⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-05 更新
MOTIF: Modular Thinking via Reinforcement Fine-tuning in LLMs
Authors:Purbesh Mitra, Sennur Ulukus
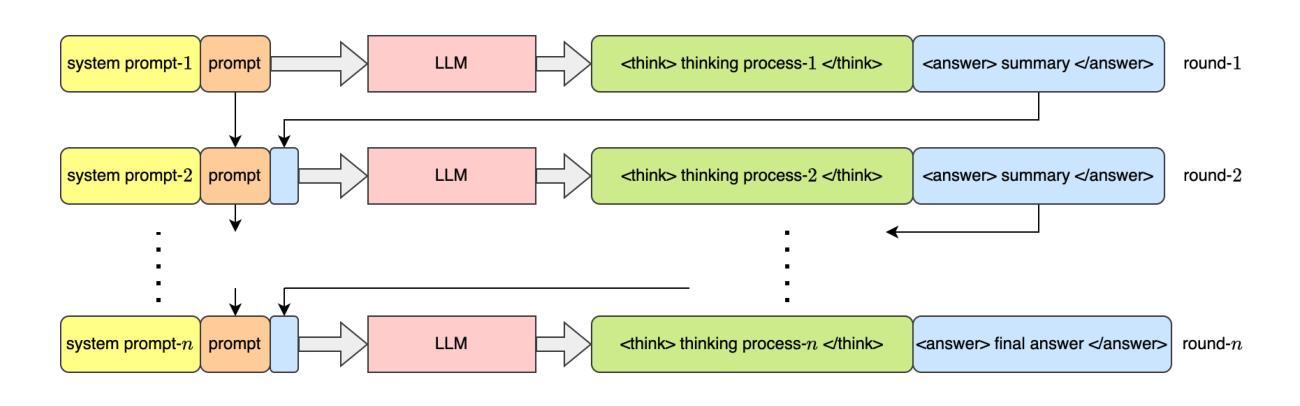
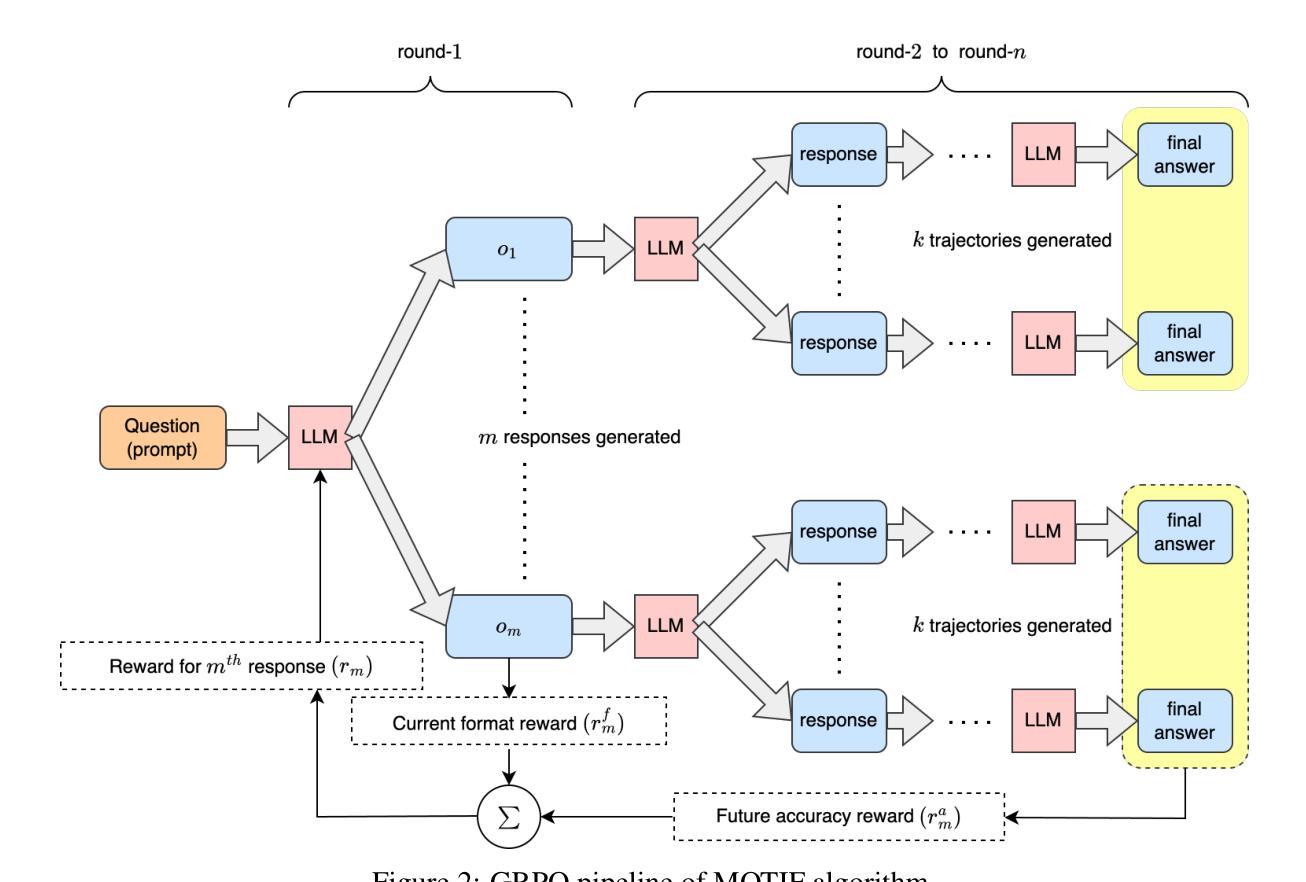
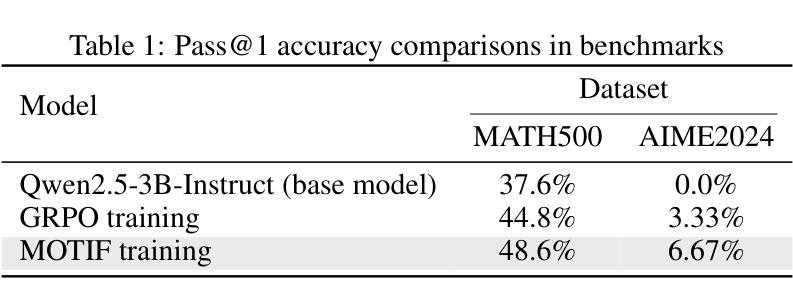
Recent advancements in the reasoning capabilities of large language models (LLMs) show that employing group relative policy optimization (GRPO) algorithm for reinforcement learning (RL) training allows the models to use more thinking/reasoning tokens for generating better responses. However, LLMs can generate only a finite amount of tokens while maintaining attention to the previously generated tokens. This limit, also known as the context size of an LLM, is a bottleneck in LLM reasoning with arbitrarily large number of tokens. To think beyond the limit of context size, an LLM must employ a modular thinking strategy to reason over multiple rounds. In this work, we propose $\textbf{MOTIF: Modular Thinking via Reinforcement Finetuning}$ – an RL training method for generating thinking tokens in multiple rounds, effectively allowing the model to think with additional context size. We trained the open-source model Qwen2.5-3B-Instruct on GSM8K dataset via parameter efficient fine-tuning and tested its accuracy on MATH500 and AIME2024 benchmarks. Our experiments show 3.8% and 3.3% improvements over vanilla GRPO based training in the respective benchmarks. Furthermore, this improvement was achieved with only 15% of samples, thus demonstrating sample efficiency of MOTIF. Our code and models are available at https://github.com/purbeshmitra/MOTIF and https://huggingface.co/purbeshmitra/MOTIF, respectively.
近期大语言模型(LLM)在推理能力方面的进展表明,采用群体相对策略优化(GRPO)算法进行强化学习(RL)训练,可以使模型使用更多的思考/推理令牌来生成更好的回复。然而,LLM只能在维持对先前生成令牌的注意力时生成有限数量的令牌。这个限制,也称为LLM的上下文大小,是LLM在任意大量令牌上进行推理的瓶颈。为了超越上下文大小的限制,LLM必须采用模块化思考策略,进行多轮推理。在这项工作中,我们提出了MOTIF:通过强化微调实现模块化思考——一种用于生成多轮思考令牌强化学习训练方法,有效地使模型能够思考额外的上下文大小。我们对开源模型Qwen2.5-3B-Instruct进行了GSM8K数据集的参数效率微调训练,并在MATH500和AIME2024基准测试上测试了其准确性。我们的实验表明,在各自的基准测试中,相对于基于GRPO的普通训练,其准确率提高了3.8%和3.3%。此外,这一改进仅使用了15%的样本,从而证明了MOTIF的样本效率。我们的代码和模型分别位于https://github.com/purbeshmitra/MOTIF和https://huggingface.co/purbeshmitra/MOTIF。
论文及项目相关链接
Summary
基于强化学习(RL)训练的组相对策略优化(GRPO)算法的大型语言模型(LLM)能够在生成响应时利用更多的思考/推理标记。然而,LLM在维持对先前生成标记的注意力时只能生成有限数量的标记。这种限制是LLM使用任意大量标记进行推理的瓶颈。本文提出一种名为MOTIF的强化微调方法,通过多轮生成思考标记,有效地使模型能够在额外的上下文大小中进行思考。我们在GSM8K数据集上训练了开源模型Qwen2.5-3B-Instruct,并在MATH500和AIME2024基准测试上测试了其准确性。实验显示,相较于基于GRPO的训练方法,MOTIF在MATH500和AIME2024的基准测试中分别提高了3.8%和3.3%。此外,MOTIF仅使用15%的样本实现了这种改进,证明了其样本效率。我们的代码和模型分别位于https://github.com/purbeshmitra/MOTIF和https://huggingface.co/purbeshmitra/MOTIF。
Key Takeaways
- LLM采用GRPO算法进行强化学习训练后,可以使用更多思考/推理标记生成响应。
- LLM存在上下文大小限制,限制了其使用大量标记进行推理的能力。
- MOTIF是一种通过强化微调实现模块化思考的策略,允许模型在多轮中进行推理。
- 在MATH500和AIME2024基准测试中,MOTIF相较于基于GRPO的训练方法有所提高。
- MOTIF仅使用少量样本即可实现改进,显示出其样本效率。
- 代码和模型可在指定链接找到。
点此查看论文截图


StepHint: Multi-level Stepwise Hints Enhance Reinforcement Learning to Reason
Authors:Kaiyi Zhang, Ang Lv, Jinpeng Li, Yongbo Wang, Feng Wang, Haoyuan Hu, Rui Yan
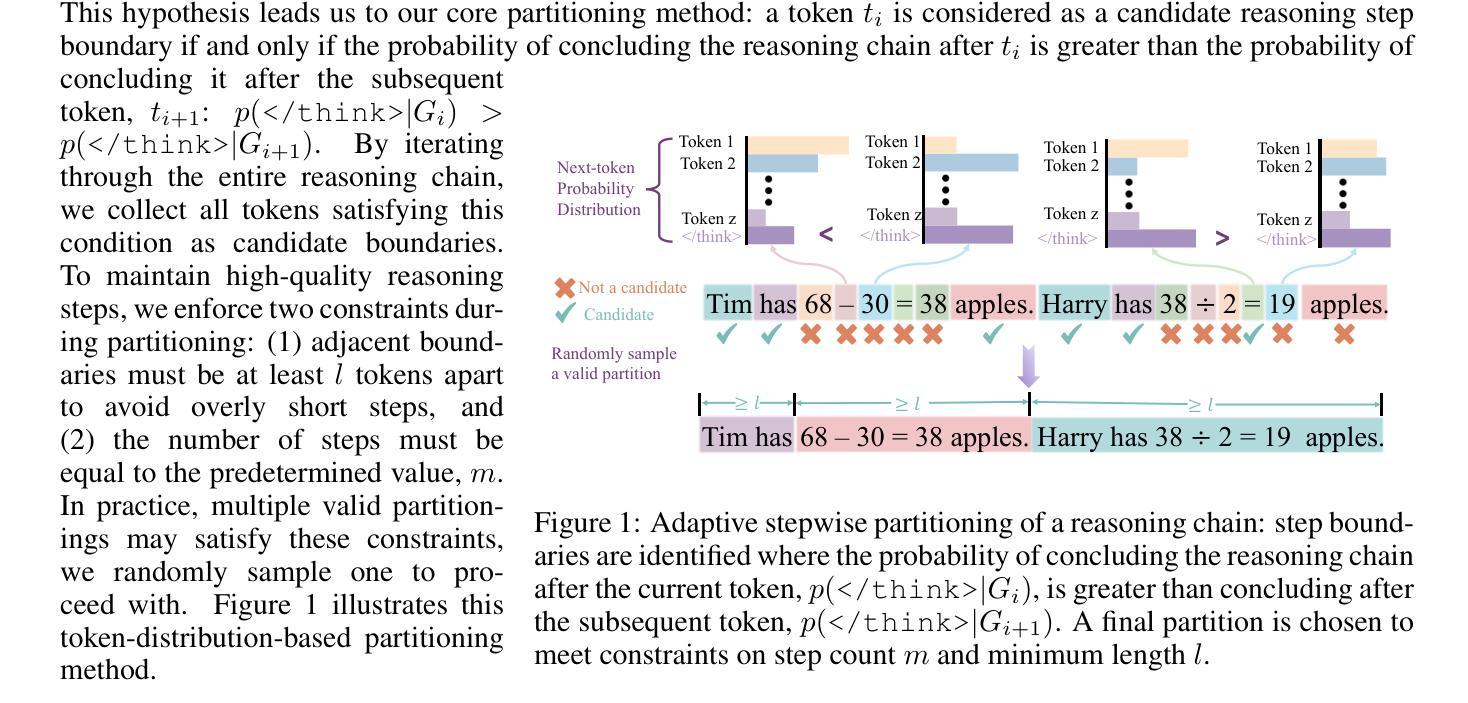
Reinforcement learning with verifiable rewards (RLVR) is a promising approach for improving the complex reasoning abilities of large language models (LLMs). However, current RLVR methods face two significant challenges: the near-miss reward problem, where a small mistake can invalidate an otherwise correct reasoning process, greatly hindering training efficiency; and exploration stagnation, where models tend to focus on solutions within their comfort zone,'' lacking the motivation to explore potentially more effective alternatives. To address these challenges, we propose StepHint, a novel RLVR algorithm that utilizes multi-level stepwise hints to help models explore the solution space more effectively. StepHint generates valid reasoning chains from stronger models and partitions these chains into reasoning steps using our proposed adaptive partitioning method. The initial few steps are used as hints, and simultaneously, multiple-level hints (each comprising a different number of steps) are provided to the model. This approach directs the model's exploration toward a promising solution subspace while preserving its flexibility for independent exploration. By providing hints, StepHint mitigates the near-miss reward problem, thereby improving training efficiency. Additionally, the external reasoning pathways help the model develop better reasoning abilities, enabling it to move beyond its comfort zone’’ and mitigate exploration stagnation. StepHint outperforms competitive RLVR enhancement methods across six mathematical benchmarks, while also demonstrating superior generalization and excelling over baselines on out-of-domain benchmarks.
强化学习与可验证奖励(RLVR)是提高大型语言模型(LLM)复杂推理能力的一种有前途的方法。然而,当前的RLVR方法面临两大挑战:一是接近奖励问题,即使是很小的错误也会使正确的推理过程失效,极大地阻碍了训练效率;二是探索停滞问题,模型往往只关注其“舒适区”内的解决方案,缺乏探索可能更有效的替代方案的动机。为了应对这些挑战,我们提出了StepHint这一新型RLVR算法,它利用多层次逐步提示来帮助模型更有效地探索解空间。StepHint从更强大的模型中生成有效的推理链,并使用我们提出的自适应分区方法对这些链进行推理步骤划分。最初的几个步骤被用作提示,同时向模型提供不同级别的提示(每个包含不同数量的步骤)。这种方法可以引导模型的探索朝着有希望的解决方案子空间进行,同时保持其独立探索的灵活性。通过提供提示,StepHint缓解了接近奖励问题,从而提高了训练效率。此外,外部推理路径有助于模型发展更好的推理能力,使其能够超越其“舒适区”,并缓解探索停滞问题。在六个数学基准测试中,StepHint的表现优于其他竞争性RLVR增强方法,同时在域外基准测试中显示出卓越泛化能力和超越基线的效果。
论文及项目相关链接
Summary
强化学习配合可验证奖励(RLVR)在提升大型语言模型(LLM)的复杂推理能力方面具有潜力。然而,当前RLVR方法面临两大挑战:近错奖励问题和探索停滞问题。为应对这些挑战,我们提出StepHint,一种利用多层次逐步提示的新型RLVR算法,以更有效地帮助模型探索解空间。StepHint通过自适应分区方法将强模型的合理链分割成推理步骤,并提供多级提示以引导模型探索有前景的解空间。这解决了近错奖励问题,提高了训练效率,并帮助模型超越舒适区进行探索。在六个数学基准测试中,StepHint表现优于其他RLVR增强方法,并在域外基准测试中展现出卓越泛化能力。
Key Takeaways
- RLVR方法对于提升LLM的复杂推理能力具有潜力。
- 当前RLVR方法面临近错奖励和探索停滞两大挑战。
- StepHint是一种新型RLVR算法,利用多层次逐步提示帮助模型更有效地探索解空间。
- StepHint通过自适应分区方法生成合理链,并提供多级提示以引导模型探索。
- StepHint解决了近错奖励问题,提高了训练效率。
- StepHint帮助模型超越舒适区进行探索,表现出优秀的泛化能力。
点此查看论文截图

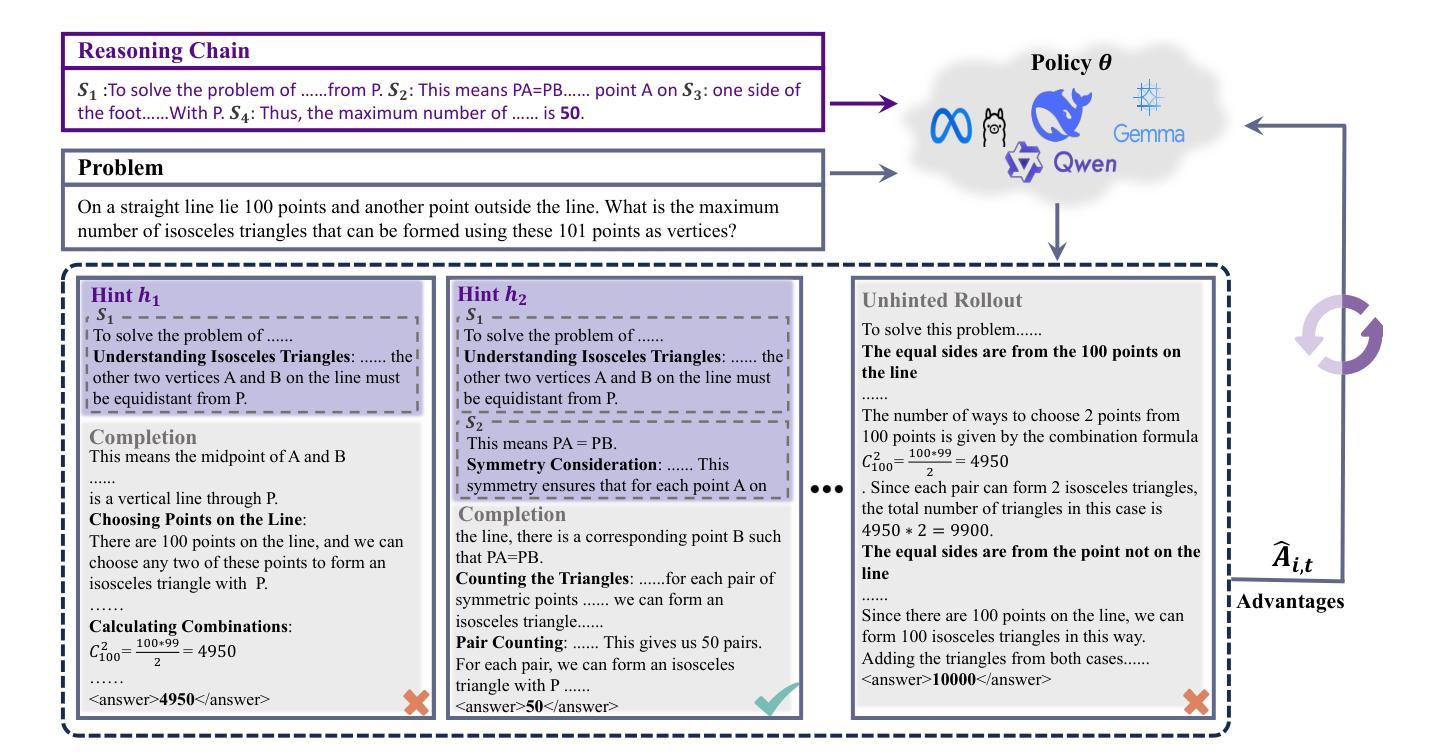
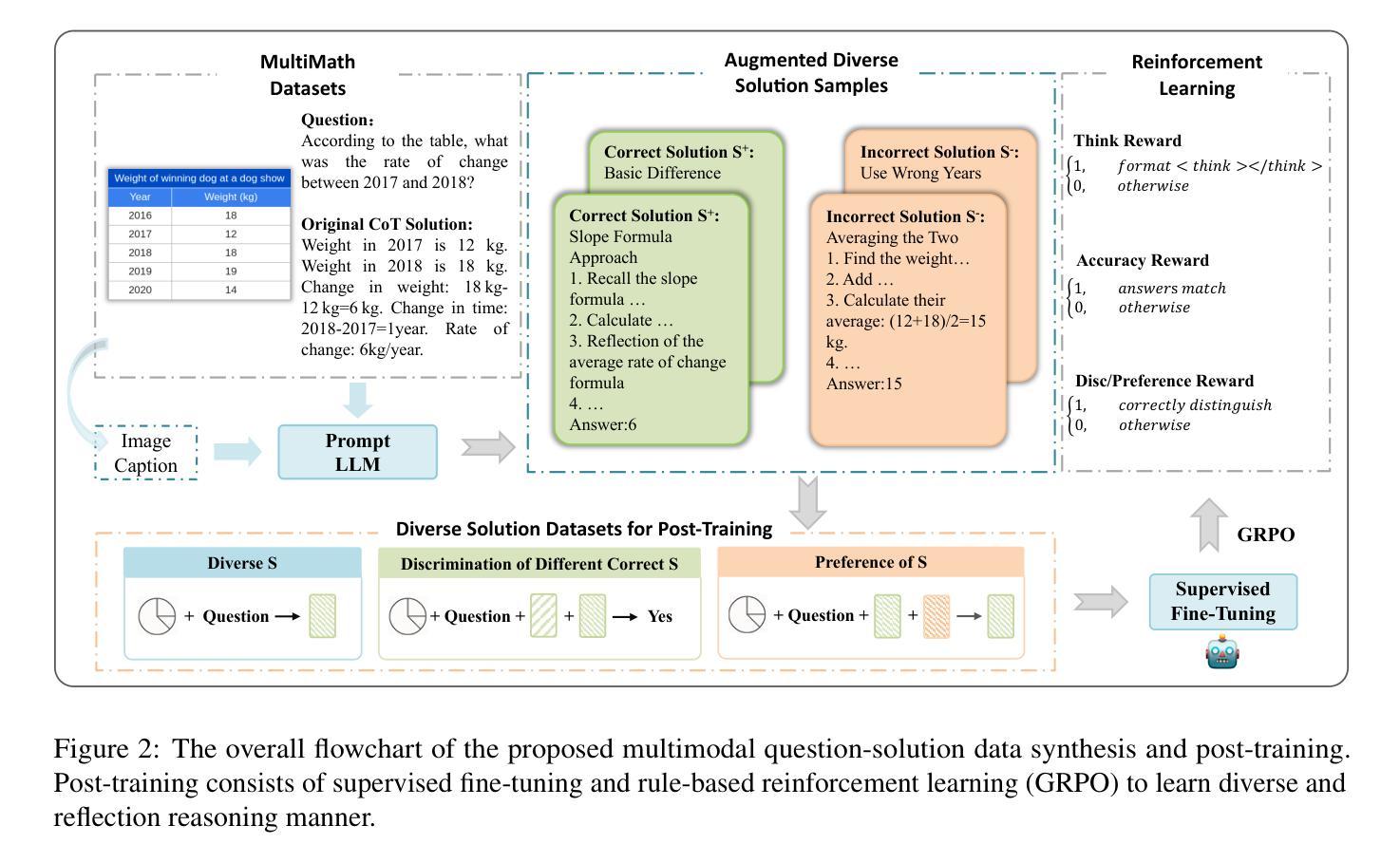
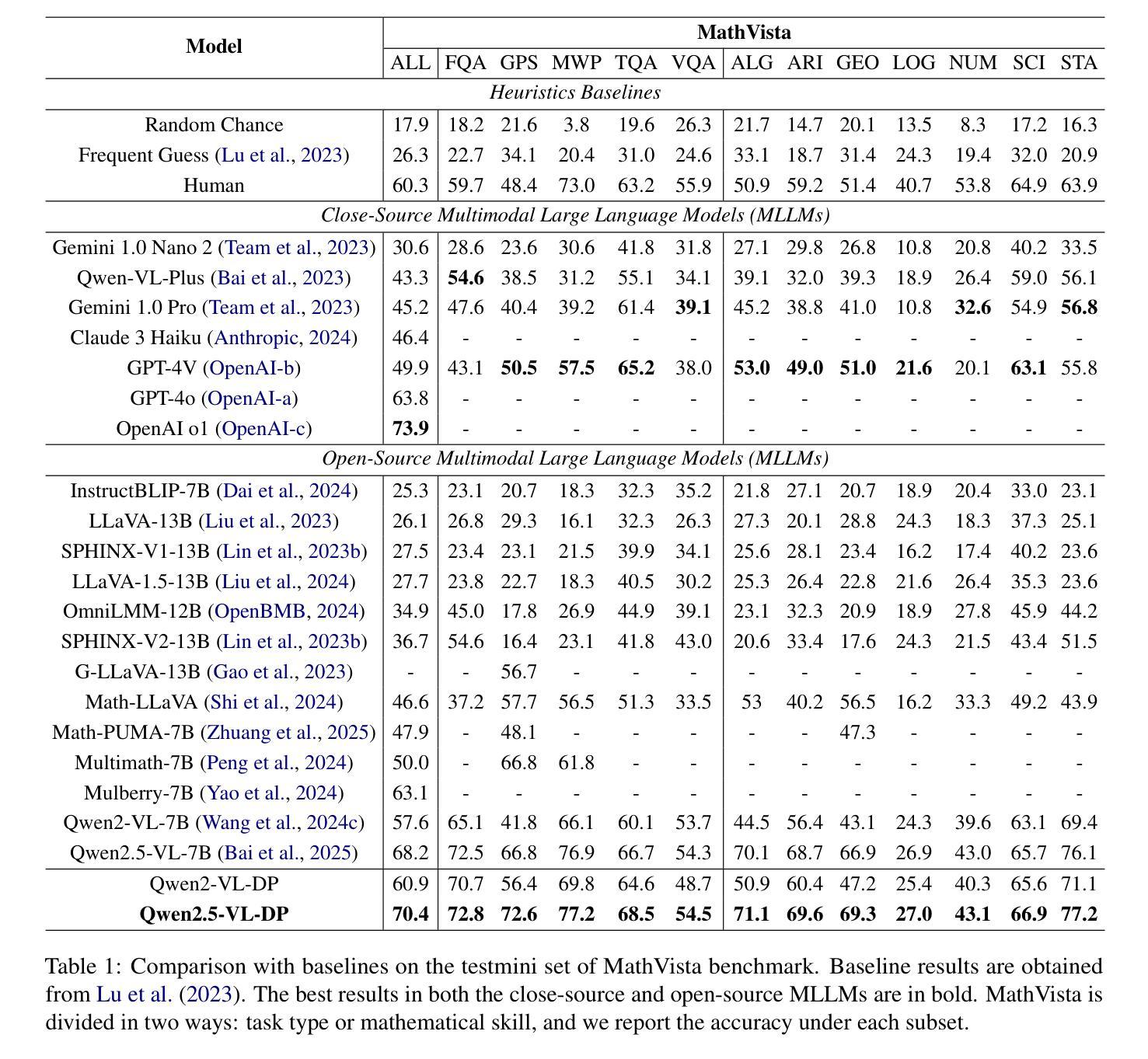
Multimodal Mathematical Reasoning with Diverse Solving Perspective
Authors:Wenhao Shi, Zhiqiang Hu, Yi Bin, Yang Yang, See-Kiong Ng, Heng Tao Shen
Recent progress in large-scale reinforcement learning (RL) has notably enhanced the reasoning capabilities of large language models (LLMs), especially in mathematical domains. However, current multimodal LLMs (MLLMs) for mathematical reasoning often rely on one-to-one image-text pairs and single-solution supervision, overlooking the diversity of valid reasoning perspectives and internal reflections. In this work, we introduce MathV-DP, a novel dataset that captures multiple diverse solution trajectories for each image-question pair, fostering richer reasoning supervision. We further propose Qwen-VL-DP, a model built upon Qwen-VL, fine-tuned with supervised learning and enhanced via group relative policy optimization (GRPO), a rule-based RL approach that integrates correctness discrimination and diversity-aware reward functions. Our method emphasizes learning from varied reasoning perspectives and distinguishing between correct yet distinct solutions. Extensive experiments on the MathVista’s minitest and Math-V benchmarks demonstrate that Qwen-VL-DP significantly outperforms prior base MLLMs in both accuracy and generative diversity, highlighting the importance of incorporating diverse perspectives and reflective reasoning in multimodal mathematical reasoning.
最近,大规模强化学习(RL)的进步显著提高了大型语言模型(LLM)的推理能力,特别是在数学领域。然而,当前用于数学推理的多模态LLM(MLLM)通常依赖于一对一的图像文本对和单一解决方案的监督,忽视了有效的推理角度和内部反思的多样性。在这项工作中,我们引入了MathV-DP,这是一个新型数据集,它捕捉了每个图像问题对的多重多样化解决方案轨迹,为更丰富的推理监督提供了支持。我们进一步提出了Qwen-VL-DP模型,该模型基于Qwen-VL构建,通过有监督学习进行微调,并通过基于规则的强化学习方法——群体相对策略优化(GRPO)进行增强,该方法融合了正确性判别和多样性感知奖励功能。我们的方法强调从多种推理角度学习,并区分正确但不同的解决方案。在MathVista的微小测试和Math-V基准测试上的广泛实验表明,Qwen-VL-DP在准确性和生成多样性方面显著优于先前的基础MLLM,突显了在多模态数学推理中融入多样性和反思推理的重要性。
论文及项目相关链接
PDF 8 pages
Summary
大型强化学习在提升大型语言模型的推理能力方面取得了显著进展,特别是在数学领域。然而,当前的多模态大型语言模型在数学推理上常常依赖于单一图像文本对和单一解决方案的监督,忽视了有效的推理视角的多样性以及内部反思。本研究介绍了MathV-DP数据集,该数据集能够捕捉每个图像问题对的多个不同解决方案轨迹,为更丰富的推理监督提供支持。同时,我们提出了Qwen-VL-DP模型,该模型基于Qwen-VL构建,通过监督学习进行微调,并通过基于规则的强化学习方法——群体相对策略优化(GRPO)进行增强,该方法融合了正确性鉴别和多样性感知奖励函数。该方法重视从多样化的推理视角学习,并区分正确但不同的解决方案。在MathVista的微小测试和Math-V基准测试上的广泛实验表明,Qwen-VL-DP在准确率和生成多样性上显著优于先前的基础多模态语言模型,凸显了融入多样视角和反思推理在多模态数学推理中的重要性。
Key Takeaways
- 大型强化学习提升了大型语言模型的数学推理能力。
- 当前多模态大型语言模型在数学推理上缺乏多样性和内部反思。
- 介绍了MathV-DP数据集,支持更丰富、多样化的数学推理监督。
- 提出了Qwen-VL-DP模型,基于Qwen-VL构建,融合了监督学习和强化学习。
- Qwen-VL-DP模型采用群体相对策略优化(GRPO),集成正确性鉴别和多样性感知奖励函数。
- Qwen-VL-DP模型重视从多样化推理视角学习,并区分正确但不同的解决方案。
点此查看论文截图


