⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-29 更新
VideoMathQA: Benchmarking Mathematical Reasoning via Multimodal Understanding in Videos
Authors:Hanoona Rasheed, Abdelrahman Shaker, Anqi Tang, Muhammad Maaz, Ming-Hsuan Yang, Salman Khan, Fahad Shahbaz Khan
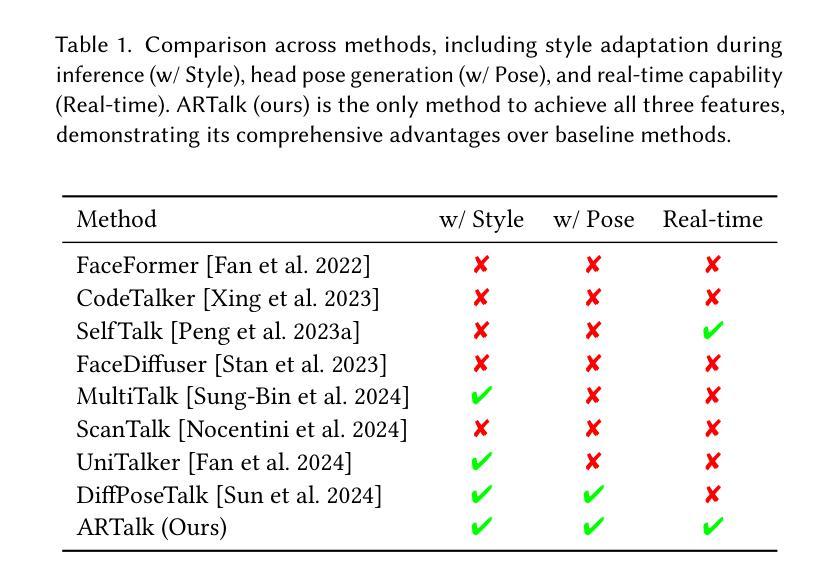
Mathematical reasoning in real-world video settings presents a fundamentally different challenge than in static images or text. It requires interpreting fine-grained visual information, accurately reading handwritten or digital text, and integrating spoken cues, often dispersed non-linearly over time. In such multimodal contexts, success hinges not just on perception, but on selectively identifying and integrating the right contextual details from a rich and noisy stream of content. To this end, we introduce VideoMathQA, a benchmark designed to evaluate whether models can perform such temporally extended cross-modal reasoning on videos. The benchmark spans 10 diverse mathematical domains, covering videos ranging from 10 seconds to over 1 hour. It requires models to interpret structured visual content, understand instructional narratives, and jointly ground concepts across visual, audio, and textual modalities. We employ graduate-level experts to ensure high quality, totaling over $920$ man-hours of annotation. To reflect real-world scenarios, questions are designed around three core reasoning challenges: direct problem solving, where answers are grounded in the presented question; conceptual transfer, which requires applying learned methods to new problems; and deep instructional comprehension, involving multi-step reasoning over extended