⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-06 更新
Enhancing Clinical Multiple-Choice Questions Benchmarks with Knowledge Graph Guided Distractor Generation
Authors:Running Yang, Wenlong Deng, Minghui Chen, Yuyin Zhou, Xiaoxiao Li
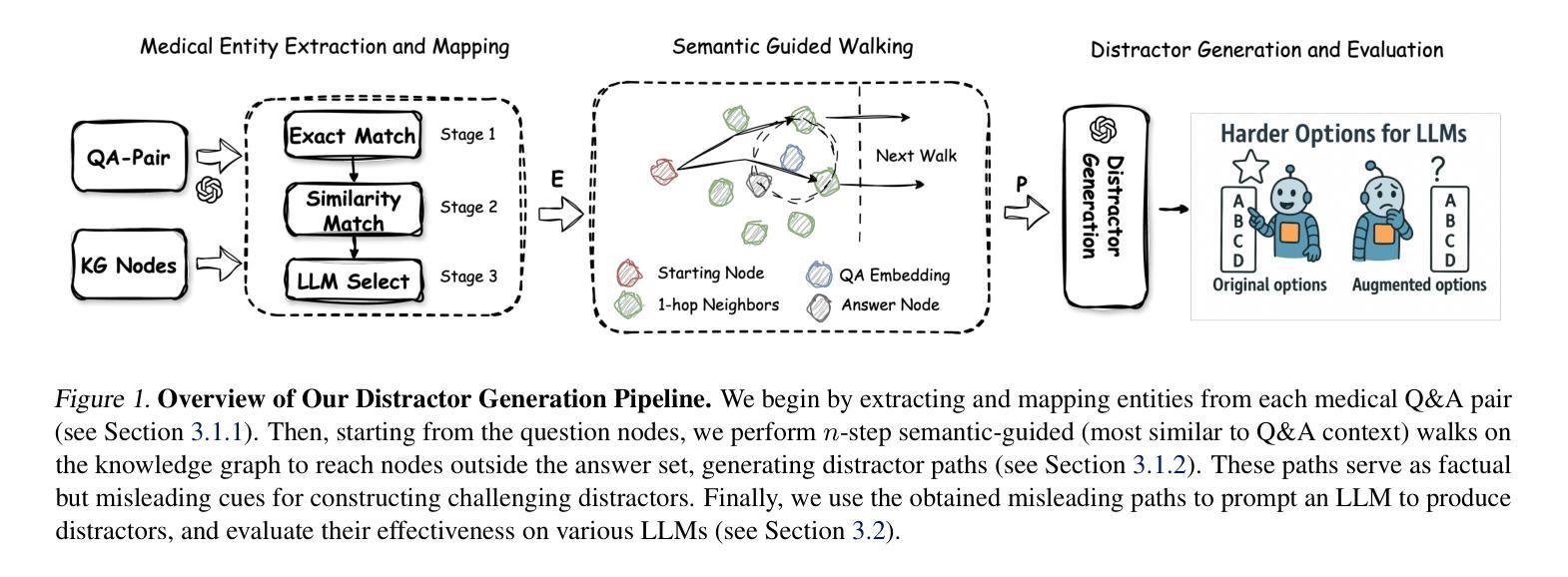
Clinical tasks such as diagnosis and treatment require strong decision-making abilities, highlighting the importance of rigorous evaluation benchmarks to assess the reliability of large language models (LLMs). In this work, we introduce a knowledge-guided data augmentation framework that enhances the difficulty of clinical multiple-choice question (MCQ) datasets by generating distractors (i.e., incorrect choices that are similar to the correct one and may confuse existing LLMs). Using our KG-based pipeline, the generated choices are both clinically plausible and deliberately misleading. Our approach involves multi-step, semantically informed walks on a medical knowledge graph to identify distractor paths-associations that are medically relevant but factually incorrect-which then guide the LLM in crafting more deceptive distractors. We apply the designed knowledge graph guided distractor generation (KGGDG) pipline, to six widely used medical QA benchmarks and show that it consistently reduces the accuracy of state-of-the-art LLMs. These findings establish KGGDG as a powerful tool for enabling more robust and diagnostic evaluations of medical LLMs.
临床任务如诊断和治疗后决策,强调需要强大的决策能力评估大语言模型的可信度的重要性。在这项工作中,我们引入了一个知识引导的数据增强框架,通过生成干扰项(即与正确答案相似但可能混淆现有大型语言模型的错误选择)来提高临床选择题集的难度。使用我们的基于知识的管道,生成的选项既符合临床合理性又故意具有误导性。我们的方法涉及在医疗知识图上执行多步语义信息驱动路径,以识别干扰项路径关联(医学相关但事实错误),然后指导大型语言模型制作更具欺骗性的干扰项。我们将设计的知识图谱引导干扰项生成管道应用于六个广泛使用的医疗问答基准测试,并证明它始终降低了最新大型语言模型的准确性。这些发现确立了知识图谱引导干扰项生成法作为进行更稳健诊断评估医疗大型语言模型的强大工具。
论文及项目相关链接
摘要
本文介绍了一个知识引导的数据增强框架,通过生成干扰项(与正确答案相似但可能混淆现有大型语言模型LLM的错误选择)来提高临床选择题集的难度。该方法涉及在医疗知识图上进行多步语义信息走查,以识别干扰项路径(医学相关但事实错误的关联),然后指导LLM制作更具欺骗性的干扰项。应用该知识图谱引导干扰项生成(KGGDG)管道于六个广泛使用的医疗问答基准测试集,表明它始终降低了最先进的大型语言模型的准确性。这为更稳健和诊断性评估医疗LLM提供了有力工具。
要点摘要
- 临床任务如诊断和治疗的决策能力至关重要,需要严格评估基准测试大型语言模型(LLM)的可靠性。
- 介绍了一个知识引导的数据增强框架,用于提高临床选择题集的难度。
- 生成干扰项,即与正确答案相似但可能混淆现有LLM的错误选择。
- 知识图谱引导干扰项生成(KGGDG)管道涉及在医疗知识图上多步语义信息走查。
- KGGDG管道能识别医学相关但事实错误的干扰项路径。
- 应用该管道于六个广泛使用的医疗问答基准测试集,显示其降低了最先进的大型语言模型的准确性。
- 为更稳健和诊断性评估医疗LLM提供了有力工具。
点此查看论文截图

