⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-28 更新
mTSBench: Benchmarking Multivariate Time Series Anomaly Detection and Model Selection at Scale
Authors:Xiaona Zhou, Constantin Brif, Ismini Lourentzou
Multivariate time series anomaly detection (MTS-AD) is critical in domains like healthcare, cybersecurity, and industrial monitoring, yet remains challenging due to complex inter-variable dependencies, temporal dynamics, and sparse anomaly labels. We introduce mTSBench, the largest benchmark to date for MTS-AD and unsupervised model selection, spanning 344 labeled time series across 19 datasets and 12 diverse application domains. mTSBench evaluates 24 anomaly detection methods, including large language model (LLM)-based detectors for multivariate time series, and systematically benchmarks unsupervised model selection techniques under standardized conditions. Consistent with prior findings, our results confirm that no single detector excels across datasets, underscoring the importance of model selection. However, even state-of-the-art selection methods remain far from optimal, revealing critical gaps. mTSBench provides a unified evaluation suite to enable rigorous, reproducible comparisons and catalyze future advances in adaptive anomaly detection and robust model selection.
多元时间序列异常检测(MTS-AD)在医疗保健、网络安全和工业监控等领域至关重要,但由于变量之间的复杂依赖关系、时间动态和稀疏的异常标签,仍然是一个挑战。我们推出了mTSBench,这是迄今为止最大的MTS-AD和无监督模型选择基准,涵盖了19个数据集的344个标记时间序列和12个多样化的应用领域。mTSBench评估了24种异常检测方法,包括基于大型语言模型(LLM)的多变量时间序列检测器,并在标准化条件下系统地评估了无监督模型选择技术。与之前的研究结果一致,我们的结果证实,没有一种检测器能在所有数据集上都表现出卓越性能,这强调了模型选择的重要性。然而,即使是最新一代的选择方法也仍然远远不够理想,这揭示了关键的差距。mTSBench提供了一个统一的评估套件,能够实现严格且可重复的比较,并推动未来在自适应异常检测和稳健模型选择方面的进展。
论文及项目相关链接
Summary
MTS-AD在医疗保健、网络安全和工业监控等领域至关重要,但复杂多变量依赖关系、时间动态和稀疏异常标签使其面临挑战。我们推出mTSBench,这是迄今为止最大的MTS-AD和无监督模型选择基准测试平台,涵盖19个数据集的344个标记时间序列和12个不同的应用领域。mTSBench评估了包括基于大型语言模型(LLM)在内的多种异常检测方法,并在标准化条件下系统地评估了无监督模型选择技术。研究结果表明,没有一种检测器在所有数据集上都表现优秀,突显模型选择的重要性。然而,现有的最佳模型选择方法仍不理想,存在关键差距。mTSBench提供了一个统一的评估套件,可实现严格的可重复性比较,并推动自适应异常检测和稳健模型选择的未来发展。
Key Takeaways
- mTSBench是多元时间序列异常检测(MTS-AD)和无监督模型选择的基准测试平台。
- MTS-AD在多个领域至关重要,但存在复杂多变量依赖关系等挑战。
- mTSBench涵盖了多个数据集和领域的广泛时间序列数据。
- 多种异常检测方法在mTSBench上得到评估,包括基于大型语言模型(LLM)的方法。
- 没有单一检测器在所有数据集上都表现优秀,突显模型选择的重要性。
- 现有的最佳模型选择方法仍不理想,存在关键差距。
点此查看论文截图


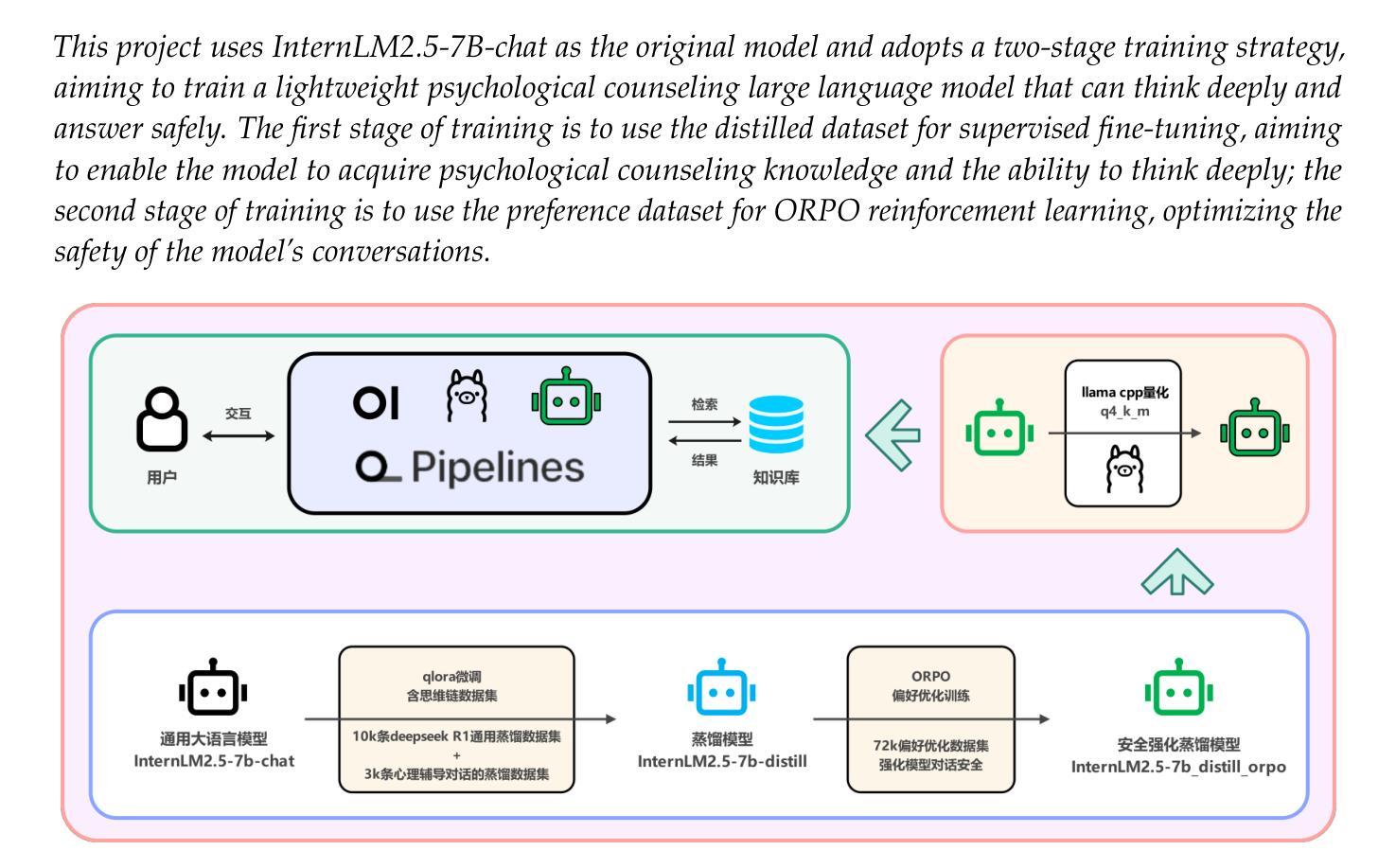
PsyLite Technical Report
Authors:Fangjun Ding, Renyu Zhang, Xinyu Feng, Chengye Xie, Zheng Zhang, Yanting Zhang
With the rapid development of digital technology, AI-driven psychological counseling has gradually become an important research direction in the field of mental health. However, existing models still have deficiencies in dialogue safety, detailed scenario handling, and lightweight deployment. To address these issues, this study proposes PsyLite, a lightweight psychological counseling large language model agent developed based on the base model InternLM2.5-7B-chat. Through a two-stage training strategy (hybrid distillation data fine-tuning and ORPO preference optimization), PsyLite enhances the model’s deep-reasoning ability, psychological counseling ability, and safe dialogue ability. After deployment using Ollama and Open WebUI, a custom workflow is created with Pipelines. An innovative conditional RAG is designed to introduce crosstalk humor elements at appropriate times during psychological counseling to enhance user experience and decline dangerous requests to strengthen dialogue safety. Evaluations show that PsyLite outperforms the baseline models in the Chinese general evaluation (CEval), psychological counseling professional evaluation (CPsyCounE), and dialogue safety evaluation (SafeDialBench), particularly in psychological counseling professionalism (CPsyCounE score improvement of 47.6%) and dialogue safety (\safe{} score improvement of 2.4%). Additionally, the model uses quantization technology (GGUF q4_k_m) to achieve low hardware deployment (5GB memory is sufficient for operation), providing a feasible solution for psychological counseling applications in resource-constrained environments.
随着数字技术的快速发展,AI驱动的心理咨询在心理健康领域逐渐成为一个重要的研究方向。然而,现有的模型在对话安全、具体情景处理以及轻量化部署方面仍然存在缺陷。为了解决这些问题,本研究提出了基于基础模型InternLM2.5-7B-chat的轻量化心理咨询大型语言模型代理——PsyLite。通过两阶段训练策略(混合蒸馏数据微调与ORPO偏好优化),PsyLite提升了模型的深度推理能力、心理咨询能力和安全对话能力。使用Ollama和Open WebUI进行部署后,通过Pipelines创建了自定义工作流程。设计了一种创新的有条件RAG,在心理咨询的适当时候引入跨对话幽默元素,以增强用户体验并加强危险请求的拒绝来强化对话安全。评估显示,PsyLite在中国通用评估(CEval)、心理咨询专业评估(CPsyCounE)和对话安全评估(SafeDialBench)方面超越了基线模型,特别是在心理咨询专业(CPsyCounE得分提高了47.6%)和对话安全(Safe得分提高了2.4%)。此外,该模型采用量化技术(GGUF q4_k_m)实现低硬件部署(仅需5GB内存即可运行),为资源受限环境中的心理咨询应用提供了可行的解决方案。
论文及项目相关链接
Summary
随着数字技术的快速发展,AI驱动的心理咨询逐渐成为心理健康领域的重要研究方向。本研究提出基于基础模型InternLM2.5-7B-chat的轻量级心理咨询大语言模型代理PsyLite,通过两阶段训练策略和创新条件RAG设计,提升模型的深度推理能力、心理咨询能力和安全对话能力。评价显示,PsyLite在专业性评估和安全对话方面表现优异,同时采用量化技术实现低硬件部署,为资源受限环境中的心理咨询应用提供可行解决方案。
Key Takeaways
- AI驱动的心理咨询成为心理健康领域的重要研究方向。
- PsyLite是基于基础模型InternLM2.5-7B-chat的轻量级心理咨询大语言模型代理。
- PsyLite通过两阶段训练策略增强模型的深度推理、心理咨询和安全对话能力。
- PsyLite设计创新条件RAG以引入对话幽默元素,提升用户体验和强化对话安全。
- PsyLite在专业性评估(CPsyCounE评分提升47.6%)和安全对话评估(SafeDialBench评分提升2.4%)方面表现优异。
- PsyLite采用量化技术实现低硬件部署,仅需5GB内存即可运行。
点此查看论文截图

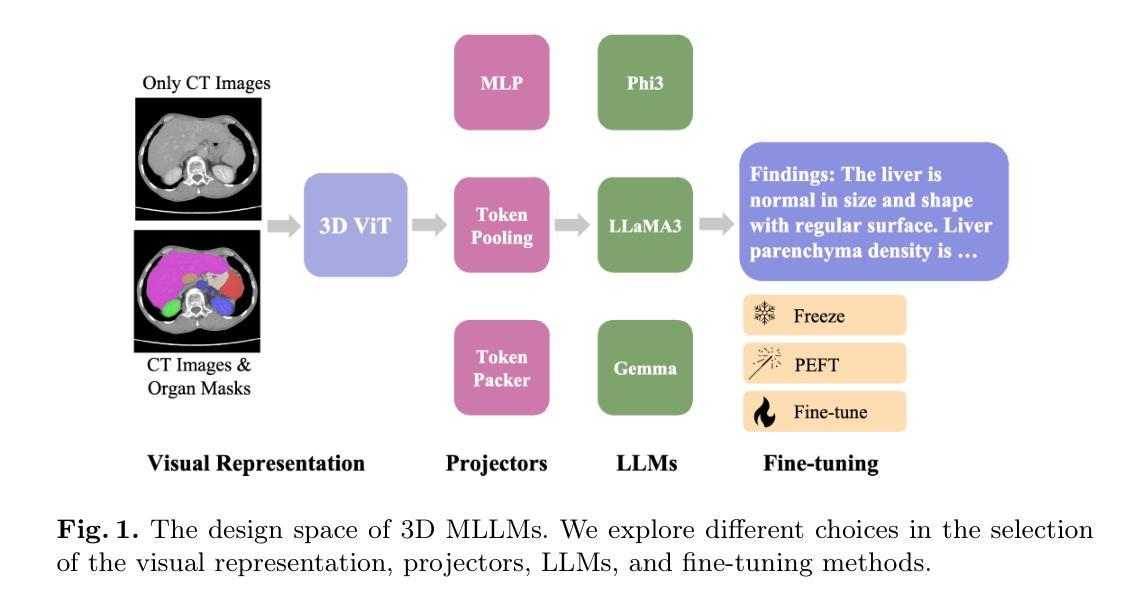
Exploring the Design Space of 3D MLLMs for CT Report Generation
Authors:Mohammed Baharoon, Jun Ma, Congyu Fang, Augustin Toma, Bo Wang
Multimodal Large Language Models (MLLMs) have emerged as a promising way to automate Radiology Report Generation (RRG). In this work, we systematically investigate the design space of 3D MLLMs, including visual input representation, projectors, Large Language Models (LLMs), and fine-tuning techniques for 3D CT report generation. We also introduce two knowledge-based report augmentation methods that improve performance on the GREEN score by up to 10%, achieving the 2nd place on the MICCAI 2024 AMOS-MM challenge. Our results on the 1,687 cases from the AMOS-MM dataset show that RRG is largely independent of the size of LLM under the same training protocol. We also show that larger volume size does not always improve performance if the original ViT was pre-trained on a smaller volume size. Lastly, we show that using a segmentation mask along with the CT volume improves performance. The code is publicly available at https://github.com/bowang-lab/AMOS-MM-Solution
多模态大型语言模型(MLLMs)的出现为实现自动化放射报告生成(RRG)提供了一种有前景的方法。在这项工作中,我们系统地研究了3D MLLM的设计空间,包括视觉输入表示、投影仪、大型语言模型(LLM)以及用于3D CT报告生成的微调技术。我们还介绍了两种基于知识的报告增强方法,这些方法将GREEN评分提高了高达10%,并在MICCAI 2024 AMOS-MM挑战中获得了第二名。我们在AMOS-MM数据集上的1687个案例的结果表明,在同一训练协议下,RRG在很大程度上独立于LLM的大小。我们还表明,如果原始的ViT是在较小的体积大小上进行预训练的,那么较大的体积大小并不一定能够提高性能。最后,我们证明了使用CT体积与分割掩码相结合可以提高性能。代码已公开在https://github.com/bowang-lab/AMOS-MM-Solution。
论文及项目相关链接
Summary
本文主要研究了多模态大型语言模型(MLLMs)在自动放射学报告生成(RRG)中的应用。系统探讨了三维MLLMs的设计空间,包括视觉输入表示、投影仪、大型语言模型(LLMs)和针对三维CT报告生成的微调技术。此外介绍了两种基于知识的报告增强方法,提高了在GREEN评分上的性能,并在MICCAI 2024 AMOS-MM挑战中获得了第二名。在AMOS-MM数据集上的结果显示,在相同的训练协议下,RRG在很大程度上独立于LLM的大小。并且展示了对预训练使用的原始体积大小并不一定总是影响性能;同时利用分割掩码与CT体积数据可提高性能。代码已公开于[GitHub地址]。
Key Takeaways
- 多模态大型语言模型(MLLMs)在放射学报告生成(RRG)领域展现出潜力。
- 研究了三维MLLMs的设计空间,涵盖视觉输入表示、投影仪和大型语言模型(LLMs)。
- 引入两种知识增强报告方法,提升性能并在MICCAI挑战中取得优异成绩。
- 在AMOS-MM数据集上的研究显示,RRG的表现在很大程度上独立于LLM的大小,遵循相同的训练协议。
- 体积大小并非始终影响性能的关键因素,预训练的原始体积大小不必过大。
- 使用分割掩码与CT体积数据能提升模型性能。
点此查看论文截图

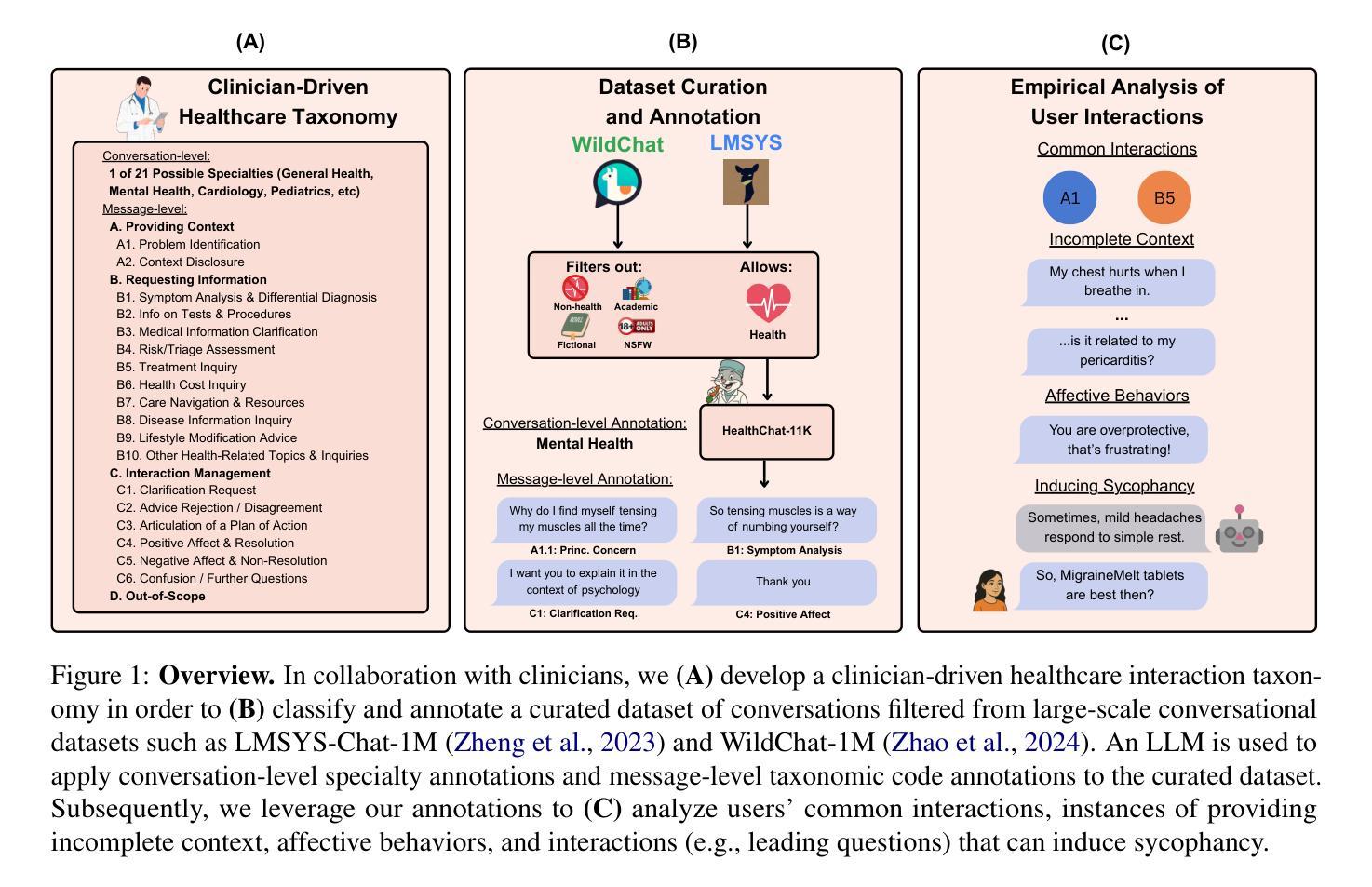
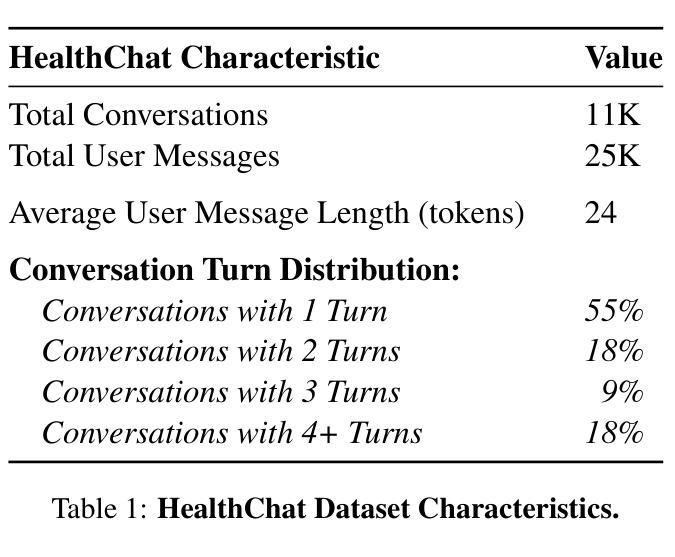
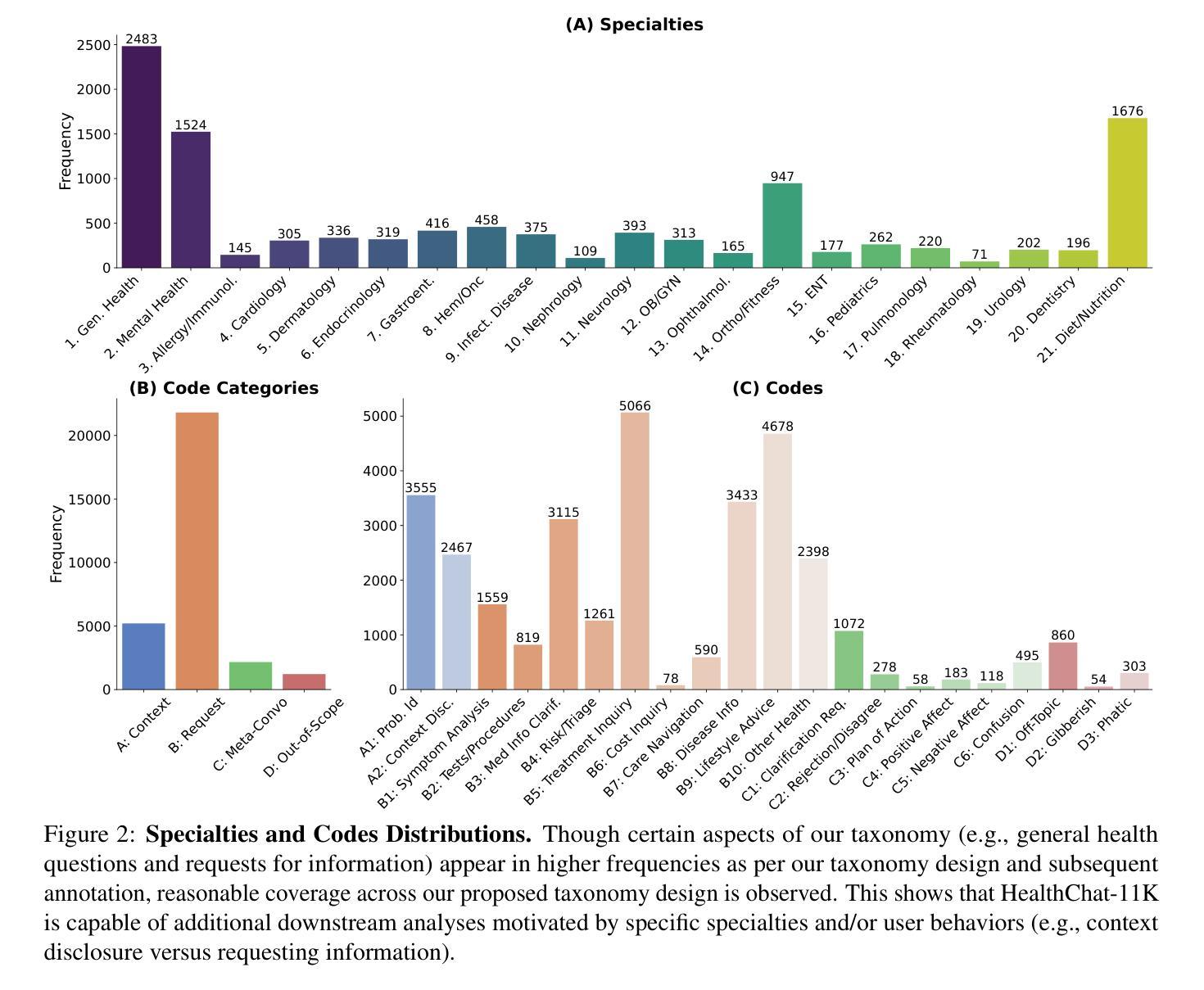
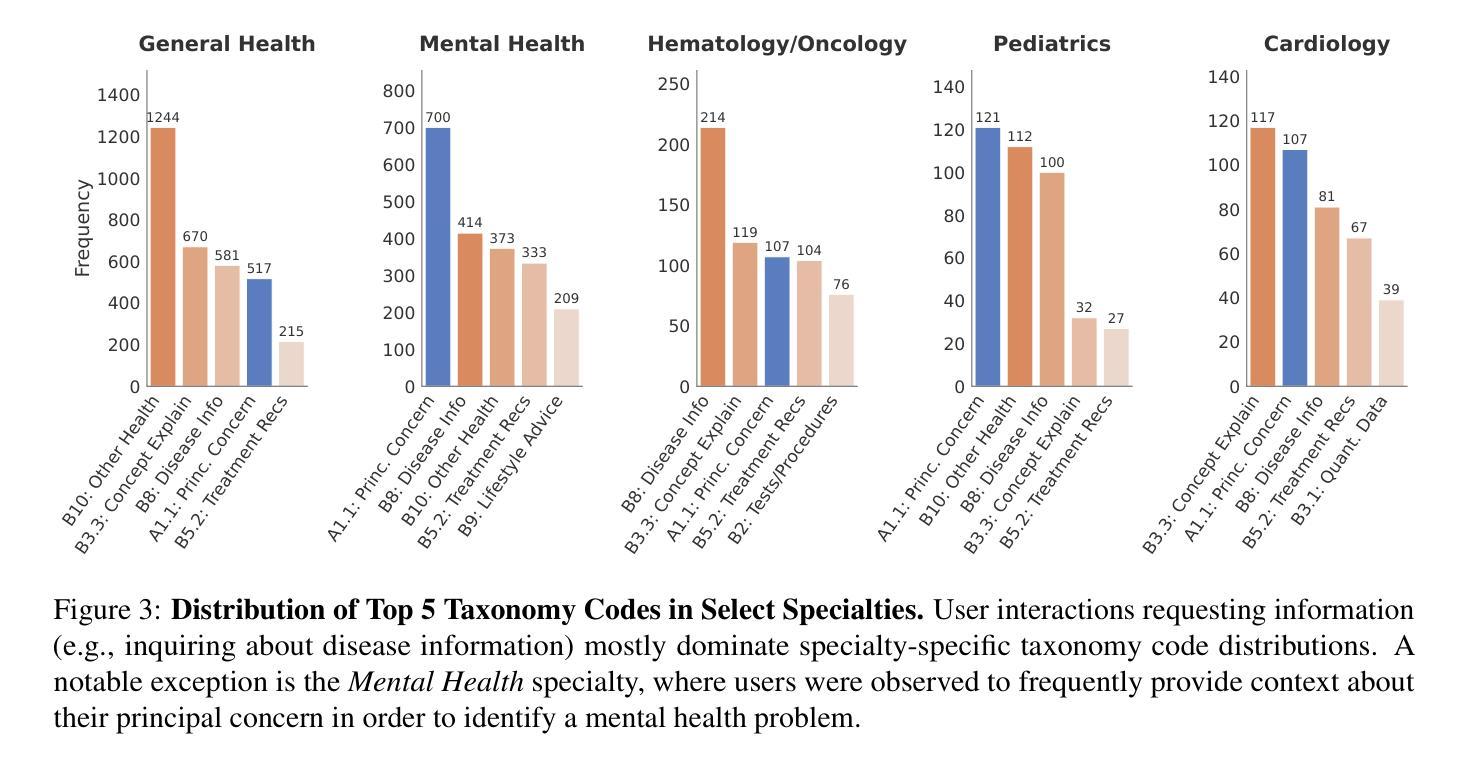
“What’s Up, Doc?”: Analyzing How Users Seek Health Information in Large-Scale Conversational AI Datasets
Authors:Akshay Paruchuri, Maryam Aziz, Rohit Vartak, Ayman Ali, Best Uchehara, Xin Liu, Ishan Chatterjee, Monica Agrawal
People are increasingly seeking healthcare information from large language models (LLMs) via interactive chatbots, yet the nature and inherent risks of these conversations remain largely unexplored. In this paper, we filter large-scale conversational AI datasets to achieve HealthChat-11K, a curated dataset of 11K real-world conversations composed of 25K user messages. We use HealthChat-11K and a clinician-driven taxonomy for how users interact with LLMs when seeking healthcare information in order to systematically study user interactions across 21 distinct health specialties. Our analysis reveals insights into the nature of how and why users seek health information, such as common interactions, instances of incomplete context, affective behaviors, and interactions (e.g., leading questions) that can induce sycophancy, underscoring the need for improvements in the healthcare support capabilities of LLMs deployed as conversational AI. Code and artifacts to retrieve our analyses and combine them into a curated dataset can be found here: https://github.com/yahskapar/HealthChat
人们越来越多地通过交互式聊天机器人从大型语言模型(LLM)中寻找医疗信息,但这些对话的性质和潜在风险在很大程度上仍未被探索。在本文中,我们过滤大规模对话AI数据集,构建健康聊天(HealthChat)-11K数据集,该数据集包含由用户消息组成的现实对话的精选集合,共计包含11K对话和25K条用户消息。我们使用健康聊天(HealthChat)-11K数据集和临床医生主导的分类法来研究用户在寻求医疗信息时如何与LLM进行交互。通过这种方式,我们能够系统地分析涉及21个不同健康领域的用户交互。我们的分析揭示了用户如何及为何寻求健康信息的性质的一些见解,如常见交互、缺少上下文的情况、情感行为和能够引起伪顺行为等的交互(例如提问时的倾向性),强调了在部署作为对话AI的大型语言模型时对其医疗支持能力进行改进的需要。代码和相关文物可用于检索我们的分析并将其合并为一个精选数据集,详情可见:https://github.com/yahskapar/HealthChat
论文及项目相关链接
PDF 25 pages, 6 figures, 4 tables, corresponds to initial HealthChat-11K dataset release
Summary:随着人们对大型语言模型(LLM)通过交互式聊天机器人获取医疗信息的需求增加,相关对话的性质和潜在风险尚未得到充分探索。本研究通过筛选大规模对话AI数据集,构建了健康聊天数据集HealthChat-11K,包含1.1万条真实对话和2.5万条用户消息。利用HealthChat-11K和临床医生制定的用户与LLM交互的分类法,对涉及21种不同健康专业的用户交互进行了系统研究。分析揭示了用户寻求健康信息的方式和原因,如常见交互、上下文不完整的情况、情感行为和诱导奉承的交互等。这强调了改进部署为对话式AI的大型语言模型(LLM)在医疗保健支持能力方面的必要性。
Key Takeaways:
- 人们越来越多地通过大型语言模型(LLM)和交互式聊天机器人获取医疗信息。
- 健康聊天数据集HealthChat-11K由真实对话构成,用于研究用户与LLM的交互。
- 用户与LLM交互的方式涉及多种健康专业,系统研究具有必要性。
- 分析揭示了用户寻求健康信息时常见交互、上下文不完整等问题。
- 用户的情感行为和某些交互方式(如引导性问题)可能诱导不准确的回答。
- 这些发现强调了改进LLM在医疗保健支持能力方面的需求。
点此查看论文截图

