⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-28 更新
Task-Aware KV Compression For Cost-Effective Long Video Understanding
Authors:Minghao Qin, Yan Shu, Peitian Zhang, Kun Lun, Huaying Yuan, Juenjie Zhou, Shitao Xiao, Bo Zhao, Zheng Liu
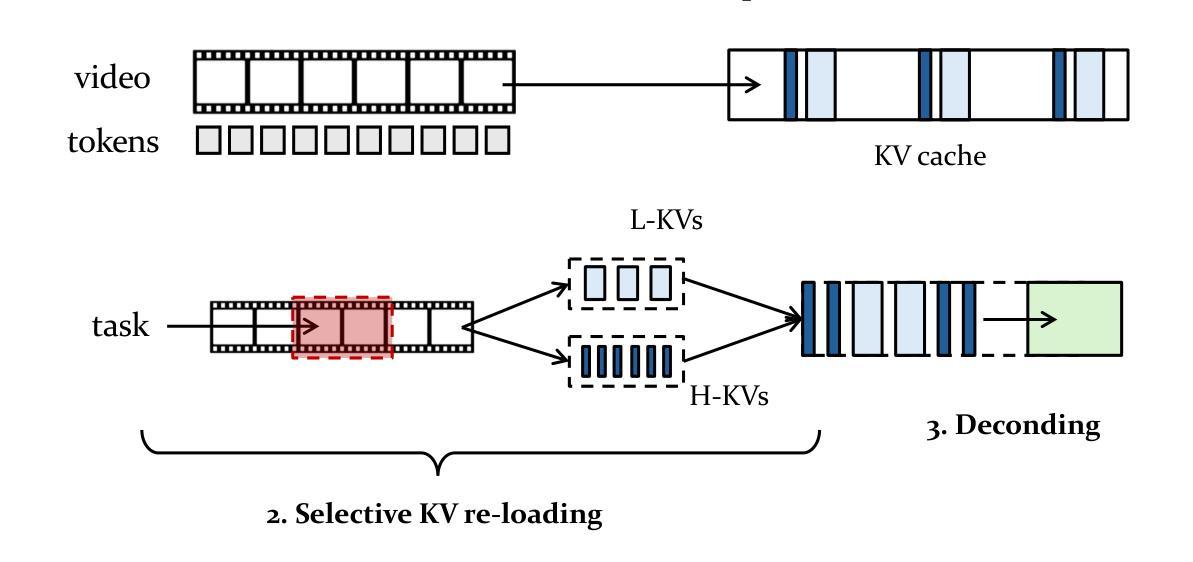
Long-video understanding (LVU) remains a severe challenge for existing multimodal large language models (MLLMs), primarily due to the prohibitive computational cost. Recent approaches have explored KV compression to mitigate this issue, but they often suffer from significant information loss at high compression ratios. In this paper, we introduce Video-X^2L, which flexibly preserves critical video information for each LVU task. Video-X^2L involves two key operations. The first one is called bi-level KV compression. During the MLLM’s pre-filling stage, Video-X^2L generates two types of compressed KVs: low-compression KVs (L-KVs) to capture fine-grained video details and high-compression KVs (H-KVs) to offer compact video representations. The second one is called selective KV re-loading. During the MLLM’s decoding stage, Video-X^2L selectively re-loads L-KVs for the most critical video chunks while using H-KVs for other less important ones. This allows the MLLM to fully utilize task-specific information while maintaining the overall compactness. Video-X^2L is simple yet effective: it is free from additional training and directly compatible with existing KV-compressible MLLMs. We evaluate Video-X^2L with a variety of popular LVU benchmarks, including VideoMME, MLVU, LongVideoBench, and VNBench. Our experiment result shows that Video-X^2L outperforms existing KV-compression methods by a huge advantage while substantially saving the computation cost.
