⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-03 更新
DICE-BENCH: Evaluating the Tool-Use Capabilities of Large Language Models in Multi-Round, Multi-Party Dialogues
Authors:Kyochul Jang, Donghyeon Lee, Kyusik Kim, Dongseok Heo, Taewhoo Lee, Woojeong Kim, Bongwon Suh
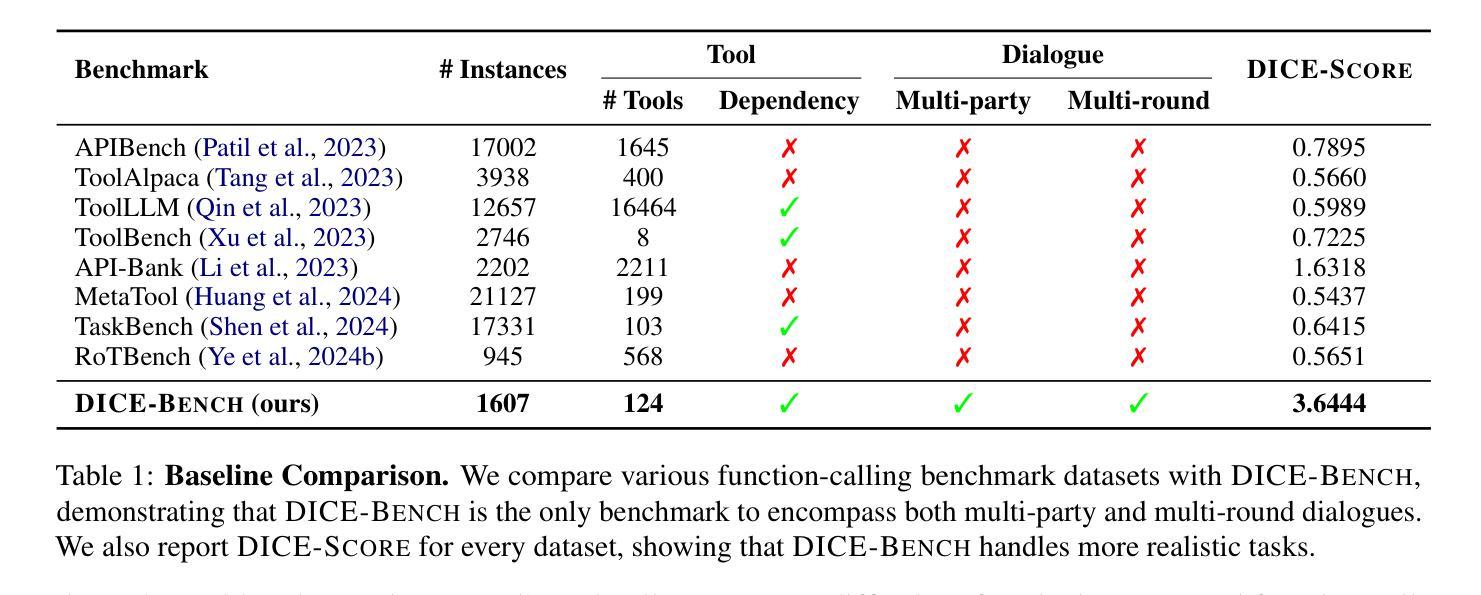
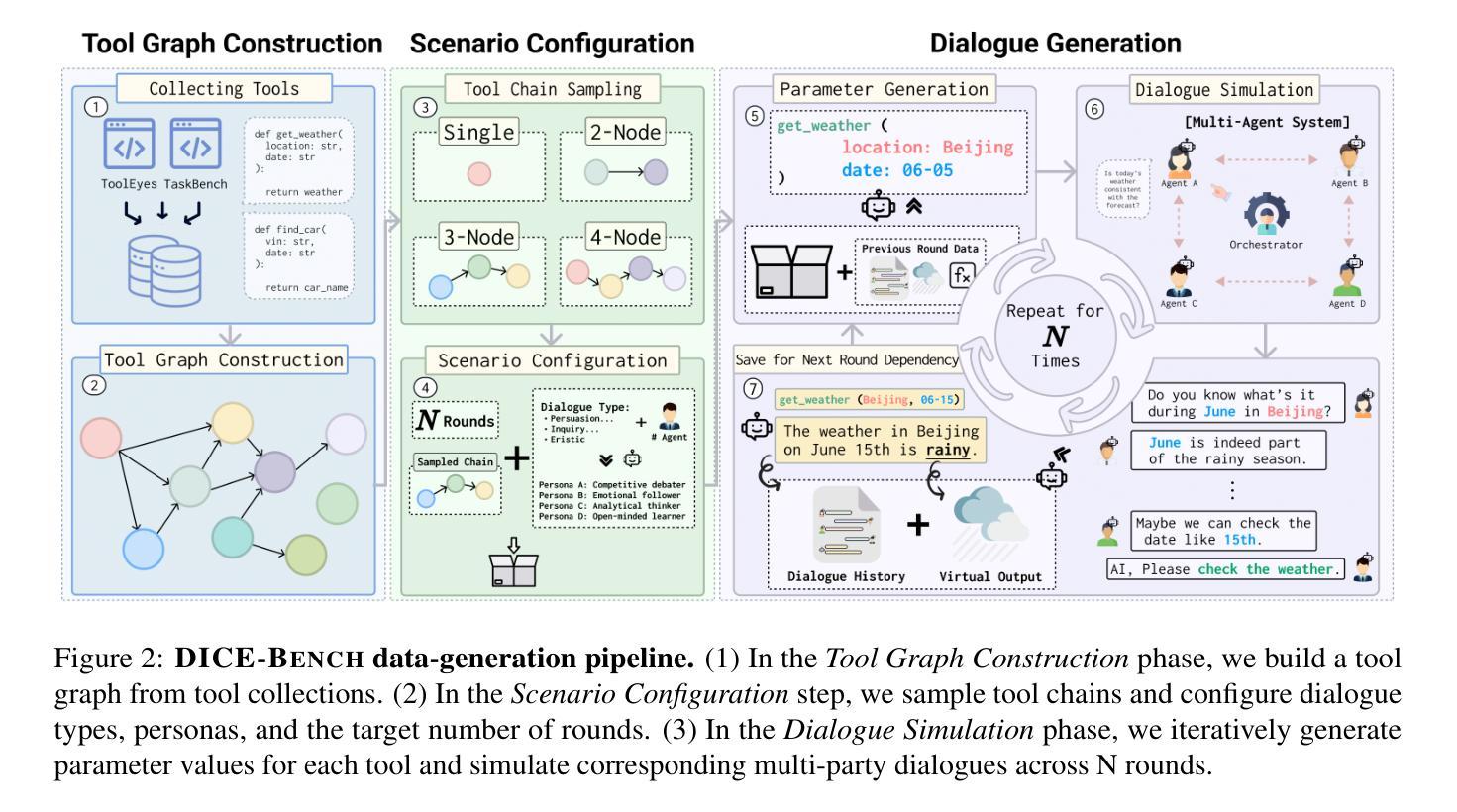
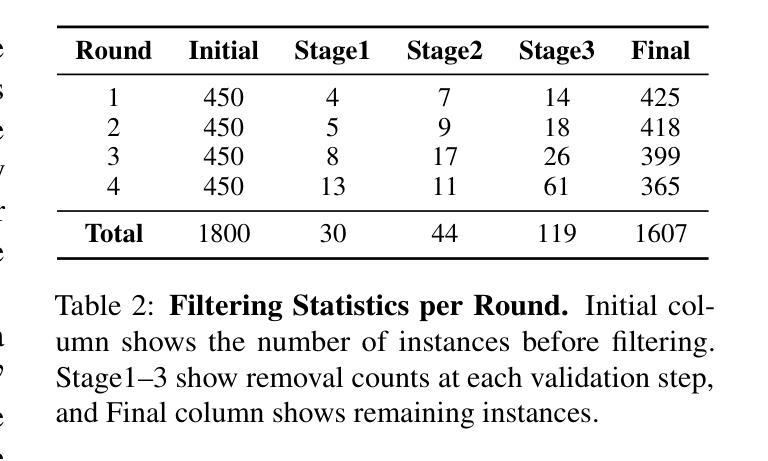
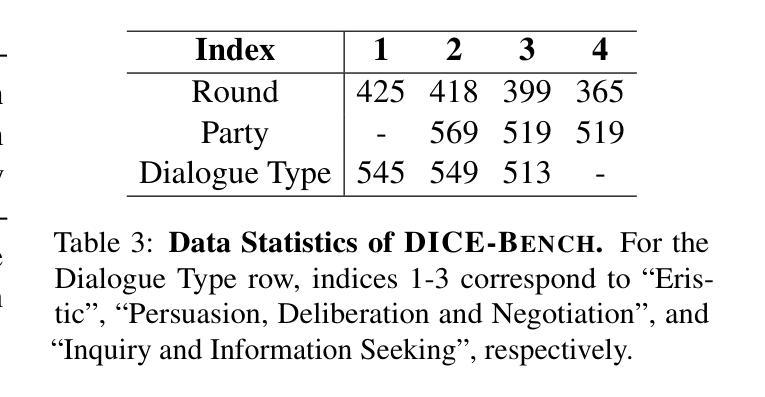
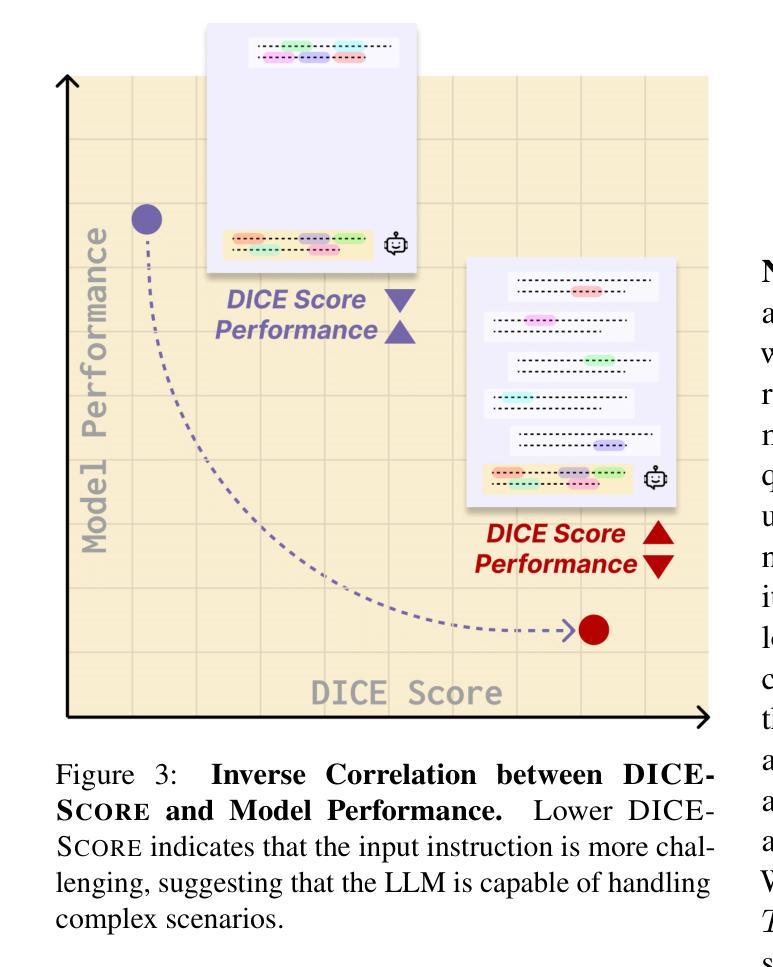
Existing function-calling benchmarks focus on single-turn interactions. However, they overlook the complexity of real-world scenarios. To quantify how existing benchmarks address practical applications, we introduce DICE-SCORE, a metric that evaluates the dispersion of tool-related information such as function name and parameter values throughout the dialogue. Analyzing existing benchmarks through DICE-SCORE reveals notably low scores, highlighting the need for more realistic scenarios. To address this gap, we present DICE-BENCH, a framework that constructs practical function-calling datasets by synthesizing conversations through a tool graph that maintains dependencies across rounds and a multi-agent system with distinct personas to enhance dialogue naturalness. The final dataset comprises 1,607 high-DICE-SCORE instances. Our experiments on 19 LLMs with DICE-BENCH show that significant advances are still required before such models can be deployed effectively in real-world settings. Our code and data are all publicly available: https://snuhcc.github.io/DICE-Bench/.
