⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-09 更新
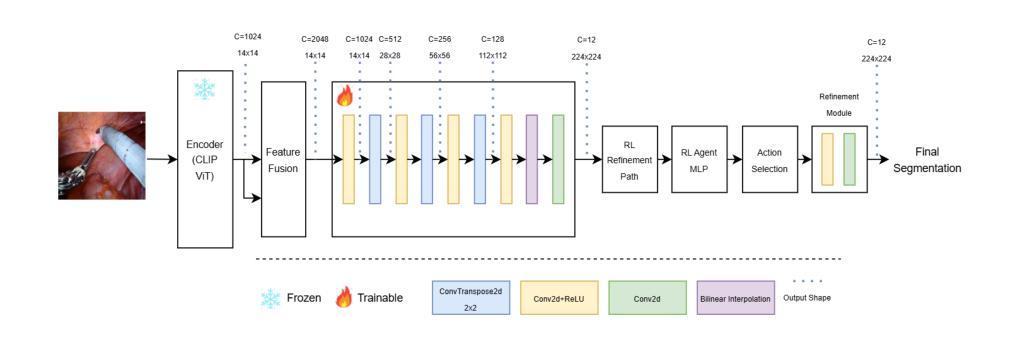
CLIP-RL: Surgical Scene Segmentation Using Contrastive Language-Vision Pretraining & Reinforcement Learning
Authors:Fatmaelzahraa Ali Ahmed, Muhammad Arsalan, Abdulaziz Al-Ali, Khalid Al-Jalham, Shidin Balakrishnan
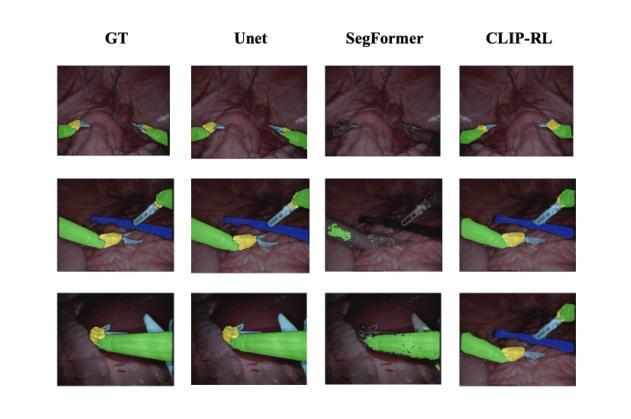
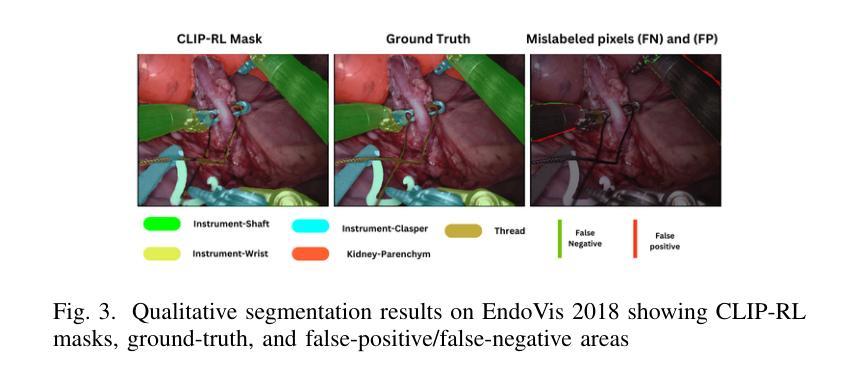
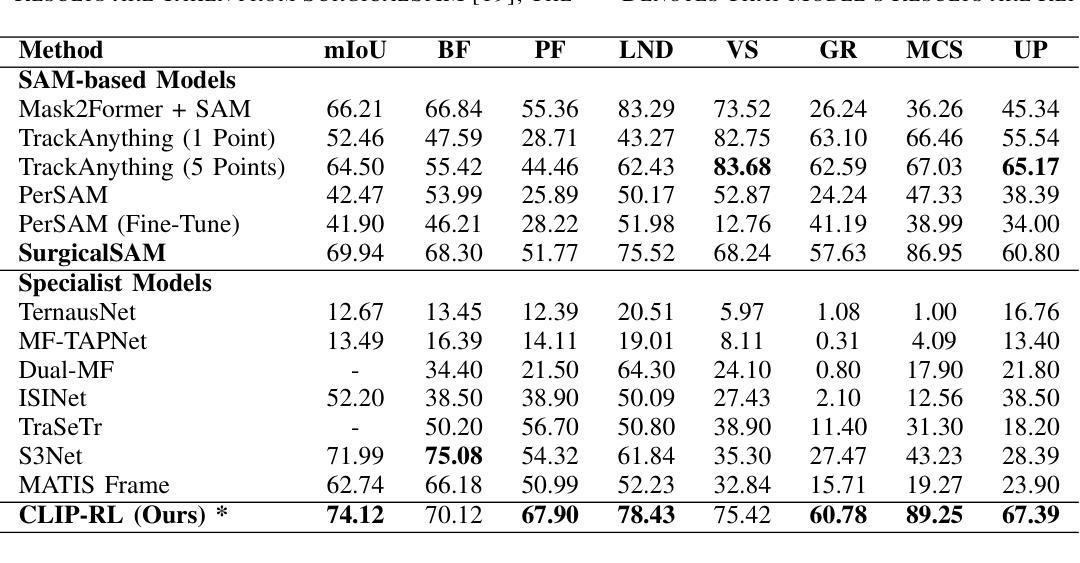
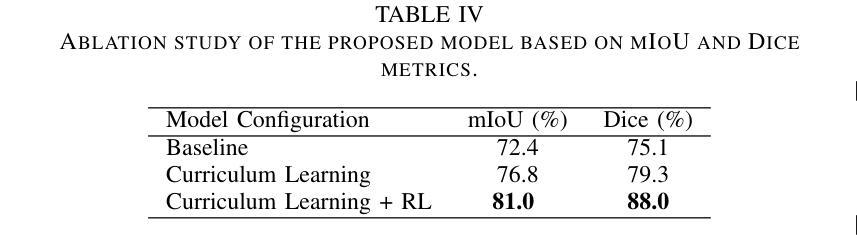
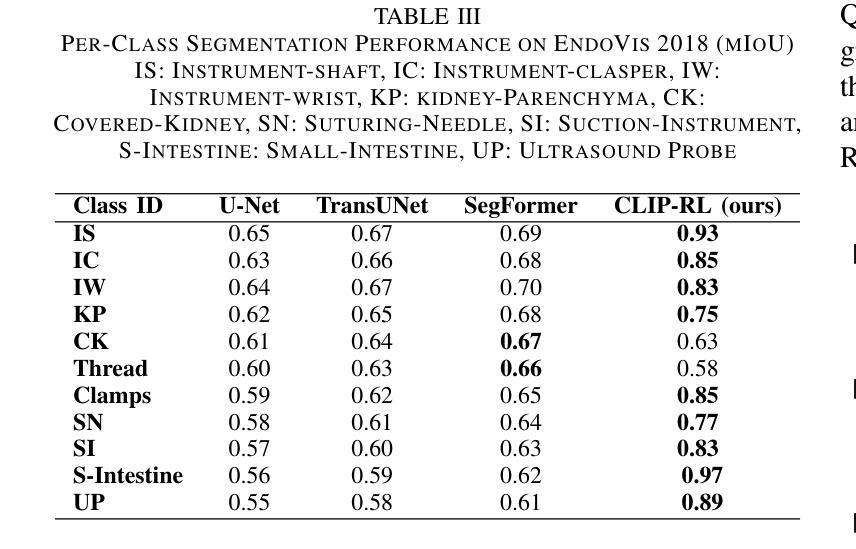
Understanding surgical scenes can provide better healthcare quality for patients, especially with the vast amount of video data that is generated during MIS. Processing these videos generates valuable assets for training sophisticated models. In this paper, we introduce CLIP-RL, a novel contrastive language-image pre-training model tailored