⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-09 更新
Grounded Gesture Generation: Language, Motion, and Space
Authors:Anna Deichler, Jim O’Regan, Teo Guichoux, David Johansson, Jonas Beskow
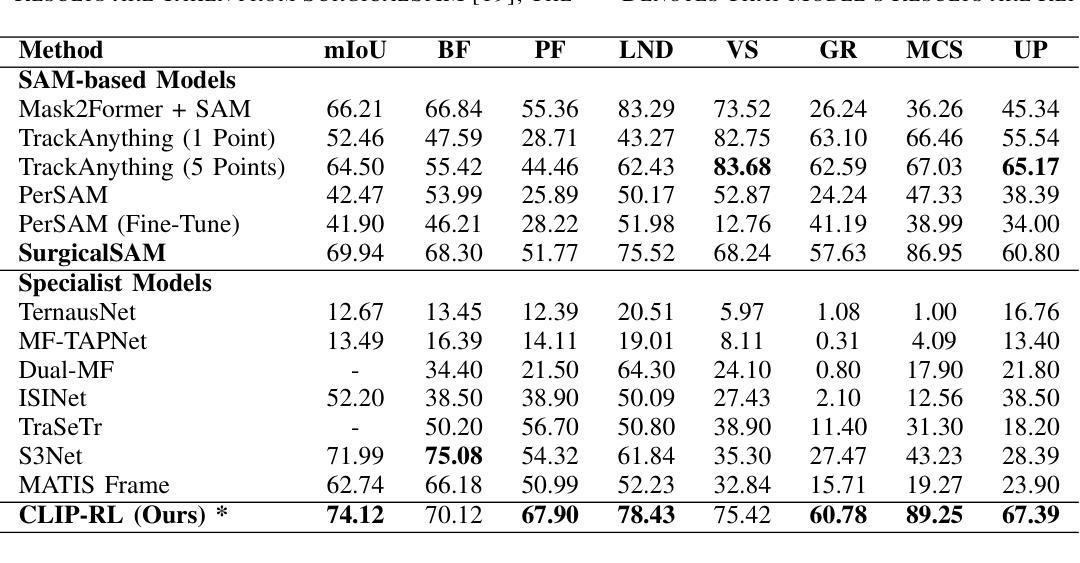
Human motion generation has advanced rapidly in recent years, yet the critical problem of creating spatially grounded, context-aware gestures has been largely overlooked. Existing models typically specialize either in descriptive motion generation, such as locomotion and object interaction, or in isolated co-speech gesture synthesis aligned with utterance semantics. However, both lines of work often treat motion and environmental grounding separately, limiting advances toward embodied, communicative agents. To address this gap, our work introduces a multimodal dataset and framework for grounded gesture generation, combining two key resources: (1) a synthetic dataset of spatially grounded referential gestures, and (2) MM-Conv, a VR-based dataset capturing two-party dialogues. Together, they provide over 7.7 hours of synchronized motion, speech, and 3D scene information, standardized in the HumanML3D format. Our framework further connects to a physics-based simulator, enabling synthetic data generation and situated evaluation. By bridging gesture modeling and spatial grounding, our contribution establishes a foundation for advancing research in situated gesture generation and grounded multimodal interaction. Project page: https://groundedgestures.github.io/
人类动作生成技术在近年来已经迅速发展,但创建具有空间性和上下文感知的手势这一关键问题却被大大忽视了。现有模型通常专注于描述性动作生成,如行走和对象交互,或在与话语语义对齐的孤立语音手势合成中。然而,这两类工作通常将动作和环境基础分开处理,限制了向着具体化、交际性代理的发展。为了弥补这一空白,我们的工作引入了基于基础手势生成的多模态数据集和框架,结合了两种关键资源:(1)空间基础参照手势的合成数据集,(2)基于VR的MM-Conv数据集,捕捉双方对话。它们共同提供了超过7.7小时同步的动作、语音和3D场景信息,以HumanML3D格式标准化。我们的框架进一步与基于物理的模拟器相连,能够实现合成数据的生成和情境评估。通过桥接手势建模和空间基础,我们的贡献为情境手势生成和基础多模式交互的研究奠定了基础。项目页面:https://groundedgestures.github.io/
论文及项目相关链接
PDF Accepted as a non-archival paper at the CVPR 2025 Humanoid Agents Workshop. Project page: https://groundedgestures.github.io
Summary
本文关注人类动作生成领域中的空间背景与语境感知手势的生成问题。现有模型主要专注于描述性动作生成或与语言语义对齐的孤立性共语手势合成,但往往将动作与环境背景分离处理,阻碍了身体性沟通代理的发展。本文提出一个综合数据集与框架来解决这一问题,包含合成的手势参考数据集和基于VR的双向对话数据集,提供超过7.7小时的同步动作、语音和3D场景信息。此外,该框架与物理模拟器连接,促进合成数据的生成和情境评估。通过连接手势建模和空间背景,本文建立了一个研究情境手势生成和基于背景的多模态交互的基础。
Key Takeaways
- 人类动作生成领域存在空间背景与语境感知手势生成的不足。
- 现有模型在动作与环境背景的处理上存在分离现象,限制了进展。
- 本文提出一个综合数据集用于解决这一问题,包含合成手势参考数据集和基于VR的双向对话数据集。
- 数据集提供了超过7.7小时的同步动作、语音和3D场景信息。
- 提出的数据集采用HumanML3D格式标准化,支持情境评估和合成数据生成。
- 通过连接手势建模和空间背景,为情境手势生成和多模态交互研究奠定基础。
点此查看论文截图


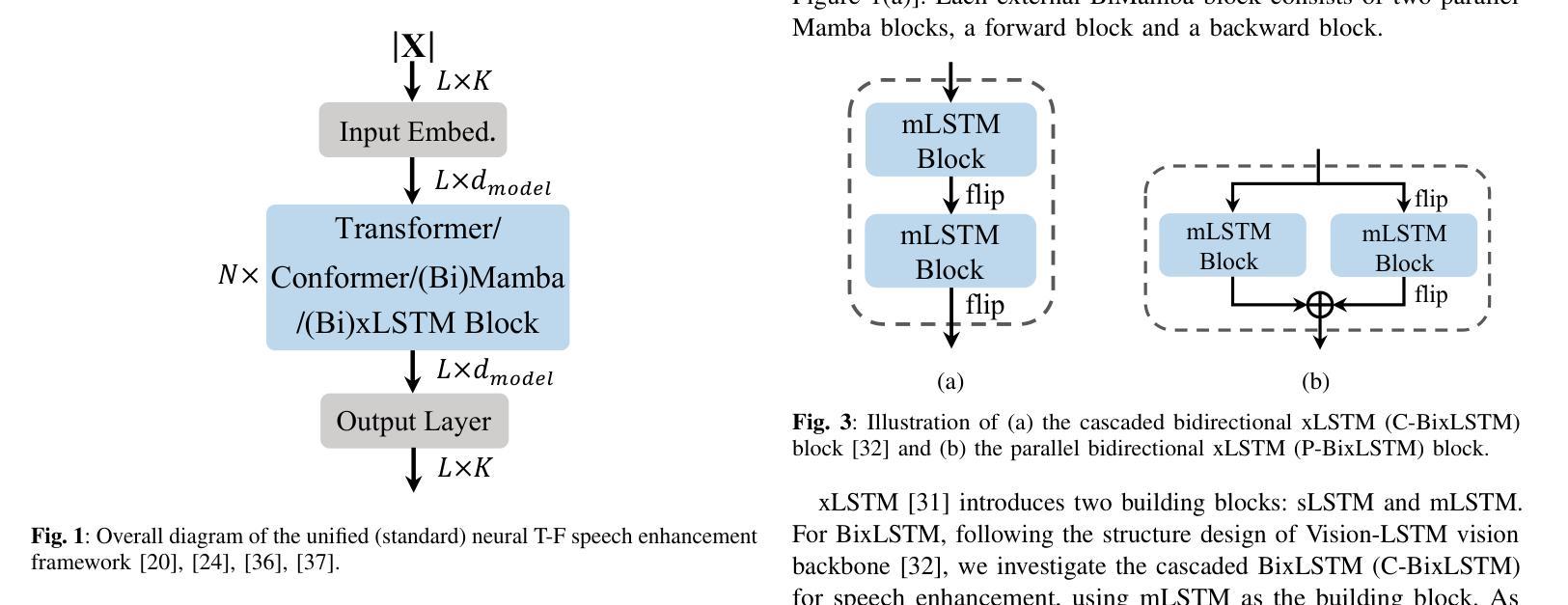
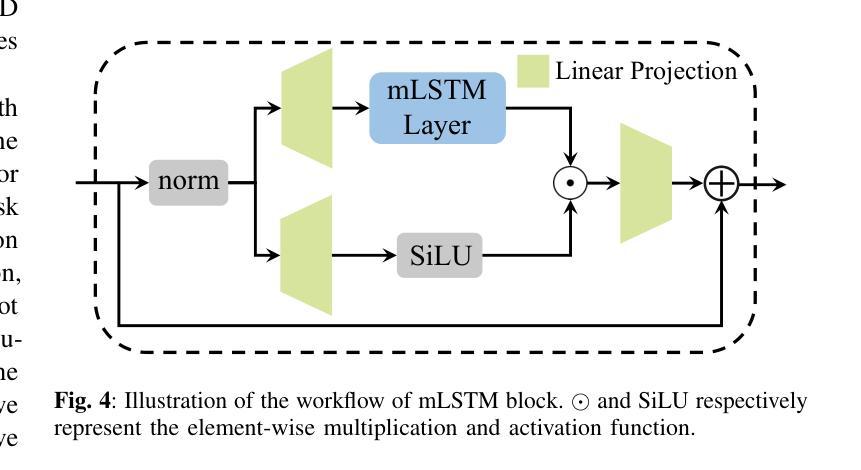
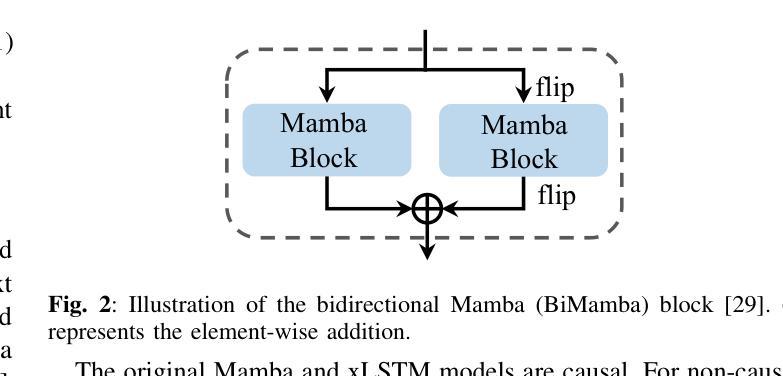
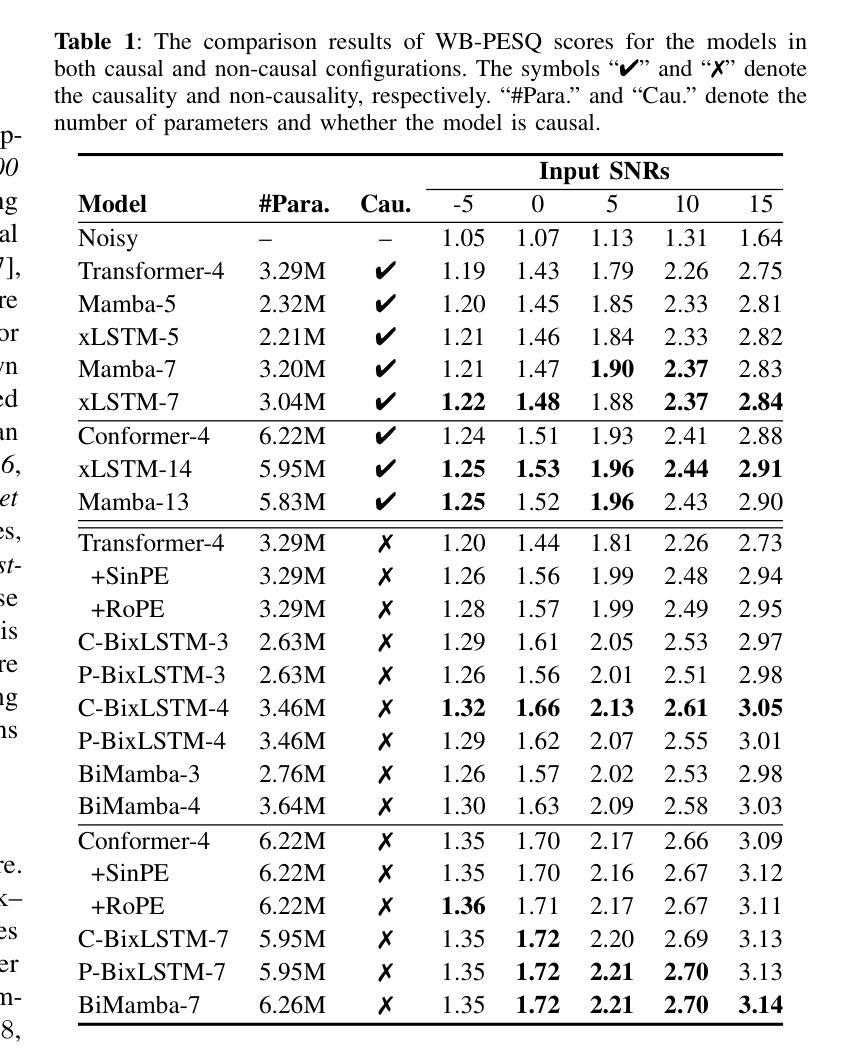
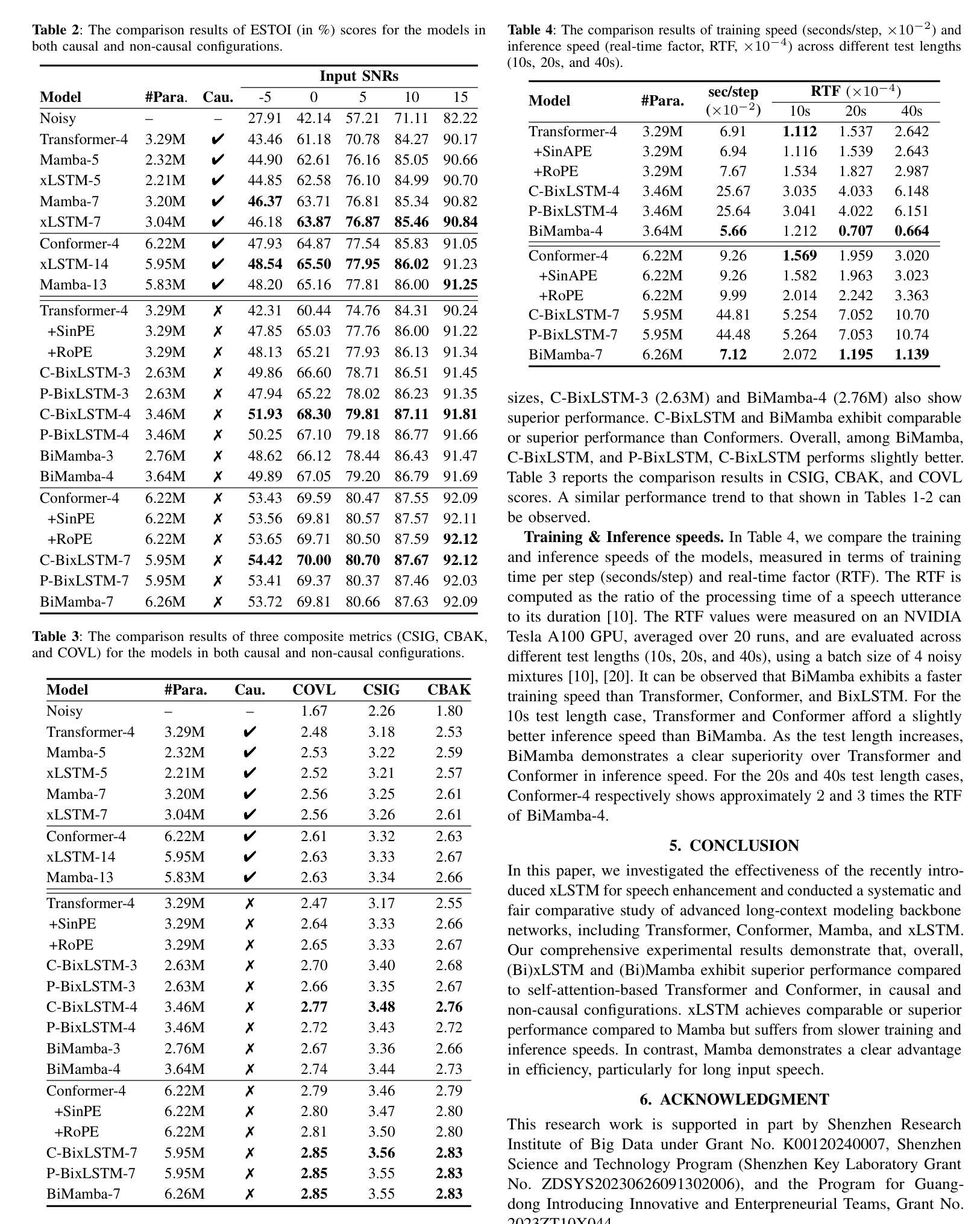
Long-Context Modeling Networks for Monaural Speech Enhancement: A Comparative Study
Authors:Qiquan Zhang, Moran Chen, Zeyang Song, Hexin Liu, Xiangyu Zhang, Haizhou Li
