⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-06 更新
JoyTTS: LLM-based Spoken Chatbot With Voice Cloning
Authors:Fangru Zhou, Jun Zhao, Guoxin Wang
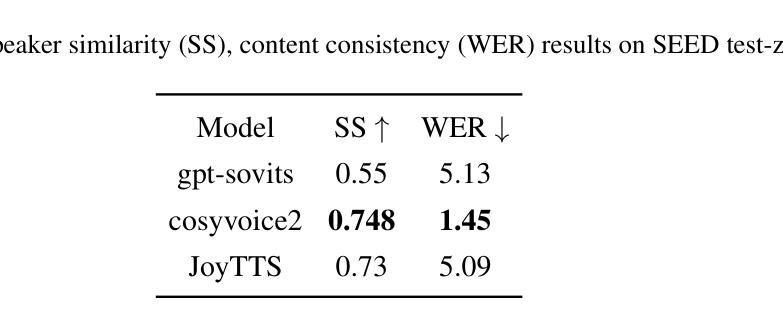
JoyTTS is an end-to-end spoken chatbot that combines large language models (LLM) with text-to-speech (TTS) technology, featuring voice cloning capabilities. This project is built upon the open-source MiniCPM-o and CosyVoice2 models and trained on 2000 hours of conversational data. We have also provided the complete training code to facilitate further development and optimization by the community. On the testing machine seed-tts-zh, it achieves a SS (speaker similarity) score of 0.73 and a WER (Word Error Rate) of 5.09. The code and models, along with training and inference scripts, are available at https://github.com/jdh-algo/JoyTTS.git.
JoyTTS是一款端到端的语音聊天机器人,它结合了大型语言模型(LLM)和文本到语音(TTS)技术,并具备语音克隆功能。该项目基于开源的MiniCPM-o和CosyVoice2模型构建,并在2000小时的对话数据上进行训练。我们还提供了完整的训练代码,以便社区进行进一步的开发和优化。在测试机器seed-tts-zh上,它达到了0.73的说话人相似度(SS)和5.09的词错误率(WER)。代码和模型以及训练和推理脚本可在https://github.com/jdh-algo/JoyTTS.git获取。
论文及项目相关链接
Summary
JoyTTS是一款结合大型语言模型(LLM)与文本转语音(TTS)技术的端到端语音聊天机器人,具备语音克隆功能。该项目基于MiniCPM-o和CosyVoice2开源模型构建,经过2000小时对话数据训练。社区可获取完整的训练代码以促进进一步开发与优化。在测试机器seed-tts-zh上,其达到SS(演讲者相似性)得分0.73,WER(单词错误率)为5.09。代码和模型及训练和推理脚本可在https://github.com/jdh-algo/JoyTTS.git获取。
Key Takeaways
