⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-03 更新
JAM-Flow: Joint Audio-Motion Synthesis with Flow Matching
Authors:Mingi Kwon, Joonghyuk Shin, Jaeseok Jung, Jaesik Park, Youngjung Uh
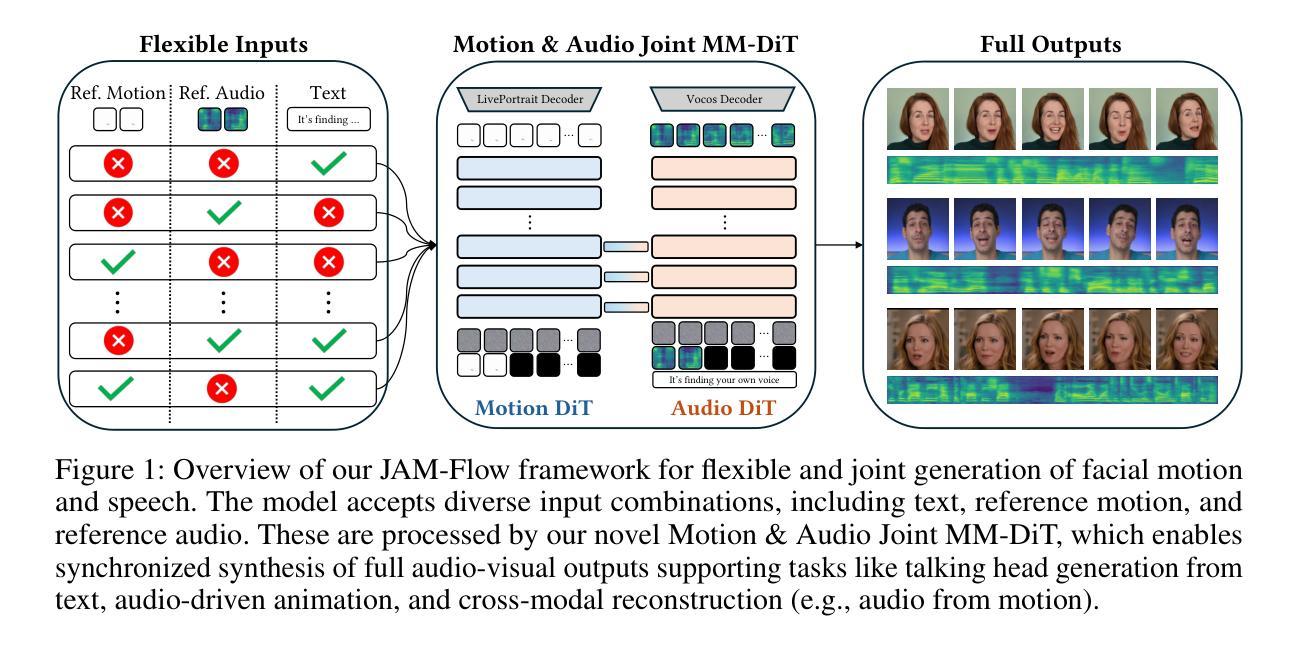
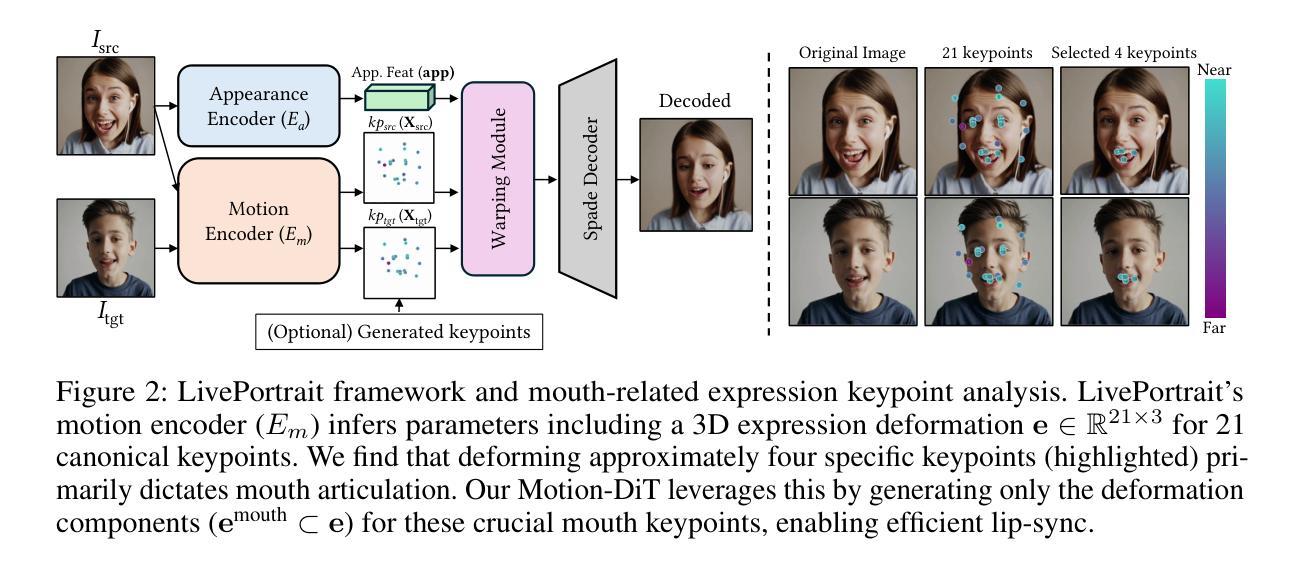
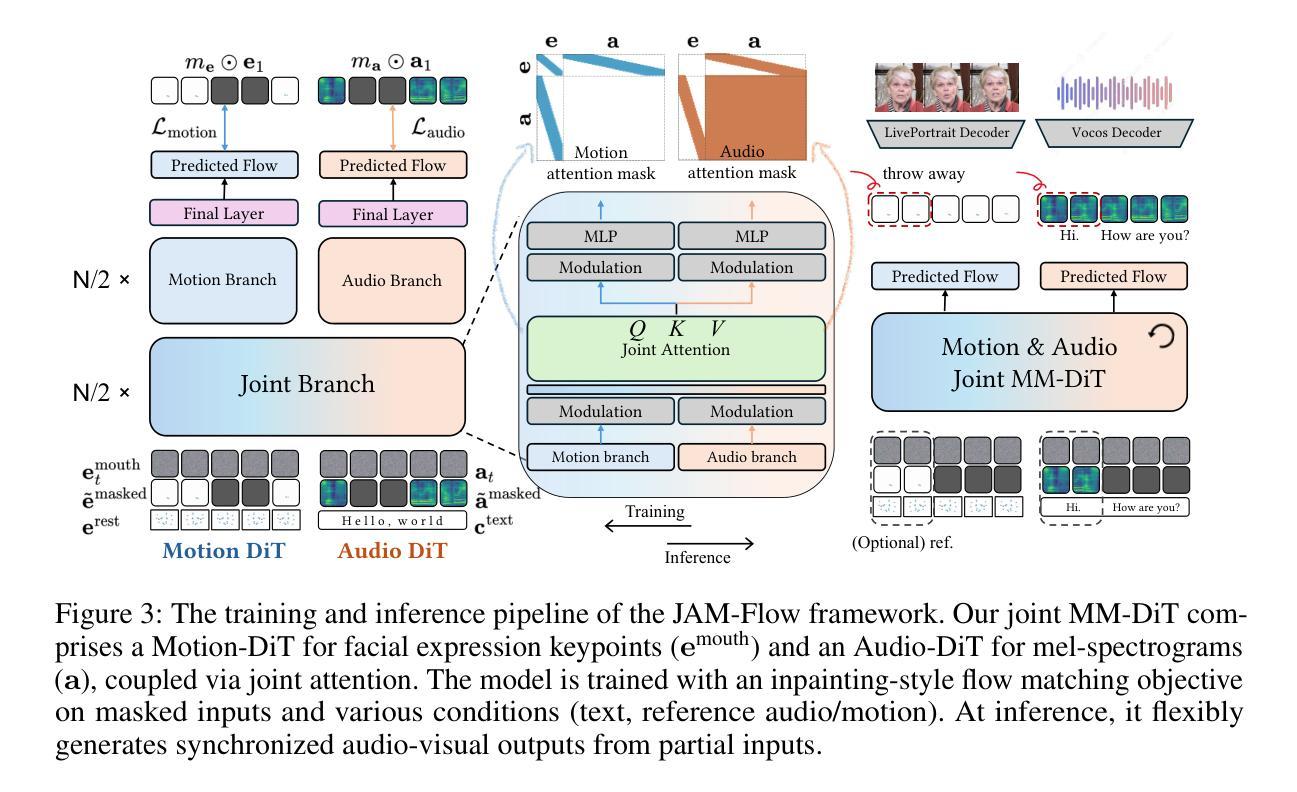
The intrinsic link between facial motion and speech is often overlooked in generative modeling, where talking head synthesis and text-to-speech (TTS) are typically addressed as separate tasks. This paper introduces JAM-Flow, a unified framework to simultaneously synthesize and condition on both facial motion and speech. Our approach leverages flow matching and a novel Multi-Modal Diffusion Transformer (MM-DiT) architecture, integrating specialized Motion-DiT and Audio-DiT modules. These are coupled via selective joint attention layers and incorporate key architectural choices, such as temporally aligned positional embeddings and localized joint attention masking, to enable effective cross-modal interaction while preserving modality-specific strengths. Trained with an inpainting-style objective, JAM-Flow supports a wide array of conditioning inputs-including text, reference audio, and reference motion-facilitating tasks such as synchronized talking head generation from text, audio-driven animation, and much more, within a single, coherent model. JAM-Flow significantly advances multi-modal generative modeling by providing a practical solution for holistic audio-visual synthesis. project page: https://joonghyuk.com/jamflow-web
面部动作与语音之间的内在联系在生成模型中经常被忽视,生成模型中通常将头部合成和文本到语音(TTS)视为单独的任务。本文介绍了JAM-Flow,这是一个统一框架,可以同时合成并基于面部动作和语音的条件进行建模。我们的方法利用流匹配和新颖的多模态扩散转换器(MM-DiT)架构,集成了专门的Motion-DiT和Audio-DiT模块。它们通过选择性联合注意层进行耦合,并采用了关键架构选择,如时间对齐位置嵌入和局部联合注意掩码,以实现有效的跨模态交互同时保留模态特定的优势。通过采用填充风格的目标进行训练,JAM-Flow支持广泛的条件输入,包括文本、参考音频和参考动作,促进诸如从文本生成同步头部、音频驱动动画等任务,在一个单一连贯的模型中实现更多功能。JAM-Flow通过为整体视听合成提供实用解决方案,从而极大地推动了多模态生成模型的发展。项目页面:https://joonghyuk.com/jamflow-web 。
论文及项目相关链接
PDF project page: https://joonghyuk.com/jamflow-web Under review. Preprint published on arXiv
Summary
