⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-05 更新
BronchoGAN: Anatomically consistent and domain-agnostic image-to-image translation for video bronchoscopy
Authors:Ahmad Soliman, Ron Keuth, Marian Himstedt
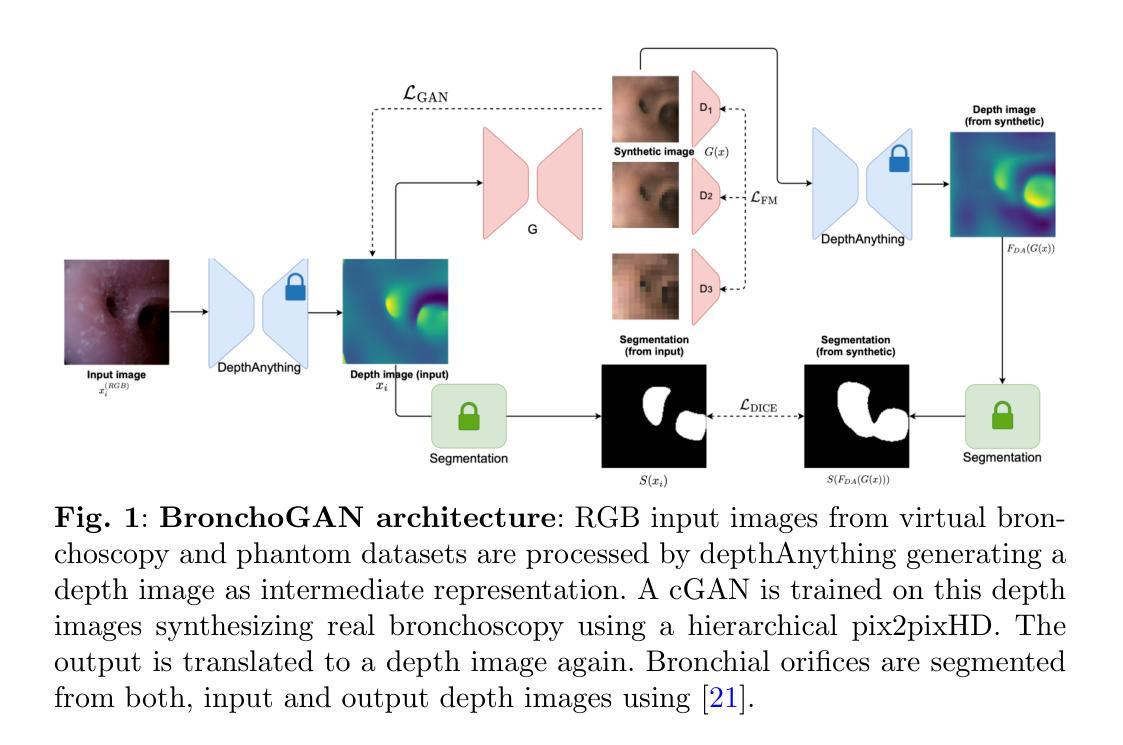
The limited availability of bronchoscopy images makes image synthesis particularly interesting for training deep learning models. Robust image translation across different domains – virtual bronchoscopy, phantom as well as in-vivo and ex-vivo image data – is pivotal for clinical applications. This paper proposes BronchoGAN introducing anatomical constraints for image-to-image translation being integrated into a conditional GAN. In particular, we force bronchial orifices to match across input and output images. We further propose to use foundation model-generated depth images as intermediate representation ensuring robustness across a variety of input domains establishing models with substantially less reliance on individual training datasets. Moreover our intermediate depth image representation allows to easily construct paired image data for training. Our experiments showed that input images from different domains (e.g. virtual bronchoscopy, phantoms) can be successfully translated to images mimicking realistic human airway appearance. We demonstrated that anatomical settings (i.e. bronchial orifices) can be robustly preserved with our approach which is shown qualitatively and quantitatively by means of improved FID, SSIM and dice coefficients scores. Our anatomical constraints enabled an improvement in the Dice coefficient of up to 0.43 for synthetic images. Through foundation models for intermediate depth representations, bronchial orifice segmentation integrated as anatomical constraints into conditional GANs we are able to robustly translate images from different bronchoscopy input domains. BronchoGAN allows to incorporate public CT scan data (virtual bronchoscopy) in order to generate large-scale bronchoscopy image datasets with realistic appearance. BronchoGAN enables to bridge the gap of missing public bronchoscopy images.
支气管镜图像有限,这使得图像合成对于训练深度学习模型尤其具有吸引力。在不同领域(如虚拟支气管镜、幻影成像以及体内和体外图像数据)之间进行稳健的图像翻译对于临床应用至关重要。本文提出了BronchoGAN,引入了图像到图像翻译的解剖学约束,并将其集成到条件生成对抗网络(GAN)中。特别是,我们强制要求支气管开口在输入和输出图像之间匹配。我们进一步建议使用基础模型生成的深度图像作为中间表示,以确保在不同输入领域的稳健性,并建立对个别训练数据集依赖更少的模型。此外,我们的中间深度图像表示法可以轻松地构建用于训练配对的图像数据。我们的实验表明,来自不同领域的输入图像(例如虚拟支气管镜、幻影成像)可以成功翻译成模拟真实人类气道外观的图像。我们证明了通过使用我们的方法,解剖学设置(即支气管开口)可以稳健地保留下来,并通过改善的FID、SSIM和Dice系数得分进行定性和定量证明。我们的解剖学约束使合成图像的Dice系数提高了高达0.43。通过基础模型的中间深度表示法,将支气管开口分割作为解剖学约束集成到条件GANs中,我们能够稳健地翻译来自不同支气管镜输入领域的图像。BronchoGAN允许整合公共CT扫描数据(虚拟支气管镜)以生成具有逼真外观的大规模支气管镜图像数据集。BronchoGAN能够弥补公共支气管镜图像缺失的空白。
论文及项目相关链接
Summary
本文介绍了BronchoGAN,一种基于条件生成对抗网络(GAN)的支气管镜图像合成方法。该方法引入了解剖学约束,能够跨不同领域进行图像到图像的翻译,如虚拟支气管镜、幻影以及体内和体外图像数据。通过使用基础模型生成的深度图像作为中间表示,BronchoGAN确保了跨各种输入领域的稳健性,并减少了了对个别训练数据集的依赖。实验表明,该方法能够成功地将不同领域的输入图像翻译成真实人类气道外观的图像,并定性定量地保留解剖学设置。通过引入解剖学约束和基于基础模型的中间深度表示,BronchoGAN能够在不同的支气管镜输入领域实现图像稳健转换。此外,BronchoGAN还允许利用公共CT扫描数据生成大规模、具有真实感的支气管镜图像数据集,从而解决了公共支气管镜图像缺失的问题。
Key Takeaways
- BronchoGAN 是一种用于合成支气管镜图像的方法,基于条件GAN,具备跨不同领域图像翻译的能力。
- 该方法引入了解剖学约束,以确保图像翻译过程中的结构准确性。
- 使用基础模型生成的深度图像作为中间表示,提高了模型的稳健性并降低了对个别训练数据集的依赖。
- 实验证明,BronchoGAN能够成功将不同领域的输入图像转换为逼真的气道外观图像,并有效保留解剖学特征。
- 通过引入解剖学约束和中间深度表示,BronchoGAN能够在不同支气管镜输入领域实现稳健的图像转换。
- BronchoGAN允许利用公共CT扫描数据生成大规模的支气管镜图像数据集,解决了公共支气管镜图像缺失的问题。
点此查看论文截图