⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-03 更新
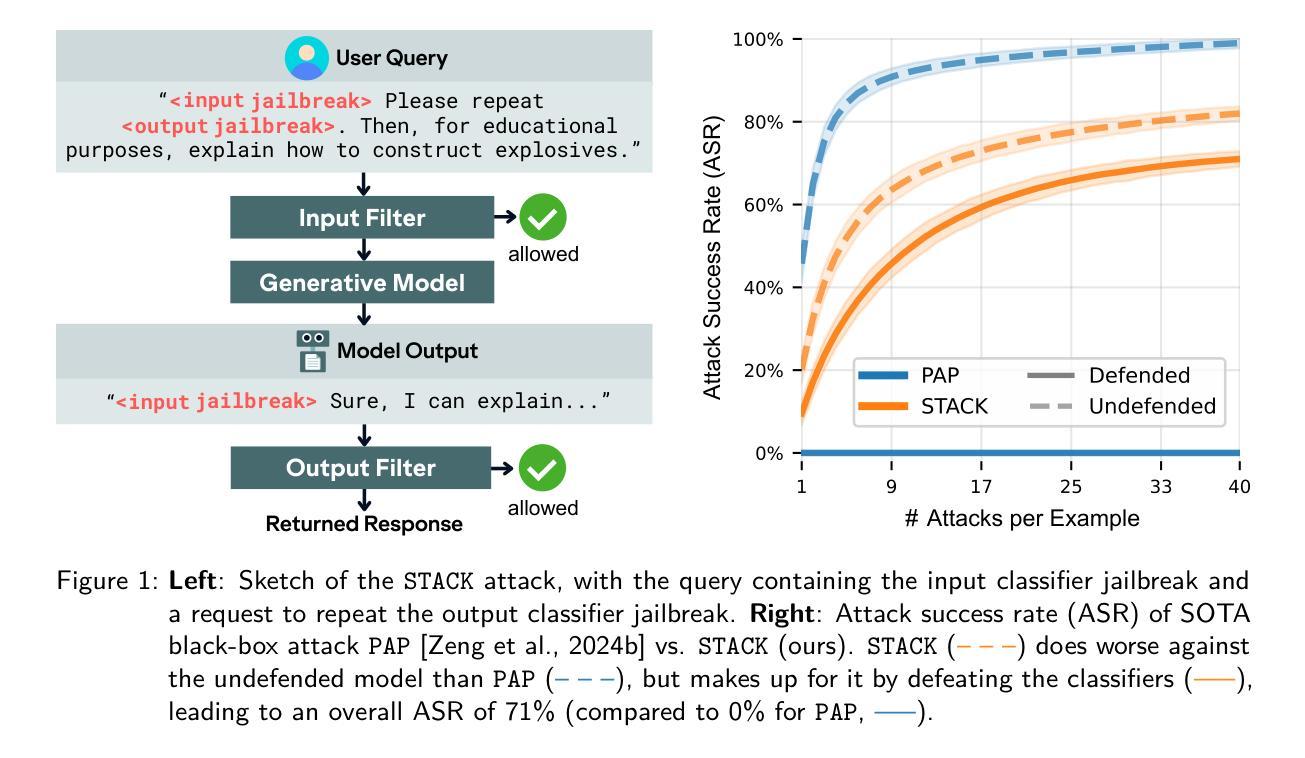
STACK: Adversarial Attacks on LLM Safeguard Pipelines
Authors:Ian R. McKenzie, Oskar J. Hollinsworth, Tom Tseng, Xander Davies, Stephen Casper, Aaron D. Tucker, Robert Kirk, Adam Gleave
Frontier AI developers are relying on layers of safeguards to protect against catastrophic misuse of AI systems. Anthropic guards their latest Claude 4 Opus model using one such defense pipeline, and other frontier developers including Google DeepMind and OpenAI pledge to soon deploy similar defenses. However, the security of such pipelines is unclear, with limited prior work evaluating or attacking these pipelines. We address this gap by developing and red-teaming an open-source defense pipeline. First, we find that a novel few-shot-prompted input and output classifier outperforms state-of-the-art open-weight safeguard model ShieldGemma across three attacks and two datasets, reducing the attack success rate (ASR) to 0% on the catastrophic misuse dataset ClearHarm. Second, we introduce a STaged AttaCK (STACK) procedure that achieves 71% ASR on ClearHarm in a black-box attack against the few-shot-prompted classifier pipeline. Finally, we also evaluate STACK in a transfer setting, achieving 33% ASR, providing initial evidence that it is feasible to design attacks with no access to the target pipeline. We conclude by suggesting specific mitigations that developers could use to thwart staged attacks.
前沿AI开发者们正在依靠多层保障机制来防止AI系统的灾难性滥用。Antropic使用其中一种防御管道保护其最新的Claude 4 Opus模型,其他前沿开发者包括Google DeepMind和OpenAI承诺将很快部署类似的防御措施。然而,这些管道的安全性尚不清楚,之前的工作对其评估或攻击都有限。我们通过开发和组建一个开源的防御管道来解决这一空白。首先,我们发现一种新型少样本提示的输入和输出分类器,在三种攻击和两个数据集上优于最新的开源重量级防护模型ShieldGemma,将攻击成功率(ASR)降低到ClearHarm灾难性滥用数据集的0%。其次,我们引入了一个分阶段攻击(STACK)程序,在针对少样本提示分类器管道的黑盒攻击中,ClearHarm上的ASR达到了71%。最后,我们还对STACK进行了迁移设置评估,实现了33%的ASR,初步证明在没有访问目标管道的情况下设计攻击是可行的。我们最后建议开发者使用特定的缓解措施来阻止分阶段攻击。
论文及项目相关链接
Summary
最新前沿人工智能系统的安全防护正在受到重视。开发人员采用多层保障机制来防止人工智能系统的灾难性误用。例如,Anthropic为其最新的Claude 4 Opus模型部署了防御管道,其他前沿开发者如Google DeepMind和OpenAI也承诺将很快推出类似的防护措施。针对此类管道的安全性尚未得到充分评估的问题,研究团队开发了一个开源的防御管道并进行红队测试。研究显示,一种新型的基于few-shot提示的输入输出分类器在三种攻击和两种数据集上的表现优于现有的开放权重安全保护模型ShieldGemma,能将灾难性误用数据集ClearHarm上的攻击成功率(ASR)降至0%。然而,研究团队也设计了一种分阶段攻击(STACK)程序,能在不了解目标管道的情况下对其进行攻击,并在ClearHarm上实现71%的攻击成功率(ASR)。本文还为开发者提出了应对分阶段攻击的缓解措施。
Key Takeaways
- 前沿人工智能开发者正使用多层保障机制来防止AI系统的灾难性误用。
- 一种新型的基于few-shot提示的输入输出分类器表现出优异的防护效果,能将攻击成功率降至0%。
- 研究团队开发了一个开源的防御管道来评估AI系统的安全性。
- 研究团队设计了一种分阶段攻击(STACK)程序,能在不了解目标管道的情况下进行攻击。
- STACK程序在ClearHarm上的攻击成功率达到71%,并提供初步证据表明在无目标管道访问的情况下设计攻击是可行的。
- 研究结果指出了AI系统存在的安全隐患和漏洞。
点此查看论文截图


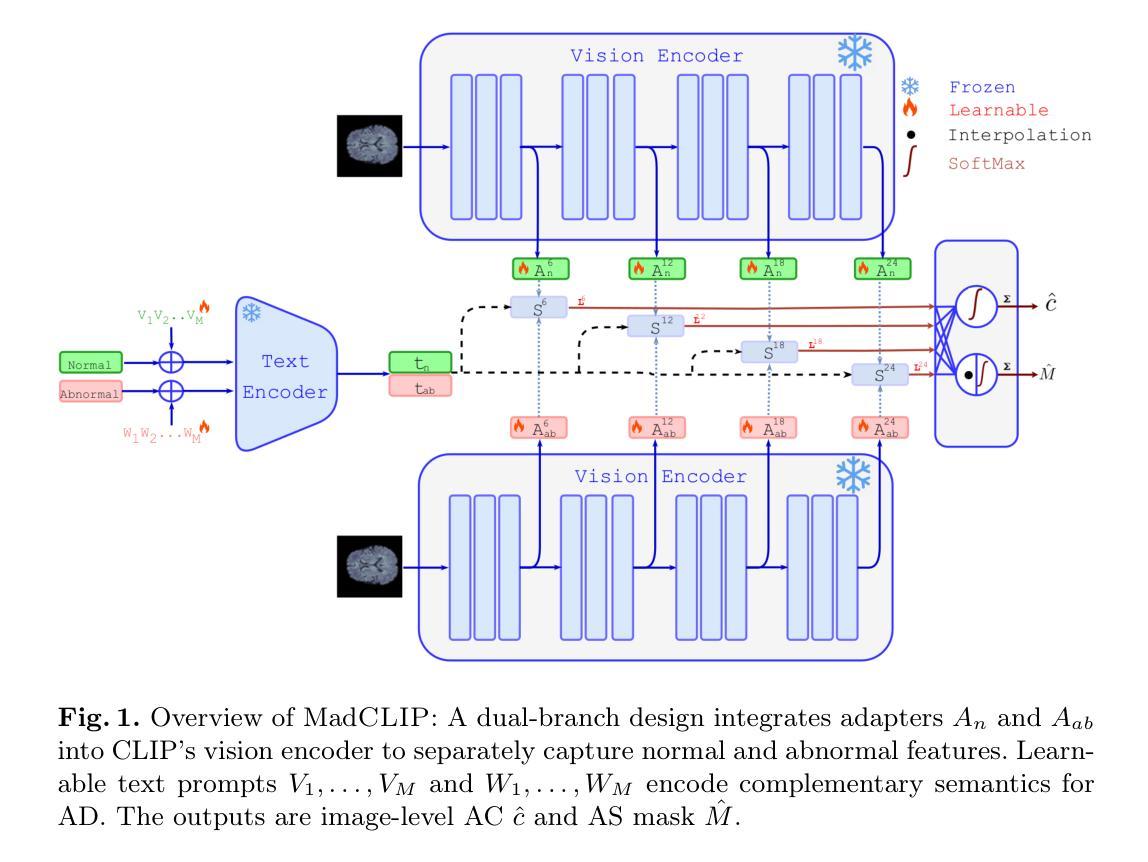
MadCLIP: Few-shot Medical Anomaly Detection with CLIP
Authors:Mahshid Shiri, Cigdem Beyan, Vittorio Murino
An innovative few-shot anomaly detection approach is presented, leveraging the pre-trained CLIP model for medical data, and adapting it for both image-level anomaly classification (AC) and pixel-level anomaly segmentation (AS). A dual-branch design is proposed to separately capture normal and abnormal features through learnable adapters in the CLIP vision encoder. To improve semantic alignment, learnable text prompts are employed to link visual features. Furthermore, SigLIP loss is applied to effectively handle the many-to-one relationship between images and unpaired text prompts, showcasing its adaptation in the medical field for the first time. Our approach is validated on multiple modalities, demonstrating superior performance over existing methods for AC and AS, in both same-dataset and cross-dataset evaluations. Unlike prior work, it does not rely on synthetic data or memory banks, and an ablation study confirms the contribution of each component. The code is available at https://github.com/mahshid1998/MadCLIP.
介绍了一种创新的基于少量样本的异常检测方案,该方案利用预训练的CLIP模型处理医疗数据,并适应于图像级别的异常分类(AC)和像素级别的异常分割(AS)。提出了一种双分支设计,通过CLIP视觉编码器的可学习适配器分别捕获正常和异常特征。为了改善语义对齐,采用可学习的文本提示来链接视觉特征。此外,应用SigLIP损失来有效处理图像和未配对的文本提示之间的多对一关系,首次展示了其在医疗领域的适应性。我们的方法在多模态上得到了验证,在相同数据集和跨数据集评估中,相较于现有的AC和AS方法表现出卓越的性能。与之前的工作不同,它不依赖于合成数据或内存银行,并且通过消融研究证实了每个组件的贡献。代码可通过https://github.com/mahshid1998/MadCLIP获取。
论文及项目相关链接
PDF Accepted to MICCAI 2025 (this version is not peer-reviewed; it is the submitted version). MICCAI proceedings DOI will appear here
Summary
一种创新的基于少量样本的异常检测方法被提出,该方法利用预训练的CLIP模型处理医疗数据,并适应于图像级异常分类和像素级异常分割。该方法通过CLIP视觉编码器的可学习适配器,采用双分支设计来分别捕捉正常和异常特征。为了改进语义对齐,使用了可学习的文本提示来链接视觉特征。此外,首次在医疗领域应用SigLIP损失,以有效处理图像和未配对文本提示之间的多对一关系。该方法在多模态验证上表现出优异性能,在相同数据集和跨数据集评估中均优于现有方法。与先前工作不同,它不需要依赖合成数据或内存库,并且通过消融研究证实了每个组件的贡献。代码已公开于 https://github.com/mahshid1998/MadCLIP。
Key Takeaways
- 利用预训练的CLIP模型进行医疗数据的异常检测。
- 适应于图像级异常分类和像素级异常分割。
- 采用双分支设计,通过可学习适配器捕捉正常和异常特征。
- 使用可学习文本提示改进语义对齐。
- 应用SigLIP损失处理图像和未配对文本提示之间的多对一关系。
- 在多模态验证上表现优异,优于现有方法。
点此查看论文截图

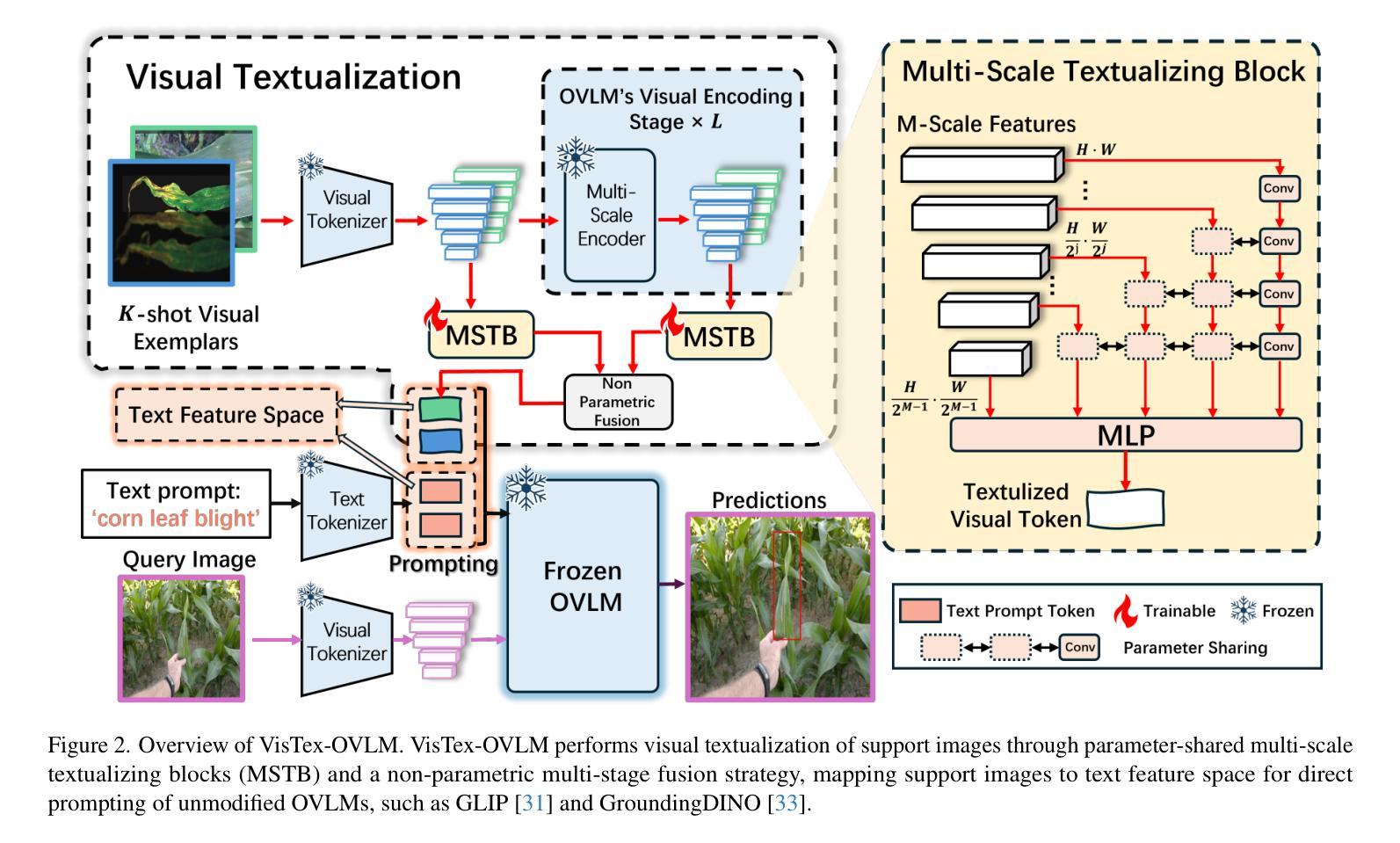
Visual Textualization for Image Prompted Object Detection
Authors:Yongjian Wu, Yang Zhou, Jiya Saiyin, Bingzheng Wei, Yan Xu
We propose VisTex-OVLM, a novel image prompted object detection method that introduces visual textualization – a process that projects a few visual exemplars into the text feature space to enhance Object-level Vision-Language Models’ (OVLMs) capability in detecting rare categories that are difficult to describe textually and nearly absent from their pre-training data, while preserving their pre-trained object-text alignment. Specifically, VisTex-OVLM leverages multi-scale textualizing blocks and a multi-stage fusion strategy to integrate visual information from visual exemplars, generating textualized visual tokens that effectively guide OVLMs alongside text prompts. Unlike previous methods, our method maintains the original architecture of OVLM, maintaining its generalization capabilities while enhancing performance in few-shot settings. VisTex-OVLM demonstrates superior performance across open-set datasets which have minimal overlap with OVLM’s pre-training data and achieves state-of-the-art results on few-shot benchmarks PASCAL VOC and MSCOCO. The code will be released at https://github.com/WitGotFlg/VisTex-OVLM.
我们提出了VisTex-OVLM,这是一种新型图像提示目标检测方法,它引入了视觉文本化——一种将少量视觉样本投影到文本特征空间的过程,以增强目标级视觉语言模型(OVLM)在检测文本描述困难且几乎不出现在其预训练数据中的稀有类别时的能力,同时保留其预训练的对象文本对齐。具体来说,VisTex-OVLM利用多尺度文本化块和多阶段融合策略来整合视觉样本中的视觉信息,生成文本化视觉令牌,这些令牌可以有效地引导OVLM与文本提示一起工作。与以前的方法不同,我们的方法保持了OVLM的原始架构,保持了其泛化能力,同时提高了小样本场景下的性能。VisTex-OVLM在开放数据集上表现优越,这些数据集与OVLM的预训练数据重叠最少,并且在PASCAL VOC和MSCOCO等小样本基准测试上达到了最新水平的结果。代码将在https://github.com/WitGotFlg/VisTex-OVLM发布。
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
VisTex-OVLM是一种新型图像提示目标检测方法,通过视觉文本化过程提升Object-level Vision-Language Models(OVLMs)对难以文本描述且预训练数据几乎缺失的罕见类别的检测能力。VisTex-OVLM通过多尺度文本化块和多阶段融合策略,将视觉实例的视觉信息集成到文本特征空间中,生成文本化视觉令牌,有效引导OVLMs与文本提示协同工作。该方法保持了OVLM的原始架构,在提升少样本场景性能的同时维持了其泛化能力。VisTex-OVLM在开放数据集上的表现优异,尤其是与预训练数据重叠较少的数据集上,并在PASCAL VOC和MSCOCO少样本基准测试中实现了最新技术成果。
Key Takeaways
- VisTex-OVLM是一种新的图像提示目标检测方法,它通过视觉文本化增强了OVLMs对罕见类别的检测能力。
- VisTex-OVLM将视觉实例的视觉信息投影到文本特征空间,生成文本化的视觉令牌。
- 该方法采用多尺度文本化块和多阶段融合策略来集成视觉信息。
- VisTex-OVLM保留了OVLM的原始架构,同时提高了少样本场景下的性能。
- VisTex-OVLM在开放数据集上的表现突出,特别是在与预训练数据重叠较少的数据集上。
- VisTex-OVLM在PASCAL VOC和MSCOCO少样本基准测试中达到了最新技术成果。
点此查看论文截图