- JoyTTS是一个结合了大型语言模型(LLM)与文本转语音(TTS)技术的端到端语音聊天机器人。
- 它具备语音克隆功能,可以模仿特定人的语音。
- JoyTTS是基于MiniCPM-o和CosyVoice2两个开源模型构建的。
- 该项目经过了2000小时对话数据的训练,以优化性能。
- 提供了完整的训练代码,便于社区进一步开发和优化。
- 在测试机器上,JoyTTS达到了较高的演讲者相似性得分(SS=0.73)和较低的单词错误率(WER=5.09)。
点此查看论文截图

Pronunciation Editing for Finnish Speech using Phonetic Posteriorgrams
Authors:Zirui Li, Lauri Juvela, Mikko Kurimo
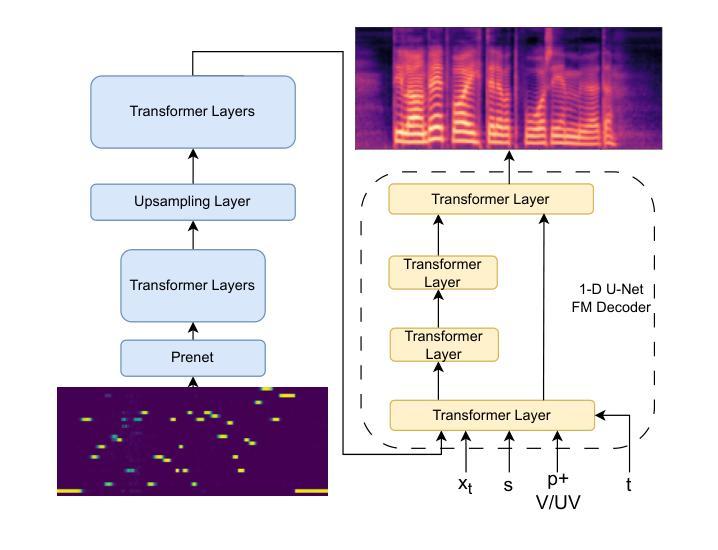
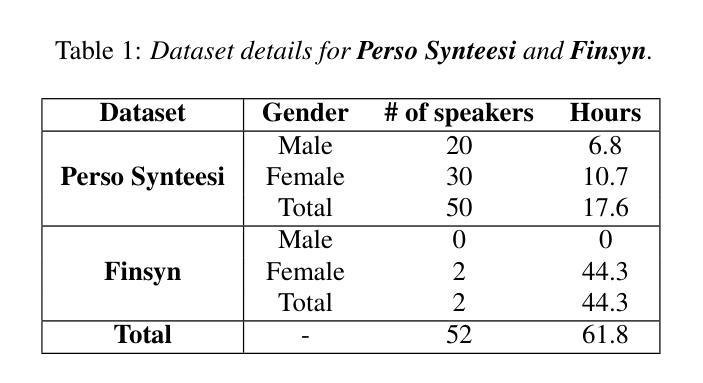
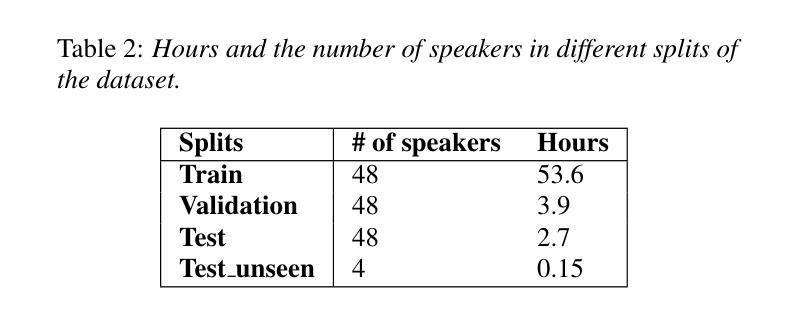
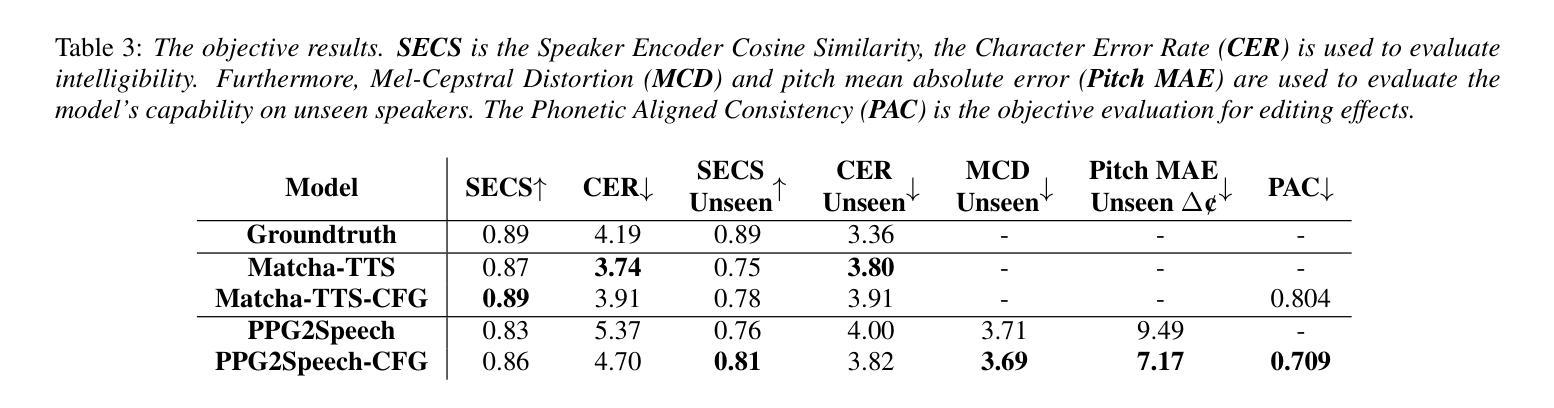
Synthesizing second-language (L2) speech is potentially highly valued for L2 language learning experience and feedback. However, due to the lack of L2 speech synthesis datasets, it is difficult to synthesize L2 speech for low-resourced languages. In this paper, we provide a practical solution for editing native speech to approximate L2 speech and present PPG2Speech, a diffusion-based multispeaker Phonetic-Posteriorgrams-to-Speech model that is capable of editing a single phoneme without text alignment. We use Matcha-TTS’s flow-matching decoder as the backbone, transforming Phonetic Posteriorgrams (PPGs) to mel-spectrograms conditioned on external speaker embeddings and pitch. PPG2Speech strengthens the Matcha-TTS’s flow-matching decoder with Classifier-free Guidance (CFG) and Sway Sampling. We also propose a new task-specific objective evaluation