⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-05 更新
Unsupervised Cardiac Video Translation Via Motion Feature Guided Diffusion Model
Authors:Swakshar Deb, Nian Wu, Frederick H. Epstein, Miaomiao Zhang
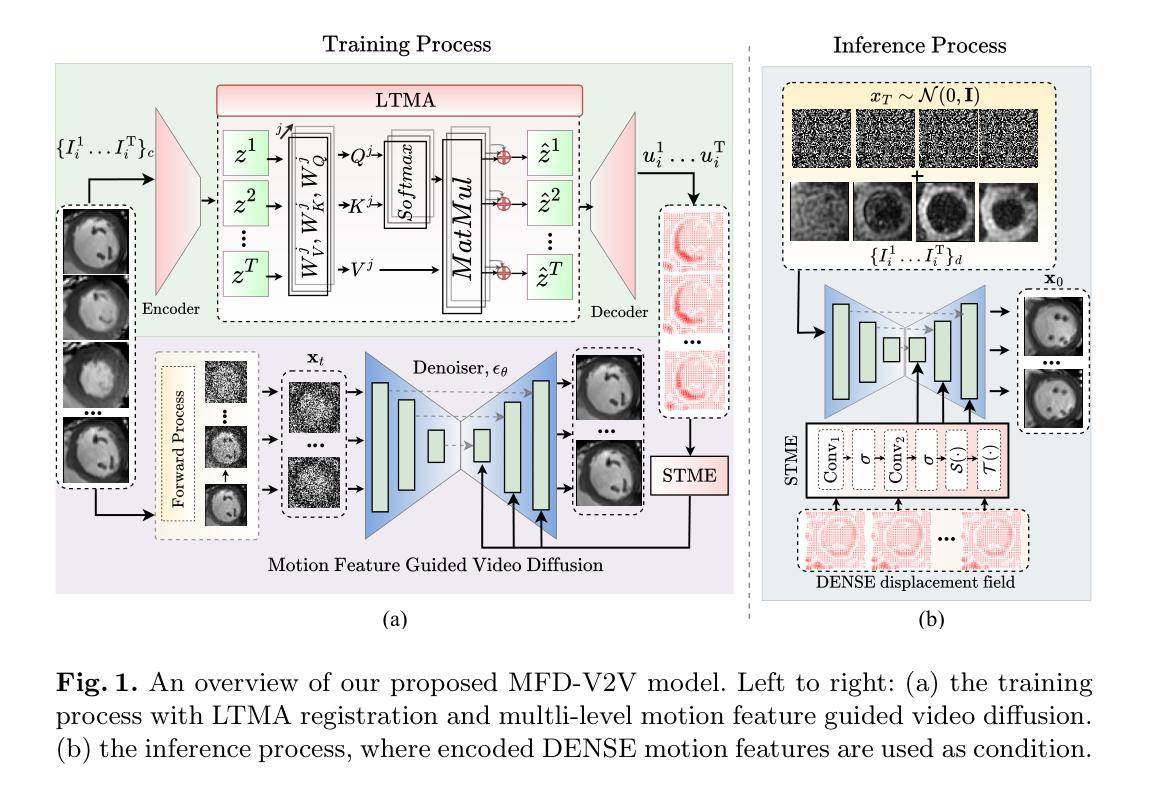
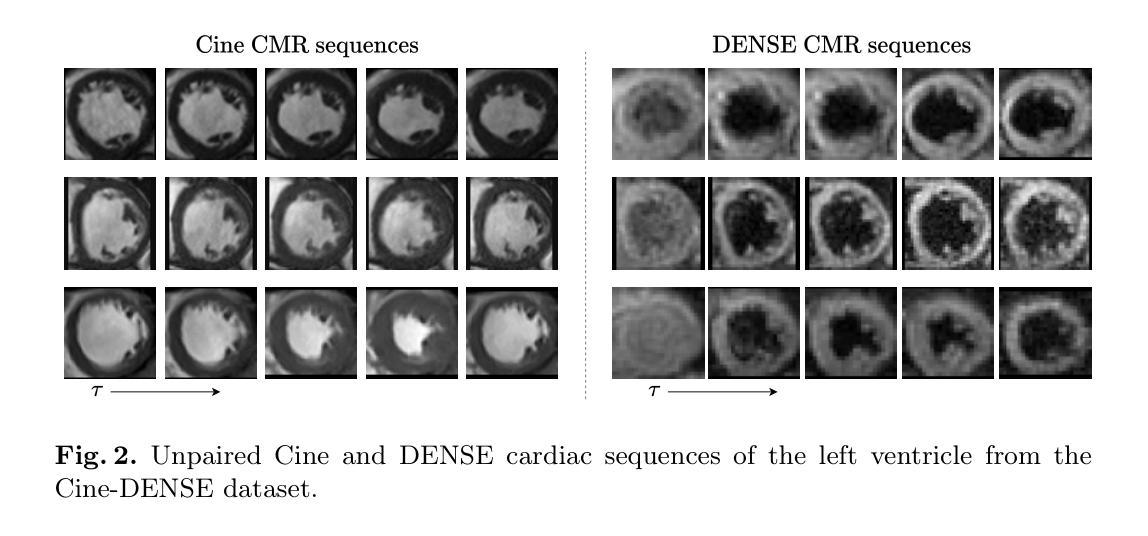
This paper presents a novel motion feature guided diffusion model for unpaired video-to-video translation (MFD-V2V), designed to synthesize dynamic, high-contrast cine cardiac magnetic resonance (CMR) from lower-contrast, artifact-prone displacement encoding with stimulated echoes (DENSE) CMR sequences. To achieve this, we first introduce a Latent Temporal Multi-Attention (LTMA) registration network that effectively learns more accurate and consistent cardiac motions from cine CMR image videos. A multi-level motion feature guided diffusion model, equipped with a specialized Spatio-Temporal Motion Encoder (STME) to extract fine-grained motion conditioning, is then developed to improve synthesis quality and fidelity. We evaluate our method, MFD-V2V, on a comprehensive cardiac dataset, demonstrating superior performance over the state-of-the-art in both quantitative metrics and qualitative assessments. Furthermore, we show the benefits of our synthesized cine CMRs improving downstream clinical and analytical tasks, underscoring the broader impact of our approach. Our code is publicly available at https://github.com/SwaksharDeb/MFD-V2V.
