⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-09 更新
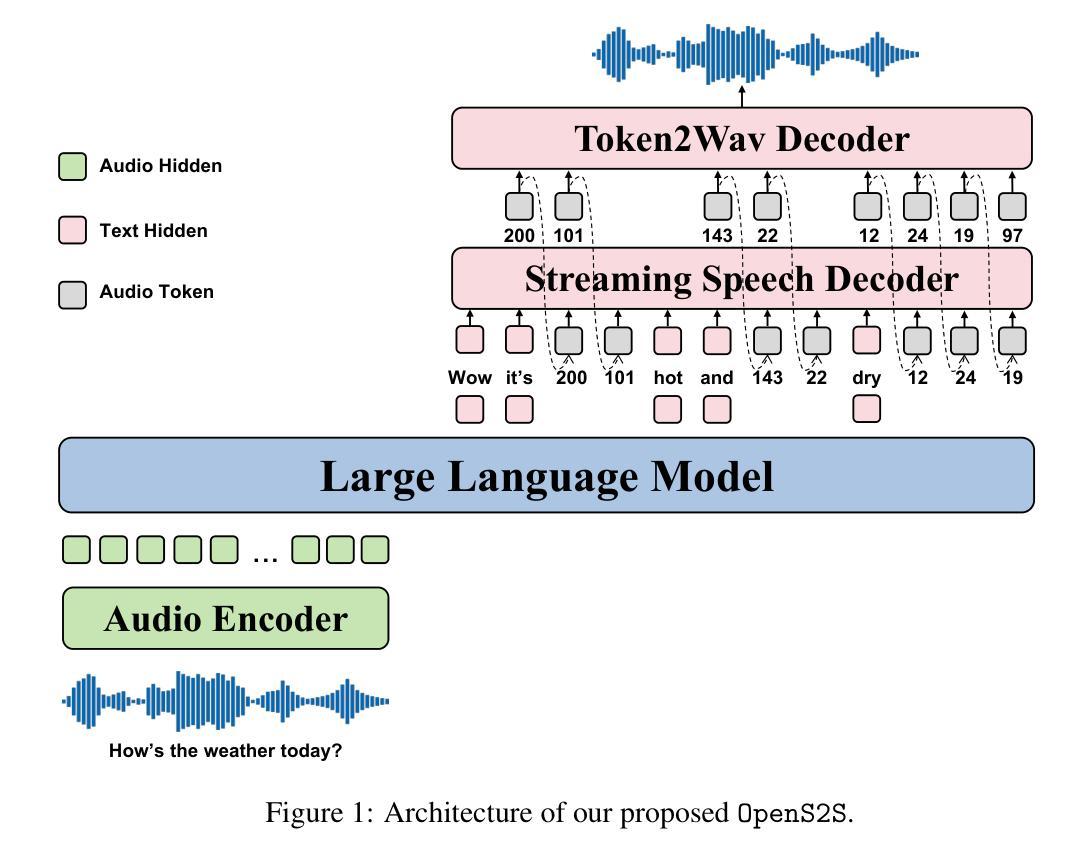
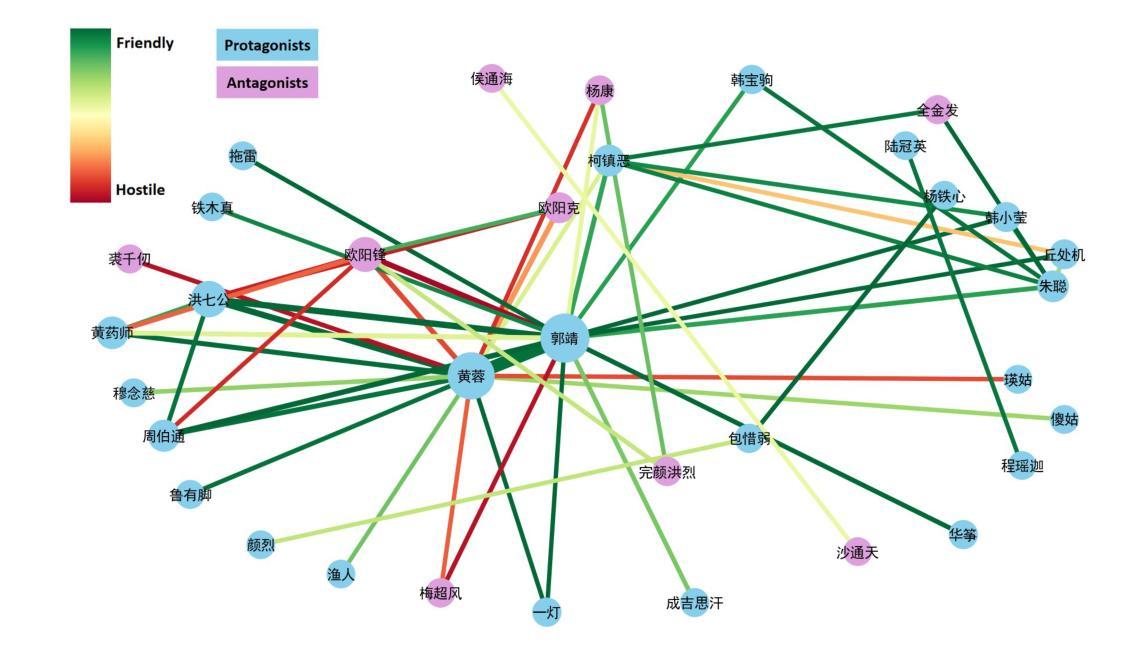
Dialogue-Based Multi-Dimensional Relationship Extraction from Novels
Authors:Yuchen Yan, Hanjie Zhao, Senbin Zhu, Hongde Liu, Zhihong Zhang, Yuxiang Jia
Relation extraction is a crucial task in natural language processing, with broad applications in knowledge graph construction and literary analysis. However, the complex context and implicit expressions in novel texts pose significant challenges for automatic character relationship extraction. This study focuses on relation extraction in the novel domain and proposes a method based on Large Language Models (LLMs). By incorporating relationship dimension separation, dialogue data construction, and contextual learning strategies, the proposed method enhances extraction performance. Leveraging dialogue structure information, it improves the model’s ability to understand implicit relationships and demonstrates strong adaptability in complex contexts. Additionally, we construct a high-quality Chinese novel relation extraction dataset to address the lack of labeled resources and support future research. Experimental results show that our method outperforms traditional baselines across multiple evaluation metrics and successfully facilitates the automated construction of character relationship networks in novels.
