⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-03 更新
Identity Preserving 3D Head Stylization with Multiview Score Distillation
Authors:Bahri Batuhan Bilecen, Ahmet Berke Gokmen, Furkan Guzelant, Aysegul Dundar
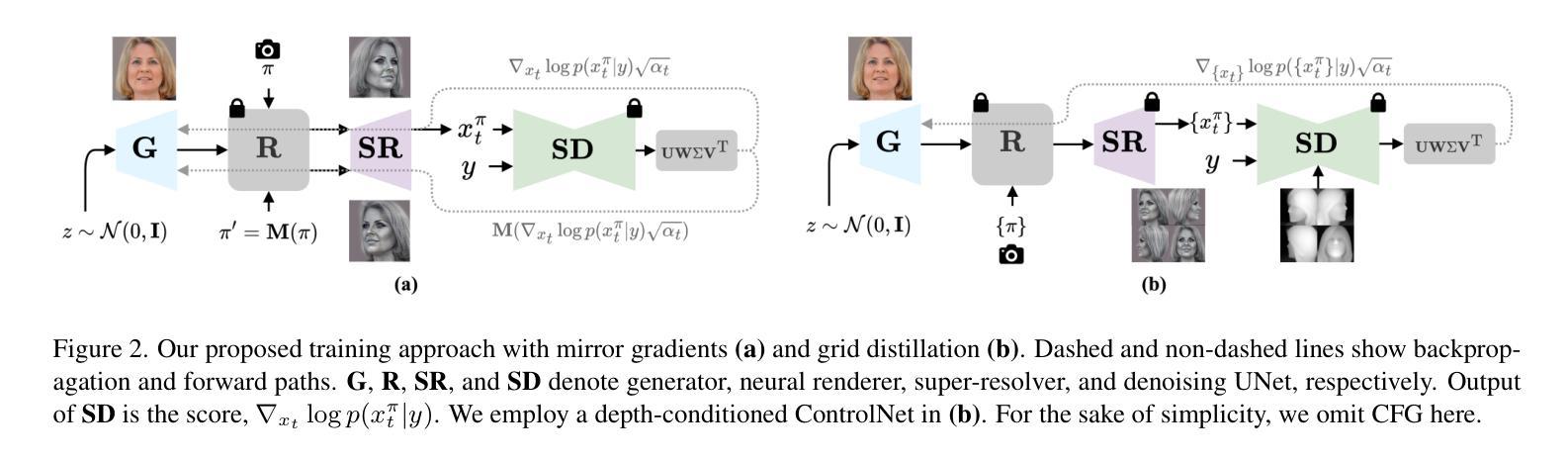
3D head stylization transforms realistic facial features into artistic representations, enhancing user engagement across gaming and virtual reality applications. While 3D-aware generators have made significant advancements, many 3D stylization methods primarily provide near-frontal views and struggle to preserve the unique identities of original subjects, often resulting in outputs that lack diversity and individuality. This paper addresses these challenges by leveraging the PanoHead model, synthesizing images from a comprehensive 360-degree perspective. We propose a novel framework that employs negative log-likelihood distillation (LD) to enhance identity preservation and improve stylization quality. By integrating multi-view grid score and mirror gradients within the 3D GAN architecture and introducing a score rank weighing technique, our approach achieves substantial qualitative and quantitative improvements. Our findings not only advance the state of 3D head stylization but also provide valuable insights into effective distillation processes between diffusion models and GANs, focusing on the critical issue of identity preservation. Please visit the https://three-bee.github.io/head_stylization for more visuals.