现有功能调用基准测试主要集中在单轮交互上,但忽略了真实场景的复杂性。为了量化现有基准测试如何应对实际应用,我们引入了DICE-SCORE这一指标,它用于评估工具相关信息(如函数名称和参数值)在对话中的分散程度。通过DICE-SCORE分析现有基准测试结果显示分数较低,这突显了更需要更现实的场景。为了解决这一差距,我们推出了DICE-BENCH框架,该框架通过工具图合成对话来构建实用的函数调用数据集,该工具图能维持各轮之间的依赖关系,并借助具有不同角色的多智能体系统来提高对话的自然性。最终的数据集包含1607个高DICE-SCORE实例。我们在包含19个大型语言模型的DICE-BENCH上进行的实验表明,在将此类模型有效部署到现实环境之前,仍需取得重大进展。我们的代码和数据都是公开可用的:https://snuhcc.github.io/DICE-Bench/(翻译)。
论文及项目相关链接
PDF 9 pages, ACL 2025 Vienna
Summary
该文介绍了现有函数调用基准测试存在的问题和不足。为了解决这些问题,提出了一种名为DICE-SCORE的新度量方法,用以评估现有测试中工具相关信息的分布状况。现有基准测试在DICE-SCORE评估下得分较低,凸显了现实场景复杂性的重要性。为了弥补这一差距,提出了DICE-BENCH框架,通过工具图和多智能体系统构建实际函数调用数据集,提升对话的自然性和连贯性。最终数据集包含高质量高评分的数据实例。通过实验表明,当前大型语言模型在现实应用环境中仍存在巨大提升空间。数据与相关代码已经公开可用。
Key Takeaways
- 现有函数调用基准测试主要集中在单一交互场景下,忽视了现实场景的复杂性。
- DICE-SCORE作为一种新的度量方法,用于评估工具相关信息的分布状况。
- 通过DICE-SCORE评估,现有基准测试的得分较低,凸显了现实场景中复杂性的重要性。
- DICE-BENCH框架用于构建实际函数调用数据集,提高对话的自然性和连贯性。
- DICE-BENCH通过工具图和多智能体系统实现数据的合成和构建。
- 最终数据集包含高质量高评分的数据实例,达到了一定规模。
点此查看论文截图

Listener-Rewarded Thinking in VLMs for Image Preferences
Authors:Alexander Gambashidze, Li Pengyi, Matvey Skripkin, Andrey Galichin, Anton Gusarov, Konstantin Sobolev, Andrey Kuznetsov, Ivan Oseledets
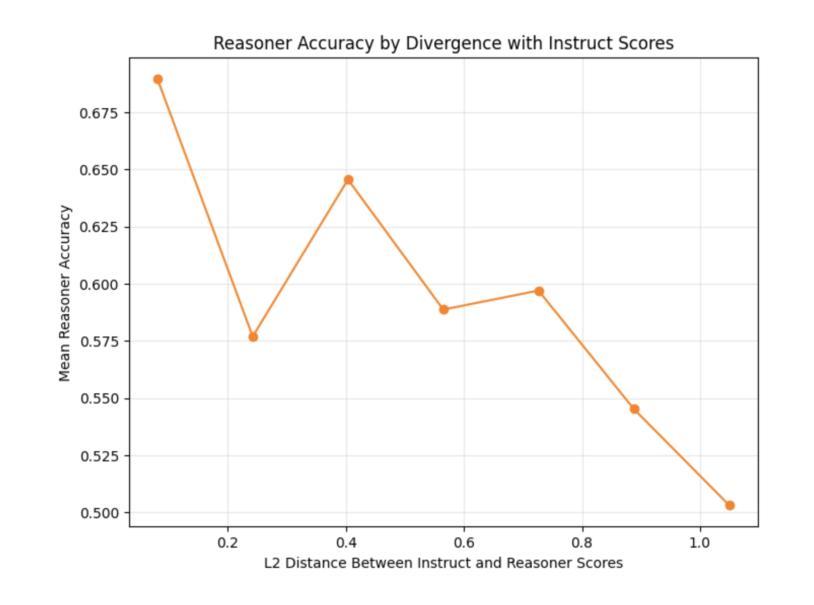
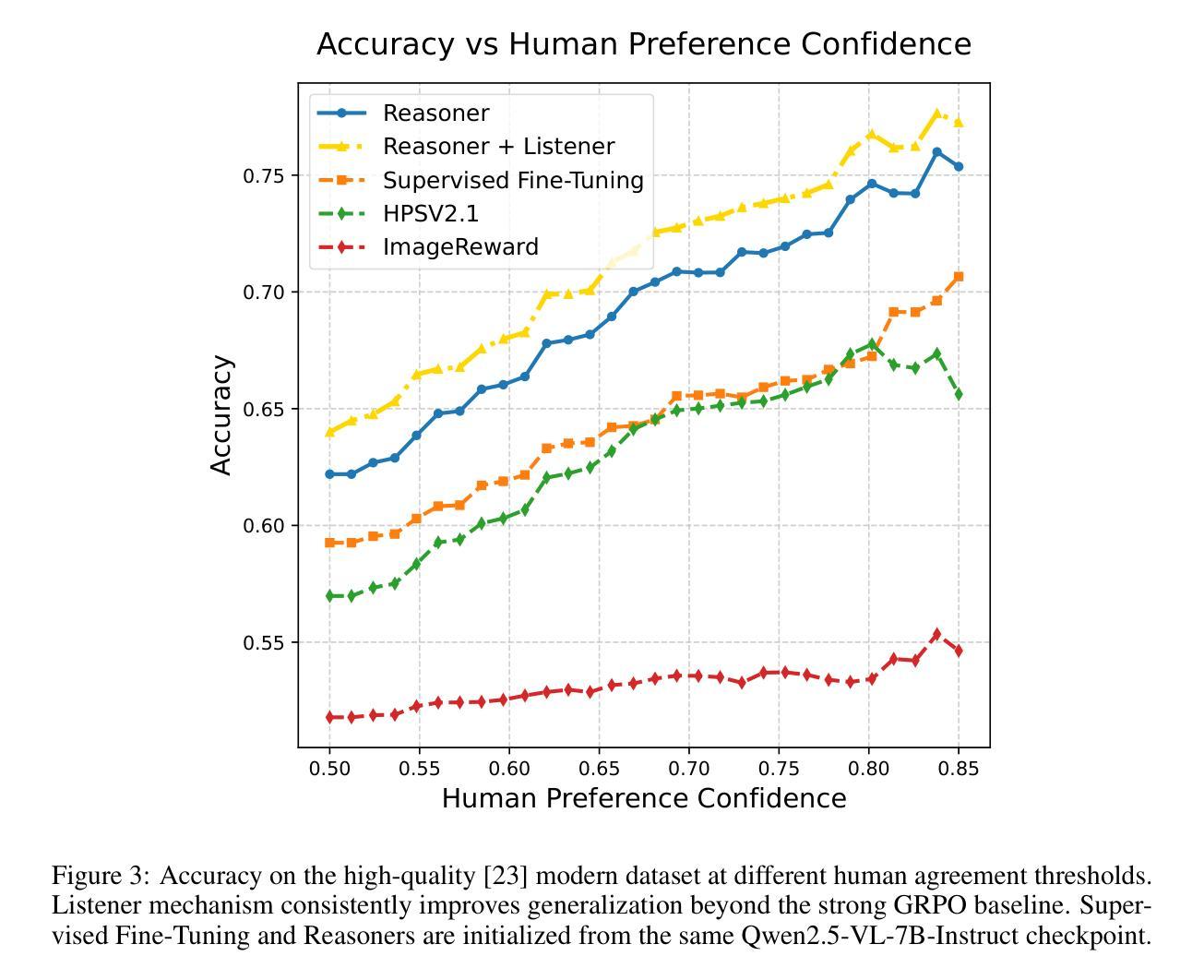