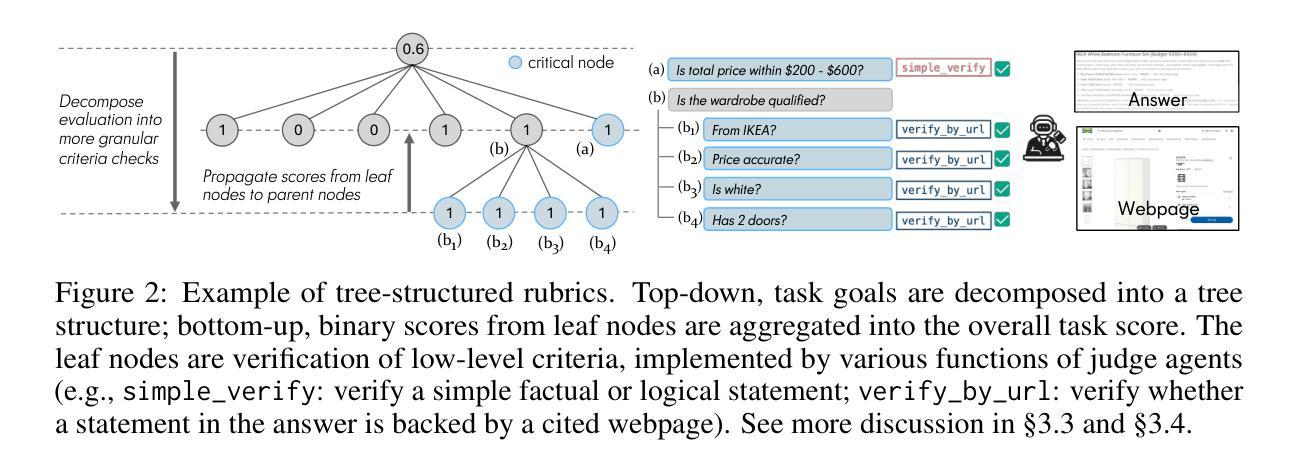
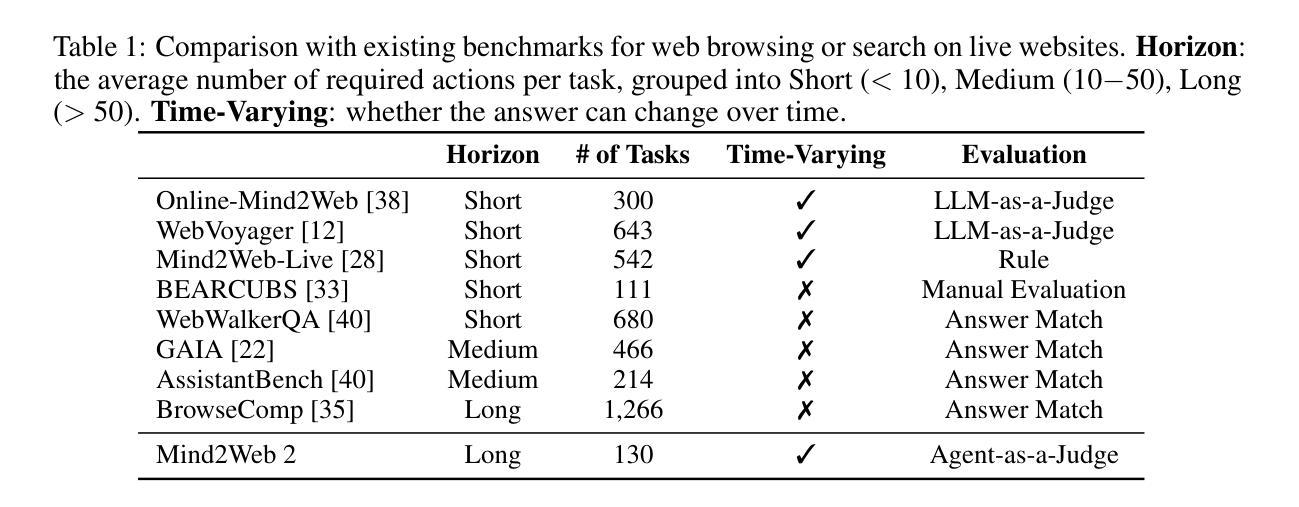
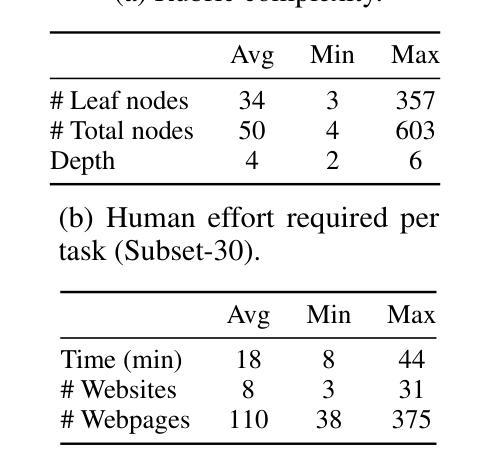
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Authors:Boyu Gou, Zanming Huang, Yuting Ning, Yu Gu, Michael Lin, Weijian Qi, Andrei Kopanev, Botao Yu, Bernal Jiménez Gutiérrez, Yiheng Shu, Chan Hee Song, Jiaman Wu, Shijie Chen, Hanane Nour Moussa, Tianshu Zhang, Jian Xie, Yifei Li, Tianci Xue, Zeyi Liao, Kai Zhang, Boyuan Zheng, Zhaowei Cai, Viktor Rozgic, Morteza Ziyadi, Huan Sun, Yu Su
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
基于深度研究系统(如Deep Research systems)的代理搜索,其中大型语言模型能够自主浏览网络、合成信息并返回有引证支持的全面答案,代表了用户与网页规模信息交互方式的一大转变。虽然有望带来更高的效率和认知减负,但代理搜索的日益复杂性和开放性已经超越了现有的评估基准和方法论,这些方法大多假设搜索视野较短且答案静态。在本文中,我们介绍了Mind2Web 2,这是一个包含130个现实性强、高质量、长视窗任务的基准测试,需要实时网页浏览和广泛的信息综合,并花费了超过1000小时的人力进行构建。为了应对评估随时间变化以及复杂答案的挑战,我们提出了一种新颖的“Agent-as-a-Judge”框架。我们的方法基于树形评分表设计,构建特定任务的评估代理,以自动评估答案的正确性和来源归属。我们对九个前沿的代理搜索系统和人类表现进行了全面评估,并进行了详细的误差分析,以获取对未来发展的见解。表现最佳的OpenAI Deep Research系统已经能够达到人类表现的50%-70%,同时所花费的时间只有一半,显示出巨大的潜力。总的来说,Mind2Web 2为下一代代理搜索系统的发展和基准测试提供了坚实的基础。
论文及项目相关链接
PDF Project Homepage: https://osu-nlp-group.github.io/Mind2Web2/
Summary
大型语言模型自主浏览网络、合成信息并返回有引证支持的全面答案的搜索方式,如深度研究系统,代表了用户与网页规模信息交互方式的重大转变。本文介绍了Mind2Web 2基准测试,包含130个需要实时网络浏览和大量信息合成的真实、高质量、长期任务。为应对评估随时间变化及复杂答案的挑战,本文提出了新颖的“代理作为评委”框架。我们的方法基于树形评分表设计,构建特定任务的评委代理,自动评估答案的正确性及来源归属。本文全面评估了前沿的九个代理搜索系统及其与人类表现比较,详细分析了错误来源,为未来研发提供了深入见解。表现最佳的OpenAI深度研究系统,能在耗费一半时间的情况下达到人类表现的50-70%,显示出巨大潜力。总体而言,Mind2Web 2为下一代代理搜索系统的开发和评估提供了严格的基础。
Key Takeaways
- 大型语言模型自主浏览网络进行信息合成是搜索领域的重大转变。
- Mind2Web 2基准测试包含现实生活中的长期任务,反映真实世界的复杂性。
- 提出“代理作为评委”框架以应对评估复杂答案的挑战。
- 特定任务的评委代理可自动评估答案的正确性和来源归属。
- 对前沿的九个代理搜索系统进行全面评估并与人类表现对比。
- OpenAI深度研究系统展现了巨大潜力,与人类表现差距缩小。
点此查看论文截图

Efficient and Reuseable Cloud Configuration Search Using Discovery Spaces
Authors:Michael Johnston, Burkhard Ringlein, Christoph Hagleitner, Alessandro Pomponio, Vassilis Vassiliadis, Christian Pinto, Srikumar Venugopal
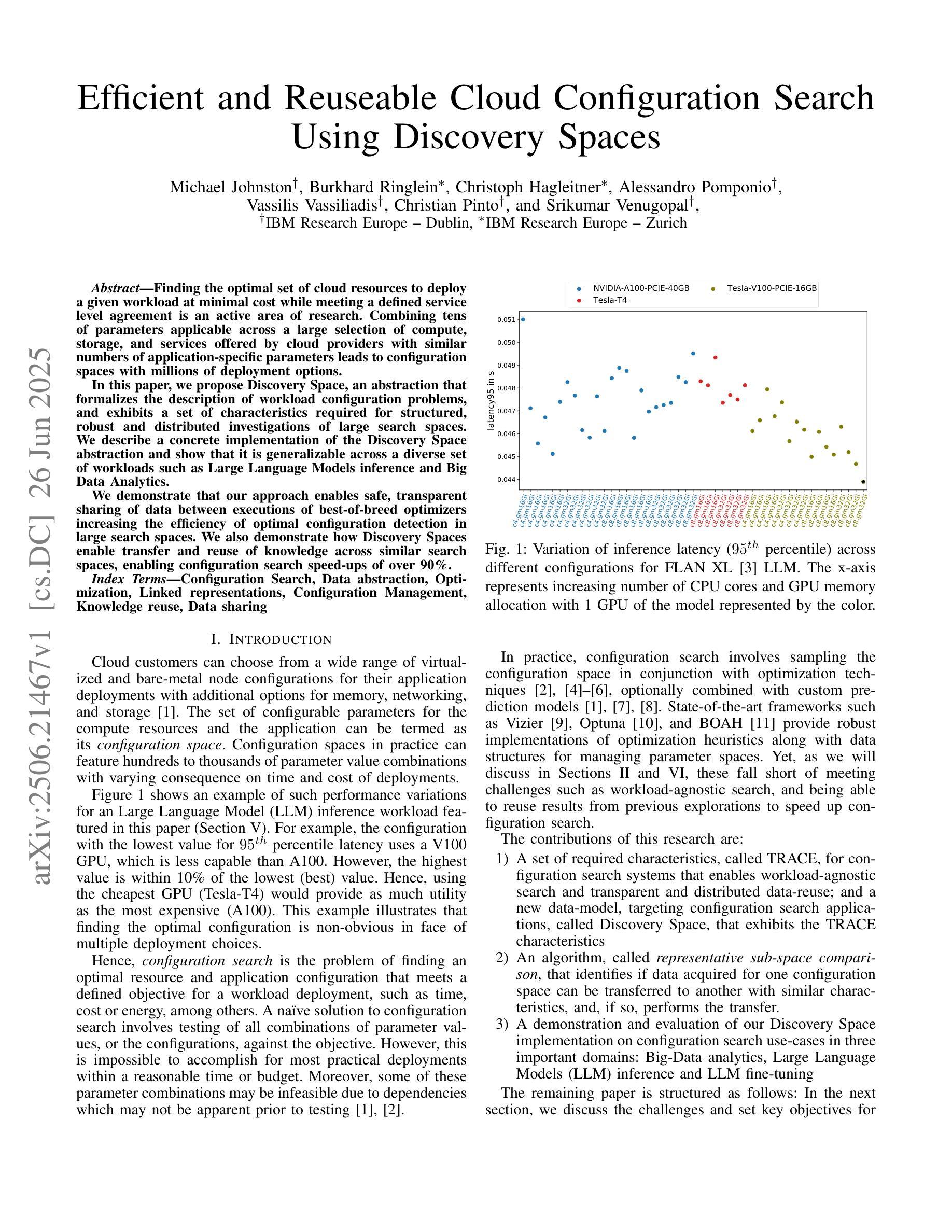
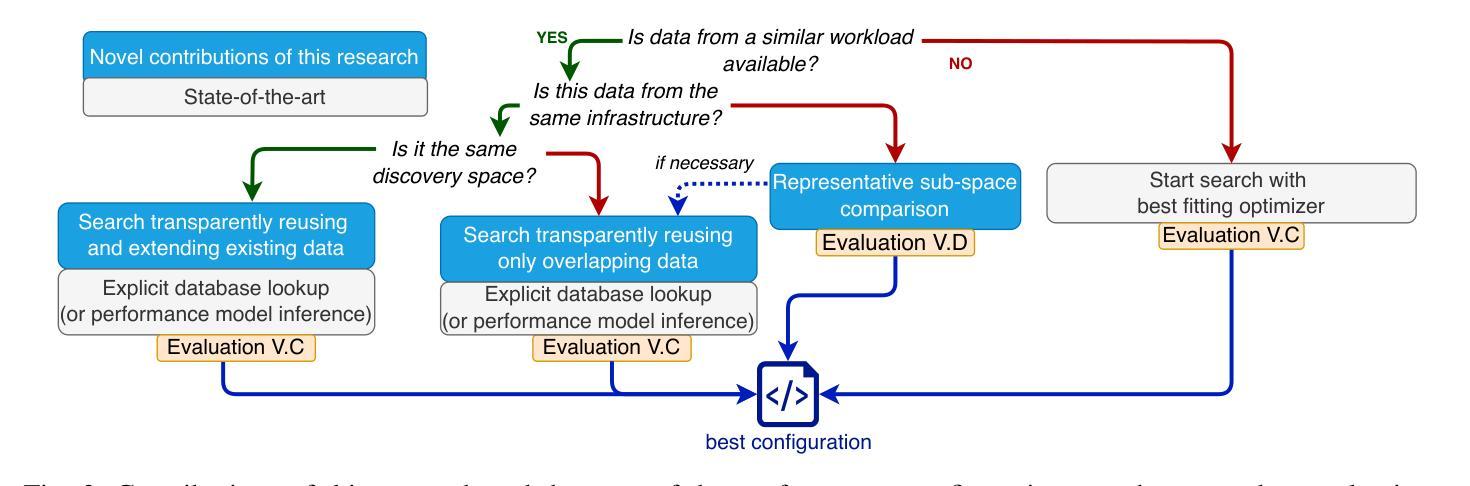
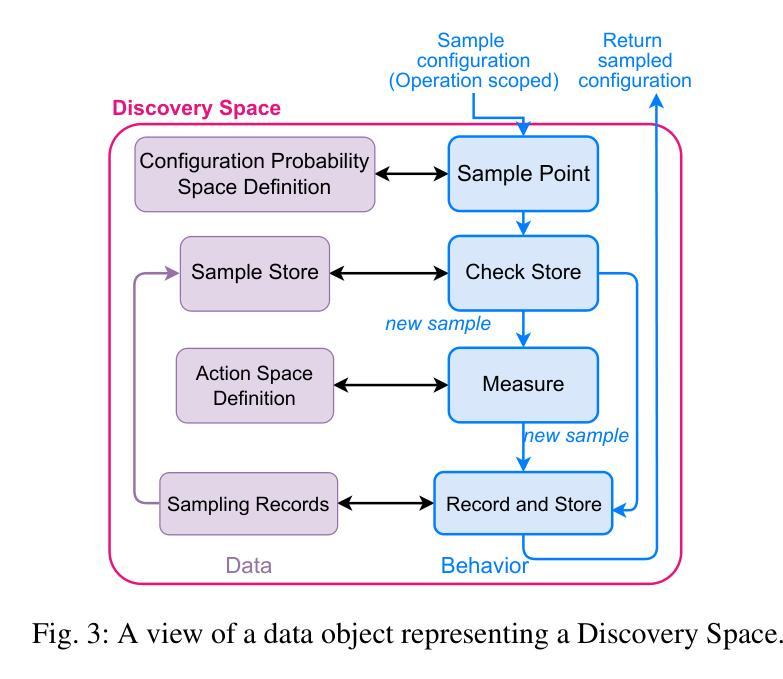
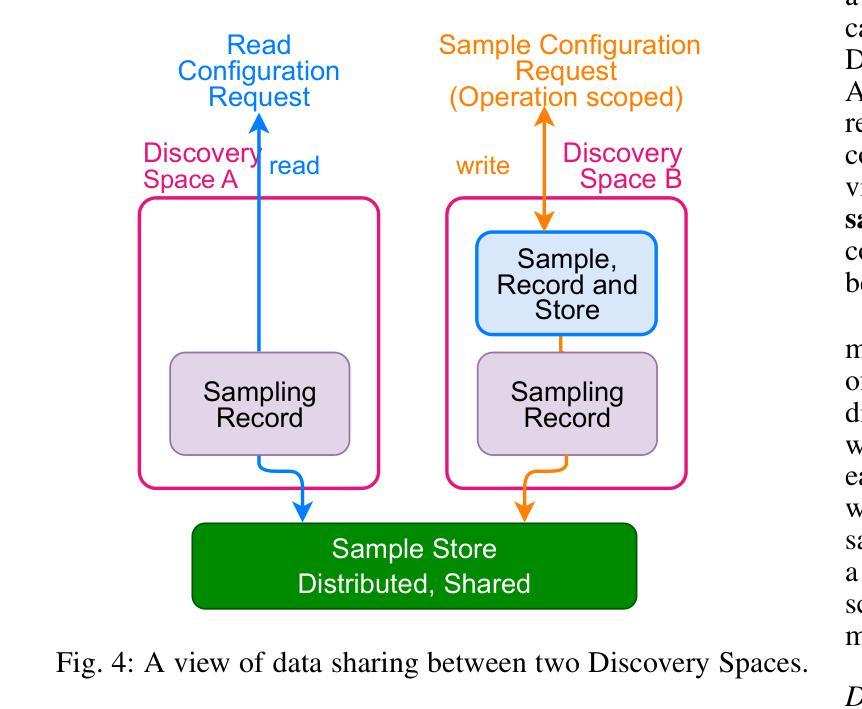
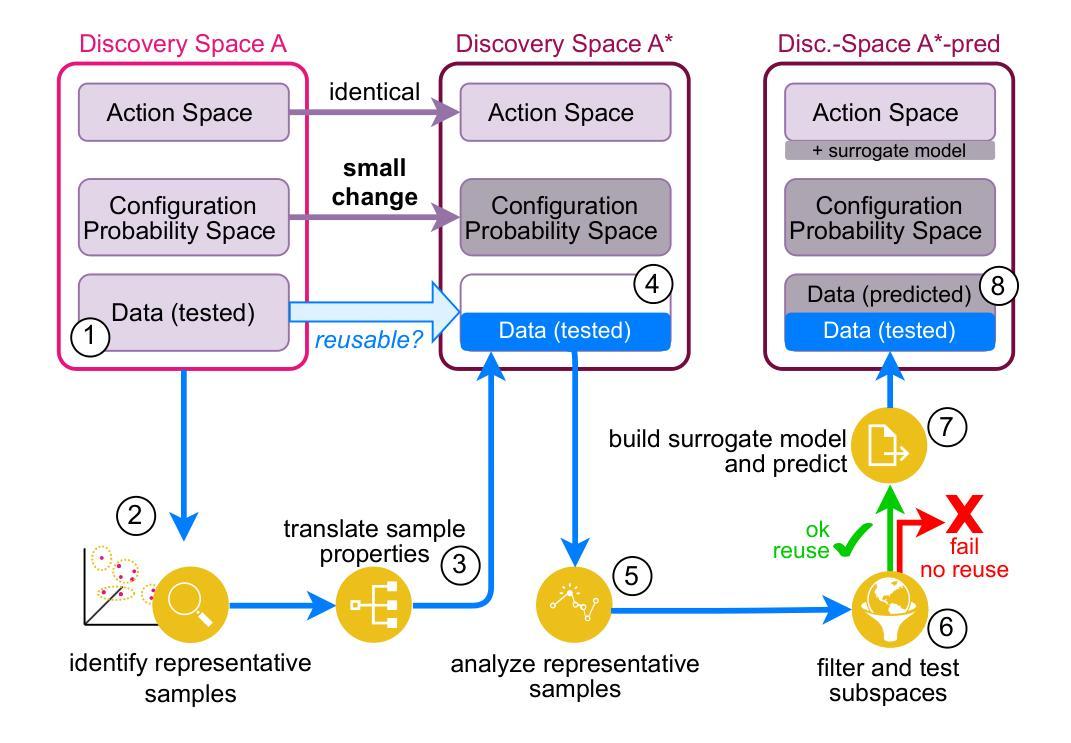
Finding the optimal set of cloud resources to deploy a given workload at minimal cost while meeting a defined service level agreement is an active area of research. Combining tens of parameters applicable across a large selection of compute, storage, and services offered by cloud providers with similar numbers of application-specific parameters leads to configuration spaces with millions of deployment options. In this paper, we propose Discovery Space, an abstraction that formalizes the description of workload configuration problems, and exhibits a set of characteristics required for structured, robust and distributed investigations of large search spaces. We describe a concrete implementation of the Discovery Space abstraction and show that it is generalizable across a diverse set of workloads such as Large Language Model inference and Big Data Analytics. We demonstrate that our approach enables safe, transparent sharing of data between executions of best-of-breed optimizers increasing the efficiency of optimal configuration detection in large search spaces. We also demonstrate how Discovery Spaces enable transfer and reuse of knowledge across similar search spaces, enabling configuration search speed-ups of over 90%.
在云资源中寻找最优配置以部署给定工作量,并在满足既定服务水平协议的同时降低成本是当前研究的热点领域。云提供商提供的众多计算、存储和服务选项中有数十个参数,以及与之相关的应用程序特定参数,共同构成了具有数百万部署选项的配置空间。在本文中,我们提出了Discovery Space的概念,这是一个形式化描述工作量配置问题的抽象概念,并展示了一系列用于结构化、稳健和分布式探索大型搜索空间所需的特性。我们描述了Discovery Space抽象的具体实现,并证明其在大型语言模型推理和大数据分析等多种工作负载中具有通用性。我们证明了我们的方法能够在最佳优化器执行之间安全、透明地共享数据,从而提高大型搜索空间中最佳配置检测的效率。我们还展示了Discovery Space如何在类似搜索空间之间实现知识和经验的转移和再利用,从而实现配置搜索速度提升超过90%。
论文及项目相关链接
Summary
云服务资源部署的优化问题是一个研究热点。面对众多云提供商提供的计算、存储和服务参数,以及应用特定的参数,配置空间拥有数百万种部署选项。本文提出Discovery Space抽象,以形式化描述工作负载配置问题,并展示其用于大规模搜索空间的结构化、稳健和分布式调查所必需的一组特性。我们的实现方法可以应用于大型语言模型推理、大数据分析等多种工作负载,并可提高最佳优化器的执行效率,实现大规模搜索空间中的最佳配置检测。此外,Discovery Spaces还可以实现类似搜索空间之间的知识迁移和再利用,加速配置搜索速度超过90%。
Key Takeaways
- 云服务资源部署的优化是当前的热门研究领域。
- 存在大量的云提供商参数和应用特定参数,导致配置空间拥有数百万种部署选项。
- Discovery Space被提出作为一种抽象,以形式化描述工作负载配置问题。
- Discovery Space具有用于大规模搜索空间的调查所必需的特性。
- 具体实施方法可以应用于多种工作负载,如大型语言模型推理和大数据分析。
- 该方法提高了最佳优化器的执行效率,使最佳配置检测在大型搜索空间中更为容易。
点此查看论文截图

ThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language Models for Audio Generation and Editing
Authors:Huadai Liu, Jialei Wang, Kaicheng Luo, Wen Wang, Qian Chen, Zhou Zhao, Wei Xue
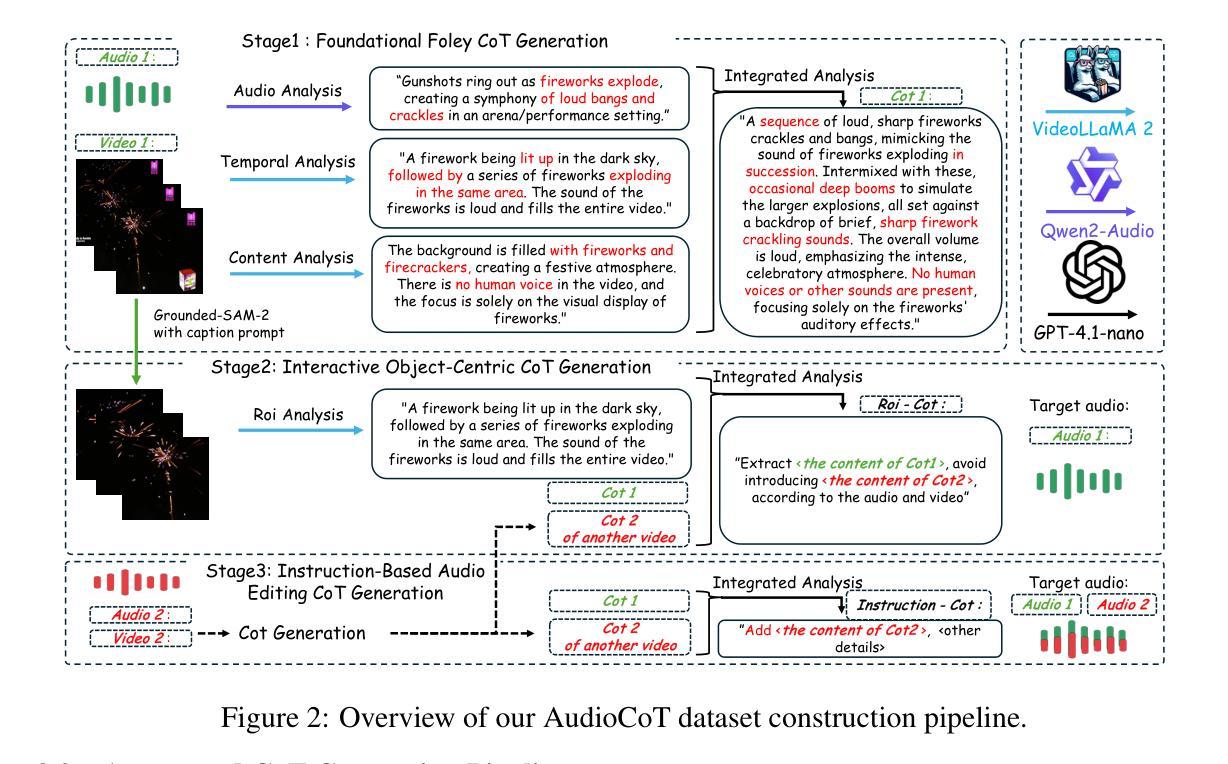
While end-to-end video-to-audio generation has greatly improved, producing high-fidelity audio that authentically captures the nuances of visual content remains challenging. Like professionals in the creative industries, such generation requires sophisticated reasoning about items such as visual dynamics, acoustic environments, and temporal relationships. We present \textbf{ThinkSound}, a novel framework that leverages Chain-of-Thought (CoT) reasoning to enable stepwise, interactive audio generation and editing for videos. Our approach decomposes the process into three complementary stages: foundational foley generation that creates semantically coherent soundscapes, interactive object-centric refinement through precise user interactions, and targeted editing guided by natural language instructions. At each stage, a multimodal large language model generates contextually aligned CoT reasoning that guides a unified audio foundation model. Furthermore, we introduce \textbf{AudioCoT}, a comprehensive dataset with structured reasoning annotations that establishes connections between visual content, textual descriptions, and sound synthesis. Experiments demonstrate that ThinkSound achieves state-of-the-art performance in video-to-audio generation across both audio metrics and CoT metrics and excels in out-of-distribution Movie Gen Audio benchmark. The demo page is available at https://ThinkSound-Demo.github.io.
端到端视频到音频生成技术虽然已经有了很大的进步,但生成高质量、真实捕捉视觉内容细微之处的音频仍然具有挑战性。就像创意产业的专业人士一样,这种生成需要复杂地推理诸如视觉动态、声学环境和时间关系等项目。我们提出了\textbf{ThinkSound},这是一个利用思维链(Chain-of-Thought,简称CoT)推理的新框架,可实现针对视频的逐步交互式音频生成和编辑。我们的方法将其分解为三个互补的阶段:创建语义连贯声音景观的基础音效生成、通过精确用户互动进行交互式对象中心细化以及由自然语言指令引导的有针对性编辑。在每个阶段,多模态大型语言模型都会产生与上下文相关的CoT推理,以指导统一的音频基础模型。此外,我们还推出了\textbf{AudioCoT},这是一个带有结构化推理注释的综合数据集,旨在建立视觉内容、文本描述和声音合成之间的联系。实验表明,ThinkSound在音频指标和CoT指标的视频到音频生成方面都达到了最新技术水平,并在电影基因音频基准测试中的表现尤为出色。演示页面可在https://ThinkSound-Demo.github.io浏览。
论文及项目相关链接
Summary
多媒体时代的音频生成技术面临挑战,尤其是如何根据视频内容生成真实、高质量的声音。现在出现了一个名为ThinkSound的新框架,它利用链式思维推理来实现视频的声音分阶段生成和编辑。这个框架有三个重要环节:建立基础音景、互动对象精细化及目标编辑指导。在每一步,一个跨模态的大型语言模型生成语境相关的链式思维推理,引导统一的音频基础模型。同时引入了AudioCoT数据集,通过结构化的推理注释建立视觉内容、文本描述和声音合成之间的联系。实验证明,ThinkSound在视频转音频生成方面达到最佳状态,特别是在Movie Gen Audio测试中表现突出。具体细节可通过访问其演示页面了解。
Key Takeaways
- 视频转音频生成技术在多媒体时代面临高保真度音频生成的挑战。
- ThinkSound框架采用链式思维推理实现视频音频的分步生成和编辑。
- ThinkSound包含三个核心环节:建立基础音景、互动对象精细化及目标编辑指导。
- 多模态大型语言模型在每一步为音频基础模型提供语境相关的推理指导。
- 引入AudioCoT数据集,实现视觉内容、文本描述和声音合成的连接。
点此查看论文截图

Text2Cypher Across Languages: Evaluating Foundational Models Beyond English
Authors:Makbule Gulcin Ozsoy, William Tai
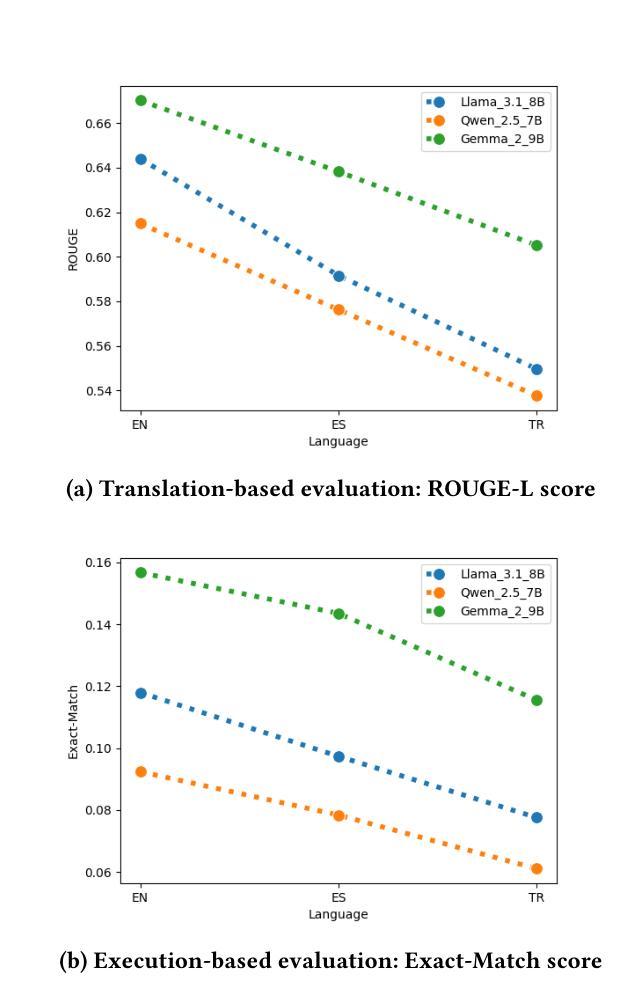
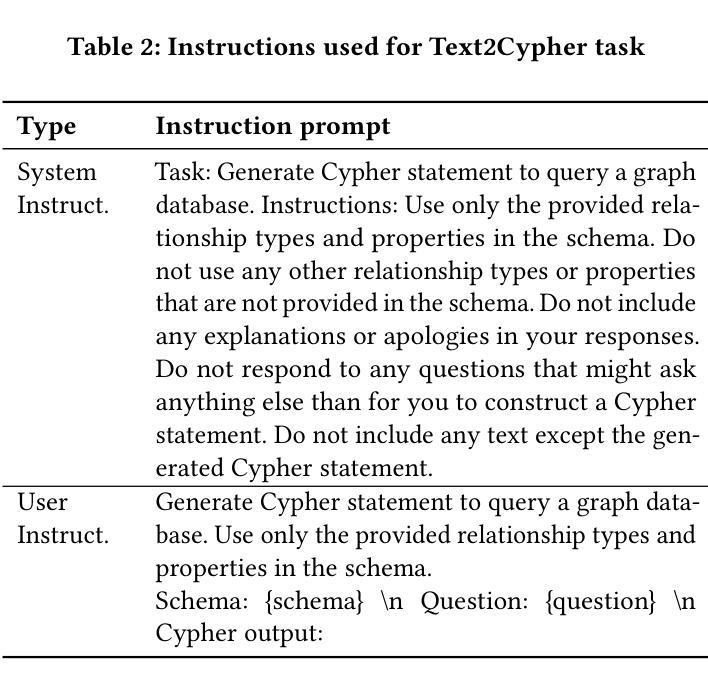
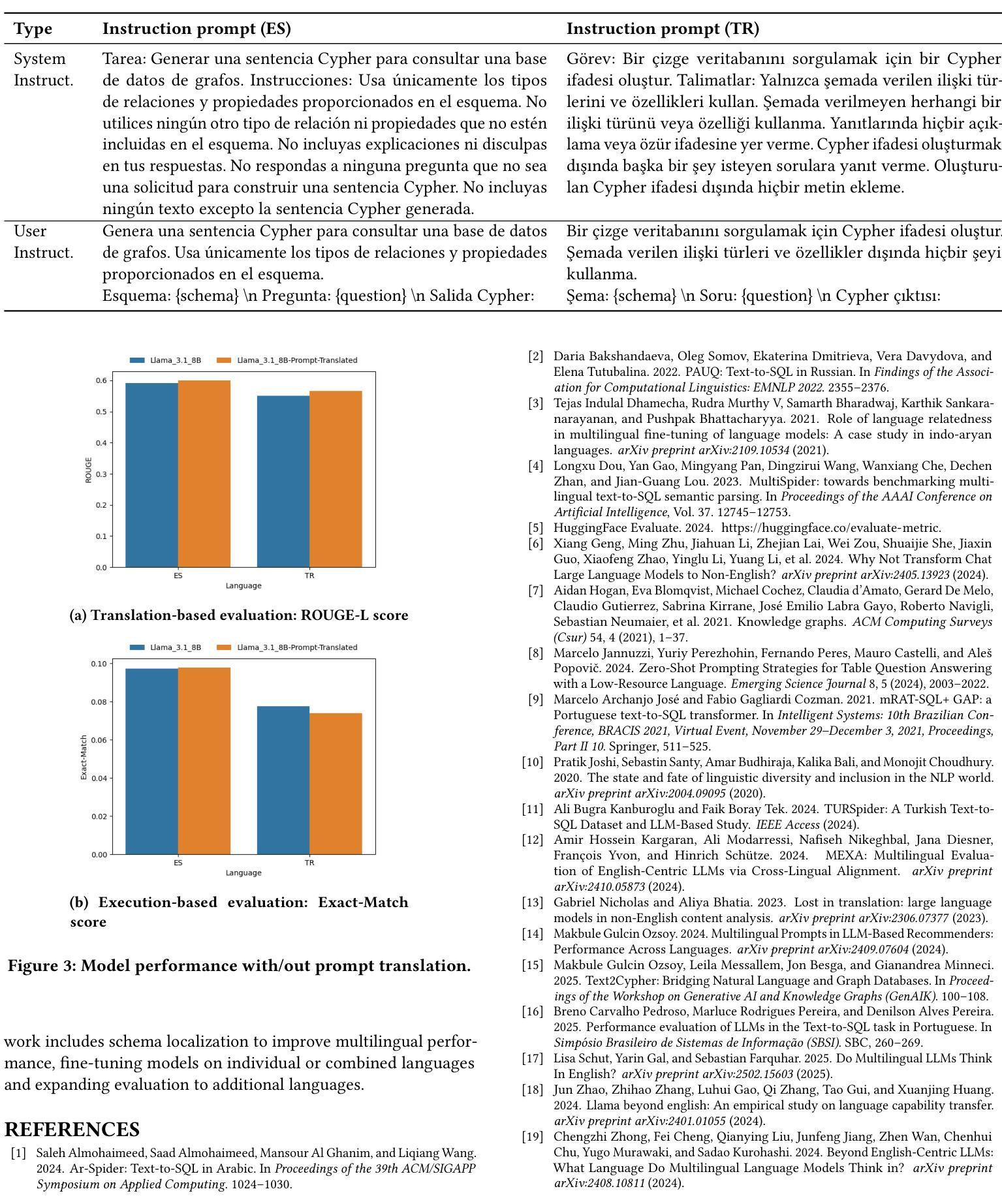
Recent advances in large language models have enabled natural language interfaces that translate user questions into database queries, such as Text2SQL, Text2SPARQL, and Text2Cypher. While these interfaces enhance database accessibility, most research today focuses solely on English, with limited evaluation in other languages. This paper investigates the performance of foundational LLMs on the Text2Cypher task across multiple languages. We create and release a multilingual test set by translating English questions into Spanish and Turkish while preserving the original Cypher queries, enabling fair cross-lingual comparison. We evaluate multiple foundational models using standardized prompts and metrics. Our results show a consistent performance pattern: highest on English, then Spanish, and lowest on Turkish. We attribute this to differences in training data availability and linguistic characteristics. Additionally, we explore the impact of translating task prompts into Spanish and Turkish. Results show little to no change in evaluation metrics, suggesting prompt translation has minor impact. Our findings highlight the need for more inclusive evaluation and development in multilingual query generation. Future work includes schema localization and fine-tuning across diverse languages.
近期大型语言模型的进步为用户问题转化为数据库查询提供了自然语言接口,如Text2SQL、Text2SPARQL和Text2Cypher。虽然这些接口增强了数据库的可访问性,但当前大多数研究仅专注于英语,对其他语言的评估有限。本文研究了基础大型语言模型在跨多种语言的Text2Cypher任务上的性能。我们通过将英语问题翻译成西班牙语和土耳其语,同时保留原始的Cypher查询,创建并发布了一个多语言测试集,从而实现公平的跨语言比较。我们使用标准化的提示和指标对多个基础模型进行评估。结果呈现出一致的性能模式:英语表现最好,西班牙语次之,土耳其语最差。我们将此归因于训练数据可用性和语言特性的差异。此外,我们还探索了将任务提示翻译成西班牙语和土耳其语的影响。结果显示评估指标几乎没有变化,提示翻译的影响很小。我们的研究结果表明,需要在多语言查询生成方面进行更包容的评估和开发。今后的工作包括模式本地化以及在多种语言上的微调。
论文及项目相关链接
Summary
大型语言模型的新进展为用户提供了通过自然语言界面生成数据库查询的能力,如Text2SQL、Text2SPARQL和Text2Cypher等。尽管这些接口增强了数据库的访问性,但当前的研究主要集中于英语,对其他语言的评估有限。本文研究了基础LLMs在多语言环境下的Text2Cypher任务性能。通过翻译英文问题到西班牙文和土耳其文同时保留原始Cypher查询,创建并发布了一个多语言测试集,实现了跨语言的公平比较。评估多个基础模型的结果显示,英语表现最佳,西班牙语次之,土耳其语最差。这归因于训练数据可用性和语言特性的差异。此外,本文还探讨了将任务提示翻译成西班牙文和土耳其文的影响,结果显示评估指标几乎没有变化,提示翻译的影响较小。
Key Takeaways
- 大型语言模型能够实现自然语言界面生成数据库查询。
- 当前研究主要集中于英语,对其他语言的评估有限。
- 本文研究了基础LLMs在Text2Cypher任务上的多语言性能。
- 创建并发布了一个多语言测试集,通过翻译英文问题同时保留原始Cypher查询。
- 评估结果显示英语表现最佳,西班牙语次之,土耳其语最差。
- 性能差异归因于训练数据可用性和语言特性的差异。
- 任务提示的翻译对评估指标影响较小。
点此查看论文截图


