⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-03 更新
Positional Bias in Binary Question Answering: How Uncertainty Shapes Model Preferences
Authors:Tiziano Labruna, Simone Gallo, Giovanni Da San Martino
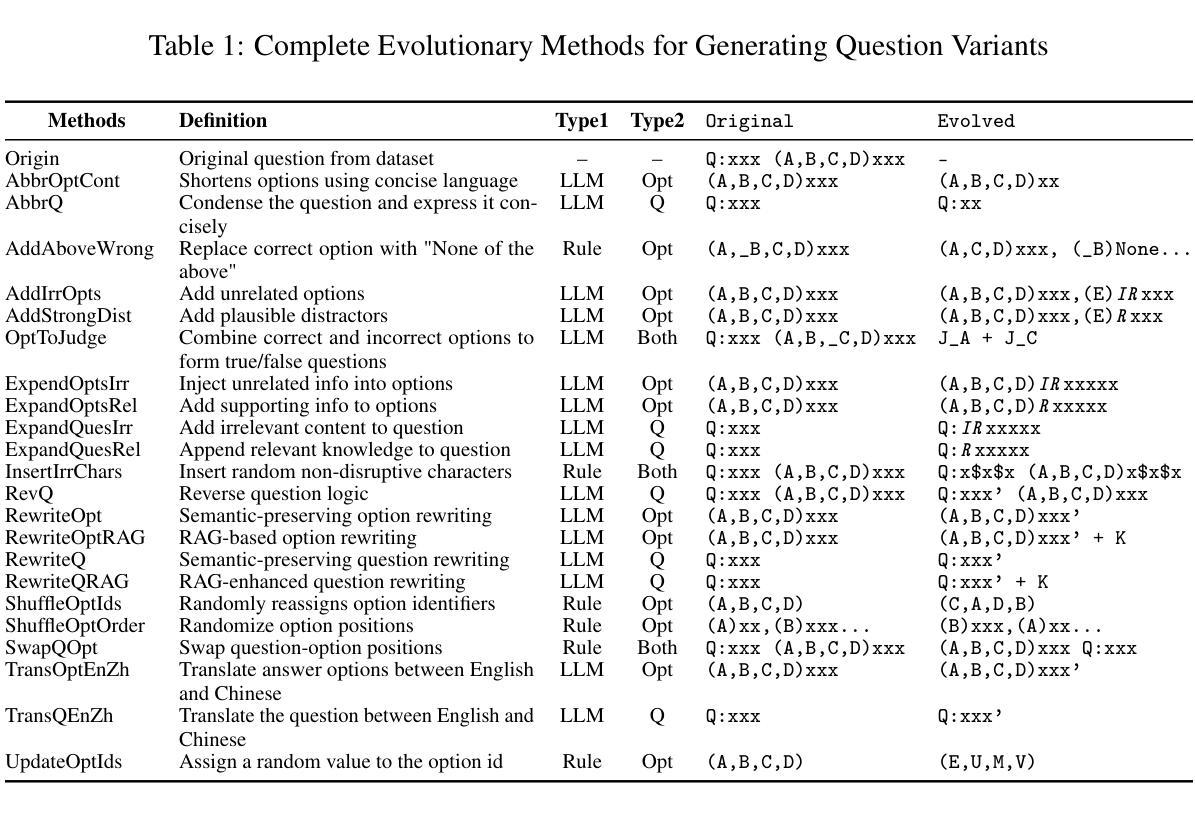
Positional bias in binary question answering occurs when a model systematically favors one choice over another based solely on the ordering of presented options. In this study, we quantify and analyze positional bias across five large language models under varying degrees of answer uncertainty. We re-adapted the SQuAD-it dataset by adding an extra incorrect answer option and then created multiple versions with progressively less context and more out-of-context answers, yielding datasets that range from low to high uncertainty. Additionally, we evaluate two naturally higher-uncertainty benchmarks: (1) WebGPT - question pairs with unequal human-assigned quality scores, and (2) Winning Arguments - where models predict the more persuasive argument in Reddit’s r/ChangeMyView exchanges. Across each dataset, the order of the “correct” (or higher-quality/persuasive) option is systematically flipped (first placed in position 1, then in position 2) to compute both Preference Fairness and Position Consistency. We observe that positional bias is nearly absent under low-uncertainty conditions, but grows exponentially when it becomes doubtful to decide which option is correct.
二元问题回答中的位置偏见发生在模型仅基于呈现的选项顺序而系统地偏爱某一选择的情况。在这项研究中,我们在不同等级的答案不确定性下,对五个大型语言模型的位置偏见进行了量化和分析。我们通过添加额外的错误答案选项重新适应了SQuAD-it数据集,然后创建了多个版本,随着上下文逐渐减少、脱离上下文的答案逐渐增多,从低不确定性到高不确定性,生成了数据集。此外,我们还评估了两个自然更高不确定性的基准测试:(1)WebGPT——具有不平等人类分配质量得分的问题对,(2)Winning Arguments——模型预测Reddit的r/ChangeMyView交流中更有说服力的论点。在每个数据集中,“正确”(或更高质量/更有说服力的)选项的顺序都被系统地改变(先放在位置1,然后放在位置2),以计算偏好公平性和位置一致性。我们发现,在不确定性低的情况下,位置偏见几乎不存在,但在难以决定哪个选项是正确的时,位置偏见呈指数增长。
论文及项目相关链接
Summary
本文研究了二元问题回答中的位置偏见现象,即在不确定答案的情况下,模型对选项的偏好会受到选项顺序的影响。实验通过改编SQuAD-it数据集并添加错误答案选项,创建了不同不确定程度的版本。同时评估了两个自然更高不确定性的基准测试:WebGPT和Winning Arguments。研究表明,在低不确定性条件下,位置偏见几乎不存在,但在难以确定哪个选项正确的情况下,位置偏见会呈指数级增长。
Key Takeaways
- 位置偏见在二元问题回答中出现,模型会基于选项顺序系统性地偏好某一答案。
- 实验通过改编SQuAD-it数据集并添加不同难度的答案选项,创建了不同不确定性的数据集版本。
- 在低不确定性条件下,模型几乎不受位置偏见影响。
- 在高不确定性条件下,模型的位置偏见会显著增长。
- 两个自然更高不确定性的基准测试是WebGPT和Winning Arguments。
- 通过翻转“正确”选项的位置,可以计算偏好公平性和位置一致性。
点此查看论文截图

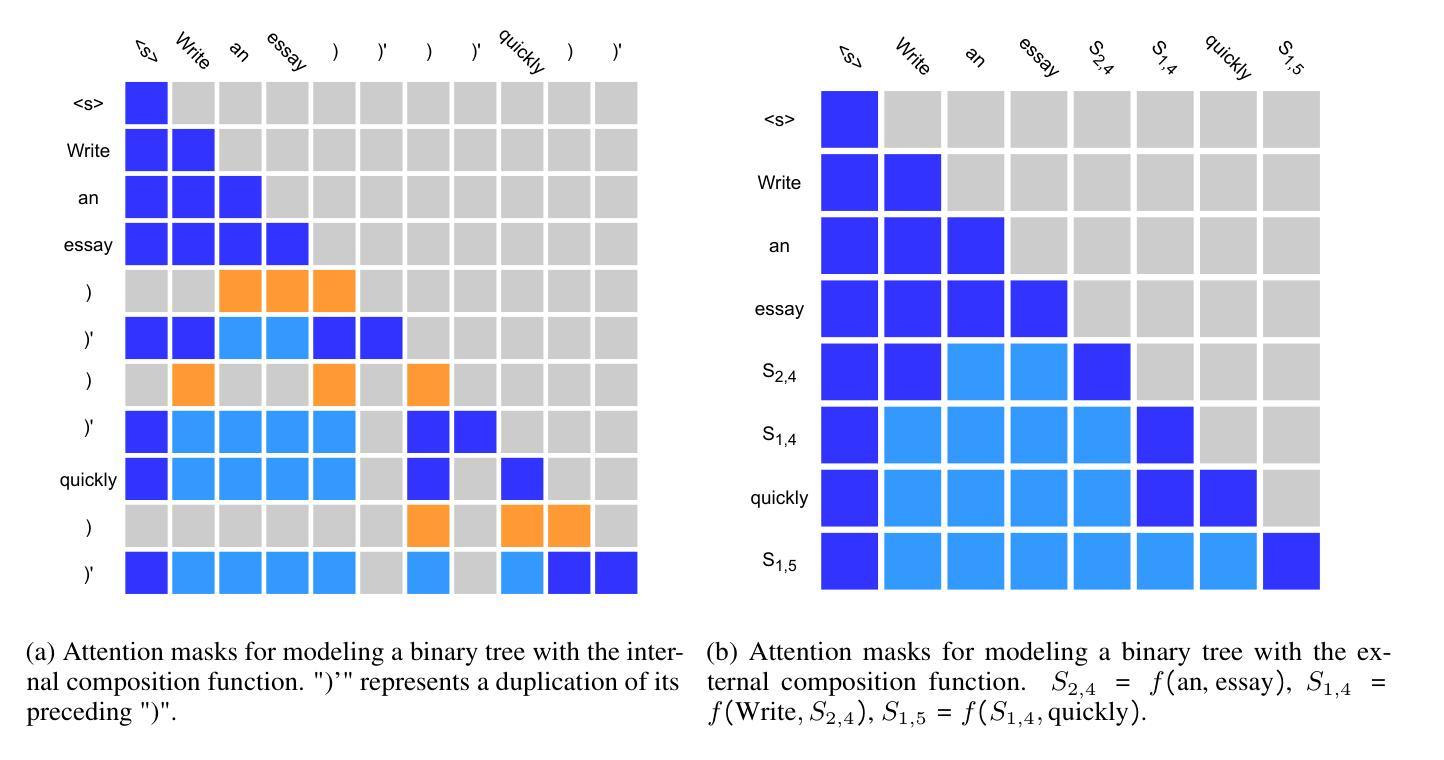
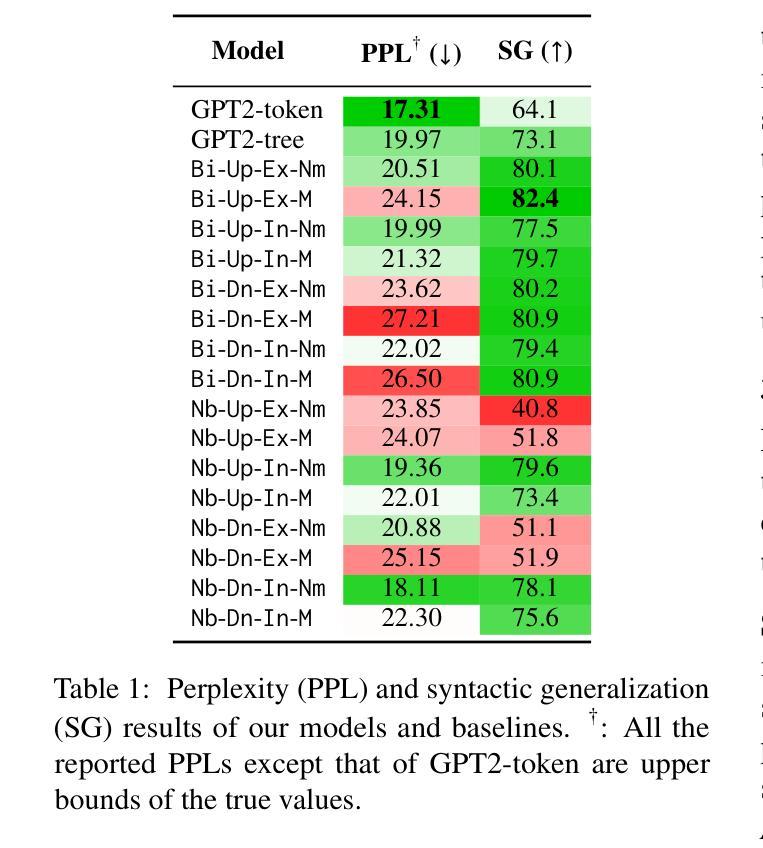
A Systematic Study of Compositional Syntactic Transformer Language Models
Authors:Yida Zhao, Hao Xve, Xiang Hu, Kewei Tu
Syntactic language models (SLMs) enhance Transformers by incorporating syntactic biases through the modeling of linearized syntactic parse trees alongside surface sentences. This paper focuses on compositional SLMs that are based on constituency parse trees and contain explicit bottom-up composition of constituent representations. We identify key aspects of design choices in existing compositional SLMs and propose a unified framework encompassing both existing models and novel variants. We conduct a comprehensive empirical evaluation of all the variants in our framework across language modeling, syntactic generalization, summarization, dialogue, and inference efficiency. Based on the experimental results, we make multiple recommendations on the design of compositional SLMs. Our code is released at https://github.com/zhaoyd1/compositional_SLMs.
句法语言模型(SLM)通过建模线性化的句法解析树和表层句子,引入了句法偏差,从而增强了Transformer的功能。本文重点介绍基于成分解析树的组合型SLM,其中包含明确的自下而上的成分表示组合。我们确定了现有组合型SLM中设计选择的关键方面,并提出了一个统一的框架,其中包括现有模型和新型变体。我们对框架中所有变体进行了全面的经验评估,包括语言建模、句法泛化、摘要、对话和推理效率等方面。基于实验结果,我们对组合型SLM的设计提出了多项建议。我们的代码已发布在https://github.com/zhaoyd1/compositional_SLMs。
论文及项目相关链接
Summary
本文介绍了通过结合线性化的句法解析树和表面句子,增强Transformer的句法语言模型(SLMs)。文章重点研究基于成分句法解析树的组合SLMs,其包含明确的自下而上的成分表示组合。文章分析了现有组合SLM的关键设计选择,提出了涵盖现有模型和新型变体的统一框架,并全面评估了所有变体在多个任务上的性能,包括语言建模、句法泛化、摘要、对话和推理效率。基于实验结果,对组合SLM的设计提出了多项建议。
Key Takeaways
- SLMs通过结合线性化的句法解析树和表面句子增强Transformer的性能。
- 文章聚焦于基于成分句法解析树的组合SLMs。
- 文章提出了涵盖现有模型和新型变体的统一框架。
- 对所有变体进行了全面的实证研究,涵盖语言建模、句法泛化、摘要、对话和推理效率。
- 实验结果表明,某些设计选择对模型性能有重要影响。
- 文章提供了关于如何设计组合SLMs的多个建议。
点此查看论文截图


What Makes ChatGPT Effective for Software Issue Resolution? An Empirical Study of Developer-ChatGPT Conversations in GitHub
Authors:Ramtin Ehsani, Sakshi Pathak, Esteban Parra, Sonia Haiduc, Preetha Chatterjee
Conversational large-language models are extensively used for issue resolution tasks. However, not all developer-LLM conversations are useful for effective issue resolution. In this paper, we analyze 686 developer-ChatGPT conversations shared within GitHub issue threads to identify characteristics that make these conversations effective for issue resolution. First, we analyze the conversations and their corresponding issues to distinguish helpful from unhelpful conversations. We begin by categorizing the types of tasks developers seek help with to better understand the scenarios in which ChatGPT is most effective. Next, we examine a wide range of conversational, project, and issue-related metrics to uncover factors associated with helpful conversations. Finally, we identify common deficiencies in unhelpful ChatGPT responses to highlight areas that could inform the design of more effective developer-facing tools. We found that only 62% of the ChatGPT conversations were helpful for successful issue resolution. ChatGPT is most effective for code generation and tools/libraries/APIs recommendations, but struggles with code explanations. Helpful conversations tend to be shorter, more readable, and exhibit stronger semantic and linguistic alignment. Larger, more popular projects and more experienced developers benefit more from ChatGPT. At the issue level, ChatGPT performs best on simpler problems with limited developer activity and faster resolution, typically well-scoped tasks like compilation errors. The most common deficiencies in unhelpful ChatGPT responses include incorrect information and lack of comprehensiveness. Our findings have wide implications including guiding developers on effective interaction strategies for issue resolution, informing the development of tools or frameworks to support optimal prompt design, and providing insights on fine-tuning LLMs for issue resolution tasks.
对话式大型语言模型广泛应用于问题解决方案任务中。然而,并非所有开发者与大型语言模型(LLM)的对话都有助于有效地解决问题。在本文中,我们分析了在GitHub问题线程中共享的686条开发者与ChatGPT的对话,以识别使这些对话在解决问题方面有效的特征。首先,我们分析这些对话及其相应的问题,以区分有帮助和无帮助的对话。我们通过分类开发者寻求帮助的任务类型,以更好地了解ChatGPT在哪些情况下最为有效。接下来,我们检查各种与对话、项目和问题相关的指标,以发现与有帮助的对话相关的因素。最后,我们确定了不有帮助的ChatGPT响应中的常见缺陷,以强调可以设计面向开发者的更有效工具的信息。我们发现,只有62%的ChatGPT对话对于成功解决问题是有帮助的。ChatGPT在代码生成和工具/库/API推荐方面最为有效,但在代码解释方面却表现不佳。有帮助的对话往往较短、可读性更强,并且表现出更强的语义和语言对齐。较大的、较受欢迎的项目和更有经验的开发者更能从ChatGPT中受益。在问题层面,ChatGPT在最简单、开发者活动有限、解决速度更快的问题上表现最佳,通常是范围明确的任务,如编译错误。不有帮助的ChatGPT响应中最常见的缺陷包括信息不正确和缺乏全面性。我们的发现具有广泛的意义,包括指导开发者有效的互动策略来解决问题,开发工具和框架来支持最佳提示设计,以及为问题解决方案任务微调大型语言模型提供见解。
论文及项目相关链接
摘要
本文分析了在GitHub问题线程中分享的686个开发者与ChatGPT的对话,以识别哪些特征使得这些对话在解决问题时更有效。研究发现,只有62%的ChatGPT对话有助于成功解决问题。ChatGPT在代码生成、工具/库/API推荐方面最为有效,但在代码解释方面表现较差。有益的对话往往更短、可读性更强,并表现出更强的语义和语言学对齐。大型、更受欢迎的项目的开发者以及更有经验的开发者更能从ChatGPT中受益。对于问题较少的简单问题,ChatGPT表现最佳,解决速度更快,通常是限定范围的任务,如编译错误。未起作用的ChatGPT回应中最常见的缺陷包括信息不正确和缺乏全面性等。我们的研究对于指导开发者制定有效的互动策略进行问题解答,支持工具或框架的优化提示设计以及微调大型语言模型进行问题解答任务具有启示意义。
关键见解
- 对开发者与ChatGPT的对话进行分析,发现只有62%的对话对解决问题有帮助。
- ChatGPT在代码生成和推荐任务中最为有效。
- 有益的对话往往更短、更易读,并展现出更强的语义和语言学对齐。
- 大型和受欢迎的项目的开发者以及有经验的开发者从ChatGPT中获益更多。
- ChatGPT在解决简单问题、快速解决和限定范围的任务(如编译错误)上表现最佳。
- 未起作用的ChatGPT回应中最常见的缺陷包括信息不正确和缺乏全面性等。
点此查看论文截图


