⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-05 更新
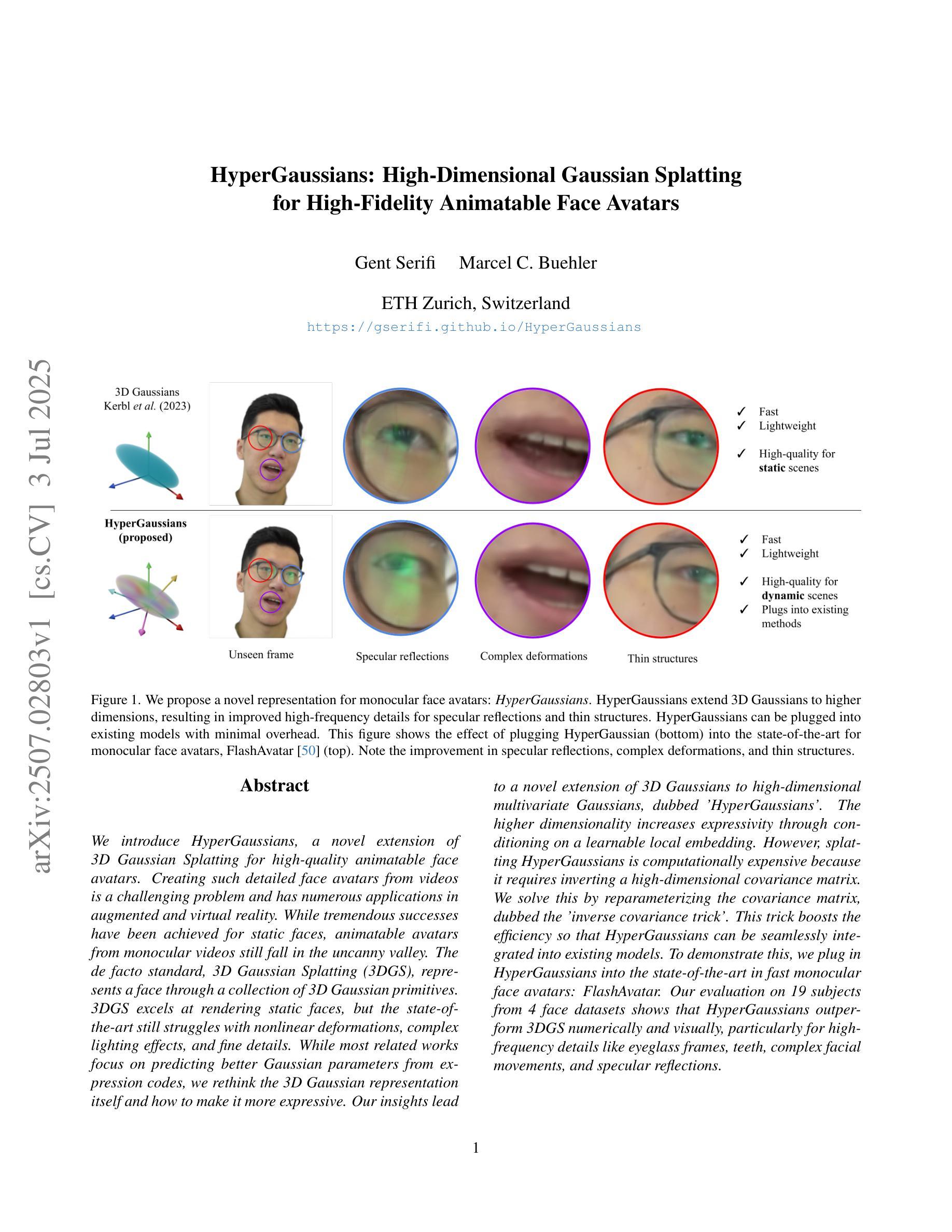
HyperGaussians: High-Dimensional Gaussian Splatting for High-Fidelity Animatable Face Avatars
Authors:Gent Serifi, Marcel C. Bühler
We introduce HyperGaussians, a novel extension of 3D Gaussian Splatting for high-quality animatable face avatars. Creating such detailed face avatars from videos is a challenging problem and has numerous applications in augmented and virtual reality. While tremendous successes have been achieved for static faces, animatable avatars from monocular videos still fall in the uncanny valley. The de facto standard, 3D Gaussian Splatting (3DGS), represents a face through a collection of 3D Gaussian primitives. 3DGS excels at rendering static faces, but the state-of-the-art still struggles with nonlinear deformations, complex lighting effects, and fine details. While most related works focus on predicting better Gaussian parameters from expression codes, we rethink the 3D Gaussian representation itself and how to make it more expressive. Our insights lead to a novel extension of 3D Gaussians to high-dimensional multivariate Gaussians, dubbed ‘HyperGaussians’. The higher dimensionality increases expressivity through conditioning on a learnable local embedding. However, splatting HyperGaussians is computationally expensive because it requires inverting a high-dimensional covariance matrix. We solve this by reparameterizing the covariance matrix, dubbed the ‘inverse covariance trick’. This trick boosts the efficiency so that HyperGaussians can be seamlessly integrated into existing models. To demonstrate this, we plug in HyperGaussians into the state-of-the-art in fast monocular face avatars: FlashAvatar. Our evaluation on 19 subjects from 4 face datasets shows that HyperGaussians outperform 3DGS numerically and visually, particularly for high-frequency details like eyeglass frames, teeth, complex facial movements, and specular reflections.
