⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-03 更新
URGENT-PK: Perceptually-Aligned Ranking Model Designed for Speech Enhancement Competition
Authors:Jiahe Wang, Chenda Li, Wei Wang, Wangyou Zhang, Samuele Cornell, Marvin Sach, Robin Scheibler, Kohei Saijo, Yihui Fu, Zhaoheng Ni, Anurag Kumar, Tim Fingscheidt, Shinji Watanabe, Yanmin Qian
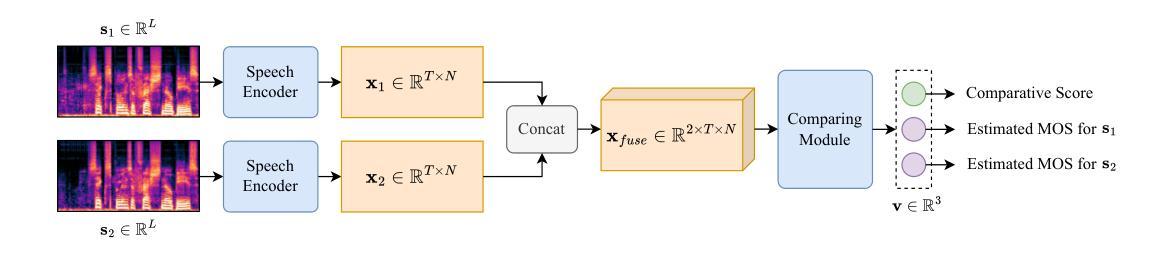
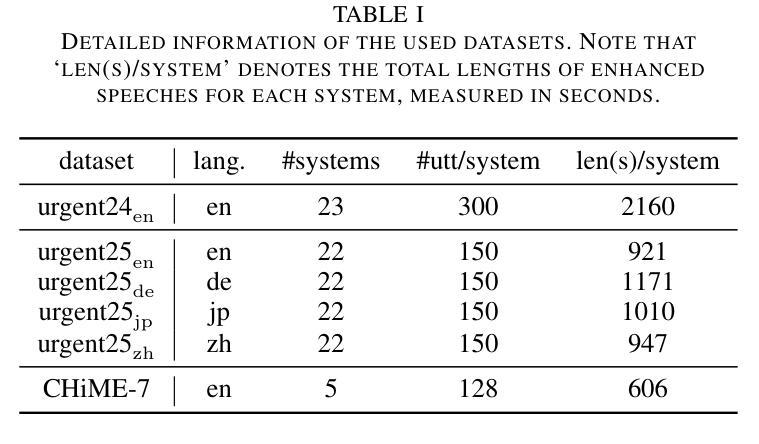
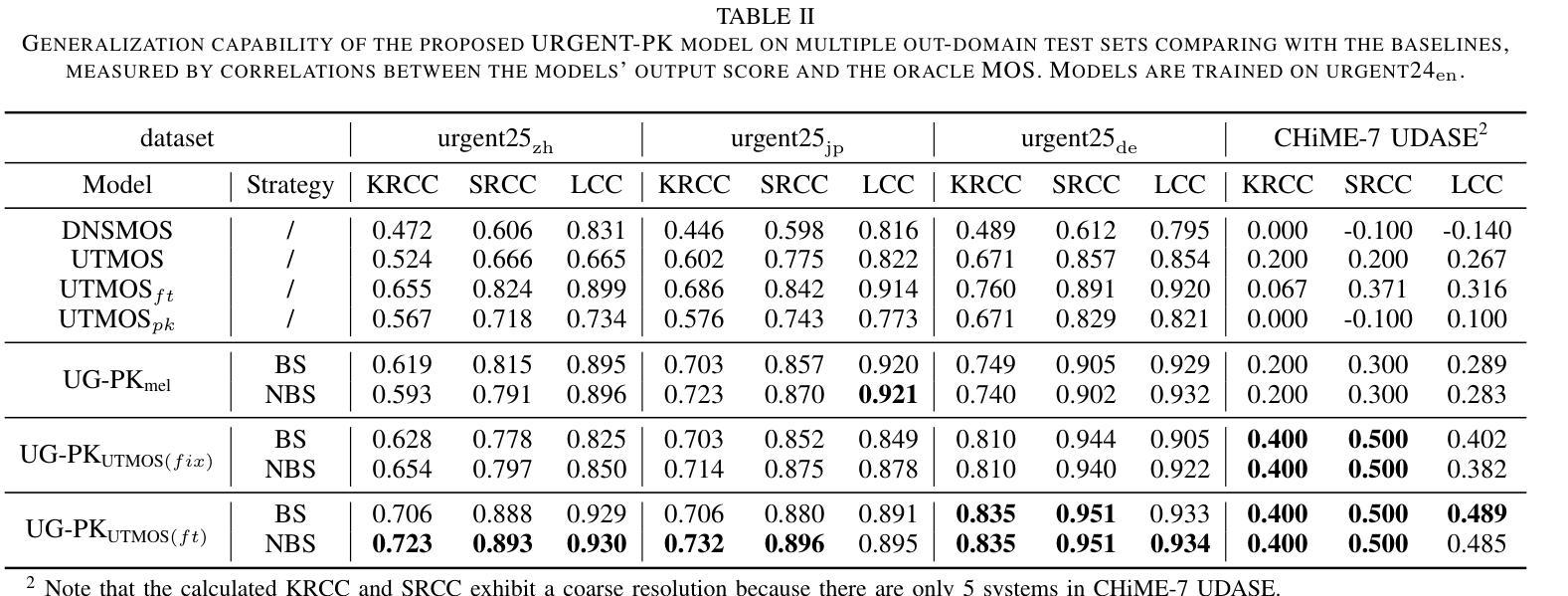
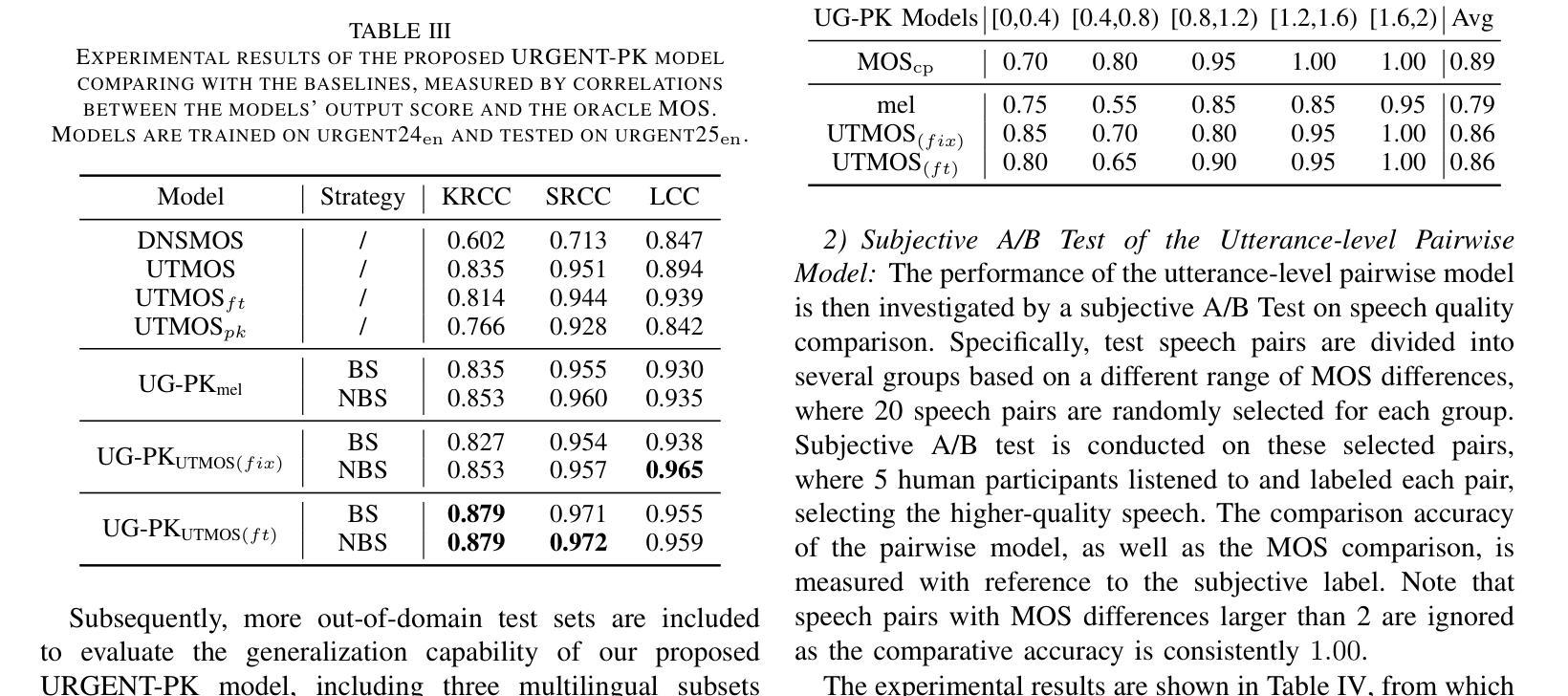
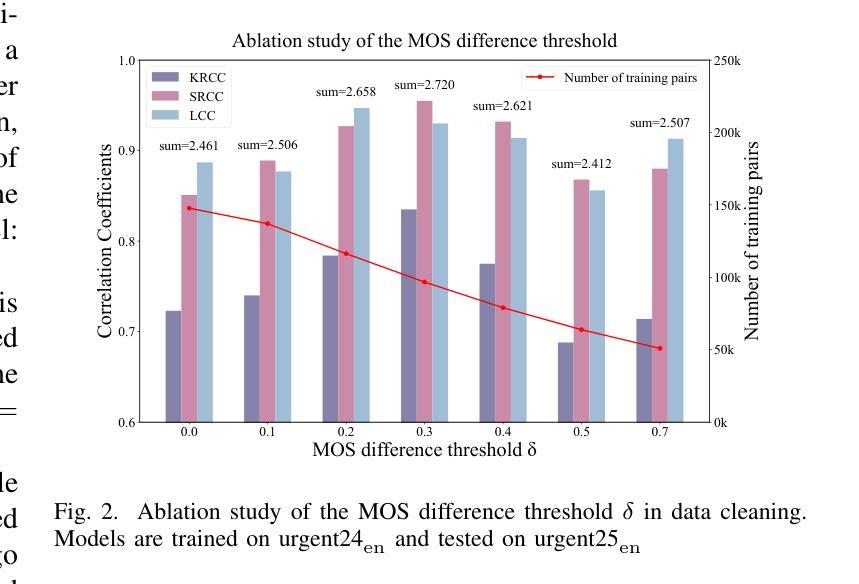
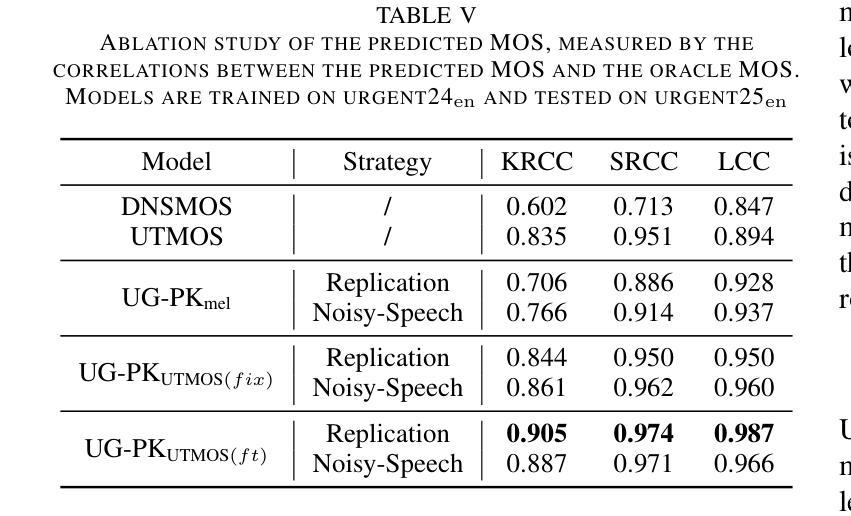
The Mean Opinion Score (MOS) is fundamental to speech quality assessment. However, its acquisition requires significant human annotation. Although deep neural network approaches, such as DNSMOS and UTMOS, have been developed to predict MOS to avoid this issue, they often suffer from insufficient training data. Recognizing that the comparison of speech enhancement (SE) systems prioritizes a reliable system comparison over absolute scores, we propose URGENT-PK, a novel ranking approach leveraging pairwise comparisons. URGENT-PK takes homologous enhanced speech pairs as input to predict relative quality rankings. This pairwise paradigm efficiently utilizes limited training data, as all pairwise permutations of multiple systems constitute a training instance. Experiments across multiple open test sets demonstrate URGENT-PK’s superior system-level ranking performance over state-of-the-art baselines, despite its simple network architecture and limited training data.
平均意见得分(MOS)在语音质量评估中具有重要作用。然而,它的获取需要大量的人工标注。尽管已经开发出深度神经网络方法(如DNSMOS和UTMOS)来预测MOS以避免这个问题,但它们通常因为训练数据不足而受到影响。考虑到语音增强(SE)系统的比较更加重视系统之间的可靠对比而非绝对分数,我们提出了URGENT-PK,这是一种利用配对比较的新型排名方法。URGENT-PK以同源增强语音对作为输入来预测相对质量排名。这种配对模式有效地利用了有限的训练数据,因为多个系统的所有配对组合构成一个训练实例。在多个公开测试集上的实验表明,尽管URGEANT-PK的网络结构简单,训练数据有限,但其系统级排名性能优于最新基线。
论文及项目相关链接
PDF Submitted to ASRU2025
Summary:针对语音质量评估中的均值意见得分(MOS)获取需要大量人工标注的问题,提出了URGE-PK方法。该方法采用配对比较的方式,以同源增强语音对为输入预测相对质量排名,有效利用了有限的训练数据。实验表明,尽管网络架构简单且训练数据量有限,但URGE-PK在系统级别排名性能上优于现有基线方法。
Key Takeaways:
- 均值意见得分(MOS)在语音质量评估中至关重要,但其获取需要大量人工标注。
- 深度神经网络方法如DNSMOS和UTMOS被用来预测MOS,但仍存在训练数据不足的问题。
- 提出了URGE-PK方法,采用配对比较的方式预测相对质量排名,以缓解训练数据不足的问题。
- URGENT-PK方法以同源增强语音对为输入,充分利用了有限的训练数据。
- URGENT-PK方法在系统级别排名性能上优于现有基线方法。
- URGENT-PK方法的网络架构相对简单。
点此查看论文截图


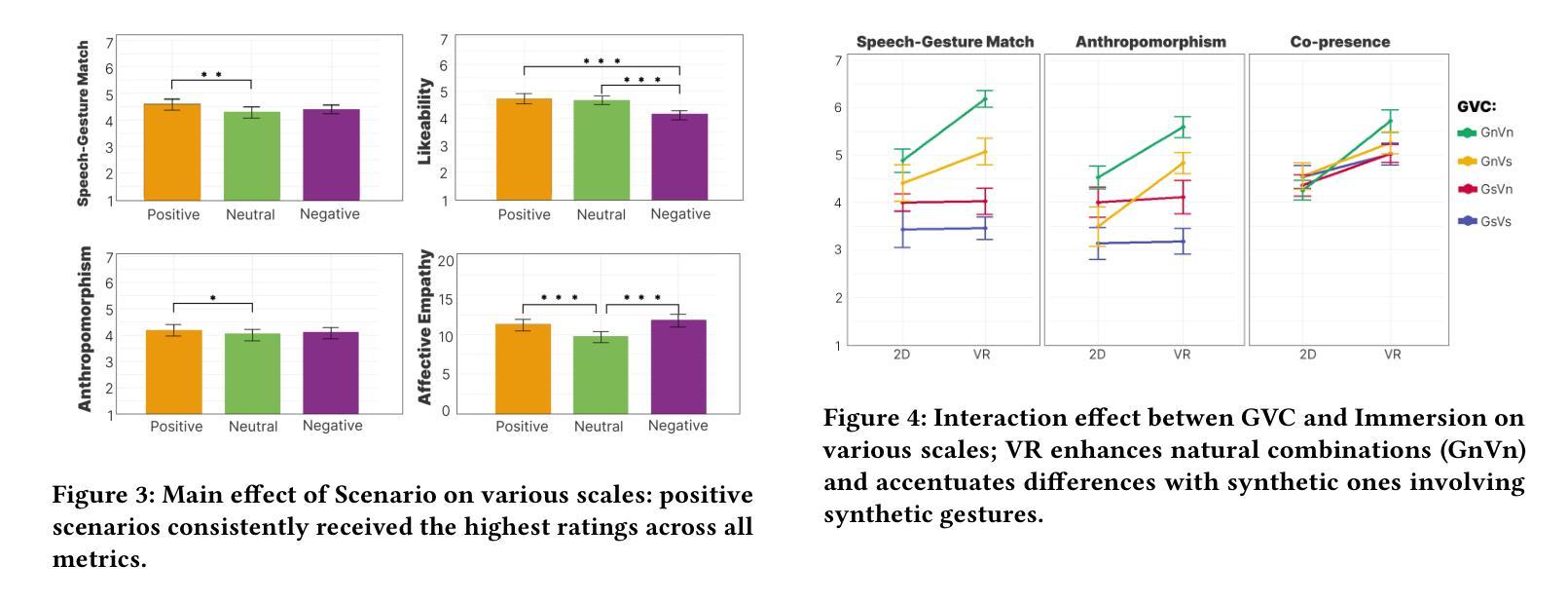
Synthetically Expressive: Evaluating gesture and voice for emotion and empathy in VR and 2D scenarios
Authors:Haoyang Du, Kiran Chhatre, Christopher Peters, Brian Keegan, Rachel McDonnell, Cathy Ennis
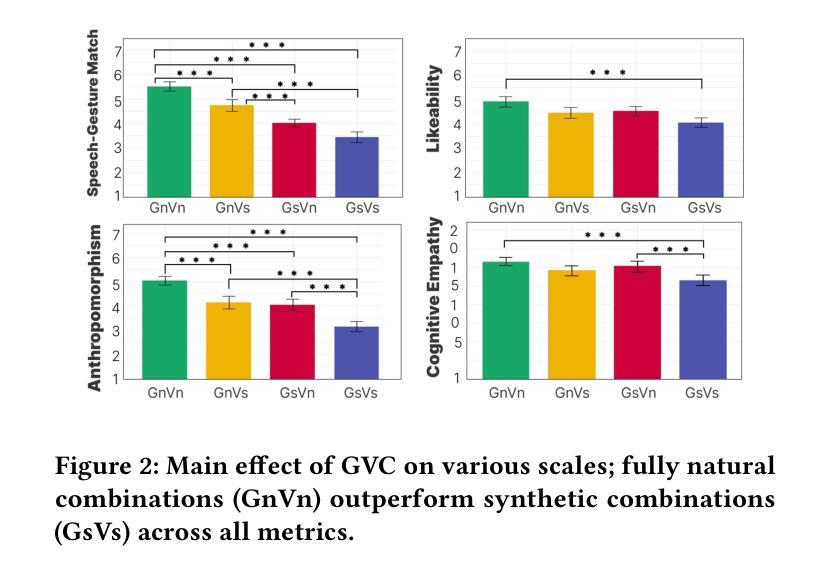
The creation of virtual humans increasingly leverages automated synthesis of speech and gestures, enabling expressive, adaptable agents that effectively engage users. However, the independent development of voice and gesture generation technologies, alongside the growing popularity of virtual reality (VR), presents significant questions about the integration of these signals and their ability to convey emotional detail in immersive environments. In this paper, we evaluate the influence of real and synthetic gestures and speech, alongside varying levels of immersion (VR vs. 2D displays) and emotional contexts (positive, neutral, negative) on user perceptions. We investigate how immersion affects the perceived match between gestures and speech and the impact on key aspects of user experience, including emotional and empathetic responses and the sense of co-presence. Our findings indicate that while VR enhances the perception of natural gesture-voice pairings, it does not similarly improve synthetic ones - amplifying the perceptual gap between them. These results highlight the need to reassess gesture appropriateness and refine AI-driven synthesis for immersive environments. Supplementary video: https://youtu.be/WMfjIB1X-dc
随着虚拟人类的创建越来越多地利用自动合成的语音和动作,能够表达情感、适应环境的代理用户得以有效参与。然而,语音和动作生成技术的独立发展,以及虚拟现实(VR)的日益普及,提出了关于这些信号的集成及其在沉浸式环境中传达情感细节的能力的重大问题。在本文中,我们评估了真实和合成的动作与语音的影响,以及不同层次的沉浸感(虚拟现实与二维显示器)和情感背景(积极、中立、消极)对用户感知的影响。我们研究了沉浸感如何影响动作与语音之间的感知匹配以及用户体验的关键方面,包括情感和共情反应以及共同存在的意识。我们的研究结果表明,虽然虚拟现实增强了自然动作-语音配对的感知,但它并没有对合成动作和语音的感知产生同样的影响,这加大了两者之间的感知差距。这些结果强调需要重估动作的适宜性并完善沉浸式环境中的AI驱动合成。补充视频:https://youtu.be/WMfjIB1X-dc。
论文及项目相关链接
总结
随着虚拟人类的创建越来越多地利用自动合成的语音和动作,表达力强、可适应的代理能够更有效地与用户进行交互。然而,语音和动作生成技术的独立发展以及虚拟现实(VR)的日益普及,提出了关于这些信号的集成及其在沉浸式环境中传达情感细节的能力的重大问题。本文评估了真实和合成动作与语音的影响,以及不同水平的沉浸式(虚拟现实与二维显示器)和情感背景(积极、中立、消极)对用户感知的影响。我们研究了沉浸感如何影响动作与语音之间感知的匹配程度以及对用户体验的关键方面的影响,包括情感和同理响应以及共同在场感。研究发现,虽然虚拟现实增强了自然动作-语音配对的感知,但它并没有同样地改善合成的感知——放大了它们之间的感知差距。这些结果强调了需要重新评估动作适当性以及改进沉浸式环境中AI驱动合成的必要性。
关键见解
- 虚拟人类的创建越来越多地依赖自动合成的语音和动作,以创造表达性强、可适应的代理。
- 虚拟现实(VR)增强了自然动作和语音配对的感知,但对合成的配对改善不明显。
- 沉浸感和情感背景对用户体验有重要影响,包括情感和同理心反应以及共同在场感。
- 用户在沉浸式环境中对虚拟人类的期望更高,需要更真实的动作和语音合成来满足这些期望。
- 虚拟现实放大了合成语音和动作之间的感知差距。
- 需要重新评估动作的适当性,特别是在沉浸式环境中。
点此查看论文截图

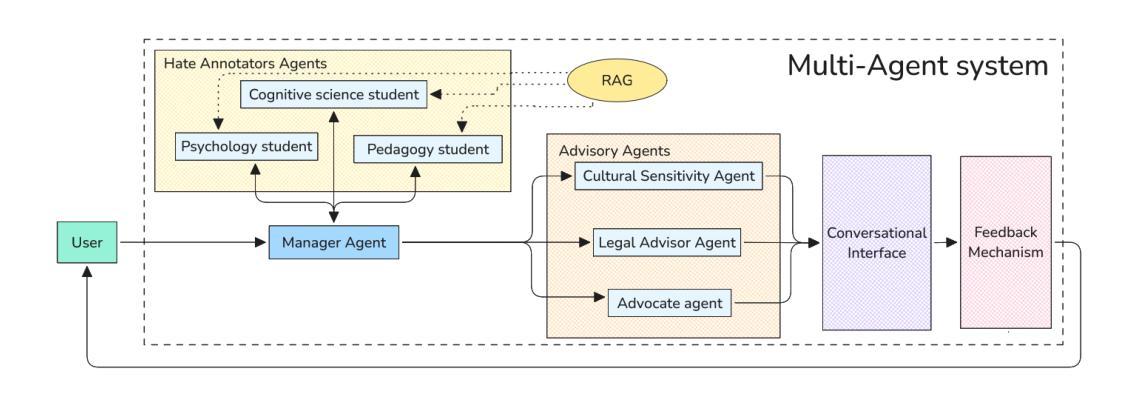
Leveraging a Multi-Agent LLM-Based System to Educate Teachers in Hate Incidents Management
Authors:Ewelina Gajewska, Michal Wawer, Katarzyna Budzynska, Jarosław A. Chudziak
Computer-aided teacher training is a state-of-the-art method designed to enhance teachers’ professional skills effectively while minimising concerns related to costs, time constraints, and geographical limitations. We investigate the potential of large language models (LLMs) in teacher education, using a case of teaching hate incidents management in schools. To this end, we create a multi-agent LLM-based system that mimics realistic situations of hate, using a combination of retrieval-augmented prompting and persona modelling. It is designed to identify and analyse hate speech patterns, predict potential escalation, and propose effective intervention strategies. By integrating persona modelling with agentic LLMs, we create contextually diverse simulations of hate incidents, mimicking real-life situations. The system allows teachers to analyse and understand the dynamics of hate incidents in a safe and controlled environment, providing valuable insights and practical knowledge to manage such situations confidently in real life. Our pilot evaluation demonstrates teachers’ enhanced understanding of the nature of annotator disagreements and the role of context in hate speech interpretation, leading to the development of more informed and effective strategies for addressing hate in classroom settings.
计算机辅助教师培训是一种先进的方法,旨在有效增强教师的专业技能,同时最小化与成本、时间限制和地理限制相关的担忧。我们调查大型语言模型(LLM)在教师教育中的潜力,以学校仇恨事件管理教学为例。为此,我们创建了一个基于多代理的LLM系统,通过结合检索增强提示和人格建模,模拟仇恨的现实情境。它被设计用来识别和分析仇恨言论的模式,预测可能的升级,并提出有效的干预策略。通过人格建模与智能LLM的整合,我们创建了仇恨事件的语境多样化模拟,模拟现实生活中的情境。该系统允许教师在安全可控的环境中分析仇恨事件的动力学,从而获得有价值的信息和实用知识,以在现实中自信地管理此类情况。我们的初步评估显示,教师们对注释者分歧的性质以及语境在仇恨言论解释中的作用有了更深的理解,从而开发出更明智、更有效的解决课堂仇恨问题的策略。
论文及项目相关链接
PDF 8 pages, 1 figure
Summary
计算机辅助教学培训是一种先进的方法,旨在有效地提高教师的专业技能,同时最小化成本、时间限制和地理限制相关的担忧。本研究探讨了大型语言模型在教师教育的潜力,以校园仇恨事件管理为例。为此,我们开发了一个基于多智能体的大型语言模型系统,该系统模拟仇恨的真实场景,结合检索增强提示和个性化建模。它旨在识别和分析仇恨言论模式,预测可能的升级,并提出有效的干预策略。通过整合个性化建模与智能体大型语言模型,我们创建了仇恨事件的上下文丰富模拟,模拟真实场景。该系统允许教师在安全和受控的环境中分析仇恨事件的动态,提供宝贵的见解和实用知识,帮助教师更自信地处理真实场景中的此类情况。初步评估显示,教师增强了对标注器分歧的理解和仇恨言论解读中的上下文角色,从而发展出更明智、更有效的应对课堂仇恨的策略。
Key Takeaways
- 计算机辅助教学培训旨在提高教师的专业技能,同时考虑成本、时间和地理限制。
- 大型语言模型在教师教育中具有潜力,可用于模拟真实的仇恨事件场景。
- 基于多智能体的大型语言模型系统可识别和分析仇恨言论模式。
- 该系统可以预测仇恨事件的潜在升级,并提出有效的干预策略。
- 通过结合个性化建模和智能体大型语言模型,创建了仇恨事件的上下文丰富模拟。
- 教师通过该系统获得对仇恨事件动态的分析和宝贵见解。
点此查看论文截图