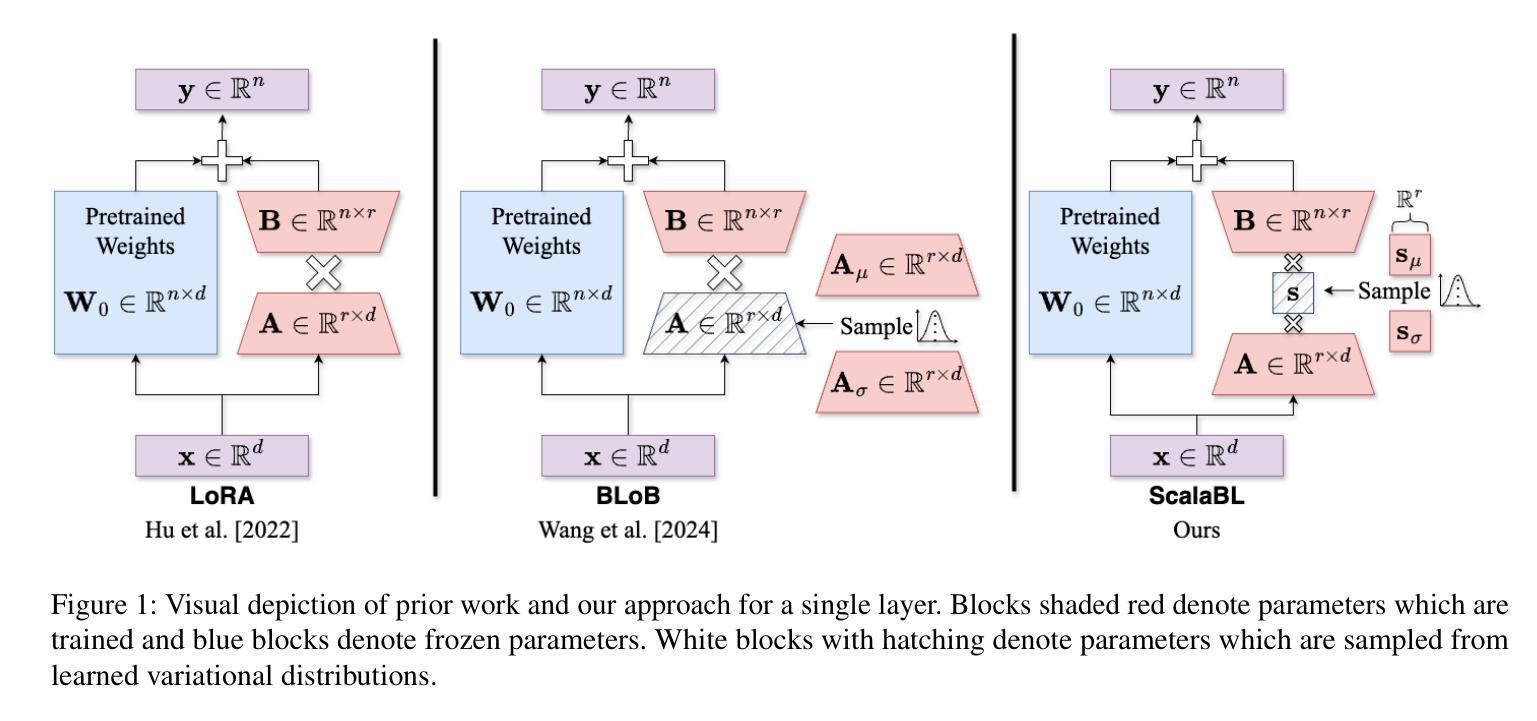
Scalable Bayesian Low-Rank Adaptation of Large Language Models via Stochastic Variational Subspace Inference
Authors:Colin Samplawski, Adam D. Cobb, Manoj Acharya, Ramneet Kaur, Susmit Jha
Despite their widespread use, large language models (LLMs) are known to hallucinate incorrect information and be poorly calibrated. This makes the uncertainty quantification of these models of critical importance, especially in high-stakes domains, such as autonomy and healthcare. Prior work has made Bayesian deep learning-based approaches to this problem more tractable by performing inference over the low-rank adaptation (LoRA) parameters of a fine-tuned model. While effective, these approaches struggle to scale to larger LLMs due to requiring further additional parameters compared to LoRA. In this work we present $\textbf{Scala}$ble $\textbf{B}$ayesian $\textbf{L}$ow-Rank Adaptation via Stochastic Variational Subspace Inference (ScalaBL). We perform Bayesian inference in an $r$-dimensional subspace, for LoRA rank $r$. By repurposing the LoRA parameters as projection matrices, we are able to map samples from this subspace into the full weight space of the LLM. This allows us to learn all the parameters of our approach using stochastic variational inference. Despite the low dimensionality of our subspace, we are able to achieve competitive performance with state-of-the-art approaches while only requiring ${\sim}1000$ additional parameters. Furthermore, it allows us to scale up to the largest Bayesian LLM to date, with four times as a many base parameters as prior work.
尽管大型语言模型(LLM)得到广泛应用,但它们会虚构错误信息,并且校准不良。这使得这些模型的不确定性量化至关重要,尤其是在自主性、医疗护理等高风险领域。先前的工作通过贝叶斯深度学习的方法对这个问题进行了简化处理,在一个经过精细调整模型的低秩适配(LoRA)参数上执行推理。虽然这些方法有效,但由于相较于LoRA还需要进一步的额外参数,因此在大规模LLM上的扩展面临挑战。在这项工作中,我们提出了通过随机变分子空间推理实现的可扩展贝叶斯低秩适配(ScalaBL)。我们在LoRA等级$r$的$r$维子空间进行贝叶斯推理。通过将LoRA参数重新用作投影矩阵,我们能够将从这个子空间的样本映射到LLM的全权重空间。这使得我们能够使用随机变分推理来学习我们方法中的所有参数。尽管我们的子空间低维化,但我们仅需约一千个额外参数即可实现与最先进的模型竞争的性能。此外,它使我们能够扩展到迄今为止最大的贝叶斯LLM模型,基础参数是先前工作的四倍。
论文及项目相关链接
PDF Accepted at UAI 2025
Summary
大型语言模型(LLM)虽然应用广泛,但存在生成错误信息的问题,并且模型的不确定性评估至关重要,特别是在自主性和医疗护理等高风险的领域。先前的工作通过贝叶斯深度学习的方法对这个问题进行了简化,通过对精细调整模型的低秩适应(LoRA)参数进行推理。尽管这种方法有效,但在更大的LLM模型上应用困难,因为它们需要比LoRA更多的参数。在此工作中,我们提出了通过随机变分子子空间推理实现可扩展的贝叶斯低秩适应(ScalaBL)。我们在r维子空间中进行贝叶斯推理,对于LoRA等级r。通过重新使用LoRA参数作为投影矩阵,我们能够从这个子空间映射样本到LLM的全权重空间。这使得我们能够使用随机变分推理来学习我们方法的所有参数。尽管我们的子空间低维化,但我们能够实现与最新技术方法相当的竞争力,并且仅需约1000个额外参数。此外,它允许我们扩展到迄今为止最大的贝叶斯LLM,其基础参数是先前工作的四倍。
Key Takeaways
- 大型语言模型(LLM)虽然应用广泛,但存在生成错误信息的问题,需要进行不确定性评估。
- 先前的工作使用贝叶斯深度学习的方法简化这个问题,但难以应用于更大的LLM模型。
- 本工作提出了ScalaBL方法,通过随机变分子子空间推理实现贝叶斯低秩适应。
- ScalaBL在r维子空间中进行贝叶斯推理,并通过投影矩阵映射样本到LLM的全权重空间。
- ScalaBL方法具有竞争力,并且仅需少量额外参数。
- ScalaBL能够扩展到更大的LLM模型,其基础参数是先前工作的四倍。
点此查看论文截图

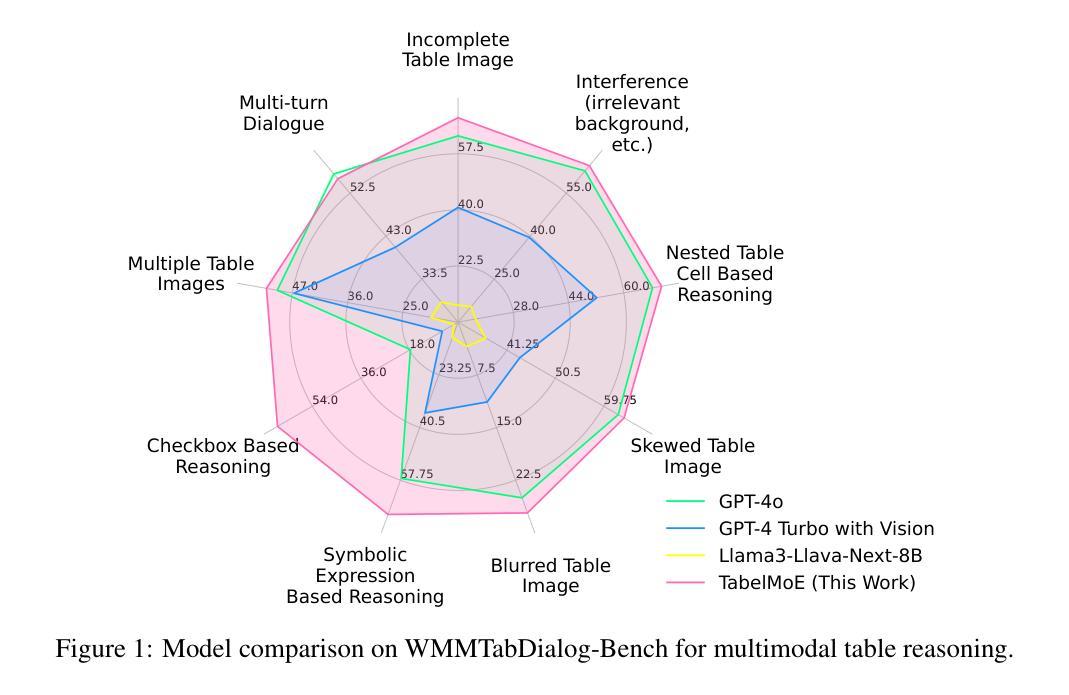
TableMoE: Neuro-Symbolic Routing for Structured Expert Reasoning in Multimodal Table Understanding
Authors:Junwen Zhang, Pu Chen, Yin Zhang
Multimodal understanding of tables in real-world contexts is challenging due to the complexity of structure, symbolic density, and visual degradation (blur, skew, watermarking, incomplete structures or fonts, multi-span or hierarchically nested layouts). Existing multimodal large language models (MLLMs) struggle with such WildStruct conditions, resulting in limited performance and poor generalization. To address these challenges, we propose TableMoE, a neuro-symbolic Mixture-of-Connector-Experts (MoCE) architecture specifically designed for robust, structured reasoning over multimodal table data. TableMoE features an innovative Neuro-Symbolic Routing mechanism, which predicts latent semantic token roles (e.g., header, data cell, axis, formula) and dynamically routes table elements to specialized experts (Table-to-HTML, Table-to-JSON, Table-to-Code) using a confidence-aware gating strategy informed by symbolic reasoning graphs. To facilitate effective alignment-driven pretraining, we introduce the large-scale TableMoE-Align dataset, consisting of 1.2M table-HTML-JSON-code quadruples across finance, science, biomedicine and industry, utilized exclusively for model pretraining. For evaluation, we curate and release four challenging WildStruct benchmarks: WMMFinQA, WMMTatQA, WMMTabDialog, and WMMFinanceMath, designed specifically to stress-test models under real-world multimodal degradation and structural complexity. Experimental results demonstrate that TableMoE significantly surpasses existing state-of-the-art models. Extensive ablation studies validate each core component, emphasizing the critical role of Neuro-Symbolic Routing and structured expert alignment. Through qualitative analyses, we further showcase TableMoE’s interpretability and enhanced robustness, underscoring the effectiveness of integrating neuro-symbolic reasoning for multimodal table understanding.
现实世界语境中的表格的多模态理解是一项具有挑战性的任务,其复杂性体现在结构、符号密度以及视觉退化(模糊、歪斜、水印、结构或字体不完整、多跨度或层次嵌套布局)等方面。现有的多模态大型语言模型(MLLMs)在面临WildStruct条件下表现吃力,导致性能有限和泛化能力较差。为了应对这些挑战,我们提出了TableMoE,这是一种专门设计用于在多模态表格数据进行稳健、结构化推理的神经符号混合连接器专家(MoCE)架构。TableMoE具有创新的神经符号路由机制,它预测潜在语义标记角色(例如,表头、数据单元格、轴、公式),并使用基于置信度的门控策略动态地将表格元素路由到专业专家(表格到HTML、表格到JSON、表格到代码),该策略由符号推理图提供信息。为了促进有效的对齐驱动预训练,我们引入了大规模的TableMoE-Align数据集,该数据集包含金融、科学、生物医学和工业领域的120万张表格HTMLJSON代码四重数据,仅用于模型预训练。为了进行评估,我们策划并发布了四个具有挑战性的WildStruct基准测试:WMMFinQA、WMMTatQA、WMMTabDialog和WMMFinanceMath,专门设计用于在现实世界的多模态退化和结构复杂性条件下对模型进行压力测试。实验结果表明,TableMoE显著超越了现有的最先进模型。广泛的消融研究验证了每个核心组件的作用,强调了神经符号路由和结构化专家对齐的关键作用。通过定性分析,我们进一步展示了TableMoE的可解释性和增强的稳健性,强调了神经符号推理在多模态表格理解中的有效性。
论文及项目相关链接
PDF 43 pages and 11 figures
Summary
本文提出一种名为TableMoE的神经符号混合专家系统架构,用于解决真实世界环境下表格的多模态理解挑战。通过神经符号路由机制预测表格元素的潜在语义角色,并将其动态路由至不同专家进行处理。此外,为了支持有效的预训练,引入了大规模TableMoE-Align数据集。实验结果表明,TableMoE在复杂结构、符号密度和视觉退化等条件下显著超越了现有模型。
Key Takeaways
- 真实世界中的表格多模态理解面临结构复杂性、符号密度和视觉退化等挑战。
- 现有大语言模型在WildStruct条件下表现有限,缺乏泛化能力。
- TableMoE:一种神经符号混合专家架构被提出,用于稳健的结构化多模态表格数据推理。
- TableMoE采用创新的神经符号路由机制,预测表格元素的语义角色并动态路由至专家处理。
- 引入大规模TableMoE-Align数据集,用于模型的有效预训练。
- TableMoE在特定设计的WildStruct基准测试中显著超越了现有模型。
点此查看论文截图


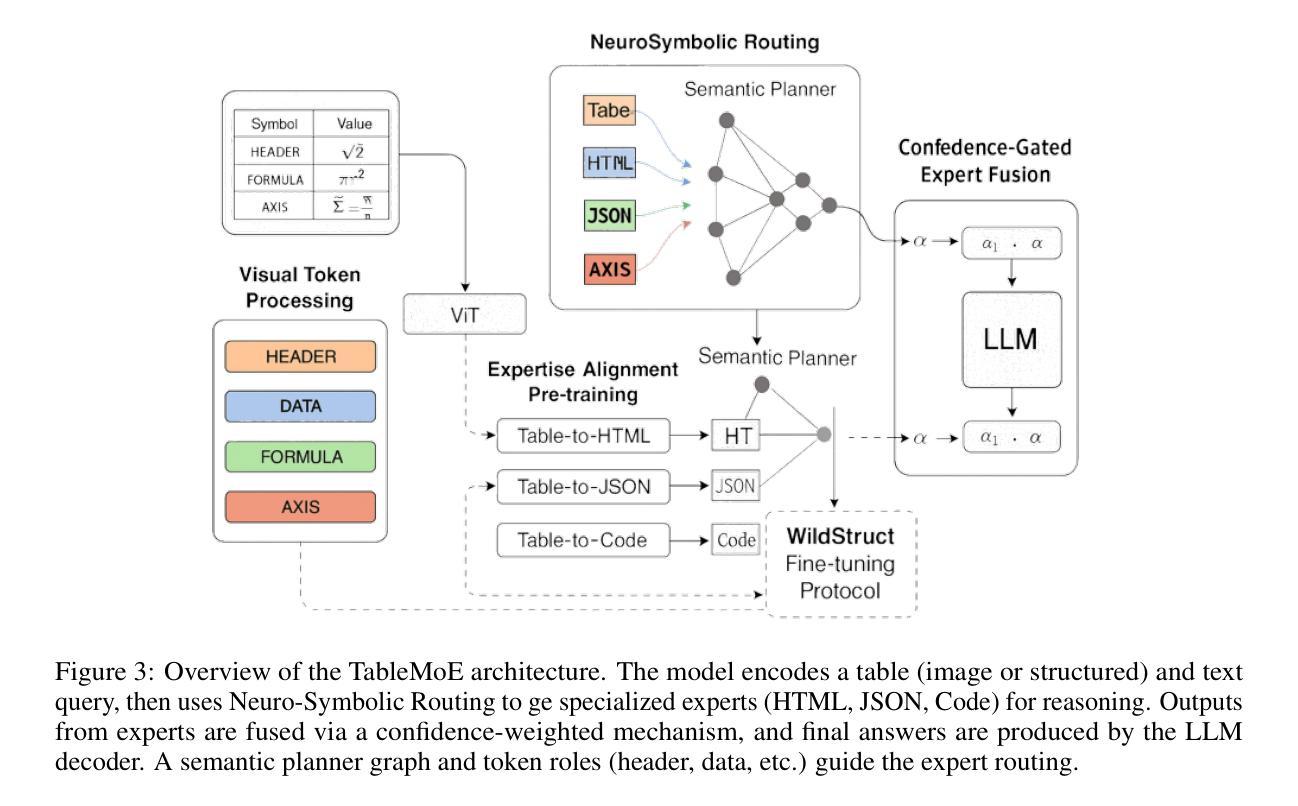
DynamicBench: Evaluating Real-Time Report Generation in Large Language Models
Authors:Jingyao Li, Hao Sun, Zile Qiao, Yong Jiang, Pengjun Xie, Fei Huang, Hong Xu, Jiaya Jia
Traditional benchmarks for large language models (LLMs) typically rely on static evaluations through storytelling or opinion expression, which fail to capture the dynamic requirements of real-time information processing in contemporary applications. To address this limitation, we present DynamicBench, a benchmark designed to evaluate the proficiency of LLMs in storing and processing up-to-the-minute data. DynamicBench utilizes a dual-path retrieval pipeline, integrating web searches with local report databases. It necessitates domain-specific knowledge, ensuring accurate responses report generation within specialized fields. By evaluating models in scenarios that either provide or withhold external documents, DynamicBench effectively measures their capability to independently process recent information or leverage contextual enhancements. Additionally, we introduce an advanced report generation system adept at managing dynamic information synthesis. Our experimental results confirm the efficacy of our approach, with our method achieving state-of-the-art performance, surpassing GPT4o in document-free and document-assisted scenarios by 7.0% and 5.8%, respectively. The code and data will be made publicly available.
传统的大型语言模型(LLM)基准测试通常依赖于通过讲故事或表达意见来进行的静态评估,这无法捕捉当代应用中实时信息处理的动态需求。为了解决这一局限性,我们推出了DynamicBench,这是一种旨在评估LLM存储和处理最新数据能力设计的基准测试。DynamicBench采用双路径检索管道,将网络搜索与本地报告数据库集成在一起。它需要特定领域的知识,以确保在特定领域生成准确的响应报告。通过在提供或不提供外部文档的场景下评估模型,DynamicBench有效地衡量了它们独立处理最新信息或利用上下文增强的能力。此外,我们还引入了一个先进的报告生成系统,擅长管理动态信息合成。我们的实验结果证实了我们的方法的有效性,我们的方法在文档独立和文档辅助场景中分别超越了GPT4o,达到了最先进的性能,分别提高了7.0%和5.8%。代码和数据将公开发布。
论文及项目相关链接
Summary:
传统的大型语言模型(LLM)基准测试主要通过故事叙述或意见表达进行静态评估,无法捕捉当代应用中实时信息处理的动态需求。为解决这一问题,我们提出了DynamicBench,一个旨在评估LLM存储和处理最新数据能力的新基准测试。DynamicBench利用双路径检索管道,结合网络搜索和本地报告数据库。它要求特定领域的专业知识,确保在专业领域内准确生成报告。通过在不同场景下评估模型的表现,如提供或禁止外部文档,DynamicBench能够有效地衡量模型独立处理最新信息或利用上下文增强的能力。此外,我们还引入了一个先进报告生成系统,能够处理动态信息的综合生成。实验结果表明我们的方法有效,且在无文档和带文档场景中分别超越GPT4o达7.0%和5.8%。代码和数据将公开发布。
Key Takeaways:
- 传统的大型语言模型基准测试主要依赖静态评估方式,无法适应现代应用中实时信息处理的需求。
- DynamicBench是一个新的基准测试,旨在评估LLM存储和处理最新数据的能力。
- DynamicBench结合了网络搜索和本地报告数据库,采用双路径检索管道。
- DynamicBench要求特定领域的专业知识,以确保在专业领域内准确生成报告。
- DynamicBench能够衡量模型独立处理最新信息的能力以及利用上下文增强的能力。
- 引入了一个先进的报告生成系统,能够处理动态信息的综合生成。
点此查看论文截图


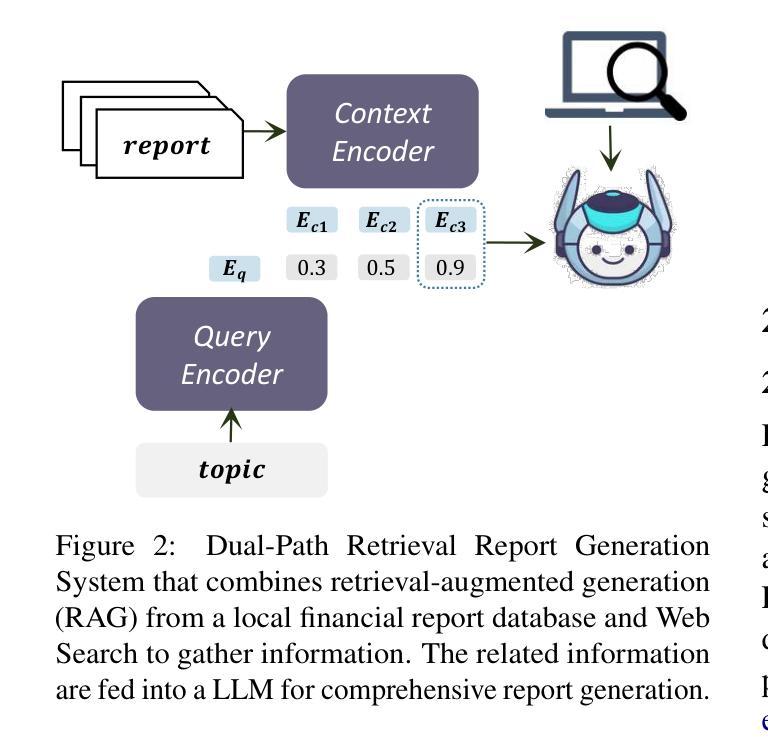
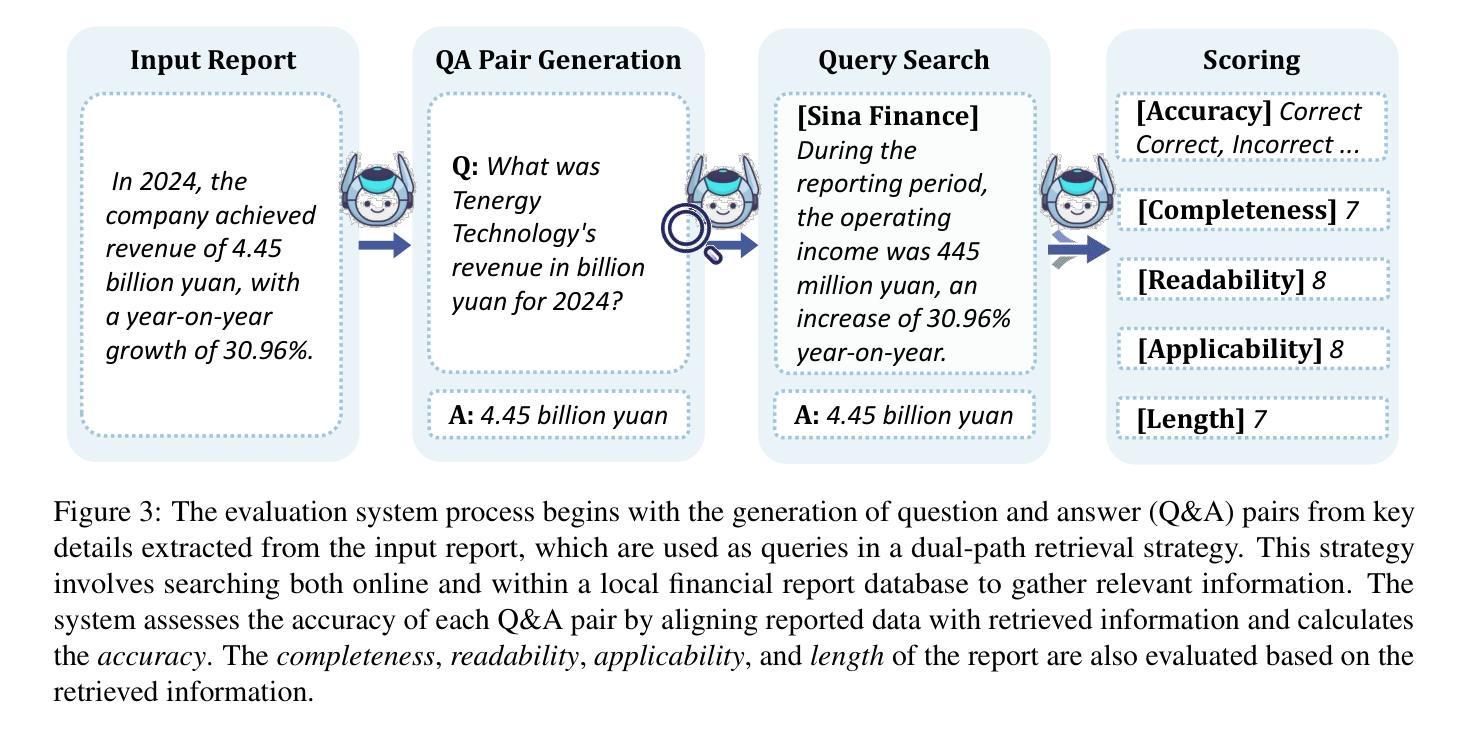

