⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
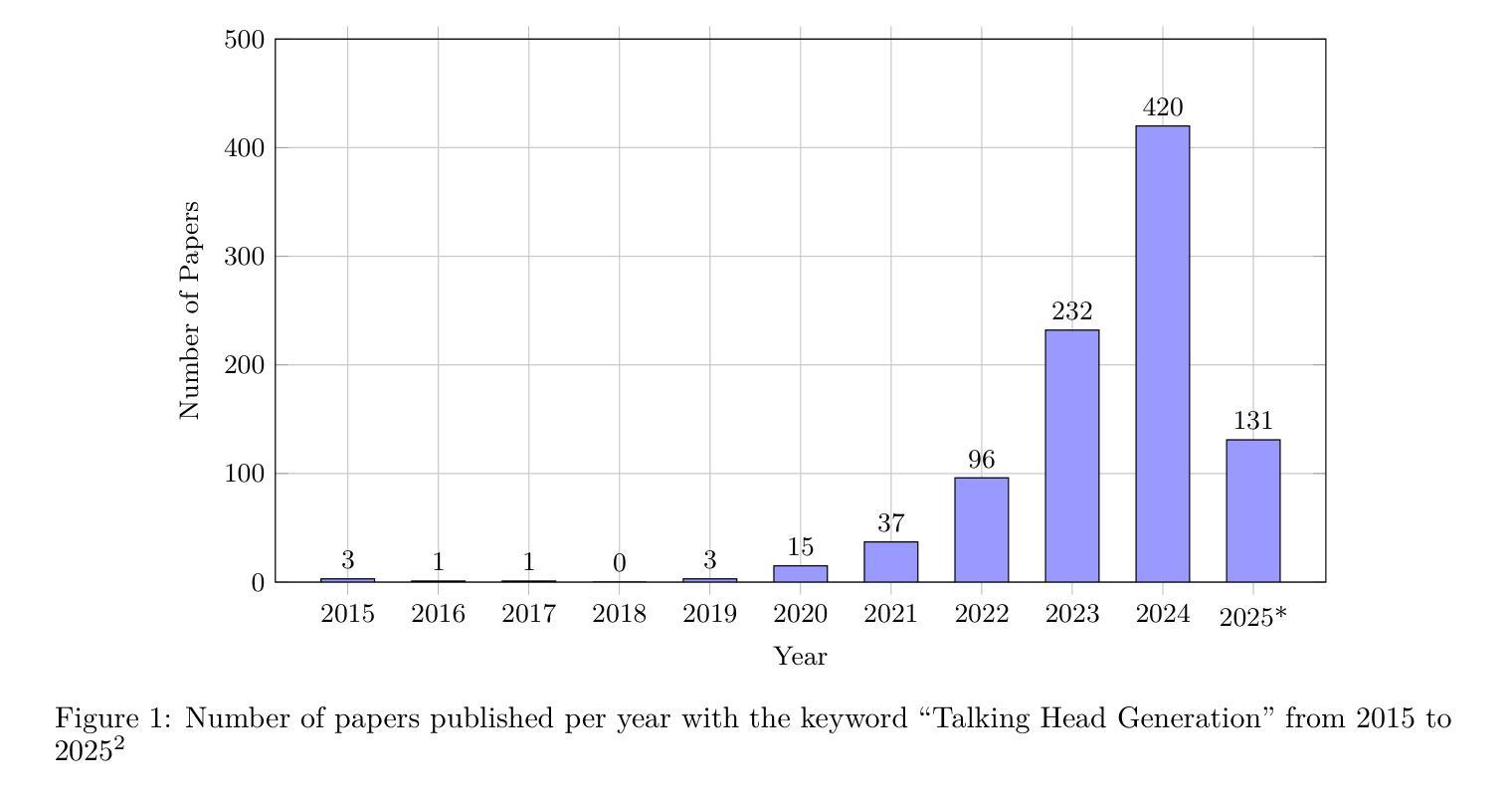
2025-07-09 更新
A View-consistent Sampling Method for Regularized Training of Neural Radiance Fields
Authors:Aoxiang Fan, Corentin Dumery, Nicolas Talabot, Pascal Fua
Neural Radiance Fields (NeRF) has emerged as a compelling framework for scene representation and 3D recovery. To improve its performance on real-world data, depth regularizations have proven to be the most effective ones. However, depth estimation models not only require expensive 3D supervision in training, but also suffer from generalization issues. As a result, the depth estimations can be erroneous in practice, especially for outdoor unbounded scenes. In this paper, we propose to employ view-consistent distributions instead of fixed depth value estimations to regularize NeRF training. Specifically, the distribution is computed by utilizing both low-level color features and high-level distilled features from foundation models at the projected 2D pixel-locations from per-ray sampled 3D points. By sampling from the view-consistency distributions, an implicit regularization is imposed on the training of NeRF. We also utilize a depth-pushing loss that works in conjunction with the sampling technique to jointly provide effective regularizations for eliminating the failure modes. Extensive experiments conducted on various scenes from public datasets demonstrate that our proposed method can generate significantly better novel view synthesis results than state-of-the-art NeRF variants as well as different depth regularization methods.
