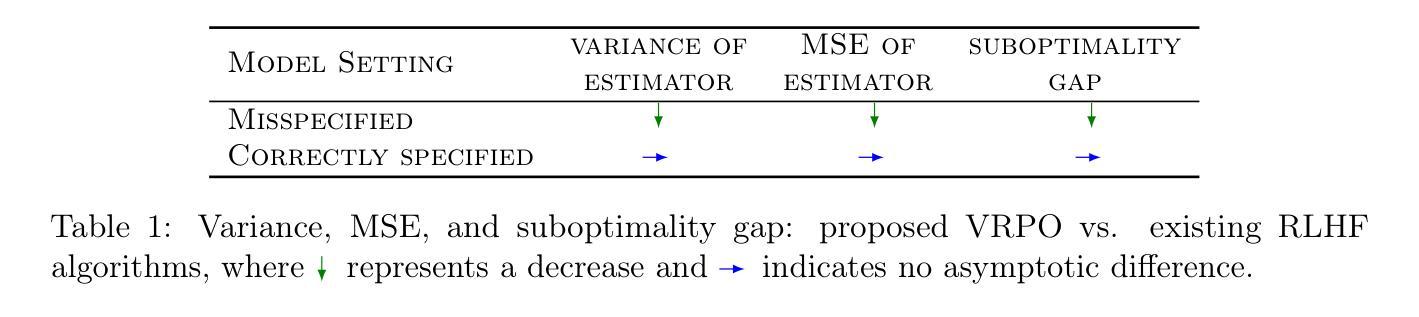⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-07 更新
REMOR: Automated Peer Review Generation with LLM Reasoning and Multi-Objective Reinforcement Learning
Authors:Pawin Taechoyotin, Daniel Acuna
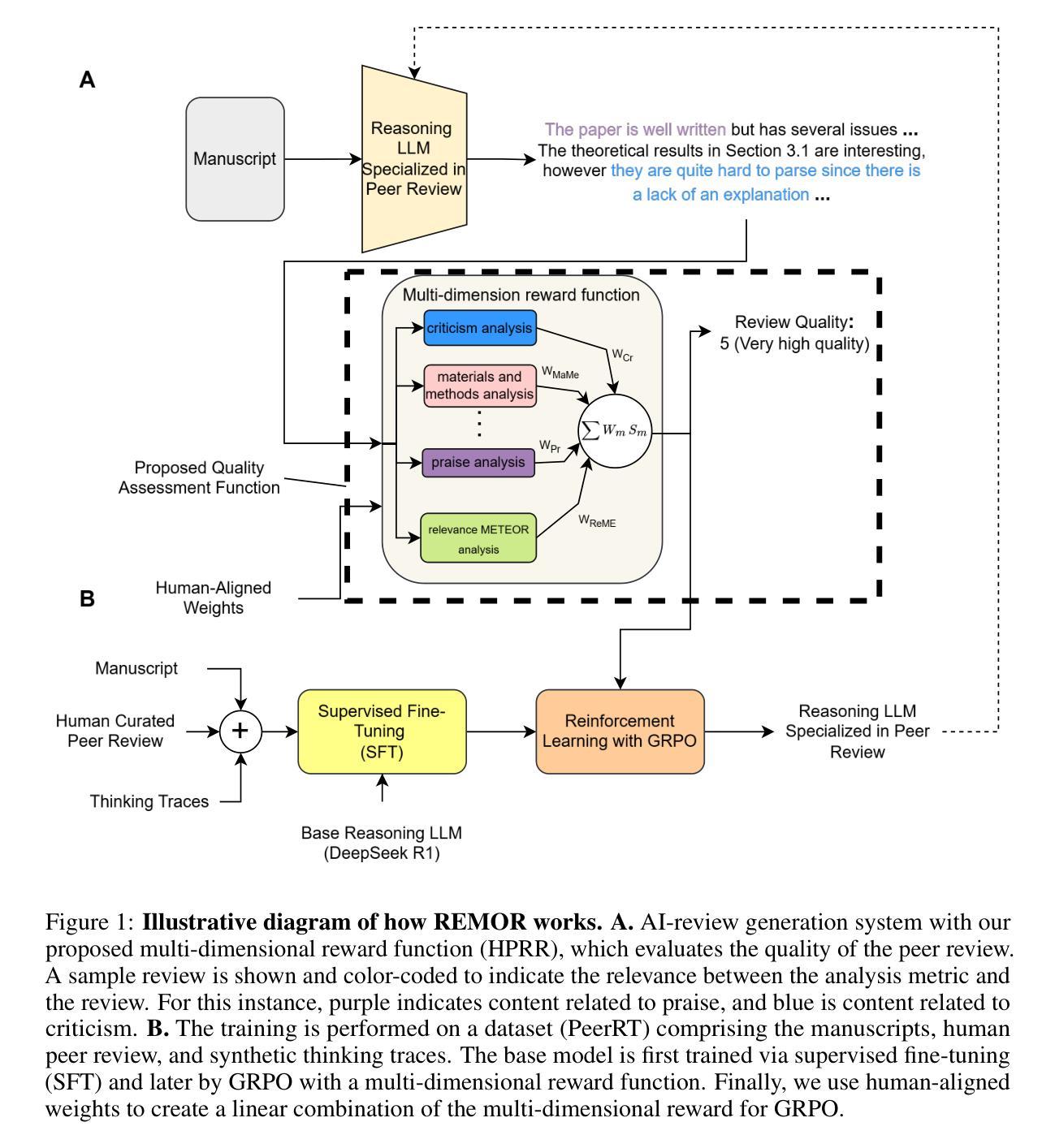
AI-based peer review systems tend to produce shallow and overpraising suggestions compared to human feedback. Here, we evaluate how well a reasoning LLM trained with multi-objective reinforcement learning (REMOR) can overcome these limitations. We start by designing a multi-aspect reward function that aligns with human evaluation of reviews. The aspects are related to the review itself (e.g., criticisms, novelty) and the relationship between the review and the manuscript (i.e., relevance). First, we perform supervised fine-tuning of DeepSeek-R1-Distill-Qwen-7B using LoRA on PeerRT, a new dataset of high-quality top AI conference reviews enriched with reasoning traces. We then apply Group Relative Policy Optimization (GRPO) to train two models: REMOR-H (with the human-aligned reward) and REMOR-U (with a uniform reward). Interestingly, the human-aligned reward penalizes aspects typically associated with strong reviews, leading REMOR-U to produce qualitatively more substantive feedback. Our results show that REMOR-U and REMOR-H achieve more than twice the average rewards of human reviews, non-reasoning state-of-the-art agentic multi-modal AI review systems, and general commercial LLM baselines. We found that while the best AI and human reviews are comparable in quality, REMOR avoids the long tail of low-quality human reviews. We discuss how reasoning is key to achieving these improvements and release the Human-aligned Peer Review Reward (HPRR) function, the Peer Review Reasoning-enriched Traces (PeerRT) dataset, and the REMOR models, which we believe can help spur progress in the area.
