⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-27 更新
EmotionTalk: An Interactive Chinese Multimodal Emotion Dataset With Rich Annotations
Authors:Haoqin Sun, Xuechen Wang, Jinghua Zhao, Shiwan Zhao, Jiaming Zhou, Hui Wang, Jiabei He, Aobo Kong, Xi Yang, Yequan Wang, Yonghua Lin, Yong Qin
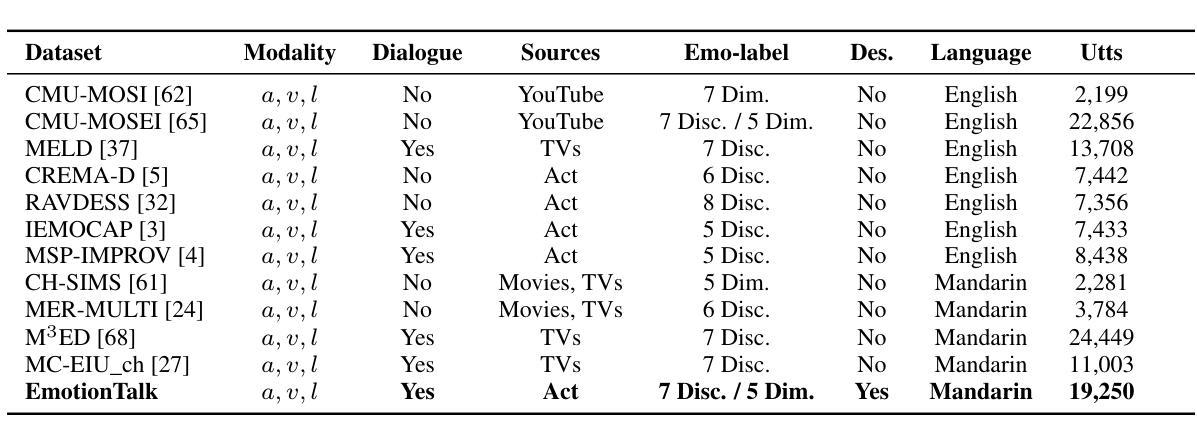
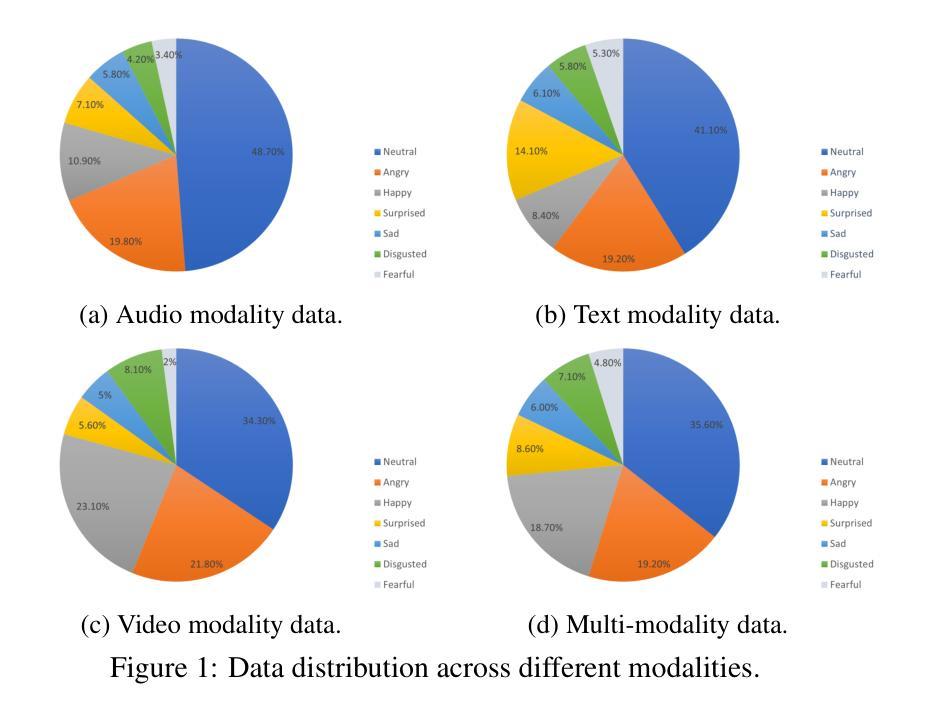
In recent years, emotion recognition plays a critical role in applications such as human-computer interaction, mental health monitoring, and sentiment analysis. While datasets for emotion analysis in languages such as English have proliferated, there remains a pressing need for high-quality, comprehensive datasets tailored to the unique linguistic, cultural, and multimodal characteristics of Chinese. In this work, we propose \textbf{EmotionTalk}, an interactive Chinese multimodal emotion dataset with rich annotations. This dataset provides multimodal information from 19 actors participating in dyadic conversational settings, incorporating acoustic, visual, and textual modalities. It includes 23.6 hours of speech (19,250 utterances), annotations for 7 utterance-level emotion categories (happy, surprise, sad, disgust, anger, fear, and neutral), 5-dimensional sentiment labels (negative, weakly negative, neutral, weakly positive, and positive) and 4-dimensional speech captions (speaker, speaking style, emotion and overall). The dataset is well-suited for research on unimodal and multimodal emotion recognition, missing modality challenges, and speech captioning