本文提出一个统一框架JAM-Flow,实现面部动作与语音的同步合成与条件控制。该框架采用流匹配技术和新型多模态扩散转换器(MM-DiT)架构,整合Motion-DiT和Audio-DiT模块,通过选择性联合注意力层进行耦合。JAM-Flow支持多种条件输入,包括文本、参考音频和参考动作,适用于从文本生成同步说话头像、音频驱动动画等任务。该框架为多模态生成建模提供了实用解决方案,实现了音频视觉合成的整体融合。
Key Takeaways
- JAM-Flow是一个统一框架,用于面部动作和语音的合成与条件控制。
- 该框架结合流匹配技术和Multi-Modal Diffusion Transformer(MM-DiT)架构。
- MM-DiT架构包括Motion-DiT和Audio-DiT模块,通过选择性联合注意力层进行交互。
- JAM-Flow支持多种条件输入,包括文本、参考音频和参考动作。
- 该框架可实现从文本生成同步说话头像、音频驱动动画等功能。
- JAM-Flow通过采用inpainting风格的目标函数进行训练。
点此查看论文截图

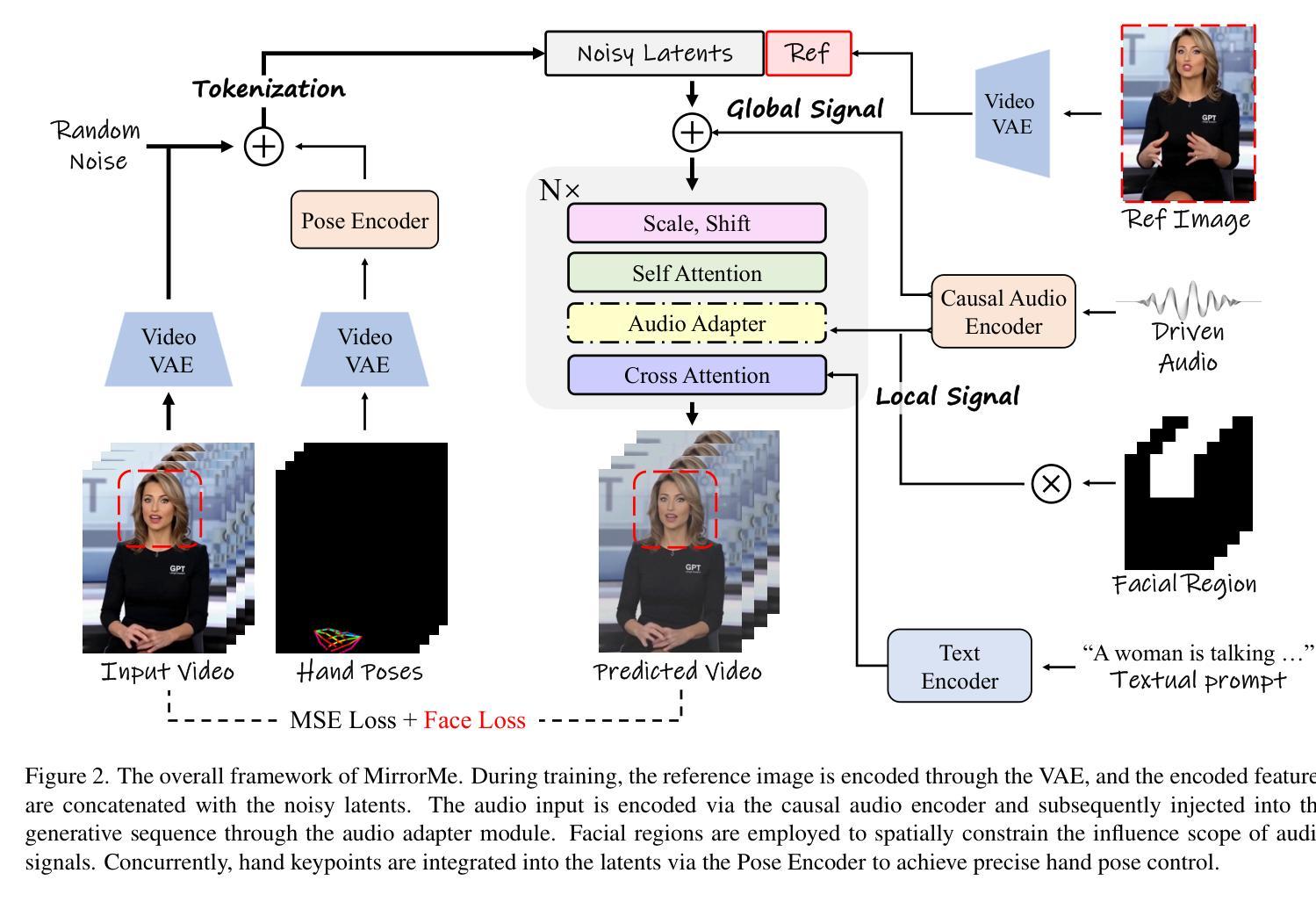
MirrorMe: Towards Realtime and High Fidelity Audio-Driven Halfbody Animation
Authors:Dechao Meng, Steven Xiao, Xindi Zhang, Guangyuan Wang, Peng Zhang, Qi Wang, Bang Zhang, Liefeng Bo
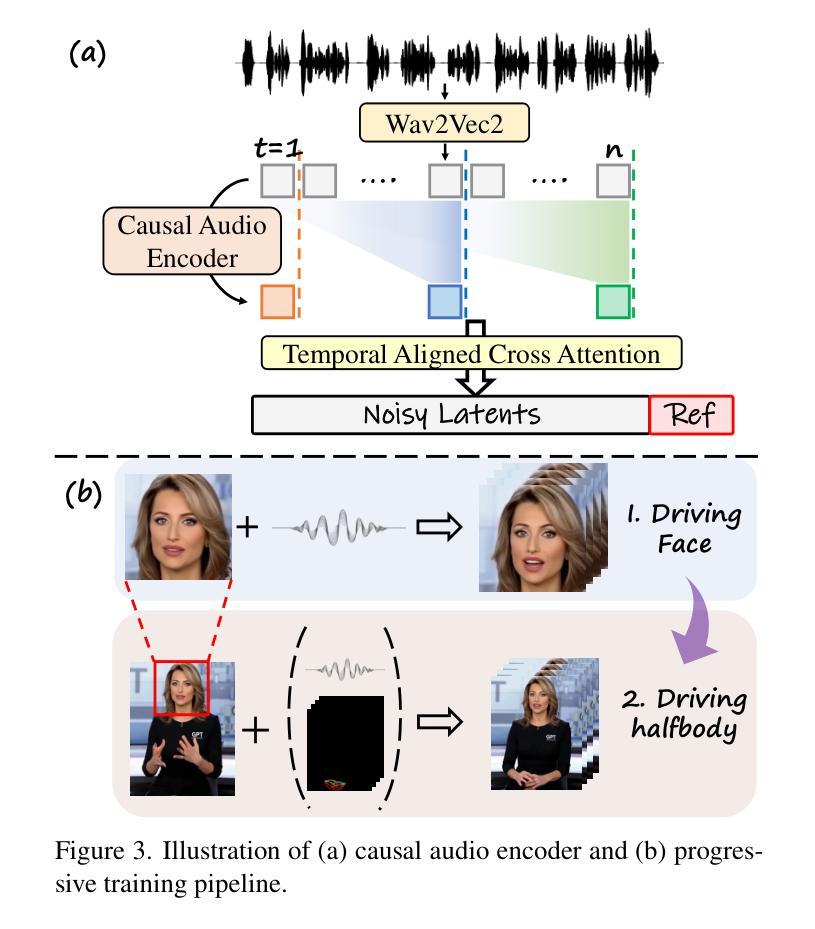
Audio-driven portrait animation, which synthesizes realistic videos from reference images using audio signals, faces significant challenges in real-time generation of high-fidelity, temporally coherent animations. While recent diffusion-based methods improve generation quality by integrating audio into denoising processes, their reliance on frame-by-frame UNet architectures introduces prohibitive latency and struggles with temporal consistency. This paper introduces MirrorMe, a real-time, controllable framework built on the LTX video model, a diffusion transformer that compresses video spatially and temporally for efficient latent space denoising. To address LTX’s trade-offs between compression and semantic fidelity, we propose three innovations: 1. A reference identity injection mechanism via VAE-encoded image concatenation and self-attention, ensuring identity consistency; 2. A causal audio encoder and adapter tailored to LTX’s temporal structure, enabling precise audio-expression synchronization; and 3. A progressive training strategy combining close-up facial training, half-body synthesis with facial masking, and hand pose integration for enhanced gesture control. Extensive experiments on the EMTD Benchmark demonstrate MirrorMe’s state-of-the-art performance in fidelity, lip-sync accuracy, and temporal stability.