基于AI的同行评审系统相比人类反馈往往会产生肤浅且过于赞扬的建议。在这里,我们评估使用多目标强化学习(REMOR)训练的推理大型语言模型如何克服这些局限性。首先,我们设计一个与人为评价相吻合的多方面奖励函数。这些方面与评论本身有关(例如,批评、新颖性等),以及与评论和手稿之间的关系(即相关性)。首先,我们使用LoRA在PeerRT上进行DeepSeek-R1-Distill-Qwen-7B的精细监督微调,PeerRT是一个新的数据集,包含高质量顶级人工智能会议审查报告,并辅以推理痕迹。然后,我们应用群组相对策略优化(GRPO)来训练两个模型:REMOR-H(使用人类对齐奖励)和REMOR-U(使用统一奖励)。有趣的是,人类对齐的奖励会惩罚通常与优秀评论相关的方面,导致REMOR-U产生实质性的反馈。我们的结果表明,REMOR-U和REMOR-H获得的奖励是人为评审、非推理的最先进的多模态AI评审系统和一般商业大型语言模型基准测试的两倍多。我们发现,虽然最佳AI评审和人为评审的质量相当,但REMOR避免了低质量人为评审的长尾问题。我们讨论了推理是如何成为实现这些改进的关键,并发布了人类对齐的同行评审奖励(HPRR)功能、同行评审推理丰富痕迹(PeerRT)数据集和REMOR模型,我们相信这有助于推动该领域的进步。
论文及项目相关链接
PDF 18 pages, 6 figures
Summary
基于人工智能的同行评审系统相较于人类反馈往往产生肤浅且过于赞扬的建议。本研究旨在评估使用多目标强化学习训练的推理大模型(REMOR)如何克服这些限制。通过设计一种与人类评价相符的多方面奖励函数,我们进行了一系列实验,对DeepSeek-R1-Distill-Qwen-7B模型进行精细化训练,并在包含推理痕迹的高品质AI会议同行评审数据集PeerRT上进行评估。研究结果显示,使用人类对齐奖励的REMOR模型能产生更具实质性的反馈,并超越了人类评审、非推理型的最先进多模态AI评审系统和一般商业大模型的平均奖励水平。虽然最好的AI和人类的评审质量相当,但REMOR避免了低质量人类评审的长尾问题。推理对于实现这些改进至关重要。我们公开了人类对齐的同行评审奖励(HPRR)函数、包含推理痕迹的PeerRT数据集以及REMOR模型,希望能推动该领域的进步。
Key Takeaways
- AI-based同行评审系统常常给出肤浅和过于正面的建议。
- 通过设计符合人类评价的多方面奖励函数来改进AI评审系统。
- 使用了多目标强化学习训练的推理大模型(REMOR)。
- REMOR模型在特定数据集上的表现优于人类和其他AI模型。
- REMOR模型能够产生实质性的反馈,避免了低质量的人类评审。
- 公开了人类对齐的同行评审奖励函数、数据集和REMOR模型,以推动该领域的进步。
点此查看论文截图

Search and Refine During Think: Autonomous Retrieval-Augmented Reasoning of LLMs
