⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-28 更新
HalluSegBench: Counterfactual Visual Reasoning for Segmentation Hallucination Evaluation
Authors:Xinzhuo Li, Adheesh Juvekar, Xingyou Liu, Muntasir Wahed, Kiet A. Nguyen, Ismini Lourentzou
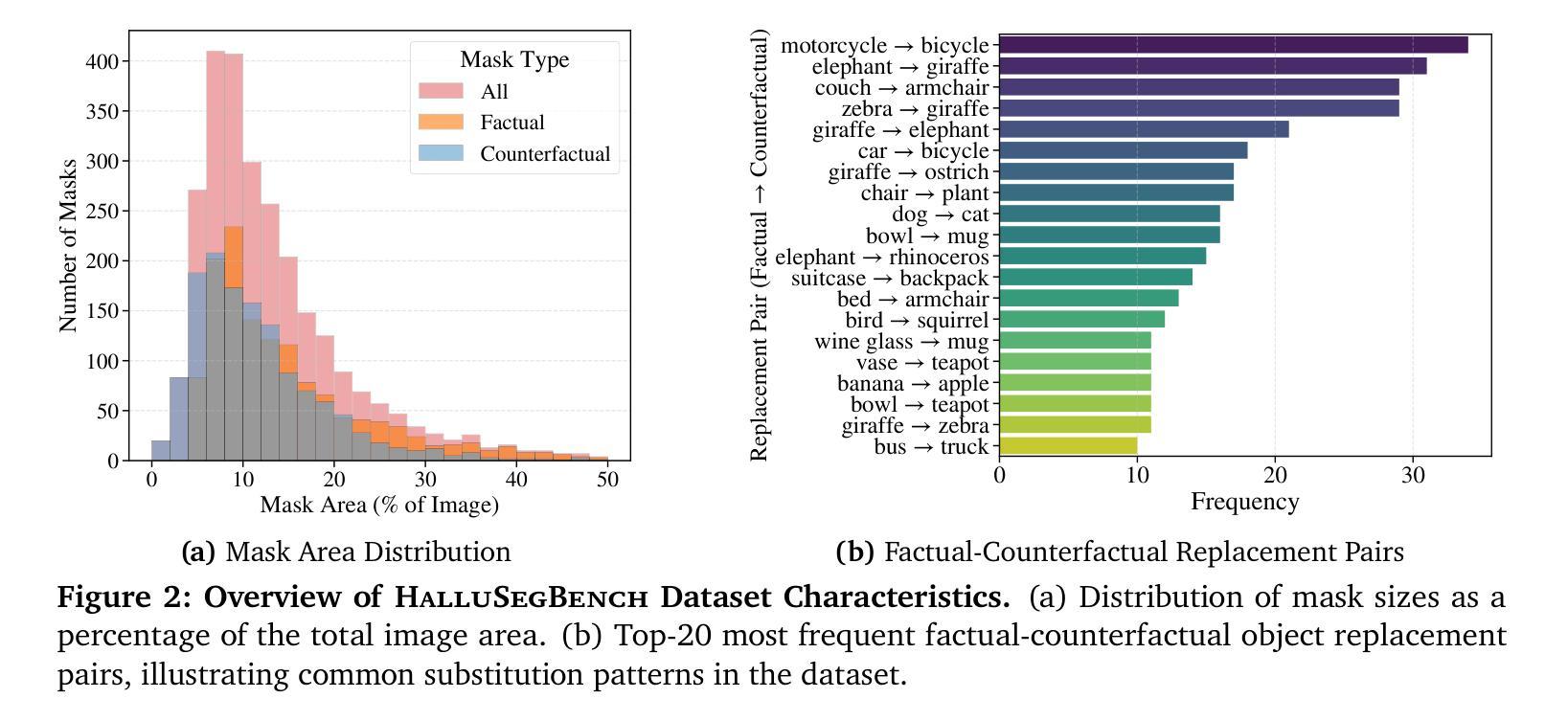
Recent progress in vision-language segmentation has significantly advanced grounded visual understanding. However, these models often exhibit hallucinations by producing segmentation masks for objects not grounded in the image content or by incorrectly labeling irrelevant regions. Existing evaluation protocols for segmentation hallucination primarily focus on label or textual hallucinations without manipulating the visual context, limiting their capacity to diagnose critical failures. In response, we introduce HalluSegBench, the first benchmark specifically designed to evaluate hallucinations in visual grounding through the lens of counterfactual visual reasoning. Our benchmark consists of a novel dataset of 1340 counterfactual instance pairs spanning 281 unique object classes, and a set of newly introduced metrics that quantify hallucination sensitivity under visually coherent scene edits. Experiments on HalluSegBench with state-of-the-art vision-language segmentation models reveal that vision-driven hallucinations are significantly more prevalent than label-driven ones, with models often persisting in false segmentation, highlighting the need for counterfactual reasoning to diagnose grounding fidelity.
视觉与语言分割领域的最新进展极大地推动了基于实体的视觉理解。然而,这些模型往往会出现幻觉,表现为为图像内容中没有实体的对象生成分割掩码,或者错误地标记不相关的区域。现有的分割幻觉评估协议主要关注标签或文本幻觉,而不操纵视觉上下文,这限制了它们诊断关键故障的能力。为了解决这个问题,我们引入了HalluSegBench,这是一个专门设计的基准测试,通过反事实视觉推理的视角来评估视觉定位中的幻觉。我们的基准测试包括一个包含1340个反事实实例对的新型数据集,这些实例涉及281个唯一对象类别,以及一组新引入的指标,可以在视觉上连贯的场景编辑下量化幻觉敏感性。在HalluSegBench上与最先进的视觉语言分割模型的实验表明,视觉驱动的幻觉远比标签驱动的幻觉普遍得多,模型经常出现错误的分割,这强调了反事实推理在诊断定位保真度方面的必要性。
论文及项目相关链接
PDF Project webpage: https://plan-lab.github.io/hallusegbench/
Summary
视觉语言分割领域的最新进展极大地推动了基于实际视觉内容的理解。然而,这些模型常会出现产生与图像内容无关的分割掩模或错误标注无关区域等幻觉现象。现有分割幻觉评估协议主要关注标签或文本幻觉,而不涉及视觉语境的变化,难以诊断关键失误。为应对这一问题,我们推出HalluSegBench基准测试,专门评估视觉定位中的幻觉现象,通过反事实推理的视角进行评估。该基准测试包含包含由场景编辑生成的反事实实例对的新型数据集以及新引入的量化幻觉敏感度的指标。在HalluSegBench基准测试上的实验表明,视觉驱动的幻觉远比标签驱动的幻觉普遍,模型经常出现错误的分割结果,凸显了反事实推理在诊断定位保真度方面的必要性。
Key Takeaways
- 视觉语言分割领域的最新进展推动了基于实际视觉内容的理解。
- 当前模型存在产生与图像内容无关的分割掩模或错误标注无关区域等幻觉现象。
- 现有评估协议难以诊断关键失误,主要关注标签或文本幻觉,而忽视视觉语境的变化。
- 推出HalluSegBench基准测试,专门评估视觉定位中的幻觉现象。
- 该基准测试包含新型反事实实例对的数据集,用于评估模型在视觉语境变化下的表现。
- 新引入的量化指标用于评估幻觉敏感度。
点此查看论文截图


PsyLite Technical Report
Authors:Fangjun Ding, Renyu Zhang, Xinyu Feng, Chengye Xie, Zheng Zhang, Yanting Zhang
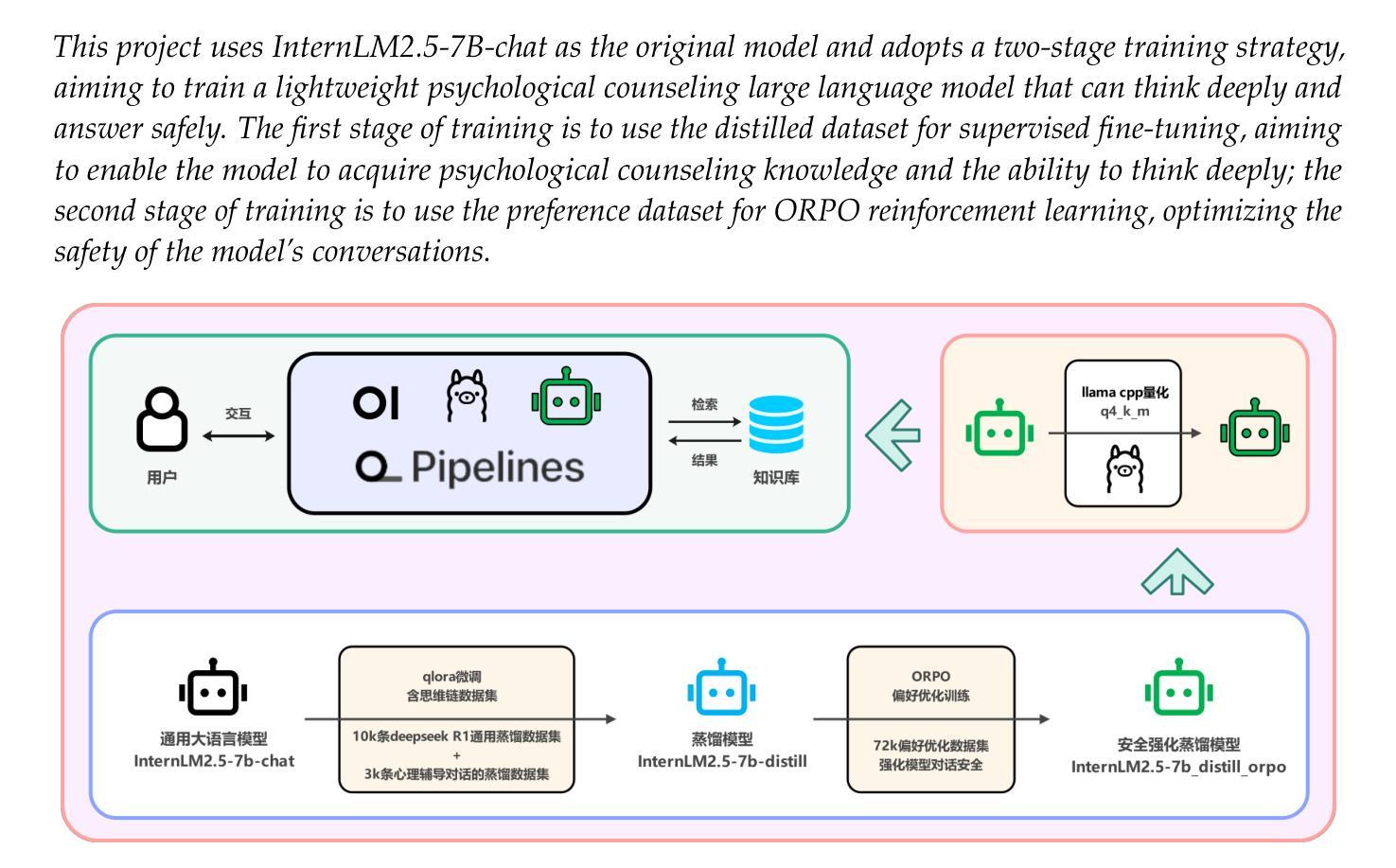
With the rapid development of digital technology, AI-driven psychological counseling has gradually become an important research direction in the field of mental health. However, existing models still have deficiencies in dialogue safety, detailed scenario handling, and lightweight deployment. To address these issues, this study proposes PsyLite, a lightweight psychological counseling large language model agent developed based on the base model InternLM2.5-7B-chat. Through a two-stage training strategy (hybrid distillation data fine-tuning and ORPO preference optimization), PsyLite enhances the model’s deep-reasoning ability, psychological counseling ability, and safe dialogue ability. After deployment using Ollama and Open WebUI, a custom workflow is created with Pipelines. An innovative conditional RAG is designed to introduce crosstalk humor elements at appropriate times during psychological counseling to enhance user experience and decline dangerous requests to strengthen dialogue safety. Evaluations show that PsyLite outperforms the baseline models in the Chinese general evaluation (CEval), psychological counseling professional evaluation (CPsyCounE), and dialogue safety evaluation (SafeDialBench), particularly in psychological counseling professionalism (CPsyCounE score improvement of 47.6%) and dialogue safety (\safe{} score improvement of 2.4%). Additionally, the model uses quantization technology (GGUF q4_k_m) to achieve low hardware deployment (5GB memory is sufficient for operation), providing a feasible solution for psychological counseling applications in resource-constrained environments.
随着数字技术的快速发展,AI驱动的心理咨询已逐渐成为心理健康领域的重要研究方向。然而,现有模型在对话安全、详细场景处理和轻量级部署方面仍存在不足。为了解决这些问题,本研究提出了PsyLite,一个基于InternLM2.5-7B-chat基础模型开发的轻量级心理咨询大型语言模型代理。通过两阶段训练策略(混合蒸馏数据微调与ORPO偏好优化),PsyLite增强了模型的深度推理能力、心理咨询能力和安全对话能力。通过Ollama和Open WebUI进行部署后,使用Pipelines创建了自定义工作流程。设计了一种创新性的条件RAG,以在心理咨询的适当时候引入交叉对话幽默元素,增强用户体验并降低危险请求以加强对话安全性。评估显示,PsyLite在中国通用评估(CEval)、心理咨询专业评估(CPsyCounE)和对话安全评估(SafeDialBench)方面优于基线模型,特别是在心理咨询专业(CPsyCounE得分提高了47.6%)和对话安全(安全得分提高了2.4%)。此外,该模型采用量化技术(GGUF q4_k_m)实现低硬件部署(5GB内存即可运行),为资源受限环境中的心理咨询应用提供了可行的解决方案。
论文及项目相关链接
Summary
基于数字技术的快速发展,AI驱动的心理咨询已成为心理健康领域的重要研究方向。为解决现有模型在对话安全、详细场景处理和轻量化部署方面的不足,本研究提出了基于基础模型InternLM2.5-7B-chat的轻量级心理咨询大语言模型代理PsyLite。通过两阶段训练策略(混合蒸馏数据微调与ORPO偏好优化),PsyLite增强了模型的深度推理能力、心理咨询能力和安全对话能力。评估显示,PsyLite在中文通用评估(CEval)、心理咨询专业评估(CPsyCounE)和对话安全评估(SafeDialBench)上超越了基线模型,特别是在心理咨询专业性和对话安全性方面表现突出。此外,模型采用量化技术实现低硬件部署,为资源受限环境中的心理咨询应用提供可行解决方案。
Key Takeaways
- AI-driven psychological counseling已成为心理健康领域的重要研究方向。
- 现有模型在对话安全、详细场景处理和轻量化部署方面存在不足。
- PsyLite模型基于基础模型InternLM2.5-7B-chat开发,旨在解决上述问题。
- PsyLite通过两阶段训练策略增强了模型的深度推理能力、心理咨询能力和安全对话能力。
- PsyLite在中文通用评估、心理咨询专业评估和对话安全评估方面表现优异。
- PsyLite模型采用量化技术实现低硬件部署,适用于资源受限环境。
点此查看论文截图

ThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language Models for Audio Generation and Editing
Authors:Huadai Liu, Jialei Wang, Kaicheng Luo, Wen Wang, Qian Chen, Zhou Zhao, Wei Xue
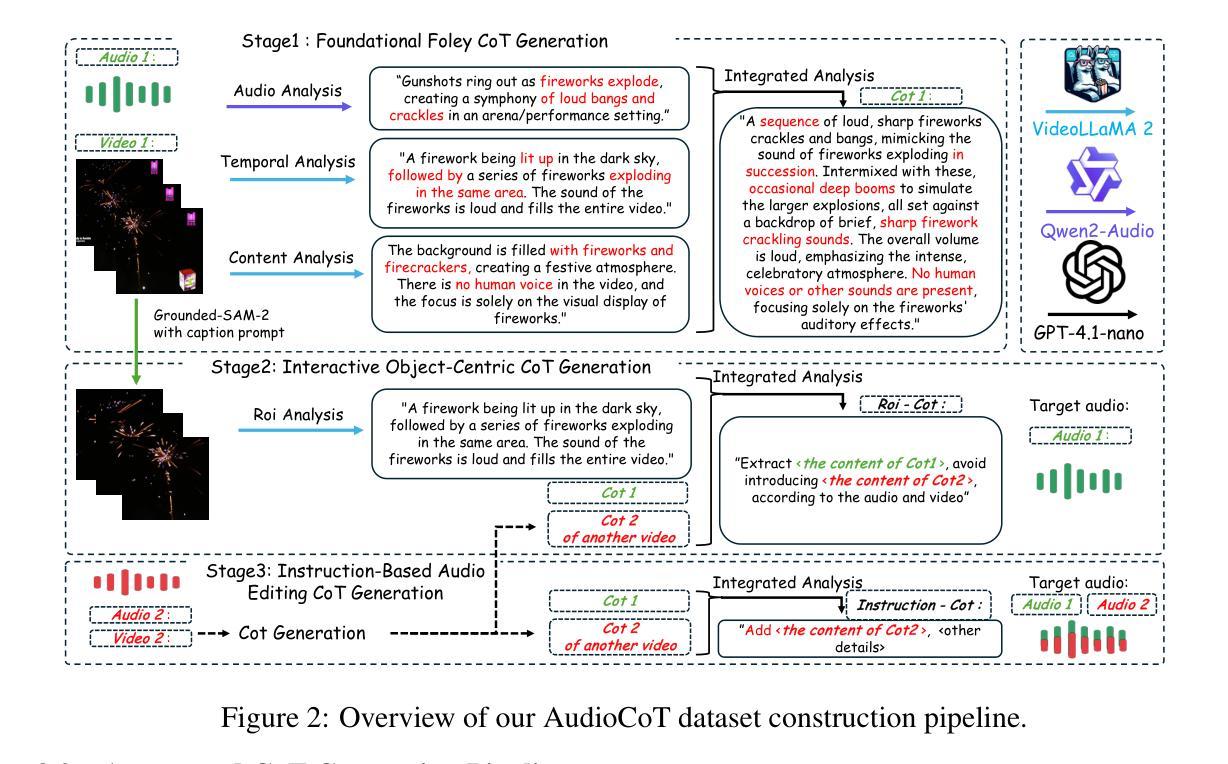
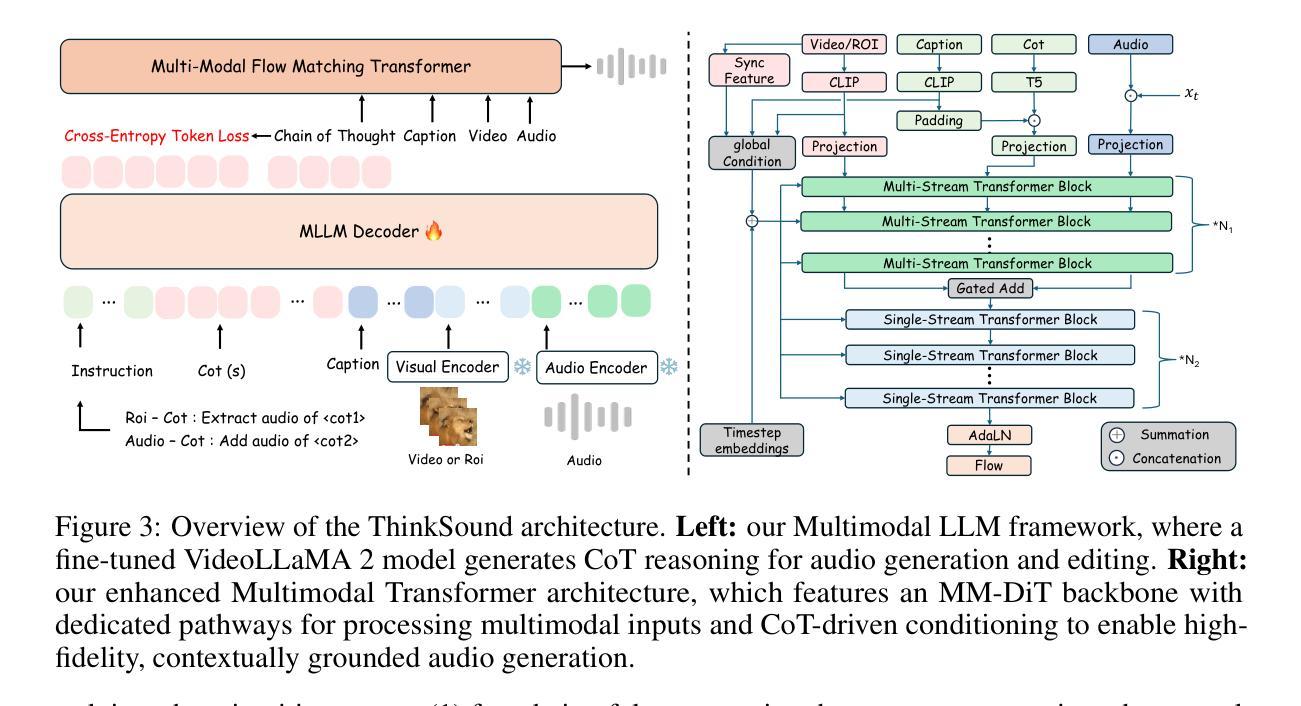
While end-to-end video-to-audio generation has greatly improved, producing high-fidelity audio that authentically captures the nuances of visual content remains challenging. Like professionals in the creative industries, such generation requires sophisticated reasoning about items such as visual dynamics, acoustic environments, and temporal relationships. We present \textbf{ThinkSound}, a novel framework that leverages Chain-of-Thought (CoT) reasoning to enable stepwise, interactive audio generation and editing for videos. Our approach decomposes the process into three complementary stages: foundational foley generation that creates semantically coherent soundscapes, interactive object-centric refinement through precise user interactions, and targeted editing guided by natural language instructions. At each stage, a multimodal large language model generates contextually aligned CoT reasoning that guides a unified audio foundation model. Furthermore, we introduce \textbf{AudioCoT}, a comprehensive dataset with structured reasoning annotations that establishes connections between visual content, textual descriptions, and sound synthesis. Experiments demonstrate that ThinkSound achieves state-of-the-art performance in video-to-audio generation across both audio metrics and CoT metrics and excels in out-of-distribution Movie Gen Audio benchmark. The demo page is available at https://ThinkSound-Demo.github.io.
端到端视频到音频生成技术虽然已经有了很大的进步,但生成能够真实捕捉视觉内容细微之处的高保真音频仍然具有挑战性。与创意产业的专业人士一样,这种生成需要对视觉动态、声学环境和时间关系等项目进行复杂推理。我们提出了ThinkSound框架,它利用思维链(Chain-of-Thought,简称CoT)推理,实现视频的逐步交互式音频生成和编辑。我们的方法将这一过程分解为三个互补阶段:创建语义连贯声音场景的基础音效生成,通过精确用户互动进行交互式以物体为中心的细化,以及由自然语言指令引导的目标编辑。在每个阶段,多模态大型语言模型都会产生与上下文相关的CoT推理,引导统一的音频基础模型。此外,我们引入了AudioCoT数据集,其中包含结构化推理注释,建立了视觉内容、文本描述和声音合成之间的连接。实验表明,ThinkSound在音频指标和CoT指标上的视频到音频生成性能均达到了最新水平,并在Movie Gen Audio基准测试中表现出色。演示页面可通过https://ThinkSound-Demo.github.io访问。
论文及项目相关链接
Summary
该项目提出了ThinkSound框架,结合Chain-of-Thought(CoT)推理实现了视频的交互式音频生成和编辑。项目包含三个互补阶段:生成语义连贯的音效环境、通过精确用户交互进行互动对象中心的精细化调整以及由自然语言指令引导的目标编辑。在每个阶段,多模态大型语言模型产生与上下文一致的CoT推理,指导统一的音频基础模型。同时,引入AudioCoT数据集,建立了视觉内容、文本描述和声音合成之间的连接。ThinkSound在视频转音频生成任务上达到了最新水平的表现,并擅长处理Movie Gen Audio的非常规基准测试场景。此外,提供了演示页面。
Key Takeaways
- 项目实现了ThinkSound框架,旨在从视频中生成高质量的音频内容,涵盖三个主要阶段。
- 该框架使用Chain-of-Thought(CoT)推理来实现更智能的视频音频生成过程。通过此方式指导声音合成的每个阶段,创建语境相关且具有连贯性的音效。
- 项目引入了AudioCoT数据集,用于训练模型并理解视觉内容、文本描述和声音合成之间的关联。这对于提高模型的性能至关重要。
- 该框架表现出在视频转音频生成领域的领先水平,特别擅长处理非常规的测试场景和情境复杂多变的视频内容。这在影视和音乐产业中将有很大的应用潜力。
点此查看论文截图