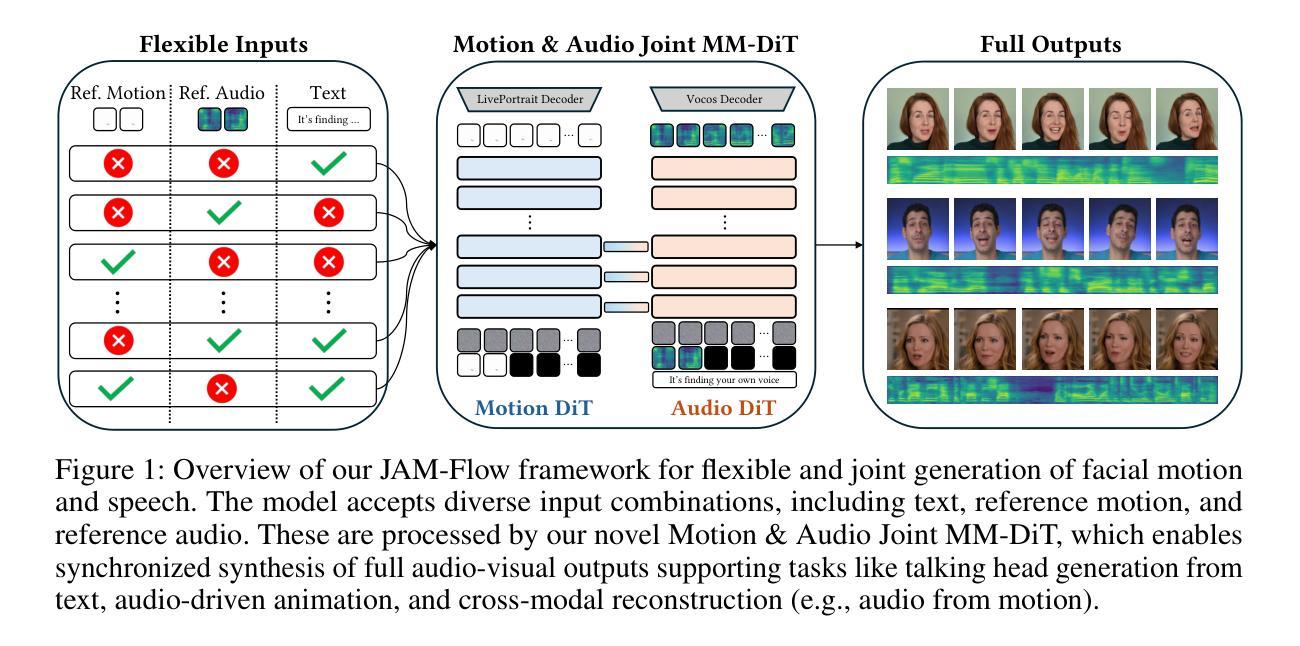
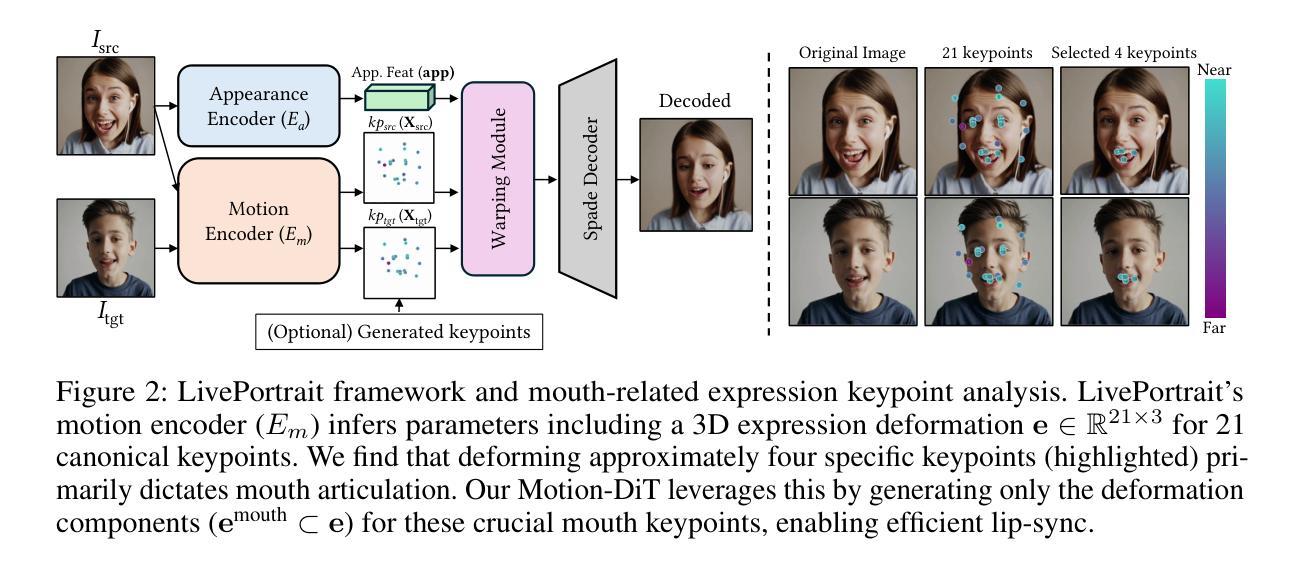
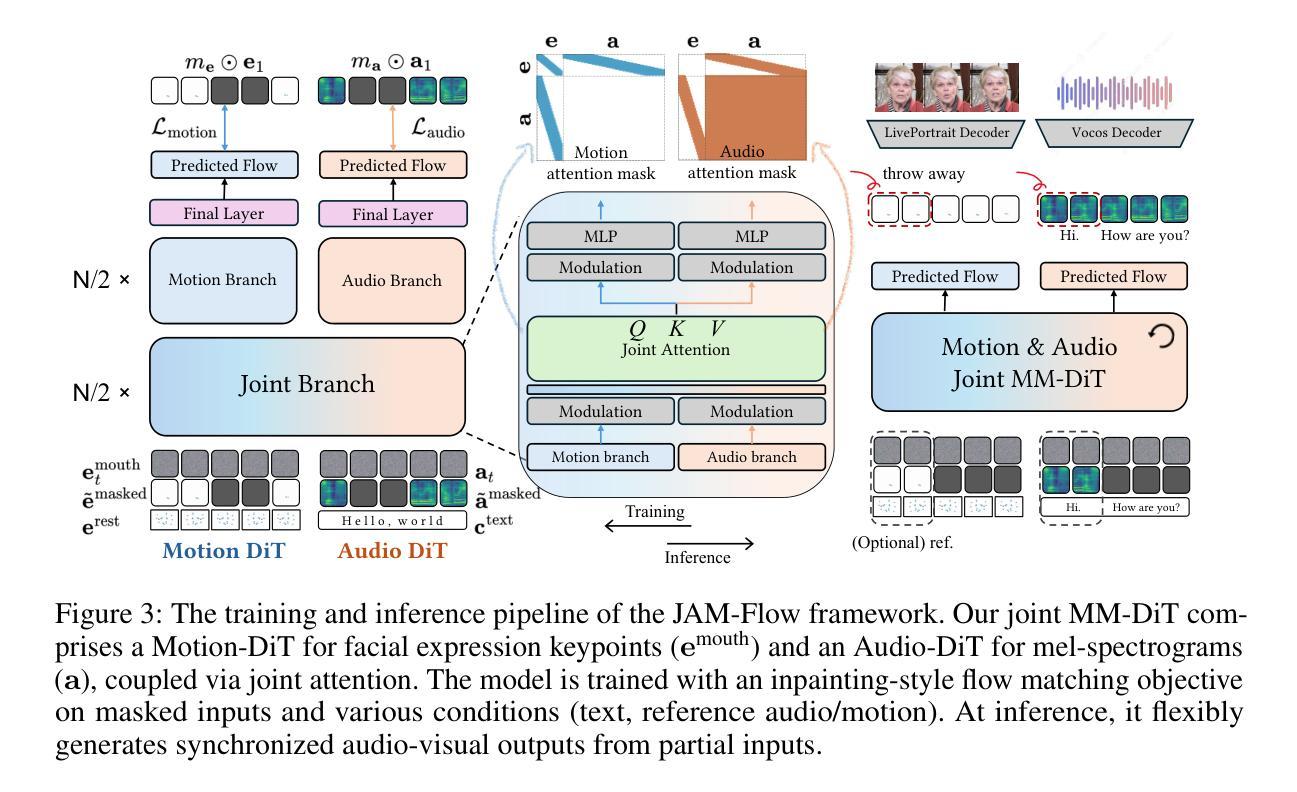
JAM-Flow: Joint Audio-Motion Synthesis with Flow Matching
Authors:Mingi Kwon, Joonghyuk Shin, Jaeseok Jung, Jaesik Park, Youngjung Uh
The intrinsic link between facial motion and speech is often overlooked in generative modeling, where talking head synthesis and text-to-speech (TTS) are typically addressed as separate tasks. This paper introduces JAM-Flow, a unified framework to simultaneously synthesize and condition on both facial motion and speech. Our approach leverages flow matching and a novel Multi-Modal Diffusion Transformer (MM-DiT) architecture, integrating specialized Motion-DiT and Audio-DiT modules. These are coupled via selective joint attention layers and incorporate key architectural choices, such as temporally aligned positional embeddings and localized joint attention masking, to enable effective cross-modal interaction while preserving modality-specific strengths. Trained with an inpainting-style objective, JAM-Flow supports a wide array of conditioning inputs-including text, reference audio, and reference motion-facilitating tasks such as synchronized talking head generation from text, audio-driven animation, and much more, within a single, coherent model. JAM-Flow significantly advances multi-modal generative modeling by providing a practical solution for holistic audio-visual synthesis. project page: https://joonghyuk.com/jamflow-web
面部动作与语音之间的内在联系在生成模型中经常被忽视,生成模型中通常将头部动作合成和文本到语音(TTS)视为单独的任务。本文介绍了JAM-Flow,这是一个统一框架,可以同时合成和基于面部动作和语音的条件进行预测。我们的方法利用流匹配和新型的多模态扩散转换器(MM-DiT)架构,集成了专业化的运动-DiT和音频-DiT模块。这些模块通过选择性联合注意力层进行耦合,并采用了关键架构选择,如时间对齐的位置嵌入和局部联合注意力掩码,以实现有效的跨模态交互同时保持模态特定的优势。使用填充风格的目标进行训练,JAM-Flow支持广泛的条件输入,包括文本、参考音频和参考动作,促进如从文本同步生成说话头部、音频驱动动画等任务,在一个单一、连贯的模型中实现更多功能。JAM-Flow通过为整体音频视觉合成提供实用解决方案,显著推动了多模态生成模型的发展。项目页面:https://joonghyuk.com/jamflow-web 。
论文及项目相关链接
PDF project page: https://joonghyuk.com/jamflow-web Under review. Preprint published on arXiv
摘要
本文介绍了JAM-Flow框架,该框架旨在同时合成并处理面部动作和语音,弥补生成模型中常被忽视的面部动作与语音的内在联系。通过采用流匹配技术和新型多模态扩散转换器(MM-DiT)架构,JAM-Flow融合了Motion-DiT和Audio-DiT模块。借助选择性联合注意层,实现在保留各模态特性的同时,进行有效跨模态交互。通过采用inpainting风格的目标进行训练,JAM-Flow支持多种条件输入,包括文本、参考音频和参考动作,可完成从文本生成同步讲话视频、音频驱动动画等任务。JAM-Flow为音频视觉合成提供了实用解决方案,显著推动了多模态生成模型的发展。
关键见解
- 强调面部动作与语音在生成模型中的内在联系,并提出JAM-Flow框架同时合成和处理两者。
- 引入流匹配技术和Multi-Modal Diffusion Transformer(MM-DiT)架构。
- MM-DiT架构融合了Motion-DiT和Audio-DiT模块。
- 通过选择性联合注意层实现跨模态交互。
- 模型保留了模态特异性,同时通过训练支持多种条件输入,如文本、参考音频和参考动作。
- 支持从文本生成同步讲话视频、音频驱动动画等任务。
点此查看论文截图

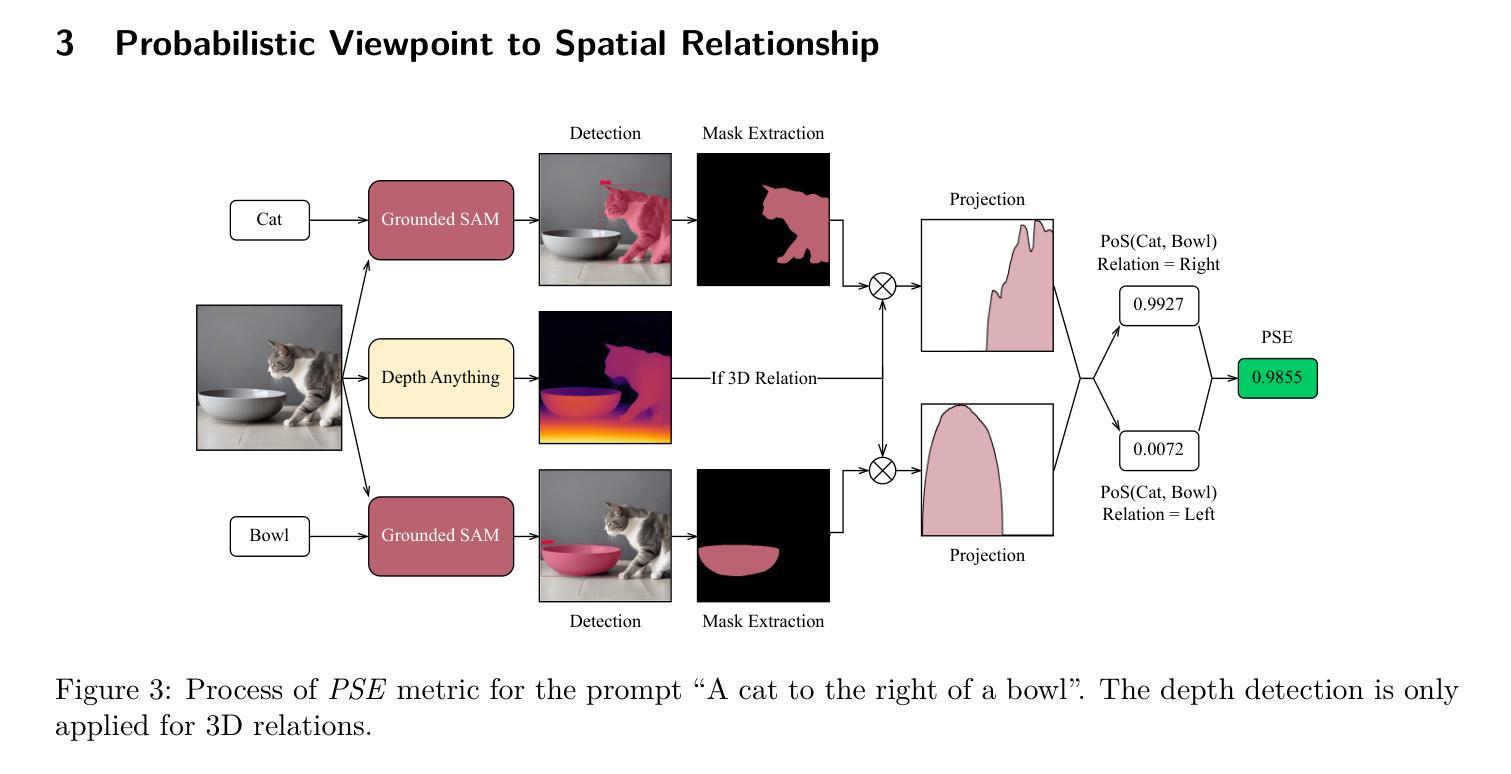
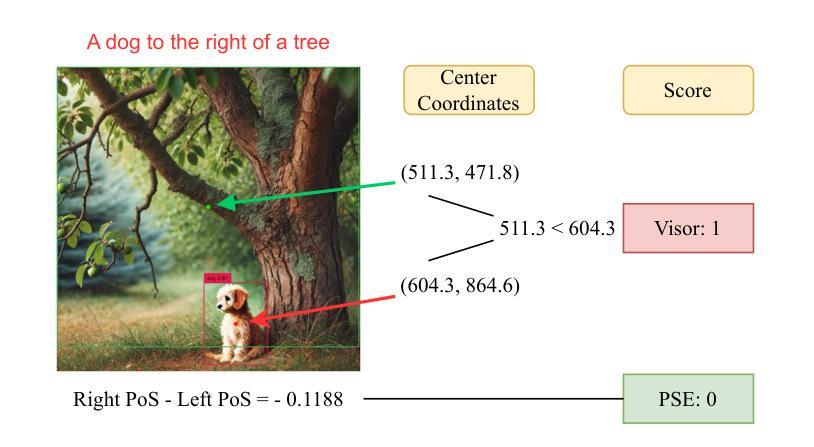
Why Settle for Mid: A Probabilistic Viewpoint to Spatial Relationship Alignment in Text-to-image Models
Authors:Parham Rezaei, Arash Marioriyad, Mahdieh Soleymani Baghshah, Mohammad Hossein Rohban
Despite the ability of text-to-image models to generate high-quality, realistic, and diverse images, they face challenges in compositional generation, often struggling to accurately represent details specified in the input prompt. A prevalent issue in compositional generation is the misalignment of spatial relationships, as models often fail to faithfully generate images that reflect the spatial configurations specified between objects in the input prompts. To address this challenge, we propose a novel probabilistic framework for modeling the relative spatial positioning of objects in a scene, leveraging the concept of Probability of Superiority (PoS). Building on this insight, we make two key contributions. First, we introduce a novel evaluation metric, PoS-based Evaluation (PSE), designed to assess the alignment of 2D and 3D spatial relationships between text and image, with improved adherence to human judgment. Second, we propose PoS-based Generation (PSG), an inference-time method that improves the alignment of 2D and 3D spatial relationships in T2I models without requiring fine-tuning. PSG employs a Part-of-Speech PoS-based reward function that can be utilized in two distinct ways: (1) as a gradient-based guidance mechanism applied to the cross-attention maps during the denoising steps, or (2) as a search-based strategy that evaluates a set of initial noise vectors to select the best one. Extensive experiments demonstrate that the PSE metric exhibits stronger alignment with human judgment compared to traditional center-based metrics, providing a more nuanced and reliable measure of complex spatial relationship accuracy in text-image alignment. Furthermore, PSG significantly enhances the ability of text-to-image models to generate images with specified spatial configurations, outperforming state-of-the-art methods across multiple evaluation metrics and benchmarks.
尽管文本到图像模型能够生成高质量、现实化和多样化的图像,但在组合生成方面仍面临挑战,往往难以准确表示输入提示中指定的细节。在组合生成中的一个普遍问题是空间关系的错位,因为模型往往无法忠实地生成反映输入提示中物体之间空间配置的图像。为了应对这一挑战,我们提出了一种新的概率框架,利用优势概率(PoS)的概念来对场景中物体的相对空间位置进行建模。基于这一见解,我们做出了两个关键贡献。首先,我们引入了一种新型评估指标——基于PoS的评估(PSE),旨在评估文本和图像之间二维和三维空间关系的对齐情况,更好地符合人类判断。其次,我们提出了基于PoS的生成(PSG)方法,这是一种推理时间方法,可提高文本到图像模型中二、三维空间关系的对齐程度,无需微调。PSG采用基于词序的PoS奖励函数,可以有两种不同的用途:(1)作为去噪步骤中跨注意力图的基于梯度的引导机制;(2)作为一种基于搜索的策略,评估一组初始噪声向量以选择最佳向量。大量实验表明,与基于中心的传统指标相比,PSE指标与人类判断的对齐程度更高,为文本图像对齐中复杂空间关系的准确性提供了更细致和可靠的衡量标准。此外,PSG显著增强了文本到图像模型生成具有指定空间配置图像的能力,在多个评估指标和基准测试上均优于最先进的方法。
论文及项目相关链接
PDF 12 main pages, 18 figures, and 16 tables
Summary
本文指出文本转图像模型在生成高质量、逼真且多样的图像时面临的挑战,特别是在组合生成方面。模型难以准确表示输入提示中指定的细节,尤其在空间关系的对齐方面存在问题。为此,本文提出一种基于概率的框架,利用优势概率(PoS)来建模场景中对象的相对空间位置。主要贡献包括:引入PoS-based Evaluation(PSE)评估指标,评估文本和图像之间2D和3D空间关系的一致性;提出PoS-based Generation(PSG),是一种无需微调即可提高文本转图像模型空间关系对齐性的推理时间方法。实验表明,PSE指标与人类判断对齐性更强,PSG显著提高了文本转图像模型生成指定空间配置图像的能力,优于多种评价指标和基准测试上的最先进方法。
Key Takeaways
- 文本转图像模型在组合生成方面面临挑战,难以准确表示输入提示中的细节,尤其在空间关系的对齐方面。
- 引入优势概率(PoS)概念,提出一种基于概率的框架来建模场景中对象的相对空间位置。
- 贡献包括PSE评估指标和PSG推理时间方法。PSE评估文本和图像之间空间关系的一致性,与人类判断对齐性更强;PSG提高模型生成指定空间配置图像的能力,性能优于其他方法。
- PSE相较于传统中心基准评估指标,提供更精细和可靠的复杂空间关系准确性的衡量。
- PSG在多个评估指标和基准测试上的表现优于最先进的方法。
- 本文提出的框架和方法为改进文本转图像模型的性能提供了新的思路。
点此查看论文截图



