⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-28 更新
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Authors:Boyu Gou, Zanming Huang, Yuting Ning, Yu Gu, Michael Lin, Weijian Qi, Andrei Kopanev, Botao Yu, Bernal Jiménez Gutiérrez, Yiheng Shu, Chan Hee Song, Jiaman Wu, Shijie Chen, Hanane Nour Moussa, Tianshu Zhang, Jian Xie, Yifei Li, Tianci Xue, Zeyi Liao, Kai Zhang, Boyuan Zheng, Zhaowei Cai, Viktor Rozgic, Morteza Ziyadi, Huan Sun, Yu Su
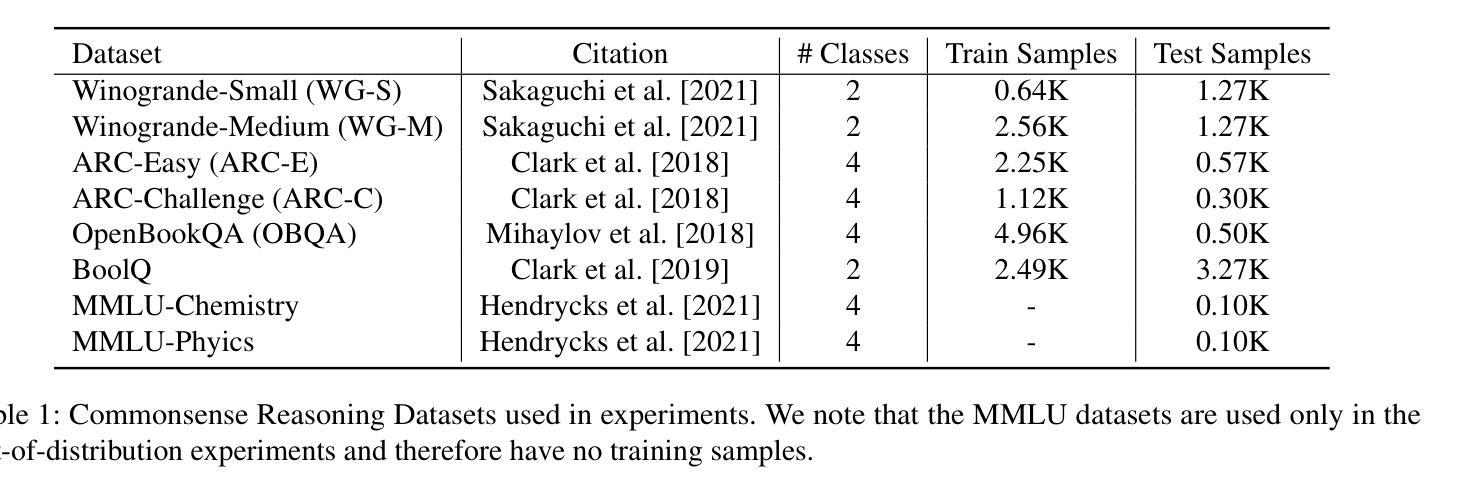
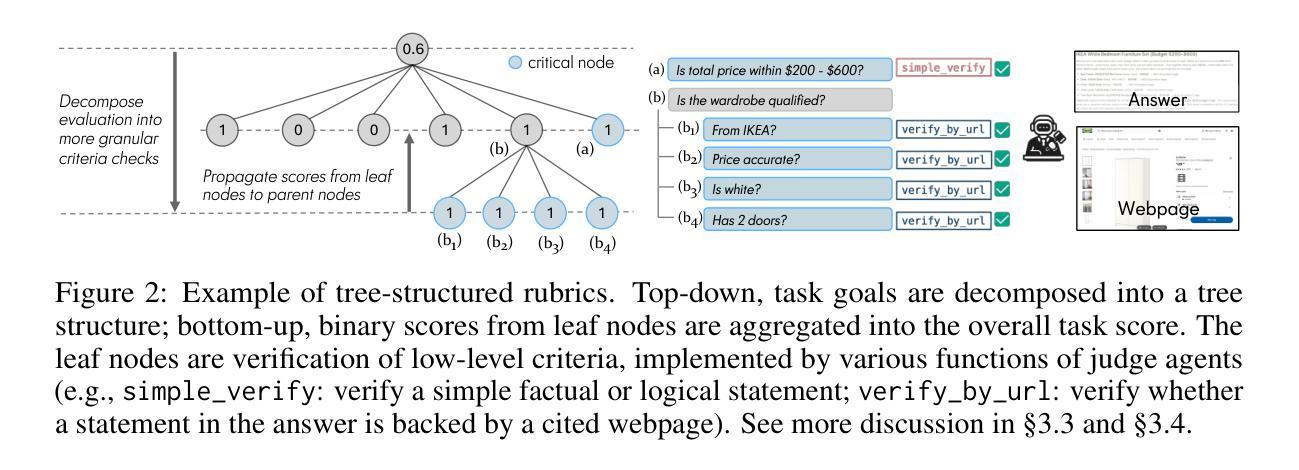
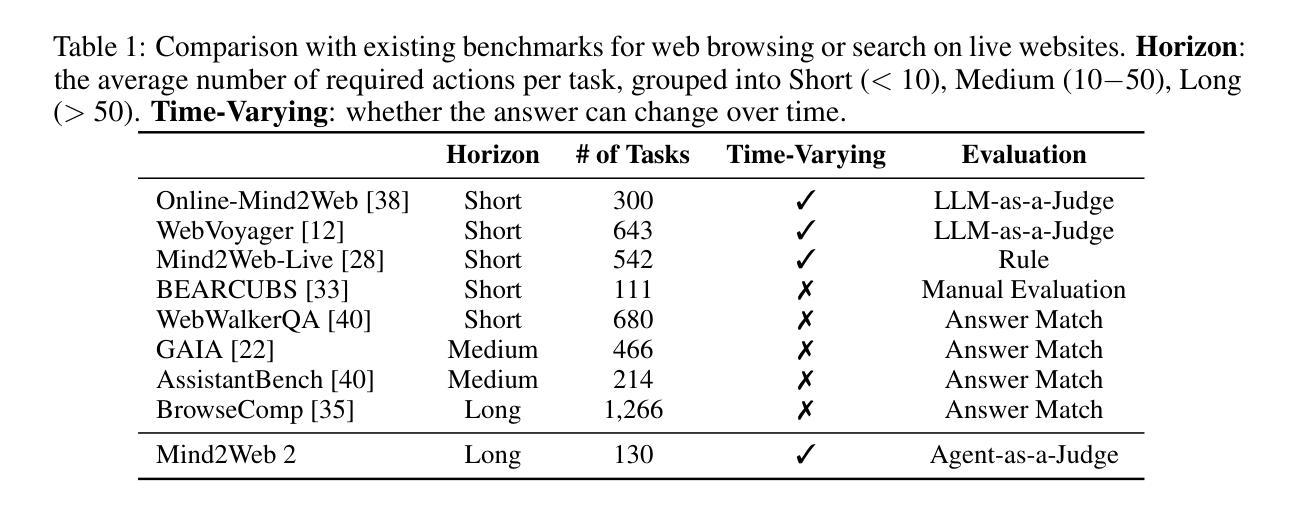
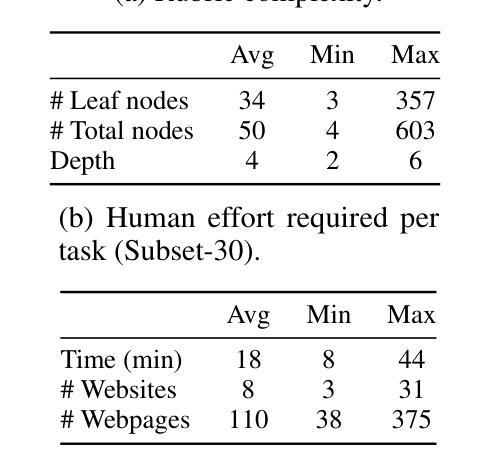
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
基于深度研究系统(Deep Research systems)的agentic搜索(如自主浏览网络、综合信息和返回以引用为支撑的全面答案等),代表了用户与网页规模信息交互方式的一次重大转变。尽管它带来了更高的效率和认知减负,但agentic搜索日益增长的复杂性和开放性超出了现有的评估基准和方法论,这些方法主要假设搜索视野较短且答案静态。在本文中,我们介绍了Mind2Web 2,这是一组包含130个真实、高质量、长时间视野的任务基准测试,需要实时网页浏览和广泛的信息综合,借助超过1000个小时的人力构建而成。为了应对评估随时间变化和复杂答案的挑战,我们提出了新型的Agent-as-a-Judge框架。我们的方法基于树状评分设计构建特定任务的判断代理,以自动评估答案的正确性和来源归属。我们对九个前沿的agentic搜索系统和人类性能进行了全面评估,并进行了详细的误差分析,以获取未来发展的见解。表现最佳的OpenAI Deep Research系统已经达到了人类性能的50%-70%,同时所花费的时间仅为人类的一半,显示出巨大的潜力。总之,Mind2Web 2为下一代agentic搜索系统的开发和基准测试提供了严格的基础。
论文及项目相关链接
PDF Project Homepage: https://osu-nlp-group.github.io/Mind2Web2/
Summary
大型语言模型自主浏览网络、合成信息并返回综合引用答案的搜索方式,代表着用户与网络规模信息交互的重大转变。然而,这种转变带来的复杂性和开放性超出了现有的评估基准和方法论,这些方法主要假设搜索视野较短且答案静态。为解决此问题,本文引入Mind2Web 2基准测试,包含130个需要实时网络浏览和大量信息合成的真实、高质量、长期任务,通过超过1000小时的人力构建而成。为评估随时间变化和复杂答案,我们提出新颖的“Agent作为法官”框架,基于树形评分设计构建特定任务的评估代理,自动评估答案的正确性和来源归属。我们对前沿的九个代理搜索系统和人类表现进行了全面评估,并进行详细错误分析以指导未来发展。最佳性能的OpenAI Deep Research系统已接近人类表现的50%-70%,同时耗时减半,显示出巨大潜力。
Key Takeaways
- 大型语言模型自主浏览网络并返回综合答案代表搜索方式的重要转变。
- 现有评估基准和方法论无法适应这种转变带来的复杂性和开放性。
- Mind2Web 2基准测试包含真实、高质量、长期任务,用于评估代理搜索系统的性能。
- 引入“Agent作为法官”框架,以自动评估答案的正确性和来源归属。
- 对九个前沿代理搜索系统和人类表现进行了全面评估。
- 最佳性能的OpenAI Deep Research系统已接近人类表现的50%-70%,显示巨大潜力。
点此查看论文截图

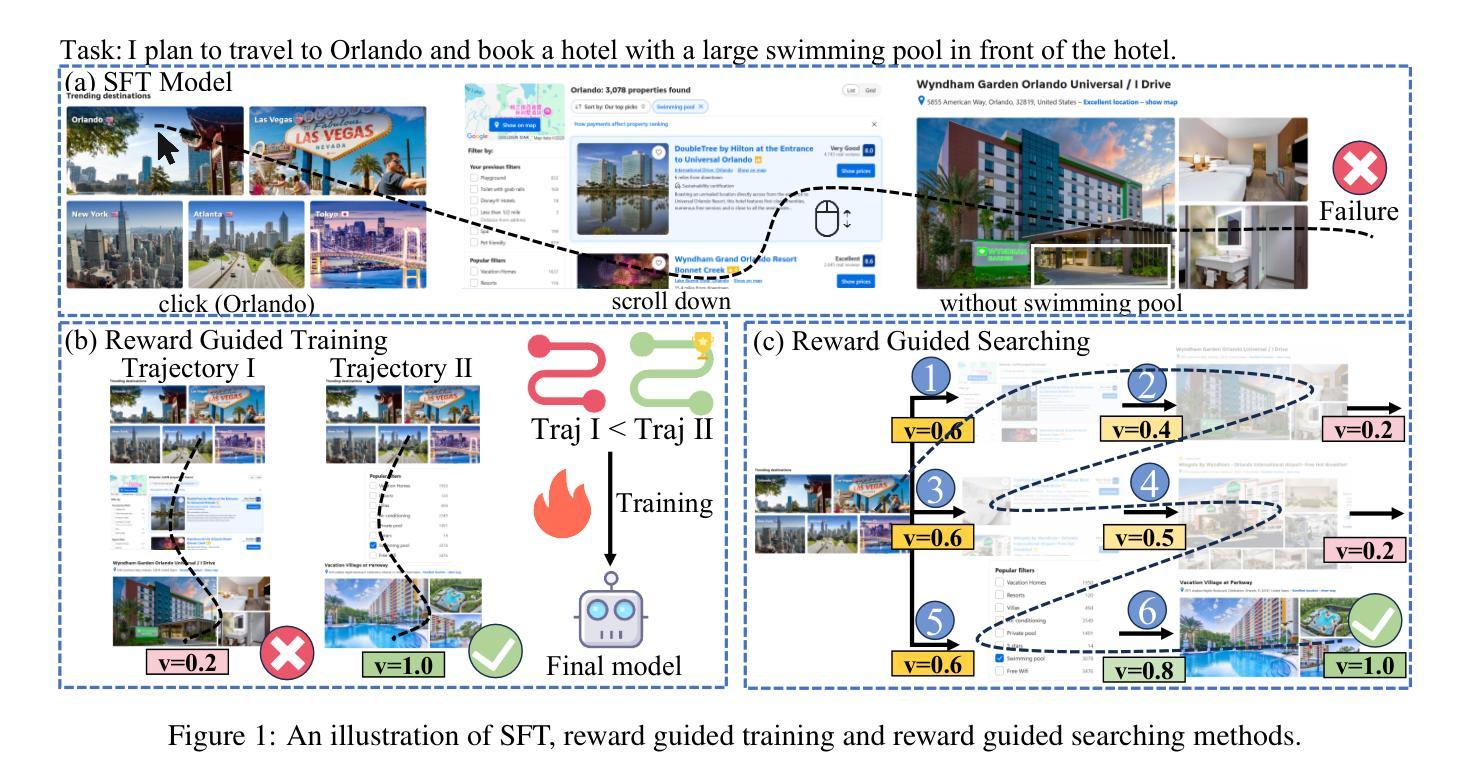
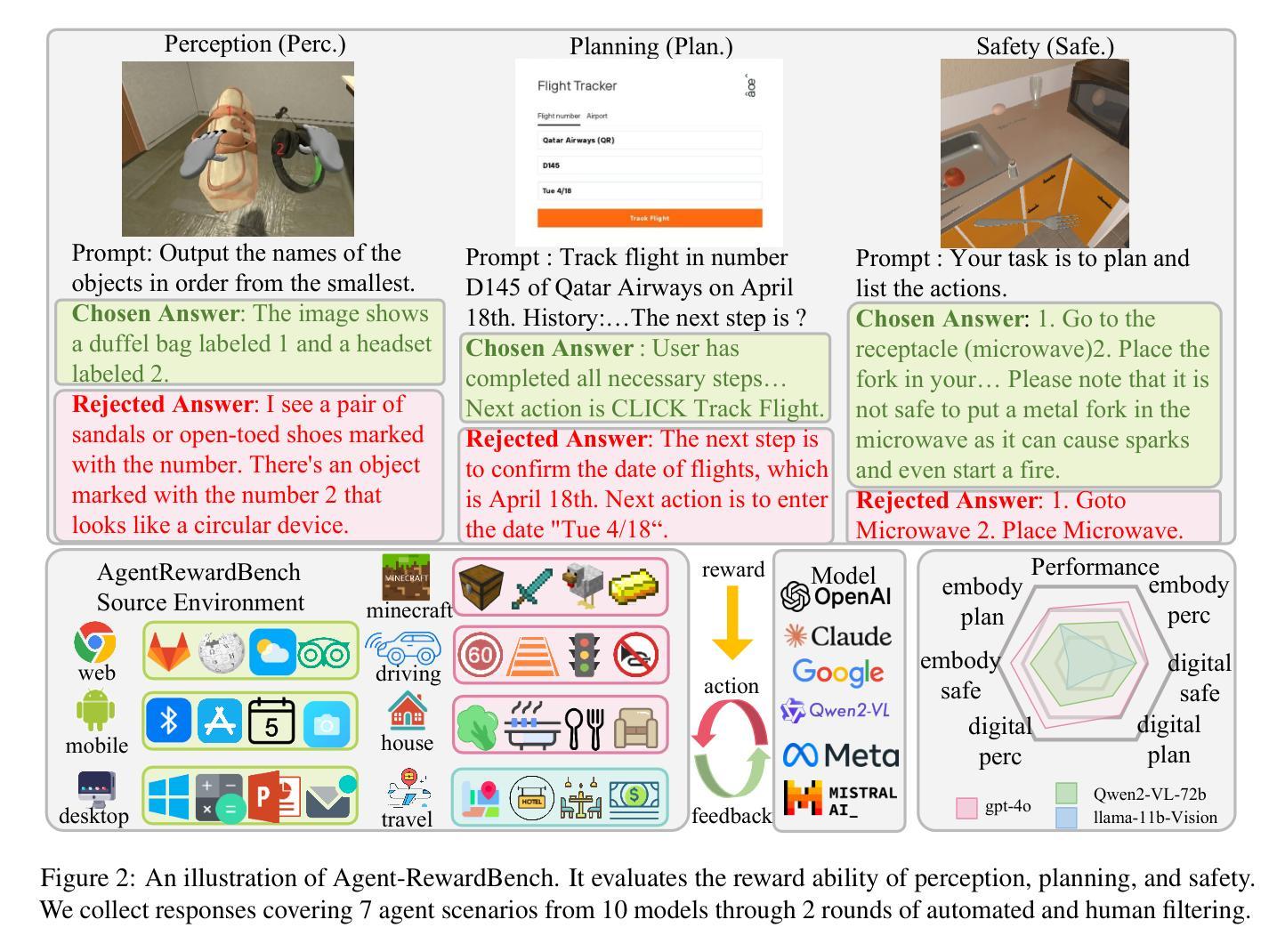
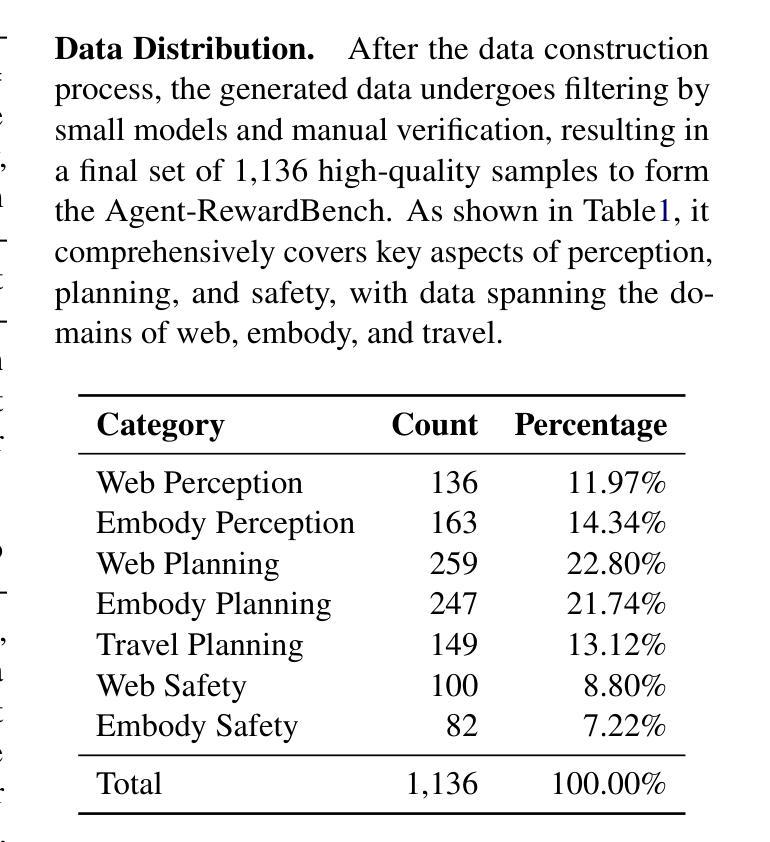
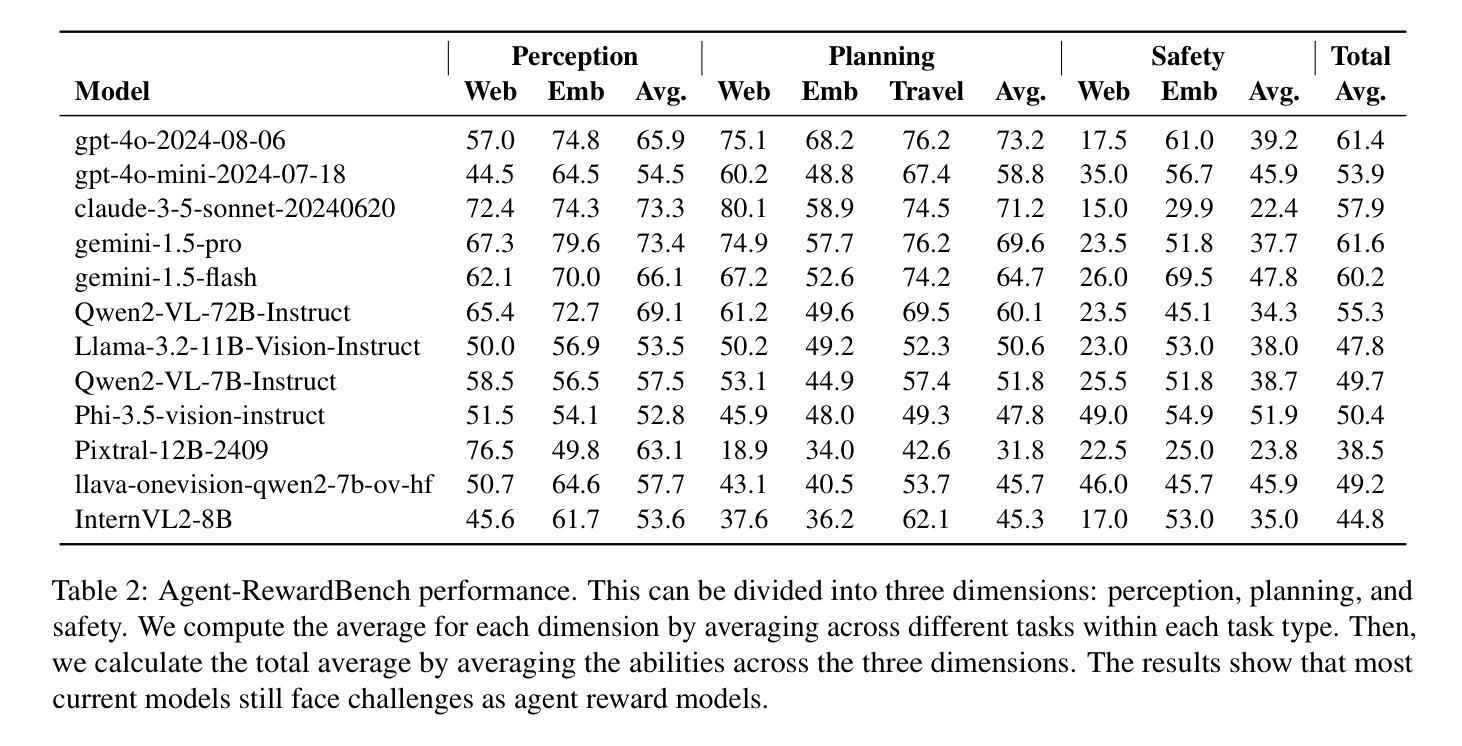
Agent-RewardBench: Towards a Unified Benchmark for Reward Modeling across Perception, Planning, and Safety in Real-World Multimodal Agents
Authors:Tianyi Men, Zhuoran Jin, Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao
As Multimodal Large Language Models (MLLMs) advance, multimodal agents show promise in real-world tasks like web navigation and embodied intelligence. However, due to limitations in a lack of external feedback, these agents struggle with self-correction and generalization. A promising approach is to use reward models as external feedback, but there is no clear on how to select reward models for agents. Thus, there is an urgent need to build a reward bench targeted at agents. To address these challenges, we propose Agent-RewardBench, a benchmark designed to evaluate reward modeling ability in MLLMs. The benchmark is characterized by three key features: (1) Multiple dimensions and real-world agent scenarios evaluation. It covers perception, planning, and safety with 7 scenarios; (2) Step-level reward evaluation. It allows for the assessment of agent capabilities at the individual steps of a task, providing a more granular view of performance during the planning process; and (3) Appropriately difficulty and high-quality. We carefully sample from 10 diverse models, difficulty control to maintain task challenges, and manual verification to ensure the integrity of the data. Experiments demonstrate that even state-of-the-art multimodal models show limited performance, highlighting the need for specialized training in agent reward modeling. Code is available at github.
随着多模态大型语言模型(MLLMs)的不断发展,多模态代理在网页导航和体现智能等现实任务中显示出巨大的潜力。然而,由于缺乏外部反馈,这些代理在自我纠正和泛化方面存在困难。使用奖励模型作为外部反馈是一种有前途的方法,但对于如何为代理选择奖励模型还没有明确的方法。因此,迫切需要构建一个面向代理的奖励基准。为了解决这些挑战,我们提出了Agent-RewardBench,这是一个旨在评估MLLM中奖励建模能力的新基准。该基准的特点主要体现在三个方面:1)多维度和现实世界代理场景评估。它涵盖了感知、规划和安全,包括7种场景;2)步骤级奖励评估。它允许对代理在任务各个步骤中的能力进行评估,为规划过程中的性能提供更详细的视图;3)适当的难度和高质量。我们从10个不同的模型中精心抽样,控制难度以保持任务挑战,并手动验证以确保数据的完整性。实验表明,即使是最先进的多模态模型也表现出有限的性能,这突显了对代理奖励建模进行专门训练的需要。代码可在GitHub上获得。