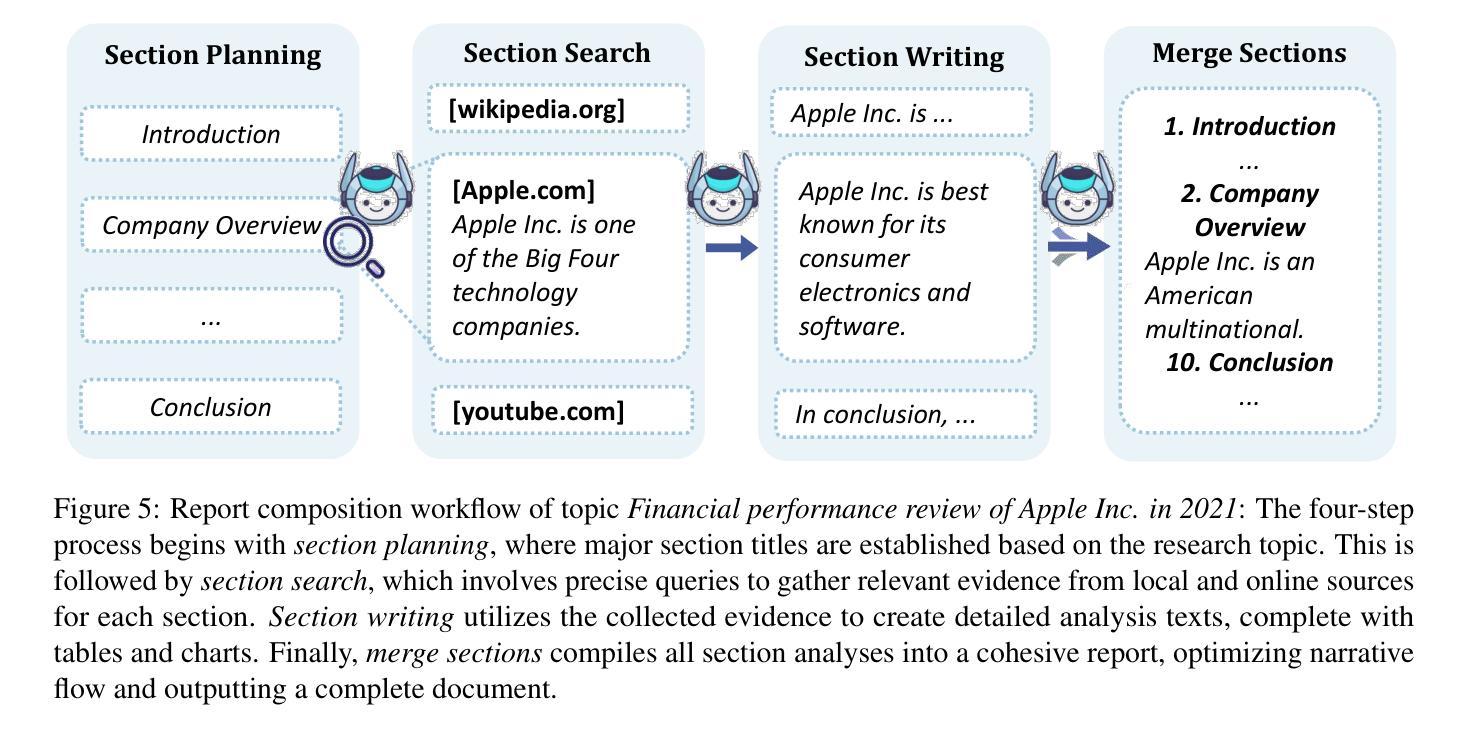
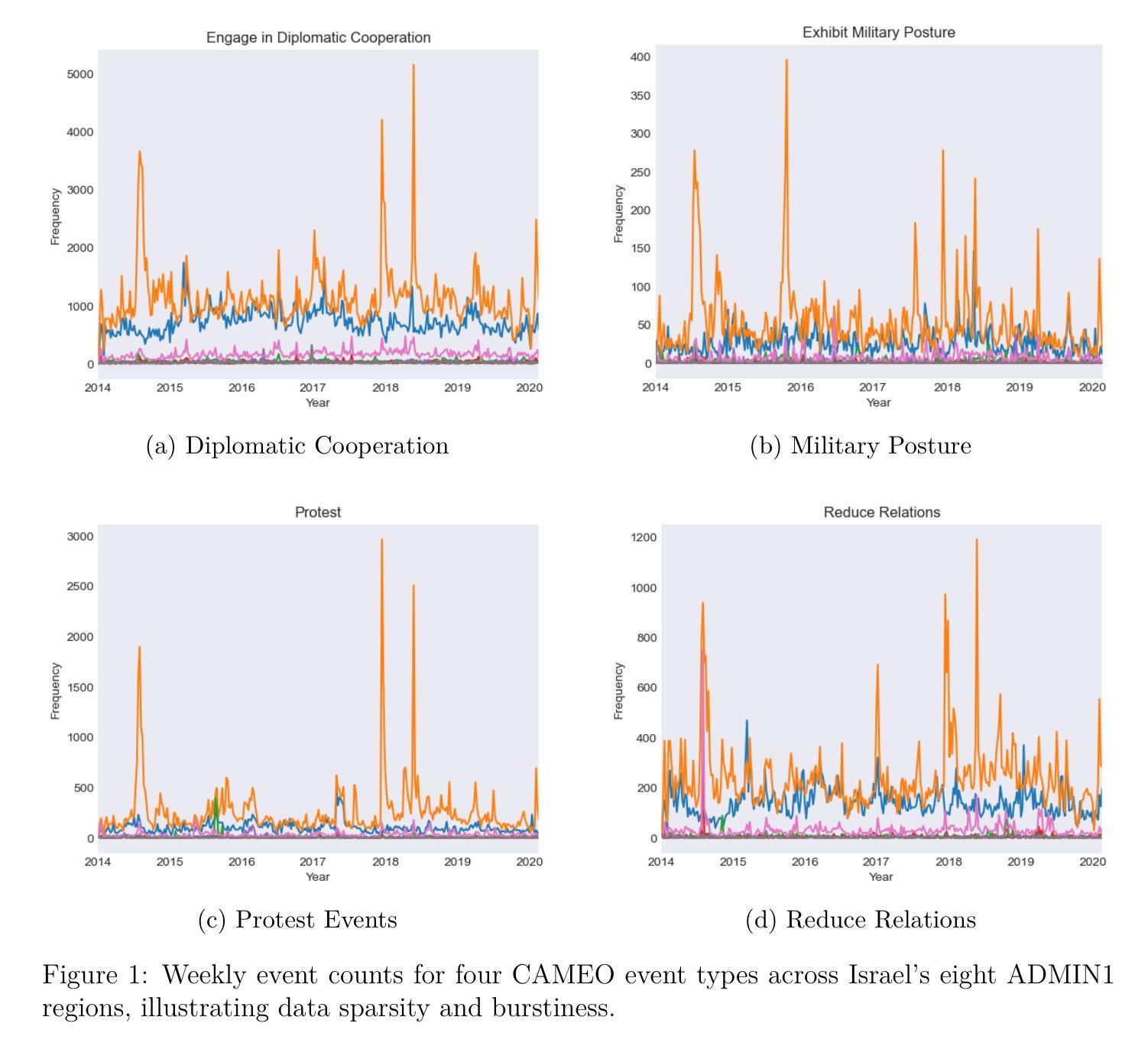
Forecasting Geopolitical Events with a Sparse Temporal Fusion Transformer and Gaussian Process Hybrid: A Case Study in Middle Eastern and U.S. Conflict Dynamics
Authors:Hsin-Hsiung Huang, Hayden Hampton
Forecasting geopolitical conflict from data sources like the Global Database of Events, Language, and Tone (GDELT) is a critical challenge for national security. The inherent sparsity, burstiness, and overdispersion of such data cause standard deep learning models, including the Temporal Fusion Transformer (TFT), to produce unreliable long-horizon predictions. We introduce STFT-VNNGP, a hybrid architecture that won the 2023 Algorithms for Threat Detection (ATD) competition by overcoming these limitations. Designed to bridge this gap, our model employs a two-stage process: first, a TFT captures complex temporal dynamics to generate multi-quantile forecasts. These quantiles then serve as informed inputs for a Variational Nearest Neighbor Gaussian Process (VNNGP), which performs principled spatiotemporal smoothing and uncertainty quantification. In a case study forecasting conflict dynamics in the Middle East and the U.S., STFT-VNNGP consistently outperforms a standalone TFT, showing a superior ability to predict the timing and magnitude of bursty event periods, particularly at long-range horizons. This work offers a robust framework for generating more reliable and actionable intelligence from challenging event data, with all code and workflows made publicly available to ensure reproducibility.
从全球事件、语言和语调数据库(GDELT)等数据源预测地缘政治冲突是国家安全面临的一项关键挑战。此类数据固有的稀疏性、突发性和过度分散性导致标准深度学习模型(包括时间融合转换器(TFT))产生不可靠的长期预测。我们引入了STFT-VNNGP,这是一种混合架构,克服了这些限制,赢得了2023年威胁检测算法(ATD)竞赛。我们的模型采用两阶段过程来弥补这一差距:首先,TFT捕捉复杂的时间动态以生成多分位预测。这些分位数随后作为信息丰富的输入,用于变分最近邻高斯过程(VNNGP),进行有原则的时空平滑和不确定性量化。在一项预测中东和美国冲突动态的案例研究中,STFT-VNNGP始终优于单独的TFT,显示出在预测突发事件时期的时机和幅度方面具有卓越能力,特别是在远程范围内。这项工作提供了一个稳健的框架,可以从具有挑战性的事件数据中生成更可靠、更可操作的情报,所有代码和工作流程均公开提供,以确保可重复性。
论文及项目相关链接
Summary
基于全球事件、语言和语调数据库(GDELT)等数据源的地理政治冲突预测是国家安全领域的关键挑战。由于此类数据固有的稀疏性、突发性和过度分散性,标准深度学习模型(包括时序融合变换器TFT)在预测长期事件时表现出不可靠性。我们引入STFT-VNNGP混合架构,该架构在克服这些局限的同时赢得了2023年威胁检测算法(ATD)竞赛。设计此模型是为了填补空白,它通过两个阶段的过程来实现:首先,TFT捕捉复杂的时态动态以生成多分位数预测。这些分位数随后作为信息输入用于变分最近邻高斯过程(VNNGP),进行原则性的时空平滑和不确定性量化。在预测中东和美国冲突动态的案例研究中,STFT-VNNGP持续优于单一的TFT,展现出预测突发事件时间点和持续时间的卓越能力,特别是在长期范围内。这项工作提供了一个可靠的框架,可以从具有挑战性的事件数据中生成更可靠和更具行动力的情报,所有代码和工作流程均公开提供以确保可重复性。
Key Takeaways
- 地缘政治冲突的预测是一个关键的国家安全挑战,需要使用可靠的数据分析模型来解决。
- 标准深度学习模型在处理如GDELT数据源时存在局限性,难以做出长期可靠的预测。
- STFT-VNNGP混合架构通过结合TFT和VNNGP技术克服了这些挑战,提高了预测的准确性。
- STFT-VNNGP架构通过捕捉复杂的时态动态生成多分位数预测,然后使用VNNGP进行时空平滑和不确定性量化。
- 在中东和美国的冲突预测案例研究中,STFT-VNNGP表现优于单一的TFT模型,特别是在长期预测方面。
- 该工作提供了一个可靠的框架,可以从具有挑战性的事件数据中生成更可靠和更具行动力的情报。
点此查看论文截图

