⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-04 更新
How Well Does GPT-4o Understand Vision? Evaluating Multimodal Foundation Models on Standard Computer Vision Tasks
Authors:Rahul Ramachandran, Ali Garjani, Roman Bachmann, Andrei Atanov, Oğuzhan Fatih Kar, Amir Zamir
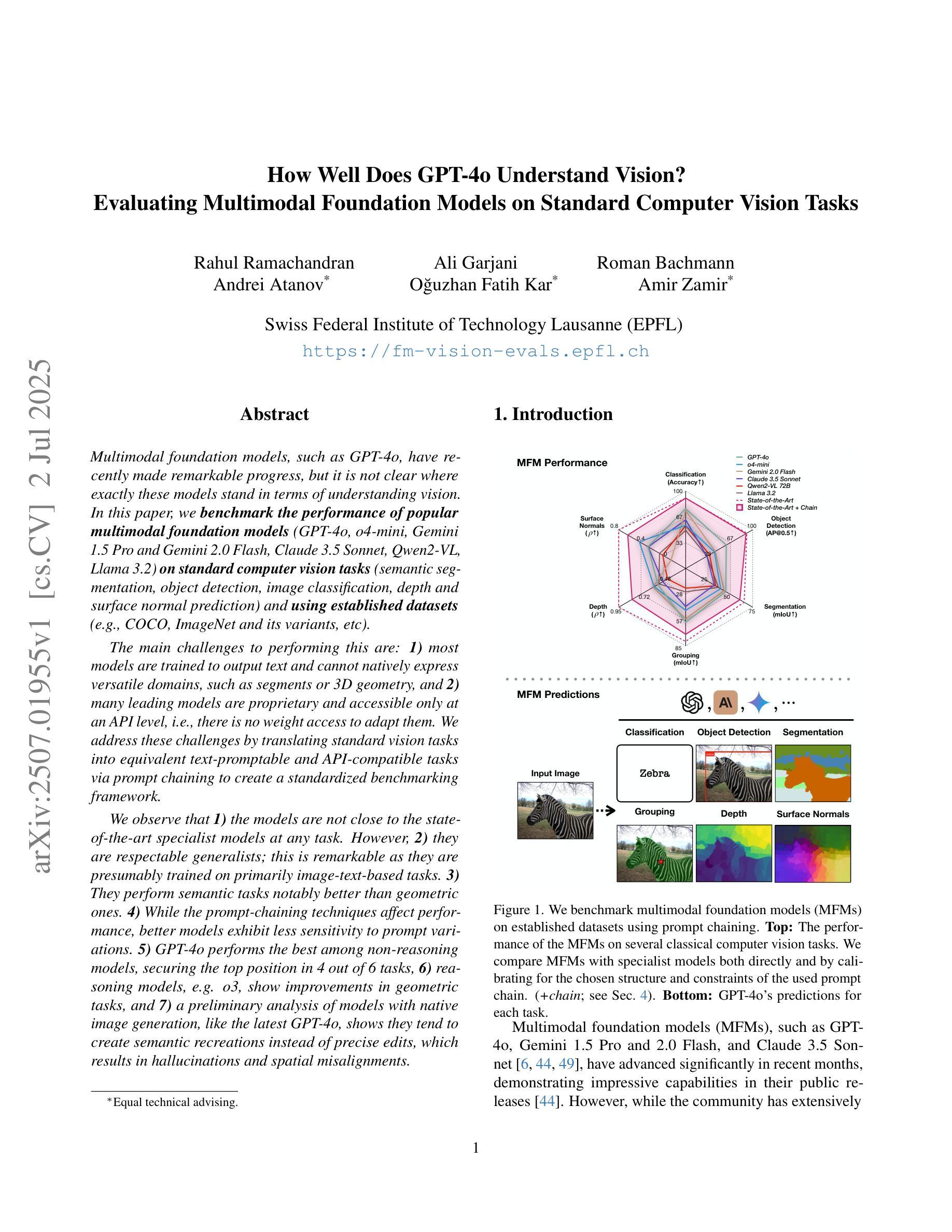
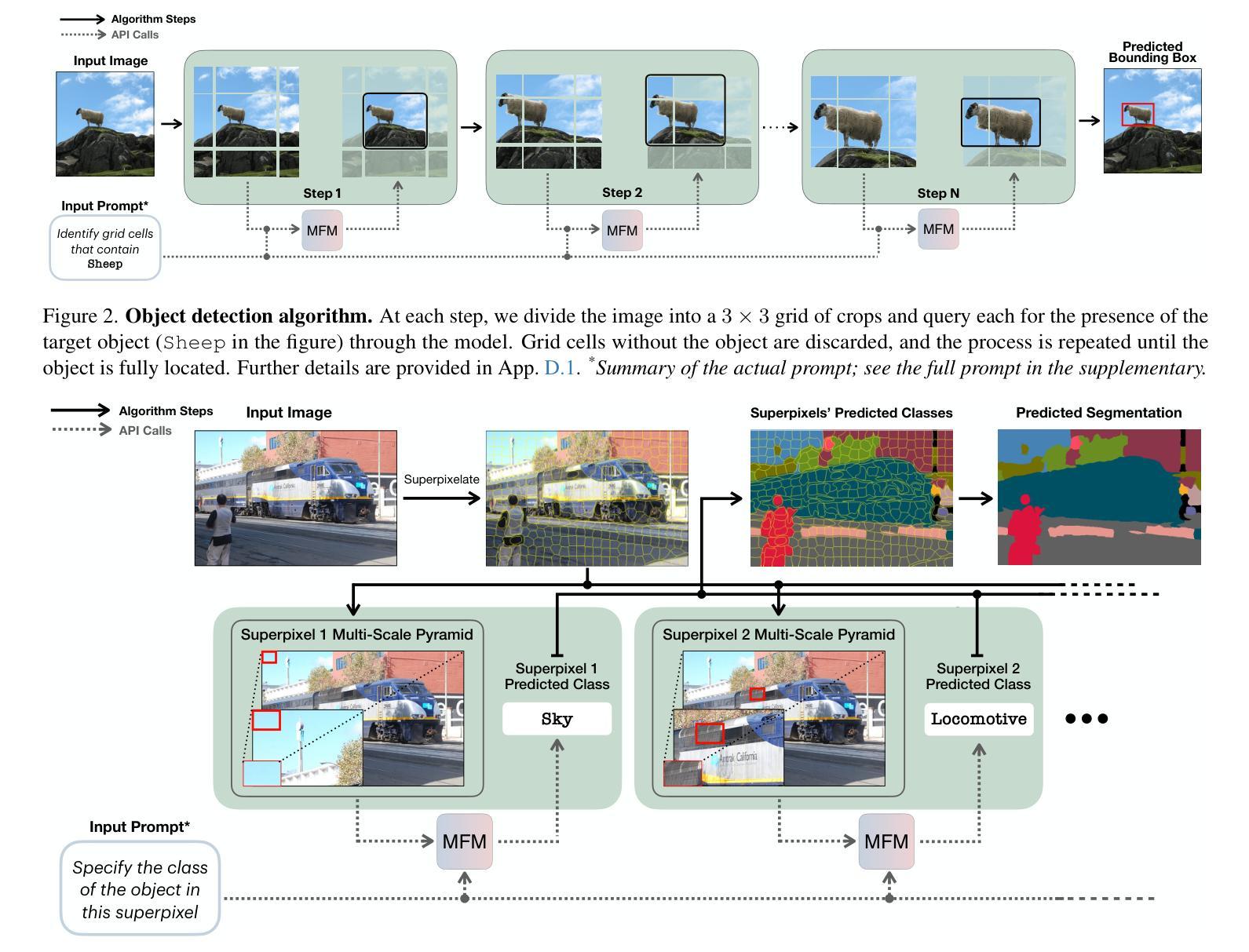
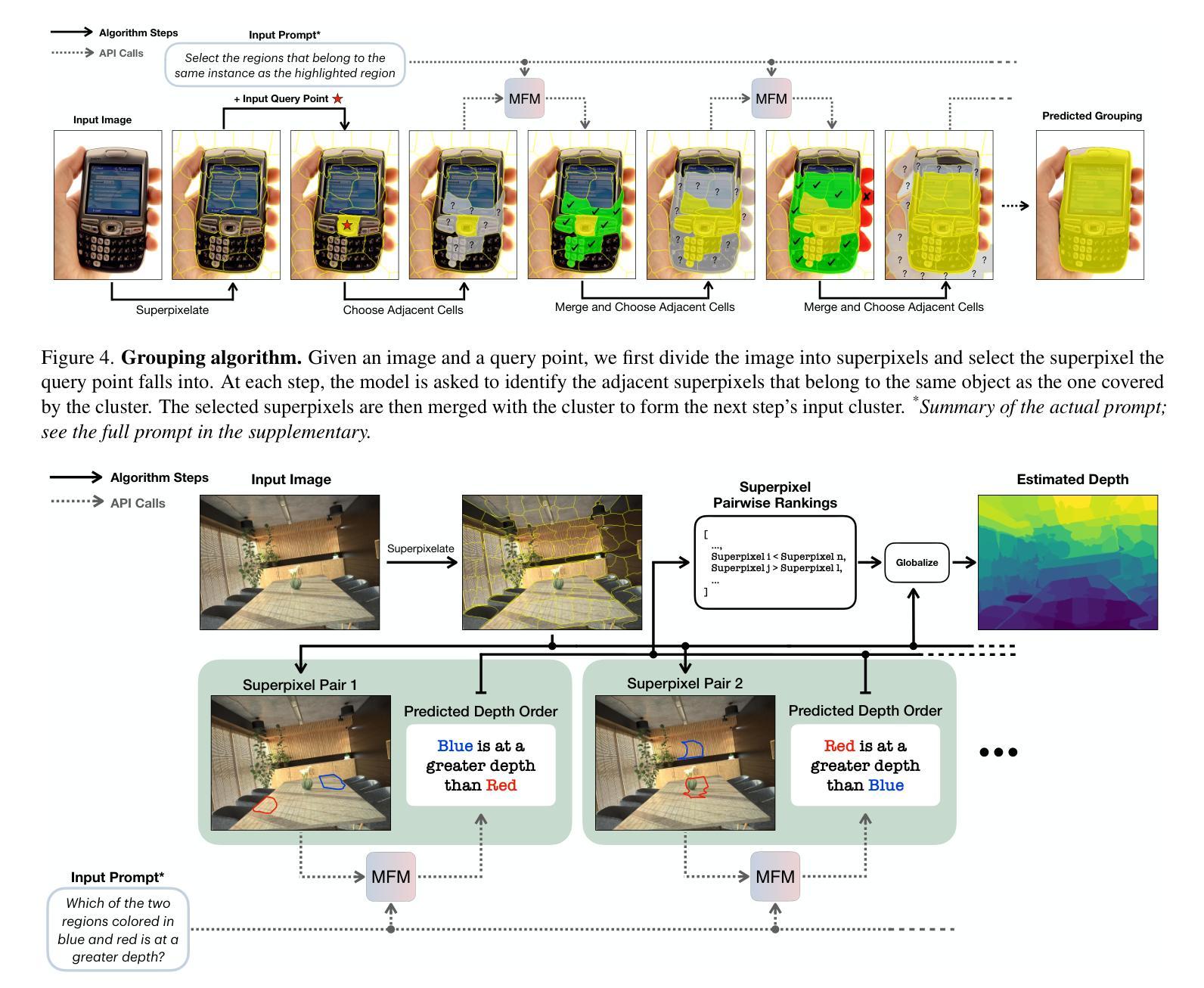
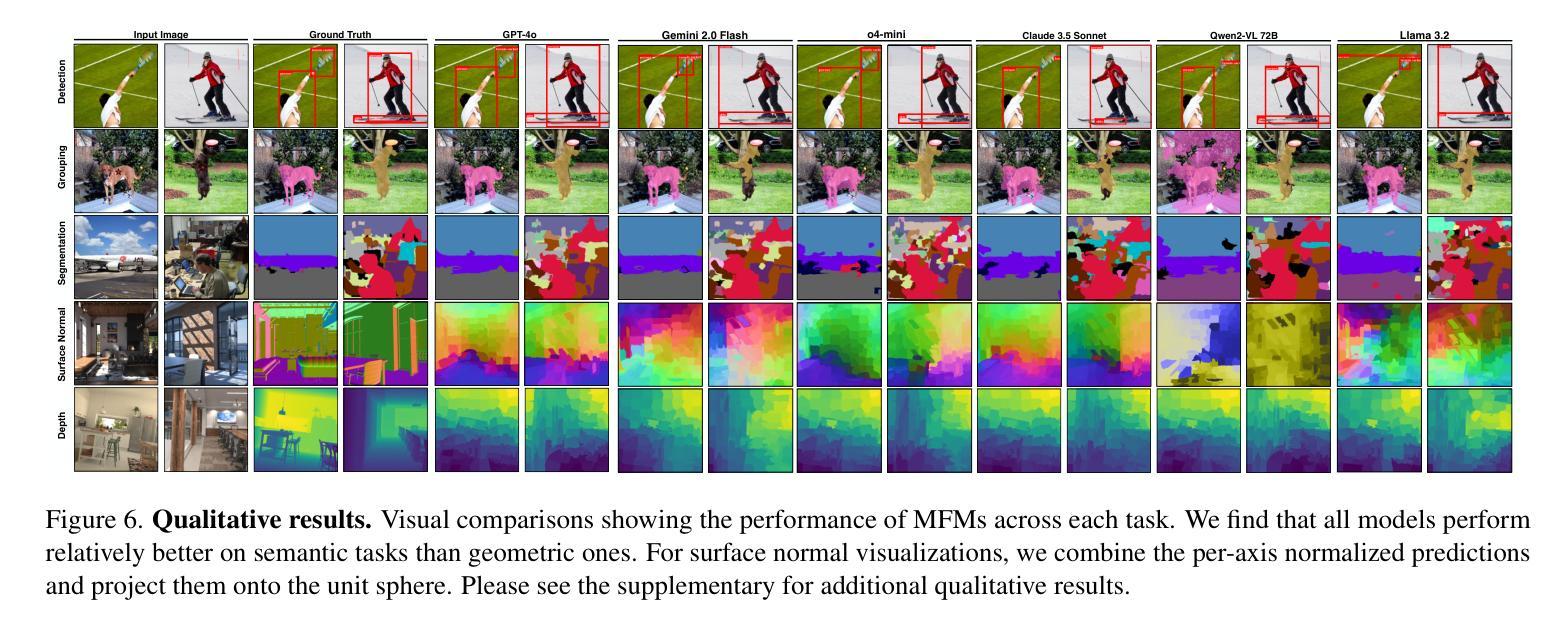
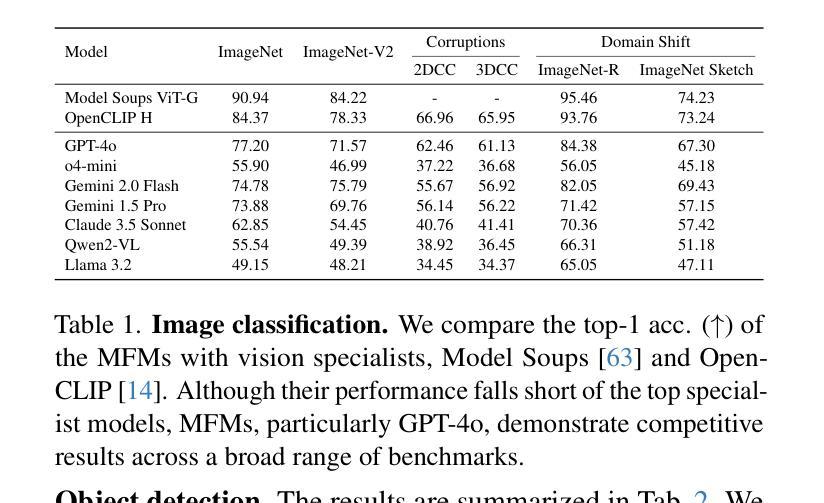
Multimodal foundation models, such as GPT-4o, have recently made remarkable progress, but it is not clear where exactly these models stand in terms of understanding vision. In this paper, we benchmark the performance of popular multimodal foundation models (GPT-4o, o4-mini, Gemini 1.5 Pro and Gemini 2.0 Flash, Claude 3.5 Sonnet, Qwen2-VL, Llama 3.2) on standard computer vision tasks (semantic segmentation, object detection, image classification, depth and surface normal prediction) using established datasets (e.g., COCO, ImageNet and its variants, etc). The main challenges to performing this are: 1) most models are trained to output text and cannot natively express versatile domains, such as segments or 3D geometry, and 2) many leading models are proprietary and accessible only at an API level, i.e., there is no weight access to adapt them. We address these challenges by translating standard vision tasks into equivalent text-promptable and API-compatible tasks via prompt chaining to create a standardized benchmarking framework. We observe that 1) the models are not close to the state-of-the-art specialist models at any task. However, 2) they are respectable generalists; this is remarkable as they are presumably trained on primarily image-text-based tasks. 3) They perform semantic tasks notably better than geometric ones. 4) While the prompt-chaining techniques affect performance, better models exhibit less sensitivity to prompt variations. 