关系抽取是自然语言处理中的一项关键任务,在知识图谱构建和文学分析等领域有广泛应用。然而,由于小说文本中上下文复杂和表达隐晦,给自动人物关系抽取带来了很大挑战。本研究重点关注小说领域的关系抽取,提出了一种基于大语言模型(LLM)的方法。该方法通过结合关系维度分离、对话数据构建和上下文学习策略,提高了抽取性能。通过利用对话结构信息,提高了模型对隐含关系的理解能力,并在复杂语境中表现出很强的适应性。此外,为了解决标注资源的缺乏问题,我们构建了一个高质量的小说人物关系抽取数据集,以支持未来的研究。实验结果表明,我们的方法在多评价指标上优于传统基线方法,并成功促进了小说中人物关系网络的自动构建。
论文及项目相关链接
PDF The paper has been accepted by NLPCC2025. 12 pages, 5 figures, 5 tables
Summary
基于自然语言处理领域中的关系抽取在知识图谱构建和文学分析中具有广泛应用的重要性,本文重点关注小说中关系抽取的研究。针对小说中复杂语境和隐晦表达带来的挑战,提出了一种基于大型语言模型的方法。通过融入关系维度分离、对话数据构建和语境学习策略,提高了抽取性能。利用对话结构信息增强了模型对隐含关系的理解能力,并在复杂语境中表现出强大的适应性。此外,为解决缺乏标注资源的问题,构建了高质量的小说关系抽取数据集。实验结果表明,该方法在多个评估指标上优于传统基线方法,成功促进了小说中人物关系网络的自动化构建。
Key Takeaways
- 关系抽取在自然语言处理中至关重要,尤其在小说领域,对于知识图谱构建和文学分析具有广泛应用。
- 小说中复杂语境和隐晦表达给关系抽取带来挑战。
- 提出了一种基于大型语言模型的方法,通过融入关系维度分离、对话数据构建和语境学习策略,提高关系抽取性能。
- 利用对话结构信息,增强模型对隐含关系的理解能力。
- 构建了一个高质量的小说关系抽取数据集,以支持未来研究。
- 实验结果表明,该方法在多个评估指标上优于传统方法。
点此查看论文截图

RateCount: Learning-Free Device Counting by Wi-Fi Probe Listening
Authors:Tianlang He, Zhangyu Chang, S. -H. Gary Chan
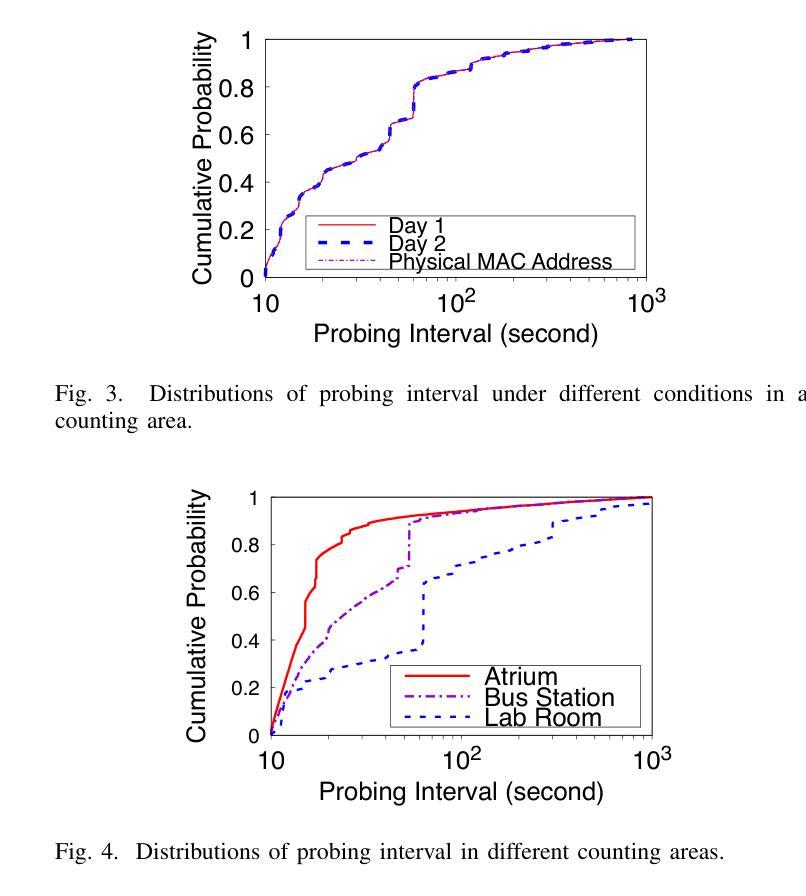
