⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-09 更新
M$^3$-Med: A Benchmark for Multi-lingual, Multi-modal, and Multi-hop Reasoning in Medical Instructional Video Understanding
Authors:Shenxi Liu, Kan Li, Mingyang Zhao, Yuhang Tian, Bin Li, Shoujun Zhou, Hongliang Li, Fuxia Yang
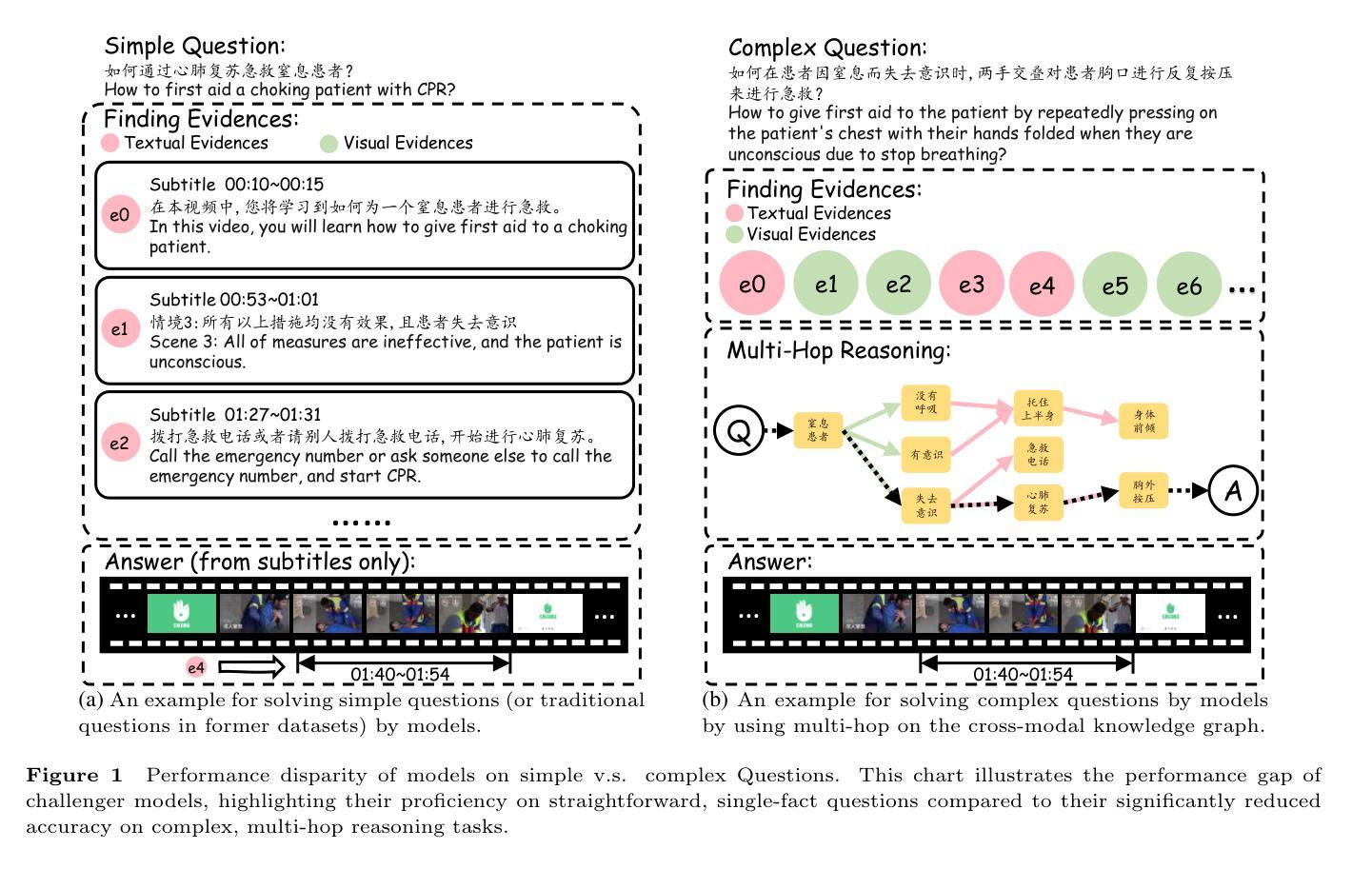
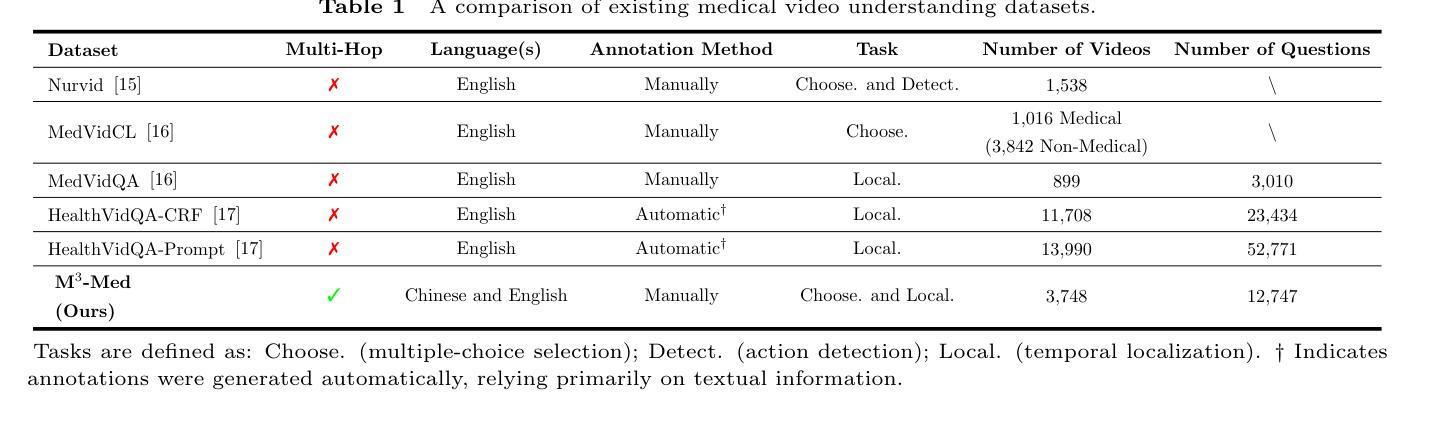
With the rapid progress of artificial intelligence (AI) in multi-modal understanding, there is increasing potential for video comprehension technologies to support professional domains such as medical education. However, existing benchmarks suffer from two primary limitations: (1) Linguistic Singularity: they are largely confined to English, neglecting the need for multilingual resources; and (2) Shallow Reasoning: their questions are often designed for surface-level information retrieval, failing to properly assess deep multi-modal integration. To address these limitations, we present M3-Med, the first benchmark for Multi-lingual, Multi-modal, and Multi-hop reasoning in Medical instructional video understanding. M3-Med consists of medical questions paired with corresponding video segments, annotated by a team of medical experts. A key innovation of M3-Med is its multi-hop reasoning task, which requires a model to first locate a key entity in the text, then find corresponding visual evidence in the video, and finally synthesize information across both modalities to derive the answer. This design moves beyond simple text matching and poses a substantial challenge to a model’s deep cross-modal understanding capabilities. We define two tasks: Temporal Answer Grounding in Single Video (TAGSV) and Temporal Answer Grounding in Video Corpus (TAGVC). We evaluated several state-of-the-art models and Large Language Models (LLMs) on M3-Med. The results reveal a significant performance gap between all models and human experts, especially on the complex multi-hop questions where model performance drops sharply. M3-Med effectively highlights the current limitations of AI models in deep cross-modal reasoning within specialized domains and provides a new direction for future research.