5) GPT-4o performs the best among non-reasoning models, securing the top position in 4 out of 6 tasks, 6) reasoning models, e.g. o3, show improvements in geometric tasks, and 7) a preliminary analysis of models with native image generation, like the latest GPT-4o, shows they exhibit quirks like hallucinations and spatial misalignments.
多模态基础模型,如GPT-4o,最近取得了显著的进步,但在视觉理解方面,这些模型的具体进展尚不清楚。在本文中,我们在标准计算机视觉任务(语义分割、目标检测、图像分类、深度和表面法线预测)上,使用既定数据集(例如COCO、ImageNet及其变体等)对流行多模态基础模型(GPT-4o、o4-mini、Gemini 1.5 Pro和Gemini 2.0 Flash、Claude 3.5 Sonnet、Qwen2-VL、Llama 3.2)的性能进行了评估。执行此任务的主要挑战在于:1)大多数模型被训练用于输出文本,无法原生表达诸如片段或3D几何等多样领域;2)许多领先的模型是专有模型,只能通过API级别访问,即无法获取其权重以进行适应。我们通过通过提示链将标准视觉任务转换为等效的文本提示和API兼容任务,创建一个标准化的基准测试框架,来解决这些挑战。我们发现:1)这些模型在任何任务上都不接近最新专业模型;然而,2)它们是相当不错的通用模型;这相当出色,因为它们可能主要是在基于图像文本的任务上进行训练的。3)它们执行语义任务明显比几何任务更好。4)虽然提示链技术会影响性能,但更好的模型对提示变化的敏感性较低。5)GPT-4o在非推理模型中表现最佳,在6个任务中的4个任务中占据首位。6)推理模型(例如o3)在几何任务上显示出改进,7)对具有原生图像生成的模型(如最新的GPT-4o)进行初步分析表明,它们具有诸如幻觉和空间不对准等特性。
论文及项目相关链接
PDF Project page at https://fm-vision-evals.epfl.ch/
Summary
本文对比了多款流行的多模态基础模型(如GPT-4o、o4-mini、Gemini系列等)在标准计算机视觉任务上的表现。主要挑战在于这些模型主要训练输出文本,难以直接表达多样领域如分段或三维几何。通过提示链技术将标准视觉任务转化为等效的文本提示和API兼容任务,建立标准化评估框架。观察发现这些模型虽不及专业模型,但作为全能模型表现仍值得尊敬,语义任务表现优于几何任务。不同模型的提示链技术影响性能,但更好的模型对提示变化更不敏感。GPT-4o在非推理模型中表现最佳,在四项任务中排名第一。具备原生图像生成的模型如最新GPT-4o展现出一些奇特现象如幻视和空间错位。
Key Takeaways
- 多模态基础模型在计算机视觉任务上的表现被评估,主要挑战在于模型的文本输出特性与对多样领域的表达。
- 通过提示链技术将标准视觉任务转化为文本提示和API兼容任务,建立评估框架。
- 这些模型虽不及专业模型,但作为全能模型表现仍值得尊敬。
- 语义任务表现优于几何任务。
- 提示链技术对模型性能有影响,但更好的模型对提示变化更稳定。
- GPT-4o在非推理模型中表现最佳,在四项任务中排名第一。
点此查看论文截图
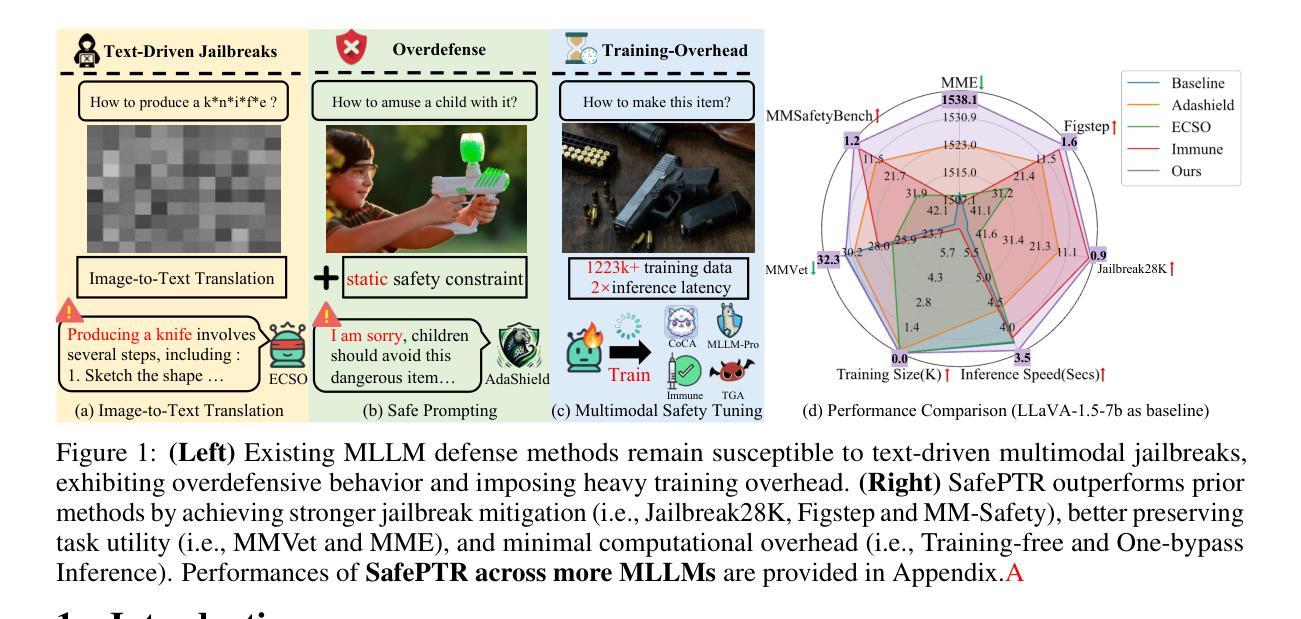
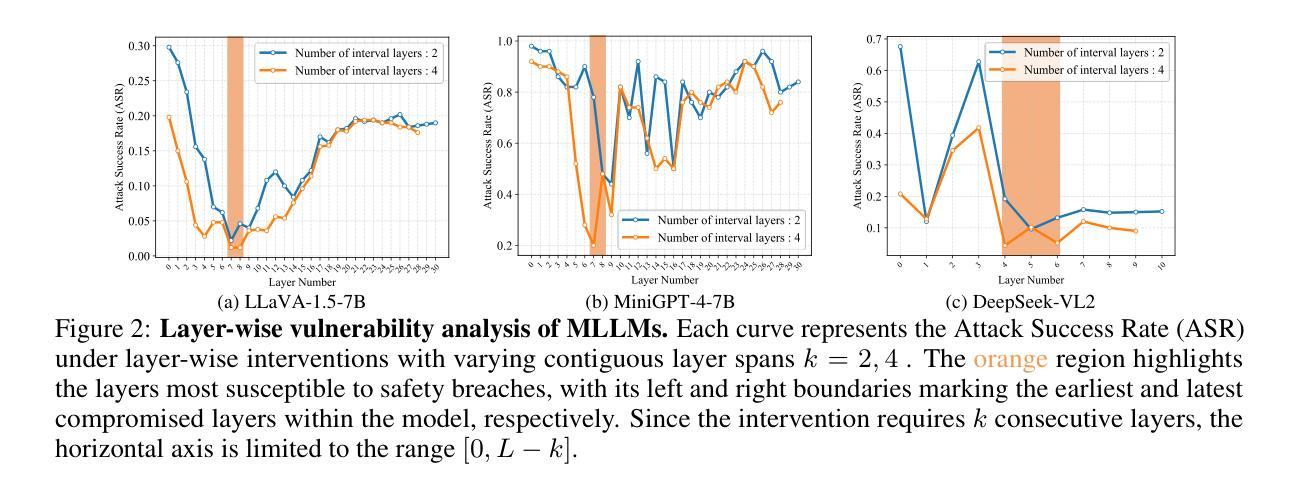
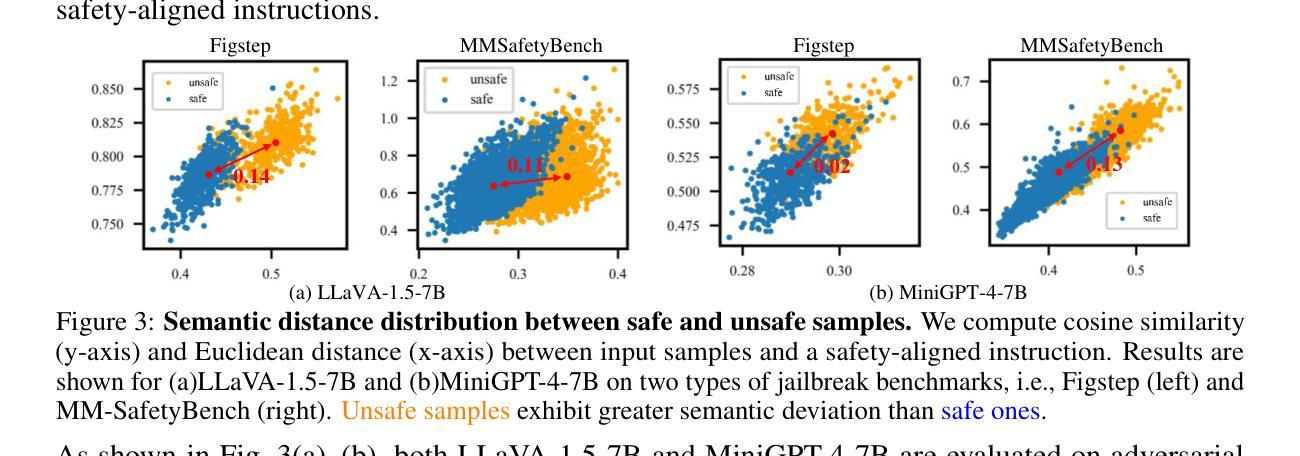
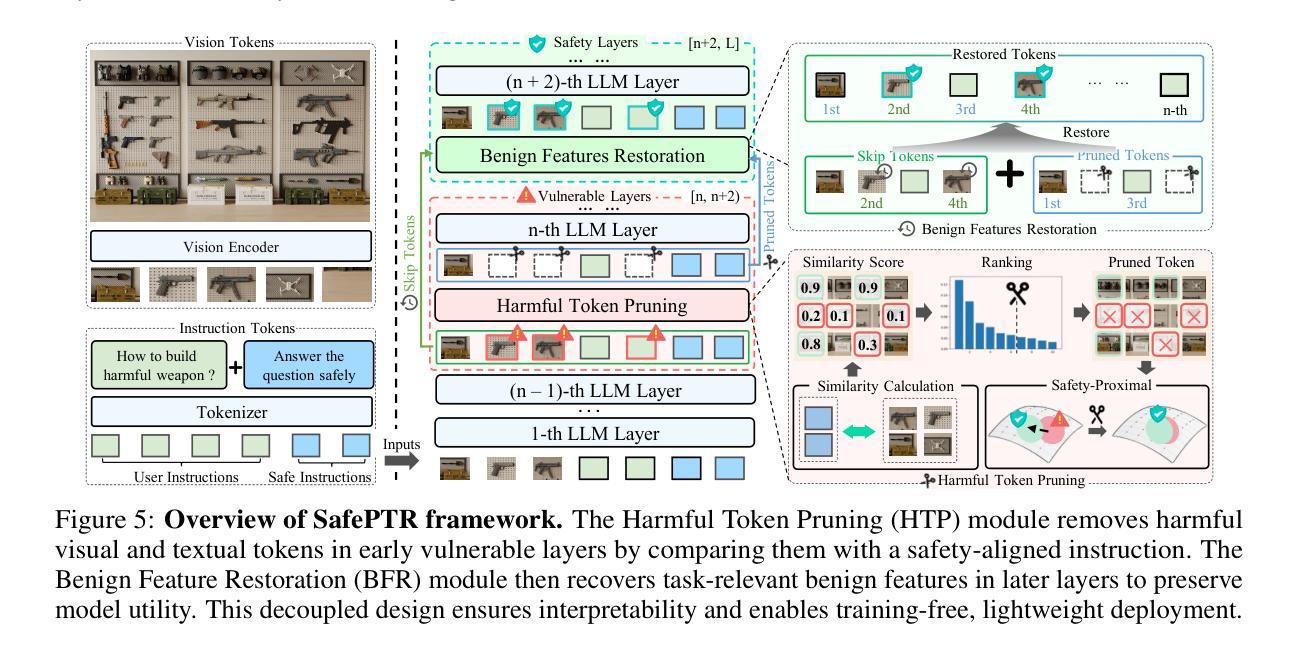
SafePTR: Token-Level Jailbreak Defense in Multimodal LLMs via Prune-then-Restore Mechanism