metric, the Phonetic Aligned Consistency (PAC), between the edited PPGs and the PPGs extracted from the synthetic speech for editing effects. We validate the effectiveness of our method on Finnish, a low-resourced, nearly phonetic language, using approximately 60 hours of data. We conduct objective and subjective evaluations of our approach to compare its naturalness, speaker similarity, and editing effectiveness with TTS-based editing. Our source code is published at https://github.com/aalto-speech/PPG2Speech.
合成第二语言(L2)语音对于L2语言学习体验和反馈具有潜在的高价值。然而,由于缺乏L2语音合成数据集,很难为资源较少的语言合成L2语音。在本文中,我们提供了一种编辑原生语音以近似L2语音的实用解决方案,并介绍了PPG2Speech,这是一种基于扩散的多人语音Phonetic-Posteriorgrams-to-Speech模型,能够在无需文本对齐的情况下编辑单个音素。我们使用Matcha-TTS的流匹配解码器作为骨干,将音素后效图(PPGs)转换为梅尔频谱图,并根据外部说话者嵌入和音调进行条件设置。PPG2Speech通过无分类指导(CFG)和摇摆采样强化了Matcha-TTS的流匹配解码器。我们还提出了一个新的特定任务目标评估指标——音素对齐一致性(PAC),用于评估编辑后的PPGs与合成语音中提取的PPGs之间的编辑效果。我们在芬兰语这种资源匮乏、近乎音素的语言上验证了我们的方法,使用了大约6 普通话发音具有很大不同。我们将公开我们的源代码:https://github.com/aalto-speech/PPG2Speech。我们对我们的方法进行了客观和主观评估,以比较其自然度、说话人相似性和编辑效果与基于TTS的编辑相比如何。
论文及项目相关链接
PDF 5 pages; 1 figure; Accepted to Speech Synthesis Workshop 2025 (SSW13)
Summary
本文提出了一种实用的解决方案,通过编辑原生语音来近似第二语言语音,并介绍了PPG2Speech模型。该模型基于扩散技术,能够将语音的音素进行编辑而无需文本对齐。使用Matcha-TTS的流匹配解码器作为骨干,该模型以音素后概率图(PPGs)为条件生成梅尔频谱图,并结合外部说话者嵌入和音调信息。通过引入无分类指导(CFG)和摇摆采样,强化了Matcha-TTS的流匹配解码器。同时,提出新的特定任务目标评估指标——语音编辑效果的音素对齐一致性(PAC)。在芬兰语这种低资源、近乎音素的语言上验证了方法的有效性,并进行了客观和主观评估。
