⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-28 更新
TCDiff++: An End-to-end Trajectory-Controllable Diffusion Model for Harmonious Music-Driven Group Choreography
Authors:Yuqin Dai, Wanlu Zhu, Ronghui Li, Xiu Li, Zhenyu Zhang, Jun Li, Jian Yang
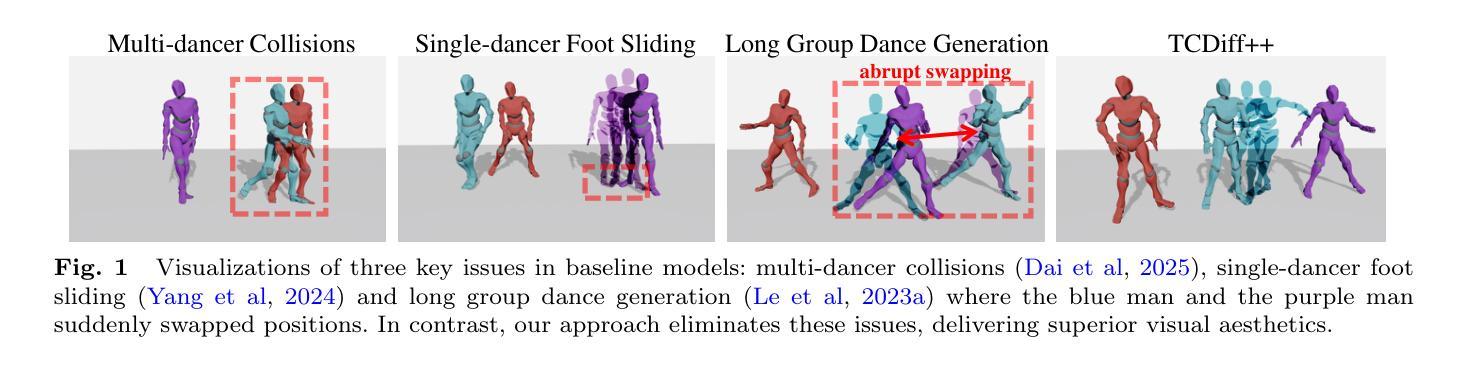
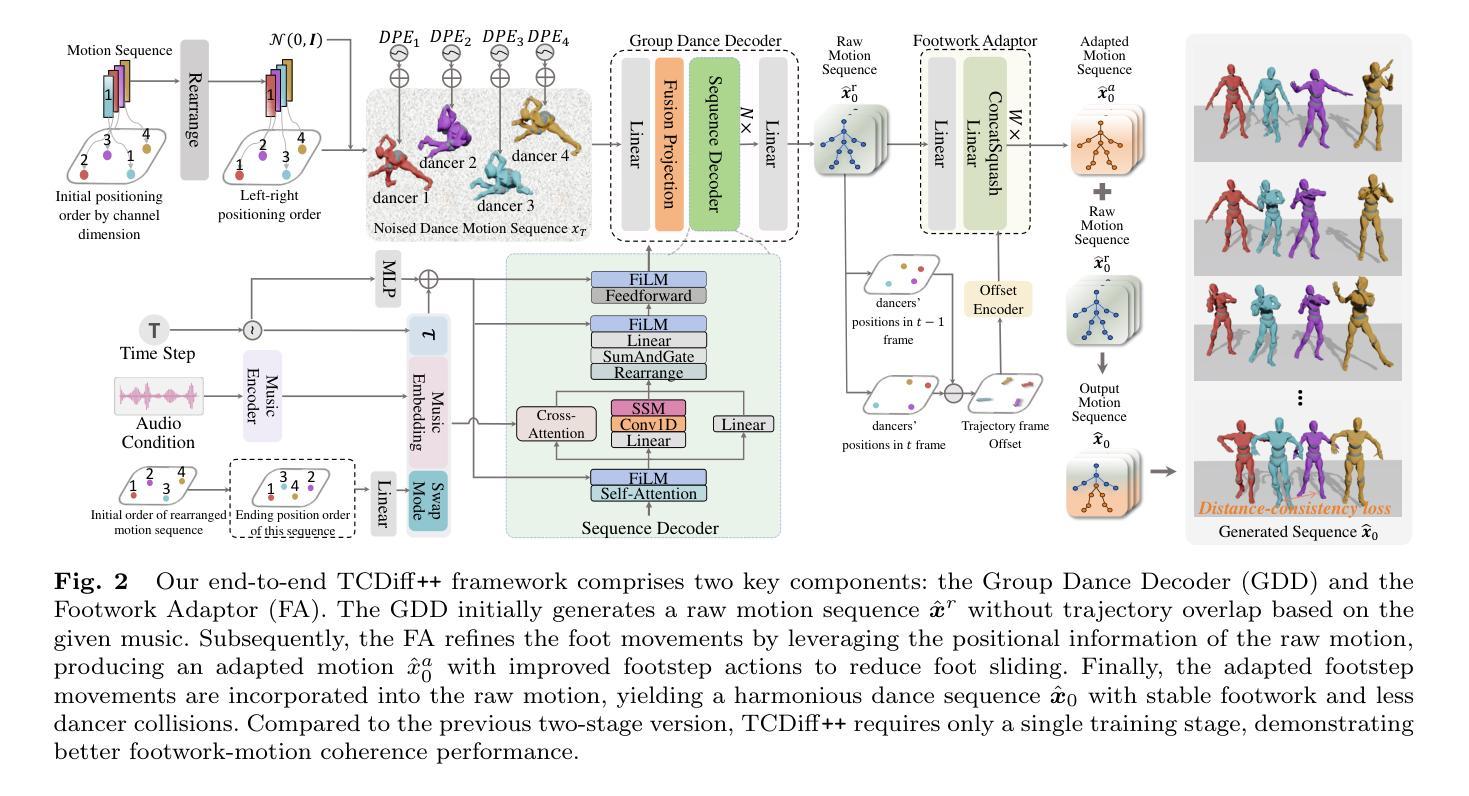
Music-driven dance generation has garnered significant attention due to its wide range of industrial applications, particularly in the creation of group choreography. During the group dance generation process, however, most existing methods still face three primary issues: multi-dancer collisions, single-dancer foot sliding and abrupt swapping in the generation of long group dance. In this paper, we propose TCDiff++, a music-driven end-to-end framework designed to generate harmonious group dance. Specifically, to mitigate multi-dancer collisions, we utilize a dancer positioning embedding to better maintain the relative positioning among dancers. Additionally, we incorporate a distance-consistency loss to ensure that inter-dancer distances remain within plausible ranges. To address the issue of single-dancer foot sliding, we introduce a swap mode embedding to indicate dancer swapping patterns and design a Footwork Adaptor to refine raw motion, thereby minimizing foot sliding. For long group