⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-08 更新
TTRL: Test-Time Reinforcement Learning
Authors:Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, Biqing Qi, Youbang Sun, Zhiyuan Ma, Lifan Yuan, Ning Ding, Bowen Zhou
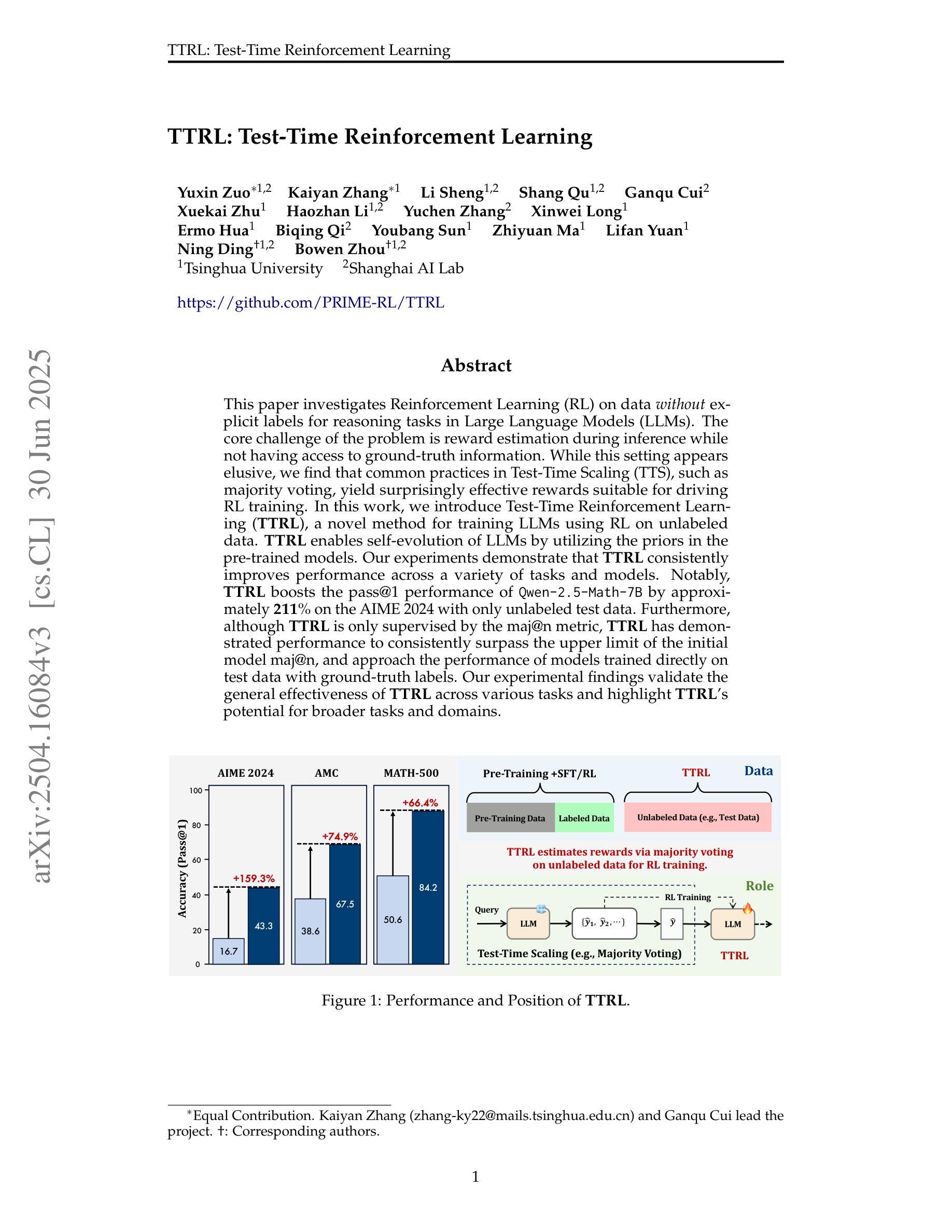
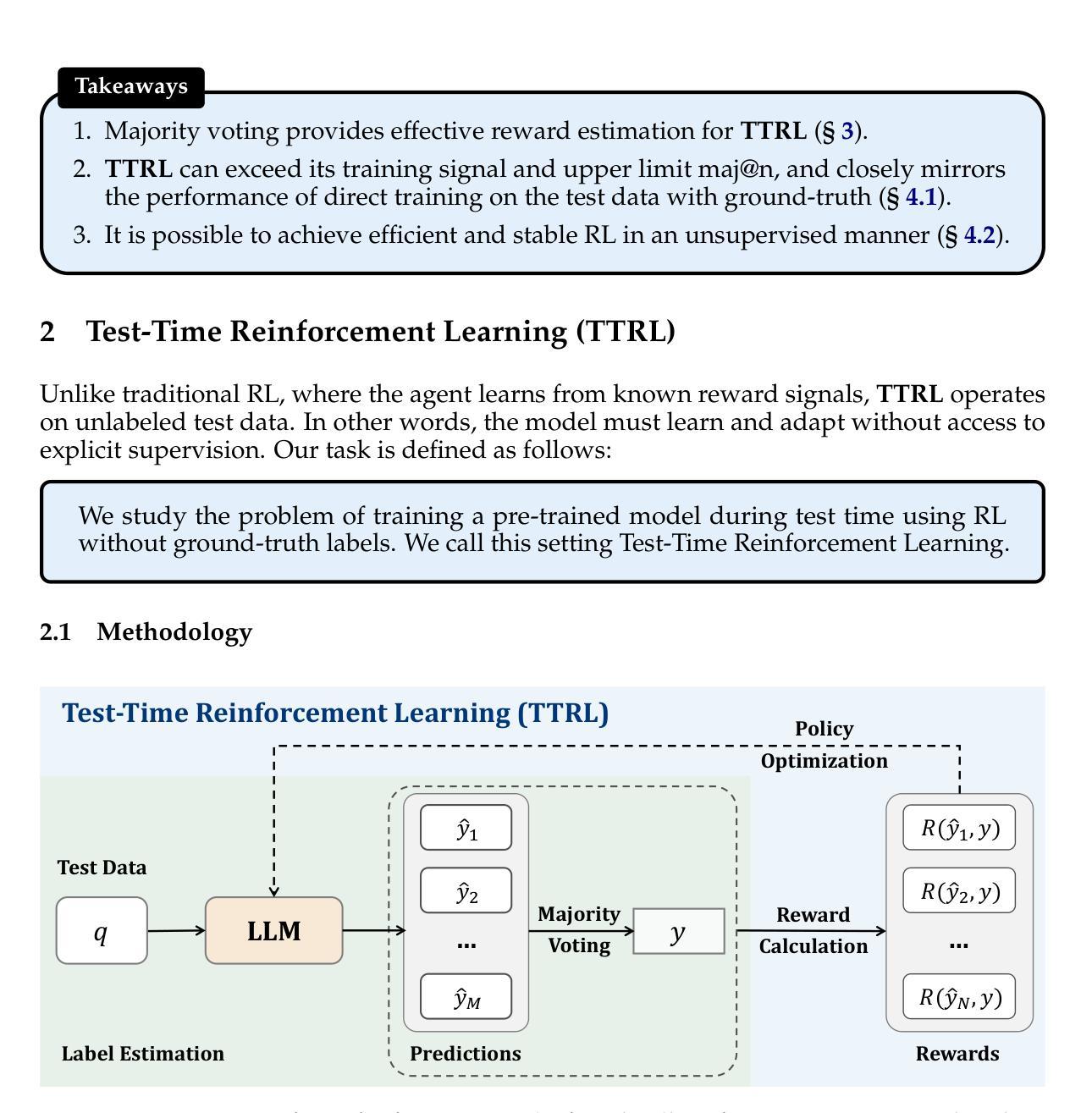
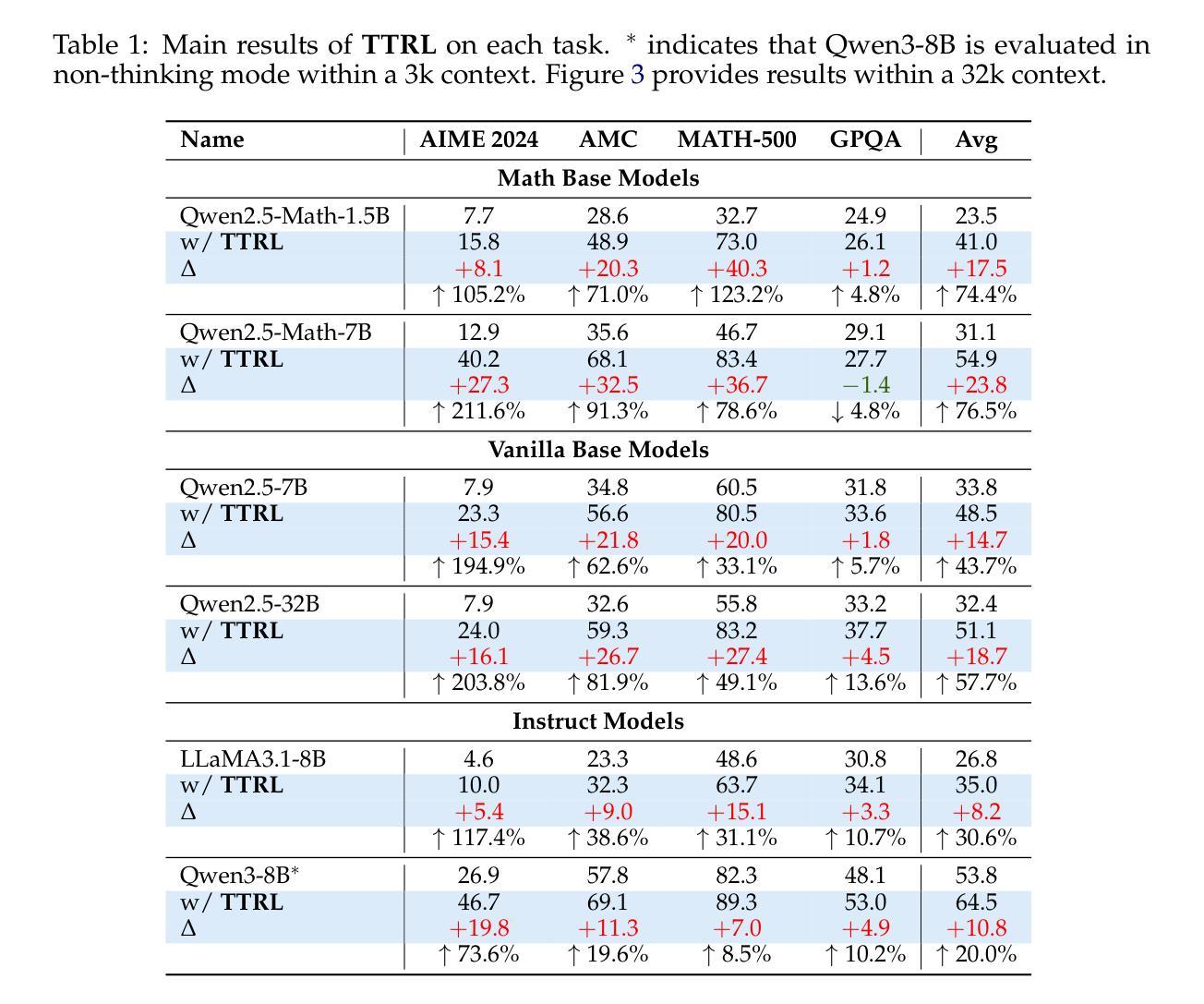
This paper investigates Reinforcement Learning (RL) on data without explicit labels for reasoning tasks in Large Language Models (LLMs). The core challenge of the problem is reward estimation during inference while not having access to ground-truth information. While this setting appears elusive, we find that common practices in Test-Time