随着人工智能在多模态理解领域的快速发展,视频理解技术在医疗教育等职业领域的应用潜力日益增强。然而,现有的基准测试存在两个主要局限性:(1)语言单一性:它们大多局限于英语,忽视了多语言资源的需求;(2)浅层推理:它们的问题往往是为了表面层的信息检索而设计的,无法适当地评估深度多模态融合。为了解决这些局限性,我们推出了M3-Med,这是医疗教学视频理解中多语言、多模态、多跳推理的首个基准测试。M3-Med由医疗问题及其对应的视频片段组成,由医疗专家团队进行注释。M3-Med的关键创新之处在于其多跳推理任务,这需要模型首先定位文本中的关键实体,然后在视频中找到相应的视觉证据,最后融合两种模态的信息来得出答案。这一设计超越了简单的文本匹配,对模型的深度跨模态理解能力构成了实质性挑战。我们定义了两个任务:单视频时序答案定位(TAGSV)和视频语料库时序答案定位(TAGVC)。我们在M3-Med上评估了几个最新模型和大型语言模型(LLMs)。结果表明,所有模型与人类专家之间仍存在显著的性能差距,尤其是在复杂的多跳问题上,模型性能急剧下降。M3-Med有效地突出了AI模型在专业化领域深度跨模态推理的当前局限性,并为未来的研究提供了新的方向。
论文及项目相关链接
PDF 19 pages, 8 figures, 7 tables
Summary
随着人工智能在多模态理解领域的快速发展,视频理解技术在医疗教育等专业领域的应用潜力日益增强。然而,现有基准测试主要存在两个局限性:一是语言单一性,大多局限于英语,忽视多语言资源的需求;二是浅层推理,问题设计往往只针对表层信息检索,无法有效评估深度多模态融合。为解决这些问题,我们提出了M3-Med基准测试,它是医疗教学视频理解中的首个多语言、多模态、多跳推理基准测试。M3-Med由医疗问题及其对应的视频片段组成,由医疗专家团队进行标注。M3-Med的关键创新在于其多跳推理任务,要求模型首先在文本中找到关键实体,然后在视频中找到相应的视觉证据,最后融合两种模态的信息得出答案。我们定义了两个任务:单视频时序答案定位(TAGSV)和视频语料库时序答案定位(TAGVC)。对现有先进模型和大语言模型在M3-Med上的评估结果表明,尤其在复杂的多跳问题上,模型性能与人类专家之间仍存在显著差距。M3-Med有效地指出了当前AI模型在特定领域深度跨模态推理方面的局限性,为未来的研究提供了新的方向。
Key Takeaways
- M3-Med是首个针对医疗教学视频理解的多语言、多模态、多跳推理基准测试。
- 现有基准测试主要存在语言单一性和浅层推理的局限性。
- M3-Med通过医疗问题及其对应的视频片段,由医疗专家团队进行标注。
- M3-Med的多跳推理任务要求模型融合文本和视觉信息。
- 定义了两个任务:单视频时序答案定位(TAGSV)和视频语料库时序答案定位(TAGVC)。