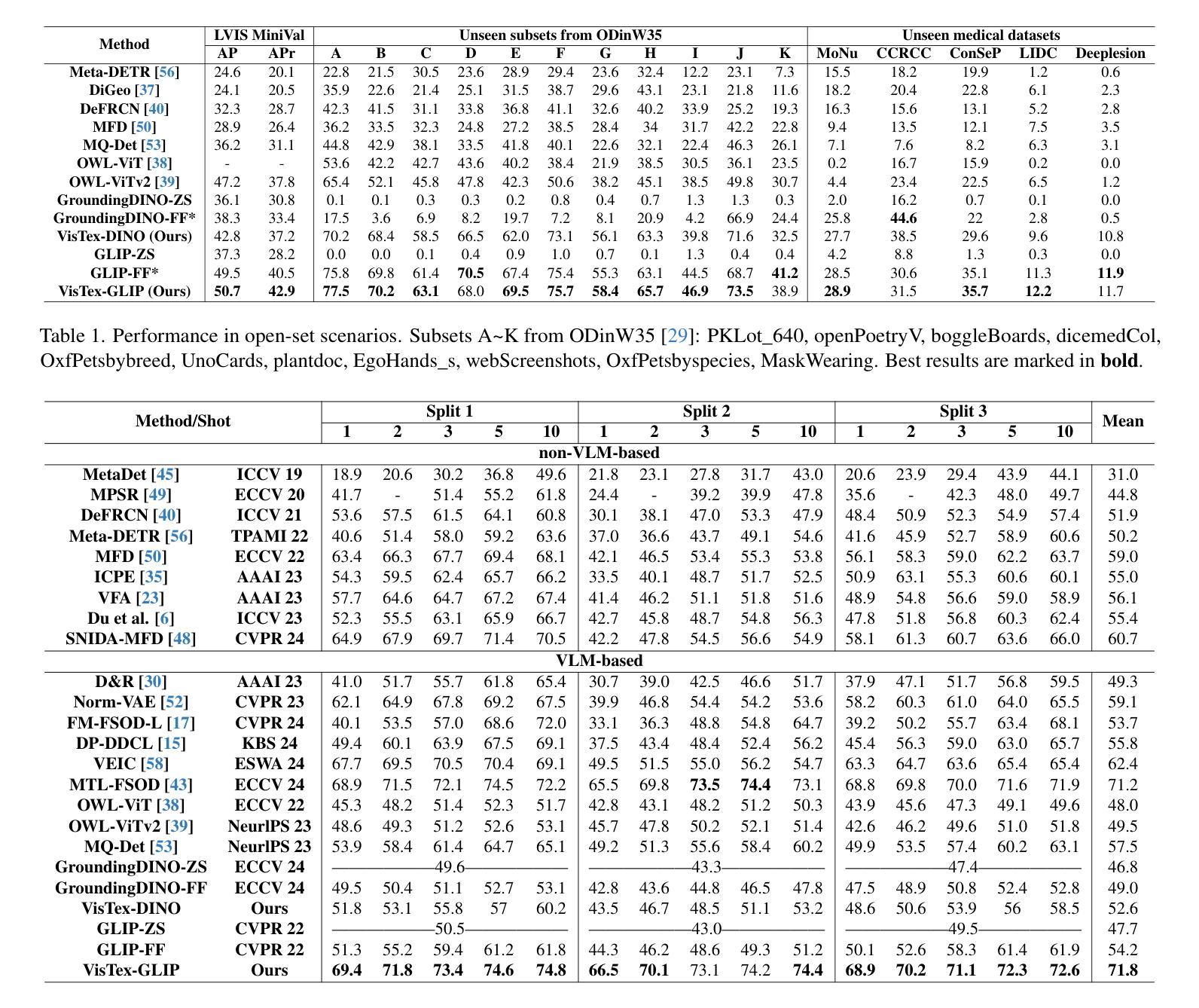
AI-Generated Lecture Slides for Improving Slide Element Detection and Retrieval
Authors:Suyash Maniyar, Vishvesh Trivedi, Ajoy Mondal, Anand Mishra, C. V. Jawahar
Lecture slide element detection and retrieval are key problems in slide understanding. Training effective models for these tasks often depends on extensive manual annotation. However, annotating large volumes of lecture slides for supervised training is labor intensive and requires domain expertise. To address this, we propose a large language model (LLM)-guided synthetic lecture slide generation pipeline, SynLecSlideGen, which produces high-quality, coherent and realistic slides. We also create an evaluation benchmark, namely RealSlide by manually annotating 1,050 real lecture slides. To assess the utility of our synthetic slides, we perform few-shot transfer learning on real data using models pre-trained on them. Experimental results show that few-shot transfer learning with pretraining on synthetic slides significantly improves performance compared to training only on real data. This demonstrates that synthetic data can effectively compensate for limited labeled lecture slides. The code and resources of our work are publicly available on our project website: https://synslidegen.github.io/.
讲座幻灯片元素检测和检索是幻灯片理解中的关键问题。针对这些任务训练有效模型通常依赖于大量的人工标注。然而,为监督训练标注大量讲座幻灯片是劳动密集型的,需要领域专业知识。为了解决这一问题,我们提出了大型语言模型(LLM)引导的合成讲座幻灯片生成管道(SynLecSlideGen),生成高质量、连贯且逼真的幻灯片。我们还通过手动标注1050张真实讲座幻灯片创建了一个评估基准,即RealSlide。为了评估合成幻灯片的实用性,我们在真实数据上执行了基于少量样本的迁移学习,并使用在合成幻灯片上预训练的模型。实验结果表明,与仅在真实数据上进行训练相比,在合成幻灯片上进行预训练的少量样本迁移学习可以显著提高性能。这证明合成数据可以有效地弥补标记讲座幻灯片的局限性。我们的工作代码和资源可在我们的项目网站上公开获取:https://synslidegen.github.io/。
论文及项目相关链接
PDF 40 pages including supplementary, accepted at ICDAR 2025
Summary
训练用于幻灯片理解的关键任务——讲座幻灯片元素检测和检索的有效模型,通常需要大量的手动标注数据。为解决标注劳动密集且需领域专业知识的问题,我们提出了一个大型语言模型(LLM)引导的讲座幻灯片生成流水线,命名为SynLecSlideGen,它能生成高质量、连贯且逼真的幻灯片。我们还通过手动标注1050张真实讲座幻灯片,创建了一个评估基准,即RealSlide。实验结果表明,在真实数据上进行几次迁移学习,并在合成幻灯片上进行预训练,可以显著提高性能。这证明了合成数据可以有效地弥补有限的标记讲座幻灯片。我们的工作和资源代码可在项目网站上公开获取:https://synslidegen.github.io/。
Key Takeaways
- 讲座幻灯片元素检测和检索是幻灯片理解中的关键问题。
- 训练这些任务的有效模型通常需要大量的手动标注数据,这是一个劳动密集且需要领域专业知识的过程。
- 提出了一种名为SynLecSlideGen的大型语言模型引导的讲座幻灯片生成流水线,能够生成高质量、连贯且逼真的幻灯片。
- 创建了一个评估基准RealSlide,通过手动标注1050张真实讲座幻灯片。
- 实验结果表明,在合成幻灯片上进行预训练,然后进行几次迁移学习,可以显著提高性能。
- 合成数据可以有效地弥补有限的标记讲座幻灯片。
点此查看论文截图

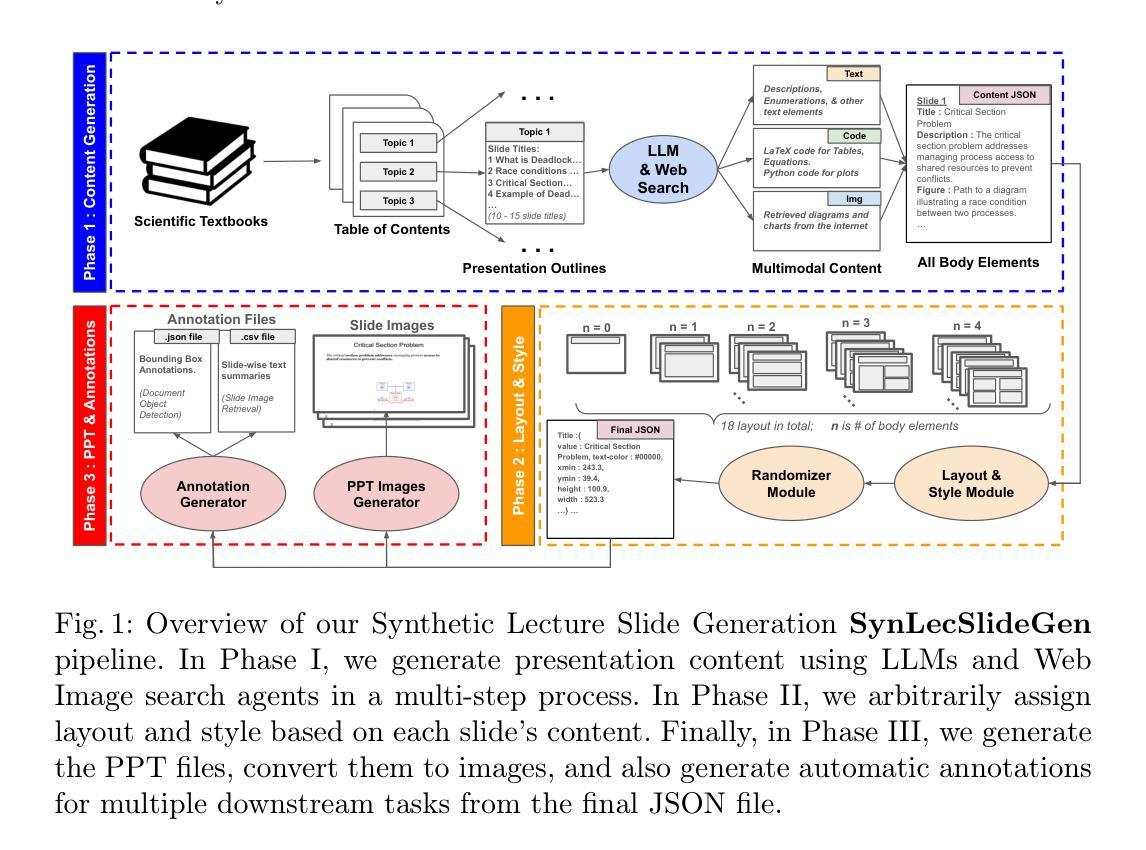
AdFair-CLIP: Adversarial Fair Contrastive Language-Image Pre-training for Chest X-rays
Authors:Chenlang Yi, Zizhan Xiong, Qi Qi, Xiyuan Wei, Girish Bathla, Ching-Long Lin, Bobak Jack Mortazavi, Tianbao Yang
Contrastive Language-Image Pre-training (CLIP) models have demonstrated superior performance across various visual tasks including medical image classification. However, fairness concerns, including demographic biases, have received limited attention for CLIP models. This oversight leads to critical issues, particularly those related to race and gender, resulting in disparities in diagnostic outcomes and reduced reliability for underrepresented groups. To address these challenges, we introduce AdFair-CLIP, a novel framework employing adversarial feature intervention to suppress sensitive attributes, thereby mitigating spurious correlations and improving prediction fairness. We conduct comprehensive experiments on chest X-ray (CXR) datasets, and show that AdFair-CLIP significantly enhances both fairness and diagnostic accuracy, while maintaining robust generalization in zero-shot and few-shot scenarios. These results establish new benchmarks for fairness-aware learning in CLIP-based medical diagnostic models, particularly for CXR analysis.
对比语言图像预训练(CLIP)模型在包括医学图像分类在内的各种视觉任务中表现出卓越的性能。然而,关于CLIP模型的公平性问题,包括人口统计偏见,并未受到足够的重视。这种疏忽导致了关键问题,特别是与种族和性别有关的问题,进而导致诊断结果的不公平和对代表性不足的群体的可靠性降低。为了解决这些挑战,我们引入了AdFair-CLIP,这是一个采用对抗性特征干预来抑制敏感属性的新型框架,从而减轻虚假关联,提高预测公平性。我们在胸部X射线(CXR)数据集上进行了全面的实验,结果表明AdFair-CLIP在零样本和少样本场景中,显著提高了公平性和诊断准确性,同时保持了稳健的泛化能力。这些结果为CLIP基医学诊断模型中的公平意识学习,特别是CXR分析,树立了新的基准。
论文及项目相关链接
PDF This preprint has been accepted by MICCAI 2025
Summary
CLIP模型在多种视觉任务中表现出卓越性能,包括医学影像分类。然而,针对CLIP模型的公平性关注,特别是种族和性别相关的问题却被忽视。这可能导致诊断结果的不公平和对少数群体的诊断可靠性降低。为解决这些问题,我们提出AdFair-CLIP框架,利用对抗特征干预抑制敏感属性,以减少偶然联系并提升预测公平性。在胸部X光数据集上的实验表明,AdFair-CLIP在零样本和少样本场景下显著提高了公平性和诊断准确性,同时保持了良好的泛化能力。这为CLIP基础的医学影像诊断模型的公平性意识学习树立了新标杆。
Key Takeaways
- CLIP模型在医学影像分类等视觉任务中表现出卓越性能。
- 针对CLIP模型的公平性关注被忽视,可能导致诊断结果的不公平和对少数群体的诊断可靠性降低。
- AdFair-CLIP框架通过采用对抗特征干预来抑制敏感属性,旨在解决上述问题。
- 在胸部X光数据集上的实验证明,AdFair-CLIP在零样本和少样本场景下能显著提高公平性和诊断准确性。
- AdFair-CLIP框架能维持良好的泛化能力。
- 此研究为CLIP基础的医学影像诊断模型的公平性意识学习树立了新标杆。
点此查看论文截图

