⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-03 更新
Flash-VStream: Efficient Real-Time Understanding for Long Video Streams
Authors:Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Xiaojie Jin
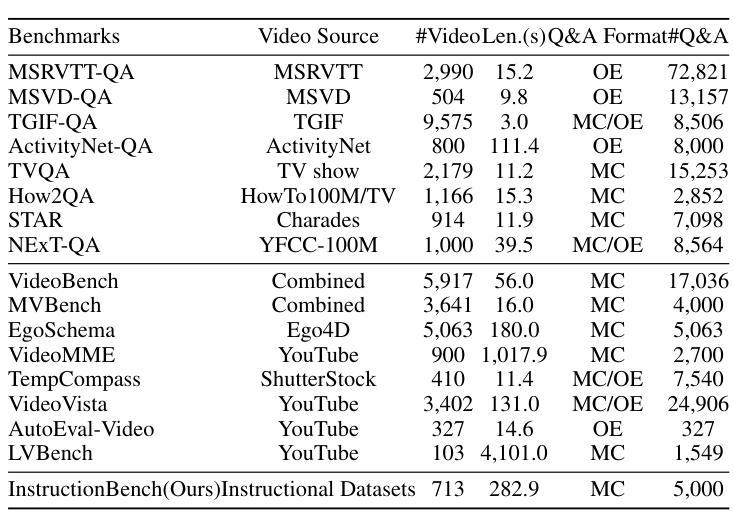
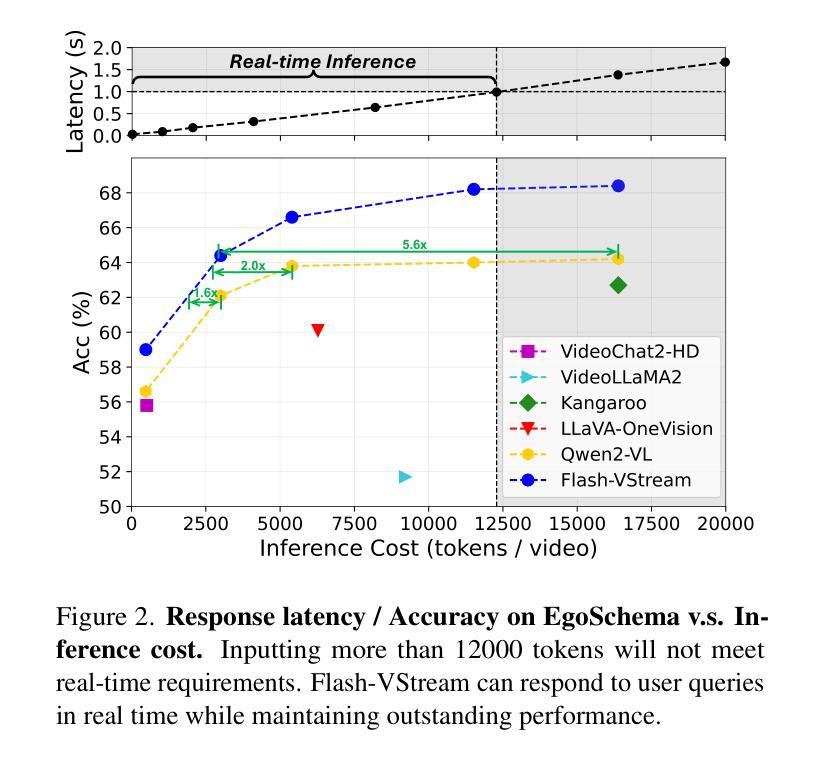
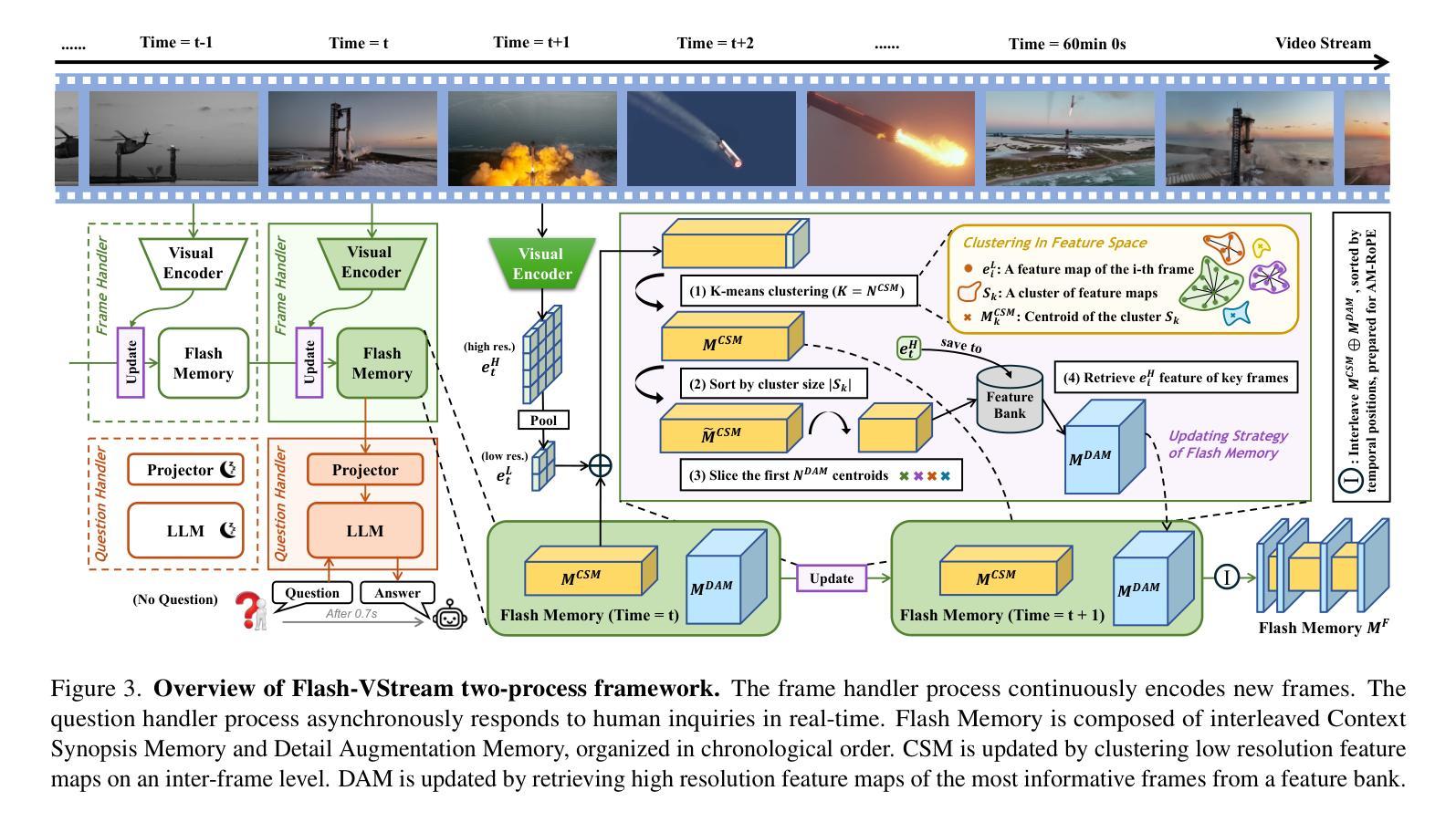
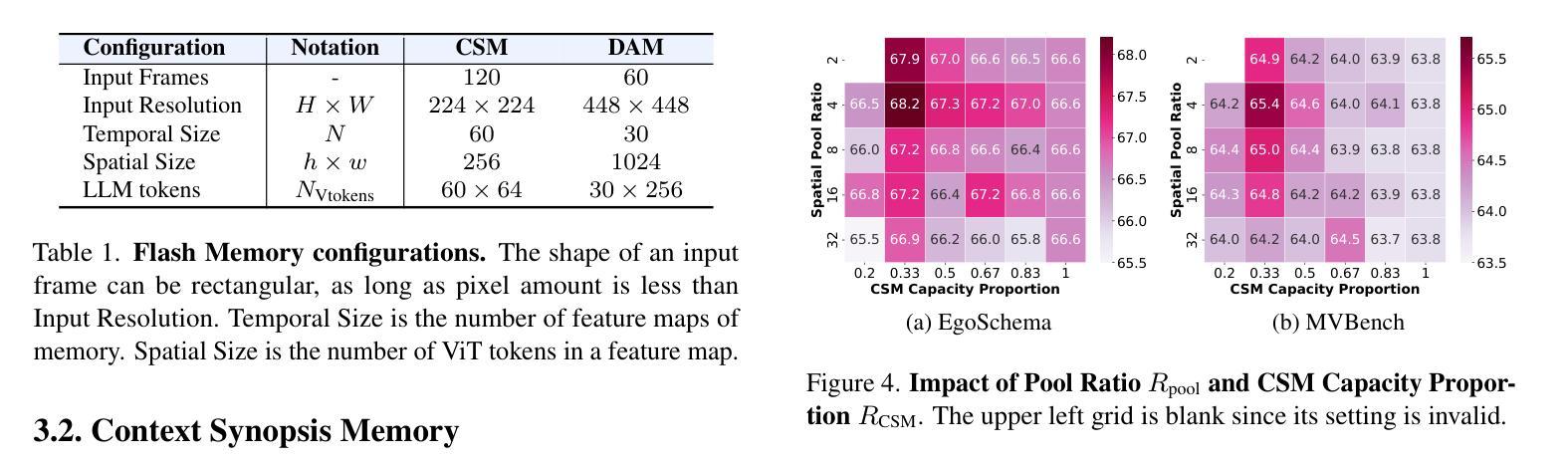
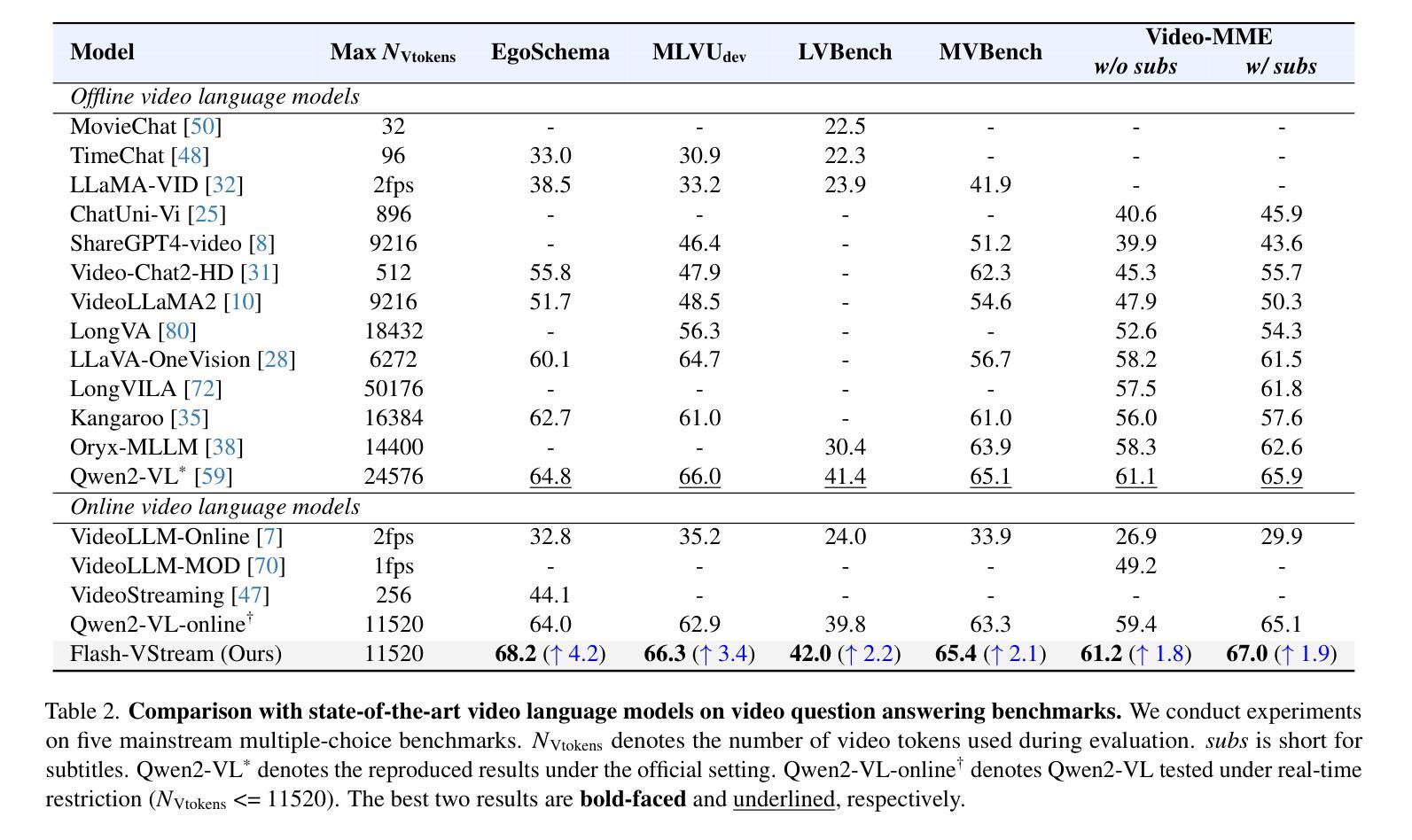
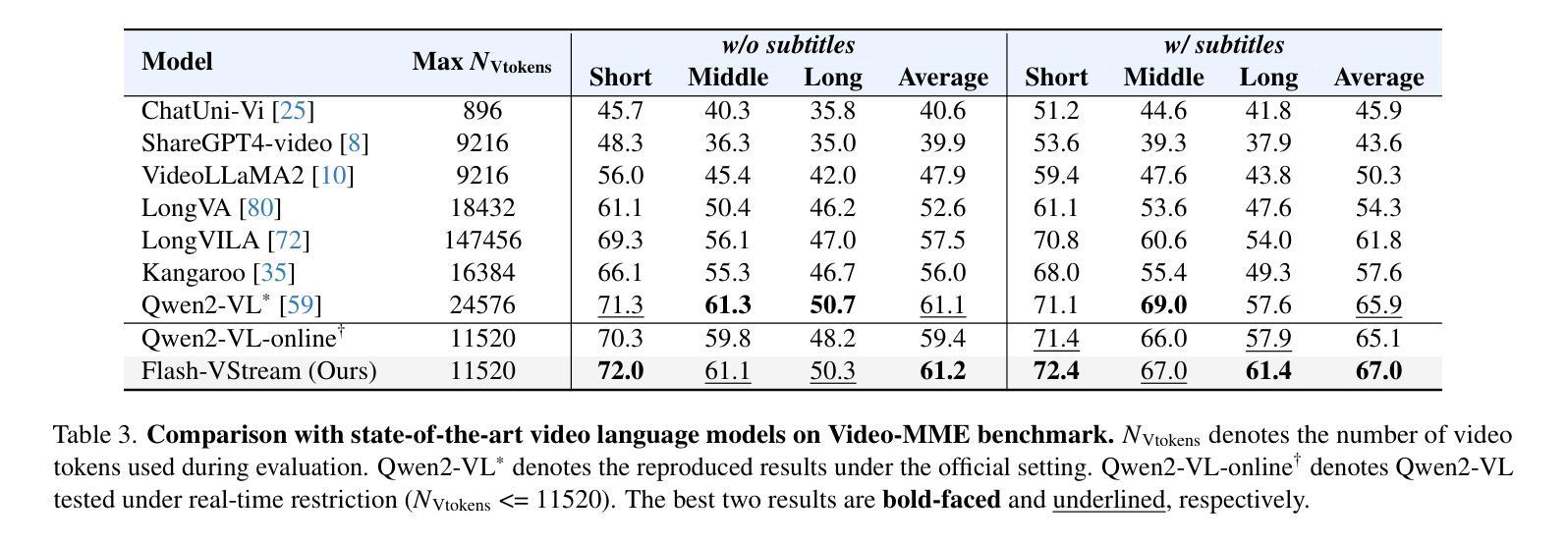
Benefiting from the advances in large language models and cross-modal alignment, existing multimodal large language models have achieved prominent performance in image and short video understanding. However, the understanding of long videos is still challenging, as their long-context nature results in significant computational and memory overhead. Most existing work treats long videos in the same way as short videos, which is inefficient for real-world applications and hard to generalize to even longer videos. To address these issues, we propose Flash-VStream, an efficient video language model capable of processing extremely long videos and responding to user queries in real time. Particularly, we design a Flash Memory module, containing a low-capacity context memory to aggregate long-context temporal information and model the distribution of information density, and a high-capacity augmentation memory to retrieve detailed spatial information based on this distribution. Compared to existing models, Flash-VStream achieves significant reductions in inference latency. Extensive experiments on long video benchmarks and comprehensive video benchmarks, i.e., EgoSchema, MLVU, LVBench, MVBench and Video-MME, demonstrate the state-of-the-art performance and outstanding efficiency of our method. Code is available at https://github.com/IVGSZ/Flash-VStream.
