⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-27 更新
Joint attitude estimation and 3D neural reconstruction of non-cooperative space objects
Authors:Clément Forray, Pauline Delporte, Nicolas Delaygue, Florence Genin, Dawa Derksen
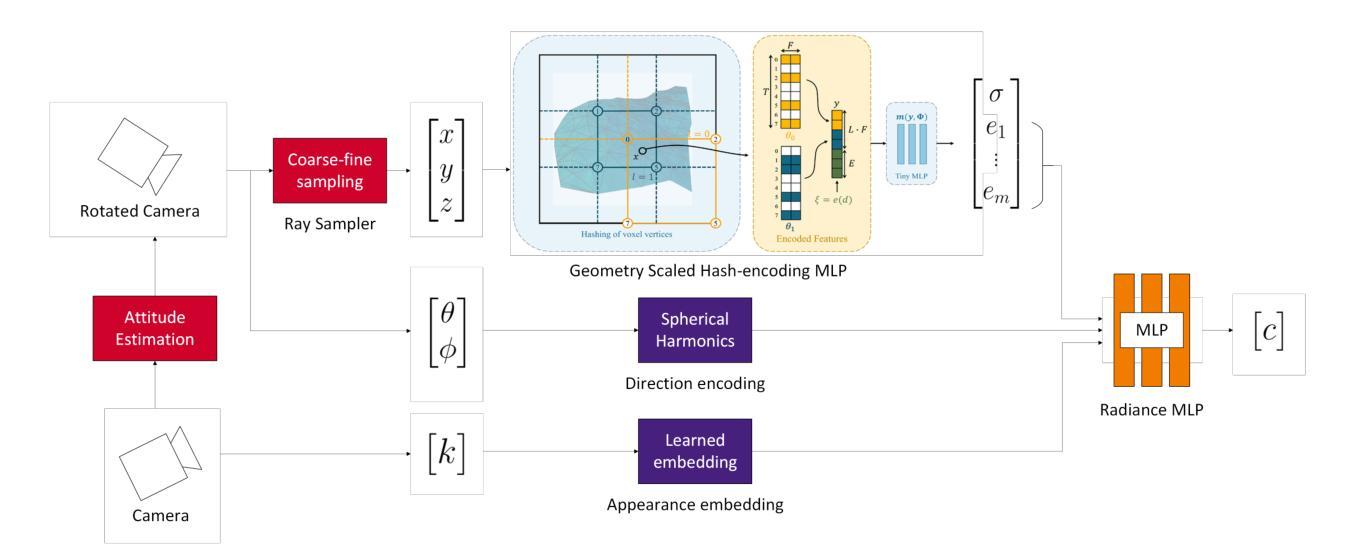
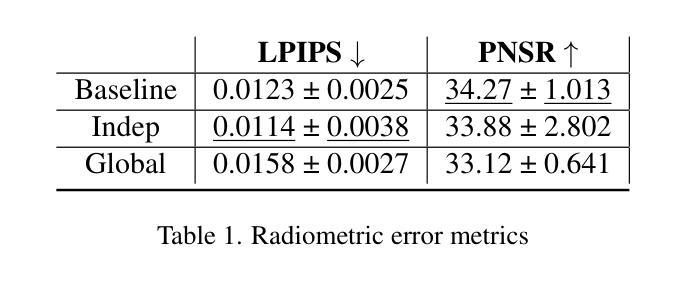
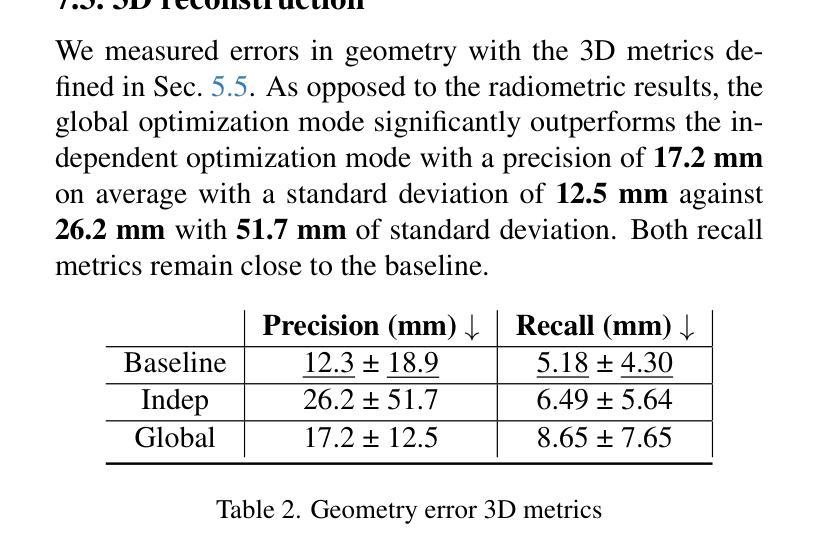
Obtaining a better knowledge of the current state and behavior of objects orbiting Earth has proven to be essential for a range of applications such as active debris removal, in-orbit maintenance, or anomaly detection. 3D models represent a valuable source of information in the field of Space Situational Awareness (SSA). In this work, we leveraged Neural Radiance Fields (NeRF) to perform 3D reconstruction of non-cooperative space objects from simulated images. This scenario is challenging for NeRF models due to unusual camera characteristics and environmental conditions : mono-chromatic images, unknown object orientation, limited viewing angles, absence of diffuse lighting etc. In this work we focus primarly on the joint optimization of camera poses alongside the NeRF. Our experimental results show that the most accurate 3D reconstruction is achieved when training with successive images one-by-one. We estimate camera poses by optimizing an uniform rotation and use regularization to prevent successive poses from being too far apart.