神经辐射场(NeRF)已成为场景表示和3D恢复的有力框架。为了提高其在真实世界数据上的性能,深度正则化已被证明是最有效的手段。然而,深度估计模型不仅在训练过程中需要昂贵的3D监督,而且还存在泛化问题。因此,在实践中,深度估计可能会出现错误,特别是对于户外无界场景。在本文中,我们提出采用视角一致分布而不是固定的深度值估计来对NeRF训练进行正则化。具体而言,该分布是通过利用来自基础模型的低级颜色特征和高级蒸馏特征来计算的,这些特征来自从每条射线采样的3D点的投影的2D像素位置。通过对视角一致性分布进行采样,对NeRF的训练施加了隐式正则化。我们还使用深度推动损失(depth-pushing loss),与采样技术相结合,共同提供有效的正则化,以消除失败模式。在公共数据集的各种场景上进行的广泛实验表明,我们提出的方法可以生成比最先进的NeRF变体以及不同的深度正则化方法更好的新颖视图合成结果。
论文及项目相关链接
PDF ICCV 2025 accepted
Summary
神经网络辐射场(NeRF)作为场景表示和三维重建的有力框架已引起广泛关注。为提高其在真实世界数据上的性能,深度正则化是最有效的手段之一。然而,深度估计模型不仅需要在训练中进行昂贵的三维监督,还存在泛化问题。特别是在户外无界场景的深度估计中,容易出现错误。本文提出采用视角一致性分布来替代固定的深度值估计,以正则化NeRF训练。该分布是通过利用来自基础模型的低级颜色特征和高级蒸馏特征,在来自每条射线采样的三维点的投影二维像素位置计算得出的。通过对视角一致性分布进行采样,对NeRF的训练施加隐式正则化。我们还使用与采样技术一起工作的深度推动损失,以联合提供有效的正则化,消除失败模式。在公共数据集的各种场景上进行的广泛实验表明,我们的方法比最先进的NeRF变种以及不同的深度正则化方法生成的新视角合成结果更好。
Key Takeaways
- NeRF作为场景表示和3D重建的框架备受关注,深度正则化是提高其性能的有效手段。
- 现有深度估计模型存在训练中的高成本三维监督及泛化问题。
- 提出了采用视角一致性分布替代固定深度值估计的方法,以正则化NeRF训练。
- 视角一致性分布是通过结合低级和高级特征计算的。
- 通过采样视角一致性分布,对NeRF训练施加隐式正则化。
- 引入深度推动损失与采样技术相结合,提供有效的正则化。
点此查看论文截图




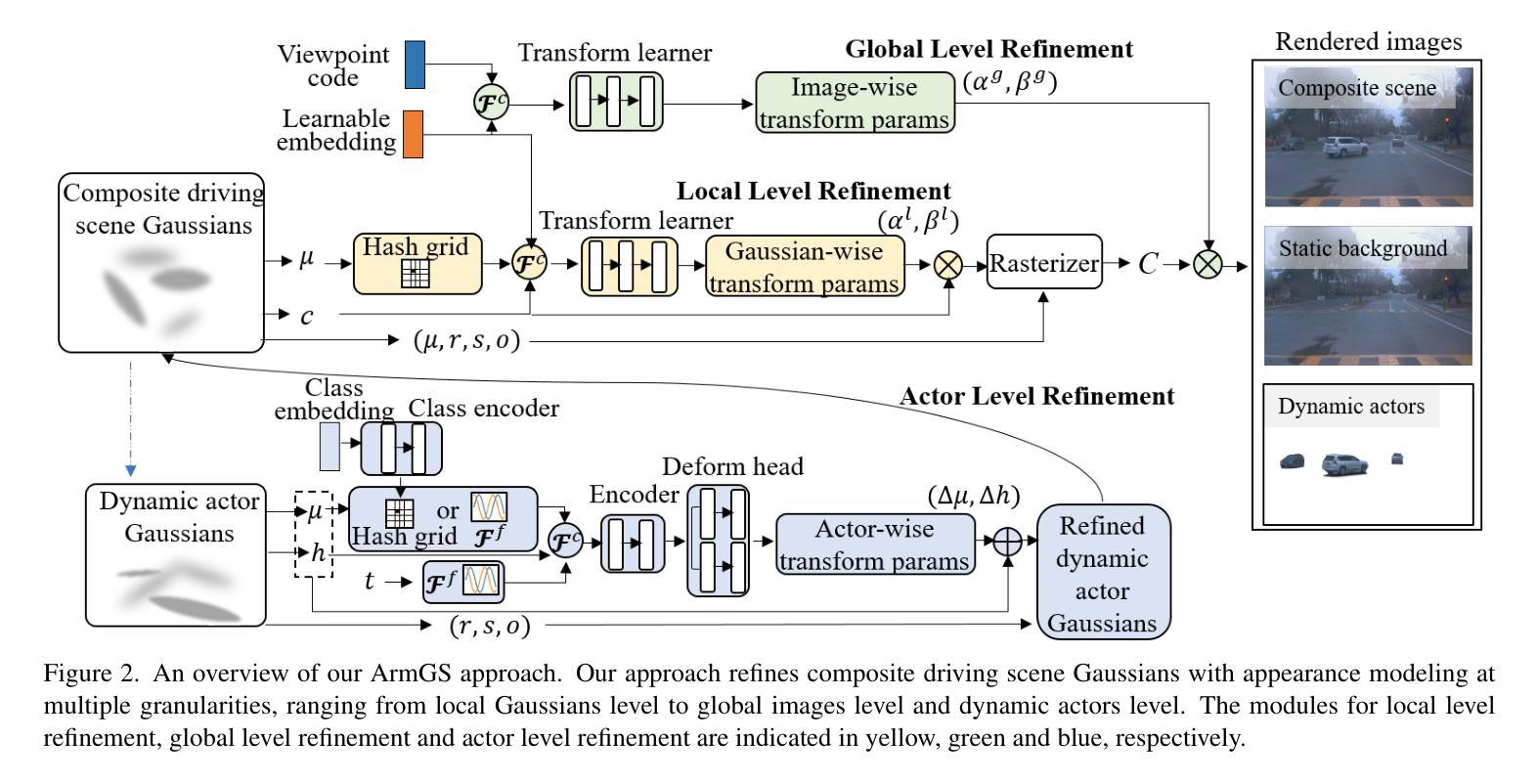
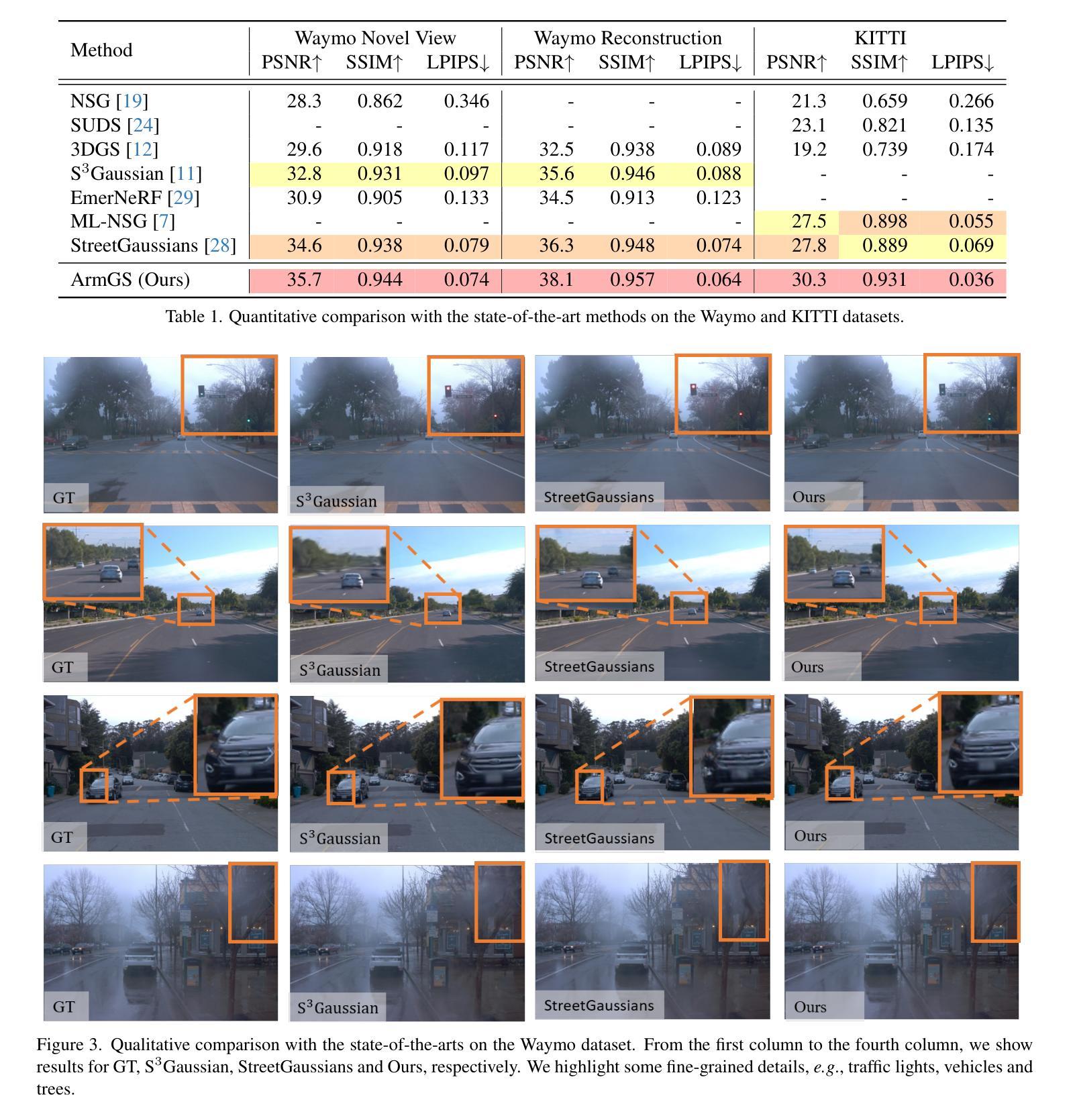
ArmGS: Composite Gaussian Appearance Refinement for Modeling Dynamic Urban Environments
Authors:Guile Wu, Dongfeng Bai, Bingbing Liu