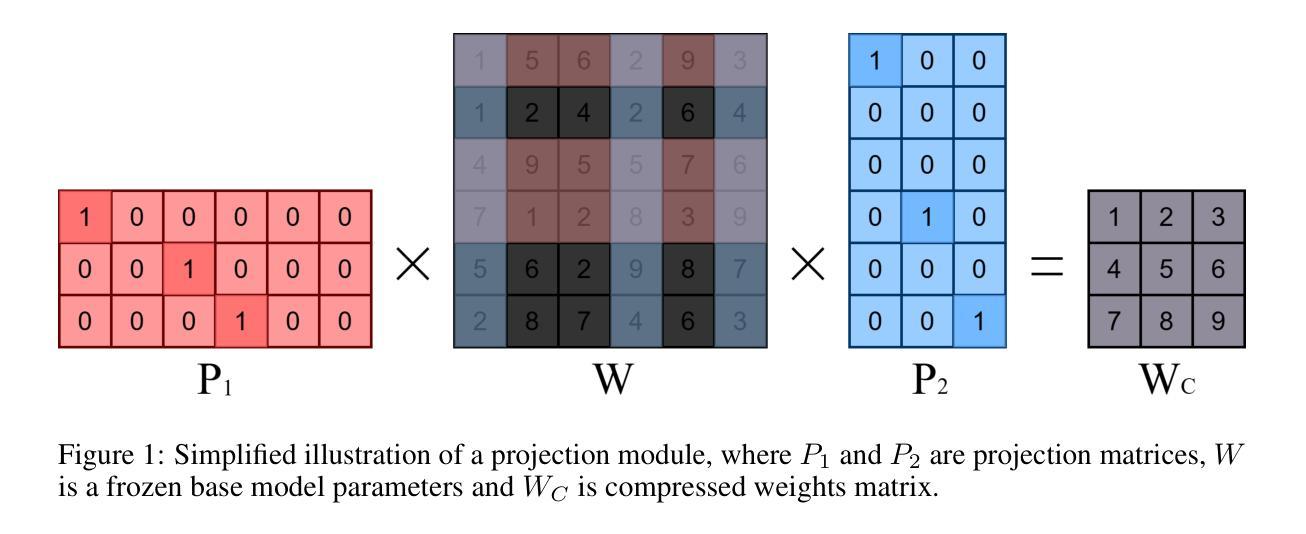
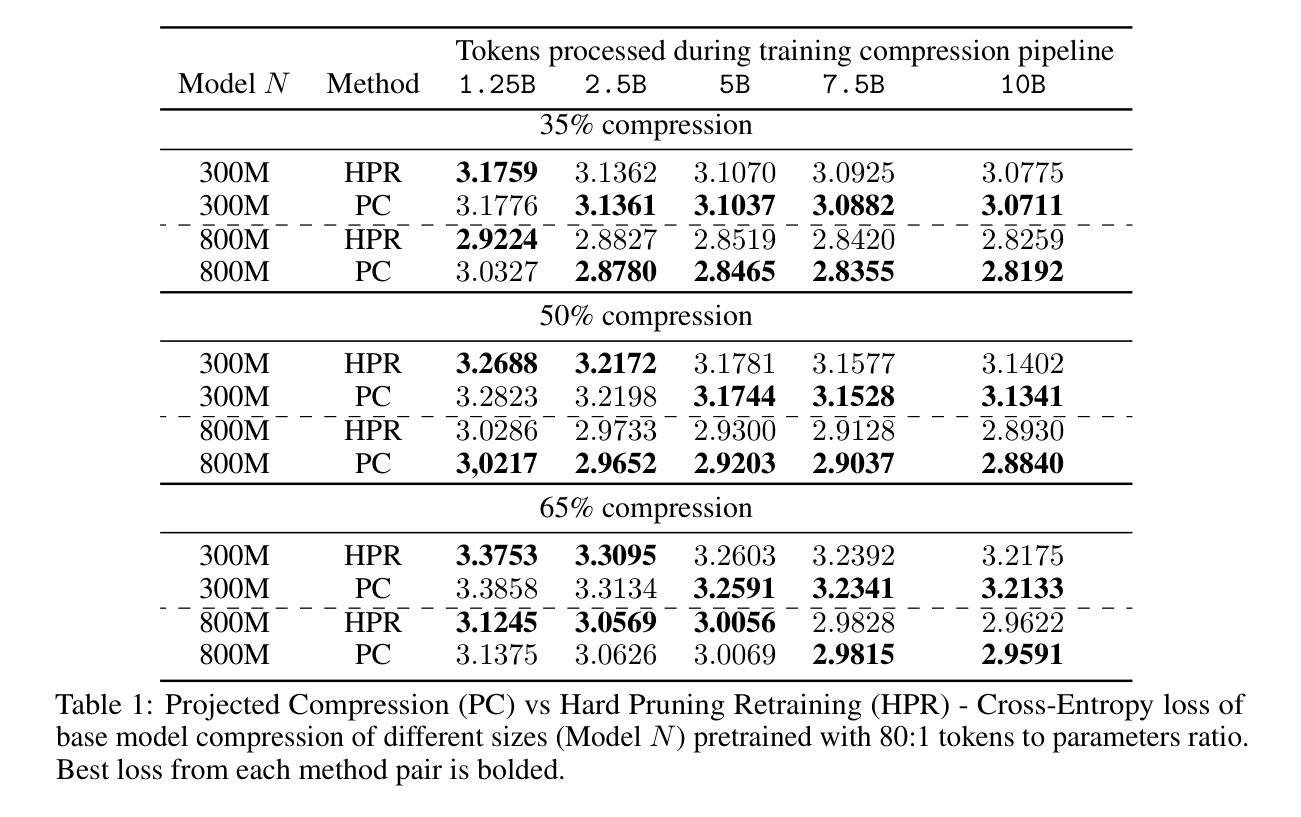
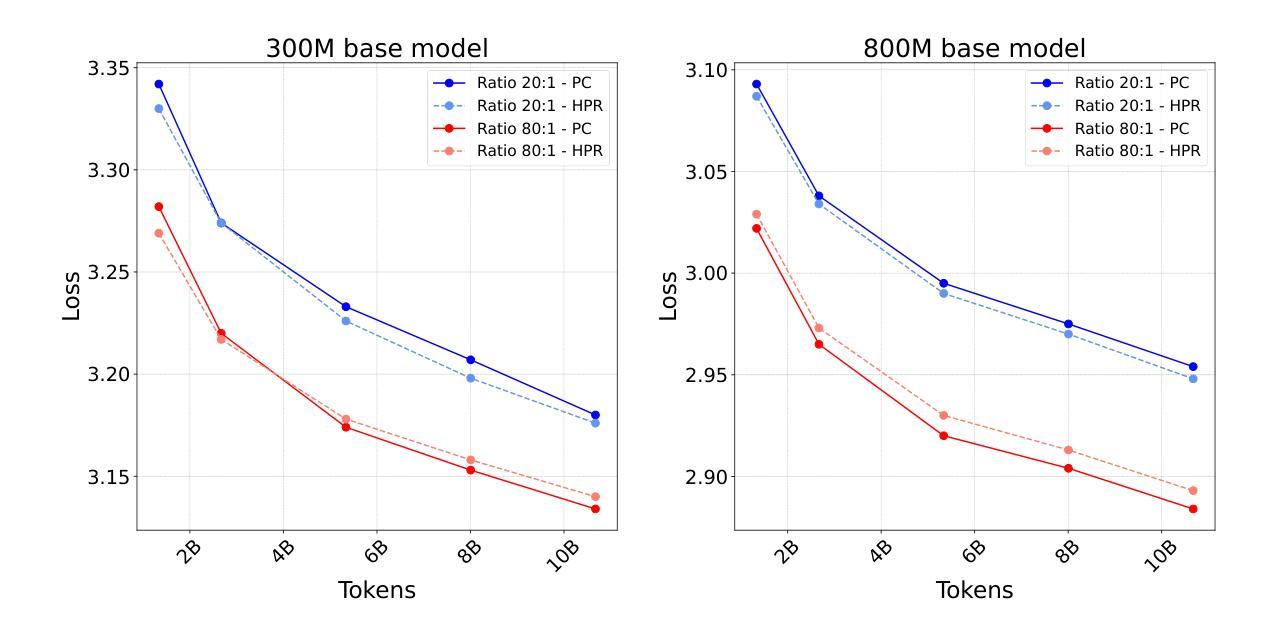
Projected Compression: Trainable Projection for Efficient Transformer Compression
Authors:Maciej Stefaniak, Michał Krutul, Jan Małaśnicki, Maciej Pióro, Jakub Krajewski, Sebastian Jaszczur, Marek Cygan, Kamil Adamczewski, Jan Ludziejewski
Large language models have steadily increased in size to achieve improved performance; however, this growth has also led to greater inference time and computational demands. Consequently, there is rising interest in model size reduction methods. To address this issue, we propose Projected Compression, a novel model compression technique, that reduces model weights by utilizing projection modules. Specifically, we first train additional trainable projections weights and preserve access to all the original model parameters. Subsequently, these projections are merged into a lower-dimensional product matrix, resulting in a reduced-size standard Transformer-based model. Unlike alternative approaches that require additional computational overhead, our method matches the base model’s per-token computation step in FLOPs. Experimental results show that Projected Compression outperforms the comparable hard pruning and retraining approach on higher quality models. Moreover, the performance margin scales well with the number of tokens.
大型语言模型的尺寸一直在增长以实现更好的性能,但这种增长也导致了推理时间和计算需求的增加。因此,人们对模型尺寸缩减方法产生了越来越浓厚的兴趣。为了解决这个问题,我们提出了Projected Compression,这是一种新型的模型压缩技术,它通过利用投影模块来减少模型权重。具体来说,我们首先训练额外的可训练投影权重并保留访问所有原始模型参数的能力。随后,这些投影被合并成一个低维产品矩阵,从而得到一个基于标准Transformer的缩减尺寸模型。与其他需要额外计算开销的方法不同,我们的方法在浮点运算量(FLOPs)上与基础模型的每个令牌计算步骤相匹配。实验结果表明,在较高质量的模型上,Projected Compression优于类似的硬剪枝和再训练方法。此外,性能差距随着令牌数量的增加而增加。
论文及项目相关链接
Summary:大型语言模型通过增长模型规模来提升性能,但这也导致了推理时间和计算需求的增加。为解决这一问题,我们提出了Projected Compression这一新型模型压缩技术,该技术通过利用投影模块来减少模型权重。实验结果表明,相较于其他硬剪枝和再训练的方法,Projected Compression在更高质量的模型上表现出更高的性能。且随着token数量的增加,性能差距也在不断扩大。该方法可在不增加计算开销的情况下,将模型参数缩减为一个更低维度的产品矩阵,从而实现基于标准Transformer的模型尺寸缩减。
Key Takeaways:
- 大型语言模型虽然性能有所提升,但也面临推理时间和计算需求的挑战。
- Projected Compression是一种新型的模型压缩技术,通过利用投影模块减少模型权重。
- 该技术保留了原始模型的全部参数并引入了可训练的投影权重。
- 通过将投影合并为一个较低维度的产品矩阵,实现了基于标准Transformer的模型尺寸缩减。
- Projected Compression与现有方法相比具有更高的性能表现,并且性能差距随token数量的增加而扩大。
点此查看论文截图

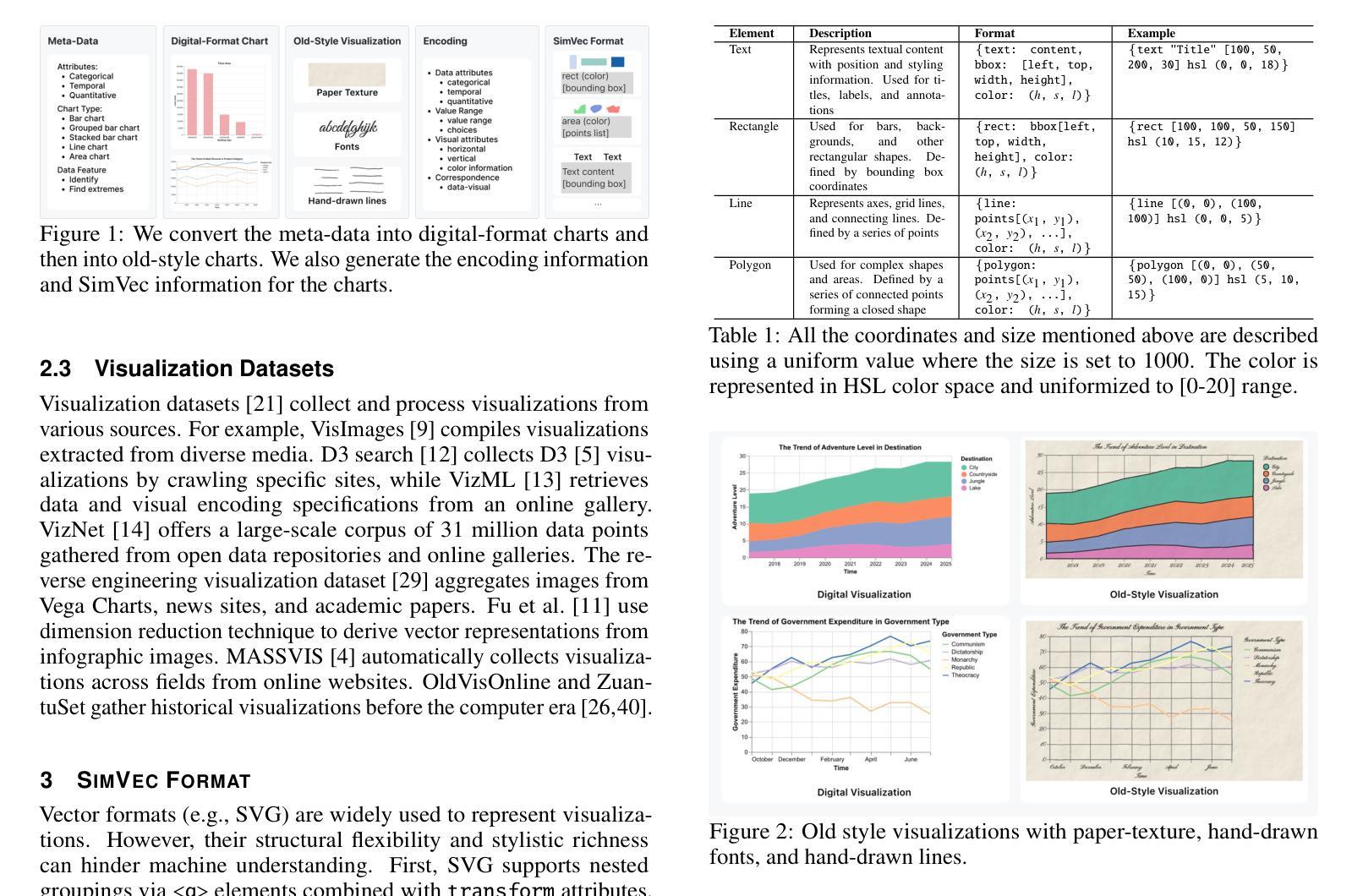
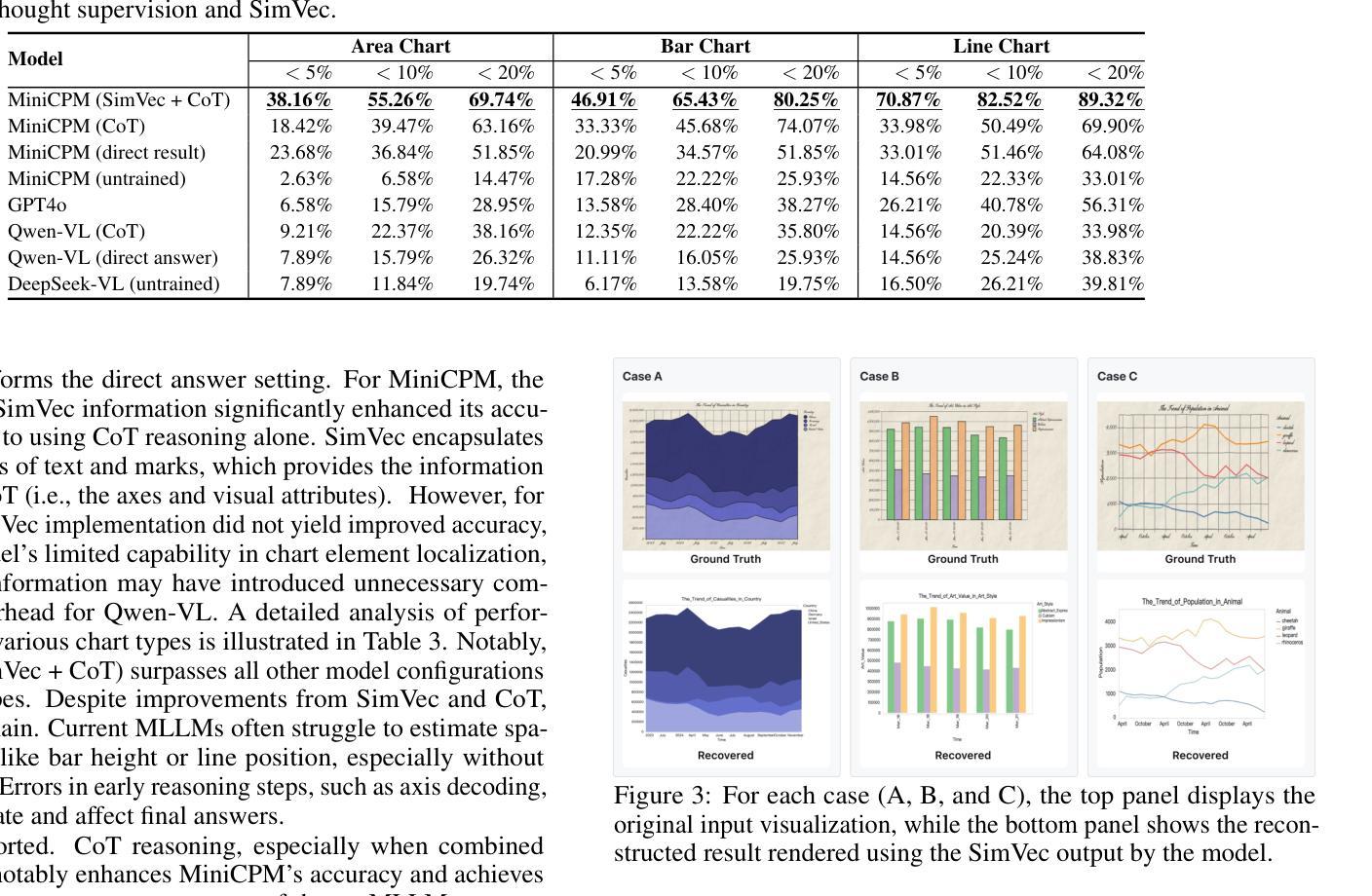
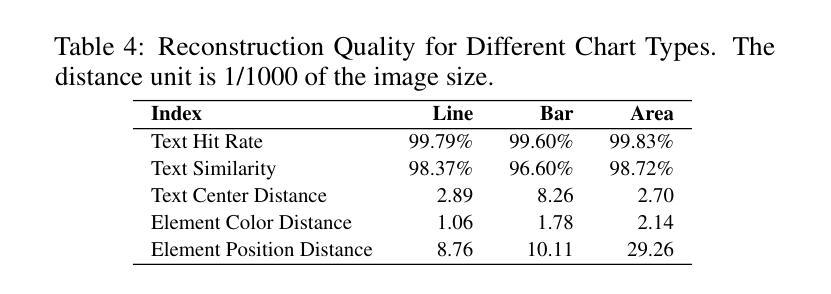
A Dataset for Enhancing MLLMs in Visualization Understanding and Reconstruction
Authors:Can Liu, Chunlin Da, Xiaoxiao Long, Yuxiao Yang, Yu Zhang, Yong Wang
Current multimodal large language models (MLLMs), while effective in natural image understanding, struggle with visualization understanding due to their inability to decode the data-to-visual mapping and extract structured information. To address these challenges, we propose SimVec, a compact and structured vector format that encodes chart elements, including mark types, positions, and sizes. Then, we present a new visualization dataset, which consists of bitmap images of charts, their corresponding SimVec representations, and data-centric question-answering pairs, each accompanied by explanatory chain-of-thought sentences. We fine-tune state-of-the-art MLLMs using our dataset. The experimental results show that fine-tuning leads to substantial improvements in data-centric reasoning tasks compared to their zero-shot versions. SimVec also enables MLLMs to accurately and compactly reconstruct chart structures from images. Our dataset and code are available at: https://github.com/VIDA-Lab/MLLM4VIS.
当前的多模态大型语言模型(MLLMs)在自然图像理解方面非常有效,但在可视化理解方面却存在困难,因为它们无法解码数据到视觉的映射并提取结构化信息。为了解决这些挑战,我们提出了SimVec,这是一种紧凑且结构化的向量格式,可以编码图表元素,包括标记类型、位置和大小。接着,我们展示了一个新的可视化数据集,该数据集包含图表的位图图像、相应的SimVec表示形式以及以数据为中心的问答对,每个问答对都附有解释性的思维链句子。我们使用我们的数据集对最新MLLMs进行了微调。实验结果表明,与零样本版本相比,微调在数据为中心的逻辑任务中带来了显著改进。SimVec还使MLLMs能够准确且紧凑地从图像中重建图表结构。我们的数据集和代码可在https://github.com/VIDA-Lab/MLLM4VIS找到。
论文及项目相关链接
Summary
SimVec是一种用于解决多模态大型语言模型在可视化理解方面的不足的创新性方案。它提出了一个紧凑且结构化的向量格式,能编码图表元素,包括标记类型、位置和大小。此外,研究团队还推出了一个新的可视化数据集,用于训练这些模型以改进其在数据为中心的任务中的推理能力。实验结果显示,经过微调的大型语言模型在数据为中心的任务上表现显著改善,并且SimVec还能使这些模型准确且紧凑地从图像中重建图表结构。相关数据和代码可在VIDA实验室的MLLM4VIS网站找到。
Key Takeaways
- SimVec是一种解决多模态大型语言模型在可视化理解方面不足的方案。
- SimVec能编码图表元素,包括标记类型、位置和大小。
- 研究团队推出了一个新的可视化数据集,用于训练大型语言模型以改进数据为中心的任务中的推理能力。
- 数据集包含位图图像、SimVec表示和问答对,每个问答对都附有解释性的思维链句子。
- 实验结果显示,经过微调的大型语言模型在数据为中心的任务上表现显著改善。
- SimVec使大型语言模型能够准确且紧凑地从图像中重建图表结构。
点此查看论文截图

Arabic Dialect Classification using RNNs, Transformers, and Large Language Models: A Comparative Analysis
Authors:Omar A. Essameldin, Ali O. Elbeih, Wael H. Gomaa, Wael F. Elsersy
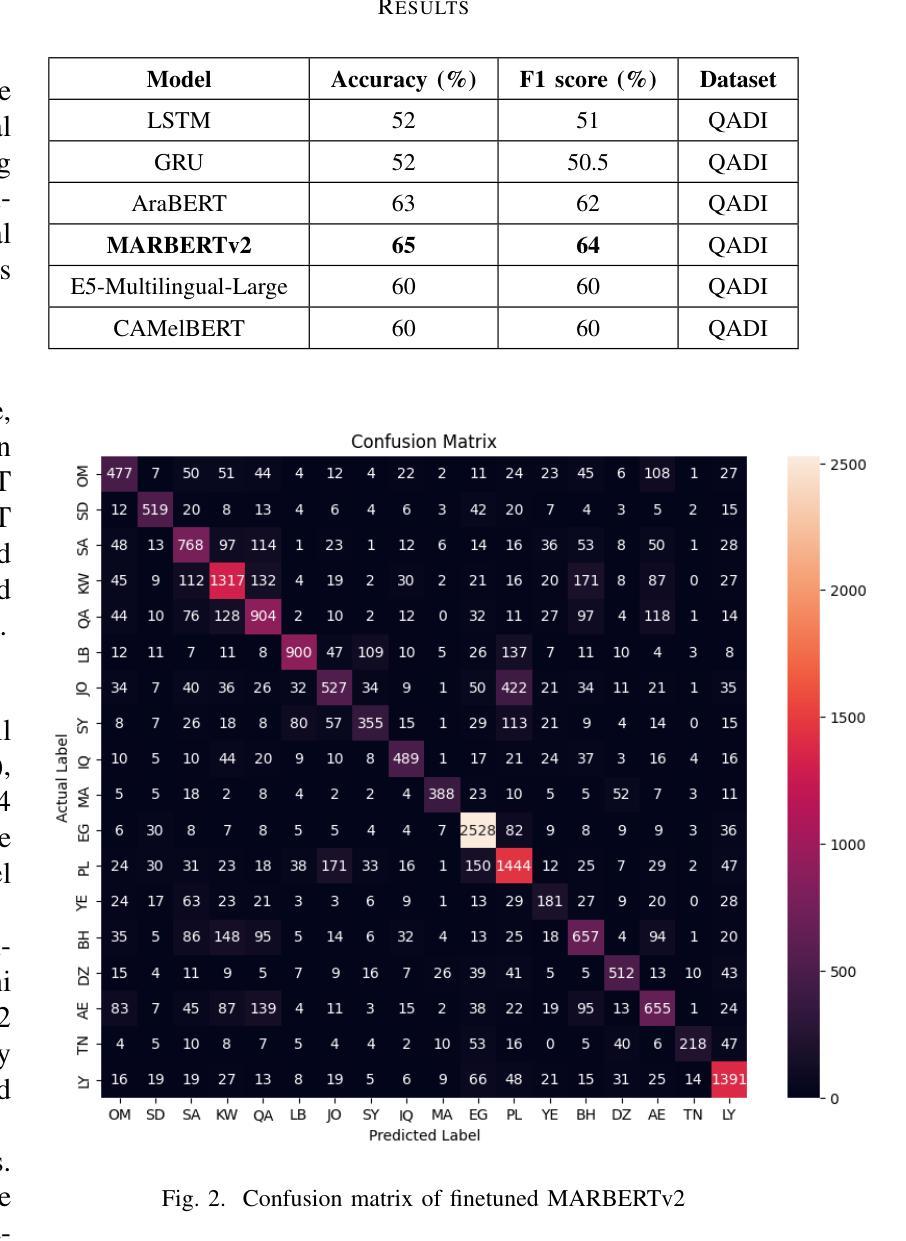
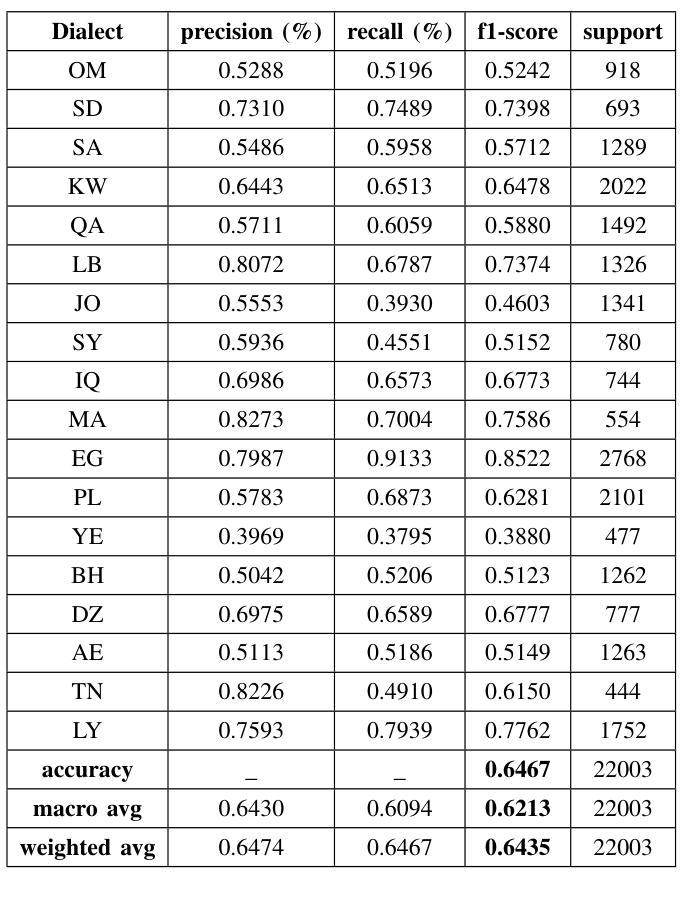
The Arabic language is among the most popular languages in the world with a huge variety of dialects spoken in 22 countries. In this study, we address the problem of classifying 18 Arabic dialects of the QADI dataset of Arabic tweets. RNN models, Transformer models, and large language models (LLMs) via prompt engineering are created and tested. Among these, MARBERTv2 performed best with 65% accuracy and 64% F1-score. Through the use of state-of-the-art preprocessing techniques and the latest NLP models, this paper identifies the most significant linguistic issues in Arabic dialect identification. The results corroborate applications like personalized chatbots that respond in users’ dialects, social media monitoring, and greater accessibility for Arabic communities.
阿拉伯语是世界上使用最广泛的语种之一,在22个国家有众多不同的方言。在这项研究中,我们解决了对阿拉伯推特数据集中的十八种阿拉伯方言进行分类的问题。通过提示工程技术创建并测试了循环神经网络模型、Transformer模型以及大型语言模型(LLM)。其中,MARBERTv2表现最佳,准确率为百分之六十五,F1分数为百分之六十四。通过运用最先进的预处理技术和最新的自然语言处理模型,本文确定了阿拉伯方言识别中最关键的语言问题。结果证实了个性化聊天机器人响应用户方言、社交媒体监控以及提高阿拉伯社区的访问量等应用程序的有效性。
论文及项目相关链接
PDF Email Typo Update
Summary
阿拉伯语言是世界上最流行的语言之一,拥有在22个国家使用的众多方言。本研究旨在解决QADI数据集阿拉伯推特方言分类的问题。创建了并测试了RNN模型、Transformer模型以及通过提示工程的大型语言模型(LLMs)。其中,MARBERTv2的表现最佳,准确率和F1分数分别为65%和64%。通过使用最新的自然语言处理模型和技术,本研究确定了阿拉伯方言识别中最显著的语言问题。其结果证实了个性化聊天机器人、社交媒体监控和增强阿拉伯社区可及性的应用程序价值。
Key Takeaways
- 阿拉伯语言在全球具有广泛的影响力,存在多种方言。
- 本研究专注于QADI数据集的18种阿拉伯语方言分类问题。
- 使用了RNN模型、Transformer模型和通过提示工程的大型语言模型(LLMs)进行解决尝试。
- MARBERTv2模型表现出最佳性能,准确率和F1分数分别为65%和64%。
- 研究采用了先进的预处理技术和最新的自然语言处理模型。
- 研究指出了阿拉伯方言识别中最重要的语言学问题。
点此查看论文截图