Advanced long-context modeling backbone networks, such as Transformer, Conformer, and Mamba, have demonstrated state-of-the-art performance in speech enhancement. However, a systematic and comprehensive comparative study of these backbones within a unified speech enhancement framework remains lacking. In addition, xLSTM, a more recent and efficient variant of LSTM, has shown promising results in language modeling and as a general-purpose vision backbone. In this paper, we investigate the capability of xLSTM in speech enhancement, and conduct a comprehensive comparison and analysis of the Transformer, Conformer, Mamba, and xLSTM backbones within a unified framework, considering both causal and noncausal configurations. Overall, xLSTM and Mamba achieve better performance than Transformer and Conformer. Mamba demonstrates significantly superior training and inference efficiency, particularly for long speech inputs, whereas xLSTM suffers from the slowest processing speed.
先进的长期上下文建模主干网络,如Transformer、Conformer和Mamba,在语音增强方面已经表现出了卓越的性能。然而,在一个统一的语音增强框架内,对这些主干网进行系统和全面的比较研究仍然缺乏。此外,xLSTM作为LSTM的更新、更高效的形式,在语言建模和通用视觉主干方面已经展现出有前景的结果。在本文中,我们研究了xLSTM在语音增强方面的能力,并在一个统一的框架内对Transformer、Conformer、Mamba和xLSTM主干进行了全面的比较和分析,同时考虑了因果和非因果配置。总体而言,xLSTM和Mamba的性能优于Transformer和Conformer。Mamba在训练和推理效率方面表现出显著的优势,特别是对于长语音输入,而xLSTM的处理速度最慢。
论文及项目相关链接
PDF Accepted by WASPAA 2025, 5 pages
Summary
高级长上下文建模主干网络如Transformer、Conformer和Mamba在语音增强方面表现出卓越的性能。然而,缺乏在一个统一的语音增强框架下对这些主干网进行系统和全面的比较研究。本研究探讨了xLSTM在语音增强中的能力,并在统一框架下对Transformer、Conformer、Mamba和xLSTM进行了全面的比较与分析,考虑了因果和非因果配置。总体而言,xLSTM和Mamba的性能优于Transformer和Conformer。Mamba在训练与推理效率上表现显著优越,尤其对于长语音输入,而xLSTM处理速度较慢。
Key Takeaways
- 高级长上下文建模主干网络如Transformer、Conformer和Mamba在语音增强方面表现出卓越性能。
- 缺乏在一个统一的语音增强框架下对这些主干网络进行系统性和全面性的比较研究。
- xLSTM在语音增强中的能力得到了研究。
- 在统一框架下进行了Transformer、Conformer、Mamba和xLSTM的全面比较。
- xLSTM和Mamba的性能总体优于Transformer和Conformer。
- Mamba在训练和推理效率上表现显著优越,尤其适用于长语音输入。
点此查看论文截图

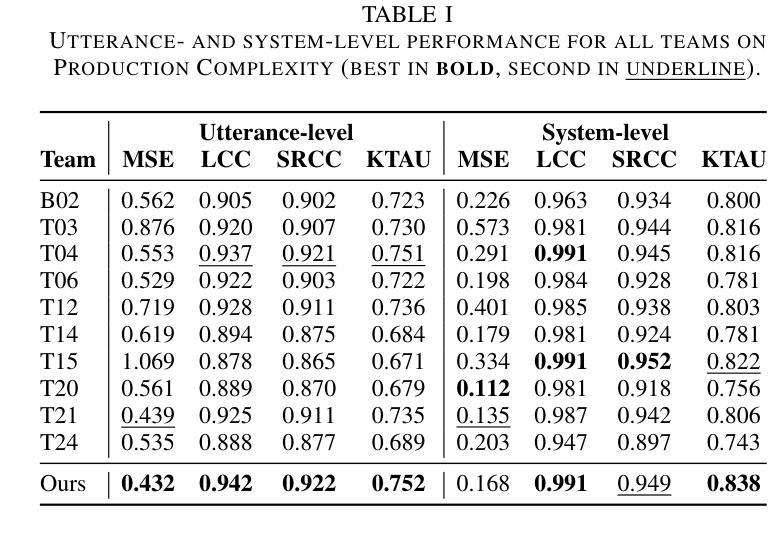
MMMOS: Multi-domain Multi-axis Audio Quality Assessment
Authors:Yi-Cheng Lin, Jia-Hung Chen, Hung-yi Lee
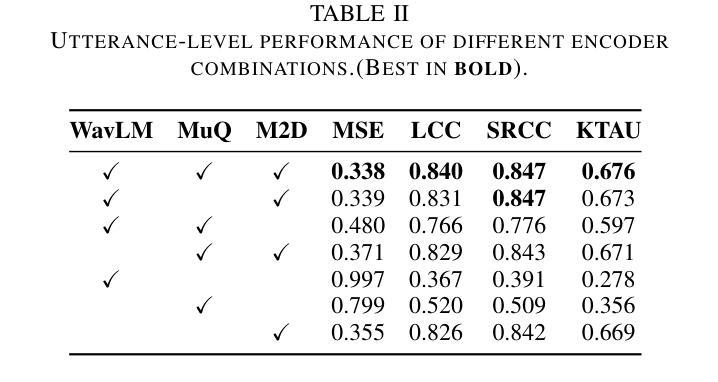
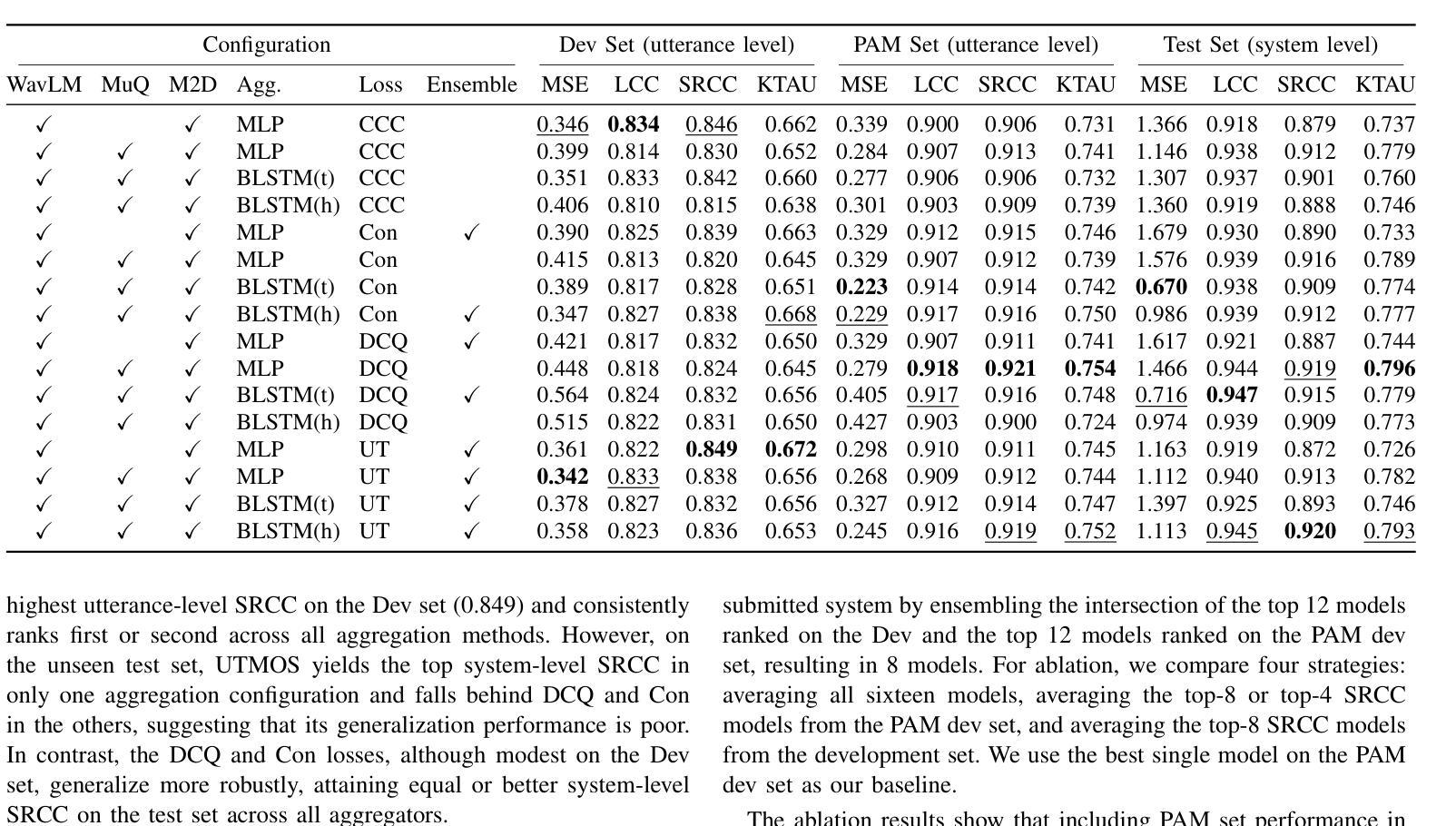
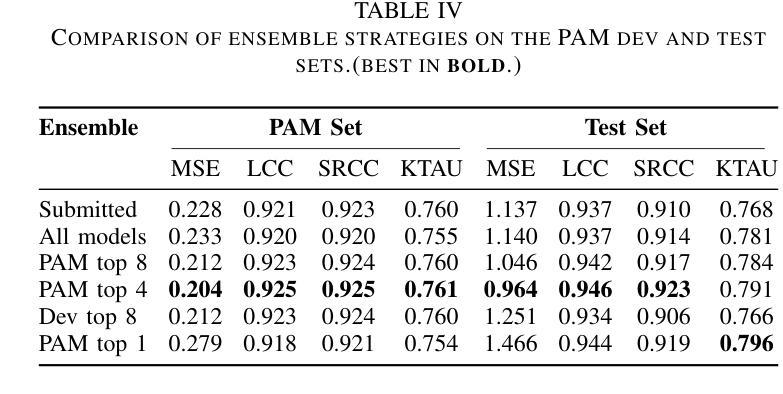
Accurate audio quality estimation is essential for developing and evaluating audio generation, retrieval, and enhancement systems. Existing non-intrusive assessment models predict a single Mean Opinion Score (MOS) for speech, merging diverse perceptual factors and failing to generalize beyond speech. We propose MMMOS, a no-reference, multi-domain audio quality assessment system that estimates four orthogonal axes: Production Quality, Production Complexity, Content Enjoyment, and Content Usefulness across speech, music, and environmental sounds. MMMOS fuses frame-level embeddings from three pretrained encoders (WavLM, MuQ, and M2D) and evaluates three aggregation strategies with four loss functions. By ensembling the top eight models, MMMOS shows a 20-30% reduction in mean squared error and a 4-5% increase in Kendall’s {\tau} versus baseline, gains first place in six of eight Production Complexity metrics, and ranks among the top three on 17 of 32 challenge metrics.