我们介绍了HyperGaussians,这是3D高斯涂抹术的一种新型扩展,用于创建高质量的可动画面部化身。从视频中创建如此详细的面部化身是一个具有挑战性的问题,并且在增强和虚拟现实中具有许多应用。虽然静态面部的成果已经相当显著,但从单目视频中创建的可动画化身仍然处于“尴尬境地”。现行标准3D高斯涂抹术(3DGS)通过一系列3D高斯原始数据来表示面部。3DGS在呈现静态面部方面表现出色,但最新技术仍然在非线性变形、复杂的灯光效果和精细细节方面遇到困难。虽然大多数相关工作都集中在从表情代码中预测更好的高斯参数,但我们重新思考了3D高斯表示本身以及如何使其更具表现力。我们的见解导致了对高维多元高斯的新型扩展,称为“HyperGaussians”。更高的维度通过依赖于可学习的局部嵌入来增加表现力。然而,涂抹HyperGaussians计算量大,因为它需要逆转高维协方差矩阵。我们通过重新参数化协方差矩阵解决了这个问题,这被称为“逆协方差技巧”。这一技巧提高了效率,使得HyperGaussians可以无缝地集成到现有模型中。为了证明这一点,我们将HyperGaussians插入到现有快速单目面部化身的最前沿技术:FlashAvatar中。我们对来自四个面部数据集的19名主体的评估表明,HyperGaussians在数值和视觉上均优于3DGS,特别是在眼镜框、牙齿、复杂面部动作和镜面反射等高频细节方面。
论文及项目相关链接
PDF Project page: https://gserifi.github.io/HyperGaussians
Summary
