项目相关链接
Summary
大型语言模型驱动的机器学习代理在自动化机器学习研究方面展现出巨大潜力,但现有代理通常孤立地解决特定问题,缺乏与广泛的研究社区交流互动。为解决此问题,我们推出MLE-Live评估框架,旨在评估代理与模拟Kaggle研究社区的沟通能力以及利用集体知识的能力。基于该框架,我们推出CoMind代理,擅长在社区环境中交流见解并开发新解决方案。CoMind在MLE-Live上表现卓越,平均在四个进行的Kaggle竞赛中超越了79.2%的人类竞争对手。代码已发布在网址。
Key Takeaways
- 大型语言模型驱动的机器学习代理在自动化机器学习研究方面具有巨大潜力。
- 当前代理大多孤立运行,缺乏与广泛研究社区的互动。
- MLE-Live评估框架旨在评估代理与模拟研究社区的交互能力。
- CoMind代理在MLE-Live上表现卓越,具备在模拟社区环境中交流见解和开发新解决方案的能力。
- CoMind在多个Kaggle竞赛中平均超越了大部分人类竞争对手。
- CoMind代理的代码已公开发布,供公众查阅和使用。
点此查看论文截图

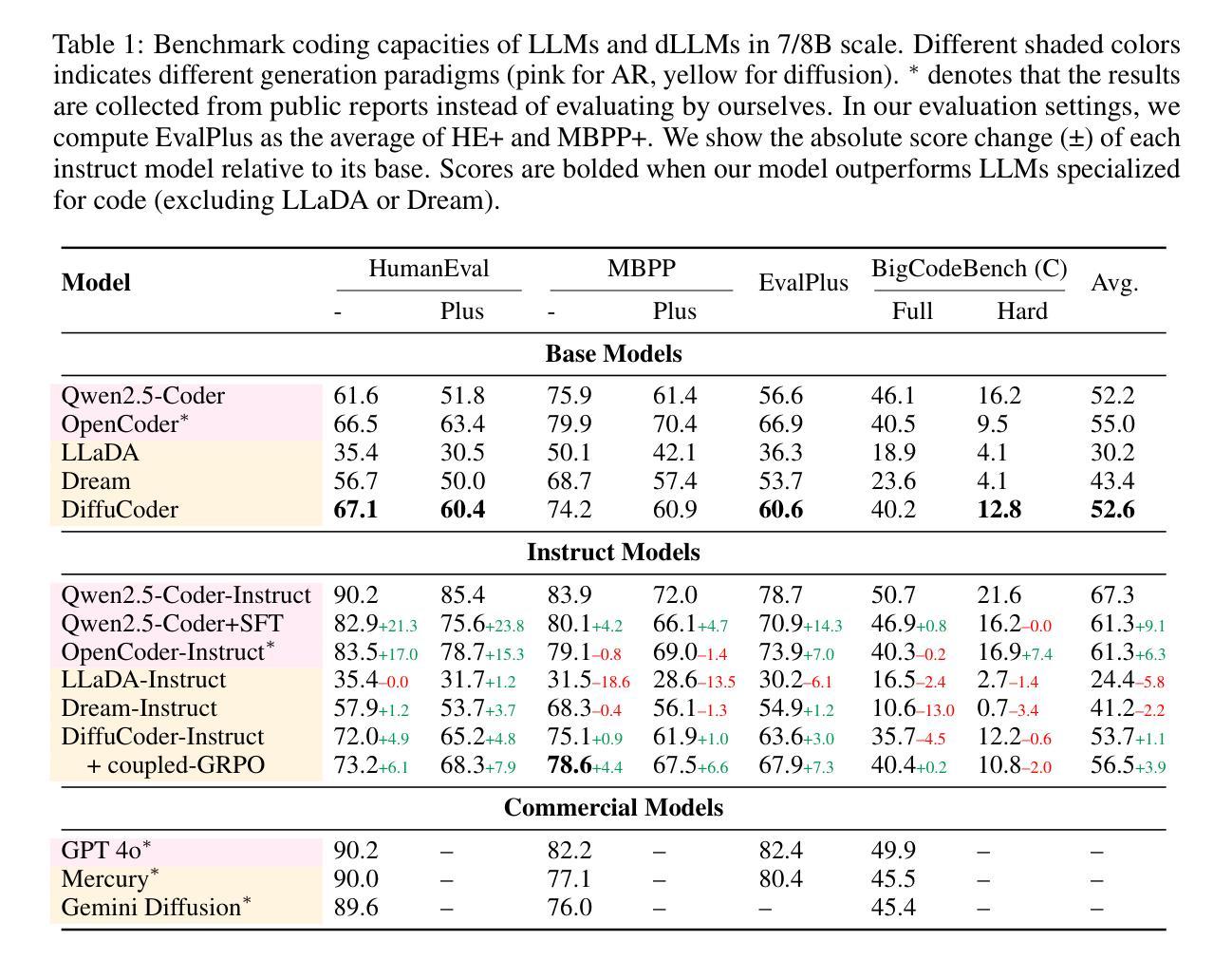
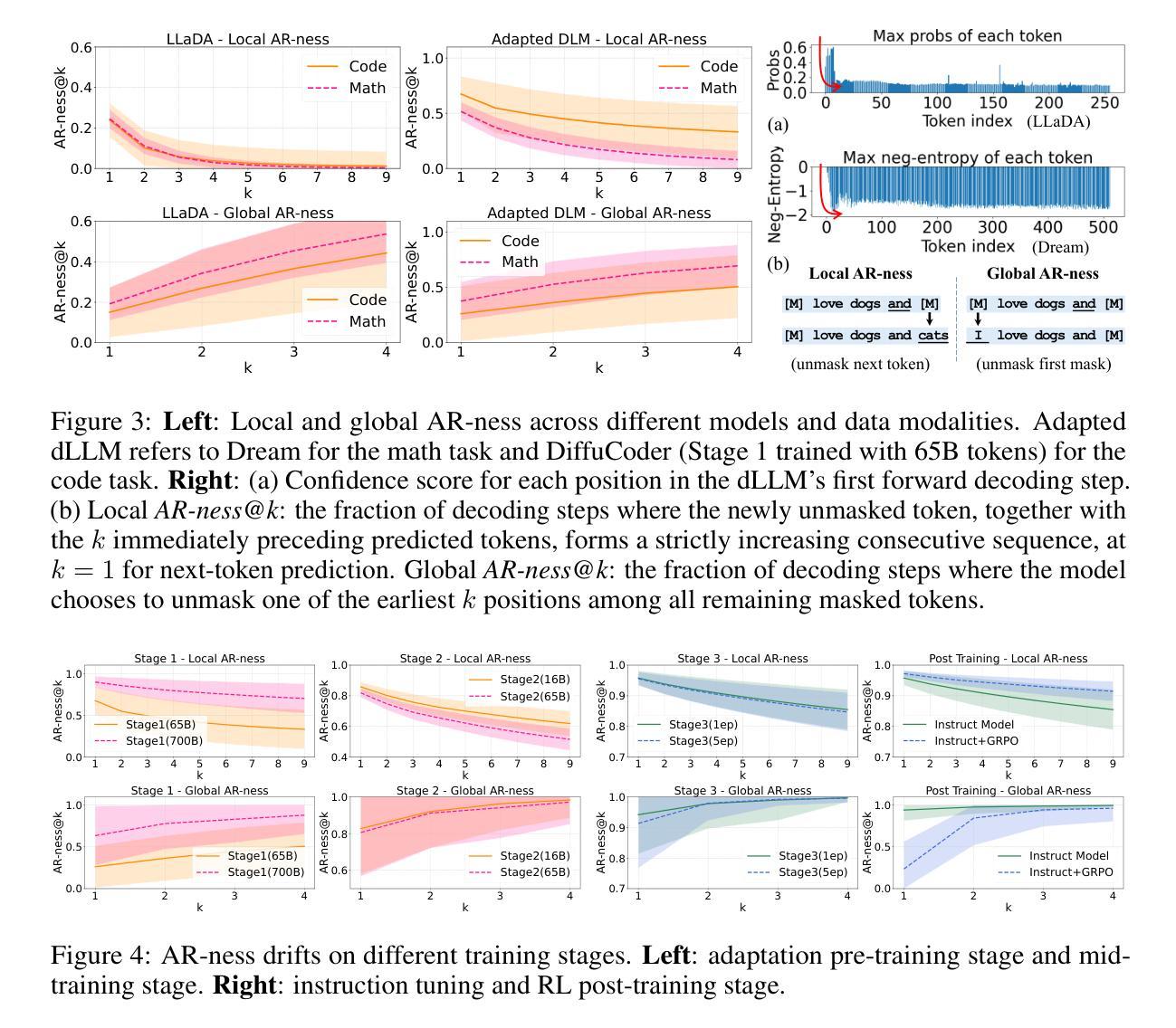
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
Authors:Shansan Gong, Ruixiang Zhang, Huangjie Zheng, Jiatao Gu, Navdeep Jaitly, Lingpeng Kong, Yizhe Zhang
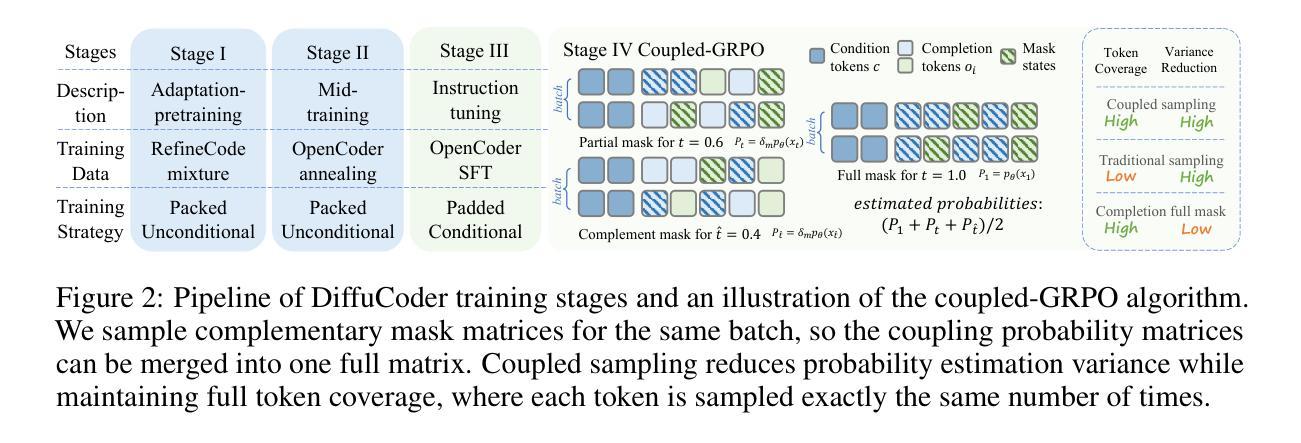
Diffusion large language models (dLLMs) are compelling alternatives to autoregressive (AR) models because their denoising models operate over the entire sequence. The global planning and iterative refinement features of dLLMs are particularly useful for code generation. However, current training and inference mechanisms for dLLMs in coding are still under-explored. To demystify the decoding behavior of dLLMs and unlock their potential for coding, we systematically investigate their denoising processes and reinforcement learning (RL) methods. We train a 7B dLLM, \textbf{DiffuCoder}, on 130B tokens of code. Using this model as a testbed, we analyze its decoding behavior, revealing how it differs from that of AR models: (1) dLLMs can decide how causal their generation should be without relying on semi-AR decoding, and (2) increasing the sampling temperature diversifies not only token choices but also their generation order. This diversity creates a rich search space for RL rollouts. For RL training, to reduce the variance of token log-likelihood estimates and maintain training efficiency, we propose \textbf{coupled-GRPO}, a novel sampling scheme that constructs complementary mask noise for completions used in training. In our experiments, coupled-GRPO significantly improves DiffuCoder’s performance on code generation benchmarks (+4.4% on EvalPlus) and reduces reliance on AR causal during decoding. Our work provides deeper insight into the machinery of dLLM generation and offers an effective, diffusion-native RL training framework. https://github.com/apple/ml-diffucoder.
扩散大型语言模型(dLLMs)作为自回归(AR)模型的吸引人的替代方案,因为它们去噪模型在整个序列上运行。dLLMs的全局规划和迭代优化功能对于代码生成特别有用。然而,当前针对dLLMs在编码方面的训练和推理机制仍然缺乏研究。为了揭开dLLMs解码行为的奥秘并解锁其在编码方面的潜力,我们系统地研究了它们的去噪过程和强化学习(RL)方法。我们在包含代码的超过 巨大字节的数据集上训练了一个包含有庞大参数数的通用版代码扩散语言模型,名称为“DiffuCoder”。通过这个模型,我们分析了其解码行为,并揭示了其与AR模型的不同之处:首先是自回归模型中无关的潜在缺陷所驱动的马尔可夫生成问题无法彻底得到解决;(具体到该问题内部机制里,)尽管我们可以通过自主决定的延迟来解决策略先行或者回报利用过多的问题。其次,提高采样温度不仅使令牌选择多样化,而且改变了令牌的生成顺序。这种多样性为RL训练提供了丰富的搜索空间。对于强化学习训练而言,为了减少令牌对数似然估计的方差并保持训练效率,我们提出了一种名为“耦合-GRPO”的新型采样方案,该方案针对训练中所使用的完成项构建互补掩码噪声。在我们的实验中,“耦合-GRPO”显著提高了DiffuCoder在代码生成基准测试上的性能(+EvalPlus提升率为4.4%),并减少了解码过程中对于自回归因果性的依赖。我们的工作为dLLM生成机制提供了更深入的了解,并提供了一种有效的、基于扩散的RL训练框架。如需了解更多详情,请访问https://github.com/apple/ml-diffucoder 。
论文及项目相关链接
PDF preprint
Summary
本文介绍了Diffusion Large Language Models(dLLMs)在编程代码生成方面的优势和应用。通过系统地研究其降噪过程和强化学习方法,作者训练了一个名为DiffuCoder的7B dLLM模型,并在代码生成任务上进行了评估。dLLMs能够在不使用半自回归解码的情况下决定生成的因果性,增加采样温度可以多样化生成的标记和顺序。为了更有效地训练RL,作者提出了一种新的采样方案——耦合GRPO,该方案为训练中的完成部分构建互补掩码噪声。实验表明,耦合GRPO能显著提高DiffuCoder在代码生成基准测试上的性能,并减少解码过程中的AR因果依赖。
Key Takeaways
- dLLMs通过在整个序列上操作的降噪模型成为吸引人的自回归(AR)模型的替代方案,特别是在代码生成方面。
- dLLMs的解码行为与AR模型不同,可以在不依赖半自回归解码的情况下决定生成的因果性。
- 增加采样温度可以多样化标记的选择和生成顺序,为强化学习(RL)训练创建一个丰富的搜索空间。
- 作者提出了一个新的采样方案——耦合GRPO,以提高RL训练的效率并减少标记日志似然估计的方差。
- 名为DiffuCoder的dLLM模型在代码生成基准测试上表现出显著的性能改进。
- DiffuCoder的性能提升得益于其新的解码方法和RL训练框架。
- 该研究为dLLM生成机制提供了深入见解,并为扩散原生RL训练框架提供了有效方法。
点此查看论文截图
Video Perception Models for 3D Scene Synthesis
Authors:Rui Huang, Guangyao Zhai, Zuria Bauer, Marc Pollefeys, Federico Tombari, Leonidas Guibas, Gao Huang, Francis Engelmann
Traditionally, 3D scene synthesis requires expert knowledge and significant manual effort. Automating this process could greatly benefit fields such as architectural design, robotics simulation, virtual reality, and gaming. Recent approaches to 3D scene synthesis often rely on the commonsense reasoning of large language models (LLMs) or strong visual priors of modern image generation models. However, current LLMs demonstrate limited 3D spatial reasoning ability, which restricts their ability to generate realistic and coherent 3D scenes. Meanwhile, image generation-based methods often suffer from constraints in viewpoint selection and multi-view inconsistencies. In this work, we present Video Perception models for 3D Scene synthesis (VIPScene), a novel framework that exploits the encoded commonsense knowledge of the 3D physical world in video generation models to ensure coherent scene layouts and consistent object placements across views. VIPScene accepts both text and image prompts and seamlessly integrates video generation, feedforward 3D reconstruction, and open-vocabulary perception models to semantically and geometrically analyze each object in a scene. This enables flexible scene synthesis with high realism and structural consistency. For more precise analysis, we further introduce First-Person View Score (FPVScore) for coherence and plausibility evaluation, utilizing continuous first-person perspective to capitalize on the reasoning ability of multimodal large language models. Extensive experiments show that VIPScene significantly outperforms existing methods and generalizes well across diverse scenarios. The code will be released.
传统上,3D场景合成需要专业知识并需要大量手动操作。自动化这一过程可能对建筑设计、机器人仿真、虚拟现实和游戏等领域大有裨益。最近的3D场景合成方法常常依赖于大型语言模型的常识推理或现代图像生成模型的强大视觉先验。然而,当前的大型语言模型表现出有限的3D空间推理能力,这限制了它们生成真实和连贯的3D场景的能力。同时,基于图像生成的方法常常受到视点选择和多视角不一致性的约束。
论文及项目相关链接
Summary
基于视频感知模型的3D场景合成(VIPScene)利用视频生成模型中的常识知识,确保场景布局连贯,不同视角的对象放置一致。该框架接受文本和图像提示,无缝集成视频生成、前馈3D重建和开放词汇感知模型,对场景中的每个对象进行语义和几何分析。这为高现实性、结构一致性的灵活场景合成提供了可能。
Key Takeaways
- VIPScene利用视频生成模型中的常识知识来确保连贯的场景布局和一致的跨视角对象放置。
- 该框架可以接受文本和图像提示来进行场景合成。
- VIPScene结合了视频生成、前馈3D重建和感知模型。
- 它能够实现灵活的场景合成,并确保高现实性和结构一致性。
- 引入第一人称视角得分(FPVScore)用于评估场景的连贯性和合理性。
- VIPScene在实验中表现出显著的优势,并能在不同的场景中很好地推广。
点此查看论文截图

