⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-28 更新
Boosting Generative Adversarial Transferability with Self-supervised Vision Transformer Features
Authors:Shangbo Wu, Yu-an Tan, Ruinan Ma, Wencong Ma, Dehua Zhu, Yuanzhang Li
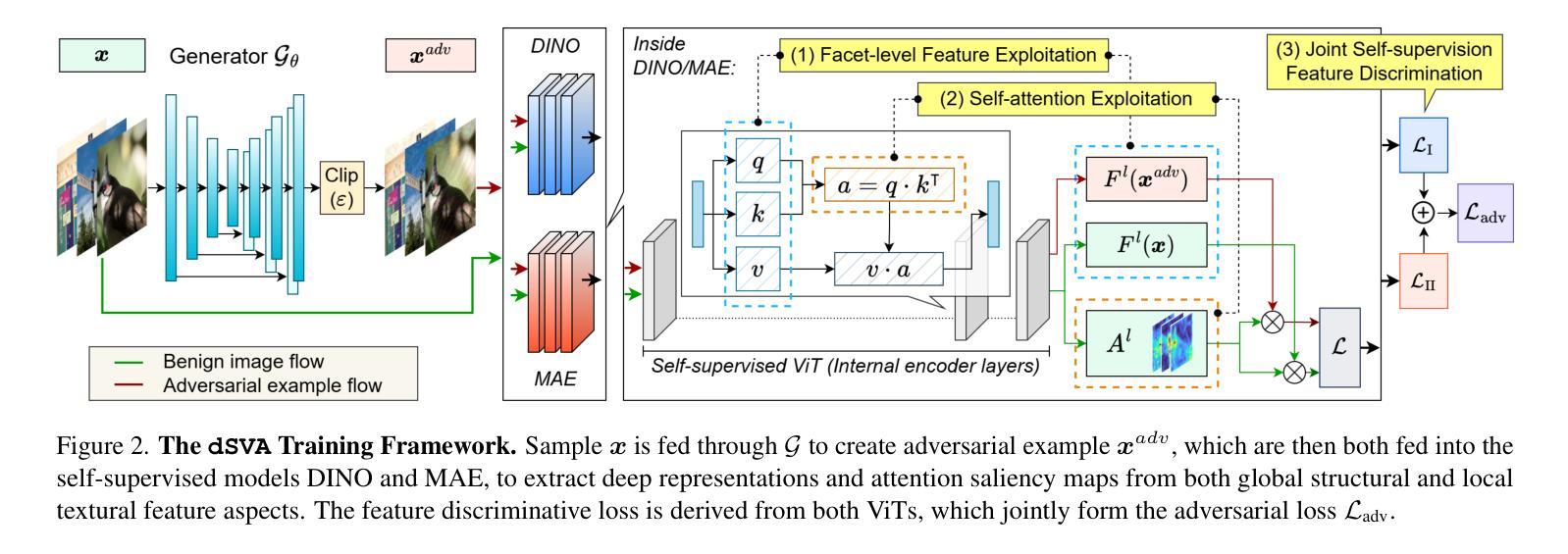
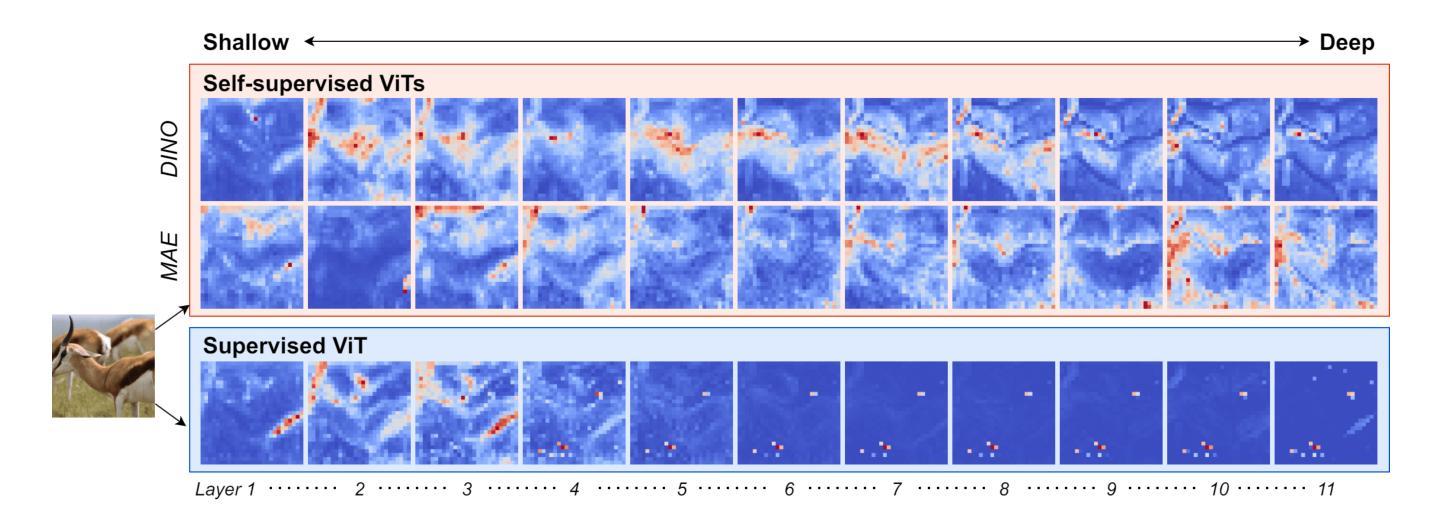
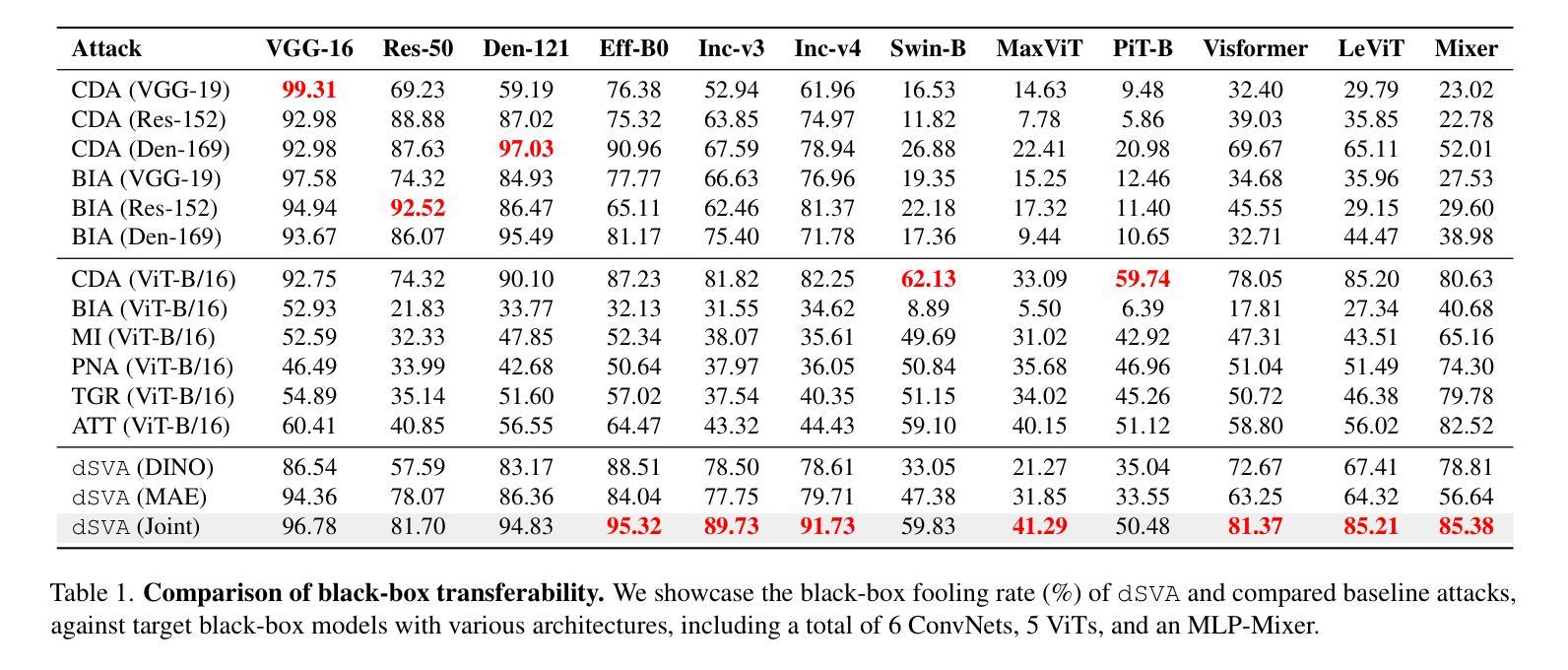
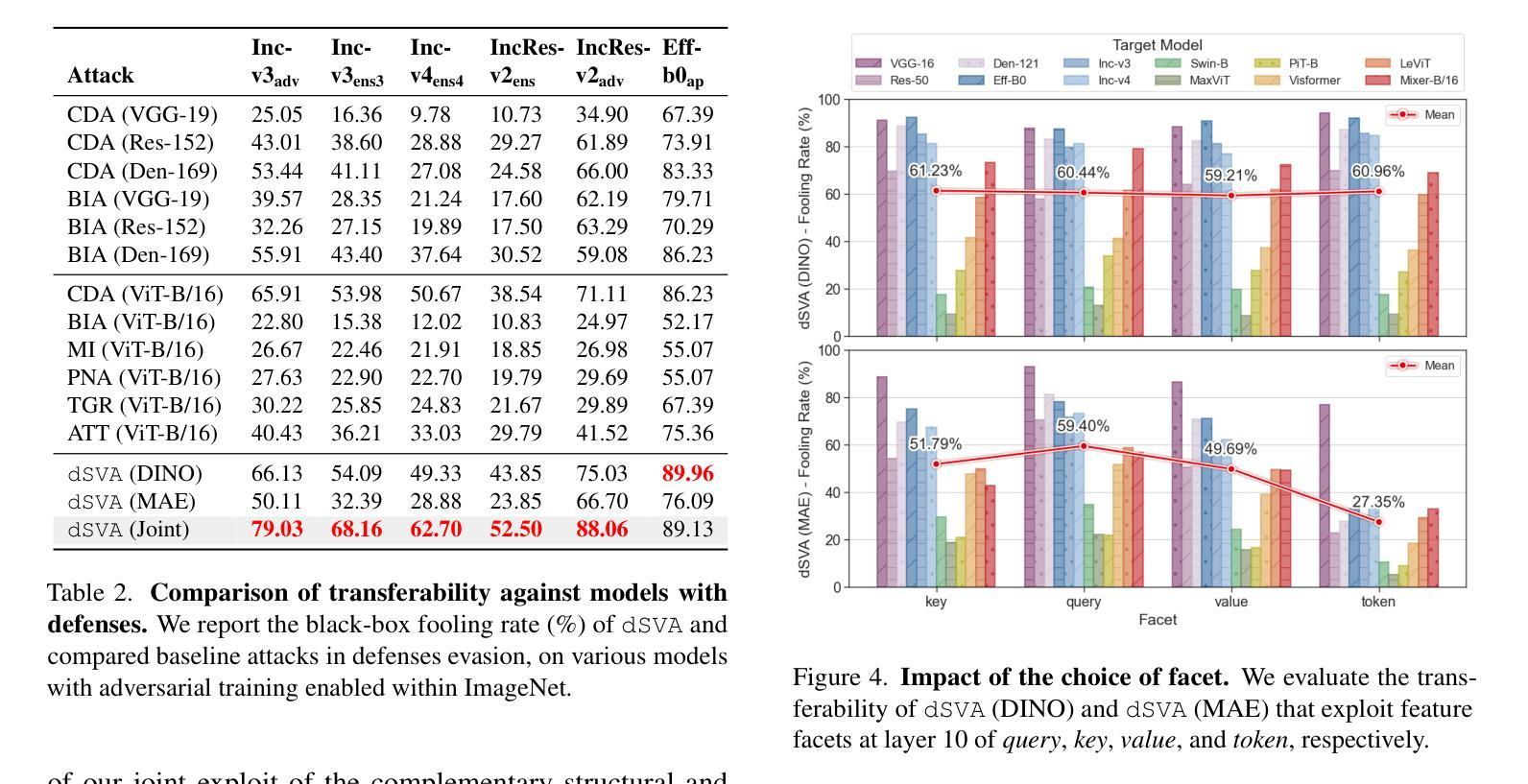
The ability of deep neural networks (DNNs) come from extracting and interpreting features from the data provided. By exploiting intermediate features in DNNs instead of relying on hard labels, we craft adversarial perturbation that generalize more effectively, boosting black-box transferability. These features ubiquitously come from supervised learning in previous work. Inspired by the exceptional synergy between self-supervised