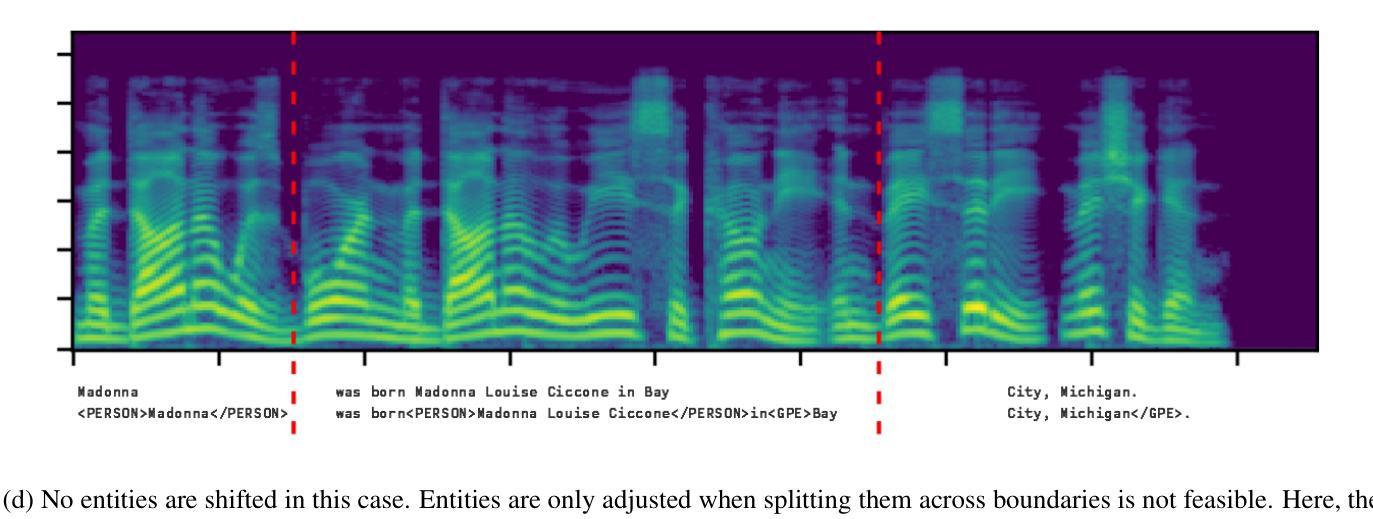
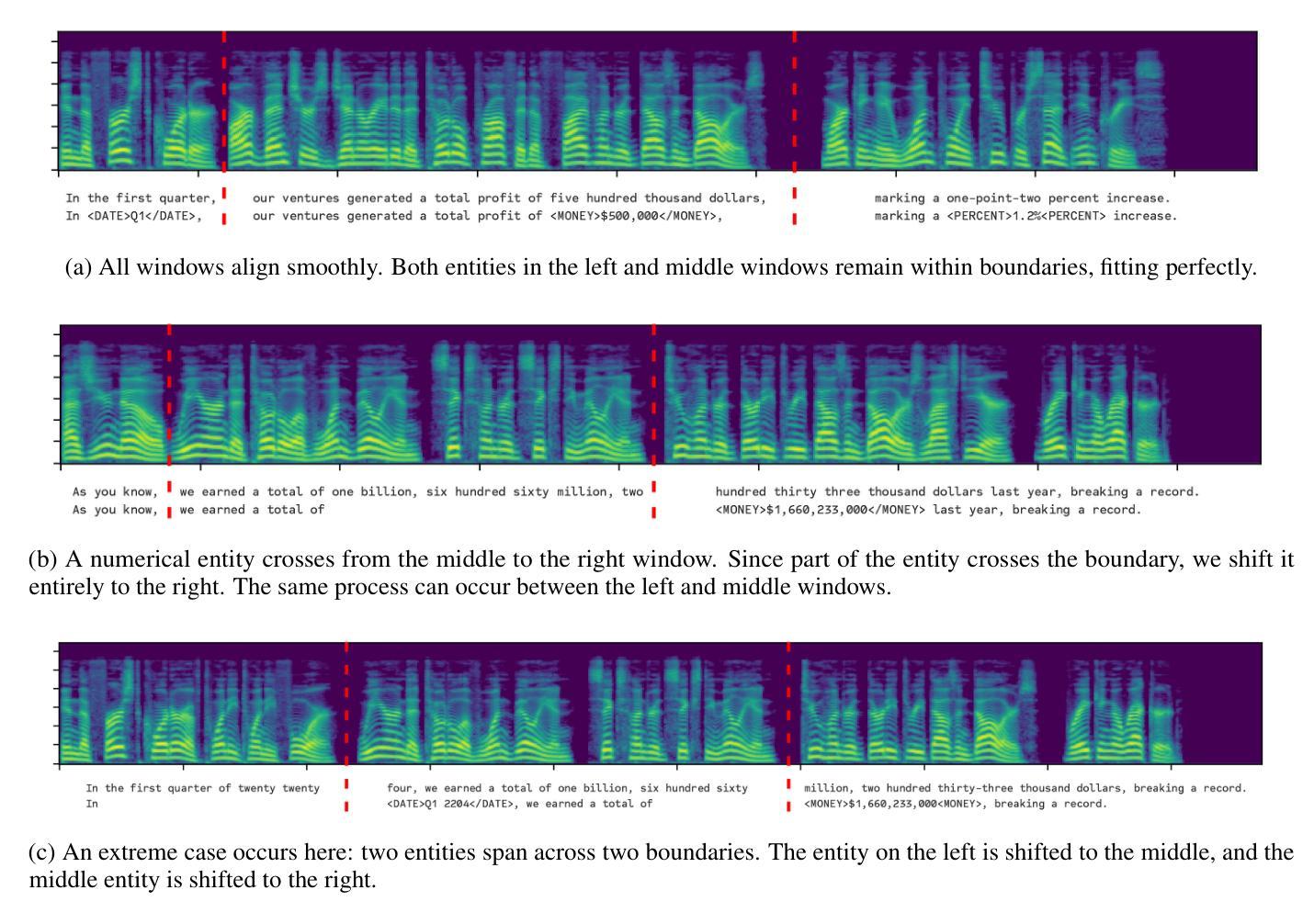
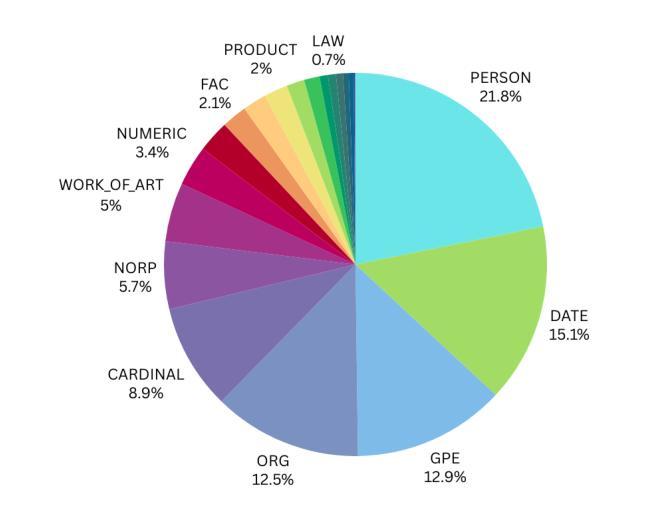
Mind the Gap: Entity-Preserved Context-Aware ASR Structured Transcriptions
Authors:Duygu Altinok
Automatic Speech Recognition (ASR) systems, such as Whisper, achieve high transcription accuracy but struggle with named entities and numerical data, especially when proper formatting is required. These issues increase word error rate (WER) and impair semantic understanding in critical domains like legal, financial, and medical applications. We propose a novel training approach that extends the semantic context of ASR models by adding overlapping context windows during training. By sliding 5-second overlaps on both sides of 30-second chunks, we create a 40-second “effective semantic window,” improving entity recognition and formatting while focusing predictions on the central 30 seconds. To address entities spanning chunk boundaries, we reassign such entities entirely to the right-hand chunk, ensuring proper formatting. Additionally, enriched training data with embedded entity labels enables the model to learn both recognition and type-specific formatting. Evaluated on the Spoken Wikipedia dataset, our method improves performance across semantic tasks, including named entity recognition (NER) and entity formatting. These results highlight the effectiveness of context-aware training in addressing ASR limitations for long-form transcription and complex entity recognition tasks.
自动语音识别(ASR)系统,如Whisper,在转录方面达到了较高的准确性,但在处理命名实体和数值数据时遇到了困难,尤其是在需要正确格式的情况下。这些问题增加了单词错误率(WER),并在法律、金融和医疗等关键领域损害了语义理解。我们提出了一种新的训练方法来扩展ASR模型的语义上下文,通过在训练过程中添加重叠的上下文窗口来实现。通过在30秒片段的两侧滑动5秒重叠窗口,我们创建了一个40秒的“有效语义窗口”,这改善了实体识别和格式化,同时将预测重点放在中央的30秒上。为了解决跨越片段边界的实体问题,我们将此类实体完全重新分配给右手片段,以确保正确的格式。此外,使用嵌入实体标签的丰富训练数据使模型能够学习识别和类型特定的格式化。在Spoken Wikipedia数据集上进行的评估表明,我们的方法在包括命名实体识别(NER)和实体格式化等语义任务上的性能得到了提高。这些结果突出了上下文感知训练在解决长形式转录和复杂实体识别任务的ASR局限性方面的有效性。
论文及项目相关链接
PDF This is the accepted version of an article accepted to the TSD 2025 conference, published in Springer Lecture Notes in Artificial Intelligence (LNAI). The final authenticated version is available online at SpringerLink
Summary
本文介绍了自动语音识别(ASR)系统在处理命名实体和数值数据时面临的挑战,特别是在需要正确格式化的场景中。为解决这些问题,提出了一种新的训练方法来扩展ASR模型的语义上下文。通过添加重叠的上下文窗口进行训练,创建了一个有效的语义窗口,提高了实体识别和格式化的性能。同时,使用带有嵌入实体标签的丰富训练数据,使模型能够学习识别和类型特定的格式化。评估结果表明,该方法在语义任务上的性能有所提高。
Key Takeaways
- ASR系统在处理命名实体和数值数据时存在挑战,特别是在需要正确格式化的领域。
- 新的训练方法通过添加重叠的上下文窗口来扩展ASR模型的语义上下文。
- 创建一个有效的语义窗口,可以提高实体识别和格式化的性能。
- 通过将实体重新分配给右手块来解决跨越块边界的实体问题,确保正确的格式化。
- 丰富的训练数据带有嵌入的实体标签,使模型能够学习识别和类型特定的格式化。
- 评估结果表明,该方法在语义任务上的性能有所提高,包括命名实体识别和实体格式化。
点此查看论文截图


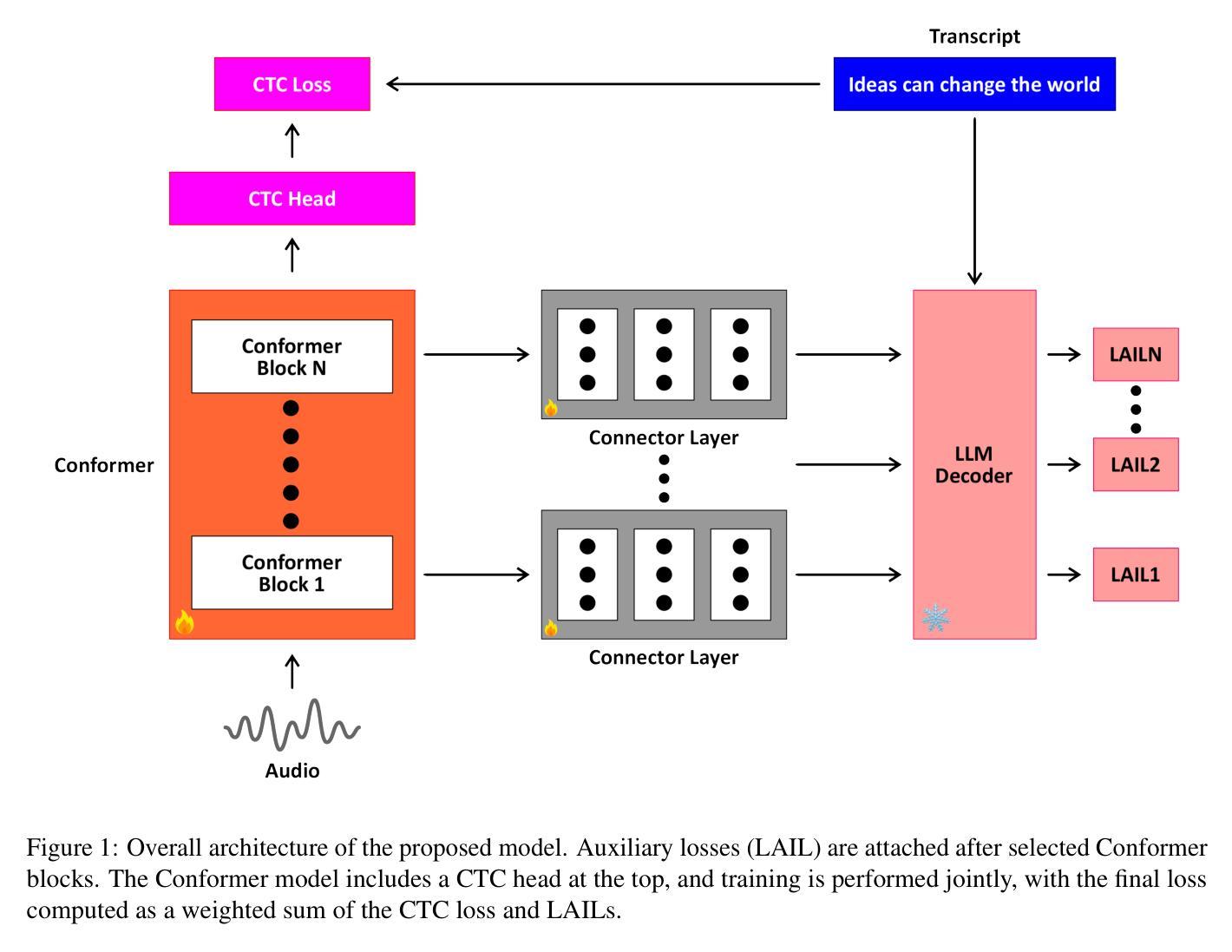
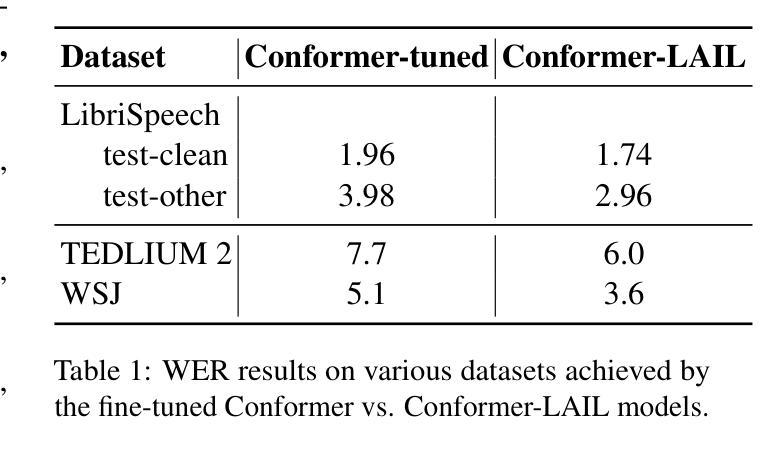
Boosting CTC-Based ASR Using LLM-Based Intermediate Loss Regularization
Authors:Duygu Altinok
End-to-end (E2E) automatic speech recognition (ASR) systems have revolutionized the field by integrating all components into a single neural network, with attention-based encoder-decoder models achieving state-of-the-art performance. However, their autoregressive decoding process limits inference speed, making them unsuitable for real-time applications. In contrast, CTC-based models offer faster, non-autoregressive decoding but struggle to model linguistic dependencies effectively. Addressing this challenge, we propose a novel auxiliary loss framework called Language-Aware Intermediate Loss (LAIL) to enhance CTC-based ASR using the linguistic knowledge of large language models (LLMs). By attaching connector layers to intermediate encoder layers, LAIL maps outputs to the embedding space of an LLM and computes a causal language modeling loss during training. This approach enhances linguistic modeling while preserving the computational efficiency of CTC decoding. Using the Conformer architecture and various LLaMA models, we demonstrate significant improvements in Word Error Rate (WER) on the LibriSpeech, TEDLIUM2, and WSJ corpora, achieving state-of-the-art performance for CTC-based ASR with minimal computational overhead.
端到端(E2E)自动语音识别(ASR)系统通过将所有组件集成到一个单一神经网络中,从而实现了领域的革命性变革,基于注意力的编码器-解码器模型取得了最先进的性能。然而,它们的自回归解码过程限制了推理速度,使其不适合实时应用。相比之下,CTC(连接时序分类)模型提供更快的非自回归解码,但在有效建模语言依赖性方面却存在困难。为了解决这一挑战,我们提出了一种名为语言感知中间损失(LAIL)的新型辅助损失框架,利用大型语言模型(LLM)的语言知识增强基于CTC的ASR。通过将连接器层附加到中间编码器层,LAIL将输出映射到LLM的嵌入空间,并在训练过程中计算因果语言建模损失。这种方法在增强语言建模的同时,保持了CTC解码的计算效率。通过使用Conformer架构和各种LLaMA模型,我们在LibriSpeech、TEDLIUM2和WSJ语料库上显著降低了词错误率(WER),在CTC-based ASR中实现了最先进的技术性能,且计算开销最小。
论文及项目相关链接
PDF This is the accepted version of an article accepted to the TSD 2025 conference, published in Springer Lecture Notes in Artificial Intelligence (LNAI). The final authenticated version is available online at SpringerLink
Summary:
端到端的自动语音识别(ASR)系统通过整合所有组件到一个单一神经网络中实现了领域的革新,其中基于注意力机制的编码器-解码器模型取得了最先进的性能。然而,它们的自回归解码过程限制了推理速度,不适合实时应用。为解决此问题,我们提出了一种名为语言感知中间损失(LAIL)的新型辅助损失框架,利用大型语言模型(LLM)的语言知识增强CTC-based ASR。LAIL通过在中间编码器层添加连接器层,将输出映射到LLM的嵌入空间,并在训练过程中计算因果语言建模损失。此方法在增强语言建模的同时,保持了CTC解码的计算效率。通过使用Conformer架构和多种LLaMA模型,我们在LibriSpeech、TEDLIUM2和WSJ语料库上显著降低了词错误率(WER),实现了CTC-based ASR的先进性能,且计算开销最小。
Key Takeaways:
- 端到端的自动语音识别(ASR)系统通过整合神经网络组件实现了突破。
- 基于注意力机制的编码器-解码器模型取得最先进的ASR性能。
- 自回归解码过程限制了ASR系统的推理速度,不适合实时应用。
- 提出了语言感知中间损失(LAIL)框架,结合大型语言模型(LLM)增强CTC-based ASR。
- LAIL通过映射输出到LLM嵌入空间并计算因果语言建模损失,增强语言建模并保留CTC解码的计算效率。
- 使用Conformer架构和LLaMA模型在多个语料库上实现了显著的性能提升。
点此查看论文截图

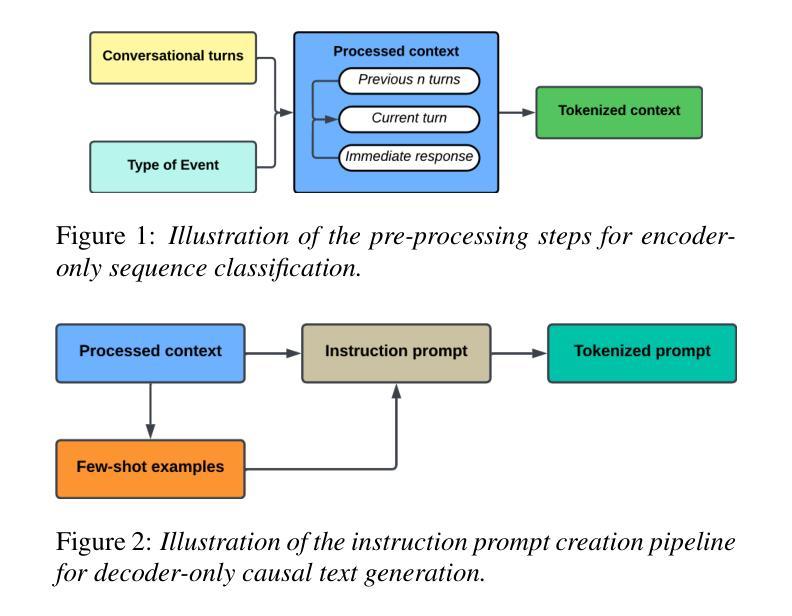
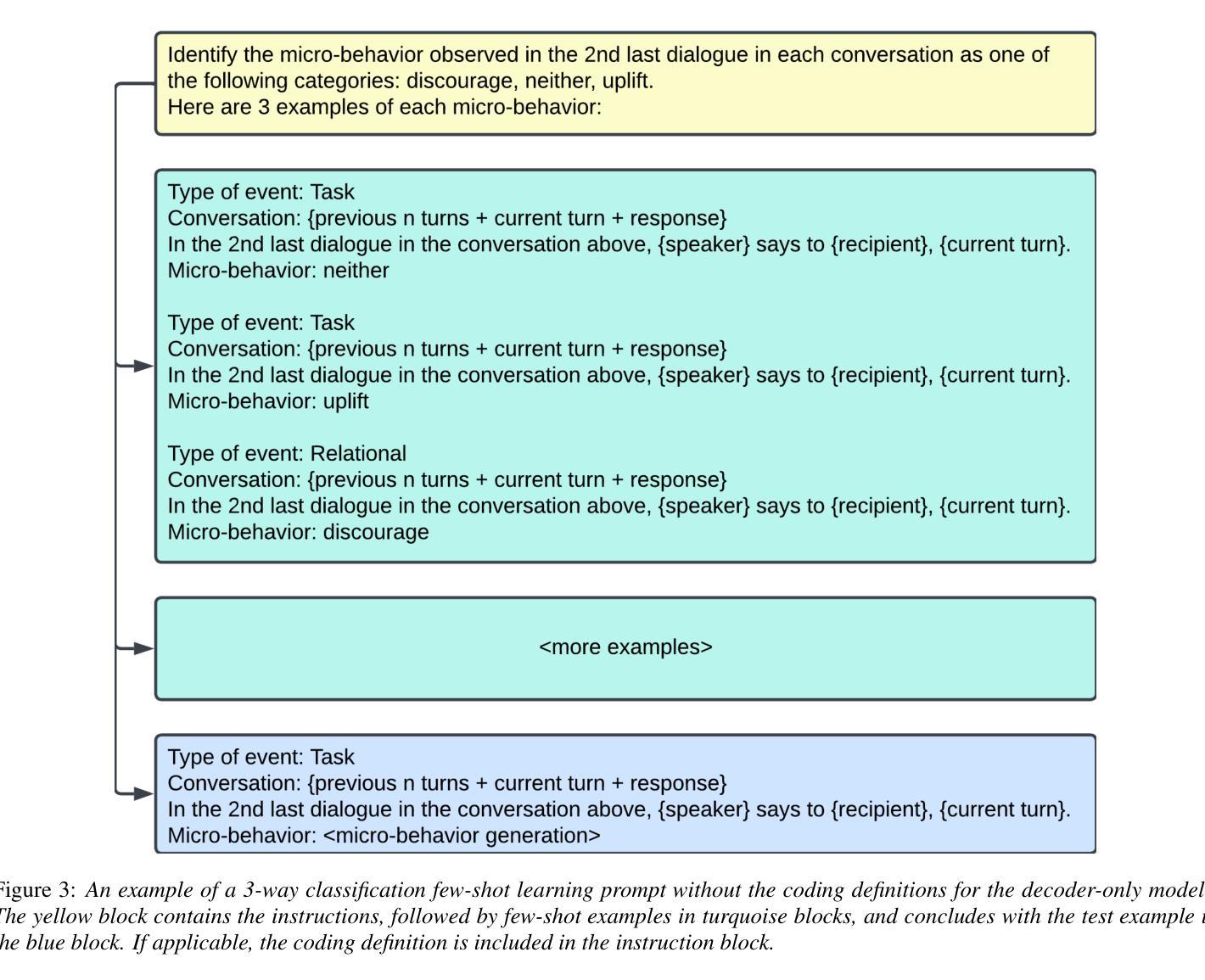
Assessing the feasibility of Large Language Models for detecting micro-behaviors in team interactions during space missions
Authors:Ankush Raut, Projna Paromita, Sydney Begerowski, Suzanne Bell, Theodora Chaspari
We explore the feasibility of large language models (LLMs) in detecting subtle expressions of micro-behaviors in team conversations using transcripts collected during simulated space missions. Specifically, we examine zero-shot classification, fine-tuning, and paraphrase-augmented fine-tuning with encoder-only sequence classification LLMs, as well as few-shot text generation with decoder-only causal language modeling LLMs, to predict the micro-behavior associated with each conversational turn (i.e., dialogue). Our findings indicate that encoder-only LLMs, such as RoBERTa and DistilBERT, struggled to detect underrepresented micro-behaviors, particularly discouraging speech, even with weighted fine-tuning. In contrast, the instruction fine-tuned version of Llama-3.1, a decoder-only LLM, demonstrated superior performance, with the best models achieving macro F1-scores of 44% for 3-way classification and 68% for binary classification. These results have implications for the development of speech technologies aimed at analyzing team communication dynamics and enhancing training interventions in high-stakes environments such as space missions, particularly in scenarios where text is the only accessible data.
我们探索大型语言模型(LLM)在检测团队会话中的微妙微观行为表达方面的可行性,使用的是在模拟太空任务期间收集的转录内容。具体来说,我们研究了零样本分类、微调以及利用编码器序列分类LLM的改写增强微调技术,以及利用解码器因果语言建模LLM的少量文本生成技术,以预测与每个会话回合(即对话)相关的微观行为。我们的研究结果表明,如RoBERTa和DistilBERT等仅使用编码器的LLM在检测表现不足的微观行为方面存在困难,尤其是劝阻性言语,即使使用加权微调也无济于事。相比之下,指令微调版本的Llama-3.1(一种仅使用解码器的LLM)表现出了卓越的性能,最佳模型的3分类宏观F1分数达到44%,二元分类达到68%。这些结果对于开发旨在分析团队沟通动态的语音技术,以及在太空任务等高风险环境中增强训练干预措施具有启示意义,特别是在只能访问文本数据的场景中。
论文及项目相关链接
PDF 5 pages, 4 figures. Accepted to Interspeech 2025
Summary
大型语言模型(LLM)在检测团队会话中的微妙表达与微行为方面的可行性研究。通过模拟太空任务期间收集的转录本,探索了零样本分类、微调、基于变体的微调与仅编码器序列分类LLM,以及仅解码器因果语言建模LLM的少量文本生成,以预测每个会话回合相关的微行为。研究发现,编码器LLM(如RoBERTa和DistilBERT)在检测低表达的微行为方面存在困难,而指令微调版的Llama-3.1表现优越,最佳模型的三类分类宏观F1分数为44%,二元分类为68%。这对开发分析团队沟通动态和提升太空任务等高压力环境下的训练干预的语音技术具有重要意义,尤其在只能获取文本数据的情况下。
Key Takeaways
- 大型语言模型(LLM)可用于检测团队会话中的微妙表达和微行为。
- 通过模拟太空任务转录本进行研究。
- 尝试了零样本分类、微调及基于变体的微调等多种方法。
- 编码器LLM在检测低表达的微行为方面存在困难。
- 指令微调版的解码器LLM(如Llama-3.1)表现优越。
- 最佳模型的宏观F1分数:三类分类为44%,二元分类为68%。
点此查看论文截图

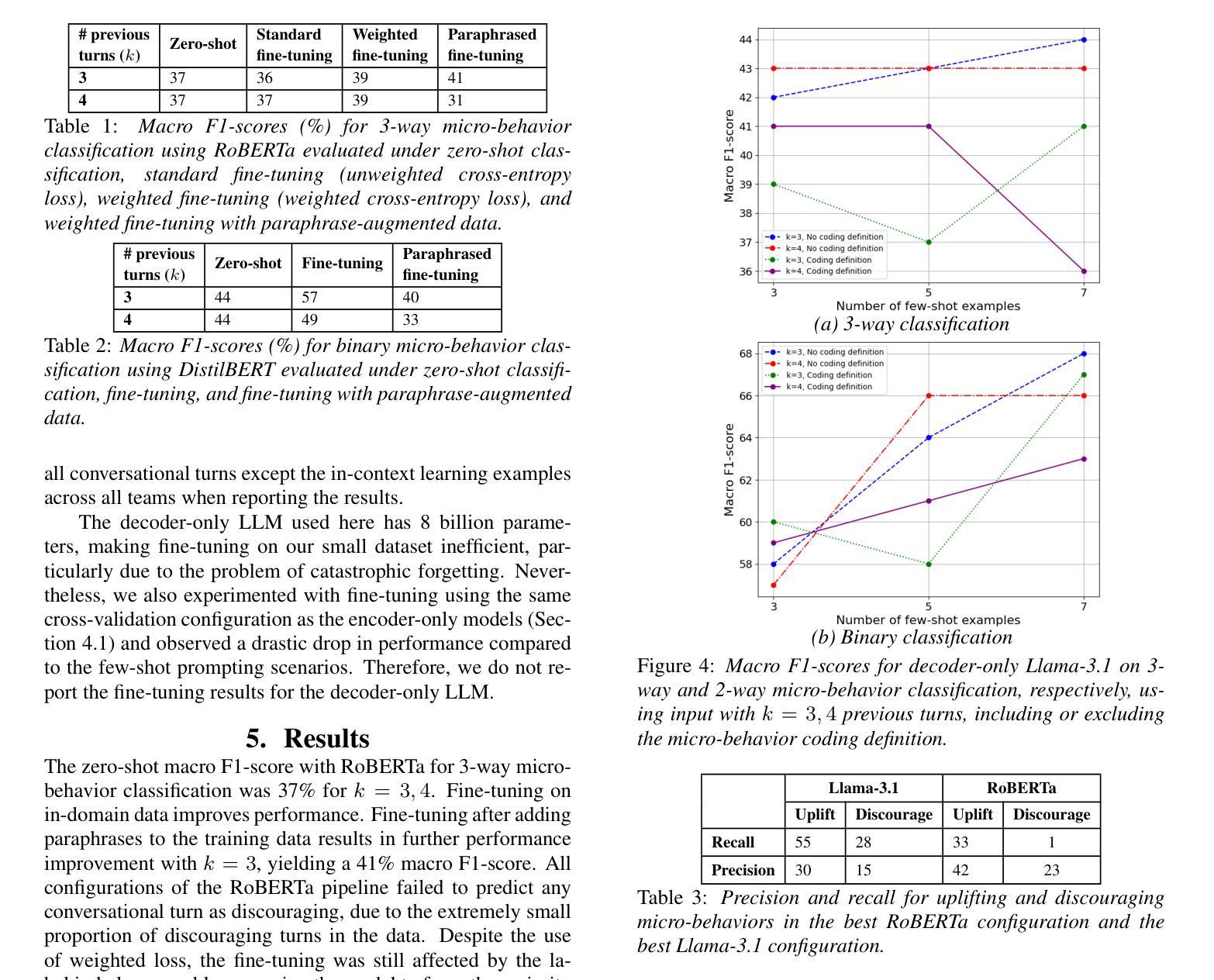
Speaker Targeting via Self-Speaker Adaptation for Multi-talker ASR
Authors:Weiqing Wang, Taejin Park, Ivan Medennikov, Jinhan Wang, Kunal Dhawan, He Huang, Nithin Rao Koluguri, Jagadeesh Balam, Boris Ginsburg
We propose a self-speaker adaptation method for streaming multi-talker automatic speech recognition (ASR) that eliminates the need for explicit speaker queries. Unlike conventional approaches requiring target speaker embeddings or enrollment audio, our technique dynamically adapts individual ASR instances through speaker-wise speech activity prediction. The key innovation involves injecting speaker-specific kernels generated via speaker supervision activations into selected ASR encoder layers. This enables instantaneous speaker adaptation to target speakers while handling fully overlapped speech even in a streaming scenario. Experiments show state-of-the-art performance in both offline and streaming scenarios, demonstrating that our self-adaptive method effectively addresses severe speech overlap through streamlined speaker-focused recognition. The results validate the proposed self-speaker adaptation approach as a robust solution for multi-talker ASR under severe overlapping speech conditions.
我们提出了一种针对流式多说话人自动语音识别(ASR)的自我说话人适配方法,该方法无需明确的说话人查询。不同于需要目标说话人嵌入或注册音频的传统方法,我们的技术通过说话人语音活动预测来动态适配单个ASR实例。关键创新之处在于将说话人特定内核注入选定的ASR编码器层,这些内核通过说话人监督激活生成。这能够实现针对目标说话人的即时说话人适配,即使在流式场景中也能处理完全重叠的语音。实验表明,无论是在离线还是流式场景中,我们的自我适应方法均表现出卓越的性能,证明其通过简化的说话人聚焦识别有效地解决了严重语音重叠问题。结果验证了所提出的自我说话人适配方法作为严重重叠语音条件下多说话人ASR的稳健解决方案。
论文及项目相关链接
PDF Accepted by INTERSPEECH 2025
总结
在流式的多说话人自动语音识别(ASR)中,我们提出了一种无需明确说话人查询的自我适应方法。不同于需要目标说话人嵌入或注册音频的传统方法,我们的技术通过说话人语音活动预测来动态适应各个ASR实例。关键创新点在于向选定ASR编码器层注入通过说话人监督激活生成的说话人特定核,以实现即时适应目标说话人,同时处理流式场景中的完全重叠语音。实验表明,无论是在离线还是流式场景中,我们的自我适应方法均表现出卓越性能,有效解决了严重的语音重叠问题,通过简化的说话人识别功能实现针对性的解决策略。结果验证了所提出的自我适应说话人适应方法作为严重重叠语音条件下的多说话人ASR的稳健解决方案。
关键见解
- 提出了一种自我适应的说话人适应方法,用于流式的多说话人自动语音识别(ASR)。
- 通过说话人语音活动预测动态适应ASR实例,无需目标说话人嵌入或注册音频。
- 通过向ASR编码器层注入说话人特定核,实现即时适应目标说话人。
- 技术能够处理流式场景中的完全重叠语音。
- 实验结果表现出卓越性能,在离线及流式场景下均达到业界先进水平。
- 自我适应方法有效解决严重语音重叠问题。
点此查看论文截图