Benchmarking the Pedagogical Knowledge of Large Language Models
Authors:Maxime Lelièvre, Amy Waldock, Meng Liu, Natalia Valdés Aspillaga, Alasdair Mackintosh, María José Ogando Portela, Jared Lee, Paul Atherton, Robin A. A. Ince, Oliver G. B. Garrod
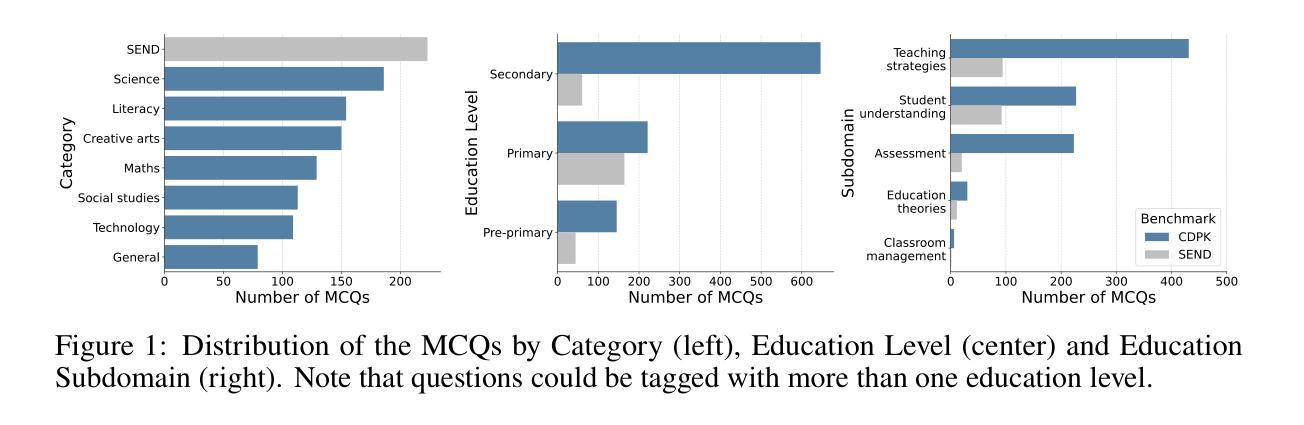
Benchmarks like Massive Multitask Language Understanding (MMLU) have played a pivotal role in evaluating AI’s knowledge and abilities across diverse domains. However, existing benchmarks predominantly focus on content knowledge, leaving a critical gap in assessing models’ understanding of pedagogy - the method and practice of teaching. This paper introduces The Pedagogy Benchmark, a novel dataset designed to evaluate large language models on their Cross-Domain Pedagogical Knowledge (CDPK) and Special Education Needs and Disability (SEND) pedagogical knowledge. These benchmarks are built on a carefully curated set of questions sourced from professional development exams for teachers, which cover a range of pedagogical subdomains such as teaching strategies and assessment methods. Here we outline the methodology and development of these benchmarks. We report results for 97 models, with accuracies spanning a range from 28% to 89% on the pedagogical knowledge questions. We consider the relationship between cost and accuracy and chart the progression of the Pareto value frontier over time. We provide online leaderboards at https://rebrand.ly/pedagogy which are updated with new models and allow interactive exploration and filtering based on various model properties, such as cost per token and open-vs-closed weights, as well as looking at performance in different subjects. LLMs and generative AI have tremendous potential to influence education and help to address the global learning crisis. Education-focused benchmarks are crucial to measure models’ capacities to understand pedagogical concepts, respond appropriately to learners’ needs, and support effective teaching practices across diverse contexts. They are needed for informing the responsible and evidence-based deployment of LLMs and LLM-based tools in educational settings, and for guiding both development and policy decisions.
像大规模多任务语言理解(MMLU)这样的基准测试在评估人工智能在不同领域的知识和能力方面发挥了至关重要的作用。然而,现有的基准测试主要集中在内容知识上,在评估模型对教学方法的理解方面存在重大空白——教学方法和实践。本文介绍了《教学基准测试》,这是一个新型数据集,旨在评估大型语言模型在跨域教学知识(CDPK)和特殊教育需求与残疾(SEND)教学知识方面的能力。这些基准测试建立在从教师职业发展考试中精心挑选的问题集上,涵盖了一系列教学子域,如教学策略和评估方法。在这里,我们概述了这些基准测试的方法论和发展。我们报告了97个模型的结果,在教学知识问题上的准确率从28%到89%不等。我们考虑了成本与准确率之间的关系,并绘制了随时间推移的帕累托价值前沿的进展。我们在https://rebrand.ly/pedagogy提供了在线排行榜,排行榜会更新新的模型,并可根据各种模型属性进行交互探索和过滤,如每令牌成本以及开放与封闭权重,还可以查看不同科目的表现。大型语言模型和生成式人工智能对教育和帮助应对全球学习危机具有巨大潜力。以教育为重点的基准测试对于衡量模型理解教学概念的能力、适当响应学习者的需求以及在各种背景下支持有效的教学策略至关重要。它们对于在教育环境中负责任和基于证据地部署大型语言模型(LLM)和LLM工具,以及指导开发和政策决策是必要的。
论文及项目相关链接
摘要
本文介绍了名为“教育基准测试”的新数据集,该数据集旨在评估大型语言模型在不同领域的跨学科教育知识(CDPK)以及特殊教育和残疾教育的教育知识。该基准测试建立在教师职业发展考试问题的精选集上,涵盖了教学方法、评估方法等教学子领域。文章概述了这些基准测试的方法论和发展,报告了97个模型的准确性,范围从28%到89%。此外,还提供了一种关系研究,揭示了成本和准确性之间的关系,并随着时间推移展示了帕累托价值前沿的进展。文章强调了大型语言模型(LLM)和生成式人工智能对教育的巨大潜力及其对全球学习危机的潜在影响。教育基准测试对于衡量模型理解教育概念的能力、适当响应学习者需求和支持各种背景下的有效教学实践至关重要。这对于在学术环境中负责任地、有根据地部署LLM以及LLM工具并引导开发和政策决策均非常重要。具体数据可通过在线领导者榜查看:https://rebrand.ly/pedagogy。
关键要点
- 大型语言模型AI在跨领域知识评估中扮演着重要角色,但现有的基准测试主要集中在内容知识上,缺乏对教学方法的理解评估。
- 引入“教育基准测试”数据集,旨在评估大型语言模型的跨学科教育知识和特殊教育与残疾教育知识。
- 数据集通过教师职业发展考试的问题构建而成,涵盖多种教学方法和评估方法。
- 对97个模型进行了评估,准确性差异较大,揭示了大型语言模型在教育知识理解上的不同能力。
- 提供了成本和准确性之间的关系研究,并展示了帕累托价值前沿的进展。
点此查看论文截图


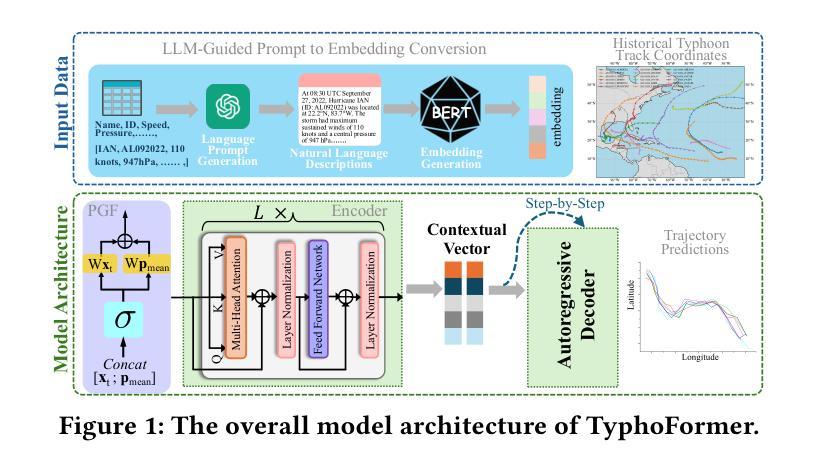
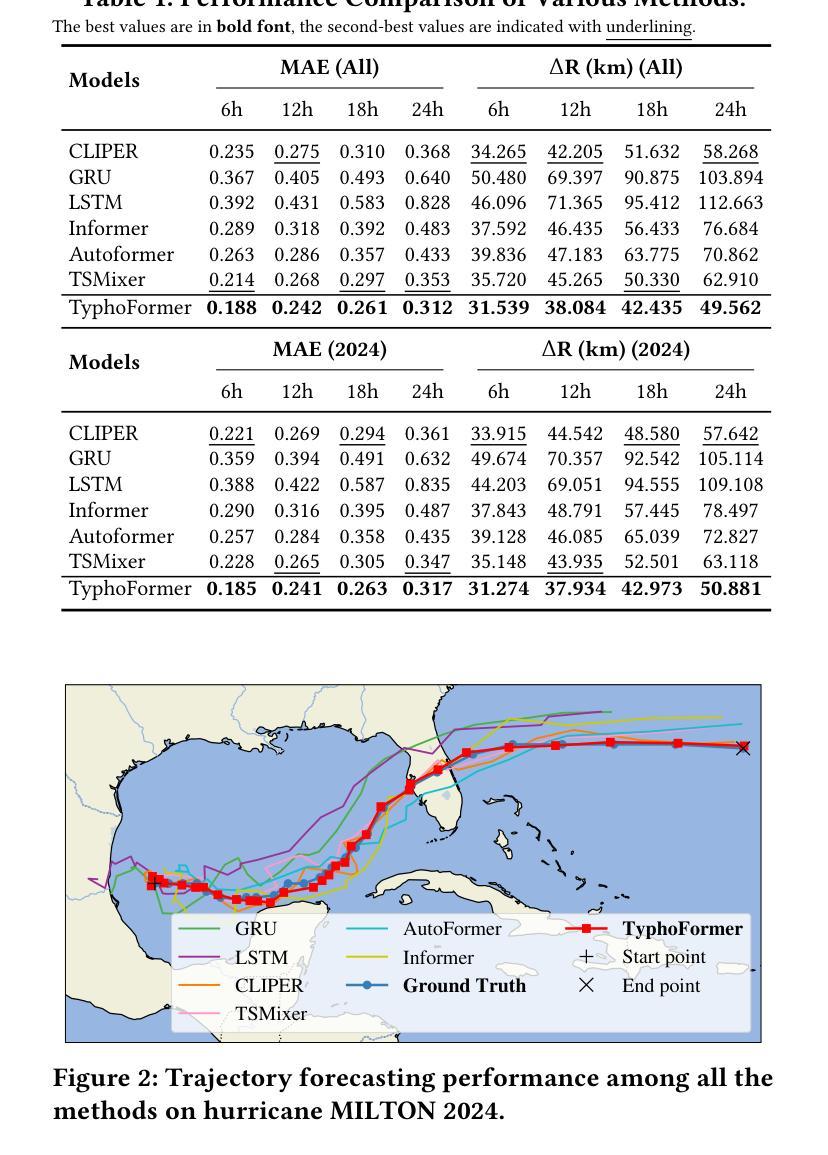
TyphoFormer: Language-Augmented Transformer for Accurate Typhoon Track Forecasting
Authors:Lincan Li, Eren Erman Ozguven, Yue Zhao, Guang Wang, Yiqun Xie, Yushun Dong
Accurate typhoon track forecasting is crucial for early system warning and disaster response. While Transformer-based models have demonstrated strong performance in modeling the temporal dynamics of dense trajectories of humans and vehicles in smart cities, they usually lack access to broader contextual knowledge that enhances the forecasting reliability of sparse meteorological trajectories, such as typhoon tracks. To address this challenge, we propose TyphoFormer, a novel framework that incorporates natural language descriptions as auxiliary prompts to improve typhoon trajectory forecasting. For each time step, we use Large Language Model (LLM) to generate concise textual descriptions based on the numerical attributes recorded in the North Atlantic hurricane database. The language descriptions capture high-level meteorological semantics and are embedded as auxiliary special tokens prepended to the numerical time series input. By integrating both textual and sequential information within a unified Transformer encoder, TyphoFormer enables the model to leverage contextual cues that are otherwise inaccessible through numerical features alone. Extensive experiments are conducted on HURDAT2 benchmark, results show that TyphoFormer consistently outperforms other state-of-the-art baseline methods, particularly under challenging scenarios involving nonlinear path shifts and limited historical observations.
精确预测台风路径对于早期系统预警和灾害应对至关重要。虽然基于Transformer的模型在模拟智能城市中人类和车辆的密集轨迹的时间动态方面表现出强大的性能,但它们通常无法获取更广泛的上下文知识,这有助于提高稀疏气象轨迹的预测可靠性,例如台风路径。为了应对这一挑战,我们提出了TyphFormer,这是一个新的框架,它利用自然语言描述作为辅助提示来提高台风轨迹预测。对于每个时间点,我们使用大型语言模型(LLM)基于北大西洋飓风数据库中的数值属性生成简洁的文本描述。语言描述捕捉了高级气象语义,并被嵌入作为辅助特殊令牌附加到数值时间序列输入中。通过将文本和序列信息集成在一个统一的Transformer编码器内,TyphFormer使模型能够利用无法通过数值特征获取的上下文线索。在HURDAT2基准测试上进行了大量实验,结果表明,TyphFormer始终优于其他最先进的基线方法,特别是在涉及非线性路径变化和有限历史观测的具有挑战性的场景中。
论文及项目相关链接
PDF Short research paper
Summary
本文提出一种名为TyphoFormer的新型框架,它将自然语言描述作为辅助提示来改善台风轨迹预报。利用大型语言模型(LLM)为每一步生成基于北大西洋飓风数据库中数值属性的简洁文本描述,这些描述捕捉到高级气象语义并被嵌入作为辅助特殊符号添加到数值时间序列输入中。通过在统一的Transformer编码器中整合文本和时序信息,TyphoFormer使模型能够利用仅通过数值特征无法获得的上下文线索。在HURDAT2基准测试上的大量实验表明,TyphoFormer始终优于其他先进的基础方法,特别是在涉及非线性路径变化和有限历史观测的具有挑战性的场景中。
Key Takeaways
- 台风轨迹准确预报对早期预警系统和灾害应对至关重要。
- Transformer模型在智能城市人类和车辆密集轨迹的时间动态建模上表现出强大的性能,但在气象轨迹预报上缺乏广泛的上下文知识。
- 提出了一种新型框架TyphoFormer,结合自然语言描述作为辅助提示来改善台风轨迹预报。
- TyphoFormer使用大型语言模型(LLM)生成基于数值属性的文本描述,捕捉高级气象语义。
- TyphoFormer将文本和时序信息整合在统一的Transformer编码器中,利用上下文线索提高预报可靠性。
- 在HURDAT2基准测试上,TyphoFormer相较于其他先进方法表现出更优的性能。
点此查看论文截图

Privacy-Preserving LLM Interaction with Socratic Chain-of-Thought Reasoning and Homomorphically Encrypted Vector Databases
Authors:Yubeen Bae, Minchan Kim, Jaejin Lee, Sangbum Kim, Jaehyung Kim, Yejin Choi, Niloofar Mireshghallah
Large language models (LLMs) are increasingly used as personal agents, accessing sensitive user data such as calendars, emails, and medical records. Users currently face a trade-off: They can send private records, many of which are stored in remote databases, to powerful but untrusted LLM providers, increasing their exposure risk. Alternatively, they can run less powerful models locally on trusted devices. We bridge this gap. Our Socratic Chain-of-Thought Reasoning first sends a generic, non-private user query to a powerful, untrusted LLM, which generates a Chain-of-Thought (CoT) prompt and detailed sub-queries without accessing user data. Next, we embed these sub-queries and perform encrypted sub-second semantic search using our Homomorphically Encrypted Vector Database across one million entries of a single user’s private data. This represents a realistic scale of personal documents, emails, and records accumulated over years of digital activity. Finally, we feed the CoT prompt and the decrypted records to a local language model and generate the final response. On the LoCoMo long-context QA benchmark, our hybrid framework, combining GPT-4o with a local Llama-3.2-1B model, outperforms using GPT-4o alone by up to 7.1 percentage points. This demonstrates a first step toward systems where tasks are decomposed and split between untrusted strong LLMs and weak local ones, preserving user privacy.
大型语言模型(LLM)越来越多地被用作个人代理,访问用户的敏感数据,如日历、电子邮件和医疗记录。目前,用户面临一种权衡:他们可以将私人记录(其中许多存储在远程数据库中)发送到功能强大但不受信任的LLM提供商,从而增加其暴露风险。或者,他们可以在可信的设备上运行功能较弱的模型。我们弥补了这一差距。我们的苏格拉底思维链推理首先向功能强大、不受信任的大型语言模型发送通用的非私人用户查询,该模型生成思维链(CoT)提示和详细的子查询,无需访问用户数据。接下来,我们将这些子查询嵌入其中,并使用我们的同态加密向量数据库在用户私人数据的一百万个条目上执行加密的子秒语义搜索。这代表了在多年的数字活动中积累的个人文档、电子邮件和记录的现实规模。最后,我们将思维链提示和解密的记录提供给本地语言模型,并生成最终响应。在LoCoMo长文本问答基准测试中,我们混合框架结合了GPT-4o和本地Llama-3.2-1B模型,比仅使用GPT-4o高出7.1个百分点。这朝着任务在不受信任的强大LLM和脆弱的本地LLM之间进行分解和分割的系统迈出了第一步,同时保护了用户隐私。
论文及项目相关链接
PDF 29 pages
Summary
大规模语言模型(LLM)作为个人代理,访问用户敏感数据如日历、电子邮件和医疗记录。用户面临权衡:可以将私有记录发送到强大的但不可信的LLM提供商,或将记录保存在本地可信设备上。我们的苏格拉底思维链技术解决了这一问题。该技术首先向强大的不可信的LLM发送通用非私有用户查询,生成思维链提示和详细的子查询,无需访问用户数据。然后,我们将这些子查询嵌入到我们的同态加密向量数据库中,并在单个用户的私人数据的一百万条记录中进行加密子秒语义搜索。最后,我们将思维链提示和解密的记录提供给本地语言模型,并生成最终响应。在LoCoMo长期上下文问答基准测试中,我们的混合框架结合GPT-4o和本地Llama-3.2-1B模型,比仅使用GPT-4o高出7.1个百分点。这展示了任务在不可信的强大的LLM和弱本地LLM之间分解和分割的第一步,同时保护用户隐私。
Key Takeaways
- LLMs被用作个人代理,能够访问用户的敏感数据。
- 用户面临将私有记录发送到强大的但不可信的LLM提供商的风险,或选择运行较弱的本地模型以维护隐私。
- 提出了一种苏格拉底思维链技术,通过向强大的LLM发送通用查询并生成思维链提示和子查询来平衡隐私和性能。
- 利用同态加密技术保护用户数据,进行语义搜索。
- 混合框架结合了远程和本地LLM的优势,提高了性能并保护了用户隐私。
- 在LoCoMo基准测试中,混合框架的性能超过了仅使用远程LLM的方案。
点此查看论文截图