准确的音频质量评估对于开发和评估音频生成、检索和增强系统至关重要。现有的非侵入性评估模型为语音预测单一的主观意见得分(MOS),融合各种感知因素,但无法推广到语音之外。我们提出MMMOS,这是一种无参考、多领域的音频质量评估系统,可以估计四个正交轴:生产质量、生产复杂性、内容享受和内容实用性,涵盖语音、音乐和环境声音。MMMOS融合了三个预训练编码器(WavLM、MuQ和M2D)的帧级嵌入,并评价了四种损失函数下的三种聚合策略。通过对前八名模型的综合评估,MMMOS将均方误差降低了20%-30%,Kendall系数提高了4%-5%,相较于基线在六个生产复杂性指标中获得第一名,并在32个挑战指标中有17个进入前三名。
论文及项目相关链接
PDF 4 pages including 1 page of reference. ASRU Audio MOS 2025 Challenge paper
摘要
无参考、多领域的音频质量评估系统MMMOS,对语音、音乐和环境声音的质量进行更全面的评估。它通过融合三种预训练编码器(WavLM、MuQ和M2D)的帧级嵌入,评价了三种聚合策略和四种损失函数。MMMOS在多个评估指标上表现优异,相对于基准测试,均方误差降低了20-30%,Kendall的τ系数提高了4-5%,在生产复杂度指标中的六个项目中获得第一名,并在32个挑战指标中的17个项目上跻身前三名。
要点
- 音频质量评估在音频生成、检索和增强系统的开发与评估中至关重要。
- 现有非侵入式评估模型在语音方面的预测存在局限性,无法概括不同的感知因素。
- MMMOS系统是一种无参考、多领域的音频质量评估方法,可估计四个正交轴:生产质量、生产复杂度、内容享受和内容有用性。
- MMMOS融合了三种预训练编码器的帧级嵌入,并评价了不同的聚合策略和损失函数。
- MMMOS在多个评估指标上表现优秀,相对基准测试有显著改善。
- MMMOS在生产复杂度指标中的六个项目中获得第一名,并在大多数挑战指标中跻身前三名。
点此查看论文截图

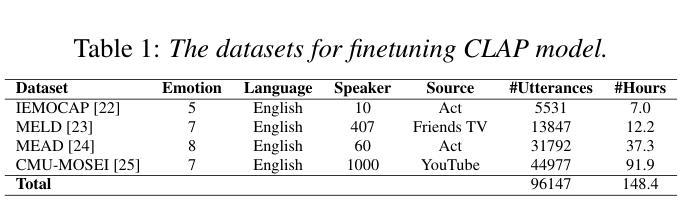
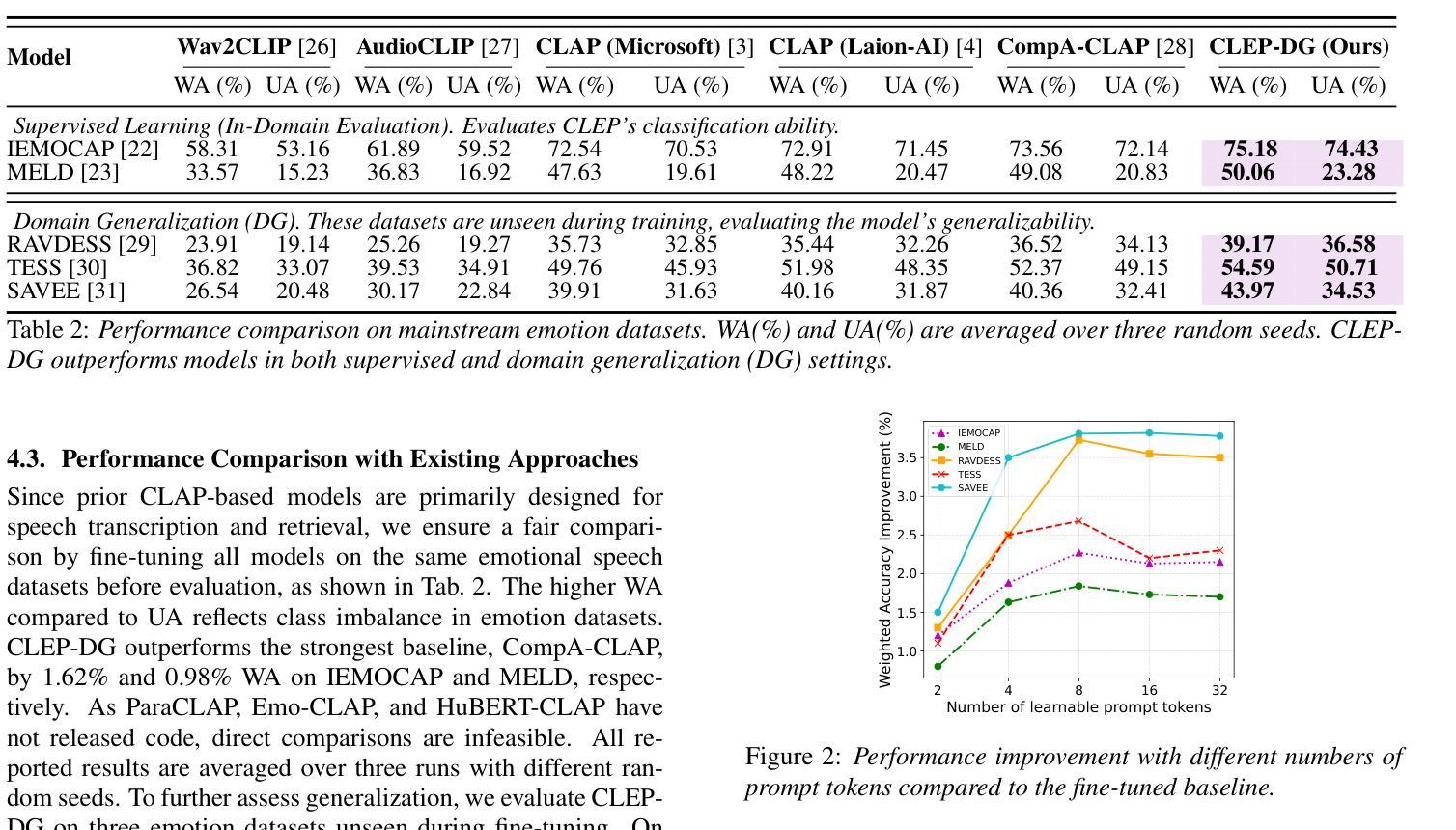
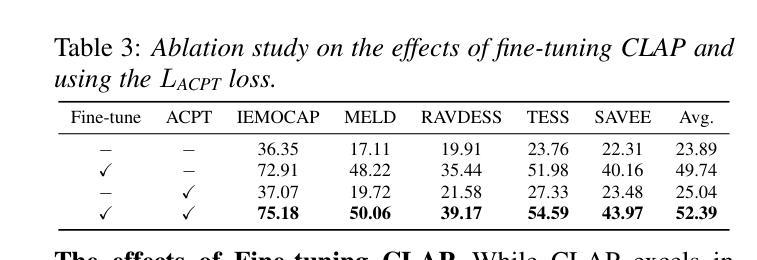
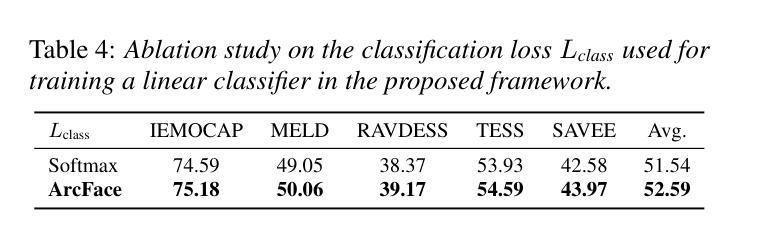
CLEP-DG: Contrastive Learning for Speech Emotion Domain Generalization via Soft Prompt Tuning
Authors:Jiacheng Shi, Yanfu Zhang, Ye Gao
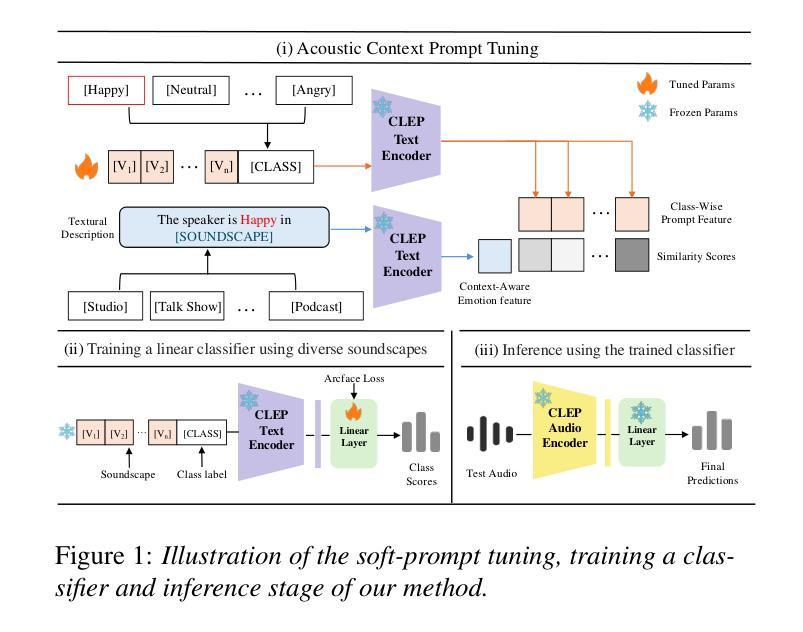
Speech Emotion Recognition (SER) is fundamental to affective computing and human-computer interaction, yet existing models struggle to generalize across diverse acoustic conditions. While Contrastive Language-Audio Pretraining (CLAP) provides strong multimodal alignment, it lacks dedicated mechanisms for capturing emotional cues, making it suboptimal for SER. To address this, we propose CLEP-DG, a framework that enhances CLAP’s robustness in emotion recognition. First, we fine-tune CLAP to obtain CLEP, adapting it on large-scale emotional speech datasets to better encode emotion-relevant features. Then, we introduce Acoustic Context Prompt Tuning (ACPT), a text-driven augmentation strategy that optimizes learnable prompt vectors to model diverse acoustic environments without additional labeled audio. Finally, leveraging cross-modal transferability, we train a classifier on text-derived embeddings and apply it to the audio encoder during inference, mitigating domain shifts between textual supervision and audio-based emotion recognition. Experiments across five benchmark datasets show that CLEP-DG outperforms prior CLAP-based approaches, achieving state-of-the-art performance in both supervised and domain generalization settings.
