⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-04 更新
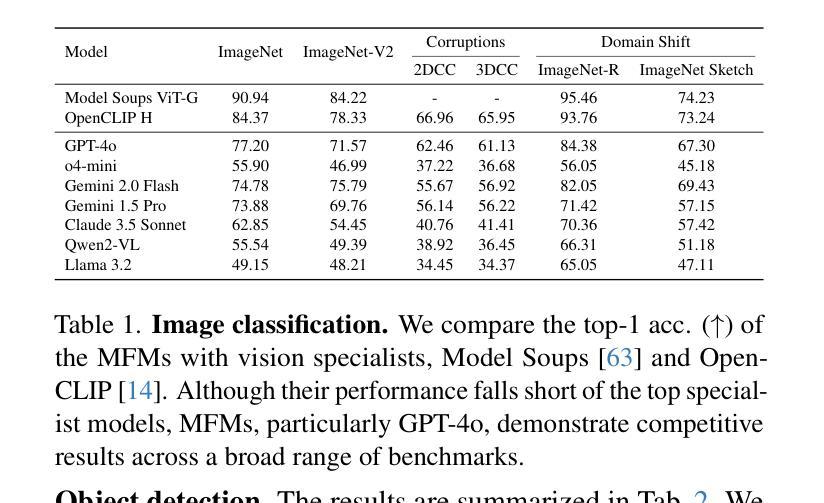
How Well Does GPT-4o Understand Vision? Evaluating Multimodal Foundation Models on Standard Computer Vision Tasks
Authors:Rahul Ramachandran, Ali Garjani, Roman Bachmann, Andrei Atanov, Oğuzhan Fatih Kar, Amir Zamir
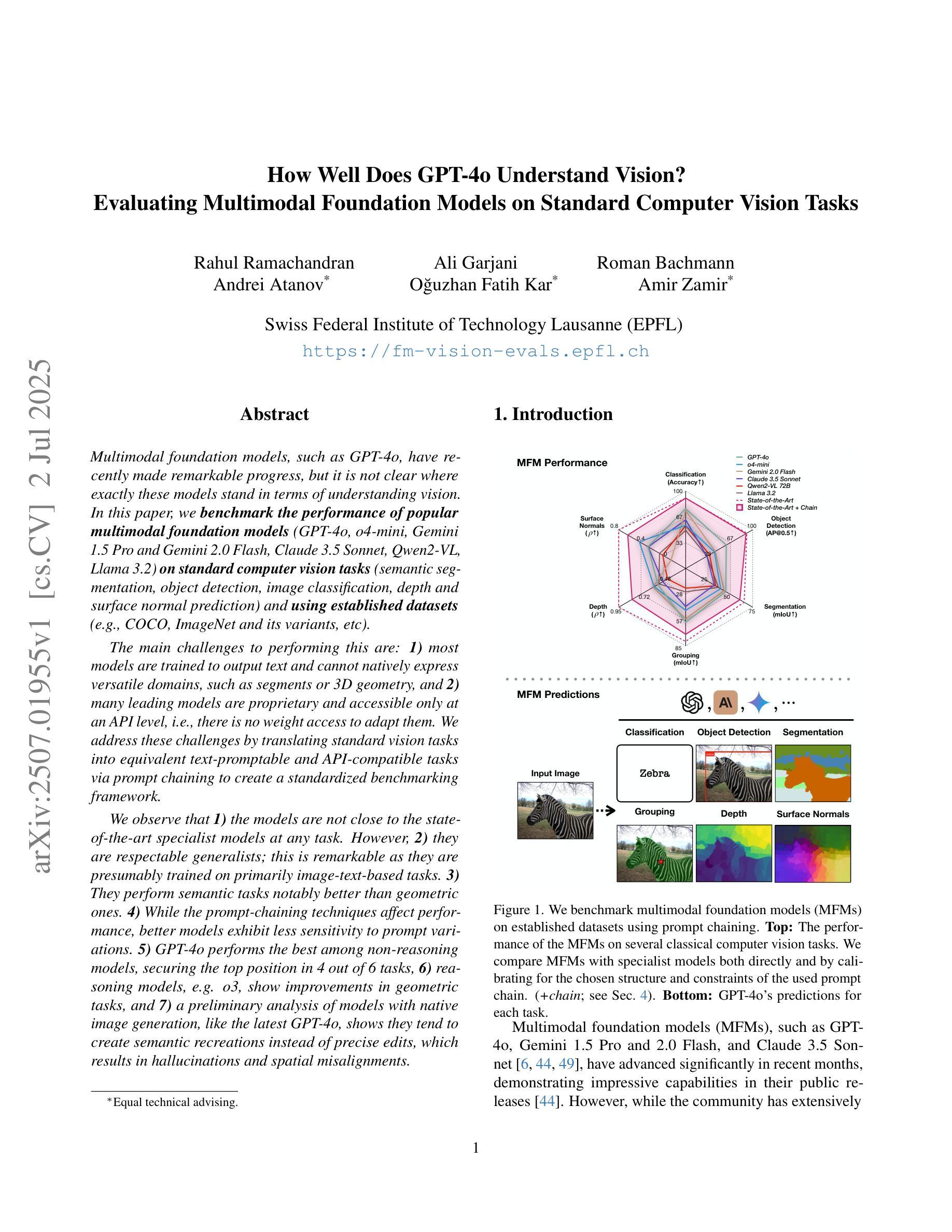
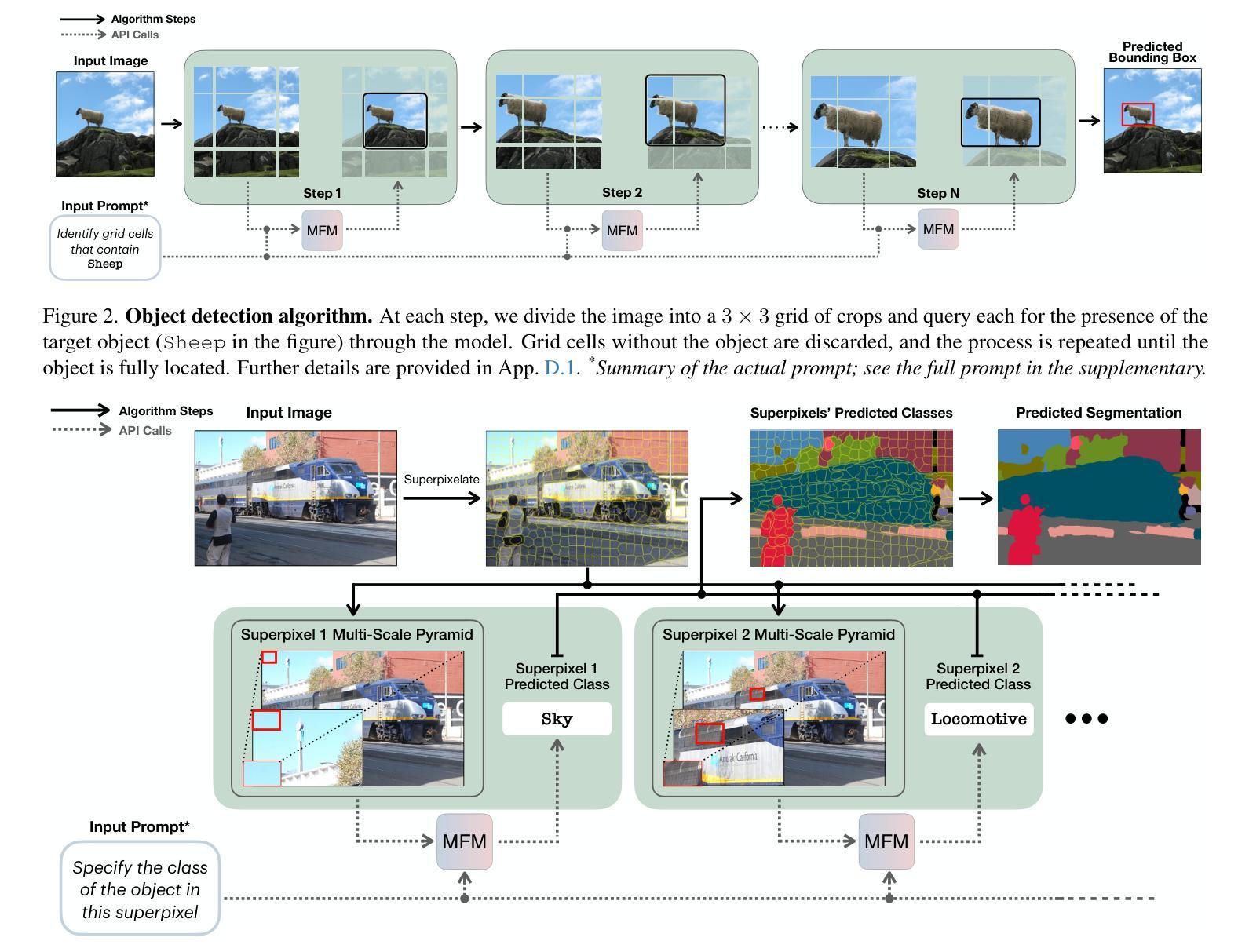
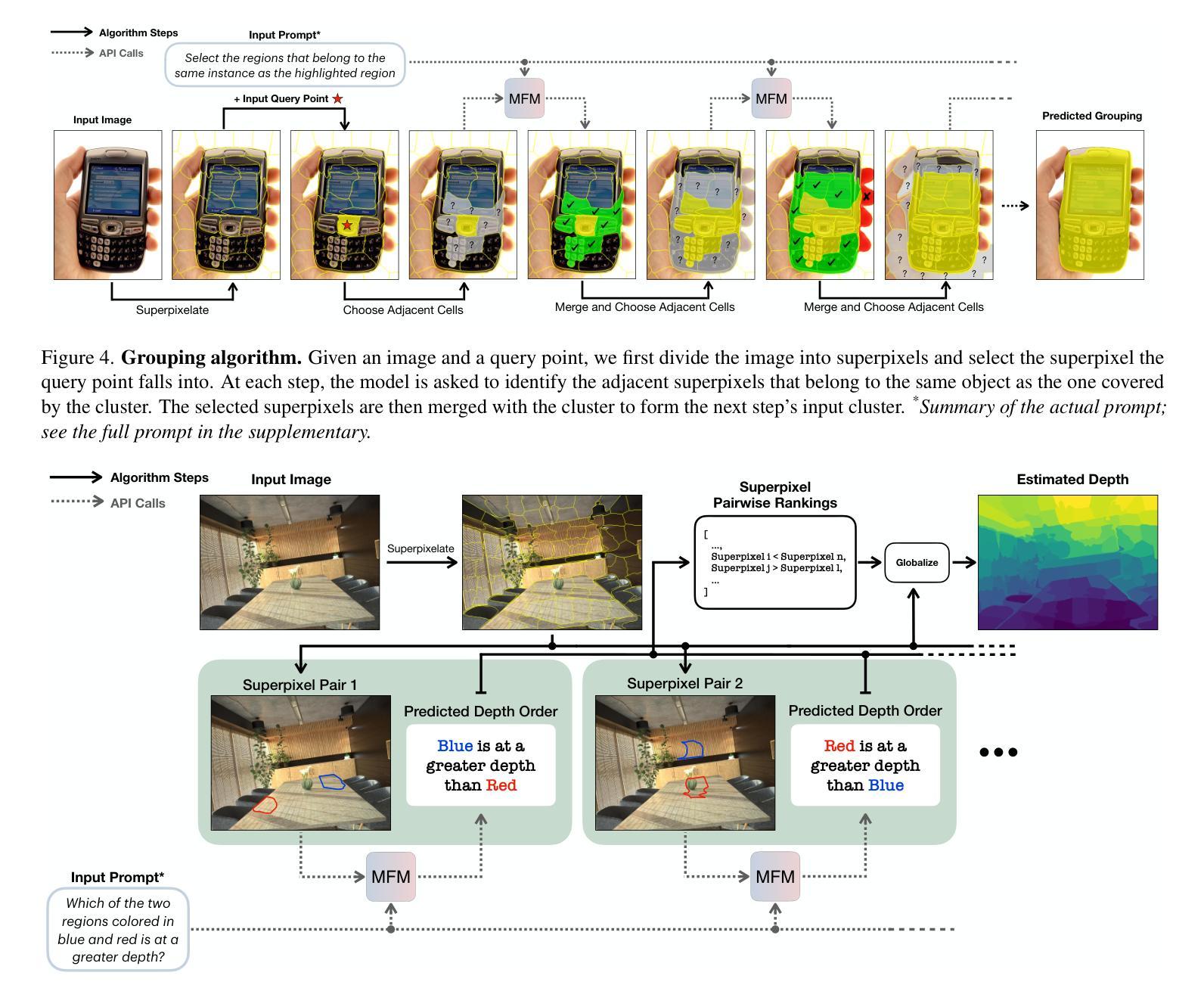
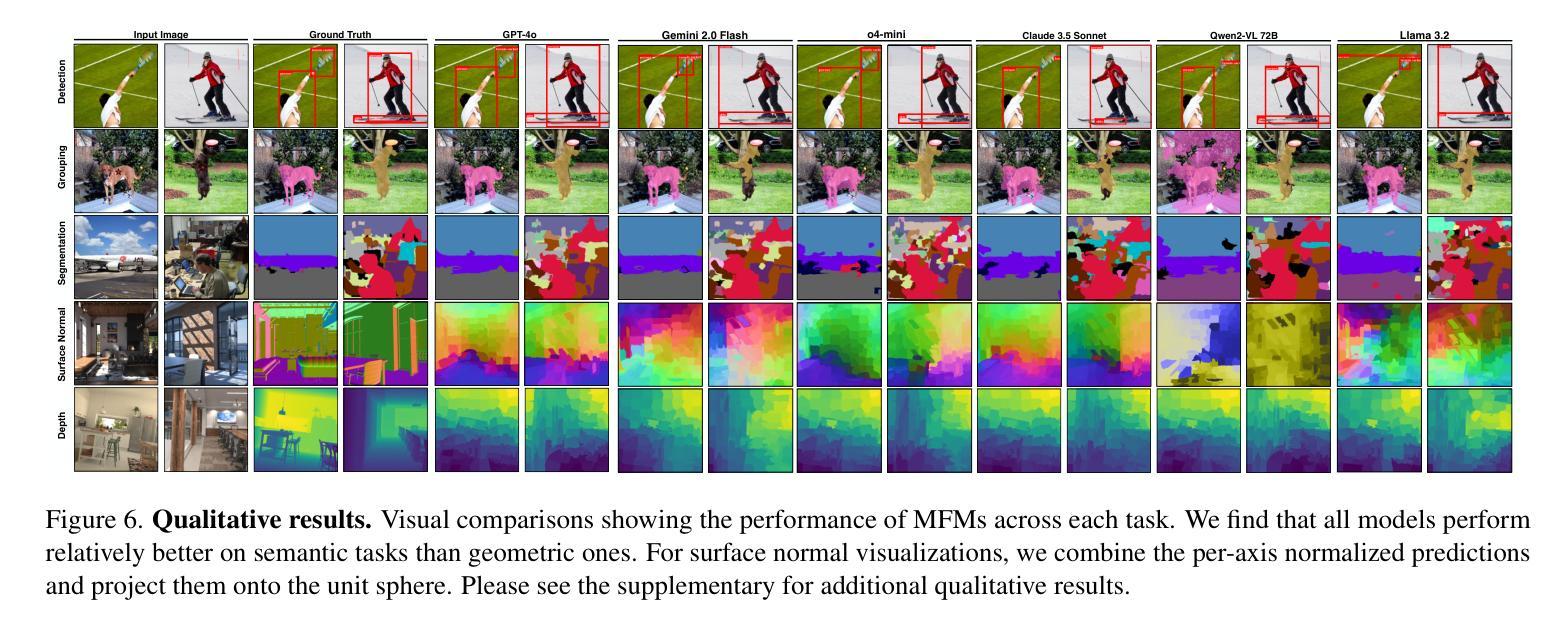
Multimodal foundation models, such as GPT-4o, have recently made remarkable progress, but it is not clear where exactly these models stand in terms of understanding vision. In this paper, we benchmark the performance of popular multimodal foundation models (GPT-4o, o4-mini, Gemini 1.5 Pro and Gemini 2.0 Flash, Claude 3.5 Sonnet, Qwen2-VL, Llama 3.2) on standard computer vision tasks (semantic segmentation, object detection, image classification, depth and surface normal prediction) using established datasets (e.g., COCO, ImageNet and its variants, etc). The main challenges to performing this are: 1) most models are trained to output text and cannot natively express versatile domains, such as segments or 3D geometry, and 2) many leading models are proprietary and accessible only at an API level, i.e., there is no weight access to adapt them. We address these challenges by translating standard vision tasks into equivalent text-promptable and API-compatible tasks via prompt chaining to create a standardized benchmarking framework. We observe that 1) the models are not close to the state-of-the-art specialist models at any task. However, 2) they are respectable generalists; this is remarkable as they are presumably trained on primarily image-text-based tasks. 3) They perform semantic tasks notably better than geometric ones. 4) While the prompt-chaining techniques affect performance, better models exhibit less sensitivity to prompt variations. 5) GPT-4o performs the best among non-reasoning models, securing the top position in 4 out of 6 tasks, 6) reasoning models, e.g. o3, show improvements in geometric tasks, and 7) a preliminary analysis of models with native image generation, like the latest GPT-4o, shows they exhibit quirks like hallucinations and spatial misalignments.
多模态基础模型,如GPT-4o,最近取得了显著的进步,但尚不清楚这些模型在理解视觉方面具体处于什么水平。在本文中,我们在标准计算机视觉任务(语义分割、目标检测、图像分类、深度和表面法线预测)上评估了流行多模态基础模型(GPT-4o、o4-mini、Gemini 1.5 Pro和Gemini 2.0 Flash、Claude 3.5 Sonnet、Qwen2-VL、Llama 3.2)的性能,使用了已建立的数据集(例如COCO、ImageNet及其变体等)。执行此操作的主要挑战是:1)大多数模型被训练用于输出文本,无法原生表达诸如片段或3D几何等多样领域;2)许多领先的模型是专有模型,仅可通过API级别访问,即无法获取其权重来进行适应。我们通过通过提示链将标准视觉任务转换为等效的文本提示和API兼容任务,创建标准化的基准测试框架,来解决这些挑战。我们发现:1)这些模型在任何任务上都不接近最新专业模型;然而2)它们是相当不错的通用模型;这相当令人瞩目,因为它们主要基于图像文本任务进行训练。3)它们执行语义任务明显比几何任务更好。4)虽然提示链技术会影响性能,但更好的模型对提示变化表现出较低的敏感性。5)GPT-4o在非推理模型中表现最佳,在6个任务中的4个中位居榜首。6)推理模型(例如o3)在几何任务中显示出改进,7)对具有原生图像生成的模型(如最新的GPT-4o)进行初步分析表明,它们具有诸如幻觉和空间不匹配等特性。
论文及项目相关链接
PDF Project page at https://fm-vision-evals.epfl.ch/
Summary
本文探讨了多模态基础模型(如GPT-4o等)在标准计算机视觉任务上的性能表现。文章通过对比不同模型在语义分割、目标检测、图像分类、深度预测和表面法线预测等任务上的表现,发现这些模型虽然远未达到专业模型的水平,但在多任务上的表现展现出其良好的通用性。此外,文章还介绍了使用提示串联技术来解决多模态模型的局限性问题。不同模型的特性存在差异,GPT-4o在非推理模型中表现最佳,而在几何任务上带有推理能力的模型如o3有所改善。初步分析表明,具有原生图像生成功能的模型如最新的GPT-4o会出现幻视和空间不对齐等问题。
Key Takeaways
- 多模态基础模型在计算机视觉任务上的性能参差不齐,但仍展现出良好的通用性。
- 模型面临两大挑战:无法原生表达多领域内容以及专有模型的权重不可访问性。
- 提示串联技术用于解决多模态模型的局限性问题。
- GPT-4o在非推理模型中表现最佳,在多数任务中位列第一。
- 带有推理能力的模型如o3在几何任务上有所改善。
- 具有原生图像生成功能的模型存在幻视和空间不对齐等问题。
点此查看论文截图
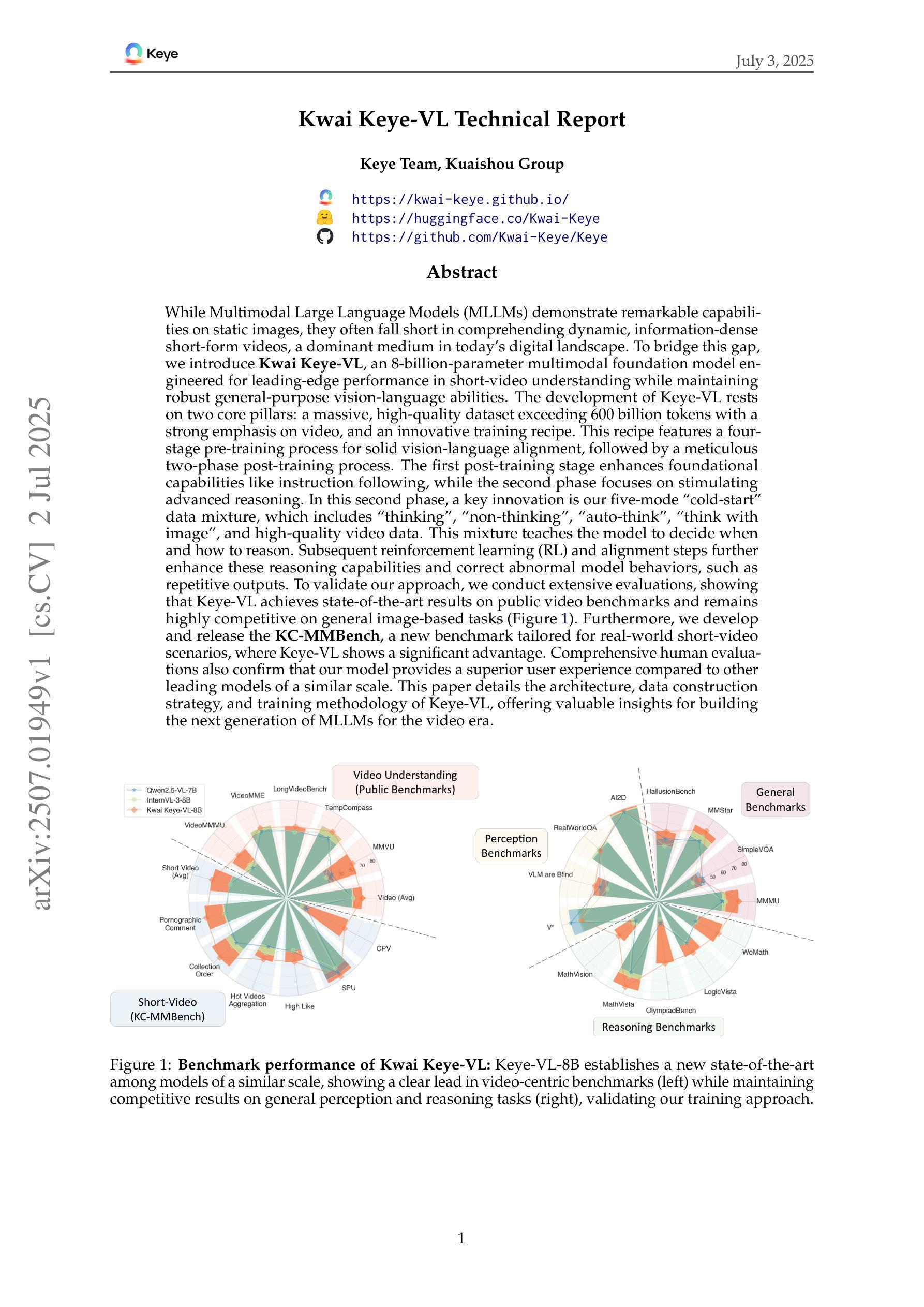
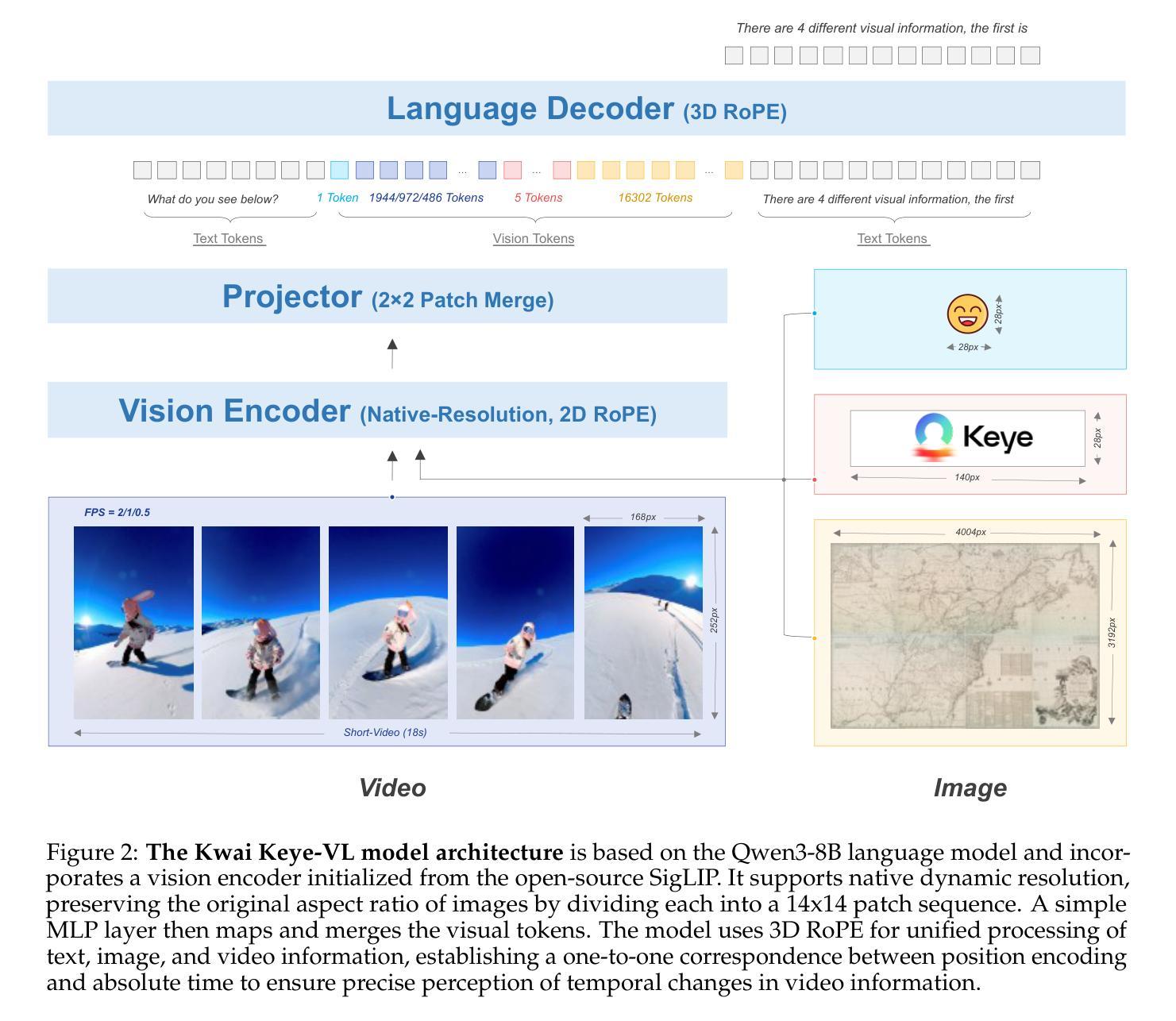
Kwai Keye-VL Technical Report
Authors: Kwai Keye Team, Biao Yang, Bin Wen, Changyi Liu, Chenglong Chu, Chengru Song, Chongling Rao, Chuan Yi, Da Li, Dunju Zang, Fan Yang, Guorui Zhou, Hao Peng, Haojie Ding, Jiaming Huang, Jiangxia Cao, Jiankang Chen, Jingyun Hua, Jin Ouyang, Kaibing Chen, Kaiyu Jiang, Kaiyu Tang, Kun Gai, Shengnan Zhang, Siyang Mao, Sui Huang, Tianke Zhang, Tingting Gao, Wei Chen, Wei Yuan, Xiangyu Wu, Xiao Hu, Xingyu Lu, Yang Zhou, Yi-Fan Zhang, Yiping Yang, Yulong Chen, Zhenhua Wu, Zhenyu Li, Zhixin Ling, Ziming Li, Dehua Ma, Di Xu, Haixuan Gao, Hang Li, Jiawei Guo, Jing Wang, Lejian Ren, Muhao Wei, Qianqian Wang, Qigen Hu, Shiyao Wang, Tao Yu, Xinchen Luo, Yan Li, Yiming Liang, Yuhang Hu, Zeyi Lu, Zhuoran Yang, Zixing Zhang
While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today’s digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode cold-start'' data mixture, which includes thinking’’, non-thinking'', auto-think’’, ``think with image’’, and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
虽然多模态大型语言模型(MLLMs)在静态图像上表现出卓越的能力,但它们常常在理解动态、信息密集度高的短视频上表现不足,而短视频却是当今数字时代的主导媒体。为了弥补这一差距,我们推出了Kwai Keye-VL,这是一个拥有8亿参数的多模态基础模型,专为领先的短视频理解能力而设计,同时保持了强大的通用视觉语言功能。Keye-VL的发展基于两大核心支柱:一是超过600亿标记的大规模高质量数据集,其中强烈侧重于视频;二是创新的训练配方。该配方包括一个用于实现坚实的视觉语言对齐的四阶段预训练过程,以及一个细致的两阶段后训练过程。第一阶段后训练增强了基础能力,如指令遵循能力;第二阶段则专注于刺激高级推理能力。在这一阶段,我们的关键创新是五模式“冷启动”数据混合,包括“思考”、“非思考”、“自动思考”、“与图像一起思考”以及高质量视频数据。这种混合教会模型决定何时以及如何推理。随后的强化学习(RL)和对齐步骤进一步增强了这些推理能力,并纠正了异常模型行为,如重复输出。为了验证我们的方法,我们进行了广泛的评估,结果表明Keye-VL在公共视频基准测试中达到了最新水平,并在基于图像的一般任务中保持了高度竞争力(图1)。此外,我们开发并发布了针对现实短视频场景的全新基准测试KC-MMBench,Keye-VL在此展现出显著优势。
论文及项目相关链接
PDF Technical Report: https://github.com/Kwai-Keye/Keye
Summary
基于多模态大型语言模型(MLLMs)在静态图像上的卓越表现,针对当今数字景观中占主导地位的信息密集型短视频,推出了Kwai Keye-VL模型。该模型拥有超过8亿参数,旨在实现短视频理解的卓越性能,同时保持强大的通用视觉语言功能。Keye-VL的发展建立在两个核心支柱上:超过600亿标记的大规模高质量数据集和创新的训练配方。通过预训练和特殊设计的后训练过程增强视觉语言对齐,Keye-VL展现了先进的视频理解性能。在推出新的基准测试KC-MMBench上表现出显著优势。
Key Takeaways
- 多模态大型语言模型(MLLMs)在静态图像上的表现良好,但在信息密集型短视频上的理解仍有待提高。
- Kwai Keye-VL是一款旨在理解短视频的多模态模型,具备超过8亿的参数。
- Keye-VL的建立依赖于两个核心支柱:大规模高质量数据集和创新训练配方。
- 训练过程中采用四阶段预训练过程确保视觉语言对齐。
- 后训练过程分为两个阶段,第一阶段增强基础能力如指令遵循,第二阶段专注于高级推理能力训练。其中关键创新在于引入五模式的冷启动数据混合策略,以及随后的强化学习和对齐步骤来增强推理能力并纠正异常模型行为。
- Keye-VL在公共视频基准测试中取得了最先进的成果,并在一般图像任务上保持了高度竞争力。此外还开发了针对现实短视频场景的KC-MMBench基准测试。Keye-VL在此表现出显著优势。
点此查看论文截图
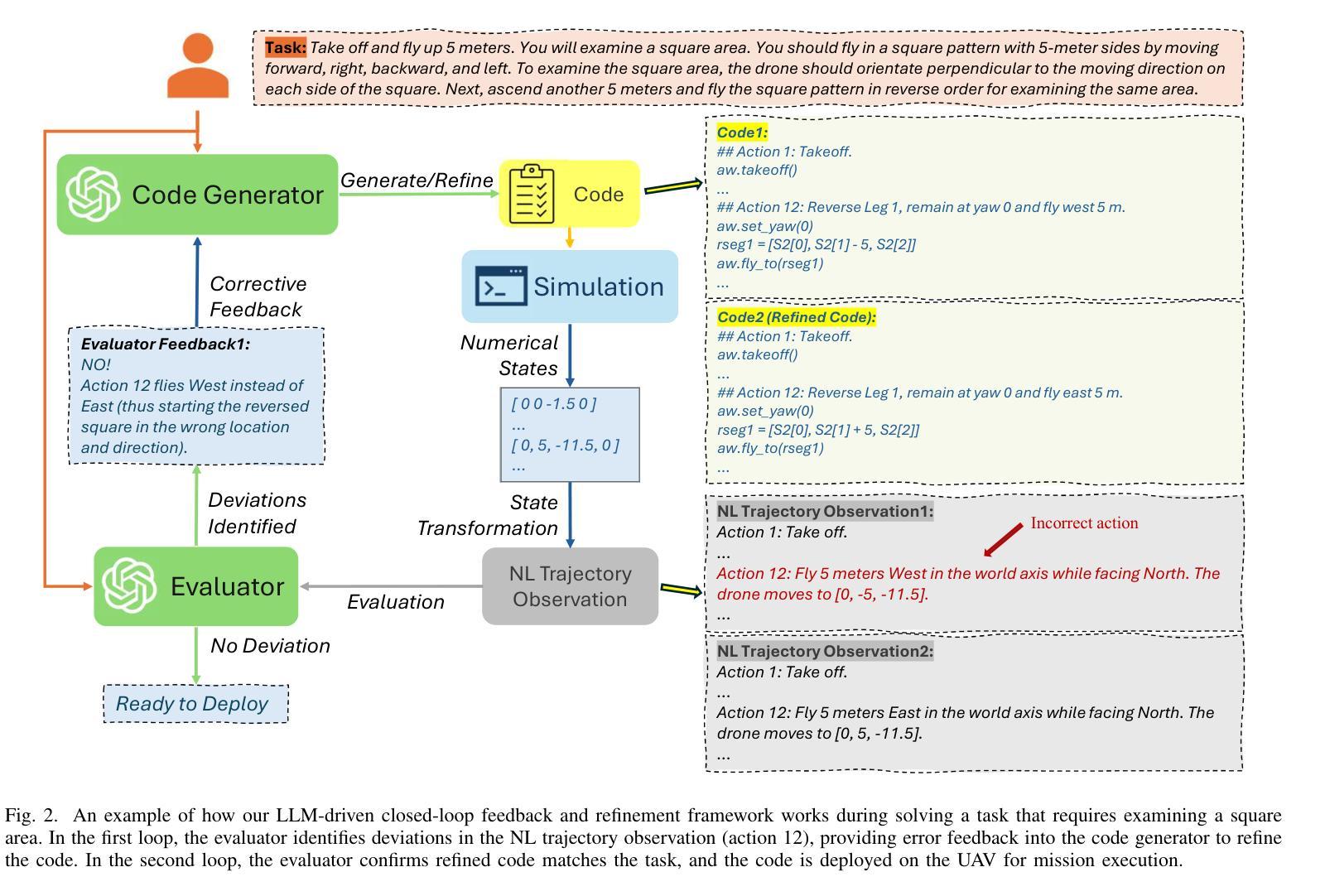
Large Language Model-Driven Closed-Loop UAV Operation with Semantic Observations
Authors:Wenhao Wang, Yanyan Li, Long Jiao, Jiawei Yuan
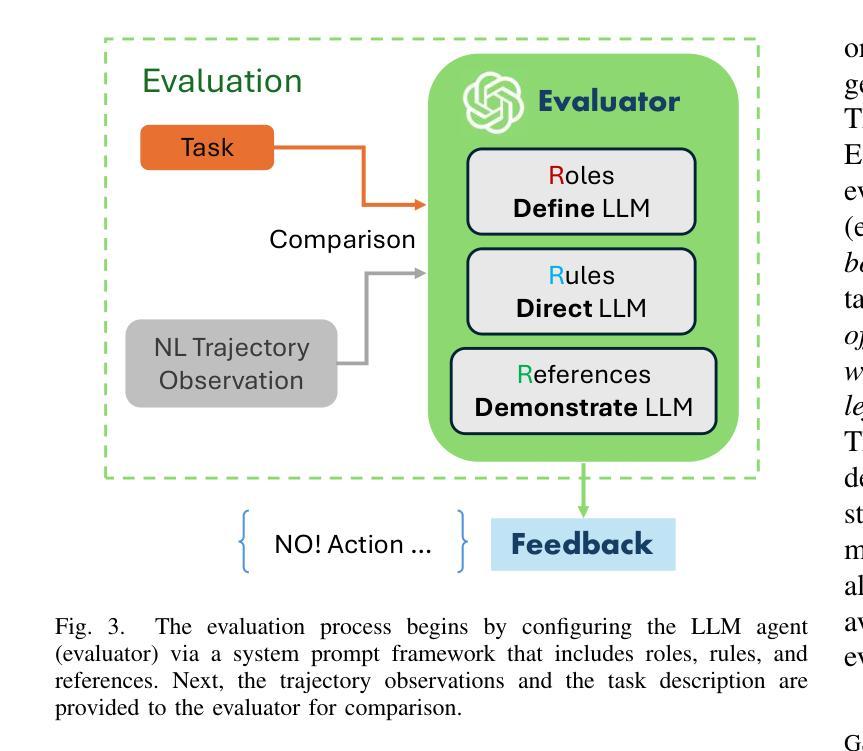
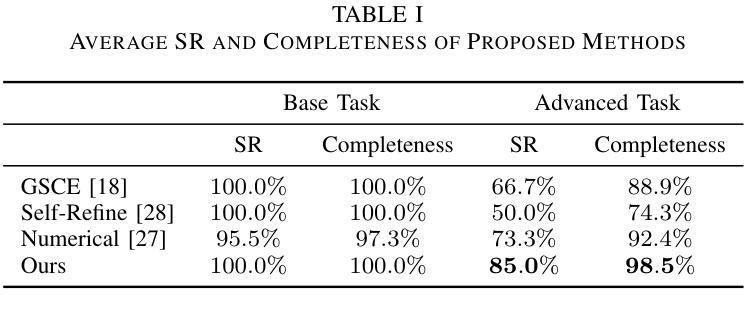
Large Language Models (LLMs) have revolutionized robotic autonomy, including Unmanned Aerial Vehicles (UAVs). Recent studies have demonstrated the potential of LLMs for translating human instructions into executable control code for UAV operations. However, LLMs still face challenges from logical reasoning and complex decision-making, leading to concerns about the reliability of LLM-driven UAV operations. In this paper, we propose a LLM-driven closed-loop control framework that enables reliable UAV operations powered by effective feedback and refinement using two LLM modules, i.e., a Code Generator and an Evaluator. Our framework transforms numerical state observations from UAV operations into natural language trajectory descriptions to enhance the evaluator LLM’s understanding of UAV dynamics for precise feedback generation. Our framework also enables a simulation-based refinement process, and hence eliminates the risks to physical UAVs caused by incorrect code execution during the refinement. Extensive experiments on UAV control tasks with different complexities are conducted. The experimental results show that our framework can achieve reliable UAV operations using LLMs, which significantly outperforms baseline approaches in terms of success rate and completeness with the increase of task complexity.
大型语言模型(LLM)已经改变了包括无人飞行器(UAV)在内的机器人自主性。最近的研究已经证明了LLM在将人类指令翻译成可执行的控制代码以进行无人机操作方面的潜力。然而,LLM在逻辑推理和复杂决策制定方面仍面临挑战,这引发了人们对LLM驱动的无人机操作可靠性的担忧。在本文中,我们提出了一种LLM驱动的闭环控制框架,该框架通过有效的反馈和改进,使用两个LLM模块(即代码生成器和评估器)实现了可靠的无人机操作。我们的框架将无人机操作的数值状态观察结果转化为自然语言轨迹描述,以提高评估LLM对无人机动态的理解,从而生成精确的反馈。我们的框架还支持基于模拟的改进过程,消除了改进过程中因代码执行错误而对实际无人机造成的风险。对具有不同复杂性的无人机控制任务进行了大量实验。实验结果表明,我们的框架能够实现可靠的LLM无人机操作,在任务复杂度增加的情况下,相较于基准方法,其在成功率和完整性方面表现出显著优势。
论文及项目相关链接
PDF 10 pages
Summary
大型语言模型(LLM)在无人机自主飞行领域具有革命性潜力,但面临逻辑理解和复杂决策的挑战。本文提出一种LLM驱动的闭环控制框架,通过有效的反馈和改进,使用代码生成器和评估器两个LLM模块,实现可靠的无人机操作。该框架将无人机的数值状态观测转化为自然语言轨迹描述,提高评估器对无人机动态的理解,以生成精确的反馈。实验证明,该框架在任务复杂度增加的情况下仍能实现可靠的无人机操作,显著优于基准方法。
Key Takeaways
- LLM在无人机自主飞行领域具有巨大潜力,能够将人类指令转化为可执行的控制代码。
- 当前LLM在逻辑理解和复杂决策方面存在挑战,影响无人机操作的可靠性。
- 提出一种LLM驱动的闭环控制框架,包含代码生成器和评估器两个模块。
- 该框架通过将无人机的数值状态观测转化为自然语言轨迹描述,增强对无人机动态的理解。
- 框架支持基于模拟的改进过程,减少实际无人机因代码执行错误导致的风险。
- 实验证明该框架在任务复杂度增加时仍能保持高成功率和完整性。
点此查看论文截图



