⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-05 更新
Linear Attention with Global Context: A Multipole Attention Mechanism for Vision and Physics
Authors:Alex Colagrande, Paul Caillon, Eva Feillet, Alexandre Allauzen
Transformers have become the de facto standard for a wide range of tasks, from image classification to physics simulations. Despite their impressive performance, the quadratic complexity of standard Transformers in both memory and time with respect to the input length makes them impractical for processing high-resolution inputs. Therefore, several variants have been proposed, the most successful relying on patchification, downsampling, or coarsening techniques, often at the cost of losing the finest-scale details. In this work, we take a different approach. Inspired by state-of-the-art techniques in $n$-body numerical simulations, we cast attention as an interaction problem between grid points. We introduce the Multipole Attention Neural Operator (MANO), which computes attention in a distance-based multiscale fashion. MANO maintains, in each attention head, a global receptive field and achieves linear time and memory complexity with respect to the number of grid points. Empirical results on image classification and Darcy flows demonstrate that MANO rivals state-of-the-art models such as ViT and Swin Transformer, while reducing runtime and peak memory usage by orders of magnitude. We open source our code for reproducibility at https://github.com/AlexColagrande/MANO.
Transformer已经成为从图像分类到物理模拟等多种任务的默认标准。尽管它们表现出令人印象深刻的效果,但标准Transformer在内存和时间方面的二次复杂性使得它们在处理高分辨率输入时变得不切实际。因此,已经提出了几种变体,最成功的那些变体依赖于补丁化、下采样或粗略化技术,但往往以损失最精细尺度的细节为代价。在这项工作中,我们采取了不同的方法。受最新一代n体数值模拟技术的启发,我们将注意力视为网格点之间的交互问题。我们引入了多极注意力神经网络运算符(MANO),它以基于距离的多尺度方式计算注意力。MANO在每个注意力头中保持全局感受野,并实现了关于网格点数量的线性时间和内存复杂度。在图像分类和达西流方面的经验结果表明,MANO与最先进的模型(如ViT和Swin Transformer)相匹敌,同时减少了运行时间和峰值内存使用量多个数量级。我们在https://github.com/AlexColagrande/MANO开源我们的代码以供重现。
简化版翻译
论文及项目相关链接
PDF Accepted at ECLR Workshop at ICCV 2025