- 先进模型在M3-Med上的性能与人类专家仍存在显著差距。
点此查看论文截图

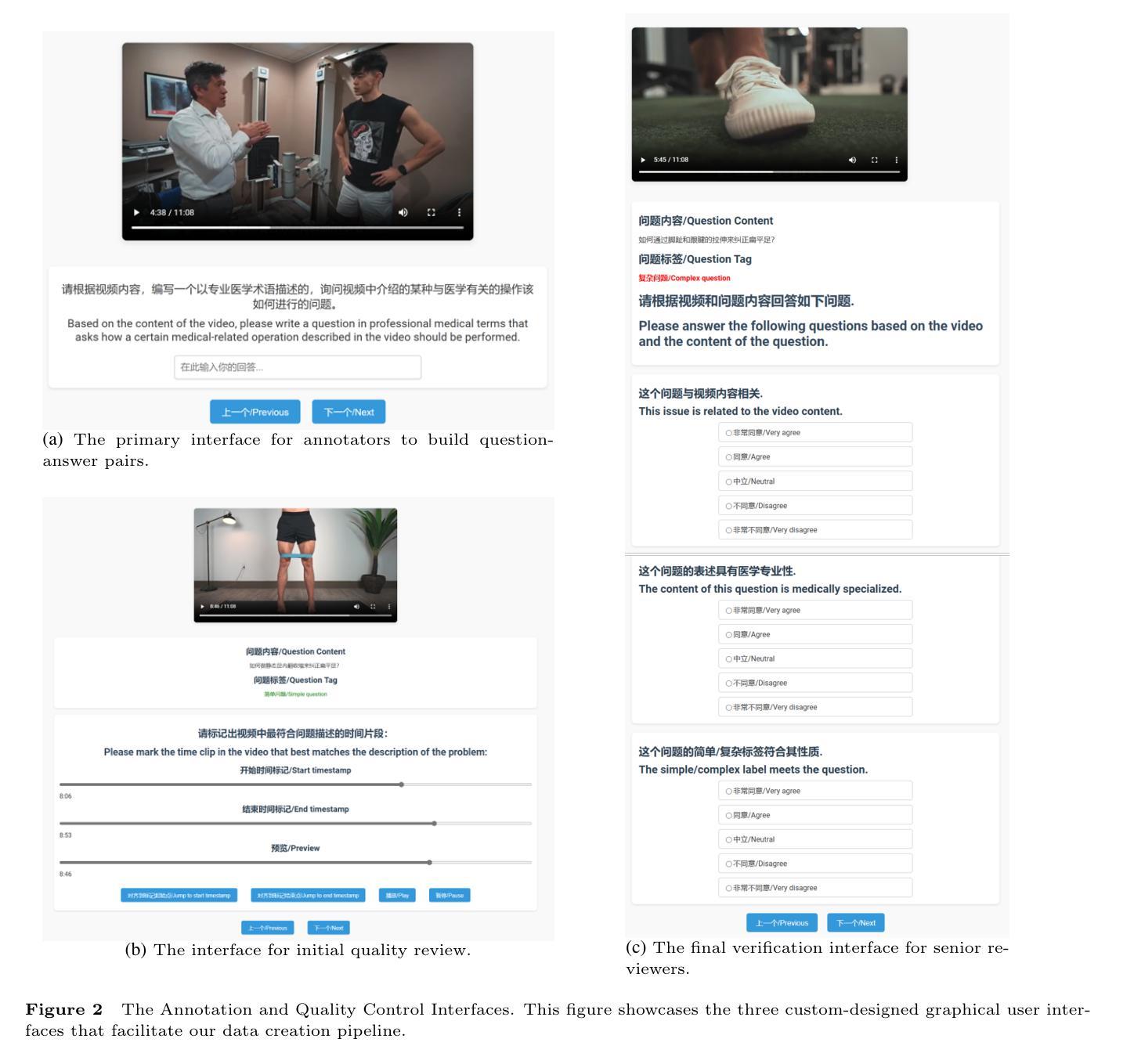
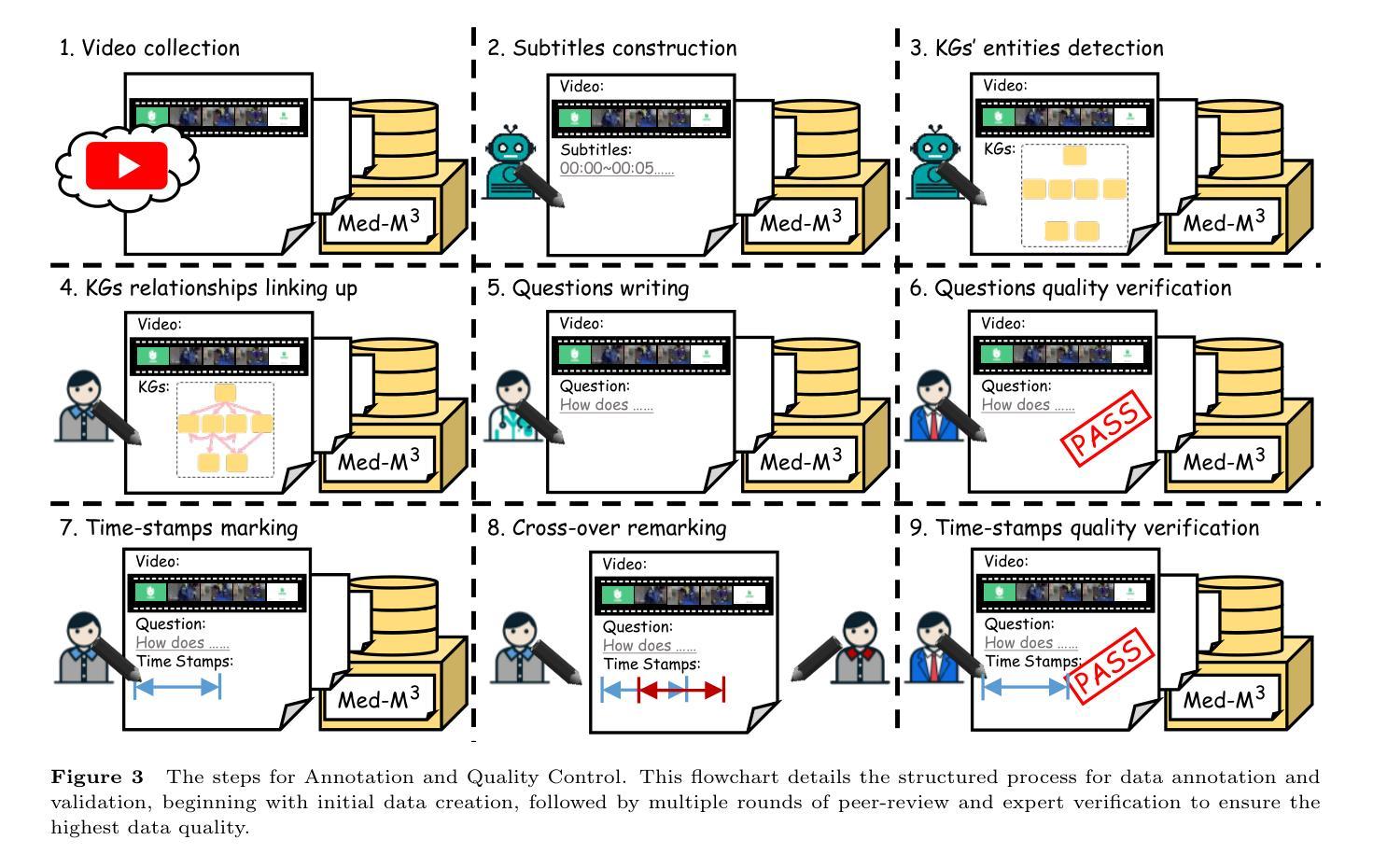
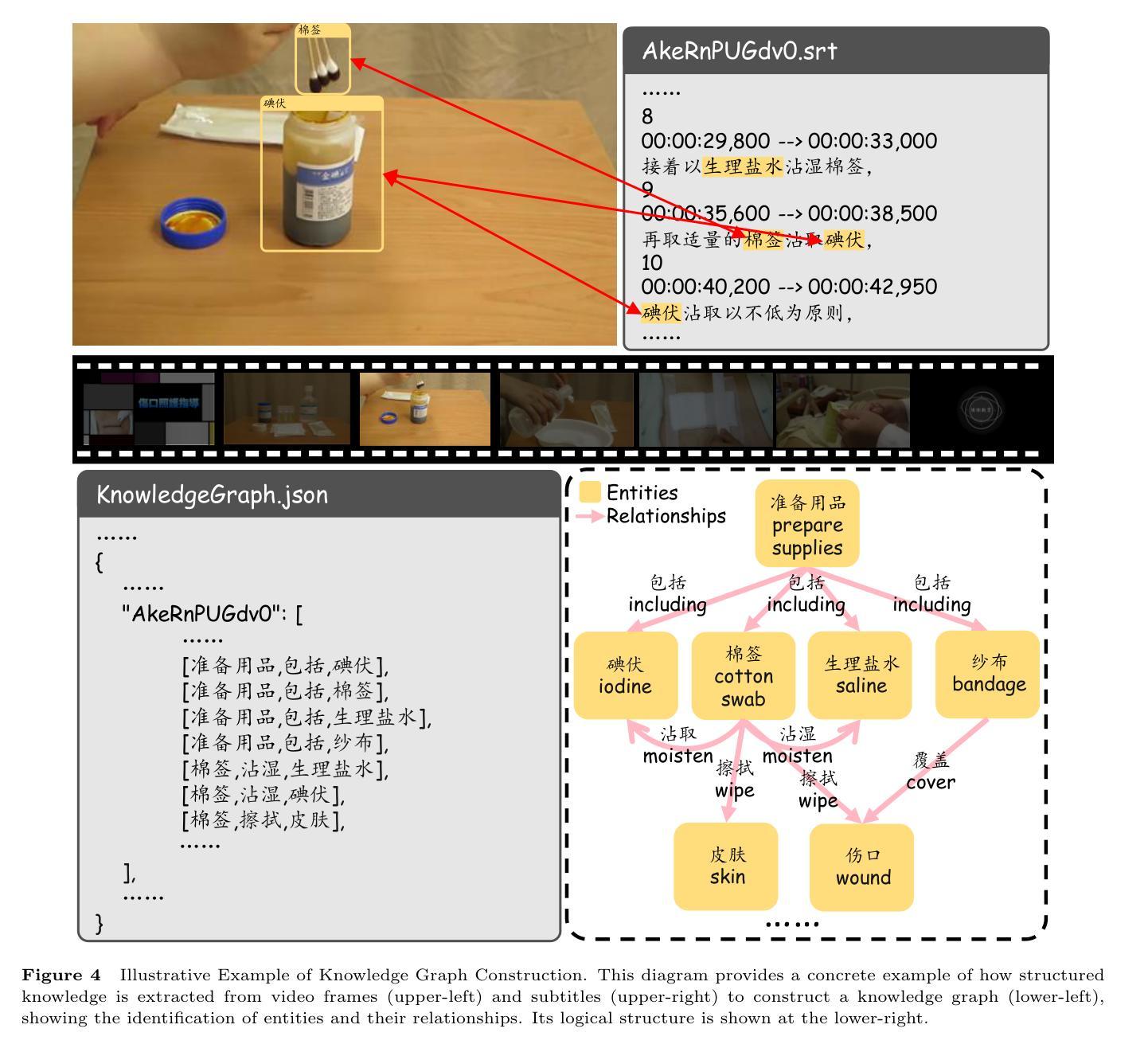
Multimodal Alignment with Cross-Attentive GRUs for Fine-Grained Video Understanding
Authors:Namho Kim, Junhwa Kim
Fine-grained video classification requires understanding complex spatio-temporal and semantic cues that often exceed the capacity of a single modality. In this paper, we propose a multimodal framework that fuses video, image, and text representations using GRU-based sequence encoders and cross-modal attention mechanisms. The model is trained using a combination of classification or regression loss, depending on the task, and is further regularized through feature-level augmentation and autoencoding techniques. To evaluate the generality of our framework, we conduct experiments on two challenging benchmarks: the DVD dataset for real-world violence detection and the Aff-Wild2 dataset for valence-arousal estimation. Our results demonstrate that the proposed fusion strategy significantly outperforms unimodal baselines, with cross-attention and feature augmentation contributing notably to robustness and performance.