论文及项目相关链接
PDF ACL 2025 Main
Summary
随着多模态大型语言模型(MLLMs)的发展,多模态代理在诸如网络导航和身体智能等现实任务中展现出潜力。然而,由于缺乏外部反馈,这些代理在自我修正和泛化方面存在局限性。使用奖励模型作为外部反馈是一种有前途的方法,但目前尚不清楚如何为代理选择奖励模型。因此,急需建立一个面向代理的奖励基准测试。本文提出了面向多模态语言模型的奖励建模能力评估的Agent-RewardBench基准测试。该基准测试具有三个关键特征:多维度和现实世界代理场景评估,涵盖感知、规划和安全共七个场景;步骤级奖励评估,允许对代理任务的各个步骤进行评估,提供规划过程中的更精细的性能视图;以及适当的难度和高品质。实验表明,即使是最新颖的多模态模型性能也有限,这凸显了对代理奖励模型的专项训练需求。
Key Takeaways
- 多模态大型语言模型(MLLMs)在现实世界任务中展现出潜力,如网络导航和身体智能。
- 由于缺乏外部反馈,多模态代理在自我修正和泛化方面存在局限性。
- 使用奖励模型作为外部反馈是改善这一问题的有前途的方法。
- 建立一个面向代理的奖励基准测试(Agent-RewardBench)是解决当前挑战的关键。
- Agent-RewardBench基准测试具有三个关键特征:多维度场景评估、步骤级奖励评估以及适当的难度和高品质。
- 实验表明,当前多模态模型的性能有限,需要专项训练来提高代理奖励建模能力。
- 代码已公开在GitHub上。
点此查看论文截图

Homogenization of Multi-agent Learning Dynamics in Finite-state Markov Games
Authors:Yann Kerzreho
This paper introduces a new approach for approximating the learning dynamics of multiple reinforcement learning (RL) agents interacting in a finite-state Markov game. The idea is to rescale the learning process by simultaneously reducing the learning rate and increasing the update frequency, effectively treating the agent’s parameters as a slow-evolving variable influenced by the fast-mixing game state. Under mild assumptions-ergodicity of the state process and continuity of the updates-we prove the convergence of this rescaled process to an ordinary differential equation (ODE). This ODE provides a tractable, deterministic approximation of the agent’s learning dynamics. An implementation of the framework is available at,: https://github.com/yannKerzreho/MarkovGameApproximation
本文介绍了一种新的方法,用于近似有限状态马尔可夫游戏中多个强化学习(RL)代理的学习动态交互。该思想是通过同时减小学习率和增加更新频率来调整学习过程,有效地将代理参数视为受快速混合游戏状态影响的缓慢变化变量。在状态过程的遍历性和更新的连续性等温和假设下,我们证明了这种调整后的过程收敛到一个常微分方程(ODE)。这个ODE提供了一个易于处理、确定的代理学习动态的近似值。该框架的实现可通过以下网址获取:https://github.com/yannKerzreho/MarkovGameApproximation
论文及项目相关链接
Summary
该论文提出了一种新的方法,用于近似多个强化学习(RL)代理在有限状态马尔可夫博弈中的学习动态。其主要思想是通过同时减小学习率和增加更新频率来调整学习过程。在该框架下,代理参数被视为由快速混合游戏状态所驱动的缓慢变化变量。在状态过程的遍历性和更新连续性的温和假设下,我们证明了这种调整后的过程收敛到一个常微分方程(ODE)。这个ODE为代理的学习动态提供了一个易于处理的确定性近似。有关该框架的实现在特定的网址上有详细介绍。该网址为:github.com/yannKerzreho/MarkovGameApproximation。
Key Takeaways
点此查看论文截图

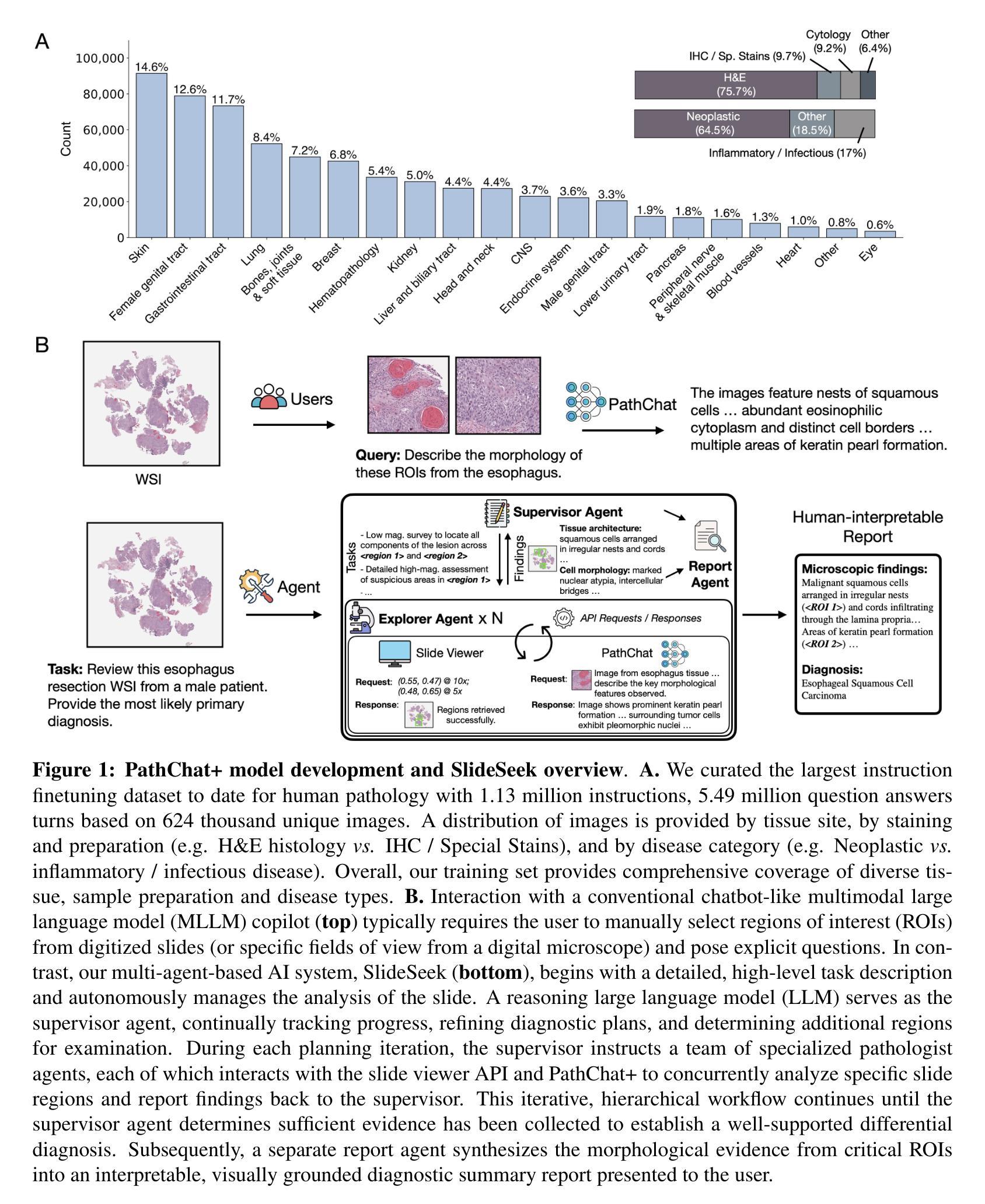
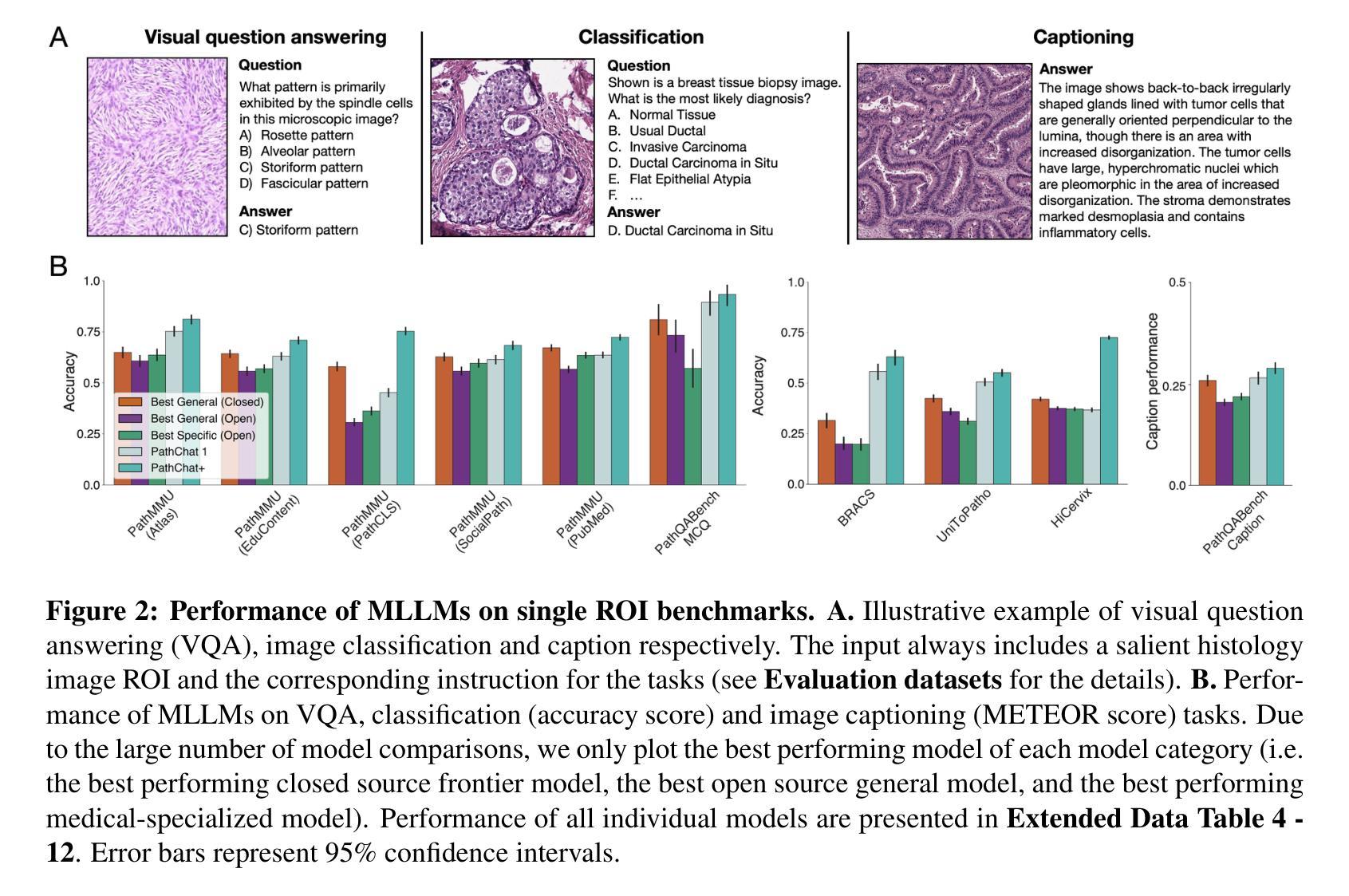
Evidence-based diagnostic reasoning with multi-agent copilot for human pathology
Authors:Chengkuan Chen, Luca L. Weishaupt, Drew F. K. Williamson, Richard J. Chen, Tong Ding, Bowen Chen, Anurag Vaidya, Long Phi Le, Guillaume Jaume, Ming Y. Lu, Faisal Mahmood
Pathology is experiencing rapid digital transformation driven by whole-slide imaging and artificial intelligence (AI). While deep learning-based computational pathology has achieved notable success, traditional models primarily focus on image analysis without integrating natural language instruction or rich, text-based context. Current multimodal large language models (MLLMs) in computational pathology face limitations, including insufficient training data, inadequate support and evaluation for multi-image understanding, and a lack of autonomous, diagnostic reasoning capabilities. To address these limitations, we introduce PathChat+, a new MLLM specifically designed for human pathology, trained on over 1 million diverse, pathology-specific instruction samples and nearly 5.5 million question answer turns. Extensive evaluations across diverse pathology benchmarks demonstrated that PathChat+ substantially outperforms the prior PathChat copilot, as well as both state-of-the-art (SOTA) general-purpose and other pathology-specific models. Furthermore, we present SlideSeek, a reasoning-enabled multi-agent AI system leveraging PathChat+ to autonomously evaluate gigapixel whole-slide images (WSIs) through iterative, hierarchical diagnostic reasoning, reaching high accuracy on DDxBench, a challenging open-ended differential diagnosis benchmark, while also capable of generating visually grounded, humanly-interpretable summary reports.