Summary
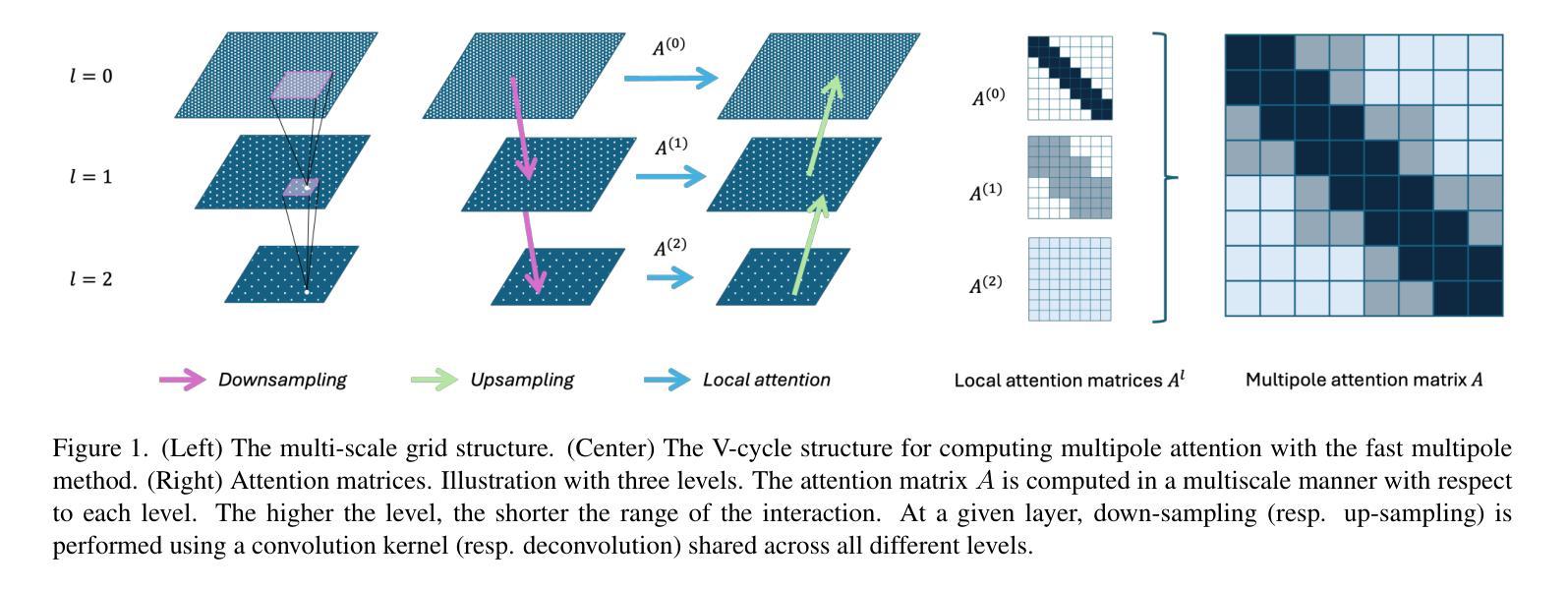
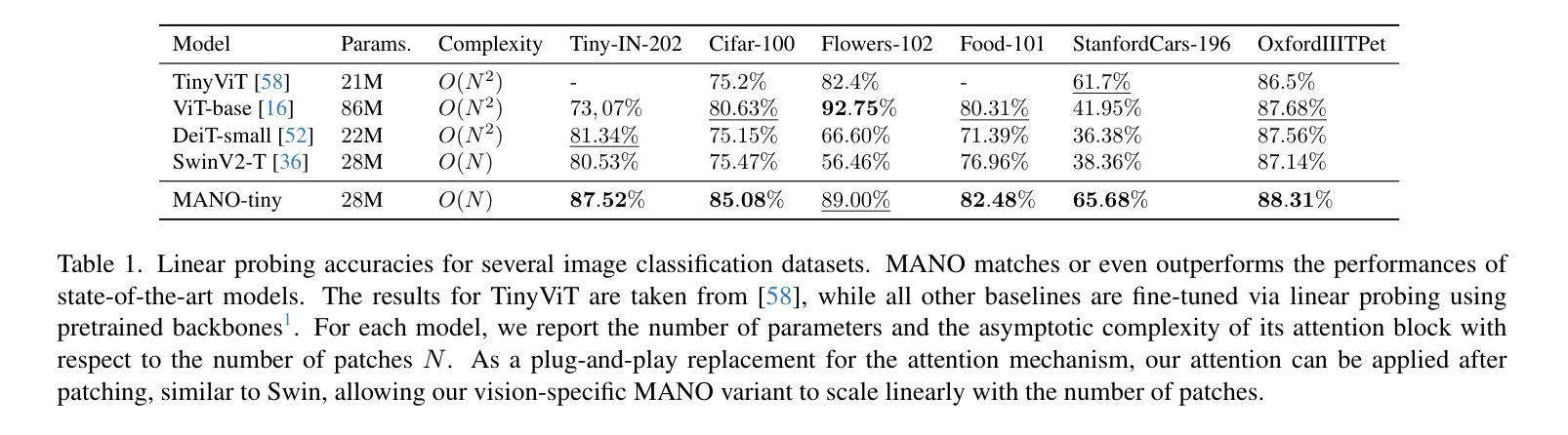
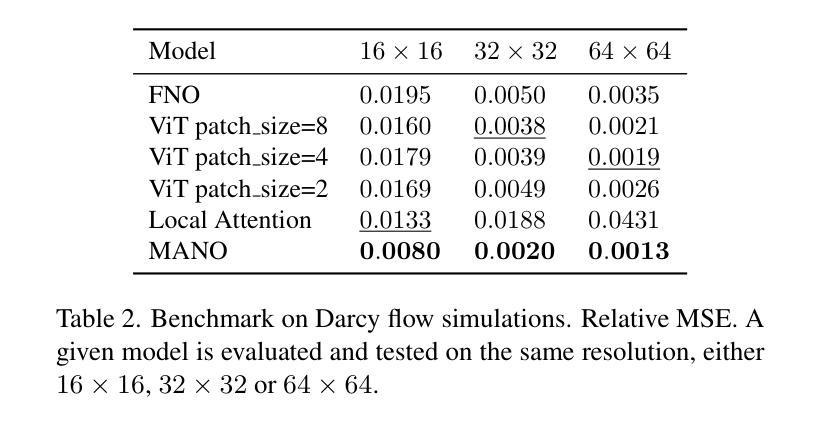
本文提出一种基于距离的多尺度计算注意力的新方法,名为MANO(Multipole Attention Neural Operator)。此方法灵感来源于最先进的n体数值模拟技术,可将注意力视为网格点间的交互问题。MANO在每个注意力头中保持全局感受野,并以线性时间和内存复杂度处理网格点数量。在图像分类和达西流方面的实证结果表明,MANO与ViT和Swin Transformer等先进模型相比表现相当,同时大幅度降低了运行时间和峰值内存使用。
Key Takeaways
- MANO是一种基于距离的多尺度注意力计算方法,用于处理网格点之间的交互。
- MANO通过借鉴n体数值模拟技术,实现了高效的注意力计算。
- MANO在每个注意力头中维持全局感受野。
- MANO具有线性的时间和内存复杂度,使其在处理高分辨率输入时更为实用。
- 实证结果表明,MANO在图像分类和达西流任务中的性能与先进模型相当。
- MANO大幅度降低了运行时间和峰值内存使用。
点此查看论文截图


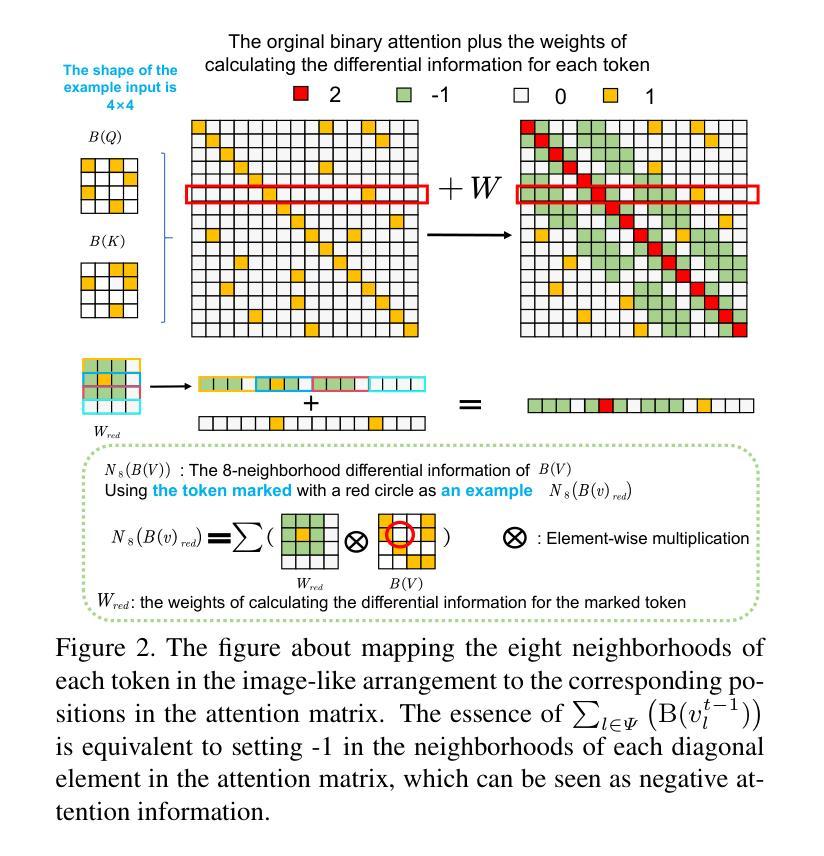
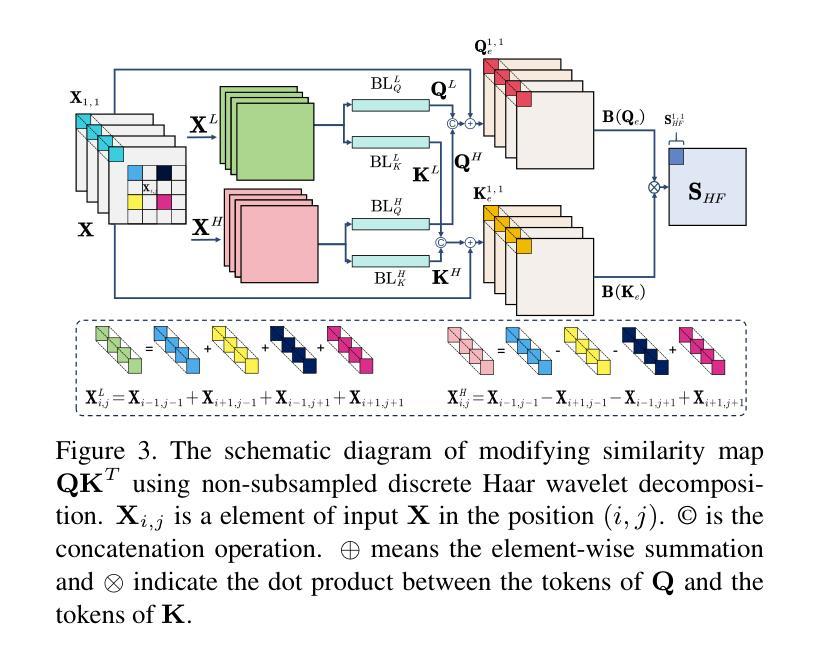
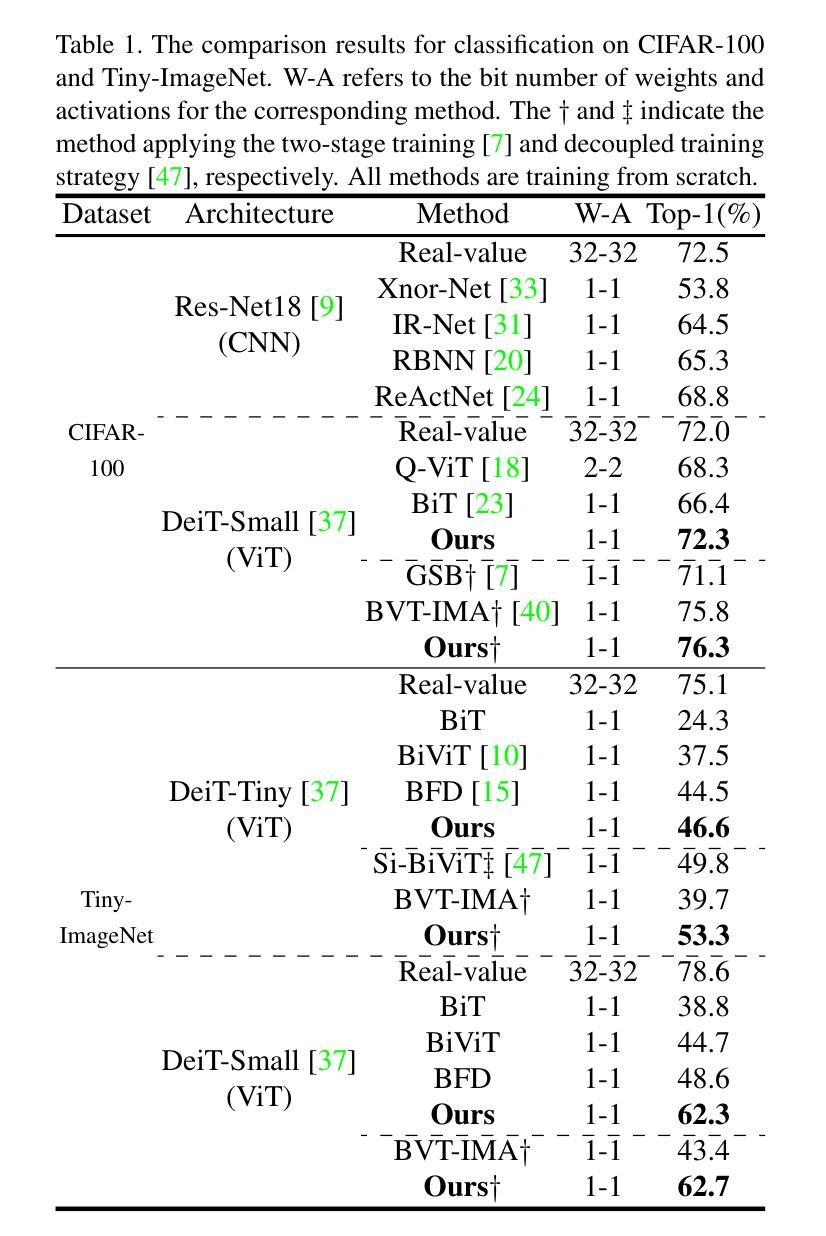
High-Fidelity Differential-information Driven Binary Vision Transformer
Authors:Tian Gao, Zhiyuan Zhang, Kaijie Yin, Xu-Cheng Zhong, Hui Kong
