⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-05 更新
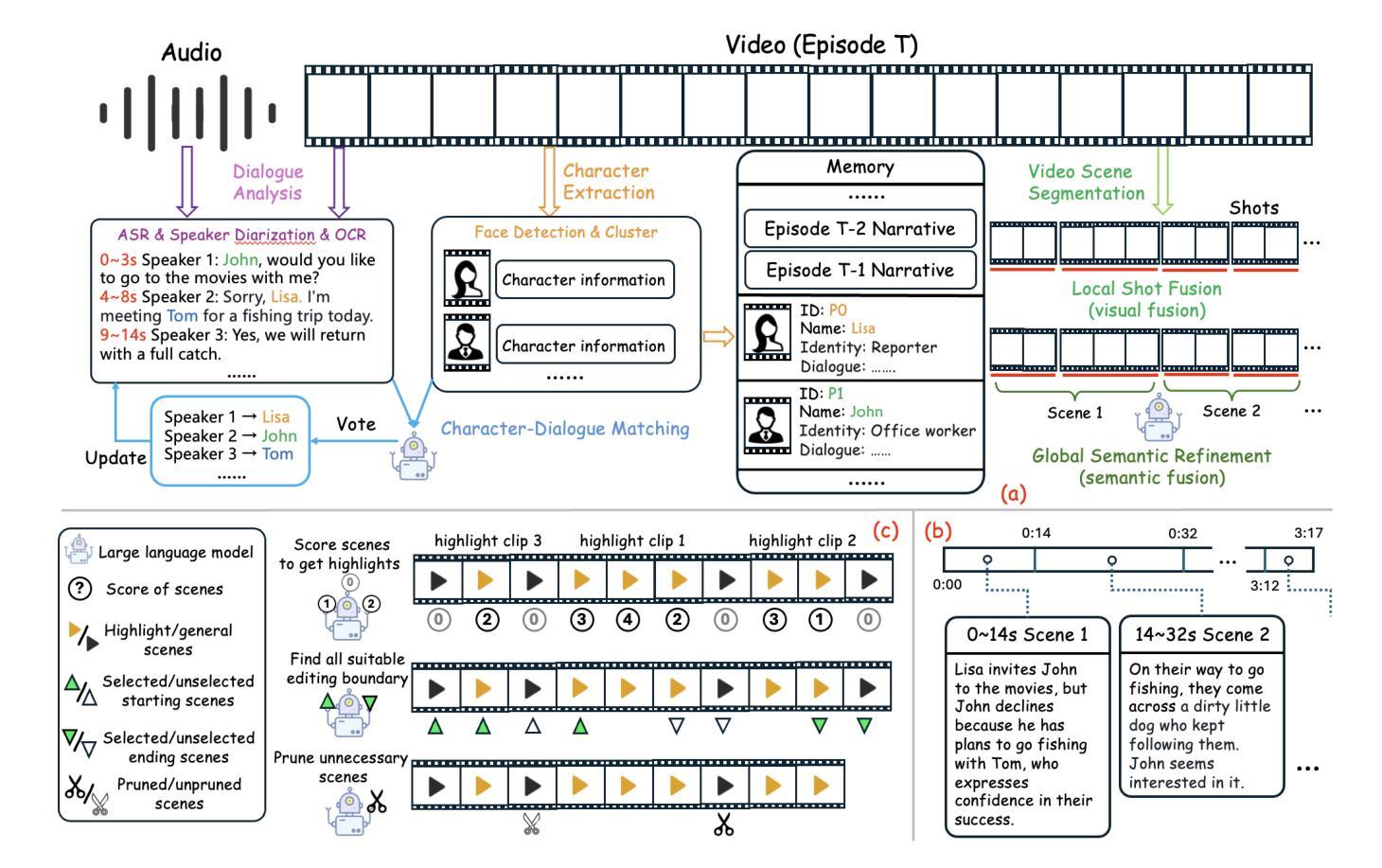
From Long Videos to Engaging Clips: A Human-Inspired Video Editing Framework with Multimodal Narrative Understanding
Authors:Xiangfeng Wang, Xiao Li, Yadong Wei, Xueyu Song, Yang Song, Xiaoqiang Xia, Fangrui Zeng, Zaiyi Chen, Liu Liu, Gu Xu, Tong Xu
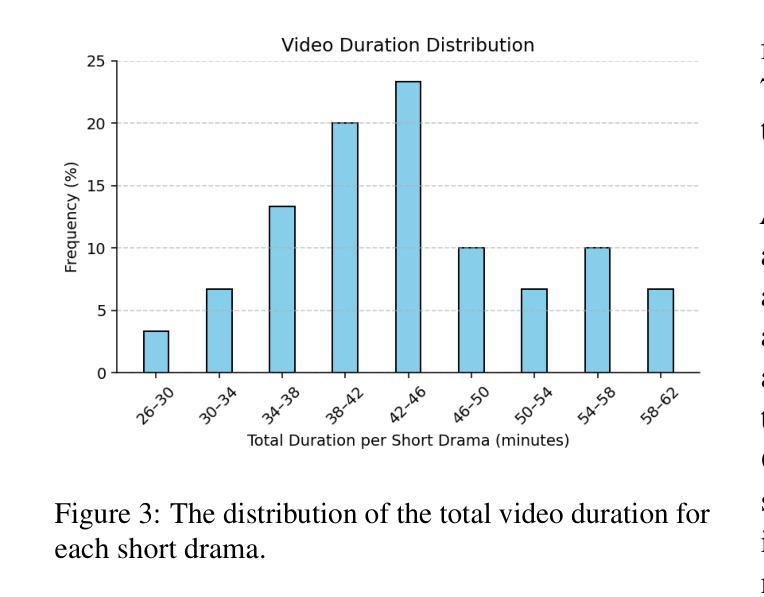
The rapid growth of online video content, especially on short video platforms, has created a growing demand for efficient video editing techniques that can condense long-form videos into concise and engaging clips. Existing automatic editing methods predominantly rely on textual cues from ASR transcripts and end-to-end