⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-28 更新
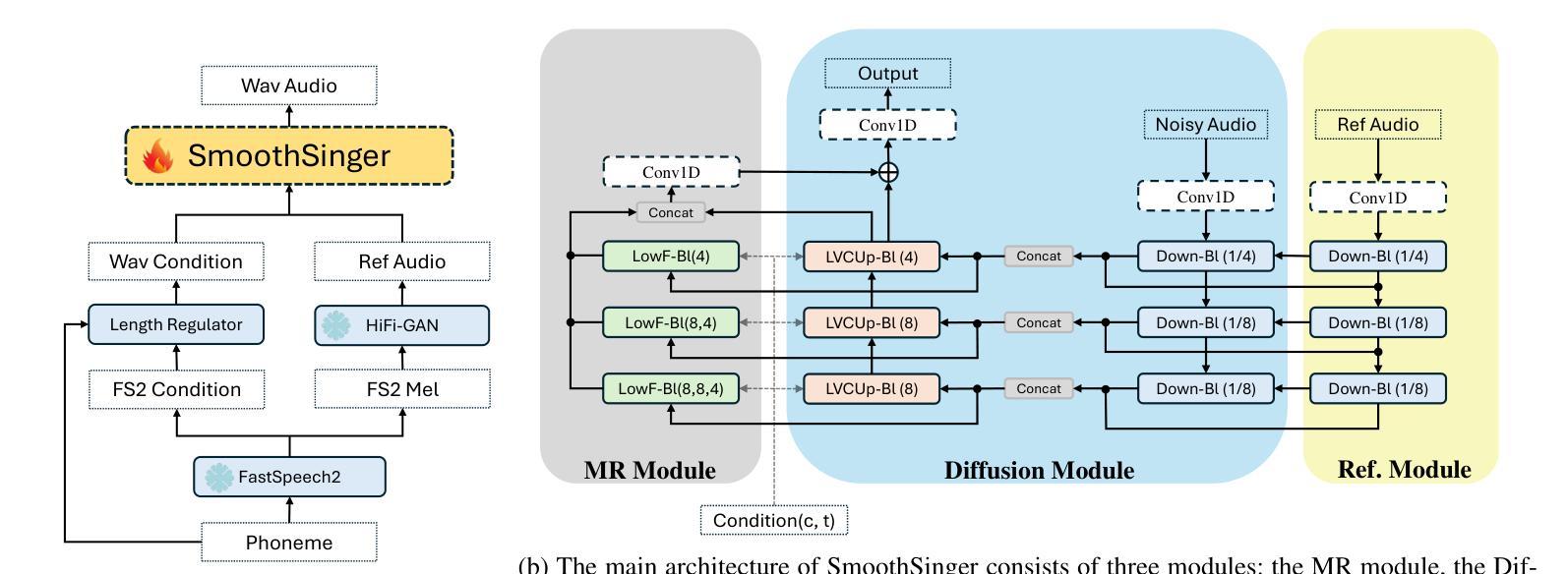
SmoothSinger: A Conditional Diffusion Model for Singing Voice Synthesis with Multi-Resolution Architecture
Authors:Kehan Sui, Jinxu Xiang, Fang Jin
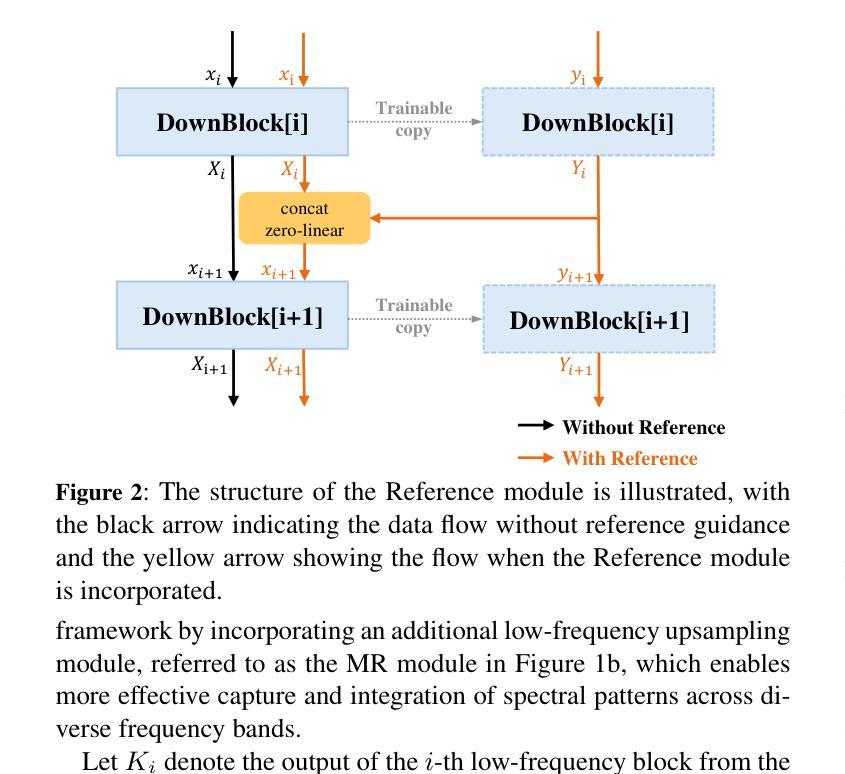
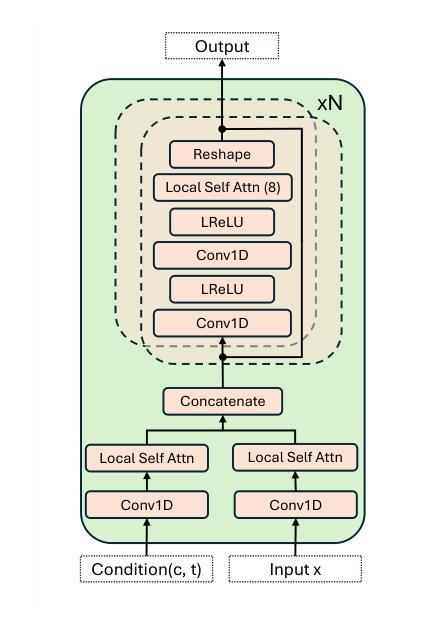
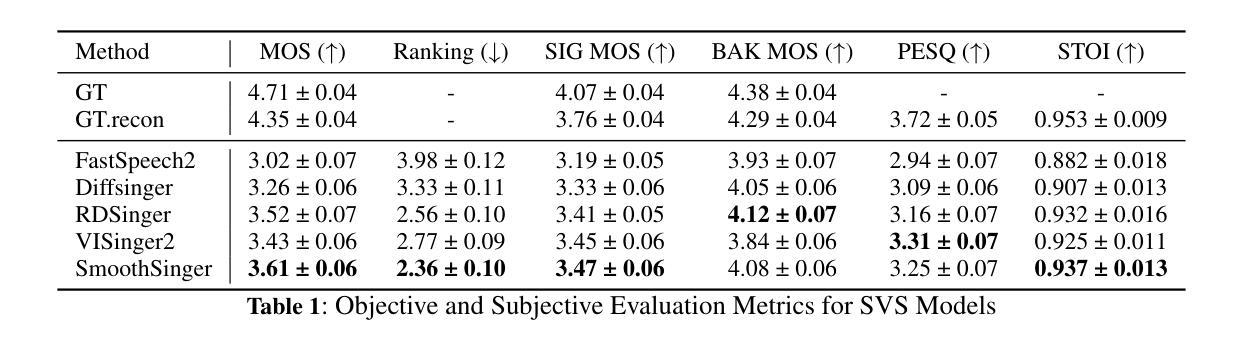
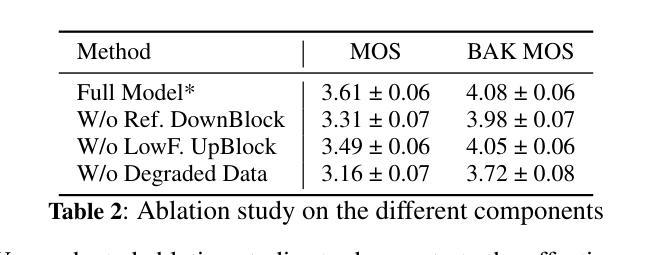
Singing voice synthesis (SVS) aims to generate expressive and high-quality vocals from musical scores, requiring precise modeling of pitch, duration, and articulation. While diffusion-based models have achieved remarkable success in image and video generation, their application to SVS remains challenging due to the complex acoustic and musical characteristics of singing, often resulting in artifacts that degrade naturalness. In this work, we propose SmoothSinger, a conditional diffusion model designed to synthesize high quality and natural singing voices. Unlike prior methods that depend on vocoders as a final stage and often introduce distortion, SmoothSinger refines low-quality synthesized audio directly in a unified framework, mitigating the degradation associated with two-stage pipelines. The model adopts a reference-guided dual-branch architecture, using low-quality audio from any baseline system as a reference to guide the denoising process, enabling more expressive and context-aware synthesis. Furthermore, it enhances the conventional U-Net with a parallel low-frequency upsampling path, allowing the model to better capture pitch contours and long term spectral dependencies. To improve alignment during training, we replace reference audio with degraded ground truth audio, addressing temporal mismatch between reference and target signals. Experiments on the Opencpop dataset, a large-scale Chinese singing corpus, demonstrate that SmoothSinger achieves state-of-the-art results in both objective and subjective evaluations. Extensive ablation studies confirm its effectiveness in reducing artifacts and improving the naturalness of synthesized voices.
唱歌声音合成(SVS)旨在从乐谱生成表达丰富、高质量的歌声,需要精确地对音调、时长和发音进行建模。虽然基于扩散模型的方法在图像和视频生成方面取得了显著的成功,但其在SVS中的应用仍然具有挑战性,这是由于歌唱的复杂声学和音乐特性,经常产生降低自然度的伪影。在这项工作中,我们提出了SmoothSinger,一个用于合成高质量自然歌声的条件扩散模型。与以往依赖于编码器作为最后阶段并经常引入失真的方法不同,SmoothSinger在一个统一框架中直接对低质量合成音频进行精细化处理,缓解了两阶段流水线带来的退化。该模型采用参考引导双分支架构,使用任何基线系统产生的低质量音频作为参考来引导去噪过程,从而实现更具表现力和上下文感知的合成。此外,它增强了传统的U-Net网络,增加了一条并行低频上采样路径,使模型能够更好地捕捉音调轮廓和长期频谱依赖性。为了提高训练过程中的对齐性,我们用退化真实音频替换参考音频,解决参考信号和目标信号之间的时间不匹配问题。在大型中文歌唱语料库Opencpop数据集上的实验表明,SmoothSinger在客观和主观评估中均达到了最新技术水平。广泛的消融研究证实了其在减少伪影和提高合成声音自然度方面的有效性。
论文及项目相关链接
Summary
本文提出了一个名为SmoothSinger的条件扩散模型,用于合成高质量的自然歌唱声音。该模型旨在解决歌唱声音合成中的挑战,通过采用参考引导的双分支架构和并行低频上采样路径,提高了音频合成的质量和自然度。此外,通过用退化真实音频替换参考音频来解决训练过程中的时间不匹配问题。在大型中文歌唱语料库Opencpop上的实验表明,SmoothSinger在客观和主观评估中都达到了最佳效果。
Key Takeaways
- SmoothSinger是一个条件扩散模型,旨在合成高质量的自然歌唱声音。
- 该模型解决了歌唱声音合成中的挑战,包括精确的音高、时长和发音建模。
- SmoothSinger采用参考引导的双分支架构,直接在统一框架内对合成音频进行精细化处理,避免了两个阶段管道处理带来的失真。
- 模型增强了传统的U-Net网络,增加了并行低频上采样路径,以更好地捕捉音高轮廓和长期频谱依赖性。
- 通过用退化真实音频替换参考音频来解决训练过程中的时间不匹配问题。
- 在大型中文歌唱语料库Opencpop上的实验表明,SmoothSinger在客观和主观评估中都优于其他方法。
点此查看论文截图

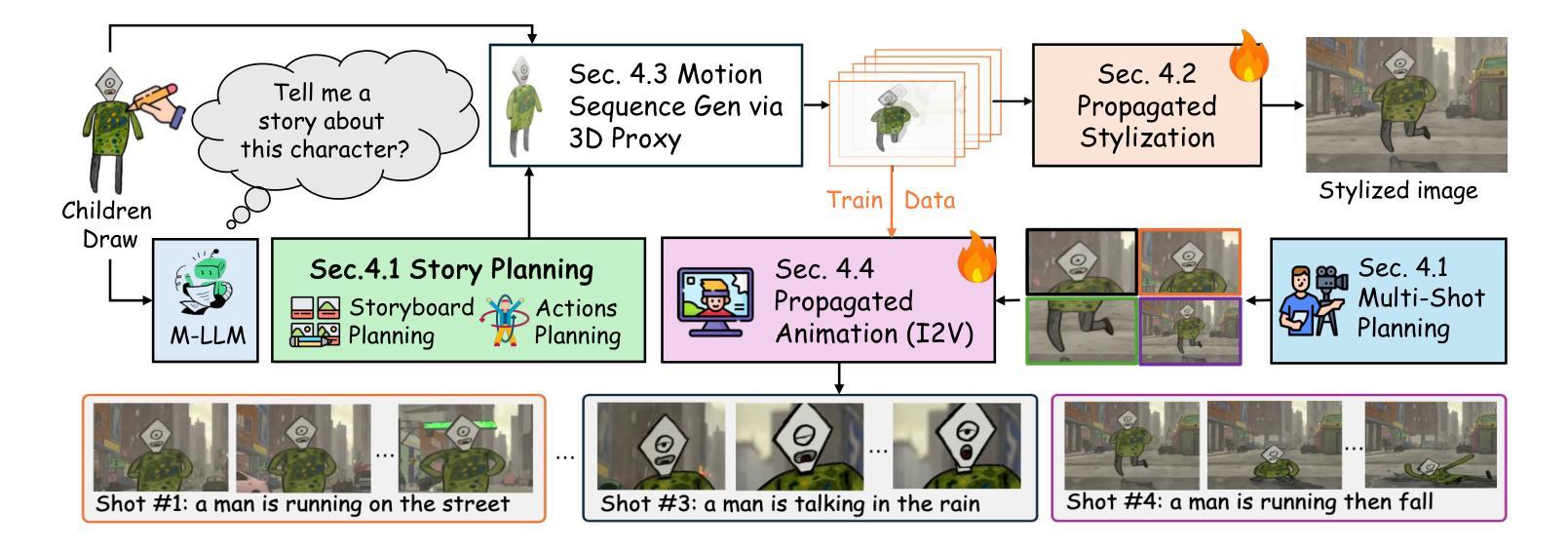
FairyGen: Storied Cartoon Video from a Single Child-Drawn Character
Authors:Jiayi Zheng, Xiaodong Cun
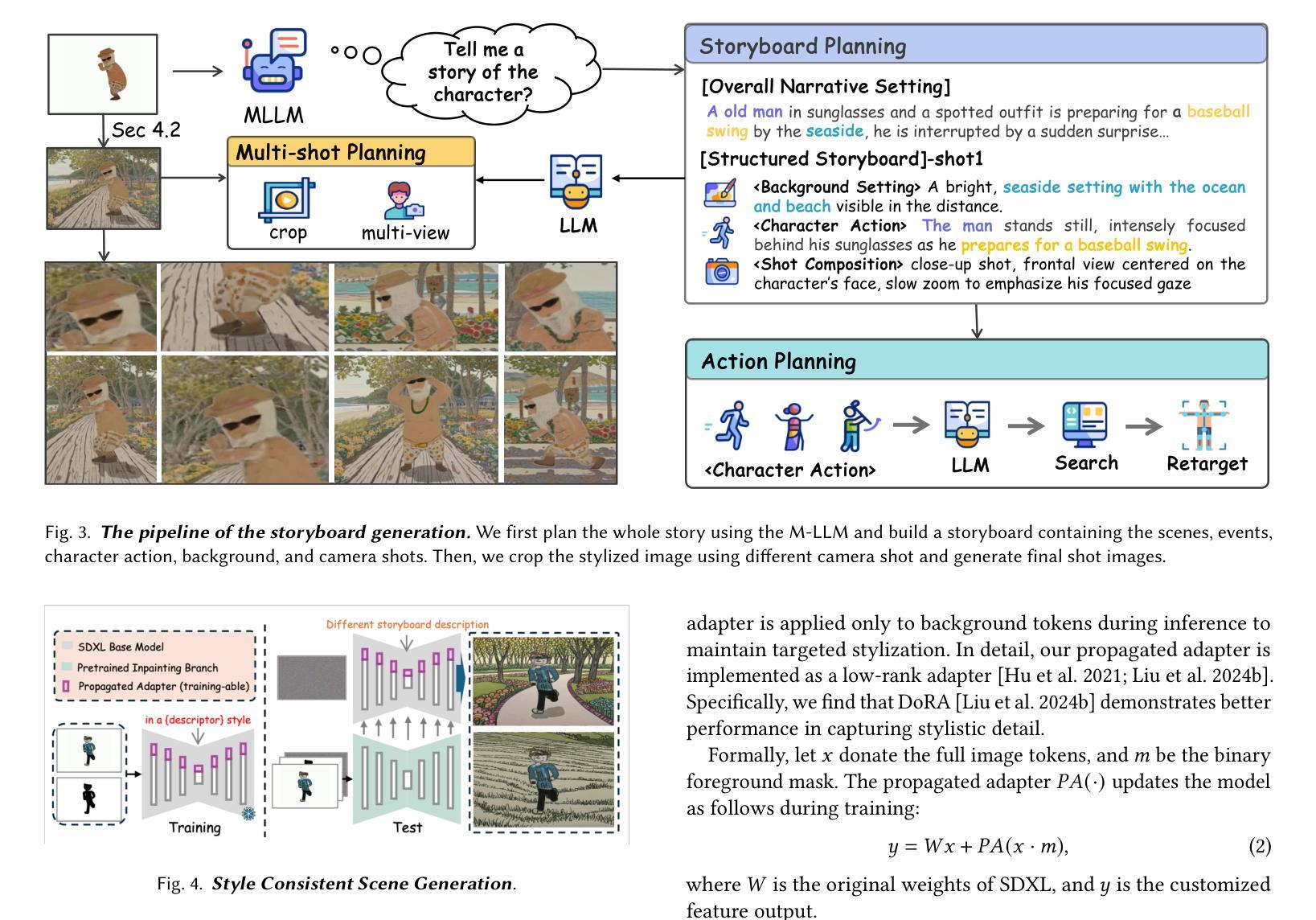
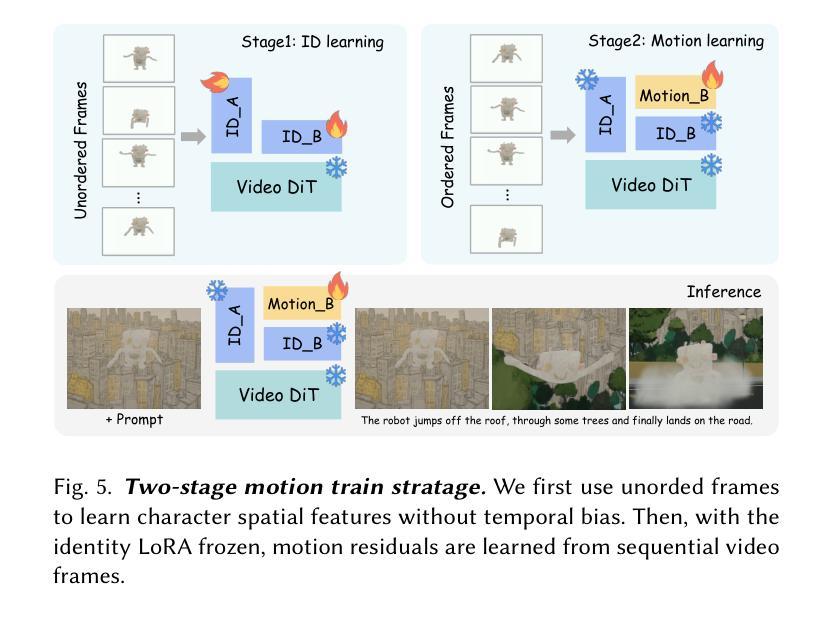
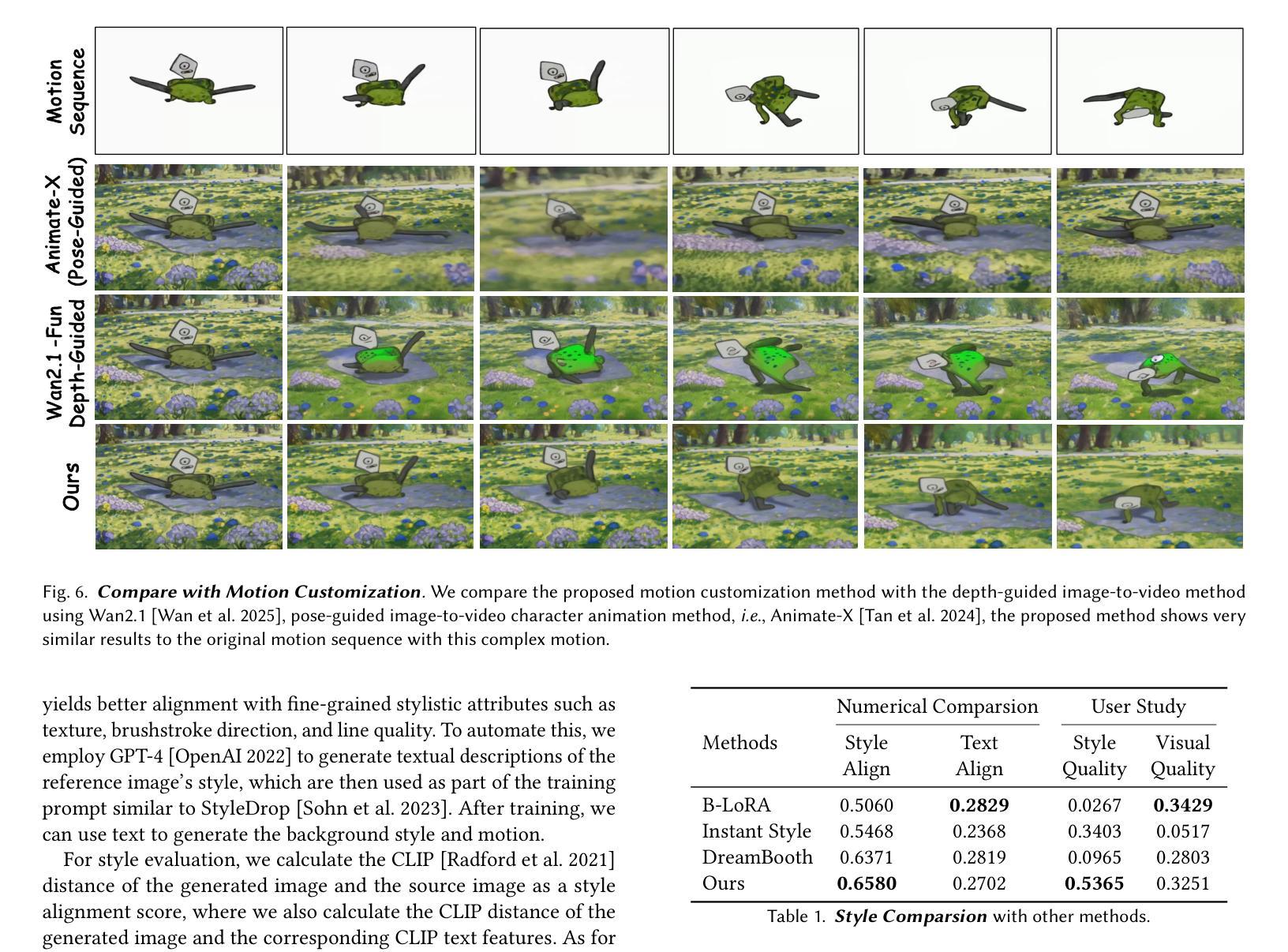
We propose FairyGen, an automatic system for generating story-driven cartoon videos from a single child’s drawing, while faithfully preserving its unique artistic style. Unlike previous storytelling methods that primarily focus on character consistency and basic motion, FairyGen explicitly disentangles character modeling from stylized background generation and incorporates cinematic shot design to support expressive and coherent storytelling. Given a single character sketch, we first employ an MLLM to generate a structured storyboard with shot-level descriptions that specify environment settings, character actions, and camera perspectives. To ensure visual consistency, we introduce