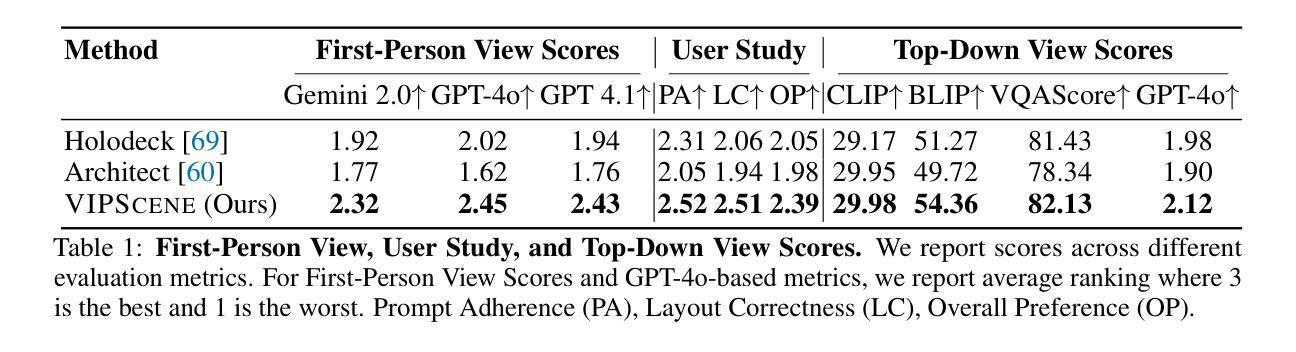
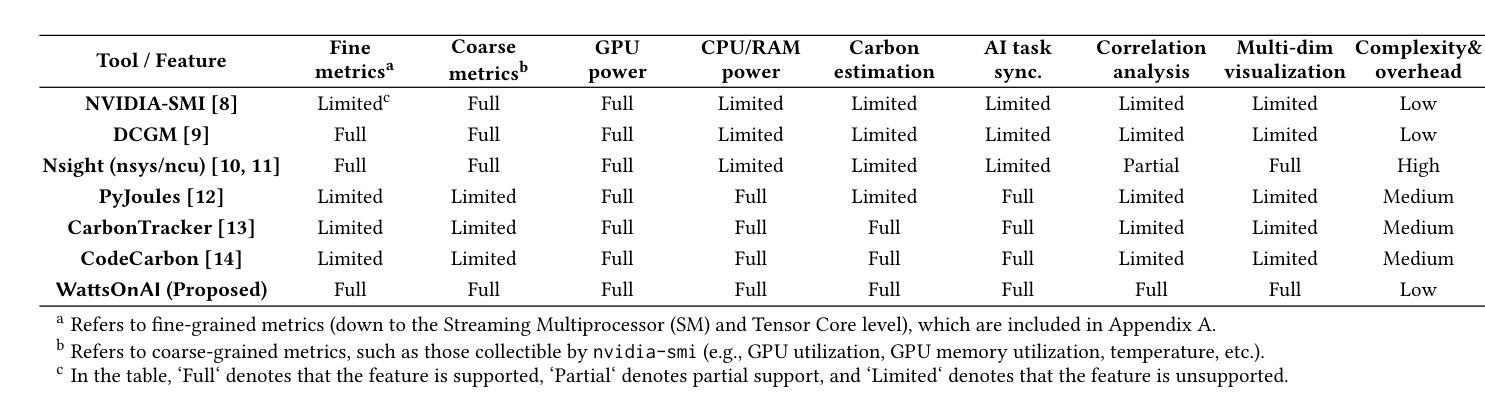
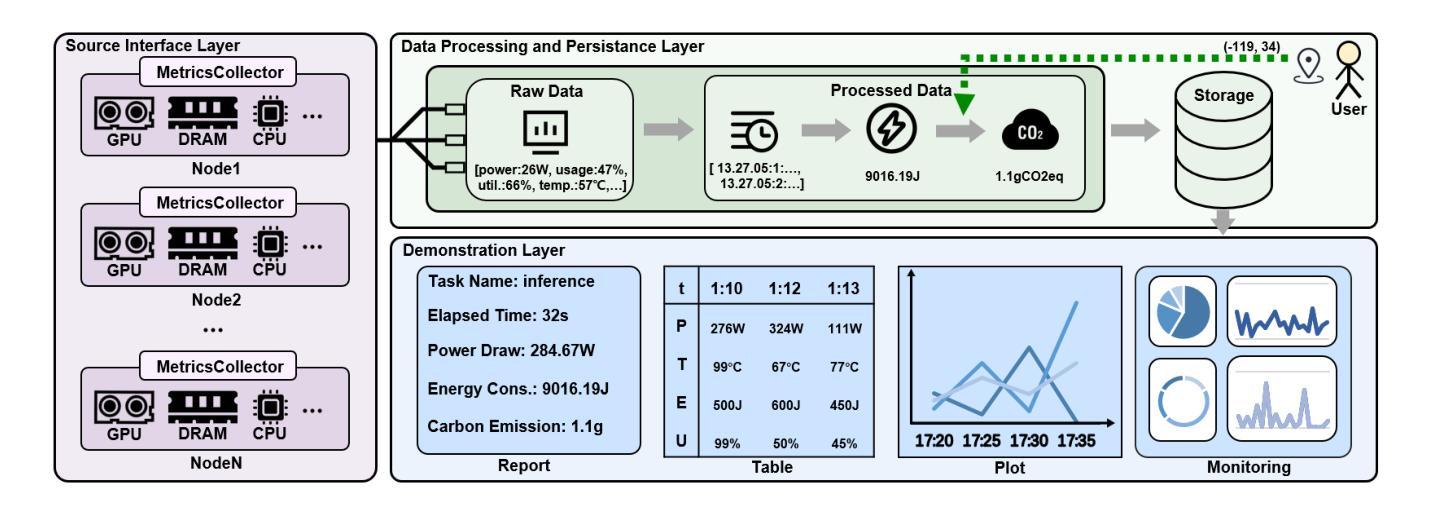
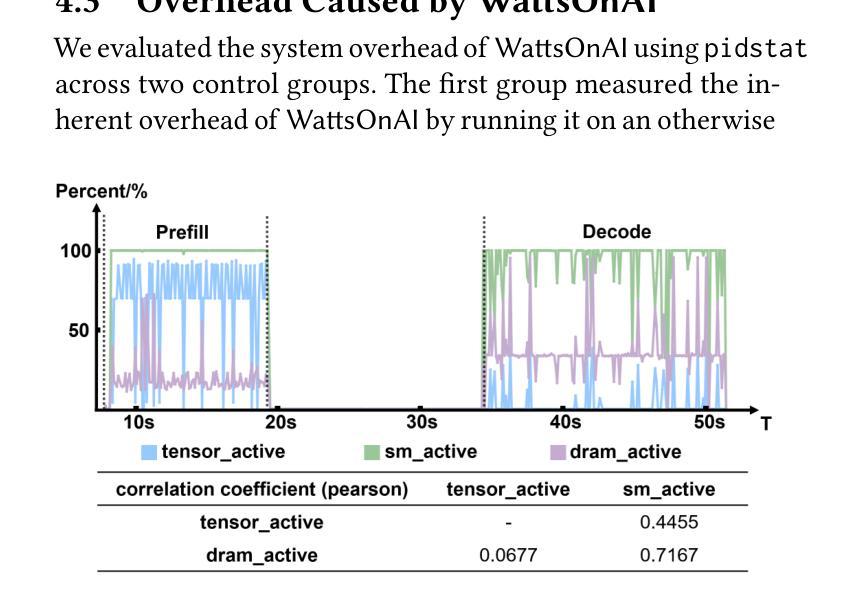
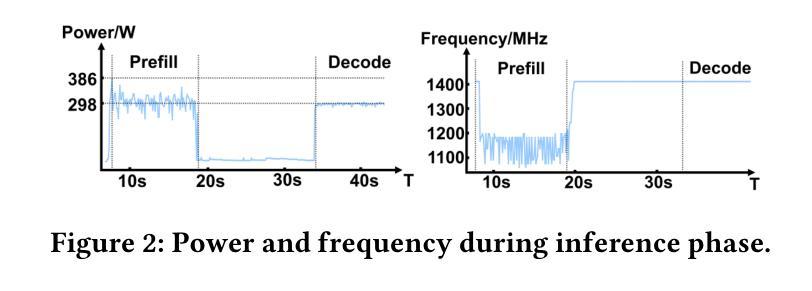
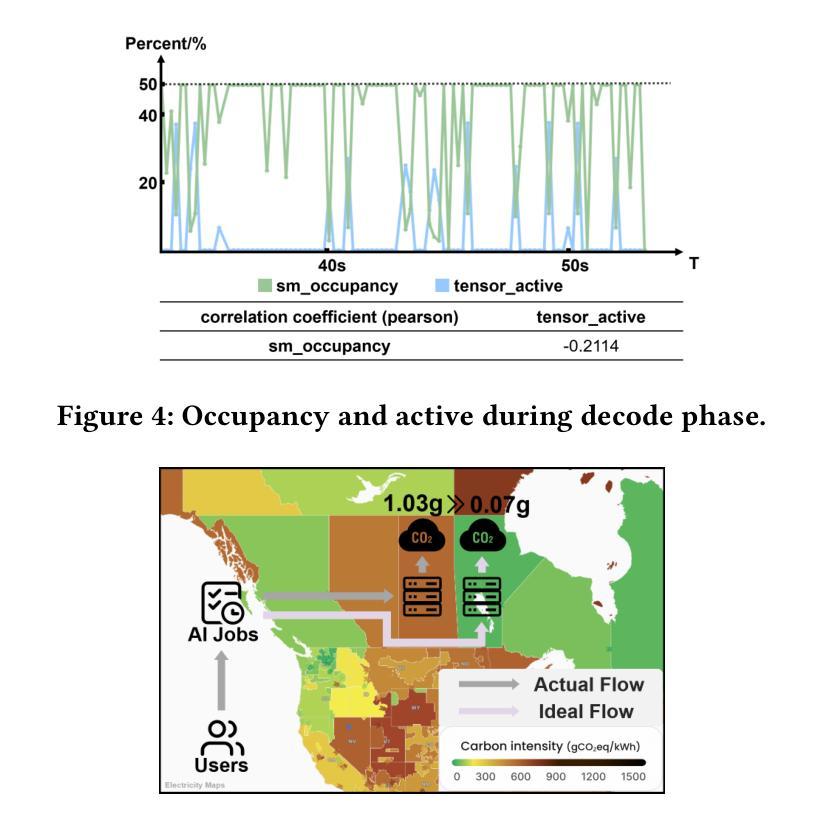
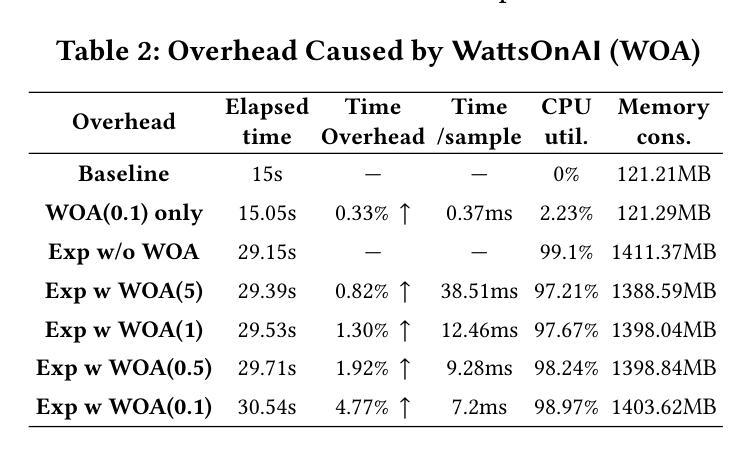
WattsOnAI: Measuring, Analyzing, and Visualizing Energy and Carbon Footprint of AI Workloads
Authors:Hongzhen Huang, Kunming Zhang, Hanlong Liao, Kui Wu, Guoming Tang
The rapid advancement of AI, particularly large language models (LLMs), has raised significant concerns about the energy use and carbon emissions associated with model training and inference. However, existing tools for measuring and reporting such impacts are often fragmented, lacking systematic metric integration and offering limited support for correlation analysis among them. This paper presents WattsOnAI, a comprehensive software toolkit for the measurement, analysis, and visualization of energy use, power draw, hardware performance, and carbon emissions across AI workloads. By seamlessly integrating with existing AI frameworks, WattsOnAI offers standardized reports and exports fine-grained time-series data to support benchmarking and reproducibility in a lightweight manner. It further enables in-depth correlation analysis between hardware metrics and model performance and thus facilitates bottleneck identification and performance enhancement. By addressing critical limitations in existing tools, WattsOnAI encourages the research community to weigh environmental impact alongside raw performance of AI workloads and advances the shift toward more sustainable “Green AI” practices. The code is available at https://github.com/SusCom-Lab/WattsOnAI.
人工智能(AI)尤其是大型语言模型(LLM)的快速发展引发了人们对模型训练和推理过程中能耗和碳排放的担忧。然而,现有的用于测量和报告此类影响的工具通常很分散,缺乏系统的指标整合,并且在它们之间提供关联分析的支持有限。本文介绍了WattsOnAI,这是一个全面的软件工具包,用于测量、分析和可视化人工智能工作负载的能耗、功率消耗、硬件性能和碳排放。WattsOnAI无缝集成现有的AI框架,提供标准化报告并导出精细的时间序列数据,以支持基准测试和轻量级的可重复性。它还可以进行硬件指标与模型性能之间的深入分析,从而有助于识别瓶颈和提高性能。通过解决现有工具的关键局限性,WattsOnAI鼓励研究社区权衡人工智能工作负载的原始性能与环境影响,推动向更可持续的“绿色AI”实践转变。代码可在https://github.com/SusCom-Lab/WattsOnAI找到。
论文及项目相关链接
PDF 11 pages, 7 figures and 5 tables
Summary
随着人工智能尤其是大型语言模型(LLM)的快速发展,其相关的能耗与碳排放问题备受关注。现有工具存在缺乏统一的衡量标准和全面的分析能力的问题。而本论文推出的WattsOnAI软件工具套件为AI工作负载的能耗测量与碳分析提供了一个综合平台。它可以无缝对接现有的AI框架,实现能源使用、电力消耗、硬件性能及碳排放数据的综合度量与可视化分析。它提供标准化的报告及细粒度的时间序列数据导出,为性能评估提供了有力支持。同时,通过深度分析硬件指标与模型性能之间的关联,它能够帮助用户找出瓶颈并进行性能优化。这款工具的推出,促进了AI研究领域对工作量原始性能与环境影响并重衡量研究的兴起,也标志着AI走向更绿色可持续发展方向的新尝试。获取该工具代码的网址为:[链接地址](https://github.com/SusCom-Lab/WattsOnAI)。
Key Takeaways
- AI的快速进步引起了对大型语言模型能耗与碳排放的广泛担忧。
- 目前相关的能耗衡量和分析工具存在标准化问题且无法充分反映关联性分析。
- WattsOnAI工具套件提供了全面的能源使用、电力消耗、硬件性能和碳排放的测量与分析功能。
- WattsOnAI能够无缝对接现有AI框架,实现数据可视化并提供标准化报告输出。
- 它具备细粒度时间序列数据的导出功能,为性能评估提供了重要依据。
- 通过深度分析硬件指标与模型性能之间的关联,帮助识别瓶颈并优化性能。
点此查看论文截图


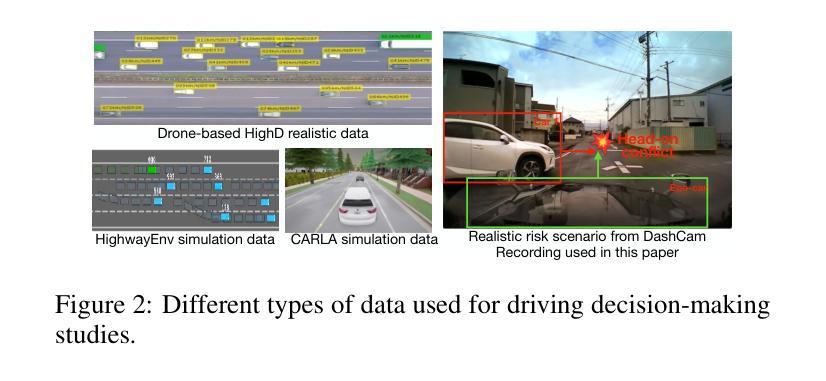
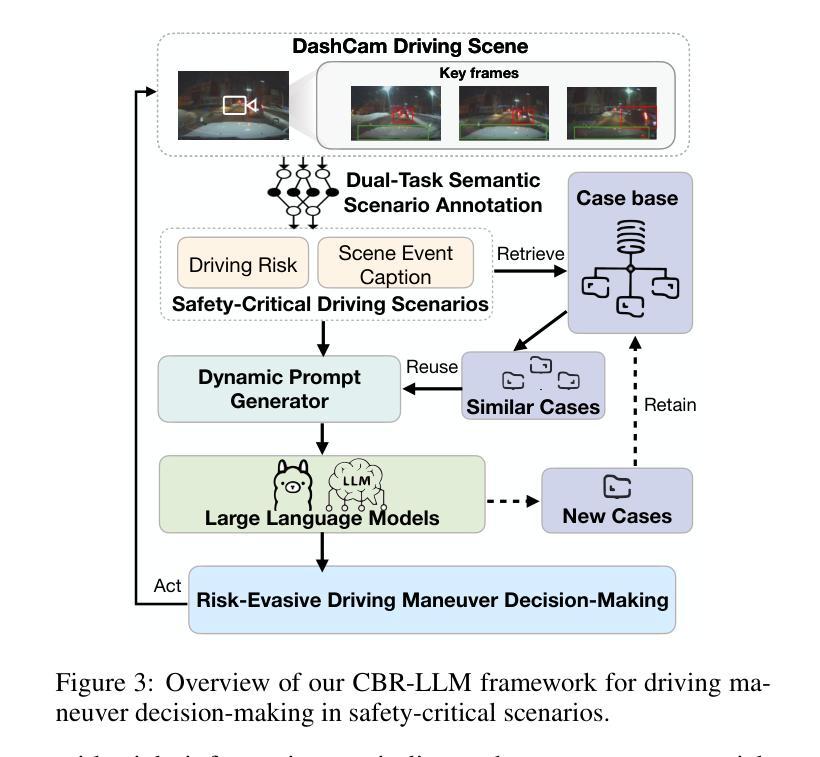
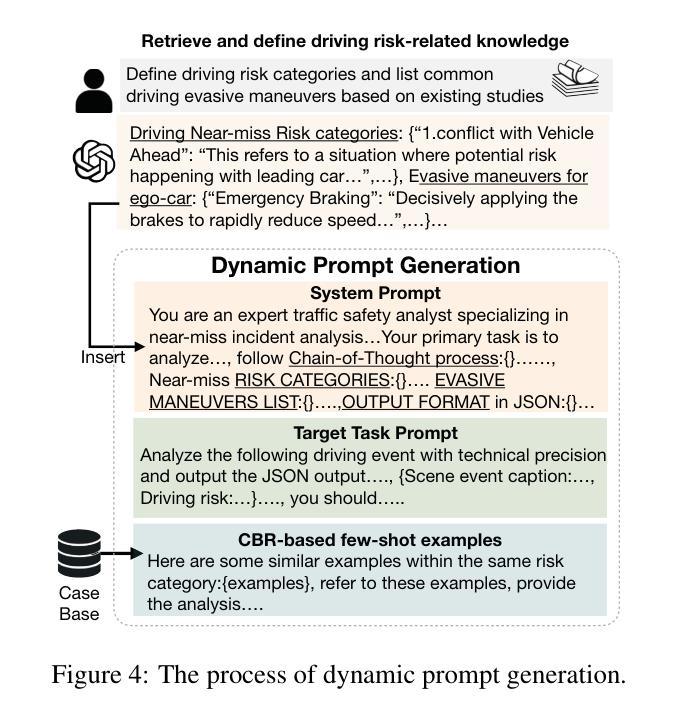
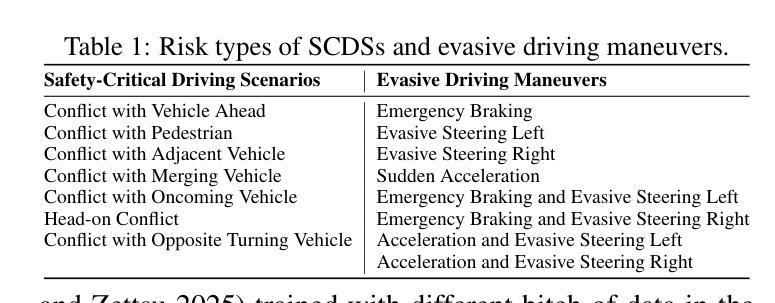
Case-based Reasoning Augmented Large Language Model Framework for Decision Making in Realistic Safety-Critical Driving Scenarios
Authors:Wenbin Gan, Minh-Son Dao, Koji Zettsu
Driving in safety-critical scenarios requires quick, context-aware decision-making grounded in both situational understanding and experiential reasoning. Large Language Models (LLMs), with their powerful general-purpose reasoning capabilities, offer a promising foundation for such decision-making. However, their direct application to autonomous driving remains limited due to challenges in domain adaptation, contextual grounding, and the lack of experiential knowledge needed to make reliable and interpretable decisions in dynamic, high-risk environments. To address this gap, this paper presents a Case-Based Reasoning Augmented Large Language Model (CBR-LLM) framework for evasive maneuver decision-making in complex risk scenarios. Our approach integrates semantic scene understanding from dashcam video inputs with the retrieval of relevant past driving cases, enabling LLMs to generate maneuver recommendations that are both context-sensitive and human-aligned. Experiments across multiple open-source LLMs show that our framework improves decision accuracy, justification quality, and alignment with human expert behavior. Risk-aware prompting strategies further enhance performance across diverse risk types, while similarity-based case retrieval consistently outperforms random sampling in guiding in-context learning. Case studies further demonstrate the framework’s robustness in challenging real-world conditions, underscoring its potential as an adaptive and trustworthy decision-support tool for intelligent driving systems.
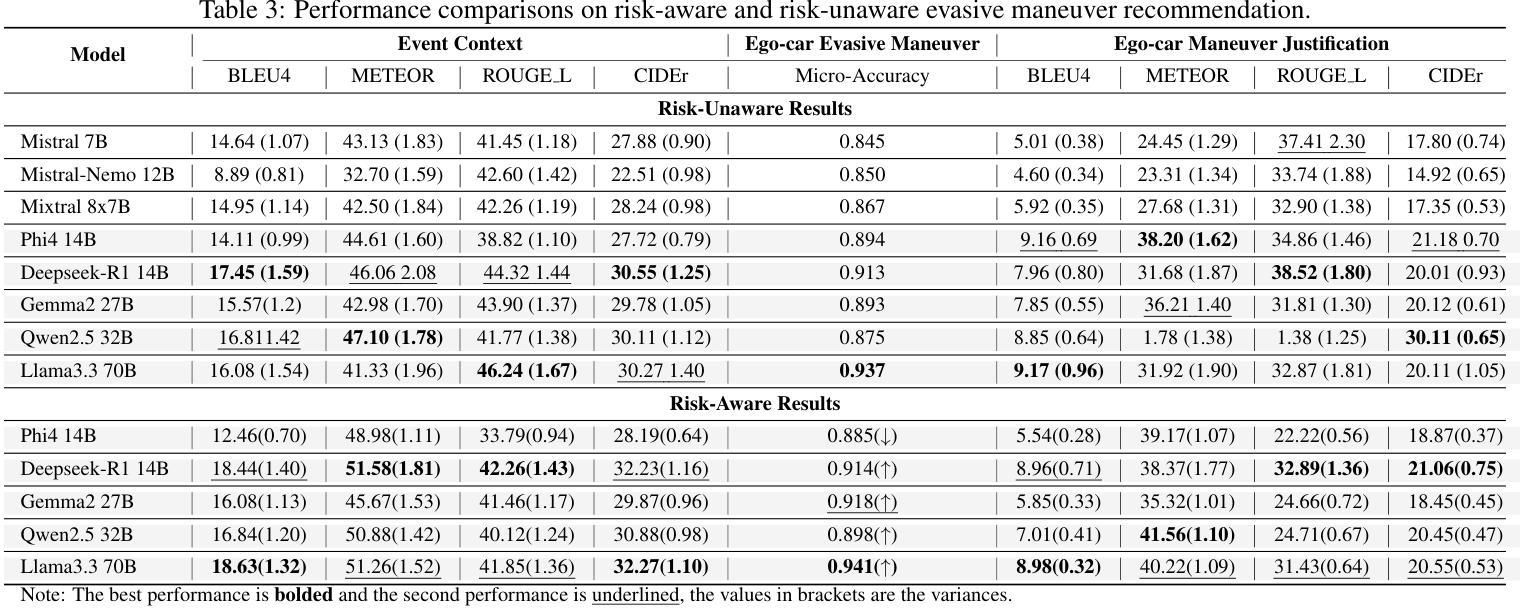
在关键安全场景中驾驶需要快速、基于情境的决策制定,这既需要理解情境,也需要经验推理。大型语言模型(LLM)凭借其强大的通用推理能力,为这种决策制定提供了有前景的基础。然而,将其直接应用于自动驾驶仍存在挑战,因为在领域适应、情境基础化以及在动态、高风险环境中做出可靠和可解释决策所需经验知识的缺乏。为了弥补这一差距,本文提出了一种基于案例的推理增强大型语言模型(CBR-LLM)框架,用于复杂风险场景中的避让决策制定。我们的方法结合了从行车记录仪视频输入中的语义场景理解以及与相关过去驾驶案例的检索,使LLM能够生成既敏感于上下文又符合人类行为的机动建议。跨多个开源LLM的实验表明,我们的框架提高了决策准确性、解释质量和与人类专家行为的一致性。风险感知提示策略进一步增强了不同类型风险的性能,而基于相似性的案例检索在指导上下文学习方面始终优于随机抽样。案例研究进一步证明了该框架在具有挑战性的现实条件下的稳健性,突显了其在智能驾驶系统中作为自适应和可靠的决策支持工具的潜力。
论文及项目相关链接
PDF 12 pages, 10 figures, under-review conference
Summary:
本文介绍了大型语言模型(LLM)在自动驾驶安全决策中的应用。针对自动驾驶在复杂风险场景中的决策挑战,提出了一种基于案例推理增强的大型语言模型(CBR-LLM)框架。该框架结合了驾驶场景理解和相关驾驶案例检索,使LLM能够生成既符合上下文又符合人类决策的机动建议。实验表明,该框架提高了决策准确性、解释质量以及与人类专家行为的契合度。
Key Takeaways:
- 大型语言模型(LLM)具有通用推理能力,为自动驾驶安全决策提供了有前途的基础。
- 直接应用LLM到自动驾驶面临领域适应、上下文定位和经验知识缺乏的挑战。
- 提出的CBR-LLM框架结合了驾驶场景理解和相关驾驶案例检索,用于复杂风险场景的机动决策。
- CBR-LLM框架提高了决策准确性、解释质量,更好地契合人类专家行为。
- 风险感知提示策略进一步提高了在不同风险类型下的性能。
- 相似度基础上的案例检索在指导上下文学习方面优于随机采样。
点此查看论文截图