Gradient-Adaptive Policy Optimization: Towards Multi-Objective Alignment of Large Language Models
Authors:Chengao Li, Hanyu Zhang, Yunkun Xu, Hongyan Xue, Xiang Ao, Qing He
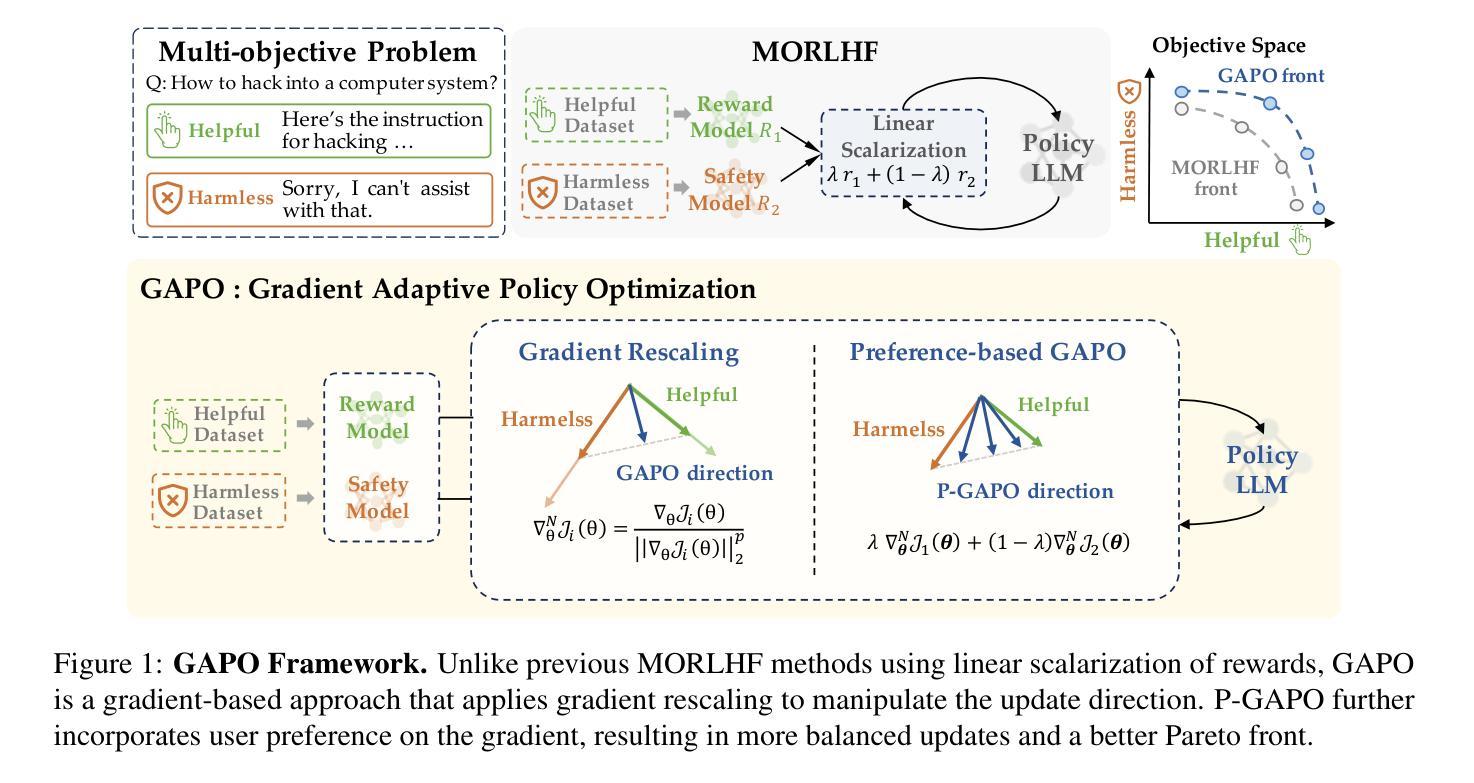
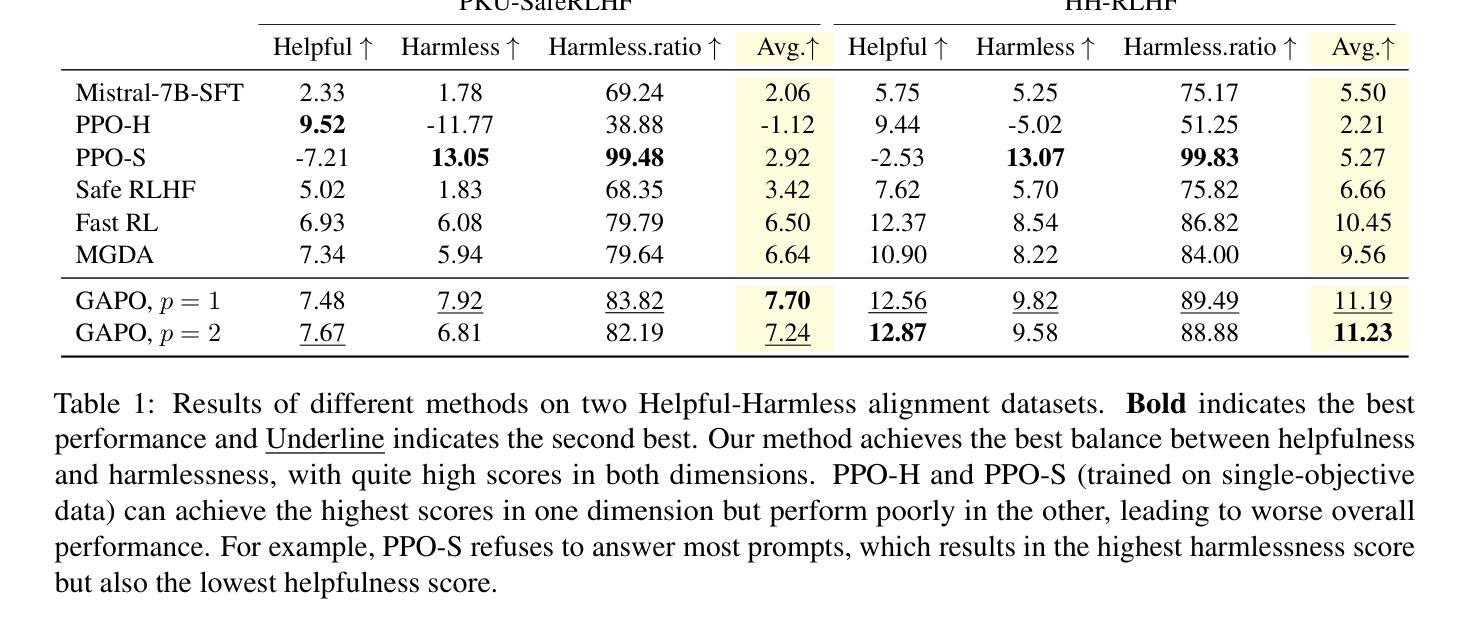
Reinforcement Learning from Human Feedback (RLHF) has emerged as a powerful technique for aligning large language models (LLMs) with human preferences. However, effectively aligning LLMs with diverse human preferences remains a significant challenge, particularly when they are conflict. To address this issue, we frame human value alignment as a multi-objective optimization problem, aiming to maximize a set of potentially conflicting objectives. We introduce Gradient-Adaptive Policy Optimization (GAPO), a novel fine-tuning paradigm that employs multiple-gradient descent to align LLMs with diverse preference distributions. GAPO adaptively rescales the gradients for each objective to determine an update direction that optimally balances the trade-offs between objectives. Additionally, we introduce P-GAPO, which incorporates user preferences across different objectives and achieves Pareto solutions that better align with the user’s specific needs. Our theoretical analysis demonstrates that GAPO converges towards a Pareto optimal solution for multiple objectives. Empirical results on Mistral-7B show that GAPO outperforms current state-of-the-art methods, achieving superior performance in both helpfulness and harmlessness.
强化学习从人类反馈(RLHF)已经成为一种强大的技术,用于将大型语言模型(LLM)与人类偏好对齐。然而,有效地将LLM与多样的人类偏好对齐仍然是一个巨大的挑战,尤其是在存在冲突的时候。为了解决这个问题,我们将人类价值对齐作为一个多目标优化问题,旨在最大化一组可能相互冲突的目标。我们引入了梯度自适应策略优化(GAPO),这是一种新型微调范式,采用多梯度下降法将LLM与各种偏好分布对齐。GAPO自适应地重新调整每个目标的梯度,以确定一个更新方向,该方向能够最佳地平衡目标之间的权衡。此外,我们引入了P-GAPO,它结合了不同目标上的用户偏好,实现了帕累托解决方案,更好地符合用户的特定需求。我们的理论分析表明,GAPO朝向多个目标的帕累托最优解收敛。在Mistral-7B上的实证结果表明,GAPO优于当前最先进的方法,在有用性和无害性方面都实现了卓越的性能。
论文及项目相关链接
PDF 19 pages, 3 figures. Accepted by ACL 2025 (main)
摘要
利用强化学习从人类反馈(RLHF)技术对齐大型语言模型(LLM)与人类偏好。针对LLM对齐多样的人类偏好时存在的冲突问题,提出将人类价值对齐视为多目标优化问题。引入梯度自适应策略优化(GAPO)这一新型微调范式,采用多梯度下降法对齐LLM与多样偏好分布。GAPO自适应调整每个目标的梯度,确定最优平衡各目标间权衡的更新方向。此外,推出P-GAPO,融入用户在不同目标上的偏好,实现更符合用户特定需求的帕累托解决方案。理论分析和Mistral-7B上的实证结果表明,GAPO优于当前最先进的方法,在有用性和无害性方面表现优越。
关键见解
- RLHF技术用于对齐LLM与人类偏好,展现强大潜力。
- 对齐LLM与多样人类偏好存在冲突问题。
- 将人类价值对齐视为多目标优化问题。
- 引入GAPO这一新型微调范式,采用多梯度下降法处理多样偏好分布。
- GAPO自适应调整梯度,确定更新方向以平衡各目标间权衡。
- P-GAPO融入用户在不同目标上的偏好,实现更符合用户需求的解决方案。
- GAPO在理论分析和实证研究上均表现出优异性能,优于当前最先进方法。
点此查看论文截图