a style propagation adapter that captures the character’s visual style and applies it to the background, faithfully retaining the character’s full visual identity while synthesizing style-consistent scenes. A shot design module further enhances visual diversity and cinematic quality through frame cropping and multi-view synthesis based on the storyboard. To animate the story, we reconstruct a 3D proxy of the character to derive physically plausible motion sequences, which are then used to fine-tune an MMDiT-based image-to-video diffusion model. We further propose a two-stage motion customization adapter: the first stage learns appearance features from temporally unordered frames, disentangling identity from motion; the second stage models temporal dynamics using a timestep-shift strategy with frozen identity weights. Once trained, FairyGen directly renders diverse and coherent video scenes aligned with the storyboard. Extensive experiments demonstrate that our system produces animations that are stylistically faithful, narratively structured natural motion, highlighting its potential for personalized and engaging story animation. The code will be available at https://github.com/GVCLab/FairyGen
我们提出了FairyGen系统,这是一个从单个儿童绘画自动生成故事驱动动画卡通视频的自动系统,同时忠实保留其独特的艺术风格。不同于主要关注角色一致性和基本运动的前述故事方法,FairyGen显式地将角色建模与风格化背景生成区分开,并结合电影镜头设计,以支持表现力和连贯性的故事叙述。给定单个角色草图,我们首先使用MLLM生成具有镜头级别描述的结构化故事板,这些描述指定环境设置、角色动作和相机视角。为了确保视觉一致性,我们引入了风格传播适配器,该适配器捕捉角色的视觉风格并将其应用于背景,在合成风格一致的场景时忠实保留角色的完整视觉身份。镜头设计模块通过帧裁剪和多视图合成进一步增强了视觉多样性和电影质量,基于故事板进行。为了动画故事,我们重建了角色的3D代理,以导出物理上可行的运动序列,然后使用这些序列来微调基于MMDiT的图像到视频的扩散模型。我们还提出了一个两阶段运动定制适配器:第一阶段从时间无序的帧中学习外观特征,将身份与运动分开;第二阶段使用时间步长策略对身份权重进行冻结,对临时动态进行建模。一旦训练完成,FairyGen将直接与故事板对齐,呈现多样化和连贯的视频场景。大量实验表明,我们的系统产生的动画在风格上忠实、叙事结构自然、运动连贯,突显其在个性化、引人入胜的故事动画中的潜力。代码将在https://github.com/GVCLab/FairyGen上提供。
论文及项目相关链接
PDF Project Page: https://jayleejia.github.io/FairyGen/ ; Code: https://github.com/GVCLab/FairyGen
Summary
本文介绍了FairyGen系统,该系统能够根据儿童单幅画作自动生成故事驱动动画卡通视频。系统通过分离角色建模和背景生成,融入电影拍摄设计,实现具有表现力和连贯性的叙事。给定一个角色草图,系统利用MLLM生成结构化故事板,并通过风格传播适配器确保视觉一致性。此外,系统还具备拍摄设计模块,通过画面裁剪和多视角合成增强视觉多样性和电影质量。通过重建角色3D代理,衍生出物理逼真的运动序列,再利用MMDiT图像到视频的扩散模型进行微调。运动定制适配器分为两个阶段,第一阶段学习从时序无序帧中提取外观特征,将身份与运动分离;第二阶段采用时间步长策略建模时序动态,冻结身份权重。实验证明,FairyGen系统能够生成风格忠实、叙事连贯、自然运动的动画,展现出其在个性化、引人入胜的故事动画领域的潜力。
Key Takeaways
- FairyGen系统能够根据儿童单幅画作自动生成故事驱动动画卡通视频。
- 系统通过分离角色建模和背景生成,并融入电影拍摄设计来支持表达和连贯的叙事。
- 使用MLLM生成结构化故事板,包括场景设置、角色动作和摄影角度描述。
- 通过风格传播适配器确保视觉一致性,同时合成风格一致的场景。
- 拍摄设计模块增强了视觉多样性和电影质量,通过画面裁剪和多视角合成实现。
- 系统通过重建角色3D代理和物理逼真的运动序列,结合MMDiT图像到视频的扩散模型进行动画创作。
点此查看论文截图


Learning to See in the Extremely Dark
Authors:Hai Jiang, Binhao Guan, Zhen Liu, Xiaohong Liu, Jian Yu, Zheng Liu, Songchen Han, Shuaicheng Liu
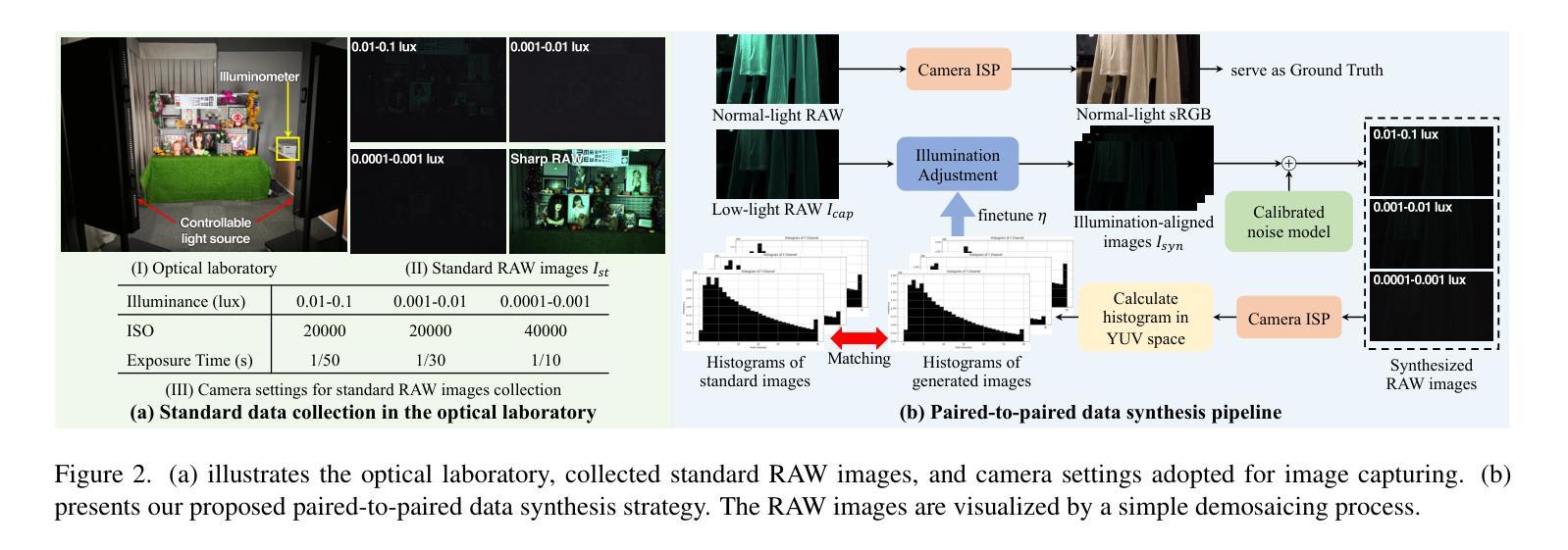
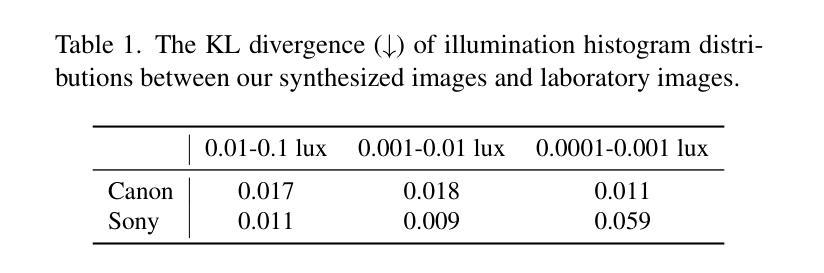
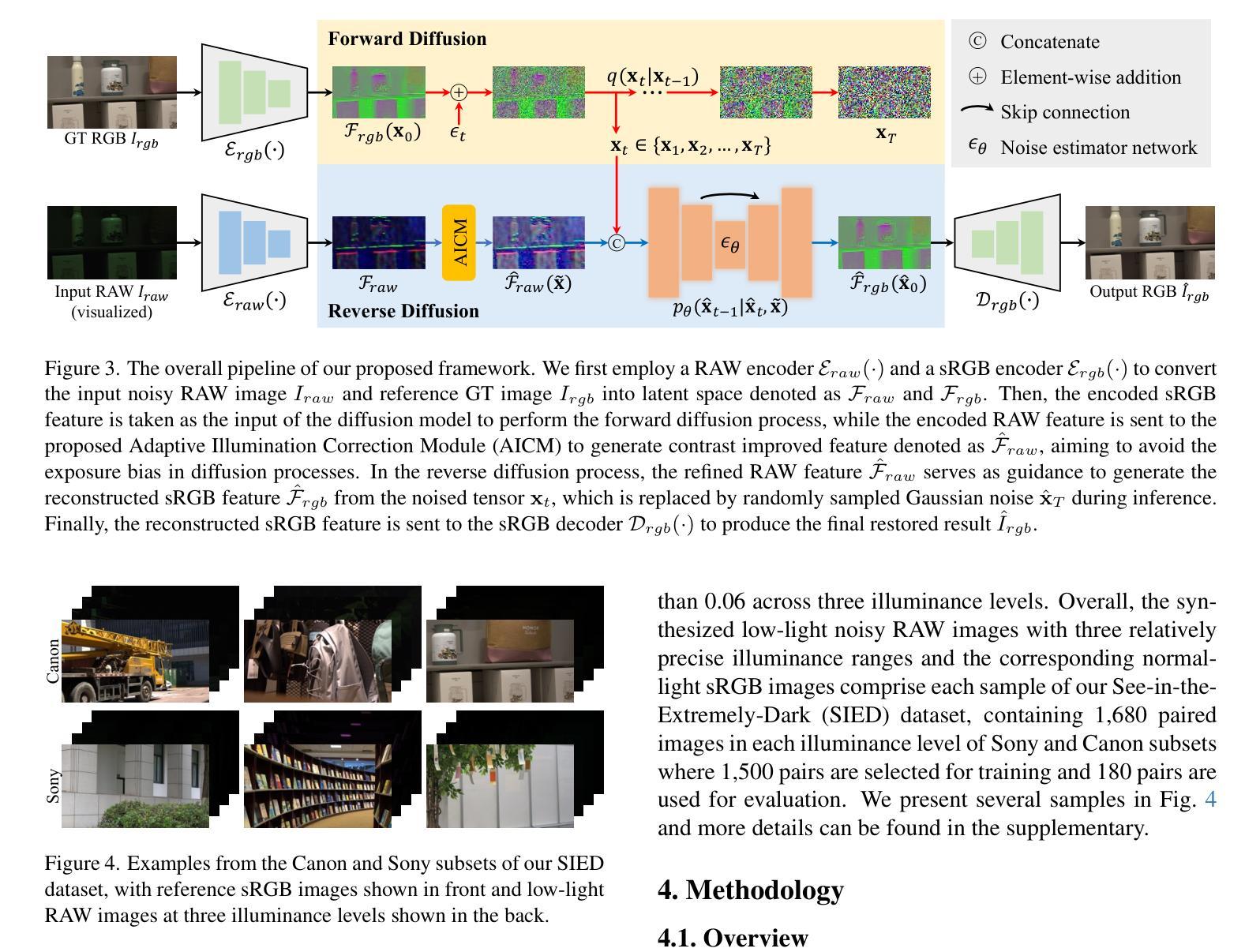
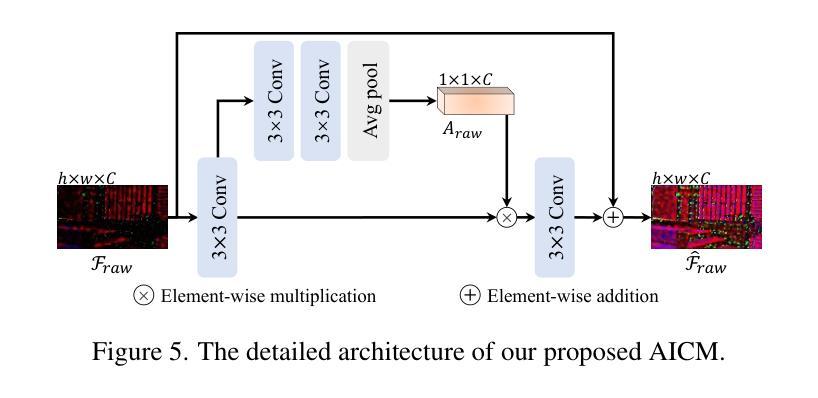
Learning-based methods have made promising advances in low-light RAW image enhancement, while their capability to extremely dark scenes where the environmental illuminance drops as low as 0.0001 lux remains to be explored due to the lack of corresponding datasets. To this end, we propose a paired-to-paired data synthesis pipeline capable of generating well-calibrated extremely low-light RAW images at three precise illuminance ranges of 0.01-0.1 lux, 0.001-0.01 lux, and 0.0001-0.001 lux, together with high-quality sRGB references to comprise a large-scale paired dataset named See-in-the-Extremely-Dark (SIED) to benchmark low-light RAW image enhancement approaches. Furthermore, we propose a diffusion-based framework that leverages the generative ability and intrinsic denoising property of diffusion models to restore visually pleasing results from extremely low-SNR RAW inputs, in which an Adaptive Illumination Correction Module (AICM) and a color consistency loss are introduced to ensure accurate exposure correction and color restoration. Extensive experiments on the proposed SIED and publicly available benchmarks demonstrate the effectiveness of our method. The code and dataset are available at https://github.com/JianghaiSCU/SIED.