learning and the Transformer architecture, this paper explores whether exploiting self-supervised Vision Transformer (ViT) representations can improve adversarial transferability. We present dSVA – a generative dual self-supervised ViT features attack, that exploits both global structural features from contrastive learning (CL) and local textural features from masked image modeling (MIM), the self-supervised learning paradigm duo for ViTs. We design a novel generative training framework that incorporates a generator to create black-box adversarial examples, and strategies to train the generator by exploiting joint features and the attention mechanism of self-supervised ViTs. Our findings show that CL and MIM enable ViTs to attend to distinct feature tendencies, which, when exploited in tandem, boast great adversarial generalizability. By disrupting dual deep features distilled by self-supervised ViTs, we are rewarded with remarkable black-box transferability to models of various architectures that outperform state-of-the-arts. Code available at https://github.com/spencerwooo/dSVA.
深度神经网络(DNNs)的能力来自于提取和解释所提供数据的特征。我们不是依赖硬标签,而是利用DNN中的中间特征,制造了更具通用性的对抗扰动,从而增强了黑盒迁移性。这些特征以前的工作大多来自监督学习。受自监督学习与Transformer架构之间出色协同的启发,本文探讨了利用自监督Vision Transformer(ViT)表示是否可以提高对抗迁移性。我们提出了dSVA——一种生成式双自监督ViT特征攻击方法,它结合了对比学习(CL)的全局结构特征和掩码图像建模(MIM)的局部纹理特征,这是ViT的自监督学习范式组合。我们设计了一个新颖的生成式训练框架,该框架包含一个生成器来创建黑盒对抗样本,以及通过利用自监督ViT的联合特征和注意力机制来训练生成器的策略。我们的研究发现,CL和MIM使ViT能够关注不同的特征倾向,当同时利用它们时,对抗的通用性大大提高。通过破坏由自监督ViT提炼的双重深度特征,我们在各种架构的模型上获得了显著的黑盒迁移性,超越了最新技术。相关代码可访问:https://github.com/spencerwooo/dSVA。
论文及项目相关链接
PDF 14 pages, 9 figures, to appear in ICCV 2025
Summary