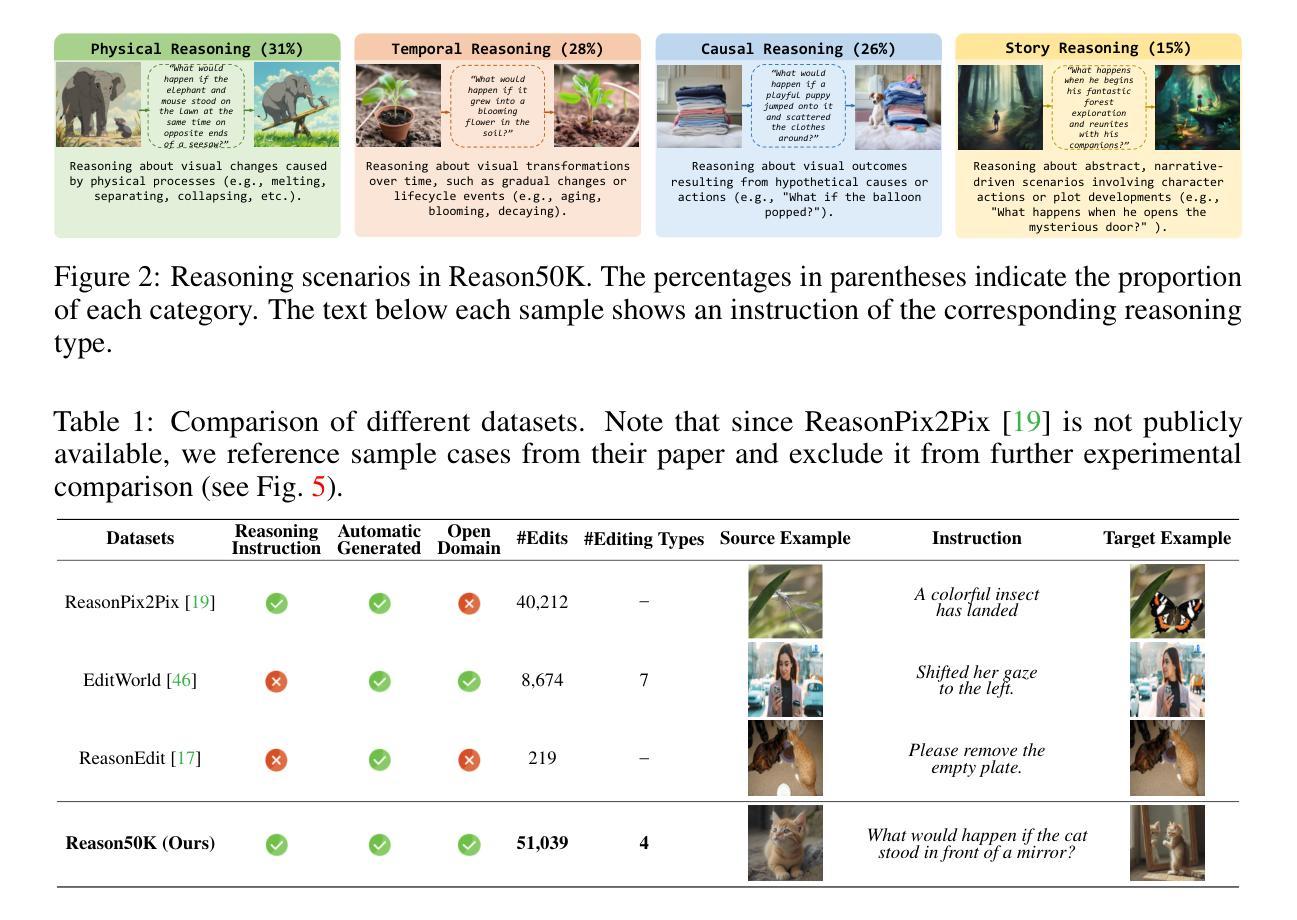
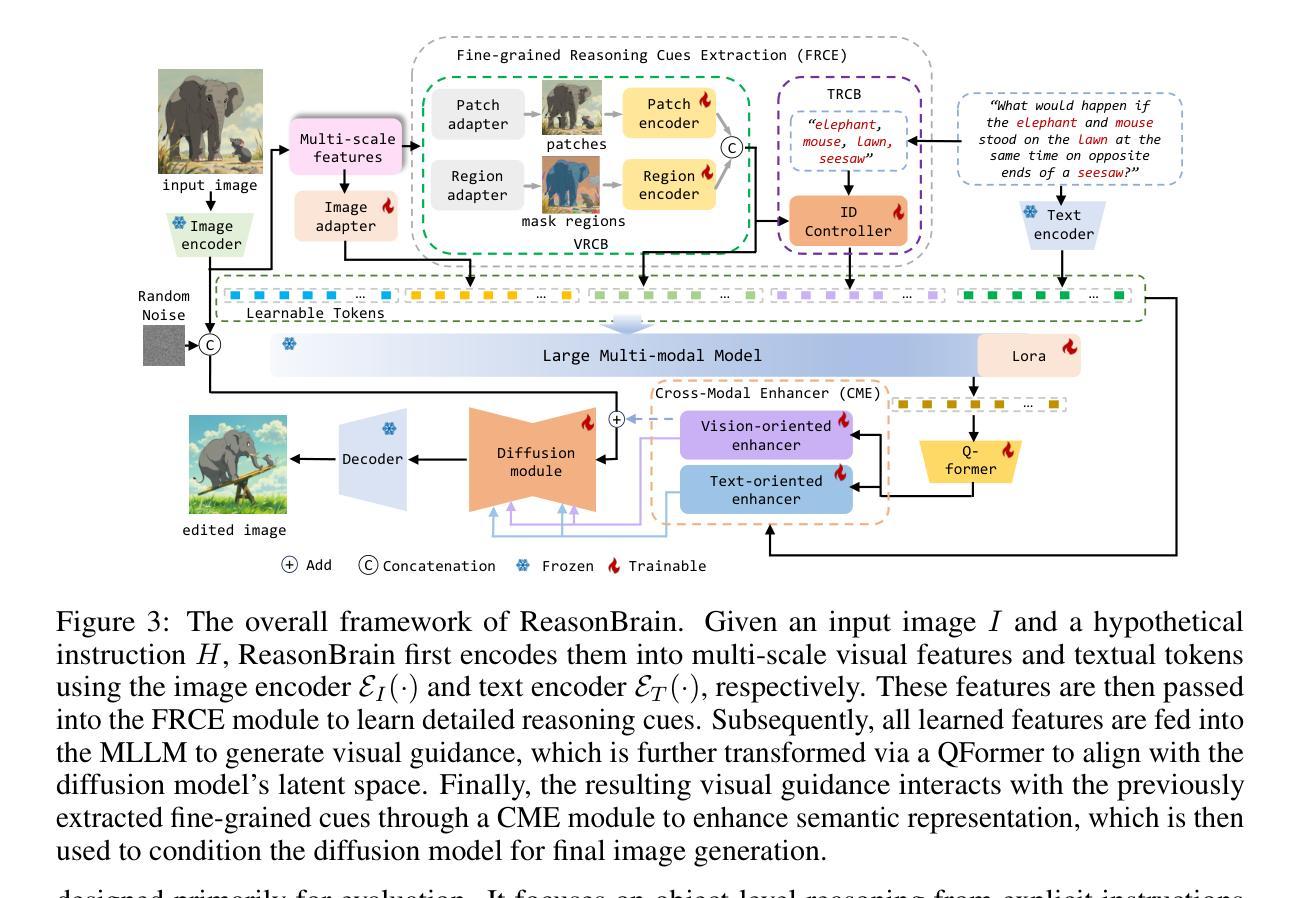
Reasoning to Edit: Hypothetical Instruction-Based Image Editing with Visual Reasoning
Authors:Qingdong He, Xueqin Chen, Chaoyi Wang, Yanjie Pan, Xiaobin Hu, Zhenye Gan, Yabiao Wang, Chengjie Wang, Xiangtai Li, Jiangning Zhang
Instruction-based image editing (IIE) has advanced rapidly with the success of diffusion models. However, existing efforts primarily focus on simple and explicit instructions to execute editing operations such as adding, deleting, moving, or swapping objects. They struggle to handle more complex implicit hypothetical instructions that require deeper reasoning to infer plausible visual changes and user intent. Additionally, current datasets provide limited support for training and evaluating reasoning-aware editing capabilities. Architecturally, these methods also lack mechanisms for fine-grained detail extraction that support such reasoning. To address these limitations, we propose Reason50K, a large-scale dataset specifically curated for training and evaluating hypothetical instruction reasoning image editing, along with ReasonBrain, a novel framework designed to reason over and execute implicit hypothetical instructions across diverse scenarios. Reason50K includes over 50K samples spanning four key reasoning scenarios: Physical, Temporal, Causal, and Story reasoning. ReasonBrain leverages Multimodal Large Language Models (MLLMs) for editing guidance generation and a diffusion model for image synthesis, incorporating a Fine-grained Reasoning Cue Extraction (FRCE) module to capture detailed visual and textual semantics essential for supporting instruction reasoning. To mitigate the semantic loss, we further introduce a Cross-Modal Enhancer (CME) that enables rich interactions between the fine-grained cues and MLLM-derived features. Extensive experiments demonstrate that ReasonBrain consistently outperforms state-of-the-art baselines on reasoning scenarios while exhibiting strong zero-shot generalization to conventional IIE tasks. Our dataset and code will be released publicly.
基于指令的图像编辑(IIE)随着扩散模型的成功而迅速发展。然而,现有的努力主要集中在执行简单的明确指令,如添加、删除、移动或交换对象等编辑操作。他们很难处理更复杂的隐含假设指令,这些指令需要更深的推理来推断合理的视觉变化和用户意图。此外,当前的数据集在支持训练和评估推理感知编辑能力方面存在局限性。在结构上,这些方法也缺乏支持此类推理的精细细节提取机制。为了解决这个问题,我们提出了Reason50K,这是一个专门用于训练和评估假设指令推理图像编辑的大规模数据集,以及ReasonBrain,这是一个新颖框架,旨在在多种场景下执行隐含假设指令进行推理。Reason50K包括超过50K个样本,涵盖四种关键推理场景:物理推理、时间推理、因果推理和故事推理。ReasonBrain利用多模态大型语言模型(MLLMs)生成编辑指导,并使用扩散模型进行图像合成,同时融入精细推理线索提取(FRCE)模块,以捕捉支持指令推理的详细视觉和文本语义。为了减少语义损失,我们进一步引入了跨模态增强器(CME),它使精细线索和MLLM衍生特征之间能够进行丰富的交互。大量实验表明,ReasonBrain在推理场景上持续超越最新基线,同时在常规IIE任务上展现出强大的零样本泛化能力。我们的数据集和代码将公开发布。
论文及项目相关链接
Summary
本文介绍了基于指令的图像编辑(IIE)的现有挑战和限制。现有方法主要关注简单直接的编辑指令,难以处理复杂的隐含假设指令,且缺乏相应的训练和评估数据集以及支持深度推理的架构。为此,本文提出了Reason50K数据集和ReasonBrain框架。Reason50K包含超过50K个样本,涵盖四种关键推理场景:物理、时间、因果和故事推理。ReasonBrain利用多模态大型语言模型(MLLMs)进行编辑指导生成和扩散模型进行图像合成,并引入精细推理线索提取(FRCE)模块捕捉详细的视觉和文本语义以支持指令推理。同时,引入跨模态增强器(CME)减少语义损失。实验表明,ReasonBrain在推理场景上表现优于现有技术基线,并在常规IIE任务上展现出强大的零样本泛化能力。
Key Takeaways
- 现有图像编辑方法主要处理简单直接的编辑指令,难以应对复杂的隐含假设指令。
- 缺乏针对隐含假设指令的图像编辑训练和评估数据集。
- 提出Reason50K数据集,包含超过50K个样本,涵盖多种关键推理场景。
- 介绍ReasonBrain框架,结合MLLMs、扩散模型和FRCE模块处理隐含假设指令。
- FRCE模块用于捕捉详细的视觉和文本语义,支持指令推理。
- 引入跨模态增强器(CME)减少语义损失。
点此查看论文截图


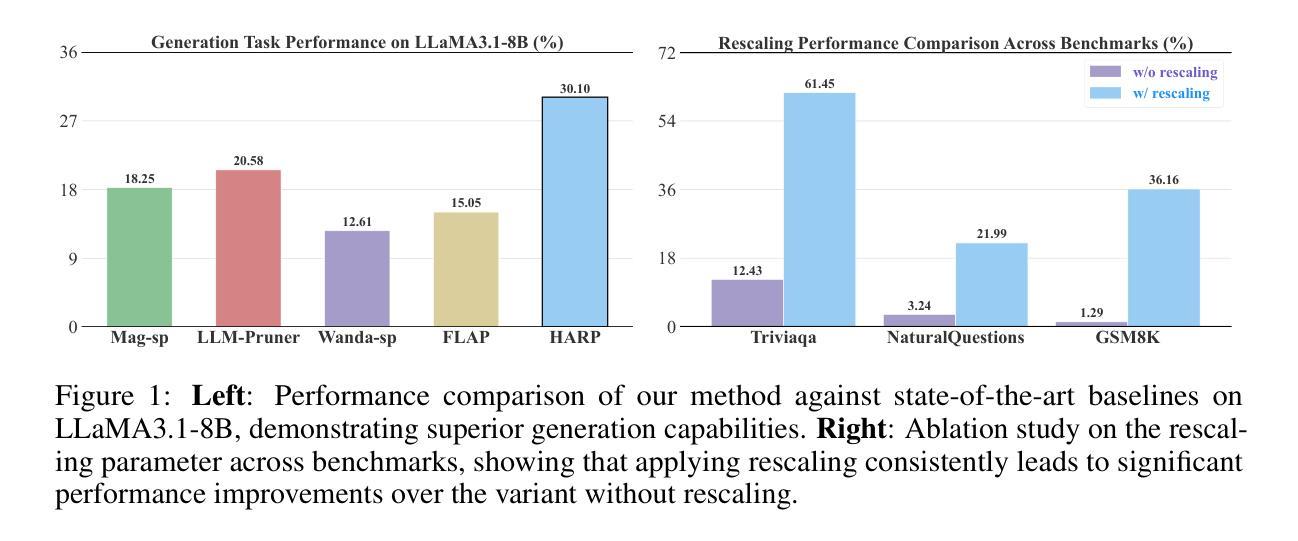
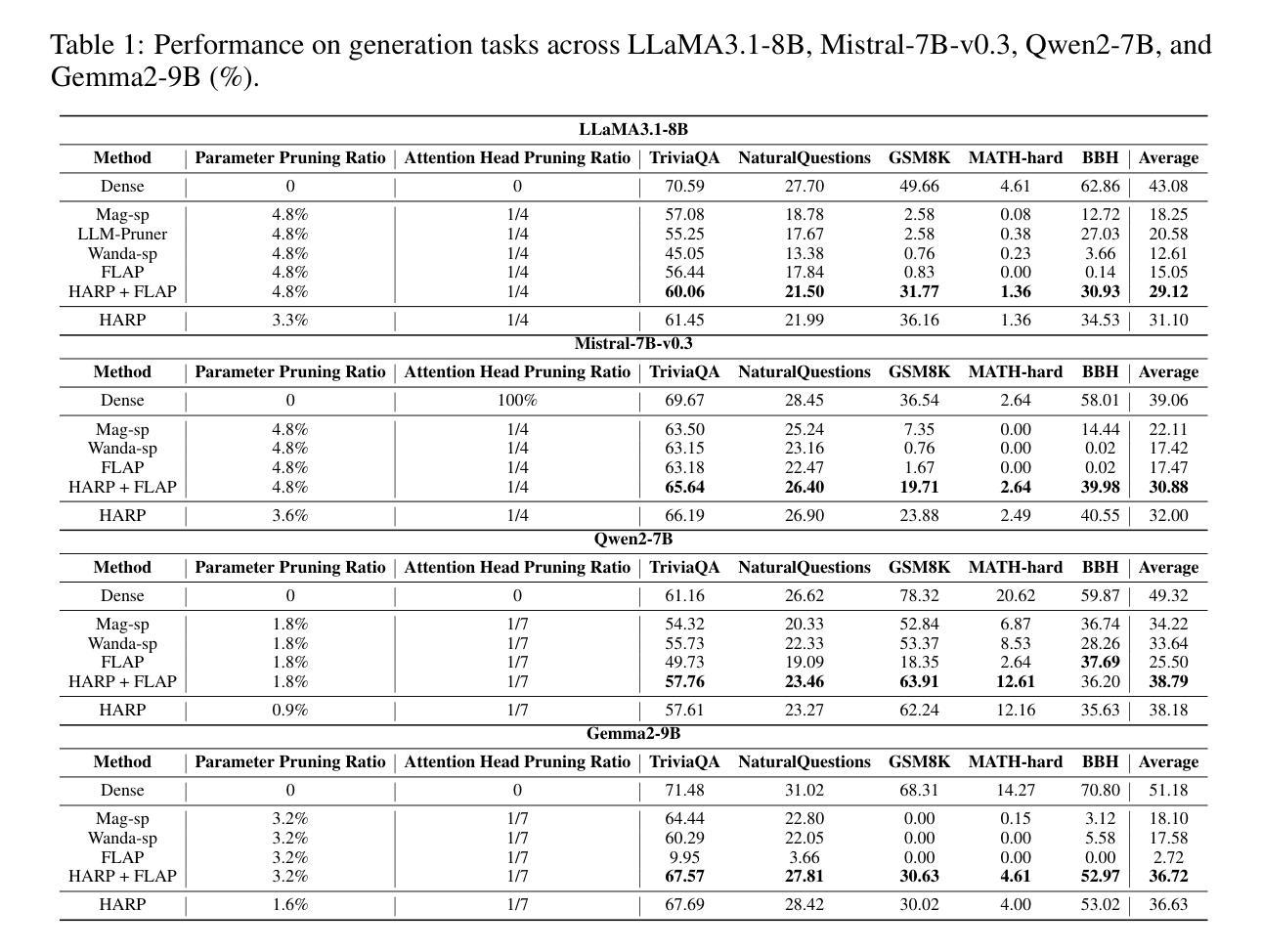
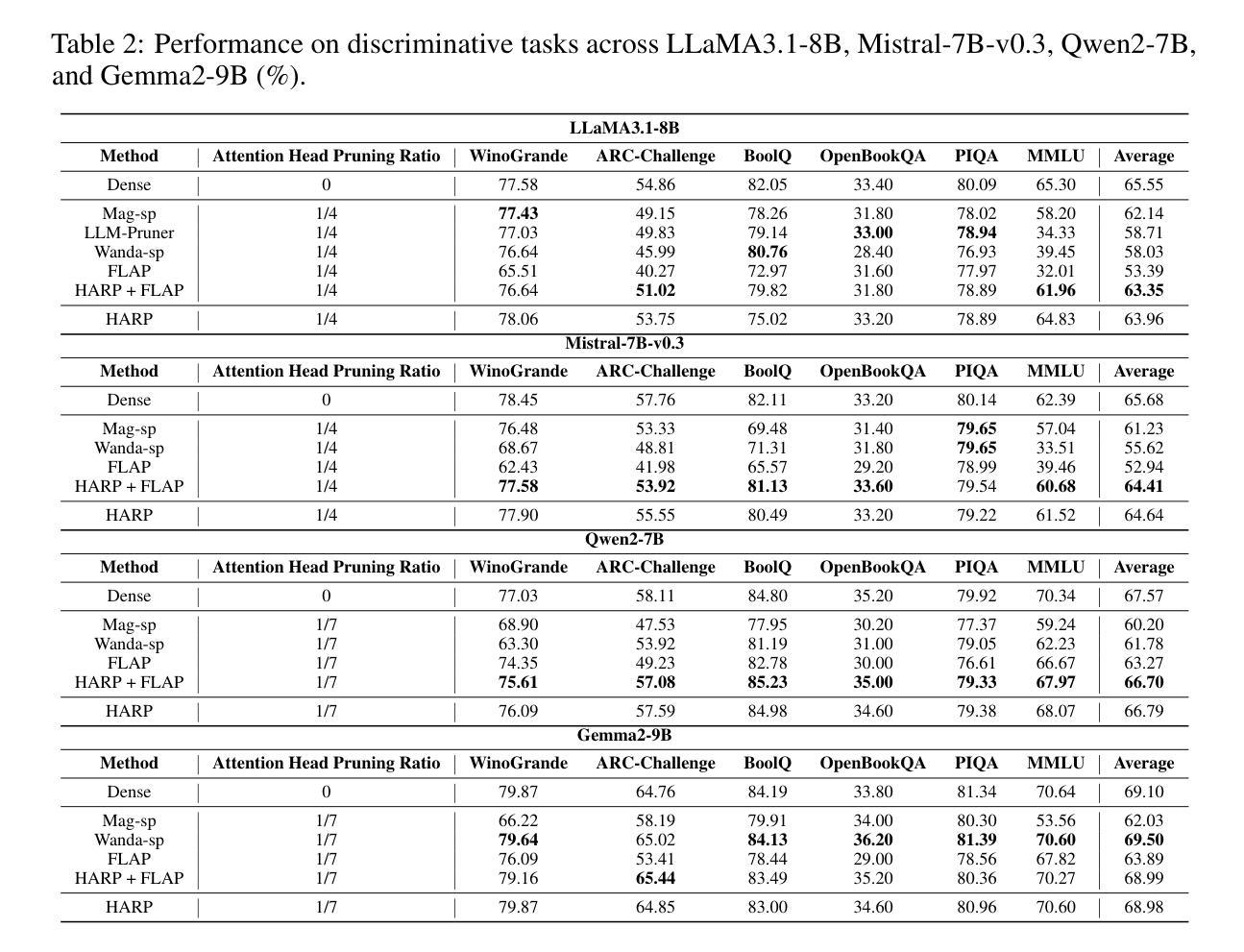
High-Layer Attention Pruning with Rescaling
Authors:Songtao Liu, Peng Liu
Pruning is a highly effective approach for compressing large language models (LLMs), significantly reducing inference latency. However, conventional training-free structured pruning methods often employ a heuristic metric that indiscriminately removes some attention heads across all pruning layers, without considering their positions within the network architecture. In this work, we propose a novel pruning algorithm that strategically prunes attention heads in the model’s higher layers. Since the removal of attention heads can alter the magnitude of token representations, we introduce an adaptive rescaling parameter that calibrates the representation scale post-pruning to counteract this effect. We conduct comprehensive experiments on a wide range of LLMs, including LLaMA3.1-8B, Mistral-7B-v0.3, Qwen2-7B, and Gemma2-9B. Our evaluation includes both generation and discriminative tasks across 27 datasets. The results consistently demonstrate that our method outperforms existing structured pruning methods. This improvement is particularly notable in generation tasks, where our approach significantly outperforms existing baselines.
剪枝是压缩大型语言模型(LLM)的一种高效方法,能显著减少推理延迟。然而,传统的无训练结构化剪枝方法通常采用启发式度量,不加区别地移除所有剪枝层中的一些注意力头,而没有考虑到它们在网络架构中的位置。在这项工作中,我们提出了一种新的剪枝算法,该算法会策略性地剪除模型中较高层的注意力头。由于移除注意力头可能会改变令牌表示的幅度,我们引入了一个自适应缩放参数,在剪枝后校准表示规模,以抵消这一影响。我们在多种LLM上进行了全面的实验,包括LLaMA3.1-8B、Mistral-7B-v0.3、Qwen2-7B和Gemma2-9B。我们的评估包括27个数据集的生成和判别任务。结果一致表明,我们的方法优于现有的结构化剪枝方法。在生成任务中,我们的方法显著优于现有基线,这一改进尤为突出。
论文及项目相关链接
Summary
本文提出了一种针对大型语言模型(LLM)的新型修剪算法,该算法策略性地修剪模型高层中的注意力头,并引入自适应缩放参数来校准修剪后的表示规模。实验证明,该方法在多种LLM上表现优异,特别是在生成任务中显著优于现有基线。
Key Takeaways
- 修剪是压缩大型语言模型的有效方法,能显著降低推理延迟。
- 传统的无训练结构化修剪方法常常使用启发式度量标准,不考虑网络架构中的注意力头位置。
- 本文提出了一种新型修剪算法,策略性地修剪模型高层中的注意力头。
- 引入自适应缩放参数来校准修剪后的表示规模,以抵消修剪注意力头对令牌表示幅度的影响。
- 该方法在多种LLM上进行了广泛实验,包括LLaMA3.1-8B、Mistral-7B-v0.3、Qwen2-7B和Gemma2-9B。
- 评价包括生成和判别任务,涉及27个数据集。
点此查看论文截图