explanations and partially worked-out solutions. Each question includes multi-step reasoning annotations, enabling fine-grained diagnosis of model capabilities. Through this benchmark, we highlight the limitations of existing approaches and establish a systematic evaluation framework for models that must reason, rather than merely perceive, across temporally extended and modality-rich mathematical problem settings. Our benchmark and evaluation code are available at: https://mbzuai-oryx.github.io/VideoMathQA
现实世界视频环境中的数学推理与静态图像或文本中的推理存在根本性的挑战差异。它要求解读精细的视觉信息,准确阅读手写或数字文本,并整合口头线索,这些线索往往随时间非线性分布。在这样的多模式背景下,成功不仅取决于感知能力,还取决于从丰富而嘈杂的内容中选择性地识别和整合正确的上下文细节。为此,我们推出了VideoMathQA基准测试,旨在评估模型在视频上执行这种时间扩展的跨模式推理的能力。该基准测试涵盖了10个不同的数学领域,包含从10秒到超过1小时的视频。它要求模型解释结构化的视觉内容,理解指令性叙述,并在视觉、音频和文本模式之间共同建立概念。我们聘请了研究生水平的专家来确保高质量,总计超过920个人工时的标注。为了反映真实世界场景,问题围绕三个核心推理挑战进行设计:直接问题解决,答案源于所提出的问题;概念迁移,需要将学到的方法应用到新问题中;深度指令理解,涉及对延伸解释和部分解决方案的多步骤推理。每个问题都包含多步骤推理注释,能够精细地诊断模型的能力。通过这个基准测试,我们强调了现有方法的局限性,并为必须在时间扩展和模式丰富的数学问题设置中进行推理的模型建立了系统的评估框架。我们的基准测试和评估代码可在链接中找到。
论文及项目相关链接
PDF VideoMathQA Technical Report
Summary
VideoMathQA基准测试旨在评估模型在视频上执行长时间跨模态推理的能力。该基准测试涵盖10个数学领域,视频长度从10秒到超过1小时不等。它要求模型解释结构化视觉内容,理解教学叙事,并在视觉、音频和文本模式之间共同定位概念。此基准测试旨在反映真实场景中的核心推理挑战,包括直接解决问题、概念转移和深度教学理解。此基准测试突显了现有方法的局限性,并为必须在时间延长和模态丰富的数学问题设置中进行推理的模型建立了系统的评估框架。
Key Takeaways
- VideoMathQA是一个针对视频的多模态推理基准测试。
- 该基准测试涵盖10个数学领域,视频长度不一。
- 模型需要解释结构化视觉内容,理解教学叙事,并在多种模式之间共同定位概念。
- 此基准测试涵盖真实场景中的核心推理挑战,包括直接解决问题、概念转移和深度教学理解。
- 现有方法在此基准测试中面临局限性。
- 此基准测试旨在评估模型在时间长且模态丰富的数学环境下的推理能力。
点此查看论文截图


SRPO: Enhancing Multimodal LLM Reasoning via Reflection-Aware Reinforcement Learning