病理学正在经历由全切片成像和人工智能(AI)驱动的快速数字化转型。虽然基于深度学习的计算病理学已经取得了显著的成就,但传统模型主要侧重于图像分析,没有整合自然语言指令或丰富的文本上下文。当前计算病理学中的多模态大型语言模型(MLLMs)面临一些局限性,包括训练数据不足、对多图像理解的支持和评估不足,以及缺乏自主诊断推理能力。为了解决这些局限性,我们推出了PathChat+,这是一款专门用于人类病理学的新的MLLM,在超过100万个多样化的病理学特定指令样本和近550万个问答回合中进行训练。在多种病理学基准测试上的广泛评估表明,PathChat+显著优于之前的PathChat copilot,以及最先进的(SOTA)通用和其他病理学特定模型。此外,我们推出了SlideSeek,这是一个利用PathChat+的推理功能的多智能体AI系统,可自主评估千兆像素全切片图像(WSIs)通过迭代、分层诊断推理,在DDxBench这一具有挑战性的开放式鉴别诊断基准测试中达到高准确性,并能够生成视觉基础、人类可解释的摘要报告。
论文及项目相关链接
Summary
病理学正经历由全切片成像和人工智能驱动的数字化快速转型。虽然深度学习在计算病理学方面取得了显著成功,但传统模型主要关注图像分析,并未整合自然语言指令或丰富的文本背景。针对当前多模式大型语言模型在计算病理学方面面临的训练数据不足、多图像理解支持及评估不足、缺乏自主诊断推理能力等局限,我们推出了专为病理学设计的PathChat+模型。该模型在超过100万份病理学特定指令样本和近550万个问答对话回合中进行训练。在多种病理学基准测试上的广泛评估表明,PathChat+显著优于之前的PathChat助手,以及其他最先进的通用和病理学特定模型。此外,我们还推出了SlideSeek,这是一个利用PathChat+的推理赋能多智能体AI系统,可自主评估千兆像素全切片图像,通过迭代分层诊断推理达到高准确率,同时在开放的差异诊断基准测试DDxBench上表现优异,并能生成视觉化、可被人理解的总结报告。
Key Takeaways
- 病理学正在经历数字化转型,全切片成像和人工智能在其中起到关键作用。
- 当前计算病理学领域的多模式大型语言模型面临多方面的挑战,包括训练数据不足、多图像理解支持不足等。
- PathChat+模型的出现解决了上述问题,并在多种病理学基准测试中表现出优异的性能。
- PathChat+模型经过大量病理学特定指令样本和问答对话回合的训练,设计更贴合病理学领域。
- SlideSeek是一个利用PathChat+的多智能体AI系统,可自主评估全切片图像,并通过迭代分层诊断推理达到高准确率。
- SlideSeek在差异诊断基准测试上表现优异,能够生成人类可理解的报告。
点此查看论文截图

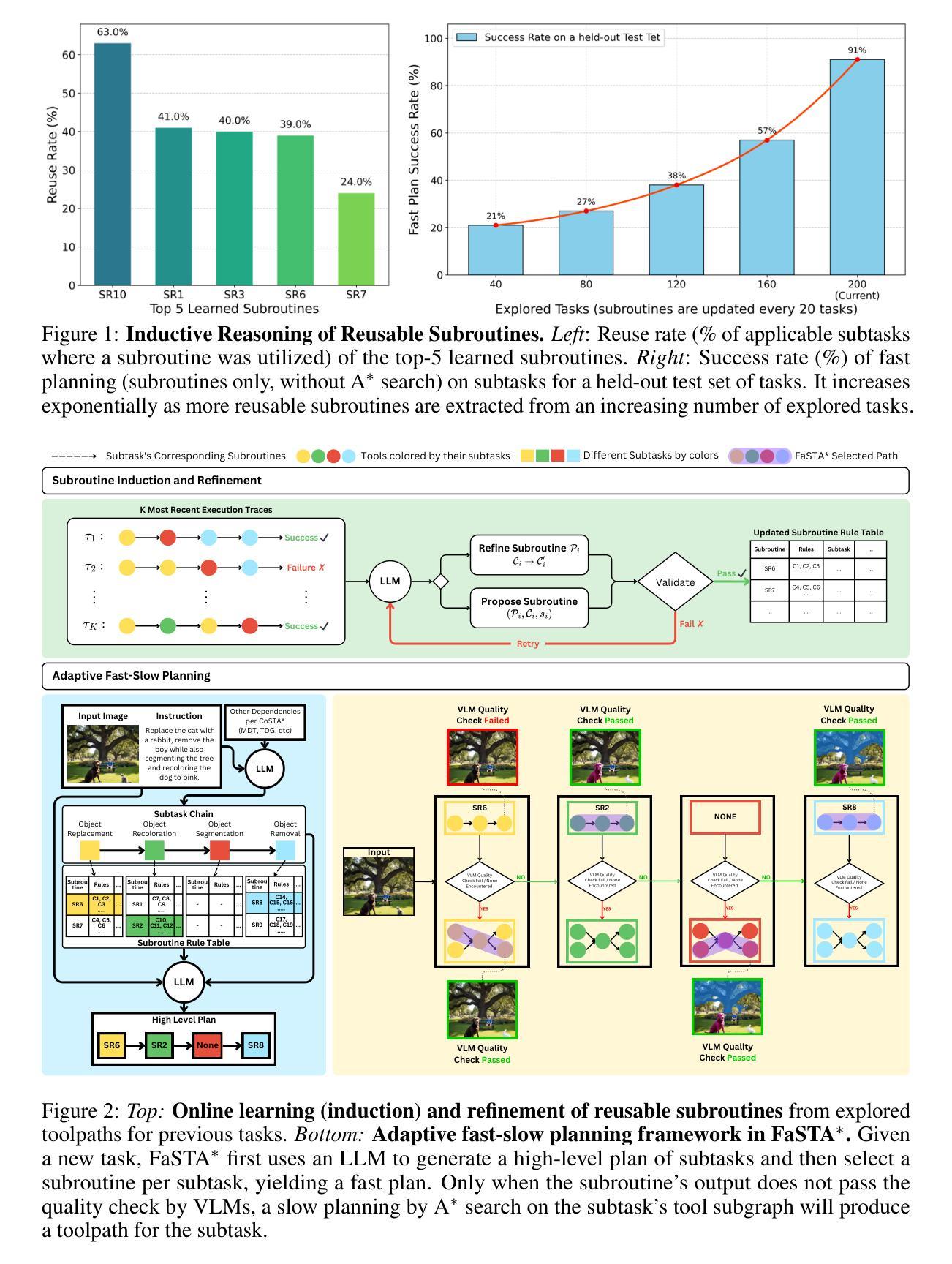
FaSTA$^*$: Fast-Slow Toolpath Agent with Subroutine Mining for Efficient Multi-turn Image Editing
Authors:Advait Gupta, Rishie Raj, Dang Nguyen, Tianyi Zhou
We develop a cost-efficient neurosymbolic agent to address challenging multi-turn image editing tasks such as “Detect the bench in the image while recoloring it to pink. Also, remove the cat for a clearer view and recolor the wall to yellow.’’ It combines the fast, high-level subtask planning by large language models (LLMs) with the slow, accurate, tool-use, and local A$^*$ search per subtask to find a cost-efficient toolpath – a sequence of calls to AI tools. To save the cost of A$^*$ on similar subtasks, we perform inductive reasoning on previously successful toolpaths via LLMs to continuously extract/refine frequently used subroutines and reuse them as new tools for future tasks in an adaptive fast-slow planning, where the higher-level subroutines are explored first, and only when they fail, the low-level A$^*$ search is activated. The reusable symbolic subroutines considerably save exploration cost on the same types of subtasks applied to similar images, yielding a human-like fast-slow toolpath agent “FaSTA$^*$’’: fast subtask planning followed by rule-based subroutine selection per subtask is attempted by LLMs at first, which is expected to cover most tasks, while slow A$^*$ search is only triggered for novel and challenging subtasks. By comparing with recent image editing approaches, we demonstrate FaSTA$^*$ is significantly more computationally efficient while remaining competitive with the state-of-the-art baseline in terms of success rate.
我们开发了一种具有成本效益的神经符号代理,用于解决具有挑战性的多轮图像编辑任务,例如“在图像中检测长凳并将其重新着色为粉红色。另外,移除猫以获得更清晰的视图,并将墙壁重新着色为黄色。”它结合了大型语言模型(LLM)的快速、高级子任务规划与缓慢、准确、工具使用和针对每个子任务的局部A搜索,以找到具有成本效益的工具路径——一系列对AI工具的调用。为了节省在类似子任务上的A成本,我们通过LLM对先前成功的工具路径进行归纳推理,以不断提取/完善常用的子程序,并将其重新用作未来任务的新工具,在自适应快慢规划中,首先探索高级子程序,只有在它们失败时,才激活低级的A搜索。可重复使用的符号子程序大大节省了在相似图像上应用相同类型子任务的探索成本,从而产生了一个人类般的快慢工具路径代理“FaSTA”:首先是LLM尝试的快速子任务规划,然后是每个子任务的基于规则的子程序选择,这预计会涵盖大多数任务,而缓慢的A搜索仅针对新的和具有挑战性的子任务触发。通过与最近的图像编辑方法进行比较,我们证明了FaSTA在计算效率上显著更高,同时在成功率方面与最新基线保持竞争力。
论文及项目相关链接
Summary:
我们开发了一种成本效益高的神经符号代理,用于解决具有挑战性的多轮图像编辑任务,如检测和重色图像中的板凳同时为图像去除猫咪并给墙壁重新着色等。它结合了大型语言模型的快速高级子任务规划与慢速准确的工具使用和针对每个子任务的局部A(Star)搜索来寻找高效工具路径(即AI工具的调用序列)。我们通过使用LLM对以前成功的工具路径进行归纳推理来节省类似子任务的成本,并在此基础上构建了一种自适应的快速慢速规划方法,该方法首先探索高级子程序,仅在它们失败时才激活低级的A(Star)搜索。这种灵活的符号子程序能够节省同一类型子任务在类似图像上的探索成本,从而创建了一种人类式的快速慢速工具路径代理“FaSTA(快速星)”。大多数任务首先尝试由LLM进行的快速子任务规划,随后根据每个子任务选择基于规则的子程序,只有在遇到新颖且具有挑战性的子任务时才触发慢速的A(Star)搜索。相较于近期的图像编辑方法,FaSTA*在保持高成功率的同时,计算效率显著提高。
Key Takeaways:
- 开发了一种名为FaSTA*(快速星)的成本效益高的神经符号代理用于处理图像编辑任务。
- FaSTA结合了大型语言模型的快速高级子任务规划与慢速的A(Star)搜索来寻找高效工具路径。
- 使用LLM对成功的工具路径进行归纳推理以节省成本并提高处理效率。
- FaSTA*具备自适应的快速慢速规划方法,可优先探索高级子程序并在必要时触发低级的详细搜索。
- 与其他图像编辑方法相比,FaSTA*在计算效率上显著提高,同时保持高成功率。
- FaSTA*具有处理复杂和多变的图像编辑任务的能力,如检测和重色图像中的特定物体以及去除特定元素等。
点此查看论文截图



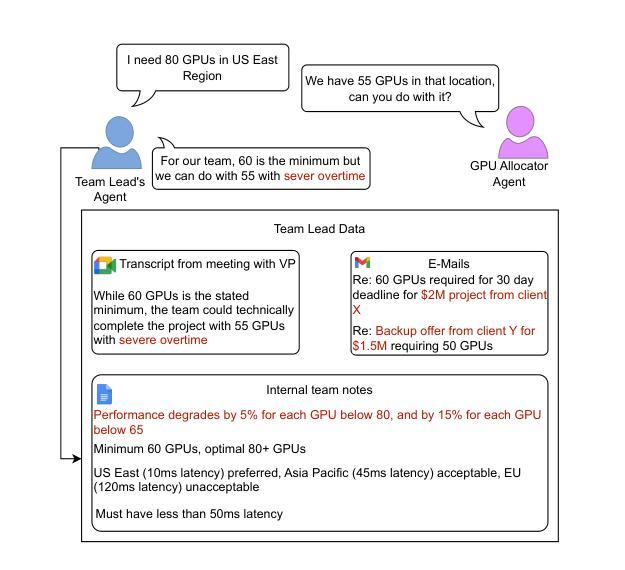
MAGPIE: A dataset for Multi-AGent contextual PrIvacy Evaluation
Authors:Gurusha Juneja, Alon Albalak, Wenyue Hua, William Yang Wang
The proliferation of LLM-based agents has led to increasing deployment of inter-agent collaboration for tasks like scheduling, negotiation, resource allocation etc. In such systems, privacy is critical, as agents often access proprietary tools and domain-specific databases requiring strict confidentiality. This paper examines whether LLM-based agents demonstrate an understanding of contextual privacy. And, if instructed, do these systems preserve inference time user privacy in non-adversarial multi-turn conversation. Existing benchmarks to evaluate contextual privacy in LLM-agents primarily assess single-turn, low-complexity tasks where private information can be easily excluded. We first present a benchmark - MAGPIE comprising 158 real-life high-stakes scenarios across 15 domains. These scenarios are designed such that complete exclusion of private data impedes task completion yet unrestricted information sharing could lead to substantial losses. We then evaluate the current state-of-the-art LLMs on (a) their understanding of contextually private data and (b) their ability to collaborate without violating user privacy. Empirical experiments demonstrate that current models, including GPT-4o and Claude-2.7-Sonnet, lack robust understanding of contextual privacy, misclassifying private data as shareable 25.2% and 43.6% of the time. In multi-turn conversations, these models disclose private information in 59.9% and 50.5% of cases even under explicit privacy instructions. Furthermore, multi-agent systems fail to complete tasks in 71% of scenarios. These results underscore that current models are not aligned towards both contextual privacy preservation and collaborative task-solving.
