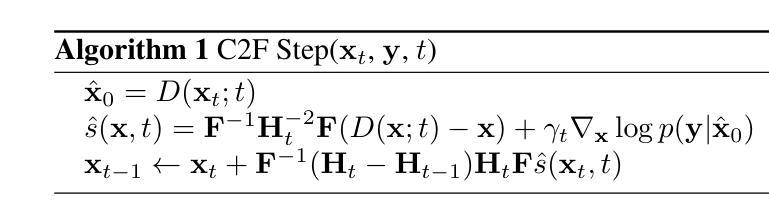⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-05 更新
AnyI2V: Animating Any Conditional Image with Motion Control
Authors:Ziye Li, Hao Luo, Xincheng Shuai, Henghui Ding
Recent advancements in video generation, particularly in diffusion models, have driven notable progress in text-to-video (T2V) and image-to-video (I2V) synthesis. However, challenges remain in effectively integrating dynamic motion signals and flexible spatial constraints. Existing T2V methods typically rely on text prompts, which inherently lack precise control over the spatial layout of generated content. In contrast, I2V methods are limited by their dependence on real images, which restricts the editability of the synthesized content. Although some methods incorporate ControlNet to introduce image-based conditioning, they often lack explicit motion control and require computationally expensive training. To address these limitations, we propose AnyI2V, a training-free framework that animates any conditional images with user-defined motion trajectories. AnyI2V supports a broader range of modalities as the conditional image, including data types such as meshes and point clouds that are not supported by ControlNet, enabling more flexible and versatile video generation. Additionally, it supports mixed conditional inputs and enables style transfer and editing via LoRA and text prompts. Extensive experiments demonstrate that the proposed AnyI2V achieves superior performance and provides a new perspective in spatial- and motion-controlled video generation. Code is available at https://henghuiding.com/AnyI2V/.
视频生成领域的最新进展,尤其是扩散模型的应用,推动了文本到视频(T2V)和图像到视频(I2V)合成的显著进步。然而,在有效集成动态运动信号和灵活空间约束方面仍存在挑战。现有的T2V方法通常依赖于文本提示,这固有地缺乏对生成内容空间布局的精确控制。相比之下,I2V方法受限于对真实图像的依赖,这限制了合成内容的可编辑性。虽然一些方法结合了ControlNet进行基于图像的调节,但它们通常缺乏明确的运动控制,并且需要计算昂贵的训练。为了解决这些局限性,我们提出了AnyI2V,这是一个无需训练的框架,可以根据用户定义的运动轨迹对任何条件图像进行动画处理。AnyI2V支持更广泛的模态作为条件图像,包括ControlNet不支持的网格和点云等数据类型,从而实现更灵活和多功能化的视频生成。此外,它支持混合条件输入,并通过LoRA和文本提示实现风格转换和编辑。大量实验表明,所提出的AnyI2V达到了卓越的性能,为空间和运动控制视频生成提供了新的视角。代码可在[https://henghuiding.com/AnyI2V/]获得。
论文及项目相关链接
PDF ICCV 2025, Project Page: https://henghuiding.com/AnyI2V/
Summary
针对文本到视频(T2V)和图像到视频(I2V)的合成,最新进展在扩散模型上取得了显著成效,但仍存在动态运动信号和灵活空间约束的整合问题。现有方法缺乏精确的空间布局控制或编辑性。为此,提出AnyI2V,一个无需训练即可根据用户定义的运动轨迹对条件图像进行动画化的框架。AnyI2V支持更广泛的模态作为条件图像,并实现混合条件输入,通过LoRA和文本提示进行风格转换和编辑。实验证明,AnyI2V实现卓越性能,为空间和运动控制的视频生成提供了新的视角。
Key Takeaways
- 扩散模型在视频生成领域取得最新进展,推动了文本到视频(T2V)和图像到视频(I2V)合成的显著发展。
- 现有方法存在空间布局控制和编辑性的限制。
- AnyI2V框架解决了这些问题,无需训练即可根据用户定义的运动轨迹对条件图像进行动画化。
- AnyI2V支持多种模态作为条件图像,包括网格和点云等数据类型。
- AnyI2V支持混合条件输入,并能够通过LoRA和文本提示进行风格转换和编辑。
- AnyI2V实现卓越性能,为视频生成提供了新的视角。
点此查看论文截图



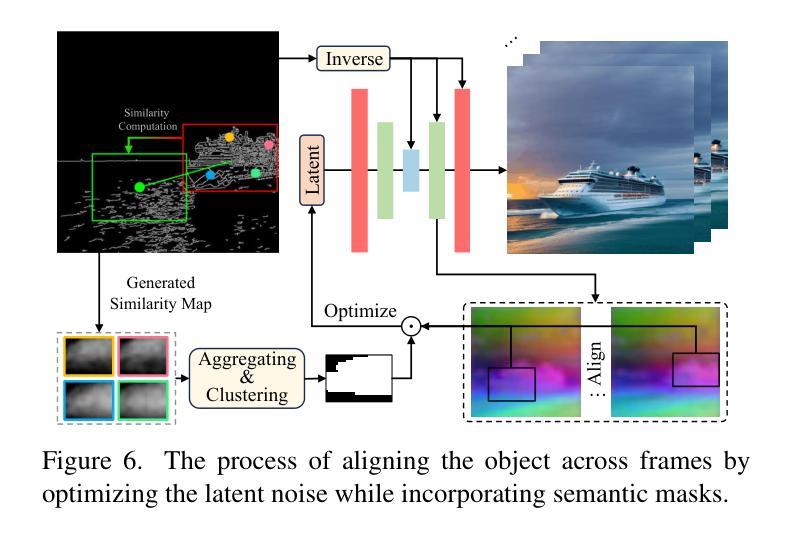
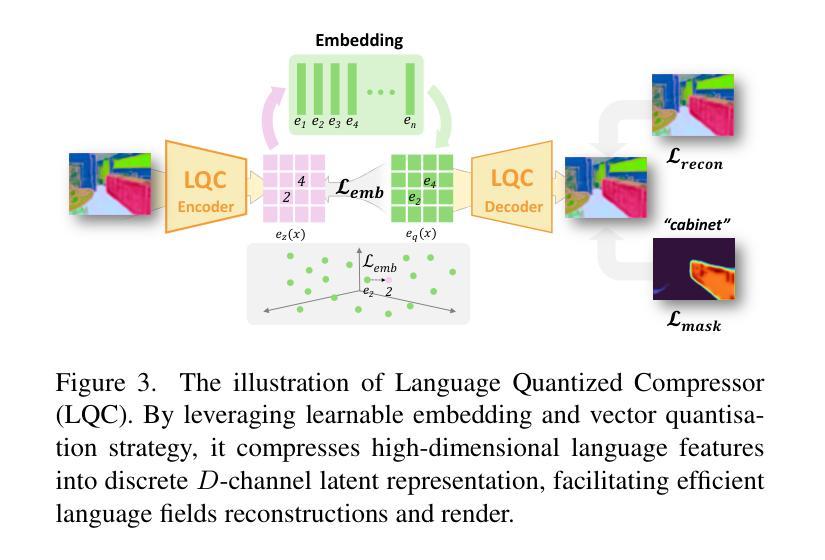
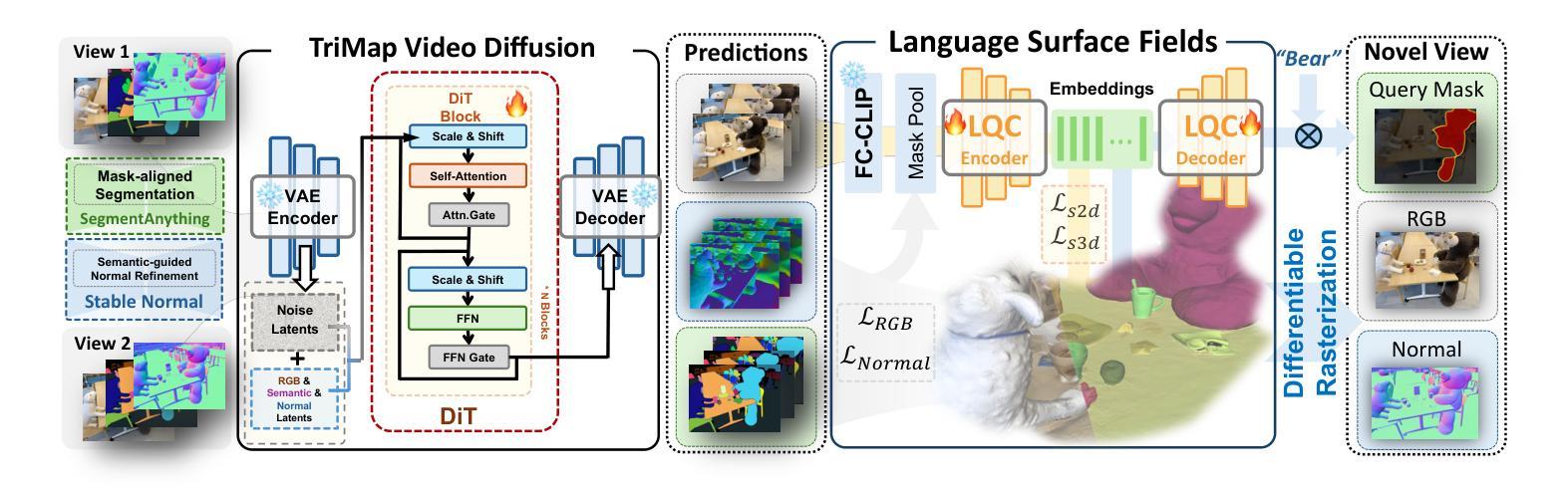
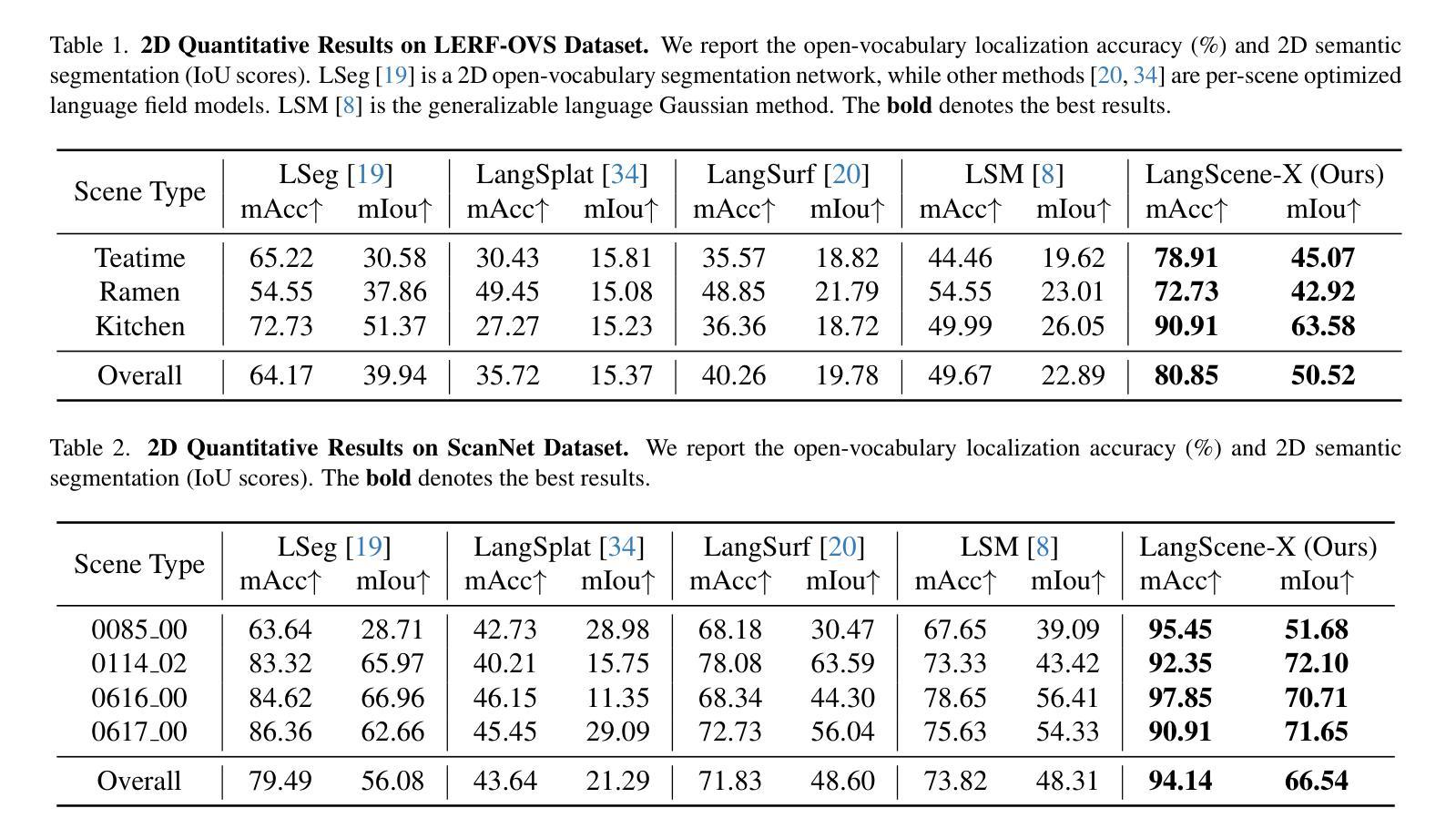
LangScene-X: Reconstruct Generalizable 3D Language-Embedded Scenes with TriMap Video Diffusion
Authors:Fangfu Liu, Hao Li, Jiawei Chi, Hanyang Wang, Minghui Yang, Fudong Wang, Yueqi Duan
Recovering 3D structures with open-vocabulary scene understanding from 2D images is a fundamental but daunting task. Recent developments have achieved this by performing per-scene optimization with embedded language information. However, they heavily rely on the calibrated dense-view reconstruction paradigm, thereby suffering from severe rendering artifacts and implausible semantic synthesis when limited views are available. In this paper, we introduce a novel generative framework, coined LangScene-X, to unify and generate 3D consistent multi-modality information for reconstruction and understanding. Powered by the generative capability of creating more consistent novel observations, we can build generalizable 3D language-embedded scenes from only sparse views. Specifically, we first train a TriMap video diffusion model that can generate appearance (RGBs), geometry (normals), and semantics (segmentation maps) from sparse inputs through progressive knowledge integration. Furthermore, we propose a Language Quantized Compressor (LQC), trained on large-scale image datasets, to efficiently encode language embeddings, enabling cross-scene generalization without per-scene retraining. Finally, we reconstruct the language surface fields by aligning language information onto the surface of 3D scenes, enabling open-ended language queries. Extensive experiments on real-world data demonstrate the superiority of our LangScene-X over state-of-the-art methods in terms of quality and generalizability. Project Page: https://liuff19.github.io/LangScene-X.
从2D图像中恢复3D结构并实现开放词汇场景理解是一项基本但艰巨的任务。最近的发展通过执行场景优化并嵌入语言信息来实现这一目标。然而,它们严重依赖于校准的密集视图重建范式,因此在可用视图有限的情况下会出现严重的渲染伪影和不可信的语义合成。在本文中,我们引入了一种新型生成框架,称为LangScene-X,以统一并生成用于重建和理解的3D一致的多模态信息。凭借创造更一致的新观测的生成能力,我们仅从稀疏视图就可以构建可泛化的3D语言嵌入场景。具体来说,我们首先训练了一个TriMap视频扩散模型,该模型可以通过渐进的知识整合从稀疏输入生成外观(RGB)、几何(法线)和语义(分割图)。此外,我们提出了一个在大型图像数据集上训练的Language Quantized Compressor(LQC),以有效地编码语言嵌入,从而实现跨场景的泛化,无需对每一个场景进行再训练。最后,我们通过将语言信息对齐到3D场景的表面上,重建了语言表面场,从而实现了开放的语言查询。在真实世界数据上的广泛实验表明,我们的LangScene-X在质量和泛化能力方面优于最先进的方法。项目页面:https://liuff19.github.io/LangScene-X。
论文及项目相关链接
PDF Project page: https://liuff19.github.io/LangScene-X
Summary
本文提出了一种新型生成框架LangScene-X,用于统一和生成用于重建和理解的3D一致的多模态信息。该框架能够从稀疏视角构建可泛化的3D语言嵌入场景,通过TriMap视频扩散模型逐步集成知识生成外观、几何和语义信息。此外,还提出了Language Quantized Compressor(LQC)以高效编码语言嵌入,实现跨场景泛化而无需针对每个场景进行再训练。最后,通过对齐语言信息到3D场景表面,重建了语言表面场,支持开放式语言查询。实验证明,LangScene-X在质量和泛化性能上优于现有方法。
Key Takeaways
- LangScene-X是一个新型生成框架,能够统一生成3D一致的多模态信息,用于从2D图像理解场景并进行3D结构恢复。
- 该框架能够从稀疏视角构建3D语言嵌入场景,具有强大的生成能力,可以创建更一致的全新观察结果。
- TriMap视频扩散模型可以生成外观、几何和语义信息,通过逐步集成知识来实现重建。
- Language Quantized Compressor(LQC)能够高效编码语言嵌入,使模型能够在不同场景间泛化,而无需针对每个场景进行再训练。
- 通过将语言信息对齐到3D场景表面,LangScene-X实现了语言表面场的重建,支持开放式语言查询。
- 实验证明,LangScene-X在质量和泛化性能上优于现有方法,特别是在有限视角下的渲染和语义合成方面。
点此查看论文截图

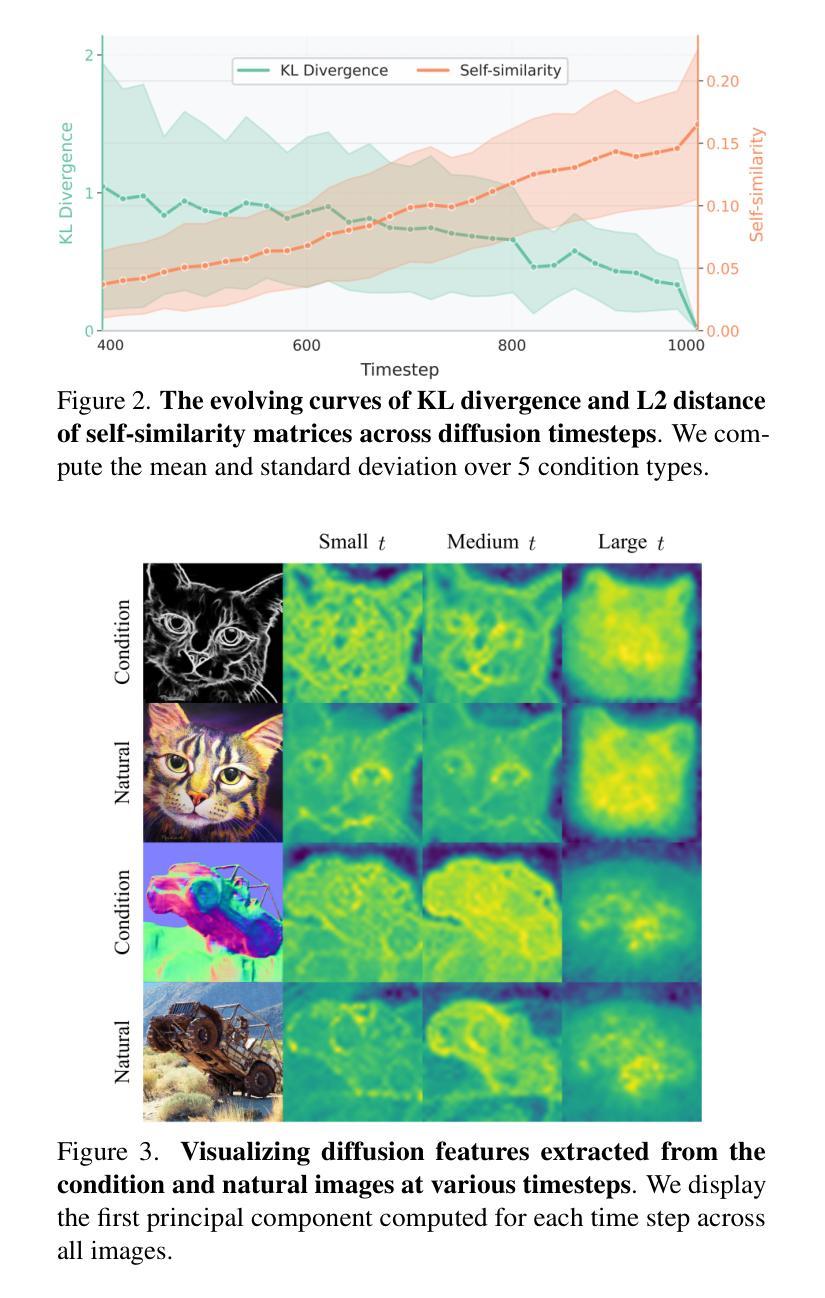
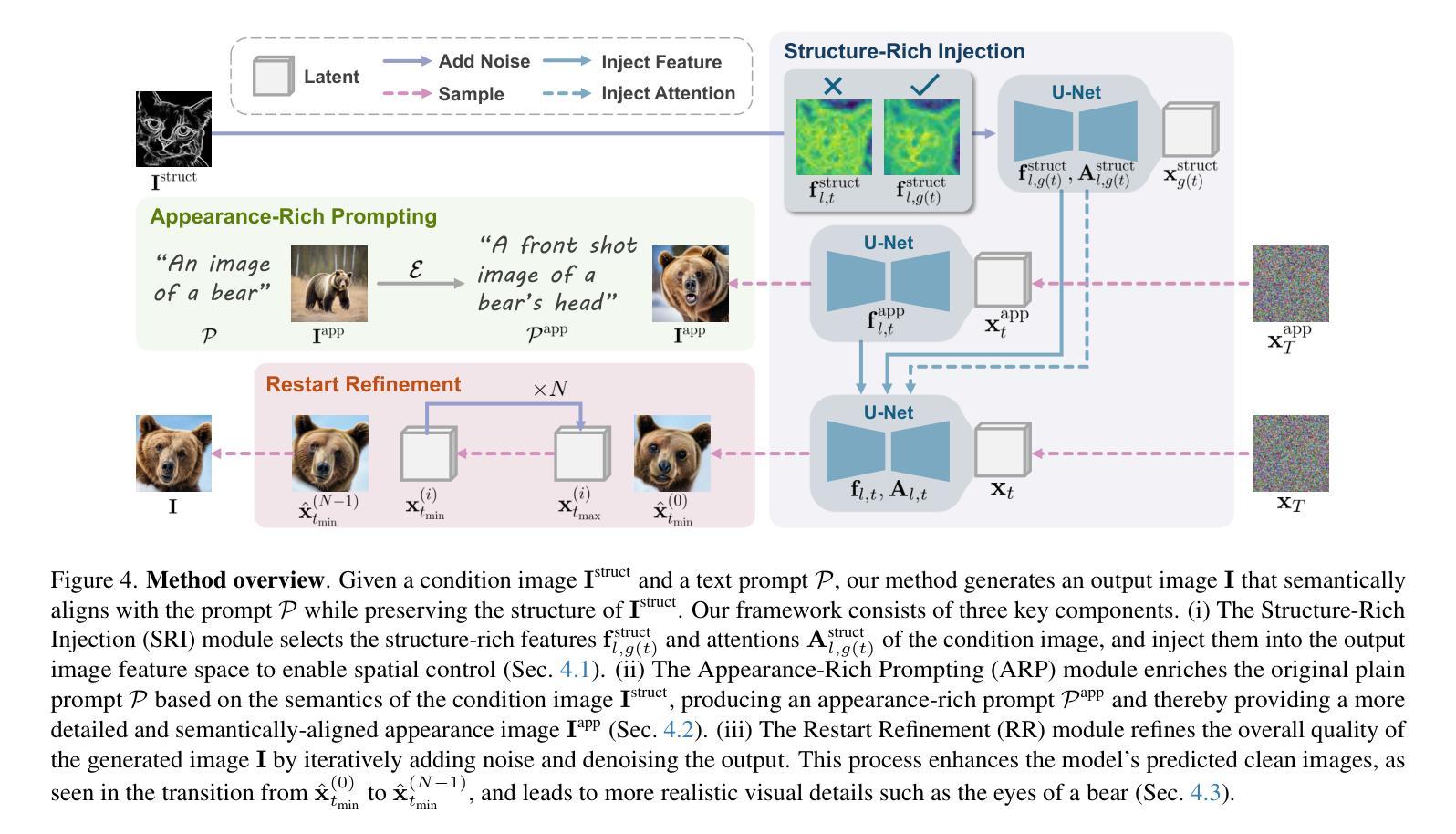
RichControl: Structure- and Appearance-Rich Training-Free Spatial Control for Text-to-Image Generation
Authors:Liheng Zhang, Lexi Pang, Hang Ye, Xiaoxuan Ma, Yizhou Wang
Text-to-image (T2I) diffusion models have shown remarkable success in generating high-quality images from text prompts. Recent efforts extend these models to incorporate conditional images (e.g., depth or pose maps) for fine-grained spatial control. Among them, feature injection methods have emerged as a training-free alternative to traditional fine-tuning approaches. However, they often suffer from structural misalignment, condition leakage, and visual artifacts, especially when the condition image diverges significantly from natural RGB distributions. By revisiting existing methods, we identify a core limitation: the synchronous injection of condition features fails to account for the trade-off between domain alignment and structural preservation during denoising. Inspired by this observation, we propose a flexible feature injection framework that decouples the injection timestep from the denoising process. At its core is a structure-rich injection module, which enables the model to better adapt to the evolving interplay between alignment and structure preservation throughout the diffusion steps, resulting in more faithful structural generation. In addition, we introduce appearance-rich prompting and a restart refinement strategy to further enhance appearance control and visual quality. Together, these designs enable training-free generation that is both structure-rich and appearance-rich. Extensive experiments show that our approach achieves state-of-the-art performance across diverse zero-shot conditioning scenarios.
文本到图像(T2I)扩散模型在根据文本提示生成高质量图像方面取得了显著的成功。最近的研究努力将这些模型扩展到结合条件图像(例如深度或姿态图)以实现精细的空间控制。其中,特征注入方法作为传统微调方法的无训练替代方法应运而生。然而,它们经常遭受结构错位、条件泄漏和视觉伪影等问题,尤其是当条件图像与自然的RGB分布相差较大时。通过对现有方法进行重新审视,我们发现了一个核心局限:条件特征的同步注入未能考虑到去噪过程中的域对齐与结构保持之间的权衡。受此观察启发,我们提出了一种灵活的特征注入框架,该框架将注入时间与去噪过程解耦。其核心是一个结构丰富的注入模块,使模型能够更好地适应扩散步骤中对齐与结构保持之间的不断演变,从而生成更真实精细的结构。此外,我们引入了外观丰富的提示和重启优化策略,以进一步增强外观控制和视觉质量。这些设计的结合实现了无训练生成,既丰富结构又丰富外观。大量实验表明,我们的方法在多种零样本条件场景下达到了最先进的性能。
论文及项目相关链接
Summary
文本到图像(T2I)扩散模型已成功实现根据文本提示生成高质量图像。近期的研究尝试将这种模型扩展到结合条件图像(例如深度或姿态图)以实现精细的空间控制。然而,现有的特征注入方法往往面临结构不对准、条件泄漏和视觉伪影等问题,尤其在条件图像与自然RGB分布相差较大时。本研究识别了现有方法的核心局限:同步注入条件特征未能考虑域对齐与结构保留之间的权衡。为此,我们提出了一个灵活的特征注入框架,将注入时间与去噪过程分离。其核心是结构丰富的注入模块,使模型能更好地适应扩散步骤中对齐与结构保留之间的平衡,从而实现更真实的结构生成。此外,我们还引入了外观丰富的提示和重启细化策略,以进一步提高外观控制和视觉质量。总体而言,我们的方法实现了无需训练的结构丰富和外观丰富的生成,并在多种零样本条件场景下取得了最佳性能。
Key Takeaways
- 文本到图像(T2I)扩散模型能够基于文本提示生成高质量图像。
- 现有特征注入方法存在结构不对准、条件泄漏和视觉伪影等问题。
- 同步注入条件特征的方法未充分考虑域对齐与结构保留之间的权衡。
- 灵活的特征注入框架通过解耦注入时间与去噪过程来解决上述问题。
- 结构丰富的注入模块能平衡对齐与结构保留,实现更真实的结构生成。
- 引入外观丰富的提示和重启细化策略,提高外观控制和视觉质量。
点此查看论文截图