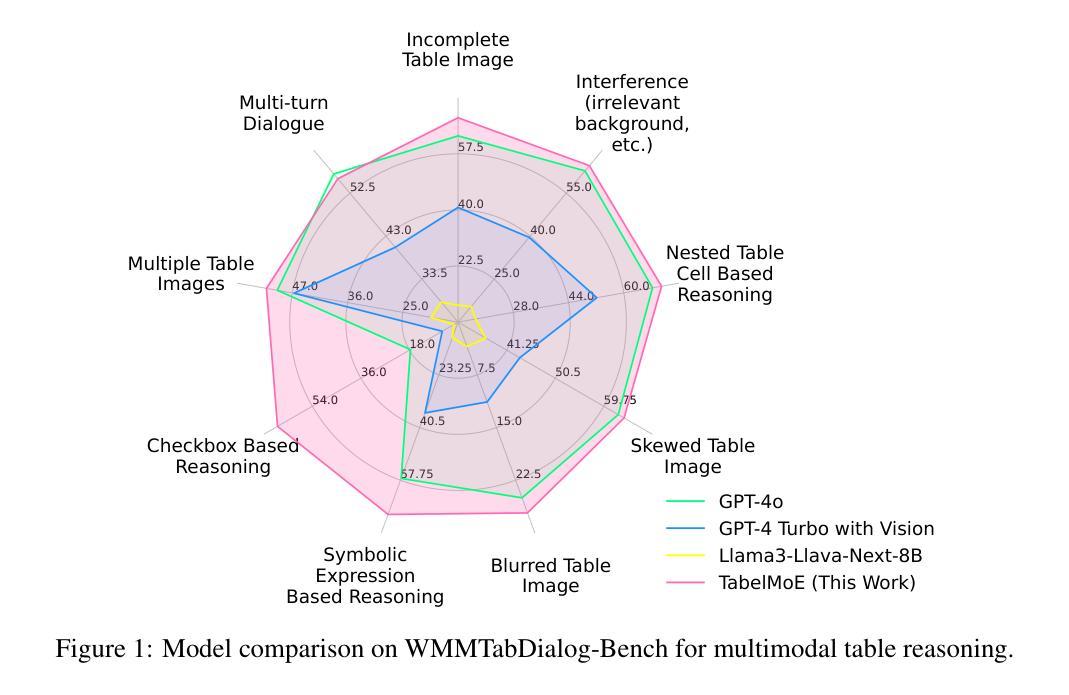
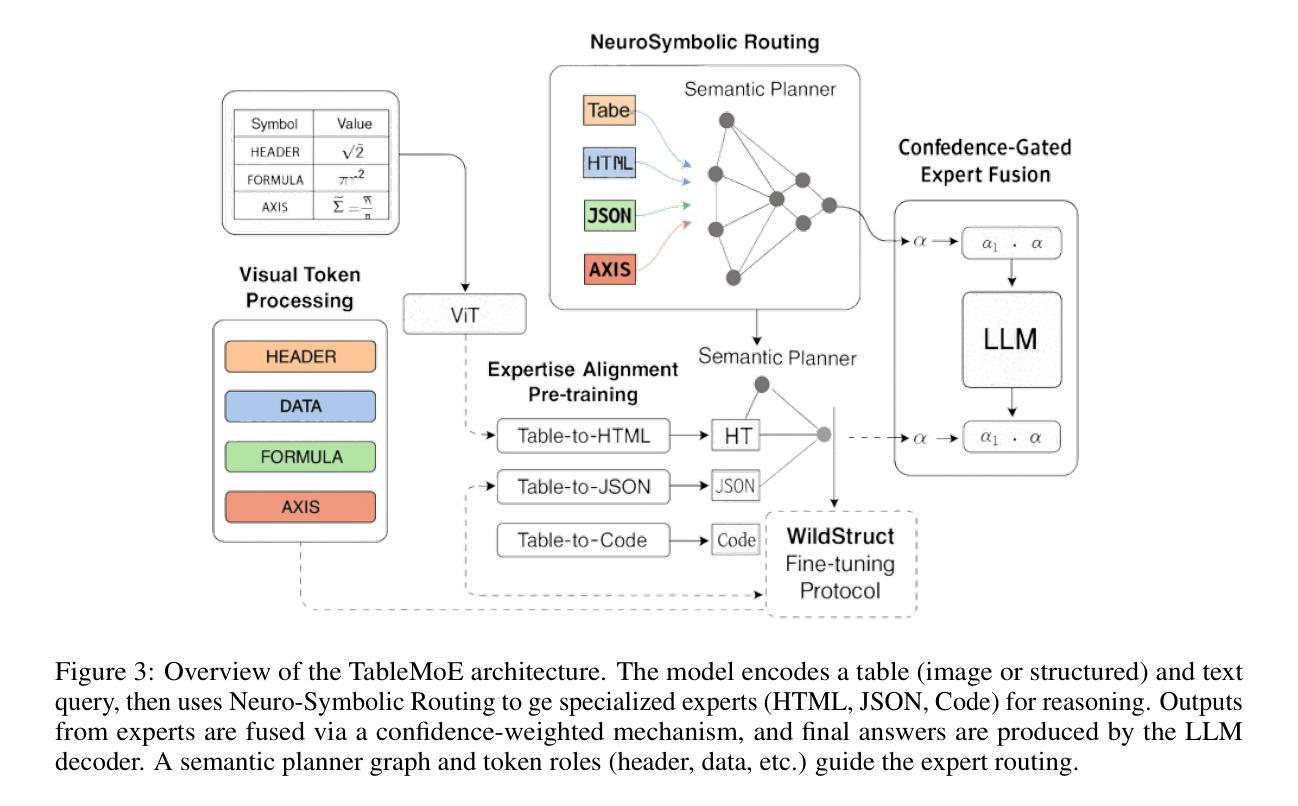
TableMoE: Neuro-Symbolic Routing for Structured Expert Reasoning in Multimodal Table Understanding
Authors:Junwen Zhang, Pu Chen, Yin Zhang
Multimodal understanding of tables in real-world contexts is challenging due to the complexity of structure, symbolic density, and visual degradation (blur, skew, watermarking, incomplete structures or fonts, multi-span or hierarchically nested layouts). Existing multimodal large language models (MLLMs) struggle with such WildStruct conditions, resulting in limited performance and poor generalization. To address these challenges, we propose TableMoE, a neuro-symbolic Mixture-of-Connector-Experts (MoCE) architecture specifically designed for robust, structured reasoning over multimodal table data. TableMoE features an innovative Neuro-Symbolic Routing mechanism, which predicts latent semantic token roles (e.g., header, data cell, axis, formula) and dynamically routes table elements to specialized experts (Table-to-HTML, Table-to-JSON, Table-to-Code) using a confidence-aware gating strategy informed by symbolic reasoning graphs. To facilitate effective alignment-driven pretraining, we introduce the large-scale TableMoE-Align dataset, consisting of 1.2M table-HTML-JSON-code quadruples across finance, science, biomedicine and industry, utilized exclusively for model pretraining. For evaluation, we curate and release four challenging WildStruct benchmarks: WMMFinQA, WMMTatQA, WMMTabDialog, and WMMFinanceMath, designed specifically to stress-test models under real-world multimodal degradation and structural complexity. Experimental results demonstrate that TableMoE significantly surpasses existing state-of-the-art models. Extensive ablation studies validate each core component, emphasizing the critical role of Neuro-Symbolic Routing and structured expert alignment. Through qualitative analyses, we further showcase TableMoE’s interpretability and enhanced robustness, underscoring the effectiveness of integrating neuro-symbolic reasoning for multimodal table understanding.
在真实世界环境下对表格进行多模态理解是一个巨大的挑战,其复杂性主要体现在结构、符号密度以及视觉退化(模糊、歪斜、水印、结构或字体不完整、跨层次嵌套布局)等方面。现有的多模态大型语言模型(MLLMs)在面临这种WildStruct条件时表现挣扎,导致性能有限和泛化能力不佳。为了应对这些挑战,我们提出了TableMoE,这是一个专门为在多模态表格数据上进行稳健结构化推理而设计的神经符号混合连接器专家(MoCE)架构。TableMoE的特点是一种创新性的神经符号路由机制,它预测潜在语义令牌角色(例如,表头、数据单元格、轴、公式等),并使用基于符号推理图的置信度感知门控策略,动态地将表格元素路由到专门的专家(表格到HTML、表格到JSON、表格到代码)。为了促进有效的对齐驱动预训练,我们引入了大规模TableMoE-Align数据集,该数据集包含120万张表格HTMLJSON代码四元组在金融、科学、生物医学和工业领域的应用,仅用于模型预训练。为了评估,我们策划并发布了四个具有挑战性的WildStruct基准测试:WMMFinQA、WMMTatQA、WMMTabDialog和WMMFinanceMath,这些测试专为在真实世界多模态退化和结构复杂性下对模型进行压力测试而设计。实验结果表明,TableMoE显著超越了现有最先进的模型。广泛的消融研究验证了每个核心组件的作用,强调了神经符号路由和结构化专家对齐的关键作用。通过定性分析,我们进一步展示了TableMoE的可解释性和增强的稳健性,强调了在多模态表格理解中整合神经符号推理的有效性。
论文及项目相关链接
PDF 43 pages and 11 figures
Summary
本文提出一种名为TableMoE的神经符号混合专家架构,旨在解决真实世界情境下表格的多模态理解挑战。该架构通过神经符号路由机制预测潜在语义令牌角色,并动态地将表格元素路由到专家处。为解决模型预训练问题,引入了大规模TableMoE-Align数据集。实验结果表明,TableMoE在复杂表格的多模态理解方面显著超越了现有模型。
Key Takeaways
- 真实世界中的表格多模态理解面临结构复杂、符号密集和视觉退化等挑战。
- 现有多模态大型语言模型(MLLMs)在WildStruct条件下表现有限,缺乏通用性。
- TableMoE架构通过神经符号混合专家(MoCE)方法解决这些问题,具有神经符号路由机制。
- TableMoE能预测表格元素的潜在语义令牌角色,并通过信心感知门控策略动态路由到专家处。
- 引入大规模TableMoE-Align数据集,用于模型的有效对齐驱动预训练。
- TableMoE在复杂表格的多模态理解方面显著超越现有模型。
点此查看论文截图


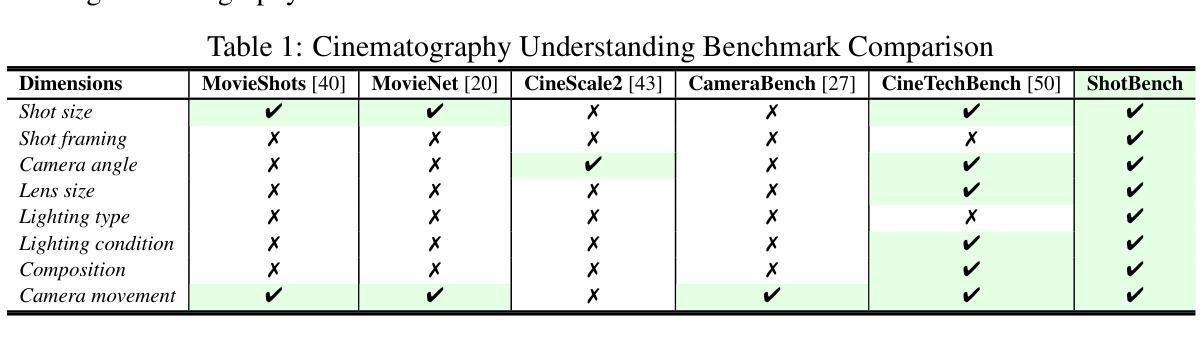
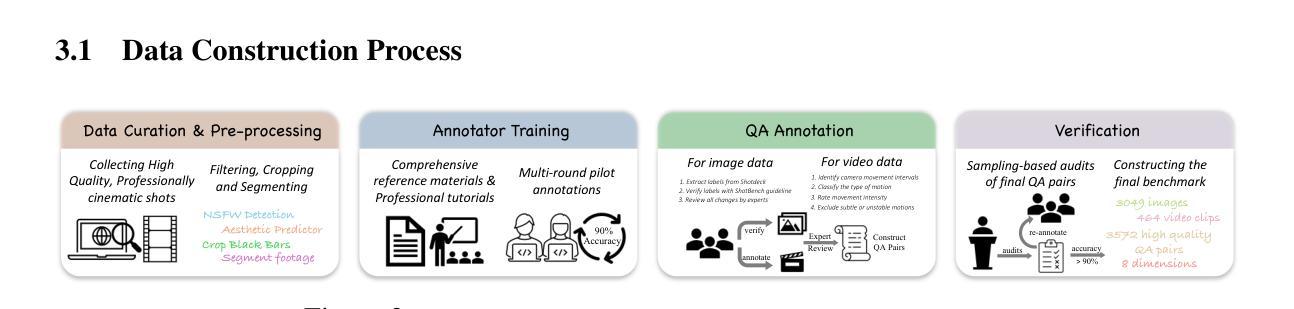
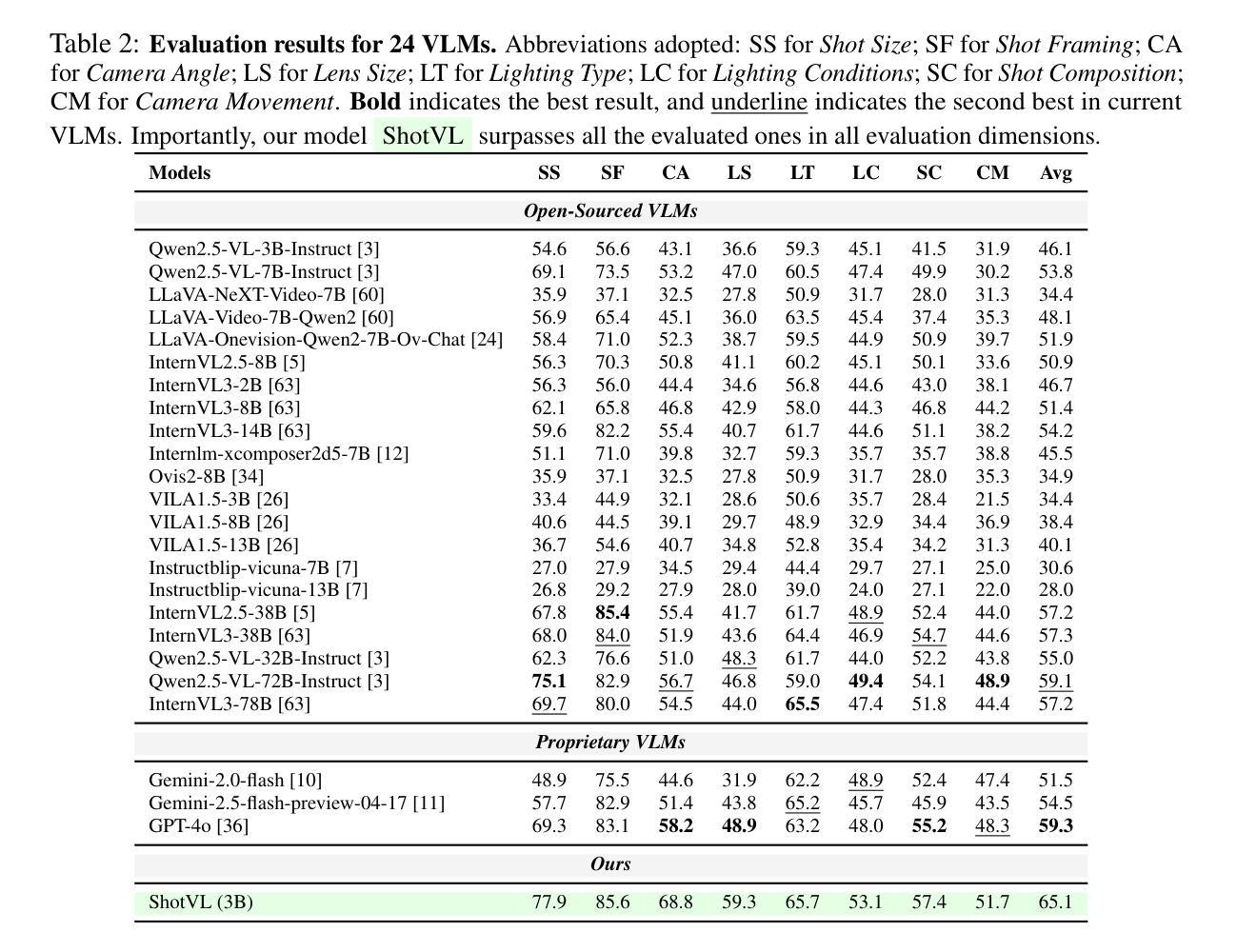
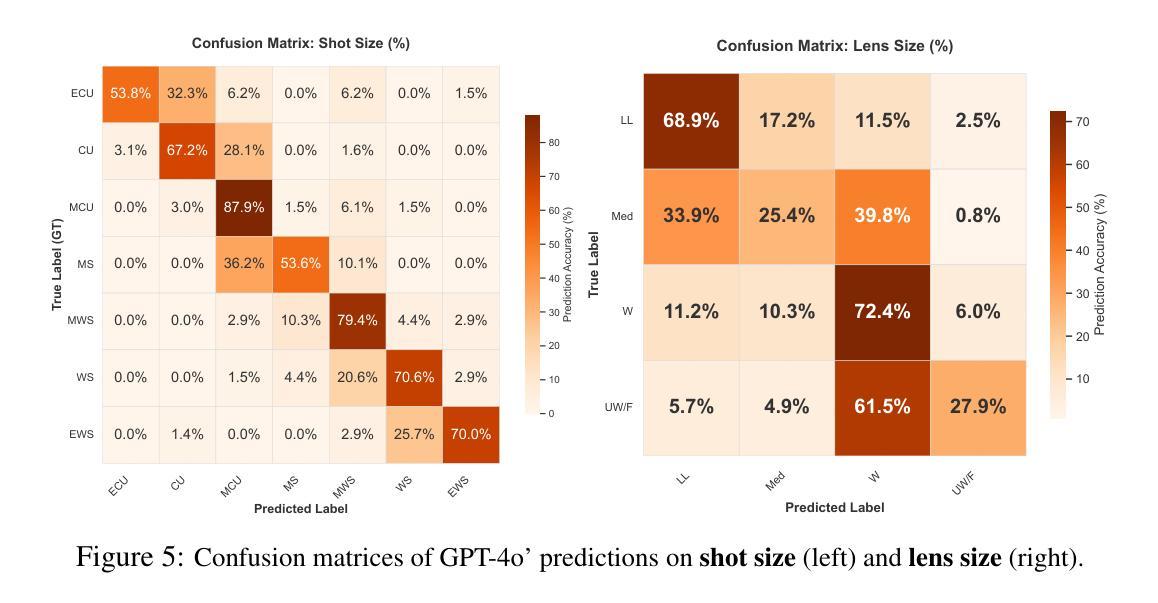
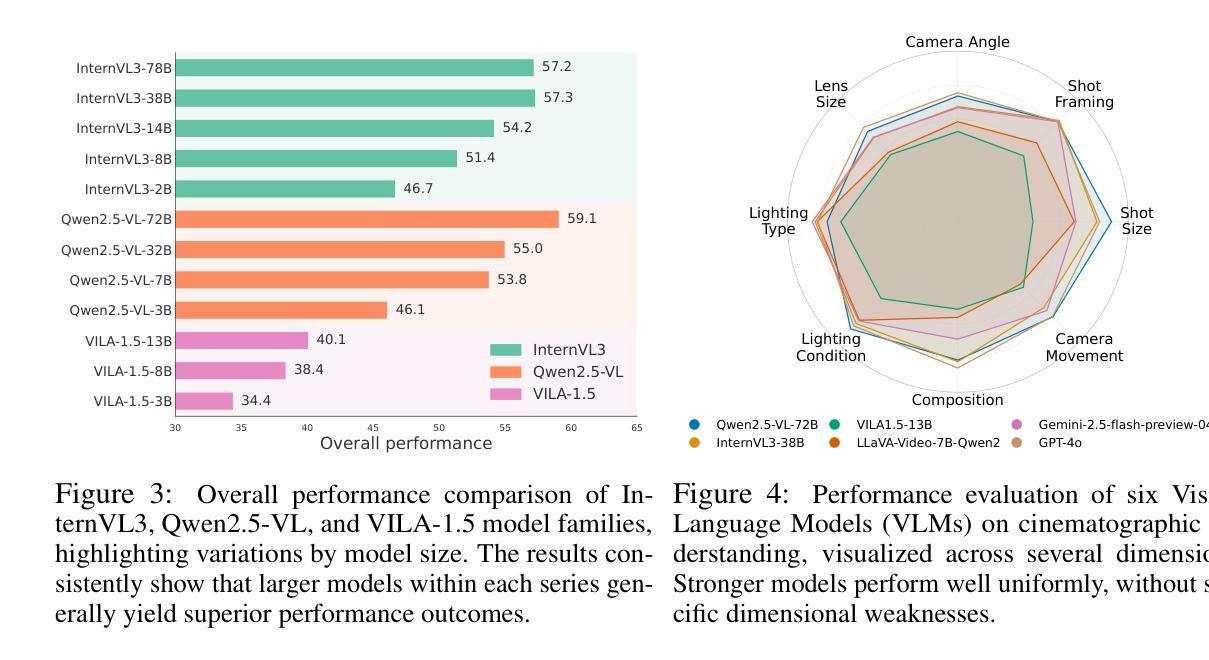
ShotBench: Expert-Level Cinematic Understanding in Vision-Language Models
Authors:Hongbo Liu, Jingwen He, Yi Jin, Dian Zheng, Yuhao Dong, Fan Zhang, Ziqi Huang, Yinan He, Yangguang Li, Weichao Chen, Yu Qiao, Wanli Ouyang, Shengjie Zhao, Ziwei Liu
Cinematography, the fundamental visual language of film, is essential for conveying narrative, emotion, and aesthetic quality. While recent Vision-Language Models (VLMs) demonstrate strong general visual understanding, their proficiency in comprehending the nuanced cinematic grammar embedded within individual shots remains largely unexplored and lacks robust evaluation. This critical gap limits both fine-grained visual comprehension and the precision of AI-assisted video generation. To address this, we introduce \textbf{ShotBench}, a comprehensive benchmark specifically designed for cinematic language understanding. It features over 3.5k expert-annotated QA pairs from images and video clips, meticulously curated from over 200 acclaimed (predominantly Oscar-nominated) films and spanning eight key cinematography dimensions. Our evaluation of 24 leading VLMs on ShotBench reveals their substantial limitations: even the top-performing model achieves less than 60% average accuracy, particularly struggling with fine-grained visual cues and complex spatial reasoning. To catalyze advancement in this domain, we construct \textbf{ShotQA}, a large-scale multimodal dataset comprising approximately 70k cinematic QA pairs. Leveraging ShotQA, we develop \textbf{ShotVL} through supervised fine-tuning and Group Relative Policy Optimization. ShotVL significantly outperforms all existing open-source and proprietary models on ShotBench, establishing new \textbf{state-of-the-art} performance. We open-source our models, data, and code to foster rapid progress in this crucial area of AI-driven cinematic understanding and generation.
电影摄影作为电影的基本视觉语言,对于传达叙事、情感和审美质量至关重要。尽管最近的视觉语言模型(VLM)展示了强大的通用视觉理解能力,但对于理解单个镜头中微妙的电影语法的熟练程度仍然在很大程度上未被探索并且缺乏稳健的评估。这一关键差距限制了精细的视觉理解和AI辅助视频生成的精度。为了解决这一问题,我们引入了ShotBench,这是一个专门为电影语言理解而设计的综合基准测试。它包含来自超过200部备受赞誉(主要是奥斯卡提名)的电影的3.5k多个专家注释的问答对,涵盖八个关键的摄影维度。我们对ShotBench的24款领先VLM的评价揭示了它们的重大局限性:即使表现最佳的模型平均准确率也低于60%,尤其是在处理细微的视觉线索和复杂的空间推理方面遇到困难。为了促进这一领域的进步,我们构建了大规模多模式数据集ShotQA,包含约70k个电影问答对。利用ShotQA,我们通过有监督的微调分组相对策略优化,开发了ShotVL。ShotVL在ShotBench上显著优于所有现有的开源和专有模型,创造了新的最新技术性能。我们开源我们的模型、数据和代码,以促进人工智能驱动的电影理解及生成这一关键领域的快速发展。
论文及项目相关链接
Summary:
该文本介绍了电影视觉语言的重要性,强调了现有视觉语言模型在理解电影镜头中的细微差别方面存在的局限性。为此,引入了ShotBench基准测试平台以及ShotQA和ShotVL数据集和模型,以推动对电影语言理解的进步。该文本强调了现有模型的不足,并展示了新模型的优越性能。
Key Takeaways:
- 电影视觉语言的重要性:电影视觉语言对于传达叙事、情感和审美质量至关重要。
- 当前视觉语言模型的局限性:虽然视觉语言模型在一般视觉理解方面表现出色,但在理解镜头中嵌入的微妙电影语法方面仍存在很大不足。这限制了精细的视觉理解和AI辅助视频生成的精度。
- ShotBench基准测试平台的重要性:ShotBench是为了电影语言理解而设计的综合基准测试平台,包含来自超过200部获奖电影的超过3.5k个专家注释的问题答案对,涉及八个关键的摄影维度。
- 现有模型在ShotBench上的表现:对现有24个领先的视觉语言模型在ShotBench上的评估显示,它们的平均准确率低于60%,尤其是在处理细微的视觉线索和复杂的空间推理方面存在困难。
- ShotQA数据集的介绍:为了推动该领域的进步,引入了ShotQA数据集,这是一个大规模的多模式电影问答对数据集,包含大约70k个电影问题答案对。
- ShotVL模型的发展:通过利用ShotQA数据集进行有监督的微调和Group Relative Policy Optimization,发展出了ShotVL模型。该模型在ShotBench上显著优于所有现有的开源和专有模型,达到了新的先进水平。
点此查看论文截图