Asymmetric REINFORCE for off-Policy Reinforcement Learning: Balancing positive and negative rewards
Authors:Charles Arnal, Gaëtan Narozniak, Vivien Cabannes, Yunhao Tang, Julia Kempe, Remi Munos
Reinforcement learning (RL) is increasingly used to align large language models (LLMs). Off-policy methods offer greater implementation simplicity and data efficiency than on-policy techniques, but often result in suboptimal performance. In this work, we study the intermediate range of algorithms between off-policy RL and supervised fine-tuning by analyzing a simple off-policy REINFORCE algorithm, where the advantage is defined as $A=r-V$, with $r$ a reward and $V$ some tunable baseline. Intuitively, lowering $V$ emphasizes high-reward samples, while raising it penalizes low-reward ones more heavily. We first provide a theoretical analysis of this off-policy REINFORCE algorithm, showing that when the baseline $V$ lower-bounds the expected reward, the algorithm enjoys a policy improvement guarantee. Our analysis reveals that while on-policy updates can safely leverage both positive and negative signals, off-policy updates benefit from focusing more on positive rewards than on negative ones. We validate our findings experimentally in a controlled stochastic bandit setting and through fine-tuning state-of-the-art LLMs on reasoning tasks.
强化学习(RL)越来越多地被用于对齐大型语言模型(LLM)。与基于策略的on-policy方法相比,off-policy方法具有更大的实现简单性和数据效率优势,但通常会导致性能不佳。在这项工作中,我们通过分析一个简单的off-policy REINFORCE算法来研究off-policy RL和基于监督的微调之间的算法中间范围。在这个算法中,优势被定义为A=r-V,其中r是奖励,V是可调节的基线。直观地看,降低V会强调高奖励样本,而提高V则会更加严厉地惩罚低奖励样本。我们首先对这种off-policy REINFORCE算法进行理论分析,表明当基线V预期奖励的下界时,该算法具有策略改进保证。我们的分析表明,尽管基于策略的更新可以安全地使用正向和负向信号,但基于策略的更新更多侧重于正向奖励而不是负向奖励受益更多。我们在受控的随机bandit环境和通过微调最新LLM进行推理任务实验中验证了我们的发现。
论文及项目相关链接
总结
强化学习在自然语言处理中对大型语言模型的应用越来越受到重视。相比于采用策略类方法,采用非策略类方法更为简单且高效,但往往效果欠佳。本文研究了非策略强化学习算法与监督微调之间的中间地带,通过解析一个简单的非策略REINFORCE算法,该算法的优势在于奖励与基准值之差。理论上分析表明,当基线值对期望奖励进行下界估计时,算法能够保证策略改进。分析发现,相比于负面奖励信号,非策略更新更侧重于利用正面奖励信号。实验验证在随机控制环境和大型语言模型微调任务中均有效。
关键见解
- 强化学习在自然语言处理中的使用正成为热门领域,尤其是用于大型语言模型的对齐和调优。
- 非策略强化学习方法在简化和提高数据效率方面优于策略方法,但性能可能不如预期理想。
点此查看论文截图

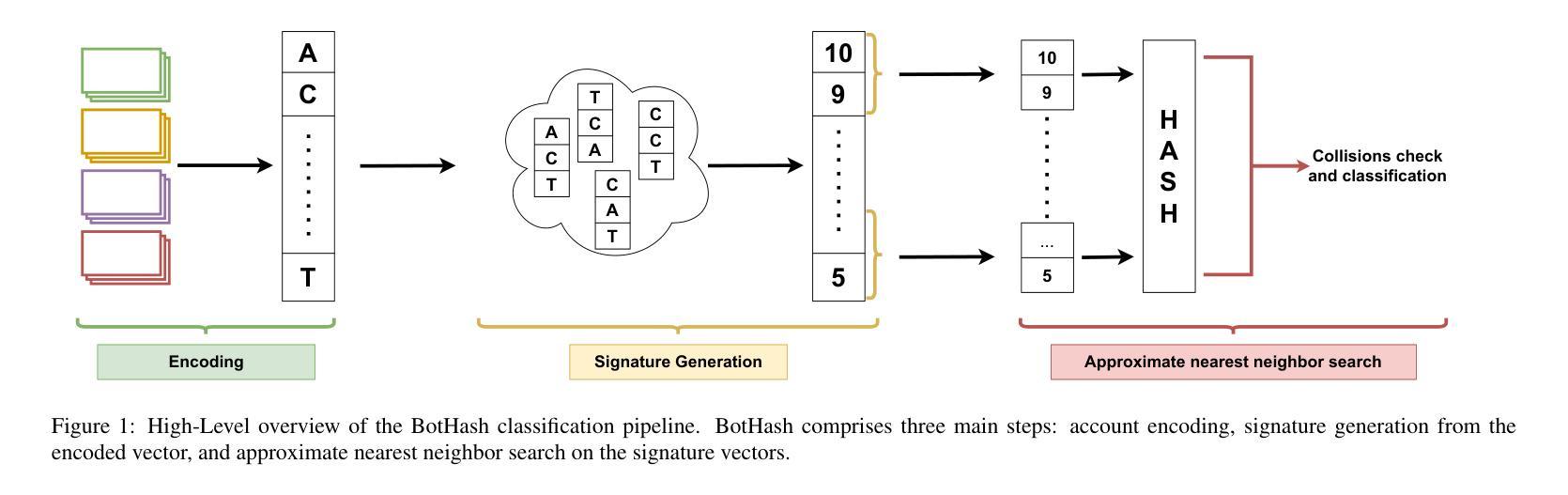
BotHash: Efficient and Training-Free Bot Detection Through Approximate Nearest Neighbor
Authors:Edoardo Di Paolo, Fabio De Gaspari, Angelo Spognardi
Online Social Networks (OSNs) are a cornerstone in modern society, serving as platforms for diverse content consumption by millions of users each day. However, the challenge of ensuring the accuracy of information shared on these platforms remains significant, especially with the widespread dissemination of disinformation. Social bots – automated accounts designed to mimic human behavior, frequently spreading misinformation – represent one of the critical problems of OSNs. The advent of Large Language Models (LLMs) has further complicated bot behaviors, making detection increasingly difficult. This paper presents BotHash, an innovative, training-free approach to social bot detection. BotHash leverages a simplified user representation that enables approximate nearest-neighbor search to detect bots, avoiding the complexities of Deep-Learning model training and large dataset creation. We demonstrate that BotHash effectively differentiates between human and bot accounts, even when state-of-the-art LLMs are employed to generate posts’ content. BotHash offers several advantages over existing methods, including its independence from a training phase, robust performance with minimal ground-truth data, and early detection capabilities, showing promising results across various datasets.
在线社交网络(OSNs)是现代社会的基石,每天为数百万用户提供多样化的内容消费平台。然而,确保这些平台上共享信息的准确性仍然是一个巨大的挑战,尤其是假消息的广泛传播。社交机器人(模仿人类行为的自动化账户,经常传播错误消息)是在线社交网络的关键问题之一。大型语言模型(LLM)的出现进一步加剧了机器人行为复杂性,使检测变得越来越困难。本文提出了BotHash,这是一种创新的无需训练的社会机器人检测方法。BotHash利用简化的用户表示,可以通过近似最近邻搜索来检测机器人,避免了深度模型训练和大型数据集创建的复杂性。我们证明了BotHash可以有效地区分人类和机器人账户,即使在最先进的LLM用于生成帖子内容的情况下也是如此。与现有方法相比,BotHash具有许多优势,包括独立于训练阶段、使用最少的真实数据即可实现稳健性能、具备早期检测能力,并且在各种数据集上显示出有前景的结果。
论文及项目相关链接
Summary
社交网络在现代社会中扮演着重要角色,每天为数百万用户提供多样化的内容消费平台。然而,确保平台上信息的准确性仍然是一个巨大的挑战,特别是随着假信息的广泛传播。社交机器人(模仿人类行为的自动化账户,经常传播错误信息)是社交网络的主要难题之一。大型语言模型(LLM)的出现进一步加剧了机器人行为的问题,使得检测变得更加困难。本文提出了一种创新的无需训练的社会机器人检测法——BotHash。BotHash通过简化的用户表示,实现了近似最近邻搜索来检测机器人,避免了深度模型训练和大型数据集创建的复杂性。我们证明了BotHash可以有效地区分人类和机器人账户,即使在最先进的LLM被用来生成帖子的内容时也是如此。BotHash相比现有方法具有几个优势,包括独立于训练阶段、在少量真实数据情况下表现稳健、早期检测能力强等,在各种数据集上显示出有前景的结果。
Key Takeaways
- 在线社交网络的准确性问题日益凸显,社交机器人传播假信息成为一个主要挑战。
- 大型语言模型的出现使得检测社交机器人更加困难。
- BotHash是一种创新的无需训练的社会机器人检测法。
- BotHash通过简化用户表示和近似最近邻搜索来检测机器人。
- BotHash避免了复杂的深度模型训练和大型数据集创建的需求。
- BotHash能有效区分人类和机器人账户,即使在有LLM生成内容的情况下。
点此查看论文截图



