⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-28 更新
A Multi-Stage Framework for Multimodal Controllable Speech Synthesis
Authors:Rui Niu, Weihao Wu, Jie Chen, Long Ma, Zhiyong Wu
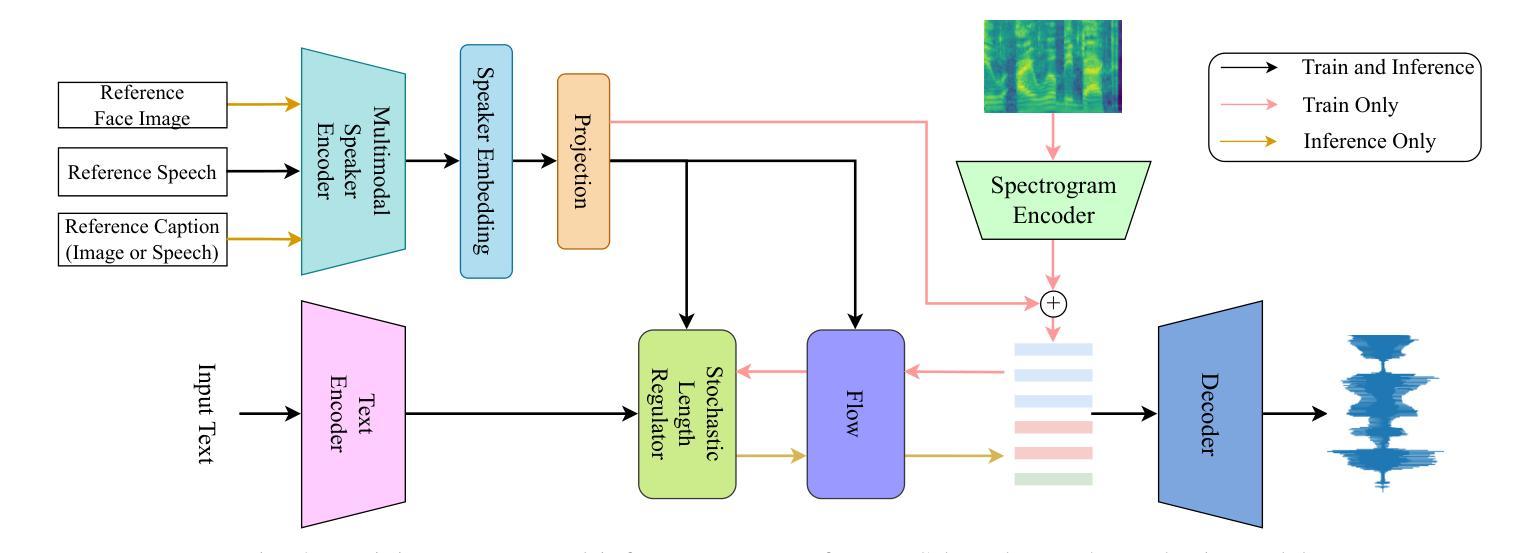
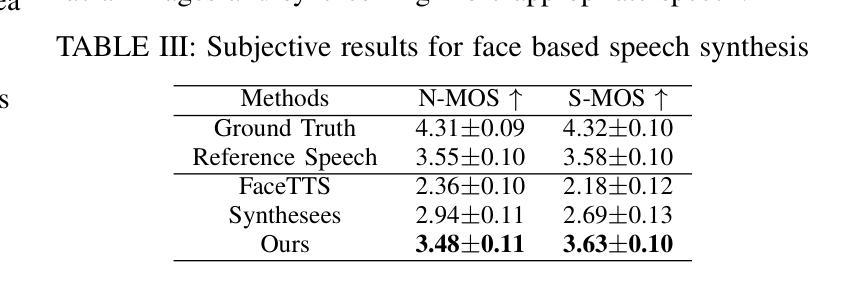
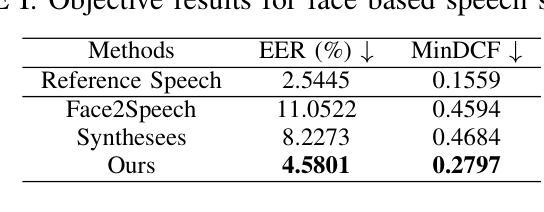
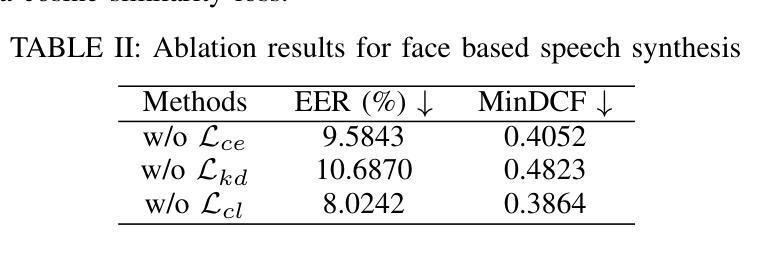
Controllable speech synthesis aims to control the style of generated speech using reference input, which can be of various modalities. Existing face-based methods struggle with robustness and generalization due to data quality constraints, while text prompt methods offer limited diversity and fine-grained control. Although multimodal approaches aim to integrate various modalities, their reliance on fully matched training data significantly constrains their performance and applicability. This paper proposes a 3-stage multimodal controllable speech synthesis framework to address these challenges. For face encoder, we use supervised learning and knowledge distillation to tackle generalization issues. Furthermore, the text encoder is trained on both text-face and text-speech data to enhance the diversity of the generated speech. Experimental results demonstrate that this method outperforms single-modal baseline methods in both face based and text prompt based speech synthesis, highlighting its effectiveness in generating high-quality speech.