长视频理解(LVU)仍然是现有多模态大型语言模型(MLLMs)面临的严峻挑战,主要是因为其计算成本高昂。虽然近期的方法已经尝试使用KV压缩来缓解这个问题,但在高压缩比下往往存在信息损失较大的情况。在本文中,我们介绍了Video-X^2L,它能够灵活地保留每个LVU任务的关键视频信息。Video-X^2L主要包括两个关键操作。第一个操作称为双级KV压缩。在MLLM的预填充阶段,Video-X^2L生成两种压缩KV:低压缩KV(L-KV)用于捕捉视频的细节信息,以及高压缩KV(H-KV)用于提供紧凑的视频表示。第二个操作是选择性KV重新加载。在MLLM的解码阶段,Video-X^2L选择性地重新加载关键的L-KV,而对其他不太重要的部分使用H-KV。这允许MLLM在保持整体紧凑性的同时,充分利用特定任务的信息。Video-X^2L简单有效:无需额外的训练,可直接与现有的KV可压缩MLLMs兼容。我们在包括VideoMME、MLVU、LongVideoBench和VNBench等多个流行的LVU基准测试上对Video-X^2L进行了评估。实验结果表明,Video-X^2L在巨大的优势上超越了现有的KV压缩方法,同时大大节省了计算成本。
论文及项目相关链接
PDF 14 pages, 3 figures, 6 tables
摘要
本文介绍了针对长视频理解(LVU)的挑战,现有的多模态大型语言模型(MLLMs)由于计算成本高昂而难以应对。为解决此问题,人们尝试使用键值(KV)压缩方法,但高压缩比会导致信息大量损失。本文提出的Video-X^2L方法通过灵活保留每个LVU任务的关键视频信息来应对这一挑战。Video-X^2L包括两个关键操作:一是双级KV压缩,在MLLM的预填充阶段生成两种压缩KV,低压缩KV(L-KVs)用于捕捉视频的细节,高压缩KV(H-KVs)用于提供紧凑的视频表示;二是选择性KV重新加载,在MLLM的解码阶段,Video-X^2L会选择性地重新加载关键的L-KVs,同时利用H-KVs处理其他不太重要的部分。这使得MLLM能够充分利用特定任务的信息,同时保持整体紧凑性。Video-X^2L简单有效,无需额外训练,且与现有的KV可压缩MLLM直接兼容。在多个流行的LVU基准测试中,Video-X^2L表现出巨大优势,显著节省了计算成本。
关键见解
- 长视频理解(LVU)对现有的多模态大型语言模型(MLLMs)是一个挑战,主要因为计算成本高昂。
- 现有方法尝试使用KV压缩来解决此问题,但在高压缩比时会导致信息损失。
- Video-X^2L被引入以解决这一问题,通过灵活保留每个LVU任务的关键视频信息。
- Video-X^2L包括两个关键操作:双级KV压缩和选择性KV重新加载。
- 双级KV压缩生成两种压缩KV,分别用于捕捉视频细节和提供紧凑的视频表示。
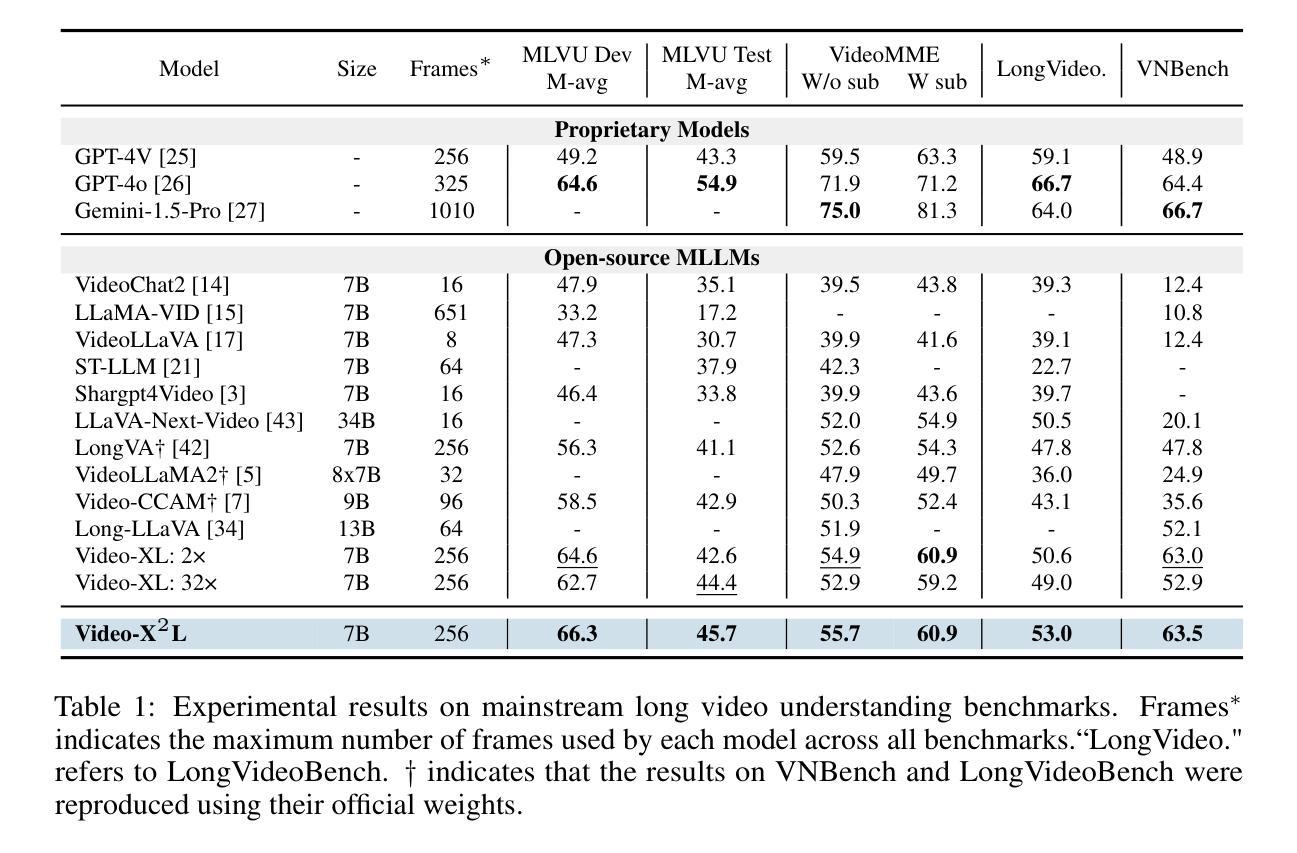
- Video-X^2L在多个流行的LVU基准测试中表现出显著优势。
点此查看论文截图