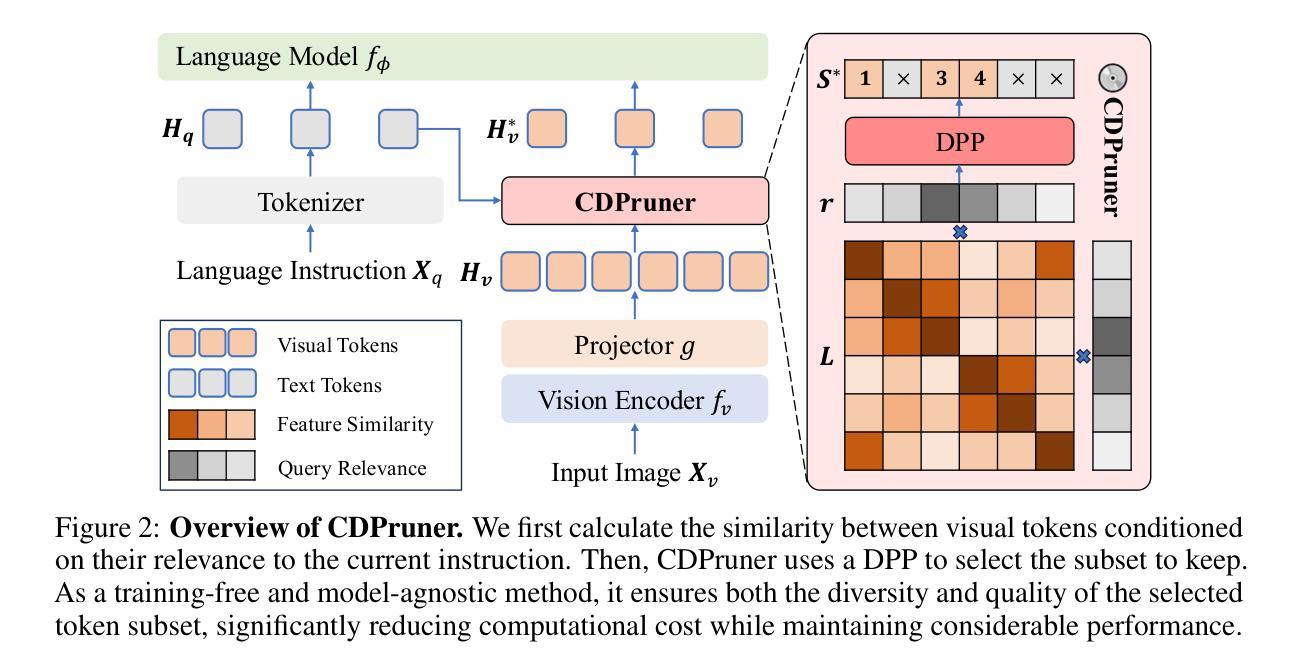
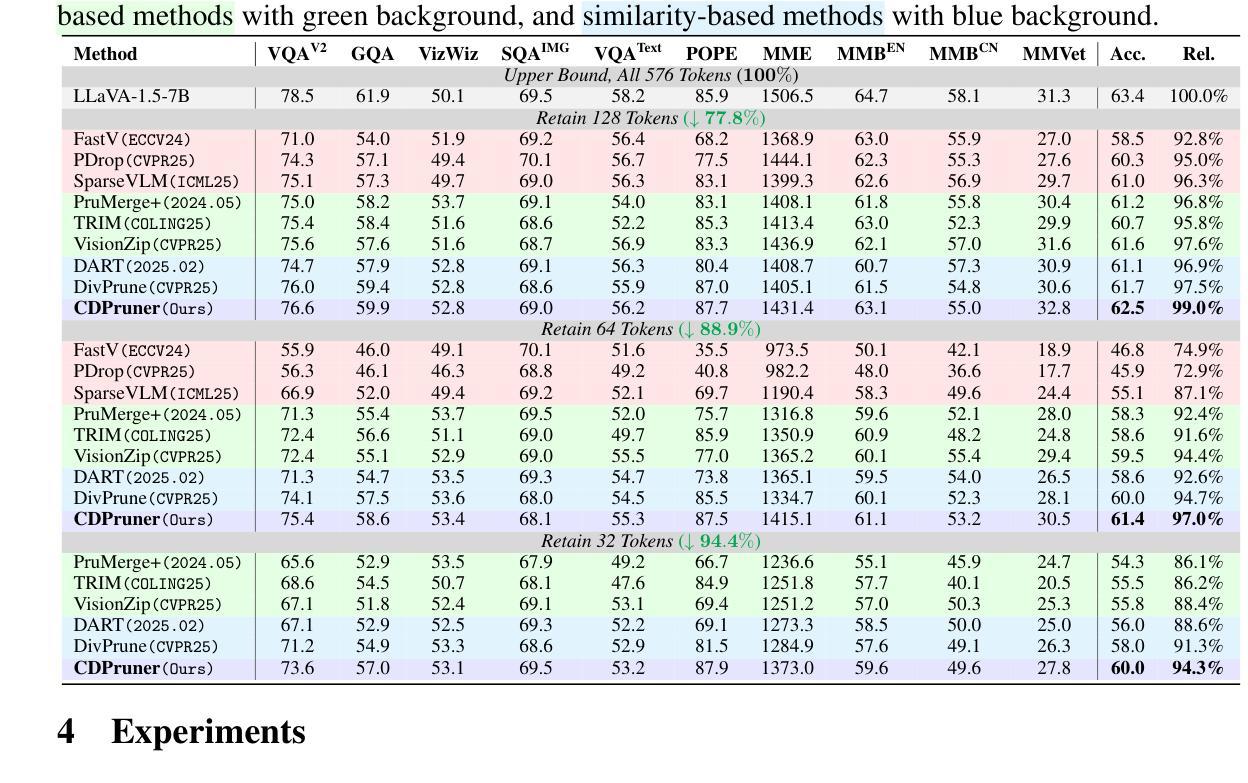
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs
Authors:Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu, Yuan Zhang, Junwen Pan, Qi She, Shanghang Zhang
In multimodal large language models (MLLMs), the length of input visual tokens is often significantly greater than that of their textual counterparts, leading to a high inference cost. Many works aim to address this issue by removing redundant visual tokens. However, current approaches either rely on attention-based pruning, which retains numerous duplicate tokens, or use similarity-based pruning, overlooking the instruction relevance, consequently causing suboptimal performance. In this paper, we go beyond attention or similarity by proposing a novel visual token pruning method named CDPruner, which maximizes the conditional diversity of retained tokens. We first define the conditional similarity between visual tokens conditioned on the instruction, and then reformulate the token pruning problem with determinantal point process (DPP) to maximize the conditional diversity of the selected subset. The proposed CDPruner is training-free and model-agnostic, allowing easy application to various MLLMs. Extensive experiments across diverse MLLMs show that CDPruner establishes new state-of-the-art on various vision-language benchmarks. By maximizing conditional diversity through DPP, the selected subset better represents the input images while closely adhering to user instructions, thereby preserving strong performance even with high reduction ratios. When applied to LLaVA, CDPruner reduces FLOPs by 95% and CUDA latency by 78%, while maintaining 94% of the original accuracy. Our code is available at https://github.com/Theia-4869/CDPruner.
在多模态大型语言模型(MLLMs)中,输入视觉标记的长度往往远长于文本标记的长度,导致推理成本很高。许多研究旨在通过消除冗余的视觉标记来解决这一问题。然而,当前的方法要么依赖于基于注意力的修剪,这种方法会保留大量重复的标记,要么使用基于相似度的修剪,忽视了指令的相关性,从而导致性能不佳。在本文中,我们提出了一种超越注意力和相似度的新型视觉标记修剪方法,名为CDPruner,它旨在最大化保留标记的条件多样性。我们首先定义了基于指令的视觉标记之间的条件相似性,然后使用确定性过程(DPP)重新表述标记修剪问题,以最大化所选子集的条件多样性。所提出的CDPruner无需训练且模型无关,可轻松应用于各种MLLMs。在多种MLLMs上的广泛实验表明,CDPruner在各项视觉语言基准测试上创下了最新记录。通过DPP最大化条件多样性,所选子集能更好地代表输入图像,同时紧密遵循用户指令,即使在高度减少的情况下也能保持强大的性能。将CDPruner应用于LLaVA时,可减少95%的FLOPs和78%的CUDA延迟,同时保持94%的原始准确率。我们的代码位于https://github.com/Theia-4869/CDPruner。
论文及项目相关链接
PDF 22 pages, 5 figures, code: https://github.com/Theia-4869/CDPruner, project page: https://theia-4869.github.io/CDPruner
Summary
本文提出一种名为CDPruner的视觉符号修剪方法,旨在最大化保留符号的条件多样性以解决多模态大型语言模型(MLLMs)中输入视觉符号长度过长导致的高推理成本问题。该方法定义指令条件下的视觉符号间条件相似性,并使用行列式点过程(DPP)重新表述符号修剪问题,以最大化所选子集的条件多样性。CDPruner方法无需训练和模型特定,可广泛应用于各种MLLMs。实验表明,CDPruner在多种视觉语言基准测试上达到最新水平。通过最大化条件多样性,所选子集能更好地代表输入图像并严格遵循用户指令,在高缩减率下仍保持良好性能。应用于LLaVA时,CDPruner将浮点运算减少95%,CUDA延迟减少78%,同时保持94%的原始准确率。
Key Takeaways
- 多模态大型语言模型(MLLMs)面临输入视觉符号长度过长导致的高推理成本问题。
- 现有方法主要通过去除冗余视觉符号来解决此问题,但存在保留过多重复符号或忽视指令相关性的问题。
- CDPruner方法旨在最大化保留符号的条件多样性,通过定义指令条件下的视觉符号间条件相似性来解决这一问题。
- 使用行列式点过程(DPP)重新表述符号修剪问题,使方法能够更容易地应用于各种MLLMs。
- CDPruner方法在多种视觉语言基准测试上表现优异,能够在高缩减率下保持良好的性能。
- 应用于LLaVA时,CDPruner能显著减少浮点运算和CUDA延迟,同时保持较高的准确率。
点此查看论文截图



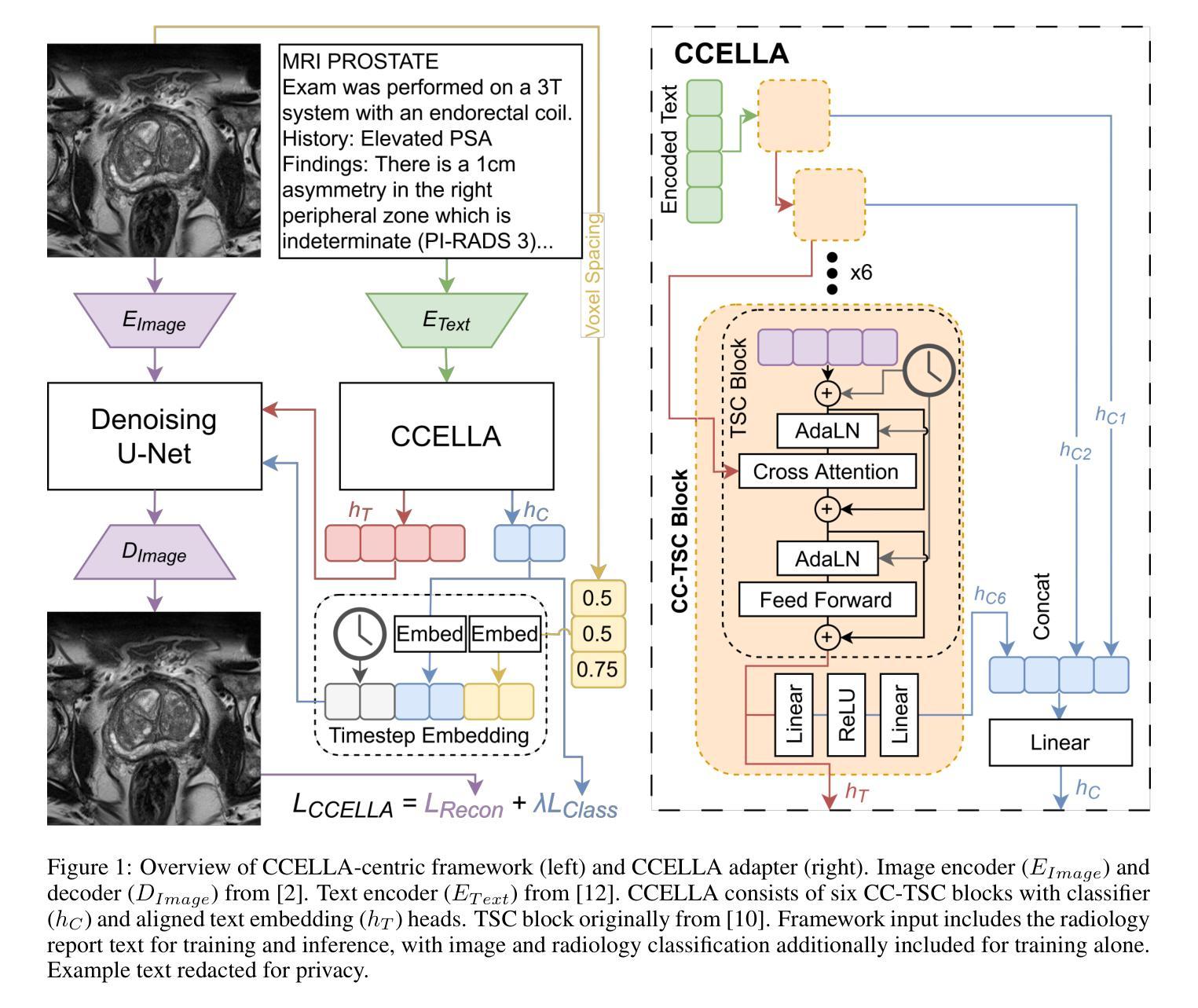
Prompt-Guided Latent Diffusion with Predictive Class Conditioning for 3D Prostate MRI Generation
Authors:Emerson P. Grabke, Masoom A. Haider, Babak Taati
Objective: Latent diffusion models (LDM) could alleviate data scarcity challenges affecting machine learning development for medical imaging. However, medical LDM strategies typically rely on short-prompt text encoders, non-medical LDMs, or large data volumes. These strategies can limit performance and scientific accessibility. We propose a novel LDM conditioning approach to address these limitations. Methods: We propose Class-Conditioned Efficient Large Language model Adapter (CCELLA), a novel dual-head conditioning approach that simultaneously conditions the LDM U-Net with free-text clinical reports and radiology classification. We also propose a data-efficient LDM framework centered around CCELLA and a proposed joint loss function. We first evaluate our method on 3D prostate MRI against state-of-the-art. We then augment a downstream classifier model training dataset with synthetic images from our method. Results: Our method achieves a 3D FID score of 0.025 on a size-limited 3D prostate MRI dataset, significantly outperforming a recent foundation model with FID 0.071. When training a classifier for prostate cancer prediction, adding synthetic images generated by our method during training improves classifier accuracy from 69% to 74%. Training a classifier solely on our method’s synthetic images achieved comparable performance to training on real images alone. Conclusion: We show that our method improved both synthetic image quality and downstream classifier performance using limited data and minimal human annotation. Significance: The proposed CCELLA-centric framework enables radiology report and class-conditioned LDM training for high-quality medical image synthesis given limited data volume and human data annotation, improving LDM performance and scientific accessibility. Code from this study will be available at https://github.com/grabkeem/CCELLA
目标:潜在扩散模型(LDM)可以缓解医学成像领域机器学习开发中的数据稀缺挑战。然而,医学LDM策略通常依赖于短提示文本编码器、非医学LDM或大量数据。这些策略可能会限制性能和科学可及性。我们提出了一种新的LDM条件处理方法来解决这些限制。
方法:我们提出Class-Conditioned Efficient Large Language模型适配器(CCELLA),这是一种新颖的双头条件处理方法,可以同时使用自由文本临床报告和放射学分类对LDM U-Net进行条件处理。我们还围绕CCELLA和一个提出的联合损失函数构建了一个高效的数据LDM框架。我们首先使用最先进的3D前列腺MRI数据评估我们的方法。然后,我们使用该方法生成的合成图像扩充下游分类器模型的训练数据集。
结果:我们的方法在规模有限的前列腺MRI数据集上实现了0.025的3D FID得分,显著优于具有FID 0.071的最新基础模型。在训练前列腺癌预测分类器时,在训练过程中添加我们方法生成的合成图像将分类器的准确度从69%提高到74%。仅使用我们方法的合成图像进行训练,其性能与仅使用真实图像进行训练相当。
论文及项目相关链接
PDF MAH and BT are co-senior authors on the work. This work has been submitted to the IEEE for possible publication
摘要
本研究针对潜在扩散模型(LDM)在医疗影像机器学习开发中面临的数据稀缺挑战,提出了一种新的LDM条件化方法。通过Class-Conditioned Efficient Large Language model Adapter(CCELLA)这一新型双头条件化方法,同时使用自由文本临床报告和放射学分类对LDM U-Net进行条件控制。此外,本研究还提出了以CCELLA为核心的数据高效LDM框架和联合损失函数。研究首先对三维前列腺MRI图像进行了评价并与当前先进技术进行了比较。然后,使用本方法生成的合成图像扩充下游分类器模型的训练数据集。结果显示,本方法在规模有限的三维前列腺MRI数据集上实现了0.025的3D FID得分,显著优于最新基础模型的0.071 FID得分。在训练前列腺癌预测分类器时,通过本方法生成的合成图像进行训练,将分类器的准确性从69%提高到74%。仅使用本方法生成的合成图像进行训练的分类器,其性能与仅使用真实图像进行训练相当。总之,本研究表明,使用有限数据和最少人工注释,本方法能同时提高合成图像质量和下游分类器性能。所提出的以CCELLA为中心的方法框架实现了以有限数据和注释进行放射学报告和类别条件化的LDM训练,提高了高质量医学图像合成的能力。相关代码可从链接获取。
关键见解
- 提出了一种新的潜在扩散模型(LDM)条件化方法,名为Class-Conditioned Efficient Large Language model Adapter(CCELLA),用于解决医学成像中的挑战。
- CCELLA结合了自由文本临床报告和放射学分类的双重头条件化方法,提高了LDM的性能。
- 提出了一种数据高效LDM框架和联合损失函数,用于提高合成图像的质量和下游分类器的性能。
- 在三维前列腺MRI数据集上的实验结果显示,本方法优于现有技术,并实现了较高的图像生成质量。
- 通过使用本方法生成的合成图像进行训练,提高了下游分类器的准确性。
- 本方法使用有限数据和最少人工注释,表现出了卓越的性能,表明其在资源有限的环境中具有实际应用潜力。
点此查看论文截图

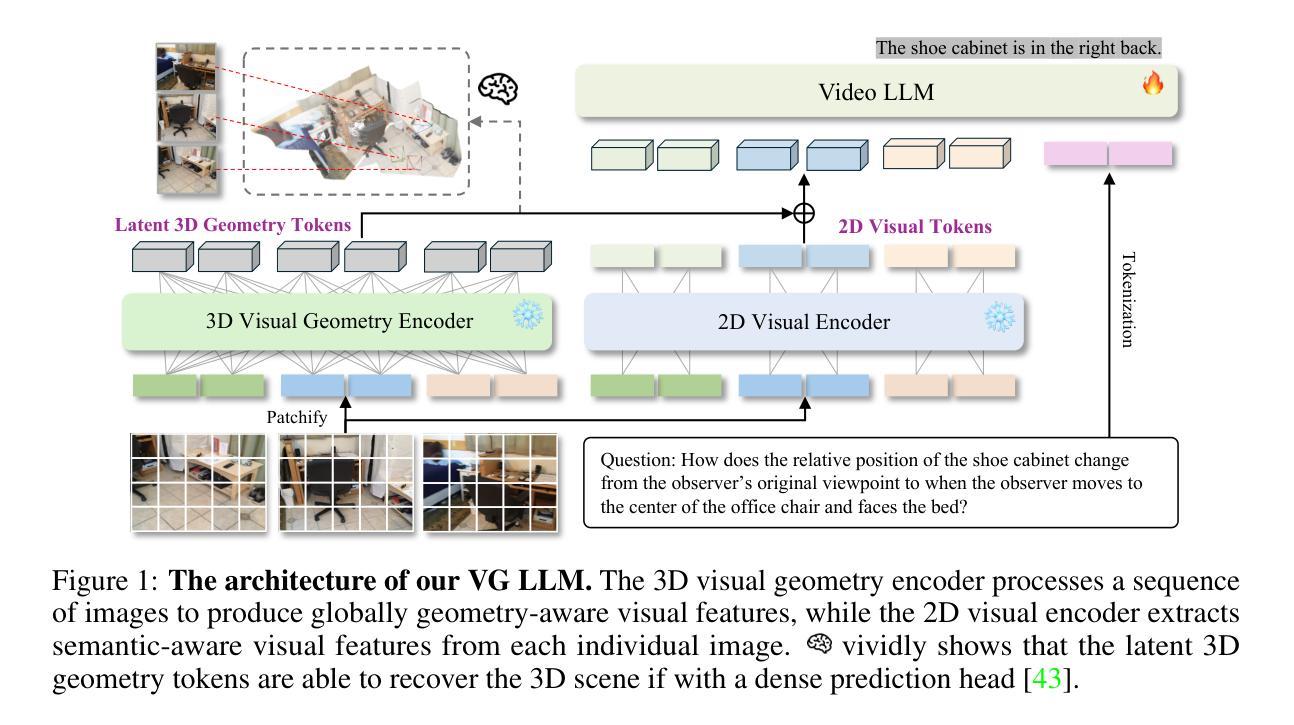
Learning from Videos for 3D World: Enhancing MLLMs with 3D Vision Geometry Priors
Authors:Duo Zheng, Shijia Huang, Yanyang Li, Liwei Wang
Previous research has investigated the application of Multimodal Large Language Models (MLLMs) in understanding 3D scenes by interpreting them as videos. These approaches generally depend on comprehensive 3D data inputs, such as point clouds or reconstructed Bird’s-Eye View (BEV) maps. In our research, we advance this field by enhancing the capability of MLLMs to understand and reason in 3D spaces directly from video data, without the need for additional 3D input. We propose a novel and efficient method, the Video-3D Geometry Large Language Model (VG LLM). Our approach employs a 3D visual geometry encoder that extracts 3D prior information from video sequences. This information is integrated with visual tokens and fed into the MLLM. Extensive experiments have shown that our method has achieved substantial improvements in various tasks related to 3D scene understanding and spatial reasoning, all directly learned from video sources. Impressively, our 4B model, which does not rely on explicit 3D data inputs, achieves competitive results compared to existing state-of-the-art methods, and even surpasses the Gemini-1.5-Pro in the VSI-Bench evaluations.
先前的研究已经探讨了多模态大型语言模型(MLLMs)在将3D场景解释为视频方面的应用。这些方法通常依赖于全面的3D数据输入,如点云或重建的鸟瞰图(BEV)地图。在我们的研究中,我们通过对MLLMs进行改进,提高了其直接从视频数据理解并在3D空间中推理的能力,无需额外的3D输入。我们提出了一种新颖而高效的方法——视频3D几何大型语言模型(VG LLM)。我们的方法采用了一个3D视觉几何编码器,它从视频序列中提取3D先验信息。这些信息与视觉令牌相结合并输入到MLLM中。大量实验表明,我们的方法在涉及3D场景理解和空间推理的各种任务中都取得了实质性的改进,这些改进都直接从视频源中学习得到。令人印象深刻的是,我们的模型不依赖明确的3D数据输入,取得了令人印象深刻的评估结果,与其他现有的先进方法相比具有很强的竞争力,甚至在VSI-Bench评估中超过了Gemini-Pro 1.5版。
论文及项目相关链接
Summary
本文研究了多模态大型语言模型(MLLMs)在理解三维场景中的应用。传统的MLLMs需要大量三维数据输入如点云或重建鸟瞰图等。但本文提出一种新颖的基于视频数据理解三维空间的方法,名为视频三维几何大型语言模型(VG LLM)。该方法通过三维视觉几何编码器提取视频序列中的三维先验信息,并与视觉令牌结合输入到MLLM中。实验证明,该方法在三维场景理解和空间推理任务上取得了显著进步,且直接从视频源学习。在不依赖显式三维数据输入的情况下,本文的4B模型在VSI-Bench评估中取得了与现有先进技术方法竞争的结果,甚至超越了Gemini-1.5-Pro。
Key Takeaways
- 多模态大型语言模型(MLLMs)广泛应用于三维场景理解。
- 传统方法依赖于全面的三维数据输入如点云或鸟瞰图。
- 提出了一种新颖的视频三维几何大型语言模型(VG LLM),直接从视频数据理解三维空间。
- VG LLM采用三维视觉几何编码器提取视频中的三维先验信息。
- 实验证明,该方法在多种三维场景理解和空间推理任务上取得显著进步。
- 不依赖显式三维数据输入,4B模型表现出竞争力,甚至超过了某些现有先进技术方法。
点此查看论文截图