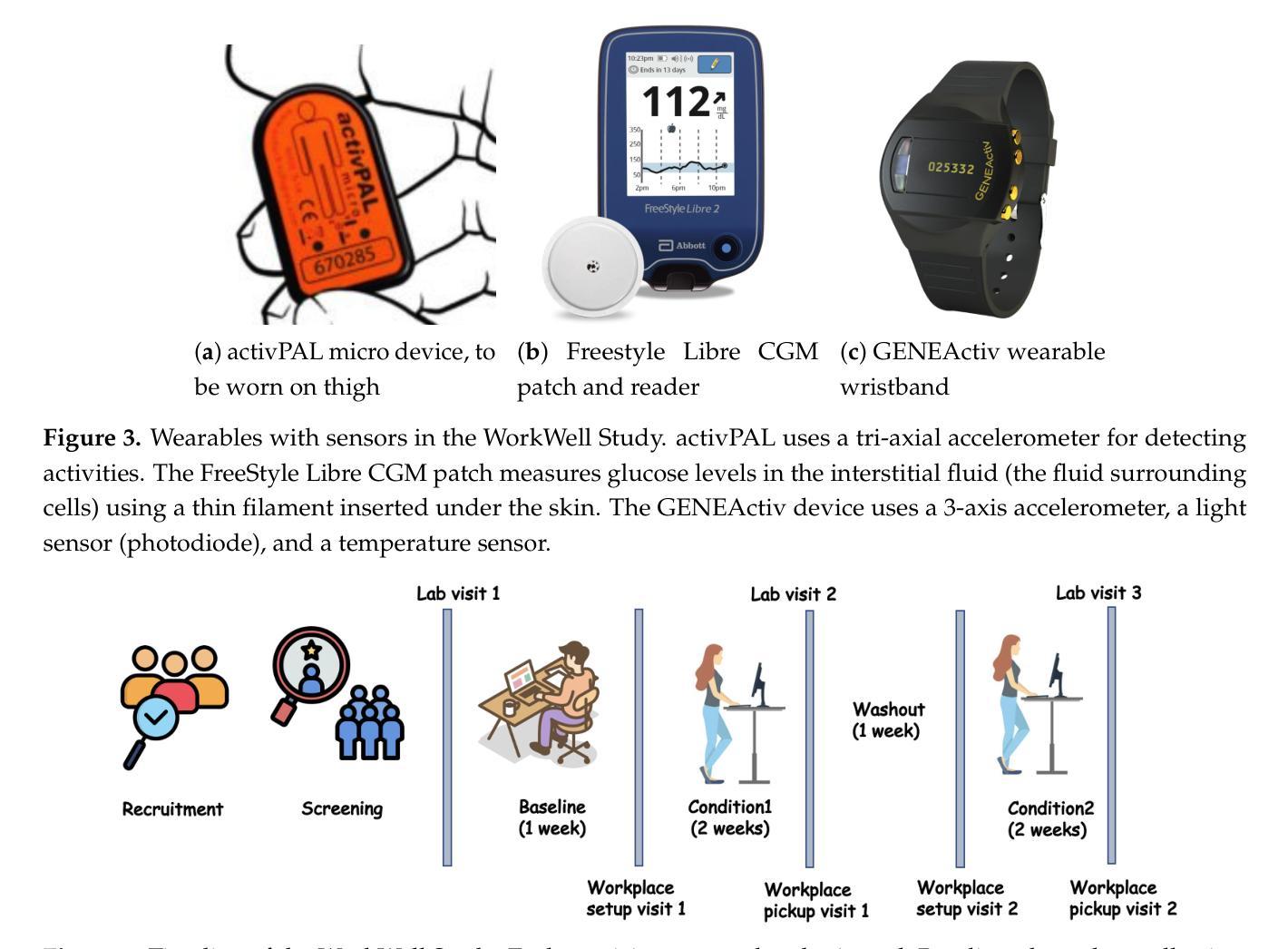
LLM-Powered Prediction of Hyperglycemia and Discovery of Behavioral Treatment Pathways from Wearables and Diet
Authors:Abdullah Mamun, Asiful Arefeen, Susan B. Racette, Dorothy D. Sears, Corrie M. Whisner, Matthew P. Buman, Hassan Ghasemzadeh
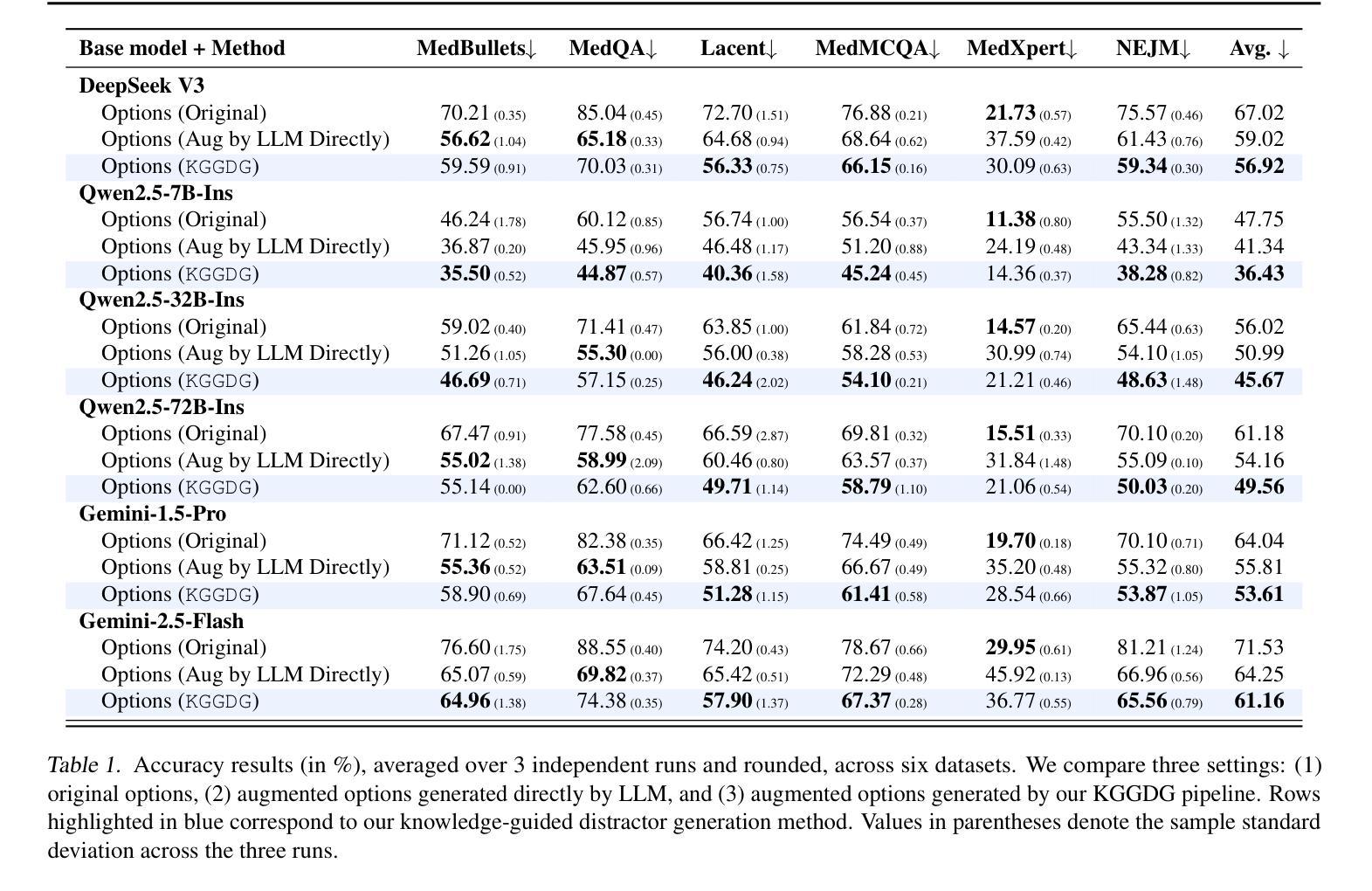
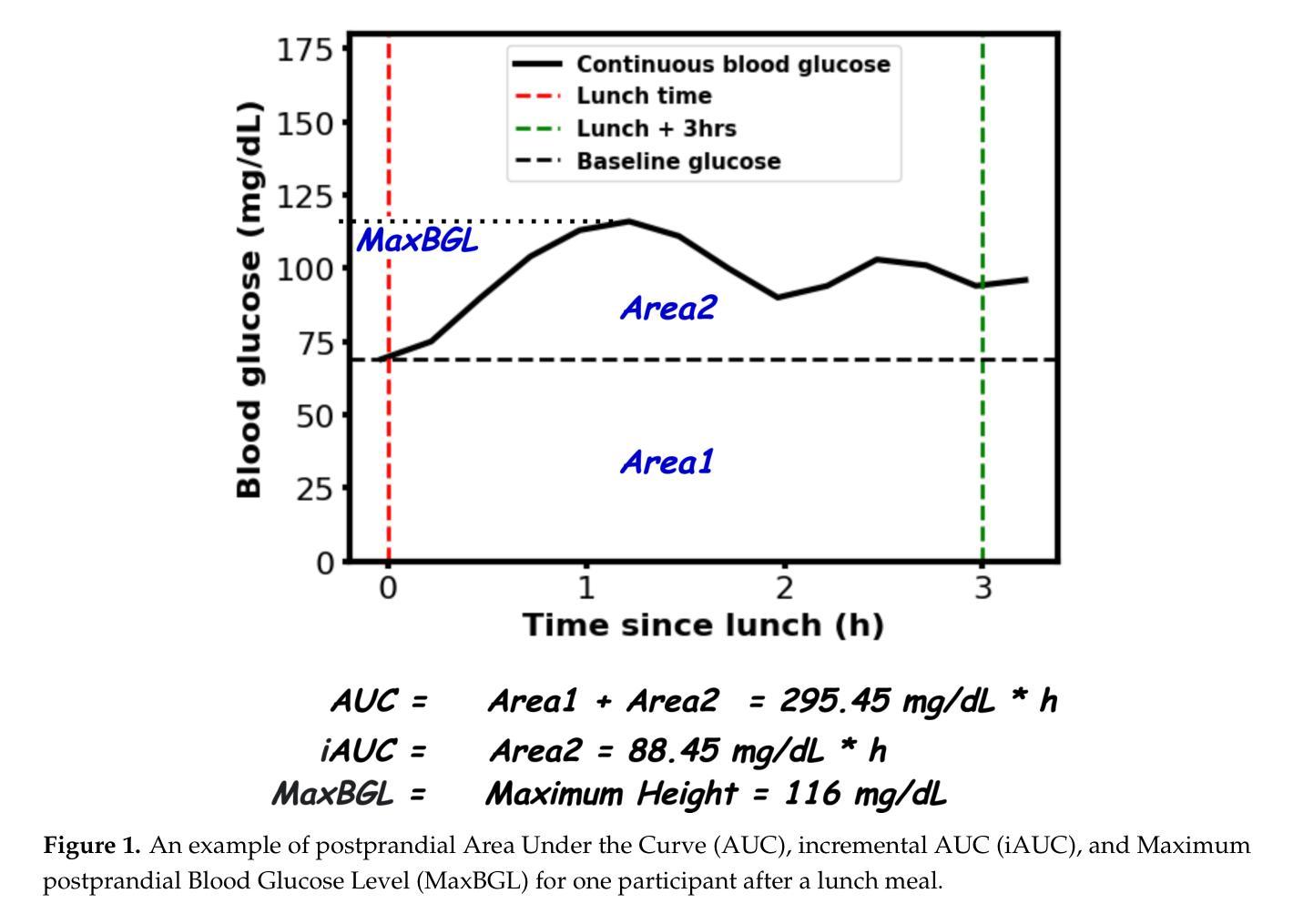
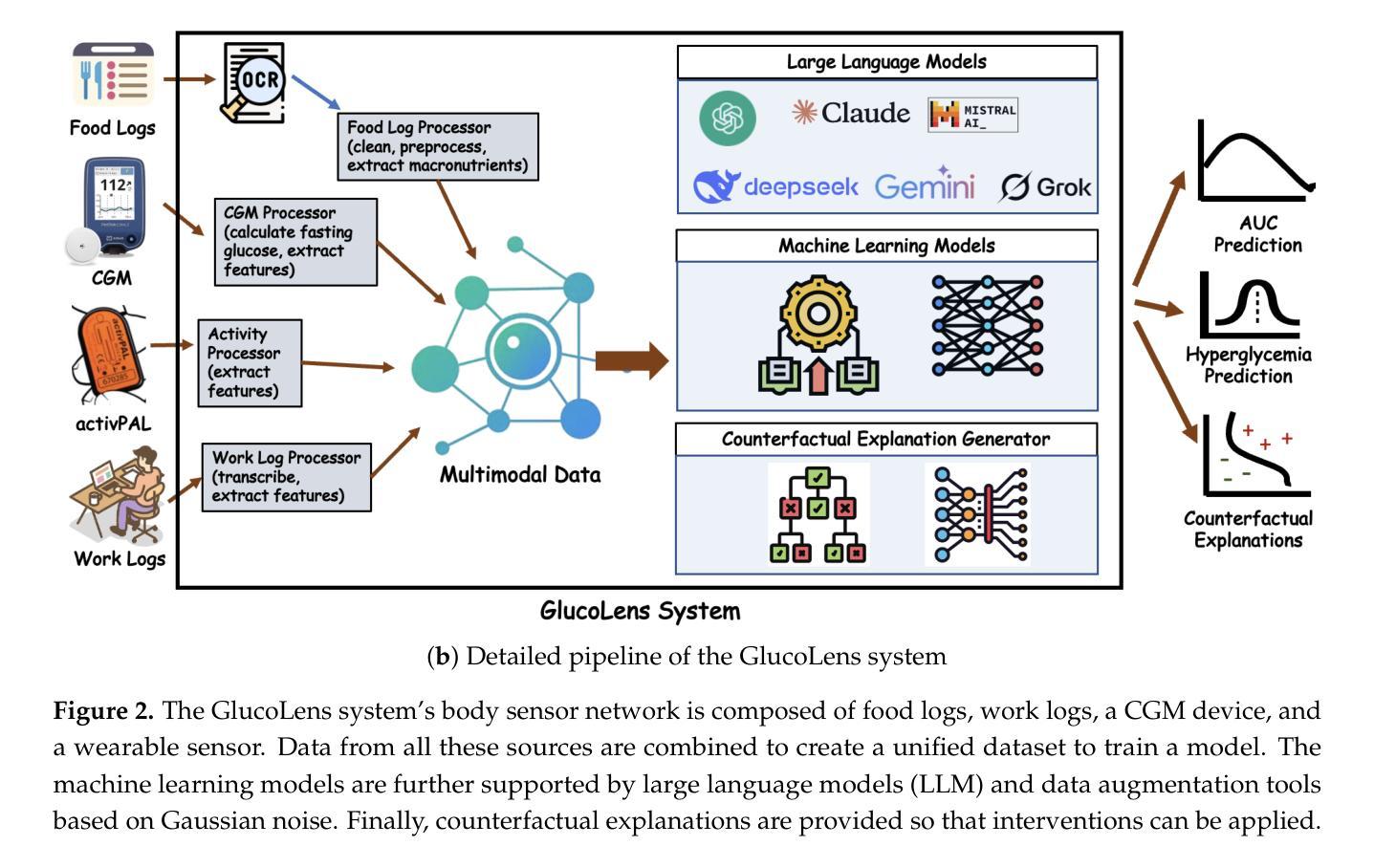
Postprandial hyperglycemia, marked by the blood glucose level exceeding the normal range after consuming a meal, is a critical indicator of progression toward type 2 diabetes in people with prediabetes and in healthy individuals. A key metric for understanding blood glucose dynamics after eating is the postprandial area under the curve (AUC). Predicting postprandial AUC in advance based on a person’s lifestyle factors, such as diet and physical activity level, and explaining the factors that affect postprandial blood glucose could allow an individual to adjust their lifestyle accordingly to maintain normal glucose levels. In this study, we developed an explainable machine learning solution, GlucoLens, that takes sensor-driven inputs and uses advanced data processing, large language models, and trainable machine learning models to predict postprandial AUC and hyperglycemia from diet, physical activity, and recent glucose patterns. We used data obtained from wearables in a five-week clinical trial of 10 adults who worked full-time to develop and evaluate the proposed computational model that integrates wearable sensing, multimodal data, and machine learning. Our machine learning model takes multimodal data from wearable activity and glucose monitoring sensors, along with food and work logs, and provides an interpretable prediction of the postprandial glucose pattern. Our GlucoLens system achieves a normalized root mean squared error (NRMSE) of 0.123 in its best configuration. On average, the proposed technology provides a 16% better performance level compared to the comparison models. Additionally, our technique predicts hyperglycemia with an accuracy of 73.3% and an F1 score of 0.716 and recommends different treatment options to help avoid hyperglycemia through diverse counterfactual explanations. Code available: https://github.com/ab9mamun/GlucoLens.