tasks. To our knowledge, it represents the first high-quality and versatile Chinese dialogue multimodal emotion dataset, which is a valuable contribution to research on cross-cultural emotion analysis and recognition. Additionally, we conduct experiments on EmotionTalk to demonstrate the effectiveness and quality of the dataset. It will be open-source and freely available for all academic purposes. The dataset and codes will be made available at: https://github.com/NKU-HLT/EmotionTalk.
近年来,情感识别在人机交互、心理健康监测和情感分析等领域的应用中发挥着至关重要的作用。虽然英语情感分析的数据集已经大量涌现,但对于具有独特语言、文化和多模态特征的中国市场,仍迫切需要高质量的综合数据集。在这项工作中,我们提出了“EmotionTalk”这一交互式中文多模态情感数据集,具有丰富的注释。该数据集包含来自19名演员在双人对话场景中的多模态信息,融合了声音、视觉和文本模式。它包含了23.6小时的语音(19,250句话),对7个话语级别的情感类别(快乐、惊讶、悲伤、厌恶、愤怒、恐惧和中性)进行注释,以及五维情感标签(负面、轻微负面、中性、轻微正面和正面)和四维语音字幕(说话者、说话风格、情感和总体)。该数据集非常适合研究单模态和多模态情感识别、缺失模态挑战和语音字幕任务。据我们所知,它是第一个高质量且通用的中文对话多模态情感数据集,对跨文化情感分析和识别研究做出了宝贵的贡献。此外,我们在EmotionTalk上进行了实验,以证明该数据集的有效性和质量。该数据集将开源并免费提供,供所有学术目的使用。数据集和代码将在以下网址提供:https://github.com/NKU-HLT/EmotionTalk。
论文及项目相关链接
摘要
近期,情感识别在人机交互、心理健康监测和情绪分析等领域起到关键作用。尽管英语的情感分析数据集已经大量涌现,但针对中文独特语言、文化和多模式特性的高质量、综合数据集需求迫切。本研究提出“EmotionTalk”互动中文多模式情感数据集,富含注释信息。该数据集来自19名演员在对话场景中的表现,包含声音、视频和文字模式。包含23.6小时的语音(19,250次发言)、7种发言级别情感类别的注释(快乐、惊讶、悲伤、厌恶、愤怒、恐惧和中性)、5维度的情感标签(负面、略负面、中性、略正面和正面)和4维度的语音字幕(说话者、说话风格、情感和总体)。该数据集适用于单模式和多模式情感识别研究、缺失模式挑战和语音字幕任务。据我们所知,它是首个高质量和通用的中文对话多模式情感数据集,对跨文化情感分析和识别研究具有重要价值。此外,我们在EmotionTalk上进行了实验,以证明数据集的有效性和质量。该数据集将面向开源并供所有学术用途免费使用。数据集和代码将在:https://github.com/NKU-HLT/EmotionTalk 提供。
要点解析
- 中文情感识别研究的现状及其在多领域的应用。随着技术进步与应用需求增长,中文情感分析数据集的需求日益迫切。
点此查看论文截图