基于学习的方法在低光RAW图像增强方面取得了有前景的进展,但由于缺乏相应的数据集,其在环境照度降至0.0001勒克斯的极暗场景下的能力尚待探索。为此,我们提出了一种配对到配对的数据合成管道,能够生成校准良好的极低光RAW图像,在0.01-0.1勒克斯、0.001-0.01勒克斯和0.0001-0.001勒克斯的三个精确照度范围内,以及高质量sRGB参考,构成大规模配对数据集,名为See-in-the-Extremely-Dark(SIED),以评估低光RAW图像增强方法。此外,我们提出了一个基于扩散的框架,利用扩散模型的生成能力和内在去噪属性,从极低的SNR RAW输入中恢复出视觉上的愉悦结果,其中引入了自适应照明校正模块(AICM)和颜色一致性损失,以确保准确的曝光校正和颜色恢复。在提出的SIED和公开可用基准测试上的广泛实验证明了我们的方法的有效性。代码和数据集可在[https://github.com/JianghaiSCU/SIED找到。]
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
该文本描述了在极低光照条件下RAW图像增强的学习方法的进展和面临的挑战。为解决缺乏相应数据集的问题,提出了一种数据合成管道,能够生成精确校准的极低光照RAW图像以及与高质量sRGB参考图像配对的大规模数据集“极暗中的视觉”(See-in-the-Extremely-Dark,简称 SIED)。此外,提出了一种基于扩散的框架,利用扩散模型的生成能力和内在去噪特性来恢复极低信噪比RAW输入的可视结果。实验结果表明,该方法在提出的 SIED 和公开基准测试上都表现出良好的性能。数据集和代码可在XXX网站上找到。
Key Takeaways
- 学习方法在低光照RAW图像增强方面已展现出前景,但在极低光照场景(环境照度低至0.0001 lux)的应用仍需探索。
- 缺乏相应的数据集是这一领域面临的主要挑战之一。
- 提出了一种数据合成管道,能够生成精确校准的极低光照RAW图像,并与高质量sRGB参考图像配对,构成大规模数据集SIED。
- 介绍了一种基于扩散的框架,利用扩散模型的生成能力和去噪特性来增强极低信噪比的RAW图像。
- 提出的框架中包含自适应照明校正模块(AICM)和色彩一致性损失,确保准确的曝光校正和色彩恢复。
- 在提出的SIED数据集和公开基准测试上的实验证明了该方法的有效性。
点此查看论文截图

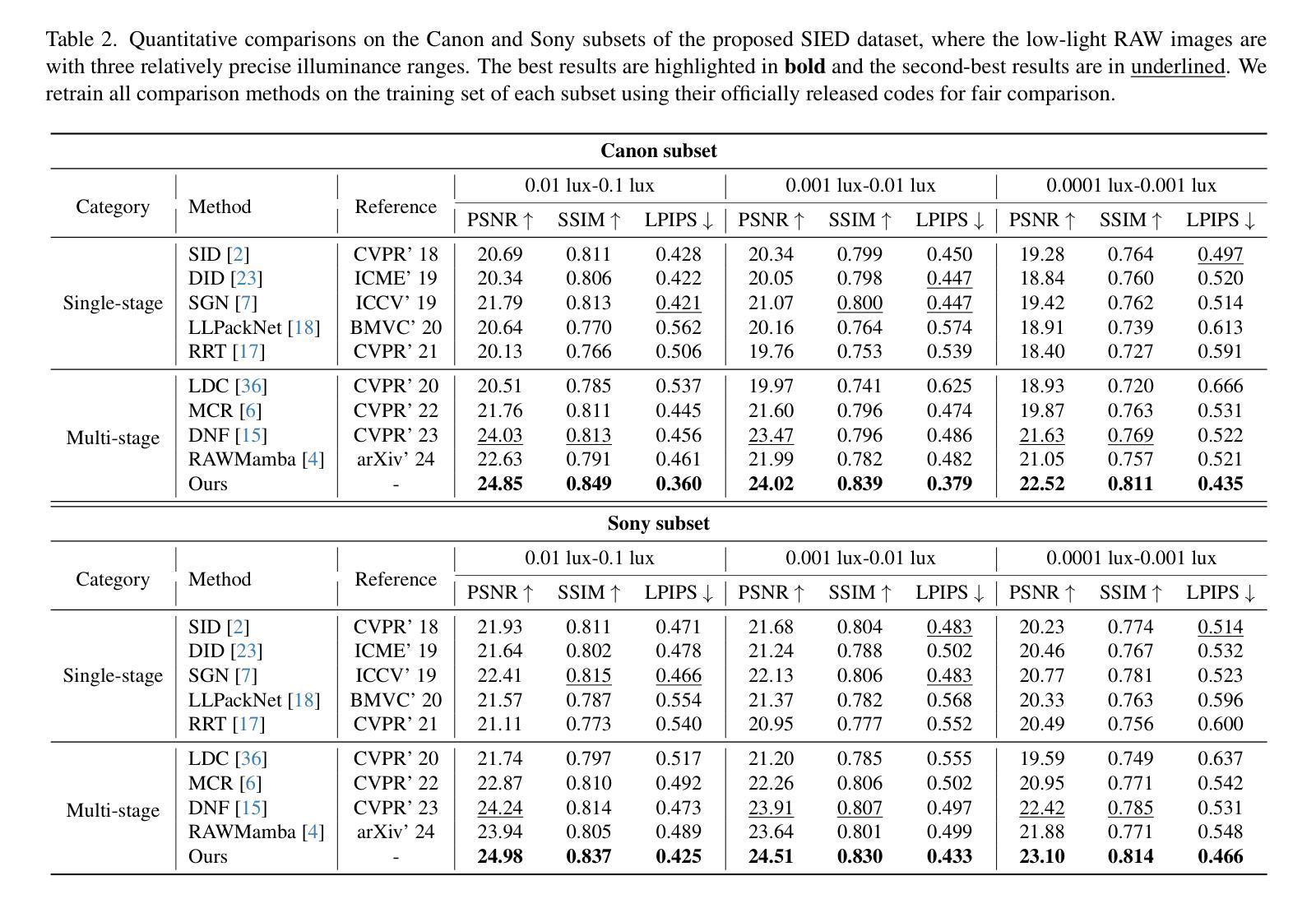
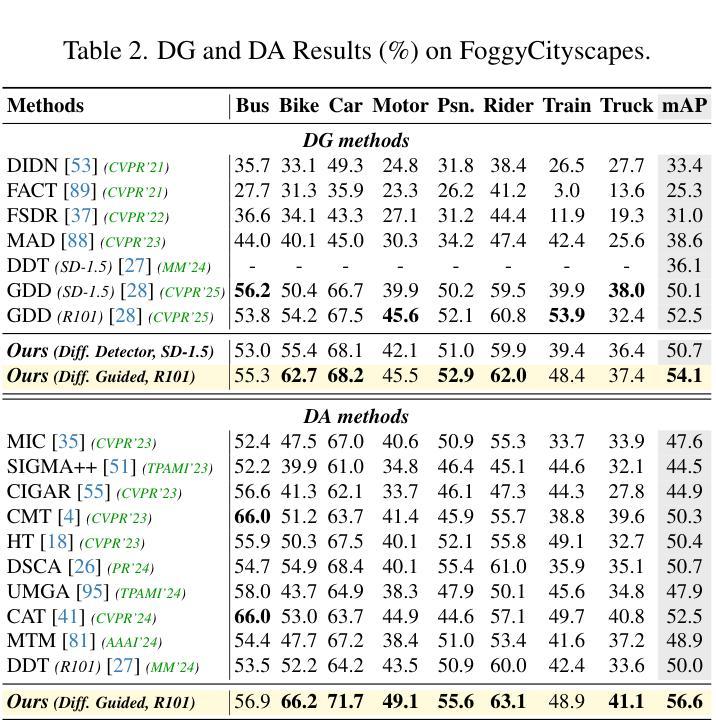
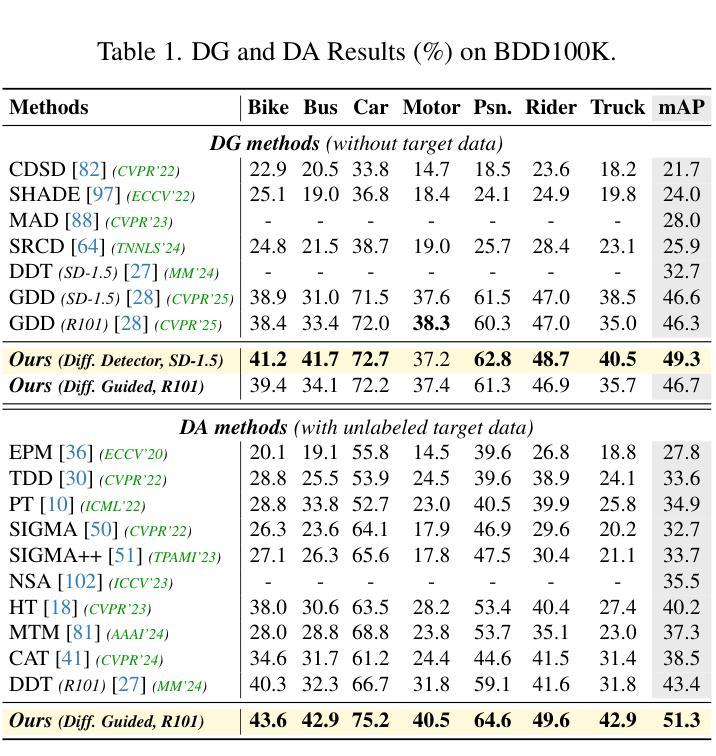
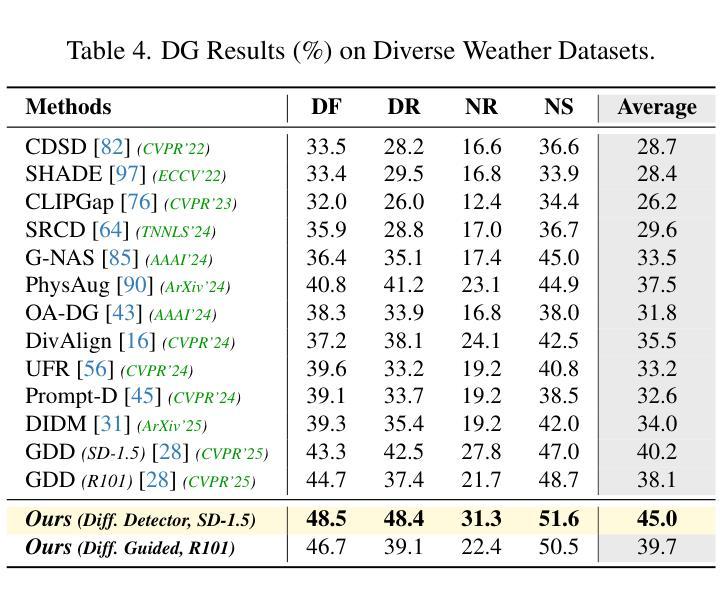
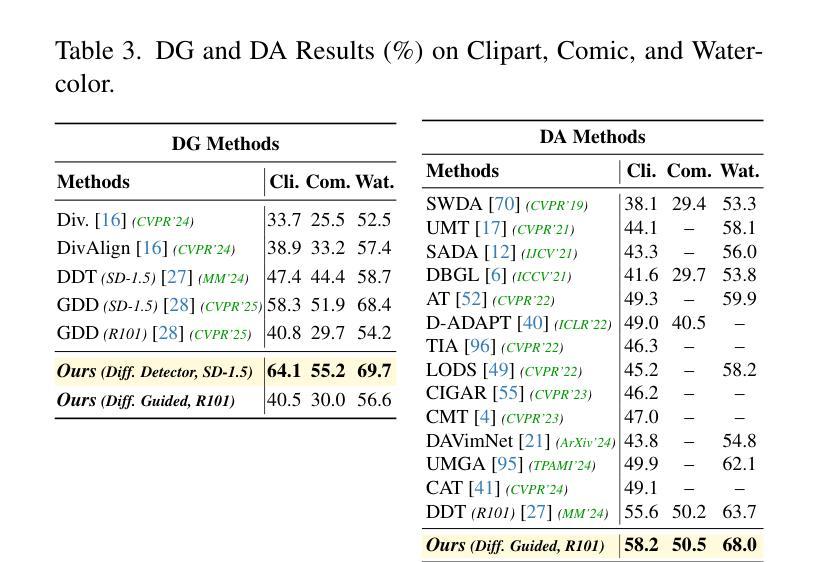
Boosting Domain Generalized and Adaptive Detection with Diffusion Models: Fitness, Generalization, and Transferability
Authors:Boyong He, Yuxiang Ji, Zhuoyue Tan, Liaoni Wu
Detectors often suffer from performance drop due to domain gap between training and testing data. Recent methods explore diffusion models applied to domain generalization (DG) and adaptation (DA) tasks, but still struggle with large inference costs and have not yet fully leveraged the capabilities of diffusion models. We propose to tackle these problems by extracting intermediate features from a single-step diffusion process, improving feature collection and fusion to reduce inference time by 75% while enhancing performance on source domains (i.e., Fitness). Then, we construct an object-centered auxiliary branch by applying box-masked images with class prompts to extract robust and domain-invariant features that focus on object. We also apply consistency loss to align the auxiliary and ordinary branch, balancing fitness and generalization while preventing overfitting and improving performance on target domains (i.e., Generalization). Furthermore, within a unified framework, standard detectors are guided by diffusion detectors through feature-level and object-level alignment on source domains (for DG) and unlabeled target domains (for DA), thereby improving cross-domain detection performance (i.e., Transferability). Our method achieves competitive results on 3 DA benchmarks and 5 DG benchmarks. Additionally, experiments on COCO generalization benchmark demonstrate that our method maintains significant advantages and show remarkable efficiency in large domain shifts and low-data scenarios. Our work shows the superiority of applying diffusion models to domain generalized and adaptive detection tasks and offers valuable insights for visual perception tasks across diverse domains. The code is available at \href{https://github.com/heboyong/Fitness-Generalization-Transferability}{Fitness-Generalization-Transferability}.