Training robust and generalizable reward models for human visual preferences is essential for aligning text-to-image and text-to-video generative models with human intent. However, current reward models often fail to generalize, and supervised fine-tuning leads to memorization, demanding complex annotation pipelines. While reinforcement learning (RL), specifically Group Relative Policy Optimization (GRPO), improves generalization, we uncover a key failure mode: a significant drop in reasoning accuracy occurs when a model’s reasoning trace contradicts that of an independent, frozen vision-language model (“listener”) evaluating the same output. To address this, we introduce a listener-augmented GRPO framework. Here, the listener re-evaluates the reasoner’s chain-of-thought to provide a dense, calibrated confidence score, shaping the RL reward signal. This encourages the reasoner not only to answer correctly, but to produce explanations that are persuasive to an independent model. Our listener-shaped reward scheme achieves best accuracy on the ImageReward benchmark (67.4%), significantly improves out-of-distribution (OOD) performance on a large-scale human preference dataset (1.2M votes, up to +6% over naive reasoner), and reduces reasoning contradictions compared to strong GRPO and SFT baselines. These results demonstrate that listener-based rewards provide a scalable, data-efficient path to aligning vision-language models with nuanced human preferences. We will release our reasoning model here: https://huggingface.co/alexgambashidze/qwen2.5vl_image_preference_reasoner.