Authors:Yaorui Shi, Sihang Li, Chang Wu, Zhiyuan Liu, Junfeng Fang, Hengxing Cai, An Zhang, Xiang Wang
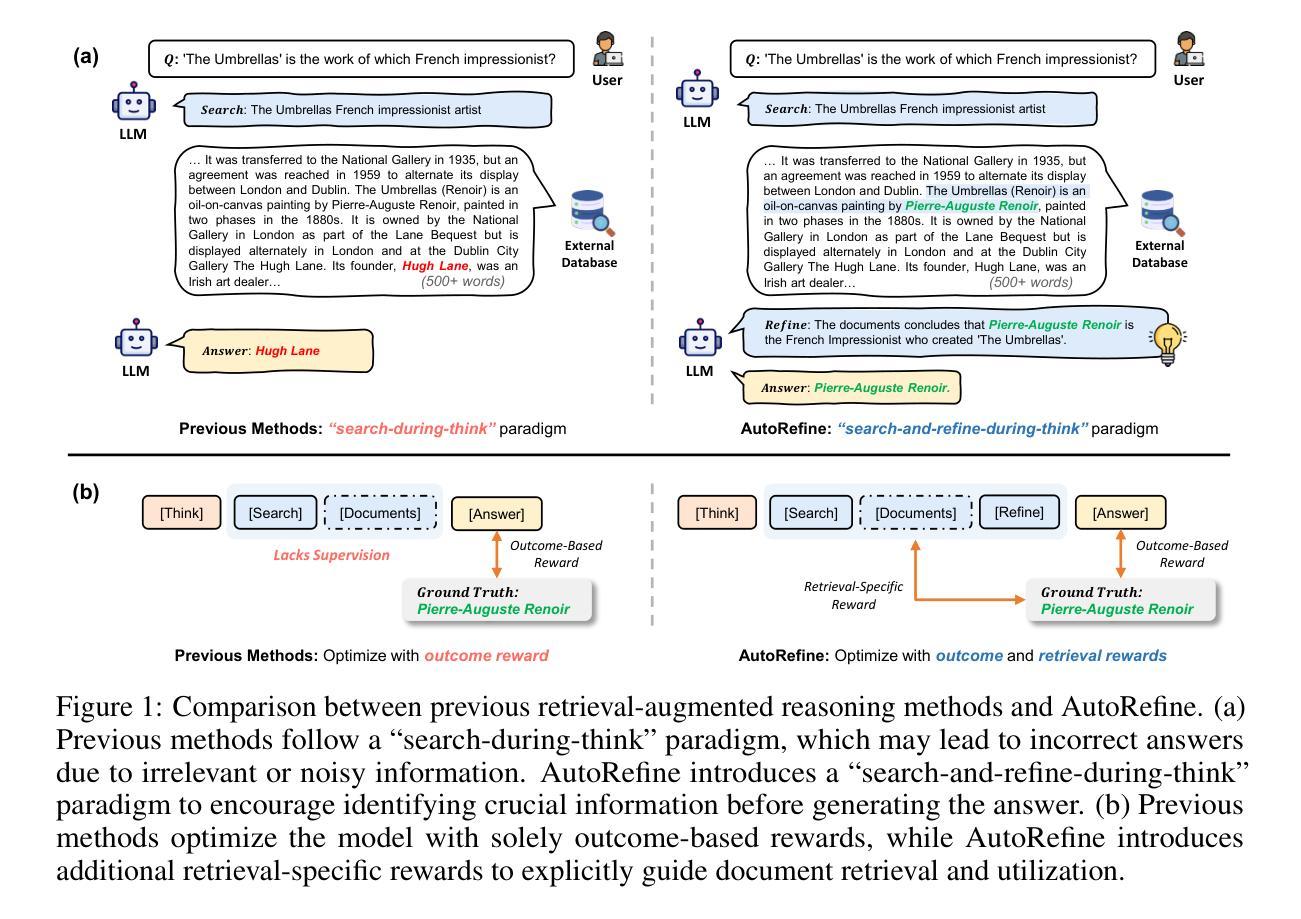
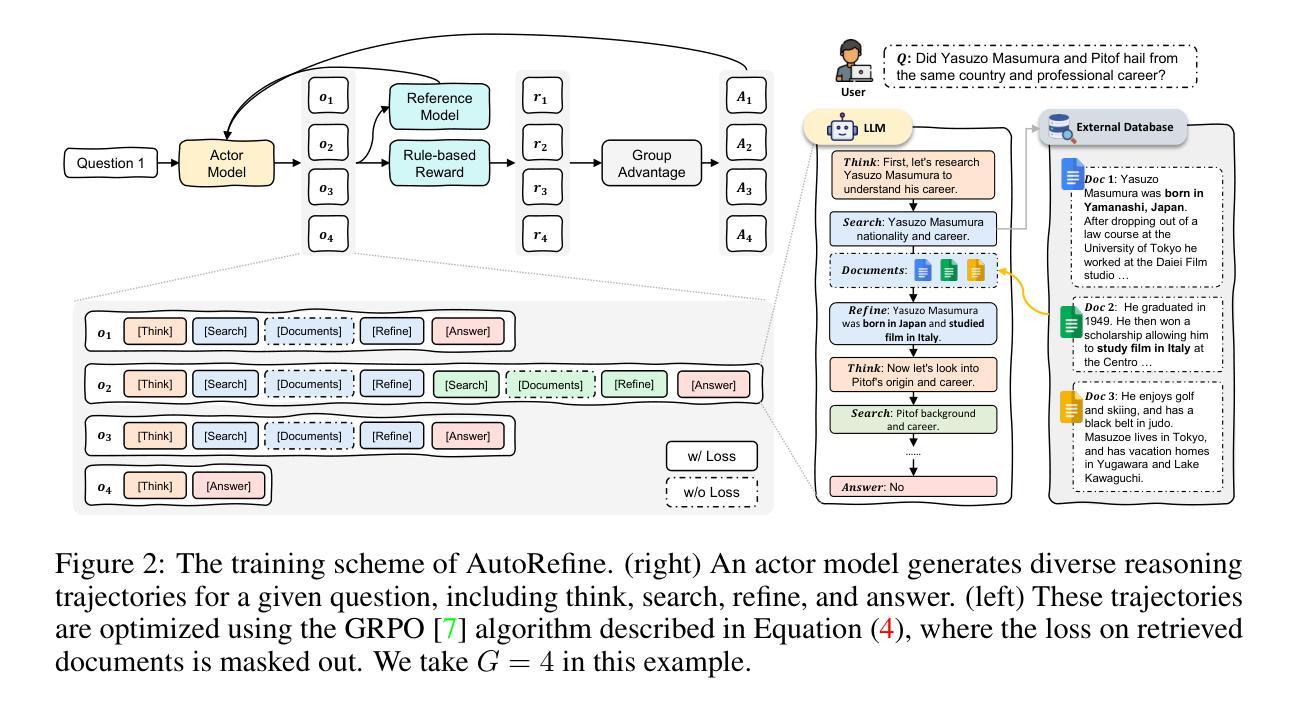
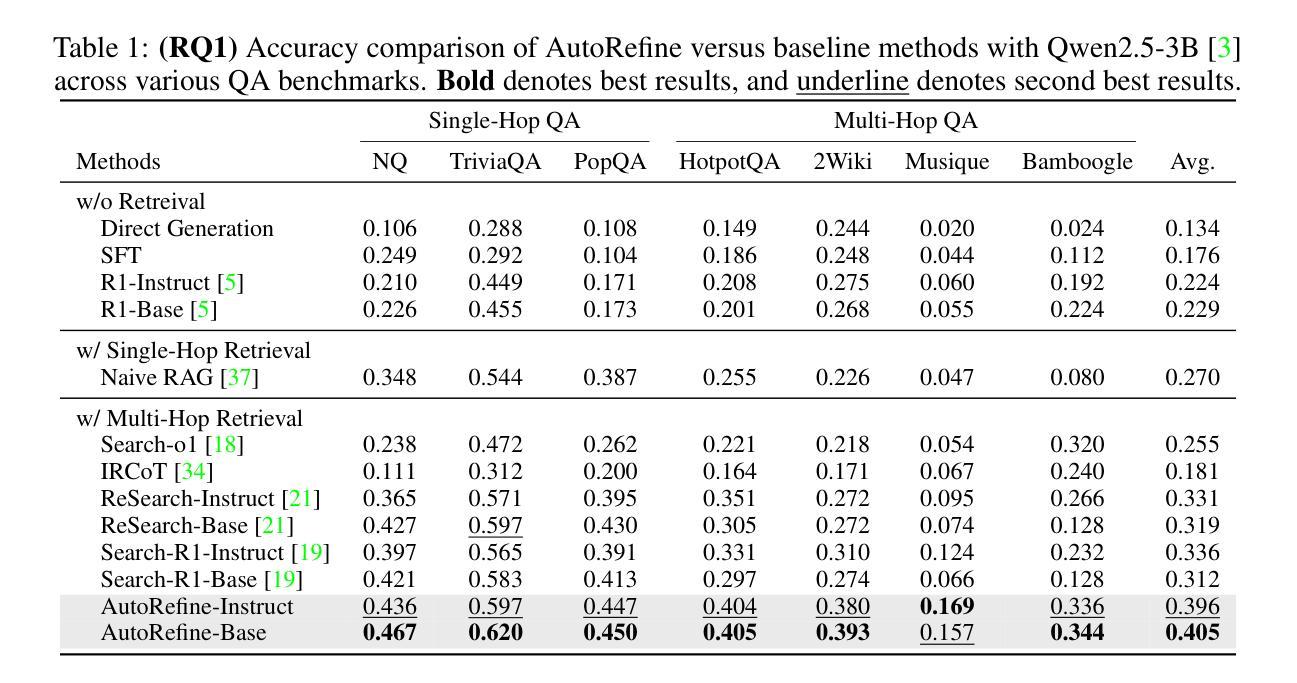
Large language models have demonstrated impressive reasoning capabilities but are inherently limited by their knowledge reservoir. Retrieval-augmented reasoning mitigates this limitation by allowing LLMs to query external resources, but existing methods often retrieve irrelevant or noisy information, hindering accurate reasoning. In this paper, we propose AutoRefine, a reinforcement learning post-training framework that adopts a new ``search-and-refine-during-think’’ paradigm. AutoRefine introduces explicit knowledge refinement steps between successive search calls, enabling the model to iteratively filter, distill, and organize evidence before generating an answer. Furthermore, we incorporate tailored retrieval-specific rewards alongside answer correctness rewards using group relative policy optimization. Experiments on single-hop and multi-hop QA benchmarks demonstrate that AutoRefine significantly outperforms existing approaches, particularly in complex, multi-hop reasoning scenarios. Detailed analysis shows that AutoRefine issues frequent, higher-quality searches and synthesizes evidence effectively.
