⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-06 更新
No time to train! Training-Free Reference-Based Instance Segmentation
Authors:Miguel Espinosa, Chenhongyi Yang, Linus Ericsson, Steven McDonagh, Elliot J. Crowley
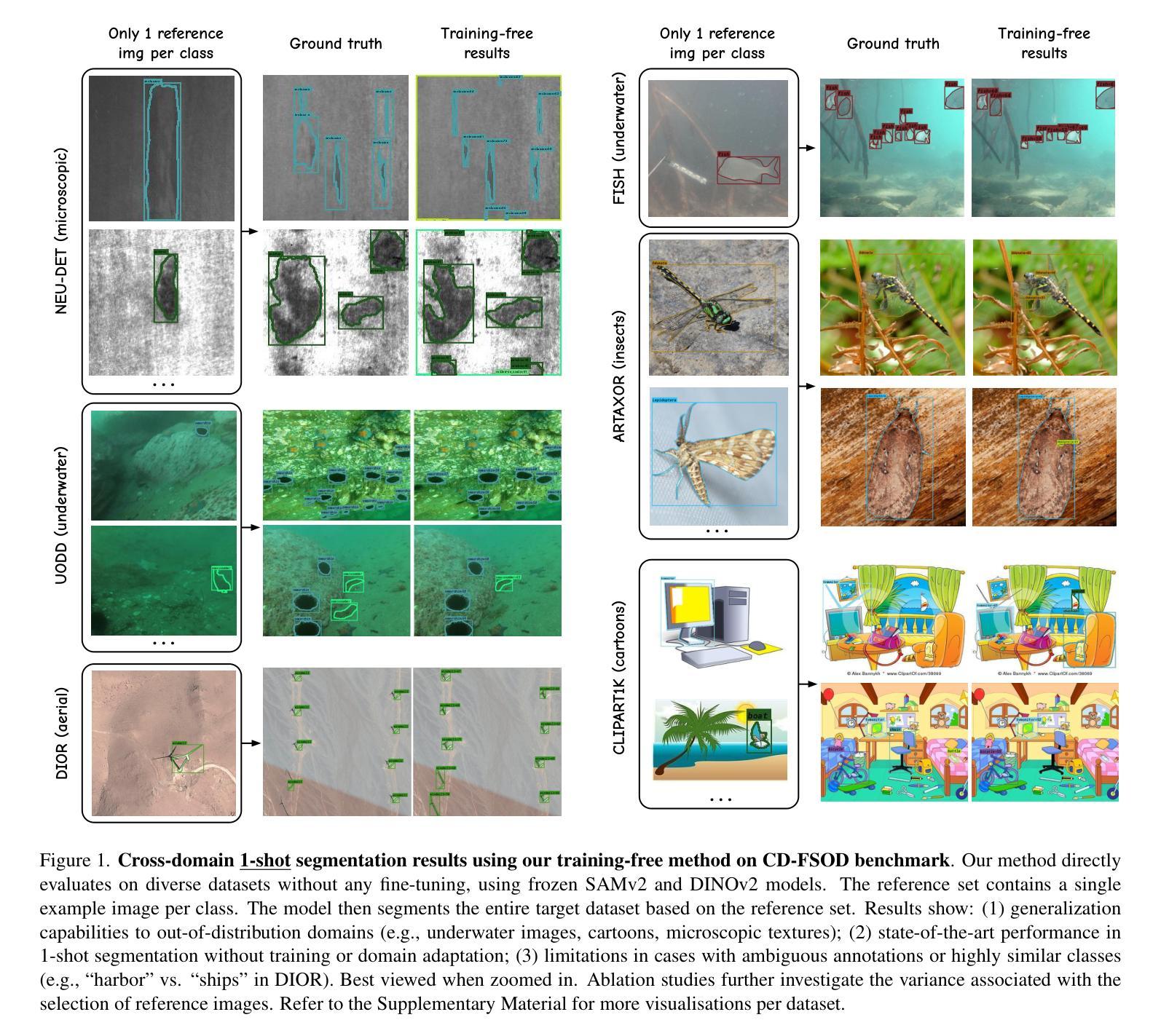
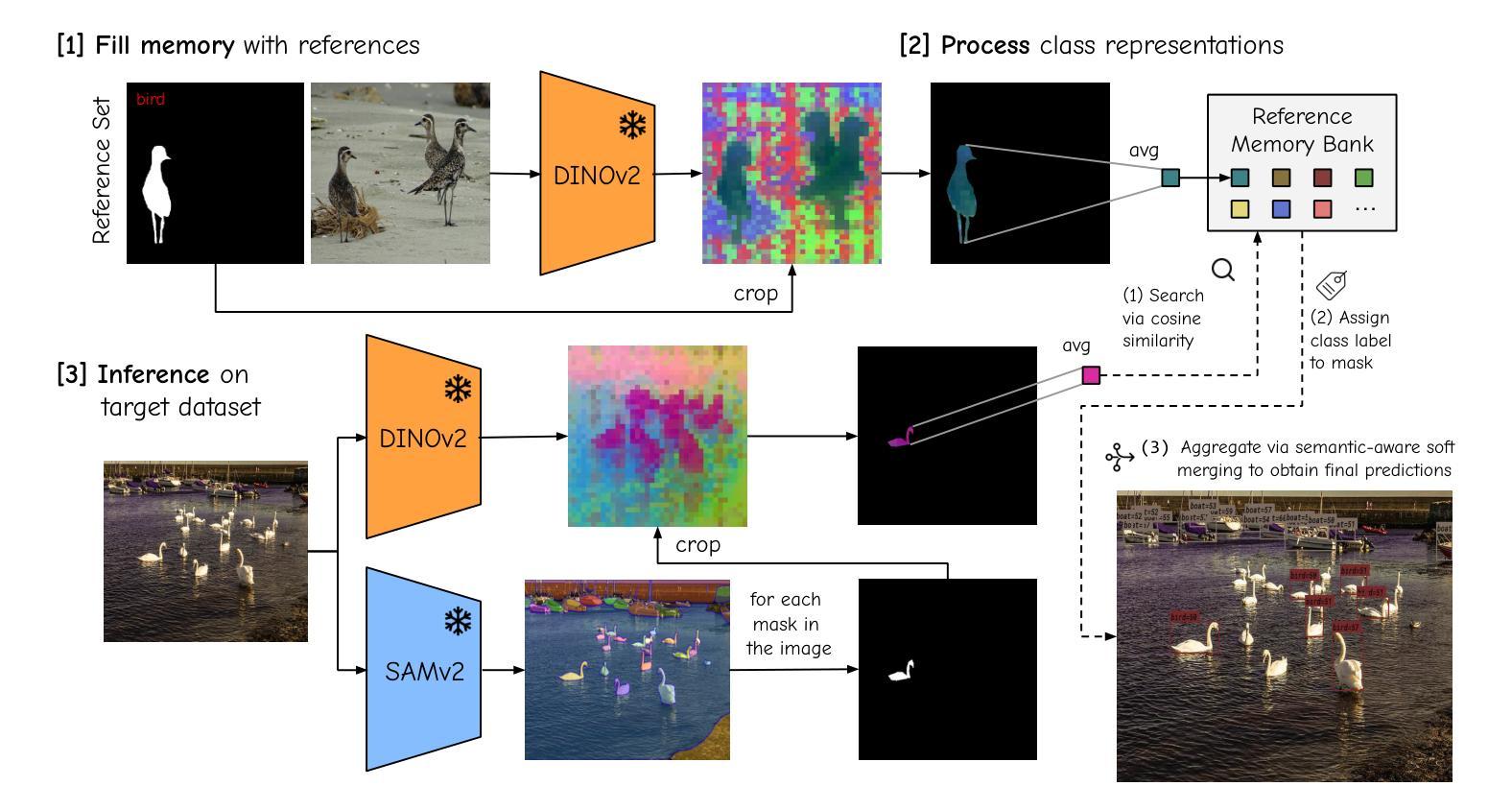
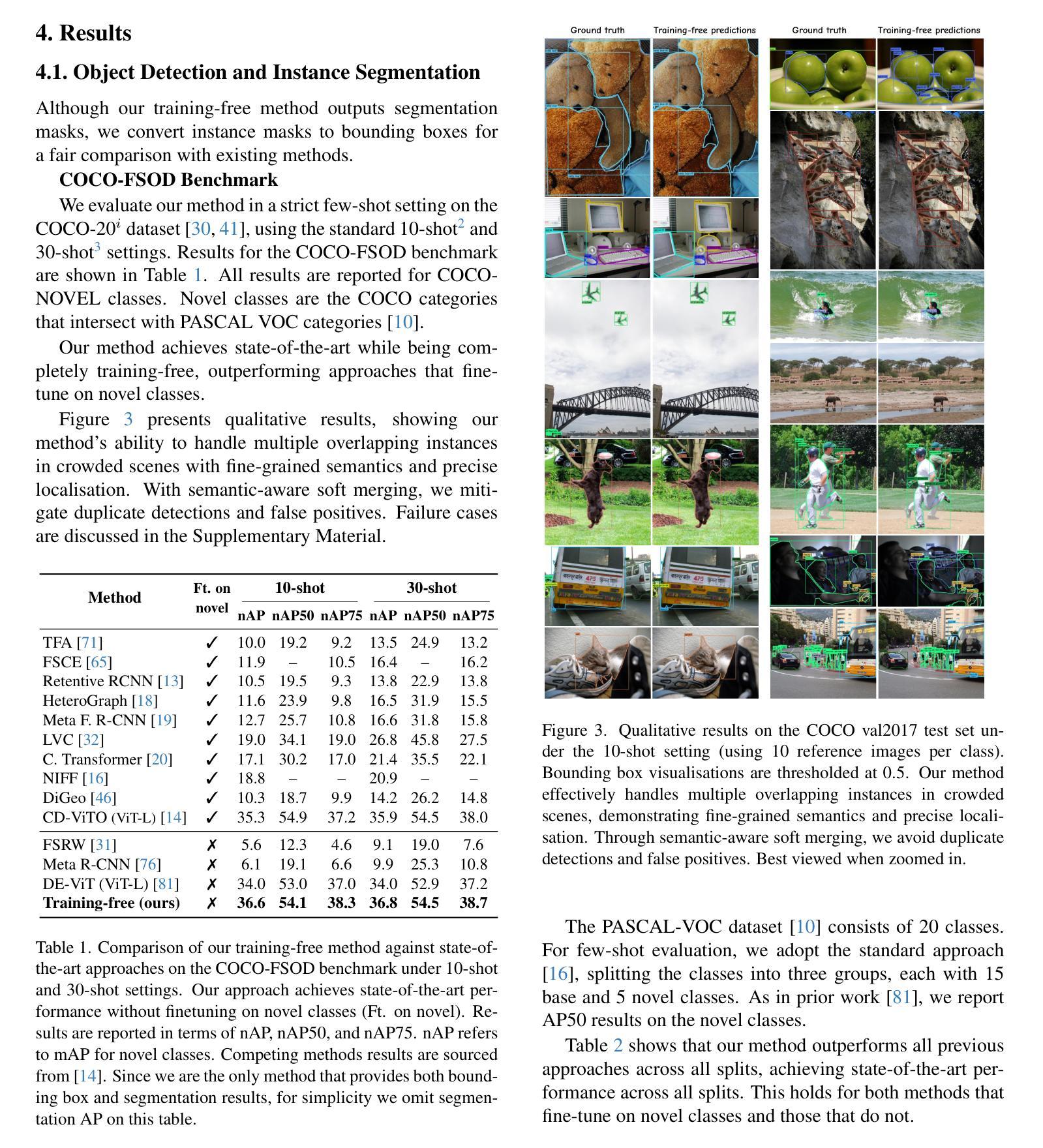
The performance of image segmentation models has historically been constrained by the high cost of collecting large-scale annotated data. The Segment Anything Model (SAM) alleviates this original problem through a promptable, semantics-agnostic, segmentation paradigm and yet still requires manual visual-prompts or complex domain-dependent prompt-generation rules to process a new image. Towards reducing this new burden, our work investigates the task of object segmentation when provided with, alternatively, only a small set of reference images. Our key insight is to leverage strong semantic priors, as learned by foundation models, to identify corresponding regions between a reference and a target image. We find that correspondences enable automatic generation of instance-level segmentation masks for downstream tasks and instantiate our ideas via a multi-stage, training-free method incorporating (1) memory bank construction; (2) representation aggregation and (3) semantic-aware feature matching. Our experiments show significant improvements on segmentation metrics, leading to state-of-the-art performance on COCO FSOD (36.8% nAP), PASCAL VOC Few-Shot (71.2% nAP50) and outperforming existing training-free approaches on the Cross-Domain FSOD benchmark (22.4% nAP).
历史上,图像分割模型的性能一直受到收集大规模标注数据的高成本的限制。Segment Anything Model(SAM)通过可提示的、与语义无关的分割范式缓解了这一原始问题,但处理新图像时仍需要手动视觉提示或复杂的域相关提示生成规则。为了减轻这一新负担,我们的工作研究了在仅提供一小部分参考图像的情况下进行对象分割的任务。我们的关键见解是利用基础模型学到的强大语义先验知识,来识别参考图像和目标图像之间的相应区域。我们发现这种对应关系能够自动生成用于下游任务的实例级分割掩膜,并通过一个多阶段、无需训练的方法实现我们的想法,包括(1)构建内存银行;(2)表示聚合和(3)语义感知特征匹配。我们的实验显示,在分割指标上取得了显著改进,达到了COCO FSOD的先进水平(36.8% nAP),PASCAL VOC Few-Shot(71.2% nAP50),并在Cross-Domain FSOD基准测试中超越了现有的无训练方法(22.4% nAP)。
论文及项目相关链接
PDF Preprint
Summary
本文提出一种基于少量参考图像进行图像分割的方法,利用基础模型学习到的语义先验知识,在参考图像和目标图像之间自动匹配对应区域,实现下游任务的实例级分割掩码生成。该方法采用无训练的多阶段方法,包括构建记忆库、表示聚合和语义感知特征匹配等步骤,实验结果显示在多个数据集上的分割度量指标显著提升。
Key Takeaways
- Segment Anything Model (SAM) 通过提示性分割模式解决大规模标注数据高成本问题。但仍需人工视觉提示或复杂规则来处理新图像。
- 研究者提出利用少量参考图像进行对象分割的新任务。
- 通过基础模型学习的语义先验知识在参考图像和目标图像间识别对应区域。
- 对应区域匹配可实现下游任务的实例级分割掩码自动生成。
- 采用无训练的多阶段方法,包括构建记忆库、表示聚合和语义感知特征匹配等步骤。
点此查看论文截图

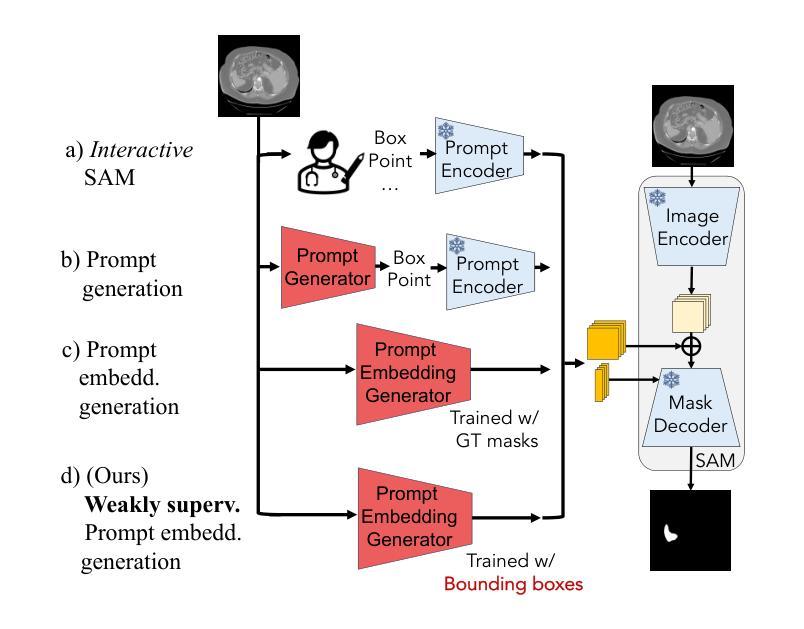
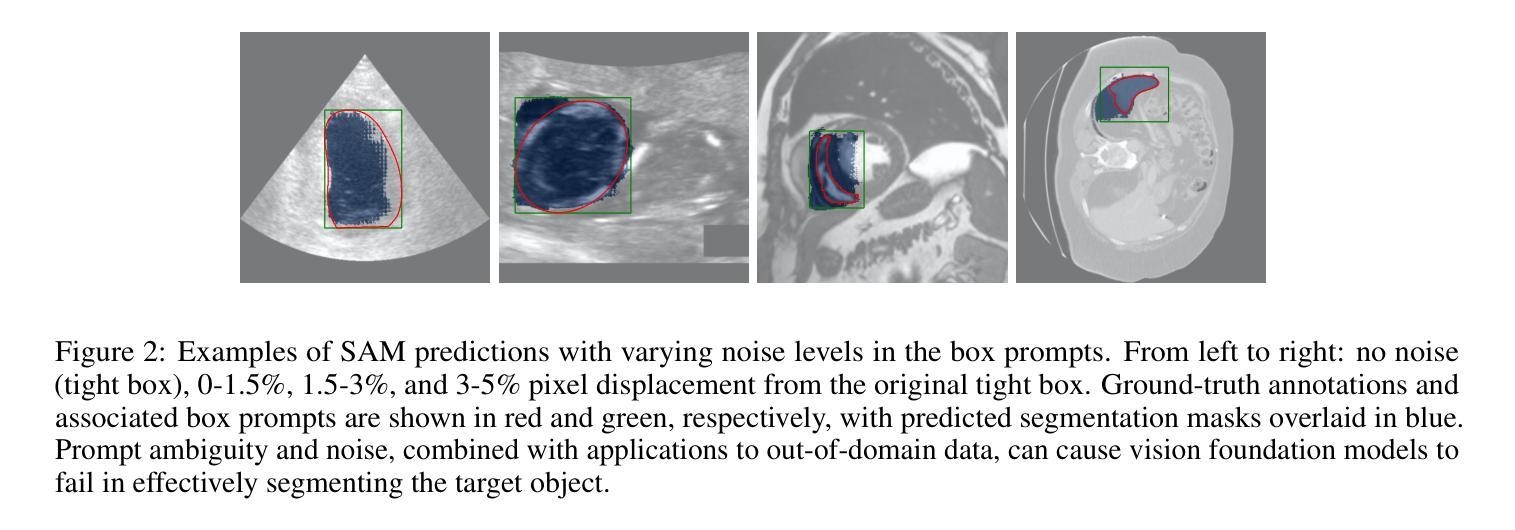
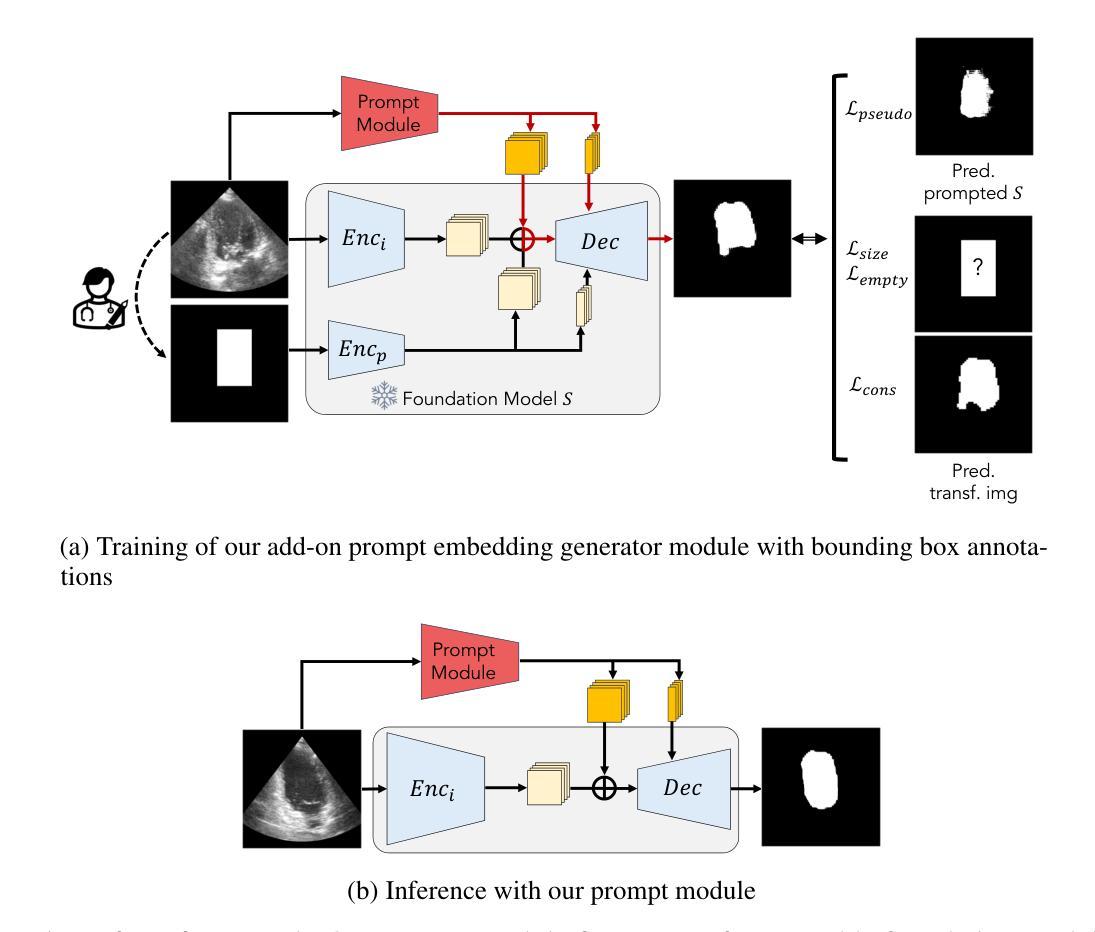
Prompt learning with bounding box constraints for medical image segmentation
Authors:Mélanie Gaillochet, Mehrdad Noori, Sahar Dastani, Christian Desrosiers, Hervé Lombaert
Pixel-wise annotations are notoriously labourious and costly to obtain in the medical domain. To mitigate this burden, weakly supervised approaches based on bounding box annotations-much easier to acquire-offer a practical alternative. Vision foundation models have recently shown noteworthy segmentation performance when provided with prompts such as points or bounding boxes. Prompt learning exploits these models by adapting them to downstream tasks and automating segmentation, thereby reducing user intervention. However, existing prompt learning approaches depend on fully annotated segmentation masks. This paper proposes a novel framework that combines the representational power of foundation models with the annotation efficiency of weakly supervised segmentation. More specifically, our approach automates prompt generation for foundation models using only bounding box annotations. Our proposed optimization scheme integrates multiple constraints derived from box annotations with pseudo-labels generated by the prompted foundation model. Extensive experiments across multimodal datasets reveal that our weakly supervised method achieves an average Dice score of 84.90% in a limited data setting, outperforming existing fully-supervised and weakly-supervised approaches. The code is available at https://github.com/Minimel/box-prompt-learning-VFM.git
医学领域中,逐像素标注的获取向来既费时又昂贵。为了减轻这一负担,基于边界框标注的弱监督方法提供了一种实用替代方案,因为边界框标注更容易获取。当提供提示(如点或边界框)时,视觉基础模型最近显示出令人印象深刻的分割性能。提示学习通过适应下游任务和自动化分割来利用这些模型,从而减少用户干预。然而,现有的提示学习方法依赖于完全注释的分割掩膜。本文提出一个结合基础模型的表示能力与弱监督分割的标注效率的新框架。更具体地说,我们的方法仅使用边界框标注来自动为基础模型生成提示。我们提出的优化方案将边界框标注生成的多个约束与由基础模型生成的伪标签相结合。在多模态数据集上的大量实验表明,在有限数据设置下,我们的弱监督方法实现了平均84.90%的Dice得分,超越了现有的全监督和弱监督方法。代码可通过以下链接获取:https://github.com/Minimel/box-prompt-learning-VFM.git 。
论文及项目相关链接
PDF Accepted to IEEE Transactions on Biomedical Engineering (TMBE), 14 pages
Summary
基于像素标注的医学图像分割标注劳动强度大且成本高,现有方法主要通过利用边界框标注等更易于获取的数据来减轻这一负担。本文提出了一种结合基础模型的表示能力与弱监督分割的标注效率的新框架。该框架能够自动化生成基础模型的提示,仅使用边界框标注,并通过整合多个由边界框标注生成的约束条件和伪标签进行优化。实验结果显示,在有限数据集上,该方法平均Dice得分为84.9%,优于现有的全监督和弱监督方法。
Key Takeaways
- 医学图像分割中的像素级标注劳动强度大且成本高。
- 弱监督方法通过使用更易于获取的标注数据(如边界框标注)作为解决方案。
- 现有提示学习方法依赖于完全注释的分割掩膜。
- 本文提出了一种新的框架,该框架结合了基础模型的表示能力与弱监督分割的标注效率。
- 该框架能够自动化生成基础模型的提示,仅使用边界框标注。
- 通过整合多个由边界框标注生成的约束条件和伪标签进行优化。
点此查看论文截图