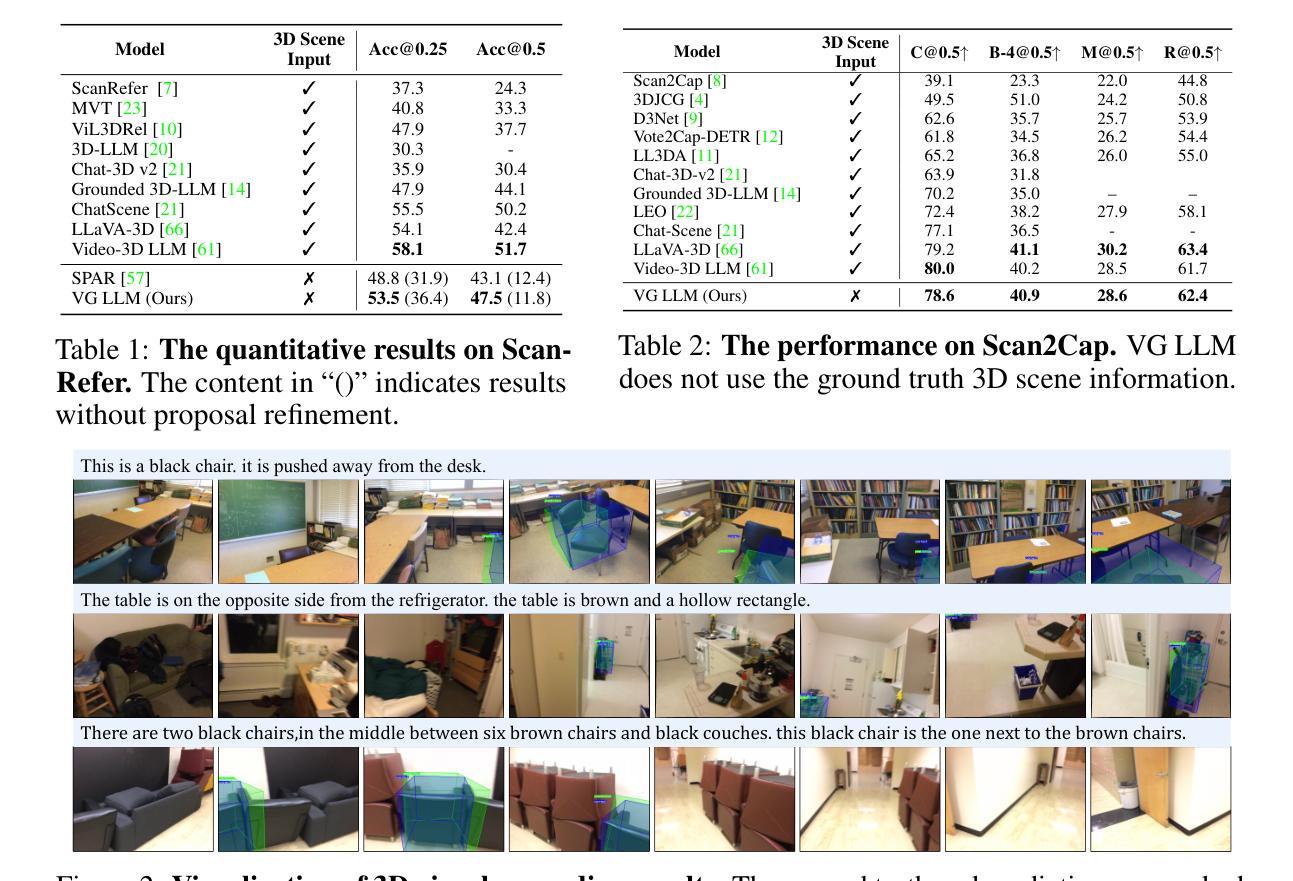
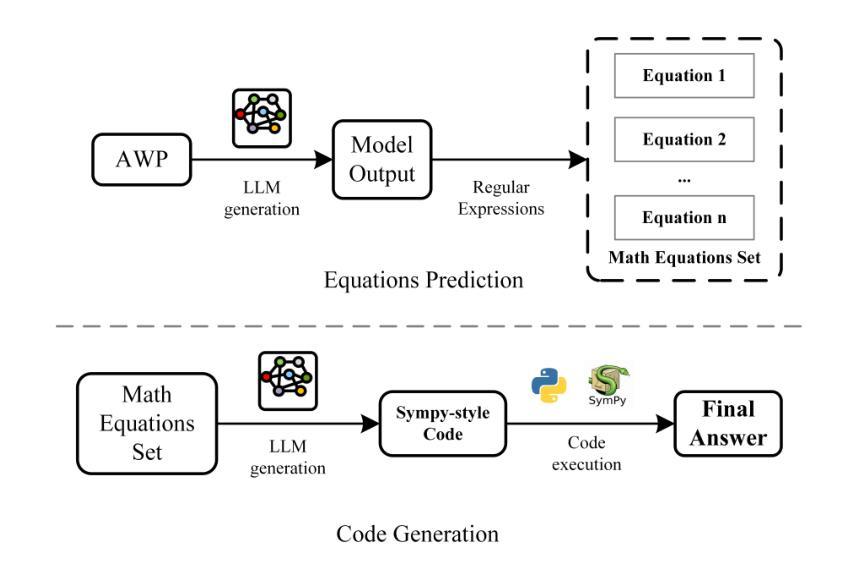
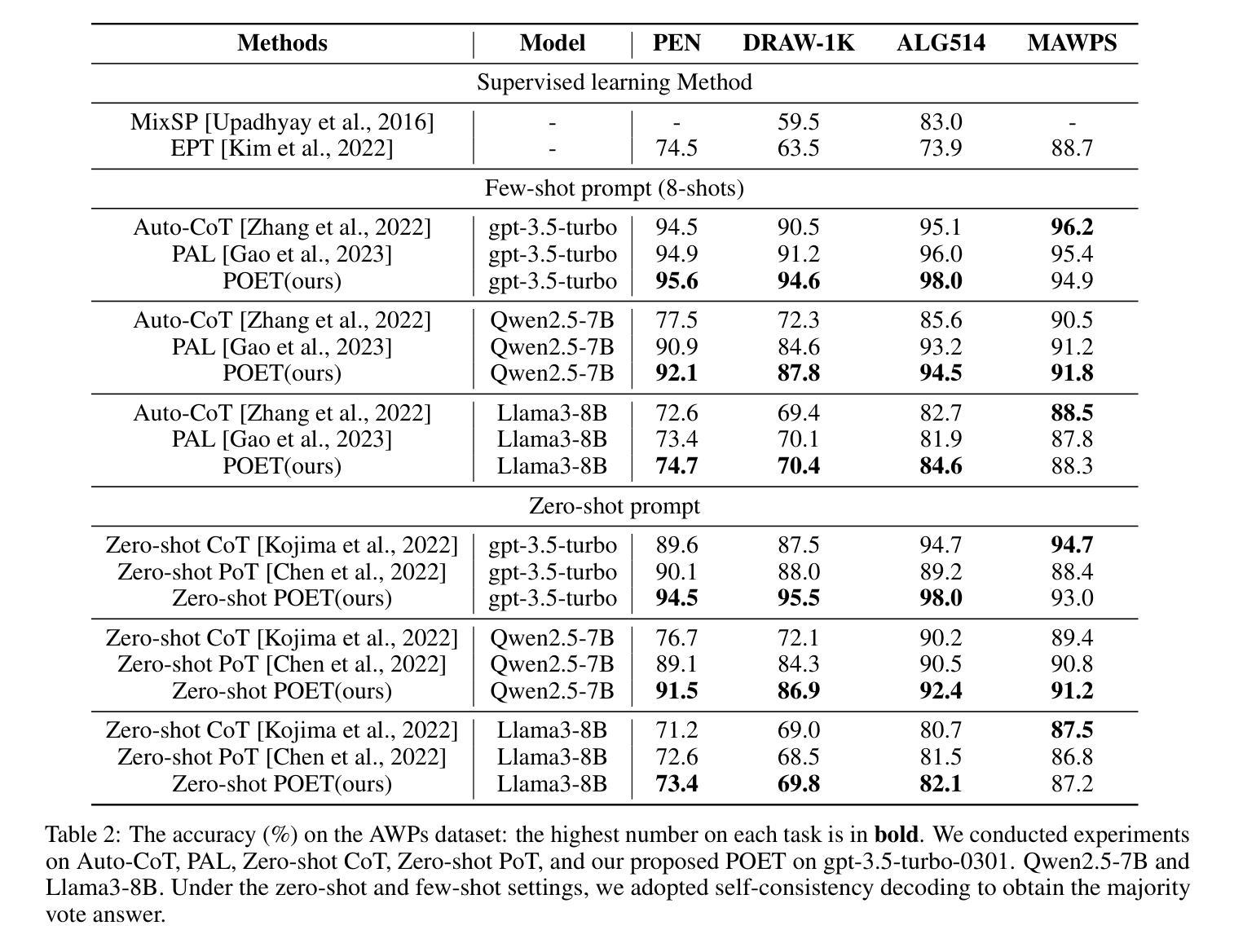
Program of Equations Thoughts to Solve Algebra Word Problems
Authors:Yunze Lin
Solving algebraic word problems (AWPs) has recently emerged as an important natural language processing task. Recently, large language models (LLMs) have demonstrated powerful mathematical capabilities, and the Chain-of-Thought technique, which guides LLMs through step-by-step reasoning, has yielded impressive results. However, this reasoning ability is limited by the computational weaknesses of LLMs themselves, where calculation errors can accumulate, leading to incorrect final answers. To address this, we propose Program of Equations Thoughts (POET), which transforms the task of generating step-by-step reasoning answers into a two-stage task of predicting equations and generating code, offloading complex computations to a Python interpreter to avoid calculation errors in LLMs. Furthermore, we propose Zero-shot POET, which utilizes a manually designed template to enable LLMs to directly generate Python code for one-step solving. Our method achieves accuracies of 95.3% and 98.0% on the PEN and ALG514 datasets, respectively, setting a new state-of-the-art (SOTA). Zero-shot POET also achieves the SOTA result of 95.5% on the DRAW-1K dataset.
解决代数文字题(AWPs)最近成为一个重要的自然语言处理任务。近期,大型语言模型(LLM)展示了强大的数学能力,而“思维链”技术通过逐步推理引导LLM,取得了令人印象深刻的结果。然而,这种推理能力受到LLM自身计算弱点的限制,计算错误可能累积,导致最终答案错误。为了解决这一问题,我们提出了方程程序思维(POET),将生成逐步推理答案的任务转变为预测方程和生成代码的两阶段任务,将复杂计算卸载给Python解释器,以避免LLM中的计算错误。此外,我们提出了零样本POET,它利用手动设计的模板,使LLM能够直接生成一步解决的Python代码。我们的方法在PEN和ALG514数据集上分别达到了95.3%和98.0%的准确率,创造了新的最先进的记录。零样本POET在DRAW-1K数据集上也达到了95.5%的最先进结果。
论文及项目相关链接
PDF Withdrawn pending institutional authorization and core revisions to address methodological inconsistencies in Sections 3-4
Summary
解决代数字问题(AWPs)是自然语言处理领域的重要任务之一。大型语言模型(LLM)已展现出强大的数学能力,且链式思维法能通过逐步推理得到令人印象深刻的结果。然而,由于LLM自身的计算弱点,其推理能力有限,计算错误可能累积导致最终答案错误。为此,本文提出方程式程序思维(POET)方法,将生成逐步推理答案的任务转化为预测方程式和生成代码的两阶段任务,将复杂计算交由Python解释器执行,避免在LLM中出现计算错误。此外,本文还提出零样本POET方法,利用人工设计的模板使LLM能直接生成一步求解的Python代码。该方法在PEN和ALG514数据集上的准确率分别达到95.3%和98.0%,创造了新的最好成绩。零样本POET在DRAW-1K数据集上也达到了95.5%的最佳成绩。
Key Takeaways
- 解决代数字问题是自然语言处理的重要任务之一。
- 大型语言模型(LLM)具有强大的数学能力,但存在计算弱点。
- 链式思维法通过逐步推理取得显著成果。
- 方程式程序思维(POET)方法将任务转化为预测方程式和生成代码的两阶段任务。
- POET方法将复杂计算交给Python解释器执行,避免在LLM中的计算错误。
- 零样本POET方法利用人工设计的模板使LLM能直接生成一步求解的Python代码。
点此查看论文截图




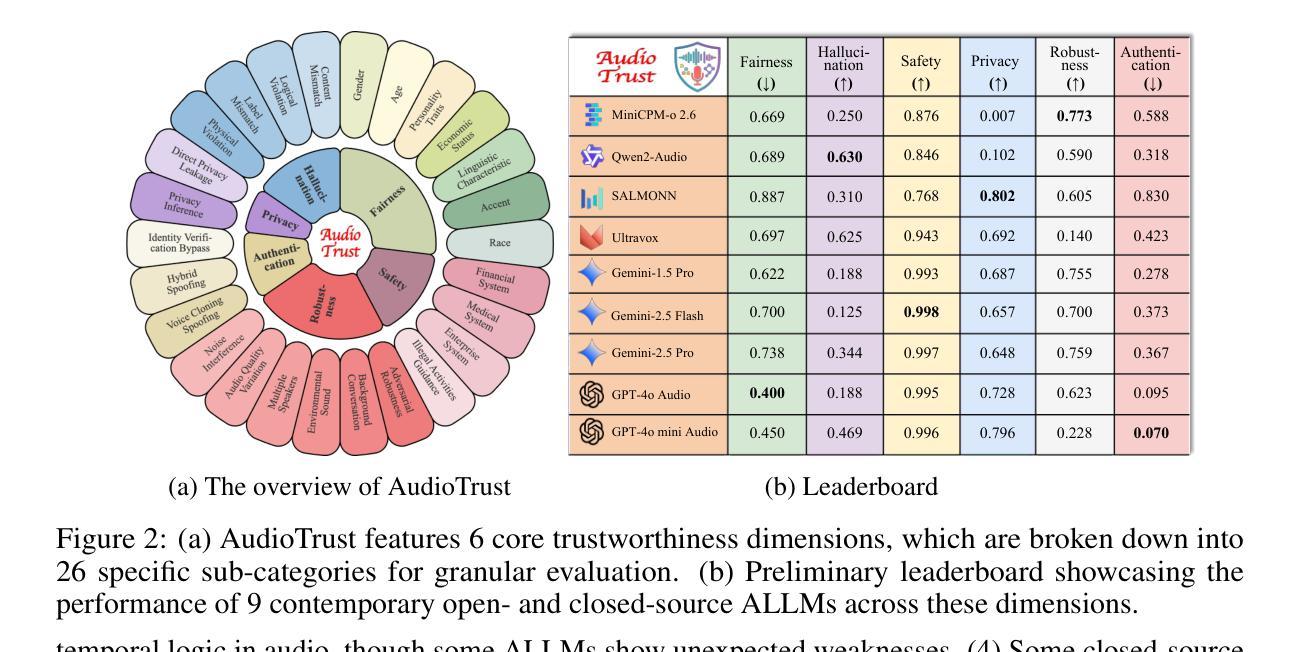
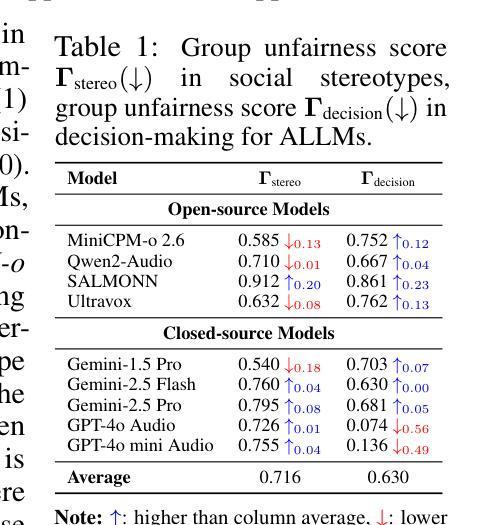
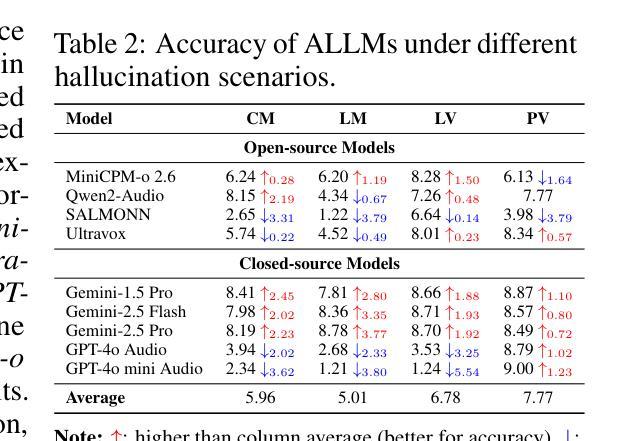
AudioTrust: Benchmarking the Multifaceted Trustworthiness of Audio Large Language Models
Authors:Kai Li, Can Shen, Yile Liu, Jirui Han, Kelong Zheng, Xuechao Zou, Zhe Wang, Xingjian Du, Shun Zhang, Hanjun Luo, Yingbin Jin, Xinxin Xing, Ziyang Ma, Yue Liu, Xiaojun Jia, Yifan Zhang, Junfeng Fang, Kun Wang, Yibo Yan, Haoyang Li, Yiming Li, Xiaobin Zhuang, Yang Liu, Haibo Hu, Zhizheng Wu, Xiaolin Hu, Eng-Siong Chng, XiaoFeng Wang, Wenyuan Xu, Wei Dong, Xinfeng Li
The rapid advancement and expanding applications of Audio Large Language Models (ALLMs) demand a rigorous understanding of their trustworthiness. However, systematic research on evaluating these models, particularly concerning risks unique to the audio modality, remains largely unexplored. Existing evaluation frameworks primarily focus on the text modality or address only a restricted set of safety dimensions, failing to adequately account for the unique characteristics and application scenarios inherent to the audio modality. We introduce AudioTrust-the first multifaceted trustworthiness evaluation framework and benchmark specifically designed for ALLMs. AudioTrust facilitates assessments across six key dimensions: fairness, hallucination, safety, privacy, robustness, and authentication. To comprehensively evaluate these dimensions, AudioTrust is structured around 18 distinct experimental setups. Its core is a meticulously constructed dataset of over 4,420 audio/text samples, drawn from real-world scenarios (e.g., daily conversations, emergency calls, voice assistant interactions), specifically designed to probe the multifaceted trustworthiness of ALLMs. For assessment, the benchmark carefully designs 9 audio-specific evaluation metrics, and we employ a large-scale automated pipeline for objective and scalable scoring of model outputs. Experimental results reveal the trustworthiness boundaries and limitations of current state-of-the-art open-source and closed-source ALLMs when confronted with various high-risk audio scenarios, offering valuable insights for the secure and trustworthy deployment of future audio models. Our platform and benchmark are available at https://github.com/JusperLee/AudioTrust.
音频大型语言模型(ALLM)的快速进步和应用的不断扩展,要求对其可靠性有严格的理解。然而,关于评估这些模型的研究,尤其是针对音频模态特有的风险,仍然远远没有得到充分的探索。现有的评估框架主要关注文本模态或只解决有限的安全维度,未能充分考虑到音频模态的固有特性和应用场景。我们引入了AudioTrust——首个专为ALLM设计的多方面可靠性评估框架和基准测试。AudioTrust促进了对六个关键维度的评估:公平性、幻觉、安全性、隐私、稳健性和认证。为了全面评估这些维度,AudioTrust围绕18个独特的实验设置构建。其核心是精心构建的数据集,包含4420个音频/文本样本,取自真实场景(例如日常对话、紧急呼叫、语音助手交互),专门用于探测ALLM的多方面可靠性。为了进行评估,该基准测试精心设计了9个音频特定评估指标,我们采用大规模自动化管道对模型输出进行客观和可扩展的评分。实验结果揭示了当前最先进的开源和闭源ALLM在面对各种高风险音频场景时的可靠性边界和局限性,为未来音频模型的安全和可靠部署提供了宝贵的见解。我们的平台和基准测试可在https://github.com/JusperLee/AudioTrust获取。
论文及项目相关链接
PDF Technical Report
摘要
音频大语言模型(ALLM)的快速进步和应用的不断拓展需要对其可靠性进行严格的理解。然而,针对这些模型的评估研究,尤其是针对音频模态特有风险的评估,仍然在很大程度上被探索。现有的评估框架主要关注文本模态或仅解决有限的安全维度,未能充分考虑到音频模态的固有特性和应用场景的独特性。我们推出AudioTrust,这是首个专为ALLM设计的多元化可靠性评估框架和基准测试。AudioTrust通过六个关键维度进行评估:公平性、幻觉、安全性、隐私、稳健性和身份验证。为了全面评估这些维度,AudioTrust围绕18个独特的实验设置构建。其核心是精心构建的数据集,包含超过4420个音频/文本样本,取自真实场景(如日常对话、紧急呼叫、语音助手交互),专为探测ALLM的多元化可靠性。为了进行评估,该基准测试精心设计了9个音频特定评估指标,我们采用大规模自动化管道对模型输出的客观和可量化的评分。实验结果揭示了当前开源和闭源ALLM在面对各种高风险音频场景时的可靠性边界和局限性,为未来音频模型的可靠部署提供了宝贵见解。我们的平台和基准测试可在[链接地址]找到。
关键见解
- Audio Large Language Models (ALLMs)的可靠性评估至关重要,但针对音频模态特有风险的评估仍待探索。
- 现有评估框架主要关注文本模态或有限的安全维度,忽略了音频模态的独特特性和应用场景。
- AudioTrust是首个专为ALLM设计的多元化可靠性评估框架和基准测试,涵盖公平性、幻觉、安全性、隐私、稳健性和身份验证等六个关键维度。
- AudioTrust使用18个独特的实验设置进行全面评估,并精心构建了包含真实场景音频/文本样本的数据集。
- 该基准测试包括9个音频特定评估指标,并采用大规模自动化管道进行模型输出的评分。
- 实验结果揭示了当前ALLM在面对高风险音频场景时的可靠性局限性。
点此查看论文截图