大型语言模型已经展现出令人印象深刻的推理能力,但其本质上受到知识库的限制。检索增强推理通过允许大型语言模型查询外部资源来缓解这一限制,但现有方法通常检索到不相关或嘈杂的信息,阻碍了准确推理。在本文中,我们提出了AutoRefine,这是一种采用新型“思考过程中的搜索与精炼”范式的强化学习后训练框架。AutoRefine在连续搜索调用之间引入了明确的知识精炼步骤,使模型能够迭代地过滤、提炼和整理证据,然后生成答案。此外,我们通过使用群体相对策略优化,将定制的检索特定奖励与答案正确性奖励相结合。在单跳和多跳问答基准测试上的实验表明,AutoRefine显著优于现有方法,特别是在复杂的多跳推理场景中。详细分析表明,AutoRefine能进行频繁的高质量搜索,并能有效地综合证据。
论文及项目相关链接
Summary
本文提出了一种基于强化学习的后训练框架AutoRefine,该框架采用新颖的“边搜索边细化思考”范式。AutoRefine在连续搜索调用之间引入显式知识细化步骤,使模型能够迭代地过滤、提炼和整理证据,从而生成答案。结合针对检索的特定奖励和基于群体相对策略优化的答案正确性奖励,实验表明,AutoRefine在单跳和多跳问答基准测试中显著优于现有方法,特别是在复杂的多跳推理场景中。
Key Takeaways
- 大型语言模型虽然具备令人印象深刻的推理能力,但其知识库本质上限制了其性能。
- 检索增强推理通过允许LLMs查询外部资源来缓解这一限制。
- 现有方法常常检索到不相关或嘈杂的信息,阻碍准确推理。
- AutoRefine是一个基于强化学习的后训练框架,采用“边搜索边细化思考”的新范式。
- AutoRefine在连续搜索之间引入知识细化步骤,以迭代地过滤、提炼和整理证据。
- 结合检索特定奖励和答案正确性奖励,使用群体相对策略优化。
- 实验表明,AutoRefine在单跳和多跳问答基准测试中显著优于现有方法。
点此查看论文截图


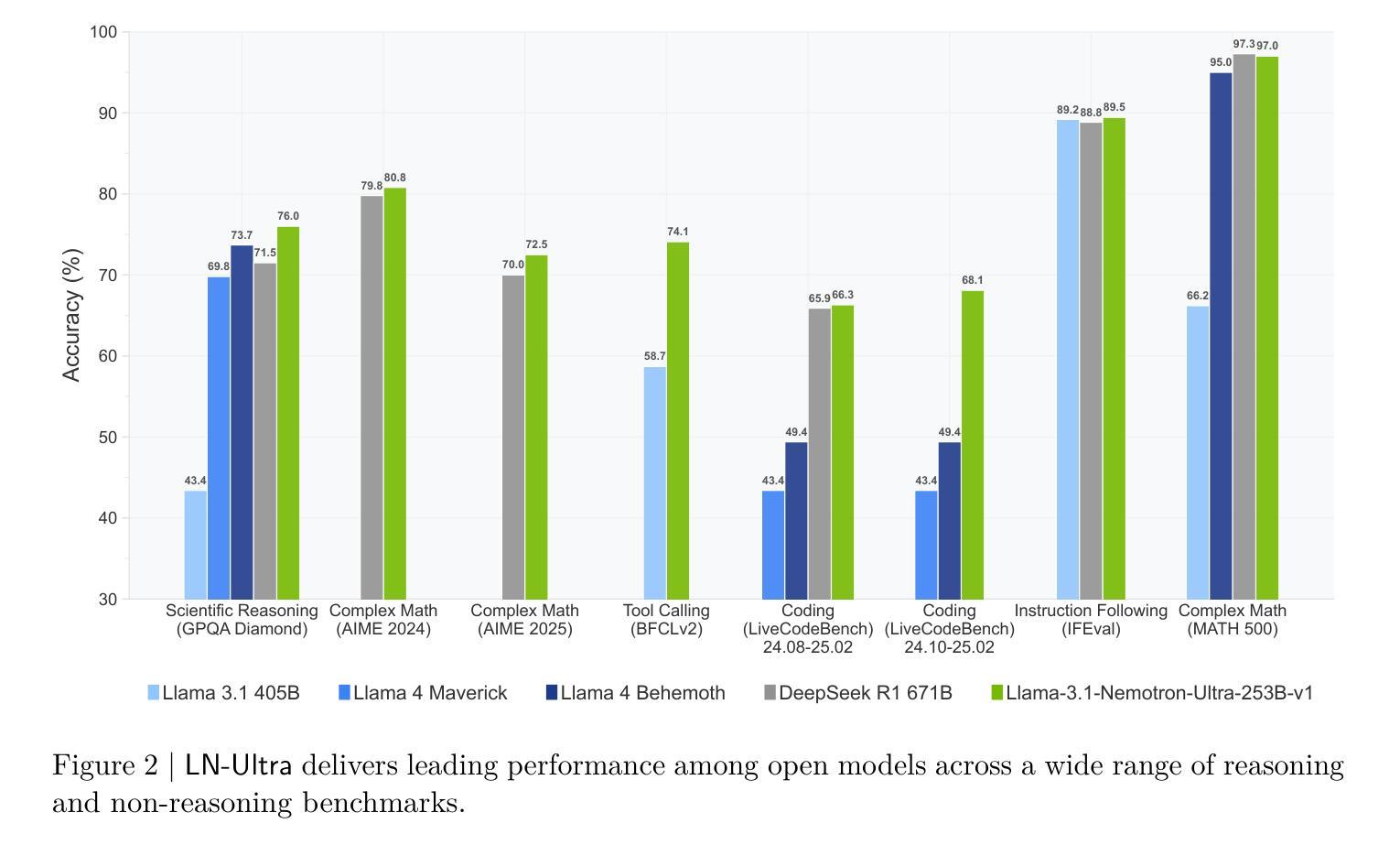
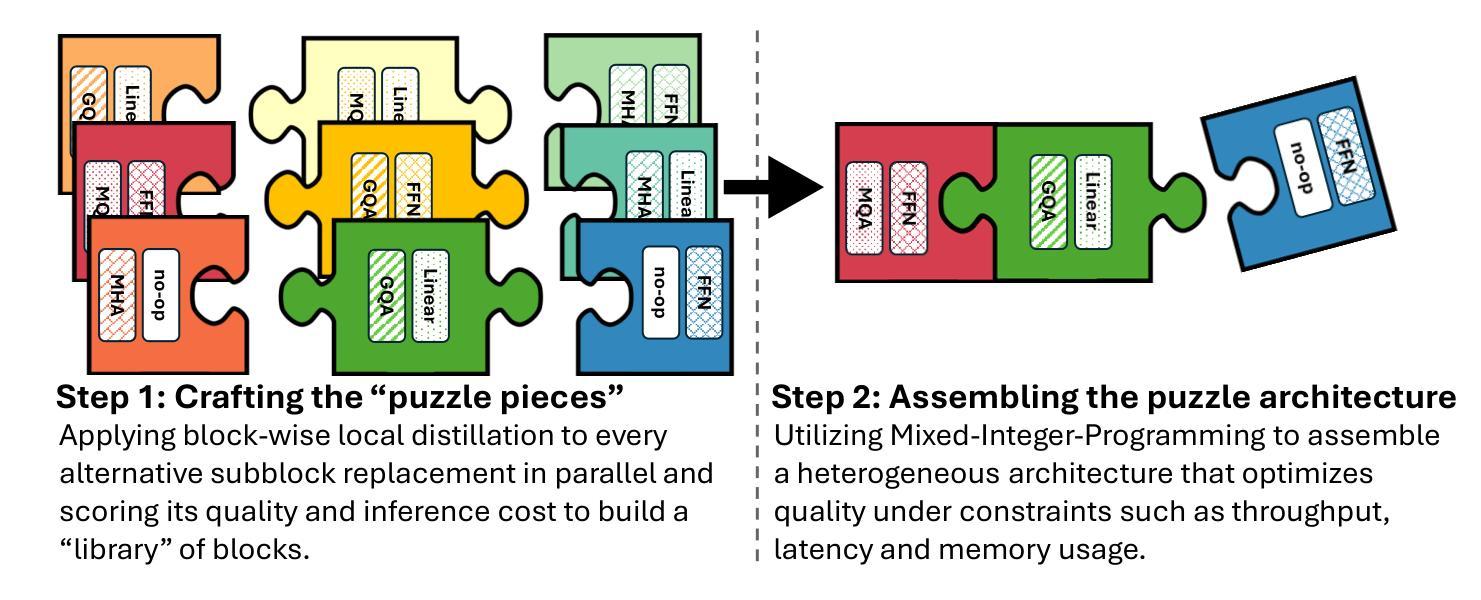
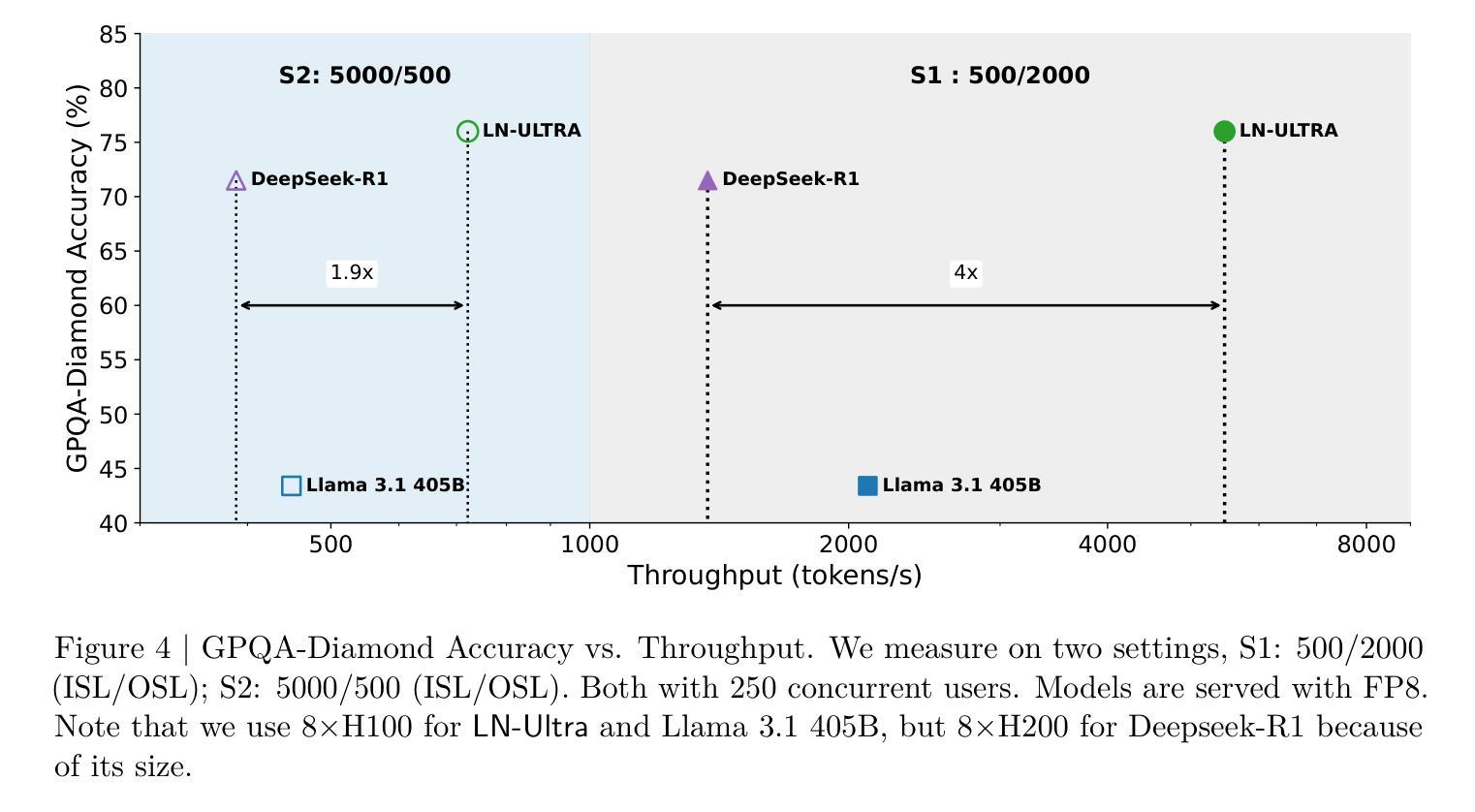
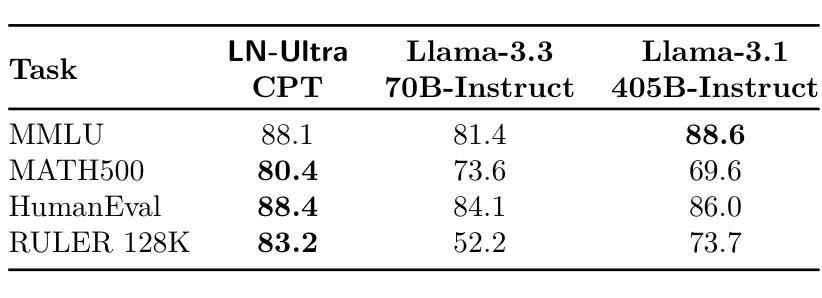
Llama-Nemotron: Efficient Reasoning Models
Authors:Akhiad Bercovich, Itay Levy, Izik Golan, Mohammad Dabbah, Ran El-Yaniv, Omri Puny, Ido Galil, Zach Moshe, Tomer Ronen, Najeeb Nabwani, Ido Shahaf, Oren Tropp, Ehud Karpas, Ran Zilberstein, Jiaqi Zeng, Soumye Singhal, Alexander Bukharin, Yian Zhang, Tugrul Konuk, Gerald Shen, Ameya Sunil Mahabaleshwarkar, Bilal Kartal, Yoshi Suhara, Olivier Delalleau, Zijia Chen, Zhilin Wang, David Mosallanezhad, Adi Renduchintala, Haifeng Qian, Dima Rekesh, Fei Jia, Somshubra Majumdar, Vahid Noroozi, Wasi Uddin Ahmad, Sean Narenthiran, Aleksander Ficek, Mehrzad Samadi, Jocelyn Huang, Siddhartha Jain, Igor Gitman, Ivan Moshkov, Wei Du, Shubham Toshniwal, George Armstrong, Branislav Kisacanin, Matvei Novikov, Daria Gitman, Evelina Bakhturina, Prasoon Varshney, Makesh Narsimhan, Jane Polak Scowcroft, John Kamalu, Dan Su, Kezhi Kong, Markus Kliegl, Rabeeh Karimi, Ying Lin, Sanjeev Satheesh, Jupinder Parmar, Pritam Gundecha, Brandon Norick, Joseph Jennings, Shrimai Prabhumoye, Syeda Nahida Akter, Mostofa Patwary, Abhinav Khattar, Deepak Narayanan, Roger Waleffe, Jimmy Zhang, Bor-Yiing Su, Guyue Huang, Terry