语音情感识别(SER)对于情感计算和人机交互至关重要,但现有模型在不同的声学条件下难以进行推广。虽然对比语言音频预训练(CLAP)提供了强大的多模式对齐,但它缺乏捕捉情感线索的专门机制,使其不适用于SER。为了解决这一问题,我们提出了CLEP-DG框架,该框架增强了CLAP在情感识别方面的稳健性。首先,我们对CLAP进行微调,获得CLEP,通过大规模情感语音数据集进行适应,以更好地编码与情感相关的特征。然后,我们引入了声学上下文提示调整(ACPT),这是一种文本驱动的数据增强策略,通过优化可学习的提示向量来模拟各种声学环境,而无需额外的标记音频。最后,利用跨模态迁移性,我们在文本派生嵌入上训练一个分类器,并在推理期间将其应用于音频编码器,从而缓解文本监督和基于音频的情感识别之间的域转移问题。在五个基准数据集上的实验表明,CLEP-DG在基于CLAP的方法上表现更好,在监督学习和域泛化设置中均达到了最先进的性能。
论文及项目相关链接
PDF Accepted to Interspeech2025
Summary
本文提出了CLEP-DG框架,旨在增强Contrastive Language-Audio Pretraining(CLAP)在情感识别方面的稳健性。通过微调CLAP获得CLEP,并引入Acoustic Context Prompt Tuning(ACPT)策略,优化可学习提示向量以模拟不同的声学环境。实验结果表明,CLEP-DG在五个基准数据集上的性能优于基于CLAP的方法,实现了监督学习和领域泛化设置中的最佳性能。
Key Takeaways
- Speech Emotion Recognition (SER) 在情感计算和人机交互中扮演重要角色,但现有模型在多样化声学条件下的泛化能力有限。
- Contrastive Language-Audio Pretraining (CLAP) 提供强大的多模式对齐,但缺乏捕捉情感线索的专门机制,对于SER来说不够理想。
- CLEP-DG框架通过微调CLAP并引入Acoustic Context Prompt Tuning (ACPT)策略,增强了CLAP在情感识别方面的稳健性。
- ACPT是一种文本驱动的数据增强策略,通过优化可学习提示向量来模拟不同的声学环境,无需额外的标记音频。
- 利用跨模态可迁移性,CLEP-DG训练了一个基于文本的嵌入分类器,并将其应用于音频编码器进行推断,减轻了文本监督和音频情感识别之间的领域差异。
- 实验结果展示了CLEP-DG在多个基准数据集上的卓越性能,优于基于CLAP的方法。
- CLEP-DG实现了监督学习和领域泛化设置中的最佳性能。
点此查看论文截图

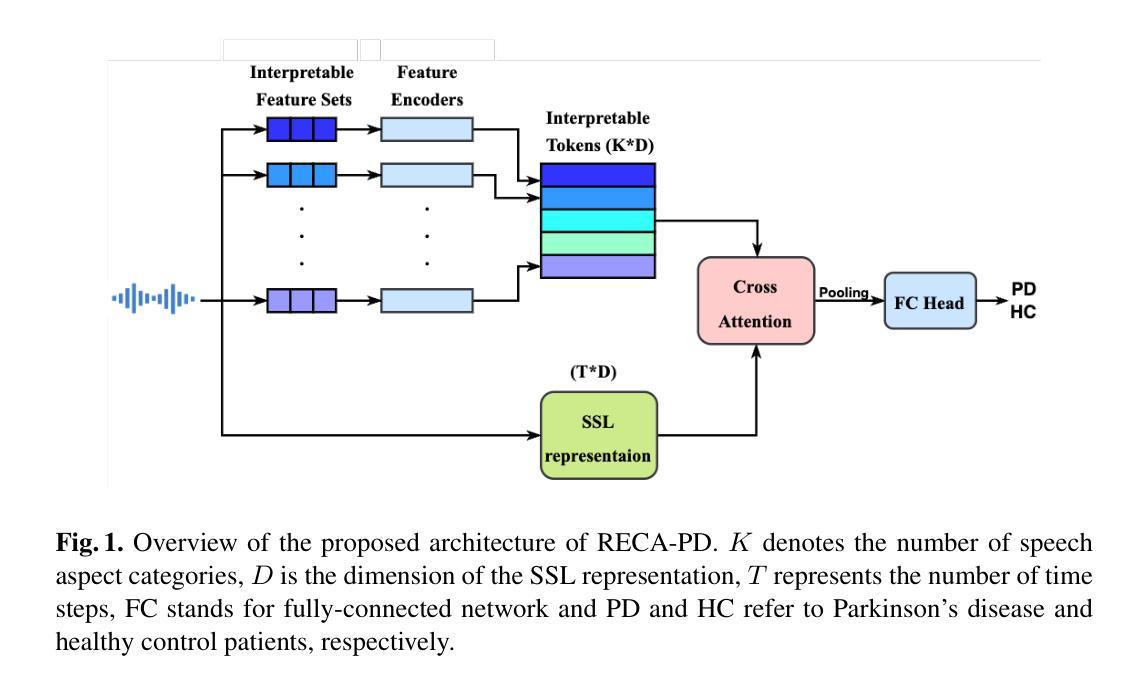
RECA-PD: A Robust Explainable Cross-Attention Method for Speech-based Parkinson’s Disease Classification
Authors:Terry Yi Zhong, Cristian Tejedor-Garcia, Martha Larson, Bastiaan R. Bloem
Parkinson’s Disease (PD) affects over 10 million people globally, with speech impairments often preceding motor symptoms by years, making speech a valuable modality for early, non-invasive detection. While recent deep-learning models achieve high accuracy, they typically lack the explainability required for clinical use. To address this, we propose RECA-PD, a novel, robust, and explainable cross-attention architecture that combines interpretable speech features with self-supervised representations. RECA-PD matches state-of-the-art performance in Speech-based PD detection while providing explanations that are more consistent and more clinically meaningful. Additionally, we demonstrate that performance degradation in certain speech tasks (e.g., monologue) can be mitigated by segmenting long recordings. Our findings indicate that performance and explainability are not necessarily mutually exclusive. Future work will enhance the usability of explanations for non-experts and explore severity estimation to increase the real-world clinical relevance.
帕金森病(PD)全球影响超过1000万人,言语障碍通常数年前先于运动症状出现,这使得言语成为早期、无创检测的有价值方式。虽然最近的深度学习模型具有很高的准确性,但它们通常缺乏临床使用所需的解释性。为解决这一问题,我们提出了RECA-PD,这是一种新颖、稳健且可解释的关注交叉架构,它结合了可解释的语音特征与自监督表示。RECA-PD在基于语音的PD检测方面达到了最先进的表现,同时提供了更加一致和临床意义更强的解释。此外,我们证明通过分段长录音可以缓解某些语音任务(如独白)中的性能下降。我们的研究结果表明,性能和解释性并不一定相互排斥。未来的工作将提高解释对于非专家的可用性,并探索严重程度评估,以增加现实世界中的临床相关性。
论文及项目相关链接
PDF Accepted for TSD 2025
Summary:帕金森病影响全球超过一千万人群,语言障碍往往早于运动症状数年出现,使得语言成为早期非侵入性检测的重要模态。针对缺乏临床使用所需解释性的问题,我们提出了RECA-PD模型,这是一种新颖、稳健且可解释的交叉注意力架构,结合了可解释的语言特征和自监督表示。RECA-PD在基于语音的帕金森病检测方面达到了先进水平,同时提供了更加一致和临床意义的解释。此外,我们的研究还显示通过分段长录音可以改善某些语音任务的性能下降问题。我们的发现表明性能和解释性并不一定相互排斥。未来的工作将提高解释对非专业人士的可用性,并探索严重程度评估以增加其在现实世界中的临床相关性。
Key Takeaways:
- 帕金森病影响全球超过一千万人,语言障碍在早期出现。
- 当前深度模型在语音帕金森病检测方面表现出高准确性,但缺乏必要的解释性。
- RECA-PD模型结合了可解释的语言特征和自监督表示,实现了高水平的性能并提供了解释性。
- RECA-PD模型提供的解释更具一致性和临床意义。
- 对长录音进行分段可以改善某些语音任务的性能下降问题。
- 研究表明性能和解释性不必相互排斥。
点此查看论文截图

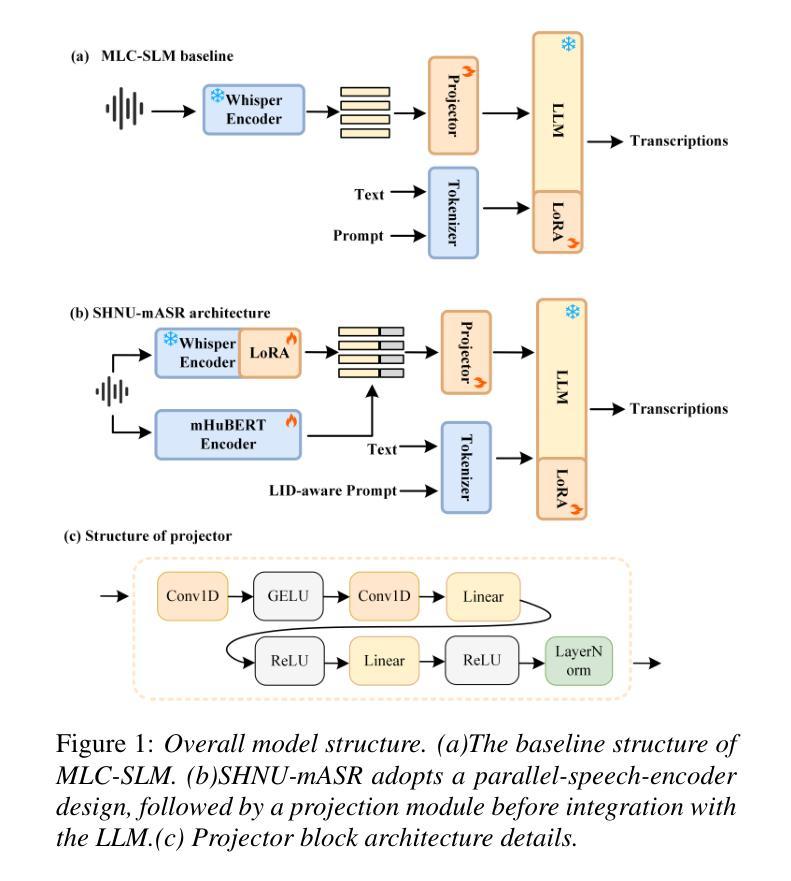
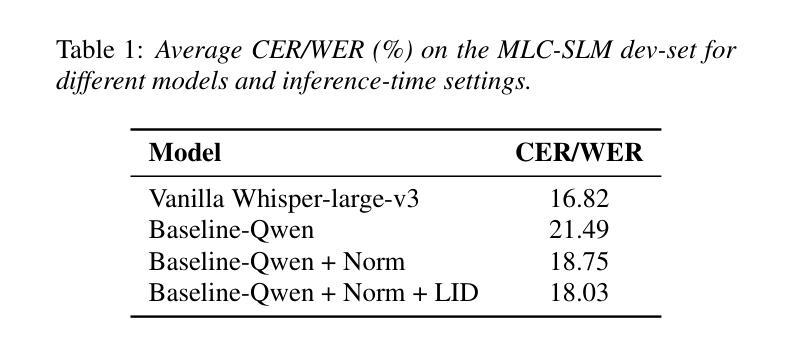
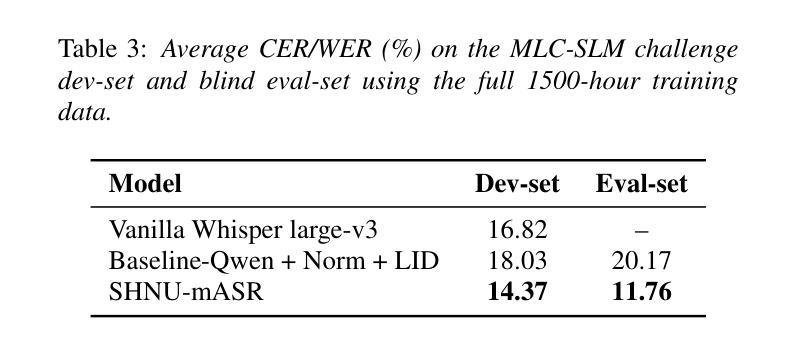
SHNU Multilingual Conversational Speech Recognition System for INTERSPEECH 2025 MLC-SLM Challenge
Authors:Yuxiang Mei, Yuang Zheng, Dongxing Xu, Yanhua Long
This paper describes SHNU multilingual conversational speech recognition system (SHNU-mASR, team name-“maybe”), submitted to Track 1 of the INTERSPEECH 2025 MLC-SLM Challenge. Our system integrates a parallel-speech-encoder architecture with a large language model (LLM) to form a unified multilingual ASR framework. The parallel-speech-encoder consists of two pre-trained encoders, the Whisper-large-v3 encoder and mHuBERT-147 encoder. Their output embeddings are concatenated and fed into the LLM, enabling the model to leverage complementary acoustic and linguistic knowledge and achieve competitive performance. Moreover, we adopt a tri-stage training strategy to jointly update the low-rank adaptation modules and projector parameters of both the speech encoders and the LLM. In addition, we incorporate an additional language-aware prompt at the LLM input to enhance language-specific text generation. The SHNU-mASR system achieves an overall character/word error rate (CER/WER) of 11.76% on the blind evaluation set of the challenge, outperforming the official MLC-SLM baseline by 8.41 absolute CER/WER, without increasing the baseline training data.
