⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-28 更新
GGTalker: Talking Head Systhesis with Generalizable Gaussian Priors and Identity-Specific Adaptation
Authors:Wentao Hu, Shunkai Li, Ziqiao Peng, Haoxian Zhang, Fan Shi, Xiaoqiang Liu, Pengfei Wan, Di Zhang, Hui Tian
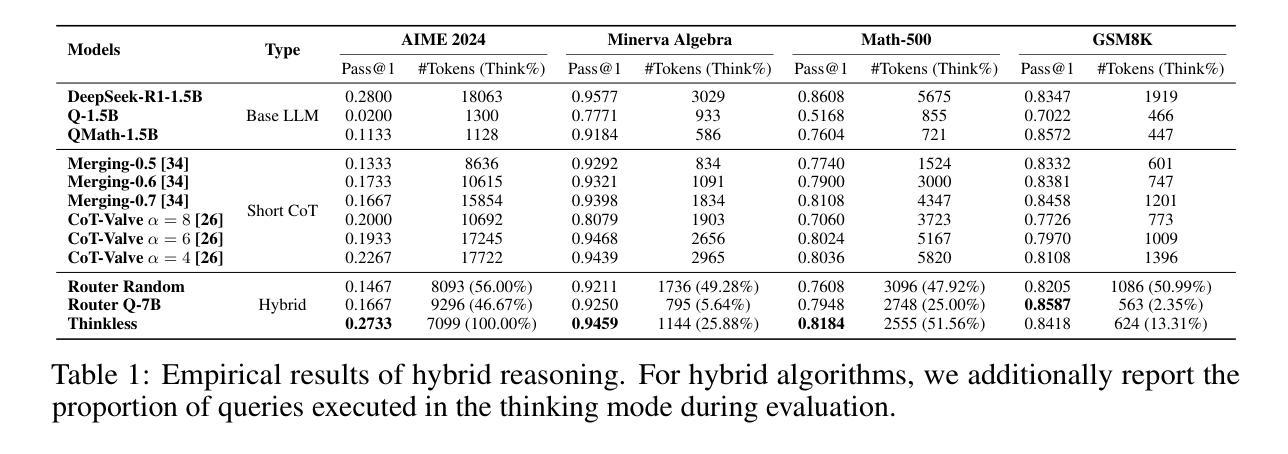
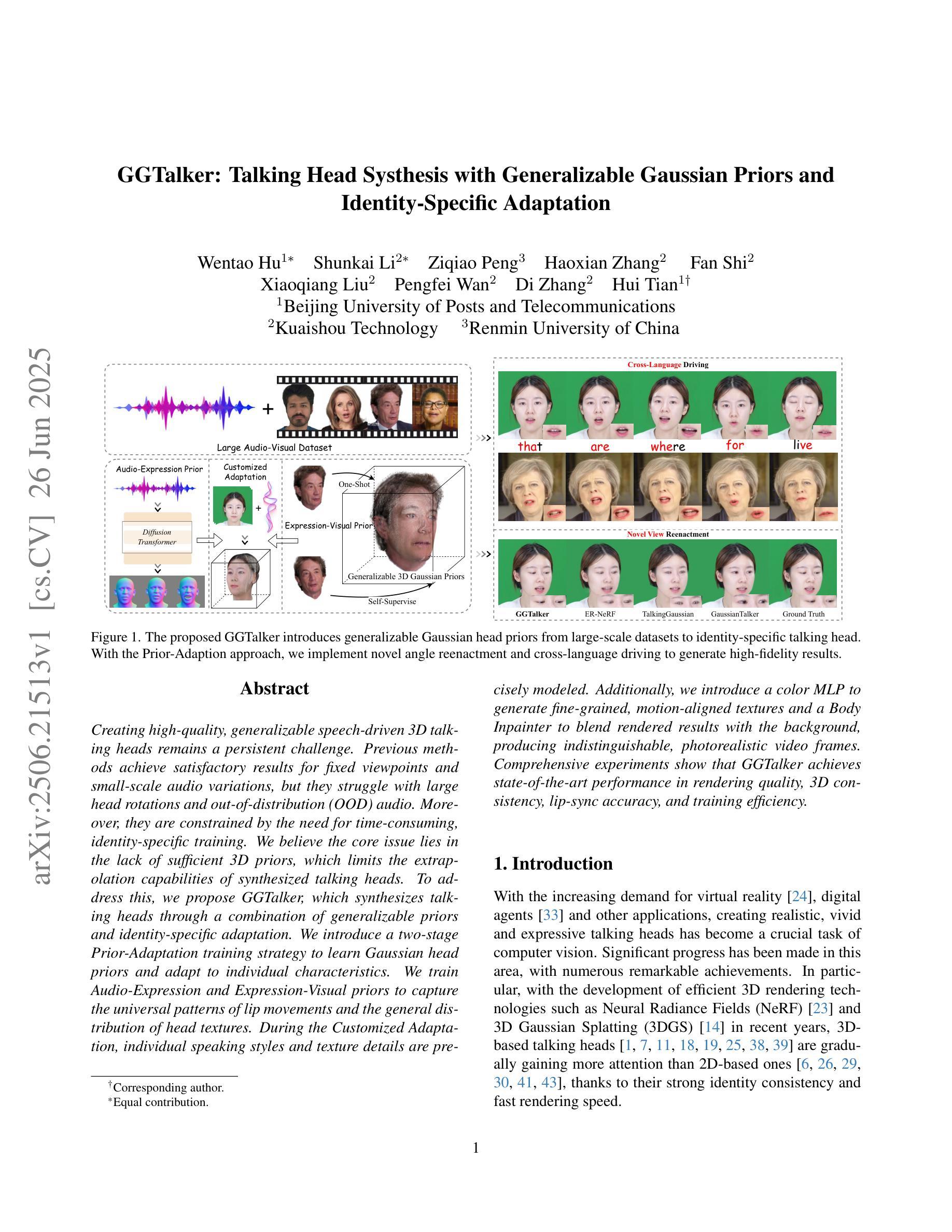
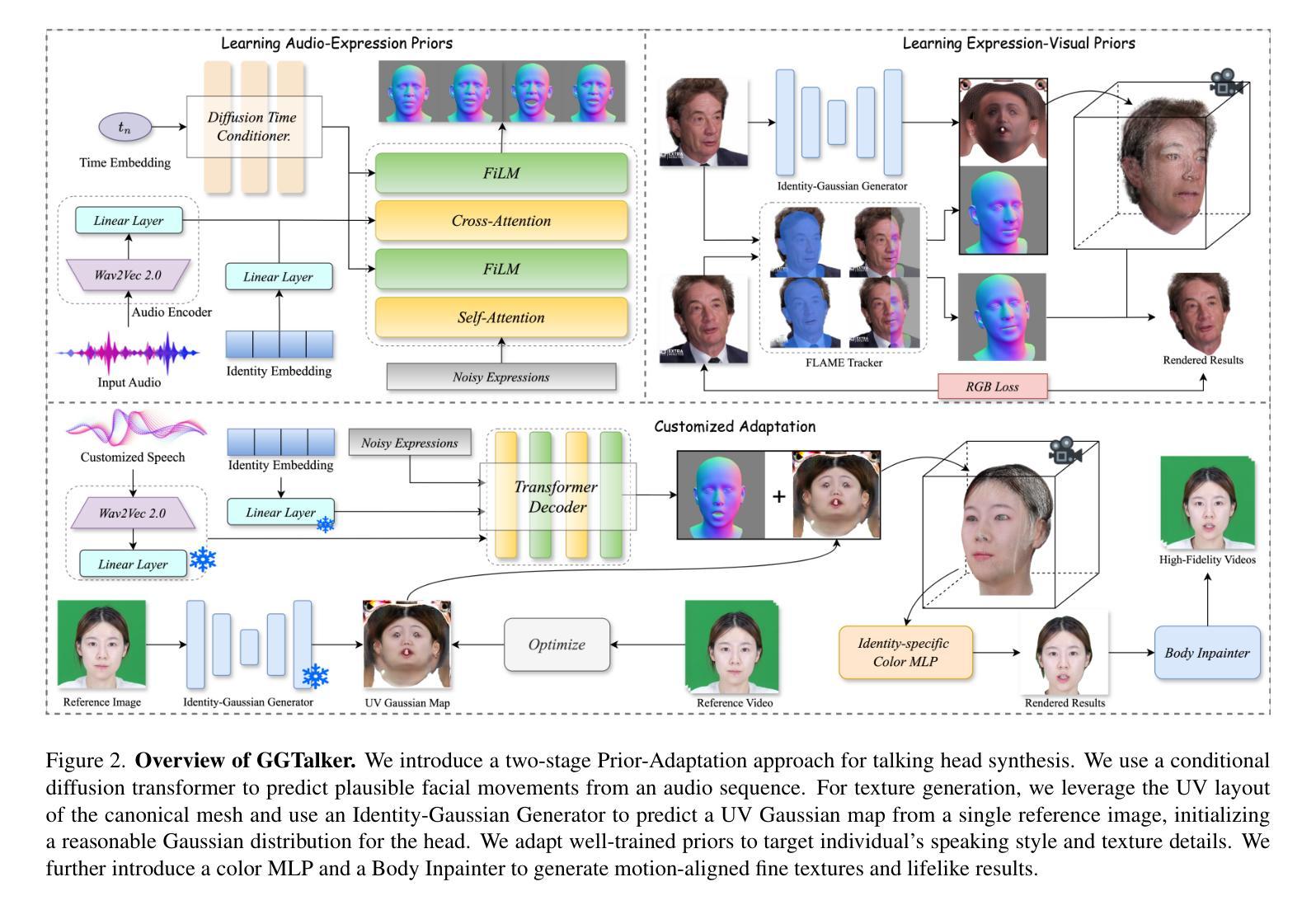
Creating high-quality, generalizable speech-driven 3D talking heads remains a persistent challenge. Previous methods achieve satisfactory results for fixed viewpoints and small-scale audio variations, but they struggle with large head rotations and out-of-distribution (OOD) audio. Moreover, they are constrained by the need for time-consuming, identity-specific training. We believe the core issue lies in the lack of sufficient 3D priors, which limits the extrapolation capabilities of synthesized talking heads. To address this, we propose GGTalker, which synthesizes talking heads through a combination of generalizable priors and identity-specific adaptation. We introduce a two-stage Prior-Adaptation training strategy to learn Gaussian head priors and adapt to individual characteristics. We train Audio-Expression and Expression-Visual priors to capture the universal patterns of lip movements and the general distribution of head textures. During the Customized Adaptation, individual speaking styles and texture details are precisely modeled. Additionally, we introduce a color MLP to generate fine-grained, motion-aligned textures and a Body Inpainter to blend rendered results with the background, producing indistinguishable, photorealistic video frames. Comprehensive experiments show that GGTalker achieves state-of-the-art performance in rendering quality, 3D consistency, lip-sync accuracy, and training efficiency.