Kong, Parth Chadha, Sahil Jain, Christine Harvey, Elad Segal, Jining Huang, Sergey Kashirsky, Robert McQueen, Izzy Putterman, George Lam, Arun Venkatesan, Sherry Wu, Vinh Nguyen, Manoj Kilaru, Andrew Wang, Anna Warno, Abhilash Somasamudramath, Sandip Bhaskar, Maka Dong, Nave Assaf, Shahar Mor, Omer Ullman Argov, Scot Junkin, Oleksandr Romanenko, Pedro Larroy, Monika Katariya, Marco Rovinelli, Viji Balas, Nicholas Edelman, Anahita Bhiwandiwalla, Muthu Subramaniam, Smita Ithape, Karthik Ramamoorthy, Yuting Wu, Suguna Varshini Velury, Omri Almog, Joyjit Daw, Denys Fridman, Erick Galinkin, Michael Evans, Shaona Ghosh, Katherine Luna, Leon Derczynski, Nikki Pope, Eileen Long, Seth Schneider, Guillermo Siman, Tomasz Grzegorzek, Pablo Ribalta, Monika Katariya, Chris Alexiuk, Joey Conway, Trisha Saar, Ann Guan, Krzysztof Pawelec, Shyamala Prayaga, Oleksii Kuchaiev, Boris Ginsburg, Oluwatobi Olabiyi, Kari Briski, Jonathan Cohen, Bryan Catanzaro, Jonah Alben, Yonatan Geifman, Eric Chung
We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes – Nano (8B), Super (49B), and Ultra (253B) – and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models – LN-Nano, LN-Super, and LN-Ultra – under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
我们介绍了Llama-Nemotron系列模型,这是一个开放的异构推理模型家族,具备出色的推理能力、推理效率和开放的企业使用许可。该家族有三种规模:Nano(8B)、Super(49B)和Ultra(253B),与最新的推理模型如DeepSeek-R1相比具有竞争力,同时提供更优越的推理吞吐量和内存效率。在本报告中,我们讨论了这些模型的训练流程,包括使用Llama 3模型的神经网络架构搜索进行加速推理、知识蒸馏和持续预训练,然后是侧重于推理的后训练阶段,主要包括两个部分:监督微调和大规模强化学习。Llama-Nemotron模型是首个支持动态推理切换的开源模型,允许用户在推理过程中切换标准聊天和推理模式。为了进一步支持开放研究和促进模型开发,我们提供了以下资源:1.我们在商业许可的NVIDIA开放模型许可协议下发布了Llama-Nemotron推理模型——LN-Nano、LN-Super和LN-Ultra。2.我们发布了完整的后训练数据集:Llama-Nemotron-Post-Training-Dataset。3.我们还发布了我们的训练代码库:NeMo、NeMo-Aligner和Megatron-LM。
论文及项目相关链接
Summary
基于Llama 3模型的神经架构搜索技术、知识蒸馏以及持续预训练的训练过程后推出的一款产品——开源的家庭模型Llama-Nemotron系列正式推出,涵盖了推理与通用对话的开源大模型,实现了优秀的推理能力、推理效率及商业授权机制。模型有三种尺寸——Nano(8B)、Super(49B)和Ultra(253B),相比于同类优秀模型DeepSeek-R1具备更佳的推理吞吐量和内存效率。首个开放式的支持动态推理切换模式推出。在此基础之上还推出训练相关的开源数据集及训练代码集资源供研究人员参考与使用。在论文中还详述了基于开源开放的发展模型提供无限潜力与发展前景的愿景展望。总之,这是一次具备创新性及重要意义的模型开发案例分享。如需更多细节信息,建议查阅论文原文内容。关于具体实现方法或训练数据集资源获取,请访问提供的官方网址进行了解。
Key Takeaways