餐后高血糖,表现为餐后血糖水平超过正常范围,是糖尿病前期患者和健康个体进展为2型糖尿病的重要标志。了解进食后血糖动态变化的关键指标是餐后曲线下面积(AUC)。根据一个人的生活方式因素,如饮食和体育活动水平,预先预测餐后AUC,并解释影响餐后血糖的因素,可以允许个人相应地调整其生活方式以保持正常的血糖水平。在这项研究中,我们开发了一种可解释的机器学习解决方案GlucoLens,它采用传感器驱动输入,使用先进的数据处理、大型语言模型和可训练的机器学习模型,根据饮食、体育活动和最近的血糖模式预测餐后AUC和餐后高血糖。我们使用来自全职工作的10名成年人进行的为期五周的临床试验期间可穿戴设备获得的数据,来开发并评估所提出的计算模型,该模型整合了可穿戴传感器、多模式数据和机器学习。我们的机器学习模型采用来自可穿戴活动和血糖监测传感器的多模式数据,以及食物和工作日志,提供可解释的餐后血糖模式预测。在我们的最佳配置中,GlucoLens系统的归一化均方根误差(NRMSE)达到0.123。平均而言,与对比模型相比,所提出的技术提供了16%的更高性能水平。此外,我们的技术以73.3%的准确率和0.716的F1分数预测高血糖,并提供不同的治疗方案,通过不同的反事实解释帮助避免高血糖。代码可用:https://github.com/ab9mamun/GlucoLens。
论文及项目相关链接
PDF 16 pages, 10 figures
Summary
该文研究了通过机器学习模型预测餐后血糖水平的方法。该模型结合了可穿戴设备感知的数据,包括活动、葡萄糖监测、饮食和工作日志等多模式数据,以预测餐后血糖曲线下的面积(AUC)和餐后高血糖情况。模型名为GlucoLens,通过高级数据处理和大型语言模型训练,实现了对餐后血糖的预测,并提供了对预防高血糖的治疗建议。模型性能良好,与对比模型相比平均提高了16%的性能水平。代码已公开在GitHub上。
Key Takeaways
- 研究重点是通过机器学习模型预测餐后血糖水平,特别是预测餐后血糖曲线下的面积(AUC)。
- 模型结合了可穿戴设备感知的多模式数据,包括活动、葡萄糖监测、饮食和工作日志等。
- 模型名为GlucoLens,采用高级数据处理和大型语言模型训练。
- 模型能预测餐后高血糖情况,并提供预防高血糖的治疗建议。
- 模型性能良好,与对比模型相比提高了16%的性能水平。
- 模型预测高血糖的准确率为73.3%,F1分数为0.716。
点此查看论文截图

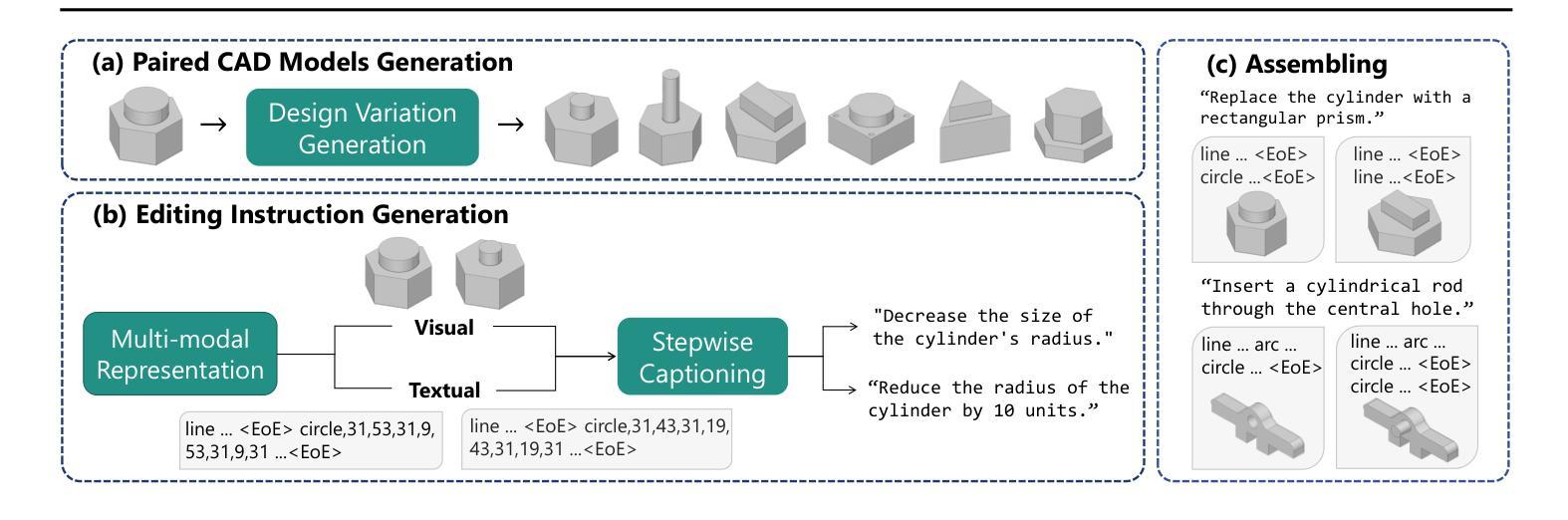
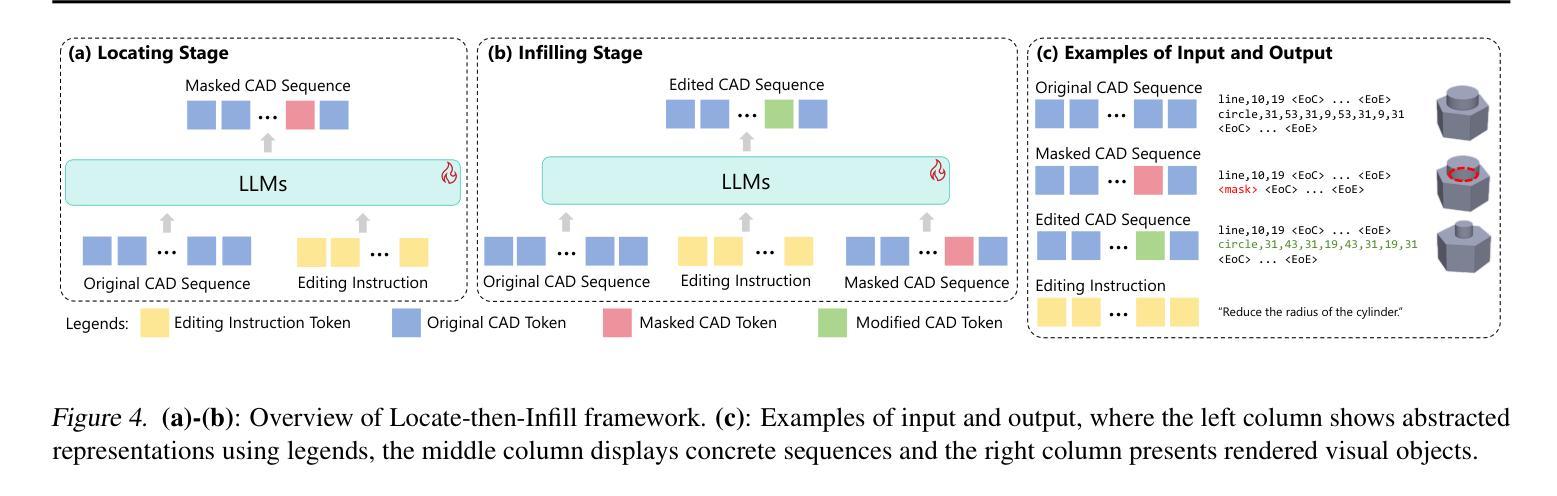
CAD-Editor: A Locate-then-Infill Framework with Automated Training Data Synthesis for Text-Based CAD Editing
Authors:Yu Yuan, Shizhao Sun, Qi Liu, Jiang Bian
Computer Aided Design (CAD) is indispensable across various industries. \emph{Text-based CAD editing}, which automates the modification of CAD models based on textual instructions, holds great potential but remains underexplored. Existing methods primarily focus on design variation generation or text-based CAD generation, either lacking support for text-based control or neglecting existing CAD models as constraints. We introduce \emph{CAD-Editor}, the first framework for text-based CAD editing. To address the challenge of demanding triplet data with accurate correspondence for training, we propose an automated data synthesis pipeline. This pipeline utilizes design variation models to generate pairs of original and edited CAD models and employs Large Vision-Language Models (LVLMs) to summarize their differences into editing instructions. To tackle the composite nature of text-based CAD editing, we propose a locate-then-infill framework that decomposes the task into two focused sub-tasks: locating regions requiring modification and infilling these regions with appropriate edits. Large Language Models (LLMs) serve as the backbone for both sub-tasks, leveraging their capabilities in natural language understanding and CAD knowledge. Experiments show that CAD-Editor achieves superior performance both quantitatively and qualitatively. The code is available at \url {https://github.com/microsoft/CAD-Editor}.
计算机辅助设计(CAD)在各行各业都是不可或缺的。基于文本的CAD编辑能够自动根据文本指令修改CAD模型,具有巨大的潜力,但尚未得到充分探索。现有方法主要集中在设计变体生成或基于文本的CAD生成上,要么不支持基于文本的控件,要么忽视现有CAD模型作为约束。我们引入了基于文本的CAD编辑首个框架——CAD-Editor。为解决训练时所需的三元组数据对应不准确的问题,我们提出了自动化数据合成管道。该管道利用设计变体模型生成原始和编辑后的CAD模型对,并采用大型视觉语言模型(LVLMs)将其差异总结为编辑指令。为解决基于文本的CAD编辑的复合性质,我们提出了先定位后填充的框架,将任务分解为两个专项子任务:定位需要修改的区域,并用适当的编辑填充这些区域。大型语言模型(LLMs)作为这两个子任务的后盾,利用其在自然语言理解和CAD知识方面的能力。实验表明,CAD-Editor在量和质上都取得了卓越的性能。代码可在\url{https://github.com/microsoft/CAD-Editor}找到。
论文及项目相关链接
Summary
文本介绍了计算机辅助设计(CAD)的重要性以及基于文本的CAD编辑的潜力。现有方法存在不足,主要关注设计变化生成或基于文本的CAD生成,缺乏文本控制或对现有CAD模型作为约束的考虑。为此,我们引入了CAD-Editor框架,采用自动化数据合成管道解决训练数据需求问题,并提出定位填充框架解决基于文本的CAD编辑的复合性质问题。实验表明,CAD-Editor在定量和定性方面都取得了卓越的性能。
Key Takeaways
- 计算机辅助设计(CAD)在各行各业中不可或缺。
- 基于文本的CAD编辑有很大的潜力,但目前尚待探索。
- 现有方法主要关注设计变化生成或基于文本的CAD生成,缺乏文本控制或对现有CAD模型的考虑。
- CAD-Editor是首个基于文本的CAD编辑框架,解决了这一挑战。
- 采用自动化数据合成管道解决训练数据需求问题。
- 提出定位填充框架以解决基于文本的CAD编辑的复合性质问题。
点此查看论文截图



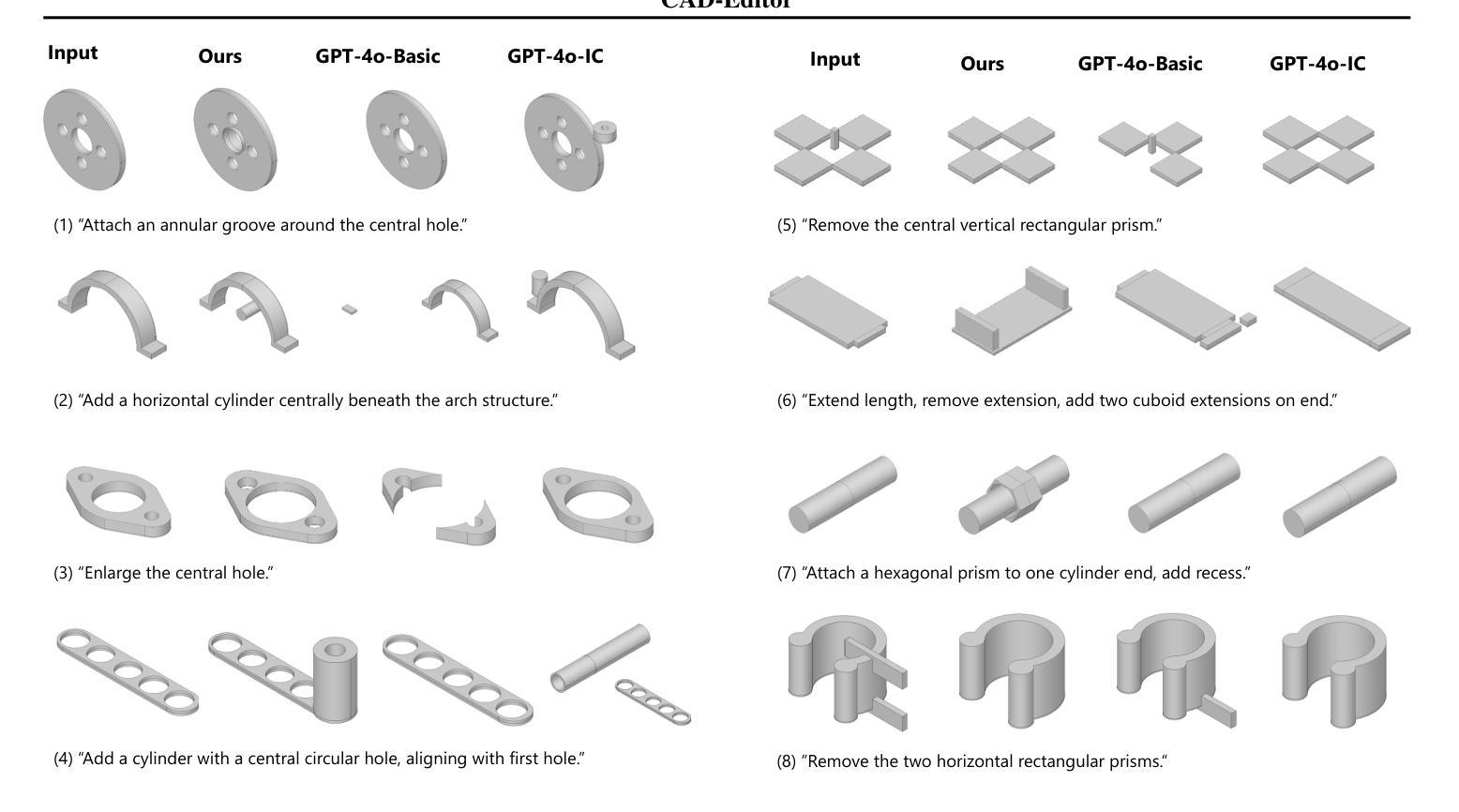
MAPS: Advancing Multi-Modal Reasoning in Expert-Level Physical Science
Authors:Erle Zhu, Yadi Liu, Zhe Zhang, Xujun Li, Jin Zhou, Xinjie Yu, Minlie Huang, Hongning Wang
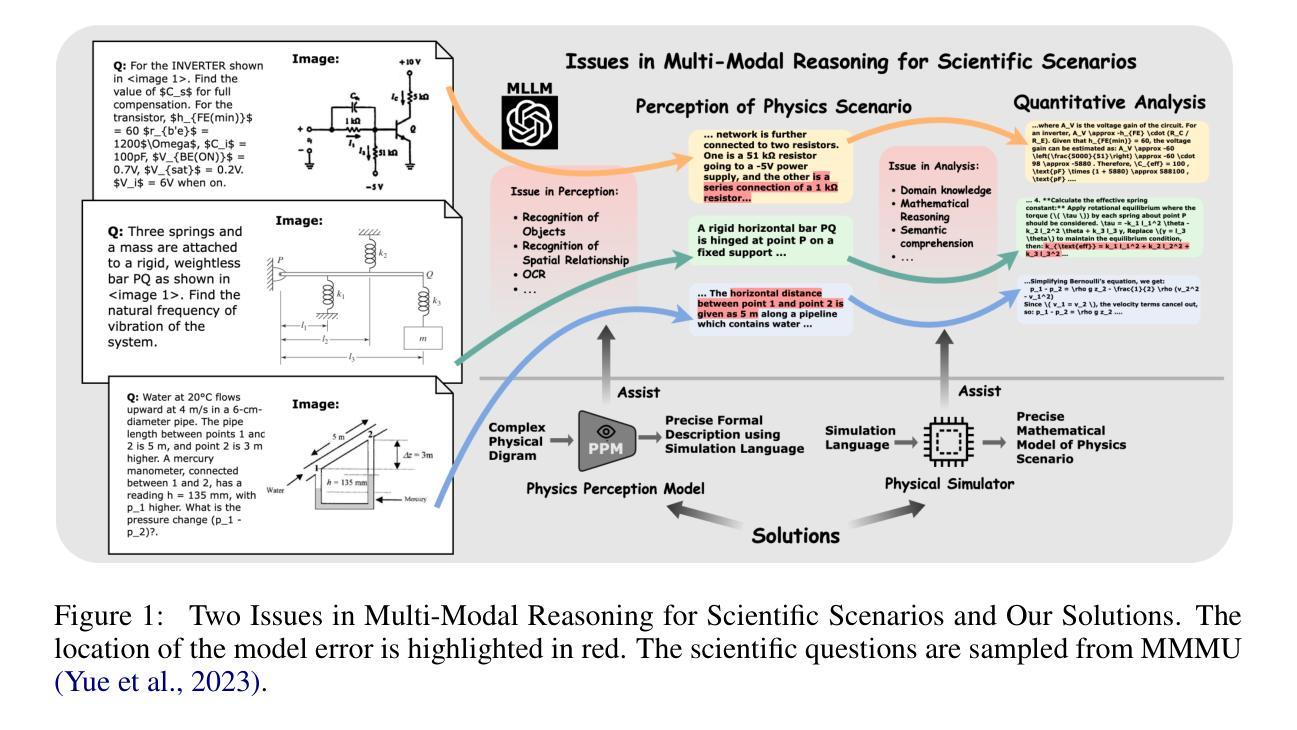
Pre-trained on extensive text and image corpora, current Multi-Modal Large Language Models (MLLM) have shown strong capabilities in general visual reasoning tasks. However, their performance is still lacking in physical domains that require understanding diagrams with complex physical structures and quantitative analysis based on multi-modal information. To address this, we develop a new framework, named Multi-Modal Scientific Reasoning with Physics Perception and Simulation (MAPS) based on an MLLM. MAPS decomposes expert-level multi-modal reasoning task into physical diagram understanding via a Physical Perception Model (PPM) and reasoning with physical knowledge via a simulator. The PPM module is obtained by fine-tuning a visual language model using carefully designed synthetic data with paired physical diagrams and corresponding simulation language descriptions. At the inference stage, MAPS integrates the simulation language description of the input diagram provided by PPM and results obtained through a Chain-of-Simulation process with MLLM to derive the underlying rationale and the final answer. Validated using our collected college-level circuit analysis problems, MAPS significantly improves reasoning accuracy of MLLM and outperforms all existing models. The results confirm MAPS offers a promising direction for enhancing multi-modal scientific reasoning ability of MLLMs. We will release our code, model and dataset used for our experiments upon publishing of this paper.