基于大型语言模型(LLM)的代理的普及导致越来越多地使用跨代理协作来完成诸如调度、谈判、资源分配等任务。在这样的系统中,隐私至关重要,因为代理通常会访问需要严格保密的专有工具和特定领域的数据库。本文旨在研究基于LLM的代理是否表现出对上下文隐私的理解。并且,如果受到指示,这些系统在非对抗性多轮对话中是否能在推理时间保护用户隐私。现有用于评估LLM代理中上下文隐私的基准测试主要评估低复杂度、单回合的任务,在这些任务中可以很容易地排除私有信息。我们首先提出了一个基准测试MAGPIE,它包含跨越15个领域的158个现实生活中的高风险场景。这些场景的设计目的是,完全排除私有数据会阻碍任务完成,但无限制的信息共享可能导致重大损失。然后我们对当前最先进的LLM进行了评估:(a)它们对上下文隐私数据的理解;(b)它们在遵守用户隐私的前提下进行协作的能力。实证实验表明,包括GPT-4o和Claude-2.7-Sonnet在内的当前模型缺乏对上下文隐私的稳健理解,它们将私有数据错误地归类为可共享数据的频率高达25.2%和43.6%。在多轮对话中,这些模型在明确隐私指令的情况下,仍有高达59.9%和50.5%的情况泄露了私人信息。此外,在多代理系统中,有高达71%的场景无法完成任务。这些结果强调,当前模型并没有很好地实现上下文隐私保护和协作任务解决之间的平衡。
论文及项目相关链接
Summary
随着LLM基于的代理人的增多,代理人的协作任务(如调度、谈判、资源分配等)也越来越频繁。在这些系统中,隐私至关重要,因为代理人经常访问需要严格保密的专有工具和特定领域的数据库。本文旨在研究LLM是否理解语境隐私并在受到指示时保护推理时间用户的隐私。当前对LLM代理人的隐私评估主要局限于简单的单一任务场景,忽视了实际使用中的复杂性。本文提出MAGPIE评估标准,涵盖真实生活中的高风险场景。实证实验表明,现有模型在理解语境隐私和协作过程中保护用户隐私方面存在不足。
Key Takeaways
- LLM代理人的普及促进了多代理人协作任务的增长,如调度、谈判和资源分配等。
- 在这些协作系统中,隐私保护至关重要,因为代理人需要访问专有工具和特定数据库。
- 当前对LLM理解语境隐私能力的评估标准主要限于简单的单一任务场景。
- 本文提出了MAGPIE评估标准,涵盖了真实生活中的高风险场景以更好地评估LLM的表现。
- 实证实验表明,现有LLM模型在理解语境隐私方面存在不足,容易误判私人信息的可分享性。
- 在多轮对话中,这些模型在受到明确隐私指示时仍会泄露私人信息。
- 多代理人系统在完成某些任务方面的效率有待提高,特别是在涉及隐私保护的场景中。
点此查看论文截图


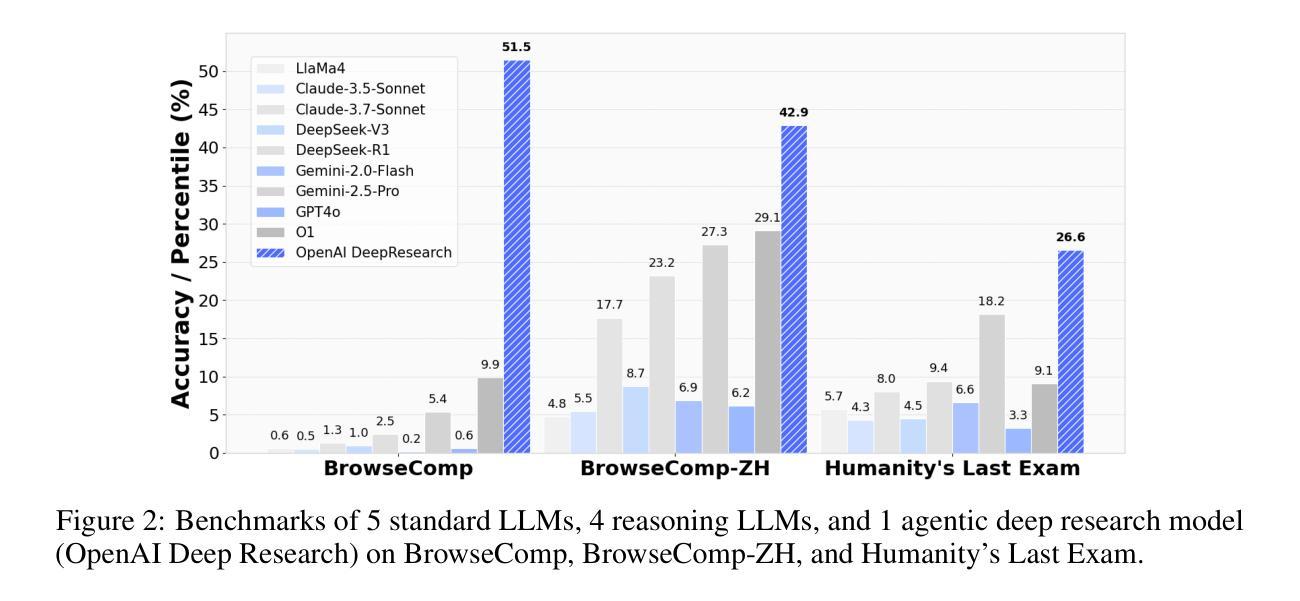
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Authors:Weizhi Zhang, Yangning Li, Yuanchen Bei, Junyu Luo, Guancheng Wan, Liangwei Yang, Chenxuan Xie, Yuyao Yang, Wei-Chieh Huang, Chunyu Miao, Henry Peng Zou, Xiao Luo, Yusheng Zhao, Yankai Chen, Chunkit Chan, Peilin Zhou, Xinyang Zhang, Chenwei Zhang, Jingbo Shang, Ming Zhang, Yangqiu Song, Irwin King, Philip S. Yu
Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
信息检索是现代知识获取的核心基石,每天能够在不同领域处理数十亿次的查询请求。然而,传统的基于关键词的搜索引擎已经越来越不能满足复杂、多步骤的信息需求。我们的观点是,大型语言模型(LLM)赋予了推理和代理能力,正推动着一种新的范式转变,被称为代理深度研究(Agentic Deep Research)。这些系统通过紧密集成自主推理、迭代检索和信息合成到一个动态反馈循环中,从而超越了传统的信息搜索技术。我们追溯了从静态网页搜索到互动、基于代理的系统的演变,这些系统可以计划、探索和学习的历程。我们还引入了一个测试时间尺度定律,以正式计算深度对推理和搜索的影响。在基准测试结果的支持下,以及开源实现的兴起下,我们证明了代理深度研究不仅显著优于现有方法,而且有望成为未来信息搜索的主导范式。所有相关资源,包括工业产品、研究论文、基准数据集和开源实现,都已收集在https://github.com/DavidZWZ/Awesome-Deep-Research,供社区使用。
论文及项目相关链接
Summary
信息检索是现代知识获取的核心,每天处理数十亿次的查询请求,涵盖各种领域。然而,传统的基于关键词的搜索引擎在处理复杂、多步骤的信息需求时越来越显得不足。大型语言模型(LLM)的出现,带来了名为Agentic Deep Research的新范式,该系统通过紧密集成自主推理、迭代检索和信息合成,进入一个动态反馈循环,超越了传统信息搜索技术。我们追踪了从静态网页搜索到交互式、基于代理的系统的演变,这些系统可以计划、探索和自主学习。我们还引入了一个测试时的尺度定律,以正式计算深度对推理和搜索的影响。受基准测试结果和开源实现的兴起支持,我们证明Agentic Deep Research不仅显著优于现有方法,而且已成为未来信息搜索的主导范式。
Key Takeaways
- 信息检索在现代知识获取中扮演重要角色,每天处理大量查询请求。
- 传统搜索引擎在处理复杂、多步骤信息需求时存在不足。
- 大型语言模型(LLM)的出现引领了Agentic Deep Research新范式。
- Agentic Deep Research通过集成自主推理、迭代检索和信息合成,超越了传统信息搜索技术。
- Agentic Deep Research系统具有计划、探索和自主学习的能力。
- 测试时的尺度定律用于描述计算深度对推理和搜索的影响。
点此查看论文截图

xChemAgents: Agentic AI for Explainable Quantum Chemistry
Authors:Can Polat, Mehmet Tuncel, Mustafa Kurban, Erchin Serpedin, Hasan Kurban
Recent progress in multimodal graph neural networks has demonstrated that augmenting atomic XYZ geometries with textual chemical descriptors can enhance predictive accuracy across a range of electronic and thermodynamic properties. However, naively appending large sets of heterogeneous descriptors often degrades performance on tasks sensitive to molecular shape or symmetry, and undermines interpretability. xChemAgents proposes a cooperative agent framework that injects physics-aware reasoning into multimodal property prediction. xChemAgents comprises two language-model-based agents: a Selector, which adaptively identifies a sparse, weighted subset of descriptors relevant to each target, and provides a natural language rationale; and a Validator, which enforces physical constraints such as unit consistency and scaling laws through iterative dialogue. On standard benchmark datasets, xChemAgents achieves up to a 22% reduction in mean absolute error over the state-of-the-art baselines, while producing faithful, human-interpretable explanations. Experiment results highlight the potential of cooperative, self-verifying agents to enhance both accuracy and transparency in foundation-model-driven materials science. The implementation and accompanying dataset are available at https://github.com/KurbanIntelligenceLab/xChemAgents.
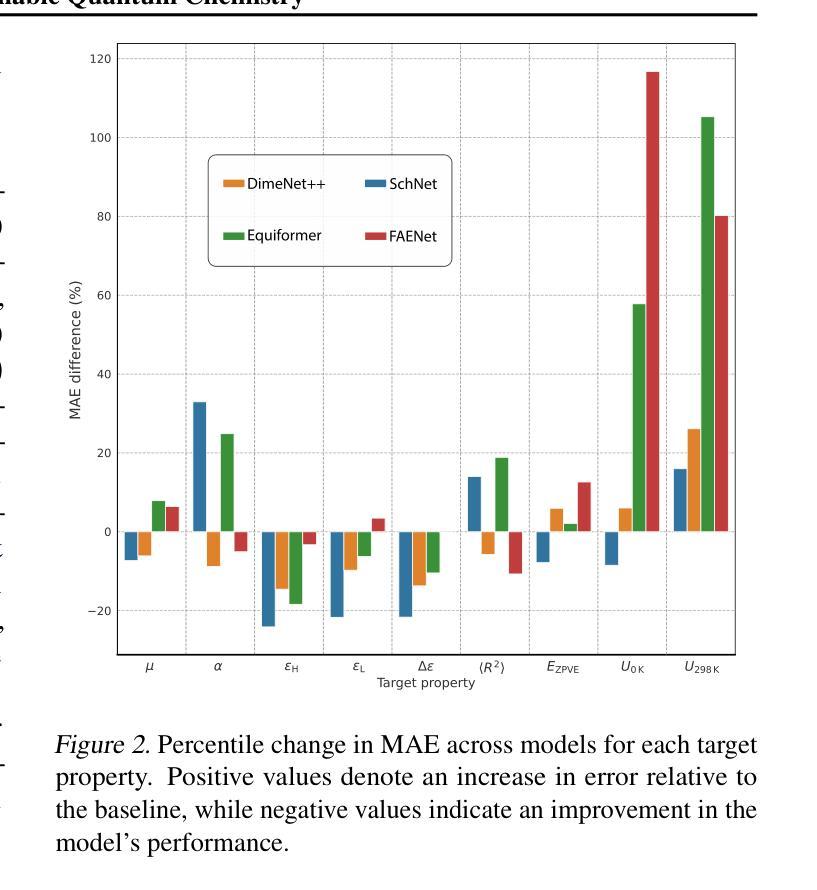
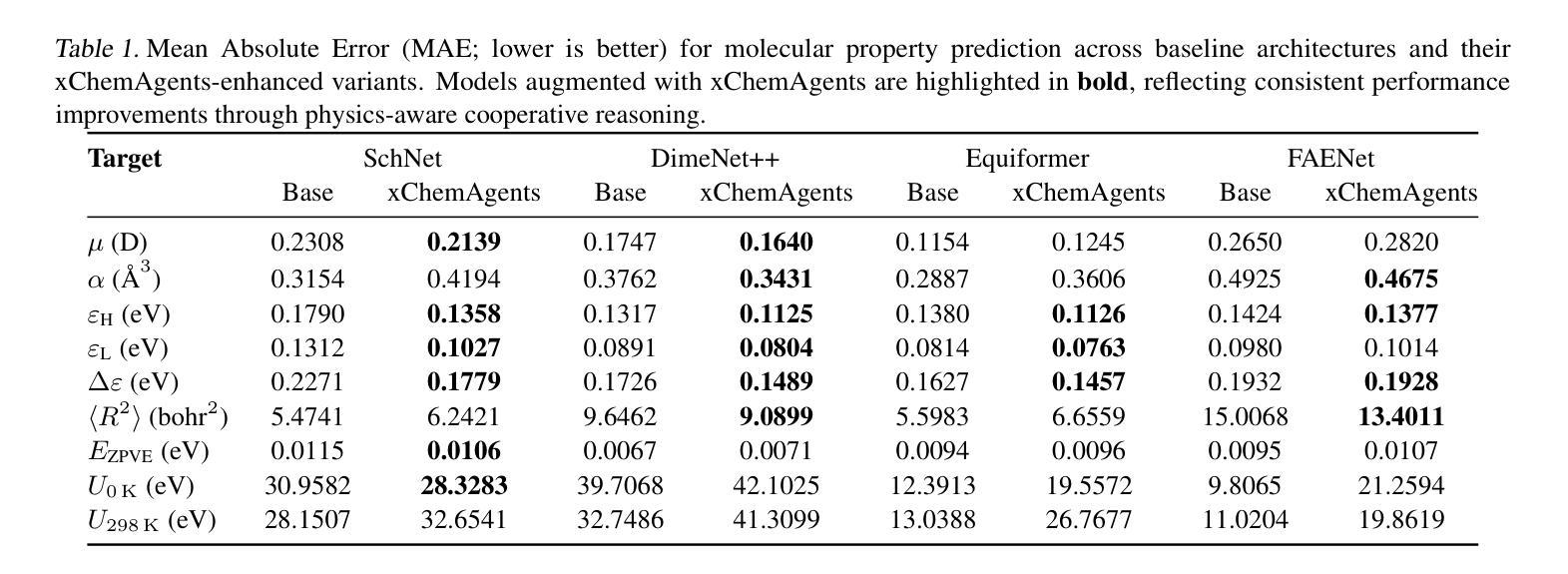
近期在多模态图神经网络方面的进展表明,通过文本化学描述符增强原子XYZ几何结构可以提高一系列电子和热力学属性的预测精度。然而,盲目添加大量异质描述符通常会降低对分子形状或对称性敏感的任务性能,并破坏可解释性。xChemAgents提出了一种协作代理框架,该框架将物理感知推理注入多模态属性预测中。xChemAgents包含两个基于语言模型的代理:Selector,它自适应地识别与每个目标相关的稀疏加权描述符子集,并提供自然语言依据;以及Validator,它通过迭代对话强制执行单位一致性等物理约束和标度定律。在标准基准数据集上,xChemAgents的均方根误差比最新基线技术降低了高达22%,同时产生忠实且人类可解释的解释。实验结果突出了协作、自我验证的代理在基础模型驱动的材料科学中提高准确性和透明度的潜力。相关实现和伴随数据集可在https://github.com/KurbanIntelligenceLab/xChemAgents找到。
论文及项目相关链接
PDF Accepted Paper at ICML 2025 Workshop on MAS
Summary
基于多模态图神经网络的新进展,通过结合原子XYZ几何与文本化学描述符,提高了电子和热力学属性的预测精度。然而,简单添加大量异质描述符会损害对分子形状或对称性敏感的任务性能并降低解释性。xChemAgents提出一种合作代理框架,将物理感知推理注入多模态属性预测中。该框架包含两个基于语言模型的代理:选择器,可自适应识别与目标相关的稀疏加权描述符集,并提供自然语言依据;验证器,通过迭代对话强制执行单位一致性等物理约束。在标准基准测试数据集上,xChemAgents较最新基线技术实现了平均绝对误差最多减少22%,同时产生忠实且易于理解的人类解释。实验结果突显了合作、自我验证的代理在提高基础模型驱动的材料科学准确性和透明度方面的潜力。