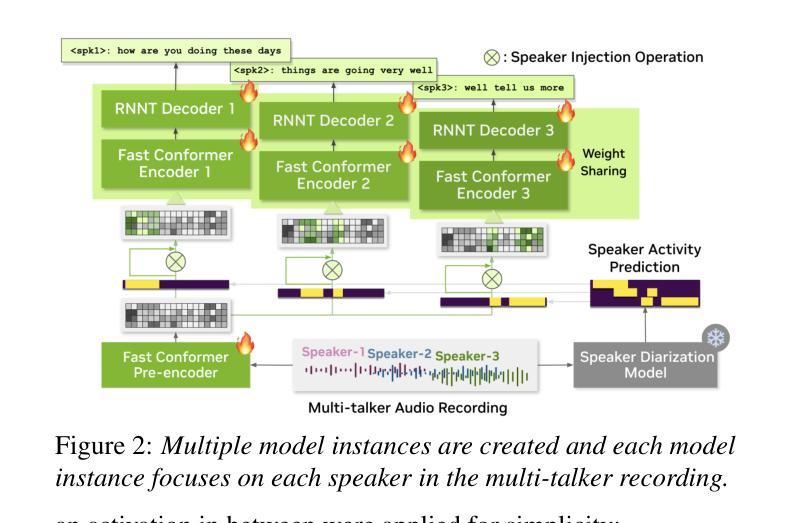
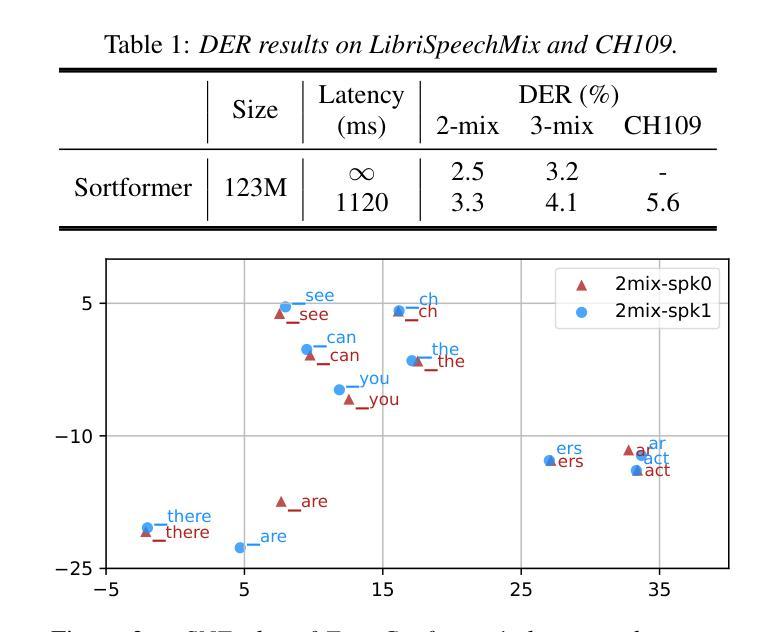
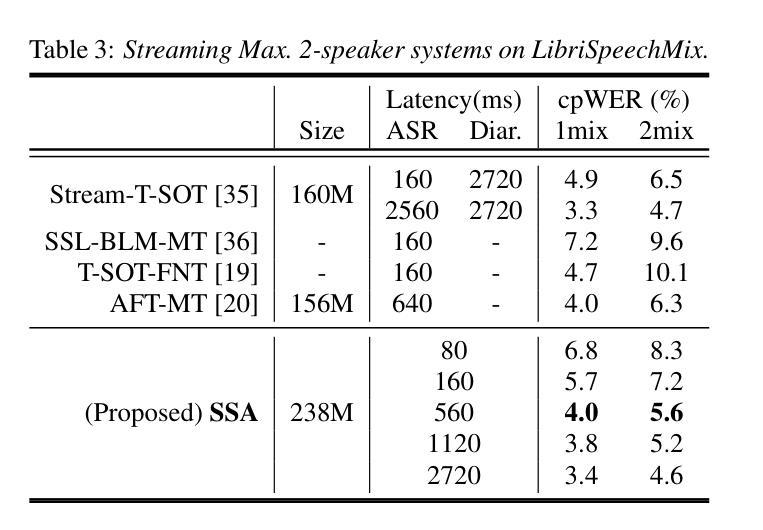
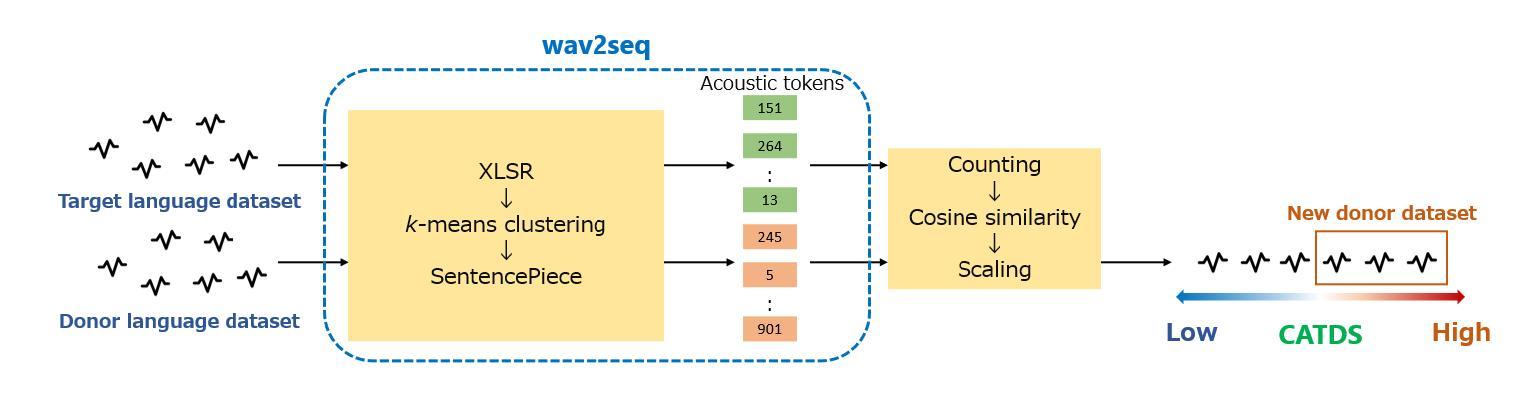
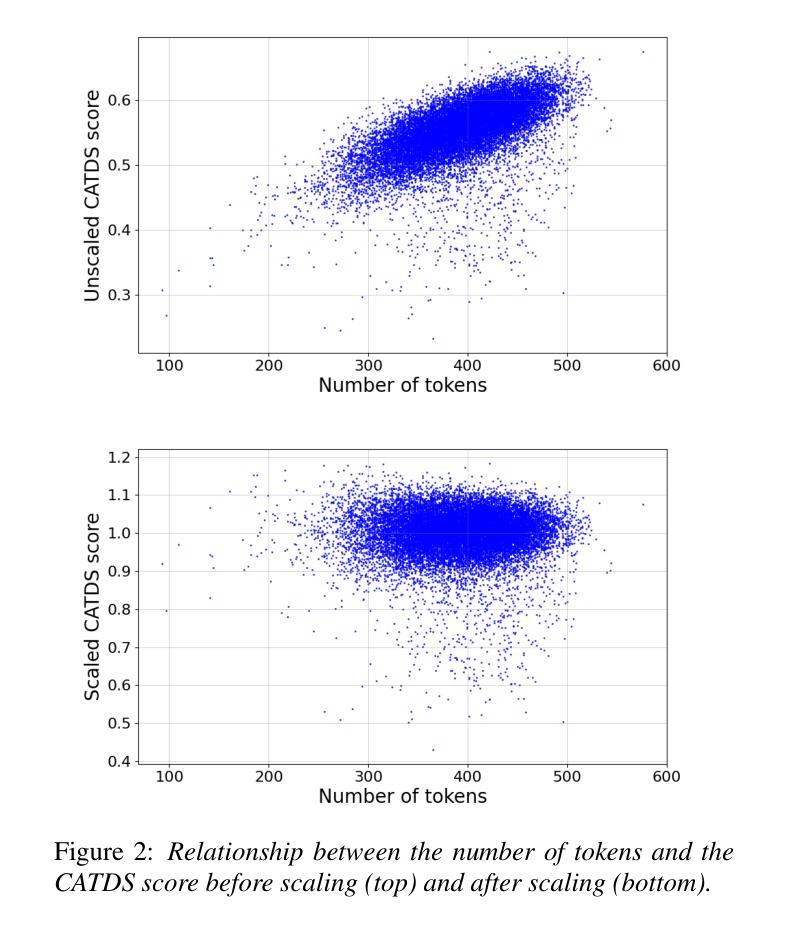
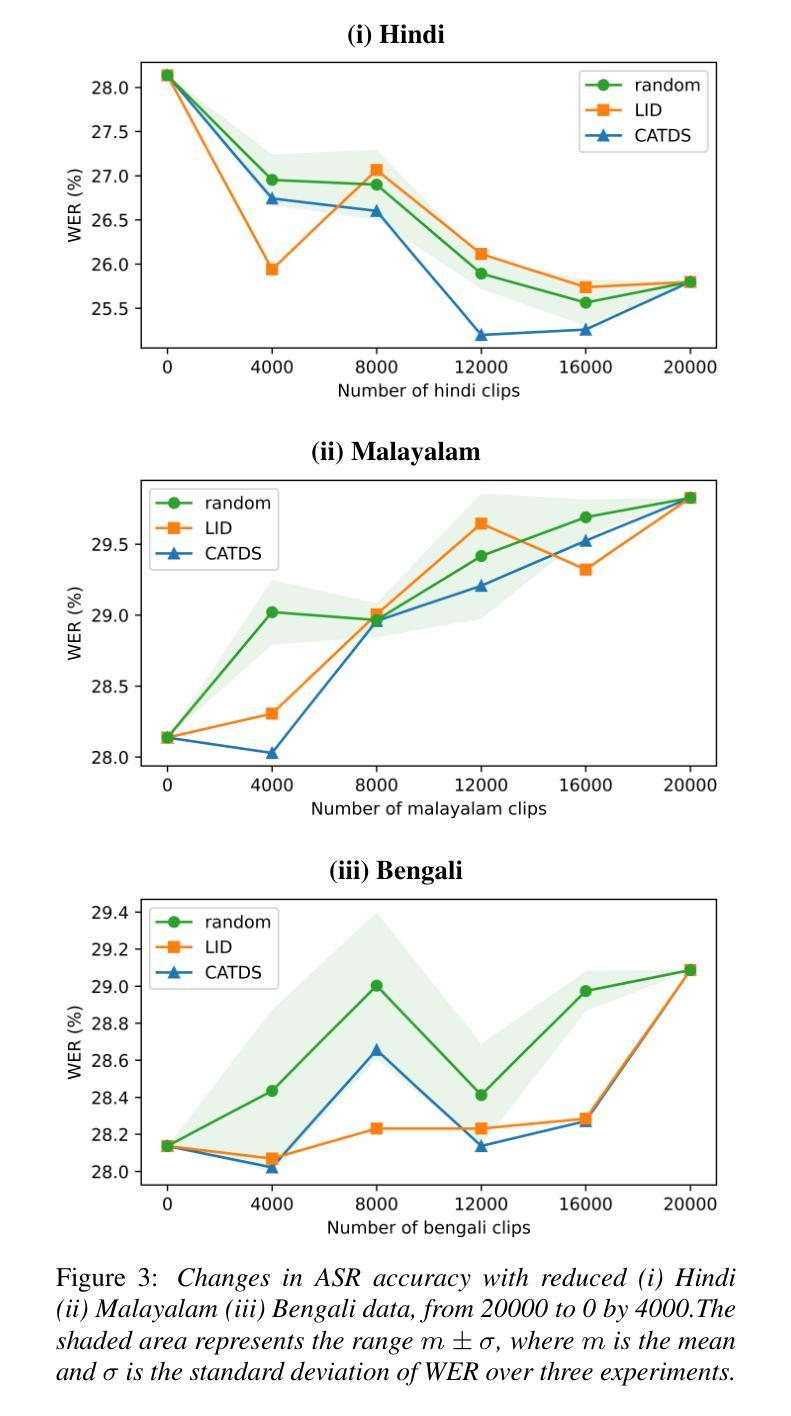
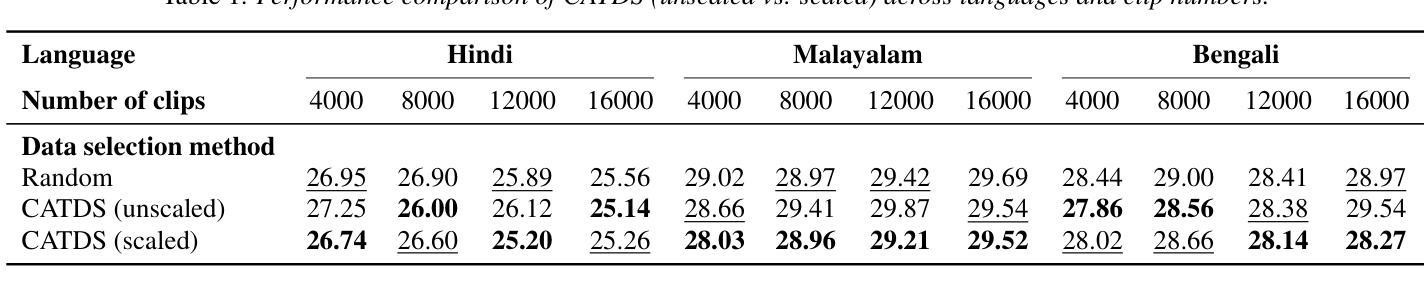
Cross-lingual Data Selection Using Clip-level Acoustic Similarity for Enhancing Low-resource Automatic Speech Recognition
Authors:Shunsuke Mitsumori, Sara Kashiwagi, Keitaro Tanaka, Shigeo Morishima
This paper presents a novel donor data selection method to enhance low-resource automatic speech recognition (ASR). While ASR performs well in high-resource languages, its accuracy declines in low-resource settings due to limited training data. A common solution is to leverage multilingual self-supervised learning (SSL) models with donor languages. However, existing methods rely on language-level similarity, overlooking clip-level variations. To address this limitation, we propose clip-wise acoustic token distribution similarity (CATDS), a fine-grained selection method that identifies acoustically relevant donor clips for better alignment with the target language. Unlike existing clip-level selection methods, our method aligns with the representation of SSL models and offers more challenging yet valuable samples. Experimental results show that CATDS outperforms traditional selection methods and can even utilize donor languages previously considered detrimental.
本文提出了一种新的捐赠者数据选择方法,以提高低资源自动语音识别(ASR)的性能。虽然ASR在高资源语言中表现良好,但在低资源环境中由于训练数据有限,其准确性会下降。一种常见的解决方案是利用具有捐赠者语言的多语言自监督学习(SSL)模型。然而,现有方法依赖于语言级别的相似性,忽略了剪辑级别的变化。为了解决这一局限性,我们提出了基于剪辑的声学令牌分布相似性(CATDS),这是一种精细的选样方法,可以识别与目标语言更匹配的声学相关捐赠剪辑。与传统的剪辑级选择方法不同,我们的方法与SSL模型的表示相一致,并提供更具挑战但更有价值的样本。实验结果表明,CATDS优于传统选择方法,甚至可以利用以前被认为有害的捐赠者语言。
论文及项目相关链接
PDF Accepted at INTERSPEECH 2025
总结
本文提出了一种新型的捐赠者数据选择方法,以提高在低资源环境下的自动语音识别(ASR)性能。在高资源语言环境中,ASR表现良好,但在低资源设置下,由于训练数据有限,其准确性会下降。常见的解决方案是利用具有捐赠者语言的多语言自监督学习(SSL)模型。然而,现有方法依赖于语言级别的相似性,忽略了剪辑级别的变化。为了解决这个问题,我们提出了基于剪辑的声学令牌分布相似性(CATDS),这是一种精细的筛选方法,可以识别与目标语言声学相关的捐赠剪辑,以实现更好的对齐。与现有的剪辑级别选择方法不同,我们的方法符合SSL模型的表示,并提供更具挑战性但更有价值的样本。实验结果表明,CATDS优于传统选择方法,甚至可以利用以前被认为有害的捐赠语言。
关键见解
- 提出了一种新型的捐赠者数据选择方法——基于剪辑的声学令牌分布相似性(CATDS),旨在提高低资源环境下的自动语音识别性能。
- 低资源设置下的ASR准确性下降问题得到了解决,通过利用多语言自监督学习(SSL)模型和捐赠者数据。
- 现有方法主要依赖语言级别的相似性来选择捐赠数据,但CATDS则关注剪辑级别的变化。
- CATDS能够识别与目标语言声学相关的捐赠剪辑,实现更好的对齐。
- CATDS与现有的剪辑级别选择方法不同,更符合SSL模型的表示方式。
- CATDS提供了更具挑战性但对提高ASR性能有价值的样本。
- 实验结果表明,CATDS在选择捐赠语言数据方面表现出色,甚至能够利用之前被认为有害的捐赠语言。
点此查看论文截图

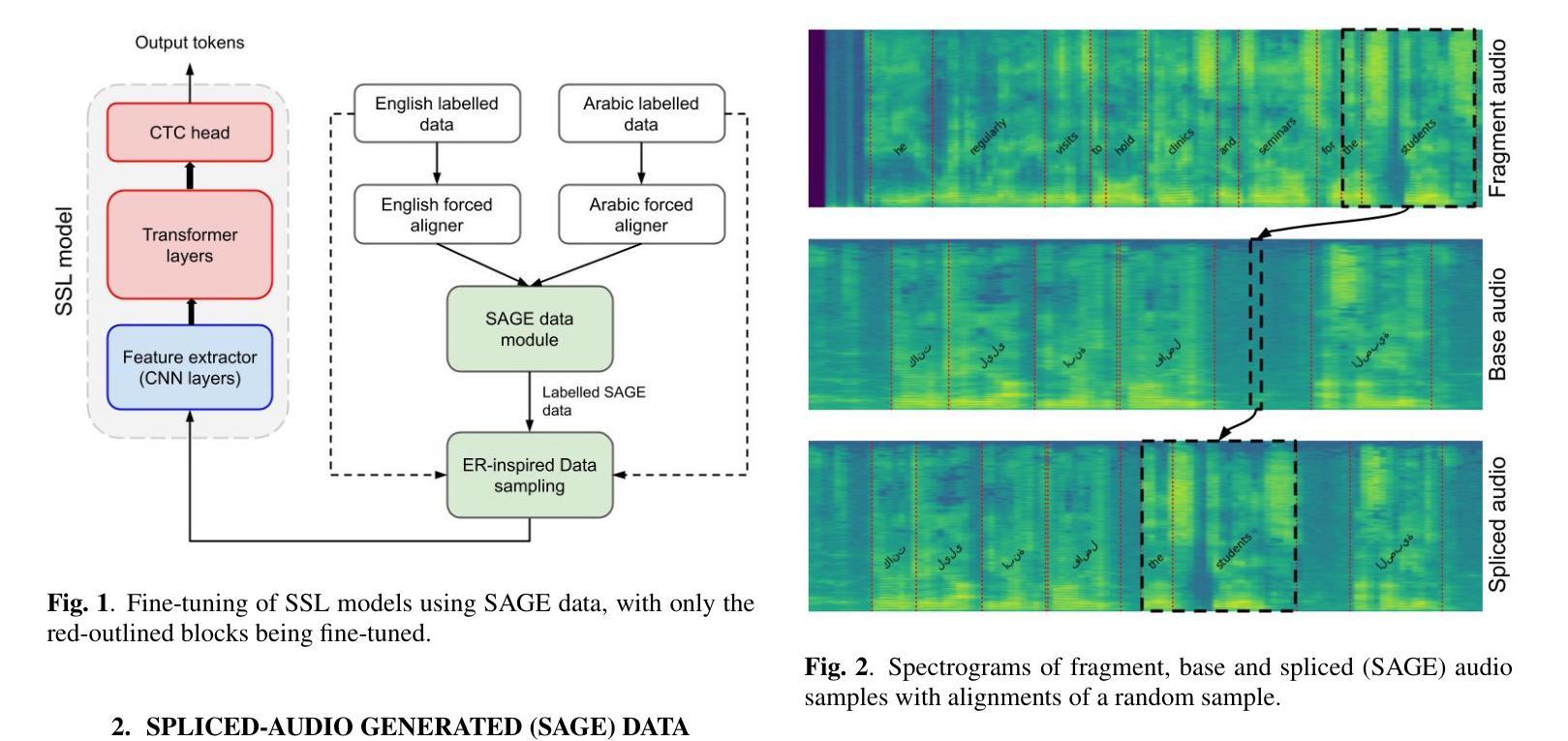
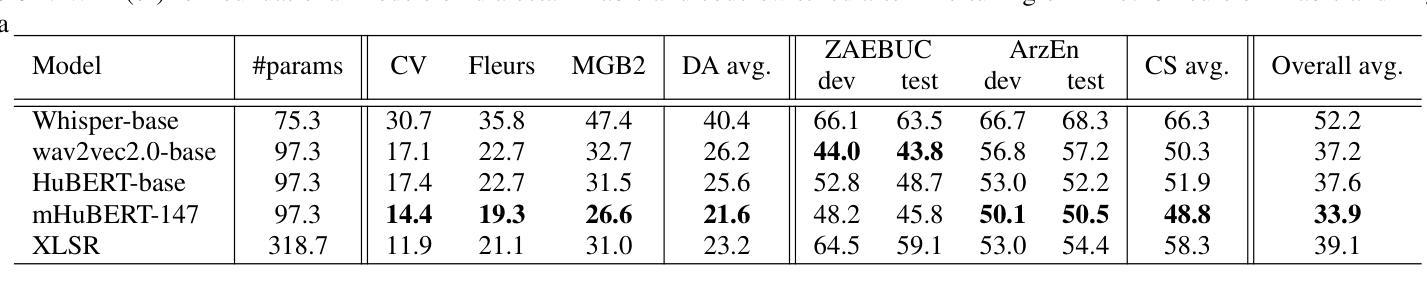
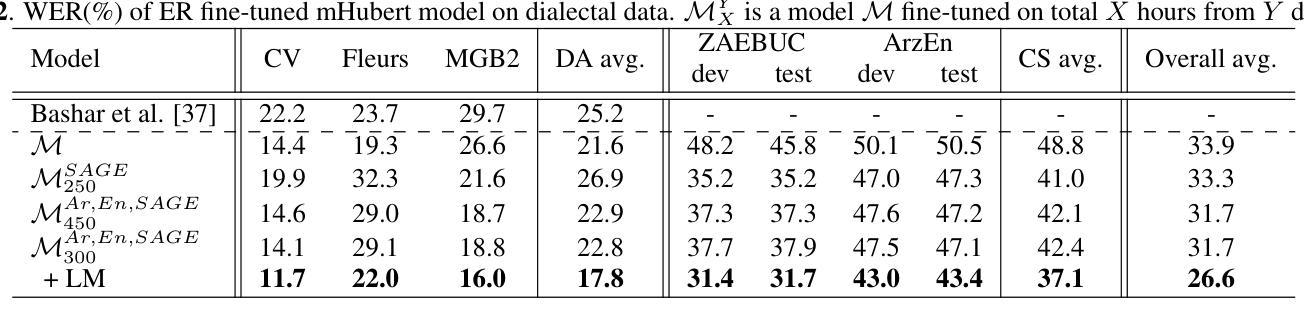
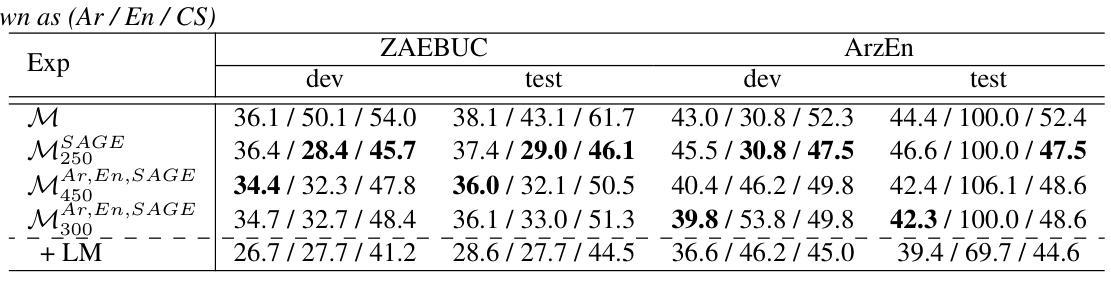
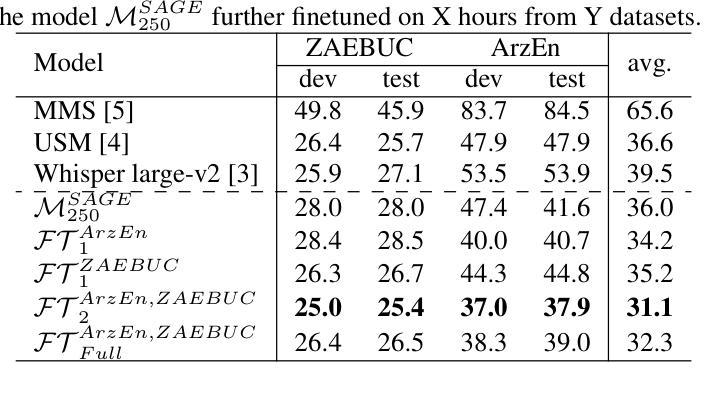
SAGE: Spliced-Audio Generated Data for Enhancing Foundational Models in Low-Resource Arabic-English Code-Switched Speech Recognition
Authors:Muhammad Umar Farooq, Oscar Saz
This paper investigates the performance of various speech SSL models on dialectal Arabic (DA) and Arabic-English code-switched (CS) speech. To address data scarcity, a modified audio-splicing approach is introduced to generate artificial CS speech data. Fine-tuning an already fine-tuned SSL model with the proposed Spliced-Audio Generated (SAGE) data results in an absolute improvement on Word Error Rate (WER) of 7.8% on Arabic and English CS benchmarks. Additionally, an Experience Replay (ER) inspired approach is proposed to enhance generalisation across DA and CS speech while mitigating catastrophic forgetting. Integrating an out-of-domain 3-gram language model reduces the overall mean WER from 31.7% to 26.6%. Few-shot fine-tuning for code-switching benchmarks further improves WER by 4.9%. A WER of 31.1% on Arabic-English CS benchmarks surpasses large-scale multilingual models, including USM and Whisper-large-v2 (both over ten times larger) by an absolute margin of 5.5% and 8.4%, respectively.
本文研究了各种语音SSL模型在方言阿拉伯语(DA)和阿拉伯语英语代码切换(CS)语音上的性能。为了解决数据稀缺的问题,引入了一种改进的音频拼接方法来生成人工CS语音数据。使用提出的拼接音频生成(SAGE)数据对已经微调过的SSL模型进行微调,在阿拉伯语和英语CS基准测试上,单词错误率(WER)绝对降低了7.8%。此外,还提出了一种受经验回放(ER)启发的策略,以提高在方言阿拉伯语和代码切换语音之间的泛化能力,同时减轻灾难性遗忘。集成一个非域3-gram语言模型将整体平均WER从31.7%降低到26.6%。针对代码切换基准的少量微调进一步将WER提高了4.9%。在阿拉伯语英语CS基准测试上达到的WER为31.1%,超过了大规模多语种模型,包括USM和Whisper-large-v2(两者都超过十倍大),分别绝对降低了5.5%和8.4%。
论文及项目相关链接
PDF Accepted for IEEE MLSP 2025
Summary
这篇论文研究了不同语音SSL模型在方言阿拉伯语(DA)和阿拉伯语-英语代码切换(CS)语音上的表现。为解决数据稀缺问题,引入了改良的音频拼接方法来生成人工CS语音数据。通过用提出Spliced-Audio Generated (SAGE)数据对已经微调过的SSL模型进行微调,在阿拉伯语和英语CS基准测试上,单词错误率(WER)绝对改善了7.8%。此外,还提出了受Experience Replay(ER)启发的方法来提高DA和CS语音的通用性,同时减轻灾难性遗忘。集成领域外的三元语言模型将总体平均WER从31.7%降低到26.6%。针对代码切换基准测试的少量微调进一步将WER提高了4.9%。在阿拉伯语-英语CS基准测试上达到的WER为31.1%,超越了大规模多语种模型,包括USM和Whisper-large-v2(两者都超过十倍大),分别绝对改善了5.5%和8.4%。
Key Takeaways
- 论文研究了不同语音SSL模型在方言阿拉伯语和阿拉伯语-英语代码切换语音上的表现。
- 引入改良的音频拼接方法生成人工CS语音数据,以解决数据稀缺问题。
- 使用SAGE数据微调SSL模型,显著改善了单词错误率(WER)。
- 提出受Experience Replay启发的方法,提高模型在DA和CS语音上的通用性,并减轻灾难性遗忘。
- 集成领域外的三元语言模型有效降低WER。
- 少量微调针对代码切换基准测试进一步提高模型性能。
点此查看论文截图