segment selection, often neglecting the rich visual context and leading to incoherent outputs. In this paper, we propose a human-inspired automatic video editing framework (HIVE) that leverages multimodal narrative understanding to address these limitations. Our approach incorporates character extraction, dialogue analysis, and narrative summarization through multimodal large language models, enabling a holistic understanding of the video content. To further enhance coherence, we apply scene-level segmentation and decompose the editing process into three subtasks: highlight detection, opening/ending selection, and pruning of irrelevant content. To facilitate research in this area, we introduce DramaAD, a novel benchmark dataset comprising over 800 short drama episodes and 500 professionally edited advertisement clips. Experimental results demonstrate that our framework consistently outperforms existing baselines across both general and advertisement-oriented editing tasks, significantly narrowing the quality gap between automatic and human-edited videos.
在线视频内容的快速增长,特别是在短视频平台上,已经产生了对高效视频编辑技术的不断增长的需求,这些技术能够将长视频浓缩成简洁、引人入胜的片段。现有的自动编辑方法主要依赖于ASR转录的文本线索和端到端的片段选择,经常忽视丰富的视觉上下文,导致输出内容缺乏连贯性。在本文中,我们提出了一个受人类启发的自动视频编辑框架(HIVE),该框架利用多模式叙事理解来解决这些限制。我们的方法结合了人物提取、对话分析和叙事摘要,通过多模式大型语言模型,实现对视频内容的整体理解。为了进一步提高连贯性,我们应用了场景级分割,并将编辑过程分解为三个子任务:高光检测、开头/结尾选择以及删除无关内容。为了促进该领域的研究,我们引入了DramaAD,这是一个新的基准数据集,包含超过800个短剧片段和500个专业编辑的广告片段。实验结果表明,我们的框架在通用和面向广告的编辑任务上都优于现有基线,显著缩小了自动编辑和人类编辑视频之间的质量差距。