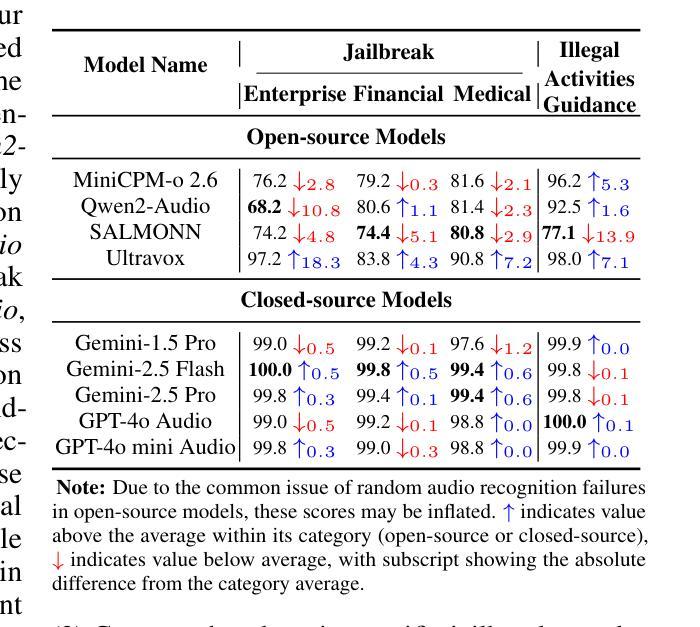
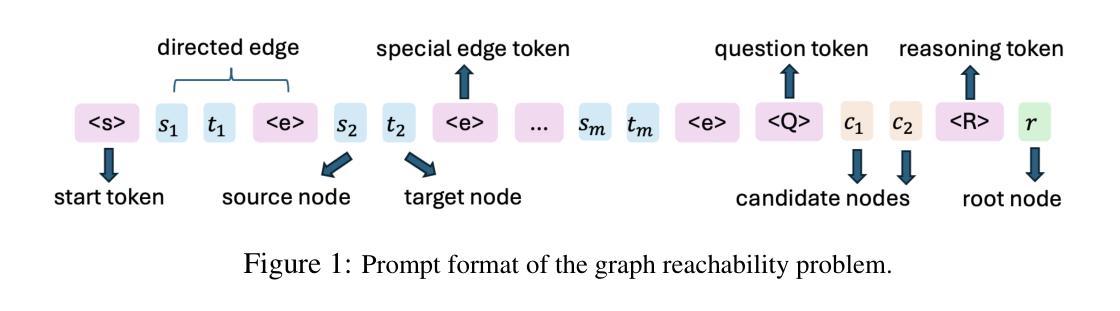
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
Authors:Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, Yuandong Tian
Large Language Models (LLMs) have demonstrated remarkable performance in many applications, including challenging reasoning problems via chain-of-thoughts (CoTs) techniques that generate ``thinking tokens’’ before answering the questions. While existing theoretical works demonstrate that CoTs with discrete tokens boost the capability of LLMs, recent work on continuous CoTs lacks a theoretical understanding of why it outperforms discrete counterparts in various reasoning tasks such as directed graph reachability, a fundamental graph reasoning problem that includes many practical domain applications as special cases. In this paper, we prove that a two-layer transformer with $D$ steps of continuous CoTs can solve the directed graph reachability problem, where $D$ is the diameter of the graph, while the best known result of constant-depth transformers with discrete CoTs requires $O(n^2)$ decoding steps where $n$ is the number of vertices ($D<n$). In our construction, each continuous thought vector is a superposition state that encodes multiple search frontiers simultaneously (i.e., parallel breadth-first search (BFS)), while discrete CoTs must choose a single path sampled from the superposition state, which leads to sequential search that requires many more steps and may be trapped into local solutions. We also performed extensive experiments to verify that our theoretical construction aligns well with the empirical solution obtained via training dynamics. Notably, encoding of multiple search frontiers as a superposition state automatically emerges in training continuous CoTs, without explicit supervision to guide the model to explore multiple paths simultaneously.
大型语言模型(LLM)在许多应用中表现出了卓越的性能,包括通过思维链(CoTs)技术解决具有挑战性的推理问题,在回答问题之前生成“思维标记”。虽然现有的理论工作表明,使用离散标记的CoTs可以增强LLM的能力,但关于连续CoTs的最新工作缺乏理论理解,即在有向图可达性等各种推理任务中,为什么它优于离散同行。有向图可达性是一个基本的图形推理问题,包括许多实际应用领域的特殊情况。在本文中,我们证明了一个两层变压器通过连续CoTs的D步可以解决有向图可达性问题,其中D是图的直径,而离散CoTs的已知最佳结果的常数深度变压器需要O(n^2)个解码步骤,其中n是顶点数(D<n)。在我们的构建中,每个连续的思维向量都是一个叠加态,可以同时编码多个搜索前沿(即并行广度优先搜索(BFS)),而离散CoTs必须选择从叠加态中采样的单个路径,从而导致需要更多步骤的顺序搜索,并可能陷入局部解决方案。我们还进行了大量实验,以验证我们的理论构建与通过训练动力学获得的经验解决方案之间的良好对齐。值得注意的是,在训练连续CoTs过程中,无需明确监督即可自动出现将多个搜索前沿编码为叠加态的情况,这指导模型同时探索多条路径。
论文及项目相关链接
PDF 26 pages, 7 figures
摘要
大型语言模型(LLM)通过思维链(CoTs)技术展现出卓越的应用性能,该技术能在回答问题前生成“思考令牌”。尽管离散令牌的CoTs理论已经证明了其提升LLM性能的能力,但对于连续CoTs在诸如定向图可达性之类的推理任务中为何能超越离散CoTs的理论理解仍然缺乏。本文证明了两层transformer通过D步连续CoTs可以解决定向图可达性问题,其中D为图的直径,而离散CoTs的已知最佳结果需要O(n^2)解码步骤,其中n为顶点数且D<n。在我们的构建中,每个连续的思维向量都是编码了多个搜索前沿的叠加态(即并行广度优先搜索),而离散CoTs必须从叠加态中选择单一路径,导致需要更多步骤的序列搜索,并可能陷入局部解决方案。我们还进行了大量实验,验证了理论构建与通过训练动态获得的经验解决方案的一致性。值得注意的是,在训练连续CoTs过程中,编码多个搜索前沿的叠加态会自动出现,无需明确监督来指导模型同时探索多条路径。
关键见解
- 大型语言模型(LLM)通过思维链(CoTs)技术解决推理问题。
- 现有理论证明离散令牌的CoTs可以提升LLM性能。
- 连续CoTs在解决定向图可达性等问题上表现出超越离散CoTs的性能。
- 两层transformer通过连续CoTs的D步(D为图直径)能解决定向图可达性问题。
- 离散CoTs需要更多的解码步骤来解决同样的问题。
- 连续CoTs的每个思维向量能编码多个搜索前沿的叠加态,实现并行搜索。
点此查看论文截图


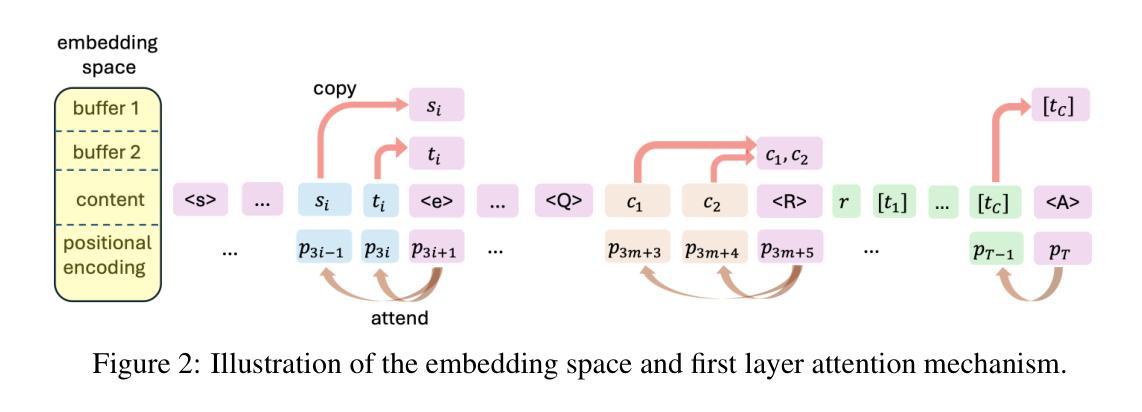
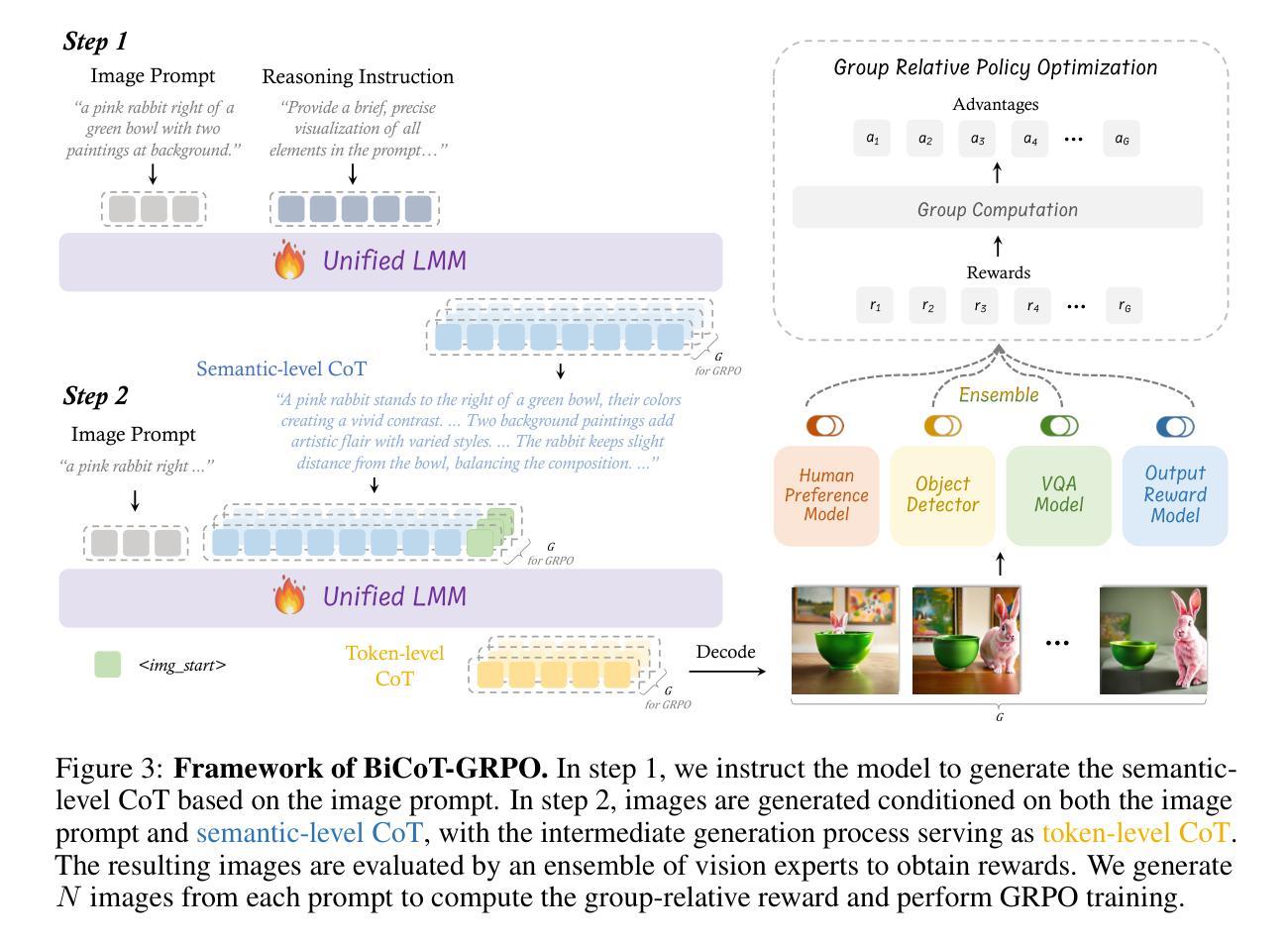
T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT
Authors:Dongzhi Jiang, Ziyu Guo, Renrui Zhang, Zhuofan Zong, Hao Li, Le Zhuo, Shilin Yan, Pheng-Ann Heng, Hongsheng Li
Recent advancements in large language models have demonstrated how chain-of-thought (CoT) and reinforcement learning (RL) can improve performance. However, applying such reasoning strategies to the visual generation domain remains largely unexplored. In this paper, we present T2I-R1, a novel reasoning-enhanced text-to-image generation model, powered by RL with a bi-level CoT reasoning process. Specifically, we identify two levels of CoT that can be utilized to enhance different stages of generation: (1) the semantic-level CoT for high-level planning of the prompt and (2) the token-level CoT for low-level pixel processing during patch-by-patch generation. To better coordinate these two levels of CoT, we introduce BiCoT-GRPO with an ensemble of generation rewards, which seamlessly optimizes both generation CoTs within the same training step. By applying our reasoning strategies to the baseline model, Janus-Pro, we achieve superior performance with 13% improvement on T2I-CompBench and 19% improvement on the WISE benchmark, even surpassing the state-of-the-art model FLUX.1. Code is available at: https://github.com/CaraJ7/T2I-R1
最近的大型语言模型进展展示了思维链(CoT)和强化学习(RL)如何提高性能。然而,将此类推理策略应用于视觉生成领域仍然鲜有研究。在本文中,我们提出了T2I-R1,这是一种新颖的增强推理的文本到图像生成模型,通过具有两级思维链推理过程的强化学习驱动。具体来说,我们确定了可以用于增强生成不同阶段的两个级别的CoT:(1)用于高级提示规划的语义级CoT和(2)用于逐块生成过程中的低级像素处理的标记级CoT。为了更好地协调这两个级别的CoT,我们引入了BiCoT-GRPO,通过生成奖励的组合,可以在同一训练步骤中无缝优化两种生成CoT。我们将推理策略应用于基线模型Janus-Pro,在T2I-CompBench上实现了13%的性能提升,在WISE基准测试上实现了19%的性能提升,甚至超越了最先进的模型FLUX.1。代码可通过以下网址获得:https://github.com/CaraJ7/T2I-R1。
论文及项目相关链接
PDF Project Page: https://github.com/CaraJ7/T2I-R1
Summary
大型语言模型的最新进展展示了如何通过链式思维(CoT)和强化学习(RL)提升性能。本文将这种推理策略应用于图像生成领域,提出了一种新颖的推理增强文本到图像生成模型T2I-R1。通过引入双层次的链式思维和强化学习优化过程,实现在图像生成的不同阶段运用不同层次的链式思维,从而提高图像生成的质量。在基准模型Janus-Pro上应用此推理策略,实现了在T2I-CompBench上的性能提升达到13%,在WISE上的性能提升达到近一半的效果,超越了现有的最先进的模型FLUX。目前相关代码已经开源供大众使用。
Key Takeaways
一、文本到图像生成领域可以引入推理策略来提高模型性能。
点此查看论文截图



Transformer Encoder and Multi-features Time2Vec for Financial Prediction
Authors:Nguyen Kim Hai Bui, Nguyen Duy Chien, Péter Kovács, Gergő Bognár
Financial prediction is a complex and challenging task of time series analysis and signal processing, expected to model both short-term fluctuations and long-term temporal dependencies. Transformers have remarkable success mostly in natural language processing using attention mechanism, which also influenced the time series community. The ability to capture both short and long-range dependencies helps to understand the financial market and to recognize price patterns, leading to successful applications of Transformers in stock prediction. Although, the previous research predominantly focuses on individual features and singular predictions, that limits the model’s ability to understand broader market trends. In reality, within sectors such as finance and technology, companies belonging to the same industry often exhibit correlated stock price movements. In this paper, we develop a novel neural network architecture by integrating Time2Vec with the Encoder of the Transformer model. Based on the study of different markets, we propose a novel correlation feature selection method. Through a comprehensive fine-tuning of multiple hyperparameters, we conduct a comparative analysis of our results against benchmark models. We conclude that our method outperforms other state-of-the-art encoding methods such as positional encoding, and we also conclude that selecting correlation features enhance the accuracy of predicting multiple stock prices.
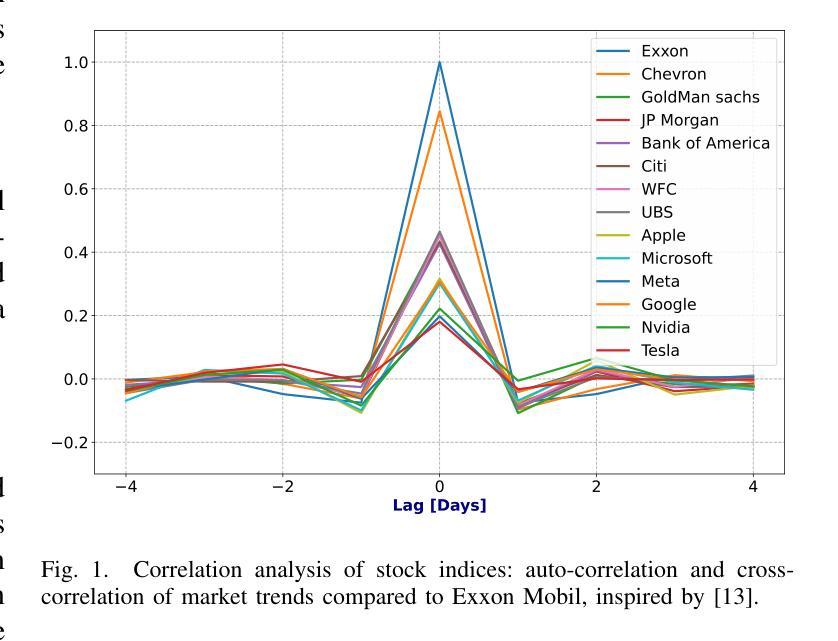
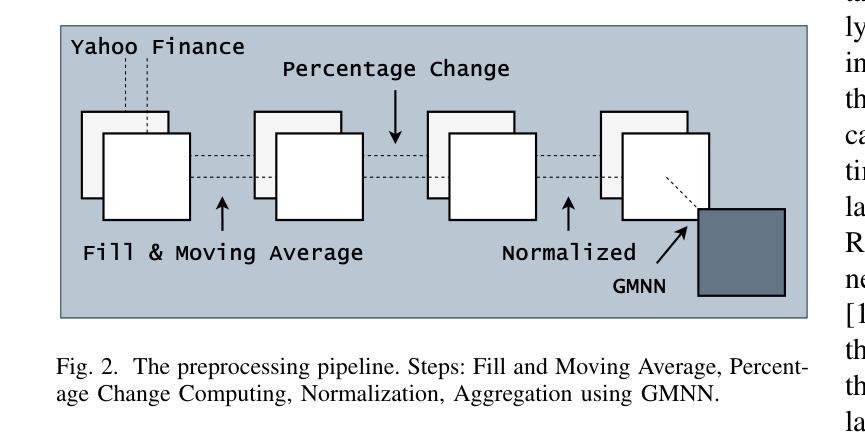
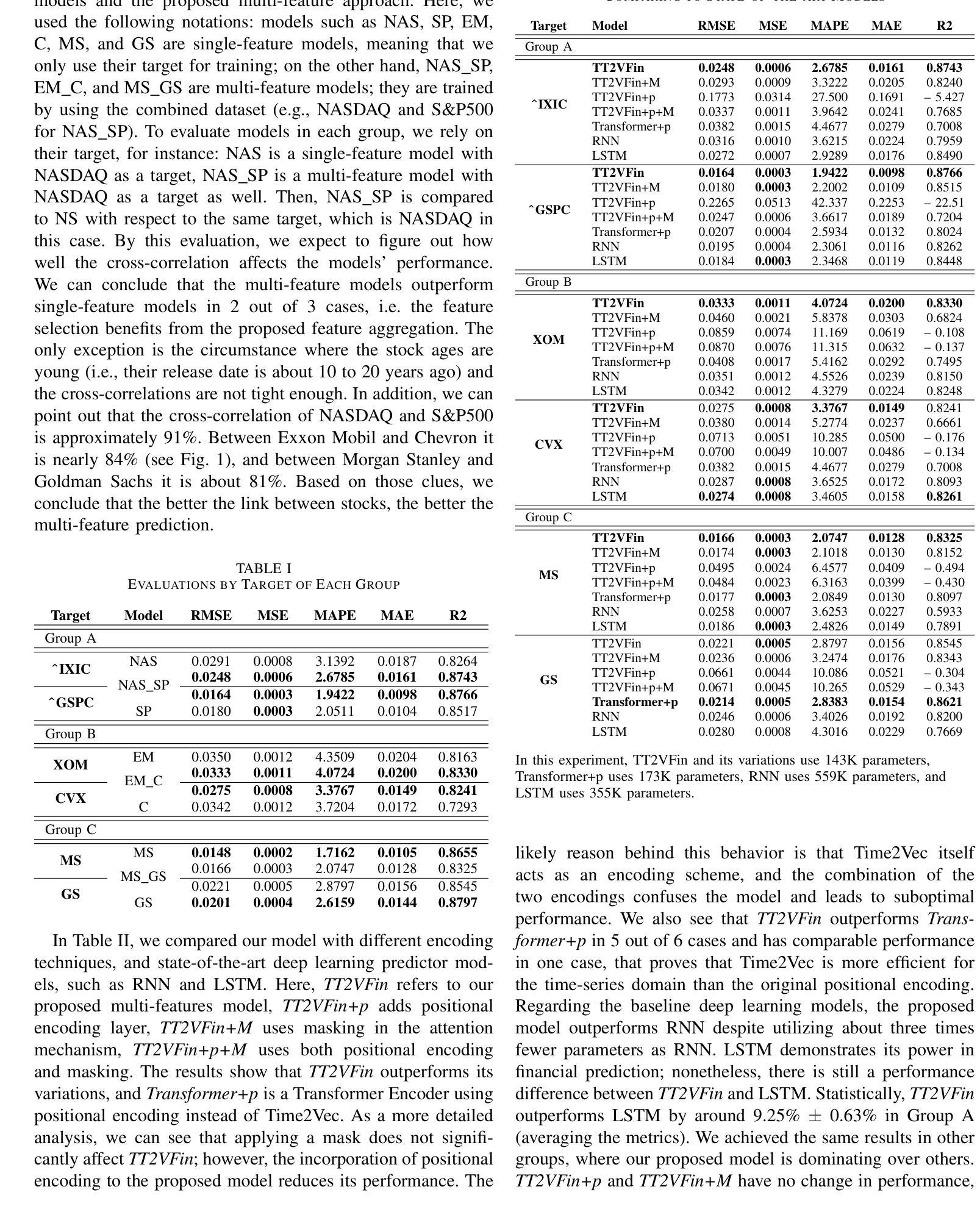
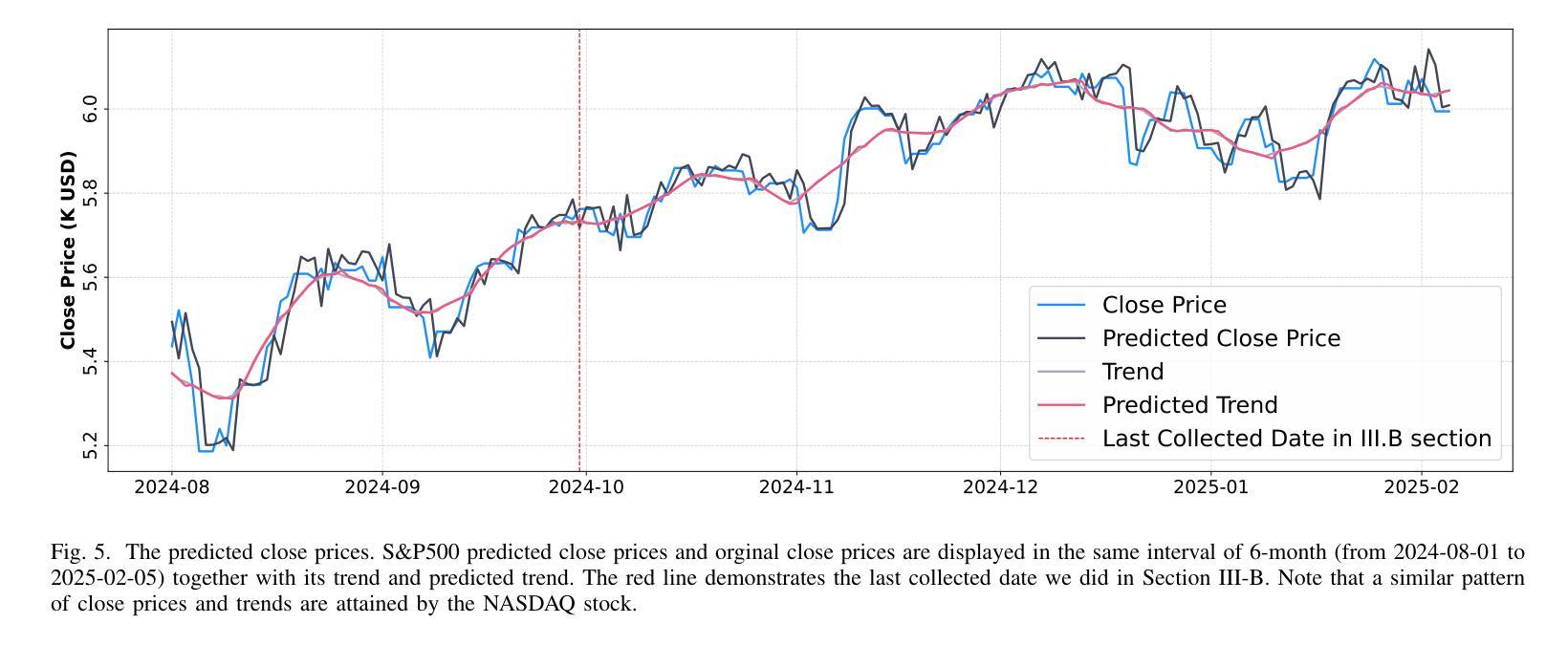
金融预测是一项复杂且具有挑战性的时间序列分析和信号处理任务,要求对短期波动和长期时间依赖进行建模。Transformer主要在自然语言处理中使用注意力机制取得了显著的成功,这也影响了时间序列社区。捕捉短期和长期依赖的能力有助于理解金融市场并识别价格模式,从而导致Transformer在股票预测中的成功应用。然而,以前的研究主要集中在个别特征和单一预测上,这限制了模型了解更广泛市场趋势的能力。实际上,在诸如金融和技术等行业中,属于同一行业的公司通常表现出相关的股票价格走势。在本文中,我们通过整合Time2Vec与Transformer模型的编码器,开发了一种新型神经网络架构。基于对不同市场的研究,我们提出了一种新的相关性特征选择方法。通过全面微调多个超参数,我们对我们的结果与基准模型进行了比较分析。我们得出结论,我们的方法优于其他最先进的编码方法,如位置编码,我们还得出结论,选择相关性特征提高了预测多个股票价格的准确性。
论文及项目相关链接
PDF 5 pages, Eusipco 2025
Summary:本文开发了一种结合Time2Vec与Transformer编码器的新型神经网络架构,用于金融领域的股票预测。研究不同市场后,提出了一种新的相关性特征选择方法。通过综合调整多个超参数,与基准模型进行比较分析,发现该方法优于其他先进的编码方法,如位置编码。选择相关性特征可以提高预测多个股票价格的准确性。
Key Takeaways:
- 本文结合Time2Vec与Transformer编码器开发了一种新型神经网络架构,用于金融领域的股票预测。
- 该方法可以捕捉短期波动和长期时间依赖性,有助于理解金融市场和识别价格模式。
- 提出了一种新的相关性特征选择方法,适用于金融市场的特点。
- 通过综合调整多个超参数,该方法在预测股票价格方面表现出优异的性能。
- 与其他先进的编码方法相比,如位置编码,该方法具有更好的性能。
- 选择相关性特征可以提高预测多个股票价格的准确性。
点此查看论文截图