The binarization of vision transformers (ViTs) offers a promising approach to addressing the trade-off between high computational/storage demands and the constraints of edge-device deployment. However, existing binary ViT methods often suffer from severe performance degradation or rely heavily on full-precision modules. To address these issues, we propose DIDB-ViT, a novel binary ViT that is highly informative while maintaining the original ViT architecture and computational efficiency. Specifically, we design an informative attention module incorporating differential information to mitigate information loss caused by binarization and enhance high-frequency retention. To preserve the fidelity of the similarity calculations between binary Q and K tensors, we apply frequency decomposition using the discrete Haar wavelet and integrate similarities across different frequencies. Additionally, we introduce an improved RPReLU activation function to restructure the activation distribution, expanding the model’s representational capacity. Experimental results demonstrate that our DIDB-ViT significantly outperforms state-of-the-art network quantization methods in multiple ViT architectures, achieving superior image classification and segmentation performance.
视觉变压器(ViT)的二元化为解决高计算/存储需求与边缘设备部署限制之间的权衡提供了一个有前途的方法。然而,现有的二元ViT方法常常面临性能严重下降的问题,或者严重依赖于全精度模块。为了解决这些问题,我们提出了DIDB-ViT,这是一种新型二元ViT,在保持原始ViT架构和计算效率的同时,具有高度的信息性。具体来说,我们设计了一个包含差异信息的信息化注意力模块,以减轻二元化造成的信息损失,并增强高频保留。为了保留二元Q和K张量之间相似性计算的保真度,我们采用离散哈尔小波进行频率分解,并整合不同频率下的相似性。此外,我们引入了一种改进的RPReLU激活函数来重构激活分布,扩大模型的表示能力。实验结果表明,我们的DIDB-ViT在多种ViT架构上显著优于最新的网络量化方法,实现了优越的图像分类和分割性能。
论文及项目相关链接
Summary
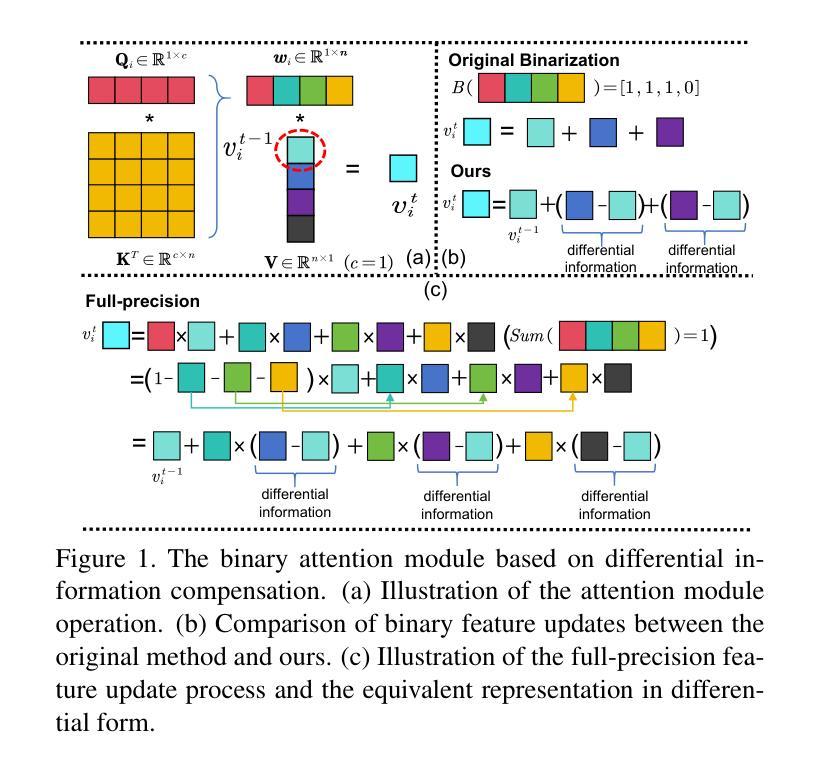
本文介绍了针对视觉变压器(ViT)的二值化方法的研究。现有二值化ViT方法存在性能下降或依赖全精度模块的问题。针对这些问题,提出了DIDB-ViT,这是一种新型的二值化ViT,既保留了原始ViT架构和计算效率,又具有高度信息性。通过设计包含差异信息的注意力模块,减轻二值化引起的信息损失,提高高频保留能力。同时采用离散哈尔小波进行频率分解,并整合不同频率的相似性计算,保持二进制Q和K张量之间的相似性计算精度。此外,还引入了改进的RPReLU激活函数来重构激活分布,扩大模型的表示能力。实验结果表明,DIDB-ViT在多种ViT架构中显著优于现有网络量化方法,实现了优越的图像分类和分割性能。
Key Takeaways
- 视觉变压器(ViT)的二值化方法有助于解决高计算/存储需求和边缘设备部署限制之间的权衡问题。
- 现有二值化ViT方法存在性能下降和对全精度模块的依赖。
- DIDB-ViT是一种新型的二值化ViT,旨在解决这些问题并保持原始ViT架构和计算效率。