Authors:Zhongwei Wan, Zhihao Dou, Che Liu, Yu Zhang, Dongfei Cui, Qinjian Zhao, Hui Shen, Jing Xiong, Yi Xin, Yifan Jiang, Chaofan Tao, Yangfan He, Mi Zhang, Shen Yan
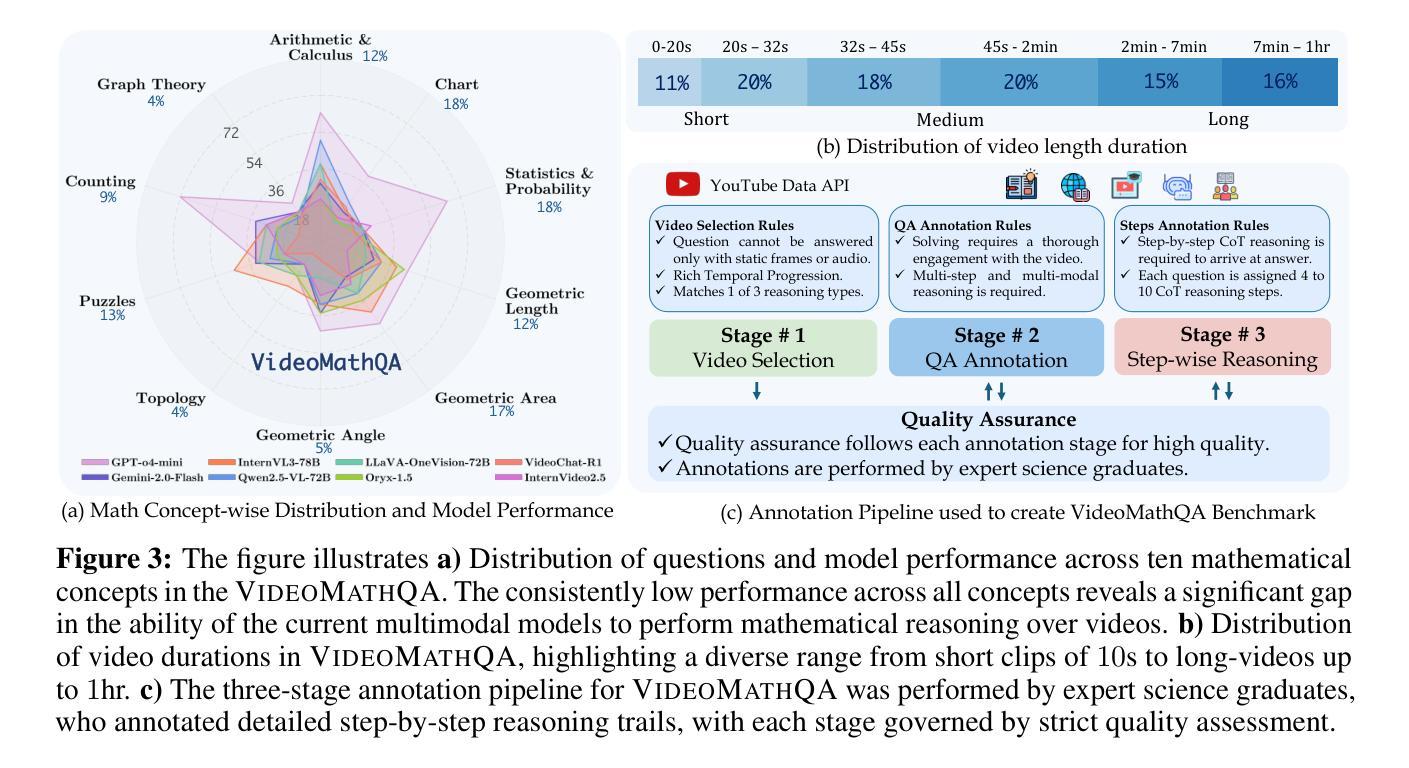
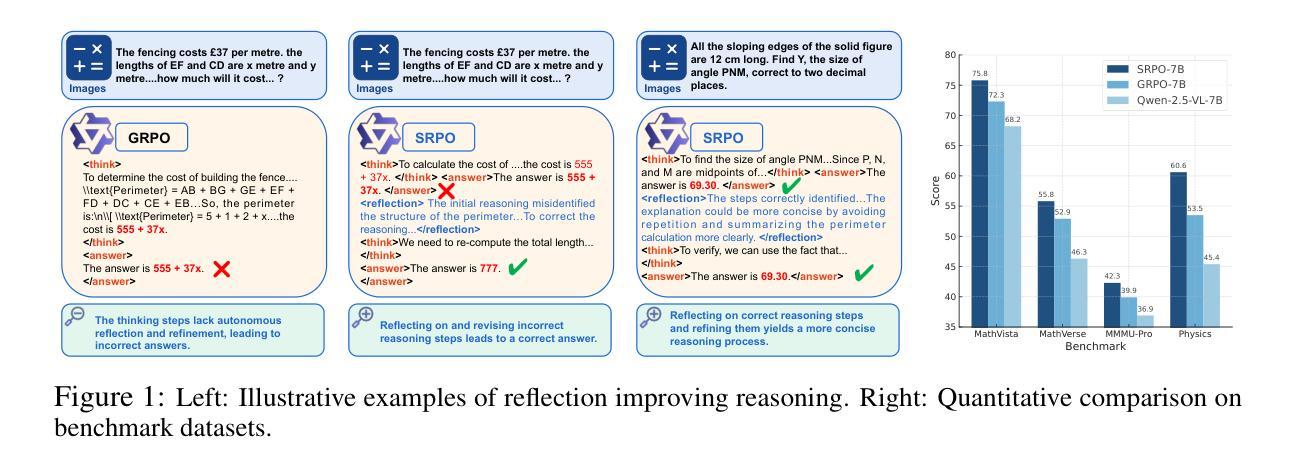
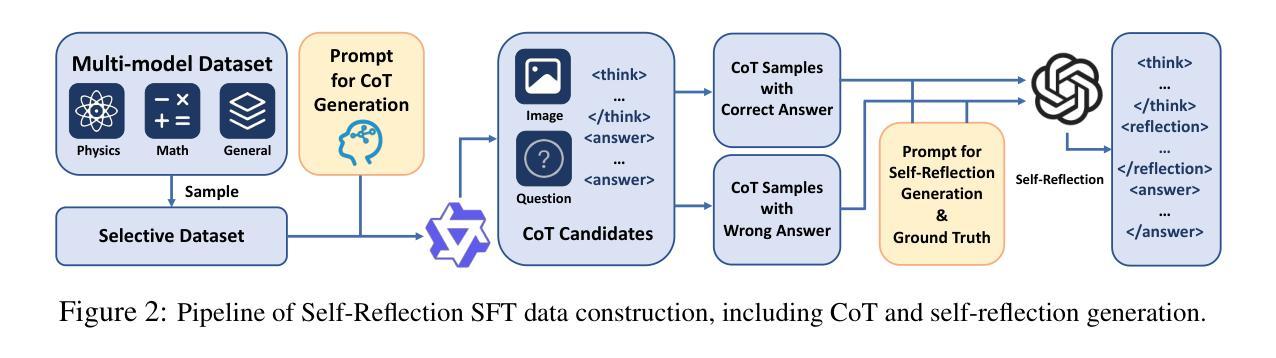
Multimodal large language models (MLLMs) have shown promising capabilities in reasoning tasks, yet still struggle with complex problems requiring explicit self-reflection and self-correction, especially compared to their unimodal text-based counterparts. Existing reflection methods are simplistic and struggle to generate meaningful and instructive feedback, as the reasoning ability and knowledge limits of pre-trained models are largely fixed during initial training. To overcome these challenges, we propose Multimodal Self-Reflection enhanced reasoning with Group Relative Policy Optimization (SRPO), a two-stage reflection-aware reinforcement learning (RL) framework explicitly designed to enhance multimodal LLM reasoning. In the first stage, we construct a high-quality, reflection-focused dataset under the guidance of an advanced MLLM, which generates reflections based on initial responses to help the policy model learn both reasoning and self-reflection. In the second stage, we introduce a novel reward mechanism within the GRPO framework that encourages concise and cognitively meaningful reflection while avoiding redundancy. Extensive experiments across multiple multimodal reasoning benchmarks, including MathVista, MathVision, MathVerse, and MMMU-Pro, using Qwen-2.5-VL-7B and Qwen-2.5-VL-32B demonstrate that SRPO significantly outperforms state-of-the-art models, achieving notable improvements in both reasoning accuracy and reflection quality.