本文探讨了通过利用PanoHead模型从全面的360度视角合成图像来解决这一问题。在三维头部风格化方面,该方法能将真实的面部特征转化为艺术表现形式,极大地提高了游戏和虚拟现实应用中的用户参与度。尽管三维感知生成器已经取得了重大进展,但许多三维风格化方法主要提供近似正面视角的图像,并且在保持原始主体的独特身份方面存在困难,这往往导致输出缺乏多样性和个性化。本文提出了一种采用负对数似然蒸馏(LD)来提高身份保留并改善风格化质量的新框架。通过在三维GAN架构中整合多视图网格评分和镜像梯度,并引入评分排名加权技术,我们的方法在质量和数量上都取得了显著的改进。我们的研究不仅推动了三维头部风格化的研究水平,而且为扩散模型和GAN之间的有效蒸馏过程提供了有价值的见解,重点关注身份保留这一关键问题。有关更多视觉效果信息,请访问[https://three-bee.github.io/head_stylization了解详情]。
论文及项目相关链接
PDF https://three-bee.github.io/head_stylization
Summary
这篇论文通过采用PanoHead模型和新型框架来解决三维头部风格化中的挑战。该框架采用负对数似然蒸馏技术增强身份保留并提高风格化质量。通过整合多视角网格评分和镜像梯度在三维GAN架构中,并引入评分排名加权技术,该研究实现了实质性的质量和数量上的改进。这些发现不仅推动了三维头部风格化的进步,还提供了扩散模型和GAN之间有效蒸馏过程的宝贵见解,并聚焦于身份保留这一关键问题。更多视觉展示请访问相关网站。
Key Takeaways
- 论文研究解决了三维头部风格化中的难题,通过PanoHead模型和新型框架实现更全面的面部特征风格化。
- 采用负对数似然蒸馏技术提升风格化质量并保留原始身份特征。
- 多视角网格评分和镜像梯度整合在三维GAN架构中提高了模型的性能。
- 评分排名加权技术被应用于改进模型结果的质量。
- 研究实现了实质性的定性定量改进,显著推进了三维头部风格化的进步。
- 论文对蒸馏过程的有效性进行深入探究,提供宝贵的见解和实践指导。
点此查看论文截图




A Wavelet Diffusion GAN for Image Super-Resolution