基于大规模文本和图像语料库的预训练,当前的多模态大型语言模型(MLLM)在一般的视觉推理任务中表现出了强大的能力。然而,它们在需要理解具有复杂物理结构的图表以及基于多模态信息进行定量分析的物理领域中的表现仍然不足。为了解决这一问题,我们开发了一个名为基于物理感知与模拟的多模态科学推理(MAPS)的新框架,该框架基于MLLM。MAPS将专家级的多模态推理任务分解为通过物理感知模型(PPM)理解物理图表和通过模拟器进行物理知识推理。PPM模块是通过使用精心设计的合成数据对视觉语言模型进行微调而获得的,这些数据包括配对的物理图表和相应的模拟语言描述。在推理阶段,MAPS结合了PPM提供的输入图表的模拟语言描述以及通过模拟链过程与MLLM获得的结果,从而得出基本理由和最终答案。使用我们收集的大学电路分析问题进行验证,MAPS显著提高了MLLM的推理准确性,并超越了所有现有模型。结果证实,MAPS为增强MLLM的多模态科学推理能力提供了一个有前途的方向。在论文发表时,我们将公布我们的代码、模型和用于实验的数据集。
论文及项目相关链接
Summary
基于多模态大型语言模型(MLLM),结合物理感知与模拟的框架(MAPS)解决了在复杂物理结构理解和多模态信息基础上的定量分析问题上的不足。MAPS将专家级的多模态推理任务分解为通过物理感知模型(PPM)理解物理图表和通过模拟器进行物理知识推理两部分。PPM模块通过精心设计的合成数据对视觉语言模型进行微调,配合模拟语言描述和仿真链过程,推导出最终答案。在电路分析问题的实验中,MAPS显著提高了MLLM的推理准确性,并优于现有模型,为增强MLLM的多模态科学推理能力提供了有前景的方向。
Key Takeaways
- 当前的多模态大型语言模型(MLLM)在一般视觉推理任务中表现出强大的能力,但在涉及复杂物理结构和多模态信息的定量分析方面仍显不足。
- 针对这一问题,提出了一种新的框架——MAPS,该框架基于MLLM,并将其分解为物理图表理解和通过模拟器进行物理知识的推理两部分。
- MAPS通过使用物理感知模型(PPM)理解物理图表,该模块通过精心设计的合成数据和配套的模拟语言描述对视觉语言模型进行微调。
- 在推理阶段,MAPS结合了PPM提供的输入图表的模拟语言描述和通过仿真链过程得到的结果,推导出答案。
- 通过电路分析问题的实验验证,MAPS显著提高了MLLM的推理准确性,且优于现有模型。
- MAPS为增强MLLM的多模态科学推理能力提供了有前景的方向。
点此查看论文截图

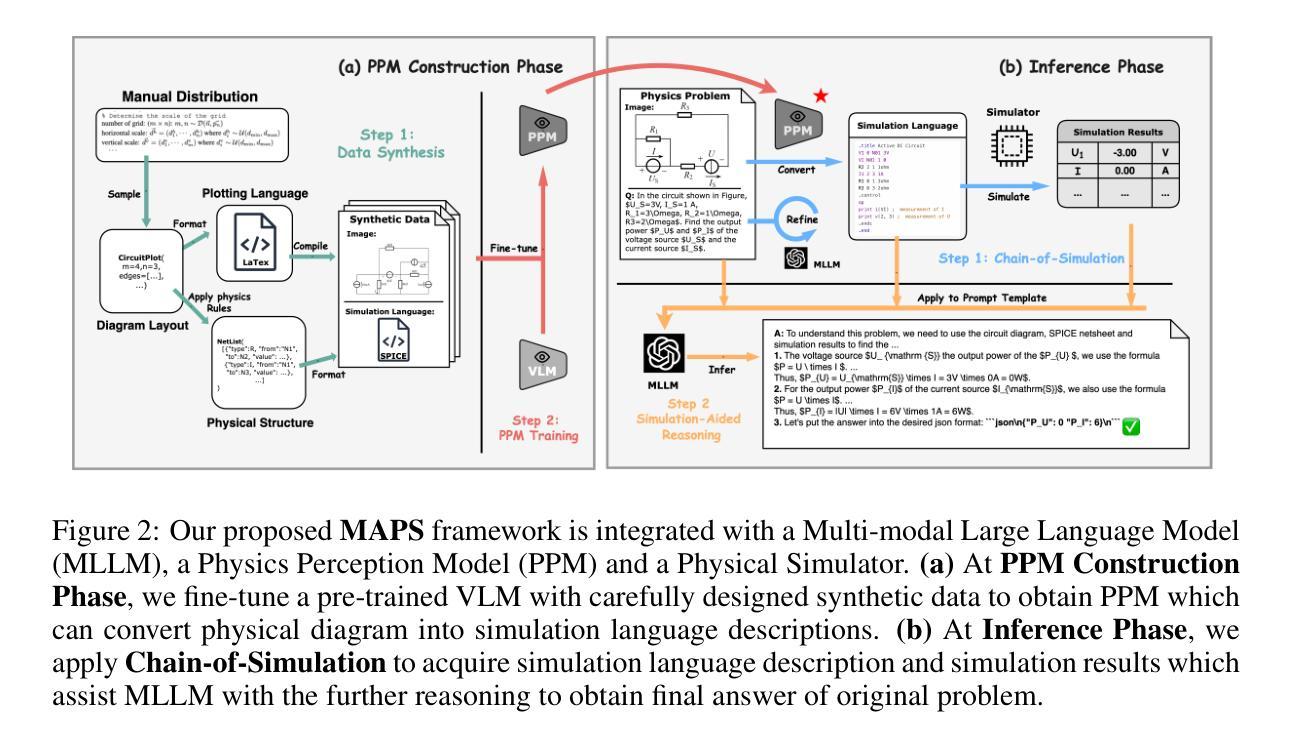
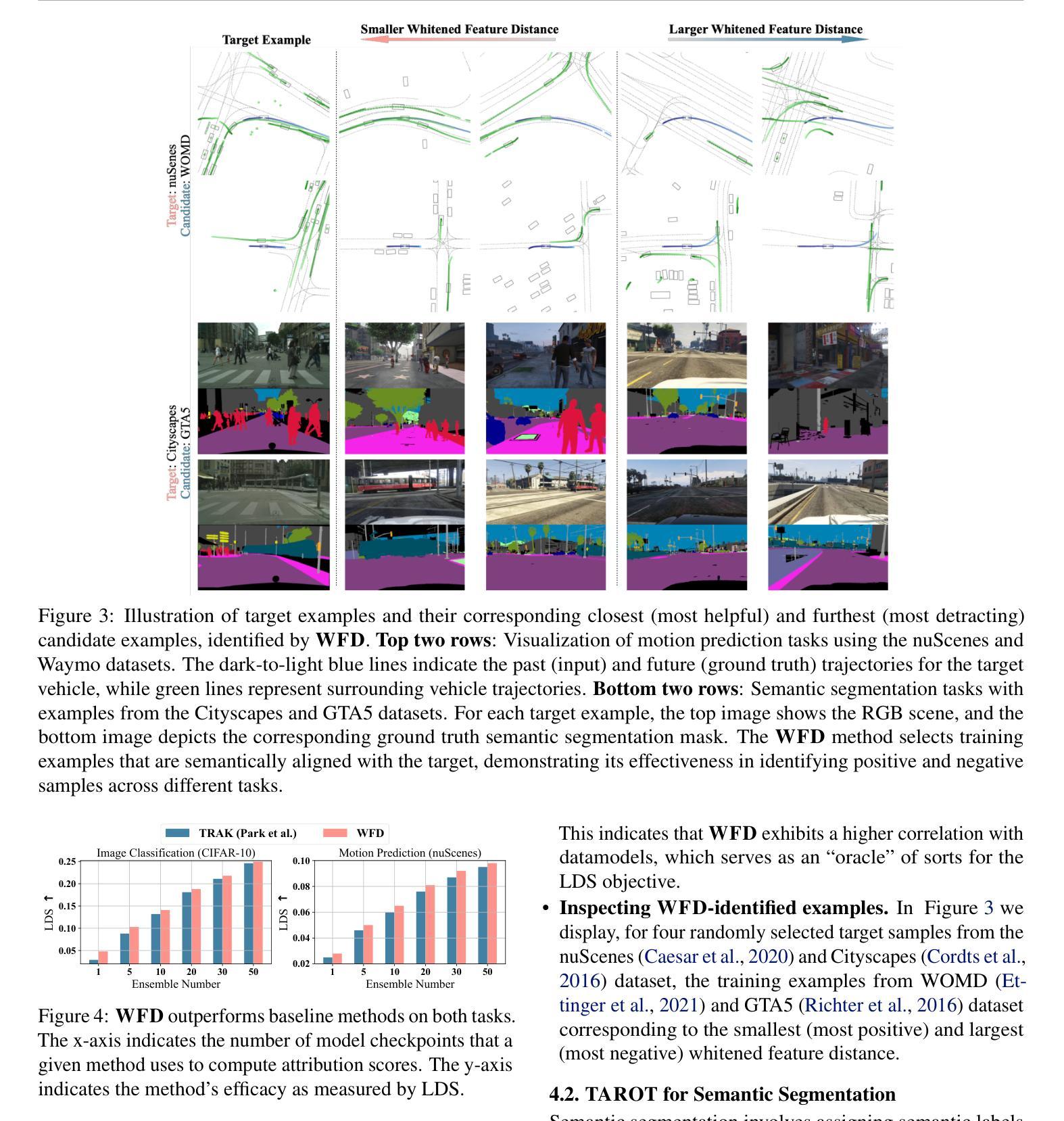
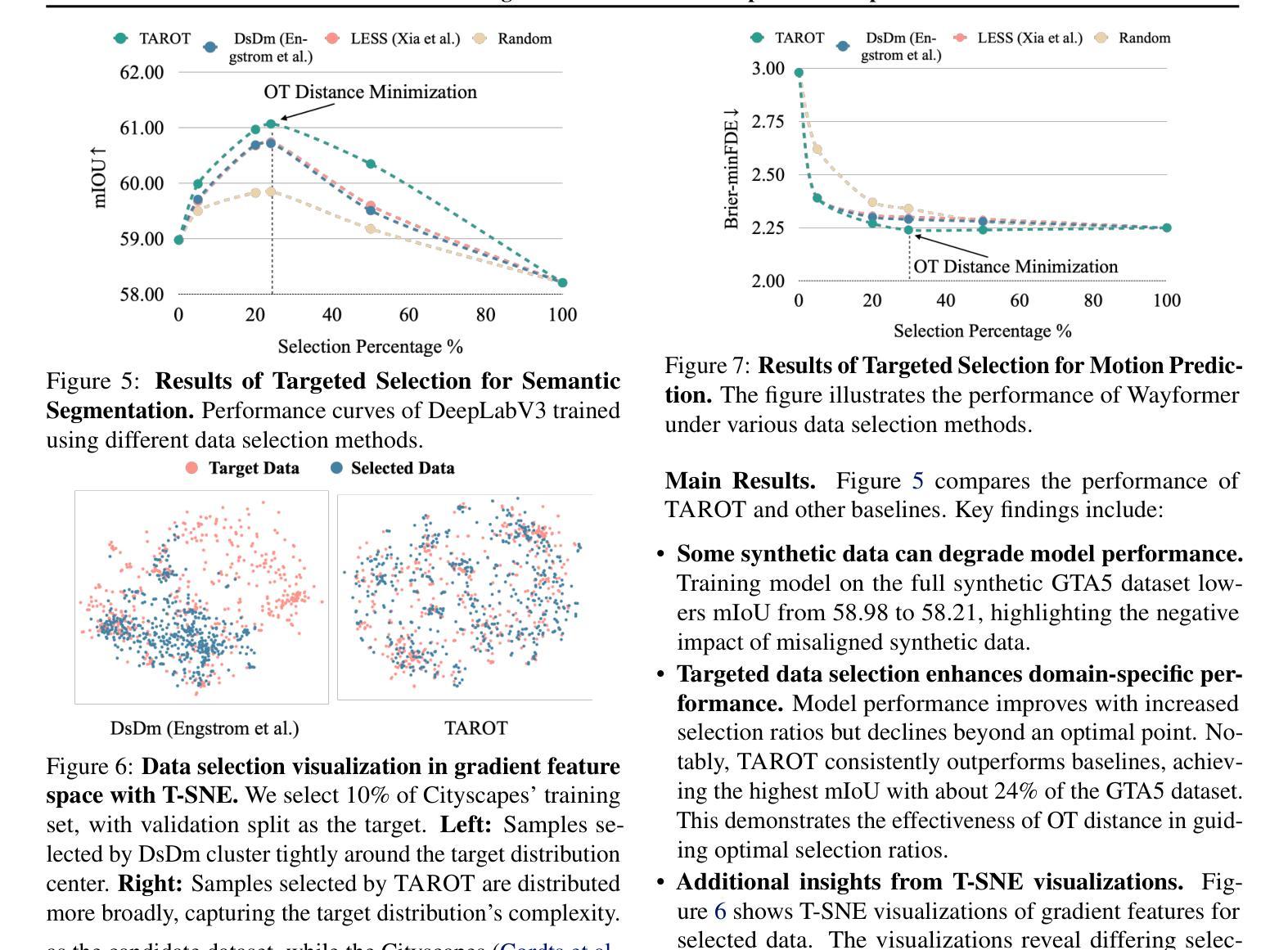
TAROT: Targeted Data Selection via Optimal Transport
Authors:Lan Feng, Fan Nie, Yuejiang Liu, Alexandre Alahi
We propose TAROT, a targeted data selection framework grounded in optimal transport theory. Previous targeted data selection methods primarily rely on influence-based greedy heuristics to enhance domain-specific performance. While effective on limited, unimodal data (i.e., data following a single pattern), these methods struggle as target data complexity increases. Specifically, in multimodal distributions, these heuristics fail to account for multiple inherent patterns, leading to suboptimal data selection. This work identifies two primary factors contributing to this limitation: (i) the disproportionate impact of dominant feature components in high-dimensional influence estimation, and (ii) the restrictive linear additive assumptions inherent in greedy selection strategies. To address these challenges, TAROT incorporates whitened feature distance to mitigate dominant feature bias, providing a more reliable measure of data influence. Building on this, TAROT uses whitened feature distance to quantify and minimize the optimal transport distance between the selected data and target domains. Notably, this minimization also facilitates the estimation of optimal selection ratios. We evaluate TAROT across multiple tasks, including semantic segmentation, motion prediction, and instruction tuning. Results consistently show that TAROT outperforms state-of-the-art methods, highlighting its versatility across various deep learning tasks. Code is available at https://github.com/vita-epfl/TAROT.