本文提出了一种新的基于运动特征引导的无配对视频到视频扩散模型(MFD-V2V),旨在从低对比度、易受伪影干扰的位移编码激励回波(DENSE)CMR序列中合成动态、高对比度的电影心脏磁共振(CMR)。为实现这一目标,我们首先引入了一种基于潜在时间多注意力(LTMA)的注册网络,该网络可以有效地从电影CMR图像视频中学习到更准确、更一致的心脏运动。然后,我们开发了一种基于多级运动特征引导扩散模型的方法,配备了一种专门的时空运动编码器(STME),以提取精细的运动条件,从而提高合成质量和保真度。我们在全面的心脏数据集上评估了我们的MFD-V2V方法,在定量指标和定性评估方面均表现出优于当前最先进技术性能的优势。此外,我们还展示了合成的电影型核磁共振图像对于下游临床和分析任务的益处,突出了我们方法的更广泛影响。我们的代码可以在 https://github.com/SwaksharDeb/MFD-V2V 上公开访问。
论文及项目相关链接
Summary
本文提出了一种新型的运动特征引导扩散模型(MFD-V2V),用于无配对视频到视频的转换。该模型旨在从低对比度、易出现伪影的位移编码激发回声(DENSE)CMR序列中合成动态、高对比度的电影心脏磁共振(CMR)。首先引入了一个潜在时间多注意力(LTMA)注册网络,有效学习更准确、更一致的电影CMR图像视频中的心脏运动。然后开发了一个多级运动特征引导扩散模型,配备了一个专门的时空运动编码器(STME),以提取精细的运动条件,以提高合成质量和保真度。在全面的心脏数据集上评估了MFD-V2V方法,在定量指标和定性评估方面都表现出优于最新技术的性能。此外,展示了我们的合成电影CMR对提高下游临床和分析任务的优势,强调了我们的方法更广泛的影响。
Key Takeaways
- 提出了一个新型运动特征引导扩散模型(MFD-V2V)用于视频转换。
- 设计用于从低对比度的DENSE CMR序列中合成高对比度的电影心脏磁共振(CMR)。
- 引入了潜在时间多注意力(LTMA)注册网络,学习更准确的心脏运动。
- 开发了一个配备时空运动编码器(STME)的多级运动特征引导扩散模型,提高合成质量和保真度。
- 在全面的心脏数据集上评估MFD-V2V,表现优于当前最新技术。
- 合成电影CMR对下游临床和分析任务有积极影响。
- 代码已公开可访问。
点此查看论文截图

MAD: Makeup All-in-One with Cross-Domain Diffusion Model
Authors:Bo-Kai Ruan, Hong-Han Shuai
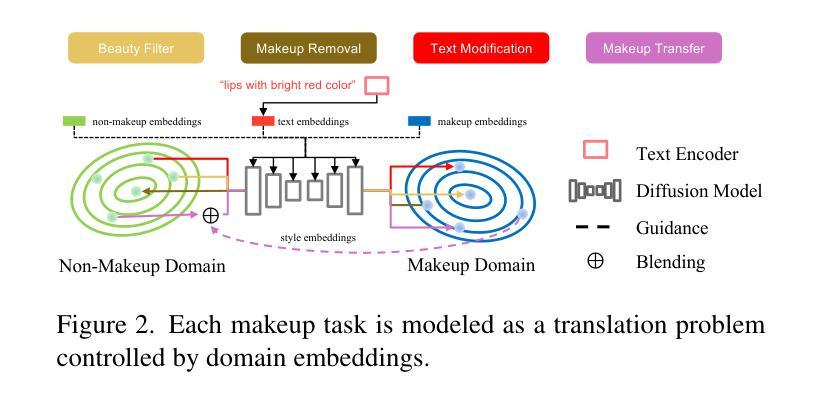