for semantic segmentation for surgical scenes. CLIP-RL presents a new segmentation approach which involves reinforcement learning and curriculum learning, enabling continuous refinement of the segmentation masks during the full training pipeline. Our model has shown robust performance in different optical settings, such as occlusions, texture variations, and dynamic lighting, presenting significant challenges. CLIP model serves as a powerful feature extractor, capturing rich semantic context that enhances the distinction between instruments and tissues. The RL module plays a pivotal role in dynamically refining predictions through iterative action-space adjustments. We evaluated CLIP-RL on the EndoVis 2018 and EndoVis 2017 datasets. CLIP-RL achieved a mean IoU of 81%, outperforming state-of-the-art models, and a mean IoU of 74.12% on EndoVis 2017. This superior performance was achieved due to the combination of contrastive learning with reinforcement learning and curriculum learning.
理解手术场景可以为患者提供更好的医疗服务质量,特别是在MIS过程中产生的大量视频数据。处理这些视频为训练复杂模型提供了宝贵的资产。在本文中,我们介绍了CLIP-RL,这是一种针对手术场景语义分割的新型对比语言图像预训练模型。CLIP-RL提出了一种新的分割方法,涉及强化学习和课程学习,使分割掩膜在整个训练过程中得到持续改进。我们的模型在不同的光学设置下表现出稳健的性能,如遮挡、纹理变化和动态照明,这些设置具有重大挑战。CLIP模型作为一个强大的特征提取器,捕捉丰富的语义上下文,增强了仪器与组织之间的区别。RL模块通过迭代动作空间调整,在动态改进预测方面发挥了关键作用。我们在EndoVis 2018和EndoVis 2017数据集上评估了CLIP-RL。CLIP-RL在EndoVis 2018数据集上实现了平均IoU为81%,超越了最先进的模型;在EndoVis 2017数据集上实现了平均IoU为74.12%。这一卓越性能是通过对比学习与强化学习和课程学习的结合而实现的。
论文及项目相关链接
Summary
基于CLIP-RL模型,本文提出了一种针对手术场景语义分割的新方法。通过结合对比学习、强化学习与课程学习,实现了手术视频数据的深度处理与精确分割。在EndoVis数据集上的实验表明,CLIP-RL模型性能卓越,相较于其他先进模型有明显提升。
Key Takeaways
- CLIP-RL模型结合了对比学习、强化学习与课程学习,针对手术场景的语义分割进行了优化。
- CLIP模型作为特征提取器,能够捕捉丰富的语义上下文,提高了仪器与组织的区分度。
- 强化学习模块在训练过程中扮演了重要角色,通过动态调整行动空间,实现了预测的持续优化。