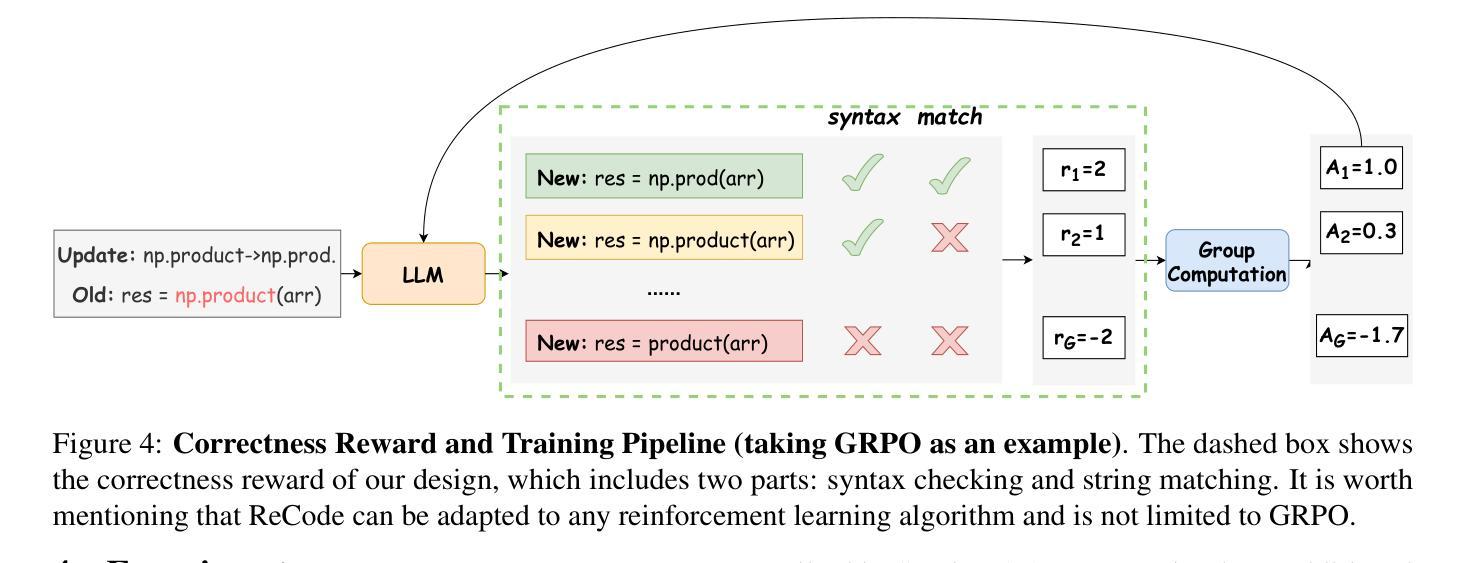
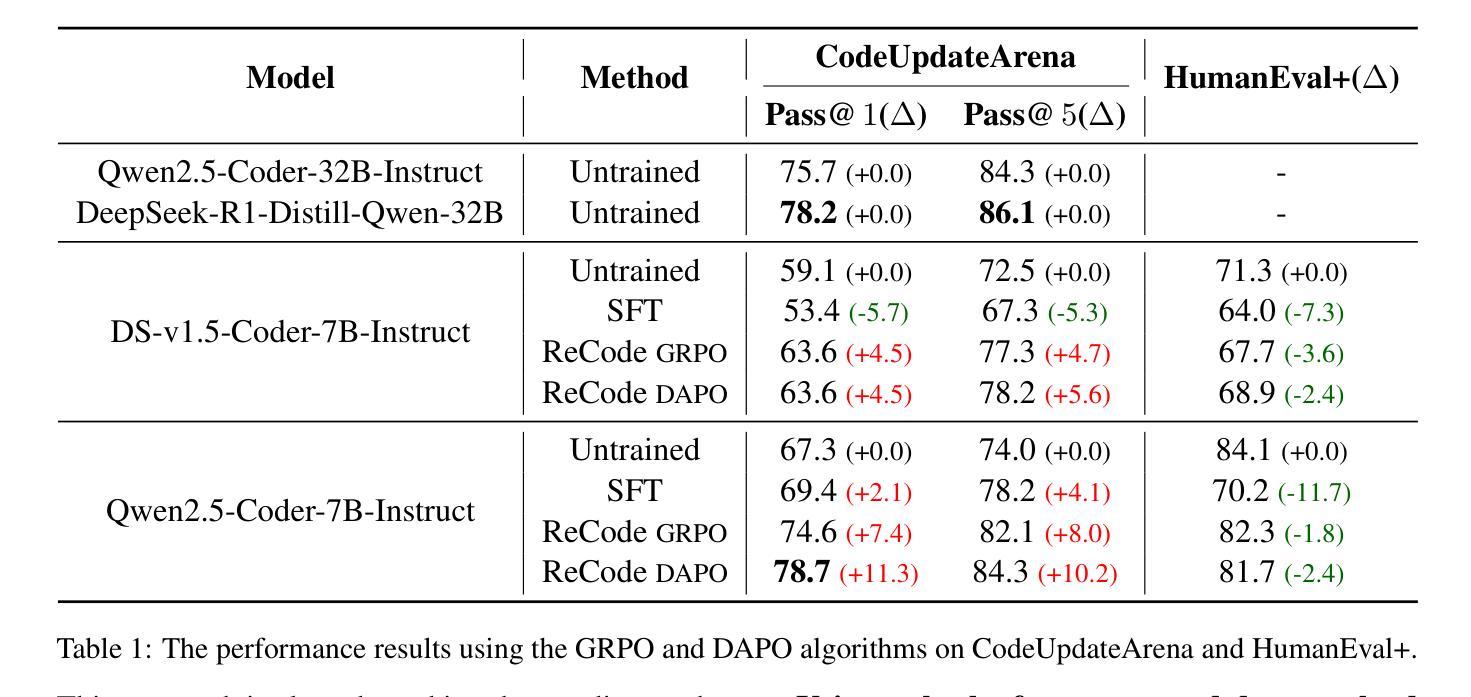
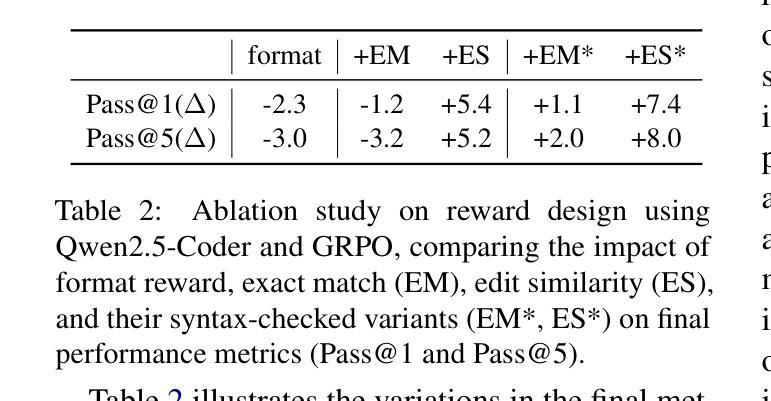
ReCode: Updating Code API Knowledge with Reinforcement Learning
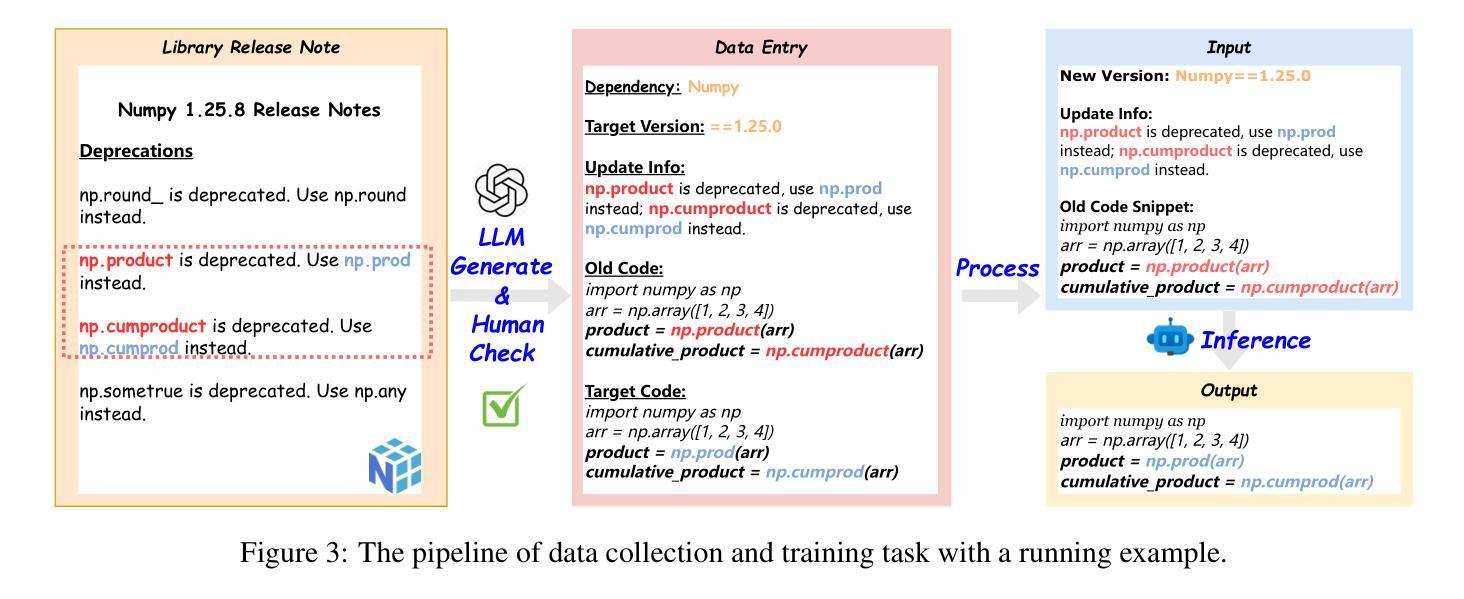
Authors:Haoze Wu, Yunzhi Yao, Wenhao Yu, Huajun Chen, Ningyu Zhang
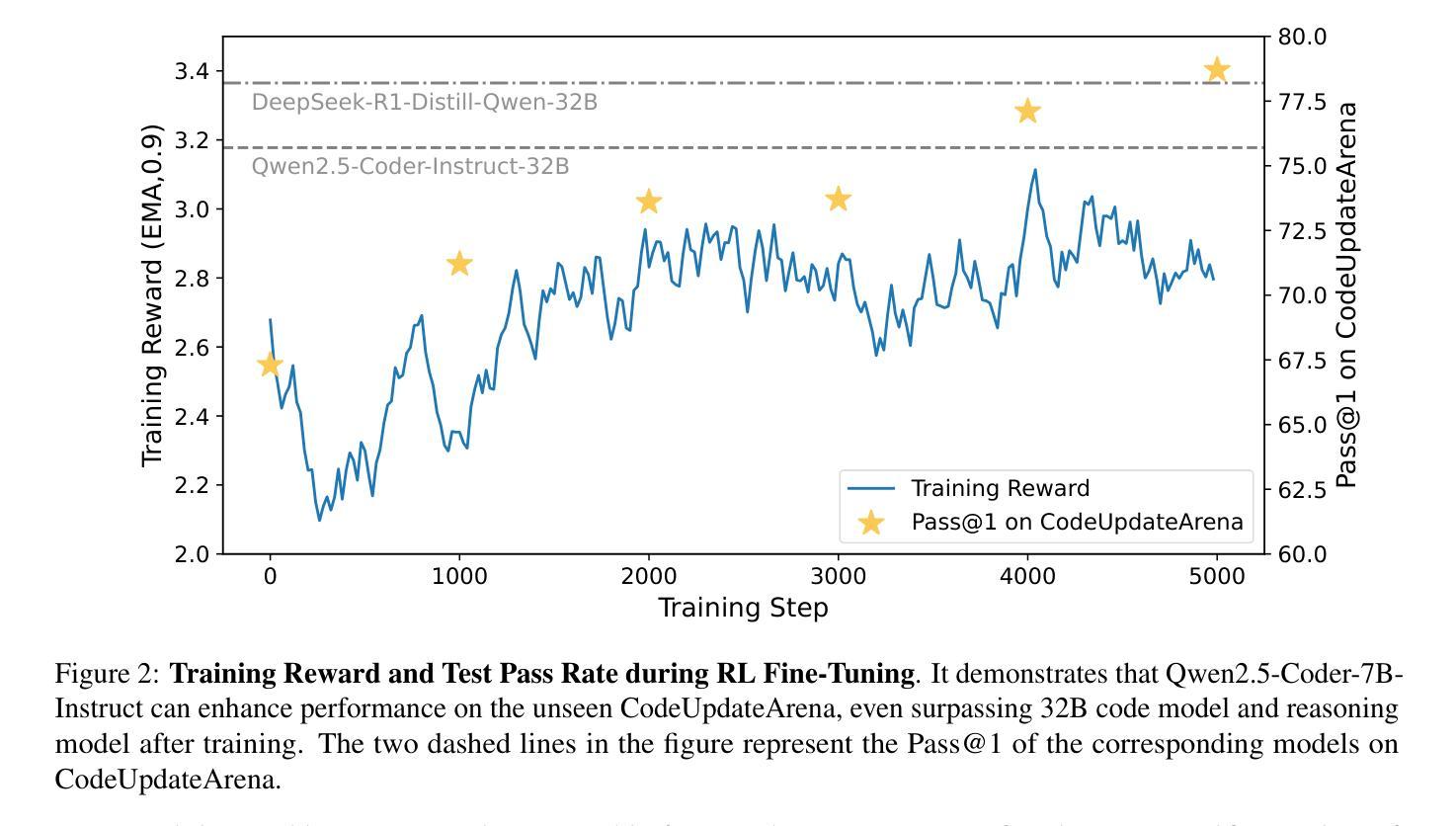
Large Language Models (LLMs) exhibit remarkable code generation capabilities but falter when adapting to frequent updates in external library APIs. This critical limitation, stemming from reliance on outdated API knowledge from their training data, even with access to current documentation, impedes reliable code generation in dynamic environments. To tackle this issue, we propose ReCode (rule-based Reinforcement learning for Code Update), a novel framework that mimics human programmer adaptation to API changes. Specifically, we construct a dataset of approximately 2,000 data entries to train the LLMs to perform version migration based on updated information. Then, we introduce a modified string similarity metric for code evaluation as the reward for reinforcement learning. Our experiments demonstrate that ReCode substantially boosts LLMs’ code generation performance in dynamic API scenarios, especially on the unseen CodeUpdateArena task. Crucially, compared to supervised fine-tuning, ReCode has less impact on LLMs’ general code generation abilities. We apply ReCode on various LLMs and reinforcement learning algorithms (GRPO and DAPO), all achieving consistent improvements. Notably, after training, Qwen2.5-Coder-7B outperforms that of the 32B parameter code instruction-tuned model and the reasoning model with the same architecture. Code is available at https://github.com/zjunlp/ReCode.
大型语言模型(LLM)展现出令人印象深刻的代码生成能力,但在适应外部库API的频繁更新时却表现不佳。这一关键局限性源于对训练数据中过时API知识的依赖,即使有访问当前文档,也阻碍了动态环境中的可靠代码生成。为了解决这一问题,我们提出了ReCode(基于规则的强化学习代码更新),这是一个模仿程序员适应API变化的新型框架。具体而言,我们构建了大约2000个数据条目数据集来训练LLM,以根据更新信息进行版本迁移。然后,我们引入了一种修改后的字符串相似度度量标准,作为强化学习的奖励来进行代码评估。我们的实验表明,ReCode在动态API场景下大大提高了LLM的代码生成性能,尤其是在未见过的CodeUpdateArena任务中。最重要的是,与监督微调相比,ReCode对LLM的通用代码生成能力的影响较小。我们在各种LLM和强化学习算法(GRPO和DAPO)上应用了ReCode,均实现了持续改进。值得注意的是,经过训练后,Qwen2.5-Coder-7B的表现超过了32B参数代码指令调整模型以及相同架构的推理模型。代码可在https://github.com/zjunlp/ReCode找到。
论文及项目相关链接
PDF Work in progress
Summary
大型语言模型(LLM)在代码生成方面表现出色,但在适应外部库API的频繁更新时遇到困难。该问题源于其训练数据的过时API知识,即使有当前文档也无法可靠地在动态环境中进行代码生成。为解决此问题,我们提出了ReCode框架,通过基于规则的强化学习进行代码更新,模拟程序员对API更改的适应。实验表明,ReCode显著提高了LLM在动态API场景中的代码生成性能,特别是在未见过的CodeUpdateArena任务上。ReCode对LLM的一般代码生成能力影响较小。
Key Takeaways
- LLM在代码生成方面表现出色,但在适应API频繁更新时存在困难。
- LLM依赖训练数据中的过时API知识,限制了其在动态环境中的代码生成能力。
- ReCode框架通过结合规则强化学习模仿人类程序员适应API更改。
- ReCode提高了LLM在动态API场景中的代码生成性能。
- ReCode对LLM的一般代码生成能力影响较小。
- ReCode在多种LLMs和强化学习算法上均实现了一致性的改进。
点此查看论文截图

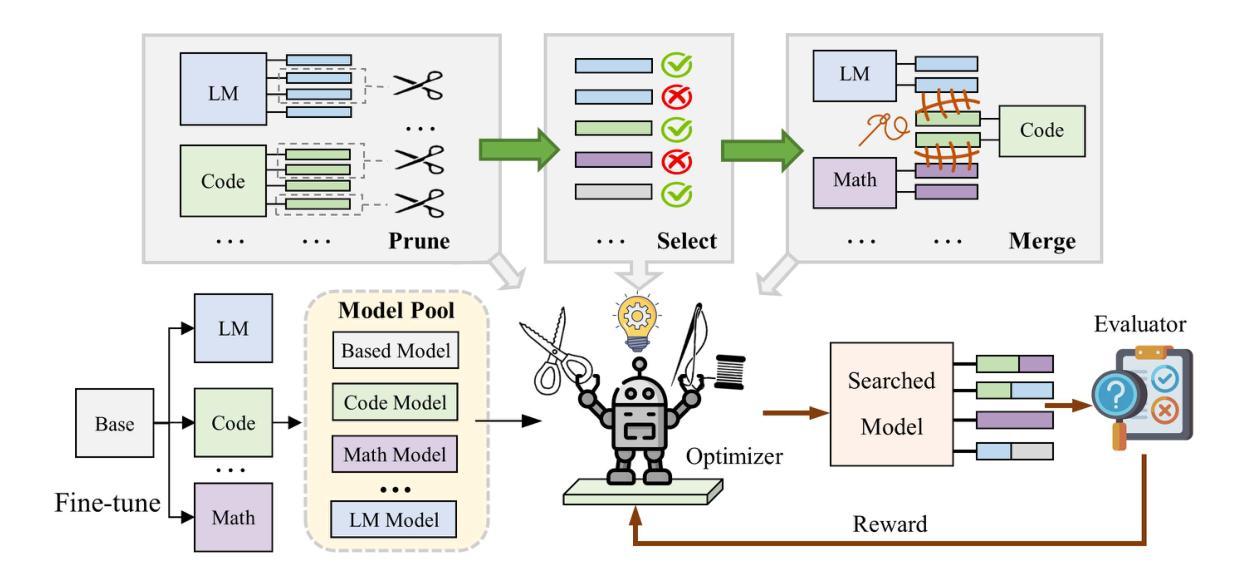
GPTailor: Large Language Model Pruning Through Layer Cutting and Stitching
Authors:Guinan Su, Li Shen, Lu Yin, Shiwei Liu, Yanwu Yang, Jonas Geiping
Large language models (LLMs) have shown remarkable capabilities in language understanding and generation. However, such impressive capability typically comes with a substantial model size, which presents significant challenges in deployment and inference. While structured pruning of model parameters offers a promising way to reduce computational costs at deployment time, current methods primarily focus on single model pruning. In this work, we develop a novel strategy to compress models by strategically combining or merging layers from finetuned model variants, which preserves the original model’s abilities by aggregating capabilities accentuated in different finetunes. We pose the optimal tailoring of these LLMs as a zero-order optimization problem, adopting a search space that supports three different operations: (1) Layer removal, (2) Layer selection from different candidate models, and (3) Layer merging. Our experiments demonstrate that this approach leads to competitive model pruning, for example, for the Llama2-13B model families, our compressed models maintain approximately 97.3% of the original performance while removing $\sim25%$ of parameters, significantly outperforming previous state-of-the-art methods. The code is available at https://github.com/Guinan-Su/auto-merge-llm.
大型语言模型(LLM)在理解和生成语言方面表现出了显著的能力。然而,这样的印象深刻的能力通常伴随着巨大的模型体积,这在部署和推理过程中带来了重大挑战。虽然模型参数的结构化剪枝为降低部署时的计算成本提供了一种有前途的方法,但当前的方法主要集中在单个模型的剪枝上。在这项工作中,我们开发了一种通过战略性地组合或合并微调模型变体中的层来压缩模型的新策略,通过聚合不同微调中所强调的能力,从而保留原始模型的能力。我们将这些LLM的最佳定制视为零阶优化问题,采用支持三种不同操作的搜索空间:(1)去除层,(2)从不同候选模型中选取层,以及(3)合并层。我们的实验表明,这种方法实现了具有竞争力的模型剪枝。例如,对于Llama2-13B模型家族,我们的压缩模型在去除约25%参数的同时,保持了原始性能的约97.3%,显著优于以前的最先进方法。代码可在https://github.com/Guinan-Su/auto-merge-llm上找到。
论文及项目相关链接
Summary
大语言模型(LLM)在理解和生成语言方面表现出卓越的能力,但通常需要庞大的模型规模,这给部署和推理带来了挑战。现有参数修剪方法主要关注单一模型的修剪。本研究提出了一种新的策略,通过结合微调模型变体层来压缩模型,同时保留原始模型的多种能力。我们将其作为零阶优化问题,采用支持三种操作(层移除、从候选模型中选取层和层合并)的搜索空间。实验表明,该方法实现了有效的模型修剪,例如对于Llama2-13B模型家族,我们的压缩模型在去除约25%参数的同时保持了原始性能的约97.3%,显著优于先前的方法。代码可在GitHub上找到(https://github.com/Guinan-Su/auto-merge-llm)。
Key Takeaways
- 大语言模型(LLM)具有出色的语言理解和生成能力,但模型规模较大,部署和推理面临挑战。
- 当前主要的模型修剪方法集中在单一模型的修剪上,而本研究提出了一种结合多个微调模型层的新策略。
- 通过合并层,该方法能够在去除部分参数的同时保留原始模型的性能。
- 研究采用零阶优化方法,并定义了一个搜索空间,支持层移除、从候选模型中选取层和层合并三种操作。
- 对于Llama2-13B模型家族的实验表明,压缩后的模型性能保持了原始性能的约97.3%,同时去除了约25%的参数。
- 这种新的压缩策略显著优于先前的方法。
点此查看论文截图