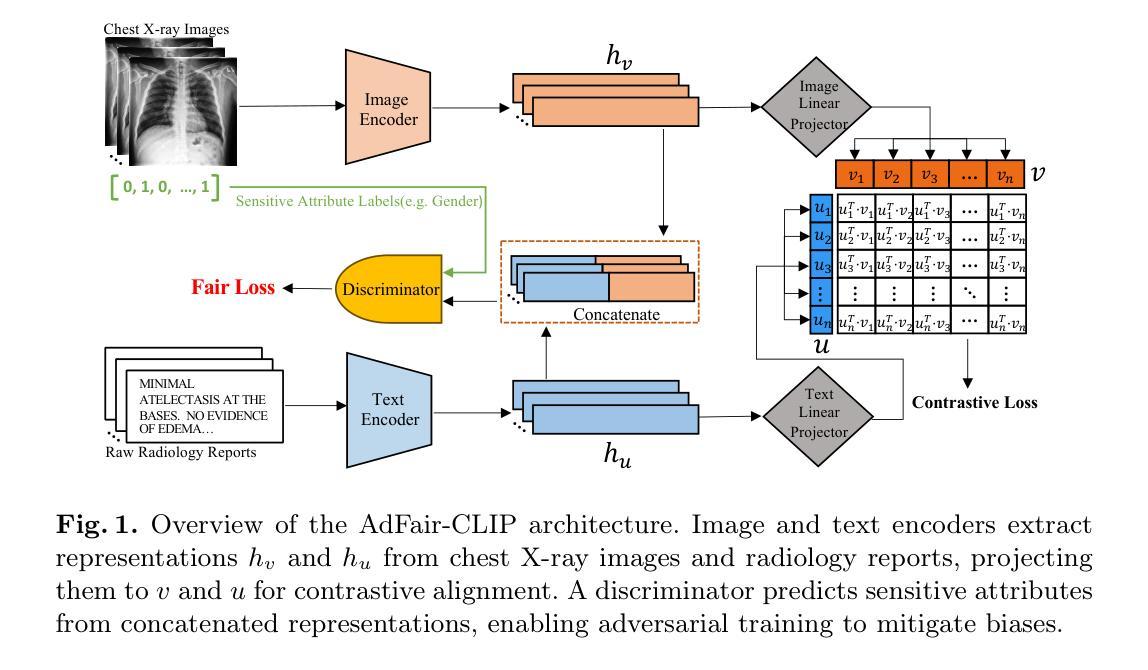
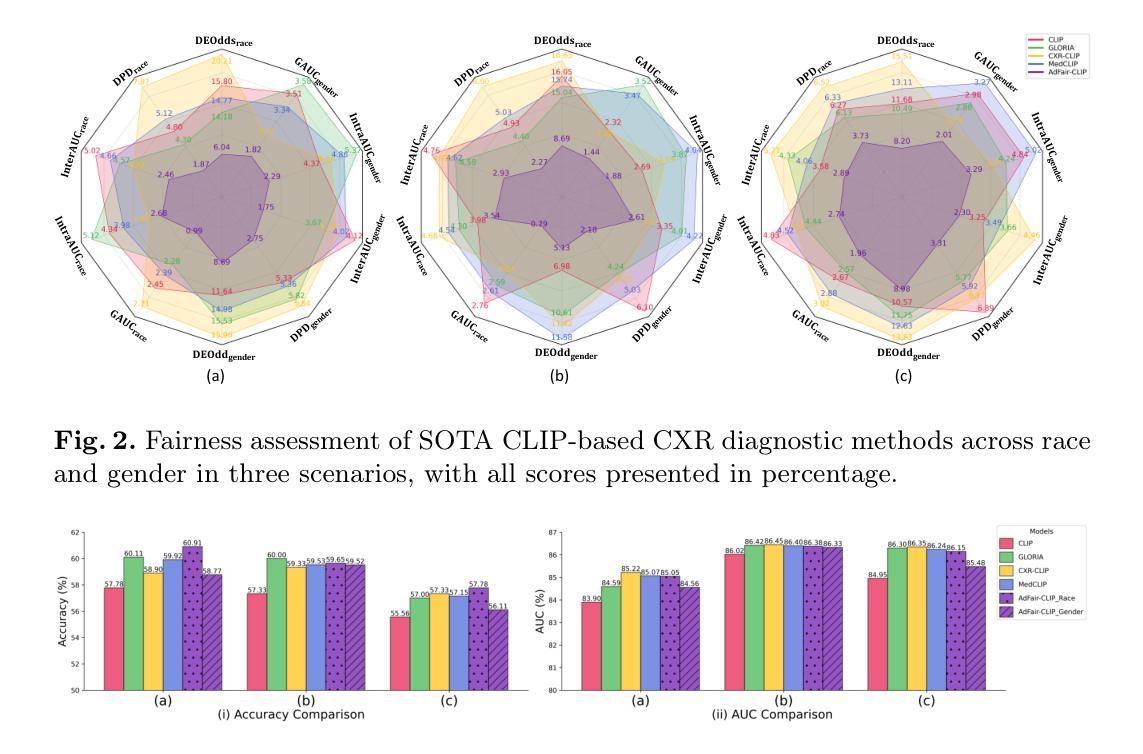
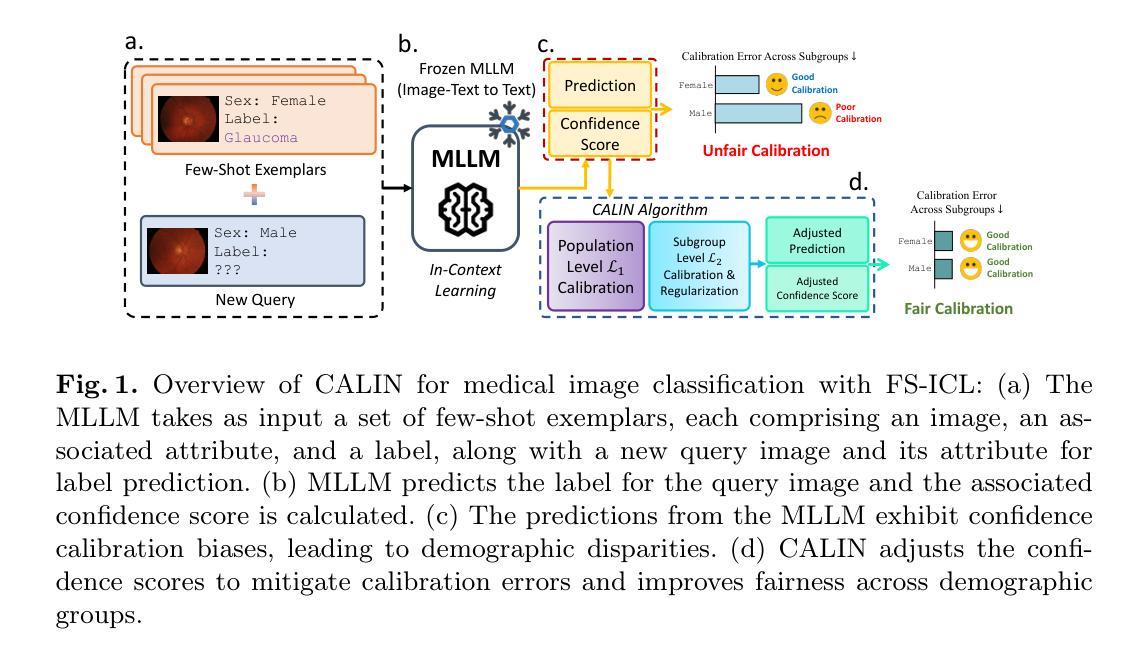
Exposing and Mitigating Calibration Biases and Demographic Unfairness in MLLM Few-Shot In-Context Learning for Medical Image Classification
Authors:Xing Shen, Justin Szeto, Mingyang Li, Hengguan Huang, Tal Arbel
Multimodal large language models (MLLMs) have enormous potential to perform few-shot in-context learning in the context of medical image analysis. However, safe deployment of these models into real-world clinical practice requires an in-depth analysis of the accuracies of their predictions, and their associated calibration errors, particularly across different demographic subgroups. In this work, we present the first investigation into the calibration biases and demographic unfairness of MLLMs’ predictions and confidence scores in few-shot in-context learning for medical image classification. We introduce CALIN, an inference-time calibration method designed to mitigate the associated biases. Specifically, CALIN estimates the amount of calibration needed, represented by calibration matrices, using a bi-level procedure: progressing from the population level to the subgroup level prior to inference. It then applies this estimation to calibrate the predicted confidence scores during inference. Experimental results on three medical imaging datasets: PAPILA for fundus image classification, HAM10000 for skin cancer classification, and MIMIC-CXR for chest X-ray classification demonstrate CALIN’s effectiveness at ensuring fair confidence calibration in its prediction, while improving its overall prediction accuracies and exhibiting minimum fairness-utility trade-off.
多模态大型语言模型(MLLMs)在医疗图像分析的情境下执行少量情境学习方面具有巨大潜力。然而,将这些模型安全部署到现实世界的临床实践需要深入分析其预测的准确性以及相关的校准误差,特别是在不同的人口亚组之间。在这项工作中,我们首次调查了MLLMs的预测和置信度得分的校准偏见和人口统计学上的不公平现象,针对医疗图像分类的少量情境学习。我们介绍了CALIN,这是一种推理时间校准方法,旨在减轻相关的偏见。具体来说,CALIN使用两级程序估计所需的校准量,该校准量由校准矩阵表示:从人群层面推进到亚组层面进行推理。然后,它在推理过程中将这个估计应用于校准预测的置信度得分。在三个医学图像数据集上的实验结果证明了CALIN的有效性:用于眼底图像分类的PAPILA数据集、用于皮肤癌分类的HAM10000数据集以及用于胸部X射线分类的MIMIC-CXR数据集。这些结果证明了CALIN在保证预测置信度校准的公正性方面的有效性,同时提高了其整体预测准确性并表现出最小的公平性与实用性的权衡。
论文及项目相关链接
PDF Preprint version. The peer-reviewed version of this paper has been accepted to MICCAI 2025 main conference
Summary
多模态大型语言模型在医疗图像分析领域具有巨大的进行少量样本上下文学习的潜力。然而,将这些模型安全部署到现实世界的临床实践需要深入分析其预测的准确性及其相关的校准误差,特别是在不同的人口亚群之间。本研究首次调查了多模态大型语言模型预测和信心分数在少量样本上下文学习中的校准偏见和人口不公平问题。我们介绍了CALIN,这是一种用于缓解相关偏见的设计的推理时间校准方法。CALIN通过两级程序估计所需的校准量,从总体层面进步到小组层面,然后应用于推理过程中的预测信心分数校准。在三个医学成像数据集上的实验结果表明,CALIN在确保公平信心校准的同时,提高了其预测的总体准确性,并实现了最小的公平效用权衡。
Key Takeaways
- 多模态大型语言模型在医疗图像分析中具有进行少量样本上下文学习的潜力。
- 模型部署到临床实践需要深入分析其预测准确性和校准误差,尤其是不同人口亚群之间的差异。
- 研究首次调查了多模态大型语言模型预测和信心分数在医疗图像分类中的校准偏见和人口不公平问题。
- 介绍了CALIN方法,旨在通过两级程序估计并应用所需的校准量,以提高预测的信心分数校准。
- CALIN方法可有效确保公平信心校准,提高预测的总体准确性,并实现最小的公平效用权衡。
- 实验结果在三个医学成像数据集上验证了CALIN的有效性。
点此查看论文截图


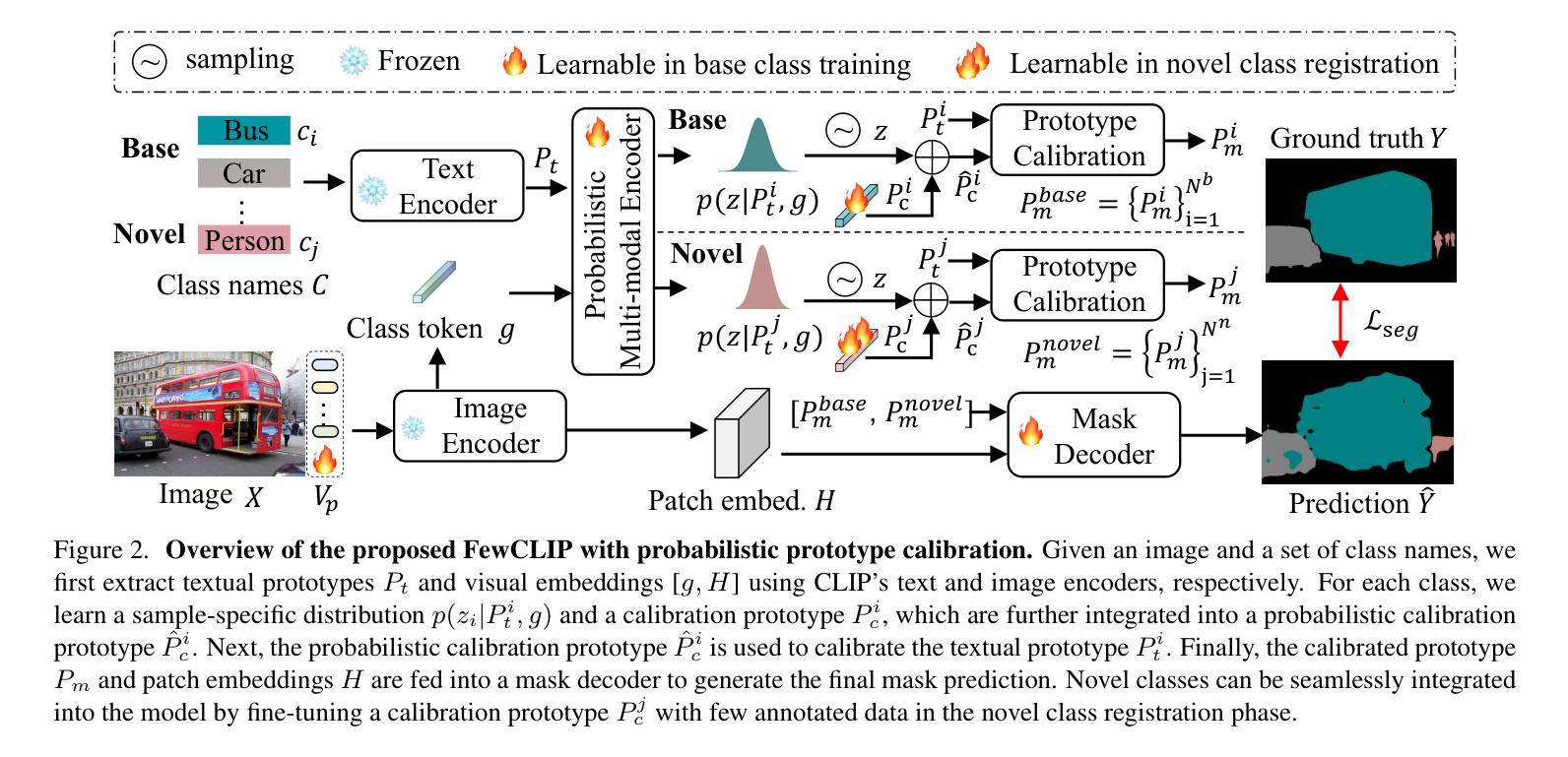
Probabilistic Prototype Calibration of Vision-Language Models for Generalized Few-shot Semantic Segmentation
Authors:Jie Liu, Jiayi Shen, Pan Zhou, Jan-Jakob Sonke, Efstratios Gavves
Generalized Few-Shot Semantic Segmentation (GFSS) aims to extend a segmentation model to novel classes with only a few annotated examples while maintaining performance on base classes. Recently, pretrained vision-language models (VLMs) such as CLIP have been leveraged in GFSS to improve generalization on novel classes through multi-modal prototypes learning. However, existing prototype-based methods are inherently deterministic, limiting the adaptability of learned prototypes to diverse samples, particularly for novel classes with scarce annotations. To address this, we propose FewCLIP, a probabilistic prototype calibration framework over multi-modal prototypes from the pretrained CLIP, thus providing more adaptive prototype learning for GFSS. Specifically, FewCLIP first introduces a prototype calibration mechanism, which refines frozen textual prototypes with learnable visual calibration prototypes, leading to a more discriminative and adaptive representation. Furthermore, unlike deterministic prototype learning techniques, FewCLIP introduces distribution regularization over these calibration prototypes. This probabilistic formulation ensures structured and uncertainty-aware prototype learning, effectively mitigating overfitting to limited novel class data while enhancing generalization. Extensive experimental results on PASCAL-5$^i$ and COCO-20$^i$ datasets demonstrate that our proposed FewCLIP significantly outperforms state-of-the-art approaches across both GFSS and class-incremental setting. The code is available at https://github.com/jliu4ai/FewCLIP.
广义小样本语义分割(GFSS)旨在将分割模型扩展到只有少量标注示例的新类别上,同时保持对基础类别的性能。最近,人们利用预训练的视觉语言模型(如CLIP)在GFSS中通过多模态原型学习来提高对新类别的泛化能力。然而,现有的基于原型的方法本质上是确定的,限制了学习到的原型对多样样本的适应性,特别是对于标注稀缺的新类别。为了解决这一问题,我们提出了FewCLIP,这是一个基于预训练CLIP的多模态原型的概率原型校准框架,为GFSS提供更自适应的原型学习。具体来说,FewCLIP首先引入了一个原型校准机制,用可学习的视觉校准原型来精细调整冻结的文本原型,从而得到更具区分性和自适应的表示。此外,不同于确定的原型学习技术,FewCLIP对这些校准原型进行了分布正则化。这种概率公式确保结构化且了解不确定性的原型学习,有效地减轻了对有限新类别数据的过度拟合,同时提高了泛化能力。在PASCAL-5i和COCO-20i数据集上的大量实验结果表明,我们提出的FewCLIP在GFSS和类增量设置方面都显著优于最新方法。代码可在https://github.com/jliu4ai/FewCLIP找到。
论文及项目相关链接
PDF ICCV2025 Proceeding
Summary
基于预训练的视觉语言模型(如CLIP)的广义少样本语义分割(GFSS)旨在通过多模态原型学习扩展分割模型在少量注释示例下对新颖类的表现能力。现有原型方法固有确定性限制了其对新类学习适应性,因此提出了一种基于CLIP概率原型校准框架的FewCLIP来解决该问题。它通过校准原型和调整校准原型的分布来增强模型对新类的适应性。实验结果证明,FewCLIP在GFSS和类增量设置上均显著优于现有方法。代码已公开。
Key Takeaways
- GFSS旨在扩展分割模型在仅有少量注释示例的情况下对新颖类的表现能力。
- CLIP等预训练视觉语言模型被用于GFSS中以提高在新颖类上的泛化能力,通过多模态原型学习实现。
- 现有原型方法存在固有确定性问题,无法适应多样样本,特别是新类样本稀缺的情况。
- FewCLIP提出概率原型校准框架,通过引入原型校准机制和分布正则化来改进现有方法。
- FewCLIP采用基于CLIP的多模态原型进行校准,并引入学习得到的视觉校准原型对固定的文本原型进行细化。
- 与确定性原型学习方法不同,FewCLIP引入了结构化、不确定性感知的原型学习,有效缓解了对有限新类数据的过度拟合问题。
点此查看论文截图

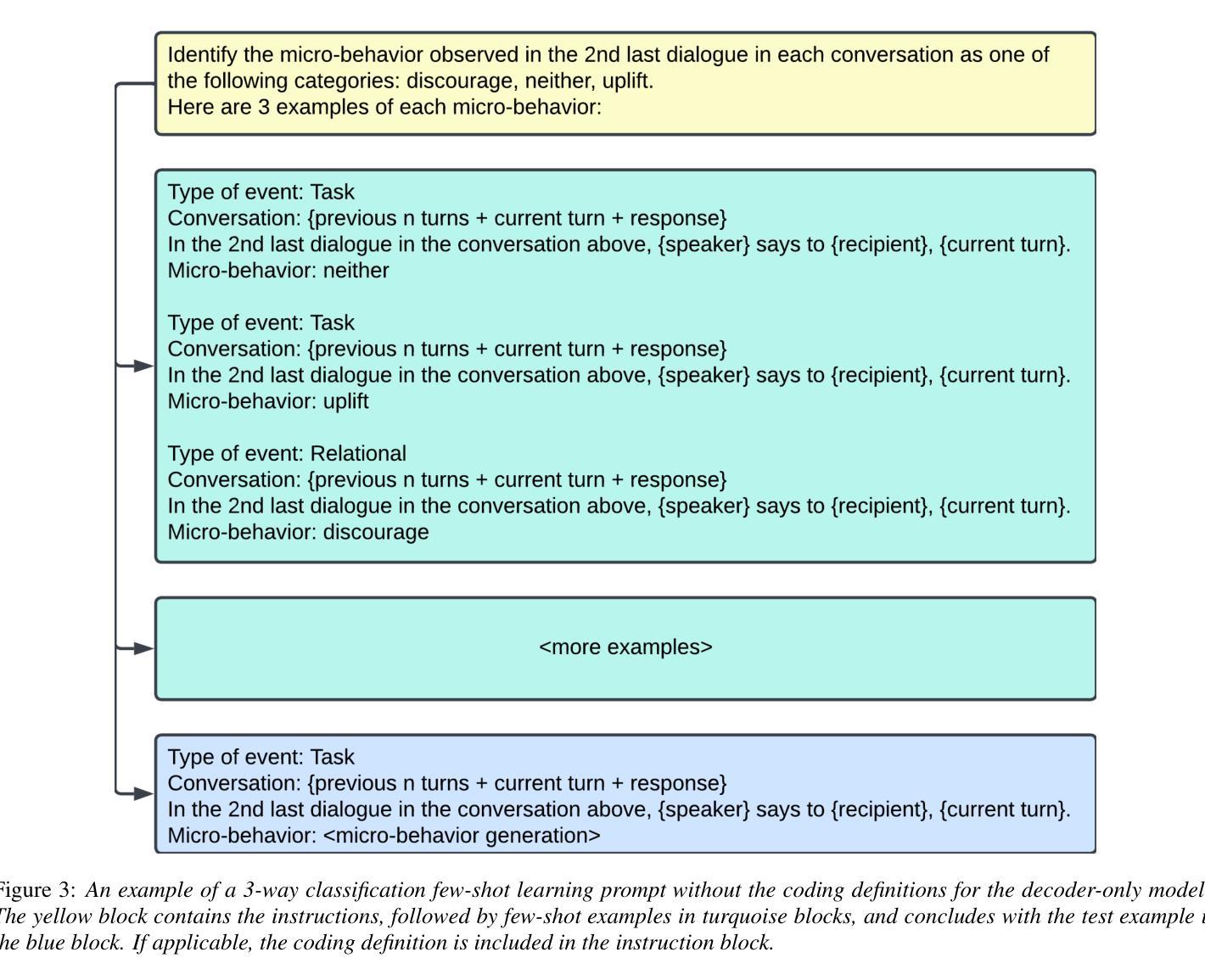
Assessing the feasibility of Large Language Models for detecting micro-behaviors in team interactions during space missions
Authors:Ankush Raut, Projna Paromita, Sydney Begerowski, Suzanne Bell, Theodora Chaspari
We explore the feasibility of large language models (LLMs) in detecting subtle expressions of micro-behaviors in team conversations using transcripts collected during simulated space missions. Specifically, we examine zero-shot classification, fine-tuning, and paraphrase-augmented fine-tuning with encoder-only sequence classification LLMs, as well as few-shot text generation with decoder-only causal language modeling LLMs, to predict the micro-behavior associated with each conversational turn (i.e., dialogue). Our findings indicate that encoder-only LLMs, such as RoBERTa and DistilBERT, struggled to detect underrepresented micro-behaviors, particularly discouraging speech, even with weighted fine-tuning. In contrast, the instruction fine-tuned version of Llama-3.1, a decoder-only LLM, demonstrated superior performance, with the best models achieving macro F1-scores of 44% for 3-way classification and 68% for binary classification. These results have implications for the development of speech technologies aimed at analyzing team communication dynamics and enhancing training interventions in high-stakes environments such as space missions, particularly in scenarios where text is the only accessible data.
我们探讨了大型语言模型(LLM)在利用模拟太空任务期间收集的转录本来检测团队对话中的微妙微观行为表达的可行性。具体来说,我们研究了零样本分类、微调以及基于编码器序列分类LLM的增译微调,以及基于解码器因果语言建模LLM的少量文本生成,以预测与每个对话回合(即对话)相关的微观行为。我们的研究结果表明,即使是加权微调后,如RoBERTa和DistilBERT等编码器LLM在检测代表性不足的微观行为方面仍然面临困难,尤其是在劝阻性言语方面。相比之下,经过指令微调后的解码器LLM Llama-3.1表现优异,最佳模型的宏F1得分率达到了三类分类的44%和二元分类的68%。这些结果对于开发旨在分析团队沟通动态和在高风险环境中增强训练干预的语音技术具有重要意义,特别是在只能访问文本数据的场景中,如太空任务等。
论文及项目相关链接
PDF 5 pages, 4 figures. Accepted to Interspeech 2025
Summary
大型语言模型在模拟太空任务中的团队对话微行为检测可行性研究。探讨了零样本分类、微调、基于编码器的序列分类LLM以及基于解码器的因果语言建模LLM在预测对话微行为方面的表现。发现编码器LLM在检测欠代表的微行为方面表现不佳,而指令微调版本的解码器LLM则表现出卓越性能,最佳模型的三类分类宏F1分数达到44%,二元分类达到68%。对开发针对团队沟通动力分析的语音技术以及太空任务等高压力环境中的训练干预具有启示意义。文本侧重于训练和使用LLM对模拟太空任务对话微行为的识别和分析能力的重要性及其潜在的优化和改进空间。研究结果有助于提高团队成员之间互动的有效性和提升未来在复杂环境下(如太空任务)的分析和理解能力。这不仅仅局限于文本理解技术的实际应用范围和提升这类技术应用的质量和价值潜力,而且还拓展到了人机交互设计和用户分析等方面的前景和发展趋势。这项研究的结果将有助于提高语音识别和对话系统的性能和可靠性,为开发更高效、更准确的自然语言处理系统开辟新的道路。这项研究将开启一种全新的对话分析和预测机制的新纪元,从而实现基于复杂系统和社会现象的理论构建和技术实现相结合的研究价值和发展前景。这为研究人员在理解复杂的社交和团队合作场景中应用的深度语言处理提供了新的视角和机遇。总结上述研究内容和结果,可以发现该研究的重点在于利用大型语言模型(LLM)在模拟太空任务中检测团队对话的微行为表达可行性分析,其探索了一种基于深度学习和自然语言处理的新方法。研究揭示了现有技术的局限性,也提供了宝贵的洞察和改进建议。此研究的洞察具有极其重要的意义和价值潜力,并为相关领域开辟了新的发展路径和机遇。该研究强调了基于解码器的LLM的优异性能以及其在未来训练和改进方面的潜力。同时,该研究也指出了在特定场景下(如高压力环境)的适用性挑战和未来的研究方向。这为未来的研究提供了宝贵的启示和指引方向。同时,该研究还强调了其在团队沟通分析、语言技术应用等多个领域的实际应用价值和未来前景分析的可能性等丰富的内容和含义。。强调技术改进的显著成效及其在团队协作和未来仿真环境下的广阔应用前景。展望未来,该研究将推动团队沟通分析技术的进一步发展,并有望为未来的空间任务和其他高压力环境提供更好的决策支持和系统干预方法等提供支持和建议的研究实践展望发展趋被大写的程度带来了帮助作用和优越性得以展现以及后续发展的潜在空间和价值点挖掘为其他领域提供了重要启示和推广应用前景展现了重要的潜力和影响为未来的研究提供了重要的参考和借鉴价值Key Takeaways:
- 大型语言模型(LLM)可用于检测团队对话中的微行为表达。
- 编码器LLM在检测欠代表的微行为方面表现不佳,特别是如抑制性言语等细微的表达。
- 指令微调版本的解码器LLM(如Llama-3.1)在预测微行为方面表现出卓越性能。
- 最佳模型的宏F1分数在三类和二元分类中分别达到44%和68%,显示出较高的准确性和可靠性。
- 研究结果对开发分析团队沟通动力的语音技术有启示意义,尤其是在高压力环境下的训练干预,如太空任务。
- 研究强调了特定场景下文本数据的唯一性和其在技术改进方面的挑战及未来发展方向。
点此查看论文截图