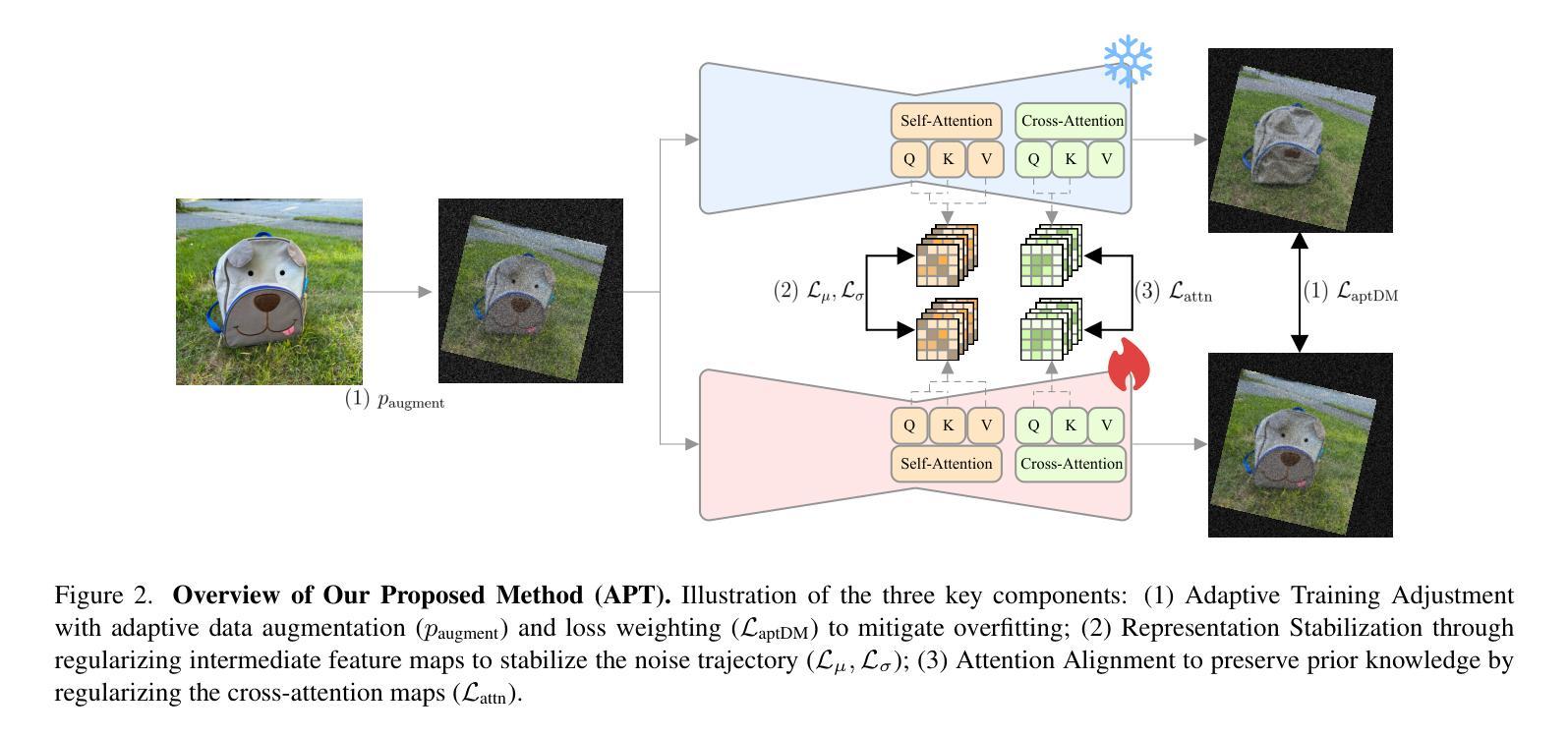
APT: Adaptive Personalized Training for Diffusion Models with Limited Data
Authors:JungWoo Chae, Jiyoon Kim, JaeWoong Choi, Kyungyul Kim, Sangheum Hwang
Personalizing diffusion models using limited data presents significant challenges, including overfitting, loss of prior knowledge, and degradation of text alignment. Overfitting leads to shifts in the noise prediction distribution, disrupting the denoising trajectory and causing the model to lose semantic coherence. In this paper, we propose Adaptive Personalized Training (APT), a novel framework that mitigates overfitting by employing adaptive training strategies and regularizing the model’s internal representations during fine-tuning. APT consists of three key components: (1) Adaptive Training Adjustment, which introduces an overfitting indicator to detect the degree of overfitting at each time step bin and applies adaptive data augmentation and adaptive loss weighting based on this indicator; (2)Representation Stabilization, which regularizes the mean and variance of intermediate feature maps to prevent excessive shifts in noise prediction; and (3) Attention Alignment for Prior Knowledge Preservation, which aligns the cross-attention maps of the fine-tuned model with those of the pretrained model to maintain prior knowledge and semantic coherence. Through extensive experiments, we demonstrate that APT effectively mitigates overfitting, preserves prior knowledge, and outperforms existing methods in generating high-quality, diverse images with limited reference data.
使用有限数据个性化扩散模型面临着重大挑战,包括过拟合、丢失先验知识和文本对齐的退化。过拟合会导致噪声预测分布发生偏移,破坏去噪轨迹,导致模型失去语义连贯性。在本文中,我们提出了自适应个性化训练(APT)这一新型框架,它通过采用自适应训练策略和正则化模型在微调期间的内部表征来缓解过拟合问题。APT包括三个关键组件:(1)自适应训练调整,它引入过拟合指标来检测每个时间步长的过拟合程度,并基于此指标应用自适应数据增强和自适应损失加权;(2)表征稳定,它正则化中间特征图的均值和方差,以防止噪声预测过度偏移;(3)保留先验知识的注意力对齐,它将微调模型的交叉注意力图与预训练模型的交叉注意力图对齐,以维持先验知识和语义连贯性。通过大量实验,我们证明APT能够有效地缓解过拟合,保留先验知识,并在使用有限参考数据时生成高质量、多样化的图像方面优于现有方法。
论文及项目相关链接
PDF CVPR 2025 camera ready. Project page: https://lgcnsai.github.io/apt
Summary:
个性化扩散模型在使用有限数据时面临过拟合、丢失先验知识和文本对齐退化等挑战。本文提出自适应个性化训练(APT)框架,通过自适应训练策略和微调时的模型内部表示正则化来缓解过拟合问题。APT包括三个关键组件:自适应训练调整、表示稳定化和注意力对齐以保留先验知识。实验表明,APT有效缓解过拟合,保留先验知识,并在有限参考数据下生成高质量、多样化的图像方面优于现有方法。
Key Takeaways:
- 扩散模型在有限数据的个性化应用面临挑战,包括过拟合、丢失先验知识和文本对齐问题。
- 过拟合会导致噪声预测分布偏移,破坏去噪轨迹并导致模型语义连贯性丧失。
- APT框架通过自适应训练策略和模型内部表示正则化来缓解过拟合问题。
- APT包括自适应训练调整、表示稳定和注意力对齐以保留先验知识的三个关键组件。
- 自适应训练调整通过引入过拟合指标来检测每个时间步长的过拟合程度,并基于此进行自适应数据增强和损失权重调整。
- 表示稳定化通过正则化中间特征图的均值和方差来防止噪声预测过度偏移。
点此查看论文截图



Learning few-step posterior samplers by unfolding and distillation of diffusion models
Authors:Charlesquin Kemajou Mbakam, Jonathan Spence, Marcelo Pereyra
Diffusion models (DMs) have emerged as powerful image priors in Bayesian computational imaging. Two primary strategies have been proposed for leveraging DMs in this context: Plug-and-Play methods, which are zero-shot and highly flexible but rely on approximations; and specialized conditional DMs, which achieve higher accuracy and faster inference for specific tasks through supervised training. In this work, we introduce a novel framework that integrates deep unfolding and model distillation to transform a DM image prior into a few-step conditional model for posterior sampling. A central innovation of our approach is the unfolding of a Markov chain Monte Carlo (MCMC) algorithm - specifically, the recently proposed LATINO Langevin sampler (Spagnoletti et al., 2025) - representing the first known instance of deep unfolding applied to a Monte Carlo sampling scheme. We demonstrate our proposed unfolded and distilled samplers through extensive experiments and comparisons with the state of the art, where they achieve excellent accuracy and computational efficiency, while retaining the flexibility to adapt to variations in the forward model at inference time.
扩散模型(DMs)作为贝叶斯计算成像中的强大图像先验已经崭露头角。针对此背景,提出了两种主要的利用扩散模型的方法:即插即用方法,它们是零样本且高度灵活但依赖于近似;以及专用条件扩散模型,通过监督训练针对特定任务实现更高的精度和更快的推理速度。在这项工作中,我们引入了一个新颖框架,该框架结合了深度展开和模型蒸馏技术,将扩散模型图像先验转化为用于后采样的一步条件模型。我们的方法的一个核心创新是展开马尔可夫链蒙特卡罗(MCMC)算法——具体来说,是最近提出的LATINO Langevin采样器(Spagnoletti等人,2025)——这代表了首次将深度展开应用于蒙特卡罗采样方案的实例。我们通过广泛的实验和与最新技术的比较来展示我们提出的展开和蒸馏采样器,它们在保持推理时前向模型变化适应性的同时,实现了出色的准确性和计算效率。
论文及项目相关链接
PDF 28 pages, 16 figures, 10 tables
Summary
扩散模型(DMs)在贝叶斯计算成像中作为图像先验展现出强大能力。本研究引入一个结合深度展开和模型蒸馏的新框架,将扩散模型图像先验转化为用于后验采样的多步条件模型。关键创新在于将马尔可夫链蒙特卡罗算法(MCMC)进行展开,尤其是Spagnoletti等人于近期提出的LATINO Langevin采样器。这是首次将深度展开应用于蒙特卡罗采样方案。实验证明,所提出的方法和蒸馏采样器在准确性和计算效率方面表现出色,同时保留了适应前向模型变化的灵活性。
Key Takeaways
- 扩散模型(DMs)在贝叶斯计算成像中作为强大的图像先验。
- 提出了结合深度展开和模型蒸馏的新框架,用于将扩散模型转化为条件模型进行后验采样。
- 创新性地展开马尔可夫链蒙特卡罗算法(MCMC),具体是Spagnoletti等人提出的LATINO Langevin采样器。
- 此为深度展开首次应用于蒙特卡罗采样方案。
- 通过广泛实验和与最新技术的比较,证明所提出的方法和蒸馏采样器具有高准确性和计算效率。
- 所提出方法能够适应不同的前向模型变化。
- 该研究为扩散模型在贝叶斯计算成像领域的应用提供了新的视角和工具。
点此查看论文截图


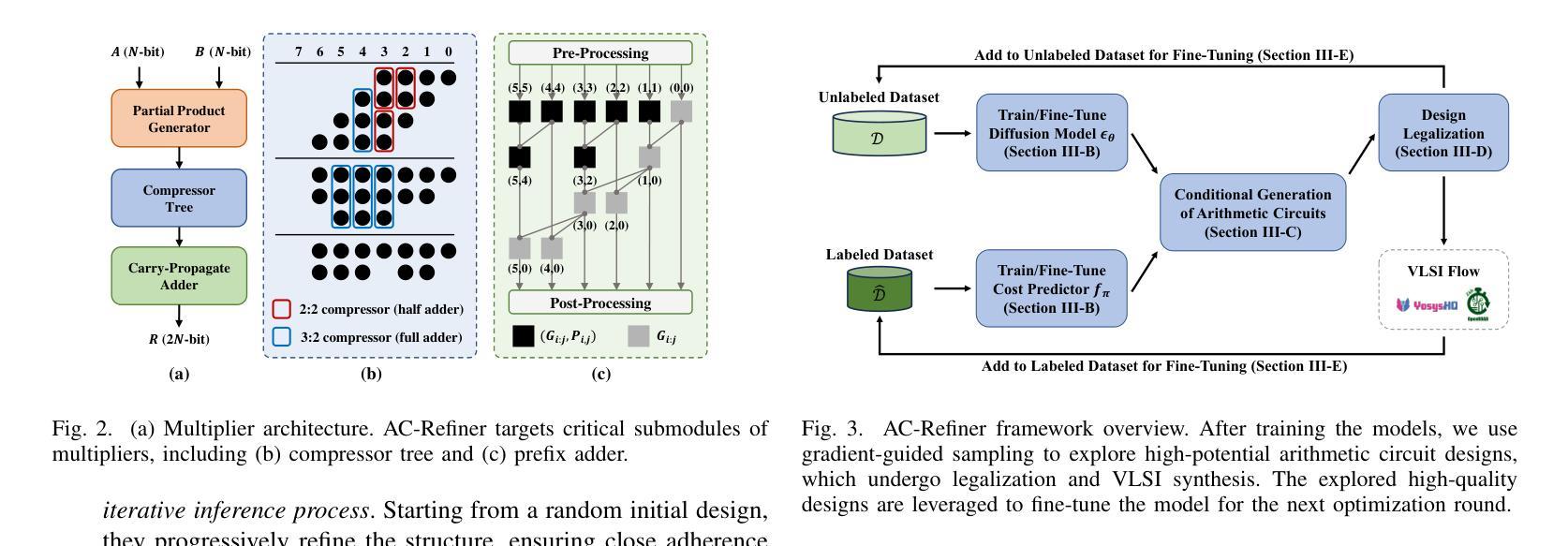
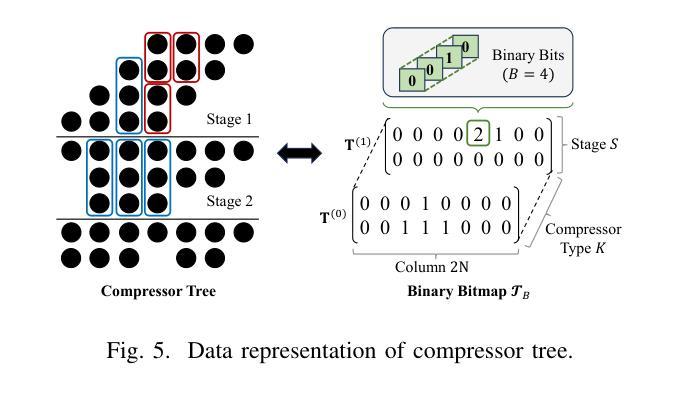
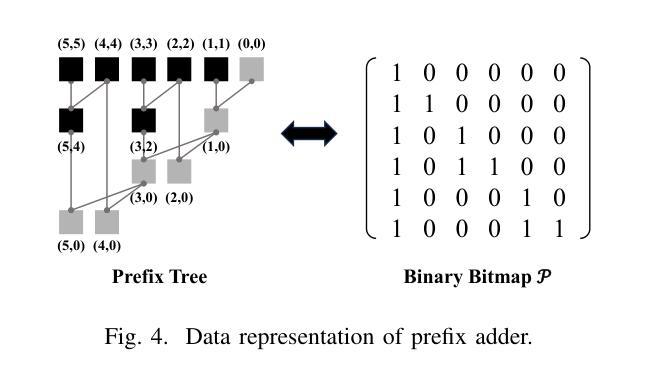
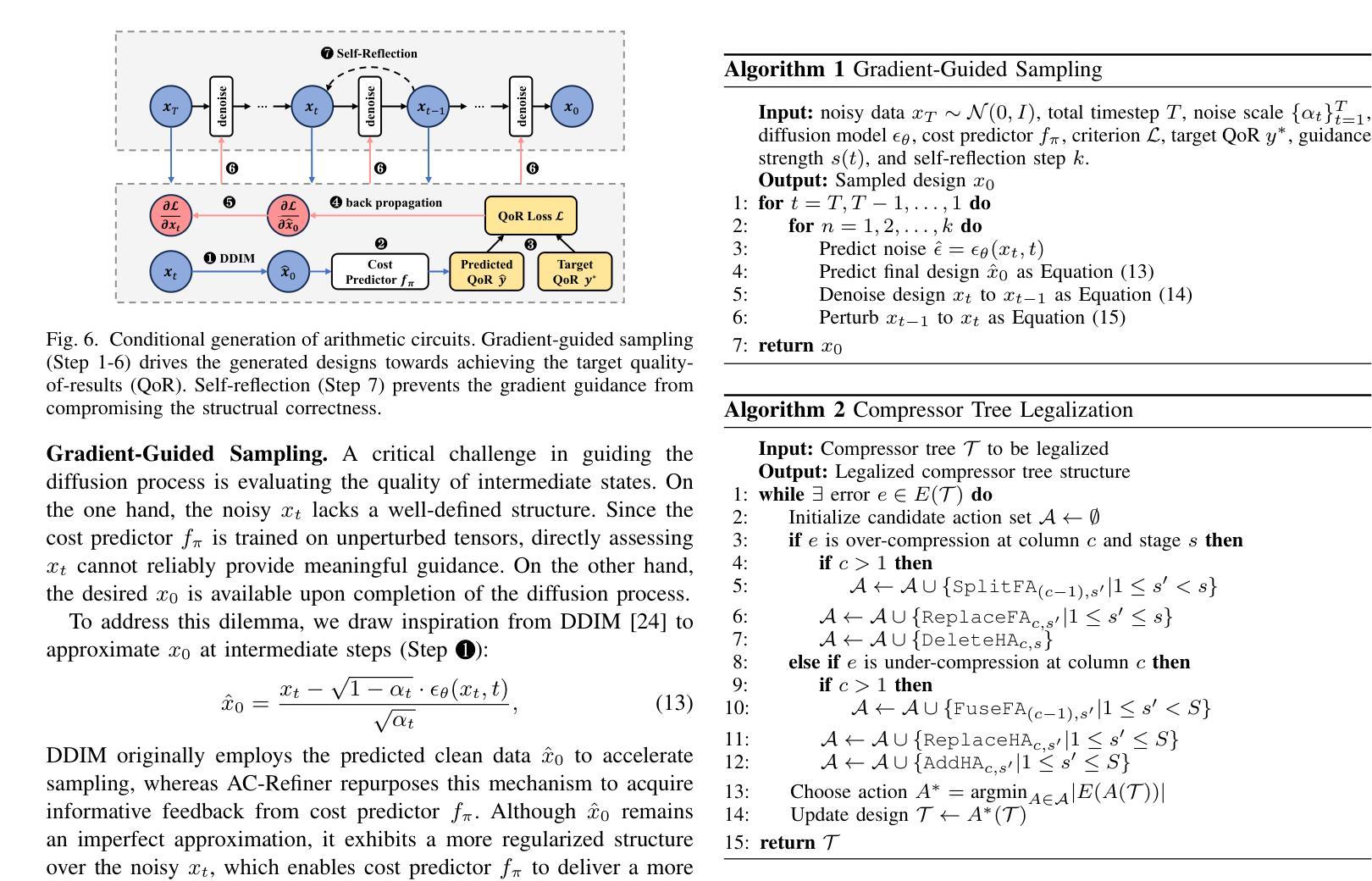
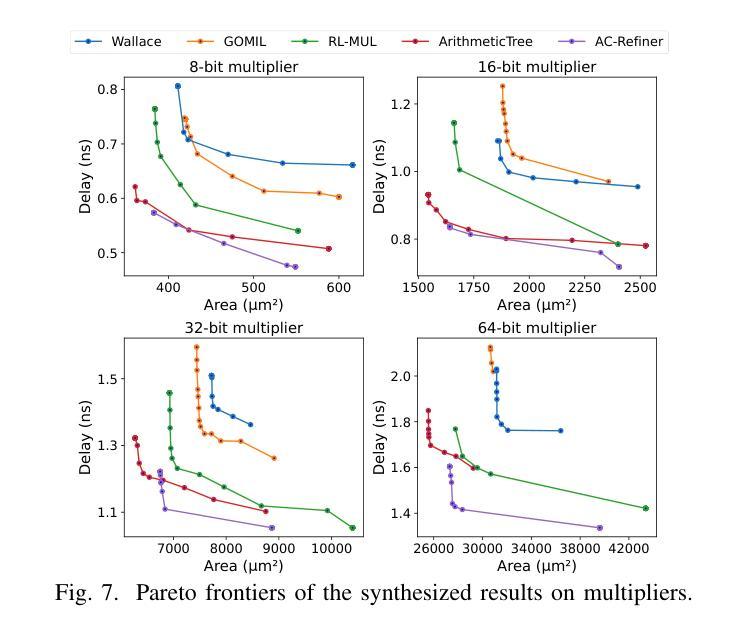
AC-Refiner: Efficient Arithmetic Circuit Optimization Using Conditional Diffusion Models
Authors:Chenhao Xue, Kezhi Li, Jiaxing Zhang, Yi Ren, Zhengyuan Shi, Chen Zhang, Yibo Lin, Lining Zhang, Qiang Xu, Guangyu Sun
Arithmetic circuits, such as adders and multipliers, are fundamental components of digital systems, directly impacting the performance, power efficiency, and area footprint. However, optimizing these circuits remains challenging due to the vast design space and complex physical constraints. While recent deep learning-based approaches have shown promise, they struggle to consistently explore high-potential design variants, limiting their optimization efficiency. To address this challenge, we propose AC-Refiner, a novel arithmetic circuit optimization framework leveraging conditional diffusion models. Our key insight is to reframe arithmetic circuit synthesis as a conditional image generation task. By carefully conditioning the denoising diffusion process on target quality-of-results (QoRs), AC-Refiner consistently produces high-quality circuit designs. Furthermore, the explored designs are used to fine-tune the diffusion model, which focuses the exploration near the Pareto frontier. Experimental results demonstrate that AC-Refiner generates designs with superior Pareto optimality, outperforming state-of-the-art baselines. The performance gain is further validated by integrating AC-Refiner into practical applications.
算术电路,如加法器和乘法器,是数字系统的基本组成部分,直接影响性能、功耗和面积占用。然而,由于巨大的设计空间和复杂的物理约束,优化这些电路仍然是一个挑战。虽然最近的基于深度学习的方法显示出了一定的潜力,但它们难以持续探索高潜力的设计变体,从而限制了优化效率。为了解决这一挑战,我们提出了AC-Refiner,这是一个利用条件扩散模型的新型算术电路优化框架。我们的关键见解是将算术电路合成重新构建为条件图像生成任务。通过仔细将去噪扩散过程调节在目标结果质量(QoR)上,AC-Refiner能够持续产生高质量的电路设计。此外,所探索的设计用于微调扩散模型,使探索集中在帕累托前沿附近。实验结果表明,AC-Refiner生成的设计具有优越的帕累托最优性,超过了最新的基线标准。通过将AC-Refiner集成到实际应用中,进一步验证了其性能提升。
论文及项目相关链接
PDF 8 pages, 12 figures
Summary
基于算术电路如加器和乘器在数字系统中的核心作用,其性能优化至关重要。然而,由于设计空间的庞大和物理约束的复杂性,优化面临挑战。近期深度学习方法虽展现出潜力,但在探索高效设计变体时存在局限。为此,我们提出利用条件扩散模型的算术电路优化框架AC-Refiner。通过把算术电路合成重新定位为条件图像生成任务,AC-Refiner能在目标结果质量指导下持续生成高质量电路设计。此外,所探索的设计用于微调扩散模型,使其聚焦于Pareto前沿的探索。实验证实AC-Refiner生成的电路设计具有更佳的Pareto最优性,超越了现有基线技术,并在实际应用中得到了性能提升验证。
Key Takeaways
- 算术电路是数字系统的核心组件,其性能优化至关重要。
- 现有深度学习方法在优化算术电路时存在局限性,难以持续探索高效设计变体。
- AC-Refiner框架利用条件扩散模型进行算术电路优化。
- AC-Refiner将算术电路合成重新定位为条件图像生成任务。
- AC-Refiner通过目标结果质量指导生成高质量的电路设计。
- 扩散模型可通过使用探索性设计进行微调,聚焦于Pareto前沿的探索。
点此查看论文截图