对于人类视觉偏好进行稳健且通用的奖励模型训练,对于文本到图像和文本到视频生成模型与人类意图的对齐至关重要。然而,当前的奖励模型通常难以实现泛化,而监督微调则会导致记忆化,需要复杂的注释管道。虽然强化学习(RL),特别是群组相对策略优化(GRPO)可以改善泛化能力,但我们发现了一个关键的失败模式:当模型的推理轨迹与独立、冻结的视觉语言模型(“监听器”)评估同一输出时的推理轨迹相矛盾时,会出现推理精度大幅下降的情况。为了解决这一问题,我们引入了增强监听器的GRPO框架。在这里,“监听器”重新评估推理者的思维链,以提供密集、校准的信心分数,塑造RL奖励信号。这鼓励推理者不仅要正确回答问题,而且要产生能够说服独立模型的解释。我们基于监听器的奖励方案在ImageReward基准测试中实现了最佳精度(67.4%),在大规模人类偏好数据集上的域外性能得到了显著改善(120万票,优于简单推理器高达+6%),并减少了与强GRPO和SFT基准测试的推理矛盾。这些结果表明,基于监听器的奖励提供了一条可扩展且数据高效的途径,以将视觉语言模型与微妙的人类偏好对齐。我们的推理模型将在此处发布:https://huggingface.co/alexgambashidze/qwen2.5vl_image_preference_reasoner。
论文及项目相关链接
Summary
本文探讨了训练能够反映人类视觉偏好的奖励模型的重要性,对于文本到图像和文本到视频的生成模型与人类意图的对接至关重要。当前奖励模型存在泛化能力不足和过度依赖监督微调导致记忆化的问题。虽然强化学习(RL)中的群组相对策略优化(GRPO)能提高泛化能力,但存在推理准确度显著下降的问题,特别是在模型推理轨迹与独立冻结的视觉语言模型(“监听器”)评估结果相悖时。为解决这一问题,本文引入了监听器增强的GRPO框架。在该框架下,监听器重新评估推理者的思维过程,提供密集、校准的信心分数,塑造RL奖励信号,激励推理者不仅回答正确,而且产生能够说服独立模型的解释。实验结果显示,该听众形状奖励方案在ImageReward基准测试上达到最高准确度(67.4%),在大规模人类偏好数据集上显著提高离群值性能(提高达+6%),并减少与强GRPO和SFT基准测试的推理矛盾。这些结果证明了基于监听器的奖励为对齐视觉语言模型与微妙人类偏好提供了一条可扩展且数据高效的路径。
Key Takeaways
- 训练反映人类视觉偏好的奖励模型对于文本到图像和文本到视频的生成模型至关重要。
- 当前奖励模型存在泛化能力不足和过度依赖监督微调的问题。
- 强化学习中的群组相对策略优化(GRPO)能提高泛化能力,但存在推理准确度下降的问题。