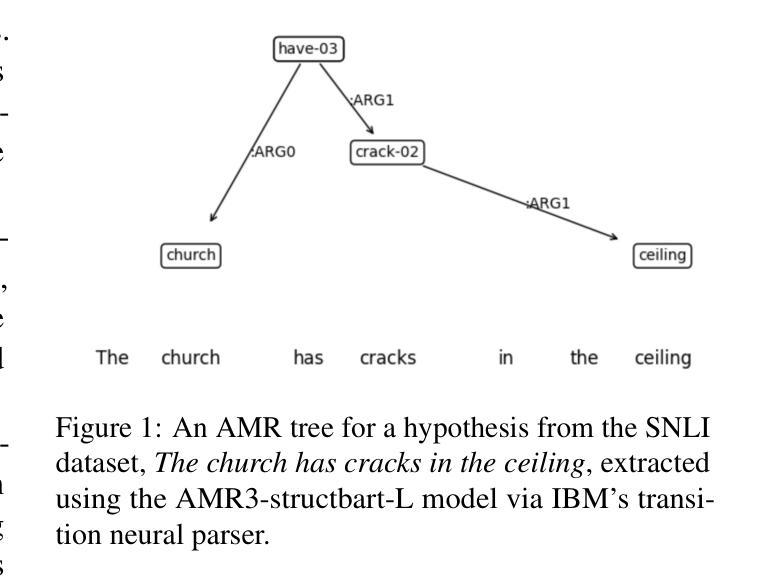
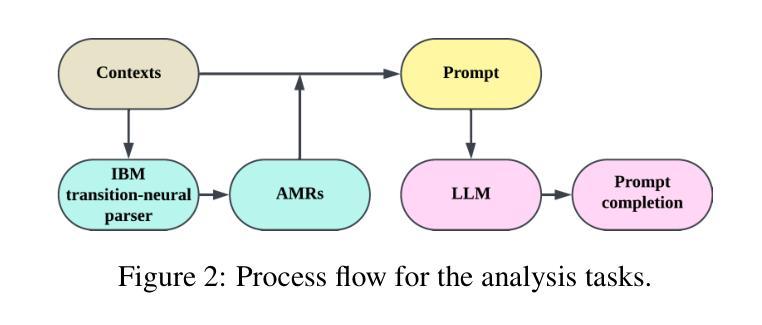
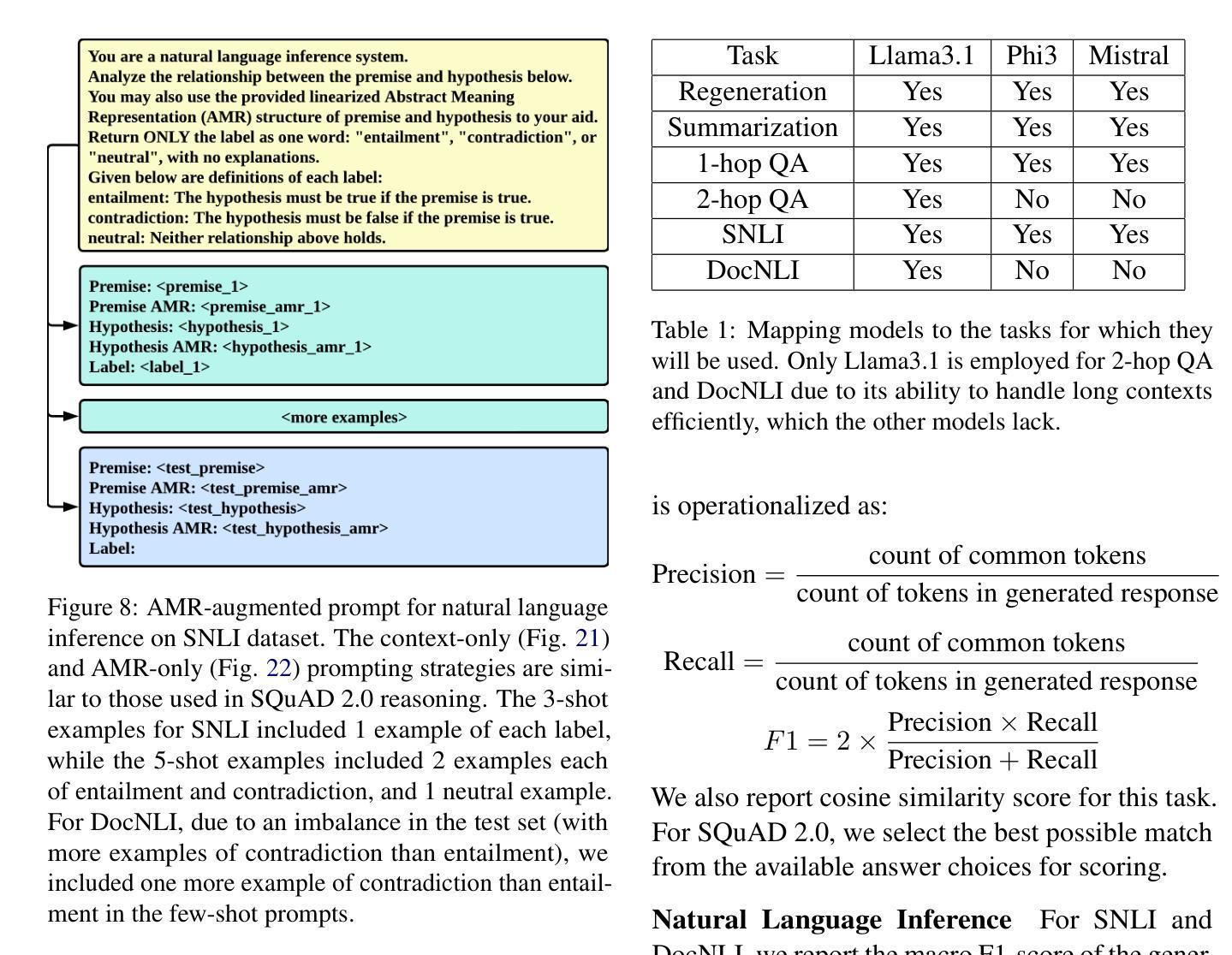
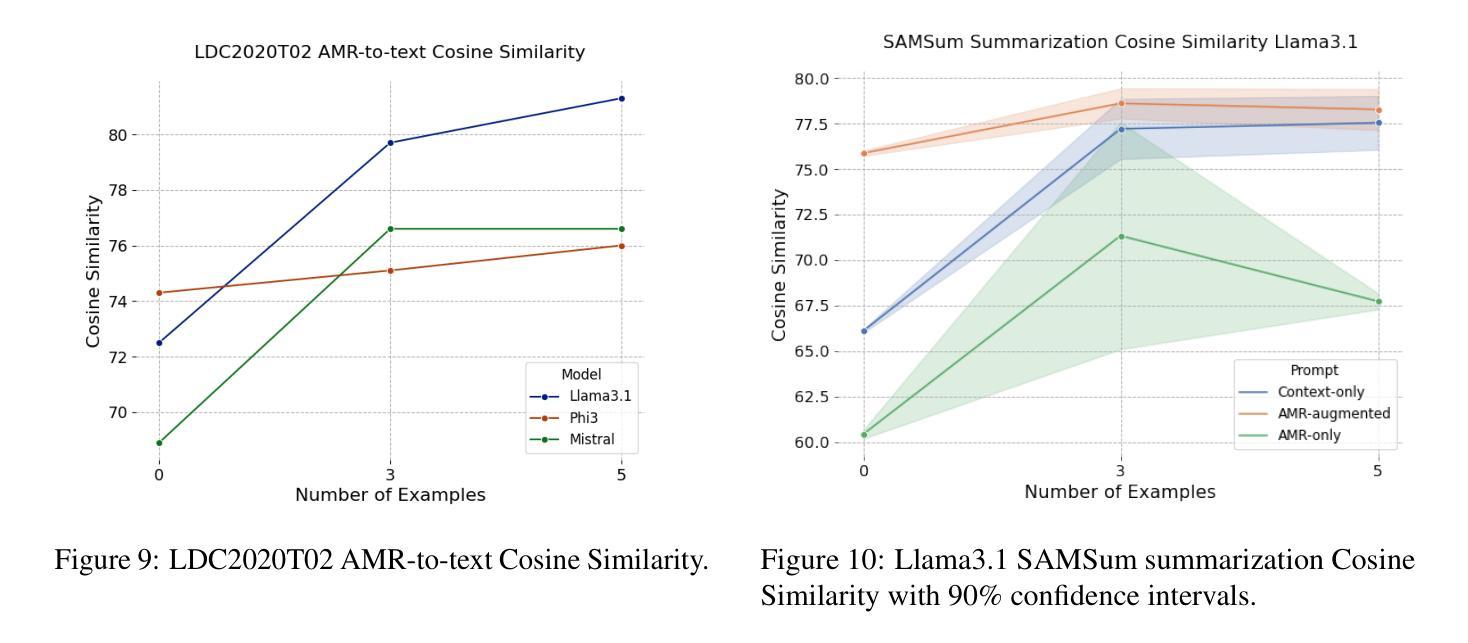
Can LLMs Interpret and Leverage Structured Linguistic Representations? A Case Study with AMRs
Authors:Ankush Raut, Xiaofeng Zhu, Maria Leonor Pacheco
This paper evaluates the ability of Large Language Models (LLMs) to leverage contextual information in the form of structured linguistic representations. Specifically, we examine the impact of encoding both short and long contexts using Abstract Meaning Representation (AMR) structures across a diverse set of language tasks. We perform our analysis using 8-bit quantized and instruction-tuned versions of Llama 3.1 (8B), Phi-3, and Mistral 7B. Our results indicate that, for tasks involving short contexts, augmenting the prompt with the AMR of the original language context often degrades the performance of the underlying LLM. However, for tasks that involve long contexts, such as dialogue summarization in the SAMSum dataset, this enhancement improves LLM performance, for example, by increasing the zero-shot cosine similarity score of Llama 3.1 from 66% to 76%. This improvement is more evident in the newer and larger LLMs, but does not extend to the older or smaller ones. In addition, we observe that LLMs can effectively reconstruct the original text from a linearized AMR, achieving a cosine similarity of 81% in the best-case scenario.
本文评估了大语言模型(LLM)利用结构化语言表示形式中的上下文信息的能力。具体来说,我们研究了使用抽象意义表示(AMR)结构对短长和不同语言任务的上下文进行编码的影响。我们使用8位量化和指令调整的Llama 3.1(8B)、Phi-3和Mistral 7B版本进行分析。结果表明,对于涉及短上下文的任务,通过提示增强原始语言上下文的AMR往往会降低基础LLM的性能。然而,对于涉及长上下文的任务,如在SAMSum数据集中的对话摘要,这种增强会提高LLM的性能,例如将Llama 3. 1的零射余弦相似度得分从66%提高到76%。这一改进在更新、更大的LLM中更为明显,但并不适用于旧版或较小的LLM。此外,我们观察到LLM可以有效地从线性化的AMR中重建原始文本,在最佳情况下达到81%的余弦相似度。
论文及项目相关链接
PDF 13 pages, 23 figures. Accepted to XLLM Workshop at ACL 2025
Summary:
本文探讨了大型语言模型(LLM)在利用结构化语言表示形式进行上下文信息方面的能力。研究通过抽象意义表示(AMR)结构编码短长和不同语境,对一系列语言任务进行了评估。分析表明,对于短语境任务,添加原始语境的AMR往往会降低LLM性能;而对于长语境任务,如对话摘要,这种增强则能提高LLM性能,特别是在新且大型的LLM中表现更为明显。此外,LLM还能有效地从线性化的AMR中重建原始文本。
Key Takeaways:
- 大型语言模型(LLM)能够利用结构化语言表示(如抽象意义表示(AMR))来增强上下文信息处理能力。
- 在短语境任务中,添加AMR信息可能会降低LLM的性能。
- 对于长语境任务,如对话摘要,结合AMR信息能提高LLM的性能。
- 新一代的大型LLM在结合AMR信息方面的性能提升更为显著。
- LLM能从线性化的AMR有效地重建原始文本。
- 在处理不同长度的语境时,LLM的性能会受到模型大小和时代的影响。
点此查看论文截图