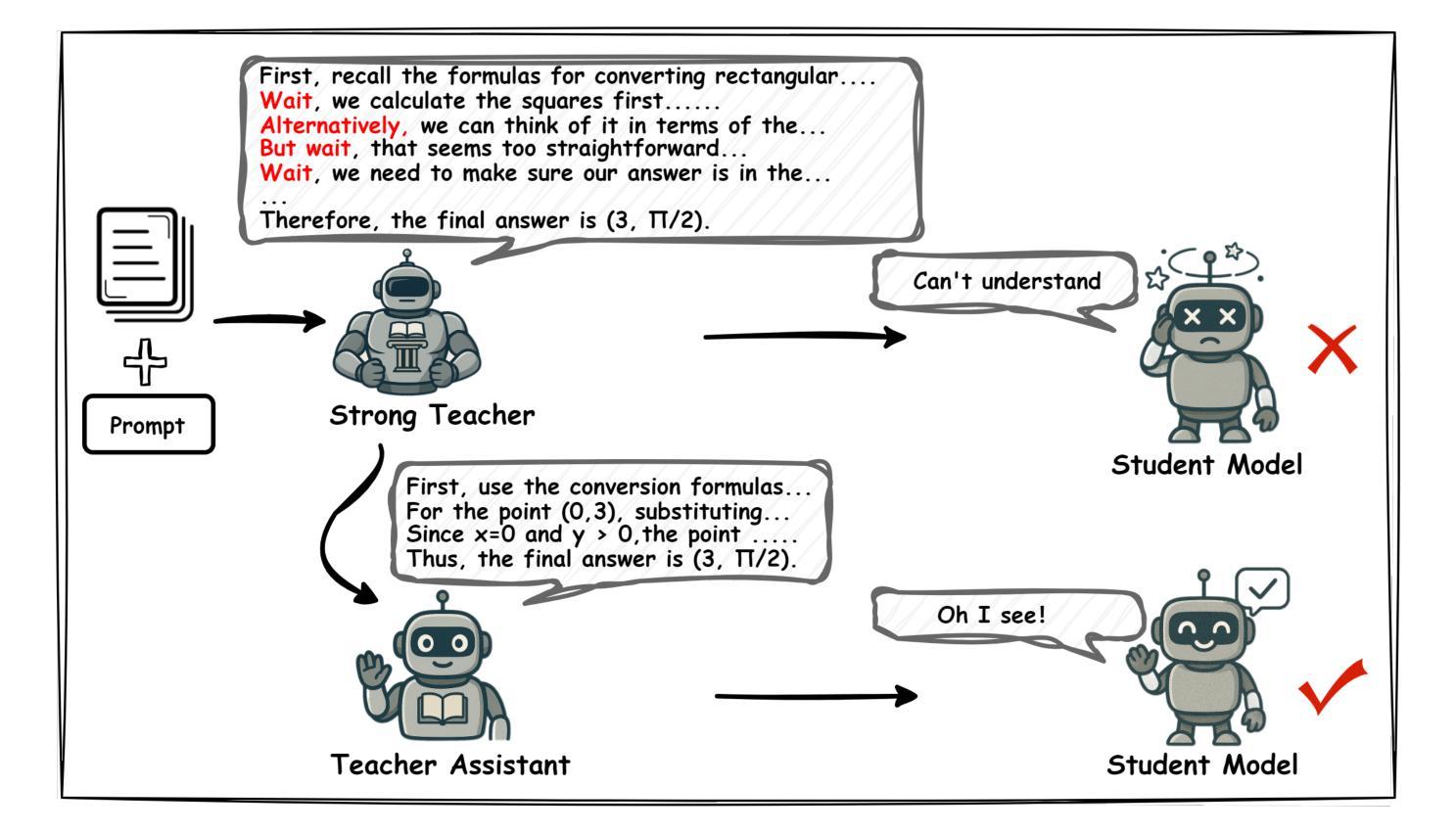
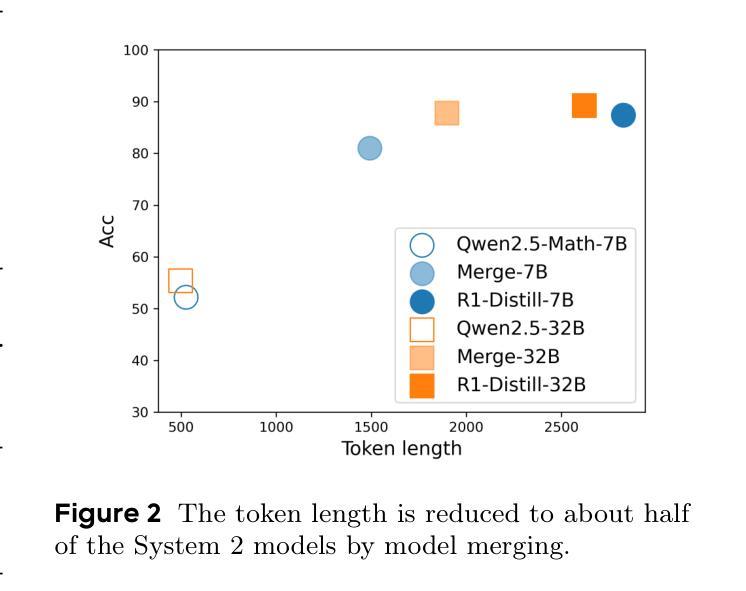
MiCoTA: Bridging the Learnability Gap with Intermediate CoT and Teacher Assistants
Authors:Dongyi Ding, Tiannan Wang, Chenghao Zhu, Meiling Tao, Yuchen Eleanor Jiang, Wangchunshu Zhou
Large language models (LLMs) excel at reasoning tasks requiring long thought sequences for planning, reflection, and refinement. However, their substantial model size and high computational demands are impractical for widespread deployment. Yet, small language models (SLMs) often struggle to learn long-form CoT reasoning due to their limited capacity, a phenomenon we refer to as the “SLMs Learnability Gap”. To address this, we introduce \textbf{Mi}d-\textbf{Co}T \textbf{T}eacher \textbf{A}ssistant Distillation (MiCoTAl), a framework for improving long CoT distillation for SLMs. MiCoTA employs intermediate-sized models as teacher assistants and utilizes intermediate-length CoT sequences to bridge both the capacity and reasoning length gaps. Our experiments on downstream tasks demonstrate that although SLMs distilled from large teachers can perform poorly, by applying MiCoTA, they achieve significant improvements in reasoning performance. Specifically, Qwen2.5-7B-Instruct and Qwen2.5-3B-Instruct achieve an improvement of 3.47 and 3.93 respectively on average score on AIME2024, AMC, Olympiad, MATH-500 and GSM8K benchmarks. To better understand the mechanism behind MiCoTA, we perform a quantitative experiment demonstrating that our method produces data more closely aligned with base SLM distributions. Our insights pave the way for future research into long-CoT data distillation for SLMs.
大型语言模型(LLM)擅长需要长期思考序列进行规划、反思和完善的推理任务。然而,它们庞大的模型尺寸和高计算需求使得难以广泛部署。然而,小型语言模型(SLM)往往因容量有限而难以学习长形式的连锁推理(CoT),这种现象我们称之为“SLMs的可学习性差距”。为了解决这一问题,我们引入了MiCoTAl(Mid-\textbf{Co}T \textbf{T}eacher \textbf{A}ssistant Distillation,中间大小的推理助手蒸馏框架),旨在改善SLM的长CoT蒸馏。MiCoTA采用中间大小的模型作为教师助手,并利用中间长度的CoT序列来弥补容量和推理长度的差距。我们在下游任务上的实验表明,虽然从大型教师蒸馏的SLM表现不佳,但通过应用MiCoTA,它们在推理性能上取得了显著改进。具体来说,Qwen2.5-7B-Instruct和Qwen2.5-3B-Instruct在AIME2024、AMC、Olympiad、MATH-500和GSM8K基准测试上的平均分数分别提高了3.47和3.93。为了更好地理解MiCoTA的机制,我们进行了一项定量实验,证明我们的方法产生的数据与基础SLM分布更加吻合。我们的见解为小型语言模型的长CoT数据蒸馏的未来研究铺平了道路。
论文及项目相关链接
PDF Work in progress
Summary:针对小型语言模型(SLM)在学习长形式链推理(CoT)时存在的“学习差距”问题,提出了MiCoTAl框架。该框架利用中等规模模型作为教师助手,并通过中间长度的CoT序列来弥补容量和推理长度的差距。实验表明,通过应用MiCoTA,SLM在推理性能上取得了显著改进。
Key Takeaways:
- 大型语言模型(LLM)擅长需要长思考序列的推理任务,但模型体积庞大、计算需求高,不利于广泛部署。
- 小型语言模型(SLM)由于容量有限,在学习长形式链推理(CoT)时存在困难,即“SLMs的学习差距”。
- MiCoTAl框架旨在改进SLM的长CoT蒸馏。它利用中等规模模型作为教师助手,并采用中间长度的CoT序列来桥接容量和推理长度的差距。
- 实验表明,应用MiCoTA的SLM在下游任务上的推理性能得到了显著提高。
- Qwen2.5-7B-Instruct和Qwen2.5-3B-Instruct在AIME2024、AMC、Olympiad、MATH-500和GSM8K基准测试上的平均分数分别提高了3.47和3.93。
- 通过定量实验,证明了MiCoTA产生的数据与基础SLM分布更为一致。
点此查看论文截图

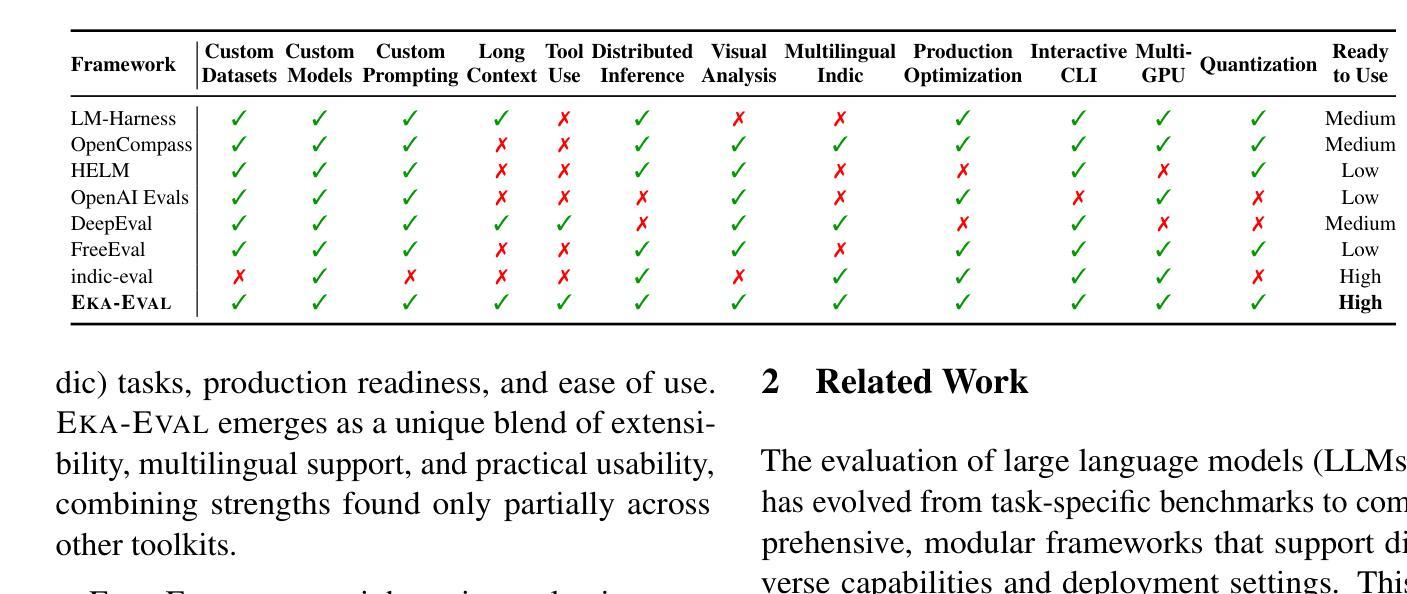
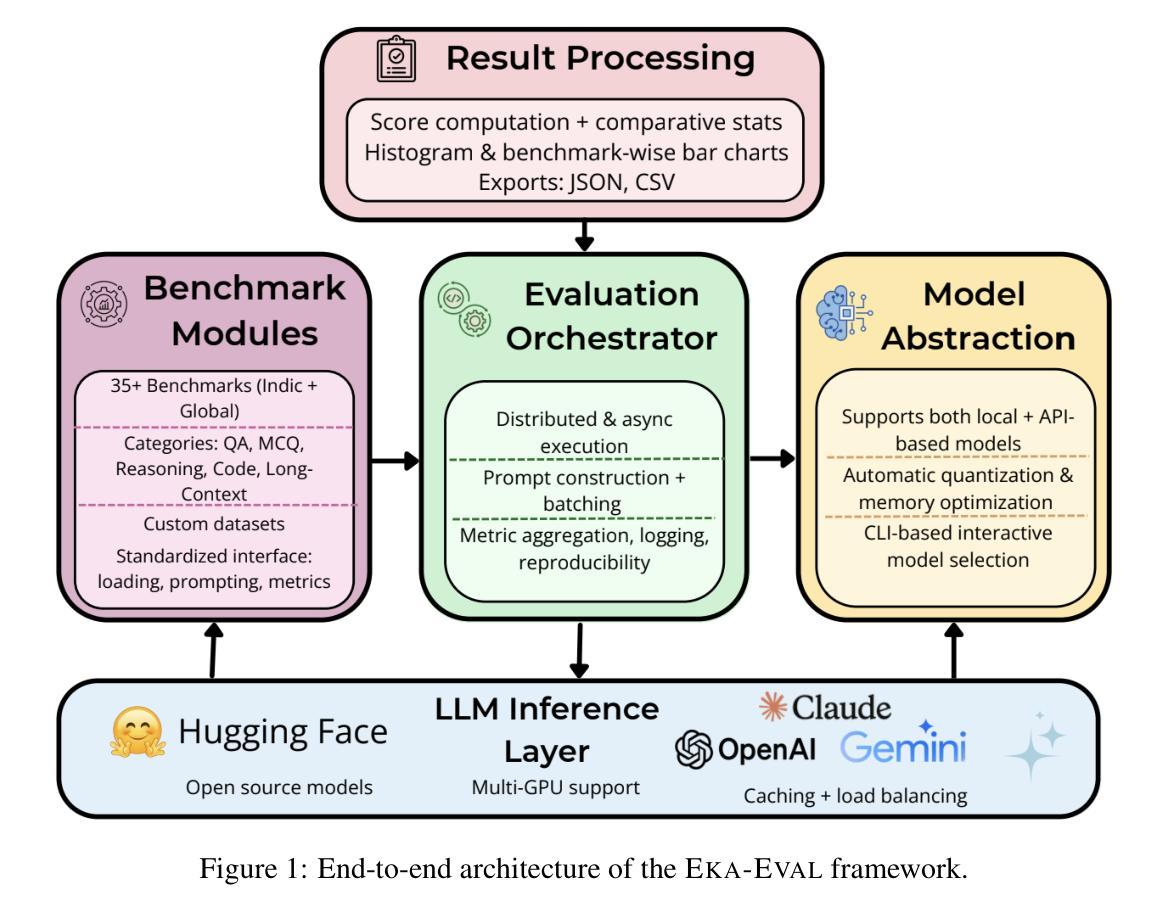
Eka-Eval : A Comprehensive Evaluation Framework for Large Language Models in Indian Languages
Authors:Samridhi Raj Sinha, Rajvee Sheth, Abhishek Upperwal, Mayank Singh
The rapid advancement of Large Language Models (LLMs) has intensified the need for evaluation frameworks that go beyond English centric benchmarks and address the requirements of linguistically diverse regions such as India. We present EKA-EVAL, a unified and production-ready evaluation framework that integrates over 35 benchmarks, including 10 Indic-specific datasets, spanning categories like reasoning, mathematics, tool use, long-context understanding, and reading comprehension. Compared to existing Indian language evaluation tools, EKA-EVAL offers broader benchmark coverage, with built-in support for distributed inference, quantization, and multi-GPU usage. Our systematic comparison positions EKA-EVAL as the first end-to-end, extensible evaluation suite tailored for both global and Indic LLMs, significantly lowering the barrier to multilingual benchmarking. The framework is open-source and publicly available at https://github.com/lingo-iitgn/ eka-eval and a part of ongoing EKA initiative (https://eka.soket.ai), which aims to scale up to over 100 benchmarks and establish a robust, multilingual evaluation ecosystem for LLMs.
大型语言模型(LLM)的快速发展加剧了对评估框架的需求,这些评估框架需要超越英语为中心的基准测试,并满足语言多样地区(如印度)的需求。我们推出了EKA-EVAL,这是一个统一且适用于生产的评估框架,集成了超过35个基准测试,包括10个印度语特定数据集,涵盖推理、数学、工具使用、长文本理解和阅读理解等类别。与现有的印度语言评估工具相比,EKA-EVAL提供了更广泛的基准测试覆盖,内置支持分布式推理、量化和多GPU使用。我们的系统比较显示,EKA-EVAL是为全球和印度语LLM量身定制的第一个端到端可扩展评估套件,大大降低了多语言基准测试的门槛。该框架是开源的,可在https://github.com/lingo-iitgn/eka-eval上公开访问,并且是正在进行中的EKA倡议(https://eka.soket.ai)的一部分,该倡议旨在扩展到超过100个基准测试,为LLM建立稳健的多语言评估生态系统。
论文及项目相关链接
Summary
随着大型语言模型(LLM)的快速发展,对评估框架的需求愈发迫切,需要超越英语为中心的基准测试,并满足语言多样地区的需要,如印度。我们推出EKA-EVAL评估框架,该框架一体化并支持生产环境使用。它集成了超过35个基准测试,包括面向印地语的特定数据集10个,涵盖推理、数学、工具使用、长语境理解和阅读理解等类别。与现有的印度语言评估工具相比,EKA-EVAL提供更广泛的基准测试覆盖,支持分布式推理、量化和多GPU使用。通过系统性比较,EKA-EVAL定位为全球和印地语大型语言模型的首个端到端可扩展评估套件,显著降低多语言基准测试的门槛。该框架开源并可在公开平台上获取。它是EKA倡议的一部分,旨在建立大型语言模型的多语言评估生态系统。
Key Takeaways
- EKA-EVAL是一个针对大型语言模型的统一评估框架,支持多种语言并特别关注印度地区的需求。
- 该框架集成了超过35个基准测试,包括针对印地语的特定数据集。
- EKA-EVAL提供了广泛的基准测试覆盖,支持分布式推理、量化和多GPU使用。
- 与现有评估工具相比,EKA-EVAL具有显著优势,特别是在长语境理解和阅读理解的类别上。
- EKA-EVAL是开源的并且可以在公开平台上获取,作为EKA倡议的一部分旨在推动大型语言模型的多语言评估生态系统的发展。
- 该框架具有可扩展性,旨在支持超过一百个基准测试的未来扩展需求。
点此查看论文截图