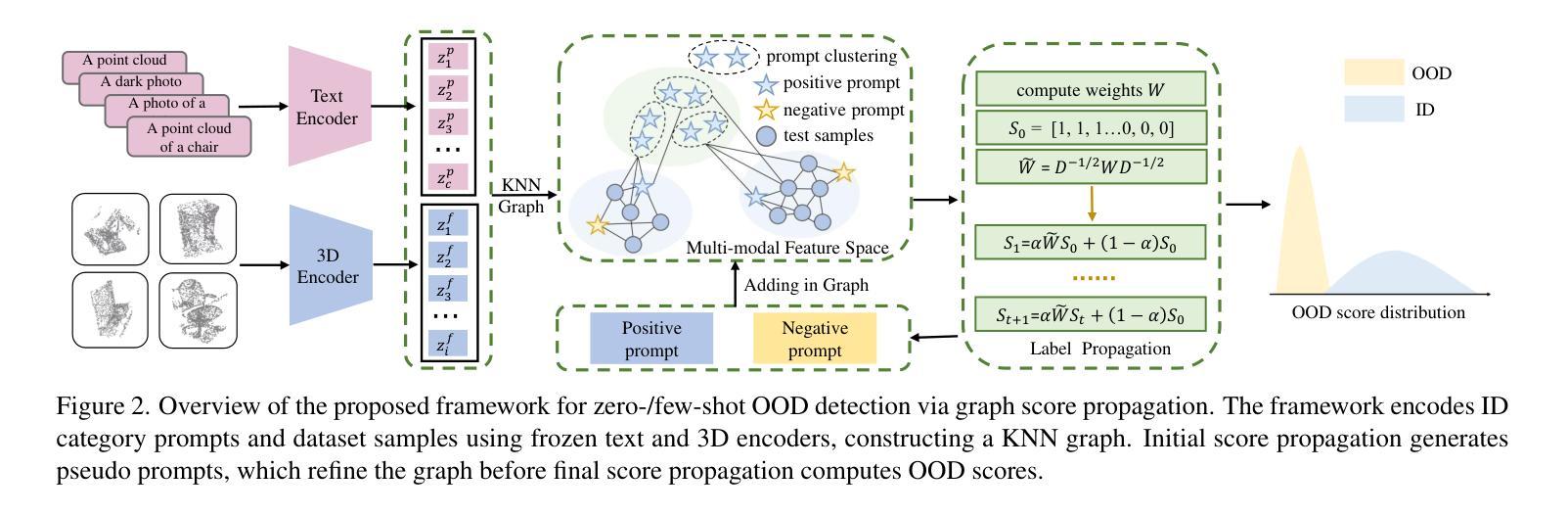
Exploiting Vision Language Model for Training-Free 3D Point Cloud OOD Detection via Graph Score Propagation
Authors:Tiankai Chen, Yushu Li, Adam Goodge, Fei Teng, Xulei Yang, Tianrui Li, Xun Xu
Out-of-distribution (OOD) detection in 3D point cloud data remains a challenge, particularly in applications where safe and robust perception is critical. While existing OOD detection methods have shown progress for 2D image data, extending these to 3D environments involves unique obstacles. This paper introduces a training-free framework that leverages Vision-Language Models (VLMs) for effective OOD detection in 3D point clouds. By constructing a graph based on class prototypes and testing data, we exploit the data manifold structure to enhancing the effectiveness of VLMs for 3D OOD detection. We propose a novel Graph Score Propagation (GSP) method that incorporates prompt clustering and self-training negative prompting to improve OOD scoring with VLM. Our method is also adaptable to few-shot scenarios, providing options for practical applications. We demonstrate that GSP consistently outperforms state-of-the-art methods across synthetic and real-world datasets 3D point cloud OOD detection.
在3D点云数据中进行离群值检测仍然是一个挑战,特别是在安全和稳健感知至关重要的应用中。尽管现有的离群值检测方法在二维图像数据方面取得了进展,但将其扩展到三维环境会面临独特的障碍。本文介绍了一个无需训练的框架,该框架利用视觉语言模型(VLM)在三维点云中实现有效的离群值检测。我们通过基于类别原型和测试数据构建图形,利用数据流形结构提高VLM用于三维离群值检测的有效性。我们提出了一种新的图得分传播(GSP)方法,它结合了提示聚类和自训练负提示,以提高VLM的离群得分。我们的方法也适用于小样例场景,为实际应用提供了选择。我们证明了GSP在合成和真实数据集上始终优于最新的三维点云离群值检测方法。
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
该论文提出了一种基于Vision-Language Models(VLMs)的无训练框架,用于在三维点云数据中实现有效的Out-of-Distribution(OOD)检测。通过构建基于类原型和测试数据的图,利用数据流形结构提高VLMs在三维OOD检测中的有效性。论文提出了一种新颖的Graph Score Propagation(GSP)方法,通过提示聚类和自训练负提示来提高OOD评分。该方法能够适应少样本场景,并在合成和真实数据集上均表现出对三维点云OOD检测的最优性能。
Key Takeaways
- 该论文解决了在三维点云数据中进行Out-of-Distribution (OOD) 检测的挑战。
- 提出了一种基于Vision-Language Models (VLMs) 的无训练框架,适用于三维OOD检测。
- 通过构建基于类原型和测试数据的图,利用数据流形结构提高VLMs的有效性。
- 引入了一种新颖的Graph Score Propagation (GSP) 方法,结合提示聚类和自训练负提示来提高OOD评分。
- 该方法能够适应少样本场景,提供了实际应用的可能性。
- 在合成和真实数据集上的实验表明,GSP在三维点云OOD检测方面表现出卓越性能。
点此查看论文截图


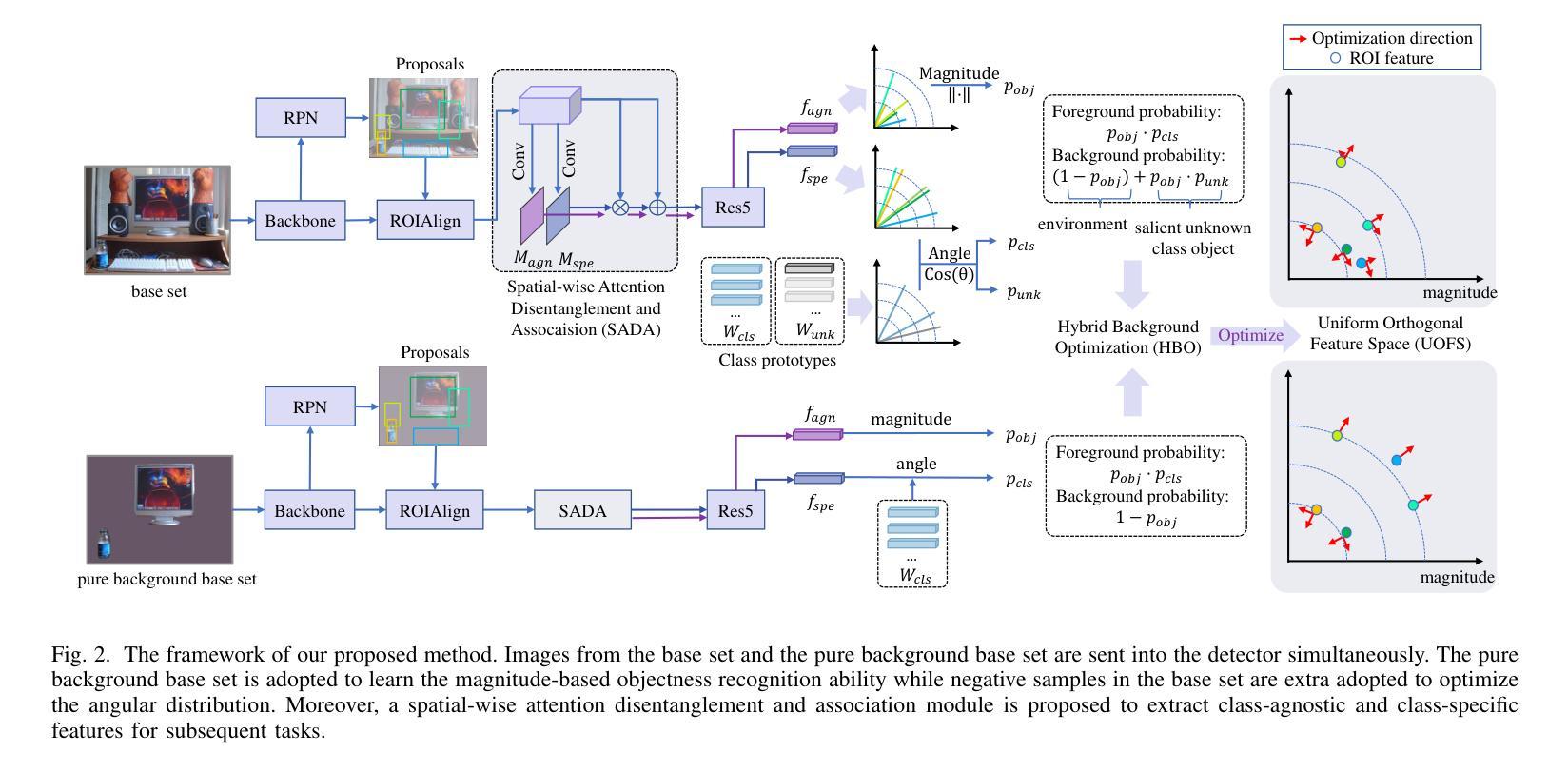
Attention-disentangled Uniform Orthogonal Feature Space Optimization for Few-shot Object Detection
Authors:Taijin Zhao, Heqian Qiu, Yu Dai, Lanxiao Wang, Fanman Meng, Qingbo Wu, Hongliang Li
Few-shot object detection (FSOD) aims to detect objects with limited samples for novel classes, while relying on abundant data for base classes. Existing FSOD approaches, predominantly built on the Faster R-CNN detector, entangle objectness recognition and foreground classification within shared feature spaces. This paradigm inherently establishes class-specific objectness criteria and suffers from unrepresentative novel class samples. To resolve this limitation, we propose a Uniform Orthogonal Feature Space (UOFS) optimization framework. First, UOFS decouples the feature space into two orthogonal components, where magnitude encodes objectness and angle encodes classification. This decoupling enables transferring class-agnostic objectness knowledge from base classes to novel classes. Moreover, implementing the disentanglement requires careful attention to two challenges: (1) Base set images contain unlabeled foreground instances, causing confusion between potential novel class instances and backgrounds. (2) Angular optimization depends exclusively on base class foreground instances, inducing overfitting of angular distributions to base classes. To address these challenges, we propose a Hybrid Background Optimization (HBO) strategy: (1) Constructing a pure background base set by removing unlabeled instances in original images to provide unbiased magnitude-based objectness supervision. (2) Incorporating unlabeled foreground instances in the original base set into angular optimization to enhance distribution uniformity. Additionally, we propose a Spatial-wise Attention Disentanglement and Association (SADA) module to address task conflicts between class-agnostic and class-specific tasks. Experiments demonstrate that our method significantly outperforms existing approaches based on entangled feature spaces.
少量样本目标检测(FSOD)旨在利用有限的样本对新型类别进行目标检测,同时依赖于基本类别的丰富数据进行辅助。现有的FSOD方法主要基于Faster R-CNN检测器,在共享特征空间内纠缠目标识别和前景分类。这种范式固有的建立了特定类别的目标性准则,并受到新型类别样本代表性不足的影响。为了解决这一局限性,我们提出了统一正交特征空间(UOFS)优化框架。首先,UOFS将特征空间解耦为两个正交组件,其中幅度编码目标性,角度编码分类。这种解耦使得可以从基本类别向新型类别转移类别无关的目标性知识。此外,实现解耦需要注意两个挑战:(1)基本集图像包含未标记的前景实例,导致潜在的新型类别实例和背景之间的混淆。(2)角度优化完全依赖于基本类别的前景实例,导致角度分布对基本类别过度拟合。为了解决这些挑战,我们提出了混合背景优化(HBO)策略:(1)通过去除原始图像中的未标记实例来构建纯背景基本集,以提供无偏的基于幅度的目标性监督。(2)将原始基本集中的未标记前景实例纳入角度优化,以提高分布均匀性。此外,为了解决类别无关任务和特定类别任务之间的任务冲突,我们还提出了空间注意力解耦和关联(SADA)模块。实验表明,我们的方法在基于纠缠特征空间的方法上显著优越。
论文及项目相关链接
Summary
本文介绍了针对少样本目标检测(Few-Shot Object Detection, FSOD)的优化框架——统一正交特征空间(UOFS)。该框架旨在解决现有方法在新类别样本有限的情况下存在的局限性。通过解耦特征空间,使幅度编码对象性,角度编码分类,实现了从基础类别到新颖类别的类无关对象性知识的迁移。同时,提出了混合背景优化(HBO)策略和空间注意力解耦与关联(SADA)模块来应对相关挑战。实验证明,该方法显著优于基于纠缠特征空间的现有方法。
Key Takeaways
- 本文提出了针对少样本目标检测的改进框架——统一正交特征空间(UOFS)。
- UOFS通过解耦特征空间实现对象性和分类的分离。
- 提出了混合背景优化(HBO)策略来解决背景干扰和过度拟合的问题。
- 介绍了空间注意力解耦与关联(SADA)模块以处理任务冲突。
- 通过实验验证了所提出方法在少样本目标检测任务上的优越性。
- 该方法能够迁移类无关的对象性知识从基础类别到新颖类别。
点此查看论文截图