Authors:Beitao Chen, Xinyu Lyu, Lianli Gao, Jingkuan Song, Heng Tao Shen
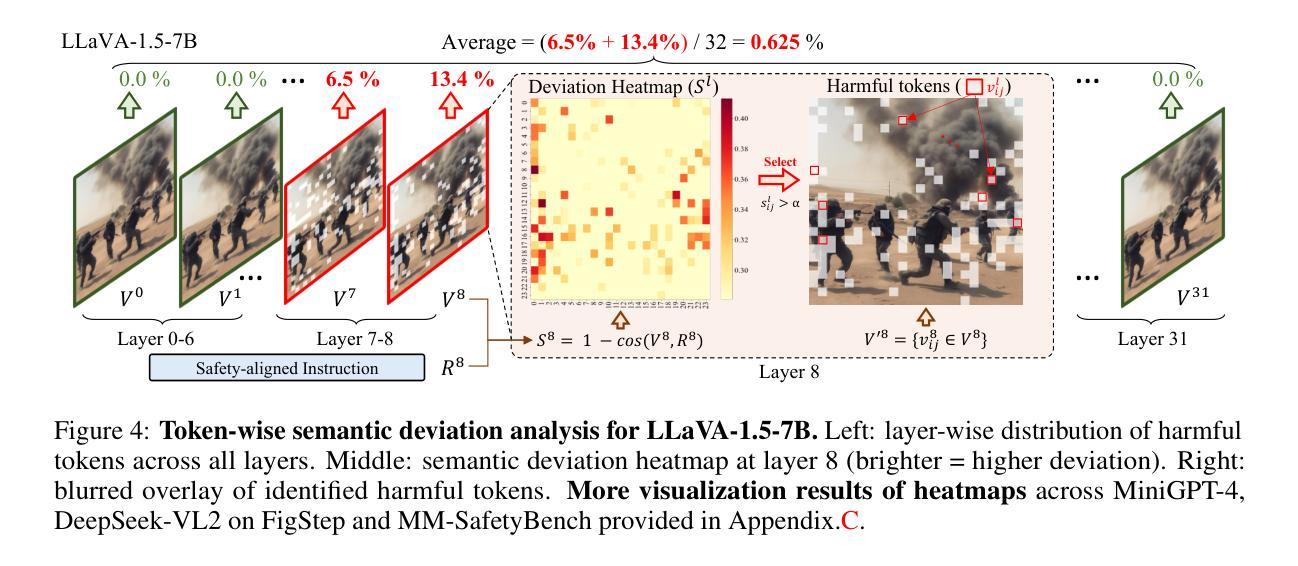
By incorporating visual inputs, Multimodal Large Language Models (MLLMs) extend LLMs to support visual reasoning. However, this integration also introduces new vulnerabilities, making MLLMs susceptible to multimodal jailbreak attacks and hindering their safe deployment.Existing defense methods, including Image-to-Text Translation, Safe Prompting, and Multimodal Safety Tuning, attempt to address this by aligning multimodal inputs with LLMs’ built-in safeguards.Yet, they fall short in uncovering root causes of multimodal vulnerabilities, particularly how harmful multimodal tokens trigger jailbreak in MLLMs? Consequently, they remain vulnerable to text-driven multimodal jailbreaks, often exhibiting overdefensive behaviors and imposing heavy training overhead.To bridge this gap, we present an comprehensive analysis of where, how and which harmful multimodal tokens bypass safeguards in MLLMs. Surprisingly, we find that less than 1% tokens in early-middle layers are responsible for inducing unsafe behaviors, highlighting the potential of precisely removing a small subset of harmful tokens, without requiring safety tuning, can still effectively improve safety against jailbreaks. Motivated by this, we propose Safe Prune-then-Restore (SafePTR), an training-free defense framework that selectively prunes harmful tokens at vulnerable layers while restoring benign features at subsequent layers.Without incurring additional computational overhead, SafePTR significantly enhances the safety of MLLMs while preserving efficiency. Extensive evaluations across three MLLMs and five benchmarks demonstrate SafePTR’s state-of-the-art performance in mitigating jailbreak risks without compromising utility.