- 介绍了Llama-Nemotron系列模型,这是一个开源的异构推理模型家族,具有出色的推理能力、推理效率和适用于企业使用的开放许可协议。
- 模型家族有三种不同尺寸,包括Nano(8B)、Super(49B)和Ultra(253B)。它们相较于现有的最先进的推理模型表现出竞争力和更高的推理吞吐量和内存效率优势。通过使用加速推理技术的开源神经架构搜索方法训练模型。
点此查看论文截图

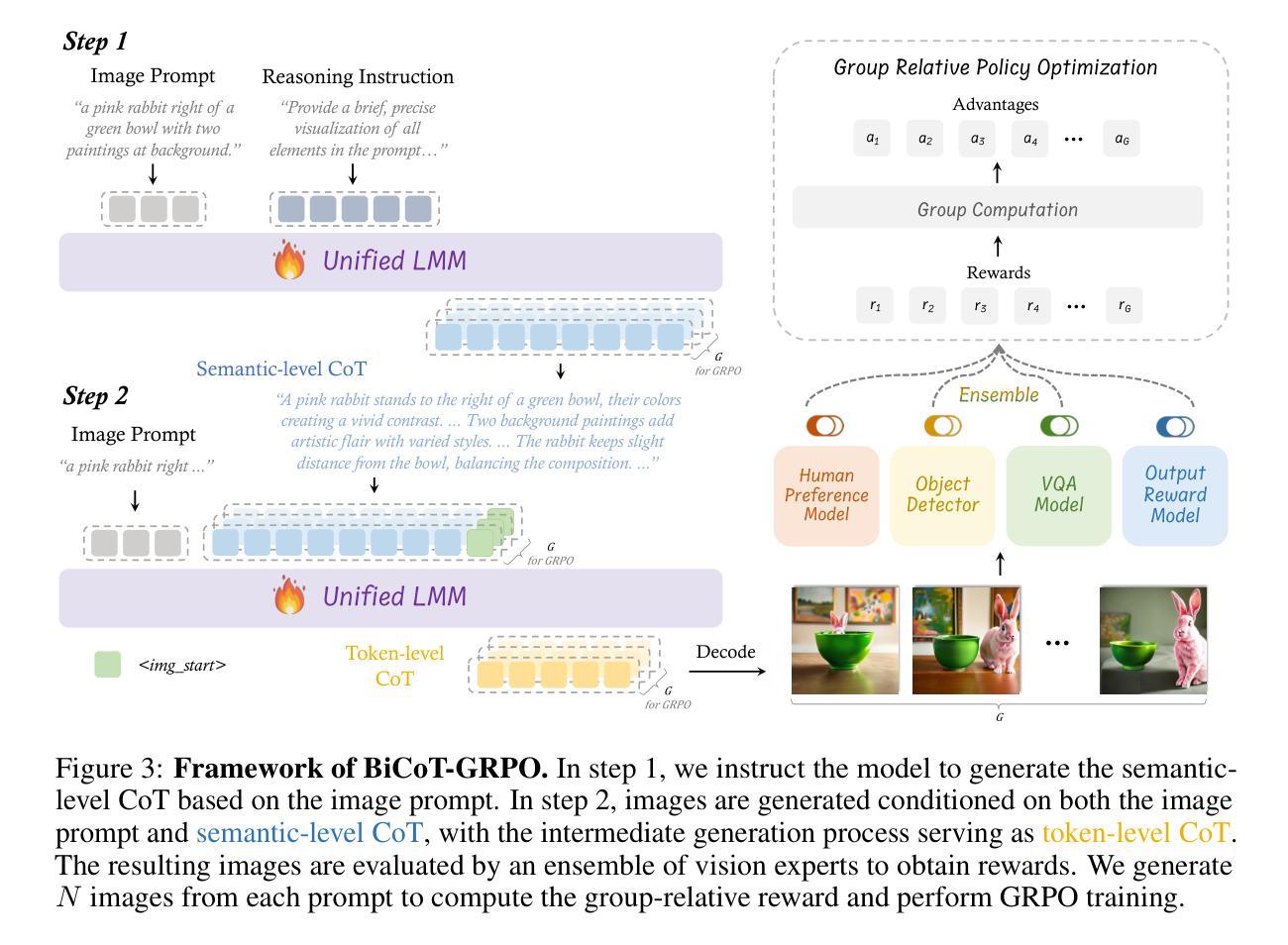
T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT
Authors:Dongzhi Jiang, Ziyu Guo, Renrui Zhang, Zhuofan Zong, Hao Li, Le Zhuo, Shilin Yan, Pheng-Ann Heng, Hongsheng Li
Recent advancements in large language models have demonstrated how chain-of-thought (CoT) and reinforcement learning (RL) can improve performance. However, applying such reasoning strategies to the visual generation domain remains largely unexplored. In this paper, we present T2I-R1, a novel reasoning-enhanced text-to-image generation model, powered by RL with a bi-level CoT reasoning process. Specifically, we identify two levels of CoT that can be utilized to enhance different stages of generation: (1) the semantic-level CoT for high-level planning of the prompt and (2) the token-level CoT for low-level pixel processing during patch-by-patch generation. To better coordinate these two levels of CoT, we introduce BiCoT-GRPO with an ensemble of generation rewards, which seamlessly optimizes both generation CoTs within the same training step. By applying our reasoning strategies to the baseline model, Janus-Pro, we achieve superior performance with 13% improvement on T2I-CompBench and 19% improvement on the WISE benchmark, even surpassing the state-of-the-art model FLUX.1. Code is available at: https://github.com/CaraJ7/T2I-R1
最近的大型语言模型进展表明,思维链(CoT)和强化学习(RL)如何提升性能。然而,将此类推理策略应用于视觉生成领域尚未得到充分探索。在本文中,我们提出了T2I-R1,这是一种新型推理增强文本到图像生成模型,通过两级CoT推理过程强化学习。具体来说,我们确定了两个层次的CoT,可以用于增强生成的不同阶段:(1)语义层次的CoT用于高级提示规划;(2)标记层次的CoT用于补丁逐补丁生成过程中的低级像素处理。为了更好地协调这两个层次的CoT,我们引入了BiCoT-GRPO与一系列生成奖励,可在同一训练步骤中无缝优化两种生成CoT。通过将我们的推理策略应用于基线模型Janus-Pro,我们在T2I-CompBench上实现了13%的改进,在WISE基准测试上实现了19%的改进,甚至超越了最先进的模型FLUX.1。代码可在以下网址找到:https://github.com/CaraJ7/T2I-R1。
论文及项目相关链接
PDF Project Page: https://github.com/CaraJ7/T2I-R1
Summary
本文介绍了一种名为T2I-R1的新型文本驱动图像生成模型,该模型采用强化学习和两级链式思维推理技术。T2I-R1能够利用两个级别的链式思维(语义级别和令牌级别)来提升生成的不同阶段,通过BiCoT-GRPO协调这两个级别的推理。该模型改进了基线模型Janus-Pro的性能,在T2I-CompBench和WISE基准测试中分别提高了13%和19%,超越了现有技术最先进的模型FLUX。