Scaling (TTS), such as majority voting, yield surprisingly effective rewards suitable for driving RL training. In this work, we introduce Test-Time Reinforcement Learning (TTRL), a novel method for training LLMs using RL on unlabeled data. TTRL enables self-evolution of LLMs by utilizing the priors in the pre-trained models. Our experiments demonstrate that TTRL consistently improves performance across a variety of tasks and models. Notably, TTRL boosts the pass@1 performance of Qwen-2.5-Math-7B by approximately 211% on the AIME 2024 with only unlabeled test data. Furthermore, although TTRL is only supervised by the maj@n metric, TTRL has demonstrated performance to consistently surpass the upper limit of the initial model maj@n, and approach the performance of models trained directly on test data with ground-truth labels. Our experimental findings validate the general effectiveness of TTRL across various tasks and highlight TTRL’s potential for broader tasks and domains. GitHub: https://github.com/PRIME-RL/TTRL
本文探讨了强化学习(RL)在大型语言模型(LLM)的推理任务中对于无明确标签数据的应用。该问题的核心挑战在于推理过程中奖励的估计,同时无法获取真实信息。尽管这一设定看似难以捉摸,但我们发现测试时间缩放(TTS)的常见做法,如多数投票,产生的奖励出乎意料地适用于驱动RL训练。在这项工作中,我们引入了测试时间强化学习(TTRL),这是一种使用无标签数据对LLM进行RL训练的新方法。TTRL利用预训练模型中的先验知识,实现LLM的自我进化。实验表明,TTRL在各种任务和模型上的性能持续提高。值得注意的是,在AIME 2024比赛中,TTRL将Qwen-2.5-Math-7B的pass@1性能提高了约211%,且仅使用无标签的测试数据。此外,尽管TTRL只受到maj@n指标的监督,但其性能始终超过初始模型的maj@n上限,并接近直接在带有真实标签的测试数据上训练的模型的性能。我们的实验验证了TTRL在多种任务中的普遍有效性,并突出了其在更广泛的任务和领域中的潜力。GitHub链接:https://github.com/PRIME-RL/TTRL