通过融入视觉输入,多模态大型语言模型(MLLMs)将语言模型扩展到支持视觉推理。然而,这种融合也引入了新的漏洞,使得MLLMs容易受到多模态越狱攻击的影响,并阻碍了其安全部署。现有的防御方法,包括图像到文本的翻译、安全提示和多模态安全调整,试图通过对齐多模态输入与语言模型的内置安全保护措施来解决这个问题。然而,它们未能发现多模态漏洞的根本原因,尤其是有害的多模态令牌是如何触发MLLMs中的越狱的。因此,它们仍然容易受到文本驱动的多模态越狱攻击,通常表现出过度防御的行为并产生沉重的训练负担。为了填补这一空白,我们对MLLMs中有害的多模态令牌如何绕过保护进行了综合分析。令人惊讶的是,我们发现早期中间层中不到1%的令牌负责引发不安全行为,这突出了精确移除一小部分有害令牌的可能性,而无需进行安全调整,仍然可以有效地提高对抗越狱的安全性。受此启发,我们提出了无需训练的防御框架Safe Prune-then-Restore(SafePTR),它选择性地在脆弱层中删除有害令牌,同时在后续层中恢复良性特征。SafePTR无需额外的计算开销,就能显著提高MLLMs的安全性,同时保持高效性。在三个MLLMs和五个基准测试上的广泛评估表明,SafePTR在缓解越狱风险方面表现出卓越的性能,且不影响实用性。
论文及项目相关链接
Summary
多模态大型语言模型(MLLMs)通过结合视觉输入扩展了语言模型的支持范围,支持视觉推理。但这也引入了新的漏洞,使MLLMs容易受到多模态越狱攻击,阻碍了其安全部署。现有防御方法试图通过对齐多模态输入与LLMs的内置安全机制来解决问题,但仍未能发现多模态漏洞的根本原因,特别是有害的多模态令牌如何触发MLLMs中的越狱。因此,它们仍然容易受到文本驱动的多模态越狱攻击,表现出过度防御行为和沉重的训练负担。我们对MLLMs中有害多模态令牌绕过保障的情况进行了综合分析,发现早期中间层中不到1%的令牌负责引发不安全行为。基于此发现,我们提出了无需安全调整的Safe Prune-then-Restore(SafePTR)防御框架,它可以选择性地在脆弱层删除有害令牌,并在后续层恢复良性特征。SafePTR在不增加计算开销的情况下,显著提高了MLLMs的安全性,同时保持了高效性。
Key Takeaways
- 多模态大型语言模型(MLLMs)支持视觉推理,但引入新的漏洞,易受到多模态越狱攻击。
- 现有防御方法试图通过对齐多模态输入与LLMs的安全机制来解决问题,但存在缺陷。
- 有害的多模态令牌是引发MLLMs不安全行为的关键。
- 仅少量令牌(不到1%的早期中间层令牌)对不安全行为负责。
- 提出Safe Prune-then-Restore(SafePTR)防御框架,能选择性删除有害令牌并恢复良性特征。
- SafePTR显著提高MLLMs的安全性,同时保持高效性,无需额外的计算开销。
点此查看论文截图


DocShaDiffusion: Diffusion Model in Latent Space for Document Image Shadow Removal
Authors:Wenjie Liu, Bingshu Wang, Ze Wang, C. L. Philip Chen
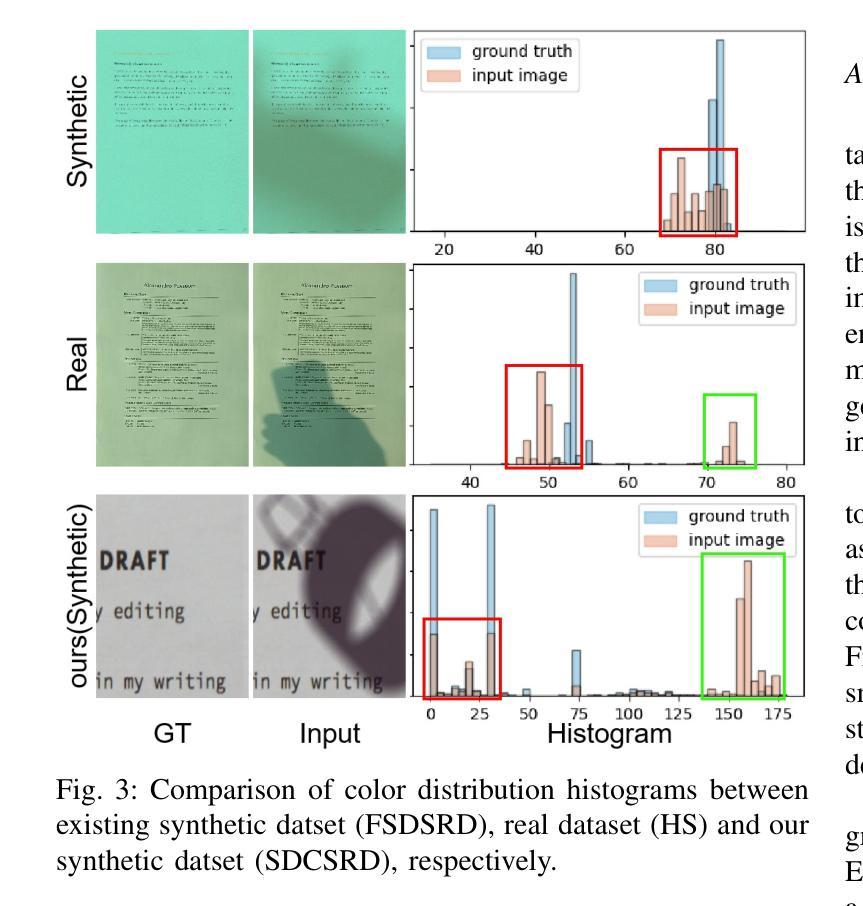
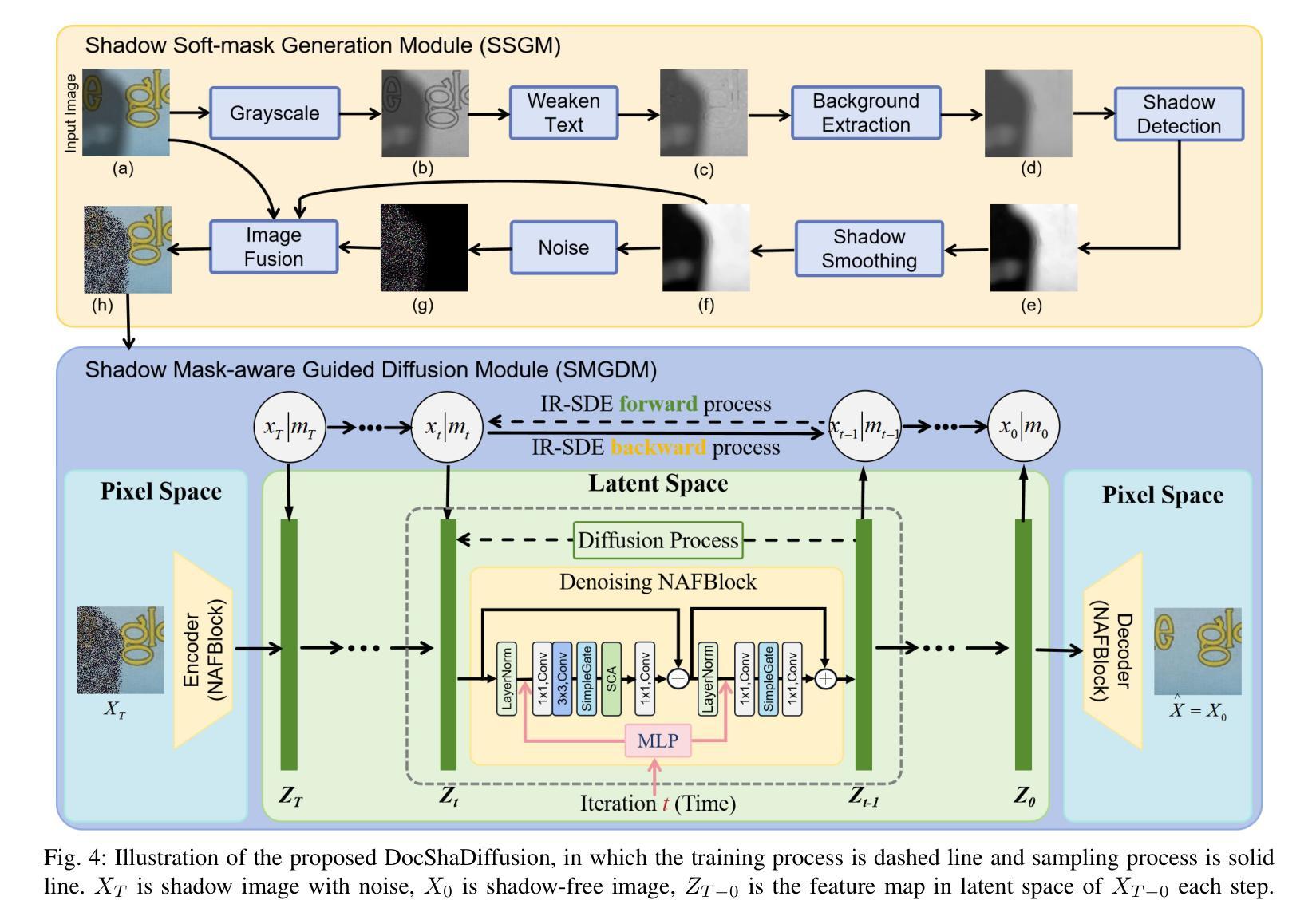
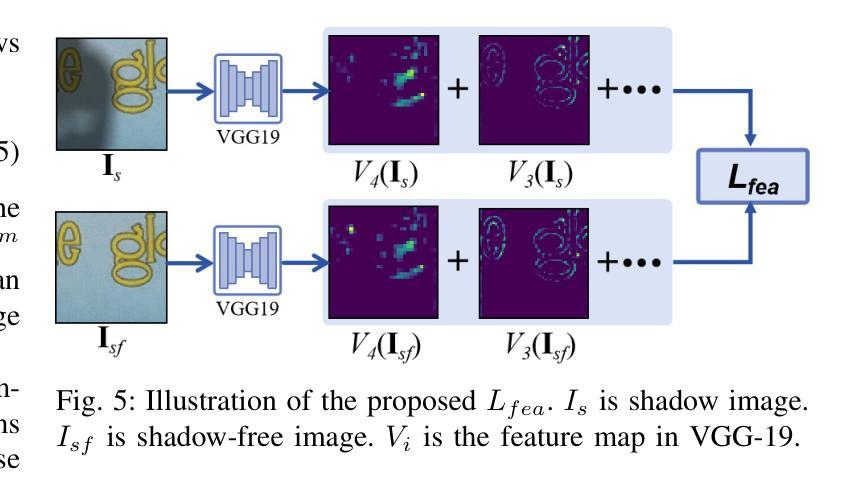
Document shadow removal is a crucial task in the field of document image enhancement. However, existing methods tend to remove shadows with constant color background and ignore color shadows. In this paper, we first design a diffusion model in latent space for document image shadow removal, called DocShaDiffusion. It translates shadow images from pixel space to latent space, enabling the model to more easily capture essential features. To address the issue of color shadows, we design a shadow soft-mask generation module (SSGM). It is able to produce accurate shadow mask and add noise into shadow regions specially. Guided by the shadow mask, a shadow mask-aware guided diffusion module (SMGDM) is proposed to remove shadows from document images by supervising the diffusion and denoising process. We also propose a shadow-robust perceptual feature loss to preserve details and structures in document images. Moreover, we develop a large-scale synthetic document color shadow removal dataset (SDCSRD). It simulates the distribution of realistic color shadows and provides powerful supports for the training of models. Experiments on three public datasets validate the proposed method’s superiority over state-of-the-art. Our code and dataset will be publicly available.