- 监听器增强的GRPO框架通过重新评估推理过程,提供密集、校准的信心分数,塑造RL奖励信号。
- 听众形状奖励方案在ImageReward基准测试上达到最高准确度。
- 该方案在大规模人类偏好数据集上显著提高离群值性能。
点此查看论文截图



SPADE: Structured Prompting Augmentation for Dialogue Enhancement in Machine-Generated Text Detection
Authors:Haoyi Li, Angela Yifei Yuan, Soyeon Caren Han, Christopher Leckie
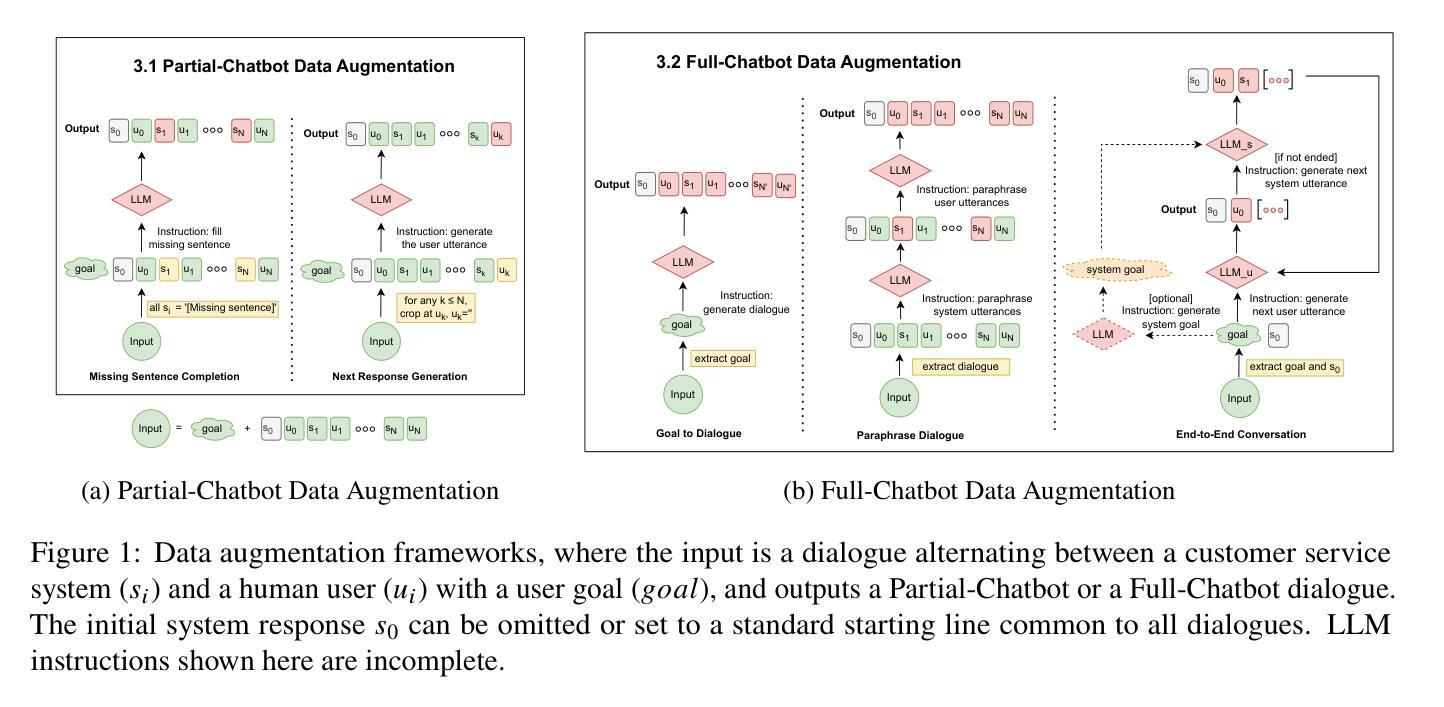
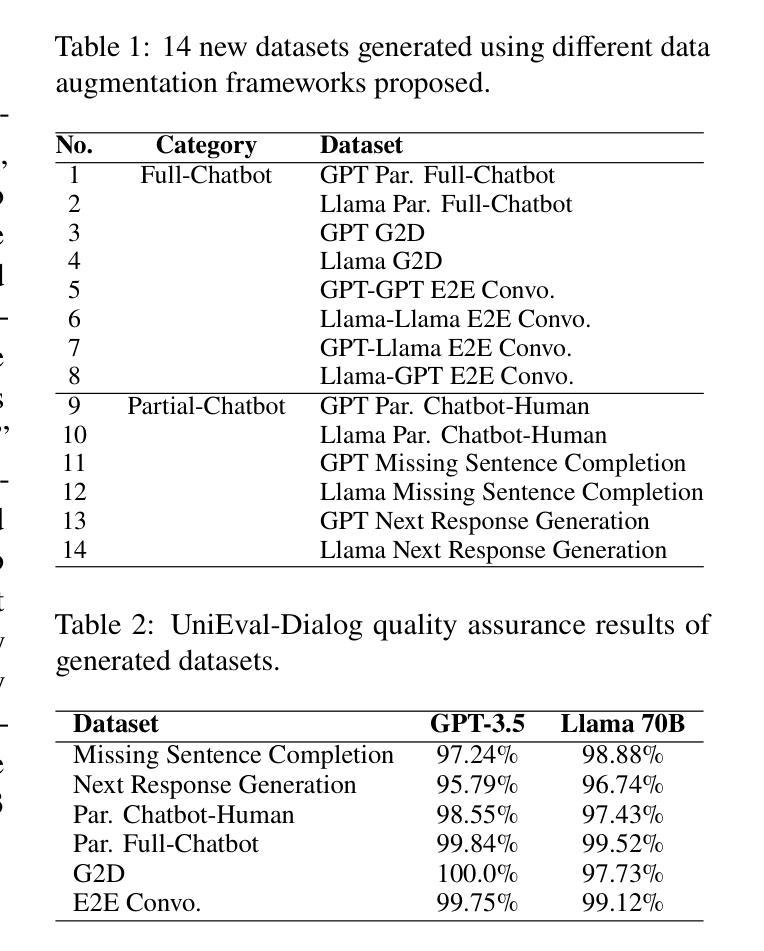
The increasing capability of large language models (LLMs) to generate synthetic content has heightened concerns about their misuse, driving the development of Machine-Generated Text (MGT) detection models. However, these detectors face significant challenges due to the lack of high-quality synthetic datasets for training. To address this issue, we propose SPADE, a structured framework for detecting synthetic dialogues using prompt-based positive and negative samples. Our proposed methods yield 14 new dialogue datasets, which we benchmark against eight MGT detection models. The results demonstrate improved generalization performance when utilizing a mixed dataset produced by proposed augmentation frameworks, offering a practical approach to enhancing LLM application