精细粒度视频分类需要理解复杂的时空和语义线索,这常常超出单一模态的能力范围。在本文中,我们提出了一种多模态框架,该框架使用基于GRU的序列编码器和跨模态注意力机制融合视频、图像和文本表示。该模型根据任务使用分类或回归损失进行训练,并通过特征级增强和自动编码技术进行进一步正则化。为了评估我们框架的通用性,我们在两个具有挑战性的基准测试集上进行了实验:用于现实暴力检测的DVD数据集和用于情感价值评估的Aff-Wild2数据集。我们的结果表明,所提出的融合策略显著优于单模态基线,其中跨注意力和特征增强对于稳健性和性能的提高贡献显著。
论文及项目相关链接
Summary
本文提出了一种多模态框架,该框架通过GRU序列编码器和跨模态注意力机制融合视频、图像和文本表示。模型采用分类或回归损失进行训练,并应用特征级增强和自编码技术进一步正则化。在DVD数据集上的真实世界暴力检测实验和在Aff-Wild2数据集上的情感唤醒评估实验中,验证了该框架的泛化能力,证明了融合策略显著优于单模态基线,且跨注意力机制和特征增强有助于提高模型的稳健性和性能。
Key Takeaways
- 提出了一种多模态框架,融合了视频、图像和文本表示。
- 使用GRU序列编码器和跨模态注意力机制进行信息融合。
- 模型训练结合了分类或回归损失。
- 应用特征级增强和自编码技术正则化模型,以提高性能。
- 在DVD数据集上进行了真实世界暴力检测实验。
- 在Aff-Wild2数据集上进行了情感唤醒评估实验。
点此查看论文截图

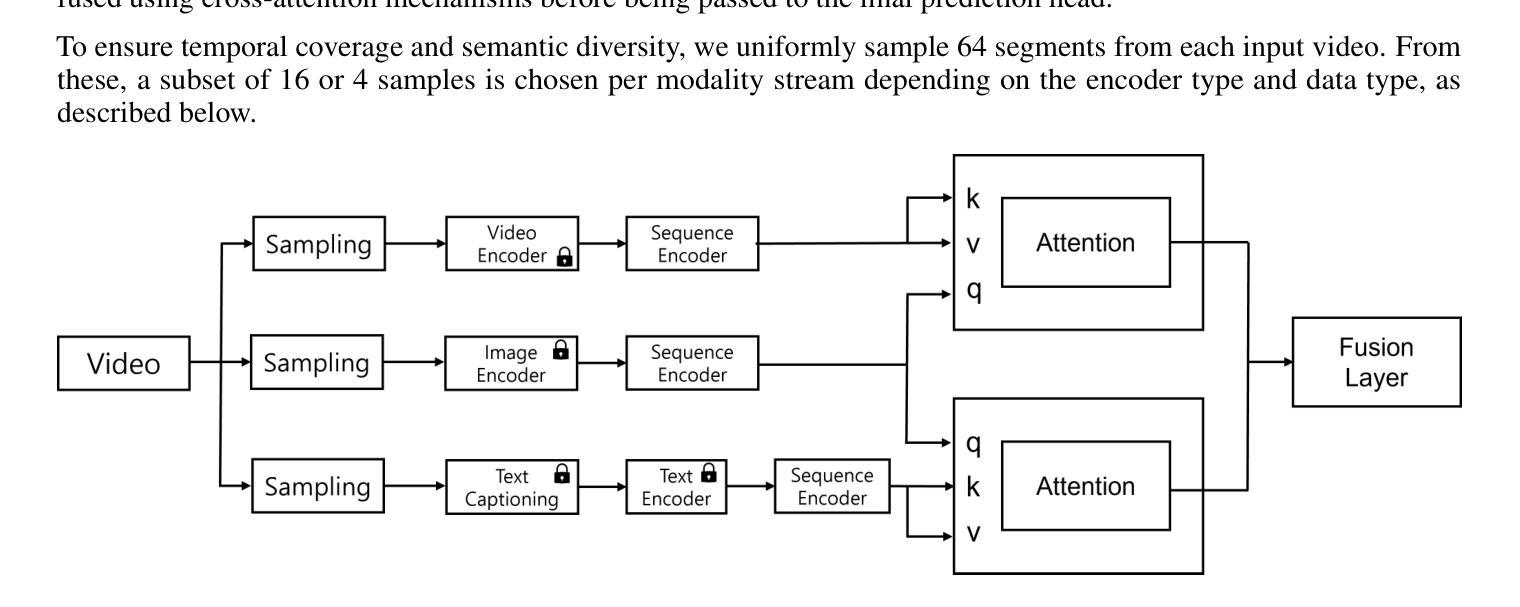

Iterative Zoom-In: Temporal Interval Exploration for Long Video Understanding
Authors:Chenglin Li, Qianglong Chen, fengtao, Yin Zhang
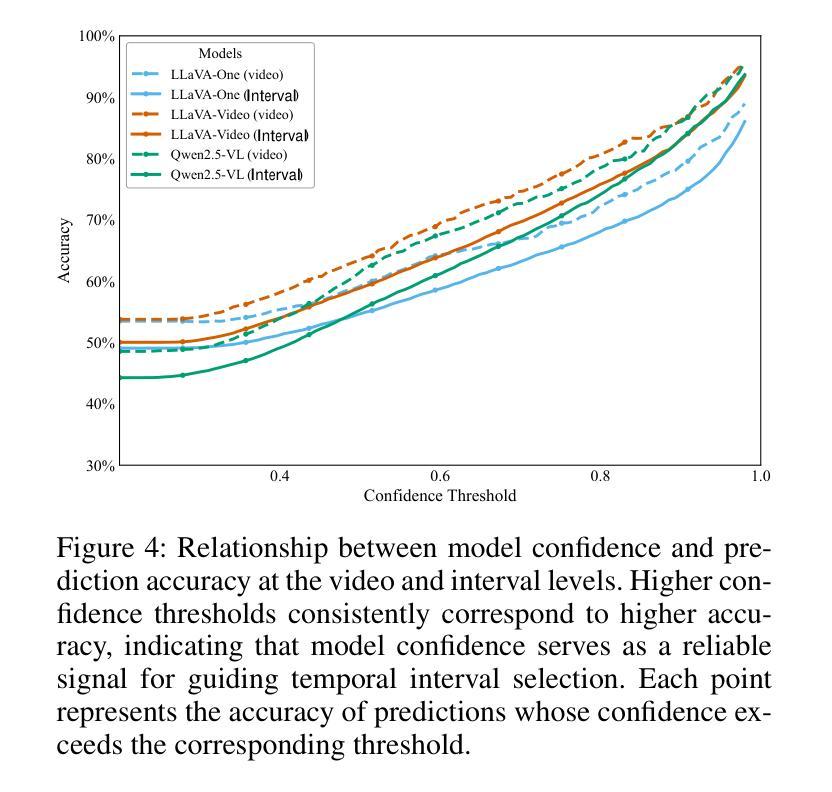
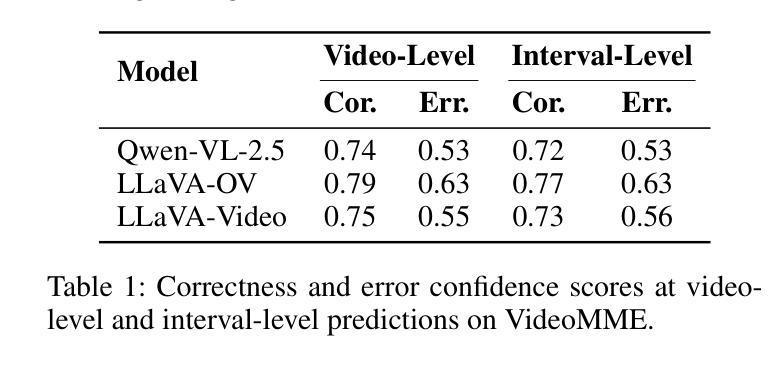
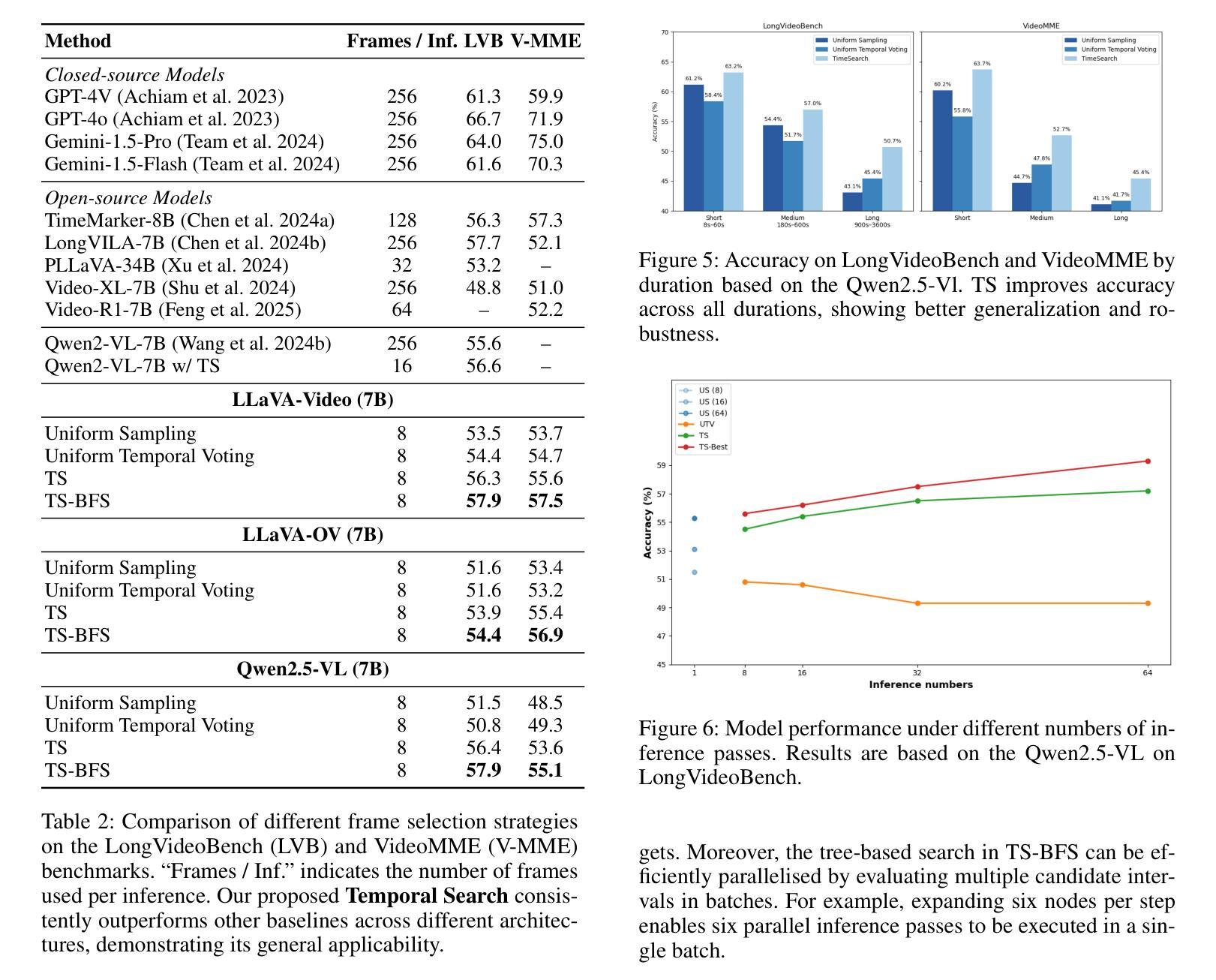
Multimodal Large Language Models (MLLMs) have shown strong performance in video understanding tasks. However, they continue to struggle with long-form videos because of an inefficient perception of temporal intervals. Unlike humans, who can dynamically adjust their temporal focus to locate query-relevant moments, current MLLMs often rely on dense, uniform sampling across the video