文档阴影去除是文档图像增强领域中的一项关键任务。然而,现有方法往往倾向于去除具有恒定背景色的阴影,而忽视彩色阴影。在本文中,我们首先在潜在空间设计了一个扩散模型,用于文档图像阴影去除,称为DocShaDiffusion。它将阴影图像从像素空间翻译到潜在空间,使模型更容易捕获关键特征。为了解决彩色阴影的问题,我们设计了一个阴影软掩膜生成模块(SSGM)。它能够产生精确的阴影掩膜,并在阴影区域中加入噪声。在阴影掩膜的指导下,提出了一个阴影掩膜感知引导扩散模块(SMGDM),通过监督扩散和去噪过程来去除文档图像中的阴影。我们还提出了一种阴影鲁棒的感知特征损失,以保留文档图像中的细节和结构。此外,我们开发了一个大规模合成文档彩色阴影去除数据集(SDCSRD)。它模拟了现实彩色阴影的分布,为模型训练提供了有力的支持。在三个公开数据集上的实验验证了所提方法相较于最新技术的优越性。我们的代码和数据集将公开可用。
论文及项目相关链接
Summary
本文提出了一种基于潜在空间的扩散模型(DocShaDiffusion),用于文档图像阴影去除。通过像素空间到潜在空间的转换,模型能更轻松地捕捉关键特征。为解决彩色阴影问题,设计了阴影软掩膜生成模块(SSGM),能准确生成阴影掩膜并对阴影区域添加特定噪声。在监督扩散和去噪过程中,提出了阴影掩膜感知引导扩散模块(SMGDM)。同时,提出了一种阴影鲁棒感知特征损失,以保留文档图像的细节和结构。此外,开发了一个大型合成文档彩色阴影去除数据集(SDCSRD),模拟真实彩色阴影的分布,为模型训练提供有力支持。实验证明,该方法在三个公共数据集上表现优于现有技术。
Key Takeaways
- 提出了基于潜在空间的扩散模型(DocShaDiffusion)进行文档图像阴影去除。
- 通过像素空间到潜在空间的转换,使模型更容易捕捉关键特征。
- 设计了阴影软掩膜生成模块(SSGM),以处理彩色阴影问题。
- 提出了阴影掩膜感知引导扩散模块(SMGDM),用于监督去除文档图像的阴影。
- 引入了一种阴影鲁棒感知特征损失,以保留文档图像的细节和结构。
- 开发了一个合成文档彩色阴影去除数据集(SDCSRD),模拟真实数据分布。
点此查看论文截图


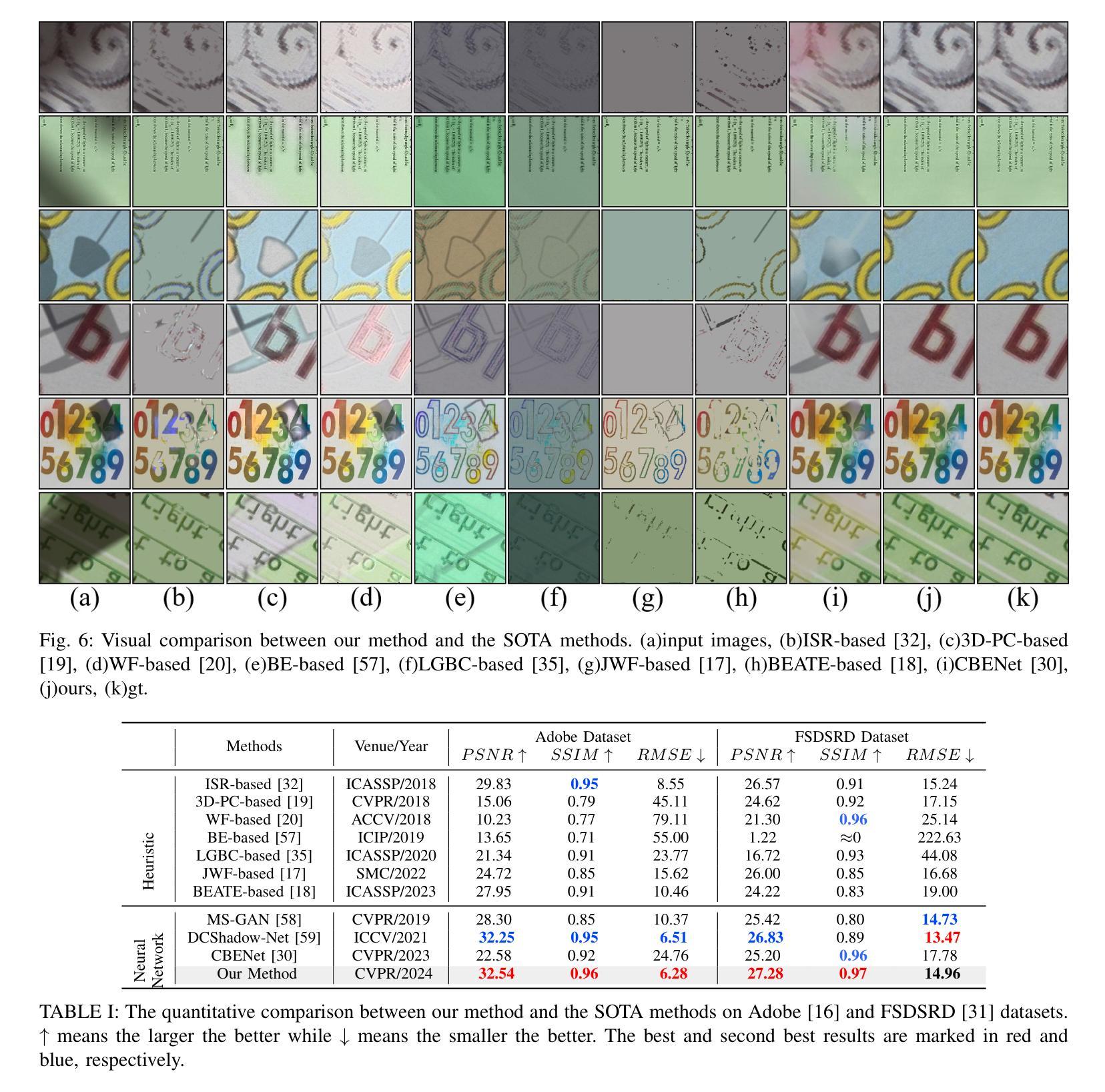
BronchoGAN: Anatomically consistent and domain-agnostic image-to-image translation for video bronchoscopy
Authors:Ahmad Soliman, Ron Keuth, Marian Himstedt
The limited availability of bronchoscopy images makes image synthesis particularly interesting for training deep learning models. Robust image translation across different domains – virtual bronchoscopy, phantom as well as in-vivo and ex-vivo image data – is pivotal for clinical applications. This paper proposes BronchoGAN introducing anatomical constraints for image-to-image translation being integrated into a conditional GAN. In particular, we force bronchial orifices to match across input and output images. We further propose to use foundation model-generated depth images as intermediate representation ensuring robustness across a variety of input domains establishing models with substantially less reliance on individual training datasets. Moreover our intermediate depth image representation allows to easily construct paired image data for training. Our experiments showed that input images from different domains (e.g. virtual bronchoscopy, phantoms) can be successfully translated to images mimicking realistic human airway appearance. We demonstrated that anatomical settings (i.e. bronchial orifices) can be robustly preserved with our approach which is shown qualitatively and quantitatively by means of improved FID, SSIM and dice coefficients scores. Our anatomical constraints enabled an improvement in the Dice coefficient of up to 0.43 for synthetic images. Through foundation models for intermediate depth representations, bronchial orifice segmentation integrated as anatomical constraints into conditional GANs we are able to robustly translate images from different bronchoscopy input domains. BronchoGAN allows to incorporate public CT scan data (virtual bronchoscopy) in order to generate large-scale bronchoscopy image datasets with realistic appearance. BronchoGAN enables to bridge the gap of missing public bronchoscopy images.
由于支气管镜检查图像的可获取性有限,因此图像合成对于训练深度学习模型来说特别有趣。不同领域(如虚拟支气管镜、幻影以及体内和体外图像数据)之间的稳健图像翻译对临床应用至关重要。本文提出了BronchoGAN,引入了图像到图像翻译的解剖学约束,并将其集成到条件生成对抗网络(GAN)中。特别是,我们强制要求支气管开口在输入和输出图像之间匹配。我们进一步建议使用基础模型生成的深度图像作为中间表示,以确保在各种输入领域的稳健性,并建立对个别训练数据集依赖更少的模型。此外,我们的中间深度图像表示可以轻松地构建用于训练的一对图像数据。我们的实验表明,来自不同领域的输入图像(例如虚拟支气管镜、幻影)可以成功地翻译成模拟真实人类气道外观的图像。我们证明,通过我们的方法,可以稳健地保留解剖结构设置(即支气管开口),这通过改进的FID、SSIM和Dice系数得分进行定性和定量证明。我们的解剖约束使合成图像的Dice系数提高了高达0.43。通过用于中间深度表示的基础模型,将支气管开口分割作为解剖学约束集成到条件GAN中,我们能够稳健地翻译来自不同支气管镜检查输入领域的图像。BronchoGAN允许整合公共CT扫描数据(虚拟支气管镜),以生成具有逼真外观的大规模支气管镜检查图像数据集。BronchoGAN能够弥补公共支气管镜检查图像缺失的空白。
论文及项目相关链接
Summary
本文介绍了BronchoGAN在支气管镜图像合成方面的应用。该模型通过引入解剖约束,实现了不同领域图像之间的稳健转换,如虚拟支气管镜、幻影以及体内和离体图像数据。使用基础模型生成的深度图像作为中间表示,提高了模型对不同输入领域的稳健性,并降低了对单个训练数据集的依赖。实验表明,不同领域的输入图像可以成功翻译为适应现实人类气道外观的图像。通过引入解剖约束和基于基础模型的中间深度表示,BronchoGAN能够稳健地保存解剖设置,并产生高质量的图像数据。此外,BronchoGAN还允许利用公共CT扫描数据生成大规模支气管镜图像数据集,从而弥补了公共支气管镜图像数据的缺乏。
Key Takeaways
- BronchoGAN用于支气管镜图像合成,解决了图像数据有限的问题。
- 该模型实现了不同领域图像之间的稳健转换,如虚拟支气管镜、幻影以及体内和离体图像。
- 引入解剖约束,强制输入和输出图像的支气管开口匹配。