Authors:Lorenzo Aloisi, Luigi Sigillo, Aurelio Uncini, Danilo Comminiello
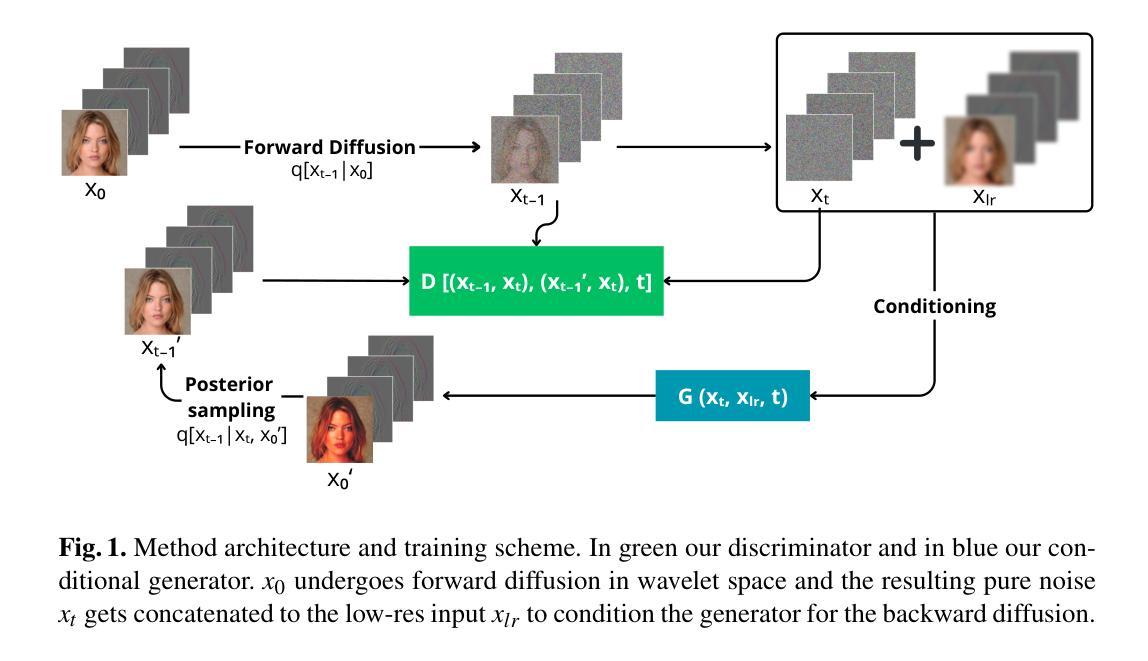
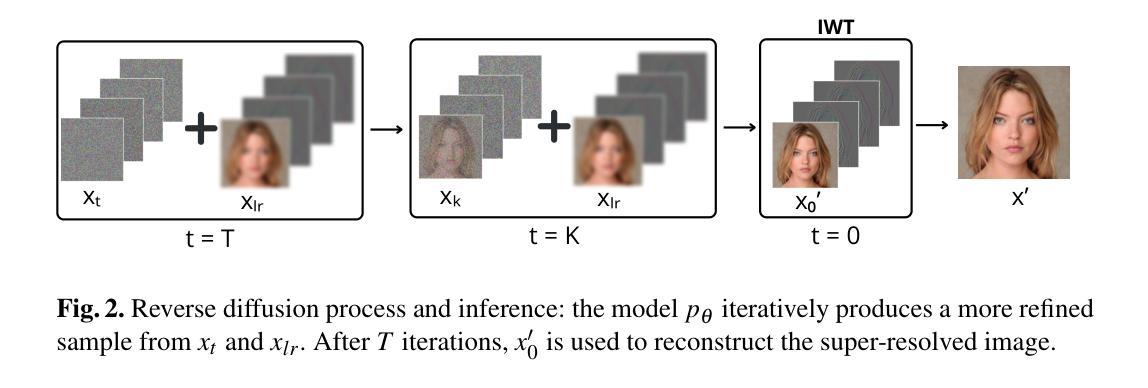
In recent years, diffusion models have emerged as a superior alternative to generative adversarial networks (GANs) for high-fidelity image generation, with wide applications in text-to-image generation, image-to-image translation, and super-resolution. However, their real-time feasibility is hindered by slow training and inference speeds. This study addresses this challenge by proposing a wavelet-based conditional Diffusion GAN scheme for Single-Image Super-Resolution (SISR). Our approach utilizes the diffusion GAN paradigm to reduce the timesteps required by the reverse diffusion process and the Discrete Wavelet Transform (DWT) to achieve dimensionality reduction, decreasing training and inference times significantly. The results of an experimental validation on the CelebA-HQ dataset confirm the