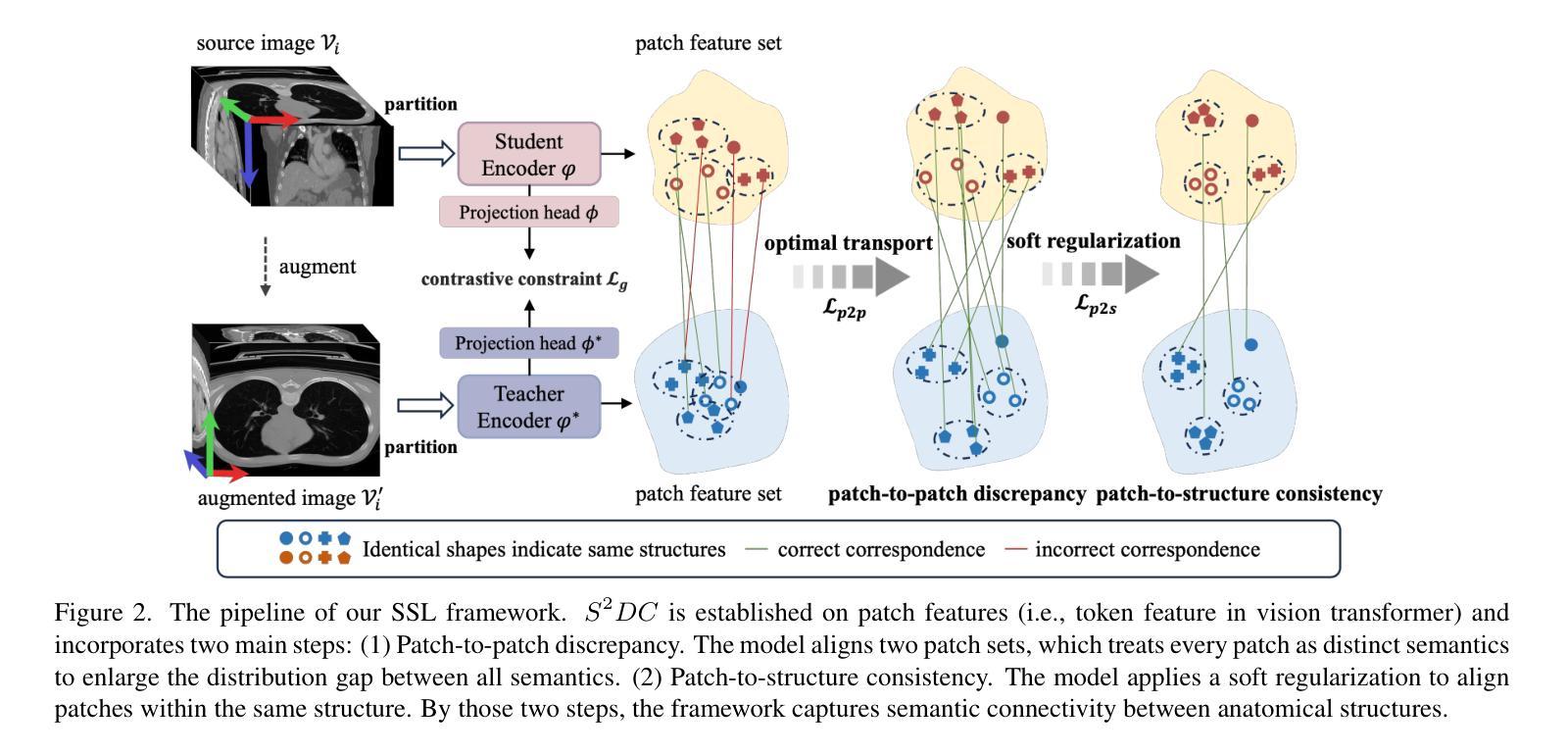
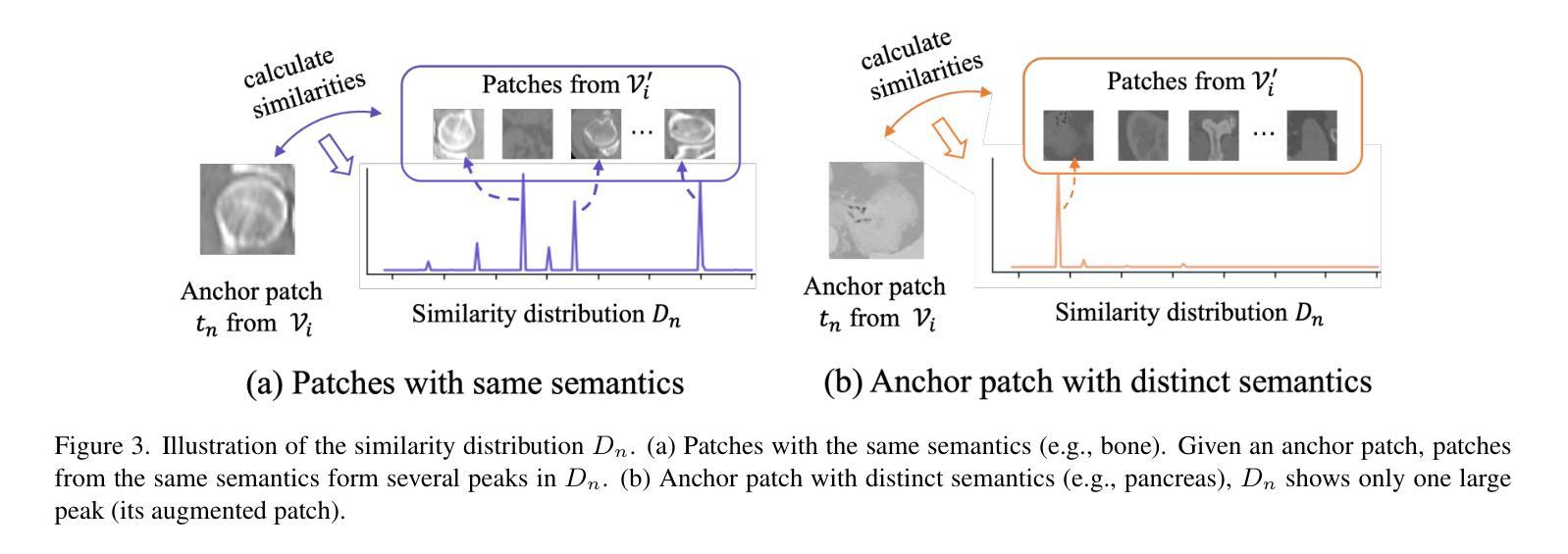
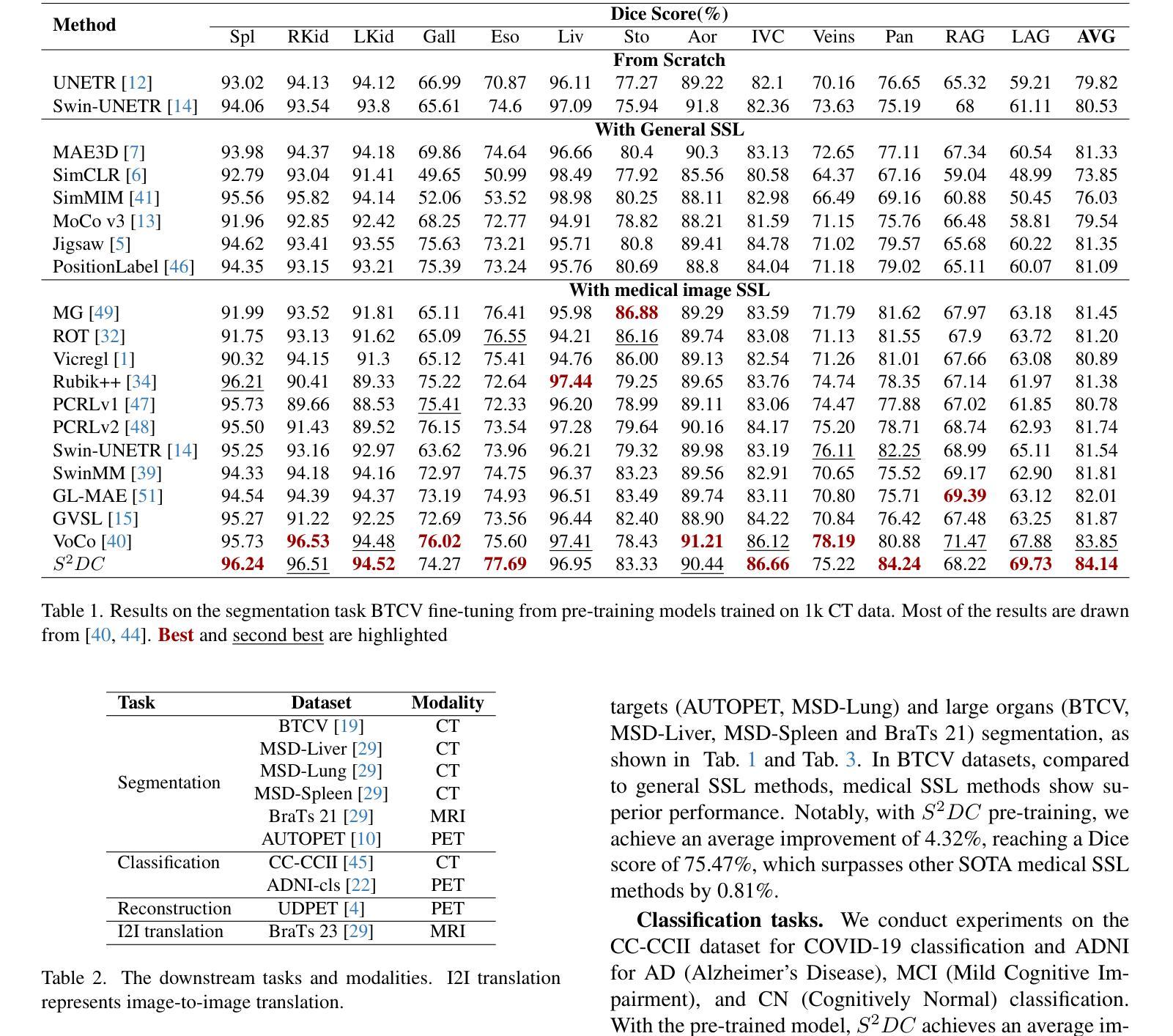
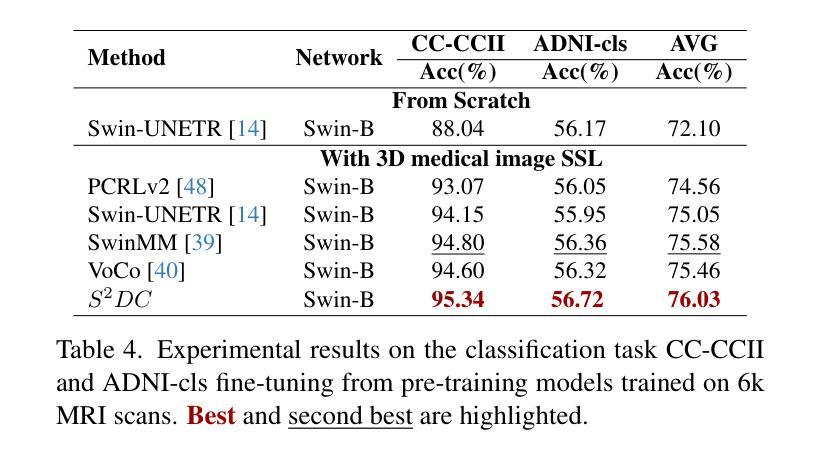
Structure-aware Semantic Discrepancy and Consistency for 3D Medical Image Self-supervised Learning
Authors:Tan Pan, Zhaorui Tan, Kaiyu Guo, Dongli Xu, Weidi Xu, Chen Jiang, Xin Guo, Yuan Qi, Yuan Cheng
3D medical image self-supervised learning (mSSL) holds great promise for medical analysis. Effectively supporting broader applications requires considering anatomical structure variations in location, scale, and morphology, which are crucial for capturing meaningful distinctions. However, previous mSSL methods partition images with fixed-size patches, often ignoring the structure variations. In this work, we introduce a novel perspective on 3D medical images with the goal of learning structure-aware representations. We assume that patches within the same structure share the same semantics (semantic consistency) while those from different structures exhibit distinct semantics (semantic discrepancy). Based on this assumption, we propose an mSSL framework named $S^2DC$, achieving Structure-aware Semantic Discrepancy and Consistency in two steps. First, $S^2DC$ enforces distinct representations for different patches to increase semantic discrepancy by leveraging an optimal transport strategy. Second, $S^2DC$ advances semantic consistency at the structural level based on neighborhood similarity distribution. By bridging patch-level and structure-level representations, $S^2DC$ achieves structure-aware representations. Thoroughly evaluated across 10 datasets, 4 tasks, and 3 modalities, our proposed method consistently outperforms the state-of-the-art methods in mSSL.
在医学分析领域,三维医学图像自监督学习(mSSL)具有巨大的潜力。为了更有效地支持更广泛的应用,需要考虑位置、尺度和形态上的解剖结构变异,这对于捕捉有意义的差异至关重要。然而,之前的mSSL方法使用固定大小的斑块对图像进行分割,经常忽略结构变异。在这项工作中,我们引入了一个关于三维医学图像的新视角,目标是学习结构感知表示。我们假设同一结构内的斑块具有相同的语义(语义一致性),而不同结构的斑块则表现出不同的语义(语义差异)。基于这一假设,我们提出了一个名为$S^2DC$的mSSL框架,分两步实现结构感知语义差异和一致性。首先,$S^2DC$强制不同斑块有不同的表示,以增加语义差异,并利用最优传输策略。其次,$S^2DC$基于邻域相似性分布在结构层面上推进语义一致性。通过桥接斑块层面和结构层面的表示,$S^2DC$实现了结构感知表示。经过在10个数据集、4项任务和3种模态上的全面评估,我们所提出的方法在mSSL中始终优于最先进的方法。
论文及项目相关链接
PDF Accepted by ICCV25
Summary
本文介绍了医学图像领域中的自监督学习(mSSL)方法,并指出传统方法在处理结构变化时存在局限性。为此,提出了一种新的视角,旨在学习结构感知表示。通过假设同一结构内的补丁具有相同的语义,而不同结构的补丁具有不同的语义,提出了名为$S^2DC$的mSSL框架,实现结构感知语义差异和一致性。该框架通过优化传输策略增强不同补丁之间的语义差异,并基于邻域相似性分布提高结构级别的语义一致性。通过对10个数据集、4个任务和3种模态的评估,本文提出的方法在mSSL中始终优于现有技术。
Key Takeaways
- 医学图像自监督学习(mSSL)在医学分析中具有巨大潜力,但需要考虑解剖结构的变异。
- 传统mSSL方法采用固定大小的图像区块划分,容易忽略结构变化。
- 提出了一种新的视角来学习结构感知表示,假设同一结构内的补丁具有相同语义,不同结构的补丁具有不同语义。
- 提出了名为$S^2DC$的mSSL框架,通过优化传输策略增强不同补丁之间的语义差异。
- $S^2DC$框架基于邻域相似性分布提高结构级别的语义一致性。
- $S^2DC$实现了跨结构感知的表示学习。
点此查看论文截图

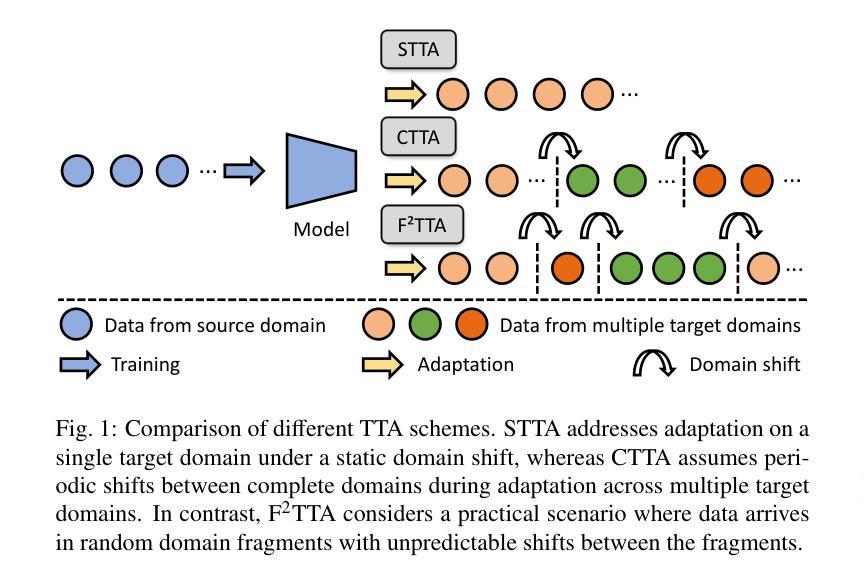
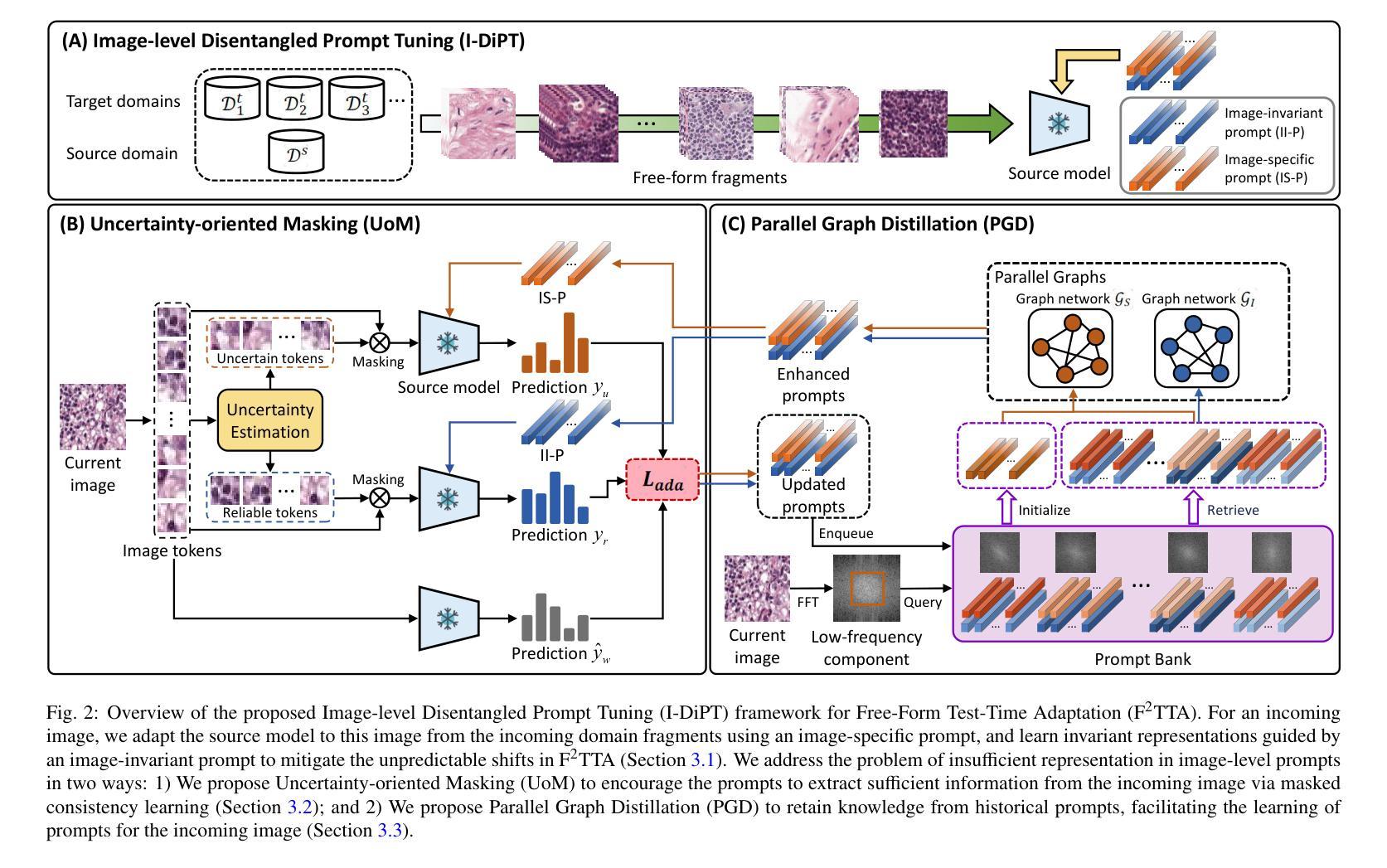
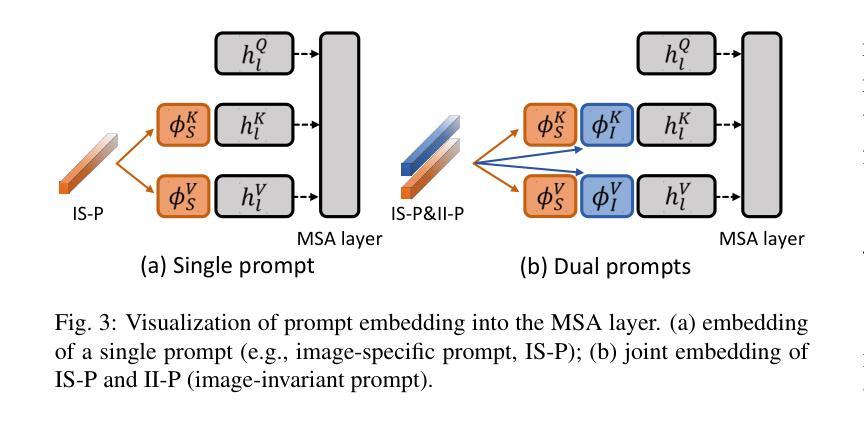
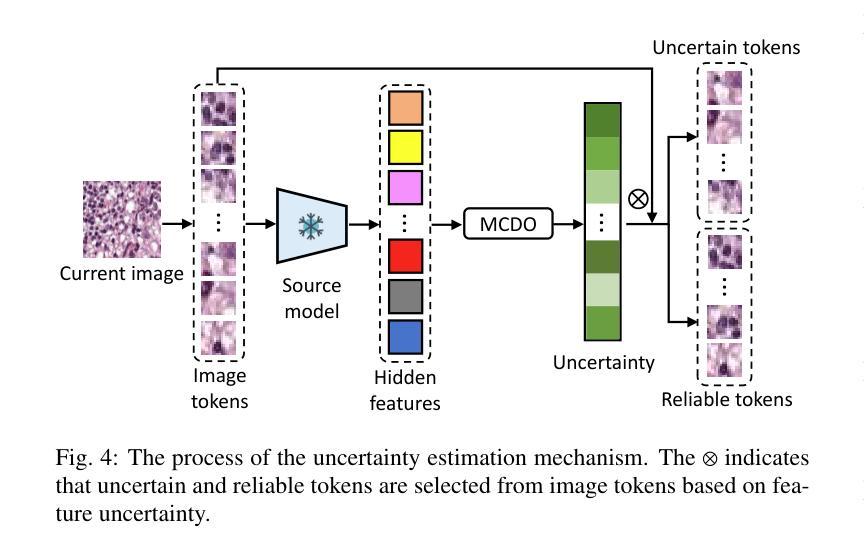
F^2TTA: Free-Form Test-Time Adaptation on Cross-Domain Medical Image Classification via Image-Level Disentangled Prompt Tuning
Authors:Wei Li, Jingyang Zhang, Lihao Liu, Guoan Wang, Junjun He, Yang Chen, Lixu Gu
Test-Time Adaptation (TTA) has emerged as a promising solution for adapting a source model to unseen medical sites using unlabeled test data, due to the high cost of data annotation. Existing TTA methods consider scenarios where data from one or multiple domains arrives in complete domain units. However, in clinical practice, data usually arrives in domain fragments of arbitrary lengths and in random arrival orders, due to resource constraints and patient variability. This paper investigates a practical Free-Form Test-Time Adaptation (F$^{2}$TTA) task, where a source model is adapted to such free-form domain fragments, with shifts occurring between fragments unpredictably. In this setting, these shifts could distort the adaptation process. To address this problem, we propose a novel Image-level Disentangled Prompt Tuning (I-DiPT) framework. I-DiPT employs an image-invariant prompt to explore domain-invariant representations for mitigating the unpredictable shifts, and an image-specific prompt to adapt the source model to each test image from the incoming fragments. The prompts may suffer from insufficient knowledge representation since only one image is available for training. To overcome this limitation, we first introduce Uncertainty-oriented Masking (UoM), which encourages the prompts to extract sufficient information from the incoming image via masked consistency learning driven by the uncertainty of the source model representations. Then, we further propose a Parallel Graph Distillation (PGD) method that reuses knowledge from historical image-specific and image-invariant prompts through parallel graph networks. Experiments on breast cancer and glaucoma classification demonstrate the superiority of our method over existing TTA approaches in F$^{2}$TTA. Code is available at https://github.com/mar-cry/F2TTA.
测试时间自适应(TTA)已成为一种有前途的解决方案,用于利用无标签的测试数据将源模型适应于未见过的医疗站点,以降低数据标注的高成本。现有的TTA方法考虑的是来自一个或多个域的数据以完整的域单元形式到达的场景。然而,在临床实践中,由于资源约束和患者差异性,数据通常以任意长度的域片段形式随机到达。本文研究了一个实用的自由形式测试时间自适应(F$^{2}$TTA)任务,其中源模型被适应于这样的自由形式域片段,片段之间的变化是不可预测的。在这种情况下,这些变化可能会扭曲适应过程。为了解决这个问题,我们提出了一种新型的图像级解耦提示调整(I-DiPT)框架。I-DiPT采用图像不变提示来探索域不变表示,以缓解不可预测的变化,并采用图像特定提示来将源模型适应于来自传入片段的每个测试图像。由于只有一张图像可用于训练,提示可能面临知识表示不足的问题。为了克服这一局限性,我们首先引入了面向不确定性的掩蔽(UoM),它通过源模型表示的不确定性来鼓励提示从传入的图像中提取足够的信息。然后,我们进一步提出了一种并行图蒸馏(PGD)方法,该方法通过并行图网络重用来自历史图像特定和图像不变提示的知识。对乳腺癌和青光眼分类的实验表明,我们的方法在F$^{2}$TTA中优于现有的TTA方法。代码可在https://github.com/mar-cry/F2TTA找到。
论文及项目相关链接
PDF This paper has been submitted to relevant journals
摘要
本文主要研究测试时间自适应(Test-Time Adaptation,TTA)在无标签测试数据的情况下如何自适应地应用至不同的医疗站点的问题。特别是在实践中常常面临不同域片段(domain fragments)任意长度以及随机顺序到达的情况,这增加了自适应过程的难度。本文提出了一种实用的自由形式测试时间自适应(F^{2}TTA)任务,并设计了一种新颖的图像级解耦提示调整(I-DiPT)框架来适应这种情况。该框架包含探索不变性域的图像不变提示来解决未知的变化以及通过特定的图像提示去适应模型在入组片段中对测试图像的建模问题。为了提高在只接受单个图像训练的条件下所隐含知识代表能力的问题,提出了基于不确定性导向掩盖的策略以通过模型的未确定性所驱动的遮掩一致性学习引导提示进行充足的信息抽取。同时提出一种并行图蒸馏方法以利用图像特定的以及图像不变的提示历史知识。实验表明在乳腺癌和青光眼分类上的性能优于现有的TTA方法。相关代码可通过公开链接访问。
关键发现
- 自由形式的测试时间自适应是一个考虑实际场景中医疗数据随机到达的新问题,要求模型能够适应任意长度的域片段和不可预测的转移变化。
- 图像级解耦提示调整框架结合了图像不变提示和特定图像提示来应对上述问题,提高了模型的适应性。
点此查看论文截图

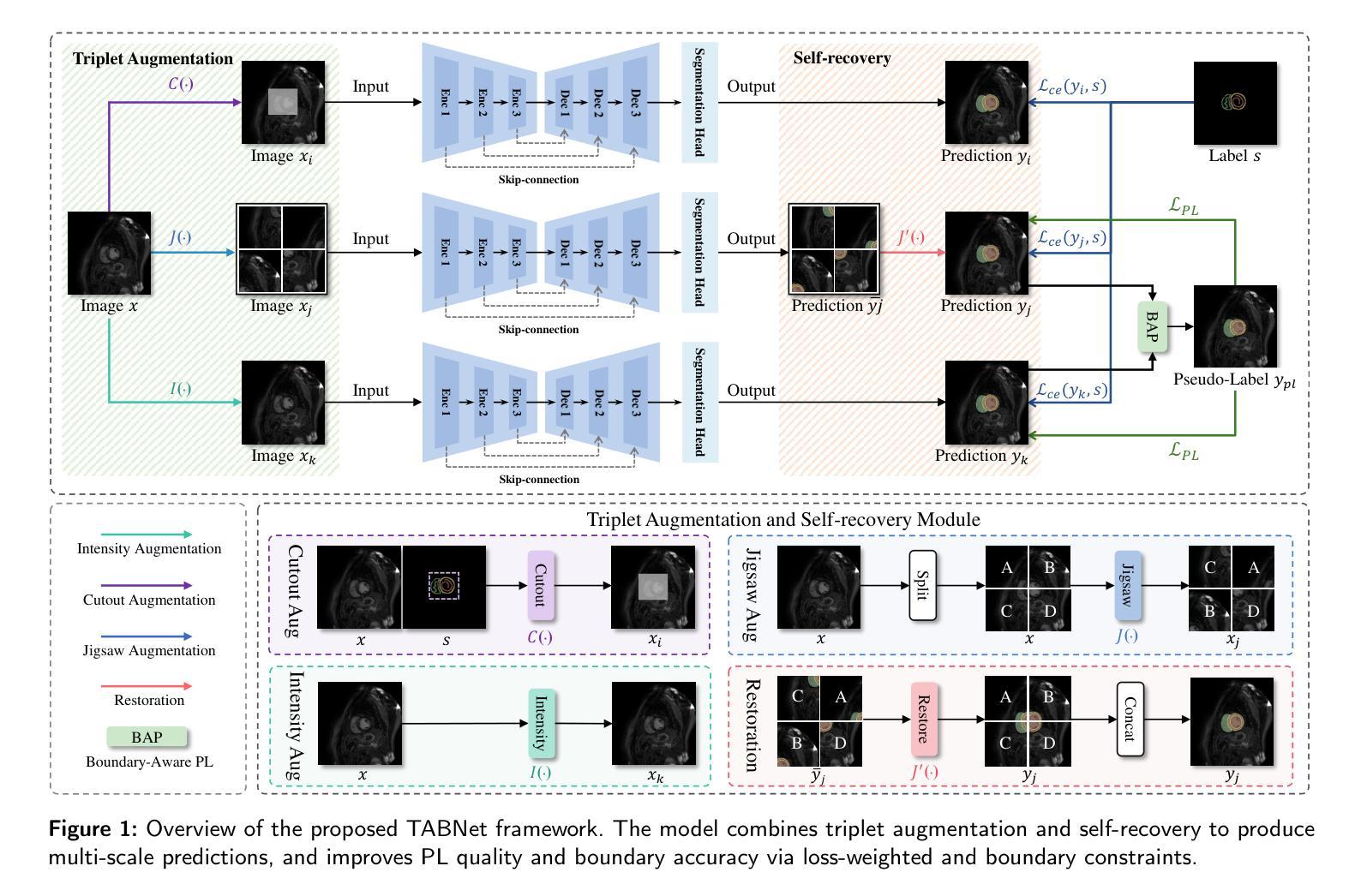
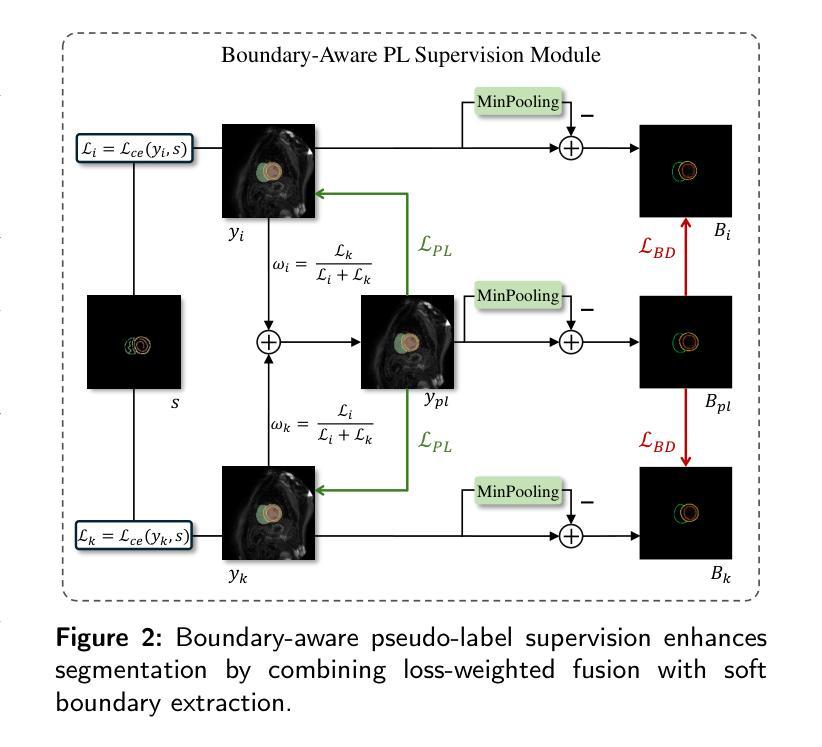
TABNet: A Triplet Augmentation Self-Recovery Framework with Boundary-Aware Pseudo-Labels for Medical Image Segmentation
Authors:Peilin Zhang, Shaouxan Wua, Jun Feng, Zhuo Jin, Zhizezhang Gao, Jingkun Chen, Yaqiong Xing, Xiao Zhang
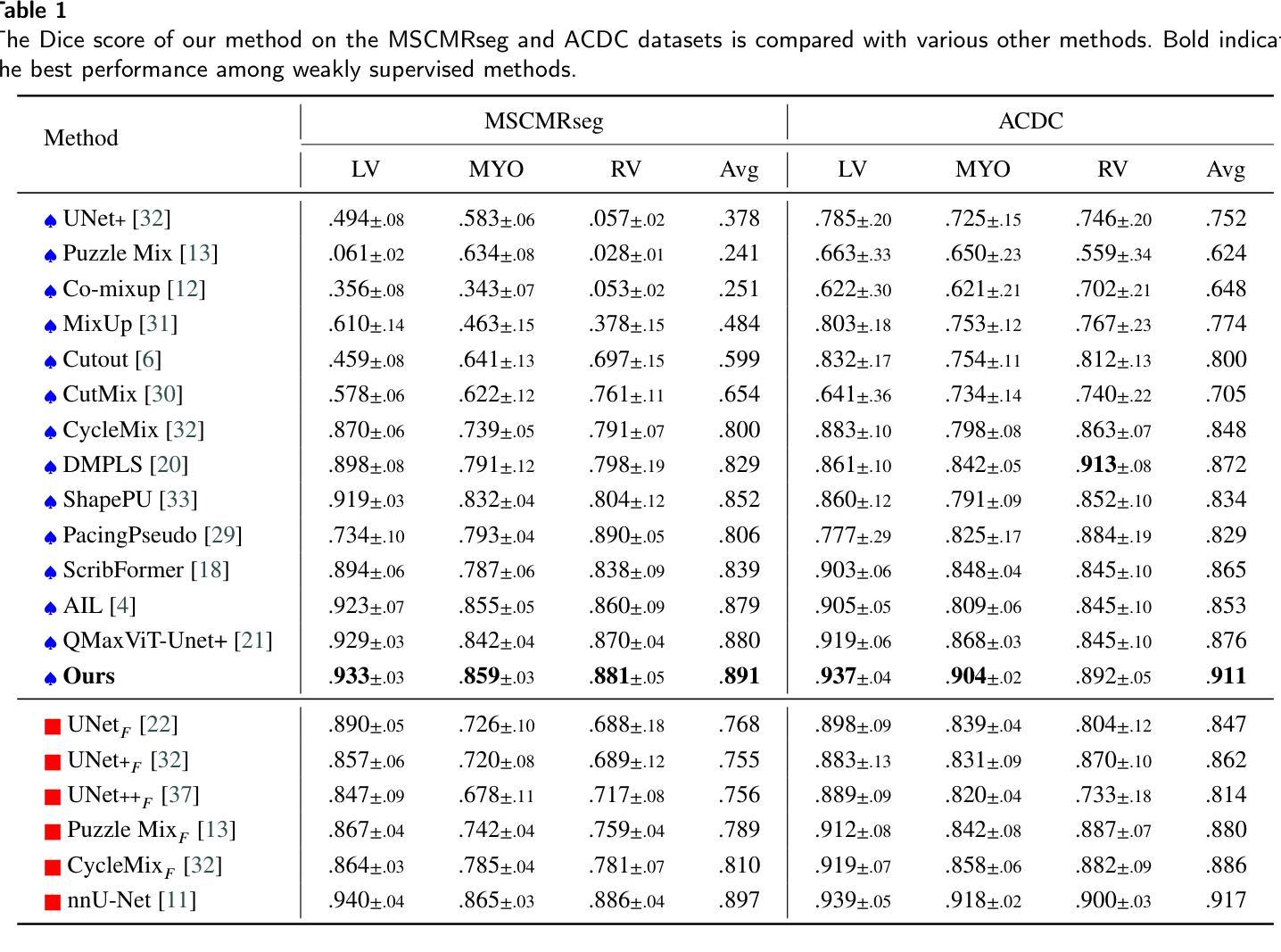
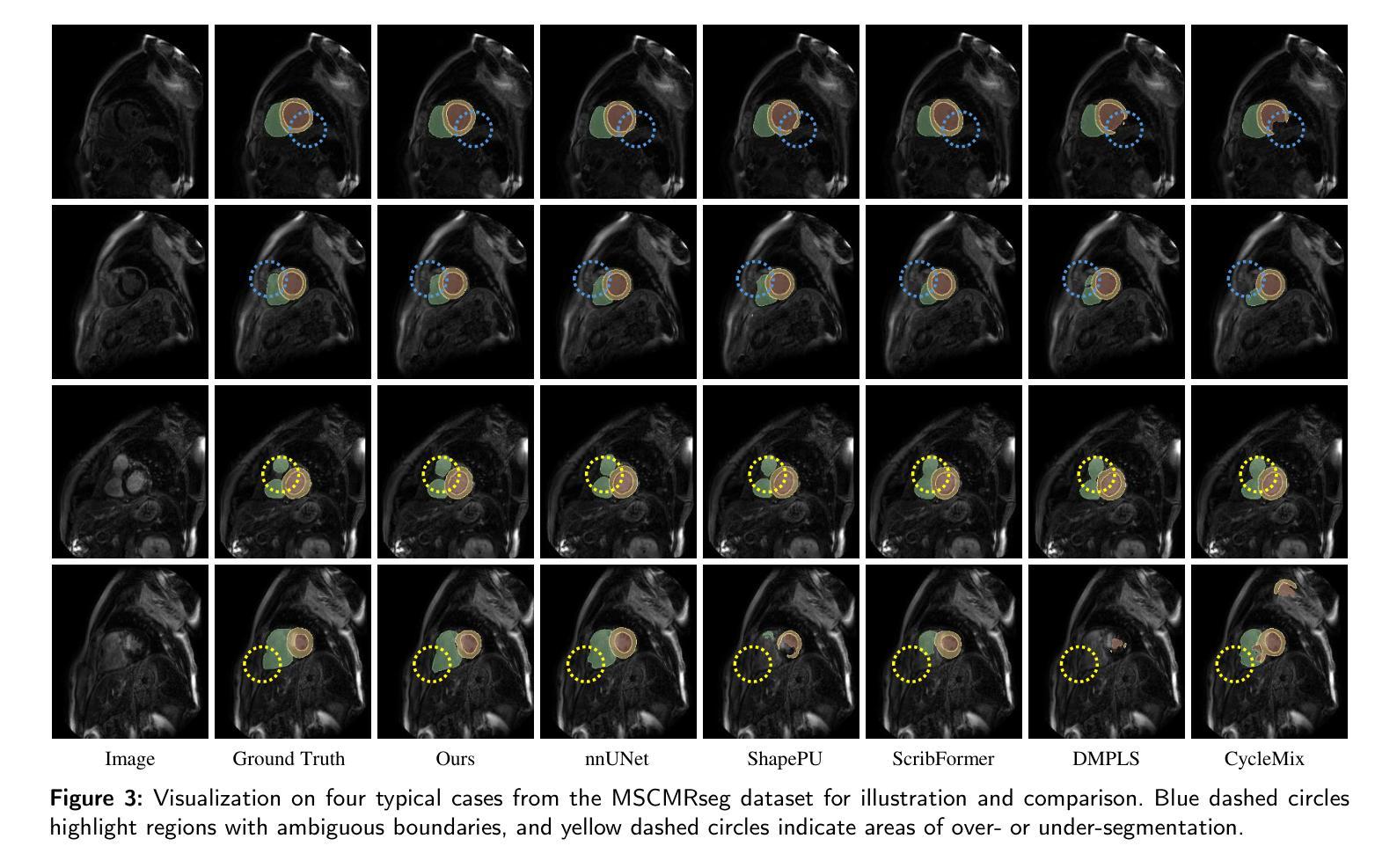
Background and objective: Medical image segmentation is a core task in various clinical applications. However, acquiring large-scale, fully annotated medical image datasets is both time-consuming and costly. Scribble annotations, as a form of sparse labeling, provide an efficient and cost-effective alternative for medical image segmentation. However, the sparsity of scribble annotations limits the feature learning of the target region and lacks sufficient boundary supervision, which poses significant challenges for training segmentation networks. Methods: We propose TAB Net, a novel weakly-supervised medical image segmentation framework, consisting of two key components: the triplet augmentation self-recovery (TAS) module and the boundary-aware pseudo-label supervision (BAP) module. The TAS module enhances feature learning through three complementary augmentation strategies: intensity transformation improves the model’s sensitivity to texture and contrast variations, cutout forces the network to capture local anatomical structures by masking key regions, and jigsaw augmentation strengthens the modeling of global anatomical layout by disrupting spatial continuity. By guiding the network to recover complete masks from diverse augmented inputs, TAS promotes a deeper semantic understanding of medical images under sparse supervision. The BAP module enhances pseudo-supervision accuracy and boundary modeling by fusing dual-branch predictions into a loss-weighted pseudo-label and introducing a boundary-aware loss for fine-grained contour refinement. Results: Experimental evaluations on two public datasets, ACDC and MSCMR seg, demonstrate that TAB Net significantly outperforms state-of-the-art methods for scribble-based weakly supervised segmentation. Moreover, it achieves performance comparable to that of fully supervised methods.
背景与目标:医学图像分割是各种临床应用中的核心任务。然而,获取大规模、完全标注的医学图像数据集既耗时又成本高昂。涂鸦标注作为一种稀疏标注形式,为医学图像分割提供了高效且经济实惠的替代方案。然而,涂鸦标注的稀疏性限制了目标区域的特征学习,并且缺乏足够的边界监督,这为训练分割网络带来了重大挑战。
方法:我们提出了TAB Net,这是一种新型的弱监督医学图像分割框架,包含两个关键组件:三元组增强自恢复(TAS)模块和边界感知伪标签监督(BAP)模块。TAS模块通过三种互补的增强策略强化特征学习:强度转换提高模型对纹理和对比度变化的敏感性,切断关键区域迫使网络捕获局部解剖结构,拼图增强通过破坏空间连续性来加强全局解剖布局的建模。通过引导网络从各种增强输入中恢复完整的掩膜,TAS在稀疏监督下促进了对医学图像的更深层次语义理解。BAP模块通过融合双分支预测结果生成一个损失加权伪标签,并引入边界感知损失来进行精细轮廓修整,从而提高伪监督的准确性和边界建模。
结果:在ACDC和MSCMR seg两个公共数据集上的实验评估表明,TAB Net在基于涂鸦的弱监督分割方法中显著优于最新方法。此外,其性能与全监督方法相当。
论文及项目相关链接
Summary
本文提出一种名为TAB Net的弱监督医学图像分割框架,旨在解决医学图像分割中标注数据获取困难且成本高昂的问题。该框架包含两个关键组件:三元组增强自恢复(TAS)模块和边界感知伪标签监督(BAP)模块。通过增强特征学习和精细的边界建模,TAB Net在公开数据集上的表现显著优于其他基于涂鸦的弱监督分割方法,并与全监督方法的表现相当。
Key Takeaways
- TAB Net是一种弱监督医学图像分割框架,旨在解决大规模标注数据获取困难的问题。
- 框架包含两个关键组件:TAS模块和BAP模块。
- TAS模块通过三种增强策略促进特征学习:强度变换、遮挡和拼图增强。
- BAP模块通过融合双分支预测和引入边界感知损失来提高伪监督准确性和边界建模精度。
- 在两个公开数据集ACDC和MSCMR seg上的实验表明,TAB Net在涂鸦基础上的弱监督分割方法表现优异。
- TAB Net的表现与全监督方法相当。
- 该框架为医学图像分割提供了一种高效且成本效益高的解决方案。
点此查看论文截图