音频驱动肖像动画利用音频信号从参考图像合成逼真的视频,在实时生成高保真、时间连贯的动画方面面临重大挑战。虽然最近的基于扩散的方法通过将音频集成到去噪过程中来提高生成质量,但它们对逐帧UNet架构的依赖导致了过高的延迟和时间连贯性问题。本文介绍了MirrorMe,一个基于LTX视频模型的实时可控框架。LTX是一个扩散变压器,可以在空间和时间上压缩视频,以实现有效的潜在空间去噪。为了解决LTX在压缩和语义保真之间的权衡,我们提出了三项创新:1.通过VAE编码的图像拼接和自我关注机制实现参考身份注入机制,确保身份一致性;2.针对LTX的时间结构设计的因果音频编码器和适配器,实现精确的音频表达同步;3.结合面部特写训练、面部遮挡的半体合成以及手势整合的渐进式训练策略,增强手势控制。在EMTD基准测试上的大量实验表明,MirrorMe在保真度、唇同步准确性和时间稳定性方面达到了最新技术水平。
论文及项目相关链接
PDF 8 pages, 6 figures
Summary
本文介绍了一种名为MirrorMe的实时可控框架,该框架基于LTX视频模型,采用扩散变压器技术,能够在空间和时间上压缩视频,实现高效的潜在空间去噪。通过三项创新技术:通过VAE编码的图像拼接和自注意力机制实现身份一致性;针对LTX的临时结构定制因果音频编码器和适配器,实现精确的音频表达同步;以及结合面部特写训练、半身合成与面部遮挡以及手势集成等逐步训练策略,提高了手势控制效果。在EMTD基准测试上的实验表明,MirrorMe在保真度、唇同步准确性和时间稳定性方面达到了最新技术水平。
Key Takeaways
- MirrorMe是一个基于LTX视频模型的实时可控框架,能够实现高效去噪和音频驱动的肖像动画。
- 该框架通过三项创新技术解决了LTX模型在压缩和语义保真度之间的权衡问题。
- 采用身份一致性机制确保参考身份在动画中的连续性。
- 精确的音频表达同步通过因果音频编码器和适配器实现。
- 逐步训练策略提高了手势控制和整体动画的逼真度。
- 在EMTD基准测试上,MirrorMe表现出优异的性能,达到了最新技术水平。
点此查看论文截图


Few-Shot Identity Adaptation for 3D Talking Heads via Global Gaussian Field
Authors:Hong Nie, Fuyuan Cao, Lu Chen, Fengxin Chen, Yuefeng Zou, Jun Yu
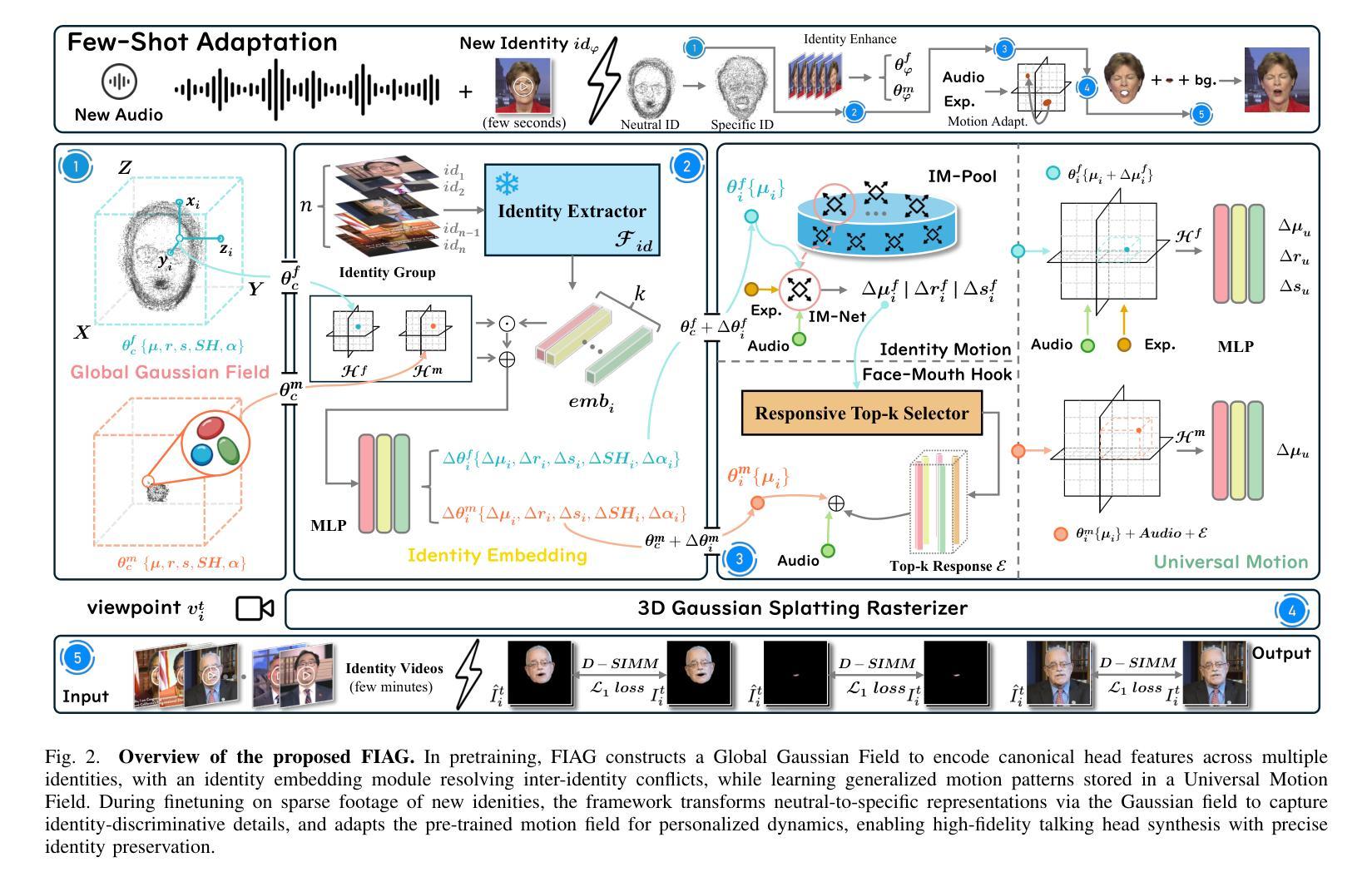
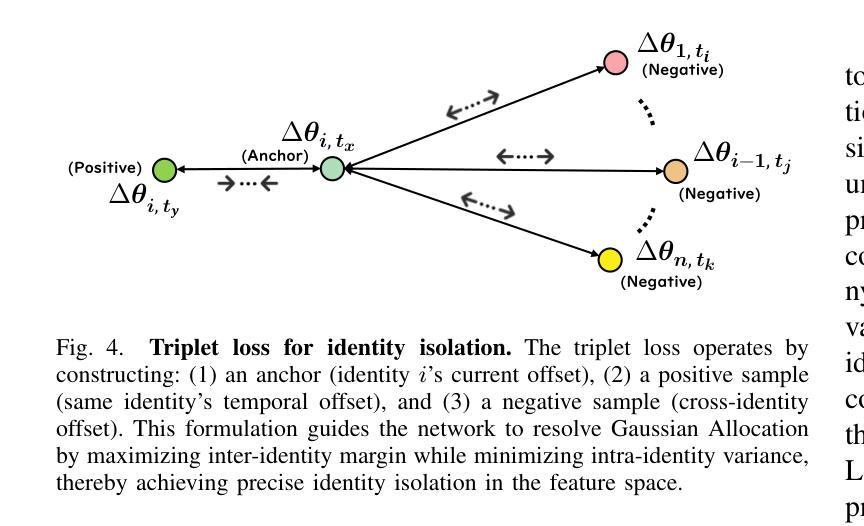
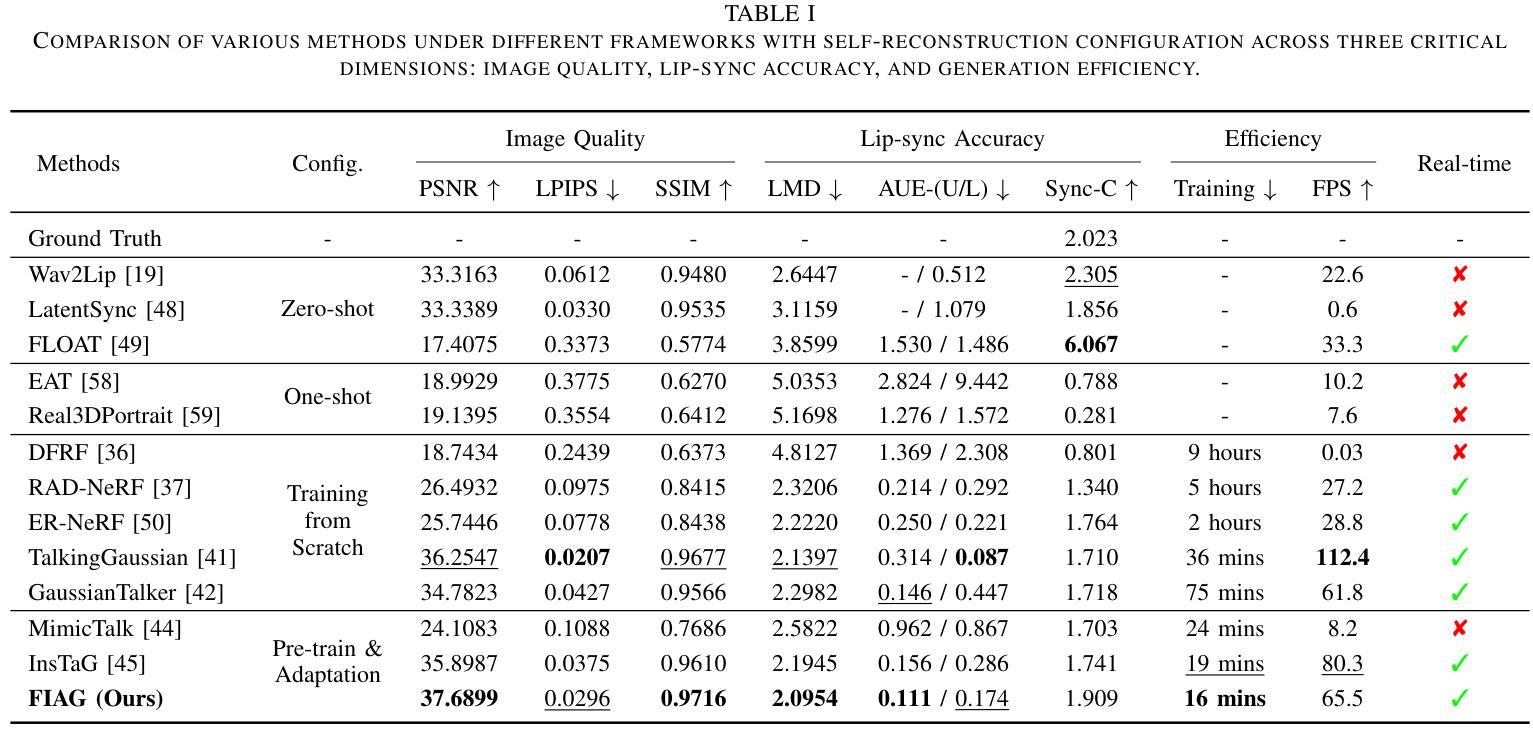
Reconstruction and rendering-based talking head synthesis methods achieve high-quality results with strong identity preservation but are limited by their dependence on identity-specific models. Each new identity requires training from scratch, incurring high computational costs and reduced scalability compared to generative model-based approaches. To overcome this limitation, we propose FIAG, a novel 3D speaking head synthesis framework that enables efficient identity-specific adaptation using only a few training footage. FIAG incorporates Global Gaussian Field, which supports the representation of multiple identities within a shared field, and Universal Motion