我们提出了TAROT,这是一个基于最优传输理论的目标数据选择框架。以往的目标数据选择方法主要依赖于基于影响的贪婪启发式策略来提高特定领域的性能。这些方法在有限、单峰数据(即遵循单一模式的数据)上很有效,但当目标数据复杂性增加时,这些方法就会遇到困难。具体来说,在多峰分布中,这些启发式方法无法考虑多个固有模式,导致数据选择不佳。这项工作确定了导致这一局限的两个主要因素:(i)在高维影响估计中,主要特征分量的不成比例影响;(ii)贪婪选择策略中固有的限制性线性假设。为了解决这些挑战,TAROT结合了白化特征距离来缓解主要特征偏见,提供更可靠的数据影响度量。在此基础上,TAROT使用白化特征距离来量化和最小化所选数据和目标域之间的最优传输距离。值得注意的是,这种最小化也促进了最佳选择比例的估计。我们在多个任务上评估了TAROT,包括语义分割、运动预测和指令调整。结果一致表明,TAROT优于最新方法,突显了其在各种深度学习任务中的通用性。代码可在https://github.com/vita-epfl/TAROT找到。
论文及项目相关链接
Summary
TAROT是一个基于最优传输理论的目标数据选择框架。与传统的基于影响力的贪婪启发式方法相比,TAROT在复杂目标数据上表现更优,特别是在多模态分布数据上。它通过采用白化特征距离来减轻主导特征偏见的影响,并提供更可靠的数据影响度量。此外,TAROT使用白化特征距离来量化和最小化所选数据与目标域之间的最优传输距离,这有助于估算最佳选择比例。在多个任务上的评估表明,TAROT优于现有方法,突显其在各种深度学习任务中的通用性。
Key Takeaways
- TAROT是一个基于最优传输理论的目标数据选择框架,旨在解决传统方法在复杂数据上的局限性。
- 传统方法主要依赖基于影响力的贪婪启发式策略,这在多模态分布数据中表现不佳。
- TAROT通过引入白化特征距离来减轻主导特征偏见,提供更可靠的数据影响度量。
- TAROT使用白化特征距离量化和最小化所选数据与目标域之间的最优传输距离。
- TAROT有助于估算最佳数据选择比例。
- 在多个任务(如语义分割、运动预测和指令调整)上的评估表明,TAROT优于现有方法。
点此查看论文截图

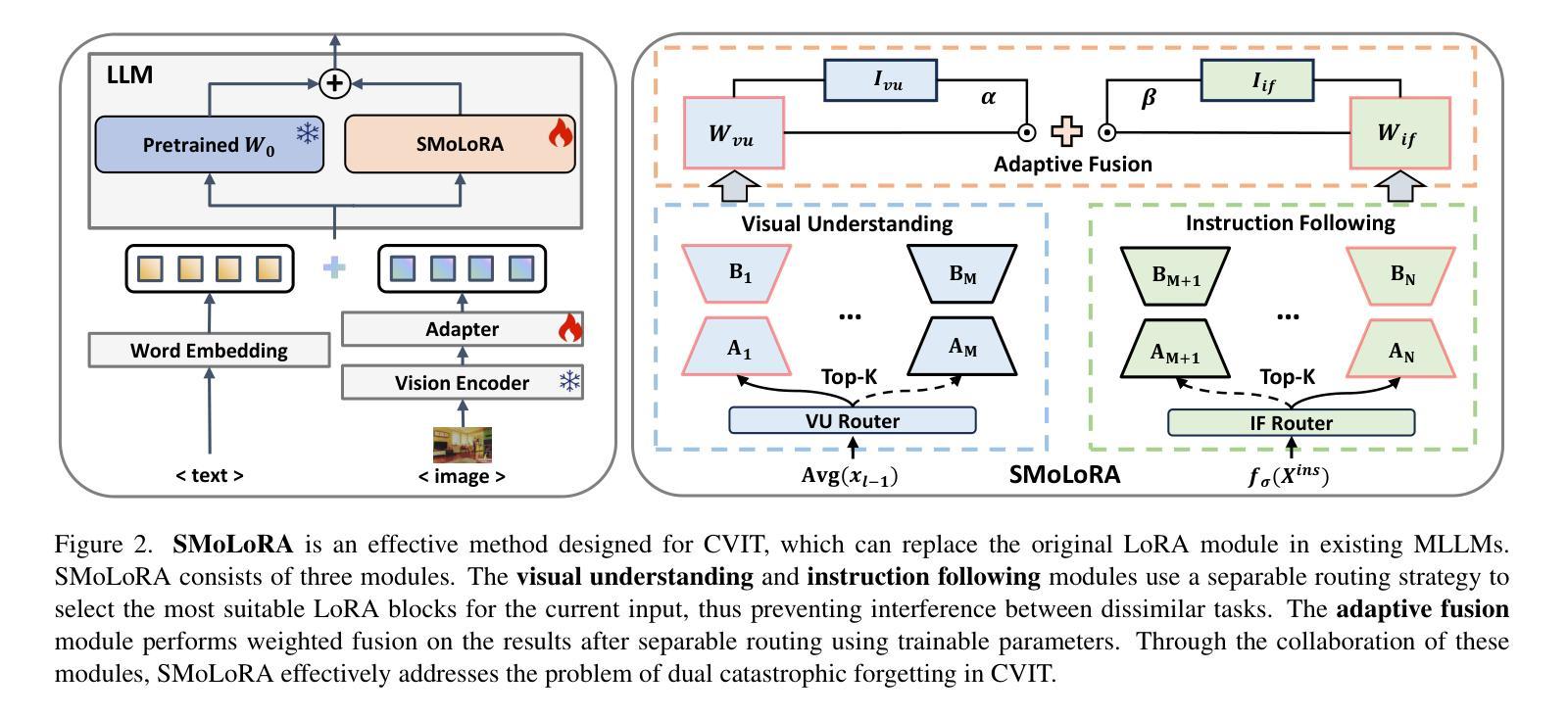
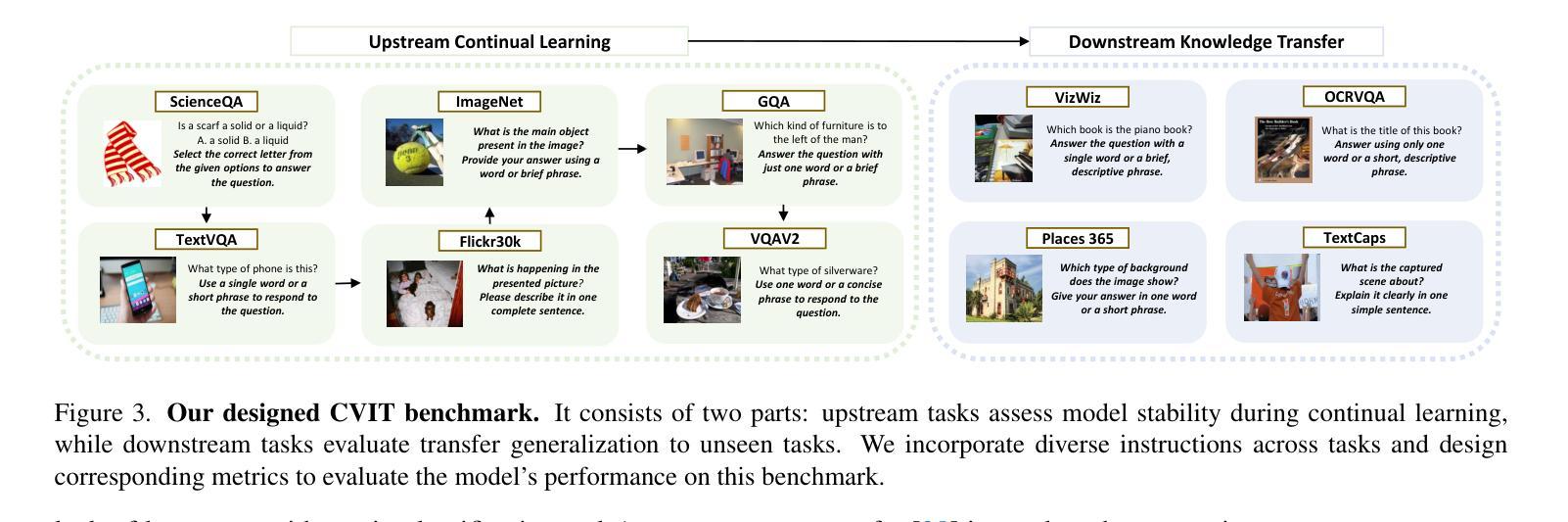
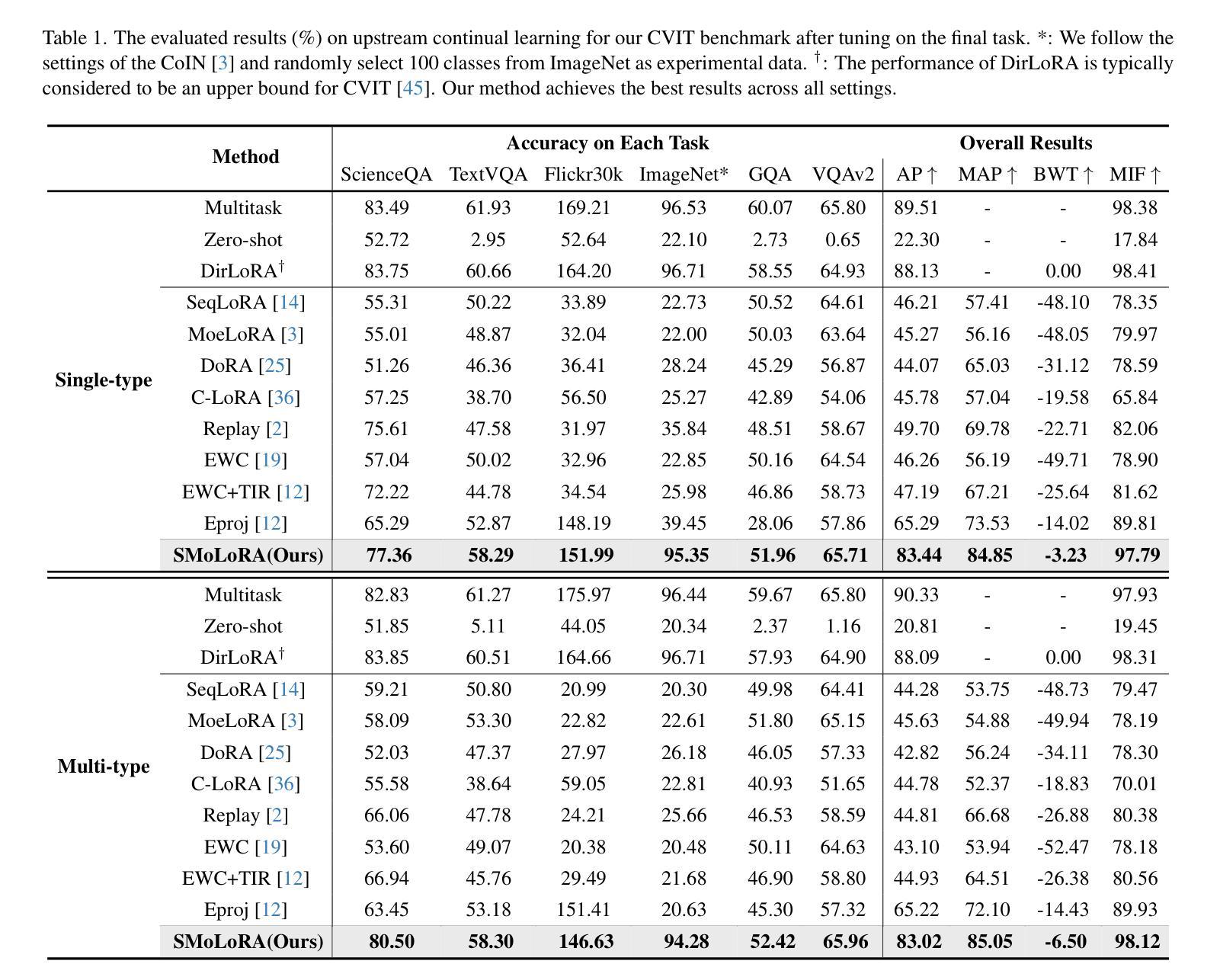
SMoLoRA: Exploring and Defying Dual Catastrophic Forgetting in Continual Visual Instruction Tuning
Authors:Ziqi Wang, Chang Che, Qi Wang, Yangyang Li, Zenglin Shi, Meng Wang
Visual instruction tuning (VIT) enables multimodal large language models (MLLMs) to effectively handle a wide range of vision tasks by framing them as language-based instructions. Building on this, continual visual instruction tuning (CVIT) extends the capability of MLLMs to incrementally learn new tasks, accommodating evolving functionalities. While prior work has advanced CVIT through the development of new benchmarks and approaches to mitigate catastrophic forgetting, these efforts largely follow traditional continual learning paradigms, neglecting the unique challenges specific to CVIT. We identify a dual form of catastrophic forgetting in CVIT, where MLLMs not only forget previously learned visual understanding but also experience a decline in instruction following abilities as they acquire new tasks. To address this, we introduce the Separable Mixture of Low-Rank Adaptation (SMoLoRA) framework, which employs separable routing through two distinct modules-one for visual understanding and another for instruction following. This dual-routing design enables specialized adaptation in both domains, preventing forgetting while improving performance. Furthermore, we propose a new CVIT benchmark that goes beyond existing benchmarks by additionally evaluating a model’s ability to generalize to unseen tasks and handle diverse instructions across various tasks. Extensive experiments demonstrate that SMoLoRA outperforms existing methods in mitigating dual forgetting, improving generalization to unseen tasks, and ensuring robustness in following diverse instructions. Code is available at https://github.com/Minato-Zackie/SMoLoRA.