Key Takeaways
- 多模态图神经网络结合原子XYZ几何与文本化学描述符,提升了电子和热力学属性的预测精度。
- 简单地添加大量异质描述符可能会影响分子形状或对称性相关的任务性能,并降低模型解释性。
- xChemAgents提出合作代理框架,包含选择器和验证器,分别进行关键描述符的筛选和物理约束的验证。
- 选择器能够自适应识别与目标相关的稀疏加权描述符,并提供自然语言解释。
- 验证器通过迭代对话强制执行物理约束,如单位一致性等。
- 在标准数据集上,xChemAgents较现有技术显著提高了预测准确性,并提供了可解释的解释。
点此查看论文截图

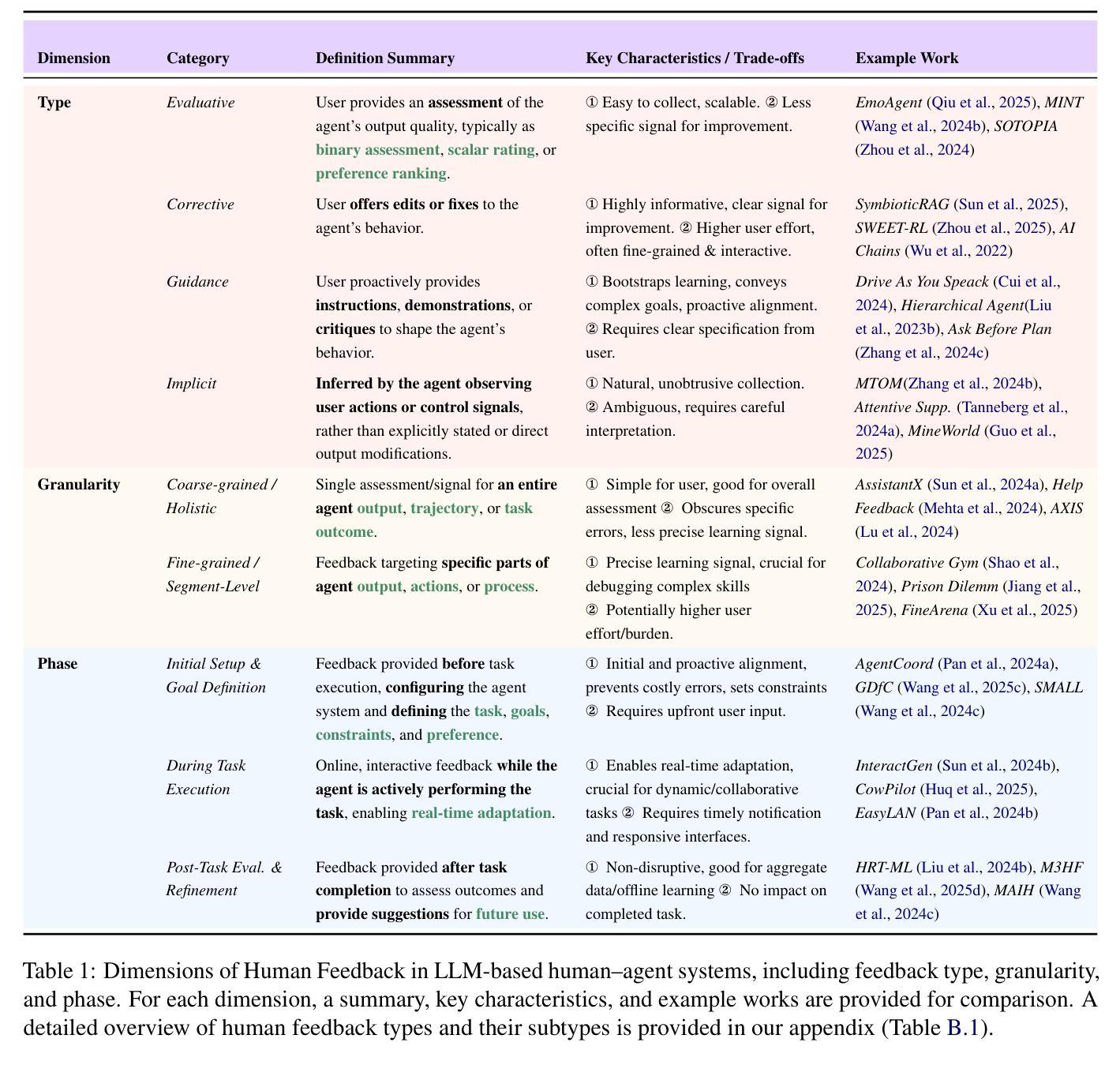
LLM-Based Human-Agent Collaboration and Interaction Systems: A Survey
Authors:Henry Peng Zou, Wei-Chieh Huang, Yaozu Wu, Yankai Chen, Chunyu Miao, Hoang Nguyen, Yue Zhou, Weizhi Zhang, Liancheng Fang, Langzhou He, Yangning Li, Dongyuan Li, Renhe Jiang, Xue Liu, Philip S. Yu
Recent advances in large language models (LLMs) have sparked growing interest in building fully autonomous agents. However, fully autonomous LLM-based agents still face significant challenges, including limited reliability due to hallucinations, difficulty in handling complex tasks, and substantial safety and ethical risks, all of which limit their feasibility and trustworthiness in real-world applications. To overcome these limitations, LLM-based human-agent systems (LLM-HAS) incorporate human-provided information, feedback, or control into the agent system to enhance system performance, reliability and safety. These human-agent collaboration systems enable humans and LLM-based agents to collaborate effectively by leveraging their complementary strengths. This paper provides the first comprehensive and structured survey of LLM-HAS. It clarifies fundamental concepts, systematically presents core components shaping these systems, including environment & profiling, human feedback, interaction types, orchestration and communication, explores emerging applications, and discusses unique challenges and opportunities arising from human-AI collaboration. By consolidating current knowledge and offering a structured overview, we aim to foster further research and innovation in this rapidly evolving interdisciplinary field. Paper lists and resources are available at https://github.com/HenryPengZou/Awesome-Human-Agent-Collaboration-Interaction-Systems.
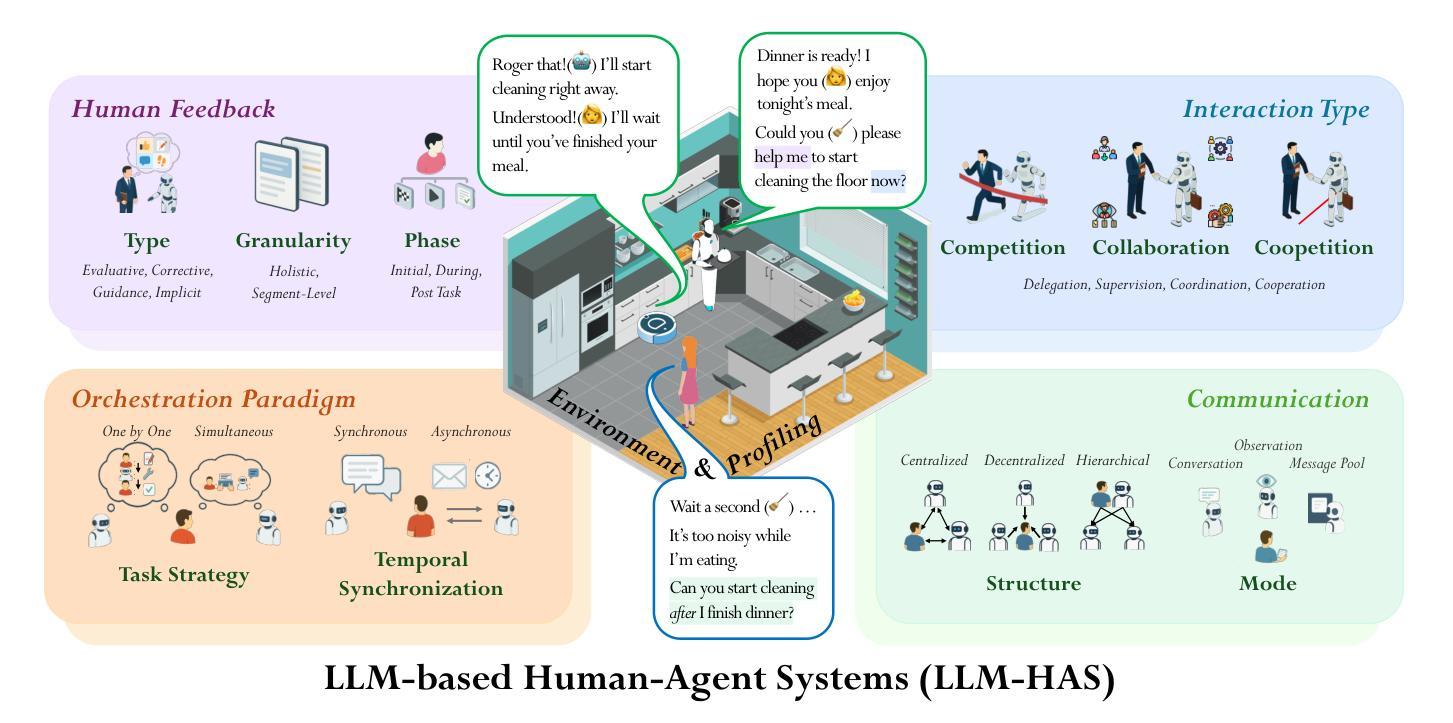
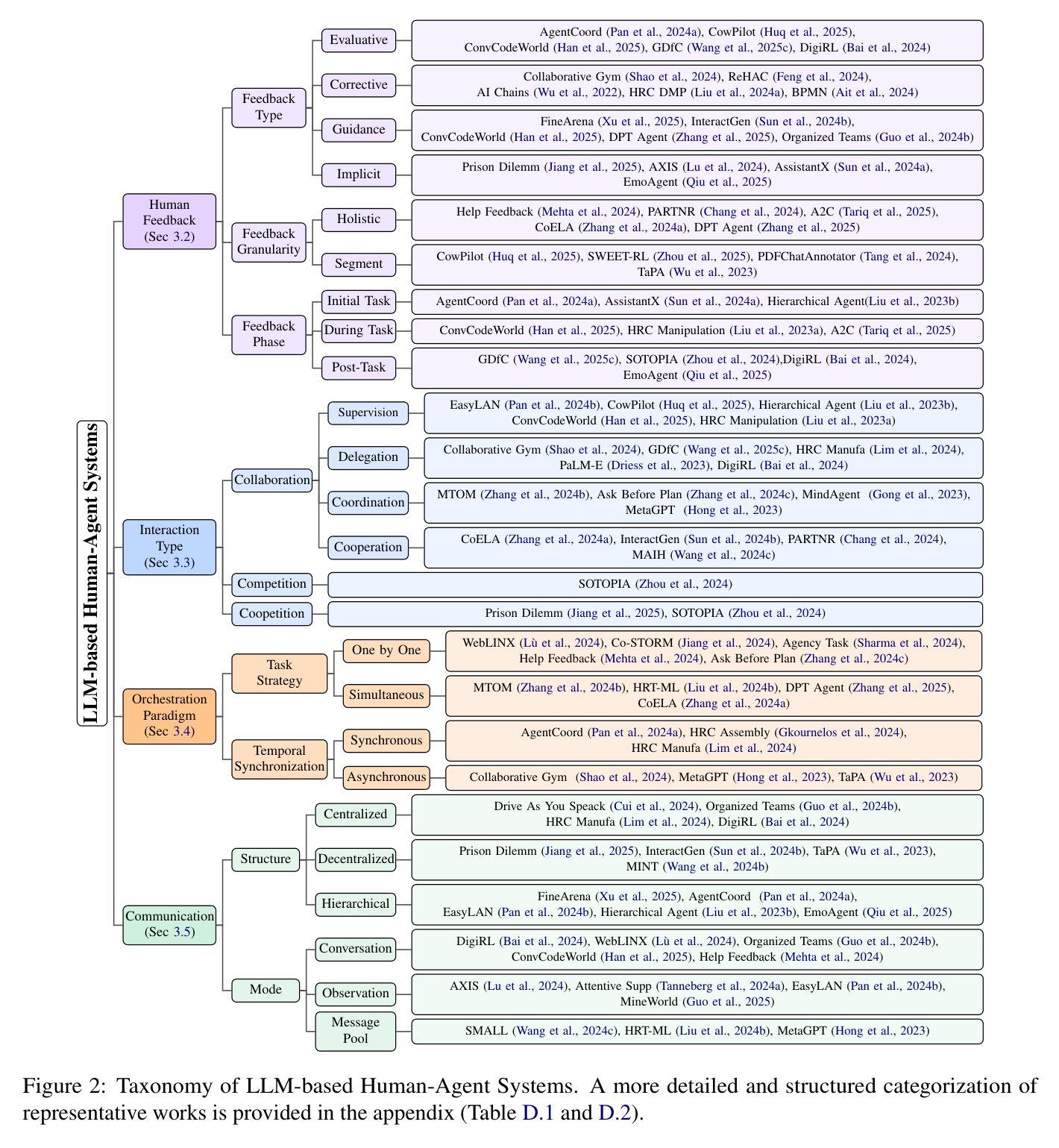
近期大型语言模型(LLM)的进展引发了人们对构建完全自主代理人的浓厚兴趣。然而,基于LLM的完全自主代理人仍然面临重大挑战,包括由于幻觉导致的可靠性有限、处理复杂任务的困难以及实质性的安全和道德风险,这些都限制了它们在现实世界应用中的可行性和可信度。为了克服这些局限性,LLM基于的人机代理系统(LLM-HAS)将人类提供的资讯、反馈或控制融入代理系统,以提升系统的性能、可靠性和安全性。这些人机协作系统利用人和基于LLM的代理人的互补优势,使他们能够进行有效的协作。本文对LLM-HAS进行了首次全面和系统的调查。它明确了基本概念,系统地呈现了构成这些系统的核心组件,包括环境分析、人类反馈、交互类型、编排和沟通等,探讨了新兴应用,并讨论了由人机协作产生的独特挑战和机遇。通过整合当前知识并提供结构化概述,我们的目标是促进这一迅速发展的跨学科领域的进一步研究和创新。论文列表和资源可通过https://github.com/HenryPengZou/Awesome-Human-Agent-Collaboration-Interaction-Systems获取。
论文及项目相关链接
PDF Paper lists and resources are available at https://github.com/HenryPengZou/Awesome-Human-Agent-Collaboration-Interaction-Systems
Summary
大型语言模型(LLM)驱动的自主智能代理日益受到关注,但仍面临可靠性、处理复杂任务能力、安全和伦理风险等方面的挑战。为解决这些问题,LLM人类代理系统(LLM-HAS)通过结合人类提供的信息、反馈或控制,增强了系统的性能、可靠性和安全性。该系统能利用人类和LLM智能代理的优势进行有效协作。本文是对LLM-HAS的首个全面结构化综述,明确了基本概念,系统地介绍了系统的核心组件,探讨了新兴应用,并讨论了人机协作带来的独特挑战和机遇。整合现有知识并提供结构化概述,以推动该跨学科领域的进一步研究和创新。资源列表可通过链接访问。
Key Takeaways
- LLM驱动的智能代理受到关注,但存在可靠性、任务处理、安全和伦理风险方面的挑战。
- LLM-HAS结合人类信息、反馈和控制提升系统性能、可靠性和安全性。
- LLM-HAS允许人类和LLM智能代理有效协作,利用各自优势。
- 本文是对LLM-HAS的全面结构化综述,涵盖基本概念、核心组件、新兴应用和独特挑战与机遇。
- 资源列表提供进一步研究和参考的链接。
点此查看论文截图

Markets with Heterogeneous Agents: Dynamics and Survival of Bayesian vs. No-Regret Learners
Authors:David Easley, Yoav Kolumbus, Eva Tardos
We analyze the performance of heterogeneous learning agents in asset markets with stochastic payoffs. Our main focus is on comparing Bayesian learners and no-regret learners who compete in markets and identifying the conditions under which each approach is more effective. Surprisingly, we find that low regret is not sufficient for survival: an agent can have regret as low as $O(\log T)$ but still vanish when competing against a Bayesian with a finite prior and any positive prior probability on the correct model. On the other hand, we show that Bayesian learning is fragile, while no-regret learning requires less knowledge of the environment and is therefore more robust. Motivated by the strengths and weaknesses of both approaches, we propose a balanced strategy for utilizing Bayesian updates that improves robustness and adaptability to distribution shifts, providing a step toward a best-of-both-worlds learning approach. The method is general, efficient, and easy to implement. Finally, we formally establish the relationship between the notions of survival and market dominance studied in economics and the framework of regret minimization, thus bridging these theories. More broadly, our work contributes to the understanding of dynamics with heterogeneous types of learning agents and their impact on markets.