Field, which captures the common motion dynamics across diverse identities. Benefiting from the shared facial structure information encoded in the Global Gaussian Field and the general motion priors learned in the motion field, our framework enables rapid adaptation from canonical identity representations to specific ones with minimal data. Extensive comparative and ablation experiments demonstrate that our method outperforms existing state-of-the-art approaches, validating both the effectiveness and generalizability of the proposed framework. Code is available at: \textit{https://github.com/gme-hong/FIAG}.
基于重建和渲染的说话人头部合成方法虽然能够达成高质量的结果并强烈保留身份特征,但它们依赖于特定身份的模型,因此存在局限性。每个新身份都需要从头开始训练,这增加了计算成本,与基于生成模型的方法相比,可扩展性降低。为了克服这一限制,我们提出了FIAG,这是一个新型的3D说话人头部合成框架,它只需少量的训练镜头就能实现高效的身份特定适应。FIAG结合了全局高斯场,支持在共享场内表示多个身份,以及通用运动场,能捕捉不同身份之间的共同运动动力学。受益于编码在全局高斯场中的共享面部结构信息和运动场中学习到的一般运动先验,我们的框架能够迅速从规范身份表示适应到特定身份表示,所需数据最少。广泛的对比和消融实验表明,我们的方法优于现有的最先进方法,验证了所提出框架的有效性和通用性。代码可在:[https://github.com/gme-hong/FIAG]上找到。
论文及项目相关链接
Summary
基于重建和渲染的说话人头部合成方法虽然能够达成高质量的结果并保留强烈的身份特征,但它们依赖于特定身份模型,为每个新身份都需要从头开始训练,计算成本高且可扩展性差。为了克服这一局限性,我们提出了FIAG,这是一个新型的3D说话人头合成框架,它使用少量的训练视频就能实现有效的身份特定适配。FIAG结合了全局高斯场,支持在共享场内表示多个身份,以及通用运动场,能捕捉不同身份的通用运动动态。得益于编码在全局高斯场中的共享面部结构信息和运动场中学习的通用运动先验知识,我们的框架能够迅速从规范身份表示适应特定身份,所需数据极少。广泛的对比和消融实验证明,我们的方法优于现有的最先进的方法,验证了所提出框架的有效性和通用性。相关代码已发布在:https://github.com/gme-hong/FIAG。
Key Takeaways
- FIAG是一个新型的3D说话人头合成框架,能有效进行身份特定适配。
- FIAG使用全局高斯场和通用运动场来分别处理身份表示和运动动态。
- 框架能够迅速适应特定身份,仅需少量数据。
- 对比和消融实验证明FIAG优于现有方法。
- FIAG框架具有有效性和通用性。
- 相关代码已发布在指定GitHub仓库。
点此查看论文截图



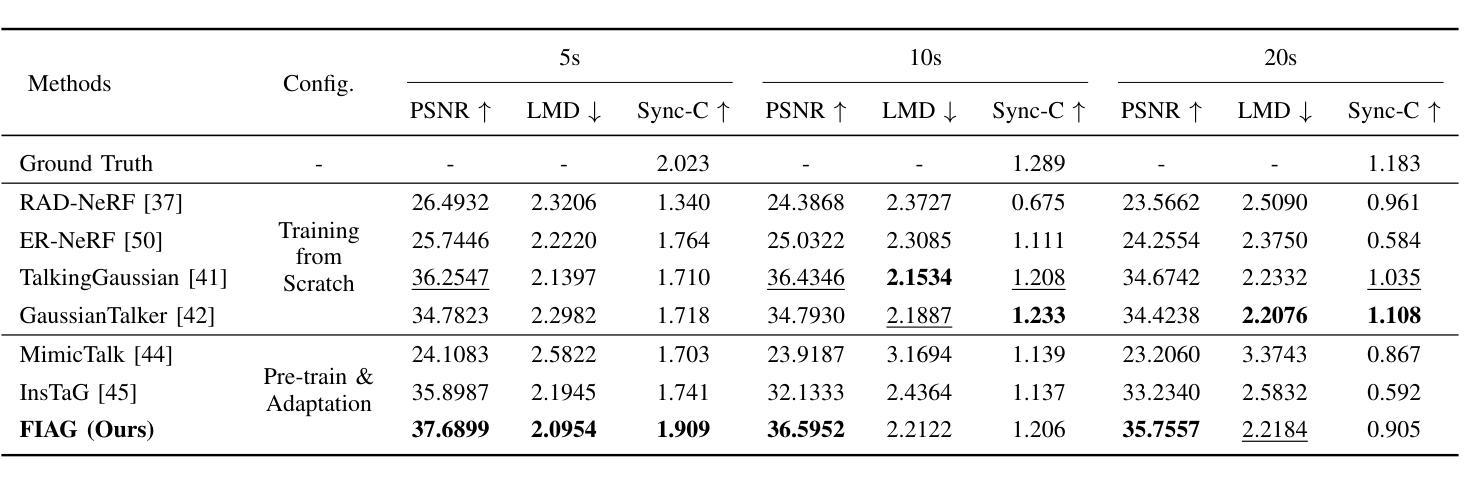
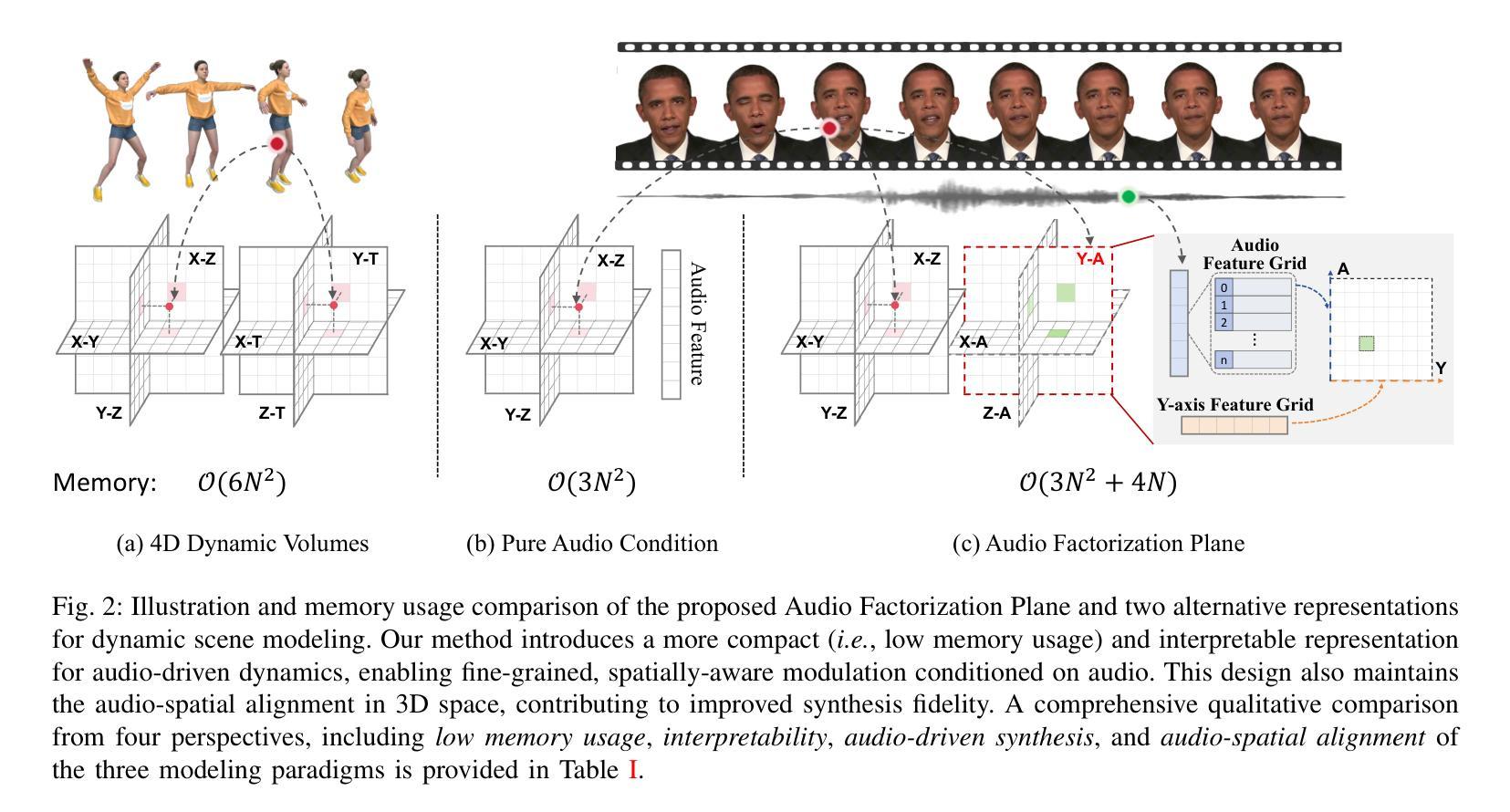
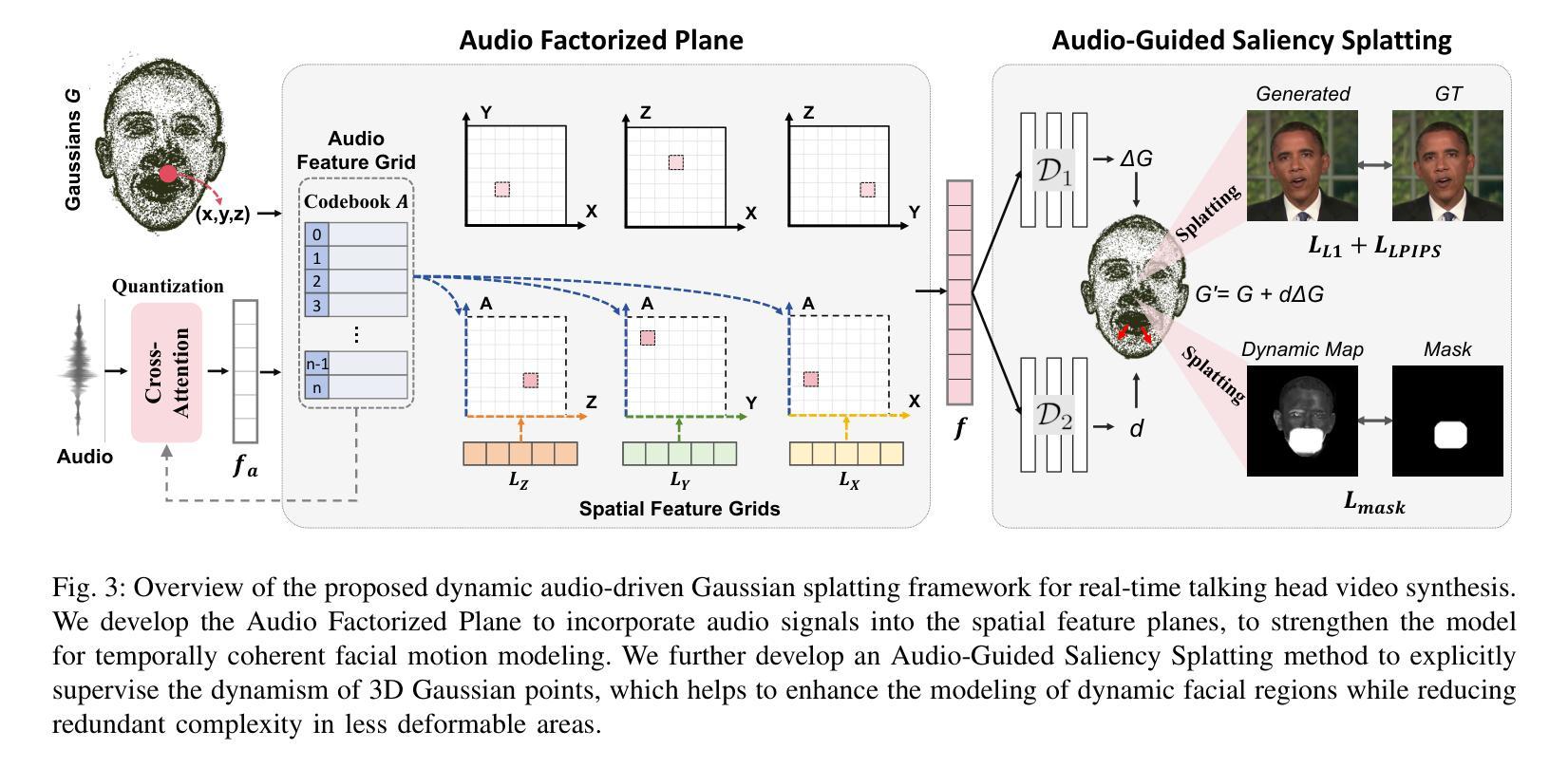
Audio-Plane: Audio Factorization Plane Gaussian Splatting for Real-Time Talking Head Synthesis
Authors:Shuai Shen, Wanhua Li, Yunpeng Zhang, Yap-Peng Tan, Jiwen Lu