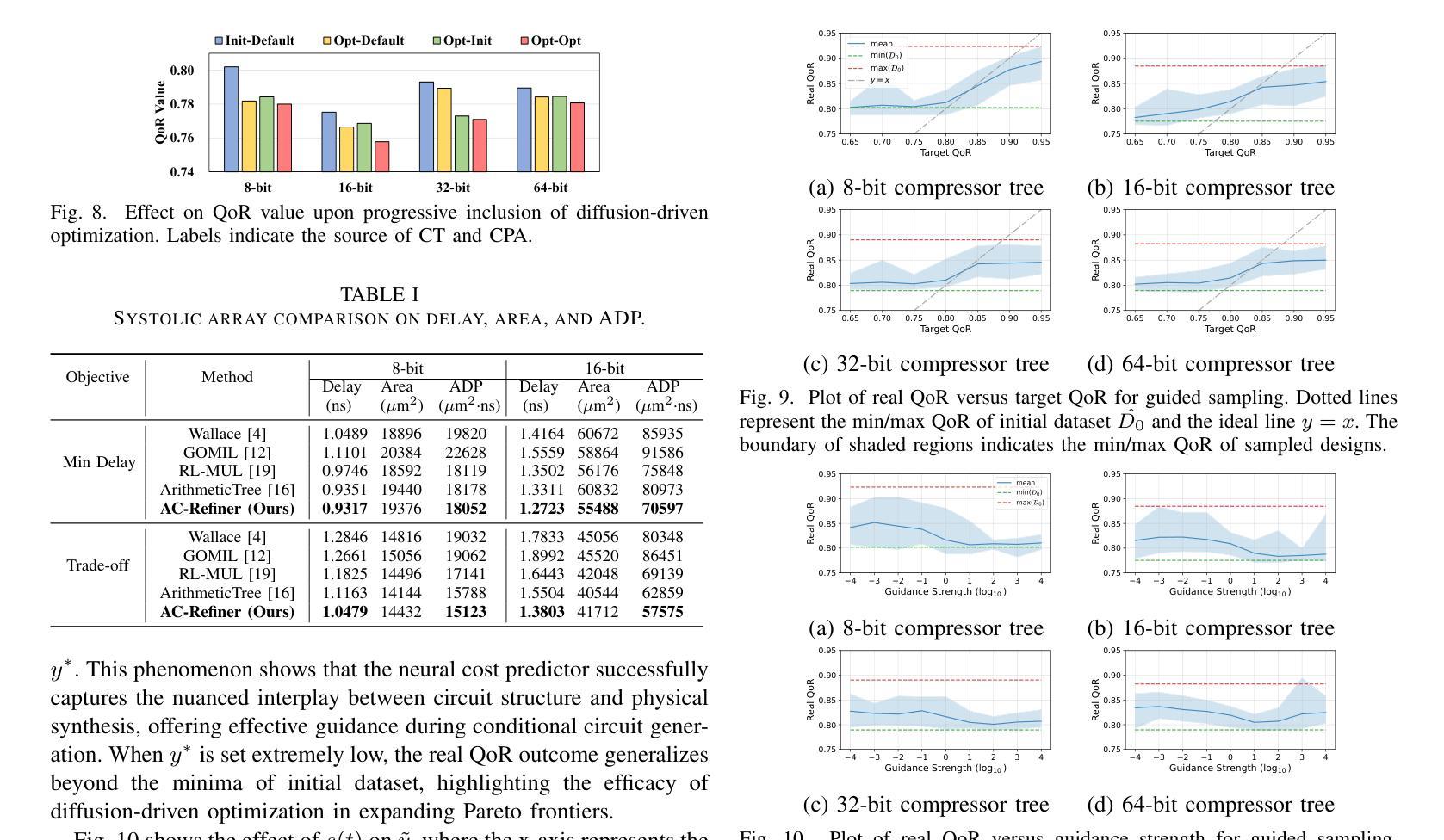
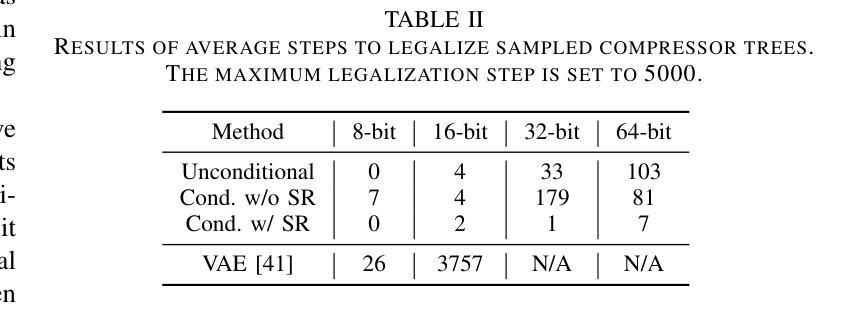
AvatarMakeup: Realistic Makeup Transfer for 3D Animatable Head Avatars
Authors:Yiming Zhong, Xiaolin Zhang, Ligang Liu, Yao Zhao, Yunchao Wei
Similar to facial beautification in real life, 3D virtual avatars require personalized customization to enhance their visual appeal, yet this area remains insufficiently explored. Although current 3D Gaussian editing methods can be adapted for facial makeup purposes, these methods fail to meet the fundamental requirements for achieving realistic makeup effects: 1) ensuring a consistent appearance during drivable expressions, 2) preserving the identity throughout the makeup process, and 3) enabling precise control over fine details. To address these, we propose a specialized 3D makeup method named AvatarMakeup, leveraging a pretrained diffusion model to transfer makeup patterns from a single reference photo of any individual. We adopt a coarse-to-fine idea to first maintain the consistent appearance and identity, and then to refine the details. In particular, the diffusion model is employed to generate makeup images as supervision. Due to the uncertainties in diffusion process, the generated images are inconsistent across different viewpoints and expressions. Therefore, we propose a Coherent Duplication method to coarsely apply makeup to the target while ensuring consistency across dynamic and multiview effects. Coherent Duplication optimizes a global UV map by recoding the averaged facial attributes among the generated makeup images. By querying the global UV map, it easily synthesizes coherent makeup guidance from arbitrary views and expressions to optimize the target avatar. Given the coarse makeup avatar, we further enhance the makeup by incorporating a Refinement Module into the diffusion model to achieve high makeup quality. Experiments demonstrate that AvatarMakeup achieves state-of-the-art makeup transfer quality and consistency throughout animation.
与现实生活中的面部美容类似,3D虚拟角色需要个性化定制以增强其视觉吸引力,但这个领域仍然没有得到足够的探索。虽然当前的3D高斯编辑方法可以适应面部化妆的目的,但这些方法无法满足实现真实化妆效果的基本需求:1)在可驱动的表情中保持外观的一致性,2)在化妆过程中保持身份特征,以及3)对细节进行精确控制。为了解决这些问题,我们提出了一种专门的3D化妆方法,名为AvatarMakeup,它利用预训练的扩散模型从任何个人的单张参考照片中转移化妆模式。我们采用由粗到细的理念,首先保持外观和身份的一致性,然后对细节进行完善。特别是,利用扩散模型生成化妆图像作为监督。由于扩散过程中的不确定性,生成的图像在不同的视角和表情上是不一致的。因此,我们提出了一种连贯复制方法,将化妆粗略地应用到目标上,同时确保动态和多视角效果的一致性。连贯复制通过重新编码生成化妆图像之间的平均面部属性来优化全局UV映射。通过查询全局UV映射,它很容易合成来自任意视角和表情的连贯化妆指导,以优化目标角色。给定粗略的化妆角色,我们进一步通过将细化模块融入扩散模型来提高化妆品质,从而实现高质量的化妆效果。实验表明,AvatarMakeup在动画中实现了最先进的化妆转移质量和一致性。
论文及项目相关链接
Summary
该研究提出了一种名为AvatarMakeup的3D虚拟角色化妆方法,利用预训练的扩散模型从单一参考照片转移妆容模式。该方法采用从粗到细的策略,先保持外观和身份的连续性,再细化细节。使用扩散模型生成妆容图像作为监督,并提出一种Coherent Duplication方法来确保动态和多视角下的妆容一致性。最后,通过引入细化模块来进一步提高妆容质量。
Key Takeaways
- 当前3D虚拟角色的化妆个性化定制需求尚未得到充分探索。
- 现有的3D高斯编辑方法在虚拟角色化妆方面存在缺陷,不能满足实现真实妆容效果的基本要求。
- AvatarMakeup方法利用预训练的扩散模型从单一参考照片转移妆容模式,弥补了现有方法的不足。
- 该方法采用从粗到细的策略,先保持外观和身份的连续性,再细化细节,确保妆容的真实性和精细度。
- 使用扩散模型生成妆容图像作为监督,并借助Coherent Duplication方法来确保动态和多视角下的妆容一致性。
- 针对生成的妆容图像在不同视角和表情下的不一致性,提出了优化全局UV地图的Coherent Duplication方法。
- 引入细化模块来进一步提高妆容质量,实现更自然、真实的虚拟角色化妆效果。
点此查看论文截图


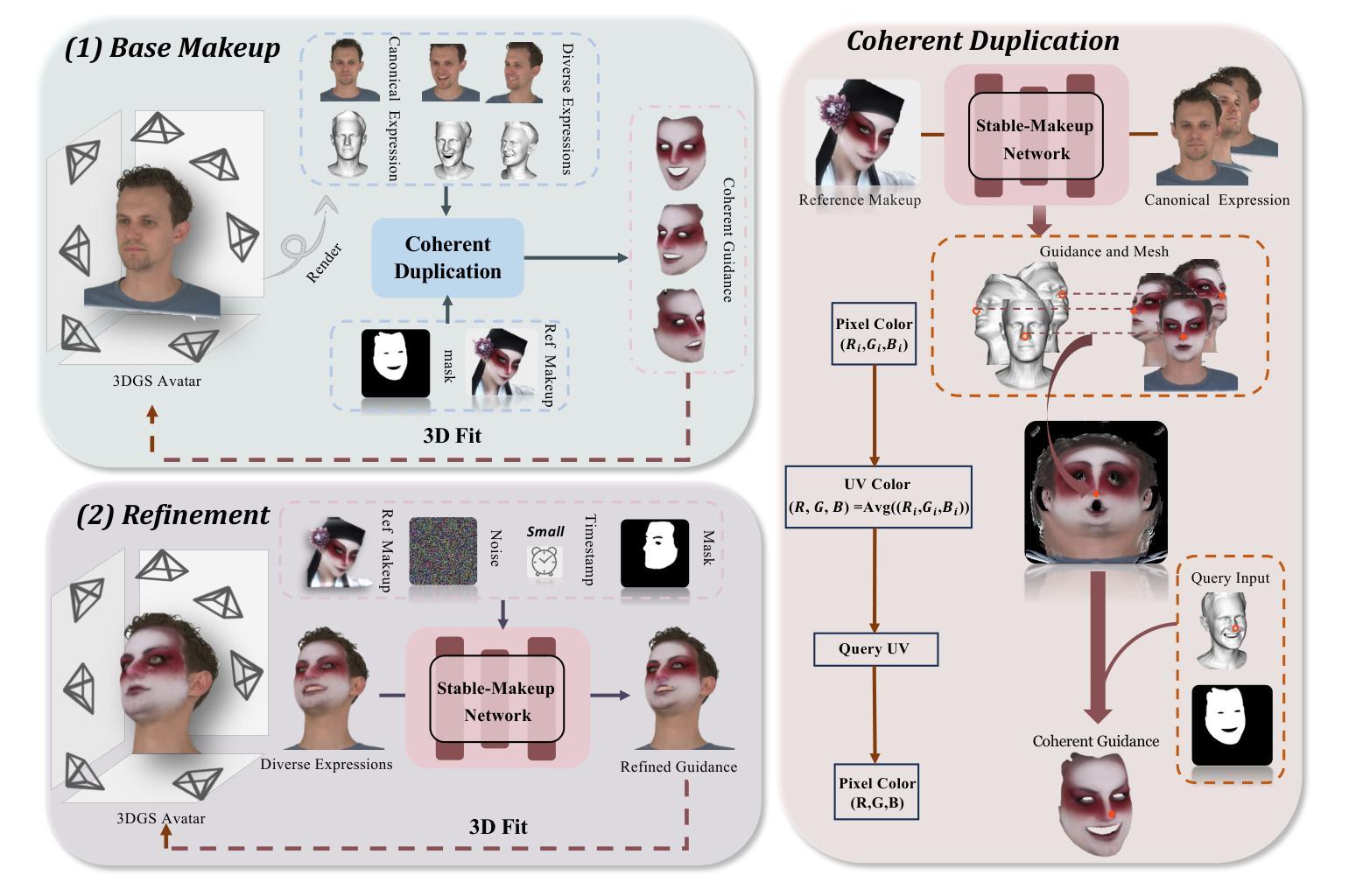

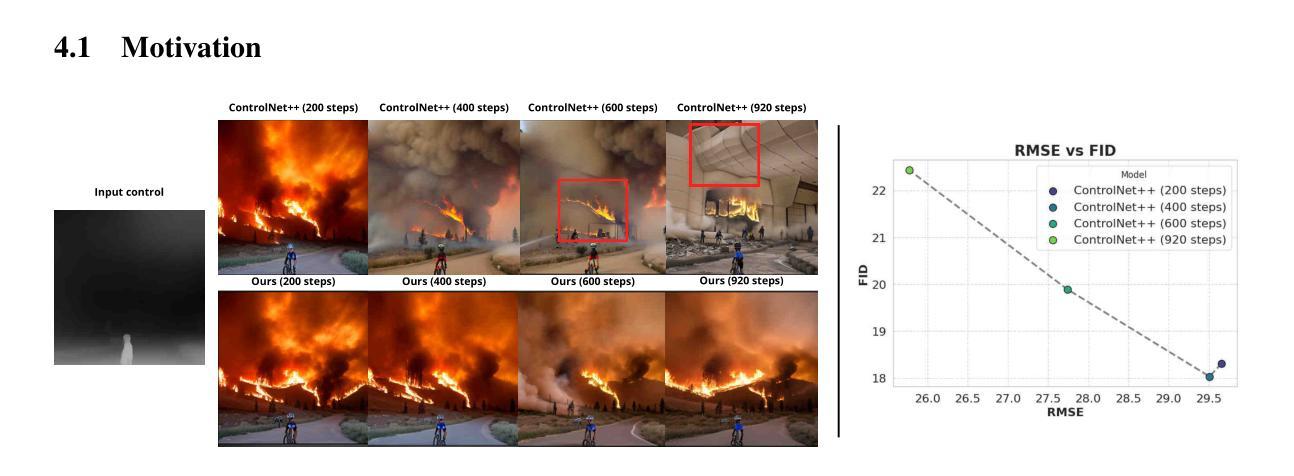
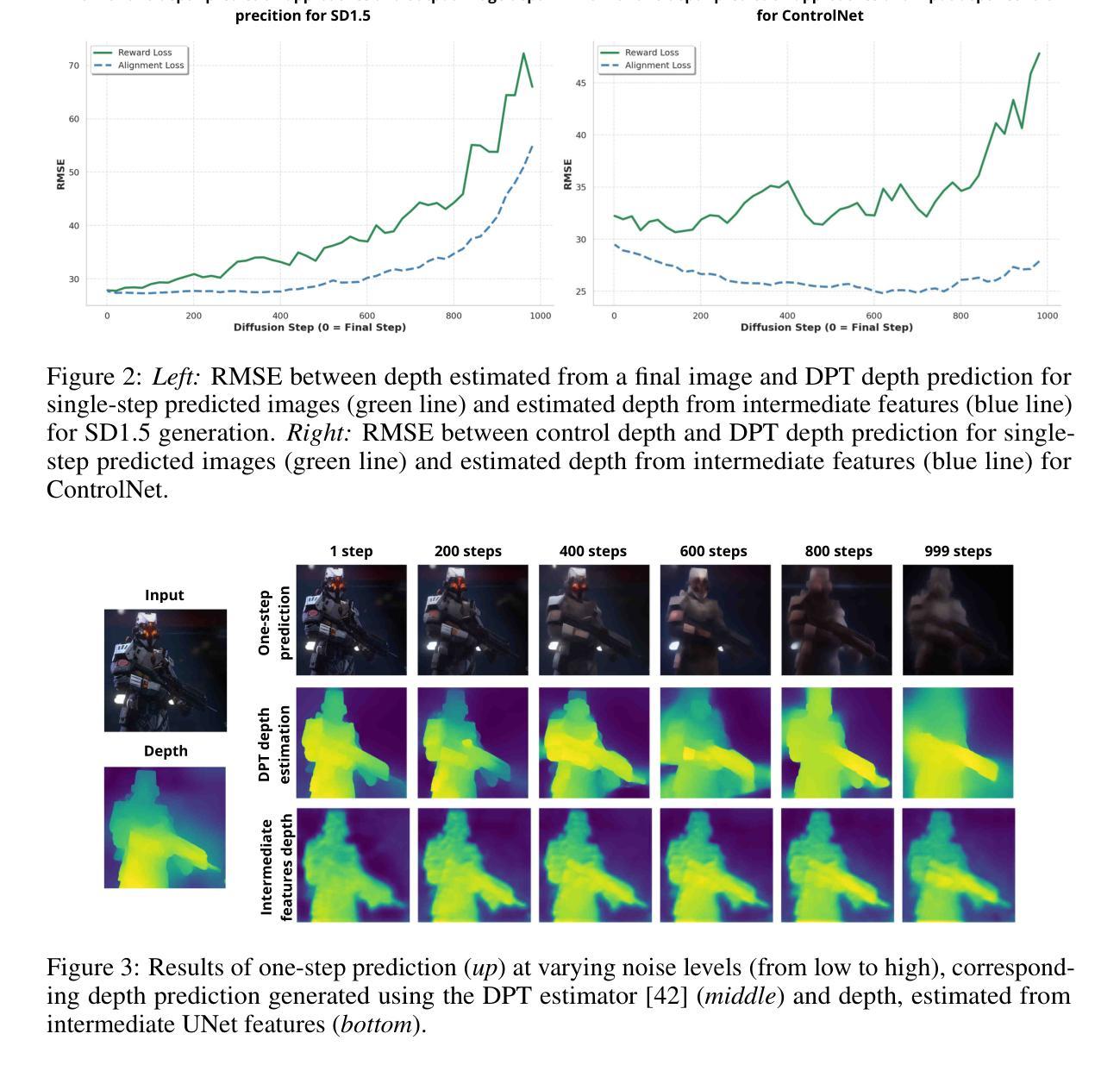
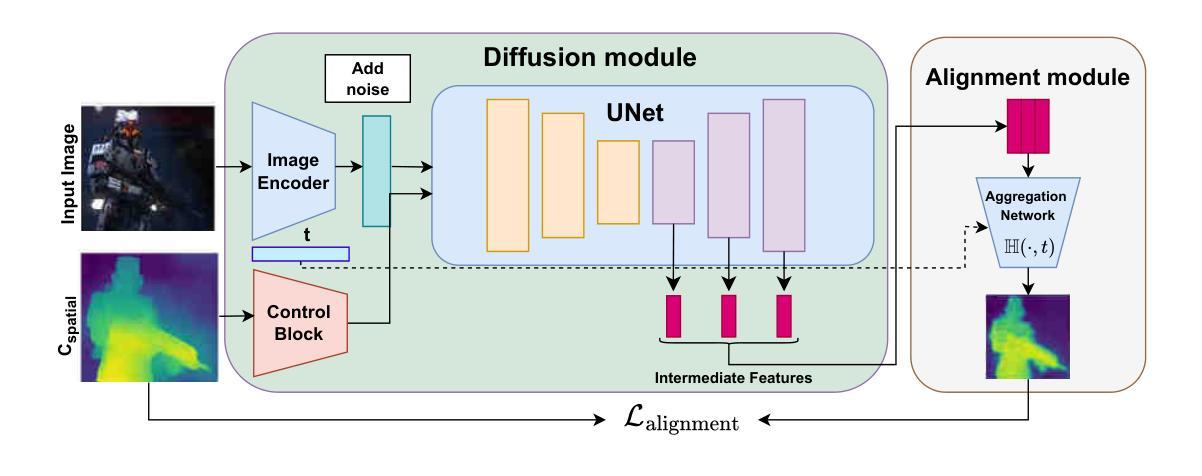
Heeding the Inner Voice: Aligning ControlNet Training via Intermediate Features Feedback
Authors:Nina Konovalova, Maxim Nikolaev, Andrey Kuznetsov, Aibek Alanov
Despite significant progress in text-to-image diffusion models, achieving precise spatial control over generated outputs remains challenging. ControlNet addresses this by introducing an auxiliary conditioning module, while ControlNet++ further refines alignment through a cycle consistency loss applied only to the final denoising steps. However, this approach neglects intermediate generation stages, limiting its effectiveness. We propose InnerControl, a training strategy that enforces spatial consistency across all diffusion steps. Our method trains lightweight convolutional probes to reconstruct input control signals (e.g., edges, depth) from intermediate UNet features at every denoising step. These probes efficiently extract signals even from highly noisy latents, enabling pseudo ground truth controls for training. By minimizing the discrepancy between predicted and target conditions throughout the entire diffusion process, our alignment loss improves both control fidelity and generation quality. Combined with established techniques like ControlNet++, InnerControl achieves state-of-the-art performance across diverse conditioning methods (e.g., edges, depth).
尽管文本到图像的扩散模型取得了显著进展,但实现对生成输出的精确空间控制仍然具有挑战性。ControlNet通过引入辅助条件模块来解决这个问题,而ControlNet++则通过仅应用于最终去噪步骤的循环一致性损失来进一步改进对齐。然而,这种方法忽略了中间生成阶段,限制了其有效性。我们提出了InnerControl,这是一种训练策略,强制所有扩散步骤中的空间一致性。我们的方法训练轻量级的卷积探针,从每一步去噪过程中的中间UNet特征重建输入控制信号(例如,边缘、深度)。这些探针即使从高度嘈杂的潜在特征中也能有效地提取信号,为训练提供伪真实控制。通过最小化整个扩散过程中预测条件与目标条件之间的差异,我们的对齐损失提高了控制保真度和生成质量。结合ControlNet++等现有技术,InnerControl在不同条件方法(例如,边缘、深度)下实现了最佳性能。
论文及项目相关链接
PDF code available at https://github.com/ControlGenAI/InnerControl
Summary
本文提出了InnerControl,一种针对文本到图像扩散模型的空间控制训练策略。通过训练轻量级卷积探针从每个去噪步骤的中间UNet特征重建输入控制信号,如边缘和深度,以在整个扩散过程中提高控制和生成质量。结合ControlNet++等技术,InnerControl实现了在各种条件下的最佳性能。
Key Takeaways
- 控制文本到图像扩散模型生成的输出物的空间位置是一个挑战。
- ControlNet通过引入辅助条件模块来解决这个问题,而ControlNet++则通过仅在最终去噪步骤中应用循环一致性损失来进一步优化对齐。
- 然而,现有方法忽略了中间生成阶段,限制了其有效性。
- InnerControl是一种新的训练策略,它通过强制所有扩散步骤的空间一致性来提高控制和生成质量。
- InnerControl使用轻量级卷积探针从每个去噪步骤的中间UNet特征重建输入控制信号(如边缘和深度)。
- 这些探针能够从高度噪声的潜在特征中提取信号,为训练提供伪真实控制。
点此查看论文截图

