⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-27 更新
ToSA: Token Merging with Spatial Awareness
Authors:Hsiang-Wei Huang, Wenhao Chai, Kuang-Ming Chen, Cheng-Yen Yang, Jenq-Neng Hwang
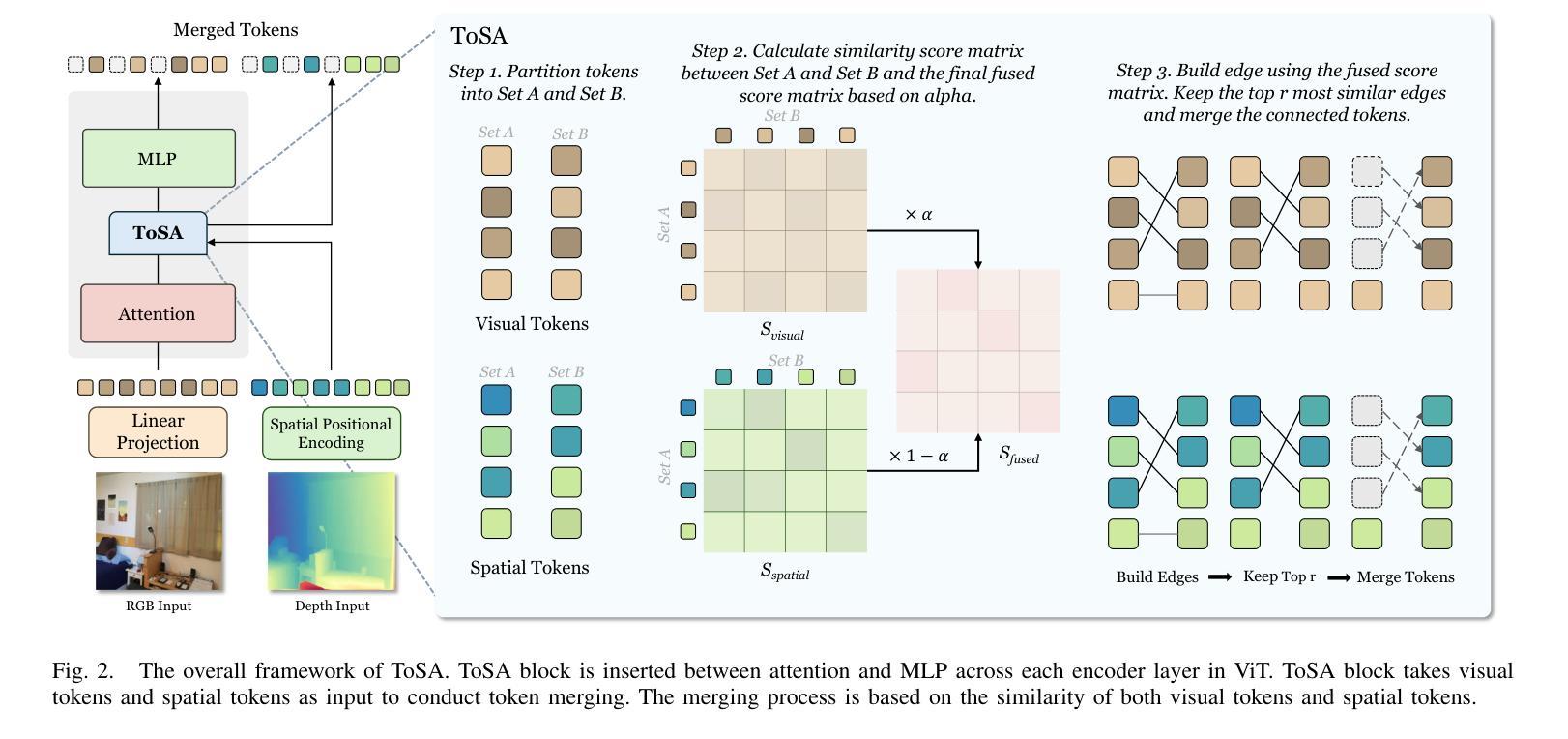
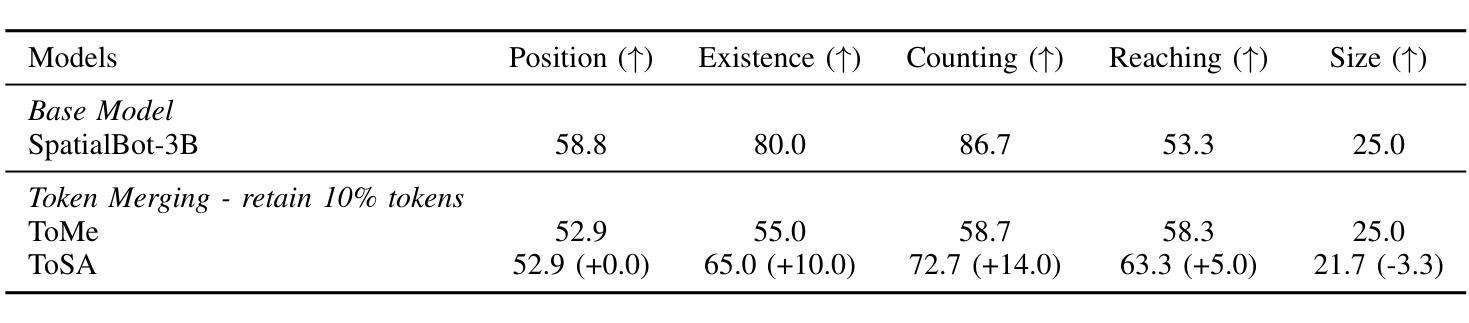
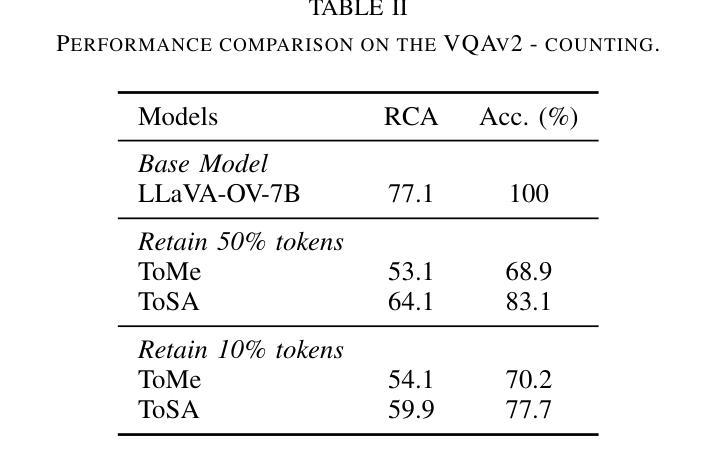
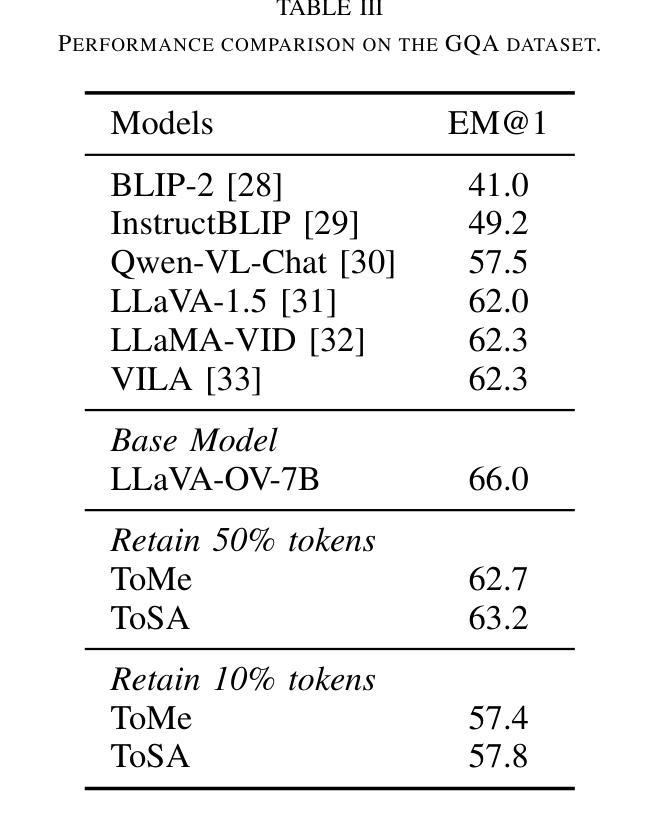
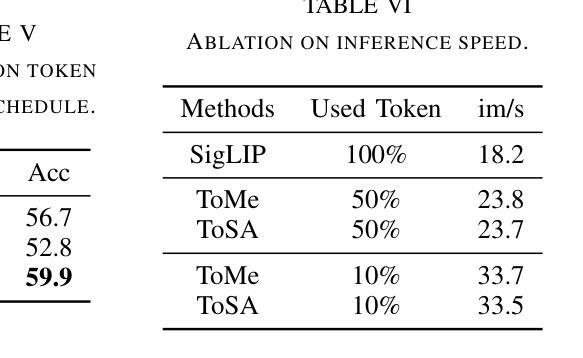
Token merging has emerged as an effective strategy to accelerate Vision Transformers (ViT) by reducing computational costs. However, existing methods primarily rely on the visual token’s feature similarity for token merging, overlooking the potential of integrating spatial information, which can serve as a reliable criterion for token merging in the early layers of ViT, where the visual tokens only possess weak visual information. In this