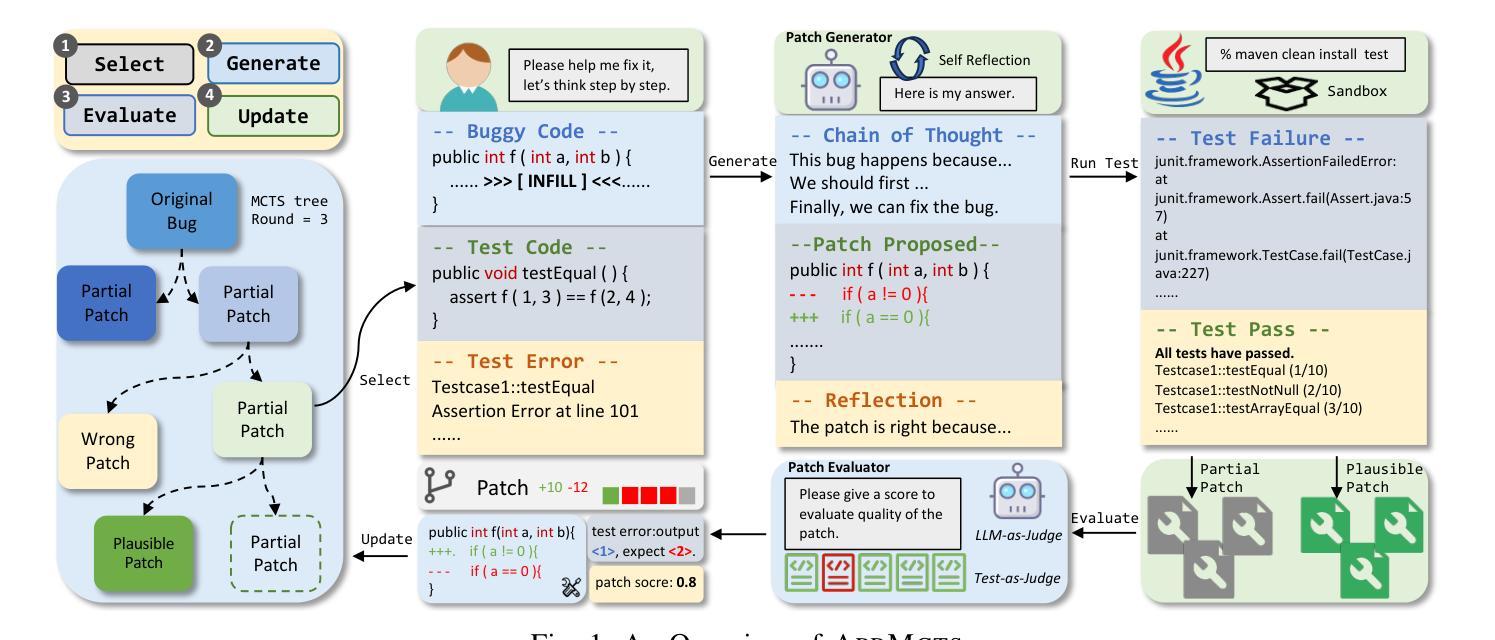
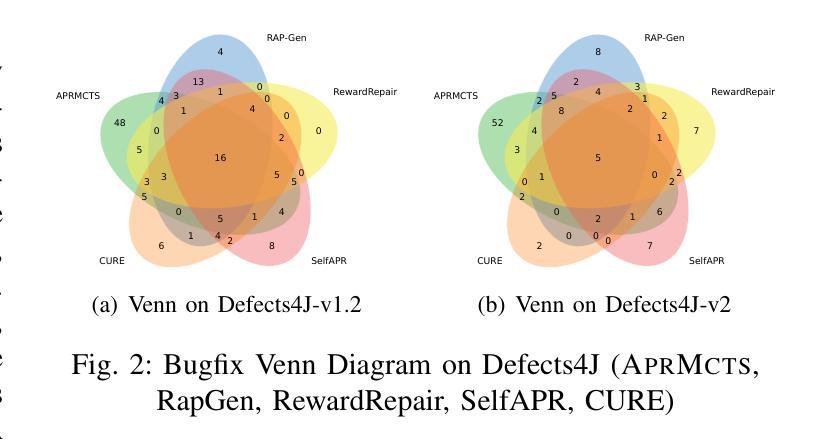
APRMCTS: Improving LLM-based Automated Program Repair with Iterative Tree Search
Authors:Haichuan Hu, Congqing He, Hao Zhang, Xiaochen Xie, Quanjun Zhang
Automated Program Repair (APR) attempts to fix software bugs without human intervention, which plays a crucial role in software development and maintenance. Recently, with the advances in Large Language Models (LLMs), a rapidly increasing number of APR techniques have been proposed with remarkable performance. However, existing LLM-based APR techniques typically adopt trial-and-error strategies, which suffer from two major drawbacks: (1) inherently limited patch effectiveness due to local exploration, and (2) low search efficiency due to redundant exploration. In this paper, we propose APRMCTS, which uses iterative tree search to improve LLM-based APR. APRMCTS incorporates Monte Carlo Tree Search (MCTS) into patch searching by performing a global evaluation of the explored patches and selecting the most promising one for subsequent refinement and generation. APRMCTS effectively resolves the problems of falling into local optima and thus helps improve the efficiency of patch searching. Our experiments on 835 bugs from Defects4J demonstrate that, when integrated with GPT-3.5, APRMCTS can fix a total of 201 bugs, which outperforms all state-of-the-art baselines. Besides, APRMCTS helps GPT-4o-mini, GPT-3.5, Yi-Coder-9B, and Qwen2.5-Coder-7B to fix 30, 27, 37, and 28 more bugs, respectively. More importantly, APRMCTS boasts a significant performance advantage while employing small patch size (16 and 32), notably fewer than the 500 and 10,000 patches adopted in previous studies. In terms of cost, compared to existing state-of-the-art LLM-based APR methods, APRMCTS has time and monetary costs of less than 20% and 50%, respectively. Our extensive study demonstrates that APRMCTS exhibits good effectiveness and efficiency, with particular advantages in addressing complex bugs.
自动化程序修复(APR)旨在无需人工干预即可修复软件错误,在软件开发和维护中扮演关键角色。最近,随着大型语言模型(LLM)的进步,已经提出了越来越多的APR技术,并表现出了卓越的性能。然而,现有的基于LLM的APR技术通常采用试错策略,这存在两个主要缺点:(1)由于局部探索,补丁有效性固有地有限;(2)由于冗余探索,搜索效率低下。在本文中,我们提出了APRMCTS,它使用迭代树搜索来改善基于LLM的APR。APRMCTS将蒙特卡洛树搜索(MCTS)融入补丁搜索,通过对探索的补丁进行全局评估,选择最有前途的补丁进行后续精炼和生成。APRMCTS有效地解决了陷入局部最优的问题,从而有助于提高补丁搜索的效率。我们在Defects4J的835个错误上的实验表明,当与GPT-3.5集成时,APRMCTS可以修复总共201个错误,优于所有最先进的基线。此外,APRMCTS帮助GPT-4o-mini、GPT-3.5、Yi-Coder-9B和Qwen2.5-Coder-7B分别修复了30、27、37和28个额外的错误。更重要的是,APRMCTS在采用较小的补丁大小(16和32)时,具有显著的性能优势,远远少于以前研究中采用的500和10000个补丁。就成本而言,与现有的最先进的基于LLM的APR方法相比,APRMCTS的时间和金钱成本分别低于20%和50%。我们的广泛研究表明,APRMCTS具有良好的有效性和效率,特别是在解决复杂的错误方面具有特别的优势。
论文及项目相关链接
Summary:
自动化程序修复(APR)技术旨在无需人工干预的情况下修复软件中的错误,这在软件的开发和维护中起到了关键作用。随着大型语言模型(LLM)的快速发展,已经提出了许多表现优异的APR技术。然而,现有的LLM-based APR技术通常采用试错策略,存在两个主要缺点:一是由于局部搜索导致的补丁有效性受限,二是由于冗余搜索导致的搜索效率低下。针对这些问题,本文提出了APRMCTS方法,该方法利用迭代树搜索改进了基于LLM的APR。APRMCTS通过将蒙特卡洛树搜索(MCTS)融入补丁搜索,通过对探索的补丁进行全局评估,选择最有前途的补丁进行后续完善和生成。APRMCTS有效地解决了陷入局部最优的问题,从而提高了补丁搜索的效率。实验表明,与GPT-3.5集成后,APRMCTS可以修复更多的错误,并显著优于其他最新基线。此外,APRMCTS在采用较小的补丁大小(16和32)时,性能优势显著,显著少于以前研究中采用的500和10,000个补丁。在成本和效率方面,APRMCTS的时间和金钱成本分别低于现有最新LLM-based APR方法的20%和50%。总的来说,APRMCTS在解决复杂错误方面表现出良好的有效性和效率。
Key Takeaways:
- 自动化程序修复(APR)是软件开发生命周期中重要的环节,尤其是基于大型语言模型(LLM)的方法近年来得到了广泛关注。
- 现有LLM-based APR技术主要采用试错策略,存在补丁有效性受限和搜索效率低下的问题。
- APRMCTS方法通过结合蒙特卡洛树搜索(MCTS)和LLM,提高了APR的效率。
- APRMCTS可以解决局部最优问题,显著提高补丁搜索效果。
- 与GPT-3.5集成后,APRMCTS可以修复更多错误,优于其他最新基线。
- APRMCTS在采用较小的补丁大小时表现出显著的性能优势。
点此查看论文截图


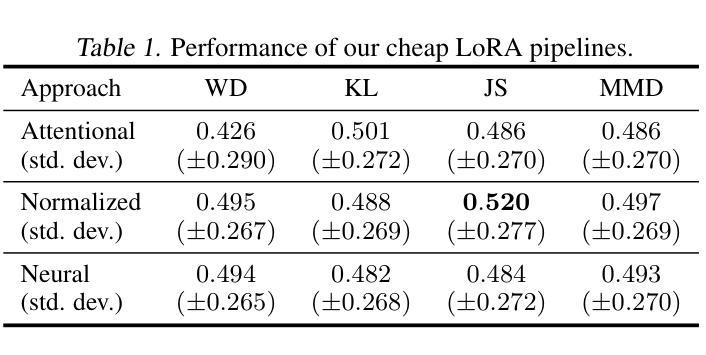
LoRA Fine-Tuning Without GPUs: A CPU-Efficient Meta-Generation Framework for LLMs
Authors:Reza Arabpour, Haitz Sáez de Ocáriz Borde, Anastasis Kratsios
Low-Rank Adapters (LoRAs) have transformed the fine-tuning of Large Language Models (LLMs) by enabling parameter-efficient updates. However, their widespread adoption remains limited by the reliance on GPU-based training. In this work, we propose a theoretically grounded approach to LoRA fine-tuning designed specifically for users with limited computational resources, particularly those restricted to standard laptop CPUs. Our method learns a meta-operator that maps any input dataset, represented as a probability distribution, to a set of LoRA weights by leveraging a large bank of pre-trained adapters for the Mistral-7B-Instruct-v0.2 model. Instead of performing new gradient-based updates, our pipeline constructs adapters via lightweight combinations of existing LoRAs directly on CPU. While the resulting adapters do not match the performance of GPU-trained counterparts, they consistently outperform the base Mistral model on downstream tasks, offering a practical and accessible alternative to traditional GPU-based fine-tuning.
低秩适配器(LoRAs)通过实现参数高效的更新,已经改变了大型语言模型(LLMs)的微调方式。然而,其广泛应用仍受限于对基于GPU的训练的依赖。在这项工作中,我们提出了一种针对计算资源有限的用户,特别是那些仅限于标准笔记本电脑CPU的用户设计的LoRA微调理论扎实的方法。我们的方法学习了一个元操作符,该操作符能够将任何输入数据集映射为一系列LoRA权重,这些权重以概率分布的形式表示,并利用大量预训练的适配器来为Mistral-7B-Instruct-v0.2模型服务。我们的管道不是在CPU上执行新的基于梯度的更新,而是通过轻量级组合现有的LoRAs直接构建适配器。虽然生成的适配器性能不如在GPU上训练的对应物,但它们在下游任务上始终优于基础Mistral模型,为传统的基于GPU的微调提供了一个实用且可访问的替代方案。
论文及项目相关链接
PDF 5-page main paper (excluding references) + 11-page appendix, 3 tables, 1 figure. Accepted to ICML 2025 Workshop on Efficient Systems for Foundation Models
Summary
低秩适配器(LoRAs)实现了对大型语言模型(LLMs)的精细调整,实现了参数高效的更新。然而,其广泛应用仍然受限于对基于GPU的训练的依赖。本研究提出了一种针对计算资源有限的用户,特别是仅限于标准笔记本电脑CPU的用户进行LoRA精细调整的理论依据方法。我们的方法学习一个元操作符,它将任何输入数据集映射为一系列LoRA权重,通过利用大量预训练适配器来实现对Mistral-7B-Instruct-v0.2模型的映射。我们的管道通过直接在CPU上结合现有的轻量级LoRAs来构建适配器,而不是执行新的基于梯度的更新,虽然生成的适配器性能不如GPU训练的对应物,但它们在下游任务上始终优于基本Mistral模型,为传统的基于GPU的微调提供了一种实用且可访问的替代方案。
Key Takeaways
- LoRAs实现了LLMs的精细调整,并推动了参数高效的更新。
- LoRAs的广泛应用受限于对GPU训练的依赖。
- 针对计算资源有限的用户(特别是标准笔记本电脑CPU用户),提出了一种新的LoRA精细调整方法。
- 新方法通过学习一个元操作符来映射输入数据集到LoRA权重,利用预训练适配器实现。
- 该方法通过结合现有轻量级LoRAs构建适配器,避免了新的基于梯度的更新。
- 虽然新生成的适配器性能不如GPU训练的适配器,但它们在下游任务上的表现优于基础模型。
点此查看论文截图

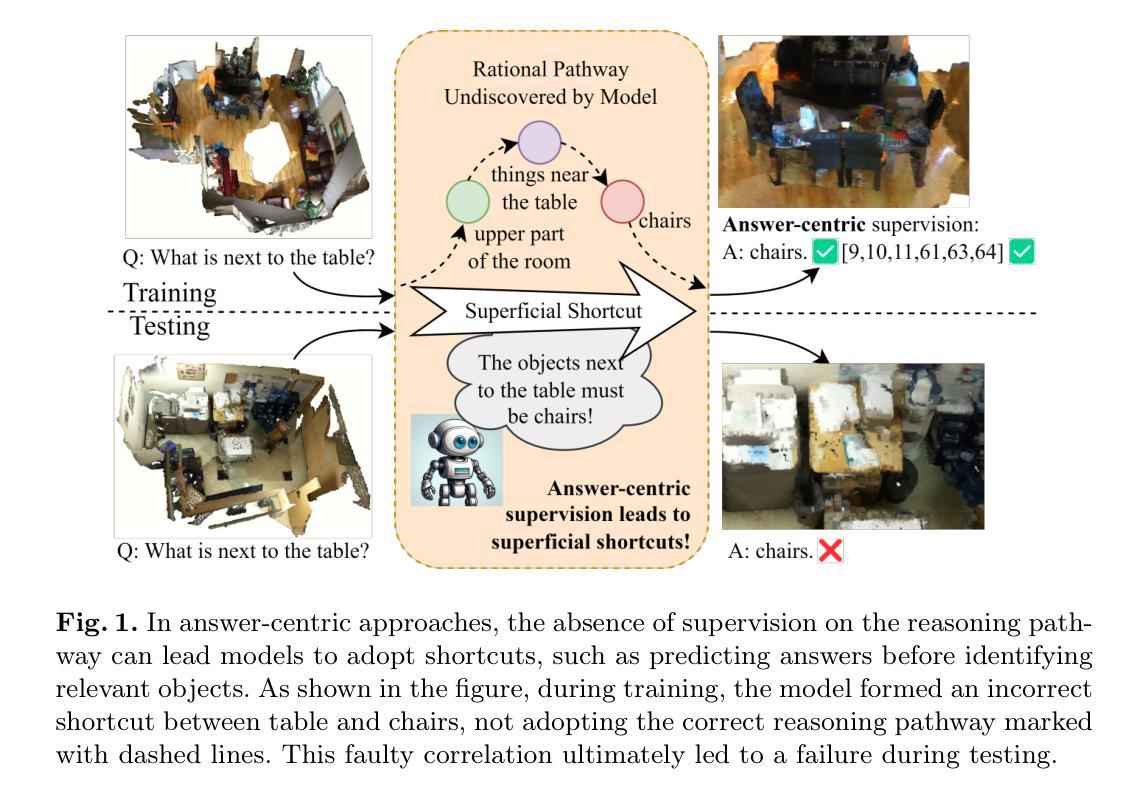
HCNQA: Enhancing 3D VQA with Hierarchical Concentration Narrowing Supervision
Authors:Shengli Zhou, Jianuo Zhu, Qilin Huang, Fangjing Wang, Yanfu Zhang, Feng Zheng
3D Visual Question-Answering (3D VQA) is pivotal for models to perceive the physical world and perform spatial reasoning. Answer-centric supervision is a commonly used training method for 3D VQA models. Many models that utilize this strategy have achieved promising results in 3D VQA tasks. However, the answer-centric approach only supervises the final output of models and allows models to develop reasoning pathways freely. The absence of supervision on the reasoning pathway enables the potential for developing superficial shortcuts through common patterns in question-answer pairs. Moreover, although slow-thinking methods advance large language models, they suffer from underthinking. To address these issues, we propose \textbf{HCNQA}, a 3D VQA model leveraging a hierarchical concentration narrowing supervision method. By mimicking the human process of gradually focusing from a broad area to specific objects while searching for answers, our method guides the model to perform three phases of concentration narrowing through hierarchical supervision. By supervising key checkpoints on a general reasoning pathway, our method can ensure the development of a rational and effective reasoning pathway. Extensive experimental results demonstrate that our method can effectively ensure that the model develops a rational reasoning pathway and performs better. The code is available at https://github.com/JianuoZhu/HCNQA.
3D视觉问答(3D VQA)对于模型感知物理世界并进行空间推理至关重要。以答案为中心的监督是3D VQA模型常用的训练方法。许多采用这种策略的模型在3D VQA任务中取得了令人鼓舞的结果。然而,以答案为中心的方法只监督模型的最终输出,允许模型自由发展推理路径。推理路径上缺乏监督使得模型可能通过问答对中的常见模式形成浅层次的捷径。此外,尽管慢思考方法促进了大型语言模型的发展,但它们却存在思考不足的问题。为了解决这些问题,我们提出了HCNQA,这是一种利用分层集中缩小监督方法的3D VQA模型。通过模仿人类在寻找答案时从广阔区域逐渐聚焦到特定对象的过程,我们的方法通过分层监督引导模型进行三个阶段集中缩小。通过对一般推理路径上的关键检查点进行监督,我们的方法可以确保形成合理有效的推理路径。大量的实验结果表明,我们的方法可以有效地确保模型形成合理的推理路径并表现更好。代码可在https://github.com/JianuoZhu/HCNQA找到。
论文及项目相关链接
PDF ICANN 2025
Summary
本文探讨了三维视觉问答(3D VQA)中答案中心监督方法的局限性,并提出了一个新的模型HCNQA。该模型采用层次化集中缩小监督方法,通过模仿人类寻找答案时的聚焦过程,引导模型进行三个阶段集中缩小。通过监督一般推理路径的关键检查点,确保模型发展出合理有效的推理路径。实验结果表明,该方法能有效提高模型性能。
Key Takeaways
- 3D VQA是模型感知现实世界并进行空间推理的关键。
- 答案中心监督是3D VQA模型的常用训练方法,虽然取得了一定的成果,但存在潜在问题。
- 答案中心监督允许模型自由发展推理路径,可能导致表面捷径和无效答案。
- HCNQA是一个新的三维视觉问答模型,采用层次化集中缩小监督方法。
- HCNQA通过模仿人类寻找答案时的聚焦过程,引导模型进行三个阶段集中缩小。
- HCNQA通过监督一般推理路径的关键检查点,确保模型发展出合理有效的推理路径。
点此查看论文截图

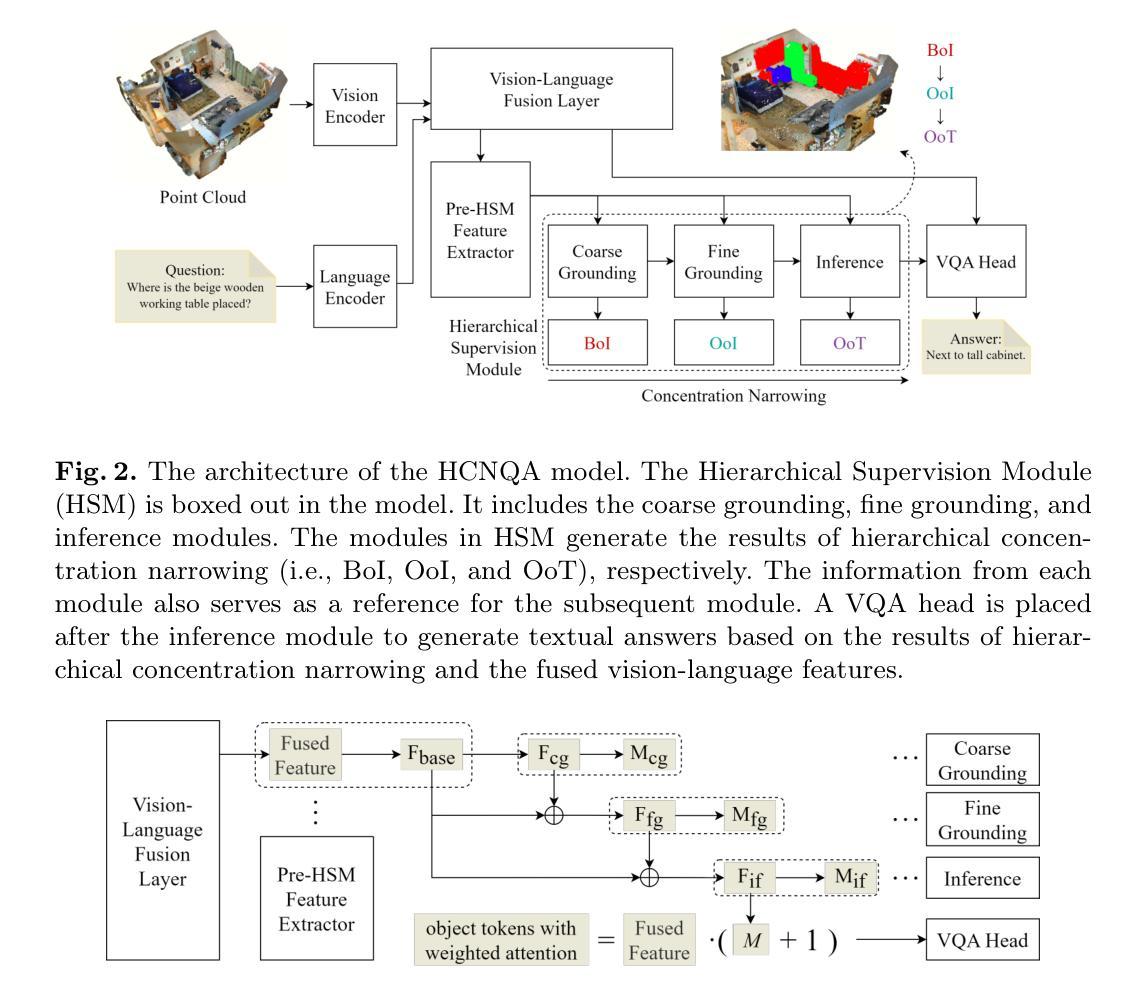
Rethinking Discrete Tokens: Treating Them as Conditions for Continuous Autoregressive Image Synthesis
Authors:Peng Zheng, Junke Wang, Yi Chang, Yizhou Yu, Rui Ma, Zuxuan Wu
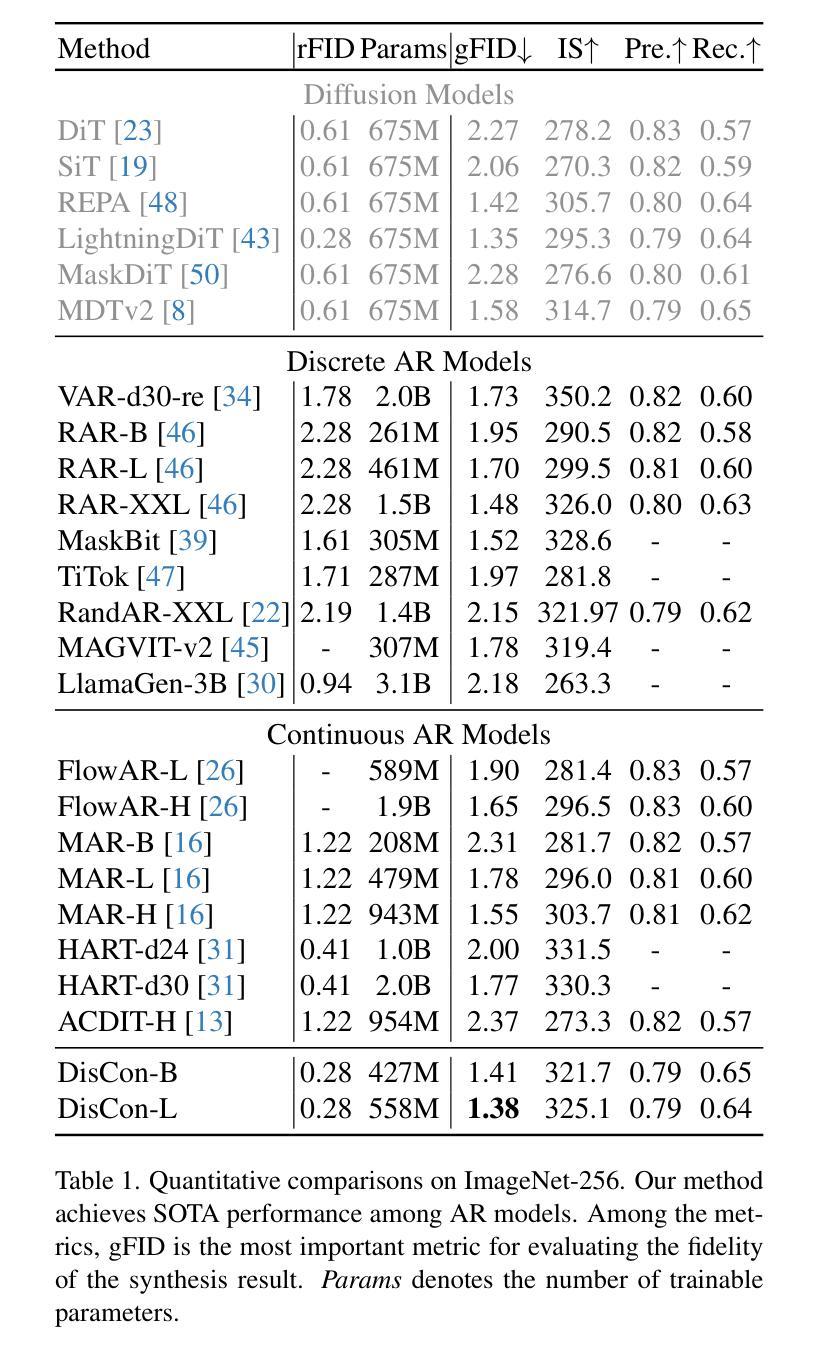
Recent advances in large language models (LLMs) have spurred interests in encoding images as discrete tokens and leveraging autoregressive (AR) frameworks for visual generation. However, the quantization process in AR-based visual generation models inherently introduces information loss that degrades image fidelity. To mitigate this limitation, recent studies have explored to autoregressively predict continuous tokens. Unlike discrete tokens that reside in a structured and bounded space, continuous representations exist in an unbounded, high-dimensional space, making density estimation more challenging and increasing the risk of generating out-of-distribution artifacts. Based on the above findings, this work introduces DisCon (Discrete-Conditioned Continuous Autoregressive Model), a novel framework that reinterprets discrete tokens as conditional signals rather than generation targets. By modeling the conditional probability of continuous representations conditioned on discrete tokens, DisCon circumvents the optimization challenges of continuous token modeling while avoiding the information loss caused by quantization. DisCon achieves a gFID score of 1.38 on ImageNet 256$\times$256 generation, outperforming state-of-the-art autoregressive approaches by a clear margin.
近期大型语言模型(LLM)的进步激发了将图像编码为离散标记并利用自回归(AR)框架进行视觉生成的兴趣。然而,AR型视觉生成模型中的量化过程会固有地引入信息损失,降低图像保真度。为了缓解这一局限性,近期研究已经探索了自回归预测连续标记的方法。与居住在结构化有界空间中的离散标记不同,连续表示存在于无界的高维空间中,这使得密度估计更具挑战性,并增加了生成离群分布伪影的风险。基于上述发现,这项工作引入了DisCon(离散条件连续自回归模型),这是一种新颖框架,它将离散标记重新解释为条件信号而不是生成目标。通过对离散标记条件下的连续表示的有条件概率建模,DisCon规避了连续标记建模的优化挑战,同时避免了量化引起的信息损失。DisCon在ImageNet 256x256生成任务上实现了1.38的gFID分数,相较于最先进的其他自回归方法有明显优势。
论文及项目相关链接
PDF accepted by iccv 2025
Summary
大型语言模型(LLM)的最新进展激发了将图像编码为离散标记并利用自回归(AR)框架进行视觉生成的兴趣。然而,AR-based视觉生成模型的量化过程会固有地造成信息损失,降低图像保真度。为解决此限制,近期研究开始探索自回归预测连续标记。不同于存在于结构化有界空间中的离散标记,连续表示存在于无界的高维空间中,使得密度估计更具挑战性,并增加了生成离群分布伪影的风险。基于上述发现,本文介绍了DisCon(离散条件连续自回归模型),这是一个新型框架,它将离散标记重新解释为条件信号而不是生成目标。通过建模离散标记条件下的连续表示的条件概率,DisCon规避了连续标记建模的优化挑战,同时避免了量化造成的信息损失。DisCon在ImageNet 256×256生成上实现了1.38的gFID分数,较先进的自回归方法有明显优势。
Key Takeaways
- 大型语言模型(LLM)在图像编码和视觉生成领域引发关注。
- 自回归(AR)模型在视觉生成中的量化过程会引入信息损失。
- 连续表示较离散表示更加复杂,密度估计更具挑战性,存在生成离群分布伪影的风险。
- DisCon框架将离散标记重新解释为条件信号,规避了连续标记建模的挑战。
- DisCon实现了在ImageNet上的高保真图像生成,gFID分数较低,性能优越。
- DisCon框架在避免信息损失的同时,实现了优化的视觉效果。
点此查看论文截图