Key Takeaways
- 本文提供了一种编辑原生语音以模拟第二语言语音的方法,解决了低资源语言第二语言语音合成的难题。
- 介绍了PPG2Speech模型,该模型基于扩散技术,能够在无需文本对齐的情况下编辑语音的音素。
- 使用Matcha-TTS的流匹配解码器作为骨干,结合音素后概率图(PPGs)和外部说话者嵌入及音调信息来生成梅尔频谱图。
- 通过引入无分类指导(CFG)和摇摆采样,增强了Matcha-TTS的流匹配解码器的性能。
- 提出了一个新的特定任务目标评估指标——语音编辑效果的音素对齐一致性(PAC),用于评估编辑效果。
- 在芬兰语这种低资源语言上验证了方法的有效性,并展示了其在自然度、说话人相似性和编辑效果上的表现。
- 公开了源代码,便于他人使用和研究。
点此查看论文截图

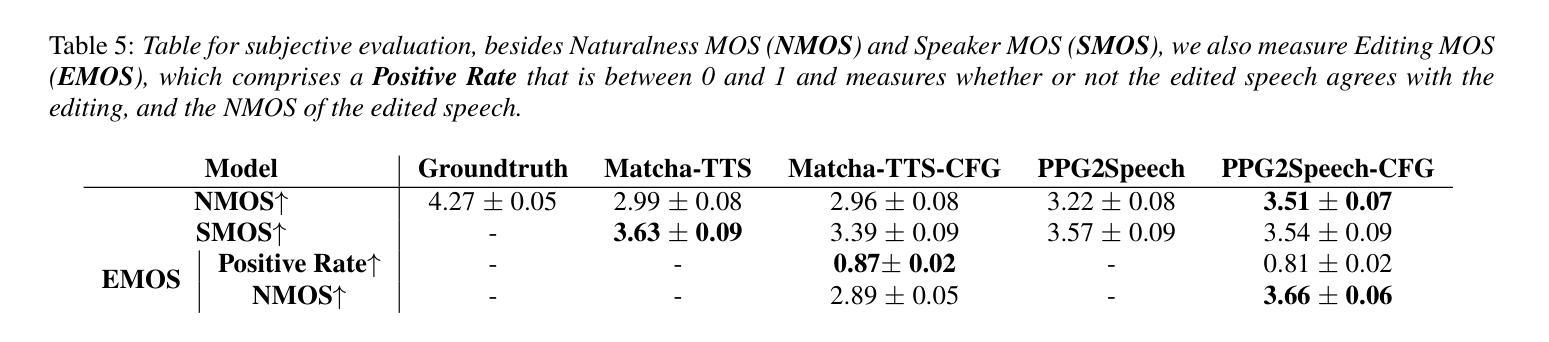
Test-Time Scaling with Reflective Generative Model
Authors:Zixiao Wang, Yuxin Wang, Xiaorui Wang, Mengting Xing, Jie Gao, Jianjun Xu, Guangcan Liu, Chenhui Jin, Zhuo Wang, Shengzhuo Zhang, Hongtao Xie
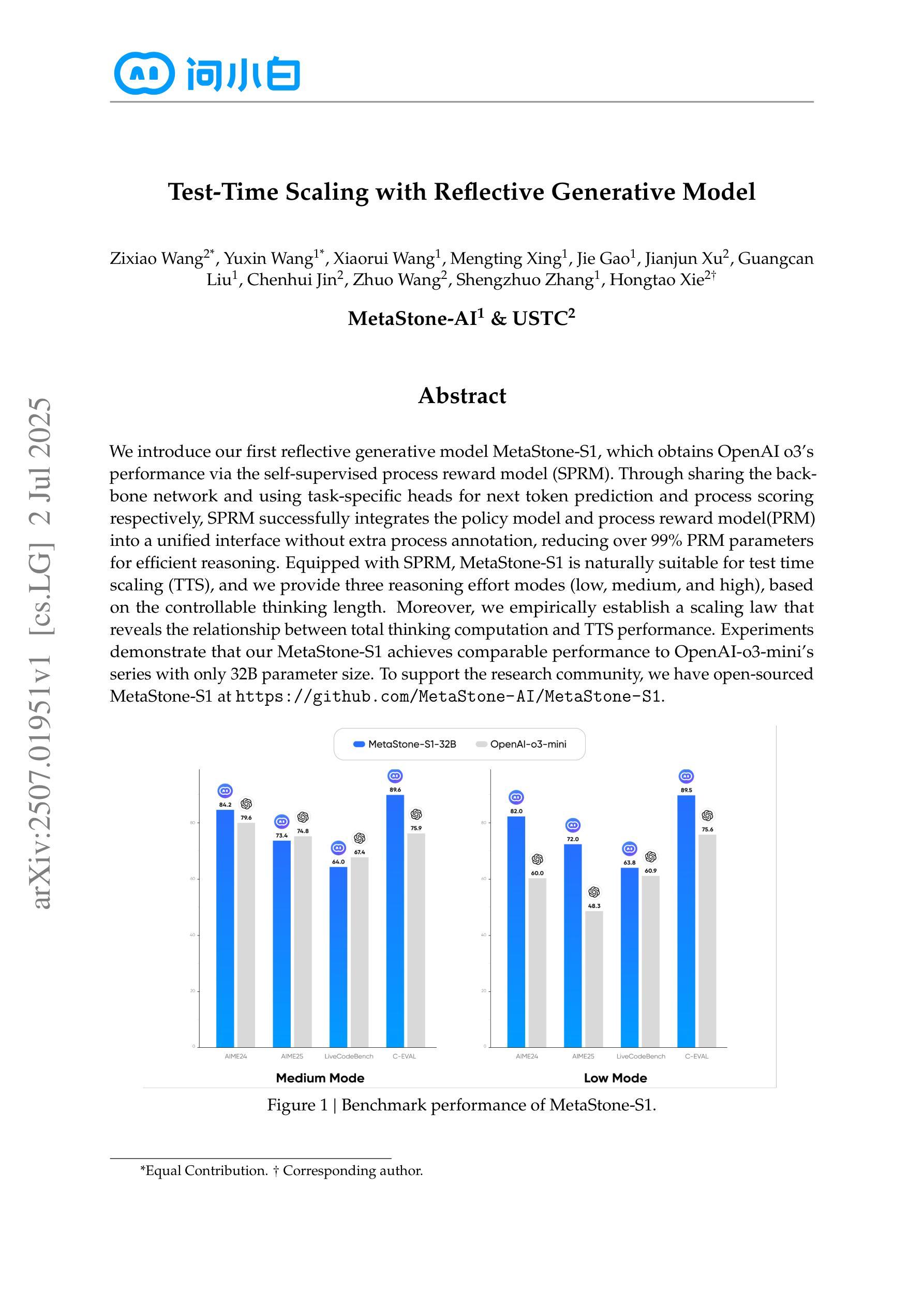
We introduce our first reflective generative model MetaStone-S1, which obtains OpenAI o3’s performance via the self-supervised process reward model (SPRM). Through sharing the backbone network and using task-specific heads for next token prediction and process scoring respectively, SPRM successfully integrates the policy model and process reward model(PRM) into a unified interface without extra process annotation, reducing over 99% PRM parameters for efficient reasoning. Equipped with SPRM, MetaStone-S1 is naturally suitable for test time scaling (TTS), and we provide three reasoning effort modes (low, medium, and high), based on the controllable thinking length. Moreover, we empirically establish a scaling