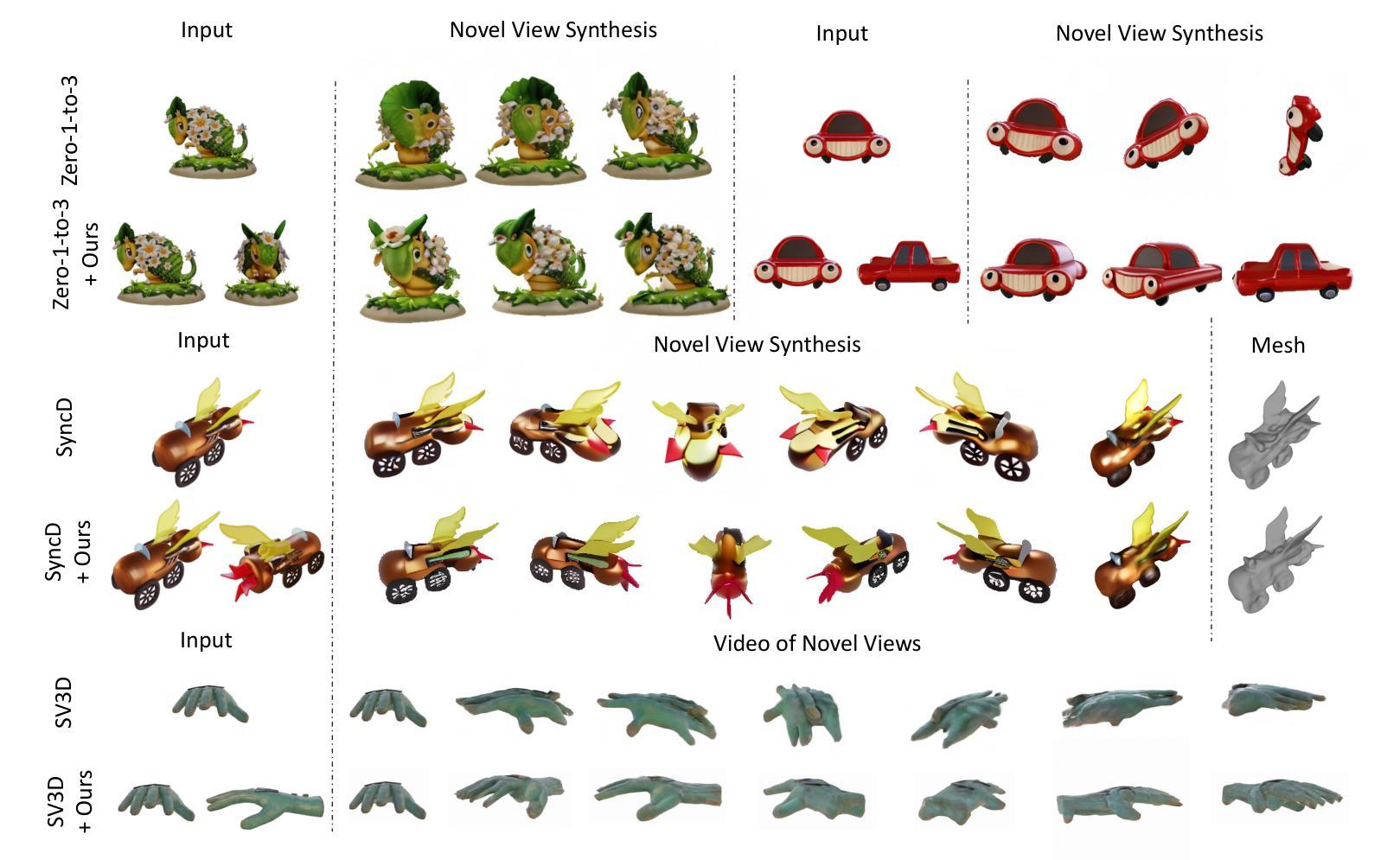
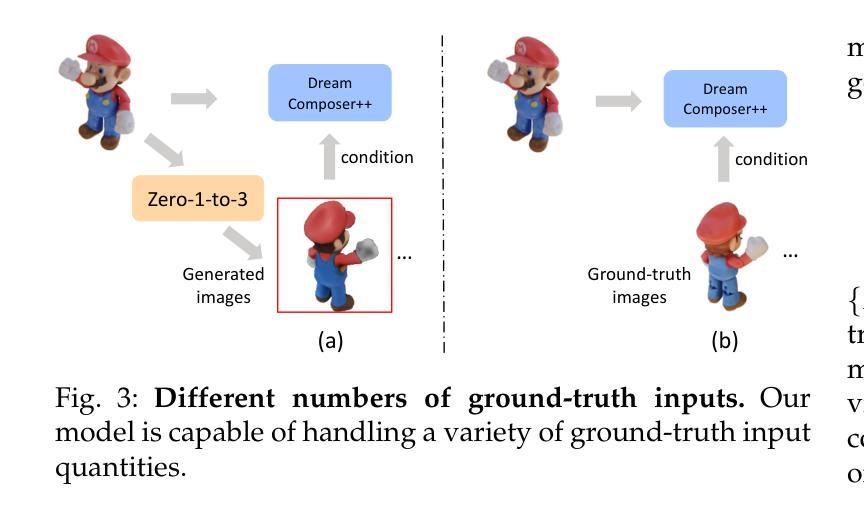
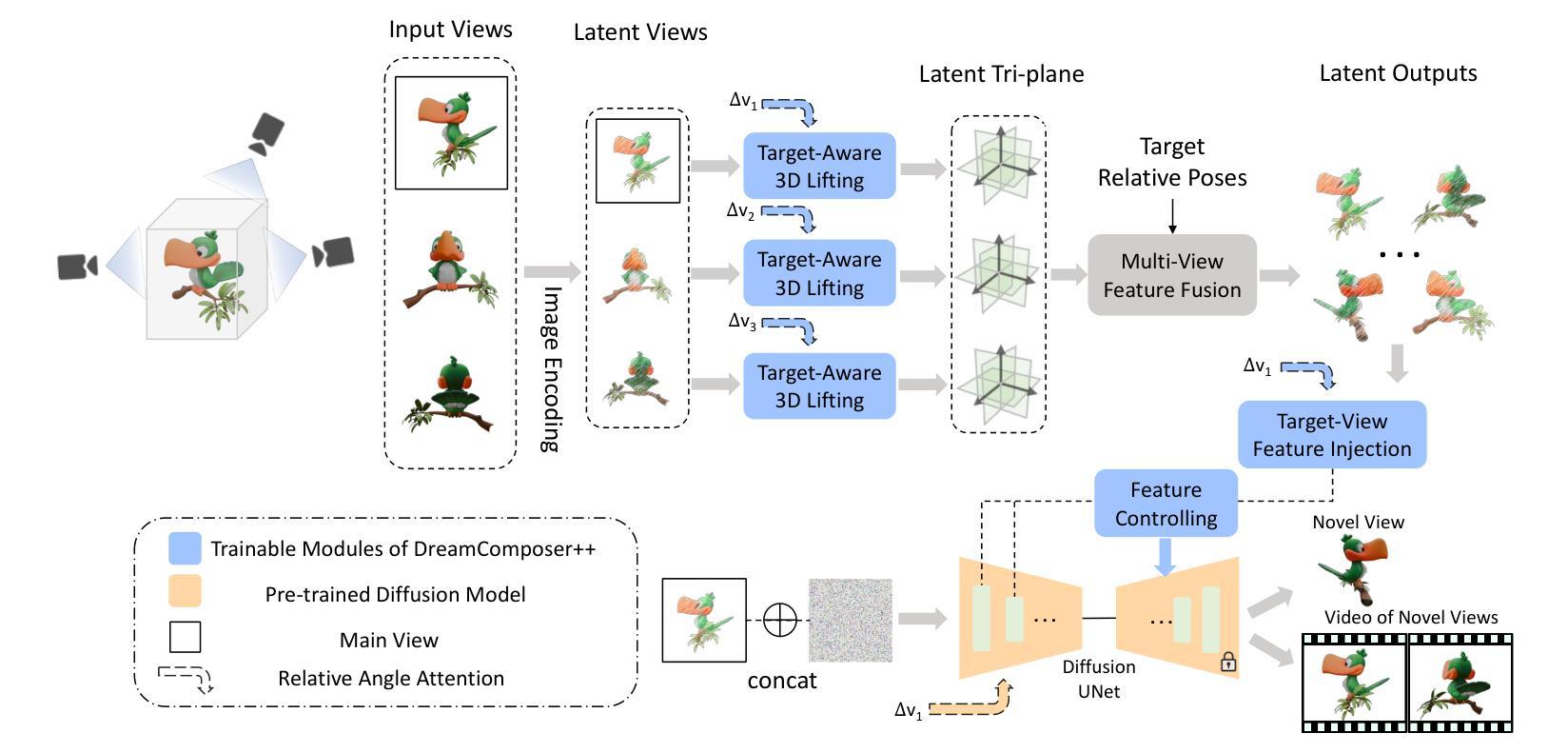
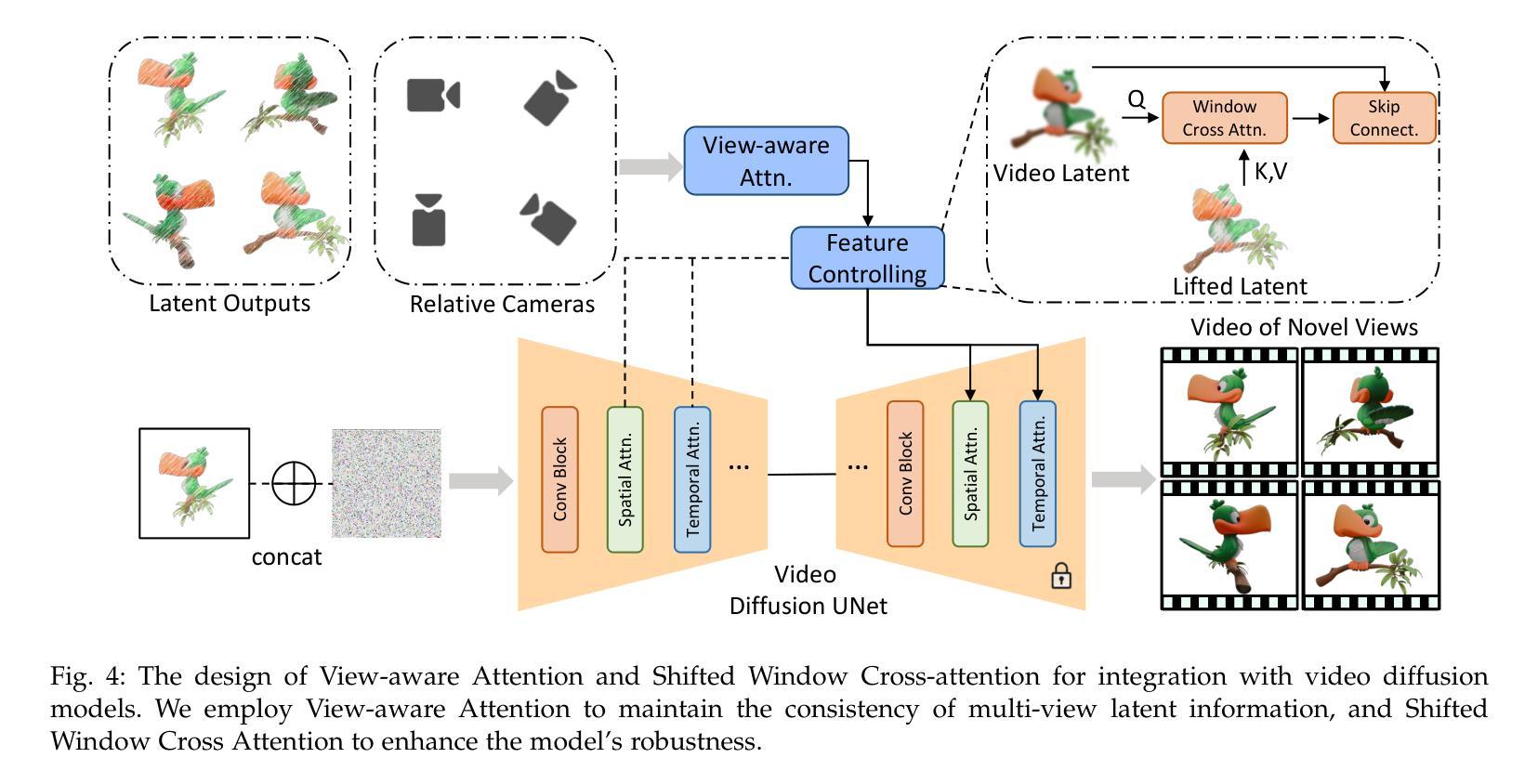
DreamComposer++: Empowering Diffusion Models with Multi-View Conditions for 3D Content Generation
Authors:Yunhan Yang, Shuo Chen, Yukun Huang, Xiaoyang Wu, Yuan-Chen Guo, Edmund Y. Lam, Hengshuang Zhao, Tong He, Xihui Liu
Recent advancements in leveraging pre-trained 2D diffusion models achieve the generation of high-quality novel views from a single in-the-wild image. However, existing works face challenges in producing controllable novel views due to the lack of information from multiple views. In this paper, we present DreamComposer++, a flexible and scalable framework designed to improve current view-aware diffusion models by incorporating multi-view conditions. Specifically, DreamComposer++ utilizes a view-aware 3D lifting module to extract 3D representations of an object from various views. These representations are then aggregated and rendered into the latent features of target view through the multi-view feature fusion module. Finally, the obtained features of target view are integrated into pre-trained image or video diffusion models for novel view synthesis. Experimental results demonstrate that DreamComposer++ seamlessly integrates with cutting-edge view-aware diffusion models and enhances their abilities to generate controllable novel views from multi-view conditions. This advancement facilitates controllable 3D object reconstruction and enables a wide range of applications.
最近,利用预训练的2D扩散模型的进展实现了从单一野外图像生成高质量新颖视角的能力。然而,现有工作由于缺少多视角信息,面临着生成可控新颖视角的挑战。在本文中,我们提出了DreamComposer++,这是一个灵活且可扩展的框架,旨在通过引入多视角条件来改善当前的视角感知扩散模型。具体来说,DreamComposer++利用视角感知的3D提升模块从各种视角提取对象的3D表示。然后,这些表示被聚合并通过多视角特征融合模块呈现为目标视角的潜在特征。最后,将目标视角的特征集成到预训练的图像或视频扩散模型中,用于合成新颖视角。实验结果表明,DreamComposer++无缝集成于前沿的视角感知扩散模型,增强了其从多视角条件生成可控新颖视角的能力。这一进展促进了可控的3D对象重建,并启用了广泛的应用。
论文及项目相关链接
PDF Accepted by TPAMI, extension of CVPR 2024 paper DreamComposer
Summary
本文介绍了DreamComposer++框架,它通过引入多视图条件,改进了当前的视图感知扩散模型,提高了从单一图像生成高质量新颖视图的能力。该框架利用视图感知的3D提升模块从各个视角提取对象的3D表示,然后通过多视图特征融合模块进行聚合和渲染,最后集成到预训练的图像或视频扩散模型中,用于合成新颖视图。实验结果表明,DreamComposer++无缝集成于前沿的视图感知扩散模型,增强了其在多视图条件下的可控新颖视图生成能力,促进了可控的3D对象重建,并启用了广泛的应用。
Key Takeaways
- DreamComposer++是一个灵活且可扩展的框架,旨在改进现有的视图感知扩散模型。
- 该框架通过引入多视图条件,提高了从单一图像生成高质量新颖视图的能力。
- DreamComposer++利用视图感知的3D提升模块提取对象的3D表示。
- 多视图特征融合模块用于聚合和渲染从不同视角提取的特征。
- 集成到预训练的图像或视频扩散模型中,用于合成新颖视图。
- 实验结果表明,DreamComposer++能够无缝集成于前沿的视图感知扩散模型,并增强其性能。
点此查看论文截图

FreeMorph: Tuning-Free Generalized Image Morphing with Diffusion Model
Authors:Yukang Cao, Chenyang Si, Jinghao Wang, Ziwei Liu
We present FreeMorph, the first tuning-free method for image morphing that accommodates inputs with different semantics or layouts. Unlike existing methods that rely on finetuning pre-trained diffusion models and are limited by time constraints and semantic/layout discrepancies, FreeMorph delivers high-fidelity image morphing without requiring per-instance training. Despite their efficiency and potential, tuning-free methods face challenges in maintaining high-quality results due to the non-linear nature of the multi-step denoising process and biases inherited from the pre-trained diffusion model. In this paper, we introduce FreeMorph to address these challenges by integrating two key innovations. 1) We first propose a guidance-aware spherical interpolation design that incorporates explicit guidance from the input images by modifying the self-attention modules, thereby addressing identity loss and ensuring directional transitions throughout the generated sequence. 2) We further introduce a step-oriented variation trend that blends self-attention modules derived from each input image to achieve controlled and consistent transitions that respect both inputs. Our extensive evaluations demonstrate that FreeMorph outperforms existing methods, being 10x ~ 50x faster and establishing a new state-of-the-art for image morphing.
我们提出了FreeMorph,这是一种无需调整的图片渐变方法,能够适应具有不同语义或布局的图像输入。与现有的依赖于微调预训练扩散模型的方法不同,这些方法受到时间限制和语义/布局差异的限制,FreeMorph无需对每个实例进行训练即可实现高保真度的图像渐变。尽管无需调整的方法具有高效性和潜力,但由于多步去噪过程的非线性性质和从预训练扩散模型继承的偏见,它们在维持高质量结果方面面临挑战。在本文中,我们引入FreeMorph来解决这些挑战,通过整合两个关键创新点。首先,我们提出了一种指导感知球形插值设计,通过修改自注意力模块来融入输入图像的明确指导,从而解决身份丢失问题,确保生成序列中的定向过渡。其次,我们进一步引入了一种面向步骤的变异趋势,通过融合来自每个输入图像的自注意力模块,实现受控且一致的过渡,同时尊重两个输入。我们的广泛评估表明,FreeMorph优于现有方法,速度提高了10倍至50倍,为图像渐变建立了新的技术标杆。
论文及项目相关链接
PDF ICCV 2025. Project page: https://yukangcao.github.io/FreeMorph/
Summary
该文介绍了FreeMorph,这是一种无需调整的图像融合方法,可适应具有不同语义或布局的图像输入。与现有方法相比,FreeMorph无需对预训练的扩散模型进行微调,且不受时间限制和语义/布局差异的限制,可在无需每次实例训练的情况下实现高保真图像融合。为了解决挑战并维持高质量的结果,该论文提出了FreeMorph的两项创新方法。首先提出了一种带有引导球面的插值设计,该设计通过修改自注意力模块融入了来自输入图像的显式引导,从而解决身份损失并确保生成的序列中始终保持方向过渡。其次,引入了基于步骤的变化趋势,通过将每个输入图像产生的自注意力模块混合,实现控制并保持一致过渡,同时尊重两个输入图像。评价结果显示,FreeMorph相较于现有方法性能更佳,速度提升达10倍至50倍,成为新的图像融合技术前沿。
Key Takeaways
- FreeMorph是首个无需调整即可实现图像融合的方法,适用于不同语义或布局的输入图像。
- 与现有方法相比,FreeMorph无需对预训练的扩散模型进行微调,具有高效性和潜力。
- FreeMorph解决了身份损失问题,通过引导球面插值设计确保生成的序列中方向过渡的自然性。
- 通过引入基于步骤的变化趋势,实现了对输入图像的自注意力模块的混合,实现了控制并保持一致过渡。
- FreeMorph在保持高质量结果的同时,解决了多步去噪过程的非线性性质和预训练扩散模型的固有偏见所带来的挑战。
- 评估表明,FreeMorph的性能优于现有方法,速度提升显著。
点此查看论文截图




Reasoning to Edit: Hypothetical Instruction-Based Image Editing with Visual Reasoning
Authors:Qingdong He, Xueqin Chen, Chaoyi Wang, Yanjie Pan, Xiaobin Hu, Zhenye Gan, Yabiao Wang, Chengjie Wang, Xiangtai Li, Jiangning Zhang
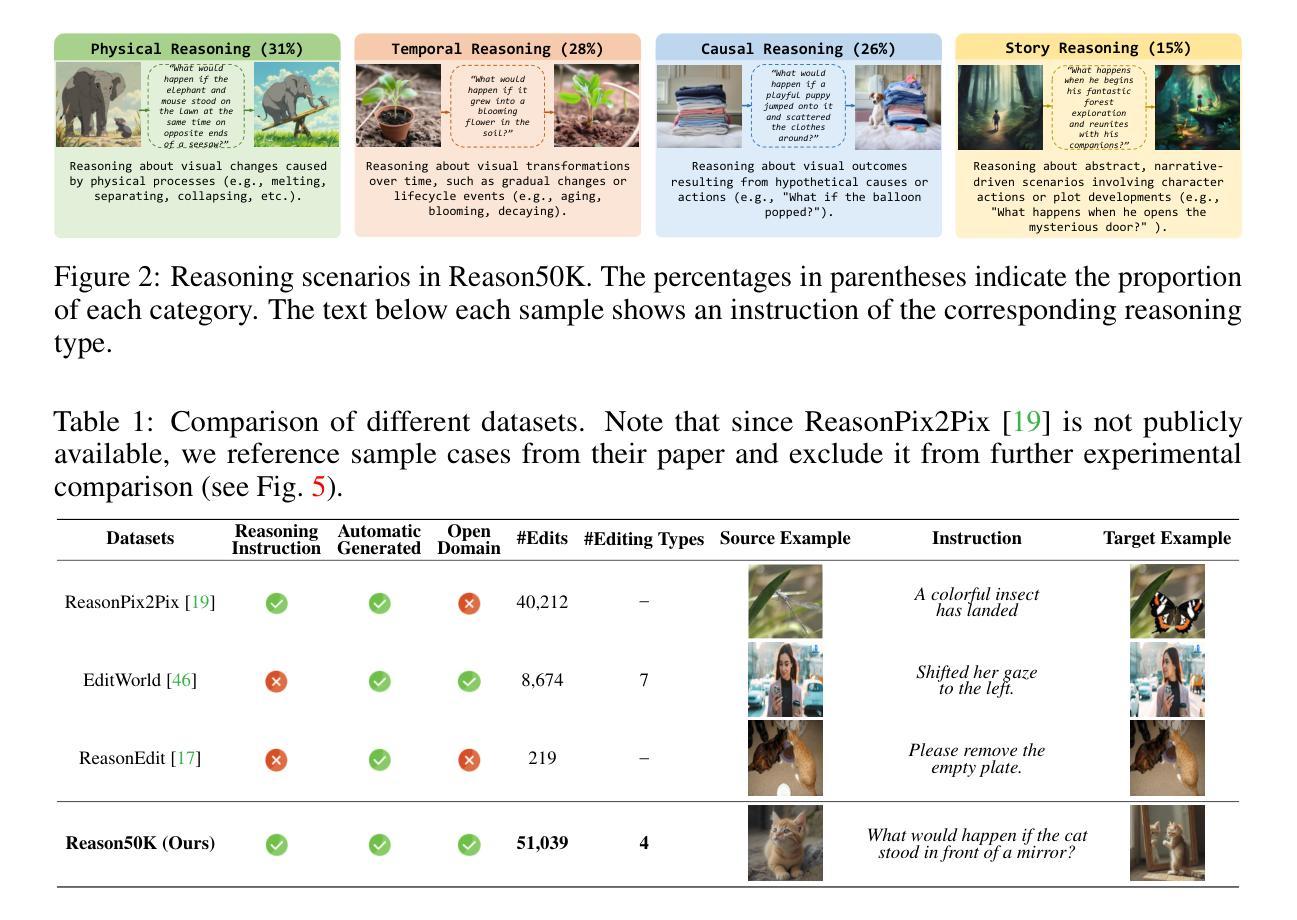
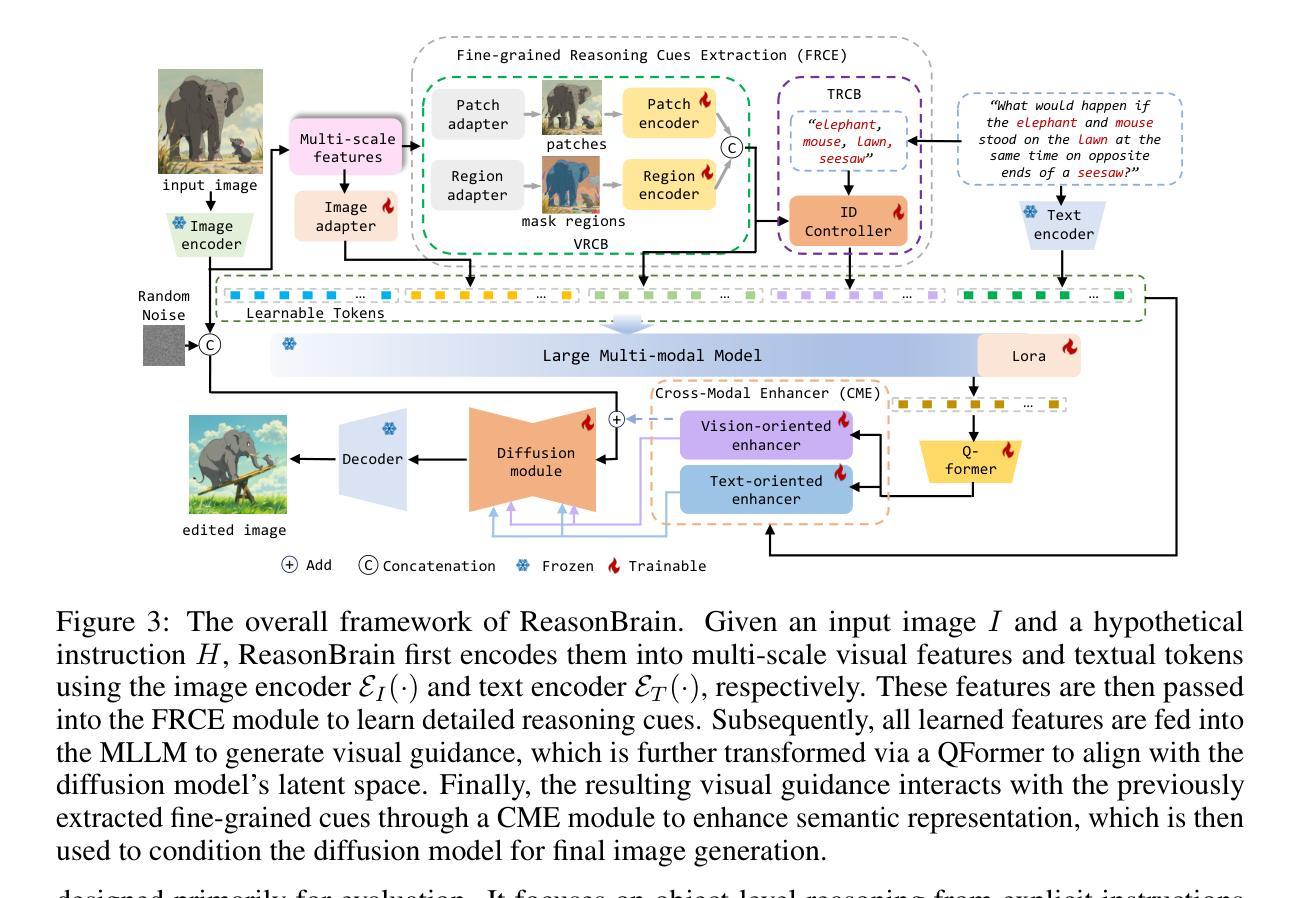
Instruction-based image editing (IIE) has advanced rapidly with the success of diffusion models. However, existing efforts primarily focus on simple and explicit instructions to execute editing operations such as adding, deleting, moving, or swapping objects. They struggle to handle more complex implicit hypothetical instructions that require deeper reasoning to infer plausible visual changes and user intent. Additionally, current datasets provide limited support for training and evaluating reasoning-aware editing capabilities. Architecturally, these methods also lack mechanisms for fine-grained detail extraction that support such reasoning. To address these limitations, we propose Reason50K, a large-scale dataset specifically curated for training and evaluating hypothetical instruction reasoning image editing, along with ReasonBrain, a novel framework designed to reason over and execute implicit hypothetical instructions across diverse scenarios. Reason50K includes over 50K samples spanning four key reasoning scenarios: Physical, Temporal, Causal, and Story reasoning. ReasonBrain leverages Multimodal Large Language Models (MLLMs) for editing guidance generation and a diffusion model for image synthesis, incorporating a Fine-grained Reasoning Cue Extraction (FRCE) module to capture detailed visual and textual semantics essential for supporting instruction reasoning. To mitigate the semantic loss, we further introduce a Cross-Modal Enhancer (CME) that enables rich interactions between the fine-grained cues and MLLM-derived features. Extensive experiments demonstrate that ReasonBrain consistently outperforms state-of-the-art baselines on reasoning scenarios while exhibiting strong zero-shot generalization to conventional IIE tasks. Our dataset and code will be released publicly.
基于指令的图像编辑(IIE)随着扩散模型的成功而迅速发展。然而,现有的努力主要集中在执行添加、删除、移动或交换对象等简单明确的编辑指令上。他们难以处理需要更深度推理来推断可能视觉变化和用户意图的更复杂隐含假设指令。此外,当前的数据集在支持训练评估推理感知编辑能力方面存在局限性。从架构上看,这些方法还缺乏支持此类推理的精细细节提取机制。为了解决这些局限性,我们提出了Reason50K,这是一个专门为训练和评估假设指令推理图像编辑的大型数据集,以及ReasonBrain,一个为执行各种场景中的隐含假设指令而设计的新型框架。Reason50K包含超过5万样本,涵盖四种关键推理场景:物理推理、时间推理、因果推理和故事推理。ReasonBrain利用多模态大型语言模型(MLLMs)进行编辑指导生成和扩散模型进行图像合成,并融入精细推理线索提取(FRCE)模块,以捕捉支持指令推理的详细视觉和文本语义。为了减少语义损失,我们进一步引入了跨模态增强器(CME),它实现了精细线索和MLLM派生特征之间的丰富交互。大量实验表明,ReasonBrain在推理场景上始终优于最新基线,同时在常规IIE任务上展现出强大的零样本泛化能力。我们的数据集和代码将公开发布。
论文及项目相关链接
Summary:基于指令的图像编辑(IIE)借助扩散模型取得了快速进展。然而,现有努力主要集中在执行添加、删除、移动或替换物体等简单明确的编辑指令上,难以处理需要更深度推理的复杂隐性假设指令,以推断出可行的视觉变化和用户意图。此外,当前数据集对训练评估推理感知编辑能力支持有限。为了解决这些局限性,我们提出了Reason50K数据集,该数据集专为假设指令推理图像编辑的训练和评估而策划,以及ReasonBrain框架,该框架旨在执行跨不同场景的隐性假设指令。ReasonBrain利用多模态大型语言模型进行编辑指导生成和扩散模型进行图像合成,并引入精细推理线索提取模块来捕捉详细的视觉和文本语义。为了减轻语义损失,我们进一步引入了跨模态增强器,以丰富精细线索与MLLM衍生特征之间的交互。实验表明,ReasonBrain在推理场景上始终优于最新基线技术,并在常规IIE任务上表现出强大的零样本泛化能力。我们的数据集和代码将公开发布。
Key Takeaways:
- 现有图像编辑技术主要处理简单明确的编辑指令,难以处理复杂的隐性假设指令。
- 缺乏针对假设指令推理图像编辑的训练和评估数据集。
- 提出了Reason50K数据集,专为假设指令推理图像编辑的训练和评估设计。
- 引入了ReasonBrain框架,结合了多模态大型语言模型和扩散模型,以执行复杂的隐性假设指令。
- ReasonBrain包含精细推理线索提取模块,用于捕捉详细的视觉和文本语义。
- 跨模态增强器的引入增强了精细线索与语言模型特征之间的交互。
点此查看论文截图