创建高质量、可推广的语音驱动3D谈话头仍然是一个持续存在的挑战。之前的方法在固定视角和小规模音频变化方面取得了令人满意的结果,但在大头部旋转和离散分布(OOD)音频方面遇到了困难。此外,它们还受到需要耗时且特定身份训练的限制。我们认为核心问题在于缺乏足够的3D先验知识,这限制了合成谈话头的推算能力。为了解决这一问题,我们提出了GGTalker,它通过通用先验知识和特定身份适应相结合来合成谈话头。我们引入了两阶段Prior-Adaptation训练策略来学习高斯头部先验知识并适应个人特征。我们训练了音频表达和情感表达视觉先验来捕捉嘴唇运动的通用模式和头部纹理的一般分布。在个性化适应过程中,个人的讲话风格和纹理细节得到了精确建模。此外,我们还引入了一个颜色MLP来生成精细粒度的、与运动对齐的纹理和一个Body Inpainter来将渲染结果与背景融合,生成无法区分的、逼真的视频帧。综合实验表明,GGTalker在渲染质量、3D一致性、唇同步精度和训练效率方面达到了最先进水平。
论文及项目相关链接
PDF ICCV 2025, Project page: https://vincenthu19.github.io/GGTalker/
摘要
高保真、通用化的语音驱动3D说话头制作是一大挑战。现有方法在处理固定视角和小规模音频变化时表现良好,但在大头部旋转和离散分布音频下表现不佳,且需要耗时的个性化训练。核心问题在于缺乏足够的3D先验知识,限制了合成说话头的推断能力。为解决这一问题,我们提出GGTalker,通过通用先验知识和个性化适应合成说话头。我们引入了两阶段先验适应训练策略,学习高斯头部先验知识并适应个人特征。我们训练了音频表达与视觉表达先验知识,捕捉唇动普遍模式与头部纹理的一般分布。在个性化适应阶段,精准建模个人讲话风格与纹理细节。