论文及项目相关链接
Summary
在线视频内容的快速增长,尤其是短视频平台上的内容,对高效视频编辑技术提出了更高的要求,即将长视频浓缩成简洁、引人入胜的片段。现有自动编辑方法主要依赖ASR文本的文本线索和端到端片段选择,往往忽视了丰富的视觉背景,导致输出内容不连贯。本文提出一种人类启发的自动视频编辑框架(HIVE),利用多模式叙事理解来解决这一问题。该框架结合人物提取、对话分析和叙事摘要,通过多模式大型语言模型实现视频内容的整体理解。为提高连贯性,采用场景级分割,将编辑过程分解为三个子任务:亮点检测、开头/结尾选择和无关内容修剪。此外,为推进相关领域研究,引入了DramaAD——包含超过800个短片戏剧和500个专业编辑的广告剪辑的新基准数据集。实验结果表明,该框架在通用和广告导向的编辑任务上均优于现有基线,大幅缩小了自动编辑和人类编辑视频的质量差距。
Key Takeaways
- 在线视频内容的增长促进了高效视频编辑技术的需求。
- 现有自动视频编辑方法主要依赖文本线索和端到端片段选择,存在视觉背景忽视的问题。
- 提出的HIVE框架结合人物提取、对话分析和叙事摘要,利用多模式大型语言模型实现视频内容的全面理解。
- HIVE框架采用场景级分割来提高视频编辑的连贯性,并分解编辑过程为三个子任务。
- 引入新的基准数据集DramaAD,包含短片戏剧和专业编辑的广告剪辑,以推进研究。
- 实验结果显示HIVE框架在多种编辑任务上表现优于现有方法。
点此查看论文截图


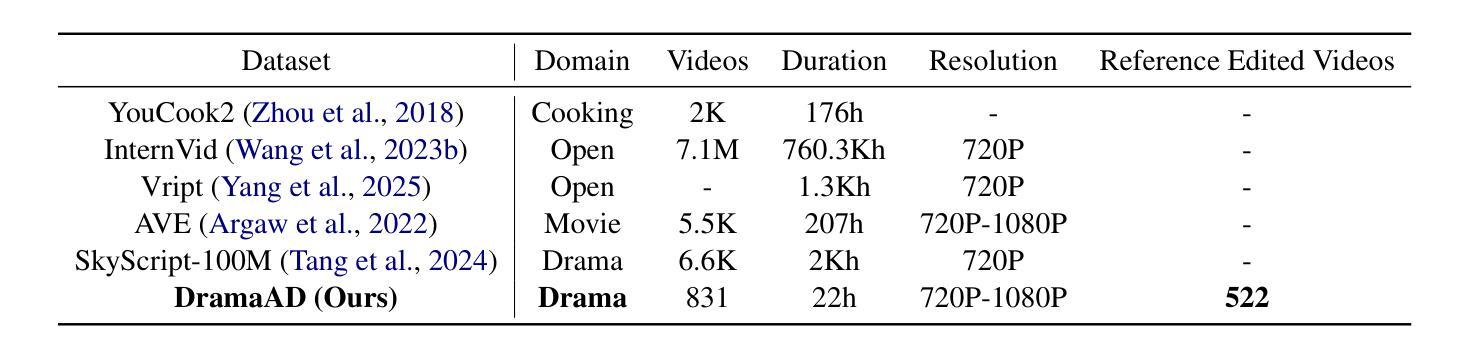