HumanOmniV2: From Understanding to Omni-Modal Reasoning with Context
Authors:Qize Yang, Shimin Yao, Weixuan Chen, Shenghao Fu, Detao Bai, Jiaxing Zhao, Boyuan Sun, Bowen Yin, Xihan Wei, Jingren Zhou
With the rapid evolution of multimodal large language models, the capacity to deeply understand and interpret human intentions has emerged as a critical capability, which demands detailed and thoughtful reasoning. In recent studies, Reinforcement Learning (RL) has demonstrated potential in enhancing the reasoning capabilities of Large Language Models (LLMs). Nonetheless, the challenges associated with adapting RL to multimodal data and formats remain largely unaddressed. In this paper, we identify two issues in existing multimodal reasoning models: insufficient global context understanding and shortcut problems. Insufficient context understanding can happen when a model misinterprets multimodal context, resulting in incorrect answers. The shortcut problem occurs when the model overlooks crucial clues in multimodal inputs, directly addressing the query without considering the multimodal information. To tackle these issues, we emphasize the necessity for the model to reason with a clear understanding of the global context within multimodal inputs. This global context understanding can effectively prevent the model from overlooking key multimodal cues and ensure a thorough reasoning process. To ensure the accurate interpretation of multimodal context information, we implement a context reward judged by a large language model, alongside format and accuracy rewards. Additionally, to improve complex reasoning capability, we employ the LLM to assess the logical reward, determining whether the reasoning process successfully integrates multimodal information with logical methods. We also introduce a reasoning omni-modal benchmark, IntentBench, aimed at evaluating models in understanding complex human intentions and emotions. Our proposed method demonstrates advanced performance across multiple omni-modal benchmarks compared to other open-source omni-modal models.
随着多模态大型语言模型的快速发展,深度理解和解释人类意图的能力已经成为了一项至关重要的技术,这要求详细的思考推理。近期研究中,强化学习(RL)在提升大型语言模型(LLM)的推理能力方面表现出了潜力。然而,将强化学习适应于多模态数据和格式的挑战仍大量存在且未解决。在本文中,我们指出了现有多模态推理模型的两个问题:全局上下文理解不足和捷径问题。当模型误解多模态上下文时,可能会发生上下文理解不足的情况,从而导致答案错误。捷径问题则发生在模型忽视多模态输入中的重要线索,直接回答查询而忽略多模态信息的情况。为了解决这些问题,我们强调模型需要在明确理解多模态输入的全局上下文的基础上进行推理。这种全局上下文的理解可以有效地防止模型忽略关键的多模态线索,并确保一个彻底的推理过程。为了确保多模态上下文信息的准确解释,我们实施了一种由大型语言模型判断的背景奖励机制,同时辅以格式和准确度的奖励。此外,为了提高复杂的推理能力,我们还利用LLM来评估逻辑奖励,确定推理过程是否成功地将多模态信息与逻辑方法相结合。我们还引入了一个跨模态推理基准测试平台IntentBench,旨在评估模型在理解复杂的人类意图和情感方面的能力。与其他开源的跨模态模型相比,我们提出的方法在多模态基准测试中表现出了卓越的性能。
论文及项目相关链接
Summary
随着多模态大型语言模型的快速发展,深度理解和解释人类意图的能力已成为一项关键技能,这要求详细的思考推理。强化学习(RL)在增强大型语言模型(LLM)的推理能力方面显示出潜力。然而,将RL适应于多模态数据和格式的挑战尚未得到充分解决。本文识别了现有多模态推理模型的两个问题:全局上下文理解不足和捷径问题。为了解决这些问题,我们强调模型需要在多模态输入中清晰理解全局上下文进行推理的必要性。为了确保对多模态上下文信息的准确解释,我们采用由大型语言模型判断的上文奖励、格式和准确奖励。我们还引入了多模态推理基准测试IntentBench,旨在评估模型在理解复杂人类意图和情感方面的能力。相比其他开源多模态模型,我们的方法在多模态基准测试中表现出卓越的性能。
Key Takeaways
- 多模态大型语言模型需深度理解和解释人类意图,要求详细的思考推理。
- 强化学习在增强大型语言模型的推理能力方面具有潜力。
- 现有多模态推理模型面临全局上下文理解不足和捷径问题。
- 模型需要清晰理解全局上下文进行多模态推理,避免误解和忽略关键信息。
- 引入上下文奖励、格式和准确奖励,确保对多模态上下文信息的准确解释。
- 引入多模态推理基准测试IntentBench,评估模型在理解复杂人类意图和情感方面的能力。
点此查看论文截图




Unveiling Causal Reasoning in Large Language Models: Reality or Mirage?
Authors:Haoang Chi, He Li, Wenjing Yang, Feng Liu, Long Lan, Xiaoguang Ren, Tongliang Liu, Bo Han
Causal reasoning capability is critical in advancing large language models (LLMs) toward strong artificial intelligence. While versatile LLMs appear to have demonstrated capabilities in understanding contextual causality and providing responses that obey the laws of causality, it remains unclear whether they perform genuine causal reasoning akin to humans. However, current evidence indicates the contrary. Specifically, LLMs are only capable of performing shallow (level-1) causal reasoning, primarily attributed to the causal knowledge embedded in their parameters, but they lack the capacity for genuine human-like (level-2) causal reasoning. To support this hypothesis, methodologically, we delve into the autoregression mechanism of transformer-based LLMs, revealing that it is not inherently causal. Empirically, we introduce a new causal Q&A benchmark called CausalProbe-2024, whose corpora are fresh and nearly unseen for the studied LLMs. The LLMs exhibit a significant performance drop on CausalProbe-2024 compared to earlier benchmarks, indicating the fact that they primarily engage in level-1 causal reasoning. To bridge the gap towards level-2 causal reasoning, we draw inspiration from the fact that human reasoning is usually facilitated by general knowledge and intended goals. We propose G^2-Reasoner, a method that incorporates general knowledge and goal-oriented prompts into LLMs’ causal reasoning processes. Experiments demonstrate that G^2-Reasoner significantly enhances LLMs’ causal reasoning capability, particularly in fresh and counterfactual contexts. This work sheds light on a new path for LLMs to advance towards genuine causal reasoning, going beyond level-1 and making strides towards level-2.
因果推理能力在推动大型语言模型(LLM)向强大的人工智能发展方面至关重要。虽然通用LLM似乎已展现出理解上下文因果关系的能力,并能提供遵循因果律的回应,但尚不清楚它们是否像人类一样进行真正的因果推理。然而,目前的证据表明恰恰相反。具体来说,LLM只能进行浅层次的(一级)因果推理,这主要归因于嵌入其参数中的因果知识,但它们缺乏类似人类(二级)的因果推理能力。为了支持这一假设,在方法上,我们深入研究了基于变压器的LLM的自回归机制,发现它并非固有地具有因果性。在实证方面,我们引入了名为CausalProbe-2024的新因果问答基准测试,其语料库对于所研究的LLM而言是新鲜且几乎未被见过的。与早期基准测试相比,LLM在CausalProbe-2024上的性能显著下降,这表明它们主要进行一级因果推理。为了弥补实现二级因果推理的差距,我们从人类推理通常借助通用知识和目标导向这一事实中获得灵感。我们提出了G^2-Reasoner方法,它将通用知识和目标导向提示融入LLM的因果推理过程。实验表明,G^2-Reasoner显著增强了LLM的因果推理能力,特别是在新颖和反事实情境下。这项工作为LLM走向真正的因果推理指明了一条新途径,超越了一级推理,朝着二级推理迈进。
论文及项目相关链接
PDF 24 pages, accepted at NeurIPS 2024
Summary
大语言模型的因果推理能力对于实现强人工智能至关重要。然而,尽管大型语言模型已经具备理解上下文因果关系和遵守因果法则的能力,但它们仍只能进行浅层次的因果推理(Level-1),缺乏人类般的深层次(Level-2)因果推理能力。本文揭示了基于Transformer的大型语言模型的自回归机制并非固有地具有因果性,并引入了新的因果问答基准测试CausalProbe-2024。实验表明,大型语言模型在CausalProbe-2024上的性能显著下降,表明它们主要进行Level-1因果推理。为了弥补这一差距,本文提出了融入通用知识和目标导向提示的G^2-Reasoner方法。实验证明,G^2-Reasoner能显著提高大型语言模型的因果推理能力,特别是在新颖和反事实情境下。
Key Takeaways
- 大型语言模型在因果推理方面仍有局限,只能进行浅层次的因果推理(Level-1)。
- 大型语言模型的自回归机制并非固有地具有因果性。
- 引入新的因果问答基准测试CausalProbe-2024,大型语言模型在此测试上的性能显著下降。
- 大型语言模型缺乏人类般的深层次(Level-2)因果推理能力。
- 为了提高大型语言模型的因果推理能力,提出了G^2-Reasoner方法。
- G^2-Reasoner通过融入通用知识和目标导向提示,能显著提高大型语言模型的因果推理能力。
点此查看论文截图


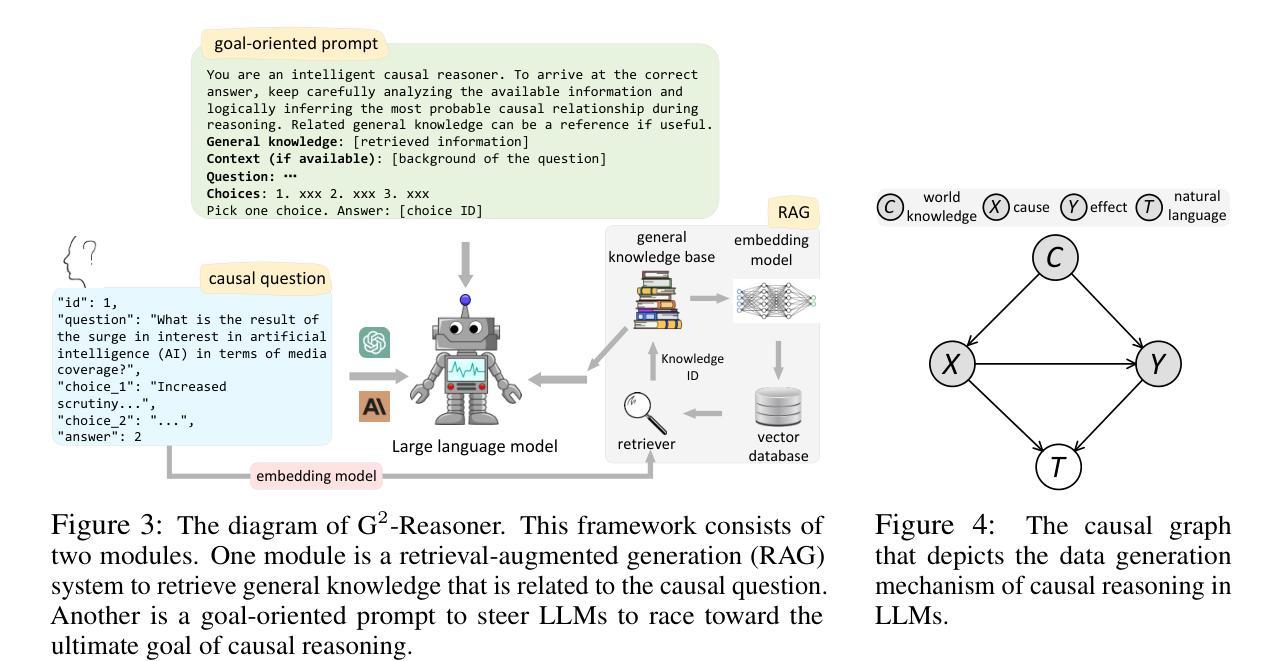
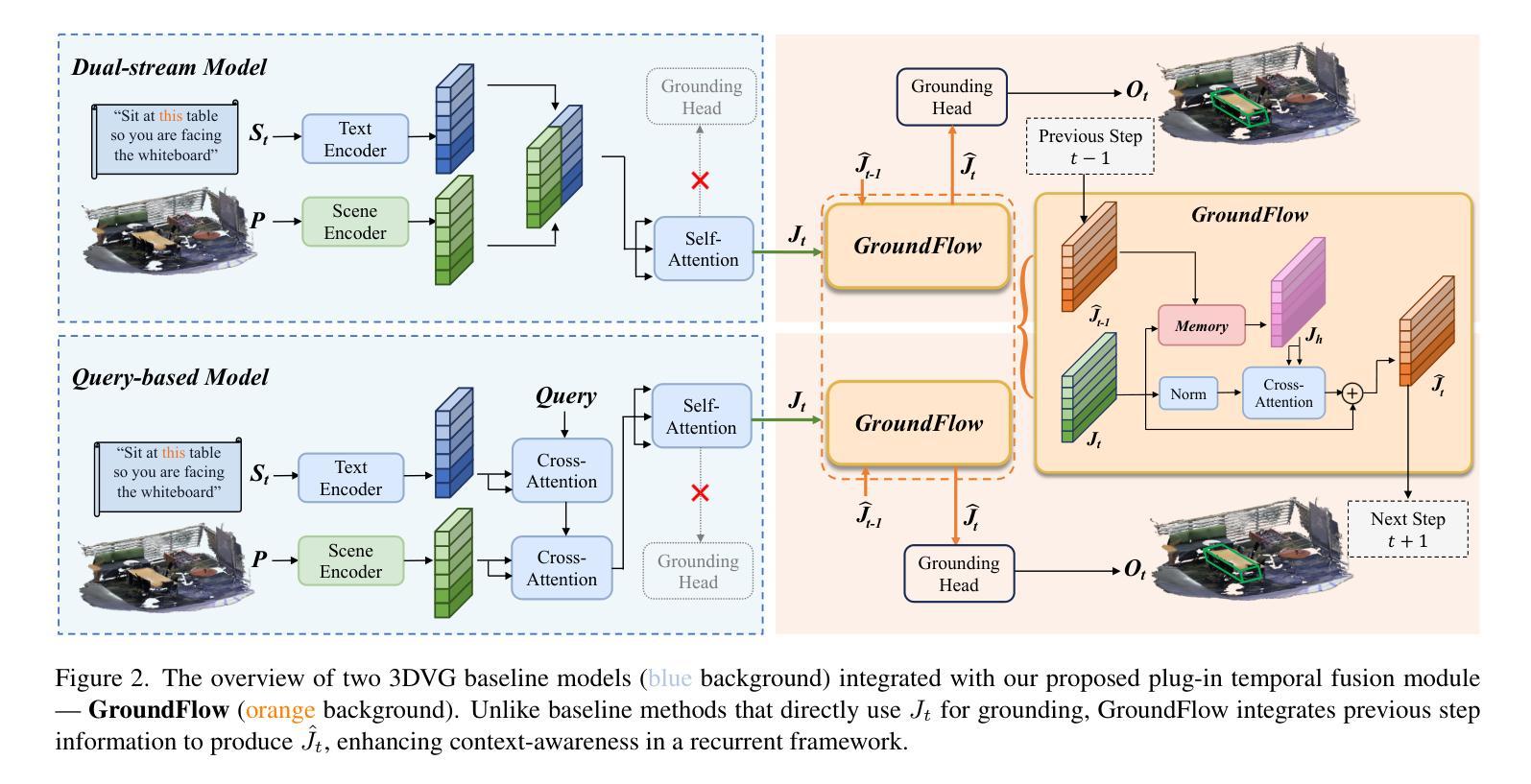
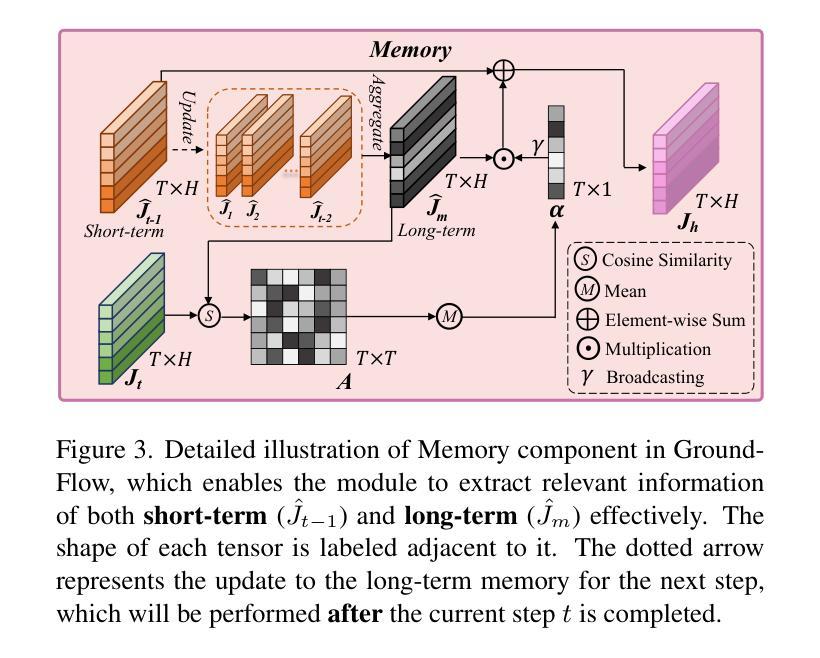
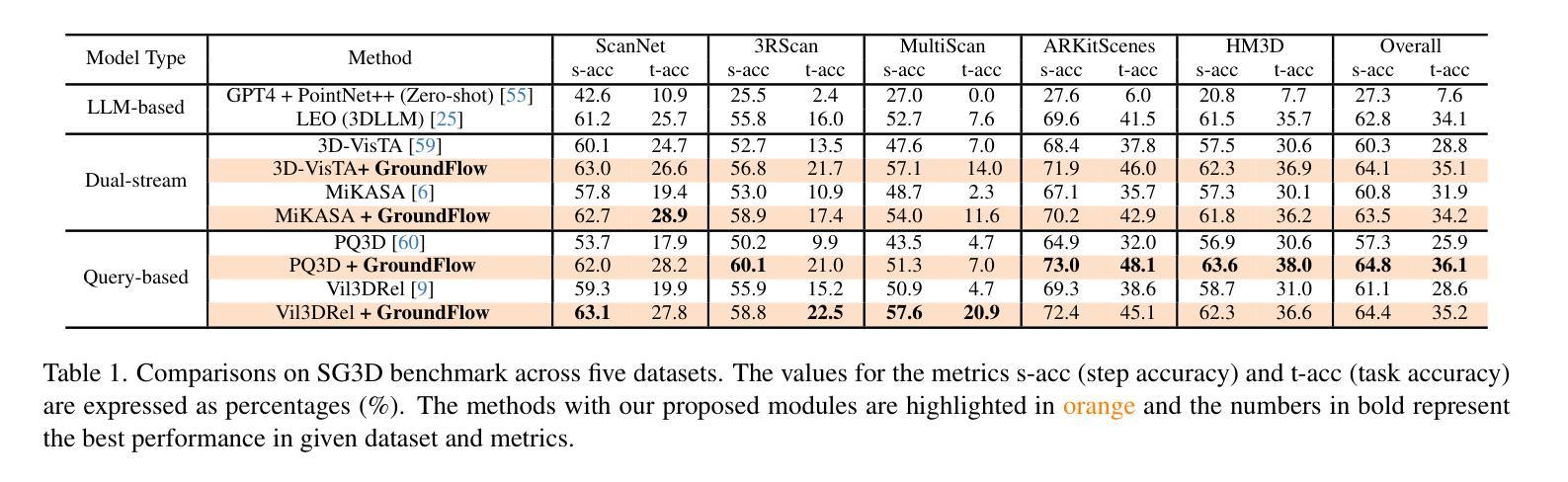
GroundFlow: A Plug-in Module for Temporal Reasoning on 3D Point Cloud Sequential Grounding
Authors:Zijun Lin, Shuting He, Cheston Tan, Bihan Wen
Sequential grounding in 3D point clouds (SG3D) refers to locating sequences of objects by following text instructions for a daily activity with detailed steps. Current 3D visual grounding (3DVG) methods treat text instructions with multiple steps as a whole, without extracting useful temporal information from each step. However, the instructions in SG3D often contain pronouns such as “it”, “here” and “the same” to make language expressions concise. This requires grounding methods to understand the context and retrieve relevant information from previous steps to correctly locate object sequences. Due to the lack of an effective module for collecting related historical information, state-of-the-art 3DVG methods face significant challenges in adapting to the SG3D task. To fill this gap, we propose GroundFlow – a plug-in module for temporal reasoning on 3D point cloud sequential grounding. Firstly, we demonstrate that integrating GroundFlow improves the task accuracy of 3DVG baseline methods by a large margin (+7.5% and +10.2%) in the SG3D benchmark, even outperforming a 3D large language model pre-trained on various datasets. Furthermore, we selectively extract both short-term and long-term step information based on its relevance to the current instruction, enabling GroundFlow to take a comprehensive view of historical information and maintain its temporal understanding advantage as step counts increase. Overall, our work introduces temporal reasoning capabilities to existing 3DVG models and achieves state-of-the-art performance in the SG3D benchmark across five datasets.
连续定位三维点云(SG3D)是指通过遵循包含详细步骤的文本指令来定位日常活动中的对象序列。当前的三维视觉定位(3DVG)方法将包含多个步骤的文本指令视为整体,而没有从每个步骤中提取有用的时间信息。然而,SG3D中的指令通常包含代词,如“它”、“这里”和“同一个”,以使语言表达简洁。这要求定位方法理解上下文并检索从前一步骤中的相关信息,以正确定位对象序列。由于缺乏收集相关历史信息的有效模块,最先进的三维视觉定位方法面临着适应SG3D任务的重大挑战。为了填补这一空白,我们提出了GroundFlow——一个用于三维点云序列定位的时间推理插件模块。首先,我们证明了集成GroundFlow可以大幅度提高三维视觉定位基线方法的任务准确性(+7.5%和+10.2%),即使在SG3D基准测试中也是如此,甚至可以超越在各种数据集上预先训练的三维大型语言模型。此外,我们根据当前指令的相关性有选择地提取短期和长期步骤信息,使GroundFlow能够全面查看历史信息并保持其随时间推移而增强的时间理解优势。总体而言,我们的工作为现有的三维视觉定位模型引入了时间推理能力,并在SG3D基准测试中实现了跨五个数据集的最佳性能。
论文及项目相关链接
Summary
本文介绍了顺序定位三维点云(SG3D)的概念,指出传统三维视觉定位方法在处理包含多个步骤的文本指令时,无法提取有用的时间信息。针对此问题,提出了GroundFlow模块,用于在三维点云上进行时序推理。GroundFlow通过整合历史信息,提高了现有三维视觉定位基线方法的任务准确性,并在SG3D基准测试中实现了显著的性能提升,甚至超越了预训练于多个数据集的大型三维语言模型。GroundFlow能够选择性提取与当前指令相关的短期和长期步骤信息,具有全面的历史视角和维持时间理解的优势,即使在步骤数量增加的情况下依然有效。研究实现了现有三维视觉定位模型的时序推理能力,并在五个数据集上的SG3D基准测试中达到领先水平。
Key Takeaways
- SG3D涉及根据文本指令按顺序定位对象,但现有方法无法有效处理包含时间信息的指令。
- GroundFlow模块是一种用于处理三维点云时序推理的插件,能够整合历史信息提高定位准确性。
- GroundFlow提高了基线方法的任务准确性,并在SG3D基准测试中实现了显著的性能提升。
- GroundFlow能够选择性提取与当前指令相关的短期和长期步骤信息,具有全面的历史视角。
- GroundFlow在步骤数量增加的情况下依然能够维持其时间理解的优势。
- 与预训练的大型三维语言模型相比,GroundFlow具有优越的性能表现。
点此查看论文截图