paper, we propose ToSA, a novel token merging method that combines both semantic and spatial awareness to guide the token merging process. ToSA leverages the depth image as input to generate pseudo spatial tokens, which serve as auxiliary spatial information for the visual token merging process. With the introduced spatial awareness, ToSA achieves a more informed merging strategy that better preserves critical scene structure. Experimental results demonstrate that ToSA outperforms previous token merging methods across multiple benchmarks on visual and embodied question answering while largely reducing the runtime of the ViT, making it an efficient solution for ViT acceleration. The code will be available at: https://github.com/hsiangwei0903/ToSA
标记合并作为一种策略已经崭露头角,通过减少计算成本来加速视觉转换器(ViT)。然而,现有方法主要依赖于视觉标记的特征相似性来进行标记合并,忽视了集成空间信息的潜力。在ViT的早期层次中,视觉标记只具有弱视觉信息,空间信息可以作为可靠的标记合并标准。本文提出了一种新的标记合并方法ToSA,它结合了语义和空间意识来指导标记合并过程。ToSA利用深度图像作为输入来生成伪空间令牌,这些令牌作为视觉标记合并过程的辅助空间信息。通过引入空间意识,ToSA实现了更加智能的合并策略,更好地保留了关键场景结构。实验结果表明,在视觉和问答等多个基准测试中,ToSA在大幅降低ViT运行时间的同时,优于先前的标记合并方法,成为加速ViT的有效解决方案。代码将发布在:https://github.com/hsiangwei0903/ToSA
论文及项目相关链接
PDF Accepted by IROS 2025
Summary
本文介绍了Token合并作为一种加速Vision Transformer(ViT)的有效策略。现有方法主要依赖视觉令牌的特征相似性进行令牌合并,但忽略了整合空间信息的潜力。本文提出了一种结合语义和空间感知的新Token合并方法ToSA,以指导Token合并过程。ToSA利用深度图像生成伪空间令牌作为视觉令牌合并过程的辅助空间信息。通过引入空间感知,ToSA实现了更智能的合并策略,更好地保留了关键场景结构。实验结果表明,ToSA在多个基准测试中优于先前的Token合并方法,在视觉和嵌入式问答方面表现出卓越性能,同时大大降低了ViT的运行时间,使其成为ViT加速的有效解决方案。
Key Takeaways
- Token合并是加速Vision Transformer(ViT)的有效策略。
- 现有方法主要依赖视觉令牌的特征相似性进行合并,但忽略了空间信息的重要性。
- ToSA是一种结合语义和空间感知的新Token合并方法。
- ToSA利用深度图像生成伪空间令牌作为辅助信息。
- ToSA实现了更智能的合并策略,更好地保留了关键场景结构。
- ToSA在多个基准测试中优于其他Token合并方法,提高了视觉和嵌入式问答的性能。
点此查看论文截图