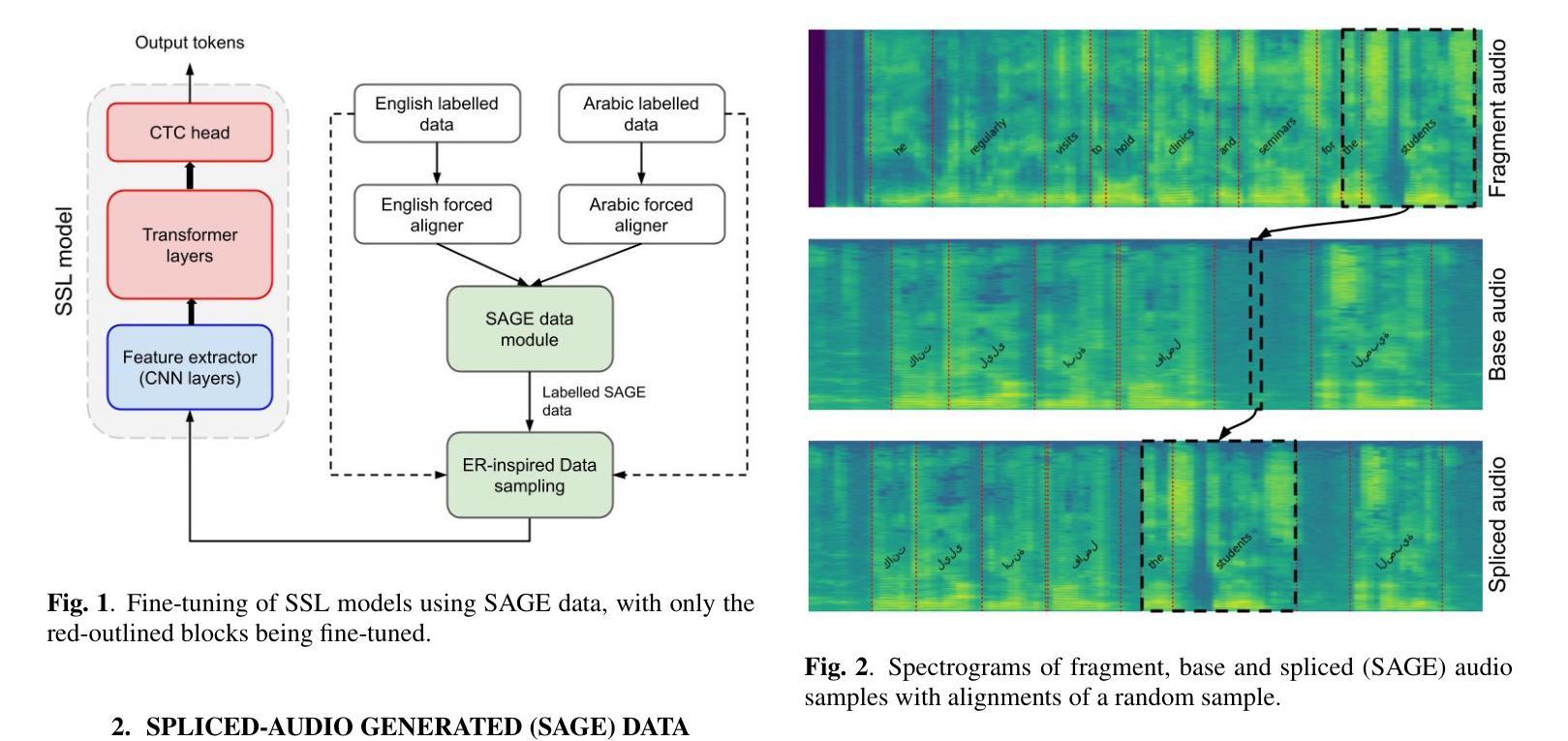
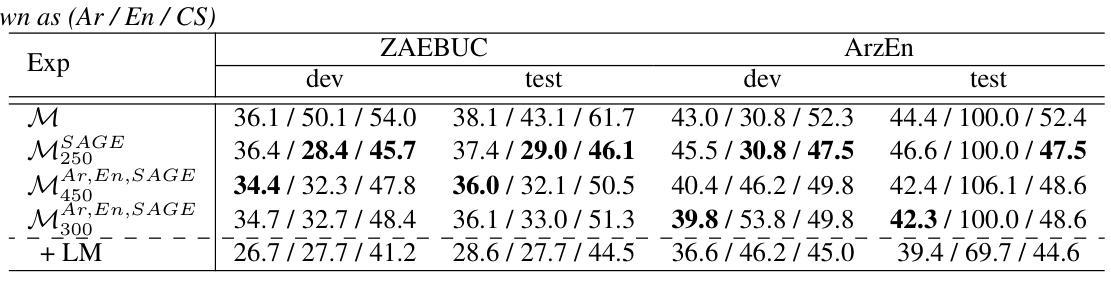
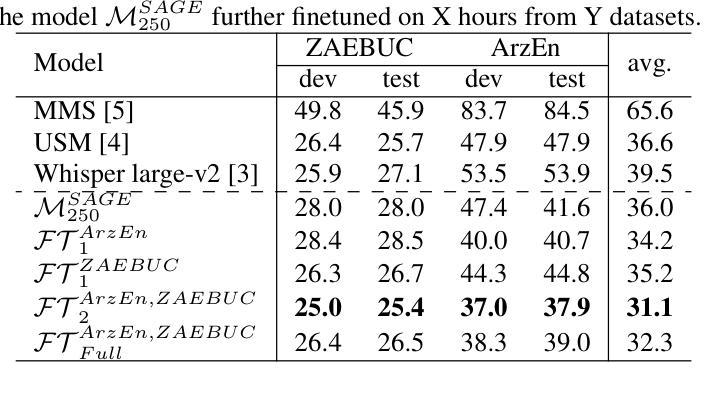
SAGE: Spliced-Audio Generated Data for Enhancing Foundational Models in Low-Resource Arabic-English Code-Switched Speech Recognition
Authors:Muhammad Umar Farooq, Oscar Saz
This paper investigates the performance of various speech SSL models on dialectal Arabic (DA) and Arabic-English code-switched (CS) speech. To address data scarcity, a modified audio-splicing approach is introduced to generate artificial CS speech data. Fine-tuning an already fine-tuned SSL model with the proposed Spliced-Audio Generated (SAGE) data results in an absolute improvement on Word Error Rate (WER) of 7.8% on Arabic and English CS benchmarks. Additionally, an Experience Replay (ER) inspired approach is proposed to enhance generalisation across DA and CS speech while mitigating catastrophic forgetting. Integrating an out-of-domain 3-gram language model reduces the overall mean WER from 31.7% to 26.6%. Few-shot fine-tuning for code-switching benchmarks further improves WER by 4.9%. A WER of 31.1% on Arabic-English CS benchmarks surpasses large-scale multilingual models, including USM and Whisper-large-v2 (both over ten times larger) by an absolute margin of 5.5% and 8.4%, respectively.
本文研究了各种语音SSL模型在方言阿拉伯语(DA)和阿拉伯语-英语代码切换(CS)语音上的性能。为了解决数据稀缺问题,引入了一种改进的音频拼接方法来生成人工CS语音数据。使用提出的拼接音频生成(SAGE)数据对已经微调过的SSL模型进行微调,结果在阿拉伯语和英语CS基准测试上的单词错误率(WER)绝对改进了7.8%。此外,提出了一种受经验回放(ER)启发的方法来提高DA和CS语音的通用性,同时减轻灾难性遗忘。集成域外3-gram语言模型将整体平均WER从31.7%降低到26.6%。针对代码切换基准测试的少量微调进一步将WER提高了4.9%。在阿拉伯语-英语CS基准测试上达到的WER为31.1%,超越了大规模多语种模型,包括USM和Whisper-large-v2(两者都超过十倍大小),分别绝对优于5.5%和8.4%。
论文及项目相关链接
PDF Accepted for IEEE MLSP 2025
Summary
本文研究了不同语音SSL模型在方言阿拉伯语和阿拉伯语-英语转码语音上的表现。为解决数据稀缺问题,引入了一种改进型音频拼接方法来生成人工转码语音数据。使用生成的SAGE数据对已经精细调整的SSL模型进行微调,在阿拉伯语和英语转码基准测试上,单词错误率(WER)绝对改善了7.8%。此外,还提出了一种受经验回放启发的策略,以提高在方言阿拉伯语和转码语音之间的通用性,同时减轻灾难性遗忘。结合领域外的三元语言模型,将整体平均WER从31.7%降低到26.6%。对转码基准测试进行小样本微调进一步将WER提高了4.9%。在阿拉伯语-英语转码基准测试上达到了31.1%的WER,较USM和Whisper-large-v2等大型多语种模型分别提高了5.5%和8.4%。
Key Takeaways
- 论文研究了不同语音SSL模型在方言阿拉伯语和阿拉伯语-英语转码语音上的表现。
- 为解决数据稀缺问题,采用了改进型音频拼接方法生成人工转码语音数据。
- 通过微调SSL模型并融合生成数据,单词错误率(WER)在阿拉伯语和英语转码基准测试上有所改善。
- 提出受经验回放启发的策略以提高模型的通用性并减轻灾难性遗忘。
- 结合领域外的三元语言模型,进一步降低WER。
- 在阿拉伯语-英语转码基准测试上达到较低WER,表现优于某些大型多语种模型。
点此查看论文截图

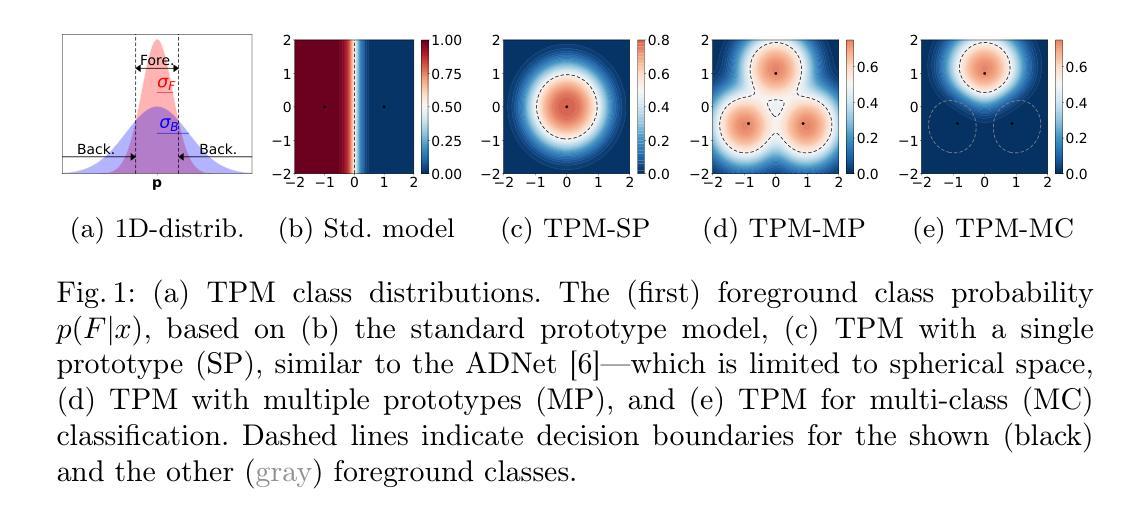
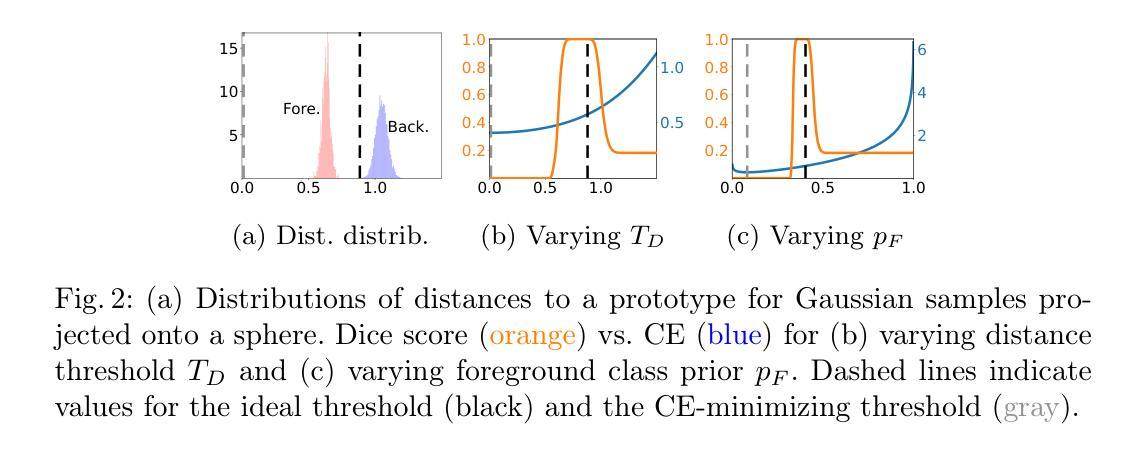
Tied Prototype Model for Few-Shot Medical Image Segmentation
Authors:Hyeongji Kim, Stine Hansen, Michael Kampffmeyer
Common prototype-based medical image few-shot segmentation (FSS) methods model foreground and background classes using class-specific prototypes. However, given the high variability of the background, a more promising direction is to focus solely on foreground modeling, treating the background as an anomaly – an approach introduced by ADNet. Yet, ADNet faces three key limitations: dependence on a single prototype per class, a focus on binary classification, and fixed thresholds that fail to adapt to patient and organ variability. To address these shortcomings, we propose the Tied Prototype Model (TPM), a principled reformulation of ADNet with tied prototype locations for foreground and background distributions. Building on its probabilistic foundation, TPM naturally extends to multiple prototypes and multi-class segmentation while effectively separating non-typical background features. Notably, both extensions lead to improved segmentation accuracy. Finally, we leverage naturally occurring class priors to define an ideal target for adaptive thresholds, boosting segmentation performance. Taken together, TPM provides a fresh perspective on prototype-based FSS for medical image segmentation. The code can be found at https://github.com/hjk92g/TPM-FSS.
常见的基于原型的医学图像少样本分割(FSS)方法使用针对特定类别的原型对前景和背景类别进行建模。然而,考虑到背景的巨大变化性,一个更有前景的方向是专注于前景建模,将背景视为异常值,ADNet就采用了这种思路。然而,ADNet面临三个主要局限:每个类别只依赖于一个原型、专注于二分类以及无法适应患者和器官可变性的固定阈值。为了解决这些不足,我们提出了联合原型模型(TPM),它是ADNet的有原则的重述,具有用于前景和背景分布的共同原型位置。基于概率论基础,TPM自然地扩展到多个原型和多类分割,同时有效地分离非典型背景特征。值得注意的是,这两个扩展都提高了分割精度。最后,我们利用自然发生的类别先验来定义自适应阈值的理想目标,从而提高分割性能。综上所述,TPM为基于原型的医学图像分割FSS提供了全新的视角。代码可在https://github.com/hjk92g/TPM-FSS找到。
论文及项目相关链接
PDF Submitted version (MICCAI). Accepted at MICCAI 2025. The code repo will be made publicly available soon
摘要
本文介绍了基于原型的医疗图像少样本分割(FSS)方法的常见做法,这些方法通过类别特定的原型对前景和背景类别进行建模。鉴于背景的高可变性,一种更有前途的方向是仅专注于前景建模,将背景视为异常值。ADNet首次采用了这种思路,但面临三个关键局限:依赖单一原型、关注二元分类以及无法适应患者和器官可变性的固定阈值。为解决这些问题,我们提出了Tied Prototype Model(TPM),它是ADNet的理论重构,为前景和背景分布提供了绑定的原型位置。基于概率论,TPM自然地扩展到多个原型和多类分割,同时有效地分离了非典型背景特征。两个扩展均提高了分割精度。最后,我们利用自然发生的类别先验来定义自适应阈值的理想目标,提高了分割性能。总的来说,TPM为基于原型的FSS医疗图像分割提供了新的视角。相关代码可通过https://github.com/hjk92g/TPM-FSS访问。
关键见解
- 现有基于原型的FSS方法主要依赖类别特定的原型对前景和背景进行建模。
- ADNet方法虽然尝试解决背景复杂性问题,但存在单一原型依赖、二元分类焦点和固定阈值不适应性的局限。
- TPM模型是对ADNet的理论重构,通过绑定前景和背景的原型位置来解决上述问题。
- TPM模型能够自然地扩展到多个原型和多类分割,有效分离非典型特征。
- TPM利用自适应阈值和类别先验来提高分割性能。
- TPM模型提供了一个新的视角来看待基于原型的FSS在医疗图像分割中的应用。
点此查看论文截图

Few-Shot Identity Adaptation for 3D Talking Heads via Global Gaussian Field
Authors:Hong Nie, Fuyuan Cao, Lu Chen, Fengxin Chen, Yuefeng Zou, Jun Yu
Reconstruction and rendering-based talking head synthesis methods achieve high-quality results with strong identity preservation but are limited by their dependence on identity-specific models. Each new identity requires training from scratch, incurring high computational costs and reduced scalability compared to generative model-based approaches. To overcome this limitation, we propose FIAG, a novel 3D speaking head synthesis framework that enables efficient identity-specific adaptation using only a few training footage. FIAG incorporates Global Gaussian Field, which supports the representation of multiple identities within a shared field, and Universal Motion Field, which captures the common motion dynamics across diverse identities. Benefiting from the shared facial structure information encoded in the Global Gaussian Field and the general motion priors learned in the motion field, our framework enables rapid adaptation from canonical identity representations to specific ones with minimal data. Extensive comparative and ablation experiments demonstrate that our method outperforms existing state-of-the-art approaches, validating both the effectiveness and generalizability of the proposed framework. Code is available at: \textit{https://github.com/gme-hong/FIAG}.
基于重建和渲染的说话人头部合成方法能够实现高质量的结果并具有很强的身份保留性,但受限于其依赖于特定身份的模型。每个新身份都需要从头开始训练,这增加了计算成本,与基于生成模型的方法相比,可扩展性降低。为了克服这一局限性,我们提出了FIAG,这是一种新型的3D说话人头合成框架,它仅使用少量训练镜头就能实现高效的身份特定适应。FIAG结合了全局高斯场,支持在共享场内表示多个身份,以及通用运动场,能捕捉不同身份之间的共同运动动态。受益于编码在全局高斯场中的共享面部结构信息和运动场中学习的通用运动先验知识,我们的框架能够迅速从规范身份表示适应到特定身份表示,所需数据最少。广泛的对比和消融实验表明,我们的方法优于现有的最先进方法,验证了所提出框架的有效性和通用性。代码可在:https://github.com/gme-hong/FIAG获取。
论文及项目相关链接
Summary
一种基于重建和渲染的说话人头部合成方法能够达成高质量的结果并强烈保留身份特征,但受限于特定身份模型的依赖。每个新身份都需要从零开始训练,导致了高的计算成本和与基于生成模型的方法相比的可扩展性降低。为了克服这一限制,我们提出了FIAG,这是一个新颖的3D说话人头部合成框架,它仅使用少量训练镜头就能实现特定身份的适应。FIAG结合了全局高斯场,支持在共享场内表示多个身份,以及通用运动场,能捕捉不同身份的通用运动动态。受益于编码在全局高斯场中的共享面部结构信息和运动场中学习到的一般运动先验,我们的框架能够从标准身份表示迅速适应特定身份,所需数据极少。广泛的对比和消融实验表明,我们的方法优于现有的最先进的方法,验证了所提出框架的有效性和通用性。
Key Takeaways
- FIAG是一个新颖的3D说话人头部合成框架,能够实现高效特定身份适应。
- 它结合全局高斯场和通用运动场,分别支持多身份表示和通用运动动态的捕捉。
- FIAG能够从标准身份表示迅速适应特定身份,只需少量数据。
- 广泛的对比和消融实验证明,FIAG在性能上超越了现有的最先进方法。
- FIAG框架具有有效性和通用性。
- 该方法的代码已公开可用。
点此查看论文截图