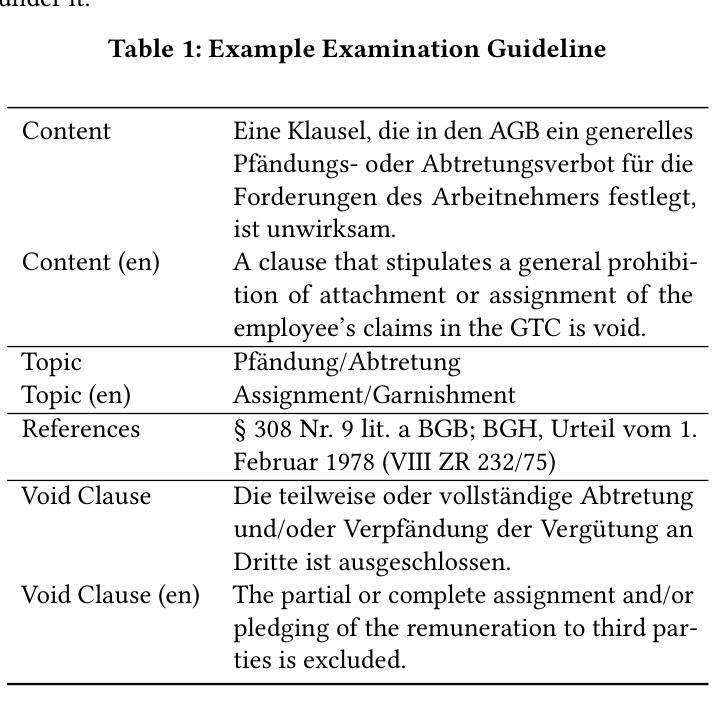
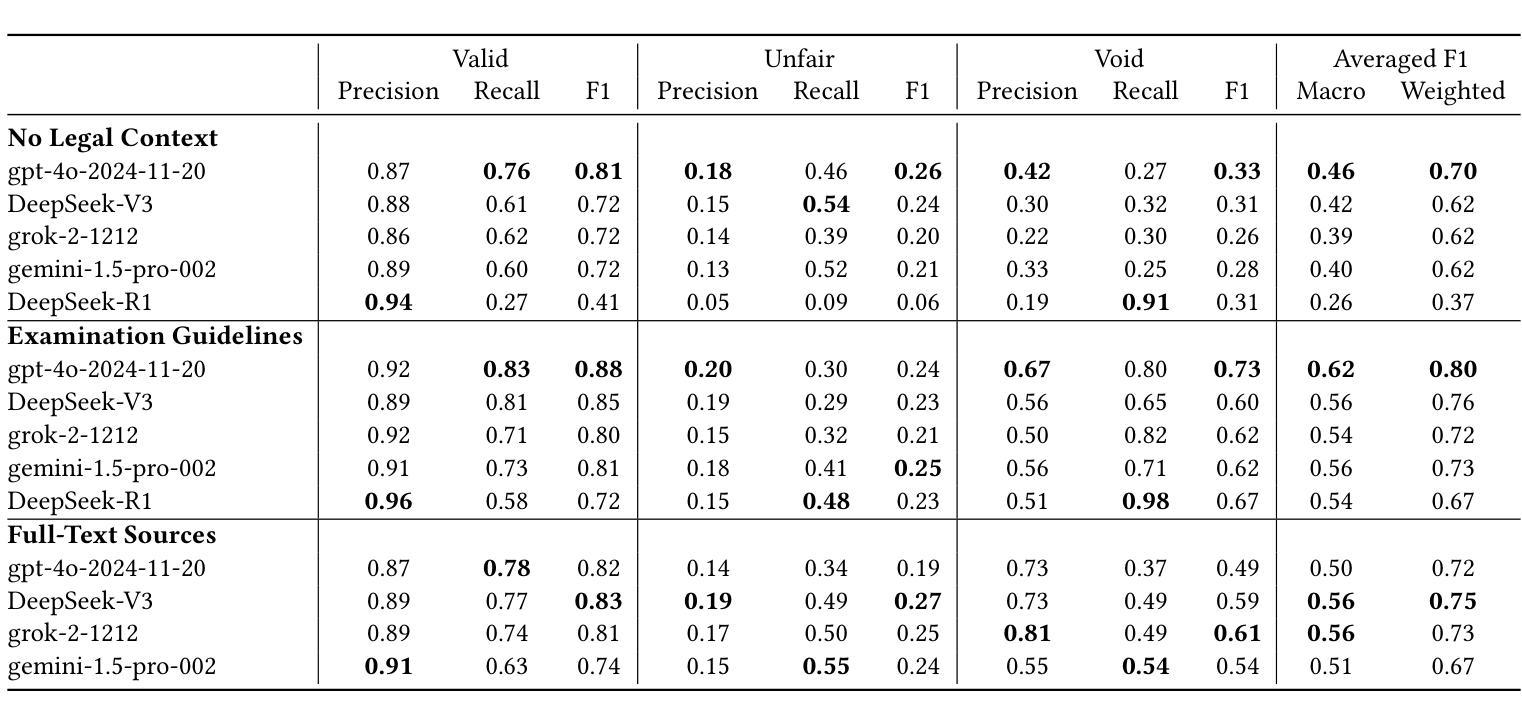
LLMs for Legal Subsumption in German Employment Contracts
Authors:Oliver Wardas, Florian Matthes
Legal work, characterized by its text-heavy and resource-intensive nature, presents unique challenges and opportunities for NLP research. While data-driven approaches have advanced the field, their lack of interpretability and trustworthiness limits their applicability in dynamic legal environments. To address these issues, we collaborated with legal experts to extend an existing dataset and explored the use of Large Language Models (LLMs) and in-context learning to evaluate the legality of clauses in German employment contracts. Our work evaluates the ability of different LLMs to classify clauses as “valid,” “unfair,” or “void” under three legal context variants: no legal context, full-text sources of laws and court rulings, and distilled versions of these (referred to as examination guidelines). Results show that full-text sources moderately improve performance, while examination guidelines significantly enhance recall for void clauses and weighted F1-Score, reaching 80%. Despite these advancements, LLMs’ performance when using full-text sources remains substantially below that of human lawyers. We contribute an extended dataset, including examination guidelines, referenced legal sources, and corresponding annotations, alongside our code and all log files. Our findings highlight the potential of LLMs to assist lawyers in contract legality review while also underscoring the limitations of the methods presented.
法律工作以其文本密集和资源密集的特点呈现出独特的挑战和机会,对自然语言处理研究亦是如此。尽管数据驱动的方法推动了该领域的发展,但由于其缺乏可解释性和可信度,在动态的法律环境中其适用性有限。为了解决这个问题,我们与法律专家合作扩展了现有数据集,并探索了使用大型语言模型(LLM)和上下文学习来评估德国就业合同条款的合法性。我们的工作评估了不同的大型语言模型在三种法律上下文变体下将条款分类为“有效”,“不公平”或“无效”的能力:无法律上下文、法律与法院判决的全文来源以及这些内容的提炼版本(称为检查指南)。结果表明,全文来源可以适度提高性能,而检查指南可以显著提高无效条款的召回率和加权F1分数,达到80%。尽管有所进展,但在使用全文来源时,大型语言模型的性能仍然远远低于人类律师。我们贡献了一个扩展的数据集,包括检查指南、引用的法律来源和相应注释,以及我们的代码和所有日志文件。我们的研究结果表明大型语言模型在协助律师审查合同合法性方面的潜力,同时也强调了所提出方法的局限性。
论文及项目相关链接
PDF PrePrint - ICAIL25, Chicago
Summary:
本文探讨了法律工作对自然语言处理(NLP)研究的独特挑战和机遇。数据驱动的方法虽然推动了该领域的发展,但其缺乏解释性和可信度,限制了其在动态法律环境中的适用性。为研究解决这些问题,研究者与法律专家合作扩展现有数据集,探索使用大型语言模型(LLM)和上下文学习来评估德国就业合同条款的合法性。研究评估了不同LLM在三种法律上下文下对条款进行分类的能力,包括无法律上下文、全文法律来源和法院判决以及精简版(称为审查指南)。结果显示,全文来源适度提高了性能,而审查指南显著提高了无效条款的召回率和加权F1分数,达到80%。尽管取得了这些进展,但使用全文来源的LLM性能仍然远低于人类律师的表现。研究者贡献了一个扩展的数据集,包括审查指南、参考法律来源和相应注释,以及代码和所有日志文件。研究发现突显了LLM在协助律师审查合同合法性方面的潜力,同时也强调了所提出方法的局限性。
Key Takeaways:
- 法律工作对NLP研究带来独特挑战和机遇,数据驱动方法需结合法律专业知识。
- LLMs和上下文学习被用于评估德国就业合同条款的合法性。
- 三种法律上下文下评估了LLMs的性能:无上下文、全文法律来源和审查指南。
- 审查指南能显著提高LLMs的性能,特别是在识别无效条款方面。
- LLMs在合同合法性审查方面的性能仍远低于人类律师。
- 贡献了一个扩展数据集,包含审查指南、法律来源和注释等。
点此查看论文截图

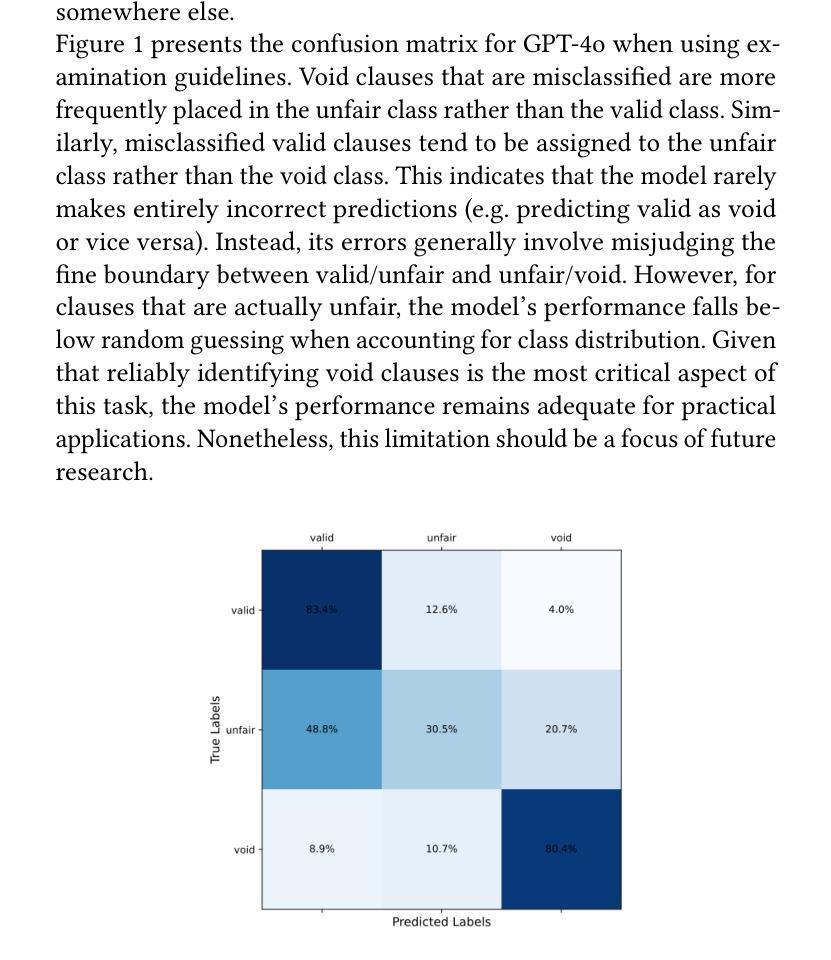
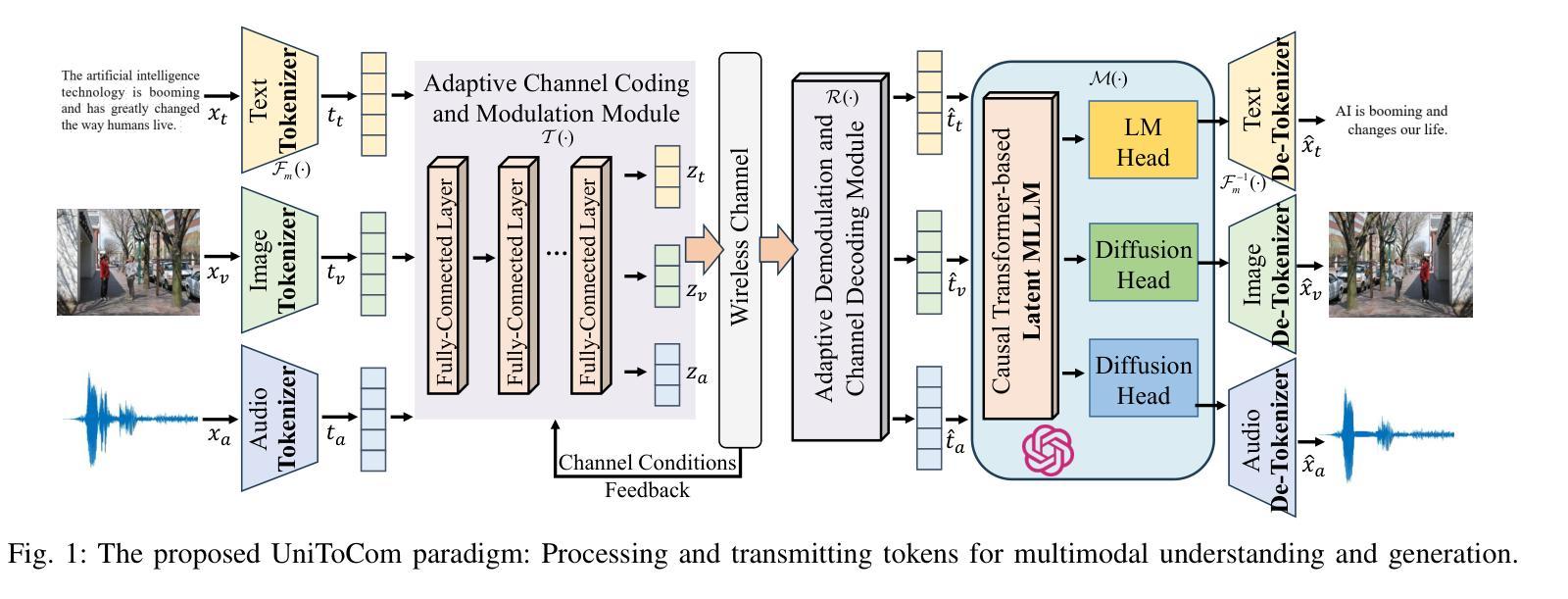
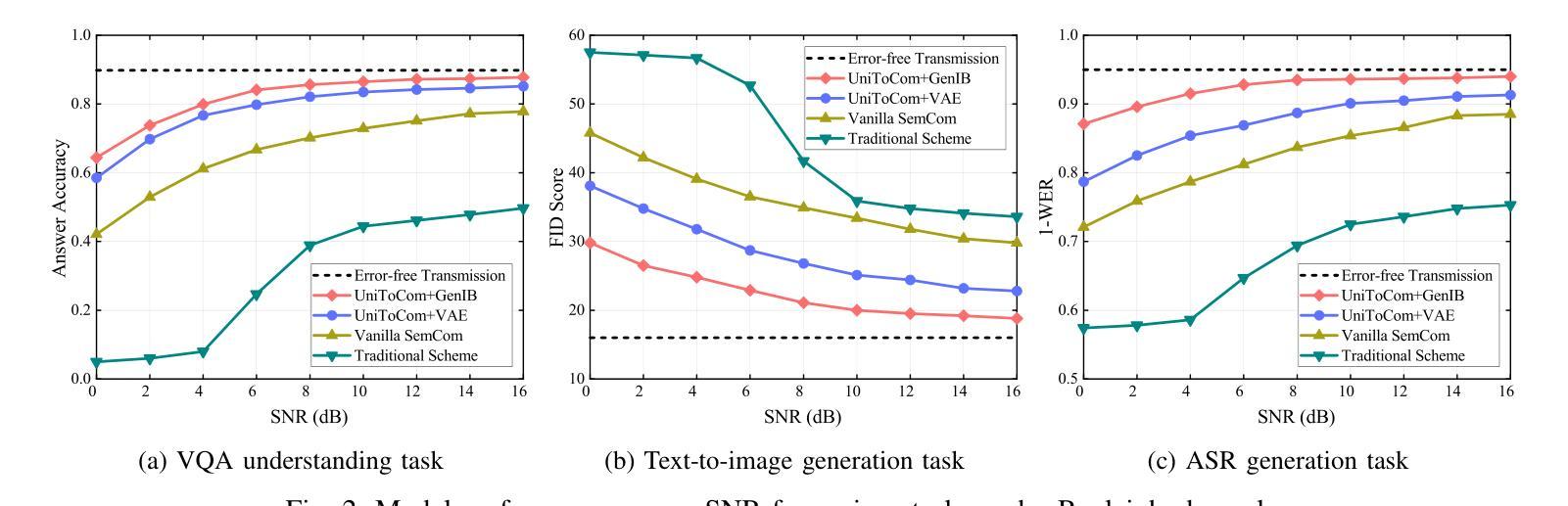
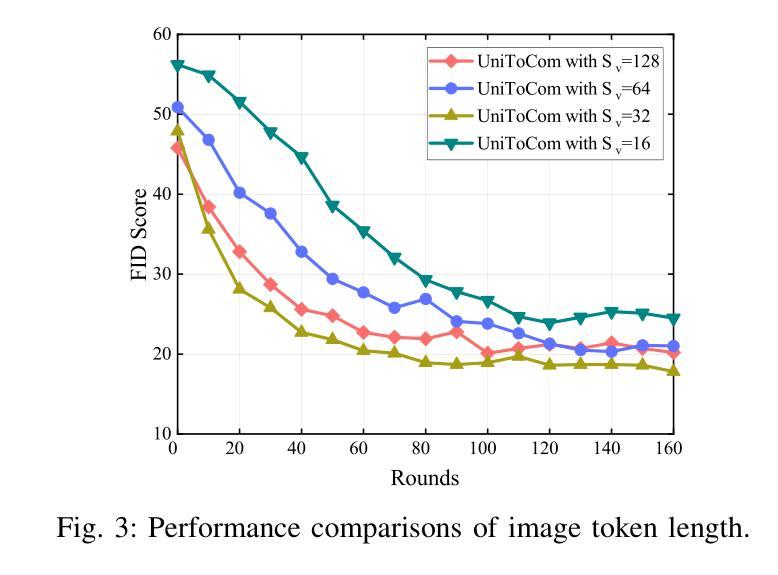
Token Communication in the Era of Large Models: An Information Bottleneck-Based Approach
Authors:Hao Wei, Wanli Ni, Wen Wang, Wenjun Xu, Dusit Niyato, Ping Zhang
This letter proposes UniToCom, a unified token communication paradigm that treats tokens as the fundamental units for both processing and wireless transmission. Specifically, to enable efficient token representations, we propose a generative information bottleneck (GenIB) principle, which facilitates the learning of tokens that preserve essential information while supporting reliable generation across multiple modalities. By doing this, GenIB-based tokenization is conducive to improving the communication efficiency and reducing computational complexity. Additionally, we develop $\sigma$-GenIB to address the challenges of variance collapse in autoregressive modeling, maintaining representational diversity and stability. Moreover, we employ a causal Transformer-based multimodal large language model (MLLM) at the receiver to unify the processing of both discrete and continuous tokens under the next-token prediction paradigm. Simulation results validate the effectiveness and superiority of the proposed UniToCom compared to baselines under dynamic channel conditions. By integrating token processing with MLLMs, UniToCom enables scalable and generalizable communication in favor of multimodal understanding and generation, providing a potential solution for next-generation intelligent communications.
这封信提出了UniToCom,一种统一的令牌通信范式,它将令牌视为处理和无线传输的基本单位。具体来说,为了实现高效的令牌表示,我们提出了生成信息瓶颈(GenIB)原则,该原则有助于学习保留重要信息的令牌,同时支持跨多种模态的可靠生成。通过这种方式,基于GenIB的令牌化有利于提高通信效率并降低计算复杂性。此外,为了解决自回归建模中的方差崩溃挑战,我们开发了σ-GenIB,以保持表示的多样性和稳定性。而且,我们在接收器端采用基于因果Transformer的多模态大型语言模型(MLLM),在下一令牌预测范式下统一离散和连续令牌的处理。仿真结果验证了所提出的UniToCom在动态信道条件下的有效性和优越性。通过将令牌处理与MLLMs集成,UniToCom使通信具有可扩展性和泛化性,有利于多模态的理解和生成,为下一代智能通信提供了潜在的解决方案。
论文及项目相关链接
Summary
本文提出了UniToCom,一种统一的令牌通信范式,将令牌作为处理和无线传输的基本单位。为实现高效的令牌表示,提出了基于生成信息瓶颈(GenIB)的原则,有助于学习能够保留关键信息并支持跨多模态可靠生成的令牌。此外,为解决自回归建模中的方差崩溃问题,开发了σ-GenIB,保持表示的多样性和稳定性。接收端采用基于因果Transformer的多模态大型语言模型(MLLM),统一处理离散和连续令牌,模拟结果表明UniToCom在动态信道条件下相比基线方法更有效和优越。UniToCom将令牌处理与MLLMs集成,为下一代智能通信提供了可扩展和通用的通信方案,有利于多模态理解和生成。
Key Takeaways
- UniToCom是一种新的统一令牌通信范式,将令牌作为处理和无线传输的基本单位。
- GenIB原则用于实现高效的令牌表示,保留关键信息并支持跨多模态的可靠生成。
- σ-GenIB解决了自回归建模中的方差崩溃问题,维持表示的多样性和稳定性。
- 接收端采用基于因果Transformer的MLLM,能统一处理离散和连续令牌。
- UniToCom在动态信道条件下相比基线方法更有效和优越。
- UniToCom有利于多模态理解和生成,为下一代智能通信提供了可扩展和通用的通信方案。
点此查看论文截图

Agent Ideate: A Framework for Product Idea Generation from Patents Using Agentic AI
Authors:Gopichand Kanumolu, Ashok Urlana, Charaka Vinayak Kumar, Bala Mallikarjunarao Garlapati
Patents contain rich technical knowledge that can inspire innovative product ideas, yet accessing and interpreting this information remains a challenge. This work explores the use of Large Language Models (LLMs) and autonomous agents to mine and generate product concepts from a given patent. In this work, we design Agent Ideate, a framework for automatically generating product-based business ideas from patents. We experimented with open-source LLMs and agent-based architectures across three domains: Computer Science, Natural Language Processing, and Material Chemistry. Evaluation results show that the agentic approach consistently outperformed standalone LLMs in terms of idea quality, relevance, and novelty. These findings suggest that combining LLMs with agentic workflows can significantly enhance the innovation pipeline by unlocking the untapped potential of business idea generation from patent data.
专利包含丰富的技术知识,能够激发创新的产品理念,然而访问和解释这些信息仍然是一个挑战。本研究探索了使用大型语言模型(LLM)和自主代理从给定专利中提取和生成产品概念的方法。在这项工作中,我们设计了Agent Ideate,这是一个从专利中自动生成基于产品的商业想法的框架。我们在计算机科学、自然语言处理和材料化学三个领域尝试了开源LLM和基于代理的架构。评估结果表明,在思想质量、相关性和新颖性方面,代理方法始终优于单独的LLM。这些发现表明,将LLM与代理工作流程相结合,可以通过解锁专利数据中尚未开发的商业理念生成潜力,从而显著增强创新管道。
论文及项目相关链接
PDF AgentScen Workshop, IJCAI 2025
Summary
专利蕴含丰富的技术知识,可激发创新产品灵感,但访问和解读这些信息仍具挑战。本研究探索使用大型语言模型(LLM)和自主代理来从给定专利中挖掘和生成产品概念。我们设计了Agent Ideate框架,可自动从专利中产生基于产品的商业想法。我们在计算机科学、自然语言处理和材料化学三个领域进行了开源LLM和基于代理的架构的实验。评估结果表明,在想法质量、相关性和新颖性方面,代理方法始终优于单独的LLM。这表明将LLM与代理工作流程相结合,可以通过解锁专利数据中未被发掘的潜力,显著增强创新管道。
Key Takeaways
- 专利蕴含丰富技术知识,是激发创新产品灵感的宝贵资源。
- 访问和解读专利信息具挑战,需借助先进技术如大型语言模型(LLM)和自主代理。
- 介绍了Agent Ideate框架,可自动从专利中产生基于产品的商业想法。
- 在计算机科学、自然语言处理和材料化学三个领域进行了实验。
- 代理方法在想法质量、相关性和新颖性方面优于单独的LLM。
- 结合LLM和代理工作流程能显著增强创新管道。
点此查看论文截图