Vision-Aided ISAC in Low-Altitude Economy Networks via De-Diffused Visual Priors
Authors:Yulan Gao, Ziqiang Ye, Zhonghao Lyu, Ming Xiao, Yue Xiao, Ping Yang, Agata Manolova
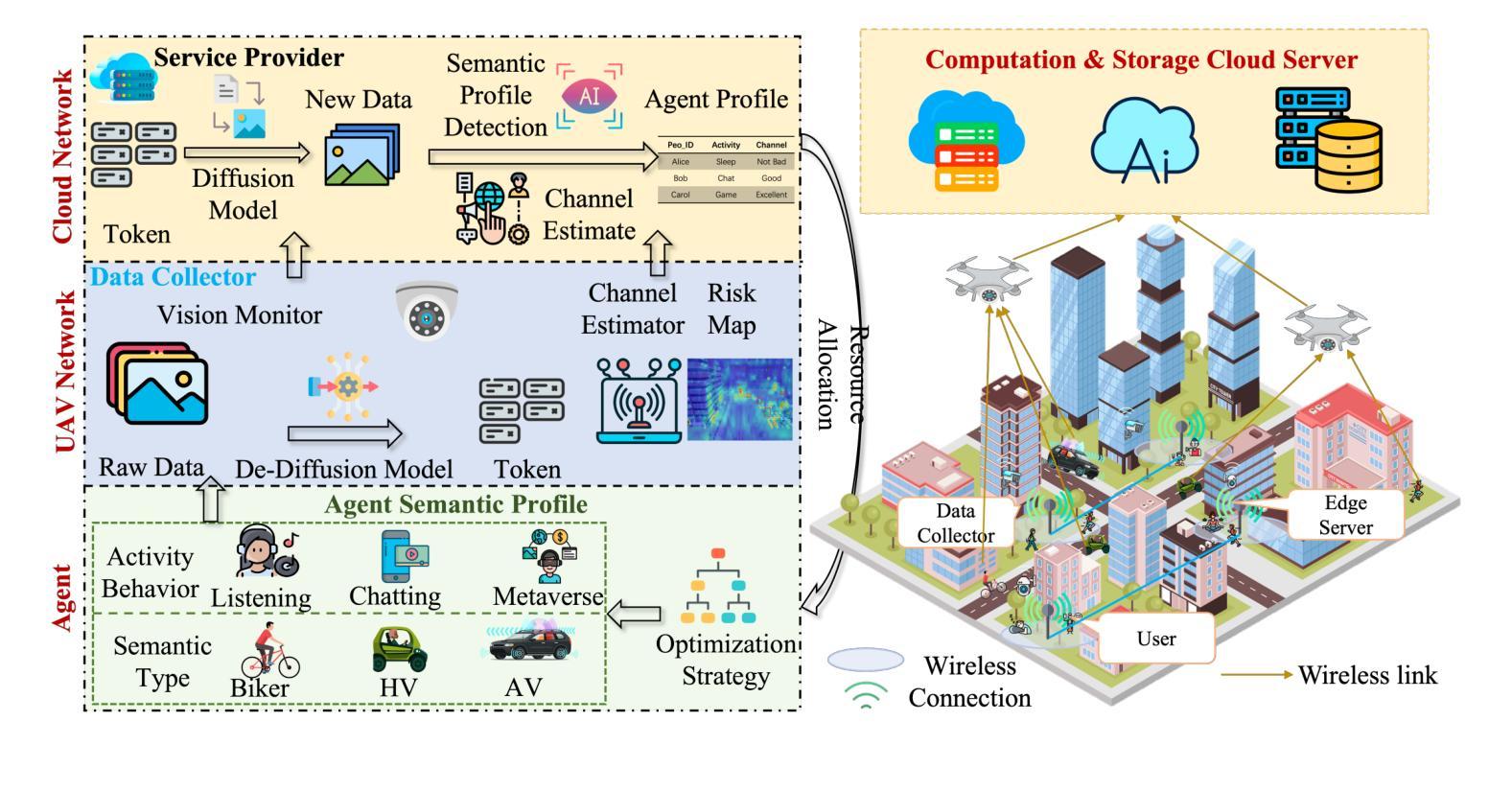
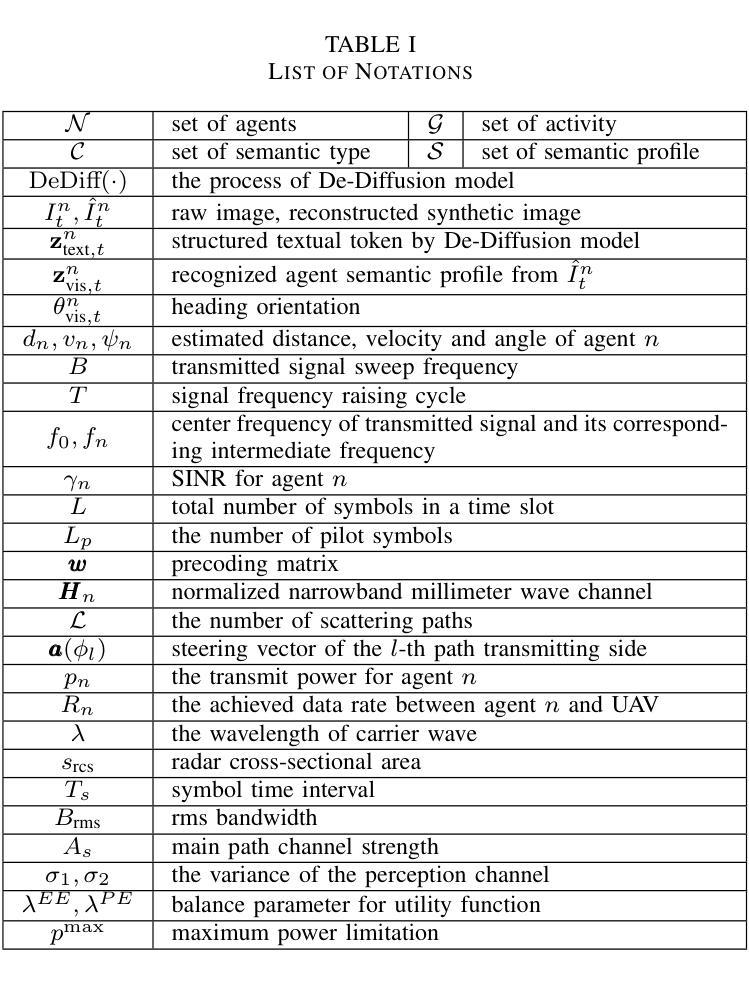
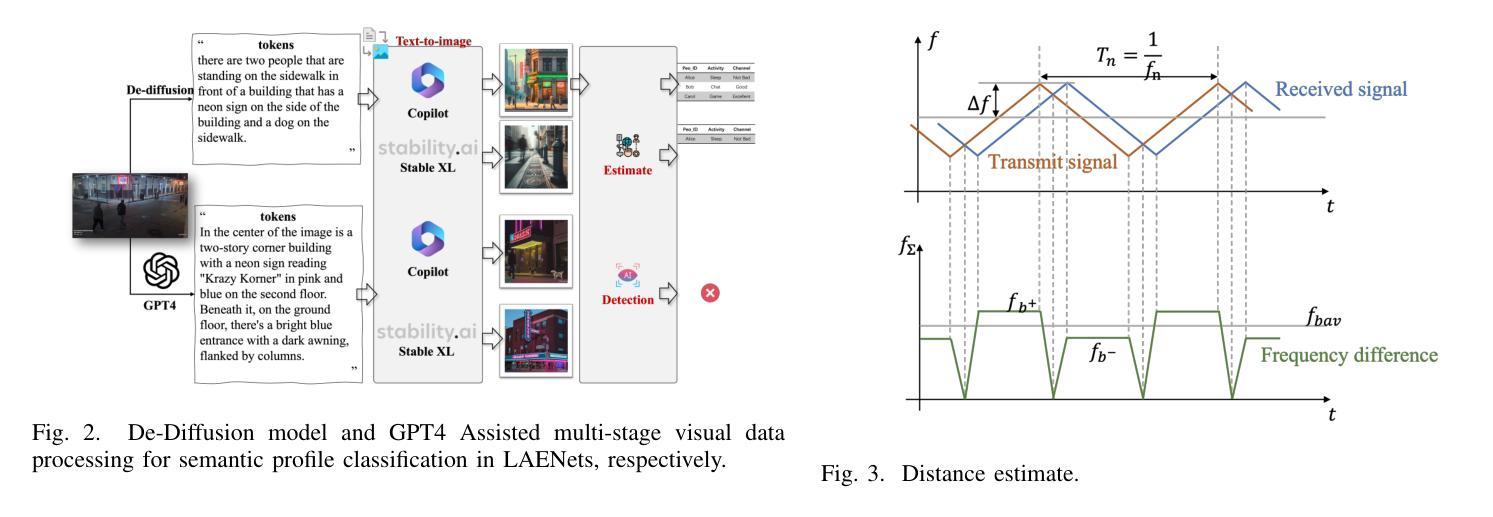
Emerging low-altitude economy networks (LAENets) require agile and privacy-preserving resource control under dynamic agent mobility and limited infrastructure support. To meet these challenges, we propose a vision-aided integrated sensing and communication (ISAC) framework for UAV-assisted access systems, where onboard masked De-Diffusion models extract compact semantic tokens, including agent type, activity class, and heading orientation, while explicitly suppressing sensitive visual content. These tokens are fused with mmWave radar measurements to construct a semantic risk heatmap reflecting motion density, occlusion, and scene complexity, which guides access technology selection and resource scheduling. We formulate a multi-objective optimization problem to jointly maximize weighted energy and perception efficiency via radio access technology (RAT) assignment, power control, and beamforming, subject to agent-specific QoS constraints. To solve this, we develop De-Diffusion-driven vision-aided risk-aware resource optimization algorithm DeDiff-VARARO, a novel two-stage cross-modal control algorithm: the first stage reconstructs visual scenes from tokens via De-Diffusion model for semantic parsing, while the second stage employs a deep deterministic policy gradient (DDPG)-based policy to adapt RAT selection, power control, and beam assignment based on fused radar-visual states. Simulation results show that DeDiff-VARARO consistently outperforms baselines in reward convergence, link robustness, and semantic fidelity, achieving within $4%$ of the performance of a raw-image upper bound while preserving user privacy and scalability in dense environments.
新兴的低空经济网络(LAENets)需要在动态代理移动和有限的基础设施支持下,实现敏捷且保护隐私的资源控制。为应对这些挑战,我们为无人机辅助访问系统提出了一个基于视觉辅助集成感知和通信(ISAC)的框架。在该框架中,机载的去扩散模型提取紧凑的语义令牌,包括代理类型、活动类别和朝向,同时显式抑制敏感视觉内容。这些令牌与毫米波雷达测量值相融合,构建反映运动密度、遮挡情况和场景复杂性的语义风险热图,从而指导访问技术选择和资源调度。我们制定了一个多目标优化问题,通过无线电访问技术(RAT)分配、功率控制和波束形成,联合最大化加权能量和感知效率,同时受到特定代理的QoS 约束。为解决这一问题,我们开发了去扩散驱动的视觉辅助风险感知资源优化算法 DeDiff-VARARO,这是一种新型的两阶段跨模态控制算法:第一阶段通过去扩散模型从令牌重建视觉场景进行语义解析;第二阶段采用基于深度确定性策略梯度(DDPG)的策略,根据融合的雷达-视觉状态来适应RAT选择、功率控制和波束分配。仿真结果表明,DeDiff-VARARO 在奖励收敛、链路鲁棒性和语义保真度方面始终优于基准线,在密集环境中实现了对原始图像上限性能的96%的同时,保护了用户隐私和可扩展性。
论文及项目相关链接
Summary
针对低空经济网络(LAENets)面临的挑战,如动态代理移动性、有限的基础设施支持和隐私保护需求,提出一种基于视觉辅助的集成感知和通信(ISAC)框架。该框架利用车载去扩散模型提取紧凑语义令牌,并与毫米波雷达测量值融合,构建反映运动密度、遮挡和场景复杂性的语义风险热图,从而实现访问技术选择和资源调度。提出一种基于多目标优化的去扩散驱动视觉辅助风险感知资源优化算法(DeDiff-VARARO),模拟结果显示其在奖励收敛、链路鲁棒性和语义保真度方面均优于基线方法,同时在保护用户隐私和密集环境中的可扩展性方面表现出色。
Key Takeaways
- 低空经济网络(LAENets)面临动态代理移动性、有限基础设施支持和隐私保护的挑战。
- 提出了基于视觉辅助的集成感知和通信(ISAC)框架,用于UAV辅助访问系统。
- 通过车载去扩散模型提取紧凑语义令牌,包括代理类型、活动类别和朝向等,同时显式抑制敏感视觉内容。
- 语义令牌与毫米波雷达测量值融合,构建反映运动密度、遮挡和场景复杂性的语义风险热图。
- 提出一种多目标优化问题,通过无线电访问技术(RAT)分配、功率控制和波束形成来联合最大化加权能量和感知效率,同时考虑代理特定的QoS 约束。
- 开发了去扩散驱动的视觉辅助风险感知资源优化算法(DeDiff-VARARO),通过两阶段跨模态控制算法实现资源优化。
点此查看论文截图

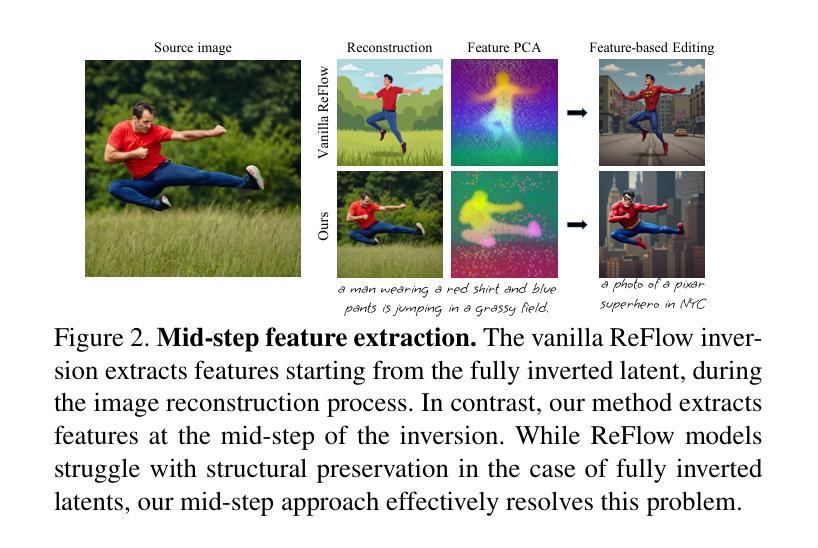
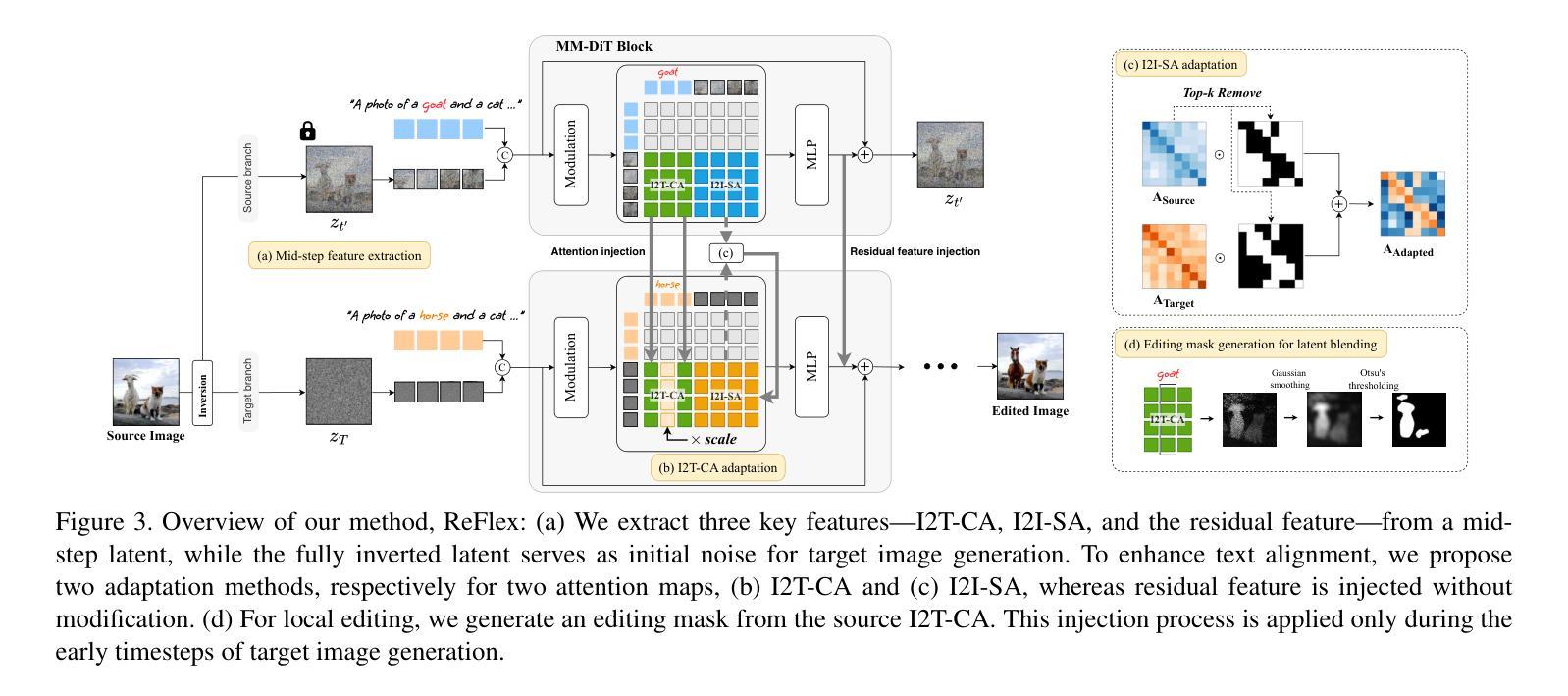
ReFlex: Text-Guided Editing of Real Images in Rectified Flow via Mid-Step Feature Extraction and Attention Adaptation
Authors:Jimyeong Kim, Jungwon Park, Yeji Song, Nojun Kwak, Wonjong Rhee
Rectified Flow text-to-image models surpass diffusion models in image quality and text alignment, but adapting ReFlow for real-image editing remains challenging. We propose a new real-image editing method for ReFlow by analyzing the intermediate representations of multimodal transformer blocks and identifying three key features. To extract these features from real images with sufficient structural preservation, we leverage mid-step latent, which is inverted only up to the mid-step. We then adapt attention during injection to improve editability and enhance alignment to the target text. Our method is training-free, requires no user-provided mask, and can be applied even without a source prompt. Extensive experiments on two benchmarks with nine baselines demonstrate its superior performance over prior methods, further validated by human evaluations confirming a strong user preference for our approach.
修正流(ReFlow)文本到图像模型的图像质量和文本对齐超越了扩散模型,但在实际图像编辑中应用ReFlow仍然具有挑战性。我们针对ReFlow提出了一种新的实际图像编辑方法,通过分析多模态transformer块的中间表示并识别三个关键特征。为了从实际图像中提取这些特征并保持足够的结构完整性,我们利用中期潜在变量,该变量只反转到中期。然后我们在注入时调整注意力以提高可编辑性和提高与目标文本的匹配度。我们的方法无需训练,无需用户提供遮罩,甚至在不提供源提示的情况下也可以应用。在两个基准上的大量实验与九个基线相比,证明了其超越先前方法的性能优势,人类评估进一步证实了用户对我们的方法有强烈的偏好。
论文及项目相关链接
PDF Published at ICCV 2025. Project page: https://wlaud1001.github.io/ReFlex/
Summary
本文提出一种基于Rectified Flow(ReFlow)文本到图像模型的真实图像编辑方法。通过分析多模态transformer块的中间表示,识别了三个关键特征,并利用中期潜在反转技术提取这些特征,改进了注入时的注意力机制,提高了编辑能力和文本对齐度。该方法无需训练,无需用户提供遮罩,即使在没有源提示的情况下也可应用。实验和人工评估均证实其性能优于其他方法,用户偏好明显。
Key Takeaways
- 提出基于ReFlow的文本到图像模型的真实图像编辑方法。
- 分析多模态transformer块的中间表示,识别关键特征。
- 利用中期潜在反转技术提取图像特征,保证足够的结构保留。
- 改进注入时的注意力机制,提高编辑能力和文本对齐度。
- 方法无需训练,无需用户提供遮罩,应用广泛。
- 实验证明其性能优于其他方法。
点此查看论文截图