深度神经网络(DNNs)通过提取和解释数据特征实现其功能。本研究通过利用DNNs的中间特征而非依赖硬标签,设计出更具通用性的对抗扰动,提高了黑箱迁移能力。本研究受自监督学习与Transformer架构之间卓越协同的启发,探索利用自监督Vision Transformer(ViT)表示是否可以提高对抗迁移能力。本研究提出dSVA——一种生成式双自监督ViT特征攻击方法,利用对比学习(CL)的全局结构特征和掩模图像建模(MIM)的局部纹理特征这两者的组合,这是ViT的自监督学习范式。设计了一种新颖的生成式训练框架,通过生成器创建黑箱对抗样本,并制定了通过利用自监督ViT的联合特征和注意力机制来训练生成器的策略。研究发现,CL和MIM使ViT能够关注不同的特征倾向,当两者结合使用时,可大大提高对抗性的通用性。通过扰乱由自监督ViT提炼的双重深度特征,实现对各种架构模型的显著黑箱迁移能力,超越了现有技术。
Key Takeaways
- 利用深度神经网络(DNNs)的中间特征设计对抗扰动,提高黑箱迁移能力。
- 受自监督学习与Transformer架构之间协同的启发,研究如何利用自监督Vision Transformer(ViT)表示提高对抗迁移性能。
- 提出dSVA攻击方法,结合对比学习(CL)的全局结构特征和掩模图像建模(MIM)的局部纹理特征。
- 设计新颖的生成式训练框架,通过生成器创建黑箱对抗样本。
- CL和MIM使ViT能够关注不同的特征倾向,结合使用可大大提高对抗性的通用性。
- 通过扰乱由自监督ViT提炼的双重深度特征,实现对各种架构模型的显著黑箱迁移能力。
点此查看论文截图

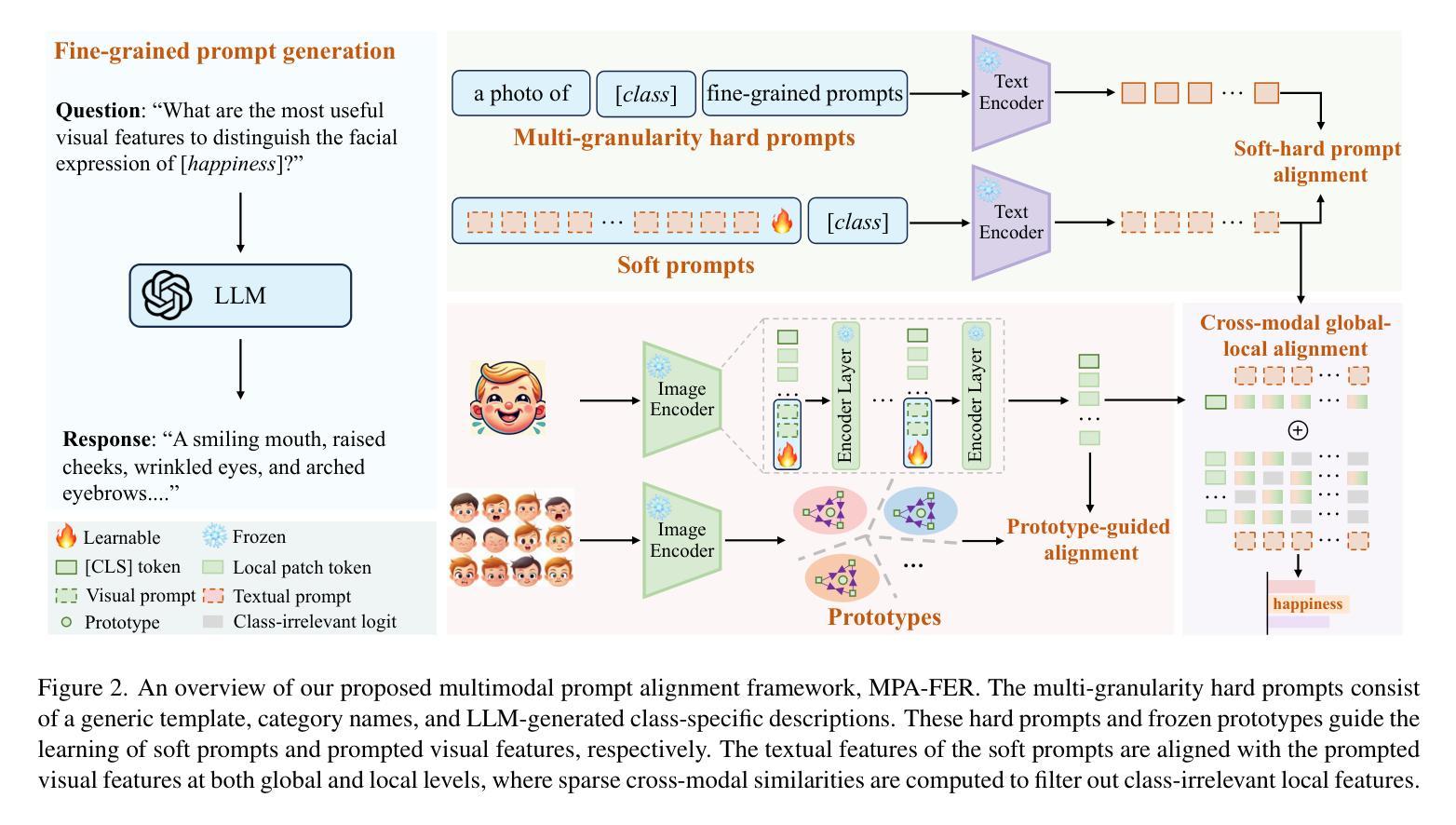
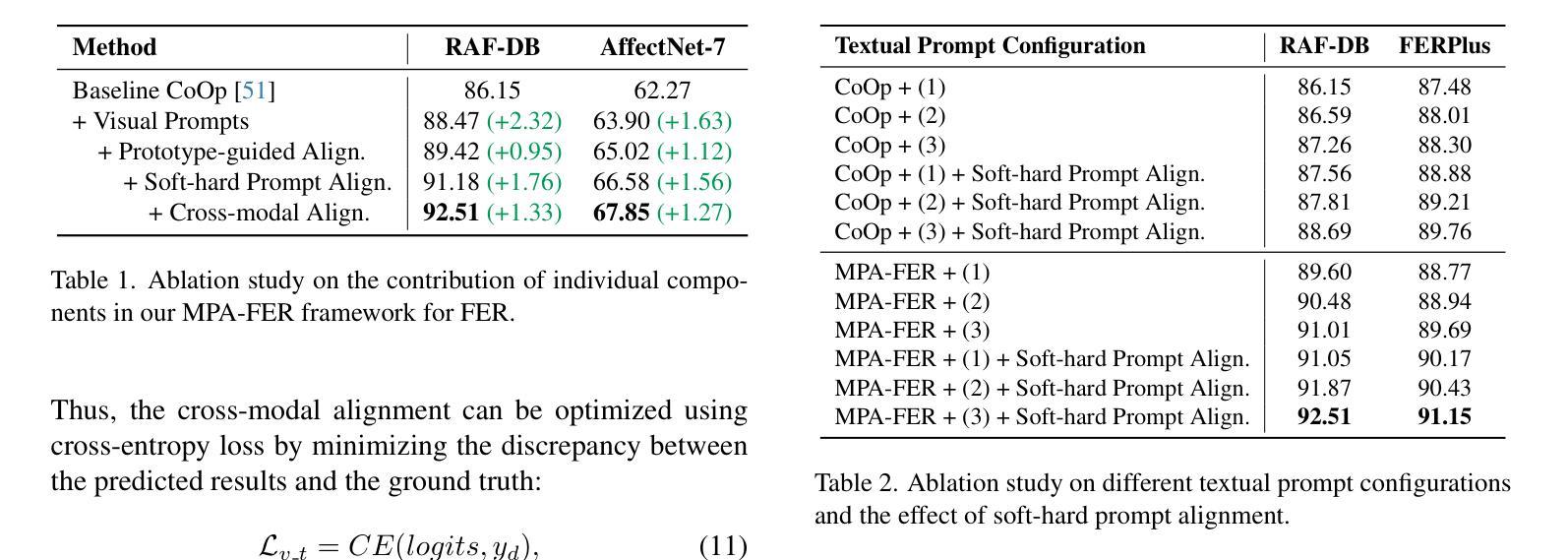
Multimodal Prompt Alignment for Facial Expression Recognition