This work focuses on modeling dynamic urban environments for autonomous driving simulation. Contemporary data-driven methods using neural radiance fields have achieved photorealistic driving scene modeling, but they suffer from low rendering efficacy. Recently, some approaches have explored 3D Gaussian splatting for modeling dynamic urban scenes, enabling high-fidelity reconstruction and real-time rendering. However, these approaches often neglect to model fine-grained variations between frames and camera viewpoints, leading to suboptimal results. In this work, we propose a new approach named ArmGS that exploits composite driving Gaussian splatting with multi-granularity appearance refinement for autonomous driving scene modeling. The core idea of our approach is devising a multi-level appearance modeling scheme to optimize a set of transformation parameters for composite Gaussian refinement from multiple granularities, ranging from local Gaussian level to global image level and dynamic actor level. This not only models global scene appearance variations between frames and camera viewpoints, but also models local fine-grained changes of background and objects. Extensive experiments on multiple challenging autonomous driving datasets, namely, Waymo, KITTI, NOTR and VKITTI2, demonstrate the superiority of our approach over the state-of-the-art methods.
本文重点关注为自动驾驶仿真建模动态城市环境。当前使用神经辐射场的数据驱动方法已经实现了驾驶场景的光照现实建模,但它们存在渲染效率较低的问题。最近,一些方法已经探索了使用3D高斯涂覆技术为动态城市场景建模,实现了高保真重建和实时渲染。然而,这些方法往往忽略了帧之间和摄像头视点之间的细微变化建模,导致结果不尽如人意。在这项工作中,我们提出了一种新的方法,名为ArmGS,它利用复合驾驶高斯涂覆技术和多粒度外观细化来进行自动驾驶场景建模。我们的方法的核心思想是设计一种多层次外观建模方案,以优化从多个粒度(从局部高斯级别到全局图像级别和动态演员级别)进行复合高斯细化的转换参数。这不仅可以模拟帧之间和摄像机视点之间的全局场景外观变化,还可以模拟背景和对象的局部细微变化。在具有挑战性的自动驾驶数据集Waymo、KITTI、NOTR和VKITTI2上的大量实验表明,我们的方法优于最新技术。
论文及项目相关链接
PDF Technical report
Summary
本文提出了一种名为ArmGS的新方法,利用复合驾驶高斯拼贴与多粒度外观优化技术,对自动驾驶场景进行建模。该方法通过多级别外观建模方案,优化从局部高斯级别到全局图像级别和动态演员级别的复合高斯精细化的转换参数,不仅模拟了全局场景外观在不同帧和摄像头视角下的变化,还模拟了背景和对象的局部细微变化。在多个具有挑战性的自动驾驶数据集上的广泛实验证明了该方法相较于现有技术方法的优越性。
Key Takeaways
- 论文聚焦于为自动驾驶仿真建模动态城市环境。
- 现有神经辐射场方法虽然能达到逼真的驾驶场景建模,但渲染效率较低。
- 近期有方法尝试用3D高斯拼贴建模动态城市场景,实现了高保真重建和实时渲染。
- 但这些方法往往忽视了帧间和摄像头视角的细微变化,导致结果不够理想。
- 本文提出的ArmGS方法利用复合驾驶高斯拼贴与多粒度外观优化技术,对自动驾驶场景进行精细建模。
- 该方法通过多级别外观建模方案,优化不同粒度的复合高斯精细化转换参数。
点此查看论文截图

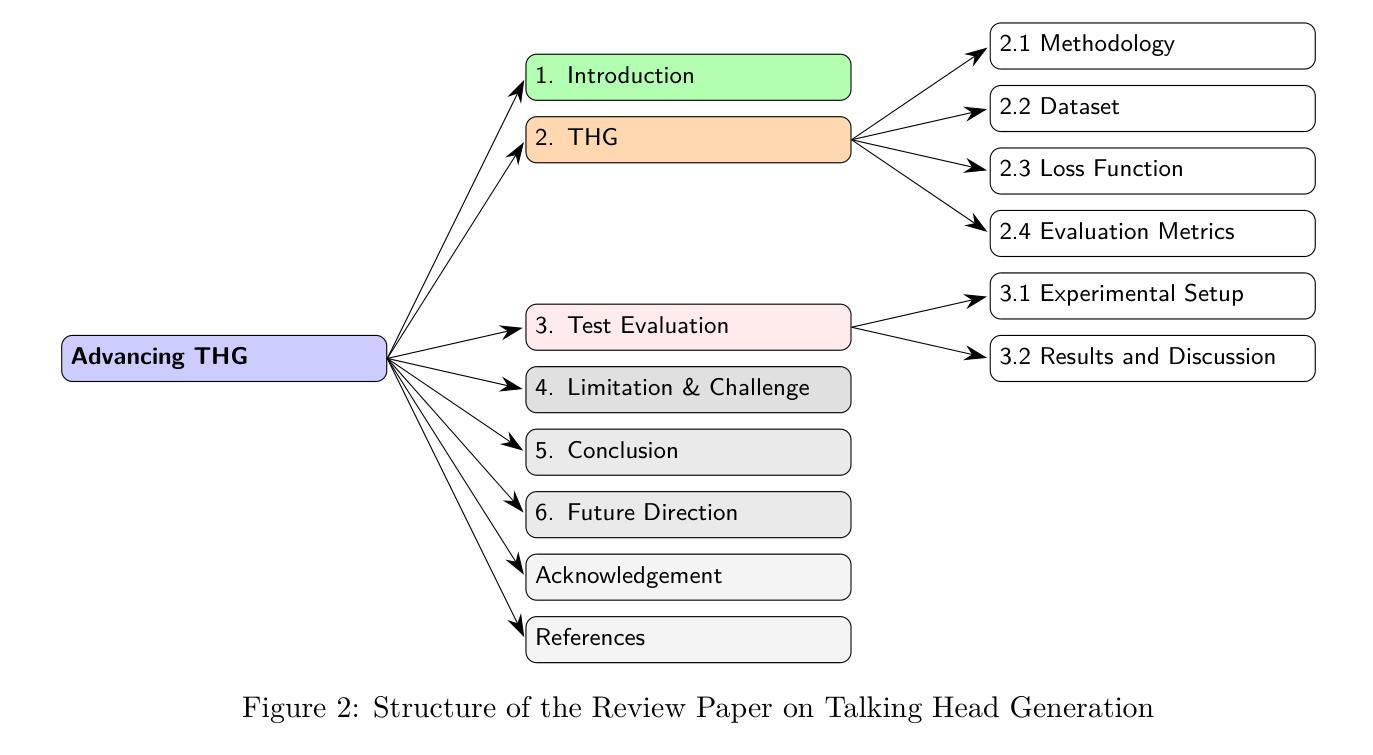
Advancing Talking Head Generation: A Comprehensive Survey of Multi-Modal Methodologies, Datasets, Evaluation Metrics, and Loss Functions
Authors:Vineet Kumar Rakesh, Soumya Mazumdar, Research Pratim Maity, Sarbajit Pal, Amitabha Das, Tapas Samanta
Talking Head Generation (THG) has emerged as a transformative technology in computer vision, enabling the synthesis of realistic human faces synchronized with image, audio, text, or video inputs. This paper provides a comprehensive review of methodologies and frameworks for talking head generation, categorizing approaches into 2D–based, 3D–based, Neural Radiance Fields (NeRF)–based, diffusion–based, parameter-driven techniques and many other techniques. It evaluates algorithms, datasets, and evaluation metrics while highlighting advancements in perceptual realism and technical efficiency critical for applications such as digital avatars, video dubbing, ultra-low bitrate video conferencing, and online education. The study identifies challenges such as reliance on pre–trained models, extreme pose handling, multilingual synthesis, and temporal consistency. Future directions include modular architectures, multilingual datasets, hybrid models blending pre–trained and task-specific layers, and innovative loss functions. By synthesizing existing research and exploring emerging trends, this paper aims to provide actionable insights for researchers and practitioners in the field of talking head generation. For the complete survey, code, and curated resource list, visit our GitHub repository: https://github.com/VineetKumarRakesh/thg.