effectiveness of our proposed scheme. Our approach outperforms other state-of-the-art methodologies successfully ensuring high-fidelity output while overcoming inherent drawbacks associated with diffusion models in time-sensitive applications.
近年来,扩散模型作为生成对抗网络(GANs)的高保真图像生成的优秀替代品崭露头角,广泛应用于文本到图像生成、图像到图像转换和超分辨率。然而,其实时可行性受到训练速度和推理速度的阻碍。本研究通过提出一种基于小波的单图像超分辨率(SISR)条件扩散GAN方案来解决这一挑战。我们的方法利用扩散GAN范式减少反向扩散过程所需的时间步长和离散小波变换(DWT)来实现降维,从而显著减少训练和推理时间。在CelebA-HQ数据集上的实验验证结果证实了我们的方案的有效性。我们的方法成功超越了其他先进的方法论,成功确保高保真输出的同时克服了与时间敏感应用中扩散模型的固有缺点。
论文及项目相关链接
PDF The paper has been accepted at Italian Workshop on Neural Networks (WIRN) 2024
Summary
扩散模型近年来已逐渐成为生成对抗网络(GANs)在高保真图像生成领域的优越替代方案,广泛应用于文本到图像生成、图像到图像翻译和超分辨率等领域。然而,其实时可行性受到训练速度慢和推理速度慢的阻碍。本研究通过提出一种基于小波的条件扩散GAN方案来解决这一挑战,用于单图像超分辨率(SISR)。该研究利用扩散GAN范式减少了反向扩散过程所需的时间步长,并利用离散小波变换(DWT)实现降维,从而显著减少训练和推理时间。在CelebA-HQ数据集上的实验验证结果证实了所提出方案的有效性。该方法成功超越了其他先进的方法,在保证高保真输出的同时,克服了扩散模型在时间敏感应用中的固有缺陷。
Key Takeaways
- 扩散模型已成为高保真图像生成领域GANs的优越替代方案。