Authors:Fuyan Ma, Yiran He, Bin Sun, Shutao Li
Prompt learning has been widely adopted to efficiently adapt vision-language models (VLMs) like CLIP for various downstream tasks. Despite their success, current VLM-based facial expression recognition (FER) methods struggle to capture fine-grained textual-visual relationships, which are essential for distinguishing subtle differences between facial expressions. To address this challenge, we propose a multimodal prompt alignment framework for FER, called MPA-FER, that provides fine-grained semantic guidance to the learning process of prompted visual features, resulting in more precise and interpretable representations. Specifically, we introduce a multi-granularity hard prompt generation strategy that utilizes a large language model (LLM) like ChatGPT to generate detailed descriptions for each facial expression. The LLM-based external knowledge is injected into the soft prompts by minimizing the feature discrepancy between the soft prompts and the hard prompts. To preserve the generalization abilities of the pretrained CLIP model, our approach incorporates prototype-guided visual feature alignment, ensuring that the prompted visual features from the frozen image encoder align closely with class-specific prototypes. Additionally, we propose a cross-modal global-local alignment module that focuses on expression-relevant facial features, further improving the alignment between textual and visual features. Extensive experiments demonstrate our framework outperforms state-of-the-art methods on three FER benchmark datasets, while retaining the benefits of the pretrained model and minimizing computational costs.