视觉指令调整(VIT)能够通过将各种视觉任务构造成基于语言的指令,使多模态大型语言模型(MLLMs)能够有效地处理广泛的视觉任务。在此基础上,持续视觉指令调整(CVIT)扩展了MLLMs逐步学习新任务的能力,以适应不断变化的功能。虽然先前的工作已通过开发新的基准测试方法和缓解灾难性遗忘的方法推动了CVIT的发展,但这些努力大多遵循传统的持续学习模式,忽略了CVIT所面临的独特挑战。我们发现了CVIT中的双重灾难性遗忘形式,其中MLLMs不仅忘记了先前学到的视觉理解能力,而且在获取新任务时还会经历指令执行能力的下降。为了解决这一问题,我们引入了可分离的混合低秩适应(SMoLoRA)框架,它通过两个不同模块的可分离路由来实现——一个用于视觉理解,另一个用于指令执行。这种双路由设计可以在两个领域实现专业适应,防止遗忘并提升性能。此外,我们提出了一个新的CVIT基准测试,它超越了现有的基准测试,通过评估模型对未见任务的泛化能力和处理各种指令的能力来实现更全面的评价。大量实验表明,SMoLoRA在缓解双重遗忘、改进对未见任务的泛化能力、以及确保在执行多样指令时的稳健性方面均优于现有方法。相关代码可访问https://github.com/Minato-Zackie/SMoLoRA。
论文及项目相关链接
Summary
视觉指令微调(VIT)使多模态大型语言模型(MLLMs)能够通过语言指令框架有效地处理广泛的视觉任务。在此基础上,持续视觉指令微调(CVIT)扩展了MLLMs逐步学习新任务的能力,以适应不断变化的功能。针对CVIT所面临的独特挑战,我们发现了双重灾难性遗忘的问题,即MLLMs不仅忘记了先前学到的视觉理解,而且在接受新任务时,指令遵循能力也会下降。为了解决这个问题,我们引入了可分离的混合低秩适应(SMoLoRA)框架,它采用可分离路由,通过两个不同模块——一个用于视觉理解和另一个用于指令遵循。这种双路由设计可以在两个领域进行专业适应,防止遗忘并改进性能。此外,我们提出了一种新的CVIT基准测试,它不仅评估模型对未见任务的泛化能力,还评估模型处理各种指令的能力。实验表明,SMoLoRA在缓解双重遗忘、提高未见任务的泛化能力和确保遵循各种指令的稳健性方面优于现有方法。代码可在https://github.com/Minato-Zackie/SMoLoRA中获得。
Key Takeaways
- VIT让MLLMs能够通过语言指令处理视觉任务。
- CVIT使MLLMs能够逐步学习新任务,适应不断变化的功能。
- MLLMs在CVIT中面临双重灾难性遗忘问题。
- SMoLoRA框架采用双路由设计,分别用于视觉理解和指令遵循,防止遗忘并提升性能。
- 新的CVIT基准测试评估模型对未见任务的泛化能力和处理各种指令的能力。
- SMoLoRA在缓解双重遗忘、提高泛化能力和确保指令遵循的稳健性方面优于现有方法。
点此查看论文截图

Federated Data-Efficient Instruction Tuning for Large Language Models
Authors:Zhen Qin, Zhaomin Wu, Bingsheng He, Shuiguang Deng
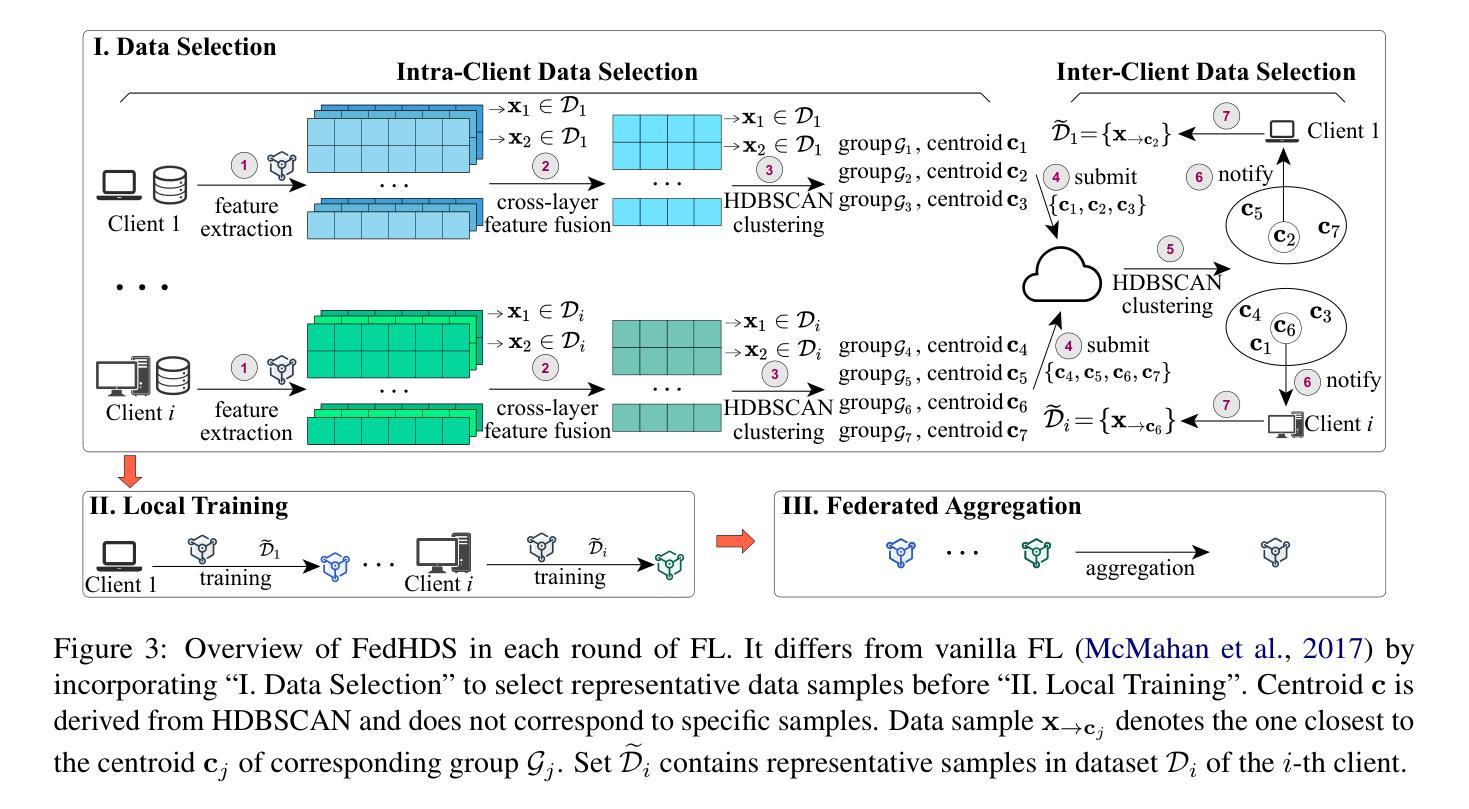
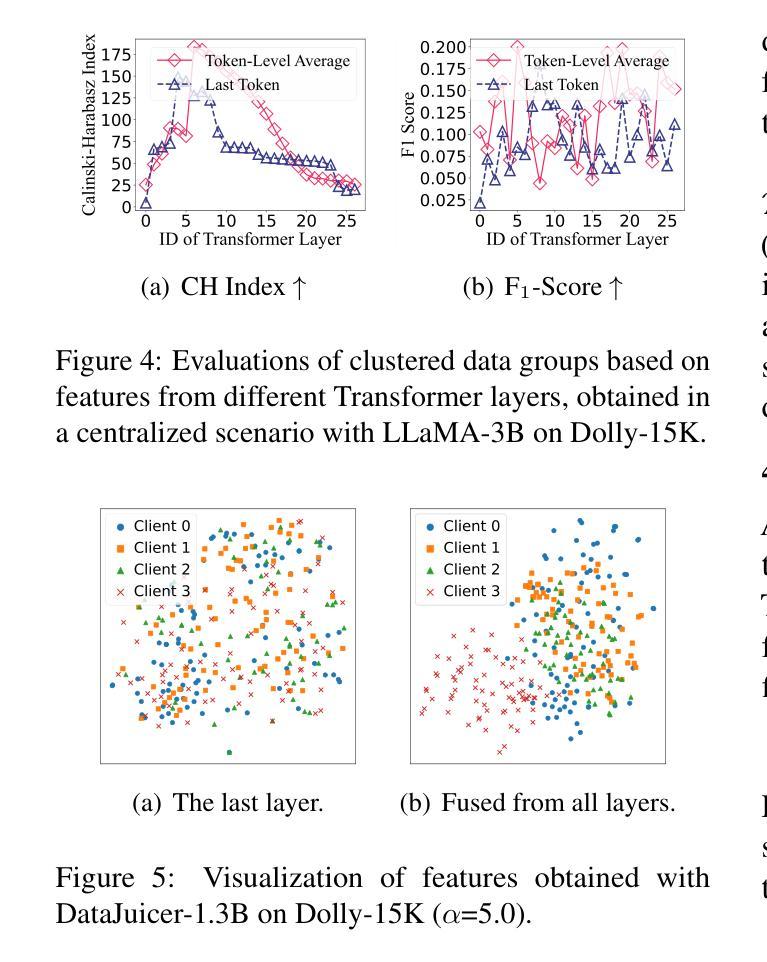
Instruction tuning is a crucial step in improving the responsiveness of pretrained large language models (LLMs) to human instructions. Federated learning (FL) helps to exploit the use of vast private instruction data from clients, becoming popular for LLM tuning by improving data diversity. Existing federated tuning simply consumes all local data, causing excessive computational overhead and overfitting to local data, while centralized data-efficient solutions are not suitable for FL due to privacy concerns. This work presents FedHDS, a federated data-efficient instruction tuning approach, which tunes LLMs with a representative subset of edge-side data. It reduces the data redundancy at both intra- and inter-client levels without sharing raw data. Experiments with various LLMs, datasets and partitions show that FedHDS improves Rouge-L on unseen tasks by an average of 10.72% over the SOTA full-data federated instruction tuning methods, while using less than 1.5% of the data samples, improving training efficiency by up to tens of times.