本文介绍了SHNU多语种对话语音识别系统(SHNU-mASR,团队名为“maybe”),该系统提交至INTERSPEECH 2025 MLC-SLM Challenge的Track 1。我们的系统将并行语音编码器架构与大型语言模型(LLM)相结合,形成一个统一的多语种ASR框架。并行语音编码器由两个预训练编码器组成,即Whisper-large-v3编码器和mHuBERT-147编码器。他们的输出嵌入进行拼接,并输入到LLM中,使模型能够利用互补的声学和语言知识,实现有竞争力的性能。此外,我们采用三阶段训练策略,联合更新低秩适应模块和语音编码器和LLM的投影仪参数。另外,我们在LLM的输入端增加了一个额外的语言感知提示,以增强特定语言的文本生成。SHNU-mASR系统在挑战盲评测数据集上实现了总体字符/单词错误率(CER/WER)为11.76%,比官方MLC-SLM基线高出8.41个绝对CER/WER,且未增加基线训练数据。
论文及项目相关链接
PDF Accepted by Interspeech 2025 MLC-SLM workshop
Summary
本文介绍了SHNU多语种对话语音识别系统(SHNU-mASR,团队名为“maybe”)。该系统结合了并行语音编码器架构和大型语言模型(LLM),形成一个统一的多语种ASR框架。通过采用双编码器结构、三阶段训练策略和语言感知提示,SHNU-mASR系统在INTERSPEECH 2025 MLC-SLM挑战中取得了出色的性能,相较于官方MLC-SLM基线模型,在挑战盲评测数据集上的字符/单词错误率(CER/WER)降低了8.41个百分点,达到11.76%。
Key Takeaways
- SHNU-mASR系统融合了并行语音编码器架构和大型语言模型,形成统一的多语种ASR框架。
- 系统采用双编码器结构,包括Whisper-large-v3编码器和mHuBERT-147编码器。
- 通过三阶段训练策略,联合更新低秩适应模块和投影参数。
- 在LLM输入端增加语言感知提示,增强语言特定文本生成能力。
- SHNU-mASR系统在INTERSPEECH 2025 MLC-SLM挑战中的盲评测数据集上取得了11.76%的CER/WER。
- 与官方MLC-SLM基线模型相比,SHNU-mASR系统的性能提高了8.41个百分点。
点此查看论文截图

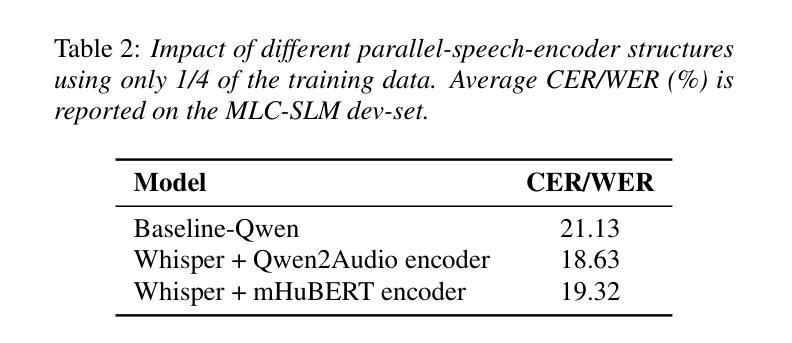
Qwen vs. Gemma Integration with Whisper: A Comparative Study in Multilingual SpeechLLM Systems
Authors:Tuan Nguyen, Long-Vu Hoang, Huy-Dat Tran
This paper presents our system for the MLC-SLM Challenge 2025, focusing on multilingual speech recognition and language modeling with large language models (LLMs). Our approach combines a fine-tuned Whisper-large-v3 encoder with efficient projector architectures and various decoder configurations. We employ a three-stage training methodology that progressively optimizes the encoder, projector, and LLM components. Our system achieves competitive performance with a private test average WER/CER result of 16.63% using the Gemma3-12B and 18.6% using the Qwen2.5-7B as decoder-only language model.
本文介绍了我们为MLC-SLM挑战2025设计的系统,重点是多语种语音识别和基于大型语言模型(LLM)的语言建模。我们的方法结合了经过微调后的Whisper-large-v3编码器、高效的投影仪架构和各种解码器配置。我们采用三阶段训练方法,逐步优化编码器、投影仪和LLM组件。我们的系统在仅使用解码器语言模型的情况下,通过Gemma3-12B取得了平均词错误率(WER)/字符错误率(CER)为16.63%,通过Qwen2.5-7B取得了平均词错误率为18.6%,表现出良好的竞争力。
论文及项目相关链接
PDF Accepted to Interspeech MLCSLM-2025 Workshop
Summary
本文介绍了针对MLC-SLM挑战的系统研究,聚焦于使用大型语言模型的多语种语音识别和语言建模。研究团队采用精细调整过的Whisper-large-v3编码器与高效投影架构和各种解码器配置相结合的方式,并通过三阶段训练法逐步优化各组件。该系统在测试中表现优异,使用Gemma3-12B和Qwen2.5-7B解码器模型分别取得了平均词错误率(WER)为16.63%和平均字符错误率(CER)为18.6%。
Key Takeaways
- 系统针对MLC-SLM挑战构建,专注于多语种语音识别和语言建模。
- 采用Whisper-large-v3编码器结合高效投影架构和多种解码器配置。
- 通过三阶段训练法逐步优化编码器、投影器和语言模型组件。
- 系统在测试中表现优异,使用Gemma3-12B解码器模型取得平均词错误率(WER)为16.63%。
- 使用Qwen2.5-7B解码器模型取得平均字符错误率(CER)为18.6%。
- 研究展示大型语言模型在语音识别领域的有效性。
点此查看论文截图

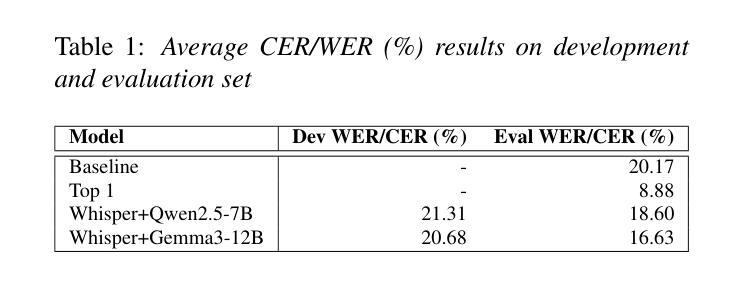
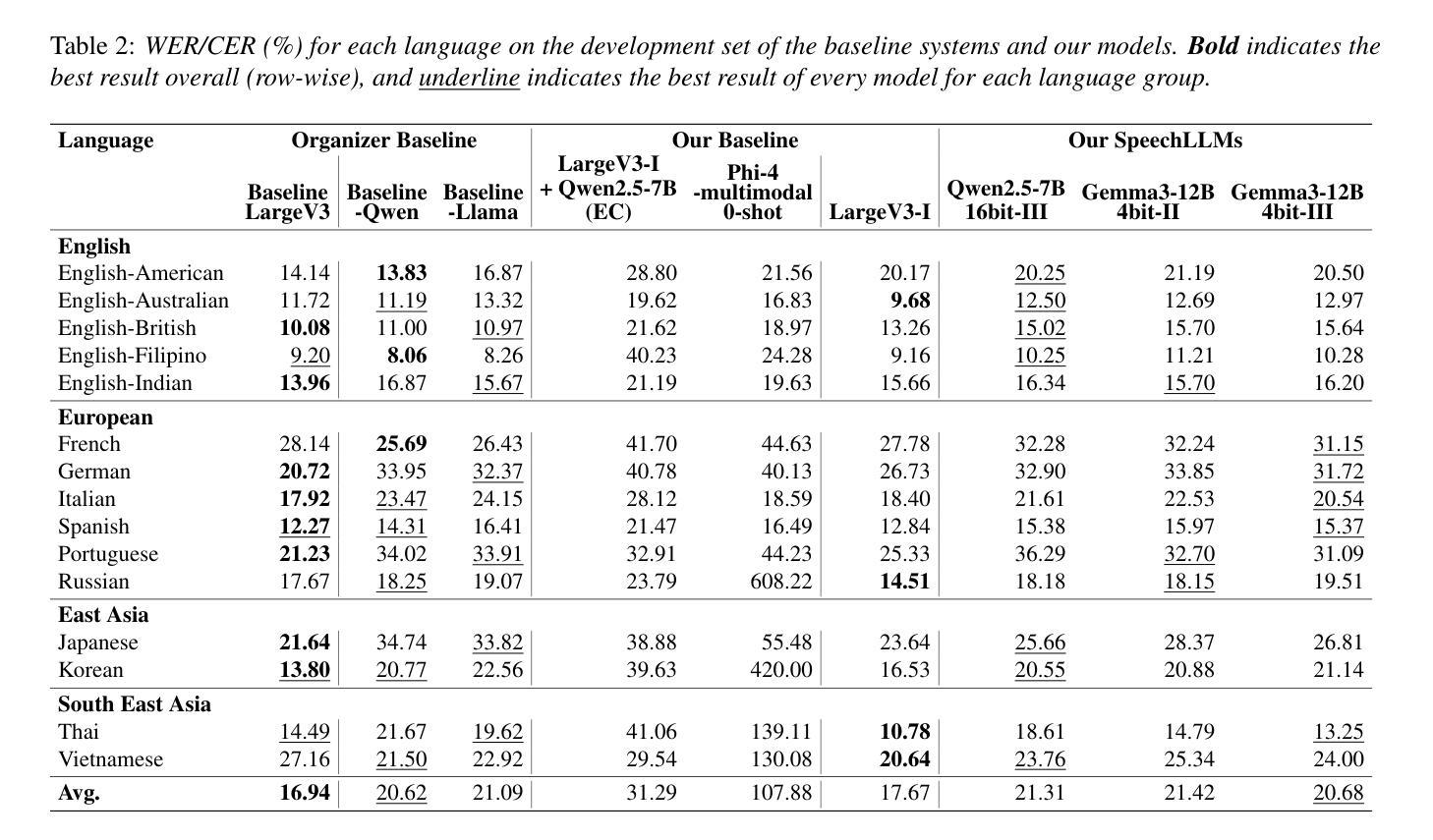
Bi-directional Context-Enhanced Speech Large Language Models for Multilingual Conversational ASR
Authors:Yizhou Peng, Hexin Liu, Eng Siong Chng
This paper introduces the integration of language-specific bi-directional context into a speech large language model (SLLM) to improve multilingual continuous conversational automatic speech recognition (ASR). We propose a character-level contextual masking strategy during training, which randomly removes portions of the context to enhance robustness and better emulate the flawed transcriptions that may occur during inference. For decoding, a two-stage pipeline is utilized: initial isolated segment decoding followed by context-aware re-decoding using neighboring hypotheses. Evaluated on the 1500-hour Multilingual Conversational Speech and Language Model (MLC-SLM) corpus covering eleven languages, our method achieves an 18% relative improvement compared to a strong baseline, outperforming even the model trained on 6000 hours of data for the MLC-SLM competition. These results underscore the significant benefit of incorporating contextual information in multilingual continuous conversational ASR.