Talking head synthesis has emerged as a prominent research topic in computer graphics and multimedia, yet most existing methods often struggle to strike a balance between generation quality and computational efficiency, particularly under real-time constraints. In this paper, we propose a novel framework that integrates Gaussian Splatting with a structured Audio Factorization Plane (Audio-Plane) to enable high-quality, audio-synchronized, and real-time talking head generation. For modeling a dynamic talking head, a 4D volume representation, which consists of three axes in 3D space and one temporal axis aligned with audio progression, is typically required. However, directly storing and processing a dense 4D grid is impractical due to the high memory and computation cost, and lack of scalability for longer durations. We address this challenge by decomposing the 4D volume representation into a set of audio-independent spatial planes and audio-dependent planes, forming a compact and interpretable representation for talking head modeling that we refer to as the Audio-Plane. This factorized design allows for efficient and fine-grained audio-aware spatial encoding, and significantly enhances the model’s ability to capture complex lip dynamics driven by speech signals. To further improve region-specific motion modeling, we introduce an audio-guided saliency splatting mechanism based on region-aware modulation, which adaptively emphasizes highly dynamic regions such as the mouth area. This allows the model to focus its learning capacity on where it matters most for accurate speech-driven animation. Extensive experiments on both the self-driven and the cross-driven settings demonstrate that our method achieves state-of-the-art visual quality, precise audio-lip synchronization, and real-time performance, outperforming prior approaches across both 2D- and 3D-based paradigms.