高维高斯分布扩展方法(HyperGaussians)是全新的动画面部化身构建技术,它解决了三维高斯表面化技术的难题,实现了高质量的动画面部外观渲染。这一技术通过将人脸表示为一组高维多元高斯分布模型(HyperGaussians),提高了表现力,解决了非线性变形、复杂光照和精细细节的问题。通过逆协方差矩阵的重参数化技巧(inverse covariance trick),提高了计算效率,并成功集成到现有模型中。在多个数据集上的实验表明,HyperGaussians在面部动画效果上优于三维高斯表面化技术。
Key Takeaways
一、提出HyperGaussians:通过引入高维多元高斯分布模型作为新型动画面部表示法。实现了对面部特征更高层次和更精细的表达。这种表示法可以解决现有技术在处理非线性变形和复杂光照效果方面的局限性。提高了对人脸精细细节的捕捉能力。如眼镜框、牙齿等细节以及复杂的面部运动和镜面反射等。
二、逆协方差矩阵的重参数化技巧:解决高维高斯分布计算量大的问题,使得HyperGaussians能无缝集成到现有模型中。提高了渲染效率。这对于实时渲染高质量动画面部外观至关重要。
三、与现有技术结合:将HyperGaussians集成到当前最先进的单眼面部动画技术FlashAvatar中,显著提高了动画面部渲染质量。在多个数据集上的实验验证了HyperGaussians的优越性。在细节丰富度和表现力方面都有显著的提升。解决了先前技术中可能存在的僵硬和不符合现实等问题。使其在虚拟现实和增强现实应用中有更广泛的应用前景。
点此查看论文截图
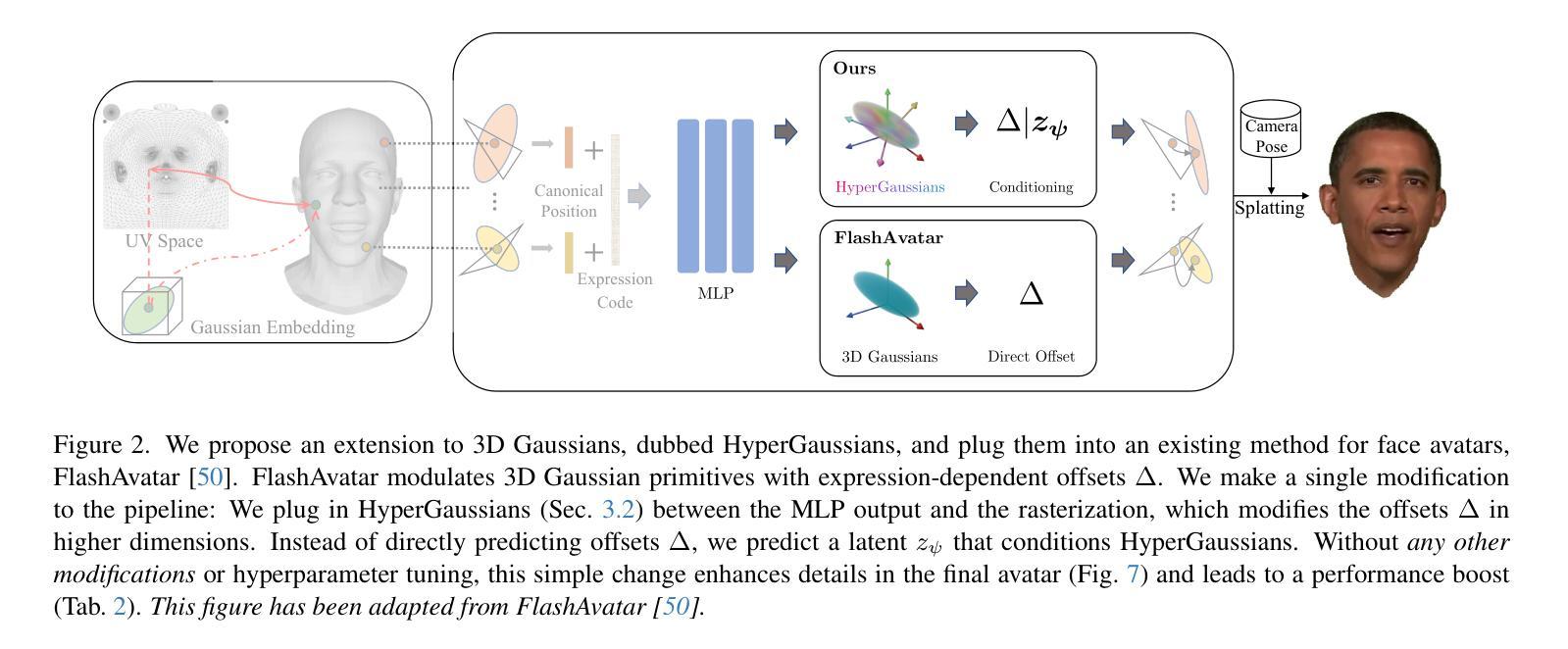
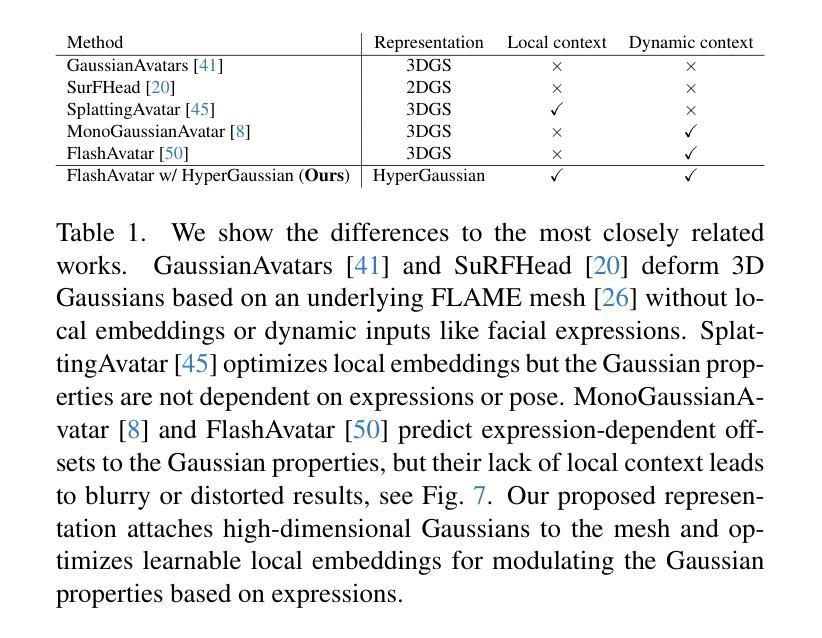

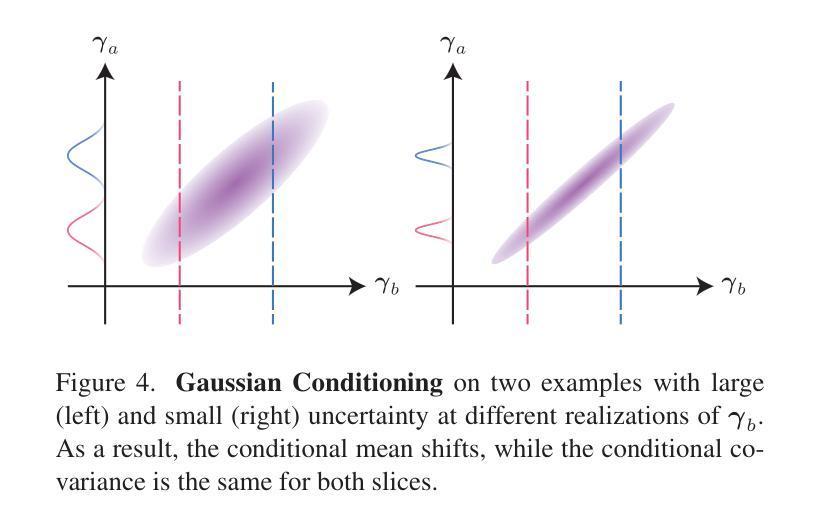
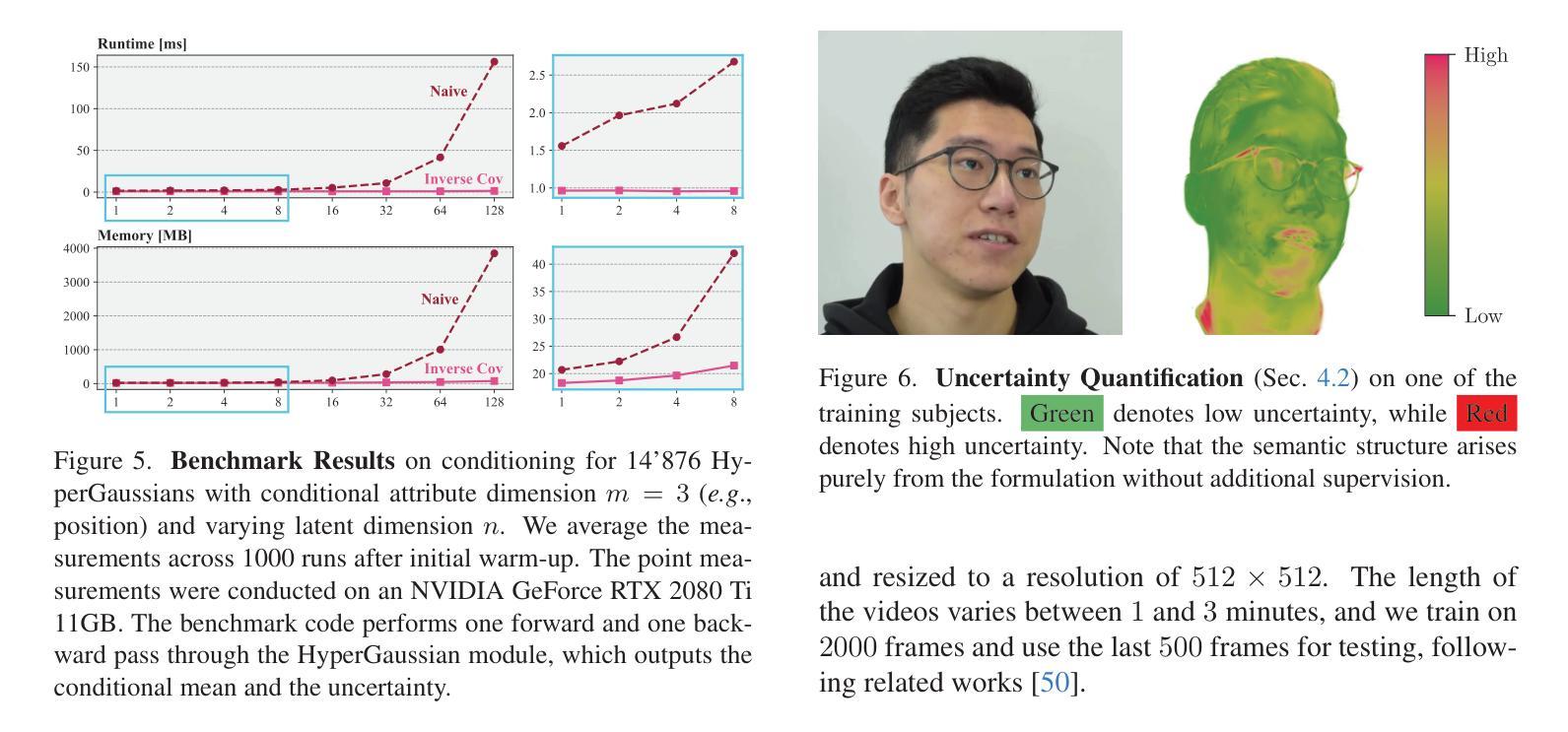