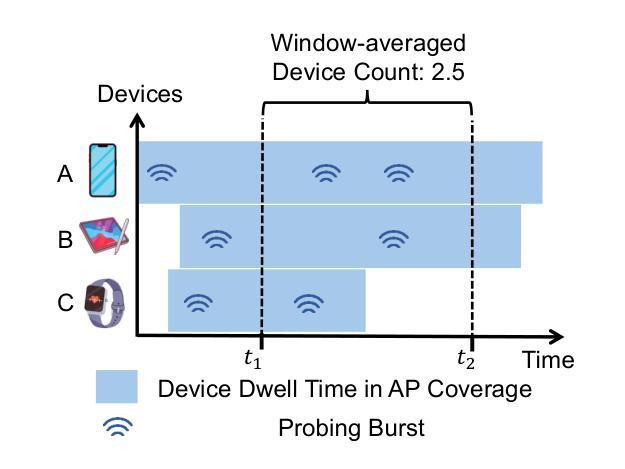
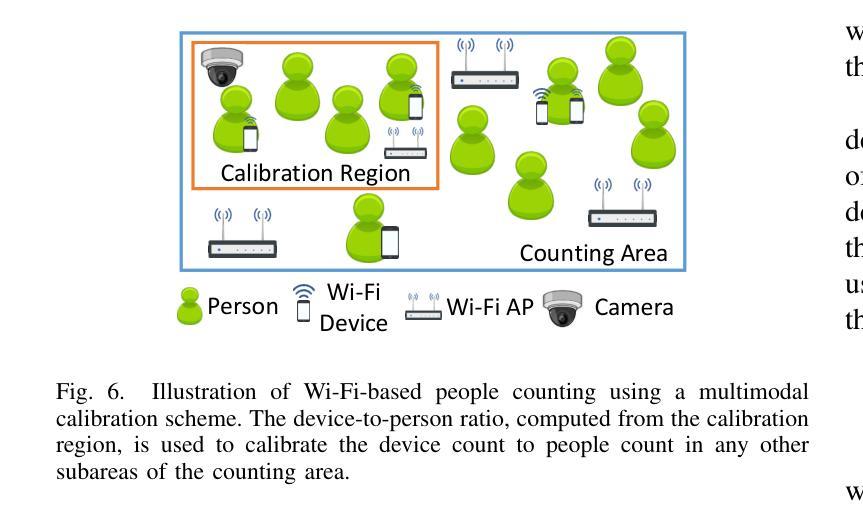
A Wi-Fi-enabled device, or simply Wi-Fi device, sporadically broadcasts probe request frames (PRFs) to discover nearby access points (APs), whether connected to an AP or not. To protect user privacy, unconnected devices often randomize their MAC addresses in the PRFs, known as MAC address randomization. While prior works have achieved accurate device counting under MAC address randomization, they typically rely on machine learning, resulting in inefficient deployment due to the time-consuming processes of data cleaning, model training, and hyperparameter tuning. To enhance deployment efficiency, we propose RateCount, an accurate, lightweight, and learning-free counting approach based on the rate at which APs receive PRFs within a window. RateCount employs a provably unbiased closed-form expression to estimate the device count time-averaged over the window and an error model to compute the lower bound of the estimation variance. We also demonstrate how to extend RateCount to people counting by incorporating a device-to-person calibration scheme. Through extensive real-world experiments conducted at multiple sites spanning a wide range of counts, we