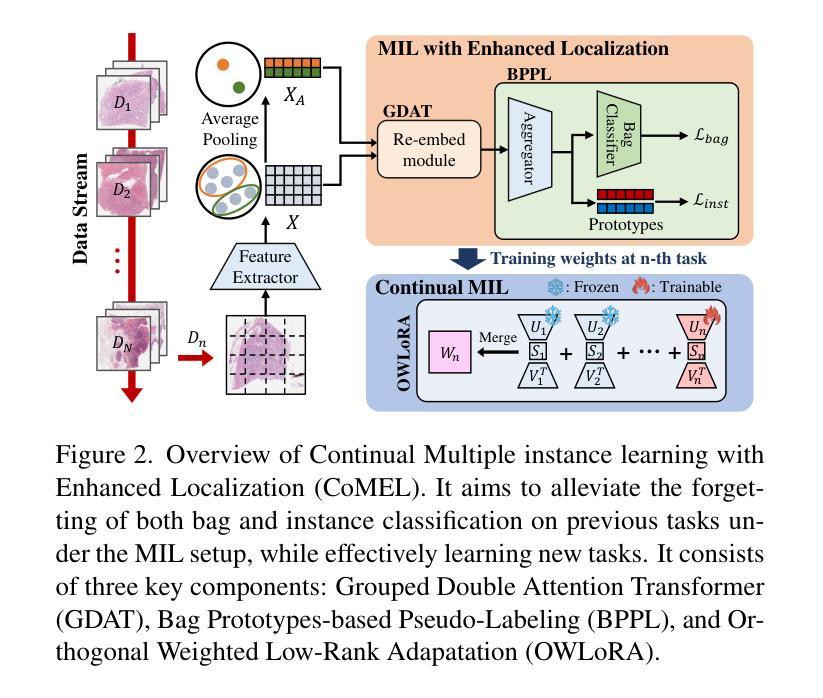
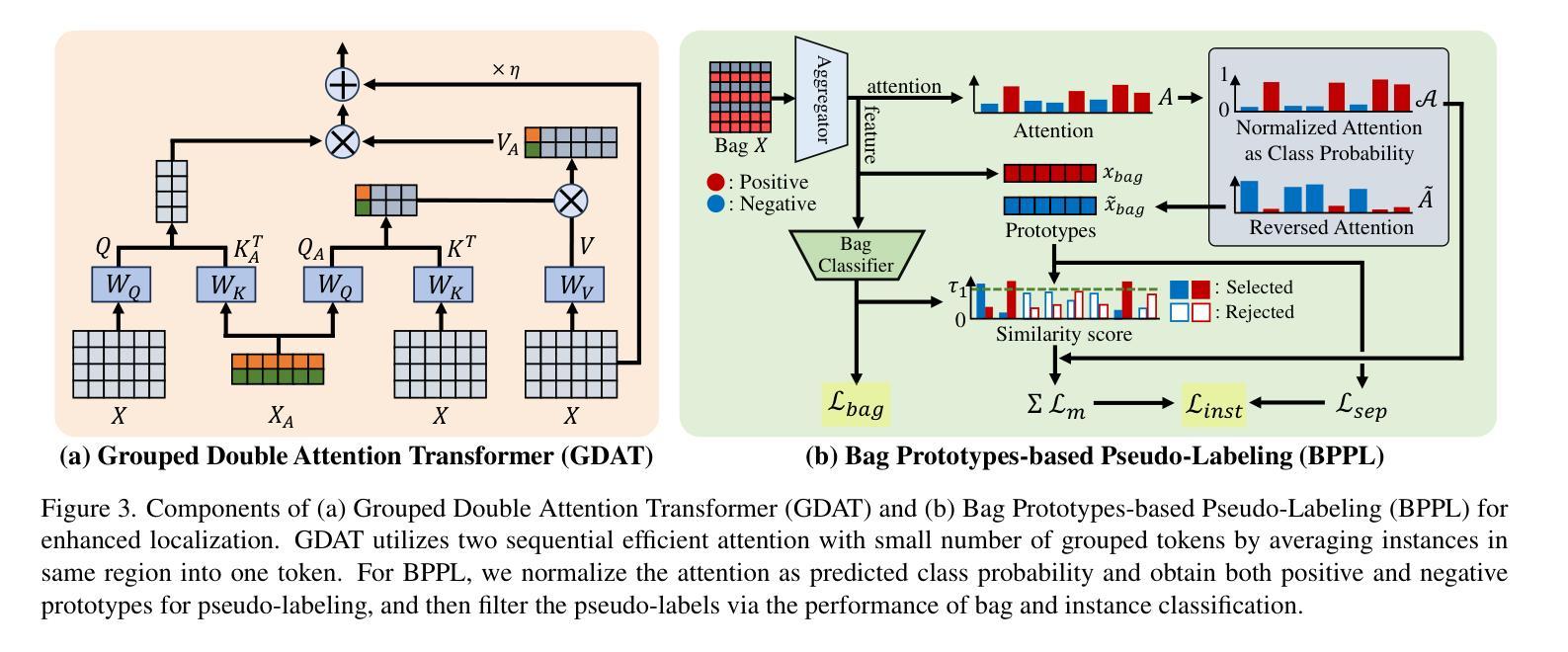
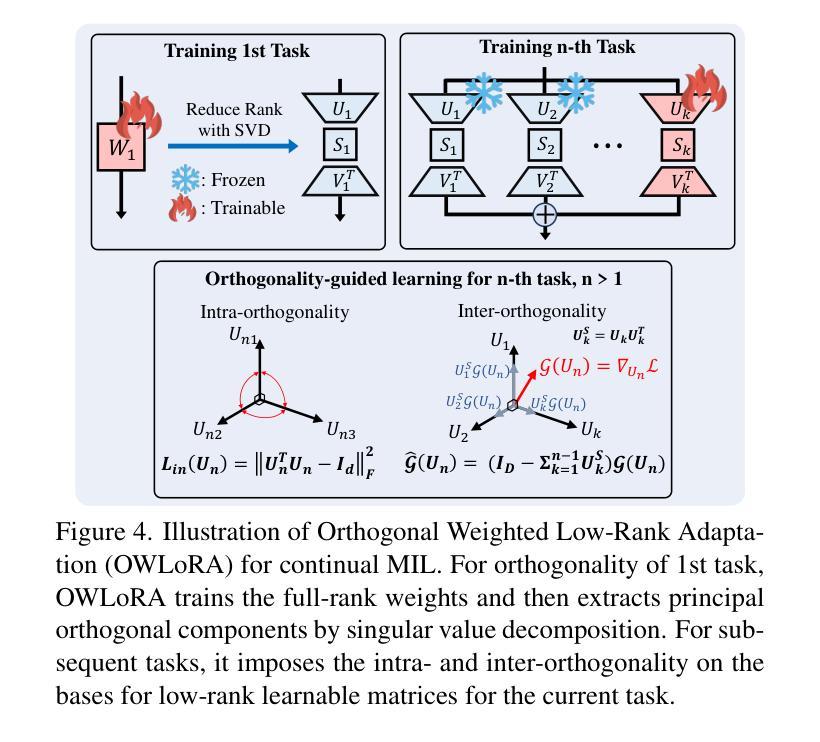
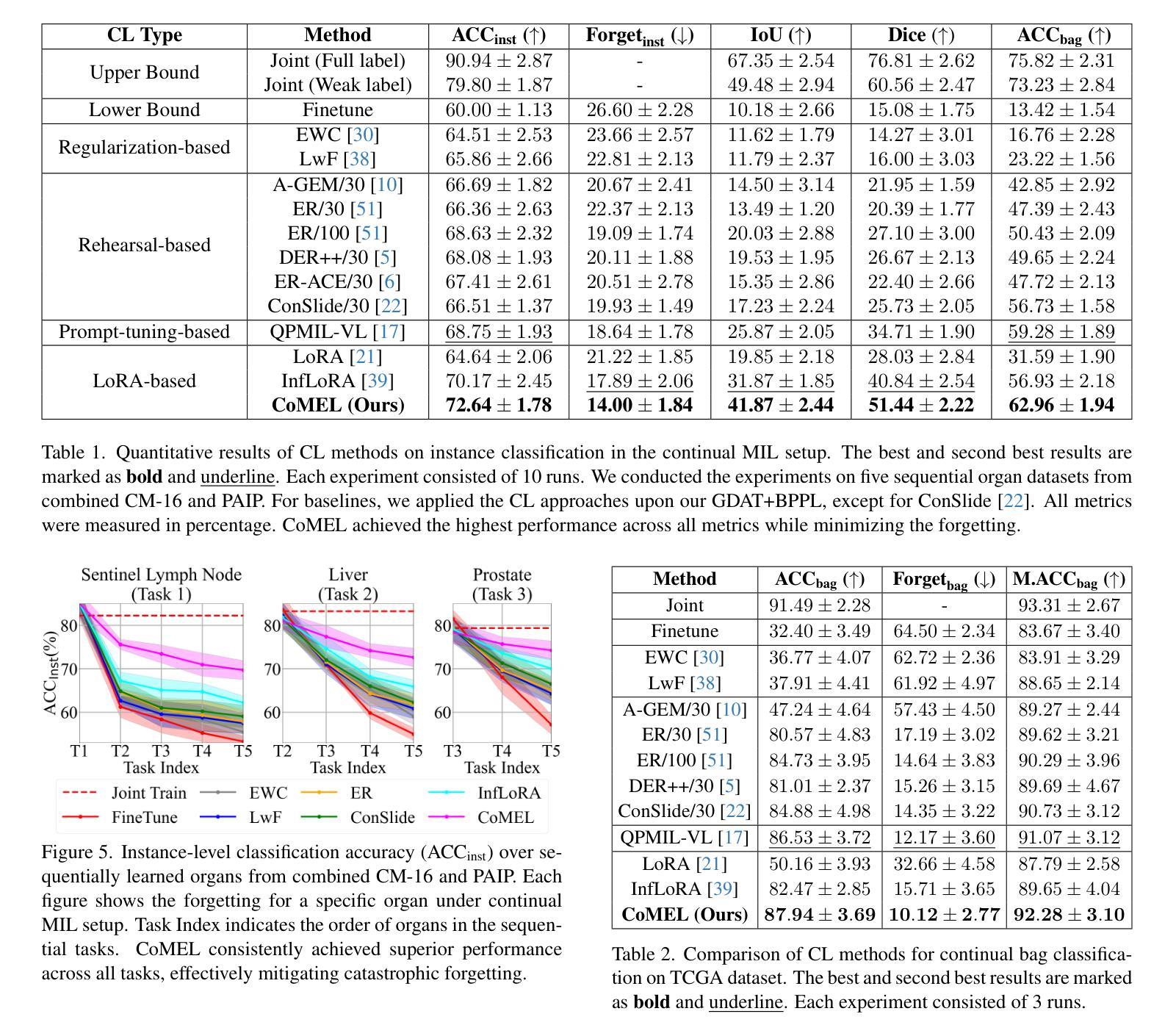
Continual Multiple Instance Learning with Enhanced Localization for Histopathological Whole Slide Image Analysis
Authors:Byung Hyun Lee, Wongi Jeong, Woojae Han, Kyoungbun Lee, Se Young Chun
Multiple instance learning (MIL) significantly reduced annotation costs via bag-level weak labels for large-scale images, such as histopathological whole slide images (WSIs). However, its adaptability to continual tasks with minimal forgetting has been rarely explored, especially on instance classification for localization. Weakly incremental learning for semantic segmentation has been studied for continual localization, but it focused on natural images, leveraging global relationships among hundreds of small patches (e.g., $16 \times 16$) using pre-trained models. This approach seems infeasible for MIL localization due to enormous amounts ($\sim 10^5$) of large patches (e.g., $256 \times 256$) and no available global relationships such as cancer cells. To address these challenges, we propose Continual Multiple Instance Learning with Enhanced Localization (CoMEL), an MIL framework for both localization and adaptability with minimal forgetting. CoMEL consists of (1) Grouped Double Attention Transformer (GDAT) for efficient instance encoding, (2) Bag Prototypes-based Pseudo-Labeling (BPPL) for reliable instance pseudo-labeling, and (3) Orthogonal Weighted Low-Rank Adaptation (OWLoRA) to mitigate forgetting in both bag and instance classification. Extensive experiments on three public WSI datasets demonstrate superior performance of CoMEL, outperforming the prior arts by up to $11.00%$ in bag-level accuracy and up to $23.4%$ in localization accuracy under the continual MIL setup.
多实例学习(MIL)通过大规模图像(如病理全切片图像)的袋级弱标签显著降低了标注成本。然而,其在连续任务中的适应性以及最小化遗忘的研究很少涉及,特别是在定位实例分类方面。对于连续定位的弱增量学习语义分割已有所研究,但主要应用于自然图像,利用数百个小补丁之间的全局关系(例如,使用预训练模型进行的 $16 \times 16$ 补丁)。由于存在大量($\sim 10^5$ 个)大型补丁(例如,$256 \times 256$)并且不存在诸如癌细胞之类的全局关系,这种方法似乎不适用于 MIL 定位。为解决这些挑战,我们提出了具有最小遗忘适应性的持续多实例学习增强定位(CoMEL),这是一个用于定位和适应性的 MIL 框架。CoMEL 包括(1)用于高效实例编码的分组双重注意力转换器(GDAT),(2)基于袋原型伪标签的可靠实例伪标签(BPPL),以及(3)正交加权低秩自适应技术(OWLoRA)来减轻在连续训练期间的包分类和实例分类中可能发生的遗忘现象。在三个公共 WSI 数据集上的广泛实验表明,CoMEL 的性能优于先前技术,在袋级准确度上高出 $11.00%$ ,在定位准确度上高出 $23.4%$ 。在连续 MIL 设置下表现尤为突出。
论文及项目相关链接
PDF Accepted at ICCV 2025
摘要
基于多实例学习(MIL)的方法利用大规模图像(如病理全切片图像)的袋级弱标签显著降低了标注成本。然而,它在连续任务中的适应性以及最小化遗忘的研究仍然有限,特别是在实例分类定位方面的应用。虽然已有研究探讨了连续语义分割的弱增量学习,但这种方法主要适用于自然图像,依赖于数百个小补丁之间的全局关系并使用预训练模型。对于具有大量大规模补丁的MIL定位来说,这种方法的适用性令人质疑。为解决这些问题,我们提出了一个持续的多实例学习框架——增强的定位能力(CoMEL)。CoMEL结合了分组双注意力转换器(GDAT)进行高效实例编码、基于袋原型伪标签(BPPL)的可靠实例伪标签以及正交加权低秩适应(OWLoRA)以缓解遗忘问题。在三个公开的全切片图像数据集上的实验证明,在连续多实例学习的环境中,CoMEL的袋级准确率和定位准确率均显著优于先前技术。
关键见解
- 多实例学习(MIL)利用大规模图像的弱标签显著降低了标注成本。但对于连续任务和最小化遗忘的应用仍存在挑战。特别是在大规模补丁的场景中(如病理全切片图像)。我们提出持续多实例学习框架——增强的定位能力(CoMEL),用于解决这些挑战。
- CoMEL采用三种策略来提高效率和性能:(a)分组双注意力转换器(GDAT)实现高效实例编码;(b)基于袋原型伪标签(BPPL)进行可靠的实例伪标签;(c)正交加权低秩适应(OWLoRA)以缓解遗忘问题。
点此查看论文截图

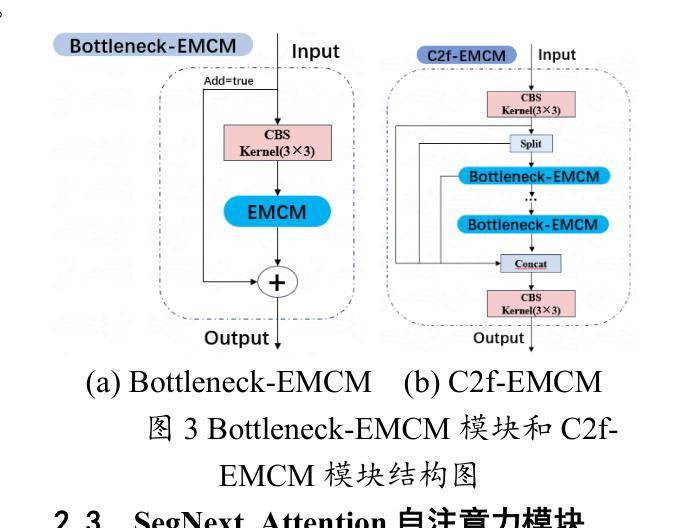
Lightweight Shrimp Disease Detection Research Based on YOLOv8n
Authors:Fei Yuhuan, Wang Gengchen, Liu Fenghao, Zang Ran, Sun Xufei, Chang Hao
Shrimp diseases are one of the primary causes of economic losses in shrimp aquaculture. To prevent disease transmission and enhance intelligent detection efficiency in shrimp farming, this paper proposes a lightweight network architecture based on YOLOv8n. First, by designing the RLDD detection head and C2f-EMCM module, the model reduces computational complexity while maintaining detection accuracy, improving computational efficiency. Subsequently, an improved SegNext_Attention self-attention mechanism is introduced to further enhance the model’s feature extraction capability, enabling more precise identification of disease characteristics. Extensive experiments, including ablation studies and comparative evaluations, are conducted on a self-constructed shrimp disease dataset, with generalization tests extended to the URPC2020 dataset. Results demonstrate that the proposed model achieves a 32.3% reduction in parameters compared to the original YOLOv8n, with a mAP@0.5 of 92.7% (3% improvement over YOLOv8n). Additionally, the model outperforms other lightweight YOLO-series models in mAP@0.5, parameter count, and model size. Generalization experiments on the URPC2020 dataset further validate the model’s robustness, showing a 4.1% increase in mAP@0.5 compared to YOLOv8n. The proposed method achieves an optimal balance between accuracy and efficiency, providing reliable technical support for intelligent disease detection in shrimp aquaculture.
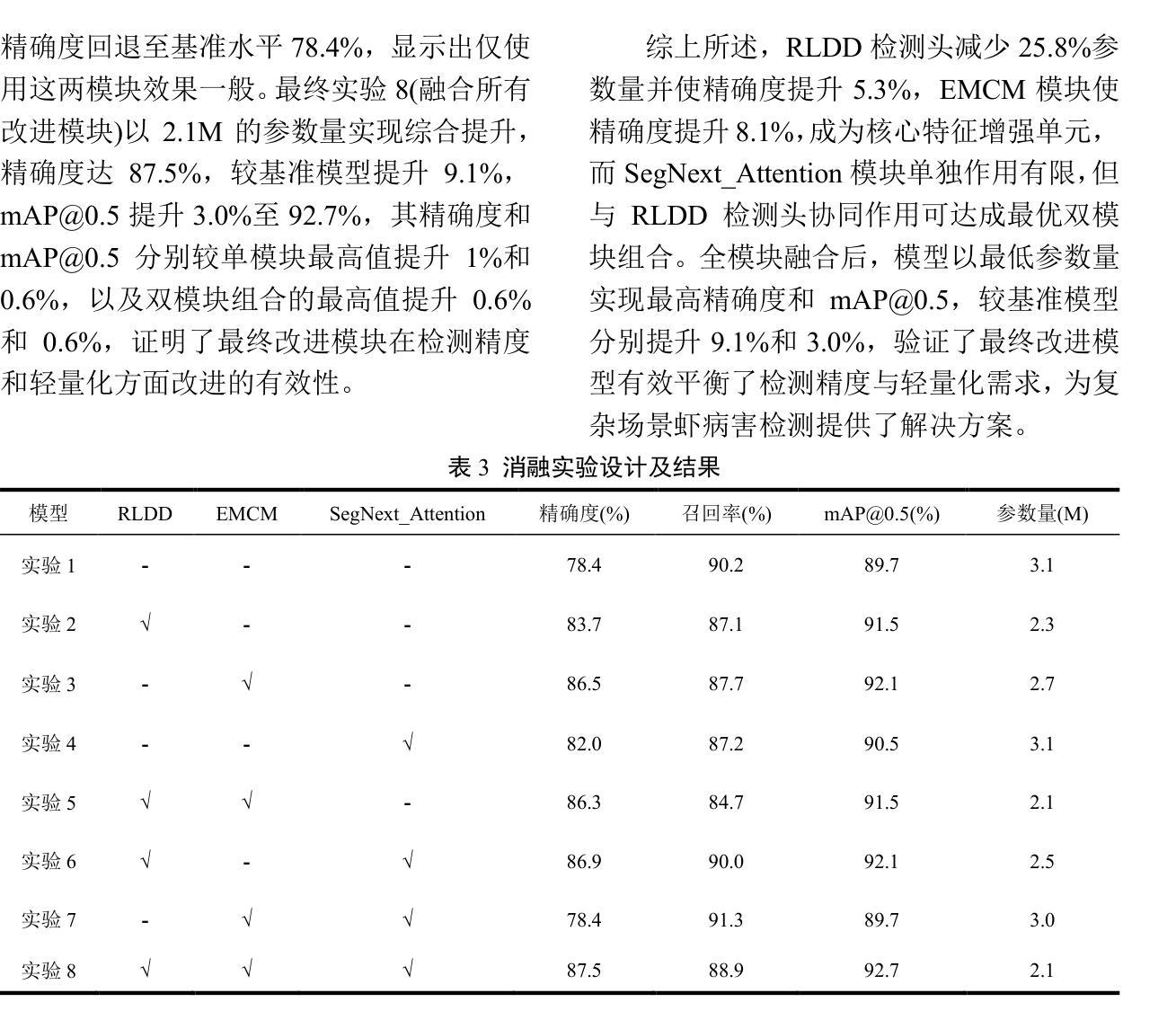
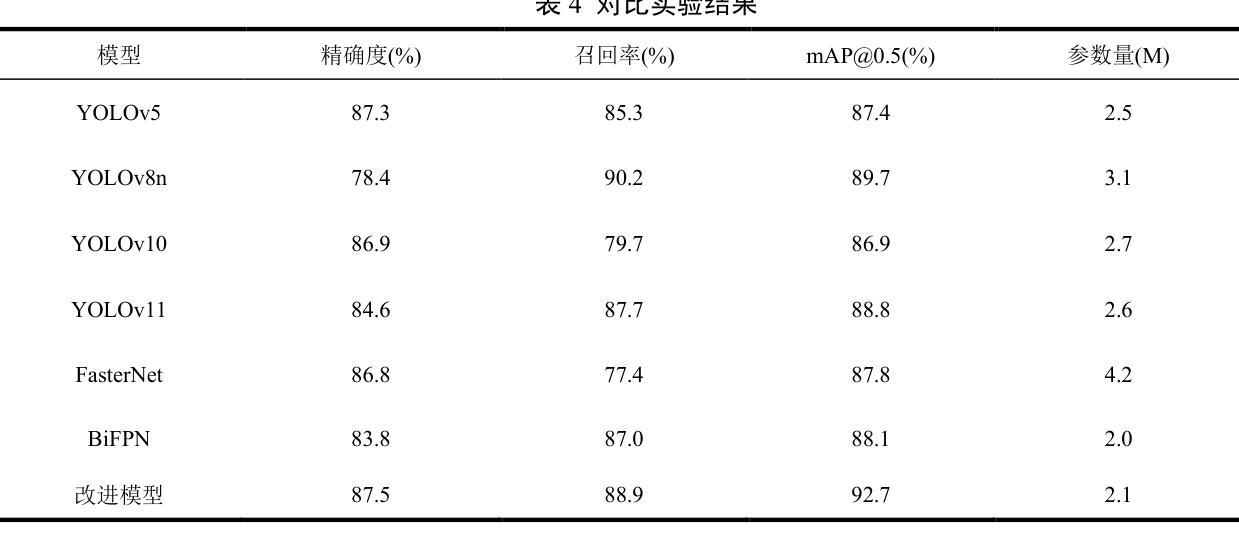
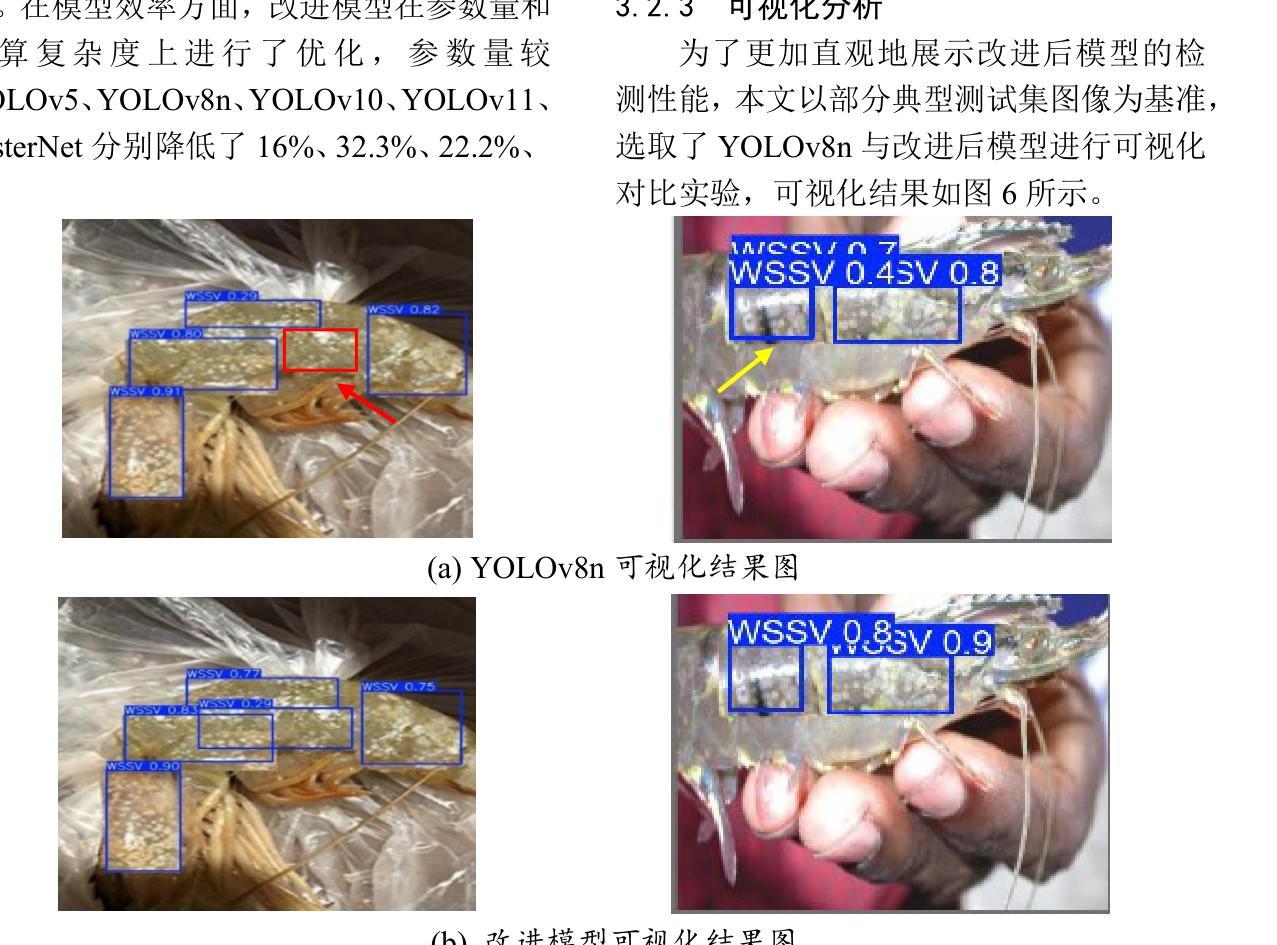
虾类疾病是导致虾类养殖业经济损失的主要原因之一。为了预防疾病传播,提高虾类养殖中的智能检测效率,本文提出了一种基于YOLOv8n的轻量化网络架构。首先,通过设计RLDD检测头和C2f-EMCM模块,该模型在保持检测精度的同时降低了计算复杂度,提高了计算效率。接着,引入改进的SegNext_Attention自注意力机制,进一步提升了模型的特征提取能力,使疾病特征识别更加精确。在自建的虾疾病数据集上进行了大量实验,包括消融研究和比较评估,并扩展了对URPC2020数据集的泛化测试。结果表明,与原始YOLOv8n相比,所提模型参数减少了32.3%,在mAP@0.5指标上达到92.7%(较YOLOv8n提高3%)。此外,该模型在mAP@0.5、参数计数和模型大小等方面均优于其他轻量级YOLO系列模型。在URPC2020数据集上的泛化实验进一步验证了模型的稳健性,较YOLOv8n在mAP@0.5上提高了4.1%。所提方法实现了精度与效率之间的最优平衡,为虾类养殖业中的智能疾病检测提供了可靠的技术支持。
论文及项目相关链接
PDF in Chinese language
Summary
基于YOLOv8n网络架构的轻量化模型被提出用于提升虾疾病检测的智能化效率。通过设计RLDD检测头和C2f-EMCM模块,该模型提高了计算效率并保持检测精度。进一步引入改进的SegNext_Attention自注意力机制,增强了模型的特征提取能力,实现了更精确的病症特征识别。实验结果显示,相较于原始YOLOv8n模型,新模型在参数上减少了32.3%,同时mAP@0.5提高了92.7%(较YOLOv8n提高了3%)。此模型在通用性实验中也展现出了良好的稳健性。此模型为虾养殖业中的智能疾病检测提供了可靠的技术支持。
Key Takeaways
- 提出基于YOLOv8n的轻量化模型以提高虾疾病检测的智能化效率。
- 通过设计RLDD检测头和C2f-EMCM模块,提高了计算效率并保持检测精度。
- 引入SegNext_Attention自注意力机制增强了模型的特征提取能力。
- 模型相较于YOLOv8n在参数上有所减少,同时保持了较高的检测准确率。
- 模型在自构建的虾疾病数据集和URPC2020数据集上均表现出良好的性能。
- 模型实现了准确性和效率之间的优化平衡。
点此查看论文截图