本文介绍了将语言特定的双向上下文集成到语音大语言模型(SLLM)中,以改进多语言连续对话自动语音识别(ASR)。我们提出了一种字符级上下文掩码策略,在训练过程中随机移除部分上下文,以增强模型的稳健性,并更好地模拟推断过程中可能发生的转录错误。对于解码,我们采用了两阶段流程:首先是初始的孤立段解码,然后是使用相邻假设进行上下文感知的重新解码。在涵盖11种语言的1500小时多语言对话语音和语言模型(MLC-SLM)语料库上进行的评估表明,我们的方法与强大的基线相比,实现了相对18%的改进,甚至超越了为MLC-SLM竞赛训练的6000小时数据模型。这些结果强调了在多语言连续对话ASR中融入上下文信息的重大益处。
论文及项目相关链接
PDF Accepted By Interspeech 2025 MLC-SLM workshop as a Research Paper
Summary:
此论文探讨了将语言特定的双向上下文集成到语音大型语言模型(SLLM)中,以改进多语言连续对话自动语音识别(ASR)。论文提出在训练过程中使用字符级别的上下文掩盖策略,通过随机移除部分上下文内容提高模型的稳健性,更好地模拟推断过程中可能出现的缺陷转录。解码时采用两阶段流程:先进行初步的独立片段解码,再利用邻近假设进行上下文感知的重新解码。在涵盖十一种语言的1500小时多语言对话语音和语言模型(MLC-SLM)语料库上评估,该方法相较于强大的基线模型实现了18%的相对改进,甚至在MLC-SLM竞赛中表现优于经过6000小时数据训练的模型。这一结果凸显了在多语言连续对话ASR中融入上下文信息的显著优势。
Key Takeaways:
- 论文介绍了一种集成语言特定双向上下文到语音大型语言模型的方法,旨在改进多语言连续对话自动语音识别(ASR)。
- 提出了字符级别的上下文掩盖策略,以增强模型的稳健性并模拟可能的缺陷转录。
- 采用两阶段解码流程,先进行初步独立片段解码,再进行上下文感知的重新解码。
- 在涵盖多种语言的语料库上评估,该方法相较于基线模型实现了显著的性能提升。
- 相较于使用更多数据训练的模型,所提方法仍然表现优异。
- 结果突显了融入上下文信息在多语言连续对话ASR中的重要作用。
点此查看论文截图

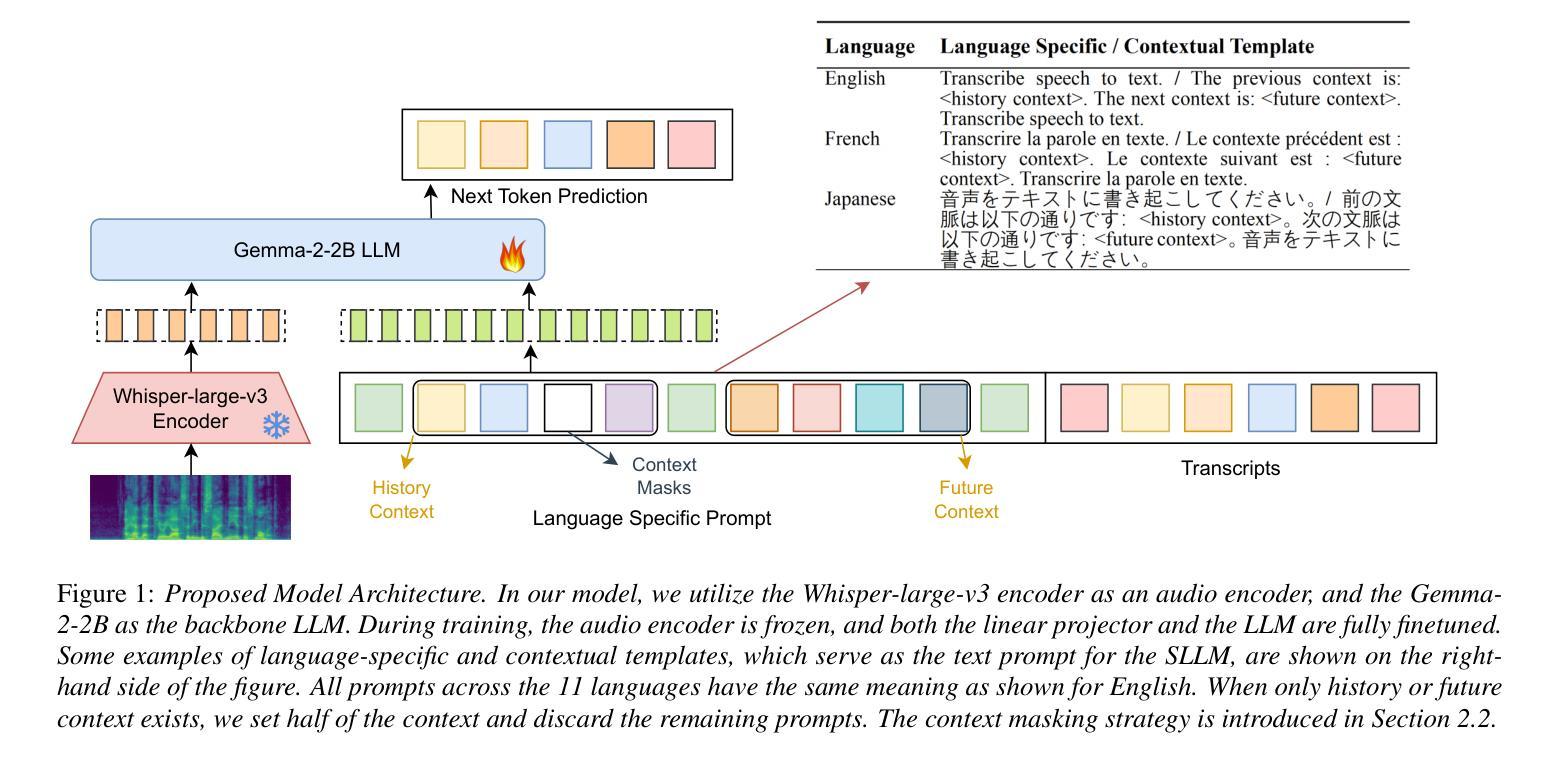

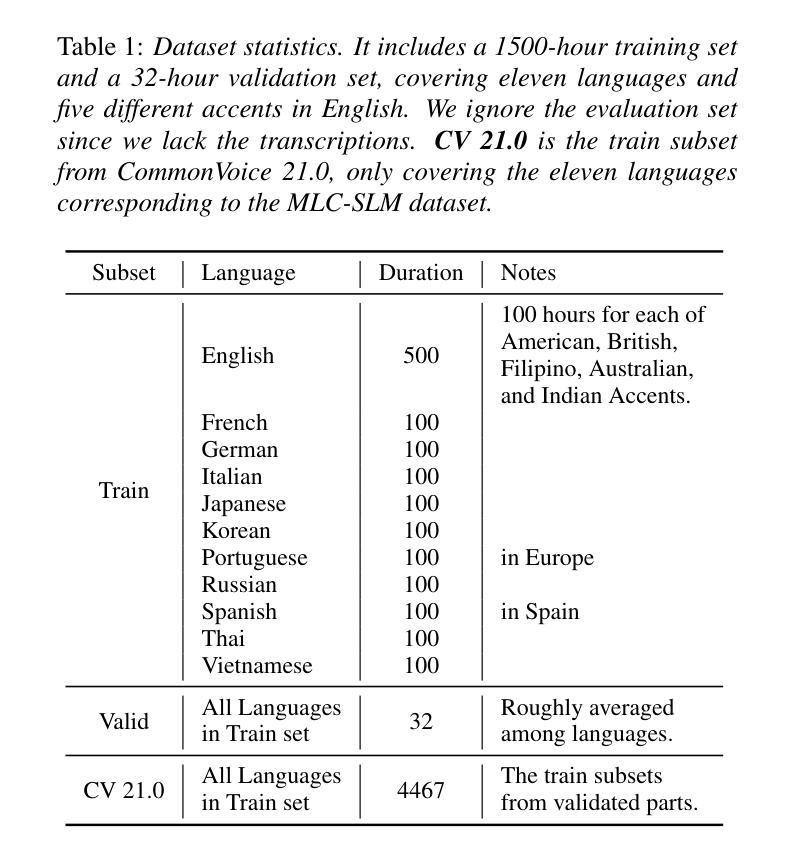
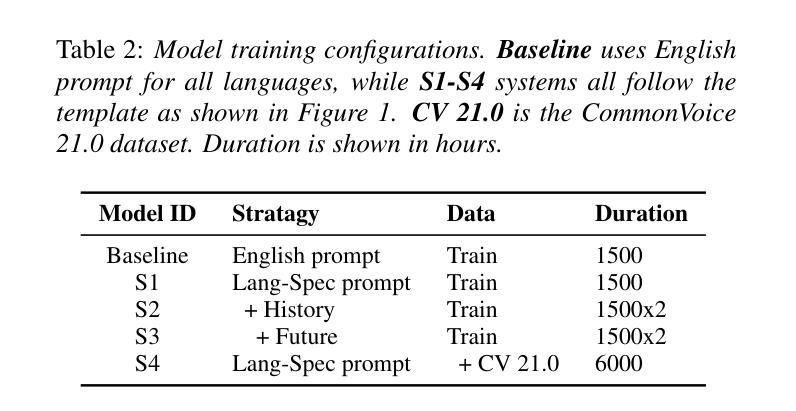
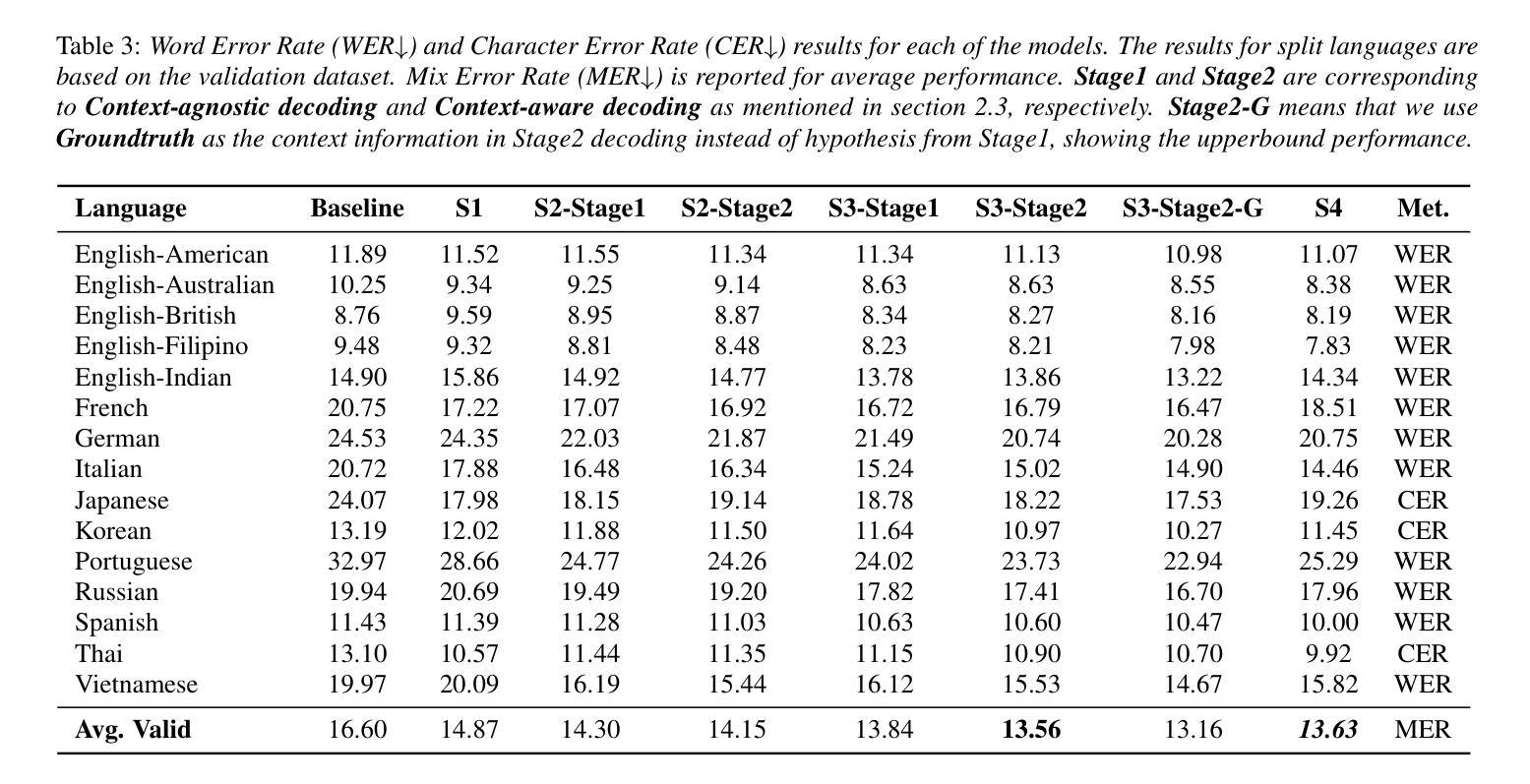
NTU Speechlab LLM-Based Multilingual ASR System for Interspeech MLC-SLM Challenge 2025
Authors:Yizhou Peng, Bin Wang, Yi-Wen Chao, Ziyang Ma, Haoyang Zhang, Hexin Liu, Xie Chen, Eng Siong Chng
This report details the NTU Speechlab system developed for the Interspeech 2025 Multilingual Conversational Speech and Language Model (MLC-SLM) Challenge (Task I), where we achieved 5th place. We present comprehensive analyses of our multilingual automatic speech recognition system, highlighting key advancements in model architecture, data selection, and training strategies. In particular, language-specific prompts and model averaging techniques were instrumental in boosting system performance across diverse languages. Compared to the initial baseline system, our final model reduced the average Mix Error Rate from 20.2% to 10.6%, representing an absolute improvement of 9.6% (a relative improvement of 48%) on the evaluation set. Our results demonstrate the effectiveness of our approach and offer practical insights for future Speech Large Language Models.