timeline, leading to high memory consumption and a risk of missing crucial information. To address this challenge, we introduce Temporal Search, a training-free framework that enables MLLMs to explore temporal regions for improved long video understanding iteratively. TS is based on a key observation: the model’s generation confidence across different temporal intervals is highly correlated with prediction accuracy. TS operates through two main iterative stages. First, the MLLM proposes a temporal interval that is likely to contain task-relevant information. Then, it samples a fixed number of frames from the interval, regardless of length, and feeds them into the model to produce a refined response and confidence score. TS refines the focus of the model by iteratively shifting attention to more fine-grained temporal intervals, improving its understanding of long videos. Additionally, keyframe-level descriptions are collected to facilitate cross-interval perception throughout the video. To further improve efficiency, we introduce TS-BFS, a best-first search strategy over a tree. Each node represents a candidate interval and is expanded via two methods: self-driven proposals and uniform partitioning. Nodes are scored based on confidence and self-evaluation, and the most promising one is selected for continued exploration.
多模态大型语言模型(MLLMs)在视频理解任务中表现出了强大的性能。然而,由于无法有效感知时间间隔,它们在处理长视频时仍面临挑战。与人类不同,人类可以动态调整他们的时间焦点来定位与查询相关的时刻,而当前的MLLMs通常依赖于视频时间线上密集且统一的采样,这导致了高内存消耗和错过重要信息的风险。为了应对这一挑战,我们引入了时序搜索(TS),这是一个无需训练即可使MLLMs能够迭代地探索时间区域以改进长视频理解的框架。TS基于一个关键观察:模型在不同时间间隔的生成置信度与预测准确性高度相关。TS主要通过两个主要迭代阶段进行操作。首先,MLLM提出一个可能包含任务相关信息的时间间隔。然后,它不论间隔长短,从该间隔中采样固定数量的帧,并将它们输入到模型中,以产生更精细的响应和置信度分数。TS通过迭代地将模型的注意力转移到更精细的时间间隔上,提高其对长视频的理解能力。此外,还收集了关键帧级别的描述,以促进整个视频的跨间隔感知。为了进一步提高效率,我们引入了TS-BFS,这是一种在树上进行最佳优先搜索的策略。每个节点代表一个候选间隔,通过两种方法进行扩展:自我驱动提案和统一划分。节点根据置信度和自我评价进行评分,并选择最有前途的一个进行继续探索。
论文及项目相关链接
Summary
本文介绍了多模态大型语言模型(MLLMs)在视频理解任务中的强大性能,但在处理长视频时存在挑战。为解决此问题,引入了训练外的框架——Temporal Search,使MLLMs能够探索时间区域,以改进对长视频的理解。TS基于关键观察:模型在不同时间间隔的生成信心与预测准确性高度相关。TS通过两个主要迭代阶段操作:首先,MLLM提出可能包含任务相关信息的临时间隔;然后,从该间隔中采样固定数量的帧,并输入模型以产生精炼的响应和信心分数。通过迭代将注意力转移到更精细的时间间隔上,提高模型对长视频的理解能力。此外,收集关键帧级别的描述以促进视频中的跨间隔感知。为提高效率,还引入了TS-BFS,这是一种在树上进行最佳优先搜索的策略。每个节点代表一个候选间隔,通过自我驱动提案和统一分区进行扩展。节点根据信心和自我评估进行评分,并选择最有前途的一个进行继续探索。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视频理解任务中表现出强大的性能,但在处理长视频时存在挑战。
- 当前MLLMs依赖于视频时间线的密集、均匀采样,导致高内存消耗和错过重要信息的风险。
- Temporal Search框架使MLLMs能够探索时间区域,提高长视频理解能力。
- TS基于模型在不同时间间隔的生成信心与预测准确性之间的关联。
- TS通过两个主要迭代阶段操作:提出临时间隔并采样固定数量的帧进行模型反馈。
- TS通过迭代转移模型注意力到更精细的时间间隔,提高模型性能。
点此查看论文截图





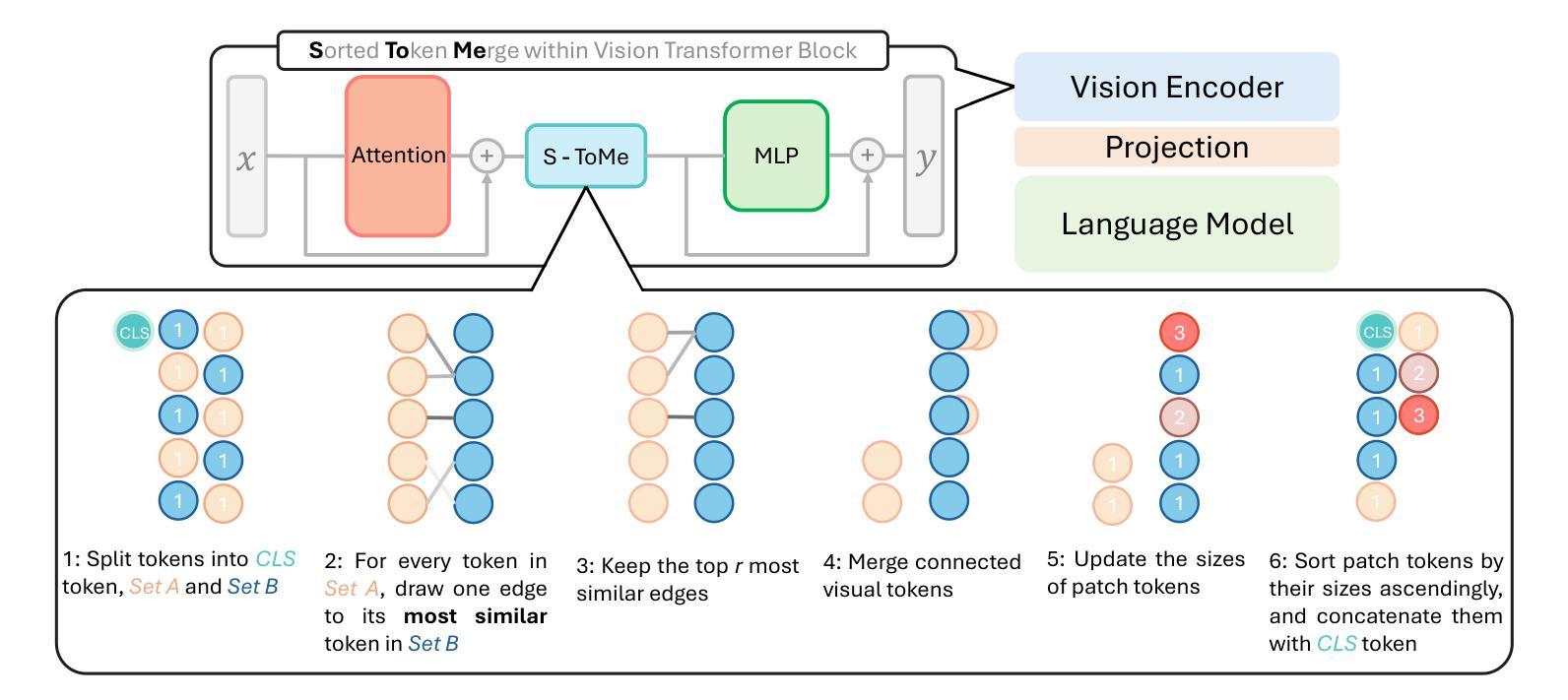
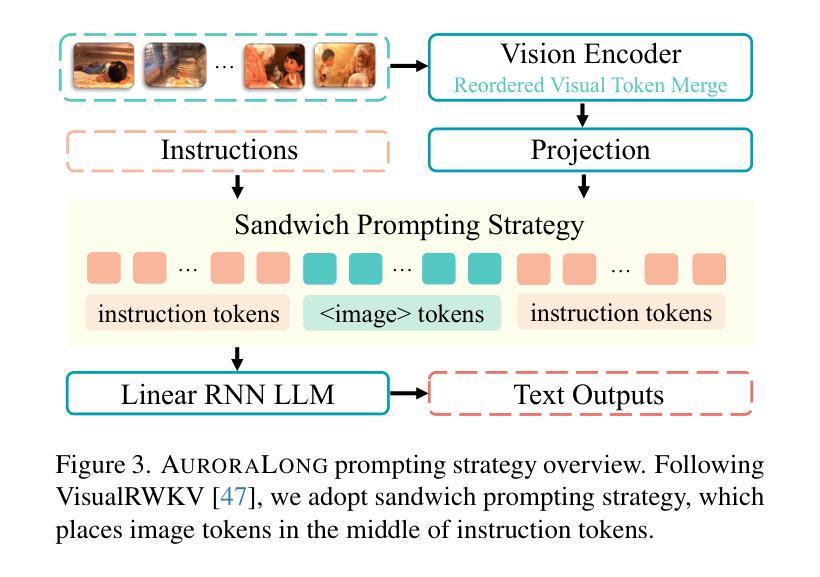
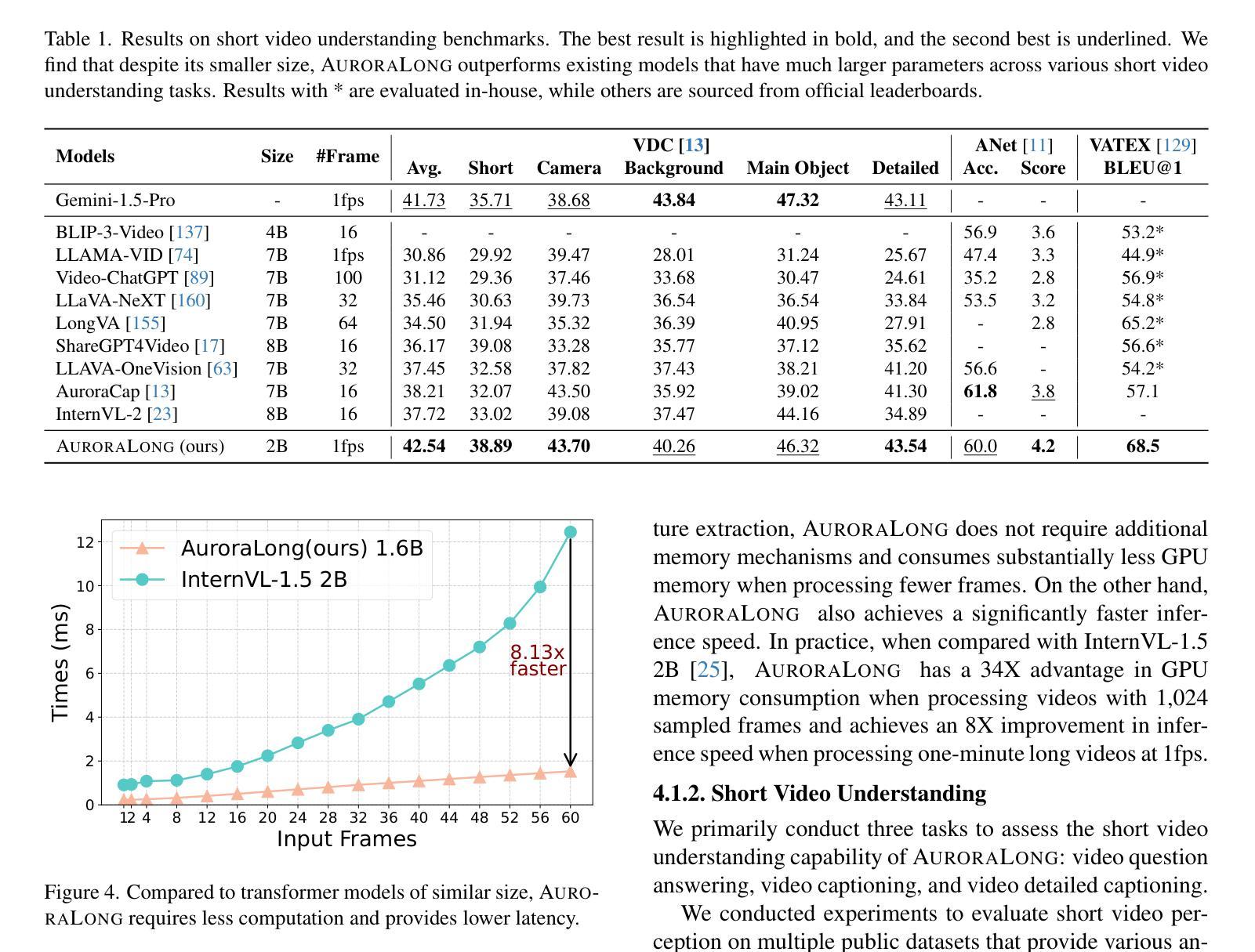