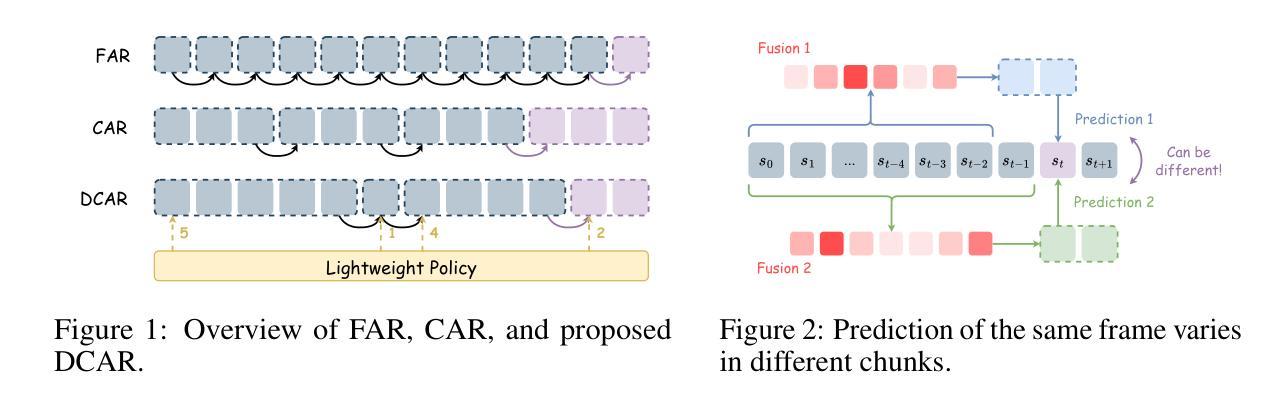
Robust and Efficient Autoregressive Speech Synthesis with Dynamic Chunk-wise Prediction Policy
Authors:Bohan Li, Zhihan Li, Haoran Wang, Hanglei Zhang, Yiwei Guo, Hankun Wang, Xie Chen, Kai Yu
Recently, autoregressive (AR) language models have emerged as a dominant approach in speech synthesis, offering expressive generation and scalable training. However, conventional AR speech synthesis models relying on the next-token prediction paradigm often encounter significant challenges when handling long speech sequences. These models often struggle to construct stable frame-to-frame attention, leading to increased latency and degraded synthesis quality, thereby limiting their feasibility for real-time applications. To address these limitations, we introduce a novel dynamic chunk-wise autoregressive synthesis framework, termed DCAR, designed to enhance both efficiency and intelligibility robustness in AR speech generation. DCAR introduces a chunk-to-frame attention mechanism through training with multi-token prediction, enabling dynamic chunk prediction in variable speech contexts using a lightweight module trained on-policy. DCAR dynamically adjusts the token prediction span, significantly reducing the sequence length dependency while obtaining high synthesis quality. Comprehensive empirical evaluations demonstrate that DCAR substantially outperforms traditional next-token prediction models, achieving up to 72.27% intelligibility improvement and 2.61x inference speedup simultaneously on the test set. Furthermore, we conduct comprehensive analysis to support it as a versatile foundation for next-generation speech synthesis systems.
最近,自回归(AR)语言模型已成为语音合成中的主流方法,提供表达性生成和可扩展训练。然而,传统的基于下一个令牌预测范式的AR语音合成模型在处理长语音序列时经常面临重大挑战。这些模型在构建稳定的帧到帧注意力方面往往遇到困难,从而导致延迟增加和合成质量下降,从而限制了它们在实时应用中的可行性。为了解决这些局限性,我们引入了一种新型的动态分段自回归合成框架,称为DCAR,旨在提高AR语音生成中的效率和清晰度稳健性。DCAR通过多令牌预测进行训练,引入了块到帧的注意力机制,使用轻量级模块进行策略训练,在可变语音环境中实现动态块预测。DCAR动态调整令牌预测范围,显著减少序列长度依赖性,同时获得高质量合成。综合实证评估表明,DCAR在测试集上显著优于传统的下一个令牌预测模型,实现了高达72.27%的清晰度提升和2.61倍的推理速度提升。此外,我们进行了综合分析,支持它作为下一代语音合成系统的多功能基础。
论文及项目相关链接
PDF 17 pages, 8 figures, 5 tables
Summary
近期,自回归语言模型在语音合成中占据主导地位,但传统自回归语音合成模型在处理长语音序列时面临挑战。为提升效率和清晰度稳健性,提出一种新型动态分段自回归合成框架DCAR。DCAR通过多令牌预测训练,引入块到帧的注意力机制,实现动态块预测。综合评价显示,DCAR显著优于传统模型,同时提高清晰度并加速推理。
Key Takeaways
- 自回归语言模型在语音合成中占据主导地位,但处理长语音序列时存在挑战。
- 传统自回归语音合成模型面临构建稳定帧到帧注意力的困难,导致延迟和合成质量下降。
- DCAR框架通过引入块到帧的注意力机制和动态块预测,提升效率和清晰度稳健性。
- DCAR通过多令牌预测训练,实现动态调整令牌预测跨度,减少序列长度依赖性。
- DCAR在测试集上相对于传统模型实现高达72.27%的清晰度提升和2.61倍的推理速度加快。
- 综合评价支持DCAR作为下一代语音合成系统的通用基础。
点此查看论文截图

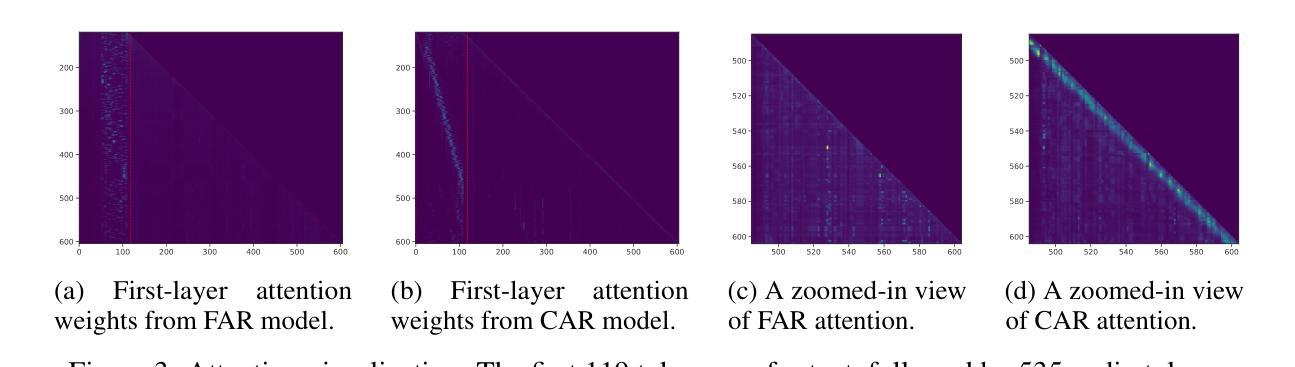
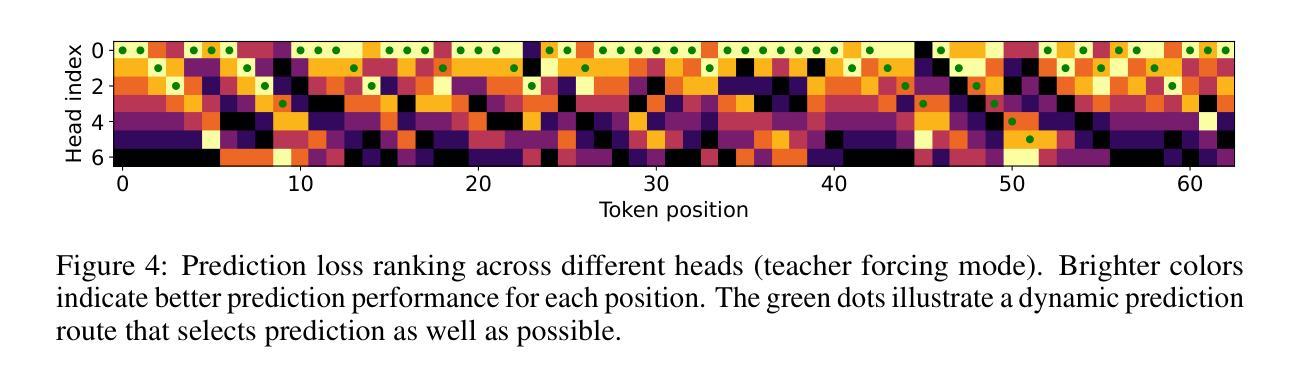
Analyzing and Fine-Tuning Whisper Models for Multilingual Pilot Speech Transcription in the Cockpit
Authors:Kartheek Kumar Reddy Nareddy, Sarah Ternus, Julia Niebling
The developments in transformer encoder-decoder architectures have led to significant breakthroughs in machine translation, Automatic Speech Recognition (ASR), and instruction-based chat machines, among other applications. The pre-trained models were trained on vast amounts of generic data over a few epochs (fewer than five in most cases), resulting in their strong generalization capabilities. Nevertheless, the performance of these models does suffer when applied to niche domains like transcribing pilot speech in the cockpit, which involves a lot of specific vocabulary and multilingual conversations. This paper investigates and improves the transcription accuracy of cockpit conversations with Whisper models. We have collected around 85 minutes of cockpit simulator recordings and 130 minutes of interview recordings with pilots and manually labeled them. The speakers are middle aged men speaking both German and English. To improve the accuracy of transcriptions, we propose multiple normalization schemes to refine the transcripts and improve Word Error Rate (WER). We then employ fine-tuning to enhance ASR performance, utilizing performance-efficient fine-tuning with Low-Rank Adaptation (LoRA). Hereby, WER decreased from 68.49 % (pretrained whisper Large model without normalization baseline) to 26.26% (finetuned whisper Large model with the proposed normalization scheme).
随着Transformer编码器-解码器架构的发展,其在机器翻译、自动语音识别(ASR)和基于指令的聊天机器人等领域取得了重大突破。预训练模型经过少量周期(大多数情况下少于五个周期)的大量通用数据训练,表现出了强大的泛化能力。然而,当这些模型应用于特定领域(如驾驶舱内的飞行员语音转录)时,性能会有所下降,这涉及大量特定词汇和多语种对话。本文使用whisper模型研究并提高了驾驶舱对话的转录准确性。我们收集了大约85分钟的驾驶舱模拟器录音和130分钟的飞行员访谈录音,并进行了手动标注。说话人是中年男性,同时使用德语和英语。为了提高转录的准确性,我们提出了多种归一化方案来优化转录本并降低单词错误率(WER)。然后,我们采用微调技术来提高ASR性能,采用性能高效的微调方法——低秩适应(LoRA)。由此,单词错误率从68.49%(未经归一化的预训练whisper大型模型基线)降低到26.26%(采用所提归一化方案的微调whisper大型模型)。
论文及项目相关链接
PDF Computer Vision and Pattern Recognition (CVPR) 2025 Workshops
Summary
本文探讨了使用Whisper模型提高驾驶舱对话语音转文字准确性。为解决特定领域(如驾驶舱对话)的特殊词汇和多语言问题,研究团队收集驾驶舱模拟录音与飞行员访谈录音并进行手动标注。通过多重标准化方案优化转录和提高字词错误率(WER)。使用性能高效的微调技术Low-Rank Adaptation(LoRA)提高语音识别性能,使WER大幅降低。
Key Takeaways
- 变压器编码器-解码器架构的发展在机器翻译、语音识别等领域取得了重大突破。
- 预训练模型在通用数据上进行训练,具有强大的泛化能力。
- 驾驶舱语音转录面临特定领域的挑战,如专业词汇和多语言交流。
- 研究团队通过收集驾驶舱模拟录音和飞行员访谈进行手动标注来解决这一问题。
- 提出了多种标准化方案来优化转录和提高字词错误率(WER)。
- 采用Low-Rank Adaptation(LoRA)微调技术提高语音识别性能。
点此查看论文截图