对地球轨道上物体的当前状态和行为有更好的了解,已被证明对于多种应用至关重要,例如主动清除碎片、轨道维护或异常检测。三维模型是空间态势感知(SSA)领域中的宝贵信息来源。在这项工作中,我们利用神经辐射场(NeRF)对模拟图像中的非合作空间对象进行三维重建。由于相机特性异常和环境条件不同,这种情况对NeRF模型来说具有挑战性:单色图像、未知对象方向、有限的视角、没有漫射照明等。在这项工作中,我们主要关注相机姿态与NeRF的联合优化。我们的实验结果表明,通过连续图像一张一张进行训练,可以实现最准确的三维重建。我们通过优化均匀旋转来估算相机姿态,并使用正则化防止连续姿态相距太远。
论文及项目相关链接
PDF accepted for CVPR 2025 NFBCC workshop
Summary
本文利用神经网络辐射场(NeRF)技术,从模拟图像中对非合作空间目标进行三维重建。针对空间环境特有的难点如单色图像、未知目标方向、有限视角和无漫射光照等条件,文章重点优化了相机姿态与NeRF技术的结合。实验结果显示,通过连续图像逐个训练,可以获得最精确的三维重建效果。通过优化均匀旋转估计相机姿态,并利用正则化防止连续姿态过于分散。
Key Takeaways
- 文章使用NeRF技术用于空间目标的三维重建。
- 通过模拟图像进行非合作空间对象的重建挑战较大。
- NeRF模型需要应对空间环境中的特定难点,如单色图像和未知目标方向等。
- 文章重点研究了相机姿态与NeRF技术的联合优化。
- 实验结果表明,逐个训练图像可获得最准确的三维重建效果。
- 通过优化均匀旋转估计相机姿态。
点此查看论文截图




Self-Supervised Multimodal NeRF for Autonomous Driving
Authors:Gaurav Sharma, Ravi Kothari, Josef Schmid