指令微调是提升预训练大型语言模型(LLM)对人类指令的响应能力的关键步骤。联邦学习(FL)有助于利用来自客户的海量私有指令数据,通过提升数据多样性在LLM微调中变得流行。现有的联邦学习微调方法简单地使用所有数据,导致计算开销过大和对本地数据的过度拟合,而集中式的提高数据效率解决方案则由于隐私问题不适合用于联邦学习。本研究提出了FedHDS,这是一种联邦数据高效指令微调方法,它通过具有代表性的边缘侧数据子集来微调LLM。它在客户和跨客户级别减少了数据冗余,同时无需共享原始数据。使用各种LLM、数据集和分区的实验显示,FedHDS在未见过的任务上平均提高了Rouge-L评分超过最新全数据联邦指令微调方法达10.72%,同时使用的数据样本不到1.5%,通过提高高达数倍的培训效率来实现这一目标。
论文及项目相关链接
PDF Accepted to ACL 2025 (Findings)
Summary
在提升预训练大型语言模型(LLM)对人类指令的响应方面,指令调优是重要步骤。联邦学习(FL)有助于利用大量私有指令数据,通过提升数据多样性来优化LLM的调优。现有联邦学习简单地消耗所有本地数据,导致计算开销过大以及对本地数据的过度拟合,而集中式的数据高效解决方案则因隐私担忧而不适用于联邦学习。本研究提出了FedHDS,这是一种联邦数据高效指令调优方法,它通过具有代表性的边缘侧数据子集来调优LLM。它减少了跨客户端和客户内部的数据冗余,同时不共享原始数据。实验表明,与最新全数据联邦指令调优方法相比,FedHDS在未完成任务上的Rouge-L平均提高了10.72%,同时使用的数据量不到1.5%,训练效率提高了数十倍。
Key Takeaways
- 指令调优是提升LLM响应人类指令的关键步骤。
- 联邦学习(FL)有助于利用私有指令数据,提高数据多样性,优化LLM。
- 现有联邦学习方法存在计算开销大、过度拟合本地数据的问题。
- 集中式数据高效解决方案因隐私担忧不适用于联邦学习。
- FedHDS是一种联邦数据高效指令调优方法,通过具有代表性的边缘侧数据子集调优LLM。
- FedHDS减少了跨客户端和客户内部的数据冗余,同时不共享原始数据。
点此查看论文截图

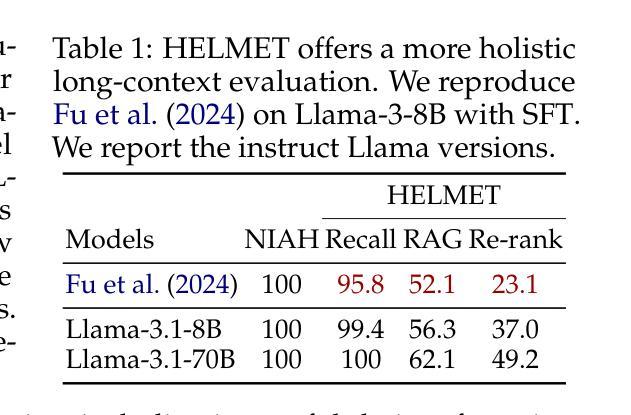
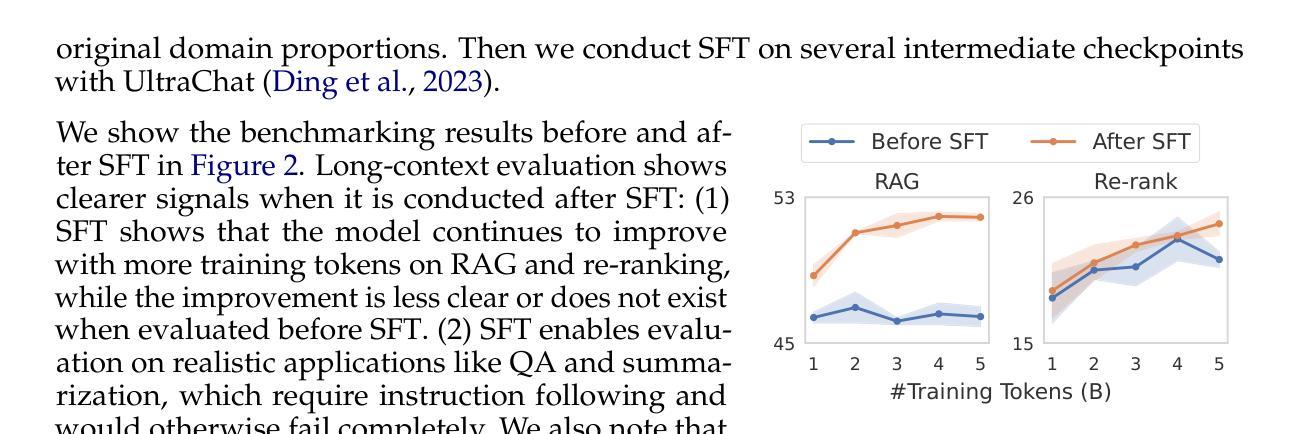
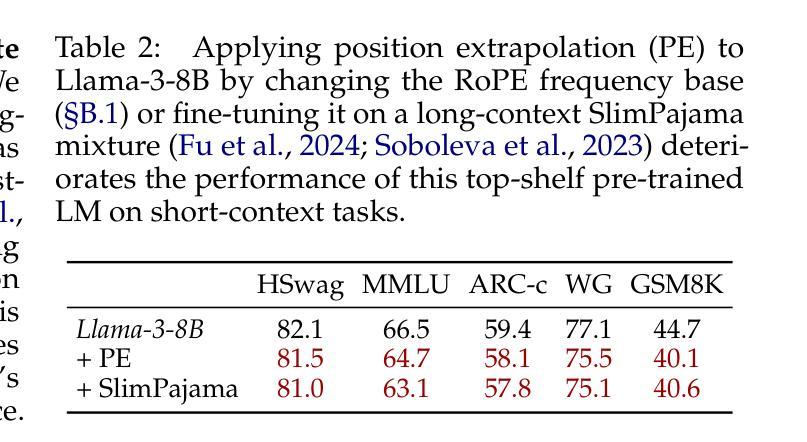
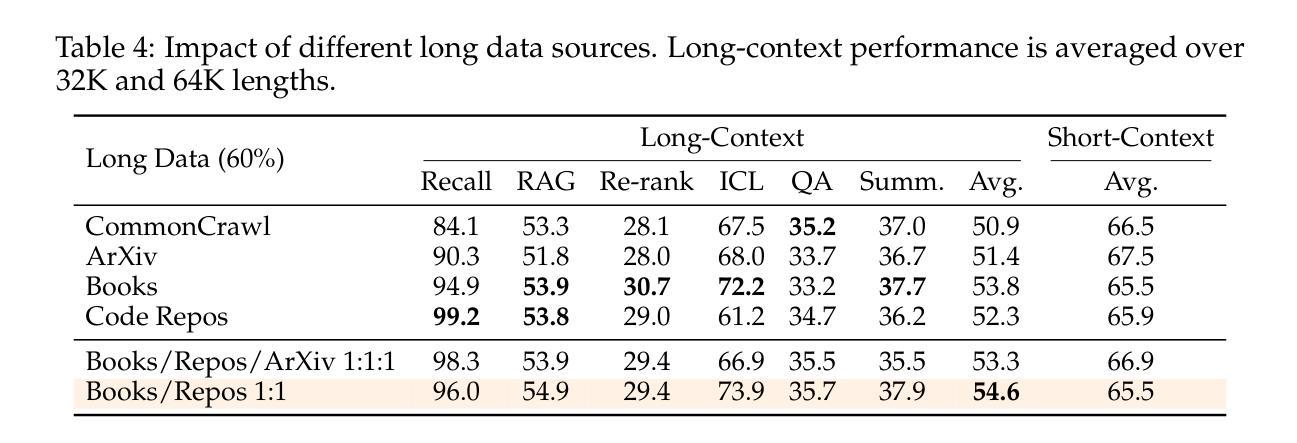
How to Train Long-Context Language Models (Effectively)
Authors:Tianyu Gao, Alexander Wettig, Howard Yen, Danqi Chen
We study continued training and supervised fine-tuning (SFT) of a language model (LM) to make effective use of long-context information. We first establish a reliable evaluation protocol to guide model development – instead of perplexity or simple needle-in-a-haystack (NIAH) tests, we use a broad set of long-context downstream tasks, and we evaluate models after SFT as this better reveals long-context abilities. Supported by our robust evaluations, we run thorough experiments to decide the data mix for continued pre-training, the instruction tuning dataset, and many other design choices such as position extrapolation. We find that (1) code repositories and books are excellent sources of long data, but it is crucial to combine them with high-quality short-context data; (2) training with a sequence length beyond the evaluation length boosts long-context performance; (3) for SFT, using only short instruction datasets yields strong performance on long-context tasks. Our final model, ProLong-8B, which is initialized from Llama-3 and trained on 40B tokens, demonstrates state-of-the-art long-context performance among similarly sized models at a length of 128K. ProLong outperforms Llama-3.1-8B-Instruct on the majority of long-context tasks despite using only 5% as many tokens during long-context training. Additionally, ProLong can effectively process up to 512K tokens, one of the longest context windows of publicly available LMs.
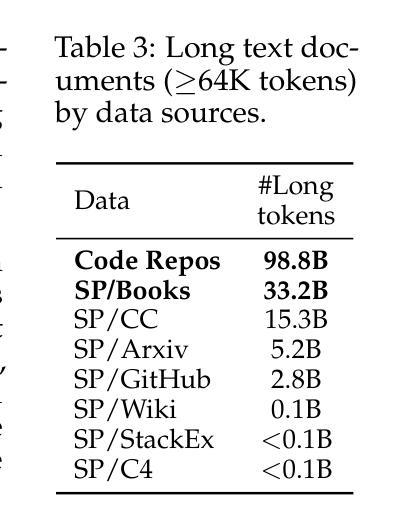
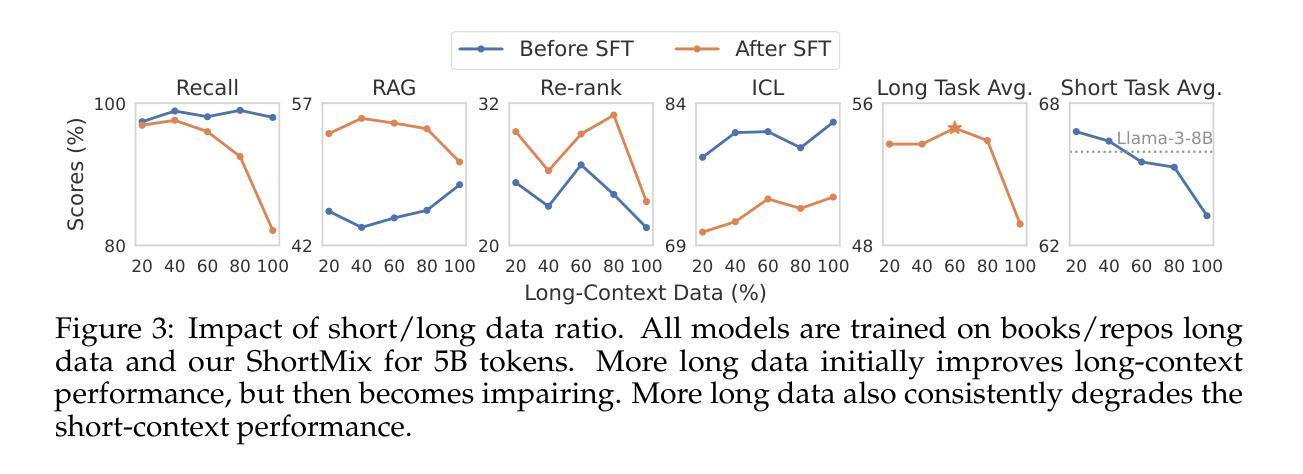
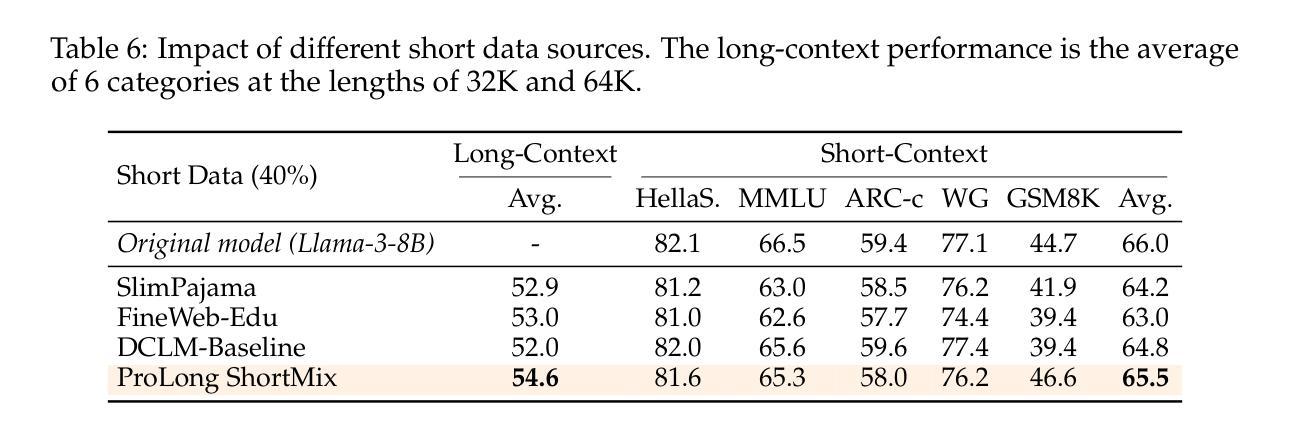
我们研究语言模型(LM)的持续训练和监督微调(SFT),以有效利用长上下文信息。首先,我们建立了一个可靠的评估协议来指导模型发展——我们不是使用困惑度或简单的“大海捞针”(NIAH)测试,而是使用一系列广泛的长期下游任务,并在SFT之后评估模型,因为这能更好地揭示长期上下文能力。在我们的稳健评估支持下,我们进行了全面的实验来决定持续预训练的数据混合、指令调整数据集,以及诸如位置外推之类的许多其他设计选择。我们发现:(1)代码仓库和书籍是长数据的极好来源,但将它们与高质量短上下文数据结合起来至关重要;(2)使用超过评估长度的序列长度进行训练可以提高长期上下文性能;(3)对于SFT,仅使用短指令数据集即可在具有长期上下文的任务上产生强大性能。我们的最终模型ProLong-8B以Llama-3为初始版本,在40B令牌上进行训练,在长度为128K的类似大小模型中表现出卓越的长上下文性能。ProLong在大多数长上下文任务上的表现都优于Llama-3.1-8B-Instruct,尽管在长上下文训练期间只使用了5%的令牌。此外,ProLong可以有效地处理长达512K的令牌,这是公开可用的语言模型中处理的最长的上下文窗口之一。
论文及项目相关链接
PDF Accepted to ACL 2025. Our code, data, and models are available at https://github.com/princeton-nlp/ProLong
摘要
本文研究了语言模型的持续训练与监督微调(SFT)以有效利用长文本信息。首先建立可靠的评估协议来指导模型发展,使用一系列长文本下游任务评估模型,并在SFT后进行评估以更好地揭示长文本能力。通过严谨的实验,确定了继续预训练的数据混合、指令微调数据集以及位置外推等设计选择。研究发现:代码仓库和书籍是长文本数据的优质来源,但需与高质量短文本数据结合;使用超过评估长度的序列长度进行训练可提高长文本性能;对于SFT,仅使用短指令数据集即可在长按任务上实现良好性能。最终,基于Llama-3初始化的ProLong-8B模型在40B标记上进行训练,展现了在相似规模模型中的最佳长文本性能,其可以在大多数长文本任务上超越Llama-3.1-8B-Instruct,尽管在长按训练期间仅使用了5%的标记。此外,ProLong可有效处理长达512K标记的文本,这是目前公开可用的语言模型中处理长文本上下文的最长窗口之一。