law that reveals the relationship between total thinking computation and TTS performance. Experiments demonstrate that our MetaStone-S1 achieves comparable performance to OpenAI-o3-mini’s series with only 32B parameter size. To support the research community, we have open-sourced MetaStone-S1 at https://github.com/MetaStone-AI/MetaStone-S1.
我们介绍第一款反思生成模型MetaStone-S1,它通过自我监督的过程奖励模型(SPRM)达到OpenAI o3的性能。通过共享主干网络并使用特定任务头进行下一个令牌预测和过程评分,SPRM成功地将策略模型和过程奖励模型(PRM)集成到一个统一接口中,无需额外的过程注释,减少了超过99%的PRM参数,以实现高效推理。配备了SPRM,MetaStone-S1自然地适用于测试时间缩放(TTS)。我们基于可控的思考长度,提供了三种推理努力模式(低、中、高)。此外,我们通过实证建立了规模定律,揭示了总思考计算与TTS性能之间的关系。实验表明,我们的MetaStone-S1仅32B参数大小就达到了与OpenAI-o3-mini系列相当的性能。为了支持研究社区,我们已在https://github.com/MetaStone-AI/MetaStone-S1开源MetaStone-S1。
论文及项目相关链接
Summary
MetaStone-S1是首个采用自我监督过程奖励模型(SPRM)的反射生成模型,实现了与OpenAI o3相当的效能。通过共享主干网络并为下一个令牌预测和任务特定头评分分别使用特定头,SPRM成功地将策略模型与过程奖励模型(PRM)集成到一个统一的接口中,无需额外过程注释,减少了超过99%的PRM参数,以实现高效推理。MetaStone-S1适合测试时间缩放(TTS),并提供三种推理努力模式(低,中,高),基于可控的思考长度。此外,建立了揭示总思考计算与TTS性能之间关系的扩展定律。实验表明,MetaStone-S1的参数规模仅有32B,但性能与OpenAI-o3-mini系列相当。我们已在GitHub上开源MetaStone-S1以支持研究社区。
Key Takeaways
- MetaStone-S1采用自我监督过程奖励模型(SPRM)实现高效推理。
- SPRM通过共享网络主干和任务特定头,成功集成策略模型和过程奖励模型(PRM)。
- SPRM减少了超过99%的PRM参数,无需额外的过程注释。
- MetaStone-S1适合测试时间缩放(TTS),并提供了基于可控思考长度的推理努力模式。
- 建立了一个揭示总思考计算与TTS性能之间关系的扩展定律。
- MetaStone-S1性能与OpenAI-o3-mini系列相当,但参数规模仅有32B。
点此查看论文截图
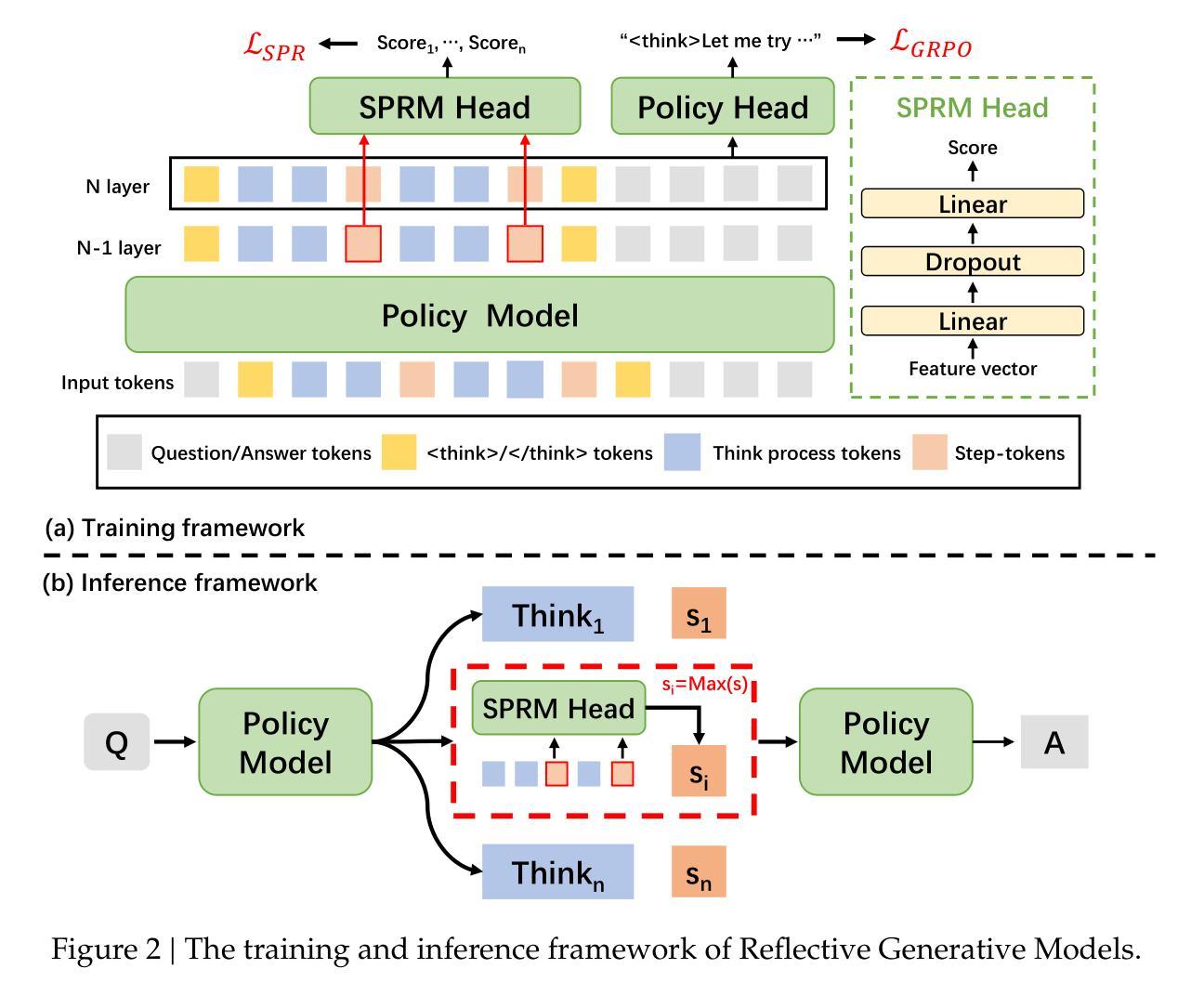