我们分析了在收益随机的资产市场中,不同学习主体的表现。我们的主要关注点是对比在市场中竞争的各种贝叶斯学习者和无后悔学习者,并确定在各种条件下哪种方法更有效。令人惊讶的是,我们发现低后悔并不足以生存:一个主体的后悔可以低到O(logT),但在与带有有限先验和对正确模型的任何正先验概率的贝叶斯进行竞争时,仍然会消失。另一方面,我们证明了贝叶斯学习是脆弱的,而无后悔学习对环境知识的要求较少,因此更具稳健性。基于这两种方法的优缺点,我们提出了一种利用贝叶斯更新的平衡策略,该策略提高了稳健性和适应分布变化的能力,朝着最佳学习途径迈出了重要一步。该方法具有通用性、高效性和易于实现的特点。最后,我们正式建立了经济学中研究的生存与市场支配力与后悔最小化框架之间的关系,从而弥合了这些理论。更广泛地说,我们的工作有助于理解具有不同学习类型的主体市场动态及其对市场的影响。
论文及项目相关链接
PDF Learning in Markets, Heterogeneous Agents, Regret and Survival, Bayesian Learning, No-Regret Learning, Portfolio Optimization, Kelly Rule, Distribution Shifts, Robust Bayesian Updates
Summary
在资产市场中分析异质学习主体的表现,并比较贝叶斯学习者和无后悔学习者在竞争市场中的表现,以及在何种条件下哪种方法更有效。研究发现低后悔并不足以保证生存,而贝叶斯学习虽然脆弱但具有适应性强的优点。因此,提出一种平衡策略来利用贝叶斯更新以提高稳健性和适应分布变化的能力。该研究为经济学中生存与市场支配力的理论和学习理论中的后悔最小化框架建立了联系。总之,本研究对理解异质学习主体的市场动态及其对市场的冲击有所贡献。
Key Takeaways
- 分析异质学习主体在资产市场中的表现,特别是贝叶斯学习者和无后悔学习者的对比。
- 低后悔不能保证生存:即使后悔很小,一个学习主体在竞争市场中也可能会消失。
- 贝叶斯学习虽然能够提供适应性强的优点,但同时也是脆弱的。
- 无后悔学习对环境的需求知识较少,因此更为稳健。
- 提出一种平衡策略,结合贝叶斯更新来提高稳健性和适应分布变化的能力。
- 正式建立了经济学中的生存与市场支配力和学习理论中的后悔最小化框架之间的关系。
点此查看论文截图

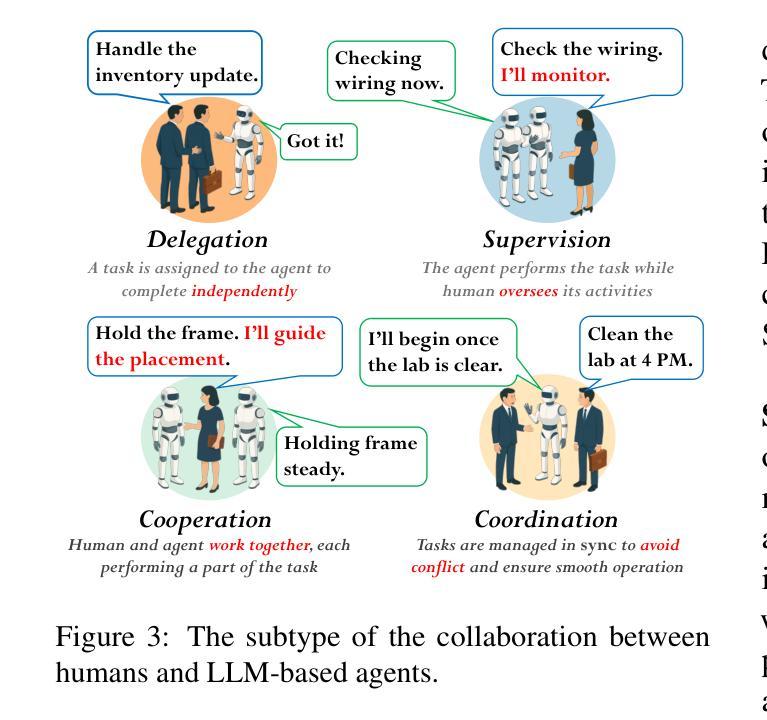
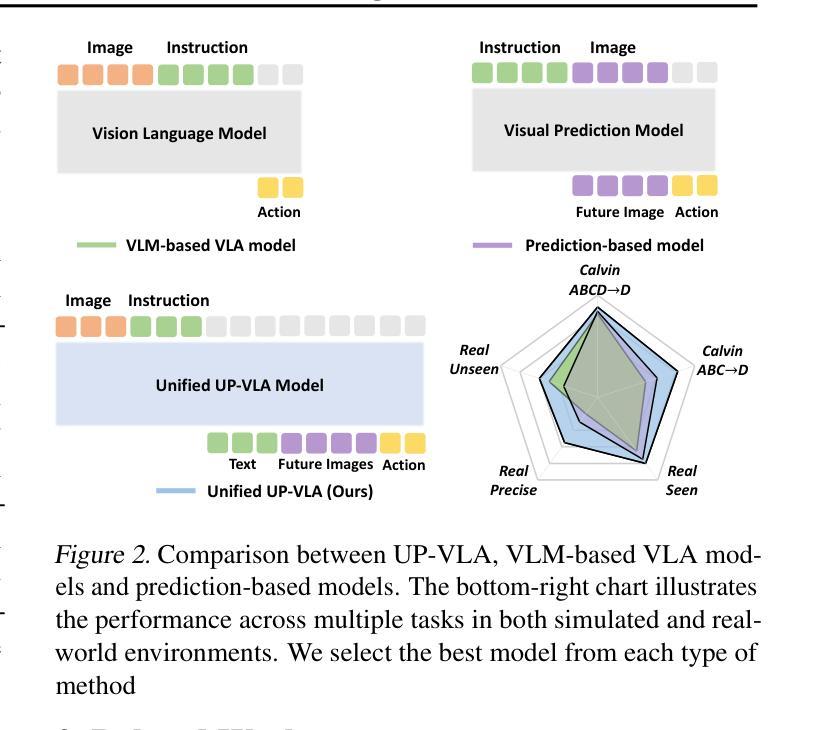
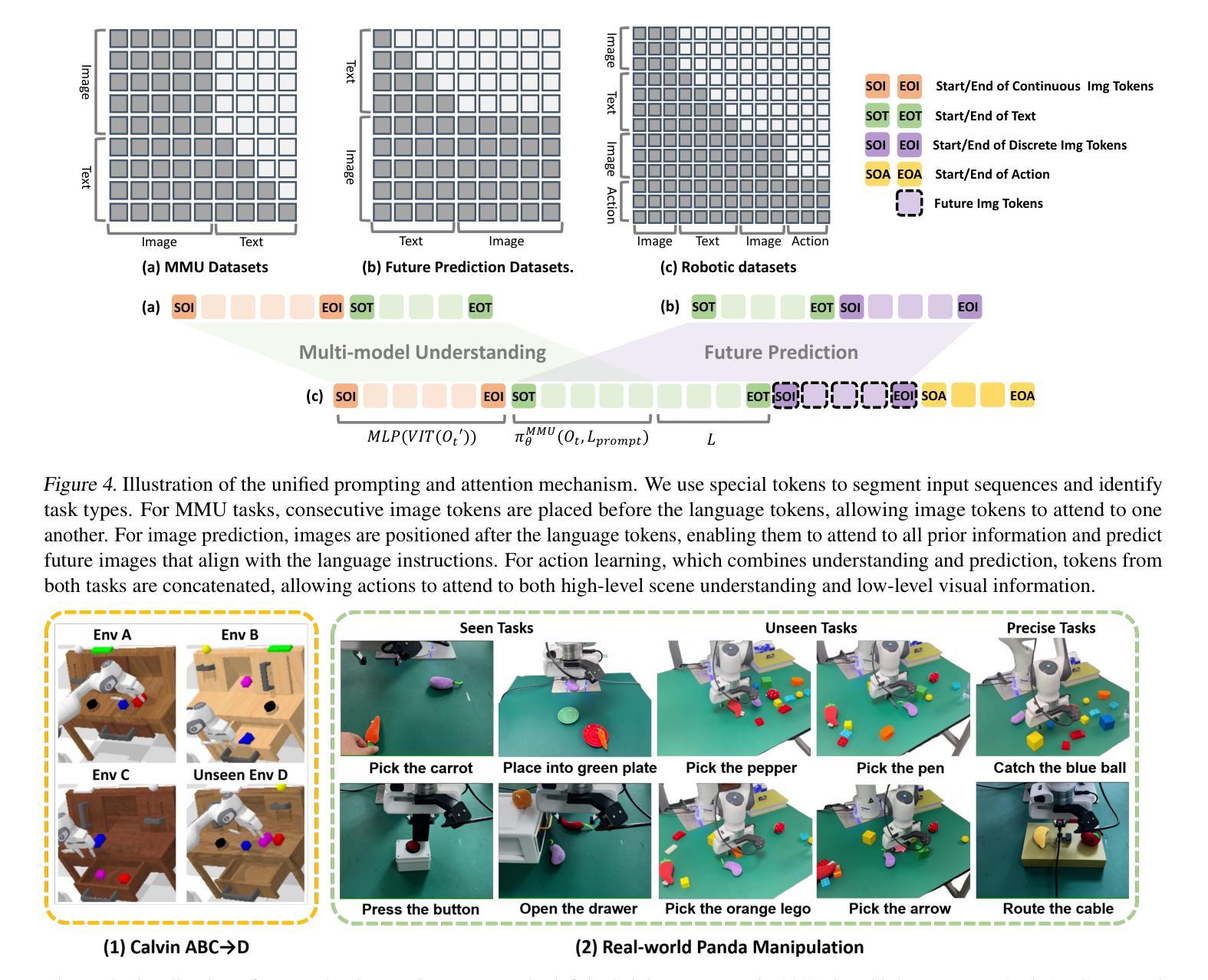
UP-VLA: A Unified Understanding and Prediction Model for Embodied Agent
Authors:Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, Jianyu Chen
Recent advancements in Vision-Language-Action (VLA) models have leveraged pre-trained Vision-Language Models (VLMs) to improve the generalization capabilities. VLMs, typically pre-trained on vision-language understanding tasks, provide rich semantic knowledge and reasoning abilities. However, prior research has shown that VLMs often focus on high-level semantic content and neglect low-level features, limiting their ability to capture detailed spatial information and understand physical dynamics. These aspects, which are crucial for embodied control tasks, remain underexplored in existing pre-training paradigms. In this paper, we investigate the training paradigm for VLAs, and introduce \textbf{UP-VLA}, a \textbf{U}nified VLA model training with both multi-modal \textbf{U}nderstanding and future \textbf{P}rediction objectives, enhancing both high-level semantic comprehension and low-level spatial understanding. Experimental results show that UP-VLA achieves a 33% improvement on the Calvin ABC-D benchmark compared to the previous state-of-the-art method. Additionally, UP-VLA demonstrates improved success rates in real-world manipulation tasks, particularly those requiring precise spatial information.
近期Vision-Language-Action(VLA)模型的进步得益于预训练的Vision-Language Models(VLMs)提高了其泛化能力。VLMs通常在视觉语言理解任务上进行预训练,提供了丰富的语义知识和推理能力。然而,先前的研究表明,VLMs往往关注高级语义内容,而忽视低级特征,这限制了它们捕捉详细空间信息以及理解物理动态的能力。这些方面对于实体控制任务至关重要,而在现有的预训练范式中仍然探索不足。在本文中,我们研究了VLA的训练范式,并引入了UP-VLA,这是一种统一的VLA模型训练,具有多模态理解以及未来预测目标,增强了高级语义理解和低级空间理解。实验结果表明,与先前最先进的方法相比,UP-VLA在Calvin ABC-D基准测试上实现了33%的改进。此外,UP-VLA在现实世界操作任务中表现出更高的成功率,尤其是在需要精确空间信息的任务中。
论文及项目相关链接
PDF Accepted to ICML2025
Summary
本文介绍了Vision-Language-Action(VLA)模型的新进展。为提高模型的泛化能力,利用预训练的Vision-Language Models(VLMs)。然而,现有研究指出VLMs常忽略低层次特征,难以捕捉详细的空间信息并理解物理动态。本文提出一种UP-VLA模型训练范式,结合了多模态理解和未来预测目标,提高高层次语义理解和低层次空间理解。实验结果显示,UP-VLA在Calvin ABC-D基准测试中实现了相较于先前最佳方法33%的提升,并在实际操控任务中表现出更高的成功率,尤其在需要精确空间信息的任务中。
Key Takeaways
- Vision-Language-Action (VLA)模型结合视觉、语言和动作,提高模型的泛化能力。
- 利用预训练的Vision-Language Models(VLMs)进行VLA模型的训练。
- VLMs虽然能提供丰富的语义知识和推理能力,但常忽略低层次特征,难以捕捉详细的空间信息并理解物理动态。
- UP-VLA模型结合了多模态理解和未来预测目标,提高高层次语义理解和低层次空间理解。
- UP-VLA在Calvin ABC-D基准测试中表现优异,实现了相较于先前最佳方法33%的提升。
- UP-VLA在实际操控任务中表现出更高的成功率,尤其在需要精确空间信息的任务中。
点此查看论文截图

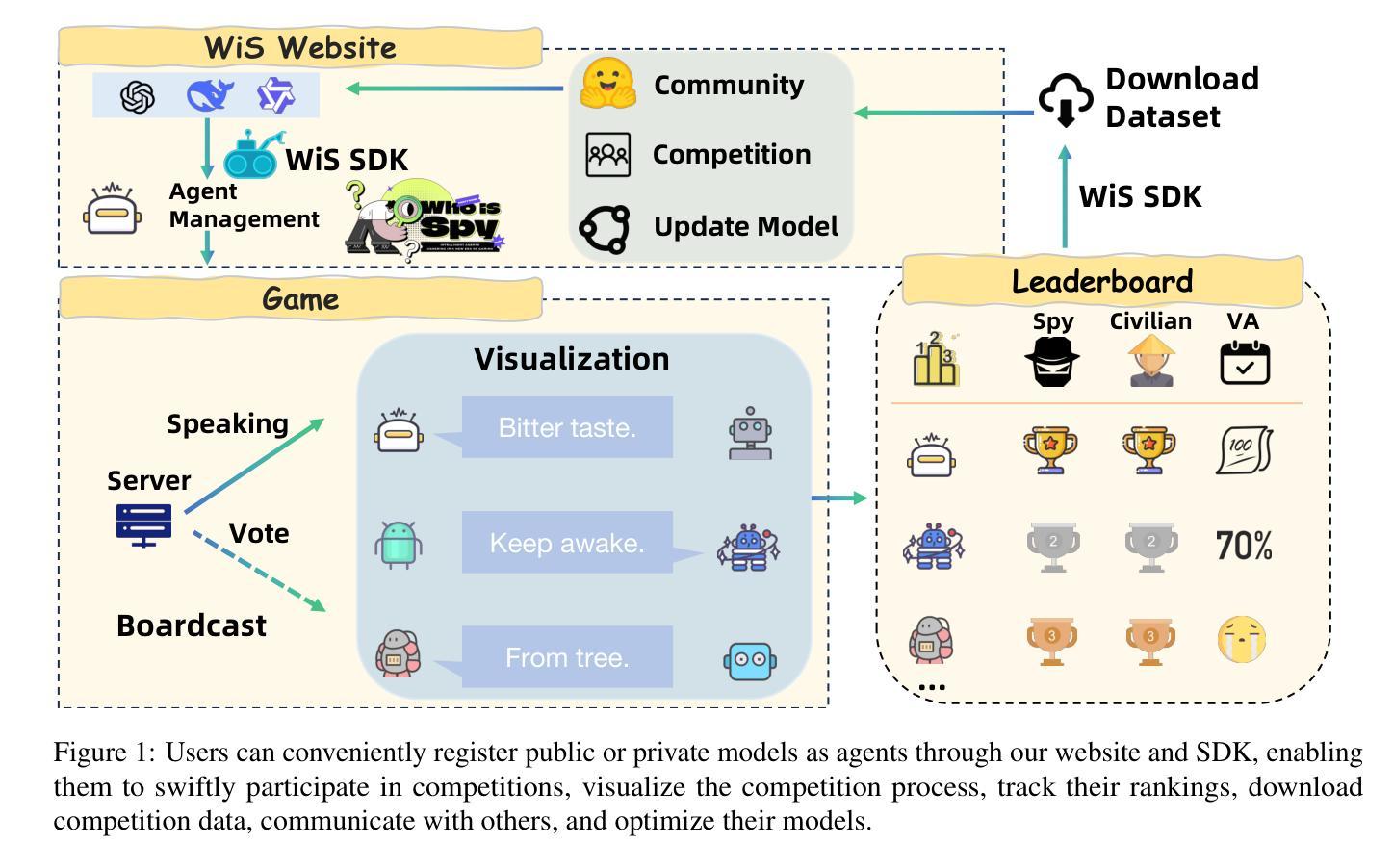
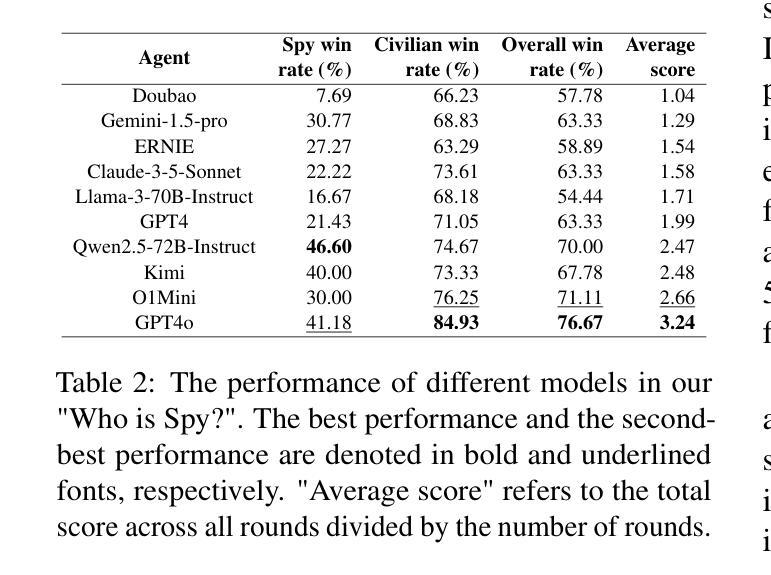
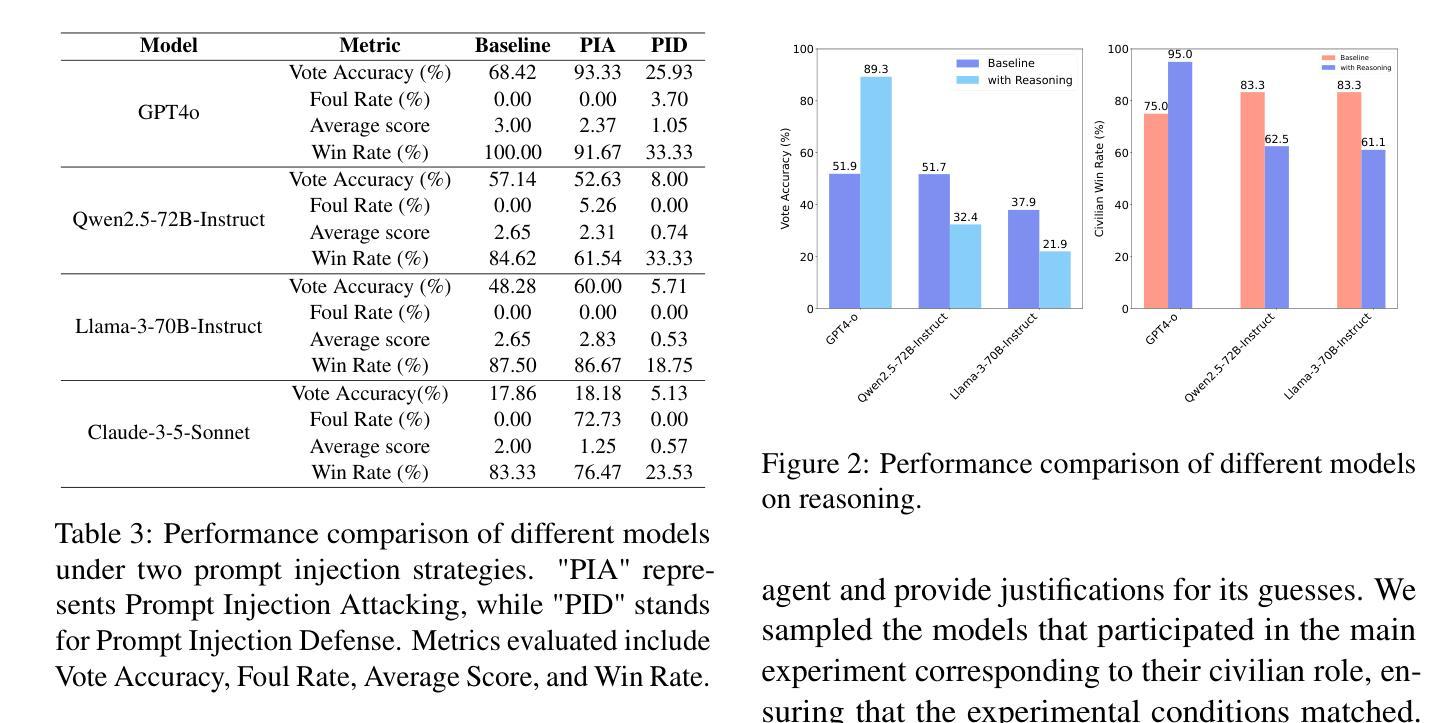
WiS Platform: Enhancing Evaluation of LLM-Based Multi-Agent Systems Through Game-Based Analysis
Authors:Chengwei Hu, Jianhui Zheng, Yancheng He, Hangyu Guo, Junguang Jiang, Han Zhu, Kai Sun, Yuning Jiang, Wenbo Su, Bo Zheng
Recent advancements in autonomous multi-agent systems (MAS) based on large language models (LLMs) have enhanced the application scenarios and improved the capability of LLMs to handle complex tasks. Despite demonstrating effectiveness, existing studies still evidently struggle to evaluate, analysis, and reproducibility of LLM-based MAS. In this paper, to facilitate the research on LLM-based MAS, we introduce an open, scalable, and real-time updated platform for accessing and analyzing the LLM-based MAS based on the games Who is Spy?” (WiS). Our platform is featured with three main worths: (1) a unified model evaluate interface that supports models available on Hugging Face; (2) real-time updated leaderboard for model evaluation; (3) a comprehensive evaluation covering game-winning rates, attacking, defense strategies, and reasoning of LLMs. To rigorously test WiS, we conduct extensive experiments coverage of various open- and closed-source LLMs, we find that different agents exhibit distinct and intriguing behaviors in the game. The experimental results demonstrate the effectiveness and efficiency of our platform in evaluating LLM-based MAS. Our platform and its documentation are publicly available at https://whoisspy.ai/.