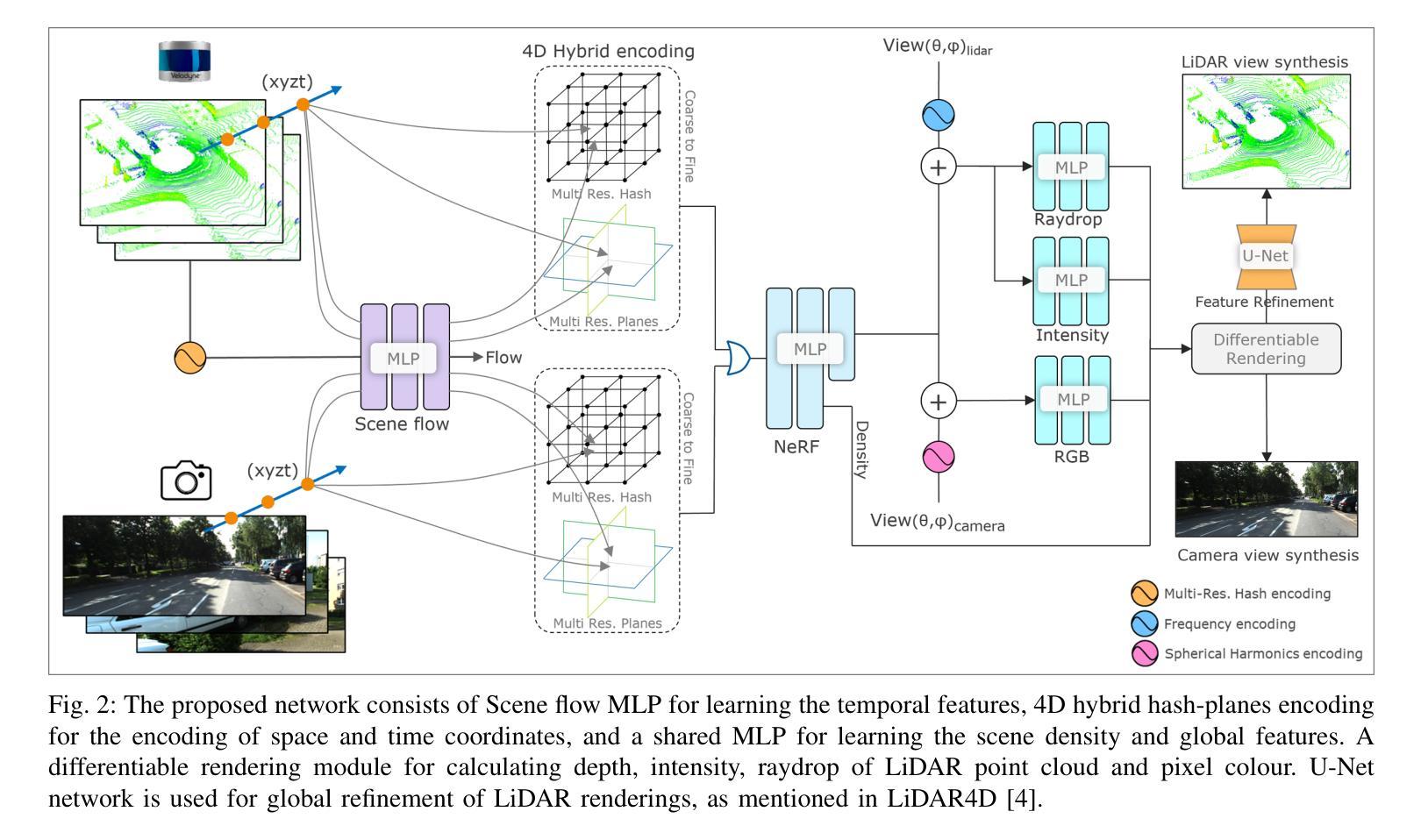
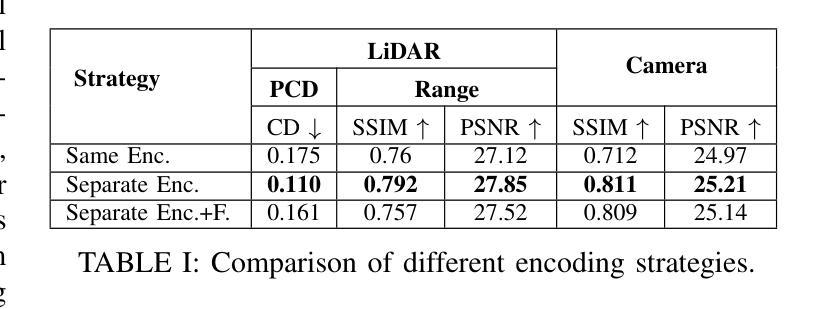
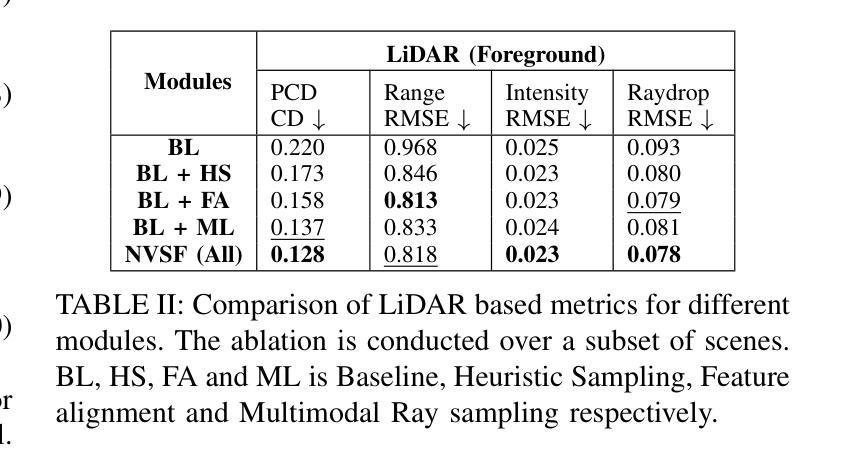
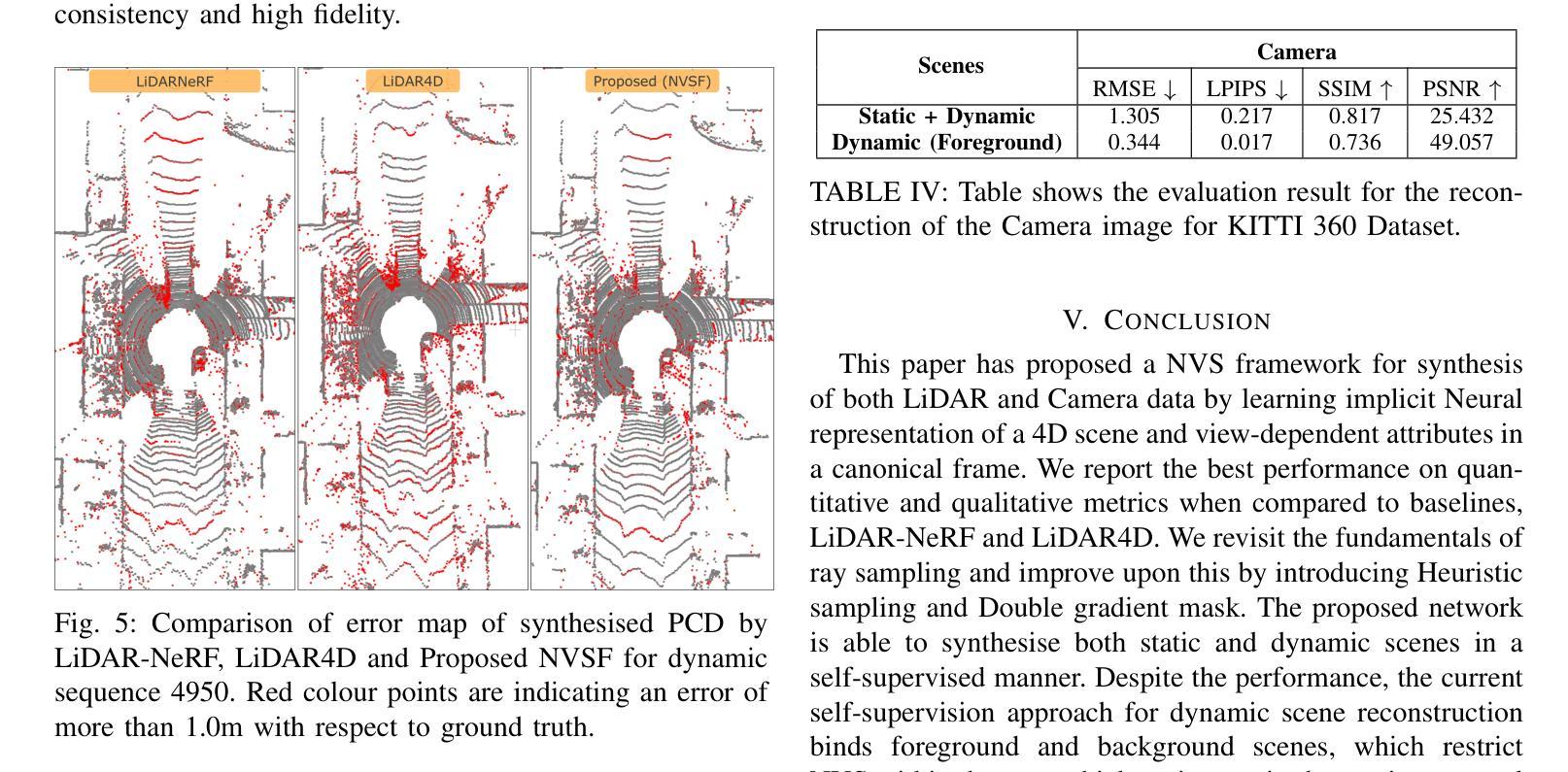
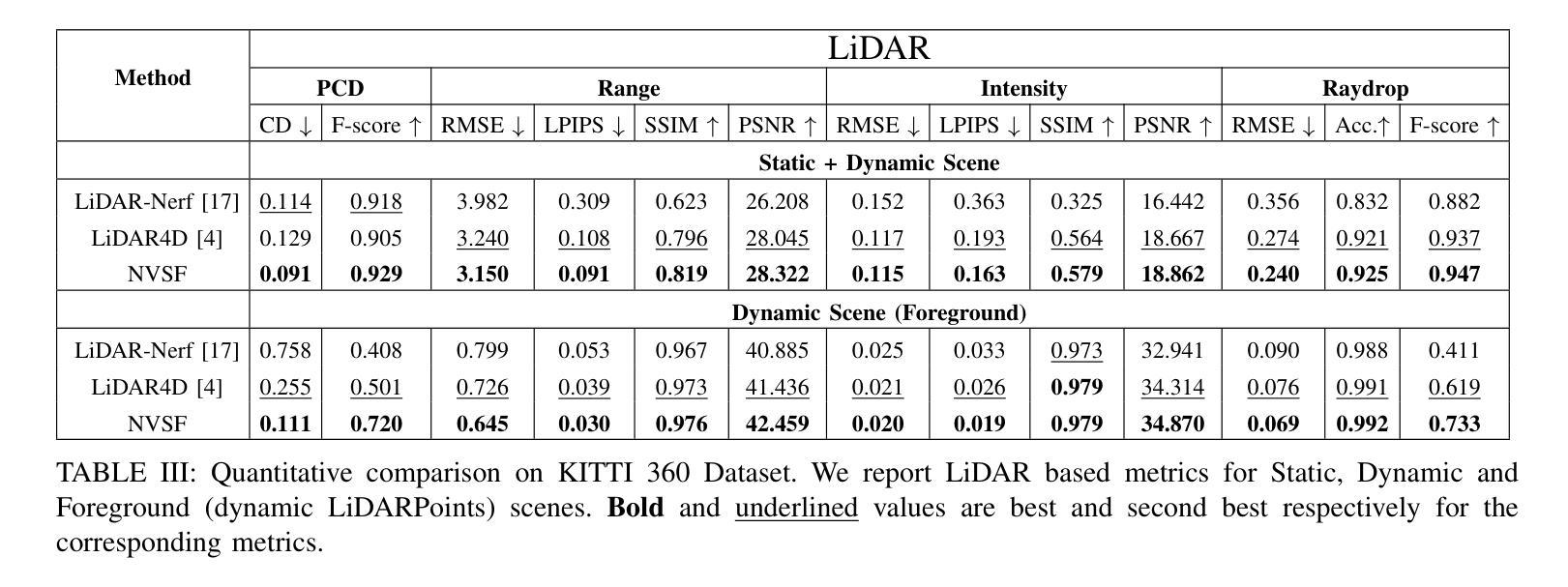
In this paper, we propose a Neural Radiance Fields (NeRF) based framework, referred to as Novel View Synthesis Framework (NVSF). It jointly learns the implicit neural representation of space and time-varying scene for both LiDAR and Camera. We test this on a real-world autonomous driving scenario containing both static and dynamic scenes. Compared to existing multimodal dynamic NeRFs, our framework is self-supervised, thus eliminating the need for 3D labels. For efficient training and faster convergence, we introduce heuristic-based image pixel sampling to focus on pixels with rich information. To preserve the local features of LiDAR