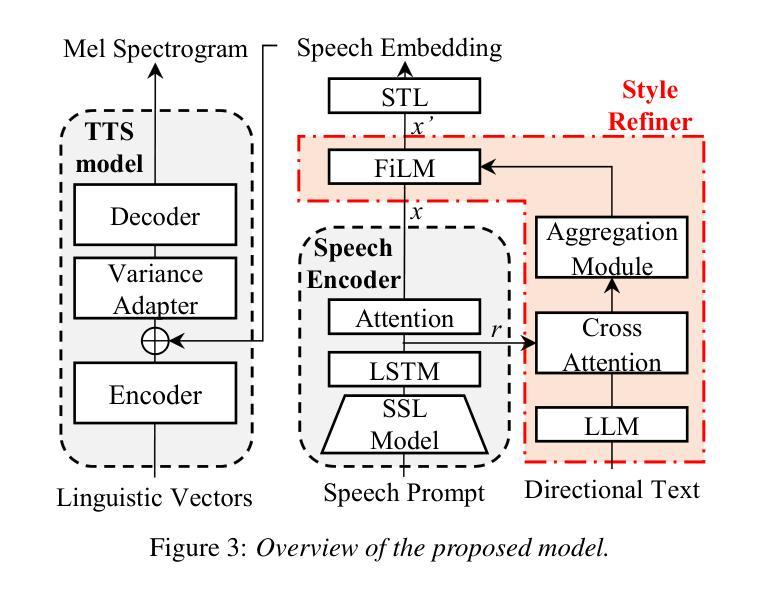
Multi-interaction TTS toward professional recording reproduction
Authors:Hiroki Kanagawa, Kenichi Fujita, Aya Watanabe, Yusuke Ijima
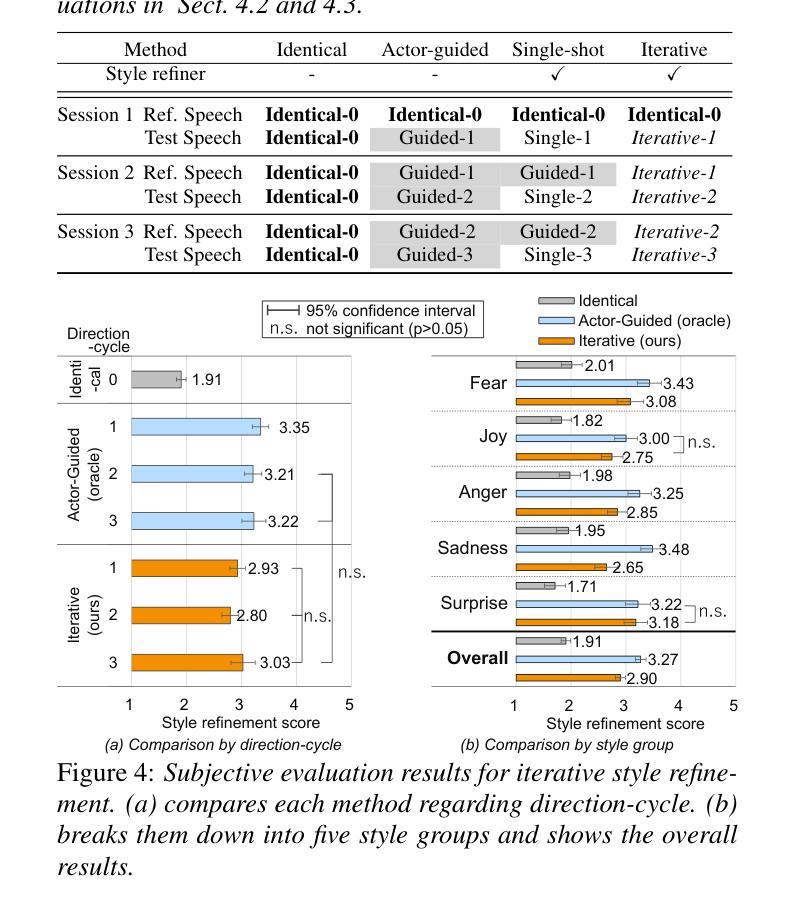
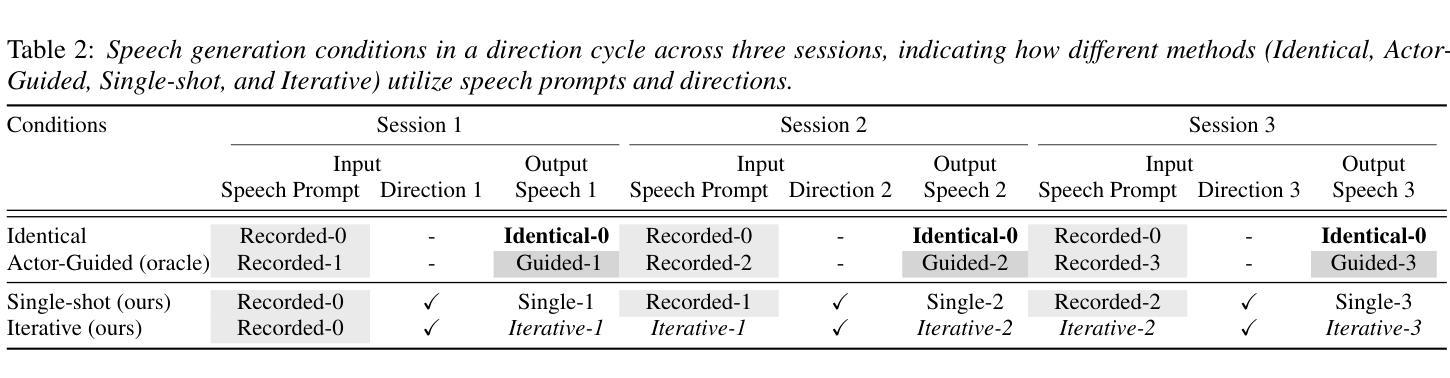
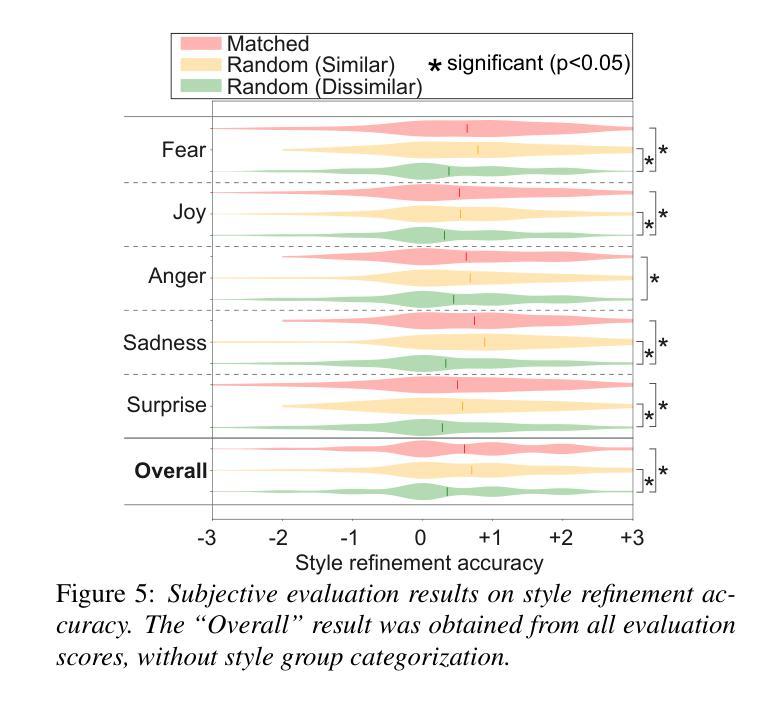
Voice directors often iteratively refine voice actors’ performances by providing feedback to achieve the desired outcome. While this iterative feedback-based refinement process is important in actual recordings, it has been overlooked in text-to-speech synthesis (TTS). As a result, fine-grained style refinement after the initial synthesis is not possible, even though the synthesized speech often deviates from the user’s intended style. To address this issue, we propose a TTS method with multi-step interaction that allows users to intuitively and rapidly refine synthesized speech. Our approach models the interaction between the TTS model and its user to emulate the relationship between voice actors and voice directors. Experiments show that the proposed model with its corresponding dataset enables iterative style refinements in accordance with users’ directions, thus demonstrating its multi-interaction capability. Sample audios are available: https://ntt-hilab-gensp.github.io/ssw13multiinteractiontts/