Key Takeaways
- T2I-R1是一个结合了强化学习和链式思维推理的文本驱动图像生成模型。
- 模型采用两级链式思维(语义级别和令牌级别)以提升生成质量。
- BiCoT-GRPO被引入以协调这两个级别的链式思维推理。
- T2I-R1改进了基线模型Janus-Pro的性能。
- 在T2I-CompBench和WISE基准测试中,T2I-R1分别实现了13%和19%的性能提升。
- T2I-R1的性能超越了现有的最先进的模型FLUX。
点此查看论文截图



DUMP: Automated Distribution-Level Curriculum Learning for RL-based LLM Post-training
Authors:Zhenting Wang, Guofeng Cui, Yu-Jhe Li, Kun Wan, Wentian Zhao
Recent advances in reinforcement learning (RL)-based post-training have led to notable improvements in large language models (LLMs), particularly in enhancing their reasoning capabilities to handle complex tasks. However, most existing methods treat the training data as a unified whole, overlooking the fact that modern LLM training often involves a mixture of data from diverse distributions-varying in both source and difficulty. This heterogeneity introduces a key challenge: how to adaptively schedule training across distributions to optimize learning efficiency. In this paper, we present a principled curriculum learning framework grounded in the notion of distribution-level learnability. Our core insight is that the magnitude of policy advantages reflects how much a model can still benefit from further training on a given distribution. Based on this, we propose a distribution-level curriculum learning framework for RL-based LLM post-training, which leverages the Upper Confidence Bound (UCB) principle to dynamically adjust sampling probabilities for different distrubutions. This approach prioritizes distributions with either high average advantage (exploitation) or low sample count (exploration), yielding an adaptive and theoretically grounded training schedule. We instantiate our curriculum learning framework with GRPO as the underlying RL algorithm and demonstrate its effectiveness on logic reasoning datasets with multiple difficulties and sources. Our experiments show that our framework significantly improves convergence speed and final performance, highlighting the value of distribution-aware curriculum strategies in LLM post-training. Code: https://github.com/ZhentingWang/DUMP.