Existing makeup techniques often require designing multiple models to handle different inputs and align features across domains for different makeup tasks, e.g., beauty filter, makeup transfer, and makeup removal, leading to increased complexity. Another limitation is the absence of text-guided makeup try-on, which is more user-friendly without needing reference images. In this study, we make the first attempt to use a single model for various makeup tasks. Specifically, we formulate different makeup tasks as cross-domain translations and leverage a cross-domain diffusion model to accomplish all tasks. Unlike existing methods that rely on separate encoder-decoder configurations or cycle-based mechanisms, we propose using different domain embeddings to facilitate domain control. This allows for seamless domain switching by merely changing embeddings with a single model, thereby reducing the reliance on additional modules for different tasks. Moreover, to support precise text-to-makeup applications, we introduce the MT-Text dataset by extending the MT dataset with textual annotations, advancing the practicality of makeup technologies.
现有的化妆技术通常需要设计多个模型来处理不同的输入,并在不同的化妆任务(如美颜滤镜、化妆迁移和化妆移除)之间跨域对齐特征,这增加了复杂性。另一个局限性是缺乏文本引导的化妆试穿,这更便于用户使用,而无需参考图像。本研究中,我们首次尝试使用单个模型来完成各种化妆任务。具体来说,我们将不同的化妆任务制定为跨域翻译,并利用跨域扩散模型来完成所有任务。与现有方法不同,这些方法依赖于单独的编码器-解码器配置或基于循环的机制,我们建议使用不同的域嵌入来促进域控制。这通过仅仅更改嵌入来使用单个模型实现无缝域切换,从而减少对不同任务附加模块的依赖。而且,为了支持精确的文字到化妆应用,我们通过扩展MT数据集并添加文本注释来介绍MT-Text数据集,从而提高化妆技术的实用性。