检测器常常因为训练数据和测试数据之间的域差距而性能下降。虽然最近的方法尝试将扩散模型应用于域泛化(DG)和域适应(DA)任务,但仍然面临较大的推理成本,并且尚未充分利用扩散模型的能力。我们提议通过从单步扩散过程中提取中间特征来解决这些问题,改进特征收集和融合,减少75%的推理时间,同时提高在源域(例如,Fitness)上的性能。接着,我们通过应用带有类别提示的框掩图像,构建一个以对象为中心的辅助分支,以提取稳健且域不变的特征,这些特征专注于对象。我们还应用一致性损失来对齐辅助分支和普通分支,在适应性和泛化性之间取得平衡,防止过拟合,并在目标域(即,泛化)上提高性能。此外,在一个统一框架内,标准检测器通过源域(用于DG)和无标签目标域(用于DA)的特征级和对象级对齐,由扩散检测器进行引导,从而提高跨域检测性能(即,可转移性)。我们的方法在3个DA基准测试和5个DG基准测试上取得了具有竞争力的结果。此外,在COCO泛化基准测试上的实验表明,我们的方法保持了显著优势,并在大域迁移和低数据场景中表现出卓越的效率。我们的工作展示了将扩散模型应用于域泛化和自适应检测任务的优越性,并为跨不同域的视觉感知任务提供了有价值的见解。代码可用在Fitness-Generalization-Transferability。
论文及项目相关链接
PDF Accepted by ICCV2025. arXiv admin note: text overlap with arXiv:2503.02101
Summary
扩散模型在领域泛化(DG)和领域适应(DA)任务中展现出潜力,但面临推理成本高和未充分利用扩散模型能力的问题。本研究通过提取单步扩散过程的中间特征,改进特征采集和融合,减少推理时间并提高源域性能。构建面向对象的辅助分支,通过应用带有类别提示的盒掩图像提取稳健且领域不变的特征。同时应用一致性损失来平衡适应性和泛化性,防止过拟合并提高目标域性能。在统一框架下,标准检测器通过源域和目标域的特征和对象级对齐,由扩散检测器引导,提高跨域检测性能。本研究在多个基准测试中表现优异,并在大领域偏移和少数据场景下保持显著优势。研究展示了扩散模型在领域泛化和自适应检测任务中的优越性,为跨域视觉感知任务提供了有价值的见解。
Key Takeaways
- 扩散模型应用于领域泛化和领域适应任务中面临推理成本高的问题。
- 通过提取单步扩散过程的中间特征,改进特征采集和融合,减少推理时间并提高源域性能。
- 构建面向对象的辅助分支以提取稳健和领域不变的特征。
- 应用一致性损失来平衡适应性和泛化性,提高目标域性能。
- 在统一框架下,标准检测器通过特征级和对象级对齐由扩散检测器引导,提高跨域检测性能。
- 研究在多个基准测试中表现优异,展示了扩散模型在领域泛化和自适应检测任务的优越性。
点此查看论文截图

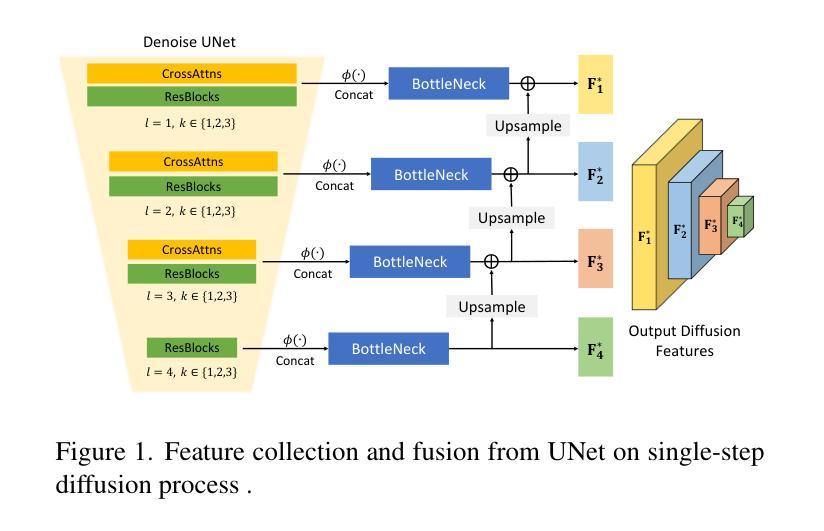
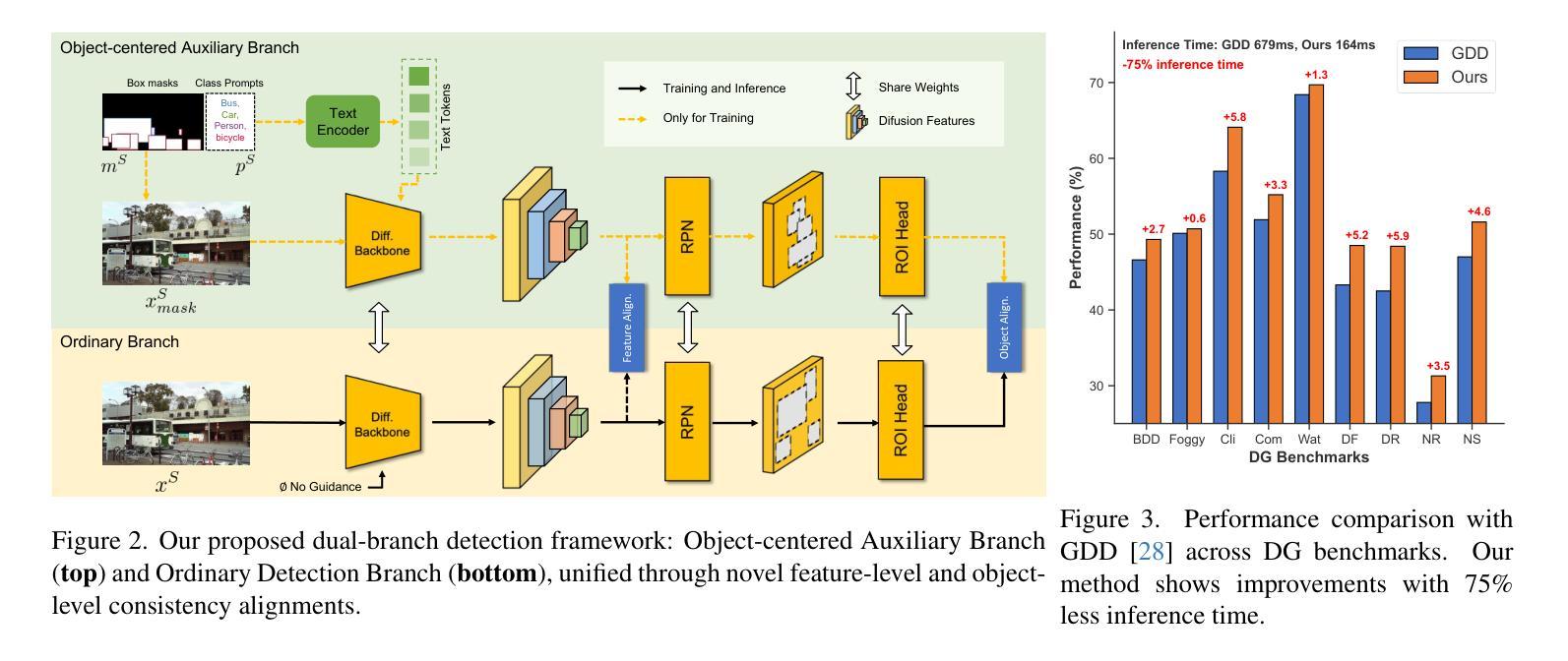
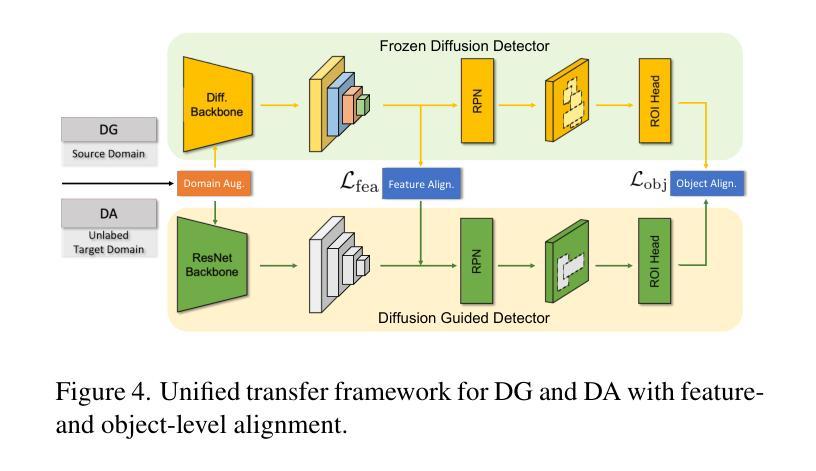
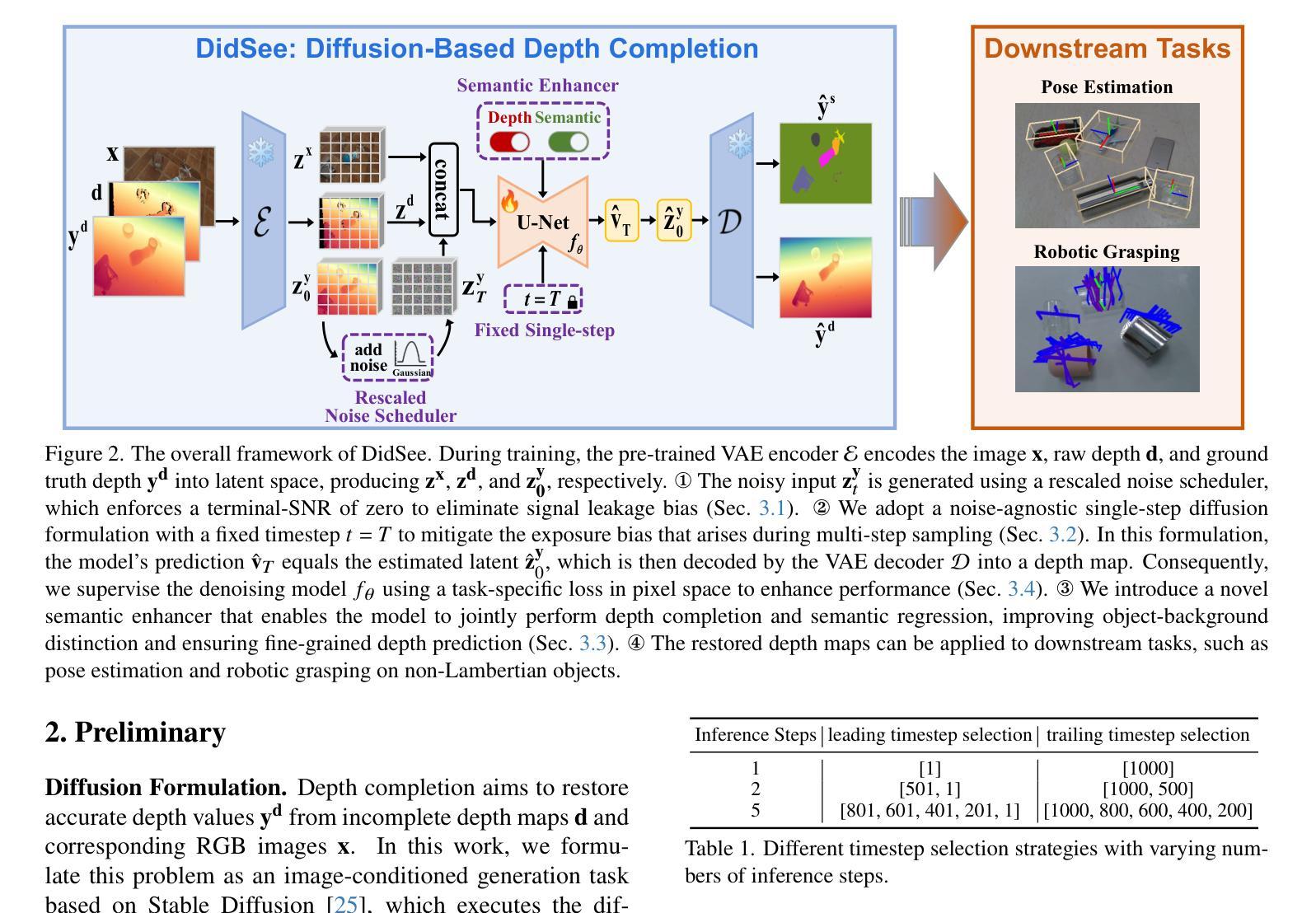
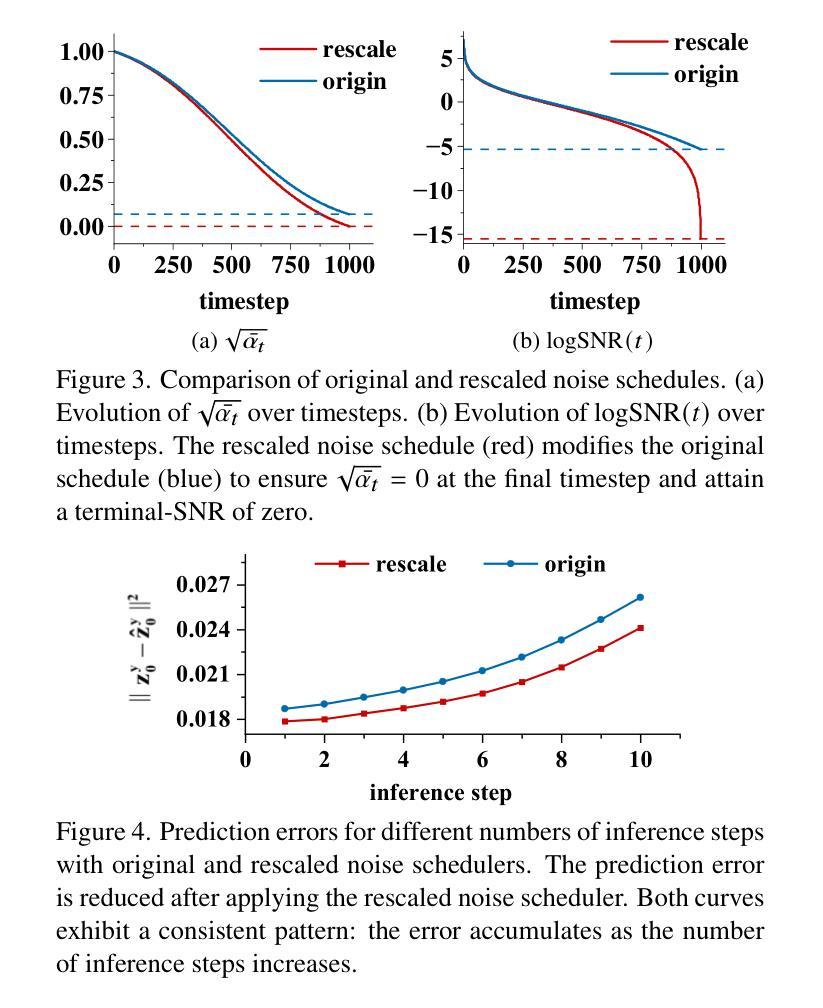
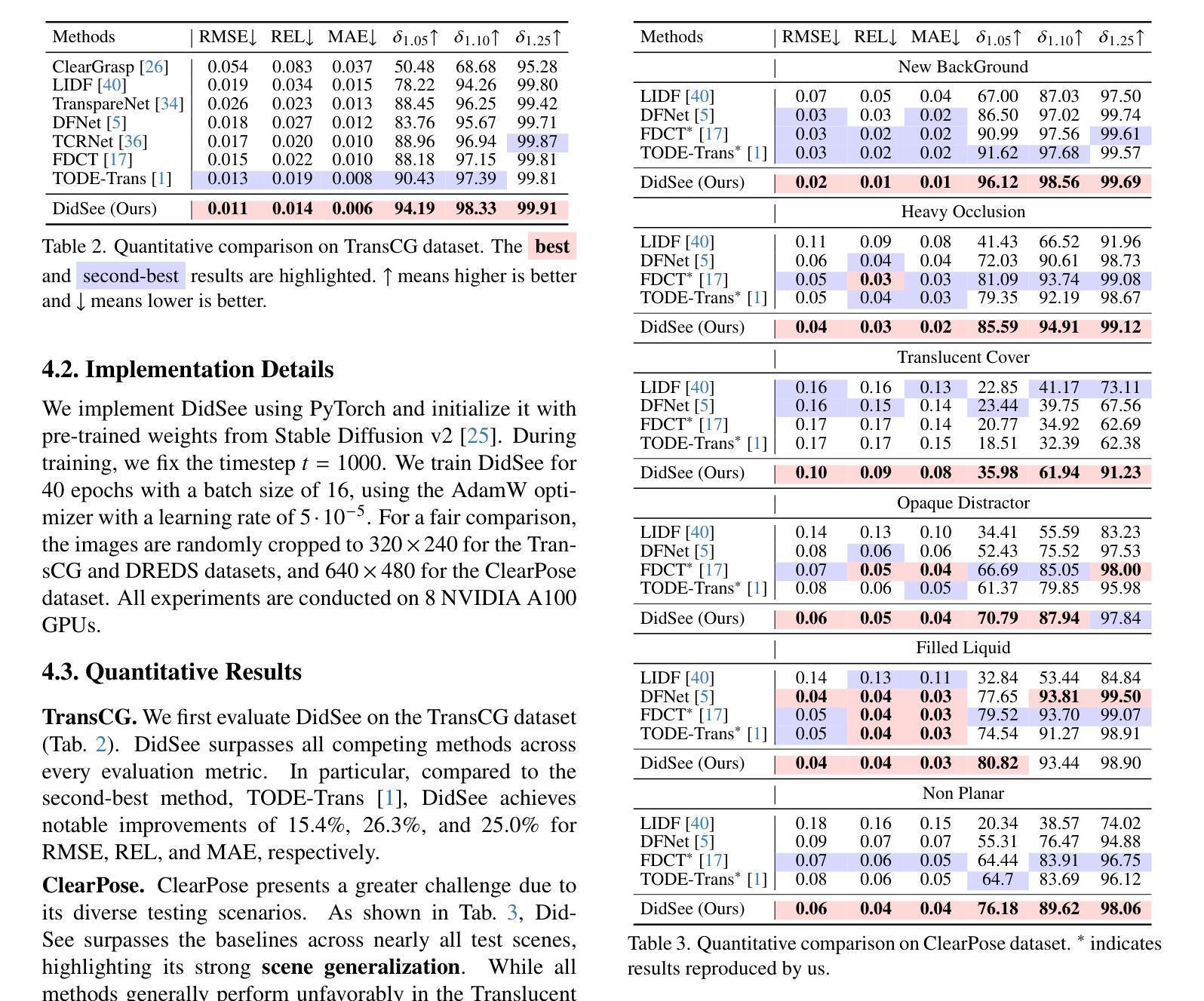
DidSee: Diffusion-Based Depth Completion for Material-Agnostic Robotic Perception and Manipulation
Authors:Wenzhou Lyu, Jialing Lin, Wenqi Ren, Ruihao Xia, Feng Qian, Yang Tang
Commercial RGB-D cameras often produce noisy, incomplete depth maps for non-Lambertian objects. Traditional depth completion methods struggle to generalize due to the limited diversity and scale of training data. Recent advances exploit visual priors from pre-trained text-to-image diffusion models to enhance generalization in dense prediction tasks. However, we find that biases arising from training-inference mismatches in the vanilla diffusion framework significantly impair depth completion performance. Additionally, the lack of distinct visual features in non-Lambertian regions further hinders precise prediction. To address these issues, we propose \textbf{DidSee}, a diffusion-based framework for depth completion on non-Lambertian objects. First, we integrate a rescaled noise scheduler enforcing a zero terminal signal-to-noise ratio to eliminate signal leakage bias. Second, we devise a noise-agnostic single-step training formulation to alleviate error accumulation caused by exposure bias and optimize the model with a task-specific loss. Finally, we incorporate a semantic enhancer that enables joint depth completion and semantic segmentation, distinguishing objects from backgrounds and yielding precise, fine-grained depth maps. DidSee achieves state-of-the-art performance on multiple benchmarks, demonstrates robust real-world generalization, and effectively improves downstream tasks such as category-level pose estimation and robotic grasping.Project page: https://wenzhoulyu.github.io/DidSee/
