⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-05 更新
CanonSwap: High-Fidelity and Consistent Video Face Swapping via Canonical Space Modulation
Authors:Xiangyang Luo, Ye Zhu, Yunfei Liu, Lijian Lin, Cong Wan, Zijian Cai, Shao-Lun Huang, Yu Li
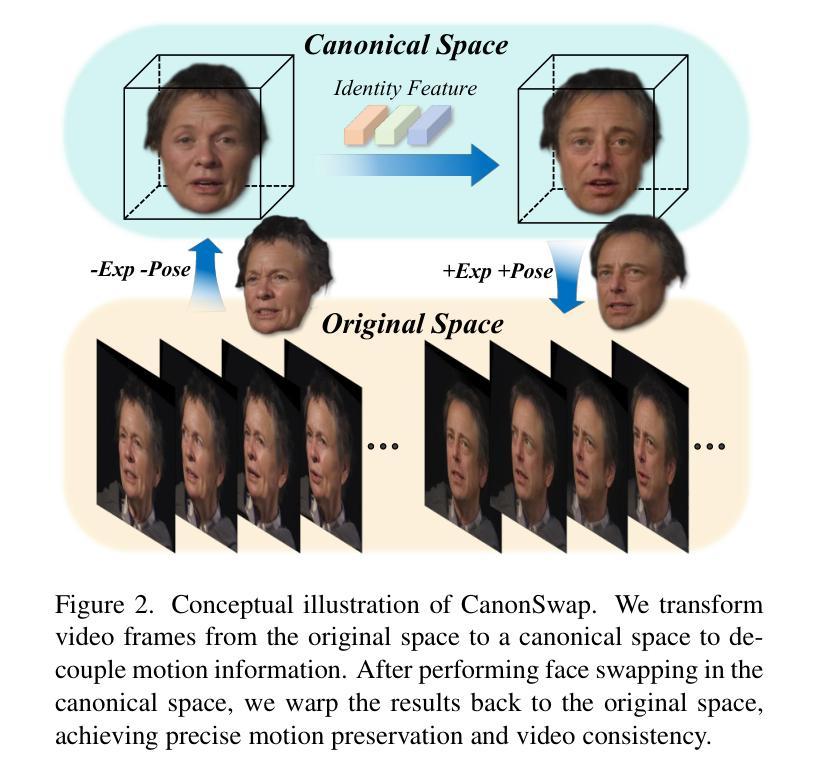
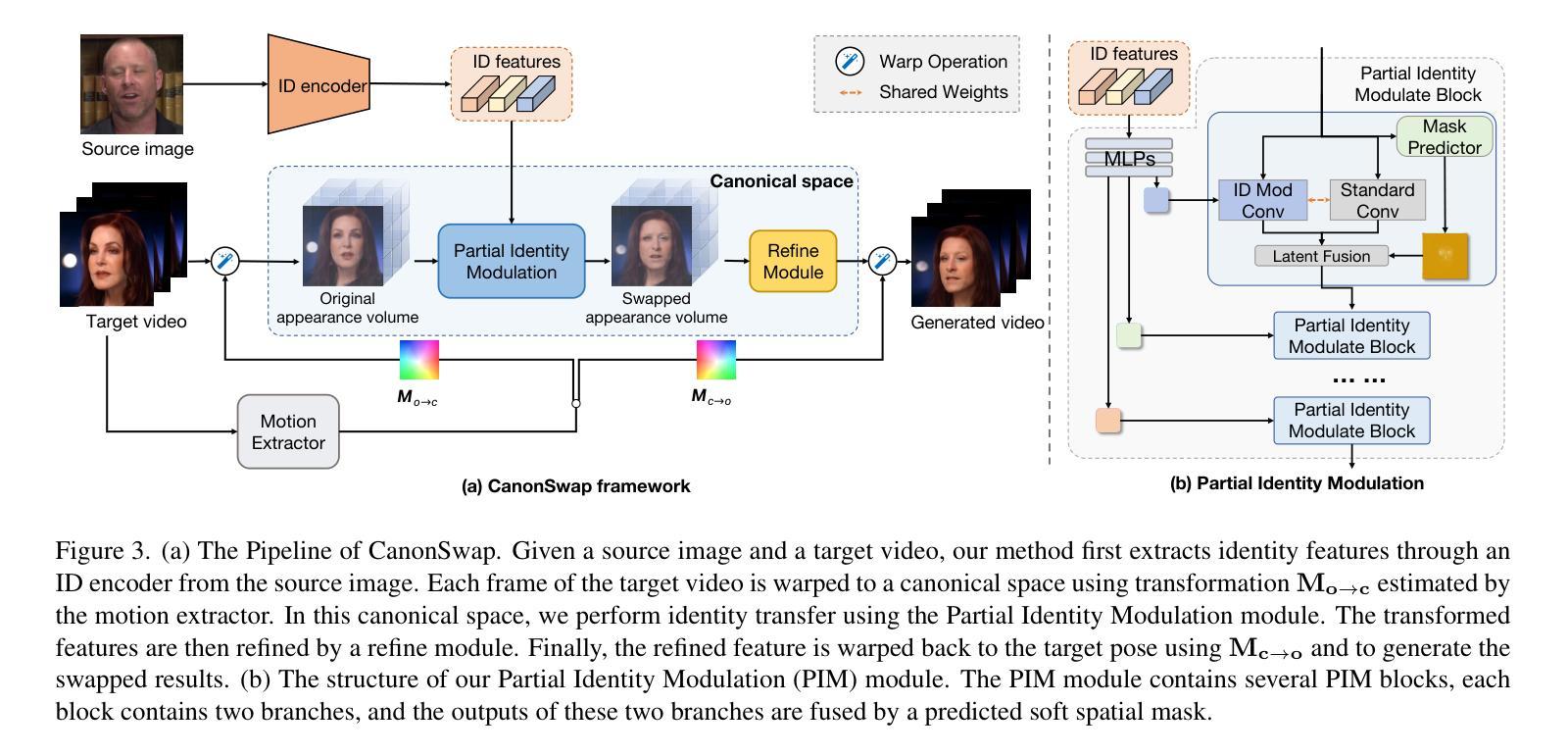
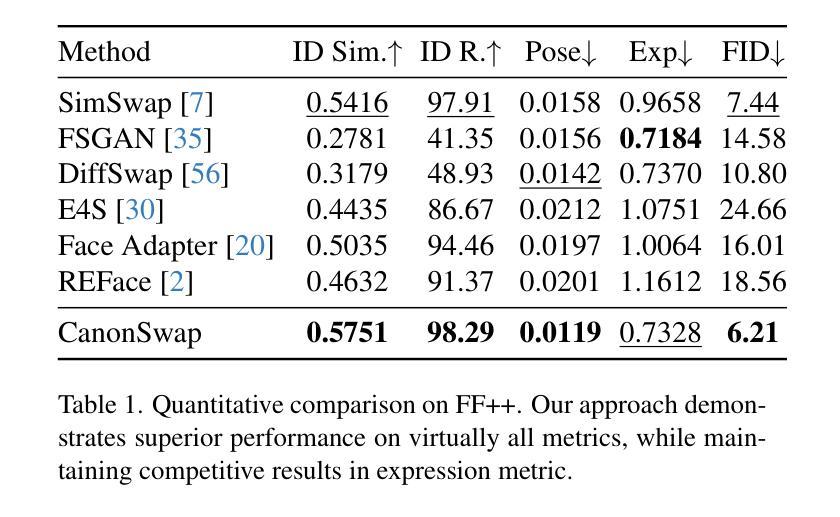
Video face swapping aims to address two primary challenges: effectively transferring the source identity to the target video and accurately preserving the dynamic attributes of the target face, such as head poses, facial expressions, lip-sync, \etc. Existing methods mainly focus on achieving high-quality identity transfer but often fall short in maintaining the dynamic attributes of the target face, leading to inconsistent results. We attribute this issue to the inherent coupling of facial appearance and motion in videos. To address this, we propose CanonSwap, a novel video face-swapping framework that decouples motion information from appearance information. Specifically, CanonSwap first eliminates motion-related information, enabling identity modification within a unified canonical space. Subsequently, the swapped feature is reintegrated into the original video space, ensuring the preservation of the target face’s dynamic attributes. To further achieve precise identity transfer with minimal artifacts and enhanced realism, we design a Partial Identity