可控语音合成的目标是使用各种形式的参考输入来控制生成语音的风格。现有的基于面部的方法由于数据质量约束而面临鲁棒性和泛化能力的问题,而基于文本提示的方法提供的多样性和精细控制有限。尽管多模式方法旨在整合各种模式,但它们对完全匹配的训练数据的依赖严重制约了其性能和适用性。针对这些挑战,本文提出了一个3阶段的多模式可控语音合成框架。在面部编码器中,我们采用有监督学习和知识蒸馏来解决泛化问题。此外,文本编码器在文本-面部和文本-语音数据上进行训练,以增强生成语音的多样性。实验结果表明,该方法在基于面部和基于文本提示的语音合成方面都优于单模态基线方法,突出了其在生成高质量语音方面的有效性。
论文及项目相关链接
PDF Accepted by ICME2025
总结
本文提出了一种3阶段的多模态可控语音合成框架,旨在解决现有方法面临的挑战,如面部编码器的通用性问题、文本编码器的多样性和精细控制以及多模态方法对完全匹配训练数据的依赖。通过采用监督学习和知识蒸馏技术来解决面部编码器的泛化问题,同时训练文本编码器以增强生成语音的多样性。实验结果表明,该方法在面部和文本提示的语音合成方面都优于单模态基线方法,有效生成高质量语音。
关键见解
- 现有可控语音合成方法面临挑战,包括面部编码器的鲁棒性和泛化能力问题以及文本提示方法的有限多样性和精细控制。
- 提出的3阶段多模态可控语音合成框架旨在解决这些问题。
- 使用监督学习和知识蒸馏技术改进面部编码器,提高其泛化能力。
- 文本编码器经过文本-面部和文本-语音数据的训练,增强了生成语音的多样性。
- 该方法结合多种模态数据,提高了语音合成的质量和灵活性。
- 实验结果表明,该方法在面部和文本提示的语音合成方面均优于单模态基线方法。
点此查看论文截图

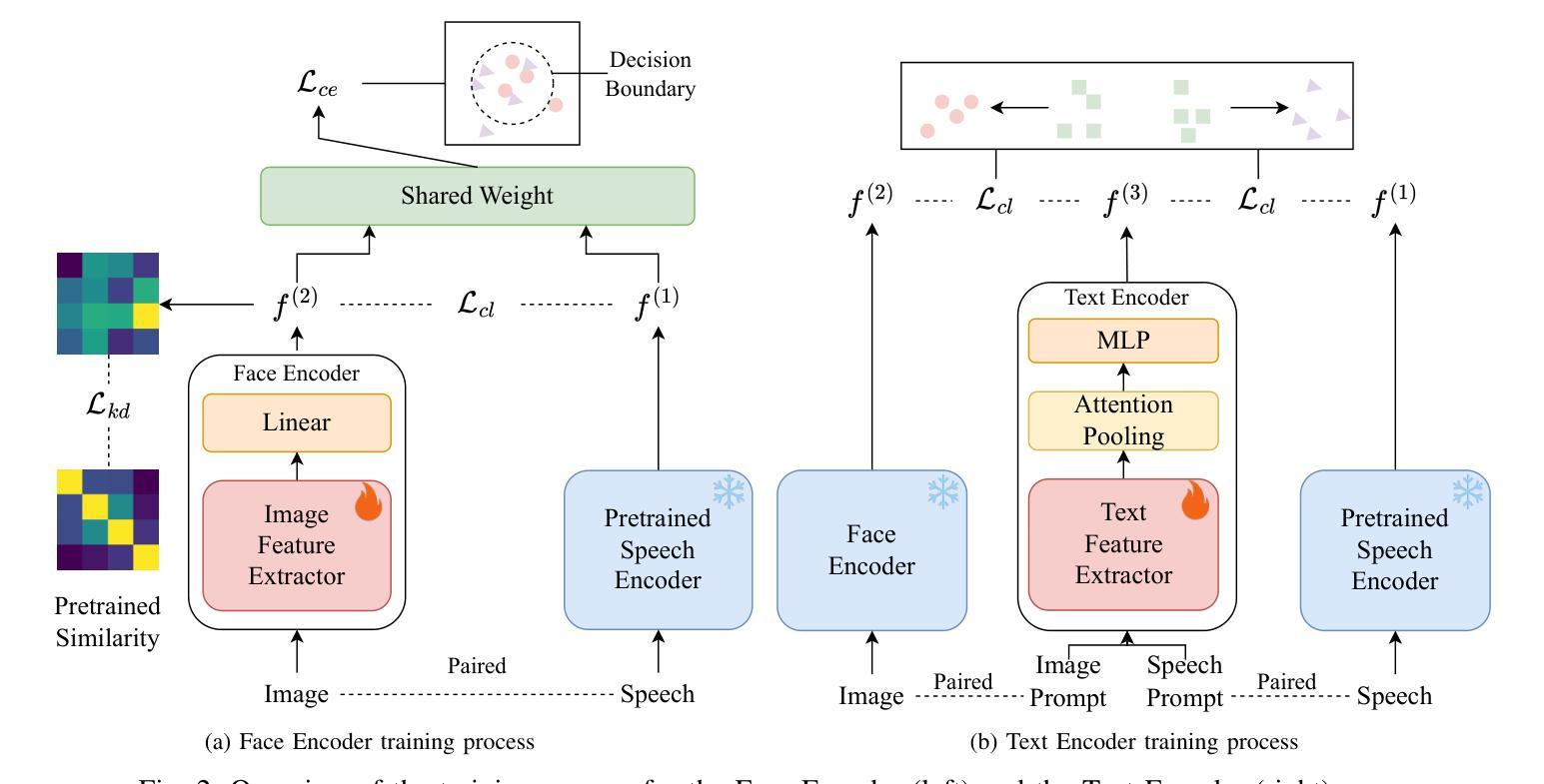
A3 : an Analytical Low-Rank Approximation Framework for Attention
Authors:Jeffrey T. H. Wong, Cheng Zhang, Xinye Cao, Pedro Gimenes, George A. Constantinides, Wayne Luk, Yiren Zhao
Large language models have demonstrated remarkable performance; however, their massive parameter counts make deployment highly expensive. Low-rank approximation offers a promising compression solution, yet existing approaches have two main limitations: (1) They focus on minimizing the output error of individual linear layers, without considering the architectural characteristics of Transformers, and (2) they decompose a large weight matrix into two small low-rank