得益于大型语言模型和跨模态对齐技术的进步,现有的多模态大型语言模型在图像和短视频理解方面取得了显著的性能。然而,对长视频的理解仍然具有挑战性,因为长视频的长上下文特性导致了巨大的计算和内存开销。大多数现有工作将长视频与短视频以相同的方式处理,这对于实际应用效率低下,并且难以推广到更长的视频。为了解决这些问题,我们提出了Flash-VStream,这是一种高效的视频语言模型,能够处理极长的视频并在实时响应用户查询。特别是,我们设计了一个Flash Memory模块,包含一个低容量的上下文内存来聚合长上下文的临时信息并建模信息密度的分布,以及一个基于这种分布检索详细空间信息的高容量增强内存。与现有模型相比,Flash-VStream在推理延迟上实现了显著减少。在Long Video Benchmarks和全面的视频基准测试(即EgoSchema、MLVU、LVBench、MVBench和视频MME)上的大量实验表明,我们的方法达到了最先进的性能和出色的效率。代码可通过https://github.com/IVGSZ/Flash-VStream获取。
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
基于大型语言模型和跨模态对齐的进步,现有的多模态大型语言模型已在图像和短视频理解方面取得了显著成效。然而,对长视频的理解仍存在挑战,因为其长上下文特性导致计算和内存开销较大。大多数现有工作将长视频与短视频以相同方式处理,这对于实际应用效率低下,且难以推广到更长的视频。为解决这些问题,我们提出了Flash-VStream高效视频语言模型,能够处理极长视频并实时响应用户查询。通过设计Flash Memory模块,包含低容量上下文内存以聚集长上下文时间信息并模拟信息密度分布,以及高容量增强内存以基于该分布检索详细的空间信息。相较于现有模型,Flash-VStream在推理延迟上实现了显著减少。在长篇视频基准测试及综合视频基准测试(如EgoSchema、MLVU、LVBench、MVBench和Video-MME)中,我们的方法展现了卓越的性能和效率。相关代码可访问 https://github.com/IVGSZ/Flash-VStream。
Key Takeaways
- 大型语言模型和跨模态对齐的进步推动了视频理解的进展。
- 长视频理解面临计算量大和内存开销高的挑战。
- 现有方法处理长视频时效率低下,难以推广至更长的视频内容。
- Flash-VStream模型通过设计Flash Memory模块来处理长视频,包含低容量上下文内存和高容量增强内存。
- 该模型能够显著降低推理延迟,提高效率和性能。
- Flash-VStream在多个基准测试中表现优异,包括EgoSchema、MLVU、LVBench、MVBench和Video-MME等。
点此查看论文截图

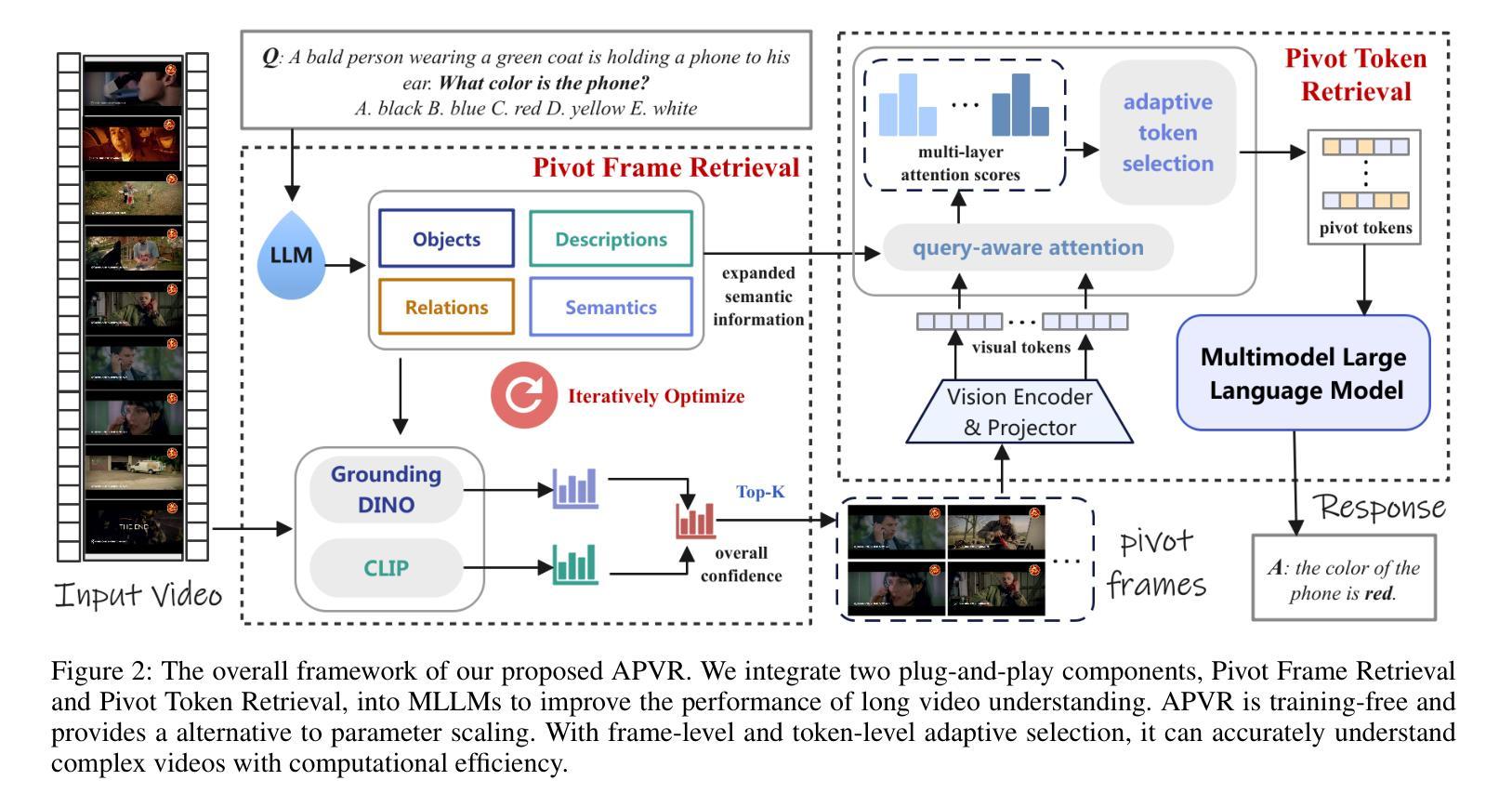
APVR: Hour-Level Long Video Understanding with Adaptive Pivot Visual Information Retrieval
Authors:Hong Gao, Yiming Bao, Xuezhen Tu, Bin Zhong, Minling Zhang
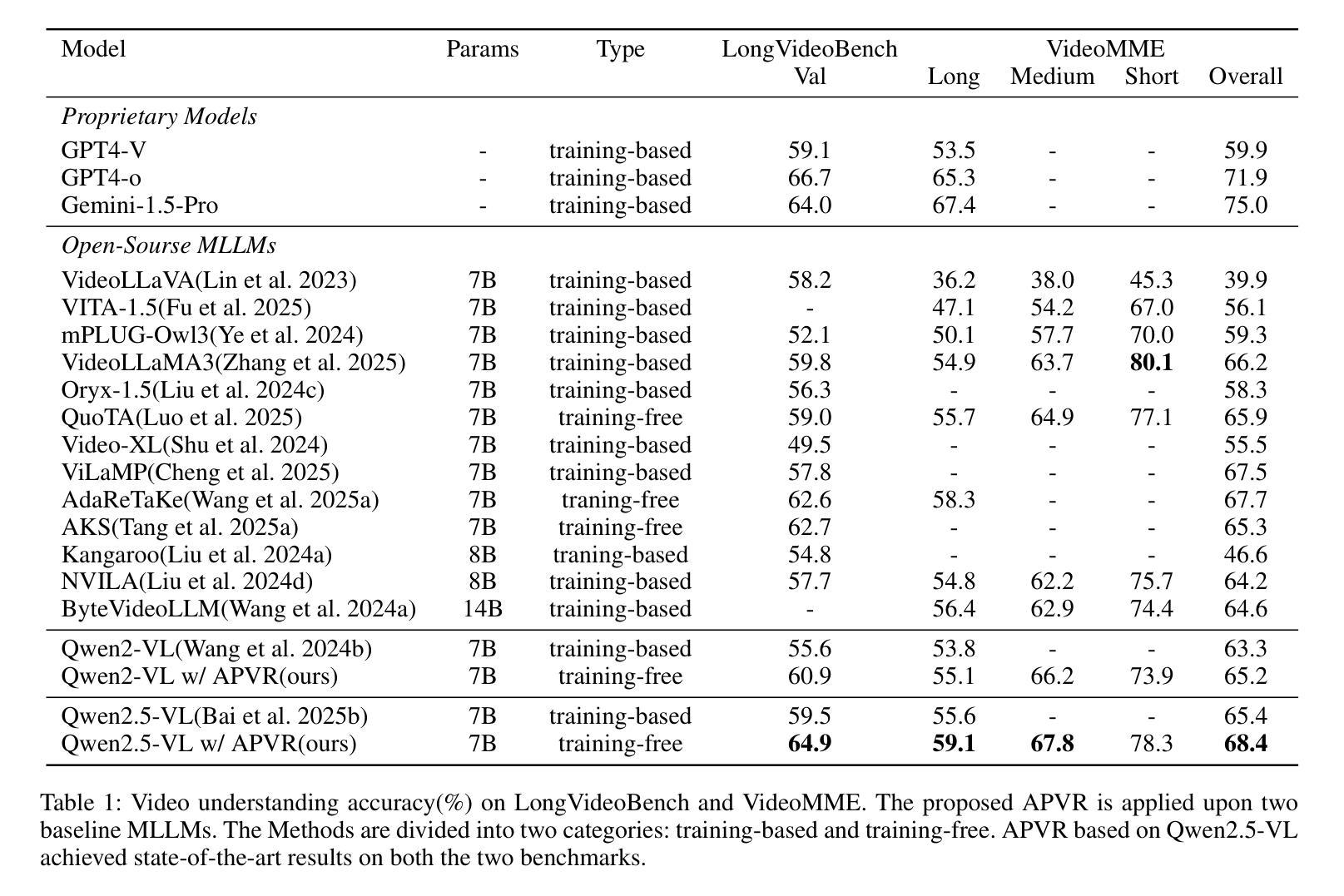
Current multimodal large language models (MLLMs) struggle with hour-level video understanding, facing significant challenges not only in modeling the substantial information volume of long videos but also in overcoming the memory wall and resource constraints during both training and inference. Although recent training-free approaches have alleviated resource demands by compressing visual features, their reliance on incomplete visual information limits the performance potential. To address these limitations, we propose \textbf{A}daptive \textbf{P}ivot \textbf{V}isual information \textbf{R}etrieval (\textbf{APVR}), a training-free framework that hierarchically retrieves and retains sufficient and important visual information. It breakthroughs the memory wall limitation via two complementary components: Pivot Frame Retrieval employs query expansion and iterative spatio-semantic confidence scoring to identify relevant video frames, and Pivot Token Retrieval performs query-aware attention-driven token selection within up to 1024 pivot frames. This dual granularity approach enables the processing of hour-long videos while maintaining semantic fidelity. Experimental validations demonstrate significant performance improvements, achieving 64.9% on LongVideoBench and 68.4% on VideoMME, which are state-of-the-art results for both training-free and training-based approaches. Meanwhile, our method provides plug-and-play integration capability with existing MLLM architectures.