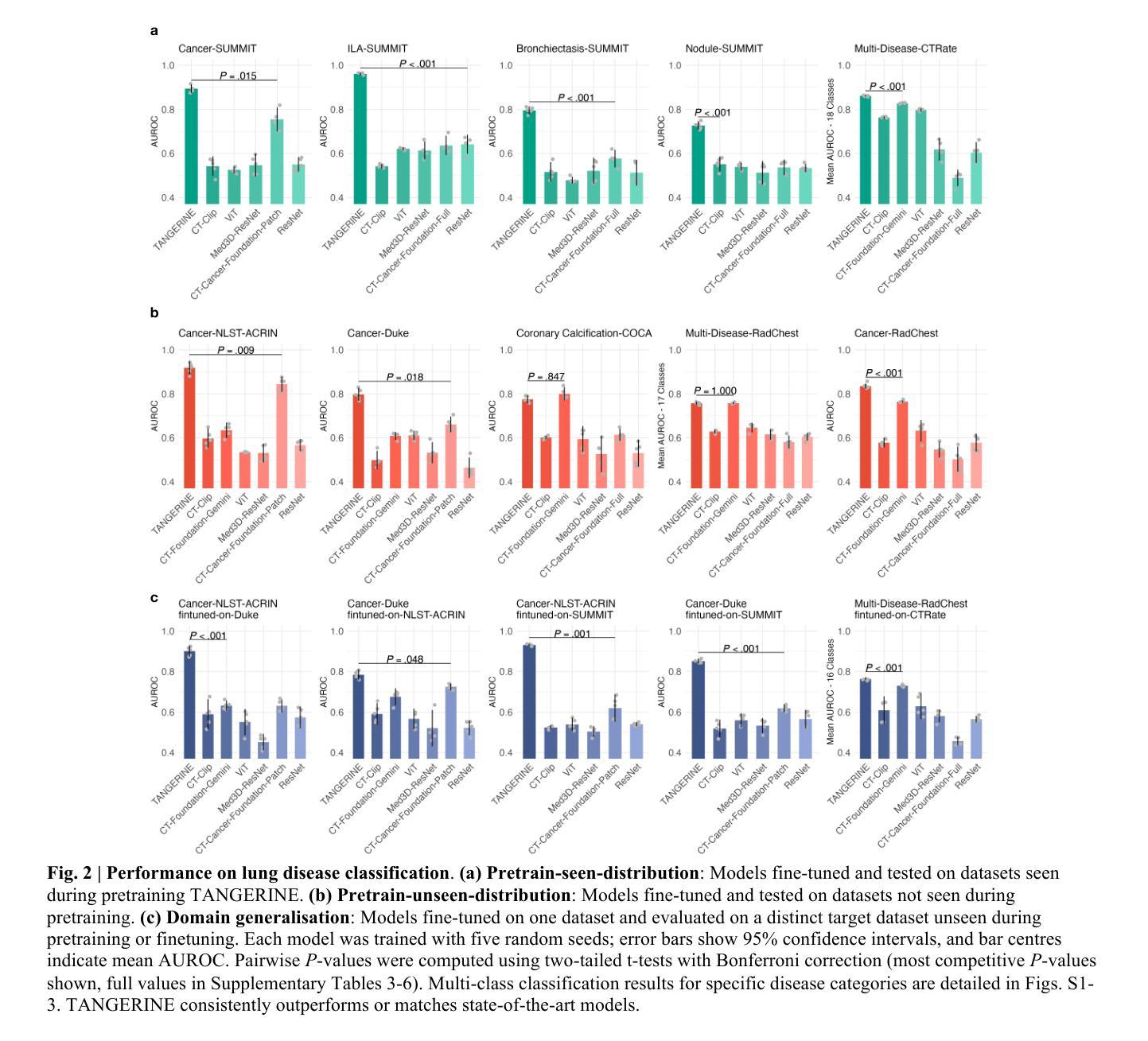
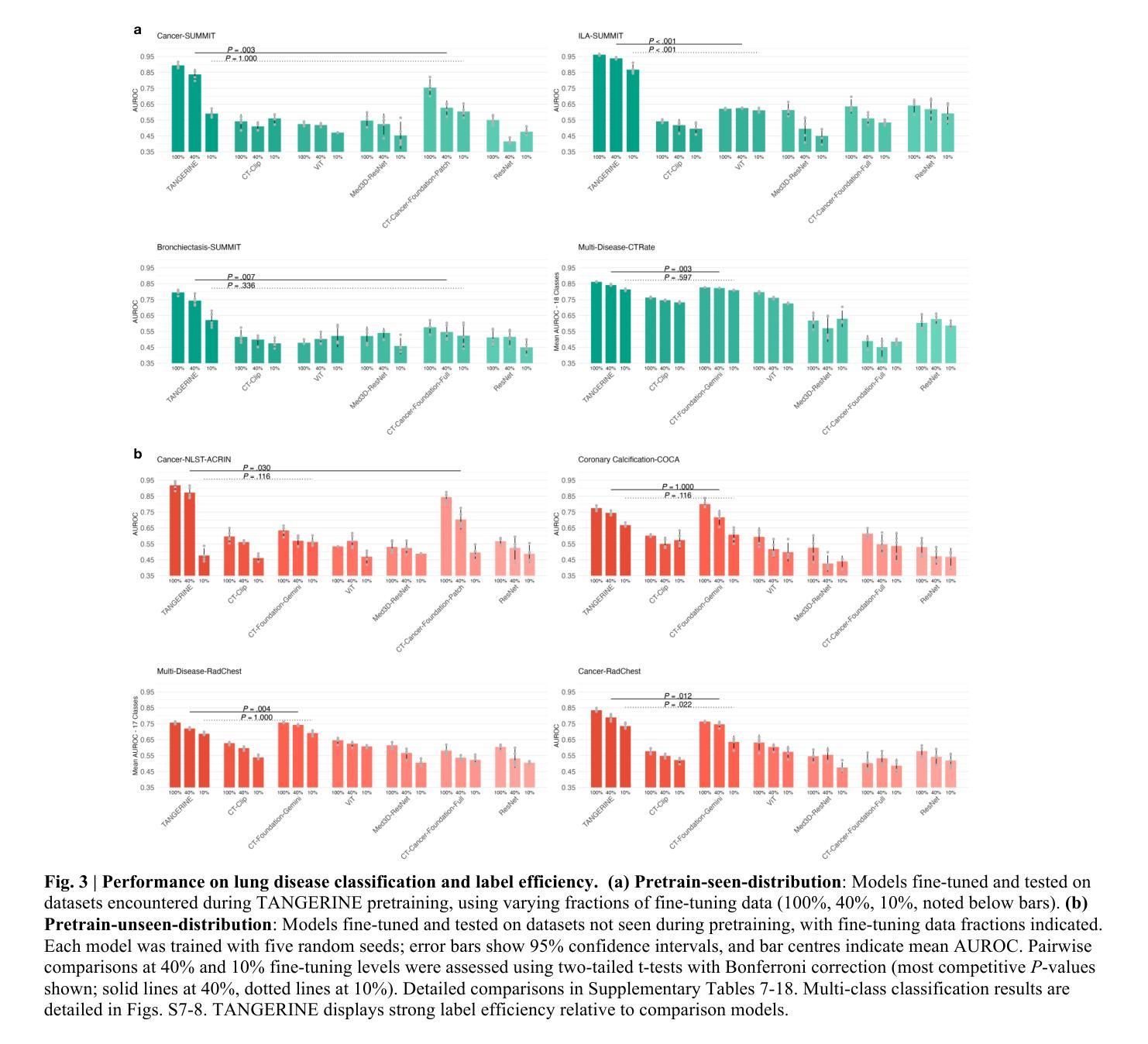
A computationally frugal open-source foundation model for thoracic disease detection in lung cancer screening programs
Authors:Niccolò McConnell, Pardeep Vasudev, Daisuke Yamada, Daryl Cheng, Mehran Azimbagirad, John McCabe, Shahab Aslani, Ahmed H. Shahin, Yukun Zhou, The SUMMIT Consortium, Andre Altmann, Yipeng Hu, Paul Taylor, Sam M. Janes, Daniel C. Alexander, Joseph Jacob
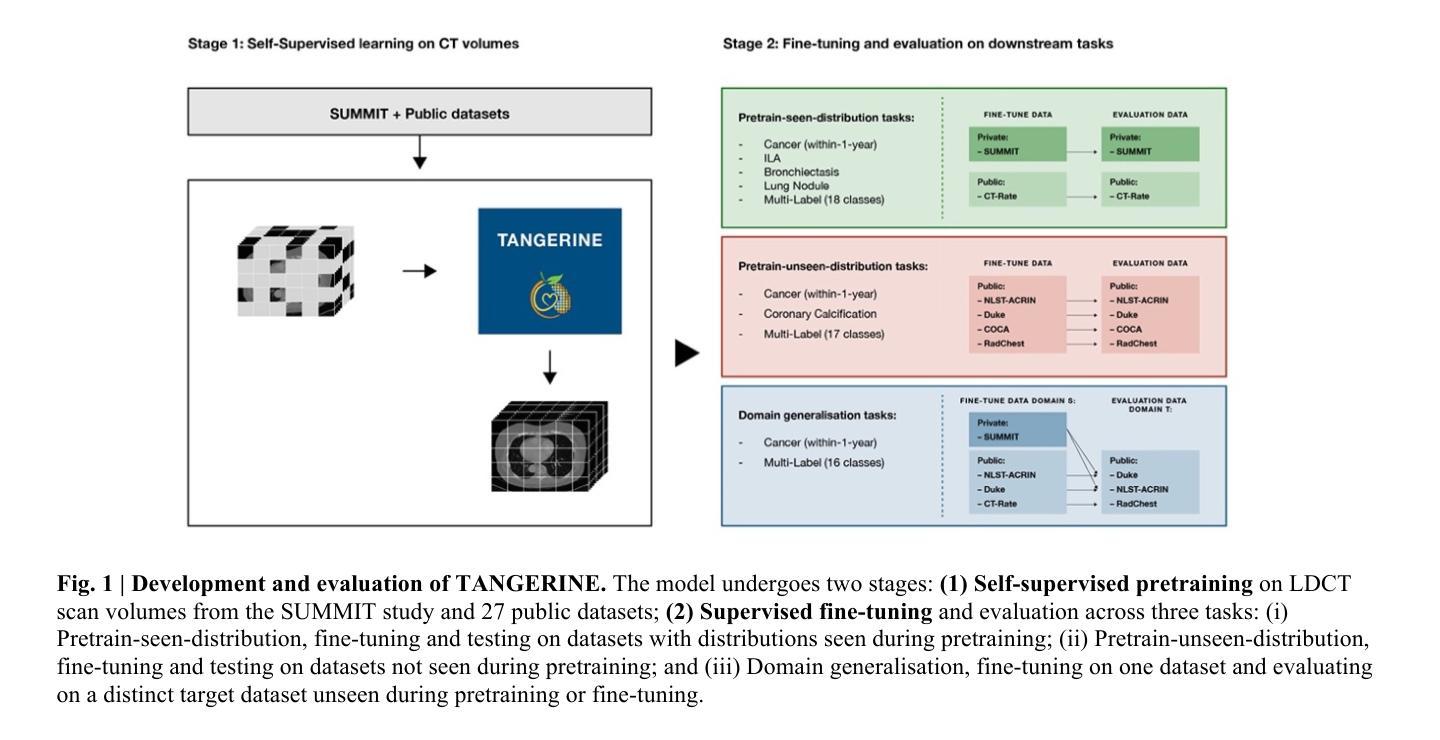
Low-dose computed tomography (LDCT) imaging employed in lung cancer screening (LCS) programs is increasing in uptake worldwide. LCS programs herald a generational opportunity to simultaneously detect cancer and non-cancer-related early-stage lung disease. Yet these efforts are hampered by a shortage of radiologists to interpret scans at scale. Here, we present TANGERINE, a computationally frugal, open-source vision foundation model for volumetric LDCT analysis. Designed for broad accessibility and rapid adaptation, TANGERINE can be fine-tuned off the shelf for a wide range of disease-specific tasks with limited computational resources and training data. Relative to models trained from scratch, TANGERINE demonstrates fast convergence during fine-tuning, thereby requiring significantly fewer GPU hours, and displays strong label efficiency, achieving comparable or superior performance with a fraction of fine-tuning data. Pretrained using self-supervised learning on over 98,000 thoracic LDCTs, including the UK’s largest LCS initiative to date and 27 public datasets, TANGERINE achieves state-of-the-art performance across 14 disease classification tasks, including lung cancer and multiple respiratory diseases, while generalising robustly across diverse clinical centres. By extending a masked autoencoder framework to 3D imaging, TANGERINE offers a scalable solution for LDCT analysis, departing from recent closed, resource-intensive models by combining architectural simplicity, public availability, and modest computational requirements. Its accessible, open-source lightweight design lays the foundation for rapid integration into next-generation medical imaging tools that could transform LCS initiatives, allowing them to pivot from a singular focus on lung cancer detection to comprehensive respiratory disease management in high-risk populations.
低剂量计算机断层扫描(LDCT)成像在肺癌筛查(LCS)计划中的应用在全球范围内不断增加。LCS计划预示着一个可以同时检测癌症和非癌症相关早期肺部疾病的机会。然而,由于缺乏大规模解读扫描结果的放射科医生,这些努力受到了阻碍。在这里,我们介绍了TANGERINE,这是一种用于体积LDCT分析的计算节约型开源视觉基础模型。TANGERINE的设计旨在实现广泛的可访问性和快速适应,可以现成微调以执行多种特定疾病任务,且计算资源和训练数据有限。相对于从头开始训练的模型,TANGERINE在微调过程中显示出快速收敛,因此需要的GPU小时数大大减少,并且表现出强大的标签效率,使用少量的微调数据即可实现相当或更好的性能。TANGERINE使用自我监督学习在超过98000个胸部LDCT上进行预训练,包括迄今为止英国最大的LCS倡议和27个公共数据集,在14个疾病分类任务上达到了最新技术性能,包括肺癌和多种呼吸道疾病,同时在多种临床中心实现了稳健的推广。通过将掩码自动编码器框架扩展到3D成像,TANGERINE为LDCT分析提供了可规模化的解决方案,它通过结合结构简洁、公众可访问和适度的计算要求,不同于最近封闭的、资源密集型的模型。其可访问的开源轻便设计奠定了迅速融入下一代医学影像工具的基础,有可能改变LCS计划,使它们从单一关注肺癌检测转向高风险人群的综合呼吸道疾病管理。
论文及项目相关链接
Summary
TANGERINE是一种用于低剂量计算机断层扫描(LDCT)分析的计算轻量型开源视觉基础模型。该模型可在广泛的疾病特定任务中进行微调,无需大量计算资源和训练数据。相较于从头开始训练的模型,TANGERINE在微调时能够快速收敛,显著减少GPU小时数,并显示出强大的标签效率,用少量的微调数据即可实现相当或更优的性能。该模型在14个疾病分类任务上达到最新技术水平,包括肺癌和多种呼吸系统疾病,并在不同的临床中心实现稳健的通用化。通过扩展3D成像的掩码自动编码器框架,TANGERINE为LDCT分析提供了可规模化的解决方案,其开放、轻量级的设计可为下一代医学影像工具提供快速集成的基础,从而推动肺癌筛查计划从单一的肺癌检测转向高风险人群的全面呼吸疾病管理。
**Key Takeaways**
1. TANGERINE是一个用于低剂量计算机断层扫描(LDCT)分析的开源视觉基础模型。
2. TANGERINE可在广泛的疾病特定任务中进行微调,且计算资源需求较小。
3. 相较于从头开始训练的模型,TANGERINE在微调时能够快速收敛,并显示出强大的标签效率。
4. TANGERINE在多个疾病分类任务上达到最新技术水平。
5. TANGERINE在多种临床环境中实现稳健的通用化性能。
6. TANGERINE通过扩展掩码自动编码器框架至3D成像,为LDCT分析提供了可规模化的解决方案。
点此查看论文截图

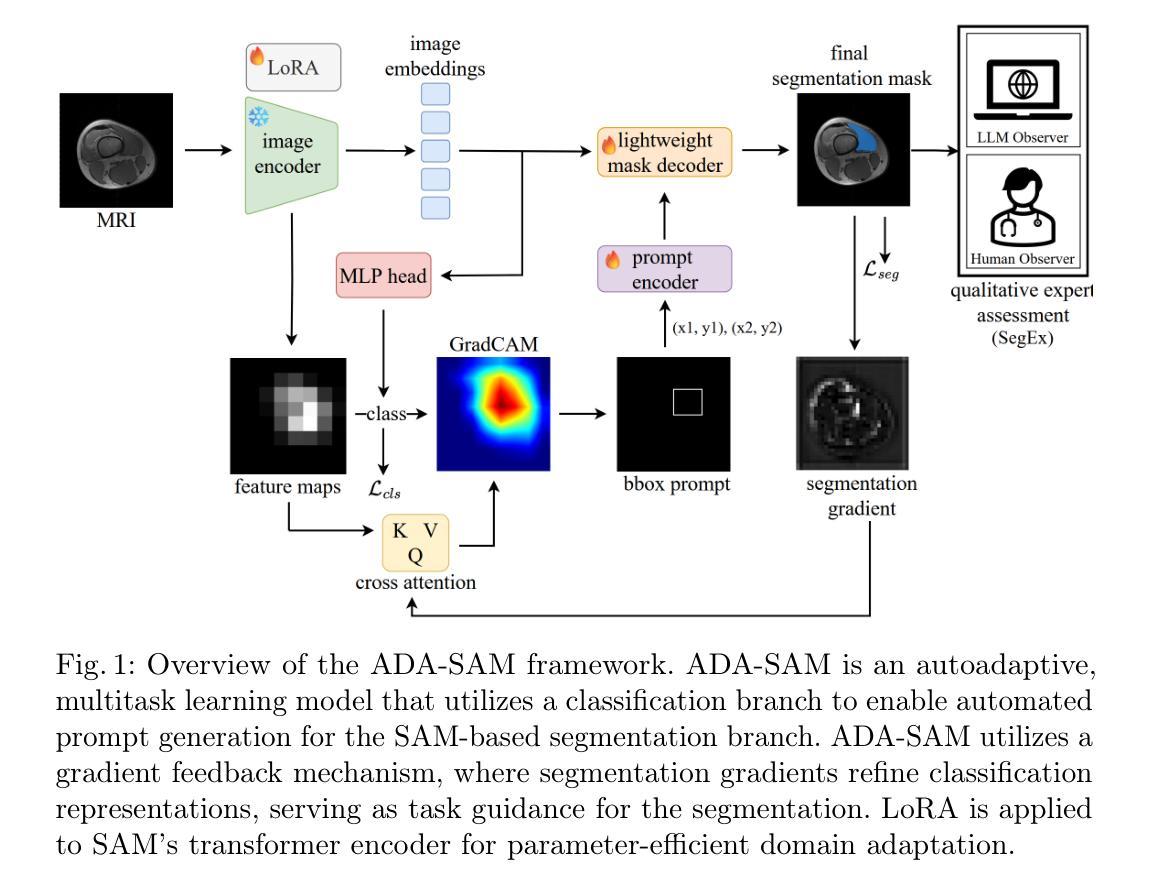
Autoadaptive Medical Segment Anything Model
Authors:Tyler Ward, Meredith K. Owen, O’Kira Coleman, Brian Noehren, Abdullah-Al-Zubaer Imran
Medical image segmentation is a key task in the imaging workflow, influencing many image-based decisions. Traditional, fully-supervised segmentation models rely on large amounts of labeled training data, typically obtained through manual annotation, which can be an expensive, time-consuming, and error-prone process. This signals a need for accurate, automatic, and annotation-efficient methods of training these models. We propose ADA-SAM (automated, domain-specific, and adaptive segment anything model), a novel multitask learning framework for medical image segmentation that leverages class activation maps from an auxiliary classifier to guide the predictions of the semi-supervised segmentation branch, which is based on the Segment Anything (SAM) framework. Additionally, our ADA-SAM model employs a novel gradient feedback mechanism to create a learnable connection between the segmentation and classification branches by using the segmentation gradients to guide and improve the classification predictions. We validate ADA-SAM on real-world clinical data collected during rehabilitation trials, and demonstrate that our proposed method outperforms both fully-supervised and semi-supervised baselines by double digits in limited label settings. Our code is available at: https://github.com/tbwa233/ADA-SAM.
医学图像分割是成像工作流程中的关键任务,影响着许多基于图像的决策。传统的完全监督分割模型依赖于大量的标记训练数据,通常通过手动标注获得,这是一个昂贵、耗时且易出错的过程。这凸显了对准确、自动和标注效率高的训练这些模型的方法的需求。我们提出了ADA-SAM(自动、特定领域和自适应分割任何事物模型),这是一种新的医学图像分割多任务学习框架,它利用辅助分类器的类激活图来指导半监督分割分支的预测,该框架基于分割任何事物(SAM)框架。此外,我们的ADA-SAM模型采用了一种新型梯度反馈机制,通过分割梯度来引导和改进分类预测,在分割和分类分支之间建立可学习的连接。我们在康复试验期间收集的真实世界临床数据上验证了ADA-SAM,结果表明,在有限标签条件下,我们提出的方法在完全监督和半监督基准测试方面都表现出两位数的优势。我们的代码可在:https://github.com/tbwa233/ADA-SAM上找到。
论文及项目相关链接
PDF 11 pages, 2 figures, 3 tables
Summary
医学图像分割是成像工作流程中的关键任务,影响许多基于图像的决定。传统全监督分割模型依赖于大量手动标注的训练数据,这一过程既昂贵又耗时,且容易出错。因此,需要准确、自动、标注效率高的模型训练方法。我们提出ADA-SAM(自动、特定领域、自适应分割任何模型),这是一种基于医学图像分割的多任务学习新框架,利用辅助分类器的类激活图来指导半监督分割分支的预测,基于Segment Anything(SAM)框架。此外,我们的ADA-SAM模型采用新型梯度反馈机制,通过分割梯度来指导和改进分类预测,在分割和分类分支之间建立可学习的联系。我们在康复试验期间收集的真实世界临床数据上验证了ADA-SAM,证明在有限标签设置下,我们的方法在全监督和半监督基准测试上的表现均超出两位数。
Key Takeaways
- 医学图像分割在成像工作流程中至关重要,影响基于图像的决策。
- 传统全监督分割模型依赖大量手动标注的训练数据,这一过程既繁琐又耗时。
- 需要更准确、自动、标注效率高的模型训练方法。
- 提出了ADA-SAM模型,这是一种基于医学图像分割的多任务学习新框架。
5.ADA-SAM利用类激活图和梯度反馈机制来指导预测并连接分割和分类分支。 - 在真实世界临床数据上验证了ADA-SAM模型的性能。
点此查看论文截图

Are Vision Transformer Representations Semantically Meaningful? A Case Study in Medical Imaging
Authors:Montasir Shams, Chashi Mahiul Islam, Shaeke Salman, Phat Tran, Xiuwen Liu
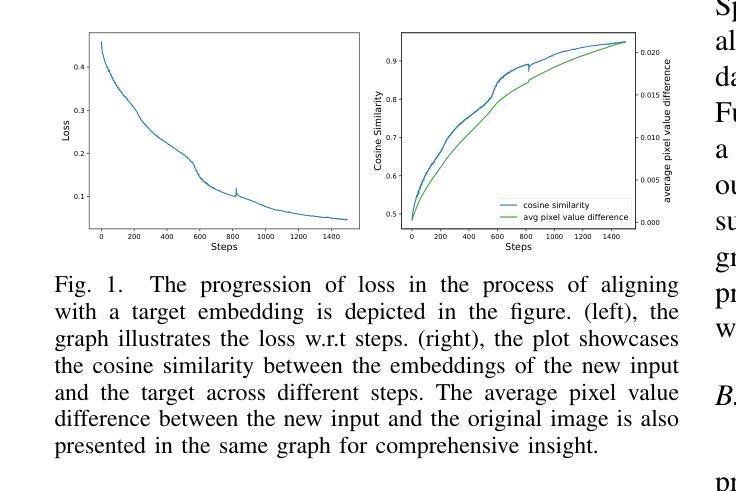
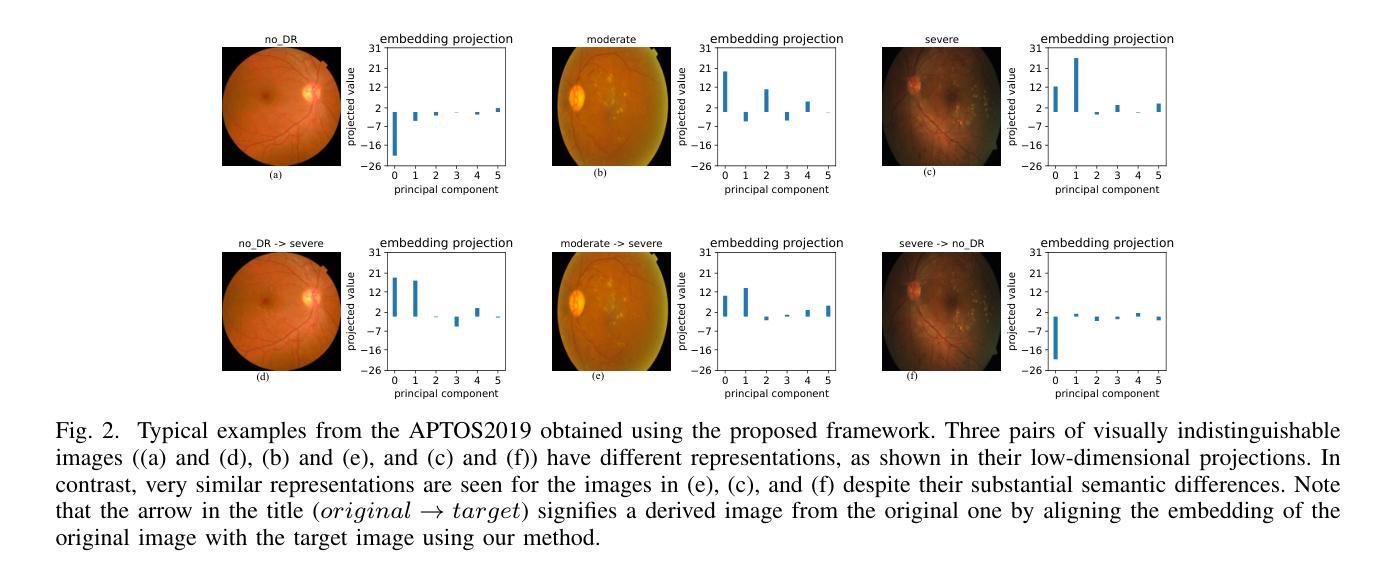
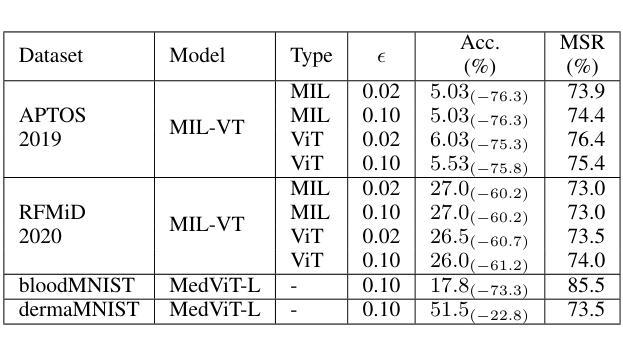
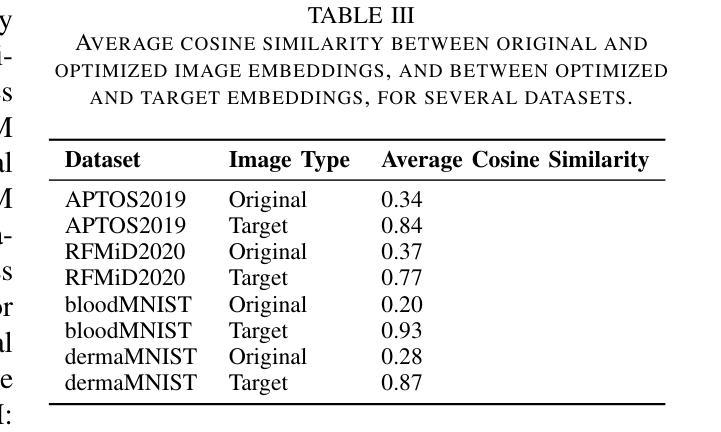
Vision transformers (ViTs) have rapidly gained prominence in medical imaging tasks such as disease classification, segmentation, and detection due to their superior accuracy compared to conventional deep learning models. However, due to their size and complex interactions via the self-attention mechanism, they are not well understood. In particular, it is unclear whether the representations produced by such models are semantically meaningful. In this paper, using a projected gradient-based algorithm, we show that their representations are not semantically meaningful and they are inherently vulnerable to small changes. Images with imperceptible differences can have very different representations; on the other hand, images that should belong to different semantic classes can have nearly identical representations. Such vulnerability can lead to unreliable classification results; for example, unnoticeable changes cause the classification accuracy to be reduced by over 60%. %. To the best of our knowledge, this is the first work to systematically demonstrate this fundamental lack of semantic meaningfulness in ViT representations for medical image classification, revealing a critical challenge for their deployment in safety-critical systems.
视觉转换器(ViTs)因其相对于传统深度学习模型的卓越准确性,在医学成像任务(如疾病分类、分割和检测)中迅速崭露头角。然而,由于其规模和通过自注意力机制产生的复杂交互,人们对其理解并不充分。尤其不清楚的是,此类模型产生的表示是否具有语义意义。在本文中,我们使用基于投影的梯度算法证明,它们的表示不具有语义意义,并且本质上易于受到微小变化的影响。具有几乎无法察觉差异的图像可以具有截然不同的表示形式;相反,本应属于不同语义类的图像却可能有几乎相同的表示形式。这种脆弱性可能导致分类结果不可靠;例如,几乎无法察觉的变化导致分类精度降低了超过60%。据我们所知,这是第一项系统证明ViT在医学图像分类中的表示缺乏基本语义意义的工作,这揭示了将其部署在安全关键系统中面临的关键挑战。
论文及项目相关链接
PDF 9 pages
Summary
ViT模型在医学图像分类、分割和检测等任务中展现出卓越准确性,但其复杂的结构和自注意力机制导致对这类模型的理解仍不够深入。本文利用梯度投影算法证明ViT模型生成的表征不具有语义意义,容易受微小变化影响。具有细微差异的图片在模型中可能有截然不同的表征,而本应属于不同语义类别的图片则可能有几乎相同的表征。这种现象可能导致分类结果不可靠,微小变化可能导致分类准确率下降超过60%。这是首次系统性地展示ViT模型在医学图像分类中缺乏语义意义的关键挑战,为部署在安全关键系统中的风险提供了重要揭示。
Key Takeaways
- Vision transformers (ViTs) 已广泛应用于医学成像任务,因其准确率优于传统深度学习模型。
- ViT模型的复杂性导致其语义理解不足。
- 使用梯度投影算法发现ViT模型生成的表征缺乏语义意义。
- ViT模型对微小变化敏感,可能导致不稳定的分类结果。
- 细微差异的图片在模型中可能有截然不同的表征。
- 本应属于不同语义类别的图片在ViT模型中可能有相似表征。
点此查看论文截图