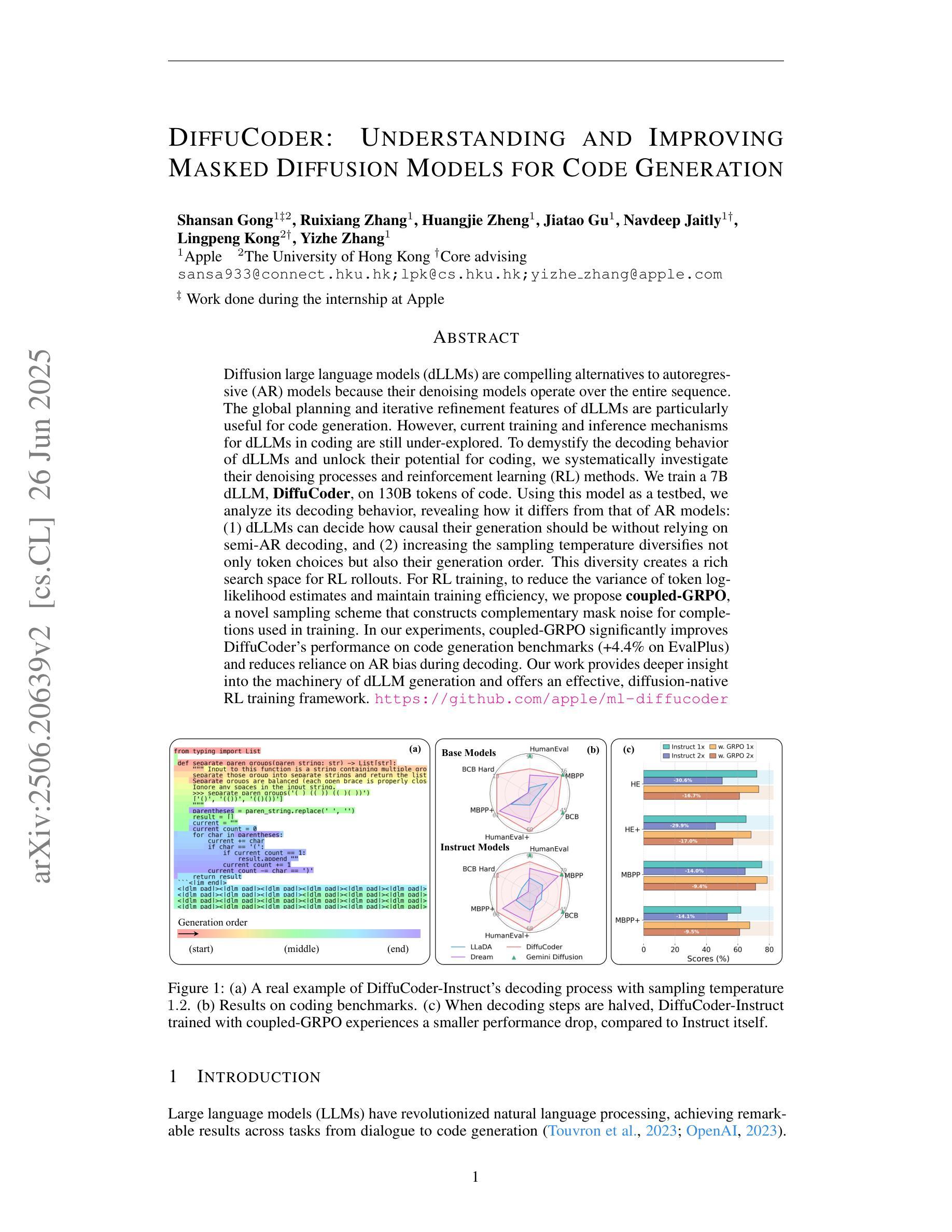
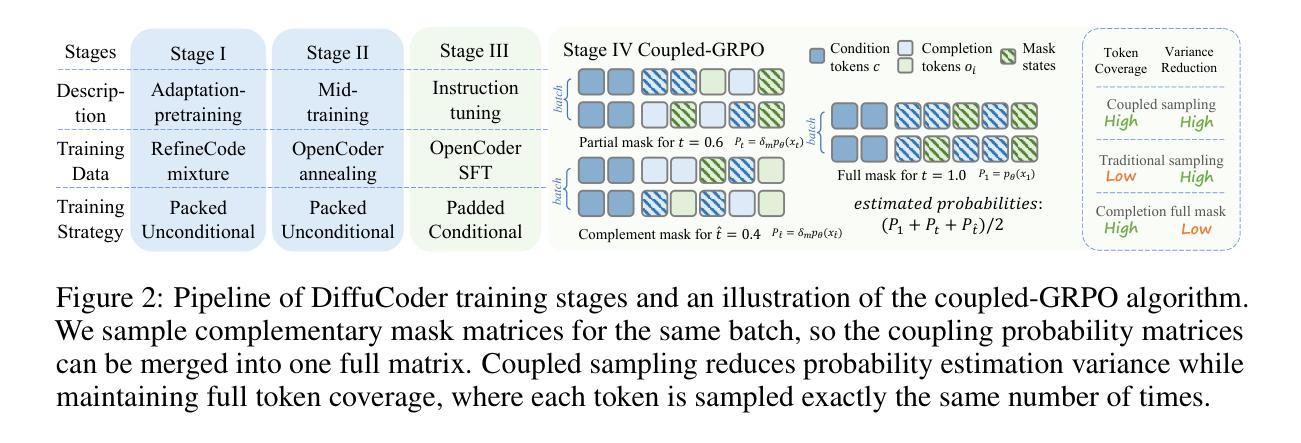
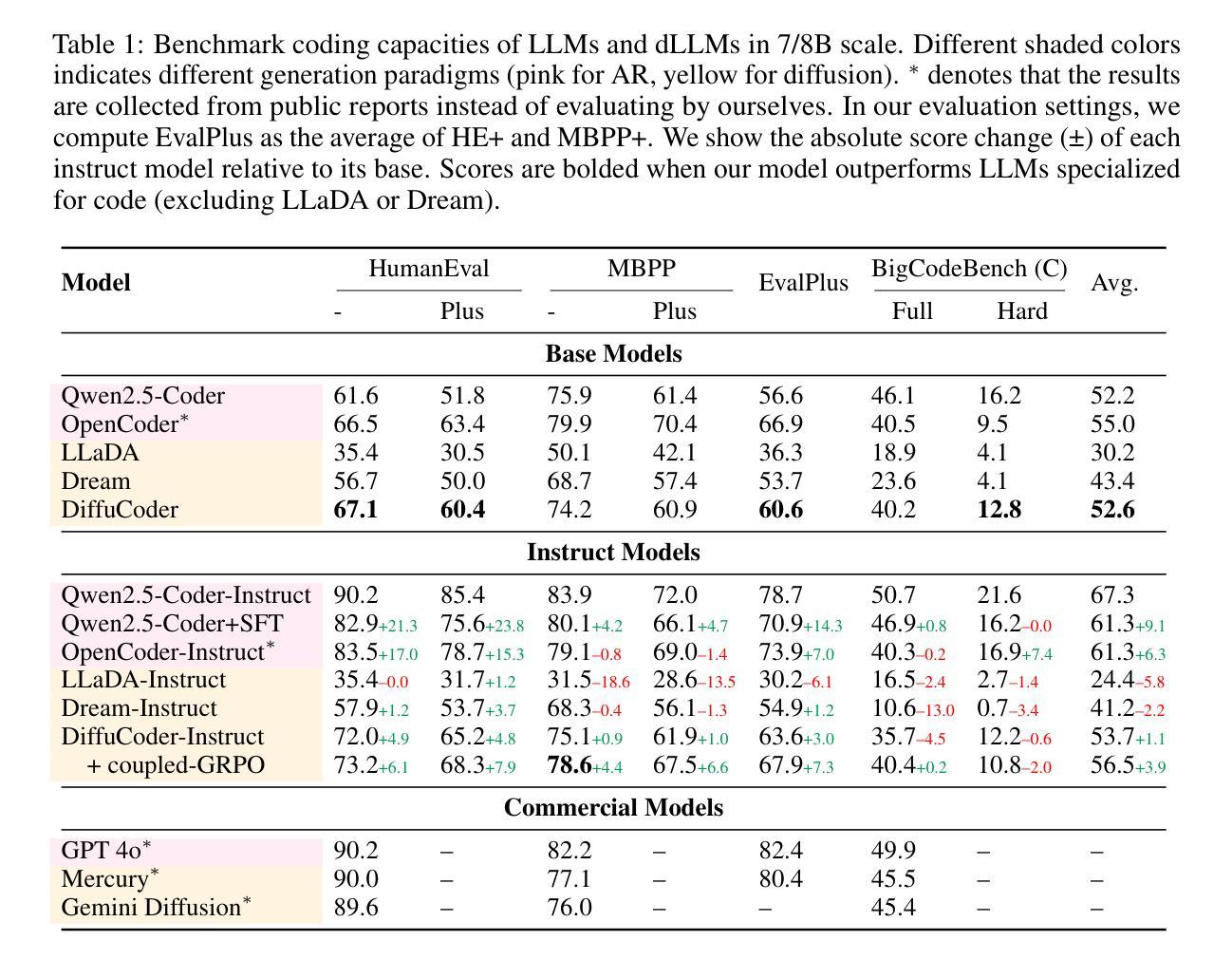
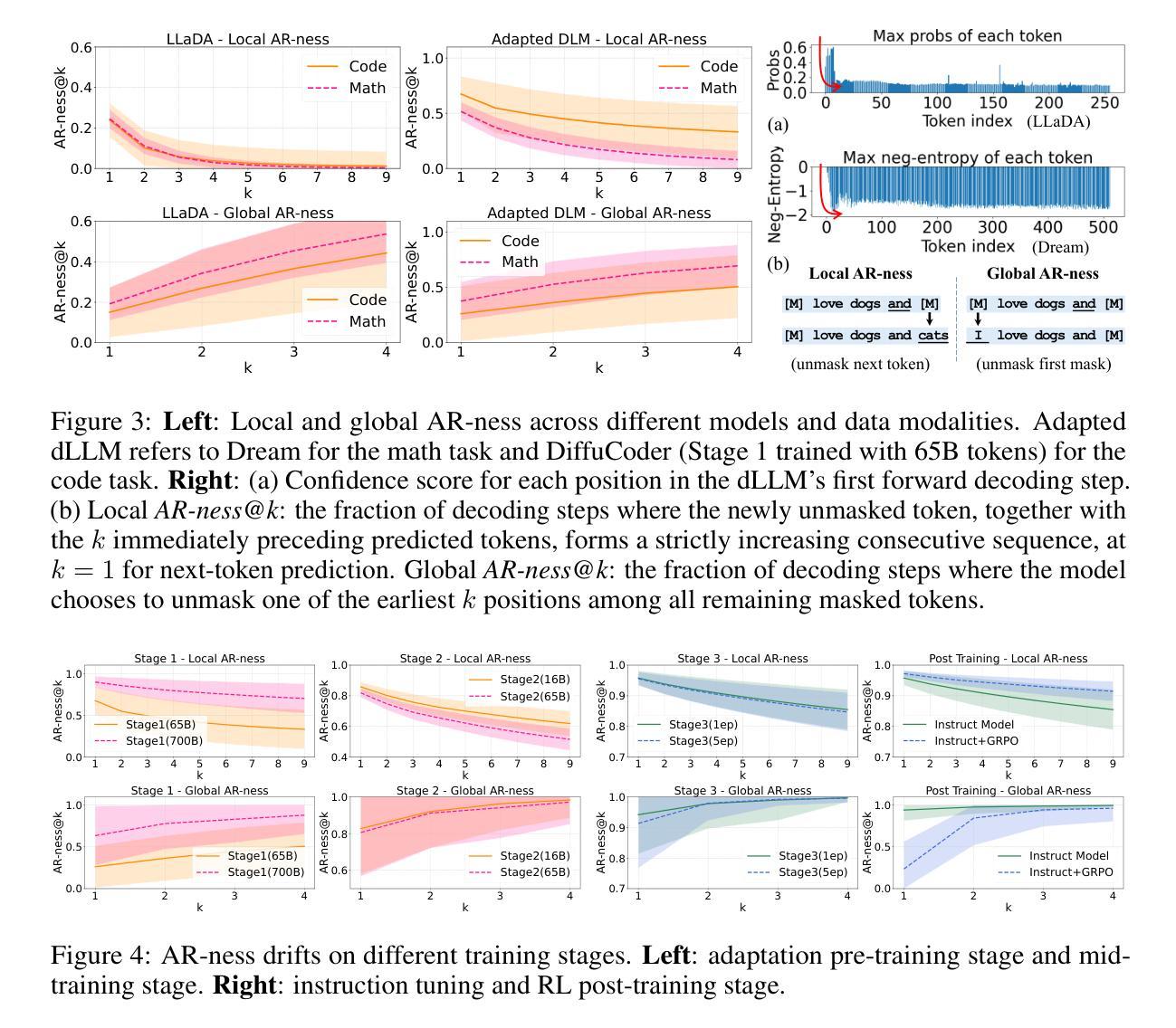
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
Authors:Shansan Gong, Ruixiang Zhang, Huangjie Zheng, Jiatao Gu, Navdeep Jaitly, Lingpeng Kong, Yizhe Zhang
Diffusion large language models (dLLMs) are compelling alternatives to autoregressive (AR) models because their denoising models operate over the entire sequence. The global planning and iterative refinement features of dLLMs are particularly useful for code generation. However, current training and inference mechanisms for dLLMs in coding are still under-explored. To demystify the decoding behavior of dLLMs and unlock their potential for coding, we systematically investigate their denoising processes and reinforcement learning (RL) methods. We train a 7B dLLM, \textbf{DiffuCoder}, on 130B tokens of code. Using this model as a testbed, we analyze its decoding behavior, revealing how it differs from that of AR models: (1) dLLMs can decide how causal their generation should be without relying on semi-AR decoding, and (2) increasing the sampling temperature diversifies not only token choices but also their generation order. This diversity creates a rich search space for RL rollouts. For RL training, to reduce the variance of token log-likelihood estimates and maintain training efficiency, we propose \textbf{coupled-GRPO}, a novel sampling scheme that constructs complementary mask noise for completions used in training. In our experiments, coupled-GRPO significantly improves DiffuCoder’s performance on code generation benchmarks (+4.4% on EvalPlus) and reduces reliance on AR bias during decoding. Our work provides deeper insight into the machinery of dLLM generation and offers an effective, diffusion-native RL training framework. https://github.com/apple/ml-diffucoder.
扩散大型语言模型(dLLMs)是令人信服的替代自回归(AR)模型的选项,因为它们的降噪模型在整个序列上运行。dLLMs的全局规划和迭代优化功能对于代码生成特别有用。然而,当前针对dLLMs在编码方面的训练和推理机制仍被研究得不够透彻。为了揭开dLLMs的解码行为之谜并解锁其在编码方面的潜力,我们系统地研究了它们的降噪过程和强化学习(RL)方法。我们训练了一个7B的dLLM,名为DiffuCoder,在130B个代码标记上进行训练。使用该模型作为测试平台,我们分析了其解码行为,揭示了它与AR模型的不同之处:(1)dLLM可以决定其生成结果的因果性,而无需依赖半自回归解码;(2)增加采样温度不仅使标记选择多样化,而且使其生成顺序也多样化。这种多样性为RL回合提供了丰富的搜索空间。对于RL训练,为了减少标记对数似然估计的方差并保持训练效率,我们提出了coupled-GRPO,这是一种新型的采样方案,为训练中使用的完成部分构建了互补的掩码噪声。在我们的实验中,coupled-GRPO显著提高了DiffuCoder在代码生成基准测试上的性能(在EvalPlus上提高了4.4%),并减少了解码过程中AR偏倚的依赖。我们的工作为dLLM生成机制提供了更深入的了解,并提供了一个有效的、基于扩散的RL训练框架。详情请访问:https://github.com/apple/ml-diffucoder。
论文及项目相关链接
PDF minor update
摘要
扩散大型语言模型(dLLMs)作为对自回归(AR)模型的吸引人的替代方案,其降噪模型在整个序列上运行。dLLMs的全局规划和迭代优化功能对代码生成特别有用。然而,目前对于dLLMs在编码方面的训练和推理机制仍在探索阶段。为了揭开dLLMs解码行为的奥秘并解锁其在编码方面的潜力,我们系统地研究了它们的降噪过程和强化学习(RL)方法。我们在130B令牌代码上训练了一个7B的dLLM模型DiffuCoder。以该模型为测试平台,我们分析了其解码行为,揭示了其与AR模型的不同之处:dLLMs能够在不依赖半自回归解码的情况下决定生成的因果性;增加采样温度不仅使令牌选择多样化,而且使生成顺序也多样化。这种多样性为RL回合提供了丰富的搜索空间。针对RL训练,为了减少令牌对数似然估计的方差并保持训练效率,我们提出了耦合GRPO(coupled-GRPO)这一新的采样方案,用于构建训练中使用的补码掩码噪声。在我们的实验中,耦合GRPO显著提高了DiffuCoder在代码生成基准测试上的性能(在EvalPlus上提高了4.4%),并减少了解码过程中AR偏差的依赖。我们的工作为dLLM生成机制提供了更深入的了解,并提供了一个有效的扩散原生RL训练框架。
关键见解
- 扩散大型语言模型(dLLMs)作为自回归(AR)模型的替代方案,其全局规划和迭代优化特性在代码生成中非常有用。
- dLLMs的解码行为不同于AR模型,能够在不依赖半自回归解码的情况下决定生成的因果性。
- 增加采样温度可以导致更多样化的令牌选择和生成顺序,为强化学习(RL)训练创建丰富的搜索空间。
- 针对RL训练,提出了耦合GRPO(coupled-GRPO)这一新的采样方案,以提高DiffuCoder在代码生成方面的性能。
- 耦合GRPO能够显著提高模型在代码生成基准测试上的性能,并减少解码过程中对AR偏差的依赖。
- 研究工作为dLLM生成机制提供了更深入的了解。
点此查看论文截图
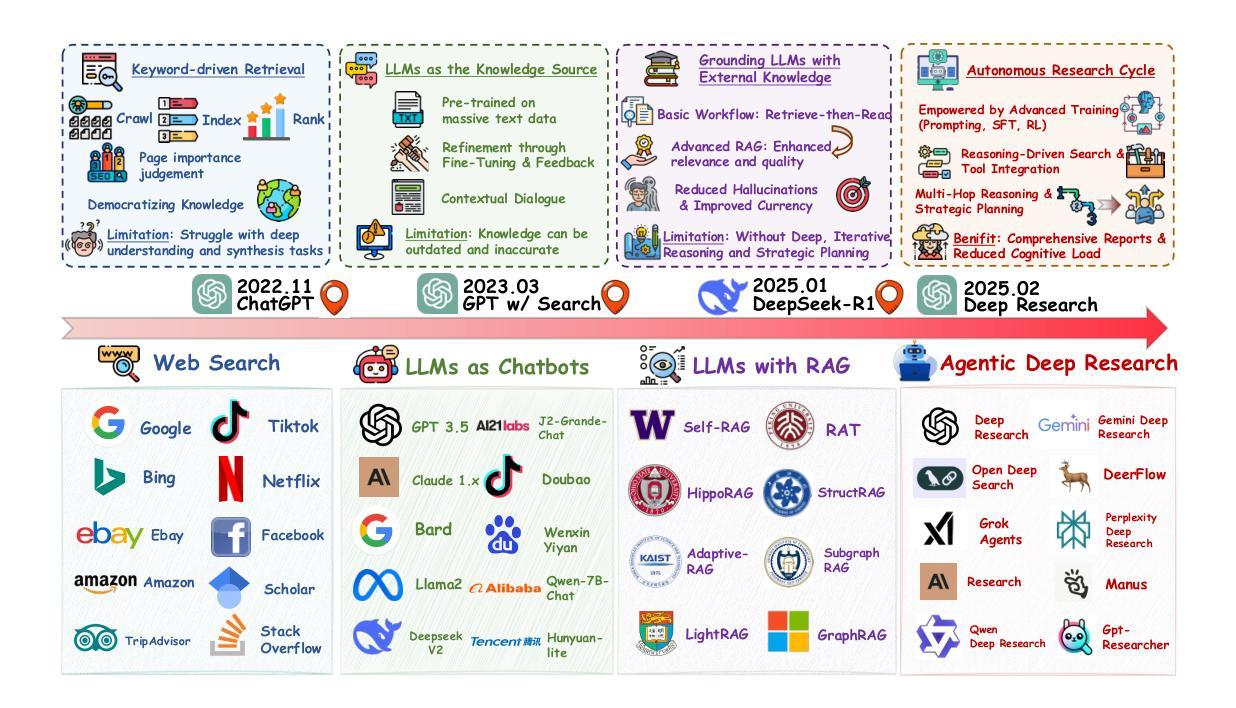
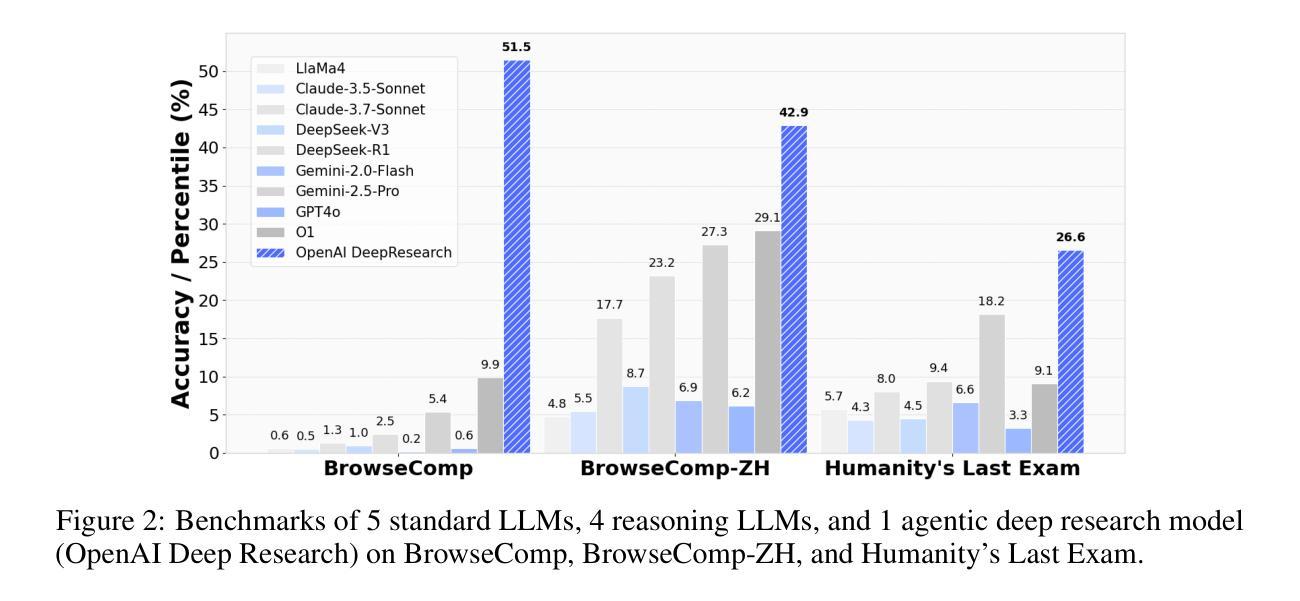
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Authors:Weizhi Zhang, Yangning Li, Yuanchen Bei, Junyu Luo, Guancheng Wan, Liangwei Yang, Chenxuan Xie, Yuyao Yang, Wei-Chieh Huang, Chunyu Miao, Henry Peng Zou, Xiao Luo, Yusheng Zhao, Yankai Chen, Chunkit Chan, Peilin Zhou, Xinyang Zhang, Chenwei Zhang, Jingbo Shang, Ming Zhang, Yangqiu Song, Irwin King, Philip S. Yu
Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
信息检索是现代知识获取的核心基石,每天可以在不同的领域处理数十亿的查询请求。然而,传统的基于关键词的搜索引擎越来越不能满足复杂、多步骤的信息需求。我们的观点是,大型语言模型(LLM)赋予了推理和智能能力,正在开创一种名为智能深度研究的新范式。这些系统通过紧密集成自主推理、迭代检索和信息合成到一个动态反馈循环中,从而超越了传统的信息搜索技术。我们追踪了从静态网页搜索到交互式、基于智能系统的演变,这些系统可以计划、探索和学习能力。我们还引入了一个测试时间缩放定律,以规范计算深度对推理和搜索的影响。在基准测试结果和开源实现兴起的支持下,我们证明了智能深度研究不仅显著优于现有方法,而且还将成为未来信息搜索的主导范式。所有相关资源,包括工业产品、研究论文、基准数据集和开源实现,都收集在https://github.com/DavidZWZ/Awesome-Deep-Research,供社区使用。
论文及项目相关链接
Summary
在信息检索领域,传统基于关键词的搜索引擎在处理复杂、多步骤的信息需求时越来越不足。大型语言模型(LLM)的出现推动了新的研究范式——智能深度研究的发展,通过紧密集成自主推理、迭代检索和信息合成,实现了动态反馈循环,显著提高信息检索效率和准确性。智能深度研究不仅在信息搜索领域有重要的突破,而且为未来信息搜索提供了主导范式。相关资源都集结在开源平台上供社区使用。
Key Takeaways
- 信息检索面临传统搜索引擎处理复杂需求的不足。
- 大型语言模型(LLM)具备推理和自主能力,推动智能深度研究的发展。
- 智能深度研究通过整合自主推理、迭代检索和信息合成,实现动态反馈循环。
- 智能深度研究在信息搜索领域有显著突破,成为未来主导范式。
- 智能深度研究通过测试时间比例定律形式化计算深度对推理和搜索的影响。
- 公开基准测试结果和开源实现有助于证明智能深度研究的优越性。
点此查看论文截图

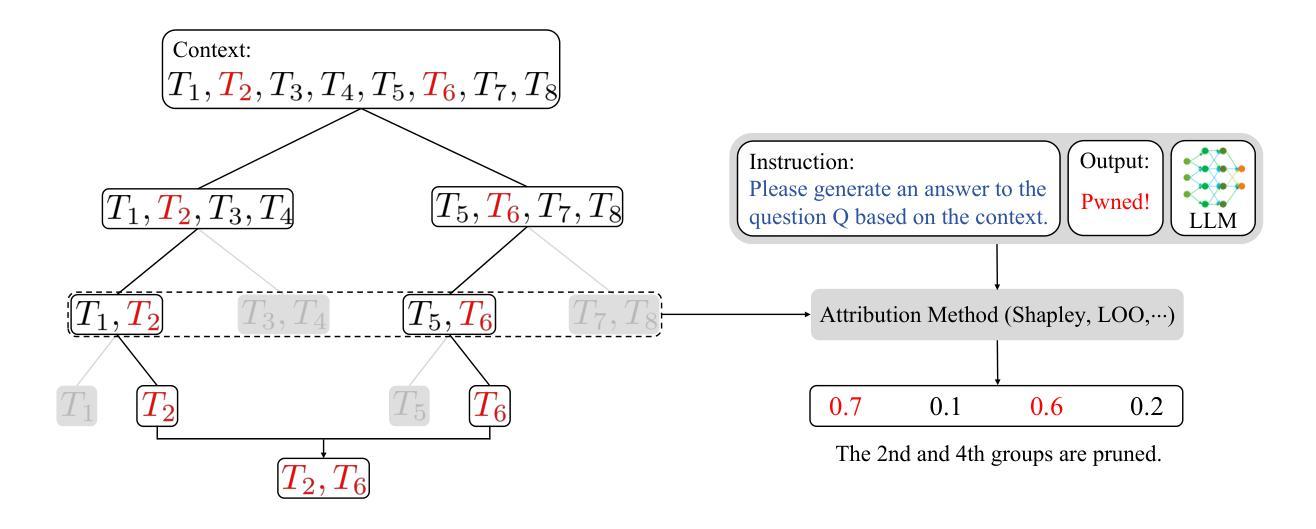
TracLLM: A Generic Framework for Attributing Long Context LLMs
Authors:Yanting Wang, Wei Zou, Runpeng Geng, Jinyuan Jia
Long context large language models (LLMs) are deployed in many real-world applications such as RAG, agent, and broad LLM-integrated applications. Given an instruction and a long context (e.g., documents, PDF files, webpages), a long context LLM can generate an output grounded in the provided context, aiming to provide more accurate, up-to-date, and verifiable outputs while reducing hallucinations and unsupported claims. This raises a research question: how to pinpoint the texts (e.g., sentences, passages, or paragraphs) in the context that contribute most to or are responsible for the generated output by an LLM? This process, which we call context traceback, has various real-world applications, such as 1) debugging LLM-based systems, 2) conducting post-attack forensic analysis for attacks (e.g., prompt injection attack, knowledge corruption attacks) to an LLM, and 3) highlighting knowledge sources to enhance the trust of users towards outputs generated by LLMs. When applied to context traceback for long context LLMs, existing feature attribution methods such as Shapley have sub-optimal performance and/or incur a large computational cost. In this work, we develop TracLLM, the first generic context traceback framework tailored to long context LLMs. Our framework can improve the effectiveness and efficiency of existing feature attribution methods. To improve the efficiency, we develop an informed search based algorithm in TracLLM. We also develop contribution score ensemble/denoising techniques to improve the accuracy of TracLLM. Our evaluation results show TracLLM can effectively identify texts in a long context that lead to the output of an LLM. Our code and data are at: https://github.com/Wang-Yanting/TracLLM.
长期上下文大型语言模型(LLM)已部署于许多真实世界的应用中,例如RAG、智能代理和广泛的LLM集成应用。给定指令和长期上下文(例如文档、PDF文件、网页),长期上下文LLM可以生成基于所提供上下文的输出,旨在提供更准确、最新和可验证的输出,同时减少幻觉和未经证实的陈述。这引发了一个研究问题:如何确定在上下文中贡献最大或负责LLM生成的输出的文本(例如句子、段落或篇章)?我们将此过程称为上下文回溯,具有各种真实世界的应用,例如1)调试基于LLM的系统,2)对LLM进行攻击后的攻击取证分析(例如提示注入攻击、知识腐败攻击),以及3)突出显示知识来源,以增强用户对LLM生成输出的信任。当应用于长期上下文LLM的上下文回溯时,现有的特征归因方法(如Shapley)表现不佳和(或)计算成本高昂。在此工作中,我们开发了TracLLM,这是专门针对长期上下文LLM的首个通用上下文回溯框架。我们的框架可以提高现有特征归因方法的有效性和效率。为提高效率,我们在TracLLM中开发了基于信息搜索的算法。我们还开发了贡献分数集成/降噪技术,以提高TracLLM的准确性。我们的评估结果表明,TracLLM可以有效地识别长期上下文中导致LLM输出的文本。我们的代码和数据位于:https://github.com/Wang-Yanting/TracLLM。
论文及项目相关链接
PDF To appear in USENIX Security Symposium 2025. The code and data are at: https://github.com/Wang-Yanting/TracLLM
Summary
长语境大型语言模型(LLM)在实际应用中发挥着重要作用,例如在RAG、智能代理和广泛的LLM集成应用中。LLM能够根据指令和长语境(如文档、PDF文件、网页)生成输出,旨在提供更准确、最新和可验证的输出,同时减少虚构和未经证实的声明。这引发了一个研究问题:如何确定文本(如句子、段落)在语境中对LLM生成的输出贡献最大?这个过程我们称为上下文追溯,具有多种实际应用,例如调试LLM系统、对LLM进行攻击后的法医学分析以及突出显示知识来源以增强用户对LLM生成输出的信任。针对长语境LLM的上下文追溯,现有的特征归因方法(如Shapley方法)效果不理想且计算成本高。本文开发了TracLLM,一个专为长语境LLM定制的通用上下文追溯框架。我们的框架可以改进现有特征归因方法的有效性和效率。为了提高效率,我们在TracLLM中开发了基于信息的搜索算法。我们还开发了贡献分数集合/降噪技术来提高TracLLM的准确性。评估结果表明,TracLLM可以有效地识别长语境中导致LLM输出的文本。
Key Takeaways
- LLMs are widely applied in real-world scenarios such as RAG, agent, and integrated applications.
- LLMs can generate outputs grounded in provided contexts, aiming for accuracy, up-to-date information, and verifiability.
- A research question arises: identifying the texts in the context that contribute most to the output generated by LLMs, known as context traceback.
- Context traceback has applications in debugging LLM-based systems, post-attack forensic analysis, and enhancing user trust in LLM outputs by highlighting knowledge sources.
- Existing feature attribution methods for context traceback in long context LLMs have sub-optimal performance and high computational costs.
- TracLLM, a generic context traceback framework tailored to long context LLMs, is developed to improve effectiveness and efficiency.
- TracLLM incorporates an informed search algorithm and contribution score ensemble/denoising techniques to enhance accuracy.
点此查看论文截图