- 扩散模型广泛应用于文本到图像生成、图像到图像翻译及超分辨率等领域。
- 实时应用中,扩散模型的训练和推理速度较慢,成为其主要瓶颈。
- 研究提出了基于小波的条件扩散GAN方案用于单图像超分辨率(SISR)。
- 该研究利用扩散GAN范式减少反向扩散过程的时间步长。
- 研究利用离散小波变换(DWT)实现降维,以提高训练和推理速度。
点此查看论文截图

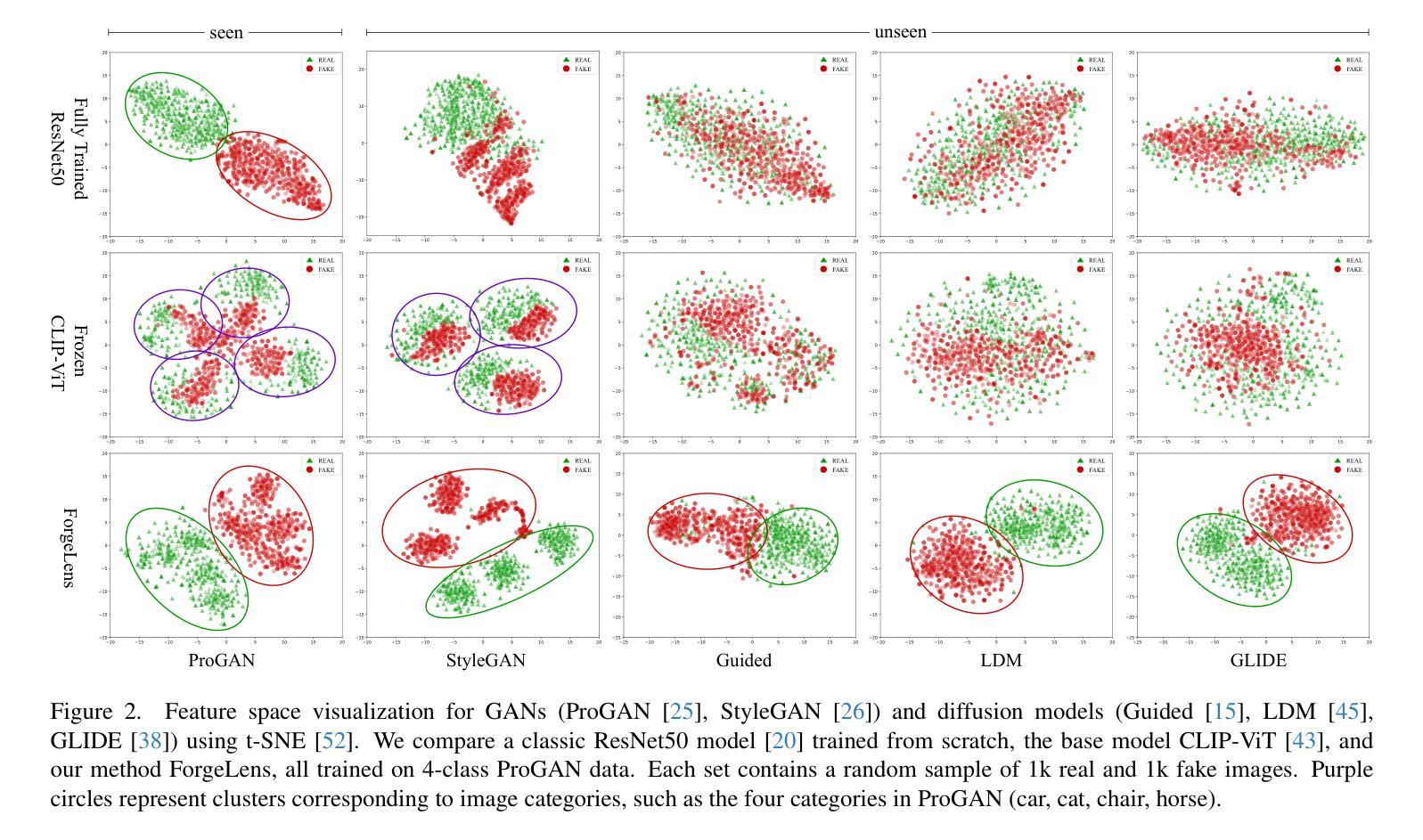
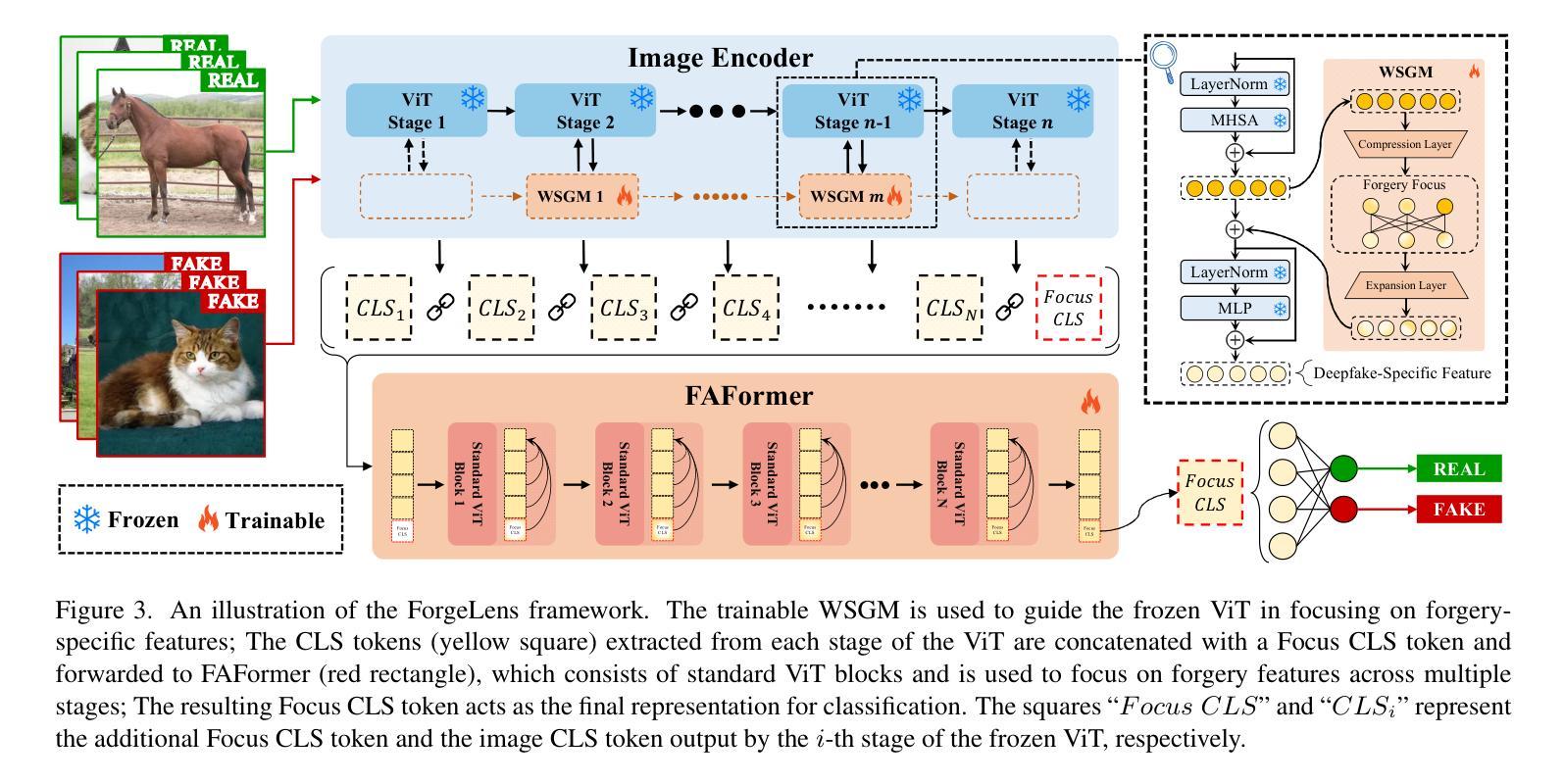
ForgeLens: Data-Efficient Forgery Focus for Generalizable Forgery Image Detection
Authors:Yingjian Chen, Lei Zhang, Yakun Niu
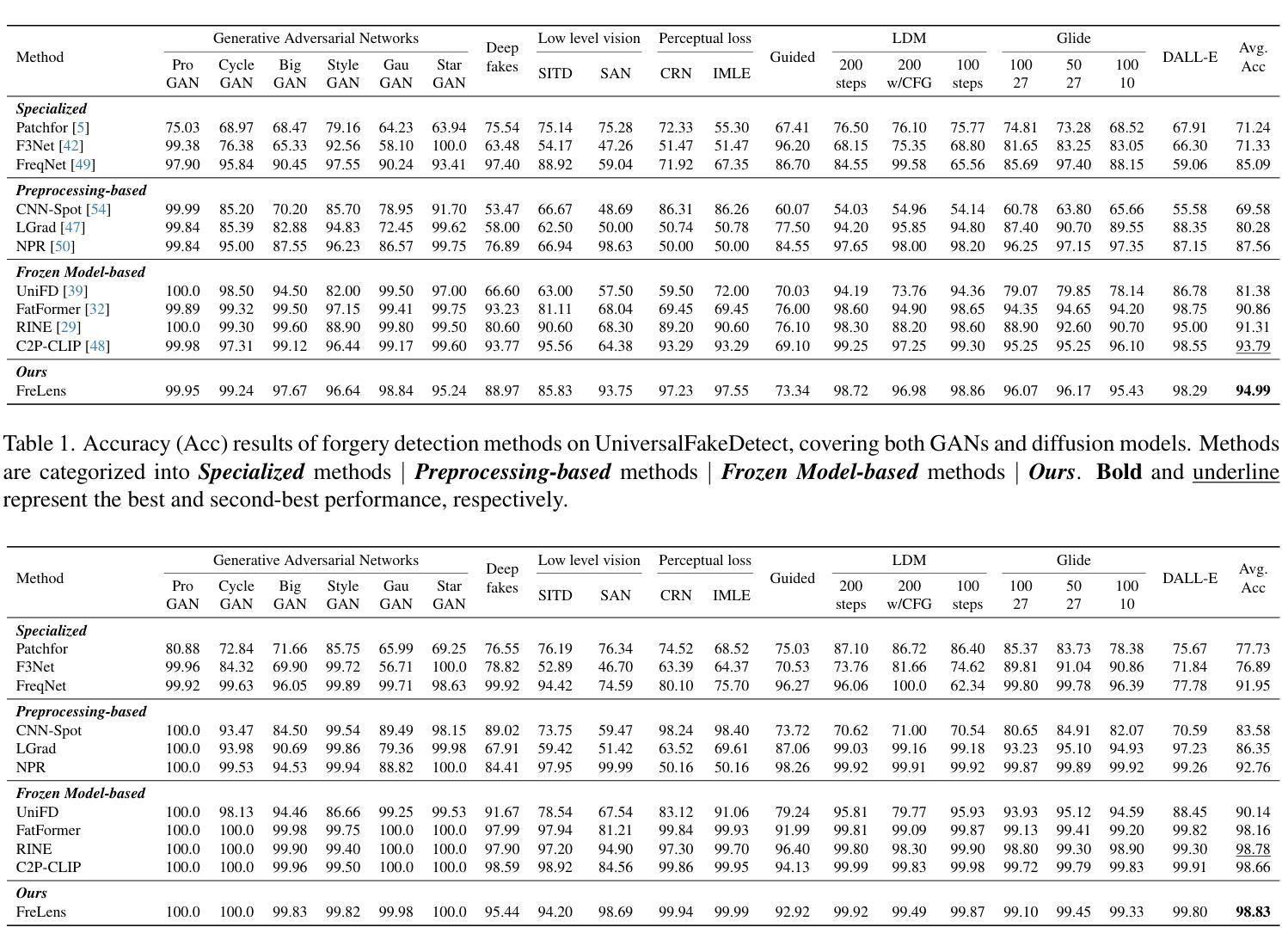
The rise of generative models has raised concerns about image authenticity online, highlighting the urgent need for a detector that is (1) highly generalizable, capable of handling unseen forgery techniques, and (2) data-efficient, achieving optimal performance with minimal training data, enabling it to counter newly emerging forgery techniques effectively. To achieve this, we propose ForgeLens, a data-efficient, feature-guided framework that incorporates two lightweight designs to enable a frozen network to focus on forgery-specific features. First, we introduce the Weight-Shared Guidance Module (WSGM), which guides the extraction of forgery-specific features during training. Second, a forgery-aware feature integrator, FAFormer, is used to effectively integrate forgery information across multi-stage features. ForgeLens addresses a key limitation of previous frozen network-based methods, where general-purpose features extracted from large datasets often contain excessive forgery-irrelevant information. As a result, it achieves strong generalization and reaches optimal performance with minimal training data. Experimental results on 19 generative models, including both GANs and diffusion models, demonstrate improvements of 13.61% in Avg.Acc and 8.69% in Avg.AP over the base model. Notably, ForgeLens outperforms existing forgery detection methods, achieving state-of-the-art performance with just 1% of the training data. Our code is available at https://github.com/Yingjian-Chen/ForgeLens.