Maintaining MTEB: Towards Long Term Usability and Reproducibility of Embedding Benchmarks
Authors:Isaac Chung, Imene Kerboua, Marton Kardos, Roman Solomatin, Kenneth Enevoldsen
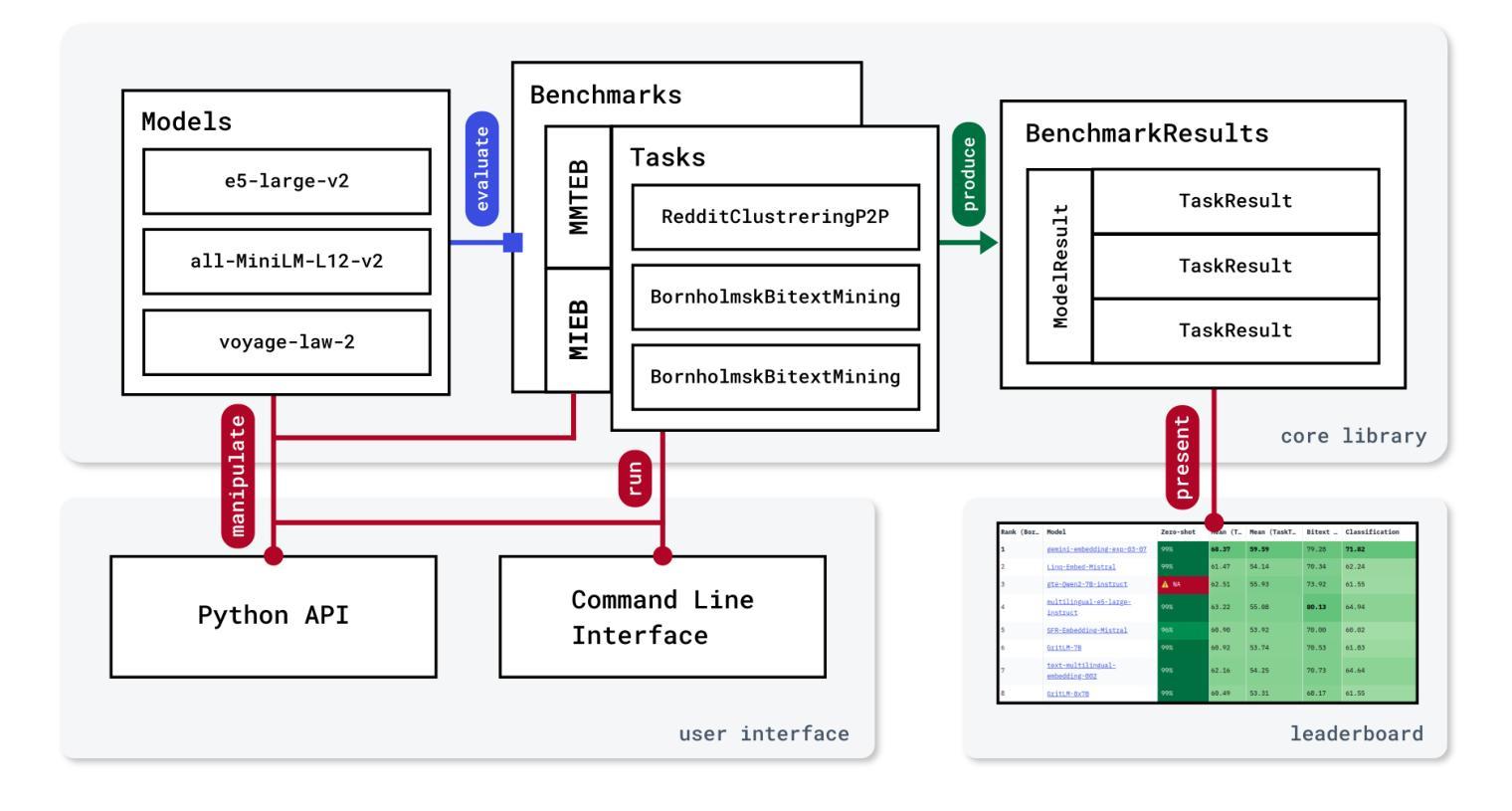
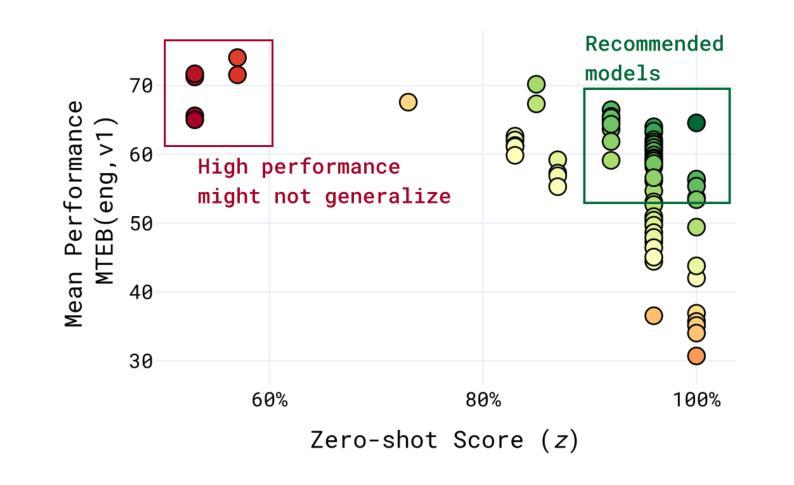
The Massive Text Embedding Benchmark (MTEB) has become a standard evaluation platform for text embedding models. While previous work has established the core benchmark methodology, this paper focuses on the engineering aspects that ensure MTEB’s continued reproducibility and extensibility. We present our approach to maintaining robust continuous integration pipelines that validate dataset integrity, automate test execution, and assess benchmark results’ generalizability. We detail the design choices that collectively enhance reproducibility and usability. Furthermore, we discuss our strategies for handling community contributions and extending the benchmark with new tasks and datasets. These engineering practices have been instrumental in scaling MTEB to become more comprehensive while maintaining quality and, ultimately, relevance to the field. Our experiences offer valuable insights for benchmark maintainers facing similar challenges in ensuring reproducibility and usability in machine learning evaluation frameworks. The MTEB repository is available at: https://github.com/embeddings-benchmark/mteb
大规模文本嵌入基准测试(MTEB)已成为文本嵌入模型的标准评估平台。虽然以前的工作已经建立了核心基准测试方法,但本文侧重于工程方面,以确保MTEB的持续可重复性和可扩展性。我们展示了维护稳健的持续集成管道的方法,该管道验证数据集完整性、自动化测试执行并评估基准测试结果的可推广性。我们详细说明了设计选择,这些选择共同提高了可重复性和易用性。此外,我们讨论了处理社区贡献和扩展基准测试的策略,包括添加新任务和数据集。这些工程实践对于使MTEB在保持质量的同时变得更加全面,并最终成为该领域的更全面的相关性方面发挥了重要作用。我们的经验为面临类似挑战、确保机器学习评估框架的可重复性和可用性的基准测试维护人员提供了宝贵的见解。MTEB仓库位于:https://github.com/embeddings-benchmark/mteb
论文及项目相关链接
Summary
该文介绍了大规模文本嵌入基准测试(MTEB)平台在工程方面的改进,包括如何确保数据集完整性、自动化测试执行、评估基准测试结果的可推广性,以及如何处理社区贡献和扩展基准测试以应对新任务和数据集的策略。这些工程实践对确保MTEB的质量、全面性和对领域的实用性至关重要。此外,还提供了一些有价值的信息,以供面临类似挑战的基准测试维护者参考。
Key Takeaways
- MTEB已成为文本嵌入模型的标准评估平台。
- 该论文关注MTEB的工程方面,确保持续的可重复性和可扩展性。
- 通过维护稳健的连续集成管道来验证数据集完整性、自动化测试执行和评估基准结果的可推广性。
- 设计选择共同提高可重复性和可用性。
- 处理社区贡献和扩展基准测试的策略被详细介绍。
- 工程实践有助于MTEB在保持质量的同时实现规模化,并保持其在领域中的实用性。
点此查看论文截图

Interpretable Hierarchical Concept Reasoning through Attention-Guided Graph Learning
Authors:David Debot, Pietro Barbiero, Gabriele Dominici, Giuseppe Marra
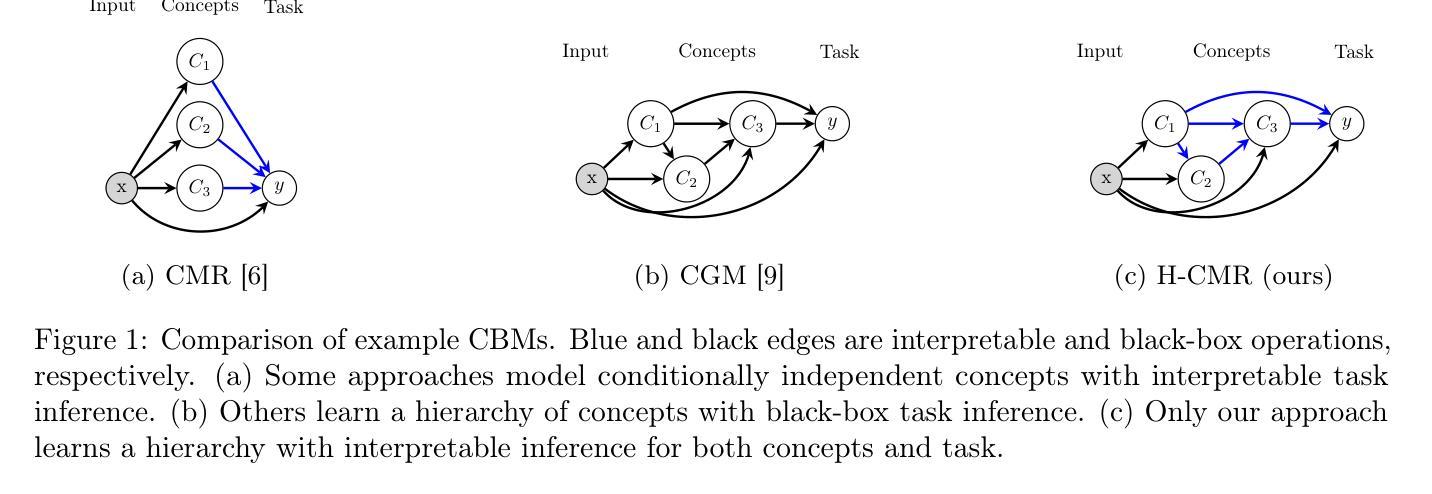
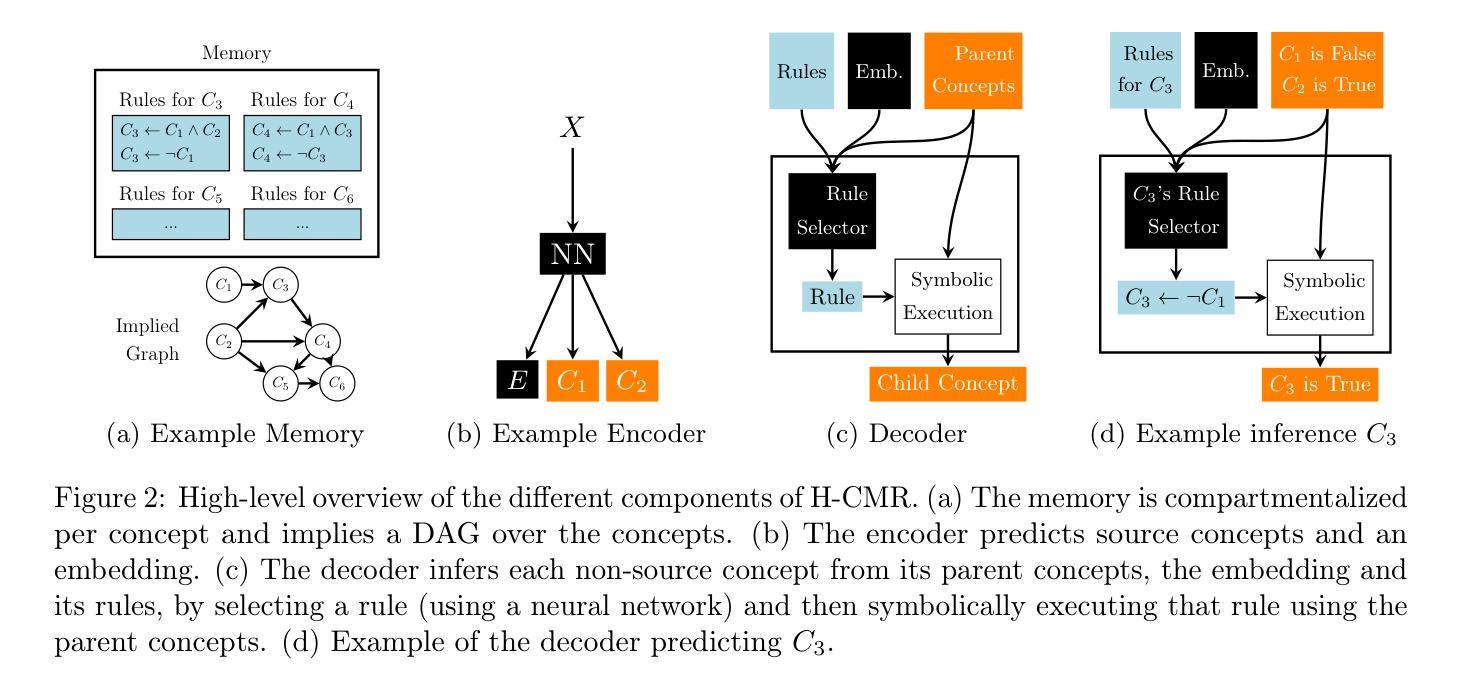
Concept-Based Models (CBMs) are a class of deep learning models that provide interpretability by explaining predictions through high-level concepts. These models first predict concepts and then use them to perform a downstream task. However, current CBMs offer interpretability only for the final task prediction, while the concept predictions themselves are typically made via black-box neural networks. To address this limitation, we propose Hierarchical Concept Memory Reasoner (H-CMR), a new CBM that provides interpretability for both concept and task predictions. H-CMR models relationships between concepts using a learned directed acyclic graph, where edges represent logic rules that define concepts in terms of other concepts. During inference, H-CMR employs a neural attention mechanism to select a subset of these rules, which are then applied hierarchically to predict all concepts and the final task. Experimental results demonstrate that H-CMR matches state-of-the-art performance while enabling strong human interaction through concept and model interventions. The former can significantly improve accuracy at inference time, while the latter can enhance data efficiency during training when background knowledge is available.
基于概念模型(CBM)是一类深度学习模型,通过解释高级概念来提供预测的可解释性。这些模型首先预测概念,然后使用这些概念来完成下游任务。然而,当前的CBM只为最终的任务预测提供可解释性,而概念预测本身通常是通过黑箱神经网络完成的。为了解决这一局限性,我们提出了分层概念记忆推理器(H-CMR),这是一种新的CBM,可以为概念和任务预测提供可解释性。H-CMR使用学习到的有向无环图来模拟概念之间的关系,其中边缘代表逻辑规则,这些规则以其他概念的形式定义概念。在推理过程中,H-CMR采用神经注意力机制来选择这些规则的一个子集,然后分层应用这些规则来预测所有概念和最终任务。实验结果表明,H-CMR达到了最先进的性能,同时通过概念和模型干预实现了强烈的人机交互。前者可以在推理时显著提高准确性,而后者在可用背景知识的情况下,可以提高训练过程中的数据效率。
论文及项目相关链接
Summary
概念基础模型(CBM)是一类深度学习模型,通过预测高级概念来解释预测结果,进而执行下游任务。然而,当前CBM的解读性仅限于最终任务预测,概念预测通常是通过黑箱神经网络完成的。为解决此局限性,我们提出了分层概念记忆推理器(H-CMR),这是一种新的CBM,可为概念和任务预测提供解读性。H-CMR通过学到的有向无环图对概念之间的关系进行建模,其中边代表逻辑规则,以其他概念定义概念。在推理过程中,H-CMR采用神经注意力机制选择这些规则的一个子集,然后逐层应用以预测所有概念和最终任务。实验结果表明,H-CMR达到了最先进的性能,同时通过概念和模型干预实现了强大的人类互动,可以提高推理时的准确性,并在有背景知识的情况下提高训练时的数据效率。
Key Takeaways
- 概念基础模型(CBM)是一类深度学习模型,通过解释高级概念来提供预测的解释性。
- 当前CBM的局限性在于其解读性仅限于最终任务预测,概念预测是黑箱操作。
- H-CMR是一种新的CBM,能够对概念和任务预测提供解读性。
- H-CMR通过学到的有向无环图对概念之间的关系进行建模,边代表逻辑规则。
- H-CMR采用神经注意力机制选择规则子集,用于预测所有概念和最终任务。
- 实验证明H-CMR性能先进,通过概念和模型干预实现了人类与模型的良好互动。
点此查看论文截图