摘要学习已被广泛应用于有效地适应诸如CLIP的视觉语言模型(VLMs)以执行各种下游任务。尽管取得了成功,但现有的基于VLM的面部表情识别(FER)方法难以捕捉细微的文本视觉关系,这对于区分面部表情之间的微妙差异至关重要。为了应对这一挑战,我们提出了一种用于面部表情识别的多模态提示对齐框架,称为MPA-FER。该框架为提示视觉特征的学习过程提供了精细的语义指导,从而产生更精确和可解释的特征表示。具体来说,我们引入了一种多粒度硬提示生成策略,利用类似ChatGPT的大型语言模型为每种面部表情生成详细描述。通过最小化软提示和硬提示之间的特征差异,将基于LLM的外部知识注入软提示中。为了保持预训练CLIP模型的泛化能力,我们的方法采用原型引导视觉特征对齐,确保来自冻结图像编码器的提示视觉特征与特定类别的原型紧密对齐。此外,我们提出了一个跨模态全局局部对齐模块,专注于与表情相关的面部特征,进一步改善了文本和视觉特征之间的对齐。大量实验表明,我们的框架在三个面部表情识别基准数据集上优于最先进的方法,同时保留了预训练模型的优势并降低了计算成本。
论文及项目相关链接
PDF To appear in ICCV2025
Summary
本文提出了一个用于面部表情识别(FER)的多模态提示对齐框架MPA-FER。它采用细粒度语义指导来优化视觉特征学习过程,并通过多粒度硬提示生成策略引入大型语言模型(LLM),以增强模型的精确度与可解释性。采用最小化软硬提示特征差异的方式将外部知识注入软提示中,同时结合原型引导视觉特征对齐技术,确保冻结图像编码器的视觉特征与类特定原型紧密对齐。此外,还提出了跨模态全局局部对齐模块,专注于表情相关的面部特征,进一步提高文本与视觉特征的对齐程度。实验证明,该框架在三个FER基准数据集上优于最新方法,同时保留预训练模型的优点并降低计算成本。
Key Takeaways
- MPA-FER框架采用多模态提示对齐技术,旨在解决当前面部表情识别(FER)方法在捕捉文本与视觉之间精细粒度关系方面的挑战。
- 提出多粒度硬提示生成策略,利用大型语言模型(LLM)如ChatGPT为每种面部表情生成详细描述,增强模型精确度与可解释性。
- 通过最小化软硬提示特征差异,将LLM的外部知识注入软提示中。
- 采用原型引导视觉特征对齐技术,确保冻结图像编码器的视觉特征与类特定原型对齐,保持预训练模型的泛化能力。
- 提出跨模态全局局部对齐模块,专注于表情相关的面部特征,提高文本与视觉特征的对齐效果。
- 实验证明,MPA-FER框架在三个FER基准数据集上的性能优于现有最佳方法。
点此查看论文截图