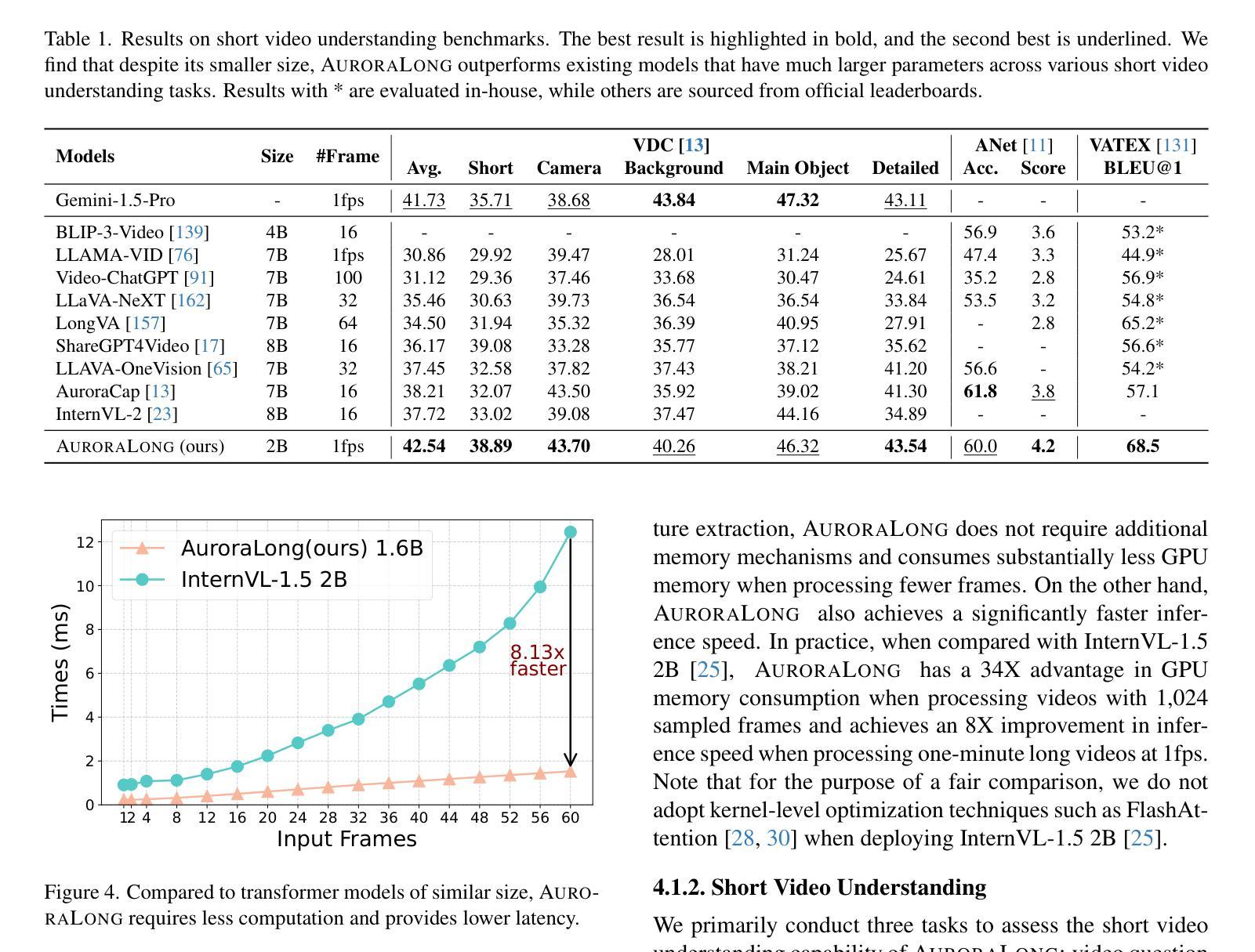
AuroraLong: Bringing RNNs Back to Efficient Open-Ended Video Understanding
Authors:Weili Xu, Enxin Song, Wenhao Chai, Xuexiang Wen, Tian Ye, Gaoang Wang
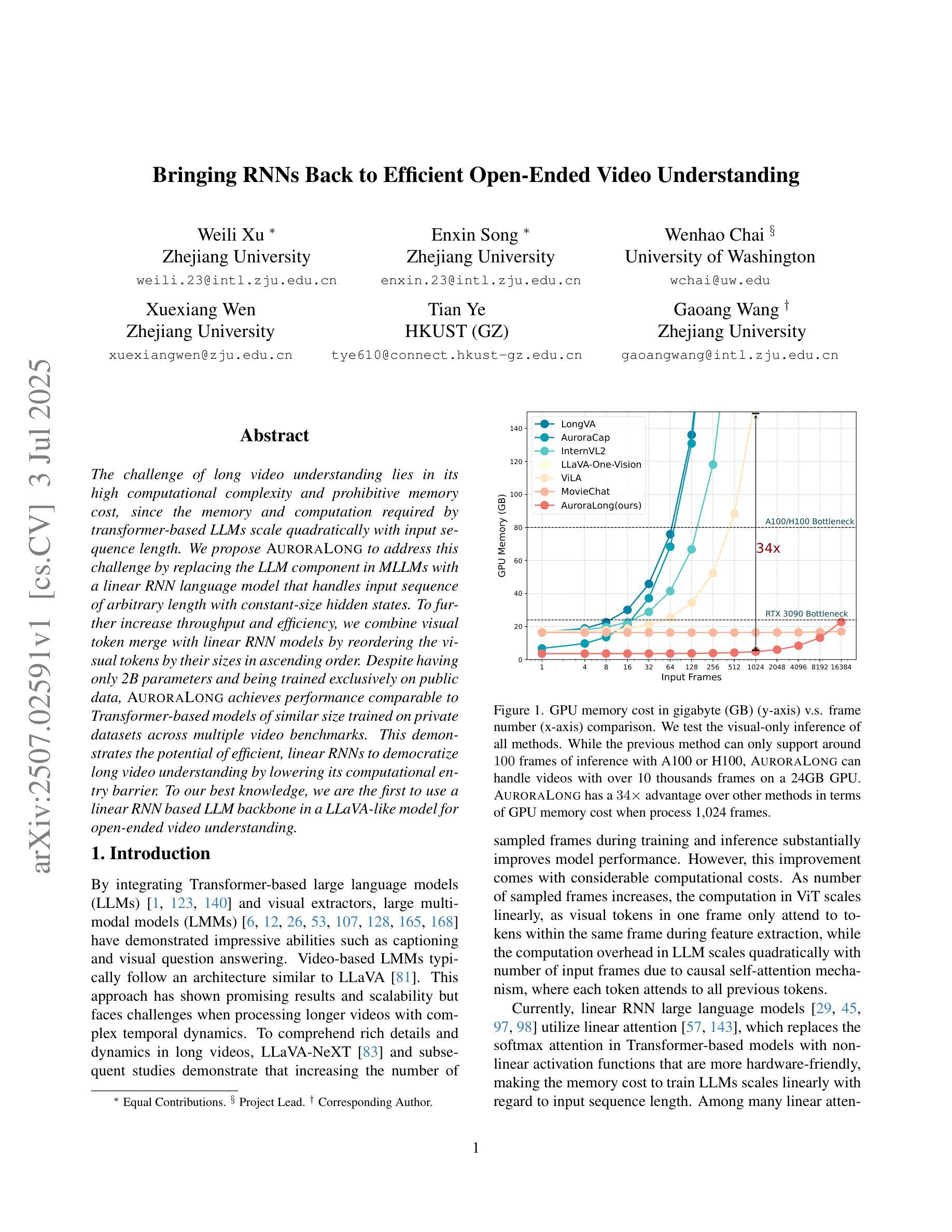
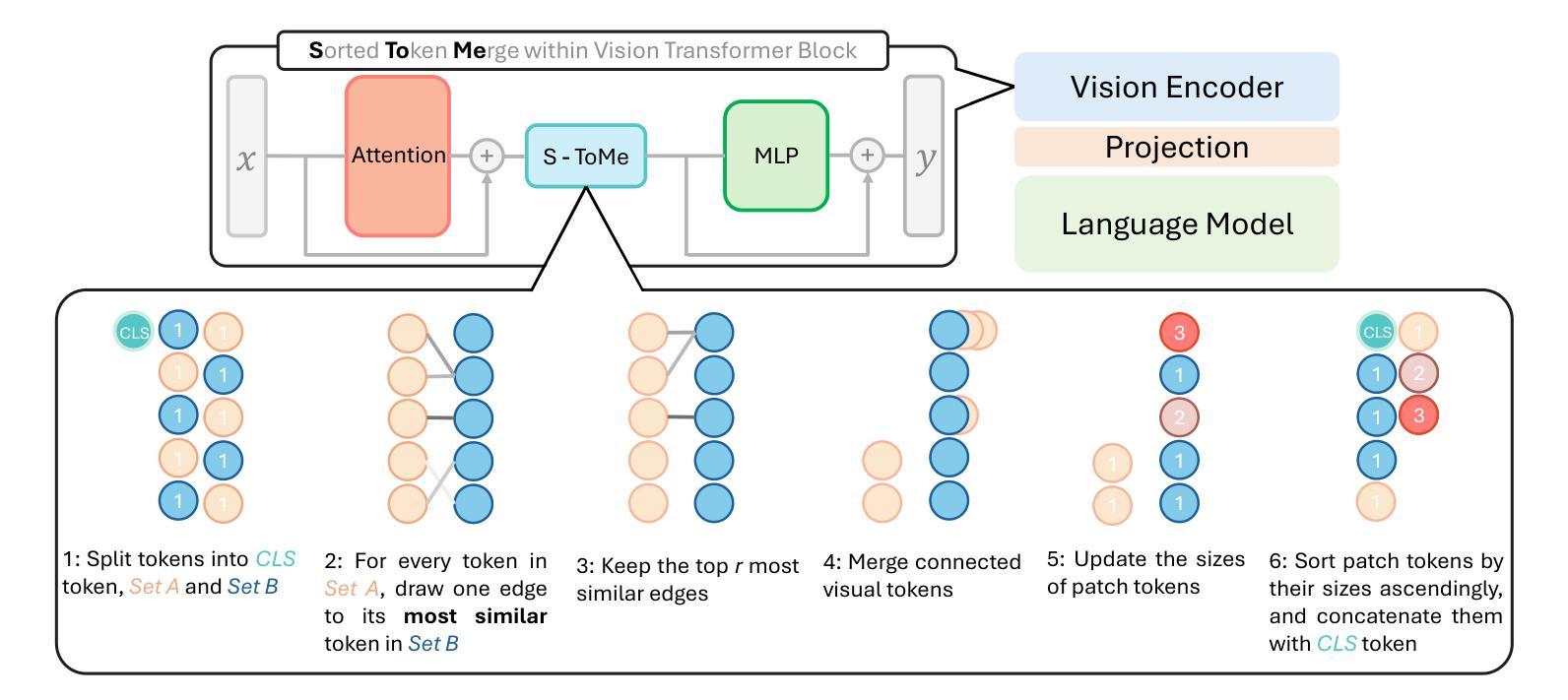
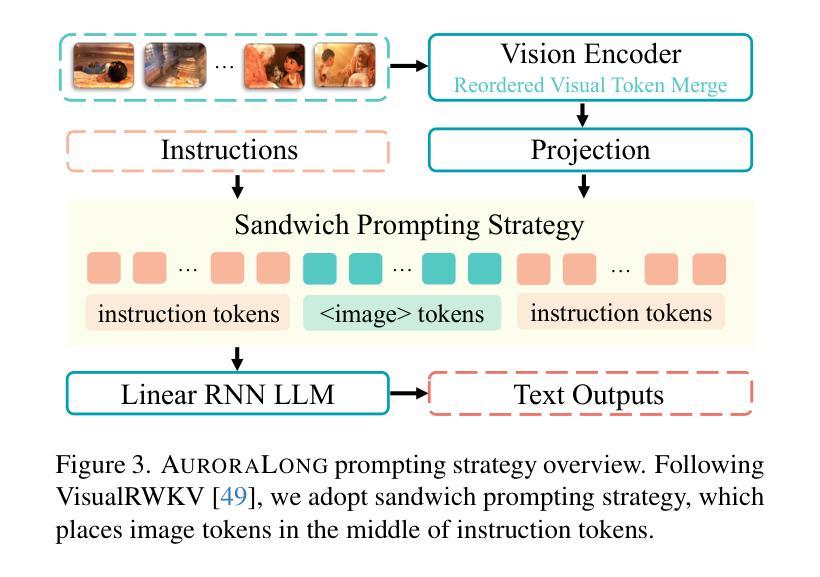
The challenge of long video understanding lies in its high computational complexity and prohibitive memory cost, since the memory and computation required by transformer-based LLMs scale quadratically with input sequence length. We propose AuroraLong to address this challenge by replacing the LLM component in MLLMs with a linear RNN language model that handles input sequence of arbitrary length with constant-size hidden states. To further increase throughput and efficiency, we combine visual token merge with linear RNN models by reordering the visual tokens by their sizes in ascending order. Despite having only 2B parameters and being trained exclusively on public data, AuroraLong achieves performance comparable to Transformer-based models of similar size trained on private datasets across multiple video benchmarks. This demonstrates the potential of efficient, linear RNNs to democratize long video understanding by lowering its computational entry barrier. To our best knowledge, we are the first to use a linear RNN based LLM backbone in a LLaVA-like model for open-ended video understanding.