最近,基于强化学习(RL)的后期训练取得了显著进展,为大型语言模型(LLM)带来了明显的改进,特别是在提高其处理复杂任务时的推理能力方面。然而,大多数现有方法将训练数据视为一个整体,忽略了现代LLM训练通常涉及来自不同分布的混合数据这一事实,这些数据的来源和难度都在不断变化。这种异质性引入了一个关键挑战:如何自适应地调度跨分布的训练以优化学习效率。在本文中,我们提出了一个基于分布级别可学习性的原理性课程学习框架。我们的核心见解是,策略优势的大小反映了模型在给定分布上进一步训练的潜在收益。基于此,我们为基于RL的LLM后训练提出了一个分布级别的课程学习框架,它利用上界置信(UCB)原则来动态调整不同分布的采样概率。该方法优先处理具有较大平均优势(利用)或低样本数量(探索)的分布,从而产生一个自适应且理论上有依据的训练计划。我们使用GRPO作为基础RL算法来实例化我们的课程学习框架,并在具有不同难度和来源的逻辑推理数据集上展示了其有效性。我们的实验表明,我们的框架显著提高了收敛速度和最终性能,突显了分布感知课程策略在LLM后训练中的价值。代码地址:https://github.com/ZhentingWang/DUMP 。
论文及项目相关链接
Summary
这篇论文针对大型语言模型(LLM)的后训练阶段,提出了一个基于分布级别可学习性的原则化课程学习框架。该框架解决了现有方法忽略数据分布多样性带来的挑战,通过利用强化学习(RL)自适应地调整不同分布的采样概率,实现了对LLM的高效优化。实验表明,该框架在逻辑推理数据集上显著提高了收敛速度和最终性能。
Key Takeaways
- 强化学习后训练在大型语言模型中的进步已经显著提高了模型处理复杂任务的能力。
- 现有方法通常将训练数据视为整体,忽略了现代LLM训练中数据分布多样性的重要性。
- 论文提出了一个基于分布级别可学习性的课程学习框架,该框架利用策略优势幅度来确定模型从特定分布中进一步训练的收益。
- 框架利用上置信界(UCB)原则动态调整不同分布的采样概率,优先处理具有高平均优势或低样本计数的分布。
- 该框架实现了自适应的训练调度,为RL在LLM后训练中的应用提供了新的视角。
- 论文使用GRPO作为底层RL算法,在具有不同难度和来源的逻辑推理数据集上验证了框架的有效性。
点此查看论文截图


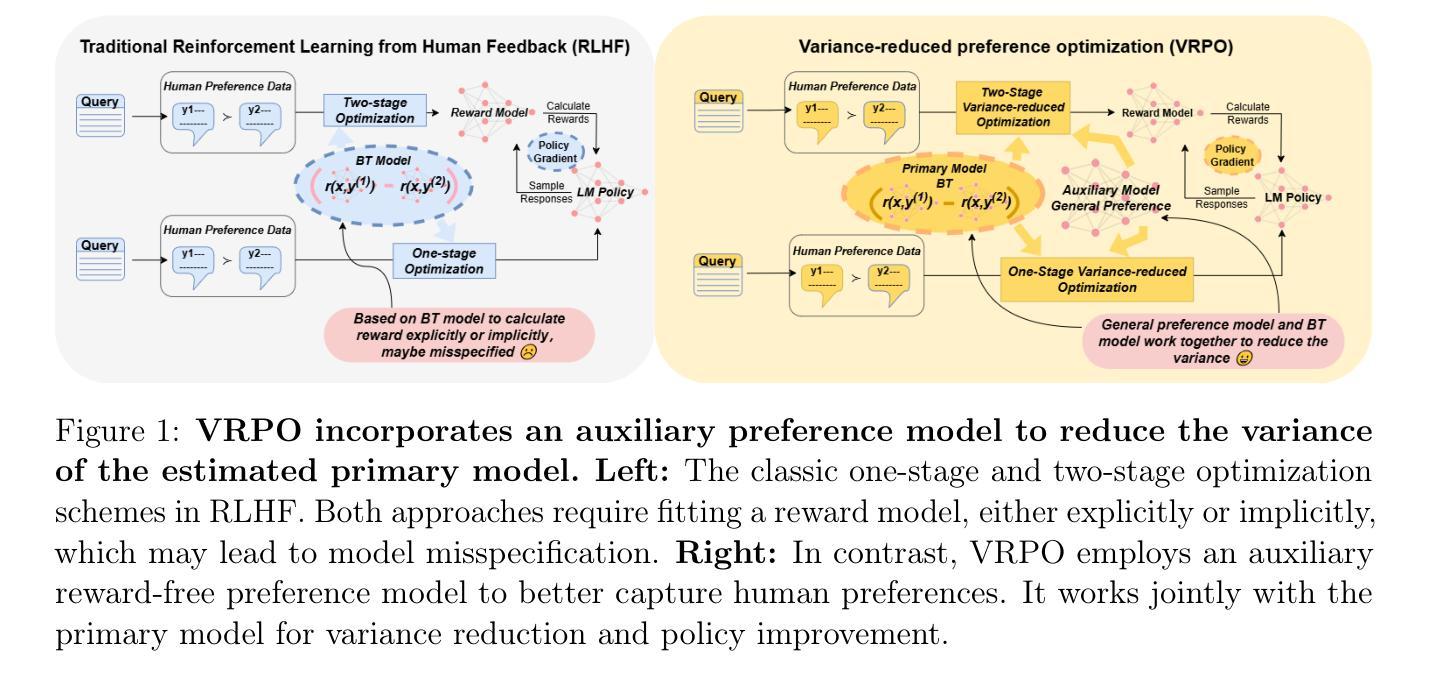
Robust Reinforcement Learning from Human Feedback for Large Language Models Fine-Tuning
Authors:Kai Ye, Hongyi Zhou, Jin Zhu, Francesco Quinzan, Chengchun Shi
Reinforcement learning from human feedback (RLHF) has emerged as a key technique for aligning the output of large language models (LLMs) with human preferences. To learn the reward function, most existing RLHF algorithms use the Bradley-Terry model, which relies on assumptions about human preferences that may not reflect the complexity and variability of real-world judgments. In this paper, we propose a robust algorithm to enhance the performance of existing approaches under such reward model misspecifications. Theoretically, our algorithm reduces the variance of reward and policy estimators, leading to improved regret bounds. Empirical evaluations on LLM benchmark datasets demonstrate that the proposed algorithm consistently outperforms existing methods, with 77-81% of responses being favored over baselines on the Anthropic Helpful and Harmless dataset.
强化学习从人类反馈(RLHF)已经成为一种关键技术,用于将大型语言模型(LLM)的输出与人类偏好对齐。为了学习奖励函数,大多数现有的RLHF算法使用Bradley-Terry模型,该模型依赖于关于人类偏好的假设,这些假设可能无法反映现实世界中判断复杂性和差异性。在本文中,我们提出了一种稳健的算法,以提高在这种奖励模型错误设定下现有方法的性能。理论上,我们的算法降低了奖励和政策估算器的方差,从而提高了后悔界限。在LLM基准数据集上的经验评估表明,该算法始终优于现有方法,在Anthropic有益和无害数据集上,有77-81%的响应优于基线。
论文及项目相关链接
Summary:强化学习从人类反馈(RLHF)已成为使大型语言模型(LLM)输出与人类偏好对齐的关键技术。大多数现有RLHF算法使用Bradley-Terry模型来学习奖励函数,这依赖于可能无法反映现实世界判断复杂性和可变性的假设。本文提出了一种增强算法,以提高在奖励模型误指定情况下的性能。理论上,该算法降低了奖励和政策估计量的方差,提高了后悔界。在LLM基准数据集上的实证评估表明,该算法始终优于现有方法,在Anthropic有益和无害数据集上,77-81%的响应优于基线。
Key Takeaways:
- RLHF已成为LLM输出与人类偏好对齐的重要技术。
- 现有RLHF算法主要使用Bradley-Terry模型,存在对现实世界判断复杂性和可变性的假设不足的问题。
- 本文提出了一种增强算法,旨在提高在奖励模型误指定情况下的性能。
- 该算法理论上可降低奖励和政策估计量的方差,提高后悔界。
- 实证评估表明,该算法在LLM基准数据集上表现优异。
- 在Anthropic有益和无害数据集上,该算法响应优于现有方法达到77-81%。
点此查看论文截图