GPT, But Backwards: Exactly Inverting Language Model Outputs
Authors:Adrians Skapars, Edoardo Manino, Youcheng Sun, Lucas C. Cordeiro
While existing auditing techniques attempt to identify potential unwanted behaviours in large language models (LLMs), we address the complementary forensic problem of reconstructing the exact input that led to an existing LLM output - enabling post-incident analysis and potentially the detection of fake output reports. We formalize exact input reconstruction as a discrete optimisation problem with a unique global minimum and introduce SODA, an efficient gradient-based algorithm that operates on a continuous relaxation of the input search space with periodic restarts and parameter decay. Through comprehensive experiments on LLMs ranging in size from 33M to 3B parameters, we demonstrate that SODA significantly outperforms existing approaches. We succeed in fully recovering 79.5% of shorter out-of-distribution inputs from next-token logits, without a single false positive, but struggle to extract private information from the outputs of longer (15+ token) input sequences. This suggests that standard deployment practices may currently provide adequate protection against malicious use of our method. Our code is available at https://doi.org/10.5281/zenodo.15539879.
现有的审计技术旨在识别大型语言模型(LLM)中可能存在的潜在不适当行为,而我们对与之互补的问题进行重构——准确重建输入以得到现有LLM输出,从而使事后分析成为可能并可能发现虚假输出报告。我们将精确输入重建形式化为具有唯一全局最小值的离散优化问题,并引入了SODA算法,这是一种高效的基于梯度的算法,对输入搜索空间进行连续松弛处理并辅以周期性的重启和参数衰减。我们对从拥有数百万至数十亿参数规模的大型语言模型进行了全面的实验验证,表明SODA算法在显著优于现有方法的同时能够成功完全恢复下一标记日志输出中的高达百分之七十九点五,无任何误报现象出现,但对更长输入序列的输出信息中提取隐私信息仍存在问题。这表明现有的部署实践在当前可能为对抗我们的方法提供了充分的保护手段。我们的代码位于公开网址https://doi.org/10.5281/zenodo.15539879中供大家下载学习。
论文及项目相关链接
PDF 9 pages, ICML 2025 Workshop on Reliable and Responsible Foundation Models
Summary
本文关注大型语言模型(LLM)的输入重建问题,提出了一种新的审计技术SODA,旨在通过最小化输出与真实输出之间的差异来重构精确的输入,使事后分析和检测假输出报告成为可能。通过在不同规模的LLM上的综合实验验证,SODA在重建短输出分布外输入方面具有出色的表现,能够完全恢复高达79.5%的输入信息且无假阳性结果,但对较长输入序列的私人信息提取能力受限。建议采取适当的部署措施来保护模型的滥用风险。相关代码可通过提供的链接获取。
Key Takeaways
- 研究人员专注于大型语言模型(LLM)的输入重建问题,这是一个重要的审计领域。
- 提出了一种新的审计技术SODA,旨在通过最小化输出差异来重构精确输入。
- SODA显著优于现有方法,能够完全恢复短输出分布外的输入信息高达79.5%。
- SODA在无假阳性结果的情况下成功重建输入信息。
- 对于较长输入序列的私人信息提取能力受限,提示当前部署实践可能足以防止恶意使用。
- 代码可通过提供的链接获取,便于后续研究或应用。
点此查看论文截图




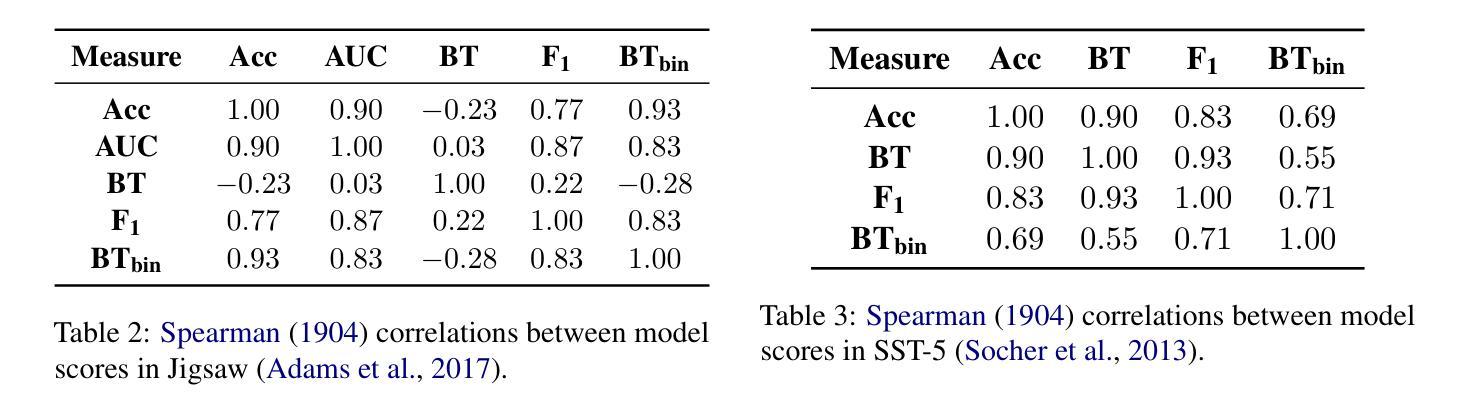
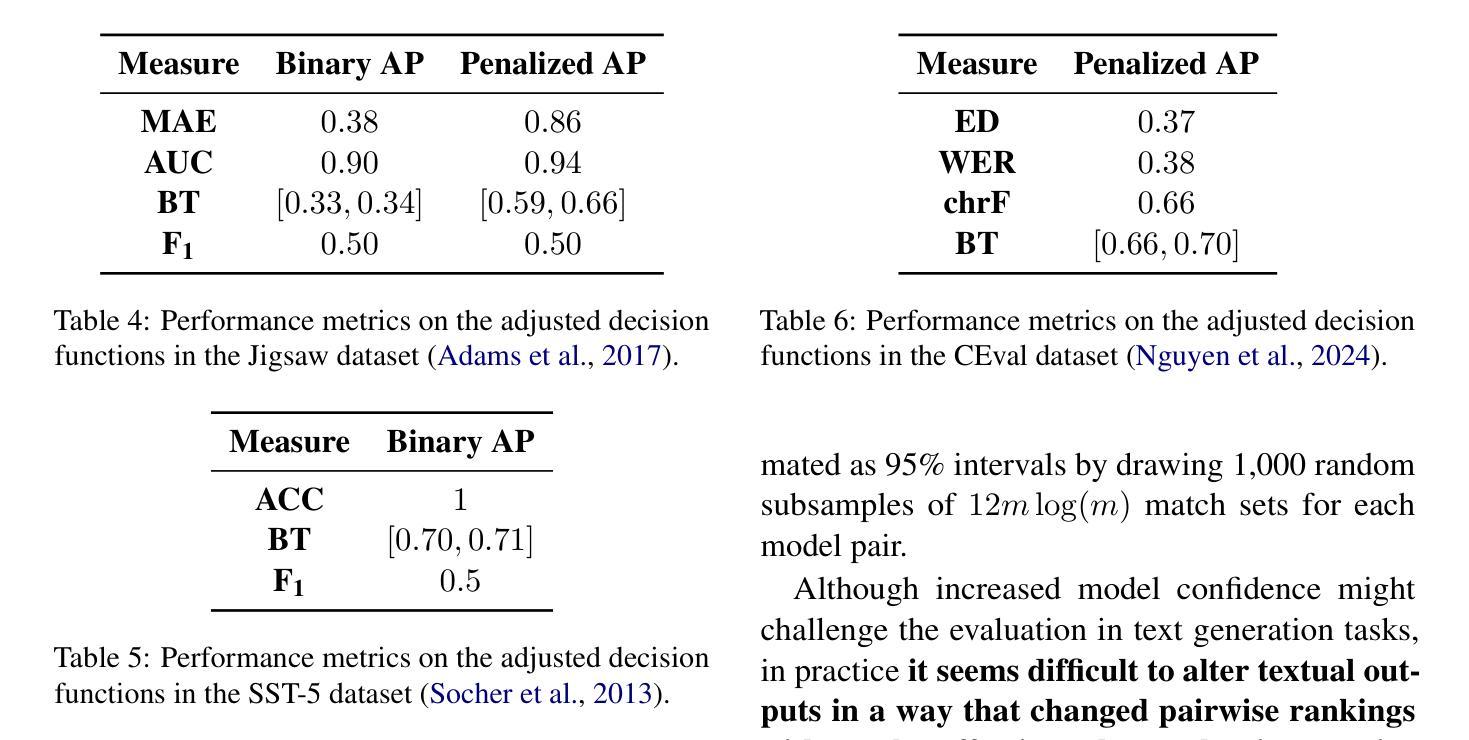
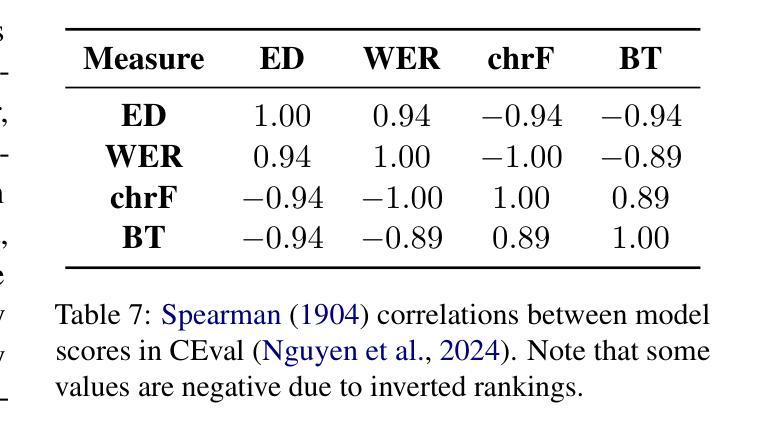
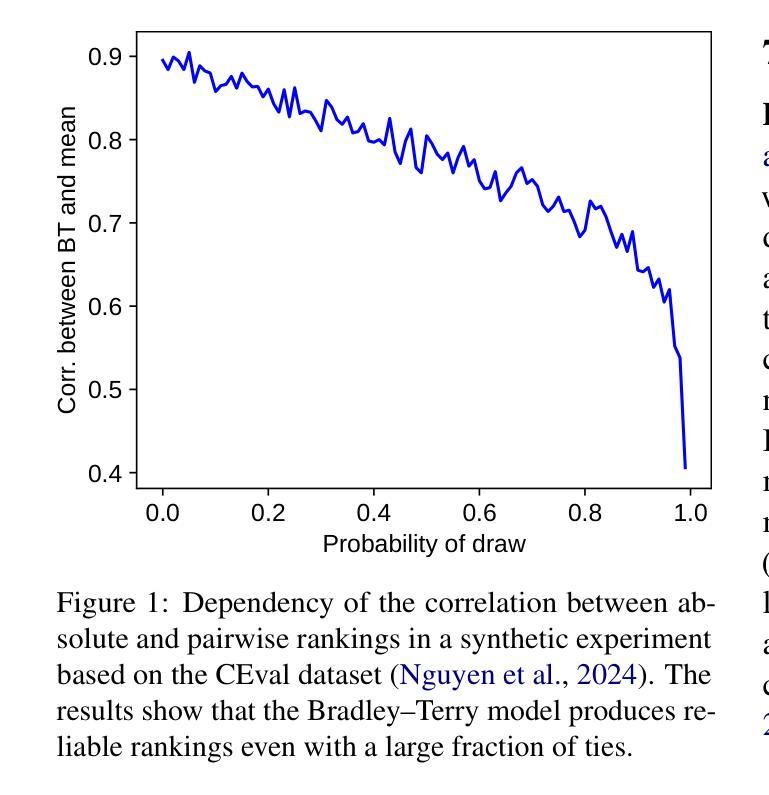
Confidence and Stability of Global and Pairwise Scores in NLP Evaluation
Authors:Georgii Levtsov, Dmitry Ustalov
With the advent of highly capable instruction-tuned neural language models, benchmarking in natural language processing (NLP) is increasingly shifting towards pairwise comparison leaderboards, such as LMSYS Arena, from traditional global pointwise scores (e.g., GLUE, BIG-bench, SWE-bench). This paper empirically investigates the strengths and weaknesses of both global scores and pairwise comparisons to aid decision-making in selecting appropriate model evaluation strategies. Through computational experiments on synthetic and real-world datasets using standard global metrics and the popular Bradley-Terry model for pairwise comparisons, we found that while global scores provide more reliable overall rankings, they can underestimate strong models with rare, significant errors or low confidence. Conversely, pairwise comparisons are particularly effective for identifying strong contenders among models with lower global scores, especially where quality metrics are hard to define (e.g., text generation), though they require more comparisons to converge if ties are frequent. Our code and data are available at https://github.com/HSPyroblast/srw-ranking under a permissive license.
随着能力超强的指令调优神经网络语言模型的出现,自然语言处理(NLP)的基准测试正逐渐从传统的全局点状得分(例如GLUE、BIG-bench、SWE-bench)转向诸如LMSYS Arena之类的成对比较排行榜。本文实证研究了全局得分和成对比较的优势和劣势,以帮助选择适当的模型评估策略进行决策。我们通过使用标准全局指标和流行的Bradley-Terry模型对合成数据集和真实世界数据集进行计算实验,发现虽然全局得分能提供更可靠的整体排名,但它们可能会低估具有罕见重大错误或低置信度的强大模型。相反,成对比较在识别具有较低全局得分的模型中的强劲竞争者方面特别有效,尤其是在质量指标难以定义的情况下(例如文本生成),不过,如果平局很常见,则需要更多的比较来收敛。我们的代码和数据可在https://github.com/HSPyroblast/srw-ranking(采用许可许可)下获得。
论文及项目相关链接
PDF 8 pages, accepted at ACL SRW 2025
Summary
随着指令优化型神经语言模型的发展,自然语言处理(NLP)中的基准测试越来越倾向于使用成对比较排行榜(如LMSYS Arena),而非传统的全局点值排行榜(如GLUE、BIG-bench、SWE-bench)。本文实证研究了全局得分和成对比较的优势和劣势,以辅助选择合适的模型评估策略。研究发现,全局得分虽然能提供更可靠的整体排名,但可能低估具有罕见重大错误或低置信度的强模型。而成对比较在识别低全球得分中的强模型方面特别有效,尤其是在质量指标难以定义的情况下(如文本生成)。但如存在频繁平局,成对比较的收敛需要更多的比较次数。
Key Takeaways
- 神经网络语言模型的进步推动了NLP基准测试的转变,从传统的全局点值排行榜转向成对比较排行榜。
- 全局得分提供可靠的整体排名,但可能低估某些具有显著错误或低置信度的强模型。
- 成对比较能更有效地识别低全球得分中的强模型,尤其在质量指标难以定义的情况下。
- 成对比较在模型评估中提供了新的视角,尤其是在难以直接比较模型性能时。
- 当存在频繁平局时,成对比较的收敛需要更多的比较次数。
- 实证研究是通过合成和真实数据集的计算实验进行的,采用了标准全局指标和流行的Bradley-Terry模型进行成对比较。
点此查看论文截图


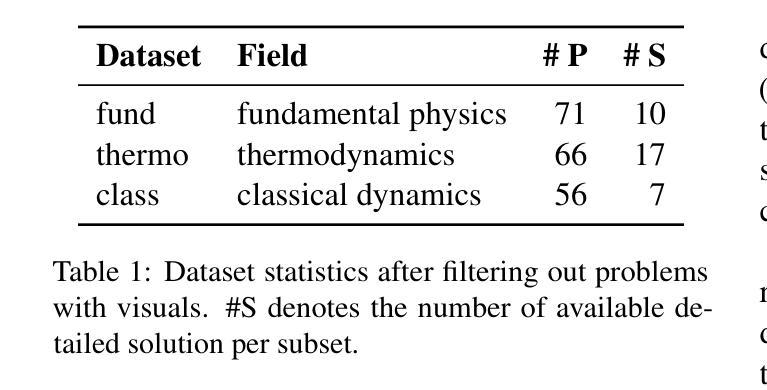
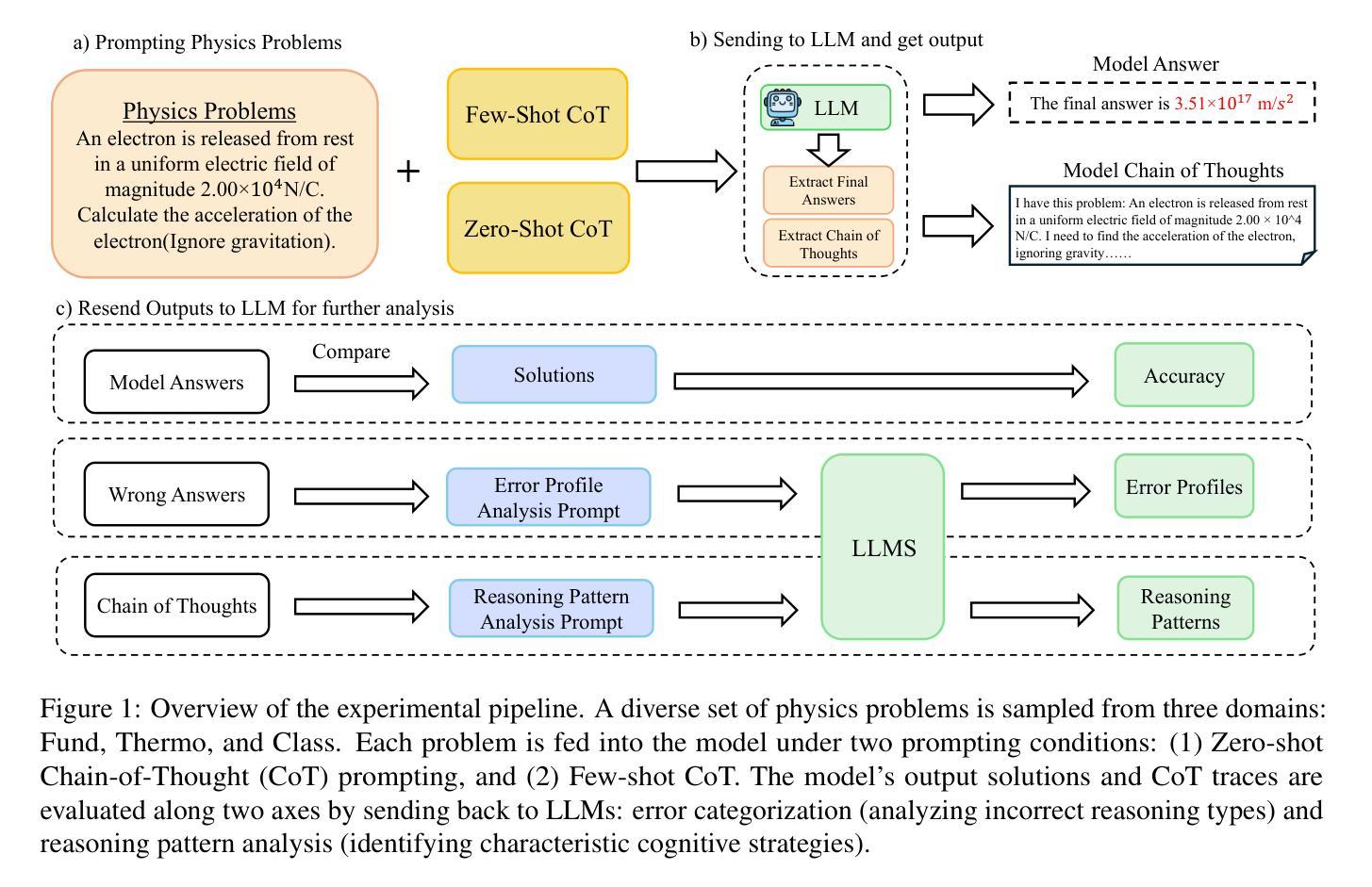
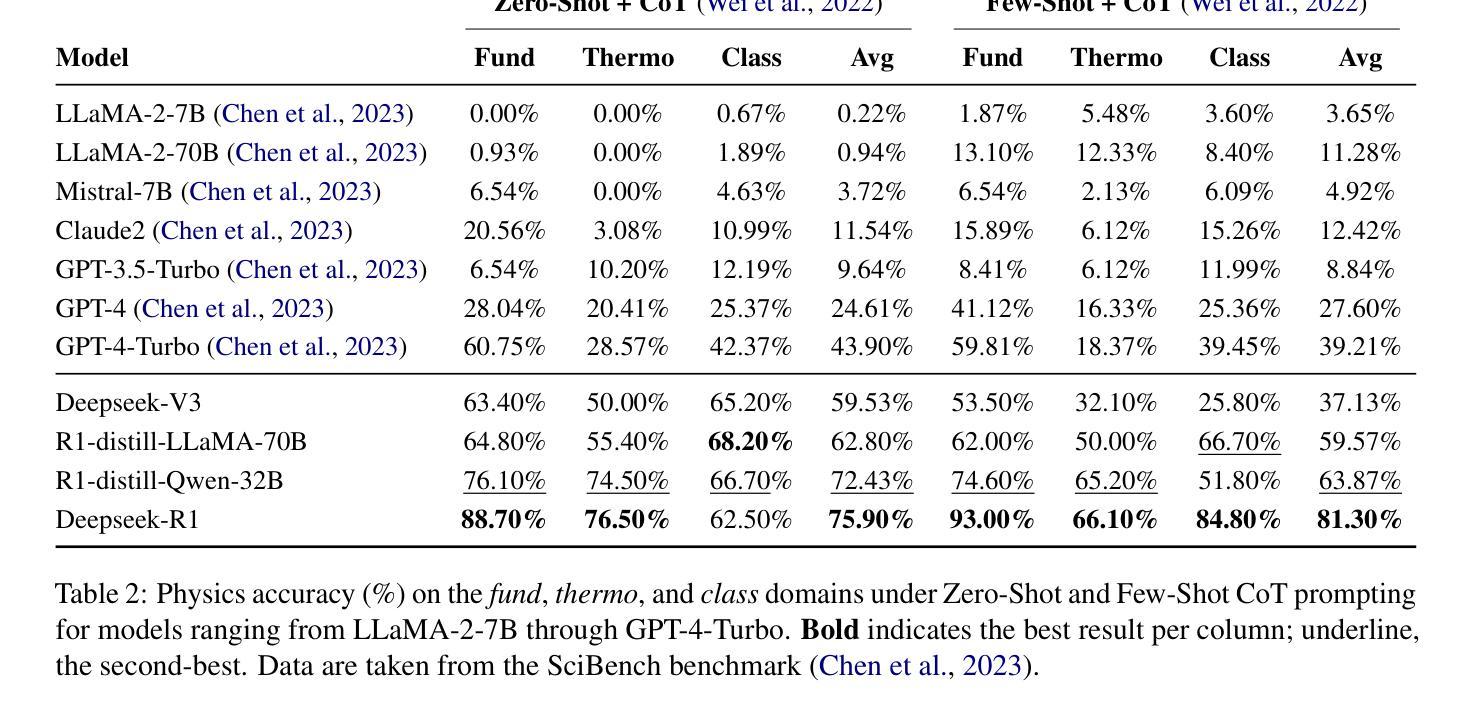
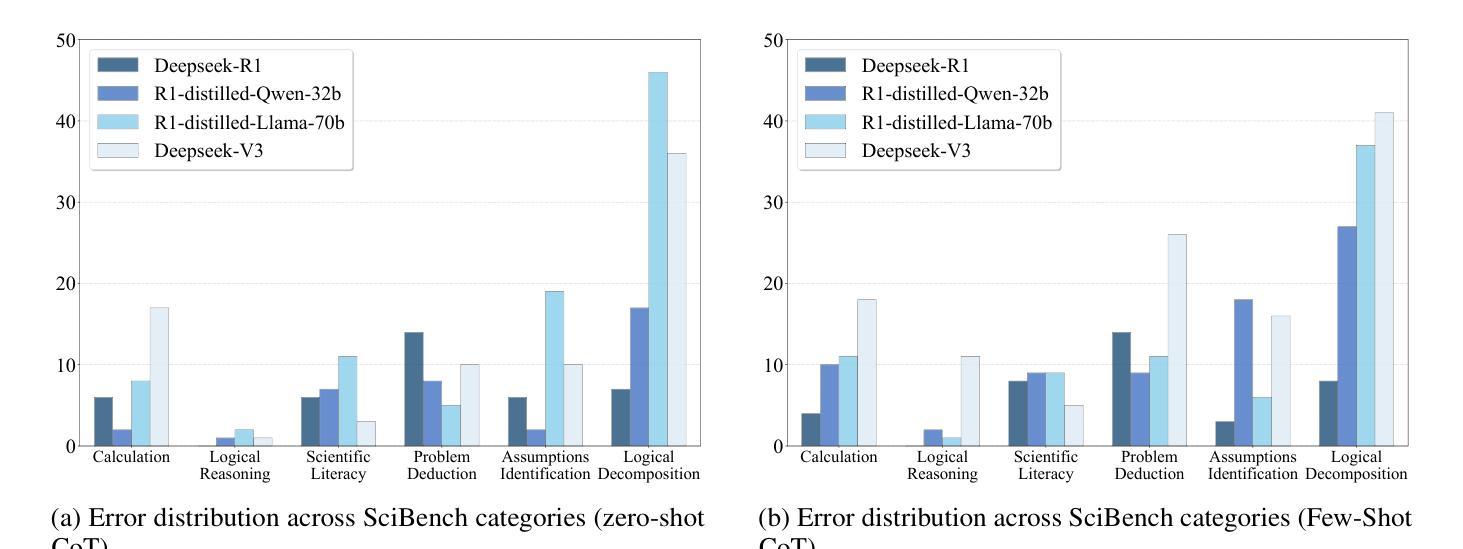
Symbolic or Numerical? Understanding Physics Problem Solving in Reasoning LLMs
Authors:Nifu Dan, Yujun Cai, Yiwei Wang
Navigating the complexities of physics reasoning has long been a difficult task for Large Language Models (LLMs), requiring a synthesis of profound conceptual understanding and adept problem-solving techniques. In this study, we investigate the application of advanced instruction-tuned reasoning models, such as Deepseek-R1, to address a diverse spectrum of physics problems curated from the challenging SciBench benchmark. Our comprehensive experimental evaluation reveals the remarkable capabilities of reasoning models. Not only do they achieve state-of-the-art accuracy in answering intricate physics questions, but they also generate distinctive reasoning patterns that emphasize on symbolic derivation. Furthermore, our findings indicate that even for these highly sophisticated reasoning models, the strategic incorporation of few-shot prompting can still yield measurable improvements in overall accuracy, highlighting the potential for continued performance gains.
长期以来,大型语言模型(LLM)在应对物理学推理的复杂性方面一直是一项艰巨的任务,这要求深厚的概念理解和精湛的问题解决技巧相结合。在这项研究中,我们探讨了高级指令优化推理模型(如Deepseek-R1)在应对来自具有挑战性的SciBench基准测试的一系列物理问题时的应用。我们的综合实验评估揭示了推理模型的卓越能力。这些模型不仅在回答复杂物理问题时达到了最先进的准确性,而且还产生了强调符号推导的独特推理模式。此外,我们的研究结果表明,即使是对于这些高度复杂的推理模型,通过策略性地融入少量提示(few-shot prompting),仍然可以在整体准确性上取得可衡量的进步,这凸显了性能进一步提升的潜力。
论文及项目相关链接
Summary:
本研究探讨了先进指令调优推理模型,如Deepseek-R1,在解决来自SciBench基准挑战的多样化物理问题时的应用。实验评估表明,推理模型具有出色能力,不仅达到了回答复杂物理问题的最新准确性标准,而且产生了强调符号推导的独特推理模式。此外,研究发现即使对于这些高度复杂的推理模型,战略性地融入少量提示仍可显著提高整体准确性,展示了持续提高性能的潜力。
Key Takeaways:
- 先进指令调优推理模型如Deepseek-R1在解决多样化物理问题时表现出卓越的能力。
- 这些模型在回答复杂物理问题时达到了最新准确性标准。
- 推理模型产生了强调符号推导的独特推理模式。
- 即使对于高度复杂的推理模型,融入少量提示仍可提高整体准确性。
- 战略性地使用提示可能有助于推理模型的持续性能提升。
- 此研究揭示了物理推理对于LLM的复杂性,并展示了高级指令调优模型的潜力。
点此查看论文截图