长视频理解的挑战在于其较高的计算复杂度和巨大的内存成本,因为基于变压器的LLM所需的内存和计算量随输入序列长度呈二次方增长。为了解决这一挑战,我们提出了AuroraLong方案,通过用线性RNN语言模型替换MLLM中的LLM组件来应对任意长度的输入序列和恒定大小的隐藏状态。为了进一步提高吞吐量和效率,我们通过按视觉令牌的大小进行升序排序,将视觉令牌合并与线性RNN模型相结合。尽管AuroraLong仅有2B个参数,且仅在公共数据上进行训练,但在多个视频基准测试中,其性能与在私有数据集上训练的类似规模的基于变压器的模型相当。这证明了高效的线性RNN降低长视频理解的计算入门门槛,从而实现民主化的潜力。据我们所知,我们是第一个在LLaVA类模型中采用基于线性RNN的LLM主干进行开放式视频理解的尝试。
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary
针对长视频理解面临的挑战,如高计算复杂度和高昂的内存成本,我们提出了AuroraLong方案。它通过采用线性循环神经网络语言模型替换MLLM中的LLM组件,以处理任意长度的输入序列并维持恒定大小的隐藏状态,从而解决这一问题。为进一步增加吞吐量和效率,我们通过按视觉令牌大小升序排列来组合视觉令牌合并和线性RNN模型。尽管AuroraLong仅拥有2B参数,且仅在公共数据上进行训练,但在多个视频基准测试中,其性能与类似大小的基于Transformer的模型相当,这些模型是在私有数据集上训练的。这证明了高效线性RNN的潜力,有望降低长视频理解的计算门槛。我们据所知是首次在LLaVA类模型中采用基于线性RNN的LLM主干进行开放式视频理解。
Key Takeaways
- 长视频理解面临高计算复杂度和内存成本挑战。
- AuroraLong通过采用线性RNN语言模型解决这一问题,能处理任意长度输入序列并保持恒定隐藏状态大小。
- 结合视觉令牌合并和线性RNN模型提升吞吐量和效率。
- AuroraLong在公共数据训练下,性能与私有数据集上的Transformer模型相当。
- 高效线性RNN有潜力推动长视频理解的普及,降低计算门槛。
- AuroraLong是首个在LLaVA类模型中采用基于线性RNN的LLM主干进行开放式视频理解。
点此查看论文截图

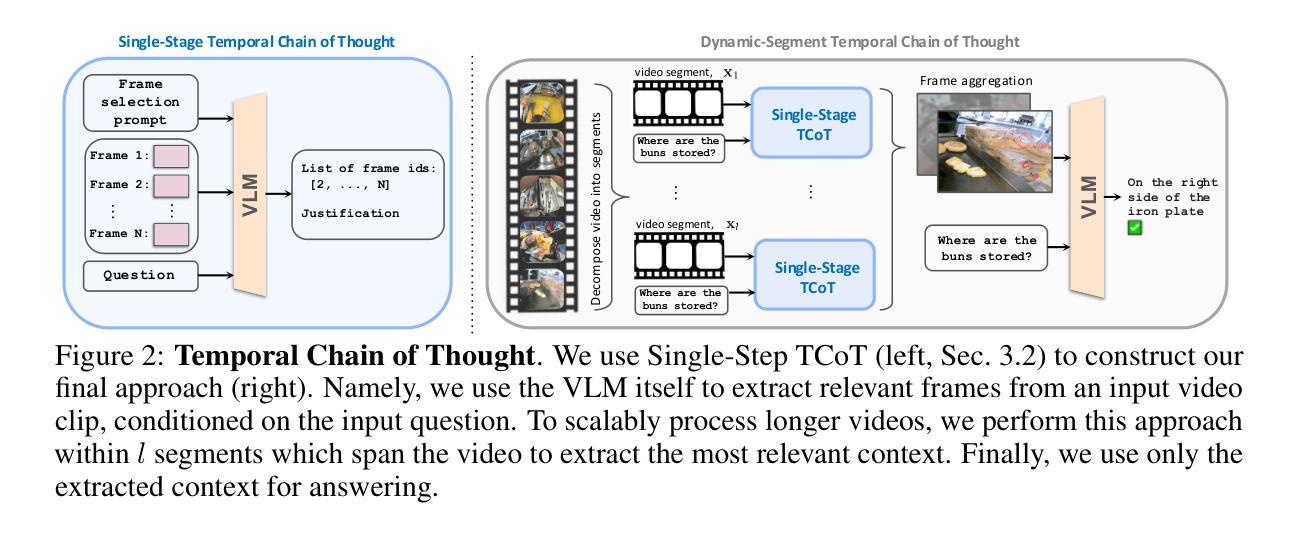
Temporal Chain of Thought: Long-Video Understanding by Thinking in Frames
Authors:Anurag Arnab, Ahmet Iscen, Mathilde Caron, Alireza Fathi, Cordelia Schmid
Despite recent advances in Vision-Language Models (VLMs), long-video understanding remains a challenging problem. Although state-of-the-art long-context VLMs can process around 1000 input frames, they still struggle to effectively leverage this sequence length, and succumb to irrelevant distractors within the context window. We present Temporal Chain of Thought, an inference strategy for video question-answering that curates the