matrices. Consequently, these methods often fall short compared to other compression techniques like pruning and quantization, and introduce runtime overhead such as the extra GEMM kernel launches for decomposed small matrices. To address these limitations, we propose $\tt A^\tt 3$, a post-training low-rank approximation framework. $\tt A^\tt 3$ splits a Transformer layer into three functional components, namely $\tt QK$, $\tt OV$, and $\tt MLP$. For each component, $\tt A^\tt 3$ provides an analytical solution that reduces the hidden dimension size inside each component while minimizing the component’s functional loss ($\it i.e.$, error in attention scores, attention outputs, and MLP outputs). This approach directly reduces model sizes, KV cache sizes, and FLOPs without introducing any runtime overheads. In addition, it provides a new narrative in advancing the optimization problem from singular linear layer loss optimization toward improved end-to-end performance. Through extensive experiments, we show that $\tt A^\tt 3$ maintains superior performance compared to SoTAs. For example, under the same reduction budget in computation and memory, our low-rank approximated LLaMA 3.1-70B achieves a perplexity of 4.69 on WikiText-2, outperforming the previous SoTA’s 7.87 by 3.18. We also demonstrate the versatility of $\tt A^\tt 3$, including KV cache compression, quantization, and mixed-rank assignments for enhanced performance.