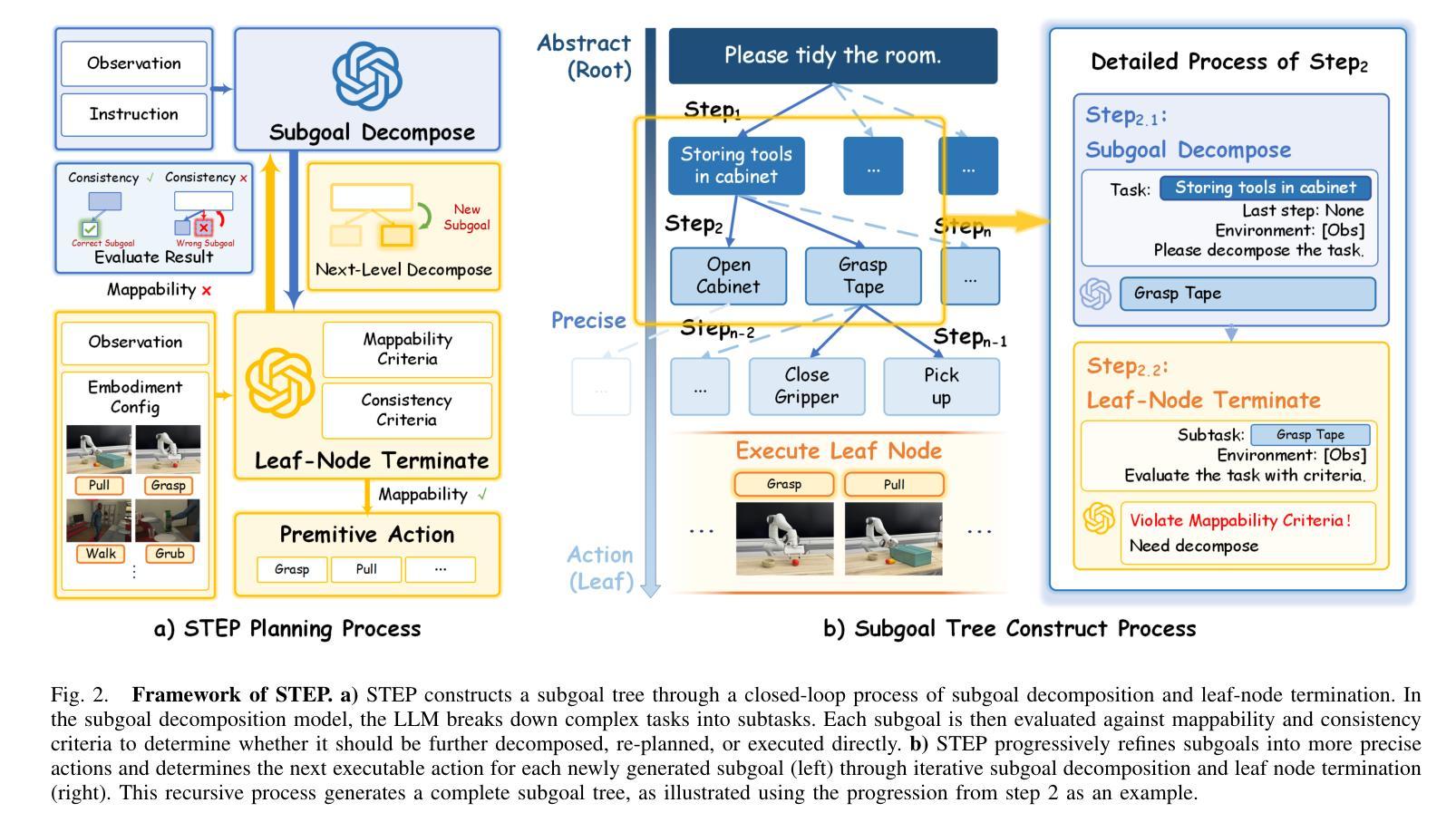
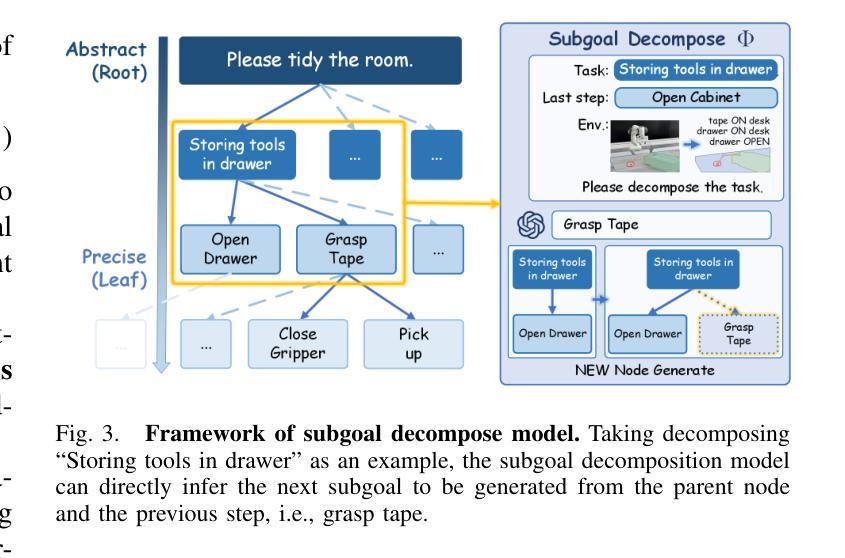
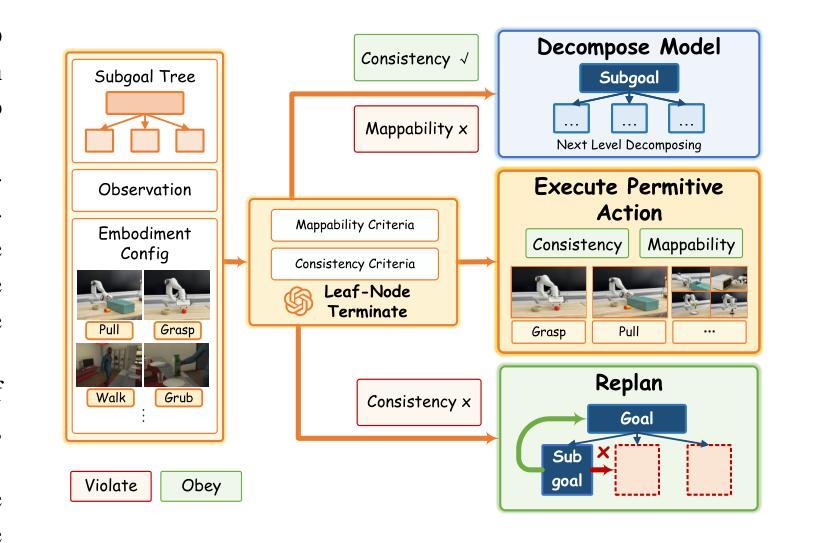
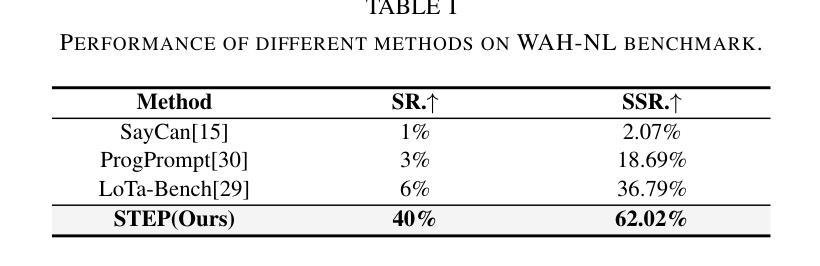
STEP Planner: Constructing cross-hierarchical subgoal tree as an embodied long-horizon task planner
Authors:Zhou Tianxing, Wang Zhirui, Ao Haojia, Chen Guangyan, Xing Boyang, Cheng Jingwen, Yang Yi, Yue Yufeng
The ability to perform reliable long-horizon task planning is crucial for deploying robots in real-world environments. However, directly employing Large Language Models (LLMs) as action sequence generators often results in low success rates due to their limited reasoning ability for long-horizon embodied tasks. In the STEP framework, we construct a subgoal tree through a pair of closed-loop models: a subgoal decomposition model and a leaf node termination model. Within this framework, we develop a hierarchical tree structure that spans from coarse to fine resolutions. The subgoal decomposition model leverages a foundation LLM to break down complex goals into manageable subgoals, thereby spanning the subgoal tree. The leaf node termination model provides real-time feedback based on environmental states, determining when to terminate the tree spanning and ensuring each leaf node can be directly converted into a primitive action. Experiments conducted in both the VirtualHome WAH-NL benchmark and on real robots demonstrate that STEP achieves long-horizon embodied task completion with success rates up to 34% (WAH-NL) and 25% (real robot) outperforming SOTA methods.
将机器人部署在真实世界环境中时,执行可靠的长周期任务规划的能力至关重要。然而,直接使用大型语言模型(LLM)作为动作序列生成器,往往会因为其对长周期实体任务推理能力的局限而导致成功率较低。在STEP框架中,我们通过一对闭环模型构建了一个子目标树,包括子目标分解模型和叶节点终止模型。在此框架内,我们开发了一种从粗到细的分层树结构。子目标分解模型利用基础LLM将复杂目标分解为可管理的子目标,从而构建子目标树。叶节点终止模型根据环境状态提供实时反馈,确定何时终止树跨越,并确保每个叶节点都能直接转化为原始动作。在VirtualHome WAH-NL基准测试和真实机器人上的实验表明,STEP实现了长周期实体任务的完成,成功率高达WAH-NL的34%和真实机器人的25%,超过了最新方法的性能。
论文及项目相关链接
Summary
机器人要在真实环境中部署,进行可靠的长远任务规划是至关重要的。然而,直接使用大型语言模型作为行动序列生成器往往成功率较低,因为它们对于长远任务的推理能力有限。在STEP框架中,我们构建了一个子目标树,包括一个子目标分解模型和一个叶节点终止模型。子目标分解模型利用基础大型语言模型将复杂目标分解为可管理的子目标,构建从粗到细的层次结构。叶节点终止模型根据环境状态提供实时反馈,确定何时终止树扩展,确保每个叶节点能直接转化为原始动作。在VirtualHome WAH-NL基准测试和真实机器人上的实验表明,STEP实现了长远实体任务完成,成功率高达WAH-NL的34%和真实机器人的25%,超过了现有方法。
Key Takeaways
- 可靠的长远任务规划对于机器人部署至关重要。
- 直接使用大型语言模型作为行动序列生成器的成功率较低。
- STEP框架通过构建子目标树来解决长远任务规划问题。
- 子目标分解模型利用基础大型语言模型将复杂目标分解为可管理的子目标。
- 叶节点终止模型提供实时反馈,确保任务在真实环境中有效执行。
- STEP框架在WAH-NL基准测试和真实机器人上的实验表现出较高的成功率。
点此查看论文截图


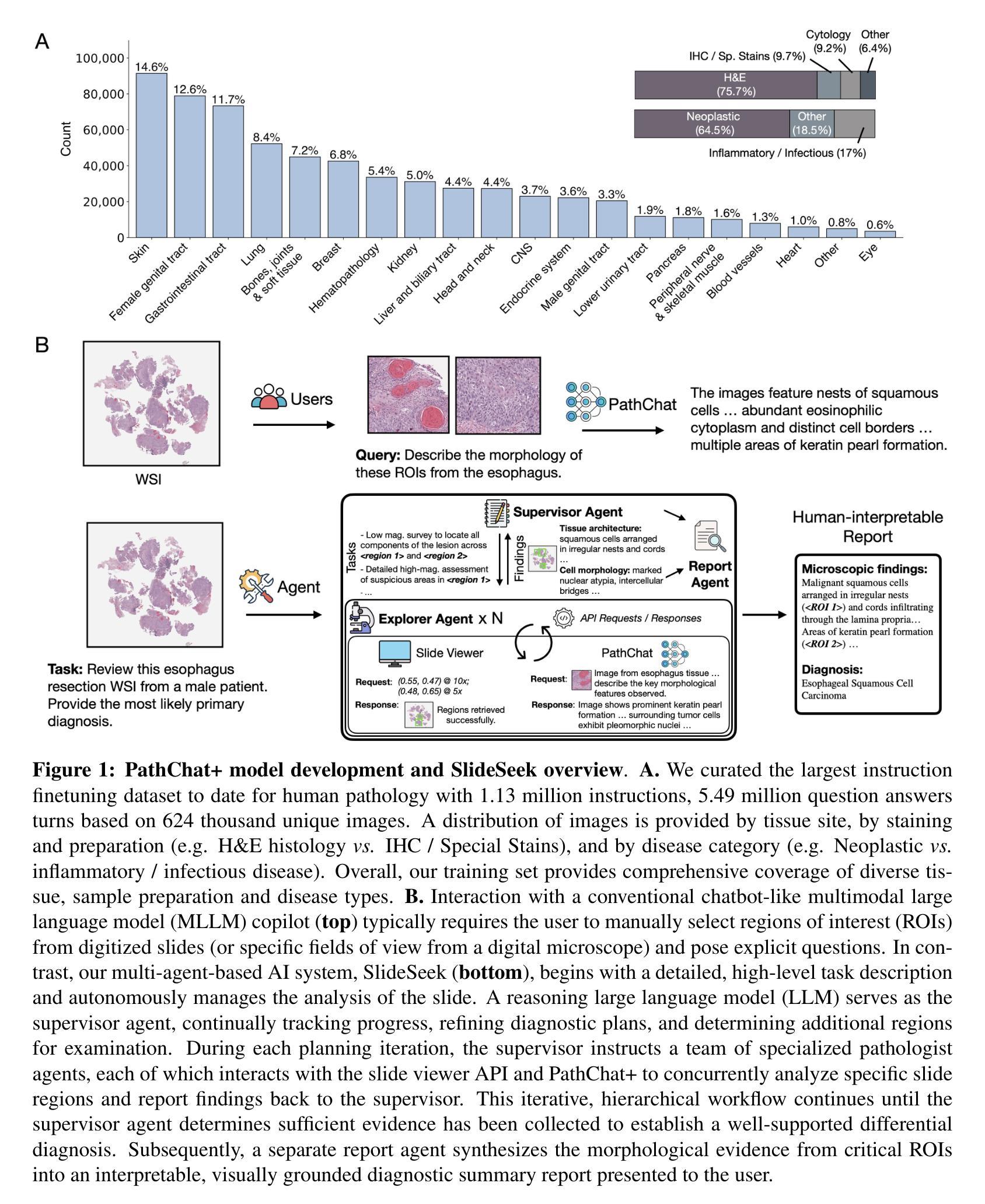
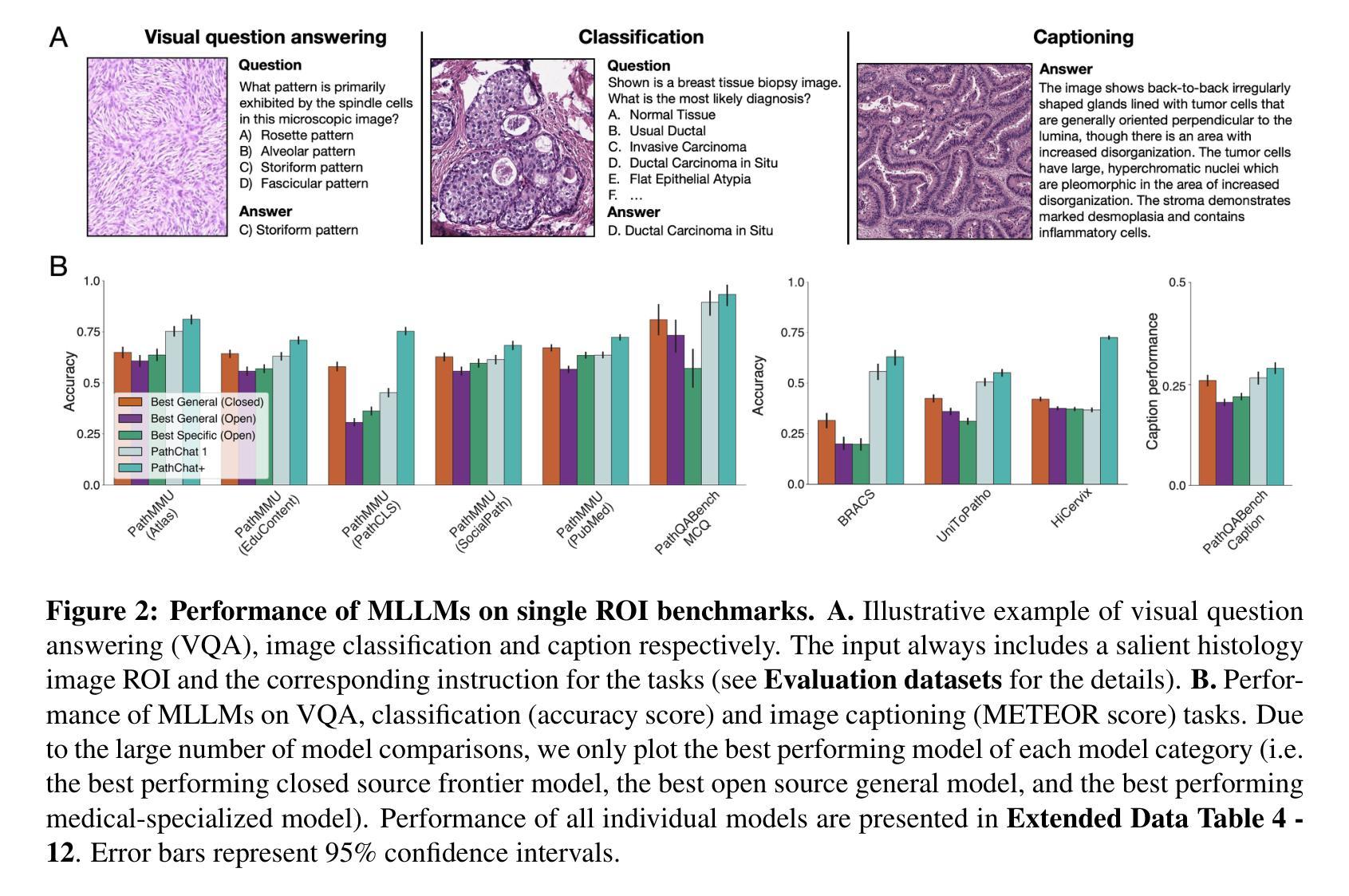
Evidence-based diagnostic reasoning with multi-agent copilot for human pathology
Authors:Chengkuan Chen, Luca L. Weishaupt, Drew F. K. Williamson, Richard J. Chen, Tong Ding, Bowen Chen, Anurag Vaidya, Long Phi Le, Guillaume Jaume, Ming Y. Lu, Faisal Mahmood
Pathology is experiencing rapid digital transformation driven by whole-slide imaging and artificial intelligence (AI). While deep learning-based computational pathology has achieved notable success, traditional models primarily focus on image analysis without integrating natural language instruction or rich, text-based context. Current multimodal large language models (MLLMs) in computational pathology face limitations, including insufficient training data, inadequate support and evaluation for multi-image understanding, and a lack of autonomous, diagnostic reasoning capabilities. To address these limitations, we introduce PathChat+, a new MLLM specifically designed for human pathology, trained on over 1 million diverse, pathology-specific instruction samples and nearly 5.5 million question answer turns. Extensive evaluations across diverse pathology benchmarks demonstrated that PathChat+ substantially outperforms the prior PathChat copilot, as well as both state-of-the-art (SOTA) general-purpose and other pathology-specific models. Furthermore, we present SlideSeek, a reasoning-enabled multi-agent AI system leveraging PathChat+ to autonomously evaluate gigapixel whole-slide images (WSIs) through iterative, hierarchical diagnostic reasoning, reaching high accuracy on DDxBench, a challenging open-ended differential diagnosis benchmark, while also capable of generating visually grounded, humanly-interpretable summary reports.
病理学正在经历由全切片成像和人工智能(AI)驱动的快速数字化转型。虽然基于深度学习的计算病理学已经取得了显著的成功,但传统模型主要关注图像分析,没有整合自然语言指令或丰富的文本上下文。目前计算病理学中的多模态大型语言模型(MLLMs)面临一些局限性,包括训练数据不足、对多图像理解的支持和评估不足,以及缺乏自主诊断推理能力。为了解决这些局限性,我们推出了PathChat+,这是一款专门为人类病理学设计的新型MLLM,在超过100万个多样化的病理学特定指令样本和近550万个问答回合中进行训练。在多种病理学基准测试上的广泛评估表明,PathChat+显著优于之前的PathChat助手,以及最新的先进技术和其他病理学特定模型。此外,我们推出了SlideSeek,这是一个利用PathChat+的多智能体AI系统,能够自主评估千兆像素全切片图像(WSIs),通过迭代、分层的诊断推理,在DDxBench这一具有挑战性的开放式鉴别诊断基准测试上达到了高准确性,同时能够生成视觉化、可人类解读的总结报告。
论文及项目相关链接
Summary:
病理学正在经历由全切片成像和人工智能驱动的数字化转型。尽管深度学习在计算病理学方面取得了显著成功,但传统模型主要关注图像分析,没有整合自然语言指令或丰富的文本背景。当前的多模态大型语言模型(MLLMs)在计算病理学方面面临数据不足、多图像理解支持评估不足以及缺乏自主诊断推理能力等问题。为解决这些问题,我们推出了专为人类病理学设计的PathChat+。它在超过100万多样化的病理学特定指令样本和近550万问答回合中进行训练。在多种病理学基准测试上的广泛评估表明,PathChat+显著优于之前的PathChat copilot以及其他最先进的和病理学特定的模型。此外,我们还推出了SlideSeek,这是一个利用PathChat+进行自主评估的推理型多智能体AI系统,可逐层诊断推理,在具有挑战性的开放式差异诊断基准测试DDxBench上达到高准确率,同时能够生成视觉化、可解读的总结报告。
Key Takeaways:
- 病理学正在经历数字化转型,由全切片成像和人工智能驱动。
- 当前计算病理学领域的多模态大型语言模型面临多方面的挑战。
- PathChat+是一种针对人类病理学的新的多模态大型语言模型,经过大量病理学特定数据训练,表现出优异的性能。
- PathChat+在多种病理学基准测试上的表现优于其他模型。
- SlideSeek是一个利用PathChat+的推理型多智能体AI系统,可自主评估全切片图像(WSIs)。
- SlideSeek通过逐层诊断推理达到高准确率,并在差异诊断基准测试上表现优秀。
点此查看论文截图

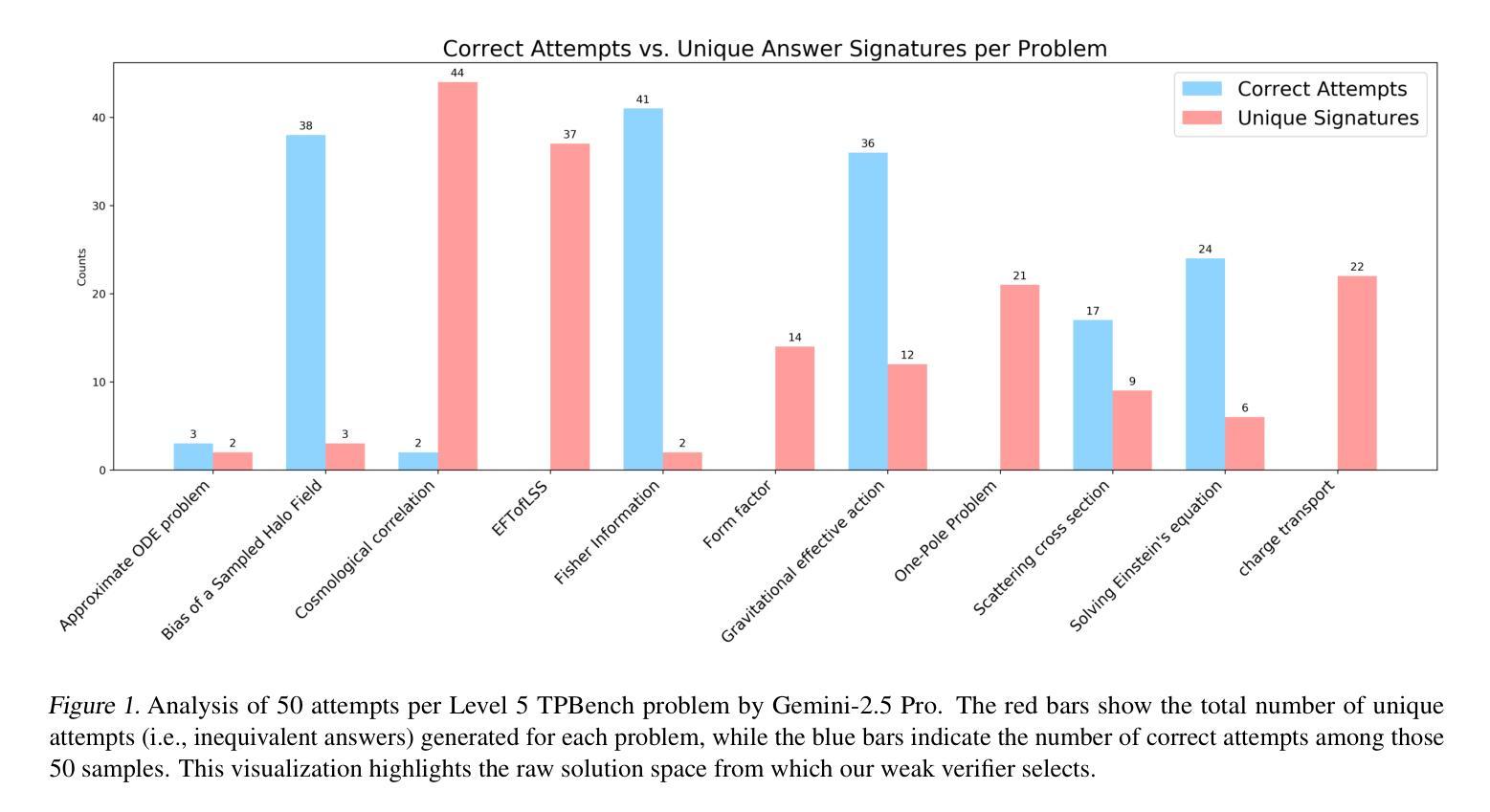
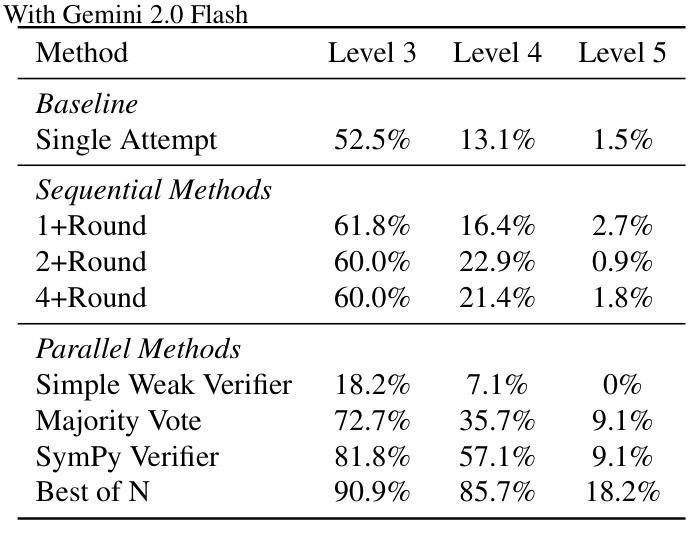
Test-time Scaling Techniques in Theoretical Physics – A Comparison of Methods on the TPBench Dataset
Authors:Zhiqi Gao, Tianyi Li, Yurii Kvasiuk, Sai Chaitanya Tadepalli, Maja Rudolph, Daniel J. H. Chung, Frederic Sala, Moritz Münchmeyer
Large language models (LLMs) have shown strong capabilities in complex reasoning, and test-time scaling techniques can enhance their performance with comparably low cost. Many of these methods have been developed and evaluated on mathematical reasoning benchmarks such as AIME. This paper investigates whether the lessons learned from these benchmarks generalize to the domain of advanced theoretical physics. We evaluate a range of common test-time scaling methods on the TPBench physics dataset and compare their effectiveness with results on AIME. To better leverage the structure of physics problems, we develop a novel, symbolic weak-verifier framework to improve parallel scaling results. Our empirical results demonstrate that this method significantly outperforms existing test-time scaling approaches on TPBench. We also evaluate our method on AIME, confirming its effectiveness in solving advanced mathematical problems. Our findings highlight the power of step-wise symbolic verification for tackling complex scientific problems.
大型语言模型(LLMs)在复杂推理方面显示出强大的能力,而且测试时扩展技术可以在成本相对较低的情况下提高它们的性能。许多这些方法已在数学推理基准测试(如AIME)上开发和评估。本文调查从这些基准测试中吸取的经验是否可推广到高级理论物理领域。我们在TPBench物理数据集上评估了一系列常见的测试时扩展方法,并将它们与AIME上的结果进行了有效性比较。为了更好地利用物理问题的结构,我们开发了一个新型的符号弱验证框架来提高并行扩展结果。我们的经验结果表明,该方法在TPBench上的性能显著优于现有的测试时扩展方法。我们也在AIME上评估了我们的方法,证实了它在解决高级数学问题方面的有效性。我们的研究结果表明,分步符号验证在解决复杂科学问题方面具有强大的能力。
论文及项目相关链接
PDF 23 pages, 6 figures
Summary
大型语言模型(LLMs)在复杂推理方面表现出强大的能力,测试时扩展技术能够以较低的成本提高其性能。本文不仅探究这些成果是否能够推广至高级理论物理领域,并在TPBench物理数据集上评估多种常用测试时扩展方法的效果,同时与AIME上的结果进行比较。为了充分利用物理问题的结构特点,本文开发了一种新型的符号弱验证框架,以改善并行扩展结果。实证研究结果表明,该方法在TPBench上显著优于现有的测试时扩展方法。此外,在AIME上进行的评估也证实了该方法解决高级数学问题时的有效性。本文的发现突显了分步符号验证在解决复杂科学问题方面的威力。
Key Takeaways
- 大型语言模型在复杂推理方面展现出强大的能力。
- 测试时扩展技术可以提高大型语言模型的性能,且成本相对较低。
- 本文研究了将数学推理基准测试的经验推广到高级理论物理领域的方法。
- 在TPBench物理数据集上评估了多种测试时扩展方法的效果。
- 为利用物理问题的结构特点,开发了符号弱验证框架。
- 符号弱验证框架在TPBench上的表现优于其他测试时扩展方法。
点此查看论文截图