语音导演往往会通过提供反馈来迭代地完善配音演员的表演,以达到预期的效果。虽然在实际的录音中,这种基于迭代反馈的完善过程非常重要,但在文本到语音合成(TTS)中却被忽视了。因此,即使在初始合成后,也无法进行精细的风格调整,尽管合成的语音往往与用户的意图风格有所偏差。为了解决这个问题,我们提出了一种具有多步交互的TTS方法,允许用户直观地快速调整合成语音。我们的方法模拟了TTS模型与用户之间的交互,以模仿配音演员和配音导演之间的关系。实验表明,所提出的模型及其对应的数据集能够根据用户的指示进行迭代的风格调整,从而证明了其多次交互的能力。样本音频可在以下链接找到:https://ntt-hilab-gensp.github.io/ssw13multiinteractiontts/
论文及项目相关链接
PDF 7 pages,6 figures, Accepted to Speech Synthesis Workshop 2025 (SSW13)
Summary
本文提出了一个具有多步交互功能的TTS方法,模拟了配音演员和配音导演之间的关系,允许用户直观地快速调整合成语音的风格。此方法通过迭代反馈机制对语音合成结果进行精细化调整,从而解决合成语音与用户期望风格偏离的问题。
Key Takeaways
- 传统TTS系统中缺少迭代反馈机制,导致无法对合成语音进行精细风格调整。
- 本文提出的TTS方法引入多步交互功能,模拟配音演员与导演间的交互过程。
- 用户可直观地根据需求快速调整合成语音的风格。
- 该方法通过构建TTS模型与用户之间的交互关系来优化语音合成结果。
- 实验表明,该方法能够根据用户指导进行迭代风格调整,展现多交互能力。
- 提供样本音频以供验证方法效果。
点此查看论文截图


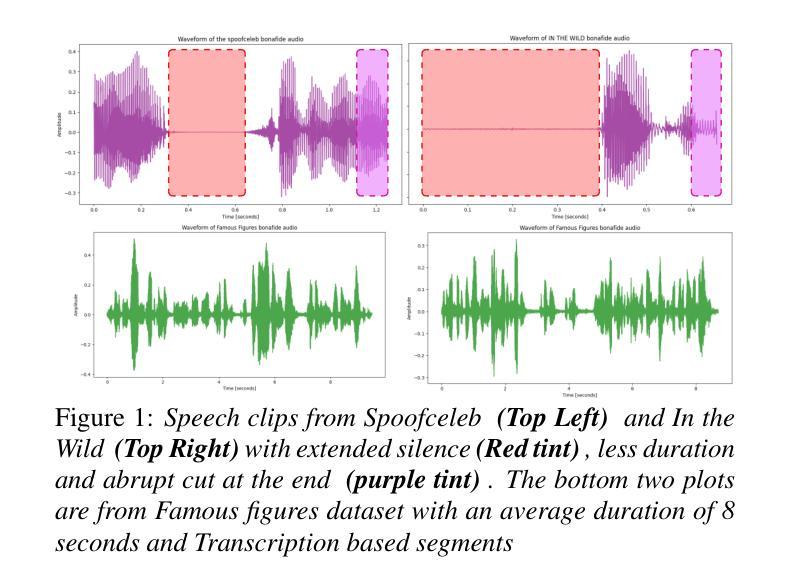
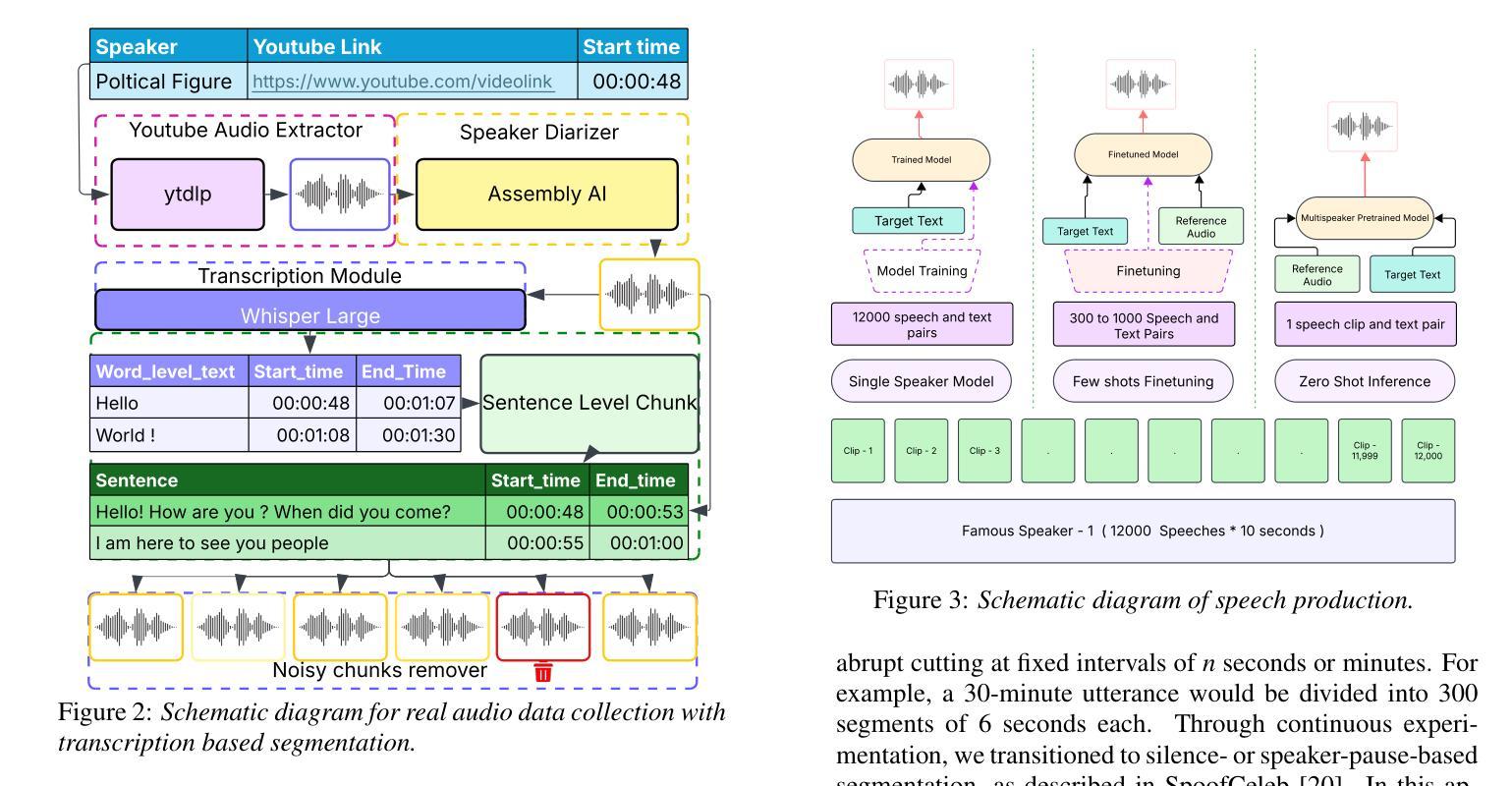
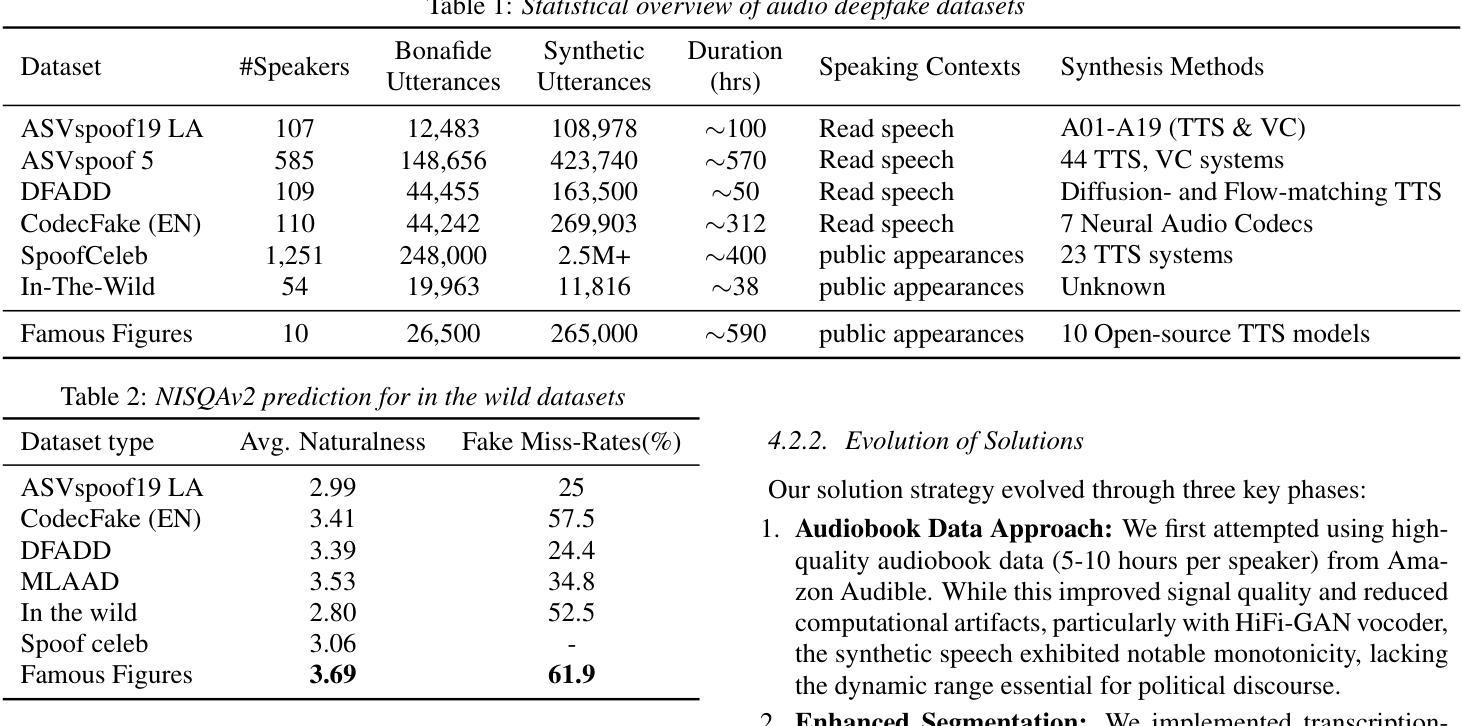
Collecting, Curating, and Annotating Good Quality Speech deepfake dataset for Famous Figures: Process and Challenges
Authors:Hashim Ali, Surya Subramani, Raksha Varahamurthy, Nithin Adupa, Lekha Bollinani, Hafiz Malik
Recent advances in speech synthesis have introduced unprecedented challenges in maintaining voice authenticity, particularly concerning public figures who are frequent targets of impersonation attacks. This paper presents a comprehensive methodology for collecting, curating, and generating synthetic speech data for political