此外,我们引入了色彩MLP生成精细、动作对齐的纹理,以及Body Inpainter将渲染结果与背景融合,生成难以区分的、逼真的视频帧。综合实验表明,GGTalker在渲染质量、3D一致性、唇形同步精度和训练效率方面达到领先水平。
关键见解
- 现有方法在创建高质量、通用化的语音驱动3D说话头时面临挑战,尤其在处理大头部旋转和离群分布音频时。
- 核心问题在于缺乏足够的3D先验知识,限制了合成说话头的推断能力。
- GGTalker通过结合通用先验知识和个性化适应来解决这一问题。
- 引入两阶段先验适应训练策略,学习高斯头部先验知识,并适应个人特征。
- 训练了音频表达与视觉表达先验知识,以捕捉唇动的普遍模式和头部纹理的一般分布。
- 在个性化适应阶段,精准建模个人讲话风格和纹理细节。
- 引入色彩MLP和Body Inpainter技术,生成精细、逼真的视频帧,与背景融合无缝。
点此查看论文截图


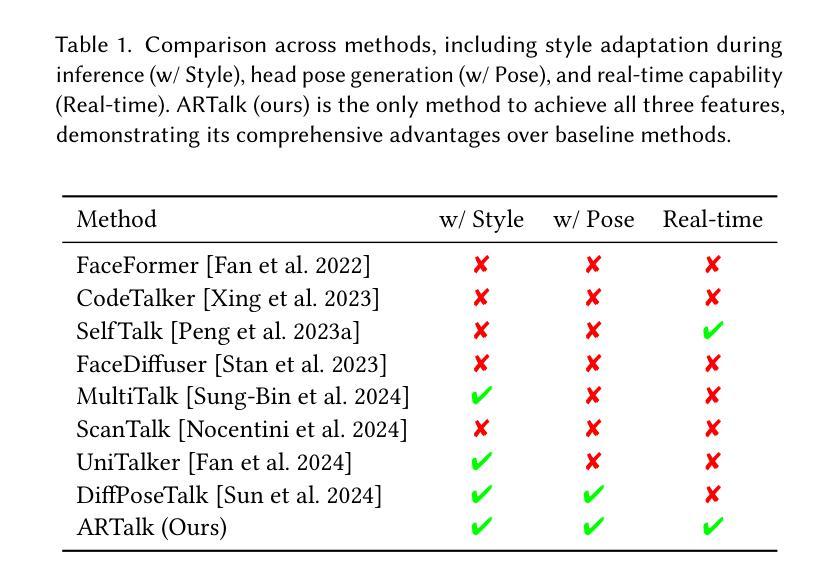
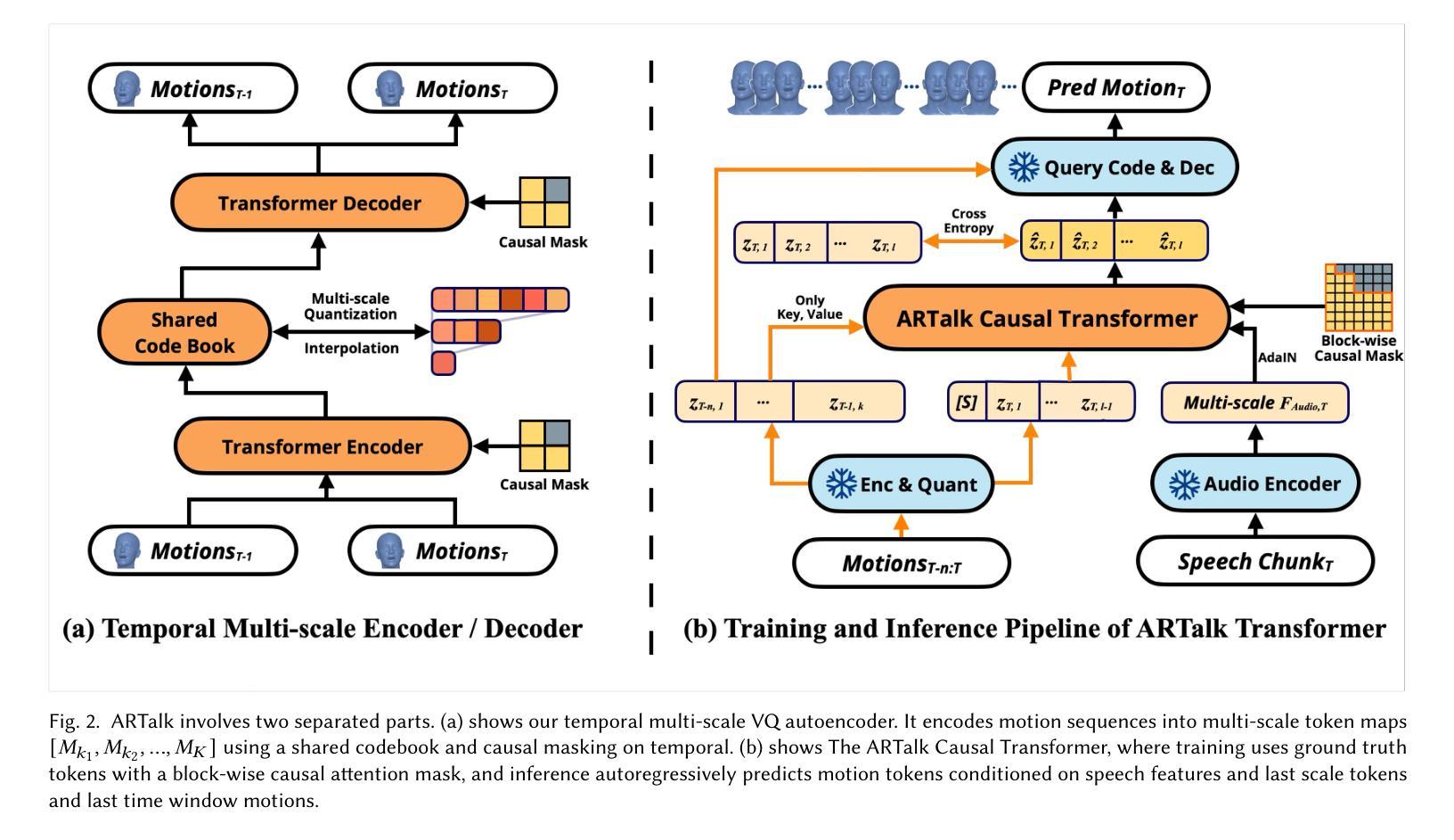
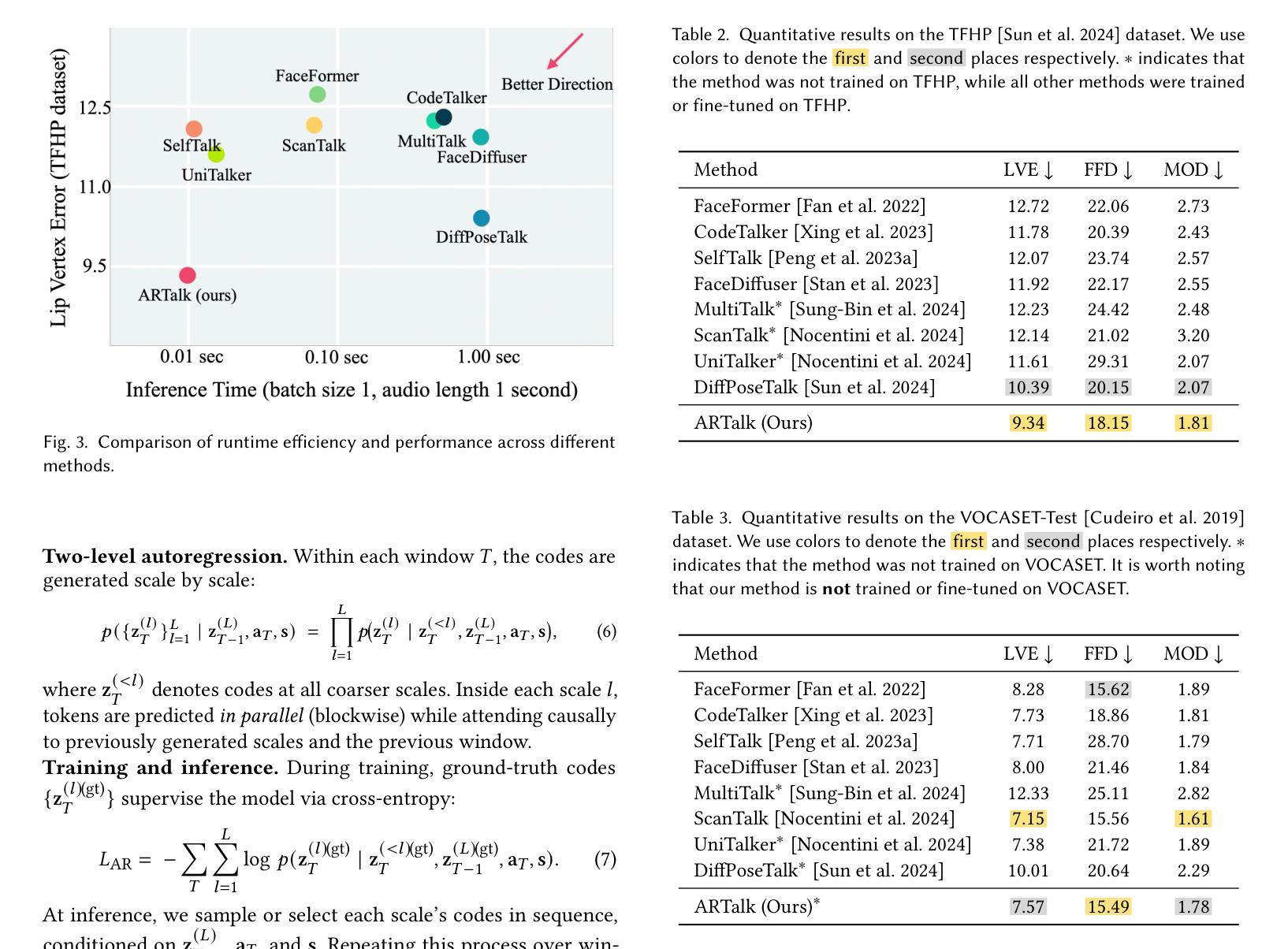
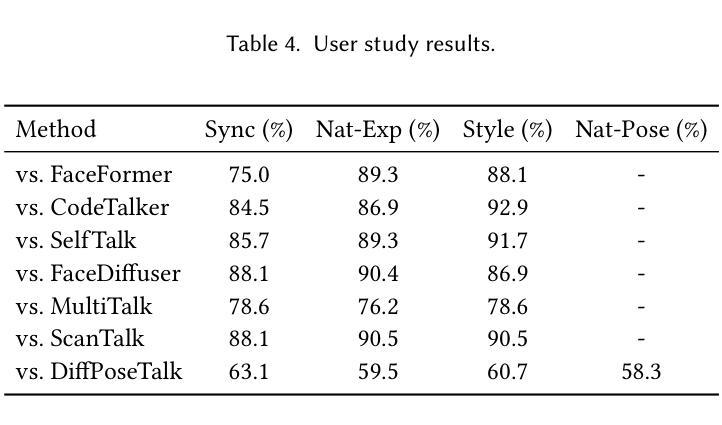
ARTalk: Speech-Driven 3D Head Animation via Autoregressive Model
Authors:Xuangeng Chu, Nabarun Goswami, Ziteng Cui, Hanqin Wang, Tatsuya Harada