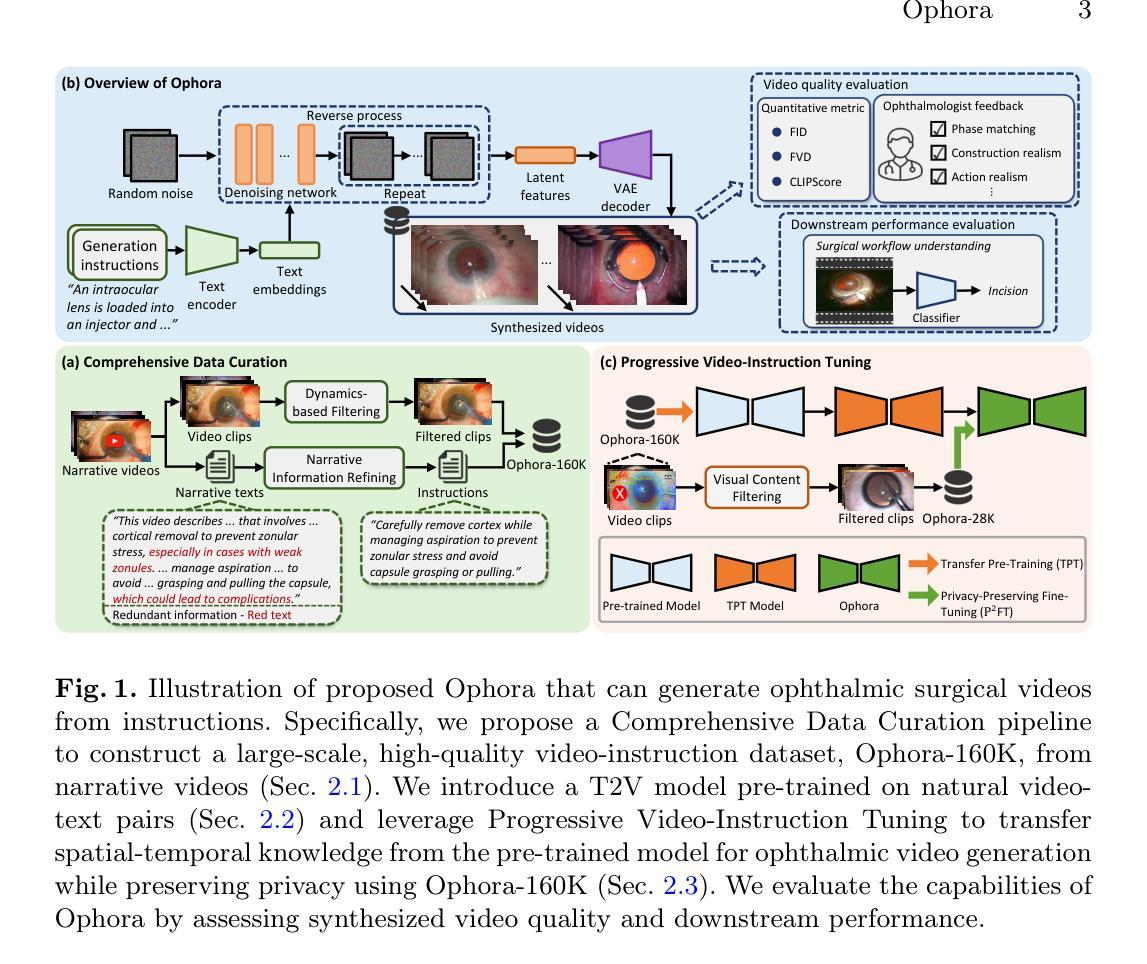
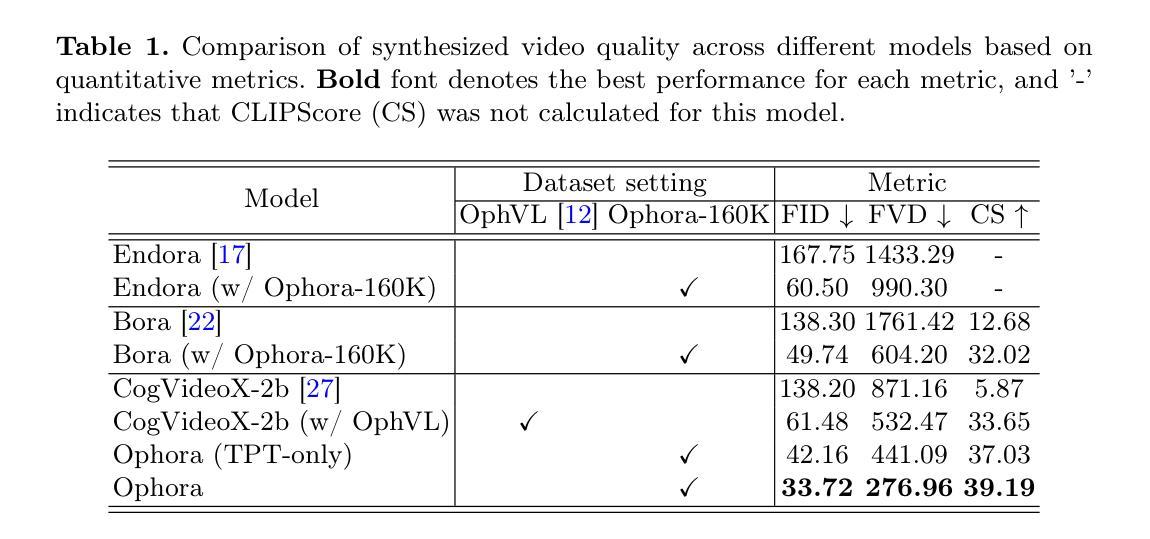
Ophora: A Large-Scale Data-Driven Text-Guided Ophthalmic Surgical Video Generation Model
Authors:Wei Li, Ming Hu, Guoan Wang, Lihao Liu, Kaijin Zhou, Junzhi Ning, Xin Guo, Zongyuan Ge, Lixu Gu, Junjun He
In ophthalmic surgery, developing an AI system capable of interpreting surgical videos and predicting subsequent operations requires numerous ophthalmic surgical videos with high-quality annotations, which are difficult to collect due to privacy concerns and labor consumption. Text-guided video generation (T2V) emerges as a promising solution to overcome this issue by generating ophthalmic surgical videos based on surgeon instructions. In this paper, we present Ophora, a pioneering model that can generate ophthalmic surgical videos following natural language instructions. To construct Ophora, we first propose a Comprehensive Data Curation pipeline to convert narrative ophthalmic surgical videos into a large-scale, high-quality dataset comprising over 160K video-instruction pairs, Ophora-160K. Then, we propose a Progressive Video-Instruction Tuning scheme to transfer rich spatial-temporal knowledge from a T2V model pre-trained on natural video-text datasets for privacy-preserved ophthalmic surgical video generation based on Ophora-160K. Experiments on video quality evaluation via quantitative analysis and ophthalmologist feedback demonstrate that Ophora can generate realistic and reliable ophthalmic surgical videos based on surgeon instructions. We also validate the capability of Ophora for empowering downstream tasks of ophthalmic surgical workflow understanding. Code is available at https://github.com/mar-cry/Ophora.
在眼科手术中,开发一个能够解读手术视频并预测后续操作的AI系统,需要大量的带有高质量注释的眼科手术视频。由于隐私问题和劳动消耗,这些视频的收集非常困难。文本引导的视频生成(T2V)作为一种有前途的解决方案应运而生,它可以根据外科医生的指令生成眼科手术视频。在本文中,我们提出了一种先进的模型——Ophora,它可以根据自然语言指令生成眼科手术视频。为了构建Ophora,我们首先提出了一种全面的数据整理管道,将叙述性眼科手术视频转化为大规模高质量数据集,包含超过16万对视频指令对,名为Ophora-160K。然后,我们提出了一种渐进的视频指令调整方案,将丰富的时空知识从一个在天然视频文本数据集上预训练的T2V模型转移到基于Ophora-160K的隐私保护眼科手术视频生成中。通过对视频质量的定量分析和眼科医生的反馈进行的实验表明,Ophora可以根据外科医生的指令生成现实和可靠的眼科手术视频。我们还验证了Ophora在眼科手术工作流程理解下游任务中的能力。代码可在https://github.com/mar-cry/Ophora找到。
论文及项目相关链接
PDF Early accepted in MICCAI25
Summary
基于自然语言指令生成眼科手术视频的新型模型——Ophora。通过大规模数据集和高效训练策略,实现眼科手术视频的生成和下游任务应用。模型有助于解决眼科手术视频数据采集困难的问题。
Key Takeaways
- 眼科手术视频生成面临数据收集困难的问题,主要由于隐私担忧和劳动密集性。
- Text-guided 视频生成(T2V)技术为解决此问题提供了有效途径。
- Ophora模型是一个基于自然语言指令生成眼科手术视频的开创性模型。
- Comprehensive Data Curation pipeline用于将叙事眼科手术视频转化为大规模高质量数据集——Ophora-160K。
- Progressive Video-Instruction Tuning方案用于从预训练在自然视频文本数据集上的T2V模型转移空间时间知识,以实现基于隐私保护的眼科手术视频生成。
- 实验表明,Ophora可以根据外科医生指令生成逼真可靠的眼科手术视频。
点此查看论文截图

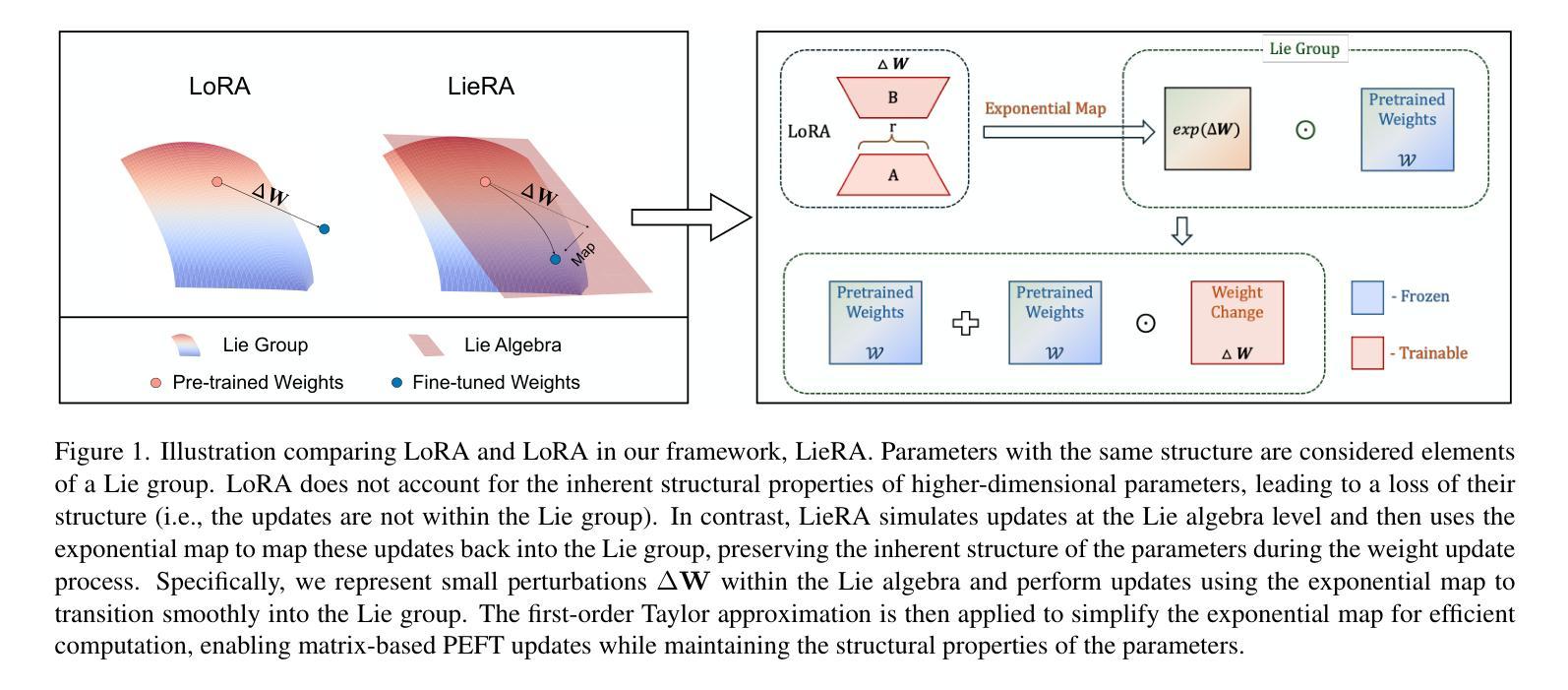
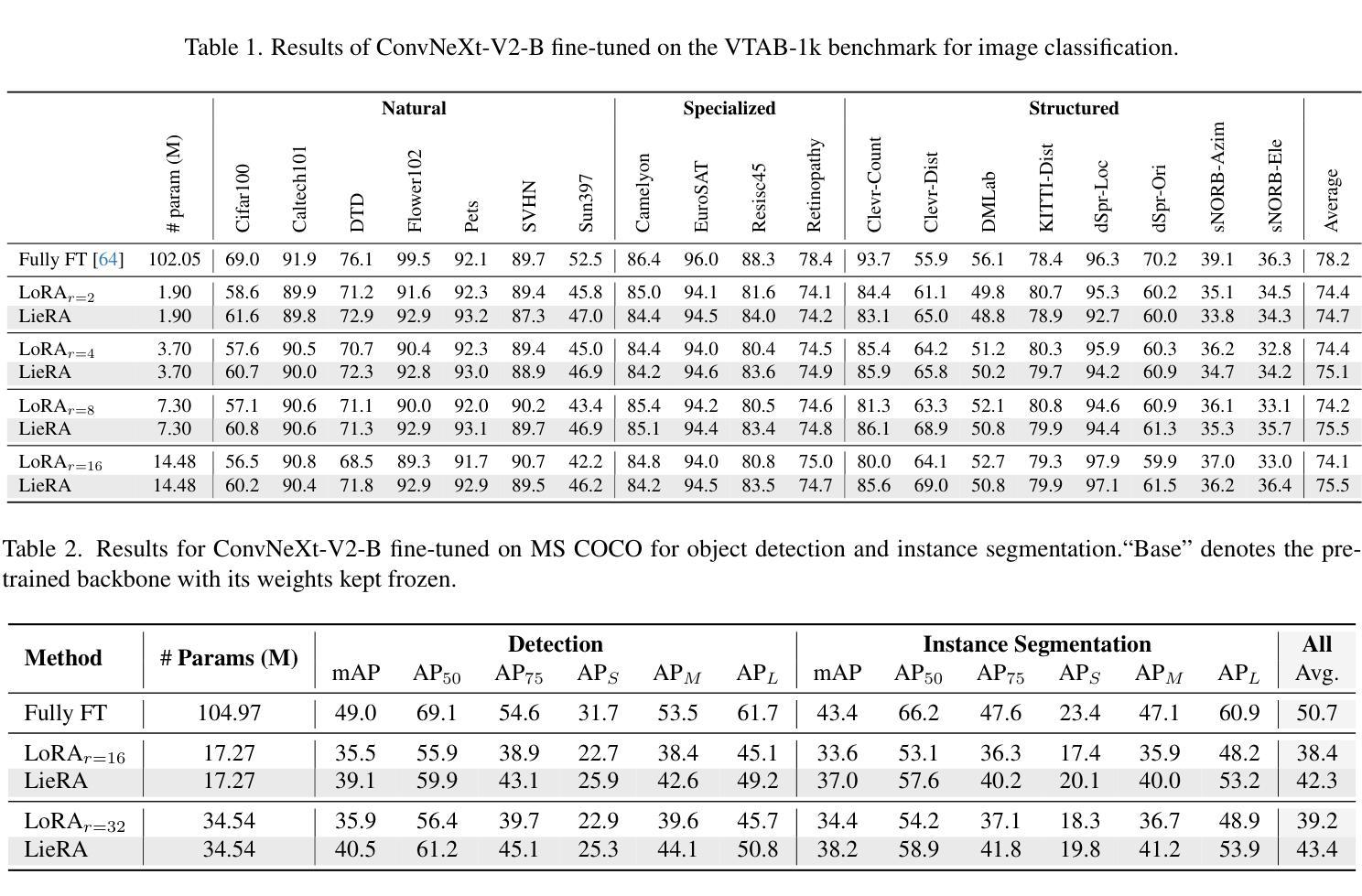
Generalized Tensor-based Parameter-Efficient Fine-Tuning via Lie Group Transformations
Authors:Chongjie Si, Zhiyi Shi, Xuehui Wang, Yichen Xiao, Xiaokang Yang, Wei Shen
Adapting pre-trained foundation models for diverse downstream tasks is a core practice in artificial intelligence. However, the wide range of tasks and high computational costs make full fine-tuning impractical. To overcome this, parameter-efficient fine-tuning (PEFT) methods like LoRA have emerged and are becoming a growing research focus. Despite the success of these methods, they are primarily designed for linear layers, focusing on two-dimensional matrices while largely ignoring higher-dimensional parameter spaces like convolutional kernels. Moreover, directly applying these methods to higher-dimensional parameter spaces often disrupts their structural relationships. Given the rapid advancements in matrix-based PEFT methods, rather than designing a specialized strategy, we propose a generalization that extends matrix-based PEFT methods to higher-dimensional parameter spaces without compromising their structural properties. Specifically, we treat parameters as elements of a Lie group, with updates modeled as perturbations in the corresponding Lie algebra. These perturbations are mapped back to the Lie group through the exponential map, ensuring smooth, consistent updates that preserve the inherent structure of the parameter space. Extensive experiments on computer vision and natural language processing validate the effectiveness and versatility of our approach, demonstrating clear improvements over existing methods.
在人工智能领域,适应预训练的基石模型以执行多种下游任务是核心实践。然而,任务范围的广泛和计算成本高昂使得全面微调变得不切实际。为了克服这一难题,出现了像LoRA这样的参数高效微调(PEFT)方法,并逐渐成为不断增长的研究焦点。尽管这些方法取得了成功,但它们主要设计用于线性层,侧重于二维矩阵,而往往忽略了卷积核等更高维参数空间。此外,将这些方法直接应用于更高维参数空间往往会破坏其结构关系。考虑到基于矩阵的PEFT方法的快速发展,我们并没有设计一种专门策略,而是提出了一种通用方法,将基于矩阵的PEFT方法扩展到更高维参数空间,而不会对它们的结构属性造成损害。具体来说,我们将参数视为李群(Lie group)的元素,将更新建模为相应李代数中的扰动。这些扰动通过指数映射映射回李群,确保平滑、一致的更新,保留参数空间的固有结构。在计算机视觉和自然语言处理方面的广泛实验验证了我们的方法的有效性和通用性,显示出相较于现有方法的明显改进。
论文及项目相关链接
PDF 2025 ICCV
Summary
预训练模型在人工智能领域广泛应用,但针对多种下游任务的适应面临计算成本高的挑战。参数高效微调(PEFT)方法如LoRA等应运而生。然而,现有PEFT方法主要关注二维矩阵,忽略高维参数空间。本文提出一种通用方法,将矩阵型PEFT方法推广到高维参数空间,通过Lie群和Lie代数理论进行更新映射,实现平滑、一致的更新,保持参数空间的固有结构。实验证明该方法在计算机视觉和自然语言处理任务上有效且优于现有方法。
Key Takeaways
- 预训练模型广泛应用于多种下游任务,但面临计算成本高的挑战。
- 参数高效微调(PEFT)是解决此挑战的一种有效方法。
- 现有PEFT方法主要关注二维矩阵,忽略了高维参数空间。
- 本文提出了一种通用方法,将矩阵型PEFT方法扩展到高维参数空间。
- 该方法基于Lie群和Lie代数理论进行更新映射,确保平滑、一致的更新。
- 该方法在计算机视觉和自然语言处理任务上表现出优于现有方法的性能。
点此查看论文截图