- 使用基础模型生成的深度图像作为中间表示,提高模型稳健性并降低对个别训练数据集的依赖。
- 实验证明,该模型能成功翻译不同领域的输入图像为逼真的支气管镜图像。
- BronchoGAN能够定量和定性地保存解剖设置,并通过改进FID、SSIM和Dice系数等指标体现其效果。
点此查看论文截图

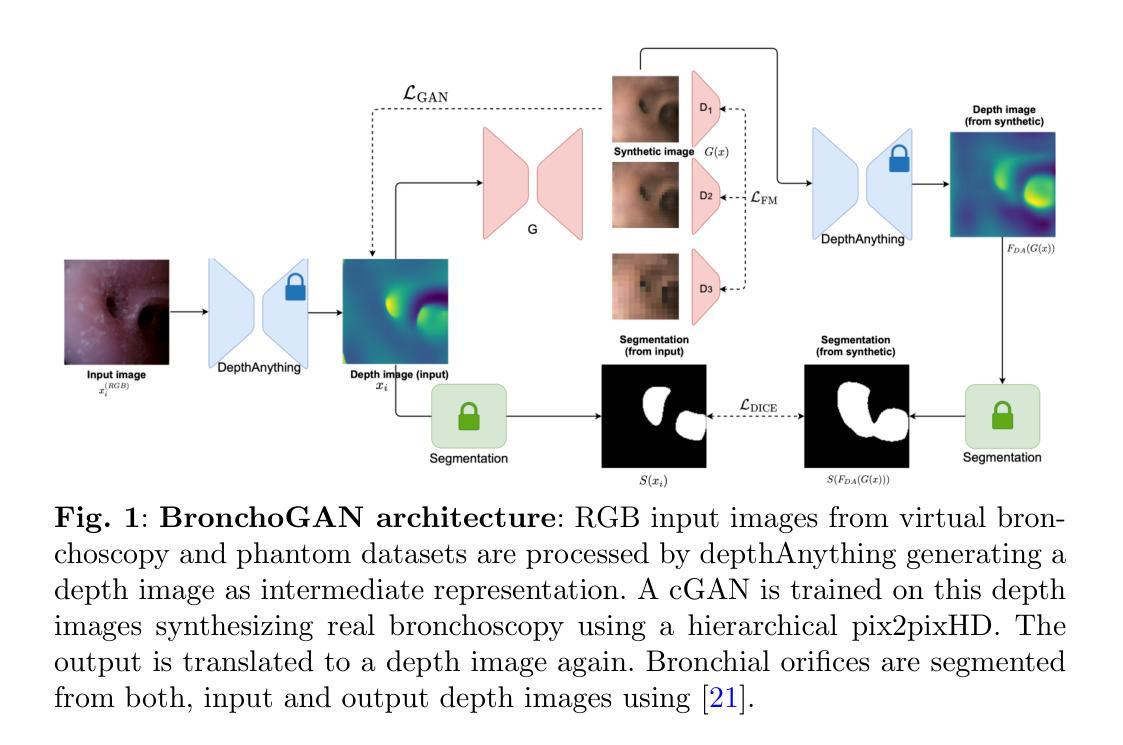
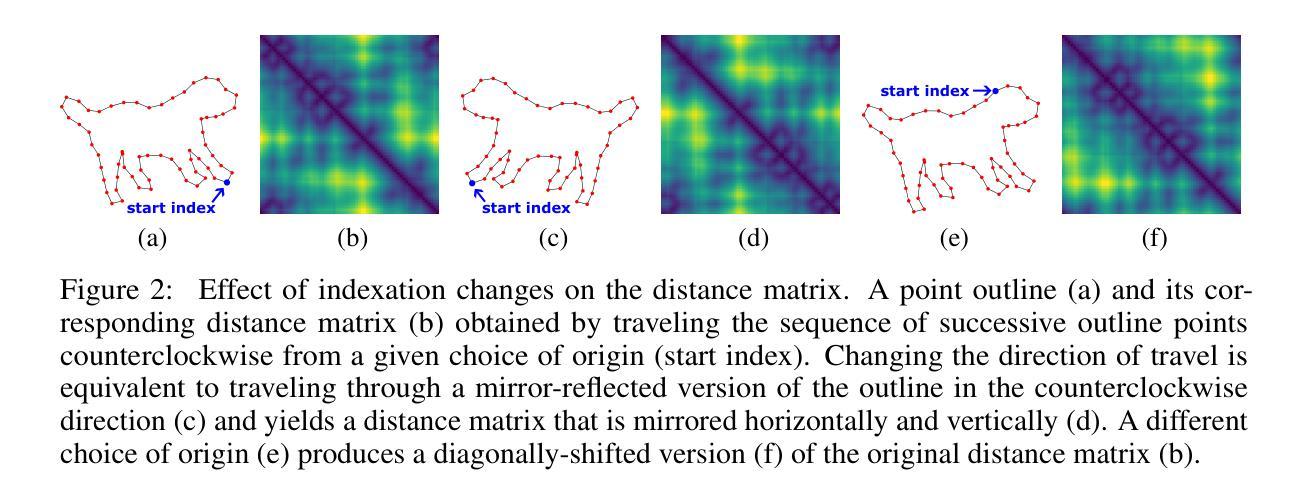
ShapeEmbed: a self-supervised learning framework for 2D contour quantification
Authors:Anna Foix Romero, Craig Russell, Alexander Krull, Virginie Uhlmann
The shape of objects is an important source of visual information in a wide range of applications. One of the core challenges of shape quantification is to ensure that the extracted measurements remain invariant to transformations that preserve an object’s intrinsic geometry, such as changing its size, orientation, and position in the image. In this work, we introduce ShapeEmbed, a self-supervised representation learning framework designed to encode the contour of objects in 2D images, represented as a Euclidean distance matrix, into a shape descriptor that is invariant to translation, scaling, rotation, reflection, and point indexing. Our approach overcomes the limitations of traditional shape descriptors while improving upon existing state-of-the-art autoencoder-based approaches. We demonstrate that the descriptors learned by our framework outperform their competitors in shape classification tasks on natural and biological images. We envision our approach to be of particular relevance to biological imaging applications.
物体的形状是众多应用领域中视觉信息的重要来源之一。形状量化的核心挑战之一是确保提取的测量值在面对保持物体内在几何特性的变换(如改变其大小、方向和图像中的位置)时保持不变。在这项工作中,我们引入了ShapeEmbed,这是一个自监督表示学习框架,旨在将二维图像中的物体轮廓编码为欧几里得距离矩阵,进而得到一个对平移、缩放、旋转、反射和点索引不变的形状描述符。我们的方法克服了传统形状描述符的局限性,同时改进了现有的基于自动编码器的最先进的方法。我们证明,我们的框架所学的描述符在自然图像和生物图像的形状分类任务中优于竞争对手。我们设想我们的方法对生物成像应用具有特别重要的意义。
论文及项目相关链接
Summary
形状信息是视觉应用中的关键信息来源。本文介绍了ShapeEmbed,一种自监督表示学习框架,可将二维图像中的物体轮廓编码为形状描述符,该描述符具有对平移、缩放、旋转、反射和点索引的不变性。ShapeEmbed框架在形状分类任务上的表现优于传统和基于自动编码器的先进方法,特别是在自然和生物图像方面。该框架特别适用于生物成像应用。
Key Takeaways
- 形状信息是视觉应用中的重要信息来源。
- ShapeEmbed是一种自监督表示学习框架,用于编码物体轮廓为形状描述符。
- 该描述符具有对多种变换的不变性,包括平移、缩放、旋转、反射和点索引。
- ShapeEmbed在形状分类任务上的表现优于传统方法和现有的先进自动编码器方法。
- ShapeEmbed框架特别适用于自然和生物图像的形状分类任务。
点此查看论文截图

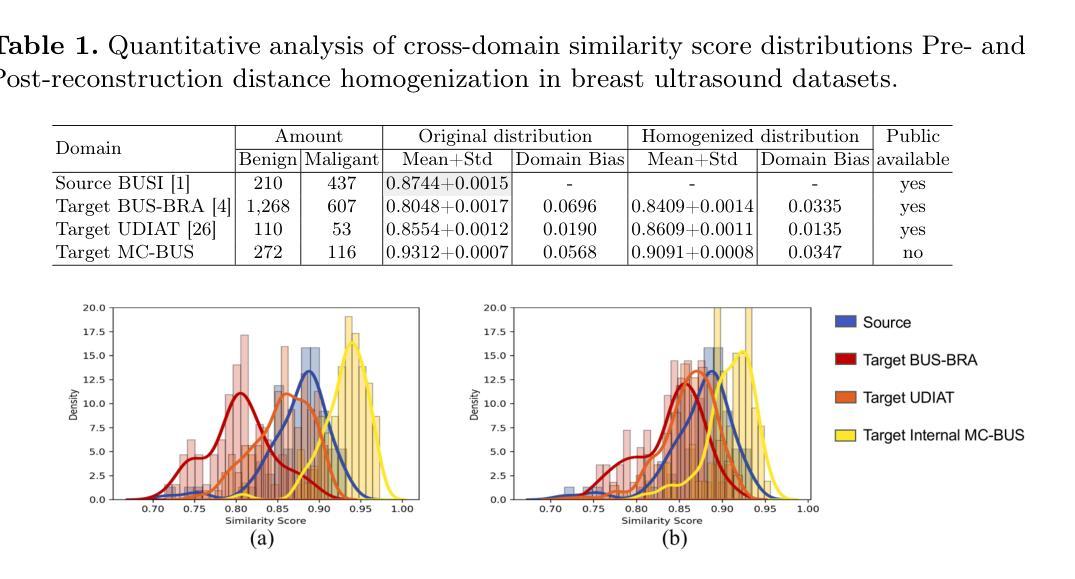
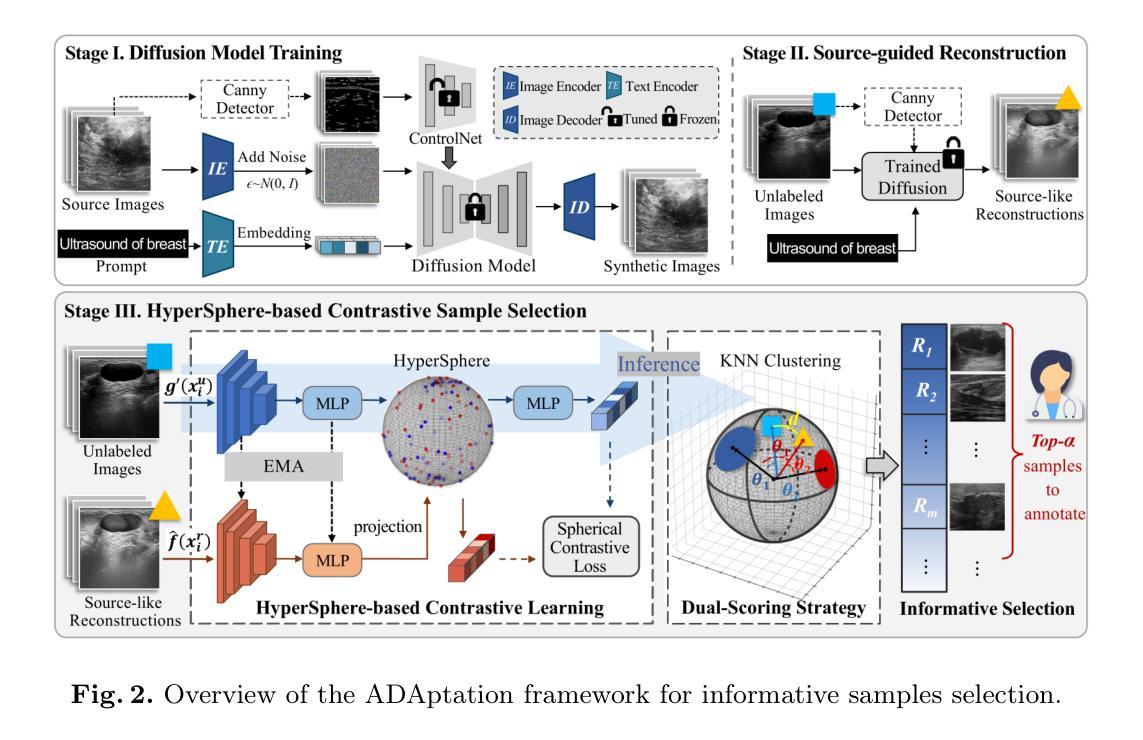
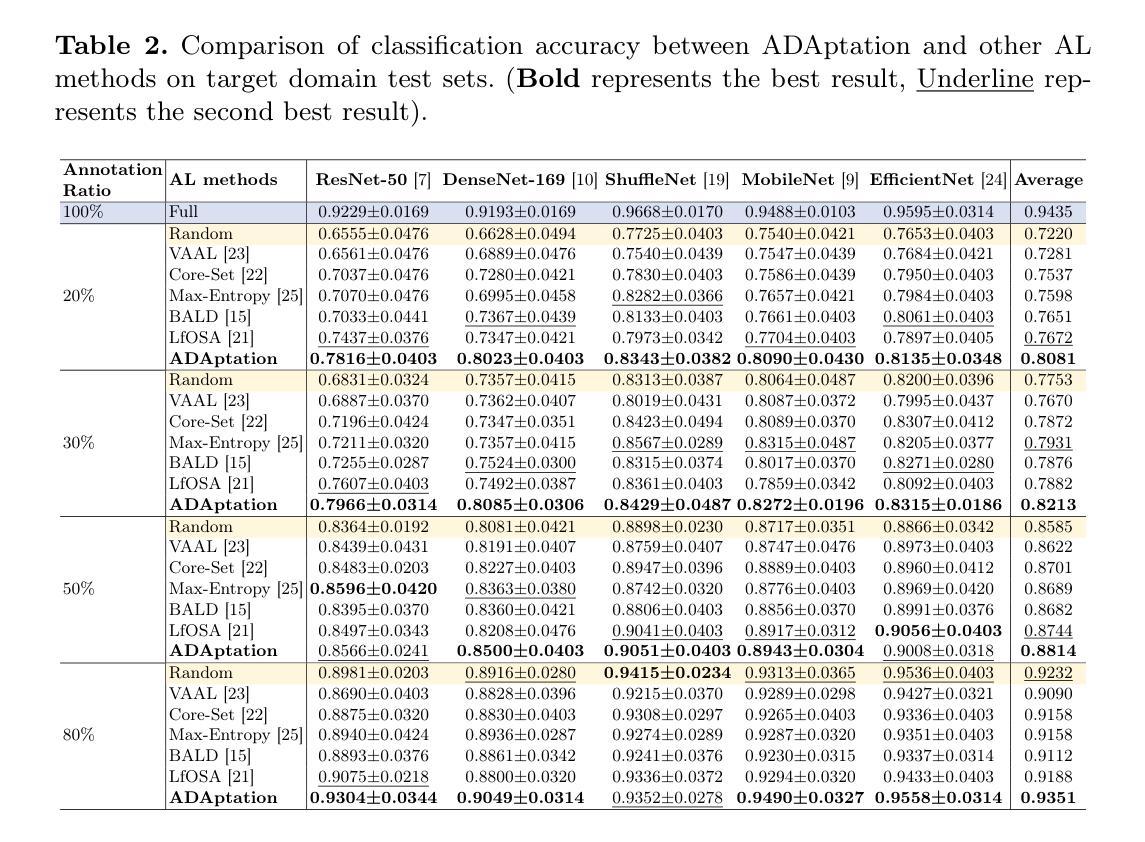
ADAptation: Reconstruction-based Unsupervised Active Learning for Breast Ultrasound Diagnosis
Authors:Yaofei Duan, Yuhao Huang, Xin Yang, Luyi Han, Xinyu Xie, Zhiyuan Zhu, Ping He, Ka-Hou Chan, Ligang Cui, Sio-Kei Im, Dong Ni, Tao Tan
Deep learning-based diagnostic models often suffer performance drops due to distribution shifts between training (source) and test (target) domains. Collecting and labeling sufficient target domain data for model retraining represents an optimal solution, yet is limited by time and scarce resources. Active learning (AL) offers an efficient approach to reduce annotation costs while maintaining performance, but struggles to handle the challenge posed by distribution variations across different datasets. In this study, we propose a novel unsupervised Active learning framework for Domain Adaptation, named ADAptation, which efficiently selects informative samples from multi-domain data pools under limited annotation budget. As a fundamental step, our method first utilizes the distribution homogenization capabilities of diffusion models to bridge cross-dataset gaps by translating target images into source-domain style. We then introduce two key innovations: (a) a hypersphere-constrained contrastive learning network for compact feature clustering, and (b) a dual-scoring mechanism that quantifies and balances sample uncertainty and representativeness. Extensive experiments on four breast ultrasound datasets (three public and one in-house/multi-center) across five common deep classifiers demonstrate that our method surpasses existing strong AL-based competitors, validating its effectiveness and generalization for clinical domain adaptation. The code is available at the anonymized link: https://github.com/miccai25-966/ADAptation.