dance generation, we present a long group diffusion sampling strategy that reduces abrupt position shifts by injecting positional information into the noisy input. Furthermore, we integrate a Sequence Decoder layer to enhance the model’s ability to selectively process long sequences. Extensive experiments demonstrate that our TCDiff++ achieves state-of-the-art performance, particularly in long-duration scenarios, ensuring high-quality and coherent group dance generation.
音乐驱动的舞蹈生成因其广泛的工业应用而受到广泛关注,特别是在群体舞蹈创作领域。然而,在群体舞蹈生成过程中,大多数现有方法仍然面临三个主要问题:舞者间的碰撞、单一舞者的足部滑动以及在长群体舞蹈生成中的突然替换。在本文中,我们提出了TCDiff++,这是一个音乐驱动端到端的框架,旨在生成和谐的群体舞蹈。具体来说,为了减少舞者间的碰撞,我们利用舞者定位嵌入来更好地保持舞者之间的相对位置。此外,我们引入了一个距离一致性损失,以确保舞者之间的距离保持在合理的范围内。为了解决单一舞者的足部滑动问题,我们引入了替换模式嵌入来表示舞者的替换模式,并设计了一个足部适配器来优化原始运动,从而最小化足部滑动。对于长群体舞蹈的生成,我们提出了一种长组扩散采样策略,通过向噪声输入中注入位置信息来减少突然的位移。此外,我们集成了一个序列解码层,以提高模型处理长序列的选择性能力。大量实验表明,我们的TCDiff++达到了最先进的性能,特别是在长时间场景中,确保了高质量和连贯的群体舞蹈生成。
论文及项目相关链接
Summary
本文提出了一种音乐驱动端到端的框架TCDiff++,用于生成和谐群体舞蹈。该框架通过舞者定位嵌入、距离一致性损失、交换模式嵌入、足工作适配器和长组扩散采样策略等技术解决了群体舞蹈生成过程中的舞者碰撞、单个舞者足部滑动以及长群体舞蹈生成中的突兀交换问题。实验证明,TCDiff++在长时间场景下实现了卓越的性能,确保了高质量和连贯的群体舞蹈生成。
Key Takeaways
- 音乐驱动舞蹈生成技术受到广泛关注,尤其在群体舞蹈创作中。
- 现有方法面临舞者碰撞、单个舞者足部滑动和长群体舞蹈中的突兀交换问题。
- TCDiff++框架通过舞者定位嵌入和距离一致性损失减轻舞者碰撞问题。
- 交换模式嵌入和足工作适配器用于解决单个舞者足部滑动问题。
- 长组扩散采样策略和序列解码层提高了长群体舞蹈生成的连贯性和质量。
- TCDiff++在长时间场景下的性能卓越,确保了高质量和连贯的群体舞蹈生成。
点此查看论文截图