- DIDB-ViT通过设计包含差异信息的注意力模块来减轻二值化引起的信息损失。
- 采用离散哈尔小波进行频率分解,整合不同频率的相似性计算,以保持二进制张量间的相似性精度。
- 引入改进的RPReLU激活函数以重构激活分布,提高模型的表示能力。
点此查看论文截图

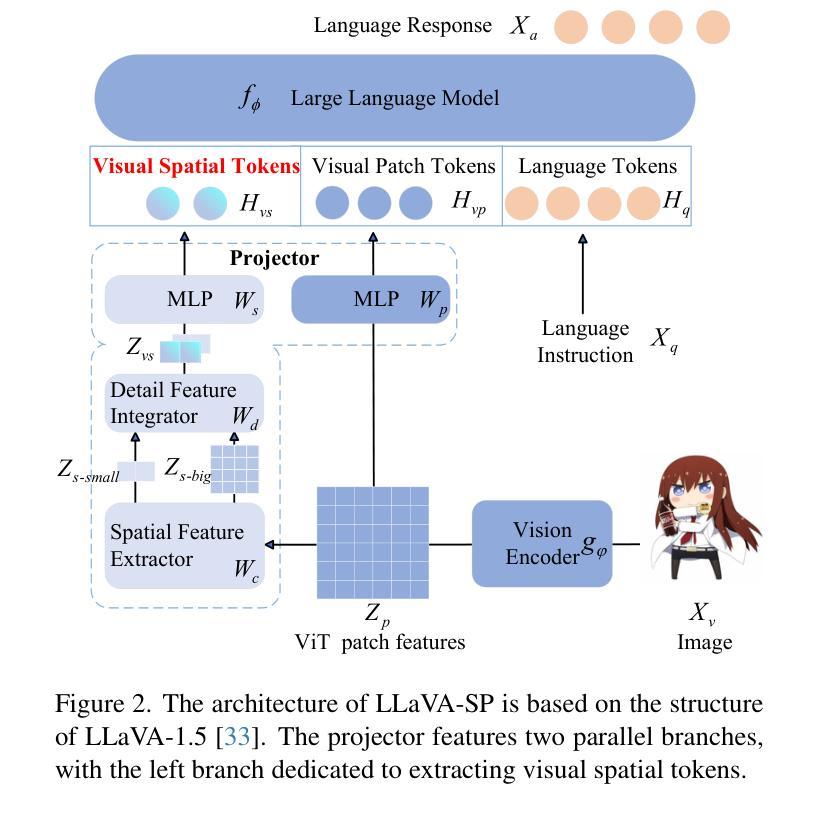
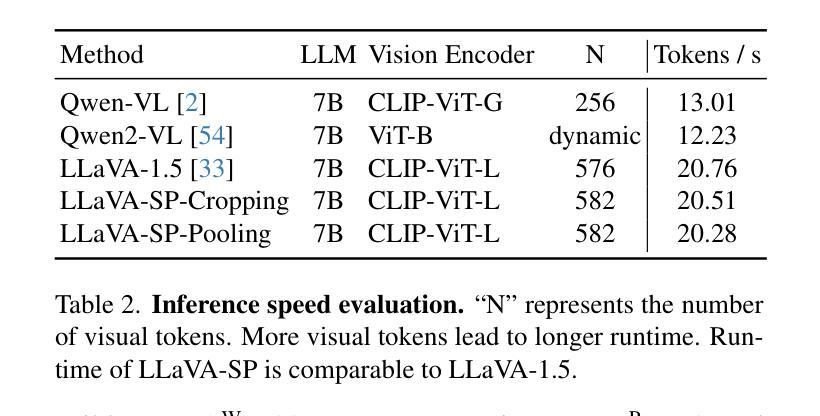
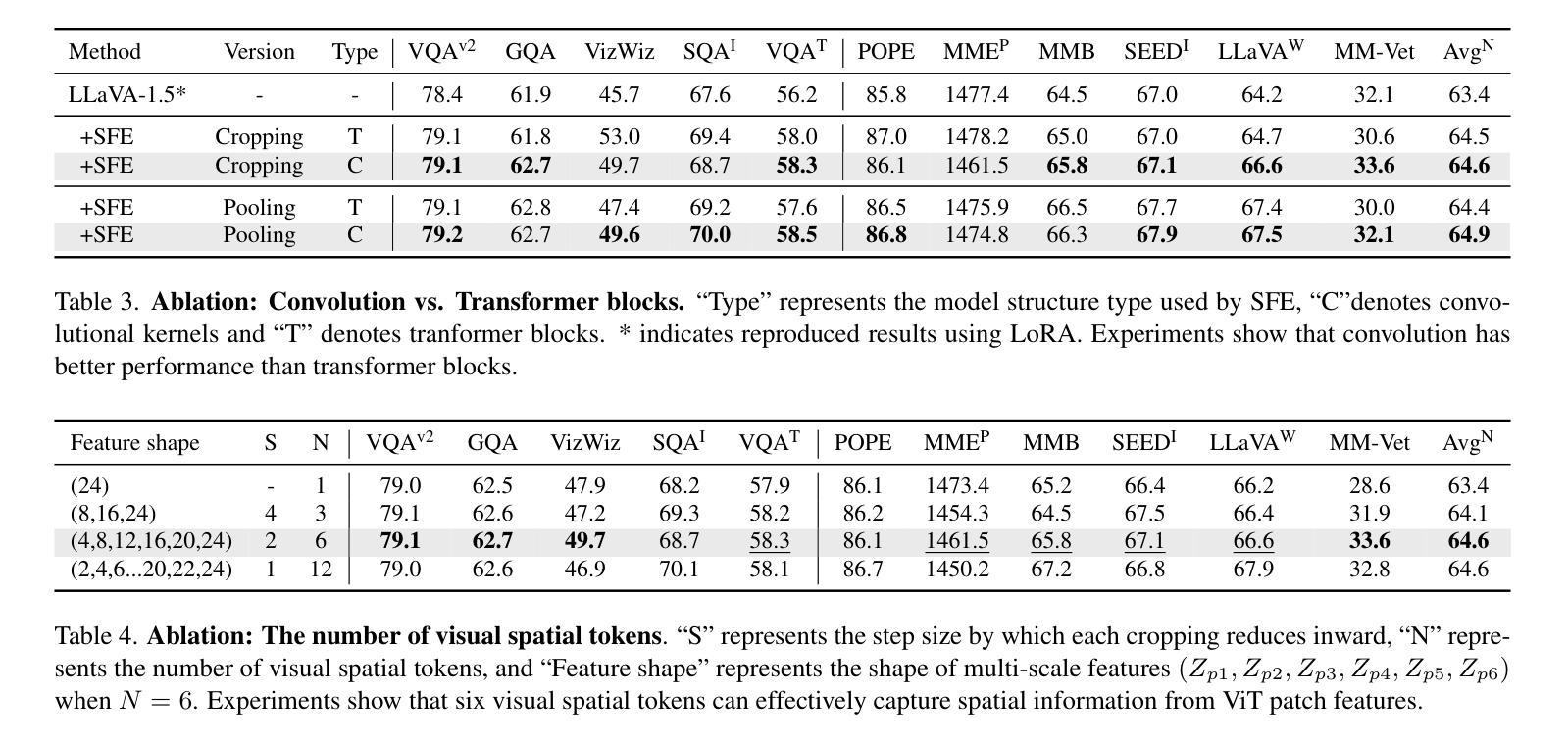
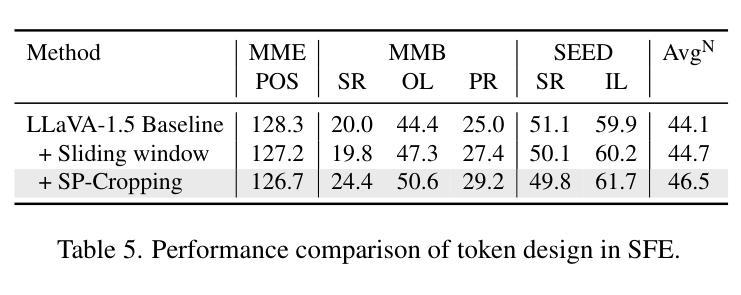
LLaVA-SP: Enhancing Visual Representation with Visual Spatial Tokens for MLLMs
Authors:Haoran Lou, Chunxiao Fan, Ziyan Liu, Yuexin Wu, Xinliang Wang
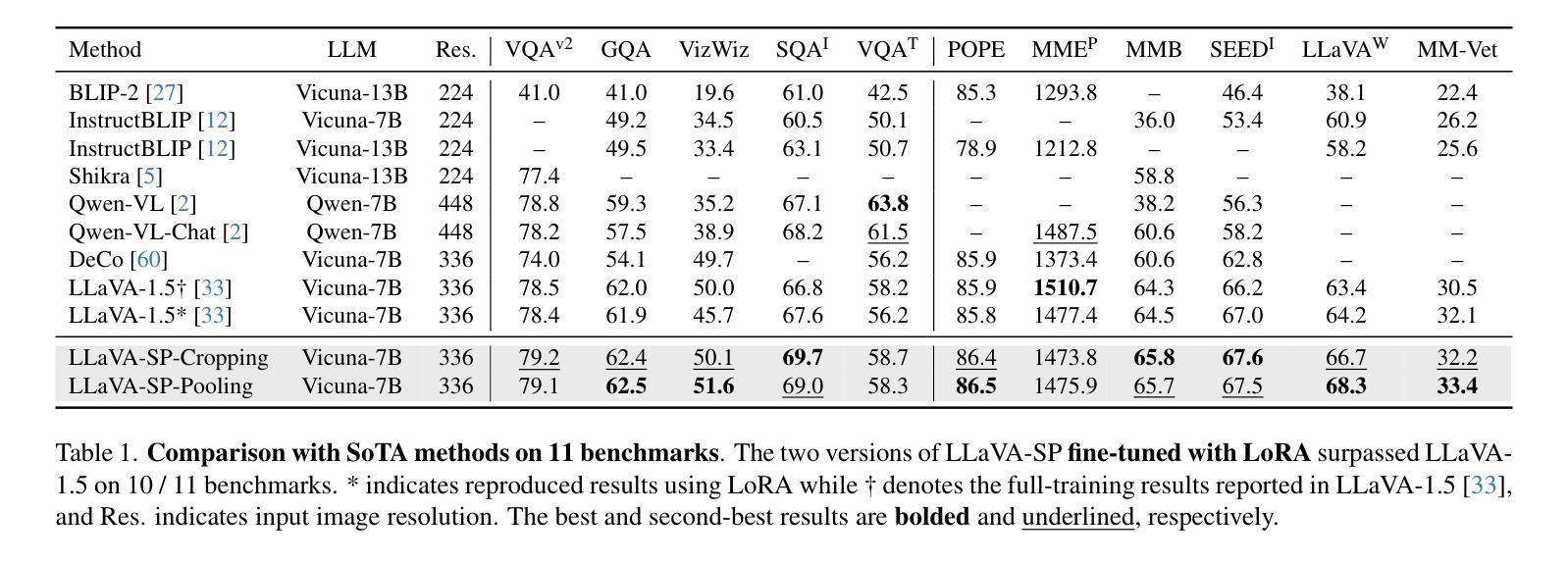
The architecture of multimodal large language models (MLLMs) commonly connects a vision encoder, often based on CLIP-ViT, to a large language model. While CLIP-ViT works well for capturing global image features, it struggles to model local relationships between adjacent patches, leading to weaker visual representation, which in turn affects the detailed understanding ability of MLLMs. To solve this, we propose LLaVA-SP, which \textbf{ only adds six spatial visual tokens} to the original visual tokens to enhance