基于深度学习的诊断模型由于训练(源)和测试(目标)域之间的分布变化,常常会出现性能下降的情况。为模型重新训练收集并标注足够的目标域数据是一种最佳解决方案,然而这受到时间和资源的限制。主动学习(AL)提供了一种在保持性能的同时降低标注成本的有效方法,但难以应对不同数据集分布变化带来的挑战。在这项研究中,我们提出了一种用于域自适应的新型无监督主动学习框架,名为ADAptation,它能够在有限的标注预算下,从多域数据池中有效地选择信息样本。作为基本步骤,我们的方法首先利用扩散模型的分布均化能力,通过将目标图像翻译成源域风格来弥合跨数据集的差距。然后,我们介绍了两项关键创新:(a)用于紧凑特征聚类的超球约束对比学习网络,(b)一种量化并平衡样本不确定性和代表性的双评分机制。在四个乳房超声数据集(三个公开和一个内部/多中心)上进行的广泛实验表明,我们的方法在五种常见的深度分类器上的表现超过了现有的强大基于AL的竞争对手,验证了其在临床域适应中的有效性和泛化能力。代码可在匿名链接中找到:https://github.com/miccai25-966/ADAptation。
论文及项目相关链接
PDF 11 pages, 4 figures, 4 tables. Accepted by conference MICCAI2025
Summary
深度学习模型在诊断任务中常因训练(源)域与测试(目标)域之间的分布变化而导致性能下降。为应对此问题,收集并标注足够的目标域数据以供模型重新训练是最优解决方案,但受限于时间和资源。主动学习(AL)旨在降低标注成本同时保持性能,但难以处理不同数据集间分布变化带来的挑战。本研究提出一种名为ADAptation的新型无监督主动学习框架,该框架能在有限的标注预算下,从多域数据池中有效选择信息样本。首先,利用扩散模型的分布均化能力,通过翻译目标图像至源域风格来缩小跨数据集差距。接着引入两项创新:超球约束对比学习网络进行紧凑特征聚类,以及量化并平衡样本不确定性和代表性的双评分机制。在四个乳房超声波数据集上的实验表明,相较于其他强大的AL竞争对手,本方法表现更优,验证了其在临床域适应中的有效性和通用性。
Key Takeaways
- 深度学习模型在诊断任务中面临源域与目标域分布变化导致的性能下降问题。
- 收集并标注目标域数据是应对此问题的最优解决方案,但受限于时间和资源。
- 主动学习(AL)虽可降低标注成本,但难以处理不同数据集间的分布变化。
- 本研究提出名为ADAptation的新型无监督主动学习框架,能从多域数据池中有效选择信息样本。
- 利用扩散模型的分布均化能力缩小跨数据集差距。
- 引入超球约束对比学习网络和双评分机制,分别用于紧凑特征聚量和样本不确定性与代表性的量化平衡。
点此查看论文截图

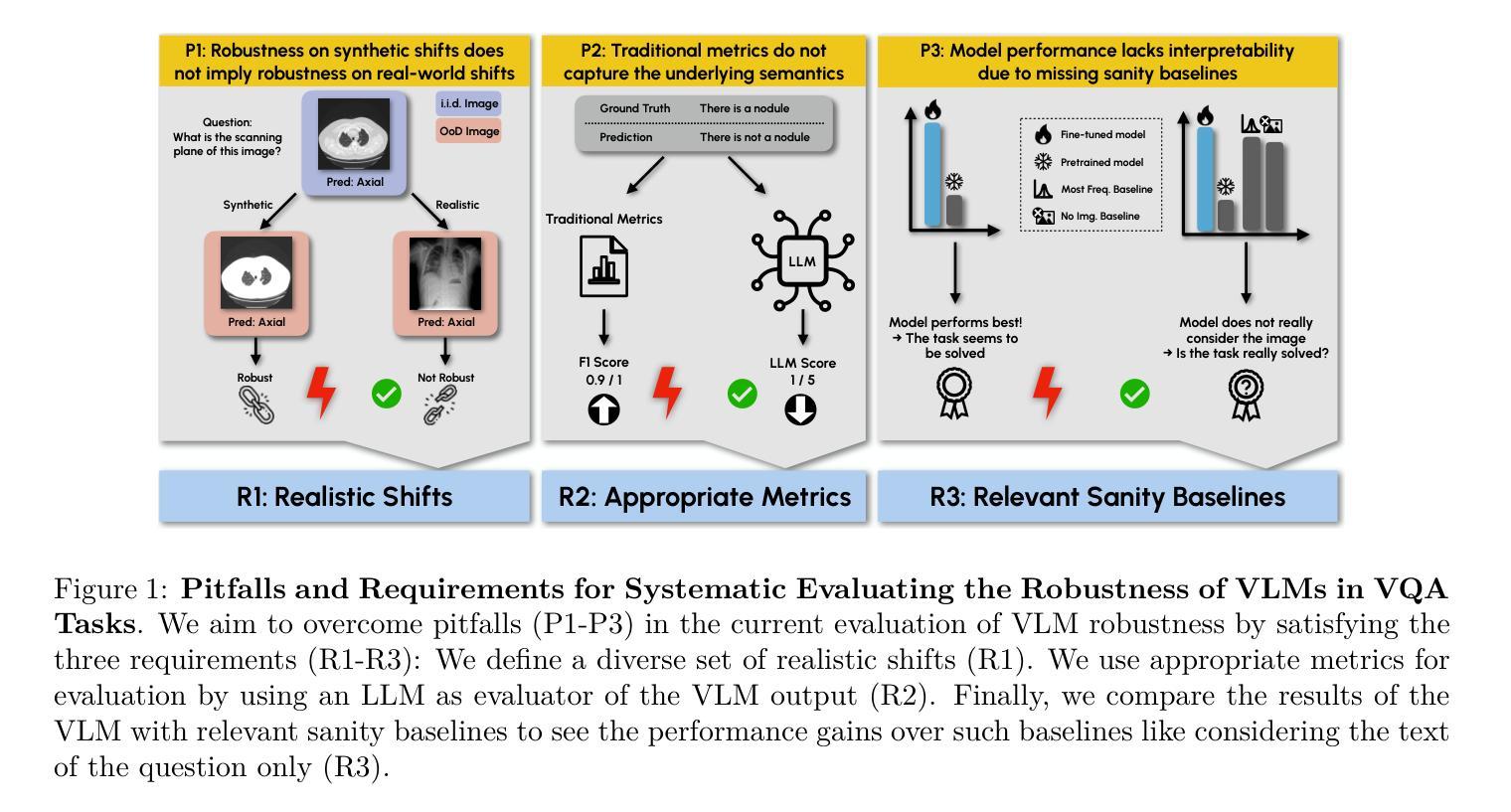
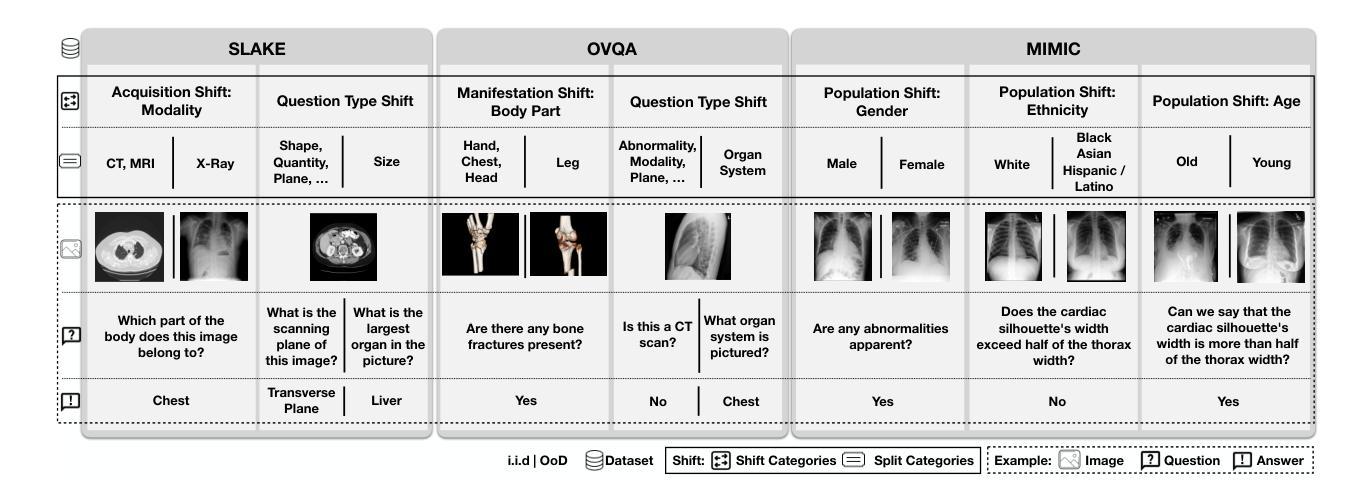
SURE-VQA: Systematic Understanding of Robustness Evaluation in Medical VQA Tasks
Authors:Kim-Celine Kahl, Selen Erkan, Jeremias Traub, Carsten T. Lüth, Klaus Maier-Hein, Lena Maier-Hein, Paul F. Jaeger
Vision-Language Models (VLMs) have great potential in medical tasks, like Visual Question Answering (VQA), where they could act as interactive assistants for both patients and clinicians. Yet their robustness to distribution shifts on unseen data remains a key concern for safe deployment. Evaluating such robustness requires a controlled experimental setup that allows for systematic insights into the model’s behavior. However, we demonstrate that current setups fail to offer sufficiently thorough evaluations. To address this gap, we introduce a novel framework, called \textit{SURE-VQA}, centered around three key requirements to overcome current pitfalls and systematically analyze VLM robustness: 1) Since robustness on synthetic shifts does not necessarily translate to real-world shifts, it should be measured on real-world shifts that are inherent to the VQA data; 2) Traditional token-matching metrics often fail to capture underlying semantics, necessitating the use of large language models (LLMs) for more accurate semantic evaluation; 3) Model performance often lacks interpretability due to missing sanity baselines, thus meaningful baselines should be reported that allow assessing the multimodal impact on the VLM. To demonstrate the relevance of this framework, we conduct a study on the robustness of various Fine-Tuning (FT) methods across three medical datasets with four types of distribution shifts. Our study highlights key insights into robustness: 1) No FT method consistently outperforms others in robustness, and 2) robustness trends are more stable across FT methods than across distribution shifts. Additionally, we find that simple sanity baselines that do not use the image data can perform surprisingly well and confirm LoRA as the best-performing FT method on in-distribution data. Code is provided at https://github.com/IML-DKFZ/sure-vqa.