本报告详细介绍了为Interspeech 2025多语言对话语音和语言模型(MLC-SLM)挑战赛(任务一)开发的NTU Speechlab系统,我们在比赛中获得第五名。我们对我们的多语言自动语音识别系统进行了全面分析,重点介绍了模型架构、数据选择和训练策略方面的关键进展。特别是,语言特定的提示和模型平均技术对提高不同语言的系统性能起到了关键作用。与初始基线系统相比,我们的最终模型将平均混合错误率从20.2%降低到10.6%,在评估集上实现了9.6%的绝对改进(相对改进48%)。我们的结果证明了我们的方法的有效性,并为未来的语音大语言模型提供了实际见解。
论文及项目相关链接
PDF Accepted by Interspeech 2025 MLC-SLM challenge (5th place). System report
Summary
系统参与了Interspeech 2025多语种对话语音和语言模型挑战赛,并在比赛中取得了第五名的好成绩。文章详细介绍了开发的NTU Speechlab系统及其多语种自动语音识别系统的关键进展,包括模型架构、数据选择和训练策略等方面的分析。采用语言特定提示和模型平均技术提高了系统在不同语言中的性能。最终模型相较于初始基线系统平均混合错误率降低了9.6%,显示出该方法的有效性,并为未来的语音大型语言模型提供了实际见解。
Key Takeaways
- NTU Speechlab系统参与了Interspeech 2025 MLC-SLM挑战赛并获得了第五名。
- 文章详细分析了该系统的多语种自动语音识别技术。
- 系统改进包括模型架构、数据选择和训练策略等方面。
- 语言特定提示和模型平均技术提高了系统性能。
- 最终模型的平均Mix Error Rate相较于初始基线系统降低了9.6%。
- 该方法的有效性得到验证。
点此查看论文截图

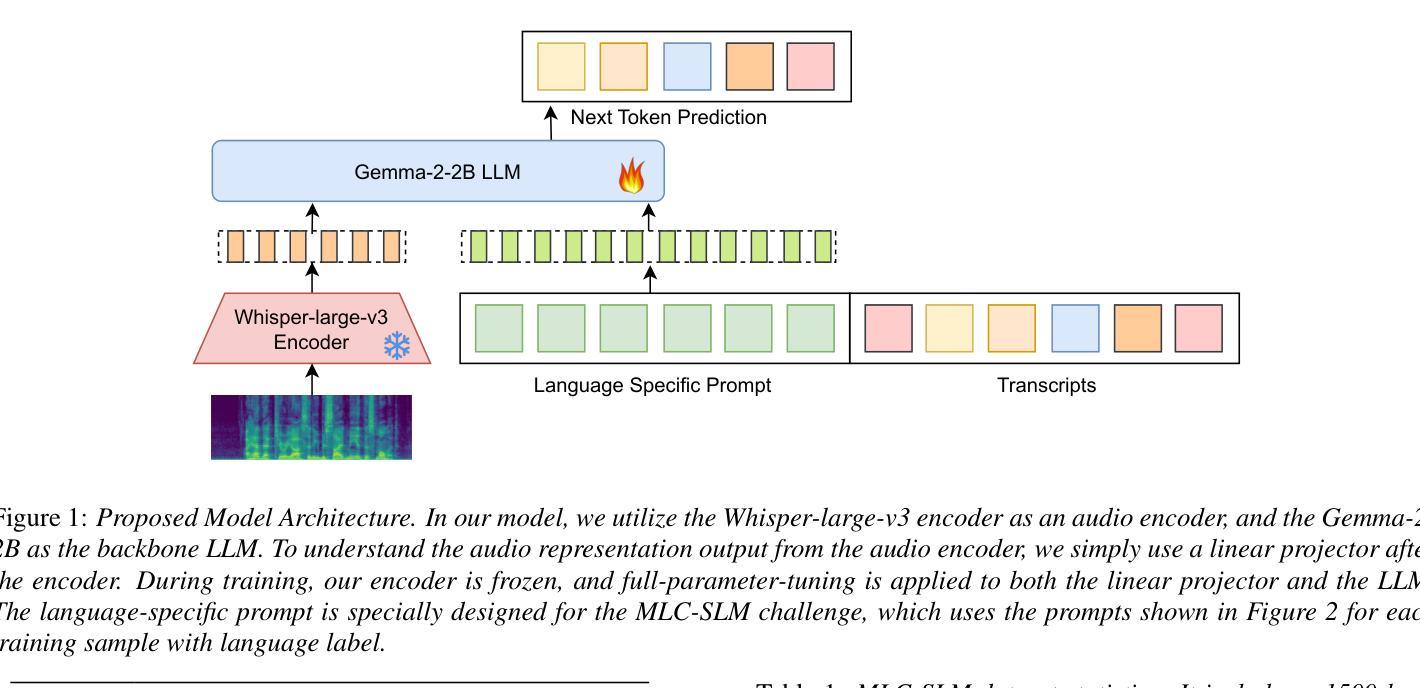
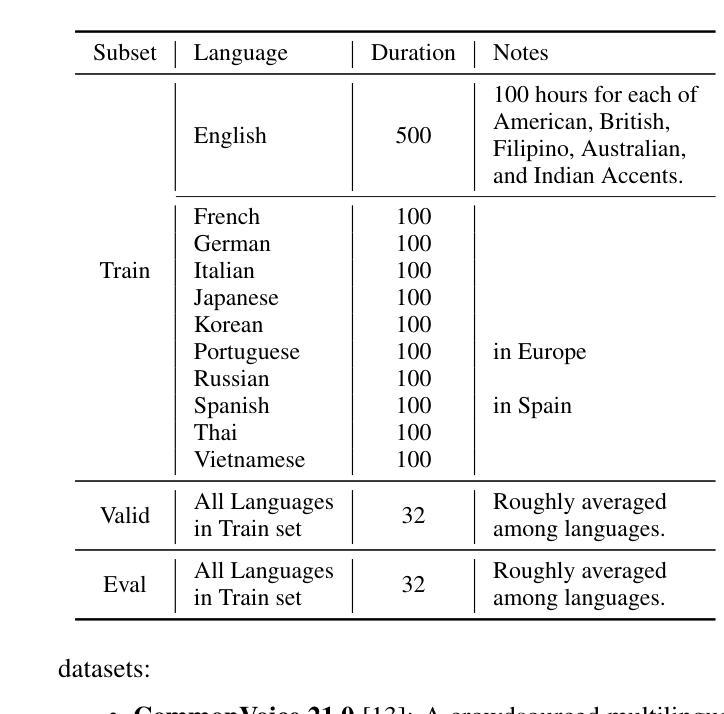

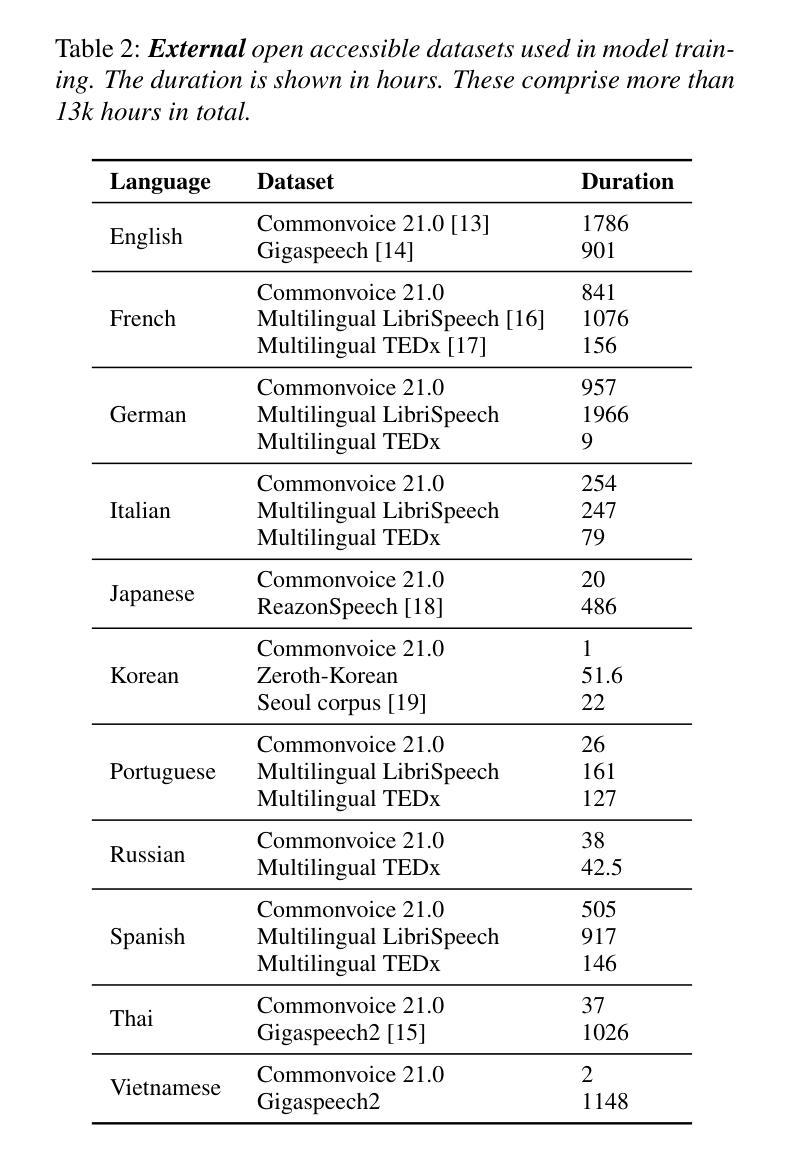
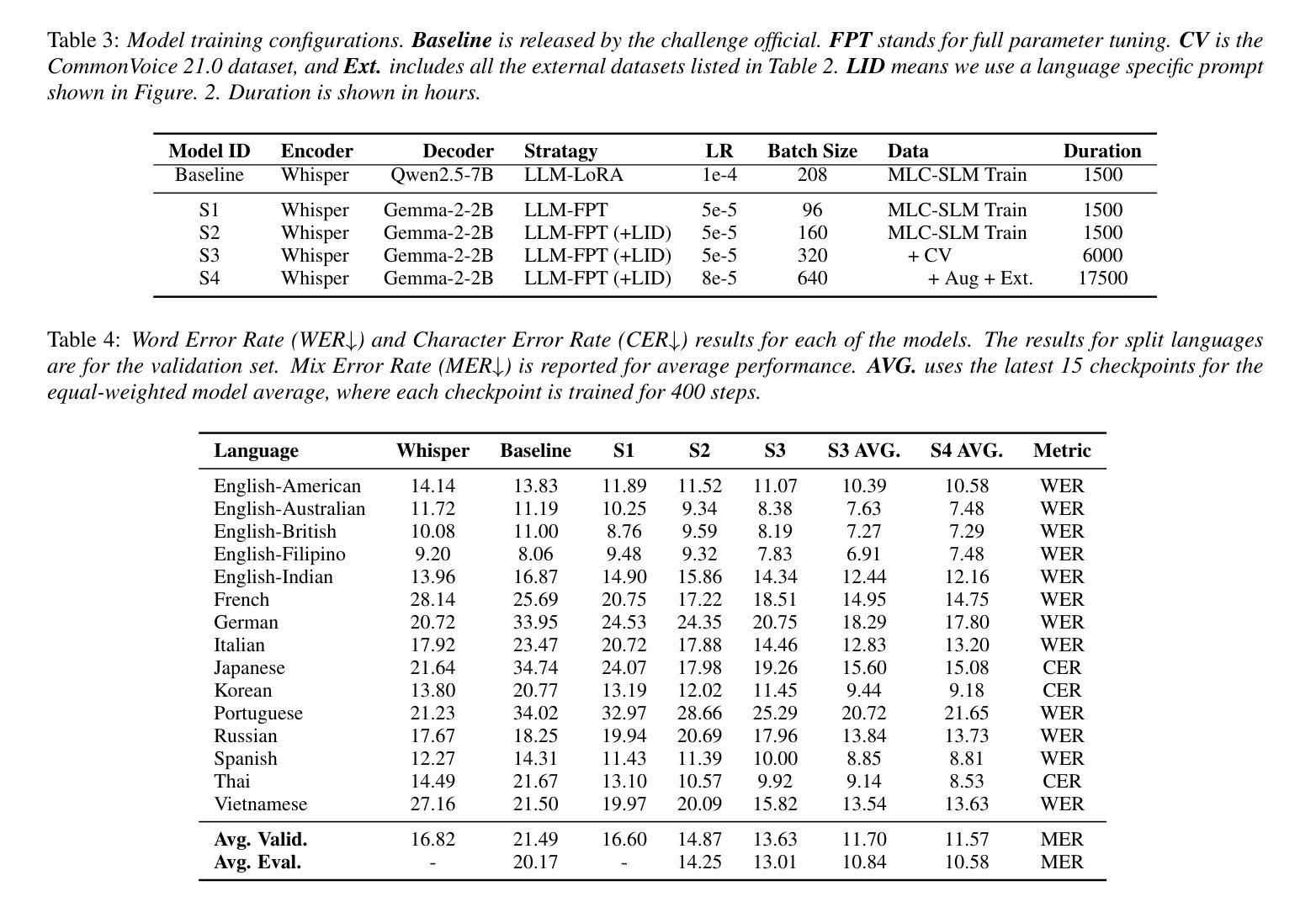
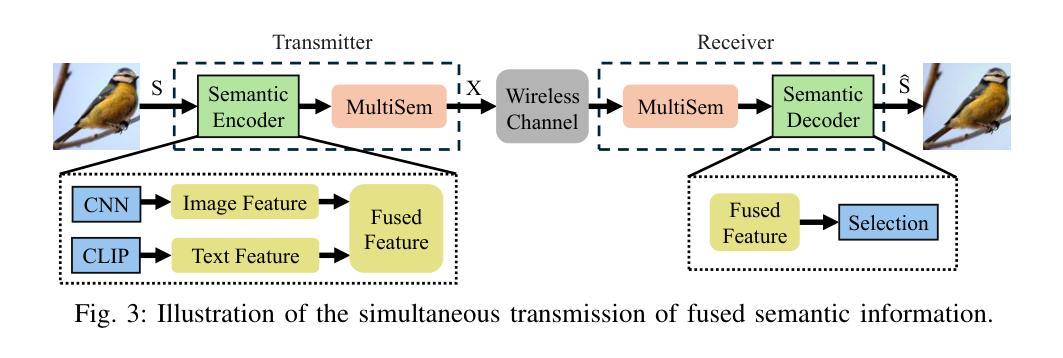
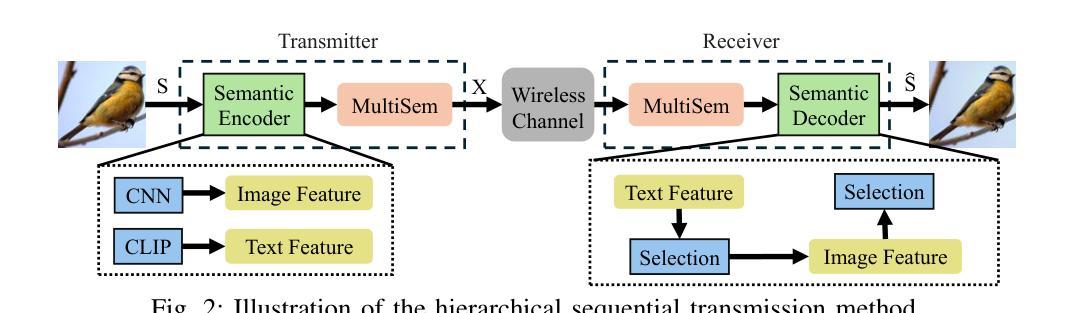
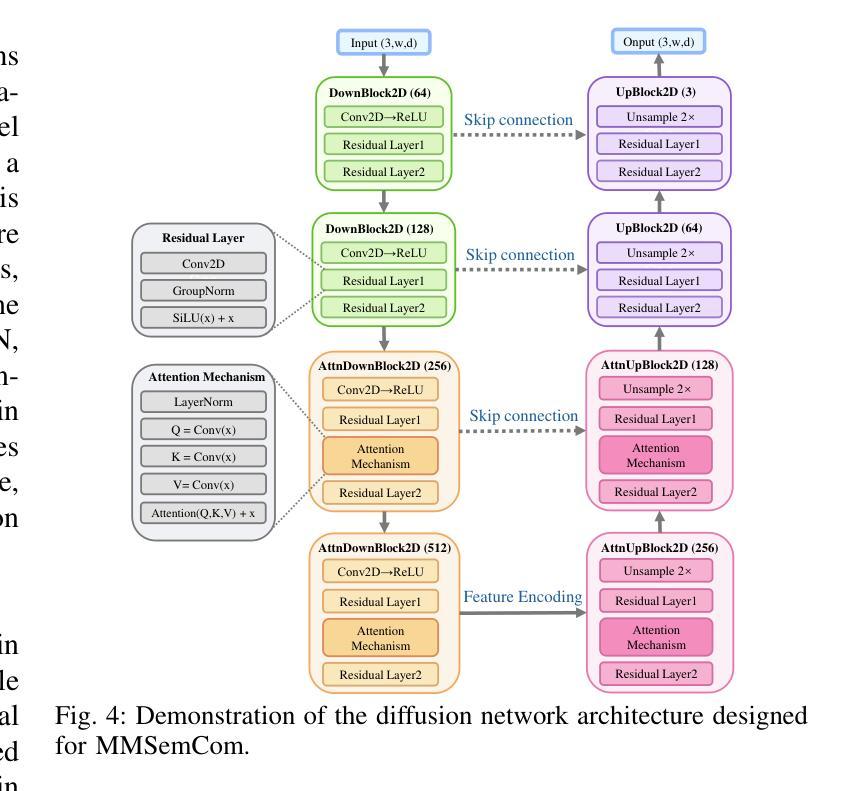
Image Generation with Supervised Selection Based on Multimodal Features for Semantic Communications
Authors:Chengyang Liang, Dong Li
Semantic communication (SemCom) has emerged as a promising technique for the next-generation communication systems, in which the generation at the receiver side is allowed with semantic features’ recovery. However, the majority of existing research predominantly utilizes a singular type of semantic information, such as text, images, or speech, to supervise and choose the generated source signals, which may not sufficiently encapsulate the comprehensive and accurate semantic information, and thus creating a performance bottleneck. In order to bridge this gap, in this paper, we propose and investigate a SemCom framework using multimodal information to supervise the generated