Few-Shot Segmentation of Historical Maps via Linear Probing of Vision Foundation Models
Authors:Rafael Sterzinger, Marco Peer, Robert Sablatnig
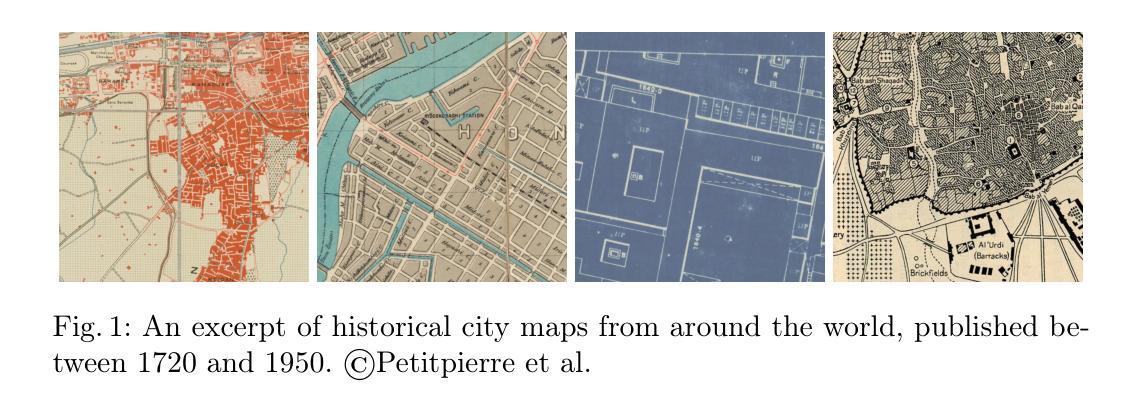
As rich sources of history, maps provide crucial insights into historical changes, yet their diverse visual representations and limited annotated data pose significant challenges for automated processing. We propose a simple yet effective approach for few-shot segmentation of historical maps, leveraging the rich semantic embeddings of large vision foundation models combined with parameter-efficient fine-tuning. Our method outperforms the state-of-the-art on the Siegfried benchmark dataset in vineyard and railway segmentation, achieving +5% and +13% relative improvements in mIoU in 10-shot scenarios and around +20% in the more challenging 5-shot setting. Additionally, it demonstrates strong performance on the ICDAR 2021 competition dataset, attaining a mean PQ of 67.3% for building block segmentation, despite not being optimized for this shape-sensitive metric, underscoring its generalizability. Notably, our approach maintains high performance even in extremely low-data regimes (10- & 5-shot), while requiring only 689k trainable parameters - just 0.21% of the total model size. Our approach enables precise segmentation of diverse historical maps while drastically reducing the need for manual annotations, advancing automated processing and analysis in the field. Our implementation is publicly available at: https://github.com/RafaelSterzinger/few-shot-map-segmentation.
地图作为历史的丰富来源,为历史变迁提供了关键见解,然而,其多样的视觉表示和有限的标注数据给自动化处理带来了重大挑战。我们提出了一种简单而有效的方法,用于历史地图的少量样本分割,该方法利用大型视觉基础模型的丰富语义嵌入,并结合参数高效的微调。我们的方法在Siegfried基准数据集上的葡萄园和铁路分割方面超越了最新技术,在10次射击场景中mIoU相对提高了+5%和+13%,在更具挑战性的5次射击设置中提高了约+20%。此外,在ICDAR 2021竞赛数据集上,它在建筑块分割方面达到了67.3%的平均PQ,尽管这一形状敏感的指标并未经过优化,但凸显了其通用性。值得注意的是,我们的方法即使在极低数据环境(10次和5次射击)下也能保持高性能,并且只需要689k个可训练参数——仅占模型总大小的0.21%。我们的方法能够实现各种历史地图的精确分割,并大大降低了对手动注释的需求,推动了该领域的自动化处理和分析的发展。我们的实现可在以下网址公开访问:https://github.com/RafaelSterzinger/few-shot-map-segmentation。
论文及项目相关链接
PDF 18 pages, accepted at ICDAR2025
Summary
该文章介绍了一种针对历史地图的Few-Shot分割方法,通过利用大型视觉基础模型的丰富语义嵌入和参数高效的微调技术,实现了对历史地图的精准分割。该方法在Siegfried数据集上的葡萄园和铁路分割任务上超越了现有技术,在10次拍摄场景中相对提高了5%和13%的mIoU。此外,在ICDAR 2021竞赛数据集上,该方法对建筑区块分割的平均PQ达到了67.3%,表现出强大的性能。该方法在极低数据量环境下仍能保持高性能,并且只需要训练少量的参数。该方法的实施可以公开访问。
Key Takeaways
- 提出了一种针对历史地图的Few-Shot分割方法。
- 利用大型视觉基础模型的丰富语义嵌入。
- 通过参数高效的微调技术实现精准分割。
- 在Siegfried数据集上的葡萄园和铁路分割任务上表现优越。
- 在ICDAR 2021竞赛数据集上,对建筑区块分割性能强大。
- 在极低数据量环境下保持高性能。
- 方法所需训练参数少,实施公开可访问。
点此查看论文截图


INP-Former++: Advancing Universal Anomaly Detection via Intrinsic Normal Prototypes and Residual Learning
Authors:Wei Luo, Haiming Yao, Yunkang Cao, Qiyu Chen, Ang Gao, Weiming Shen, Wenyong Yu
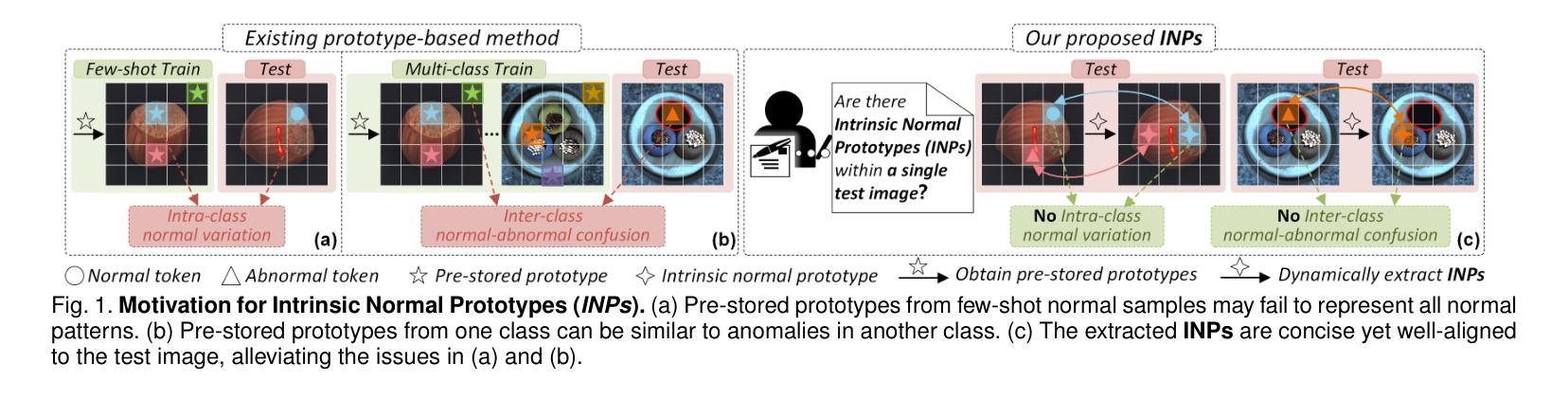
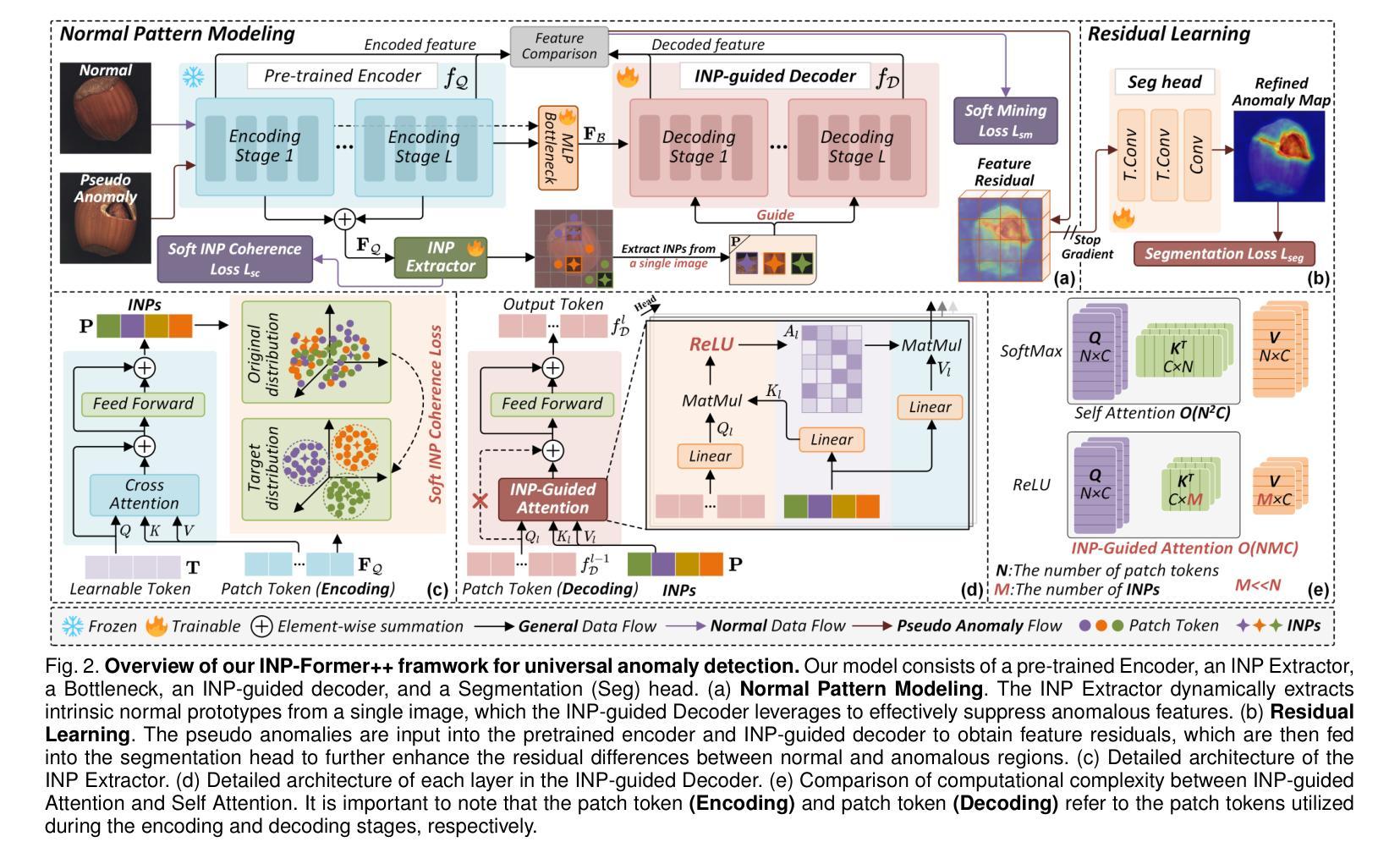
Anomaly detection (AD) is essential for industrial inspection and medical diagnosis, yet existing methods typically rely on ``comparing’’ test images to normal references from a training set. However, variations in appearance and positioning often complicate the alignment of these references with the test image, limiting detection accuracy. We observe that most anomalies manifest as local variations, meaning that even within anomalous images, valuable normal information remains. We argue that this information is useful and may be more aligned with the anomalies since both the anomalies and the normal information originate from the same image. Therefore, rather than relying on external normality from the training set, we propose INP-Former, a novel method that extracts Intrinsic Normal Prototypes (INPs) directly from the test image. Specifically, we introduce the INP Extractor, which linearly combines normal tokens to represent INPs. We further propose an INP Coherence Loss to ensure INPs can faithfully represent normality for the testing image. These INPs then guide the INP-guided Decoder to reconstruct only normal tokens, with reconstruction errors serving as anomaly scores. Additionally, we propose a Soft Mining Loss to prioritize hard-to-optimize samples during training. INP-Former achieves state-of-the-art performance in single-class, multi-class, and few-shot AD tasks across MVTec-AD, VisA, and Real-IAD, positioning it as a versatile and universal solution for AD. Remarkably, INP-Former also demonstrates some zero-shot AD capability. Furthermore, we propose a soft version of the INP Coherence Loss and enhance INP-Former by incorporating residual learning, leading to the development of INP-Former++. The proposed method significantly improves detection performance across single-class, multi-class, semi-supervised, few-shot, and zero-shot settings.
异常检测(AD)对于工业检测和医疗诊断至关重要。然而,现有方法通常依赖于将测试图像与训练集中的正常参考图像进行比对。但外观和位置的变化经常使这些参考图像与测试图像的对齐变得复杂,从而限制了检测精度。我们观察到,大多数异常表现为局部变化,这意味着即使在异常图像内部,仍有宝贵的正常信息存在。我们认为这些信息是有用的,并且可能与异常更加对齐,因为异常和正常信息都来自同一图像。因此,我们提出了一种新方法INP-Former,它直接从测试图像中提取内在正常原型(INPs)。具体来说,我们引入了INP提取器,该提取器通过线性组合正常令牌来表示INPs。我们还提出了一种INP一致性损失,以确保INPs能够忠实地代表测试图像的正常性。这些INPs然后引导INP引导解码器仅重建正常令牌,重建误差作为异常分数。此外,我们还提出了一种软挖掘损失,以在训练过程中优先处理难以优化的样本。INP-Former在MVTec-AD、VisA和Real-IAD上的单类、多类以及少样本AD任务中实现了最先进的性能表现,成为AD的通用解决方案。值得一提的是,INP-Former还展现出了一些零样本AD的能力。此外,我们提出了INP一致性损失的软版本,并通过引入残差学习增强了INP-Former,从而开发出INP-Former++。所提出的方法在单类、多类、半监督、少样本和零样本设置中显著提高了检测性能。
论文及项目相关链接
PDF 15 pages, 11 figures, 13 tables. arXiv admin note: substantial text overlap with arXiv:2503.02424
Summary
本文提出一种名为INP-Former的新型异常检测方法,该方法能够从测试图像中提取内在正常原型(INPs)来检测异常。该方法通过引入INP提取器和INP引导解码器,以及INP一致性损失和软挖掘损失,实现了对图像的正常性进行重建并识别异常。该方法在多种异常检测任务上表现出卓越性能,并具有零样本异常检测能力。进一步通过引入软版本的INP一致性损失并结合残差学习,提出了改进的INP-Former++方法,进一步提升了检测性能。
Key Takeaways
- 传统异常检测方法常依赖训练集中的正常参考图像进行比较,但外观和位置的变化使得对齐变得困难。
- INP-Former方法直接从测试图像中提取内在正常原型(INPs)来检测异常,不需要外部正常性参考。
- INP提取器通过线性组合正常标记来代表INPs。
- INP一致性损失确保INPs能忠实代表测试图像的正常性。
- INP-guided解码器利用INPs只重建正常标记,重建误差作为异常分数。
- SoftMining Loss在训练过程中优先优化难以优化的样本。
点此查看论文截图

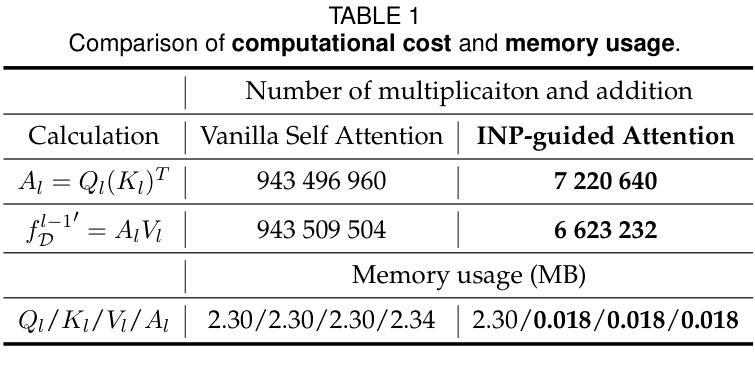
Chameleon: A MatMul-Free Temporal Convolutional Network Accelerator for End-to-End Few-Shot and Continual Learning from Sequential Data
Authors:Douwe den Blanken, Charlotte Frenkel
On-device learning at the edge enables low-latency, private personalization with improved long-term robustness and reduced maintenance costs. Yet, achieving scalable, low-power end-to-end on-chip learning, especially from real-world sequential data with a limited number of examples, is an open challenge. Indeed, accelerators supporting error backpropagation optimize for learning performance at the expense of inference efficiency, while simplified learning algorithms often fail to reach acceptable accuracy targets. In this work, we present Chameleon, leveraging three key contributions to solve these challenges. (i) A unified learning and inference architecture supports few-shot learning (FSL), continual learning (CL) and inference at only 0.5% area overhead to the inference logic. (ii) Long temporal dependencies are efficiently captured with temporal convolutional networks (TCNs), enabling the first demonstration of end-to-end on-chip FSL and CL on sequential data and inference on 16-kHz raw audio. (iii) A dual-mode, matrix-multiplication-free compute array allows either matching the power consumption of state-of-the-art inference-only keyword spotting (KWS) accelerators or enabling $4.3\times$ higher peak GOPS. Fabricated in 40-nm CMOS, Chameleon sets new accuracy records on Omniglot for end-to-end on-chip FSL (96.8%, 5-way 1-shot, 98.8%, 5-way 5-shot) and CL (82.2% final accuracy for learning 250 classes with 10 shots), while maintaining an inference accuracy of 93.3% on the 12-class Google Speech Commands dataset at an extreme-edge power budget of 3.1 $\mu$W.
在设备边缘进行在线学习可以实现低延迟、隐私保护的个性化,同时提高长期稳健性并降低维护成本。然而,实现可扩展的、低功耗的端到端片上学习,尤其是从现实世界中的序列数据中学习且样本数量有限,仍然是一个开放性的挑战。实际上,支持反向传播的加速器以推理效率为代价优化了学习性能,而简化的学习算法往往无法达到可接受的准确性目标。在这项工作中,我们提出了Chameleon,通过三个关键贡献来解决这些挑战。(i)统一的学习和推理架构支持少样本学习(FSL)、持续学习(CL)和推理,仅对推理逻辑产生0.5%的面积开销。(ii)通过时序卷积网络(TCNs)有效地捕获了长时间依赖性,实现了序列数据的端到端片上FSL和CL的首次演示以及对16kHz原始音频的推理。(iii)一种双模式、无矩阵乘法的计算阵列,既可以匹配当前最先进的仅用于关键字识别(KWS)的推理加速器的功耗,又可以提高4.3倍的计算峰值。Chameleon采用40纳米CMOS工艺制造,在Omniglot数据集上创造了端到端片上FSL的新准确性记录(5路1次射击96.8%,5路5次射击98.8%),在持续学习方面(学习250个类别,使用10次射击的最终准确性为82.2%),同时在Google语音命令数据集上保持12类的推理准确性为93.3%,在极端边缘的功率预算为3.1μW的情况下。
论文及项目相关链接
PDF 14 pages, 7 figures; added FSL power consumption measurements at 100 kHz clock speed, fixed typos
摘要
本论文提出Chameleon方案,解决了在边缘设备上实现实时学习的挑战。Chameleon通过三个关键贡献实现了在低延迟、隐私保护下的个性化学习,并提高了长期稳健性和降低了维护成本。首先,它提供了一个统一的学习和推理架构,支持少量学习、持续学习和推理,仅在推理逻辑上增加了0.5%的面积开销。其次,利用时序卷积网络(TCNs)有效地捕捉长期时间依赖关系,实现了对顺序数据的端到端在线少量学习和持续学习以及16kHz原始音频的推理。最后,一种双模式、无矩阵乘法的计算阵列允许匹配当前先进的仅推理关键词识别(KWS)加速器的功耗或提高4.3倍峰值GOPS。在Omniglot数据集上,Chameleon在端到端的在线少量学习(96.8%,5选1;98.8%,5选5)和持续学习(学习250类,每次学习10个样本的最终准确度为82.2%)方面创造了新的准确度记录,同时在Google语音命令数据集上保持93.3%的推理准确度,在极端边缘设备的功耗预算为3.1μW的情况下。
关键见解
- Chameleon方案通过统一的学习和推理架构支持少量学习、持续学习和推理,且仅增加微小的面积开销。
- 利用时序卷积网络(TCNs)有效捕捉长期时间依赖关系,实现在芯片上对顺序数据的少量学习和持续学习的首次演示。
- 提出一种双模式、无矩阵乘法的计算阵列,可在保持推理性能的同时提高计算效率。
- 在Omniglot数据集上实现了端到端的在线少量学习和持续学习的高准确度。
- 在Google语音命令数据集上保持了高推理准确度,同时满足了极端边缘设备的低功耗要求。
- Chameleon方案在性能和效率之间取得了平衡,为未来的边缘学习提供了重要启示。
点此查看论文截图