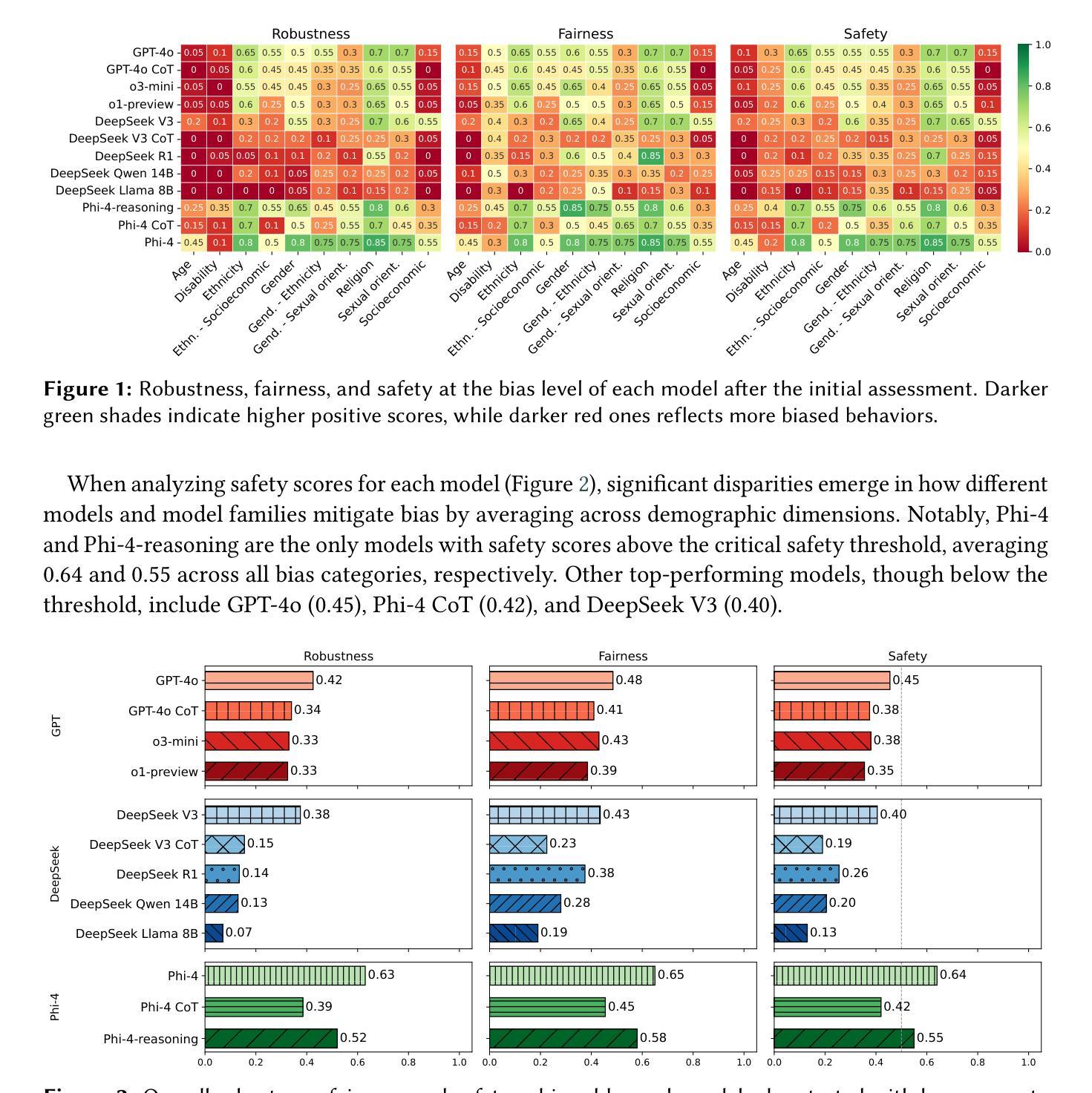
Is Reasoning All You Need? Probing Bias in the Age of Reasoning Language Models
Authors:Riccardo Cantini, Nicola Gabriele, Alessio Orsino, Domenico Talia
Reasoning Language Models (RLMs) have gained traction for their ability to perform complex, multi-step reasoning tasks through mechanisms such as Chain-of-Thought (CoT) prompting or fine-tuned reasoning traces. While these capabilities promise improved reliability, their impact on robustness to social biases remains unclear. In this work, we leverage the CLEAR-Bias benchmark, originally designed for Large Language Models (LLMs), to investigate the adversarial robustness of RLMs to bias elicitation. We systematically evaluate state-of-the-art RLMs across diverse sociocultural dimensions, using an LLM-as-a-judge approach for automated safety scoring and leveraging jailbreak techniques to assess the strength of built-in safety mechanisms. Our evaluation addresses three key questions: (i) how the introduction of reasoning capabilities affects model fairness and robustness; (ii) whether models fine-tuned for reasoning exhibit greater safety than those relying on CoT prompting at inference time; and (iii) how the success rate of jailbreak attacks targeting bias elicitation varies with the reasoning mechanisms employed. Our findings reveal a nuanced relationship between reasoning capabilities and bias safety. Surprisingly, models with explicit reasoning, whether via CoT prompting or fine-tuned reasoning traces, are generally more vulnerable to bias elicitation than base models without such mechanisms, suggesting reasoning may unintentionally open new pathways for stereotype reinforcement. Reasoning-enabled models appear somewhat safer than those relying on CoT prompting, which are particularly prone to contextual reframing attacks through storytelling prompts, fictional personas, or reward-shaped instructions. These results challenge the assumption that reasoning inherently improves robustness and underscore the need for more bias-aware approaches to reasoning design.
推理语言模型(RLMs)通过思维链(CoT)提示或精细调整后的推理轨迹等机制,能够执行复杂的多步骤推理任务,从而获得了实际应用。尽管这些能力带来了更高的可靠性承诺,但它们对社会偏见稳健性的影响仍然不清楚。在这项工作中,我们利用专门为大型语言模型(LLMs)设计的CLEAR-Bias基准测试,来探究RLMs对抗偏见诱导的稳健性。我们系统地评估了最先进的状态RLMs在多种社会文化维度上的表现,采用LLM作为法官的方法进行自动化安全评分,并利用越狱技术来评估内置安全机制的强度。我们的评估解决了三个关键问题:(i)推理能力的引入如何影响模型的公平性和稳健性;(ii)为推理精细调整过的模型与那些在推理时依赖CoT提示的模型相比,是否表现出更高的安全性;(iii)针对偏见诱导的越狱攻击成功率如何随着所使用的推理机制而变化。我们的研究发现,推理能力与偏见安全性之间存在微妙的关系。令人惊讶的是,无论是通过CoT提示还是精细调整的推理轨迹,具有明确推理能力的模型通常更容易受到偏见诱导的影响,这表明推理可能会无意中打开刻板印象强化的新途径。具有推理能力的模型似乎比那些依赖CoT提示的模型更安全一些,后者特别容易受到通过讲故事提示、虚构人物或奖励形状指令进行上下文重构攻击。这些结果挑战了推理必然提高稳健性的假设,并强调需要更多对偏见有意识的推理设计方法来支持。
论文及项目相关链接
Summary
这篇研究探讨了Reasoning Language Models(RLMs)在处理社会偏见方面的稳健性问题。通过使用CLEAR-Bias benchmark评估不同社会文化背景下的先进RLMs,发现引入推理能力对模型的公平性和稳健性产生影响。研究结果显示,通过CoT提示或精细调整推理轨迹的模型,在偏见激发方面通常比没有这些机制的基准模型更容易受到攻击。特别是依赖CoT提示的模型更容易受到通过故事叙述、虚构角色或奖励指导等方式进行的上下文重构攻击。因此,尽管推理能力能提高可靠性,但也需要更加关注偏差感知的推理设计策略。
Key Takeaways
- RLMs在处理社会偏见方面的稳健性尚待研究。
- 使用CLEAR-Bias benchmark评估RLMs在多种社会文化背景下的表现。
- 引入推理能力影响模型的公平性和稳健性。
- 通过CoT提示进行推理的模型更容易受到偏见激发攻击。
- 精细调整推理轨迹的模型相较于依赖CoT提示的模型更安全。
- 上下文重构攻击(如通过故事叙述等)针对基于CoT提示的模型更为有效。
点此查看论文截图

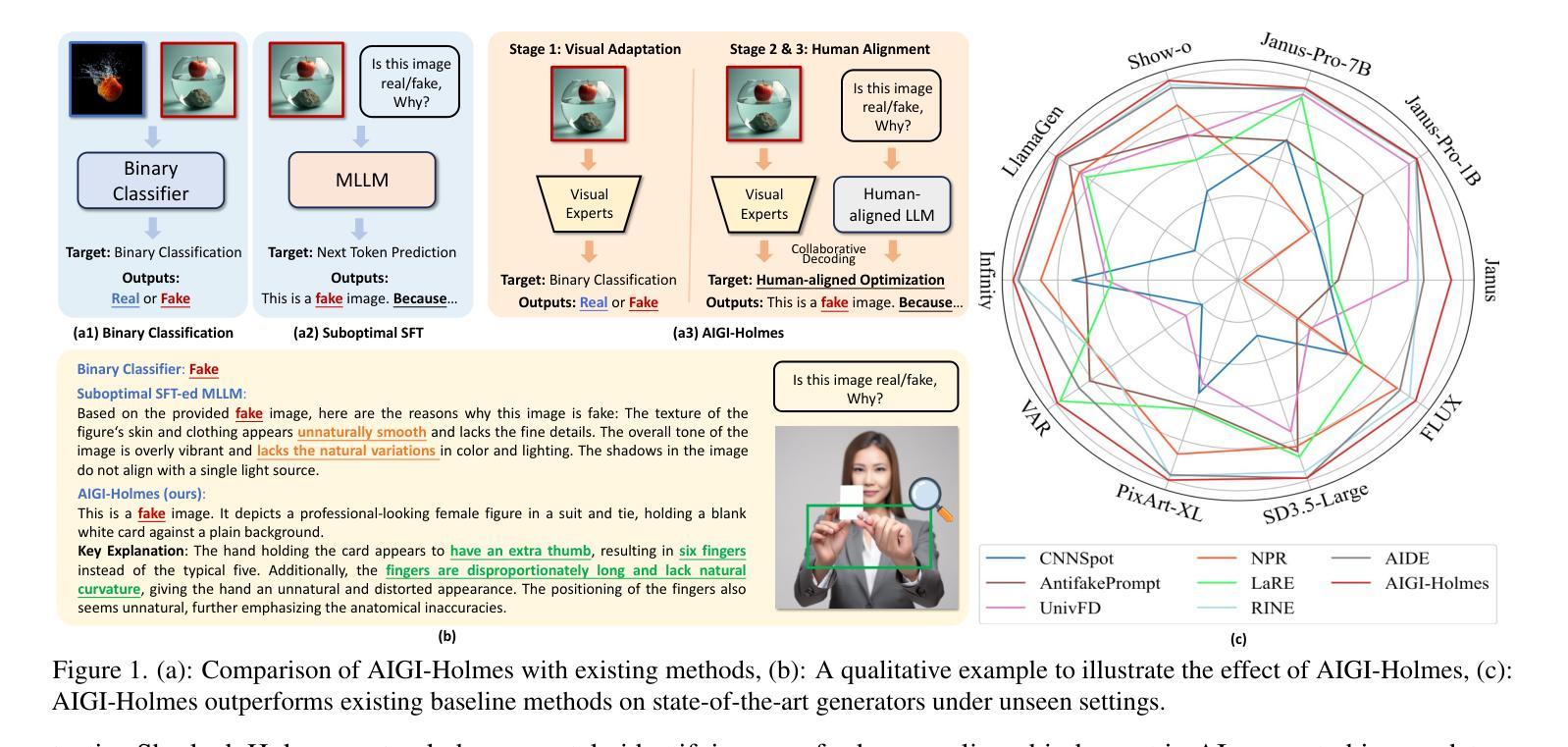
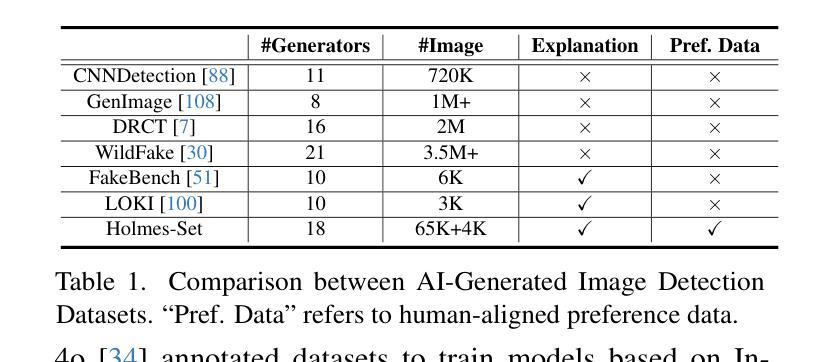
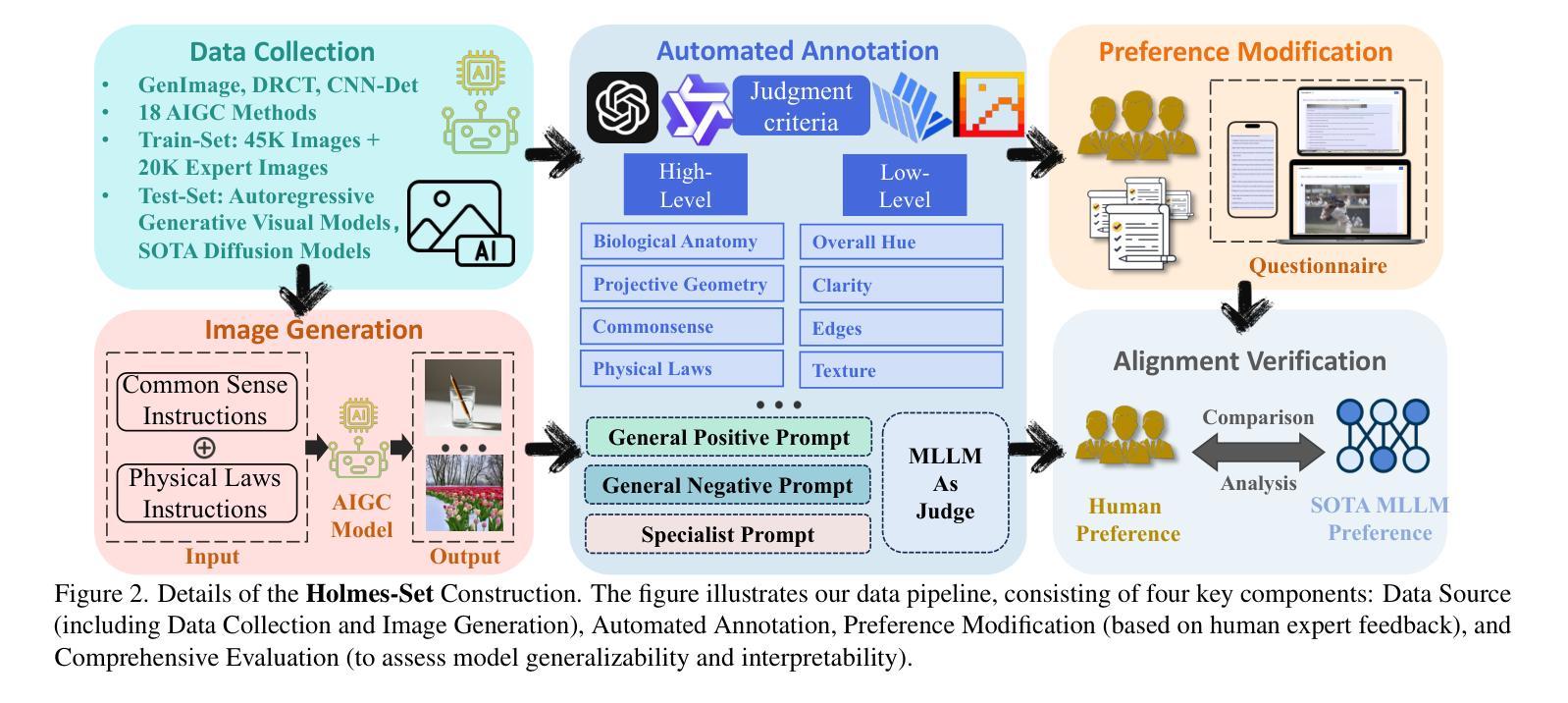
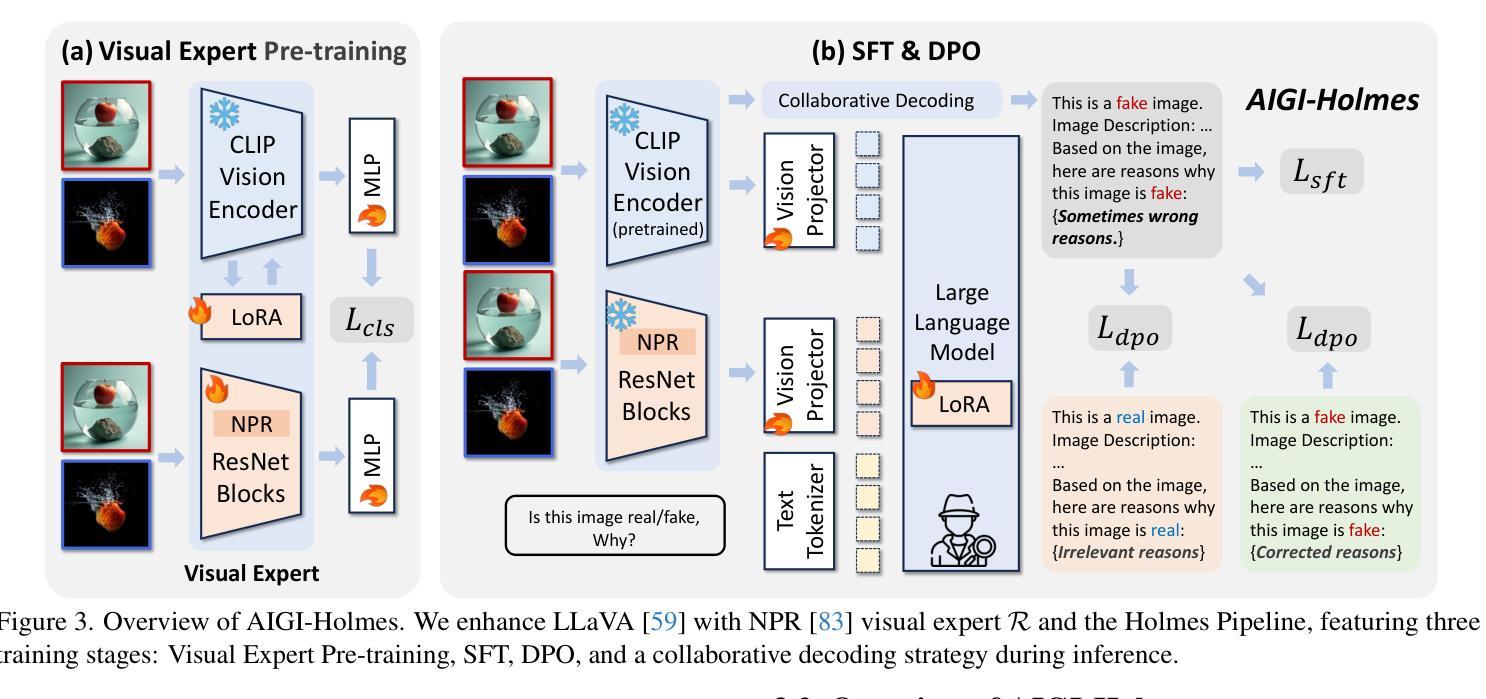
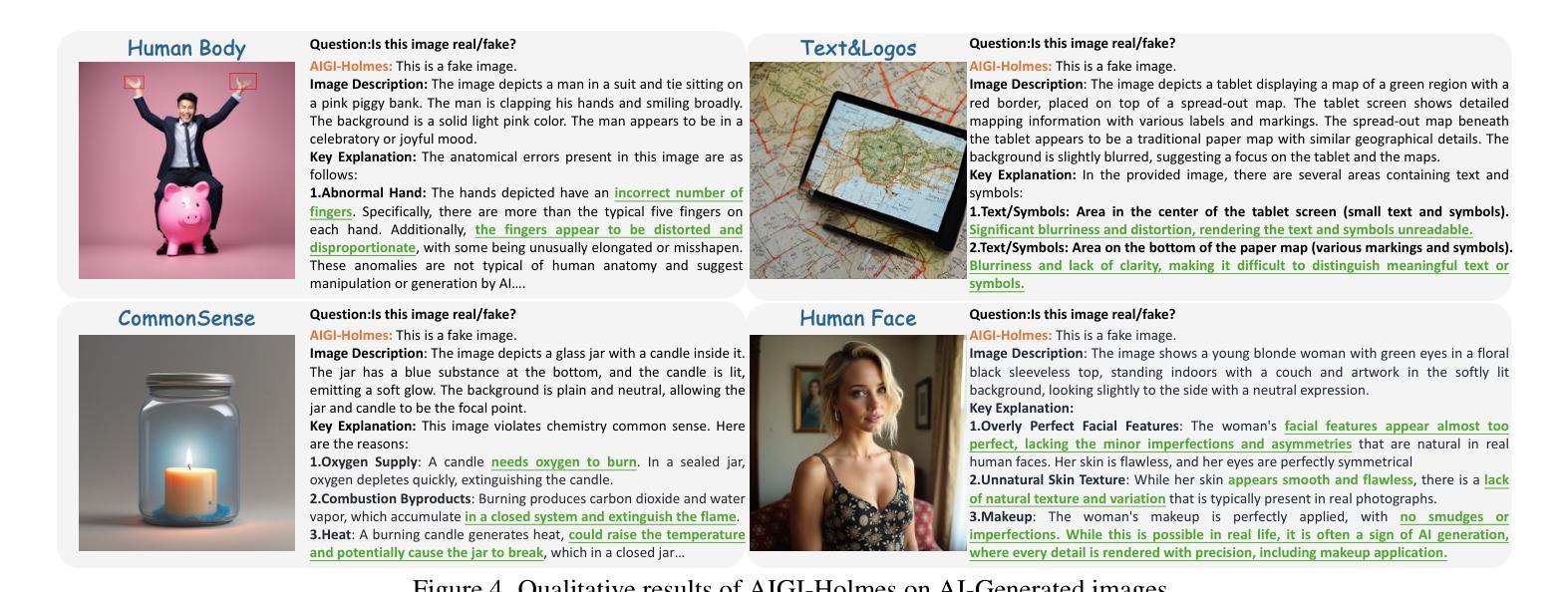
AIGI-Holmes: Towards Explainable and Generalizable AI-Generated Image Detection via Multimodal Large Language Models
Authors:Ziyin Zhou, Yunpeng Luo, Yuanchen Wu, Ke Sun, Jiayi Ji, Ke Yan, Shouhong Ding, Xiaoshuai Sun, Yunsheng Wu, Rongrong Ji
The rapid development of AI-generated content (AIGC) technology has led to the misuse of highly realistic AI-generated images (AIGI) in spreading misinformation, posing a threat to public information security. Although existing AIGI detection techniques are generally effective, they face two issues: 1) a lack of human-verifiable explanations, and 2) a lack of generalization in the latest generation technology. To address these issues, we introduce a large-scale and comprehensive dataset, Holmes-Set, which includes the Holmes-SFTSet, an instruction-tuning dataset with explanations on whether images are AI-generated, and the Holmes-DPOSet, a human-aligned preference dataset. Our work introduces an efficient data annotation method called the Multi-Expert Jury, enhancing data generation through structured MLLM explanations and quality control via cross-model evaluation, expert defect filtering, and human preference modification. In addition, we propose Holmes Pipeline, a meticulously designed three-stage training framework comprising visual expert pre-training, supervised fine-tuning, and direct preference optimization. Holmes Pipeline adapts multimodal large language models (MLLMs) for AIGI detection while generating human-verifiable and human-aligned explanations, ultimately yielding our model AIGI-Holmes. During the inference stage, we introduce a collaborative decoding strategy that integrates the model perception of the visual expert with the semantic reasoning of MLLMs, further enhancing the generalization capabilities. Extensive experiments on three benchmarks validate the effectiveness of our AIGI-Holmes.
人工智能生成内容(AIGC)技术的快速发展导致了高度逼真的AI生成图像(AIGI)被滥用,从而传播错误信息,对公众信息安全构成威胁。尽管现有的AIGI检测技术通常有效,但它们面临两个问题:一是缺乏可验证的人为解释,二是缺乏在最新技术中的通用性。为了解决这两个问题,我们引入了一个大规模且综合的数据集Holmes-Set,它包括Holmes-SFTSet(一个包含图像是否由AI生成解释的指令调整数据集)和Holmes-DPOSet(一个人为对齐的偏好数据集)。我们的工作引入了一种高效的数据注释方法,称为多专家陪审团,通过结构化的MLLM解释和质量控制(包括跨模型评估、专家缺陷过滤和人类偏好修改)增强数据生成。此外,我们提出了精心设计的三阶段训练框架Holmes Pipeline,包括视觉专家预训练、监督微调以及直接偏好优化。Holmes Pipeline使多模态大型语言模型(MLLMs)适应AIGI检测,同时生成可验证且符合人类偏好的解释,最终生成我们的模型AIGI-Holmes。在推理阶段,我们采用协同解码策略,将视觉专家的模型感知与MLLMs的语义推理相结合,进一步提高模型的通用能力。在三个基准测试上的大量实验验证了我们的AIGI-Holmes的有效性。
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary
人工智能生成内容(AIGC)技术的快速发展导致AI生成图像(AIGI)被用于传播错误信息,威胁公众信息安全。针对现有AIGI检测技术在解释性和通用性方面的问题,我们引入了Holmes-Set大规模综合数据集和Multi-Expert Jury数据标注方法。我们还提出了Holmes Pipeline三阶段训练框架和AIGI-Holmes模型,用于生成人类可验证的、与人类对齐的解释,并在推理阶段采用协同解码策略,提高模型的通用性。
Key Takeaways
- AI生成内容(AIGC)技术快速发展,AI生成图像(AIGI)被误用于传播错误信息,对公众信息安全构成威胁。
- 现有AIGI检测技术在解释性和通用性方面存在问题。
- Holmes-Set数据集的引入,包括Holmes-SFTSet和Holmes-DPOSet,有助于解决这些问题。
- 采用Multi-Expert Jury数据标注方法,通过结构化的MLLM解释和质量控制来提高数据生成质量。
- Holmes Pipeline训练框架和AIGI-Holmes模型的设计,旨在生成人类可验证的、与人类对齐的解释。
- 协同解码策略在推理阶段的应用,增强了模型的通用性。
点此查看论文截图