论文及项目相关链接
PDF Accepted by CVPRW2025
Summary
本文主要介绍了使用单一模型完成多种化妆任务的研究。通过跨域扩散模型实现不同化妆任务,利用不同域嵌入来实现域控制,提高模型的通用性和实用性。此外,为支持文本到化妆应用的精确应用,扩展了MT数据集并引入文本注释,推动了化妆技术的实用性。
Key Takeaways
- 研究使用单一模型处理多种化妆任务,简化复杂性。
- 采用跨域扩散模型实现化妆任务,如美颜滤镜、妆容迁移和妆容移除等。
- 利用不同域嵌入实现域控制,通过改变嵌入实现无缝域切换。
- 引入MT-Text数据集,通过扩展MT数据集并添加文本注释,提高化妆技术的实用性。
- 研究突破现有化妆技术的限制,如需要设计多个模型来处理不同输入和跨域特征对齐。
- 支持文本指导的化妆试戴,更用户友好,无需参考图像。
点此查看论文截图



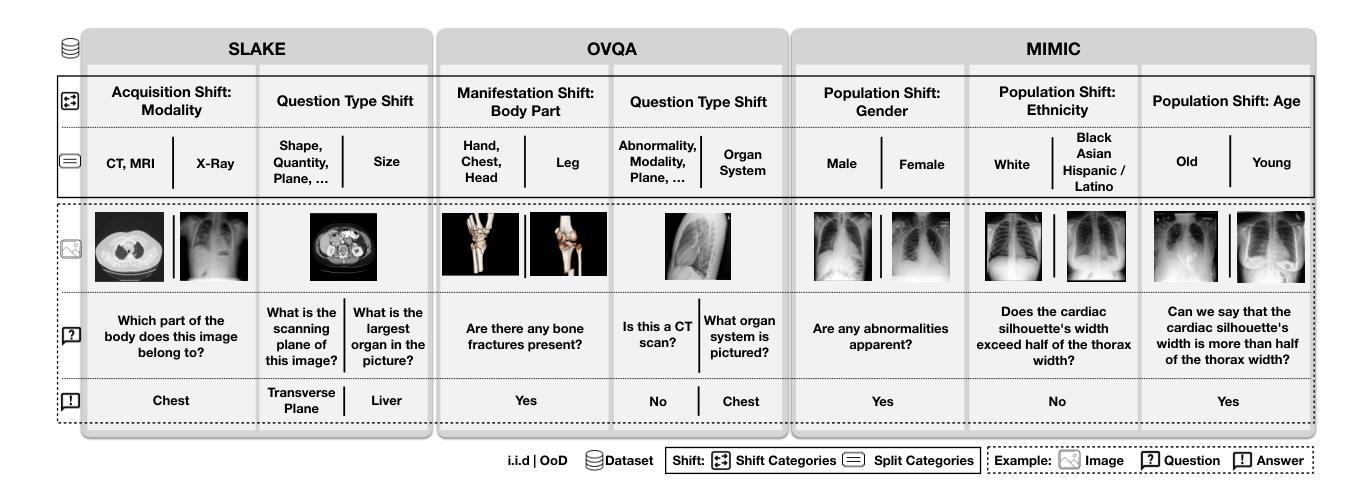
SURE-VQA: Systematic Understanding of Robustness Evaluation in Medical VQA Tasks
Authors:Kim-Celine Kahl, Selen Erkan, Jeremias Traub, Carsten T. Lüth, Klaus Maier-Hein, Lena Maier-Hein, Paul F. Jaeger
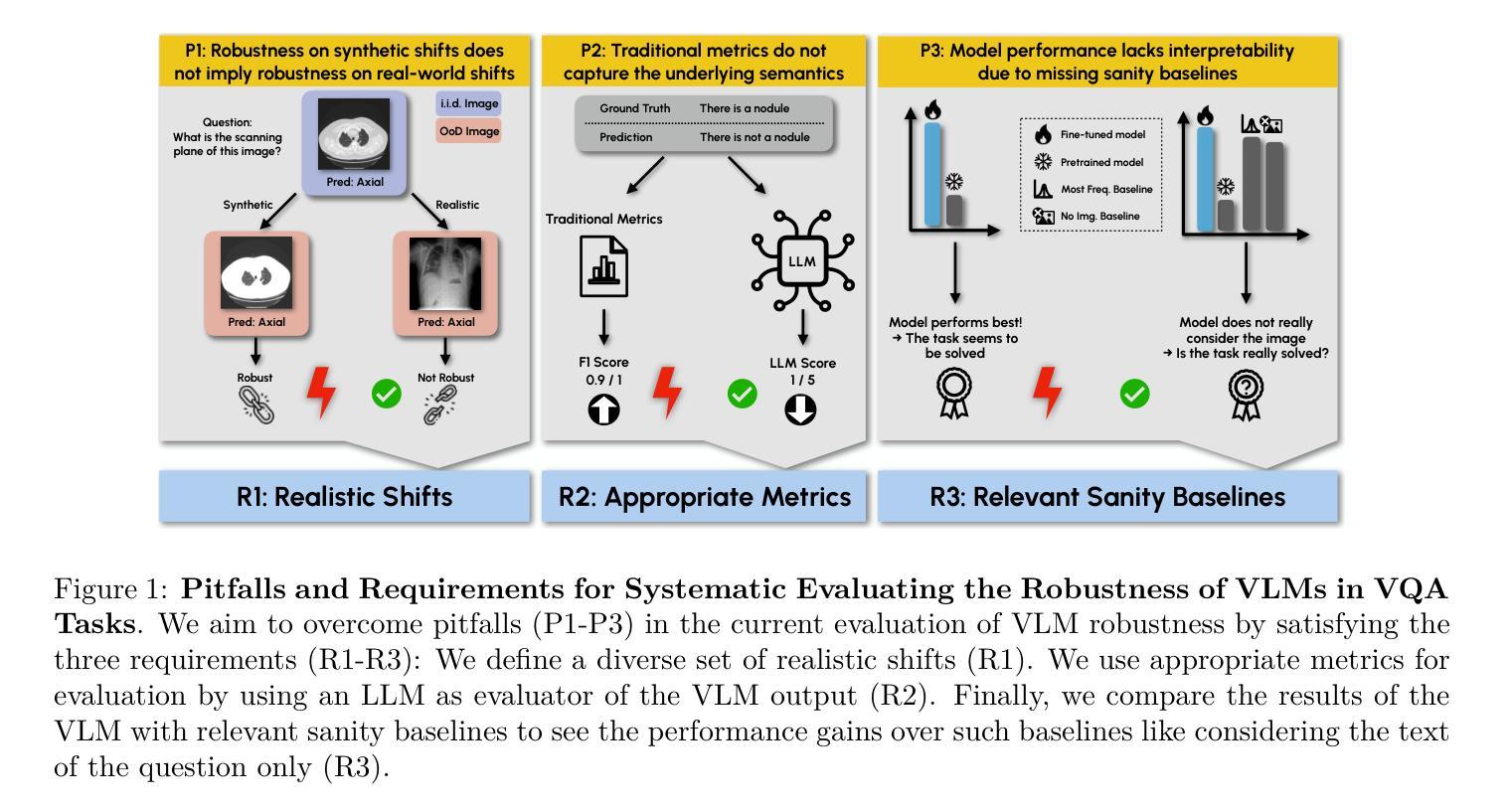
Vision-Language Models (VLMs) have great potential in medical tasks, like Visual Question Answering (VQA), where they could act as interactive assistants for both patients and clinicians. Yet their robustness to distribution shifts on unseen data remains a key concern for safe deployment. Evaluating such robustness requires a controlled experimental setup that allows for systematic insights into the model’s behavior. However, we demonstrate that current setups fail to offer sufficiently thorough evaluations. To address this gap, we introduce a novel framework, called SURE-VQA, centered around three key requirements to overcome current pitfalls and systematically analyze VLM robustness: 1) Since robustness on synthetic shifts does not necessarily translate to real-world shifts, it should be measured on real-world shifts that are inherent to the VQA data; 2) Traditional token-matching metrics often fail to capture underlying semantics, necessitating the use of large language models (LLMs) for more accurate semantic evaluation; 3) Model performance often lacks interpretability due to missing sanity baselines, thus meaningful baselines should be reported that allow assessing the multimodal impact on the VLM. To demonstrate the relevance of this framework, we conduct a study on the robustness of various Fine-Tuning (FT) methods across three medical datasets with four types of distribution shifts. Our study highlights key insights into robustness: 1) No FT method consistently outperforms others in robustness, and 2) robustness trends are more stable across FT methods than across distribution shifts. Additionally, we find that simple sanity baselines that do not use the image data can perform surprisingly well and confirm LoRA as the best-performing FT method on in-distribution data. Code is provided at https://github.com/IML-DKFZ/sure-vqa.