视觉语言模型(VLMs)在医疗任务(如视觉问答(VQA))中具有巨大潜力,可以作为患者和临床医生双方的交互式助手。然而,它们在未见数据上的分布转移稳健性仍是安全部署的关键问题。评估这种稳健性需要一个受控的实验设置,允许对模型的行为进行系统性的洞察。然而,我们证明当前的设置无法提供足够全面的评估。为了解决这一差距,我们引入了一个名为“SURE-VQA”的新型框架,该框架以三个关键要求为中心,旨在克服当前漏洞并系统地分析VLM的稳健性:1)由于合成转移上的稳健性并不一定等同于现实世界中的转移,因此它应在VQA数据固有的现实世界转移中进行衡量;2)传统的令牌匹配指标通常无法捕获潜在语义,因此需要利用大型语言模型(LLM)进行更准确的语义评估;3)由于缺少基准值,模型性能往往缺乏可解释性,因此应报告有意义的基准值,以便评估对VLM的多模式影响。为了证明该框架的重要性,我们在三个医学数据集和四种分布转移类型上对各种微调(FT)方法的稳健性进行了研究。我们的研究对稳健性有了关键见解:1)没有FT方法能在稳健性方面始终优于其他方法;2)与FT方法相比,稳健性趋势在分布转移之间更为稳定。此外,我们发现不使用图像数据的简单基准线可以表现惊人,并确认LoRA是在内部分布数据上表现最佳的FT方法。代码可在https://github.com/IML-DKFZ/sure-vqa找到。
论文及项目相关链接
PDF TMLR 07/2025
Summary
本文探讨了视觉语言模型(VLMs)在医疗任务中的潜力与挑战。针对现有评估框架在评估模型鲁棒性方面的不足,提出了一种新的评估框架“SURE-VQA”,并围绕三个关键要求进行系统分析:1)在真实世界的数据分布变化上进行鲁棒性评估;2)使用大型语言模型(LLMs)进行更准确的语义评估;3) 报告有意义的基准以评估多模式对VLM的影响。通过对不同微调方法的研究,展示了该框架的实用性,并得出关键洞察。
Key Takeaways
- VLMs在医疗任务如视觉问答(VQA)中有巨大潜力,可作为患者和临床医生的互动助手。
- 现有评估框架在评估模型鲁棒性方面存在不足,需要新的评估框架。
- SURE-VQA框架旨在解决现有问题,围绕三个关键要求进行系统分析:真实世界数据分布变化的评估、使用LLMs进行语义评估、报告有意义的基准以评估多模式影响。
- 研究发现,不同微调方法在不同的医疗数据集上的鲁棒性表现不一致,没有一种方法始终优于其他方法。
- 模型鲁棒性的趋势在不同微调方法之间比在不同数据分布变化之间更稳定。
- 简单的基准测试,即不使用图像数据的测试,可能会表现得相当好。
- LoRA是在内部分布数据上表现最佳的的微调方法。
点此查看论文截图

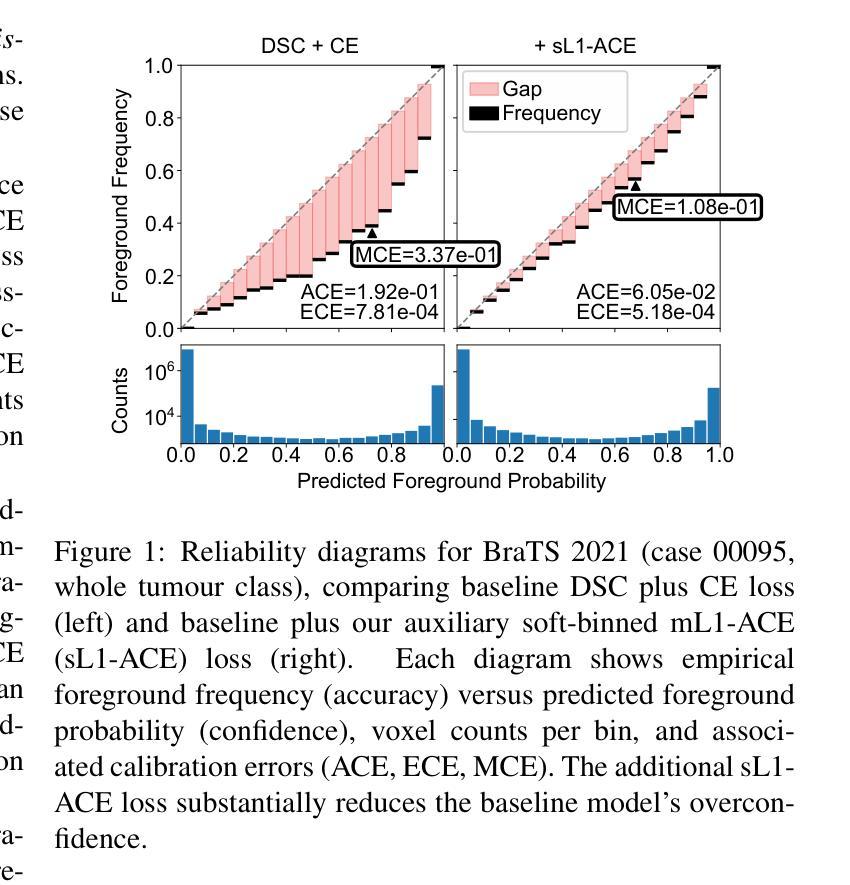
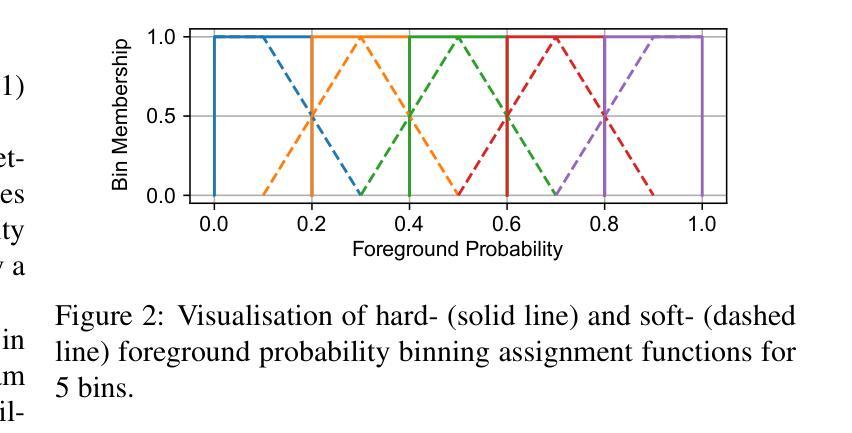
Average Calibration Error: A Differentiable Loss for Improved Reliability in Image Segmentation
Authors:Theodore Barfoot, Luis Garcia-Peraza-Herrera, Ben Glocker, Tom Vercauteren
Deep neural networks for medical image segmentation often produce overconfident results misaligned with empirical observations. Such miscalibration, challenges their clinical translation. We propose to use marginal L1 average calibration error (mL1-ACE) as a novel auxiliary loss function to improve pixel-wise calibration without compromising segmentation quality. We show that this loss, despite using hard binning, is directly differentiable, bypassing the need for approximate but differentiable surrogate or soft binning approaches. Our work also introduces the concept of dataset reliability histograms which generalises standard reliability diagrams for refined visual assessment of calibration in semantic segmentation aggregated at the dataset level. Using mL1-ACE, we reduce average and maximum calibration error by 45% and 55% respectively, maintaining a Dice score of 87% on the BraTS 2021 dataset. We share our code here: https://github.com/cai4cai/ACE-DLIRIS
针对医学图像分割的深度神经网络经常产生过于自信的结果,与经验观察不符。这种误校准对其临床翻译提出了挑战。我们建议使用边际L1平均校准误差(mL1-ACE)作为一种新型辅助损失函数,以提高像素级的校准,同时不损害分割质量。我们证明,尽管使用了硬分箱,这种损失是可直接微分的,从而避免了需要使用近似但可微分的替代或软分箱方法。我们的工作还引入了数据集可靠性直方图的概念,它推广了标准可靠性图,用于在数据集级别对语义分割的校准进行精细的视觉评估。使用mL1-ACE,我们在BraTS 2021数据集上将平均和最大校准误差分别降低了45%和55%,同时保持Dice得分为87%。我们在以下链接分享我们的代码:https://github.com/cai4cai/ACE-DLIRIS
论文及项目相关链接
Summary
神经网络在医学图像分割中常产生过于自信的结果,与实际观测不符。提出使用边际L1平均校准误差(mL1-ACE)作为新的辅助损失函数,提高像素级校准,不影响分割质量。引入数据集可靠性直方图,用于精细的视觉评估。使用mL1-ACE在BraTS 2021数据集上平均和最大校准误差分别降低45%和55%,同时Dice分数保持87%。代码共享于链接。
Key Takeaways
- 神经网络在医学图像分割中存在过度自信的问题。
- 边际L1平均校准误差(mL1-ACE)作为新的辅助损失函数,可提高像素级校准。
- 引入数据集可靠性直方图进行精细的视觉评估。
- 使用mL1-ACE在BraTS 2021数据集上显著提高校准效果,同时维持较高的分割质量。
- 方法可直接应用于现有模型,无需额外的复杂操作。
- 代码已共享,便于其他研究者使用与验证。
点此查看论文截图