多模态大型语言模型(MLLMs)在推理任务中展现出有前景的能力,但在需要明确的自我反思和自我纠正的复杂问题上仍然面临挑战,尤其是与基于单模态文本的同类型模型相比。现有的反思方法过于简单,难以生成有意义和有益的反馈,因为预训练模型的推理能力和知识局限在初始训练阶段就已基本固定。为了克服这些挑战,我们提出了基于多模态自我反思增强推理与群体相对策略优化(SRPO)的方法,这是一个两阶段的反思感知强化学习(RL)框架,专门设计用于增强多模态LLM推理能力。在第一阶段,我们在先进MLLM的指导下,构建一个高质量的以反思为重点的数据集,该数据集基于初始响应生成反思,以帮助策略模型学习推理和自反思。在第二阶段,我们在GRPO框架中引入了一种新型奖励机制,以鼓励简洁且认知上有意义的反思,同时避免冗余。在多模态推理基准上的大量实验,包括MathVista、MathVision、MathVerse和MMMU-Pro,使用Qwen-2.5-VL-7B和Qwen-2.5-VL-32B模型进行验证,结果表明SRPO显著优于最新模型,在推理准确性和反思质量上都有显著的提升。
论文及项目相关链接
PDF Technical report
Summary
基于多模态大型语言模型(MLLMs)在推理任务中的潜力,但面临需要明确自我反思和自我纠正的复杂问题的挑战。为此,提出了多模态自我反思增强推理与群体相对策略优化(SRPO)的框架,这是一个两阶段的反思感知强化学习框架,旨在增强多模态LLM的推理能力。第一阶段构建高质量、以反思为重点的数据集;第二阶段引入GRPO框架内的新型奖励机制,鼓励简洁且富有认知意义的反思,避免冗余。实验证明,SRPO在多个多模态推理基准测试中显著优于最新模型,在推理准确性和反思质量方面均有显著提高。
Key Takeaways
- 多模态大型语言模型(MLLMs)在推理任务中展现出潜力,但在需要自我反思和纠正的复杂问题上存在挑战。
- 现有反思方法过于简单,难以生成有意义和指导性的反馈。
- 提出的SRPO框架是一个两阶段的反思感知强化学习框架,旨在增强多模态LLM的推理能力。
- 第一阶段构建高质量、以反思为重点的数据集,帮助政策模型学习推理和自反思。
- 第二阶段引入新型奖励机制,鼓励简洁且富有认知意义的反思。
- SRPO在多个多模态推理基准测试中显著优于最新模型。
点此查看论文截图

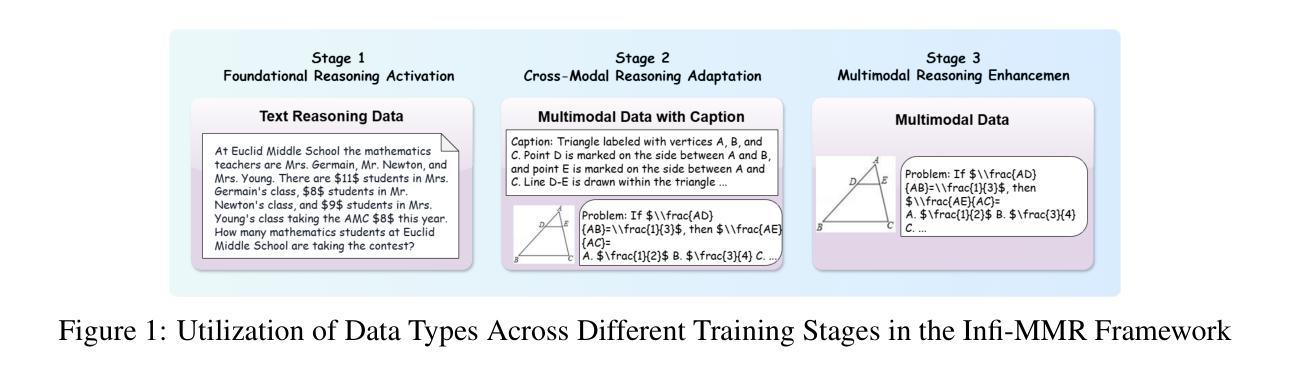
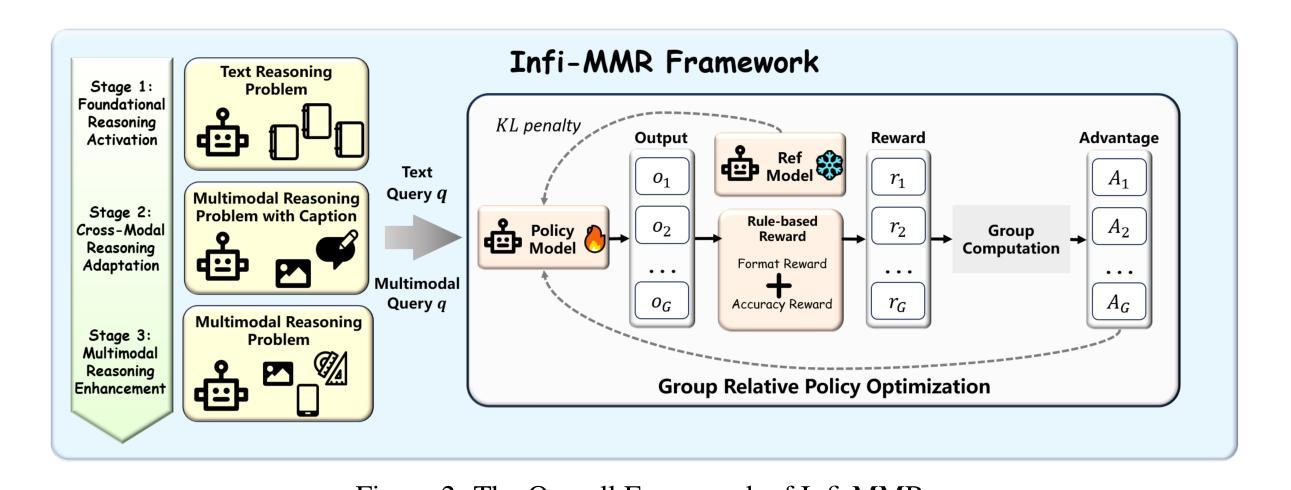
Infi-MMR: Curriculum-based Unlocking Multimodal Reasoning via Phased Reinforcement Learning in Multimodal Small Language Models
Authors:Zeyu Liu, Yuhang Liu, Guanghao Zhu, Congkai Xie, Zhen Li, Jianbo Yuan, Xinyao Wang, Qing Li, Shing-Chi Cheung, Shengyu Zhang, Fei Wu, Hongxia Yang
Recent advancements in large language models (LLMs) have demonstrated substantial progress in reasoning capabilities, such as DeepSeek-R1, which leverages rule-based reinforcement learning to enhance logical reasoning significantly. However, extending these achievements to multimodal large language models (MLLMs) presents critical challenges, which are frequently more pronounced for Multimodal Small Language Models (MSLMs) given their typically weaker foundational reasoning abilities: (1) the scarcity of high-quality multimodal reasoning datasets, (2) the degradation of reasoning capabilities due to the integration of visual processing, and (3) the risk that direct application of reinforcement learning may produce