points, a Double Gradient based mask is employed. Extensive experiments on the KITTI-360 dataset show that, compared to the baseline models, our framework has reported best performance on both LiDAR and Camera domain. Code of the model is available at https://github.com/gaurav00700/Selfsupervised-NVSF
在这篇论文中,我们提出了一个基于神经辐射场(NeRF)的框架,称为新型视图合成框架(NVSF)。该框架联合学习激光雷达和相机的时空变化场景的隐式神经表示。我们在包含静态和动态场景的真实世界自动驾驶场景中对该框架进行了测试。与现有的多模式动态NeRF相比,我们的框架是自我监督的,从而消除了对3D标签的需求。为了进行高效的训练和更快的收敛,我们引入了基于启发式图像像素采样,以专注于信息丰富的像素。为了保留激光雷达点的局部特征,采用了基于双重梯度的掩膜。在KITTI-360数据集上的大量实验表明,与基准模型相比,我们的框架在激光雷达和相机领域均取得了最佳性能。模型代码可在[https://github.com/gaurav00700/Selfsupervised-NVSF找到。]
论文及项目相关链接
Summary
本文提出了一种基于神经辐射场(NeRF)的框架,称为新型视图合成框架(NVSF)。该框架能够联合学习空间和时变场景的隐式神经表示,适用于激光雷达和相机数据。在真实世界自动驾驶场景(包含静态和动态场景)中进行测试,无需3D标签,通过启发式图像像素采样提高训练效率和收敛速度,采用双重梯度掩膜保留激光雷达点的局部特征。在KITTI-360数据集上的实验表明,与基准模型相比,该框架在激光雷达和相机领域均表现最佳。