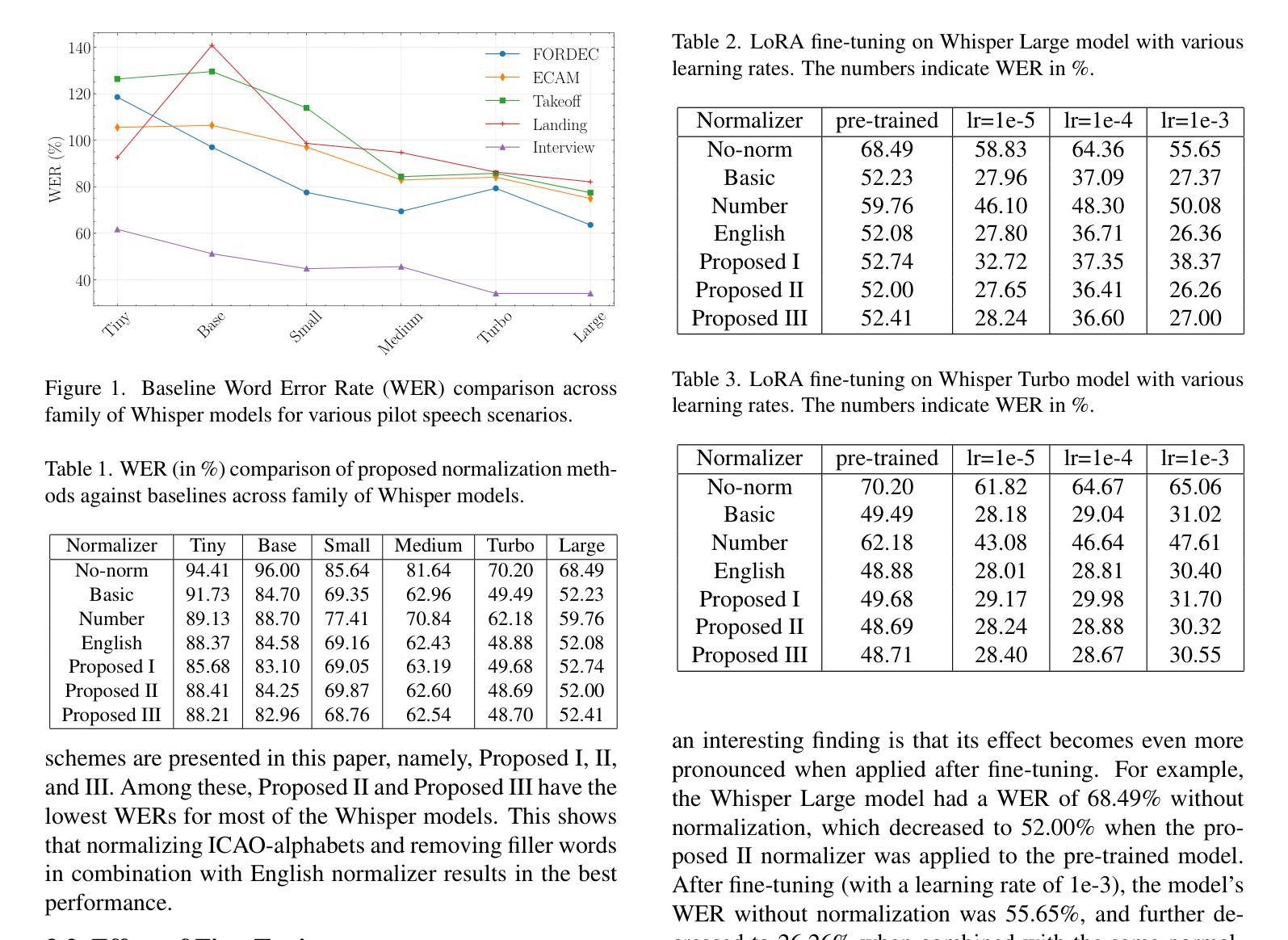
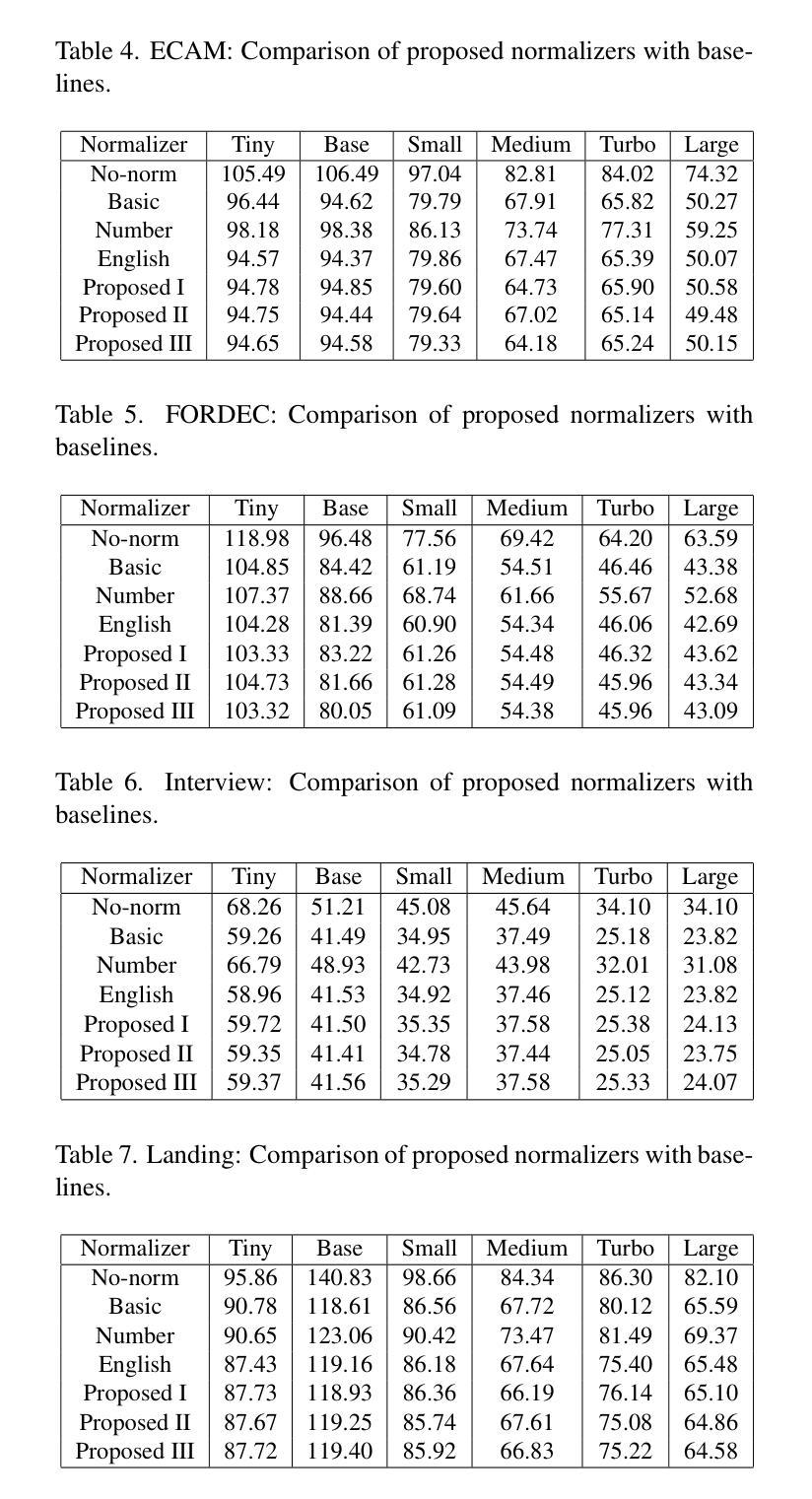
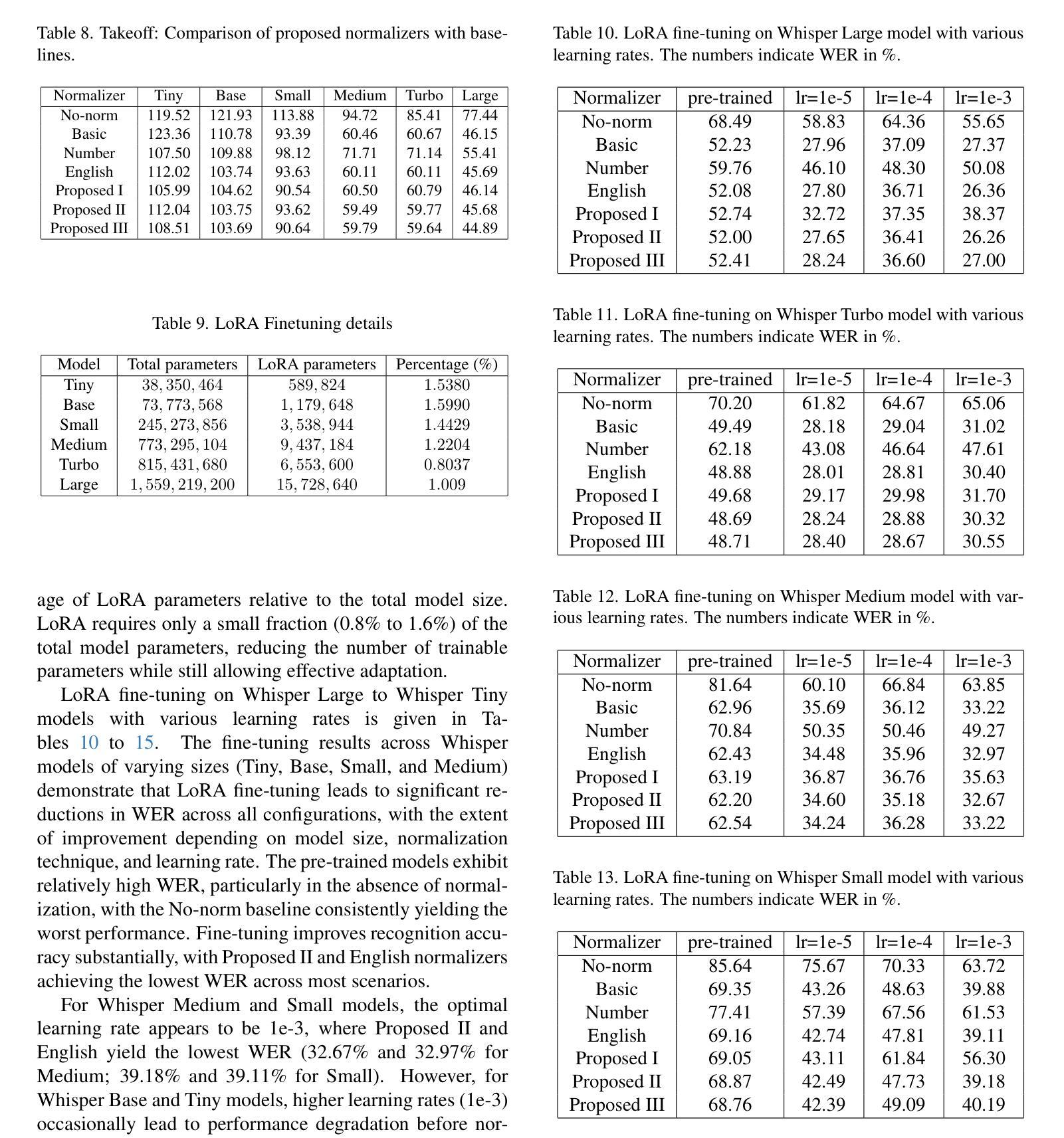
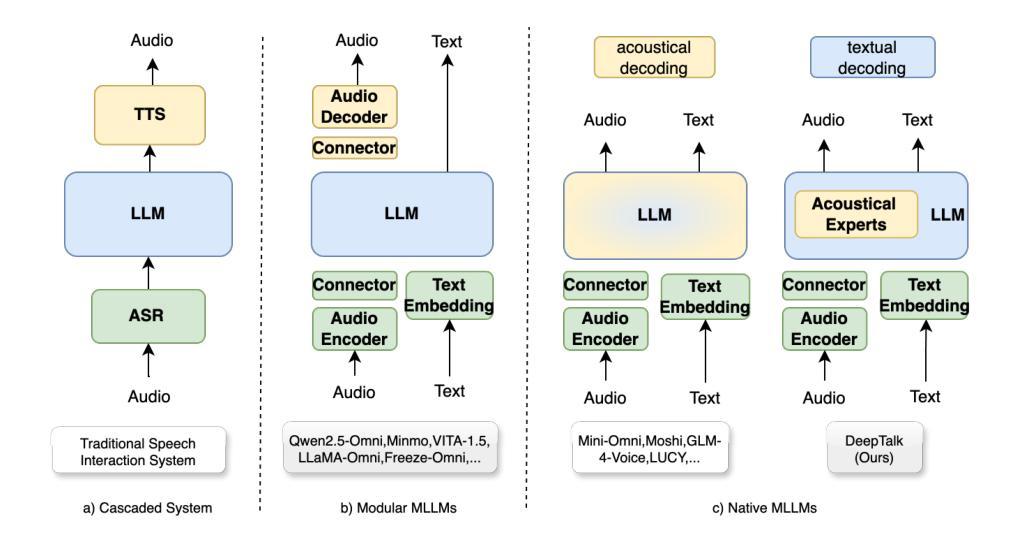
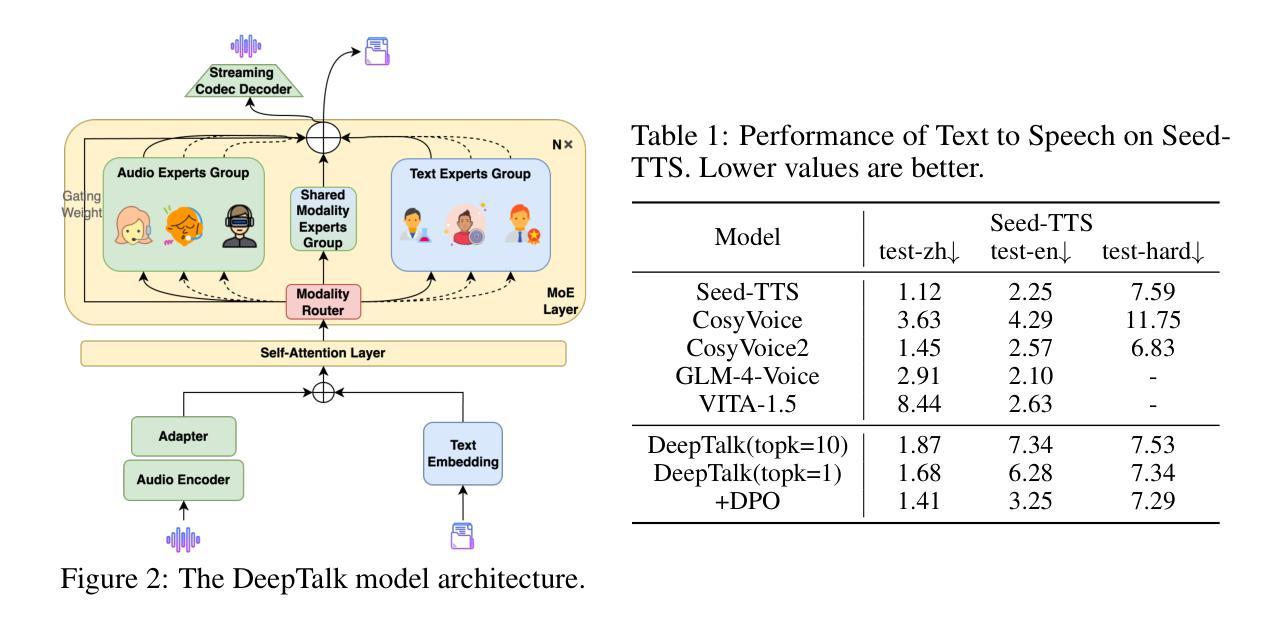
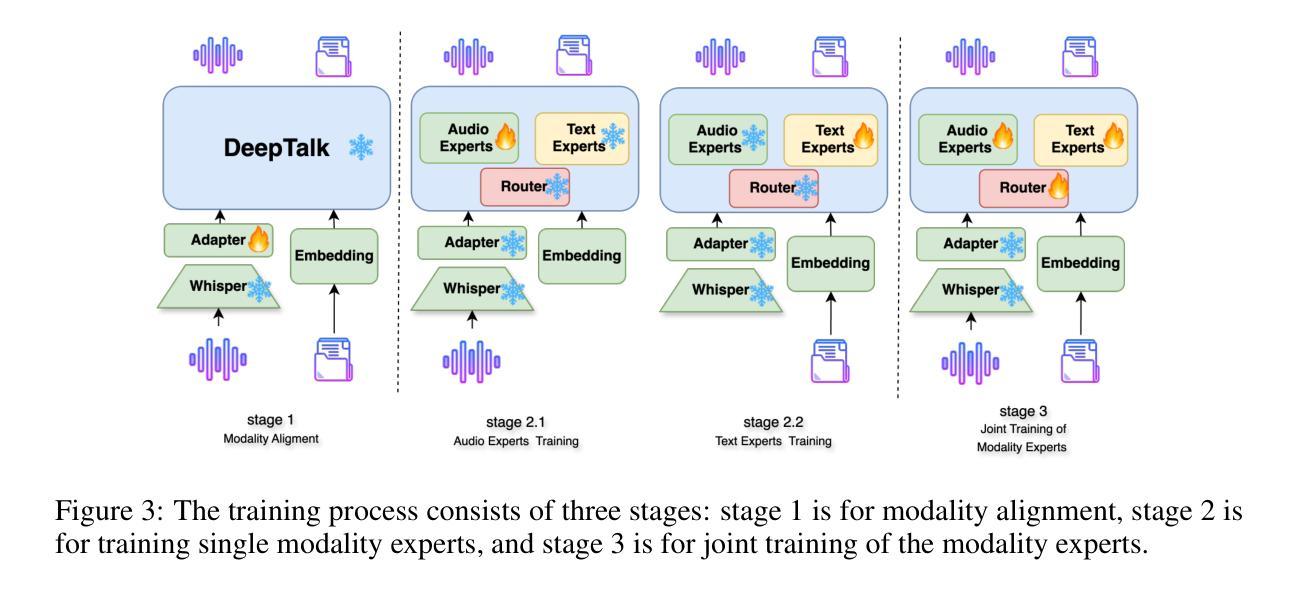
DeepTalk: Towards Seamless and Smart Speech Interaction with Adaptive Modality-Specific MoE
Authors:Hang Shao, Heting Gao, Yunhang Shen, Jiawei Chen, Lijiang Li, Zuwei Long, Bo Tong, Ke Li, Xing Sun
Native multimodal large language models (MLLMs) restructure a single large language model (LLM) into a spoken language model (SLM) capable of both speech and text generation. Compared to modular and aligned MLLMs, native MLLMs preserve richer paralinguistic features such as emotion and prosody, and generate speech responses directly within the backbone LLM rather than using a separate speech decoder. This integration also results in lower response latency and smoother interaction. However, native MLLMs suffer from catastrophic forgetting and performance degradation because the available paired speech-text data is insufficient to support the pretraining of MLLMs compared to the vast amount of text data required to pretrain text LLMs. To address this issue, we propose DeepTalk, a framework for adaptive modality expert learning based on a Mixture of Experts (MoE) architecture. DeepTalk first adaptively distinguishes modality experts according to their modality load within the LLM. Each modality expert then undergoes specialized single-modality training, followed by joint multimodal collaborative training. As a result, DeepTalk incurs only a 5.5% performance drop compared to the original LLM, which is significantly lower than the average performance drop of over 20% typically seen in native MLLMs (such as GLM-4-Voice), and is on par with modular MLLMs. Meanwhile, the end-to-end dialogue latency remains within 0.5 seconds, ensuring a seamless and intelligent speech interaction experience. Code and models are released at https://github.com/talkking/DeepTalk.
原生多模态大型语言模型(MLLMs)将单一的大型语言模型(LLM)重构为能够同时处理语音和文本生成的口语语言模型(SLM)。与模块化和对齐的MLLMs相比,原生MLLMs保留了更丰富的副语言特征,如情感和语调,并在主干LLM内直接生成语音响应,而不是使用单独的语音解码器。这种集成还带来了更低的响应延迟和更流畅的互动。然而,由于可用的配对语音-文本数据不足以支持MLLMs的预训练,与需要预训练文本LLM的大量文本数据相比,原生MLLMs遭受了灾难性的遗忘和性能下降。为了解决这个问题,我们提出了DeepTalk,这是一个基于专家混合(MoE)架构的自适应模态专家学习框架。DeepTalk首先根据LLM内的模态负载自适应地区分模态专家。然后,每个模态专家进行专门的单模态训练,接着进行联合多模态协同训练。因此,与原始LLM相比,DeepTalk只会导致5.5%的性能下降,这远低于原生MLLMs(如GLM-4-Voice)通常出现的超过20%的平均性能下降,并与模块化MLLMs相当。同时,端到端对话延迟保持在0.5秒内,确保无缝且智能的语音交互体验。代码和模型已发布在https://github.com/talkking/DeepTalk。
论文及项目相关链接
PDF Under Review
Summary
基于模态混合专家学习架构,提出DeepTalk框架解决大型语言模型在语音和文本生成方面的缺陷。通过自适应区分模态专家,并结合单一模态训练和联合多模态协作训练,实现了与原生多模态大型语言模型相当的效能表现,但降低了模型遗忘现象并提高了性能稳定性。通过这一技术优化,确保了流畅的智能化语音交互体验。代码和模型已发布在GitHub上。
Key Takeaways
- 原生多模态大型语言模型通过整合语音和文本生成功能,表现出丰富的语言处理能力。
- DeepTalk框架基于模态混合专家学习架构提出,以解决语音与文本生成融合的问题。
- DeepTalk框架包括自适应区分模态专家、单一模态训练和联合多模态协作训练等环节。
- DeepTalk减少了原生多模态大型语言模型的性能损失至仅5.5%,低于传统原生多模态大型语言模型的平均性能损失(超过20%)。
- 该技术优化降低了模型遗忘现象,提高了性能稳定性。
- 通过端到端的对话延迟控制在0.5秒内,保证了智能语音交互的流畅体验。
点此查看论文截图

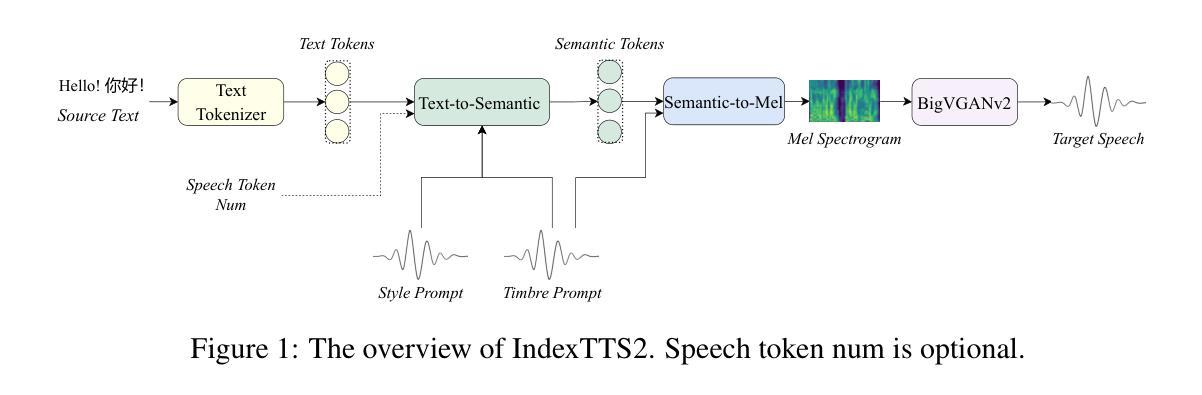
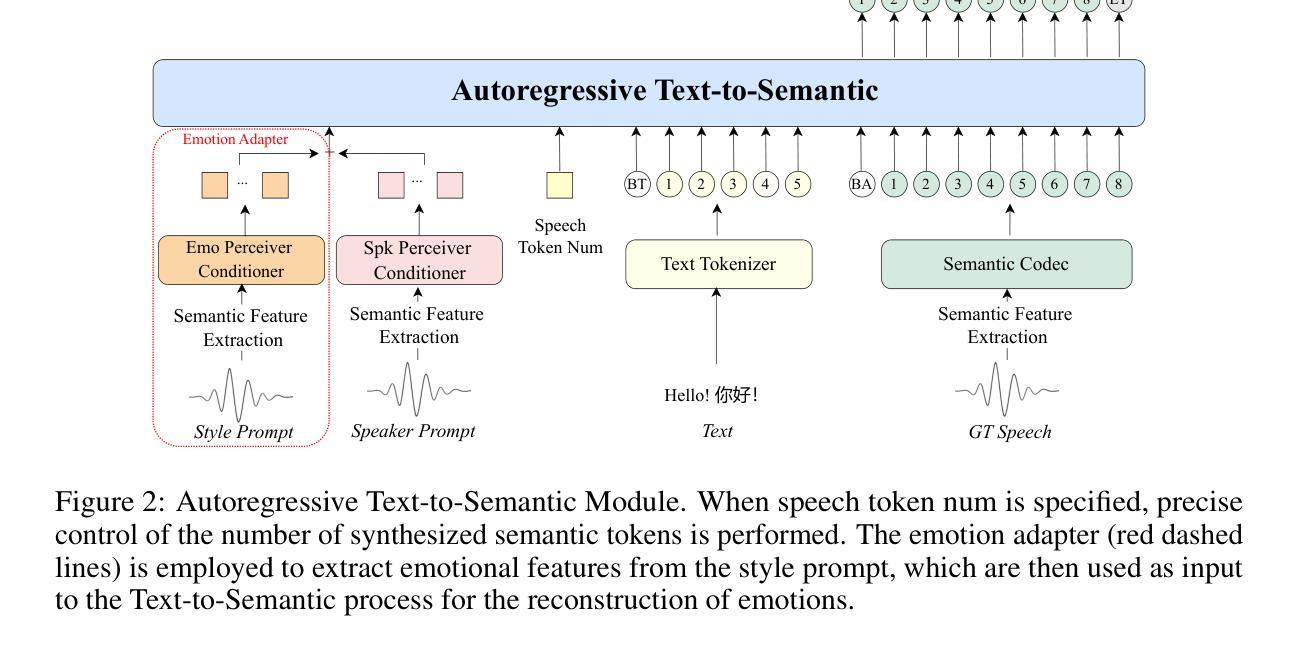
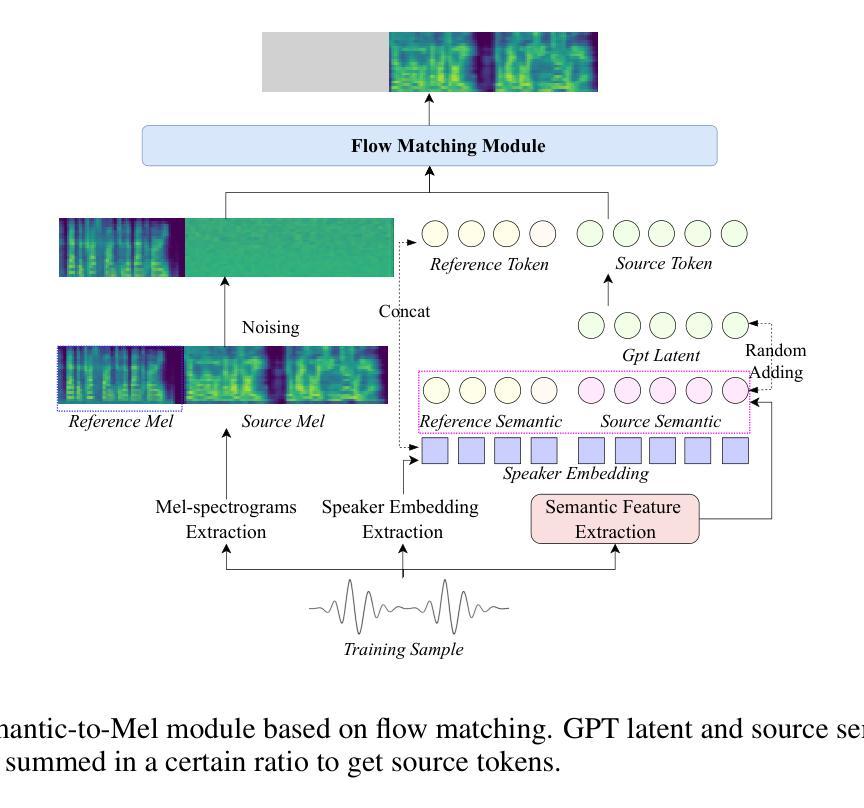
IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech
Authors:Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, Jingchen Shu
Large-scale text-to-speech (TTS) models are typically categorized into autoregressive and non-autoregressive systems. Although autoregressive systems exhibit certain advantages in speech naturalness, their token-by-token generation mechanism makes it difficult to precisely control the duration of synthesized speech. This is a key limitation in applications such as video dubbing that require strict audio-visual synchronization. This paper introduces IndexTTS2, which proposes a novel and autoregressive-model-friendly method for speech duration control. The method supports two generation modes: one allows explicit specification of the number of generated tokens for precise duration control; the other does not require manual input and lets the model freely generate speech while preserving prosodic characteristics from the input prompt. Furthermore, IndexTTS2 achieves disentanglement between emotional expression and speaker identity, enabling independent control of timbre and emotion. In the zero-shot setting, the model can perfectly reproduce the emotional characteristics of the input prompt. Users may also provide a separate emotion prompt, even from a different speaker, allowing the model to reconstruct the target timbre while conveying the desired emotion. To enhance clarity during strong emotional expressions, we incorporate GPT latent representations to improve speech stability. Meanwhile, to lower the barrier for emotion control, we design a soft instruction mechanism based on textual descriptions by fine-tuning Qwen3. This enables effective guidance of speech generation with desired emotional tendencies using natural language input. Experimental results demonstrate that IndexTTS2 outperforms existing state-of-the-art zero-shot TTS models in word error rate, speaker similarity, and emotional fidelity.
大规模文本到语音(TTS)模型通常分为自回归和非自回归系统两类。尽管自回归系统在语音自然度方面具有一定的优势,但其逐个标记的生成机制使得难以精确控制合成语音的持续时间。在诸如需要严格音视频同步的视频配音等应用中,这是一个关键限制。本文介绍了IndexTTS2,它提出了一种新颖且适用于自回归模型的语音持续时间控制方法。该方法支持两种生成模式:一种允许明确指定生成的标记数量以实现精确的持续时间控制;另一种则不需要手动输入,让模型在保留输入提示的韵律特征的同时自由生成语音。此外,IndexTTS2实现了情感表达和说话人身份的解耦,能够实现音调和情感的独立控制。在零样本设置下,模型可以完美地再现输入提示的情感特征。用户还可以提供来自不同说话人的单独情感提示,让模型在传达所需情感的同时重建目标音调。为了提高强烈情感表达时的清晰度,我们结合了GPT的潜在表示来提高语音的稳定性。同时,为了降低情感控制的障碍,我们设计了一种基于文本描述的软指令机制,通过微调Qwen3来实现。这使用自然语言输入有效地引导了具有所需情感倾向的语音生成。实验结果表明,IndexTTS2在词错误率、说话人相似度和情感保真度方面优于现有的最先进的零样本TTS模型。
论文及项目相关链接
Summary
本文介绍了IndexTTS2系统,这是一种针对文本转语音(TTS)的新的自动回归模型友好方法。该方法实现了对合成语音的持续时间的精确控制,支持两种不同的生成模式,可在保证语音韵律特性的同时自由生成语音。此外,它还实现了情感和说话人身份的解耦,能单独控制音色和情感表达。在零样本情境下,该模型可完美再现输入提示的情感特征。
Key Takeaways
- IndexTTS2是一种新型的文本转语音(TTS)模型,适用于自动回归系统。
- 该模型能够实现精确的语音持续时间控制,支持两种生成模式。
- IndexTTS2在保持语音韵律特性的同时,可以自由地生成语音。
- 情感和说话人身份在IndexTTS2中得以解耦,可以独立控制。
- 在零样本情境下,IndexTTS2能够完美复制输入提示的情感特征。
- 用户可以提供单独的情感提示,模型能够在传达期望情感的同时重建目标音色。
点此查看论文截图