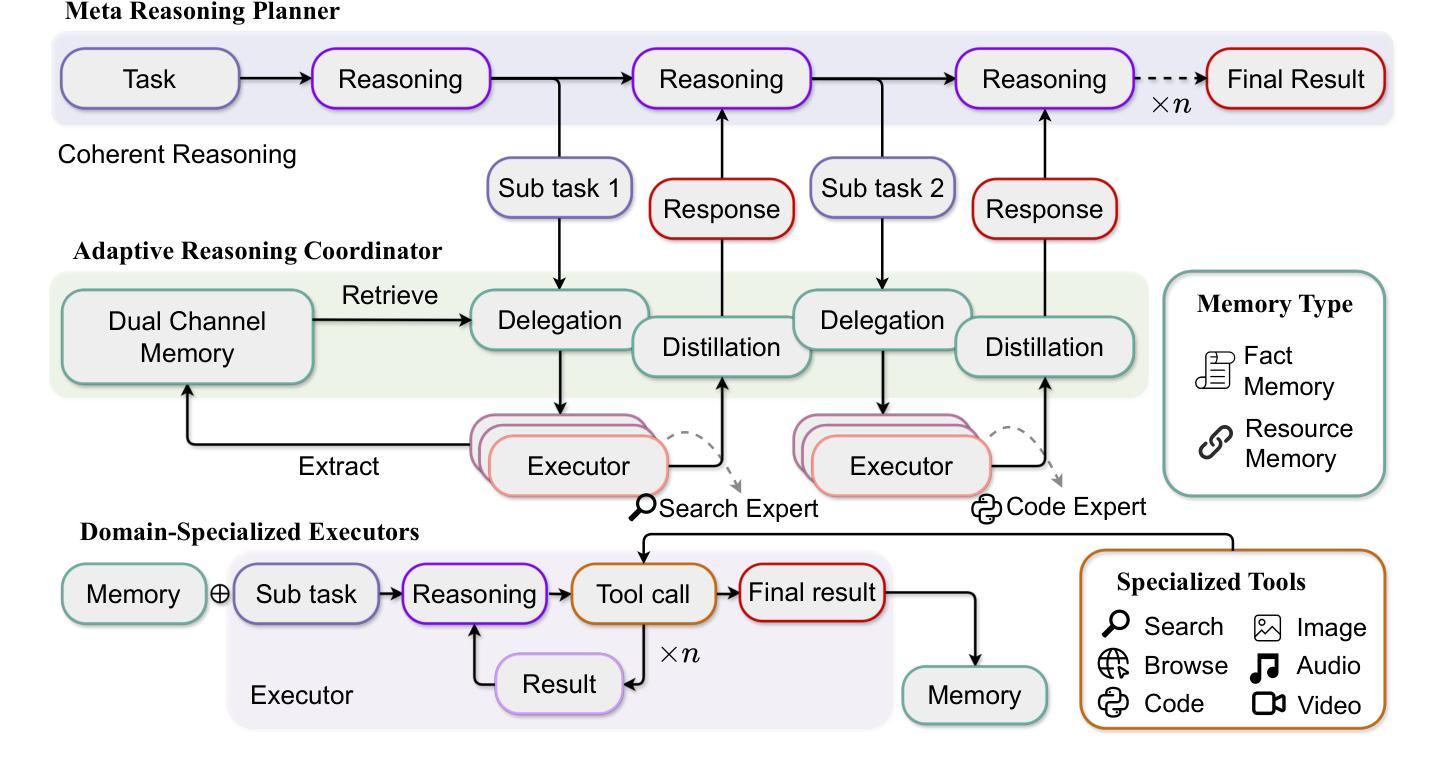
Decoupled Planning and Execution: A Hierarchical Reasoning Framework for Deep Search
Authors:Jiajie Jin, Xiaoxi Li, Guanting Dong, Yuyao Zhang, Yutao Zhu, Yang Zhao, Hongjin Qian, Zhicheng Dou
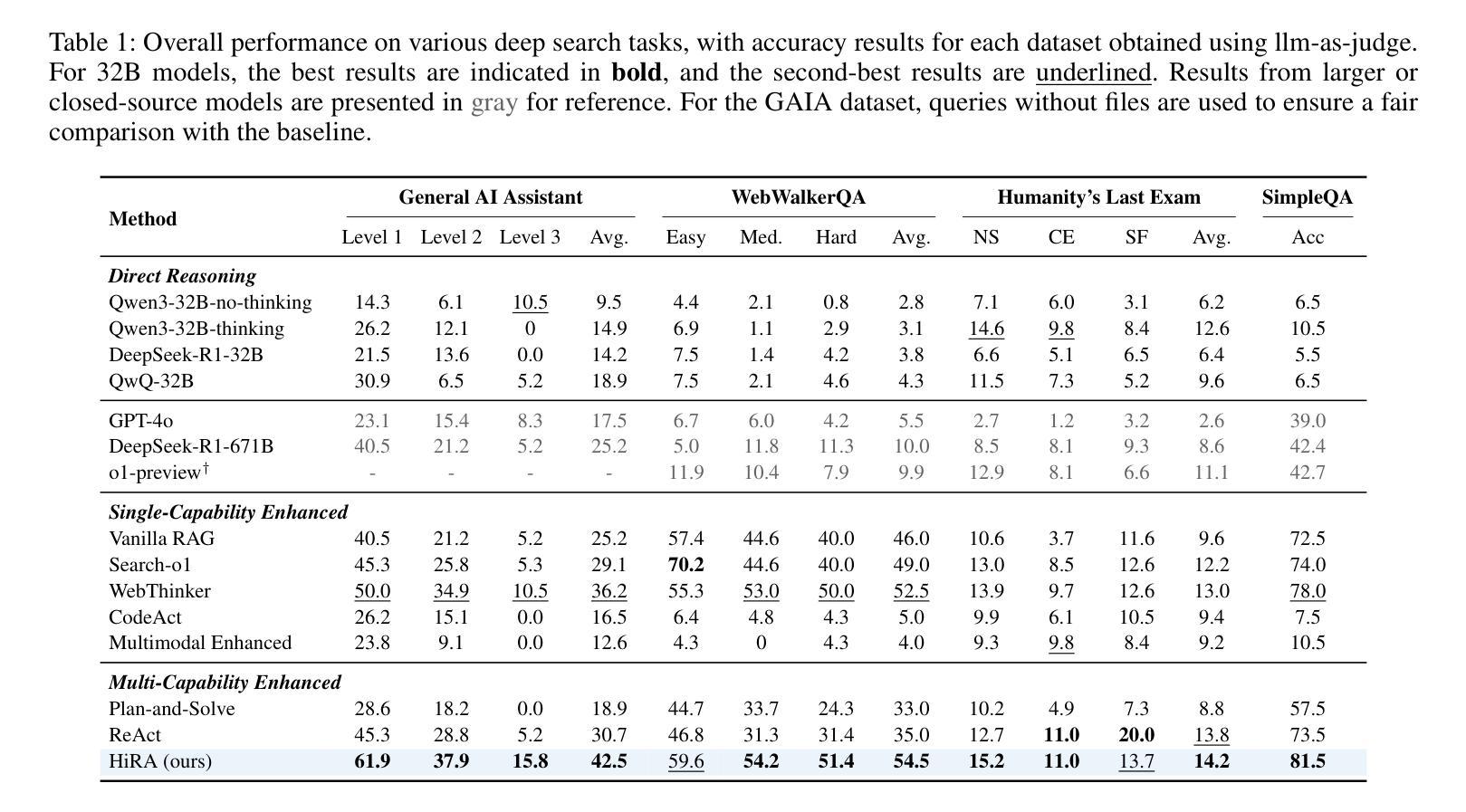
Complex information needs in real-world search scenarios demand deep reasoning and knowledge synthesis across diverse sources, which traditional retrieval-augmented generation (RAG) pipelines struggle to address effectively. Current reasoning-based approaches suffer from a fundamental limitation: they use a single model to handle both high-level planning and detailed execution, leading to inefficient reasoning and limited scalability. In this paper, we introduce HiRA, a hierarchical framework that separates strategic planning from specialized execution. Our approach decomposes complex search tasks into focused subtasks, assigns each subtask to domain-specific agents equipped with external tools and reasoning capabilities, and coordinates the results through a structured integration mechanism. This separation prevents execution details from disrupting high-level reasoning while enabling the system to leverage specialized expertise for different types of information processing. Experiments on four complex, cross-modal deep search benchmarks demonstrate that HiRA significantly outperforms state-of-the-art RAG and agent-based systems. Our results show improvements in both answer quality and system efficiency, highlighting the effectiveness of decoupled planning and execution for multi-step information seeking tasks. Our code is available at https://github.com/ignorejjj/HiRA.
现实世界搜索场景中的复杂信息需求需要跨不同源进行深度推理和知识综合,而传统的增强检索生成(RAG)管道在有效解决这方面存在困难。当前基于推理的方法存在根本性的局限:它们使用单个模型同时处理高级规划和详细执行,导致推理效率低下和可扩展性有限。在本文中,我们介绍了HiRA,一个层次框架,将战略规划与专业执行相分离。我们的方法将复杂的搜索任务分解为有针对性的子任务,将每个子任务分配给配备外部工具和推理能力的领域特定代理,并通过结构化整合机制协调结果。这种分离防止执行细节破坏高级推理,同时使系统能够利用不同类型的信息处理的专业知识。在四个复杂、跨模态深度搜索基准测试上的实验表明,HiRA显著优于最新的RAG和基于代理的系统。我们的结果提高了答案质量和系统效率,突出了针对多步骤信息搜索任务的解耦规划和执行的有效性。我们的代码可在https://github.com/ignorejjj/HiRA找到。
论文及项目相关链接
PDF 9 pages
Summary
面对真实世界搜索场景中复杂的深度推理和知识合成需求,传统基于检索的生成(RAG)管道和当前基于推理的方法存在局限性。本文提出HiRA,一个层次框架,将战略规划与专项执行分离,以处理复杂的搜索任务。HiRA将复杂任务分解为专项子任务,并为每个子任务分配具备外部工具和推理能力的专项代理,通过结构化整合机制协调结果。这种方法避免了执行细节干扰高级推理,同时使系统能够针对不同类型的信息处理利用专业专长。在四个复杂、跨模态深度搜索基准测试上的实验表明,HiRA显著优于最先进的RAG和基于代理的系统,在答案质量和系统效率方面都有改进。
Key Takeaways
- 真实世界的搜索需求需要深度推理和知识合成。
- 传统RAG管道和当前基于推理的方法存在局限性。
- HiRA是一个层次框架,将战略规划与专项执行分离,以处理复杂的搜索任务。
- HiRA将复杂任务分解为专项子任务,并为每个子任务分配专项代理。
- HiRA通过结构化整合机制协调代理的结果。
- HiRA避免了执行细节干扰高级推理。
- HiRA在多个基准测试上表现优于其他系统,展示了其在多步信息寻找任务中的有效性。
点此查看论文截图
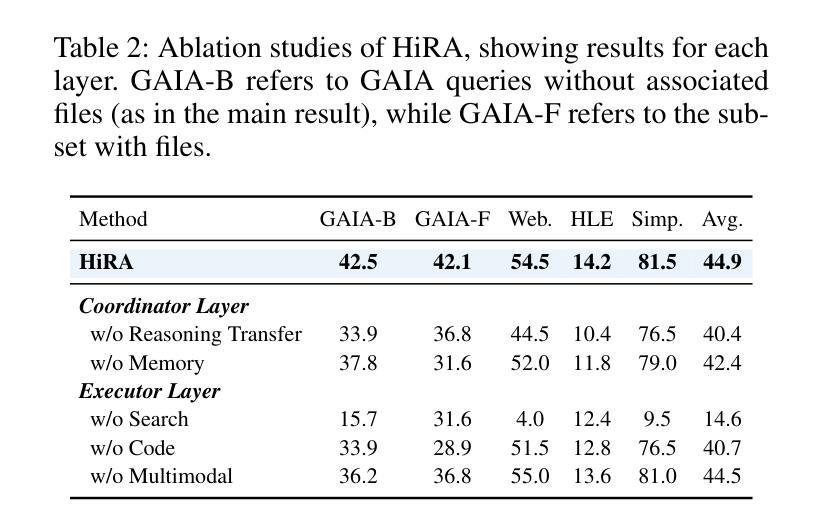
VRAgent-R1: Boosting Video Recommendation with MLLM-based Agents via Reinforcement Learning
Authors:Siran Chen, Boyu Chen, Chenyun Yu, Yuxiao Luo, Ouyang Yi, Lei Cheng, Chengxiang Zhuo, Zang Li, Yali Wang
Owing to powerful natural language processing and generative capabilities, large language model (LLM) agents have emerged as a promising solution for enhancing recommendation systems via user simulation. However, in the realm of video recommendation, existing studies predominantly resort to prompt-based simulation using frozen LLMs and encounter the intricate challenge of multimodal content understanding. This frequently results in suboptimal item modeling and user preference learning, thereby ultimately constraining recommendation performance. To address these challenges, we introduce VRAgent-R1, a novel agent-based paradigm that incorporates human-like intelligence in user simulation. Specifically, VRAgent-R1 comprises two distinct agents: the Item Perception (IP) Agent and the User Simulation (US) Agent, designed for interactive user-item modeling. Firstly, the IP Agent emulates human-like progressive thinking based on MLLMs, effectively capturing hidden recommendation semantics in videos. With a more comprehensive multimodal content understanding provided by the IP Agent, the video recommendation system is equipped to provide higher-quality candidate items. Subsequently, the US Agent refines the recommended video sets based on in-depth chain-of-thought (CoT) reasoning and achieves better alignment with real user preferences through reinforcement learning. Experimental results on a large-scale video recommendation benchmark have demonstrated the effectiveness of our proposed VRAgent-R1 method, e.g., the IP Agent achieves a 6.0% improvement in NDCG@10 on the MicroLens-100k dataset, while the US Agent shows approximately 45.0% higher accuracy in user decision simulation compared to state-of-the-art baselines.
由于强大的自然语言处理和生成能力,大型语言模型(LLM)代理用户模拟已经成为增强推荐系统的一种有前途的解决方案。然而,在视频推荐领域,现有研究主要依赖于基于提示的模拟使用冻结的LLM,并面临复杂的多媒体内容理解挑战。这经常导致项目建模和用户偏好学习不理想,从而最终限制推荐性能。为了应对这些挑战,我们引入了VRAgent-R1,这是一种新型基于代理的范式,将人类智能融入用户模拟中。具体来说,VRAgent-R1包括两个独特的代理:项目感知(IP)代理和用户模拟(US)代理,用于交互式用户项目建模。首先,IP代理基于MLLMs模拟人类渐进思考的方式,有效地捕捉视频中的隐藏推荐语义。通过IP代理提供的更全面的多媒体内容理解,视频推荐系统能够提供更高质量的候选项目。其次,US代理基于深入的链式思维(CoT)推理来完善推荐的视频集,并通过强化学习更好地符合真实用户偏好。在大规模视频推荐基准测试上的实验结果表明了我们提出的VRAgent-R1方法的有效性,例如IP代理在MicroLens-100k数据集上实现了NDCG@10的6.0%改进,而US代理在用户决策模拟方面的准确性比最新基线高出约45.0%。
论文及项目相关链接
Summary
本文介绍了大型语言模型(LLM)代理在推荐系统中的应用,特别是在视频推荐方面的挑战。为解决现有研究中存在的问题,提出了一种新的基于代理的方法VRAgent-R1,其中包括用于交互式用户建模的物品感知(IP)代理和用户模拟(US)代理。IP代理基于MLLM模拟人类的渐进思维,更有效地捕捉视频中的推荐语义;而US代理通过深度链思维推理来精炼推荐的视频集并通过强化学习更好地符合真实用户偏好。实验结果表明,VRAgent-R1方法有效提高了视频推荐的性能。
Key Takeaways
- 大型语言模型(LLM)代理被用于增强推荐系统,特别是在视频推荐方面。
- 现有研究主要使用基于提示的模拟方法,面临多模态内容理解的挑战。
- VRAgent-R1包括物品感知(IP)代理和用户模拟(US)代理,用于交互式用户建模。
- IP代理模拟人类的渐进思维,更有效地捕捉视频中的推荐语义。
- US代理通过深度链思维推理来精炼推荐的视频集,并更好地符合真实用户偏好。
- VRAgent-R1方法在实验上被证明能有效提高视频推荐性能。
点此查看论文截图