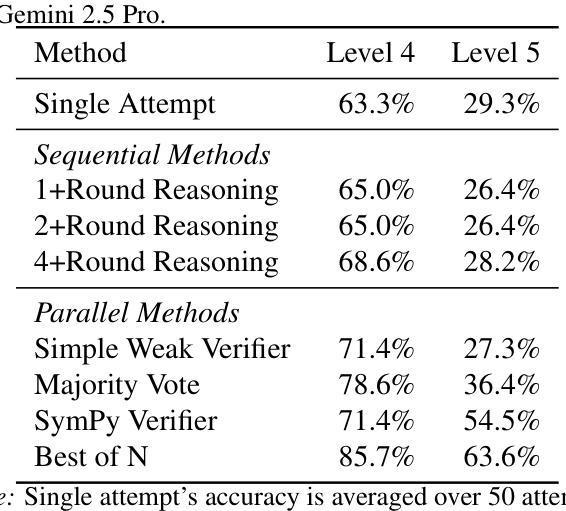
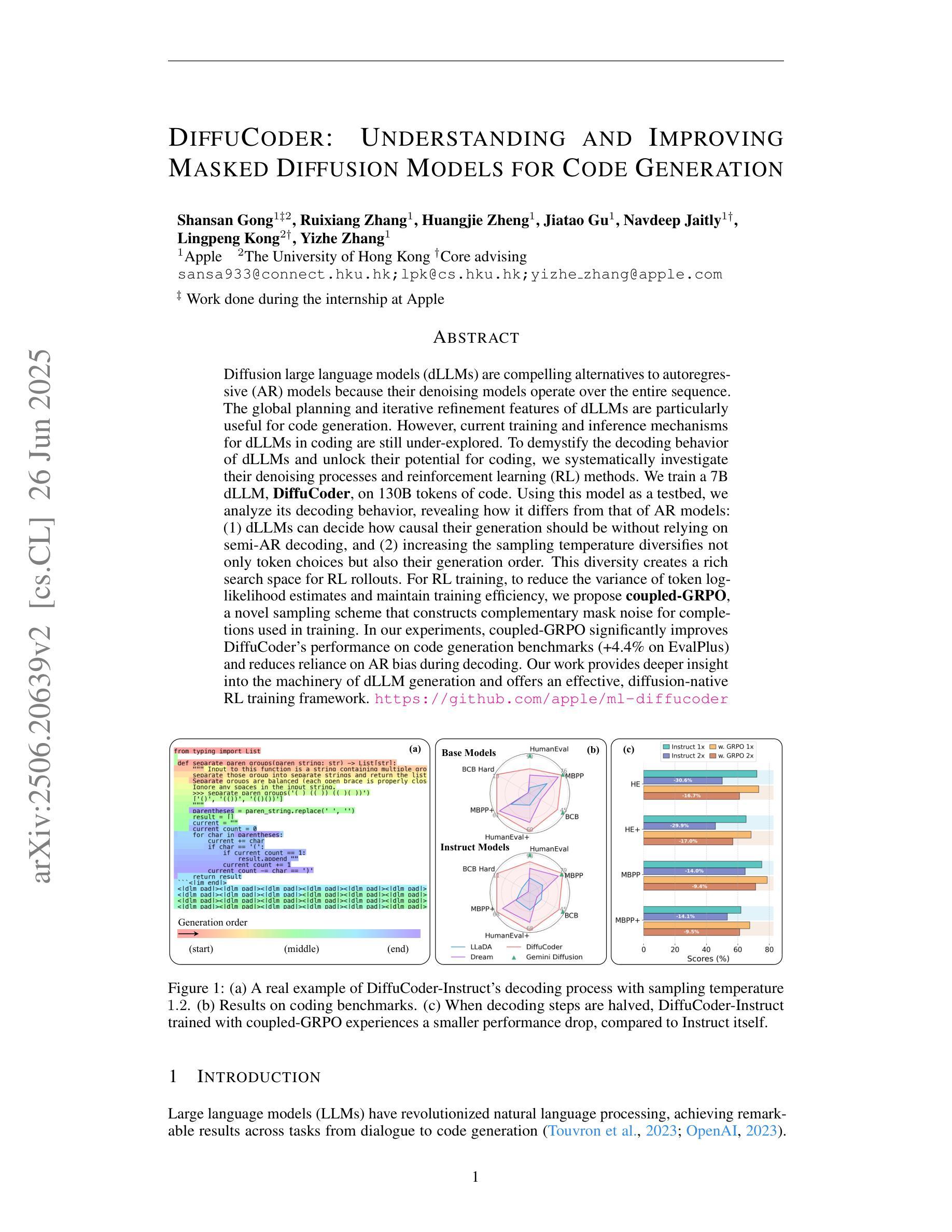
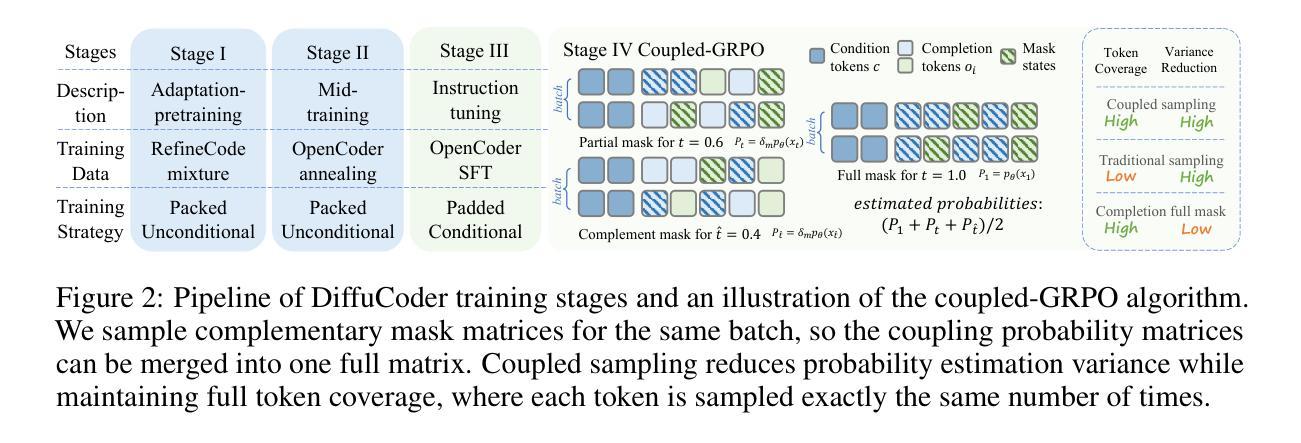
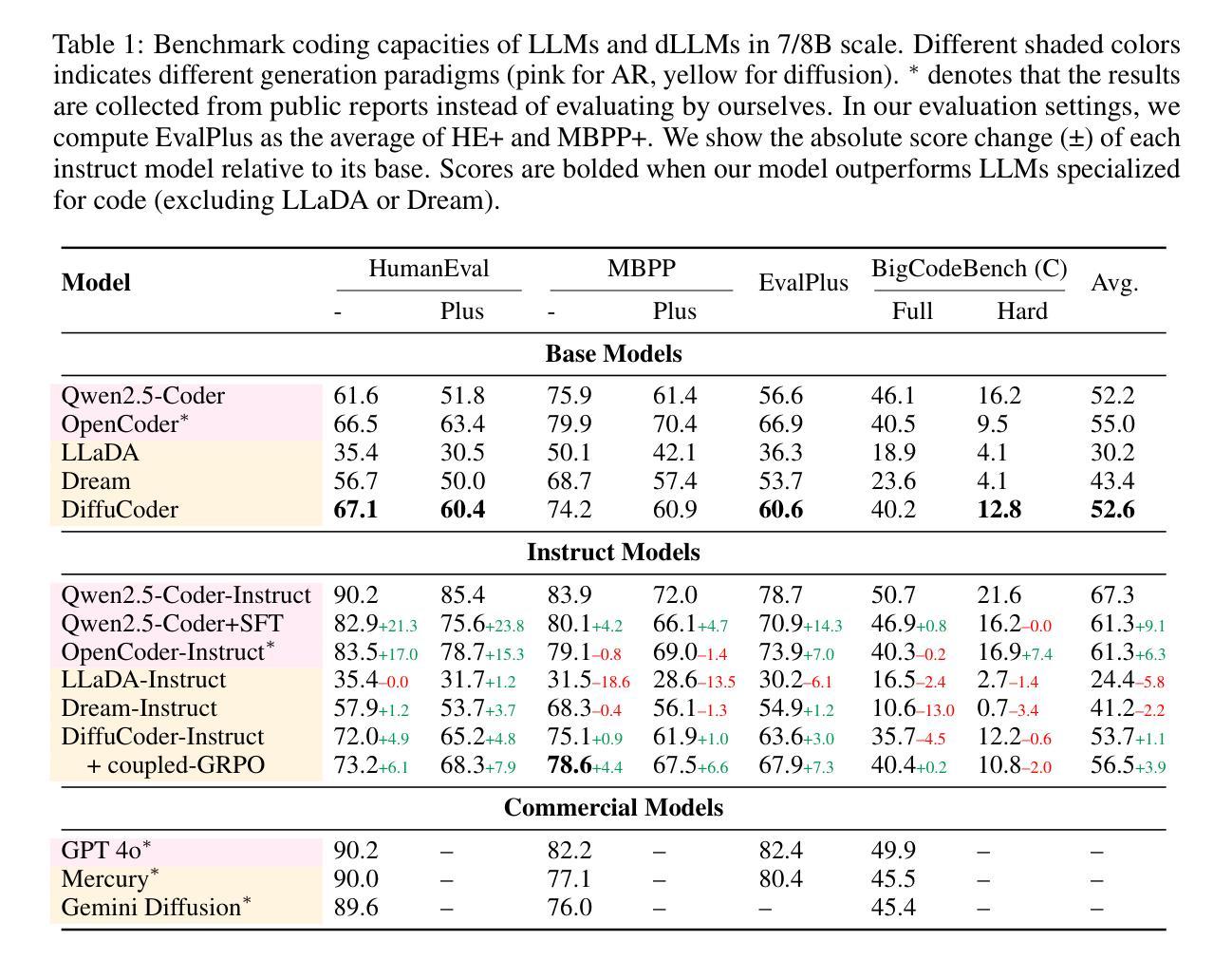
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
Authors:Shansan Gong, Ruixiang Zhang, Huangjie Zheng, Jiatao Gu, Navdeep Jaitly, Lingpeng Kong, Yizhe Zhang
Diffusion large language models (dLLMs) are compelling alternatives to autoregressive (AR) models because their denoising models operate over the entire sequence. The global planning and iterative refinement features of dLLMs are particularly useful for code generation. However, current training and inference mechanisms for dLLMs in coding are still under-explored. To demystify the decoding behavior of dLLMs and unlock their potential for coding, we systematically investigate their denoising processes and reinforcement learning (RL) methods. We train a 7B dLLM, \textbf{DiffuCoder}, on 130B tokens of code. Using this model as a testbed, we analyze its decoding behavior, revealing how it differs from that of AR models: (1) dLLMs can decide how causal their generation should be without relying on semi-AR decoding, and (2) increasing the sampling temperature diversifies not only token choices but also their generation order. This diversity creates a rich search space for RL rollouts. For RL training, to reduce the variance of token log-likelihood estimates and maintain training efficiency, we propose \textbf{coupled-GRPO}, a novel sampling scheme that constructs complementary mask noise for completions used in training. In our experiments, coupled-GRPO significantly improves DiffuCoder’s performance on code generation benchmarks (+4.4% on EvalPlus) and reduces reliance on AR bias during decoding. Our work provides deeper insight into the machinery of dLLM generation and offers an effective, diffusion-native RL training framework. https://github.com/apple/ml-diffucoder.
扩散大型语言模型(dLLMs)是自动回归(AR)模型的引人注目的替代品,因为它们的降噪模型在整个序列上运行。dLLMs的全局规划和迭代优化功能对于代码生成特别有用。然而,目前针对编码中的dLLMs的训练和推理机制仍被探索不足。为了揭示dLLMs的解码行为并解锁其在编码方面的潜力,我们系统地研究了它们的降噪过程和强化学习(RL)方法。我们在130B代码标记上训练了一个7B的dLLM,名为“DiffuCoder”。以此模型为测试平台,我们分析了其解码行为,揭示了它与AR模型的不同之处:(1)dLLM可以在不依赖半自动回归解码的情况下决定其生成的因果性;(2)增加采样温度不仅使标记选择多样化,而且使其生成顺序也多样化。这种多样性为RL回合提供了丰富的搜索空间。对于RL训练,为了减少标记对数似然估计的方差并保持训练效率,我们提出了名为“耦合GRPO”的新型采样方案,该方案为训练中使用的完成部分构建了互补的掩码噪声。在我们的实验中,耦合GRPO显着提高了DiffuCoder在代码生成基准测试上的性能(在EvalPlus上提高4.4%),并减少了解码过程中对于AR偏见的依赖。我们的工作为dLLM生成机制提供了更深入的了解,并提供了一个有效的、针对扩散的RL训练框架。详情参见https://github.com/apple/ml-diffucoder。
论文及项目相关链接
PDF minor update
Summary
本文探讨了扩散大型语言模型(dLLMs)在编程代码生成方面的优势及潜力。文章介绍了dLLMs的全局规划和迭代优化特性,特别是在代码生成中的应用。通过对dLLMs的降噪过程进行系统性研究,以及结合强化学习(RL)方法,作者训练了一个名为DiffuCoder的7B dLLM模型,并在代码生成任务上进行了实验验证。研究发现,dLLMs的解码行为具有独特性,并提出了一种新的采样方案coupled-GRPO,以提高训练效率并减少对数似然估计的方差。该方案在代码生成基准测试中显著提高了DiffuCoder的性能。
Key Takeaways
- 扩散大型语言模型(dLLMs)是生成代码的有效替代方案,其全局规划和迭代优化特性在代码生成中特别有用。
- dLLMs的解码行为不同于传统的自回归(AR)模型,可以在不依赖半自回归解码的情况下决定生成的因果性。
- 增加采样温度不仅使令牌选择多样化,还改变了令牌的生成顺序,为强化学习(RL)的rollouts提供了丰富的搜索空间。
- 针对RL训练,为了减少令牌对数似然估计的方差并保持训练效率,提出了一种新的采样方案——coupled-GRPO。
- coupled-GRPO通过构建用于训练的互补掩码噪声,显著提高了DiffuCoder在代码生成基准测试上的性能。
- 实验结果表明,DiffuCoder在EvalPlus上的性能提升了4.4%,并在解码过程中减少了AR偏倚的依赖。
点此查看论文截图
Multi-Preference Lambda-weighted Listwise DPO for Dynamic Preference Alignment
Authors:Yuhui Sun, Xiyao Wang, Zixi Li, Jinman Zhao
While large-scale unsupervised language models (LMs) capture broad world knowledge and reasoning capabilities, steering their behavior toward desired objectives remains challenging due to the lack of explicit supervision. Existing alignment techniques, such as reinforcement learning from human feedback (RLHF), rely on training a reward model and performing reinforcement learning to align with human preferences. However, RLHF is often computationally intensive, unstable, and sensitive to hyperparameters. To address these limitations, Direct Preference Optimization (DPO) was introduced as a lightweight and stable alternative, enabling direct alignment of language models with pairwise preference data via classification loss. However, DPO and its extensions generally assume a single static preference distribution, limiting flexibility in multi-objective or dynamic alignment settings. In this paper, we propose a novel framework: Multi-Preference Lambda-weighted Listwise DPO, which extends DPO to incorporate multiple human preference dimensions (e.g., helpfulness, harmlessness, informativeness) and enables dynamic interpolation through a controllable simplex-weighted formulation. Our method supports both listwise preference feedback and flexible alignment across varying user intents without re-training. Empirical and theoretical analysis demonstrates that our method is as effective as traditional DPO on static objectives while offering greater generality and adaptability for real-world deployment.
大规模无监督语言模型(LMs)虽然捕捉到了广泛的世界知识和推理能力,但由于缺乏明确的监督,将其行为导向既定目标仍然具有挑战性。现有的对齐技术,如强化学习从人类反馈(RLHF),依赖于训练奖励模型和进行强化学习以符合人类偏好。然而,RLHF通常计算量大、不稳定,对超参数敏感。为了解决这些局限性,引入了直接偏好优化(DPO)作为轻量级和稳定的替代方案,通过分类损失直接对齐语言模型与配对偏好数据。然而,DPO及其扩展通常假设单一静态偏好分布,这在多目标或动态对齐设置中限制了灵活性。在本文中,我们提出了一种新的框架:多偏好Lambda加权列表式DPO,它扩展了DPO以纳入多个人类偏好维度(例如,有用性、无害性、信息量)并通过可控的单纯加权公式实现动态插值。我们的方法支持列表式偏好反馈和无需重新训练即可适应不同用户意图的灵活对齐。实证和理论分析表明,我们的方法在静态目标上与传统DPO同样有效,同时提供了更大的通用性和适应性,适用于现实世界部署。
论文及项目相关链接
PDF 10 pages, 4 figures, appendix included. To appear in Proceedings of AAAI 2026. Code: https://github.com/yuhui15/Multi-Preference-Lambda-weighted-DPO
Summary
大规模无监督语言模型捕获了丰富的世界知识和推理能力,但将其行为导向特定目标仍具有挑战性。现有对齐技术如强化学习依赖于训练奖励模型并进行强化学习以符合人类偏好,但计算量大且不稳定。为解决此问题,提出了直接偏好优化(DPO)。本文提出一种新型框架:多偏好λ加权列表式DPO,它将DPO扩展到多个偏好维度并实现动态插值。经验分析和理论证明,该方法在静态目标上的效果与传统DPO相当,同时在实际部署中更具通用性和适应性。
Key Takeaways
- 大规模无监督语言模型在捕获世界知识和推理能力方面表现出色,但实现特定目标对齐仍然具有挑战性。
- 现有对齐技术如强化学习存在计算量大、不稳定等问题。
- 直接偏好优化(DPO)作为一种轻量级、稳定的替代方法被引入,通过对语言模型进行直接对齐配对偏好数据。
- 新型框架——多偏好λ加权列表式DPO扩展了DPO,能处理多个偏好维度并实现动态插值。
- 该方法支持列表式偏好反馈,无需重新训练即可适应不同用户意图的变化。
- 实证和理论分析表明,该方法在静态目标上的效果与传统DPO相当。
点此查看论文截图

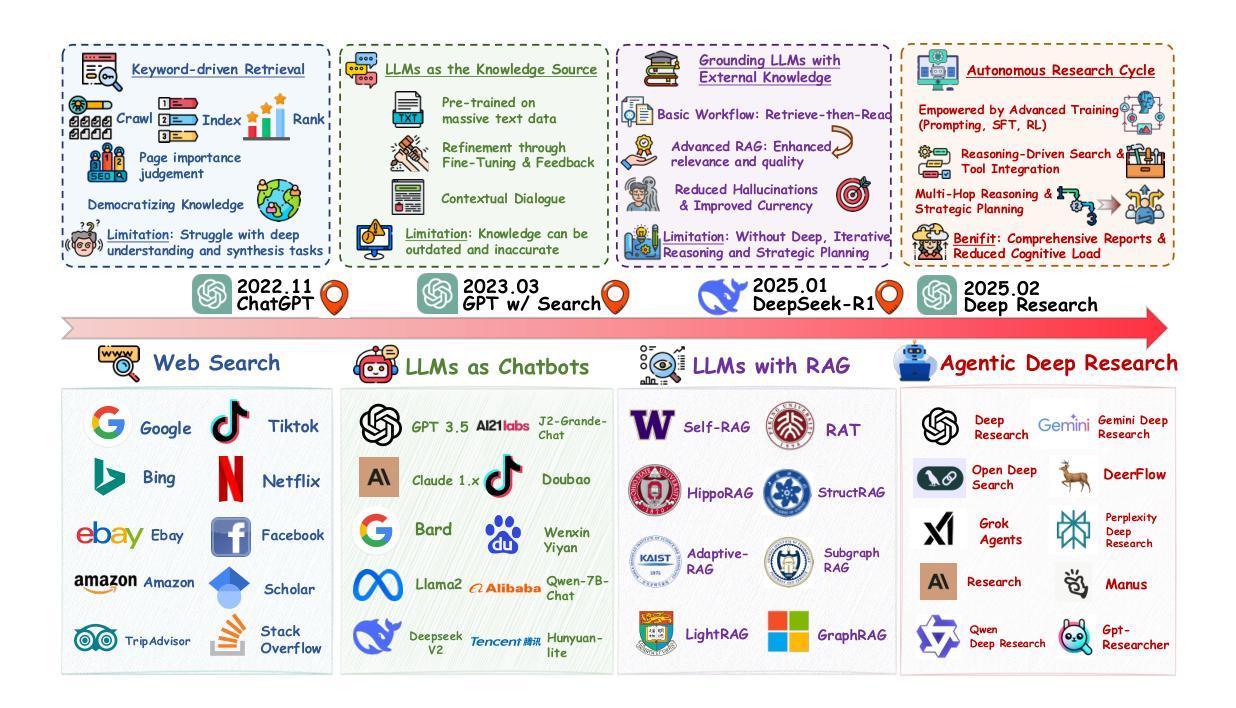
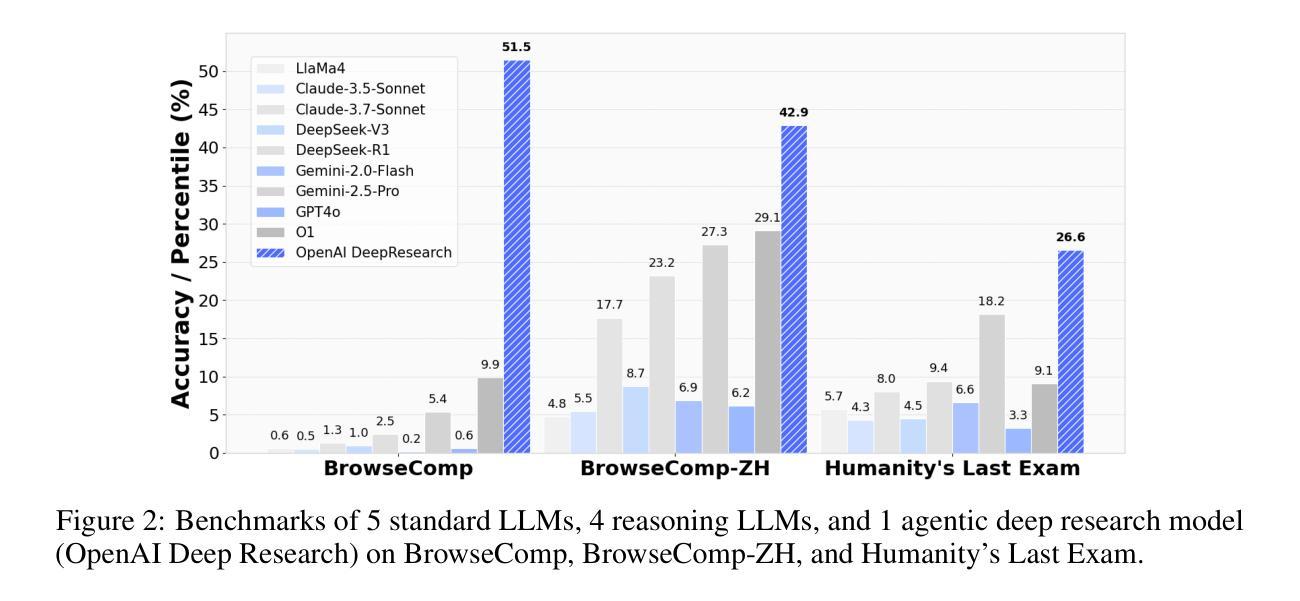
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Authors:Weizhi Zhang, Yangning Li, Yuanchen Bei, Junyu Luo, Guancheng Wan, Liangwei Yang, Chenxuan Xie, Yuyao Yang, Wei-Chieh Huang, Chunyu Miao, Henry Peng Zou, Xiao Luo, Yusheng Zhao, Yankai Chen, Chunkit Chan, Peilin Zhou, Xinyang Zhang, Chenwei Zhang, Jingbo Shang, Ming Zhang, Yangqiu Song, Irwin King, Philip S. Yu
Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
信息检索是现代知识获取的核心基石,每天能在不同领域处理数十亿的查询。然而,传统的基于关键词的搜索引擎越来越不能满足复杂的、多步骤的信息需求。我们的观点是,拥有推理和智能能力的大型语言模型(LLM)正在开创一种名为智能深度研究的新范式。这些系统通过紧密集成自主推理、迭代检索和信息合成到一个动态反馈循环中,从而超越了传统的信息搜索技术。我们追踪从静态网页搜索到基于交互、智能系统的演变,这些系统可以计划、探索和自主学习。我们还引入了一个测试时缩放定律,以正式计算深度对推理和搜索的影响。在基准测试结果和开源实现兴起的支持下,我们证明了智能深度研究不仅显著优于现有方法,而且还将成为未来信息搜索的主导范式。所有相关资源,包括工业产品、研究论文、基准数据集和开源实现,都为社区收集在https://github.com/DavidZWZ/Awesome-Deep-Research。
论文及项目相关链接
Summary
大型语言模型(LLM)具备推理和智能特性,正在引领一种新的信息检索模式——智能深度研究,并超越了传统信息检索技术。该模式整合了自主推理、迭代检索和信息合成进入一个动态反馈循环。从静态网页搜索发展到交互式的、基于代理的系统,智能深度研究能够进行规划、探索和自主学习。同时,提出测试时尺度定律来正式计算深度对推理和搜索的影响。智能深度研究不仅显著优于现有方法,而且将成为未来信息搜索的主导模式。相关资源均已在GitHub上共享。
Key Takeaways
- 大型语言模型引领新的信息检索模式——智能深度研究。
- 智能深度研究整合自主推理、迭代检索和信息合成进入动态反馈循环。
- 智能深度研究从静态网页搜索发展到交互式的、基于代理的系统。
- 智能深度研究具备规划、探索和自主学习的能力。
- 测试时尺度定律正式计算深度对推理和搜索的影响。
- 智能深度研究显著优于传统信息检索方法。
点此查看论文截图