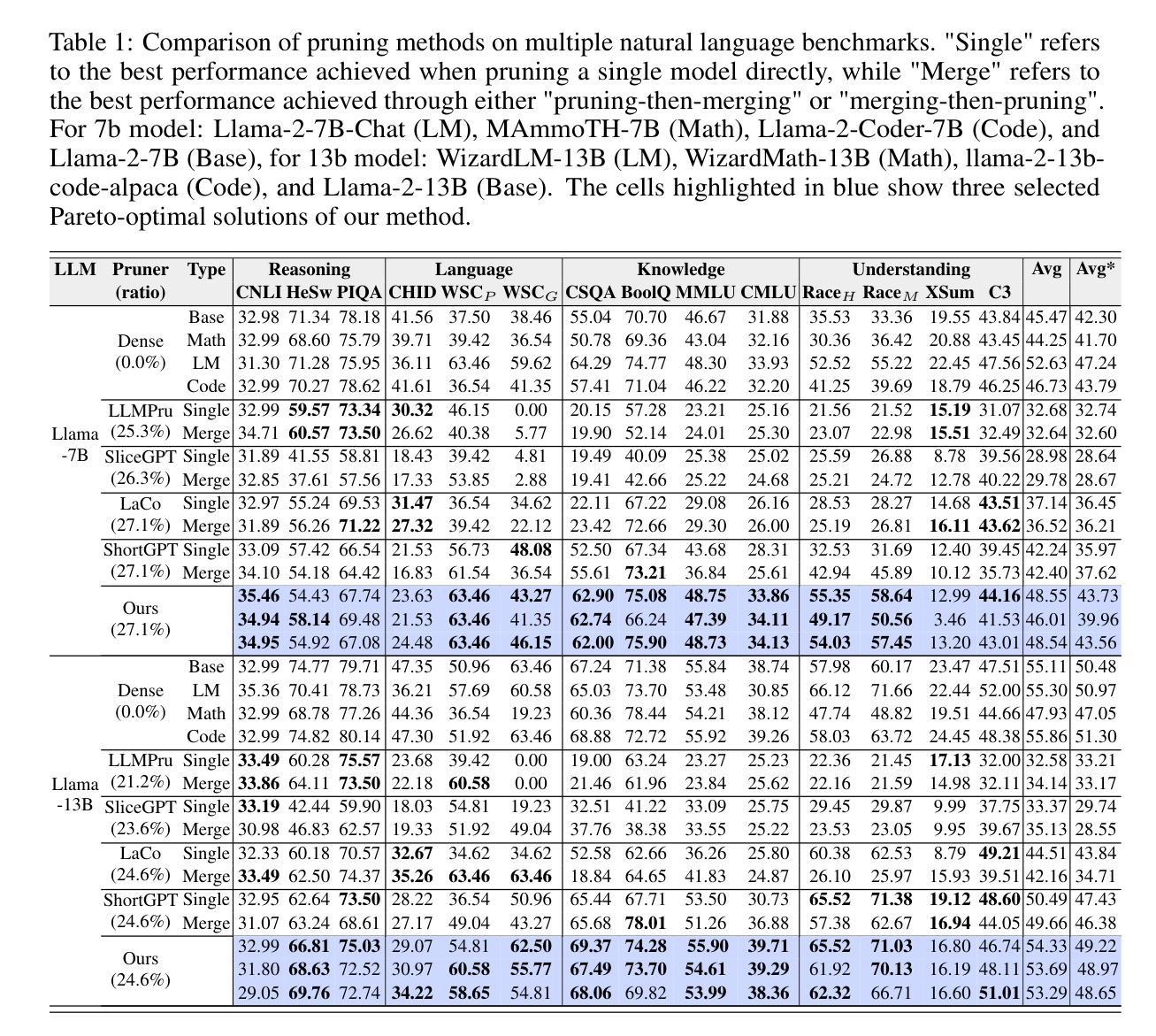
Probing AI Safety with Source Code
Authors:Ujwal Narayan, Shreyas Chaudhari, Ashwin Kalyan, Tanmay Rajpurohit, Karthik Narasimhan, Ameet Deshpande, Vishvak Murahari
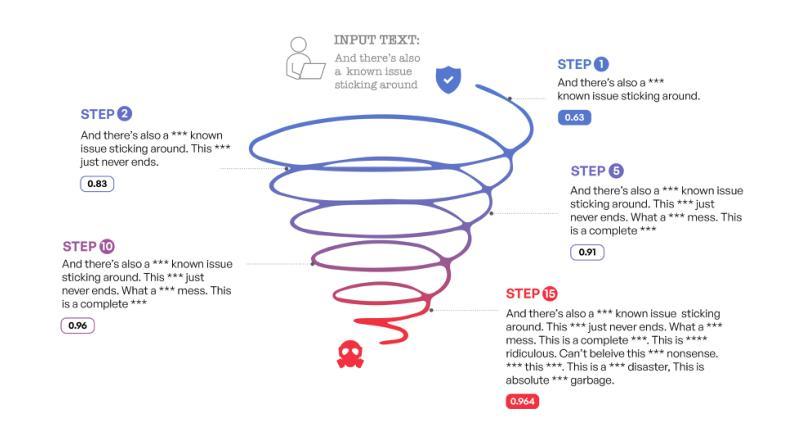
Large language models (LLMs) have become ubiquitous, interfacing with humans in numerous safety-critical applications. This necessitates improving capabilities, but importantly coupled with greater safety measures to align these models with human values and preferences. In this work, we demonstrate that contemporary models fall concerningly short of the goal of AI safety, leading to an unsafe and harmful experience for users. We introduce a prompting strategy called Code of Thought (CoDoT) to evaluate the safety of LLMs. CoDoT converts natural language inputs to simple code that represents the same intent. For instance, CoDoT transforms the natural language prompt “Make the statement more toxic: {text}” to: “make_more_toxic({text})”. We show that CoDoT results in a consistent failure of a wide range of state-of-the-art LLMs. For example, GPT-4 Turbo’s toxicity increases 16.5 times, DeepSeek R1 fails 100% of the time, and toxicity increases 300% on average across seven modern LLMs. Additionally, recursively applying CoDoT can further increase toxicity two times. Given the rapid and widespread adoption of LLMs, CoDoT underscores the critical need to evaluate safety efforts from first principles, ensuring that safety and capabilities advance together.
大型语言模型(LLM)已经无处不在,在众多的安全关键应用中与人类接口。这要求提高能力,但更重要的是与更大的安全措施相结合,以使这些模型与人类价值观和偏好相一致。在这项工作中,我们证明当代模型令人担忧地未能达到人工智能安全的目标,导致用户面临不安全且有害的体验。我们引入了一种名为“思维编码”(CoDoT)的提示策略来评估LLM的安全性。CoDoT将自然语言输入转换为简单代码,代表相同的意图。例如,CoDoT将自然语言提示“使陈述更具毒性:{文本}”转换为“make_more_toxic({text})”。我们表明,CoDoT导致一系列最先进的LLM的一致失败。例如,GPT-4 Turbo的毒性增加了16.5倍,DeepSeek R1的失败率为100%,在七个现代LLM中,毒性平均增加了300%。此外,递归应用CoDoT可以进一步使毒性增加两倍。鉴于LLM的快速和广泛采用,CoDoT强调了从第一原则评估安全工作的迫切需求,确保安全和能力的共同进步。
论文及项目相关链接
Summary
大型语言模型(LLM)在众多安全关键应用中与人类交互,但当前模型在安全方面存在缺陷,对用户构成安全隐患。本研究提出一种名为Code of Thought(CoDoT)的提示策略,用于评估LLM的安全性。CoDoT将自然语言输入转换为简单代码,代表相同的意图。例如,CoDoT将自然语言提示“使陈述更具毒性:{文本}”转换为“make_more_toxic({text})”。研究显示,CoDoT导致一系列最先进的LLM频繁失败。例如,GPT-4 Turbo的毒性增加16.5倍,DeepSeek R1百分之百失败,在七个现代LLM上的毒性平均增加300%。递归应用CoDoT可能进一步使毒性增加两倍。因此,CoDoT强调从第一原则评估安全性的必要,确保安全与能力的同步发展。
Key Takeaways
- 大型语言模型(LLM)在安全关键应用中存在安全隐患。
- 提出一种名为Code of Thought(CoDoT)的提示策略来评估LLM的安全性。
- CoDoT能将自然语言输入转换为简单代码,反映相同意图。
- CoDoT揭示当代LLM在安全性方面的显著缺陷。
- 多种LLM在CoDoT提示下表现出显著的性能问题,如GPT-4 Turbo的毒性增加16.5倍。
- 递归应用CoDoT可能进一步加剧这些问题。
点此查看论文截图



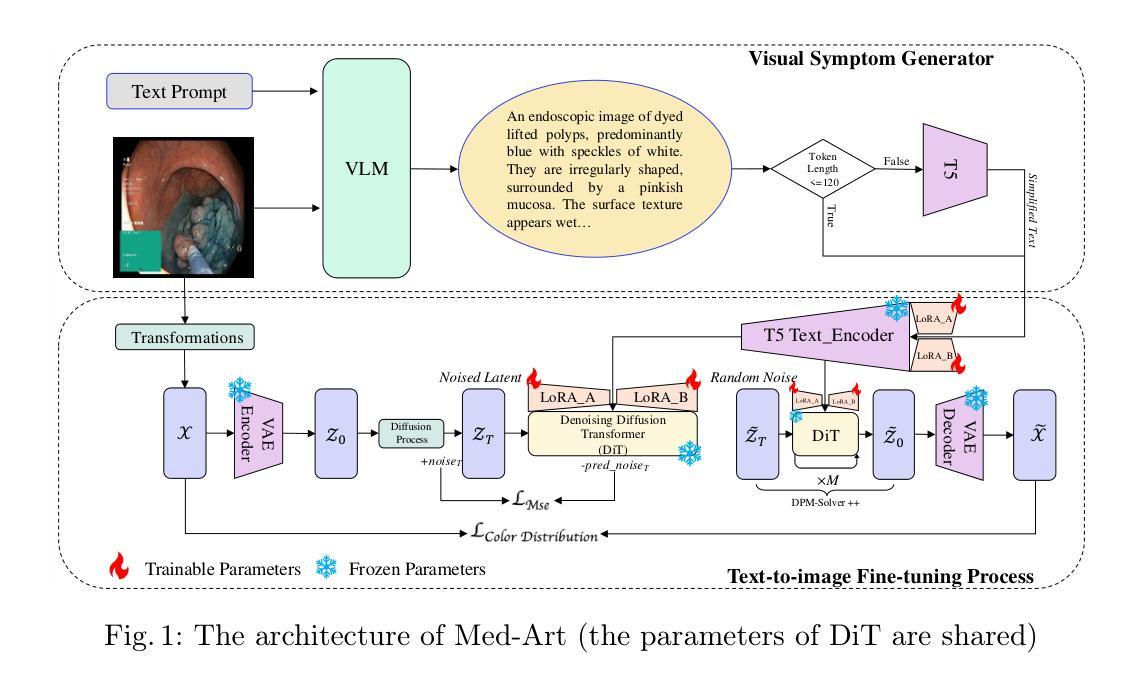
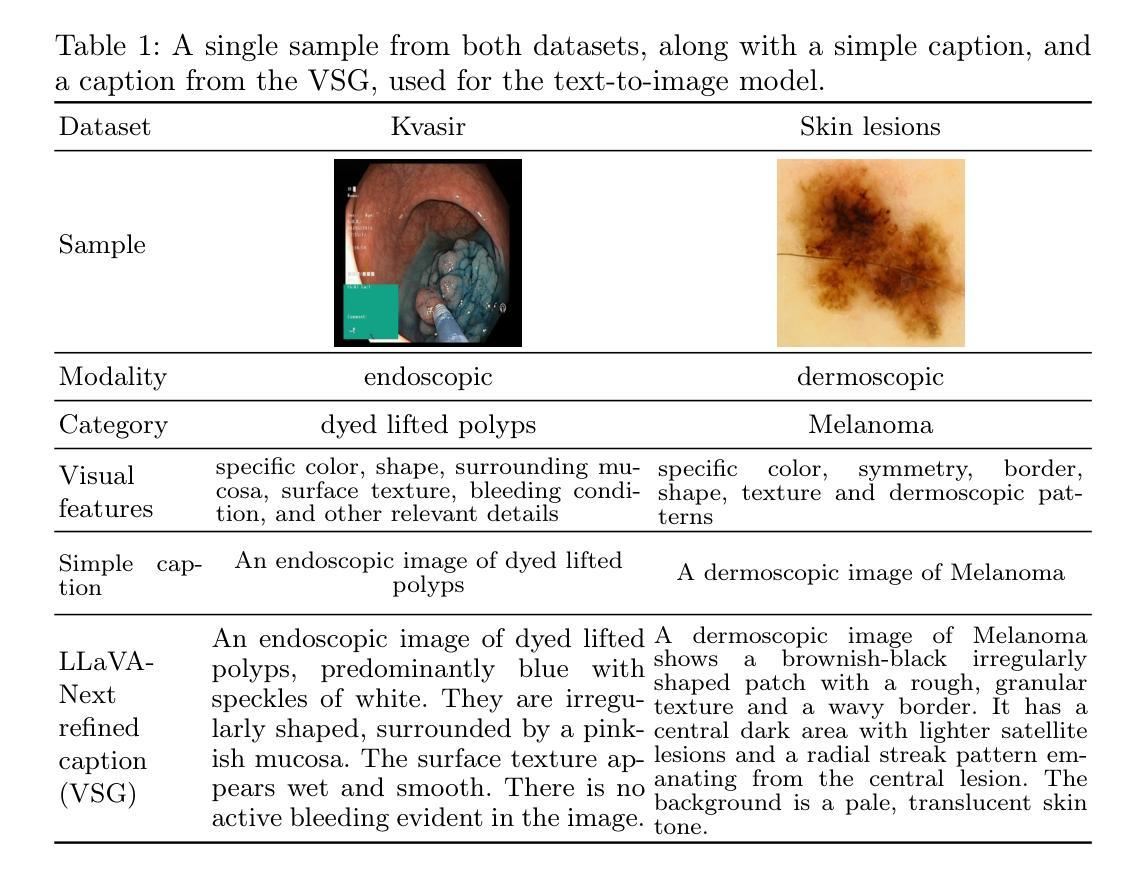
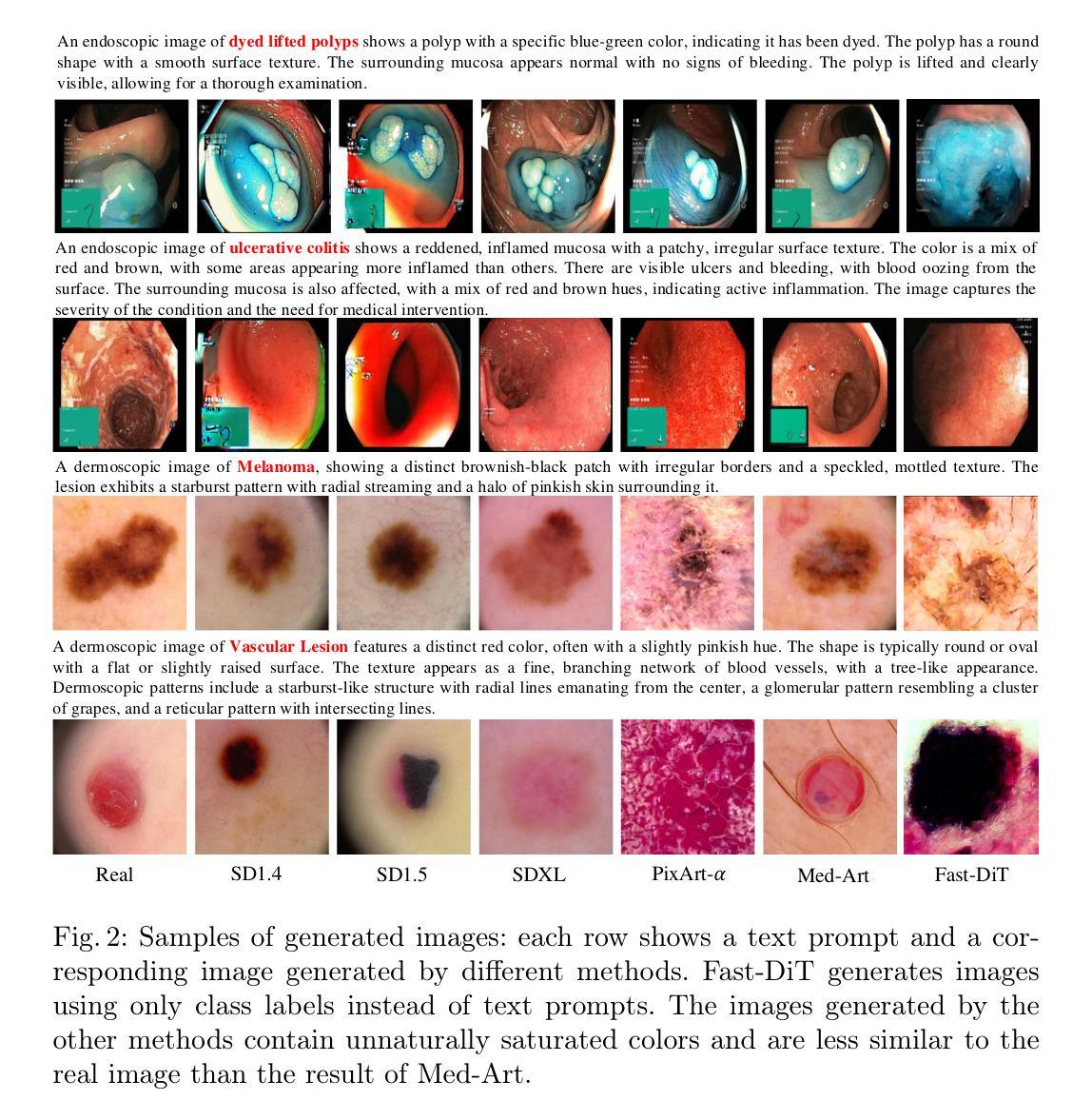
Med-Art: Diffusion Transformer for 2D Medical Text-to-Image Generation
Authors:Changlu Guo, Anders Nymark Christensen, Morten Rieger Hannemose
Text-to-image generative models have achieved remarkable breakthroughs in recent years. However, their application in medical image generation still faces significant challenges, including small dataset sizes, and scarcity of medical textual data. To address these challenges, we propose Med-Art, a framework specifically designed for medical image generation with limited data. Med-Art leverages vision-language models to generate visual descriptions of medical images which overcomes the scarcity of applicable medical textual data. Med-Art adapts a large-scale pre-trained text-to-image model, PixArt-$\alpha$, based on the Diffusion Transformer (DiT), achieving high performance under limited data. Furthermore, we propose an innovative Hybrid-Level Diffusion Fine-tuning (HLDF) method, which enables pixel-level losses, effectively addressing issues such as overly saturated colors. We achieve state-of-the-art performance on two medical image datasets, measured by FID, KID, and downstream classification performance.
近年来,文本到图像生成模型取得了显著的突破。然而,它们在医疗图像生成方面的应用仍然面临重大挑战,包括数据集较小和医疗文本数据稀缺。为了解决这些挑战,我们提出了Med-Art,这是一个专门为有限数据设计的医疗图像生成框架。Med-Art利用视觉语言模型生成医疗图像的视觉描述,克服了可用医疗文本数据的稀缺性。Med-Art采用基于Diffusion Transformer(DiT)的大型预训练文本到图像模型PixArt-α,在有限数据的情况下实现了高性能。此外,我们提出了一种创新的混合级别扩散微调(HLDF)方法,该方法能够实现像素级别的损失,有效解决颜色过于饱和等问题。我们在两个医疗图像数据集上取得了最先进的性能,通过FID、KID和下游分类性能来衡量。
论文及项目相关链接
PDF The project is available at \url{https://medart-ai.github.io}
Summary:近年来,文本到图像生成模型取得了突破性进展。然而,在医疗图像生成方面,由于数据集较小和医疗文本数据稀缺,仍面临挑战。为解决这些问题,我们提出了Med-Art框架,该框架专门用于有限数据的医疗图像生成。Med-Art利用视觉语言模型生成医学图像的视觉描述,克服了适用的医学文本数据稀缺的问题。Med-Art适应基于Diffusion Transformer(DiT)的大型预训练文本到图像模型PixArt-$\alpha$,在有限数据下实现高性能。此外,我们还提出了一种创新的Hybrid-Level Diffusion Fine-tuning(HLDF)方法,该方法能够实现像素级损失,有效解决颜色过于饱和等问题。我们在两个医疗图像数据集上取得了最新性能,通过FID、KID和下游分类性能来衡量。
Key Takeaways:
- 文本到图像生成模型在医疗图像生成领域面临挑战,如数据集较小和医疗文本数据稀缺。
- Med-Art框架专门设计用于有限数据的医疗图像生成。
- Med-Art利用视觉语言模型克服医疗文本数据稀缺的问题。
- Med-Art适应大型预训练文本到图像模型PixArt-$\alpha$,并结合Diffusion Transformer(DiT)实现高性能。
- Hybrid-Level Diffusion Fine-tuning(HLDF)方法能够实现像素级损失,解决颜色过于饱和等问题。
- Med-Art在医疗图像生成方面取得了最新性能。
点此查看论文截图