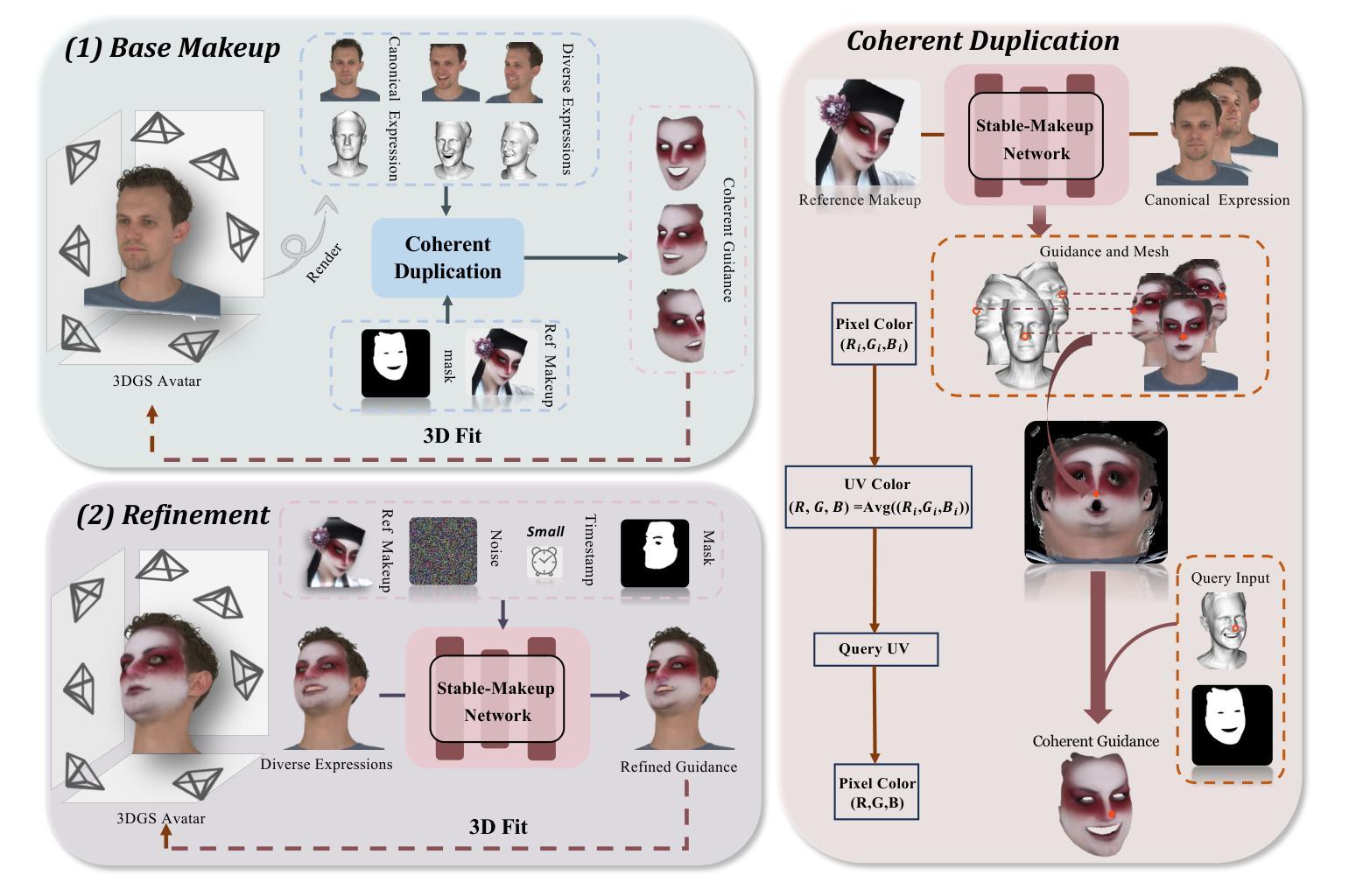
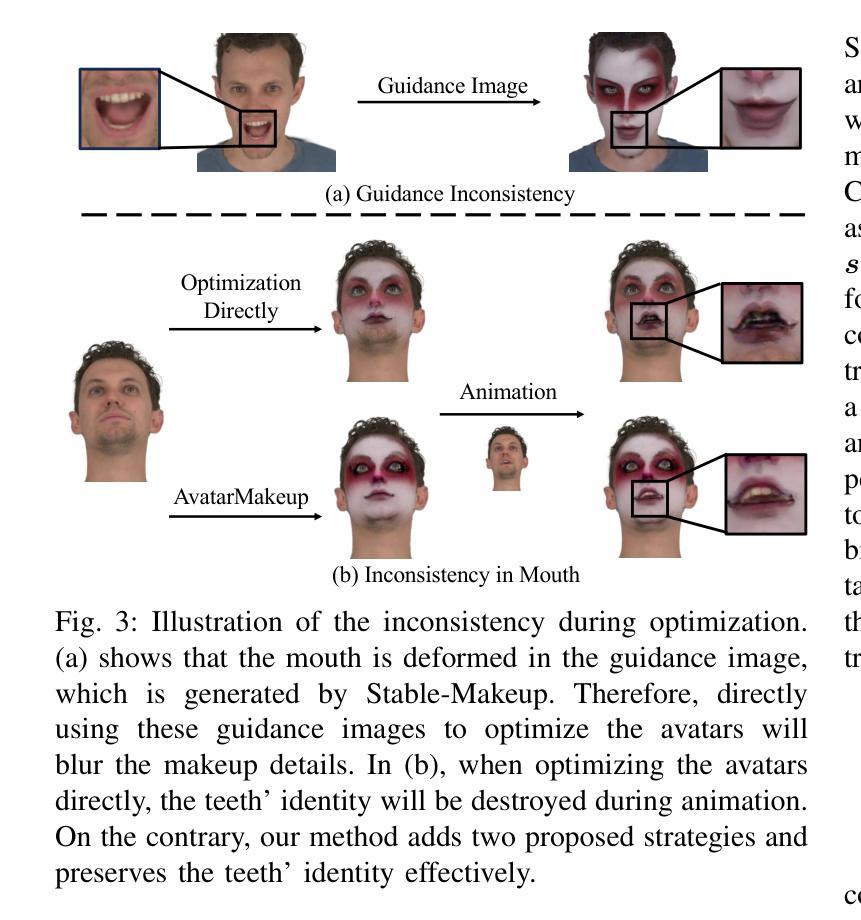
AvatarMakeup: Realistic Makeup Transfer for 3D Animatable Head Avatars
Authors:Yiming Zhong, Xiaolin Zhang, Ligang Liu, Yao Zhao, Yunchao Wei
Similar to facial beautification in real life, 3D virtual avatars require personalized customization to enhance their visual appeal, yet this area remains insufficiently explored. Although current 3D Gaussian editing methods can be adapted for facial makeup purposes, these methods fail to meet the fundamental requirements for achieving realistic makeup effects: 1) ensuring a consistent appearance during drivable expressions, 2) preserving the identity throughout the makeup process, and 3) enabling precise control over fine details. To address