论文及项目相关链接
Summary
强化学习在无标签数据的大型语言模型上应用于推理任务进行了研究。核心挑战在于推理时如何估计奖励,同时没有访问真实标签信息。研究发现测试时间缩放(TTS)的常见方法,如多数投票,能产生有效的奖励来驱动强化学习训练。本文提出了测试时间强化学习(TTRL)这一新方法,用于使用无标签数据训练大型语言模型。实验表明,TTRL在各种任务和模型上的性能均有所提升。GitHub:https://github.com/PRIME-RL/TTRL。
Key Takeaways
- 研究采用强化学习(RL)在无标签数据的大型语言模型(LLM)上进行推理任务。
- 面临的核心挑战在于在缺乏真实标签信息的情况下进行推理时的奖励估计。
- 测试时间缩放(TTS)的常见方法,如多数投票,能生成有效的奖励,适用于驱动RL训练。
- 引入了一种新的方法——测试时间强化学习(TTRL),用于使用无标签数据训练LLM。
- TTRL通过利用预训练模型中的先验信息,使LLM能够自我进化。
- 实验结果显示TTRL在各种任务上的性能有所提升,特别是对Qwen-2.5-Math-7B在AIME 2024上的pass@1性能提升了约211%。
- 尽管TTRL仅受maj@n指标的监督,但其性能始终超过初始模型的maj@n上限,并接近直接在测试数据上使用真实标签训练的模型性能。
点此查看论文截图