Modulation module that adaptively integrates source identity features using a spatial mask to restrict modifications to facial regions. Additionally, we introduce several fine-grained synchronization metrics to comprehensively evaluate the performance of video face swapping methods. Extensive experiments demonstrate that our method significantly outperforms existing approaches in terms of visual quality, temporal consistency, and identity preservation. Our project page are publicly available at https://luoxyhappy.github.io/CanonSwap/.
视频换脸技术主要解决两个挑战:有效将源身份转移到目标视频,并准确保留目标脸部的动态属性,如头部姿势、面部表情、唇部同步等。现有方法主要集中在实现高质量的身份转移,但往往难以保持目标脸部的动态属性,导致结果不一致。我们认为这个问题源于视频中面部外观和动作的固有耦合。为了解决这一问题,我们提出了CanonSwap,一种新型视频换脸框架,能够将动作信息与外观信息解耦。具体来说,CanonSwap首先消除与动作相关的信息,在统一的标准空间内进行身份修改。随后,将交换后的特征重新整合到原始视频空间中,确保目标脸部的动态属性得以保留。为了进一步实现精确的身份转移,减少伪影,提高逼真度,我们设计了一个局部身份调制模块,该模块自适应地集成源身份特征,使用空间掩膜来限制面部区域的修改。此外,我们还引入了几种精细的同步指标,以全面评估视频换脸方法的性能。大量实验表明,我们的方法在视觉质量、时间一致性和身份保留方面显著优于现有方法。我们的项目页面可在https://luoxyhappy.github.io/CanonSwap/公开访问。
论文及项目相关链接
PDF ICCV Accepted
Summary
本文介绍了视频换脸技术面临的主要挑战及现有方法的不足,并提出了一个新的视频换脸框架CanonSwap。该框架通过解耦运动信息和外观信息,实现了身份修改和目标脸动态属性的保留。采用部分身份调制模块自适应集成身份特征,并引入精细同步指标全面评估视频换脸性能。实验表明,该方法在视觉质量、时间一致性和身份保留方面显著优于现有方法。
Key Takeaways
- 视频换脸技术面临两大挑战:有效转移源身份并准确保留目标脸的动态属性。
- 现有方法主要关注高质量身份转移,但在保持目标脸动态属性方面表现不足。
- CanonSwap框架通过解耦运动信息和外观信息,解决这一问题。
- CanonSwap先消除运动相关信息,在统一规范空间进行身份修改。
- 随后将交换的特征重新整合到原始视频空间,保留目标脸的动态属性。
- 部分身份调制模块自适应集成源身份特征,采用空间掩膜限制修改面部区域。
点此查看论文截图