- CLIP-RL模型在不同光学条件下表现出稳健性能,如遮挡、纹理变化和动态光照等。
- 在EndoVis 2018数据集上,CLIP-RL模型实现了平均IoU为81%,优于其他先进模型。
- 在EndoVis 2017数据集上,CLIP-RL模型实现了平均IoU为74.12%。
点此查看论文截图


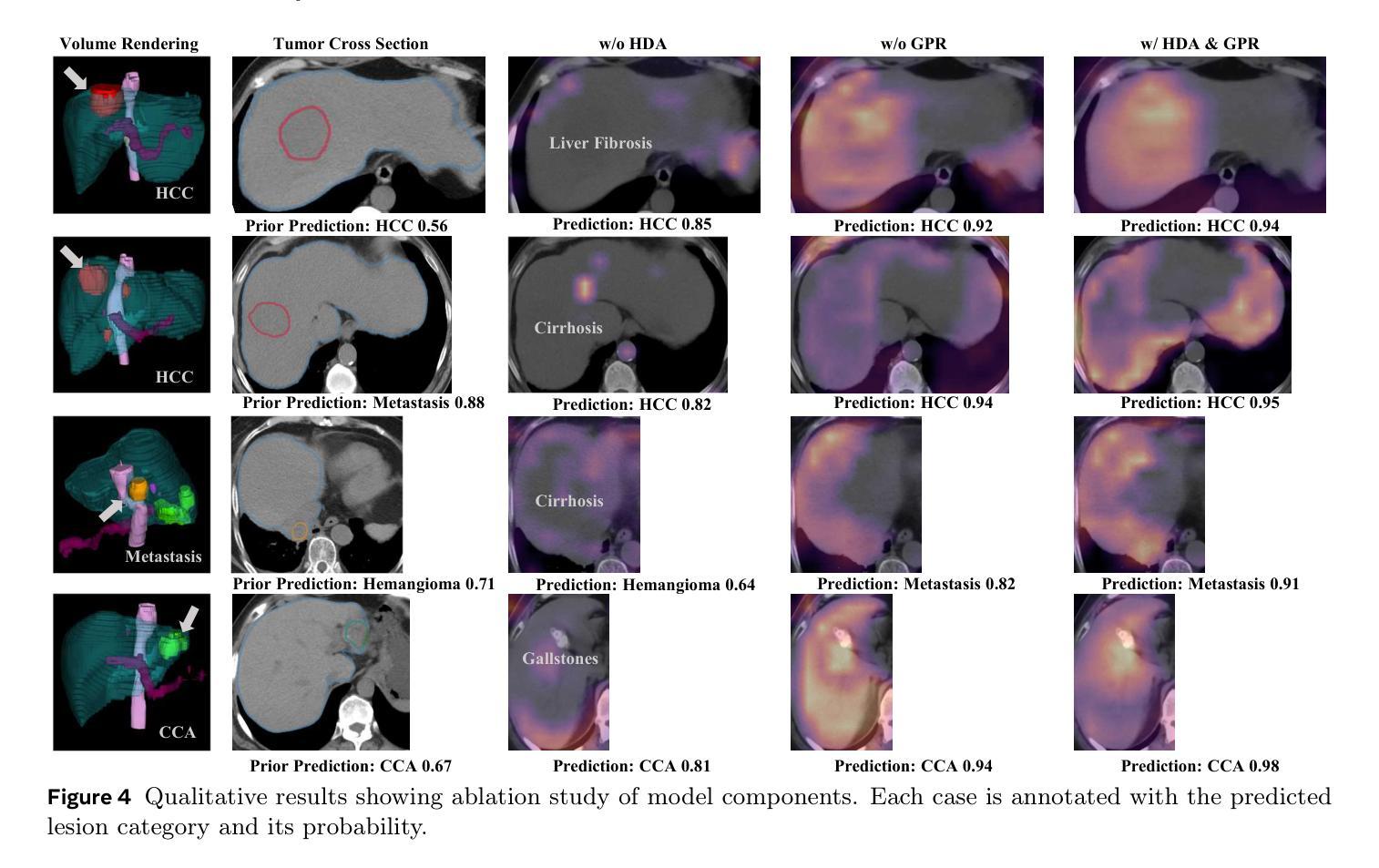
PLUS: Plug-and-Play Enhanced Liver Lesion Diagnosis Model on Non-Contrast CT Scans
Authors:Jiacheng Hao, Xiaoming Zhang, Wei Liu, Xiaoli Yin, Yuan Gao, Chunli Li, Ling Zhang, Le Lu, Yu Shi, Xu Han, Ke Yan
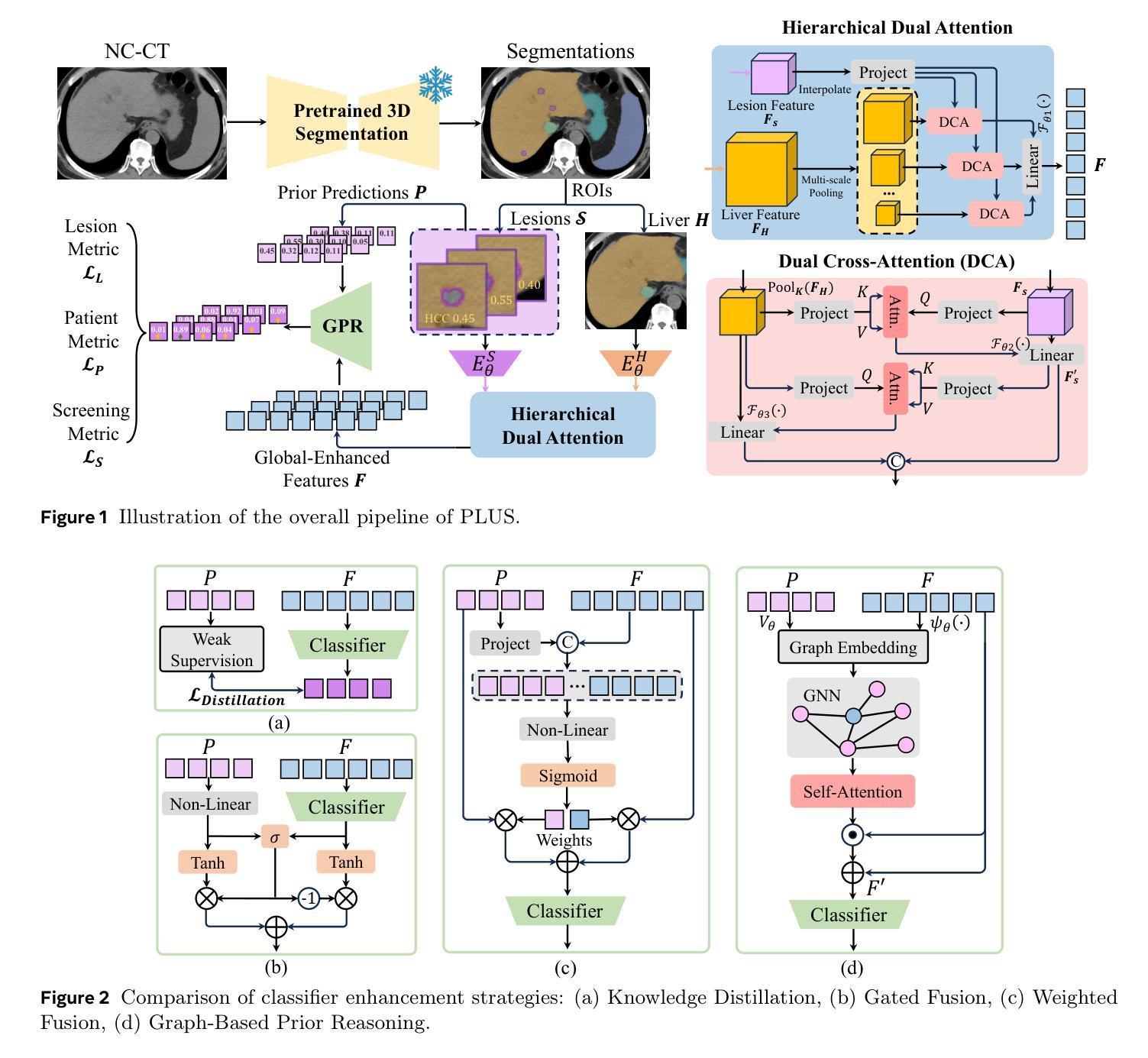
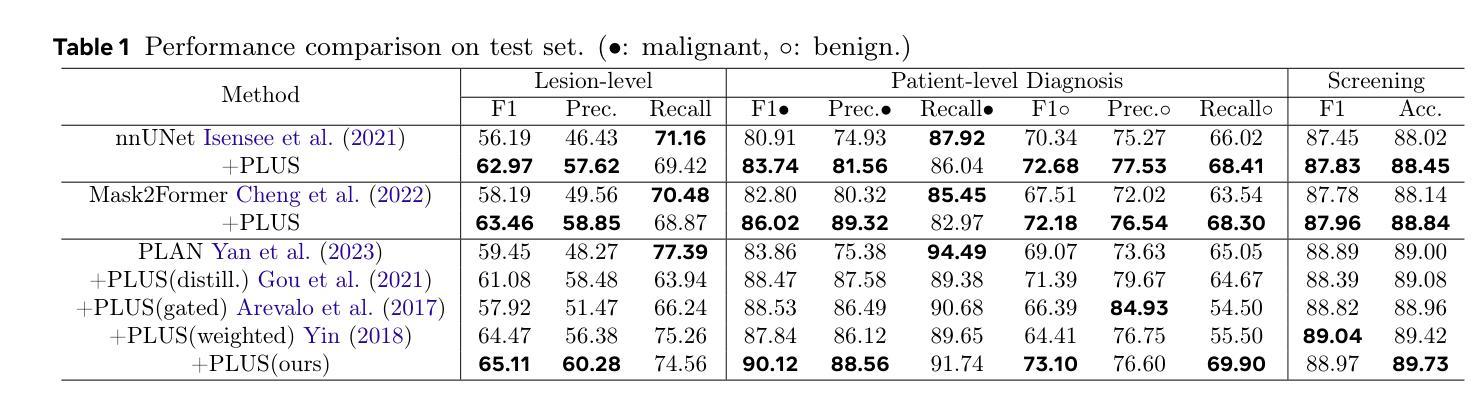
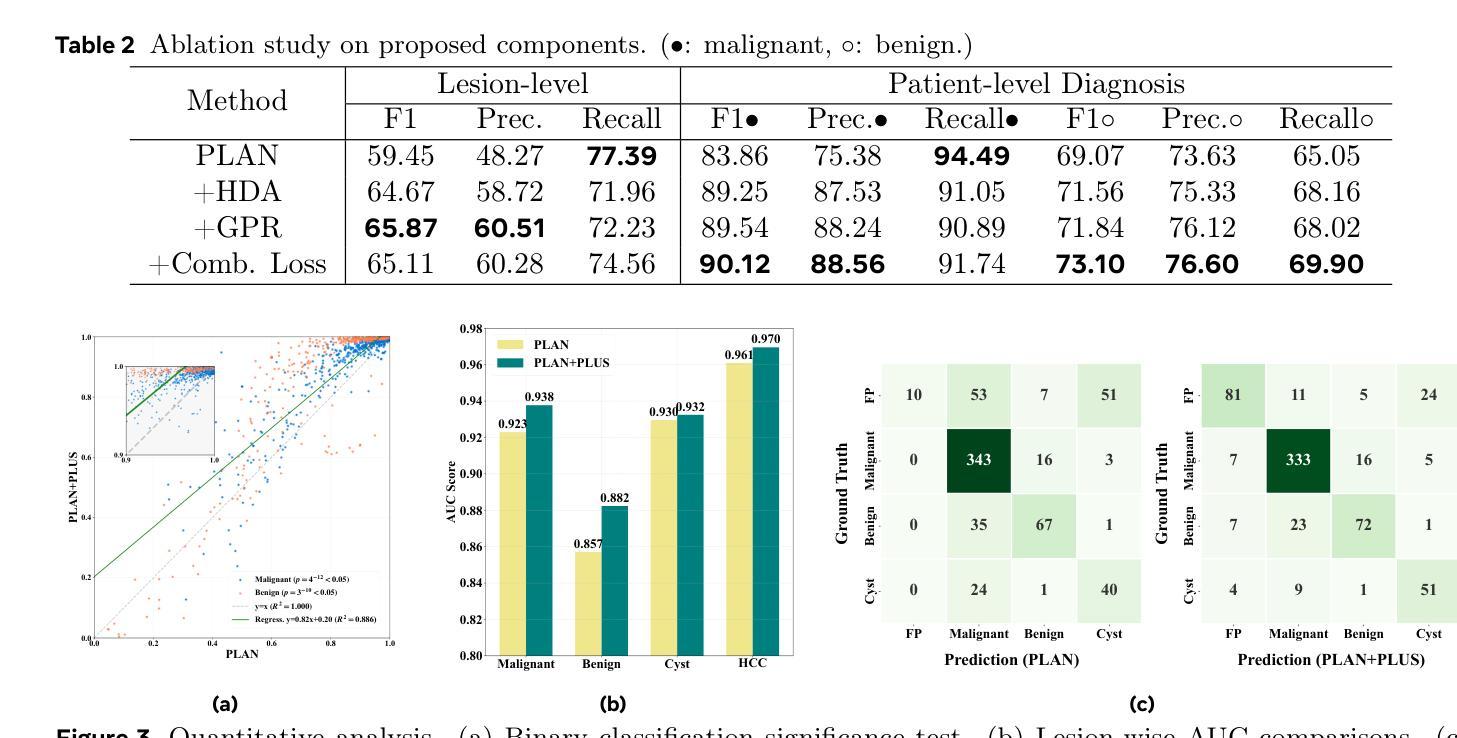
Focal liver lesions (FLL) are common clinical findings during physical examination. Early diagnosis and intervention of liver malignancies are crucial to improving patient survival. Although the current 3D segmentation paradigm can accurately detect lesions, it faces limitations in distinguishing between malignant and benign liver lesions, primarily due to its inability to differentiate subtle variations between different lesions. Furthermore, existing methods predominantly rely on specialized imaging modalities such as multi-phase contrast-enhanced CT and magnetic resonance imaging, whereas non-contrast CT (NCCT) is more prevalent in routine abdominal imaging. To address these limitations, we propose PLUS, a plug-and-play framework that enhances FLL analysis on NCCT images for arbitrary 3D segmentation models. In extensive experiments involving 8,651 patients, PLUS demonstrated a significant improvement with existing methods, improving the lesion-level F1 score by 5.66%, the malignant patient-level F1 score by 6.26%, and the benign patient-level F1 score by 4.03%. Our results demonstrate the potential of PLUS to improve malignant FLL screening using widely available NCCT imaging substantially.