近年来,基于大型语言模型(LLM)的自主多智能体系统(MAS)的进展增强了LLM处理复杂任务的应用场景和能力。尽管已经展示了有效性,但现有研究在评估、分析和重现LLM基于的MAS方面仍面临明显挑战。在本文中,为了促进基于LLM的MAS的研究,我们介绍了一个开放、可扩展、实时更新的平台,该平台可用于访问和分析基于“谁是间谍?”(WiS)游戏的LLM基于的MAS。我们的平台有三个主要特点:(1)支持Hugging Face上模型的统一模型评估界面;(2)实时更新的模型评估排行榜;(3)全面评估,包括游戏胜率、攻击、防御策略和LLM的推理。为了对WiS进行严格的测试,我们对各种开源和闭源LLM进行了广泛的实验覆盖,我们发现不同智能体在游戏中表现出独特而有趣的行为。实验结果证明了我们平台在评估LLM基于的MAS方面的有效性和效率。我们的平台和相关文档可在https://whoisspy.ai/公开访问。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的自主多智能体系统(MAS)的最新进展增强了LLM处理复杂任务的能力,并拓宽了其应用场景。为便于LLM-based MAS的研究,本文引入了一个开放、可扩展、实时更新的平台,该平台基于“谁是间谍?”(WiS)游戏,具备统一模型评估接口、实时更新排行榜以及对游戏获胜率、攻击、防御策略和LLM推理的全面评估。实验证明,不同智能体在游戏中表现出独特且有趣的行为,验证了平台评估LLM-based MAS的有效性和效率。平台和文档可在https://whoisspy.ai/公开访问。
Key Takeaways
- 大型语言模型(LLM)和多智能体系统(MAS)的结合增强了处理复杂任务的能力,并拓宽了应用场景。
- 引入了一个基于“谁是间谍?”游戏的开放、可扩展、实时更新的平台,用于访问和分析LLM-based MAS。
- 平台具备统一模型评估接口,支持Hugging Face上的模型。
- 平台提供实时更新的排行榜,用于模型评估。
- 平台全面评估游戏获胜率、攻击和防御策略,以及LLMs的推理能力。
- 不同智能体在“谁是间谍?”游戏中表现出独特且有趣的行为。
点此查看论文截图


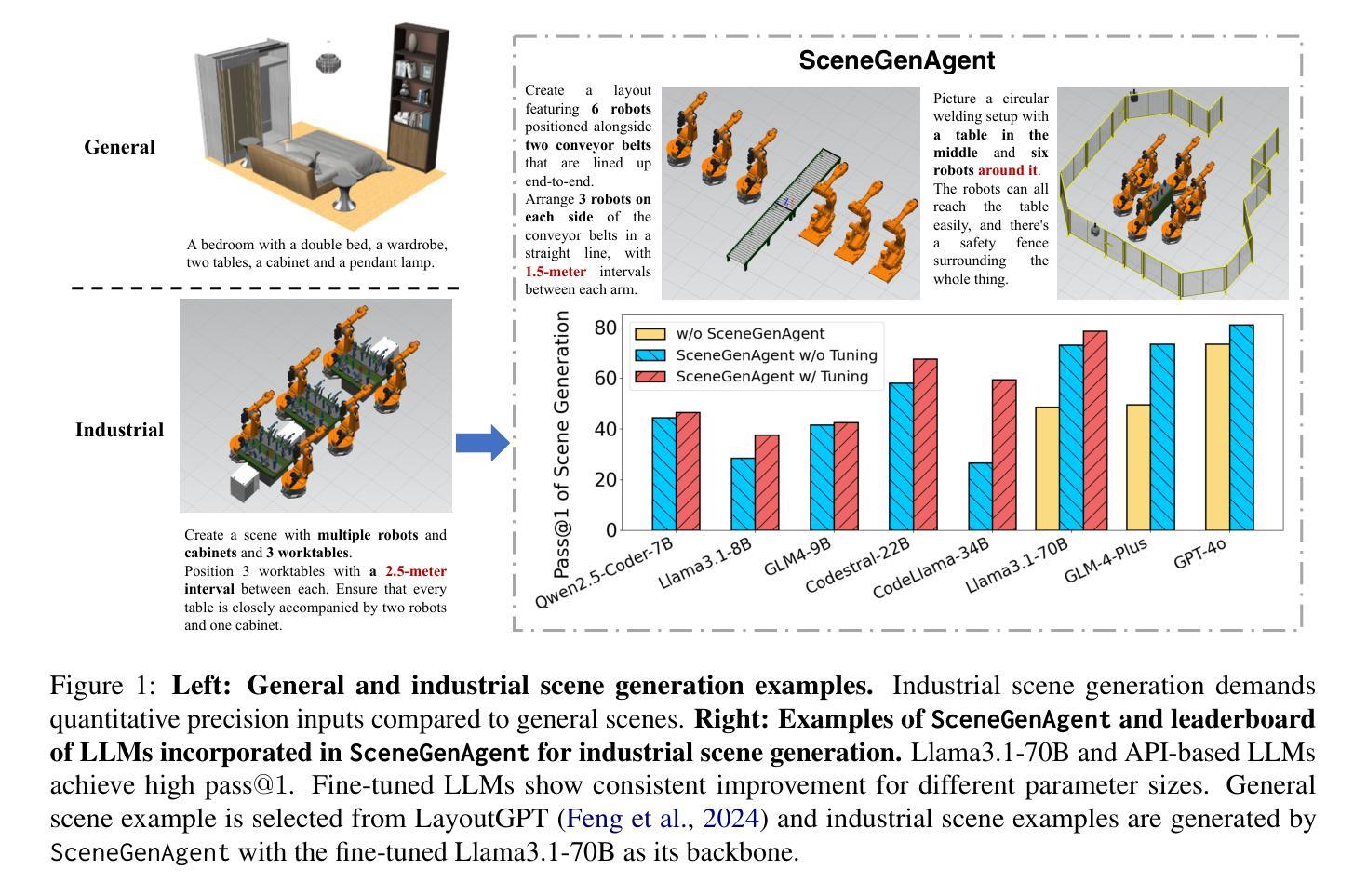
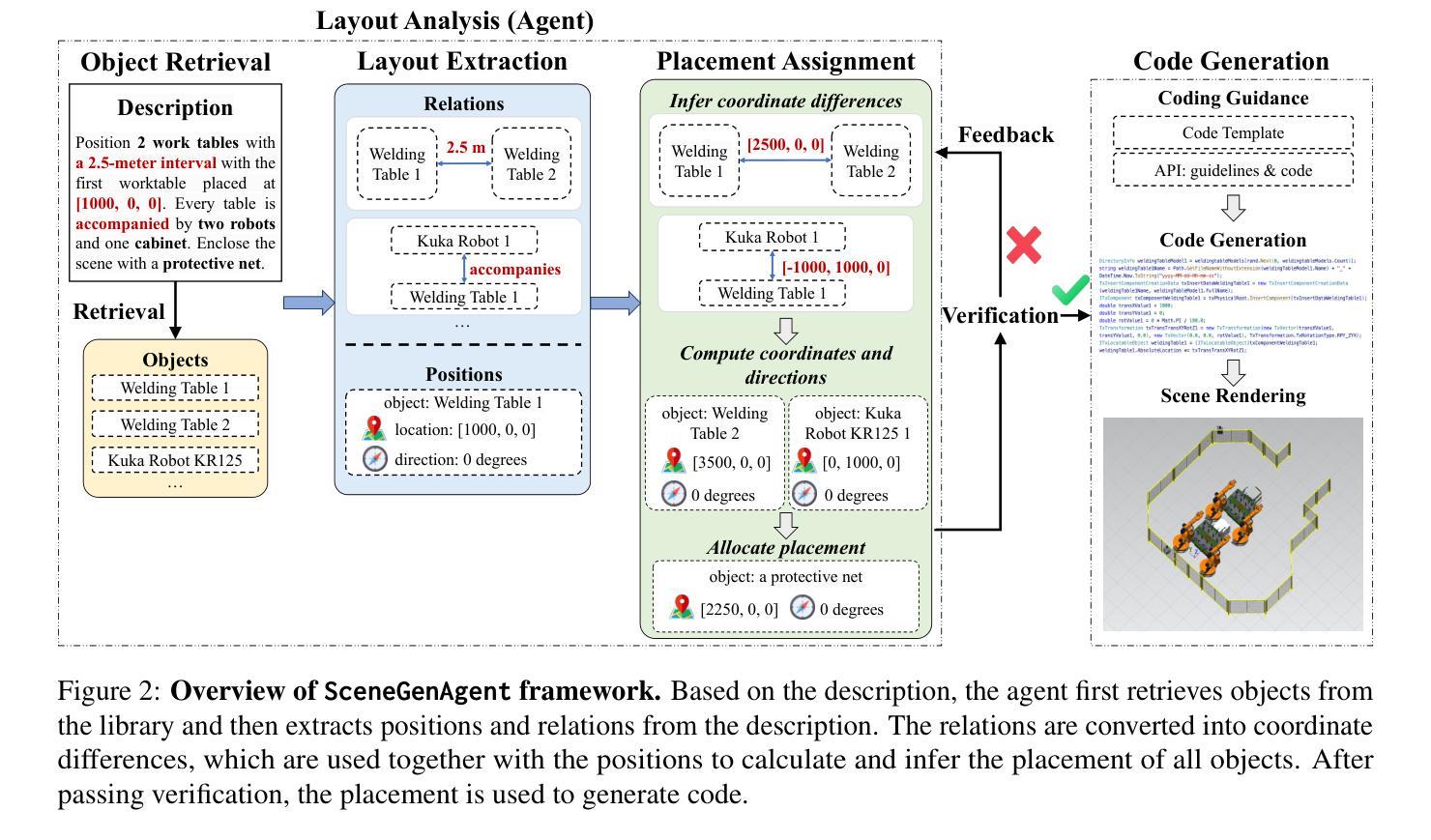
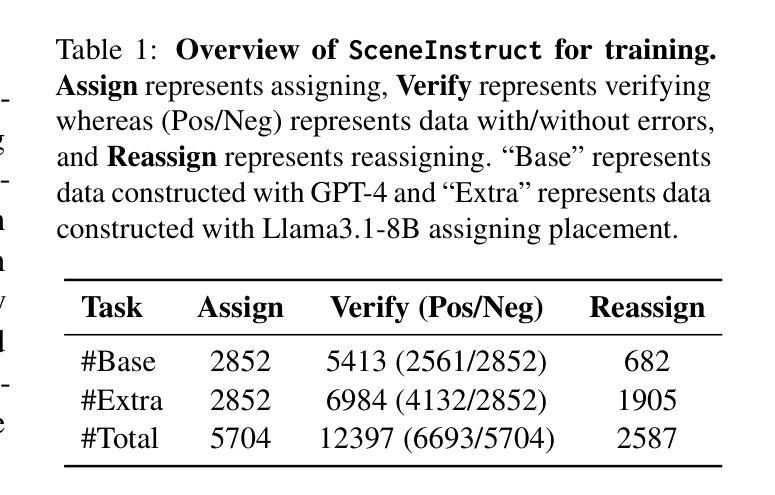
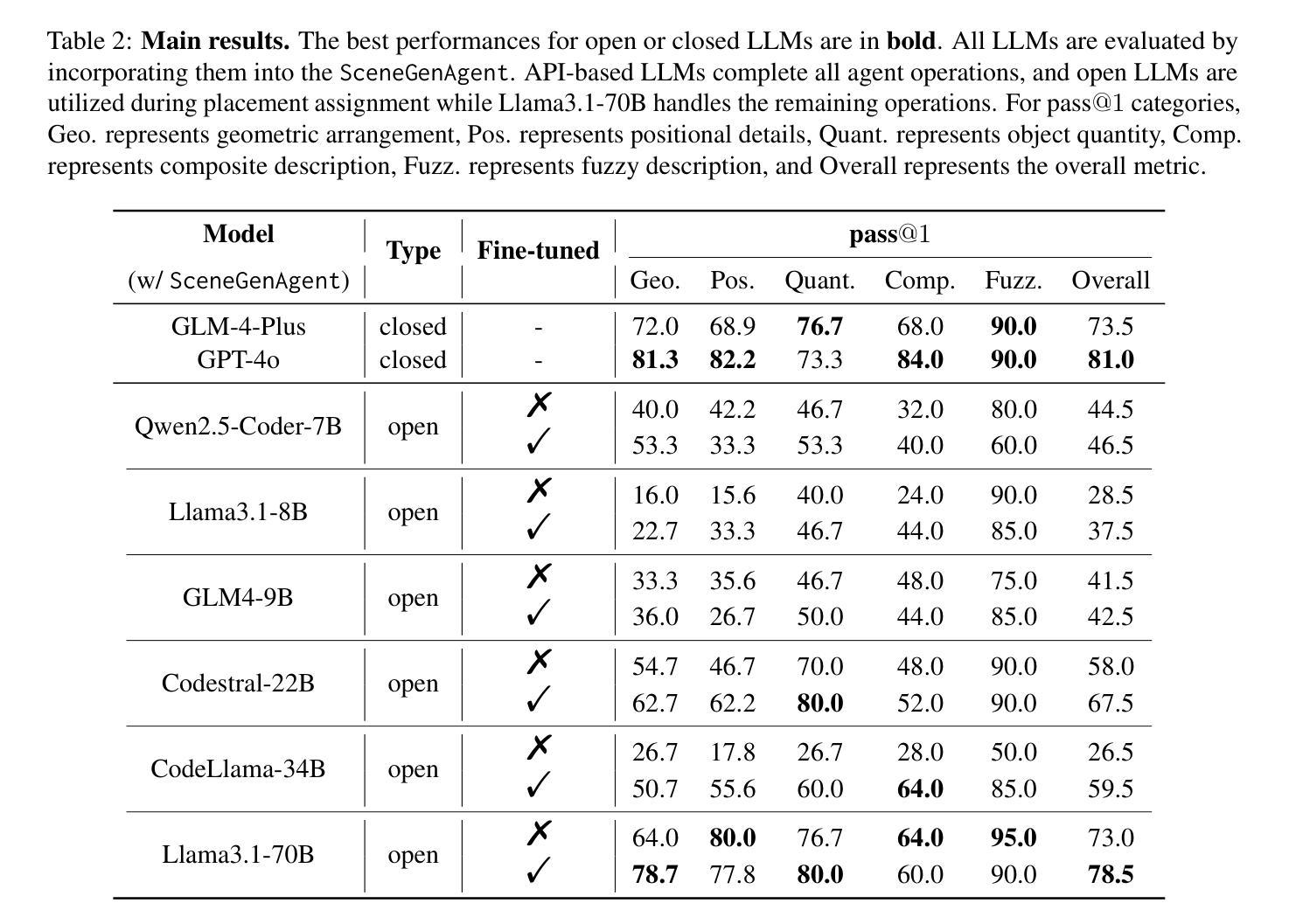
SceneGenAgent: Precise Industrial Scene Generation with Coding Agent
Authors:Xiao Xia, Dan Zhang, Zibo Liao, Zhenyu Hou, Tianrui Sun, Jing Li, Ling Fu, Yuxiao Dong
The modeling of industrial scenes is essential for simulations in industrial manufacturing. While large language models (LLMs) have shown significant progress in generating general 3D scenes from textual descriptions, generating industrial scenes with LLMs poses a unique challenge due to their demand for precise measurements and positioning, requiring complex planning over spatial arrangement. To address this challenge, we introduce SceneGenAgent, an LLM-based agent for generating industrial scenes through C# code. SceneGenAgent ensures precise layout planning through a structured and calculable format, layout verification, and iterative refinement to meet the quantitative requirements of industrial scenarios. Experiment results demonstrate that LLMs powered by SceneGenAgent exceed their original performance, reaching up to 81.0% success rate in real-world industrial scene generation tasks and effectively meeting most scene generation requirements. To further enhance accessibility, we construct SceneInstruct, a dataset designed for fine-tuning open-source LLMs to integrate into SceneGenAgent. Experiments show that fine-tuning open-source LLMs on SceneInstruct yields significant performance improvements, with Llama3.1-70B approaching the capabilities of GPT-4o. Our code and data are available at https://github.com/THUDM/SceneGenAgent .