商业RGB-D相机为非朗伯体对象生成的深度图常常带有噪声且不完整。由于训练数据有限多样性和规模,传统深度完成方法很难实现泛化。最近的进展利用预训练的文本到图像扩散模型的视觉先验知识,以增强密集预测任务的泛化能力。然而,我们发现从原始扩散框架中的训练推理不匹配所产生的偏见严重损害了深度完成性能。此外,非朗伯体区域缺乏独特的视觉特征也阻碍了精确预测。为了解决这些问题,我们提出了一个基于扩散的深度完成框架“DidSee”,适用于非朗伯体对象。首先,我们整合了一个重新标定的噪声调度器,强制终端信号与噪声比为零,以消除信号泄漏偏见。其次,我们设计了一种噪声无关的单步训练公式,以减少曝光偏见引起的误差累积,并用特定任务的损失来优化模型。最后,我们加入了一个语义增强器,能够实现联合深度完成和语义分割,区分物体与背景,生成精确、精细的深度图。DidSee在多个基准测试中达到了领先水平,展现了稳健的泛化能力,并能有效提高下游任务如类别级姿态估计和机器人抓取等。项目页面:https://wenzhoulyu.github.io/DidSee/。
论文及项目相关链接
Summary
针对非朗伯体深度完成任务,现有商业RGB-D相机产生的深度图存在噪声和不完整问题,传统方法因训练数据有限而难以推广。最新研究利用预训练文本到图像的扩散模型提高密集预测任务的泛化能力,但仍存在训练与推理不匹配导致的偏差及非朗伯体区域缺乏特征影响精确预测的问题。为此,提出基于扩散模型的深度完成框架DidSee,通过调整噪声调度器、单步训练公式和语义增强器等技术,实现精确、细粒度的深度图生成,并在多个基准测试中达到最佳性能,有效推广至实际场景并提升下游任务如类别级别姿态估计和机器人抓取等。
Key Takeaways
- 商业RGB-D相机在非朗伯体对象上产生噪声和不完整的深度图。
- 传统深度完成方法由于训练数据有限和多样性不足,难以推广。
- 最新研究利用预训练的文本到图像扩散模型提高泛化能力。
- 存在训练与推理不匹配导致的偏差影响深度完成性能。
- 非朗伯体区域缺乏特征进一步阻碍精确预测。
- 提出的DidSee框架通过调整噪声调度器、单步训练公式和语义增强器等技术解决上述问题。
- DidSee框架在多个基准测试中达到最佳性能,有效推广至实际场景并提升下游任务效果。
点此查看论文截图


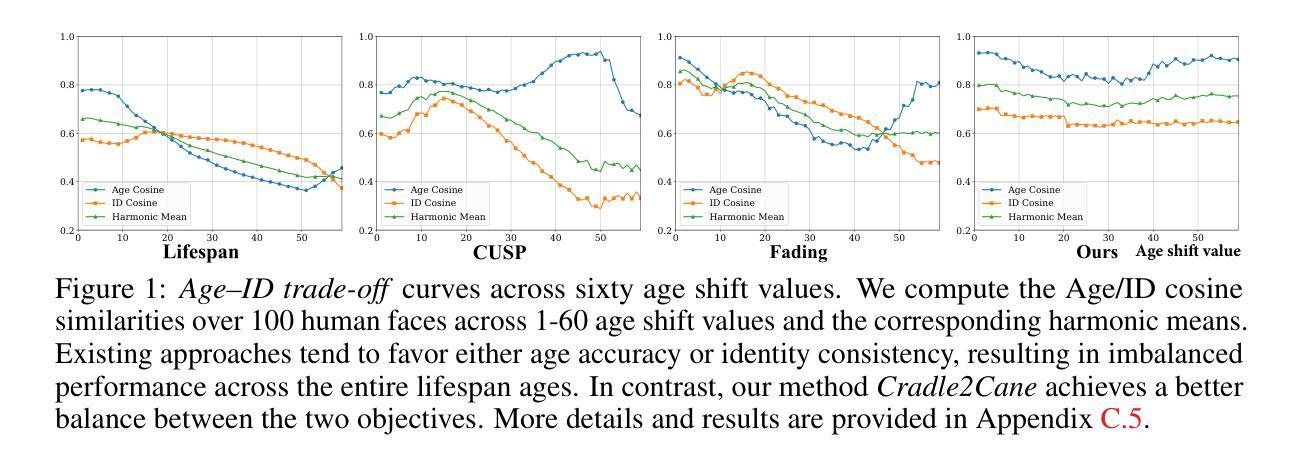
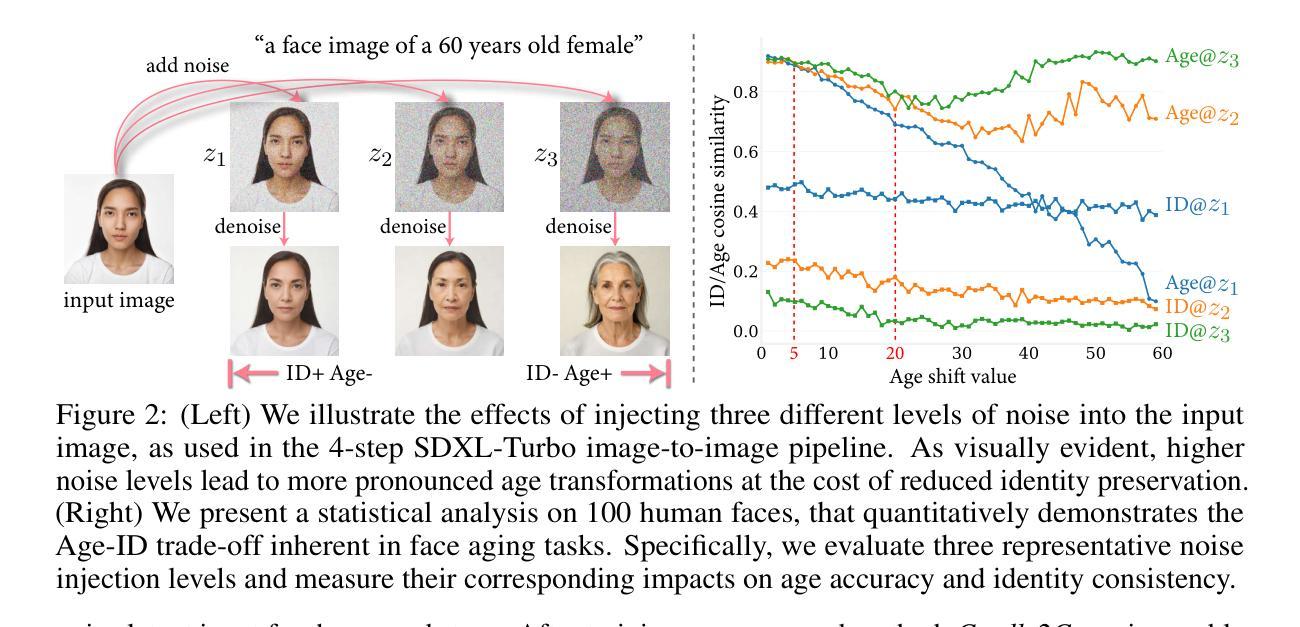
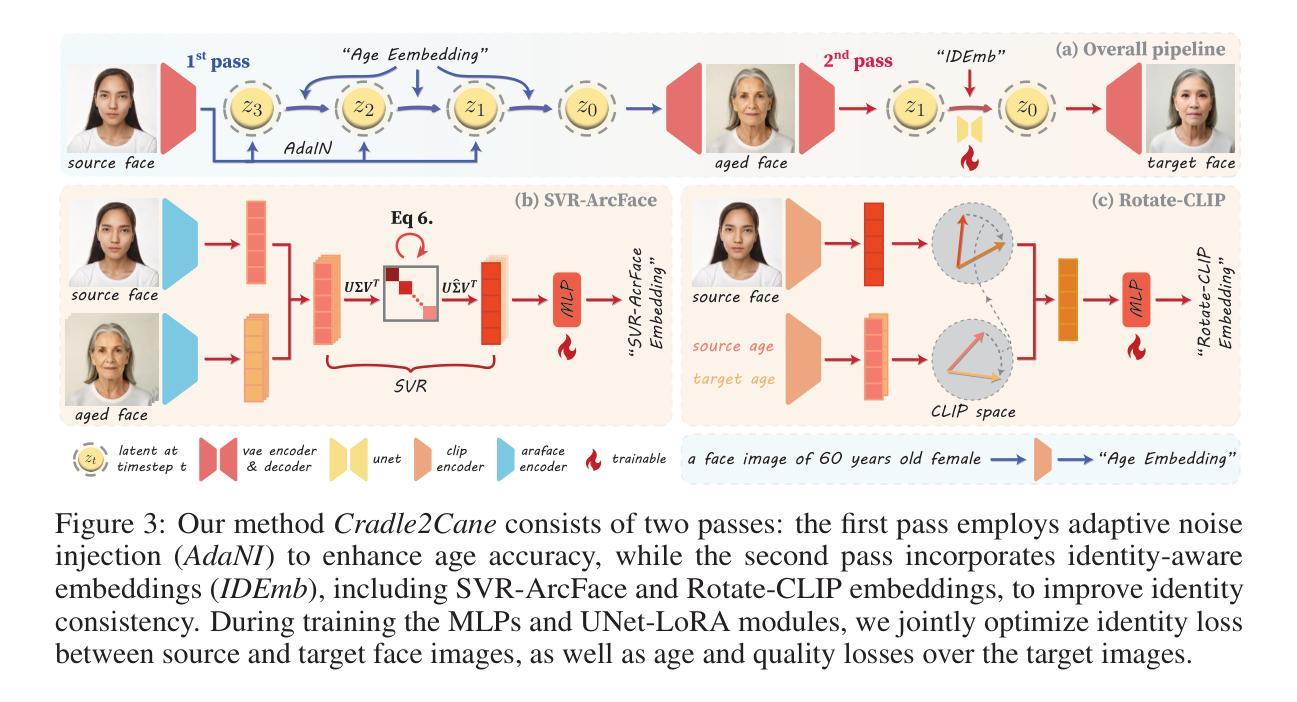
From Cradle to Cane: A Two-Pass Framework for High-Fidelity Lifespan Face Aging
Authors:Tao Liu, Dafeng Zhang, Gengchen Li, Shizhuo Liu, Yongqi Song, Senmao Li, Shiqi Yang, Boqian Li, Kai Wang, Yaxing Wang
Face aging has become a crucial task in computer vision, with applications ranging from entertainment to healthcare. However, existing methods struggle with achieving a realistic and seamless transformation across the entire lifespan, especially when handling large age gaps or extreme head poses. The core challenge lies in balancing age accuracy and identity preservation–what we refer to as the Age-ID trade-off. Most prior methods either prioritize age transformation at the expense of identity consistency or vice versa. In this work, we address this issue by proposing a two-pass face aging framework, named Cradle2Cane, based on few-step text-to-image (T2I) diffusion models. The first pass focuses on solving age accuracy by introducing an adaptive noise injection (AdaNI) mechanism. This mechanism is guided by including prompt descriptions of age and gender for the given person as the textual condition. Also, by adjusting the noise level, we can control the strength of aging while allowing more flexibility in transforming the face. However, identity preservation is weakly ensured here to facilitate stronger age transformations. In the second pass, we enhance identity preservation while maintaining age-specific features by conditioning the model on two identity-aware embeddings (IDEmb): SVR-ArcFace and Rotate-CLIP. This pass allows for denoising the transformed image from the first pass, ensuring stronger identity preservation without compromising the aging accuracy. Both passes are jointly trained in an end-to-end way. Extensive experiments on the CelebA-HQ test dataset, evaluated through Face++ and Qwen-VL protocols, show that our Cradle2Cane outperforms existing face aging methods in age accuracy and identity consistency.