头部生成技术(Talking Head Generation,THG)已成为计算机视觉领域的一项革新性技术,它能够根据图像、音频、文本或视频输入合成逼真的人脸。本文全面回顾了头部生成技术的各种方法和框架,包括基于二维、基于三维、基于神经辐射场(NeRF)、基于扩散、参数驱动技术以及其他多种技术的方法。文章对算法、数据集和评价指标进行了评估,同时强调了数字化身、视频配音、超低比特率视频会议和在线教育等应用中感知真实性和技术效率方面的进展。研究指出了面临的挑战,如依赖预训练模型、极端姿态处理、多语言合成和时序一致性等。未来的发展方向包括模块化架构、多语言数据集、混合预训练和任务特定层的混合模型以及创新的损失函数。本文通过综合现有研究和探索新兴趋势,旨在为头部生成技术领域的研究人员和实践者提供可行的见解。欲获取完整的调查报告、代码和精选资源列表,请访问我们的GitHub仓库:链接地址。
论文及项目相关链接
Summary
本文全面综述了说话人头像生成(THG)的技术方法和框架,包括2D、3D、基于神经辐射场(NeRF)、扩散模型、参数驱动等多种技术。文章评价了各种算法、数据集和评估指标,并强调了数字化身、视频配音、超低码率视频会议和在线教育等应用中感知真实性和技术效率的重要性。同时,文章也指出了挑战和未来发展方向。
Key Takeaways
- 说话人头像生成(THG)已成为计算机视觉中的变革性技术。
- THG技术方法和框架包括多种类型,如2D、3D、基于NeRF等。
- 文章评价了各种算法、数据集和评估指标,并强调了感知真实性和技术效率的重要性。
- THG应用于数字化身、视频配音、超低码率视频会议和在线教育等领域。
- THG面临的挑战包括依赖预训练模型、极端姿态处理、多语言合成和时序一致性。
- 未来发展方向包括模块化架构、多语言数据集、混合模型和创新的损失函数。
点此查看论文截图

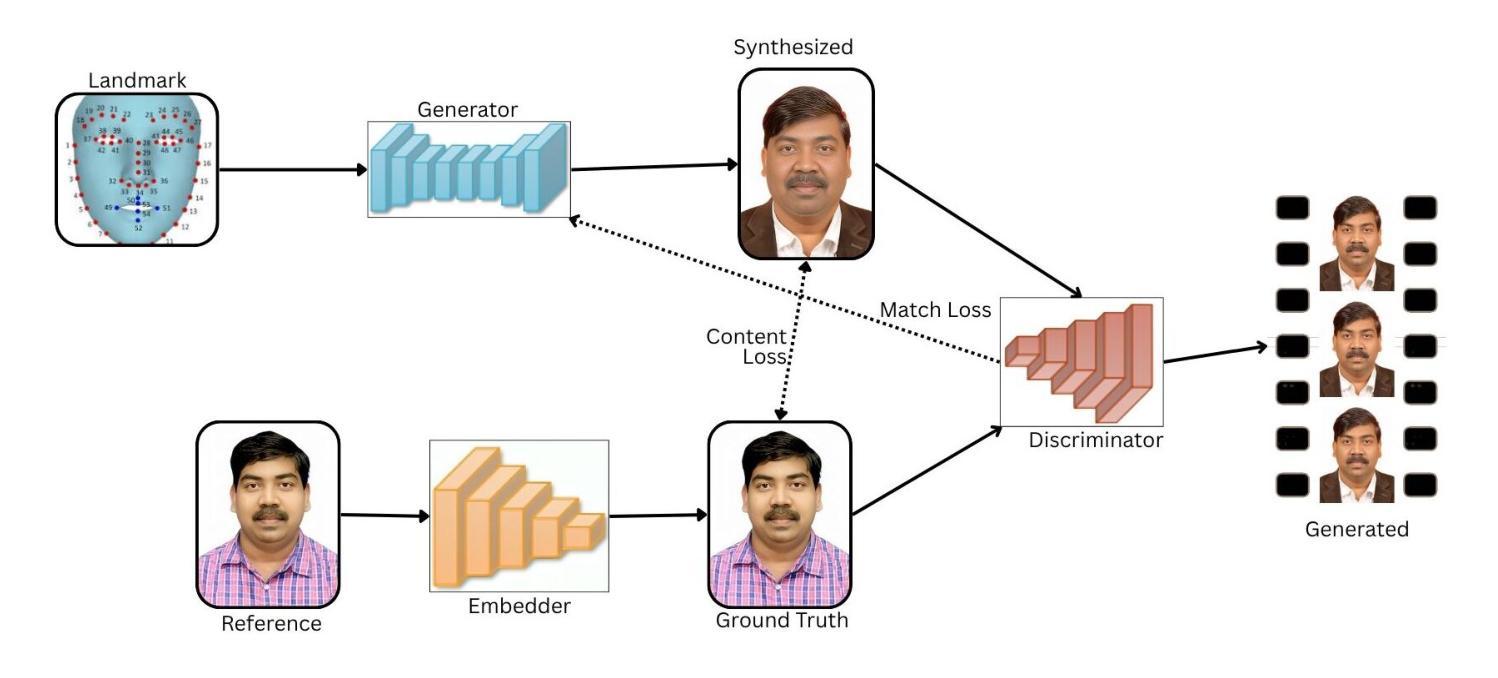
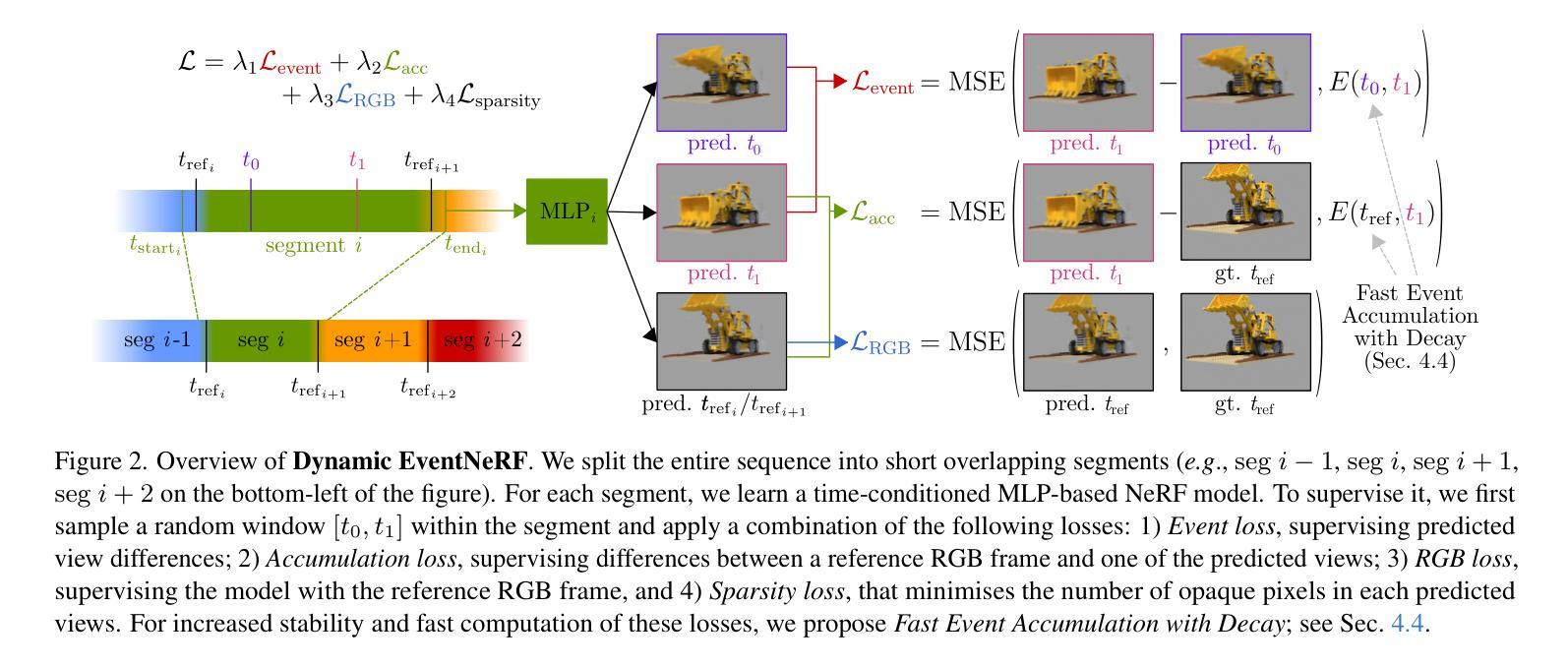
Dynamic EventNeRF: Reconstructing General Dynamic Scenes from Multi-view RGB and Event Streams
Authors:Viktor Rudnev, Gereon Fox, Mohamed Elgharib, Christian Theobalt, Vladislav Golyanik