complex yet incorrect reasoning processes. To address these challenges, we design a novel framework Infi-MMR to systematically unlock the reasoning potential of MSLMs through a curriculum of three carefully structured phases and propose our multimodal reasoning model Infi-MMR-3B. The first phase, Foundational Reasoning Activation, leverages high-quality textual reasoning datasets to activate and strengthen the model’s logical reasoning capabilities. The second phase, Cross-Modal Reasoning Adaptation, utilizes caption-augmented multimodal data to facilitate the progressive transfer of reasoning skills to multimodal contexts. The third phase, Multimodal Reasoning Enhancement, employs curated, caption-free multimodal data to mitigate linguistic biases and promote robust cross-modal reasoning. Infi-MMR-3B achieves both state-of-the-art multimodal math reasoning ability (43.68% on MathVerse testmini, 27.04% on MathVision test, and 21.33% on OlympiadBench) and general reasoning ability (67.2% on MathVista testmini). Resources are available at https://huggingface.co/Reallm-Labs/Infi-MMR-3B.
近期大型语言模型(LLM)的进步在推理能力方面取得了显著成效,例如DeepSeek-R1,它利用基于规则的强化学习来显著增强逻辑推理能力。然而,将这些成就扩展到多模态大型语言模型(MLLM)却面临重大挑战,对于多模态小型语言模型(MSLM)而言,这些挑战通常更为突出,因为它们通常具有较弱的基础推理能力:一是高质量的多模态推理数据集的稀缺性;二是由于集成视觉处理而导致的推理能力下降;三是直接应用强化学习可能产生复杂而错误的推理过程的风险。为了应对这些挑战,我们设计了一种新型框架Infi-MMR,通过三个精心构建的阶段来系统地解锁MSLM的推理潜力,并提出了我们的多模态推理模型Infi-MMR-3B。第一阶段,基础推理激活,利用高质量文本推理数据集来激活和加强模型的逻辑推理能力。第二阶段,跨模态推理适应,利用标题辅助多模态数据来促进推理技能向多模态情境的逐步转移。第三阶段,多模态推理增强,采用精选的无标题多模态数据来缓解语言偏见并促进稳健的跨模态推理。Infi-MMR-3B不仅达到了最先进的跨模态数学推理能力(MathVerse测试成绩为43.68%,MathVision测试成绩为27.04%,OlympiadBench测试成绩为21.33%),而且具有一般推理能力(MathVista测试成绩为67.2%)。资源可通过https://huggingface.co/Reallm-Labs/Infi-MMR-3B获取。
论文及项目相关链接
Summary
大型语言模型(LLM)在推理能力方面取得了显著进展,如DeepSeek-R1,它利用基于规则的强化学习大幅提升了逻辑推理能力。然而,将这些成果扩展到多模态大型语言模型(MLLMs)面临挑战,对于多模态小型语言模型(MSLMs)尤其如此,因为它们的基础推理能力通常较弱。挑战包括高质量多模态推理数据集的稀缺、由于集成视觉处理导致的推理能力下降、以及直接应用强化学习可能产生复杂而错误的推理过程的风险。为解决这些挑战,本文设计了一个新型框架Infi-MMR,通过三个精心构建的阶段系统地解锁MSLMs的推理潜力,并提出了多模态推理模型Infi-MMR-3B。该模型经历基础推理激活、跨模态推理适应和多模态推理增强三个阶段,实现了先进的多模态数学推理能力和通用推理能力。
Key Takeaways