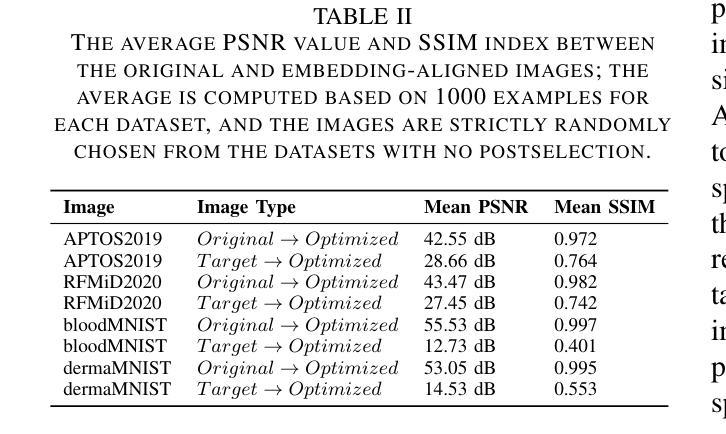
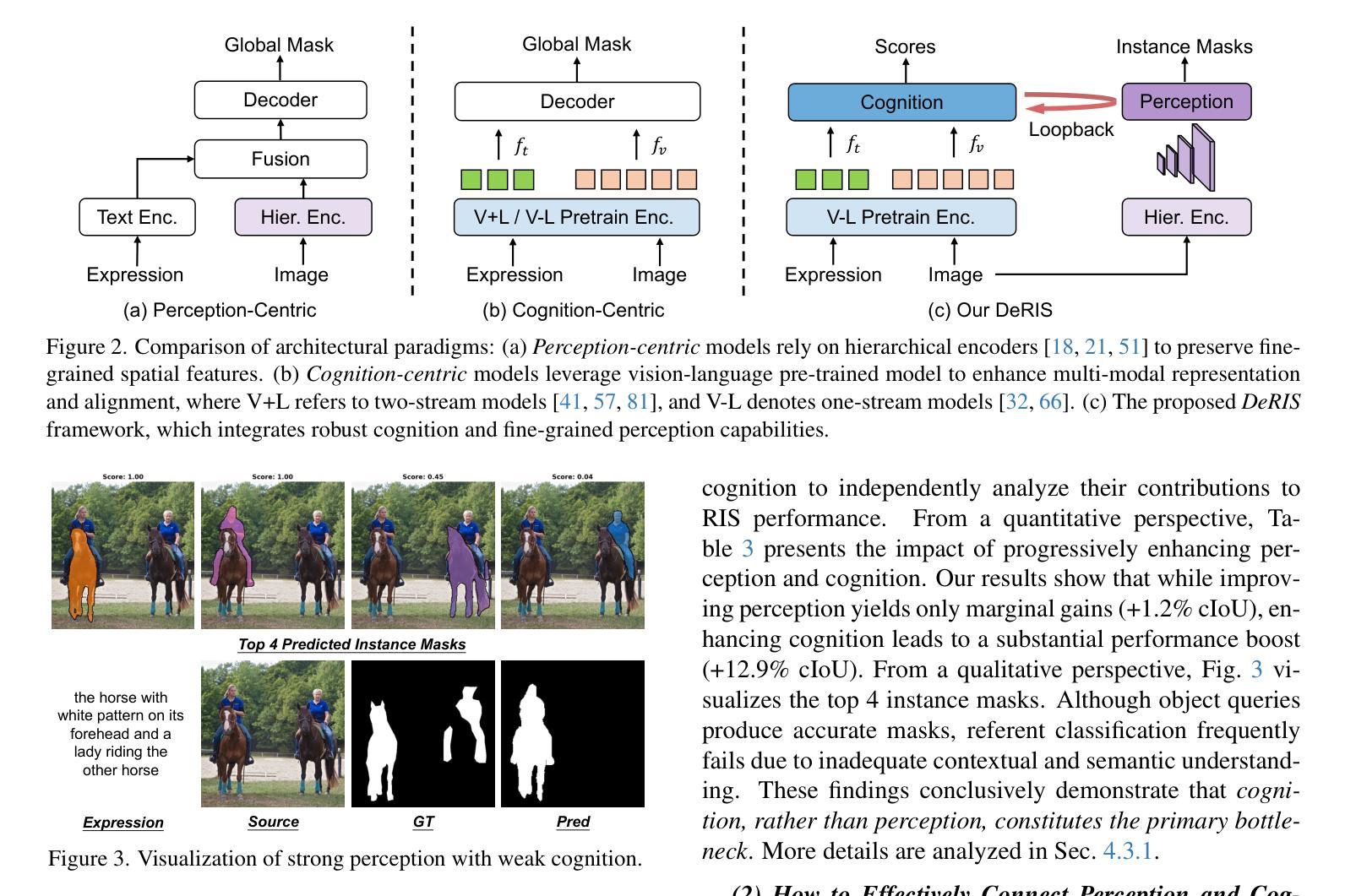
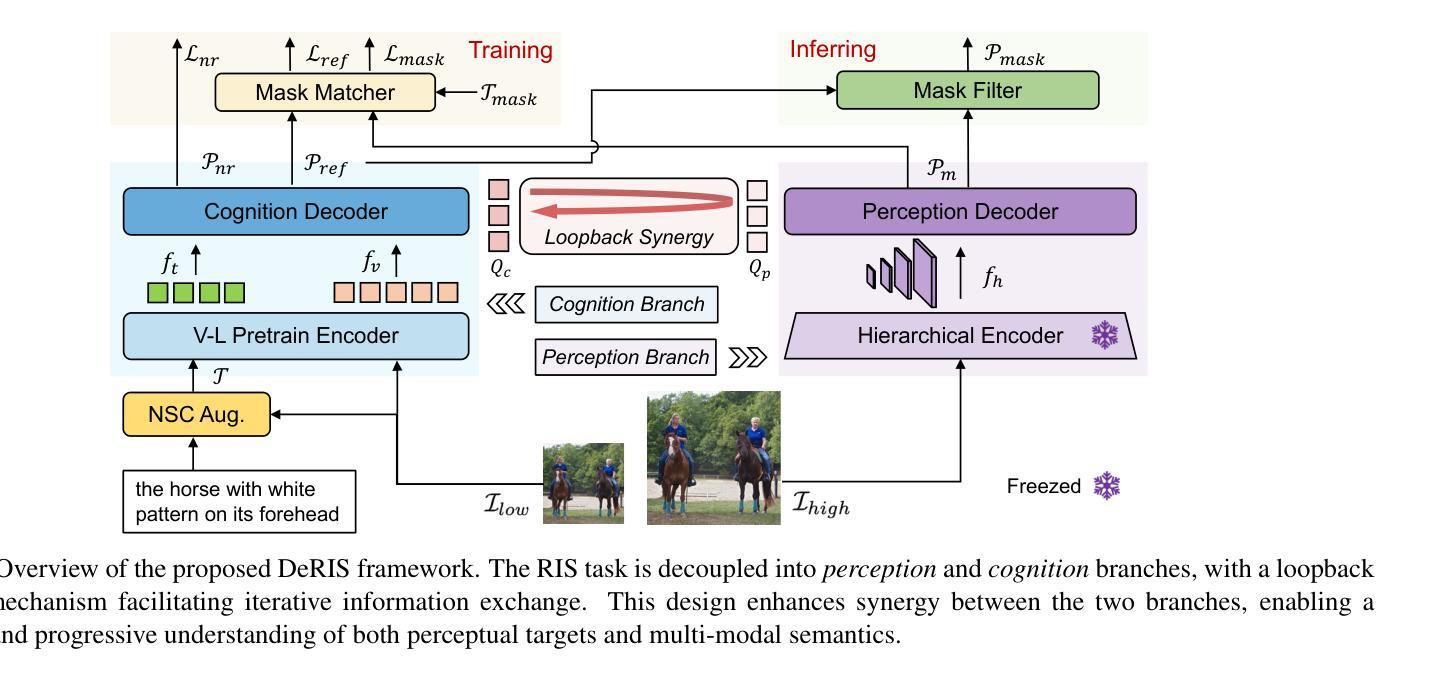
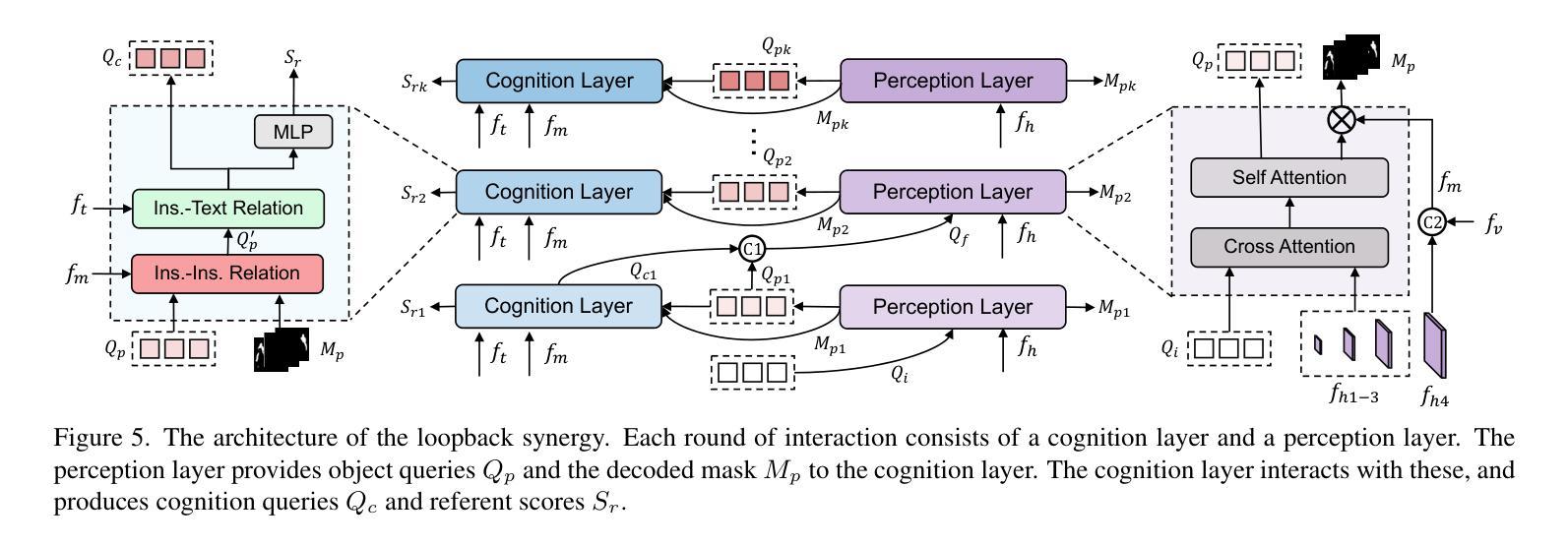
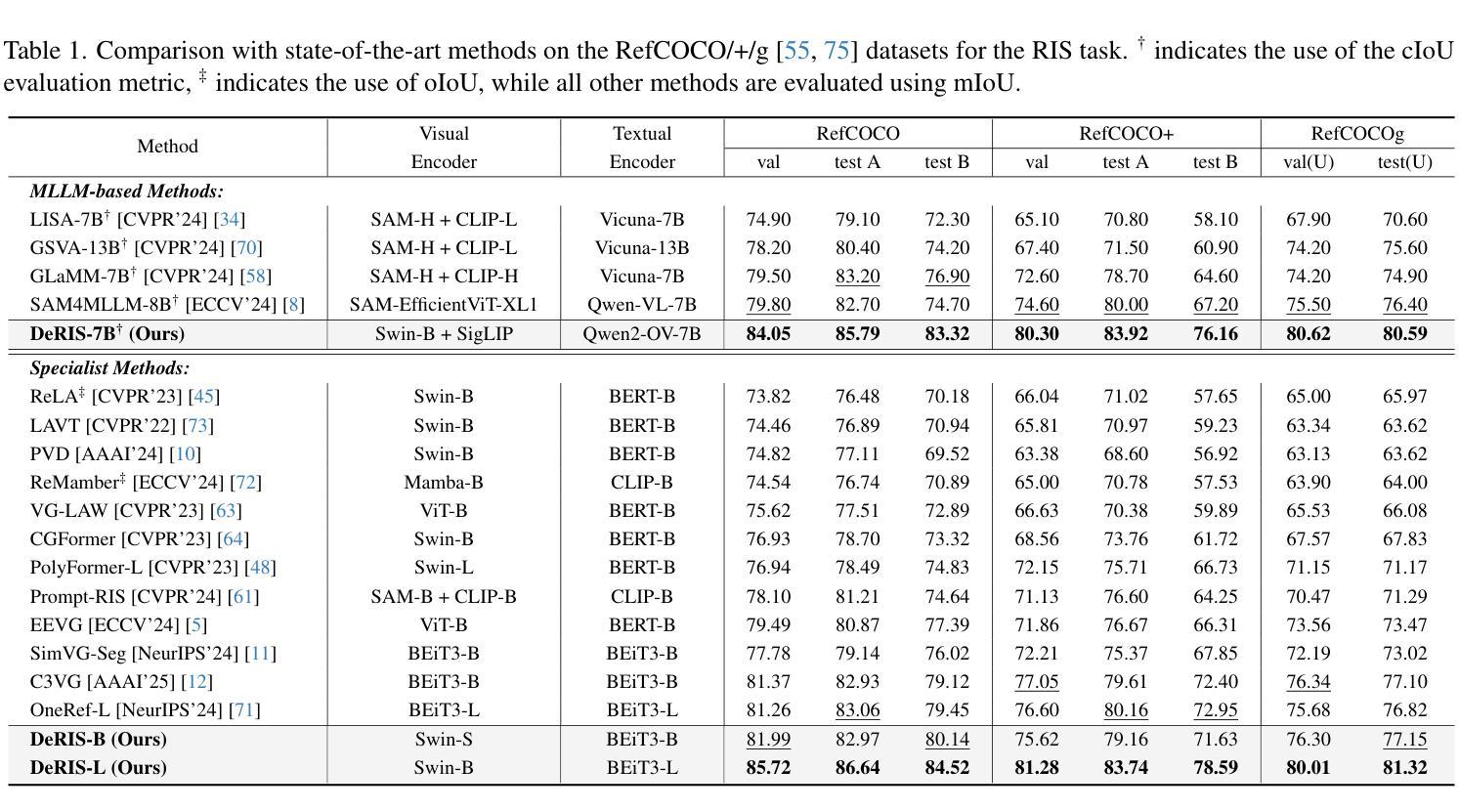
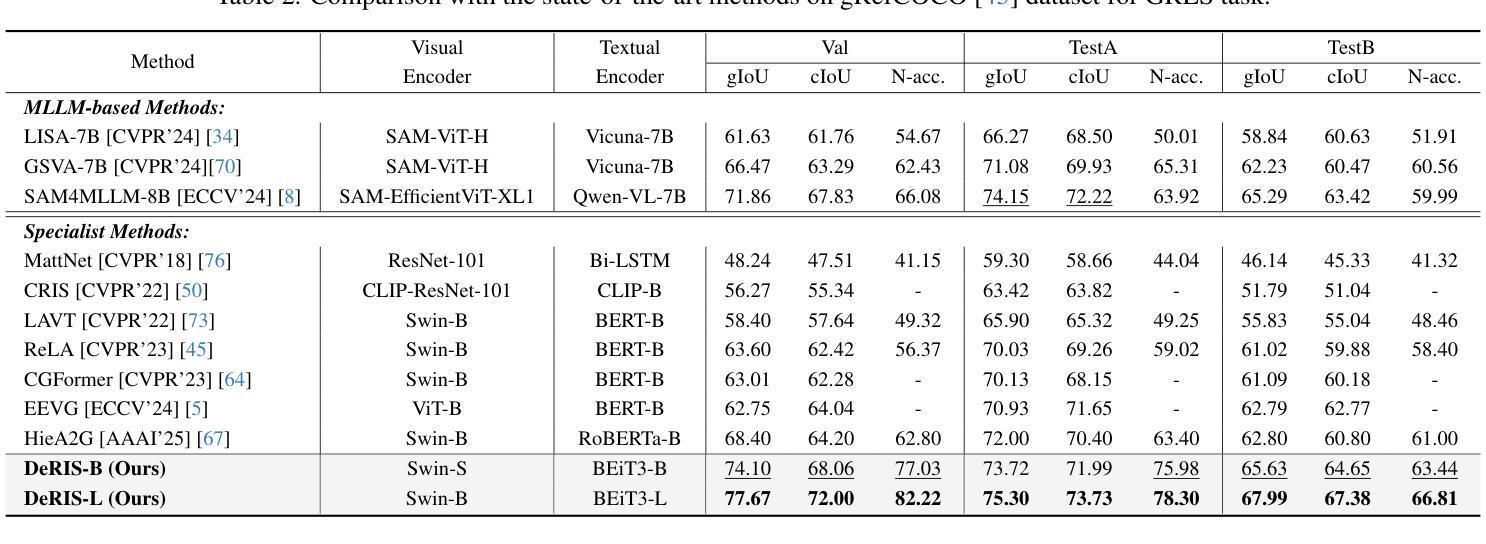
DeRIS: Decoupling Perception and Cognition for Enhanced Referring Image Segmentation through Loopback Synergy
Authors:Ming Dai, Wenxuan Cheng, Jiang-jiang Liu, Sen Yang, Wenxiao Cai, Yanpeng Sun, Wankou Yang
Referring Image Segmentation (RIS) is a challenging task that aims to segment objects in an image based on natural language expressions. While prior studies have predominantly concentrated on improving vision-language interactions and achieving fine-grained localization, a systematic analysis of the fundamental bottlenecks in existing RIS frameworks remains underexplored. To bridge this gap, we propose DeRIS, a novel framework that decomposes RIS into two key components: perception and cognition. This modular decomposition facilitates a systematic analysis of the primary bottlenecks impeding RIS performance. Our findings reveal that the predominant limitation lies not in perceptual deficiencies, but in the insufficient multi-modal cognitive capacity of current models. To mitigate this, we propose a Loopback Synergy mechanism, which enhances the synergy between the perception and cognition modules, thereby enabling precise segmentation while simultaneously improving robust image-text comprehension. Additionally, we analyze and introduce a simple non-referent sample conversion data augmentation to address the long-tail distribution issue related to target existence judgement in general scenarios. Notably, DeRIS demonstrates inherent adaptability to both non- and multi-referents scenarios without requiring specialized architectural modifications, enhancing its general applicability. The codes and models are available at https://github.com/Dmmm1997/DeRIS.
图像引用分割(RIS)是一项具有挑战性的任务,旨在根据自然语言表达式对图像中的对象进行分割。尽管先前的研究主要集中在改进视觉与语言的交互作用和实现精细定位上,但对现有RIS框架中基本瓶颈的系统性分析仍然被忽视。为了弥补这一差距,我们提出了DeRIS这一新型框架,它将RIS分解为两个关键组成部分:感知和认知。这种模块化分解有助于系统地分析阻碍RIS性能的主要瓶颈。我们的研究发现,主要局限不在于感知缺陷,而在于当前模型的多模式认知能力不足。为了缓解这一问题,我们提出了Loopback协同机制,它增强了感知和认知模块之间的协同作用,从而实现了精确分割,同时提高了图像文本理解的稳健性。此外,我们分析和引入了一种简单的非参照样本转换数据增强方法,以解决一般场景中与目标存在判断相关的长尾分布问题。值得注意的是,DeRIS对非参照和多参照场景具有固有的适应性,无需进行专门的架构修改,提高了其通用性。相关代码和模型可在https://github.com/Dmmm1997/DeRIS获取。
论文及项目相关链接
PDF ICCV 2025
Summary
本文提出一种名为DeRIS的新型框架,用于解决图像参照分割(RIS)任务中的瓶颈问题。该框架将RIS分解为感知和认知两个关键组件,并发现主要限制不在于感知缺陷,而在于当前模型的多模态认知能力不足。为解决这一问题,DeRIS提出了Loopback Synergy机制,增强了感知和认知模块之间的协同作用,实现了精确分割,并提高了图像文本理解。此外,它还引入了一种简单的非参照样本转换数据增强方法,以解决一般场景中目标存在判断的长尾分布问题。DeRIS具有适应非参照和多参照场景的能力,增强了其通用性。
Key Takeaways
- DeRIS框架旨在解决图像参照分割(RIS)任务中的瓶颈问题。
- 该框架将RIS分解为感知和认知两个组件进行系统分析。
- 研究发现,主要限制在于当前模型的多模态认知能力不足。
- 提出Loopback Synergy机制,增强感知和认知模块的协同作用。
- DeRIS能实现精确分割,并提高图像文本理解。
- 引入非参照样本转换数据增强方法,解决目标存在判断的长尾分布问题。
点此查看论文截图

Learning from Random Subspace Exploration: Generalized Test-Time Augmentation with Self-supervised Distillation
Authors:Andrei Jelea, Ahmed Nabil Belbachir, Marius Leordeanu
We introduce Generalized Test-Time Augmentation (GTTA), a highly effective method for improving the performance of a trained model, which unlike other existing Test-Time Augmentation approaches from the literature is general enough to be used off-the-shelf for many vision and non-vision tasks, such as classification, regression, image segmentation and object detection. By applying a new general data transformation, that randomly perturbs multiple times the PCA subspace projection of a test input, GTTA forms robust ensembles at test time in which, due to sound statistical properties, the structural and systematic noises in the initial input data is filtered out and final estimator errors are reduced. Different from other existing methods, we also propose a final self-supervised learning stage in which the ensemble output, acting as an unsupervised teacher, is used to train the initial single student model, thus reducing significantly the test time computational cost, at no loss in accuracy. Our tests and comparisons to strong TTA approaches and SoTA models on various vision and non-vision well-known datasets and tasks, such as image classification and segmentation, speech recognition and house price prediction, validate the generality of the proposed GTTA. Furthermore, we also prove its effectiveness on the more specific real-world task of salmon segmentation and detection in low-visibility underwater videos, for which we introduce DeepSalmon, the largest dataset of its kind in the literature.
我们引入了广义测试时间增强(GTTA)这一高度有效的方法,用于提升已训练模型的表现。与传统的测试时间增强方法不同,GTTA具有足够的通用性,可广泛应用于许多视觉和非视觉任务,例如分类、回归、图像分割和对象检测。通过应用新的通用数据转换,多次随机扰动测试输入的PCA子空间投影,GTTA在测试时形成稳健的集合。由于具有良好的统计特性,初始输入数据中的结构和系统噪声被过滤掉,最终估计器误差得以降低。与其他现有方法不同,我们还提出了一个最终的自我监督学习阶段,其中集合输出作为无监督教师,用于训练初始单一的学生模型,从而在不影响精度的情况下,显著降低了测试时间的计算成本。我们在各种视觉和非视觉的知名数据集和任务上进行了测试,并与强大的TTA方法和最新模型进行了比较,如图像分类和分割、语音识别和房屋价格预测等,验证了所提GTTA的通用性。此外,在更具挑战性的实际任务——低可见度水下视频的鲑鱼分割和检测中,我们也证明了其有效性。为此,我们引入了DeepSalmon,这是文献中同类最大的数据集。
论文及项目相关链接
Summary
本文提出了广义测试时增强(GTTA)方法,该方法能有效提升训练模型性能。与其他测试时增强方法不同,GTTA具有通用性,可广泛应用于视觉和非视觉任务,如分类、回归、图像分割和对象检测。通过新的通用数据转换,GTTA在测试时形成稳健集合,过滤掉初始输入数据的结构和系统噪声,降低最终估计器误差。此外,GTTA还采用自我监督学习阶段,利用集合输出作为无监督教师,对初始单一学生模型进行训练,显著降低测试时间计算成本,同时不损失准确性。在多个视觉和非视觉数据集上的实验验证了GTTA的通用性和有效性。
Key Takeaways
- 引入广义测试时增强(GTTA)方法,适用于多种任务,如分类、回归、图像分割和对象检测。
- 通过新的数据转换技术,随机扰动测试输入数据的PCA子空间投影,形成稳健集合。
- 集合中的稳健性通过过滤初始输入数据的结构和系统噪声,降低最终估计器误差。
- 提出自我监督学习阶段,利用集合输出作为无监督教师,对初始模型进行再训练,降低测试时间成本。
- 实验证明GTTA在多个视觉和非视觉数据集上的有效性和通用性。
- 引入DeepSalmon数据集,为水下视频中的三文鱼分割和检测任务提供大规模数据集。
点此查看论文截图

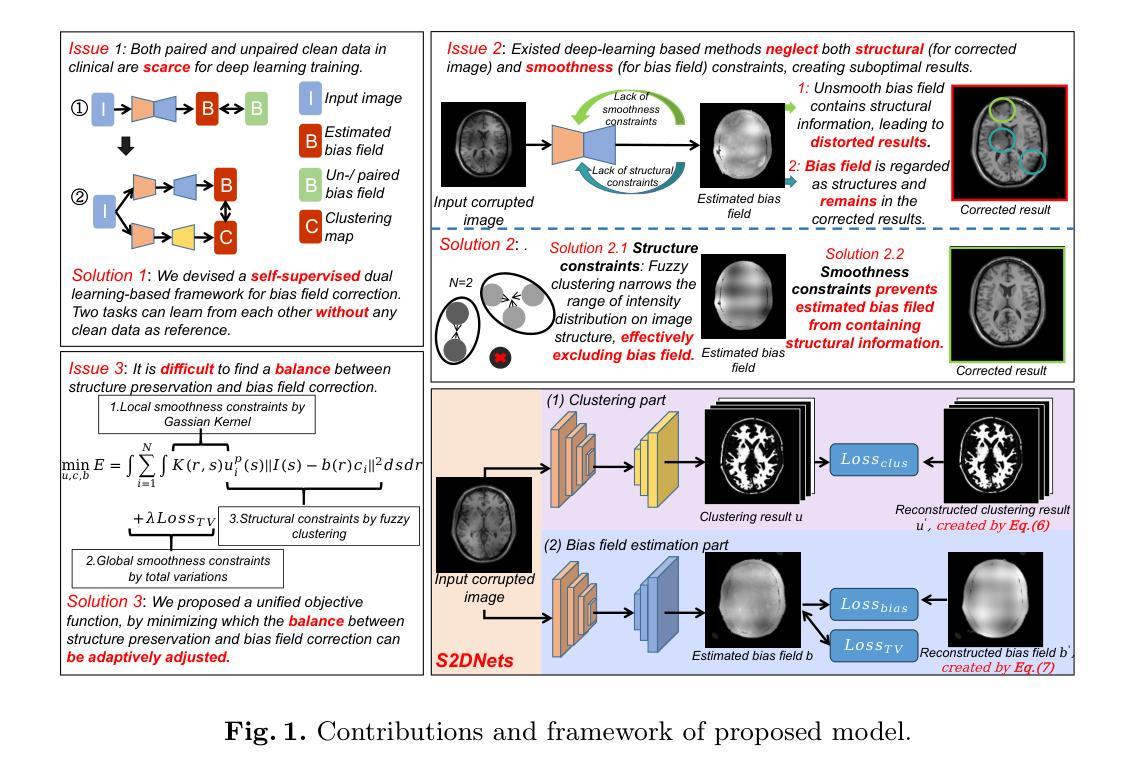
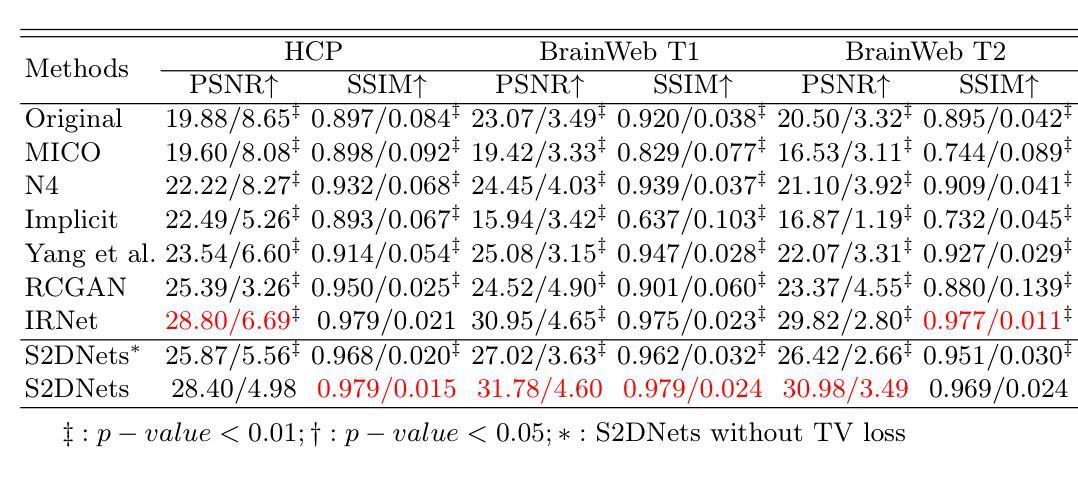
Structure and Smoothness Constrained Dual Networks for MR Bias Field Correction
Authors:Dong Liang, Xingyu Qiu, Yuzhen Li, Wei Wang, Kuanquan Wang, Suyu Dong, Gongning Luo
MR imaging techniques are of great benefit to disease diagnosis. However, due to the limitation of MR devices, significant intensity inhomogeneity often exists in imaging results, which impedes both qualitative and quantitative medical analysis. Recently, several unsupervised deep learning-based models have been proposed for MR image improvement. However, these models merely concentrate on global appearance learning, and neglect constraints from image structures and smoothness of bias field, leading to distorted corrected results. In this paper, novel structure and smoothness constrained dual networks, named S2DNets, are proposed aiming to self-supervised bias field correction. S2DNets introduce piece-wise structural constraints and smoothness of bias field for network training to effectively remove non-uniform intensity and retain much more structural details. Extensive experiments executed on both clinical and simulated MR datasets show that the proposed model outperforms other conventional and deep learning-based models. In addition to comparison on visual metrics, downstream MR image segmentation tasks are also used to evaluate the impact of the proposed model. The source code is available at: https://github.com/LeongDong/S2DNets}{https://github.com/LeongDong/S2DNets.
磁共振成像技术对于疾病诊断具有极大的益处。然而,由于磁共振设备的限制,成像结果中常常存在显著的强度不均匀性,这阻碍了定性和定量医学分析。最近,提出了几种基于深度学习的无监督模型来改善磁共振图像。然而,这些模型仅关注全局外观学习,忽视了图像结构和偏置场的平滑性约束,导致校正结果失真。本文提出了新型结构和平滑度约束双网络,名为S2DNets,旨在进行自监督偏置场校正。S2DNets引入分段结构约束和偏置场的平滑度用于网络训练,以有效地去除非均匀强度并保留更多的结构细节。在临床和模拟磁共振数据集上进行的广泛实验表明,所提出的模型优于其他传统和基于深度学习的模型。除了视觉指标的对比,还使用下游磁共振图像分割任务来评估所提出模型的影响。源代码可在以下网址找到:https://github.com/LeongDong/S2DNets 。
论文及项目相关链接
PDF 11 pages, 3 figures, accepted by MICCAI
Summary
MR影像技术对疾病诊断有重要意义,但设备限制导致的影像结果强度不均匀性影响了定性和定量分析。现有深度学习模型主要关注全局外观学习,忽略了图像结构和偏置场的平滑性约束,导致校正结果失真。本文提出新型结构和平滑约束双网络(S2DNets),旨在实现自我监督偏置场校正。S2DNets引入分段结构约束和偏置场平滑性,有效消除非均匀强度,保留更多结构细节。实验证明,该模型在临床医学和模拟MR数据集上优于传统和深度学习模型。除视觉指标对比外,还通过下游MR图像分割任务评估模型影响。
Key Takeaways
- MR影像技术对疾病诊断有重要作用,但设备限制导致的影像结果强度不均匀性是医学分析的一个挑战。
- 现有深度学习模型在MR图像改进方面主要关注全局外观学习,忽略了图像结构和偏置场的平滑性约束。
- S2DNets模型旨在通过自我监督实现偏置场校正,引入分段结构约束和偏置场平滑性。
- S2DNets模型能有效消除影像结果中的非均匀强度,同时保留更多结构细节。
- 临床试验和模拟数据集的广泛实验表明,S2DNets模型在性能上优于传统和深度学习模型。
- 除了通过视觉指标对比模型性能外,还通过下游MR图像分割任务来评估模型的实际影响。
点此查看论文截图