Speech-driven 3D facial animation aims to generate realistic lip movements and facial expressions for 3D head models from arbitrary audio clips. Although existing diffusion-based methods are capable of producing natural motions, their slow generation speed limits their application potential. In this paper, we introduce a novel autoregressive model that achieves real-time generation of highly synchronized lip movements and realistic head poses and eye blinks by learning a mapping from speech to a multi-scale motion codebook. Furthermore, our model can adapt to unseen speaking styles, enabling the creation of 3D talking avatars with unique personal styles beyond the identities seen during training. Extensive evaluations and user studies demonstrate that our method outperforms existing approaches in lip synchronization accuracy and perceived quality.
语音驱动的3D面部动画旨在从任意音频片段中为3D头部模型生成逼真的嘴唇动作和面部表情。尽管现有的基于扩散的方法能够产生自然运动,但其较慢的生成速度限制了其应用潜力。在本文中,我们引入了一种新型自回归模型,通过学习与多尺度运动字典之间的映射关系,实现高度同步的嘴唇运动、逼真的头部姿态和眨眼动作的实时生成。此外,我们的模型能够适应未见过的说话风格,从而能够创建具有独特个人风格的3D对话头像,超越训练期间所见的身份。广泛的评估和用户研究表明,我们的方法在嘴唇同步准确性和感知质量方面优于现有方法。
论文及项目相关链接
PDF More video demonstrations, code, models and data can be found on our project website: http://xg-chu.site/project_artalk/
Summary
本文介绍了一种新型的基于语音驱动的3D面部动画技术。该技术通过引入一种自回归模型,实现了从任意音频剪辑生成高度同步的唇部动作和逼真的头部姿态以及眨眼动作。该模型学习从语音到多尺度运动代码库的映射,并能适应未见过的说话风格,从而创建具有独特个人风格的3D对话头像。评估和用户研究表明,该方法在唇同步准确性和感知质量方面优于现有方法。
Key Takeaways
- 引入了自回归模型用于语音驱动的3D面部动画。
- 实现高度同步的唇部动作和逼真的头部姿态及眨眼动作生成。
- 模型能从语音映射到多尺度运动代码库。
- 模型能够适应未见过的说话风格。
- 创建具有独特个人风格的3D对话头像。
- 该方法在唇同步准确性和感知质量方面优于现有方法。
点此查看论文截图