figures and a detailed analysis of challenges encountered. We introduce a systematic approach incorporating an automated pipeline for collecting high-quality bonafide speech samples, featuring transcription-based segmentation that significantly improves synthetic speech quality. We experimented with various synthesis approaches; from single-speaker to zero-shot synthesis, and documented the evolution of our methodology. The resulting dataset comprises bonafide and synthetic speech samples from ten public figures, demonstrating superior quality with a NISQA-TTS naturalness score of 3.69 and the highest human misclassification rate of 61.9%.
近期语音合成技术的进展为保持语音真实性带来了前所未有的挑战,特别是对于经常被冒充攻击的目标公众人物。本文提出了一种收集、整理和生成政治人物合成语音数据的综合方法,以及对所遇到挑战的详细分析。我们引入了一种系统的方法,结合自动化管道收集高质量的真实语音样本,采用基于转录的分割技术,显著提高了合成语音的质量。我们实验了各种合成方法,从单讲者到零样本合成,并记录了我们的方法演变。结果数据集包含来自十位公众人物的真实和合成语音样本,表现出优越的质量,NISQA-TTS自然度得分为3.69,人类误分类率最高达61.9%。
论文及项目相关链接
总结
随着语音合成技术的最新进展,维持语音的真实性尤其是针对经常被冒充攻击公共人物这一挑战变得尤为重要。本文提出了一种针对政治人物收集、整理和生成合成语音数据的全面方法,并对所遇挑战进行了详细分析。引入自动化管道以收集高质量的真实语音样本,利用基于转录的分割技术显著提高了合成语音质量。实验了各种合成方法,从单讲者到零样本合成,并记录了方法的演变。所建立的数据集包含来自十位公众人物的真实和合成语音样本,显示出了出色的质量,其NISQA-TTS自然度得分为3.69,人类误分类率高达61.9%。
要点分析
- 最新语音合成技术进展带来了保持语音真实性的挑战,特别是对于经常被冒充的公众人物。
- 提出了一种全面方法收集、整理和生成针对政治人物的合成语音数据。
- 引入自动化管道收集高质量真实语音样本。
- 利用基于转录的分割技术显著提高合成语音质量。
- 实验了多种合成方法,包括单讲者和零样本合成,并记录了方法的演变过程。
- 所建立数据集包含来自十位公众人物的真实和合成语音样本,显示出卓越质量。
点此查看论文截图