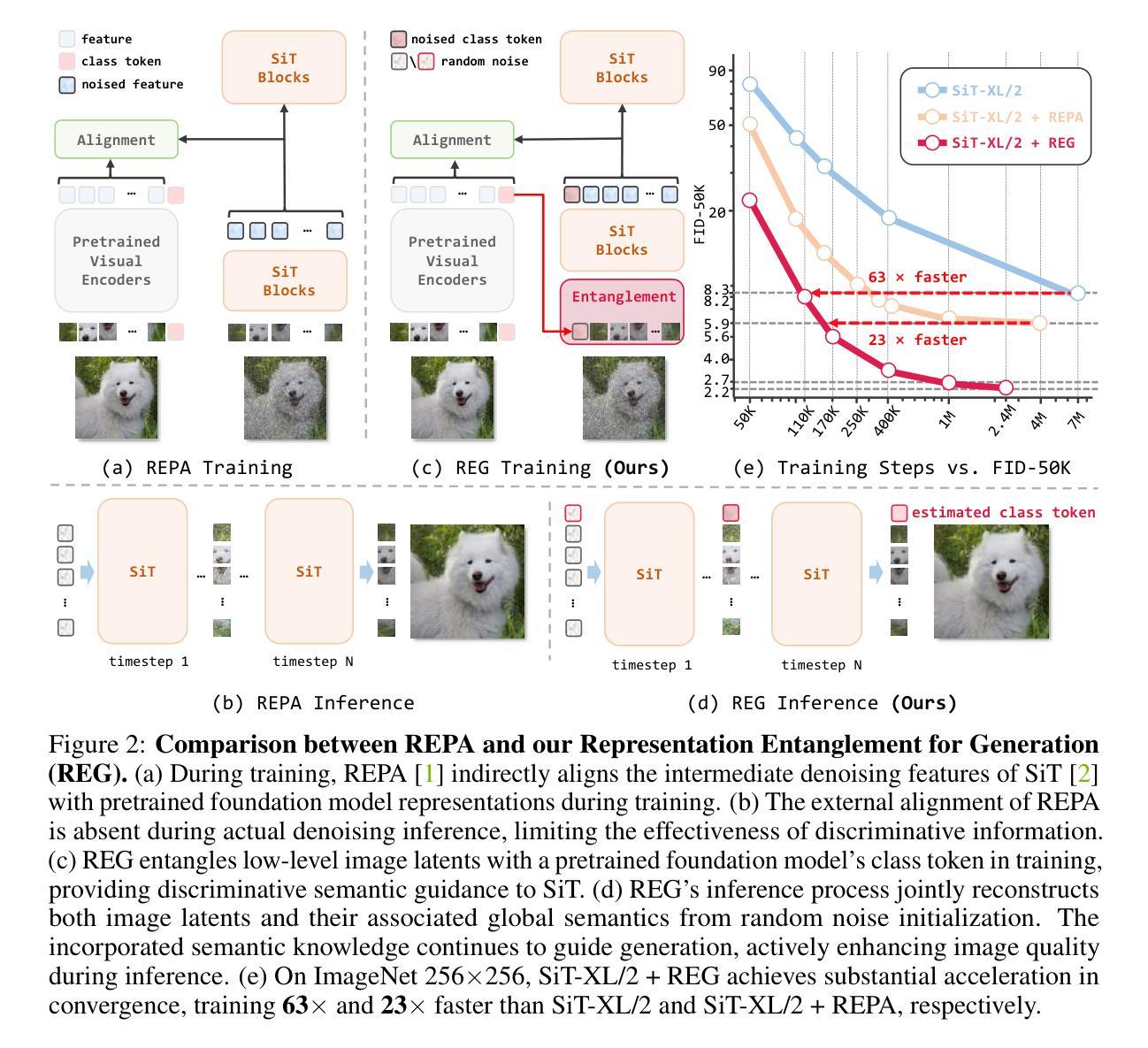
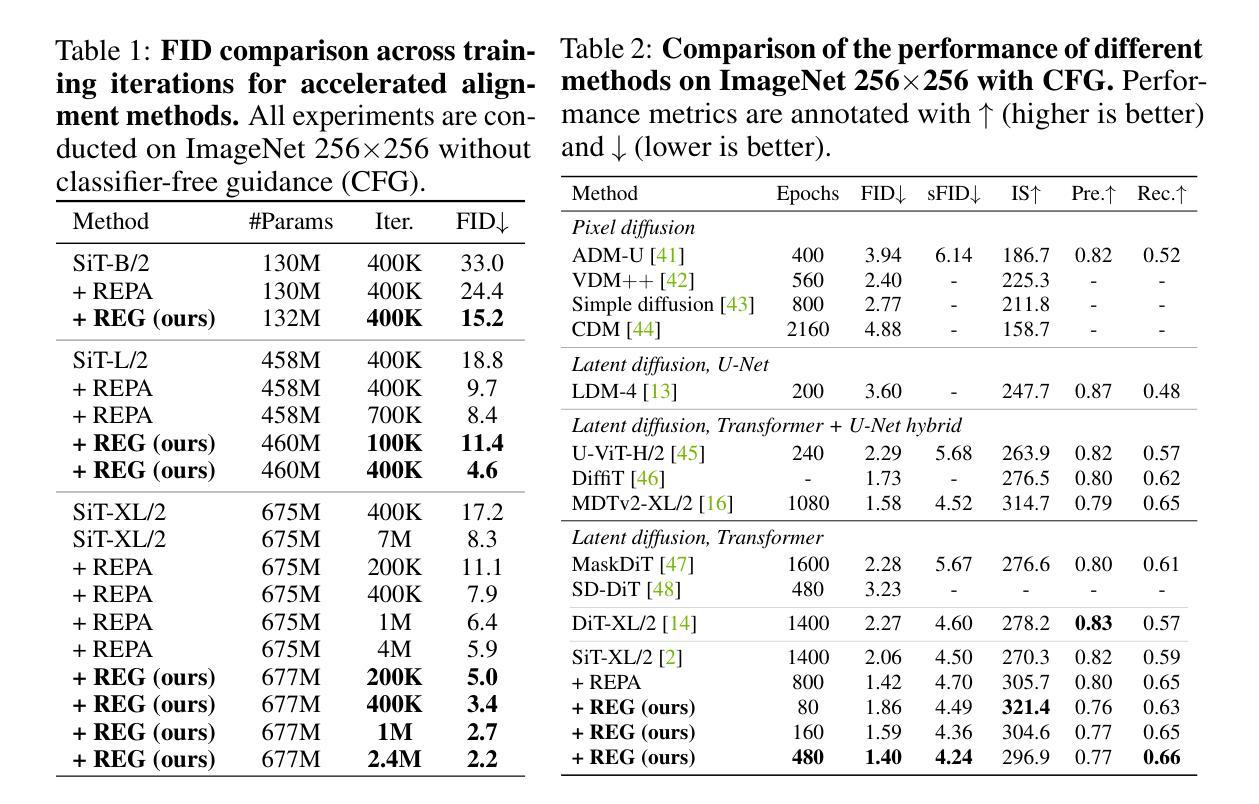
Representation Entanglement for Generation:Training Diffusion Transformers Is Much Easier Than You Think
Authors:Ge Wu, Shen Zhang, Ruijing Shi, Shanghua Gao, Zhenyuan Chen, Lei Wang, Zhaowei Chen, Hongcheng Gao, Yao Tang, Jian Yang, Ming-Ming Cheng, Xiang Li
REPA and its variants effectively mitigate training challenges in diffusion models by incorporating external visual representations from pretrained models, through alignment between the noisy hidden projections of denoising networks and foundational clean image representations. We argue that the external alignment, which is absent during the entire denoising inference process, falls short of fully harnessing the potential of discriminative representations. In this work, we propose a straightforward method called Representation Entanglement for Generation (REG), which entangles low-level image latents with a single high-level class token from pretrained foundation models for denoising. REG acquires the capability to produce coherent image-class pairs directly from pure noise, substantially improving both generation quality and training efficiency. This is accomplished with negligible additional inference overhead, requiring only one single additional token for denoising (<0.5% increase in FLOPs and latency). The inference process concurrently reconstructs both image latents and their corresponding global semantics, where the acquired semantic knowledge actively guides and enhances the image generation process. On ImageNet 256$\times$256, SiT-XL/2 + REG demonstrates remarkable convergence acceleration, achieving $\textbf{63}\times$ and $\textbf{23}\times$ faster training than SiT-XL/2 and SiT-XL/2 + REPA, respectively. More impressively, SiT-L/2 + REG trained for merely 400K iterations outperforms SiT-XL/2 + REPA trained for 4M iterations ($\textbf{10}\times$ longer). Code is available at: https://github.com/Martinser/REG.
REPA及其变体通过结合预训练模型的外部视觉表征,通过对去噪网络的噪声隐藏投影和基本的干净图像表征之间的对齐,有效缓解了扩散模型中的训练挑战。我们认为,在整个去噪推理过程中缺失的外部对齐无法充分利用判别表征的潜力。在这项工作中,我们提出了一种名为生成表示纠缠(REG)的直观方法,它将低级别图像潜能与预训练基础模型的单个高级类别标记纠缠在一起进行去噪。REG能够直接从纯噪声中产生连贯的图像类别对,从而大大提高了生成质量和训练效率。这几乎不需要额外的推理开销,仅需要一个额外的标记进行去噪(FLOPs和延迟增加不到0.5%)。推理过程同时重建图像潜力和其对应的全局语义,所获得的语义知识积极引导和增强图像生成过程。在ImageNet 256×256上,SiT-XL/2 + REG显示了令人瞩目的收敛加速,与SiT-XL/2相比加速了63倍,与SiT-XL/2 + REPA相比加速了23倍。更令人印象深刻的是,仅训练40万次的SiT-L/2 + REG超越了训练4百万次(时间长10倍)的SiT-XL/2 + REPA。代码可在https://github.com/Martinser/REG找到。
论文及项目相关链接
摘要
REPA及其变体通过融入预训练模型的外部视觉表征,有效缓解了扩散模型在训练过程中的挑战。本文提出一种名为REG(生成表示纠缠)的直观方法,通过将低级别图像潜能与预训练基础模型的单个高级类别标记纠缠,实现了对REPA的超越。REG能够在纯噪声中直接生成连贯的图像类别对,显著提高了生成质量和训练效率。该过程仅需一个额外的标记用于去噪,无需增加额外的推理开销(FLOPs延迟增加不到0.5%)。在ImageNet 256×256上,SiT-XL/2 + REG展现了出色的收敛加速能力,相较于SiT-XL/2和SiT-XL/2 + REPA分别达到了63倍和23倍的加速效果。更令人印象深刻的是,仅训练40万次的SiT-L/2 + REG超越了训练4百万次的SiT-XL/2 + REPA(时间长达其十倍)。相关代码可通过链接获取:https://github.com/Martinser/REG。
关键见解
- REPA及其相关方法通过引入外部视觉表征缓解了扩散模型在训练中的挑战。
- 本文提出的REG方法通过纠缠图像低级别潜能与预训练模型的高级类别标记,改善了生成质量和训练效率。
- REG在纯噪声中直接生成连贯的图像类别对,显示了强大的生成能力。
- REG的去噪过程仅需要一个额外的标记,未显著增加推理开销。
- 在ImageNet上,REG显著加速了模型的训练收敛,相较于对比方法有明显优势。
- REG在较短的训练时间内即表现出优异的性能,显示出其高效性。
点此查看论文截图

DiffMark: Diffusion-based Robust Watermark Against Deepfakes
Authors:Chen Sun, Haiyang Sun, Zhiqing Guo, Yunfeng Diao, Liejun Wang, Dan Ma, Gaobo Yang, Keqin Li
Deepfakes pose significant security and privacy threats through malicious facial manipulations. While robust watermarking can aid in authenticity verification and source tracking, existing methods often lack the sufficient robustness against Deepfake manipulations. Diffusion models have demonstrated remarkable performance in image generation, enabling the seamless fusion of watermark with image during generation. In this study, we propose a novel robust watermarking framework based on diffusion model, called DiffMark. By modifying the training and sampling scheme, we take the facial image and watermark as conditions to guide the diffusion model to progressively denoise and generate corresponding watermarked image. In the construction of facial condition, we weight the facial image by a timestep-dependent factor that gradually reduces the guidance intensity with the decrease of noise, thus better adapting to the sampling process of diffusion model. To achieve the fusion of watermark condition, we introduce a cross information fusion (CIF) module that leverages a learnable embedding table to adaptively extract watermark features and integrates them with image features via cross-attention. To enhance the robustness of the watermark against Deepfake manipulations, we integrate a frozen autoencoder during training phase to simulate Deepfake manipulations. Additionally, we introduce Deepfake-resistant guidance that employs specific Deepfake model to adversarially guide the diffusion sampling process to generate more robust watermarked images. Experimental results demonstrate the effectiveness of the proposed DiffMark on typical Deepfakes. Our code will be available at https://github.com/vpsg-research/DiffMark.
深度伪造技术通过恶意面部操作对安全性和隐私构成重大威胁。虽然鲁棒性水印有助于验证真实性和追踪来源,但现有方法通常缺乏对深度伪造操作的足够鲁棒性。扩散模型在图像生成方面表现出了惊人的性能,能够在生成过程中无缝融合水印和图像。本研究提出了一种基于扩散模型的新型鲁棒水印框架,称为DiffMark。通过修改训练和采样方案,我们将面部图像和水印作为条件来指导扩散模型逐步去噪并生成相应的水印图像。在构建面部条件时,我们根据时间步长因素对面部图像进行加权,随着噪声的减少逐渐降低指导强度,从而更好地适应扩散模型的采样过程。为了实现水印条件的融合,我们引入了一个交叉信息融合(CIF)模块,该模块利用可学习的嵌入表自适应地提取水印特征,并通过交叉注意力将它们与图像特征结合在一起。为了提高水印对深度伪造操作的鲁棒性,我们在训练阶段整合了一个冻结的自编码器来模拟深度伪造操作。此外,我们还引入了深度伪造抵抗指导,采用特定的深度伪造模型对抗性地指导扩散采样过程,生成更鲁棒的水印图像。实验结果证明了DiffMark在典型深度伪造上的有效性。我们的代码将在https://github.com/vpsg-research/DiffMark上提供。
论文及项目相关链接
Summary
本文介绍了一种基于扩散模型的新型稳健水印框架DiffMark,用于应对深度伪造技术带来的安全和隐私威胁。通过修改训练与采样方案,将面部图像与水印作为条件引导扩散模型逐步去噪并生成相应的水印图像。采用跨信息融合模块实现水印与图像特征的融合,并通过冻结的自编码器增强水印对深度伪造操作的鲁棒性。相关代码可在链接找到。
Key Takeaways
- 深度伪造技术带来了严重的安全与隐私威胁,需要新的方法应对。
- 扩散模型在水印应用中表现优异,可以无缝融合水印与图像。
- 提出基于扩散模型的新型稳健水印框架DiffMark。
- 通过修改训练与采样方案,将面部图像与水印作为条件引导扩散模型生成水印图像。
- 采用跨信息融合模块实现水印与图像特征的融合。
- 通过冻结的自编码器模拟深度伪造操作,增强水印的鲁棒性。
点此查看论文截图

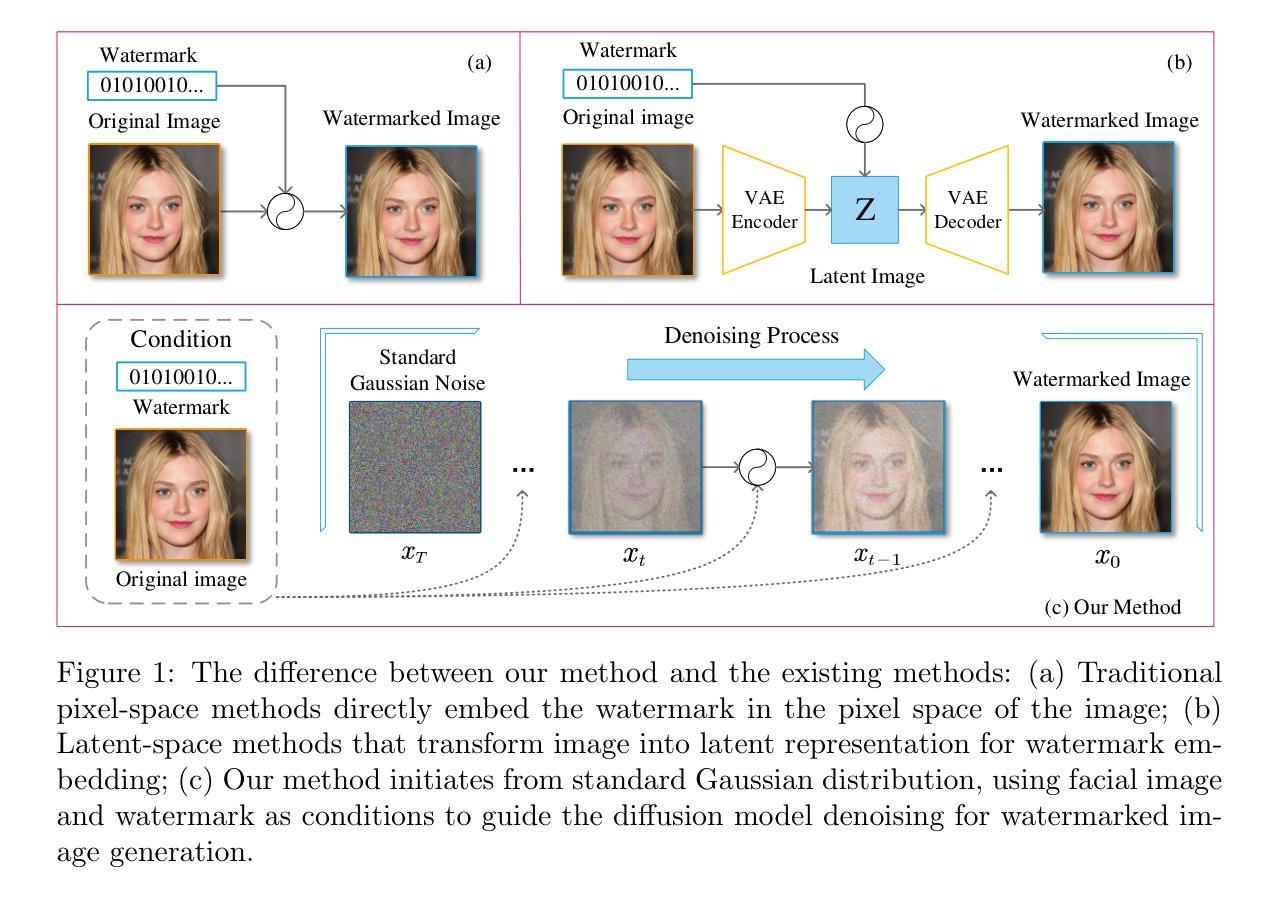
DocShaDiffusion: Diffusion Model in Latent Space for Document Image Shadow Removal
Authors:Wenjie Liu, Bingshu Wang, Ze Wang, C. L. Philip Chen
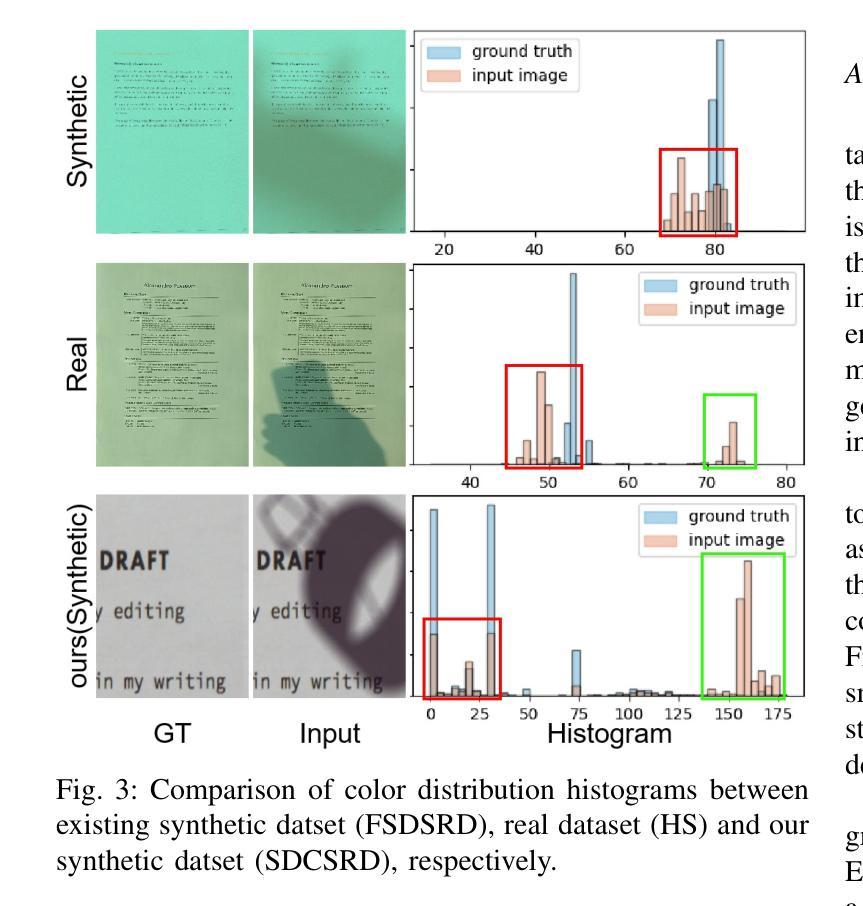
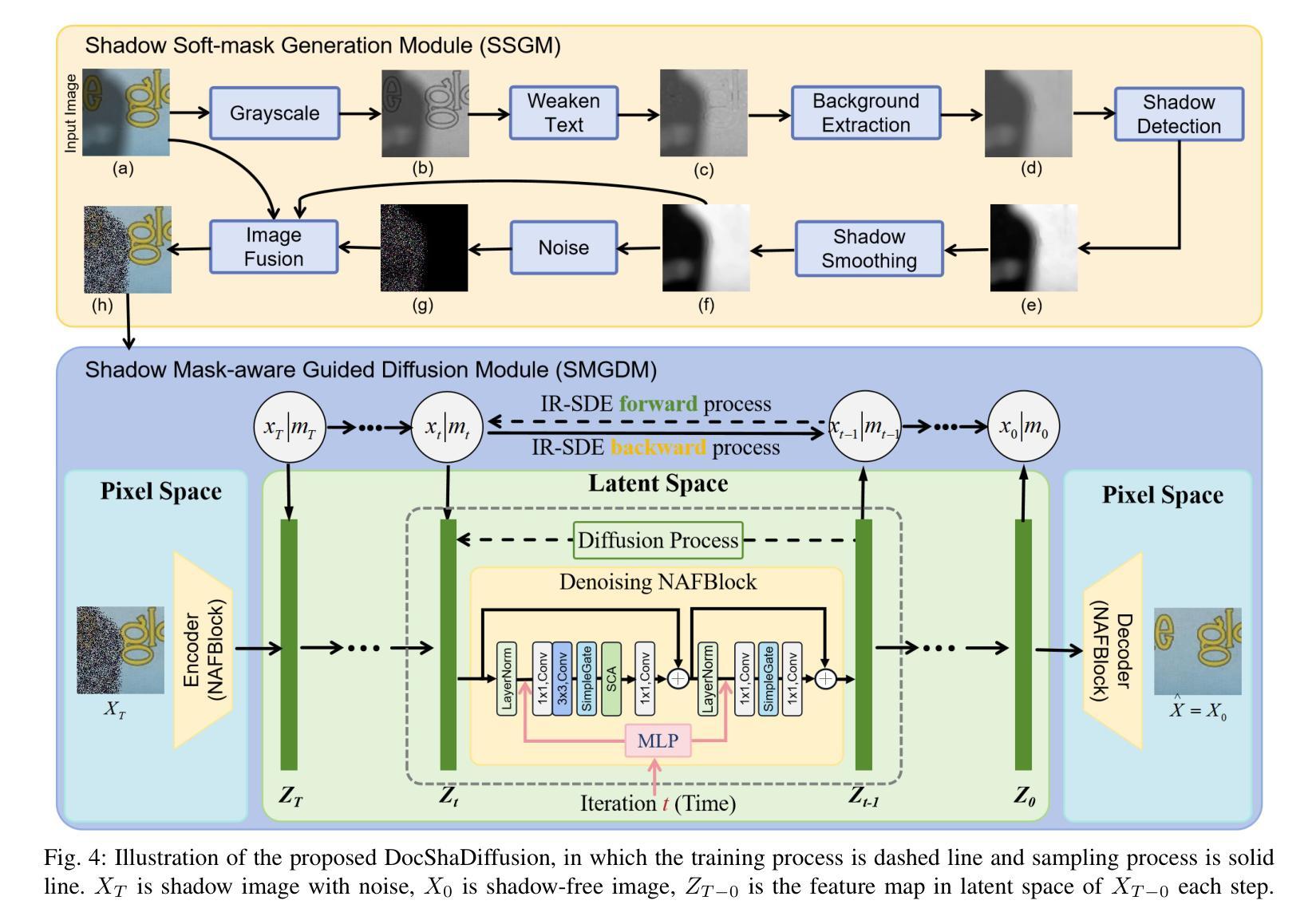
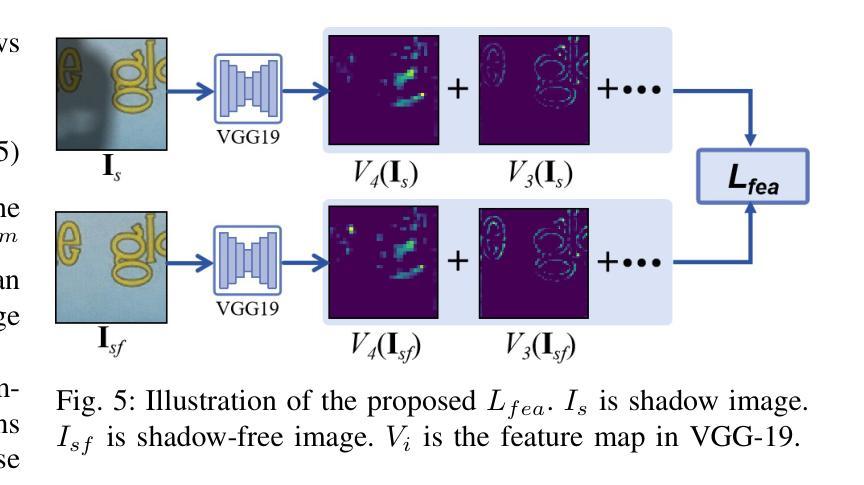
Document shadow removal is a crucial task in the field of document image enhancement. However, existing methods tend to remove shadows with constant color background and ignore color shadows. In this paper, we first design a diffusion model in latent space for document image shadow removal, called DocShaDiffusion. It translates shadow images from pixel space to latent space, enabling the model to more easily capture essential features. To address the issue of color shadows, we design a shadow soft-mask generation module (SSGM). It is able to produce accurate shadow mask and add noise into shadow regions specially. Guided by the shadow mask, a shadow mask-aware guided diffusion module (SMGDM) is proposed to remove shadows from document images by supervising the diffusion and denoising process. We also propose a shadow-robust perceptual feature loss to preserve details and structures in document images. Moreover, we develop a large-scale synthetic document color shadow removal dataset (SDCSRD). It simulates the distribution of realistic color shadows and provides powerful supports for the training of models. Experiments on three public datasets validate the proposed method’s superiority over state-of-the-art. Our code and dataset will be publicly available.
文档阴影去除是文档图像增强领域中的一项关键任务。然而,现有方法往往只能去除具有恒定背景色的阴影,而忽略了彩色阴影。在本文中,我们首先在潜在空间设计一个扩散模型,用于文档图像阴影去除,称为DocShaDiffusion。它将阴影图像从像素空间翻译到潜在空间,使模型更容易捕捉关键特征。为了解决彩色阴影的问题,我们设计了一个阴影软掩膜生成模块(SSGM)。它能够产生准确的阴影掩膜,并在阴影区域添加特定噪声。在阴影掩膜的指导下,提出了阴影掩膜感知引导扩散模块(SMGDM),通过监督扩散和去噪过程来去除文档图像中的阴影。我们还提出了一种阴影鲁棒感知特征损失,以保留文档图像中的细节和结构。此外,我们开发了一个大规模合成文档彩色阴影去除数据集(SDCSRD)。它模拟了现实彩色阴影的分布,为模型训练提供了有力支持。在三个公开数据集上的实验验证了所提方法相较于最新技术的优越性。我们的代码和数据集将公开可用。
论文及项目相关链接
Summary
本文提出了一种基于扩散模型的文档图像阴影去除方法。通过设计潜伏空间的扩散模型(DocShaDiffusion),将阴影图像从像素空间翻译到潜伏空间,更易于捕捉关键特征。为解决彩色阴影问题,设计了阴影软掩膜生成模块(SSGM),能准确生成阴影掩膜,并在阴影区域添加噪声。在阴影掩膜的引导下,提出了阴影掩膜感知的扩散模块(SMGDM),通过监督扩散和去噪过程来去除文档图像中的阴影。同时,提出了阴影鲁棒感知特征损失,以保留文档图像中的细节和结构。此外,还开发了一个大规模的文档彩色阴影去除合成数据集(SDCSRD),模拟现实彩色阴影的分布,为模型训练提供有力支持。实验证明,该方法在三个公共数据集上的表现均优于现有技术。
Key Takeaways
- 提出了基于扩散模型的文档图像阴影去除方法。
- 设计了潜伏空间的扩散模型(DocShaDiffusion),实现从像素空间到潜伏空间的翻译。
- 引入阴影软掩膜生成模块(SSGM)以处理彩色阴影。
- 提出了阴影掩膜感知的扩散模块(SMGDM),通过监督扩散和去噪过程进行阴影去除。
- 引入了阴影鲁棒感知特征损失,以保留文档图像的细节和结构。
- 开发了一个文档彩色阴影去除合成数据集(SDCSRD),用于模型训练。
点此查看论文截图