Key Takeaways
- 提出了基于NeRF的新型视图合成框架(NVSF),能联合学习空间和时变场景的隐式神经表示。
- 框架适用于激光雷达和相机数据,并在真实世界自动驾驶场景中进行测试。
- 框架采用自监督学习,消除了对3D标签的需求。
- 引入启发式图像像素采样,以提高训练效率和收敛速度。
- 采用双重梯度掩膜保留激光雷达点的局部特征。
- 在KITTI-360数据集上的实验表现优于基准模型。
点此查看论文截图



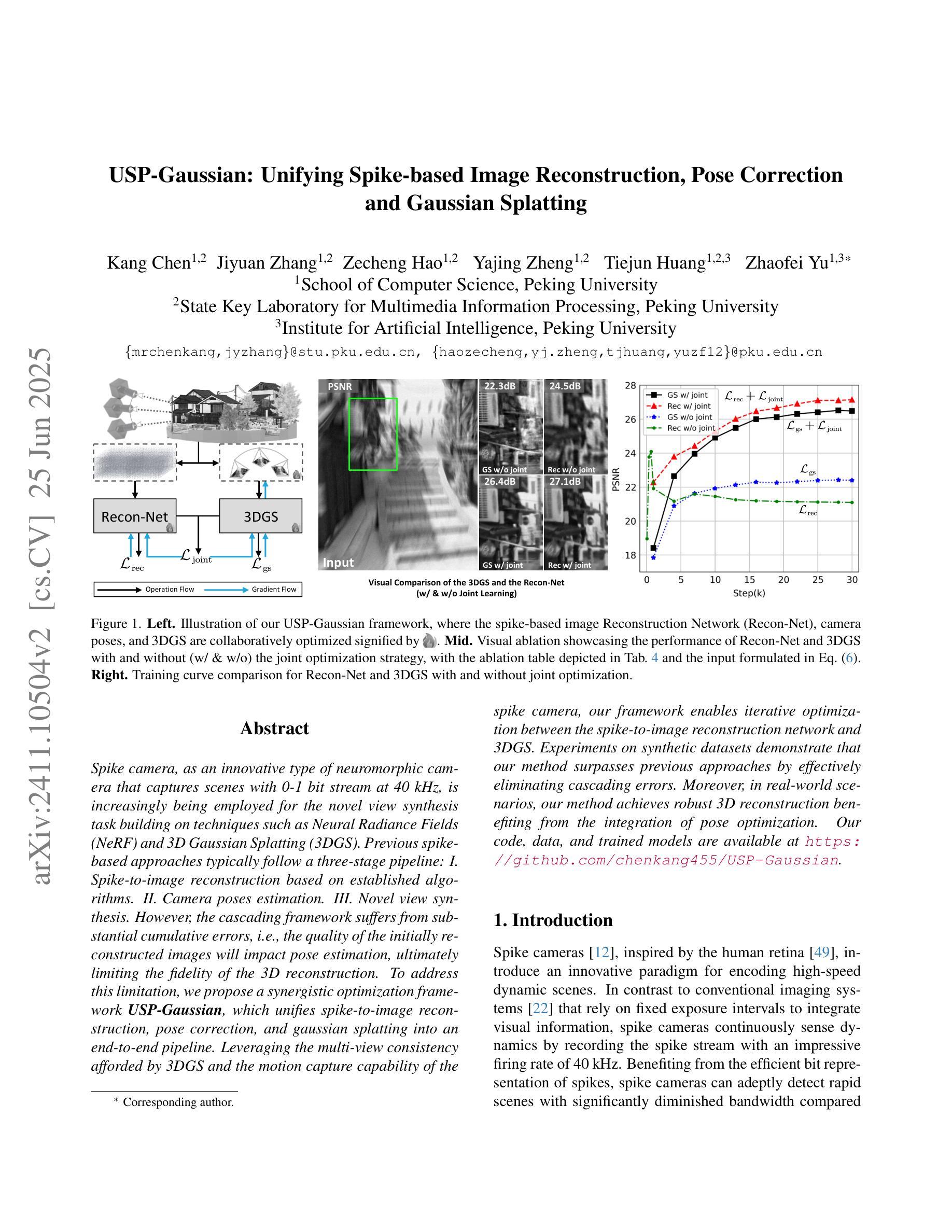
USP-Gaussian: Unifying Spike-based Image Reconstruction, Pose Correction and Gaussian Splatting
Authors:Kang Chen, Jiyuan Zhang, Zecheng Hao, Yajing Zheng, Tiejun Huang, Zhaofei Yu
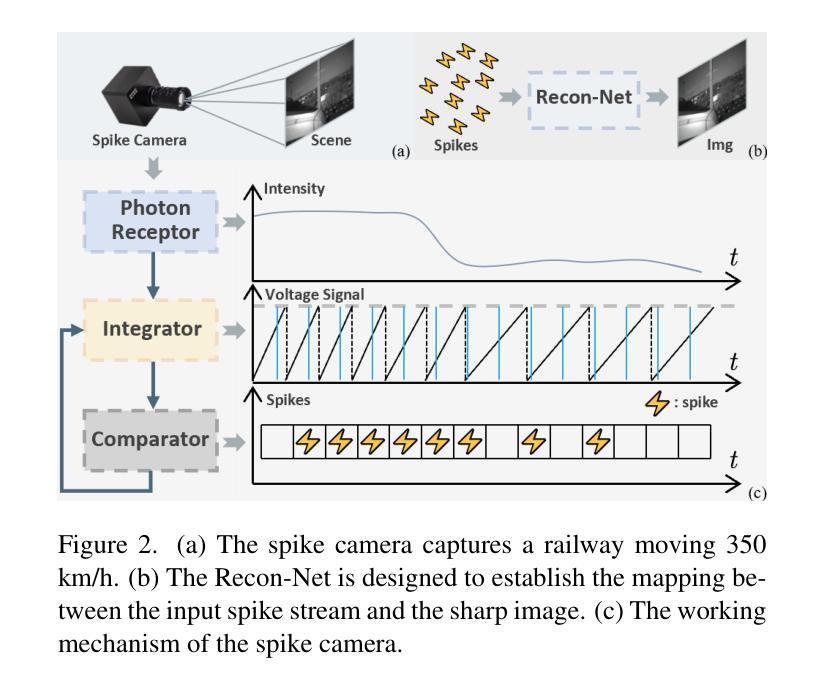
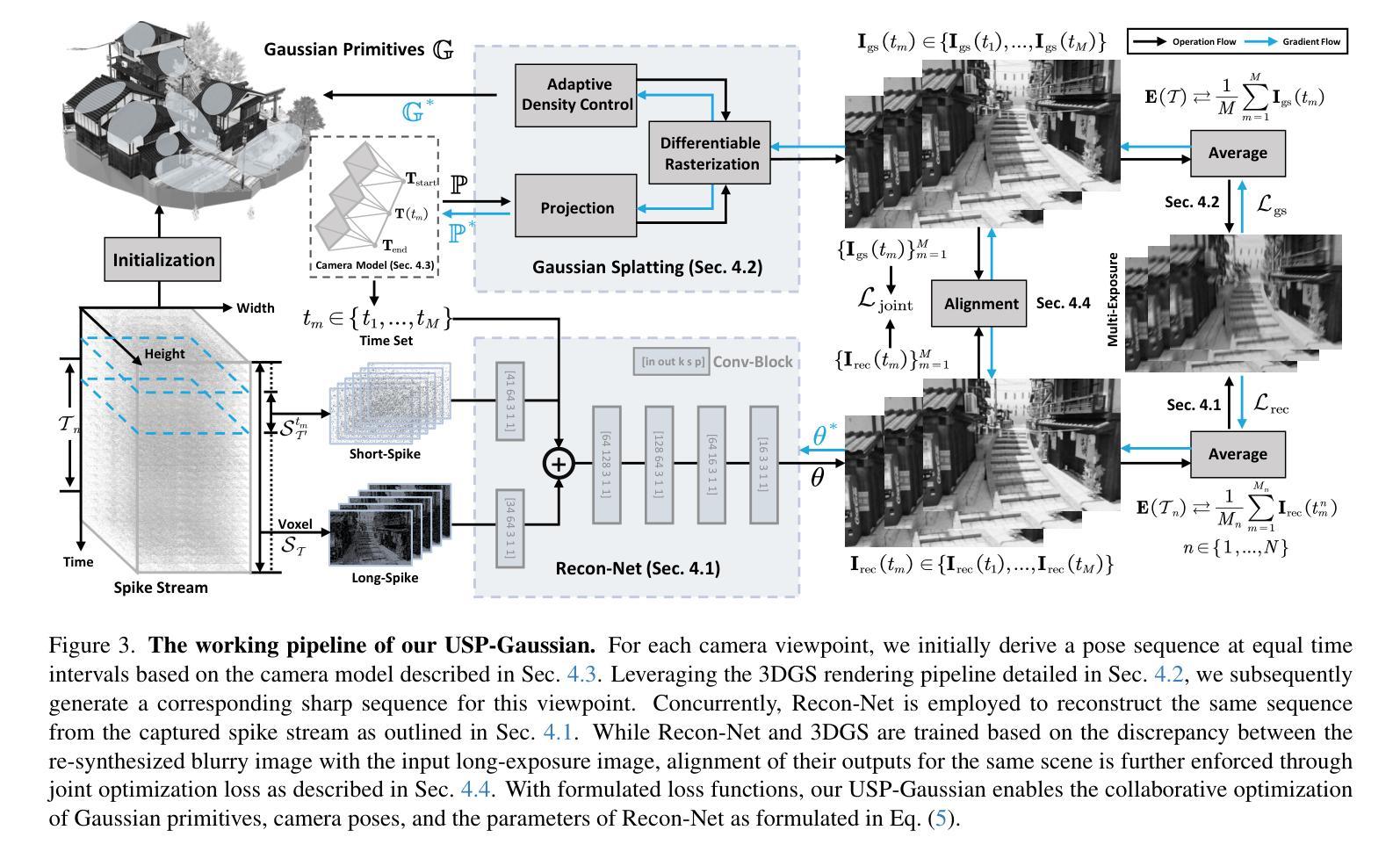
Spike cameras, as an innovative neuromorphic camera that captures scenes with the 0-1 bit stream at 40 kHz, are increasingly employed for the 3D reconstruction task via Neural Radiance Fields (NeRF) or 3D Gaussian Splatting (3DGS). Previous spike-based 3D reconstruction