面部衰老已成为计算机视觉中的一项重要任务,其应用从娱乐到医疗保健都有涉及。然而,现有方法在实现整个生命周期的真实无缝转换方面存在困难,尤其是在处理大年龄差距或极端头部姿势时。核心挑战在于平衡年龄准确性和身份保留之间的权衡,我们称之为Age-ID权衡。大多数之前的方法要么优先考虑年龄转换而忽视身份一致性,要么反之。在这项工作中,我们通过提出一个两阶段的面部衰老框架来解决这个问题,该框架名为Cradle2Cane,基于少步骤的文本到图像(T2I)扩散模型。第一阶段专注于解决年龄准确性问题,通过引入自适应噪声注入(AdaNI)机制。该机制通过包括给定人的年龄和性别的提示描述作为文本条件来引导。此外,通过调整噪声水平,我们可以控制衰老的强度,同时允许面部转换时更大的灵活性。然而,这里对身份保留的保证较弱,以促进更强的年龄转换。在第二阶段,我们通过使模型依赖于两个身份感知嵌入(IDEmb):SVR-ArcFace和Rotate-CLIP,在保持年龄特征的同时增强身份保留。这一关允许对第一阶段的转换图像进行去噪处理,确保在保持年龄准确性的同时增强身份保留。两个阶段以端到端的方式进行联合训练。在CelebA-HQ测试数据集上进行的广泛实验,通过Face++和Qwen-VL协议进行评估,结果表明我们的Cradle2Cane在年龄准确性和身份一致性方面优于现有的面部衰老方法。
论文及项目相关链接
PDF 30 pages, 12 figures
Summary
本摘要专注于计算机视觉中的人脸衰老技术挑战。该文提出一种新的解决策略,采用基于文本到图像(T2I)扩散模型的双阶段框架(Cradle2Cane),旨在解决人脸衰老过程中的年龄准确性和身份一致性之间的权衡问题。通过自适应噪声注入机制提高年龄准确性,并通过身份感知嵌入强化身份一致性。在CelebA-HQ测试数据集上的实验表明,Cradle2Cane在年龄准确性和身份一致性方面优于现有方法。
Key Takeaways
- 人脸衰老在计算机视觉中具有重要应用,但现有方法面临年龄准确性和身份一致性之间的权衡挑战。
- Cradle2Cane框架采用双阶段策略,第一阶段侧重于提高年龄准确性,通过自适应噪声注入机制实现。第二阶段专注于强化身份一致性,同时保持年龄特征。
- 通过在T2I扩散模型的基础上引入条件控制,实现对人脸衰老过程的灵活调整。
- 使用身份感知嵌入(IDEmb)提高身份一致性,包括SVR-ArcFace和Rotate-CLIP。
- 方法在CelebA-HQ测试数据集上进行广泛实验验证,表现出优良性能,尤其在年龄准确性和身份一致性方面。
- 所提方法的优点在于能够在不同年龄段和不同头部姿态下实现更真实无缝的转换。这是当前研究的重点与难点。
点此查看论文截图

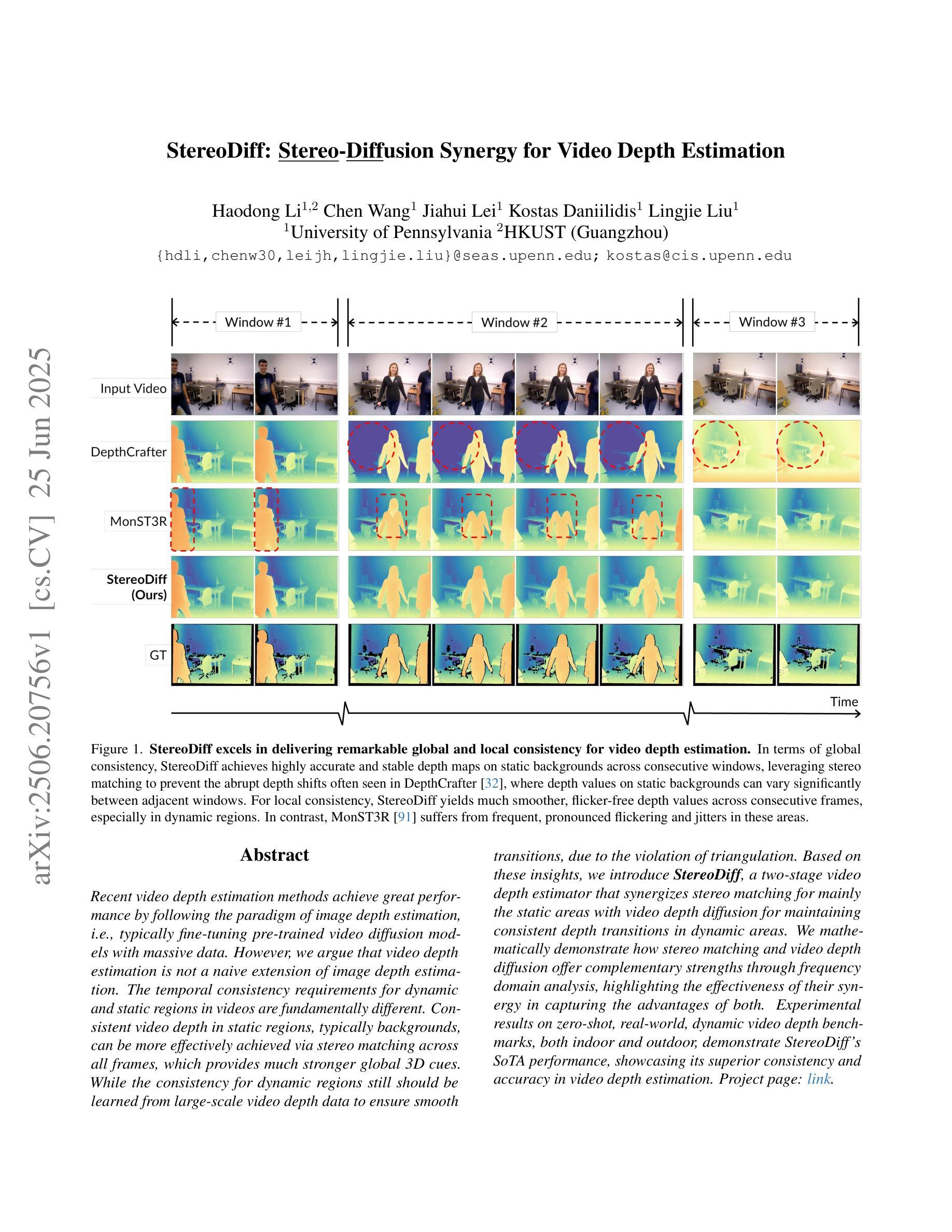
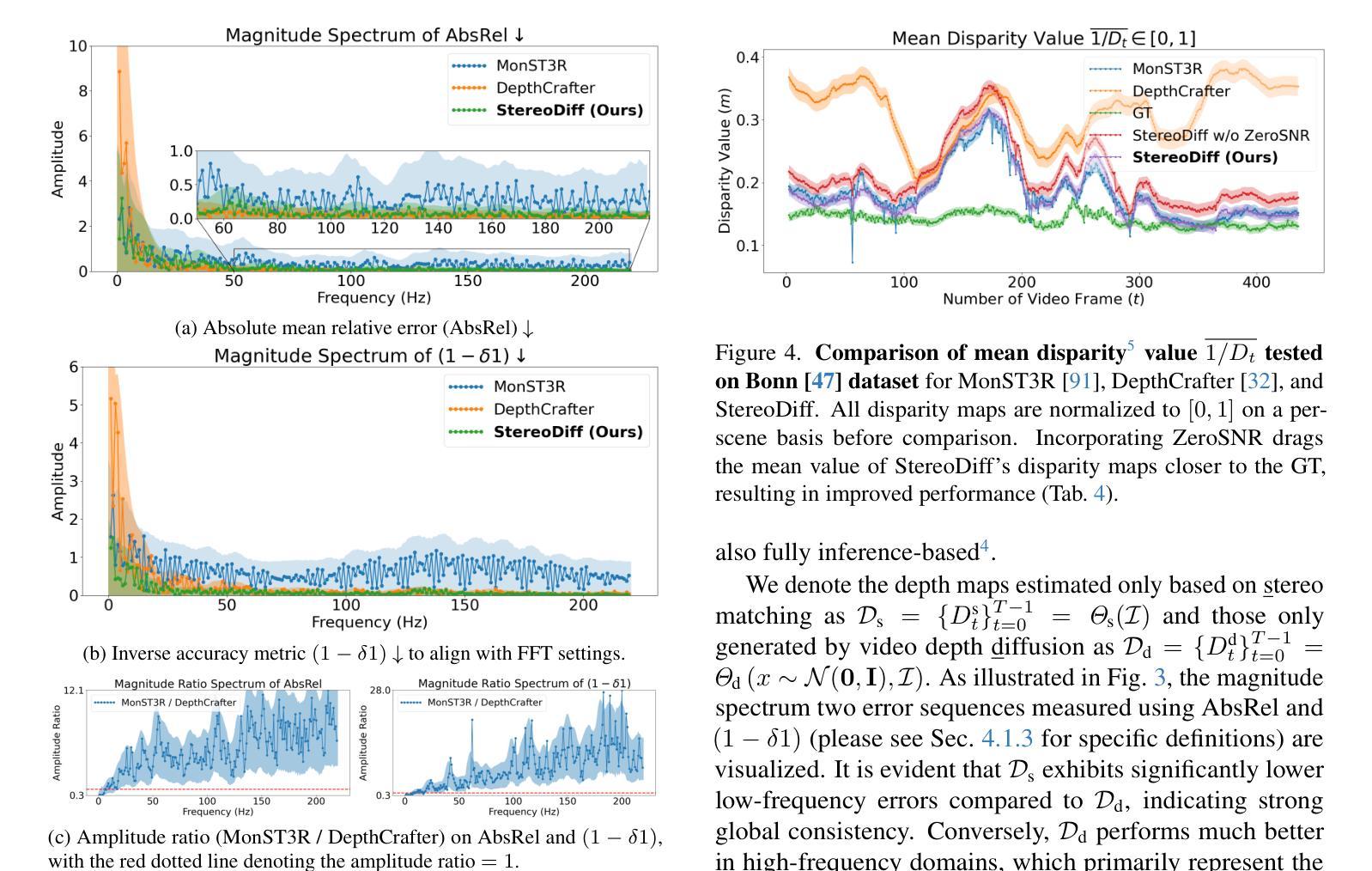
StereoDiff: Stereo-Diffusion Synergy for Video Depth Estimation
Authors:Haodong Li, Chen Wang, Jiahui Lei, Kostas Daniilidis, Lingjie Liu
Recent video depth estimation methods achieve great performance by following the paradigm of image depth estimation, i.e., typically fine-tuning pre-trained video diffusion models with massive data. However, we argue that video depth estimation is not a naive extension of image depth estimation. The temporal consistency requirements for dynamic and static regions in videos are fundamentally different. Consistent video depth in static regions, typically backgrounds, can be more effectively achieved via stereo matching across all frames, which provides much stronger global 3D cues. While the consistency for dynamic regions still should be learned from large-scale video depth data to ensure smooth transitions, due to the violation of triangulation constraints. Based on these insights, we introduce StereoDiff, a two-stage video depth estimator that synergizes stereo matching for mainly the static areas with video depth diffusion for maintaining consistent depth transitions in dynamic areas. We mathematically demonstrate how stereo matching and video depth diffusion offer complementary strengths through frequency domain analysis, highlighting the effectiveness of their synergy in capturing the advantages of both. Experimental results on zero-shot, real-world, dynamic video depth benchmarks, both indoor and outdoor, demonstrate StereoDiff’s SoTA performance, showcasing its superior consistency and accuracy in video depth estimation.
最近的视频深度估计方法遵循图像深度估计的模式,即通常通过对大量数据进行预训练的视频扩散模型进行微调,取得了很好的性能。然而,我们认为视频深度估计并不是图像深度估计的简单扩展。视频中的动态和静态区域的时序一致性要求存在根本差异。对于通常为背景的静态区域的视频深度一致性,可以通过所有帧的立体匹配更有效地实现,这提供了更强的全局3D线索。而对于动态区域的一致性,由于违反了三角约束,仍需要从大规模视频深度数据中学习,以确保平滑过渡。基于这些见解,我们引入了StereoDiff,这是一种两阶段的视频深度估计器,它将主要用于静态区域的立体匹配与用于保持动态区域中一致深度过渡的视频深度扩散相结合。我们通过频域分析从数学上证明了立体匹配和视频深度扩散如何提供互补优势,突显了它们在捕捉各自优势上的协同有效性。在零样本、现实世界、室内和室外的动态视频深度基准测试上的实验结果表明,StereoDiff的性能达到了最新水平,展示了其在视频深度估计中的卓越一致性和准确性。
论文及项目相关链接
PDF Work done in Nov. 2024. Project page: https://stereodiff.github.io/
Summary
本文介绍了视频深度估计的新方法StereoDiff,该方法结合立体匹配和视频深度扩散两个阶段,针对静态区域和动态区域的不同要求实现视频深度估计。立体匹配用于静态区域的深度估计,提供更强的全局3D线索;视频深度扩散则用于动态区域,确保平滑过渡。实验结果表明,StereoDiff在零样本、真实世界、室内外的动态视频深度评估中达到领先水平,展现出卓越的一致性和准确性。
Key Takeaways
- 视频深度估计不能简单地视为图像深度估计的扩展,因为视频中的动态和静态区域对时间一致性的要求存在根本差异。
- 立体匹配在静态区域的视频深度估计中更有效,能提供更强的全局3D线索。
- 动态区域的深度一致性需要通过大规模视频深度数据学习实现,以确保平滑过渡。
- 介绍了新方法StereoDiff,该方法结合立体匹配和视频深度扩散,分别针对静态和动态区域进行优化。
- StereoDiff通过频率域分析数学地证明了立体匹配和视频深度扩散的互补优势。
- 实验结果表明,StereoDiff在视频深度估计的零样本、真实世界、室内外的评估中表现优异,具有一流的一致性和准确性。
点此查看论文截图
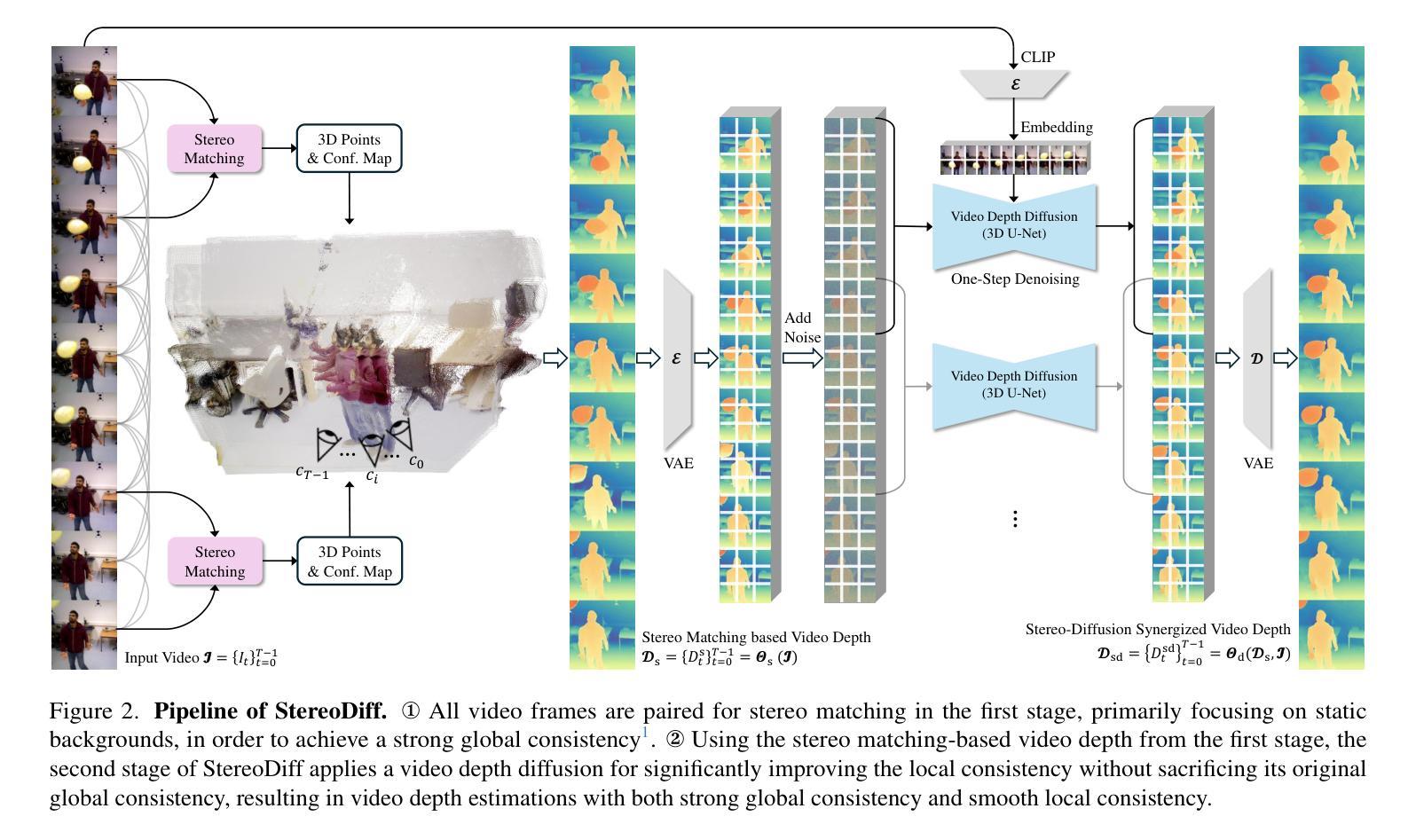
On Convolutions, Intrinsic Dimension, and Diffusion Models
Authors:Kin Kwan Leung, Rasa Hosseinzadeh, Gabriel Loaiza-Ganem
The manifold hypothesis asserts that data of interest in high-dimensional ambient spaces, such as image data, lies on unknown low-dimensional submanifolds. Diffusion models (DMs) – which operate by convolving data with progressively larger amounts of Gaussian noise and then learning to revert this process – have risen to prominence as the most performant generative models, and are known to be able to learn distributions with low-dimensional support. For a given datum in one of these submanifolds, we should thus intuitively expect DMs to have implicitly learned its corresponding local intrinsic dimension (LID), i.e. the dimension of the submanifold it belongs to. Kamkari et al. (2024b) recently showed that this is indeed the case by linking this LID to the rate of change of the log marginal densities of the DM with respect to the amount of added noise, resulting in an LID estimator known as FLIPD. LID estimators such as FLIPD have a plethora of uses, among others they quantify the complexity of a given datum, and can be used to detect outliers, adversarial examples and AI-generated text. FLIPD achieves state-of-the-art performance at LID estimation, yet its theoretical underpinnings are incomplete since Kamkari et al. (2024b) only proved its correctness under the highly unrealistic assumption of affine submanifolds. In this work we bridge this gap by formally proving the correctness of FLIPD under realistic assumptions. Additionally, we show that an analogous result holds when Gaussian convolutions are replaced with uniform ones, and discuss the relevance of this result.