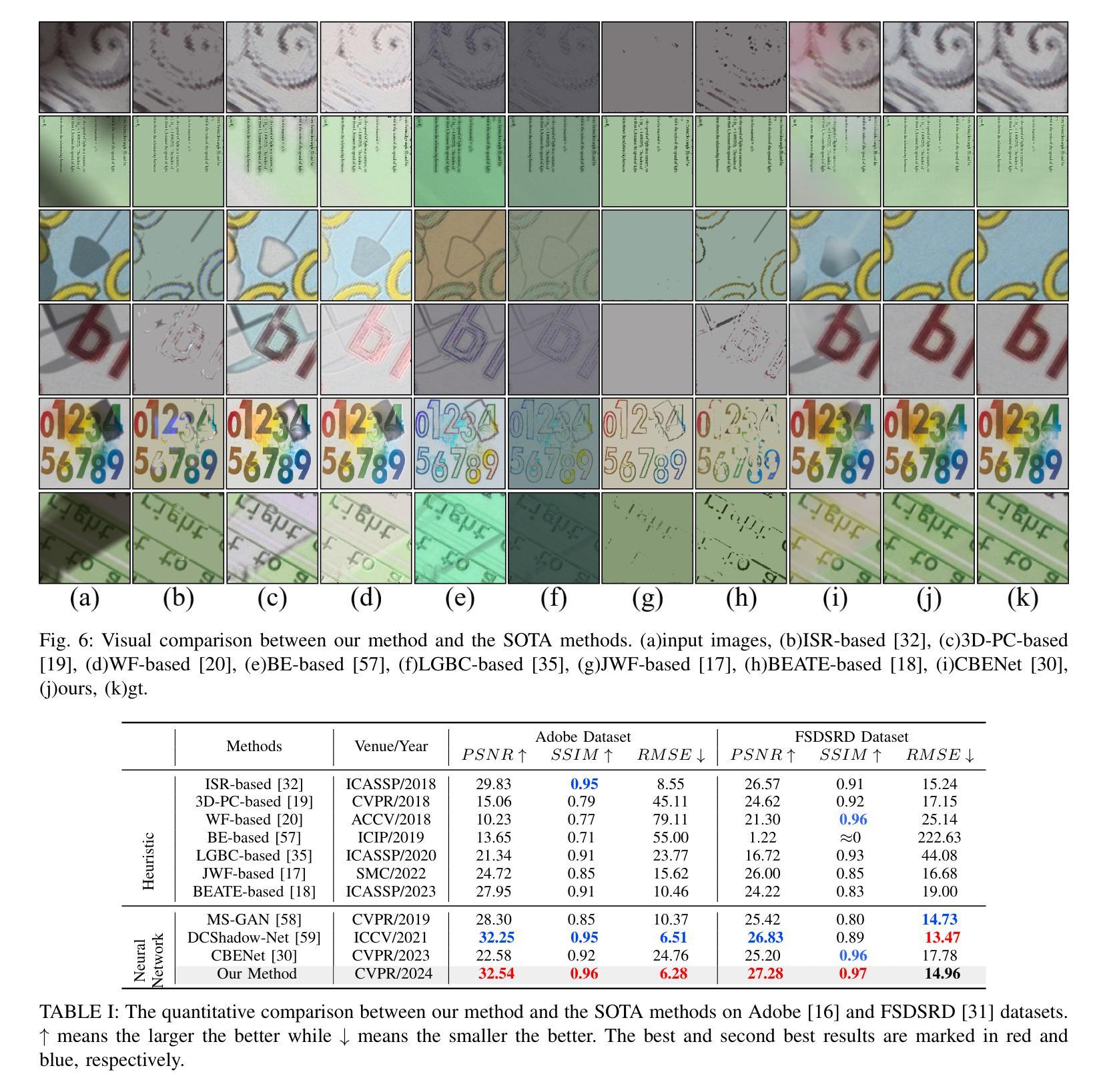
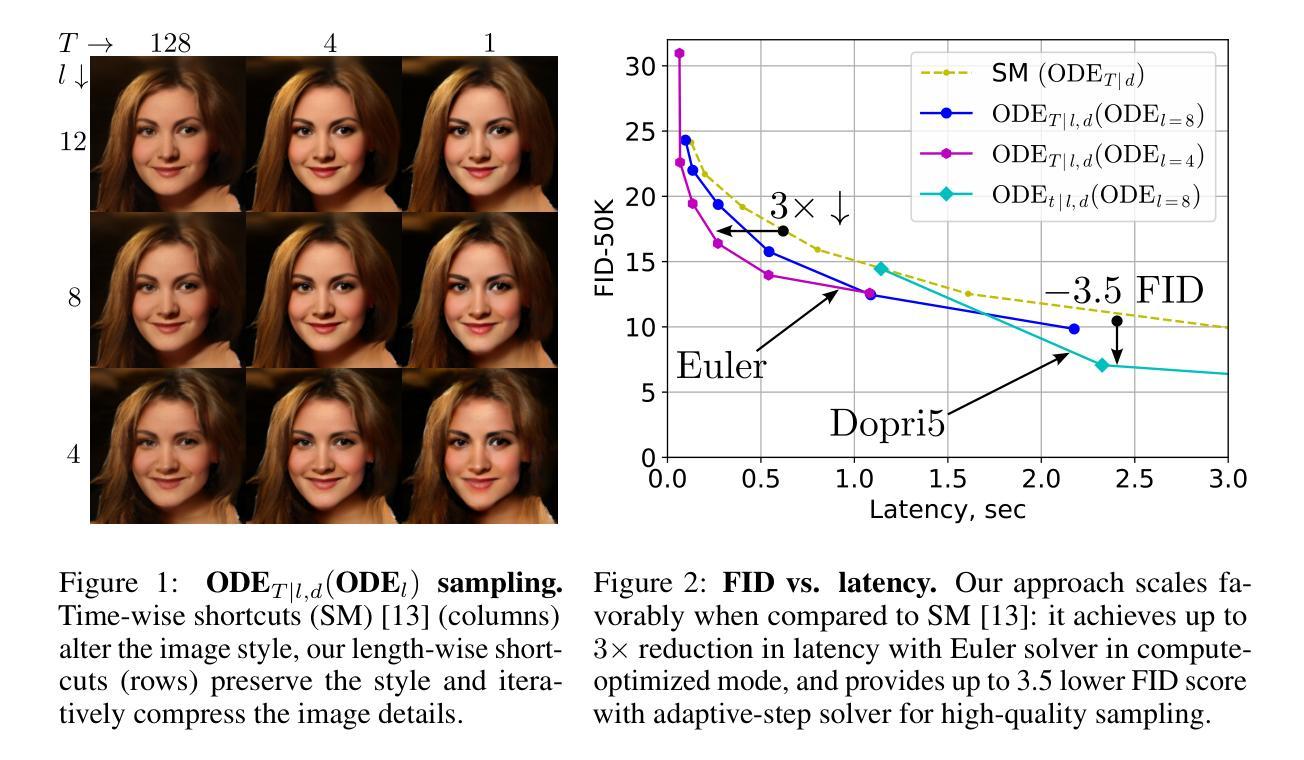
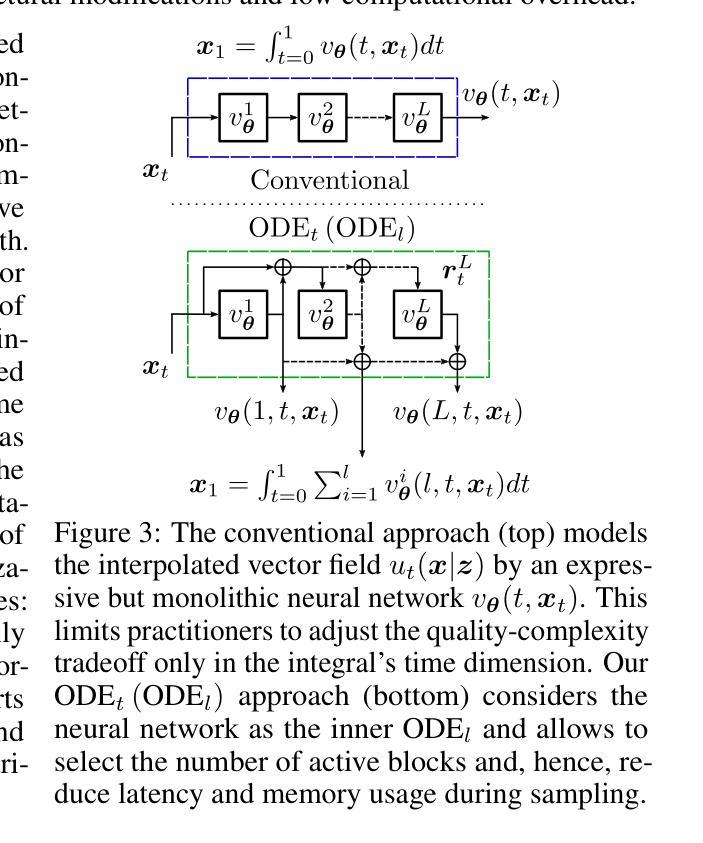
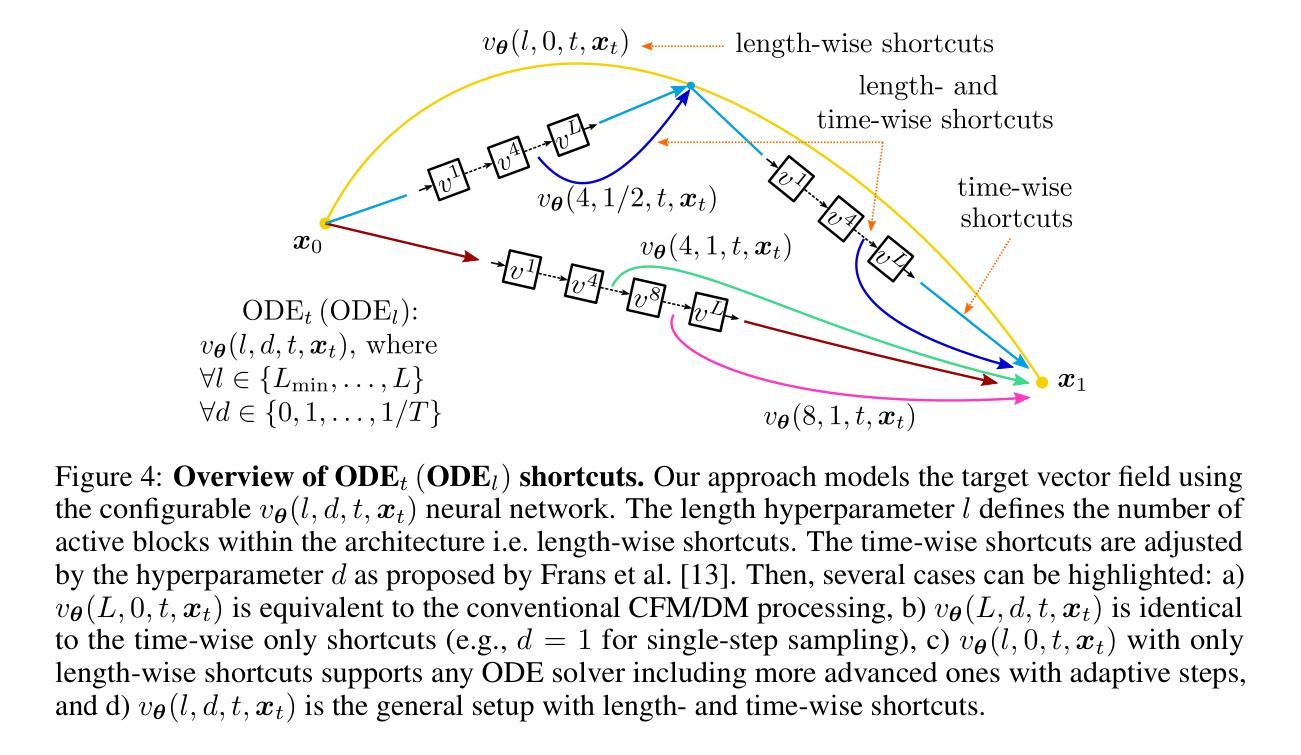
ODE$_t$(ODE$_l$): Shortcutting the Time and Length in Diffusion and Flow Models for Faster Sampling
Authors:Denis Gudovskiy, Wenzhao Zheng, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer
Recently, continuous normalizing flows (CNFs) and diffusion models (DMs) have been studied using the unified theoretical framework. Although such models can generate high-quality data points from a noise distribution, the sampling demands multiple iterations to solve an ordinary differential equation (ODE) with high computational complexity. Most existing methods focus on reducing the number of time steps during the sampling process to improve efficiency. In this work, we explore a complementary direction in which the quality-complexity tradeoff can be dynamically controlled in terms of time steps and in the length of the neural network. We achieve this by rewiring the blocks in the transformer-based architecture to solve an inner discretized ODE w.r.t. its length. Then, we employ time- and length-wise consistency terms during flow matching training, and as a result, the sampling can be performed with an arbitrary number of time steps and transformer blocks. Unlike others, our ODE$_t$(ODE$_l$) approach is solver-agnostic in time dimension and decreases both latency and memory usage. Compared to the previous state of the art, image generation experiments on CelebA-HQ and ImageNet show a latency reduction of up to 3$\times$ in the most efficient sampling mode, and a FID score improvement of up to 3.5 points for high-quality sampling. We release our code and model weights with fully reproducible experiments.
最近,连续归一化流(CNFs)和扩散模型(DMs)已经使用统一的理论框架进行了研究。尽管这些模型能够从噪声分布中生成高质量的数据点,但采样需要多次迭代来解决具有高超算复杂度的常微分方程(ODE)。大多数现有方法专注于减少采样过程中的时间步长数量以提高效率。在这项工作中,我们探索了一个可以动态控制质量复杂性权衡的方向,涉及时间步长和神经网络长度。我们通过在基于变压器的架构中重新连接块来解决问题,解决了一个关于其长度的内部离散化ODE。然后,我们在流匹配训练过程中引入了时间和长度一致性项,因此,采样可以使用任意数量的时间步长和变压器块进行。与其他方法不同,我们的ODEt(ODEl)方法是时间维度上的求解器无关,减少了延迟和内存使用。与先前的研究相比,在CelebA-HQ和ImageNet上的图像生成实验显示,在最有效的采样模式下延迟降低了高达三倍,高质量采样的FID分数提高了高达3.5分。我们发布了我们的代码和模型权重,并提供了可完全重复的实验。
论文及项目相关链接
PDF Preprint. Github page: github.com/gudovskiy/odelt
Summary
该文本介绍了近期对连续归一化流(CNFs)和扩散模型(DMs)的研究,这些模型能够从噪声分布生成高质量数据点,但采样需要解决具有计算复杂性的常微分方程(ODE)。本文探索了一个新方向,可以通过动态控制时间步长和神经网络长度来进行质量复杂度的权衡。通过重新连接变压器架构的块来解决内部离散化的ODE,并引入时间和长度一致性术语进行流匹配训练,实现了可在任意数量的时间步长和变压器块上进行采样的能力。本文的方法在时间和长度维度上是求解器无关的,可以降低延迟并减少内存使用。在CelebA-HQ和ImageNet上的图像生成实验表明,在最有效的采样模式下,延迟降低了三倍,高质量采样的FID分数提高了最多3.5分。
Key Takeaways
- CNFs和DMs使用统一的理论框架进行研究,能够生成高质量数据点,但采样涉及解决ODE,计算复杂度高。
- 现有方法主要关注减少采样过程中的时间步长以提高效率。
- 本文探索了一个新方向,通过动态控制时间步长和神经网络长度来权衡质量复杂度。
- 通过重写基于变压器的架构来解决内部离散化的ODE,并引入时间和长度一致性术语进行训练。
- 采样可以在任意数量的时间步长和变压器块上进行,方法在时间维度上是求解器无关的。
- 与现有技术相比,在CelebA-HQ和ImageNet上的图像生成实验中,延迟降低了三倍,FID分数有所提高。
点此查看论文截图


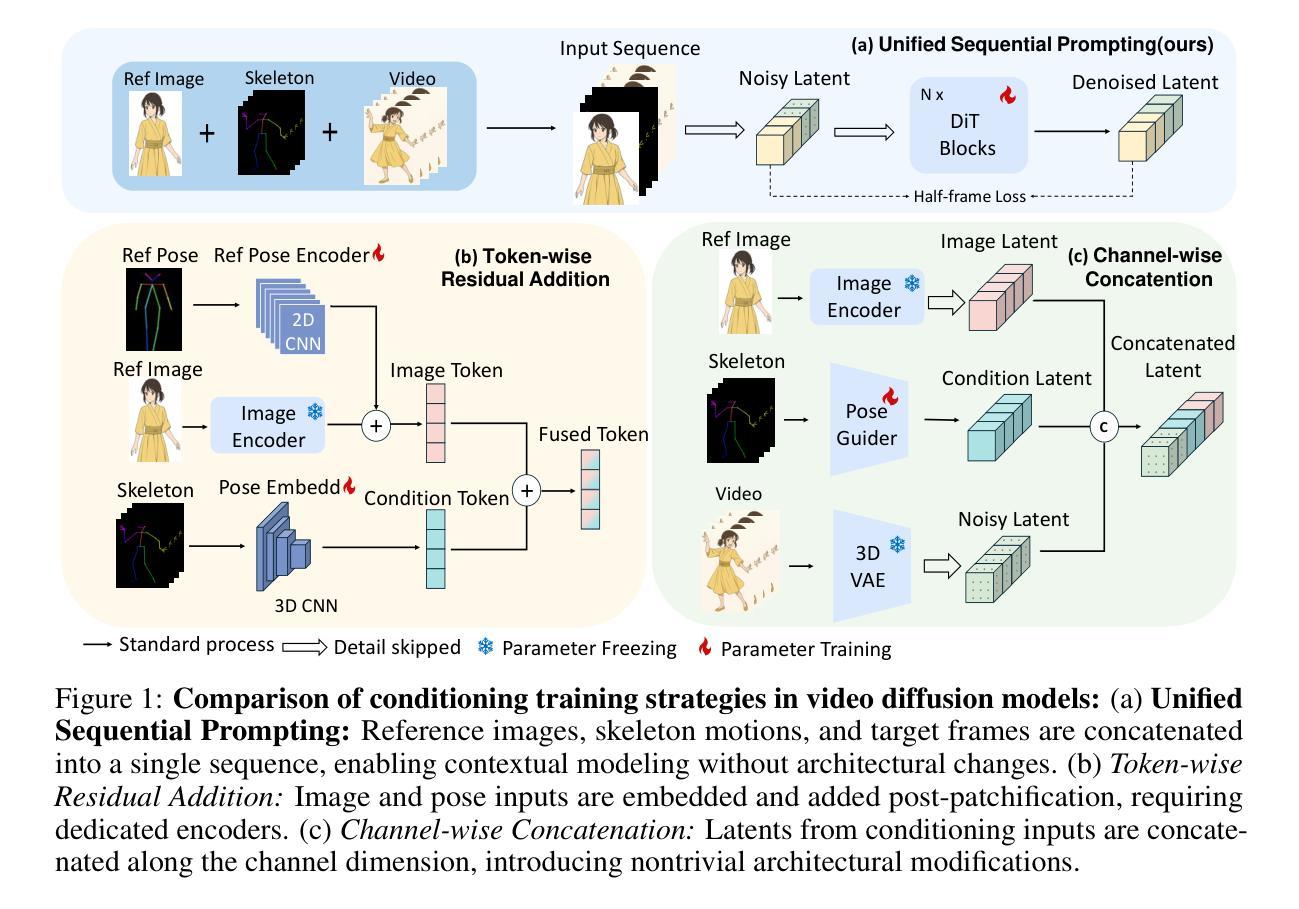
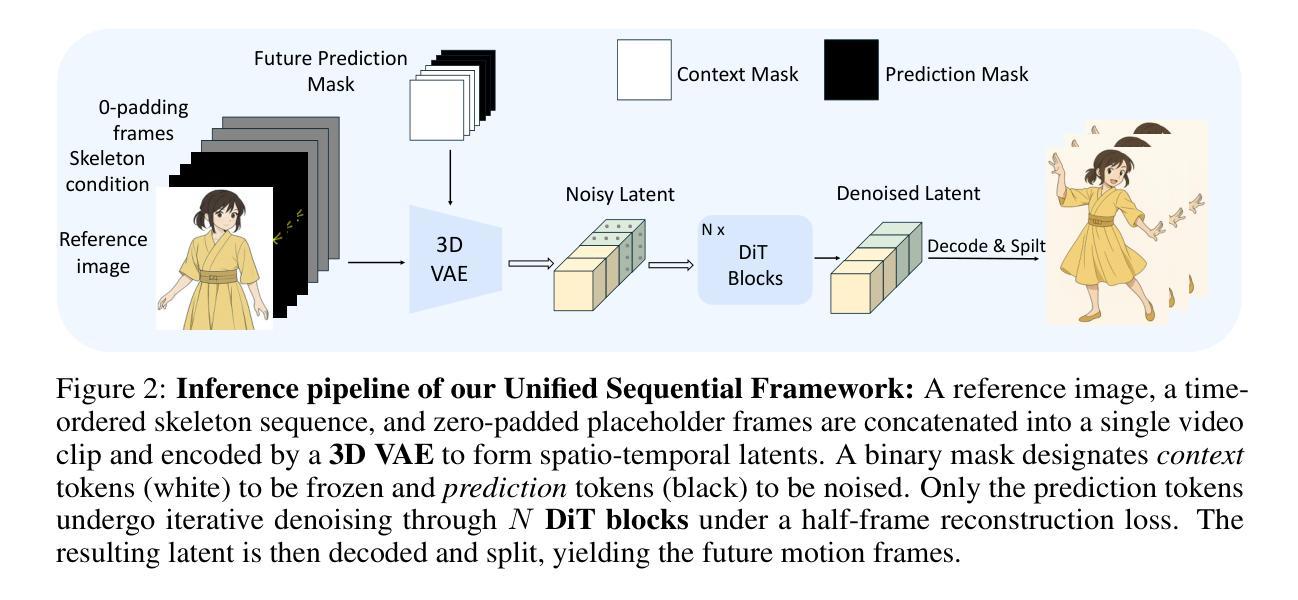
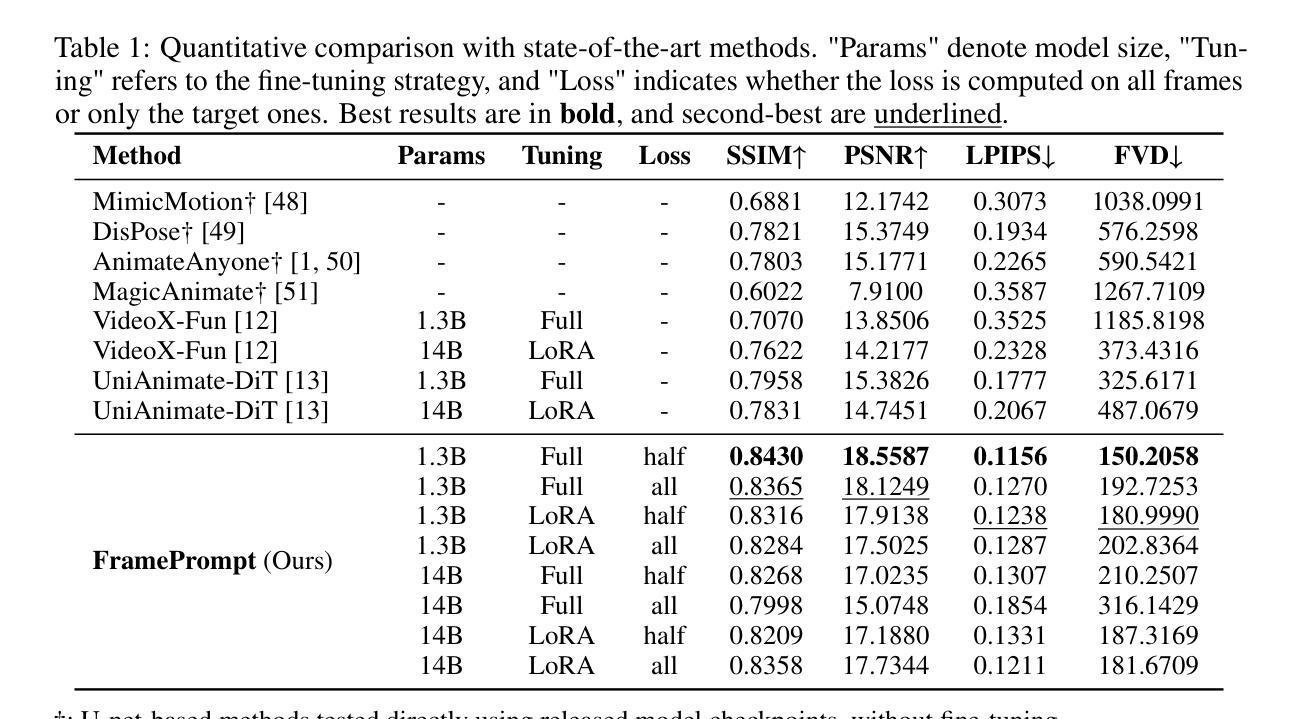
FramePrompt: In-context Controllable Animation with Zero Structural Changes
Authors:Guian Fang, Yuchao Gu, Mike Zheng Shou
Generating controllable character animation from a reference image and motion guidance remains a challenging task due to the inherent difficulty of injecting appearance and motion cues into video diffusion models. Prior works often rely on complex architectures, explicit guider modules, or multi-stage processing pipelines, which increase structural overhead and hinder deployment. Inspired by the strong visual context modeling capacity of pre-trained video diffusion transformers, we propose FramePrompt, a minimalist yet powerful framework that treats reference images, skeleton-guided motion, and target video clips as a unified visual sequence. By reformulating animation as a conditional future prediction task, we bypass the need for guider networks and structural modifications. Experiments demonstrate that our method significantly outperforms representative baselines across various evaluation metrics while also simplifying training. Our findings highlight the effectiveness of sequence-level visual conditioning and demonstrate the potential of pre-trained models for controllable animation without architectural changes.
从参考图像和运动指导生成可控角色动画仍然是一个具有挑战性的任务,因为将外观和运动线索注入视频扩散模型固有的难度。以前的工作经常依赖于复杂的架构、明确的指导模块或多阶段处理管道,这增加了结构上的额外负担并阻碍了部署。受到预训练视频扩散变压器强大视觉上下文建模能力的启发,我们提出了FramePrompt,这是一个极简而强大的框架,将参考图像、骨架引导的运动和目标视频片段视为统一视觉序列。通过重新制定动画作为条件未来预测任务,我们不需要指导网络和结构修改。实验表明,我们的方法在多种评估指标上显著优于代表性基线,同时简化了训练。我们的研究结果表明序列级视觉调节的有效性,并展示了预训练模型在无需架构更改的情况下进行可控动画的潜力。
论文及项目相关链接
PDF Project page: https://frameprompt.github.io/
摘要
该文针对从参考图像和运动指导生成可控角色动画的挑战,提出了FramePrompt框架。该框架利用预训练的视频扩散变压器强大的视觉上下文建模能力,将参考图像、骨架引导的运动和目标视频片段视为统一视觉序列。通过将其重新表述为条件未来预测任务,避开了对指导网络的结构修改需求。实验表明,该方法在多种评估指标上显著优于代表性基线,同时简化了训练。研究强调了序列级视觉条件的有效性,并展示了预训练模型在无需架构更改的情况下进行可控动画的潜力。
要点
- 生成从参考图像和运动指导的可控角色动画是一个具有挑战性的任务。
- 此前的方法常常依赖复杂的架构、明确的引导模块或多阶段处理管道,这增加了结构上的负担并阻碍了部署。
- FramePrompt框架利用预训练的视频扩散变压器的视觉上下文建模能力,将参考图像、骨架引导的运动和目标视频片段视为统一视觉序列。
- 通过将动画重新表述为条件未来预测任务,避开了对指导网络和结构修改的需求。
- 实验表明,FramePrompt在多种评估指标上优于现有方法。
- 研究强调了序列级视觉条件的有效性。
- 预训练模型在可控动画方面具有潜力,且无需进行架构更改。
点此查看论文截图