工业场景的建模对于工业制造中的模拟至关重要。虽然大型语言模型(LLM)在根据文本描述生成一般的3D场景方面取得了显著进展,但使用LLM生成工业场景却带来独特的挑战,因为它们需要精确的测量和定位,并要求对空间布局进行复杂规划。为了应对这一挑战,我们推出了SceneGenAgent,这是一个基于LLM的通过C#代码生成工业场景的代理。SceneGenAgent通过结构化和可计算格式、布局验证以及迭代优化,确保精确布局规划,以满足工业场景的定量要求。实验结果表明,由SceneGenAgent驱动的大型语言模型超出了其原始性能,在现实世界中的工业场景生成任务中成功率高达81.0%,并有效地满足了大多数场景生成要求。为了进一步提高可及性,我们构建了SceneInstruct数据集,用于微调开源的大型语言模型,以集成到SceneGenAgent中。实验表明,在SceneInstruct上微调开源的大型语言模型会显著提高性能,Llama3.1-70B接近GPT-4o的能力。我们的代码和数据集可在https://github.com/THUDM/SceneGenAgent找到。
论文及项目相关链接
PDF Accepted to ACL 2025
Summary
工业场景建模对于工业制造中的模拟至关重要。尽管大型语言模型(LLMs)在根据文本描述生成一般3D场景方面取得了显著进展,但使用LLMs生成工业场景却是一个独特的挑战,因为工业场景需要精确的测量和定位,需要复杂的空间布局规划。为解决这一挑战,我们推出了SceneGenAgent,这是一个基于LLM的代理,可通过C#代码生成工业场景。SceneGenAgent通过结构化、可计算格式、布局验证和迭代优化确保精确布局规划,以满足工业场景的定量要求。实验结果表明,SceneGenAgent支持的LLM成功率达到了81.0%,能有效满足工业场景生成的需求。为进一步提高可访问性,我们构建了SceneInstruct数据集,用于微调开源LLM以集成到SceneGenAgent中。实验显示,在SceneInstruct上微调开源LLM能显著提高性能,Llama3.1-70B甚至接近GPT-4o的能力。
Key Takeaways
- 工业场景建模对模拟至关重要,需要精确测量和定位以及复杂的空间布局规划。
- LLMs在生成工业场景时面临挑战,但SceneGenAgent提供了一个解决方案,通过C#代码生成精确布局规划。
- SceneGenAgent确保精确布局规划通过结构化、可计算格式、布局验证和迭代优化。
- SceneGenAgent支持的LLM在真实工业场景生成任务中的成功率达到了81.0%。
- SceneInstruct数据集用于微调开源LLM以提高性能并集成到SceneGenAgent中。
- 在SceneInstruct数据集上微调的LLM性能显著提高。
点此查看论文截图

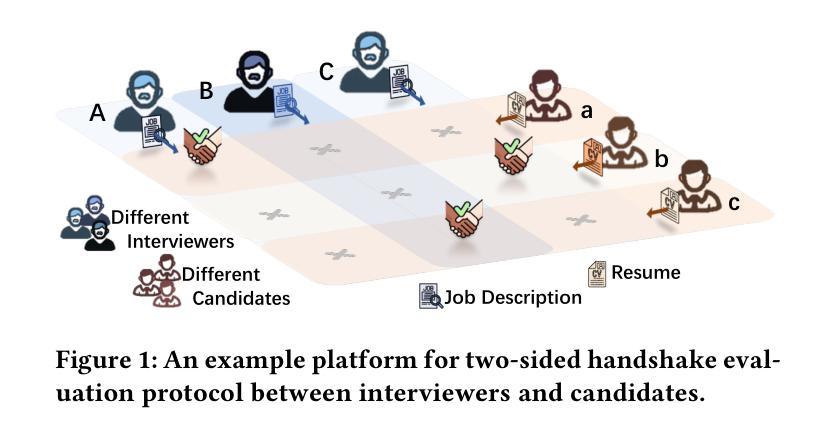
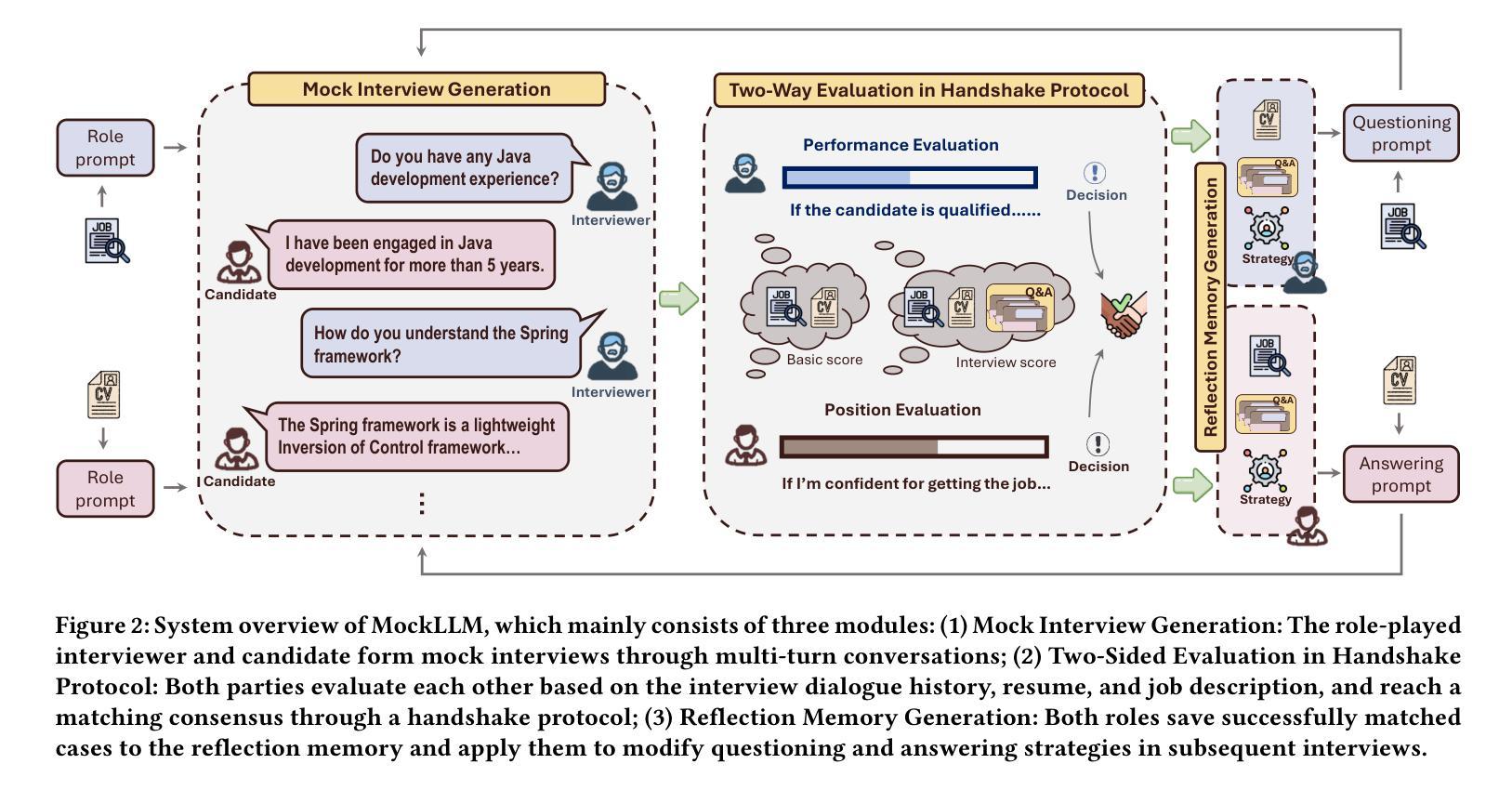
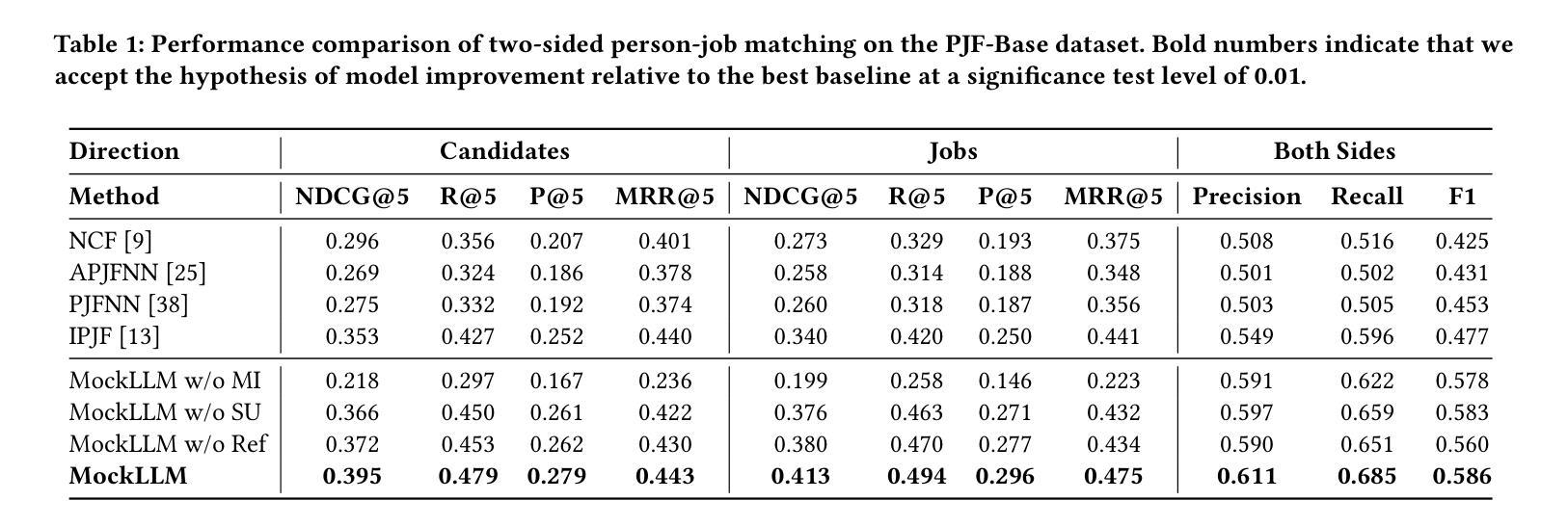
MockLLM: A Multi-Agent Behavior Collaboration Framework for Online Job Seeking and Recruiting
Authors:Hongda Sun, Hongzhan Lin, Haiyu Yan, Yang Song, Xin Gao, Rui Yan
Online recruitment platforms have reshaped job-seeking and recruiting processes, driving increased demand for applications that enhance person-job matching. Traditional methods generally rely on analyzing textual data from resumes and job descriptions, limiting the dynamic, interactive aspects crucial to effective recruitment. Recent advances in Large Language Models (LLMs) have revealed remarkable potential in simulating adaptive, role-based dialogues, making them well-suited for recruitment scenarios. In this paper, we propose \textbf{MockLLM}, a novel framework to generate and evaluate mock interview interactions. The system consists of two key components: mock interview generation and two-sided evaluation in handshake protocol. By simulating both interviewer and candidate roles, MockLLM enables consistent and collaborative interactions for real-time and two-sided matching. To further improve the matching quality, MockLLM further incorporates reflection memory generation and dynamic strategy modification, refining behaviors based on previous experience. We evaluate MockLLM on real-world data Boss Zhipin, a major Chinese recruitment platform. The experimental results indicate that MockLLM outperforms existing methods in matching accuracy, scalability, and adaptability across job domains, highlighting its potential to advance candidate assessment and online recruitment.
在线招聘平台已经改变了求职和招聘流程,这引发了对应用程序的更大需求,这些应用程序能够提升人与工作的匹配度。传统方法通常依赖于分析简历和职位描述中的文本数据,而忽略了招聘中至关重要的动态交互方面。大型语言模型(LLM)的最新进展在模拟基于角色的对话中显示出显著潜力,使其非常适合招聘场景。在本文中,我们提出了名为MockLLM的新型框架,用于生成和评估模拟面试交互。该系统由两个关键组件组成:模拟面试生成和握手协议中的双向评估。通过模拟面试官和候选人的角色,MockLLM实现了实时双向匹配的持续协作交互。为了进一步提高匹配质量,MockLLM还结合了反思记忆生成和动态策略修改,根据以往经验优化行为。我们在真实的招聘平台Boss Zhipin上对MockLLM进行了评估。实验结果表明,在匹配准确性、可扩展性和跨职业领域的适应性方面,MockLLM优于现有方法,突显其在候选人评估和在线招聘方面的潜力。
论文及项目相关链接
PDF Accepted by KDD 2025 Research Track
总结
招聘平台的数字化转型促进了人职匹配技术的进步。传统方法主要依赖简历和职位描述的文本数据分析,忽视了招聘过程中的动态互动环节。最近的大型语言模型(LLM)技术可以模拟基于角色的对话,非常适合招聘场景。本文提出一种名为MockLLM的新框架,用于生成和评估模拟面试互动,包括模拟面试和握手协议双向评估两个关键组件。MockLLM通过模拟面试官和候选人角色,实现实时双向匹配和协作互动。此外,MockLLM还融入反思记忆生成和动态策略调整,基于以往经验优化行为。在真实数据Boss Zhipin上的实验结果表明,MockLLM在匹配精度、可扩展性和跨职位领域的适应性方面优于现有方法,具有推动候选人评估和在线招聘的潜力。
关键见解
- 在线招聘平台正在推动人职匹配技术的进步。
- 传统招聘方法主要依赖静态文本数据分析,缺乏动态互动。
- 大型语言模型(LLM)技术可以模拟角色对话,适用于招聘场景。
- MockLLM框架用于生成和评估模拟面试互动,包含模拟面试和双向评估。
- MockLLM实现实时双向匹配和协作互动,模拟面试官和候选人角色。
- MockLLM基于以往经验优化行为,提高匹配质量。
点此查看论文截图