视觉语言模型(VLMs)在医疗任务(如视觉问答(VQA))中具有巨大潜力,可以作为患者和临床医生之间的交互式助手。然而,它们在未见数据上的分布转移稳健性仍是安全部署的关键问题。评估这种稳健性需要一个受控的实验设置,允许对模型的行为进行系统性的深入了解。然而,我们证明当前的设置无法提供足够全面的评估。为了弥补这一差距,我们引入了一个名为SURE-VQA的新型框架,该框架以三个关键要求为中心,旨在克服当前漏洞并系统地分析VLM的稳健性:1)由于合成转移上的稳健性并不一定转化为现实世界的转移,因此应在固有于VQA数据的现实世界的转移上进行衡量;2)传统的令牌匹配指标往往无法捕获潜在的语义,因此需要利用大型语言模型(LLM)进行更准确的语义评估;3)由于缺少合理性基准,模型性能往往缺乏可解释性,因此应报告有意义的基准,以评估对VLM的多模式影响。为了证明该框架的重要性,我们在三个医学数据集上对各种微调(FT)方法的稳健性进行了研究,这些数据集存在四种类型的分布转移。我们的研究揭示了关于稳健性的关键见解:1)没有FT方法在各种情况下都表现出稳健性方面的优势;2)稳健性趋势在FT方法之间比在分布转移之间更稳定。此外,我们发现不使用图像数据的简单合理性基准可以表现得相当好,并确认LoRA是在内部分布数据上表现最佳的FT方法。代码详见https://github.com/IML-DKFZ/sure-vqa。
论文及项目相关链接
PDF TMLR 07/2025
Summary
本文探讨了视觉语言模型(VLMs)在医疗任务中的潜力,特别是在视觉问答(VQA)中作为患者和临床医生的互动助手的应用。文章指出了模型在未见数据上的分布转移稳健性对于安全部署的重要性。然而,现有的评估体系未能提供足够的全面评估。为解决此问题,文章提出了一个名为SURE-VQA的新型框架,该框架围绕三个关键要求来克服当前漏洞并系统地分析VLM的稳健性:测量真实世界的数据转移、使用大型语言模型进行更准确的语义评估以及报告有意义的基准点以评估VLM的多模式影响。通过对三种医学数据集的四种分布转移方法的精细调整(FT)方法的稳健性研究,文章展示了该框架的实际应用,并揭示了关于稳健性的关键见解。
Key Takeaways
- 视觉语言模型(VLMs)在医疗任务中具有巨大潜力,特别是在视觉问答(VQA)中作为患者和临床医生的交互助手。