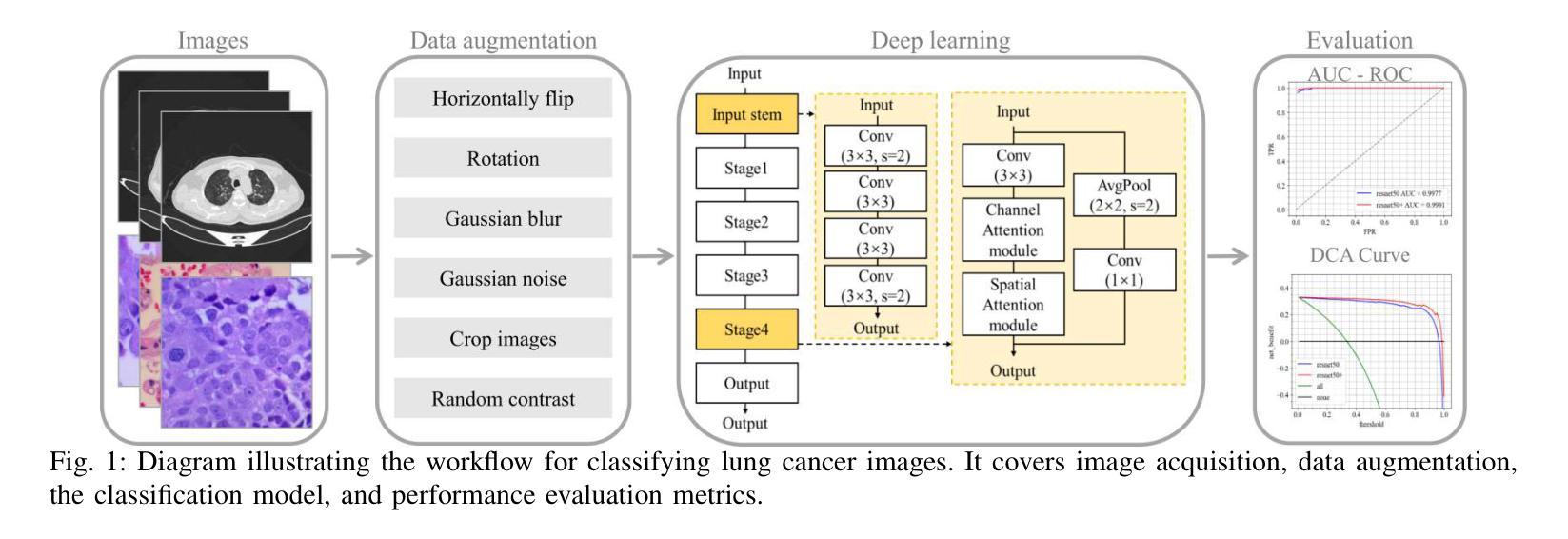
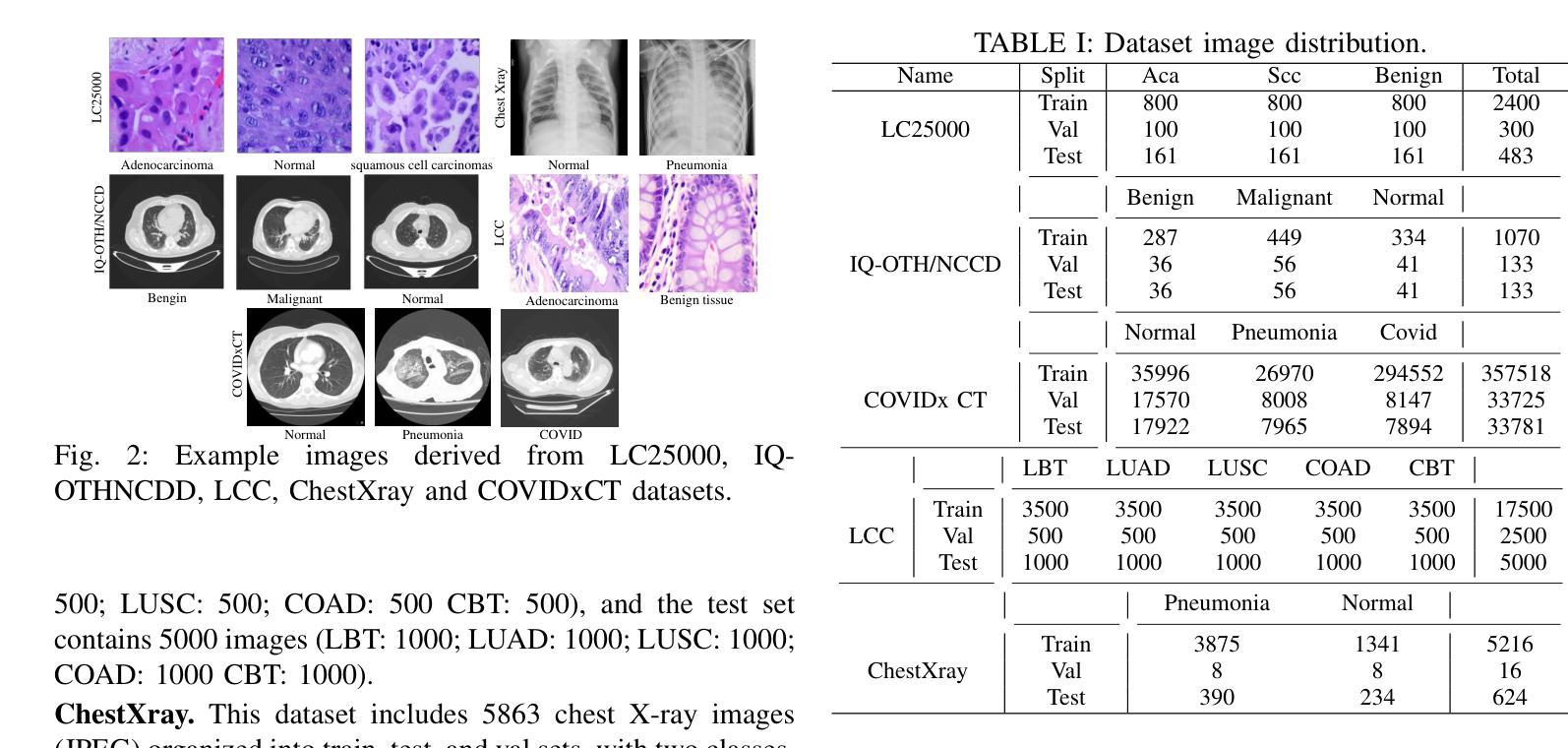
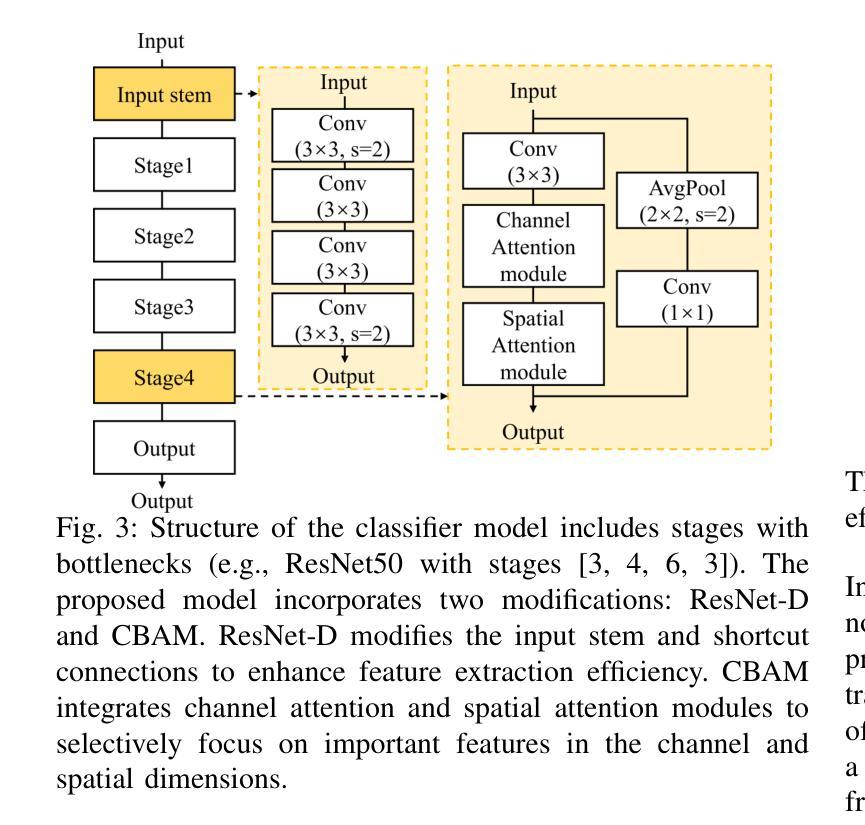
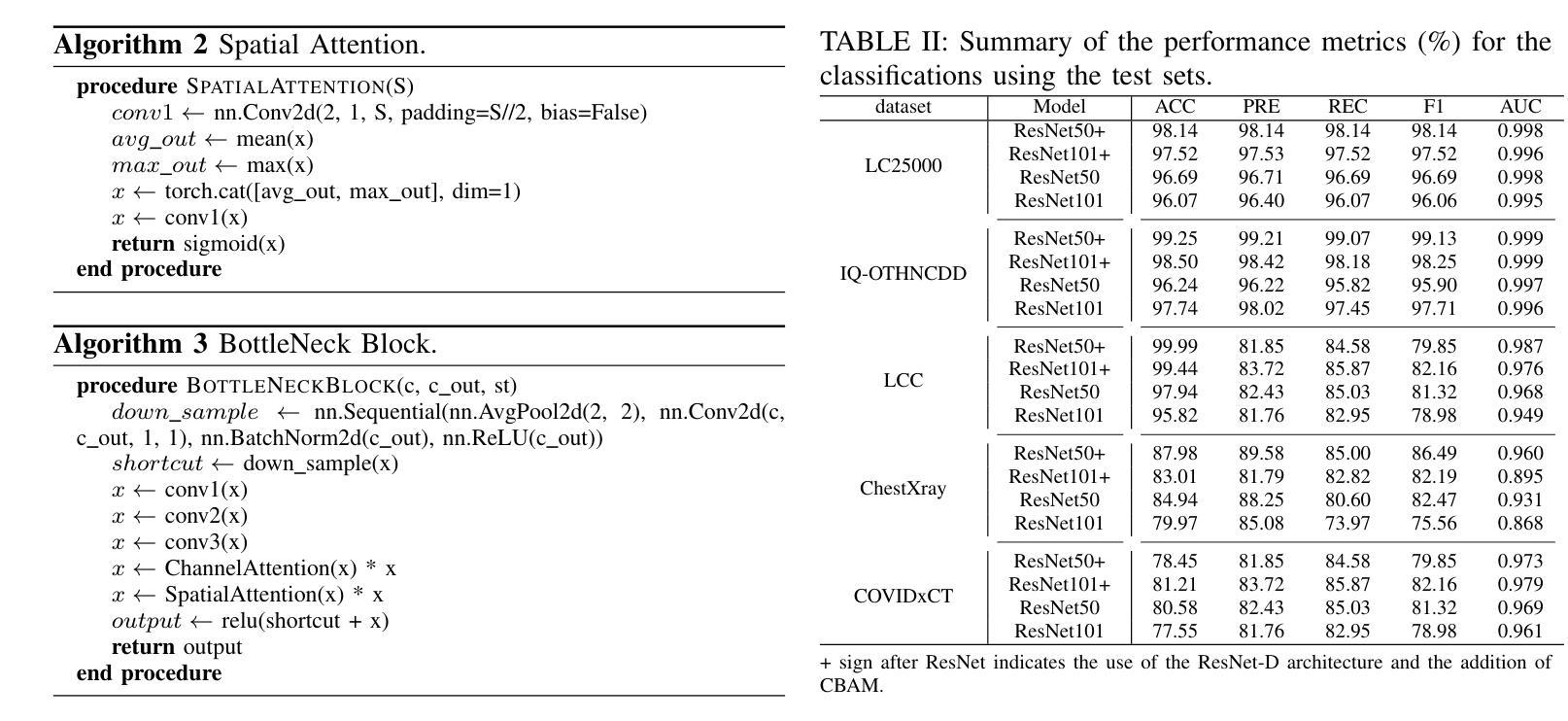
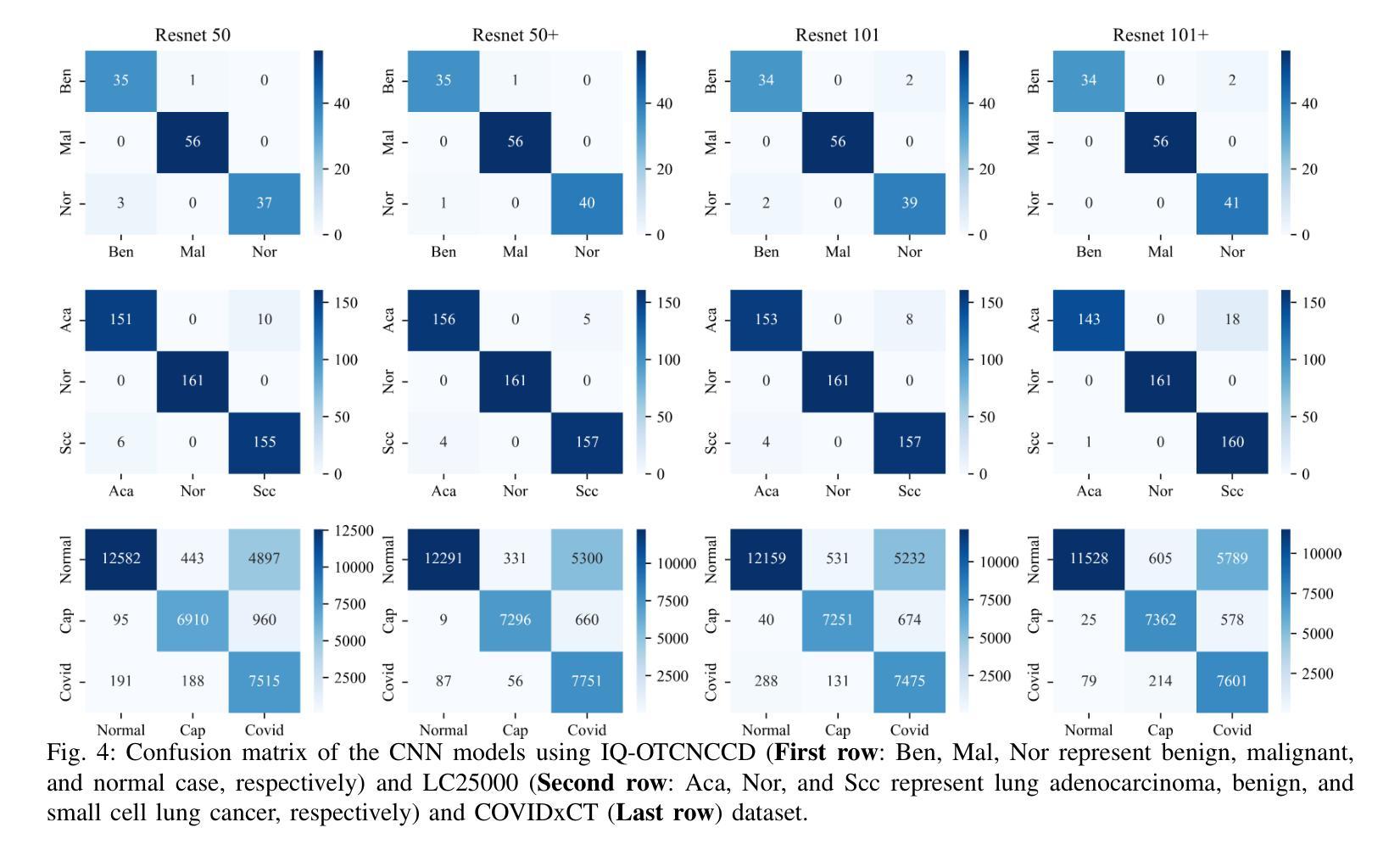
Classification based deep learning models for lung cancer and disease using medical images
Authors:Ahmad Chaddad, Jihao Peng, Yihang Wu
The use of deep learning (DL) in medical image analysis has significantly improved the ability to predict lung cancer. In this study, we introduce a novel deep convolutional neural network (CNN) model, named ResNet+, which is based on the established ResNet framework. This model is specifically designed to improve the prediction of lung cancer and diseases using the images. To address the challenge of missing feature information that occurs during the downsampling process in CNNs, we integrate the ResNet-D module, a variant designed to enhance feature extraction capabilities by modifying the downsampling layers, into the traditional ResNet model. Furthermore, a convolutional attention module was incorporated into the bottleneck layers to enhance model generalization by allowing the network to focus on relevant regions of the input images. We evaluated the proposed model using five public datasets, comprising lung cancer (LC2500 $n$=3183, IQ-OTH/NCCD $n$=1336, and LCC $n$=25000 images) and lung disease (ChestXray $n$=5856, and COVIDx-CT $n$=425024 images). To address class imbalance, we used data augmentation techniques to artificially increase the representation of underrepresented classes in the training dataset. The experimental results show that ResNet+ model demonstrated remarkable accuracy/F1, reaching 98.14/98.14% on the LC25000 dataset and 99.25/99.13% on the IQ-OTH/NCCD dataset. Furthermore, the ResNet+ model saved computational cost compared to the original ResNet series in predicting lung cancer images. The proposed model outperformed the baseline models on publicly available datasets, achieving better performance metrics. Our codes are publicly available at https://github.com/AIPMLab/Graduation-2024/tree/main/Peng.
深度学习(DL)在医学图像分析中的应用大大提高了预测肺癌的能力。在这项研究中,我们引入了一种基于已建立的ResNet框架的新型深度卷积神经网络(CNN)模型,名为ResNet+。该模型专门设计用于利用图像预测肺癌和肺部疾病。为了解决CNN在下采样过程中缺失特征信息的问题,我们将ResNet-D模块集成到传统ResNet模型中。这种变体旨在通过修改下采样层增强特征提取能力。此外,还在瓶颈层中加入了卷积注意力模块,通过允许网络关注输入图像的相关区域,增强模型的泛化能力。我们使用五个公共数据集对提出的模型进行了评估,包括肺癌(LC2500 n=3183、IQ-OTH/NCCD n=1336和LCC n=25000图像)和肺部疾病(ChestXray n=5856和COVIDx-CT n=425024图像)。为了解决类别不平衡问题,我们采用数据增强技术人为增加训练数据集中代表性不足的类别的表示。实验结果表明,ResNet+模型在LC25000数据集上表现出卓越的准确率和F1分数,达到98.14%/98.14%,在IQ-OTH/NCCD数据集上达到99.25%/99.13%。此外,ResNet+模型在预测肺癌图像时比原始ResNet系列节省了计算成本。该模型在公开数据集上的表现优于基线模型,取得了更好的性能指标。我们的代码可公开访问:https://github.com/AIPMLab/Graduation-2024/tree/main/Peng。
论文及项目相关链接
PDF Accepted in IEEE Transactions on Radiation and Plasma Medical Sciences
Summary
基于深度学习(DL)的医学图像分析在预测肺癌方面取得了显著进展。本研究引入了一种新型的深度卷积神经网络(CNN)模型——ResNet+,该模型基于成熟的ResNet框架构建,旨在提高利用图像预测肺癌及其他疾病的能力。为解决CNN中下采样过程中特征信息丢失的问题,研究者将ResNet-D模块集成到传统ResNet模型中,以增强特征提取能力。此外,还在瓶颈层引入了卷积注意力模块,以提高模型的泛化能力,使网络能够关注输入图像的相关区域。使用五个公开数据集对提出的模型进行了评估,包括肺癌数据集和肺部疾病数据集。为解决类别不平衡问题,采用了数据增强技术来人为增加训练数据集中代表性不足的类别的表示。实验结果表明,ResNet+模型在LC2500和IQ-OTH/NCCD数据集上分别达到了98.14%的准确率和F1值,以及在ChestXray和COVIDx-CT数据集上也取得了很高的准确率。此外,ResNet+模型在预测肺癌图像时,相较于原始ResNet系列,节省了计算成本。该模型在公开数据集上的表现优于基线模型,取得了更好的性能指标。
Key Takeaways
- 研究引入了名为ResNet+的新型深度卷积神经网络模型,用于改进肺癌及肺部疾病的预测。
- 为解决CNN中下采样过程中的特征信息丢失问题,集成了ResNet-D模块。
- 在模型中加入了卷积注意力模块,以提高对输入图像相关区域的关注,进而增强模型泛化能力。
- 使用五个公开数据集对模型进行了评估,包括肺癌和肺部疾病数据集。
- 采用数据增强技术解决类别不平衡问题。
- ResNet+模型在多个数据集上表现出高准确率和F1值,且相较于原始ResNet系列,计算成本更低。
点此查看论文截图

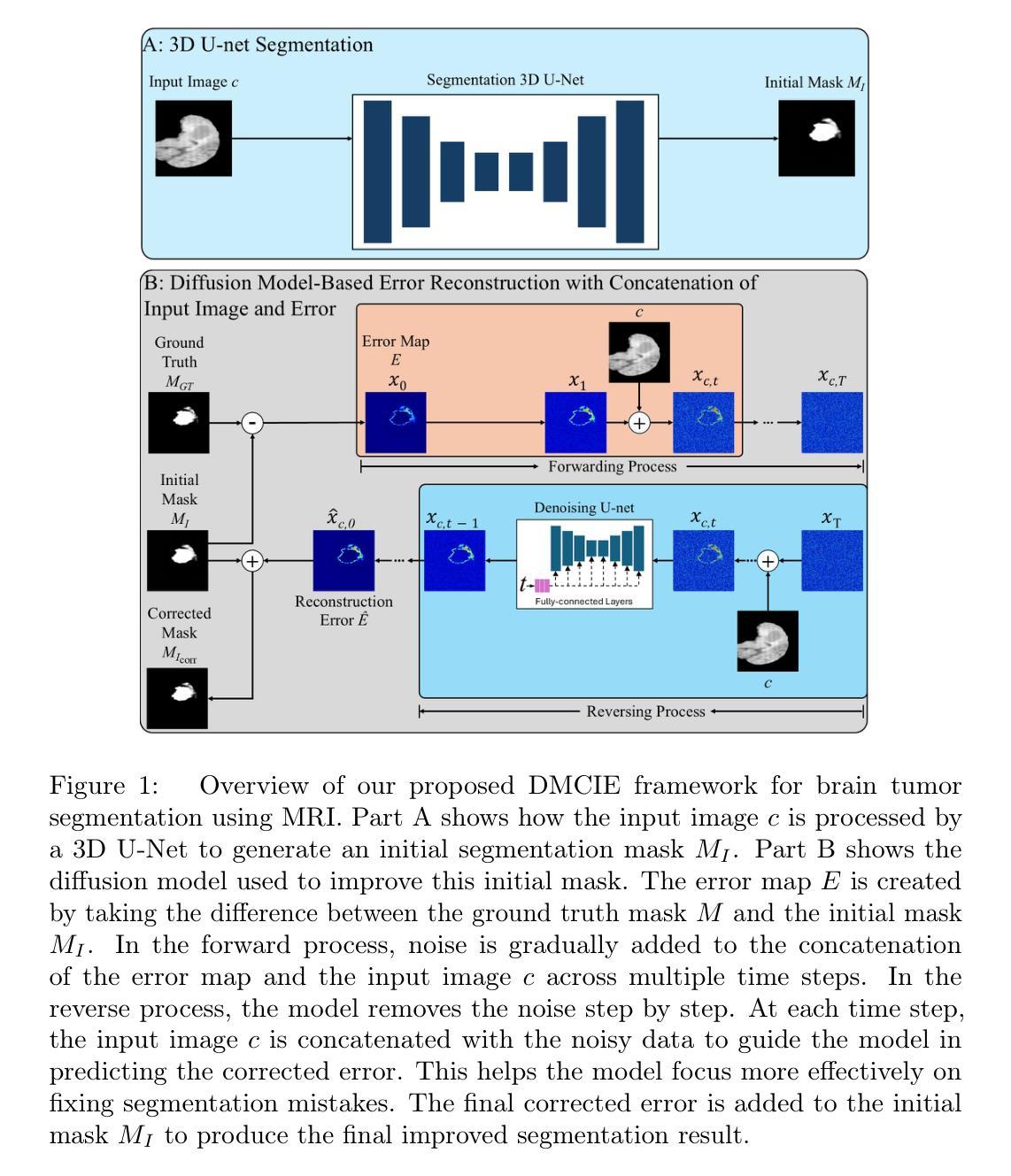
DMCIE: Diffusion Model with Concatenation of Inputs and Errors to Improve the Accuracy of the Segmentation of Brain Tumors in MRI Images
Authors:Sara Yavari, Rahul Nitin Pandya, Jacob Furst
Accurate segmentation of brain tumors in MRI scans is essential for reliable clinical diagnosis and effective treatment planning. Recently, diffusion models have demonstrated remarkable effectiveness in image generation and segmentation tasks. This paper introduces a novel approach to corrective segmentation based on diffusion models. We propose DMCIE (Diffusion Model with Concatenation of Inputs and Errors), a novel framework for accurate brain tumor segmentation in multi-modal MRI scans. We employ a 3D U-Net to generate an initial segmentation mask, from which an error map is generated by identifying the differences between the prediction and the ground truth. The error map, concatenated with the original MRI images, are used to guide a diffusion model. Using multimodal MRI inputs (T1, T1ce, T2, FLAIR), DMCIE effectively enhances segmentation accuracy by focusing on misclassified regions, guided by the original inputs. Evaluated on the BraTS2020 dataset, DMCIE outperforms several state-of-the-art diffusion-based segmentation methods, achieving a Dice Score of 93.46 and an HD95 of 5.94 mm. These results highlight the effectiveness of error-guided diffusion in producing precise and reliable brain tumor segmentations.
在MRI扫描中对脑肿瘤进行准确的分割对于可靠的临床诊断和有效的治疗计划至关重要。最近,扩散模型在图像生成和分割任务中表现出了显著的有效性。本文介绍了一种基于扩散模型的新型修正分割方法。我们提出了DMCIE(输入和误差组合的扩散模型),这是一种用于多模态MRI扫描中脑肿瘤精确分割的新型框架。我们采用3D U-Net生成初始分割掩膜,通过识别预测与真实标签之间的差异来生成误差图。误差图与原始MRI图像组合,用于指导扩散模型。使用多模态MRI输入(T1、T1ce、T2、FLAIR),DMCIE通过关注误分类区域,在原始输入的引导下,有效地提高了分割精度。在BraTS2020数据集上评估,DMCIE优于几种先进的基于扩散的分割方法,实现了Dice得分为93.46,HD95为5.94毫米。这些结果突显了误差引导扩散在产生精确可靠的脑肿瘤分割中的有效性。
论文及项目相关链接
Summary
本文介绍了一种基于扩散模型的新型脑肿瘤矫正分割方法——DMCIE。该方法采用3D U-Net生成初始分割掩膜,通过识别预测结果与真实标签之间的差异生成误差图。误差图与原始MRI图像结合,指导扩散模型的运行。使用多模态MRI输入(T1、T1ce、T2、FLAIR),DMCIE能够专注于误分类区域,提高分割精度。在BraTS2020数据集上的评估结果表明,DMCIE优于其他先进的扩散分割方法,Dice得分为93.46,HD95为5.94mm,凸显了误差引导扩散在精确可靠的脑肿瘤分割中的有效性。
Key Takeaways
- DMCIE是一种基于扩散模型的新型脑肿瘤矫正分割方法。
- 使用3D U-Net生成初始分割掩膜。
- 通过识别预测与真实标签之间的差异生成误差图。
- 误差图与原始MRI图像结合,指导扩散模型的运行。
- 多模态MRI输入(T1、T1ce、T2、FLAIR)用于提高分割精度。
- DMCIE在BraTS2020数据集上的表现优于其他先进的扩散分割方法。
点此查看论文截图