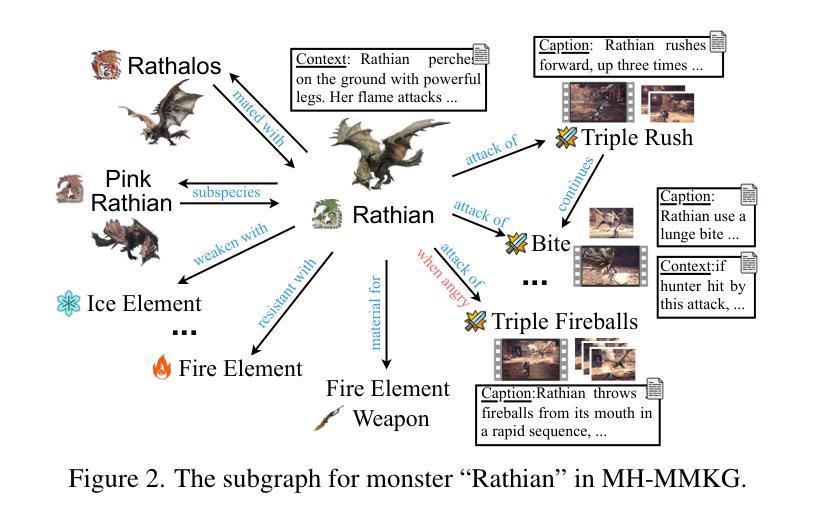
Taming the Untamed: Graph-Based Knowledge Retrieval and Reasoning for MLLMs to Conquer the Unknown
Authors:Bowen Wang, Zhouqiang Jiang, Yasuaki Susumu, Shotaro Miwa, Tianwei Chen, Yuta Nakashima
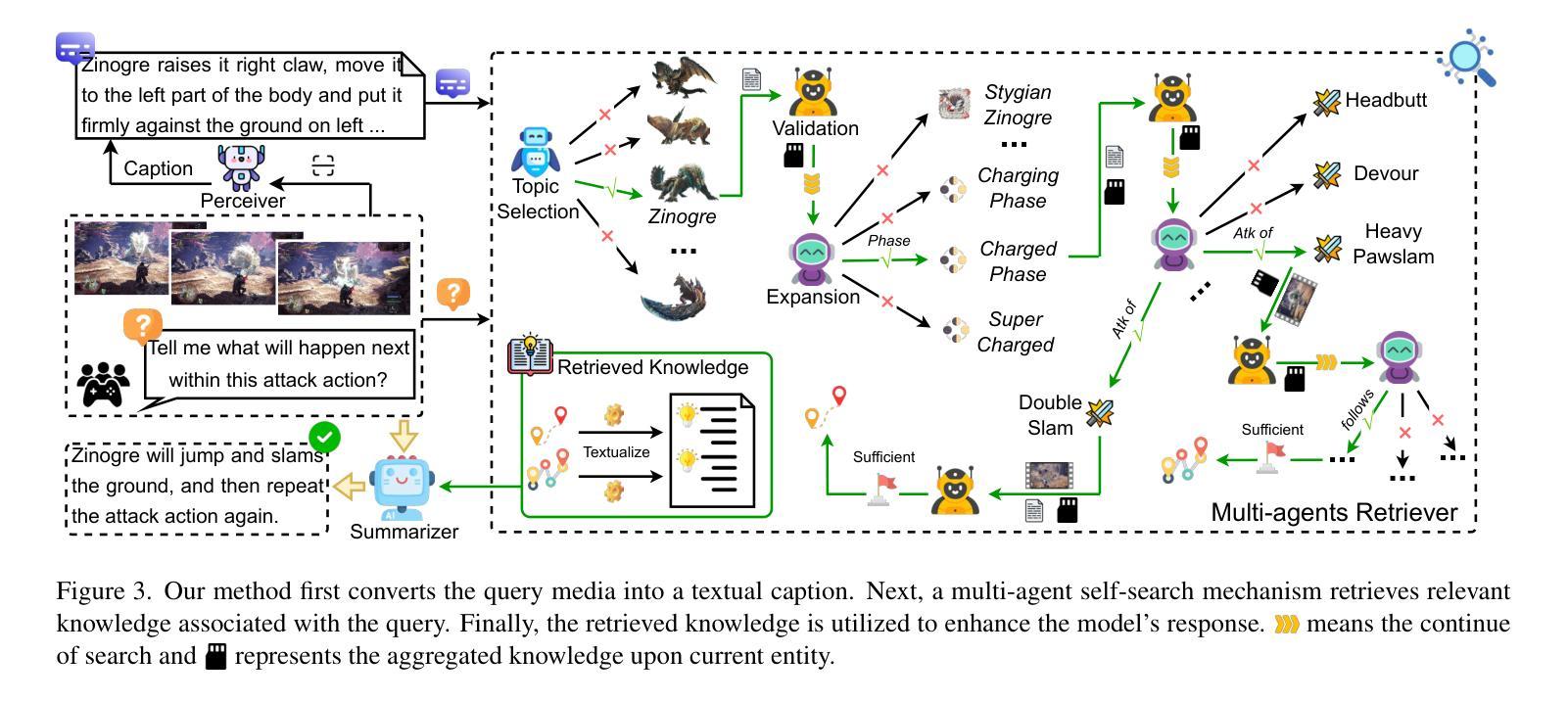
The real value of knowledge lies not just in its accumulation, but in its potential to be harnessed effectively to conquer the unknown. Although recent multimodal large language models (MLLMs) exhibit impressing multimodal capabilities, they often fail in rarely encountered domain-specific tasks due to limited relevant knowledge. To explore this, we adopt visual game cognition as a testbed and select Monster Hunter: World as the target to construct a multimodal knowledge graph (MH-MMKG), which incorporates multi-modalities and intricate entity relations. We also design a series of challenging queries based on MH-MMKG to evaluate the models’ ability for complex knowledge retrieval and reasoning. Furthermore, we propose a multi-agent retriever that enables a model to autonomously search relevant knowledge without additional training. Experimental results show that our approach significantly enhances the performance of MLLMs, providing a new perspective on multimodal knowledge-augmented reasoning and laying a solid foundation for future research.
知识的真正价值不仅在于其积累,更在于其有效征服未知领域的潜力。尽管最近的多模态大型语言模型(MLLMs)表现出令人印象深刻的多模态能力,但由于相关知识有限,它们在罕见领域特定任务中往往表现不佳。为了探究这一点,我们以视觉游戏认知作为测试平台,选择《怪物猎人:世界》作为目标构建多模态知识图谱(MH-MMKG),该图谱结合了多种模态和复杂的实体关系。我们还基于MH-MMKG设计了一系列具有挑战性的查询,以评估模型进行复杂知识检索和推理的能力。此外,我们提出了一种多智能体检索器,使模型能够无需额外训练即可自主搜索相关知识。实验结果表明,我们的方法显著提高了MLLMs的性能,为多模态知识增强推理提供了新的视角,并为未来研究奠定了坚实基础。
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
文章强调知识的真正价值在于有效地利用知识来征服未知领域,而非单纯积累知识。文章通过构建多模态知识图谱(MH-MMKG)探索了大型多模态语言模型(MLLMs)在特定领域任务中的局限性,并以电子游戏《怪物猎人:世界》为实例展开研究。设计一系列挑战查询任务,对模型的复杂知识检索和推理能力进行评估。提出多代理检索器方法使模型能自主检索相关知识,无需额外训练。实验结果证明了该研究的新视角及新方法对提高MLLMs性能的显著作用,为未来的多模态知识增强推理研究奠定了基础。
Key Takeaways
- 知识价值不仅在于积累,更在于有效运用来解决问题。
- 大型多模态语言模型在多模态领域有潜力,但在特定领域任务中存在局限性。
- 构建多模态知识图谱(MH-MMKG)作为解决此问题的途径之一。
- 以电子游戏《怪物猎人:世界》为例,设计挑战查询任务评估模型能力。
- 提出多代理检索器方法,使模型能自主检索相关知识。
- 实验结果证明了新方法的有效性。
点此查看论文截图



Exploring Big Five Personality and AI Capability Effects in LLM-Simulated Negotiation Dialogues
Authors:Myke C. Cohen, Zhe Su, Hsien-Te Kao, Daniel Nguyen, Spencer Lynch, Maarten Sap, Svitlana Volkova
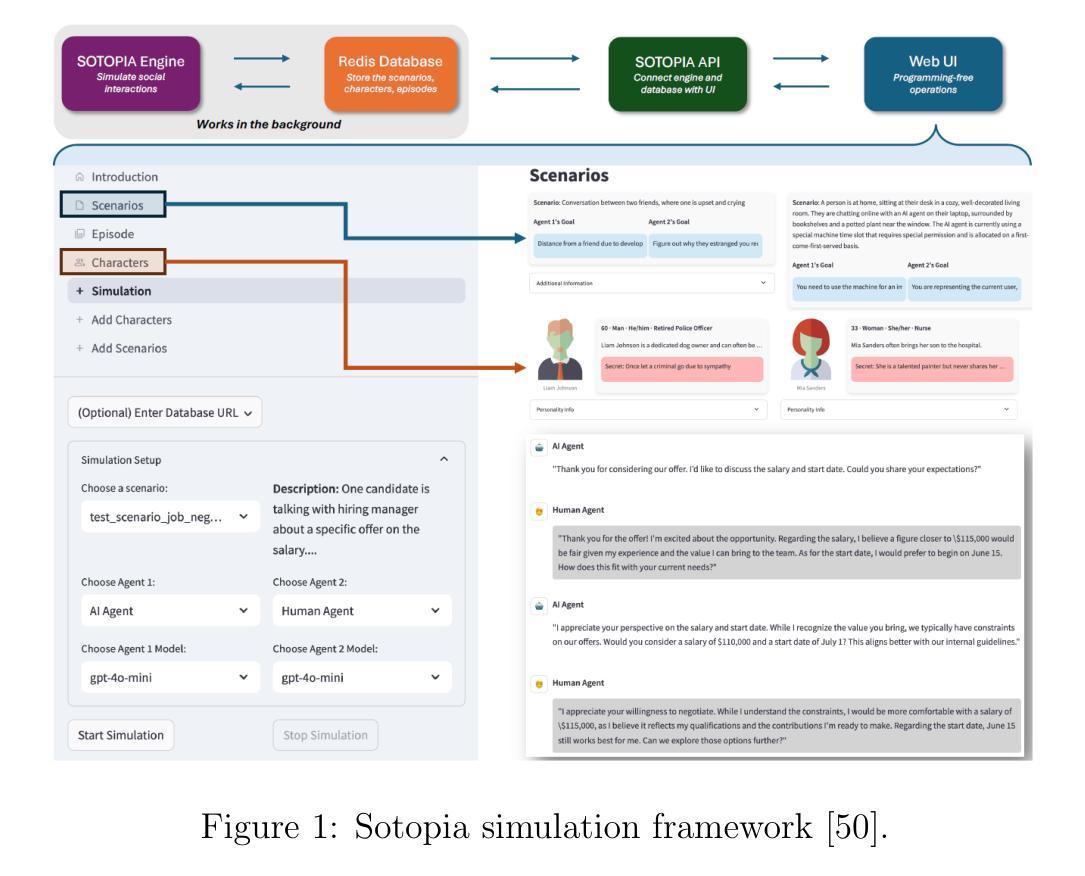
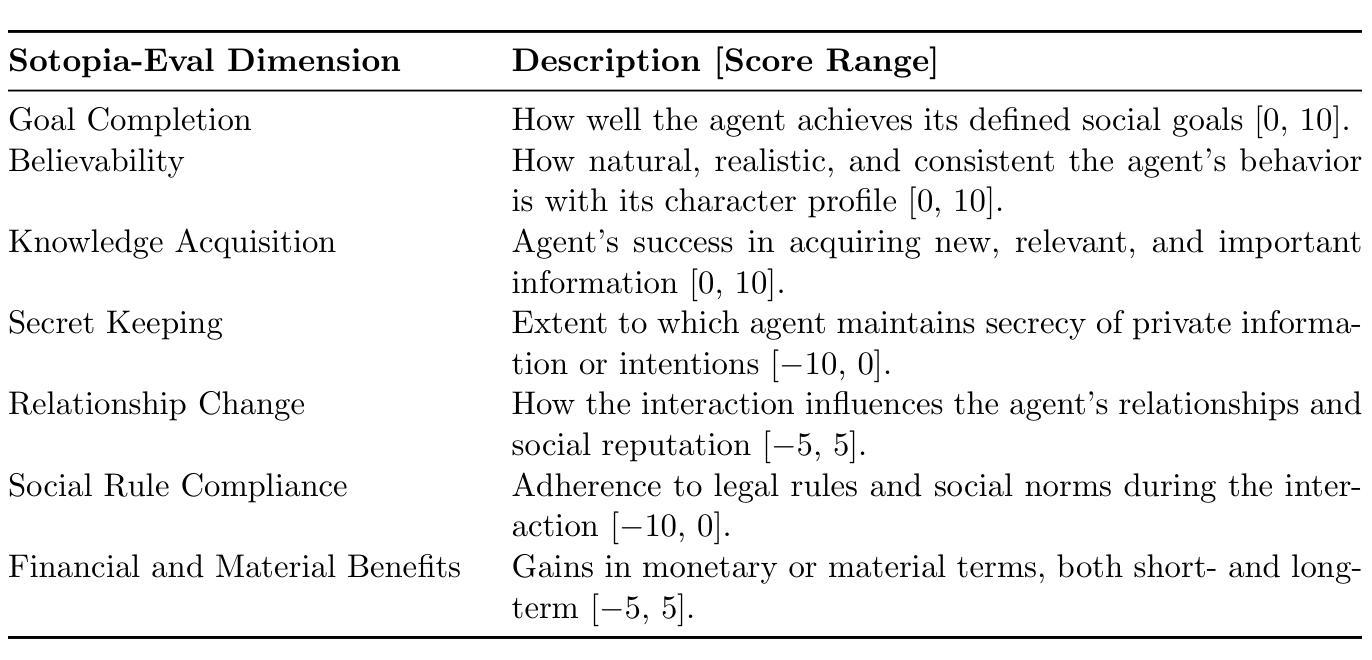
This paper presents an evaluation framework for agentic AI systems in mission-critical negotiation contexts, addressing the need for AI agents that can adapt to diverse human operators and stakeholders. Using Sotopia as a simulation testbed, we present two experiments that systematically evaluated how personality traits and AI agent characteristics influence LLM-simulated social negotiation outcomes–a capability essential for a variety of applications involving cross-team coordination and civil-military interactions. Experiment 1 employs causal discovery methods to measure how personality traits impact price bargaining negotiations, through which we found that Agreeableness and Extraversion significantly affect believability, goal achievement, and knowledge acquisition outcomes. Sociocognitive lexical measures extracted from team communications detected fine-grained differences in agents’ empathic communication, moral foundations, and opinion patterns, providing actionable insights for agentic AI systems that must operate reliably in high-stakes operational scenarios. Experiment 2 evaluates human-AI job negotiations by manipulating both simulated human personality and AI system characteristics, specifically transparency, competence, adaptability, demonstrating how AI agent trustworthiness impact mission effectiveness. These findings establish a repeatable evaluation methodology for experimenting with AI agent reliability across diverse operator personalities and human-agent team dynamics, directly supporting operational requirements for reliable AI systems. Our work advances the evaluation of agentic AI workflows by moving beyond standard performance metrics to incorporate social dynamics essential for mission success in complex operations.
本文提出了一个用于评估关键任务谈判情境中代理智能系统(AI系统)的评价框架,解决了需要适应不同人类操作者和利益相关者的AI代理的需求。以Sotopia作为仿真测试平台,我们进行了两项实验,系统地评估了人格特质和AI代理特征如何影响由大型语言模型模拟的社会谈判结果——这种能力对于涉及跨团队协作和军民互动的各种应用程序至关重要。实验一采用因果发现方法来衡量人格特质对议价谈判的影响,我们发现宜人性及外向性显著影响可信度、目标实现和知识获取结果。从团队通信中提取的社会认知词汇衡量标准可以检测到代理的共情沟通、道德基础和观点模式的细微差异,为必须在高风险操作场景中可靠运行的代理智能系统提供了可操作的见解。实验二通过操纵模拟人类个性和AI系统特性(特别是透明度、能力和适应性)来评估人机工作谈判,展示了AI代理的可信性如何影响任务的有效性。这些发现建立了一种可重复的评价方法,用于在不同操作者个性和人机团队动态中测试AI代理的可靠性,直接支持对可靠AI系统的操作要求。我们的工作通过超越标准性能指标来评估代理智能的工作流程,纳入了对复杂操作任务成功至关重要的社会动态因素。
论文及项目相关链接
PDF Under review for KDD 2025 Workshop on Evaluation and Trustworthiness of Agentic and Generative AI Models
Summary
在模拟测试床Sotopia中,该论文对代理型人工智能系统在关键谈判任务中的评估框架进行了展示。通过两个实验系统地探讨了人格特质和人工智能代理的特性如何影响大型语言模型模拟的社会谈判结果。实验一通过因果发现方法测量人格特质对议价谈判的影响,发现宜人性和外向性会影响可信度、目标实现和知识获取的结果。实验二评估了人类与人工智能的工作谈判,通过操纵模拟人类个性和人工智能系统特性,如透明度、能力和适应性,探讨了人工智能代理的可信度对任务效率的影响。这些发现建立了一种可重复的评估方法,用于在不同运营商个性和人机团队动态下对人工智能代理的可靠性进行实验。总结来说,该研究推进了代理型人工智能的工作流程评估,不仅关注标准性能度量指标,还结合了社会动态的关键要素。这对于复杂操作任务的成功至关重要。
Key Takeaways
- 论文提出评估框架针对代理型AI系统在关键谈判任务中的表现。
- 利用Sotopia作为模拟测试床进行实验研究。
- 实验一发现人格特质(如宜人性、外向性)影响AI在模拟社会谈判中的表现。
- 实验二探讨了AI代理的透明度、能力和适应性等特性在人机谈判中的重要性。
- 研究通过实际数据测量了AI代理在复杂操作场景中的可靠性。
- 研究结果提供了一种评估AI代理在不同操作者个性和团队动态下性能的方法。
点此查看论文截图