- 模型在未见数据上的分布转移稳健性对于安全部署至关重要。
- 当前评估体系未能提供足够全面的评估,因此需要新型框架如SURE-VQA来克服这一缺陷。
- SURE-VQA框架围绕三个关键要求构建:测量真实世界的数据转移、使用大型语言模型进行语义评估以及增加模型性能的可解释性。
- 研究展示了在三种医学数据集上,各种精细调整(FT)方法的稳健性表现。
- 没有一种FT方法在所有情况下都表现最佳,说明没有一致的最佳方法。
点此查看论文截图

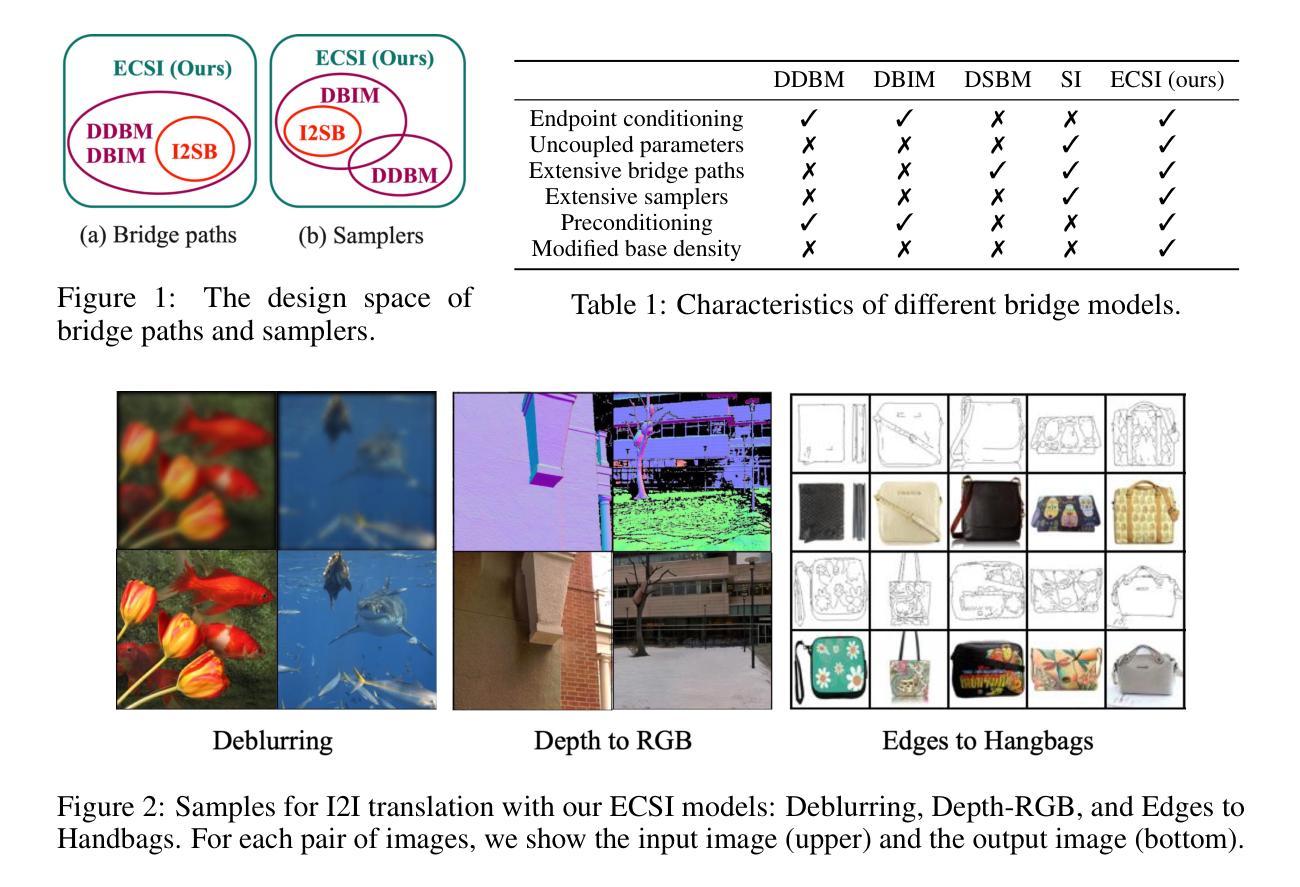
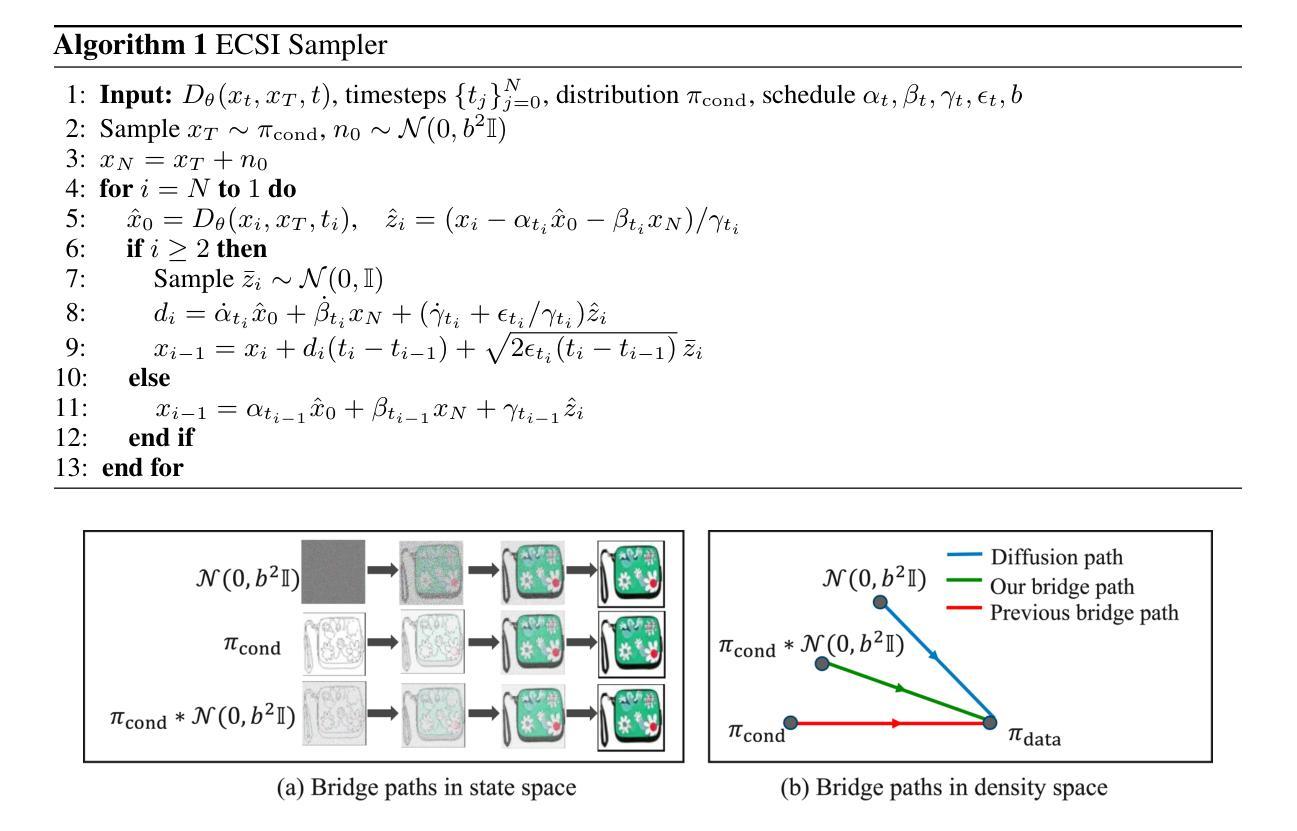
Exploring the Design Space of Diffusion Bridge Models
Authors:Shaorong Zhang, Yuanbin Cheng, Greg Ver Steeg
Diffusion bridge models and stochastic interpolants enable high-quality image-to-image (I2I) translation by creating paths between distributions in pixel space. However, the proliferation of techniques based on incompatible mathematical assumptions have impeded progress. In this work, we unify and expand the space of bridge models by extending Stochastic Interpolants (SIs) with preconditioning, endpoint conditioning, and an optimized sampling algorithm. These enhancements expand the design space of diffusion bridge models, leading to state-of-the-art performance in both image quality and sampling efficiency across