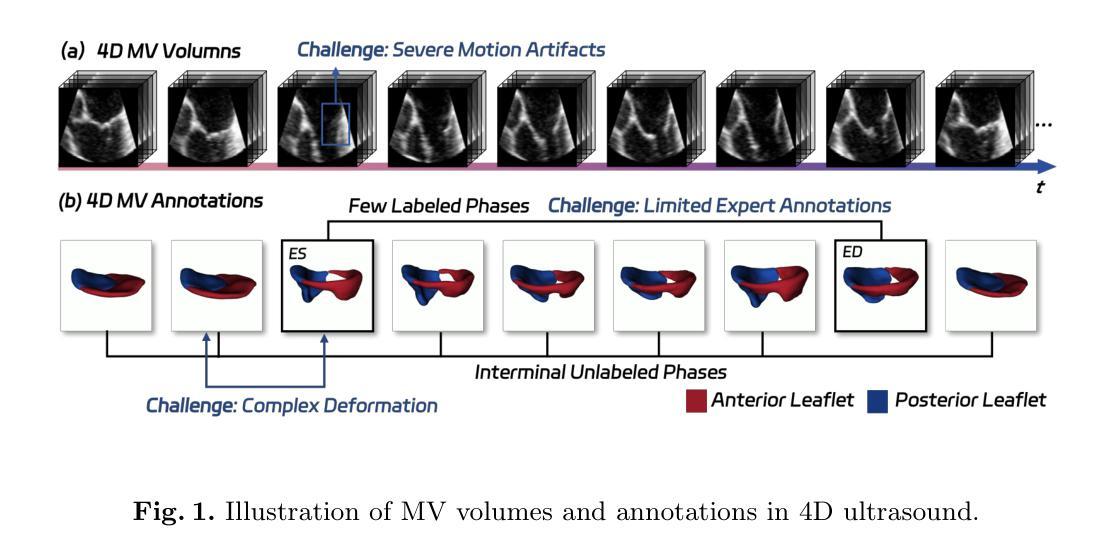
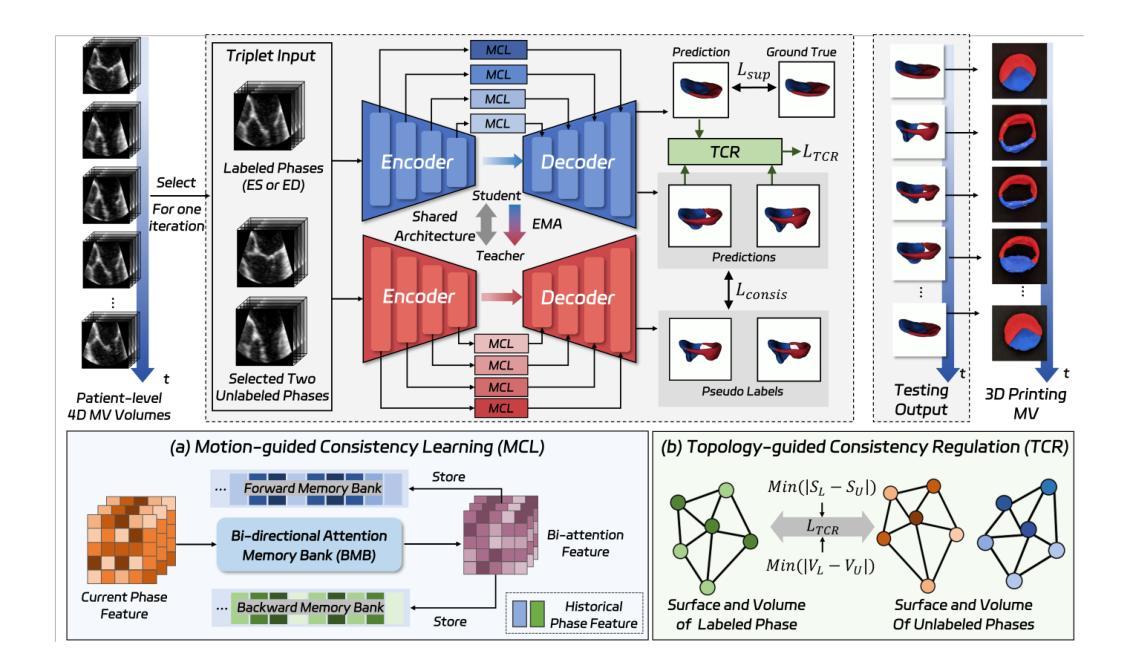
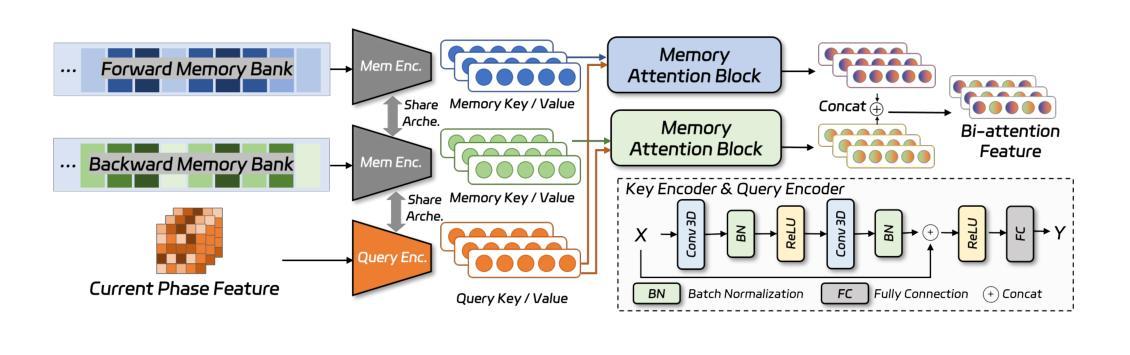
MTCNet: Motion and Topology Consistency Guided Learning for Mitral Valve Segmentationin 4D Ultrasound
Authors:Rusi Chen, Yuanting Yang, Jiezhi Yao, Hongning Song, Ji Zhang, Yongsong Zhou, Yuhao Huang, Ronghao Yang, Dan Jia, Yuhan Zhang, Xing Tao, Haoran Dou, Qing Zhou, Xin Yang, Dong Ni
Mitral regurgitation is one of the most prevalent cardiac disorders. Four-dimensional (4D) ultrasound has emerged as the primary imaging modality for assessing dynamic valvular morphology. However, 4D mitral valve (MV) analysis remains challenging due to limited phase annotations, severe motion artifacts, and poor imaging quality. Yet, the absence of inter-phase dependency in existing methods hinders 4D MV analysis. To bridge this gap, we propose a Motion-Topology guided consistency network (MTCNet) for accurate 4D MV ultrasound segmentation in semi-supervised learning (SSL). MTCNet requires only sparse end-diastolic and end-systolic annotations. First, we design a cross-phase motion-guided consistency learning strategy, utilizing a bi-directional attention memory bank to propagate spatio-temporal features. This enables MTCNet to achieve excellent performance both per- and inter-phase. Second, we devise a novel topology-guided correlation regularization that explores physical prior knowledge to maintain anatomically plausible. Therefore, MTCNet can effectively leverage structural correspondence between labeled and unlabeled phases. Extensive evaluations on the first largest 4D MV dataset, with 1408 phases from 160 patients, show that MTCNet performs superior cross-phase consistency compared to other advanced methods (Dice: 87.30%, HD: 1.75mm). Both the code and the dataset are available at https://github.com/crs524/MTCNet.
二尖瓣反流是最常见的心脏疾病之一。四维(4D)超声已成为评估动态瓣膜形态的主要成像方式。然而,由于相位注释有限、运动伪影严重以及成像质量不佳,4D二尖瓣(MV)分析仍然具有挑战性。然而,现有方法缺乏相位间的依赖性,阻碍了4D MV分析。为了弥补这一差距,我们提出了一种运动拓扑引导的一致性网络(MTCNet),用于半监督学习(SSL)中准确的4D MV超声分割。MTCNet仅需要稀疏的舒张末期和收缩末期注释。首先,我们设计了一种跨相位运动引导的一致性学习策略,利用双向注意力存储库传播时空特征。这使得MTCNet在跨相位内和跨相位间都能实现卓越的性能。其次,我们设计了一种新型拓扑引导相关性正则化,利用物理先验知识来保持解剖上的合理性。因此,MTCNet可以有效地利用有标签和无标签相位之间的结构对应关系。在首个最大的4D MV数据集上进行了广泛评估,该数据集包含来自160名患者的1408个相位,结果表明MTCNet在跨相位一致性方面优于其他先进方法(Dice:87.30%,HD:1.75mm)。代码和数据集均可在https://github.com/crs524/MTCNet获取。
论文及项目相关链接
PDF Accepted by MICCAI 2025
Summary
本文介绍了一种针对4D超声心动图分析中MV分析的挑战,提出一种名为MTCNet的模型,该模型通过运动拓扑引导的一致性网络,实现了在半监督学习下的准确4D MV超声分割。模型利用稀疏的舒张末期和收缩末期注释,通过跨相位运动引导的一致性学习策略实现优秀性能。同时,模型结合了物理先验知识的拓扑引导相关性正则化,以实现解剖上的合理分割。在大型4D MV数据集上的评估显示,MTCNet相较于其他先进方法具有更好的跨相位一致性。
Key Takeaways
- 四维超声心动图(4D超声)是目前评估动态瓣膜形态的主要成像方式。
- 4D二尖瓣(MV)分析面临诸多挑战,如相位注释有限、运动伪影和成像质量不佳等。
- MTCNet模型通过运动拓扑引导的一致性网络解决了这些问题,实现了在半监督学习下的准确4D MV超声分割。
- MTCNet仅需要稀疏的舒张末期和收缩末期注释。
- MTCNet采用跨相位运动引导的一致性学习策略,利用双向注意力记忆库传播时空特征,实现优秀性能。
- 模型结合了物理先验知识的拓扑引导相关性正则化,确保解剖上的合理分割。
点此查看论文截图

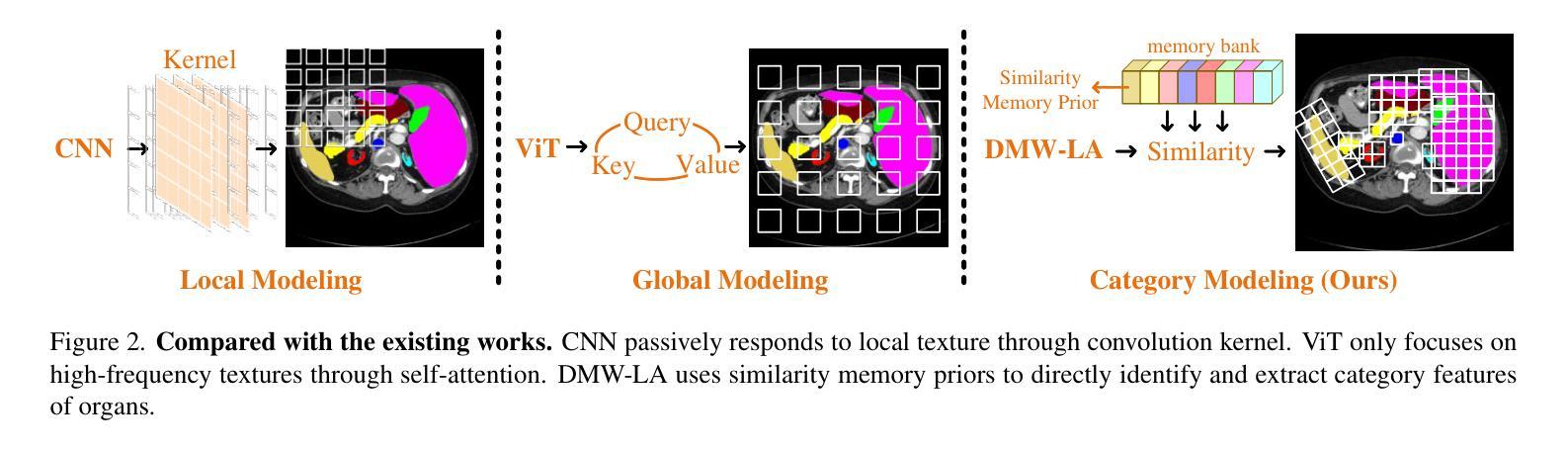
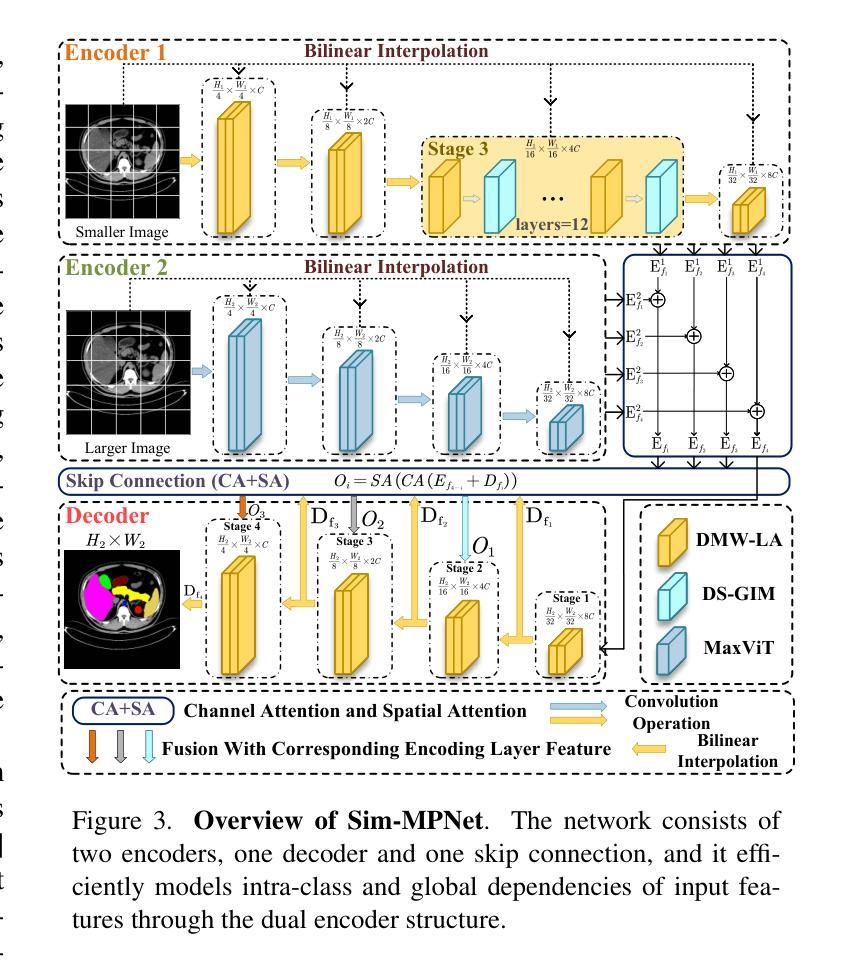
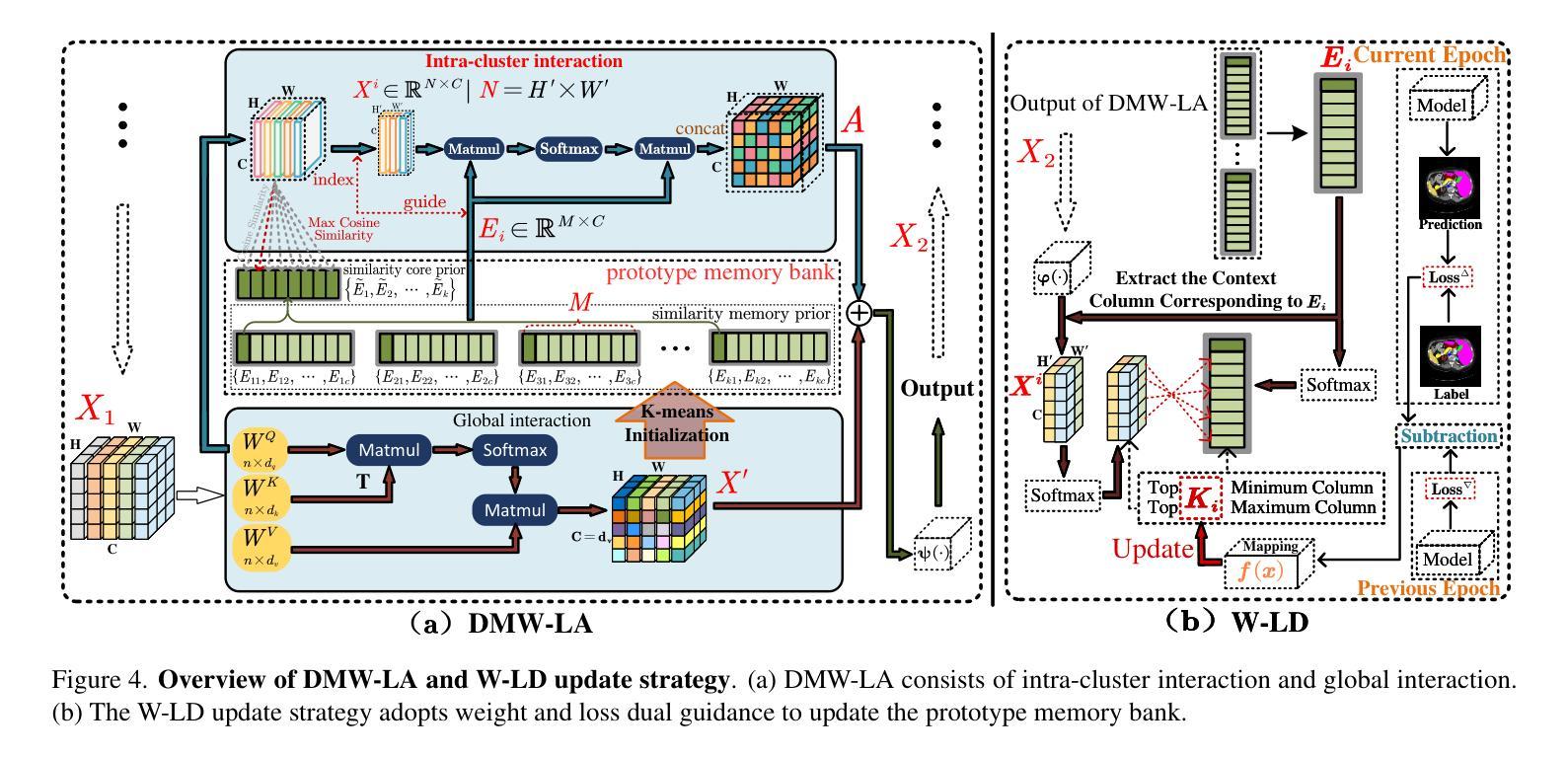
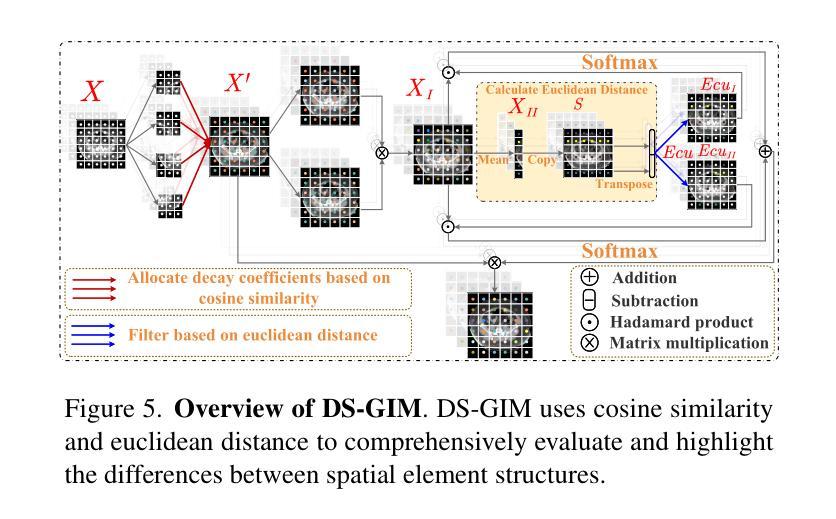
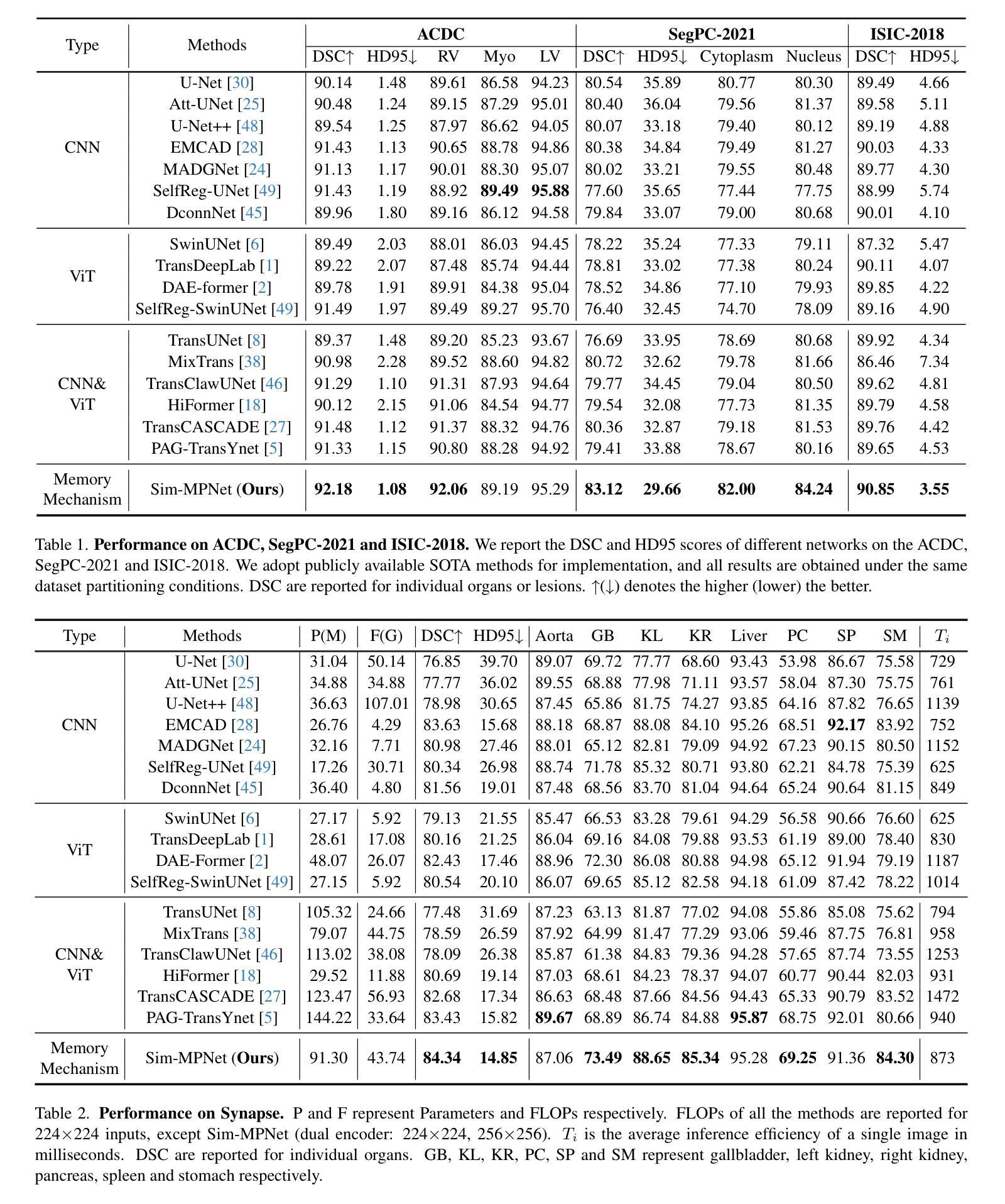
Similarity Memory Prior is All You Need for Medical Image Segmentation
Authors:Tang Hao, Guo ZhiQing, Wang LieJun, Liu Chao
In recent years, it has been found that “grandmother cells” in the primary visual cortex (V1) of macaques can directly recognize visual input with complex shapes. This inspires us to examine the value of these cells in promoting the research of medical image segmentation. In this paper, we design a Similarity Memory Prior Network (Sim-MPNet) for medical image segmentation. Specifically, we propose a Dynamic Memory Weights-Loss Attention (DMW-LA), which matches and remembers the category features of specific lesions or organs in medical images through the similarity memory prior in the prototype memory bank, thus helping the network to learn subtle texture changes between categories. DMW-LA also dynamically updates the similarity memory prior in reverse through Weight-Loss Dynamic (W-LD) update strategy, effectively assisting the network directly extract category features. In addition, we propose the Double-Similarity Global Internal Enhancement Module (DS-GIM) to deeply explore the internal differences in the feature distribution of input data through cosine similarity and euclidean distance. Extensive experiments on four public datasets show that Sim-MPNet has better segmentation performance than other state-of-the-art methods. Our code is available on https://github.com/vpsg-research/Sim-MPNet.
近年来,研究发现猕猴初级视觉皮层(V1)中的“祖母细胞”能直接识别具有复杂形状的视觉输入,这激发了我们探索这些细胞在推动医学图像分割研究中的价值。在本文中,我们为医学图像分割设计了一种相似性记忆先验网络(Sim-MPNet)。具体来说,我们提出了一种动态记忆权重损失注意力(DMW-LA),它通过原型记忆库中的相似性记忆先验来匹配和记忆医学图像中特定病变或器官的分类特征,从而帮助网络学习类别之间的细微纹理变化。DMW-LA还通过权重损失动态(W-LD)更新策略反向动态更新相似性记忆先验,有效地帮助网络直接提取类别特征。此外,我们提出了双相似性全局内部增强模块(DS-GIM),通过余弦相似度和欧几里得距离深入探索输入数据特征分布的内部差异。在四个公共数据集上的大量实验表明,Sim-MPNet的分割性能优于其他最先进的方法。我们的代码可在https://github.com/vpsg-research/Sim-MPNet上获取。
论文及项目相关链接
Summary
本文研究了医学图像分割领域的新进展,特别是关于猕猴初级视觉皮层V1中的“祖母细胞”对复杂形状视觉输入的识别能力。受此启发,研究人员设计了一种名为Sim-MPNet的医学图像分割网络,并引入了Dynamic Memory Weights-Loss Attention(DMW-LA)和Double-Similarity Global Internal Enhancement Module(DS-GIM)两大模块,以通过相似性记忆先验来匹配和记忆医学图像中特定病变或器官的特征类别,从而提高网络对类别间细微纹理变化的学习能力,并深入探索输入数据特征分布的内部差异。实验表明,Sim-MPNet在四个公共数据集上的分割性能优于其他最新方法。
Key Takeaways
- “祖母细胞”在医学图像分割研究中具有启示作用,能够直接识别具有复杂形状的视觉输入。
- 提出了名为Sim-MPNet的医学图像分割网络。
- DMW-LA模块通过相似性记忆先验匹配和记忆医学图像中的特定病变或器官的特征类别。
- DMW-LA采用Weight-Loss Dynamic(W-LD)更新策略,可动态更新相似性记忆先验。
- DS-GIM模块用于深入探索输入数据特征分布的内部差异。
- Sim-MPNet在四个公共数据集上的医学图像分割性能优于其他最新方法。
点此查看论文截图

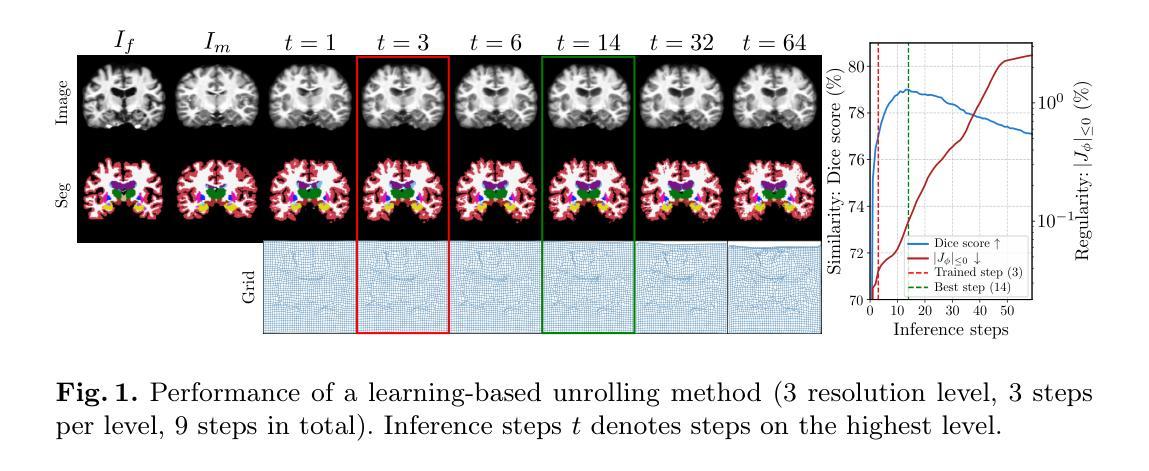
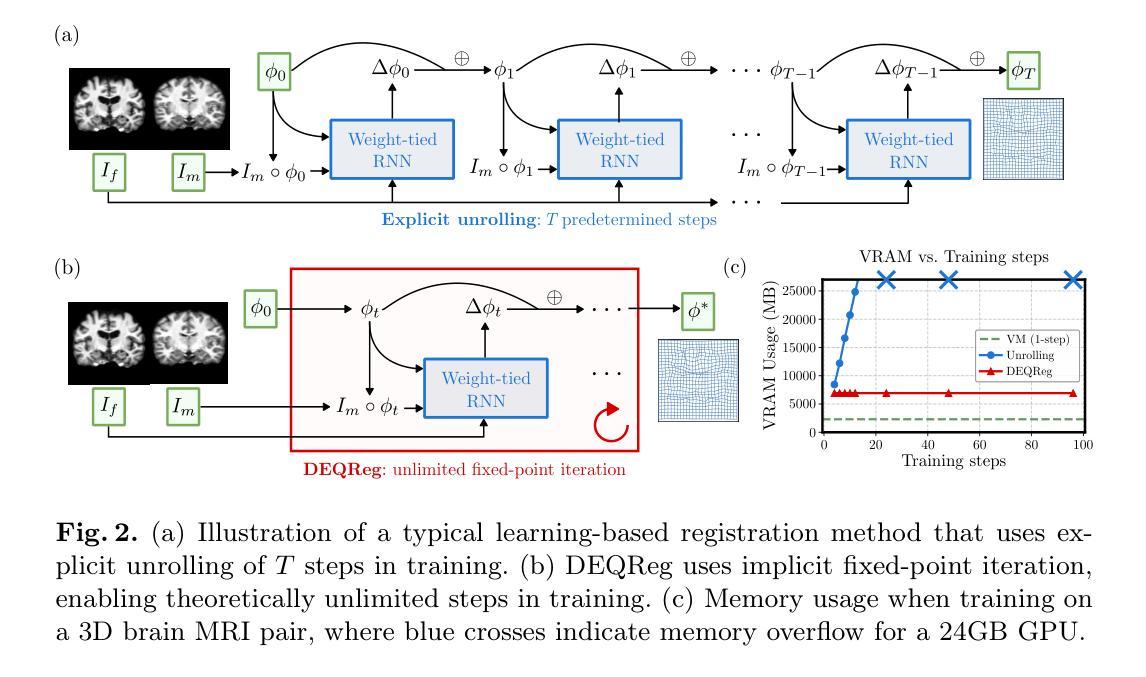
Bridging Classical and Learning-based Iterative Registration through Deep Equilibrium Models
Authors:Yi Zhang, Yidong Zhao, Qian Tao
Deformable medical image registration is traditionally formulated as an optimization problem. While classical methods solve this problem iteratively, recent learning-based approaches use recurrent neural networks (RNNs) to mimic this process by unrolling the prediction of deformation fields in a fixed number of steps. However, classical methods typically converge after sufficient iterations, but learning-based unrolling methods lack a theoretical convergence guarantee and show instability empirically. In addition, unrolling methods have a practical bottleneck at training time: GPU memory usage grows linearly with the unrolling steps due to backpropagation through time (BPTT). To address both theoretical and practical challenges, we propose DEQReg, a novel registration framework based on Deep Equilibrium Models (DEQ), which formulates registration as an equilibrium-seeking problem, establishing a natural connection between classical optimization and learning-based unrolling methods. DEQReg maintains constant memory usage, enabling theoretically unlimited iteration steps. Through extensive evaluation on the public brain MRI and lung CT datasets, we show that DEQReg can achieve competitive registration performance, while substantially reducing memory consumption compared to state-of-the-art unrolling methods. We also reveal an intriguing phenomenon: the performance of existing unrolling methods first increases slightly then degrades irreversibly when the inference steps go beyond the training configuration. In contrast, DEQReg achieves stable convergence with its inbuilt equilibrium-seeking mechanism, bridging the gap between classical optimization-based and modern learning-based registration methods.
可变形医学图像配准传统上被制定为一个优化问题。虽然经典方法通过迭代来解决这个问题,但最近的基于学习的方法使用循环神经网络(RNN)来模拟这个过程,通过在固定数量的步骤中展开变形场的预测。然而,经典方法通常在足够的迭代后收敛,但基于展开的学习方法缺乏理论收敛保证,并且在经验上显示出不稳定。此外,展开方法在训练时间方面存在实际瓶颈:由于时间反向传播(BPTT),GPU内存使用量随展开步骤线性增长。为了解决理论上的挑战和实践上的困难,我们提出了基于深度平衡模型(DEQ)的新型配准框架DEQReg。它将配准公式化为平衡寻找问题,在经典优化方法和基于学习的展开方法之间建立了自然的联系。DEQReg保持恒定的内存使用,实现理论上无限迭代步骤。通过对公共脑MRI和肺部CT数据集进行全面评估,我们证明了DEQReg在达到竞争性的配准性能的同时,与最先进的展开方法相比大大减少了内存消耗。我们还揭示了一个有趣的现象:现有展开方法的性能在推断步骤超出训练配置时首先会略有提高,然后不可逆地下降。相反,DEQReg凭借其内置的均衡寻找机制实现了稳定的收敛,弥合了基于经典优化的和基于现代学习的配准方法之间的差距。
论文及项目相关链接
PDF Submitted version. Accepted by MICCAI 2025
摘要
本文介绍了基于深度均衡模型(DEQ)的新型医学图像注册框架DEQReg。传统医学图像注册被制定为一个优化问题,而DEQReg将其制定为平衡寻求问题,建立了经典优化与基于学习的滚动方法之间的自然联系。相较于当前流行的滚动方法,DEQReg在理论上实现了恒定的内存使用并可以支持理论上的无限迭代步骤,在保证注册性能的同时极大地降低了内存消耗。在公共脑MRI和肺部CT数据集上的评估表明DEQReg的有效性。此外,本文还揭示了一个有趣的现象:当推理步骤超出训练配置时,现有滚动方法的性能会先略有提高然后不可逆地下降,而DEQReg凭借其内置的均衡寻求机制实现了稳定的收敛,缩小了基于经典优化和现代基于学习的注册方法之间的差距。
关键见解
- 传统医学图像注册是通过优化问题来解决的,而最近的学习型方法是基于递归神经网络(RNNs)模拟这一过程的。
- 学习型展开方法缺乏理论收敛保证,并在实践中显示出不稳定性和GPU内存使用随着展开步骤的增加而线性增长的瓶颈。
- DEQReg是一种新型的基于深度均衡模型(DEQ)的注册框架,解决了上述理论上的挑战并维持了恒定的内存使用。
- DEQReg实现了理论上无限的迭代步骤,实现了稳定的收敛。
- 在公共脑MRI和肺部CT数据集上的评估显示DEQReg具有竞争力的注册性能并显著减少了与最新展开方法的内存消耗。
- 现有展开方法的性能在推理步骤超出训练配置时会发生不可逆的下降,而DEQReg通过其均衡寻求机制避免了这一问题。
点此查看论文截图