approaches often employ a casecased pipeline: starting with high-quality image reconstruction from spike streams based on established spike-to-image reconstruction algorithms, then progressing to camera pose estimation and 3D reconstruction. However, this cascaded approach suffers from substantial cumulative errors, where quality limitations of initial image reconstructions negatively impact pose estimation, ultimately degrading the fidelity of the 3D reconstruction. To address these issues, we propose a synergistic optimization framework, \textbf{USP-Gaussian}, that unifies spike-based image reconstruction, pose correction, and Gaussian splatting into an end-to-end framework. Leveraging the multi-view consistency afforded by 3DGS and the motion capture capability of the spike camera, our framework enables a joint iterative optimization that seamlessly integrates information between the spike-to-image network and 3DGS. Experiments on synthetic datasets with accurate poses demonstrate that our method surpasses previous approaches by effectively eliminating cascading errors. Moreover, we integrate pose optimization to achieve robust 3D reconstruction in real-world scenarios with inaccurate initial poses, outperforming alternative methods by effectively reducing noise and preserving fine texture details. Our code, data and trained models will be available at https://github.com/chenkang455/USP-Gaussian.
基于脉冲的相机作为一种创新型的神经形态相机,能够以40kHz的0-1位流捕捉场景,越来越多地被用于基于神经网络辐射场(NeRF)或3D高斯扩展(3DGS)的3D重建任务。之前基于脉冲的3D重建方法通常采用级联管道:首先使用已建立的脉冲到图像重建算法,基于脉冲流进行高质量图像重建,然后进行相机姿态估计和3D重建。然而,这种级联方法存在大量的累积误差,初始图像重建的质量限制会对姿态估计产生负面影响,最终降低3D重建的保真度。