image. To be specific, in this framework, we first extract semantic features at both the image and text levels utilizing the Convolutional Neural Network (CNN) architecture and the Contrastive Language-Image Pre-Training (CLIP) model before transmission. Then, we employ a generative diffusion model at the receiver to generate multiple images. In order to ensure the accurate extraction and facilitate high-fidelity image reconstruction, we select the “best” image with the minimum reconstruction errors by taking both the aided image and text semantic features into account. We further extend multimodal semantic communication (MMSemCom) system to the multiuser scenario for orthogonal transmission. Experimental results demonstrate that the proposed framework can not only achieve the enhanced fidelity and robustness in image transmission compared with existing communication systems but also sustain a high performance in the low signal-to-noise ratio (SNR) conditions.
语义通信(SemCom)已成为下一代通信系统的有前途的技术。在该技术中,接收端的生成允许恢复语义特征。然而,现有的大多数研究主要利用单一类型的语义信息(如文本、图像或语音)来监督和选择生成的源信号。这种方式可能无法充分包含全面和准确的语义信息,从而限制了性能提升。为了弥补这一差距,本文提出了一个使用多模态信息监督生成图像的SemCom框架,并进行了深入研究。具体来说,在此框架中,我们首先在传输前利用卷积神经网络(CNN)架构和对比语言图像预训练(CLIP)模型在图像和文本层面提取语义特征。然后,我们在接收端采用生成扩散模型生成多个图像。为了确保准确的提取和高质量的图像重建,我们通过考虑辅助图像和文本语义特征来选择重建误差最小的“最佳”图像。我们将多模态语义通信(MMSemCom)系统进一步扩展到多用户场景,以实现正交传输。实验结果表明,所提出的框架与现有通信系统相比,在图像传输中不仅提高了保真度和稳健性,而且在低信噪比(SNR)条件下也保持了高性能。
论文及项目相关链接
摘要
本研究针对语义通信(SemCom)中的性能瓶颈问题,提出了一种基于多模态信息的SemCom框架。该框架在传输前利用卷积神经网络(CNN)和对比语言图像预训练(CLIP)模型提取图像和文本级别的语义特征。在接收端采用生成性扩散模型生成多张图像,并通过考虑辅助图像和文本语义特征来选取重建误差最小的“最佳”图像。此外,该研究还将多模态语义通信(MMSemCom)系统扩展到多用户场景,实现正交传输。实验结果表明,该框架在图像传输中不仅提高了保真度和稳健性,而且在低信噪比条件下也保持了高性能。
关键见解
- 多模态信息被用于监督生成的图像,旨在解决现有SemCom中性能瓶颈的问题。
- 利用CNN和CLIP模型在传输前提取图像和文本级别的语义特征。
- 在接收端采用生成性扩散模型生成多个图像。
- 通过考虑辅助图像和文本语义特征,选择重建误差最小的“最佳”图像。
- 多模态语义通信(MMSemCom)系统被扩展到多用户场景,支持正交传输。
- 实验结果显示,新框架在图像传输的保真度和稳健性上有所提升。
- 该框架在低信噪比条件下也能保持高性能。
点此查看论文截图