关键见解
- 代码仓库和书籍是长文本数据优质来源,需结合高质量短文本数据。
- 使用超过评估长度的序列长度进行训练可以提高长文本性能。
- 对于监督微调(SFT),仅使用短指令数据集即可在长按任务上实现良好性能。
- ProLong-8B模型在类似规模的模型中展现了卓越的长文本性能。
- ProLong在大多数长文本任务上表现超过其他模型,尽管使用的训练标记较少。
- ProLong可以处理长达512K标记的文本,这是目前公开可用语言模型中最长的上下文窗口之一。
点此查看论文截图

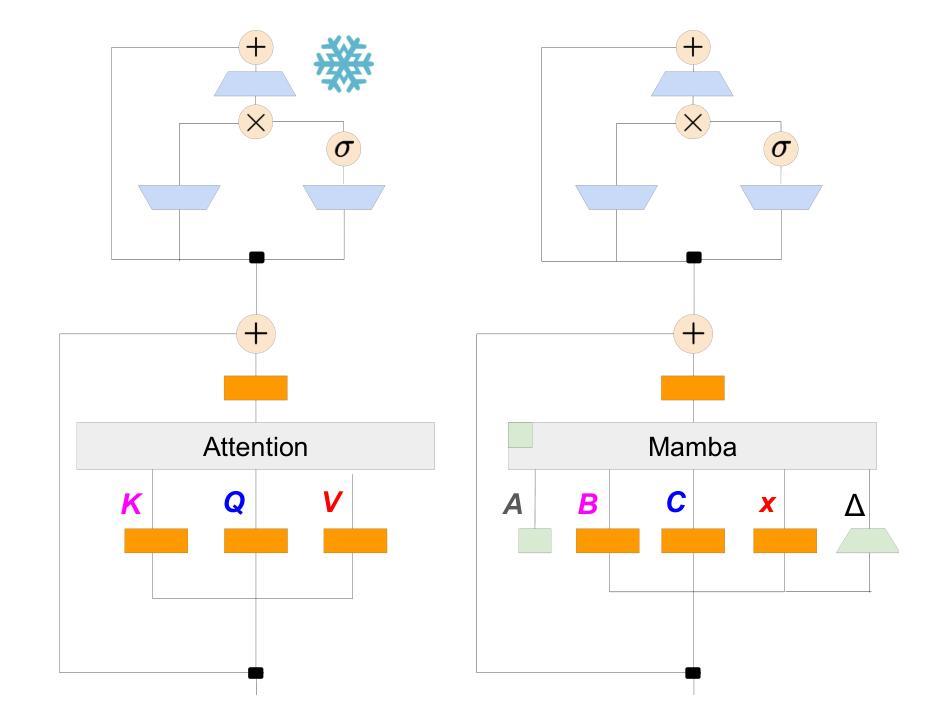
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
Authors:Junxiong Wang, Daniele Paliotta, Avner May, Alexander M. Rush, Tri Dao
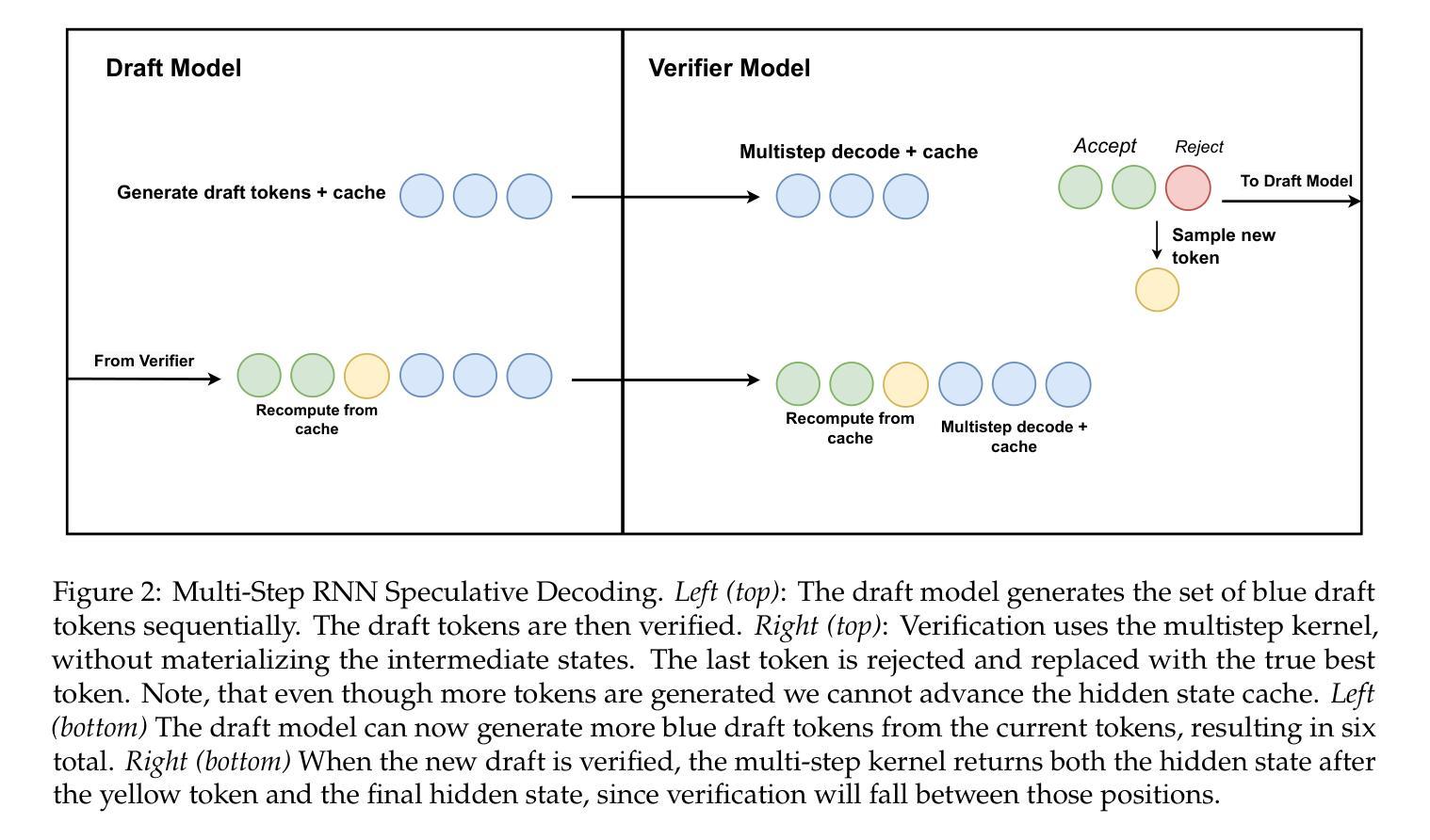
Linear RNN architectures, like Mamba, can be competitive with Transformer models in language modeling while having advantageous deployment characteristics. Given the focus on training large-scale Transformer models, we consider the challenge of converting these pretrained models for deployment. We demonstrate that it is feasible to distill large Transformers into linear RNNs by reusing the linear projection weights from attention layers with academic GPU resources. The resulting hybrid model, which incorporates a quarter of the attention layers, achieves performance comparable to the original Transformer in chat benchmarks and outperforms open-source hybrid Mamba models trained from scratch with trillions of tokens in both chat benchmarks and general benchmarks. Moreover, we introduce a hardware-aware speculative decoding algorithm that accelerates the inference speed of Mamba and hybrid models. Overall we show how, with limited computation resources, we can remove many of the original attention layers and generate from the resulting model more efficiently. Our top-performing model, distilled from Llama3-8B-Instruct, achieves a 29.61 length-controlled win rate on AlpacaEval 2 against GPT-4 and 7.35 on MT-Bench, surpassing the best 8B scale instruction-tuned linear RNN model. We also find that the distilled model has natural length extrapolation, showing almost perfect accuracy in the needle-in-a-haystack test at 20x the distillation length. Code and pre-trained checkpoints are open-sourced at https://github.com/jxiw/MambaInLlama and https://github.com/itsdaniele/speculative_mamba.
线性RNN架构(如Mamba)在语言建模方面可以与Transformer模型竞争,同时拥有优势部署特性。鉴于目前关注于训练大规模Transformer模型,我们考虑将这些预训练模型转换为部署的挑战。我们证明了通过利用注意力层的线性投影权重以及学术GPU资源,将大型Transformer蒸馏成线性RNN是可行的。所得到的混合模型仅包含了四分之一的注意力层,在聊天基准测试中性能与原始Transformer相当,并且在聊天基准测试和一般基准测试中均优于从头开始训练的开源Mamba混合模型(使用了数万亿个令牌)。此外,我们引入了一种硬件感知的投机解码算法,该算法可以加速Mamba和混合模型的推理速度。总体而言,我们展示了如何在有限的计算资源下,移除许多原始注意力层并从所得模型中更有效地生成数据。我们的高性能模型从Llama3-8B-Instruct中提炼出来,在AlpacaEval 2上与GPT-4相比达到了29.61的受控长度胜率,并在MT-Bench上达到了7.35,超过了最佳8B规模指令调整线性RNN模型。我们还发现,提炼后的模型具有自然的长度扩展性,在蒸馏长度增加了20倍的情况下,几乎达到了完美的准确率在“needle-in-a-haystack”测试中。代码和预先训练的模型检查点已公开在:https://github.com/jxiw/MambaInLlama和:https://github.com/itsdaniele/speculative_mamba。
论文及项目相关链接
PDF NeurIPS 2024. v4 updates: mention concurrent work of speculative decoding for SSM
Summary
线性RNN架构(如Mamba)在语言建模方面可与Transformer模型竞争,并具有优势部署特性。研究挑战在于如何将预训练的Transformer模型进行部署转换。通过利用GPU资源进行大型Transformer蒸馏到线性RNN的尝试,我们发现可复用注意力层的线性投影权重。所得的混合模型采用原模型注意力层的四分之一,在聊天基准测试中表现与原始Transformer相当,并在通用基准测试中超越了从头开始训练的开源混合Mamba模型。此外,我们引入了一种面向硬件的投机解码算法,加快了Mamba和混合模型的推理速度。总的来说,我们以有限的计算资源展示如何通过移除多数原始注意力层并生成更高效的模型来实现性能提升。我们的顶尖模型从Llama3-8B-Instruct蒸馏而来,在AlpacaEval 2对GPT-4的比赛中取得29.61的长度控制胜率,并在MT-Bench上得分为7.35,超越了最佳8B规模指令微调线性RNN模型。我们还发现蒸馏模型具有自然长度外推能力,在蒸馏长度20倍的情况下几乎达到完美准确度。代码和预先训练的模型检查点已公开在链接和链接。
Key Takeaways
- 线性RNN架构(如Mamba)在语言建模方面可与Transformer模型竞争。
- 可将大型Transformer蒸馏成线性RNN。
- 复用注意力层的线性投影权重能提升模型的性能。
- 混合模型在某些基准测试中表现优越,如聊天基准测试和通用基准测试。
- 引入了一种面向硬件的投机解码算法以加速模型推理速度。
- 通过移除多数原始注意力层并生成更高效的模型实现性能提升。
点此查看论文截图