大规模语言模型已经展现出卓越的性能,但其庞大的参数数量使得部署成本高昂。低秩近似提供了一种有前景的压缩解决方案,但现有方法存在两个主要局限性:(1)它们专注于最小化单个线性层的输出误差,而没有考虑到Transformer的架构特性;(2)它们将大的权重矩阵分解为两个小的低秩矩阵。因此,与诸如修剪和量化等其他压缩技术相比,这些方法常常表现不足,并引入了运行时开销,例如分解小矩阵所需的额外GEMM内核启动。为了解决这些局限性,我们提出了$\tt A^\tt 3$,这是一种训练后的低秩近似框架。$\tt A^\tt 3$将Transformer层划分为三个功能组件,即$\tt QK$、$\tt OV$和$\tt MLP$。对于每个组件,$\tt A^\tt 3$提供了一个解析解决方案,该方案在减少每个组件内的隐藏维度大小的同时,最小化组件的功能损失(即注意分数的误差、注意输出和MLP输出)。这种方法直接减小了模型大小、KV缓存大小并减少了浮点运算次数,且没有引入任何运行时开销。此外,它从单一的线性层损失优化问题出发,朝着改进端到端性能的方向提供了新的叙事。通过广泛的实验,我们证明了$\tt A^\tt 3$在保持优于现有技术的同时,还取得了卓越的性能。例如,在相同的计算和内存减少预算下,我们的低秩估计LLaMA 3.1-7 结架构能够在WikiText-2上实现困惑度(perplexity)为4.69的成绩,超过了先前最佳技术的困惑度(perplexity)为7.87的成绩的原有记录。我们还证明了$\tt A^\tt 3$的通用性,包括KV缓存压缩、量化和混合排名分配以增强性能。
论文及项目相关链接
Summary
大型语言模型表现出色,但部署成本高昂。低秩近似是一种有前途的压缩解决方案,但现有方法存在两个主要局限性。为解决这些问题,我们提出了$\tt A^\tt 3$,一种用于训练后的低秩近似框架。它通过拆分Transformer层并减少隐藏维度大小来直接减小模型大小、KV缓存大小和浮点运算量,同时不引入任何运行时开销。实验表明,与最新技术相比,$\tt A^\tt 3$在维持优越性能的同时实现了计算与内存的显著减少。
Key Takeaways
- 大型语言模型虽然表现出色,但部署成本高昂,需要寻求有效的压缩解决方案。
- 现有低秩近似方法存在两个主要局限性:忽略Transformer架构特性和分解大型权重矩阵的方法引入运行时开销。
- $\tt A^\tt 3$框架通过拆分Transformer层并减少隐藏维度大小来直接减小模型大小、KV缓存大小和浮点运算量。
- $\tt A^\tt 3$方法不引入任何运行时开销,同时通过优化叙事层损失来提高端到端性能。
- 实验表明,$\tt A^\tt 3$在维持模型性能的同时实现了计算与内存的显著减少。
- $\tt A^\tt 3$具有通用性,可用于KV缓存压缩、量化和混合排名分配以增强性能。
点此查看论文截图