- 大型语言模型(LLMs)在推理能力上已有显著进展,但扩展到多模态语言模型时面临挑战。
- 多模态小型语言模型(MSLMs)的基础推理能力较弱,面临高质量多模态推理数据集稀缺、视觉处理导致的推理能力下降以及强化学习应用风险等问题。
- Infi-MMR框架旨在通过三个阶段的课程设计来解锁MSLMs的推理潜力。
- 第一阶段是基础推理激活,利用高质量文本推理数据集来激活和加强模型的逻辑推理能力。
- 第二阶段是跨模态推理适应,利用带有描述的多媒体数据来促进推理技能向多模态环境的逐步转移。
- 第三阶段是多模态推理增强,采用精选的、无描述的多媒体数据来减轻语言偏见并促进稳健的跨模态推理。
- Infi-MMR-3B模型实现了先进的多模态数学推理能力和通用推理能力,在多个测试中表现出卓越性能。
点此查看论文截图

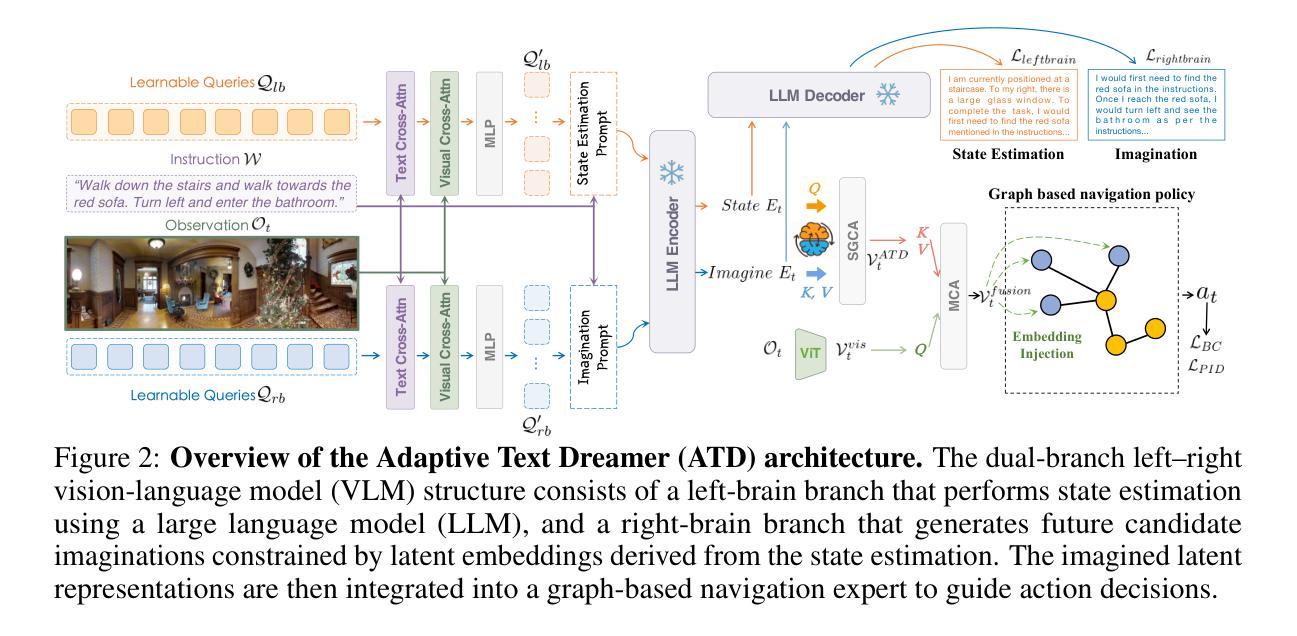
Cross from Left to Right Brain: Adaptive Text Dreamer for Vision-and-Language Navigation
Authors:Pingrui Zhang, Yifei Su, Pengyuan Wu, Dong An, Li Zhang, Zhigang Wang, Dong Wang, Yan Ding, Bin Zhao, Xuelong Li
Vision-and-Language Navigation (VLN) requires the agent to navigate by following natural instructions under partial observability, making it difficult to align perception with language. Recent methods mitigate this by imagining future scenes, yet they rely on vision-based synthesis, leading to high computational cost and redundant details. To this end, we propose to adaptively imagine key environmental semantics via \textit{language} form, enabling a more reliable and efficient strategy. Specifically, we introduce a novel Adaptive Text Dreamer (ATD), a dual-branch self-guided imagination policy built upon a large language model (LLM). ATD is designed with a human-like left-right brain architecture, where the left brain focuses on logical integration, and the right brain is responsible for imaginative prediction of future scenes. To achieve this, we fine-tune only the Q-former within both brains to efficiently activate domain-specific knowledge in the LLM, enabling dynamic updates of logical reasoning and imagination during navigation. Furthermore, we introduce a cross-interaction mechanism to regularize the imagined outputs and inject them into a navigation expert module, allowing ATD to jointly exploit both the reasoning capacity of the LLM and the expertise of the navigation model. We conduct extensive experiments on the R2R benchmark, where ATD achieves state-of-the-art performance with fewer parameters. The code is \href{https://github.com/zhangpingrui/Adaptive-Text-Dreamer}{here}.