头部谈话合成已成为计算机图形学和多媒体领域的一个突出研究话题。然而,大多数现有方法往往难以在生成质量和计算效率之间取得平衡,特别是在实时约束下。在本文中,我们提出了一个新颖框架,该框架结合了高斯贴图(Gaussian Splatting)与结构化音频分解平面(Audio-Plane),以实现高质量、音频同步、实时头部谈话生成。为了模拟动态谈话头部,通常需要一种4D体积表示,其由三维空间中的三个轴和与音频进展对齐的时间轴组成。然而,直接存储和处理密集的4D网格是不切实际的,因为这会消耗大量内存和计算资源,并且对于更长时间的模拟缺乏可扩展性。我们通过将4D体积表示分解为一系列音频独立的空间平面和音频依赖的平面来解决这一挑战,形成一种紧凑且可解释的谈话头部模型表示,我们称之为Audio-Plane。这种分解设计允许进行高效且精细的音频感知空间编码,并极大地提高了模型捕捉由语音信号驱动的复杂嘴唇动态的能力。为了进一步改进区域特定的运动建模,我们引入了一种基于区域感知调制的音频引导显著性贴图机制,该机制自适应地强调高度动态的区域,如嘴巴区域。这允许模型将学习能力集中在对于语音驱动动画最重要的地方。在自我驱动和交叉驱动两种设置下的广泛实验表明,我们的方法实现了最先进的视觉质量、精确的音频-嘴唇同步和实时性能,在二维和三维基于范式的方法中都超越了先前的方法。
论文及项目相关链接
PDF Demo video at \url{https://sstzal.github.io/Audio-Plane/}
Summary
本文提出了一种新的结合高斯融合与结构化音频分解平面(Audio-Plane)的框架,实现了高质量、音频同步、实时的人头生成。该框架通过分解四维体积表示,形成紧凑且可解释的音频平面表示法,有效解决了直接存储和处理密集四维网格的不切实际问题。此外,引入了音频引导显著性融合机制,自适应强调高度动态区域,如口腔区域,进一步提高区域特定运动建模的精确度。实验表明,该方法在自驱动和跨驱动设置中均实现了最佳视觉质量、精确的音频唇同步和实时性能,在2D和3D基础上均超越了先前的方法。
Key Takeaways
- 介绍了说话人头合成领域的研究现状和挑战。
- 提出了一种新的框架,结合了高斯融合和结构化音频分解平面(Audio-Plane),旨在实现高质量、音频同步和实时的说话人头生成。
- 通过分解四维体积表示法来解决直接处理密集四维网格的问题,提出了一种紧凑且可解释的音频平面表示法。
- 引入了音频引导显著性融合机制,以提高区域特定运动建模的精确度。
- 实验表明,该方法在视觉质量、音频唇同步和实时性能方面都达到了最先进的水平,且在自驱动和跨驱动设置中都优于以前的方法。
- 该方法提供了一种有效的平衡生成质量和计算效率的手段,特别是在实时约束下。
点此查看论文截图


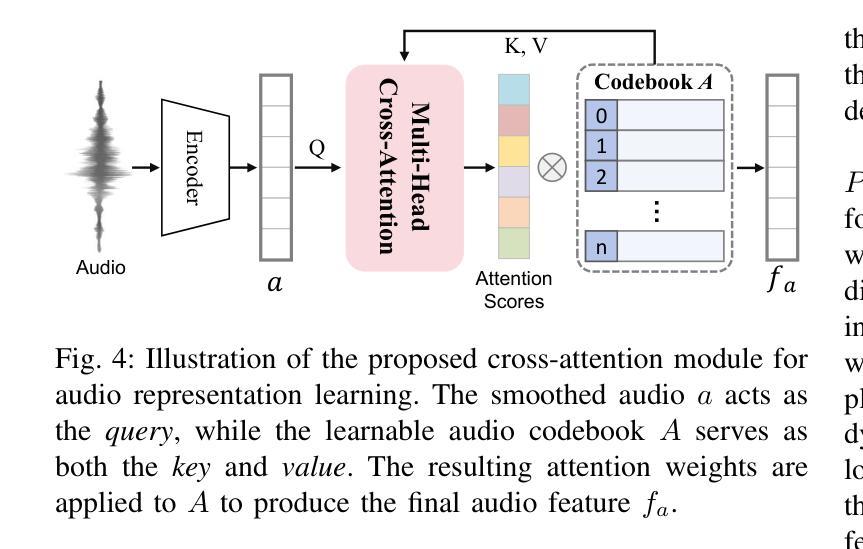
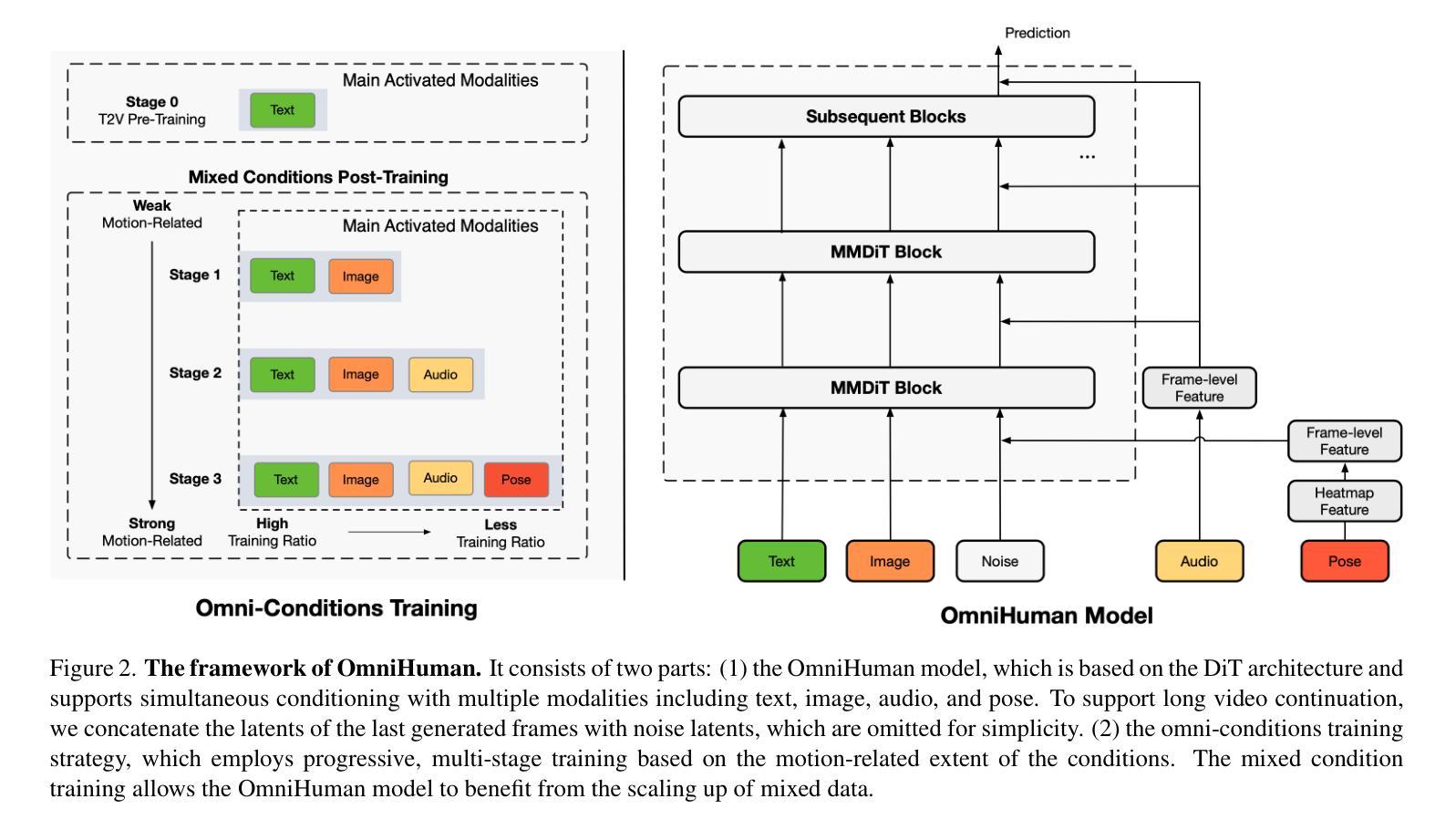
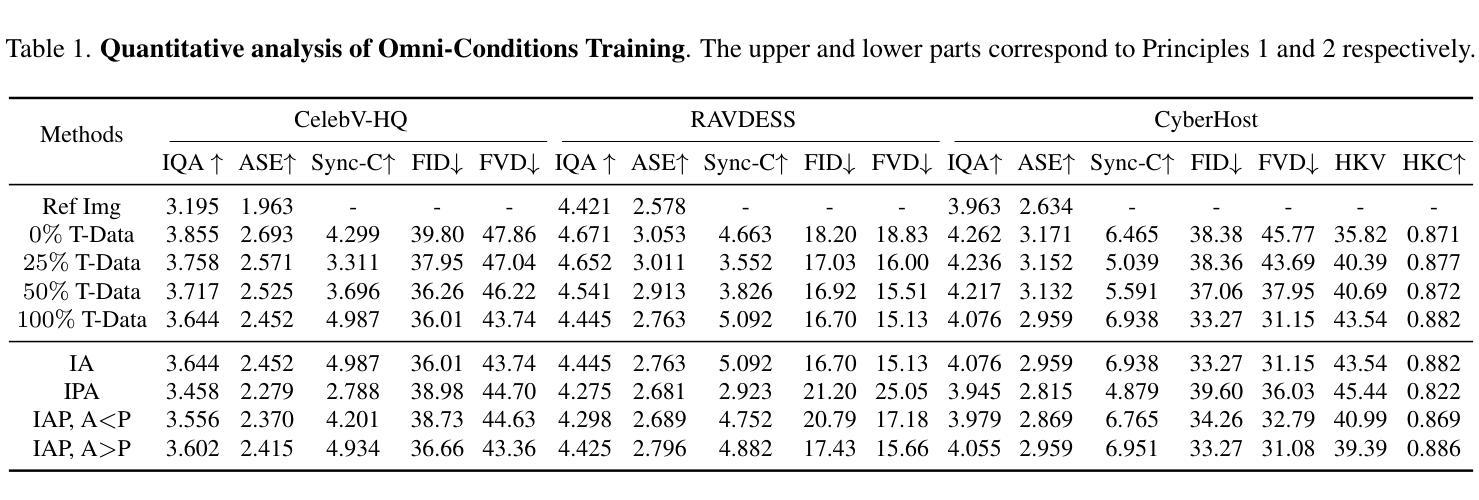
OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models
Authors:Gaojie Lin, Jianwen Jiang, Jiaqi Yang, Zerong Zheng, Chao Liang
End-to-end human animation, such as audio-driven talking human generation, has undergone notable advancements in the recent few years. However, existing methods still struggle to scale up as large general video generation models, limiting their potential in real applications. In this paper, we propose OmniHuman, a Diffusion Transformer-based framework that scales up data by mixing motion-related conditions into the training phase. To this end, we introduce two training