肝局部病灶(Focal liver lesions,简称FLL)是体检中常见的临床发现。对肝脏恶性肿瘤进行早期诊断和治疗对改善患者生存率至关重要。虽然现有的3D分割范式可以准确地检测病灶,但在区分恶性和良性肝病灶时仍面临局限性,这主要是因为其不能区分不同病灶之间的微妙差异。此外,现有方法主要依赖于多期增强CT和磁共振成像等专业成像模式,而非增强CT(NCCT)在常规腹部成像中更为普遍。为了解决这些局限性,我们提出了PLUS,这是一个即插即用的框架,可增强NCCT图像上的FLL分析,适用于任意的3D分割模型。在涉及8651名患者的广泛实验中,PLUS与现有方法相比表现出了显著改进,病灶级别的F1分数提高了5.66%,恶性患者级别的F1分数提高了6.26%,良性患者级别的F1分数提高了4.03%。我们的结果证明了PLUS在利用广泛可用的NCCT成像技术提高恶性FLL筛查方面的潜力。
论文及项目相关链接
PDF MICCAI 2025 (Early Accepted)
Summary
本文介绍了一种名为PLUS的即插即用框架,用于增强非对比增强计算机断层扫描(NCCT)图像上的焦点肝病变(FLL)分析。该框架旨在解决当前3D分割模型在区分恶性与良性肝病变方面的局限性,并提高了对细微病变差异的识别能力。通过大量实验验证,PLUS显著提高了病变级别的F1分数,恶性患者级别的F1分数和良性患者级别的F1分数,显示出在恶性FLL筛查方面的大幅潜力。
Key Takeaways
- PLUS框架旨在增强非对比增强计算机断层扫描(NCCT)图像上的焦点肝病变(FLL)分析的准确性。
- 当前3D分割模型在区分恶性与良性肝病变方面存在局限性。
- PLUS通过提高细微病变差异的识别能力来解决这一局限性。
- PLUS在大量实验中验证了其效果,显著提高了病变级别、恶性患者级别和良性患者级别的F1分数。
- 该框架具有广泛的应用前景,特别是在恶性FLL筛查方面。
- PLUS可以与其他任意3D分割模型结合使用,具有即插即用的特性。
点此查看论文截图


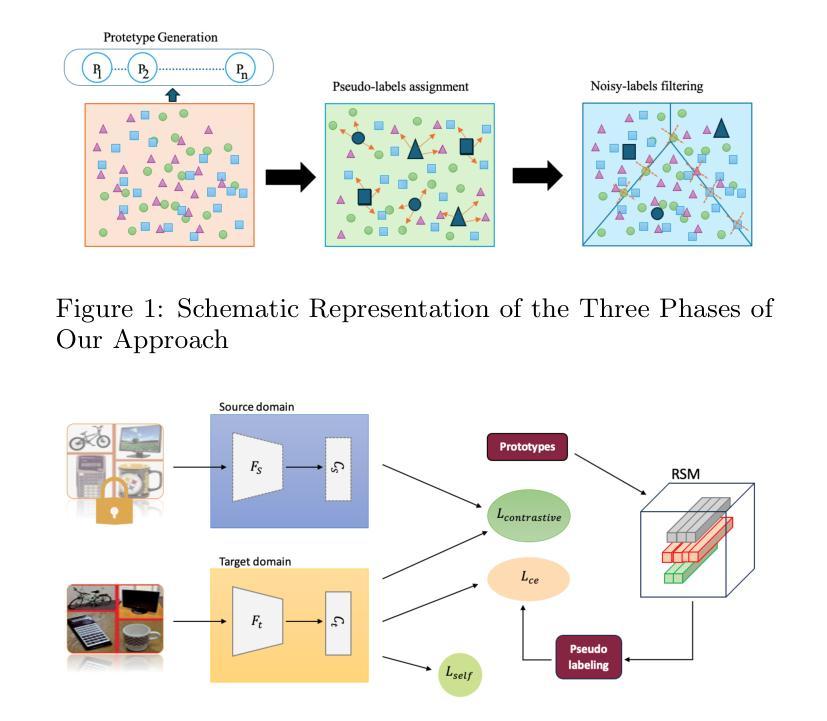
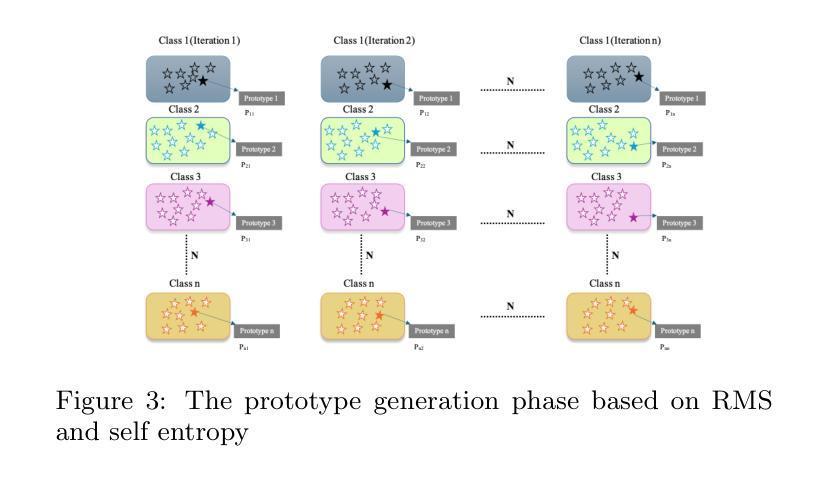
Source-Free Domain Adaptation via Multi-view Contrastive Learning
Authors:Amirfarhad Farhadi, Naser Mozayani, Azadeh Zamanifar
Domain adaptation has become a widely adopted approach in machine learning due to the high costs associated with labeling data. It is typically applied when access to a labeled source domain is available. However, in real-world scenarios, privacy concerns often restrict access to sensitive information, such as fingerprints, bank account details, and facial images. A promising solution to this issue is Source-Free Unsupervised Domain Adaptation (SFUDA), which enables domain adaptation without requiring access to labeled target domain data. Recent research demonstrates that SFUDA can effectively address domain discrepancies; however, two key challenges remain: (1) the low quality of prototype samples, and (2) the incorrect assignment of pseudo-labels. To tackle these challenges, we propose a method consisting of three main phases. In the first phase, we introduce a Reliable Sample Memory (RSM) module to improve the quality of prototypes by selecting more representative samples. In the second phase, we employ a Multi-View Contrastive Learning (MVCL) approach to enhance pseudo-label quality by leveraging multiple data augmentations. In the final phase, we apply a noisy label filtering technique to further refine the pseudo-labels. Our experiments on three benchmark datasets - VisDA 2017, Office-Home, and Office-31 - demonstrate that our method achieves approximately 2 percent and 6 percent improvements in classification accuracy over the second-best method and the average of 13 well-known state-of-the-art approaches, respectively.