show that RateCount, without any deployment costs for machine learning, achieves comparable counting accuracy with the state-of-the-art learning-based device counting and improves previous people counting schemes by a large margin.
Wi-Fi设备会间歇性地广播探测请求帧(PRFs),以发现附近接入点(AP),无论其是否已连接到AP。为了保护用户隐私,未连接的设备经常在PRF中进行MAC地址随机化。尽管先前的研究工作在MAC地址随机化条件下实现了准确的设备计数,但它们通常依赖于机器学习,由于数据清理、模型训练和超参数调整等耗时过程,导致部署效率低下。为了提高部署效率,我们提出了RateCount,这是一种基于窗口内AP接收PRF速率的准确、轻便且无需学习的计数方法。RateCount采用可证明的偏斜闭合表达式来估计窗口时间平均的设备计数,并使用误差模型计算估计方差的下限。我们还展示了如何通过引入设备到人员的校准方案,将RateCount扩展到人数计数。我们在多个站点进行了广泛的实际世界实验,实验范围涵盖了广泛的计数范围。实验结果表明,无需为机器学习支付任何部署成本的RateCount,实现了与最新学习型设备计数技术相当的计数精度,并在人数计数方案上大幅度改进了以前的方案。
论文及项目相关链接
摘要
Wi-Fi设备会不定时发送探测请求帧(PRFs)以发现附近接入点(APs)。为保隐私,未连接设备会在PRFs中随机化其MAC地址。虽然现有技术能在MAC地址随机化情况下进行设备计数,但它们大多依赖机器学习,导致数据清理、模型训练和超参数调整等过程耗时,部署效率低下。为提高部署效率,本文提出RateCount,一种基于AP在窗口期内接收PRF速率的精确、轻量级、无需学习的计数方法。RateCount采用无偏封闭形式表达式估算窗口时间平均的设备计数,并建立误差模型计算估计方差的下限。此外,本文通过引入设备到人的校准方案,展示了如何将RateCount扩展到人数计数。在多个站点进行的大量现实实验表明,无需为机器学习付出部署成本的RateCount,在设备计数方面达到了最新学习方法的水平,并且在人数计数方面大大改进了以前的方法。
关键见解
- Wi-Fi设备会发送探测请求帧以发现附近接入点。
- 未连接设备会随机化MAC地址以保护隐私。
- 现有设备计数方法大多依赖机器学习,导致部署效率低下。
- RateCount是一种基于PRF接收速率的计数方法,无需机器学习。
- RateCount采用封闭形式表达式进行设备计数估算,并建立误差模型。
- RateCount可通过设备到人的校准方案扩展至人数计数。
点此查看论文截图