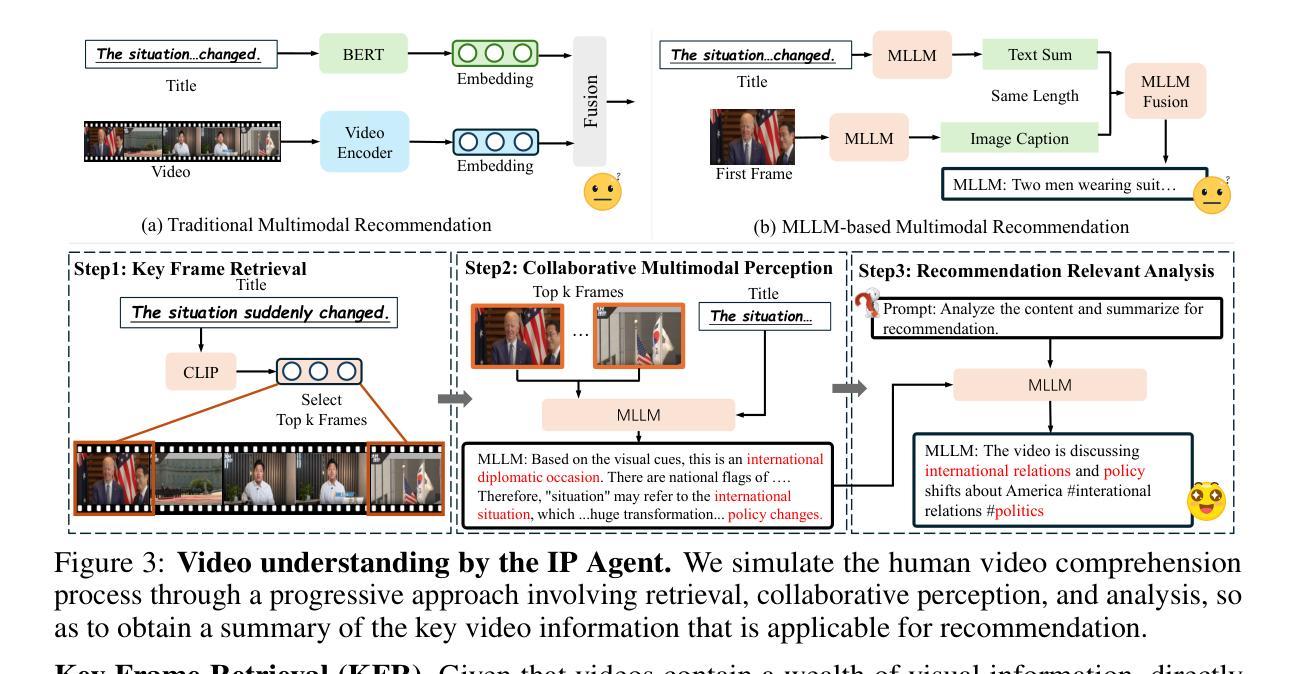
WebSailor: Navigating Super-human Reasoning for Web Agent
Authors:Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, Weizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi Wu, Yong Jiang, Ming Yan, Pengjun Xie, Fei Huang, Jingren Zhou
Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all opensource agents in complex information-seeking tasks, matching proprietary agents’ performance and closing the capability gap.
突破人类认知局限是大型语言模型训练中的一项关键前沿技术。DeepResearch等专有智能系统已在BrowseComp等极为复杂的信息检索基准测试中展现出超人类的能力,这是以前无法实现的。我们认为,它们的成功依赖于一种开源模型中不存在的复杂推理模式:在浏览广阔的信息景观时,系统地减少极端不确定性的能力。基于这一见解,我们推出了WebSailor,这是一种完整的训练后方法,旨在培养这种至关重要的能力。我们的方法是通过结构化采样、信息模糊处理、RFT冷启动和高效的智能强化学习训练算法DUPO(复制采样策略优化),生成具有新颖性、高不确定性的任务。通过这一综合管道,WebSailor在复杂的信息检索任务中大大超越了所有开源智能体,达到了专有智能体的性能水平,并弥补了能力差距。
论文及项目相关链接
Summary
深研的专有代理系统在复杂信息检索基准测试(如BrowseComp)中展现出超越人类的性能。其成功源于处理高不确定性信息时的精细推理模式。为赋予开源模型这种能力,我们推出WebSailor,一种全新的训练后方法。它通过结构化采样、信息模糊处理、RFT冷启动以及高效的代理强化学习训练算法DUPO,显著提升了在复杂信息检索任务中的表现,与专有代理性能相当,缩小了能力差距。
Key Takeaways
- 专有代理系统在复杂信息检索中超越人类表现。
- 深研的代理系统成功源于处理高不确定性信息时的精细推理。
- WebSailor是一种新的训练后方法,旨在提升开源模型在信息检索中的性能。
- WebSailor通过结构化采样、信息模糊等手段生成高不确定性任务。
- RFT冷启动技术提高了代理系统的效率。
- DUPO算法是WebSailor的核心,有效提升了代理在复杂任务中的性能。
点此查看论文截图
Reconstructing Close Human Interaction with Appearance and Proxemics Reasoning
Authors:Buzhen Huang, Chen Li, Chongyang Xu, Dongyue Lu, Jinnan Chen, Yangang Wang, Gim Hee Lee
Due to visual ambiguities and inter-person occlusions, existing human pose estimation methods cannot recover plausible close interactions from in-the-wild videos. Even state-of-the-art large foundation models~(\eg, SAM) cannot accurately distinguish human semantics in such challenging scenarios. In this work, we find that human appearance can provide a straightforward cue to address these obstacles. Based on this observation, we propose a dual-branch optimization framework to reconstruct accurate interactive motions with plausible body contacts constrained by human appearances, social proxemics, and physical laws. Specifically, we first train a diffusion model to learn the human proxemic behavior and pose prior knowledge. The trained network and two optimizable tensors are then incorporated into a dual-branch optimization framework to reconstruct human motions and appearances. Several constraints based on 3D Gaussians, 2D keypoints, and mesh penetrations are also designed to assist the optimization. With the proxemics prior and diverse constraints, our method is capable of estimating accurate interactions from in-the-wild videos captured in complex environments. We further build a dataset with pseudo ground-truth interaction annotations, which may promote future research on pose estimation and human behavior understanding. Experimental results on several benchmarks demonstrate that our method outperforms existing approaches. The code and data are available at https://www.buzhenhuang.com/works/CloseApp.html.
由于视觉模糊和人与人之间的遮挡,现有的人体姿态估计方法无法从野生视频中恢复出合理的紧密交互。即使是最先进的大型基础模型(例如SAM)也无法在这种具有挑战性的场景中准确区分人类语义。在这项工作中,我们发现人类外观可以提供一种直接的线索来解决这些障碍。基于这一观察,我们提出了一个双分支优化框架,通过人类外观、社交空间学、物理定律的约束来重建准确的交互动作和合理的身体接触。具体来说,我们首先训练一个扩散模型来学习人类的空间行为姿态先验知识。然后,将训练好的网络和两个可优化的张量纳入双分支优化框架中,以重建人类动作和外观。还设计了基于3D高斯、2D关键点以及网格穿透的多个约束来帮助优化。通过空间学先验知识和多样的约束,我们的方法能够从复杂环境中捕捉到的野生视频中估计出准确的人体交互。我们进一步建立了一个带有伪真实交互注释的数据集,这可能会促进未来对人体姿态估计和行为理解的研究。在几个基准测试上的实验结果证明,我们的方法优于现有方法。代码和数据集可在https://www.buzhenhuang.com/works/CloseApp.html访问。
论文及项目相关链接
Summary
本文提出一种基于人类外观的双分支优化框架,用于从野外视频中重建准确的人体交互动作。该框架通过结合人类行为学和物理规律,利用扩散模型学习人类行为模式和姿势先验知识,再通过优化算法重建人体动作和外观。实验结果表明,该方法在多个基准测试中表现优于现有方法。
Key Takeaways
- 现有的人体姿态估计方法无法从野外视频恢复出可信的近距离交互动作,原因在于视觉模糊和人与人之间的相互遮挡。
- 人类外观可以作为一种直观线索来解决这一问题。
- 提出了一个双分支优化框架,能够结合人类外观、社交空间学(proxemics)和物理定律来重建准确的人体交互动作。
- 通过训练扩散模型来学习人类的行为模式和姿势先验知识。
- 通过多种约束(如基于3D高斯分布、2D关键点、网格穿透的约束)来辅助优化过程。
- 建立了一个带有伪地面真实交互注释的数据集,以促进未来对人体姿态估计和人类行为理解的研究。
点此查看论文截图

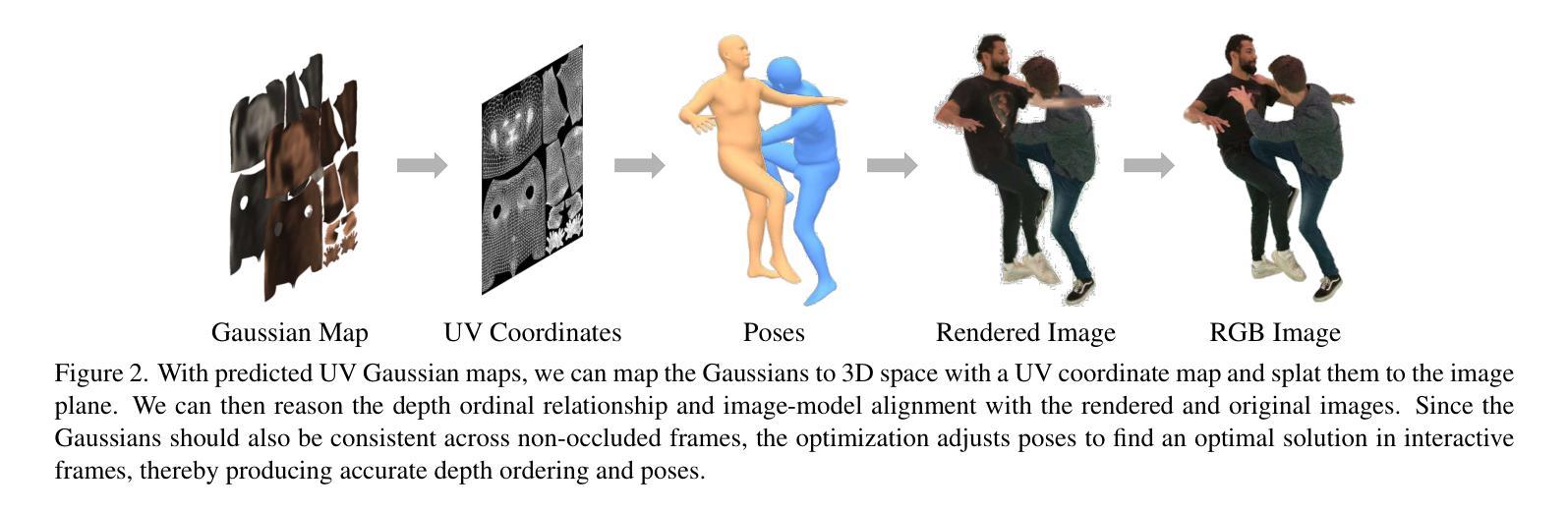
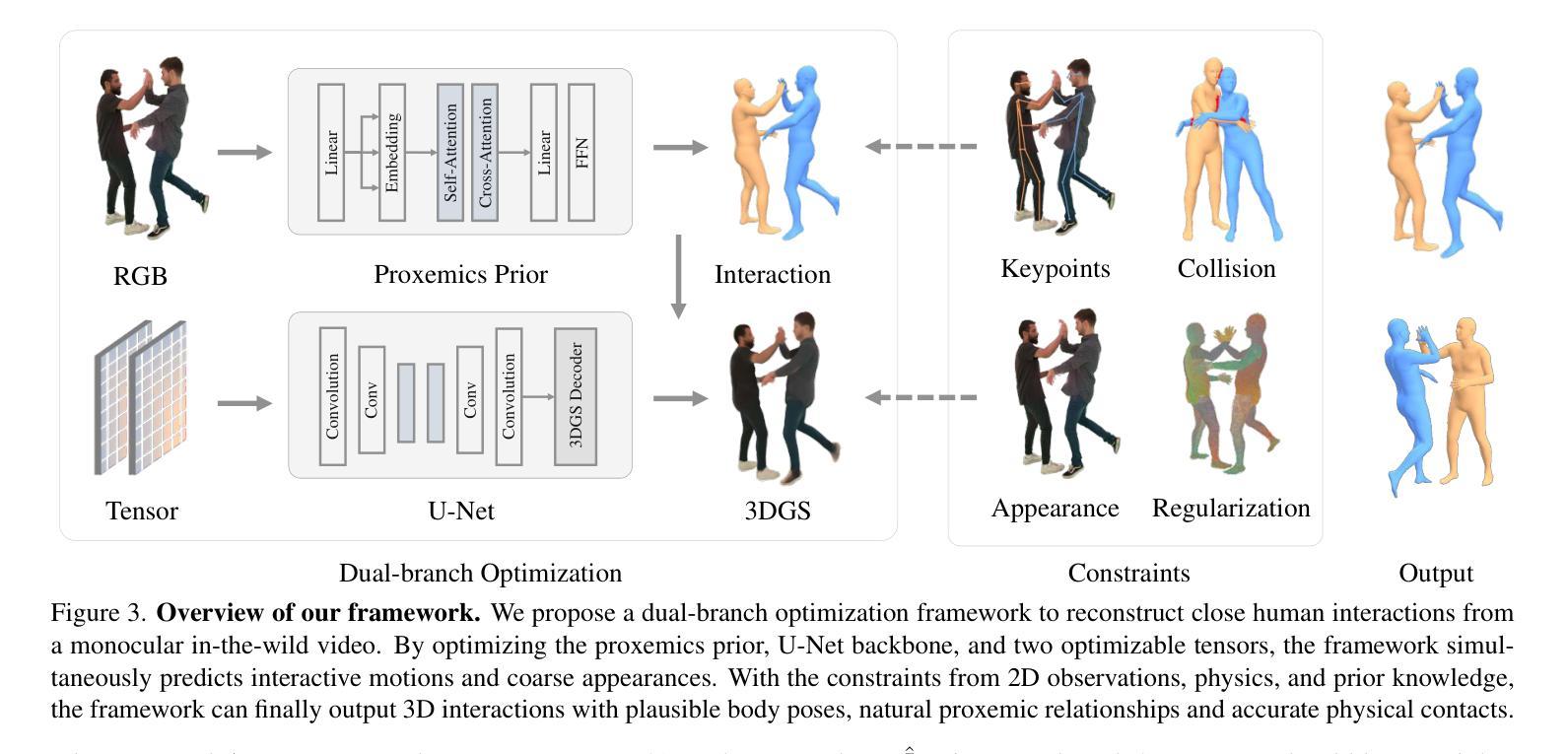

Clarifying Before Reasoning: A Coq Prover with Structural Context
Authors:Yanzhen Lu, Hanbin Yang, Xiaodie Wang, Ge Zhang, Biao Li, Chenxu Fu, Chao Li, Yang Yuan, Andrew Chi-Chih Yao
In this work, we investigate whether improving task clarity can enhance reasoning ability of large language models, focusing on theorem proving in Coq. We introduce a concept-level metric to evaluate task clarity and show that adding structured semantic context to the standard input used by modern LLMs, leads to a 1.85$\times$ improvement in clarity score (44.5%$\rightarrow$82.3%). Using the general-purpose model \texttt{DeepSeek-V3}, our approach leads to a 2.1$\times$ improvement in proof success (21.8%$\rightarrow$45.8%) and outperforms the previous state-of-the-art \texttt{Graph2Tac} (33.2%). We evaluate this on 1,386 theorems randomly sampled from 15 standard Coq packages, following the same evaluation protocol as \texttt{Graph2Tac}. Furthermore, fine-tuning smaller models on our structured data can achieve even higher performance (48.6%). Our method uses selective concept unfolding to enrich task descriptions, and employs a Planner–Executor architecture. These findings highlight the value of structured task representations in bridging the gap between understanding and reasoning.
在这项工作中,我们研究了提高任务清晰度是否能增强大型语言模型的推理能力,重点关注Coq中的定理证明。我们引入了一个概念层面的指标来评估任务清晰度,并表明向现代大型语言模型的标准输入添加结构化语义上下文,可以提高清晰度评分(从44.5%提高到82.3%),提高幅度为1.85倍。使用通用模型DeepSeek-V3,我们的方法使证明成功率提高了2.1倍(从21.8%提高到45.8%),并超越了之前的最佳模型Graph2Tac(33.2%)。我们在从15个标准Coq软件包中随机抽取的1386个定理上进行了评估,遵循与Graph2Tac相同的评估协议。此外,在结构化数据上微调较小的模型可以获得更高的性能(48.6%)。我们的方法使用选择性概念展开来丰富任务描述,并采用Planner-Executor架构。这些发现突显了结构化任务表示在理解和推理之间架起桥梁的价值。
论文及项目相关链接
Summary
本工作研究提高任务清晰度是否能提升大语言模型的推理能力,重点研究Coq中的定理证明。我们引入了一种概念层面的指标来评估任务清晰度,并显示向现代大型语言模型的标准输入添加结构化语义上下文,可以提高清晰度评分(从44.5%提高到82.3%),提高了约1.85倍。使用通用模型DeepSeek-V3,我们的方法使得证明成功的概率提高了约两倍(从21.8%提高到45.8%),并优于先前的最佳模型Graph2Tac(成功率为33.2%)。我们在从标准Coq软件包中随机抽取的1,386个定理上进行了评估,遵循Graph2Tac相同的评估协议。此外,通过细化我们的结构化数据对小模型进行微调可以实现更高的性能(成功率为48.6%)。我们的方法通过使用选择性概念展开来丰富任务描述,并采用Planner-Executor架构实现上述成果。这些发现突显了结构化任务表示在理解和推理之间架起桥梁的价值。
Key Takeaways
- 研究了提高任务清晰度对大型语言模型推理能力的影响,特别是在Coq中的定理证明。
- 引入概念层面的指标来评估任务清晰度,并发现添加结构化语义上下文可显著提高清晰度评分。
- 使用DeepSeek-V3模型,在定理证明方面取得了显著的成功率提升,优于先前的最佳模型Graph2Tac。
- 在大量随机抽取的Coq定理上进行了评估,遵循了Graph2Tac的评估协议。
- 通过使用选择性概念展开和Planner-Executor架构丰富任务描述来实现成果。
- 细调小模型在结构化数据上可以达到更高的性能表现。
点此查看论文截图