当前的多模态大型语言模型(MLLMs)在小时级视频理解方面遇到了困难,不仅面临建模长视频大量信息的挑战,而且在训练和推理过程中都面临着突破内存墙和资源约束的挑战。虽然最近的无需训练的方法通过压缩视觉特征减轻了资源需求,但它们对不完整视觉信息的依赖限制了性能潜力。为了解决这些局限性,我们提出了自适应枢轴视觉信息检索(APVR),这是一个无需训练的框架,可以分层检索和保留充足且重要的视觉信息。它通过两个互补的组件突破了内存墙的限制:枢轴帧检索采用查询扩展和迭代的空间语义置信度打分来识别相关的视频帧,而枢轴令牌检索则在上至1024个枢轴帧内执行查询感知的注意力驱动令牌选择。这种双重粒度的方法能够处理长达一小时的视频,同时保持语义保真。实验验证显示,在LongVideoBench上达到了64.9%,在VideoMME上达到了68.4%,无论是无需训练的方法还是基于训练的方法,这都是最新的结果。同时,我们的方法提供了与现有MLLM架构的即插即用集成能力。
论文及项目相关链接
Summary
视频理解是当前研究的热点,现有方法在处理长视频时面临诸多挑战,如信息量大、训练与推理时的资源限制等。针对这些问题,本文提出了一种名为APVR的训练无关框架,通过分层检索和保留关键视觉信息来解决挑战。该框架包括两种互补的组件,能够突破内存限制,实现在保持语义完整性的同时处理长达数小时的视频。实验验证显示,该方法在LongVideoBench和VideoMME上取得了最先进的性能。
Key Takeaways
- 当前多模态大型语言模型在处理长视频时面临诸多挑战。
- 训练无关的方法可以缓解资源需求,但依赖不完全的视觉信息限制了性能。
- APVR框架通过分层检索和保留关键视觉信息来解决这些挑战。
- APVR框架包括两种互补的组件:Pivot Frame Retrieval和Pivot Token Retrieval。
- Pivot Frame Retrieval通过查询扩展和迭代的空间语义置信度评分来识别相关视频帧。
- Pivot Token Retrieval执行查询感知的注意力驱动令牌选择在多达1024个关键帧内。
点此查看论文截图



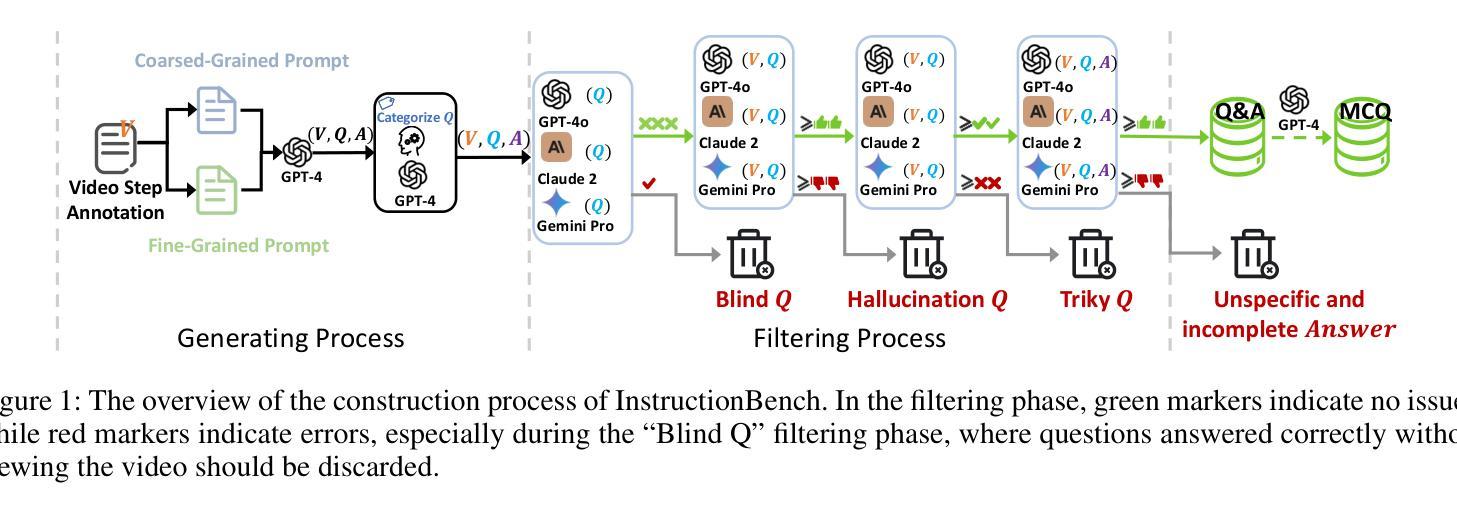
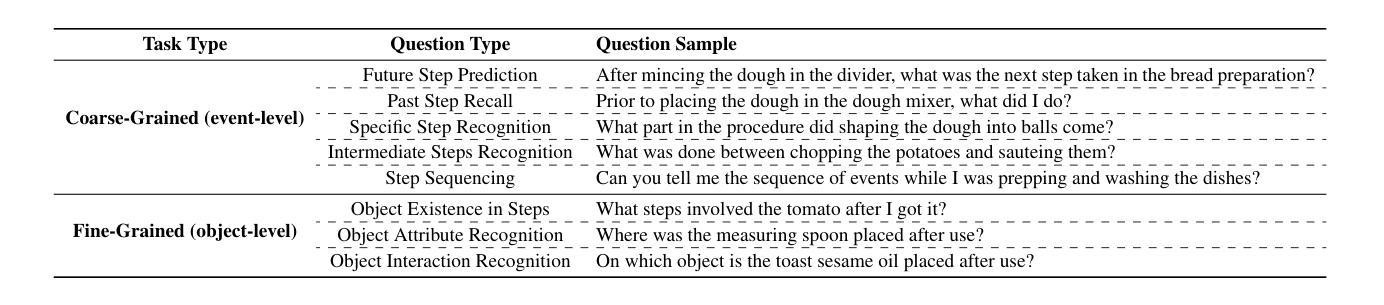
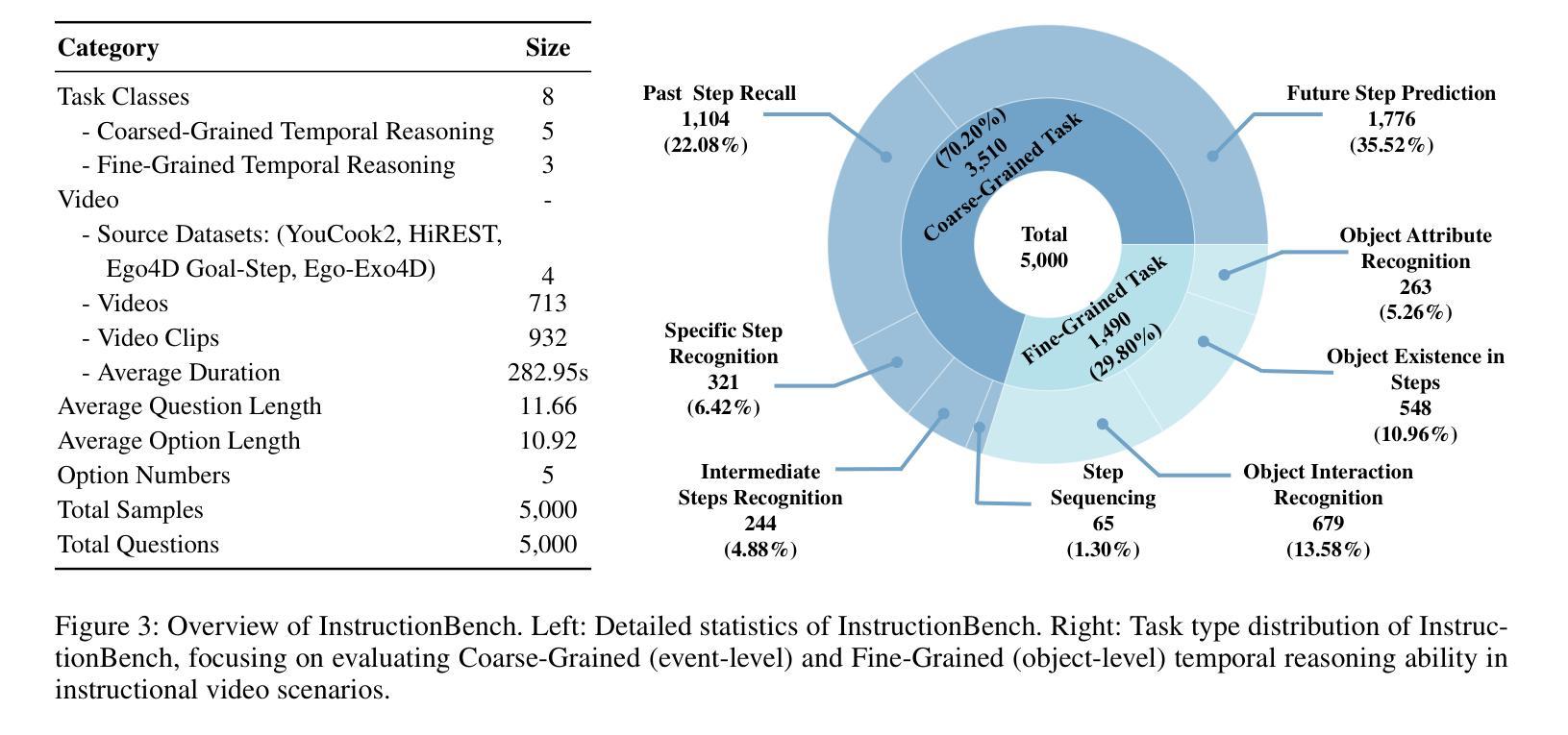
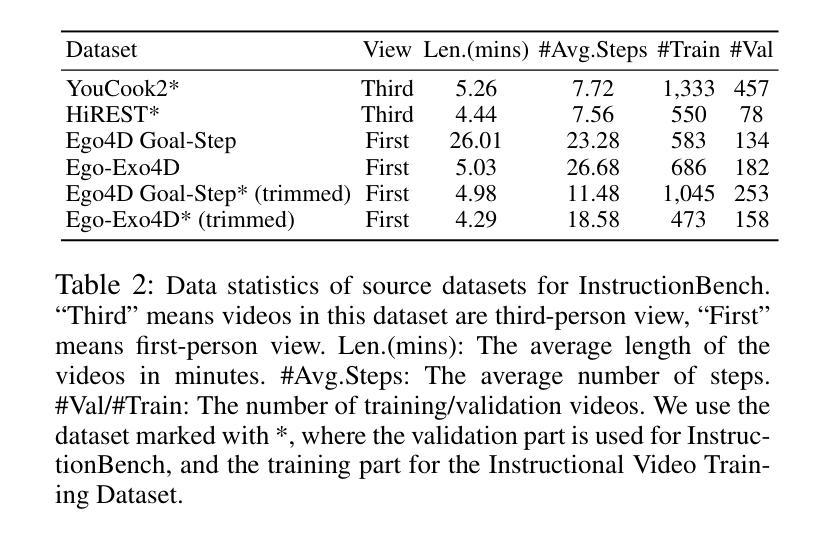
InstructionBench: An Instructional Video Understanding Benchmark
Authors:Haiwan Wei, Yitian Yuan, Xiaohan Lan, Wei Ke, Lin Ma
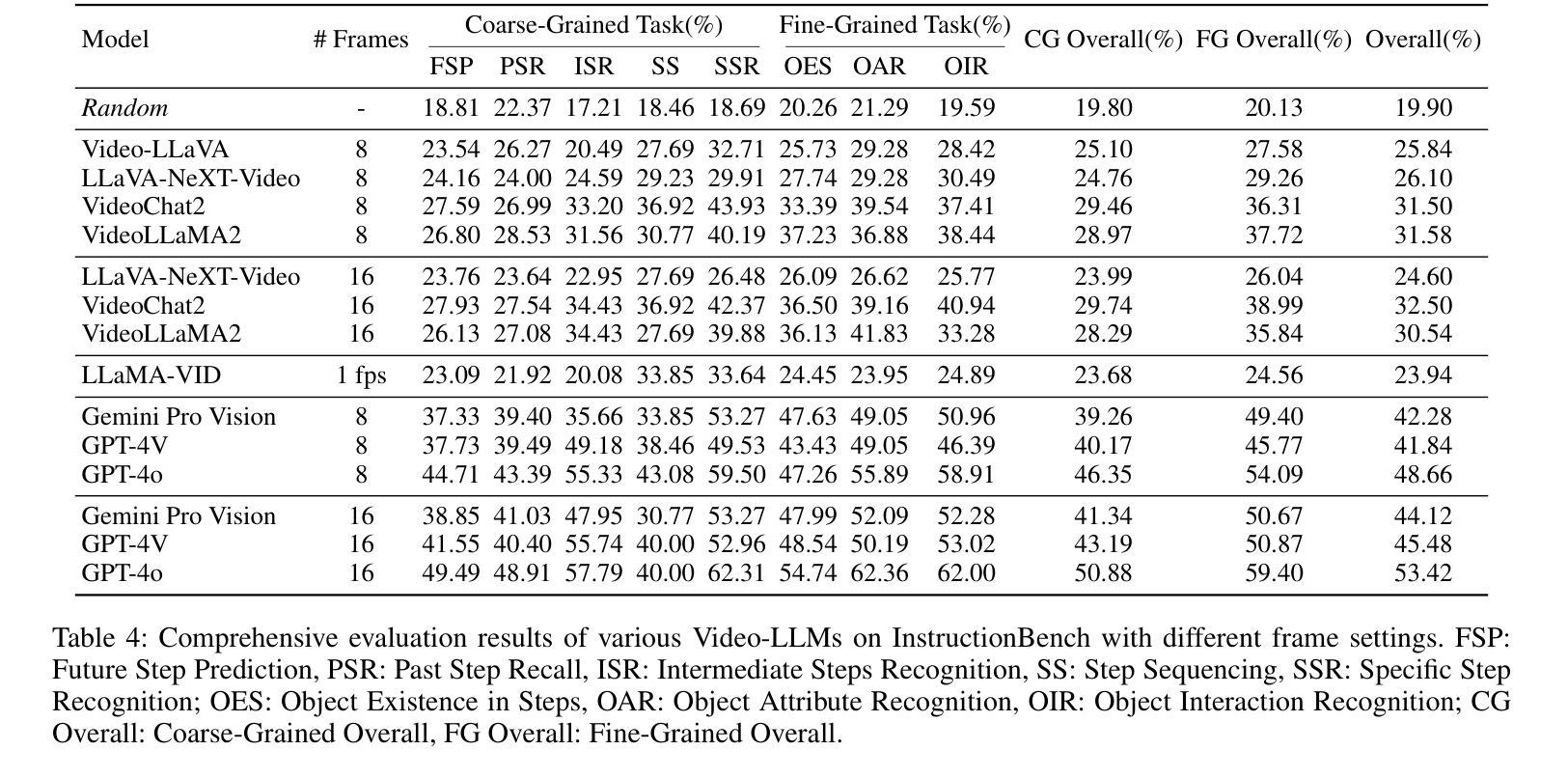