领域适应(Domain Adaptation)因标注数据的成本高昂而在机器学习领域得到广泛应用。通常在有标签源域数据可用的情况下会采用领域适应技术。然而,在现实场景中,隐私顾虑经常限制对敏感信息的访问,如指纹、银行账户详情和面部图像等。一种对此问题的有前景的解决方案是无需源标签的无监督领域适应(SFUDA),它能够在不需要访问有标签的目标域数据的情况下实现领域适应。最近的研究表明,SFUDA可以有效地解决领域差异问题,但仍然存在两个主要挑战:(1)原型样本质量低下,(2)伪标签分配不正确。为了应对这些挑战,我们提出了一个由三个阶段组成的方法。在第一阶段,我们引入可靠样本内存(RSM)模块,通过选择更具代表性的样本来提高原型质量。在第二阶段,我们采用多视图对比学习(MVCL)方法,通过利用多种数据增强来提高伪标签质量。在第三阶段,我们应用噪声标签过滤技术来进一步优化伪标签。我们在VisDA 2017、Office-Home和Office-31三个基准数据集上的实验表明,我们的方法在分类准确率上比第二名的方法和平均的13种最新先进技术分别提高了大约2%和6%。
论文及项目相关链接
Summary
该文本介绍了源无监督域自适应(SFUDA)方法,它是一种解决领域适应问题的方法,无需访问目标域的标签数据。针对原型样本质量低和伪标签分配不正确的问题,提出了包含可靠样本内存(RSM)模块、多视图对比学习(MVCL)方法和噪声标签过滤技术的方法。在三个基准数据集上的实验表明,该方法在分类精度上取得了显著的改进。
Key Takeaways
- 源无监督域自适应(SFUDA)是解决领域适应问题的一种有效方法,尤其适用于无法访问目标域标签数据的情况。
- 当前方法面临原型样本质量低和伪标签分配不正确两大挑战。
- 可靠样本内存(RSM)模块通过选择更具代表性的样本,提高了原型质量。
- 多视图对比学习(MVCL)方法利用多种数据增强手段,提高了伪标签的质量。
- 噪声标签过滤技术进一步细化了伪标签。
- 在三个基准数据集上的实验表明,该方法在分类精度上较第二好的方法和平均的13种最新方法分别提高了约2%和6%。
点此查看论文截图

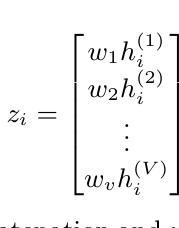
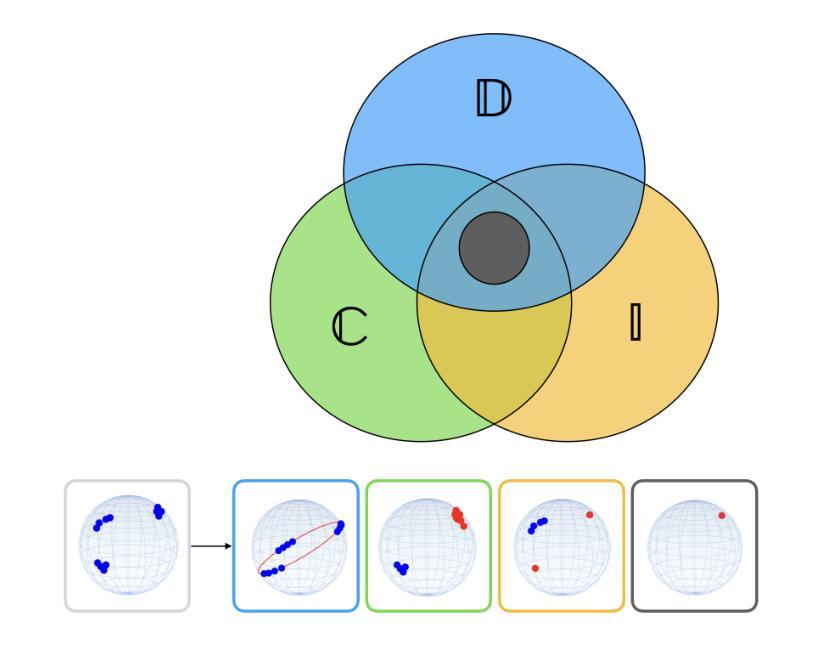
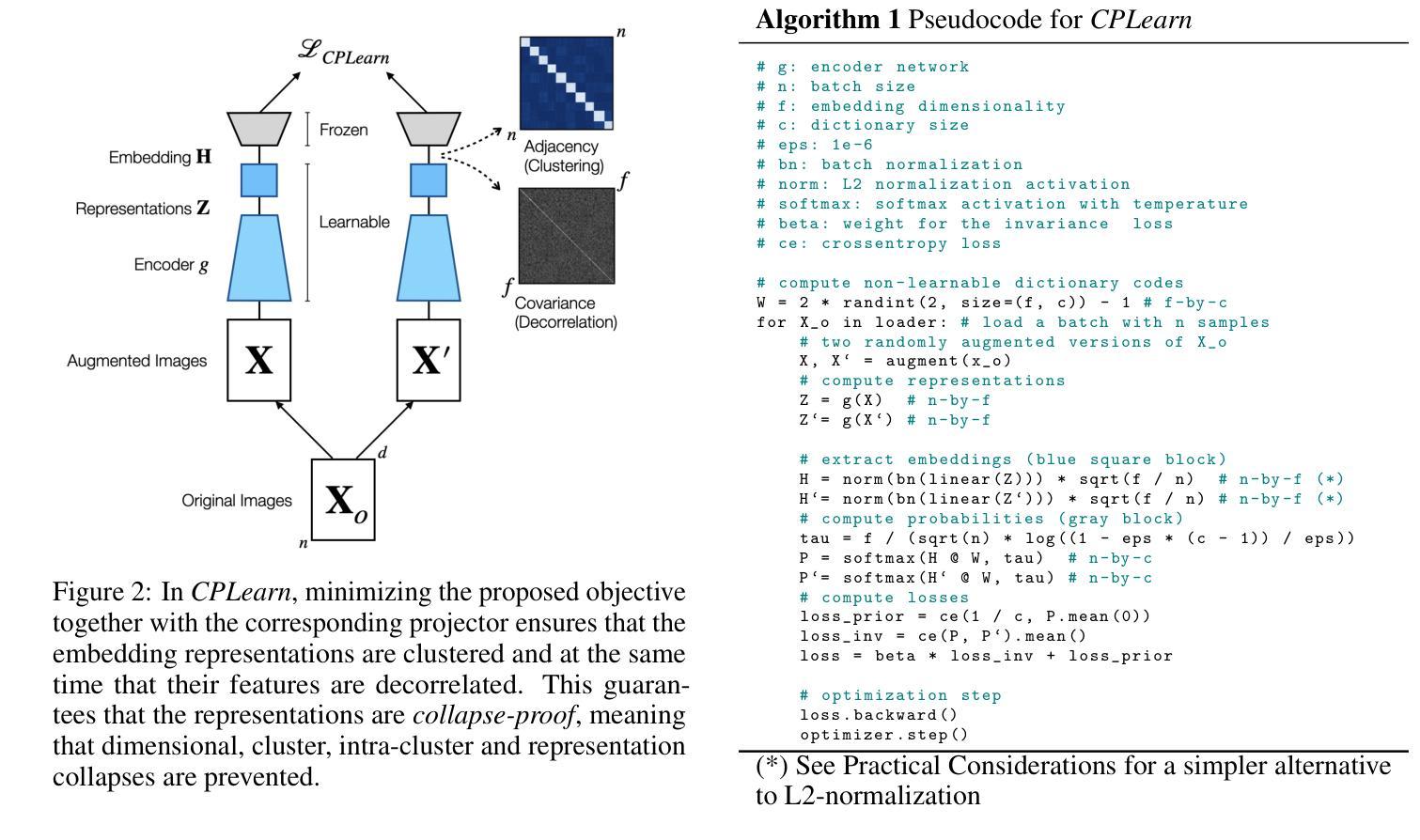
Collapse-Proof Non-Contrastive Self-Supervised Learning
Authors:Emanuele Sansone, Tim Lebailly, Tinne Tuytelaars
We present a principled and simplified design of the projector and loss function for non-contrastive self-supervised learning based on hyperdimensional computing. We theoretically demonstrate that this design introduces an inductive bias that