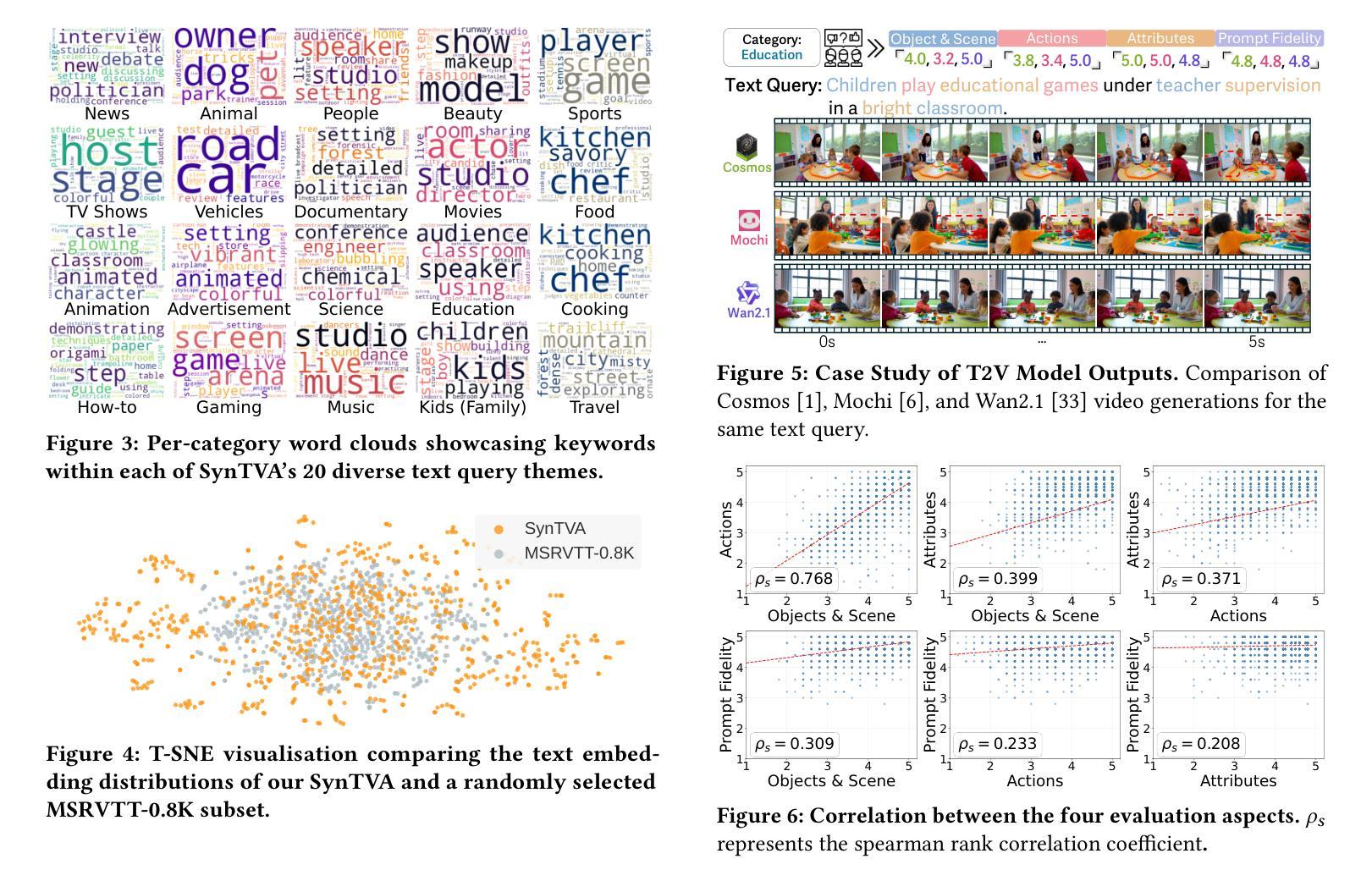
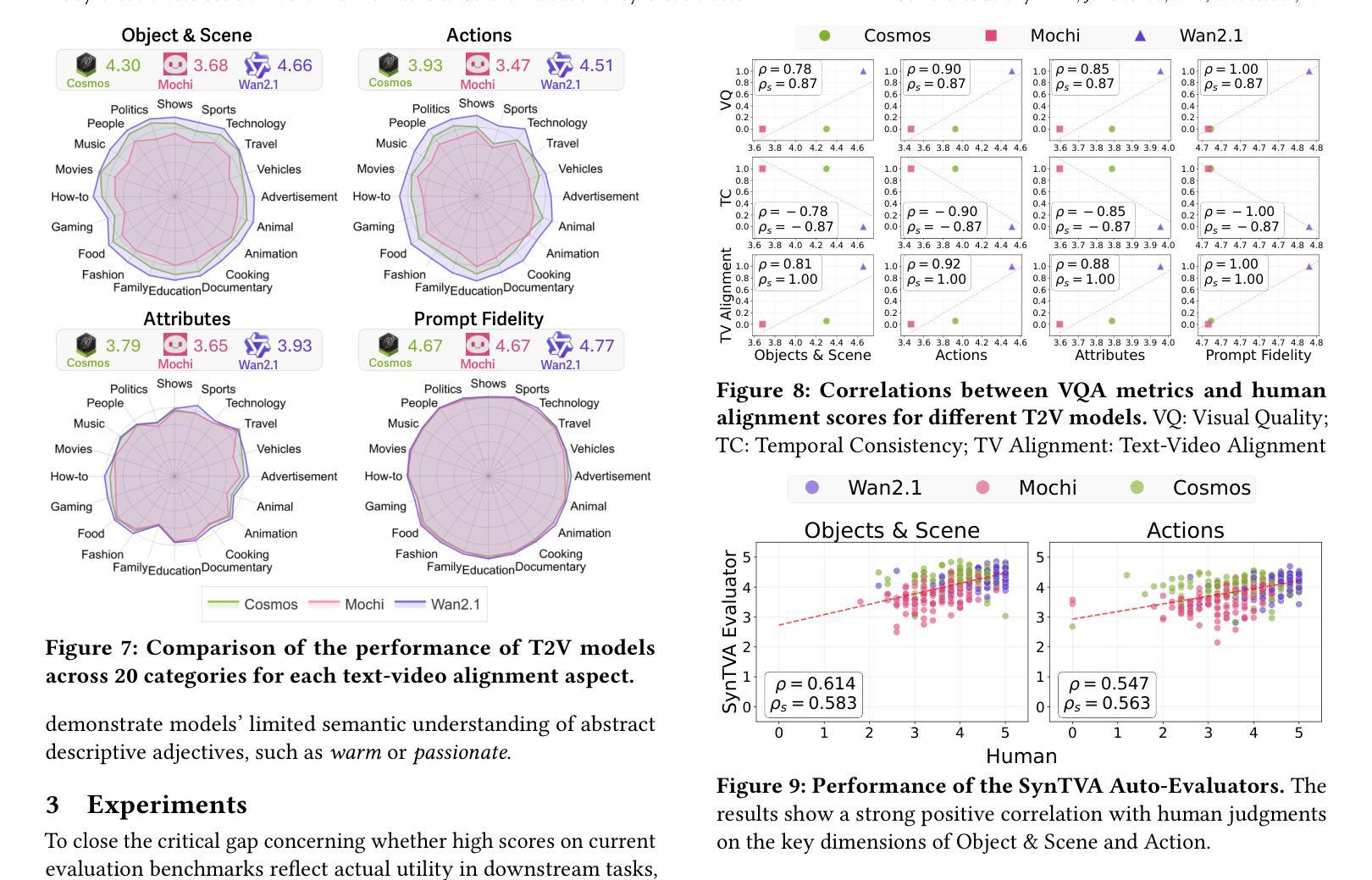
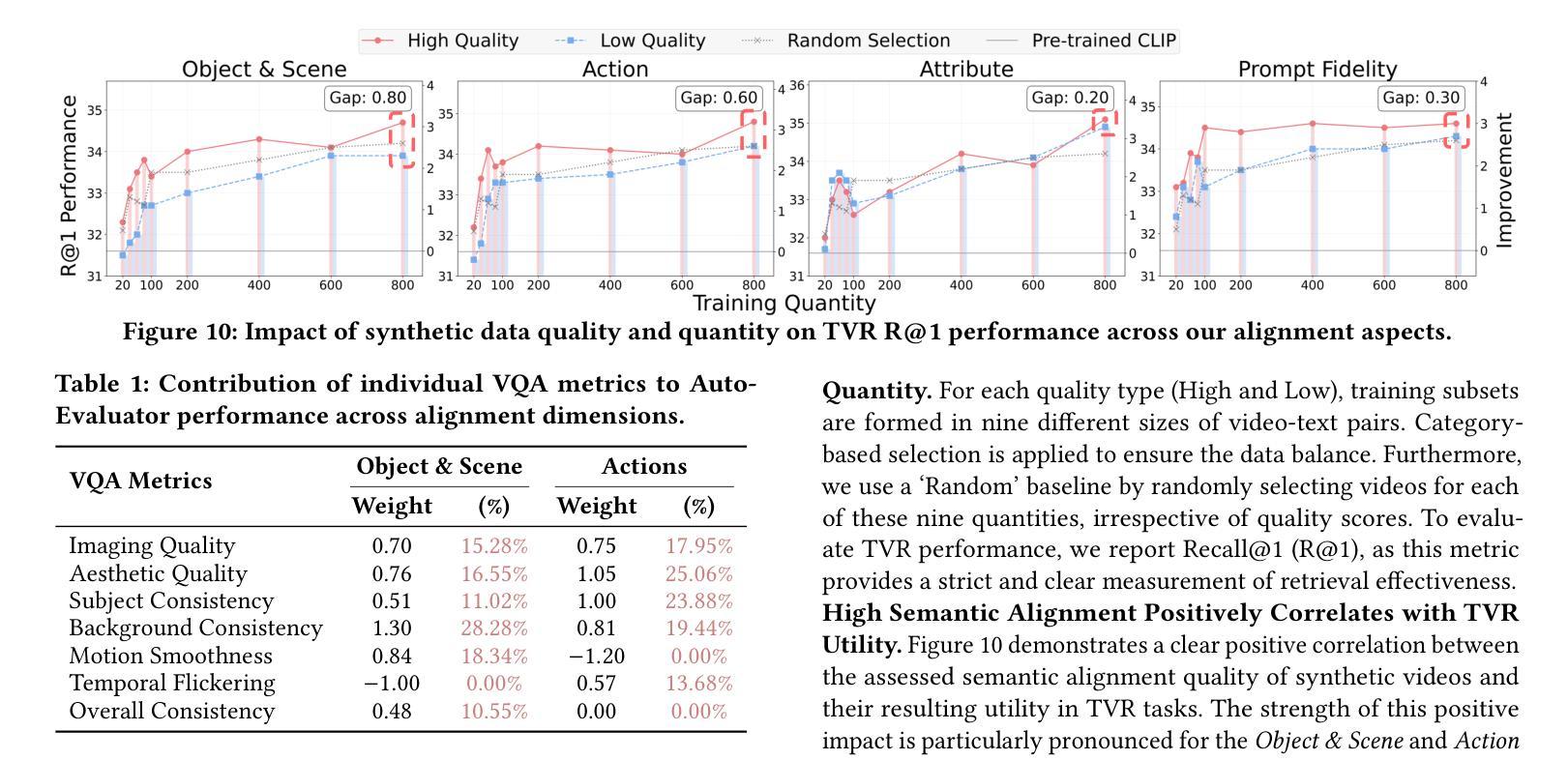
Are Synthetic Videos Useful? A Benchmark for Retrieval-Centric Evaluation of Synthetic Videos
Authors:Zecheng Zhao, Selena Song, Tong Chen, Zhi Chen, Shazia Sadiq, Yadan Luo
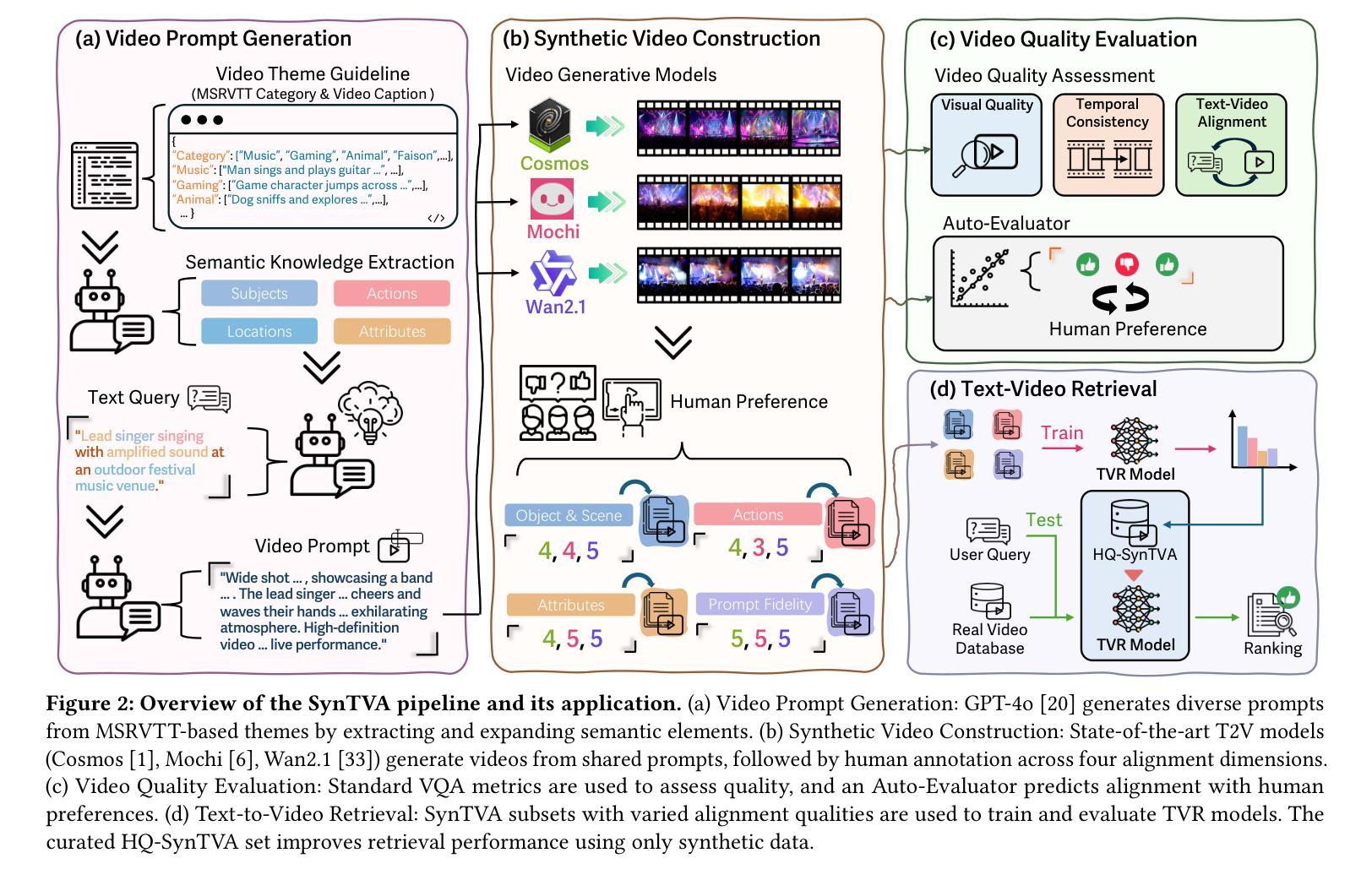
Text-to-video (T2V) synthesis has advanced rapidly, yet current evaluation metrics primarily capture visual quality and temporal consistency, offering limited insight into how synthetic videos perform in downstream tasks such as text-to-video retrieval (TVR). In this work, we introduce SynTVA, a new dataset and benchmark designed to evaluate the utility of synthetic videos for building retrieval models. Based on 800 diverse user queries derived from MSRVTT training split, we generate synthetic videos using state-of-the-art T2V models and annotate each video-text pair along four key semantic alignment dimensions: Object & Scene, Action, Attribute, and Prompt Fidelity. Our evaluation framework correlates general video quality assessment (VQA) metrics with these alignment scores, and examines their predictive power for downstream TVR performance. To explore pathways of scaling up, we further develop an Auto-Evaluator to estimate alignment quality from existing metrics. Beyond benchmarking, our results show that SynTVA is a valuable asset for dataset augmentation, enabling the selection of high-utility synthetic samples that measurably improve TVR outcomes. Project page and dataset can be found at https://jasoncodemaker.github.io/SynTVA/.
文本转视频(T2V)合成技术已经迅速发展,然而当前的评估指标主要捕捉视觉质量和时间一致性,对于合成视频在下游任务(如文本转视频检索(TVR))中的表现提供了有限的洞察。在这项工作中,我们介绍了SynTVA,这是一个新的数据集和基准测试,旨在评估合成视频在构建检索模型时的实用性。基于从MSRVTT训练集中得出的800个不同用户查询,我们使用最先进的T2V模型生成合成视频,并沿四个关键语义对齐维度对每个视频文本对进行注释:对象与场景、动作、属性和提示保真度。我们的评估框架将这些对齐分数与通用视频质量评估(VQA)指标相关联,并检查它们对下游TVR性能的预测能力。为了探索扩大规模的方法,我们进一步开发了一个自动评估器,以根据现有指标估计对齐质量。除了基准测试外,我们的结果表明,SynTVA是数据集增强的宝贵资产,能够选择高实用性的合成样本,这些样本可以显著提高TVR的结果。项目页面和数据集可在https://jasoncodemaker.github.io/SynTVA/找到。
论文及项目相关链接
PDF 7 pages, 10 figures
Summary
本文介绍了针对文本转视频(T2V)合成的新数据集SynTVA,该数据集旨在评估合成视频对于构建检索模型的有用性。数据集基于MSRVTT训练集分割的800个不同用户查询生成合成视频,并沿四个关键语义对齐维度对视频文本对进行标注:对象与场景、动作、属性和提示忠实度。评估框架将一般视频质量评估(VQA)指标与这些对齐分数相关联,并检查它们对下游TVR性能的预测能力。此外,为了扩大规模,还开发了一个自动评估器,用于根据现有指标估计对齐质量。除了作为基准测试,SynTVA对于数据集增强也显示出其价值,能够选择高质量合成样本,显著提高TVR结果。
Key Takeaways
- SynTVA是一个新的数据集和基准测试,旨在评估文本转视频合成视频对于构建检索模型的有用性。
- 数据集基于MSRVTT训练集分割生成合成视频,并沿四个关键语义对齐维度进行标注。
- 评估框架关联了一般视频质量评估(VQA)指标与语义对齐分数。
- 框架检查了这些指标对下游文本转视频检索(TVR)性能的预测能力。
- 为了扩大规模,开发了一个自动评估器来估计对齐质量。
- SynTVA不仅用于基准测试,还显示出在数据集增强方面的价值,能够选择提高文本转视频检索(TVR)结果的高质量合成样本。
点此查看论文截图

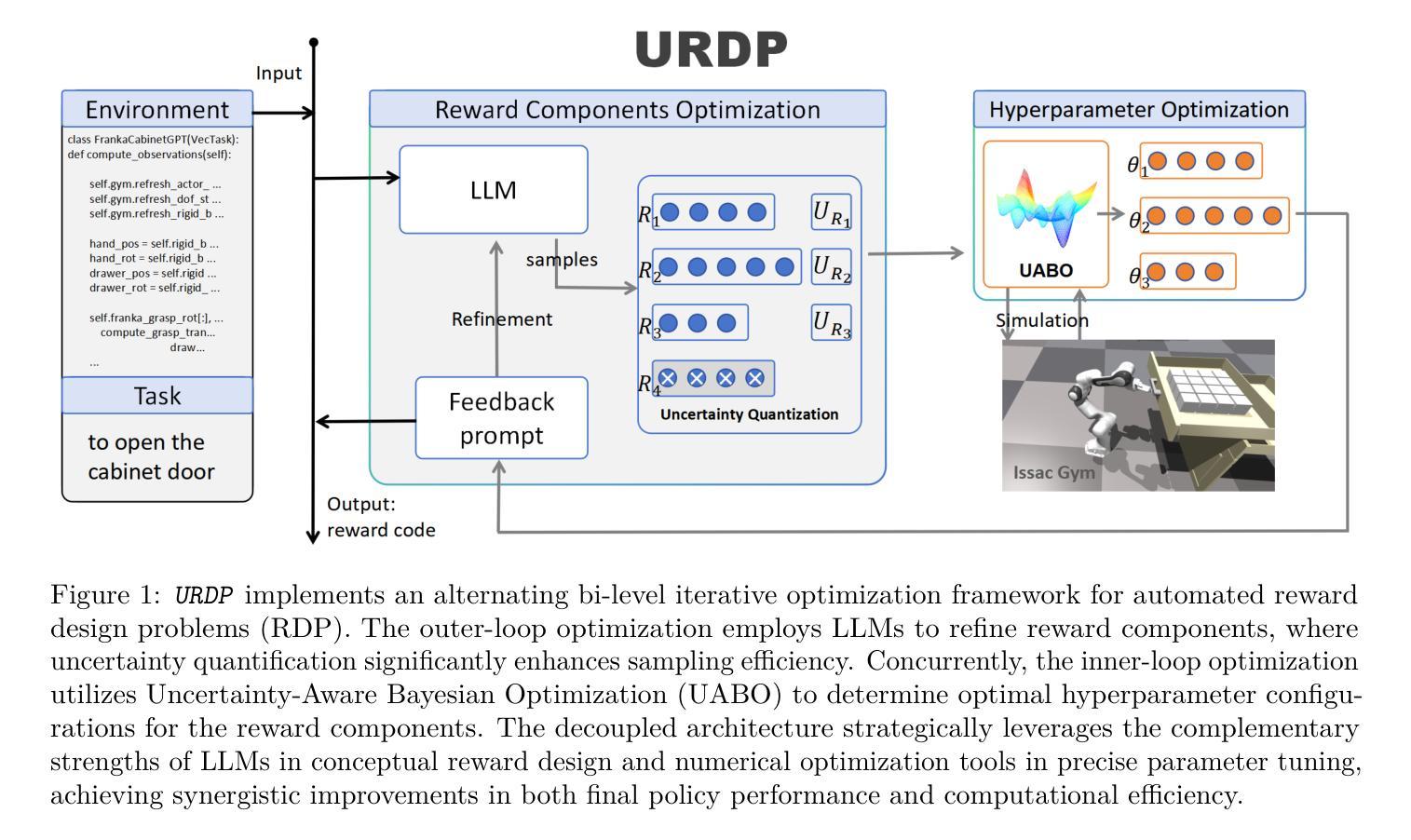
Uncertainty-aware Reward Design Process
Authors:Yang Yang, Xiaolu Zhou, Bosong Ding, Miao Xin
Designing effective reward functions is a cornerstone of reinforcement learning (RL), yet it remains a challenging process due to the inefficiencies and inconsistencies inherent in conventional reward engineering methodologies. Recent advances have explored leveraging large language models (LLMs) to automate reward function design. However, their suboptimal performance in numerical optimization often yields unsatisfactory reward quality, while the evolutionary search paradigm demonstrates inefficient utilization of simulation resources, resulting in prohibitively lengthy design cycles with disproportionate computational overhead. To address these challenges, we propose the Uncertainty-aware Reward Design Process (URDP), a novel framework that integrates large language models to streamline reward function design and evaluation in RL environments. URDP quantifies candidate reward function uncertainty based on self-consistency analysis, enabling simulation-free identification of ineffective reward components while discovering novel reward components. Furthermore, we introduce uncertainty-aware Bayesian optimization (UABO), which incorporates uncertainty estimation to significantly enhance hyperparameter configuration efficiency. Finally, we construct a bi-level optimization architecture by decoupling the reward component optimization and the hyperparameter tuning. URDP orchestrates synergistic collaboration between the reward logic reasoning of the LLMs and the numerical optimization strengths of the Bayesian Optimization. We conduct a comprehensive evaluation of URDP across 35 diverse tasks spanning three benchmark environments. Our experimental results demonstrate that URDP not only generates higher-quality reward functions but also achieves significant improvements in the efficiency of automated reward design compared to existing approaches.
设计有效的奖励函数是强化学习(RL)的核心,但由于传统奖励工程方法中的效率低和不一致性,这仍然是一个具有挑战性的过程。最近的进展已经探索了利用大型语言模型(LLM)来自动设计奖励函数。然而,它们在数值优化中的次优性能导致的奖励质量令人不满意,而进化搜索模式表现出模拟资源利用不足,导致设计周期过长且计算开销不成比例。为了解决这些挑战,我们提出了基于不确定性的奖励设计过程(URDP),这是一种新型框架,旨在整合大型语言模型来简化RL环境中的奖励函数设计和评估。URDP基于自我一致性分析量化候选奖励函数的不确定性,实现在无需模拟的情况下识别无效的奖励组件,同时发现新颖的奖励组件。此外,我们引入了基于不确定性的贝叶斯优化(UABO),它通过结合不确定性估计,极大地提高了超参数配置的效率。最后,我们建立了一个双层优化架构,通过解耦奖励组件优化和超参数调整。URDP协同调度大型语言模型的奖励逻辑推理和贝叶斯优化的数值优化能力。我们在三个基准环境中的35个不同任务上全面评估了URDP。实验结果表明,URDP不仅生成更高质量的奖励函数,而且在自动化奖励设计的效率方面实现了显著的改进,相较于现有方法。
论文及项目相关链接
PDF 34 pages, 9 figures
Summary
强化学习中设计有效的奖励函数是核心环节,但传统方法存在效率低下和结果不一致的问题。最近开始尝试利用大型语言模型自动化设计奖励函数,但数值优化中存在性能不足的问题。为此,我们提出了基于不确定性感知的奖励设计过程(URDP),利用大型语言模型来优化奖励函数的设计和评估。URDP通过自我一致性分析量化候选奖励函数的不确定性,无需模拟即可识别无效的奖励组件并发现新的奖励组件。此外,我们还引入了基于不确定性的贝叶斯优化(UABO),以提高超参数配置的调整效率。通过构建两级优化架构,实现奖励组件优化和超参数调整的解耦。在多个基准环境和任务上的实验结果表明,URDP不仅生成了更高质量的奖励函数,而且在自动化奖励设计方面也有显著效率提升。
Key Takeaways
- 强化学习中奖励函数设计是核心挑战之一。
- 传统奖励函数设计方法的效率和一致性存在问题。
- 利用大型语言模型自动化奖励函数设计是一种新兴趋势。
- 数值优化在大型语言模型的应用中存在性能不足的问题。
- URDP框架结合了大型语言模型和贝叶斯优化,提高了奖励函数设计的效率和质量。
- URDP通过自我一致性分析量化奖励函数的不确定性。
点此查看论文截图

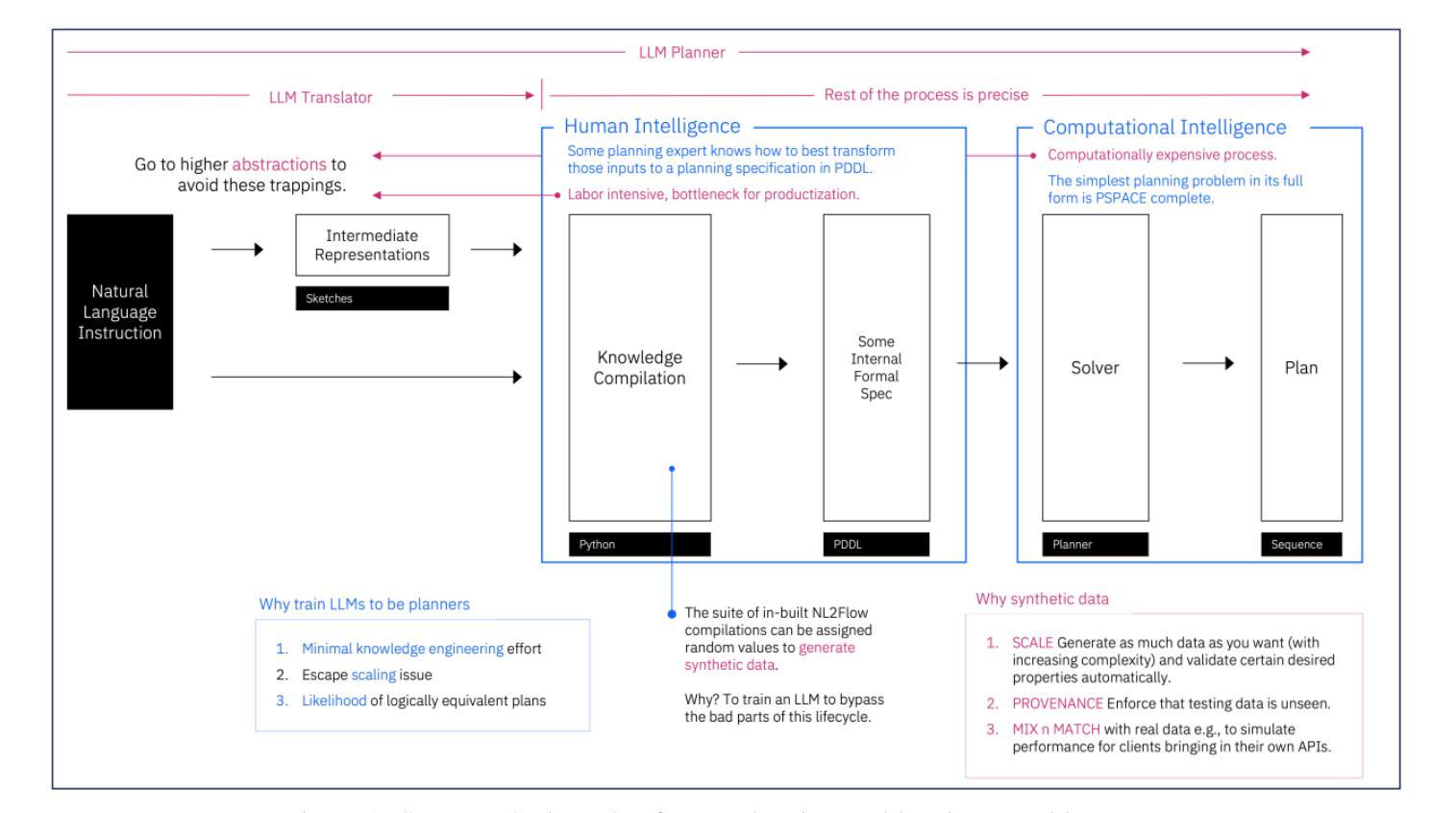
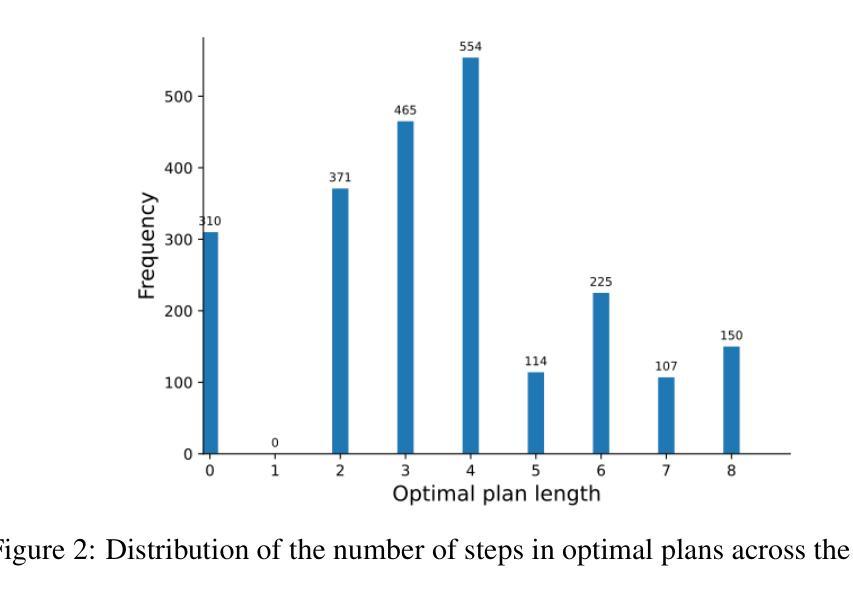
Scaling LLM Planning: NL2FLOW for Parametric Problem Generation and Rigorous Evaluation
Authors:Jungkoo Kang
Progress in enhancing large language model (LLM) planning and reasoning capabilities is significantly hampered by the bottleneck of scalable, reliable data generation and evaluation. To overcome this, I introduce NL2FLOW, a fully automated system for parametrically generating planning problems - expressed in natural language, a structured intermediate representation, and formal PDDL - and rigorously evaluating the quality of generated plans. I demonstrate NL2FLOW’s capabilities by generating a dataset of 2296 problems in the automated workflow generation domain and evaluating multiple open-sourced, instruct-tuned LLMs. My results reveal that the highest performing models achieved 86% success in generating valid plans and 69% in generating optimal plans, specifically for problems with feasible solutions. Regression analysis shows that the influence of problem characteristics on plan generation is contingent on both model and prompt design. Notably, I observed that the highest success rate for translating natural language into a JSON representation of a plan was lower than the highest rate of generating a valid plan directly. This suggests that unnecessarily decomposing the reasoning task - introducing intermediate translation steps - may actually degrade performance, implying a benefit to models capable of reasoning directly from natural language to action. As I scale LLM reasoning to increasingly complex problems, the bottlenecks and sources of error within these systems will inevitably shift. Therefore, a dynamic understanding of these limitations - and the tools to systematically reveal them - will be crucial for unlocking the full potential of LLMs as intelligent problem solvers.
在提升大型语言模型(LLM)规划和推理能力方面,可扩展的可靠数据生成和评估瓶颈显著阻碍了其进展。为了克服这一难题,我推出了NL2FLOW系统,这是一个全自动的参数化生成规划问题的系统,该系统以自然语言、结构化中间表示和正式PDDL表达问题,并严格评估生成计划的质量。我通过生成自动化工作流程生成领域中的2296个问题数据集来展示NL2FLOW的功能,并评估多个开源的、经过指令调整的大型语言模型。我的结果表明,表现最佳的模型在生成有效计划方面达到了86%的成功率,在生成最优计划方面达到了69%,特别是在具有可行解的问题上。回归分析表明,问题特性对计划生成的影响取决于模型和提示设计。值得注意的是,我观察到将自然语言翻译成计划JSON表示形式的最高成功率低于直接生成有效计划的最高成功率。这表明,不必要地分解推理任务(引入中间翻译步骤)实际上可能会降低性能,暗示那些能够直接从自然语言进行推理的模型具有优势。随着我将大型语言模型推理扩展到越来越复杂的问题,这些系统中的瓶颈和错误来源将不可避免地发生变化。因此,对这些限制的动态理解以及系统地揭示它们的工具,对于解锁大型语言模型作为智能问题求解器的潜力至关重要。
论文及项目相关链接
PDF 20 pages, 7 figures
Summary
在自然语言模型规划能力生成和评估瓶颈的问题中,提出了一种全新的解决方案NL2FLOW。它全自动参数化生成规划问题,并能对生成的规划质量进行严格评估。通过实验生成了自动化工作流程领域的2296个问题数据集,并评估了多个开源的指令调优大型语言模型。实验结果显示,最佳模型生成有效计划的成功率达到86%,生成最优计划的成功率达到69%。同时发现,将推理任务分解成不必要的中间翻译步骤可能会降低性能,直接根据自然语言进行推理的模型可能具有优势。随着大型语言模型解决越来越复杂的问题,其瓶颈和错误来源也会发生变化,因此需要动态理解这些限制和系统揭示工具,以解锁大型语言模型作为智能问题求解器的潜力。
Key Takeaways
- NL2FLOW系统解决了大型语言模型在规划能力生成和评估方面的瓶颈问题。
- NL2FLOW能全自动参数化生成规划问题,并严格评估生成的规划质量。
- 通过实验生成了自动化工作流程领域的数据集,并评估了多个大型语言模型的性能。
- 最佳模型生成有效计划的成功率为86%,生成最优计划的成功率为69%。
- 不必要的中间翻译步骤可能会降低大型语言模型的推理性能。
- 直接从自然语言进行推理的模型可能具有优势。
点此查看论文截图