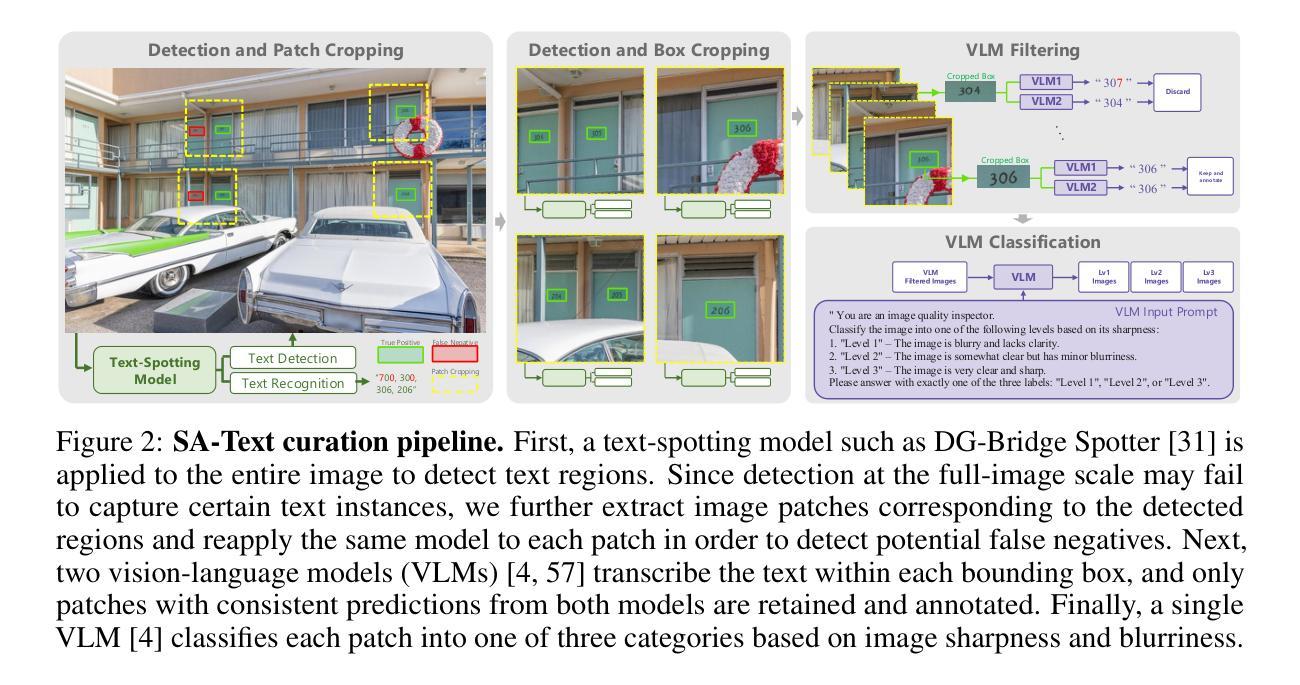
Text-Aware Image Restoration with Diffusion Models
Authors:Jaewon Min, Jin Hyeon Kim, Paul Hyunbin Cho, Jaeeun Lee, Jihye Park, Minkyu Park, Sangpil Kim, Hyunhee Park, Seungryong Kim
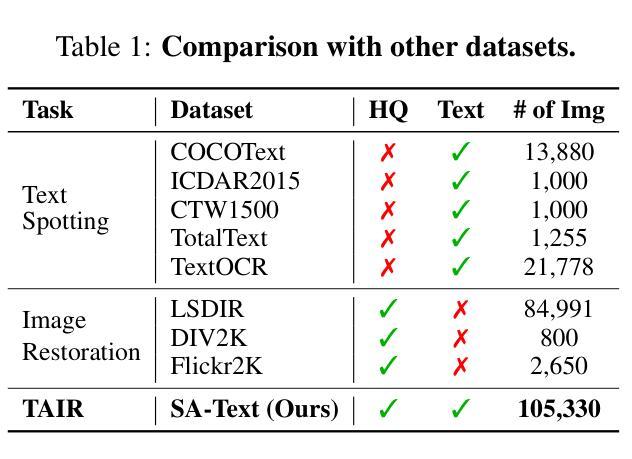
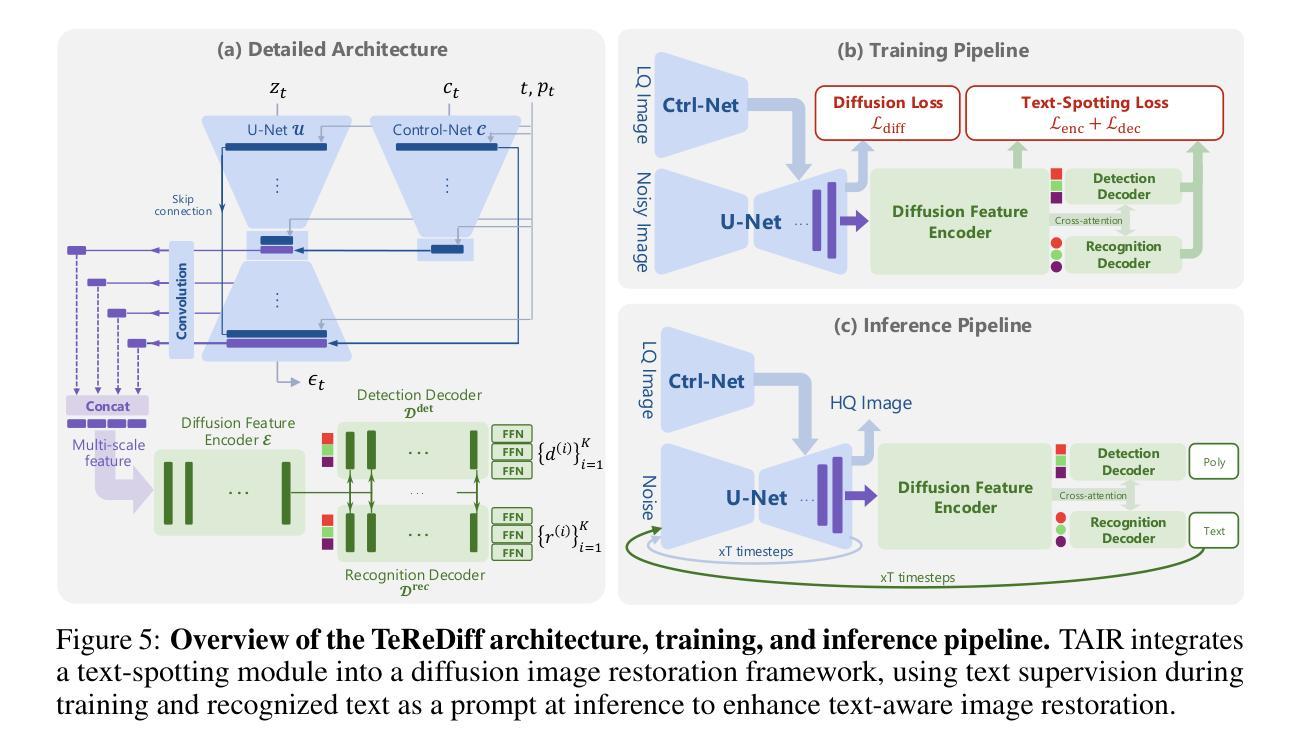
Image restoration aims to recover degraded images. However, existing diffusion-based restoration methods, despite great success in natural image restoration, often struggle to faithfully reconstruct textual regions in degraded images. Those methods frequently generate plausible but incorrect text-like patterns, a phenomenon we refer to as text-image hallucination. In this paper, we introduce Text-Aware Image Restoration (TAIR), a novel restoration task that requires the simultaneous recovery of visual contents and textual fidelity. To tackle this task, we present SA-Text, a large-scale benchmark of 100K high-quality scene images densely annotated with diverse and complex text instances. Furthermore, we propose a multi-task diffusion framework, called TeReDiff, that integrates internal features from diffusion models into a text-spotting module, enabling both components to benefit from joint training. This allows for the extraction of rich text representations, which are utilized as prompts in subsequent denoising steps. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art restoration methods, achieving significant gains in text recognition accuracy. See our project page: https://cvlab-kaist.github.io/TAIR/
图像修复旨在恢复退化图像。然而,现有的基于扩散的修复方法虽然在自然图像修复中取得了巨大成功,但在退化图像的文本区域重建中却常常难以忠实还原。这些方法经常生成看似合理但错误的文本模式,我们将这种现象称为文本图像幻觉。在本文中,我们引入了文本感知图像修复(TAIR)这一新的修复任务,该任务要求同时恢复视觉内容和文本忠实度。为解决此任务,我们推出了SA-Text,这是一个大规模基准测试,包含10万张高质量场景图像,密集标注了多样且复杂的文本实例。此外,我们提出了一个多任务扩散框架,称为TeReDiff,它将扩散模型的内部特征集成到文本点模块中,使两个组件都能从联合训练中受益。这允许提取丰富的文本表示,用作后续去噪步骤中的提示。大量实验表明,我们的方法始终优于最先进的修复方法,在文本识别准确性方面取得了显著的提升。请访问我们的项目页面:https://cvlab-kaist.github.io/TAIR/
论文及项目相关链接
PDF Project page: https://cvlab-kaist.github.io/TAIR/
Summary
文本介绍了图像修复的目标和现有扩散模型在处理文本区域时的挑战。为解决这一问题,本文提出了文本感知图像修复(TAIR)任务,并介绍了针对该任务的大型基准数据集SA-Text。此外,提出了一种多任务扩散框架TeReDiff,它通过整合扩散模型的内部特征与文本识别模块,提高了文本识别的准确性。实验证明,该方法在文本识别准确率上明显优于现有修复方法。
Key Takeaways
- 图像修复的目标:恢复受损图像。
- 现有扩散模型挑战:在自然图像恢复方面表现出色,但在文本区域重建时往往出现问题。
- 文本感知图像修复任务介绍:需要同时恢复视觉内容和文本保真度。
- 大型基准数据集SA-Text介绍:包含10万张高质量场景图像,密集标注了多样且复杂的文本实例。
- 多任务扩散框架TeReDiff:整合扩散模型的内部特征与文本识别模块进行联合训练。
- TeReDiff的优势:提取丰富的文本表示,用于后续去噪步骤中的提示。
- 实验结果:该方法在文本识别准确率上优于现有修复方法。
点此查看论文截图



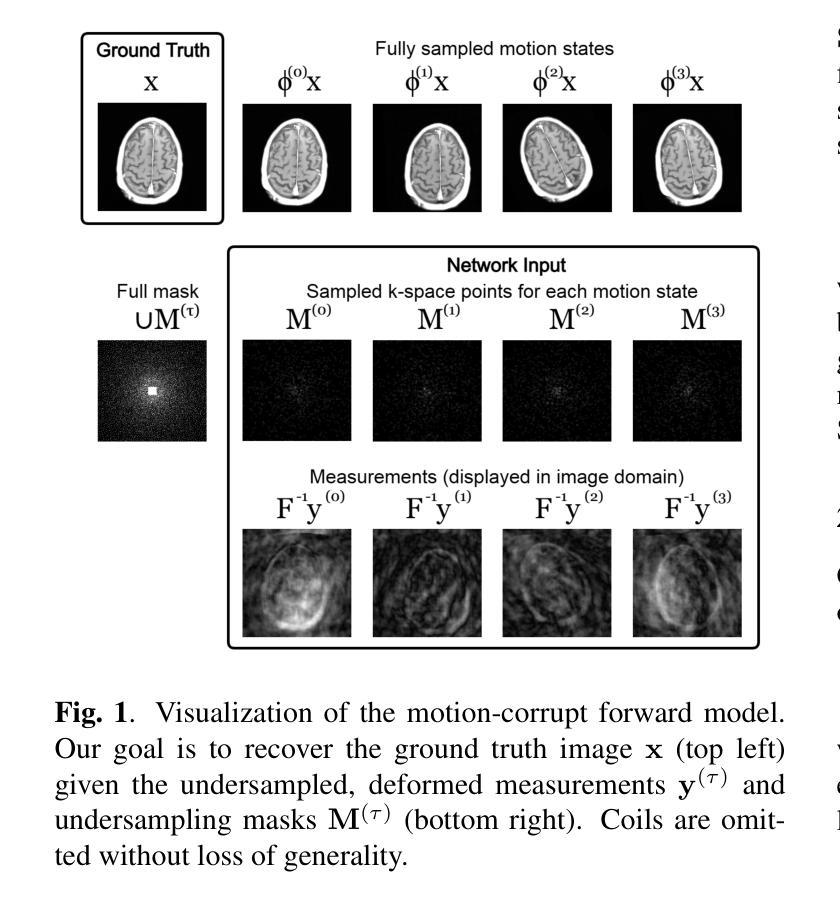
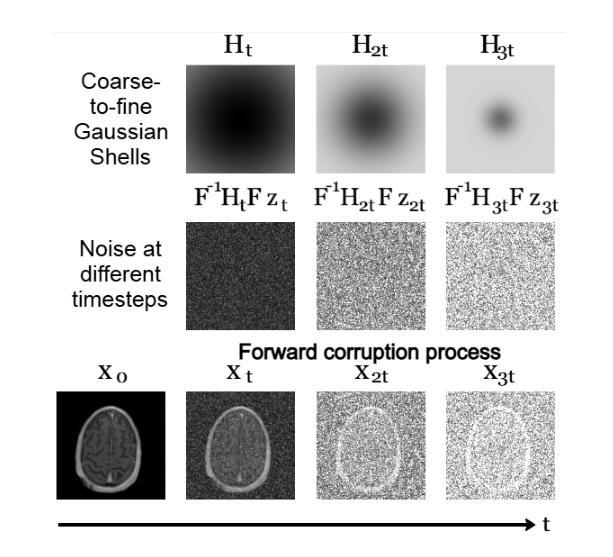
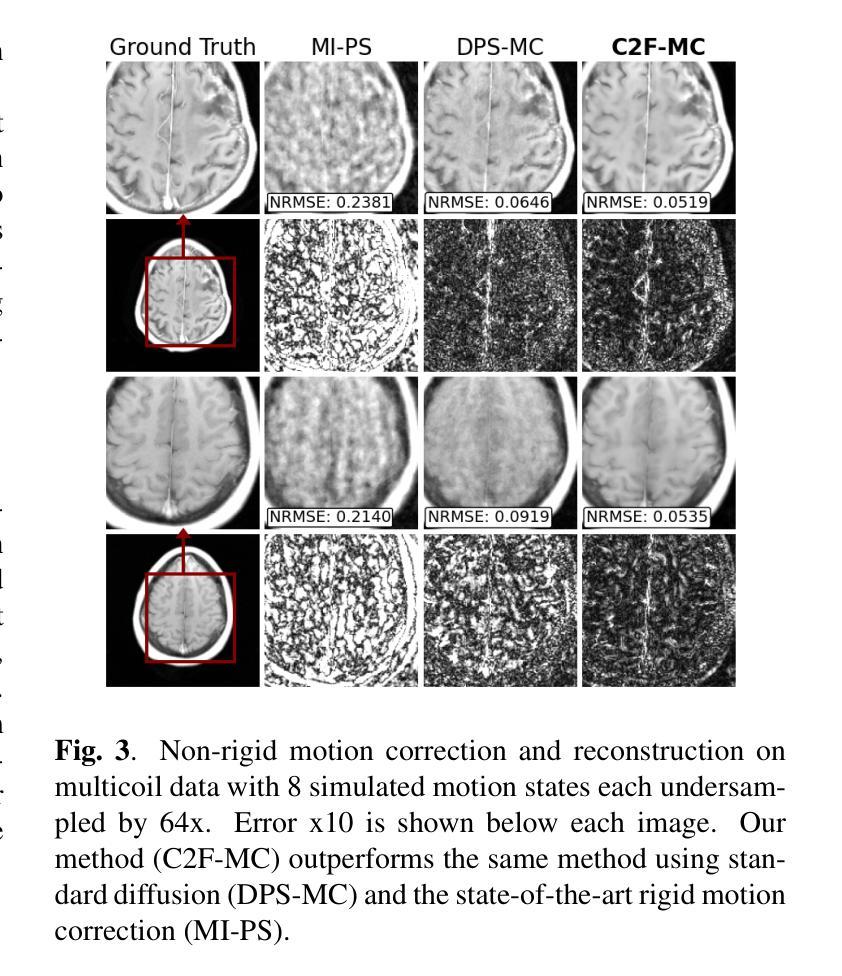
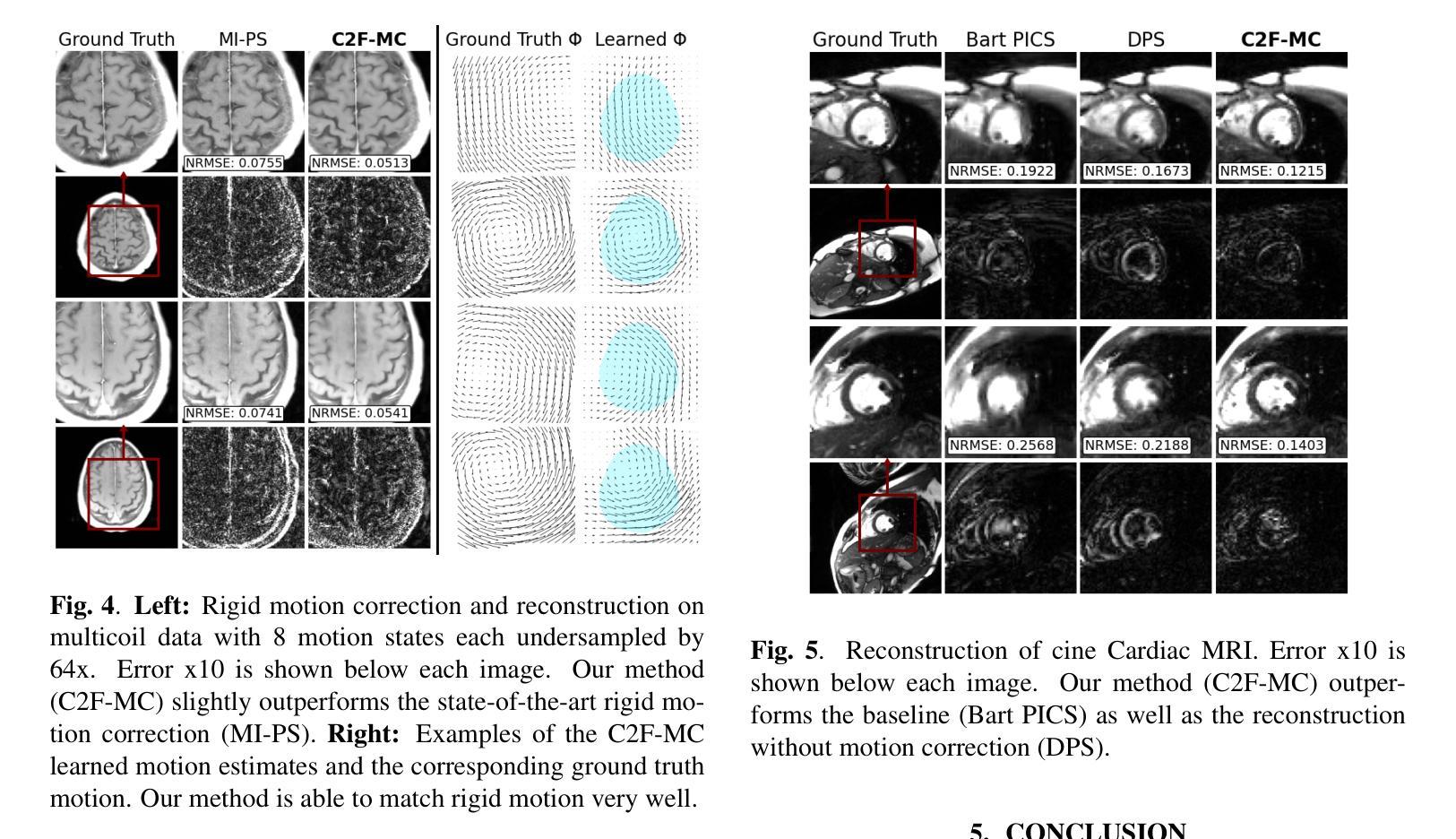
Non-rigid Motion Correction for MRI Reconstruction via Coarse-To-Fine Diffusion Models
Authors:Frederic Wang, Jonathan I. Tamir
Magnetic Resonance Imaging (MRI) is highly susceptible to motion artifacts due to the extended acquisition times required for k-space sampling. These artifacts can compromise diagnostic utility, particularly for dynamic imaging. We propose a novel alternating minimization framework that leverages a bespoke diffusion model to jointly reconstruct and correct non-rigid motion-corrupted k-space data. The diffusion model uses a coarse-to-fine denoising strategy to capture large overall motion and reconstruct the lower frequencies of the image first, providing a better inductive bias for motion estimation than that of standard diffusion models. We demonstrate the performance of our approach on both real-world cine cardiac MRI datasets and complex simulated rigid and non-rigid deformations, even when each motion state is undersampled by a factor of 64x. Additionally, our method is agnostic to sampling patterns, anatomical variations, and MRI scanning protocols, as long as some low frequency components are sampled during each motion state.
磁共振成像(MRI)由于k空间采样所需的长采集时间,很容易受到运动伪影的影响。这些伪影可能会降低诊断的效用,特别是在动态成像中。我们提出了一种新型交替最小化框架,它利用专用扩散模型联合重建和纠正非刚性运动损坏的k空间数据。扩散模型采用由粗到细的降噪策略,首先捕捉整体大运动并重建图像的低频部分,为运动估计提供比标准扩散模型更好的归纳偏见。我们在现实世界的心脏电影MRI数据集和复杂的模拟刚性和非刚性变形上展示了我们的方法性能,即使在每个运动状态下以64倍欠采样的情况下也是如此。此外,我们的方法对采样模式、解剖变化和MRI扫描协议没有特定的要求,只要在每个运动状态下采样一些低频成分即可。
论文及项目相关链接
PDF ICIP 2025
Summary
本文提出了一种利用定制的扩散模型的新交替最小化框架,联合重建和校正非刚性运动受干扰的k-空间数据。扩散模型采用从粗到细的降噪策略,首先捕捉整体大运动并重建图像的低频部分,为运动估计提供更好的归纳偏置。该模型对真实世界的电影心脏MRI数据集和复杂的模拟刚性及非刚性变形都有良好表现,即使在每个运动状态欠采样64倍的情况下也是如此。此外,该方法对采样模式、解剖变化和MRI扫描协议都具有鲁棒性,只要每个运动状态期间都采样了一些低频成分即可。
Key Takeaways
- 扩散模型用于MRI中的非刚性运动校正。
- 模型结合了重建和校正运动受干扰的k-空间数据。
- 采用从粗到细的降噪策略来处理整体大运动和低频图像重建。
- 模型在真实和模拟的MRI数据集上都表现出良好的性能。
- 模型对多种运动状态具有良好的适应性,即使在高度欠采样的情况下也能工作。
- 方法对各种采样模式、解剖变化和MRI扫描协议具有鲁棒性。
点此查看论文截图