视觉与语言导航(VLN)要求智能体在部分可观察性的情况下遵循自然语言指令进行导航,这使得感知与语言的对齐变得困难。最近的方法通过想象未来的场景来缓解这个问题,但它们依赖于基于视觉的合成,导致计算成本高和细节冗余。为此,我们提出通过语言形式来适应性地想象关键环境语义,从而实现更可靠和高效的策略。具体来说,我们引入了一种新型的自适应文本梦想家(ATD),这是一种基于大型语言模型(LLM)的双分支自我引导想象策略。ATD的设计具有人类左右脑架构,左脑专注于逻辑整合,右脑负责对未来场景进行想象预测。为了实现这一点,我们只微调了左右脑中的Q-former,以有效激活LLM中的领域特定知识,从而在导航过程中实现逻辑和想象的动态更新。此外,我们引入了一种交叉交互机制来规范想象输出并将其注入导航专家模块,使ATD能够同时利用LLM的推理能力和导航模型的专长。我们在R2R基准测试上进行了大量实验,ATD以较少的参数实现了最先进的性能。代码在这里:链接。
论文及项目相关链接
Summary
本文提出了一个名为Adaptive Text Dreamer(ATD)的新方法,用于解决Vision-and-Language Navigation(VLN)任务中的感知与语言对齐问题。该方法通过自适应地想象关键环境语义并采用语言形式,实现更可靠和高效的策略。ATD是一个基于大型语言模型(LLM)的双分支自我引导想象策略,具有类似人脑的左右架构,分别专注于逻辑整合和想象预测未来场景。通过微调Q-former,该方法能够激活LLM中的领域特定知识,并在导航过程中实现动态的逻辑推理和想象力更新。此外,还引入了一种跨交互机制,将想象输出注入到导航专家模块中,使ATD能够同时利用LLM的推理能力和导航模型的专长。在R2R基准测试上,ATD取得了最先进的性能,且参数更少。
Key Takeaways
- 提出了Adaptive Text Dreamer(ATD)解决VLN中的感知与语言对齐问题。
- ATD采用自适应想象关键环境语义并通过语言形式表现。
3.ATD基于大型语言模型(LLM)构建,具有类似人脑的左右架构,分别处理逻辑和想象力。 - 通过微调Q-former激活LLM中的领域特定知识。
- 引入跨交互机制,结合LLM的推理能力和导航模型的专长。
- 在R2R基准测试上,ATD性能达到最新水平,且参数更少。
点此查看论文截图


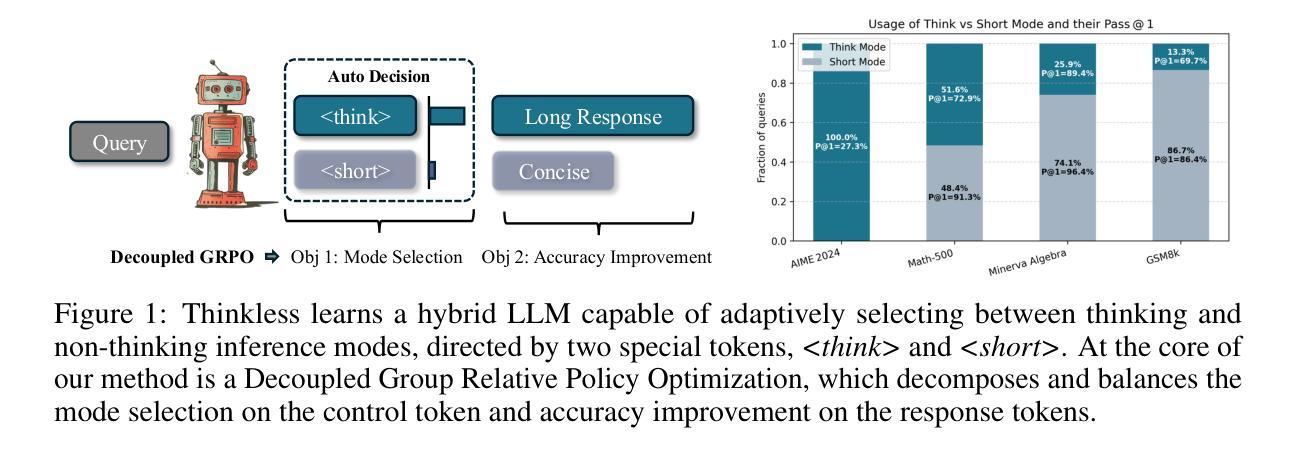
Thinkless: LLM Learns When to Think
Authors:Gongfan Fang, Xinyin Ma, Xinchao Wang
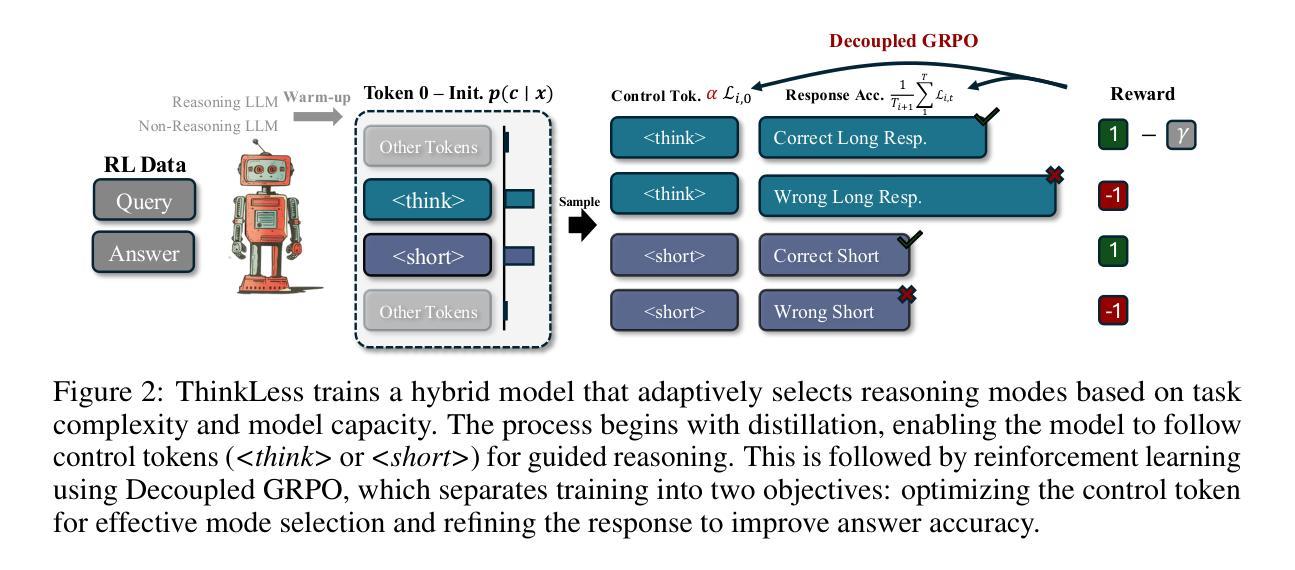
Reasoning Language Models, capable of extended chain-of-thought reasoning, have demonstrated remarkable performance on tasks requiring complex logical inference. However, applying elaborate reasoning for all queries often results in substantial computational inefficiencies, particularly