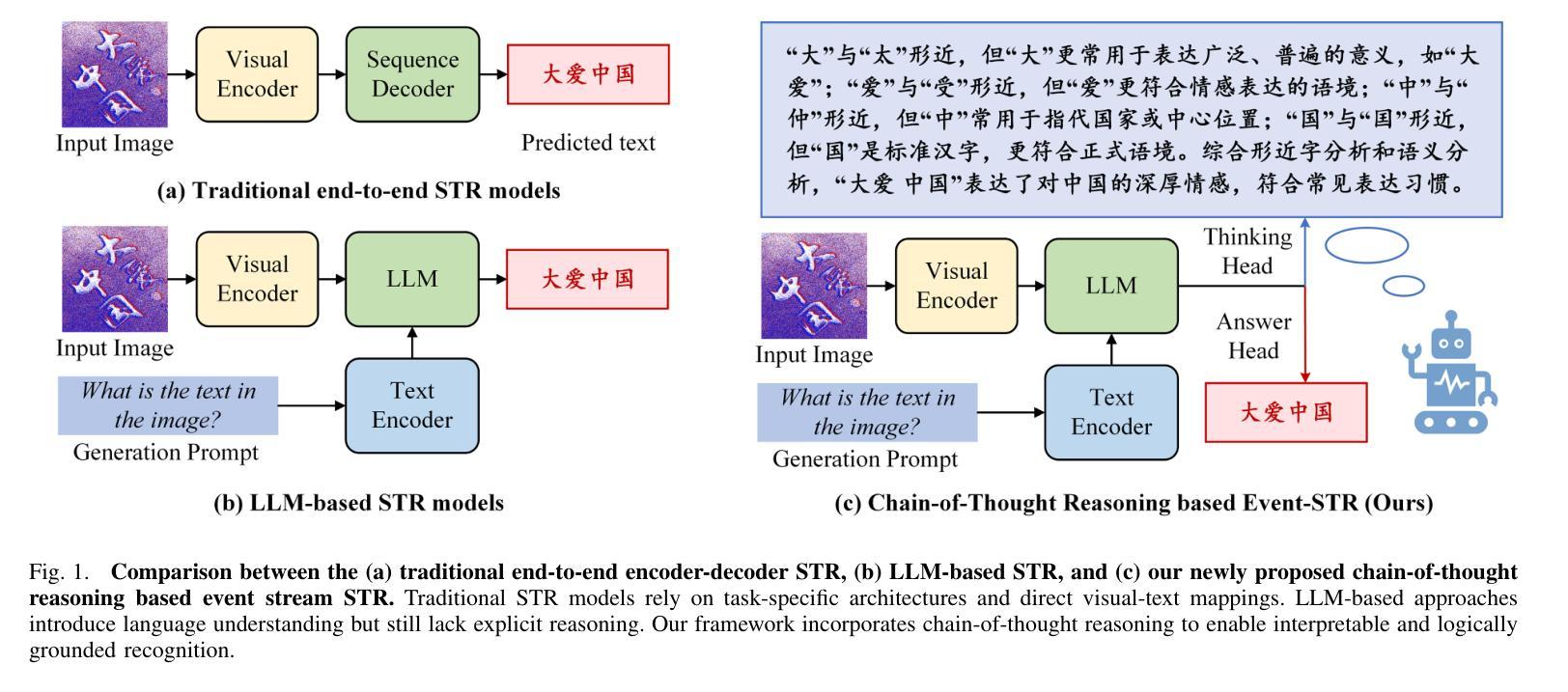
ESTR-CoT: Towards Explainable and Accurate Event Stream based Scene Text Recognition with Chain-of-Thought Reasoning
Authors:Xiao Wang, Jingtao Jiang, Qiang Chen, Lan Chen, Lin Zhu, Yaowei Wang, Yonghong Tian, Jin Tang
Event stream based scene text recognition is a newly arising research topic in recent years which performs better than the widely used RGB cameras in extremely challenging scenarios, especially the low illumination, fast motion. Existing works either adopt end-to-end encoder-decoder framework or large language models for enhanced recognition, however, they are still limited by the challenges of insufficient interpretability and weak contextual logical reasoning. In this work, we propose a novel chain-of-thought reasoning based event stream scene text recognition framework, termed ESTR-CoT. Specifically, we first adopt the vision encoder EVA-CLIP (ViT-G/14) to transform the input event stream into tokens and utilize a Llama tokenizer to encode the given generation prompt. A Q-former is used to align the vision token to the pre-trained large language model Vicuna-7B and output both the answer and chain-of-thought (CoT) reasoning process simultaneously. Our framework can be optimized using supervised fine-tuning in an end-to-end manner. In addition, we also propose a large-scale CoT dataset to train our framework via a three stage processing (i.e., generation, polish, and expert verification). This dataset provides a solid data foundation for the development of subsequent reasoning-based large models. Extensive experiments on three event stream STR benchmark datasets (i.e., EventSTR, WordArt*, IC15*) fully validated the effectiveness and interpretability of our proposed framework. The source code and pre-trained models will be released on https://github.com/Event-AHU/ESTR-CoT.
基于事件流的场景文本识别是近年来新兴的研究课题,它在极端挑战场景(尤其是低光照、快速运动)中的表现优于广泛使用的RGB相机。现有的工作要么采用端到端的编码器-解码器框架,要么采用大型语言模型进行增强识别,然而,它们仍然面临着解释性不足和上下文逻辑推理能力弱的挑战。
在这项工作中,我们提出了一种基于思维链推理的事件流场景文本识别新框架,称为ESTR-CoT。具体来说,我们首先采用视觉编码器EVA-CLIP(ViT-G/14)将输入的事件流转换为令牌,并使用Llama令牌生成器对给定的生成提示进行编码。Q-former用于将视觉令牌与预训练的大型语言模型Vicuna-7B对齐,并同时输出答案和思维链(CoT)推理过程。我们的框架可以通过端到端的监督微调来进行优化。
此外,我们还提出了一个大规模CoT数据集,通过三个阶段(即生成、润色和专家验证)来训练我们的框架。该数据集为随后基于推理的大型模型的发展提供了坚实的数据基础。在三个事件流STR基准数据集(即EventSTR、WordArt和IC15)上的大量实验充分验证了我们所提出框架的有效性和可解释性。源代码和预训练模型将在https://github.com/Event-AHU/ESTR-CoT上发布。
论文及项目相关链接
PDF A Strong Baseline for Reasoning based Event Stream Scene Text Recognition
Summary
本文提出一种基于事件流场景文本识别的新框架,称为ESTR-CoT。它采用链式思维推理,能应对低光照、快速运动等挑战场景下的文本识别。该框架利用视觉编码器EVA-CLIP和Q-former,将事件流转换为令牌并与预训练的大型语言模型Vicuna-7B对齐,同时输出答案和推理过程。此外,还通过三阶段处理流程构建了一个大规模的CoT数据集用于训练。在多个事件流STR基准数据集上的实验验证了框架的有效性和可解释性。
Key Takeaways
- ESTR-CoT是一个基于事件流场景文本识别的新框架,适用于低光照和快速运动等挑战场景。
- 该框架结合了视觉编码器EVA-CLIP和Q-former技术,用于将事件流转换为令牌并与大型语言模型对齐。
- 框架能同时输出答案和链式思维(CoT)推理过程,增强了可解释性。
- 提出了一种大规模CoT数据集的构建方法,通过三阶段处理流程用于框架训练。
- 框架通过端到端的监督微调方式可以进行优化。
- 在多个基准数据集上的实验验证了框架的有效性和优越性。
点此查看论文截图

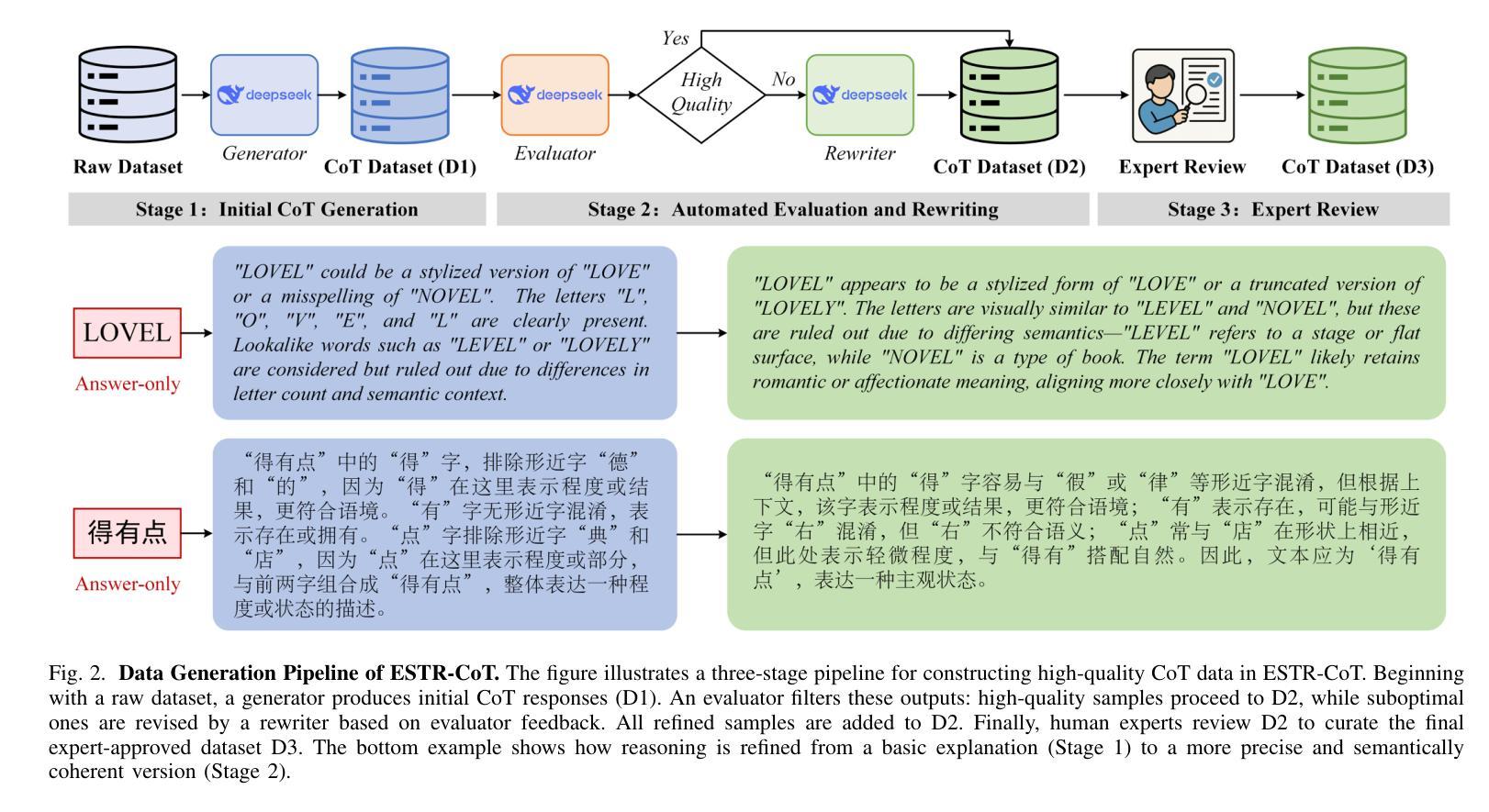

Data Diversification Methods In Alignment Enhance Math Performance In LLMs
Authors:Berkan Dokmeci, Qingyang Wu, Ben Athiwaratkun, Ce Zhang, Shuaiwen Leon Song, James Zou
While recent advances in preference learning have enhanced alignment in human feedback, mathematical reasoning remains a persistent challenge. We investigate how data diversification strategies in preference optimization can improve the mathematical reasoning abilities of large language models (LLMs). We evaluate three common data generation methods: temperature sampling, Chain-of-Thought prompting, and Monte Carlo Tree Search (MCTS), and introduce Diversified-ThinkSolve (DTS), a novel structured approach that systematically decomposes problems into diverse reasoning paths. Our results show that with strategically diversified preference data, models can substantially improve mathematical reasoning performance, with the best approach yielding gains of 7.1% on GSM8K and 4.2% on MATH over the base model. Despite its strong performance, DTS incurs only a marginal computational overhead (1.03x) compared to the baseline, while MCTS is nearly five times more costly with lower returns. These findings demonstrate that structured exploration of diverse problem-solving methods creates more effective preference data for mathematical alignment than traditional approaches.
虽然偏好学习方面的最新进展增强了人类反馈的对齐性,但数学推理仍然是一个持续存在的挑战。我们研究了偏好优化中的数据多样化策略如何改善大型语言模型(LLM)的数学推理能力。我们评估了三种常见的数据生成方法:温度采样、思维链提示和蒙特卡洛树搜索(MCTS),并引入了多样化思考求解(DTS)这一新型结构化方法,该方法能够系统地将问题分解为多样化的推理路径。我们的结果表明,通过采用策略性的多样化偏好数据,模型能够显著提高数学推理性能,其中最佳方法能够在GSM8K上提升7.1%,在MATH上提升4.2%,超过基准模型。尽管DTS表现出强大的性能,但其相对于基准的计算开销仅略有增加(1.03倍),而MCTS的计算成本则高出近五倍且回报较低。这些发现表明,与传统方法相比,对多样化问题解决方法进行结构化探索能够创建更有效的偏好数据,以实现数学对齐。
论文及项目相关链接
Summary
近期偏好学习领域的进展已提高了人类反馈的契合度,但数学推理仍是一个挑战。本研究探讨了偏好优化中的数据多样化策略如何提升大型语言模型的数学推理能力。我们评估了三种常见的数据生成方法:温度采样、Chain-of-Thought提示和蒙特卡洛树搜索(MCTS),并引入了Diversified-ThinkSolve(DTS)这一新型结构化方法,该方法能系统化地将问题分解为多样化的推理路径。结果显示,通过策略性地采用多样化偏好数据,模型能在GSM8K上提高7.1%、MATH上提高4.2%的数学推理性能。尽管DTS表现强劲,但相比基础模型只产生了轻微的计算开销(1.03倍),而MCTS成本几乎是五倍且回报较低。这表明与传统方法相比,多样化问题解决方法的结构化探索能为数学对齐创造更有效的偏好数据。
Key Takeaways
- 近期偏好学习进展提高了人类反馈契合度,但数学推理仍是挑战。
- 研究了数据多样化策略在提升大型语言模型数学推理能力中的应用。
- 评估了三种数据生成方法:温度采样、Chain-of-Thought提示和蒙特卡洛树搜索(MCTS)。
- 引入了Diversified-ThinkSolve(DTS)这一新型结构化方法,能系统化分解问题为多样化推理路径。
- 通过策略性采用多样化偏好数据,模型在数学推理性能上取得了显著提升。
- DTS相比基础模型仅产生轻微计算开销,而MCTS成本高昂且回报较低。
点此查看论文截图

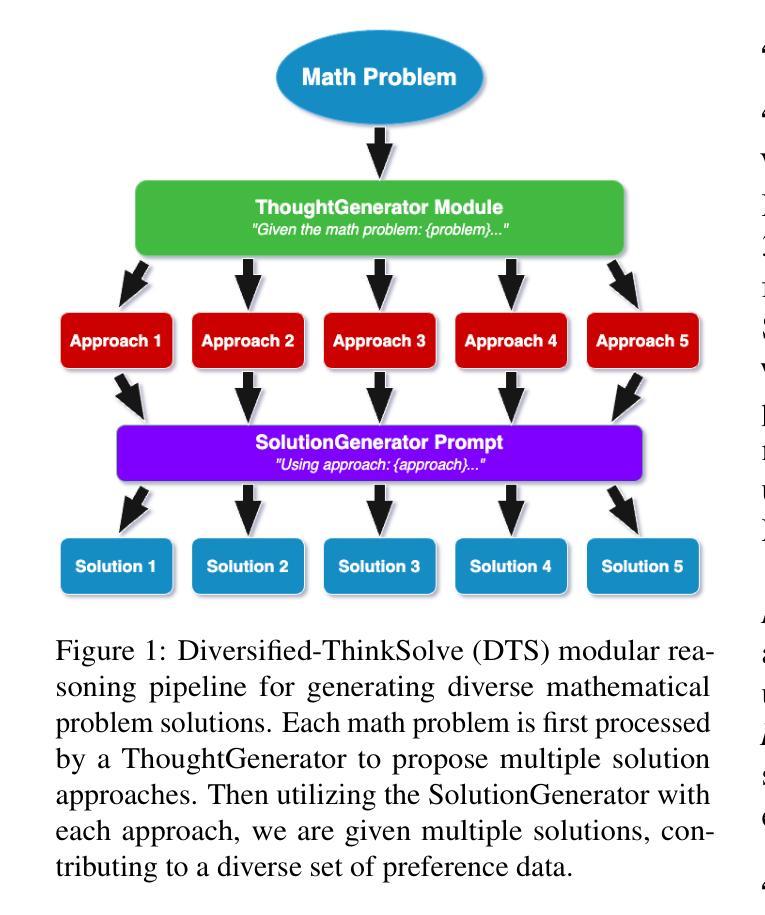
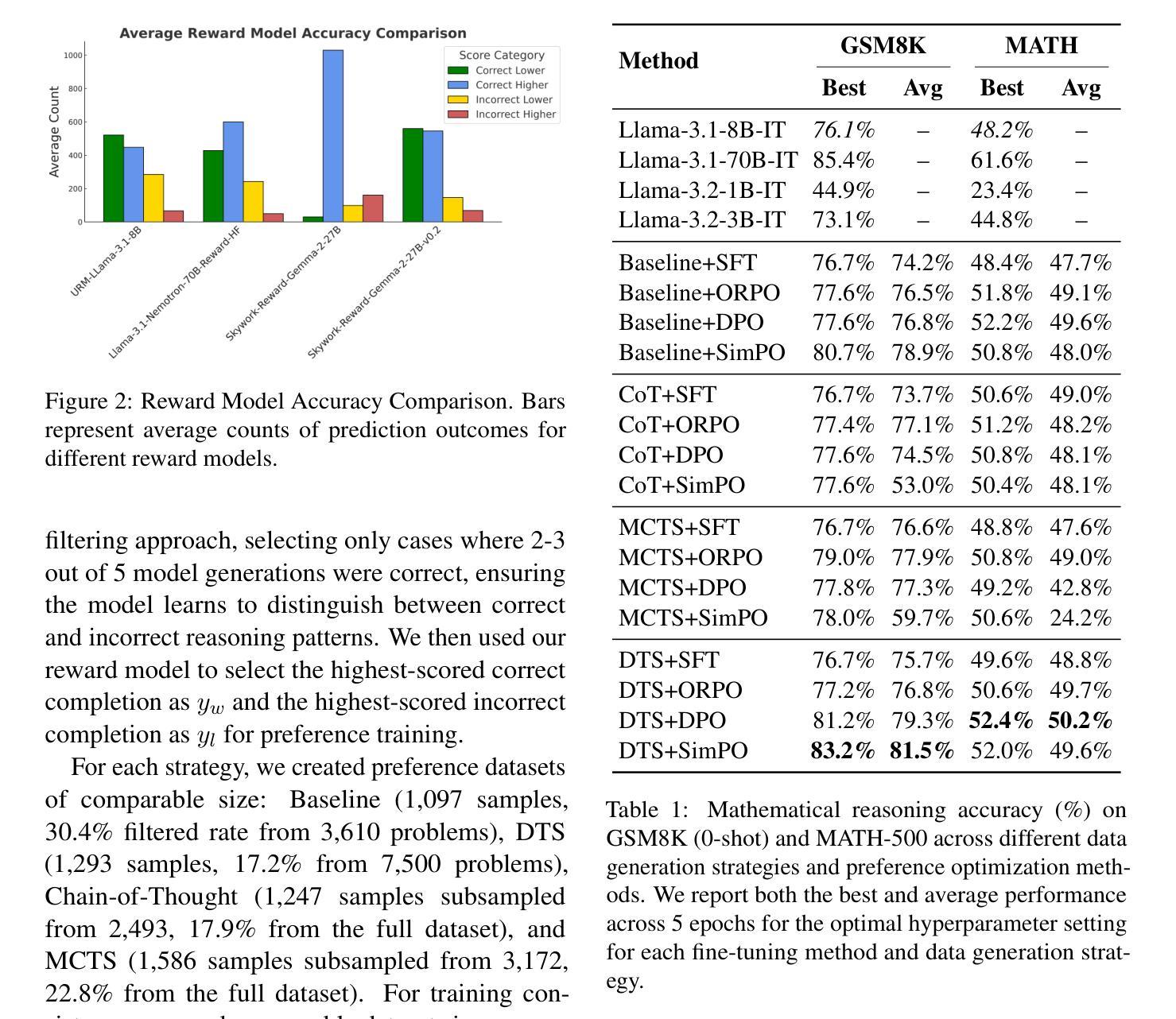
Reasoning or Not? A Comprehensive Evaluation of Reasoning LLMs for Dialogue Summarization
Authors:Keyan Jin, Yapeng Wang, Leonel Santos, Tao Fang, Xu Yang, Sio Kei Im, Hugo Gonçalo Oliveira
Dialogue summarization is a challenging task with significant practical value in customer service, meeting analysis, and conversational AI. Although large language models (LLMs) have achieved substantial progress in summarization tasks, the performance of step-by-step reasoning architectures-specifically Long Chain-of-Thought (CoT) implementations such as OpenAI-o1 and DeepSeek-R1-remains unexplored for dialogue scenarios requiring concurrent abstraction and conciseness. In this work, we present the first comprehensive and systematic evaluation of state-of-the-art reasoning LLMs and non-reasoning LLMs across three major paradigms-generic, role-oriented, and query-oriented dialogue summarization. Our study spans diverse languages, domains, and summary lengths, leveraging strong benchmarks (SAMSum, DialogSum, CSDS, and QMSum) and advanced evaluation protocols that include both LLM-based automatic metrics and human-inspired criteria. Contrary to trends in other reasoning-intensive tasks, our findings show that explicit stepwise reasoning does not consistently improve dialogue summarization quality. Instead, reasoning LLMs are often prone to verbosity, factual inconsistencies, and less concise summaries compared to their non-reasoning counterparts. Through scenario-specific analyses and detailed case studies, we further identify when and why explicit reasoning may fail to benefit-or even hinder-summarization in complex dialogue contexts. Our work provides new insights into the limitations of current reasoning LLMs and highlights the need for targeted modeling and evaluation strategies for real-world dialogue summarization.
对话摘要是一项具有客户服务的实际应用价值的挑战任务,在会议分析和对话人工智能中也有重要价值。尽管大型语言模型(LLM)在摘要任务中取得了重大进展,但在需要并发抽象和简洁的对话场景中,逐步推理架构尤其是长思考链(CoT)的实施方案(如OpenAI-o1和DeepSeek-R1)的表现尚未被探索。在这项工作中,我们对最先进的推理LLM和非推理LLM进行了首次全面系统的评估,涵盖了三种主要的范式:通用、面向角色和面向查询的对话摘要。我们的研究涵盖了多种语言、领域和摘要长度,利用强大的基准测试(SAMSum、DialogSum、CSDS和QMSum)和高级评估协议,包括基于LLM的自动指标和人类启发标准。与其他推理密集型任务的趋势相反,我们的研究结果表明,明确的逐步推理并不一定能提高对话摘要的质量。相反,推理LLM往往容易产生冗长、事实不一致和不够简洁的摘要,与非推理的同行相比表现较差。通过针对特定场景的分析和详细的案例研究,我们进一步确定了何时以及为什么明确的推理可能无法在给复杂的对话环境带来好处,甚至可能产生阻碍。我们的工作提供了对当前推理LLM局限性的新见解,并强调了为现实世界对话摘要进行有针对性的建模和评估策略的必要性。
论文及项目相关链接
Summary:
对话摘要是一项具有实际价值的挑战任务,涉及客户服务、会议分析和对话人工智能等领域。尽管大型语言模型(LLMs)在摘要任务中取得了重大进展,但在需要并发抽象和简洁性的对话场景中,逐步推理架构(如长链思维)的性能仍未探索。本研究首次全面系统地评估了最先进的推理LLM和非推理LLM在三种主要范式下的表现,包括通用、面向角色和面向查询的对话摘要。研究涉及多种语言、领域和摘要长度,利用强大的基准测试(SAMSum、DialogSum、CSDS和QMSum)和先进的评估协议,包括基于LLM的自动指标和人类启发标准。研究结果表明,在对话摘要中,明确的逐步推理并不总是能提高质量。相反,推理LLM往往容易产生冗长、事实不一致和不够简洁的摘要,相比非推理模型表现不佳。通过情景特定分析和详细案例研究,我们进一步确定了何时以及为什么显式推理可能不利于复杂对话上下文中的摘要。我们的研究提供了对当前推理LLM局限性的新见解,并强调了针对真实世界对话摘要进行有针对性的建模和评估策略的必要性。
Key Takeaways:
- 对话摘要是一项具有实际价值的挑战任务,尤其在客户服务、会议分析和对话人工智能等领域。
- 目前对对话场景中逐步推理架构的性能仍不了解,特别是针对长链思维等实现的研究缺失。
- 研究首次全面评估了推理LLM和非推理LLM在对话摘要中的表现差异。
- 研究涉及多种语言、领域和摘要长度,并采用了强大的基准测试和先进的评估协议来确保研究的全面性和准确性。
- 逐步推理并不总是能提高对话摘要的质量。反而可能导致冗长、事实不一致的摘要。
- 推理LLM在复杂对话上下文中的表现不佳,需要进一步的建模和评估策略改进。
点此查看论文截图