生成模型的兴起引发了人们对在线图像真实性的关注,这突显了对检测器的迫切需求,该检测器需要(1)高度通用化,能够处理未见过的伪造技术;(2)数据效率高,用最少量的训练数据实现最佳性能,能够有效应对新出现的伪造技术。为此,我们提出了ForgeLens,一个数据效率高、特征引导的框架,它采用了两种轻型设计,使冻结的网络能够专注于伪造特定特征。首先,我们引入了共享权重引导模块(WSGM),它在训练过程中引导伪造特定特征的提取。其次,使用感知伪造的特性集成器FAFormer,以有效整合多阶段特征中的伪造信息。ForgeLens解决了基于先前冻结网络的方法的关键局限性,这些方法从大型数据集中提取的通用特征往往包含过多的与伪造无关的信息。因此,它实现了强大的泛化能力,并用最少的训练数据达到了最佳性能。在19个生成模型(包括GAN和扩散模型)上的实验结果表明,与基础模型相比,Avg.Acc提高了13.61%,Avg.AP提高了8.69%。值得注意的是,ForgeLens在仅使用1%的训练数据的情况下,就达到了最先进的伪造检测性能。我们的代码可在https://github.com/Yingjian-Chen/Forgelens处获得。
论文及项目相关链接
Summary
生成模型的发展引发了关于在线图像真实性的关注,迫切需要一种检测器,该检测器需要具有高度泛化能力,能够处理未见过的伪造技术,并且数据效率高,用最少量的训练数据实现最优性能,以便有效应对新出现的伪造技术。为此,我们提出了ForgeLens,一个数据高效、特征引导框架,采用两种轻型设计,使冻结的网络能够专注于伪造特定特征。一是引入权重共享引导模块(WSGM),在训练过程中引导提取伪造特定特征。二是使用伪造感知特征集成器FAFormer,有效整合多阶段特征的伪造信息。ForgeLens解决了基于冻结网络方法的关键局限性,即从大型数据集中提取的通用特征往往包含过多的与伪造无关的信息。因此,它实现了强大的泛化能力,并用最少的训练数据达到最佳性能。在19个生成模型上的实验结果表明,与基础模型相比,ForgeLens在平均准确率和平均精度上分别提高了13.61%和8.69%。值得注意的是,ForgeLens仅需1%的训练数据便达到了最先进的性能表现。相关代码可在链接中查阅:https://github.com/Yingjian-Chen/Forgelens。
Key Takeaways
- 生成模型的发展引发了关于图像真实性的关注。
- 提出了一种名为ForgeLens的数据高效、特征引导框架来解决伪造检测问题。
- ForgeLens具有两个核心组件:Weight-Shared Guidance Module(WSGM)和FAFormer。
- WSGM模块在训练过程中引导提取伪造特定特征。
- FAFormer能有效整合多阶段特征的伪造信息。
- ForgeLens解决了现有伪造检测方法的局限性,实现了强大的泛化能力并优化了训练数据的使用效率。
点此查看论文截图