when many problems admit straightforward solutions. This motivates an open question: Can LLMs learn when to think? To answer this, we propose Thinkless, a learnable framework that empowers an LLM to adaptively select between short-form and long-form reasoning, based on both task complexity and the model’s ability. Thinkless is trained under a reinforcement learning paradigm and employs two control tokens,
具备扩展性链式思维能力的推理语言模型在需要复杂逻辑推断的任务中表现出了卓越的性能。然而,对所有查询进行精细推理常常导致大量的计算效率低下,特别是当许多问题都有简单直接的解决方案时。这引发了一个开放性的问题:语言大模型能否学会何时思考?为了回答这个问题,我们提出了Thinkless,这是一个可学习的框架,能够让语言大模型根据任务的复杂性和模型自身的能力自适应地选择短形式和长形式的推理方式。Thinkless是在强化学习模式下训练的,它使用两个控制令牌:
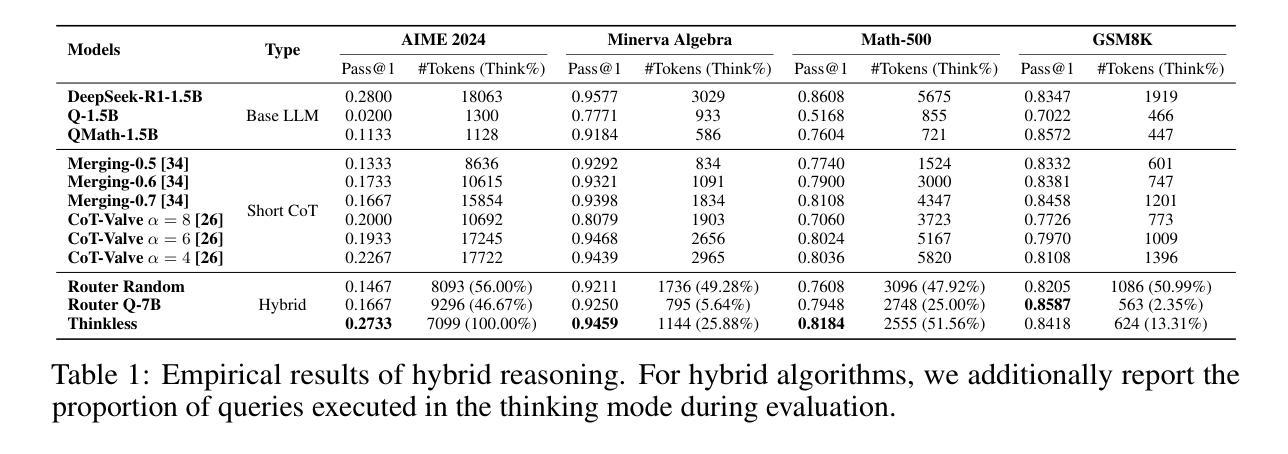
用于简洁的回应, 用于详细的推理。我们的方法的核心是解耦组相对策略优化(DeGRPO)算法,该算法将混合推理的学习目标分解为两个部分:(1)控制令牌损失,它控制推理模式的选择;(2)响应损失,它提高生成答案的准确性。这种解耦的公式使每个目标的贡献得到精细控制,稳定了训练,并有效地防止了原始GRPO中观察到的崩溃。在Minerva Algebra、MATH-500和GSM8K等多个基准测试中,Thinkless能够减少长链思考的使用率50%~90%,显著提高了推理语言模型的效率。代码可在https://github.com/VainF/Thinkless上找到。
论文及项目相关链接
Summary
一篇关于推理语言模型的文章,提出一种名为Thinkless的可学习框架,能够根据任务复杂度和模型能力自适应选择简短或长程推理。文章介绍了Thinkless的核心方法——解耦组相对策略优化算法(DeGRPO),并指出该框架在多个基准测试中能显著减少长链思考的使用,提高推理语言模型的效率。代码已公开在GitHub上。
Key Takeaways
- 推理语言模型具备复杂的逻辑推理能力,但有时会对简单问题做过多的复杂推理,造成计算效率低下。
- Thinkless框架旨在解决这一问题,通过自适应选择简短或长程推理来平衡计算效率和准确性。
- Thinkless采用强化学习的方式进行训练,使用两个控制标记
和 来控制推理模式。 - 核心方法是解耦组相对策略优化(DeGRPO)算法,该算法将学习目标分解为两个组成部分:控制标记损失和响应损失。
- 解耦的公式化使得每个目标贡献更为精细,稳定了训练过程,并有效防止了策略优化中的崩溃现象。
- Thinkless框架在多个基准测试中表现出色,能显著减少长链思考的使用,提高了推理语言模型的效率。
点此查看论文截图