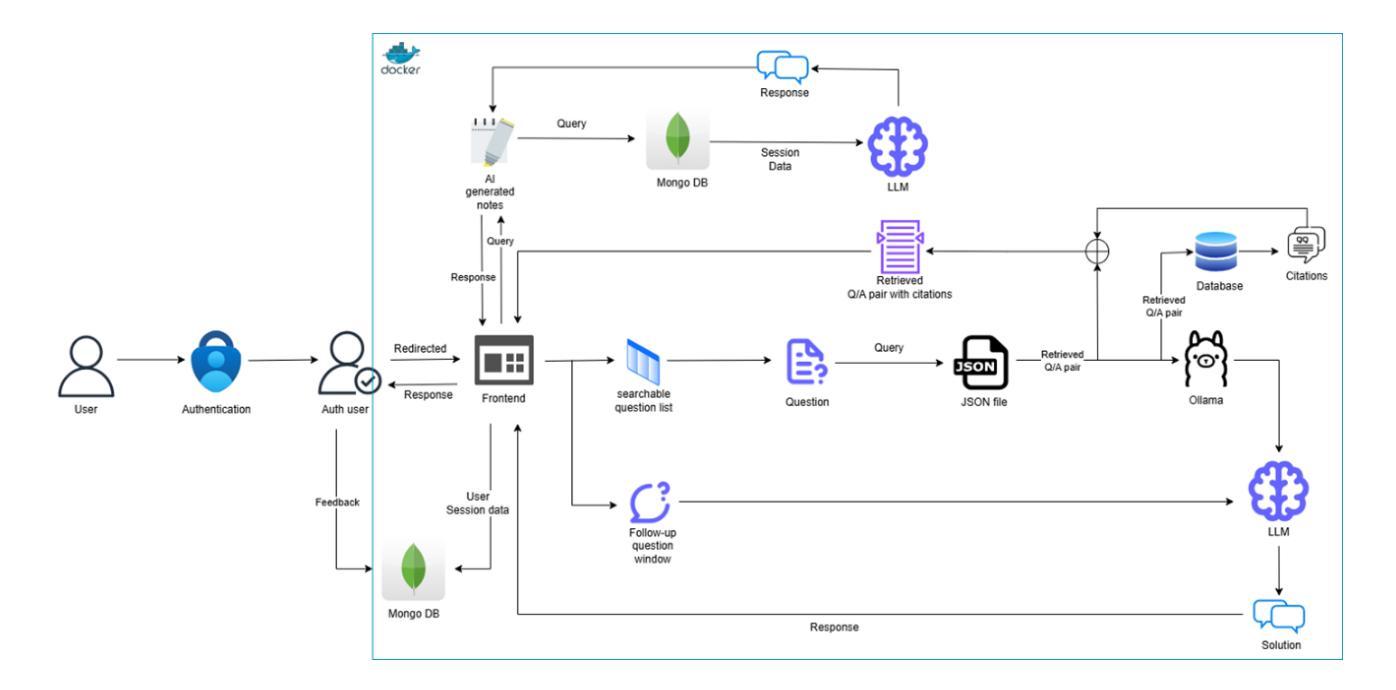
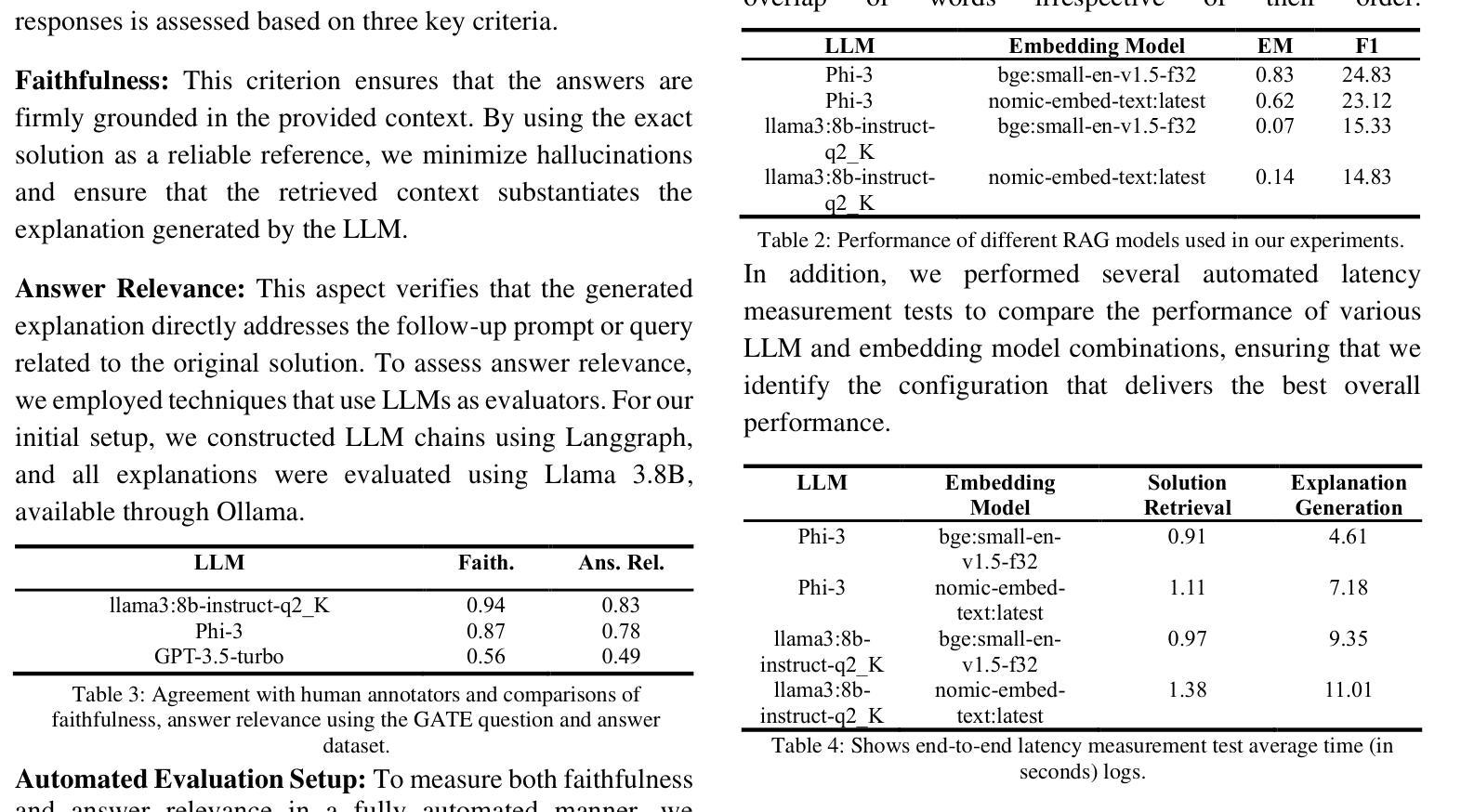
Towards Efficient Educational Chatbots: Benchmarking RAG Frameworks
Authors:Umar Ali Khan, Ekram Khan, Fiza Khan, Athar Ali Moinuddin
Large Language Models (LLMs) have proven immensely beneficial in education by capturing vast amounts of literature-based information, allowing them to generate context without relying on external sources. In this paper, we propose a generative AI-powered GATE question-answering framework (GATE stands for Graduate Aptitude Test in Engineering) that leverages LLMs to explain GATE solutions and support students in their exam preparation. We conducted extensive benchmarking to select the optimal embedding model and LLM, evaluating our framework based on criteria such as latency, faithfulness, and relevance, with additional validation through human evaluation. Our chatbot integrates state-of-the-art embedding models and LLMs to deliver accurate, context-aware responses. Through rigorous experimentation, we identified configurations that balance performance and computational efficiency, ensuring a reliable chatbot to serve students’ needs. Additionally, we discuss the challenges faced in data processing and modeling and implemented solutions. Our work explores the application of Retrieval-Augmented Generation (RAG) for GATE Q/A explanation tasks, and our findings demonstrate significant improvements in retrieval accuracy and response quality. This research offers practical insights for developing effective AI-driven educational tools while highlighting areas for future enhancement in usability and scalability.
大型语言模型(LLM)通过捕获大量文献信息,生成上下文而不依赖外部资源,在教育领域证明具有巨大的优势。在本文中,我们提出了一种基于生成式人工智能的GATE问答框架(GATE代表工程研究生入学考试),该框架利用LLM来解释GATE解决方案并支持学生备考。我们进行了广泛的标准测试,以选择最佳的嵌入模型和LLM,并根据延迟、忠诚度和相关性等标准评估我们的框架,并通过人工评估进行额外验证。我们的聊天机器人集成了最先进的嵌入模型和LLM,以提供准确、语境感知的响应。通过严格的实验,我们确定了平衡性能和计算效率的配置,确保可靠的聊天机器人可以满足学生的需求。此外,我们还讨论了数据处理和建模所面临的挑战,并实施了解决方案。我们的工作探索了用于GATE问答解释任务的检索增强生成(RAG)的应用,研究结果表明在检索准确性和响应质量方面取得了显著改进。该研究为开发有效的AI驱动教育工具提供了实际见解,同时强调了未来在可用性和可扩展性方面的改进方向。
论文及项目相关链接
PDF One of the co-authors is having conflict in the submission to arXiv due to many edits (we have to make changes in evaluation strategies, i.e. section 5); in the paper there are still formatting issues
Summary
大型语言模型在教育领域的应用具有显著优势,能够捕捉大量文献信息并生成上下文内容,无需依赖外部资源。本研究提出了一种基于生成式人工智能的GATE问答框架,利用大型语言模型解释GATE解题方案,支持学生备考。经过广泛评估,我们选择了最佳嵌入模型和大型语言模型,并基于延迟、忠实度和相关性等标准对框架进行了验证。我们的聊天机器人集成了最先进的嵌入模型和大型语言模型,提供准确、语境化的回应。研究还探讨了数据处理和建模的挑战及解决方案,并探索了用于GATE问答解释的检索增强生成技术的实际应用,显示出显著提高的检索准确性和响应质量。
Key Takeaways
- 大型语言模型在教育领域的应用具有显著优势,能够捕捉大量文献信息并生成上下文内容。
- 研究提出了一种基于生成式人工智能的GATE问答框架,利用大型语言模型支持学生备考。
- 广泛评估后选择了最佳嵌入模型和大型语言模型。
- 框架验证基于延迟、忠实度和相关性等标准。
- 聊天机器人集成了最先进的嵌入模型和大型语言模型。
- 研究探讨了数据处理和建模的挑战及解决方案。
点此查看论文截图


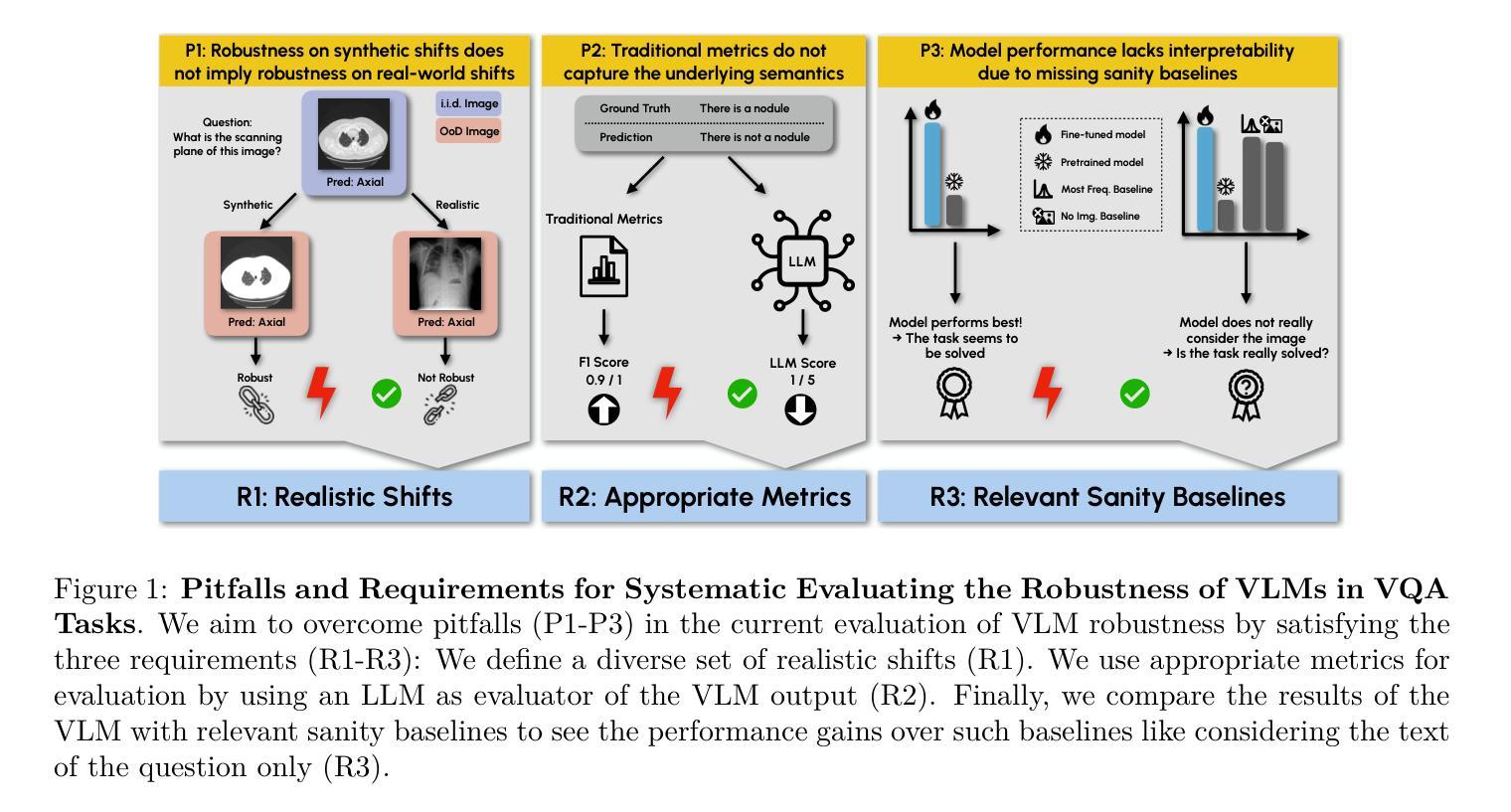
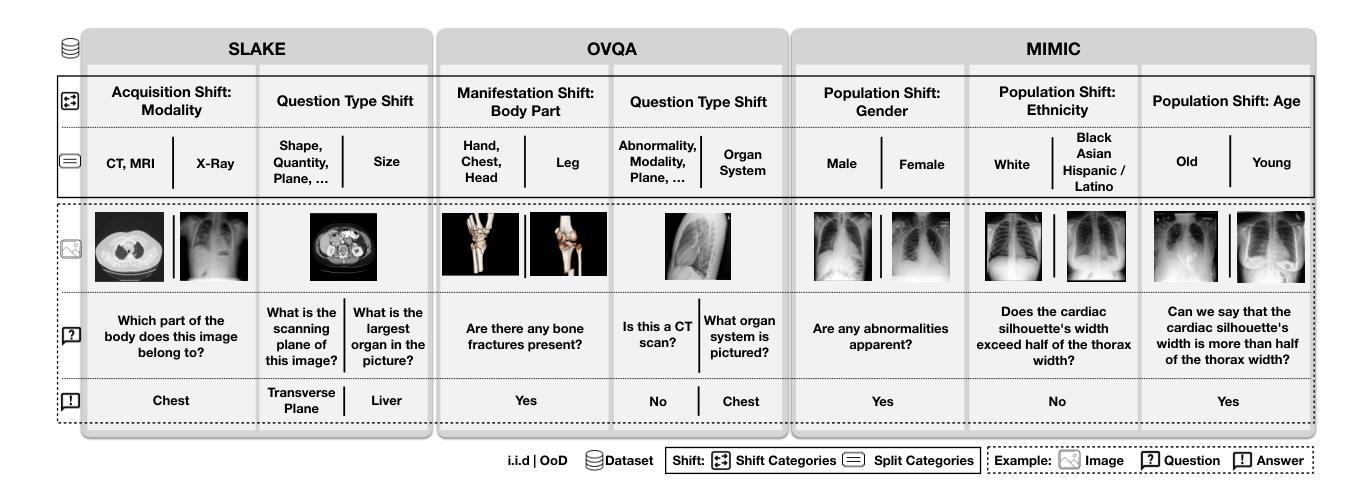
SURE-VQA: Systematic Understanding of Robustness Evaluation in Medical VQA Tasks
Authors:Kim-Celine Kahl, Selen Erkan, Jeremias Traub, Carsten T. Lüth, Klaus Maier-Hein, Lena Maier-Hein, Paul F. Jaeger
Vision-Language Models (VLMs) have great potential in medical tasks, like Visual Question Answering (VQA), where they could act as interactive assistants for both patients and clinicians. Yet their robustness to distribution shifts on unseen data remains a key concern for safe deployment. Evaluating such robustness requires a controlled experimental setup that allows for systematic insights into the model’s behavior. However, we demonstrate that current setups fail to offer sufficiently thorough evaluations. To address this gap, we introduce a novel framework, called \textit{SURE-VQA}, centered around three key requirements to overcome current pitfalls and systematically analyze VLM robustness: 1) Since robustness on synthetic shifts does not necessarily translate to real-world shifts, it should be measured on real-world shifts that are inherent to the VQA data; 2) Traditional token-matching metrics often fail to capture underlying semantics, necessitating the use of large language models (LLMs) for more accurate semantic evaluation; 3) Model performance often lacks interpretability due to missing sanity baselines, thus meaningful baselines should be reported that allow assessing the multimodal impact on the VLM. To demonstrate the relevance of this framework, we conduct a study on the robustness of various Fine-Tuning (FT) methods across three medical datasets with four types of distribution shifts. Our study highlights key insights into robustness: 1) No FT method consistently outperforms others in robustness, and 2) robustness trends are more stable across FT methods than across distribution shifts. Additionally, we find that simple sanity baselines that do not use the image data can perform surprisingly well and confirm LoRA as the best-performing FT method on in-distribution data. Code is provided at https://github.com/IML-DKFZ/sure-vqa.
视觉语言模型(VLMs)在医疗任务(如视觉问答(VQA))中具有巨大潜力,可以作为患者和临床医生之间的交互式助手。然而,它们在未见数据上的分布转移鲁棒性仍是安全部署的关键问题。评估这种鲁棒性需要一个受控的实验设置,允许对模型的行为进行系统性的洞察。然而,我们证明当前的设置无法提供足够全面的评估。为了弥补这一空白,我们引入了一个名为“SURE-VQA”的新型框架,该框架围绕三个关键要求来克服当前的问题并系统地分析VLM的鲁棒性:1)由于合成转移上的鲁棒性并不一定转化为现实世界的转移,因此它应该在VQA数据所固有的现实世界的转移上进行衡量;2)传统的令牌匹配指标往往无法捕捉潜在的语义,因此需要利用大型语言模型(LLM)进行更准确的语义评估;3)由于缺少基准线,模型性能往往缺乏可解释性,因此应报告有意义的基准线,以便评估对VLM的多模式影响。为了证明该框架的重要性,我们在三个医疗数据集上对各种微调(FT)方法的鲁棒性进行了研究,这些数据集包含四种类型的分布转移。我们的研究对鲁棒性提供了关键的见解:1)没有一种FT方法在所有情况下都在鲁棒性方面表现最好;并且2)与分布转移相比,FT方法在鲁棒性趋势方面更加稳定。此外,我们发现不使用图像数据的简单基准线可能会表现得令人惊讶地好,并确认LoRA是在内部分布数据上表现最佳的FT方法。代码可在https://github.com/IML-DKFZ/sure-vqa找到。
论文及项目相关链接
PDF TMLR 07/2025
Summary
本文探讨了视觉语言模型(VLMs)在医疗任务中的潜力与挑战。针对现有评估框架在评估模型对未见数据分布转移鲁棒性方面的不足,提出了一种新的评估框架“SURE-VQA”,并围绕三个关键要求进行构建:测量真实世界的数据分布转移、使用大型语言模型(LLMs)进行更准确的语义评估以及报告有意义的基准点以评估模型的性能。通过对不同微调方法在三个医疗数据集上四种分布转移的研究,发现没有一种方法在所有情况下均表现出最佳的鲁棒性,并且稳定性在不同方法之间比在分布转移之间更为一致。同时发现简单的基准模型在没有使用图像数据的情况下也能表现良好,并且确认LoRA在常规数据上表现最佳。
Key Takeaways
- 视觉语言模型(VLMs)在医疗任务中具有潜力,如视觉问答(VQA),可作为患者和临床医生的交互式助手。
- 当前评估框架在评估模型对未见数据分布转移的鲁棒性方面存在不足。
- 引入新的评估框架“SURE-VQA”,围绕三个关键要求:测量真实世界的数据分布转移、使用大型语言模型进行语义评估以及报告有意义的基准点。
- 在三个医疗数据集上进行了不同微调方法的研究,发现没有一种方法在所有情况下均表现出最佳的鲁棒性。
- 不同微调方法的鲁棒性稳定性比分布转移的稳定性更高。
- 研究表明简单的基准模型即使没有使用图像数据也能表现得很好。
点此查看论文截图