these, we propose a specialized 3D makeup method named AvatarMakeup, leveraging a pretrained diffusion model to transfer makeup patterns from a single reference photo of any individual. We adopt a coarse-to-fine idea to first maintain the consistent appearance and identity, and then to refine the details. In particular, the diffusion model is employed to generate makeup images as supervision. Due to the uncertainties in diffusion process, the generated images are inconsistent across different viewpoints and expressions. Therefore, we propose a Coherent Duplication method to coarsely apply makeup to the target while ensuring consistency across dynamic and multiview effects. Coherent Duplication optimizes a global UV map by recoding the averaged facial attributes among the generated makeup images. By querying the global UV map, it easily synthesizes coherent makeup guidance from arbitrary views and expressions to optimize the target avatar. Given the coarse makeup avatar, we further enhance the makeup by incorporating a Refinement Module into the diffusion model to achieve high makeup quality. Experiments demonstrate that AvatarMakeup achieves state-of-the-art makeup transfer quality and consistency throughout animation.
与现实生活中的面部美容类似,3D虚拟化身需要个性化定制以增强其视觉吸引力,但这个领域仍然没有得到足够的探索。尽管当前的3D高斯编辑方法可以被改编用于面部化妆,但这些方法未能满足实现真实化妆效果的基本要求:1)在可驱动的表情中保持外观的一致性,2)在化妆过程中保持身份识别,3)对细节进行精确控制。为了解决这个问题,我们提出了一种专门的3D化妆方法,名为AvatarMakeup,它利用预训练的扩散模型从任何个人的单张参考照片转移化妆模式。我们采用由粗到细的理念,首先保持外观和身份的的一致性,然后改进细节。特别是,扩散模型被用于生成化妆图像作为监督。由于扩散过程中的不确定性,生成的图像在不同的观点和表情上是不一致的。