为了解决这些问题,我们提出了一种协同优化框架USP-Gaussian,它将基于脉冲的图像重建、姿态校正和高斯扩展统一到一个端到端的框架中。利用3DGS提供的多视图一致性以及脉冲相机的运动捕获能力,我们的框架能够实现脉冲到图像网络之间的无缝集成信息,并进行联合迭代优化。在具有准确姿态的合成数据集上的实验表明,我们的方法通过有效消除级联误差,超越了以前的方法。此外,我们对姿态优化进行了整合,以实现在实际场景中具有不准确初始姿态的稳健3D重建,通过有效降低噪声并保留精细纹理细节,优于其他方法。我们的代码、数据和训练模型将在https://github.com/chenkang455/USP-Gaussian上提供。
论文及项目相关链接
Summary
本文介绍了一种名为USP-Gaussian的协同优化框架,该框架解决了基于脉冲的3D重建中的级联误差问题。通过统一脉冲图像重建、姿态校正和高斯喷绘,实现了端对端的解决方案,有效提高了3D重建的精度和鲁棒性。该框架能够在合成数据集和具有不准确初始姿态的真实场景中进行鲁棒的3D重建,减少了噪声并保留了精细的纹理细节。
Key Takeaways
- 脉冲相机通过0-1位流以40 kHz的频率捕获场景,越来越多地被用于通过NeRF或3DGS进行3D重建任务。
- 传统的基于脉冲的3D重建方法采用级联管道,从基于脉冲流的图像重建到姿态估计和最终的3D重建,存在累积误差问题。
- USP-Gaussian框架实现了脉冲图像重建、姿态校正和高斯喷绘的统一,通过端对端的解决方案解决了级联误差问题。
- 利用3DGS的多视角一致性和脉冲相机的运动捕捉能力,USP-Gaussian框架实现了迭代优化的联合,无缝集成了脉冲到图像网络和3DGS之间的信息。
- 在合成数据集上的实验表明,USP-Gaussian方法有效消除了级联误差,超越了以前的方法。
- 该框架整合了姿态优化,实现了在具有不准确初始姿态的真实场景中的鲁棒3D重建。
点此查看论文截图