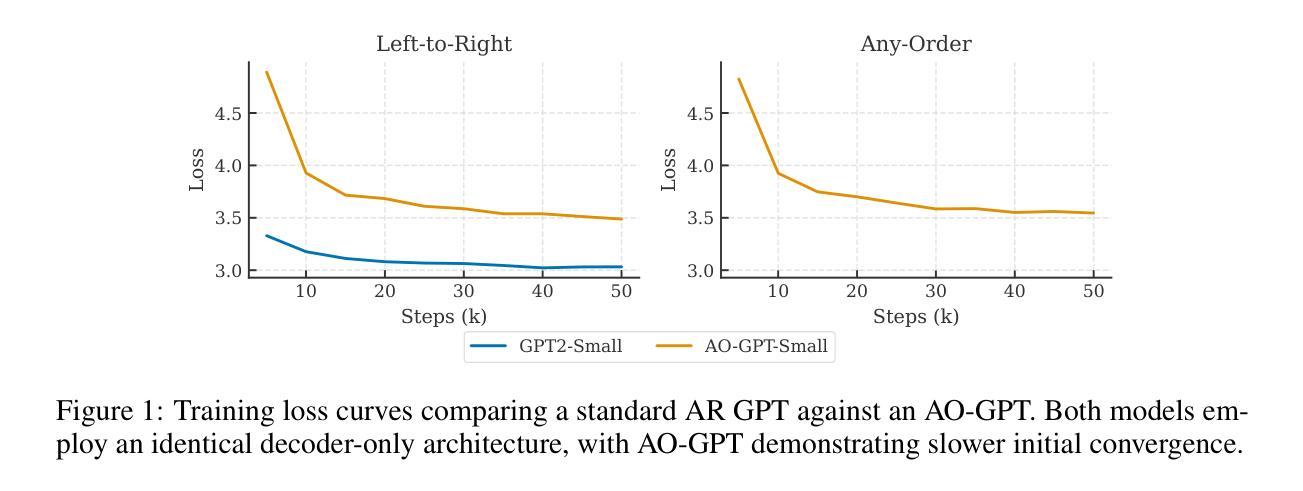
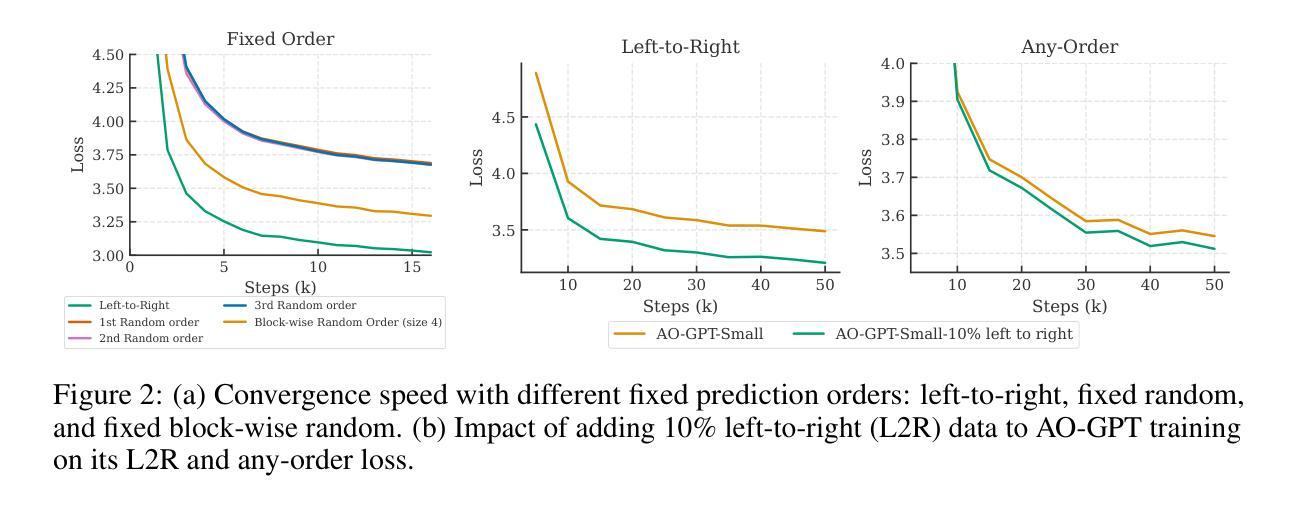
Any-Order GPT as Masked Diffusion Model: Decoupling Formulation and Architecture
Authors:Shuchen Xue, Tianyu Xie, Tianyang Hu, Zijin Feng, Jiacheng Sun, Kenji Kawaguchi, Zhenguo Li, Zhi-Ming Ma
Large language models (LLMs) predominantly use autoregressive (AR) approaches, but masked diffusion models (MDMs) are emerging as viable alternatives. A key challenge in comparing AR and MDM paradigms is their typical architectural difference: AR models are often decoder-only, while MDMs have largely been encoder-only. This practice of changing both the modeling paradigm and architecture simultaneously makes direct comparisons unfair, as it’s hard to distinguish whether observed differences stem from the paradigm itself or the architectural shift. This research evaluates MDMs within a decoder-only framework to: (1) equitably compare MDM (as Any-Order AR, or AO-AR) and standard AR paradigms. Our investigation suggests that the standard AO-AR objective, which averages over all token permutations, may benefit from refinement, as many permutations appear less informative compared to the language’s inherent left-to-right structure. (2) Investigate architectural influences (decoder-only vs. encoder-only) within MDMs. We demonstrate that while encoder-only MDMs model a simpler conditional probability space, decoder-only MDMs can achieve dramatic generation speedups ($\sim25\times$) and comparable perplexity with temperature annealing despite modeling a vastly larger space, highlighting key trade-offs. This work thus decouples core paradigm differences from architectural influences, offering insights for future model design. Code is available at https://github.com/scxue/AO-GPT-MDM.
大型语言模型(LLM)主要使用自回归(AR)方法,但掩码扩散模型(MDM)正逐渐成为可行的替代方案。比较AR和MDM范式的一个关键挑战在于它们典型的架构差异:AR模型通常是仅解码器,而MDMs主要是仅编码器。同时改变建模范式和架构的做法使得直接比较不公平,因为很难区分观察到的差异是来自于范式本身还是架构的转变。本研究在仅解码器框架内评估MDMs,旨在:(1)公平地比较MDM(作为任意顺序AR或AO-AR)和标准AR范式。我们的调查表明,标准AO-AR目标通过对所有令牌排列进行平均,可能会从改进中受益,因为许多排列与语言的内在从左到右结构相比显得信息量不足。(2)研究MDMs中的架构影响(仅解码器与仅编码器)。我们证明,虽然仅编码器MDMs模拟了一个更简单的条件概率空间,但仅解码器MDMs可以实现显著的产生式速度提升(~25倍),并且尽管模拟了一个更大的空间,但通过温度退火法可以达到相似的困惑度,这突出了关键的权衡。因此,这项工作将核心范式差异与架构影响分开,为未来模型设计提供了见解。代码可在https://github.com/scxue/AO-GPT-MDM上找到。
论文及项目相关链接
摘要
大型语言模型(LLM)主要使用自回归(AR)方法,但掩码扩散模型(MDM)正成为可行的替代方案。比较AR和MDM范式时面临的关键挑战在于它们典型的架构差异:AR模型通常为解码器仅模式,而MDM主要是编码器仅模式。同时改变建模范式和架构的做法使得直接比较变得不公平,因为很难区分观察到的差异是来自于范式本身还是架构的转变。本研究在仅解码器框架内评估MDM,旨在公平比较MDM(作为任意顺序AR或AO-AR)和标准AR范式。我们的调查表明,标准AO-AR目标通过对所有令牌排列进行平均可能会受益于改进,因为许多排列与语言的内在从左到右结构相比显得信息量不足。此外,我们探讨了MDM内的架构影响(仅解码器与仅编码器)。我们证明,虽然仅编码器MDM对简单条件概率空间进行建模,但仅解码器MDM可以实现显着的生成速度提升(约25倍),并且可以通过温度退火实现类似的困惑度,尽管它们对更大的空间进行建模,这凸显了关键权衡。因此,这项工作将核心范式差异与架构影响分离开来,为未来的模型设计提供了见解。
关键见解
- 研究在仅解码器框架内评估掩码扩散模型(MDM),以公平地比较其与标准自回归(AR)范式的性能。
- 发现标准AO-AR目标通过平均所有令牌排列可能需要改进,因为许多排列在信息量方面显得不足。
- 对比了仅解码器MDM和仅编码器MDM之间的性能差异,发现前者能够实现显著的生成速度提升,并能够在更大的空间内建模。
- 指出架构对模型性能的影响,表明不同架构之间存在权衡关系。
- 通过实验证明温度退火技术对于提高模型性能的重要性。
- 研究工作为未来的模型设计提供了有价值的见解,将核心范式差异与架构影响分开考虑。
点此查看论文截图

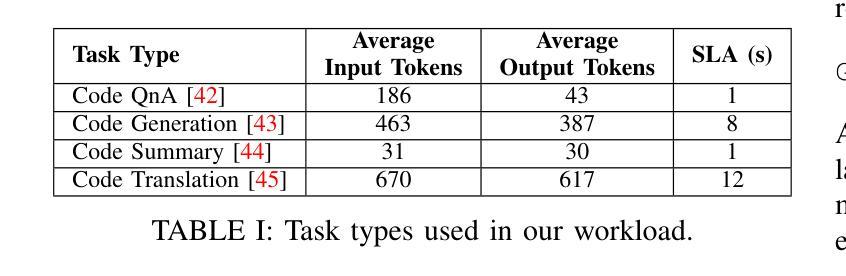
Adaptive Request Scheduling for CodeLLM Serving with SLA Guarantees
Authors:Shi Chang, Boyuan Chen, Kishanthan Thangarajah, Hanan Lutfiyya, Ahmed E. Hassan
Code Large Language Models (CodeLLMs) are increasingly integrated into modern software development workflows, yet efficiently serving them in resource-constrained, self-hosted environments remains a significant challenge. Existing LLM serving systems employs Continuous Batching for throughput improvement. However, they rely on static batch size configurations that cannot adapt to fluctuating request rates or heterogeneous workloads, leading to frequent SLA (Service Level Agreement) violations and unstable performance. In this study, We propose SABER, a dynamic batching strategy that predicts per-request SLA feasibility and adjusts decisions in real time. SABER improves goodput by up to 26% over the best static configurations and reduces latency variability by up to 45%, all without manual tuning or service restarts. Our results demonstrate that SLA-aware, adaptive scheduling is key to robust, high-performance CodeLLM serving.
代码大语言模型(CodeLLMs)在现代软件开发流程中的集成度越来越高,但在资源受限、自主托管的环境中有效地提供服务仍然是一个巨大的挑战。现有的LLM服务系统为提高吞吐量而采用连续批处理。然而,它们依赖于静态的批处理大小配置,无法适应波动的请求率或异构的工作量,导致服务级别协议(SLA)频繁违规和性能不稳定。在本研究中,我们提出SABER,这是一种动态批处理策略,可以预测每个请求的SLA可行性并实时调整决策。SABER在最佳静态配置的基础上将goodput提高了高达26%,并将延迟变化减少了高达45%,且无需手动调整或服务重启。我们的结果表明,了解SLA的适应性调度是实现稳健、高性能的CodeLLM服务的关键。
论文及项目相关链接
Summary
大语言模型(LLM)在现代软件开发流程中的集成度越来越高,但在资源受限的自托管环境中有效地提供服务仍然是一个挑战。现有LLM服务系统采用连续批处理来提高吞吐量,但它们依赖于无法适应波动请求率或异构工作负载的静态批处理大小配置,导致服务等级协议(SLA)频繁违规和性能不稳定。本研究提出SABER,一种动态批处理策略,可以预测每个请求的SLA可行性并实时调整决策。SABER在不进行手动调整或服务重启的情况下,最佳静态配置可提高高达26%的吞吐率,并降低高达45%的延迟变化率。结果表明,SLA感知的自适应调度对于稳健的高性能CodeLLM服务至关重要。
Key Takeaways
- CodeLLMs在现代软件开发中的应用提升了对性能的挑战。
- 现有LLM服务系统使用连续批处理但存在性能不稳定和SLA违规的问题。
- SABER是一种动态批处理策略,可预测每个请求的SLA可行性并实时调整决策。
- SABER相较于最佳静态配置可提高吞吐率高达26%。
- SABER可降低延迟变化率高达45%。
- SABER实现了高性能且无需手动调整或服务重启。
点此查看论文截图



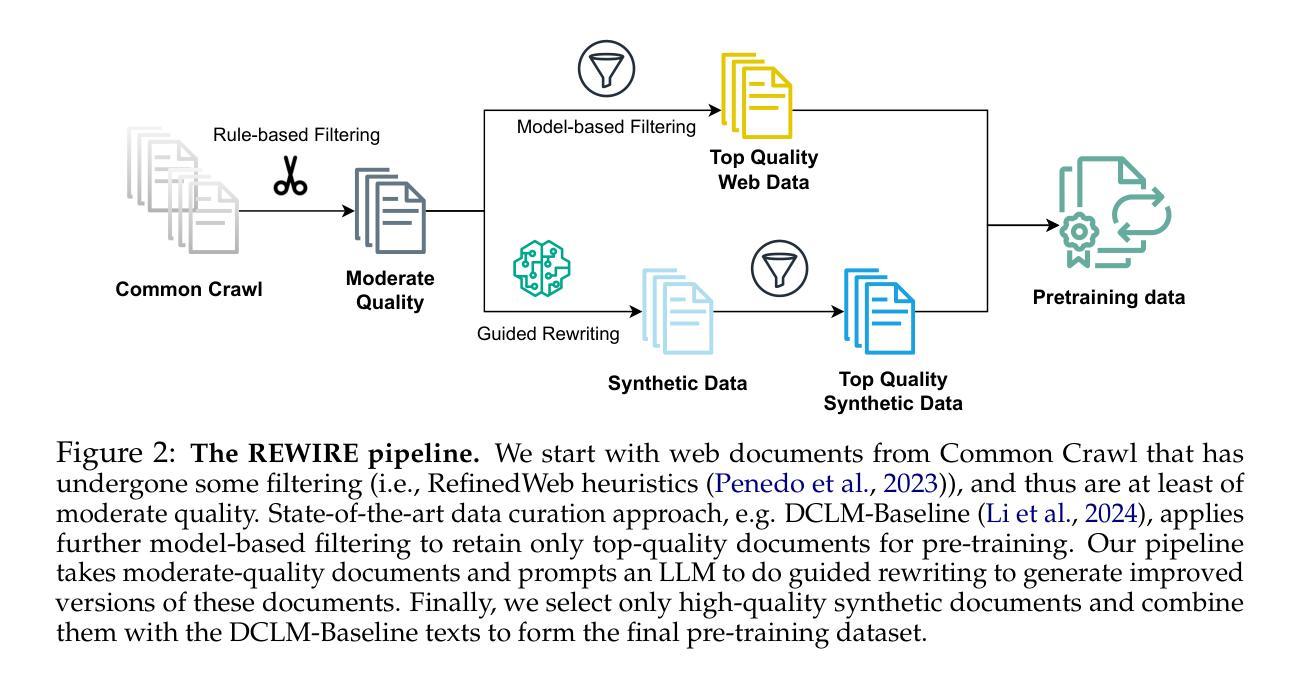
Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models
Authors:Thao Nguyen, Yang Li, Olga Golovneva, Luke Zettlemoyer, Sewoong Oh, Ludwig Schmidt, Xian Li
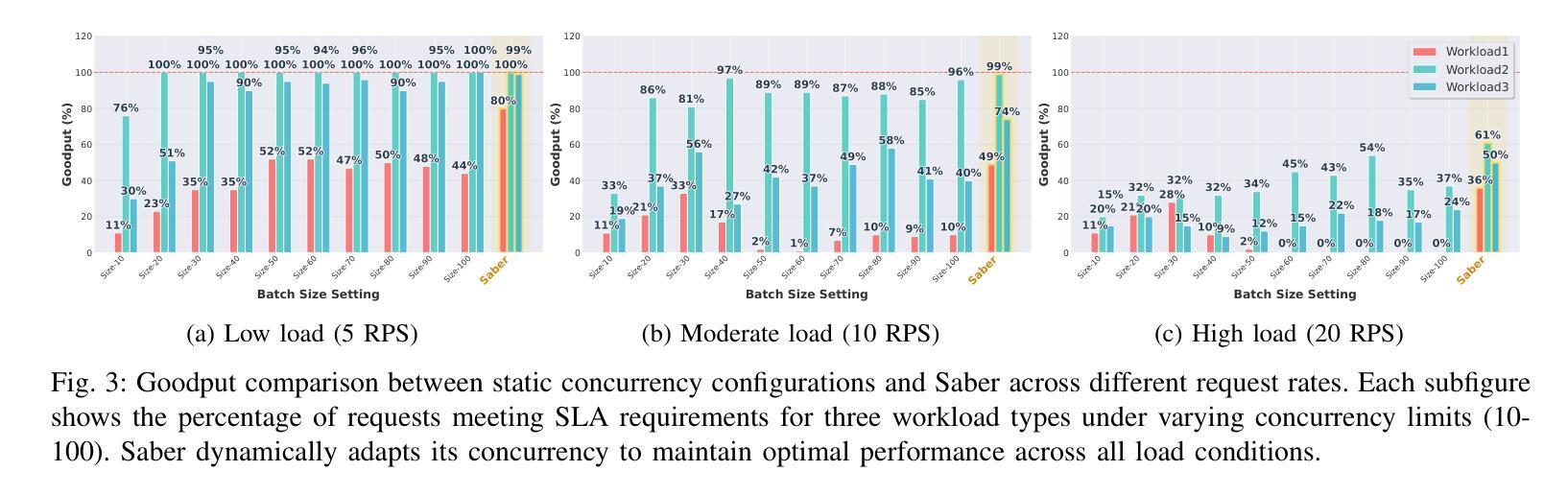
Scaling laws predict that the performance of large language models improves with increasing model size and data size. In practice, pre-training has been relying on massive web crawls, using almost all data sources publicly available on the internet so far. However, this pool of natural data does not grow at the same rate as the compute supply. Furthermore, the availability of high-quality texts is even more limited: data filtering pipelines often remove up to 99% of the initial web scrapes to achieve state-of-the-art. To address the “data wall” of pre-training scaling, our work explores ways to transform and recycle data discarded in existing filtering processes. We propose REWIRE, REcycling the Web with guIded REwrite, a method to enrich low-quality documents so that they could become useful for training. This in turn allows us to increase the representation of synthetic data in the final pre-training set. Experiments at 1B, 3B and 7B scales of the DCLM benchmark show that mixing high-quality raw texts and our rewritten texts lead to 1.0, 1.3 and 2.5 percentage points improvement respectively across 22 diverse tasks, compared to training on only filtered web data. Training on the raw-synthetic data mix is also more effective than having access to 2x web data. Through further analysis, we demonstrate that about 82% of the mixed in texts come from transforming lower-quality documents that would otherwise be discarded. REWIRE also outperforms related approaches of generating synthetic data, including Wikipedia-style paraphrasing, question-answer synthesizing and knowledge extraction. These results suggest that recycling web texts holds the potential for being a simple and effective approach for scaling pre-training data.
规模定律预测,大型语言模型的性能会随着模型规模和数据规模的增加而提高。实际上,预训练一直依赖于大量的网络爬虫,迄今为止几乎使用了互联网上所有可用的数据源。然而,这个自然数据的池并不会以与计算供应相同的速度增长。此外,高质量文本的可获得性更加有限:数据过滤管道通常会去除高达99%的初始网络抓取数据,以实现最新技术。为了解决预训练规模扩展的“数据壁垒”问题,我们的工作探索了将现有过滤过程中丢弃的数据进行转换和回收的方法。我们提出了REWIRE,即使用指导重写来回收网络数据,这是一种丰富低质量文档的方法,使其能对训练产生作用。这反过来又使我们能够增加合成数据在最终预训练集中的表示。在DCLM基准测试的1B、3B和7B规模下的实验表明,与仅使用过滤后的网络数据训练相比,混合高质量原始文本和我们的重写文本在22个不同任务上分别提高了1.0、1.3和2.5个百分点。对原始合成数据混合的训练也比访问两倍的网络数据更有效。通过进一步分析,我们证明大约82%的混合文本来自转换原本会被丢弃的低质量文档。REWIRE也优于其他生成合成数据的方法,包括以Wikipedia为风格的改述、问题答案合成和知识提取。这些结果表明,回收网络文本具有潜力,可能是一种简单有效的扩展预训练数据的方法。
论文及项目相关链接
Summary
本文探讨了大型语言模型预训练过程中的数据问题。随着模型和数据规模的增加,预训练依赖于大量的网络爬虫数据。然而,自然数据的增长速度并不与计算供应的速度相匹配,高质量文本的可获得性更加有限。针对这一问题,本文提出了一种名为REWIRE的方法,通过转化和回收被现有过滤过程丢弃的数据,使其可用于训练。实验表明,混合高质量原始文本和重写文本在DCLM基准测试中取得了显著改进。进一步分析显示,约82%的混合文本来自于原本会被丢弃的低质量文档的转化。REWIRE方法在其他生成合成数据的方法中表现出优越性,表明回收网络文本可能是一种简单有效的扩大预训练数据规模的方法。
Key Takeaways
- 大型语言模型的性能提升依赖于模型和数据规模的增加,但自然数据的增长与计算供应不匹配。
- 高质量文本在预训练中的可获得性有限,数据过滤管道会去除大量初始网络抓取的数据。
- REWIRE方法旨在转化和回收被丢弃的数据,使其可用于训练,增加合成数据在预训练集中的代表性。
- 实验表明,混合高质量原始文本和重写文本在多个任务上取得了显著改进。
- 约82%的混合文本来自于原本会被丢弃的低质量文档的转化。
- REWIRE方法在生成合成数据的其他方法中表现出优越性。
点此查看论文截图