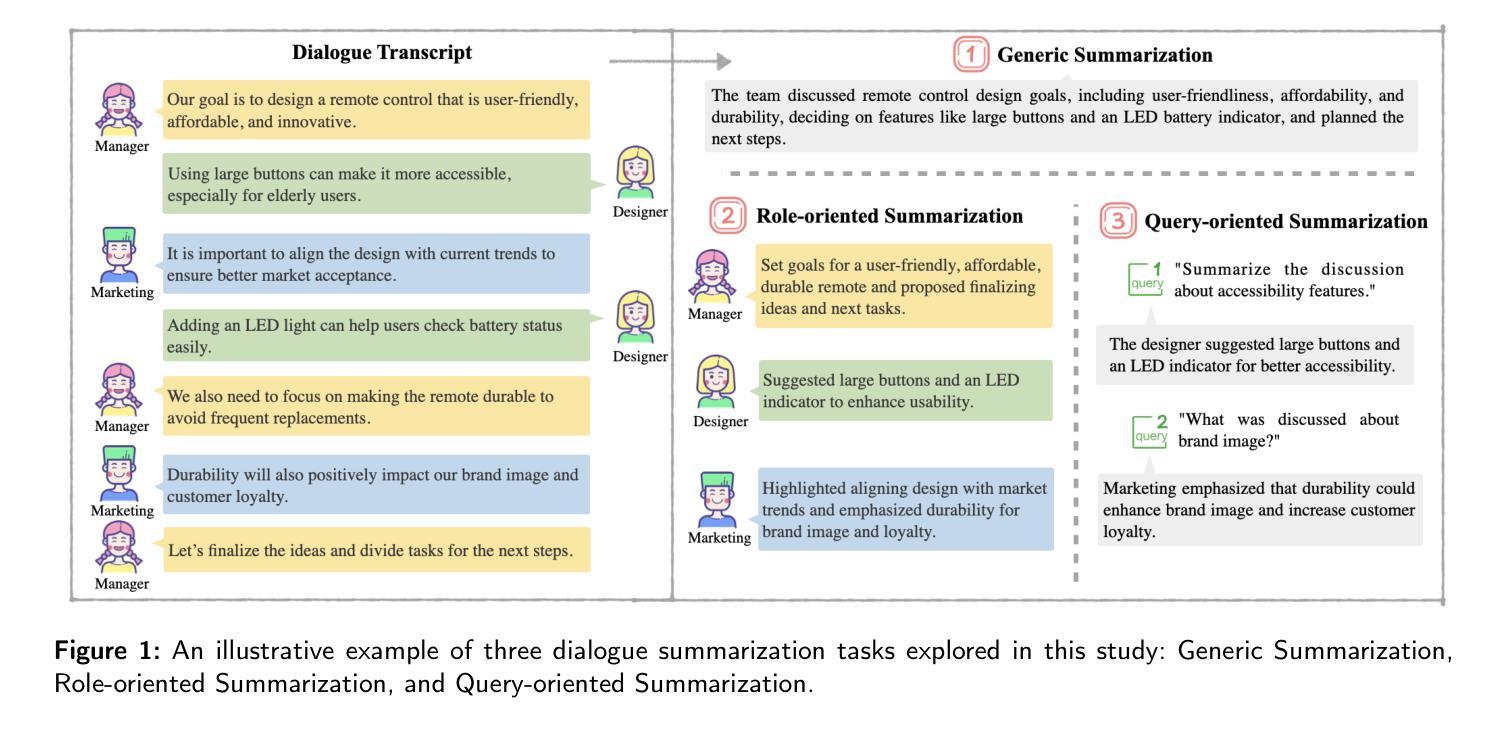
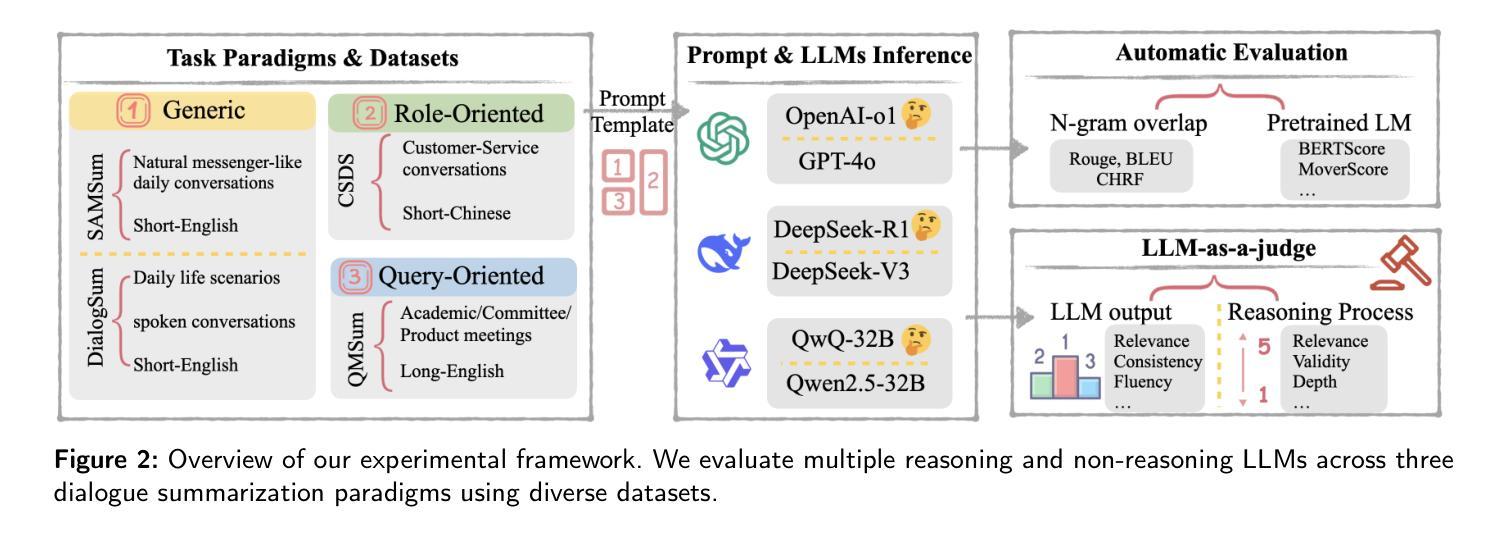
Large Language Model-Driven Closed-Loop UAV Operation with Semantic Observations
Authors:Wenhao Wang, Yanyan Li, Long Jiao, Jiawei Yuan
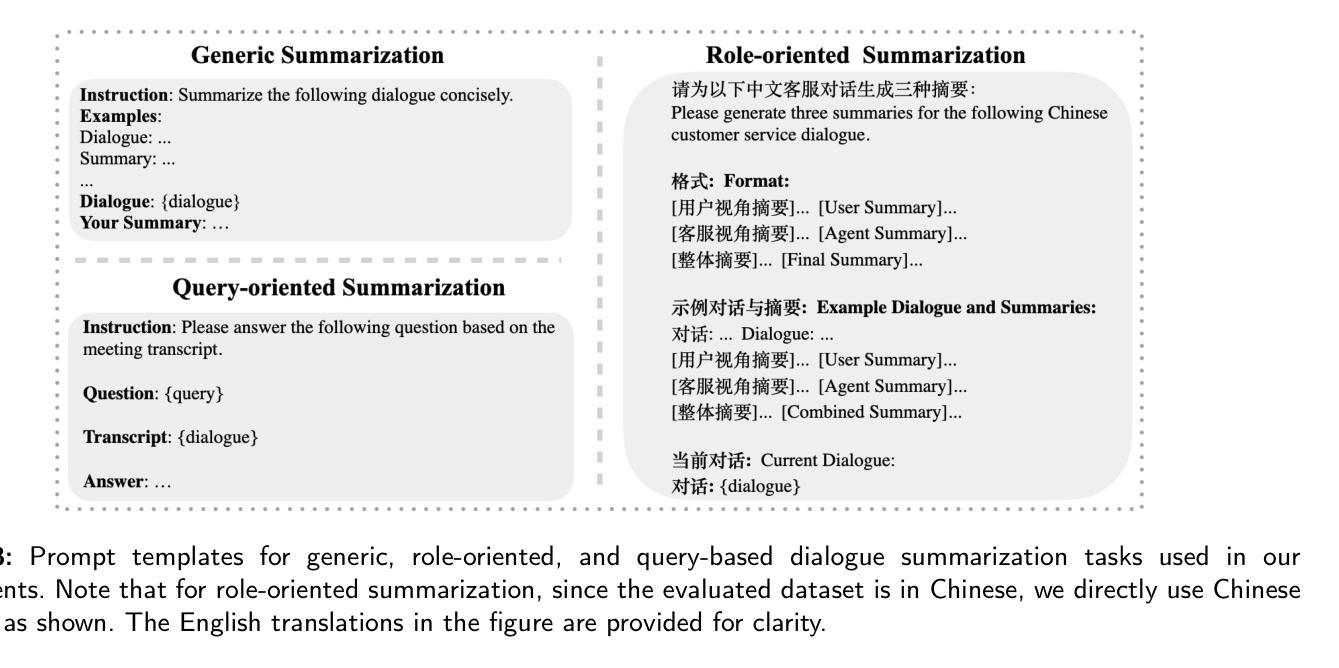
Recent advances in large Language Models (LLMs) have revolutionized mobile robots, including unmanned aerial vehicles (UAVs), enabling their intelligent operation within Internet of Things (IoT) ecosystems. However, LLMs still face challenges from logical reasoning and complex decision-making, leading to concerns about the reliability of LLM-driven UAV operations in IoT applications. In this paper, we propose a LLM-driven closed-loop control framework that enables reliable UAV operations powered by effective feedback and refinement using two LLM modules, i.e., a Code Generator and an Evaluator. Our framework transforms numerical state observations from UAV operations into natural language trajectory descriptions to enhance the evaluator LLM’s understanding of UAV dynamics for precise feedback generation. Our framework also enables a simulation-based refinement process, and hence eliminates the risks to physical UAVs caused by incorrect code execution during the refinement. Extensive experiments on UAV control tasks with different complexities are conducted. The experimental results show that our framework can achieve reliable UAV operations using LLMs, which significantly outperforms baseline approaches in terms of success rate and completeness with the increase of task complexity.
近年来,大型语言模型(LLM)的进展在移动机器人领域引起了革命性的变革,包括无人驾驶航空器(UAVs)。这使得它们在物联网(IoT)生态系统中的智能操作成为可能。然而,LLM仍然面临逻辑推理和复杂决策方面的挑战,这引发了人们对物联网应用中LLM驱动的无人机操作可靠性的担忧。在本文中,我们提出了一种LLM驱动的闭环控制框架,该框架通过两个LLM模块即代码生成器和评估器,利用有效的反馈和改进,实现了可靠的无人机操作。我们的框架将无人机操作的数值状态观察转化为自然语言轨迹描述,以增强评估器LLM对无人机动力学的理解,从而实现精确反馈生成。我们的框架还支持基于模拟的改进过程,从而消除了改进过程中错误代码执行对实际无人机造成的风险。我们对具有不同复杂程度的无人机控制任务进行了广泛的实验。实验结果表明,我们的框架能够使用LLM实现可靠的无人机操作,在成功率和完整性方面显著优于基准方法,并随着任务复杂性的增加而表现出优势。
论文及项目相关链接
PDF 9 pages, 7 figures
Summary
大型语言模型(LLM)在移动机器人领域(包括无人机)的应用实现了其在物联网生态系统中的智能操作,但仍然存在逻辑推理和复杂决策的挑战。本文提出了一种LLM驱动的闭环控制框架,通过两个LLM模块即代码生成器和评估器,实现可靠的无人机操作。该框架将无人机的数值状态观察转化为自然语言轨迹描述,增强评估器对无人机动态的理解,以生成精确反馈。框架还通过模拟优化过程,减少因代码执行错误导致的物理无人机的风险。实验结果显示,该框架在复杂任务中实现了可靠的无人机操作,并在成功率和完整性方面显著优于基准方法。
Key Takeaways
- 大型语言模型(LLM)已应用于移动机器人领域,推动无人机在物联网生态系统中的智能操作。
- LLM在逻辑推理和复杂决策方面仍面临挑战,影响无人机操作的可靠性。
- 提出了一种LLM驱动的闭环控制框架,包含代码生成器和评估器两个模块。
- 框架能将无人机的数值状态观察转化为自然语言轨迹描述,增强评估器对无人机动态的理解。
- 框架支持模拟优化过程,减少物理无人机因代码执行错误而产生的风险。
- 实验证明该框架在复杂任务中实现了可靠的无人机操作。
点此查看论文截图