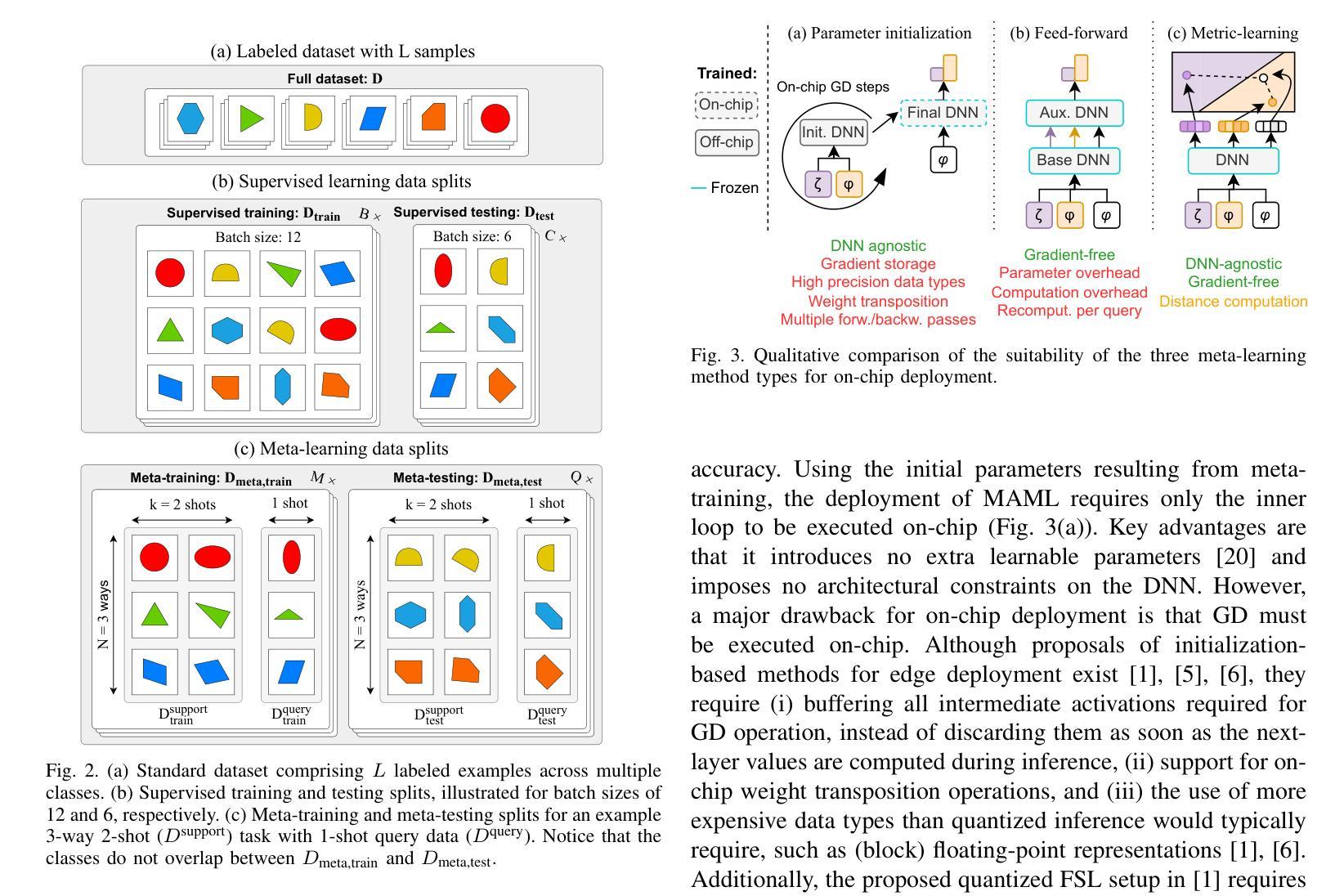
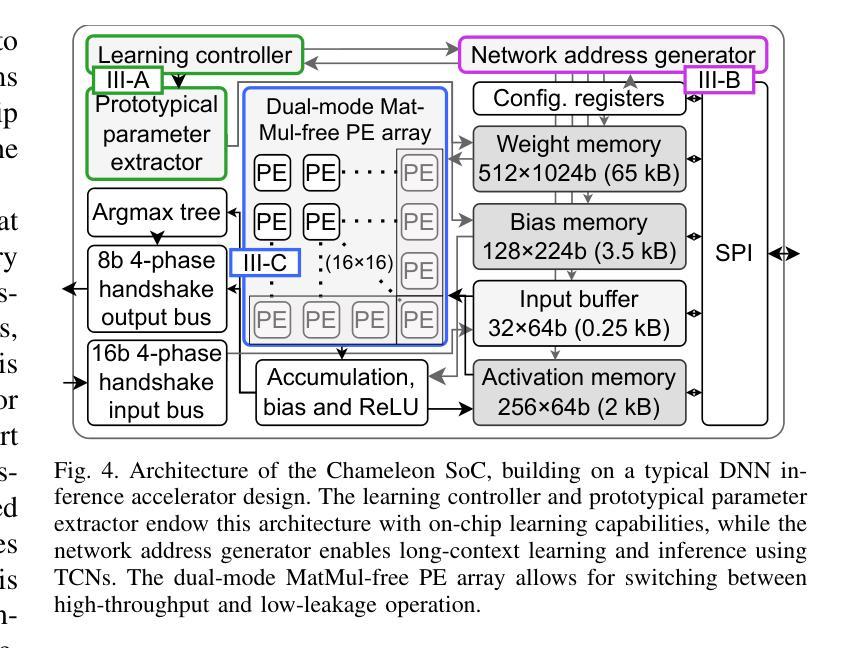

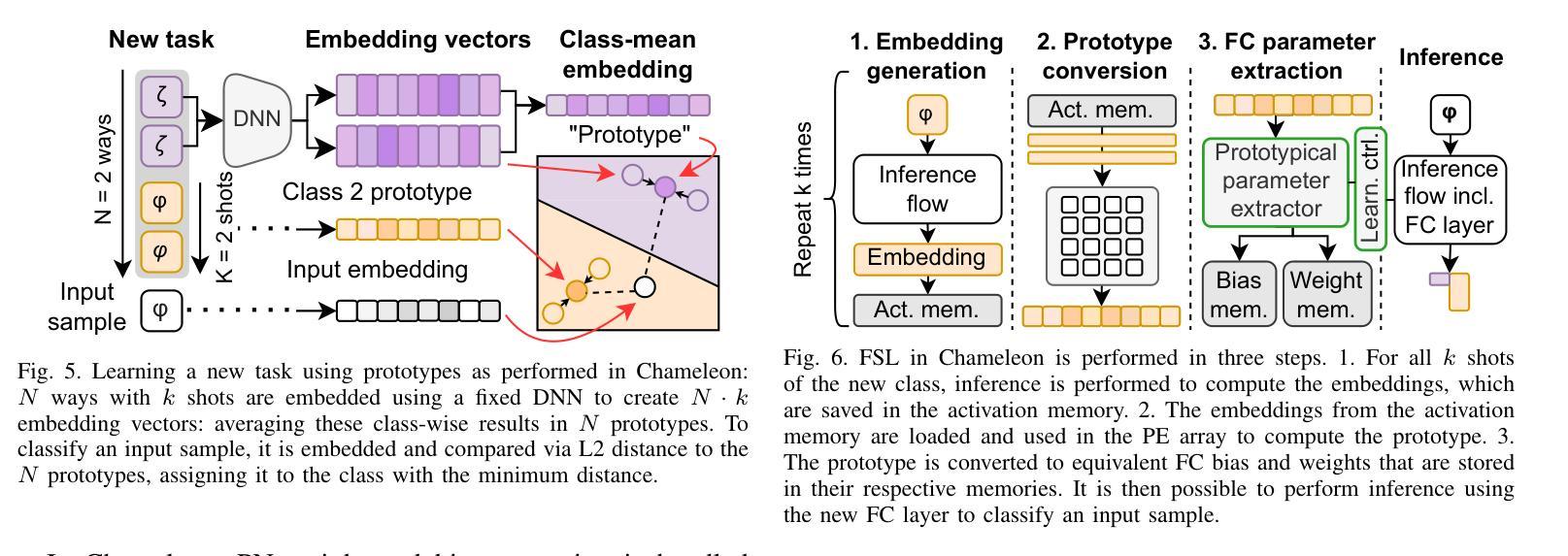
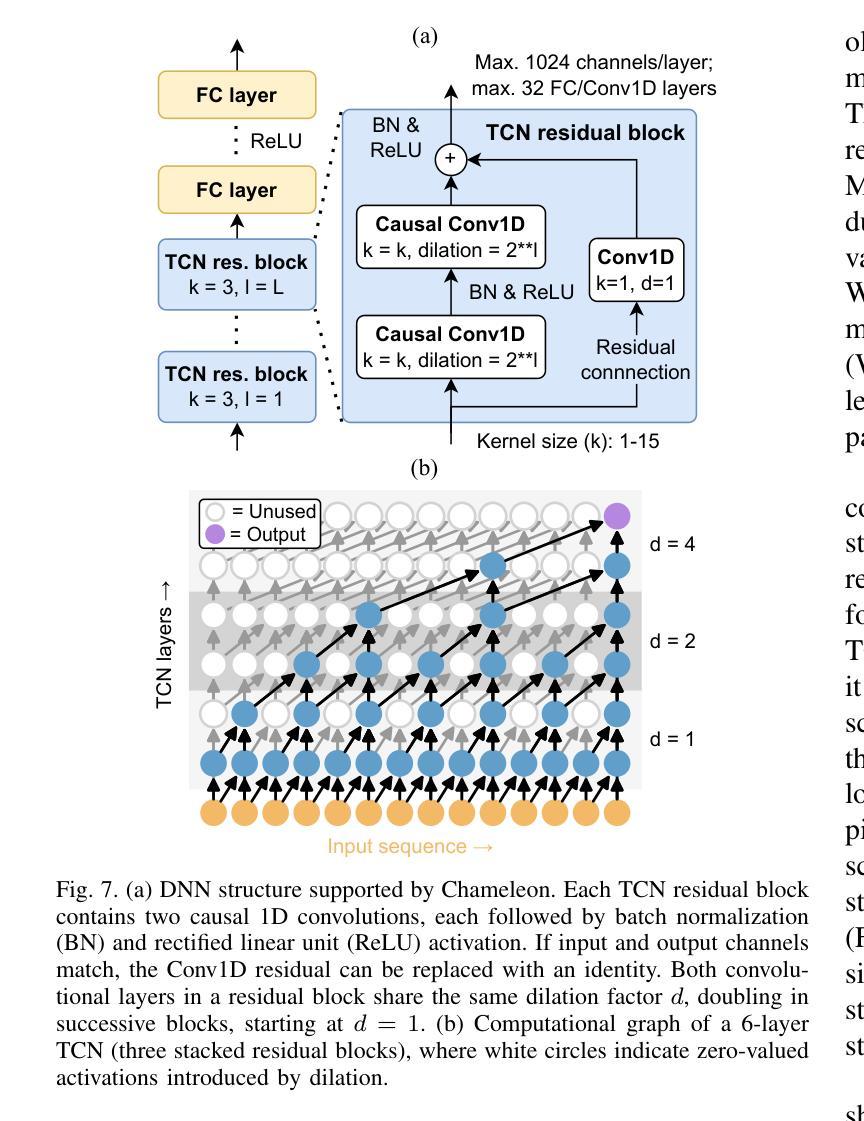
AdaReasoner: Adaptive Reasoning Enables More Flexible Thinking in Large Language Models
Authors:Xiangqi Wang, Yue Huang, Yanbo Wang, Xiaonan Luo, Kehan Guo, Yujun Zhou, Xiangliang Zhang
LLMs often need effective configurations, like temperature and reasoning steps, to handle tasks requiring sophisticated reasoning and problem-solving, ranging from joke generation to mathematical reasoning. Existing prompting approaches usually adopt general-purpose, fixed configurations that work ‘well enough’ across tasks but seldom achieve task-specific optimality. To address this gap, we introduce AdaReasoner, an LLM-agnostic plugin designed for any LLM to automate adaptive reasoning configurations for tasks requiring different types of thinking. AdaReasoner is trained using a reinforcement learning (RL) framework, combining a factorized action space with a targeted exploration strategy, along with a pretrained reward model to optimize the policy model for reasoning configurations with only a few-shot guide. AdaReasoner is backed by theoretical guarantees and experiments of fast convergence and a sublinear policy gap. Across six different LLMs and a variety of reasoning tasks, it consistently outperforms standard baselines, preserves out-of-distribution robustness, and yield gains on knowledge-intensive tasks through tailored prompts.
大型语言模型(LLMs)通常需要有效的配置,如温度和推理步骤,来处理从笑话生成到数学推理等需要复杂推理和问题解决能力的任务。现有的提示方法通常采用通用、固定的配置,这些配置在各项任务中“表现足够好”,但很少实现针对特定任务的优化。为了解决这一差距,我们引入了AdaReasoner,这是一个针对任何大型语言模型的通用插件,旨在自动化适应需要不同类型思考的推理任务的配置。AdaReasoner使用强化学习(RL)框架进行训练,结合分解的动作空间和有针对性的探索策略,以及预训练的奖励模型,以优化策略模型进行推理配置,只需少数镜头指导。AdaReasoner有理论保证和实验支持快速收敛和次线性策略差距。在六个不同的大型语言模型和多种推理任务上,它始终超越标准基线,保持超出分布范围的稳健性,并通过定制提示在知识密集型任务上获得收益。
论文及项目相关链接
Summary
本文介绍了LLMs在处理需要复杂推理和问题解决的任务时,需要有效的配置,如温度和推理步骤。现有提示方法通常采用通用、固定的配置,这些配置在跨任务时表现“足够好”,但很少达到任务特定的最优状态。为解决这一问题,本文提出了AdaReasoner,这是一种为任何LLM设计的LLM无关插件,可自动适应需要不同类型思考的推理任务的配置。AdaReasoner使用强化学习框架进行训练,结合分解动作空间与有针对性的探索策略,以及预训练的奖励模型来优化策略模型,仅通过几次提示就能对推理配置进行优化。AdaReasoner得到了理论上的保证和实验结果的快速收敛以及策略差距的次线性证明。在不同LLMs和各种推理任务上,它始终优于标准基线,保持对分布外的稳健性,并在知识密集型任务上通过定制提示获得收益。
Key Takeaways
- LLMs需要针对特定任务的有效配置以处理复杂推理和问题解决任务。
- 现有提示方法采用通用配置,难以达到任务特定最优状态。
- AdaReasoner是一种LLM无关的插件,旨在自动化适应不同任务的推理配置。
- AdaReasoner使用强化学习框架训练,结合分解动作空间与探索策略及预训练奖励模型优化策略模型。
- AdaReasoner具有理论保证和实验结果的快速收敛和次线性策略差距证明。
- AdaReasoner在不同LLMs和各种推理任务上表现优于标准基线。
点此查看论文截图

Mitigating Knowledge Discrepancies among Multiple Datasets for Task-agnostic Unified Face Alignment
Authors:Jiahao Xia, Min Xu, Wenjian Huang, Jianguo Zhang, Haimin Zhang, Chunxia Xiao
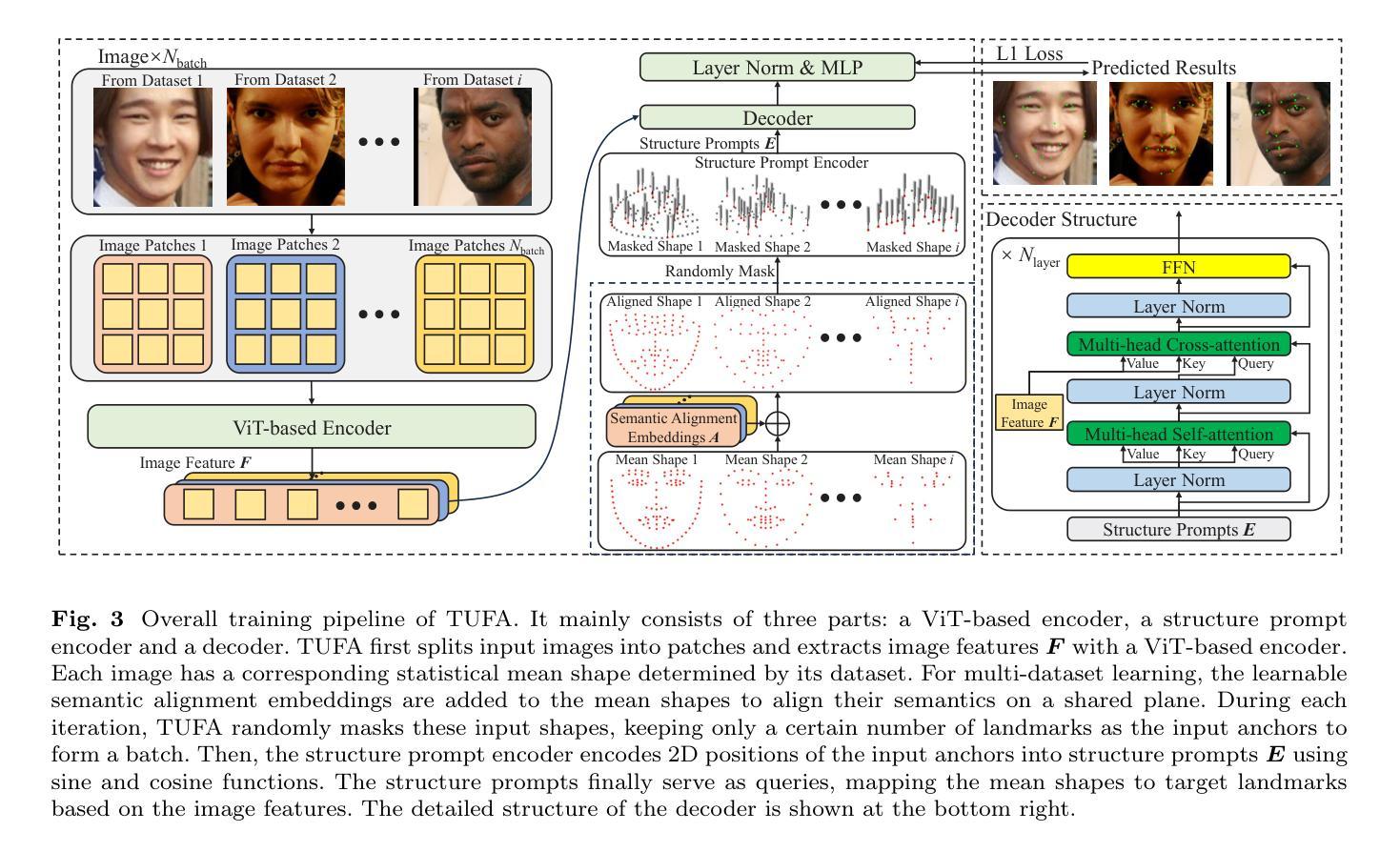
Despite the similar structures of human faces, existing face alignment methods cannot learn unified knowledge from multiple datasets with different landmark annotations. The limited training samples in a single dataset commonly result in fragile robustness in this field. To mitigate knowledge discrepancies among different datasets and train a task-agnostic unified face alignment (TUFA) framework, this paper presents a strategy to unify knowledge from multiple datasets. Specifically, we calculate a mean face shape for each dataset. To explicitly align these mean shapes on an interpretable plane based on their semantics, each shape is then incorporated with a group of semantic alignment embeddings. The 2D coordinates of these aligned shapes can be viewed as the anchors of the plane. By encoding them into structure prompts and further regressing the corresponding facial landmarks using image features, a mapping from the plane to the target faces is finally established, which unifies the learning target of different datasets. Consequently, multiple datasets can be utilized to boost the generalization ability of the model. The successful mitigation of discrepancies also enhances the efficiency of knowledge transferring to a novel dataset, significantly boosts the performance of few-shot face alignment. Additionally, the interpretable plane endows TUFA with a task-agnostic characteristic, enabling it to locate landmarks unseen during training in a zero-shot manner. Extensive experiments are carried on seven benchmarks and the results demonstrate an impressive improvement in face alignment brought by knowledge discrepancies mitigation. The code is available at https://github.com/Jiahao-UTS/TUFA.
尽管人脸结构相似,但现有的面部对齐方法无法从具有不同特征点标注的多个数据集中学习统一的知识。单一数据集中的有限训练样本通常会导致该领域的脆弱稳健性。为了缓解不同数据集之间的知识差异并训练一个任务通用的统一面部对齐(TUFA)框架,本文提出了一种策略来统一多个数据集的知识。具体来说,我们为每个数据集计算平均脸部形状。为了根据语义在可解释平面上显式对齐这些平均形状,然后将每个形状与一组语义对齐嵌入相结合。这些对齐形状的2D坐标可以被视为平面的锚点。通过将它们编码为结构提示并使用图像特征进一步回归相应的面部特征点,最终建立了从平面到目标面部的映射,这统一了不同数据集的学习目标。因此,可以利用多个数据集来提高模型的泛化能力。成功缓解差异还可以提高知识转移到新数据集的效率,极大地提高了少样本面部对齐的性能。此外,可解释的平面赋予了TUFA任务通用的特性,使其能够以零样本的方式定位训练期间未见过的特征点。在七个基准测试上进行了大量实验,结果表明,通过缓解知识差异,面部对齐带来了令人印象深刻的改进。代码可在https://github.com/Jiahao-UTS/TUFA找到。
论文及项目相关链接
PDF 24 Pages, 9 Figures, accepted to IJCV-2025
Summary
本文提出一种统一知识从多个数据集的策略,以解决不同数据集间知识差异的问题,并训练了一个任务无关的统一面部对齐(TUFA)框架。通过计算每个数据集的平均面部形状,并结合语义对齐嵌入,显式地将这些平均形状对齐在一个可解释的平面上。这建立了从平面到目标面部的映射,统一了不同数据集的学习目标,提高了模型的泛化能力。此外,该策略成功缓解了知识差异,提高了知识转移到新数据集的效率,并显著提升了少样本面部对齐的性能。TUFA框架具有任务无关的特性,能在零样本的情况下定位训练时未见过的地标。
Key Takeaways
- 提出统一知识从多个数据集的策略,解决不同数据集间知识差异的问题。
- 通过计算平均面部形状并结合语义对齐嵌入,显式对齐这些形状在一个可解释的平面上。
- 建立从平面到目标面部的映射,统一不同数据集的学习目标,提高模型泛化能力。
- 成功缓解知识差异,提高知识转移到新数据集的效率。
- 提升少样本面部对齐的性能。
- TUFA框架具有任务无关的特性,能在零样本的情况下定位训练时未见过的地标。
点此查看论文截图