流形假设认为,在图像数据等感兴趣的高维环境空间中,数据位于未知的低维子流形上。扩散模型(DMs)通过用逐渐增加的高斯噪声对数据进行卷积,然后学习反转这一过程,已成为性能最佳的生成模型,并且已知能够学习低维支持的分布。因此,对于其中一个子流形中的给定数据,我们应该直觉地期望DM已经隐式学习了其相应的局部内蕴维数(LID),即它所属的子流形的维数。Kamkari等人(2024b)最近通过将LID与DM对数边缘密度相对于所添加噪声的变化率联系起来,证明了这一点确实如此,从而得到了一个称为FLIPD的LID估计器。像FLIPD这样的LID估计器有很多用途,例如量化给定数据的复杂性,并可用于检测异常值、对抗性示例和人工智能生成的文本。FLIPD在LID估计方面达到了最先进的性能水平,但其理论基础尚不完整,因为Kamkari等人(2024b)只在高度不切实际的仿射子流形的假设下证明了其正确性。在这项工作中,我们通过建立合理的假设正式证明了FLIPD的正确性,从而填补了这一空白。此外,我们还证明了当高斯卷积被均匀卷积取代时,会出现类似的结果,并讨论了这一结果的现实意义。
论文及项目相关链接
Summary
本文探讨了扩散模型(DMs)与局部内在维度(LID)之间的关系。文章指出,由于扩散模型在处理高维数据时可以学习低维分布,因此应该能够学习数据的局部内在维度。近期的研究已经通过关联DMs的边际对数密度与添加噪声的量来估计LID,产生了一种名为FLIPD的LID估计器。尽管FLIPD在LID估计方面表现出卓越的性能,但其理论支撑并不完整。本文旨在填补这一空白,在更现实的假设下证明FLIPD的正确性,并讨论了当高斯卷积被均匀卷积替代时的类似结果。
Key Takeaways
- 扩散模型(DMs)在处理高维数据时表现出优异的性能,并能学习数据的低维分布。
- 局部内在维度(LID)是描述数据所属子流形维度的概念。
- FLIPD是一种基于扩散模型的LID估计器,它通过关联DMs的边际对数密度与添加噪声的量来工作。
- FLIPD在LID估计方面表现出卓越的性能,但其在之前的研究中理论支撑不完整。
- 本文在更现实的假设下证明了FLIPD的正确性,为FLIPD的理论基础提供了重要补充。
- 除了高斯卷积,本文还探讨了当使用均匀卷积时FLIPD的类似结果。
点此查看论文截图

Diffusion Tree Sampling: Scalable inference-time alignment of diffusion models
Authors:Vineet Jain, Kusha Sareen, Mohammad Pedramfar, Siamak Ravanbakhsh
Adapting a pretrained diffusion model to new objectives at inference time remains an open problem in generative modeling. Existing steering methods suffer from inaccurate value estimation, especially at high noise levels, which biases guidance. Moreover, information from past runs is not reused to improve sample quality, resulting in inefficient use of compute. Inspired by the success of Monte Carlo Tree Search, we address these limitations by casting inference-time alignment as a search problem that reuses past computations. We introduce a tree-based approach that samples from the reward-aligned target density by propagating terminal rewards back through the diffusion chain and iteratively refining value estimates with each additional generation. Our proposed method, Diffusion Tree Sampling (DTS), produces asymptotically exact samples from the target distribution in the limit of infinite rollouts, and its greedy variant, Diffusion Tree Search (DTS$^\star$), performs a global search for high reward samples. On MNIST and CIFAR-10 class-conditional generation, DTS matches the FID of the best-performing baseline with up to $10\times$ less compute. In text-to-image generation and language completion tasks, DTS$^\star$ effectively searches for high reward samples that match best-of-N with up to $5\times$ less compute. By reusing information from previous generations, we get an anytime algorithm that turns additional compute into steadily better samples, providing a scalable approach for inference-time alignment of diffusion models.
在生成模型中,将预训练的扩散模型适应于推理时间的新目标仍然是一个开放性问题。现有的引导方法存在价值估计不准确的问题,特别是在高噪声水平下,这会导致引导出现偏差。此外,过去运行的信息没有被重新利用来提高样本质量,导致计算使用效率低下。受到蒙特卡洛树搜索成功的启发,我们通过将推理时间对齐转化为一个搜索问题来解决这些限制,该问题可重用过去的计算。我们引入了一种基于树的方法,通过反向传播扩散链中的终端奖励,从奖励对齐的目标密度中进行采样,并随着每一代的增加,通过迭代改进价值估计。我们提出的方法——扩散树采样(DTS)在无限迭代次数的情况下,从目标分布中产生了渐近精确的样本;其贪心变体——扩散树搜索(DTS)则在全球范围内搜索高奖励样本。在MNIST和CIFAR-10的条件类生成中,DTS与表现最佳的基准线相匹配,计算量减少了高达10倍。在文本到图像生成和语言完成任务中,DTS有效地搜索高奖励样本,与最佳N匹配的计算量减少高达5倍。通过重用前几代的信息,我们获得了一种任何时候都可以使用的算法,该算法可将额外的计算转化为更好的样本,为扩散模型在推理时间上的对齐提供了一种可扩展的方法。
论文及项目相关链接
Summary
针对预训练扩散模型在推理阶段适应新目标的问题,现有引导方法存在估值不准确(尤其在高噪声水平下)和信息未有效利用的问题。本文采用蒙特卡罗树搜索的思想,将推理阶段的对齐问题转化为搜索问题,重用过去的计算来提高样本质量。提出的基于树的方法通过反向传播目标密度奖励,迭代优化价值估计,生成渐近精确样本。在MNIST和CIFAR-10分类生成任务上,该方法与最佳基线模型的FID相匹配,计算效率提高10倍。在文本到图像生成和语言补全任务中,通过搜索高奖励样本,与最佳基线模型的匹配度更高,计算效率提高5倍。通过重用之前的计算信息,该算法在额外计算的情况下可生成更好的样本,为扩散模型推理阶段的对齐问题提供了可伸缩的解决方案。
Key Takeaways
- 扩散模型在推理阶段适应新目标时面临挑战,包括估值不准确和信息未有效利用的问题。
- 本文通过蒙特卡罗树搜索思想,将推理阶段的对齐问题转化为搜索问题。
- 引入基于树的方法,通过反向传播目标密度奖励,迭代优化价值估计。
- 提出的方法在MNIST和CIFAR-10分类生成任务上匹配最佳基线模型的FID,计算效率显著提高。
- 在文本到图像生成和语言补全任务中,通过搜索高奖励样本,提高了与最佳基线模型的匹配度。
- 通过重用之前的计算信息,该算法能更有效地生成样本,转化为可伸缩的解决方案。
点此查看论文截图




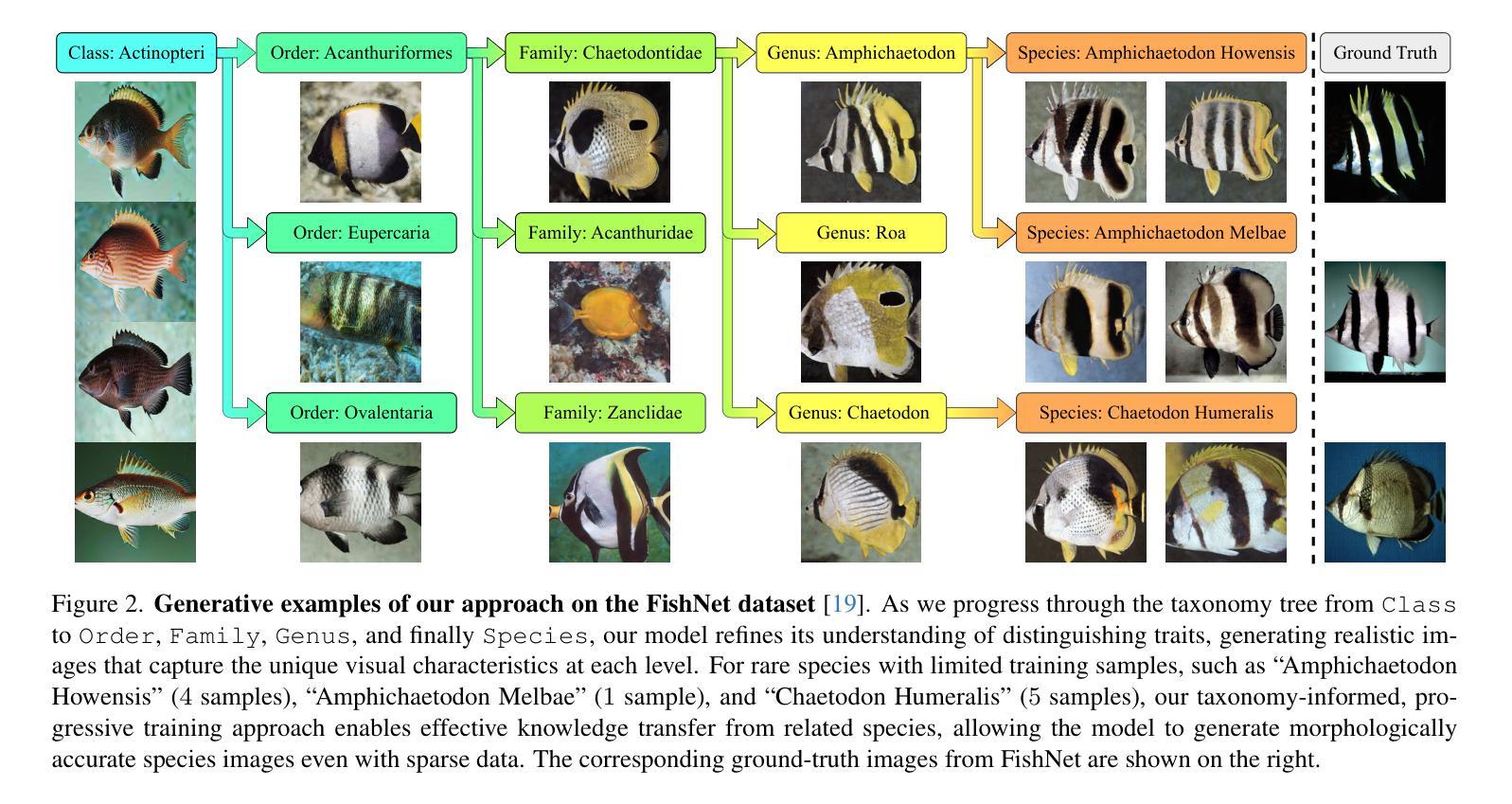
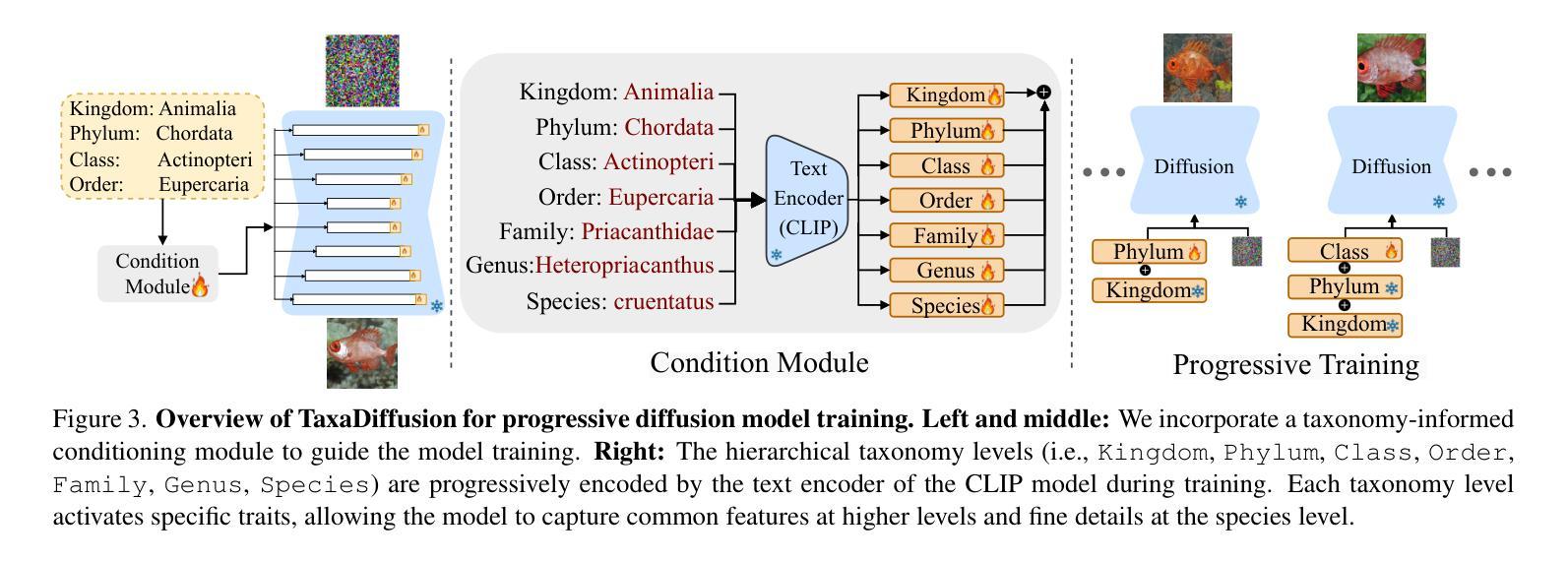
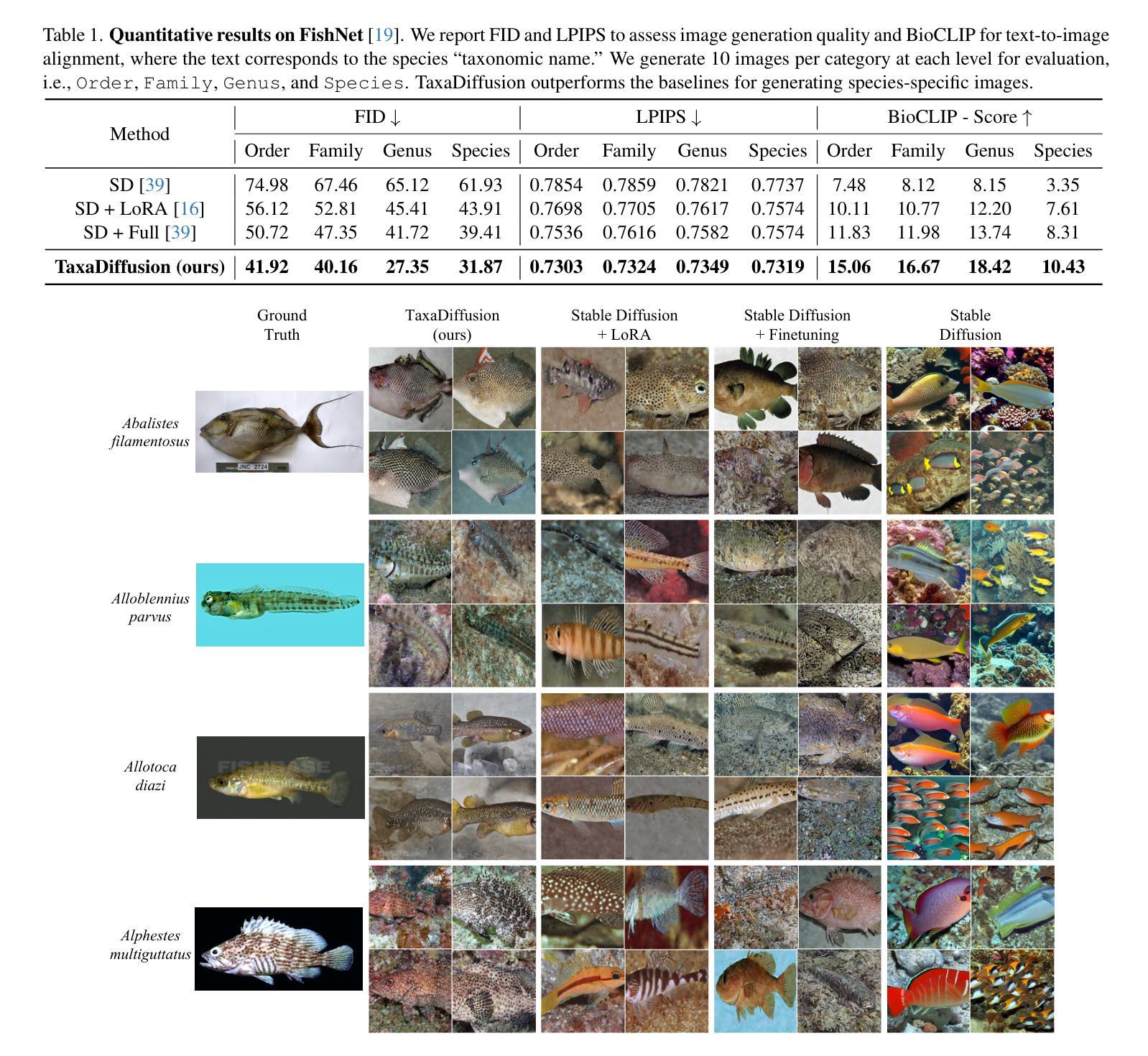
TaxaDiffusion: Progressively Trained Diffusion Model for Fine-Grained Species Generation
Authors:Amin Karimi Monsefi, Mridul Khurana, Rajiv Ramnath, Anuj Karpatne, Wei-Lun Chao, Cheng Zhang