security. Considering that real-world agents lack knowledge of future opponent utterances, we simulate online dialogue detection and examine the relationship between chat history length and detection accuracy. Our open-source datasets, code and prompts can be downloaded from https://github.com/AngieYYF/SPADE-customer-service-dialogue.
随着大型语言模型(LLM)生成合成内容的能力日益增强,人们对它们被误用的担忧也在加剧,这推动了机器生成文本(MGT)检测模型的发展。然而,由于缺乏高质量的合成数据集进行训练,这些检测器面临着巨大的挑战。为了解决这个问题,我们提出了SPADE,这是一个使用基于提示的正负样本检测合成对话的结构化框架。我们提出的方法产生了14个新的对话数据集,我们对八个MGT检测模型进行了基准测试。结果证明,利用所提出的增强框架产生的混合数据集可以提高泛化性能,为增强LLM应用安全提供了实用方法。考虑到现实世界的代理不知道未来对手的发言,我们模拟在线对话检测,并研究对话历史长度与检测准确度之间的关系。我们的开源数据集、代码和提示可从https://github.com/AngieYYF/SPADE-customer-service-dialogue下载。
论文及项目相关链接
PDF ACL LLMSEC
Summary
大型语言模型(LLMs)生成合成内容的能力提升,引发对其滥用的担忧,推动了机器生成文本(MGT)检测模型的发展。然而,由于缺乏高质量的合成数据集进行训练,这些检测器面临挑战。我们提出SPADE框架,通过提示正负样本检测合成对话。我们的方法产生了14个新的对话数据集,对8个MGT检测模型进行基准测试。结果证明,利用提出的增强框架产生的混合数据集可以提高泛化性能,为增强LLM应用安全性提供了实用方法。我们还模拟了在线对话检测,并探讨了对话历史长度与检测准确率的关系。
Key Takeaways
- 大型语言模型(LLMs)生成合成内容的能力提升引发关注。
- MGT检测模型的发展面临缺乏高质量合成数据集的挑战。
- 提出SPADE框架,通过提示正负样本检测合成对话。
- 生成了14个新的对话数据集进行基准测试。
- 利用混合数据集提高泛化性能,增强LLM应用的安全性。
- 模拟在线对话检测,考虑真实对话中的未知因素。
点此查看论文截图