Volumetric reconstruction of dynamic scenes is an important problem in computer vision. It is especially challenging in poor lighting and with fast motion. This is partly due to limitations of RGB cameras: To capture frames under low lighting, the exposure time needs to be increased, which leads to more motion blur. In contrast, event cameras, which record changes in pixel brightness asynchronously, are much less dependent on lighting, making them more suitable for recording fast motion. We hence propose the first method to spatiotemporally reconstruct a scene from sparse multi-view event streams and sparse RGB frames. We train a sequence of cross-faded time-conditioned NeRF models, one per short recording segment. The individual segments are supervised with a set of event- and RGB-based losses and sparse-view regularisation. We assemble a real-world multi-view camera rig with six static event cameras around the object and record a benchmark multi-view event stream dataset of challenging motions. Our work outperforms RGB-based baselines, producing state-of-the-art results, and opens up the topic of multi-view event-based reconstruction as a new path for fast scene capture beyond RGB cameras. The code and the data are released at https://4dqv.mpi-inf.mpg.de/DynEventNeRF/
动态场景的体积重建是计算机视觉领域的一个重要问题。在低光照和快速运动的条件下,这个问题尤为具有挑战性。这在一定程度上是由于RGB相机的局限性所致:在低光照条件下捕捉帧时,需要增加曝光时间,从而导致运动模糊。相比之下,事件相机能够异步记录像素亮度的变化,对光照的依赖程度较低,因此它们更适合记录快速运动。因此,我们提出了第一种从稀疏的多视角事件流和稀疏的RGB帧中时空重建场景的方法。我们训练了一系列跨淡化的时间条件NeRF模型,每个短期记录片段一个模型。各个片段受到事件和RGB基损失以及稀疏视图正则化的监督。我们使用六台静态事件相机围绕物体组成了一个现实世界的多视角相机装置,并记录了一个具有挑战性运动的多视角事件流基准数据集。我们的工作在RGB基线基础上表现出色,取得了最新结果,并开启了基于多视角事件重建的主题作为超越RGB相机的快速场景捕获的新途径。代码和数据已发布在https://4dqv.mpi-inf.mpg.de/DynEventNeRF/。
论文及项目相关链接
PDF 17 pages, 13 figures, 7 tables; CVPRW 2025
Summary
该文本介绍了动态场景体积重建的重要问题及其面临的挑战,特别是光照不足和快速运动的情况。文章提出了一种基于稀疏多视角事件流和稀疏RGB帧进行时空场景重建的方法。通过训练一系列跨淡入时间条件NeRF模型,对每个短时间记录片段进行建模,并利用事件和RGB损失以及稀疏视图正则化进行监督。此外,文章还介绍了一个由六个静态事件相机组成的真实世界多视角相机装置,并记录了具有挑战性运动的多视角事件流数据集。这项工作超越了基于RGB相机的重建方法,取得了最新结果,并开启了多视角事件重建作为快速场景捕获的新途径。
Key Takeaways
- 动态场景体积重建在计算机视觉中是一个重要问题,特别是在光照不足和快速运动的情况下。
- 事件相机在记录快速运动和低光照场景时具有优势,相比RGB相机更适合这些场景。
- 提出了一种结合稀疏多视角事件流和RGB帧进行时空场景重建的方法。
- 通过训练一系列时间条件NeRF模型,对每个短时间记录片段进行建模。
- 该方法利用事件和RGB损失以及稀疏视图正则化进行监督。
- 建立一个真实世界多视角相机装置,记录具有挑战性运动的多视角事件流数据集。
点此查看论文截图