principles for these mixed conditions, along with the corresponding model architecture and inference strategy. These designs enable OmniHuman to fully leverage data-driven motion generation, ultimately achieving highly realistic human video generation. More importantly, OmniHuman supports various portrait contents (face close-up, portrait, half-body, full-body), supports both talking and singing, handles human-object interactions and challenging body poses, and accommodates different image styles. Compared to existing end-to-end audio-driven methods, OmniHuman not only produces more realistic videos, but also offers greater flexibility in inputs. It also supports multiple driving modalities (audio-driven, video-driven and combined driving signals). Video samples are provided on the ttfamily project page (https://omnihuman-lab.github.io)
端到端的人类动画,例如音频驱动的人类谈话生成,在最近几年经历了显著的进步。然而,现有方法仍然难以扩展为大型通用视频生成模型,限制了其在真实应用中的潜力。在本文中,我们提出了OmniHuman,这是一个基于Diffusion Transformer的框架,通过混合运动相关条件来扩展数据训练阶段。为此,我们介绍了两种针对这些混合条件的训练原则,以及相应的模型结构和推理策略。这些设计使OmniHuman能够充分利用数据驱动的运动生成,最终实现高度逼真的人类视频生成。更重要的是,OmniHuman支持各种肖像内容(特写、肖像、半身、全身)、支持对话和歌唱、处理人与物体互动和具有挑战性的身体姿势,并适应不同的图像风格。与现有的端到端音频驱动方法相比,OmniHuman不仅生成更逼真的视频,而且在输入方面提供了更大的灵活性。它还支持多种驱动模式(音频驱动、视频驱动和组合驱动信号)。视频样本请参见ttfamily项目页面(https://omnihuman-lab.github.io)。
论文及项目相关链接
PDF ICCV 2025, Homepage: https://omnihuman-lab.github.io/
Summary
基于Diffusion Transformer框架的OmniHuman模型,通过混合运动条件进行训练,实现了大规模数据的扩展,提高了在真实应用场景中的潜力。该模型可以支持多种肖像内容、说话和唱歌、人机交互和复杂动作,并兼容不同的图像风格。相较于现有的端到端音频驱动方法,OmniHuman不仅能生成更逼真的视频,而且在输入上具有更大的灵活性,并支持多种驱动模式(音频驱动、视频驱动和组合驱动信号)。
Key Takeaways
- OmniHuman模型基于Diffusion Transformer框架构建。
- 通过混合运动条件进行训练,实现了数据的扩展。
- 支持多种肖像内容、说话和唱歌、人机交互和复杂动作。
- 兼容不同的图像风格。
- 相较于现有方法,OmniHuman能生成更逼真的视频。
- 输入具有更大的灵活性,支持多种驱动模式。
- 视频样本可在ttfamily项目页面查看。
点此查看论文截图

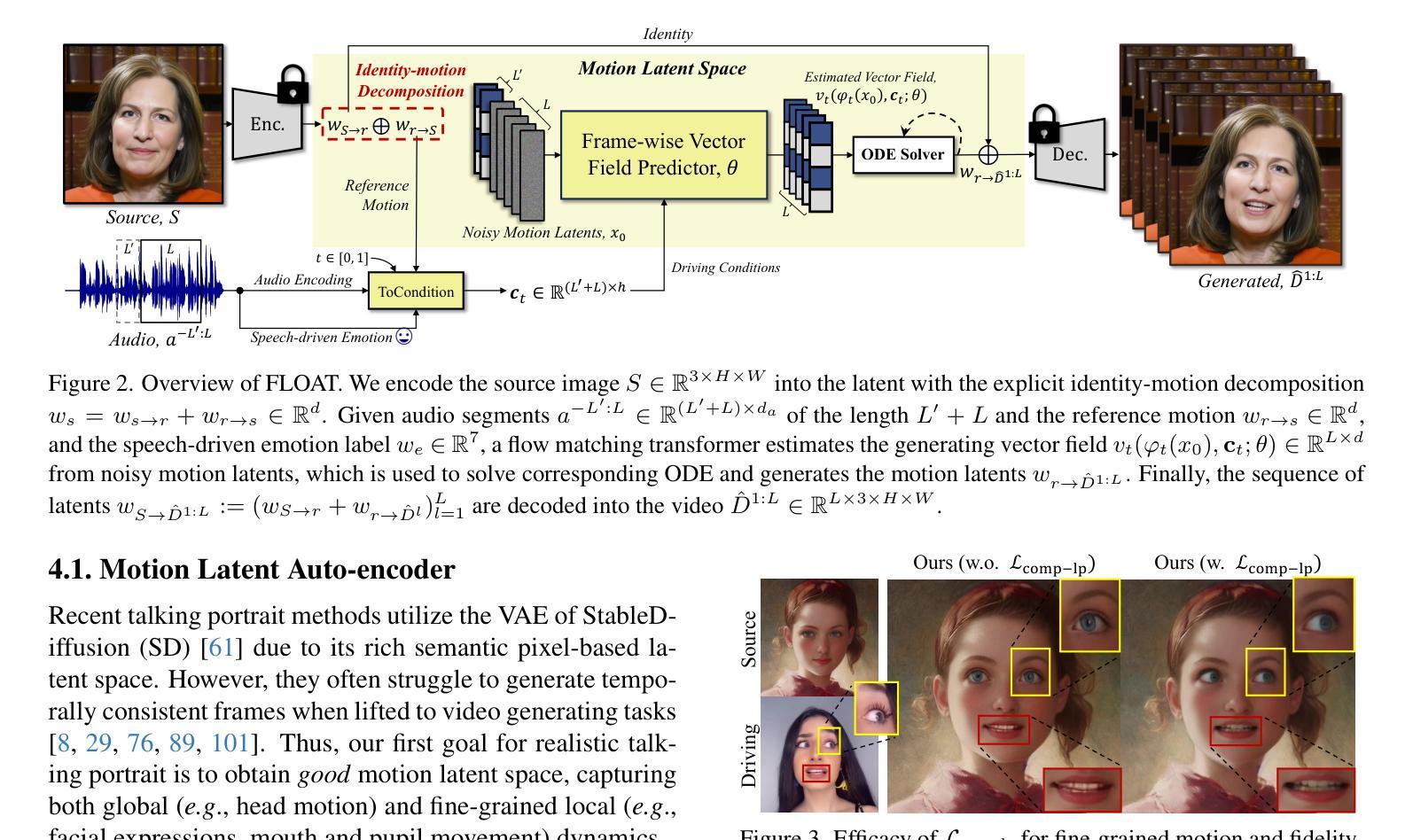
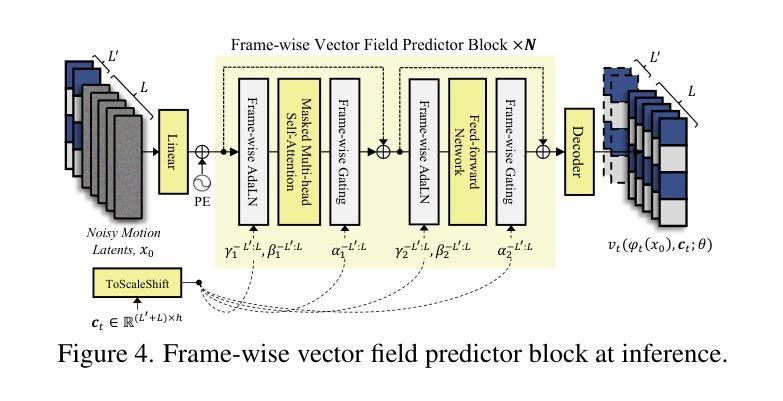
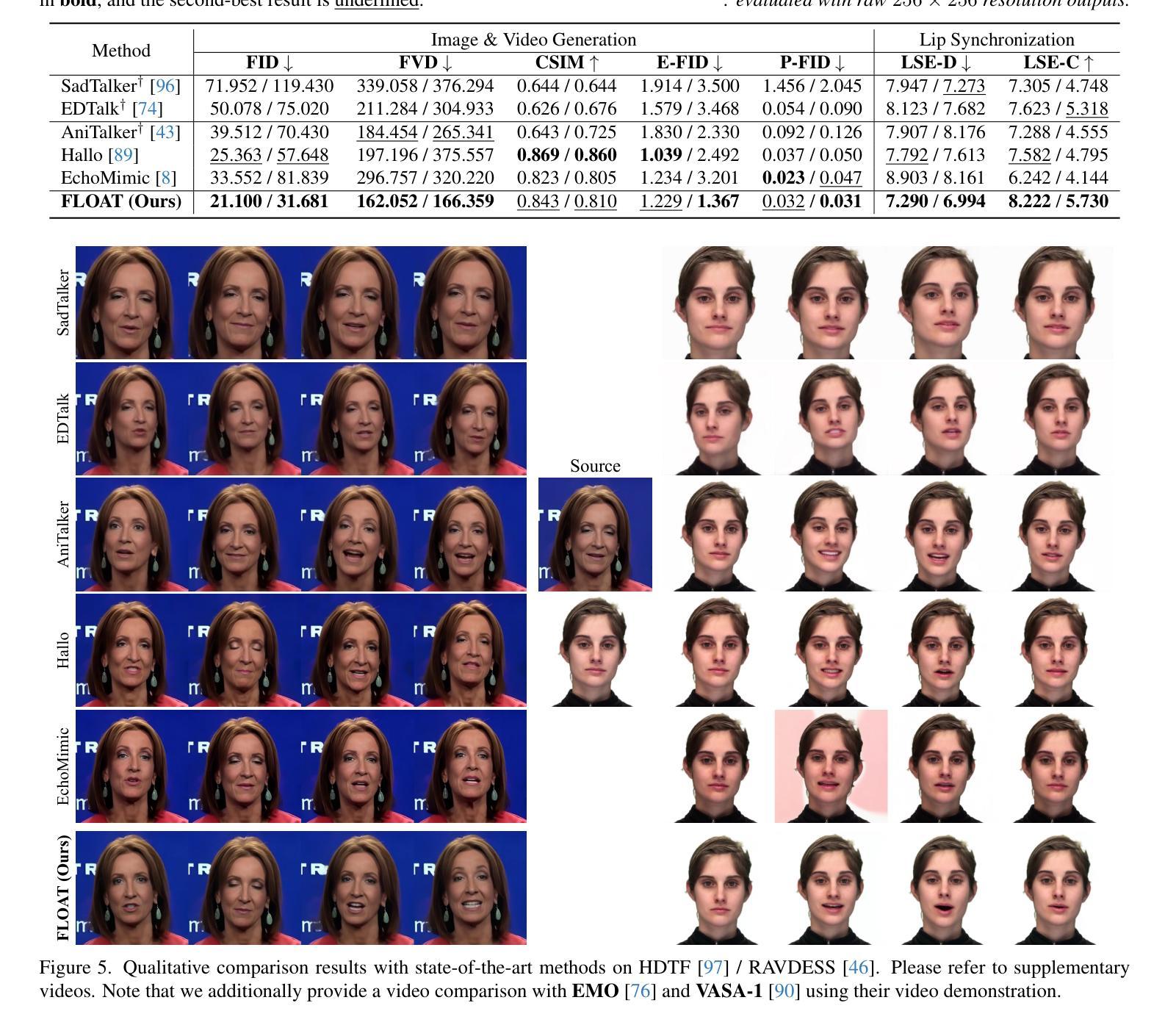