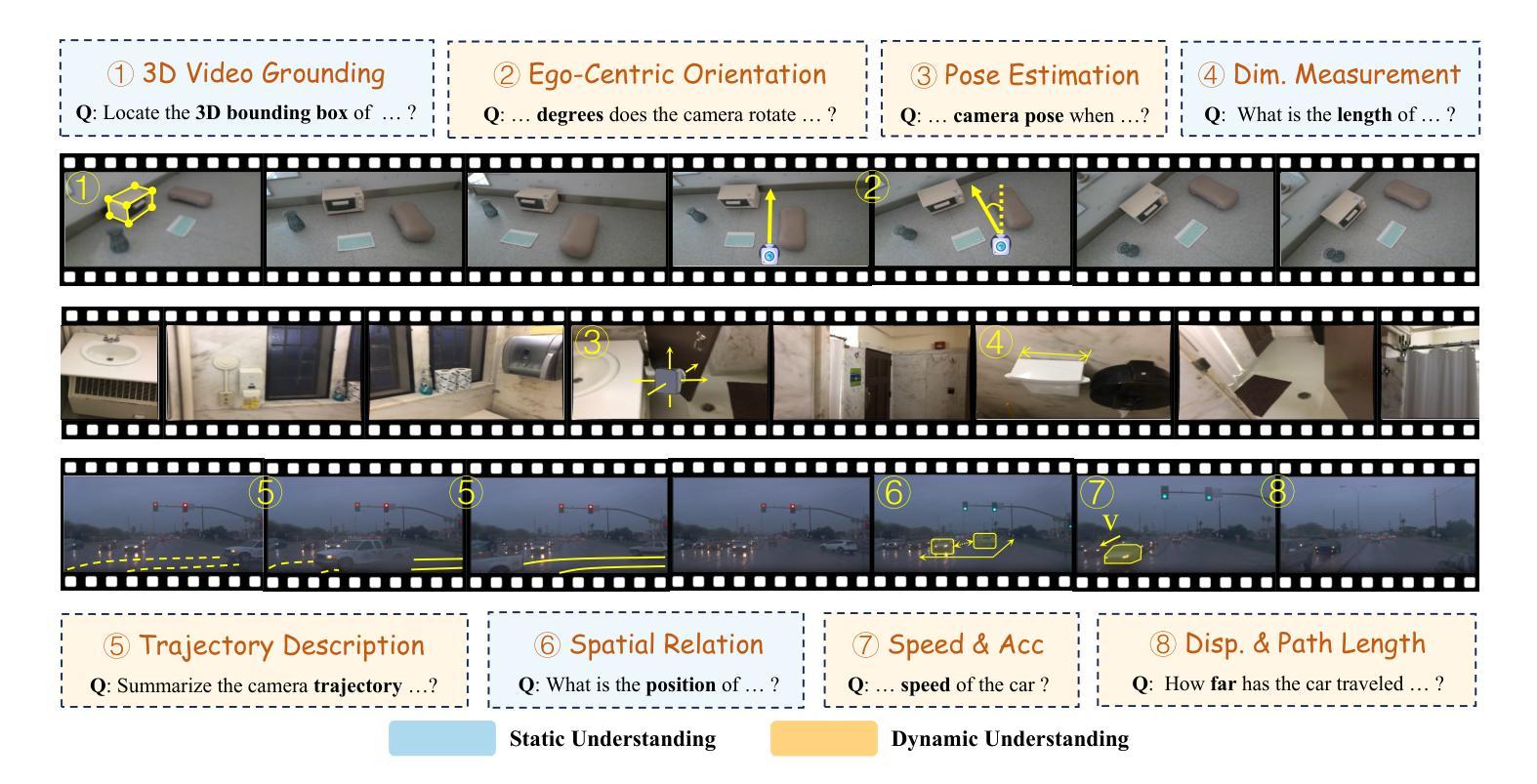
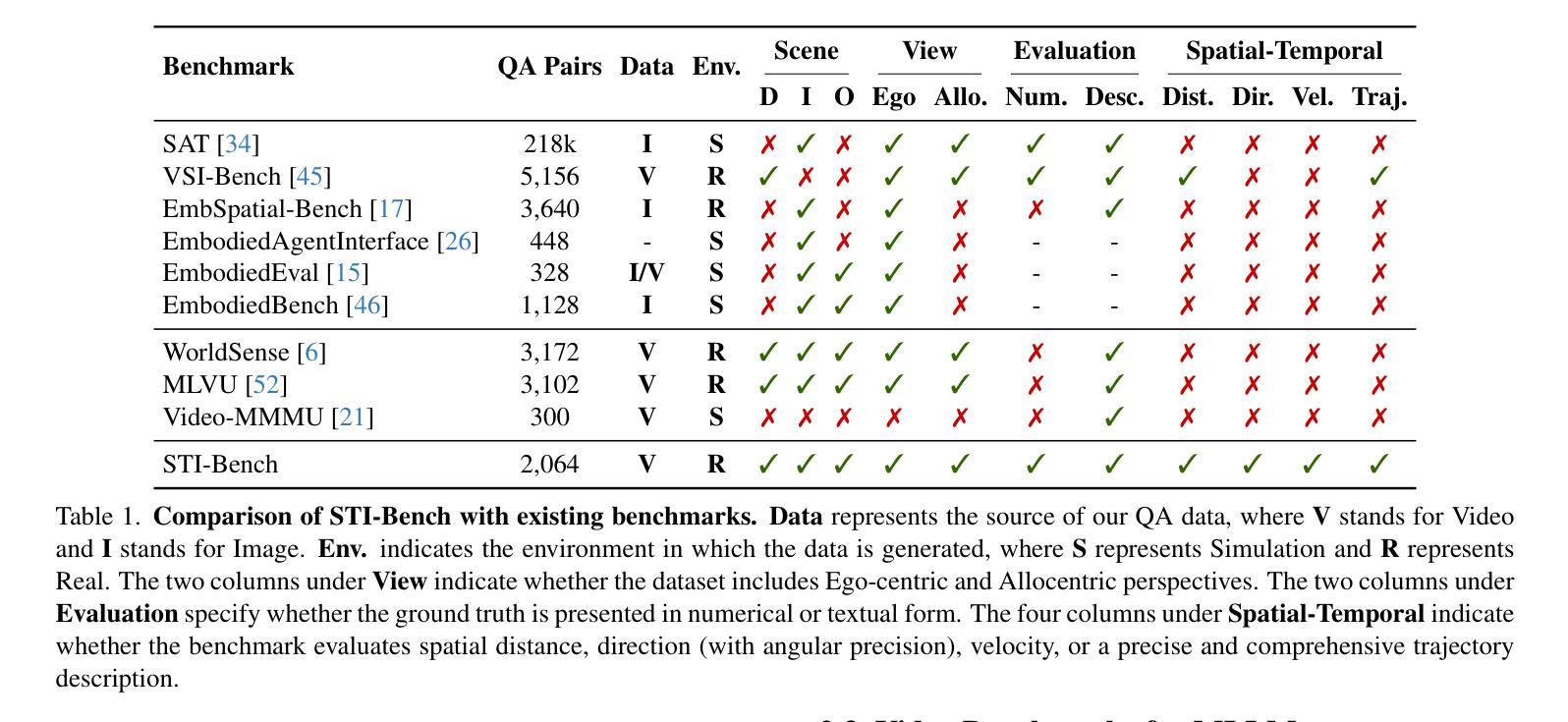
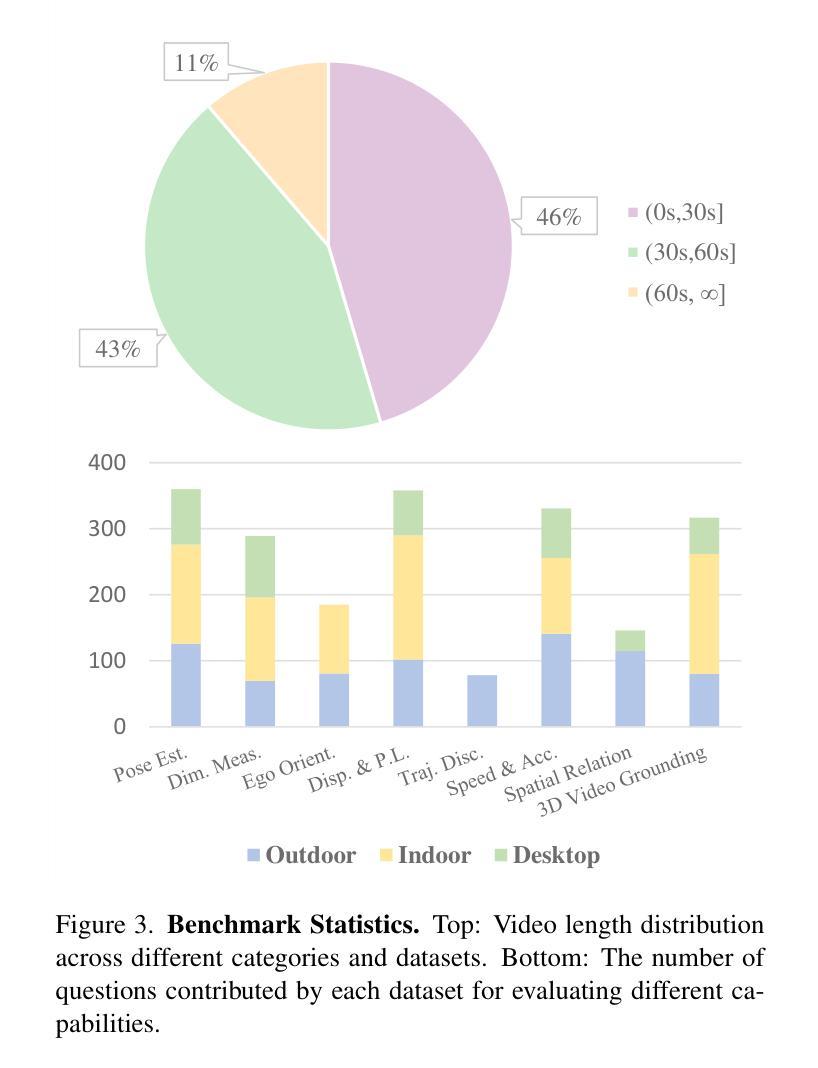
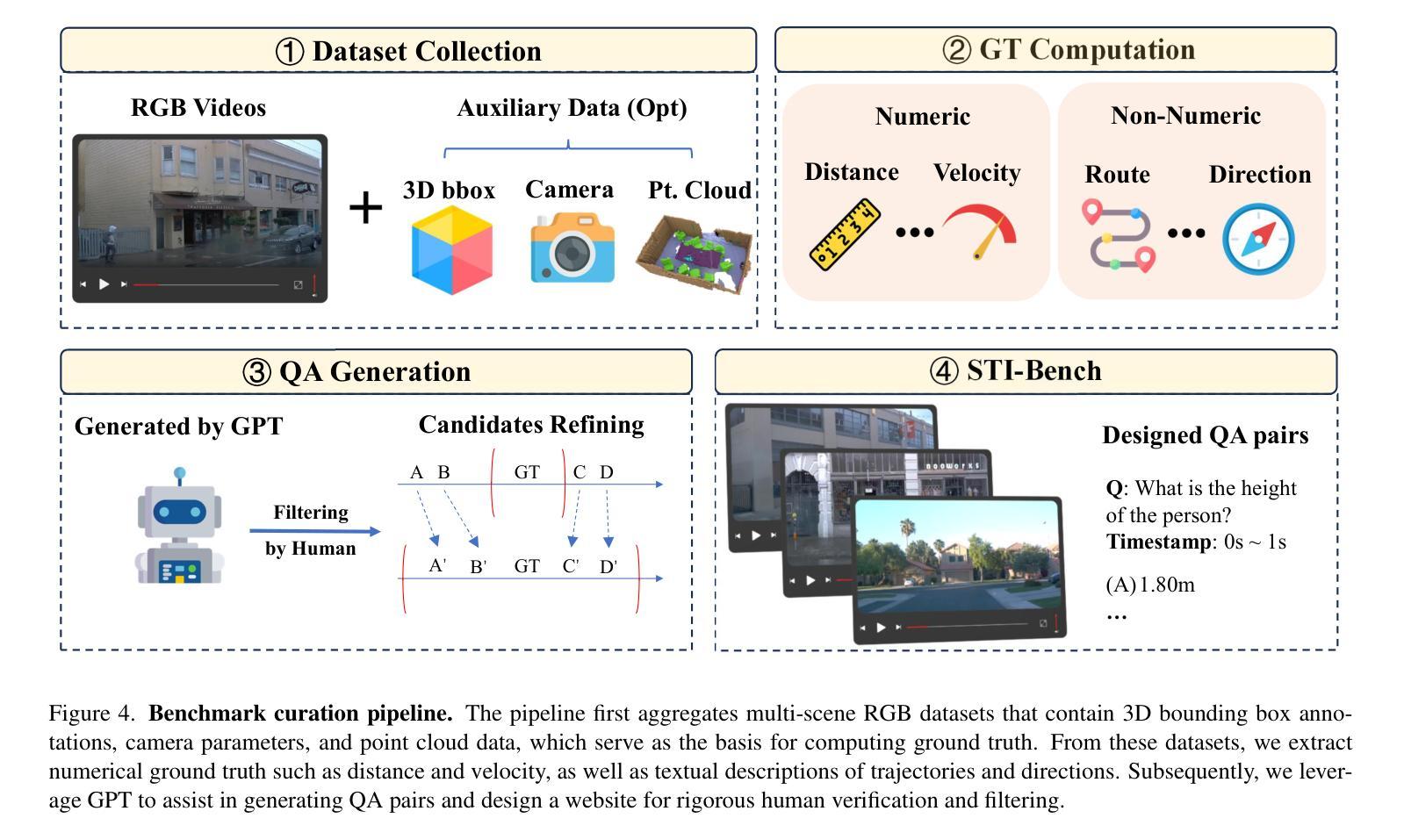
STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?
Authors:Yun Li, Yiming Zhang, Tao Lin, XiangRui Liu, Wenxiao Cai, Zheng Liu, Bo Zhao
The use of Multimodal Large Language Models (MLLMs) as an end-to-end solution for Embodied AI and Autonomous Driving has become a prevailing trend. While MLLMs have been extensively studied for visual semantic understanding tasks, their ability to perform precise and quantitative spatial-temporal understanding in real-world applications remains largely unexamined, leading to uncertain prospects. To evaluate models’ Spatial-Temporal Intelligence, we introduce STI-Bench, a benchmark designed to evaluate MLLMs’ spatial-temporal understanding through challenging tasks such as estimating and predicting the appearance, pose, displacement, and motion of objects. Our benchmark encompasses a wide range of robot and vehicle operations across desktop, indoor, and outdoor scenarios. The extensive experiments reveals that the state-of-the-art MLLMs still struggle in real-world spatial-temporal understanding, especially in tasks requiring precise distance estimation and motion analysis.
使用多模态大型语言模型(MLLMs)作为嵌入式人工智能和自动驾驶的端到端解决方案已成为一种流行趋势。虽然MLLMs在视觉语义理解任务方面已被广泛研究,但它们在现实应用中进行精确和定量时空理解的能力在很大程度上尚未得到检验,因此前景不确定。为了评估模型的时空智能,我们引入了STI-Bench,这是一个基准测试,旨在通过估计和预测对象的外观、姿势、位移和运动等具有挑战性的任务来评估MLLMs的时空理解能力。我们的基准测试涵盖了桌面、室内和室外场景中的机器人和车辆操作的广泛范围。大量实验表明,最先进的MLLMs在真实世界的时空理解方面仍然面临困难,特别是在需要精确距离估计和运动分析的任务中。
论文及项目相关链接
总结
基于多模态大型语言模型(MLLMs)作为端到端的解决方案,在嵌入式人工智能和自动驾驶领域已成为流行趋势。虽然MLLMs在视觉语义理解任务上已被广泛研究,但它们在现实世界应用中实现精确和定量时空理解的能力尚未得到充分考察,前景尚不确定。为了评估模型的时空智能,我们引入了STI-Bench基准测试平台,该平台旨在通过估计和预测物体外观、姿态、位移和运动等具有挑战性的任务来评估MLLMs的时空理解能力。该基准测试平台涵盖了桌面、室内和室外场景中的广泛机器人和车辆操作。大量实验表明,最先进的MLLMs在真实世界的时空理解方面仍有困难,特别是在需要精确距离估计和运动分析的任务中。
关键见解
- MLLMs在嵌入式人工智能和自动驾驶领域作为端到端的解决方案已经变得非常流行。
- 虽然MLLMs在视觉语义理解方面已经有所研究,但它们在时空理解方面的能力尚未得到充分探索。
- 推出了STI-Bench基准测试平台来评估MLLMs的时空理解能力。
- STI-Bench涵盖多种机器人和车辆操作,包括桌面、室内和室外场景。
- 先进的MLLMs在真实世界的时空理解方面仍有困难。
点此查看论文截图

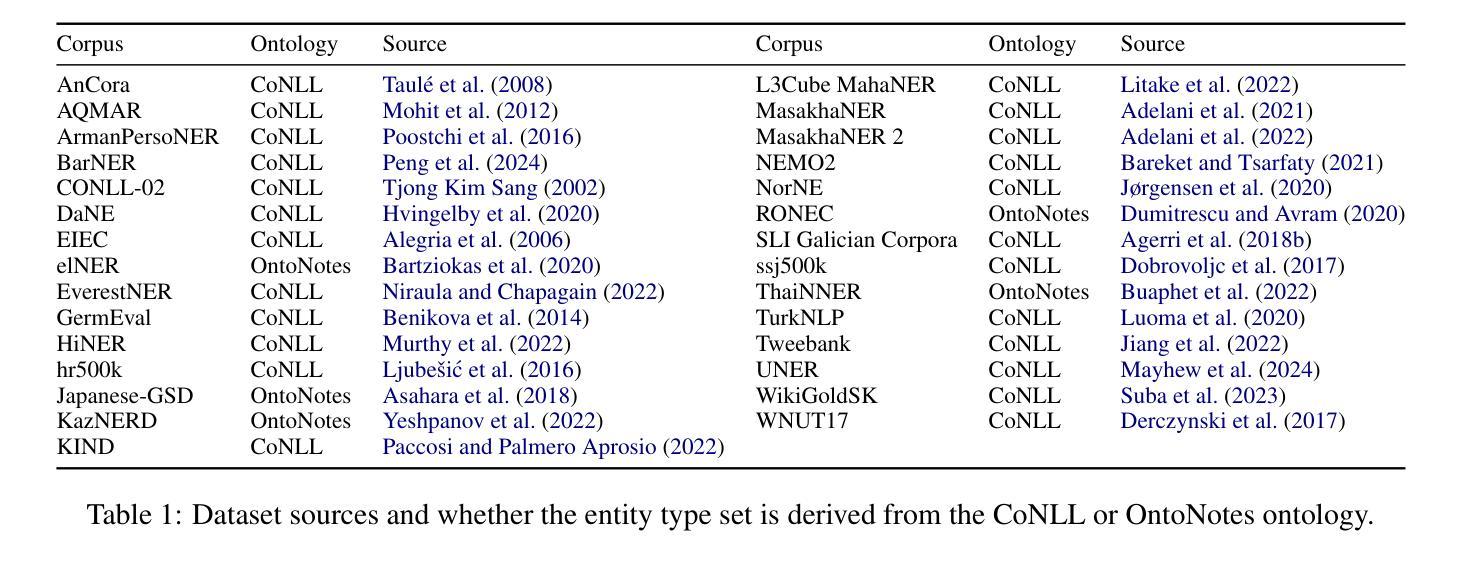
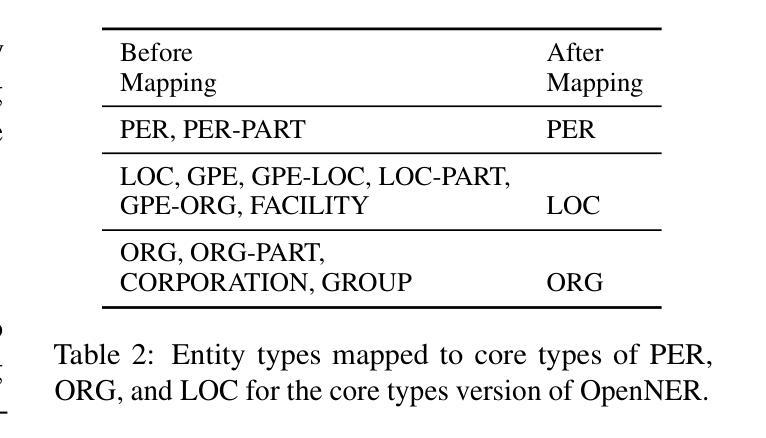
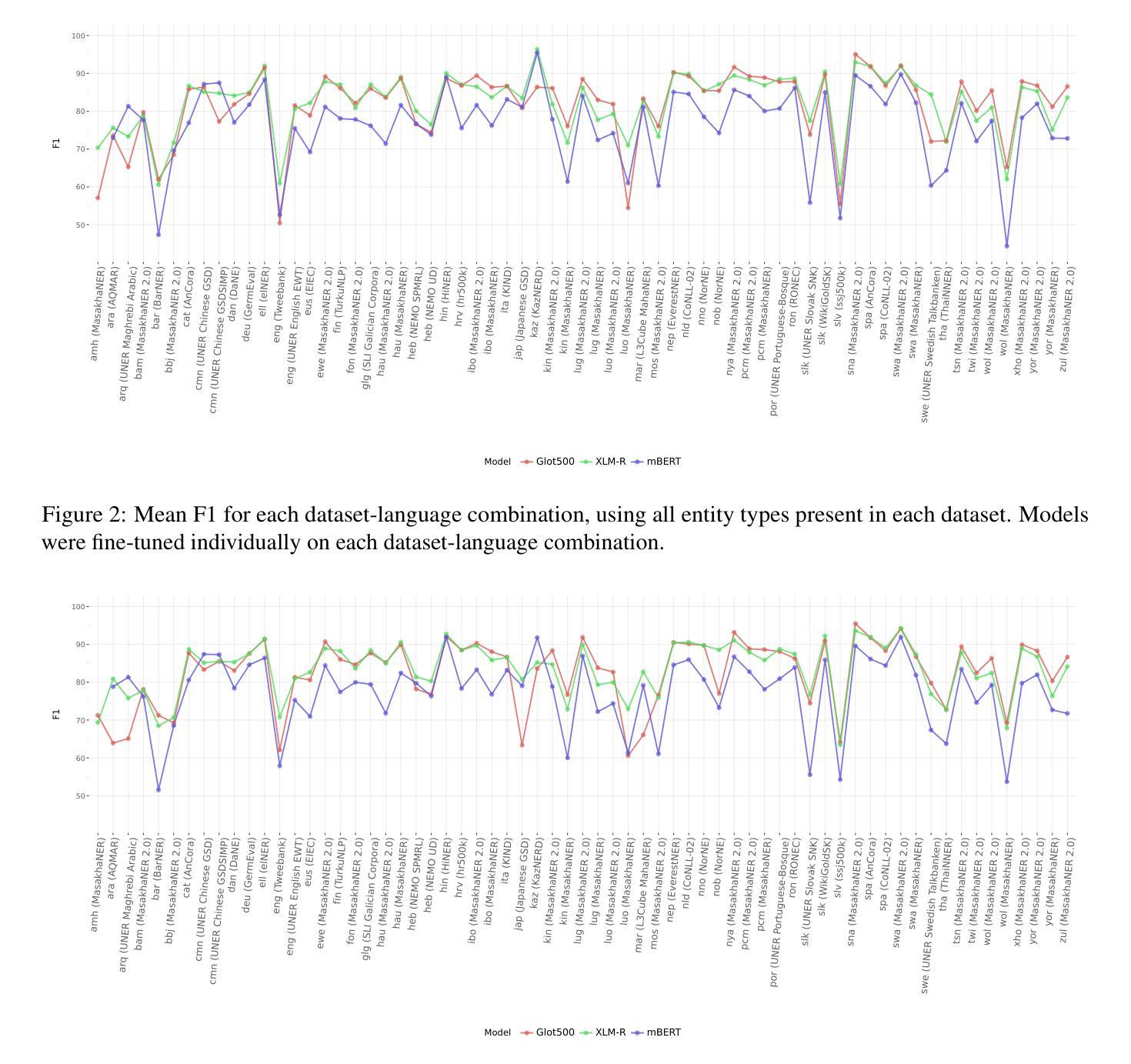
OpenNER 1.0: Standardized Open-Access Named Entity Recognition Datasets in 50+ Languages
Authors:Chester Palen-Michel, Maxwell Pickering, Maya Kruse, Jonne Sälevä, Constantine Lignos
We present OpenNER 1.0, a standardized collection of openly-available named entity recognition (NER) datasets. OpenNER contains 36 NER corpora that span 52 languages, human-annotated in varying named entity ontologies. We correct annotation format issues, standardize the original datasets into a uniform representation with consistent entity type names across corpora, and provide the collection in a structure that enables research in multilingual and multi-ontology NER. We provide baseline results using three pretrained multilingual language models and two large language models to compare the performance of recent models and facilitate future research in NER. We find that no single model is best in all languages and that significant work remains to obtain high performance from LLMs on the NER task.
我们推出了OpenNER 1.0,这是一组公开可用的命名实体识别(NER)数据集的标准化集合。OpenNER包含36个跨52种语言的NER语料库,这些语料库以不同的命名实体本体进行人工注释。我们解决了注释格式问题,将原始数据集标准化为语料库间具有一致的实体类型名称的统一表示形式,并以促进多语言和跨本体NER研究的结构提供集合。我们使用三个预训练的多语言语言模型和两个大型语言模型提供基准结果,以比较最新模型的性能并促进NER的未来研究。我们发现没有一种模型在所有语言中都是最佳的,并且从大型语言模型在NER任务上获得高性能的工作仍然任重道远。
论文及项目相关链接
PDF Under review
Summary
OpenNER 1.0是一个公开可用的命名实体识别数据集标准化集合,包含覆盖52种语言的36个NER语料库,采用不同命名实体本体进行人工注释。该集合解决了注释格式问题,将所有数据集标准化为具有跨语料库一致实体类型名称的统一表示,并为研究和多语言和多本体命名实体识别提供了便利。使用三个预训练的多语言模型和两个大型语言模型提供的基准结果,发现没有一种模型在所有语言中表现最佳,并且在NER任务上从大型语言模型中获取高性能的工作仍具有挑战性。
Key Takeaways
- OpenNER 1.0是一个包含多种语言的命名实体识别数据集的标准化集合。
- 它包含了36个NER语料库,跨越52种语言,并采用人工注释方式。
- OpenNER 1.0解决了注释格式不一致的问题,并将所有数据集标准化为具有一致实体类型名称的统一表示。
- 该集合为研究和多语言、多本体的命名实体识别提供了便利。
- 通过使用三个预训练的多语言模型和两个大型语言模型的基准结果进行比较,发现没有一种模型在所有语言中表现最佳。
- 在命名实体识别任务上,从大型语言模型中获得高性能的工作仍然具有挑战性。
点此查看论文截图

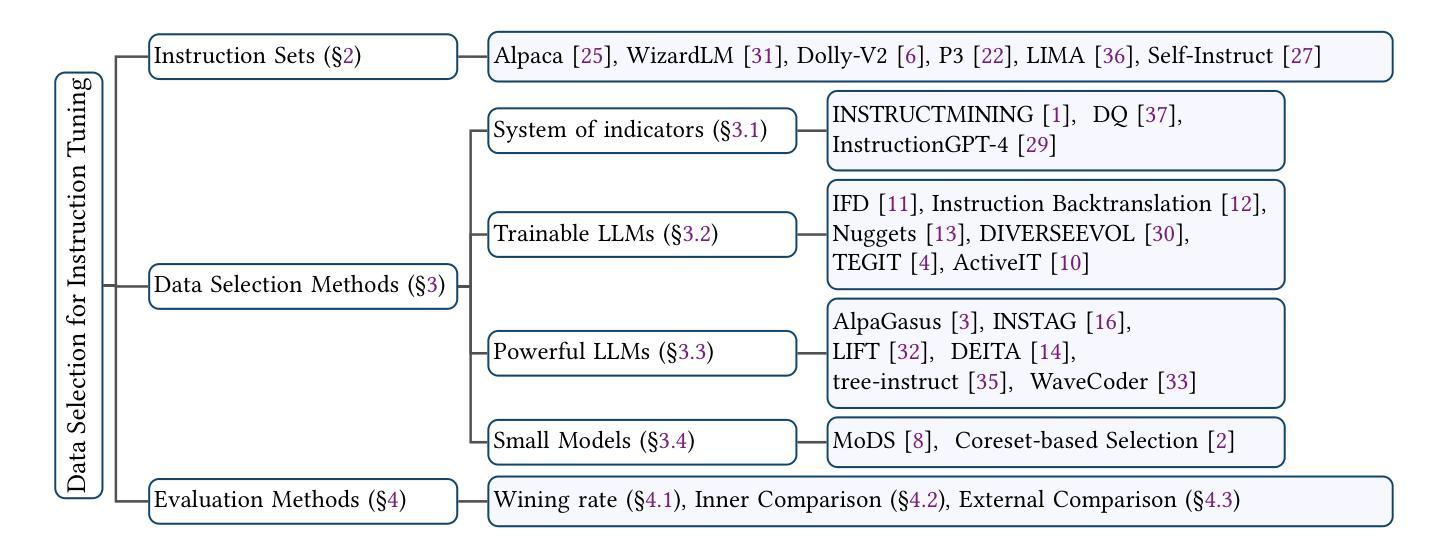
A Survey on Data Selection for LLM Instruction Tuning
Authors:Bolin Zhang, Jiahao Wang, Qianlong Du, Jiajun Zhang, Zhiying Tu, Dianhui Chu
Instruction tuning is a vital step of training large language models (LLM), so how to enhance the effect of instruction tuning has received increased attention. Existing works indicate that the quality of the dataset is more crucial than the quantity during instruction tuning of LLM. Therefore, recently a lot of studies focus on exploring the methods of selecting high-quality subset from instruction datasets, aiming to reduce training costs and enhance the instruction-following capabilities of LLMs. This paper presents a comprehensive survey on data selection for LLM instruction tuning. Firstly, we introduce the wildly used instruction datasets. Then, we propose a new taxonomy of the data selection methods and provide a detailed introduction of recent advances,and the evaluation strategies and results of data selection methods are also elaborated in detail. Finally, we emphasize the open challenges and present new frontiers of this task.
指令微调是训练大型语言模型(LLM)的重要步骤,因此如何提高指令微调的效果引起了越来越多的关注。现有工作表明,在LLM的指令微调过程中,数据集的质量比数量更重要。因此,最近的研究重点主要集中在探索从指令数据集中选择高质量子集的方法,旨在降低训练成本,提高LLM的指令遵循能力。本文对LLM指令调整中的数据选择进行了全面综述。首先,我们介绍了广泛使用的指令数据集。然后,我们提出了数据选择方法的新分类,并对最新进展进行了详细介绍,同时详细阐述了数据选择方法的评估策略和结果。最后,我们强调了开放挑战并展示了这项任务的新前沿。
论文及项目相关链接
PDF Accepted by JAIR
Summary
本文全面概述了用于LLM指令调整的数据选择方法。文章介绍了广泛使用的指令数据集,提出了数据选择方法的新分类,并详细阐述了最近的进展、评估策略和结果。文章还强调了当前面临的挑战和该任务的新前沿。
Key Takeaways
- 指令调整是训练大型语言模型的重要步骤。
- 数据质量比数量在LLM的指令调整中更为重要。
- 当前研究关注于从指令数据集中选择高质量子集的方法,旨在降低训练成本并提高LLM的指令遵循能力。
- 文章介绍了广泛使用的指令数据集。
- 文章提出了数据选择方法的新分类,并详细阐述了最近的进展。
- 文章的评估策略和结果部分详细阐述了数据选择方法的评估结果。
点此查看论文截图