diverse I2I tasks. Furthermore, we identify and address a previously overlooked issue of low sample diversity under fixed conditions. We introduce a quantitative analysis for output diversity and demonstrate how we can modify the base distribution for further improvements.
扩散桥模型与随机插值法通过在像素空间中的分布之间建立路径,实现了高质量的图片到图片(I2I)转换。然而,基于不兼容数学假设的技术层出不穷,阻碍了研究的进展。在这项工作中,我们通过扩展随机插值法(SI),将其与预处理、端点条件以及优化采样算法相结合,统一并扩展了桥模型的空间。这些增强功能扩展了扩散桥模型的设计空间,在多种I2I任务中实现了图像质量和采样效率方面的最先进的性能。此外,我们还发现并解决了一个之前被忽略的问题,即在固定条件下样本多样性较低的问题。我们对输出多样性进行了定量分析,并展示了如何修改基础分布以进一步改进。
论文及项目相关链接
PDF 23 pages, 9 figures
Summary
本文介绍了扩散桥模型与随机插值法在高质量图像到图像(I2I)翻译中的应用,通过像素空间中的分布路径创建实现。文章通过扩展随机插值法(SI),增加预处理、端点条件以及优化采样算法,统一并扩展了桥模型的空间。这些增强设计不仅提升了图像质量与采样效率,也在多种I2I任务中达到领先水平。此外,文章还解决了一个之前被忽视的问题——固定条件下的样本多样性较低,并引入了一种输出多样性的定量分析,展示了如何通过修改基础分布来实现进一步的改进。
Key Takeaways
- 扩散桥模型与随机插值法能够实现高质量的图像到图像(I2I)翻译。
- 通过扩展随机插值法(SI),增加了预处理、端点条件及优化采样算法,统一并扩展了桥模型空间。
- 这些增强设计提升了图像质量与采样效率,并在多种I2I任务中达到领先水平。
- 文章解决了一个被忽视的问题:固定条件下的样本多样性较低。
- 引入了一种输出多样性的定量分析。
- 展示了如何通过修改基础分布来实现进一步的图像质量改进。
点此查看论文截图