the visual representation. Our approach offers three key advantages: 1)We propose a novel Projector, which uses convolutional kernels to derive visual spatial tokens from ViT patch features, simulating two visual spatial ordering approaches: from central region to global" and from abstract to specific”. Then, a cross-attention mechanism is applied to fuse fine-grained visual information, enriching the overall visual representation. 2) We present two model variants: LLaVA-SP-Cropping, which focuses on detail features through progressive cropping, and LLaVA-SP-Pooling, which captures global semantics through adaptive pooling, enabling the model to handle diverse visual understanding tasks. 3) Extensive experiments show that LLaVA-SP, fine-tuned with LoRA, achieves significant performance improvements across various multimodal benchmarks, outperforming the state-of-the-art LLaVA-1.5 model in multiple tasks with nearly identical inference latency. The code and models are available at https://github.com/CnFaker/LLaVA-SP.
多模态大型语言模型的架构通常将基于CLIP-ViT的视觉编码器与大型语言模型相连接。虽然CLIP-ViT在捕捉全局图像特征方面表现良好,但在建模相邻补丁之间的局部关系方面存在困难,导致视觉表示较弱,进而影响了MLLMs的详细理解能力。为了解决这个问题,我们提出了LLaVA-SP,它只向原始视觉符号添加六个空间视觉符号来增强视觉表示。我们的方法提供了三个关键优势:
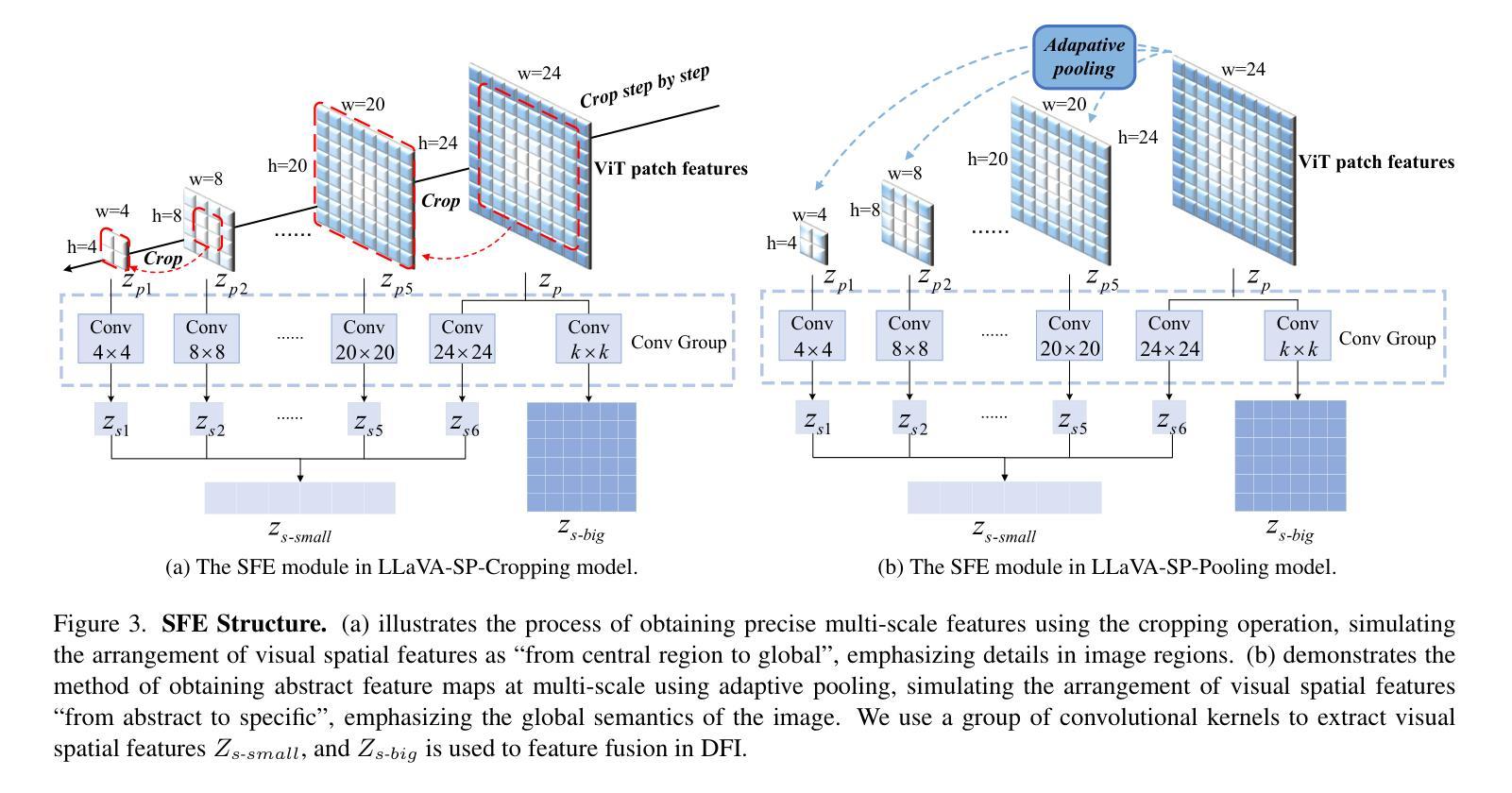
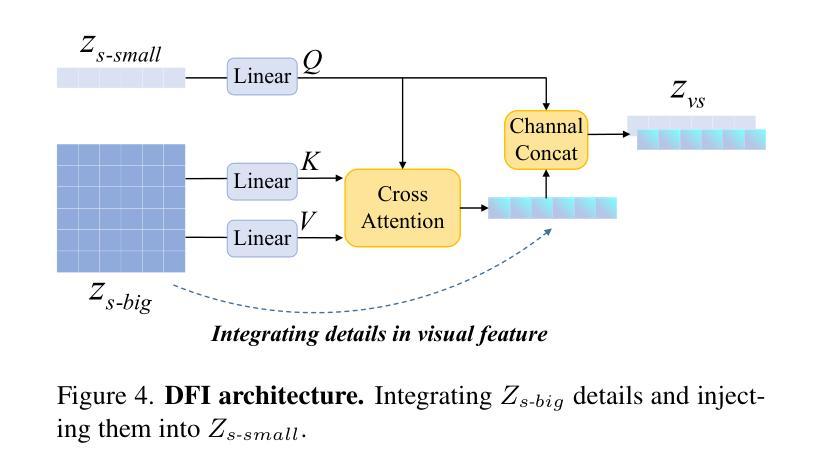
- 我们提出了一个新的投影器,它使用卷积核从ViT补丁特征中推导出视觉空间符号,模拟两种视觉空间排序方法:“从中心区域到全局”和“从抽象到具体”。然后,应用交叉注意力机制融合精细的视觉信息,丰富整体的视觉表示。
- 我们推出了两个模型变体:LLaVA-SP-Cropping,通过渐进裁剪关注细节特征;LLaVA-SP-Pooling,通过自适应池化捕捉全局语义,使模型能够处理各种视觉理解任务。
论文及项目相关链接
PDF ICCV
Summary
针对多模态大型语言模型(MLLMs)在视觉表示方面的不足,提出LLaVA-SP架构。通过添加仅六个空间视觉令牌来增强原始视觉令牌的表示,实现更精细的视觉理解。提供两种模型变体,并通过实验证明其在多模态基准测试上的性能显著提高。
Key Takeaways
- 多模态大型语言模型(MLLMs)通常将视觉编码器(基于CLIP-ViT)与大型语言模型连接在一起。
- CLIP-ViT在捕捉全局图像特征方面表现良好,但在建模局部相邻斑块之间的关系时遇到困难,导致视觉表示较弱。
- LLaVA-SP通过添加六个空间视觉令牌来增强视觉表示,仅对原始视觉令牌进行补充。
- LLaVA-SP提供两种模型变体:LLaVA-SP-Cropping和LLaVA-SP-Pooling,分别侧重于细节特征和全局语义。
- LLaVA-SP使用新颖投影仪模拟两种视觉空间排序方法,并通过交叉注意力机制融合精细视觉信息,丰富总体视觉表示。
- 实验表明,使用LoRA微调后的LLaVA-SP在各种多模态基准测试上实现了显著的性能提升。
点此查看论文截图