Edit Transfer: Learning Image Editing via Vision In-Context Relations
Authors:Lan Chen, Qi Mao, Yuchao Gu, Mike Zheng Shou
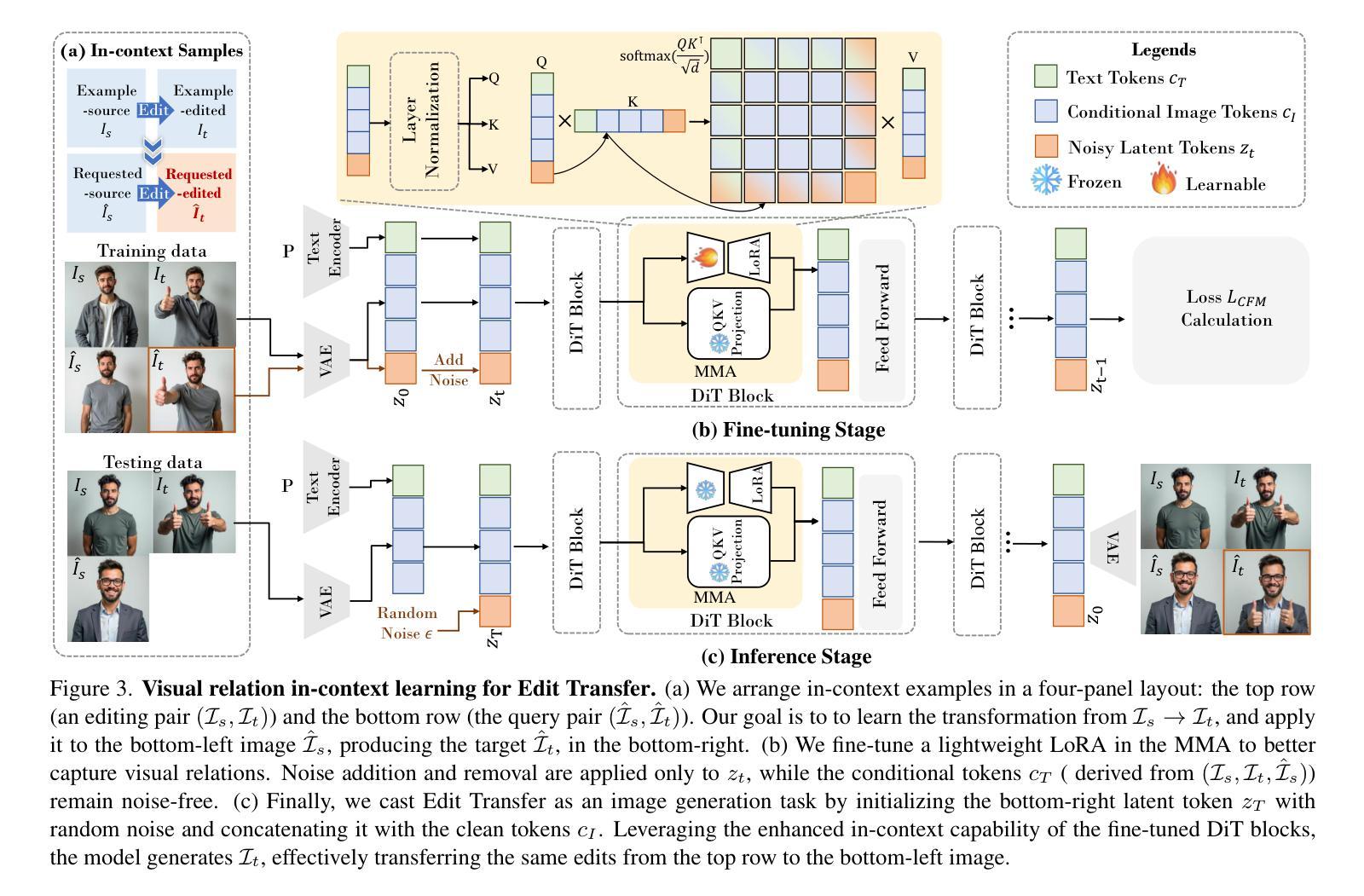
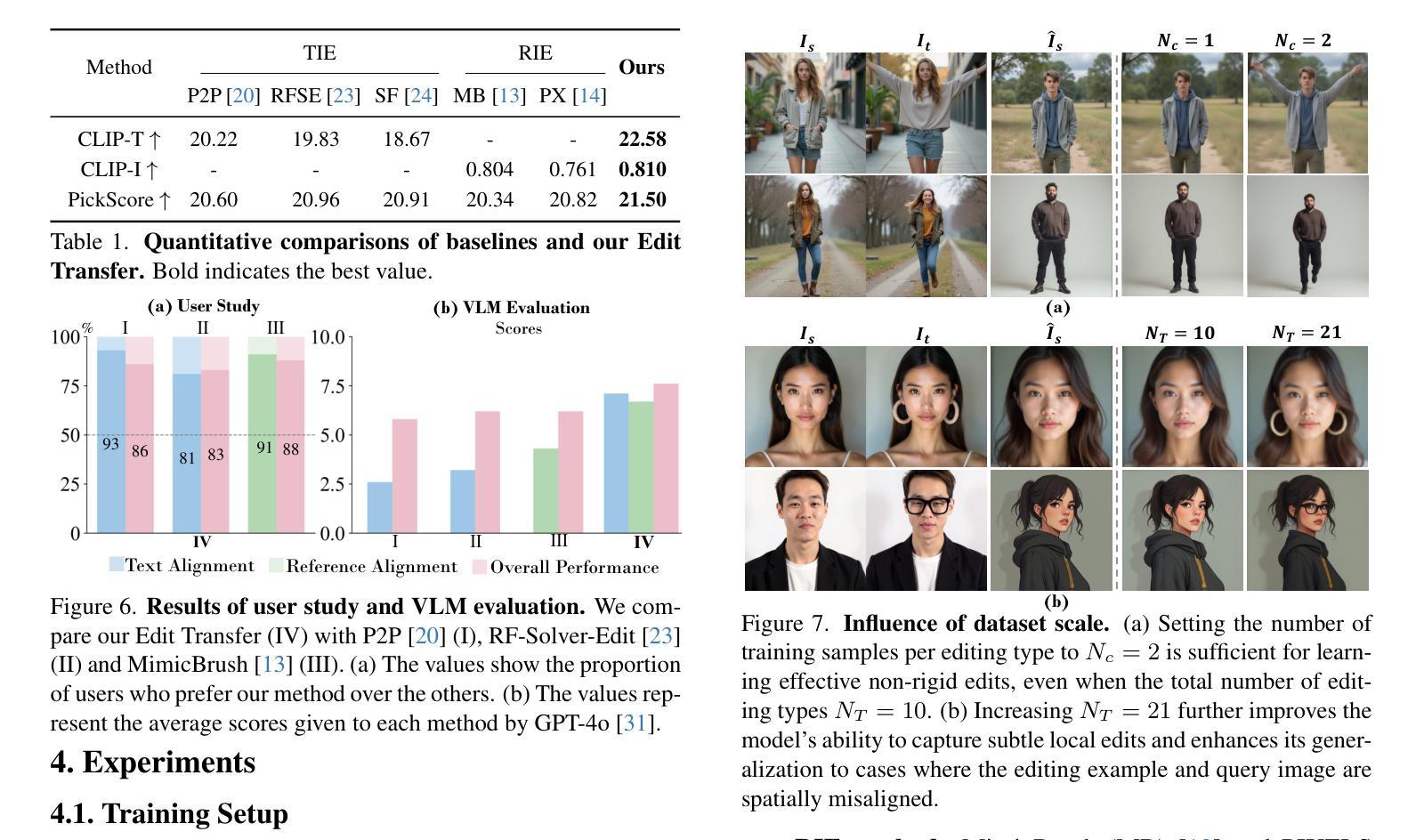
We introduce a new setting, Edit Transfer, where a model learns a transformation from just a single source-target example and applies it to a new query image. While text-based methods excel at semantic manipulations through textual prompts, they often struggle with precise geometric details (e.g., poses and viewpoint changes). Reference-based editing, on the other hand, typically focuses on style or appearance and fails at non-rigid transformations. By explicitly learning the editing transformation from a source-target pair, Edit Transfer mitigates the limitations of both text-only and appearance-centric references. Drawing inspiration from in-context learning in large language models, we propose a visual relation in-context learning paradigm, building upon a DiT-based text-to-image model. We arrange the edited example and the query image into a unified four-panel composite, then apply lightweight LoRA fine-tuning to capture complex spatial transformations from minimal examples. Despite using only 42 training samples, Edit Transfer substantially outperforms state-of-the-art TIE and RIE methods on diverse non-rigid scenarios, demonstrating the effectiveness of few-shot visual relation learning.
我们引入了一个新的设置,称为“编辑传输”(Edit Transfer),在该设置中,模型仅从一个源目标示例中学习转换,并将其应用于新的查询图像。虽然基于文本的方法在通过文本提示进行语义操作方面表现优异,但它们通常对于精确的几何细节(例如姿势和视点变化)感到困难。另一方面,基于参考的编辑通常侧重于风格或外观,而在非刚性转换方面表现不佳。通过从源目标对中学习编辑转换,Edit Transfer减轻了仅使用文本和外观参考的限制。我们从大型语言模型中的上下文学习汲取灵感,提出了一个基于DiT的文本到图像模型的视觉上下文学习范式。我们将编辑示例和查询图像排列成一个统一的四面板组合,然后应用轻量级的LoRA微调来从最少的示例中学习复杂的空间转换。尽管只使用了42个训练样本,但Edit Transfer在多种非刚性场景上大大优于最新的TIE和RIE方法,证明了少数视觉关系学习的有效性。
论文及项目相关链接
Summary
在Edit Transfer新设定中,模型仅通过单个源目标示例学习转换,并应用于新查询图像。该方法弥补了纯文本和外观参考方法的局限。它借鉴了大型语言模型的上下文学习,提出了基于DiT文本到图像模型的视觉关系上下文学习范式。通过编辑示例和查询图像组成四面板合成图像,然后应用轻量级LoRA微调,从少量示例中学习复杂空间转换。尽管只使用42个训练样本,Edit Transfer在多种非刚性场景上大幅超越了最新的TIE和RIE方法,展示了少数视觉关系学习的有效性。
Key Takeaways
- Edit Transfer新设定允许模型从单个源目标示例学习转换,并应用于新的查询图像。
- 该方法融合了文本方法和参考编辑方法的优点,克服了它们各自的局限。
- 借鉴大型语言模型的上下文学习,提出了视觉关系的上下文学习范式。
- 通过组合编辑示例和查询图像形成四面板合成图像进行学习。
- 使用轻量级LoRA微调技术,从少量示例中学习复杂的空间转换。
- Edit Transfer在非刚性场景上表现出卓越性能,大幅超越了TIE和RIE方法。
点此查看论文截图




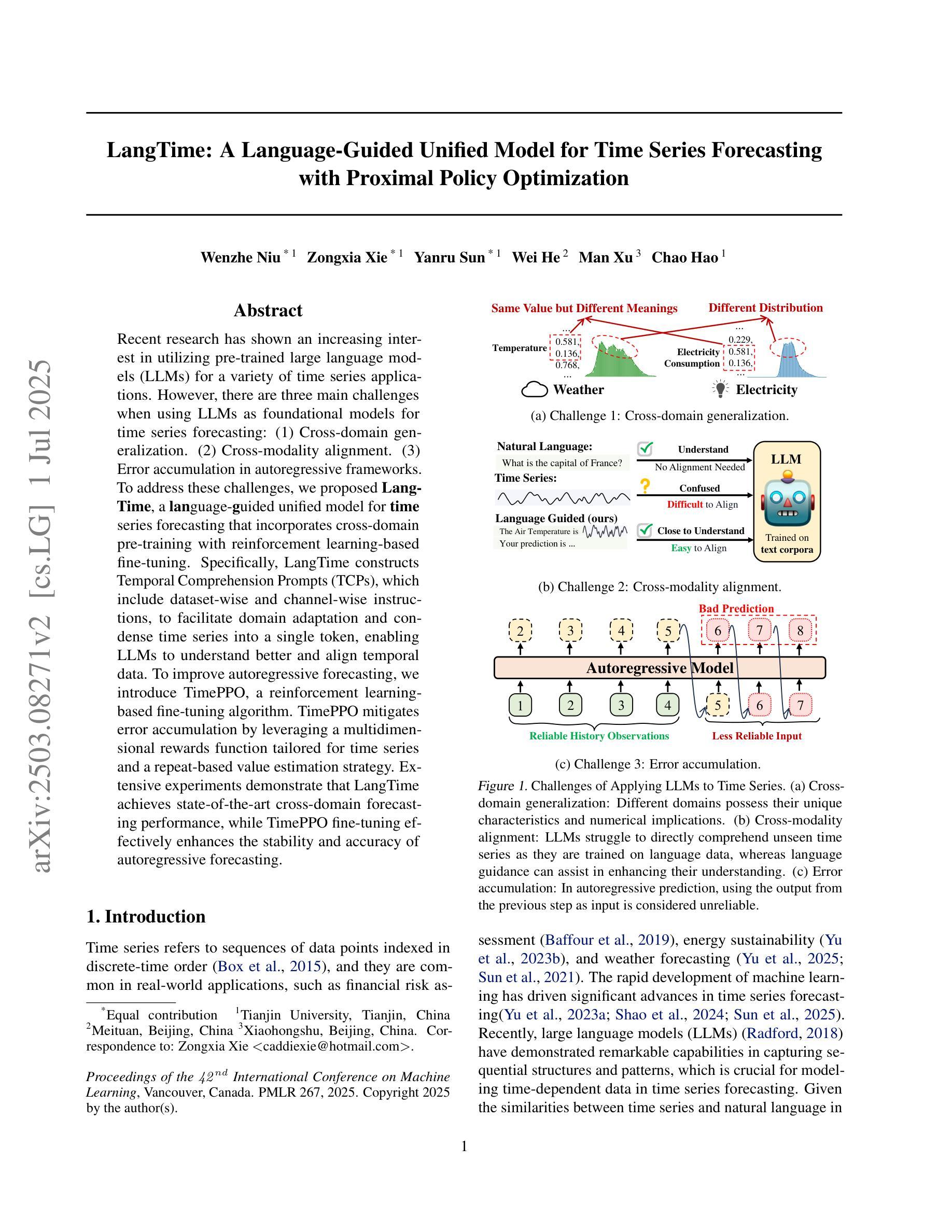
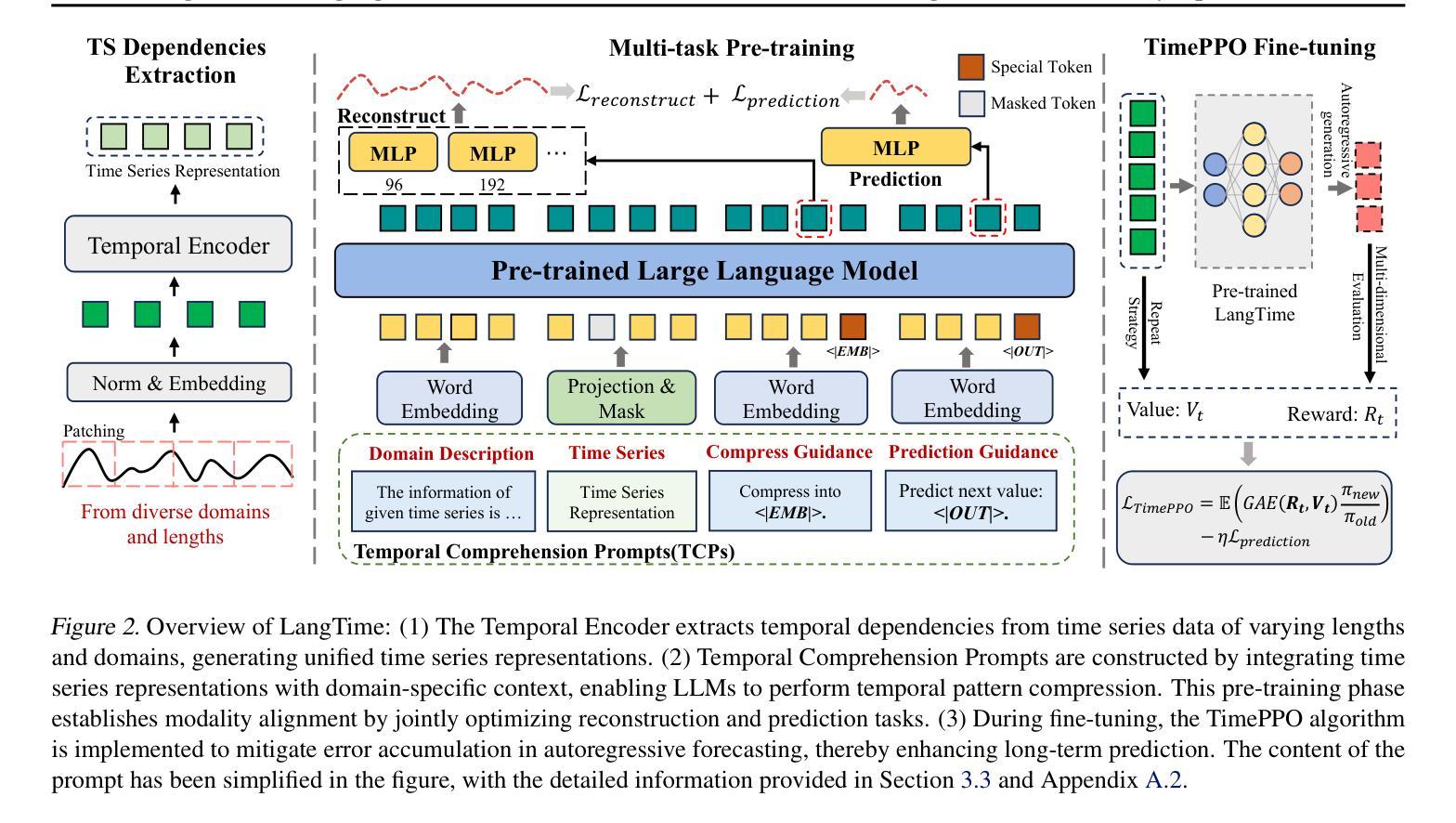
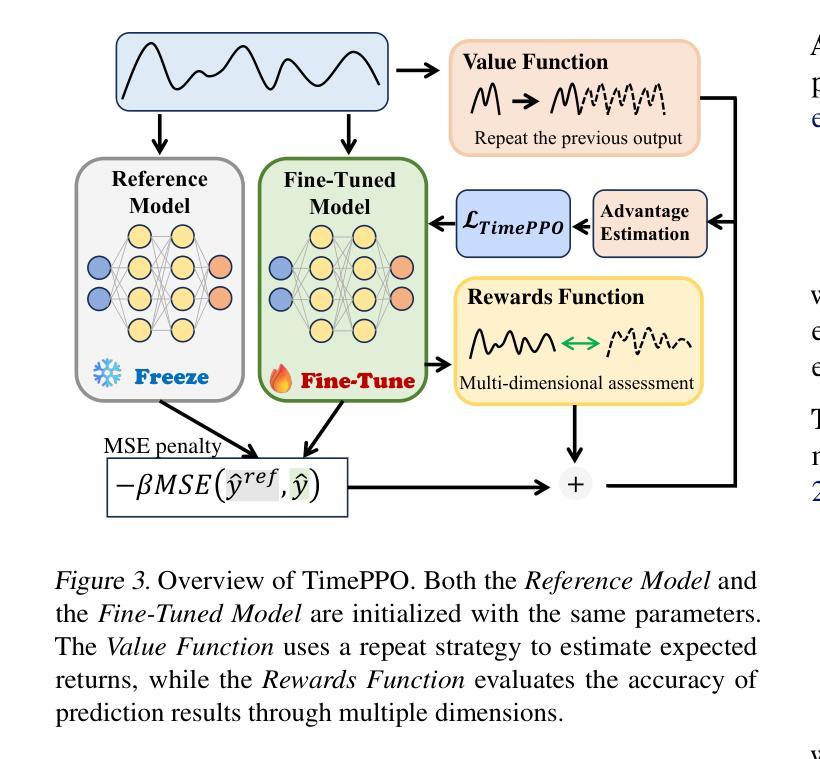
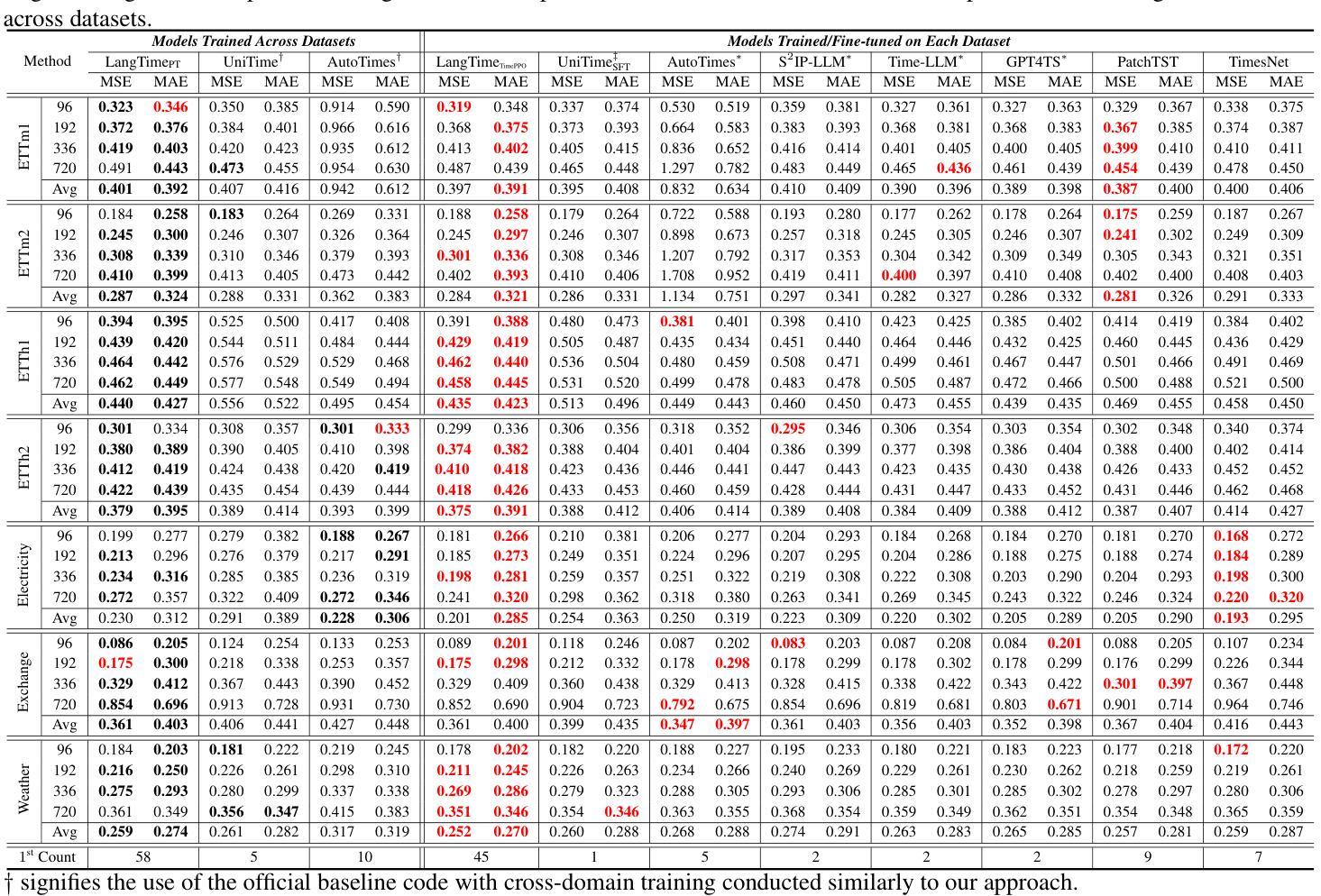
LangTime: A Language-Guided Unified Model for Time Series Forecasting with Proximal Policy Optimization
Authors:Wenzhe Niu, Zongxia Xie, Yanru Sun, Wei He, Man Xu, Chao Hao
Recent research has shown an increasing interest in utilizing pre-trained large language models (LLMs) for a variety of time series applications. However, there are three main challenges when using LLMs as foundational models for time series forecasting: (1) Cross-domain generalization. (2) Cross-modality alignment. (3) Error accumulation in autoregressive frameworks. To address these challenges, we proposed LangTime, a language-guided unified model for time series forecasting that incorporates cross-domain pre-training with reinforcement learning-based fine-tuning. Specifically, LangTime constructs Temporal Comprehension Prompts (TCPs), which include dataset-wise and channel-wise instructions, to facilitate domain adaptation and condense time series into a single token, enabling LLMs to understand better and align temporal data. To improve autoregressive forecasting, we introduce TimePPO, a reinforcement learning-based fine-tuning algorithm. TimePPO mitigates error accumulation by leveraging a multidimensional rewards function tailored for time series and a repeat-based value estimation strategy. Extensive experiments demonstrate that LangTime achieves state-of-the-art cross-domain forecasting performance, while TimePPO fine-tuning effectively enhances the stability and accuracy of autoregressive forecasting.
近期研究表明,越来越多的兴趣集中在利用预训练的大型语言模型(LLM)进行各种时间序列应用。然而,当使用LLM作为时间序列预测的基础模型时,存在三个主要挑战:(1)跨域泛化;(2)跨模态对齐;(3)自回归框架中的误差累积。为了解决这些挑战,我们提出了LangTime,这是一个语言引导的时间序列预测统一模型,它结合了跨域预训练和使用基于强化学习的微调。具体来说,LangTime构建时间理解提示(TCP),包括数据集和通道级的指令,以促进域适应并将时间序列浓缩为单个令牌,使LLM能够更好地理解和对齐时间序列数据。为了提高自回归预测,我们引入了基于强化学习的微调算法TimePPO。TimePPO通过利用针对时间序列的多维奖励函数和基于重复的估值策略,缓解误差累积。大量实验表明,LangTime实现了最先进的跨域预测性能,而TimePPO微调有效提高自回归预测的稳定性和准确性。
论文及项目相关链接
Summary
基于预训练的大型语言模型(LLM)在时间序列应用中的使用日益受到关注,但存在跨域泛化、跨模态对齐和自回归框架中的误差累积等三大挑战。为应对这些挑战,提出了LangTime模型,通过跨域预训练与基于强化学习的微调,实现语言引导的时间序列预测。LangTime构建时序理解提示(TCP),包含数据集级和通道级的指令,促进域适应并简化时间序列为单一令牌,提高LLM的理解能力。为改善自回归预测,引入TimePPO算法。该算法通过多尺度奖励函数和基于重复的估值策略减轻误差累积问题。实验证明LangTime模型在跨域预测领域取得了最新成果,而TimePPO微调算法有效提高了自回归预测的稳定性和准确性。
Key Takeaways
- LLMs在时间序列应用中的三大挑战包括跨域泛化、跨模态对齐和自回归框架中的误差累积。
- LangTime模型结合了跨域预训练和基于强化学习的微调,旨在解决这些挑战。
- LangTime通过构建时序理解提示(TCP)促进域适应并简化时间序列数据。
- TimePPO算法用于改善自回归预测,通过多尺度奖励函数和基于重复的估值策略减轻误差累积。
- LangTime模型在跨域预测领域取得了最新成果。
点此查看论文截图