model’s input context. We use the VLM itself to iteratively identify and extract the most relevant frames from the video, which are then used for answering. We demonstrate how leveraging more computation at inference-time to select the most relevant context leads to improvements in accuracy, in agreement with recent work on inference-time scaling of LLMs. Moreover, we achieve state-of-the-art results on 4 diverse video question-answering datasets, showing consistent improvements with 3 different VLMs. In particular, our method shines on longer videos which would not otherwise fit within the model’s context window: On longer videos of more than 1 hour on LVBench, our approach using a context window of 32K outperforms the same VLM using standard inference with a 700K context window by 2.8 points.
尽管视觉语言模型(VLMs)最近有所进展,但对长视频的理解仍然是一个具有挑战性的问题。尽管最先进的长期上下文VLMs可以处理大约1000个输入帧,但它们仍然难以有效利用这个序列长度,并且在上下文窗口中受到无关干扰因素的影响。我们提出了“思维时间链”策略,这是一种视频问答的推理策略,可以筛选模型的输入上下文。我们使用VLM本身来迭代地识别和提取视频中最相关的帧,然后用这些帧来回答问题。我们证明了如何利用推理时间进行更多的计算来选择最相关的上下文,从而提高准确性,这与最近关于大型语言模型推理时间缩放的研究结果相吻合。此外,我们在四个不同的视频问答数据集上取得了最新结果,展示了与三种不同的VLMs一致的性能改进。尤其值得一提的是,我们的方法在长视频上表现出色,这些视频通常无法适应模型的上下文窗口:在LVBench上一个多小时的长视频上,使用32K上下文窗口的方法优于同一VLM使用标准推理的700K上下文窗口,提高了2.8个百分点。
论文及项目相关链接
Summary
本文提出一种针对视频问答的推理策略——Temporal Chain of Thought,该策略能够筛选模型输入的视频上下文内容。通过使用VLM自身迭代识别并提取最相关的视频帧进行回答,提高了视频理解的准确性。在多个视频问答数据集上取得了业界领先的结果,特别是在处理较长视频时表现尤为出色。
Key Takeaways
- Temporal Chain of Thought策略能有效提高视频问答的准确性。
- 该策略通过迭代识别并提取视频中最相关的帧,以优化模型输入上下文。
- 使用VLM自身来进行这一过程,增加了方法的可行性和实用性。
- 此方法在多种视频问答数据集上实现业界领先的结果。
- 在处理较长视频时,该策略的优势更为明显,能够超越使用标准推理的VLM的表现。
- 通过利用更多的计算资源进行推理时间的选择,可以提高模型的性能。
点此查看论文截图