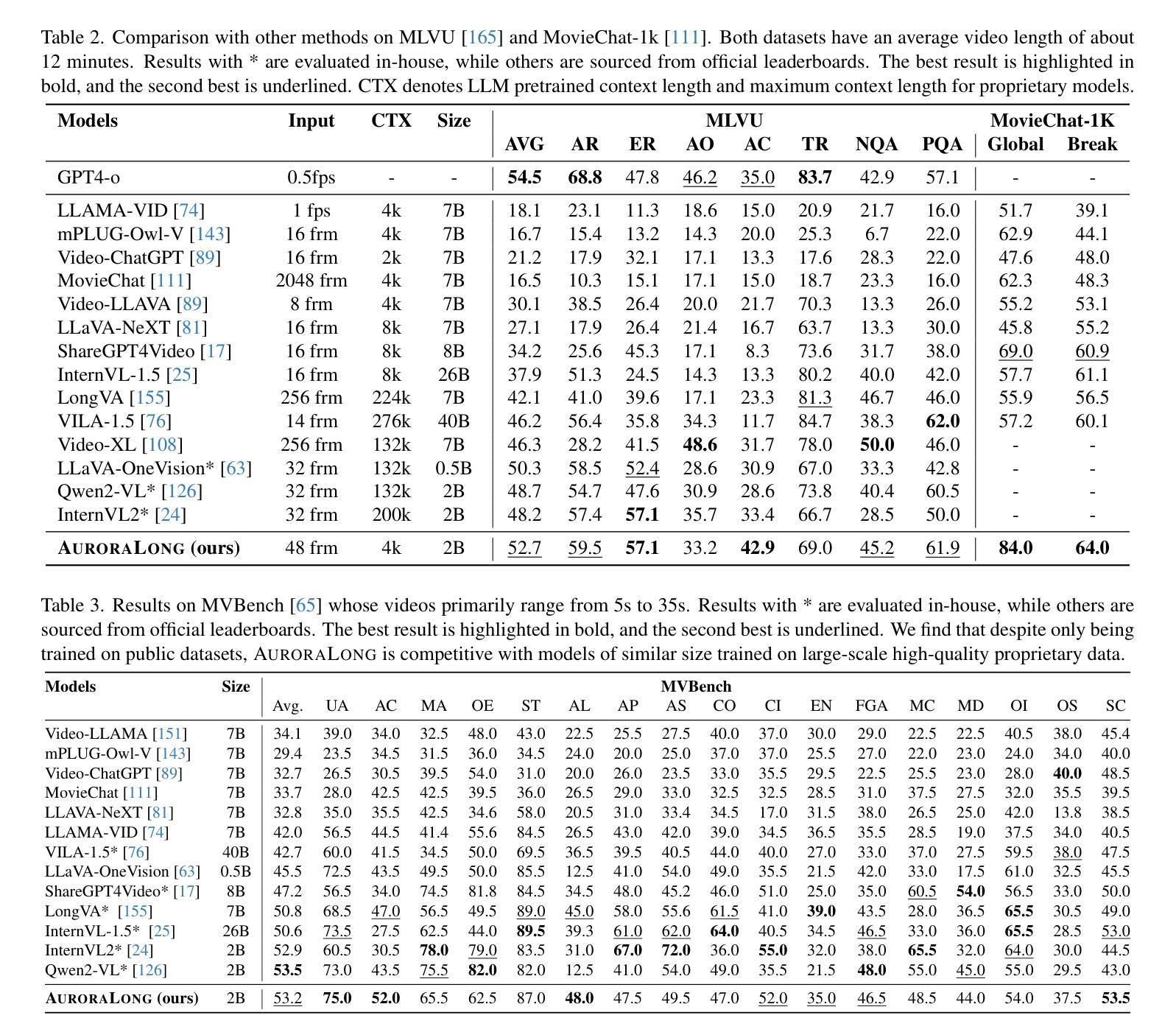
AuroraLong: Bringing RNNs Back to Efficient Open-Ended Video Understanding
Authors:Weili Xu, Enxin Song, Wenhao Chai, Xuexiang Wen, Tian Ye, Gaoang Wang
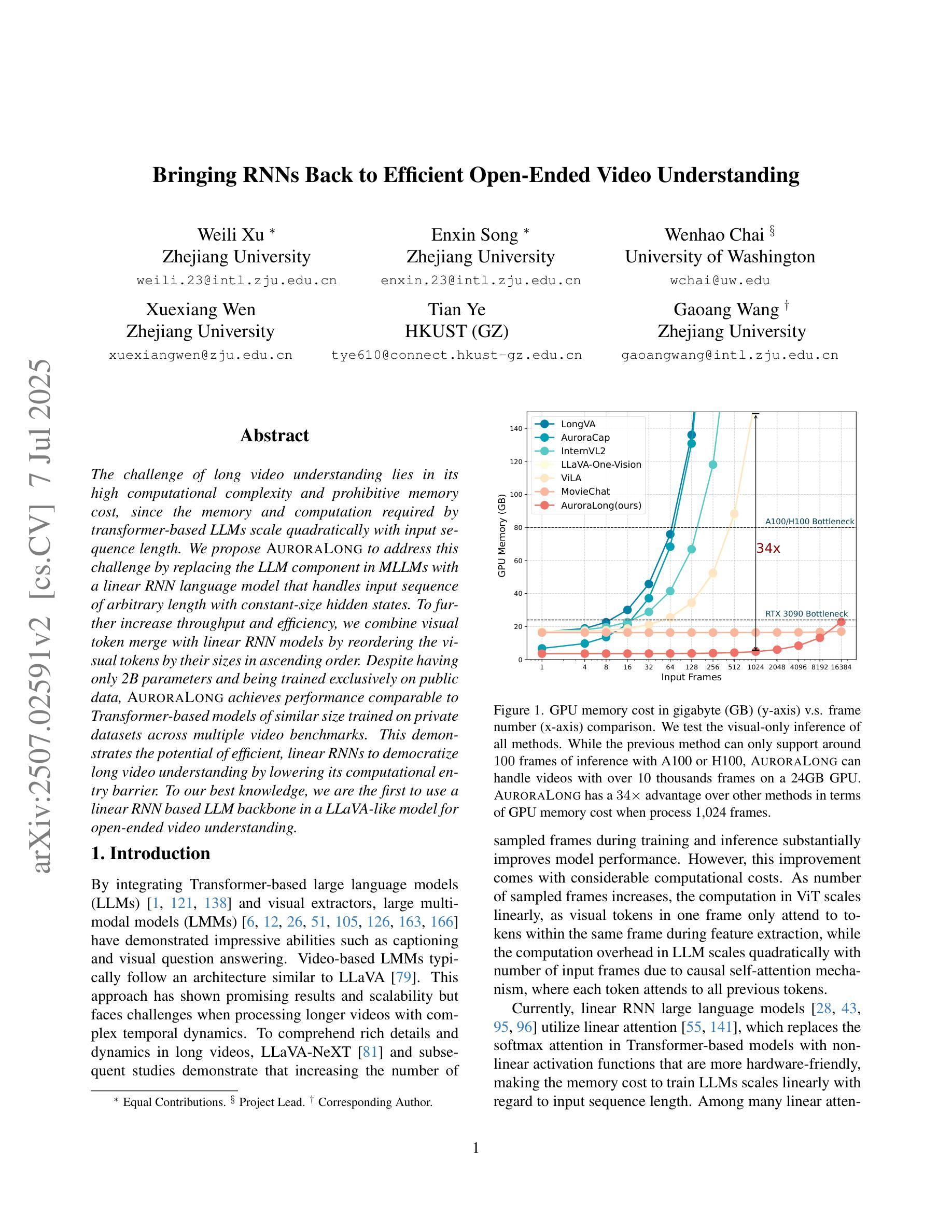
The challenge of long video understanding lies in its high computational complexity and prohibitive memory cost, since the memory and computation required by transformer-based LLMs scale quadratically with input sequence length. We propose AuroraLong to address this challenge by replacing the LLM component in MLLMs with a linear RNN language model that handles input sequence of arbitrary length with constant-size hidden states. To further increase throughput and efficiency, we combine visual token merge with linear RNN models by reordering the visual tokens by their sizes in ascending order. Despite having only 2B parameters and being trained exclusively on public data, AuroraLong achieves performance comparable to Transformer-based models of similar size trained on private datasets across multiple video benchmarks. This demonstrates the potential of efficient, linear RNNs to democratize long video understanding by lowering its computational entry barrier. To our best knowledge, we are the first to use a linear RNN based LLM backbone in a LLaVA-like model for open-ended video understanding.