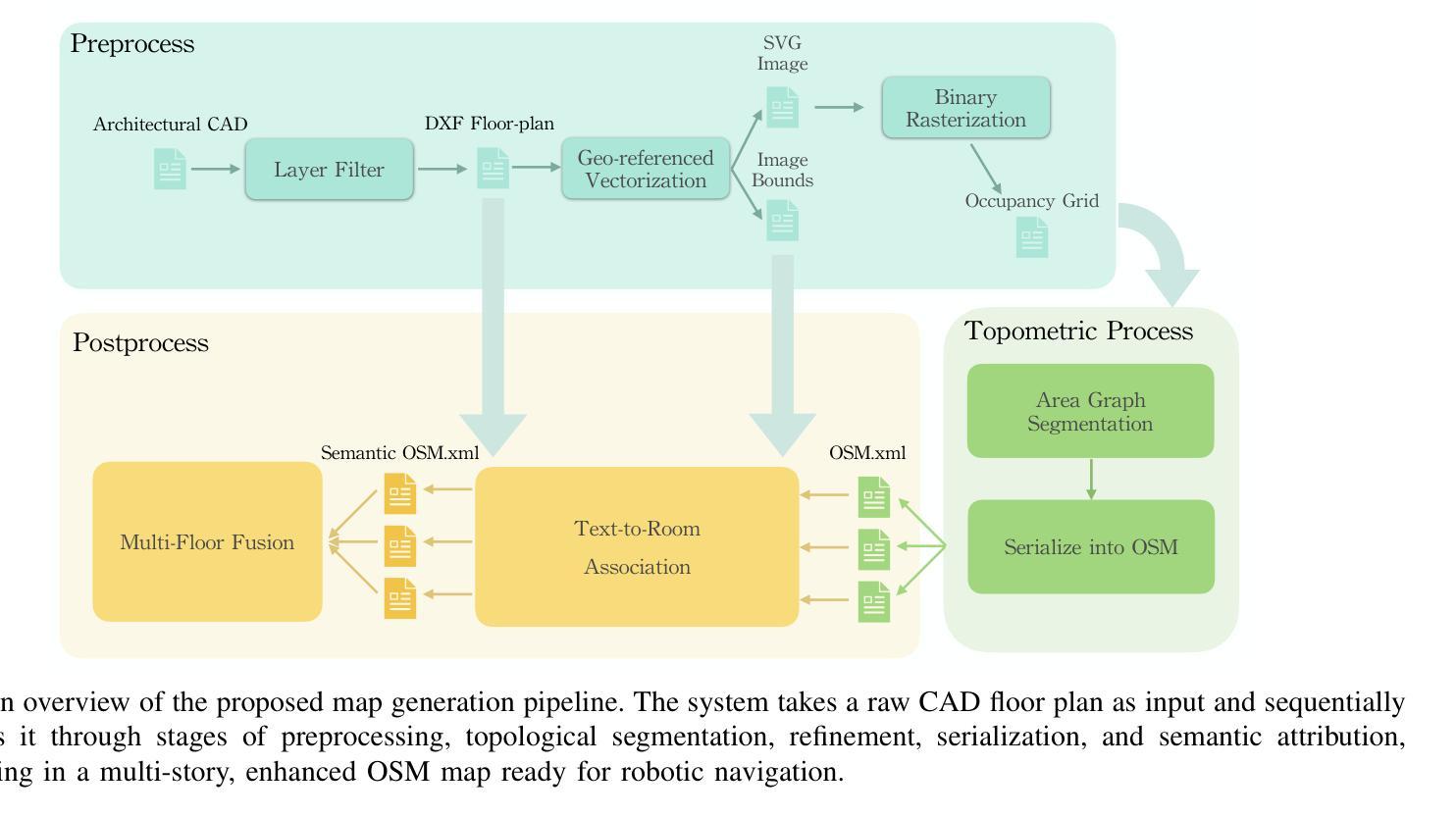
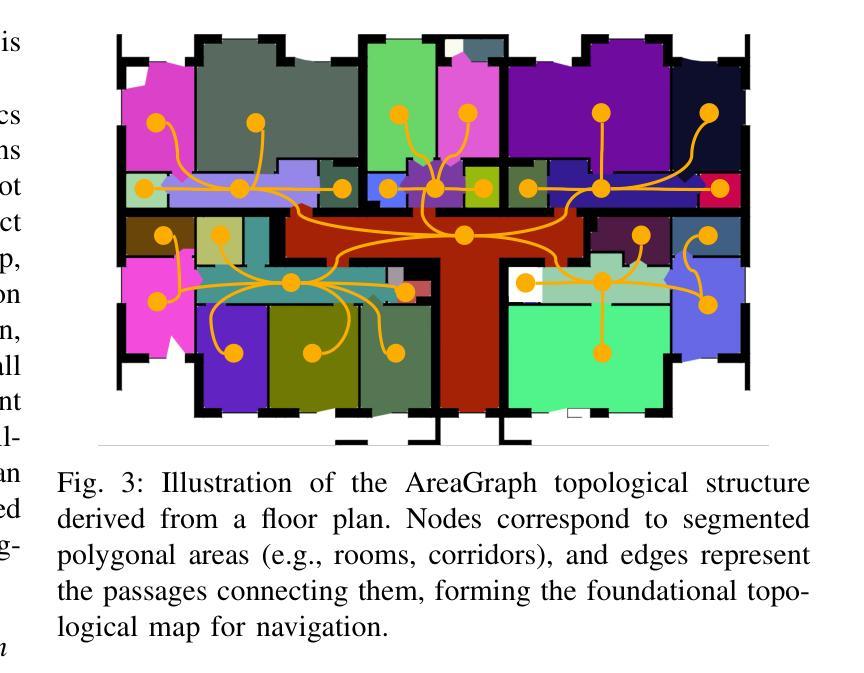
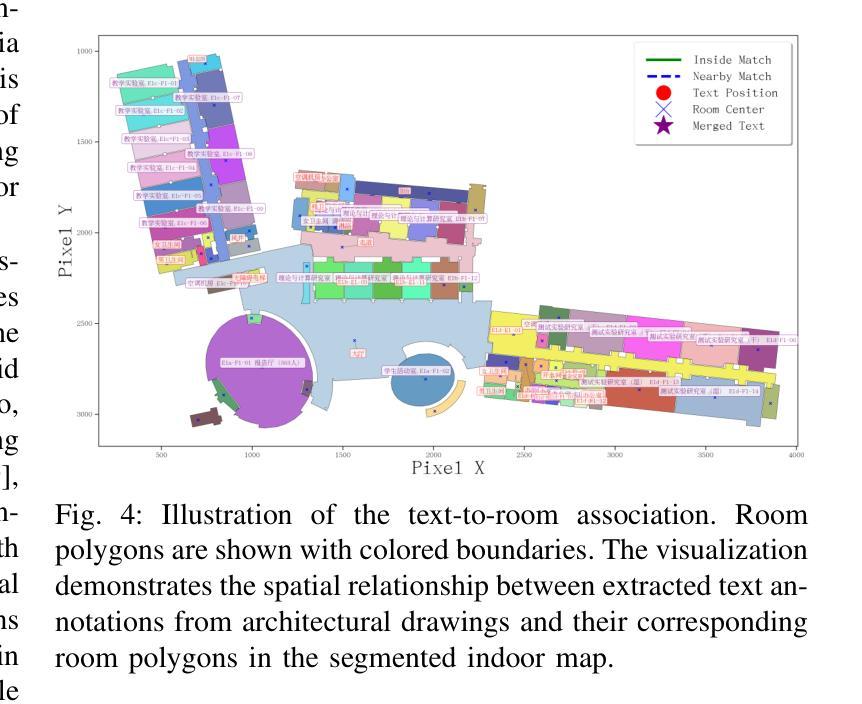
Generation of Indoor Open Street Maps for Robot Navigation from CAD Files
Authors:Jiajie Zhang, Shenrui Wu, Xu Ma, Sören Schwertfeger
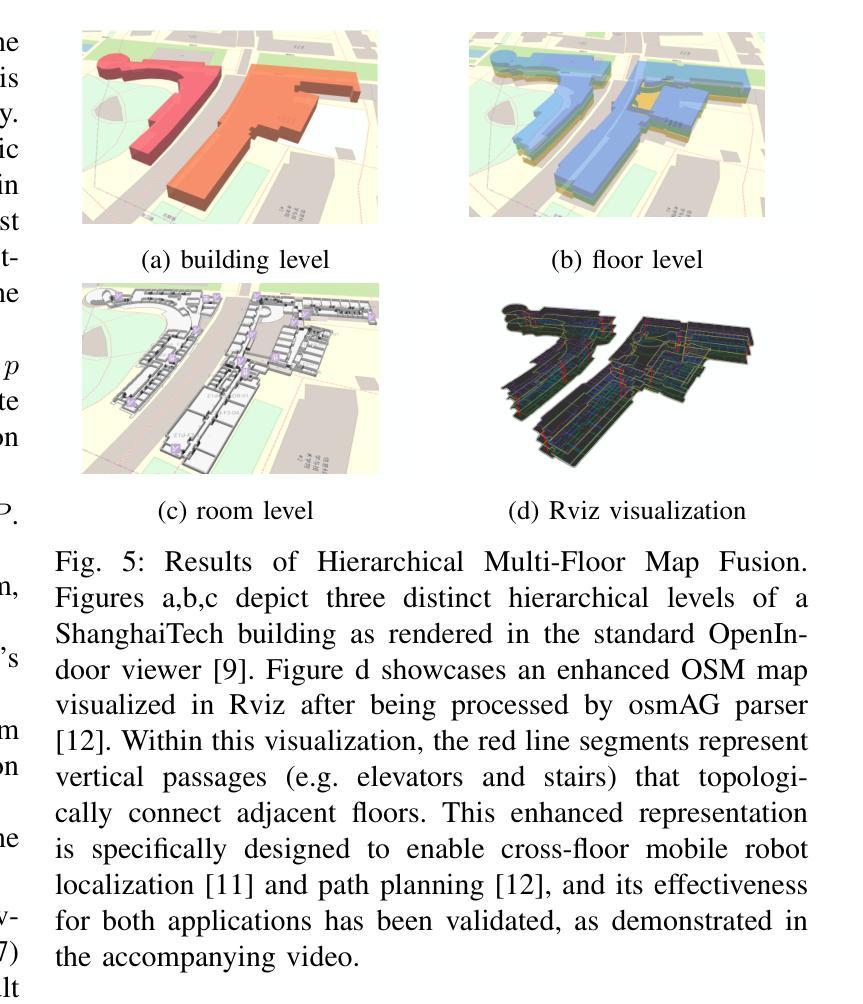
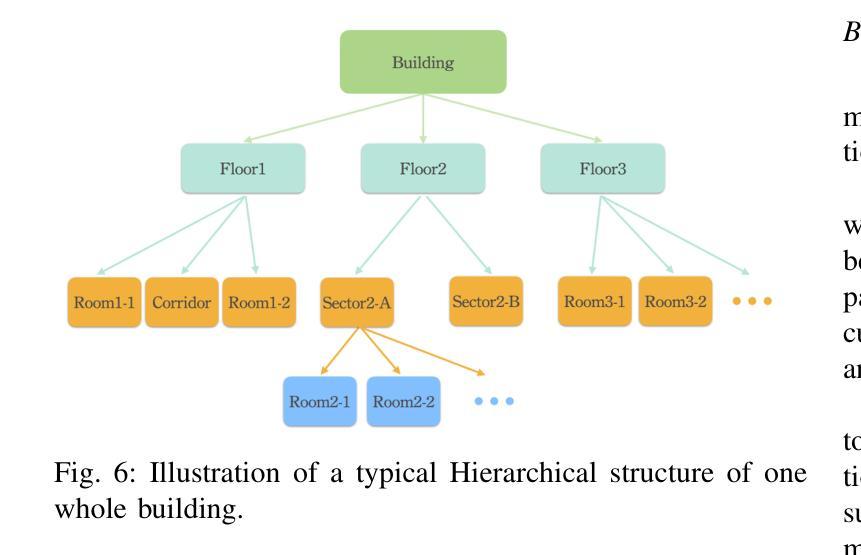
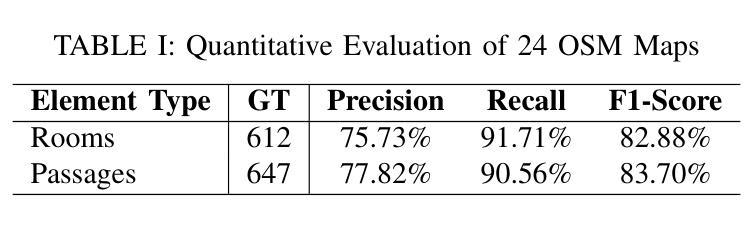
The deployment of autonomous mobile robots is predicated on the availability of environmental maps, yet conventional generation via SLAM (Simultaneous Localization and Mapping) suffers from significant limitations in time, labor, and robustness, particularly in dynamic, large-scale indoor environments where map obsolescence can lead to critical localization failures. To address these challenges, this paper presents a complete and automated system for converting architectural Computer-Aided Design (CAD) files into a hierarchical topometric OpenStreetMap (OSM) representation, tailored for robust life-long robot navigation. Our core methodology involves a multi-stage pipeline that first isolates key structural layers from the raw CAD data and then employs an AreaGraph-based topological segmentation to partition the building layout into a hierarchical graph of navigable spaces. This process yields a comprehensive and semantically rich map, further enhanced by automatically associating textual labels from the CAD source and cohesively merging multiple building floors into a unified, topologically-correct model. By leveraging the permanent structural information inherent in CAD files, our system circumvents the inefficiencies and fragility of SLAM, offering a practical and scalable solution for deploying robots in complex indoor spaces. The software is encapsulated within an intuitive Graphical User Interface (GUI) to facilitate practical use. The code and dataset are available at https://github.com/jiajiezhang7/osmAG-from-cad.
自主移动机器人的部署依赖于环境地图的可用性,然而,传统的通过SLAM(同时定位与地图构建)生成地图的方法在时间、劳动力和稳健性方面存在重大局限性,特别是在动态、大规模室内环境中,地图失效可能导致关键定位失败。为了解决这些挑战,本文提出了一种完整、自动化的系统,将建筑计算机辅助设计(CAD)文件转换为分层的拓扑OpenStreetMap(OSM)表示形式,适用于稳健的终身机器人导航。我们的核心方法涉及一个多阶段管道,首先从原始CAD数据中隔离出关键结构层,然后采用基于AreaGraph的拓扑分割将建筑布局分割成可导航空间的层次图。这一过程产生了全面且语义丰富的地图,通过自动关联来自CAD源的文本标签,并将多个楼层合并为一个统一、拓扑正确的模型,进一步增强了地图的功能。通过利用CAD文件中固有的永久结构信息,我们的系统避免了SLAM的不效率和脆弱性,为在复杂室内空间部署机器人提供了实用且可扩展的解决方案。该软件被封装在一个直观的用户图形界面(GUI)中,以便于实际应用。代码和数据集可在https://github.com/jiajiezhang7/osmAG-from-cad找到。
论文及项目相关链接
PDF 8 pages, 8 figures
Summary
基于自主移动机器人的部署对地图信息的依赖以及传统的SLAM地图生成方法在处理动态、大规模室内环境时的局限性,本文提出了一种由建筑计算机辅助设计(CAD)文件自动化转换为层次化的OpenStreetMap(OSM)地图表示的系统。该系统通过多阶段管道处理,从CAD数据中隔离关键结构层,并利用AreaGraph进行拓扑分割,为机器人导航生成丰富的语义地图。借助CAD文件中的永久结构信息,该系统克服了SLAM方法的不效率和脆弱性,为复杂室内空间的机器人部署提供了实用且可扩展的解决方案。
Key Takeaways
- 自主移动机器人的部署依赖于环境地图的可用性。
- 传统SLAM地图生成方法在动态、大规模室内环境中有时间、劳动力和稳健性的限制。
- 本文提出了一种由建筑CAD文件自动化转换为OSM地图的系统,用于机器人导航。
- 系统通过多阶段管道处理,包括隔离关键结构层和利用AreaGraph进行拓扑分割。
- 系统能生成丰富的语义地图,并自动关联CAD源中的文本标签。
- 利用CAD文件中的永久结构信息,系统克服了SLAM的不效率和脆弱性。
点此查看论文截图


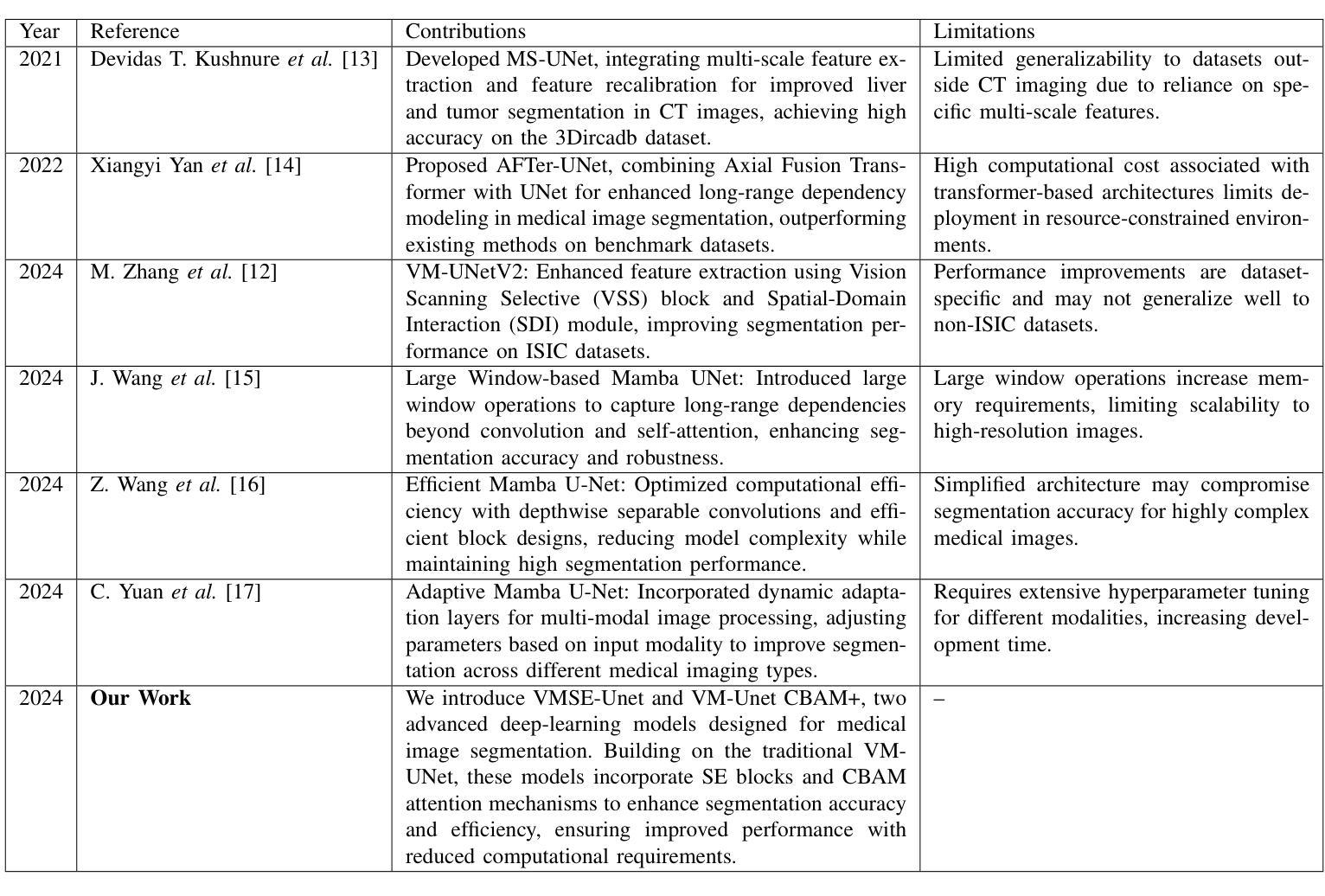
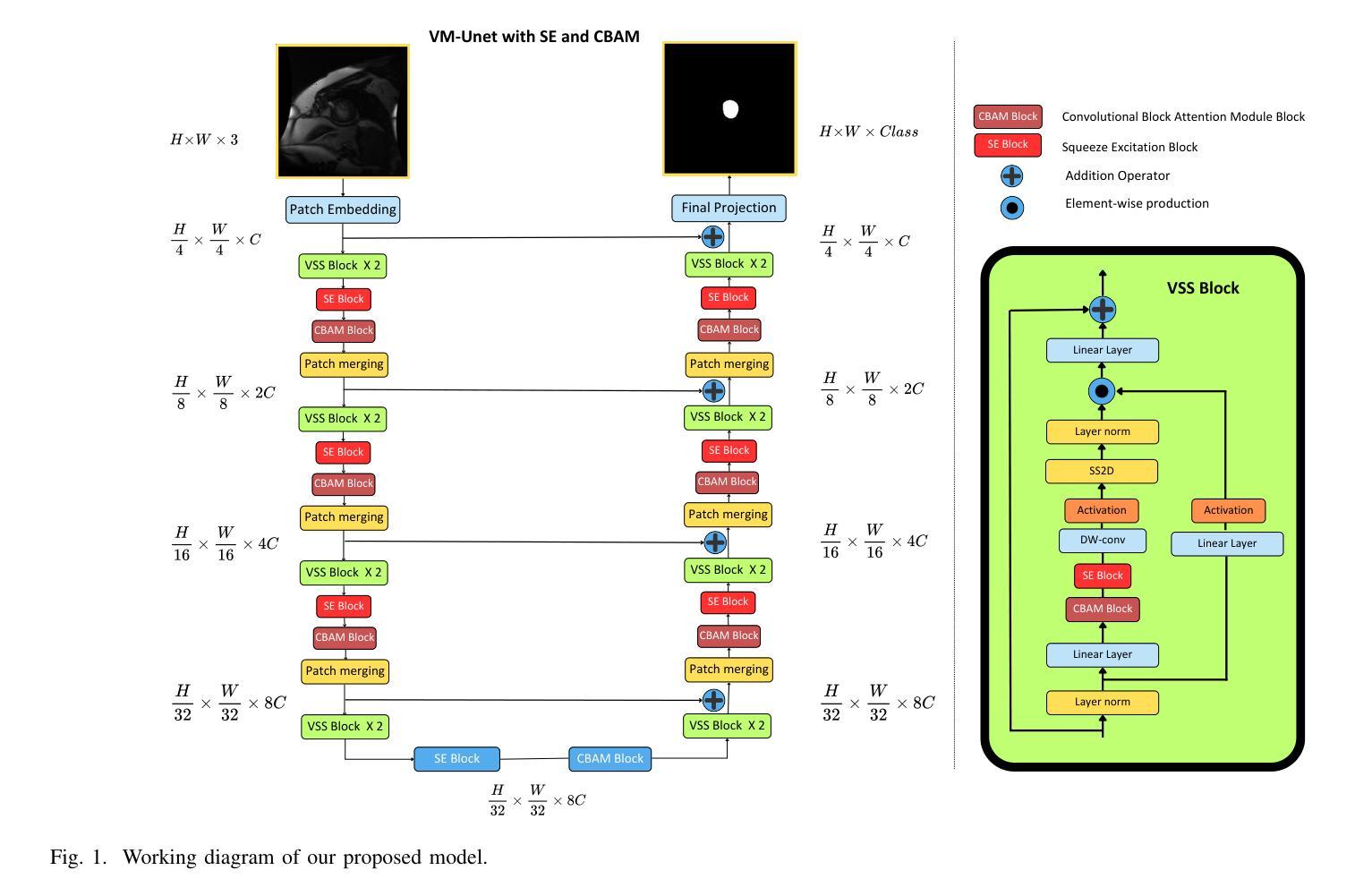
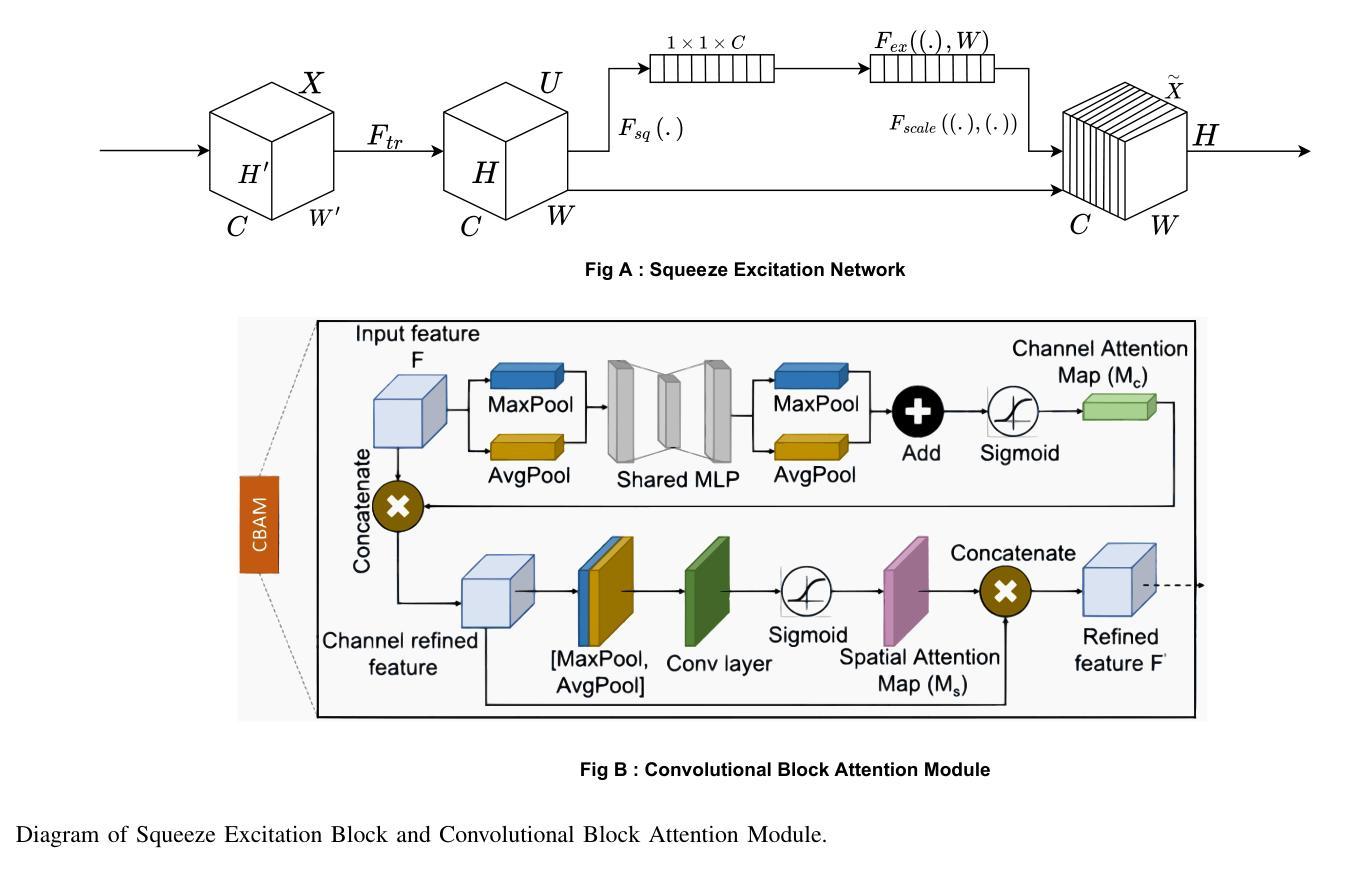
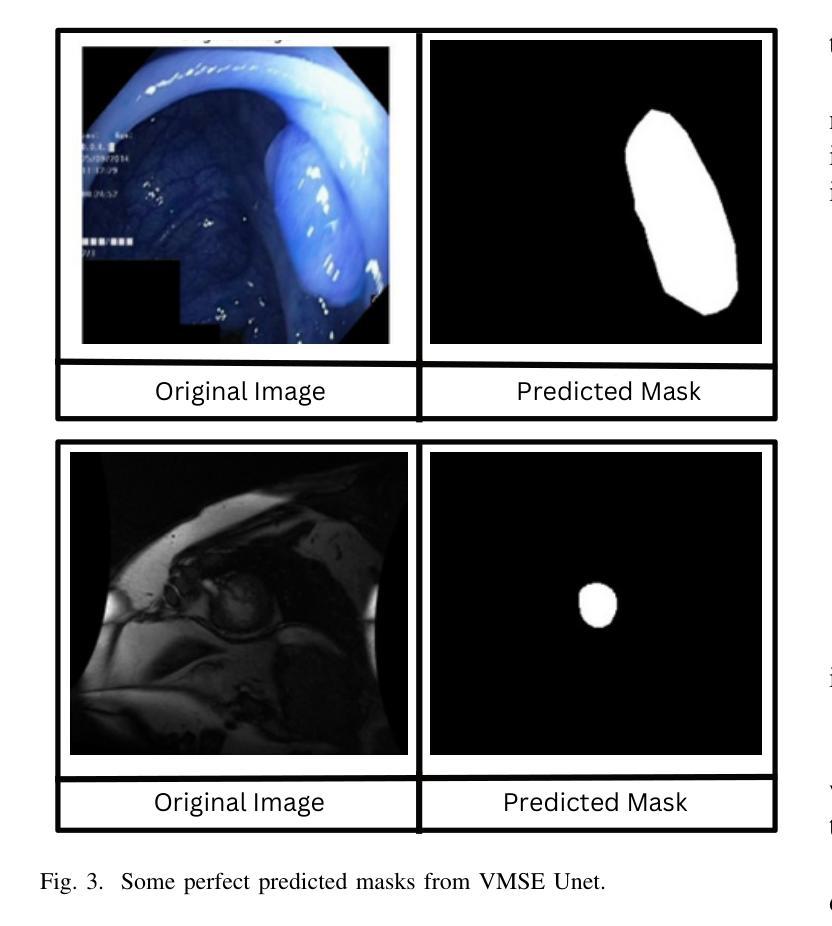
Medical Image Segmentation Using Advanced Unet: VMSE-Unet and VM-Unet CBAM+
Authors:Sayandeep Kanrar, Raja Piyush, Qaiser Razi, Debanshi Chakraborty, Vikas Hassija, GSS Chalapathi
In this paper, we present the VMSE U-Net and VM-Unet CBAM+ model, two cutting-edge deep learning architectures designed to enhance medical image segmentation. Our approach integrates Squeeze-and-Excitation (SE) and Convolutional Block Attention Module (CBAM) techniques into the traditional VM U-Net framework, significantly improving segmentation accuracy, feature localization, and computational efficiency. Both models show superior performance compared to the baseline VM-Unet across multiple datasets. Notably, VMSEUnet achieves the highest accuracy, IoU, precision, and recall while maintaining low loss values. It also exhibits exceptional computational efficiency with faster inference times and lower memory usage on both GPU and CPU. Overall, the study suggests that the enhanced architecture VMSE-Unet is a valuable tool for medical image analysis. These findings highlight its potential for real-world clinical applications, emphasizing the importance of further research to optimize accuracy, robustness, and computational efficiency.
本文介绍了VMSE U-Net和VM-Unet CBAM+模型,这两种先进的深度学习架构旨在增强医学图像分割。我们的方法将压缩和激励(SE)和卷积块注意力模块(CBAM)技术集成到传统的VM U-Net框架中,显著提高了分割精度、特征定位和计算效率。与基线VM-Unet相比,两个模型在多数据集上均表现出卓越的性能。值得注意的是,VMSEUnet在保持低损失值的同时,实现了最高的准确度、IoU、精确度和召回率。此外,它在GPU和CPU上都表现出出色的计算效率,推理时间更快,内存使用更低。总体而言,研究结果表明,增强的VMSE-Unet架构是医学图像分析的有价值的工具。这些发现强调了其在现实世界临床应用中的潜力,并强调了进一步优化准确度、稳健性和计算效率的研究的重要性。
论文及项目相关链接
PDF under review
Summary
本文介绍了VMSE U-Net和VM-Unet CBAM+两个先进的深度学习架构,它们被设计用于提高医学图像分割的效果。通过集成Squeeze-and-Excitation(SE)和卷积块注意力模块(CBAM)技术到传统的VM U-Net框架中,显著提高了分割精度、特征定位能力和计算效率。其中,VMSE U-Net在多个数据集上的表现均优于基准VM-Unet模型,实现了最高的准确性、IoU、精确度和召回率,同时保持较低的损失值。它还在GPU和CPU上表现出卓越的计算效率,具有更快的推理速度和更低的内存使用率。总体而言,优化后的VMSE U-Net架构对于医学图像分析具有重要价值,并有望在真实临床环境中得到应用。
Key Takeaways
- VMSE U-Net和VM-Unet CBAM+是专为医学图像分割设计的深度学习架构。
- 这些模型通过集成SE和CBAM技术,提高了分割精度、特征定位和计算效率。
- VMSE U-Net在多个数据集上的表现优于基准VM-Unet模型。
- VMSE U-Net实现了高准确性、IoU、精确度和召回率,同时保持了较低损失值。
- VMSE U-Net在GPU和CPU上展现出卓越的计算效率,具有更快的推理速度和更低的内存使用。
- 整体而言,VMSE U-Net架构对于医学图像分析具有重要价值。
点此查看论文截图