Edit Transfer: Learning Image Editing via Vision In-Context Relations
Authors:Lan Chen, Qi Mao, Yuchao Gu, Mike Zheng Shou
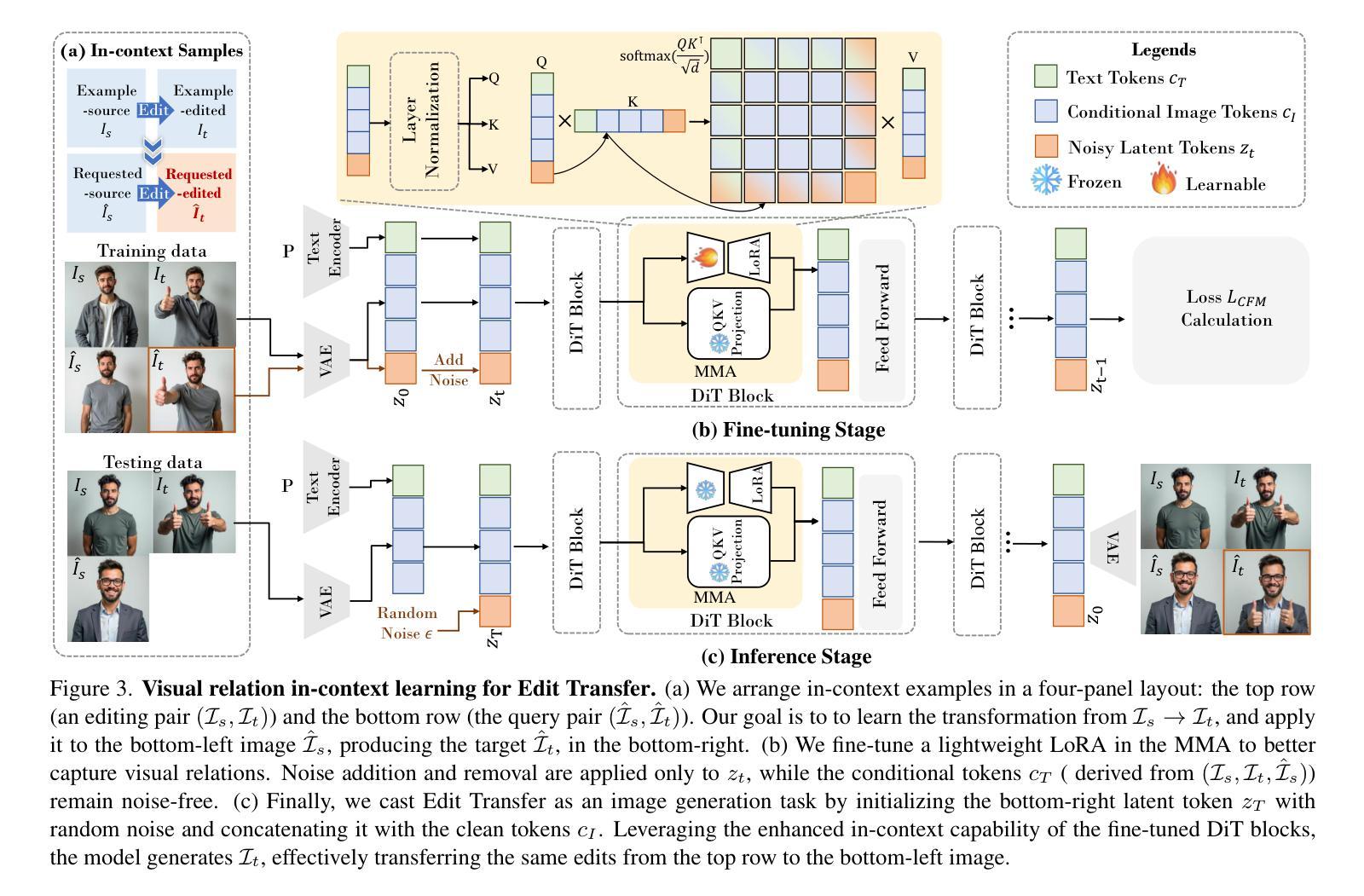
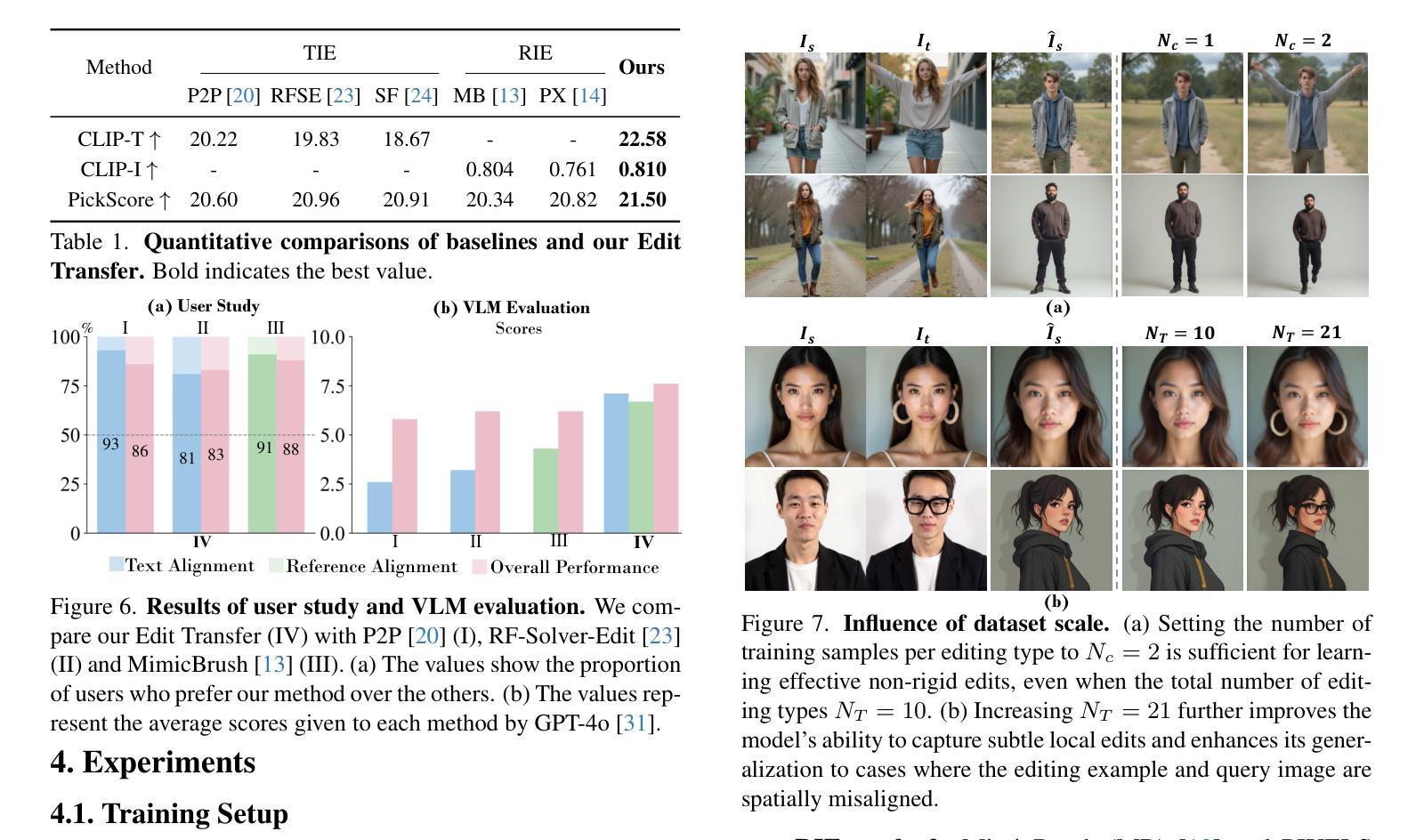
We introduce a new setting, Edit Transfer, where a model learns a transformation from just a single source-target example and applies it to a new query image. While text-based methods excel at semantic manipulations through textual prompts, they often struggle with precise geometric details (e.g., poses and viewpoint changes). Reference-based editing, on the other hand, typically focuses on style or appearance and fails at non-rigid transformations. By explicitly learning the editing transformation from a source-target pair, Edit Transfer mitigates the limitations of both text-only and appearance-centric references. Drawing inspiration from in-context learning in large language models, we propose a visual relation in-context learning paradigm, building upon a DiT-based text-to-image model. We arrange the edited example and the query image into a unified four-panel composite, then apply lightweight LoRA fine-tuning to capture complex spatial transformations from minimal examples. Despite using only 42 training samples, Edit Transfer substantially outperforms state-of-the-art TIE and RIE methods on diverse non-rigid scenarios, demonstrating the effectiveness of few-shot visual relation learning.
我们引入了一种新设置,名为“编辑传输”(Edit Transfer),在该设置中,模型仅从一个源目标示例中学习转换,并将其应用于新的查询图像。虽然基于文本的方法在通过文本提示进行语义操作方面表现出色,但它们通常难以处理精确的几何细节(例如姿势和视点变化)。另一方面,基于参考的编辑通常侧重于风格或外观,而在非刚体转换方面表现不佳。通过从源目标对中学习编辑转换,Edit Transfer缓解了仅使用文本和外观中心参考的局限性。我们从大型语言模型的上下文学习中汲取灵感,提出了一个基于DiT文本到图像模型的视觉关系上下文学习范式。我们将编辑示例和查询图像排列成一个统一的四面板组合,然后应用轻量级的LoRA微调技术,从最少的示例中学习复杂的空间转换。尽管只使用了42个训练样本,但在多种非刚体场景下,Edit Transfer大幅超越了最新的TIE和RIE方法,证明了少视觉关系学习的有效性。
论文及项目相关链接
Summary
编辑转移技术通过学习从单一源目标示例的转换,并应用于新查询图像,实现了图像编辑的新设置。该技术弥补了纯文本和外观为中心的参考方法的局限性,能够处理复杂的空间转换。
Key Takeaways
- 编辑转移技术通过学习从源到目标的转换,并应用于新查询图像,创造了新的图像编辑设置。
- 传统文本方法和基于参考的编辑方法在特定情况下存在局限性,而编辑转移技术可以克服这些局限性。
- 编辑转移技术能够处理复杂的空间转换,如姿势和视角变化。
- 该技术从少量示例中学习视觉关系,并应用于图像编辑任务。
- 使用仅42个训练样本,编辑转移技术在多种非刚性场景上显著优于当前先进的TIE和RIE方法。
- 编辑转移技术受到大型语言模型中上下文学习的启发,建立了基于文本到图像模型的视觉关系上下文学习范式。
点此查看论文截图




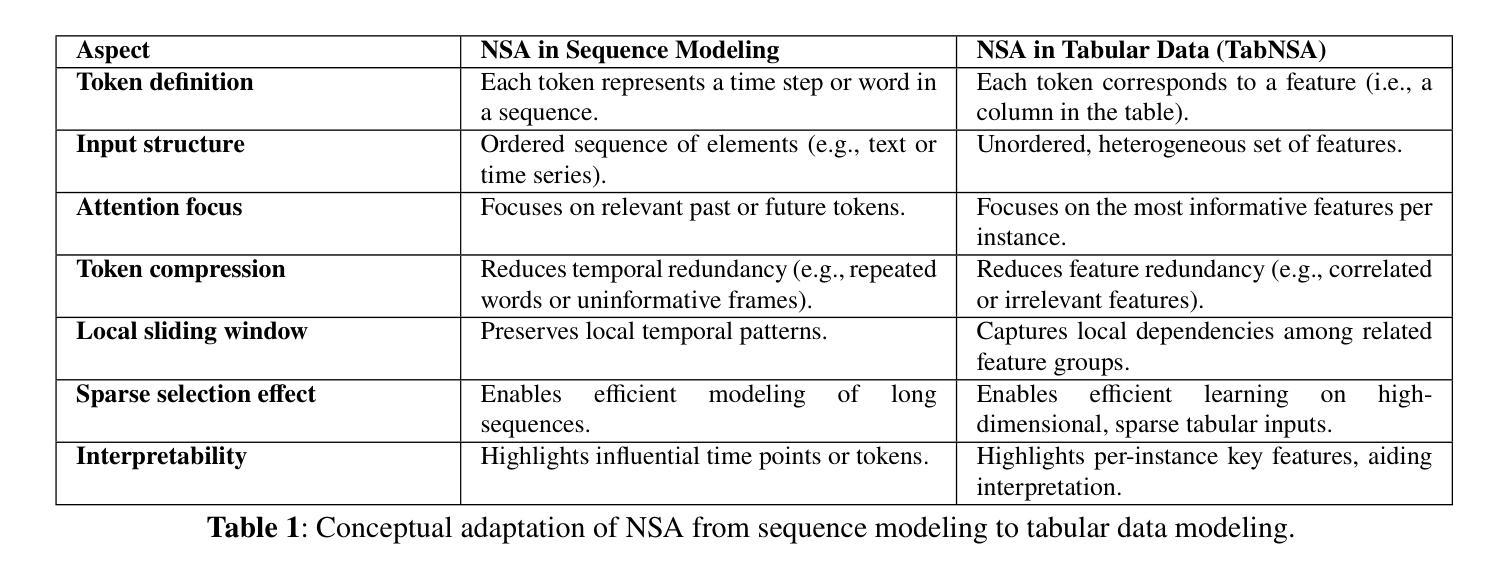
TabNSA: Native Sparse Attention for Efficient Tabular Data Learning
Authors:Ali Eslamian, Qiang Cheng
Tabular data poses unique challenges for deep learning due to its heterogeneous feature types, lack of spatial structure, and often limited sample sizes. We propose TabNSA, a novel deep learning framework that integrates Native Sparse Attention (NSA) with a TabMixer backbone to efficiently model tabular data. TabNSA tackles computational and representational challenges by dynamically focusing on relevant feature subsets per instance. The NSA module employs a hierarchical sparse attention mechanism, including token compression, selective preservation, and localized sliding windows, to significantly reduce the quadratic complexity of standard attention operations while addressing feature heterogeneity. Complementing this, the TabMixer backbone captures complex, non-linear dependencies through parallel multilayer perceptron (MLP) branches with independent parameters. These modules are synergistically combined via element-wise summation and mean pooling, enabling TabNSA to model both global context and fine-grained interactions. Extensive experiments across supervised and transfer learning settings show that TabNSA consistently outperforms state-of-the-art deep learning models. Furthermore, by augmenting TabNSA with a fine-tuned large language model (LLM), we enable it to effectively address Few-Shot Learning challenges through language-guided generalization on diverse tabular benchmarks.
表格数据因其多样化的特征类型、缺乏空间结构以及通常有限的样本量而给深度学习带来了独特的挑战。我们提出了TabNSA,这是一个新型的深度学习框架,它集成了原生稀疏注意力(NSA)和TabMixer骨干网,以有效地对表格数据进行建模。TabNSA通过动态关注每个实例的相关特征子集来解决计算和表征挑战。NSA模块采用分层稀疏注意力机制,包括令牌压缩、选择性保留和局部滑动窗口,以显著降低标准注意力操作的二次复杂性,同时解决特征异质性问题。作为补充,TabMixer骨干网通过具有独立参数的并行多层感知器(MLP)分支捕获复杂的非线性依赖关系。这些模块通过逐元素求和和平均池化进行协同组合,使TabNSA能够同时对全局上下文和精细交互进行建模。在监督学习和迁移学习环境下的广泛实验表明,TabNSA始终优于最先进的深度学习模型。此外,通过用微调的大型语言模型(LLM)增强TabNSA,我们使其能够通过语言引导在多种表格基准测试上进行泛化,从而有效解决小样本学习挑战。
论文及项目相关链接
PDF 26 pages, 11 tables
Summary
TabNSA是一种针对表格数据的新型深度学习框架,通过整合原生稀疏注意力(NSA)和TabMixer骨干网,实现对表格数据的高效建模。它解决了计算和表征挑战,通过动态关注每个实例的相关特征子集来减少标准注意力操作的二次复杂性,并处理特征异质性。在监督和迁移学习环境中进行的广泛实验表明,TabNSA持续超越最新深度学习模型的表现。通过与大型语言模型(LLM)的微调相结合,TabNSA能够有效解决小样学习挑战,在多样化的表格基准测试上实现语言引导泛化。
Key Takeaways
- TabNSA是一个针对表格数据的深度学习框架,结合了原生稀疏注意力(NSA)和TabMixer骨干网。
- NSA模块采用分层稀疏注意力机制,包括令牌压缩、选择性保留和局部滑动窗口,以减少标准注意力操作的二次复杂性,并处理特征异质性。
- TabMixer骨干网通过并行多层感知器(MLP)分支捕获复杂的非线性依赖关系。
- TabNSA通过动态关注相关特征子集,解决了表格数据带来的计算和表征挑战。
- TabNSA在监督和迁移学习环境中表现出卓越性能,持续超越最新深度学习模型。
- 通过与大型语言模型(LLM)结合,TabNSA能够解决小样学习挑战。
点此查看论文截图