Despite progress in video large language models (Video-LLMs), research on instructional video understanding, crucial for enhancing access to instructional content, remains insufficient. To address this, we introduce InstructionBench, an Instructional video understanding Benchmark, which challenges models’ advanced temporal reasoning within instructional videos characterized by their strict step-by-step flow. Employing GPT-4, we formulate Q&A pairs in open-ended and multiple-choice formats to assess both Coarse-Grained event-level and Fine-Grained object-level reasoning. Our filtering strategies exclude questions answerable purely by common-sense knowledge, focusing on visual perception and analysis when evaluating Video-LLM models. The benchmark finally contains 5k questions across over 700 videos. We evaluate the latest Video-LLMs on our InstructionBench, finding that closed-source models outperform open-source ones. However, even the best model, GPT-4o, achieves only 53.42% accuracy, indicating significant gaps in temporal reasoning. To advance the field, we also develop a comprehensive instructional video dataset with over 19k Q&A pairs from nearly 2.5k videos, using an automated data generation framework, thereby enriching the community’s research resources. All data are available at https://huggingface.co/datasets/sunwhw/InstructionBench.
尽管视频大型语言模型(Video-LLMs)领域已经取得了一定的进展,但对于教学视频理解的研究,对于增强教学内容的可访问性至关重要,这方面的研究仍然不足。为了解决这个问题,我们引入了InstructionBench,一个教学视频理解基准测试,它挑战了模型在教学视频中的高级时间推理能力,这些视频的特点是步骤严格、循序渐进。我们利用GPT-4,以开放式和选择题格式制定问答对,评估粗粒度事件级和细粒度对象级的推理能力。我们的过滤策略排除了仅通过常识知识就能回答的问题,在评估Video-LLM模型时侧重于视觉感知和分析。该基准测试最终包含5000多个问题,涉及700多个视频。我们在InstructionBench上评估了最新的Video-LLMs,发现封闭式模型的表现优于开源模型。然而,即使表现最佳的GPT-4o模型也只有53.42%的准确率,表明在时间推理方面仍存在较大差距。为了推动该领域的发展,我们还使用自动化数据生成框架,从近2.5万个视频中构建了包含超过1.9万个问答对的大型教学视频数据集,从而丰富了社区的研究资源。所有数据都可以在https://huggingface.co/datasets/sunwhw/InstructionBench上获得。
论文及项目相关链接
Summary:
随着视频大语言模型(Video-LLMs)的进步,对指令性视频理解的研究仍然不足,这对增强指令性内容的访问至关重要。为解决此问题,我们推出了InstructionBench,一个指令性视频理解基准测试,它挑战了模型在指令性视频中的高级时间推理能力。我们使用GPT-4,以开放问题和多项选择题的形式制定问答对,评估粗粒度事件级和细粒度对象级推理。我们的过滤策略排除了仅凭常识知识就能回答的问题,侧重于评估Video-LLM模型的视觉感知和分析能力。最终基准测试包含超过700个视频的5k个问题。我们对最新的Video-LLMs在InstructionBench上进行了评估,发现封闭源模型优于开源模型。然而,即使是最优秀的模型GPT-4o,其准确率也只有53.42%,表明时间推理仍存在显著差距。为了推动该领域的发展,我们还使用自动化数据生成框架,开发了一个包含超过2.5k个视频的综合性指令性视频数据集,其中包含超过1.9万个问答对,丰富了社区的研究资源。所有数据均可在https://huggingface.co/datasets/sunwhw/InstructionBench获取。
Key Takeaways:
- 指令性视频理解研究仍显不足,对于增强指令内容的访问至关重要。
- InstructionBench基准测试挑战了模型在指令性视频中的高级时间推理能力。
- GPT-4被用于制定问答对以评估模型的粗粒度事件级和细粒度对象级推理能力。
- 过滤策略侧重于评估模型的视觉感知和分析能力而非常识知识。
- 最新Video-LLMs评估显示封闭源模型表现较好,但最佳模型的准确率仍然较低。
- 为了推动研究发展,开发了一个包含超过2.5k视频的综合性指令性视频数据集。
点此查看论文截图