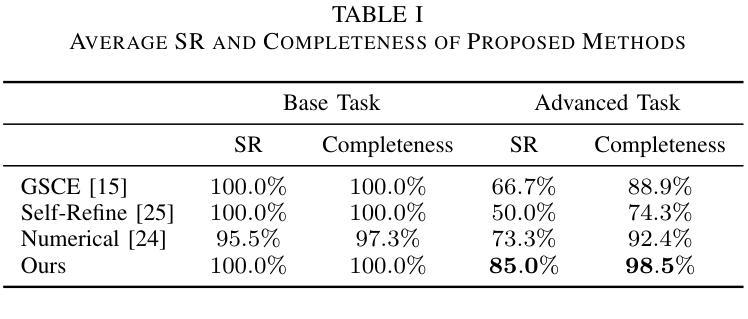
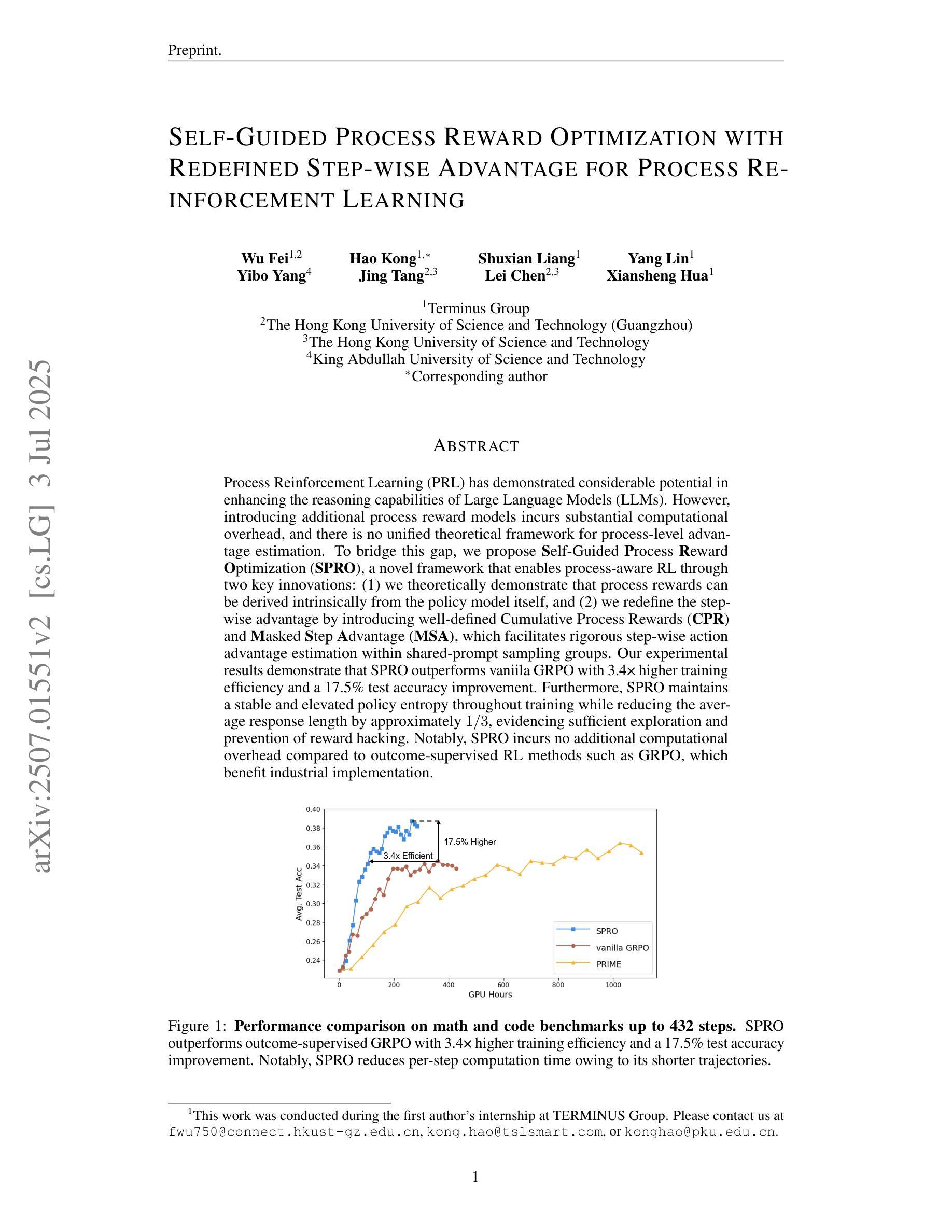
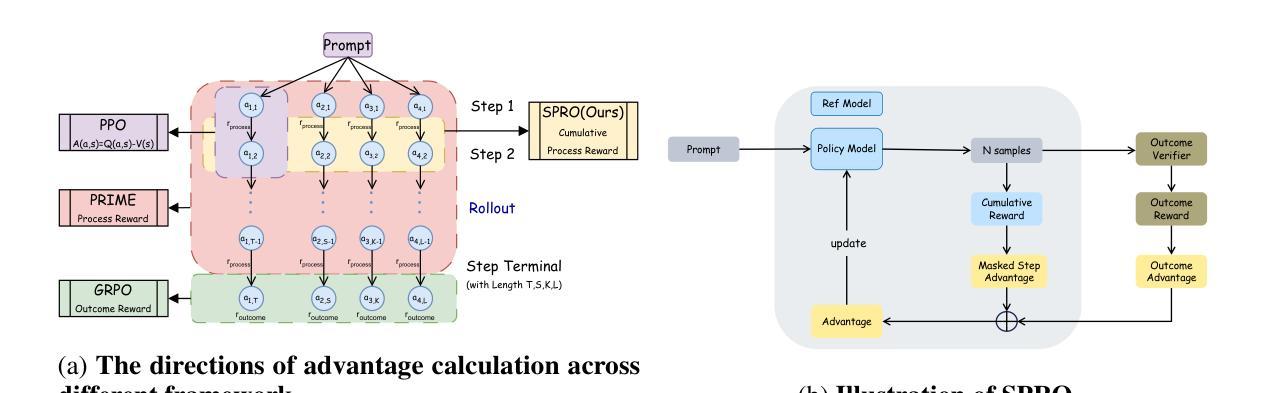
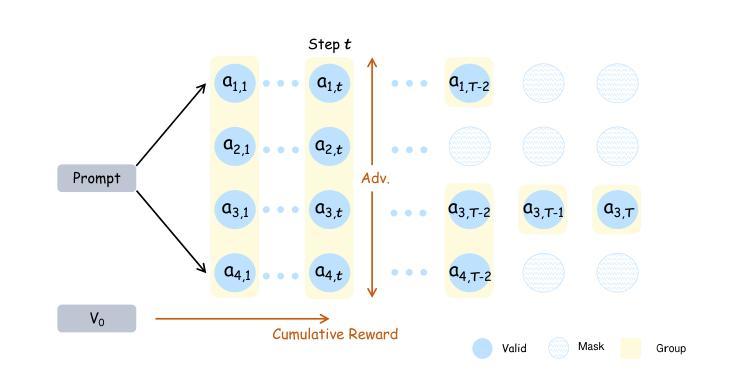
Self-Guided Process Reward Optimization with Redefined Step-wise Advantage for Process Reinforcement Learning
Authors:Wu Fei, Hao Kong, Shuxian Liang, Yang Lin, Yibo Yang, Jing Tang, Lei Chen, Xiansheng Hua
Process Reinforcement Learning(PRL) has demonstrated considerable potential in enhancing the reasoning capabilities of Large Language Models(LLMs). However, introducing additional process reward models incurs substantial computational overhead, and there is no unified theoretical framework for process-level advantage estimation. To bridge this gap, we propose \textbf{S}elf-Guided \textbf{P}rocess \textbf{R}eward \textbf{O}ptimization~(\textbf{SPRO}), a novel framework that enables process-aware RL through two key innovations: (1) we first theoretically demonstrate that process rewards can be derived intrinsically from the policy model itself, and (2) we introduce well-defined cumulative process rewards and \textbf{M}asked \textbf{S}tep \textbf{A}dvantage (\textbf{MSA}), which facilitates rigorous step-wise action advantage estimation within shared-prompt sampling groups. Our experimental results demonstrate that SPRO outperforms vaniila GRPO with 3.4x higher training efficiency and a 17.5% test accuracy improvement. Furthermore, SPRO maintains a stable and elevated policy entropy throughout training while reducing the average response length by approximately $1/3$, evidencing sufficient exploration and prevention of reward hacking. Notably, SPRO incurs no additional computational overhead compared to outcome-supervised RL methods such as GRPO, which benefit industrial implementation.
过程强化学习(PRL)在提升大型语言模型(LLM)的推理能力方面展现出了巨大的潜力。然而,引入额外的流程奖励模型会产生大量的计算开销,并且没有统一的理论框架来进行流程级别的优势估计。为了弥补这一空白,我们提出了自引导流程奖励优化(SPRO)这一新型框架,它通过两个关键创新点实现了流程感知的RL:(1)我们首先从理论上证明,流程奖励可以内在地从策略模型本身推导出来;(2)我们引入了定义良好的累积流程奖励和掩码步骤优势(MSA),这有助于在共享提示采样组内进行严格的逐步行动优势估计。我们的实验结果表明,SPRO相较于标准的GRPO方法,训练效率提高了3.4倍,测试精度提高了17.5%。此外,SPRO在整个训练过程中保持了稳定和较高的策略熵,同时平均响应长度减少了大约三分之一,证明了其充分的探索能力和防止奖励操纵的效果。值得注意的是,相较于结果监督的RL方法(如GRPO),SPRO没有额外的计算开销,有利于工业实施。
论文及项目相关链接
Summary
过程强化学习(PRL)在提升大型语言模型(LLM)的推理能力方面展现出巨大潜力。然而,引入额外的过程奖励模型会带来很大的计算开销,并且缺乏统一的过程级优势估计理论框架。为此,我们提出自我导向的过程奖励优化(SPRO)框架,通过两个关键创新填补这一空白:(1)从理论上证明过程奖励可以内在地从策略模型本身衍生出来;(2)引入定义明确的过程累积奖励和遮罩步骤优势(MSA),有助于在共享提示采样组内进行严格的步骤级行动优势估计。实验结果表明,SPRO在训练效率上优于基础GRPO方法,实现了3.4倍的训练效率提升和17.5%的测试精度改进。同时,SPRO在整个训练过程中保持了稳定的策略熵提升,并成功将平均响应长度减少了约三分之一,证明了其在充分探索和预防奖励破解方面的有效性。值得注意的是,相较于结果监督的RL方法(如GRPO),SPRO没有引入额外的计算开销,更适合工业应用。
Key Takeaways
- 过程强化学习(PRL)能提升大型语言模型(LLM)的推理能力。
- 引入SPRO框架来优化过程奖励,包含两个关键创新点:从策略模型中推导过程奖励和定义累积过程奖励及遮罩步骤优势(MSA)。
- SPRO框架能提高训练效率,实现更高的测试精度。
- SPRO保持稳定的策略熵提升,并减少平均响应长度。
- SPRO相较于其他方法没有额外的计算开销,适合工业应用。
- SPRO框架在理论上有充分的验证,并已经过实验验证其有效性。
点此查看论文截图
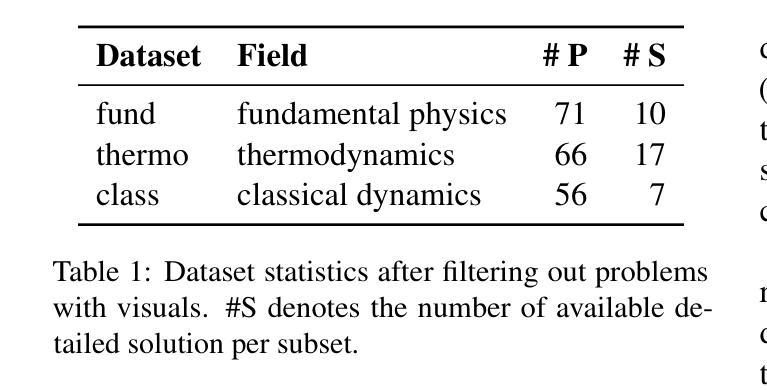
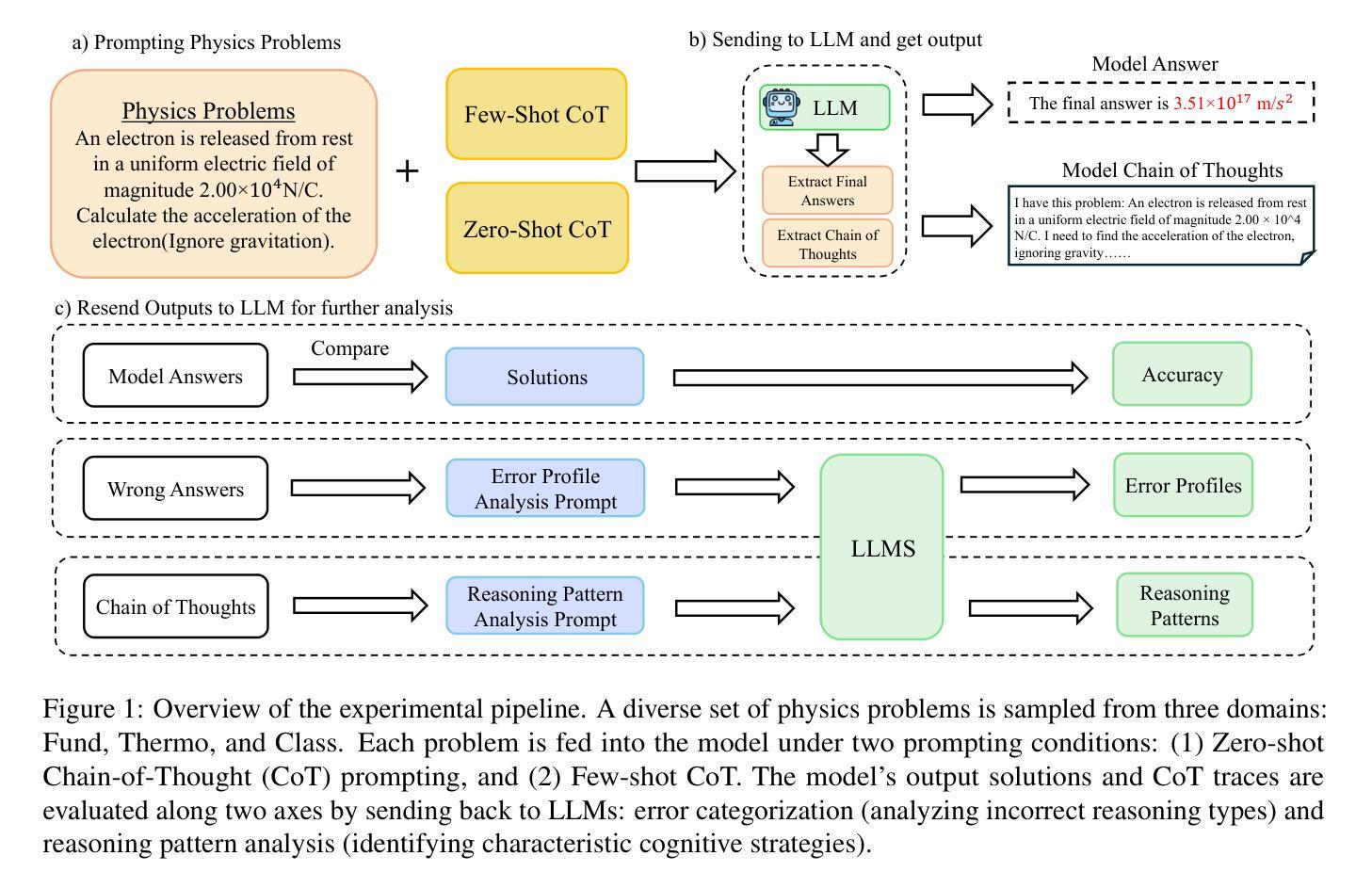
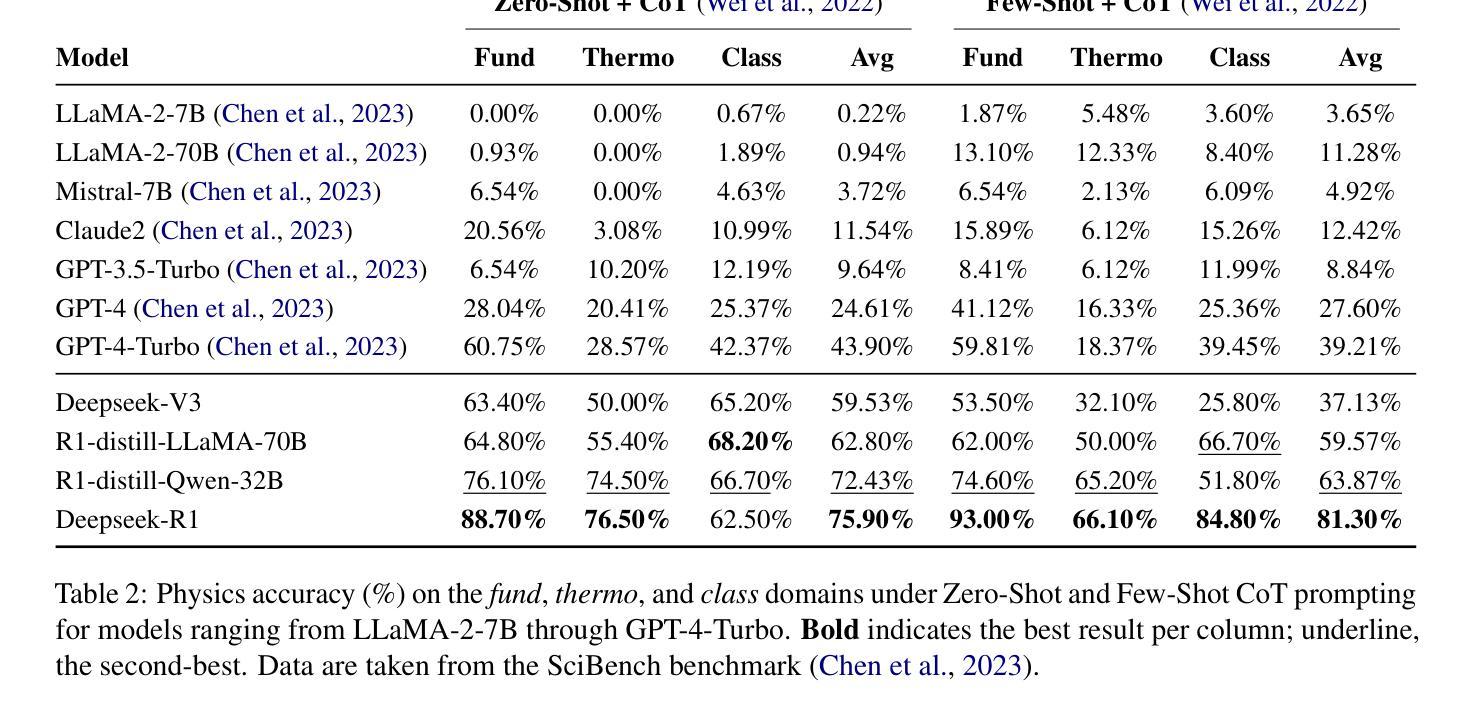
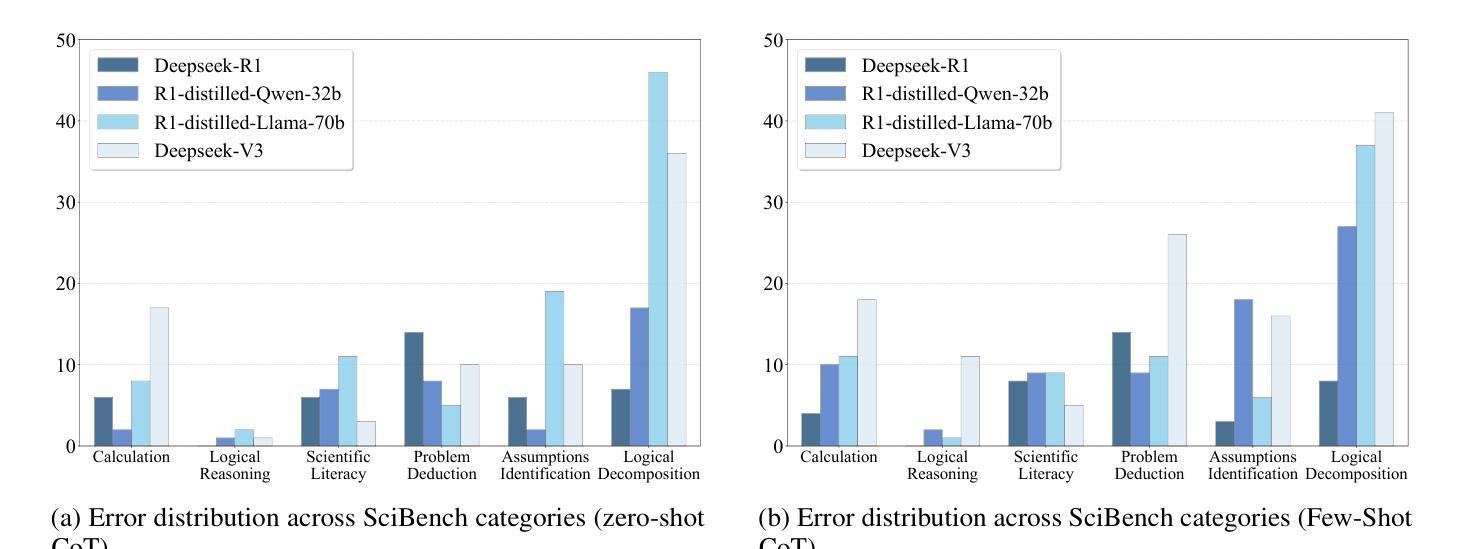
Symbolic or Numerical? Understanding Physics Problem Solving in Reasoning LLMs
Authors:Nifu Dan, Yujun Cai, Yiwei Wang
Navigating the complexities of physics reasoning has long been a difficult task for Large Language Models (LLMs), requiring a synthesis of profound conceptual understanding and adept problem-solving techniques. In this study, we investigate the application of advanced instruction-tuned reasoning models, such as Deepseek-R1, to address a diverse spectrum of physics problems curated from the challenging SciBench benchmark. Our comprehensive experimental evaluation reveals the remarkable capabilities of reasoning models. Not only do they achieve state-of-the-art accuracy in answering intricate physics questions, but they also generate distinctive reasoning patterns that emphasize on symbolic derivation. Furthermore, our findings indicate that even for these highly sophisticated reasoning models, the strategic incorporation of few-shot prompting can still yield measurable improvements in overall accuracy, highlighting the potential for continued performance gains.
驾驭物理推理的复杂性对大型语言模型(LLM)来说一直是一项艰巨的任务,需要深厚的概念理解和熟练的问题解决技巧的结合。在这项研究中,我们研究了先进指令调整推理模型的应用,如Deepseek-R1,以解决从具有挑战性的SciBench基准测试中精选的各种物理问题。我们的综合实验评估显示了推理模型的卓越能力。它们不仅在回答复杂物理问题时达到了最新技术水平,而且产生了强调符号推导的独特推理模式。此外,我们的研究结果表明,即使是对于这些高度复杂的推理模型,通过策略性地引入少量提示,仍然可以提高总体准确性,这突显了持续提高性能的潜力。
论文及项目相关链接
Summary:
本研究探讨了先进的教学推理模型,如Deepseek-R1,在应对来自SciBench基准测试的挑战性物理问题时的应用。实验评估表明,这些推理模型不仅能够在回答复杂物理问题方面达到最新技术的准确性,而且还表现出独特的强调符号推导的推理模式。此外,研究还发现,即使是对于这些高度复杂的推理模型,通过战略性地融入少量提示,仍可以提高整体准确性,显示出潜在的性能提升空间。
Key Takeaways:
- 先进的教学推理模型,如Deepseek-R1,能够应对多样化的物理问题,达到前沿的准确率。
- 这些推理模型展现出独特的推理模式,重视符号推导。
- 即使是高度复杂的推理模型,融入少量提示仍可提升整体准确性。
- LLM在物理推理方面存在挑战,需要深刻的概念理解和熟练的问题解决技巧。
- SciBench基准测试的物理问题具有挑战性。
- 战略性地使用提示方法可能有助于进一步提高模型性能。
点此查看论文截图

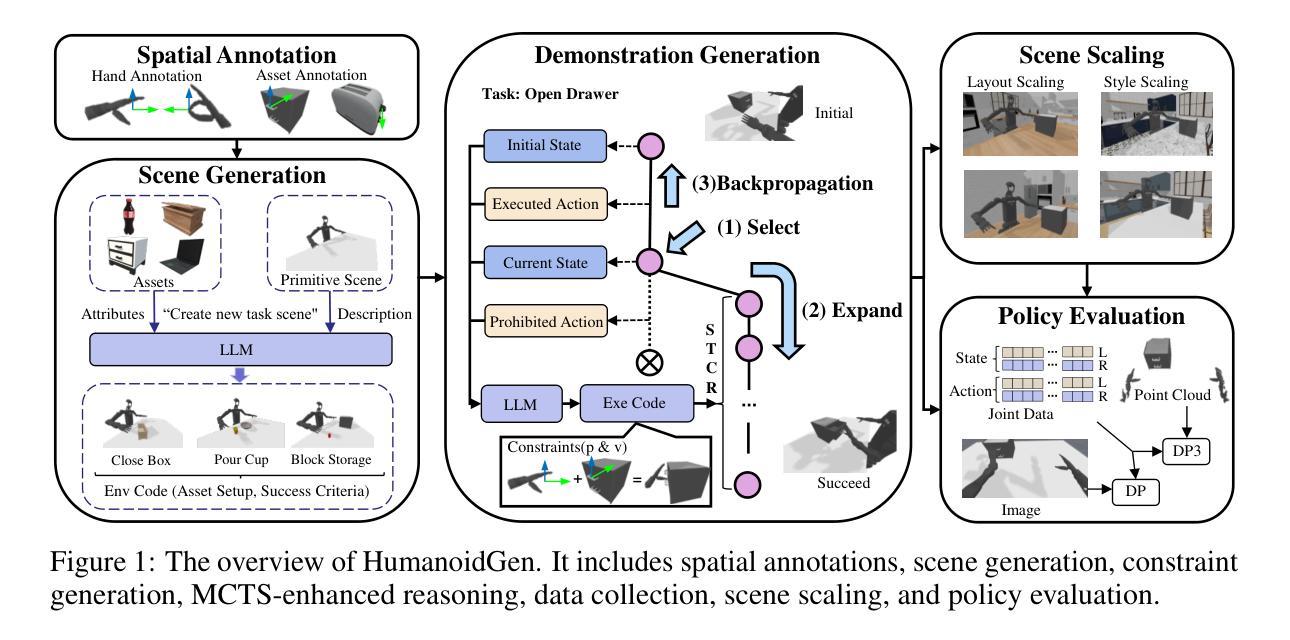
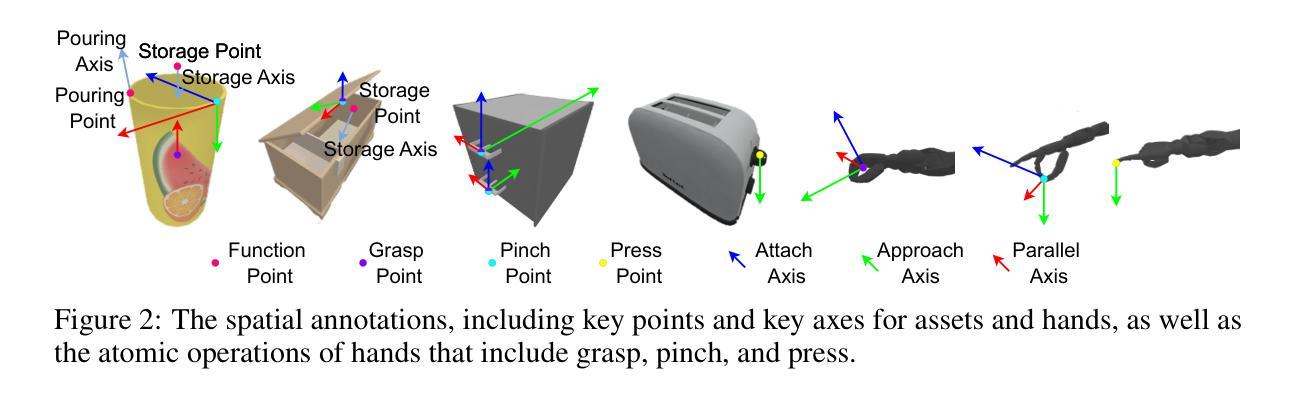
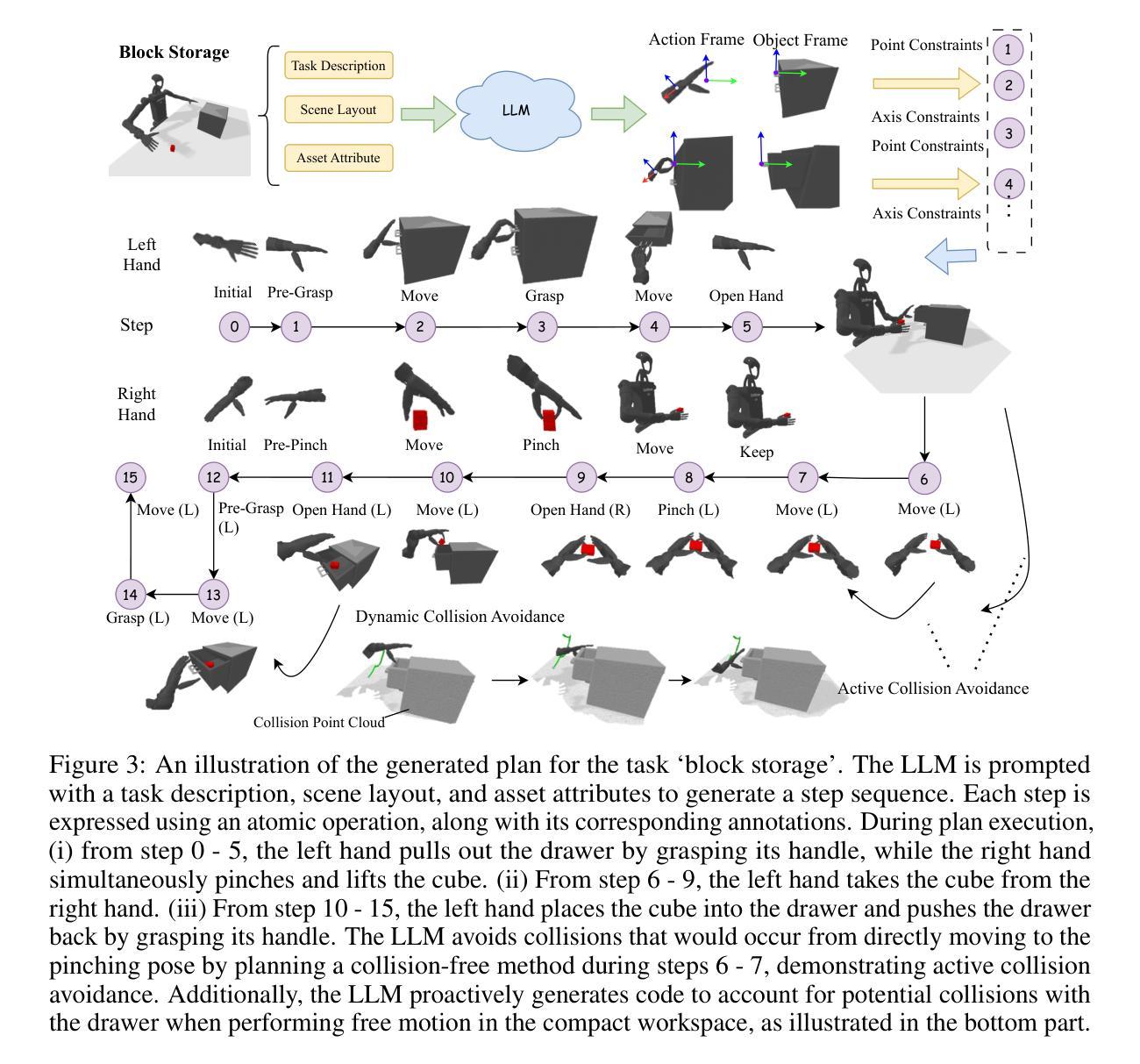
HumanoidGen: Data Generation for Bimanual Dexterous Manipulation via LLM Reasoning
Authors:Zhi Jing, Siyuan Yang, Jicong Ao, Ting Xiao, Yugang Jiang, Chenjia Bai
For robotic manipulation, existing robotics datasets and simulation benchmarks predominantly cater to robot-arm platforms. However, for humanoid robots equipped with dual arms and dexterous hands, simulation tasks and high-quality demonstrations are notably lacking. Bimanual dexterous manipulation is inherently more complex, as it requires coordinated arm movements and hand operations, making autonomous data collection challenging. This paper presents HumanoidGen, an automated task creation and demonstration collection framework that leverages atomic dexterous operations and LLM reasoning to generate relational constraints. Specifically, we provide spatial annotations for both assets and dexterous hands based on the atomic operations, and perform an LLM planner to generate a chain of actionable spatial constraints for arm movements based on object affordances and scenes. To further improve planning ability, we employ a variant of Monte Carlo tree search to enhance LLM reasoning for long-horizon tasks and insufficient annotation. In experiments, we create a novel benchmark with augmented scenarios to evaluate the quality of the collected data. The results show that the performance of the 2D and 3D diffusion policies can scale with the generated dataset. Project page is https://openhumanoidgen.github.io.
对于机器人操作而言,现有的机器人数据集和模拟基准测试主要面向机器人手臂平台。然而,对于配备有双臂和灵巧双手的人形机器人,模拟任务和高质量的演示明显缺乏。双手动作操作本质上更为复杂,因为它需要协调手臂运动和手部操作,使得自主的数据收集变得具有挑战性。本文提出了HumanoidGen,一个自动化任务创建和演示收集框架,它利用原子灵巧操作和大型语言模型推理来生成关系约束。具体来说,我们基于原子操作为资产和灵巧双手提供空间注释,并使用大型语言模型规划器根据物体功能和场景生成一系列可操作的空间约束链,用于手臂运动。为了进一步提高规划能力,我们采用了一种蒙特卡洛树搜索的变种来增强大型语言模型对长期任务和不足注释的推理。在实验中,我们创建了一个带有增强场景的新基准测试来评估收集数据的质量。结果表明,二维和三维扩散策略的性能可以随着生成的数据集而扩展。项目页面为https://openhumanoidgen.github.io。
论文及项目相关链接
PDF Project Page: https://openhumanoidgen.github.io
Summary
基于原子操作的人类灵巧模拟数据收集框架HumanoidGen用于机器人双臂操控。此框架采用LLM规划器生成动作约束链,解决人形机器人双臂灵巧操控的复杂性挑战。通过空间标注和蒙特卡洛树搜索增强LLM推理能力,提高长周期任务的规划能力。新型数据集与模拟场景的融合展示对收集的实时性产生影响。Key Takeaways:
- 现有机器人数据集主要针对机器人手臂平台,但人形机器人双臂灵巧操控模拟任务和数据集缺乏。
- HumanoidGen框架利用原子灵巧操作和LLM规划器生成空间约束动作链来解决双臂操控复杂性。
- 利用空间标注进行资产和手部数据记录。
- 采用蒙特卡洛树搜索增强LLM推理能力,提高长周期任务和不足标注的应对能力。
- 创建新型数据集与增强场景融合的评价标准来评估数据质量。
点此查看论文截图