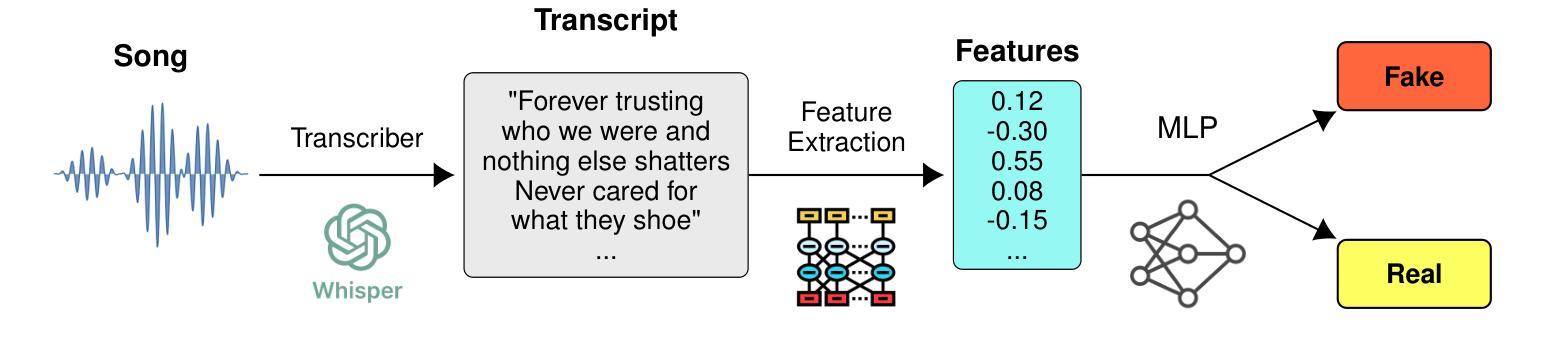
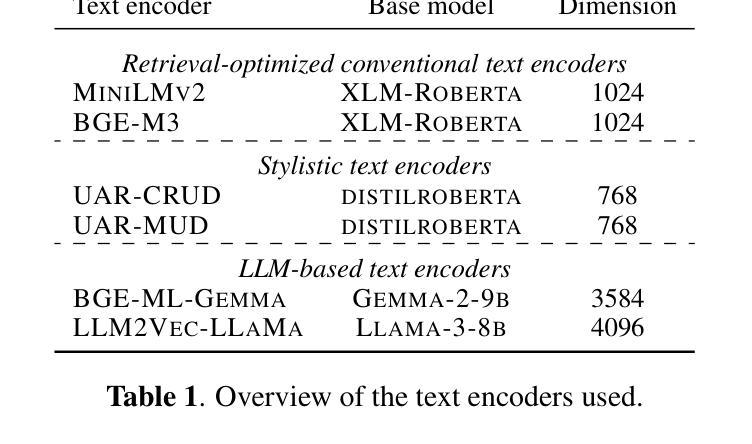
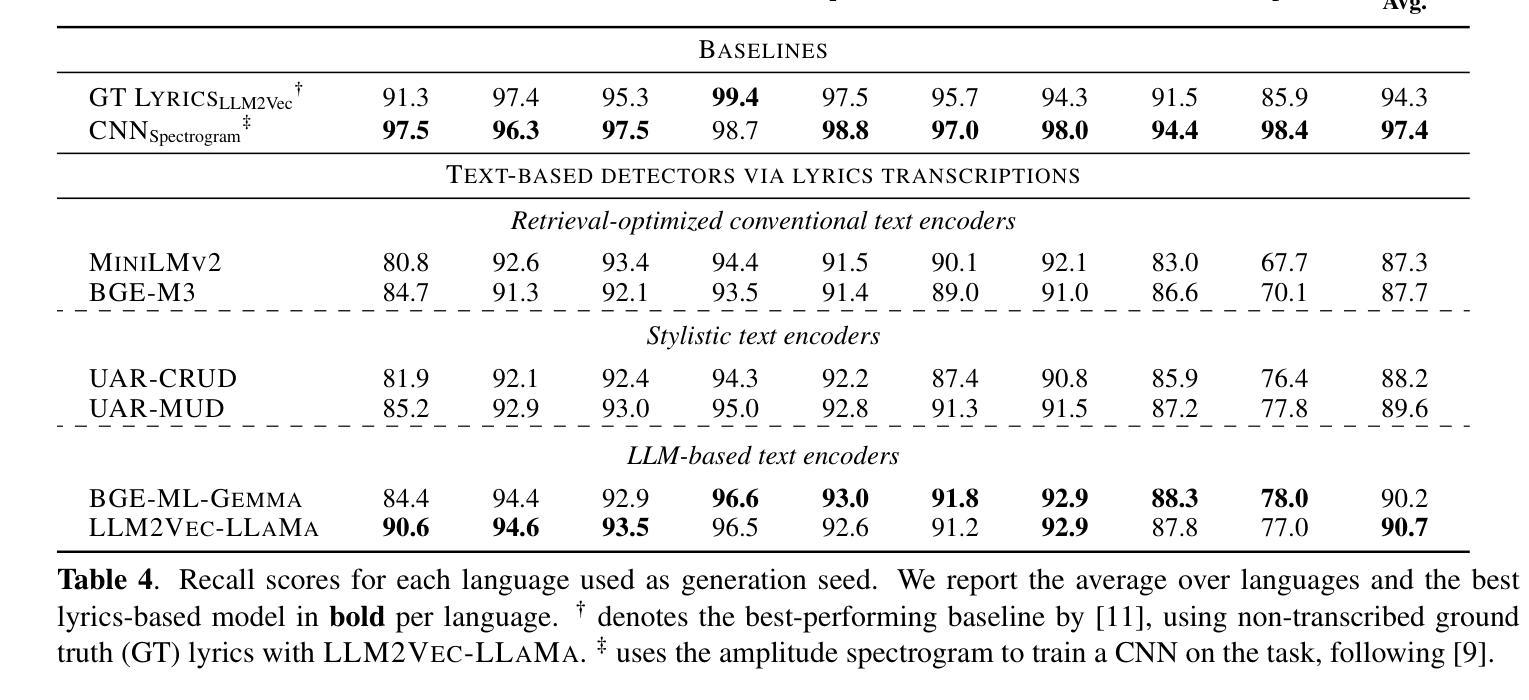
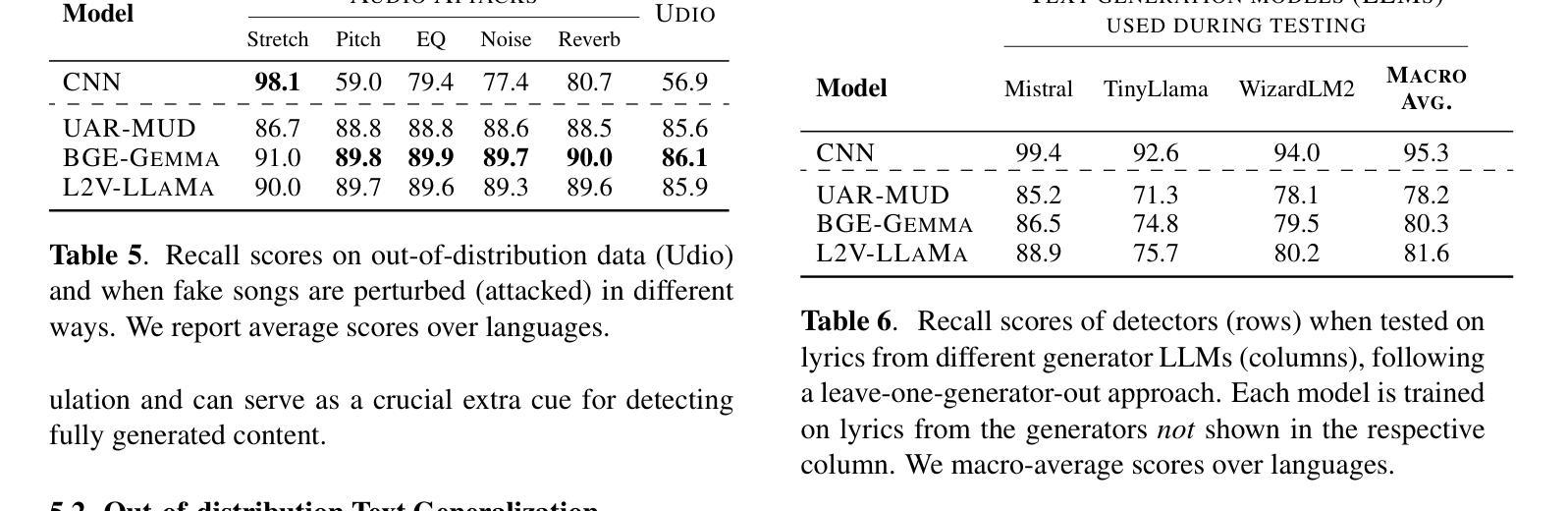
AI-Generated Song Detection via Lyrics Transcripts
Authors:Markus Frohmann, Elena V. Epure, Gabriel Meseguer-Brocal, Markus Schedl, Romain Hennequin
The recent rise in capabilities of AI-based music generation tools has created an upheaval in the music industry, necessitating the creation of accurate methods to detect such AI-generated content. This can be done using audio-based detectors; however, it has been shown that they struggle to generalize to unseen generators or when the audio is perturbed. Furthermore, recent work used accurate and cleanly formatted lyrics sourced from a lyrics provider database to detect AI-generated music. However, in practice, such perfect lyrics are not available (only the audio is); this leaves a substantial gap in applicability in real-life use cases. In this work, we instead propose solving this gap by transcribing songs using general automatic speech recognition (ASR) models. We do this using several detectors. The results on diverse, multi-genre, and multi-lingual lyrics show generally strong detection performance across languages and genres, particularly for our best-performing model using Whisper large-v2 and LLM2Vec embeddings. In addition, we show that our method is more robust than state-of-the-art audio-based ones when the audio is perturbed in different ways and when evaluated on different music generators. Our code is available at https://github.com/deezer/robust-AI-lyrics-detection.
近期,基于人工智能的音乐生成工具的能力提升在音乐产业中引起了巨大变革,因此需要创建准确的方法来检测这种AI生成的内容。这可以通过基于音频的检测器来完成;然而,研究表明,它们在推广到未见过的生成器或音频受到干扰时表现挣扎。此外,近期的工作使用从歌词提供商数据库中的准确且格式整洁的歌词来检测AI生成的音乐。然而,实际上,这样的完美歌词并不可用(只有音频);这在实际使用场景中留下了巨大的适用性差距。在这项工作中,我们提议通过利用通用的自动语音识别(ASR)模型来转录歌曲来解决这个问题。我们使用了多种检测器来完成此任务。在多样化、多风格和多语言的歌词上的结果表明,我们的模型在语言和风格上都有很强的检测性能,特别是使用Whisper large-v2和LLM2Vec嵌入的最佳性能模型。此外,我们还证明了我们的方法在音频以不同方式受到干扰时以及在不同的音乐生成器上进行评估时,比最新的音频检测方法更稳健。我们的代码位于https://github.com/deezer/robust-AI-lyrics-detection。
论文及项目相关链接
PDF Accepted to ISMIR 2025
Summary
AI音乐生成工具的崛起对音乐产业造成了冲击,因此需要开发准确的方法来检测AI生成的内容。现有音频检测器存在局限性,难以适应未见过的生成器或音频扰动情况。研究采用从歌词提供商数据库获取的准确、整洁的歌词进行检测,但在实际应用中完美歌词并不可用,存在应用上的空白。为解决此问题,本研究提出使用通用语音识别(ASR)模型转录歌曲进行检测。使用多个检测器在不同语言、不同流派的音乐上取得了良好的检测效果。同时,该方法在音频受到不同干扰和不同音乐生成器上的表现优于现有音频检测方法。相关研究代码已公开。
Key Takeaways
- AI音乐生成工具的进步对音乐产业产生了影响,需要开发准确的方法来检测AI生成的内容。
- 现有音频检测器在适应不同生成器和音频扰动方面存在局限性。
- 研究采用从歌词提供商数据库获取的准确歌词进行检测,但实际应用中完美歌词的获取并不可行。
- 为解决实际应用中的空白,研究提出使用通用语音识别(ASR)模型进行歌曲转录和检测。
- 使用多个检测器取得了良好的检测效果,适用于不同语言和流派的音乐。
- 该方法在音频受到不同干扰和不同音乐生成器上的表现优于现有音频检测方法。
点此查看论文截图



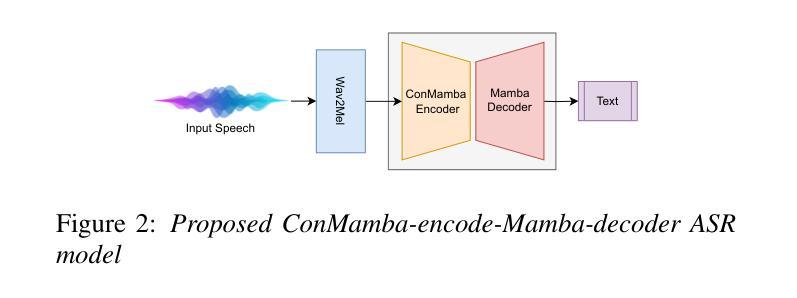
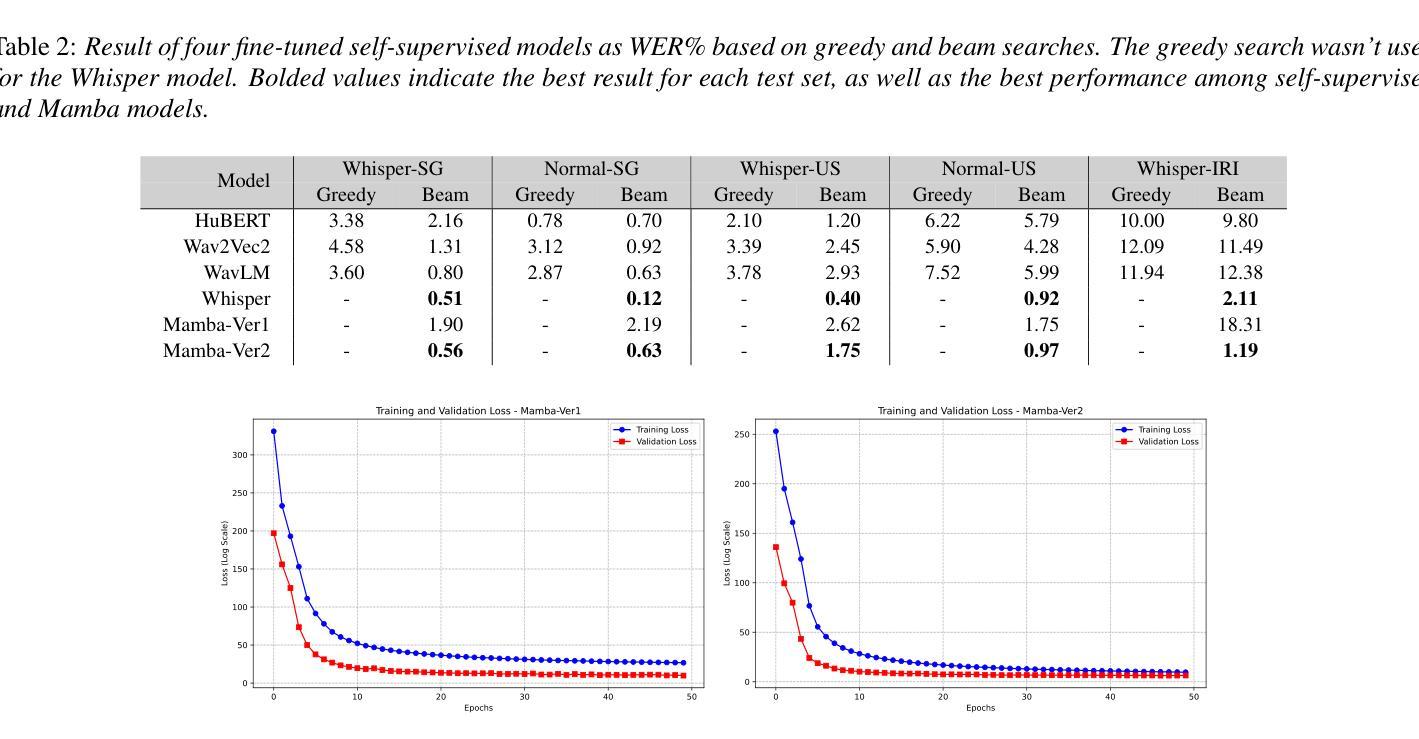
State-Space Models in Efficient Whispered and Multi-dialect Speech Recognition
Authors:Aref Farhadipour, Homayoon Beigi, Volker Dellwo, Hadi Veisi
Whispered speech recognition presents significant challenges for conventional automatic speech recognition systems, particularly when combined with dialect variation. However, utilizing an efficient method to solve this problem using a low-range dataset and processing load is beneficial. This paper proposes a solution using a Mamba-based state-space model and four fine-tuned self-supervised models consisting of Wav2Vec2, WavLM, HuBERT, and Whisper to address the dual challenges of whispered speech and dialect diversity. Based on our knowledge, this represents the best performance reported on the wTIMIT and CHAINS datasets for whispered speech recognition. We trained the models using whispered and normal speech data across Singaporean, US, and Irish dialects. The findings demonstrated that utilizing the proposed Mamba-based model could work as a highly efficient model trained with low amounts of whispered data to simultaneously work on whispered and normal speech recognition. The code for this work is freely available.
轻声语音识别对于传统的自动语音识别系统来说呈现出重大挑战,特别是当与方言变化相结合时。然而,利用有效的方法解决此问题,使用低范围数据集和处理负载是非常有益的。本文提出了一种基于Mamba的状态空间模型和四个经过微调的自监督模型(包括Wav2Vec2、WavLM、HuBERT和Whisper)的解决方案,以解决轻声和方言多样性所带来的双重挑战。据我们所知,这在wTIMIT和CHAINS数据集上代表了轻声识别的最佳性能。我们使用新加坡、美国和爱尔兰方言的轻声和正常语音数据对模型进行了训练。研究结果表明,使用基于Mamba的模型可以作为用少量轻声数据训练的高效模型,可同时用于轻声和正常语音识别。该工作的代码可免费获取。
论文及项目相关链接
PDF paper is in 4+1 pages
摘要
本文提出一种基于Mamba的状态空间模型,结合四种精细调整的自监督模型(Wav2Vec2、WavLM、HuBERT和Whisper),解决低声语音和方言多样性带来的双重挑战。该模型在wTIMIT和CHAINS数据集上的低声语音识别表现最佳。通过在新加坡方言、美国方言和爱尔兰方言的轻声和正常语音数据上训练模型,研究结果表明,采用基于Mamba的模型能以高效率使用少量的轻声数据,同时处理轻声和正常语音识别。该工作的代码已公开发布。
关键见解
- 低声语音识别对于传统的自动语音识别系统存在挑战,特别是与方言变化相结合时。
- 提出一种基于Mamba的状态空间模型来解决这个问题,该模型在解决低声语音和方言多样性方面表现出色。
- 在wTIMIT和CHAINS数据集上,该模型的表现是目前已知的最佳。
- 模型在轻声和正常语音数据上进行训练,包括新加坡方言、美国方言和爱尔兰方言。
- 利用少量轻声数据训练的模型可以非常高效。
- 该模型可以同时处理低声和正常语音识别。
点此查看论文截图


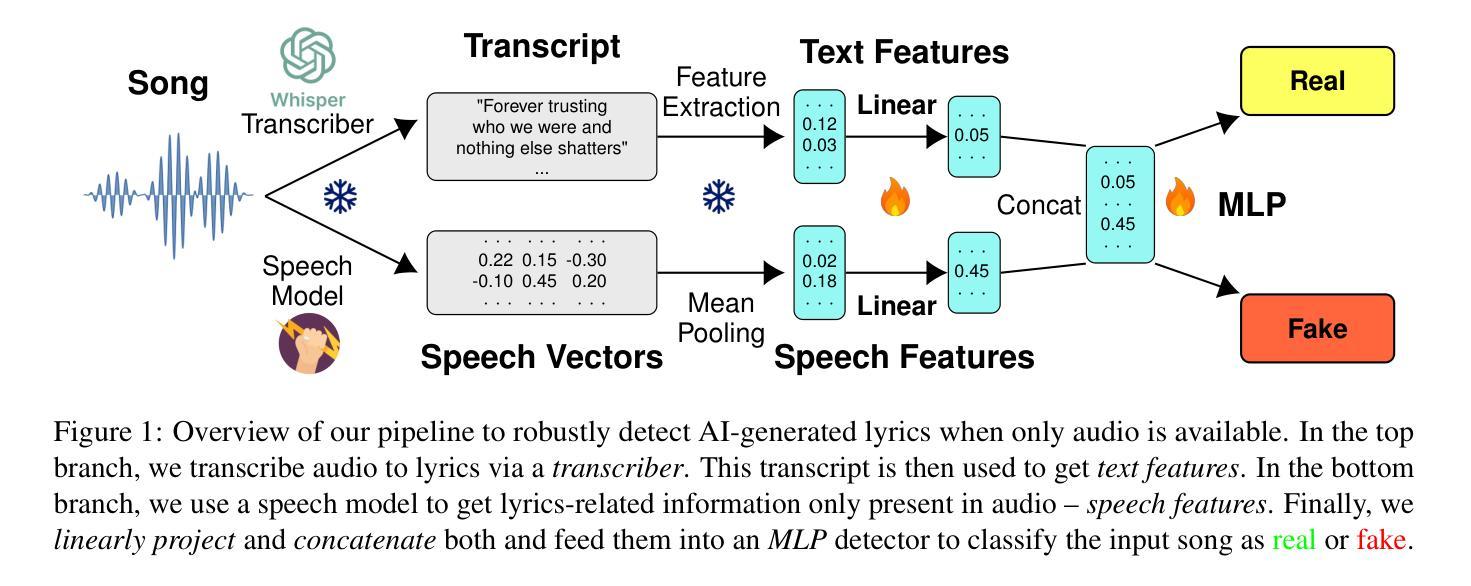
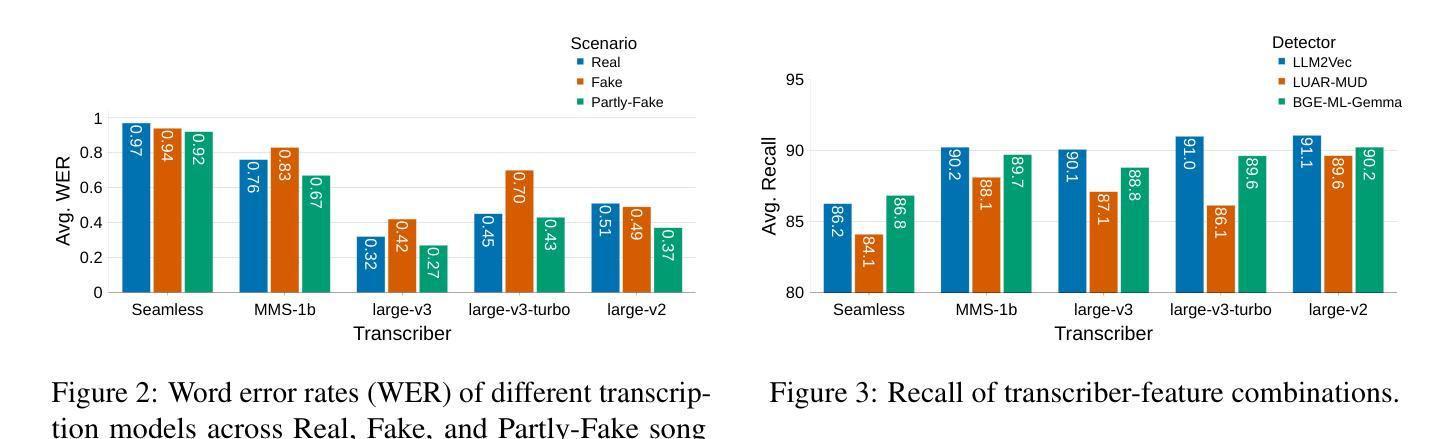
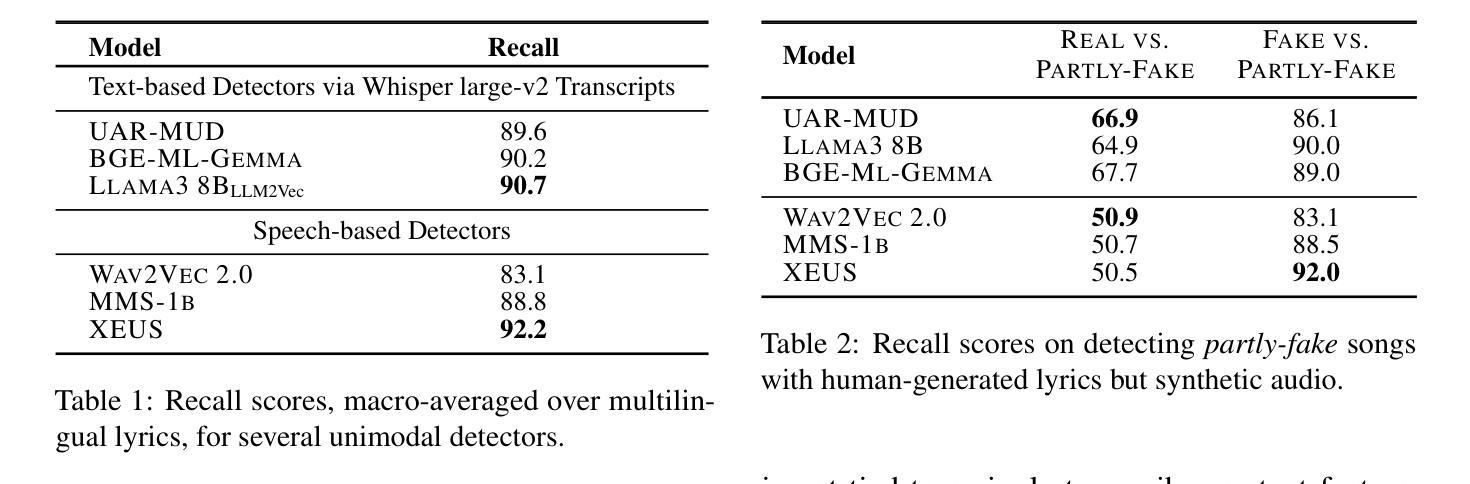
Double Entendre: Robust Audio-Based AI-Generated Lyrics Detection via Multi-View Fusion
Authors:Markus Frohmann, Gabriel Meseguer-Brocal, Markus Schedl, Elena V. Epure
The rapid advancement of AI-based music generation tools is revolutionizing the music industry but also posing challenges to artists, copyright holders, and providers alike. This necessitates reliable methods for detecting such AI-generated content. However, existing detectors, relying on either audio or lyrics, face key practical limitations: audio-based detectors fail to generalize to new or unseen generators and are vulnerable to audio perturbations; lyrics-based methods require cleanly formatted and accurate lyrics, unavailable in practice. To overcome these limitations, we propose a novel, practically grounded approach: a multimodal, modular late-fusion pipeline that combines automatically transcribed sung lyrics and speech features capturing lyrics-related information within the audio. By relying on lyrical aspects directly from audio, our method enhances robustness, mitigates susceptibility to low-level artifacts, and enables practical applicability. Experiments show that our method, DE-detect, outperforms existing lyrics-based detectors while also being more robust to audio perturbations. Thus, it offers an effective, robust solution for detecting AI-generated music in real-world scenarios. Our code is available at https://github.com/deezer/robust-AI-lyrics-detection.
基于人工智能的音乐生成工具的快速发展正在革命性地改变音乐行业,同时也给艺术家、版权所有者和提供商带来了挑战。这迫切需要可靠的方法来检测这种AI生成的内容。然而,现有的检测器,无论是依赖音频还是歌词,都面临关键的实际局限性:基于音频的检测器无法推广到新的或未见过的生成器,并容易受到音频干扰的影响;基于歌词的方法需要整洁格式化和准确的歌词,这在实践中是得不到的。为了克服这些局限性,我们提出了一种新的、实用的方法:多模态、模块化延迟融合管道,它结合了自动转录的歌唱歌词和捕捉音频中歌词相关信息的语音特征。通过直接从音频中依赖歌词方面,我们的方法提高了稳健性,减轻了对低级伪造的敏感性,并实现了实际应用的可行性。实验表明,我们的方法DE-detect优于现有的基于歌词的检测器,同时对音频干扰更稳健。因此,它为检测现实场景中的AI生成音乐提供了有效且稳健的解决方案。我们的代码可在https://github.com/deezer 找到一个非常有用的AI歌词检测网站并提供了源代码和链接用于进一步研究和实践应用。我们的论文也被放在了开源平台以供下载阅读和研究。如果您对我们的研究感兴趣并希望了解更多关于如何实施此检测器的信息或有任何其他相关问题或想法需要讨论和交流的话请随时与我们联系我们会很乐意为您提供帮助并讨论进一步合作的可能性。
论文及项目相关链接
PDF Accepted to ACL 2025 Findings
Summary
人工智能音乐生成工具的快速发展正在颠覆音乐行业,对艺术家、版权所有者和提供商带来挑战。为了解决这些问题,研究人员提出了一种新型的AI生成音乐内容检测方法DE-detect,该方法结合了自动转录的歌词和音频中的歌词相关信息特征。该方法提高了稳健性,减轻了低级伪造的干扰,并可在实践中应用。DE-detect方法优于现有的歌词检测方法,并对音频扰动具有更强的鲁棒性,为真实场景中检测AI生成的音乐提供了有效且稳健的解决方案。
Key Takeaways
- AI音乐生成工具的快速发展正在改变音乐行业,对各方带来挑战。
- 目前存在的检测工具存在局限性,无法有效检测新的或未知的生成器,且容易受到音频干扰。
- 为了解决这些问题,提出了一种新型的多模式、模块化延迟融合管道方法,结合了自动转录的歌词和音频中的歌词相关信息特征。
- 该方法提高了稳健性,降低了受低级伪造的干扰风险。
- 实验显示,新方法优于现有歌词检测方法,对音频扰动具有更强的鲁棒性。
- 该方法提供了一个有效且稳健的解决方案,用于检测真实场景中的AI生成音乐。
点此查看论文截图