FLOAT: Generative Motion Latent Flow Matching for Audio-driven Talking Portrait
Authors:Taekyung Ki, Dongchan Min, Gyeongsu Chae
With the rapid advancement of diffusion-based generative models, portrait image animation has achieved remarkable results. However, it still faces challenges in temporally consistent video generation and fast sampling due to its iterative sampling nature. This paper presents FLOAT, an audio-driven talking portrait video generation method based on flow matching generative model. Instead of a pixel-based latent space, we take advantage of a learned orthogonal motion latent space, enabling efficient generation and editing of temporally consistent motion. To achieve this, we introduce a transformer-based vector field predictor with an effective frame-wise conditioning mechanism. Additionally, our method supports speech-driven emotion enhancement, enabling a natural incorporation of expressive motions. Extensive experiments demonstrate that our method outperforms state-of-the-art audio-driven talking portrait methods in terms of visual quality, motion fidelity, and efficiency.
随着基于扩散的生成模型的快速发展,肖像图像动画已经取得了显著成果。然而,由于其迭代采样的性质,它在时间一致的视频生成和快速采样方面仍然面临挑战。本文提出了FLOAT,这是一种基于流匹配生成模型的音频驱动式肖像视频生成方法。我们利用学习得到的正交运动潜在空间,而不是基于像素的潜在空间,实现了时间一致运动的有效生成和编辑。为了实现这一点,我们引入了一个基于变压器的矢量场预测器,并配备了一种有效的帧条件机制。此外,我们的方法支持语音驱动的情感增强,能够实现表达性运动的自然融合。大量实验表明,我们的方法在视觉质量、运动保真度和效率方面优于最先进的音频驱动式肖像动画方法。
论文及项目相关链接
PDF ICCV 2025. Project page: https://deepbrainai-research.github.io/float/
Summary
随着扩散生成模型的快速发展,肖像动画已经取得了显著成果。然而,由于其迭代采样的特性,它在生成时序一致的视频和快速采样方面仍面临挑战。本文提出了基于流匹配生成模型的音频驱动肖像视频生成方法FLOAT。我们利用学习到的正交运动潜在空间,实现了高效且时序一致的运动生成和编辑。为此,我们引入了一个基于变压器的向量场预测器,并设计了一个有效的帧条件机制。此外,我们的方法还支持语音驱动的情感增强,能够自然融入表达性动作。实验证明,我们的方法在视觉质量、运动保真度和效率方面优于现有的音频驱动肖像方法。
Key Takeaways
- 扩散生成模型的快速发展推动了肖像动画的显著成果。
- 肖像动画在生成时序一致的视频方面仍面临挑战,尤其是快速采样问题。
- FLOAT方法基于流匹配生成模型,解决了上述问题。
- FLOAT利用正交运动潜在空间实现高效且时序一致的运动生成和编辑。
- 通过引入基于变压器的向量场预测器和有效的帧条件机制,FLOAT表现出优越性能。
- FLOAT支持语音驱动的情感增强,能自然融入表达性动作。
点此查看论文截图