因此,我们提出了一种一致复制的方法,将化妆粗略地应用到目标上,同时确保动态和多视图效果的一致性。一致复制通过重新编码生成化妆图像的平均面部属性来优化全局UV地图。通过查询全局UV地图,它很容易合成来自任意视角和表情的连贯化妆指导,以优化目标化身。给定粗略的化妆化身,我们进一步通过将细化模块融入到扩散模型中,以提高化妆品质。实验表明,AvatarMakeup达到了最先进的化妆转移质量和动画一致性。
论文及项目相关链接
Summary
该文探讨了在元宇宙中的虚拟角色个性化化妆技术。现有方法难以满足虚拟角色化妆过程中的一致性、身份保持和精细控制要求。因此,提出了一种名为AvatarMakeup的专门化妆方法,利用预训练的扩散模型从单一参考照片转移妆容。该方法采用由粗到细的策略,先保证外观和身份的一致性,再精细处理细节。通过优化全局UV地图和结合细化模块,提高了妆容的质量和一致性。此方法可实现高质量的虚拟角色化妆效果。
Key Takeaways
- 虚拟角色需要个性化化妆以增强吸引力,但现有技术在这一领域尚未得到充分探索。
- 当前3D高斯编辑方法虽然可用于面部化妆,但无法满足虚拟角色化妆的基本要求,如一致性、身份保持和精细控制。
- 提出了一种名为AvatarMakeup的专门化妆方法,利用预训练的扩散模型从单一参考照片转移妆容。
- AvatarMakeup采用由粗到细的策略,先保证外观和身份的一致性,然后通过细化模块进一步提高妆容质量。
- 扩散模型用于生成妆容图像作为监督,但存在不确定性,因此提出一种Coherent Duplication方法来粗略应用妆容,确保动态和多视角效果的一致性。
- 通过优化全局UV地图,AvatarMakeup能够轻松合成任意视角和表情下的连贯妆容指导。
点此查看论文截图