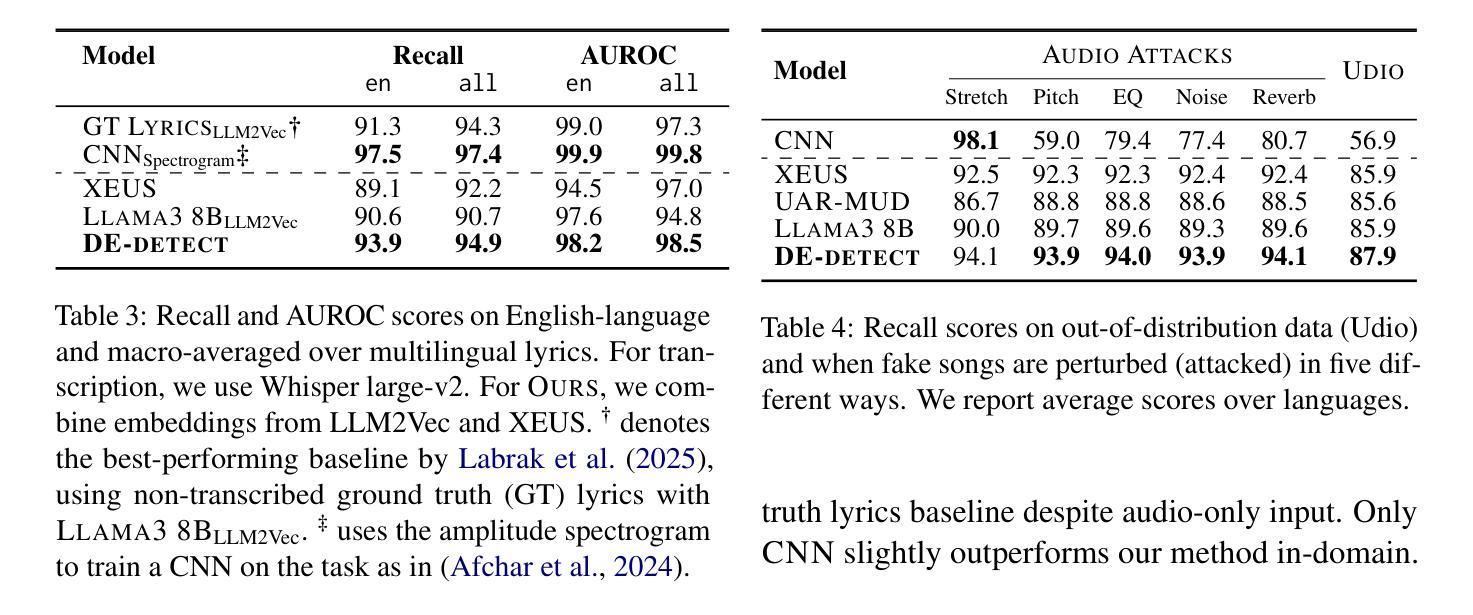
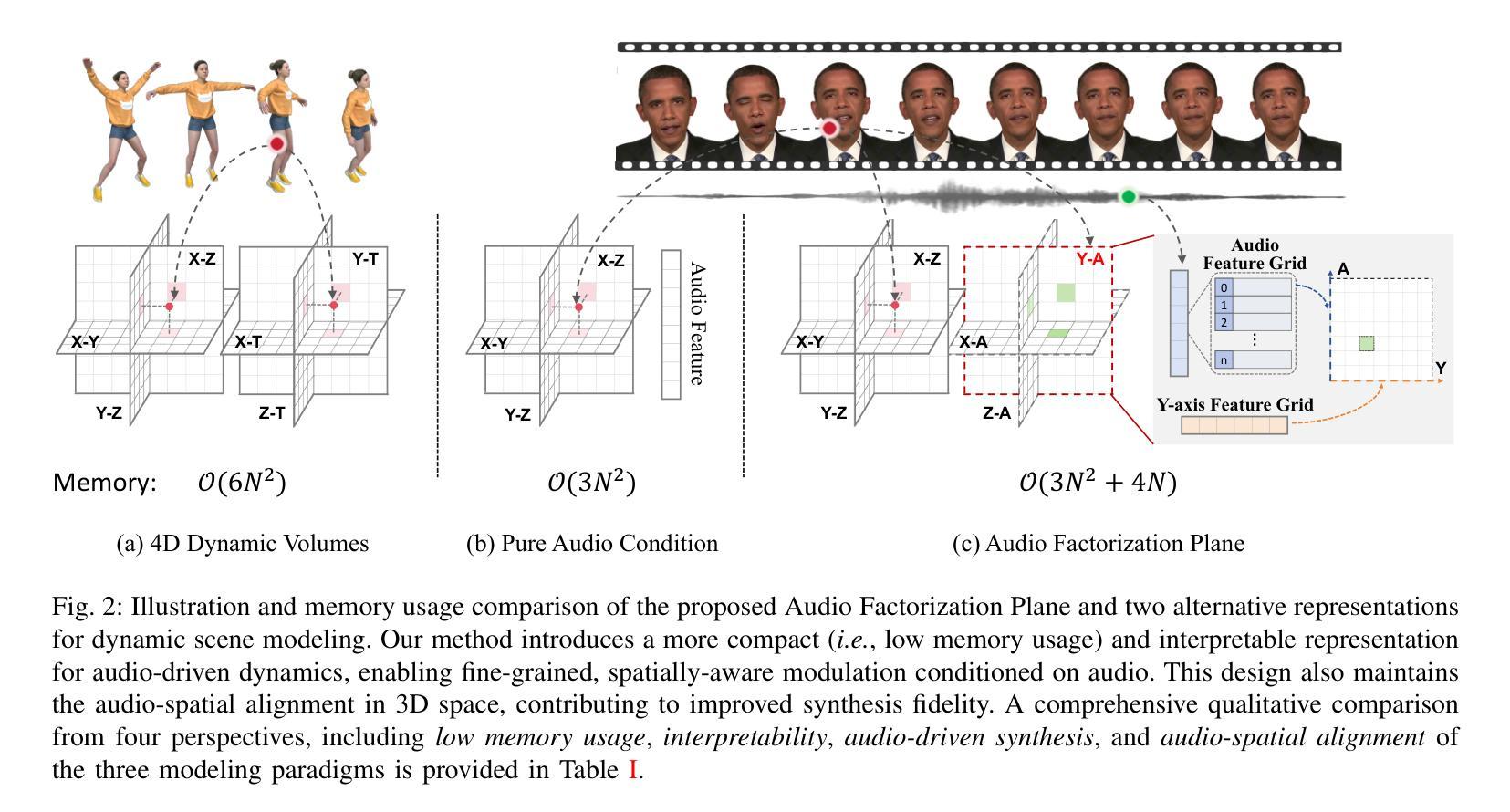
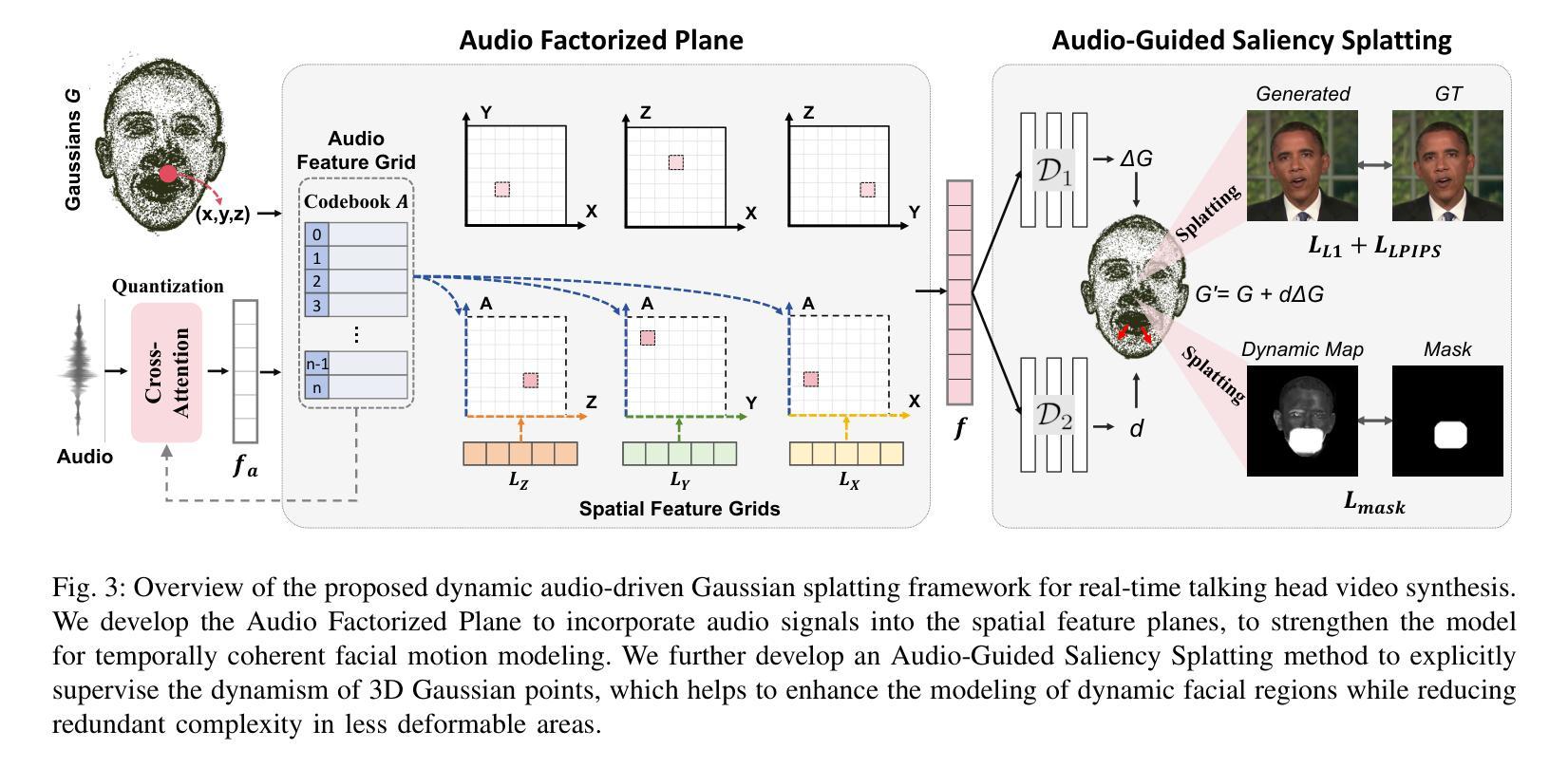
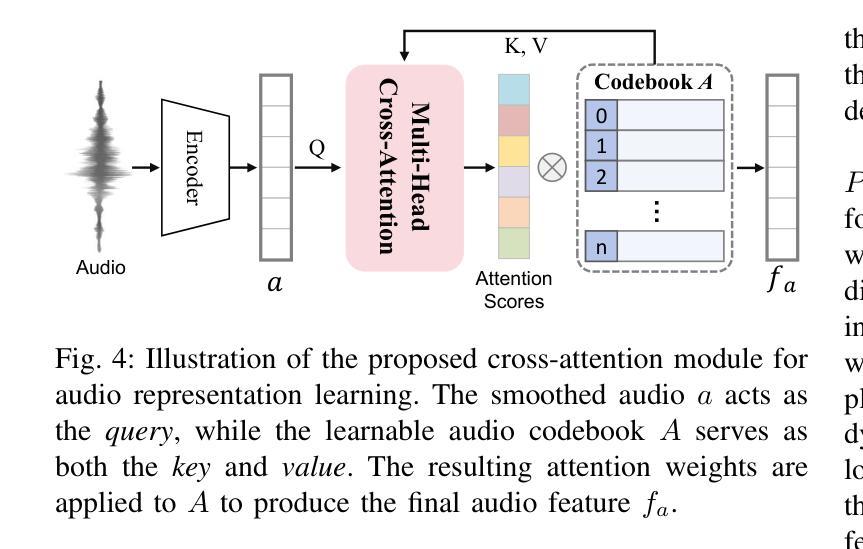
Audio-Plane: Audio Factorization Plane Gaussian Splatting for Real-Time Talking Head Synthesis
Authors:Shuai Shen, Wanhua Li, Yunpeng Zhang, Yap-Peng Tan, Jiwen Lu
Talking head synthesis has emerged as a prominent research topic in computer graphics and multimedia, yet most existing methods often struggle to strike a balance between generation quality and computational efficiency, particularly under real-time constraints. In this paper, we propose a novel framework that integrates Gaussian Splatting with a structured Audio Factorization Plane (Audio-Plane) to enable high-quality, audio-synchronized, and real-time talking head generation. For modeling a dynamic talking head, a 4D volume representation, which consists of three axes in 3D space and one temporal axis aligned with audio progression, is typically required. However, directly storing and processing a dense 4D grid is impractical due to the high memory and computation cost, and lack of scalability for longer durations. We address this challenge by decomposing the 4D volume representation into a set of audio-independent spatial planes and audio-dependent planes, forming a compact and interpretable representation for talking head modeling that we refer to as the Audio-Plane. This factorized design allows for efficient and fine-grained audio-aware spatial encoding, and significantly enhances the model’s ability to capture complex lip dynamics driven by speech signals. To further improve region-specific motion modeling, we introduce an audio-guided saliency splatting mechanism based on region-aware modulation, which adaptively emphasizes highly dynamic regions such as the mouth area. This allows the model to focus its learning capacity on where it matters most for accurate speech-driven animation. Extensive experiments on both the self-driven and the cross-driven settings demonstrate that our method achieves state-of-the-art visual quality, precise audio-lip synchronization, and real-time performance, outperforming prior approaches across both 2D- and 3D-based paradigms.
说话人头部合成已成为计算机图形学和多媒体领域的一个突出研究主题。然而,现有的大多数方法往往难以在生成质量和计算效率之间取得平衡,特别是在实时约束下。在本文中,我们提出了一种新的框架,它结合了高斯溅出技术和结构化音频因子化平面(音频平面),以实现高质量、音频同步和实时的说话人头部生成。为了模拟动态的说话人头部,通常需要一种4D体积表示,其由三个空间轴和一个与音频进展对齐的时间轴组成。然而,由于直接存储和处理密集的4D网格涉及高内存和计算成本,并且对于更长时间的模拟缺乏可扩展性,因此这种做法并不实用。我们通过将4D体积表示分解为一系列音频独立的空间平面和音频依赖的平面来解决这一挑战,形成一种紧凑且可解释的说话人头部模型的表示形式,我们称之为音频平面。这种因子化设计允许高效且精细的音频感知空间编码,并显着提高了模型捕捉由语音信号驱动的复杂嘴唇动态的能力。为了进一步改进特定区域的运动建模,我们引入了一种基于区域感知调制的音频引导显著性溅出机制,该机制自适应地强调高度动态的区域,如口腔区域。这使模型能够专注于学习最重要部分以准确实现语音驱动动画。在自我驱动和交叉驱动环境下的广泛实验表明,我们的方法实现了最先进的视觉质量、精确的音频-嘴唇同步和实时性能,在二维和三维基于范式的方法中都优于先前的方法。
论文及项目相关链接
PDF Demo video at \url{https://sstzal.github.io/Audio-Plane/}
Summary
该研究提出了一种新的框架,集成了高斯涂斑技术和结构化音频因子平面(Audio-Plane),以实时生成高质量、音频同步的说话人头像。针对动态说话头的建模,采用了一个创新的四维体积表示法。为应对直接存储和处理密集四维网格带来的高内存和计算成本问题,该研究提出了一种分解四维体积表示法的方法,将其转化为一系列音频独立的空间平面和音频依赖的平面,形成了一个紧凑且易于理解的说话头模型表示方法——音频平面。这种分解设计实现了高效且精细的音频感知空间编码,显著提高了模型捕捉复杂唇部动作的能力。此外,该研究还引入了一种基于区域感知调制的音频引导显著性涂斑机制,该机制可以自适应地强调高度动态的区域,如口部区域。在自我驱动和跨驱动两种设置下的实验表明,该方法在视觉质量、精确的音频唇同步和实时性能方面达到了最先进的水平,在二维和三维范式中均优于以前的方法。
Key Takeaways
- 提出了一种新颖的集成Gaussian Splatting与结构化Audio Factorization Plane(Audio-Plane)的框架,用于高质量、音频同步、实时的说话头生成。
- 采用四维体积表示法来建模动态说话头,包括三个空间轴和时间轴与音频进展对齐。
- 通过将四维体积表示法分解为音频独立的空间平面和音频依赖的平面,解决了直接处理密集四维网格带来的挑战。
- 引入了音频平面这一紧凑且可解释的表示方法,实现了高效且精细的音频感知空间编码。
- 引入了音频引导的显著性涂斑机制,可自适应强调高度动态区域,如口部区域,以提高区域特定的运动建模。
- 实验表明,该方法在视觉质量、音频唇同步和实时性能上达到了先进水准。
点此查看论文截图


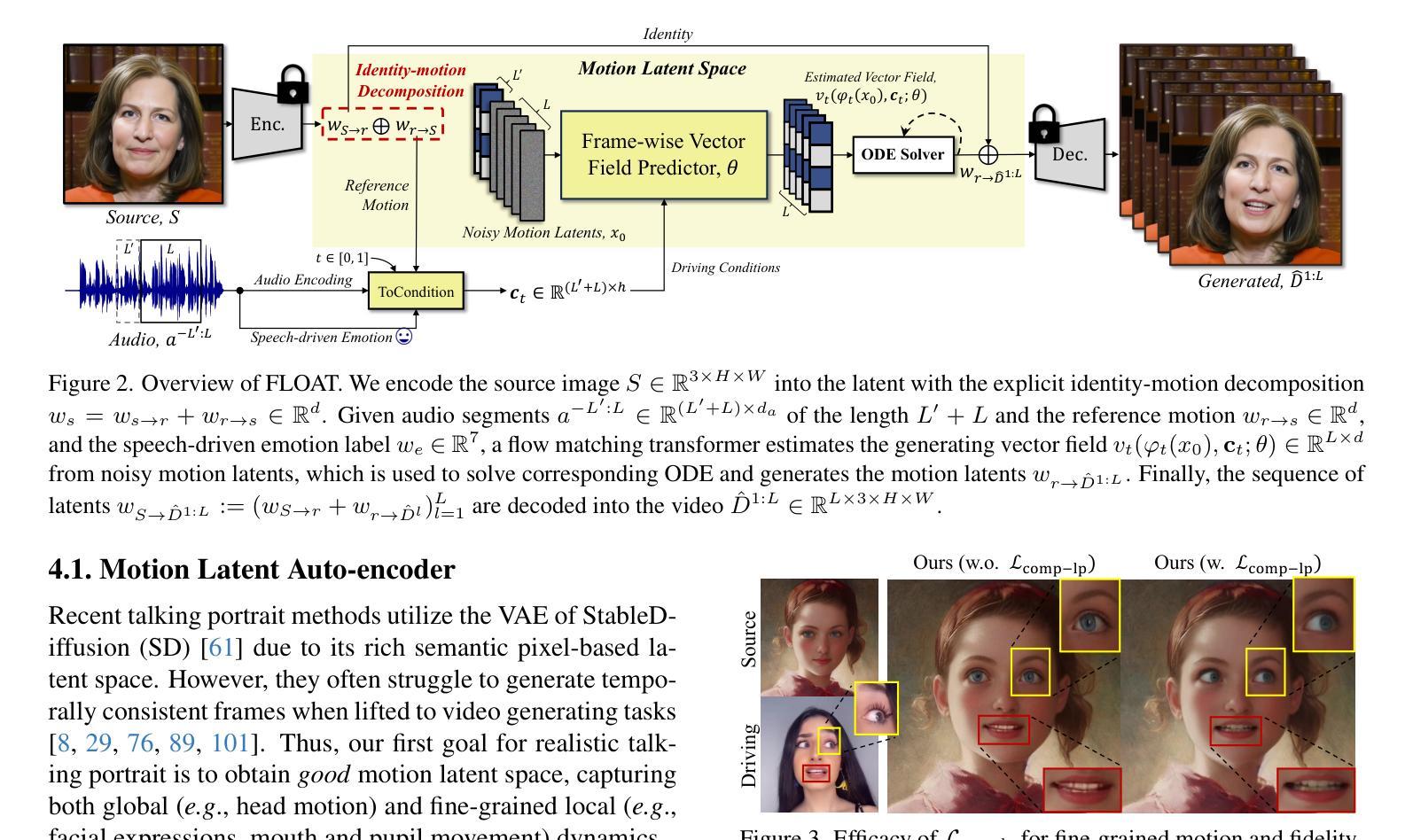
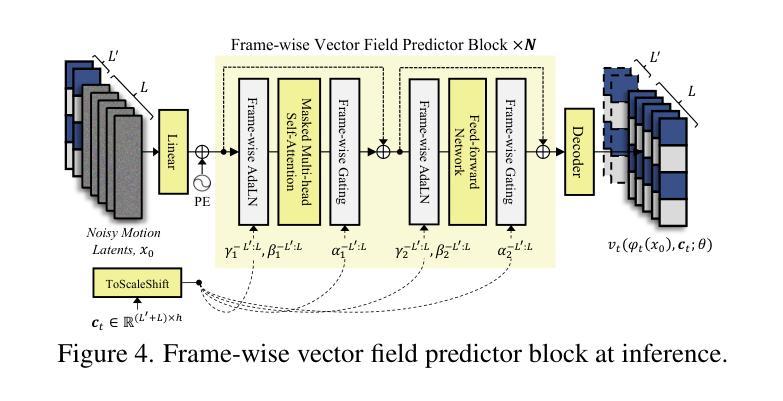
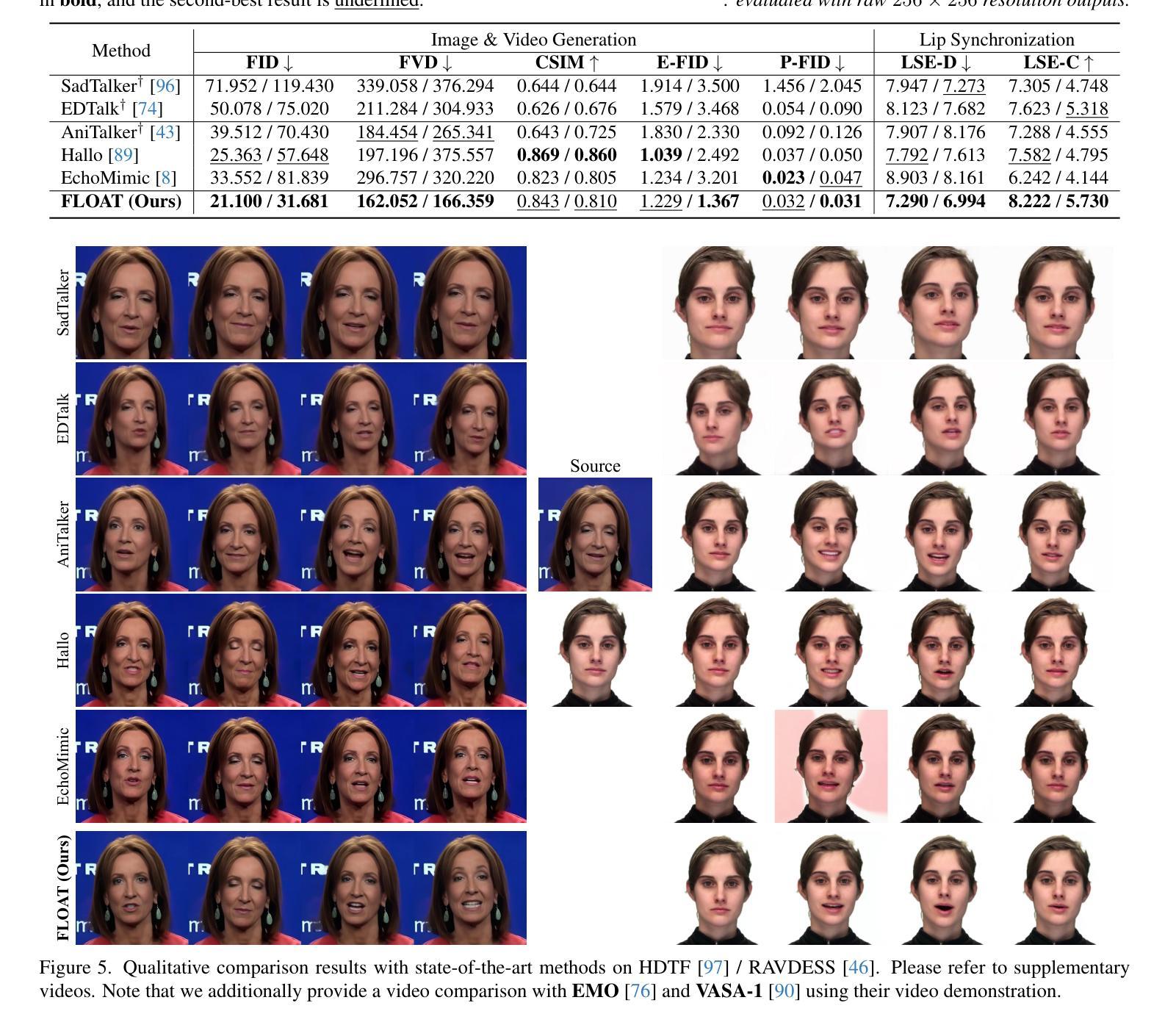
FLOAT: Generative Motion Latent Flow Matching for Audio-driven Talking Portrait
Authors:Taekyung Ki, Dongchan Min, Gyeongsu Chae
With the rapid advancement of diffusion-based generative models, portrait image animation has achieved remarkable results. However, it still faces challenges in temporally consistent video generation and fast sampling due to its iterative sampling nature. This paper presents FLOAT, an audio-driven talking portrait video generation method based on flow matching generative model. Instead of a pixel-based latent space, we take advantage of a learned orthogonal motion latent space, enabling efficient generation and editing of temporally consistent motion. To achieve this, we introduce a transformer-based vector field predictor with an effective frame-wise conditioning mechanism. Additionally, our method supports speech-driven emotion enhancement, enabling a natural incorporation of expressive motions. Extensive experiments demonstrate that our method outperforms state-of-the-art audio-driven talking portrait methods in terms of visual quality, motion fidelity, and efficiency.
随着基于扩散的生成模型的快速发展,肖像图像动画已经取得了显著成果。然而,由于它迭代采样的特性,它在时间一致的视频生成和快速采样方面仍然面临挑战。本文提出了FLOAT,一种基于流匹配生成模型的音频驱动对话肖像视频生成方法。我们利用学习到的正交运动潜在空间,而不是基于像素的潜在空间,实现了时间一致运动的有效生成和编辑。为了实现这一点,我们引入了一个基于变压器的矢量场预测器,并配备了一个有效的帧条件机制。此外,我们的方法支持语音驱动的情感增强,能够实现表达性运动的自然融合。大量实验表明,我们的方法在视觉质量、运动保真度和效率方面优于最先进的音频驱动对话肖像方法。
论文及项目相关链接
PDF ICCV 2025. Project page: https://deepbrainai-research.github.io/float/
Summary
随着扩散生成模型的快速发展,肖像动画已经取得了显著成果,但仍面临临时一致性视频生成和快速采样方面的挑战。本文提出FLOAT方法,一种基于流匹配生成模型的音频驱动肖像视频生成法。与传统的像素级潜在空间不同,本文利用学习到的正交运动潜在空间实现高效且临时一致的动画生成与编辑。此外,通过引入基于变换器的矢量场预测器与有效的帧条件机制,实现语音驱动的情感增强功能,让表情动作的自然融合成为可能。实验证明,相较于先进的音频驱动肖像动画技术,FLOAT在视觉质量、动作真实度与效率上表现更优。
Key Takeaways
- 扩散生成模型的快速发展推动了肖像动画技术的显著进步。
- 肖像动画仍面临临时一致性视频生成和快速采样方面的挑战。
- FLOAT方法利用流匹配生成模型实现音频驱动的肖像视频生成。
- 相较于传统的像素级潜在空间,利用正交运动潜在空间提高动画生成的效率与临时一致性。
- 基于变换器的矢量场预测器与帧条件机制支持语音驱动的情感增强功能。
- 实验结果显示FLOAT在视觉质量、动作真实度与效率方面优于其他先进音频驱动肖像动画技术。
点此查看论文截图