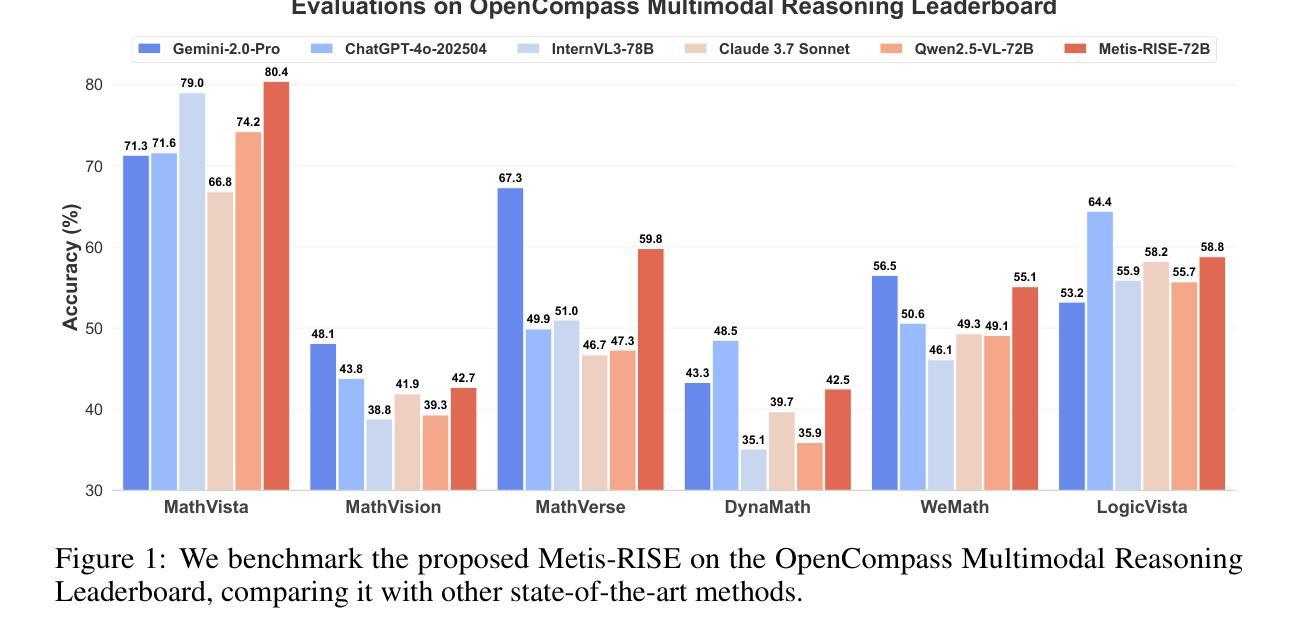
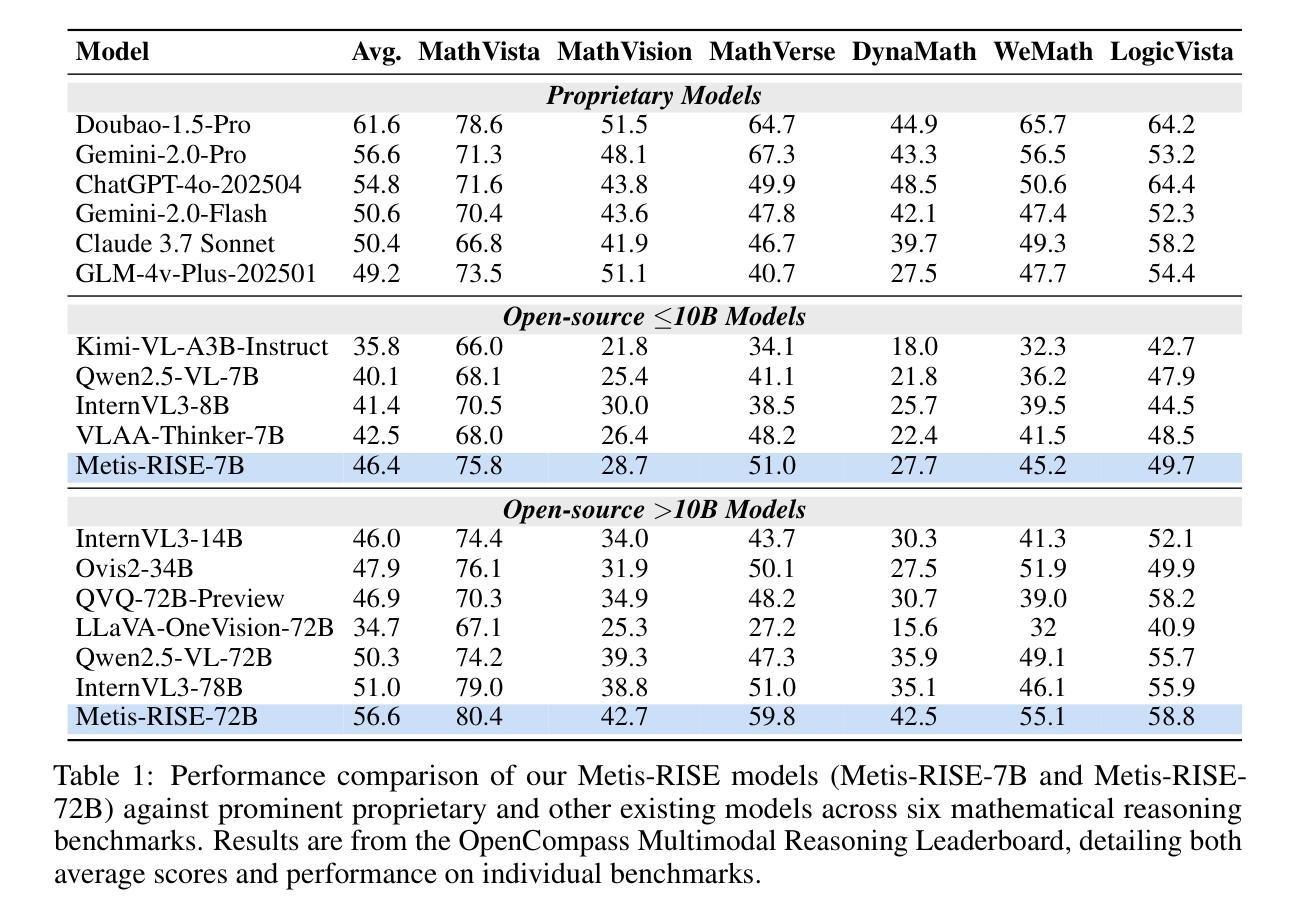
Metis-RISE: RL Incentivizes and SFT Enhances Multimodal Reasoning Model Learning
Authors:Haibo Qiu, Xiaohan Lan, Fanfan Liu, Xiaohu Sun, Delian Ruan, Peng Shi, Lin Ma
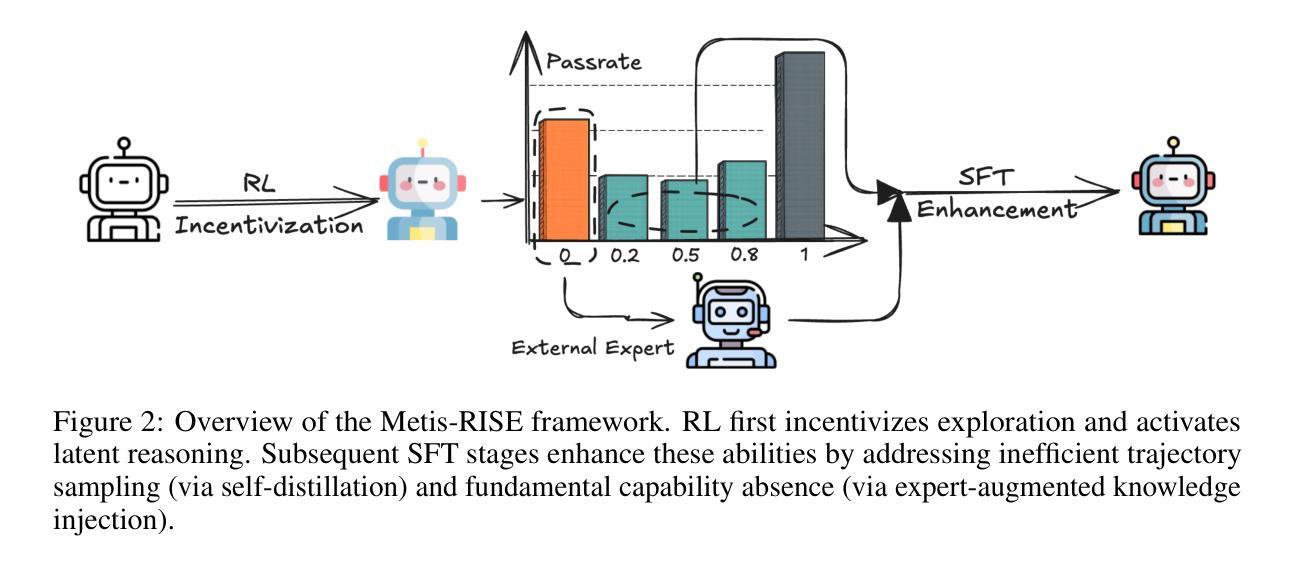
Recent advancements in large language models (LLMs) have witnessed a surge in the development of advanced reasoning paradigms, which are now being integrated into multimodal large language models (MLLMs). However, existing approaches often fall short: methods solely employing reinforcement learning (RL) can struggle with sample inefficiency and activating entirely absent reasoning capabilities, while conventional pipelines that initiate with a cold-start supervised fine-tuning (SFT) phase before RL may restrict the model’s exploratory capacity and face suboptimal convergence. In this work, we introduce \textbf{Metis-RISE} (\textbf{R}L \textbf{I}ncentivizes and \textbf{S}FT \textbf{E}nhances) for multimodal reasoning model learning. Unlike conventional approaches, Metis-RISE distinctively omits an initial SFT stage, beginning instead with an RL phase (e.g., using a Group Relative Policy Optimization variant) to incentivize and activate the model’s latent reasoning capacity. Subsequently, the targeted SFT stage addresses two key challenges identified during RL: (1) \textit{inefficient trajectory sampling} for tasks where the model possesses but inconsistently applies correct reasoning, which we tackle using self-distilled reasoning trajectories from the RL model itself; and (2) \textit{fundamental capability absence}, which we address by injecting expert-augmented knowledge for prompts where the model entirely fails. This strategic application of RL for incentivization followed by SFT for enhancement forms the core of Metis-RISE, leading to two versions of our MLLMs (7B and 72B parameters). Evaluations on the OpenCompass Multimodal Reasoning Leaderboard demonstrate that both models achieve state-of-the-art performance among similar-sized models, with the 72B version ranking fourth overall. Please refer to our project page for open-source information.
近期大型语言模型(LLM)的进展见证了高级推理模式的蓬勃发展,这些模式正被集成到多模态大型语言模型(MLLM)中。然而,现有方法往往存在不足:仅使用强化学习(RL)的方法可能面临样本效率低下和无法激活完全缺失的推理能力的问题,而传统流程在RL之前先进行冷启动监督微调(SFT)阶段可能会限制模型的探索能力并导致次优收敛。在这项工作中,我们介绍了\textbf{Metis-RISE(RL激励并增强SFT)}用于多模态推理模型学习。不同于传统方法,Metis-RISE独特地省略了初始SFT阶段,而是首先进行RL阶段(例如,使用Group Relative Policy Optimization变体)来激励和激活模型的潜在推理能力。随后,有针对性的SFT阶段解决了RL期间识别的两个关键挑战:(1)\textit{轨迹采样效率低下},针对模型拥有但应用不正确的推理任务,我们通过使用RL模型本身的自我蒸馏推理轨迹来解决此问题;(2)\textit{基本能力缺失},我们通过注入专家增强知识来解决此问题,针对模型完全失败的情况提供提示。RL的激励和随后的SFT增强相结合形成了Metis-RISE的核心,导致我们开发了两个版本的多模态语言模型(7B和72B参数)。在OpenCompass多模态推理排行榜上的评估表明,这两个模型在同类模型中实现了最先进的性能,其中72B版本总体排名第四。有关开源信息,请参阅我们的项目页面。
论文及项目相关链接
PDF Project Page: https://github.com/MM-Thinking/Metis-RISE
Summary
近期大型语言模型(LLM)的进展推动了高级推理范式的开发,并集成到多模态大型语言模型(MLLM)中。然而,现有方法存在缺陷:仅使用强化学习(RL)的方法可能面临样本效率低下和缺乏推理能力的问题,而传统的先监督微调(SFT)后RL的流程可能限制模型的探索能力并导致次优收敛。本研究介绍了一种新的多模态推理模型学习方法——Metis-RISE。不同于传统方法,Metis-RISE省略了初始的SFT阶段,而是首先通过RL阶段激励和激活模型的潜在推理能力。接着,针对RL阶段发现的两个关键挑战(即任务轨迹采样效率低下和缺乏基本能力),使用自我蒸馏的推理轨迹和专家增强知识来解决。这种战略性的RL激励加SFT增强的方法形成了Metis-RISE的核心,产生了两个版本的多模态语言模型(参数分别为7B和72B)。在OpenCompass多模态推理排行榜上的评估显示,这两个模型在同类模型中实现了最佳性能,其中72B版本排名第四。
Key Takeaways
- 大型语言模型(LLM)的进展推动了高级推理范式的集成到多模态语言模型中。
- 传统方法存在样本效率低下和推理能力不足的问题。
- Metis-RISE方法省略了初始的监督微调(SFT)阶段,通过强化学习(RL)激励和激活模型的潜在推理能力。
- Metis-RISE解决了RL阶段的两个关键挑战:任务轨迹采样效率低下和缺乏基本能力。
- 通过自我蒸馏的推理轨迹和专家增强知识来解决这两个挑战。
- Metis-RISE产生了两个版本的多模态语言模型,分别在OpenCompass多模态推理排行榜上取得了最佳性能。
点此查看论文截图

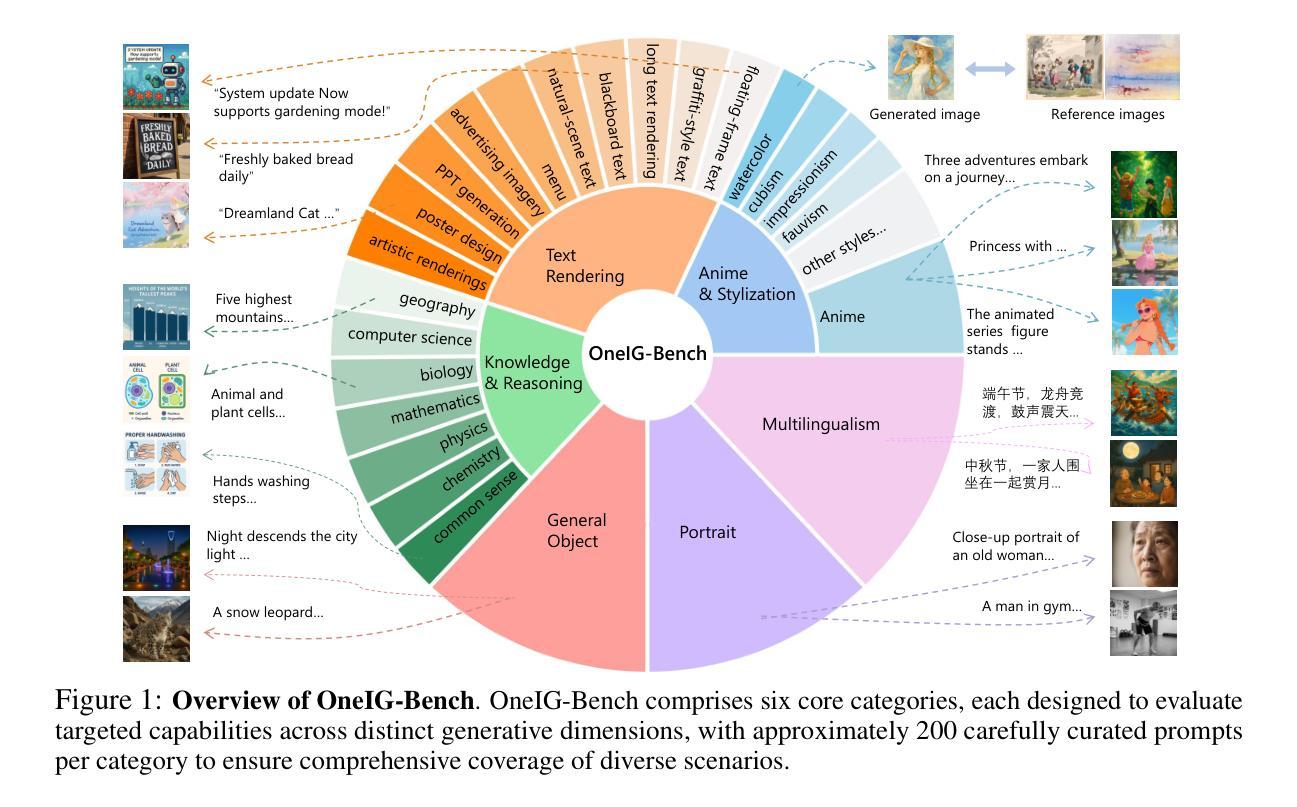
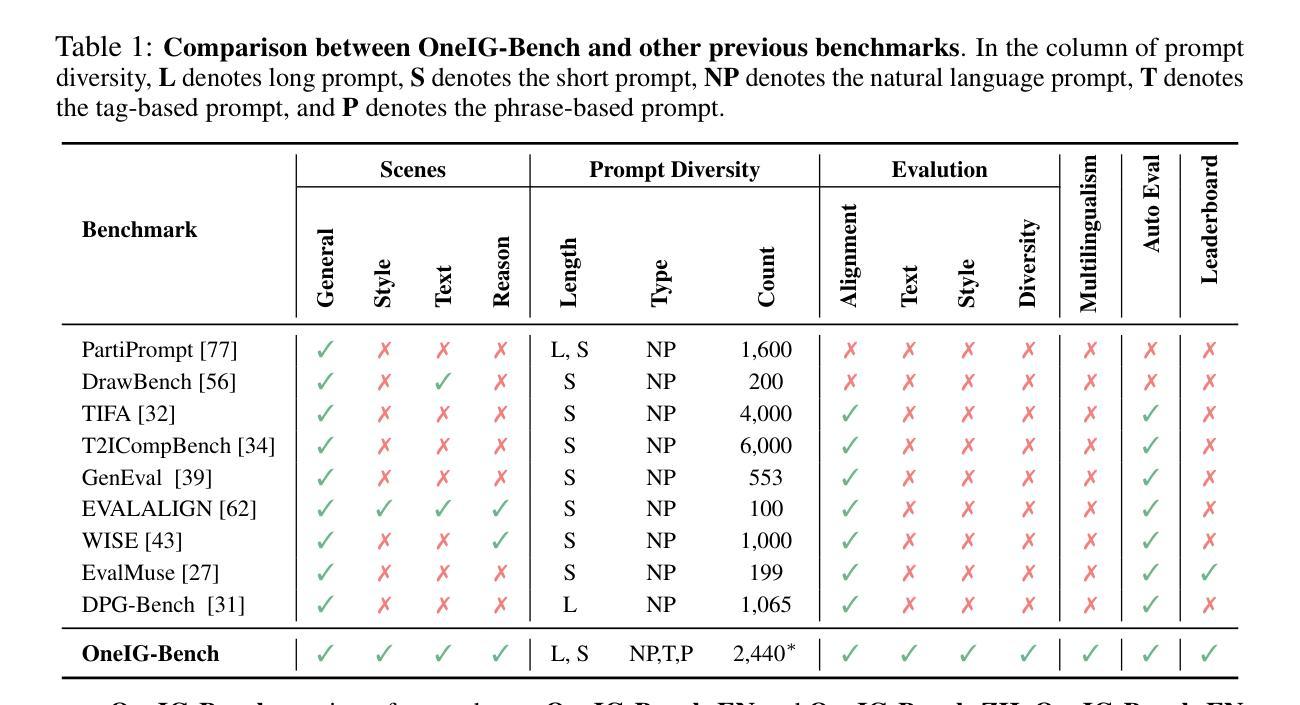
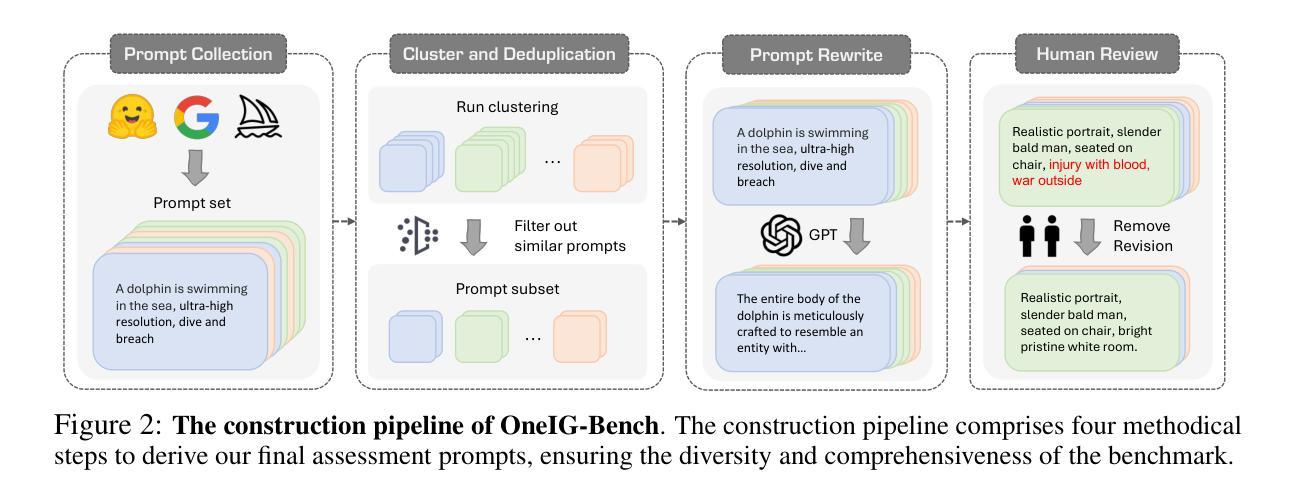
OneIG-Bench: Omni-dimensional Nuanced Evaluation for Image Generation
Authors:Jingjing Chang, Yixiao Fang, Peng Xing, Shuhan Wu, Wei Cheng, Rui Wang, Xianfang Zeng, Gang Yu, Hai-Bao Chen
Text-to-image (T2I) models have garnered significant attention for generating high-quality images aligned with text prompts. However, rapid T2I model advancements reveal limitations in early benchmarks, lacking comprehensive evaluations, for example, the evaluation on reasoning, text rendering and style. Notably, recent state-of-the-art models, with their rich knowledge modeling capabilities, show promising results on the image generation problems requiring strong reasoning ability, yet existing evaluation systems have not adequately addressed this frontier. To systematically address these gaps, we introduce OneIG-Bench, a meticulously designed comprehensive benchmark framework for fine-grained evaluation of T2I models across multiple dimensions, including prompt-image alignment, text rendering precision, reasoning-generated content, stylization, and diversity. By structuring the evaluation, this benchmark enables in-depth analysis of model performance, helping researchers and practitioners pinpoint strengths and bottlenecks in the full pipeline of image generation. Specifically, OneIG-Bench enables flexible evaluation by allowing users to focus on a particular evaluation subset. Instead of generating images for the entire set of prompts, users can generate images only for the prompts associated with the selected dimension and complete the corresponding evaluation accordingly. Our codebase and dataset are now publicly available to facilitate reproducible evaluation studies and cross-model comparisons within the T2I research community.
文本到图像(T2I)模型在生成与文本提示对齐的高质量图像方面引起了极大的关注。然而,T2I模型的快速发展显示出早期基准测试的局限性,缺乏全面评估,例如对推理、文本渲染和风格的评估。值得注意的是,最近的最先进模型凭借其丰富的知识建模能力,在需要强大推理能力的图像生成问题上显示出有希望的结果,但现有的评估系统尚未充分解决这一前沿问题。为了系统地解决这些差距,我们引入了OneIG-Bench,这是一个精心设计的综合基准框架,用于对T2I模型进行跨多个维度的精细评估,包括提示图像对齐、文本渲染精度、推理生成内容、风格化和多样性。通过结构化评估,此基准测试能够深入分析模型性能,帮助研究人员和实践者确定图像生成整个流程中的优势和瓶颈。特别是,OneIG-Bench通过允许用户关注特定的评估子集来实现灵活评估。用户不必为整个提示集生成图像,而可以只为与所选维度相关的提示生成图像,并相应地完成评估。我们的代码库和数据集现已公开可用,以促进T2I研究社区内的可重复评估研究和跨模型比较。
论文及项目相关链接
Summary
本文介绍了一个针对文本到图像(T2I)模型的综合性评估框架——OneIG-Bench。该框架旨在精细地评估T2I模型在多个维度上的性能,包括文本提示与图像对齐、文本渲染精度、基于推理的内容生成、风格化以及多样性。OneIG-Bench提供了灵活的评价方式,允许用户仅针对特定评价子集进行评估,以深入了解模型在不同方面的表现,有助于研究人员和实践者发现图像生成流程中的优势和瓶颈。OneIG-Bench的代码库和数据集现已公开,以促进T2I研究领域内的可重复性评估研究和跨模型比较。
Key Takeaways
- OneIG-Bench是一个针对文本到图像(T2I)模型的综合性评估框架。
- 该框架旨在精细地评估T2I模型在多个维度上的性能,包括提示与图像对齐、文本渲染精度等。
- OneIG-Bench提供了灵活的评价方式,允许用户仅针对特定评价子集进行评估。
- 该框架有助于深入了解模型在不同方面的表现,并发现图像生成流程中的优势和瓶颈。
- OneIG-Bench支持丰富多样的评价维度,包括基于推理的内容生成、风格化和多样性等。
- 该框架的代码库和数据集现已公开,以促进T2I研究领域内的可重复性评估研究和跨模型比较。
点此查看论文截图