We propose TaxaDiffusion, a taxonomy-informed training framework for diffusion models to generate fine-grained animal images with high morphological and identity accuracy. Unlike standard approaches that treat each species as an independent category, TaxaDiffusion incorporates domain knowledge that many species exhibit strong visual similarities, with distinctions often residing in subtle variations of shape, pattern, and color. To exploit these relationships, TaxaDiffusion progressively trains conditioned diffusion models across different taxonomic levels – starting from broad classifications such as Class and Order, refining through Family and Genus, and ultimately distinguishing at the Species level. This hierarchical learning strategy first captures coarse-grained morphological traits shared by species with common ancestors, facilitating knowledge transfer before refining fine-grained differences for species-level distinction. As a result, TaxaDiffusion enables accurate generation even with limited training samples per species. Extensive experiments on three fine-grained animal datasets demonstrate that outperforms existing approaches, achieving superior fidelity in fine-grained animal image generation. Project page: https://amink8.github.io/TaxaDiffusion/
我们提出了TaxaDiffusion,这是一种针对扩散模型的分类学启发训练框架,用于生成具有高精度形态和身份特征的精细动物图像。不同于标准方法将每个物种视为独立类别的方式,TaxaDiffusion结合了领域知识,即许多物种表现出强烈的视觉相似性,差异通常在于形状、图案和颜色的微妙变化。为了利用这些关系,TaxaDiffusion在不同的分类学层次上逐步训练条件扩散模型——从大类如类和目开始,通过家族和属进行精炼,最终在物种水平上做出区分。这种层次化的学习策略首先捕捉由共同祖先共有的粗粒度形态特征,在细化物种水平的差异之前促进知识转移。因此,即使每个物种的训练样本有限,TaxaDiffusion也能实现准确的生成。在三个精细动物数据集上的广泛实验表明,其性能优于现有方法,在精细动物图像生成方面表现出卓越的效果。项目页面:https://amink8.github.io/TaxaDiffusion/
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary
本文介绍了TaxaDiffusion,一种用于生成精细动物图像的分类学指导的扩散模型训练框架。与传统方法不同,TaxaDiffusion通过在不同分类等级上逐步训练条件扩散模型来利用物种间的视觉相似性。该框架能够从粗粒度分类(如类、目)开始学习,逐渐细化到科、属,并最终达到物种级别。这种层次化的学习策略能够首先捕捉物种之间共同祖先所带来的粗粒度形态特征,然后再区分细微差别,达到物种级别的识别。TaxaDiffusion能够实现在有限的训练样本下生成准确的图像,并在三个精细动物数据集上的实验证明了其优越性。
Key Takeaways
- TaxaDiffusion是一个利用分类学信息的扩散模型训练框架,用于生成精细动物图像。
- 与传统方法不同,TaxaDiffusion通过在不同分类等级上逐步训练模型来利用物种间的视觉相似性。
- TaxaDiffusion采用层次化的学习策略,从粗粒度分类开始,逐渐细化到物种级别。
- 该框架能够捕捉物种之间共同祖先所带来的形态特征,并区分细微差别。
- TaxaDiffusion在有限的训练样本下能够实现准确的图像生成。
- 在三个精细动物数据集上的实验证明了TaxaDiffusion的优越性。
点此查看论文截图

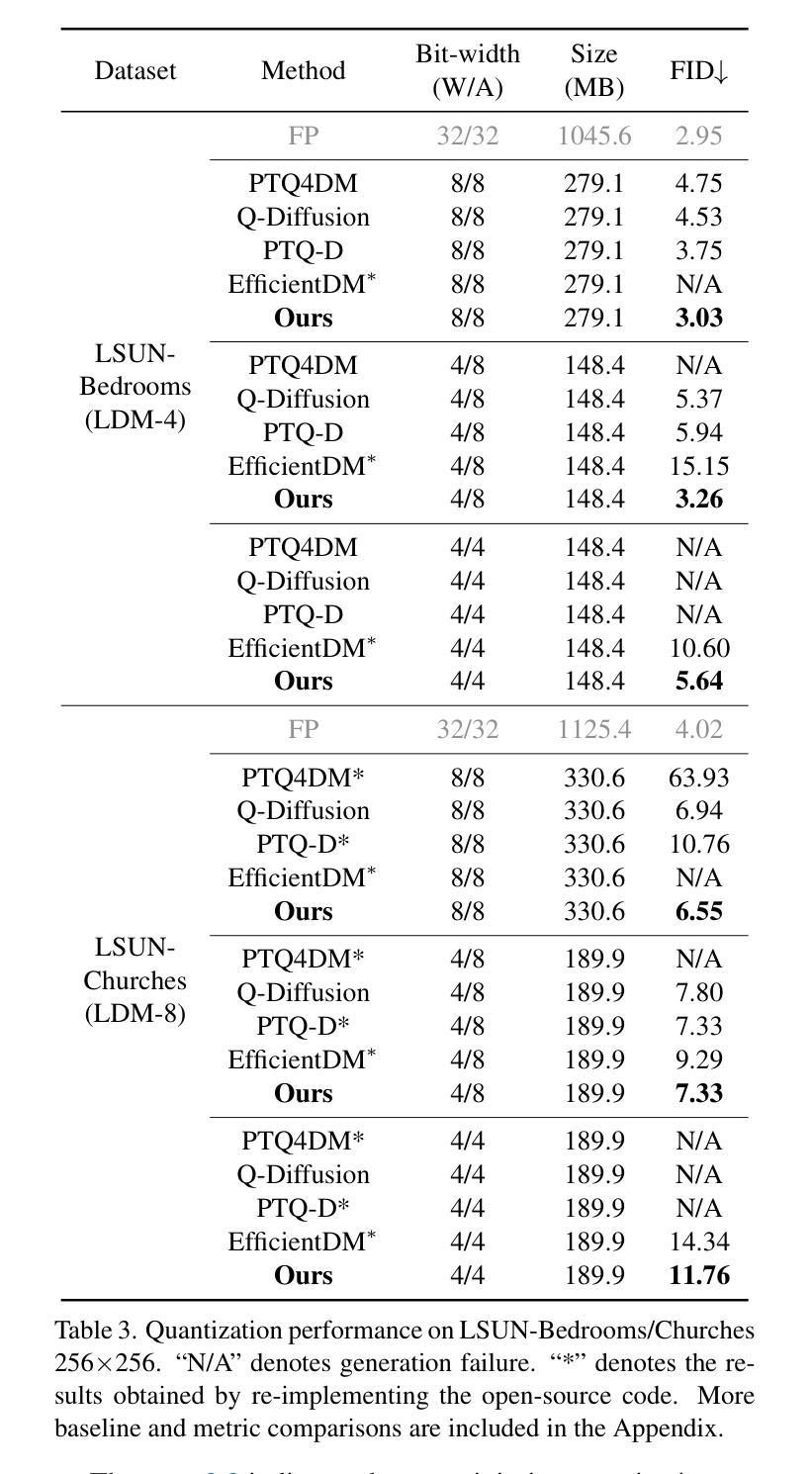
QuEST: Low-bit Diffusion Model Quantization via Efficient Selective Finetuning
Authors:Haoxuan Wang, Yuzhang Shang, Zhihang Yuan, Junyi Wu, Junchi Yan, Yan Yan
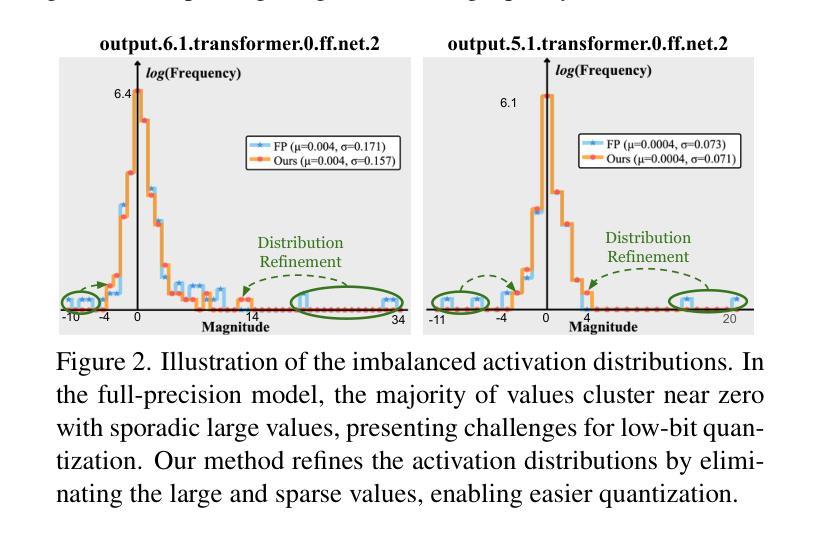
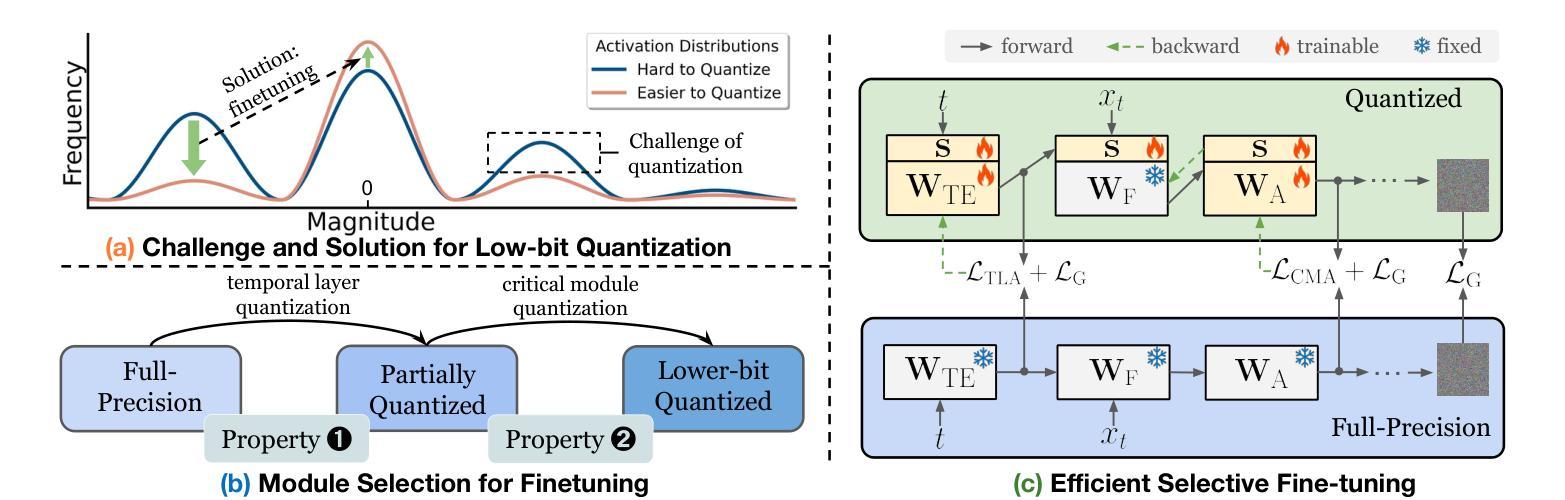
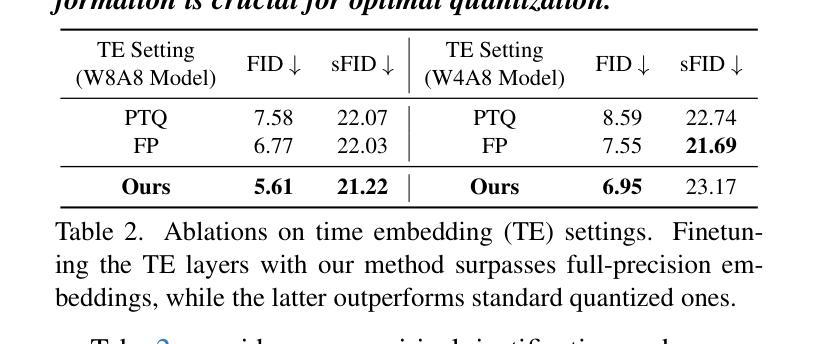
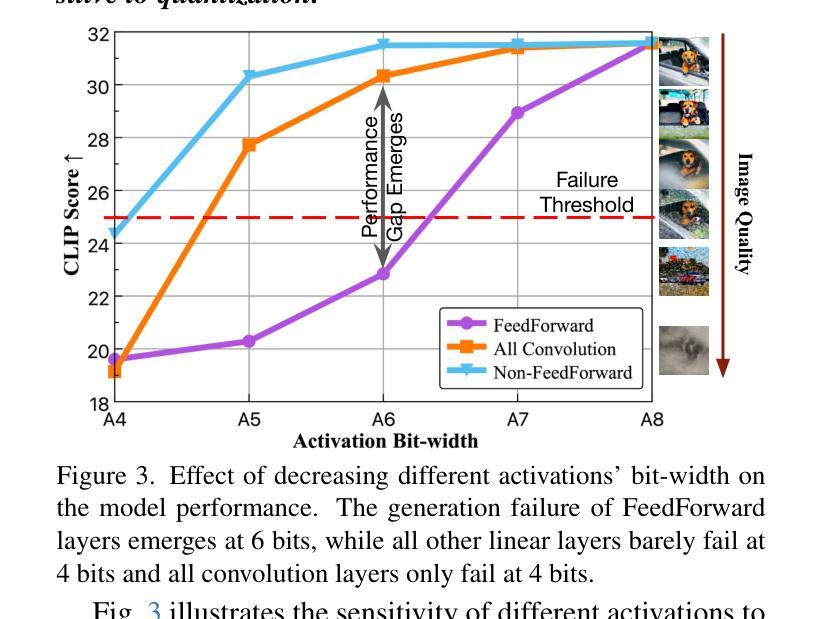
The practical deployment of diffusion models is still hindered by the high memory and computational overhead. Although quantization paves a way for model compression and acceleration, existing methods face challenges in achieving low-bit quantization efficiently. In this paper, we identify imbalanced activation distributions as a primary source of quantization difficulty, and propose to adjust these distributions through weight finetuning to be more quantization-friendly. We provide both theoretical and empirical evidence supporting finetuning as a practical and reliable solution. Building on this approach, we further distinguish two critical types of quantized layers: those responsible for retaining essential temporal information and those particularly sensitive to bit-width reduction. By selectively finetuning these layers under both local and global supervision, we mitigate performance degradation while enhancing quantization efficiency. Our method demonstrates its efficacy across three high-resolution image generation tasks, obtaining state-of-the-art performance across multiple bit-width settings.
扩散模型的实际应用仍然受到高内存和计算开销的阻碍。尽管量化可以为模型压缩和加速铺平道路,但现有方法在实现低位量化时面临挑战。在本文中,我们识别出失衡的激活分布是量化的主要困难来源,并提出通过权重微调调整这些分布,使其更利于量化。我们提供了理论和实证证据,支持微调作为一种实用可靠的解决方案。在此基础上,我们进一步区分了两种关键的量化层:那些负责保留重要时间信息的层和那些对位宽减少特别敏感的层。通过局部和全局监督下有选择地对这些层进行微调,我们在提高量化效率的同时缓解了性能下降。我们的方法在三高分辨率图像生成任务中证明了其有效性,并在多个位宽设置下获得了最先进的性能。
论文及项目相关链接
PDF ICCV 2025. Code is available at https://github.com/hatchetProject/QuEST
Summary
本文探讨扩散模型的实用部署中面临的高内存和计算开销问题。针对现有量化方法面临的挑战,提出通过权重微调调整不平衡激活分布以实现友好量化。本文在理论支撑的同时进行实证研究验证微调方法的有效性和可靠性。通过选择性微调量化层,在本地和全局监督下提高量化效率并降低性能下降的风险。该方法在三项高分辨率图像生成任务中表现卓越,在不同位宽设置下均达到最新技术水平。
Key Takeaways
- 扩散模型部署面临高内存和计算开销问题。
- 现有量化方法面临实现低比特量化的挑战。
- 不平衡的激活分布是量化困难的主要原因之一。
- 通过权重微调调整激活分布以实现友好量化。
- 提出了选择性微调特定量化层的方法,以提高量化效率和性能。
- 方法在三个高分辨率图像生成任务中表现优越。
点此查看论文截图