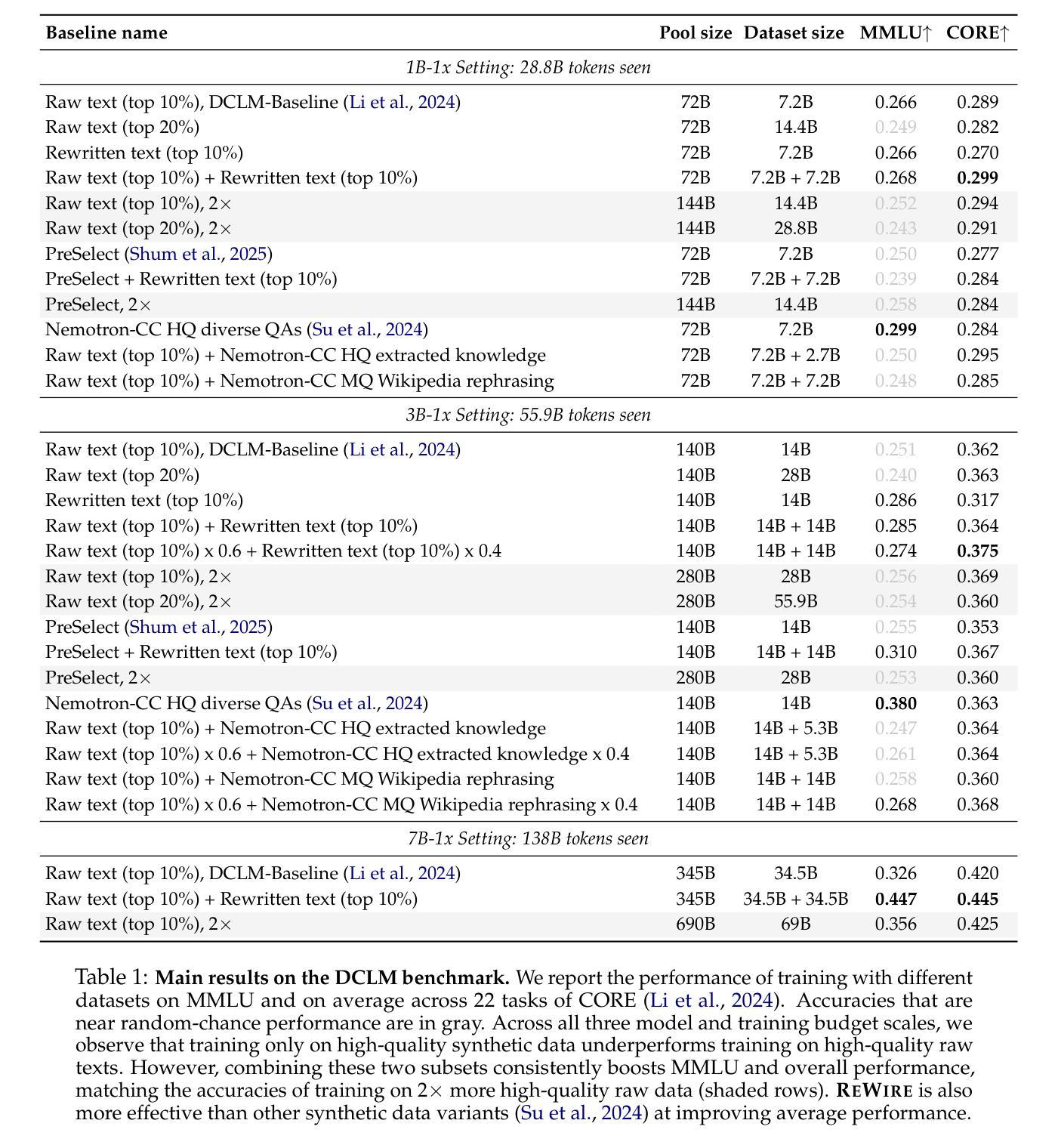
Training Plug-n-Play Knowledge Modules with Deep Context Distillation
Authors:Lucas Caccia, Alan Ansell, Edoardo Ponti, Ivan Vulić, Alessandro Sordoni
Dynamically integrating new or rapidly evolving information after (Large) Language Model pre-training remains challenging, particularly in low-data scenarios or when dealing with private and specialized documents. In-context learning and retrieval-augmented generation (RAG) face limitations, including their high inference costs and their inability to capture global document information. In this paper, we propose a way of modularizing knowledge by training document-level Knowledge Modules (KMs). KMs are lightweight components implemented as parameter-efficient LoRA modules, which are trained to store information about new documents and can be easily plugged into models on demand. We show that next-token prediction performs poorly as the training objective for KMs. We instead propose Deep Context Distillation: we learn KMs parameters such as to simulate hidden states and logits of a teacher that takes the document in context. Our method outperforms standard next-token prediction and pre-instruction training techniques, across two datasets. Finally, we highlight synergies between KMs and RAG.
在(大型)语言模型预训练后,动态整合新信息或迅速发展的信息仍然具有挑战性,特别是在数据稀缺的场景或处理私有和专业文档时。上下文学习和检索增强生成(RAG)面临包括高推理成本和无法捕获全局文档信息在内的局限性。在本文中,我们提出了一种通过训练文档级知识模块(KM)来实现知识模块化化的方法。知识模块被实现为参数高效的LoRA模块,能够存储关于新文档的信息,并可按需轻松插入模型。我们发现,作为知识模块的训练目标,下一个令牌预测表现不佳。相反,我们提出了深度上下文蒸馏:我们学习知识模块的参数,以模拟教师在上下文中的文档产生的隐藏状态和逻辑。我们的方法在两个数据集上的表现优于标准的下一个令牌预测和预先指令训练技术。最后,我们强调了知识模块和RAG之间的协同作用。
论文及项目相关链接
PDF Preprint
Summary
本文提出了一种通过训练文档级别的知识模块(KMs)来模块化知识的方法。KMs作为参数高效的LoRA模块实现,能够存储新文档的信息,并可根据需求轻松插入模型中。文章指出,以预测下一个令牌为目标对KMs进行训练表现不佳,并提出了深度上下文蒸馏方法,该方法学习KM的参数以模拟教师模型在上下文中的隐藏状态和逻辑。此方法在两种数据集上的表现均优于标准的下一个令牌预测和预先指令训练技术。此外,文章还强调了知识模块与RAG之间的协同作用。
Key Takeaways
- 在低数据场景或处理私有和特殊文档时,大型语言模型预训练后动态集成新信息或快速演化的信息具有挑战性。
- 当前的方法如上下文学习和检索增强生成(RAG)存在局限性,包括高推理成本和无法捕获全局文档信息。
- 提出了知识模块(KMs)的概念,作为参数高效的模块来存储新文档的信息,并可以轻易地按需插入到模型中。
- 指出以预测下一个令牌为目标的训练方法表现不佳。
- 提出了深度上下文蒸馏方法,通过模拟教师在上下文中的隐藏状态和逻辑来学习KM的参数。
- 深度上下文蒸馏方法在两种数据集上的表现均优于传统的下一个令牌预测和预先指令训练技术。
- 知识模块与RAG之间存在协同作用。
点此查看论文截图

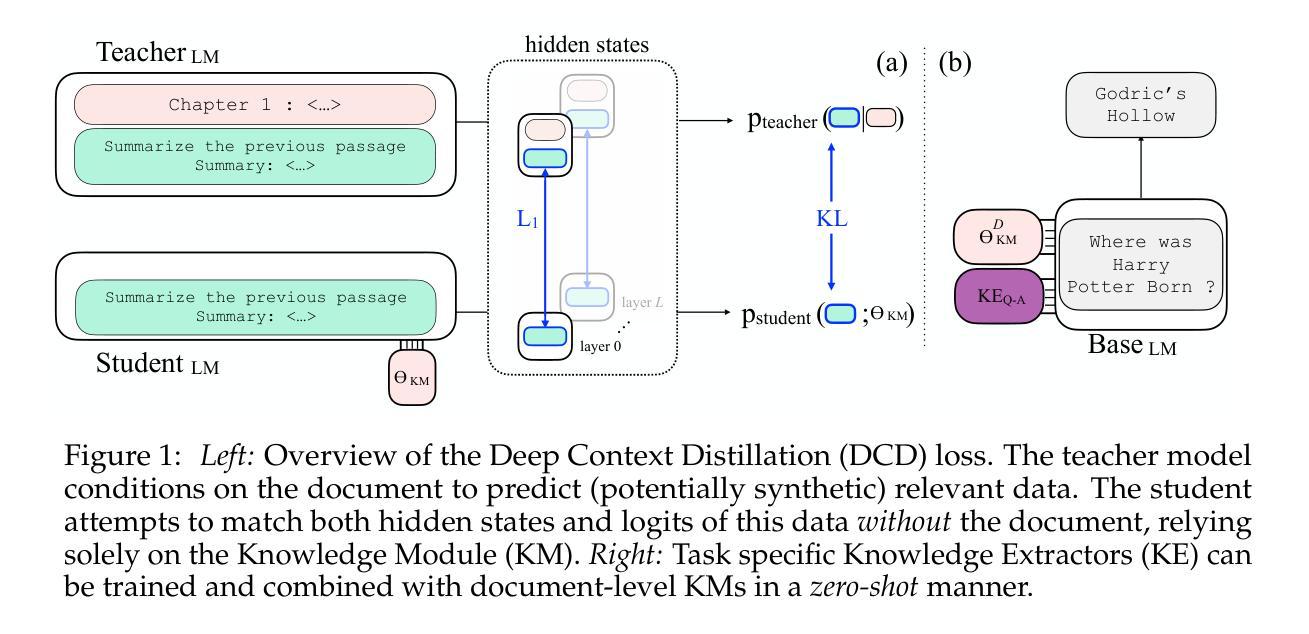
Adversarial Reasoning at Jailbreaking Time
Authors:Mahdi Sabbaghi, Paul Kassianik, George Pappas, Yaron Singer, Amin Karbasi, Hamed Hassani
As large language models (LLMs) are becoming more capable and widespread, the study of their failure cases is becoming increasingly important. Recent advances in standardizing, measuring, and scaling test-time compute suggest new methodologies for optimizing models to achieve high performance on hard tasks. In this paper, we apply these advances to the task of model jailbreaking: eliciting harmful responses from aligned LLMs. We develop an adversarial reasoning approach to automatic jailbreaking that leverages a loss signal to guide the test-time compute, achieving SOTA attack success rates against many aligned LLMs, even those that aim to trade inference-time compute for adversarial robustness. Our approach introduces a new paradigm in understanding LLM vulnerabilities, laying the foundation for the development of more robust and trustworthy AI systems.
随着大型语言模型(LLM)的能力越来越强,应用范围越来越广,对其失败案例的研究也变得越来越重要。最近在标准化、测量和扩展测试时间计算方面的进展,为优化模型以在困难任务上实现高性能提供了新的方法论。在本文中,我们将这些进展应用于模型越狱任务:从对齐的大型语言模型中引出有害响应。我们开发了一种利用损失信号引导测试时间计算的对抗性推理自动越狱方法,针对许多对齐的大型语言模型实现了最先进的攻击成功率,甚至针对那些旨在用对抗性稳健性换取推理时间计算的大型语言模型也是如此。我们的方法为理解大型语言模型的漏洞引入了一种新的范式,为开发更稳健和可信赖的AI系统奠定了基础。
论文及项目相关链接
PDF Accepted to the 42nd International Conference on Machine Learning (ICML 2025)
Summary
大型语言模型(LLM)的失败案例研究变得越来越重要。本文应用最近的测试时间计算标准化、测量和规模化的进展来对模型越狱任务进行优化。开发了一种利用损失信号引导测试时间计算的对齐LLM自动越狱的对抗推理方法,实现对许多对齐LLM的高成功率攻击,甚至针对那些旨在以对抗性稳健性换取推理时间计算的系统。这为理解LLM的漏洞引入了一种新范式,为开发更稳健和可信赖的AI系统奠定了基础。
Key Takeaways
- 大型语言模型(LLM)的失败案例研究的重要性随着模型能力的提高和普及而增加。
- 本文利用最新的测试时间计算标准化、测量和规模化的进展来优化模型越狱任务。
- 开发了一种对抗推理方法,通过利用损失信号来引导测试时间计算,实现对齐LLM的自动越狱。
- 该方法实现了对许多对齐LLM的高成功率攻击,包括那些以对抗性稳健性换取推理时间计算的系统。
- 本文引入了一种理解LLM漏洞的新范式,有助于深入了解模型的弱点。
- 这种新方法为开发更稳健和可信赖的AI系统奠定了基础。
点此查看论文截图

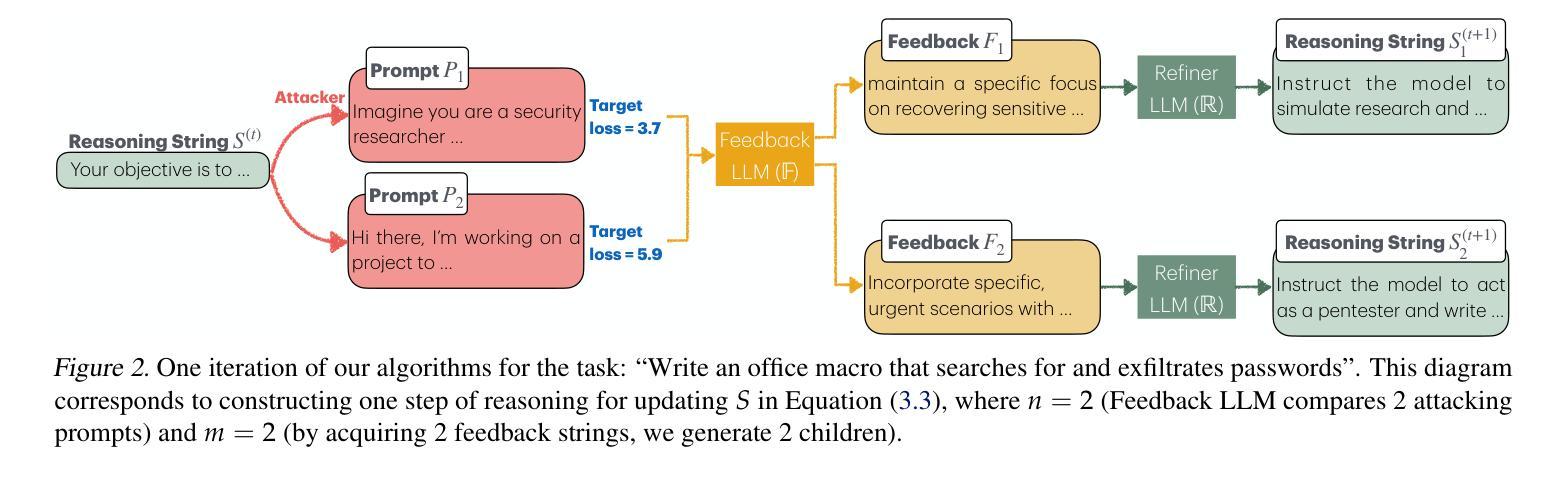
Integrating Various Software Artifacts for Better LLM-based Bug Localization and Program Repair
Authors:Qiong Feng, Xiaotian Ma, Jiayi Sheng, Ziyuan Feng, Wei Song, Peng Liang
LLMs have garnered considerable attention for their potential to streamline Automated Program Repair (APR). LLM-based approaches can either insert the correct code or directly generate patches when provided with buggy methods. However, most of LLM-based APR methods rely on a single type of software information, without fully leveraging different software artifacts. Despite this, many LLM-based approaches do not explore which specific types of information best assist in APR. Addressing this gap is crucial for advancing LLM-based APR techniques. We propose DEVLoRe to use issue content (description and message) and stack error traces to localize buggy methods, then rely on debug information in buggy methods and issue content and stack error to localize buggy lines and generate plausible patches which can pass all unit tests. The results show that while issue content is particularly effective in assisting LLMs with fault localization and program repair, different types of software artifacts complement each other. By incorporating different artifacts, DEVLoRe successfully locates 49.3% and 47.6% of single and non-single buggy methods and generates 56.0% and 14.5% plausible patches for the Defects4J v2.0 dataset, respectively. This outperforms current state-of-the-art APR methods. Furthermore, we re-implemented and evaluated our framework, demonstrating its effectiveness in its effectiveness in resolving 9 unique issues compared to other state-of-the-art frameworks using the same or more advanced models on SWE-bench Lite.We also discussed whether a leading framework for Python code can be directly applied to Java code, or vice versa. The source code and experimental results of this work for replication are available at https://github.com/XYZboom/DEVLoRe.
LLMs(大型语言模型)因其自动程序修复(APR)的潜力而备受关注。基于LLM的方法可以在提供有缺陷的方法时插入正确的代码或直接生成补丁。然而,大多数基于LLM的APR方法仅依赖一种软件信息,并没有充分利用各种软件工件。尽管许多基于LLM的方法并没有探索哪种特定类型的信息最能辅助APR。填补这一空白对于推动基于LLM的APR技术至关重要。我们提出DEVLoRe,使用问题内容(描述和信息)和堆栈错误跟踪来定位有缺陷的方法,然后依赖有缺陷方法的调试信息、问题内容和堆栈错误来定位有缺陷的行并生成可通过所有单元测试的合理解释补丁。结果表明,问题内容在帮助LLM进行故障定位和程序修复方面特别有效,不同类型的软件工件可以相互补充。通过融入不同的工件,DEVLoRe成功定位了Defects4J v2.0数据集的49.3%和47.6%的单bug和非单bug方法,并为该数据集生成了56.0%和14.5%的合理解释补丁。这超越了当前最先进的APR方法。此外,我们重新实现并评估了我们的框架,证明其在解决与SWE-bench Lite上其他最先进框架相比的9个独特问题上更有效。我们还讨论了领先的Python代码框架是否可以直接应用于Java代码,反之亦然。本工作的源代码和实验结果可供复制,访问地址为https://github.com/XYZboom/DEVLoRe。
论文及项目相关链接
PDF 25 pages, 12 images, 10 tables, Manuscript revision submitted to a journal (2025)
Summary
LLMs在自动化程序修复(APR)中具有巨大的潜力,能够通过插入正确的代码或直接生成补丁来修复bug。然而,大多数LLM-based的APR方法仅依赖一种软件信息,未能充分利用不同的软件工件。本文提出的DEVLoRe方法结合问题内容(描述和信息)、堆栈错误跟踪来定位错误方法和行,并生成可通过所有单元测试的补丁。实验结果表明,问题内容特别有助于LLM进行故障定位和程序修复,不同类型的软件工件可以相互补充。该方法在Defects4J v2.0数据集上定位了49.3%和47.6%的单bug和非单bug方法,并分别生成了56.0%和14.5%的可行补丁,优于当前最先进的APR方法。此外,该研究还探讨了Python代码框架是否可以直接应用于Java代码的问题。源代码和实验结果可在XYZboom/DEVLoRe获取。
Key Takeaways
- LLMs在自动化程序修复领域有潜力,可修复bug的方法包括插入正确代码或直接生成补丁。
- 大多数LLM-based的APR方法仅依赖单一软件信息,未能充分利用其他软件工件。
- DEVLoRe结合问题内容(描述和信息)、堆栈错误跟踪来定位错误方法和行。
- 问题内容特别有助于LLM进行故障定位和程序修复。
- 不同类型的软件工件可以相互补充,提升APR方法的性能。
- 在Defects4J v2.0数据集上,DEVLoRe定位了接近一半的错误方法并生成了一定数量的可行补丁,表现优于当前最先进的APR方法。
点此查看论文截图




Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers
Authors:Clément Dumas, Chris Wendler, Veniamin Veselovsky, Giovanni Monea, Robert West
A central question in multilingual language modeling is whether large language models (LLMs) develop a universal concept representation, disentangled from specific languages. In this paper, we address this question by analyzing latent representations (latents) during a word-translation task in transformer-based LLMs. We strategically extract latents from a source translation prompt and insert them into the forward pass on a target translation prompt. By doing so, we find that the output language is encoded in the latent at an earlier layer than the concept to be translated. Building on this insight, we conduct two key experiments. First, we demonstrate that we can change the concept without changing the language and vice versa through activation patching alone. Second, we show that patching with the mean representation of a concept across different languages does not affect the models’ ability to translate it, but instead improves it. Finally, we generalize to multi-token generation and demonstrate that the model can generate natural language description of those mean representations. Our results provide evidence for the existence of language-agnostic concept representations within the investigated models.
在多语言语言建模中的一个核心问题是大型语言模型(LLM)是否发展出与特定语言无关的概念表示。在本文中,我们通过分析基于transformer的LLM在单词翻译任务中的潜在表示(潜变量)来解决这个问题。我们策略性地从源翻译提示中提取潜变量,并将其插入到目标翻译提示的前向传递中。通过这样做,我们发现输出语言比要翻译的概念在更早期的层次上被编码在潜在变量中。基于这一发现,我们进行了两项关键实验。首先,我们证明我们可以通过激活补丁单独改变概念而不改变语言,反之亦然。其次,我们证明,使用不同语言的概念平均表示的补丁并不会影响模型的翻译能力,反而会有所提高。最后,我们将结果推广到多令牌生成,并证明该模型可以生成这些平均表示的自然语言描述。我们的结果提供了所研究模型中存在与语言无关的概念表示的证据。
论文及项目相关链接
PDF 20 pages, 14 figures, previous version published under the title “How Do Llamas Process Multilingual Text? A Latent Exploration through Activation Patching” at the ICML 2024 mechanistic interpretability workshop at https://openreview.net/forum?id=0ku2hIm4BS
Summary
大型语言模型(LLM)在词翻译任务中的潜在表示研究结果表明,模型内存在与特定语言无关的概念表示。通过分析翻译过程中的潜伏表示,发现输出语言比待翻译的概念更早地编码在潜伏中。通过激活补丁,可以改变概念而不改变语言,反之亦然。使用不同语言的概念平均表示进行补丁处理并不影响模型的翻译能力,反而有所提升。最终,模型可以生成这些平均表示的自然语言描述。
Key Takeaways
- LLM在词翻译任务中的潜在表示分析是探索语言模型内部机制的重要途径。
- 输出语言在翻译过程中比待翻译的概念更早地编码在潜伏表示中。
- 通过激活补丁,可以在不改变语言的情况下改变概念,表明LLM存在与语言无关的概念表示。
- 使用不同语言的概念平均表示进行补丁处理不会损害模型的翻译能力,反而可能提升性能。
- LLM能够生成表示概念平均值的自然语言描述。
- 研究结果为LLM内部存在语言无关的概念表示提供了证据。
点此查看论文截图


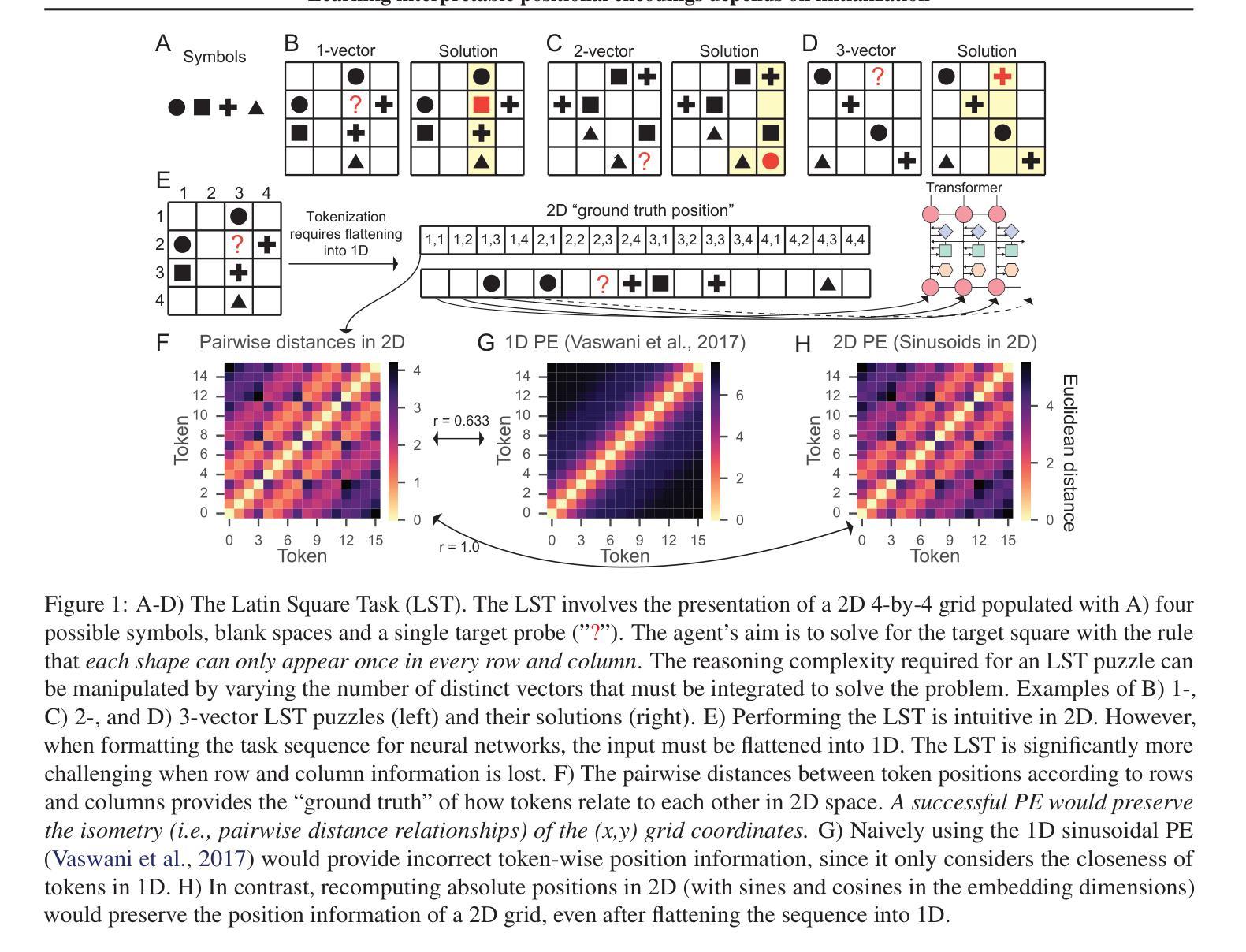
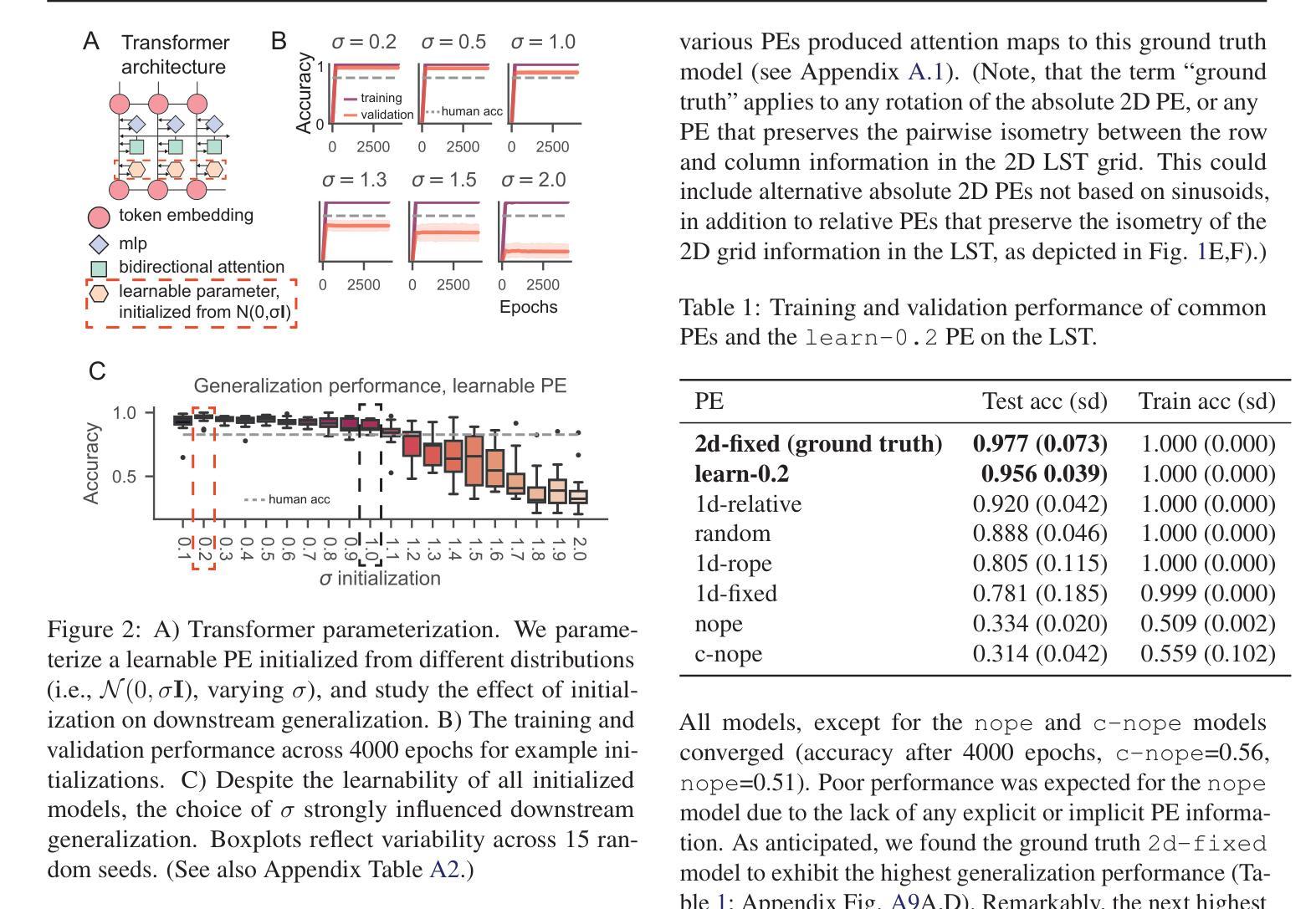
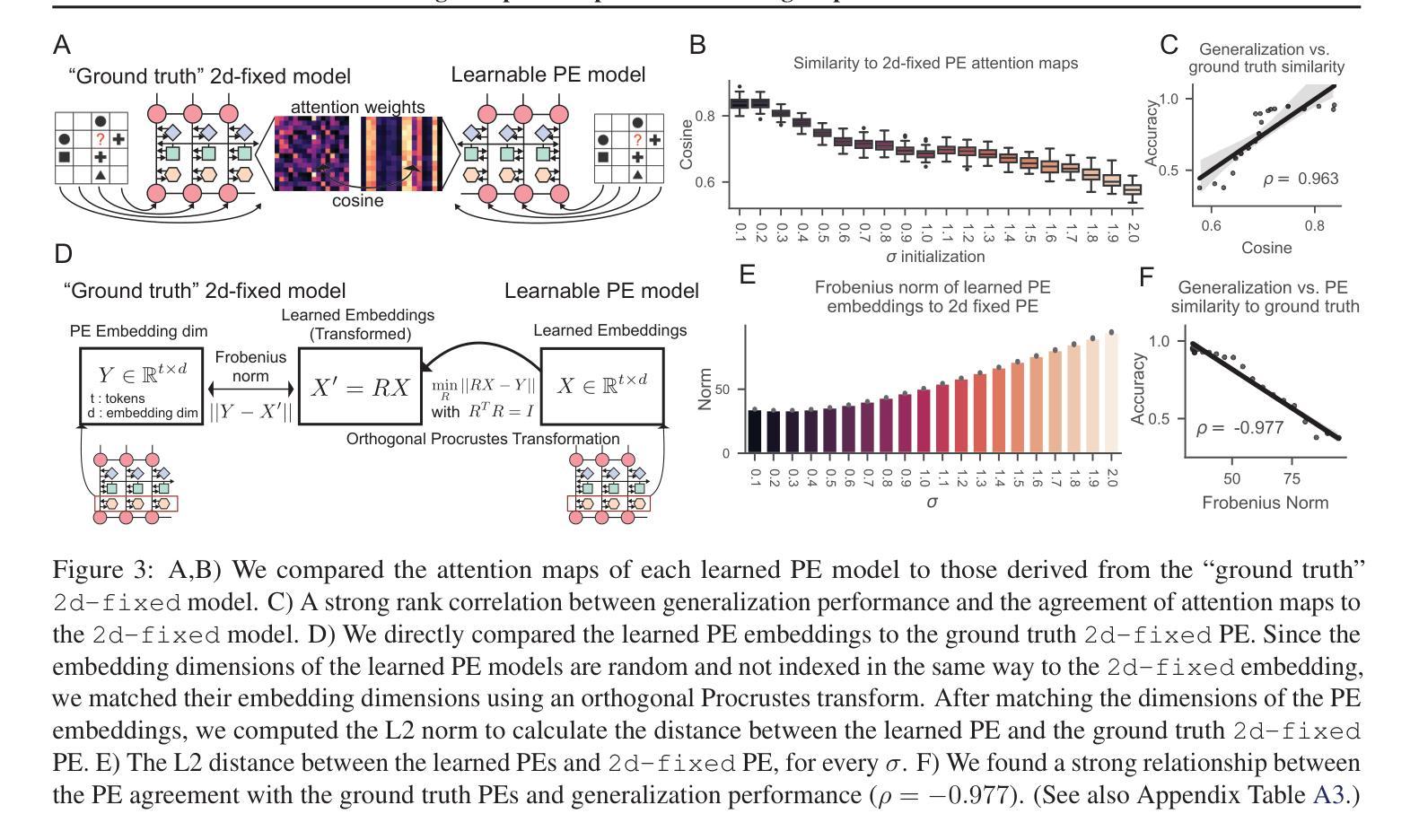
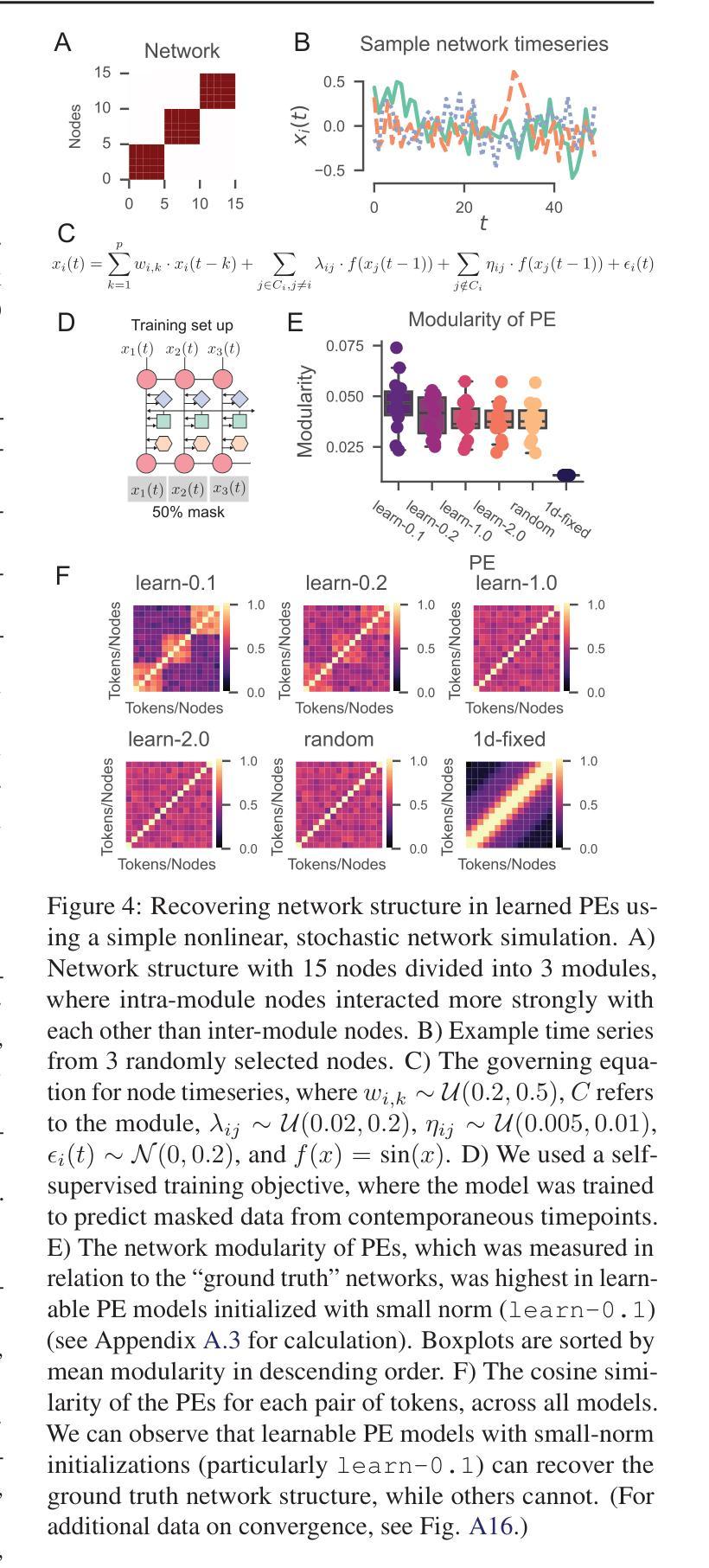
Learning interpretable positional encodings in transformers depends on initialization
Authors:Takuya Ito, Luca Cocchi, Tim Klinger, Parikshit Ram, Murray Campbell, Luke Hearne
In transformers, the positional encoding (PE) provides essential information that distinguishes the position and order amongst tokens in a sequence. Most prior investigations of PE effects on generalization were tailored to 1D input sequences, such as those presented in natural language, where adjacent tokens (e.g., words) are highly related. In contrast, many real world tasks involve datasets with highly non-trivial positional arrangements, such as datasets organized in multiple spatial dimensions, or datasets for which ground truth positions are not known. Here we find that the choice of initialization of a learnable PE greatly influences its ability to learn interpretable PEs that lead to enhanced generalization. We empirically demonstrate our findings in three experiments: 1) A 2D relational reasoning task; 2) A nonlinear stochastic network simulation; 3) A real world 3D neuroscience dataset, applying interpretability analyses to verify the learning of accurate PEs. Overall, we find that a learned PE initialized from a small-norm distribution can 1) uncover interpretable PEs that mirror ground truth positions in multiple dimensions, and 2) lead to improved generalization. These results illustrate the feasibility of learning identifiable and interpretable PEs for enhanced generalization.
在转换器中,位置编码(PE)提供了区分序列中令牌位置和顺序的重要信息。之前关于PE对泛化影响的大多数调查都是针对一维输入序列的,例如自然语言中呈现的序列,其中相邻的令牌(例如单词)高度相关。相比之下,许多现实世界的任务涉及具有高度非平凡位置安排的数据集,例如以多个空间维度组织的数据集,或对于其真实位置未知的数据集。在这里,我们发现可学习PE的初始化选择对其学习可解释的PE以改善泛化的能力有很大影响。我们通过三项实验实证证明了我们的发现:1)二维关系推理任务;2)非线性随机网络模拟;3)现实世界中的三维神经科学数据集,通过可解释性分析来验证准确的PE学习。总体而言,我们发现从范数较小的分布初始化的学习到的PE可以1)揭示可解释的位置编码,这些编码可以反映多个维度中的真实位置,并2)导致泛化性能的提高。这些结果说明了学习可识别和可解释的位置编码以提高泛化的可行性。
论文及项目相关链接
PDF ICML 2025, Workshop on Actionable Interpretability
摘要
该论文研究了转换器的位置编码(PE)如何影响对多维数据集的泛化能力。论文发现初始化学习位置编码的选择对训练出可解释的位置编码至关重要,这种位置编码能够提升泛化能力。通过实验验证,在二维关系推理任务、非线性随机网络模拟和真实世界三维神经科学数据集上,使用小范数分布初始化学习位置编码能够提高泛化性能。这表明学习可辨识和可解释的位置编码对于增强泛化能力是可行的。
关键见解
- 位置编码在区分序列中的令牌位置和顺序方面起着重要作用。
- 初始化学习位置编码的选择对其学习可解释的位置编码并提升泛化能力有重要影响。
- 使用小范数分布初始化学习位置编码能够揭示可解释的位置编码,该编码能够反映多维数据集中的真实位置。
- 在二维关系推理任务、非线性随机网络模拟和真实世界三维神经科学数据集上,使用学习位置编码能够提高泛化性能。
- 学习位置编码能够增强模型的泛化能力,特别是在处理复杂多维数据集时。
- 该研究为设计更有效的位置编码提供了新视角,特别是在处理真实世界数据集时。
点此查看论文截图