encourages representations to be simultaneously decorrelated and clustered, without explicitly enforcing these properties. This bias provably enhances generalization and suffices to avoid known training failure modes, such as representation, dimensional, cluster, and intracluster collapses. We validate our theoretical findings on image datasets, including SVHN, CIFAR-10, CIFAR-100, and ImageNet-100. Our approach effectively combines the strengths of feature decorrelation and cluster-based self-supervised learning methods, overcoming training failure modes while achieving strong generalization in clustering and linear classification tasks.
我们提出了一种基于超维计算非对比性自监督学习的投影器和损失函数的设计原则及简化方案。从理论上讲,这种设计引入了一种归纳偏置,这种偏置鼓励表示同时进行去相关和聚类,而无需显式地执行这些属性。这种偏置可以明确增强泛化能力,并且足以避免已知的训练失败模式,例如表示、维度、聚类和聚类内崩溃。我们在图像数据集上验证了我们的理论发现,包括SVHN、CIFAR-10、CIFAR-100和ImageNet-100。我们的方法有效地结合了特征去相关和基于聚类的自监督学习方法的优点,克服了训练失败的模式,同时在聚类和线性分类任务中实现了强大的泛化能力。
论文及项目相关链接
PDF ICML 2025
摘要
基于超维计算,我们提出一种非对比式自我监督学习的投影器和损失函数设计的原则与简化方案。理论上,我们证明了这种设计引入了一种归纳偏置,该偏置鼓励表示同时去相关和聚类,而无需明确执行这些属性。这种偏置可增强泛化能力,足以避免已知的训练失败模式,如表示、维度、聚类和群内崩溃。我们在图像数据集上验证了我们的理论发现,包括SVHN、CIFAR-10、CIFAR-100和ImageNet-100。我们的方法有效地结合了特征去相关和基于聚类的自我监督学习方法的优点,克服了训练失败模式,同时在聚类和线性分类任务中实现了强大的泛化能力。
关键见解
- 提出了基于超维计算的非对比式自我监督学习的简化设计。
- 理论上证明了该设计引入了归纳偏置,鼓励表示的去相关和聚类。
- 归纳偏置增强了模型的泛化能力。
- 该设计可以避免出现已知的训练失败模式,如表示、维度、聚类和群内崩溃。
- 在多个图像数据集上验证了理论发现。
- 方法结合了特征去相关和基于聚类的自我监督学习方法的优点。
- 在聚类和线性分类任务中实现了强大的泛化能力。
点此查看论文截图