长视频理解的挑战在于其较高的计算复杂度和巨大的内存成本,因为基于变压器的LLM所需的内存和计算量随输入序列长度呈二次方增长。为了解决这一挑战,我们提出了AuroraLong方案,通过用线性RNN语言模型替换MLLMs中的LLM组件来解决这一问题,该语言模型能够以恒定大小的隐藏状态处理任意长度的输入序列。为了进一步提高吞吐量和效率,我们通过按视觉令牌的大小进行升序排列,将视觉令牌合并与线性RNN模型相结合。尽管只有2B个参数并且仅在公共数据上进行训练,AuroraLong在多个视频基准测试中实现了与在私有数据集上训练的类似规模的基于转换器的模型相当的性能。这证明了有效的线性RNN在降低长视频理解的计算入门门槛方面具有潜力。据我们所知,我们是首次在LLaVA类模型中采用基于线性RNN的LLM主干进行开放式视频理解。
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary
针对长视频理解面临的挑战,如高计算复杂度和昂贵内存成本,我们提出AuroraLong方案。它通过采用线性RNN语言模型替换MLLMs中的LLM组件,以处理任意长度的输入序列并维持恒定大小的隐藏状态,从而提高效率和吞吐量。结合视觉令牌合并和线性RNN模型,通过按大小升序重新排序视觉令牌,AuroraLong在多个视频基准测试中实现了与基于Transformer的模型相当的性能,即使其仅有2B参数且仅在公共数据上进行训练。这证明了高效线性RNN在降低长视频理解的计算入门门槛方面的潜力。我们是首次在LLaVA类模型中使用基于线性RNN的LLM主干进行开放视频理解。
Key Takeaways
- AuroraLong解决了长视频理解的高计算复杂性和内存成本问题。
- 采用线性RNN语言模型处理任意长度的输入序列。
- 线性RNN模型具有恒定大小的隐藏状态,提高效率和吞吐量。
- 通过视觉令牌合并和重新排序,进一步优化性能。
- AuroraLong在多个视频基准测试中性能优异,与基于Transformer的模型相当。
- 即使有限的参数和仅在公共数据上的训练,AuroraLong仍表现出强大的性能。
点此查看论文截图

Domain Adaptation of VLM for Soccer Video Understanding
Authors:Tiancheng Jiang, Henry Wang, Md Sirajus Salekin, Parmida Atighehchian, Shinan Zhang
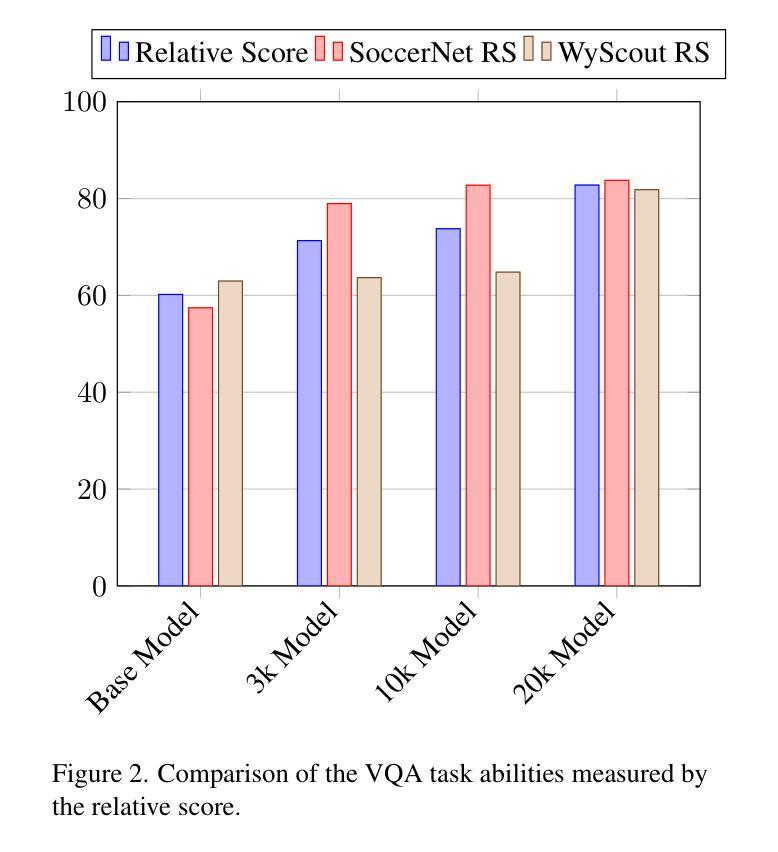
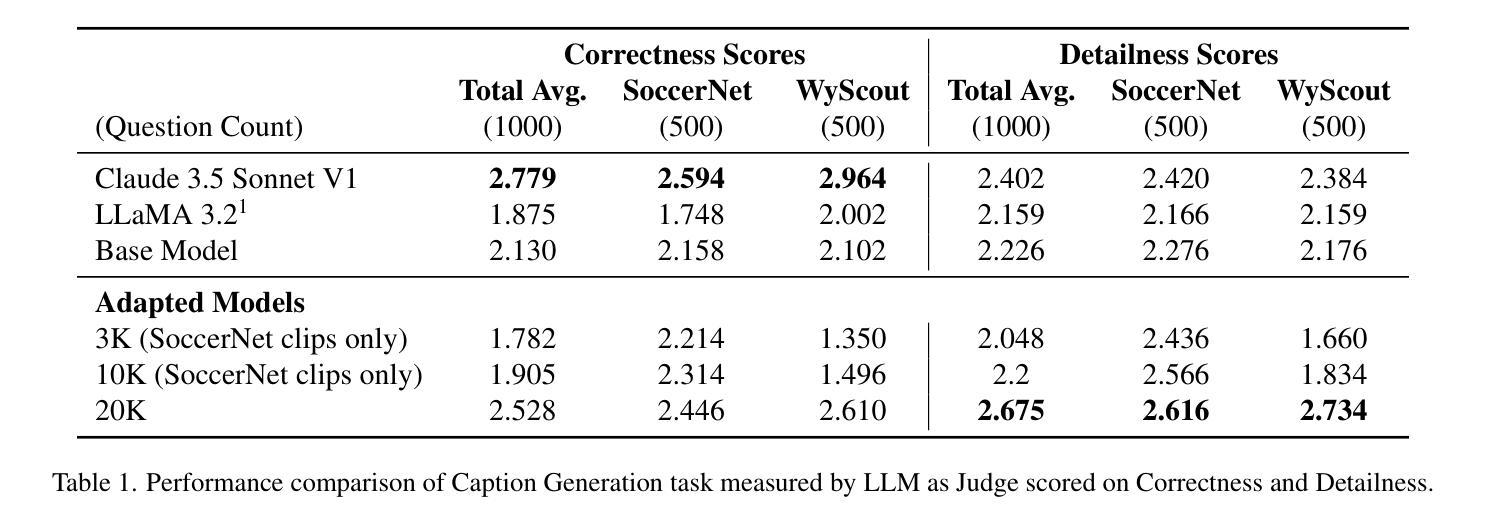
Vision Language Models (VLMs) have demonstrated strong performance in multi-modal tasks by effectively aligning visual and textual representations. However, most video understanding VLM research has been domain-agnostic, leaving the understanding of their transfer learning capability to specialized domains under-explored. In this work, we address this by exploring the adaptability of open-source VLMs to specific domains, and focusing on soccer as an initial case study. Our approach uses large-scale soccer datasets and LLM to create instruction-following data, and use them to iteratively fine-tune the general-domain VLM in a curriculum learning fashion (first teaching the model key soccer concepts to then question answering tasks). The final adapted model, trained using a curated dataset of 20k video clips, exhibits significant improvement in soccer-specific tasks compared to the base model, with a 37.5% relative improvement for the visual question-answering task and an accuracy improvement from 11.8% to 63.5% for the downstream soccer action classification task.
视觉语言模型(VLMs)通过有效地对齐视觉和文本表示,在多模态任务中表现出了强大的性能。然而,大多数视频理解VLM研究都是领域无关的,导致对其转移到特定领域的学习能力的研究不足。在这项工作中,我们通过探索开源VLMs对特定领域的适应性来解决这个问题,并以足球作为初步案例研究。我们的方法使用大规模的足球数据集和大型语言模型来创建指令跟随数据,并以课程学习的形式迭代微调通用领域的VLM(首先向模型教授关键的足球概念,然后进行问答任务)。最终模型使用精选的包含2万个视频剪辑的数据集进行训练,相较于基础模型在足球特定任务上表现出显著的提升。在视觉问答任务上相对提升了37.5%,下游的足球动作分类任务的准确率从11.8%提升至63.5%。
论文及项目相关链接
PDF 8 pages, 5 figures, accepted to the 11th IEEE International Workshop on Computer Vision in Sports (CVSports) at CVPR 2025; supplementary appendix included
Summary
开源视觉语言模型(VLMs)在多模态任务中表现出强大的性能,通过有效对齐视觉和文本表示。然而,大多数视频理解VLM研究都是跨领域的,对于它们在特定领域的迁移学习能力了解不足。本研究解决了这一问题,探讨了开源VLM对特定领域的适应性,并以足球为初步案例进行研究。通过大规模足球数据集和大型语言模型(LLM)创建指令遵循数据,以课程学习的方式迭代微调通用领域VLM(先教授模型关键的足球概念,然后进行问答任务)。最终经过训练的模型,在特定的足球任务上表现显著优于基础模型,视觉问答任务相对提高了37.5%,下游足球动作分类任务的准确率从11.8%提高到63.5%。
Key Takeaways
- VLM在多模态任务中表现优秀,通过有效对齐视觉和文本表示提升性能。
- 大多数视频理解VLM研究是跨领域的,特定领域的迁移学习能力尚待探索。
- 本研究关注开源VLM对特定领域的适应性,并以足球为案例进行研究。
- 通过大规模足球数据集和LLM创建指令遵循数据,以课程学习方式微调通用领域VLM。
- 先教授模型关键的足球概念,再进行问答任务。
- 最终经过训练的模型在特定足球任务上表现显著优于基础模型。
点此查看论文截图